From Molecules 🧬🧪 to Genomic Variations 🩺💊: Accelerating Genome Analysis via Intelligent Algorithms and Architectures
We describe the ongoing journey in significantly improving the performance, accuracy, and efficiency of genome analysis using intelligent algorithms and hardware architectures. We need to read, analyze, and interpret our genomes not only quickly, but also accurately and efficiently enough to scale the analysis to population level. There currently exist major computational bottlenecks and inefficiencies throughout the entire genome analysis pipeline, because state-of-the-art genome sequencing technologies are still not able to read a genome in its entirety. Our paper is the first to provide a comprehensive survey of a prominent set of algorithmic improvement and hardware acceleration efforts for the entire genome analysis pipeline.
We explain state-of-the-art algorithmic methods and hardware-based acceleration approaches for each step of the genome analysis pipeline and provide experimental evaluations. Algorithmic approaches exploit the structure of the genome as well as the structure of the underlying hardware. Hardware-based acceleration approaches exploit specialized microarchitectures or various execution paradigms (e.g., processing inside or near memory) along with algorithmic changes, leading to new hardware/software co-designed systems. We conclude with a foreshadowing of future challenges, benefits, and research directions triggered by the development of both very low cost yet highly error prone new sequencing technologies and specialized hardware chips for genomics. We hope that these efforts and the challenges we discuss provide a foundation for future work in making genome analysis more intelligent.
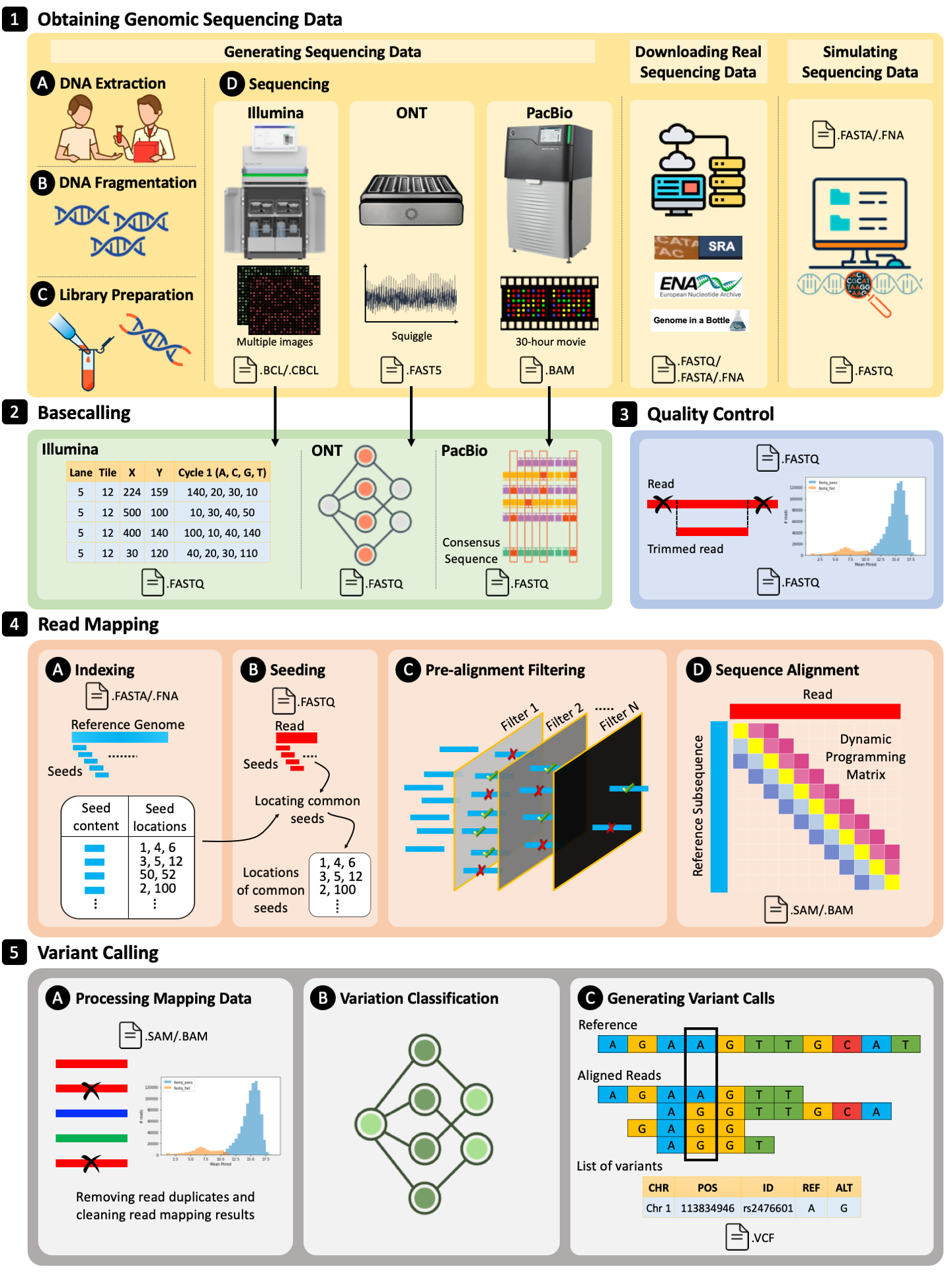
The paper covers the following topics in detail with a focus on intelligent algorithms, intelligent hardware accelerators, and intelligent hardware/software co-design.
Computer algorithms and hardware architectures are called intelligent if they are able to efficiently satisfy three principles, data-centric, data-driven, and architecture/algorithm/data-aware.
- First, we would like to process genomic data efficiently by minimizing data movement and maximizing the efficiency with which data is handled, i.e., stored, accessed, and processed.
- Second, we would like to take advantage of the vast amounts of genomic data and metadata to continuously improve decision making (self-optimizing decisions) for many different use cases in science, medicine, and technology.
- Third, we would like to orchestrate the multiple components across the entire analysis system and adapt algorithms by understanding the structure of the underlying hardware, understanding analysis algorithms, and understanding various properties (i.e., the structure of the genome, type of sequencing data, quality of sequencing data) of each piece of data.
- Introduction
- Obtaining Genomic Sequencing Data
- Generating Sequencing Data
- Downloading Real Sequencing Data
- Simulating Sequencing Data
- Types of Genomic Sequencing Data
- Short Reads
- Ultra-long Reads
- Accurate Long Reads
- Discussion on Types of Sequencing Reads
- Genome Analysis Using Different Types of Sequencing Reads
- Basecalling
- Illumina
- ONT
- PacBio
- Quality Control
- Read Mapping
- Accelerating Indexing and Seeding
- Sampling Seeds
- Improving Data Structures for Seed Lookups
- Reducing Data Movement During Indexing
- Accelerating Pre-Alignment Filtering
- Pigeonhole Principle
- Base Counting
- q-gram Filtering Approach
- Sparse Dynamic Programming
- Accelerating Sequence Alignment
- Accurate Alignment Accelerators
- Alignment Accelerators with Limited Functionality
- Accelerating Indexing and Seeding
- Variant Calling
- Discussion and Future Opportunities
If you use this paper in your work, please cite:
Mohammed Alser, Joel Lindegger, Can Firtina, Nour Almadhoun, Haiyu Mao, Gagandeep Singh, Juan Gomez-Luna, Onur Mutlu. "From Molecules to Genomic Variations: Accelerating Genome Analysis via Intelligent Algorithms and Architectures" arXiv preprint arXiv (2022). https://arxiv.org/abs/2205.07957
Below is bibtex format for citation.
@misc{https://doi.org/10.48550/arxiv.2205.07957,
doi = {10.48550/ARXIV.2205.07957},
url = {https://arxiv.org/abs/2205.07957},
author = {Alser, Mohammed and Lindegger, Joel and Firtina, Can and Almadhoun, Nour and Mao, Haiyu and Singh, Gagandeep and Gomez-Luna, Juan and Mutlu, Onur},
title = {Going From Molecules to Genomic Variations to Scientific Discovery: Intelligent Algorithms and Architectures for Intelligent Genome Analysis},
publisher = {arXiv},
year = {2022}
}