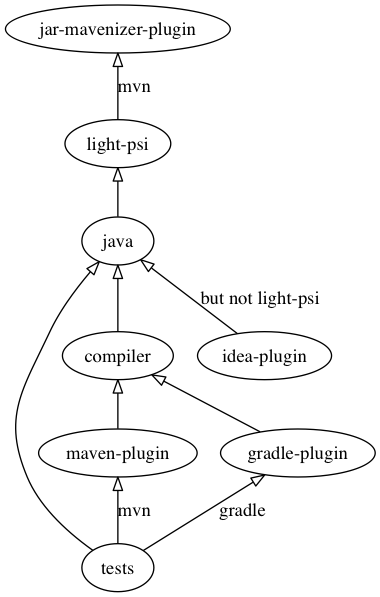
project structure
Epigraph project consists of the following groups:
-
jar-mavenizer-plugin. Maven plugin for installing pre-built artifacts. Required forlight-psiinstallation -
light-psi. PSI classes from IntelliJ required to run GrammarKit-generated parsers in stand-alone mode- Depends on
jar-mavenizer-plugin(for Maven builds)
- Depends on
-
java. Java implementation of Epigraph data structures, clients and servers.- Some modules depend on
light-psifor schema parsing
- Some modules depend on
-
scala. (incomplete) Scala implementation of Epigraph data structures, clients and servers. -
compiler. Epigraph schema compiler, builds in-memory representation of schema files and validates them.- Depends on a number of
javamodules for data structures and schema parsers
- Depends on a number of
-
maven-plugin. Maven plugin for compiling schema files- Depends on
compiler
- Depends on
-
gradle-plugin. Gradle plugin for compiling schema files- Depends on
compiler
- Depends on
-
tests. Test schemas and services.- Depends on
javaandmaven-pluginorgradle-plugin
- Depends on
-
idea-plugin.- Depends on
javafor data structures and parsers, but must not depend onlight-psi, see below for details.
- Depends on
Java implementation of Epigraph uses GrammarKit to generate schema and request URL parsers.
Parsers translate text into PSI
structures and are also used by IDEA plugin. Naturally, generated code
depends on PSI classes which come bundled with IntelliJ. Stand-alone parsers
use light-psi instead, which contains PSI plus a minimal subset of IntelliJ
platform required by them.
light-psi jar comes pre-assembled and is checked in into Epigraph git repo.
Gradle build contains a task for re-creating it from IntelliJ and GrammarKit
installations (see comments in the build file). Unfortunately this jar is not
available from any Maven repository yet.
Generated parsers can't be simply shared between IDEA plugin and standalone code for two reasons. First, PSI distributions are different. Second, generated code depends on some manually written parts that are also different between the two.
In order to solve this problem generated code was moved into it's own folder,
java/schema-parser-common. IDEA plugin includes it at the source level and
uses PSI classes bundled with IntelliJ platform. Standalone java/schema-parser
includes it at the source level too and depends on light-psi.
psi-parsers are responsible for processing PSI trees built by parsers and
producing Epigraph in-memory representations such as projections or resource
declarations. These data structures are then used both by services and servers
at service run-time and by compiler at schema compile-time. psi-parsers are used
by the compiler and also by some java module unit tests to construct
projection or service declaration instances. This creates a problem since
psi-parser unit tests use schema and generated classes from tests, which uses
compiler (at build time), which again depends on psi-parsers.
One solution here would be to replicate all necessary data structures and
psi-parsers for compiler (in Scala). psi-parsers for schema should not be needed
at run-time anymore and may be removed, remaining unit tests should be
refactored to use generated classes.
Current solution is for compiler to simply include all required psi-parsers at
the source level, omitting unit tests. This was simple enough to do, eliminates
code duplication and breaks circular dependency at the expense of build
complication.