Гибкий, мощный, автономный, распределённый фреймворк для веб-скрейпинга.
Цель SeimiCrawler — стать самым удобным и практичным фреймворком для веб-скрейпинга в мире Java.
SeimiCrawler — это гибкий, автономно развёртываемый, поддерживающий распределённые вычисления фреймворк на Java для веб-скрейпинга. Он направлен на максимальное снижение порога вхождения для новичков в разработку эффективных и производительных систем веб-скрейпинга, а также на повышение эффективности разработки таких систем. В мире SeimiCrawler большинству пользователей достаточно заботиться о написании бизнес-логики для сбора данных, всё остальное Seimi берёт на себя. Концептуально SeimiCrawler вдохновлён фреймворком Scrapy для Python, но адаптирован под характеристики языка Java и Spring. Он также направлен на облегчение и упрощение использования XPath для разбора HTML в китайском контексте, поэтому SeimiCrawler использует в качестве стандартного разборщика HTML JsoupXpath (независимый расширяемый проект, не входит в состав jsoup), а стандартная работа по извлечению данных из HTML выполняется с использованием XPath (как известно, для обработки данных также можно выбрать другие разборщики). В сочетании с SeimiAgent он полностью решает проблемы сбора данных с сложных динамических страниц. Фреймворк полностью поддерживает SpringBoot, позволяя вам максимально использовать вашу фантазию и творческие способности.
JDK1.8+
<dependency>
<groupId>cn.wanghaomiao</groupId>
<artifactId>SeimiCrawler</artifactId>
<version>см. последнюю версию на GitHub</version>
</dependency>
Список версий на GitHub Список версий на Maven
Создайте стандартный проект на SpringBoot, добавьте правила скрейпинга в пакете crawlers, например:
@Crawler(name = "basic")
public class Basic extends BaseSeimiCrawler {
@Override
public String[] startUrls() {
// Два URL для тестирования уникальности
return new String[]{"http://www.cnblogs.com/","http://www.cnblogs.com/"};
}
@Override
public void start(Response response) {
JXDocument doc = response.document();
try {
List<Object> urls = doc.sel("//a[@class='titlelnk']/@href");
logger.info("{}", urls.size());
for (Object s : urls) {
push(Request.build(s.toString(), Basic::getTitle));
}
} catch (Exception e) {
e.printStackTrace();
}
}
public void getTitle(Response response) {
JXDocument doc = response.document();
try {
logger.info("url:{} {}", response.getUrl(), doc.sel("//h1[@class='postTitle']/a/text()|//a[@id='cb_post_title_url']/text()"));
// выполните необходимые действия
} catch (Exception e) {
e.printStackTrace();
}
}
}
Настройте application.properties:
# Запуск SeimiCrawler
seimi.crawler.enabled=true
seimi.crawler.names=basic
Стандартный запуск SpringBoot
@SpringBootApplication
public class SeimiCrawlerApplication {
public static void main(String[] args) {
SpringApplication.run(SeimiCrawlerApplication.class, args);
}
}Более сложное использование можно найти в более подробной документации или в демо на GitHub.
Создайте обычный Maven-проект и добавьте правила爬虫 в пакете crawlers, например:
@Crawler(name = "basic")
public class Basic extends BaseSeimiCrawler {
@Override
public String[] startUrls() {
// два URL для тестирования удаления дубликатов
return new String[]{"http://www.cnblogs.com/","http://www.cnblogs.com/"};
}
@Override
public void start(Response response) {
JXDocument doc = response.document();
try {
List<Object> urls = doc.sel("//a[@class='titlelnk']/@href");
logger.info("{}", urls.size());
for (Object s : urls) {
push(Request.build(s.toString(), Basic::getTitle));
}
} catch (Exception e) {
e.printStackTrace();
}
}
public void getTitle(Response response) {
JXDocument doc = response.document();
try {
logger.info("url:{} {}", response.getUrl(), doc.sel("//h1[@class='postTitle']/a/text()|//a[@id='cb_post_title_url']/text()"));
// выполните какие-либо действия
} catch (Exception e) {
e.printStackTrace();
}
}
}Затем добавьте метод main в любом пакете для запуска SeimiCrawler:
public class Boot {
public static void main(String[] args) {
Seimi s = new Seimi();
s.start("basic");
}
}Таким образом,above представляет собой простейший процесс разработки системы веб-скрапинга.
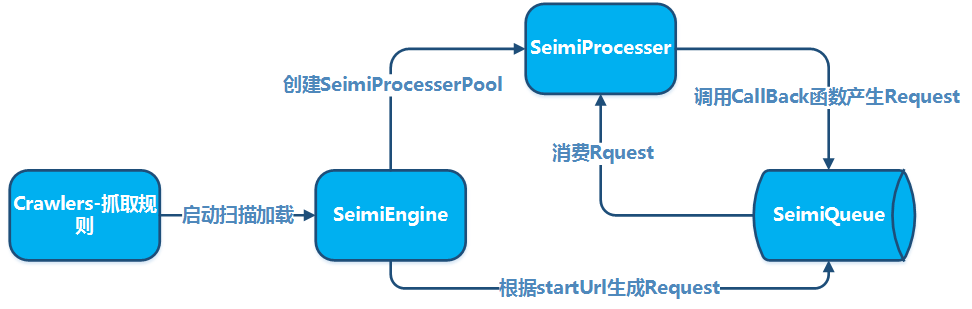
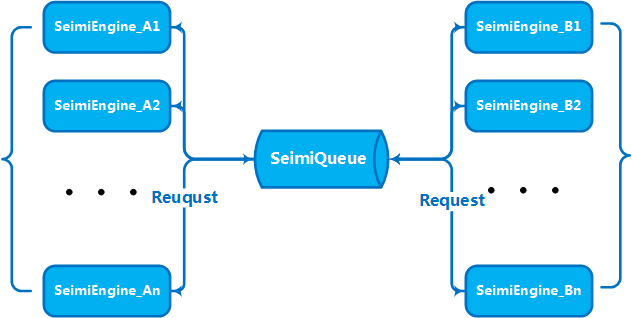
Конвенции необходимы для того, чтобы исходный код системы веб-скрапинга, разработанной с использованием SeimiCrawler, был более структурированным и легким для чтения. Если все придерживаются одной и той же конвенции, код проекта будет легче читать и изменять для других членов команды, что снижает вероятность того, что один человек ищет классы, разработанные другим, в неправильном месте. Мы стремимся к созданию мощной, простой и удобной в использовании системы. Конвенции не делают SeimiCrawler менее гибким.
- Поскольку контекст SeimiCrawler основан на Spring, поддерживаются几乎所有Spring格式的配置文件和 usual Spring usage. SeimiCrawler будет扫描工程classpath下所有的XML格式配置文件,但只有文件名以
seimi开头的XML配置文件才能被SeimiCrawler识别并加载。 - SeimiCrawler使用slf4j进行日志记录,可以自行配置具体的实现。
- Seimi开发时需要注意的约定将在下面的开发要点中逐一介绍。
Исправление:
- Поскольку контекст SeimiCrawler основан на Spring, поддерживаются几乎所有Spring格式的配置文件 и usual Spring usage. SeimiCrawler будет сканировать все XML-файлы в classpath проекта, но только XML-файлы с именами, начинающимися на
seimi, будут идентифицированы и загружены SeimiCrawler. - SeimiCrawler использует slf4j для ведения журнала, что позволяет самостоятельно настраивать конкретную реализацию.
- Конвенции, которые следует соблюдать при разработке с использованием Seimi, будут подробно описаны в следующих разделах разработки.
Класс правил веб-скрейпинга является наиболее важной частью при разработке веб-скрейпера с использованием SeimiCrawler. В примере быстрого старта класс Basic является базовым классом веб-скрейпера. При написании веб-скрейпера необходимо учитывать следующие моменты:
- Необходимо наследоваться от
BaseSeimiCrawler - Необходимо использовать аннотацию
@Crawler, атрибутnameв аннотации является необязательным. Если он задан, то веб-скрейпер будет называться так, как вы его определили. В противном случае, по умолчанию будет использоваться имя вашего класса. - Все веб-скрейперы, которые вы хотите, чтобы SeimiCrawler сканировал, должны быть размещены в пакете crawlers, например:
cn.wanghaomiao.xxx.crawlers. Также можно ознакомиться с примером проекта, прилагаемым к проекту. После инициализации веб-скрейпера, вам необходимо реализовать два основных метода:public String[] startUrls();иpublic void start(Response response). После реализации этих методов простой веб-скрейпер считается завершенным.
В настоящее время аннотация @Crawler имеет следующие атрибуты:
name- пользовательское имя правила веб-скрейпинга. В пределах одного проекта, который может просканировать Seimi, не должно быть двух веб-скрейперов с одинаковым именем. По умолчанию используется имя класса.proxy- определяет, использует ли веб-скрейпер прокси-серверы, и какие именно. В настоящее время поддерживаются три формата:http|https|socket://host:port. В этой версии еще не поддерживается использование прокси-серверов с авторизацией.useCookie- определяет, следует ли использовать cookies. Если включено, то запросы будут сохранять свое состояние, как в браузере, что также делает их менее анонимными.queue- указывает очередь данных, которую должен использовать данный веб-скрейпер. По умолчанию используется реализация локальной очередиDefaultLocalQueue.class. Также можно настроить использование стандартной реализации на основе Redis или создать собственную реализацию на основе других систем очередей. О более подробной настройке очереди будет рассказано позже.delay- задает интервал времени между запросами в секундах. По умолчанию интервал равен 0, то есть запросы выполняются без задержек.httpType- тип реализации загрузчика, по умолчанию используется Apache HttpClient. Через этот параметр можно изменить реализацию обработки сетевых запросов на OkHttp3.httpTimeOut- позволяет задать пользовательское значение таймаута в миллисекундах. По умолчанию таймаут равен 15000 мс.
Этот метод является точкой входа для веб-скрейпинга и возвращает массив URL-адресов. По умолчанию стартовые URL-адреса обрабатываются как GET-запросы. Если в особых случаях вам нужно, чтобы Seimi обрабатывал ваши стартовые URL-адреса методом POST, вы можете добавить ##post в конец URL-адреса, например: http://passport.cnblogs.com/user/signin?ReturnUrl=http%3a%2f%2fi.cnblogs.com%2f##post. Это правило не зависит от регистра и применяется только к обработке стартовых URL-адресов.
Этот метод является обработчиком ответов, полученных по стартовым URL-адресам, то есть он определяет, как Seimi должен обрабатывать данные, полученные в ответ на запросы к стартовым URL-адресам.
- Текстовые результаты
Seimi по умолчанию рекомендует использовать XPath для извлечения данных из HTML. Хотя изначально может быть немного трудно усвоить XPath, это значительно облегчает разработку после того, как вы его освоите.
JXDocument doc = response.document();позволяет получитьJXDocument(объект документа JsoupXpath), после чего можно извлекать любые необходимые данные с помощьюdoc.sel("xpath"). Извлечение любой информации обычно требует только одной строки XPath. Для тех, кто хочет узнать больше о синтаксисе XPath в Seimi, пожалуйста, посетите JsoupXpath. Если же вам не нравится XPath, вы всегда можете использовать оригинальные данные ответа и другой парсер для их обработки. - Файловые результаты
Если результатом является файл, можно использовать
response.saveTo(File targetFile)для его сохранения, либо получить поток байтов файлаbyte[] getData()для других операций.
private BodyType bodyType;
private Request request;
private String charset;
private String referer;
private byte[] data;
private String content;
/**
* Это主要用于存储上级传递的一些自定义数据
*/
private Map<String, String> meta;
private String url;
private Map<String, String> params;
/**
* Реальный источник содержимого веб-страницы
*/
private String realUrl;
/**
* Тип HTTP-обработчика для этого запроса
*/
private SeimiHttpType seimiHttpType;
Использование стандартного обратного вызова очевидно не удовлетворит ваши потребности. Если вы хотите извлечь определенные URL с начальной страницы startURL, выполнить новые запросы и обработать полученные данные, вам придется создать собственный обратный вызов. Важные моменты:
- С версии 2.0 поддерживаются ссылки на методы, что делает установку обратного вызова более естественной, например:
Basic::getTitle. - Внутри обратного вызова можно создавать новые
Request, задавая для них другие обратные вызовы или сам обратный вызов. - Обратный вызов должен иметь формат:
public void callbackName(Response response), то есть быть публичным, иметь только один параметрResponseи не возвращать значения. - Для установки обратного вызова в
Requestдостаточно указать имя метода обратного вызова типаString, например,getTitleв секции быстрого старта. - Краулеры, унаследованные от
BaseSeimiCrawler, могут вызывать метод родительского классаpush(Request request)внутри обратного вызова для отправки новых запросов в очередь. Requestможно создать с помощьюRequest.build().
public class Request {
public static Request build(String url, String callBack, HttpMethod httpMethod, Map<String, String> params, Map<String, String> meta);
public static Request build(String url, String callBack, HttpMethod httpMethod, Map<String, String> params, Map<String, String> meta, int maxReqcount);
public static Request build(String url, String callBack);
public static Request build(String url, String callBack, int maxReqCount);
@NotNull
private String crawlerName;
/**
* URL для запроса
*/
@NotNull
private String url;
/**
* Тип метода запроса: GET, POST, PUT...
*/
private HttpMethod httpMethod;
/**
* Параметры запроса, если они нужны
*/
private Map<String,String> params;
/**
* Это主要用于存储传递给下级回调函数的一些自定义数据
*/
private Map<String,Object> meta;
/**
* Имя метода обратного вызова
*/
@NotNull
private String callBack;
/**
* Является ли обратный вызов лямбда-выражением
*/
private transient boolean lambdaCb = false;
/**
* Обратный вызов
*/
private transient SeimiCallbackFunc callBackFunc;
/**
* Сигнал остановки, при получении которого обрабатывающий поток выходит
*/
private boolean stop = false;
/**
* Максимальное количество разрешенных повторных запросов
*/
private int maxReqCount = 3;
/**
* Используется для записи количества выполнений текущего запроса
*/
private int currentReqCount = 0;
/**
* Используется для указания, должен ли запрос проходить через фильтр дубликатов
*/
private boolean skipDuplicateFilter = false;
/**
* Включено ли использование SeimiAgent для этого запроса
*/
private boolean useSeimiAgent = false;
/**
* Пользовательские HTTP-заголовки запроса
*/
private Map<String,String> header;
/**
* Определяет время рендеринга SeimiAgent, в миллисекундах
*/
private long seimiAgentRenderTime = 0;
/**
* Используется для выполнения указанного JS-скрипта на SeimiAgent
*/
private String seimiAgentScript;
/**
* Указывает, следует ли использовать cookie для запросов, отправляемых в SeimiAgent
*/
private Boolean seimiAgentUseCookie;
/**
* Определяет, в каком формате должны быть отображены результаты, возвращенные SeimiAgent, по умолчанию HTML
*/
private SeimiAgentContentType seimiAgentContentType = SeimiAgentContentType.HTML;
/**
* Поддерживает добавление пользовательских cookie
*/
private List<SeimiCookie> seimiCookies;
/**
* Поддерживает добавление JSON-тела запроса
*/
private String jsonBody;
}
По умолчанию UserAgent SeimiCrawler — это SeimiCrawler/JsoupXpath. Если вам требуется настроить собственный UserAgent, вы можете переопределить метод public String getUserAgent() в BaseSeimiCrawler. SeimiCrawler будет запрашивать UserAgent при каждом обработке запроса, поэтому если вы хотите подделывать UserAgent, вы можете реализовать свою библиотеку UserAgent, которая будет случайным образом возвращать один из них.
В description аннотации @Crawler уже упоминалось, здесь снова подчеркнем это для удобства быстрого просмотра основных функций. Включение cookies настраивается через атрибут useCookie в аннотации @Crawler. Также можно настроить пользовательские cookies через метод Request.setSeimiCookies(List<SeimiCookie> seimiCookies) или Request.setHeader(Map<String, String> header). Объект Request предлагает множество возможностей для пользовательской настройки, изучите его для получения более полного понимания и расширения ваших возможностей.
Настройка proxy осуществляется через атрибут proxy в аннотации @Crawler,详情请参阅@Crawler的介绍。如果希望动态指定代理,请参阅下文“设置动态代理”。目前支持三种格式http|https|socket://host:port。
通过@Crawler注解中的delay属性进行配置,设置请求抓取的时间间隔,单位为秒,默认为0即没有间隔。在很多情况下,内容提供方都会将请求频率的限制作为反爬虫的手段,因此在需要的情况下可以自行调整添加这个参数来实现更好的抓取效果。
Note: The last two paragraphs have been partially translated from Russian to Chinese in the original text. For consistency, they are translated to Russian:
Конфигурация задержки осуществляется через атрибут delay в аннотации @Crawler, задает интервал между запросами в секундах, по умолчанию 0, то есть без задержки. В большинстве случаев контент-провайдеры используют ограничение частоты запросов как средство защиты от парсинга, поэтому при необходимости можно настроить этот параметр для достижения лучших результатов при сборе данных.
Через переопределение public String[] allowRules() в BaseSeimiCrawler устанавливаются правила белого списка URL-запросов. Правила представляют собой регулярные выражения, и при совпадении с любым из них запрос будет разрешен.
Через переопределение public String[] denyRules() в BaseSeimiCrawler устанавливаются правила черного списка URL-запросов. Правила представляют собой регулярные выражения, и при совпадении с любым из них запрос будет заблокирован.
Через переопределение public String proxy() в BaseSeimiCrawler указывается, какой прокси-адрес использовать для конкретного запроса. Здесь можно возвратить прокси-адрес из имеющейся библиотеки прокси по порядку или случайно. Если этот прокси-адрес не пуст, то настройки свойства proxy в аннотации @Crawler игнорируются. Поддерживаются три формата: http|https|socket://host:port.
Через свойство useUnrepeated в аннотации @Crawler контролируется, включена ли система удаления дубликатов. По умолчанию включена.
В настоящее время SeimiCrawler поддерживает перенаправления 301, 302 и meta refresh. Для таких перенаправлений можно получить конечный URL через метод getRealUrl() объекта Response.
Если при обработке запроса возникает исключение, запрос трижды помещается обратно в очередь для повторной обработки. Если после этого обработка все же завершается неудачно, система вызовет метод public void handleErrorRequest(Request request) в краулерe для обработки этого проблемного запроса. По умолчанию исключение записывается в лог, но разработчик может переопределить этот метод для добавления собственной реализации обработки.
Этот раздел стоит детально обсудить. Те, кто не знаком с SeimiAgent, могут ознакомиться с домашней страницей проекта SeimiAgent. Суть в том, что SeimiAgent — это браузерное ядро, работающее на серверной стороне, основанное на QtWebkit и предоставляющее услуги по стандартному HTTP-интерфейсу. Он предназначен для решения задач сложной динамической веб-страницы, таких как рендеринг, создание снимков экрана, мониторинг и т.д. Обработка страниц производится на уровне стандартного браузера, то есть вы можете использовать его для получения любой информации, доступной в обычном браузере.
Для того чтобы SeimiCrawler поддерживал SeimiAgent, необходимо указать адрес службы SeimiAgent.
Через конфигурацию SeimiConfig, например
SeimiConfig config = new SeimiConfig();
config.setSeimiAgentHost("127.0.0.1");
Seimi s = new Seimi(config);
s.goRun("basic");
В application.properties
seimi.crawler.seimi-agent-host=xx
seimi.crawler.seimi-agent-port=xx
Определяет, какие запросы должны быть обработаны SeimiAgent и как SeimiAgent должен их обрабатывать. Это уровень Request.
Request.useSeimiAgent()Сказывает SeimiCrawler, что этот запрос должен быть передан SeimiAgent.Request.setSeimiAgentRenderTime(long seimiAgentRenderTime)Устанавливает время рендеринга SeimiAgent (после загрузки всех ресурсов, сколько времени дать SeimiAgent для выполнения JavaScript и других скриптов для рендеринга конечной страницы), единица времени — миллисекунды.Request.setSeimiAgentUseCookie(Boolean seimiAgentUseCookie)Сказывает SeimiAgent, использовать ли cookie. Если здесь не установлено, используется глобальная настройка cookie в seimiCrawler.- Другое Если ваш Crawler установлен с использованием прокси, то при передаче этого запроса SeimiAgent seimiCrawler также автоматически заставит SeimiAgent использовать этот прокси.
- Демо Для практического применения можно посмотреть демо в репозитории
Конфигурация в application.properties
seimi.crawler.enabled=true
# Укажите имена crawler, для которых нужно отправить start запрос
seimi.crawler.names=basic,test
После этого стандартный запуск SpringBoot:
@SpringBootApplication
public class SeimiCrawlerApplication {
public static void main(String[] args) {
SpringApplication.run(SeimiCrawlerApplication.class, args);
}
}
Добавьте метод main, лучше в отдельном запускном классе, как в демонстрационном проекте. В методе main инициализируйте объект Seimi и, при необходимости, настройте конкретные параметры с помощью SeimiConfig, такие как информация о кластере Redis для дistributed очередей, если используется seimiAgent,相应地配置host信息等。当然,SeimiConfig是可选的。例如:
public class Boot {
public static void main(String[] args){
SeimiConfig config = new SeimiConfig();
// config.setSeimiAgentHost("127.0.0.1");
// config.redisSingleServer().setAddress("redis://127.0.0.1:6379");
Seimi s = new Seimi(config);
s.goRun("basic");
}
}
Seimi содержит следующие функции запуска:
public void start(String... crawlerNames)Запускает один или несколько указанных Crawler для выполнения сбора данных.public void startAll()Запускает все загруженные Crawler.public void startWithHttpd(int port, String... crawlerNames)Запускает указанный Crawler для выполнения сбора данных и запускает HTTP-сервис на указанном порту. Можно отправить запрос на сбор данных соответствующему Crawler по пути/push/crawlerName, параметр запроса —req, поддерживаются POST и GET.public void startWorkers()Инициализирует все загруженные Crawler и监听抓取请求。这个启动函数主要用于在分布式部署的情况下启动一个或多个单纯的worker系统,关于如何进行和支持分布式部署将在后面进行更详细的介绍。
Выполните следующую команду в проекте для упаковки и вывода всего проекта,
В Windows для того, чтобы избежать проблем с кодировкой логов в консоли, измените формат вывода в консоль в файле конфигурации logback на
GBK, по умолчанию этоUTF-8.
mvn clean package&&mvn -U compile dependency:copy-dependencies -DoutputDirectory=./target/seimi/&&cp ./target/*.jar ./target/seimi/
После этого в каталоге target проекта будет создана папка под названием seimi, которая будет содержать готовый к развертыванию проект. Для запуска выполните следующую команду:
В Windows:
java -cp .;./target/seimi/* cn.wanghaomiao.main.Boot
В Linux:
java -cp .:./target/seimi/* cn.wanghaomiao.main.Boot
Приведенные команды можно записать в скрипты, а путь к каталогам можно корректировать в зависимости от ситуации. Приведенный выше пример предназначен для демонстрации на примере демонстрационного проекта. В реальных сценариях развертывания можно использовать специализированный инструмент для упаковки maven-seimicrawler-plugin для упаковки и публикации проектов. Детальное описание предоставления в разделе «Инженерная упаковка и развертывание» ниже.
Рекомендуется использовать Spring Boot для создания проектов, так как это позволяет использовать расширенные возможности экосистемы Spring Boot. Для упаковки проекта на Spring Boot можно следовать стандартным методам, описанным на официальном сайте Spring Boot.
mvn package
Приведенные выше методы удобны для разработки и отладки и могут также использоваться в качестве способа запуска в производственной среде. Однако, для удобства инженерного развертывания и распространения, SeimiCrawler предоставляет специальный плагин для упаковки проектов, что позволяет моментально распространять и развертывать упакованный проект. Вам нужно выполнить всего несколько шагов:
Добавьте плагин в pom.xml
<plugin>
<groupId>cn.wanghaomiao</groupId>
<artifactId>maven-seimicrawler-plugin</artifactId>
<version>1.0.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>build</goal>
</goals>
</execution>
</executions>
</plugin>
Выполните команду mvn clean package, после чего структура упакованного каталога будет следующей:
.
├── bin # В соответствующих скриптах также есть подробное описание параметров запуска, здесь мы не будем вдаваться в детали
│ ├── run.bat # Скрипт для запуска в Windows
│ └── run.sh # Скрипт для запуска в Linux
└── seimi
├── classes # Каталог с классами и конфигурационными файлами проекта Crawler
└── lib # Каталог с зависимостями проекта
Теперь этот проект можно использовать для распространения и развертывания.
Пользовательская настройка планирования в SeimiCrawler может быть полностью реализована с использованием аннотации @Scheduled из Spring, без необходимости в дополнительной настройке. Например, можно прямо в файле правил Crawler определить следующее:
@Scheduled(cron = "0/5 * * * * ?")
public void callByCron(){
logger.info("Я - планировщик, выполняющийся по выражению cron, каждые 5 секунд");
// Можно периодически отправлять запрос
// push(Request.build(startUrls()[0],"start").setSkipDuplicateFilter(true));
}
Если вы хотите определить независимый класс сервиса, важно убедиться, что этот класс может быть обнаружен.有关@Scheduled的信息,开发者可以自行查阅Spring的资料来了解其参数细节,也可以参考SeimiCrawler在GitHub上的Demo示例。
Если вы хотите определить Bean, SeimiCrawler может автоматически извлекать данные согласно вашим правилам и заполнять соответствующие поля. Для этого вам понадобится эта функция.
Давайте посмотрим на пример:
public class BlogContent {
@Xpath("//h1[@class='postTitle']/a/text()|//a[@id='cb_post_title_url']/text()")
private String title;
// Также можно записать @Xpath("//div[@id='cnblogs_post_body']//text()")
@Xpath("//div[@id='cnblogs_post_body']/allText()")
private String content;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}
Класс BlogContent — это Bean, который вы определяете. Аннотация @Xpath должна быть применена к полям, в которые вы хотите вводить данные, и ей должен быть задан правило извлечения XPath. Поле может быть как приватным, так и публичным, и не обязательно должно иметь getter и setter.
После определения Bean, в методе обратного вызова вы можете использовать встроенную функцию Response public <T> T render(Class<T> bean) для получения Bean объекта, заполненного данными.
SeimiCrawler также поддерживает добавление перехватчиков к конкретным или всем методам обратного вызова. Для реализации перехватчика обратите внимание на следующие моменты:
- Необходимо использовать аннотацию
@Interceptor - Необходимо реализовать интерфейс
SeimiInterceptor - Все перехватчики, которые вы хотите использовать, должны быть размещены в пакете interceptors, например,
cn.wanghaomiao.xxx.interceptors, образец также доступен в демо-проекте. - Необходимо создать пользовательскую аннотацию для обозначения, какие методы должны быть перехвачены или все методы.
Эта аннотация используется для информирования Seimi, что класс, помеченный ею, может быть перехватчиком (поскольку для того, чтобы быть настоящим перехватчиком Seimi, класс также должен соответствовать вышеупомянутым другим условиям). У нее есть одно свойство:
everyMethodпо умолчаниюfalse, используется для указания, должен ли этот перехватчик перехватывать все методы обратного вызова.
Приведем интерфейс:
public interface SeimiInterceptor {
/**
* Получение аннотации, которой должна быть помечена целевая метод
* @return Аннотация
*/
public Class<? extends Annotation> getTargetAnnotationClass();
/**
* При необходимости контроля порядка выполнения нескольких перехватчиков, этот метод можно переопределить
* @return Вес, чем больше вес, тем ближе к внешнему слою и тем выше приоритет перехвата
*/
public int getWeight();
/**
* Здесь можно определить логику, которая будет выполнена до выполнения целевого метода
*/
public void before(Method method, Response response);
/**
* Здесь можно определить логику, которая будет выполнена после выполнения целевого метода
*/
public void after(Method method, Response response);
}
В комментариях уже достаточно подробно объяснено, поэтому здесь не будем повторяться.
Смотри пример DemoInterceptor в демо-проекте, прямая ссылка на GitHub
SeimiQueue — это единственный канал для передачи данных и коммуникации между различными частями системы SeimiCrawler. По умолчанию используется локальная потокобезопасная блокирующая очередь. Также SeimiCrawler поддерживает реализацию SeimiQueue на базе Redis — DefaultRedisQueue, и вы можете создать собственную реализацию, соответствующую соглашениям Seimi. Конкретную реализацию можно указать через атрибут queue аннотации @Crawler.
Установите аннотацию Crawler следующим образом: @Crawler(name = "xx", queue = DefaultRedisQueue.class)
Настройте application.properties:
# Запуск SeimiCrawler
seimi.crawler.enabled=true
seimi.crawler.names=DefRedis,test
# Включение распределенной очереди
seimi.crawler.enable-redisson-queue=true
# Настройка ожидаемого количества вставок в bloomFilter (необязательно)
#seimi.crawler.bloom-filter-expected-insertions=
# Настройка ожидаемого процента ошибок в bloomFilter (0.001 — 1 ошибка на 1000 вставок, необязательно)
#seimi.crawler.bloom-filter-false-probability=
В файле seimi-app.xml настройте redisson. С версии 2.0 распределенная очередь по умолчанию реализована с использованием redisson, поэтому необходимо в конфигурационном файле Spring включить实现redissonClient的具体实现。然后就可以正常使用分布式队列了。
<redisson:client
id="redisson"
name="test_redisson"
>
属性name和子元素qualifier不能同时使用。
id和name的属性都可以作为qualifier的备选值。
-->
<redisson:single-server
idle-connection-timeout="10000"
ping-timeout="1000"
connect-timeout="10000"
timeout="3000"
retry-attempts="3"
retry-interval="1500"
reconnection-timeout="3000"
failed-attempts="3"
subscriptions-per-connection="5"
client-name="none"
address="redis://127.0.0.1:6379"
subscription-connection-minimum-idle-size="1"
subscription-connection-pool-size="50"
connection-minimum-idle-size="10"
connection-pool-size="64"
database="0"
dns-monitoring="false"
dns-monitoring-interval="5000"
/>
</redisson:client>
Настройте SeimiConfig, указав основную информацию кластера Redis, например:
SeimiConfig config = new SeimiConfig();
config.setSeimiAgentHost("127.0.0.1");
config.redisSingleServer().setAddress("redis://127.0.0.1:6379");
Seimi s = new Seimi(config);
s.goRun("basic");
Обычно две встроенные реализации SeimiCrawler достаточно для большинства сценариев использования, но если они не подходят, вы также можете самостоятельно реализовать SeimiQueue и настроить её использование. Для самостоятельной реализации обратите внимание на следующие моменты:
- Необходимо пометить аннотацией
@Queue, чтобы сообщить Seimi, что помеченный класс может быть SeimiQueue (для того чтобы стать SeimiQueue также должны быть выполнены другие условия). - Необходимо реализовать интерфейс
SeimiQueue, как показано ниже:
/**
* Определяет основной интерфейс системы очередей, можно свободно выбирать реализацию, главное чтобы она соответствовала规范.
* @author Ван Хао-мао [email protected]
* @since 2015/6/2.
*/
public interface SeimiQueue extends Serializable {
/**
* Заблокировать операцию выгрузки одного запроса
* @param crawlerName --
* @return --
*/
Request bPop(String crawlerName);
/**
* Добавить один запрос в очередь
* @param req запрос
* @return --
*/
boolean push(Request req);
/**
* Оставшаяся длина очереди задач
* @param crawlerName --
* @return число
*/
long len(String crawlerName);
/**
* Проверка, была ли обработана URL
* @param req --
* @return --
*/
boolean isProcessed(Request req);
/**
* Запись обработанного запроса
* @param req --
*/
void addProcessed(Request req);
/**
* Общее количество выполненных сборок
* @param crawlerName --
* @return число
*/
long totalCrawled(String crawlerName);
/**
* Очистить записи сборки
* @param crawlerName --
*/
void clearRecord(String crawlerName);
}
- Все SeimiQueue, которые должны быть сканированы и включены в работу, должны размещаться в пакете
queues, например,cn.wanghaomiao.xxx.queues. В демонстрационном проекте также есть примеры. После выполнения всех требований и написания собственной SeimiQueue, её можно настроить с помощью аннотации@Crawler(name = "xx",queue = YourSelfRedisQueueImpl.class).
См. пример DefaultRedisQueueEG в демонстрационном проекте (прямая ссылка на GitHub)
Поскольку SeimiCrawler использует Spring для управления бинами и внедрения зависимостей, легко интегрировать её с имеющимися решениями для постоянного хранения данных, такими как Mybatis, Hibernate, Paoding-jade и т.д. Здесь используется Mybatis.
Добавьте зависимости Mybatis и соединения с базой данных:
```xml
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-spring</artifactId>
<version>1.3.0</version>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.4.1</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-dbcp2</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.4.2</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.37</version>
</dependency>
Добавьте файл конфигурации XML seimi-mybatis.xml (помните, что все файлы конфигурации должны начинаться с seimi)
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="propertyConfigurer" class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer">
<property name="locations">
<list>
<value>classpath:**/*.properties</value>
</list>
</property>
</bean>
<bean id="mybatisDataSource" class="org.apache.commons.dbcp2.BasicDataSource">
<property name="driverClassName" value="${database.driverClassName}"/>
<property name="url" value="${database.url}"/>
<property name="username" value="${database.username}"/>
<property name="password" value="${database.password}"/>
</bean>
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean" abstract="true">
<property name="configLocation" value="classpath:mybatis-config.xml"/>
</bean>
<bean id="seimiSqlSessionFactory" parent="sqlSessionFactory">
<property name="dataSource" ref="mybatisDataSource"/>
</bean>
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="cn.wanghaomiao.dao.mybatis"/>
<property name="sqlSessionFactoryBeanName" value="seimiSqlSessionFactory"/>
</bean>
</beans>Так как в демо-проекте существует единый файл конфигурации seimi.properties, то информация о подключении к базе данных также вводится через properties. Конечно, вы также можете напрямую указать эту информацию. Конфигурация properties следующая:
database.driverClassName=com.mysql.jdbc.Driver
database.url=jdbc:mysql://127.0.0.1:3306/xiaohuo?useUnicode=true&characterEncoding=UTF8&autoReconnect=true&autoReconnectForPools=true&zeroDateTimeBehavior=convertToNull
database.username=xiaohuo
database.password=xiaohuo
На данный момент проект готов, осталось создать базу данных и таблицу для хранения информации о тестах. Демо-проект предоставляет структуру таблицы, имя базы данных можно изменить по вашему усмотрению:
CREATE TABLE `blog` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(300) DEFAULT NULL,
`content` text,
`update_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
Создайте файл DAO для Mybatis:
public interface MybatisStoreDAO {
@Insert("insert into blog (title,content,update_time) values (#{blog.title},#{blog.content},now())")
@Options(useGeneratedKeys = true, keyProperty = "blog.id")
int save(@Param("blog") BlogContent blog);
}
Настройки Mybatis, вероятно, вам уже знакомы, поэтому не будем подробно останавливаться. Больше информации можно найти в демо-проекте или в официальной документации Mybatis.
Для прямого внедрения в соответствующий Crawler, как, например:
@Crawler(name = "mybatis")
public class DatabaseMybatisDemo extends BaseSeimiCrawler {
@Autowired
private MybatisStoreDAO storeToDbDAO;
@Override
public String[] startUrls() {
return new String[]{"http://www.cnblogs.com/"};
}
@Override
public void start(Response response) {
JXDocument doc = response.document();
try {
List<Object> urls = doc.sel("//a[@class='titlelnk']/@href");
logger.info("{}", urls.size());
for (Object s : urls) {
push(Request.build(s.toString(), DatabaseMybatisDemo::renderBean));
}
} catch (Exception e) {
e.printStackTrace();
}
}
public void renderBean(Response response) {
try {
BlogContent blog = response.render(BlogContent.class);
logger.info("bean resolve res={},url={}", blog, response.getUrl());
// использование paoding-jade для хранения в базе данных
int changeNum = storeToDbDAO.save(blog);
int blogId = blog.getId();
logger.info("store success, blogId = {}, changeNum={}", blogId, changeNum);
} catch (Exception e) {
e.printStackTrace();
}
}
}
Если ваш бизнес-процесс сложен, рекомендуется добавить дополнительный уровень абстракции, создав сервис, который затем можно внедрить в Crawler.
Когда объем ваших бизнес-задач и данных достигает определенного уровня, возникает необходимость горизонтально масштабировать несколько машин для создания кластерной службы, чтобы повысить производительность. Это был один из ключевых аспектов, на которые ориентировалась разработка SeimiCrawler. Таким образом, SeimiCrawler поддерживает распределенную развертку из коробки. С учетом описания SeimiQueue, умный читатель уже понимает, как настроить распределенную среду. Для распределенной развертки SeimiCrawler необходимо использовать DefaultRedisQueue в качестве默认的SeimiQueue并在每台要部署的机器上配置相同的Redis连接信息。启用 DefaultRedisQueue 后,在作为worker的机器上通过 new Seimi().startWorkers() 初始化seimi的处理器,Seimi的worker进程就会开始监听消息队列。当主服务发出抓取请求后,整个集群就会通过消息队列进行通信,分工合作、热火朝天地干活了。从2.0版本开始默认的分布式队列改用Redisson实现,并引入BloomFilter。
Если вам нужно отправить SeimiCrawler пользовательский запрос на извлечение, то запрос должен содержать следующие параметры:
url— Адрес для извлеченияcrawlerName— Имя правилаcallBack— Функция обратного вызова
Вы完全可以构建一个SpringBoot проект и самостоятельно написать контроллер Spring MVC для обработки таких запросов. Вот простой пример, на основе которого вы можете создавать более интересные и полезные приложения.
Если вы не хотите запускать приложение в виде проекта SpringBoot, вы можете использовать встроенные интерфейсы. SeimiCrawler может запускаться с указанием порта, чтобы начать встроенную HTTP-службу для приема запросов на извлечение через HTTP API или проверки состояния соответствующего Crawler.
Отправка JSON-запросов Request в SeimiCrawler через HTTP-интерфейс. После получения запроса на извлечение через HTTP-интерфейс и успешной проверки, запрос будет обработан вместе с запросами, сгенерированными правилами обработки.
- Адрес запроса: http://host:port/push/${YourCrawlerName}
- Метод вызова: GET/POST
- Входные параметры:
| Название параметра | Обязательный | Тип параметра | Описание параметра |
|---|---|---|---|
| req | true | str | Содержит строку JSON, представляющую запрос Request, в виде одного объекта или массива JSON |
- Пример структуры параметров:
{
"callBack": "start",
"maxReqCount": 3,
"meta": {
"listPageSomeKey": "xpxp"
},
"params": {
"paramName": "xxxxx"
},
"stop": false,
"url": "http://www.github.com"
}
или
[
{
"callBack": "start",
"maxReqCount": 3,
"meta": {
"listPageSomeKey": "xpxp"
},
"params": {
"paramName": "xxxxx"
},
"stop": false,
"url": "http://www.github.com"
},
{
"callBack": "start",
"maxReqCount": 3,
"meta": {
"listPageSomeKey": "xpxp"
},
"params": {
"paramName": "xxxxx"
},
"stop": false,
"url": "http://www.github.com"
}
]
Описание полей структуры:
| Json поле | Обязательно | Тип поля | Описание поля |
|---|---|---|---|
| url | true | str | Целевой адрес запроса |
| callBack | true | str | Функция обратного вызова для соответствующего результата запроса |
| meta | false | map | Необязательные пользовательские данные, которые могут быть переданы в контекст |
| params | false | map | Параметры запроса, которые могут быть необходимы для текущего запроса |
| stop | false | bool | Если true, то поток работы, обрабатывающий этот запрос, прекратит свою работу |
| maxReqCount | false | int | Максимальное количество перезапросов, разрешенное при неполадках с запросом |
Запрос по адресу: /status/${YourCrawlerName} позволяет увидеть базовое состояние сбора для указанного Crawler, формат данных — JSON.
См. 5.2.13. Настройка динамического прокси
См. 5.2.8. Включение cookies (опция)
- Краулеры с одинаковыми именами в разных экземплярах SeimiCrawler будут синхронизироваться через один и тот же Redis (общая очередь просмотра и потребления)
- Убедитесь, что машины, на которых запускается SeimiCrawler, корректно подключены к Redis
- В примере указано пароль Redis, но если ваш Redis не требует пароля, не указывайте его
- Многие пользователи сталкиваются с сетевыми ошибками. В таких случаях необходимо проверить сетевые настройки, включая, но не ограничиваясь: целевые сайты не блокируют вас, свобода доступа через прокси, прокси не заблокирован, прокси имеет доступ к Интернету, машина имеет свободный доступ к Интернету и т.д.
Перепишите реализацию public List<Request> startRequests(), здесь можно свободно определить сложные начальные запросы. В этом случае public String[] startUrls() может возвращать null. Пример:
@Crawler(name = "usecookie",useCookie = true)
public class UseCookie extends BaseSeimiCrawler {
@Override
public String[] startUrls() {
return null;
}
@Override
public List<Request> startRequests() {
List<Request> requests = new LinkedList<>();
Request start = Request.build("https://www.oschina.net/action/user/hash_login","start");
Map<String,String> params = new HashMap<>();
params.put("email","[email protected]");
params.put("pwd","xxxxxxxxxxxxxxxxxxx");
params.put("save_login","1");
params.put("verifyCode","");
start.setHttpMethod(HttpMethod.POST);
start.setParams(params);
requests.add(start);
return requests;
}
@Override
public void start(Response response) {
logger.info(response.getContent());
push(Request.build("http://www.oschina.net/home/go?page=blog","minePage"));
}
public void minePage(Response response){
JXDocument doc = response.document();
try {
logger.info("uname:{}", StringUtils.join(doc.sel("//div[@class='name']/a/text()"),""));
logger.info("httpType:{}",response.getSeimiHttpType());
} catch (XpathSyntaxErrorException e) {
logger.debug(e.getMessage(),e);
}
}
}
<dependency>
<groupId>cn.wanghaomiao</groupId>
<artifactId>SeimiCrawler</artifactId>
<version>2.1.2</version>
</dependency>
Пожалуйста, убедитесь, что используется версия 2.1.2 или выше, которая поддерживает установку свойства jsonBody в Request для выполнения запроса с JSON-телом.
Если у вас есть вопросы или предложения, теперь можно обсуждать их через следующий mailing list. Перед первым сообщением необходимо подписаться и дождаться одобрения (главным образом, для блокировки рекламы и создания благоприятной обстановки для обсуждений)
- Подписка: отправьте письмо на
[email protected] - Сообщение: отправьте письмо на
[email protected] - Отписка: отправьте письмо на
[email protected]
Кстати: Приглашаем заслать
starна github ^_^