Pika搭配Codis的使用模式选择与集群搭建
Pika的配置文件中的instance-mode配置项有classic和sharding两个选项可以选择,这两个选项代表的意思是不一样的。
- classic代表Pika的运行模式是经典的多DB版本(DB的概念类似于Redis的DB),可以通过select命令选择所使用的DB,在所选择的DB上执行命令。DB默认从0开始,Pika的配置项databases可以设置最大DB数量。DB在Pika上的物理存在形式是一个文件目录。比如有2个DB,那么在配置项db-path所在的目录下就会有2个子文件目录,名称分别为db0/,db1/,这两个DB的数据就会分别存储在这两个子目录中,Pika只有DB0的话就只有db0/这一个文件子目录了。
- sharding代表Pika的运行模式是多分片版本。分片存储的意思是把DB中存储的数据进行切分,每一个分片(shard/partition)存储的是一部分数据。对于某一个KEY的数据存储在哪个分片中是由算法决定(目前和Redis分片算法一致crc32(key)%slot数量)。分片数目由配置文件中的default-slot-num这个配置项决定。分片在Pika上的物理存在形式也是文件目录。比如DB0有10个分片分别为0,1,2,...,9,那么在目录db0下就会有10个文件子目录分别是:0/,1/,...,9/。
在Pika Cluster问世之前,为解决海量KV存储问题,把Codis和Pika进行配合使用是很多用户的临时选择。 目前我们推荐 Codis+Pika(sharding模式)。
这种选择的优点是:扩容和缩容比较容易,并且由于Pika是用独立的rocksdb实例来实现slot的,相对于以key为单位的迁移,这种以slot为单位的迁移会使得扩容速度大大加快。缺点也是有的:由于目前Pika版本还没有实现不同slot的文件目录可配置成不同地址(目前都在dp-path文件目录下),也就没办法让不同slot使用不同的磁盘,这样,如果同一个Pika实例下slots数量多的话,实际上会对磁盘进行了随机写,写入速度也会大大下降,目录过多也受文件系统的约束。初始化搭建主要过程:
- 搭建好Codis环境(codis-dashboard, codis-proxy, codis-fe)和确认slots数目(Codis官方版本默认1024).
- 启动Pika masters多个实例(sharding模式),一般default-slot-num会跟Codis默认slots数目相同。
- Codis中增加Group(数量),并把Pika masters多个实例增加到Codis对应的Group中
- Codis中初始化slots,一般会用rebalance all slots操作
- 按照Codis中初始化后的slots信息,在对应Pika master实例中执行
pkcluster addslots $slots命令,比如:pkcluster addslots 0-100,添加slot操作失误可通过pkcluster delslots $slot命令进行删除.相关命令:相关命令 - 测试只添加了Pika masters时的可用性(Codis中slots的分布和pika sharding分布是否一致,不一致会返回错误)
- 启动Pika slaves多个实例(sharding模式),一般default-slot-num会跟Codis默认slots数目相同。
- Pika slave和对应的master一样执行
pkcluster addslots $slot命令和pkcluster slotsslaveof $masterIp $masterPort $slot命令($slot应于master实例上存在的slots相对应)。添加slot操作失误可通过pkcluster delslots $slot命令进行删除。相关命令 - 测试加入Pika slave后数据的同步情况(可在master上通过
pkcluster info slot $slot查看某个slot的同步情况)
此时,初始化完成。由于Codis默认最大slots分片数量是1024,如果slots在节点较少的Pika实例中进行分布的话,每个Pika实例分得的slots数量会比较多。对于文件系统来说在一个文件目录中创建大量的子目录进行读写响应延迟会大大增加。因此不推荐使用较少数量的Pika实例。另外一个办法就是(自己动手)修改一下Codis,改成可配置的最大slots分片数量。但是slots数量过少可能会存在key在Pika实例之间的分布不均匀的情况。
由于Pika的slot在物理上以文件目录的形式存在(类似一个rocksdb实例存储),相对于Codis-Redis扩容使用以key为单位做迁移来说要快的多。迁移一个slot相当于移动一个文件目录。解决了在数据量巨大时扩容、迁移时间过长的问题。
- 现有pika实例:pika1,pika2,pika3,pika4
- pika1和pika2属于group1(pika2 是pika1 的全量备份,也就是pika2上面的slots全是pika1的slave, pika1异常时可以让pika2执行 pkcluster slotsslaveof no one all,然后切到pika2上)
- pika3和pika4属于group2
- group1上的slots有:0-511
- group2上的slots有:512-1023
- 新建group3
- 新建Pika实例:pika5,pika6,加入group3, 计划pika5做master, pika6做slave。
原始拓扑 如下图
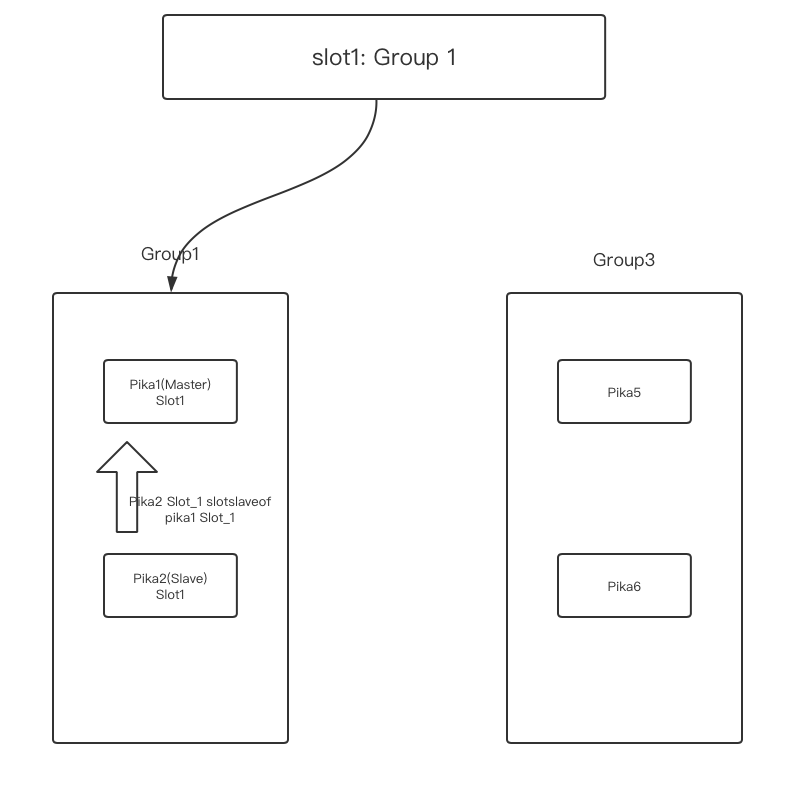
-
pika5中执行命令
pkcluster addslots 1创建slot 1。 -
在pika5中执行命令
pkcluster slotsslaveof pika1_ip pika1_port 1把slot1 的数据同步到pika5上。 -
确认pika5中slot1中的数据全同步完成后,在pika6中执行命令
pkcluster slotsslaveof pika5_ip pika5_port 1把slot1 同步到pika6上 保证顺序,先建立pika5 和pika1 的同步关系,再建立pika6 和pika5的同步关系。
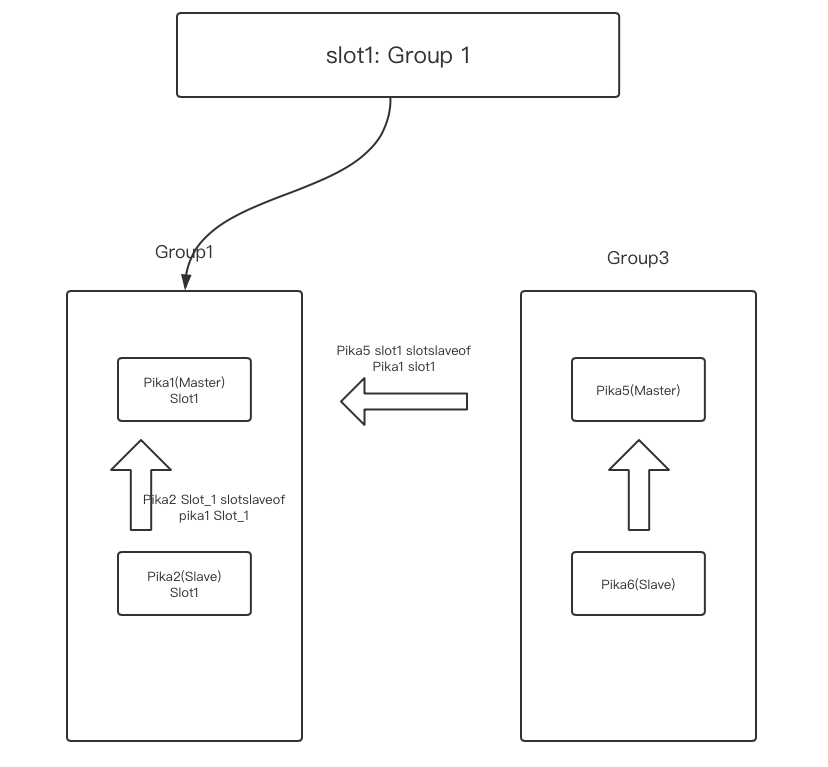
- 在pika1上用
pkcluster info slot 1观察pika5的lag很小的时候,通过Codis slots migrate,将slot1指向 group3(pika5)。
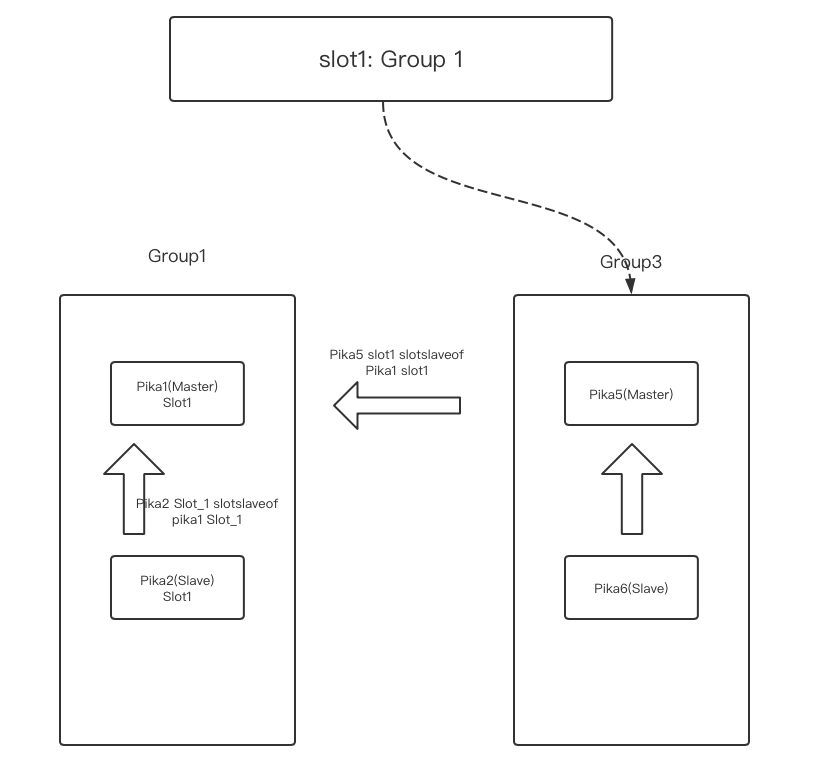
- 观察pika1上lag为0,pika5 做
pkcluster slotsslaveof no one 1
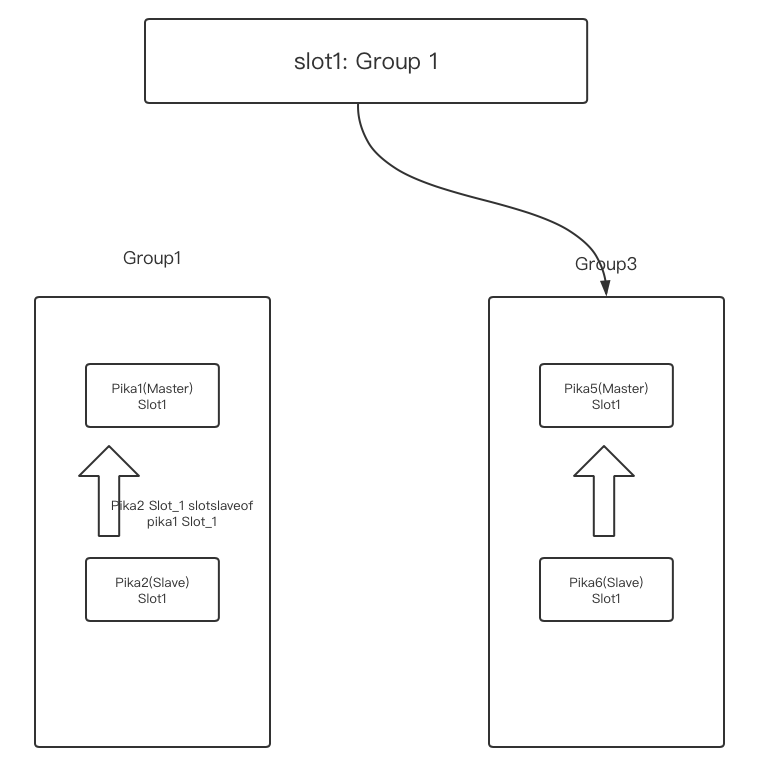
- pika2执行命令:
pkcluster slotsslaveof no one 1,pkcluster delslots 1清理slot1 数据 - pika1执行命令
pkcluster delslots 1清理slot1 数据
整个过程可以参考:扩容 缩容与扩容相似