3. CSV Import

This documentation applies to the import of data into Rock using comma separated value (CSV) files. These are text files where columns of data are separated by commas. These files can be prepared in a text editor or in any spreadsheet application that can write to the CSV format (including Excel, Open Office, Libre Office, and Google Sheets).
What's Currently Supported?
What's In Development?
What Won't Be Covered?
General Import Rules
How to Prepare Individual Information
How to Prepare Family Information
How To Import Your Files
FAQ and Hints
Solutions to Common Import Errors
How to Report Bugs or Request Enhancements
Known Issues
Excavator.CSV currently supports the following:
- Individual data
- Custom attributes for individuals
- Family relationships
- Visitor relationships
- Household locations
Transactions (maybe).
Bulk loading of Person Attributes post import (maybe).
Everything else.
The following general import rules apply:
- The CSV files must start with 'Individual' and 'Family' in the name. Other file names will not work.
- Your CSV file must have a column header line and columns must be in the exact order shown.
- The CSV file must use "," as the separator. If you are using a text editor and have fields that contain a "," then the field content must be enclosed in quotes, e.g. "Flat 1, This Street".
Note: Excel and other smart .CSV editors will do this for you automatically. To check, open up the file in Notepad and examine what your field's content looks like. If it's wrapped in quotes, then you're good to go.
- FamilyId must be unique for each family.
- PersonId must be unique for each individual.
- The FamilyName from the Individual.csv file will be used when setting up the family, unless you are just importing the Family.csv file. The first FamilyName encountered for a family group will be used as the family name.
- Dates can also be formatted as MM/DD/YYYY or MM/DD/YY, although it's best to use YYYY-MM-DD ISO 8601 because attribute dates will be saved as text in the format you provide.
- Custom Defined Types should be set up prior to import. (See How to set up Defined Types below.)
- Custom attributes will be added to the appropriate person. If the person attribute does not exist, it will be created with the column header name (e.g. 'MyNewAttribute', or 'My New Attribute').
Defined Types are pre-defined attributes that have a limited set of options in Rock. For example - Marital Status can be 'Single', 'Married' etc. Here are some guidelines for setting up defined types.
- If you have additional values in your data for defined types, you should add them to the default list before starting the import.
- Excavator will add any values that do not already exist in any of the lists - but it is good practice for you to know that you have all the values you want.
- The list of Defined Types used in Excavator.CSV is: Prefix (Title), Suffix, Marital Status, Connection Status, Record Status, School, State, Country and Campuses.
Hint:
You can use Rock to view and maintain Defined Types. Navigate to Admin Tools, General Settings, Campuses or Defined Types.
You can also go straight to the following URL:
http://rock.rocksolidchurchdemo.com/page/119?definedTypeId=3
Change 'http://rock.rocksolidchurchdemo.com' to the address for your database. Change '3' to the ID number from the defined type you want to view or maintain. See the table below.
Or you can run the following SQL commands to confirm that Rock is loaded with all the defined values you need:
For Campus:
select * from campus;
For all the others:
select * from definedvalue where definedtypeid = {ID} order by [order];
Replace {ID} with one of these IDs:
Use this ID to get a list of 2 Record Status 3 Inactive Record Reason 4 Connection Status 5 Title (Prefix) 6 Suffix 7 Marital Status 28 Address State 34 School 45 Countries
When Excel opens a CSV file it parses anything that looks like a date as a date. So if you open a CSV file that has a date that looks like this: "08/05/2010" or "2010-05-08" it will turn it into this: "8/5/2010" (depending on your settings). You should also specify that all the date columns are Text, not Date or General.
In general, use Excel to prepare your files and save them as Excel files (XLS or XLSX) until you are ready to import. When you are ready to import, save the files as CSV files. The dates will be saved in the format you see on your screen - "08/05/2010" will be saved as "08/05/2010". Then import the CSV file.
If you need to make changes - edit the XLS file and export again to CSV.
Each person listed on a separate row in the Individual.csv file will be added to the Person table in the Rock database as individuals. They will be linked to their corresponding Family based on the FamilyId that you specify.
The Individual.csv file should have the following columns in this order:
| Column | Type | Comment |
|---|---|---|
| FamilyId | string | Mandatory. Must be unique for each family. |
| FamilyName | string | Used to set the Family Group name. |
| CreatedDate | string | Parses to date. If not set then the date of import will be used. |
| PersonId | string | Mandatory. Must be unique. |
| Prefix | string | Rock Defined Type: Title (Mr., Mrs. etc). Punctuation will be ignored: Mr and Mr. are treated the same. |
| FirstName | string | |
| NickName | string | The Rock Nickname. Will default to FirstName if no NickName is given. |
| MiddleName | string | |
| LastName | string | |
| Suffix | string | Rock Defined Type: Suffix (Sr., Jr., etc.). |
| FamilyRole | string | Either 'Adult' or 'Child'. |
| MaritalStatus | string | Rock Defined Type: Marital Status (Married, Single, etc.) |
| ConnectionStatus | string | Rock Defined Type - Connection Status. (Visitor, Member, Attendee, etc.) |
| RecordStatus | string | Rock Defined Type: Record Status (Active, Inactive). |
| IsDeceased | string | (Yes/No/blank). If Yes then RecordStatus will be set to Inactive. |
| HomePhone | string | |
| MobilePhone | string | |
| WorkPhone | string | |
| SMS Allowed? | string | (Yes, No, blank). Set's the SMS Allowed flag for the MobilePhone number only. Defaults to 'No' if not specified. |
| string | Email address. Make sure all email addresses are in a valid format - email address not formatted correctly will stop the import. | |
| IsEmailActive | string | (Yes, No, blank). Set's the Email Active flag for Email. Defaults to 'Yes' (Email Active) if not set. |
| Allow Bulk Email? | string | (Yes, No, blank). Set's the Person's Email Preference setting to Email Allowed (Yes), or No Mass Emails (No). |
| Gender | string | m/male f/female - not case sensitive. |
| DateOfBirth | string | Parses to date. |
| School | string | Rock Defined Type: School. Any new schools in your import file will be added to your database. |
| GraduationDate | string | Parses to date. Can be the start of the graduating year, e.g. 2014-01-01 - used to set individual's Grade. |
| AnniversaryDate | string | Parses to date. |
| GeneralNote | string | Rock Timeline general note. |
| MedicalNote | string | Rock Timeline private note. |
| SecurityNote | string | Rock Timeline private note. |
The only mandatory fields are FamilyId and PersonId. You could leave all the other columns blank (but that wouldn't make a lot of sense).
Remember! Dates not correctly formatted, or invalid dates, will be ignored.
###Person Attributes
You may add another 101 columns of your own Person Attributes after the SecurityNote column. These attributes will be added if they are not already set up. The maximum number of columns in the Individual.csv file is 131.
Excavator will not set up any new Person Attributes if there are no values in any of the rows for that column. So, if you have an empty column that attribute will not be added.
Here is a list of suggested Person Attributes you might consider. These are listed here as suggestions only. They are not required.
| Column | Type | Comment |
|---|---|---|
| FormerName | string | Person Attribute: The person' maiden name or former name. |
| SecondaryEmail | string | Person Attribute. Secondary email address. Make sure all email addresses are in a valid format. |
| MembershipDate | string | Parses to date. The date the person became a member. |
| SalvationDate | string | Parses to date. The date the person was saved. |
| BaptismDate | string | Parses to date. The date the person was baptised. |
| FirstVisit | string | Parses to date. The date the Person first visited your church. Note: This date is used by Rock's 'Attendance Duration' badge. |
| PreviousChurch | string | Person Attribute. The previous church the person attended. |
| Occupation | string | Person Attribute: The person's work Position. |
| Employer | string | Person Attribute. The person's employer or school. |
| string | Person Attribute. The person's Facebook address. | |
| string | Person Attribute. The person's Instagram address. | |
| string | Person Attribute. The person's Twitter address. |
Note: School is actually a Person Attribute, but it is included in the mandatory columns in Individual.csv because of the special coding required to link Schools to previously configured schools.
Hint: If you would prefer to save the notes fields (GeneralNote, MedicalNote, SecurityNote) as Person Attributes, not as Timeline notes, then use additional Person Attribute columns with different names. For example, to add a medical note field that you can view in Extended Attributes and display in the Childhood Information group, than add a column named something different, like 'MedicalNoteAttribute.' This will then be saved as a Person Attribute which you can allocate to the Childhood Information group.
What if I don't use any of these Person Attributes?
Then don't add them to your Individual.csv file.
Are spaces in the column headers important?
Excavator removes spaces from Person Attribute column names during the import. So 'Previous Church' and 'PreviousChurch' will be treated the same. (You can edit the names of the attributes in Rock after the import.)
Is the spelling of column headers important?
Yes, for any attributes that already exist in your database prior to the import. If you do not spell the column header the same, then a new attribute will be created with your new spelling, and the values will not be saved to the existing attribute. If the attribute does not already exist, then whatever spelling you use will be used to create the new attribute key.
Each family listed in the Family.csv file will be added to the Group table in the Rock database as family groups.
The Family.csv file should have these columns:
| Column | Type | Comment |
|---|---|---|
| FamilyId | string | Mandatory. Must be unique. |
| FamilyName | string | |
| CreatedDate | string | Parses to date. If not set then the date of import will be used. |
| Campus | string | Must be a valid Rock Campus, e.g. Main Campus. You can use the Campus name (Main Campus) or the Campus code (MAIN). |
| Address | string | |
| Address2 | string | |
| City | string | |
| State | string | Rock Defined Type: Address State. Must be a valid state for the country. |
| ZipCode | string | |
| Country | string | Rock Defined Type: Countries. Use the country code not the country name, e.g. US not United States. |
| SecondaryAddress | string | |
| SecondaryAddress2 | string | |
| SecondaryCity | string | |
| SecondaryState | string | Rock Defined Type: Address State. Must be a valid state for the Secondary Country. |
| SecondaryZip | string | |
| SecondaryCountry | string | Rock Define Type: Countries. Use the country code not the country name, e.g. US not United States. |
The only mandatory field is FamilyId. You could leave all the other columns blank (but that wouldn't make a lot of sense).
The primary address will be loaded with an address type of 'Home.' The secondary address will be loaded with an address type of 'Work.' The 'Mailing' and 'Location' flags will be turned on for both addresses.
Follow these steps to download and install the Excavator:
-
Click the Excavator.zip link on the main https://github.com/NewSpring/Excavator/ page. Right click the 'View the full file' link, and select 'Save link as.' Specify where, on your PC, you want to save the Excavator.zip file.
-
Unzip the downloaded Excavator file. You will have these four files:
- Excavator.exe
- Excavator.CSV.dll
- Excavator.F1.dll
- Excavator.exe.config
You are now ready to Excavate!
Warning! Remember to take a backup of your database before you run Excavator. Then you'll be able to recover if anything goes wrong during your import.
Follow these steps to import your files:
-
Prepare your Family.csv and Individual.csv files ready for import.
-
Run Excavator.exe.
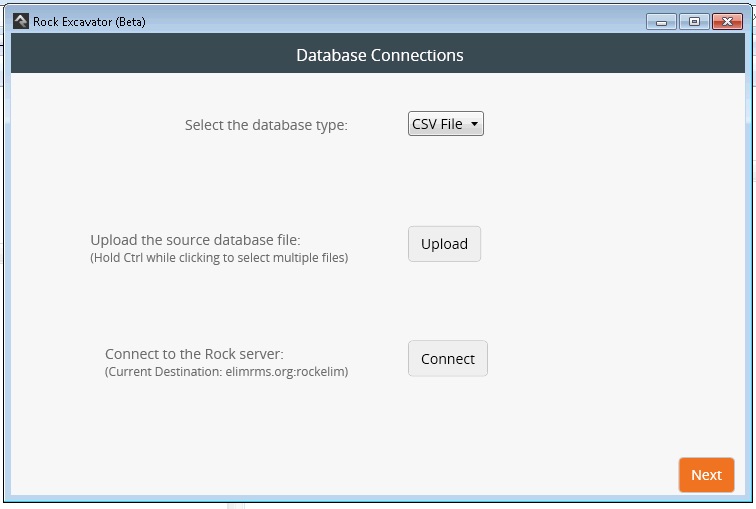
Hint: Make sure you don't have the import files open when you try to run Excavator - you will get an error message if you do.
-
Make sure 'CSV' download is selected.
-
Click Upload. Select your files for import and click Open. You should get a green message, "Successfully read import file."
-
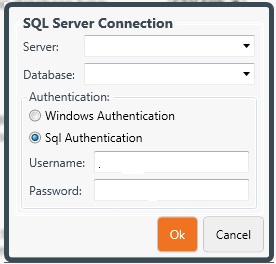
Click Connect. This will open a dialog box where you specify the connection details for your database. Enter the address of your database (e.g. http://rock.rocksolidchurchdemo.com or localhost), the name of your database, and a user name and password to access the database. Click OK. (Give the connection a couple of seconds before you click OK to allow the database connection to be established.) If a connection can be established you will be given a green message saying 'Successfully connected to the Rock database.'
-
Click Ok.
-
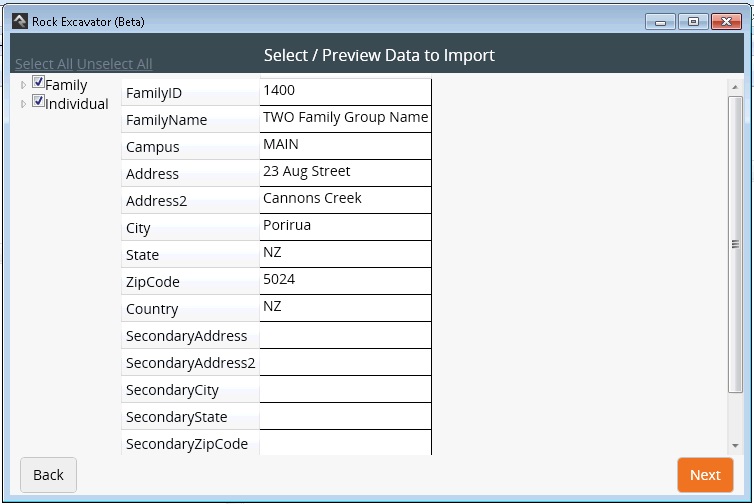
You can preview the structure of your data by viewing the first row of the import tables you have selected. Click Next.
-
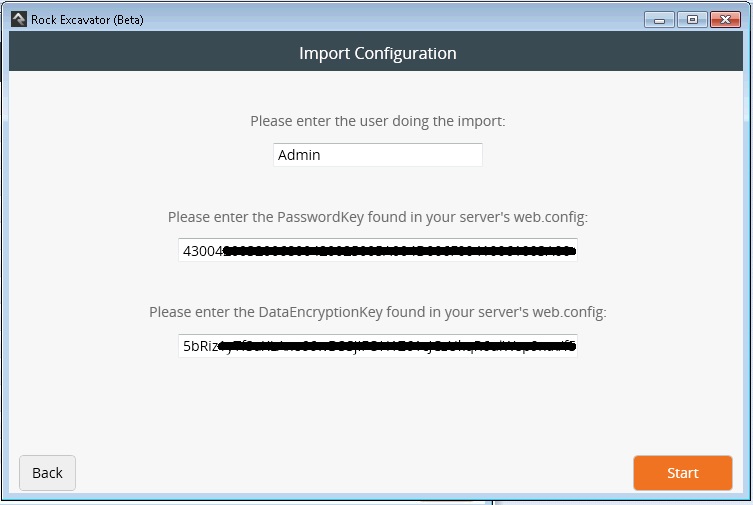
Enter the Rock User who will be running the import. The default user is Admin but if you want a specific import user to be tied to the imported records (for later reporting purposes) you should create this user in Rock beforehand.
-
Currently the PasswordKey and PasswordEncryption values are not used with the CSV import. You can type whatever text you want. In the future, those two keys will be required to import transactions and would need to come from the web.config file in the root of your web site. Do not include quotes.
-
Click Next. This will start the import.
-
If something goes wrong an error message will be displayed. The error message will be copied to a log file in the Log subdirectory where you installed Excavator.exe. Click the 'OK' at the bottom of the error message to close the error screen. If an error occurs like this then NO changes since the last "Saving..." message will be made to your database: the source or the cause of the error will need to be fixed in order to proceed. Fix the cause of the problem, restore your database, and run the import again from the beginning.
-
If all goes well, you will see a screen like this:
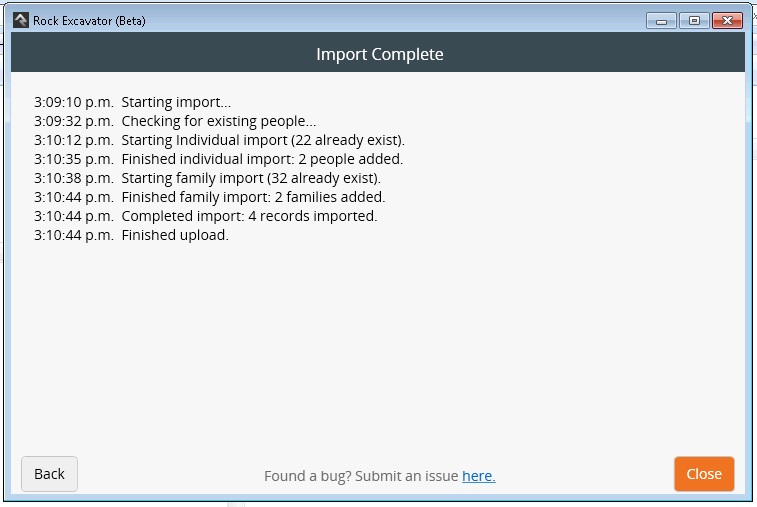
-
Click Close.
Should I cull my data before I bring it across, or just bring over everybody?
This is a matter of personal choice. Here are some things to consider:
- You could just bring over everybody if you're in a hurry to get going, then either make unwanted people inactive, or merge them to a 'TO-DELETE' person to get rid of them.
- It is much quicker to purge your data in your spreadsheet before you run the import.
- If you track visit dates, before you run the import, you could use Excel to set an inactive status on anyone who hasn't attended in the last 3 years.
- The downside of not bringing everyone over is feeling like a big church whenever someone makes a return visit. They think, "I already did this" when we want them to feel welcomed and remembered.
- Here is someone else's experience: "We went through the process of culling our data and ultimately we decided to bring it all over. We have about 10 years worth of person data and Rock enables us to easily deactivate people or assign an inactive status. Plus there's no extra cost per person like there is with other systems."
How can I create unique FamilyIds and IndividualIds?
Here are some hints on generating unique FamilyIds and PersonIds, if you don't have unique values in your data already. Copy these formulas all the way down the Id columns.
- FamilyId generation: =IF(B4<>B3,A3+1,A3)
- PersonId generation: =ROW()-1
If you want PersonId based on FamilyId then make sure your rows are sorted by FamilyId, then copy this formula all the way down the PersonId column (column C).
- =IF(A2=A1,D1+1,(A2*100)+1)
Hint: In Excel you can use VLOOKUP to check for matching FamilyIds and FamilyNames between the Family and Individual worksheets.
- =VLOOKUP(A2,'[Family-South.xlsx]Family'!$A$2:$P$200,2,FALSE)
Do my files need to be sorted in any particular order?
Yes: The Individual.csv file must be grouped by FamilyId. The easiest way to do this is to sort the rows by FamilyId.
Do I have to put the columns in the exact order as shown?
Yes, the columns listed in the sample files must be included in your files in exactly the same order.
In the Individual.csv file, any columns you add after the SecurityNote column can be in any order you choose.
Warning! If you are loading from both Family.csv and Individual.csv at the same time, note that the Family Name will be set from the Individual.csv file, and it will be taken from the first row encountered for that FamilyId.
What about empty values - do I need to put NULL, or leave the field blank?
Leave the field blank.
I have problems in my data. How can I find the row causing the problem?
Excavator.CSV imports 100 rows at a time by default. If you want to slow this down you can edit the setting 'ReportingNumber' in the Excavator.exe.config file. Drop the Value parameter down from 100 to a smaller number. Do not go lower than 2. This will allow you to step through your import files in smaller row sets. This will help you narrow down any data errors.
How long does the import take?
Our experience is that to import 100 families and 100 individuals takes around 12 minutes. But the speed depends on how fast your connection to the database server is - running Excavator on the local server hosting the ROCK database is much faster (one user on a local VM reported 9,000 records in under 20 minutes). The time taken to import is also impacted by the number of Person attributes you have added.
The import program doesn't look like it's doing anything. Is it still working?
Yes - just be patient. You will get a process completed message at the end.
How can I abort the import?
Close the Import windows by clicking the close window [X] button. Don't forget to do a database restore if you aborted while the import was running to reset your database.
Can I run multiple imports? (Can I run batch imports?)
Yes.
- Make sure that each import batch has unique FamilyIds and PersonIds.
- The import will not fail if you do have a duplicate FamilyId or PersonId. Instead the Family or Person will be skipped.
- You cannot add new people to a previously loaded FamilyId. You will need to use a new FamilyId, then merge the people.
- The import will not fail if it doesn't have anything to import. It will just report back to the main UI and display complete.
Can I run another import at a later date?
Yes. Just make sure you are using unique FamilyIds and PersonIds.
How can I check if I have already added this family or this person?
Follow these steps to check if you have already added a family or a person in a previous import. Note this checking is only based on FamilyId and PersonId.
To check if any of your PersonId's already exist in your db run the SQL:
select foreignid,nickname,lastname from person where foreignid is not null order by foreignid
Export the output to a new worksheet in Excel. Use VLOOKUP to look for matches between PersonId and foreignid. If you find a match - this PersonID already exsts in your database.
To check if any of your FamilyId's already exist in your db run the SQL:
select foreignid,name from [group] where grouptypeid=10 and foreignid is not null order by foreignid
Export the output to a new worksheet in Excel. Use VLOOKUP to look for matches between FamilyId and foreignid. If you find a match - this FamilyId already exists in your database.
Can I import only the Family.csv file, or only the Individual.csv file?
You can import the Family.csv by itself, as long as you match the FamilyID's to the FamilyIDs you use in the Individual.csv you are going to import. The Individual import looks for a pre-existing FamilyID to add people to before creating a new one.
You can import the Individual.csv file by itself. This will look for a pre-existing Family group with a matching FamilyID. If it finds one, it will add individuals to this family. If it doesn't find an existing family it create a new family group with the family name in the Individual.csv file. If you import Individual.csv only then Family groups will be created, but the family will have no campus links and no addresses.
Note: Import uses the FamilyName from the Individual.csv file if you are importing both Family.csv and Individual.csv at the same time.
How can I flag a person that I need to follow up after the import?
If you want to flag a person or family for follow up action after the import you could do this:
- Add these columns to your Individual.csv file: ActionRequired, ActionRequiredComment.
- Set ActionRequired to Yes and add an appropriate comment to those individuals that you need to follow up.
- Optional: After import allocate the ActionRequired and ActionRequiredComment Person Attributes to an appropriate Attribute Category (e.g. Data Integrity).
- Set up a data view to select Individuals where ActionRequired is equal to Yes.
- Create a report based on this data view listing the ActionRequiredComment.
How can I import dates to Person Attributes?
Dates are imported, parsed to the YYYY-MM-DD format, then stored as text fields. You can change the format and behavior of a date Person Attribute by changing it's type from 'Text' to 'Date' after the import.
How can I import lists?
Follow these steps if you want to import lists of values. For example:
T-shirt size: Small,Medium,Large,XLarge
Favorite t-shirt color: Red,Blue,Green,White,Black
- Add the columns to your Individual.csv file: T-shirt Size, T-shirt Color.
- Set each individual's values from your data.
- You can allow the import to create the Person Attributes, or you can set them up prior to the import.
- The import will give the attribute a Type of 'Text.' After the import (or before if you set up the attribute prior to import), modify the Person Attribute, change the type from Text to 'Single-Select' or 'Multi-Select', and add the list of possible values - e.g. 'Red,Blue,Green,White,Black' for 'Favorite T-shirt Color'.
Now, whenever you edit this person's extended attributes you will have a drop down showing the possible values for these attributes.
Important!
If you do not add all the list options for a Person Attribute Value (e.g. you only add 'Red,Blue,Green,White', and someone has a value of 'Black'), their attribute will not be displayed when you view their Extended Attributes, and they will lose this value when the Person's Extended Attributes are next saved.
If you are importing lists of multi-select values, e.g. "Red,Blue" (this person's favorite T-shirt colors are red AND blue), or "Has done course 1,Has done course 2", then make sure there is no space after the comma. I.e. don't do this: "Red, Blue" (note the space after the comma); do this: "Red,Blue" (no spaces after comma).
How can I put people into groups, like the Ministries they serve in?
You can not do this directly, but it is possible without too much trouble. Follow these steps to put people into groups:
- Make an extra column after the Twitter column in the Individual.csv file called "Ministries".
- On each person's individual row in that column, list the ministries they are involved in, separated by a pipe character "|" or something similar (see the warnings above if you choose to use a comma in a .csv file). It will be more reliable later on if you also begin and end the list with the same separating character. For example, if a user served on both the worship team and on the planning team, their "Ministries" column might look like |Worship team|Planning team|.
- Once your people are imported, create a "Data View" which searches for people whose "Ministry" person attribute contains the ministry name surrounded by your separating character. To continue the above example, you'd want to create a Data View which searched for people whose Ministries attribute contains the phrase "|Worship team|".
- Once your filter is set up, view the people it shows and check the checkbox in the header row to select everyone. Then click the "Bulk Update" button below the list (it looks like a truck) and choose "Add to group"- and select your Ministry group (create it first if you haven't already).
- Repeat steps 3 and 4 for each ministry.
- Once everyone is in the correct ministry, you can delete the "Ministries" person attribute to eliminate redundancy. You can also delete the data views you created for each ministry.
Here are some common import errors and what to do about them.
I get an error message when I hit Next on the Configuration Page
Make sure you don't have the Family.csv or Individual.csv file open in another application. If you do it will be locked and will not be available to Excavator.
I get an error message during the Import process
The most likely cause for this is that you have invalid data. You need to identify the row that is causing the problem. You can do this by creating a new import file (e.g. Individual.csv) with just the rows from the last set of rows that are unsaved. Then progressively delete rows until you locate the offending row - then look for the data on that row causing the error. Or you can edit the ReportingNumber value in the Excavator.exe.config file. Drop the Value parameter down from 100 to a smaller number. Do not go lower than 2. This will allow you to step through your import files in smaller row sets.
Watch out for invalid email addresses. Look for spaces, more than one email address, or invalid characters like $. Invalid email addresses will be written to a log file during the import process, and you will be given an error message to let you know.
I can't see the Person Attributes values I've imported
After Import you will need to allocate any newly-added Person Attributes to Attribute Categories in order to display them. All new Person Attributes added by Excavator as a part of the import process are added with no allocated Attribute Category.
Hint: Follow these steps to set up Rock to show Extended Attributes at the bottom of the Person Edit Page (Edit Individual):
- Open an Edit Person page.
- Open Page Zones.
- Expand the Page Blocks for the Main page zone.
- Add a Page Zone. Give it the name of your Attribute Category, and select 'Attribute Values' (from under CRM > Person Details group.)
- Click Save and Done.
- Refresh the screen.
- Open the page's Block Configuration.
- Open the Block Properties for the newly added block.
- Select the Category of attribute values you want to display.
- Click Save and refresh the page.
- Repeat this process for as many of the Attribute Categories you want to display on the Edit Person page.
If something goes wrong you can log an issue here.
You can log an enhancement request here.
Watch https://github.com/NewSpring/Excavator/issues for a list of current issues. Set the filter to "is:issue is:open csv is:title" to see only Excavator.CSV issues.