Document classification is one of the important classification problem that we deal nowadays, and is slightly different from text classification. Documents are available in many different formats and in huge numbers in enterprises and need to be classified for different purposes and end goals.
This code helps to build different classification model to classify documents to different classes. In this case into five different categories:
TAX, AGGREMENTS, VALUATION, HUMAN RESOURCES, DEEDS. This code can be modified for your purpose
-
The raw data folder contains different file formats in different folders. Textual data needs to be extracted from them. Here doc files have been converted to PDF format first before extraction. I had issues while installing textract library which extracts test from the doc files directly, so I converted them to PDF and used pdfminer to extract texts. Texts are extracted on folder basis because the extracted texts need to be labeled.
-
Each data point of the extracted text belongs to one page of the document. One data point doesn't correspond to one whole document. The reason for this approach was because every document size is different, some 3 pages while some 40 pages and this doesn't create a normalized dataset to deal with.
-
Another approach would be to convert the PDFs to HTML form and then extract the data from the tags. The PDFs when converted to HTML give the data inside tags, however when I converted them the data was all embedded in the 'div' tags with no access to the unique heading tags or other data. So ended up extracting from PDFs.
-
The next step involves pre-processing the texts. Approaches taken include lowercasing, removing special characters, removing number between words and digits itself, removing stop words and converting words to their dictionary form through lemmatization.

- Here I counted the top 5 occuring words in the extracted texts from each classification folder. This proves to be one of the useful feature which can be included while building the dataframe for the model building.

- This process is done for each classification folder and then merged together for final data frame which can be used for further processing.
- This step involves analyzing the text data and deciding what to do with it. On analysis, we can see that there are lot data points for one particular class and it drastically reduces for other classes.

-
This is an example of imbalanced dataset and needs to be taken care of before building model. The two options are oversampling or undersmapling the data. Undersampling is not a option due to small dataset and model would not be able to predict the classification, so I went with oversampling.
-
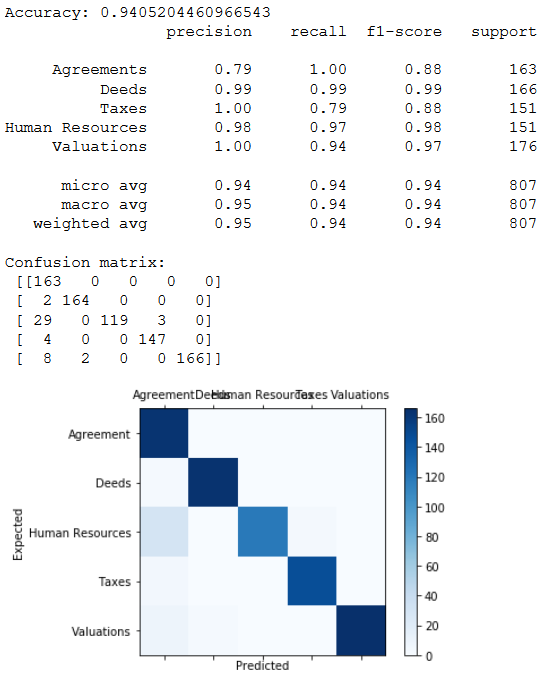
After oversampling each class gets 807 data points to work with.
- Built 5 different models (Naive Bayes, Random Forest, XGBoost, Word2Vec, Doc2Vec for this classification problem and compared them how they performed with prediction of classes. You can see the deatils and its performance in the jupyter notebook.
- For the Word2Vec model, I used a pre-trained google news vector model to predict the vectors for the words in my dataset. Built a logistic regression model to the classifcation process. The Doc2Vec is similar but without the pretrained vectors.
- After tuning the models, the next step was to test it on a random file.


As you can see that the model predicted the class of the document accurately as Human Resources.
The saved model has correctly predicted the class of the input file. The saved model had predicting accuracy of around 94% with a good precision for all classes above 90%. Different classification models can be trained for this task and compared for their perfomances.