The purpose of naming and style convention allows you and others to identify the type and purpose of database objects. Our goal is to create legible, concise, and consistent names for our database objects.
Never use a descriptive prefix such as tbl_. This 'reverse-Hungarian' notation has never been a standard for SQL and clashes with SQL Server's naming conventions. Some system procedures and functions were given prefixes sp_, fn_, xp_ or dt_ to signify that they were "special" and should be searched for in the master database first.
The use of the tbl_prefix for a table, often called "tibbling", came from databases imported from Access when SQL Server was first introduced. Unfortunately, this was an access convention inherited from Visual Basic, a loosely typed language.
SQL Server is a strongly typed language. There is never a doubt what type of object something is in SQL Server if you know its name, schema, and database, because its type is there in sys.objects: Also, it is obvious from the usage. Columns can be easily identified as such and character columns would have to be checked for length in the Object Browser anyway or Intellisense tool-tip hover in SQL Server Management Studio.
Do not prefix your columns with fld_, col_, f_, u_ as it should be obvious in SQL statements which items are columns (before or after the FROM clause). Do not use a data type prefix for the column either, for example, "ntCustomerId for a numeric type or VcName for a varchar() type.
Table and view names should be singular, for example, Customer instead of Customers. This rule is applicable because tables are patterns for storing an entity as a record – they are analogous to Classes serving up class instances. And if for no other reason than readability, you avoid errors due to the pluralization of English nouns in the process of database development. For instance, activity becomes activities, ox becomes oxen, person becomes people or persons, alumnus becomes alumni, while data remains data.
If writing code for a data integration and the source is plural keep the staging/integration tables the same as the source so there is no confusion.
For all parts of the table name, including prefixes, use Pascal Case. PascalCase also reduces the need for underscores to visually separate words in names.
Using reserved or future reserved words makes code more difficult to read, can cause problems to code formatters, and can cause errors when writing code.
Sometimes SSMS will color code a word making you think it is a reserved keyword. It might just be a "special" word that is used in a database backup function somewhere. Check the Reserved Keyword link below. If the highlighted word in SSMS is not on the current or future reserved list, you are safe to use it as an object name.
Special characters should not be used in names. Using PascalCase for your table name allows for the upper-case letter to denote the first letter of a new word or name. Thus, there is no need to do so with an underscore character. Do not use numbers in your table names either. This usually points to a poorly designed data model or irregularly partitioned tables. Do not use spaces in your table names either. While most database systems can handle names that include spaces, systems such as SQL Server require you to add brackets around the name when referencing it (like [table name] for example) which goes against the rule of keeping things as short and simple as possible.
- TODO: See Use PascalCase
Avoid using abbreviations if possible. Use Account instead of Acct and Hour instead of Hr. Not everyone will always agree with you on what your abbreviations stand for - and - this makes it simple to read and understand for both developers and non-developers.
Acct, AP, AR, Hr, Rpt, Assoc, Desc
Beware of numbers in any object names, especially table names. It normally flags up clumsy denormalization where data is embedded in the name, as in Year2017, Year2018 etc. Usually, the significance of the numbers is obvious to the perpetrator, but not to the maintainers of the system.
It is far better to use partitions than to create dated tables such as Invoice2018, Invoice2019, etc. If old data is no longer used, archive the data, store only aggregations, or both.
Database schemas act as a container for SQL Server objects like tables, views, stored procedures, and functions. A schema logically groups objects that are related, keeping them separate from other database objects.
Schemas allow for simplified security management, where you can assign user permissions for a group of objects. By using schemas to group database objects, you will no longer need to maintain permissions on each individual object like tables. Schemas allow you to merge multiple databases that might have been previously separated into one using security to segment the data and objects from each other.
Schemas allow for duplicate object names like tables and views in different schemas should the need arise. You will get nice groupings in client data tools like SSMS (SQL Server Management Studio) object explorer.
- Application or App - can be used to store objects and data that are used in the webapp
- Person - This would allow you to control who has access to Personally Identifiable Information (PII) data
- Purchasing - Purchase department related data
- Sales - Sales related data
- HumanResources or HR - Locked down to only HR staff
- Report - Curated views that are consumed either by users or a reporting system
- Dim or Dimension- Dimensions for a dimensional data warehouse
- Fact - Facts for a dimensional data warehouse
- Staging - Tables used to ingest data source data, generally temporary data, end users would not have access to these tables
- Integration - Tables used to ingest data from other systems, end users would not have access to these tables
- DBA - Stored procedures and table data used by the database administrator
- Et Cetera
A lookup, reference, list, enumeration, code, or domain table in a database is for storing commonly used characteristics or property values that are referenced by other tables. Lookup tables contain unique values like types, categories, codes, tags and/or descriptions and are designed to eliminate data redundancy and improve data integrity in a database. Other metadata values like SortOrderNumber and IsDefault can be included in the lookup table if the project warrants the functionality.
One True Lookup Table (OTLT) or Massively Unified Code-Key (MUCK) table is not a best practice, breaks normal form, and breaks enforcing data integrity where you put all the lookup values into only one large table rather than a table for each. 'Junk Dimensions' in a dimensional warehouse are a best practice.
Lookup tables should follow the EntityAttribute (AccountStatus, AccountType, ProductCategory) naming convention. Entities in this case can represent a real-world object or concept, such as a customer, an order, a product, or a process.
- EntityStatus - Reflects the state of being for an entity like an account
- Grouping and Organizing Data - In general, categories are the broadest grouping of data, while classes and types are increasingly specific subsets of that data. Classes and types are often used to add more detail and specificity to categories, making it easier to organize and manage large amounts of data.
- EntityCategory - A category is a broad grouping of items or entities that share similar characteristics or properties. Categories are often used to organize data into high-level groups or classes. For example, in an e-commerce database, products might be grouped into categories such as "electronics", "clothing", or "home goods".
- EntityClass - A class is a more specific grouping of items or entities that share a particular set of characteristics or properties. Classes are often used to define subsets of categories or to further classify data based on more specific criteria. For example, within the "electronics" category, products might be further classified into classes such as "computers", "televisions", or "smartphones".
- EntityType - A type is a particular variation or instance of a class or category, often defined by a specific set of properties or attributes. Types are used to describe specific objects or entities within a class or category. For example, within the "computers" class, types might include "desktops", "laptops", or "tablets".
- EntityCode - A code is generally a standard maintained by a trusted outside source. Zip and Postal codes are maintained by the United States Postal Services.
- EntityNumber - This is a string of numbers or alphanumerics that provide uniqueness. SQL Server also provides sequence number functionality if no gaps are required.
- EntityDate - Dates are generally not referenced to lookup tables in transactional databases but analytical data warehouses use them as dimensions lookups.
- EntityGender - Person genders would fall into this category. If you need to allow gender lookups for a person and an animal, you might need to have a superclass of 'Biological Entity' with subclasses.
- EntityMeasure - Unit of measure sometimes role-plays as an entity and attribute based on its use.
- EntityMethod - Shipping method sometimes role-plays as an entity and attribute based on its use.
- Entity[...] - Other businesses might have domain specific attributes.
CREATE TABLE Application.AddressType (
AddressTypeId int NOT NULL IDENTITY(1, 1)
,AddressTypeCode nvarchar(10) NOT NULL
,AddressTypeName nvarchar(50) NOT NULL
,AddressTypeDescription nvarchar(300) NULL
,SortOrderNumber int NULL
,IsDefault bit NOT NULL CONSTRAINT Application_AddressType_IsDefault_Default DEFAULT (0)
,IsLocked bit NOT NULL CONSTRAINT Application_AddressType_IsLocked_Default DEFAULT (0)
,IsActive bit NOT NULL CONSTRAINT Application_AddressType_IsActive_Default DEFAULT (1)
,RowModifyPersonId int NOT NULL CONSTRAINT Application_AddressType_Application_RowModifyPerson FOREIGN KEY REFERENCES Application.Person (PersonId)
,RowCreatePersonId int NOT NULL CONSTRAINT Application_AddressType_Application_RowCreatePerson FOREIGN KEY REFERENCES Application.Person (PersonId)
,RowModifyTime datetimeoffset(7) NOT NULL CONSTRAINT Application_AddressType_RowModifyTime_Default DEFAULT (SYSDATETIMEOFFSET())
,RowCreateTime datetimeoffset(7) NOT NULL CONSTRAINT Application_AddressType_RowCreateTime_Default DEFAULT (SYSDATETIMEOFFSET())
,RowVersionStamp rowversion NOT NULL
,CONSTRAINT Application_AddressType_AddressTypeId PRIMARY KEY CLUSTERED (AddressTypeId ASC)
,INDEX Application_AddressType_AddressTypeName_AddressTypeShortName UNIQUE NONCLUSTERED (AddressTypeCode ASC, AddressTypeName ASC)
,INDEX Application_AddressType_RowModifyPersonId NONCLUSTERED (RowModifyPersonId ASC)
,INDEX Application_AddressType_RowCreatePersonId NONCLUSTERED (RowCreatePersonId ASC)
);Avoid, where possible, concatenating two table names together to create the name of a relationship (junction, cross-reference, intersection, many-to-many) table when there is already a word to describe the relationship. e.g. use Subscription instead of NewspaperReader.
If you have a table named Product and a lookup table named ProductCategory and you need to create a many-to-many table, Catalog would be a good name.
When a word does not exist to describe the relationship use Table1Table2 with no underscores. If you are at a loss for a relationship name and Table1Table2 is one of the table names Table1Table2Relationship will work.
Choose a column name to reflect precisely what is contained in the attribute of the entity
- Avoid repeating the table name for column names except for:
- Table Primary Key: TODO: See Primary Key Column Naming
- Common or Natural Words or Terms: When you come across common or natural names like
PatientNumber,PurchaseOrderNumberorDriversLicenseNumber,GLAccount,ARAccount,Line1,Line2,FirstName,LastName,Title,Suffixyou will want to use them as they commonly are used. - Generic or Class Words: When using generic names like
Name,Description,Number,Code,Type,Status,Amount,Date,Quantity,Rate,Key,Value,Deleted,Active,Permission,Primary,Locked,Default… you should prefix the class word with a modifier like the table name if appropriate.- Instead use
AccountNumber,AddressTypeName,ProductDescription&StateCode - SELECT queries will need aliases when two tables use generic columns like
Name
- Instead use
- Use abbreviations rarely in attribute names. If your organization has a TPS "thing" that is commonly used and referred to in general conversation as a TPS, you might use this abbreviation
- Pronounced abbreviations: It is better to use a natural abbreviation like id instead of identifier
- Columns without common, or natural words, or terms, end the column name with a suffix (class word) that denotes general usage. These suffixes are not data types that are used in Hungarian notations. There can be names where a suffix would not apply.
- InvoiceId is the identity of the invoice record
- InvoiceNumber is an alternate key
- StartDate is the date something started
- LineAmount is a currency amount not dependent on the data type like
decimal(19, 4) - GroupName is the text string not dependent on the data type like
varchar()ornvarchar() - StateCode indicates the short form of something
- Booleans - TODO: See Affirmative Boolean Naming
- UnitPrice is the price of a product unit
- WebsiteURL is the internet address - TODO: See URL or URI Naming
- ModifyPersonId is the person who last updated a record
- CreatePersonId is the person who created a record
- ModifyTime is the date and time something was modified
- CreateTime is the date and time something was created
- VersionStamp is the
rowversion/timestamp(unique binary numbers) to increment for each insert or update - ValidFromTime is the period start for a system-versioned temporal tables
- ValidToTime is the period end for a system-versioned temporal tables
For columns that are the primary key for a table and uniquely identify each record in the table, the name should be [TableName] + Id (e.g. On the Make table, the primary key column would be MakeId).
Though MakeId conveys no more information about the field than Make.Id and is a far wordier implementation, it is still preferable to Id.
Naming a primary key column Id is also "bad" when you query from several tables you will need to rename the Id columns so you can distinguish them in result set.
When you have the same column names in joins it will mask errors that would otherwise be more obvious.
/* This has an error that is not obvious at first sight */
SELECT
C.Name
,M.Id AS MakeId
FROM
Car AS C
INNER JOIN Make AS MK ON C.Id = MK.Id
INNER JOIN Model AS MD ON MD.Id = C.Id
INNER JOIN Color AS CL ON MK.Id = C.Id;
/* Now you can see MK.MakeId does not equal C.ColorId in the last table join */
SELECT
C.Name
,M.MakeId
FROM
Car AS C
INNER JOIN Make AS MK ON C.MakeId = MK.MakeId
INNER JOIN Model AS MD ON MD.ModelId = C.ModelId
INNER JOIN Color AS CL ON MK.MakeId = C.ColorId;Foreign key columns should have the exact same name as they do in the parent table where the column is the primary. For example, in the Customer table the primary key column might be CustomerId. In an Order table where the customer id is kept, it would also be CustomerId.
There is one exception to this rule, which is when you have more than one foreign key column per table referencing the same primary key column in another table. In this situation, it is helpful to add a descriptor before the column name. An example of this is if you had an Address table. You might have a Person table with foreign key columns like HomeAddressId, WorkAddressId, MailingAddressId, or ShippingAddressId.
This naming combined with TODO: Primary Key Column Naming naming makes for much more readable SQL:
SELECT
F.FileName
FROM
dbo.File AS F
INNER JOIN dbo.Directory AS D ON F.FileId = D.FileId;whereas this has a lot of repeating and confusing information:
SELECT
F.FileName
FROM
dbo.File AS F
INNER JOIN dbo.Directory AS D ON F.Id = D.FileId;Bit columns should be given affirmative boolean names like IsActive, IsDeleted, HasPermission, or IsValid so that the meaning of the data in the column is not ambiguous; negative boolean names are harder to read when checking values in T-SQL because of double-negatives (e.g. IsNotDeleted).
- IsActive indicates a status
- IsDeleted indicates a soft delete status
- IsLocked indicates if a record is immutable
- IsDefault indicates if a record is defaulted
- IsPrimary indicates first in an order
- IsValid indicated validity
- HasPermission indicated permissions
- CanExport indicates permission to export
In 99% of everyday cases, you should use URL instead of URI because both are technically true, but URL is more specific. The difference between a URI and a URL is that a URI can be just a name by itself (emergentsoftware.net), or a name with a protocol (https://emergentsoftware.net, ftp://emergentsoftware.net, mailto://[email protected], file://emergentsoftware/~user/file.csv) that tells you how to reach it—which is a URL.
Use the format of [FOREIGN-KEY-TABLE]_[PRIMARY-KEY-TABLE] in most cases. This gives you a quick view of the tables that are involved in the relationship. The first table named depends on the second table named.
Example: Invoice_Product
In cases where there are multiple foreign key relationships to one primary key table like Address, Date, Time, ... your foreign key relationship name should include the context of the relationship.
Example: Invoice_ShippingAddress or Invoice_BillingAddress
In a more rare case when not referencing the primary key of the primary key table you should use the format of [FOREIGN-KEY-TABLE]_[CHILD-COLUMN]_[PRIMARY-KEY-TABLE]_[PARENT-COLUMN].
Example: Invoice_ProductCode_Product_ProductCode
If utilizing schemas other than dbo, prefix the schema name before the [TABLE-NAME].
Example: Purchasing_PurchaseOrderLine_Application_Product
In addition to the general naming standards regarding no special characters, no spaces, and limited use of abbreviations and acronyms, common sense should prevail in naming variables and parameters; variable and parameter names should be meaningful and natural.
All variables and parameters must begin with the @ symbol. Do not use @@ to prefix a variable as this signifies a SQL Server system global variable and will affect performance.
All variables and parameters should be written in PascalCase, e.g., @FirstName or @City or @SiteId.
Variable and parameter names should contain only letters and numbers. No special characters or spaces should be used.
Parameter and variable and names should be named identically as the column names for the data they represent other than the @ symbol.
-
Index Names should be
[SchemaName_]TableName_Column1_Column2_Column3 -
Index Names should indicate if there are included columns with
[SchemaName_]TableName_Column1_Column2_Column3_Includes -
When using
uniqueidentifier/guidcolumns for clustered index you can use[SchemaName_]TableName_ColumnName_INDEX_REBUILD_ONLYto signify special index maintenance handling. -
TODO: See uniqueidentifier in a Clustered Index
Use the format of [TABLE-NAME]_[COLUMN-NAME]
Basic Example: Invoice_InvoiceId
If utilizing schemas other than dbo, prefix the schema name before the [TABLE-NAME].
Example: Purchasing_PurchaseOrder_PurchaseOrderId
- TODO: See Unique Indexes
If utilizing schemas other than dbo, prefix the schema name before the [TABLE-NAME] below.
Use the format [TABLE-NAME]_[COLUMN-NAME]_Default
CONSTRAINT Person_RowUpdateTime_Default DEFAULT (SYSDATETIMEOFFSET())
Use the format [TABLE-NAME]_[COLUMN-NAME]_[DESCRIPTION]
Examples
CONSTRAINT ProductItem_RegularPrice_Minimum CHECK (RegularPrice > 0)
CONSTRAINT ProductItem_SalePrice_Less_To_RegularPrice CHECK (SalePrice < RegularPrice)
CONSTRAINT Feedback_Stars_Range CHECK (Stars BETWEEN 0 AND 5)
TODO: See: Unique Indexes
Create explicit object names and do not let SQL Server name objects.
If you do not specify an object name, SQL Server will create one for you. This causes issues when comparing different environments that would have differently generated names.
CREATE TABLE dbo.TableName (
TableNameId int NOT NULL PRIMARY KEY /* This creates a primary key with a name like "PK__TableNam__38F491856B661278" */
,ParentTableNameId int NOT NULL FOREIGN KEY REFERENCES dbo.TableName (TableNameId)/* This creates a ParentTableNameId foreign key with a name like "FK__TableName__Paren__4A0EDAD1" */
,SomeCheck char(1) NOT NULL CHECK (SomeCheck IN ('A', 'B', 'C')) /* This creates a SomeCheck constraint with a name like "CK__TableName__Speci__49C3F6B7" */
,SomeDefault varchar(50) NOT NULL DEFAULT ('') /* This creates a SomeDefault default constraint with a name like "DF__TableName__SomeN__4AB81AF0" */
,SomeUniqueIndex nvarchar(100) NOT NULL UNIQUE NONCLUSTERED /* This creates a SomeUniqueIndex nonclustered index with a name like "UQ__TableNam__2A2E95CE05DDEAFE" */
,SomeUniqueConstraint nvarchar(100) NOT NULL UNIQUE /* This creates a SomeUniqueConstraint constraint with a name like "UQ__TableNam__4F58406D42E8D6BD" */
);
/* Drop the bad version of the table */
DROP TABLE dbo.TableName;
/* Create a better version of the table with actual constraint names */
CREATE TABLE dbo.TableName (
TableNameId int NOT NULL CONSTRAINT TableName_TableNameId PRIMARY KEY
,ParentTableNameId int NOT NULL CONSTRAINT TableName_TableName FOREIGN KEY REFERENCES dbo.TableName (TableNameId)
,SomeCheck char(1) NOT NULL CONSTRAINT TableName_SomeCheck_InList CHECK (SomeCheck IN ('A', 'B', 'C'))
,SomeDefault varchar(50) NOT NULL CONSTRAINT TableName_SomeDefault_Default DEFAULT ('')
,SomeUniqueIndex nvarchar(100) NOT NULL CONSTRAINT TableName_SomeUniqueIndex_Unique UNIQUE NONCLUSTERED
,SomeUniqueConstraint nvarchar(100) NOT NULL CONSTRAINT TableName_SomeUniqueConstraint_Unique UNIQUE
);- TODO: See Naming Constraint Usage
- TODO: See Naming Primary Keys
Stored procedures and functions should be named so they can be ordered by the table/business entity (ObjectAction) they perform a database operation on, and adding the database activity "Get, Update, Insert, Upsert, Delete, Merge" as a suffix, e.g., (ProductGet or OrderUpdate).
Table design matters because it is essential for building software applications that are scalable and capable of performing during high workload.
TODO: WIP: Write up about using inline indexes on the table creation statement that have been around since SQL Server 2014. Prior to SQL Server 2014, the CREATE/ALTER TABLE only accepted CONSTRAINT. Write about indexes with includes not being supported yet.
Database Normalizing tables are regarded as a best practice methodology for relational databases design. Relational database tables should be normalized to at least the Boyce–Codd normal form (BCNF or 3.5NF).
These normalizing principles are used to reduce data duplication, avoid data anomalies, ensure table relationship integrity, and make data management simplified.
A normalized table design like addresses and phone numbers in separate tables allows for extensibility when the requirements today might only call for a single phone number or address. You can utilize a UNIQUE constraint/index to ensure only a single row can exist but allows for flexibility in the future. You will already have the Phone table so you will not have to create a new table and migrate the data and drop the UNIQUE constraint/index.
You should always normalize the database schema unless you have a really good reason not to. Denormalizing has been performed in the past with the saying "Normalize until it hurts, denormalize until it works". Denormalization almost always leads to eventual issues. Denormalization complicates updates, deletes & inserts making the database difficult to modify. We have tools like indexes or materialized views and covering indexes to remediate performance issues. There are query rewriting techniques that can make queries more performant.
A legally binding entity like a contract that will be created as an immutable snapshot can contain redundant data. This helps with possible future reprinting of documents. Consider using an auditable append-only Ledger table.
If your tables have many columns like 20+ or many nullable columns, you have what is called a wide or "God Object" and you might need to assess your modeling. Each table should be an entity and columns be an attribute of the entity.
If data is denormalized there are methods of keeping denormalized or duplicated data values correct. The data should be strongly consistent instead of eventually consistent.
Strongly consistent is with the use of transactions that will not allow the data to be out-of-sync like in a stored procedure, triggers are the next best option, but triggers have performance issues.
Eventually consistent methods are something like jobs that run at a predetermined or event-based time to synchronize the denormalized (duplicate) data. Eventually consistent leaves a gap of time, even if for milliseconds, which could cause data consistency issues.
- See Keeping Denormalized Values Correct article by Kenneth Downs
Use the Table Per Type (TPT) table design pattern.
The Table Per Concrete (TPC) design is not good as it would have redundant data and no relationship between the sub tables. The redundant data would just be in multiple tables vs squished into one table with Table Per Hierarchy (TPH). TPC would help with the extra nullable columns compared to TPH.
The Table Per Type (TPT) table design pattern is performant with proper indexes well into the 100s of millions of rows and beyond. With proper indexes a query can join multiple tables and still execute in less than a second even for costly queries that scan indexes like exporting of data. Seeking on indexes for row-level queries like finding a specific CustomerId, should only take on order of 10s of milliseconds. Until multiple of billions of rows are a consideration there is no performance reason not to follow database norm form best practices. If you have slow joined table queries, you're probably not using your database correctly.
TPC & TPH do not follow normal form.
- TODO: See Not Normalizing Tables.
An entity is a table and is a single set of attributes. There is a need sometimes for entity/table inheritance when you might have a parent entity/table named Person, you would need another inherited entity/table for Employee. The Employee entity/table will store attributes (Salary, Job Title, ...) that are not attributes in the Person entity/table.
A use case exception for using proper table entities is for security purposes. You might encounter a requirement for security that utilizing a linking table makes it impossible to have a discriminator like PhoneTypeId to prevent read or modifications to a row based on how the software was/is written.
This exception use can lead to table schema development issues for cases when you have a multiple entity/tables like dbo.BuyerPhone, dbo.SellerPhone, dbo.ServicerPhone, dbo.VendorPhone. With the address entity not being materialized in one dbo.Phone entity/table, the table schemas need to be kept in sync which might not occur. Ask me how I know. ;-(
Use the proper weak or strong table type based on the entity.
A weak table is one that can only exist when owned by another table. For example: a 'Room' can only exist in a 'Building'.
An 'Address' is a strong table because it exists with or without a person or organization.
With an 'Address' table you would have a linking, or many-to-many table.
| ResidenceId | AddressTypeId | PersonId | AddressId |
|---|---|---|---|
| 1 | 1 | 456 | 233 |
| 2 | 1 | 234 | 167 |
| 3 | 2 | 622 | 893 |
A 'Phone Number' is a weak table because it generally does not exist without a person or organization.
With a 'Phone Number' table you would not use a linking table. The 'Phone Number' table would reference back to the person table.
| PersonId | FistName | LastName |
|---|---|---|
| 1 | Kevin | Martin |
| 2 | Han | Solo |
| 3 | Mace | Windu |
| PersonPhoneId | PhoneTypeId | PersonId | PhoneNumber |
|---|---|---|---|
| 1 | 1 | 1 | 555-899-5543 |
| 2 | 1 | 2 | (612) 233-2255 |
| 3 | 2 | 3 | 1+ (453) 556-9902 |
By default, the history table is PAGE compressed for System Versioned Temporal Tables. There are cases where the compression is removed or not deployed.
The SQL script below will check for the issue and provide an ALTER TSQL statement to apply page compression. Do not forget to change ONLINE to ON OR OFF.
SELECT
SchemaName = S.name
,TableName = T.name
,DataCompression = P.data_compression_desc
,[ALTER TSQL] = N'ALTER INDEX ' + CAST(QUOTENAME(I.name) AS nvarchar(128)) + N' ON ' + CAST(QUOTENAME(S.name) AS nvarchar(128)) + N'.' + CAST(QUOTENAME(T.name) AS nvarchar(128)) + N' REBUILD PARTITION = ALL WITH (STATISTICS_NORECOMPUTE = OFF, ONLINE = ?, DATA_COMPRESSION = PAGE);'
FROM
sys.partitions AS P
INNER JOIN sys.indexes AS I
ON I.object_id = P.object_id
AND I.index_id = P.index_id
INNER JOIN sys.objects AS O
ON I.object_id = O.object_id
INNER JOIN sys.tables AS T
ON O.object_id = T.object_id
INNER JOIN sys.schemas AS S
ON T.schema_id = S.schema_id
WHERE
T.temporal_type = 1 /* HISTORY_TABLE */
AND I.type <> 5 /* CLUSTERED */
AND P.data_compression <> 2 /* Not Page compressed, which is the default for system-versioned temporal tables */
ORDER BY
S.name ASC
,T.name ASC;Database table partitions should not be used to "speed up" query performance. Use an index instead.
Partitioning can make your workload run slower if the partitions are not set up correctly and your queries cannot remain within a single partition. Instead of thinking about a partition, think about an index.
Partitioning can be used as a maintenance tool for either distributing data between cold or hot storage.
Partition switching/swapping/truncating is another use case for managing large amounts of table data like in a data warehouse.
The Entity–Attribute–Value (EAV) model falls victim to the Inner-platform effect.
The inner-platform effect is the tendency of software architects to create a system so customizable as to become a replica, and often a poor replica, of the software development platform they are using. This is generally inefficient and such systems are often considered to be examples of an anti-pattern.
In the database world, developers are sometimes tempted to bypass the SQL Server relations database, for example by storing everything in one big table with three columns labelled EntityId, Key, and Value. While this entity-attribute-value model allows the developer to break out from the structure imposed by a SQL Server database, it loses out on all the benefits, since all of the work that could be done efficiently by the SQL Server relational database is forced onto the application instead. Queries become much more convoluted, the indexes and query optimizer can no longer work effectively, and data validity constraints are not enforced. Performance and maintainability can be extremely poor.
Data that meets the following criteria might be okay to use the EAV pattern at the discretion of the software or database architect.
- The definition of the data is highly dynamic and is likely to change numerous times of the course of the development and/or life of the application.
- The data has no intrinsic value outside the context of the application itself.
- The data will not be materialized in models but simply passed through the application layers as key value pairs.
Examples of valid use cases that meet this criteria are:
- Application user preferences
- User interface styling & custom layouts
- Saved user interface state
- Front-end application configuration
Another use case exception for utilizing an EAV model in a database is where the attributes are user defined and a developer will not have control over them.
Another use case exception for utilizing an EAV model is for something like a multiple product (entity) type shopping cart. Where each specific product (entity) type has its own list of attributes. If the product (entity) catalog only sells a manageable number of product different types the attributes, the attributes should be materialized as physical columns in the table schema. This type of EAV model will have diminishing returns for performance with more data housed in the database. Caching this type of EAV model will allow for a larger data set as to lessen the chance of performance issues. Ensure this is communicated to the stakeholders.
Basic table model for a product catalog that supports multiple product types
CREATE TABLE dbo.Attribute (
AttributeId int IDENTITY(1, 1) NOT NULL
,AttributeName nvarchar(100) NOT NULL
,CONSTRAINT Attribute_AttributeId PRIMARY KEY CLUSTERED (AttributeId ASC)
);
/* Insert values like "Size", "Color" */
CREATE TABLE dbo.AttributeTerm (
AttributeTermId int IDENTITY(1, 1) NOT NULL
,AttributeId int NOT NULL CONSTRAINT AttributeTerm_Attribute FOREIGN KEY REFERENCES dbo.Attribute (AttributeId)
,TermName nvarchar(100) NOT NULL
,CONSTRAINT AttributeTerm_AttributeTermId PRIMARY KEY CLUSTERED (AttributeTermId ASC)
);
/* Insert values like "Small", "Large", "Red", "Green" */
CREATE TABLE dbo.Product (
ProductId int IDENTITY(1, 1) NOT NULL
,ProductName nvarchar(200) NOT NULL
,ProductSlug nvarchar(400) NOT NULL
,ProductDescription nvarchar(MAX) NULL
,CONSTRAINT Product_ProductId PRIMARY KEY CLUSTERED (ProductId ASC)
,CONSTRAINT Product_ProductName UNIQUE NONCLUSTERED (ProductName ASC)
,CONSTRAINT Product_ProductSlug UNIQUE NONCLUSTERED (ProductSlug ASC)
);
/* Insert values like "Shirt", "Pants" */
CREATE TABLE dbo.ProductItem (
ProductItemId int IDENTITY(1, 1) NOT NULL
,ProductId int NOT NULL CONSTRAINT ProductItem_Product FOREIGN KEY REFERENCES dbo.Product (ProductId)
,UPC varchar(12) NULL
,RegularPrice decimal(18, 2) NOT NULL
,SalePrice decimal(18, 2) NULL
,CONSTRAINT ProductItem_ProductItemId PRIMARY KEY CLUSTERED (ProductItemId ASC)
);
/* Insert values product UPC codes and prices */
CREATE TABLE dbo.ProductVariant (
ProductVariantId int IDENTITY(1, 1) NOT NULL
,ProductItemId int NOT NULL CONSTRAINT ProductVariant_ProductItem FOREIGN KEY REFERENCES dbo.ProductItem (ProductItemId)
,AttributeTermId int NOT NULL CONSTRAINT ProductVariant_AttributeTerm FOREIGN KEY REFERENCES dbo.AttributeTerm (AttributeTermId)
,CONSTRAINT ProductVariant_ProductVariantId PRIMARY KEY CLUSTERED (ProductVariantId ASC)
);
/* Insert values that link Shirt or Pants product items to the attributes available for sale */Every table should have a column that uniquely identifies one and only one row. It makes it much easier to maintain the data. The best practice is for each row to have a surrogate key. It is best practice to use int or bigint.
- TODO: See Primary Key Column Naming
Using uniqueidentifier/guid as primary keys causes issues with SQL Server databases. uniqueidentifier/guid are unnecessarily wide (4x wider than an int).
uniqueidentifiers/guids are not user friendly when working with data. PersonId = 2684 is more user friendly than PersonId = 0B7964BB-81C8-EB11-83EC-A182CB70C3ED.
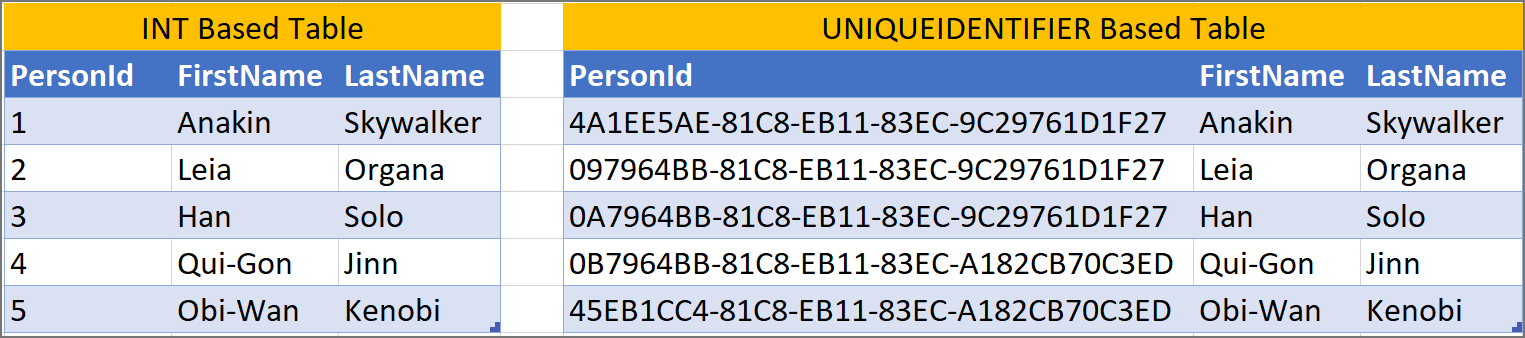
A use case for when you can use uniqueidentifier/guid as primary keys, is when there are separate systems and merging rows would be difficult. The uniqueness of uniqueidentifier/guid simplifies the data movements.
If the row data in the table does not contain any NULL values you should assess setting the column to not 'Allow Nulls'.
Null-ness does more than constraining the data, it factors in on performance optimizer decisions.
For data warehouses do not allow NULL values for dimensional tables. You can create a -1 identifier with the value of [UNKNOWN]. This helps business analysts who might not understand the difference between INNER and OUTER JOINs exclude data in their TSQL queries.
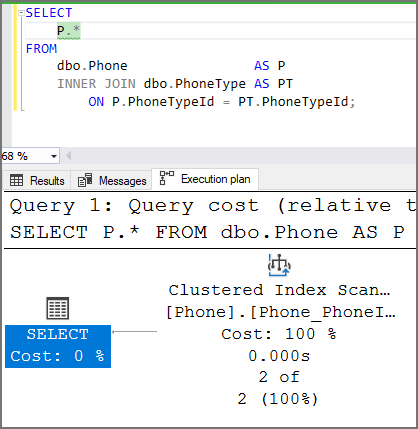
If a column has a foreign key and nullable, it will not be trusted and JOIN Elimination will not occur, forcing your query to perform more query operations than needed.
This execution plan shows how JOIN elimination works. There is a foreign key on the column and the column does not allow null. There is only one index operation in the execution plan. SQL Server is able to eliminate JOINs because it "trusts" the data relationship.
- TODO: See Untrusted Foreign Key
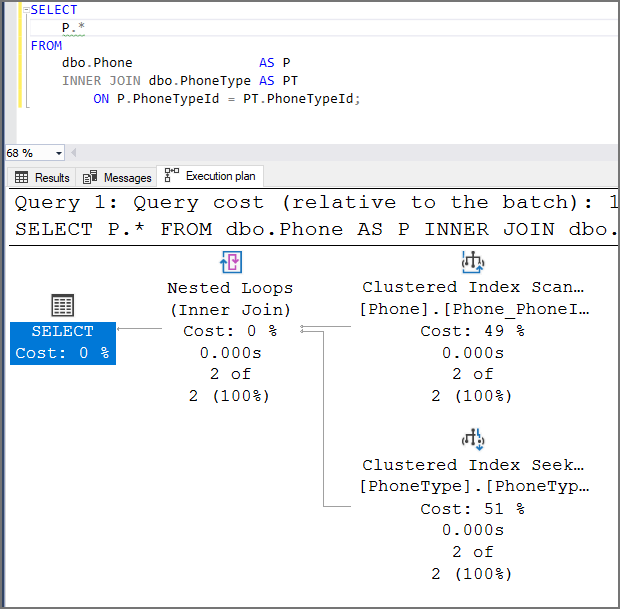
This execution plan shows JOIN elimination has not occurred. While there is a foreign key on the column, the column allows null. There are two index operations and a merge operation causing SQL Server to perform more work.
You should always explicitly define NULL or NOT NULL for columns when creating or declaring a table. The default of allowing NULLs can be changed with the database setting ANSI_NULL_DFLT_ON.
If the row data in the table does not contain any NULL values, you should assess setting the column to not 'Allow Nulls'.
Null-ness does more than constraining the data, it factors in on performance optimizer decisions.
For data warehouses do not allow NULL values for dimensional tables. You can create a -1 identifier with the value of [UNKNOWN]. This helps business analysts who might not understand the difference between INNER and OUTER JOINs exclude data in their TSQL queries.
If a column has a foreign key and nullable, it will not be trusted and JOIN Elimination will not occur, forcing your query to perform more query operations than needed.
This execution plan shows how JOIN elimination works. There is a foreign key on the column and the column does not allow null. There is only one index operation in the execution plan. SQL Server is able to eliminate JOINs because it "trusts" the data relationship.
TODO: - See Untrusted Foreign Key
This execution plan shows JOIN elimination has not occurred. While there is a foreign key on the column, the column allows null. There are two index operations and a merge operation causing SQL Server to perform more work.
TODO: This could cause issues if the code is not aware of different collations and does include features to work with them correctly.
Each foreign key in your table should be included in an index. Start off with an index on just the foreign key column if you have no workload to tune a multi-column index. There is a really good chance the indexes will be used when queries join on the parent table.
You will not get JOIN Eliminations without a foreign key and a column that allows NULLs.
Use a stored procedure or SQL command in your software code to delete data in multiple related tables instead of ON DELETE CASCADE on the foreign key.
Foreign keys with cascading actions like ON DELETE CASCADE or ON UPDATE ? perform slowly due to SQL Server taking out serializable locks (RANGEX-X) to guarantee referential integrity so that it can trust the foreign keys.
You may also receive the error message below when you utilize ON DELETE CASCADE.
Msg 1785, Level 16, State 0, Line 190
Introducing FOREIGN KEY constraint [ForeignKeyName] on table [TableName] may cause cycles or multiple cascade paths.
Specify ON DELETE NO ACTION or ON UPDATE NO ACTION, or modify other FOREIGN KEY constraints.
Msg 1750, Level 16, State 1, Line 190
Could not create constraint or index. See previous errors.
A general rule is to aim for 5 indexes per table, with around 5 columns or less on each index. This is not a set-in-stone rule, but if you go beyond the general rule you should ensure you are only creating indexes that are required for the SQL Server query workload. If you have a read-only database, there will be no inserts, updates, or deletes to maintain on all those indexes. The more you have the less performant insert, update & deletes are.
You or your DBA should implement an index tuning strategy like below.
- Dedupe - reduce overlapping indexes
- Eliminate - unused indexes
- Add - badly needed missing indexes
- Tune - indexes for specific queries
- Heap - usually need clustered indexes
The Index Tuning Wizard and Database Tuning Advisor are not known for generating the best indexes and you should not blindly implement the recommendations without understanding the overall consequences. Feel free to reach out to your local DBA for assistance.
The SQL Server Missing Indexes recommendations feature has limitations and even recommends you create indexes that already exist. It is not meant for you fine tune and only provides sometimes adequate recommendations.
You should assess the missing index recommendation but create a fine-tuned custom index that includes all that is excluded items.
See the Books Online: Limitations of the Missing Indexes Feature
The missing index feature has the following limitations:
- It is not intended to fine tune an indexing configuration.
- It cannot gather statistics for more than 500 missing index groups.
- It does not specify an order for columns to be used in an index.
- For queries involving only inequality predicates, it returns less accurate cost information.
- It reports only include columns for some queries, so index key columns must be manually selected.
- It returns only raw information about columns on which indexes might be missing.
- It does not suggest filtered indexes.
- It can return different costs for the same missing index group that appears multiple times in XML Showplans.
- It does not consider trivial query plans.
You should always explicitly define ascending (ASC) or descending (DESC) for indexes. This allows others who review or edit the code to not know that ASC is the default sort order.
CREATE NONCLUSTERED INDEX Application_Person_LastName ON Application.Person
(
LastName ASC
/* ↑ Look Here */
);An index rebuild or reorganization will enabled disabled indexes. It is now best practices to delete instead of disable if not needed.
Add the filtered columns in the INCLUDE() on your index so your queries do not need to perform a key lookup. By including the filtered columns, SQL Server generates statistics on the columns.
Instead Of:
CREATE NONCLUSTERED INDEX Account_Greater_Than_Half_Million
ON dbo.Account (AccountName, AccountId)
WHERE Balance > 500000;Do This:
CREATE NONCLUSTERED INDEX Account_Greater_Than_Half_Million
ON dbo.Account (AccountName, AccountId)
INCLUDE (Balance)
WHERE Balance > 500000;SQL Server storage is built around the clustered index as a fundamental part of the data storage and retrieval engine. The data itself is stored with the clustered key. All this makes having an appropriate clustered index a vital part of database design. The places where a table without a clustered index is preferable are rare, which is why a missing clustered index is a common code smell in database design.
A table without a clustered index is a heap, which is a particularly bad idea when its data is usually returned in an aggregated form, or in a sorted order. Paradoxically, though, it can be rather good for implementing a log or a ‘staging’ table used for bulk inserts, since it is read very infrequently, and there is less overhead in writing to it.
A table with a non-clustered index, but without a clustered index can sometimes perform well even though the index must reference individual rows via a Row Identifier rather than a more meaningful clustered index. The arrangement can be effective for a table that isn’t often updated if the table is always accessed by a non-clustered index and there is no good candidate for a clustered index.
Heaps have performance issues like table scans, forward fetches.
The default fill factor is (100 or 0) for SQL Server. Best practice is to ONLY use a low fill factor on indexes where you know you need it. Setting a low fill factor on too many indexes will hurt your performance:
- Wasted space in storage
- Wasted space in memory (and therefore greater memory churn)
- More IO, and with it, higher CPU usage
Add the filtered columns in the INCLUDE() on your index so your queries do not need to perform a key lookup. By including the filtered columns, SQL Server generates statistics on the columns. This is also known as a covering index.
Instead Of:
CREATE NONCLUSTERED INDEX Account_Greater_Than_Half_Million
ON dbo.Account (AccountName, AccountId)
WHERE Balance > 500000;Do This:
CREATE NONCLUSTERED INDEX Account_Greater_Than_Half_Million
ON dbo.Account (AccountName, AccountId)
INCLUDE (Balance)
WHERE Balance > 500000;uniqueidentifier/guid columns should not be in a clustered index. Even NEWSEQUENTIALID() should not be used in a clustered index. The sequential uniqueidentifier/guid is based on the SQL Server's MAC address. When an Availability Group fails over the next uniqueidentifier/guid will not be sequential anymore.
SQL Server will bad page split and fragment an index when a new record is inserted instead of being inserted on the last page using standard best practices for index maintenance. The clustered index will become fragmented because of randomness of uniqueidentifier/guid. Index maintenance set to the default fill factor of 0 (packed 100%) will force bad page splits.
A use case for when you can use uniqueidentifier/guid as a primary key & clustered index, is when there are separate systems and merging rows would be difficult. The uniqueness of uniqueidentifier/guid simplifies the data movements.
DBAs have historically not implemented uniqueidentifier/guid as primary keys and/or clustered indexes. The traditional index maintenance jobs would keep the uniqueidentifier/guid indexes in a perpetual state of fragmentation causing bad page splits, which is an expensive process.
A new index maintenance strategy is to name these uniqueidentifier/guid indexes with the ending "*_INDEX_REBUILD_ONLY" and create a customized index maintenance plan. One job step will perform the standard index maintenance ignoring the uniqueidentifier/guid indexes and another job step will only perform an index rebuild, skipping index reorganizations. Ola Hallengren maintenance scripts is recommended.
These uniqueidentifier/guid indexes should be created and rebuilt with a custom fill factor to account for at least a weeks' worth of data. This is not a "set it, and forget it" maintenance plan and will need some looking after.
These are a 400 level tasks and please feel free to reach out to a DBA for assistance.
Create unique indexes instead of unique constraints (unique key). Doing so removes a dependency of a unique key to the unique index that is created automatically and tightly coupled.
Instead of: CONSTRAINT AddressType_AddressTypeName_Unique UNIQUE (AddressTypeName ASC)
Use: INDEX AddressType_AddressTypeName UNIQUE NONCLUSTERED (AddressTypeName ASC)
In some table design cases you might need to create uniqueness for one or more columns. This could be for a natural [composite] key or to ensure a person can only have one phone number and phone type combination.
There is no functional or performance difference between a unique constraint (unique key) and a unique index. With both you get a unique index, but with a unique constraint (unique key) the 'Ignore Duplicate Keys' and 'Re-compute statistics' index creation options are not available.
The only possible benefit of a unique constraint (unique key) has over a unique index is to emphasize the purpose of the index and is displayed in the SSMS (SQL Server Management Studio) table 'Keys' folder in the 'Object Explorer' side pane.
SQL Server is not going to consider using untrusted constraints to compile a better execution plan. This can have a huge performance impact on your database queries.
You might have disabled a constraint instead of dropping and recreating it for bulk loading data. This is fine, as long as your remember to enable it correctly.
ALTER TABLE dbo.TableName WITH CHECK CHECK CONSTRAINT ConstraintName;
GOThe CHECK CHECK syntax is correct. The 1st CHECK is the end of WITH CHECK statement. The 2nd CHECK is the start of the CHECK CONSTRAINT clause to enable the constraint
To find untrusted foreign keys and check constraints in your database run the script below to identify and create an ALTER statement to correct the issue. In Redgate SQL Prompt the snippet code is fk. If you receive an error with the generated ALTER statement it means past constraint violations have been being suppressed by WITH NOCHECK. You will have to figure out how to fix the rows that do not comply with the constraint.
SELECT
SchemaName = S.name
,TableName = T.name
,ObjectName = FK.name
,ObjectType = 'FOREIGN KEY'
,FixSQL = 'ALTER TABLE ' + QUOTENAME(S.name) + '.' + QUOTENAME(T.name) + ' WITH CHECK CHECK CONSTRAINT ' + FK.name + ';'
FROM
sys.foreign_keys AS FK
INNER JOIN sys.tables AS T
ON FK.parent_object_id = T.object_id
INNER JOIN sys.schemas AS S
ON T.schema_id = S.schema_id
WHERE
FK.is_not_trusted = 1
AND FK.is_not_for_replication = 0
UNION ALL
SELECT
SchemaName = S.name
,TableName = T.name
,ObjectName = CC.name
,ObjectType = 'CHECK CONSTRAINT'
,FixSQL = 'ALTER TABLE ' + QUOTENAME(S.name) + '.' + QUOTENAME(T.name) + ' WITH CHECK CHECK CONSTRAINT ' + CC.name + ';'
FROM
sys.check_constraints AS CC
INNER JOIN sys.tables AS T
ON CC.parent_object_id = T.object_id
INNER JOIN sys.schemas AS S
ON T.schema_id = S.schema_id
WHERE
CC.is_not_trusted = 1
AND CC.is_not_for_replication = 0
AND CC.is_disabled = 0
ORDER BY
SchemaName ASC
,TableName ASC
,ObjectName ASC;Generally, there should not be a reason check constraint should be disabled. Check constraints can be disabled before bulk loading but should be enabled afterwards.
Poor data type choices can have significant impact on a database design and performance. A best practice is to right size the data type by understanding the data.
- A
varchar, ornvarcharthat is declared without an explicit length will use a default length. It is safer to be explicit. decimal,numeric. If no precision and scale are provided, SQL Server will use (18, 0), and that might not be what you want.- Explicitly define data type default lengths instead of excluding them.
[n][var]char(1)or[n][var]char(30)- The default length is 1 when n isn't specified in a data definition or variable declaration statement. When n isn't specified with the CAST function, the default length is 30.
datetime2(7)datetimeoffset(7)float(53)[var]binary(1)or[var]binary(30)- The default length is 1 when n isn't specified in a data definition or variable declaration statement. When n isn't specified with the CAST function, the default length is 30.
If the length of the type will be very small (size 1 or 2) and consistent, declare them as a type of fixed length, such as char, nchar, and binary.
When you use data types of variable length such as varchar, nvarchar, and varbinary, you incur an additional storage cost to track the length of the value stored in the data type. In addition, columns of variable length are stored after all columns of fixed length, which can have performance implications.
Columns, parameters, and variables used in a JOIN and WHERE clauses should have the same data type.
There are two situations where not doing this is going to hurt performance. When you have a mismatch of data types in a JOIN and a WHERE clause. SQL Server will need to convert one of them to match the other data type. This is called an implicit conversion.
What will it hurt
- Indexes will not be used correctly
- Missing index requests will not be logged in the Dynamic Management Views (DMVs)
- Extra CPU cycles are going to be required for the conversion
- Do not use the deprecated data types below.
textntextimagetimestamp
There is no good reason to use text or ntext. They were a flawed attempt at BLOB storage and are there only for backward compatibility. Likewise, the WRITETEXT, UPDATETEXT and READTEXT statements are also deprecated. All this complexity has been replaced by the varchar(MAX) and nvarchar(MAX) data types, which work with all of SQL Server’s string functions.
Use nvarchar(128) when storing database object names. Database object names include table names, column names, and view names.
sysname is a special data type used for database objects like database names, table names, column names, et cetera. When you need to store database, table or column names in a table use nvarchar(128).
- See Microsoft docs
Minimize the use of (n)varchar(MAX) on your tables.
(n)varchar(MAX) columns can be included in an index but not as a key. Queries will not be able to perform an index seek on this column.
(n)varchar(MAX) should only every be used if the size of the field is known to be over 8K for varchar and 4K for nvarchar.
Since SQL Server 2016 if the size of the cell is < 8K characters for varchar(MAX) it will be treated as Row data. If > 8K it will be treated as a Large Object (LOB) for storage purposes.
Use the bit data type for boolean columns, parameters, and variables. These columns will have names like IsSpecialSale.
Only use the float and real data types for scientific use cases.
The float (8 byte) and real (4 byte) data types are suitable only for specialist scientific use since they are approximate types with an enormous range (-1.79E+308 to -2.23E-308, 0 and 2.23E-308 to 1.79E+308, in the case of float). Any other use needs to be regarded as suspect, and a float or real used as a key or found in an index needs to be investigated. The decimal type is an exact data type and has an impressive range from -10^38+1 through 10^38-1. Although it requires more storage than the float or real types, it is generally a better choice.
Do not use the sql_variant data type.
The sql_variant type is not your typical data type. It stores values from a number of different data types and is used internally by SQL Server. It is hard to imagine a valid use in a relational database. It cannot be returned to an application via ODBC except as binary data, and it isn’t supported in Microsoft Azure SQL Database.
User-defined data types should be avoided whenever possible. They are an added processing overhead whose functionality could typically be accomplished more efficiently with simple data type variables, table variables, temporary tables, or JSON.
Use the datetimeoffset data type when time zone awareness is needed.
datetimeoffset defines a date that is combined with a time of a day that has time zone awareness and is based on a 24-hour clock. This allows you to use datetimeoffset AT TIME ZONE [timezonename] to convert the datetime to a local time zone.
Use this query to see all the timezone names:
SELECT * FROM sys.time_zone_info;Use the date data type when time values are not required or the smalldatetime data type when precision of minute is acceptable.
Even with data storage being so cheap, a saving in a data type adds up and makes comparison and calculation easier. When appropriate, use the date or smalldatetime type. Narrow tables perform better and use fewer resources.
Use the time data type when date values are not required.
Being frugal with memory is important for large tables, not only to save space but also to reduce I/O activity during access. When appropriate, use the time or smalldatetime type. Queries too are generally simpler on the appropriate data type.
Use the decimal data type instead of the money data type.
The money data type confuses the storage of data values with their display, though it clearly suggests, by its name, the sort of data held. Use decimal(19, 4) instead. It is proprietary to SQL Server.
money has limited precision (the underlying type is a bigint or in the case of smallmoney an int) so you can unintentionally get a loss of precision due to roundoff errors. While simple addition or subtraction is fine, more complicated calculations that can be done for financial reports can show errors.
Although the money data type generally takes less storage and takes less bandwidth when sent over networks, it is generally far better to use a data type such as the decimal(19, 4) type that is less likely to suffer from rounding errors or scale overflow.
Use the nvarchar data type instead of the varchar data type for Unicode National Language Character Set values. Kevin in Chinese is 凯文. You cannot store 凯文 in a varchar column, it will be stored as ??. You must use a nvarchar column to be safely stored and queried.
You can't require everyone to stop using national characters or accents any more. Names are likely to have accents in them if spelled properly, and international addresses and language strings will almost certainly have accents and national characters that can’t be represented by 8-bit ASCII!
Column names to check:
- FirstName
- MiddleName
- LastName
- FullName
- Suffix
- Title
- ContactName
- CompanyName
- OrganizationName
- BusinessName
- Line1
- Line2
- CityName
- TownName
- StateName
- ProvinceName
An email address column, parameter, or variable should be set to nvarchar(254) to leave 2 characters for <> if needed.
This was accepted by the IETF following submitted erratum. The original version of RFC 3696 described 320 as the maximum length, but John Klensin subsequently accepted an incorrect value, since a Path is defined as Path = "<" [ A-d-l ":" ] Mailbox ">"
A URL column, parameter, or variable should be set to nvarchar(2083).
RFC 2616, "Hypertext Transfer Protocol -- HTTP/1.1," does not specify any requirement for URL length. A web server will should return RFC 7231, section 6.5.12: 414 URI Too Long
The Internet Explorer browser has the shortest allowed URL max length in the address bar at 2083 characters.
TODO: - See URL or URI Naming
Use Case Exception
If your application requires more than 2083 characters, ensure the users are not utilizing IE and increase the nvarchar length.
Your database objects (tables, views, stored procedures, functions, triggers, users, roles, schemas, static data, ...) should be in a version control system.
Source control lets you see who made what changes, when, and why. Automate SQL changes during deployment. Rollback any changes you don't want. Source control helps when you develop branch features.
Most importantly, you work from a single source of truth, greatly reducing the risk of downtime at deployment.
Your choices are Redgate SQL Source Control or a SSDT (SQL Server Data Tools) database project backed by DevOps or GitHub depending on the client requirements.
It is recommended that the database project source control be kept separate from the application code. Database and reporting team members might/should not need access to the app source code. The data and business intelligence development team might have their own changes (performance tuning, data warehouse, reporting) in a "dev" branch, but their version is not ready for production yet.
Reasons to use a monorepo for multiple projects
- All the projects have the same permissions and access needs
- All the projects are fully aligned in terms of versioning
- All the projects must always be deployed together by the CI/CD pipeline(s)
- All the projects cannot be built separately unless they are in the same solution
If you choose to use a monorepo, please ensure you have accounted for the issues that can occur if not all the bullet points are fully true.
- See Should the Database and Application projects be in the same Repository? article by Eitan Blumin.
You should have a Development, Testing & Production environment.
SQL Server development is a continuous process to avoid the issues caused by development and reduce the risks of blocking business.
Accidents happen! Imagine you accidentally made an update to thousands of records that you cannot undo without hours of work. Imagine that you do not have access to original data before you changed it. Feeling scared yet? This is where a development and test environment save effort.
A development environment allows developers to program and perform test ensuring their code is correct before pushing to a centralized testing environment for UAT (User Acceptance Testing) or staging for production.
When a feature is marked deprecated, it means:
- The feature is in maintenance mode only. No new changes will be made, including those related to addressing inter-operability with new features.
- Microsoft strives not to remove a deprecated feature from future releases to make upgrades easier. However, under rare situations, they may choose to permanently discontinue (remove) the feature from SQL Server if it limits future innovations.
- For new development work, do not use deprecated features. For existing aplications, plan to modify applications that currently use these features as soon as possible.
A discontinued feature means it is no longer available. If a discontinued feature is being used, when we upgrade to a new SQL Server version, the code will break.
See:
- Deprecated database engine features in SQL Server 2022
- Deprecated database engine features in SQL Server 2019
- Deprecated Database Engine Features in SQL Server 2017
- No Discontinued features in SQL Server 2017
- Deprecated Database Engine Features in SQL Server 2016
- Discontinued Database Engine Functionality in SQL Server 2014
- Discontinued Features in SQL Server 2012
Put data access code (T-SQL) in the database and not in the application/ORM layer.
Utilizing an ORM or application generated database commands has downsides. ORM or app generated SQL code that sticks with basic CRUD (Create, Read, Update, Delete) are not too bad but they do not generate reasonable queries for reporting or beyond the basic CRUD commands.
The benefit of using stored procedures is with query performance tuning. Eventually the queries will outgrow the ORMs ability to generate optimal queries and execution plans. You end up attempting to rewrite software code to force the ORM to produce more performant SQL code.
With stored procedures there are a lot more options to tune a query. You can split up complex SQL code so the SQL Server engine can generate better execution plans, convert to dynamic SQL, use different hints, trace flags, and isolation levels, etc.
The free opensource sp_CRUDGen can be utilized to create eleven different stored procedures from basic your Create, Read, Update, Delete, Upsert stored procedures to extremely advanced safe dynamic Search stored procedures otherwise known as optional parameters, kitchen sink, Swiss army knife, catch-all queries. The generated stored procedure code utilizes the SQL Server community best practices.
- See Database-First: Stored Procedure in Entity Framework
- See Simple C# Data Access with Dapper and SQL - Minimal API Project Part 1
- See Simple C# Data Access with Dapper and SQL - Minimal API Project Part 2
The BEGIN...END control-of-flow statement block is optional for stored procedures and IF statements but is required for multi-line user-defined functions. It is best to avoid confusion and be consistent and specific.
Always included BEGIN...END blocks for IF statements with a semicolon to terminate the statement. Using BEGIN...END in an IF statement and semicolon is critical in some cases.
Use this:
IF @@TRANCOUNT > 0
BEGIN
ROLLBACK TRANSACTION;
END;Instead of this:
IF @@TRANCOUNT > 0
ROLLBACK TRANSACTION;Instead of this:
IF @@TRANCOUNT > 0 ROLLBACK TRANSACTION;Use this:
CREATE OR ALTER PROCEDURE dbo.BusinessEntityAction
AS
BEGIN
SET NOCOUNT ON;
/* [T-SQL GOES HERE] */
END;
GOInstead of this:
CREATE OR ALTER PROCEDURE dbo.BusinessEntityAction
AS
SET NOCOUNT ON;
/* [T-SQL GOES HERE] */
GOUse SET NOCOUNT ON; at the beginning of your SQL batches, stored procedures for report output and triggers in production environments, as this suppresses messages like '(10000 row(s) affected)' after executing INSERT, UPDATE, DELETE and SELECT statements. This improves the performance of stored procedures by reducing network traffic.
SET NOCOUNT ON; is a procedural level instructions and as such there is no need to include a corresponding SET NOCOUNT OFF; command as the last statement in the batch.
SET NOCOUNT OFF; can be helpful when debugging your queries in displaying the number of rows impacted when performing INSERTs, UPDATEs and DELETEs.
CREATE OR ALTER PROCEDURE dbo.PersonInsert
@PersonId int
,@JobTitle nvarchar(100)
,@HiredOn date
,@Gender char(1)
AS
BEGIN
SET NOCOUNT ON;
INSERT INTO
dbo.Person (PersonId, JobTitle, HiredOn, Gender)
SELECT
PersonId = @PersonId,
JobTitle = 'CEO',
HiredOn = '5/2/1971',
Gender = 'M';
END;Using WITH (NOLOCK), WITH (READUNCOMMITTED) and TRANSACTION ISOLATION LEVEL READ UNCOMMITTED does not mean your SELECT query does not take out a lock, it does not obey locks.
Can NOLOCK be used when the data is not changing? Nope. It has the same problems.
Problems
- You can see rows twice
- You can skip rows altogether
- You can see records that were never committed
- Your query can fail with an error "could not continue scan with
NOLOCKdue to data movement"
These problems will cause non-reproducible errors. You might end up blaming the issue on user error which will not be accurate.
Only use NOLOCK when the application stakeholders understand the problems and approve of them occurring. Get their approval in writing to CYA.
Alternatives
- Index Tuning
- Use
READ COMMITTED SNAPSHOT ISOLATION (RCSI)- On by default in Azure SQL Server databases, local SQL Servers should be checked for TempDB latency before enabling
So, while DISTINCT and GROUP BY are identical in a lot of scenarios, there is one case where the GROUP BY approach leads to better performance (at the cost of less clear declarative intent in the query itself).
You also might be using SELECT DISTINCT to mask a JOIN problem. It is much better to determine why rows are being duplicated and fix the problem.
Use aliases for your table names in most multi-table T-SQL statements; a useful convention is to make the alias out of the first or first two letters of each capitalized table name, e.g., `Phone" becomes "P" and "PhoneType" becomes "PT".
If you have duplicate two-character aliases, choose a third letter from each. "PhoneType" becomes "PHT" and "PlaceType" becomes "PLT".
Ensure you use AS between the table name and the alias like [TABLE-Name] AS [ALIAS]. AS should be used to make it clear that something is being given a new name and easier to spot. This rule also applies for column aliases if the column aliases is not listed first.
Do not use table aliases like S1, S2, S3. Make your aliases meaningful.
SELECT
P.PhoneId
,P.PhoneNumber
,PT.PhoneTypeName
FROM
dbo.Phone AS P
INNER JOIN dbo.PhoneType AS PT
ON P.PhoneTypeId = PT.PhoneTypeId;Because the SQL Server Query Optimizer typically selects the best execution plan for a query, we recommend that table hints and query hints be used only as a last resort by experienced developers and database administrators.
Search ARGument..able. Avoid having a column or variable used within an expression or used as a function parameter. You will get a table scan instead of an index seek which will hurt performance.
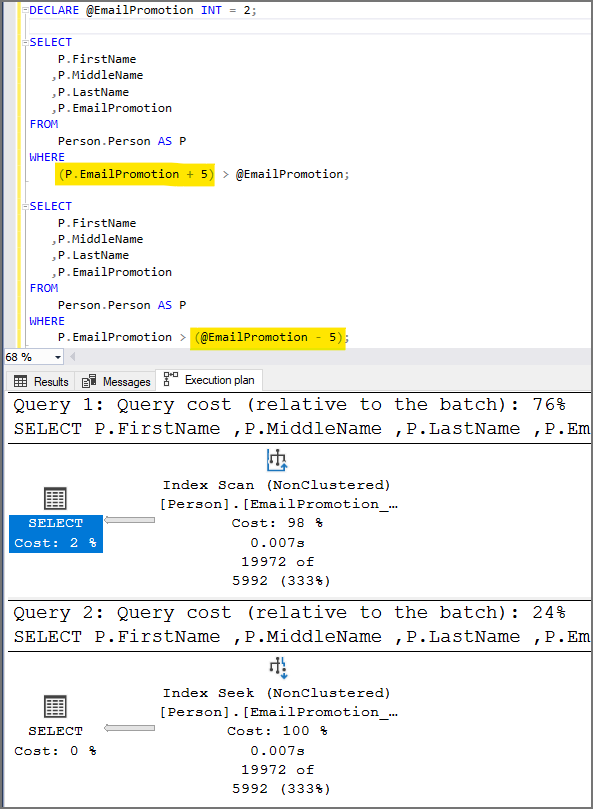
Another issue with non-sargable queries besides the forced table scan is SQL Server will not be able to provide a recommended index.
- TODO: See Using Missing Indexes Recommendations
Changing the WHERE clause to not use the YEAR() function and doing a bit more typing allows SQL Server to understand what you want it to do.
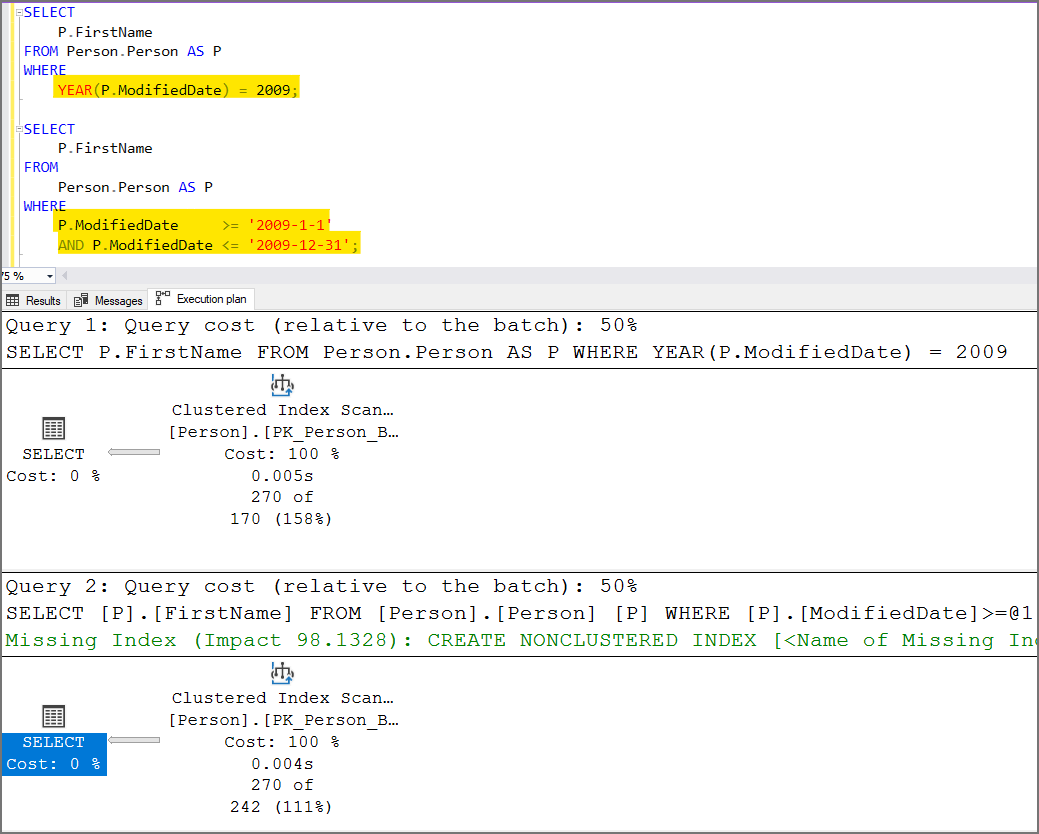
SQL Server is the second most expensive sorting system. Make all attempts to sort the data results in the application layer.
2020 Pricing
- Oracle Enterprise Edition = $47,500 per core
- Microsoft SQL Server Enterprise Edition = $7,128 per core
- ⬇
- Microsoft Access $159.99
You should always explicitly define ascending (ASC) or descending (DESC) for ORDER BY expressions. This allows others who review or edit the code to not know that ASC is the default sort order.
SELECT
P.PersonId,
P.Title,
P.FirstName,
P.LastName,
P.NickName
FROM
Application.Person AS P
ORDER BY
P.LastName ASC;
/* ↑ Look Here */Use the column name in your ORDER BY expressions instead of the column number. The use of constants in the ORDER BY is deprecated for future removal. It makes it difficult to understand the code at a glance and leads to issue when alter the order of the columns in the SELECT.
Instead Of:
SELECT
P.FirstName
,P.LastName
FROM
dbo.Person AS P
ORDER BY
2 ASC;
/* ↑ Look Here */Do This:
SELECT
P.FirstName
,P.LastName
FROM
dbo.Person AS P
ORDER BY
P.LastName ASC;
/* ↑ Look Here */Queries should be parameterized so SQL Server can reuse the execution plan. Ensure your application code is not hardcoding the query values in the WHERE clause or using some sort of dynamic T-SQL and not doing it correctly.
A temporary fix is to force parameterization until you can refactor the code and include some @parameters.
To determine whether an expression is NULL, use IS NULL or IS NOT NULL instead of using comparison operators such as = or <>. Comparison operators return UNKNOWN when either or both arguments are NULL.
DECLARE @NULL AS varchar(10) = NULL;
DECLARE @NOTNULL AS varchar(10) = 'Some Value';
SELECT 'No Result' WHERE @NULL = NULL;
SELECT 'No Result' WHERE @NULL <> NULL;
SELECT 'Has Result' WHERE @NULL IS NULL;
SELECT 'Has Result' WHERE @NOTNULL IS NOT NULL;Use EXISTS or NOT EXISTS if referencing a subquery, and IN or NOT IN when using a list of literal values.
EXISTS used to be faster than IN when comparing data from a subquery. Using EXISTS would stop searching as soon as it found the first row. IN would collect all the results. SQL Server got smarter and treats EXISTS and IN the same way so performance is not an issue.
Option 1 (NOT IN)
The NOT IN operator causes issues when the subquery data contains NULL values. NOT EXIST or LEFT JOIN / IS NULL should be used below.
SELECT
P.FirstName
,P.LastName
FROM
dbo.Person AS P
WHERE
P.PersonId NOT IN (SELECT L.PersonId FROM dbo.List AS L);Option 2 (LEFT JOIN / IS NULL) Option 2 & 3 are semantically equivalent
SELECT
P.FirstName
,P.LastName
FROM
dbo.Person AS P
LEFT OUTER JOIN dbo.List AS L ON P.PersonId = L.PersonId
WHERE
L.PersonId IS NULL;Option 3 (NOT EXISTS) Option 2 & 3 are semantically equivalent
SELECT
P.FirstName
,P.LastName
FROM
dbo.Person AS P
WHERE
NOT EXISTS (SELECT * FROM dbo.List AS L WHERE P.PersonId = L.PersonId);Option 4 (IN)
Option 4 here uses IN with a list of literal values.
SELECT
EmailAddress
FROM
dbo.PersonEmail
WHERE
EmailTypeId IN (1, 2);You will not get an index seek using the percent wildcard (%) first in your search predicate. If you intend on performing this type of "Contains" or "Ends With" type of search, understand it will not be as performant.
SELECT
P.FirstName
,P.MiddleName
,P.LastName
FROM
dbo.Person AS P
WHERE
P.LastName LIKE '%son';Check WHERE clauses for columns that are not included in an index. Might want to exclude checking for tables with small (5k or less) number of records.
An example is if your SQL code uses the LastName column in the WHERE clause, you should ensure there is an index where the LastName column is the leading key on an index.
Check IN() predicates for columns that are not included in an index. Might want to exclude check for tables with small (5k or less) number of records.
When you utilize NOT IN in your WHERE clause the SQL Server optimizer will likely perform a table scan instead of an index seek. Index seeks are generally more performant than table scans.
Try rewriting the query to use LEFT OUTER JOIN and check for NULL on the right-handed side table.
Don't convert dates to strings to compare. Dates should be stored with the pattern YYYY-MM-DD. Not all are and string comparisons can provide the wrong results.
Transactions allow for database operations to be atomic. A group of related SQL commands that must all complete successfully or not at all and must be rolled back.
If you are performing a funds transfer and updating multiple bank account tables with debiting one and crediting the other, they must all complete successfully or there will be an imbalance.
- When
SET XACT_ABORT ON, if a T-SQL statement raises a run-time error, the entire transaction is terminated and rolled back. - When
SET XACT_ABORT OFF, in some cases only the T-SQL statement that raised the error is rolled back and the transaction continues processing. Depending upon the severity of the error, the entire transaction may be rolled back even when SET XACT_ABORT is OFF. OFF is the default setting in a T-SQL statement, while ON is the default setting in a trigger.
A use case for SET XACT_ABORT OFF is when debugging to trap an error.
SET NOCOUNT, XACT_ABORT ON;
/* Exclude SQL code that does not need to be inclued in the transaction. Keep transactions shrt. */
BEGIN TRY
BEGIN TRANSACTION;
UPDATE dbo.Account SET Balance = -100.00 WHERE AccountId = 1;
UPDATE dbo.Account SET Balance = 'not a decimal' WHERE AccountId = 2;
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
BEGIN
ROLLBACK TRANSACTION;
END;
/* Handle the error here, cleanup, et cetera.
In most cases it is best to bubble up (THROW) the error to the application/client to be displayed to the user and logged.
*/
THROW;
END CATCH;SET NOCOUNT, XACT_ABORT ON;
BEGIN TRY
DECLARE @ErrorMessageText nvarchar(2048);
BEGIN TRANSACTION;
/* Debit the first account */
UPDATE dbo.Account SET Balance = -100.00 WHERE AccountId = 1;
/* Check the first account was debited */
IF @@ROWCOUNT <> 1
BEGIN
SET @ErrorMessageText = N'The debited account failed to update.';
END;
/* Credit the second account */
UPDATE dbo.Account SET Balance = 100.00 WHERE AccountId = 2;
/* Check the second account was credited */
IF @@ROWCOUNT <> 1
BEGIN
SET @ErrorMessageText = N'The credited account failed to update.';
END;
/* Check if we have any errors to throw */
IF @ErrorMessageText <> ''
BEGIN
; THROW 50001, @ErrorMessageText, 1;
END;
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
BEGIN
ROLLBACK TRANSACTION;
END;
/* Handle the error here, cleanup, et cetera.
In most cases it is best to bubble up (THROW) the error to the application/client to be displayed to the user and logged.
*/
THROW;
END CATCH;- TODO: See Not Using SET XACT_ABORT ON
- TODO: See Not Using BEGIN END
- TODO: See Not Using Semicolon THROW
- TODO: See Using RAISERROR Instead of THROW
Do not use SET IMPLICIT_TRANSACTIONS ON.
The default behavior of SQL Servers is IMPLICIT_TRANSACTIONS OFF that does not keep TSQL commands open waiting for a ROLLBACK TRANSACTION or COMMIT TRANSACTION command. When OFF, we say the transaction mode is autocommit.
When IMPLICIT_TRANSACTIONS ON is used, it could appear that the command finished instantly, but there will be an exclusive lock on the row(s) until either a roll back or commit command is issued. This makes IMPLICIT_TRANSACTIONS ON not popular as they can cause considerable blocking and locking.
When a connection is operating in implicit transaction mode IMPLICIT_TRANSACTIONS ON, the instance of the SQL Server Database Engine automatically starts a new transaction after the current transaction is committed or rolled back. You do nothing to delineate the start of a transaction; you only commit or roll back each transaction. Implicit transaction mode generates a continuous chain of transactions.
- See Transaction locking and row versioning guide > Implicit Transactions
- See SET IMPLICIT_TRANSACTIONS ON Is One Hell of a Bad Idea
Locating the row to confirm it exists is doing the work twice.
IF EXISTS (SELECT * FROM dbo.Person WHERE PersonId = @PersonId)
BEGIN
UPDATE dbo.Person SET FirstName = @FirstName WHERE PersonId = @PersonId;
END;
ELSE
BEGIN
INSERT dbo.Person (PersonId, FirstName) VALUES (@PersonId, @FirstName);
END;Don't worry about checking for a records existence just perform the update.
Consider using sp_CRUDGen to generate an UPSERT stored procedure at least as starting point.
SET NOCOUNT, XACT_ABORT ON;
BEGIN TRANSACTION;
UPDATE
dbo.Person WITH (UPDLOCK, SERIALIZABLE)
SET
FirstName = 'Kevin'
WHERE
LastName = 'Martin';
IF @@ROWCOUNT = 0
BEGIN
INSERT dbo.Person (FirstName, LastName) VALUES ('Kevin', 'Martin');
END;
COMMIT TRANSACTION;Use this UPSERT pattern when a record insert is more likely: Don't worry about checking for a records existence just perform the insert.
SET NOCOUNT, XACT_ABORT ON;
BEGIN TRY
BEGIN TRANSACTION;
INSERT dbo.Person
(
FirstName,
LastName
)
SELECT
'Kevin',
'Martin'
WHERE NOT EXISTS
(
SELECT
1
FROM dbo.Person WITH (UPDLOCK, SERIALIZABLE)
WHERE LastName = 'Martin'
);
IF @@ROWCOUNT = 0
BEGIN
UPDATE dbo.Person SET FirstName = 'Kevin' WHERE LastName = 'Martin';
END;
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
BEGIN
ROLLBACK TRANSACTION;
END;
THROW;
END CATCH;Ensure you handle the exception in your code.
SET NOCOUNT, XACT_ABORT ON;
BEGIN TRANSACTION;
BEGIN TRY
INSERT dbo.Person (FirstName, LastName) VALUES ('Kevin', 'Martin');
END TRY
BEGIN CATCH
UPDATE dbo.Person SET FirstName = 'Kevin' WHERE LastName = 'Martin';
THROW;
END CATCH;
COMMIT TRANSACTION;Use this UPSERT pattern for upserting multiple rows: You can use a table-valued parameter, JSON, XML or comma-separated list.
For JSON, XML or comma-separated list ensure you insert the records into a temporary table for performance considerations.
SET NOCOUNT, XACT_ABORT ON;
BEGIN TRY
BEGIN TRANSACTION;
/***************************************************************
** Create temp table to store the updates
****************************************************************/
CREATE TABLE #Update
(
FirstName varchar(50) NOT NULL,
LastName varchar(50) NOT NULL
);
INSERT INTO #Update
(
FirstName,
LastName
)
VALUES
('Kevin', 'Martin'),
('Jean-Luc', 'Picard');
/***************************************************************
** Perform Updates (WHEN MATCHED)
****************************************************************/
UPDATE
P WITH (UPDLOCK, SERIALIZABLE)
SET
P.FirstName = U.FirstName
FROM dbo.Person AS P
INNER JOIN #Update AS U
ON P.LastName = U.LastName;
/***************************************************************
** Perform Inserts (WHEN NOT MATCHED [BY TARGET])
****************************************************************/
INSERT dbo.Person
(
FirstName,
LastName
)
SELECT
U.FirstName,
U.LastName
FROM #Update AS U
WHERE NOT EXISTS
(
SELECT * FROM dbo.Person AS P WHERE P.LastName = U.LastName
);
/***************************************************************
** Perform Deletes (WHEN NOT MATCHED BY SOURCE)
****************************************************************/
DELETE P
FROM dbo.Person AS P
LEFT OUTER JOIN #Update AS U
ON P.LastName = U.LastName
WHERE U.LastName IS NULL;
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
BEGIN
ROLLBACK TRANSACTION;
END;
THROW;
END CATCH;In general, do not use MERGE statements in transactional (OLTP) databases, even though they are valid in ETL processes. If you do encounter MERGE statements in OLTP databases, be sure to address potential concurrency issues as described below. MERGE can be used for ETL processing if it is assured to NOT be run concurrently.
- See What To Avoid If You Want To Use MERGE article by Michael J. Swart
- See Use Caution with SQL Server's MERGE Statement article by Aaron Bertrand
MERGE INTO dbo.Person WITH (HOLDLOCK) AS T
USING (
SELECT FirstName = 'Kevin', LastName = 'Martin'
) AS S
ON (S.LastName = T.LastName)
WHEN MATCHED AND EXISTS (
SELECT
S.FirstName
,S.LastName
EXCEPT
SELECT
T.FirstName
,T.LastName
) THEN
UPDATE SET
T.FirstName = S.FirstName
WHEN NOT MATCHED BY TARGET THEN
INSERT (FirstName, LastName)
VALUES
(S.FirstName, S.LastName)
WHEN NOT MATCHED BY SOURCE THEN
DELETE;If an update is not wanted for a reason like system-versioned temporal table history pollution the WITH (UPDLOCK, SERIALIZABLE) hint below should be used.
UPDLOCK is used to protect against deadlocks and let other session wait instead of falling victim to a deadlock event. SERIALIZABLE will protect against changes to the data in the transaction and ensure no other transactions can modify data that has been read by the current transaction until the current transaction completes.
This method will not prevent a race condition and the last update will win.
BEGIN TRY
BEGIN TRANSACTION;
IF EXISTS (SELECT * FROM dbo.Person WITH (UPDLOCK, SERIALIZABLE) WHERE PersonId = @PersonId)
BEGIN
UPDATE dbo.Person SET FirstName = @FirstName WHERE PersonId = @PersonId;
END;
ELSE
BEGIN
INSERT dbo.Person (PersonId, FirstName) VALUES (@PersonId, @FirstName);
END;
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
BEGIN
ROLLBACK TRANSACTION;
END;
THROW;
END CATCH;Even though you'll hear DBAs and other experts say, "never use cursors!", there are a few cases were cursors come in handy and there are a few important pointers.
SQL Server originally supported cursors to more easily port dBase II applications to SQL Server, but even then, you can sometimes use a WHILE loop (TODO: See Using WHILE Loop) as an effective substitute. Modern versions of SQL Server provide window functions and the CROSS/OUTER APPLY syntax to cope with some of the traditional valid uses of the cursor.
- Executing a complex stored procedure or series of stored procedures based on a set of data. It is true this can be handled with a
WHILEloop and grabbing each record from the database, but a read-only, fast-forward cursor well and can be easier to manage. - Import scripts
It is likely a bad idea to use any cursor other than one that is read-only and fast-forward. However, you need to declare your cursor correctly in order to create the right type:
DECLARE MyCursor CURSOR LOCAL FAST_FORWARD FOR
DECLARE
@MyId int
,@MyName nvarchar(50)
,@MyDescription nvarchar(MAX);
DECLARE MyCursor CURSOR LOCAL FAST_FORWARD FOR
SELECT
MT.MyId
,MT.MyName
,MT.MyDescription
FROM
dbo.MyTable AS MT
WHERE
MT.DoProcess = 1;
OPEN MyCursor;
FETCH NEXT FROM MyCursor
INTO
@MyId
,@MyName
,@MyDescription;
WHILE @@FETCH_STATUS = 0
BEGIN
--Do something or a series of things for each record
DECLARE @Result int;
EXEC @Result = dbo.SomeStoredProcedure @MyId = @MyId;
FETCH NEXT FROM MyCursor
INTO
@MyId
,@MyName
,@MyDescription;
END;
CLOSE MyCursor;
DEALLOCATE MyCursor;WHILE loop is really a type of cursor. Although a WHILE loop can be useful for several inherently procedural tasks, you can usually find a better relational way of achieving the same results. The database engine is heavily optimized to perform set-based operations rapidly.
Here is a WHILE loop pattern. You might be able to create a SQL statement that does a bulk update instead.
CREATE TABLE #Person (
PersonId int NOT NULL IDENTITY(1, 1) PRIMARY KEY
,FirstName nvarchar(100) NOT NULL
,LastName nvarchar(128) NOT NULL
,IsProcessed bit NOT NULL DEFAULT (0)
);
INSERT INTO
#Person (FirstName, LastName, IsProcessed)
VALUES
(N'Joel', N'Miller', 0);
DECLARE
@PersonId INT
,@FirstName nvarchar(100)
,@LastName nvarchar(100);
WHILE EXISTS (SELECT * FROM #Person WHERE IsProcessed = 0)
BEGIN
SELECT TOP (1)
@PersonId = P.PersonId
,@FirstName = P.FirstName
,@LastName = P.LastName
FROM
#Person AS P
WHERE
P.IsProcessed = 0
ORDER BY
P.PersonId ASC;
UPDATE
dbo.Person
SET
FirstName = @FirstName
,LastName = @LastName
WHERE
PersonId = @PersonId;
UPDATE #Person SET IsProcessed = 1 WHERE PersonId = @PersonId;
END;Use Temporary Tables and not Table Variables.
- There is optimization limitations like lack of statistics that very frequently lead to performance issues. The advice of "use table variables if you have less than NNN rows" is flawed. It might seem like temporary tables are performant, but they are not scalable with a couple more years of data.
- There are two use cases for table variable and are infrequently called for.
- Extremely highly called code where recompiles from temporary table activity is a problem
- Audit scenarios when you need to keep data after a transaction is rolled back.
Instead Of:
DECLARE @DoNotUseMe table (
DoNotUseMeId int NOT NULL IDENTITY(1, 1) PRIMARY KEY
,FirstName nvarchar(100) NOT NULL
,LastName nvarchar(100) NOT NULL
);Do This:
CREATE TABLE #UseMe (
UseMeId int NOT NULL IDENTITY(1, 1) PRIMARY KEY
,FirstName nvarchar(100) NOT NULL
,LastName nvarchar(100) NOT NULL
);Parameters and variables should match the column data type, length, and precision.
The example below is how not to create parameters and variables with mismatching types (nvarchar vs. varchar) and lengths (50 vs. 100).
CREATE OR ALTER PROCEDURE dbo.BusinessEntityAction (
@FirstName AS nvarchar(100) /* ← 100 characters */
)
AS
BEGIN
SET NOCOUNT ON;
/* ↓ 50 characters */
SELECT LastName FROM dbo.Person WHERE FirstName = @FirstName;
/* ↓ 100 characters and varchar() */
DECLARE @LastName AS varchar(100) = N'martin'
/* ↓ 50 characters and nvarchar() */
SELECT FirstName FROM dbo.Person WHERE LastName = @LastName;
END;Source: When To Break Down Complex Queries
Microsoft SQL Server is able to create very efficient query plans in most cases. However, there are certain query patterns that can cause problems for the query optimizer. These problematic query patterns generally create situations in which SQL Server must either make multiple passes through data sets or materialize intermediate result sets for which statistics cannot be maintained. Or, these patterns create situations in which the cardinality of the intermediate result sets cannot be accurately calculated.
Breaking these single queries into multiple queries or multiple steps can sometimes provide SQL Server with an opportunity to compute a different query plan or to create statistics on the intermediate result set. Taking this approach instead of using query hints lets SQL Server continue to react to changes in the data characteristics as they evolve over time.
When To Break Down Complex Queries focuses on the following four problematic query patterns:
In this pattern, the condition on each side of the OR operator in the WHERE or JOIN clause evaluates different tables. This can be resolved by use of a UNION operator instead of the OR operator in the WHERE or JOIN clause.
This pattern has joins on aggregated data sets, which can result in poor performance. This can be resolved by placing the aggregated intermediate result sets in temporary tables.
This pattern has a large number of joins, especially joins on ranges, which can result in poor performance because of progressively degrading estimates of cardinality. This can be resolved by breaking down the query and using temporary tables.
This pattern has CASE operators in the WHERE or JOIN clauses, which cause poor estimates of cardinality. This can be resolved by breaking down the cases into separate queries and using the Transact-SQL IF statement to direct the flow for the conditions.
An understanding of the concepts introduced in these four cases can help you identify other situations in which these or similar patterns are causing poor or inconsistent performance; you can then construct a replacement query which will give you better, more consistent performance.
SQL injection is an attack in which malicious code is inserted into strings that are later passed to an instance of SQL Server for parsing and execution. Any procedure that constructs SQL statements should be reviewed for injection vulnerabilities because SQL Server will execute all syntactically valid queries that it receives. Even parameterized data can be manipulated by a skilled and determined attacker.
- Source SQL Injection
- TODO: See Using EXECUTE
aka. Catch-All Query or Kitchen Sink Query
If your stored procedure has multiple parameters where any one (or more) number are parameters are optional, you have a dynamic search query.
If your query is moderately complex you should use OPTION (RECOMPILE). If your query is complex, you should build the query with dynamic SQL.
You will also know this based on the WHERE clause of the query. You will see @ProductId IS NULL or have parameters wrapped in an ISNULL().
CREATE PROCEDURE dbo.SearchHistory
@ProductId int = NULL
,@OrderId int = NULL
,@TransactionType char(1) = NULL
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
SELECT
TH.ProductId
FROM
dbo.TransactionHistory AS TH
WHERE
(TH.ProductId = @ProductId OR @ProductId IS NULL)
AND (TH.ReferenceOrderId = @OrderId OR @OrderId IS NULL)
AND (TH.TransactionType = @TransactionType OR @TransactionType IS NULL)
AND (TH.Quantity = ISNULL(@childFilter, m.Child));
END;The problem is that we already have a query plan when we hit the IF @CreationDate IS NULL segment of TSQL.
CREATE OR ALTER PROCEDURE dbo.PersonSearch (@CreationDate datetime2(7) = NULL)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
IF @CreationDate IS NULL
BEGIN
SET @CreationDate = '20080101';
END;
SELECT FirstName, LastName FROM dbo.Person WHERE CreationDate = @CreationDate;
END;For simple to moderately complex queries add OPTION (RECOMPILE).
CREATE PROCEDURE dbo.SearchHistory
@ProductId int = NULL
,@OrderId int = NULL
,@TransactionType char(1) = NULL
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
SELECT
TH.ProductId
FROM
dbo.TransactionHistory AS TH
WHERE
(TH.ProductId = @ProductId OR @ProductId IS NULL)
AND (TH.ReferenceOrderId = @OrderId OR @OrderId IS NULL)
AND (TH.TransactionType = @TransactionType OR @TransactionType IS NULL)
AND (TH.Quantity = ISNULL(@childFilter, m.Child))
OPTION (RECOMPILE)/* <-- Added this */;
END;- See Dynamic Search Conditions in T‑SQL by Erland Sommarskog
Consider using sp_CRUDGen to generate the dynamic SQL query for you.
The default window function frame RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW is less performant than ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW.
Source: What is the Difference between ROWS and RANGE?
Use a Common Table Expression (CTE) to make SQL statements easier to understand and for recursive statements. Generally anything beyond the basic use of CTEs provides extra overhead and causes performance issues.
A CTE will be evaluated every time you reference it. If a CTE is referenced only once it will give the same performance as a temporary table or subquery.
Correlated subqueries can have a performance impact. Most correlated subqueries can be rewritten with joins or window functions and perform much faster.
See SQL Server Uncorrelated and Correlated Subquery
Mixing data types cause implicit conversion and they are bad for performance. Implicit conversions ruin SARGability, makes index unusable and utilize more CPU resource than required.
In the WHERE clause below you will notice the "!" mark on the SELECT indicating there is an implicit conversion. In this example the EmailPromotion column is an INT but we are treating it like a string by performing a LIKE. We get a slow table scan instead of a faster index seek.
The performance issue is that indexes won’t be used efficiently, you’ll burn CPU in the conversion process, and in the case of inadequate indexing, no missing index request will be logged. Now, SQL Server’s missing index requests aren’t anywhere near perfect, but they’re a good place to start identifying cries for help from the optimizer.

SQL code statements should be arranged in an easy-to-read manner. When statements are written all on one line or not broken into smaller easy-to-read chunks, it is hard to decipher.
Your SQL code should be formatted in a consistent manner so specific elements like keywords, data types, table names, functions can be identified at a quick glance.
Use one of the two RedGate SQL Prompt formatting styles "Team Collapsed" or "Team Expanded". If you edit T-SQL code that was in a one of the two styles, put the style back to its original style after you completed editing.
TODO: - See RedGate SQL Server Prompt
Although the semicolon isn't required for most statements prior to SQL Server 2016, it will be required in a future version. If you do not include them now database migration in the future will need to add them. Terminating semicolon are required by the ANSI SQL Standard.
Continued use of deprecated features will cause database migrations fail. An example is RAISERROR in the format RAISERROR 15600 'MyCreateCustomer'; is discontinued. RAISERROR (15600, -1, -1, 'MyCreateCustomer'); is the current syntax. A database will not migrate to a newer SQL Server version without refactoring the TSQL code.
For new development work, do not use deprecated features. For existing aplications, plan to modify applications that currently use these features as soon as possible. See Microsoft Docs.
- TODO: See Using Deprecated or Discontinued Feature
SET NOCOUNT, XACT_ABORT ON; /* <-- semicolon goes at the end here */
DECLARE @FirstName nvarchar(100); /* <-- semicolon goes at the end here */
SET @FirstName = N'Kevin'; /* <-- semicolon goes at the end here */
SELECT LastName FROM dbo.Person WHERE FirstName = @FirstName; /* <-- semicolon goes at the end here */
SELECT Balance FROM dbo.Account; /* <-- semicolon goes at the end here */
IF EXISTS (SELECT * FROM dbo.Person)
BEGIN
SELECT PersonId, FirstName, LastName FROM dbo.Person; /* <-- semicolon goes at the end here */
END; /* <-- semicolon goes at the end here */
BEGIN TRY
BEGIN TRANSACTION; /* <-- semicolon goes at the end here */
UPDATE dbo.Account SET Balance = 100.00 WHERE AccountId = 1; /* <-- semicolon goes at the end here */
UPDATE dbo.Account SET Balance = 'a' WHERE AccountId = 2; /* <-- semicolon goes at the end here */
COMMIT TRANSACTION; /* <-- semicolon goes at the end here */
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
BEGIN
ROLLBACK TRANSACTION; /* <-- semicolon goes at the end here */
END; /* <-- semicolon goes at the end here */
THROW; /* <-- semicolon goes at the end here */
END CATCH; /* <-- semicolon goes at the end here */Using square brackets [] is unnecessarily for object names. If object names are valid and not reserved words, there is no need to use square brackets. Use them only for invalid names.
Instead Of:
SELECT
P.[FirstName]
,P.[MiddleName]
,P.[LastName]
FROM
[dbo].[Person] AS PDo This:
/* Use this instead */
SELECT
P.FirstName
,P.MiddleName
,P.LastName
FROM
dbo.Person AS PYou need to put an N in from of your strings to ensure the characters are converted to Unicode before being placed into a nvarchar column.
In the example below FirstName is varchar(100) and LastName is nvarchar(100).
INSERT INTO dbo.Person (FirstName, LastName)
VALUES ('Kevin', N'马丁');Not converting to Unicode for nvarchar() columns will also cause implicit conversions which will make a query non-SARGable in WHERE clauses.
TODO: - See Using a Non-SARGable Expression in a WHERE Clause
Use the full name like in DATEDIFF(YEAR, StartDate, EndDate) vs DATEDIFF(YY, StartDate, EndDate).
You should inline your scalar function in SQL queries. This means duplicate the code you would put in the scalar function in your SQL code. SQL Server 2019 & Azure SQL Database (150 database compatibility level) can inline some scalar functions.
Microsoft has been removing (instead of fixing) the inlineablity of scalar functions with every cumulative update. If your query requires scalar functions you should ensure they are being inlined. Reference: Inlineable scalar UDFs requirements
Run this query to check if your function is inlineable. (SQL Server 2019+ & Azure SQL Server)
SELECT
[Schema] = SCHEMA_NAME(O.schema_id)
,Name = O.name
,FunctionType = O.type_desc
,CreatedDate = O.create_date
FROM
sys.sql_modules AS SM
INNER JOIN sys.objects AS O ON O.object_id = SM.object_id
WHERE
SM.is_inlineable = 1;Scalar UDFs typically end up performing poorly due to the following reasons:
Iterative invocation: UDFs are invoked in an iterative manner, once per qualifying tuple. This incurs additional costs of repeated context switching due to function invocation. Especially, UDFs that execute Transact-SQL queries in their definition are severely affected.
Lack of costing: During optimization, only relational operators are costed, while scalar operators are not. Prior to the introduction of scalar UDFs, other scalar operators were generally cheap and did not require costing. A small CPU cost added for a scalar operation was enough. There are scenarios where the actual cost is significant, and yet remains underrepresented.
Interpreted execution: UDFs are evaluated as a batch of statements, executed statement-by-statement. Each statement itself is compiled, and the compiled plan is cached. Although this caching strategy saves some time as it avoids recompilations, each statement executes in isolation. No cross-statement optimizations are carried out.
Serial execution: SQL Server does not allow intra-query parallelism in queries that invoke UDFs.
If your scalar function is not inlineable it will perform poorly.
Review the Inlineable scalar UDFs requirements to determine what changes you can make so it can go inline. If you cannot, you should in-line your scalar function in SQL query. This means duplicate the code you would put in the scalar function in your SQL code. SQL Server 2019 & Azure SQL Database (150 database compatibility level) can inline some scalar functions.
- See 05c Blueprint Functions Scalar Function Rewrites Demo video by Erik Darling to see how to rewrite T-SQL Scalar User Defined Function into a Inline Table Valued function.
Microsoft has been removing (instead of fixing) the inlineablity of scalar functions with every cumulative update. If your query requires scalar functions, you should ensure they are being inlined. Reference: Inlineable scalar UDFs requirements
Run this query to check if your function is inlineable. (SQL Server 2019+ & Azure SQL Server)
SELECT
[Schema] = SCHEMA_NAME(O.schema_id)
,Name = O.name
,FunctionType = O.type_desc
,CreatedDate = O.create_date
FROM
sys.sql_modules AS SM
INNER JOIN sys.objects AS O ON O.object_id = SM.object_id
WHERE
SM.is_inlineable = 1;Avoid using the ISNUMERIC() function, because it can often lead to data type conversion errors. If you’re working on SQL Server 2012 or later, it’s much better to use the TRY_CONVERT() or TRY_CAST() function instead. On earlier SQL Server versions, the only way to avoid it is by using LIKE expressions.
The ISNULL function and the COALESCE expression have a similar purpose but can behave differently.
- Because
ISNULLis a function, it's evaluated only once. As described above, the input values for theCOALESCEexpression can be evaluated multiple times. - Data type determination of the resulting expression is different.
ISNULLuses the data type of the first parameter,COALESCEfollows theCASEexpression rules and returns the data type of value with the highest precedence. - The NULLability of the result expression is different for
ISNULLandCOALESCE. - Validations for
ISNULLandCOALESCEare also different. For example, a NULL value forISNULLis converted to int though forCOALESCE, you must provide a data type. ISNULLtakes only two parameters. By contrastCOALESCEtakes a variable number of parameters.
Source: Microsoft Docs: Comparing COALESCE and ISNULL
- Use
TRIM(string)instead ofLTRIM(RTRIM(string)) - When comparing a string for blank it is unnecessary to trim the string before the comparison. The examples below are two ways to check for parameter/variable blanks.
DECLARE @String nvarchar(100) = N' '
IF @String = N''
BEGIN
/* Do the thing here */
END
IF LEN(@String) = 0
BEGIN
/* Do the thing here */
END- If your database is set to 'case insensitive', you do not need to use the
LOWER(string)function when comparing two strings.- Execute the query
SELECT CONVERT(varchar(256), SERVERPROPERTY('collation'));to verify the database shows it is a 'case insensitive' collation (_CI_). The default SQL Server collation is 'SQL_Latin1_General_CP1_CI_AS'.
- Execute the query
Do not use EXECUTE('SQL script'); to execute T-SQL command. The EXEC() or EXECUTE() command is retained for backward compatibility and is susceptible to SQL injection.
Instead use sp_executesql as it allows parameter substitutions. Using parameters allows SQL Server to reuse the execution plan and avoid execution plan pollution.
DATALENGTH() can give you an incorrect length with fixed length data types like char() use LEN().
Sample Query
DECLARE @FixedString AS char(10) = 'a';
SELECT
WrongLength = DATALENGTH(@FixedString)
,CorrectLength = LEN(@FixedString);Query Results
| WrongLength | CorrectLength |
|---|---|
| 10 | 1 |
- Use
TRIM(string)instead ofLTRIM(RTRIM(string)) - When comparing a string for blank it is unnecessary to trim the string before the comparison. The examples below are two ways to check for parameter/variable blanks.
DECLARE @String nvarchar(100) = N' ';
IF @String = N''
BEGIN
/* Do the thing here */
END;
IF LEN(@String) = 0
BEGIN
/* Do the thing here */
END;- If your database is set to 'case insensitive', you do not need to use the
LOWER(string)function when comparing two strings.- Execute the query
SELECT CONVERT(varchar(256), SERVERPROPERTY('collation'));to verify the database shows it is a 'case insensitive' collation (_CI_). The default SQL Server collation is 'SQL_Latin1_General_CP1_CI_AS'.
- Execute the query
Excessive use of parentheses () makes code difficult to understand and maintain.
If the query has multiple AND OR conditions, then it is necessary to use parentheses to ensure correct order of operation.
There are different methodologies for handling errors that originate in a database. New applications should use the THROW methodologies.
In most cases it is best to bubble up (THROW) the error to the application/client to be displayed to the user and logged.
The sample stored procedures below can be used to wire up and test software code to ensure errors are bubbled up, and the user is notified, and error data is logged. After each sample stored procedure below is commented out code to execute each of them.
TODO:- See Using RAISERROR Instead of THROW TODO:- See Not Using Transactions
This error catching and trowing methodology is the newest. THROW, introduced in SQL Server 2012 and raises an exception and transfers execution to a CATCH block of a TRY...CATCH construct.
The return code methodology utilizes RETURN. RETURN, exits unconditionally from a query or procedure. RETURN is immediate and complete and can be used at any point to exit from a procedure, batch, or statement block. Statements that follow RETURN are not executed.
When THROW is utilized, a return code is not assigned. RETURN was commonly utilized with RAISERROR which never aborts execution, so RETURN could be used afterwards. (TODO:See Using RAISERROR Instead of THROW). Utilizing RAISERROR with the return code would provide context to the error that occurred to present to the user and log the error.
This methodology utilizes stored procedure OUTPUT parameters. Here you can set a return code and a return message that is passed back to the software code to present to the user and log the error
New applications should use THROW instead of RAISERROR
TODO:- See Using RAISERROR Instead of THROW.
/**********************************************************************************************************************/
CREATE OR ALTER PROCEDURE dbo.TestTHROW (
@ThowSystemError bit = 0
,@ThowCustomError bit = 0
,@ThrowMultipleErrors bit = 0 /* Only works on SQL Server and not Azure SQL Databases. */
)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
IF @ThowSystemError = 1
BEGIN
BEGIN TRY
BEGIN TRANSACTION;
SELECT DivideByZero = 1 / 0 INTO
#IgnoreMe1;
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
BEGIN
ROLLBACK TRANSACTION;
END;
/* Handle the error here, cleanup, et cetera.
In most cases it is best to bubble up (THROW) the error to the application/client to be displayed to the user and logged.
*/
THROW;
END CATCH;
END;
IF @ThowCustomError = 1
BEGIN
DECLARE @ErrorMessageText nvarchar(2048);
BEGIN TRY
BEGIN TRANSACTION;
SELECT JustAOne = 1 INTO
#IgnoreMe2;
/* Custom error check */
IF @@ROWCOUNT = 1
BEGIN
SET @ErrorMessageText = N'Two rows were expected to be impacted.';
END;
/* Another custom error check */
IF @@ROWCOUNT = 3
BEGIN
/* https://docs.microsoft.com/en-us/sql/t-sql/language-elements/throw-transact-sql?view=sql-server-ver15#c-using-formatmessage-with-throw */
SET @ErrorMessageText = N'Three rows were expected to be impacted.';
END;
/* Check if we have any errors to throw */
IF @ErrorMessageText <> ''
BEGIN
; THROW 50001, @ErrorMessageText, 1;
END;
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
BEGIN
ROLLBACK TRANSACTION;
END;
/* Handle the error here, cleanup, et cetera.
In most cases it is best to bubble up (THROW) the error to the application/client to be displayed to the user and logged.
*/
THROW;
END CATCH;
END;
IF @ThrowMultipleErrors = 1
BEGIN
BEGIN TRY
BACKUP DATABASE master TO DISK = 'E:\FOLDER_NOT_EXISTS\test.bak';
END TRY
BEGIN CATCH
/* Handle the error here, cleanup, et cetera.
In most cases it is best to bubble up (THROW) the error to the application/client to be displayed to the user and logged.
*/
THROW;
END CATCH;
END;
END;
GO
/* Execute stored procedure
DECLARE @ReturnCode int = NULL;
EXECUTE @ReturnCode = dbo.TestTHROW
-- Set both parameters to 0 (zero) will not throw an error --
@ThowSystemError = 0 -- Set to 1 will throw a system generated error (8134: Divide by zero error encountered.) --
,@ThowCustomError = 0 -- Set to 1 will throw a custom error (50001: Two rows were expected to be impacted.) --
,@ThrowMultipleErrors = 0; -- Set to 1 will throw multiple error (3201: Cannot open backup device...) OR (911: Database 'AdventureWorks2019' does not exist. Make sure that the name is entered correctly.) AND (3013: BACKUP DATABASE is terminating abnormally.) NOTE: Will not work on an Azure SQL Database. --
-- NOTE: There is no return code when an error is THROWN --
SELECT ReturnCode = @ReturnCode;
GO
*/
/**********************************************************************************************************************/
CREATE OR ALTER PROCEDURE dbo.TestReturnCode (
@ReturnDefaultReturnCode bit = 0
,@ReturnSystemErrorReturnCode bit = 0
,@ReturnCustomReturnCode bit = 0
)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
IF @ReturnDefaultReturnCode = 1
BEGIN
/* The return code will automatically be 0 (zero) even if it is not specified */
SELECT JustAOne = 1 INTO
#IgnoreMe1;
END;
IF @ReturnSystemErrorReturnCode = 1
BEGIN
BEGIN TRY
SELECT DivideByZero = 1 / 0 INTO
#IgnoreMe2;
END TRY
BEGIN CATCH
/* Handle the error here, cleanup, et cetera.
In most cases it is best to bubble up (THROW) the error to the application/client to be displayed to the user and logged.
*/
RETURN ERROR_NUMBER();
END CATCH;
END;
IF @ReturnCustomReturnCode = 1
BEGIN
DECLARE @ReturnCode int;
SELECT JustAOne = 1 INTO
#IgnoreMe3;
IF @@ROWCOUNT <> 2
BEGIN
SET @ReturnCode = 123123;
END;
/* Handle the error here, cleanup, et cetera.
In most cases it is best to bubble up (THROW) the error to the application/client to be displayed to the user and logged.
*/
RETURN @ReturnCode;
END;
END;
GO
/* Execute stored procedure
DECLARE @ReturnCode int;
EXECUTE @ReturnCode = dbo.TestReturnCode
@ReturnDefaultReturnCode = 0 -- Set to 1 to see the default return code 0 (zero). All parameters set to 0 will also be the default return code of 0 (zero). --
,@ReturnSystemErrorReturnCode = 0 -- Set to 1 to see a system error return code (8134:) --
,@ReturnCustomReturnCode = 0; -- Set to 1 to see a custom return code (123123:) --
SELECT ReturnCode = @ReturnCode;
GO
*/
/**********************************************************************************************************************/
CREATE OR ALTER PROCEDURE dbo.TestReturnCodeParameter (
@ReturnError bit = 0
,@ReturnCode int = 0 OUTPUT
,@ReturnMessage nvarchar(2048) = N'' OUTPUT
)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
IF @ReturnError = 0
BEGIN
SET @ReturnCode = 0;
SET @ReturnMessage = N'';
END;
ELSE
BEGIN
BEGIN TRY
SELECT DivideByZero = 1 / 0 INTO
#IgnoreMe2;
END TRY
BEGIN CATCH
/* Handle the error here, cleanup, et cetera.
In most cases it is best to bubble up (THROW) the error to the application/client to be displayed to the user and logged.
*/
SET @ReturnCode = ERROR_NUMBER();
SET @ReturnMessage = ERROR_MESSAGE();
END CATCH;
END;
END;
GO
/* Execute stored procedure
DECLARE
@ReturnCode int
,@ReturnMessage nvarchar(2048);
EXECUTE dbo.TestReturnCodeParameter
@ReturnError = 0 -- Set to 1 will simulate a return code (8134) and return message (Divide by zero error encountered.) in the output parameters. --
,@ReturnCode = @ReturnCode OUTPUT
,@ReturnMessage = @ReturnMessage OUTPUT;
SELECT ReturnCode = @ReturnCode, ReturnMessage = @ReturnMessage;
GO
*/
/**********************************************************************************************************************/
CREATE OR ALTER PROCEDURE dbo.TestRAISERROR (@ThowSystemError bit = 0, @ThowCustomError bit = 0)
AS
BEGIN
/* New applications should use THROW instead of RAISERROR. https://docs.microsoft.com/en-us/sql/t-sql/language-elements/raiserror-transact-sql?view=sql-server-ver15#:~:text=the%20raiserror%20statement%20does%20not%20honor%20set%20xact_abort.%20new%20applications%20should%20use%20throw%20instead%20of%20raiserror. */
/* SET NOCOUNT, XACT_ABORT ON; */
SET NOCOUNT ON; /* The RAISERROR statement does not honor SET XACT_ABORT. */
IF @ThowSystemError = 1
BEGIN
BEGIN TRY
BEGIN TRANSACTION;
SELECT DivideByZero = 1 / 0 INTO
#IgnoreMe1;
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
BEGIN
ROLLBACK TRANSACTION;
END;
/* Handle the error here, cleanup, et cetera.
In most cases it is best to bubble up (THROW) the error to the application/client to be displayed to the user and logged.
*/
DECLARE @ErrorMessage nvarchar(2048) = ERROR_MESSAGE();
RAISERROR(@ErrorMessage, 16, 1);
RETURN 1;
END CATCH;
END;
IF @ThowCustomError = 1
BEGIN
BEGIN TRY
BEGIN TRANSACTION;
SELECT DivideByZero = 1 / 0 INTO
#IgnoreMe2;
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
BEGIN
ROLLBACK TRANSACTION;
END;
/* Handle the error here, cleanup, et cetera.
In most cases it is best to bubble up (THROW) the error to the application/client to be displayed to the user and logged.
*/
RAISERROR(N'My Custom Error.', 16, 1);
RETURN 1;
END CATCH;
END;
END;
GO
/* Execute stored procedure
DECLARE @ReturnCode int;
EXECUTE @ReturnCode = dbo.TestRAISERROR
-- Set both parameters to 0 (zero) will not throw an error --
@ThowSystemError = 0 -- Set to 1 will throw a system generated error (50000: Divide by zero error encountered.) --
,@ThowCustomError = 0; -- Set to 1 will throw a system generated error (50000: My Custom Error.) --
SELECT ReturnCode = @ReturnCode
GO
*/New applications should use THROW instead of RAISERROR
The RAISERROR statement does not honor SET XACT_ABORT.
TODO:- See Not Using SET XACT_ABORT ON
RAISERROR never aborts execution, so execution will continue with the next statement.
A use case exception for using RAISERROR instead of THROW is for legacy compatibility reasons. THROW was introduced in SQL Server 2012 so when making modification on this code THROW can break the current code.
TODO:- See Not Using Transactions
THROW is not a reserved keyword so it could be used as a transaction name or savepoint. Always use a BEGIN...END block after the IF statement in the BEGIN CATCH along with a terminating semicolon.
TODO:- See Not Using BEGIN END TODO:- See Not Using Semicolon to Terminate Statements
Use this:
SET NOCOUNT, XACT_ABORT ON;
BEGIN TRY
BEGIN TRANSACTION;
SELECT 1 / 0;
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
BEGIN
ROLLBACK TRANSACTION;
END;
THROW;
END CATCH;Instead of this:
SET NOCOUNT, XACT_ABORT ON;
BEGIN TRY
BEGIN TRANSACTION;
SELECT 1 / 0;
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
ROLLBACK TRANSACTION
THROW;
END CATCH;Overview
This test was run with 10 million header table rows and 100 million detail table rows. The stored procedure code summarized 10-11 detail amounts for 10 thousand header rows. This query type was chosen as a sort of simulation for querying the database for an export file or report. If your use case is a lighter weight query like a operational search to display totals in a paginated table, it will be much more performant.
There was no significant difference in execution times between summarizing just the detail amount and summarizing the detail amount and subtracting from a header starting balance, to not have to separate results in this assessment.
Test Methods
- A 'header total' view was created that summed the 'detail total' column and grouped by a header record primary key.
- A stored procedure was created where the less than or equals to (<=) operator was used in the
WHEREpredicate.
- A stored procedure was created where the less than or equals to (<=) operator was used in the
- A 'header balance' view was created that subtracted a 'starting amount' from the summed 'detail total' column and grouped by a header record primary key.
- A stored procedure was created where the less than or equals to (<=) operator was used in the
WHEREpredicate.
- A stored procedure was created where the less than or equals to (<=) operator was used in the
Assessment
The stored procedure is run twice, once to warm up the memory cache, and run again against the data pages in cache. Note: if you scale your Azure SQL Database to save on costs you will need to endure the 1st execution time after each tier scaling.
SQL Server is performant with this type of calculated total value query, but you still need to run it on an instance tier that is meant for a dev/test environment. Use the results below to assess how fast you need the query to perform.
100 Million Detail Rows

Overview
Using a totaled or balanced value for a search parameter will always scan the index. In order for the SQL Server engine to output a result set it must load the data from storage first. That is why seeks are generally much faster. This scan for a calculated totaled or balance value must load the entire table index into memory.
Your performance outcome will be based on factors like database rows count, indexing, compute, storage, memory, and SQL Server edition. Ensure the end user/client/customer understands and approves the performance impact on using a transaction processing (OLTP) system for these types of queries instead of analytical processing (OLAP) system. OLAP/data warehouse systems that pre-aggregated data can be cost prohibitive for some.
The test was performed with three different calculated total or balance value and operator methods. There were some differences in the execution times for the three different methods but close enough to not have to separate the results in this assessment.
The test tables are as lightweight as a table could be, so this is the fastest you should ever expect a query to execute. Pay close attention to creating slim, single purpose indexes that includes the amount column for calculating total or balance value functionality to minimize pulling data from disk into memory cache. SQL Server Enterprise edition will do a better job at this with the read-ahead read feature.
Some of the execution times double or half based on deleting the execution plans and the next execution plan created went parallel or did not go parallel.
It did not matter for performance whether a CTE, view, or derived table is used to calculate the total or balance values.
Test Methods
- A 'header total' view was created that summed the 'detail total' column and grouped by a header record primary key.
- A stored procedure was created where the equals (=) operator was used in the
WHEREpredicate. - A stored procedure was created where the greater than (>) operator was used in the
WHEREpredicate.
- A stored procedure was created where the equals (=) operator was used in the
- A 'header balance' view was created that subtracted a 'starting amount' from the summed 'detail total' column and grouped by a header record primary key.
- A stored procedure was created where the greater than (>) operator was used in the
WHEREpredicate.
- A stored procedure was created where the greater than (>) operator was used in the
Assessment
Each of the three stored procedures are run twice, once to warm up the memory cache, then run again against the data pages in cache. Note: if you scale your Azure SQL Database to save on costs you will need to endure the 1st execution time after each tier scaling.
You can note below how the more database table rows you have, and the more thinly provisioned instance you have, the longer the execution times are.
Use the results below to assess how fast you need the query to perform and talk with the client or end user on how many future rows will be added to the tables and how that will impact the performance.
10 Thousand Detail Rows

100 Thousand Detail Rows

1 Million Detail Rows

10 Million Detail Rows

100 Million Detail Rows

You will need to determine if the personal data like PII, and PHI needs to be protected at rest, in transit or both.
With SQL Server you have a couple of choices to implement hashing or encryption
- SQL Server Always Encrypt
- SQL Server Transparent Data Encryption (TDE)
- You could develop your own or utilize a development framework pattern to implement a custom one-way hashing, hashing with salting or encryption using AES-128, AES-192, AES-256.
A placeholder is an empty row/record that is created to hold the place of some potential future data in the row that may or may not be necessary.
While placeholder rows do not violate database normalization rules, it is not considered a best practice to create "empty" rows. Row data should only be created when it is materialized. If the row data does not exist, it should not be inserted. If the row data is removed, the row should be hard or soft deleted. Empty rows are not free, there is overhead space allocated with placeholder rows, which can impact performance.
Having the unnecessary placeholder rows can muddy queries that now would need to include IS NOT NULL or LEN(PhoneNumber) > 0 to exclude these placeholder rows on other queries.
Use the default Collation of “SQL_Latin1_General_CP1_CI_AS” unless you fully understand when to use a different collation. Collation differences between user databases and tempdb can cause conflicts especially when comparing string values.
Application connection strings should be set up to be scalable. 3 different connection strings are recommended.
In the beginning, all three connection strings below will have the same content – they will all point to your production database server. When you need to scale, though, the production DBA can use different techniques to scale out each of those tiers.
- Writes with Real-Time Reads
- This connection is hard to scale, so keep the number of queries here to a minimum.
- Treat this like a valuable resource.
- Functions like inserting or modifing database rows, then redirecting or displaying the data directly afterwards would fall into the use case pattern. Determine if it is necessary to redirect to a display UI, or just notify the user of the action. In high usage databases, performing additional database queries could consume resources unnecessarly.
- Indicate on the connection string
ApplicationIntent=ReadWrite. - Determine the
MultiSubnetFailoverproperty ofTrueorFalse
- No Writes with Reads That Can Tolerate Data Older Than 15 Seconds
- This connection string has more options to scale out. This is where the majority of queries should go.
- Think of this as the default connection string.
- Indicate on the connection string
ApplicationIntent=ReadOnly. - Determine the
MultiSubnetFailoverproperty ofTrueorFalse
- No Writes with Reads That Can Tolerate Data Older Than Several Hours
- This connection is for operational reporting, and not to be confused with analytical reporting aggregations like
SUM(),COUNT(),AVG(), ... reporting. True analytical reporting should be performed in a system like a data warehouse or Online Analytical Arocessing (OLAP) system. - Queries of these types utilize higher amounts of CPU and storage Input/Output.
- Stakeholders will eventually have to decide whether to prioritize near-real-time data for reports at the expense of slowing down production, or to separate these resource-intensive queries to a data source with a longer delay.
- Indicate on the connection string
ApplicationIntent=ReadOnly. - Determine the
MultiSubnetFailoverproperty ofTrueorFalse
- This connection is for operational reporting, and not to be confused with analytical reporting aggregations like
It is best practice to implement client code to mitigate connection errors and transient errors that your client application encounters when communicating with a SQL Server (On-premises SQL Server, Azure SQL Database, Azure SQL Managed Instance and Azure Synapse Analytics).
SQL Server might be in the process of shifting hardware resources to better load-balance or fail over in a HA/DR (High Availability / Disaster Recover). When this occurs, there will be a time normally 60 seconds where your app might have issues with connecting to the database.
Applications that connect to a SQL Server should be built to expect these transient errors. To handle them, implement retry logic in their code instead of surfacing them to users as application errors.
.NET 4.6.1 or later (or .NET Core) can use the .NET SqlConnection parameters for connection retry.
Ensure you are using the failover group name or availability group listener name in your connection string. The SQL Server name should not be something like 'SQL01'. This indicates you are connecting directly to a specific SQL Server instance instead of a group of SQL Servers.
Users that only access one database should generally be created as contained users which means they do not have a SQL Server Login and are not found as users in the master database. This makes the database portable by not requiring a link to a SQL Server Login. A database with contained users can be restored to your development SQL Server or a migration event needs to occur in production to a different SQL Server.
You will want to give an account or process only those privileges which are essential to perform its intended function. Start your development with the app user account only a member of the db_reader, db_writer and db_executor roles.
When a vulnerability is found in the code, service, or operating system the "Principle of least privilege" lessens the blast radius of damage caused by hackers and malware.
There are query execution defaults included in SSMS (SQL Server Management Studio) and Visual Studio. These defaults must be maintained or overridden at the connection or session level if needed. If the defaults are not consistently used certain TSQL script, stored procedures or functions might not behave as developed.
When dealing with indexes on computed columns and indexed views, four of these defaults (ANSI_NULLS, ANSI_PADDING, ANSI_WARNINGS, and QUOTED_IDENTIFIER) must be set to ON. These defaults are among seven SET options that must be assigned the required values when you are creating and changing indexes on computed columns and indexed views.
The other three SET options are ARITHABORT (ON), CONCAT_NULL_YIELDS_NULL (ON), and NUMERIC_ROUNDABORT (OFF). For more information about the required SET option settings with indexed views and indexes on computed columns, see Considerations When You Use the SET Statement.
It is not best practice to modify these query execution settings at the SQL Server level.
In SSMS (SQL Server Management Studio) and Visual Studio these 5 ANSI execution settings are on by default: QUOTED_IDENTIFIER, ANSI_PADDING, ANSI_WARNINGS, ANSI_NULLS, ANSI_NULL_DFLT_ON
These two advanced execution settings are on by default: ARITHABORT, CONCAT_NULL_YIELDS_NULL
Visual Studio database projects should be setup with the 7 query execution SET defaults (Project Settings > ‘Database Settings’ button). If there have been publish database objects without these query execution defaults, they will need to be updated. It is possible to check the “Ignore quoted identifiers” and “Ignore ANSI Nulls” under the ‘Advanced’ button when manually publishing the database project.
- See SET Statements
- Source SET ANSI_DEFAULTS (Transact-SQL)