![]()

This is the fifth homework of the course "Python in the Enterprise", as requested has been analyze Credit Approval Data Set. The dataset analysed in this report is the Credit Approval dataset taken from the archives of the machine learning repository of University of California, Irvine (UCI). It contains data from credit card applications. In its initial, unaltered form, the datasetmade available by UCI contains 690 cases, representing 690 individuals, and 16 variables named A1 – A16. The first 15 variables represent various attributes of the individuals submitting the application and the 16 th variable contains the outcome of the application, either positive (represented by “+”) meaning granted or negative (represented by "-") meaning rejected.
From the source of the dataset, it was observed that the names and values of the attributes have been changed to some generic and meaningless symbols to ensure the confidentiality and privacy of the applicants. So as to avoid confusion and for simplicity, the labels of some variables in our analysis have been assumed to be some working names according to the values in the attributes like:
- A1 changed to Sex
- A2 changed to Age
- A8 changed to Years of work
- A15 changed to Income
- A16 changed to Approved
This assumption is common to find in any credit approval dataset and somewhat fit our data.
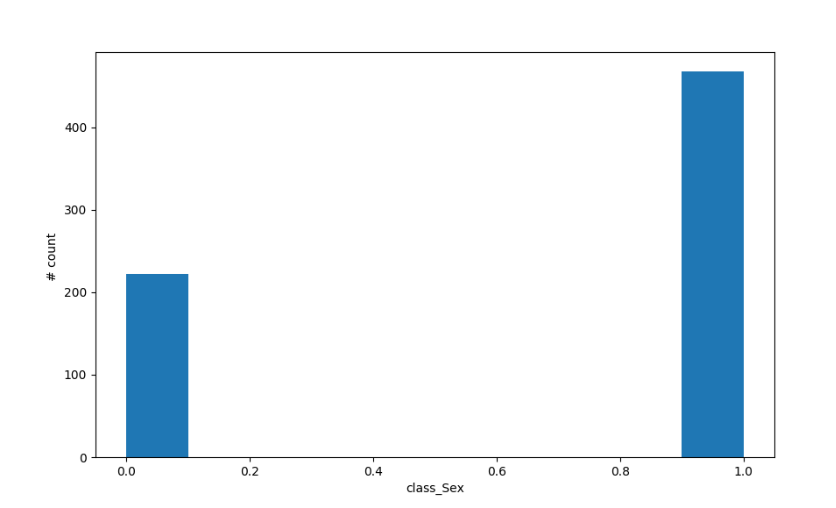
As mentioned, the data in this analysis contains categorical values that are transformed to binary values or factors 1s and 0s. Approved variable have values '+' and '-' in original dataset and with our assumption '+' means granted changed to 1 and '-' changed to 0. Similarly, with attributes Sex having values 'a' changed to 0 representing male and 'b' changed to 1.
On investigating the dataset, the missing values are labelled as '?'; so in case that we consider attribute with continous values, we replace this label with the mean of all values of the attribute, in case that we consider binary attribute we replace tha label of missing values with a random choice between 0 and 1.
Prerequisites
-
In order to run this project is important to use python version 3 or upper.
Install it with:$ sudo apt-get install python3
now check your version:
$ python --version
-
In order to run this project is also important use numpy, pandas and matplotlib. Install it with:
$ pip install --user numpy $ pip install --user pandas $ pip install --user matplotlib
In order to make our analysis, we have been concentrating this whole time on the main attributes that are common in any credit approval dataset, like Age, Years of york, Sex or Income of the applicant. We choose to study first of all this attributes individually and afther we've been trying to figure out the correlation that each of these have with the positive or negative approval.
Differnt type of Attributes
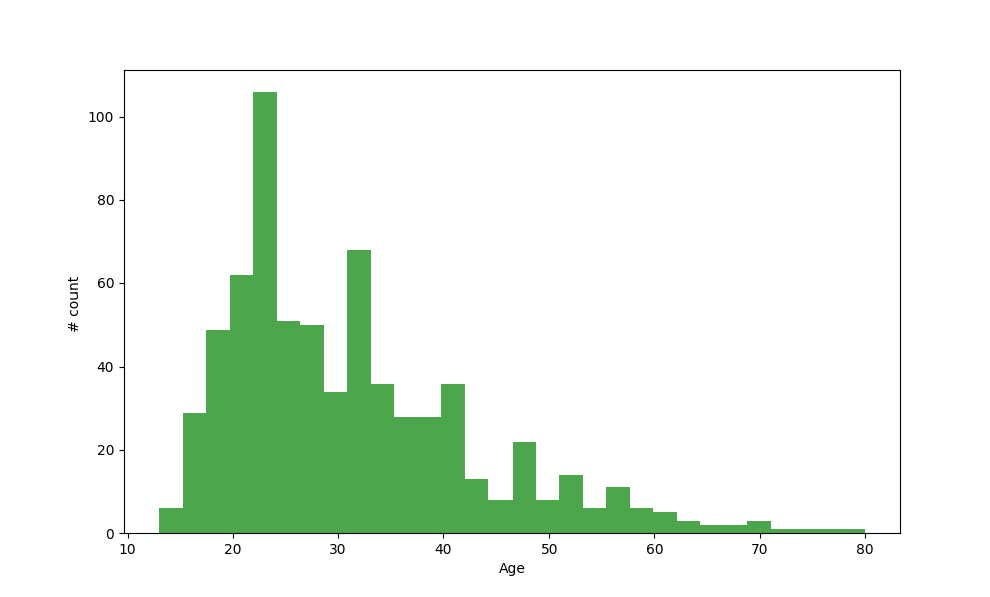
- Distribution of Attribute Age
- Label attribute Sex
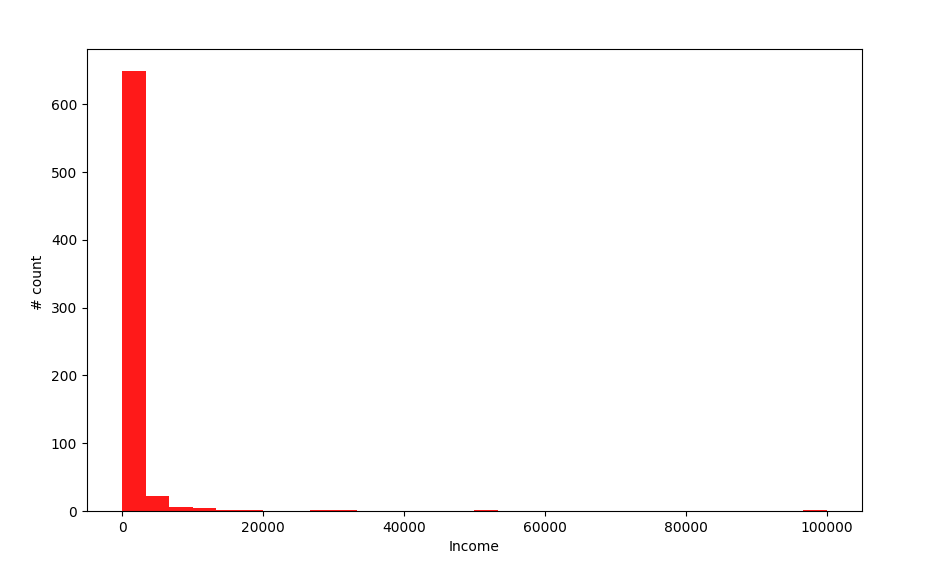
- Distribution of Income Attribute
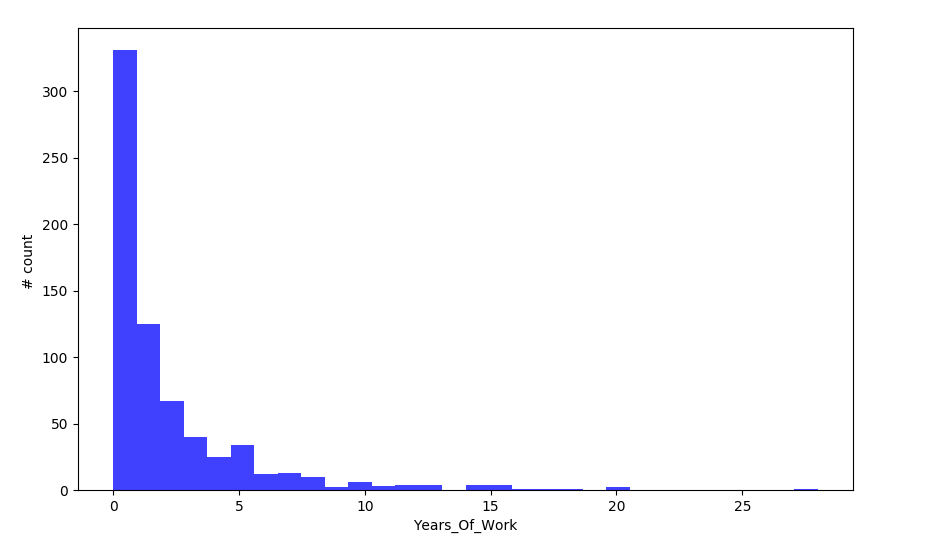
- Distribution of Years of Work Attribute
Correlation between Attribute and Approval state
- Correlation between Sex and Approval
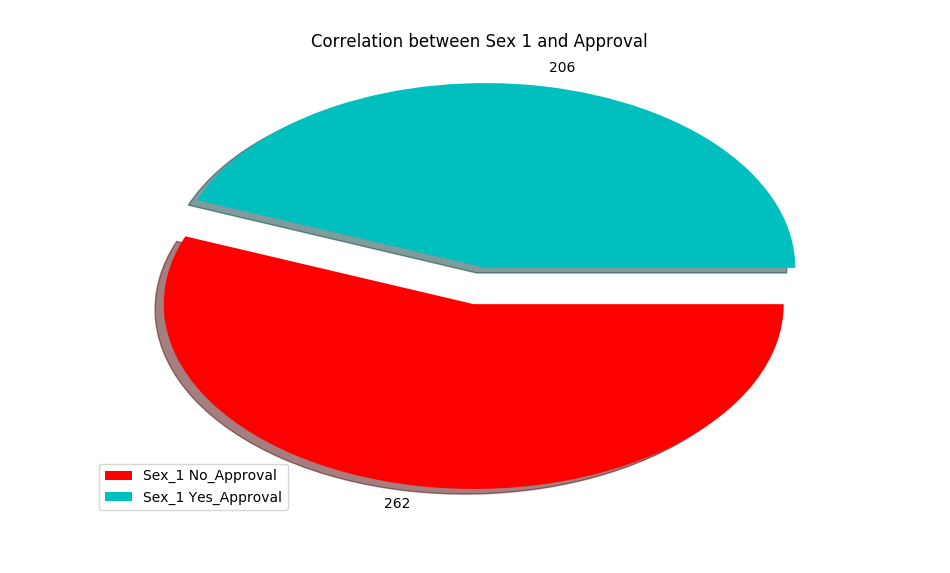
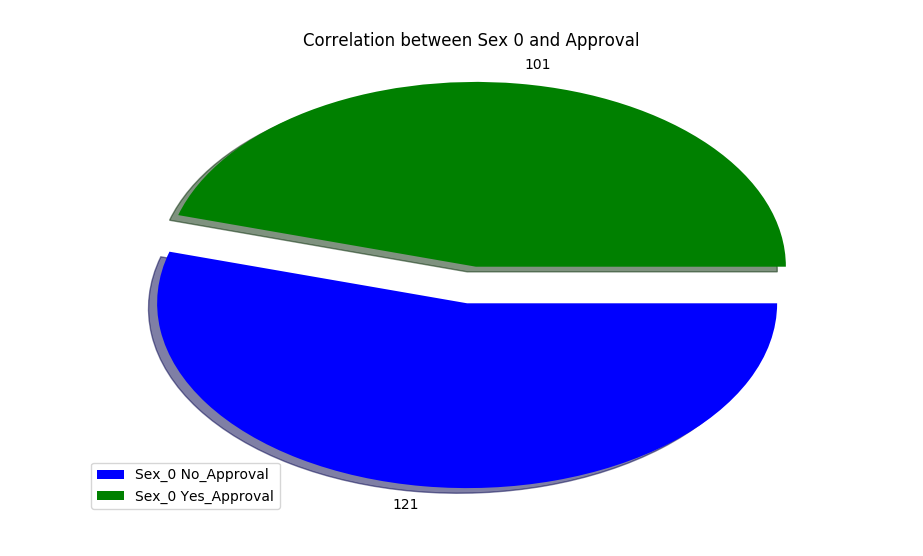
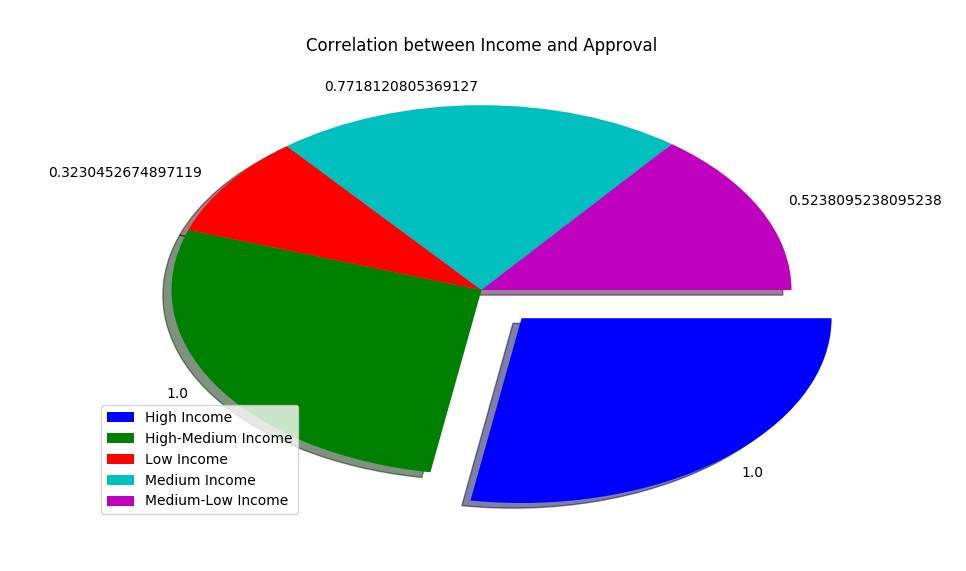
- Correlation between Income and Approval
- Mario Egidio Carricato - Erasmus student AGH - other projects
- Marco Amato - Erasmus student AGH - other projects