Home
UpSet is a visualization technique for set-based data. On this page you can find the documentation of UpSet for users. Currently this covers only the custom data import, but more will follow in the future.
Please go to the about page for general information and look at the live version of the visualization technique itself.
In addition to using UpSet with the demo datasets, you can also provide your own data files. Currently, you can provide data for our public UpSet instance by hosting a dataset and a data description file on a publicly accessible web server or in your Public Dropbox folder. If you cannot share your data publicly, you can also deploy UpSet locally.
UpSet uses a binary encoding for sets. Here is a simple example, with sets A, B and C, and three elements, represented in the rows (R1, R2, R3):
Row;A;B;C
R1;1;0;0
R2;0;1;0
R3;0;0;1
To make UpSet understand this data format, you have to provide a simple JSON data description file. The data description file for the above dataset looks like this:
{
"file": "http://vcg.github.io/upset/data/test/test.csv",
"name": "Test",
"header": 0,
"separator": ";",
"skip": 0,
"meta": [
{ "type": "id", "index": 0, "name": "Name" }
],
"sets": [
{ "format": "binary", "start": 1, "end": 3 }
]
}
You can also look at this configuration/dataset combination in UpSet.
The meaning of the attributes in this JSON file is as follows:
-
filedescribes the path to the data file. This path typically should be a globally accessible URL, unless you run UpSet locally, in which case you can use relative paths. -
nameis a custom name that you can give to your dataset. The name will then be shown in UpSet. -
headerdefines the row in the dataset where your column IDs are stored (the sets and the attributes). Notice that both columns and rows are addressed using indices starting at 0! -
separatordefines which symbols are used to separate the cells in the matrix. Common symbols used are semicolon;, colon,, and tab\t. Here we use;. -
skipis currently not in use but will provide the ability to skip rows at the beginning of the file, to exclude, for example, comments. -
metais an array of metadata that specifies the id column and attribute columns. The above example defines the first column in the file (the column with index 0) to contain the identifiers for the elements. The name of the identifiers is "Name".metais also used for attributes, which we will discussed later. Notice that identifiers have to be unique. -
setsdefines the sets in the dataset. They are specified in an array to allow multiple ranges of sets within a file. Here only one range of sets is defined, from thestartindex 1 (the second column) to theendindex 3 (the fourth column). UpSet currently only supportsbinaryformat, other formats will be added in the future.
A key feature of UpSet is the visualization of attributes associated with elements contained in sets and their intersections. Here is the movie dataset that we use to demonstrate the visualization of attributes:
Name;ReleaseDate;Action;Adventure;Children;Comedy;Crime;Documentary;Drama;Fantasy;Noir;Horror;Musical;Mystery;Romance;SciFi;Thriller;War;Western;AvgRating;Watches
Toy Story (1995);1995;0;0;1;1;0;0;0;0;0;0;0;0;0;0;0;0;0;4.15;2077
Jumanji (1995);1995;0;1;1;0;0;0;0;1;0;0;0;0;0;0;0;0;0;3.2;701
Grumpier Old Men (1995);1995;0;0;0;1;0;0;0;0;0;0;0;0;1;0;0;0;0;3.02;478
Waiting to Exhale (1995);1995;0;0;0;1;0;0;1;0;0;0;0;0;0;0;0;0;0;2.73;170
Father of the Bride Part II (1995);1995;0;0;0;1;0;0;0;0;0;0;0;0;0;0;0;0;0;3.01;296
As you can see, the first column (index 0) contains the name of the movie (the element ID), the second column (index 1) the release year, which is an attribute, columns of index 2-18 contain the sets, i.e., the movie genres, while the last two columns contain additional attributes.
Here is the data description file for this data set:
{
"file": "https://dl.dropboxusercontent.com/u/36962787/UpSet/movies.csv",
"name": "Online Movies Genres ",
"header": 0,
"separator": ";",
"skip": 0,
"meta": [
{ "type": "id", "index": 0, "name": "Name" },
{ "type": "integer", "index": 1, "name": "Release Date" },
{ "type": "float", "index": 19, "name": "Average Rating", "min": 1, "max": 5 },
{ "type": "integer", "index": 20, "name": "Times Watched" }
],
"sets": [
{ "format": "binary", "start": 2, "end": 18 }
]
}
It is very similar to the definition we used before, with the exception of additional attributes in the meta tag. Here we see three attribute definitions; Release Date as an integer attribute, Average Rating as a float (a real number) attribute, and Times Watched, also as an integer attribute. In addition, UpSet can handle text, defined as string type.
You can also add meta information to your dataset that is then displayed in UpSet. Here is an example of how the previous dataset is extended with some meta information:
{
"file": "data/movies/movies.csv",
"name": "Movies Genres",
"header": 0,
"separator": ";",
"skip": 0,
"meta": [
{ "type": "id", "index": 0, "name": "Name" },
{ "type": "integer", "index": 1, "name": "Release Date" },
{ "type": "float", "index": 19, "name": "Average Rating", "min": 1, "max": 5 },
{ "type": "integer", "index": 20, "name": "Times Watched" }
],
"sets": [
{ "format": "binary", "start": 2, "end": 18 }
],
"author": "grouplens",
"description": "MovieLens ratings dataset, curated and filtered by Alsallakh.",
"source": "http://grouplens.org/datasets/movielens/"
}
Notice the last three lines that provide information about the author of the dataset, a brief description and a source, which can be a link or a reference, etc.
Once you've wrangled your data into the right format and have written the data description file, you must put it on a publicly accessible web server. Unfortunately, not every web server will work due to security and configuration reasons. There are two options that work reliably, one using Dropbox public folders, the other using Google Drive.
You can host your files through Github.
- Put the JSON file and the data file in a public github repository, and use the "raw" links, that you can reveal by clicking this button:
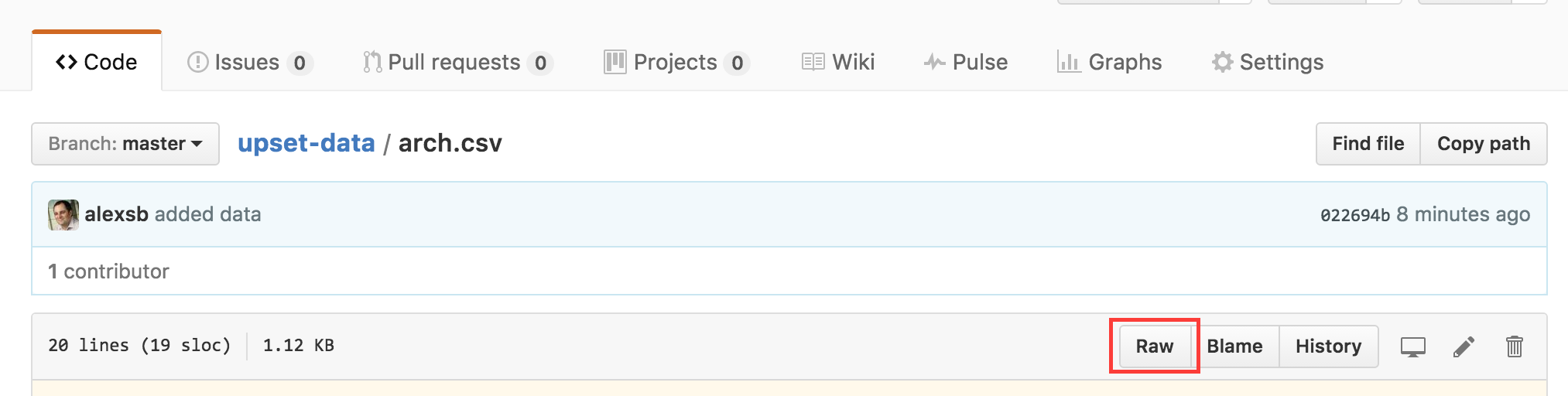
- Find the proper URL for your data file and put it in the "file" field in the JSON. A raw data link will look like this:
https://raw.githubusercontent.com/alexsb/upset-data/master/movies.csv
The corresponding JSON content must also be accessible via a raw link:
https://raw.githubusercontent.com/alexsb/upset-data/master/movies.json
- You can then copy the link to the JSON file from your browser into the UpSet data loading field.
You can go ahead and try this with this JSON file: https://raw.githubusercontent.com/alexsb/upset-data/master/movies.json
You can host your data through the Public folder in your Dropbox. Note that public links out of other Dropbox folders do not work and that Dropbox accounts created after 2012 do not have a public folder unless you have a pro or business account, in which case you can turn it on by clicking here.
To make this work, move both your JSON data description file and your CSV dataset file to your Public Dropbox folder. Now, put the public link to your CSV file into your JSON file. You can obtain the public link by right-clicking on the file in your Public Dropbox folder and choosing Get public link in the Dropbox web interface or in your local dropbox client.
Once you have a public link to your data, open UpSet and click on Load Data in the upper right corner. You will see a text field where you can paste the link to your JSON data description file. The field is already pre-filled with the movie example from above so you can test it.
Once you hit submit you will see your dataset appear in UpSet! Congratulations!