We read every piece of feedback, and take your input very seriously.
To see all available qualifiers, see our documentation.
Have a question about this project? Sign up for a free GitHub account to open an issue and contact its maintainers and the community.
By clicking “Sign up for GitHub”, you agree to our terms of service and privacy statement. We’ll occasionally send you account related emails.
Already on GitHub? Sign in to your account
大型复杂前端工程的优化方法前言对于前端来讲,如果是去写一个简单页面,其实在写的过程中,很少会考虑到性能优化、
对于前端来讲,如果是去写一个简单页面,其实在写的过程中,很少会考虑到性能优化、错误监控这些。因为就一个页面而言,并不会对整个项目造成影响。但是就一个大型合作的前端项目而言,如果每个人不考虑性能优化的话,轻一点的问题就是:页面卡顿,操作不流畅。重一点的问题就是:页面卡死,内存崩溃,各种告警。所以基于了解,实践与收集,本人在此收集了大型前端项目中的一些性能优化方法,用以分享。不对地方还请斧正~
所谓的容器,即对于不同的文档,打开时,不再加载重复的代码,只需加载不同的文档数据即可。容器化有两种实现思路:
典型场景:列表页-->选定文档-->打开文档
用户选定文档后,点击链接进行打开的时候,并不会真的去打开一个新的 webview,而是进行 webview 的切换,APP 会一直保留一个 webview(代码已经加载好,是文档容器),此时将文档链接赋予容器,容器只需要拉取对应数据,不再重新加载新代码。
当打开列表页后,然后迅速懒加载对应的文档容器代码。用户点击指定文档时,不再打开新的 webview 页面,而只是当前页面进行容器切换。用户退回列表页,仍然是在当前页面。
离线缓存处理的核心难点在于:离线数据的处理。离线资源处理现在一般有两种方案:
典型场景:打开列表页。
当网页打开请求 html/js/css/图片的时候,APP 拦截网络请求,查找是否命中本地的资源,命中即直接返回。此场景需要注意客户端要建立代码更新机制,更新离线代码包。
将资源注册后便能使用。但是必须使用 https 协议,同时还有 ios webview 兼容性问题。
可以参考这篇文章:前端离线化探索(http://www.alloyteam.com/2019/07/web-applications-offline/)
典型场景:打开文档拉取后台数据的时候。
数据序列化即:将数据结构或对象编码,然后在网络间传输。
常见的协议有 XML/JSON/PB 等。对于一个很大的文档来言,xml 或者 json 用来传输数据,太过于冗余。但是如果采用复杂度太高的压缩算法如:Pako.js, 那这样反而提高了解压缩时间,得不偿失,所以找到一个适合的数据序列化方法至关重要。
典型场景:打开文档拉取文档代码的时候。
读写分离也是按需加载的一种形式。
读写分离即:将用户区分开来,并不是所有的用户都要加载所有的代码,读的用户只需要加载读的代码,写的用户才需要读写的代码,这样对于读的用户较为友好。
典型场景:开发中进行第三方库引入。
按需引入即只引用需要的代码。
按需引入常常会在开发中被忽略。如 只需要 lodash 中一个函数 isEqual,却将整个工具库进行了引入。 import_from'lodash',无形增加更多冗余代码。通过引入单个函数即可改正: importisEqualfrom'lodash.isEqual'。
isEqual
import_from'lodash'
importisEqualfrom'lodash.isEqual'
典型场景:文档中一些比较不常用的功能。
懒加载即:对于部分功能代码等到需要的时候再进行加载。
懒加载有利于首屏打开时间。文档中一些不常用的功能,对于用户来讲,如果每次打开都去加载对应的代码,无疑是冗余的。通过拆分代码,等到用户需要时或者点击时,再去加载对应的代码。
典型场景:文档中打开时有大量复杂计算时。
web worker 是运行在后台的 JavaScript,不会影响页面的性能。
web worker 无疑是解决 js 计算能力弱的一大利器。如果将文档中复杂计算放到主线程中,页面卡顿不说,打开复杂文档的时候还很有可能崩溃掉。将计算挪入 web worker 中,将计算结果事件回调的方式返回,可以让用户使用更加流畅。
典型场景: 文档中的函数或者文本进行匹配的时候。
不好的正则表达式极易引起性能问题。其核心问题在于:js 的正则匹配是基于 NFA 的,易引起回溯问题。
正则引擎分为 NFA(非确定性有限状态自动机),和 DFA(确定性有限状态自动机)。
DFA 对于给定的任意一个状态和输入字符,DFA 只会转移到一个确定的状态。并且 DFA 不允许出现没有输入字符的状态转移。而 NFA 对于任意一个状态和输入字符,NFA 所能转移的状态是一个非空集合。模糊匹配、贪婪匹配、惰性匹配都会带来回溯问题。典型的正则匹配如 (.\*)+\d ,便会进行回溯。那么平时开发的时候,
(.\*)+\d
正则要越精确越好
改用 DFA 的正则引擎
具体可以参考:浅谈正则表达式原理
典型场景:一堆非常需要耗时的数据,每次更新都需要重新计算,但是更新的频率并不高。
使用缓存可以有效的减少查找时间。
js 引擎是单线程的,对于大量复杂耗时的计算,会导致页面卡顿。可以通过将计算挪入 worker 中计算,也可以对于更新不频繁的计算进行缓存。
function complexCompute(){
对于这种复杂计算,如果每次需要用到数据的时候都要去进行计算,那就得不偿失了,通过缓存,便能有效减少计算次数。
这样便只会在更新的时候才会进行计算。
典型场景:查找一堆复杂数据,并且每个数据都有唯一 key。
建立索引的方式可以快速的提高查找速度。如一堆数据用数组进行存储。
const persons = [
和用对象的方式进行存储。
const persons = {
进行查找 zhangsan 的 age,那么用数组的方式进行查找的时间复杂度是o(N),用对象的时间复杂度是o(1)。
五大原则和一个法则:
单一职责原则(Single Responsibility Principle, SRP): 一个类只负责一个功能领域中的相应职责,或者可以定义为:就一个类而言,应该只有一个引起它变化的原因
开闭原则(Open-Closed Principle, OCP): 一个软件实体应当对扩展开放,对修改关闭
里氏代换原则(Liskov Substitution Principle, LSP): 所有引用基类(父类)的地方必须能透明地使用其子类的对象
依赖倒转原则(Dependency Inversion Principle, DIP): 抽象不应该依赖于细节,细节应当依赖于抽象。换言之,要针对接口编程,而不是针对实现编程
接口隔离原则(Interface Segregation Principle, ISP): 使用多个专门的接口,而不使用单一的总接口,即客户端不应该依赖那些它不需要的接口。
迪米特法则(Law of Demeter, LoD)(最少知识法则): 一个软件实体应当尽可能少地与其他实体发生相互作用。
它的核心意义在于代码复用。功能相对单一或者独立,在整个系统的代码层次上位于最底层,被其他代码所依赖。比如说我们常用的一些 UI 组件,逻辑组件等。
组件的核心在于:
通用性
与业务无关
兼容性
通过将一些通用的 UI 和逻辑拆分成组件,不仅可以让代码更简洁,更容易维护,而且高内聚,低耦合。
当一个大的项目库代码量剧增之后,管理起来就是一件比较麻烦的事情,为了方便代码的共享,就需要将代码库拆分成独立的包。Lerna 便是优化和管理 JS 多包项目的利器。
典型目录如下所示:
base/package.json;
典型场景:excel 的 openxml 规范。
享元模式(Flyweight Pattern)主要用于减少创建对象的数量,以减少内存占用和提高性能。这种类型的设计模式属于结构型模式,它提供了减少对象数量从而改善应用所需的对象结构的方式。
openxml 中对于数据的管理,基本上都是用享元模式实现的。
如 1 个文档中有 1000 个相同的字符串。
excel 并不会真的就存储 1000 个字符串。他只会存储一个字符串。
而具体每个格子存储的是这个字符的下标索引。
这样无疑大大节省了存储空间。
webpack3 是用的CommonsChunkPlugin用以实现提取第三方库和公共模块如 node_modules 下面的文件。
webpack4 进行了改进,用optimization.splitChunks代替了 CommonsChunkPlugin。 commonschunkPlugin 的问题在于:它将所有的公共包合成了一个 commonChunk,但是并不是所有的子模块需要这个 commonChunk 的所有内容。
与 CommonsChunkPlugin 的父子关系思路不同的是,SplitChunksPlugin 引入了 chunkGroup 的概念,在入口 chunk 和异步 chunk 中发现被重复使用的模块,将重叠的模块以 vendor-chunk 的形式分离出来,也就是 vendor-chunk 可能有多个,不再受限于是所有 chunk 中都共同存在的模块。
splitChunks 是开箱即用的,常见配置如下:
optimization: {
可以通过 cacheGroup 制定更细的规则。
通过动态导入进而实现懒加载和代码分离,进而可以用于获取更小的 bundle,以及控制资源加载优先级,如果使用合理,会极大影响加载时间。
当涉及到动态代码拆分时,webpack 提供了两个类似的技术。对于动态导入,第一种,也是优先选择的方式是,使用符合 ECMAScript 提案 的 import()语法。如下所示:
import()
return import( "lodash").then((_) => {
tree-shaking 通常用于描述移除 JavaScript 上下文中的未引用代码(dead-code)。比如:
index.js
import { cube } from "./math.js";
cube.js
export function square(x) {
其中 cube.js 中的square就属于未引用代码,打包时不需要。 通过在依赖包中的 package.json 里面写入:
"sideEffects": false,
即可开启依赖包的 tree-shaking。
但是使用 tree-shaking 要有三条规则。
使用 ES2015 模块语法(即 import 和 export)。
在项目 package.json 文件中,添加一个 "sideEffects" 入口。
引入一个能够删除未引用代码(dead code)的压缩工具(minifier)(例如 UglifyJSPlugin)。
具体的例子可以看 https://github.com/webpack/webpack/tree/master/examples/side-effects 这个。
Source
The text was updated successfully, but these errors were encountered:
No branches or pull requests
大型复杂前端工程的优化方法
前言
对于前端来讲,如果是去写一个简单页面,其实在写的过程中,很少会考虑到性能优化、错误监控这些。因为就一个页面而言,并不会对整个项目造成影响。但是就一个大型合作的前端项目而言,如果每个人不考虑性能优化的话,轻一点的问题就是:页面卡顿,操作不流畅。重一点的问题就是:页面卡死,内存崩溃,各种告警。所以基于了解,实践与收集,本人在此收集了大型前端项目中的一些性能优化方法,用以分享。不对地方还请斧正~
1.实现优化
1.1 容器化
所谓的容器,即对于不同的文档,打开时,不再加载重复的代码,只需加载不同的文档数据即可。容器化有两种实现思路:
1. 借助于客户端
典型场景:列表页-->选定文档-->打开文档
用户选定文档后,点击链接进行打开的时候,并不会真的去打开一个新的 webview,而是进行 webview 的切换,APP 会一直保留一个 webview(代码已经加载好,是文档容器),此时将文档链接赋予容器,容器只需要拉取对应数据,不再重新加载新代码。
2. 将代码集合到一个页面中(SPA 方案)
典型场景:列表页-->选定文档-->打开文档
当打开列表页后,然后迅速懒加载对应的文档容器代码。用户点击指定文档时,不再打开新的 webview 页面,而只是当前页面进行容器切换。用户退回列表页,仍然是在当前页面。
1.2 离线缓存
离线缓存处理的核心难点在于:离线数据的处理。离线资源处理现在一般有两种方案:
1. 借助于客户端
典型场景:打开列表页。
当网页打开请求 html/js/css/图片的时候,APP 拦截网络请求,查找是否命中本地的资源,命中即直接返回。此场景需要注意客户端要建立代码更新机制,更新离线代码包。
2. service workers
典型场景:打开列表页。
将资源注册后便能使用。但是必须使用 https 协议,同时还有 ios webview 兼容性问题。
1.3 数据序列化
典型场景:打开文档拉取后台数据的时候。
数据序列化即:将数据结构或对象编码,然后在网络间传输。
常见的协议有 XML/JSON/PB 等。对于一个很大的文档来言,xml 或者 json 用来传输数据,太过于冗余。但是如果采用复杂度太高的压缩算法如:Pako.js, 那这样反而提高了解压缩时间,得不偿失,所以找到一个适合的数据序列化方法至关重要。
1.4 按需加载
1.4.1 读写分离
典型场景:打开文档拉取文档代码的时候。
读写分离也是按需加载的一种形式。
读写分离即:将用户区分开来,并不是所有的用户都要加载所有的代码,读的用户只需要加载读的代码,写的用户才需要读写的代码,这样对于读的用户较为友好。
1.4.2 按需引入
典型场景:开发中进行第三方库引入。
按需引入即只引用需要的代码。
按需引入常常会在开发中被忽略。如 只需要 lodash 中一个函数
isEqual,却将整个工具库进行了引入。import_from'lodash',无形增加更多冗余代码。通过引入单个函数即可改正:importisEqualfrom'lodash.isEqual'。1.5 懒加载
典型场景:文档中一些比较不常用的功能。
懒加载即:对于部分功能代码等到需要的时候再进行加载。
懒加载有利于首屏打开时间。文档中一些不常用的功能,对于用户来讲,如果每次打开都去加载对应的代码,无疑是冗余的。通过拆分代码,等到用户需要时或者点击时,再去加载对应的代码。
1.6 使用 web worker
典型场景:文档中打开时有大量复杂计算时。
web worker 是运行在后台的 JavaScript,不会影响页面的性能。
web worker 无疑是解决 js 计算能力弱的一大利器。如果将文档中复杂计算放到主线程中,页面卡顿不说,打开复杂文档的时候还很有可能崩溃掉。将计算挪入 web worker 中,将计算结果事件回调的方式返回,可以让用户使用更加流畅。
1.7 正则表达式
典型场景: 文档中的函数或者文本进行匹配的时候。
不好的正则表达式极易引起性能问题。其核心问题在于:js 的正则匹配是基于 NFA 的,易引起回溯问题。
正则引擎分为 NFA(非确定性有限状态自动机),和 DFA(确定性有限状态自动机)。
DFA 对于给定的任意一个状态和输入字符,DFA 只会转移到一个确定的状态。并且 DFA 不允许出现没有输入字符的状态转移。而 NFA 对于任意一个状态和输入字符,NFA 所能转移的状态是一个非空集合。模糊匹配、贪婪匹配、惰性匹配都会带来回溯问题。典型的正则匹配如
(.\*)+\d,便会进行回溯。那么平时开发的时候,正则要越精确越好
改用 DFA 的正则引擎
具体可以参考:浅谈正则表达式原理
1.8 使用缓存
典型场景:一堆非常需要耗时的数据,每次更新都需要重新计算,但是更新的频率并不高。
使用缓存可以有效的减少查找时间。
js 引擎是单线程的,对于大量复杂耗时的计算,会导致页面卡顿。可以通过将计算挪入 worker 中计算,也可以对于更新不频繁的计算进行缓存。
对于这种复杂计算,如果每次需要用到数据的时候都要去进行计算,那就得不偿失了,通过缓存,便能有效减少计算次数。
这样便只会在更新的时候才会进行计算。
1.9 建立索引
典型场景:查找一堆复杂数据,并且每个数据都有唯一 key。
建立索引的方式可以快速的提高查找速度。如一堆数据用数组进行存储。
和用对象的方式进行存储。
进行查找 zhangsan 的 age,那么用数组的方式进行查找的时间复杂度是o(N),用对象的时间复杂度是o(1)。
2.1 设计模式六大基本原则
五大原则和一个法则:
单一职责原则(Single Responsibility Principle, SRP): 一个类只负责一个功能领域中的相应职责,或者可以定义为:就一个类而言,应该只有一个引起它变化的原因
开闭原则(Open-Closed Principle, OCP): 一个软件实体应当对扩展开放,对修改关闭
里氏代换原则(Liskov Substitution Principle, LSP): 所有引用基类(父类)的地方必须能透明地使用其子类的对象
依赖倒转原则(Dependency Inversion Principle, DIP): 抽象不应该依赖于细节,细节应当依赖于抽象。换言之,要针对接口编程,而不是针对实现编程
接口隔离原则(Interface Segregation Principle, ISP): 使用多个专门的接口,而不使用单一的总接口,即客户端不应该依赖那些它不需要的接口。
迪米特法则(Law of Demeter, LoD)(最少知识法则): 一个软件实体应当尽可能少地与其他实体发生相互作用。
2.2 组件库
它的核心意义在于代码复用。功能相对单一或者独立,在整个系统的代码层次上位于最底层,被其他代码所依赖。比如说我们常用的一些 UI 组件,逻辑组件等。
组件的核心在于:
通用性
与业务无关
兼容性
通过将一些通用的 UI 和逻辑拆分成组件,不仅可以让代码更简洁,更容易维护,而且高内聚,低耦合。
2.3 lerna 管理
当一个大的项目库代码量剧增之后,管理起来就是一件比较麻烦的事情,为了方便代码的共享,就需要将代码库拆分成独立的包。Lerna 便是优化和管理 JS 多包项目的利器。
典型目录如下所示:
2.4 享元模式
典型场景:excel 的 openxml 规范。
享元模式(Flyweight Pattern)主要用于减少创建对象的数量,以减少内存占用和提高性能。这种类型的设计模式属于结构型模式,它提供了减少对象数量从而改善应用所需的对象结构的方式。
openxml 中对于数据的管理,基本上都是用享元模式实现的。
如 1 个文档中有 1000 个相同的字符串。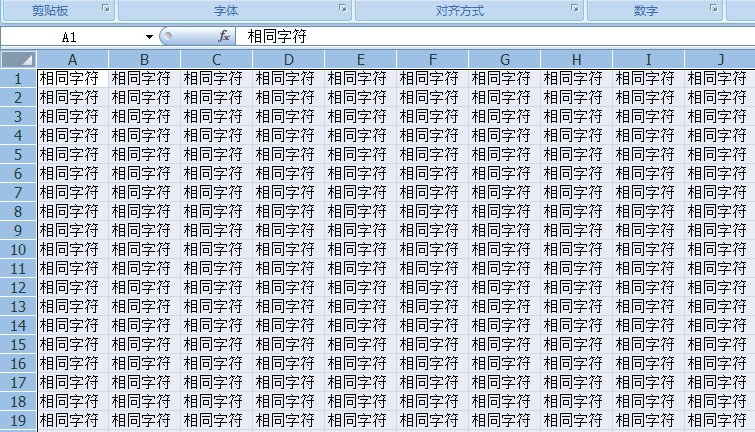
excel 并不会真的就存储 1000 个字符串。他只会存储一个字符串。
而具体每个格子存储的是这个字符的下标索引。
这样无疑大大节省了存储空间。
3.1 webpack 打包优化
3.1.1 公共包
webpack3 是用的CommonsChunkPlugin用以实现提取第三方库和公共模块如 node_modules 下面的文件。
webpack4 进行了改进,用optimization.splitChunks代替了 CommonsChunkPlugin。 commonschunkPlugin 的问题在于:它将所有的公共包合成了一个 commonChunk,但是并不是所有的子模块需要这个 commonChunk 的所有内容。
与 CommonsChunkPlugin 的父子关系思路不同的是,SplitChunksPlugin 引入了 chunkGroup 的概念,在入口 chunk 和异步 chunk 中发现被重复使用的模块,将重叠的模块以 vendor-chunk 的形式分离出来,也就是 vendor-chunk 可能有多个,不再受限于是所有 chunk 中都共同存在的模块。
splitChunks 是开箱即用的,常见配置如下:
可以通过 cacheGroup 制定更细的规则。
3.1.2 动态导入(dynamic imports)
通过动态导入进而实现懒加载和代码分离,进而可以用于获取更小的 bundle,以及控制资源加载优先级,如果使用合理,会极大影响加载时间。
当涉及到动态代码拆分时,webpack 提供了两个类似的技术。对于动态导入,第一种,也是优先选择的方式是,使用符合 ECMAScript 提案 的
import()语法。如下所示:3.1.3 tree-shaking
tree-shaking 通常用于描述移除 JavaScript 上下文中的未引用代码(dead-code)。比如:
index.js
cube.js
其中 cube.js 中的square就属于未引用代码,打包时不需要。 通过在依赖包中的 package.json 里面写入:
即可开启依赖包的 tree-shaking。
但是使用 tree-shaking 要有三条规则。
使用 ES2015 模块语法(即 import 和 export)。
在项目 package.json 文件中,添加一个 "sideEffects" 入口。
引入一个能够删除未引用代码(dead code)的压缩工具(minifier)(例如 UglifyJSPlugin)。
具体的例子可以看 https://github.com/webpack/webpack/tree/master/examples/side-effects 这个。
Source
The text was updated successfully, but these errors were encountered: