Architectural Overview
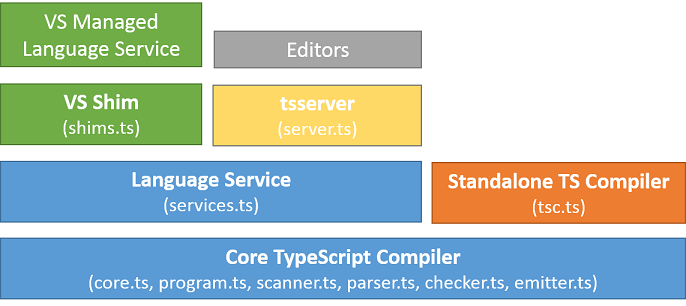
-
Core TypeScript Compiler
-
Parser: Starting from a set of sources, and following the productions of the language grammar, to generate an Abstract Syntax Tree (AST)
-
Binder: Linking declarations contributing to the same structure using a Symbol (e.g. different declarations of the same interface or module, or a function and a module with the same name). This allows the type system to reason about these named declarations.
-
Type resolver/ Checker: Resolving types of each construct, checking semantic operations and generate diagnostics as appropriate.
-
Emitter: Output generated from a set of inputs (.ts and .d.ts) files can be one of: JavaScript (.js), definitions (.d.ts), or source maps (.js.map)
-
Pre-processor: The "Compilation Context" refers to all files involved in a "program". The context is created by inspecting all files passed in to the compiler on the command line, in order, and then adding any files they may reference directory or indirectly through
importstatements and/// <reference path=... >tags. The result of walking the reference graph is an ordered list of source files, that constitute the program. When resolving imports, preference is given to ".ts" files over ".d.ts" files to ensure the most up-to-date files are processed. The compiler does a node-like process to resolve imports by walking up the directory chain to find a source file with a .ts or .d.ts extension matching the requested import. Failed import resolution does not result in an error, as an ambient module could be already declared. -
Standalone compiler (tsc): The batch compilation CLI. Mainly handle reading and writing files for different supported engines (e.g. Node.js)
-
Language Service: The "Language Service" exposes an additional layer around the core compiler pipeline that are best suiting editor-like applications. The language service supports the common set of a typical editor operations like statement completions, signature help, code formatting and outlining, colorization, etc... Basic re-factoring like rename, Debugging interface helpers like validating breakpoints as well as TypeScript-specific features like support of incremental compilation (--watch equivalent on the command-line). The language service is designed to efficiently handle scenarios with files changing over time within a long-lived compilation context; in that sense, the language service provides a slightly different perspective about working with programs and source files from that of the other compiler interfaces.
Please refer to the Using the Language Service API page for more details.
-
Node: The basic building block of the Abstract Syntax Tree (AST). In general node represent non-terminals in the language grammar; some terminals are kept in the tree such as identifiers and literals.
-
SourceFile: The AST of a given source file. A SourceFile is itself a Node; it provides an additional set of interfaces to access the raw text of the file, references in the file, the list of identifiers in the file, and mapping from a position in the file to a line and character numbers.
-
Program: A collection of SourceFiles and a set of compilation options that represent a compilation unit. The program is the main entry point to the type system and code generation.
-
Symbol: A named declaration. Symbols are created as a result of binding. Symbols connect declaration nodes in the tree to other declarations contributing to the same entity. Symbols are the basic building block of the semantic system.
-
Type: Types are the other part of the semantic system. Types can be named (e.g. classes and interfaces), or anonymous (e.g. object types).
-
Signature: There are three types of signatures in the language: call, construct and index signatures.
The process starts with preprocessing.
The preprocessor figures out what files should be included in the compilation by following references (/// <reference path=... /> tags and import statements).
The parser then generates AST Nodes.
These are just an abstract representation of the user input in a tree format.
A SourceFile object represents an AST for a given file with some additional information like the file name and source text.
The binder then passes over the AST nodes and generates and binds Symbols.
One Symbol is created for each named entity.
There is a subtle distinction but several declaration nodes can name the same entity.
That means that sometimes different Nodes will have the same Symbol, and each Symbol keeps track of its declaration Nodes.
For example, a class and a namespace with the same name can merge and will have the same Symbol.
The binder also handles scopes and makes sure that each Symbol is created in the correct enclosing scope.
Generating a SourceFile (along with its Symbols) is done through calling the createSourceFile API.
So far, Symbols represent named entities as seen within a single file, but several declarations can merge multiple files, so the next step is to build a global view of all files in the compilation by building a Program.
A Program is a collection of SourceFiles and a set of CompilerOptions.
A Program is created by calling the createProgram API.
From a Program instance a TypeChecker can be created.
TypeChecker is the core of the TypeScript type system.
It is the part responsible for figuring out relationships between Symbols from different files, assigning Types to Symbols, and generating any semantic Diagnostics (i.e. errors).
The first thing a TypeChecker will do is to consolidate all the Symbols from different SourceFiles into a single view, and build a single Symbol Table by "merging" any common Symbols (e.g. namespaces spanning multiple files).
After initializing the original state, the TypeChecker is ready to answer any questions about the program.
Such "questions" might be:
- What is the
Symbolfor thisNode? - What is the
Typeof thisSymbol? - What
Symbols are visible in this portion of the AST? - What are the available
Signatures for a function declaration? - What errors should be reported for a file?
The TypeChecker computes everything lazily; it only "resolves" the necessary information to answer a question.
The checker will only examine Nodes/Symbols/Types that contribute to the question at hand and will not attempt to examine additional entities.
An Emitter can also be created from a given Program.
The Emitter is responsible for generating the desired output for a given SourceFile; this includes .js, .jsx, .d.ts, and .js.map outputs.
Tokens themselves have what we call a "full start" and a "token start". The "token start" is the more natural version, which is the position in the file where the text of a token begins. The "full start" is the point at which the scanner began scanning since the last significant token. When concerned with trivia, we are often more concerned with the full start.
| Function | Description |
|---|---|
ts.Node.getStart |
Gets the position in text where the first token of a node started. |
ts.Node.getFullStart |
Gets the position of the "full start" of the first token owned by the node. |
Syntax trivia represent the parts of the source text that are largely insignificant for normal understanding of the code, such as whitespace, comments, and even conflict markers.
Because trivia are not part of the normal language syntax (barring ECMAScript ASI rules) and can appear anywhere between any two tokens, they are not included in the syntax tree. Yet, because they are important when implementing a feature like refactoring and to maintain full fidelity with the source text, they are still accessible through our APIs on demand.
Because the EndOfFileToken can have nothing following it (neither token nor trivia), all trivia naturally precedes some non-trivia token, and resides between that token's "full start" and the "token start"
It is a convenient notion to state that a comment "belongs" to a Node in a more natural manner though. For instance, it might be visually clear that the genie function declaration owns the last two comments in the following example:
var x = 10; // This is x.
/**
* Postcondition: Grants all three wishes.
*/
function genie([wish1, wish2, wish3]: [Wish, Wish, Wish]) {
while (true) {
}
} // End functionThis is despite the fact that the function declaration's full start occurs directly after var x = 10;.
We follow Roslyn's notion of trivia ownership for comment ownership. In general, a token owns any trivia after it on the same line up to the next token. Any comment after that line is associated with the following token. The first token in the source file gets all the initial trivia, and the last sequence of trivia in the file is tacked onto the end-of-file token, which otherwise has zero width.
For most basic uses, comments are the "interesting" trivia. The comments that belong to a Node which can be fetched through the following functions:
| Function | Description |
|---|---|
ts.getLeadingCommentRanges |
Given the source text and position within that text, returns ranges of comments between the first line break following the given position and the token itself (probably most useful with ts.Node.getFullStart). |
ts.getTrailingCommentRanges |
Given the source text and position within that text, returns ranges of comments until the first line break following the given position (probably most useful with ts.Node.getEnd). |
As an example, imagine this portion of a source file:
debugger;/*hello*/
//bye
/*hi*/ functionThe full start for the function keyword begins at the /*hello*/ comment, but getLeadingCommentRanges will only return the last 2 comments:
d e b u g g e r ; / * h e l l o * / _ _ _ _ _ [CR] [NL] _ _ _ _ / / b y e [CR] [NL] _ _ / * h i * / _ _ _ _ f u n c t i o n
↑ ↑ ↑ ↑ ↑
full start look for first comment second comment token start
leading comments
starting here
Appropriately, calling getTrailingCommentRanges on the end of the debugger statement will extract the /*hello*/ comment.
In the event that you are concerned with richer information of the token stream, createScanner also has a skipTrivia flag which you can set to false, and use setText/setTextPos to scan at different points in a file.