The World's Largest Open Multilingual Language Model - BLOOM
 BigScience Large Open-science Open-access Multilingual Language Model
BigScience is an open and collaborative workshop around the study and creation of very large language models gathering more than 1000 researchers around the worlds.
With its 176 billion parameters, BLOOM is able to generate text in 46 natural languages and 13 programming languages. For almost all of them, such as Spanish, French and Arabic, BLOOM will be the first language model with over 100B parameters ever created.
BLOOM is an autoregressive Large Language Model (LLM), trained to continue text from a prompt on vast amounts of text data using industrial-scale computational resources. As such, it is able to output coherent text in 46 languages and 13 programming languages that is hardly distinguishable from text written by humans. BLOOM can also be instructed to perform text tasks it hasn't been explicitly trained for, by casting them as text generation tasks.
BigScience Large Open-science Open-access Multilingual Language Model
BigScience is an open and collaborative workshop around the study and creation of very large language models gathering more than 1000 researchers around the worlds.
With its 176 billion parameters, BLOOM is able to generate text in 46 natural languages and 13 programming languages. For almost all of them, such as Spanish, French and Arabic, BLOOM will be the first language model with over 100B parameters ever created.
BLOOM is an autoregressive Large Language Model (LLM), trained to continue text from a prompt on vast amounts of text data using industrial-scale computational resources. As such, it is able to output coherent text in 46 languages and 13 programming languages that is hardly distinguishable from text written by humans. BLOOM can also be instructed to perform text tasks it hasn't been explicitly trained for, by casting them as text generation tasks.
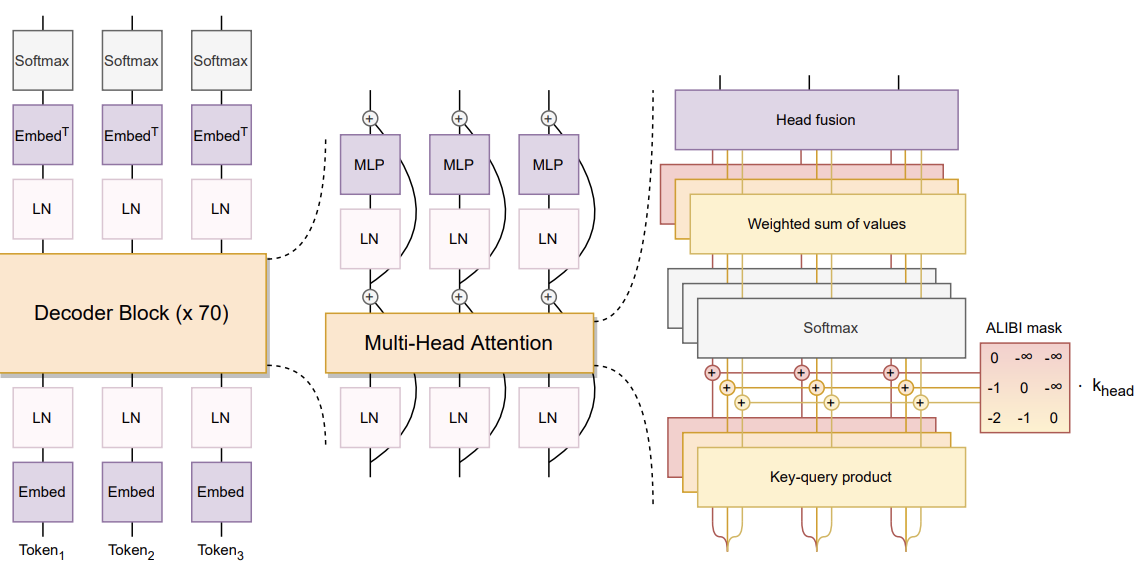
Model Architecture and Objective Modified from Megatron-LM GPT2 (see paper, BLOOM Megatron code):
Decoder-only architecture
Layer normalization applied to word embeddings layer (StableEmbedding; see code, paper)
ALiBI positional encodings (see paper), with GeLU activation functions
176,247,271,424 parameters:
3,596,615,680 embedding parameters
70 layers, 112 attention heads
Hidden layers are 14336-dimensional
Sequence length of 2048 tokens used (see BLOOM tokenizer, tokenizer description)
Objective Function: Cross Entropy with mean reduction (see API documentation).
Compute infrastructure Jean Zay Public Supercomputer, provided by the French government (see announcement).
Hardware 384 A100 80GB GPUs (48 nodes)
Additional 32 A100 80GB GPUs (4 nodes) in reserve
8 GPUs per node Using NVLink 4 inter-gpu connects, 4 OmniPath links
CPU: AMD
CPU memory: 512GB per node
GPU memory: 640GB per node
Inter-node connect: Omni-Path Architecture (OPA)
NCCL-communications network: a fully dedicated subnet
Disc IO network: shared network with other types of nodes
Software Megatron-DeepSpeed (Github link)
DeepSpeed (Github link)
PyTorch (pytorch-1.11 w/ CUDA-11.5; see Github link)
apex (Github link)
Training data includes:
46 natural languages
13 programming languages
In 1.6TB of pre-processed text, converted into 350B unique tokens (see the tokenizer section for more.)
Languages The pie chart shows the distribution of languages in training data.
pie chart showing the distribution of languages in training data
The following tables shows the further distribution of Niger-Congo & Indic languages and programming languages in the training data.
Distribution of Niger Congo and Indic languages.
Niger Congo Percentage Indic Percentage Chi Tumbuka 0.00002 Assamese 0.01 Kikuyu 0.00004 Odia 0.04 Bambara 0.00004 Gujarati 0.04 Akan 0.00007 Marathi 0.05 Xitsonga 0.00007 Punjabi 0.05 Sesotho 0.00007 Kannada 0.06 Chi Chewa 0.0001 Nepali 0.07 Setswana 0.0002 Telugu 0.09 Lingala 0.0002 Malayalam 0.10 Northern Sotho 0.0002 Urdu 0.10 Fon 0.0002 Tamil 0.20 Kirundi 0.0003 Bengali 0.50 Wolof 0.0004 Hindi 0.70 Luganda 0.0004 Chi Shona 0.001 Isi Zulu 0.001 Igbo 0.001 Xhosa 0.001 Kinyarwanda 0.003 Yoruba 0.006 Swahili 0.02 Distribution of programming languages.
Extension Language Number of files java Java 5,407,724 php PHP 4,942,186 cpp C++ 2,503,930 py Python 2,435,072 js JavaScript 1,905,518 cs C# 1,577,347 rb Ruby 6,78,413 cc C++ 443,054 hpp C++ 391,048 lua Lua 352,317 go GO 227,763 ts TypeScript 195,254 C C 134,537 scala Scala 92,052 hh C++ 67,161 H C++ 55,899 tsx TypeScript 33,107 rs Rust 29,693 phpt PHP 9,702 c++ C++ 1,342 h++ C++ 791 php3 PHP 540 phps PHP 270 php5 PHP 166 php4 PHP 29 Preprocessing Tokenization: The BLOOM tokenizer (link), a learned subword tokenizer trained using:
A byte-level Byte Pair Encoding (BPE) algorithm
A simple pre-tokenization rule, no normalization
A vocabulary size of 250,680
It was trained on a subset of a preliminary version of the corpus using alpha-weighting per language.
Speeds, Sizes, Times Training logs: Tensorboard link
Dates:
Started 11th March, 2022 11:42am PST
Estimated end: 5th July, 2022
Checkpoint size:
Bf16 weights: 329GB
Full checkpoint with optimizer states: 2.3TB
Training throughput: About 150 TFLOP per GPU per second
Number of epochs: 1
Estimated cost of training: Equivalent of $2-5M in cloud computing (including preliminary experiments)
Server training location: Île-de-France, France
Environmental Impact The training supercomputer, Jean Zay (website), uses mostly nuclear energy. The heat generated by it is reused for heating campus housing. https://images.datacamp.com/image/upload/v1705691049/image3_f103a8c688.png
{kind=link}
Estimated carbon emissions: (Forthcoming.)
Estimated electricity usage: (Forthcoming.) https://huggingface.co/bigscience/bloom