Un marco de trabajo de rastreo ágil, poderoso, independiente y distribuido.
El objetivo de SeimiCrawler es convertirse en el mejor marco de trabajo de rastreo más práctico en el mundo de Java.
SeimiCrawler es un marco de trabajo de rastreo de Java ágil, desplegable de manera independiente y compatible con distribución, que busca reducir al mínimo la barrera de entrada para que los principiantes desarrollen un sistema de rastreo con alta utilidad y rendimiento aceptable, así como aumentar la eficiencia de desarrollo de sistemas de rastreo. En el mundo de SeimiCrawler, la mayoría de las personas solo tienen que preocuparse por escribir la lógica de negocio de la captura, mientras SeimiCrawler se encarga del resto. En terms de diseño, SeimiCrawler toma inspiración del marco de trabajo de rastreo Scrapy de Python, al mismo tiempo incorpora las características del lenguaje Java y Spring, y busca facilitar y popularizar el uso eficiente de XPath para analizar HTML en China. Por lo tanto, el analizador HTML predeterminado de SeimiCrawler es JsoupXpath (proyecto de extensión independiente, no incluido en jsoup), y el análisis y extracción de datos HTML se realizan por defecto usando XPath (aunque también puedes optar por otras bibliotecas de análisis de datos). Además, SeimiCrawler se combina con SeimiAgent para resolver completamente el problema de la captura de páginas dinámicas complejas. Soporta perfectamente SpringBoot, permitiéndote maximizar tu imaginación y creatividad.
JDK1.8+
<dependency>
<groupId>cn.wanghaomiao</groupId>
<artifactId>SeimiCrawler</artifactId>
<version>referencia a la versión más reciente en github</version>
</dependency>
Lista de versiones de Github Lista de versiones de Maven
Crea un proyecto SpringBoot estándar y agrega reglas de rastreo en el paquete crawlers, por ejemplo:
@Crawler(name = "basic")
public class Basic extends BaseSeimiCrawler {
@Override
public String[] startUrls() {
// dos son para pruebas de deduplicación
return new String[]{"http://www.cnblogs.com/","http://www.cnblogs.com/"};
}
@Override
public void start(Response response) {
JXDocument doc = response.document();
try {
List<Object> urls = doc.sel("//a[@class='titlelnk']/@href");
logger.info("{}", urls.size());
for (Object s:urls){
push(Request.build(s.toString(),Basic::getTitle));
}
} catch (Exception e) {
e.printStackTrace();
}
}
public void getTitle(Response response){
JXDocument doc = response.document();
try {
logger.info("url:{} {}", response.getUrl(), doc.sel("//h1[@class='postTitle']/a/text()|//a[@id='cb_post_title_url']/text()"));
// hacer algo
} catch (Exception e) {
e.printStackTrace();
}
}
}
Configura en application.properties
# Inicia SeimiCrawler
seimi.crawler.enabled=true
seimi.crawler.names=basic
Inicia SpringBoot estándar
@SpringBootApplication
public class SeimiCrawlerApplication {
public static void main(String[] args) {
SpringApplication.run(SeimiCrawlerApplication.class, args);
}
}
Para usos más complejos, puede consultar los documentos más detallados a continuación o el demo en Github.
Cree un proyecto Maven normal y agregue reglas de crawler en el paquete crawlers, por ejemplo:
@Crawler(name = "basic")
public class Basic extends BaseSeimiCrawler {
@Override
public String[] startUrls() {
// Dos URLs son para pruebas de desduplicación
return new String[]{"http://www.cnblogs.com/","http://www.cnblogs.com/"};
}
@Override
public void start(Response response) {
JXDocument doc = response.document();
try {
List<Object> urls = doc.sel("//a[@class='titlelnk']/@href");
logger.info("{}", urls.size());
for (Object s:urls){
push(Request.build(s.toString(),Basic::getTitle));
}
} catch (Exception e) {
e.printStackTrace();
}
}
public void getTitle(Response response){
JXDocument doc = response.document();
try {
logger.info("url:{} {}", response.getUrl(), doc.sel("//h1[@class='postTitle']/a/text()|//a[@id='cb_post_title_url']/text()"));
// Realizar alguna acción
} catch (Exception e) {
e.printStackTrace();
}
}
}
A continuación, agregue una función principal en cualquier paquete para iniciar SeimiCrawler:
public class Boot {
public static void main(String[] args){
Seimi s = new Seimi();
s.start("basic");
}
}
Lo anterior es un flujo de desarrollo de sistema de crawler básico.
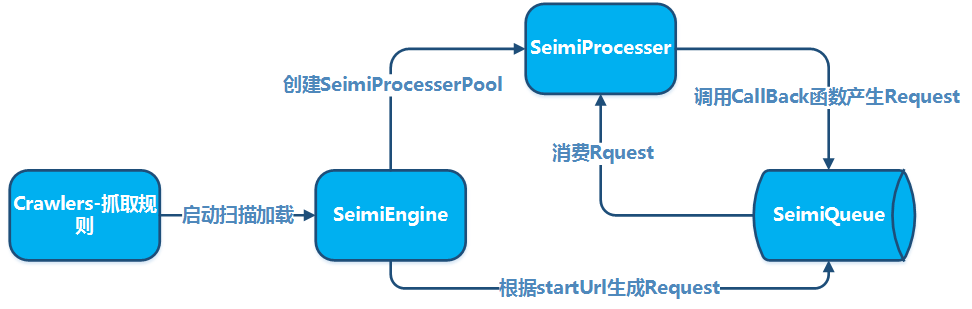
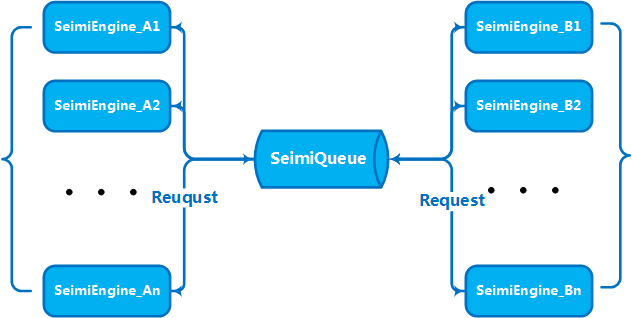
Las convenciones son necesarias principalmente para que el código fuente del sistema de crawler desarrollado con SeimiCrawler sea más normativo y legible. Al seguir un conjunto de convenciones, el código del proyecto de negocios será más fácil de leer y modificar entre los miembros del equipo durante el desarrollo colaborativo. No queremos que una persona desarrolle una lógica de negocio y que otra persona tenga dificultades para encontrar sus clases. Queremos que sea potente, simple y fácil de usar. Finalmente, tener convenciones no significa que SeimiCrawler no sea flexible.
- Como el contexto de SeimiCrawler se basa en Spring, se admite casi cualquier formato de archivo de configuración de Spring y su uso común. SeimiCrawler escaneará todos los archivos de configuración XML en el classpath del proyecto, pero solo los archivos de configuración XML cuyo nombre comienza con
seimiserán reconocidos y cargados por SeimiCrawler. - SeimiCrawler utiliza slf4j para los registros, y se puede configurar la implementación específica.
- Las convenciones a las que debe prestar atención al desarrollar con SeimiCrawler se explicarán en los puntos clave del desarrollo a continuación.
La clase de reglas de crawler es la parte más esencial al desarrollar un crawler utilizando SeimiCrawler. La clase Basic en el tutorial de inicio rápido es un ejemplo básico de una clase de crawler. Al escribir un crawler, debes tener en cuenta los siguientes puntos:
- Debe heredar de
BaseSeimiCrawler - Debe estar anotada con
@Crawler, el atributonameen la anotación es opcional. Si se establece, el crawler se nombra según el nombre que definas; de lo contrario, se usa el nombre de la clase por defecto. - Todos los crawlers que deseas que SeimiCrawler escanee deben colocarse en el paquete crawlers, por ejemplo:
cn.wanghaomiao.xxx.crawlers. También puedes referirte a la demostración incluida en el proyecto. Una vez que hayas inicializado el Crawler, necesitas implementar dos métodos básicospublic String[] startUrls();ypublic void start(Response response). Después de implementar estos, habrás completado un crawler simple.
Actualmente, la anotación @Crawler tiene las siguientes propiedades:
nameNombre personalizado para una regla de crawler. No puede haber nombres duplicados en un proyecto que sea escaneable por SeimiCrawler. Por defecto, se usa el nombre de la clase.proxyIndica a Seimi si este crawler debe usar un proxy y qué tipo de proxy usar. Se admiten tres formatoshttp|https|socket://host:port. En esta versión no se admite el uso de proxies con nombre de usuario y contraseña.useCookieIndica si se deben usar cookies. Si se habilita, se mantendrá el estado de la solicitud como lo hace un navegador, y también será rastreable.queueEspecifica la cola de datos que este crawler debe usar. Por defecto, se usa la implementación de cola localDefaultLocalQueue.class, aunque también puedes configurar para usar la implementación por defecto de redis u otras implementaciones basadas en sistemas de cola. Se proporcionará una introducción más detallada de esto más adelante.delayEstablece el intervalo de tiempo entre las solicitudes de captura en segundos. El valor predeterminado es 0, lo que significa que no hay intervalo.httpTypeTipo de implementación del Descargador. La implementación predeterminada del Descargador es Apache Httpclient, pero puedes cambiar la implementación del manejo de solicitudes de red a OkHttp3.httpTimeOutSoporta la personalización del tiempo de espera, en milisegundos. El valor predeterminado es 15000ms.
Este es el punto de entrada del crawler. El valor de retorno es un array de URLs. Por defecto, startURL se maneja con una solicitud GET. Si en situaciones especiales necesitas que Seimi maneje tu startURL con el método POST, simplemente agrega ##post al final de la URL, por ejemplo: http://passport.cnblogs.com/user/signin?ReturnUrl=http%3a%2f%2fi.cnblogs.com%2f##post. Esta especificación no distingue entre mayúsculas y minúsculas. Esta regla solo se aplica al manejo de startURL.
Este método es el manejador de respuesta para startURL, es decir, le dice a Seimi cómo procesar los datos devueltos por la solicitud a startURL.
- Resultados de texto
Seimi recomienda por defecto usar XPath para extraer datos HTML. Aunque al principio aprender XPath tiene un pequeño costo de aprendizaje, en comparación con la eficiencia de desarrollo que te aporta una vez que lo entiendes, este es insignificante.
JXDocument doc = response.document();te permite obtener unJXDocument(objeto de documento de JsoupXpath), y luego puedes extraer cualquier dato que desees mediantedoc.sel("xpath"). Cualquier tipo de extracción de datos puede hacerse con una sola sentencia XPath. Para los usuarios que quieran aprender más sobre el analizador de sintaxis XPath de Seimi y profundizar en XPath, diríjanse a JsoupXpath. Naturalmente, si no te sientes cómodo con XPath, siempre tienes la opción de usar otros analizadores de datos con los datos de respuesta originales. - Resultados de archivo
Si el resultado es un archivo, puedes usar
response.saveTo(File targetFile)para almacenar el archivo, o obtener un flujo de bytes del archivo mediantebyte[] getData()para realizar otras operaciones.
private BodyType bodyType;
private Request request;
private String charset;
private String referer;
private byte[] data;
private String content;
/**
* Esto se usa principalmente para almacenar datos personalizados pasados desde arriba
*/
private Map<String, String> meta;
private String url;
private Map<String, String> params;
/**
* La dirección de origen real del contenido de la página web
*/
private String realUrl;
/**
* El tipo de procesador HTTP del resultado de esta solicitud
*/
private SeimiHttpType seimiHttpType;
Usar una función de devolución de llamada por defecto obviamente no cubrirá todas tus necesidades. Si deseas extraer ciertas URLs de la página startURL y realizar solicitudes para obtener y procesar datos, necesitarás definir tu propia función de devolución de llamada. Aquí tienes algunos puntos a tener en cuenta:
- A partir de la versión 2.0, se admite la referencia de métodos, lo que hace que la configuración de funciones de devolución de llamada sea más natural, como:
Basic::getTitle. - Los
Requestgenerados en la función de devolución de llamada pueden especificar otra función de devolución de llamada o a sí mismos como función de devolución de llamada. - Una función de devolución de llamada debe seguir este formato:
public void callbackName(Response response), es decir, debe ser pública, tener un solo parámetroResponsey no tener valor de retorno. - Para configurar una función de devolución de llamada en un
Request, solo necesitas proporcionar el nombre de la función de devolución de llamada como unString, por ejemplo: elgetTitledel inicio rápido. - Los
Crawlerque heredan deBaseSeimiCrawlerpueden llamar directamente al métodopush(Request request)de la clase base en la función de devolución de llamada para enviar nuevas solicitudes de crawling a la cola de solicitudes. - Puedes crear un
RequestmedianteRequest.build().
public class Request {
public static Request build(String url, String callBack, HttpMethod httpMethod, Map<String, String> params, Map<String, String> meta);
public static Request build(String url, String callBack, HttpMethod httpMethod, Map<String, String> params, Map<String, String> meta,int maxReqcount);
public static Request build(String url, String callBack);
public static Request build(String url, String callBack, int maxReqCount);
@NotNull
private String crawlerName;
/**
* La URL que se va a solicitar
*/
@NotNull
private String url;
/**
* El tipo de método de solicitud: get, post, put...
*/
private HttpMethod httpMethod;
/**
* Si la solicitud necesita parámetros, colócalos aquí
*/
private Map<String,String> params;
/**
* Esto se usa principalmente para almacenar datos personalizados que se pasarán a las funciones de devolución de llamada subordinadas
*/
private Map<String,Object> meta;
/**
* Nombre del método de devolución de llamada
*/
@NotNull
private String callBack;
/**
* Si la función de devolución de llamada es una expresión Lambda
*/
private transient boolean lambdaCb = false;
/**
* Función de devolución de llamada
*/
private transient SeimiCallbackFunc callBackFunc;
/**
* Señal de si se debe detener, el hilo de procesamiento que recibe esta señal saldrá
*/
private boolean stop = false;
/**
* Número máximo de veces que puede ser solicitado nuevamente
*/
private int maxReqCount = 3;
/**
* Para registrar cuántas veces se ha ejecutado la solicitud actual
*/
private int currentReqCount = 0;
/**
* Para especificar si una solicitud debe pasar por el mecanismo de eliminación de duplicados
*/
private boolean skipDuplicateFilter = false;
/**
* Si se debe habilitar SeimiAgent para esta solicitud
*/
private boolean useSeimiAgent = false;
/**
* Encabezados de protocolo HTTP personalizados
*/
private Map<String,String> header;
/**
* Define el tiempo de renderizado de SeimiAgent, en milisegundos
*/
private long seimiAgentRenderTime = 0;
/**
* Para soportar la ejecución de scripts JavaScript específicos en SeimiAgent
*/
private String seimiAgentScript;
/**
* Especifica si la solicitud enviada a SeimiAgent debe usar cookies
*/
private Boolean seimiAgentUseCookie;
/**
* Le dice a SeimiAgent en qué formato debe devolver el resultado, por defecto HTML
*/
private SeimiAgentContentType seimiAgentContentType = SeimiAgentContentType.HTML;
/**
* Soporta la adición de cookies personalizadas
*/
private List<SeimiCookie> seimiCookies;
/**
* Agrega soporte para el cuerpo de la solicitud JSON
*/
private String jsonBody;
}
El UserAgent predeterminado de SeimiCrawler es SeimiCrawler/JsoupXpath. Si deseas personalizar el UserAgent, puedes sobrescribir public String getUserAgent() en BaseSeimiCrawler. SeimiCrawler obtendrá el UserAgent cada vez que se procese una solicitud, por lo que si deseas mimetizar el UserAgent, puedes implementar una biblioteca de UA que devuelva uno diferente de manera aleatoria.
Esto ya se mencionó en la introducción de la anotación @Crawler, pero lo repetimos aquí para facilitar una revisión rápida de estas funciones básicas. La habilitación de cookies se configura a través de la propiedad useCookie de la anotación @Crawler. También puedes configurar cookies personalizadas usando Request.setSeimiCookies(List<SeimiCookie> seimiCookies) o Request.setHeader(Map<String, String> header). El objeto Request permite muchas personalizaciones, te recomendamos que explores el objeto Request para familiarizarte más con él, lo que puede abrir muchas posibilidades.
Se configura a través de la propiedad proxy de la anotación @Crawler, consulta la introducción de la anotación @Crawler para más detalles. Si deseas especificar un proxy dinámicamente, consulta la sección "Configuración de proxy dinámico" a continuación. Actualmente se admiten tres formatos: http|https|socket://host:port.
Se configura a través de la propiedad delay de la anotación @Crawler, que establece el intervalo de tiempo en segundos entre las solicitudes de extracción, con un valor predeterminado de 0 (sin intervalo). En muchos casos, los proveedores de contenido limitan la frecuencia de las solicitudes como una medida contra el scraping, por lo que, según sea necesario, puedes ajustar y agregar este parámetro para lograr mejores resultados en la extracción.
Configura las reglas de la lista blanca de URL de solicitud anulando el método public String[] allowRules() de BaseSeimiCrawler. Las reglas son expresiones regulares, y un URL que coincide con alguna de ellas será permitido.
Configura las reglas de la lista negra de URL de solicitud anulando el método public String[] denyRules() de BaseSeimiCrawler. Las reglas son expresiones regulares, y un URL que coincide con alguna de ellas será bloqueado.
Configura el proxy que Seimi debe utilizar para una solicitud específica anulando el método public String proxy() de BaseSeimiCrawler. Puedes seleccionar un proxy de una biblioteca de proxies existente de manera secuencial o aleatoria. Si el proxy devuelto no es nulo, la configuración del atributo proxy en @Crawler no tendrá efecto. Actualmente, Seimi admite tres formatos de proxy: http|https|socket://host:port.
Controla si se habilita la eliminación de duplicados del sistema a través del atributo useUnrepeated en la anotación @Crawler, que está habilitado por defecto.
SeimiCrawler actualmente admite redirecciones 301, 302 y meta refresh. Para obtener la URL real a la que se ha redirigido o saltado, puedes usar el método getRealUrl() del objeto Response.
Si se produce un error al procesar una solicitud, esta tendrá tres oportunidades de ser reintroducida en la cola de procesamiento para su reintentativa. Si finalmente falla, el sistema llamará al método public void handleErrorRequest(Request request) del crawler para manejar la solicitud con errores. La implementación predeterminada registra el error, aunque los desarrolladores pueden anular este método para proporcionar su propia lógica de manejo.
Es importante mencionar que SeimiAgent es una herramienta que puede ayudar significativamente con larenderización y manejo de páginas web dinámicas y complejas. Para quienes no estén familiarizados, SeimiAgent es un núcleo de navegador que se ejecuta en el servidor, desarrollado con QtWebkit y que proporciona servicios a través de una interfaz HTTP estándar. Está diseñado para manejar la renderización de páginas web complejas, la captura de instantáneas y la supervisión. En resumen, el manejo de páginas por parte de SeimiAgent es a nivel de navegador estándar, lo que significa que puedes obtener cualquier información que esté disponible en un navegador.
Para que SeimiCrawler pueda utilizar SeimiAgent, primero debes proporcionar la dirección del servicio de SeimiAgent.
A través de SeimiConfig, por ejemplo:
SeimiConfig config = new SeimiConfig();
config.setSeimiAgentHost("127.0.0.1");
Seimi s = new Seimi(config);
s.goRun("basic");
Configura en application.properties:
seimi.crawler.seimi-agent-host=xx
seimi.crawler.seimi-agent-port=xx
Decide cuáles solicitudes se enviarán a SeimiAgent para su procesamiento y cómo SeimiAgent las procesará. Esto se hace a nivel de solicitud.
Request.useSeimiAgent()Indica a SeimiCrawler que esta solicitud debe ser enviada a SeimiAgent.Request.setSeimiAgentRenderTime(long seimiAgentRenderTime)Establece el tiempo de renderización de SeimiAgent (el tiempo que SeimiAgent tiene para ejecutar scripts de JavaScript y otros recursos una vez que todos los recursos se han cargado), el tiempo se mide en milisegundos.Request.setSeimiAgentUseCookie(Boolean seimiAgentUseCookie)Indica a SeimiAgent si debe usar cookies. Si no se establece aquí, SeimiCrawler usará la configuración global de cookies.- Otros Si tu Crawler está configurado con un proxy, SeimiCrawler también enviará automáticamente esta configuración de proxy a SeimiAgent cuando se transfiera la solicitud.
- Demo Para un uso práctico, puedes referirte al demo en el repositorio
Configura en application.properties
seimi.crawler.enabled=true
# Especifica el nombre del crawler al que se envía la solicitud start
seimi.crawler.names=basic,test
Luego, sigue el arranque estándar de SpringBoot
@SpringBootApplication
public class SeimiCrawlerApplication {
public static void main(String[] args) {
SpringApplication.run(SeimiCrawlerApplication.class, args);
}
}
Añade una función main en una clase independiente, similar a la del proyecto demo. En la función main, inicializa el objeto Seimi y configura algunos parámetros específicos a través de SeimiConfig, como la información del clúster de Redis necesario para las colas distribuidas, o la configuración del host de seimiAgent si es necesario. SeimiConfig es opcional. Por ejemplo:
public class Boot {
public static void main(String[] args){
SeimiConfig config = new SeimiConfig();
// config.setSeimiAgentHost("127.0.0.1");
// config.redisSingleServer().setAddress("redis://127.0.0.1:6379");
Seimi s = new Seimi(config);
s.goRun("basic");
}
}
Seimi incluye las siguientes funciones de inicio:
public void start(String... crawlerNames)Inicia la ejecución de uno o más crawlers especificados.public void startAll()Inicia todos los crawlers que se han cargado.public void startWithHttpd(int port, String... crawlerNames)Inicia la ejecución de un crawler especificado y arranca un servicio http en un puerto específico, a través del cual se puede enviar una solicitud deextracción a un crawler específico a través de/push/crawlerName, aceptando el parámetroreq, soportando POST y GET.public void startWorkers()Solo inicializa todos los crawlers que se han cargado y escucha solicitudes de extracción. Esta función de inicio se usa principalmente para iniciar uno o más sistemas de trabajadores simples en un entorno de despliegue distribuido, lo cual se explicará en detalle en las secciones posteriores sobre cómo realizar y soportar el despliegue distribuido.
Ejecuta el siguiente comando en el proyecto para empaquetar y outputar todo el proyecto,
Para evitar que la salida de logs se vea mal en la consola de Windows, por favor modifica el formato de salida de la consola en el archivo de configuración de logback a
GBK, por defecto esUTF-8.
mvn clean package&&mvn -U compile dependency:copy-dependencies -DoutputDirectory=./target/seimi/&&cp ./target/*.jar ./target/seimi/
En este momento, en el directorio target del proyecto, habrá un directorio llamado seimi, este directorio es nuestro proyecto final compilado y listo para despliegue, luego ejecuta el siguiente comando para iniciar,
En Windows:
java -cp .;./target/seimi/* cn.wanghaomiao.main.Boot
En Linux:
java -cp .:./target/seimi/* cn.wanghaomiao.main.Boot
Puedes escribir los comandos anteriores en un script, y también puedes ajustar los directorios según tu situación. Lo anterior es solo un ejemplo para el proyecto demo. Para escenarios de despliegue real, se puede utilizar la herramienta de empaquetado específica de SeimiCrawler maven-seimicrawler-plugin para empaquetar y desplegar. A continuación, se detalla en la sección Despliegue y empaquetado de proyectos.
Se recomienda utilizar Spring Boot para construir el proyecto, ya que esto permite aprovechar la ecosistema existente de Spring Boot para expandir las funcionalidades de formas inesperadas. Para empaquetar un proyecto de Spring Boot, puedes seguir la guía oficial de Spring Boot para empaquetado.
mvn package
La forma anterior puede ser útil para el desarrollo o la depuración, y también puede ser una opción para iniciar en un entorno de producción. Sin embargo, para facilitar el despliegue y distribución en proyectos, SeimiCrawler proporciona un plugin de empaquetado específico para empaquetar proyectos de SeimiCrawler, los paquetes resultantes pueden ser distribuidos y desplegados directamente. Solo necesitas hacer lo siguiente:
Agrega el plugin en el pom
<plugin>
<groupId>cn.wanghaomiao</groupId>
<artifactId>maven-seimicrawler-plugin</artifactId>
<version>1.0.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>build</goal>
</goals>
</execution>
</executions>
</plugin>
Ejecuta mvn clean package y todo estará listo, la estructura del directorio empaquetado es la siguiente:
.
├── bin # En los scripts respectivos se detallan los parámetros de inicio, no se abordará aquí
│ ├── run.bat # Script de inicio para Windows
│ └── run.sh # Script de inicio para Linux
└── seimi
├── classes # Directorio de clases de negocio y archivos de configuración del proyecto Crawler
└── lib # Directorio de paquetes dependientes del proyecto
Ahora ya puedes utilizarlo para su distribución y despliegue.
La programación personalizada en SeimiCrawler puede lograrse directamente usando la anotación @Scheduled de Spring, sin necesidad de configuración adicional. Por ejemplo, se puede definir directamente en el archivo de reglas del Crawler de la siguiente manera:
@Scheduled(cron = "0/5 * * * * ?")
public void callByCron(){
logger.info("Soy un programador que se ejecuta según la expresión cron, cada 5 segundos");
// Se puede programar para enviar una solicitud Request
// push(Request.build(startUrls()[0],"start").setSkipDuplicateFilter(true));
}
Si se desea definir en una clase de servicio independiente, se debe asegurar que dicha clase de servicio pueda ser escaneada. Para @Scheduled, los desarrolladores pueden consultar la documentación de Spring para conocer los detalles de sus parámetros, o también pueden referirse al ejemplo Demo de SeimiCrawler en GitHub.
Si desea definir un Bean, SeimiCrawler puede extraer automáticamente los datos según las reglas que haya definido y llenar los campos correspondientes, para lo cual necesitará esta función.
Primero, veamos un ejemplo:
public class BlogContent {
@Xpath("//h1[@class='postTitle']/a/text()|//a[@id='cb_post_title_url']/text()")
private String title;
//También se puede escribir así @Xpath("//div[@id='cnblogs_post_body']//text()")
@Xpath("//div[@id='cnblogs_post_body']/allText()")
private String content;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}
La clase BlogContent es un Bean objetivo que ha definido, y @Xpath debe colocarse en los campos donde desee inyectar datos, y configurar una regla de extracción XPath para ellos. No se requiere que los campos sean privados o públicos, ni que necesariamente existan getter y setter.
Una vez preparado el Bean, se puede utilizar la función integrada public <T> T render(Class<T> bean) en el método de llamada de retorno para obtener el objeto Bean con los datos llenados.
SeimiCrawler también admite la adición de interceptores a funciones de llamada de retorno específicas o a todas. Para implementar un interceptor, tenga en cuenta los siguientes puntos:
- Debe usar la anotación
@Interceptor - Debe implementar la interfaz
SeimiInterceptor - Todos los interceptores que desee que sean escaneados y efectivos deben colocarse en el paquete interceptors, como
cn.wanghaomiao.xxx.interceptors, y hay ejemplos en el proyecto de demostración. - Debe crear una anotación personalizada para marcar qué funciones deben ser interceptadas o si todas deben ser interceptadas.
Esta anotación se utiliza para indicar a Seimi que la clase anotada puede ser un interceptor (ya que para ser un interceptador verdadero de Seimi también debe cumplir con otras convenciones mencionadas anteriormente). Tiene una propiedad,
everyMethodcon valor predeterminado defalse, que se usa para indicar a Seimi si este interceptor debe interceptar todas las funciones de llamada de retorno.
Directamente a la interfaz,
public interface SeimiInterceptor {
/**
* Obtener la anotación que debe marcarse en el método objetivo
* @return Annotation
*/
public Class<? extends Annotation> getTargetAnnotationClass();
/**
* Este método puede ser sobrescrito cuando se necesita controlar el orden de ejecución de múltiples interceptores
* @return Peso, cuanto mayor sea el peso, más externo será, y tendrá prioridad para interceptar
*/
public int getWeight();
/**
* Se pueden definir algunas lógicas de procesamiento antes de la ejecución del método objetivo
*/
public void before(Method method, Response response);
/**
* Se pueden definir algunas lógicas de procesamiento después de la ejecución del método objetivo
*/
public void after(Method method, Response response);
}
Las anotaciones ya explican claramente, no necesitamos entrar en más detalles.
Referirse al DemoInterceptor en el proyecto demo, dirección directa de GitHub
SeimiQueue es el único canal para la transferencia de datos y la comunicación interna y entre sistemas en SeimiCrawler. Por defecto, SeimiQueue utiliza una implementación basada en una cola de bloqueo segura para subprocesos local. SeimiCrawler también admite una implementación de SeimiQueue basada en Redis llamada DefaultRedisQueue, y es posible implementar su propio SeimiQueue que cumpla con las especificaciones de Seimi. Se puede especificar qué implementación utilizar a través de la propiedad queue en la anotación @Crawler.
Configuración de la anotación de Crawler: @Crawler(name = "xx", queue = DefaultRedisQueue.class)
Configuración en application.properties
# Iniciar SeimiCrawler
seimi.crawler.enabled=true
seimi.crawler.names=DefRedis,test
# Habilitar la cola distribuida
seimi.crawler.enable-redisson-queue=true
# Establecer el número de inserciones esperadas para el filtro bloom personalizado, si no se establece se utilizará el valor predeterminado
#seimi.crawler.bloom-filter-expected-insertions=
# Establecer la tasa de error esperada para el filtro bloom personalizado, 0.001 permite un error por cada 1000 inserciones. Si no se establece, se utiliza el valor predeterminado (0.001)
#seimi.crawler.bloom-filter-false-probability=
En seimi-app.xml, configure Redisson. A partir de la versión 2.0, la cola distribuida predeterminada es implementada con Redisson, por lo que se debe inyectar la implementación específica de redissonClient en el archivo de configuración de Spring. Luego, se puede usar la cola distribuida normalmente.
<redisson:client
id="redisson"
name="test_redisson"
>
Las propiedades name y el elemento hijo qualifier no pueden usarse simultáneamente.
Tanto las propiedades id y name pueden ser utilizadas como valores de qualifier.
-->
<redisson:single-server
idle-connection-timeout="10000"
ping-timeout="1000"
connect-timeout="10000"
timeout="3000"
retry-attempts="3"
retry-interval="1500"
reconnection-timeout="3000"
failed-attempts="3"
subscriptions-per-connection="5"
client-name="none"
address="redis://127.0.0.1:6379"
subscription-connection-minimum-idle-size="1"
subscription-connection-pool-size="50"
connection-minimum-idle-size="10"
connection-pool-size="64"
database="0"
dns-monitoring="false"
dns-monitoring-interval="5000"
/>
</redisson:client>
Configure SeimiConfig, configure los detalles básicos del clúster Redis, por ejemplo:
SeimiConfig config = new SeimiConfig();
config.setSeimiAgentHost("127.0.0.1");
config.redisSingleServer().setAddress("redis://127.0.0.1:6379");
Seimi s = new Seimi(config);
s.goRun("basic");
En general, las dos implementaciones predeterminadas de SeimiCrawler son suficientes para la mayoría de los casos de uso. Sin embargo, si existen situaciones que no pueden ser manejadas, también puedes implementar tu propia SeimiQueue y configurarla para su uso. Al implementarla, es importante tener en cuenta los siguientes puntos:
- Debes anotar la clase con
@Queuepara indicar a Seimi que esta clase marcada podría ser un SeimiQueue (aunque también debe cumplir con otras condiciones). - Debes implementar la interfaz
SeimiQueue, como se muestra a continuación:
/**
* Define la interfaz básica de la cola del sistema, puedes elegir la implementación según tus necesidades, siempre y cuando cumpla con las normas.
* @author 汪浩淼 [email protected]
* @since 2015/6/2.
*/
public interface SeimiQueue extends Serializable {
/**
* Bloquea y saca una solicitud de la cola
* @param crawlerName --
* @return --
*/
Request bPop(String crawlerName);
/**
* Agrega una solicitud a la cola
* @param req Solicitud
* @return --
*/
boolean push(Request req);
/**
* Retorna la longitud restante de la cola de tareas
* @param crawlerName --
* @return num
*/
long len(String crawlerName);
/**
* Determina si una URL ha sido procesada
* @param req --
* @return --
*/
boolean isProcessed(Request req);
/**
* Registra una solicitud procesada
* @param req --
*/
void addProcessed(Request req);
/**
* Retorna el total de capturas procesadas hasta el momento
* @param crawlerName --
* @return num
*/
long totalCrawled(String crawlerName);
/**
* Limpia los registros de las capturas
* @param crawlerName --
*/
void clearRecord(String crawlerName);
}
- Todas las implementaciones de SeimiQueue que desees que sean escaneadas y activas deben estar ubicadas en el paquete
queues, comocn.wanghaomiao.xxx.queues, y en el proyecto de demostración también hay ejemplos. Una vez que cumplas estos requisitos y hayas implementado tu propia SeimiQueue, configúrala para su uso con la anotación@Crawler(name = "xx", queue = YourSelfRedisQueueImpl.class).
Revisa el DefaultRedisQueueEG en el proyecto de demostración (enlace directo de Github)
Dado que SeimiCrawler utiliza spring para gestionar beans y realizar la inyección de dependencias, resulta bastante sencillo integrar las soluciones de persistencia de datos principales actuales, como Mybatis, Hibernate, Paoding-jade, entre otras. En este caso, se utiliza Mybatis.
Agrega las dependencias de Mybatis y la conexión a la base de datos:
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-spring</artifactId>
<version>1.3.0</version>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.4.1</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-dbcp2</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.4.2</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.37</version>
</dependency>Añada un archivo de configuración xml seimi-mybatis.xml (recuerde que todos los archivos de configuración deben comenzar con seimi)
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="propertyConfigurer" class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer">
<property name="locations">
<list>
<value>classpath:**/*.properties</value>
</list>
</property>
</bean>
<bean id="mybatisDataSource" class="org.apache.commons.dbcp2.BasicDataSource">
<property name="driverClassName" value="${database.driverClassName}"/>
<property name="url" value="${database.url}"/>
<property name="username" value="${database.username}"/>
<property name="password" value="${database.password}"/>
</bean>
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean" abstract="true">
<property name="configLocation" value="classpath:mybatis-config.xml"/>
</bean>
<bean id="seimiSqlSessionFactory" parent="sqlSessionFactory">
<property name="dataSource" ref="mybatisDataSource"/>
</bean>
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="cn.wanghaomiao.dao.mybatis"/>
<property name="sqlSessionFactoryBeanName" value="seimiSqlSessionFactory"/>
</bean>
</beans>Dado que el proyecto de demo contiene un archivo de configuración unificado seimi.properties, la información de conexión de la base de datos también se inyecta a través de properties, por supuesto, también puede escribirlo directamente. La configuración de properties es la siguiente:
database.driverClassName=com.mysql.jdbc.Driver
database.url=jdbc:mysql://127.0.0.1:3306/xiaohuo?useUnicode=true&characterEncoding=UTF8&autoReconnect=true&autoReconnectForPools=true&zeroDateTimeBehavior=convertToNull
database.username=xiaohuo
database.password=xiaohuo
El proyecto está listo hasta ahora, lo que queda es que usted cree una base de datos y una tabla para almacenar la información de la prueba, el proyecto de demo proporciona la estructura de la tabla, el nombre de la base de datos puede ajustarse según lo desee:
CREATE TABLE `blog` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(300) DEFAULT NULL,
`content` text,
`update_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
Cree un archivo DAO de Mybatis:
public interface MybatisStoreDAO {
@Insert("insert into blog (title,content,update_time) values (#{blog.title},#{blog.content},now())")
@Options(useGeneratedKeys = true, keyProperty = "blog.id")
int save(@Param("blog") BlogContent blog);
}
Todos deben estar familiarizados con la configuración de Mybatis, no entraremos en muchos detalles. Para más información, pueden ver el proyecto de demo o referirse a la documentación oficial de Mybatis.
Inyecta directamente en el Crawler correspondiente, por ejemplo:
@Crawler(name = "mybatis")
public class DatabaseMybatisDemo extends BaseSeimiCrawler {
@Autowired
private MybatisStoreDAO storeToDbDAO;
@Override
public String[] startUrls() {
return new String[]{"http://www.cnblogs.com/"};
}
@Override
public void start(Response response) {
JXDocument doc = response.document();
try {
List<Object> urls = doc.sel("//a[@class='titlelnk']/@href");
logger.info("{}", urls.size());
for (Object s : urls) {
push(Request.build(s.toString(), DatabaseMybatisDemo::renderBean));
}
} catch (Exception e) {
e.printStackTrace();
}
}
public void renderBean(Response response) {
try {
BlogContent blog = response.render(BlogContent.class);
logger.info("bean resolve res={},url={}", blog, response.getUrl());
// Usar paoding-jade para almacenar en la base de datos
int changeNum = storeToDbDAO.save(blog);
int blogId = blog.getId();
logger.info("store success,blogId = {},changeNum={}", blogId, changeNum);
} catch (Exception e) {
e.printStackTrace();
}
}
}
Por supuesto, si el negocio es muy complejo, es recomendable encapsular una capa de servicio y luego inyectar el servicio en el Crawler.
Cuando tu volumen de negocio y datos alcanza cierto nivel, necesitarás expandir horizontalmente varias máquinas para crear un servicio en clúster para mejorar la capacidad de procesamiento. Este es un problema que SeimiCrawler consideró desde el principio de su diseño. Por lo tanto, SeimiCrawler es compatible con la implementación distribuida desde su inicio. Como ya se mencionó con SeimiQueue, creo que el astuto lector ya sabe cómo realizar la implementación distribuida. SeimiCrawler implementa la distribución utilizando DefaultRedisQueue como SeimiQueue predeterminado y configurando la misma información de conexión de redis en cada máquina donde se desea implementar. En el texto anterior ya se explicó esto, por lo que no entraremos en más detalles aquí. Al habilitar DefaultRedisQueue, en las máquinas que actuarán como workers, inicializa los procesadores de Seimi con new Seimi().startWorkers(). Los procesos worker de Seimi comenzarán a escuchar la cola de mensajes, y cuando el servicio principal emita una solicitud de extracción, el clúster completo comenzará a comunicarse a través de la cola de mensajes, colaborando y trabajando de manera dinámica. A partir de la versión 2.0, la cola distribuida predeterminada se implementa utilizando Redisson y se introduce BloomFilter.
Si deseas enviar una solicitud de extracción personalizada a Seimicrawler, la solicitud debe incluir los siguientes parámetros:
urlLa dirección a extraercrawlerNameEl nombre de la reglacallBackLa función de llamada
Podemos construir un proyecto de SpringBoot y escribir controladores de spring MVC para manejar este tipo de solicitudes. Aquí tienes un simple DEMO, puedes basarte en esto para hacer cosas más divertidas e interesantes.
Si no deseas ejecutarlo como un proyecto de SpringBoot, puedes usar la interfaz interna. SeimiCrawler puede iniciar un servicio HTTP integrado en un puerto específico para recibir solicitudes de extracción a través de HTTP API o para verificar el estado de extracción del Crawler correspondiente.
Envía una solicitud de Request en formato JSON a SeimiCrawler a través de la interfaz HTTP. Una vez que la interfaz HTTP recibe la solicitud de extracción y la verifica correctamente, la solicitud se procesará junto con las demás generadas por las reglas de procesamiento.
- Dirección de la solicitud: http://host:port/push/${YourCrawlerName}
- Método de llamada: GET/POST
- Parámetros de entrada:
| Nombre del parámetro | Obligatorio | Tipo de parámetro | Descripción del parámetro |
|---|---|---|---|
| req | true | str | Contenido en forma de JSON de una solicitud Request, ya sea un solo elemento o un array JSON |
- Ejemplo de estructura de parámetros:
{
"callBack": "start",
"maxReqCount": 3,
"meta": {
"listPageSomeKey": "xpxp"
},
"params": {
"paramName": "xxxxx"
},
"stop": false,
"url": "http://www.github.com"
}
o bien
[
{
"callBack": "start",
"maxReqCount": 3,
"meta": {
"listPageSomeKey": "xpxp"
},
"params": {
"paramName": "xxxxx"
},
"stop": false,
"url": "http://www.github.com"
},
{
"callBack": "start",
"maxReqCount": 3,
"meta": {
"listPageSomeKey": "xpxp"
},
"params": {
"paramName": "xxxxx"
},
"stop": false,
"url": "http://www.github.com"
}
]
Descripción de los campos de la estructura:
| Campo Json | Obligatorio | Tipo de campo | Descripción del campo |
|---|---|---|---|
| url | true | str | Dirección de la solicitud |
| callBack | true | str | Función de devolución de llamada para el resultado de la solicitud correspondiente |
| meta | false | map | Datos personalizados que pueden ser pasados al contexto |
| params | false | map | Parámetros de solicitud que pueden ser necesarios para la solicitud actual |
| stop | false | bool | Si es true, el hilo de trabajo que recibe esta solicitud detendrá su trabajo |
| maxReqCount | false | int | Número máximo de reintentos permitidos si el procesamiento de esta solicitud falla |
Dirección de solicitud: /status/${YourCrawlerName} para ver el estado actual de captura del Crawler especificado, el formato de datos es Json.
Consulte 5.2.13. Configuración de proxy dinámico
Consulte 5.2.8. Activación de cookies (opcional)
- Los mismos Crawlers en diferentes instancias de SeimiCrawler trabajarán de manera colaborativa a través del mismo redis (compartiendo una cola de producción y consumo)
- Asegúrese de que la máquina en la que se inicia SeimiCrawler y el redis estén correctamente conectadas, es absolutamente necesario.
- El demo configura la contraseña de redis, pero si su redis no requiere contraseña, no la configure.
- Muchos usuarios han experimentado problemas de red, lo que indica que necesitan verificar su configuración de red. SeimiCrawler utiliza una biblioteca de red madura, por lo que si se producen problemas de red, es seguro que el problema radica en la red. Se deben verificar situaciones como, pero no limitado a: si el sitio objetivo ha implementado un bloqueo específico, si la conexión a los proxies es fluida, si los proxies están bloqueados, si los proxies tienen la capacidad de acceder a Internet, y si la máquina en la que se encuentra tiene acceso a Internet.
Reescribe la implementación de public List<Request> startRequests(), aquí se puede definir libremente solicitudes de inicio complejas. Al implementarlo, public String[] startUrls() puede devolver null. Un ejemplo es el siguiente:
@Crawler(name = "usecookie",useCookie = true)
public class UseCookie extends BaseSeimiCrawler {
@Override
public String[] startUrls() {
return null;
}
@Override
public List<Request> startRequests() {
List<Request> requests = new LinkedList<>();
Request start = Request.build("https://www.oschina.net/action/user/hash_login","start");
Map<String,String> params = new HashMap<>();
params.put("email","[email protected]");
params.put("pwd","xxxxxxxxxxxxxxxxxxx");
params.put("save_login","1");
params.put("verifyCode","");
start.setHttpMethod(HttpMethod.POST);
start.setParams(params);
requests.add(start);
return requests;
}
@Override
public void start(Response response) {
logger.info(response.getContent());
push(Request.build("http://www.oschina.net/home/go?page=blog","minePage"));
}
public void minePage(Response response){
JXDocument doc = response.document();
try {
logger.info("uname:{}", StringUtils.join(doc.sel("//div[@class='name']/a/text()"),""));
logger.info("httpType:{}",response.getSeimiHttpType());
} catch (XpathSyntaxErrorException e) {
logger.debug(e.getMessage(),e);
}
}
}
<dependency>
<groupId>cn.wanghaomiao</groupId>
<artifactId>SeimiCrawler</artifactId>
<version>2.1.2</version>
</dependency>
Por favor, asegúrate de que estás utilizando la versión 2.1.2 o superior, ya que esta versión soporta la configuración de la propiedad jsonBody en Request para enviar solicitudes con cuerpo Json.
Si tienes alguna pregunta o sugerencia, ahora puedes participar en la discusión a través de la lista de correo a continuación. Antes de tu primera participación, necesitas suscribirte y esperar la aprobación (esto se hace principalmente para filtrar publicidad y otros contenidos no deseados, para crear un buen ambiente de discusión).
- Suscripción: envía un correo electrónico a
[email protected] - Participación: envía un correo electrónico a
[email protected] - Baja: envía un correo electrónico a
[email protected]
BTW: ¡Bienvenido a
staren github ^_^!