-
Notifications
You must be signed in to change notification settings - Fork 49
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
2024.11.7新增 技术分享 | 大语言模型增强灰盒模糊测试技术探索
- Loading branch information
1 parent
6351460
commit d1d2cfc
Showing
4 changed files
with
97 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,97 @@ | ||
| --- | ||
| layout: post | ||
| title: "技术分享 | 大语言模型增强灰盒模糊测试技术探索" | ||
| date: 2024-11-07 16:00:00 | ||
| author: "安全极客" | ||
| header-img: "img/post-bg-unix-linux.jpg" | ||
| catalog: true | ||
| tags: | ||
| - Security | ||
| - AIGC | ||
| - LLMS | ||
| --- | ||
|
|
||
| 大语言模型凭借其庞大的参数规模,能够通过无监督学习从海量文本中获取知识,从而不仅能够深刻理解文本语义,还能准确识别文本的格式和结构。凭借对不同数据结构的深度理解,大语言模型已在众多领域得到广泛应用。其中,尤其是在软件测试任务中的灰盒模糊测试中,大语言模型展现出了独特的优势。本文旨在深入探讨大语言模型如何增强灰盒模糊测试技术,并展望其在未来测试领域的应用前景。 | ||
|
|
||
| ## 灰盒模糊测试概述 | ||
|
|
||
| 模糊测试是一种自动化测试方法,其通过向目标程序输入大量随机或变异的数据,观察程序是否发生崩溃或产生异常行为,进而检测出潜在的漏洞。模糊测试主要有三种类型:黑盒模糊测试、白盒模糊测试和灰盒模糊测试。黑盒模糊测试完全不依赖程序的内部结构,而是通过盲目生成数据进行测试;白盒模糊测试则依赖程序的源代码,结合静态分析进行测试;灰盒模糊测试则介于两者之间,通过运行时动态分析来指导测试用例生成,优化测试效果。 | ||
|
|
||
| 灰盒模糊测试通过覆盖率信息(Coverage Information)来指导输入生成,利用程序执行中的反馈信息(如代码覆盖率)调整输入数据的生成方式,以最大化程序路径的覆盖范围。尽管灰盒模糊测试在测试效率和效果上优于黑盒测试,但其仍面临一些挑战,尤其是在输入生成和变异策略方面难以触及深层次的逻辑漏洞。 | ||
|
|
||
| ## 大语言模型应用 | ||
|
|
||
| 近年来,随着深度学习的快速发展,大语言模型展现出强大的自然语言理解和生成能力。具体到软件测试领域,大语言模型可以帮助分析程序的输入和输出,生成更加语义化的测试数据,从而提高模糊测试的覆盖率和深度。 | ||
|
|
||
| 大语言模型的引入为灰盒模糊测试带来了全新的思路。传统的模糊测试主要依赖随机或基于启发式的输入生成和变异策略,难以有效触发复杂逻辑漏洞。而大语言模型具备对自然语言、代码语义和数据结构的深刻理解,能够在测试过程中生成更加符合上下文的输入数据,这使得其在提高测试用例的多样性和覆盖率方面具有天然优势。 | ||
|
|
||
| **1. 测试用例生成** | ||
|
|
||
| 大语言模型在模糊测试中的一个核心应用场景是测试用例生成。不同于传统的模糊测试工具依赖随机变异或固定模板生成输入数据,LLMs可以基于目标程序的API、文档和注释,智能地推断出合理的输入格式和结构。例如,针对一个需要JSON格式数据的程序,LLMs能够分析并生成符合JSON格式的输入,同时保留一定的变异性,以测试程序在处理不同输入格式时的鲁棒性。 | ||
|
|
||
| 此外,LLMs在生成输入时可以结合语义信息。例如,在处理API测试时,LLMs不仅能理解API的输入参数类型,还能根据API的功能推断出可能的输入场景,从而生成更具针对性的测试用例。这种语义化的输入生成能力,极大地提升了模糊测试的有效性。 | ||
|
|
||
| **2. 代码覆盖率优化** | ||
|
|
||
| 在灰盒模糊测试中,代码覆盖率是衡量测试质量的一个重要指标。高覆盖率意味着测试工具能够更好地探索程序的不同执行路径,从而提高发现漏洞的机会。大语言模型的引入使得灰盒模糊测试能够更有效地提升代码覆盖率,特别是在面对复杂逻辑或特定格式的输入时,大语言模型能够通过理解代码中的语义信息,生成更具针对性的输入,从而触发更多代码路径。 | ||
|
|
||
| 通过大语言模型生成的测试用例,灰盒模糊测试工具能够突破传统工具难以覆盖的深层逻辑区域。例如,针对具有复杂输入约束的函数,大语言模型可以推断出更符合逻辑的输入,从而触发隐藏的代码分支,显著提高代码覆盖率。 | ||
|
|
||
| **3. 变异策略优化** | ||
|
|
||
| 模糊测试的核心在于输入的变异,传统的模糊测试工具通常依赖随机或基于启发式的变异策略,这些策略虽然在简单场景下表现良好,但在复杂逻辑面前往往难以奏效。大语言模型凭借其对上下文语义的理解,可以生成更加智能化的变异策略。 | ||
|
|
||
| 通过分析程序的输入格式和逻辑,大语言模型能够识别出哪些部分的输入数据可以进行变异,以及如何进行变异以触发新的代码路径。例如,针对一个文件解析程序,大语言模型能够生成不同的文件格式变种,测试程序在处理不同文件结构时的行为。这种智能化的变异策略,不仅能够显著提升模糊测试的效率,还能帮助发现一些深层次的逻辑漏洞。 | ||
|
|
||
| **4. 错误检测与输入语义分析** | ||
|
|
||
| 大语言模型在模糊测试中的另一个重要应用是错误检测与输入语义分析。传统的模糊测试工具通常依赖程序的崩溃或异常输出来判断漏洞的存在,而大语言模型则能够通过对程序运行结果的语义分析,识别出潜在的错误模式。 | ||
|
|
||
| 例如,大语言模型可以通过分析程序的日志输出,推断出程序在处理某些输入时是否存在潜在的逻辑错误或安全漏洞。相比于单纯依赖程序的崩溃或异常,大语言模型的语义分析能力可以帮助测试人员更早发现问题,并提供更为详细的错误报告。这种基于语义的错误检测机制,使得模糊测试不局限于发现程序崩溃,还能捕捉到更深层次的逻辑漏洞。 | ||
|
|
||
| **5. 反馈机制智能化** | ||
|
|
||
| 灰盒模糊测试中的反馈机制是指导输入生成的关键。通过分析程序运行时的反馈信息(如代码覆盖率、执行路径等),模糊测试工具可以调整输入生成策略,以最大化测试覆盖范围。大语言模型结合这些反馈信息,可以动态优化输入生成过程。 | ||
|
|
||
| 例如,当测试工具发现某些输入类型能够触发更多的代码路径时,大语言模型可以根据这一反馈生成更多类似的输入,从而进一步提高覆盖率。通过这种智能化的反馈机制,大语言模型能够帮助模糊测试工具在测试过程中不断优化自身,提高测试效率。 | ||
|
|
||
| ## 模糊测试智能体 | ||
|
|
||
| 大语言模型在应用于模糊测试时,显著增强了原有技术的能力。基于此思路,云起无垠研发设计了无垠模糊测试智能体,该智能体在软件安全漏洞挖掘和修复的场景中获得了广泛应用,并且取得了十分显著的效果。 | ||
|
|
||
| **1. AI Agent赋能漏洞自动化挖掘** | ||
|
|
||
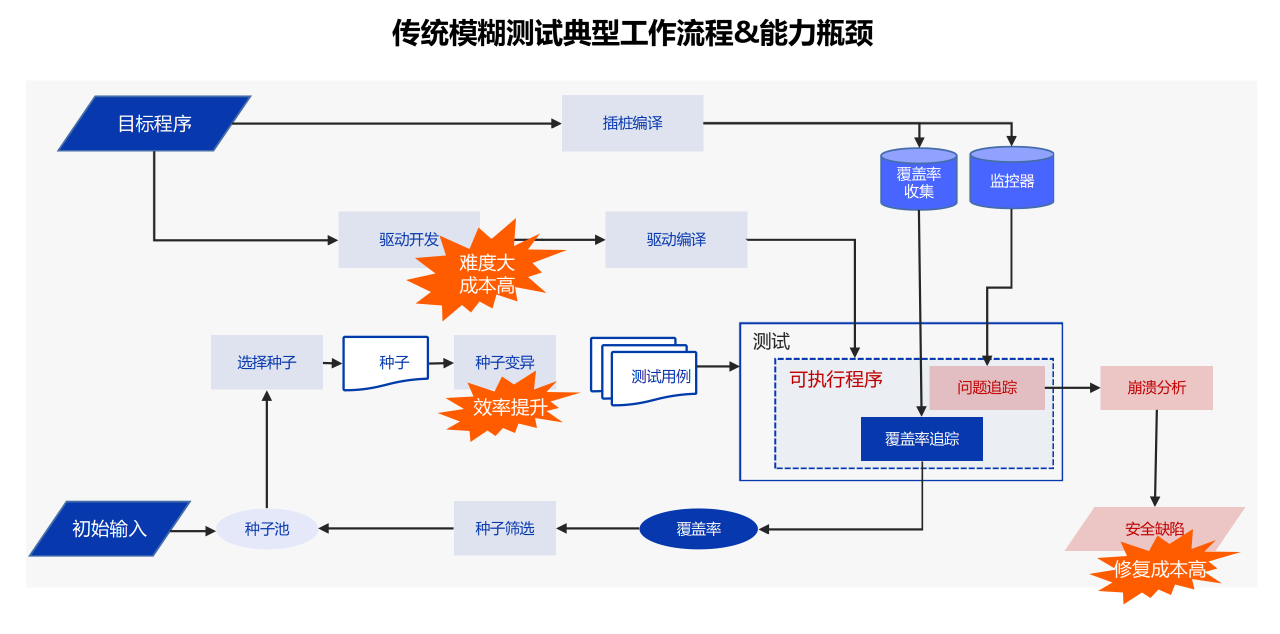
| 模糊测试是一种公认的强大软件测试技术,能够有效检测安全漏洞。然而,在实际应用中,这一技术面临测试驱动开发难度大、种子变异效率低,以及安全缺陷修复成本高等挑战。 | ||
|
|
||
|  | ||
|
|
||
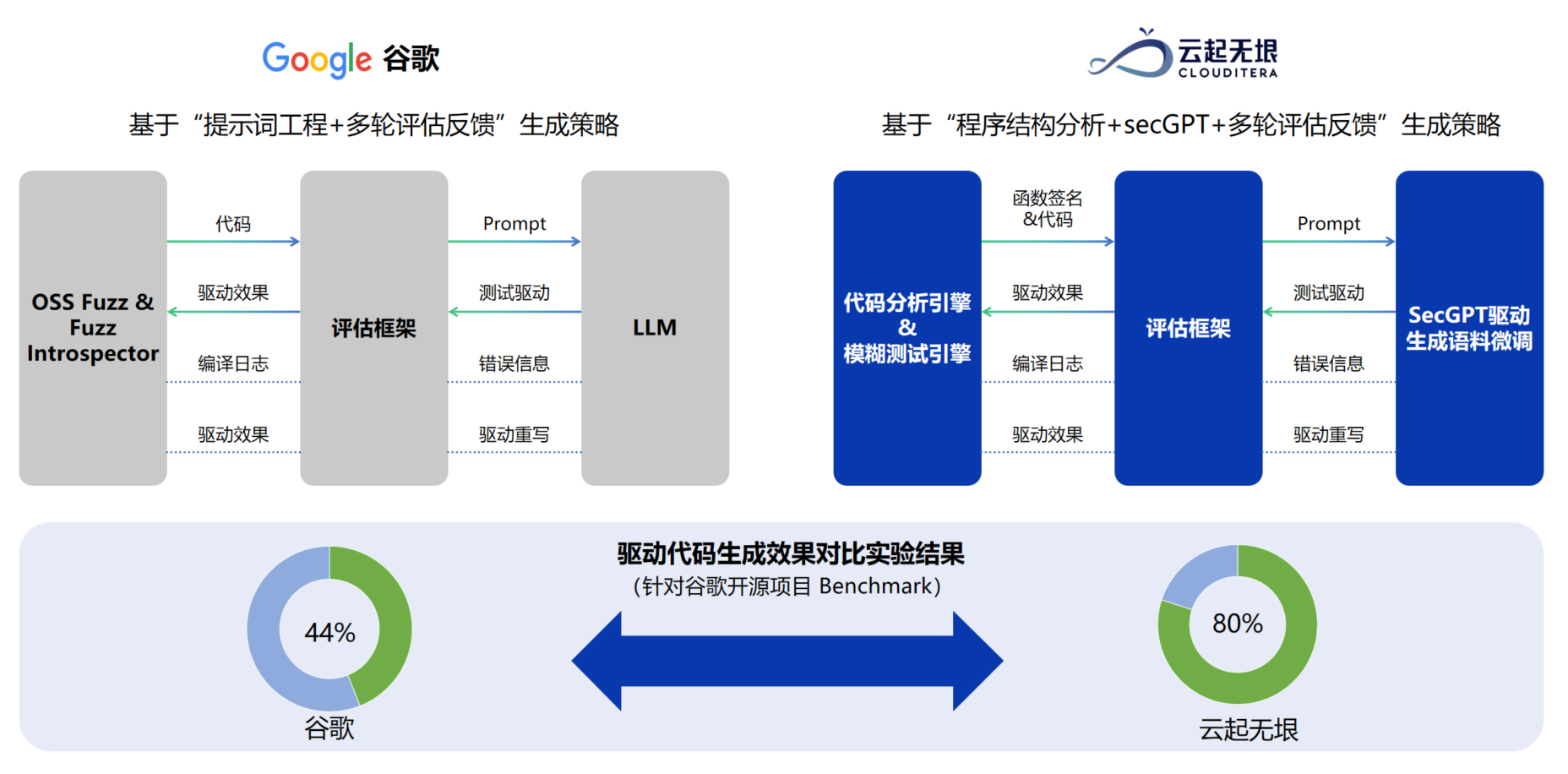
| 传统的测试驱动生成大多基于专家知识或语法分析,技术门槛高且使用困难。为解决这一难题,云起无垠提出了基于“微调代码模型+代码详细结构+反馈”的驱动生成方案。其核心思路如下: | ||
|
|
||
| **· 专家模型训练**:根据驱动生成训练语料,训练专用于驱动生成的代码大模型。 | ||
|
|
||
| **· 驱动生成**:通过静态分析引擎提取被测函数的上下文信息,构造生成测试驱动的提示词,再通过强化学习后的代码大模型输出测试驱动代码。 | ||
|
|
||
| **· 反馈优化**:运行生成的驱动,监控运行情况,获取反馈信息,优化生成驱动的提示词,最终实现更高的验证通过率。 | ||
|
|
||
| 经过Google benchmark验证,云起无垠的生成策略生成了24个测试驱动,仅有22%无效驱动,优于Google的方案,表现出更高的可编译驱动比例和更低的无效驱动比例。 | ||
|
|
||
|  | ||
|
|
||
| **2. AI Agent赋能漏洞自动化修复** | ||
|
|
||
| 在漏洞修复方面,传统漏洞检测工具提供的修复建议通常呈现模板化特点,实际修复工作主要依赖专家经验和人工操作。高危漏洞的修复难度大、时间长,已成为企业的核心痛点。在这种背景下,自动化修复工具成为刚性需求。 | ||
|
|
||
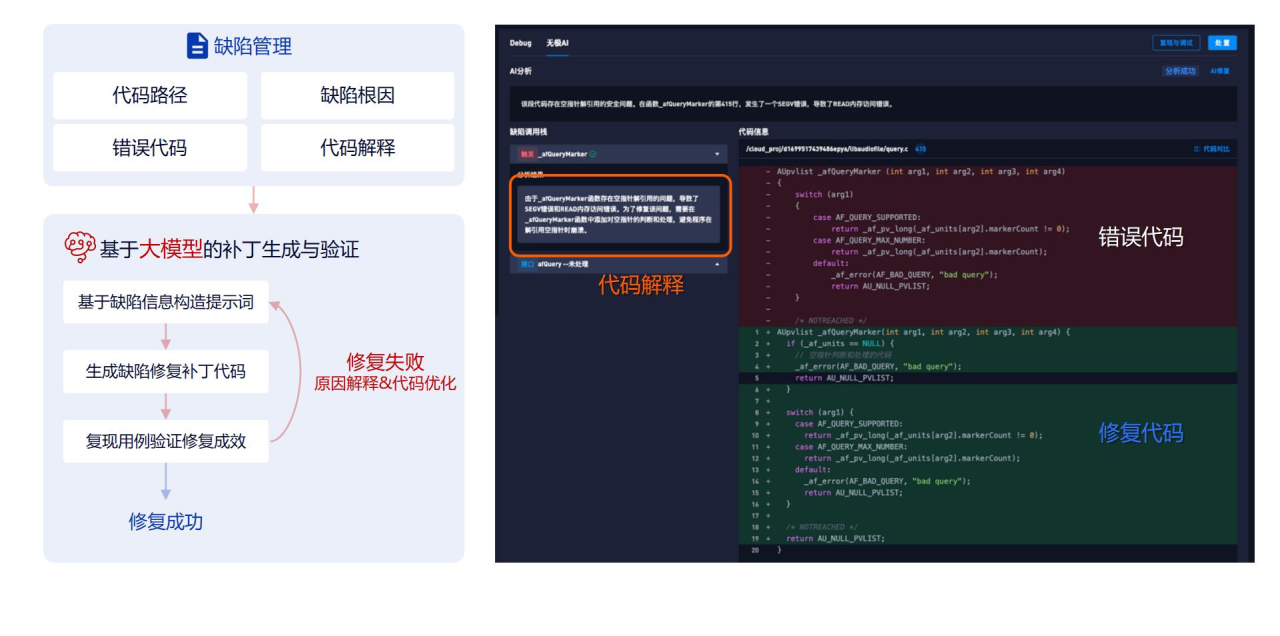
| 通过模糊测试引擎与训练后的代码大模型协同,不仅能够精准定位存在漏洞的代码片段,还能够分析漏洞成因。然后,利用缺陷信息生成提示词,作为大模型的输入。大模型根据这些提示词生成修复代码。更重要的是,模糊测试作为一种动态软件测试方案,可以重新运行漏洞的真实触发用例,验证缺陷修复效果。若漏洞修复失败,则进一步分析缺陷信息,优化测试代码的生成提示词。 | ||
|
|
||
| 经过验证,这一“大模型修复+模糊测试动态验证”的方案保障了代码修复率达到85%左右。 | ||
|
|
||
|  | ||
|
|
||
| ## 写在最后 | ||
|
|
||
| 随着大语言模型技术的不断发展,其在模糊测试中的应用前景广阔。未来,大语言模型可以与其他AI技术,如强化学习、知识图谱等相结合,进一步提升自动化漏洞检测的能力。例如,强化学习可以帮助大语言模型在模糊测试中更好地探索不同的输入策略,而知识图谱可以帮助大语言模型理解更复杂的程序逻辑,从而生成更加有效的测试用例。 | ||
|
|
||
| 此外,随着大语言模型技术的普及,其在模糊测试中的应用将更加广泛和多样化。未来,基于大语言模型的智能模糊测试有望成为自动化安全测试中的重要工具,帮助测试人员发现更多高危漏洞。 | ||
|
|
||
|
|
||
|  |
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.