- 4.0.0描述这个项目遵从那个版本,最低是4.0.0,maven官方要求
- Maven项目聚合做法 假设现在有项目A,项目A1,项目A2,要求项目A是负责聚合项目A1和A2,实现多个模块联合编译,实现起来很简单 只需要在A的pom文件中,添加这么一段配置
<modules>
<module>A1</module>
<module>A2</module>
</modules>
这样,编译A项目,就会把A1和A2项目一起编译
3. 模块间的聚合
接下来有个需求,项目A1和A2使用同一个依赖,难道要各自使用各自的依赖包吗?
以上叫做模块聚合,接下来就是模块间的继承,这继承,第一个就是能子项目继承父项目引用的依赖包
假设父项目的pom文件是这样的
<modelVersion>4.0.0</modelVersion>
<groupId>com.Example.main</groupId>
<artifactId>Parent-Moduel</artifactId>
<version>1.0.2</version>
<packaging>pom</packaging>
<name>Simple-main</name>
那么子项目就可以这么写:
<parent>
<groupId>com.Example.main</groupId>
<artifactId>Parent-Moduel</artifactId>
<version>1.0.2</version>
<relativePath>../pom.xml</relativePath> <!--本例中此处是可选的-->
</parent>
值得注意的是<relativePath>标签,如果pom的层次关系就像本例中的那样只隔一层,则可以省略这个。
maven同样可以找到子pom。
子pom中引入标签后,就会从父pom继承等属性了
父类添加这样的依赖:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>servlet-api</artifactId>
<version>2.5</version>
</dependency>
</dependencies>
</dependencyManagement>
子pom如果需要引用该jar包,则直接引用即可!不需要加入,便于统一管理。当然如果你加version的话,表明这个依赖是子项目特有的 然后插件也可以这么管理 主项目:
<build>
<pluginManagement>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-source-plugin</artifactId>
<version>2.1.1</version>
</plugin>
</plugins>
</pluginManagement>
</build>
子项目:
org.apache.maven.plugins maven-source-plugin不用加version了,便于管理。
如下代码所示
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.7</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>
经测试可以成功
1:在Eclipse运行Maven命令没反应或者爆这个错:
-Dmaven.multiModuleProjectDirectory system property is not set. Check $M2_HOME environment variable and mvn script match.
理由。安装的Maven太高级了,Eclipse不认识他,安装个旧版本的
或者进入eclipse的Window->Preference->Java->Installed JREs->Edit,在Default VM arguments中设置-Dmaven.multiModuleProjectDirectory=$M2_HOME
告诉Eclipse去哪里找这个高版本的Maven..前提一定要设置M2_HOME这个环节变量啊,别告诉我你不会设置。
2:有时候下载依赖失败后再次下载就不行了。你得手动去删除依赖的那个文件夹的_maven.repositories和_lastUpdate....这两个文件,然后重新update项目。
还有,仓库有时候依赖是个pom文件,建议不要引用该依赖,要下那些有jar包的该依赖
无论clean install多少次,resource文件夹里面的配置文件都没有发布到war包中。 最后发现是resource写错了,应该是resources
老实说,这个BUG早知道了,也有应对之策。
可是应对之策忘了,所以特此补充
具体BUg的描述就是用Maven打包的项目后,包里面没有Mybatis的实体类映射文件
众所周知,这个映射文件一般是跟着实体类放在一起的,也就是src/main/java文件夹里面,
但是Maven打包只打包src/main/java文件夹里面的java文件,xml配置文件不会打包。
所以我们需要这个配置
<resource>
<directory>src/main/java</directory>
<includes>
<include>**/*.properties</include>
<include>**/*.xml</include>
</includes>
<filtering>false</filtering>
</resource>
<resource>
<directory>src/main/resources</directory>
<includes>
<include>**/*.properties</include>
<include>**/*.xml</include>
</includes>
<filtering>false</filtering>
</resource>
这下就可以把实体类的映射文件一起打包了,爽不?
项目的maven依赖视图能找到某依赖,但是在其pom文件找不到。
这样编译时总是找不到某程序包
原因:pom文件没写依赖。。。
这个BUG主要是install时出现的
在pom文件尝试加上这段话
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.7</source>
<target>1.7</target>
<encoding>utf8</encoding>
</configuration>
</plugin>
当然最重要的就是那个encoding标签了
在setting文件中,补上这份代码
<profile>
<id>jdk1.6</id>
<activation>
<activeByDefault>true</activeByDefault>
<jdk>1.6</jdk>
</activation>
<properties>
<maven.compiler.source>1.6</maven.compiler.source>
<maven.compiler.target>1.6</maven.compiler.target> <maven.compiler.compilerVersion>1.6</maven.compiler.compilerVersion>
</properties>
</profile>
保存即可
如果全局设置失败,试下局部设置
在pom 文件中补上这个代码
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.6</source>
<target>1.6</target>
<encoding>${project.build.sourceEncoding}</encoding>
</configuration>
</plugin>
用处很大,可以根据不同的环境,打包不同的配置文件
其实要完成这样的功能,其实有很多方式。这里讲的只是通过打包的方式
现在,假设你的webapp项目遵循Maven目录规范
那么就会有src/main/resources/ 这层目录
- 首先把各个环境的配置文件放在自己的文件夹内,示例
-src/main/resources/
-dev
-local
-prd
-test
- 在项目根pom里面,加上这个
<profiles>
<profile>
<id>local</id>
<properties>
<env>local</env>
</properties>
<activation>
<activeByDefault>true</activeByDefault>
</activation>
</profile>
<profile>
<id>dev</id>
<properties>
<env>dev</env>
</properties>
</profile>
<profile>
<id>test</id>
<properties>
<env>test</env>
</properties>
</profile>
<profile>
<id>prd</id>
<properties>
<env>prd</env>
</properties>
</profile>
</profiles>
其中,profile是maven提出的一种用于构建配置文件的一个方案,它可以通过不同的触发,使env里面的环境变量生效。
其中一个触发方式,便是在maven命令行指定。
如clean package -P prd
如此一来,就触发了prd的构建配置,使环境变量prd注入到env这个环境变量里面
顺便一提activeByDefault标签的作用。
如果你没指定任何触发方式,使profile生效的话。默认就会启用activeByDefault标签所在的profile配置
- 配置打包的资源目录
上面仅仅只是设置某个环境变量的值
接下里就要使用这个环境变量来指定特定的配置文件
配置如下
<build>
<resources>
<resource>
<directory>src/main/resources</directory>
<excludes>
<exclude>local/*</exclude>
<exclude>dev/*</exclude>
<exclude>test/*</exclude>
<exclude>prd/*</exclude>
</excludes>
</resource>
<resource>
<directory>src/main/resources/${env}</directory>
</resource>
</resources>
</build>
稍微解释下
<directory>src/main/resources</directory>
就是将项目里面这个文件夹里面的所有文件,都复制到打包后的资源文件目录
excludes标签就是排除啦,毕竟你也看到了。
各个环境的配置文件就在local、pro文件夹里面。没必要把所有环境的配置文件都打包在一起。
最关键的还是
<directory>src/main/resources/${env}</directory>
之前说过的环境变量env可有用武之地了。
把环境变量的值替换掉,拿到目标文件夹,再把里面的所有文件,复制到打包后的资源目录。
这样就可以完成各个环境的配置文件打包。
以上。
另外一提。
有一种更简单的打包方式,就是将触发方式设置为系统环境变量触发。
根据打包所在系统的环境变量不同,来自动选择配置文件。
可以说,只要设置一次系统环境变量,之后什么环境配置就不用管了。
但是Maven的方式用起来有点尴尬。
推荐使用Spring Boot的profile
这东西可以做到启动时,根据环境变量的不同,自动选择配置文件。
目前最新阶段的最新版本的依赖
xml <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> <version>4.5.2</version> </dependency>
其HttpPost对象可以设置实体内容。而get不行!
其HttpClient对象这么创建:CloseableHttpClient httpclient = HttpClients.createDefault();
写接口时切记沟通发送报文和接受报文的编码! 接口一定要用HTTPClient测试一下!
- 注意把逻辑分为几部分,在方法里面分由其他几个私有方法来处理。程序看起来会更清晰
定义接口的错误信息时,不要总是想自定义错误信息。一旦你的程序需要事务管理的话,你返回错误信息,相当于程序不报错,不抛异常。事务管理自然失效。。
正确的做法是既能抛异常,又能把错误传递给对方。。
其实很简单,就跟打包成jar包一样
jar -cvf web.war .
最后一个小点不要去掉,这表示当前目录下(不包括该目录)下的所有目录都归档。
什么,最后一个小点你要换成path。你的想法很好,可惜,这样打成的包会把路径信息也保留下来。。。
什么玩意啊。。
这属于基础。。不过我忘了
如果二进制有小数点的话,则以小数点为分界线,向左或者向右每三位取一组。每组的的二进制都转成十进制。
然后倒序把数字连起来,就是八进制,如果没有小数点,就以最右边开始。
如11010111以小数点为分界,向左每三位取一组111 ,010 ,011
每组转成十进制分别是7 2 3
所以最后转成八进制是327
liunx的chmod经常使用
照应上题,所以有必要学一下二进制如何转十进制
其实很简单,就是从二进制的左边开始计算,第0位的权值是2的0次方,第1位的权值是2的1次方,第2位的权值是2的2次方,依次递增下去,把最后的结果相加的值就是十进制的值了。
比如说有一个二进制数为101011
则计算结果是这样的
第0位 1 x 2^0 = 1;
第1位 1 x 2^1 = 2;
第2位 0 x 2^2 = 0;
第3位 1 x 2^3 = 8;
第4位 0 x 2^4 = 0;
第5位 1 x 2^5 = 32;
读数,把结果值相加,1+2+0+8+0+32=43,即(101011)B=(43)D
其实跟二进制转十进制的差不多
从八进制的左边开始算起,第0位的权值是8的0次方,第一位的权值是8的1次方,这样依次递增算下去,把结果相加就是十进制的值了.
具体怎么算,在算法项目里面有相关的算法实现,可以去看看
NOSQL意为非关系型数据库,分为几种
1:基于键值对的-redis最强
2:列存储,Hbase、Cassandra这种
3:文档存储:MongoDB
4:图片存储:Neo4j、Versant
5:xml存储:Berkeley DB Xml还有XBASE,
很早已经支持这种存储方式了
1:多web项目中共享一个session
2:分布式缓存,由于redis提供了几大语言的接口,比如java,.net,c等语言。
因此对于异质平台间进行数据交换起到了作用,因此它可以用作大型系统的分布式缓存,
并且其setnx的锁常被用于”秒杀“,”抢红包“这种电商活动场景中。
Springmvc控制器方法上的produces 要注意一下,仅当Accept请求头和produces注解指明的媒体类型一致时, 比如说produces=text/plain 发来请求的请求头中Accept=text/plain ,该请求才会被接受!否则报错!
@ResponseBody 其返回的数据类型主要看你的classpath有没有相关的第三方jar包,比如说jackson.jar
这样的话返回的数据就会转成json格式输出
一般情况下开发的框架都是加了json相关的jar包,也就是说@ResponseBody返回的都是json数据。
所以要返回一个xml格式的。。。你还是老老实实的用响应流来输出吧。。
注:就算@ResponseBody返回一个字符串,就平台来说,也会给你字符串加上两个隐形的翅膀(字符串首尾加括号)
什么,你想setContentType("text/plain; charset=utf-8");
@ResponseBody到最后还是会变成application/javascript;charset=utf-8的。。。
@RequestParam(value = "custom", required = false)可以非必传参数。 多个Springmvc参数,字符串形式,必须加@RequestParam("factoryCode")标注参数名 一个参数就不需要
看来最新版本的SpringMVC不是默认为你添加Json支持,只是说,你在mvc的配置文件加上
<mvc:annotation-driven />
自动为你配置
DefaultAnnotationHandlerMapping和AnnotationMethodHandlerAdapter两个bean,配置一些messageconverter
当然也包括Json支持
- 3个*号作为一行即可创建一个分割线
- 数字加英语句点即可创建一个有序列表
- 虽然 *``*可以写入代码,但是结构上是不换行的,代码最好写在三个音引号括起来的行内
- JSON数据其实也有数据格式。比如json对象某个字段值没加引号,并且是数字形式,那这个值其实就是json中的数字类型
-
eclipse的构建路径中的order and export 作用是
order就是使用class的顺序(因为可能出现class同名的情况)
export就是把用到的一些的lib和project同时发布. -
问题描述 :改了项目的jre和编译jdk版本,但是一执行maven update 全都打回解放前了。
经查,settting.xml配置了jre版本,pom文件也设置了jre版本,仍是不见效。 已知:本人用的Eclipse不支持jdk1.8.所以pom文件即使追加了jre版本,也依然无效
最后改了jdk版本为1.7.重新update。版本恢复为1.7了。。
付代码
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
未知:setting文件改jdk版本为1.7仍然无效。这个小妖精。。。。
-
这个问题也不是Eclipse的坑,但却是Eclipse的svn插件,所以也一并放到这里。 在svn,如果你想恢复的文件夹的父文件夹不存在那么复原是失败的。 比如说你想复原/web/server 的server文件夹,但是本地系统中web文件夹已经消失了。 那么复原是失败的,你得先复原web文件夹,才能往下继续复原。。
这个特性真糟糕。 -
怎么修改svn用户
假设你Eclipse用的svn插件是JavaHL。
可以到这个目录下
C:\Users\用户\AppData\Roaming\Subversion\auth\svn.simple一般来说,用户都是
Administrator吧。然后你可以看到有很多是乱码文件,没错,那就是svn的用户密码文件。
要不试试删几个文件试试?
然后看看你想要的svn仓库有没有要求重新登录?
目前来说,只能这么做了
以上
-
目前测试得知,java1.7 不支持捕获组里面写无限匹配量词,也就是'+'和'{2,}' 不能用 eg:(?<=package\s{1,}) or (?<=package\s+) 可以匹配'package '后面的位置,但是java不支持这种写法 考虑可以换成(?<=package\s{1,10000}) 顺便贴上msg:Look-behind group does not have an obvious maximum length near index {num}
-
常用的正则表达式
-
只要源字符串出现某一个字符,则匹配不通过
感谢StackOverFlow想出的正则表达式
^[^-]+$该正则表达式的效果是,如果字符串含有
-字符,则匹配不通过换言之,只要字符串不含
-,都是匹配的这个正则表达式解释起来也还算简单
[^-]表示匹配除了-以外的所有字符+表示一个或者多次^$匹配字符串的开始和结束把这几个概念结合起来
就是从头到尾匹配字符串,其中
_字符串,不得出现一次或者多次居然还挺简单的。2333
-
netstat -ano|findstr "8080" 查看占用该端口的piD taskkill /pid 2472 -t -f;
YAML是新一代的配置文件,其文件名的后缀是yml
- 大小写敏感
- 使用缩进表示层级关系
- 缩进时不允许使用Tab键,只允许使用空格。
- 缩进的空格数目不重要,只要相同层级的元素左侧对齐即可
- 不允许莫名奇妙的空行
- 用# 号表示注释
步骤:
- 在你的项目依赖管理上面加上这个依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
注意:如果你在用这个依赖后,报log的栈溢出。 那就是这个依赖引起的,需要把里面的一个依赖去掉
- 然后在项目的test源码文件夹里面创建一个测试类,里面大概是酱紫的
@RunWith(SpringJUnit4ClassRunner.class)
@SpringApplicationConfiguration(classes = WebApplication.class)
@WebAppConfiguration
public class Test{
@Autowired
private ApplicationContext applicationContext;
@Autowired
private MyService myService;
@Test
public void test(){
myService.run();
}
}解释一下
- @RunWith(SpringJUnit4ClassRunner.class)表示Junit测试运行在Spring上
- SpringApplicationConfiguration这个是指定配置类,通过这个配置类引出单元测试所需要的测试类,这个配置类可以是Spring Boot启动类。
- WebAppConfiguration 开启使用web环境
一个系统要能稳定的对外提供服务,容灾能力是必须的。
这里的容灾,指的是系统对灾难的容忍能力。
一般容灾能力可以做到三级
- 数据容灾。简单的说,就是有一个备用数据库,在主数据库因为某种原因down掉时,备用数据库可以顶上。
- 系统容灾。就是另做一个备用系统,主系统down掉时,备用系统可以顶上
- 系统容灾。 备份一些业务技术文档之类的数据
而一个容灾系统至少要做到以下功能
-
检测灾难位置,是哪个组件挂掉了
-
实施切换,主从数据库或系统能实时切换,保证业务的平滑过渡
-
数据一致性,主从数据库的数据要一致
如何实现
- 热备份,即实时对数据进行备份
- 冷备份,定期对数据库进行备份
大致留个映像,等待有架构师实施我们再去涨经验
分库,指的是将其他表迁移到其他数据库中。
分表,指的是一张含有多个列的表,按照某种切分逻辑,分成多张表
分库分表有两种实现方式
垂直分库:如果是因为数据库里面表太多,而导致数据多的话。可以将关联性高的表单独分在一个库中。
垂直分表:如果是因为某个表的字段多,可以将多的字段、不常用的字段抽取出来,形成一张扩展表
因为数据库是以表为单位,加载到内存中,分表之后,常用的字段都在同一个内存区域内,可以使查询命中率提示
该方式又分为库内分表和分库分表。
主要适用于单个表记录量较大,那么我们就把一部分父记录分到其他表或者库中,从而减轻表的记录量。
但是,这种划分也需要讲究技巧的
-
按照数值范围进行分表,比如说把前10000条记录分到一个表中,另外的部分分在另一张表中。
优点:单表的数据可控
缺点:热点数据不能保证分在同一张表中,这样查询时就会涉及到多张表。甚至联库查询。
-
按照数值取模
比如说对ID进行hash,然后得到一个结果,根据这个结果进行划分数据。
再举个例子,我们要将一张表的数据分到四个库中,而且刚好该表的ID是数值型。
那么我们可以用这个ID和4进行取模
为1的话就分在第一库中、为2的话就分在第二库中。
优点:业务相近的数据在同一张表中,不太容易出现热点数据的访问问题
缺点:数据迁移遭老罪了。不能按照自己喜欢分隔指定的数据进行迁移。
微服务架构设计的系统,可以提供更高的容灾性和并发性,事实上已经成为互联网公司开发的标配了。
这里主要简介一个微服务系统应该是什么架构,每个组件应该承担什么功能
一个传统的微服务架构如下所示
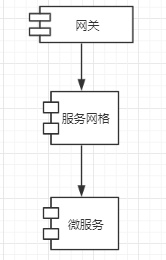
emmmm,很简单?其实简单就是美(逃....
由上图可以得知,微服务最简的话只有三个组件,分别是:网关,服务网格,微服务。
接下来一一讲解这三个的区别
这个网关和路由器上面的网关有点相像,但是它可不是用在路由器上面的。
它的功能有:
-
鉴权
不是鉴定你有没有登录,而是鉴定你有没有访问服务的权限。毕竟如果都能从外网访问到你的微服务的话,这也太随意了。
怎么鉴权的,目前来说,可以让所有有权能访问你的应用都分配一个appid。
应用凭这个appid就能通过鉴权的检测。
不过说实在,用处不大 ,只要在浏览器上抓包分析一下,就知道哪些参数是作为appid的。照此传过去就可以鉴权成功。
不过过滤低等级的爬虫倒是可以的
可以改进下:
-
appid加密,当然只能在浏览器上加密,加密代码弄得复杂一点,变量名使用a,b,c,d命名,总之除了自己,谁都看不懂最好。
-
appid在服务器上设置时效性,这样想访问服务器资源,就得重新申请一遍。
其实对于爬虫开发者来说,只不过再找一下申请接口罢了
-
-
转发请求,作为所有应用流量的出口和入口(反向代理第一层)
就是转发请求到下一个组件-服务网格
没啥技术含量,提取原请求数据,再塞到一个新请求中,如此而已
不过这个功能,正是网关的核心功能。
-
请求限流,某IP访问次数过多,直接告诉对方你需要xxxx时间才能再次访问
其实服务网格才是微服务的核心。他的功能有:
-
接受来自网关的请求,并将请求分发给对应的微服务
各种请求分发,说的高大上,就是反向代理,这里是第二次反向代理了
-
接受来自微服务的请求,并将请求分发给对应的微服务
-
服务注册,只有通过服务注册,服务网格处理新的请求才能找到对应微服务,进行请求转发
-
服务心跳监测,微服务你还活着吗?死了吗?
-
负载均衡,哎呀A负载太大了,下一个请求扔给B服务
两种实现
- 循环同种服务进行请求
- 记录同种服务的请求量,选择最少的请求量进行请求
-
服务熔断,A服务不可达了?直接告诉请求方服务不可达了,不浪费时间去请求了
-
请求限流。最大能同时访问的并发数有多少
如何实现,用golang的chan来实现
首先设置一个chan的大小,也就是最大的并发数
每个请求来的时候,都往这个通道赛一个数据
请求结束后,把数据取出来。借用golang的select语法,当请求太多又没有及时结束时,chan里面的数据将达到预先设置的最大值
这个时候
select case:chan<-data就走不了了于是就走default进行限流提醒
略微简单粗暴,而且是对所有请求进行限流,而不是单独一个IP。防止不了恶意请求,但是全局限流,起码能保障服务器不会炸,只不过对于普通用户使用,不太友好。
通过以上功能,应该可以得出服务网格的几个好处:
-
对微服务的侵入性不太大
也就是,服务本身不用太关注微服务的底层细节。
这主要通过以下两个关注点来实现的
-
服务与服务之间通讯不用关注太多微服务细节
服务在请求另一个服务的资源时,不用关注什么负载均衡,熔断什么的
这些鬼东西全都由服务网格负责。
之前SpringCould的Fegin框架,在处理服务之间转发就做的不太好
它把负载均衡和熔断机制集成在了微服务里面。
-
服务要集成到微服务里面,只需要做两件事。这就允许微服务本身是可以由不同的语言编写的,只要微服务能满足下面两件事
- 注册到服务网格里面,一般服务网格设计一个http接口,提供微服务的信息,就可以注册
- 提供心跳监测接口,服务网格可以调用此接口来判断微服务是否挂了。该接口可以极其简单,只需返回200状态即可
这样,服务本身不需要依赖太多微服务的类库,减少了微服务的体量
-
最后结语
服务网格的实现可以采取开源手段,也可以自己实现,或者组装而来。
比如说服务发现,注册什么的,交给第三方开源去完成,至于反向代理,负载均衡,自己来实现
第三方开源,有Eurrka(这货闭源了好像),Consul(比较轻量级)
另外,服务网格的设计,应该是只能由内网访问,而不能从外网访问。
要保证这一点,除了将服务网格部署在内网中外,最好再检测下每一个请求是否是从内网的服务发过来的。
这里微服务,就是处理业务功能的一个单元,它可以由各种编程语言开发,只要能满足服务网格的几个规定即可
这货虽然在微服务处于最底层的存在,但是对业务进行划分也不是一件容易的事。需要业务能力拔群才行。
对了,微服务和服务网格一样,都要设计从只能从内网访问,要么是服务内之间的访问,要么是从网关转调过来的。
没有配置中心的微服务架构是没有灵魂的。上面的图没有画出配置中心,是因为配置中心贯穿整个微服务。
网关需要他,服务网格需要他,微服务也需要他
配置中心主要存储什么配置?
对于网关:最简单的网关实现不需要这货,等到业务体量上来了,可能就需要它了
比如说存储同个IP最大能请求多少
对于服务网格:最简单的服务网格实现不需要这货,等到业务体量上来了,可能就需要它了
存储秘钥什么的,保证请求合法
对于微服务:取数据库连接,取自定义的配置
配置中心的选择:
由于配置中心的功能很简单,实际也没必要自己实现,使用开源产品就行了,开源产品有
- consul 想不到吧,它其实也有配置中心的功能
- SpringConfig 嗯,这货使用git仓库作为配置数据源,使用体验不算好。
日志中心其实也是微服务其中的一种,主要是记录微服务运行过程中产生的日志的。
你肯定不想登陆linux上面一个个去查日志文件吧,更何况启用微服务体系的系统,微服务肯定不止两三个。
出了问题,你知道是哪台机子的服务出了问题吗?
所以,日志中心,在微服务体系中,就显得尤为重要
那么,日志中心,要怎么设计呢?,至少,它应该要满足一下几个要求
- 能收集所有微服务运行过程中产生的日志
- 能根据关键字,搜索日志,最常见的是用错误码去查询
- 高可用
根据这些要求,能选择的开源产品有
- ELK全家桶
- 未完待续
在往日志中心记录日志时,应该不能花费太大开销。
一般采取的手段是
- 启动一个多线程/协程去塞日志
- 启动一个多线程/协程将日志塞到队列中,由队列专门将日志记录到日志中心
JWT技术是为了克服传统的session身份验证所导致的问题的。
传统的身份验证是这样的
-
用户登录
-
服务器验证通过。在服务器创建一个session,并返回cookie给客户端
-
客户端以后每次请求都携带这个cookie,服务器根据此cookie来验证有没有对应的session存在
如果存在,用户就是登录状态
如果不存在,用户就是没登录
传统的Session暴露的问题:
-
一个用户还好说,只要在服务器存储一个session就行,但是规模如果大起来的话。
给个一千万个用户同时登录,意味着服务器要存储一千万个session。
服务器得累死
反论:目前session外部存储其实已经很成熟,一千万用户的登录信息也没什么可怕的
-
为CSRF攻击提供便利,只要骗子网站伪造请求,且用户没退出登录。
服务器就会根据请求头的cookie判断用户已经登录,骗子就可以为所欲为了
-
天生不支持分布式,由于session 只存在于单台服务器的内存里上,一旦用户的请求被其他服务处理的话,是无法拿到session的,会误判为未登录。
外部session存储可以解决
基于此,JWT横空出世,JWT做了几件事
- 登录成功后,服务器返回一个加密后的字符串,称之为token
- 客户端每次登录后请求,都会带token过去
- 服务器验证token数据的有效性,有效,则证明客户已登录,无效,则是伪造的
如何验证?首先解密token,然后验证过期时间,用户信息是否正确等等
JWT 如何克服Session的缺点?
- JWT里面携带的,就是用户的凭证信息,服务器不需要保存,这样就可以克服session的第一个缺点
- JWT的传输需要前端手动设置到请求头上,不像cookie,浏览器默认每次请求都会自动带上
- 客户端的登录凭证完全由客户端进行存储,服务端没有存储,所以哪台服务器都可以验证用户的登录情况
这又是一个非关系型数据库,它和redis不太一样,redis比较轻量,更适合做键值对存储。
而MongoDB更适合做文档存储。
哪些文档?
官网给的示例是一个特别像json的数据,把它称之为bjson,作为文档用。
其实直接存json也是可以的,据说bjson是json的父集,自然也就包含json了。
它里面的数据结构是这样的。
最上层是集。类似于数据库的表
集里面是文档,类似于表中的记录。
就这样。
先介绍他的安装
很简单,把安装程序打开一路next即可,有几个小问题
-
注意中间有一个复选框
install MongoDB compass注意把它去掉这货要联网下载,中国的外网链接情况,emmmm,你懂得
-
安装到最后一步,可能会弹出一个框告诉你,启动mongoDB服务器失败,请确认你有足够的权限启动。
这个时候,我也不知道是这么肥事,你可以先尝试几遍,不行再点击忽略掉,这样会安装成功,只不过没有启动服务器,也没有注册为系统服务
安装后,找到那货的安装目录,进入
/data/新建一个文件夹叫db然后回到上一层进入
bin目录执行命令
mongod.exe --dbpath="{你刚刚创建的db文件夹路径}"然后看看里面展现的一大批日志,稍微看一遍,没什么大问题就OK,
服务器就启动完毕了
进入客户端
进入bin目录下,执行此目录mongo.exe
就OK
增查
请先进入客户端再执行以下操作
删改就算了,应该也没什么难度
怎么增加一个文档进去呢?
执行命令
db.inventory.insertOne(
{ item: "canvas", qty: 100, tags: ["cotton"], size: { h: 28, w: 35.5, uom: "cm" } }
)
这样就创建了一个集,名称叫inventory
里面有一个文档,文档的内容是
{ item: "canvas", qty: 100, tags: ["cotton"], size: { h: 28, w: 35.5, uom: "cm" } }
如果插入的文档中没有_id字段,Mongodb会自动生成,
插入成功后,接下来就是查询了。
查询可以根据集中某文档的字段为某值为条件查询记录
比如说针对刚刚插入的数据进行查询,查询命令是
db.inventory.find( { item: "canvas" } )
这样就是查询inventory集里面,某文档的item字段为canvas的记录。
查询的结果是
{ "_id" : ObjectId("5d53cccc879b5858513a8108"), "item" : "canvas", "qty" : 100, "tags" : [ "cotton" ], "size" : { "h" : 28, "w" : 35.5, "uom" : "cm" } }
是不是跟上面你插入的数据不太一样?
没错,因为插入时我们没指定ID字段,所以MongolDB就会自动生成。
其他查询的语法也很强大,但限于篇幅所限,就不展开了。
总结
MongoDB比起redis来,更偏向是一个数据库了,当然不完全是数据库。
它虽然也可以存键值对,但是对于单纯的键值对存储来说,有点杀鸡焉用宰牛刀的意思。
所以市面上,用redis还是比较多
但是MongoDB还是有它的立足之地的。
它擅长存储文档,特别是json结构的文档,这使得它在前端的中间件可以发挥比较大的作用,比如将后端的整合数据先进行存储,要用的时候再拿出来,起一个缓存中间件的作用。
对于保存业务对象,也是很有帮助的,或者可以考虑把它作为文章的存储件,毕竟它的特点就是存储文档嘛
作为一个架构师,竟然不了解加密,那可就太辣鸡了。
所以这次,先学学AES加密。毕竟是美国联邦政府采用的一种区块加密标准,当今时代的加密标准
首先扫盲,何谓AES加密,其实是从它的英文单词的首字母组成了
即Advanced Encryption Standard (高级加密标准),他是一种对称加密,也就是说,加密用的密钥和解密的密钥用的是同一个。
注意:既然是加密标准了,那就代表它将会有很多实现,有时候,实现方式不同,即使是同样的密钥和明文,最后加密的密文也会不同,加密的双方要协调好加密细节哦
加密的细节是这样的
-
首先先把明文转成一个个16字节(128bit)的字节块
如果选择的密钥是16字节,那明文块每一个字节就是16.
如果选择的密钥是24字节,那明文块每一个字节就是24.
补0也是按照这个明文块的大小进行补0的,不一定是16字节
如果明文本身的长度不是16字节的整数倍,那就意味着需要补足空位。
补足空位也是有几种方式的
-
NoPadding
其实也是不补空位的意思,但是要求明文的长度必须是16字节的整数倍。
-
PKCS5Padding
如果明文块少于16个字节,则补足相应数量的字符,每个字符的值都是缺失的空位数
比如说
我们把明文处理成块了,但是发现其中一个块的数据是
1,2,3,4,5,a,b,c,d,e只有10个字节,少了6个字节,那么补足空位后,这个数据块就变成了{1,2,3,4,5,a,b,c,d,e,6,6,6,6,6,6}没错,缺少了6个字节,那我全都是补6 -
ISO10126Padding
和PKCS5Padding类似,也是用缺少的空位数补空位,不过补的是最后的空位,前面的空位用随机数搞定
不同的补空位的方式会导致加密块的不同,所以对接时,一定要告诉对方加密用的是什么方式补空格
-
-
到这一步,所有明文块都有了,接下来就是把每一个明文块和密钥送进加密算法,得到加密块
就加密算法的工作模式,也是有多种的
-
ECB模式(电码本模式 Electronic Codebook Book)
-
CBC模式 (密码分组链接模式 Cipher Block Chaining)
这个模式后面还有一个加盐的参数,这个参数影响到加密结果,所以嘛,你要告诉对方哦
-
CTR模式:(计算器模式 Counter)
-
CFB模式:(密码反馈模式 Cipher FeedBack)
-
OFB模式:(输出反馈模式 Output FeedBack)
加密模式影响的只是明文块的处理,但是加密算法的处理都是一样的
最后把加密块组合起来,形成加密数据。不同的加密模式,生成的密文也会不一样,所以对接时,要把加密模式告诉对方
-
-
得到的加密数据是一个字节数组,当然你可以直接传加密块给对方,不过一般的操作是,要把他变成字符串
不过,把字节变成字符串的操作,也有很多细节,比如说字符集等等。
当然这个细节也要跟解密方说
加密细节就是这样的了。
综上所述,针对加解密双方,要协调好以下几件事
-
加密算法,本文所述的,自然就是aes加密算法了
-
密钥,16位(AES128),24(AES192),32(AES256)字节的密钥任君选择,
-
补零方式,上面有写,例如
NoPadding,PKCS5PaddingISO10126Padding -
加密模式,上面有写,例如
ECBCBCCTR如果加密方式用的是CBC,要告诉对方加密的盐是什么
-
字节数组变成字符串的处理
以上,至于上面的加密核心算法就不学了,理解这一点,起码就可以借用sdk来封装自己的AES加密了
这个东西啊,讲的是字符数组如何转换成字符串的。
有人会说,用utff-8或者ascll码转啊,这不送分题吗?
如果要真这么想的话,这道题其实是送命题来着。
实际上,如果传输的本来就是字符信息,比如说,你传一个中文过去,那么编解码的方式确实可以用utf-8
但是如果你传的是二进制呢?那就不能用utf-8来编解码了,理由:
- 对于编码来说,utf-8要求的是几个字节组成一个字符,但是如果你的字节数不符合要求呢?或者你的字节数据在utf-8字符集找不到对应的字符呢?
那么utf-8就会找一些预制字符来填充。
- 对于解码来说,utf-8在解码会遇到一些预制字符,将这些预制字符转成的字节数组,可以肯定的是,和对方传的字节数组是不一样的
举个栗子,你要传的字节数组是
byte[]{-125,127,3,1};然后用UTF-8编码为����然后对方接受到这个
����字符串后,解码成字符数组,是[-17, -65, -67, 127, 3, 1]这样就丢失了字符数组的信息
utf-8编解码只是举例,其实用ascll进行编解码其实也是同样的结论
好吧,不能用内置的字符串编解码,那我直接传字节数组过去总可以吧?
没毛病,而且当然可以,但是,这不在我们的讨论范围内,而且有些网络协议是不能直接传字节数组的。
比如说http协议,这货是文本协议,也就是说你只能传文本。
那么接下来就只能请出今天的主角了,Base64
这货可以把字节数组转成字符串,再把字符串转成字节数组,这中间不会有消息的丢失。
怎么做到的?
-
对于编码
把字节数组每6位字节分成一组,每一组可以表示64个字符,这样把每一组的字符拼起来,就得到一个字符串
一般来说,分成的字节组要尽可能是4的倍数,这样就可以用4个Base64字符来表示3个传统的8bit字符
边界条件:如果字节数组不是6的倍数,则后面要补0,使字节数组的长度达到6的倍数
边界条件:如果分成的字节数组不足3,则以0补全四个字节数组,这样可能会出现全是0的字节数组,它们转变成base64的字符是
=
-
对于解码:其实就是编码的逆操作
没了
后续:
只是单纯的Base64编解码到这里确实就可以结束了,但是Base64编码后,谁也不能保证出来的字符串漂漂亮亮的,它可能含有某些特殊字符,而那些特殊字符在某种运输方式下,会被转义(万恶的http转义)
你那转义后的字符串去解码得到的字节数组,肯定也不是原来的那个了。
这个时候,我们其实还要对Base64解码做一些改进,以便适用某些特殊情况。
所以你现在看到Base64的编解码工具,一般还会让你选择用哪种模式,是URL编解码安全的,还是普通的编解码。
编码和解码都要用统一的模式,才可以解出正确的字节数组。
另外一提,URL编码得到的字符串,可以直接带到URL作为参数传递。
-
缓存击穿:某一条数据的缓存失效,而同时又有很多并发请求,来请求这条失效数据,导致数据库并发请求太多,从而奔溃。
解决办法:
-
针对这个经常有并发请求的缓存做预先缓存处理,假如说这条缓存数据2小时后失效,那么在两小时前的15分钟,就去获取这个新的缓存数据,然后替换掉
-
设置缓存永不过期(糟糕的解决方案)
-
针对缓存的获取代码,加并发锁,即使这条缓存失效了,并且有n多并发请求要来获取缓存。
但同一时间,只能有一条线程在请求数据库,获取设置新缓存。
获取缓存的代码可以参考单例设计模式的懒汉模式
并发锁可以参考redis的并发锁
-
-
缓存雪崩:这是缓存击穿的升级版本,也就是,同时有很多的缓存数据一起失效,又同时有很多的并发请求来请求缓存数据。数据库同时接受到超级多的并发请求,很容易就gg了
解决办法:
-
把多条缓存数据的过期时间设置为各不相同,且保持均匀分布。
-
将多条缓存数据的数据来源,也就是数据库,改为各不相同,也就是从不同的数据库读取缓存数据。不要只在一个数据库上吊死。
。。。。前提是你的数据库是分布式部署。
-
设置缓存永不过期(糟糕的解决方案)
-
-
缓存穿透:大量的请求缓存中不存在,且数据库也不存在的数据,这通常是一种恶意的攻击手段。
由于缓存中不存在,那下一步肯定就去数据库查了,同时又有大量请求,这导致数据库并发量巨大,从而gg。
解决办法:
-
比较高端,提供一个永久缓存,保存数据库全部数据的某个关键部分,如果请求的数据在永久缓存层查不到,就意味着数据库也没有,不用去找数据库的麻烦了。
不过,怎么快速的从永久缓存层确定数据的有无,就比较高端。
可以通过布隆过滤器来实现,虽然这个算法有一个缺点,有可能在永久缓存区没有这个数据,但是由于哈希碰撞,这个算法会返回
有这个结果。但总的来说,哈希碰撞的可能性比较小,这个算法还是可用的
-
针对可能出现攻击请求参数作处理。
比如说,攻击方比较喜欢用id<0的数据做请求参数,让缓存雪崩。
那么可以在业务处理层前加拦截,拦截那些非法的请求参数
又或者说,把数据库没有的数据也做一层缓存,缓存值置空,缓存时间小点。
-
限流,并发请求不是很多吗?那就在路由上面对请求数进行限流。技术难点也不是很高。
不过可能会错杀就是了。
这应该是大多数互联网应用的解决方式了
-
其实以上的问题都有一个终极解决方法,同时也是最糟糕的解决方案。。。把数据库的并发请求数设置大点。。(逃。。。
其实通俗讲,就是将内网的机器映射到外网,使不在同一局域网的另一台机子,能访问那个内网机子。
目前已有成熟的技术实现了,这里介绍一种,natapp
-
下载natapp客户端
-
注册账号
-
实名认证
-
购买免费隧道
-
利用免费隧道的token配置客户端
-
开启客户端
-
根据你预先配置的开放端口,会给一个公网的地址。
访问这个公网地址,就可以访问到你主机的这个端口。
以上
这个东西叫做跨站伪造请求攻击。其实听名字就大致能理解是干什么的
设想一种场景:
- 你登录了xx银行
- 忘了退出登录,然后又进入了澳门在线xxxx网站
- 攻击完成了
当进入澳门在线xxxx网站后,这个网站会隐式的执行一个ajax请求,请求xx银行的转账,由于你的登录信息还没过期,所以请求过去之后银行的服务器会认为你还在操作,于是就转账成功了。
不过可别以为浏览器的跨域限制能够帮你解决这个攻击,浏览器的跨域限制只是不能显示服务器的响应罢了,但是请求是可以执行成功的。
解决办法:
-
银行转账的页面默认带出一个token,这个token保存在服务器中,点击转账时,请求会携带token去服务器。
服务器则会验证token是否有效。
保证转账的发起,一定是从转账页面发起的。