{kind=link}
{kind=link}
This is a module for face detection with convolutional neural networks (CNNs). It uses a small CNN as a binary classifier to distinguish between faces and non-faces. A simple sliding window (with multiple windows of varying size) is used to locaize the faces in the image.
Requirements
1. TensorFlow
2. OpenCV for Python
Network topology
The network consists of 3 convolution layers
Input: 32x32 black and white image
1. Layer 1: 5x5 convolutions
4 feature maps
2. Layer 2: 3x3 convolutions
16 feature maps
3. Layer 3: 3x3 feature maps
32 feature maps
Layer 3 outputs 32 4x4 feature maps
4. Layer 4: Fully connected layer
600 units
5. Layer 5: Softmax layer
2 units
Training parameters
The network was trained with TensorFlow's AdamOptimzer
lrate: 1e-4
epsilon: 1e-16
mini-batch size: 100
number of epochs: 8
The validation accuracy was 98.762% and the final accuracy on the test set was 98.554%.
Dataset
Positive samples (images of faces) for the classification were taken from 2 sources:
1. Cropped labelled faces in the wild (http://conradsanderson.id.au/lfwcrop/)
2. MIT CBCL face recognition database (http://cbcl.mit.edu/software-datasets/heisele/facerecognition-database.html)
The horizontal mirror images of these images were included in the dataset.
Negative samples (non-faces) were taken from 4 sources:
1. Fifteen scene categories (http://www-cvr.ai.uiuc.edu/ponce_grp/data/)
2. Texture database (http://www-cvr.ai.uiuc.edu/ponce_grp/data/)
3. Caltech cars (Rear) background dataset (http://www.robots.ox.ac.uk/~vgg/data3.html)
4. Caltech houses dataset (http://www.robots.ox.ac.uk/~vgg/data3.html)
Random snapshots from these images were generated by taking sub-images of a random lengths at random positions in the images. These snapshots were mixed in the dataset along with the complete images.
The final dataset consists of the 32,000 images from each class (positive and negative). Training, validation and test sets were generated from this with a 0.6 split for training, 0.2 for validation and 0.2 for test. Each of these sets have 50% positive and 50% negative samples.
Localization
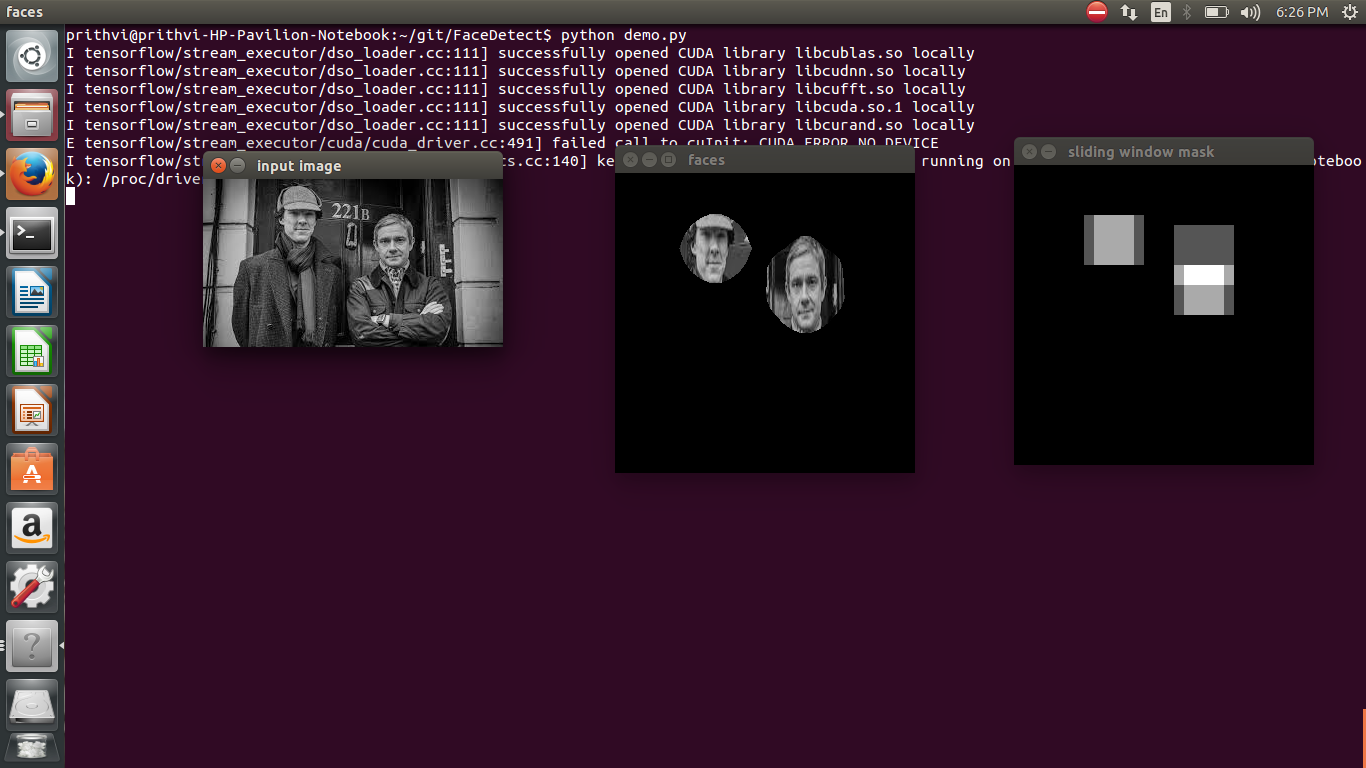
The module uses a simple sliding window localizer. The input image is reshaped to (300,300). Square windows of side lengths 40,50... 100 are slid along the image. Each sub image seen through the window is reshaped to (32,32) and fed to the network. If the sub image is a face with a minimum confidence of 0.99, the window is marked in the mask. After running all different sized windows on the image, the final mask is blurred with a 50x50 Gaussian filter and binarized. This final binarized mask is used to extract only the faces from the image. The localizer returns two images: an image with only the faces and the raw mask (before blurring and binarization).
Demo
The repo includes a pre-trained model: face_model. This can directly be used for localization. Sample usage of this model with FaceDetect.py can be seen in demo.py. Running the demo should display the result of running the localizer on demo.jpg. Demos with other images can be seen here: https://youtu.be/N4GIGVnyNBo
Output of demo.py: