Home
微服务时代的日志系统,彻底解决日志七零八落看不清楚的问题。
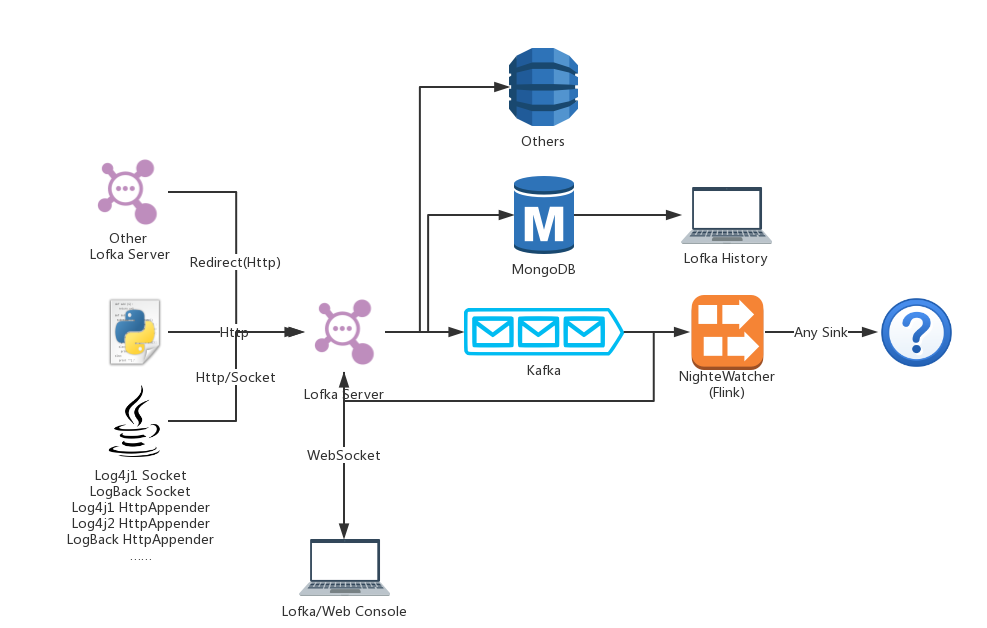
Lofka = Logger + Kafka
其架构设计,日志数据规范和参见Wiki
开源出于如下的考虑:
- 希望能帮助广大开发者方便的看日志
- 目前没有一个好的Web页面(或者做成Electron App也可以)能直接看日志,看日志仍然需要安装复杂的Python环境,在下区区一只机器学习工程师,写前端实在有点费力。
- 目前只支持Java/Python的日志收集,至于其他语言的(.Net(C#/VB/F#/...),Go语言,Ruby,C++等等目前并不支持,希望汇聚开源的力量完善这个项目)
- 目前只支持持久化到MongoDB,甚至持久化到ElasticSearch都没有支持,大家在内部都有自己的数据架构,希望能有多种持久化架构
- 大家多多Star/Fork我啊哈哈哈
并不是所有的组件都开源了,例如心跳包,日志流处理工具,一些统计脚本都没有开源,主要出于2个方面的考虑
- 涉及公司内部业务,开源了也没什么用
- 涉及公司内部业务,不便开源
- 环境依赖比较复杂,全写出来好累
还有就是删除了一些内网使用的地址,更改了包的名称(没办法,我在Sonatype上只能以com.github.tsingjyujing的身份上传Maven库)
这个项目使用了 Apache License v2.0,应该是相当宽松了,使用的时候请注意License。
随着系统庞大,参与的人数增加,就容易产生严重的碎片化(碎片化也算是一种艺术,碎片化的极致就是微服务(大误))。
有的时候一次调用可能涉及到多个串联的系统,其中一个系统出问题就容易产生Fail,这个时候需要针对每个系统去查询日志文件或者tail -f以后再来一次。 显得很不方便。 使用统一的日志收集管理系统就可以收集和管理来自于所有平台的日志。 这个时候可以在同一个控制台中看到指定的某些系统输出的日志,快速定位问题。
日志文件很庞大,更重要的是,99%的日志其实是“没有用”的——在详细调试的时候我们希望看到DEBUG甚至TRACE层级的信息,但是在正常运行的时候也按照这个等级输出,日志文件大小很快会教做人。
更重要的是,及时有限制大小,并且滚动删除的机制——删除的越多、保留的越少,很多重要日志都没有了,输出的时候分等级输出不同文件也是一个办法,但是日志JOIN起来看又是一个很头疼的问题。
本日志系统有TTL的功能,会针对不同的日志等级保留不同的时间,一些低级的信息可能几分钟就消失了,一些WARN到FATAL级别的信息可能会保留数月到数年。
同时还具有自动识别测试平台的功能——测试平台可能产生大量的ERROR日志,这些日志其实并不需要像生产环境保留一样久,本程序具有智能设定保留时间的功能。
日志想要实时监控,一般都是tail -f,可是这样并不能控制日志等级(如果用grep可以稍微控制一下),如果入库,再想实时输出只能轮询,对数据库造成很大的压力。
这里采用了Kafka作为消息队列,可以将实时的数据快速输出,而且不会占用大量计算资源。
不同等级的日志保留的时间是不一样的,防止Trace或者Debug日志占用过多的磁盘资源。
Java写的部分:
- lofka-server 日志服务器前端,现在支持HTTP以及Log4J 1.x/Logback的SocketAppender
- lofka-utils 日志服务器使用的类库,主要针对Java,包装了一些常用的类和方法。
Python写的部分:
- lofka-console-py 一个Python语言开发的、输出优美的日志控制台
- lofka-mongo-writer 日志服务器持久化工具,将队列中的数据持久化到MongoDB
- lofka-python-utils Python的日志Handler,将Python的日志统一收集到Lofka
其设计思路最早来源于RobertStewart/log4mongo-java。
后来本人在其基础上做了一版ShinonomeLaboratory/log4mongo-java。
最早做这个的动机是希望使用MongoDB存储非结构化文档和TTL(过期删除)的特性做日志持久化。
目前只支持Java和Python,其中:
- Java支持:Log4j(1.x/2.x) Logback
- Python支持:原生日志系统
但是这个收集器存在:
- 不能开放处理流数据的接口;
- 对代码的侵入较深;
- 需要开放数据库,不是很安全。
等问题,最后考虑使用Http/Socket(当然最后发现Socket很坑爹)接收日志,统一存放到Kafka(或者其他消息队列)中,再从Kafka中消费数据持久化到任意数据库(只实现了MongoDB)。
后来的设计越改越骚,加入了批量接口,随后又给批量和单个日志的接口加了Gzip压缩功能,lofka-utils加入了心跳包,同步日志发送器改为异步发送器,加入了转发服务器这种东西。
在lofka-console里面,也加入了由命令行参数生成mongodb aggregate pipeline和JavaScript Function,还给服务端加上了JS引擎用来做服务端过滤。