アジャイル、強力、スタンドアロン、分散型のクローリングフレームワーク。
SeimiCrawlerの目標は、Javaの世界で最も使いやすく実用的なクローリングフレームワークになることです。
SeimiCrawlerは、アジャイルで、スタンドアロンでデプロイできる、分散型のJavaクローリングフレームワークです。主な目的は、初心者が高性能かつ高可用性のクローリングシステムを開発する際のハードルを最低限にし、クローリングシステムの開発効率を向上させることです。SeimiCrawlerの世界では、たいていの人がデータ取得のビジネスロジックに集中するだけで、その他のことはSeimiが担当します。設計思想はPythonのクローリングフレームワークScrapyからヒントを得ていますが、Java言語の特徴とSpringの特性を融合させました。さらに、XPathを使用してHTMLを効率的に解析するために、SeimiCrawlerではJsoupXpath(独立した拡張プロジェクト、jsoupに組み込まれていません)がデフォルトのHTML解析器として使用されます。データ抽出作業はすべてXPathを使用して行われますが(もちろん、他の解析器を自由に選択することもできます)。また、SeimiAgentを使用することで、複雑な動的ページのレンダリングと取得の問題を完全に解決します。SpringBootを完全にサポートし、あなたの想像力と創造性を最大限に発揮できるように設計されています。
JDK1.8+
<dependency>
<groupId>cn.wanghaomiao</groupId>
<artifactId>SeimiCrawler</artifactId>
<version>GitHubの最新バージョンを参照</version>
</dependency>
標準的なSpringBootプロジェクトを作成し、crawlersパッケージにクロールルールを追加します。例えば:
@Crawler(name = "basic")
public class Basic extends BaseSeimiCrawler {
@Override
public String[] startUrls() {
// 重複のテスト用
return new String[]{"http://www.cnblogs.com/","http://www.cnblogs.com/"};
}
@Override
public void start(Response response) {
JXDocument doc = response.document();
try {
List<Object> urls = doc.sel("//a[@class='titlelnk']/@href");
logger.info("{}", urls.size());
for (Object s:urls){
push(Request.build(s.toString(),Basic::getTitle));
}
} catch (Exception e) {
e.printStackTrace();
}
}
public void getTitle(Response response){
JXDocument doc = response.document();
try {
logger.info("url:{} {}", response.getUrl(), doc.sel("//h1[@class='postTitle']/a/text()|//a[@id='cb_post_title_url']/text()"));
// 処理を追加
} catch (Exception e) {
e.printStackTrace();
}
}
}
application.propertiesに設定を追加します。
# SeimiCrawlerを起動
seimi.crawler.enabled=true
seimi.crawler.names=basic
標準的なSpringBootの起動方法で起動します。
@SpringBootApplication
public class SeimiCrawlerApplication {
public static void main(String[] args) {
SpringApplication.run(SeimiCrawlerApplication.class, args);
}
}
より複雑な使い方については、以下の詳細なドキュメントを参照するか、Githubのデモを参照してください。
通常のMavenプロジェクトを作成し、パッケージcrawlersの下にクローリング規則を追加します。たとえば:
@Crawler(name = "basic")
public class Basic extends BaseSeimiCrawler {
@Override
public String[] startUrls() {
// これは重複チェックのためのテスト用です
return new String[]{"http://www.cnblogs.com/","http://www.cnblogs.com/"};
}
@Override
public void start(Response response) {
JXDocument doc = response.document();
try {
List<Object> urls = doc.sel("//a[@class='titlelnk']/@href");
logger.info("{}", urls.size());
for (Object s:urls){
push(Request.build(s.toString(),Basic::getTitle));
}
} catch (Exception e) {
e.printStackTrace();
}
}
public void getTitle(Response response){
JXDocument doc = response.document();
try {
logger.info("url:{} {}", response.getUrl(), doc.sel("//h1[@class='postTitle']/a/text()|//a[@id='cb_post_title_url']/text()"));
//何か処理をする
} catch (Exception e) {
e.printStackTrace();
}
}
}
その後、任意のパッケージに起動用のMain関数を追加し、SeimiCrawlerを起動します:
public class Boot {
public static void main(String[] args){
Seimi s = new Seimi();
s.start("basic");
}
}
以上が最も基本的なクローラーシステムの開発手順です。
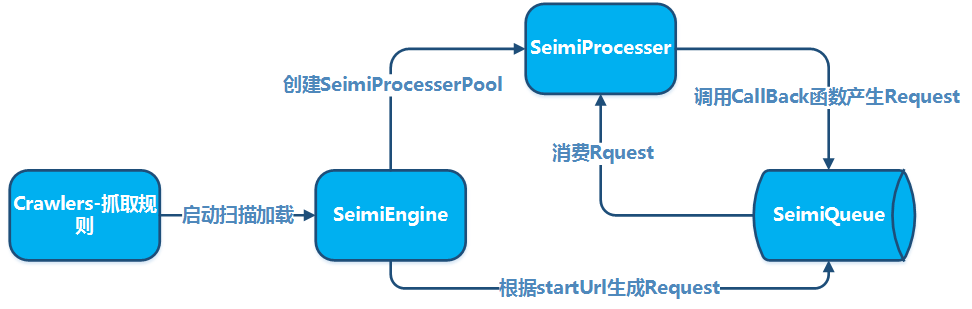
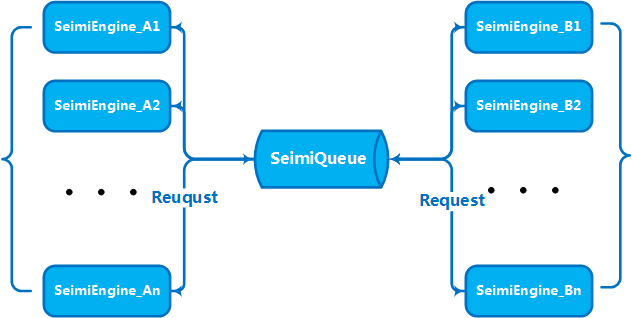
SeimiCrawlerを使用してクロールシステムを開発するために、いくつかの約束が必要です。主要な目的はソースコードをより規範的で読みやすいようにすることです。同じ約束に従うことで、チーム内のメンバーが相互に協力して開発を行う際、ビジネスプロジェクトのコードがより読みやすく、修正しやすくなります。ある人がビジネスロジックを開発し、他の人が引き継ぐ際にクラスがどこにあるのかを見つけるのが困難な状況は避けるべきです。我々が目指すのは、強力で簡単で使いやすいシステムです。最後に、約束があるからといって、SeimiCrawlerが柔軟性に欠けるわけではありません。
- SeimiCrawlerのコンテキストはSpringに基づいているため、ほぼすべてのSpring形式の設定ファイルとSpringの一般的な使い方がサポートされます。SeimiCrawlerはプロジェクトのクラスパス下にあるすべてのXML形式の設定ファイルをス캔しますが、
seimiで始まるファイル名のXML設定ファイルのみがSeimiCrawlerによって認識され、読み込まれます。 - SeimiCrawlerのログはslf4jを使用しており、具体的な実装を自分で設定できます。
- Seimiを開発する際に注意すべき約束については、以下の開発上のポイントで詳細に説明します。
クローラー規則クラスは、SeimiCrawlerを使用してクローラーを開発する最も重要な部分です。クイックスタートのBasicクラスは基本的なクローラークラスの一例です。クローラーを作成する際は以下の点に注意してください:
BaseSeimiCrawlerを継承する必要があります。@Crawlerアノテーションを使用する必要があります。アノテーション内のname属性は任意ですが、設定するとそのクローラーは定義された名前で識別されます。設定しない場合は、作成したクラス名が使用されます。- SeimiCrawlerがスキャンできるように、すべてのクローラーは
crawlersパッケージ以下に配置する必要があります。例:cn.wanghaomiao.xxx.crawlers。プロジェクトに付属のデモプロジェクトを参照することもできます。 Crawlerを初期化したら、public String[] startUrls();とpublic void start(Response response)という2つの最も基本的なメソッドを実装する必要があります。これらを実装することで、シンプルなクローラーの作成が完了します。
現在の@Crawlerアノテーションには以下の属性があります:
nameクローラー規則の名前をカスタマイズします。同一の名前のクローラーはSeimiCrawlerがスキャンする範囲内のプロジェクトで重複してはいけません。デフォルトはクラス名を使用します。proxySeimiがこのクローラーでプロキシを使用するかどうか、使用するプロキシの種類を指定します。現在サポートされている形式はhttp|https|socket://host:portで、ユーザ名とパスワードが含まれるプロキシはこのバージョンではサポートされていません。useCookieクッキーを有効にするかどうかを指定します。有効にすると、ブラウザと同様にリクエスト状態を保持できますが、同時に追跡されることにもなります。queueこのクローラーで使用するデータキューを指定します。デフォルトはローカルキューの実装DefaultLocalQueue.classですが、デフォルトのRedis版実装やその他のキューシステムに基づく実装を使用することもできます。この部分について後で詳しく説明します。delayリクエストの取得間隔を秒単位で設定します。デフォルトは0で、つまり間隔なしです。httpTypeDownloaderの実装タイプを指定します。デフォルトのDownloader実装はApache Httpclientですが、OkHttp3を使用するように変更することもできます。httpTimeOutタイムアウト時間をミリ秒単位でカスタマイズできます。デフォルトは15000msです。
これはクローラーのエントリーポイントで、URLの配列を返します。デフォルトではstartURLはGETリクエストとして処理されますが、特定の状況下でSeimiがstartURLをPOSTメソッドで処理することを必要とする場合は、そのURLの末尾に##postを追加するだけでよいです。例えばhttp://passport.cnblogs.com/user/signin?ReturnUrl=http%3a%2f%2fi.cnblogs.com%2f##post。この指定は大文字小文字を区別しません。このルールはstartURLの処理にのみ適用されます。
このメソッドはstartURLのコールバック関数であり、startURLのリクエストからのデータ処理方法をSeimiに指示します。
- テキスト類の結果
SeimiではデフォルトでXPathを使用してHTMLデータを抽出することを推奨しています。XPathの初期学習には少しのコストがかかりますが、その効果は学習後すぐに感じることができます。
JXDocument doc = response.document();でJXDocument(JsoupXpathのドキュメントオブジェクト)を取得し、その後doc.sel("xpath")を使用して任意のデータを抽出できます。ほとんどすべてのデータは1つのXPath文で抽出可能です。Seimiで使用されるXPath文法解析器やXPathについて詳しく知りたい方はJsoupXpathをご覧ください。XPathに抵抗感がある場合は、responseには元のレスポンスデータが含まれているため、他のデータ解析器を使用することもできます。 - ファイル類の結果
ファイル形式のレスポンス结果の場合は、
response.saveTo(File targetFile)を使用して保存することが可能です。あるいは、ファイルのバイト列をbyte[] getData()で取得して他の操作を行います。
private BodyType bodyType;
private Request request;
private String charset;
private String referer;
private byte[] data;
private String content;
/**
* この主に上流から伝わる一部のカスタムデータを保存するために使用されます
*/
private Map<String, String> meta;
private String url;
private Map<String, String> params;
/**
* ウェブページコンテンツの実際のソースURL
*/
private String realUrl;
/**
* 今回のリクエスト結果のHTTPプロセッサタイプ
*/
private SeimiHttpType seimiHttpType;
デフォルトのコールバック関数だけでは要求を満たすことは難しいでしょう。始点URLページ内の一部のURLを抽出し、さらにリクエストしてデータを取得・処理したい場合は、独自のコールバック関数を定義する必要があります。以下に注意点を示します:
- V2.0からメソッド参照がサポートされ、コールバック関数の設定がより自然に行えます。例:
Basic::getTitle。 - コールバック関数内で生成された
Requestは、他のコールバック関数を指定したり、自身をコールバック関数に設定することもできます。 - コールバック関数は、
public void callbackName(Response response)という形式でなければなりません。つまり、メソッドはパブリックで、パラメータはResponse型1つだけ、返り値はありません。 Requestにコールバック関数を設定する際は、コールバック関数の名前をString型で提供すればよいです。例えば、クイックスタートのgetTitle。BaseSeimiCrawlerを継承したクローラーは、コールバック関数内で親クラスのpush(Request request)を直接呼び出して新しい取得要求をキューに追加できます。Request.build()を使用してRequestを作成できます。
public class Request {
public static Request build(String url, String callBack, HttpMethod httpMethod, Map<String, String> params, Map<String, String> meta);
public static Request build(String url, String callBack, HttpMethod httpMethod, Map<String, String> params, Map<String, String> meta,int maxReqcount);
public static Request build(String url, String callBack);
public static Request build(String url, String callBack, int maxReqCount);
@NotNull
private String crawlerName;
/**
* リクエストするURL
*/
@NotNull
private String url;
/**
* リクエストするメソッドのタイプ get, post, put...
*/
private HttpMethod httpMethod;
/**
* リクエストにパラメータが必要な場合は、ここでパラメータを設定します
*/
private Map<String,String> params;
/**
* これは主に下位のコールバック関数に渡すカスタムデータを保存するために使用されます
*/
private Map<String,Object> meta;
/**
* コールバック関数のメソッド名
*/
@NotNull
private String callBack;
/**
* コールバック関数がラムダ式かどうか
*/
private transient boolean lambdaCb = false;
/**
* コールバック関数
*/
private transient SeimiCallbackFunc callBackFunc;
/**
* 停止信号、この信号を受け取った処理スレッドは終了する
*/
private boolean stop = false;
/**
* 最大再リクエスト回数
*/
private int maxReqCount = 3;
/**
* 現在のリクエストが実行された回数を記録する
*/
private int currentReqCount = 0;
/**
* リクエストが重複チェックを経由するかどうかを指定する
*/
private boolean skipDuplicateFilter = false;
/**
* このリクエストに対してSeimiAgentを使用するかどうかを指定する
*/
private boolean useSeimiAgent = false;
/**
* カスタムHTTPリクエストヘッダー
*/
private Map<String,String> header;
/**
* SeimiAgentのレンダリング時間を定義する、単位はミリ秒
*/
private long seimiAgentRenderTime = 0;
/**
* SeimiAgent上で指定されたJSスクリプトを実行するために使用される
*/
private String seimiAgentScript;
/**
* SeimiAgentへのリクエストでcookieを使用するかどうかを指定する
*/
private Boolean seimiAgentUseCookie;
/**
* SeimiAgentに結果をどのようにレンダリングするかを指示する、デフォルトはHTML
*/
private SeimiAgentContentType seimiAgentContentType = SeimiAgentContentType.HTML;
/**
* カスタムcookieの追加をサポートする
*/
private List<SeimiCookie> seimiCookies;
/**
* JSONリクエストボディのサポートを追加する
*/
private String jsonBody;
}
SeimiCrawlerのデフォルトのUAはSeimiCrawler/JsoupXpathです。カスタムUserAgentを使用したい場合、BaseSeimiCrawlerのpublic String getUserAgent()をオーバーライドします。SeimiCrawlerは各リクエスト処理時にUserAgentを取得するため、UserAgentを偽装したい場合は独自のUAライブラリを実装し、ランダムに返すことができます。
@Crawlerアノテーションの紹介時に説明しましたが、ここでも再度強調します。これは、基本機能を素早く把握できるようにするためです。cookiesの启用は、@CrawlerアノテーションのuseCookieプロパティで構成されます。さらに、Request.setSeimiCookies(List<SeimiCookie> seimiCookies)またはRequest.setHeader(Map<String, String> header)を使用してカスタム設定することもできます。Requestオブジェクトは多くのカスタム機能をサポートしていますので、詳細を確認し、使いこなすことで多くのアイデアが広がるでしょう。
@Crawlerアノテーションのproxyプロパティを使用して構成します。詳細は@Crawlerの紹介を参照してください。動的なproxyを指定したい場合は、次のセクション「動的proxy設定」をご覧ください。現在、http|https|socket://host:portの3つの形式がサポートされています。
@Crawlerアノテーションのdelayプロパティを使用して構成します。リクエストの取得間隔の単位は秒で、デフォルトは0(つまり、間隔なし)です。多くの場合、コンテンツ提供者はリクエスト頻度の制限を逆クロールの一種として利用します。必要に応じて、このパラメータを調整することで、より効果的な取得効果を達成できます。
BaseSeimiCrawlerのpublic String[] allowRules()をオーバーライドして、URLリクエストのホワイトリストルールを設定します。ルールは正規表現であり、任意の1つにマッチするとリクエストが許可されます。
BaseSeimiCrawlerのpublic String[] denyRules()をオーバーライドして、URLリクエストのブラックリストルールを設定します。ルールは正規表現であり、任意の1つにマッチするとリクエストがブロックされます。
BaseSeimiCrawlerのpublic String proxy()をオーバーライドして、Seimiにどのプロキシアドレスを使用するかを通知します。ここでは、既存のプロキシライブラリから順序またはランダムにプロキシアドレスを返すことができます。プロキシアドレスが非空である場合、@Crawlerのproxy属性設定は無効になります。現在、以下の3つの形式がサポートされています:http|https|socket://host:port。
@CrawlerアノテーションのuseUnrepeated属性を使用して、システム重複の有効化を制御します。デフォルトでは有効になっています。
現在、SeimiCrawlerは301、302、およびmeta refreshのリダイレクトをサポートしています。このようなリダイレクトURLについては、ResponseオブジェクトのgetRealUrl()を使用して、リダイレクトまたはジャンプ先の実際のURLを取得できます。
リクエストの処理中にエラーが発生した場合、そのリクエストは3回の再試行の機会が与えられます。それでも失敗した場合、システムはcrawlerのpublic void handleErrorRequest(Request request)メソッドを呼び出して、問題のあるリクエストを処理します。デフォルトの実装ではログ記録が行われますが、開発者はこのメソッドをオーバーライドして独自の処理を追加できます。
SeimiAgentについて詳しく解説します。SeimiAgentに詳しくない方は、まずSeimiAgentプロジェクトのホームペ〖ジをご覧ください。簡単に説明すると、SeimiAgentはサーバー上で動作するブラウザエンジンで、QtWebkitに基づいて開発され、標準のHTTPインタフェースを提供しています。複雑な動的ウェブページのレンダリング、スナップショットの取得、監視などの需要に対応しています。ページの処理は標準のブラウザレベルであり、ブラウザ上で取得できる情報をすべて取得することができます。
seimiCrawlerがSeimiAgentをサポートするようにするには、まずSeimiAgentのサービスアドレスを通知する必要があります。
SeimiConfigを設定することで行います。例えば、
SeimiConfig config = new SeimiConfig();
config.setSeimiAgentHost("127.0.0.1");
Seimi s = new Seimi(config);
s.goRun("basic");
application.propertiesで設定します。
seimi.crawler.seimi-agent-host=xx
seimi.crawler.seimi-agent-port=xx
どのリクエストをSeimiAgentに提出するかを決定し、SeimiAgentがどのように処理するかを指定します。これはRequestレベルです。
Request.useSeimiAgent()SeimiCrawlerにこのリクエストをSeimiAgentに提出することを伝えます。Request.setSeimiAgentRenderTime(long seimiAgentRenderTime)SeimiAgentのレンダリング時間を設定します(すべてのリソースがロードされた後、SeimiAgentにどのくらいの時間を割り当てるか、JavaScriptなどのスクリプトを実行して最終的なページをレンダリングするために)。時間の単位はミリ秒です。Request.setSeimiAgentUseCookie(Boolean seimiAgentUseCookie)SeimiAgentにcookieを使用するかどうかを伝えます。ここで設定されていない場合、seimiCrawlerのグローバルなcookie設定を使用します。- その他の注意事項 あなたのクローラーにプロキシが設定されている場合、このリクエストがSeimiAgentに転送されるときに、seimiCrawlerは自動的にSeimiAgentにこのプロキシを使用させます。
- デモ 実際の使用方法については、リポジトリ内のデモを参照してください。
application.properties で設定します
seimi.crawler.enabled=true
# 起動時にstartリクエストを発行するクローラーの名前を指定
seimi.crawler.names=basic,test
その後は標準的なSpringBootの起動方法です
@SpringBootApplication
public class SeimiCrawlerApplication {
public static void main(String[] args) {
SpringApplication.run(SeimiCrawlerApplication.class, args);
}
}
main関数を追加し、独立した起動クラスを作成します。デモプロジェクトのようにします。main関数でSeimiオブジェクトを初期化し、SeimiConfigを介して特定のパラメータを設定できます。例如、分散キューに使用するRedisクラスタの情報、seimiAgentのホスト情報の設定などです。ただし、SeimiConfigはオプションです。例:
public class Boot {
public static void main(String[] args){
SeimiConfig config = new SeimiConfig();
// config.setSeimiAgentHost("127.0.0.1");
// config.redisSingleServer().setAddress("redis://127.0.0.1:6379");
Seimi s = new Seimi(config);
s.goRun("basic");
}
}
Seimiには以下の起動メソッドが含まれています:
public void start(String... crawlerNames)1つ以上のクローラーを開始し、スクレイピングを実行します。public void startAll()全てのロードされたクローラーを開始します。public void startWithHttpd(int port, String... crawlerNames)指定されたポートでHTTPサービスを開始し、1つのクローラーを開始します。このサービスは/push/crawlerNameエンドポイントを通じて指定されたクローラーにスクレイピングリクエストをプッシュします。受け付けられるパラメータはreqで、POSTとGETをサポートします。public void startWorkers()すべてのロードされたクローラーを初期化し、スクレイピングリクエストを待機します。この起動メソッドは、分散展開の際に1つ以上の单纯的なworkerシステムを開始するためのものです。詳細は後で紹介します。
プロジェクトのルートディレクトリで以下のコマンドを実行して、プロジェクト全体をパッケージ化します。
Windowsのコマンドプロンプトでログ出力の文字化けを避けるために、logbackの設定ファイルのコンソール出力形式を
GBKに変更してください。デフォルトはUTF-8です。
mvn clean package&&mvn -U compile dependency:copy-dependencies -DoutputDirectory=./target/seimi/&&cp ./target/*.jar ./target/seimi/
これにより、プロジェクトのtargetディレクトリにseimiというディレクトリが作成されます。このディレクトリには最終的にデプロイできるパッケージ化されたプロジェクトが含まれています。次に、以下のコマンドを実行して起動します。
Windowsの場合:
java -cp .;./target/seimi/* cn.wanghaomiao.main.Boot
Linuxの場合:
java -cp .:./target/seimi/* cn.wanghaomiao.main.Boot
上記はサンプルプロジェクトに基づいたもので、スクリプト化やディレクトリ構造の調整は自由に行ってください。実際のデプロイメントシナリオでは、maven-seimicrawler-pluginを使用してSeimiCrawlerプロジェクトをパッケージ化してデプロイすることを推荐します。以下の「プロジェクトのパッケージ化とデプロイ」で詳しく説明します。
Spring Bootを使用してプロジェクトを構築することを推奨します。これにより、現存のSpring Bootエコシステムを活用し、多くの予想外の機能を展開できます。Spring Bootプロジェクトのパッケージ化については、Spring Boot公式の標準的なパッケージ化方法を参照してください。
mvn package
上述の方法は開発やデバッグに便利で、生産環境での起動方法としても利用できます。しかし、プロジェクトの展開と配布を容易にするために、SeimiCrawlerはパッケージ化用の専用プラグインを提供しています。これを使用してパッケージ化されたパッケージを直接配布してデプロイできます。以下の手順を実施してください:
pom.xmlにプラグインを追加します。
<plugin>
<groupId>cn.wanghaomiao</groupId>
<artifactId>maven-seimicrawler-plugin</artifactId>
<version>1.0.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>build</goal>
</goals>
</execution>
</executions>
</plugin>
mvn clean packageを実行するだけです。正しくパッケージ化されたディレクトリ構造は以下のようになります:
.
├── bin # 起動スクリプトに具体的な起動パラメータの説明も含まれており、ここでは詳しく説明しません
│ ├── run.bat # Windows用の起動スクリプト
│ └── run.sh # Linux用の起動スクリプト
└── seimi
├── classes # Crawlerプロジェクトのビジネスクラスと関連構成ファイルのディレクトリ
└── lib # プロジェクトの依存ライブラリのディレクトリ
これで、配布とデプロイに直接使用できます。
SeimiCrawlerのカスタムスケジューリングは、Springのアノテーション@Scheduledを使用して直接実現できます。他の設定は不要です。例えば、クローリングルールファイルに以下のように定義できます:
@Scheduled(cron = "0/5 * * * * ?")
public void callByCron(){
logger.info("私はcron式に基づいて実行されるスケジューラーです。5秒ごとに実行されます");
// 定期的にリクエストを送信することもできます
// push(Request.build(startUrls()[0],"start").setSkipDuplicateFilter(true));
}
独立したサービスクラスに定義したい場合は、そのサービスクラスがスキャンされるようにすることが必要です。@Scheduledについて、開発者はSpringのドキュメントを参照してパラメータの詳細を確認することができます。また、SeimiCrawlerのGitHub上的デモ例を参照することもできます。
ビーンを定義し、SeimiCrawlerが定義したルールに基づいてデータを抽出して関連フィールドに自動的に埋め込みたい場合は、この機能を使用します。
まずは例を見てみましょう:
public class BlogContent {
@Xpath("//h1[@class='postTitle']/a/text()|//a[@id='cb_post_title_url']/text()")
private String title;
// 以下のように記述することも可能です @Xpath("//div[@id='cnblogs_post_body']//text()")
@Xpath("//div[@id='cnblogs_post_body']/allText()")
private String content;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}
BlogContentクラスは、あなたが定義した目標ビーンです。@Xpathアノテーションは、データを注入したいフィールドに配置し、XPath抽出ルールを設定します。フィールドのプライベートまたはパブリックである必要はありませんし、getterやsetterが存在することも必ずしも要求されません。
ビーンを準備したら、コールバック関数でResponseの内部関数public <T> T render(Class<T> bean)を使用して、データが埋め込まれたビーンオブジェクトを取得できます。
SeimiCrawlerは、特定またはすべてのコールバック関数にインターセプターを追加することをサポートしています。インターセプターを実装する際には以下の点に注意してください:
@Interceptorアノテーションを付ける必要がありますSeimiInterceptorインターフェースを実装する必要があります- スキャンされて有効になるすべてのインターセプターはinterceptorsパッケージ下に配置する必要があります、例:
cn.wanghaomiao.xxx.interceptors。デモプロジェクトにもサンプルが含まれています。 - 監視したい関数やすべての関数をマークするために、独自のアノテーションを定義する必要があります。
このアノテーションは、Seimiがそのアノテーションでマークされたクラスがインターセプターである可能性があることを示すために使用します(実際のSeimiインターセプターとして機能するためには、上述の他の規約を満たしている必要があります)。属性は1つあります。
everyMethodデフォルトはfalseで、このインターセプターがすべてのコールバック関数をインターセプトするかどうかをSeimiに通知します。
直接にインターフェースを示します。
public interface SeimiInterceptor {
/**
* 対象メソッドに付けられるべき注釈を取得する
* @return Annotation
*/
public Class<? extends Annotation> getTargetAnnotationClass();
/**
* 複数のインターセプターの実行順序を制御する必要がある場合、このメソッドをオーバーライドする
* @return 重み、重みが大きいほど外側で、先にインターセプトされる
*/
public int getWeight();
/**
* 対象メソッドの実行前にいくつかの処理ロジックを定義できる
*/
public void before(Method method, Response response);
/**
* 対象メソッドの実行後にいくつかの処理ロジックを定義できる
*/
public void after(Method method, Response response);
}
コメントはすでに十分に説明していますので、ここでは詳細に説明しません。
DemoInterceptorを参照してください。GitHubリポジトリの直接リンク
SeimiQueueは、SeimiCrawlerがデータ中継およびシステム内部とシステム間の通信を行う唯一の経路です。システムはデフォルトで、ローカルのスレッドセーフなブロッキングキューの実装を使用しています。SeimiCrawlerでは、さらにRedisベースのSeimiQueueの実装(DefaultRedisQueue)もサポートしています。もちろん、Seimiの規約に準拠した独自のSeimiQueueを実装することも可能です。具体的には、注解@Crawlerのqueue属性を指定して使用します。
Crawlerの注解を@Crawler(name = "xx", queue = DefaultRedisQueue.class)に設定します。
application.propertiesで設定します。
# SeimiCrawlerを起動
seimi.crawler.enabled=true
seimi.crawler.names=DefRedis,test
# 分散キューを有効化
seimi.crawler.enable-redisson-queue=true
# BloomFilterの予想挿入回数をカスタマイズ(設定しない場合はデフォルト値を使用)
# seimi.crawler.bloom-filter-expected-insertions=
# BloomFilterの許容誤差率をカスタマイズ(設定しない場合はデフォルト値0.001を使用)
# seimi.crawler.bloom-filter-false-probability=
seimi-app.xmlでredissonを設定します。2.0版以降、デフォルトの分散キューはredissonで実装されるため、springの設定ファイルにredissonClientの実装を注入する必要があります。これで分散キューを正常に使用できます。
<redisson:client
id="redisson"
name="test_redisson"
>
name属性とqualifierサブ要素を同時には使用できません。
idおよびname属性のいずれかを使用してqualifierの候補値を指定できます。
-->
<redisson:single-server
idle-connection-timeout="10000"
ping-timeout="1000"
connect-timeout="10000"
timeout="3000"
retry-attempts="3"
retry-interval="1500"
reconnection-timeout="3000"
failed-attempts="3"
subscriptions-per-connection="5"
client-name="none"
address="redis://127.0.0.1:6379"
subscription-connection-minimum-idle-size="1"
subscription-connection-pool-size="50"
connection-minimum-idle-size="10"
connection-pool-size="64"
database="0"
dns-monitoring="false"
dns-monitoring-interval="5000"
/>
</redisson:client>
SeimiConfigを設定し、Redisクラスタの基本情報を設定します。例えば:
SeimiConfig config = new SeimiConfig();
config.setSeimiAgentHost("127.0.0.1");
config.redisSingleServer().setAddress("redis://127.0.0.1:6379");
Seimi s = new Seimi(config);
s.goRun("basic");
通常、SeimiCrawlerが提供する2つの実装では、ほとんどの使用シナリオに十分対応できます。しかし、対応できない場合でも、自分でSeimiQueueを実装し、それを設定して使用することができます。自分で実装する際の注意点は以下の通りです:
@Queueアノテーションを付ける必要があります。これはSeimiに、このマークが付けられたクラスがSeimiQueueである可能性があることを示します(SeimiQueueになるためには他の条件も満たす必要があります)。SeimiQueueインターフェースを実装する必要があります。以下のようにします:
/**
* システムキューの基本インタフェースを定義します。規約に従って自由に実装できます。
* @author 汪浩淼 [email protected]
* @since 2015/6/2.
*/
public interface SeimiQueue extends Serializable {
/**
* ブロッキングでキューからリクエストを取得します
* @param crawlerName --
* @return --
*/
Request bPop(String crawlerName);
/**
* キューにリクエストを追加します
* @param req リクエスト
* @return --
*/
boolean push(Request req);
/**
* タスクキューの残りの長さを取得します
* @param crawlerName --
* @return num
*/
long len(String crawlerName);
/**
* URLが既に処理されているか否かを判断します
* @param req --
* @return --
*/
boolean isProcessed(Request req);
/**
* 処理が完了したリクエストを記録します
* @param req --
*/
void addProcessed(Request req);
/**
* 現在までの総クロール数を取得します
* @param crawlerName --
* @return num
*/
long totalCrawled(String crawlerName);
/**
* クロール記録をクリアします
* @param crawlerName --
*/
void clearRecord(String crawlerName);
}
- すべてのスキャンして有効にしたいSeimiQueueは、
queuesパッケージの下に配置する必要があります。例えばcn.wanghaomiao.xxx.queuesなどです。デモプロジェクトでもサンプルが用意されています。 以上の要件を満たし、独自のSeimiQueueを実装した後、@Crawler(name = "xx", queue = YourSelfRedisQueueImpl.class)というアノテーションで使用を設定します。
デモプロジェクトのDefaultRedisQueueEGを参照してください。(githubリンク)
SeimiCrawlerはspringを使用してbeanの管理と依存性の注入を行っていますので、Mybatis、Hibernate、Paoding-jadeなどの主流のデータ永続化ソリューションを簡単に統合できます。ここではMybatisを使用します。
Mybatisとデータベース接続に関連する依存関係を追加します:
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-spring</artifactId>
<version>1.3.0</version>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.4.1</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-dbcp2</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.4.2</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.37</version>
</dependency>seimi-mybatis.xmlというXML設定ファイルを追加します(設定ファイルはすべてseimiで始まることを覚えておいてください)
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="propertyConfigurer" class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer">
<property name="locations">
<list>
<value>classpath:**/*.properties</value>
</list>
</property>
</bean>
<bean id="mybatisDataSource" class="org.apache.commons.dbcp2.BasicDataSource">
<property name="driverClassName" value="${database.driverClassName}"/>
<property name="url" value="${database.url}"/>
<property name="username" value="${database.username}"/>
<property name="password" value="${database.password}"/>
</bean>
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean" abstract="true">
<property name="configLocation" value="classpath:mybatis-config.xml"/>
</bean>
<bean id="seimiSqlSessionFactory" parent="sqlSessionFactory">
<property name="dataSource" ref="mybatisDataSource"/>
</bean>
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="cn.wanghaomiao.dao.mybatis"/>
<property name="sqlSessionFactoryBeanName" value="seimiSqlSessionFactory"/>
</bean>
</beans>デモンプロジェクトでは統一設定ファイルseimi.propertiesが存在するため、データベース接続に関する情報もプロパティファイルから注入されます。もちろん、ここで直接記述することも可能です。プロパティ設定は以下の通りです:
database.driverClassName=com.mysql.jdbc.Driver
database.url=jdbc:mysql://127.0.0.1:3306/xiaohuo?useUnicode=true&characterEncoding=UTF8&autoReconnect=true&autoReconnectForPools=true&zeroDateTimeBehavior=convertToNull
database.username=xiaohuo
database.password=xiaohuo
プロジェクトはこれで準備完了です。次に、実験情報を保存するためにデータベースとテーブルを作成する必要があります。デモンプロジェクトでは以下のテーブルの構造が示されています。データベース名は任意に調整できます:
CREATE TABLE `blog` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(300) DEFAULT NULL,
`content` text,
`update_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
MybatisのDAOファイルを作成します:
public interface MybatisStoreDAO {
@Insert("insert into blog (title,content,update_time) values (#{blog.title},#{blog.content},now())")
@Options(useGeneratedKeys = true, keyProperty = "blog.id")
int save(@Param("blog") BlogContent blog);
}
Mybatisの設定については、デモンプロジェクトやMybatisの公式ドキュメントを参照してください。
対応するCrawlerに直接インジェクションを行うことができます。例:
@Crawler(name = "mybatis")
public class DatabaseMybatisDemo extends BaseSeimiCrawler {
@Autowired
private MybatisStoreDAO storeToDbDAO;
@Override
public String[] startUrls() {
return new String[]{"http://www.cnblogs.com/"};
}
@Override
public void start(Response response) {
JXDocument doc = response.document();
try {
List<Object> urls = doc.sel("//a[@class='titlelnk']/@href");
logger.info("{}", urls.size());
for (Object s : urls) {
push(Request.build(s.toString(), DatabaseMybatisDemo::renderBean));
}
} catch (Exception e) {
e.printStackTrace();
}
}
public void renderBean(Response response) {
try {
BlogContent blog = response.render(BlogContent.class);
logger.info("bean resolve res={},url={}", blog, response.getUrl());
// パオディン-ジャデを使ってDBに保存
int changeNum = storeToDbDAO.save(blog);
int blogId = blog.getId();
logger.info("store success,blogId = {},changeNum={}", blogId, changeNum);
} catch (Exception e) {
e.printStackTrace();
}
}
}
もちろん、ビジネスが複雑な場合は、さらに一層サービスをラップして、Crawlerに注入することをお勧めします。
ビジネス量やデータ量が一定のスケールに達した場合、水平方向に複数のマシンを拡張してクラスタサービスを構築し、処理能力を向上させる必要があります。これは、SeimiCrawlerが設計段階で考慮した問題です。したがって、SeimiCrawlerは分散デプロイを先天的にサポートしています。上記のSeimiQueueについて説明した通り、賢明なあなたにとっては、どのように分散デプロイを行うのか既に理解いただけたことと思います。SeimiCrawlerは、DefaultRedisQueueをデフォルトのSeimiQueueとして有効化し、デプロイ予定の各マシンに同じRedis接続情報を設定することで分散デプロイを実現します。具体的な手順については上記で既に説明しているため、ここでは改めて説明しません。DefaultRedisQueueを有効化した後、ワーカーマシンでnew Seimi().startWorkers()を実行してSeimiのプロセッサを初期化します。Seimiのワーカープロセスはメッセージキューを監視し、メインサービスが取得リクエストを発行すると、整个集群就会通过消息队列进行通信,分工合作、热火朝天的干活了。从2.0版本开始,默认的分布式队列改用Redisson实现,并引入BloomFilter。
如果需要向Seimicrawler发送自定义抓取请求,那么request必须包含以下参数
url要抓取的地址crawlerName规则名callBack回调函数
大家完全可以构建SpringBoot项目,自行编写spring MVC controller来处理这类需求。这里是一个简单的DEMO,你可以在这基础上做更多好玩和有意思的事情。
如果不想以SpringBoot项目形式运行的话,可以使用内建接口,SeimiCrawler可以通过选择启动函数指定一个端口开始内嵌http服务用来通过httpAPI接收抓取请求或是查看对应的Crawler抓取状态。
通过http接口发送给SeimiCrawler的Json格式的Request请求。http接口接收到抓取请求进行基本校验没有问题后就会与处理规则中产生的请求一起处理了。
- 请求地址: http://host:port/push/${YourCrawlerName}
- 调用方式: GET/POST
- 输入参数:
(注意:最后的"接口描述"部分没有完全翻译,因为缺少具体的输入参数列表。如果需要完整的翻译,请提供完整的输入参数列表。)
| パラメーター名 | 必須 | パラメータータイプ | パラメーター説明 |
|---|---|---|---|
| req | true | str | 内容はRequestリクエストのJSON形式、単一またはJSON配列です |
- パラメーター構造の例:
{
"callBack": "start",
"maxReqCount": 3,
"meta": {
"listPageSomeKey": "xpxp"
},
"params": {
"paramName": "xxxxx"
},
"stop": false,
"url": "http://www.github.com"
}
または
[
{
"callBack": "start",
"maxReqCount": 3,
"meta": {
"listPageSomeKey": "xpxp"
},
"params": {
"paramName": "xxxxx"
},
"stop": false,
"url": "http://www.github.com"
},
{
"callBack": "start",
"maxReqCount": 3,
"meta": {
"listPageSomeKey": "xpxp"
},
"params": {
"paramName": "xxxxx"
},
"stop": false,
"url": "http://www.github.com"
}
]
構造フィールドの説明:
| Jsonフィールド | 必須 | フィールドタイプ | フィールド説明 |
|---|---|---|---|
| url | true | str | リクエストの目標アドレス |
| callBack | true | str | 対応するリクエスト結果のコールバック関数 |
| meta | false | map | コンテキストに渡すことができる一部のカスタムデータ |
| params | false | map | 現在のリクエストに必要な可能性のあるリクエストパラメータ |
| stop | false | bool | trueの場合、そのリクエストを受け取ったワーカースレッドは作業を停止します |
| maxReqCount | false | int | このリクエストの処理が異常な場合、最大再処理回数 |
リクエストアドレス:/status/${YourCrawlerName} で、指定したクローラーの現在の基本的なクロール状態を確認できます。データ形式はJsonです。
- 同じ名前のクローラーが異なるSeimiCrawlerインスタンスで同じredisを使用して協調作業(同じプロダクション消費キューを共有)します
- SeimiCrawlerが起動するマシンとredisが正しく接続可能であることを確認してください
- demoではredisのパスワードを設定していますが、パスワードが必要ない場合は設定しないでください
- また、多くのユーザーがネットワークエラーに遭遇する場合、これは自身のネットワーク状況を確認する必要があります。SeimiCrawlerは成熟したネットワークライブラリを使用していますので、ネットワークエラーが発生した場合は、ネットワークに問題があると確信できます。具体的には、目標サイトによるターゲットスクリーニング、プロキシへの接続、プロキシのスクリーニング、プロキシの外部ネットワークへのアクセス能力、マシンの外部ネットワークへのアクセス能力などを確認してください。
public List<Request> startRequests()の実装を書き換えると、複雑な開始リクエストを自由に定義できます。この場合、public String[] startUrls()はnullを返すことができます。例えば:
@Crawler(name = "usecookie",useCookie = true)
public class UseCookie extends BaseSeimiCrawler {
@Override
public String[] startUrls() {
return null;
}
@Override
public List<Request> startRequests() {
List<Request> requests = new LinkedList<>();
Request start = Request.build("https://www.oschina.net/action/user/hash_login","start");
Map<String,String> params = new HashMap<>();
params.put("email","[email protected]");
params.put("pwd","xxxxxxxxxxxxxxxxxxx");
params.put("save_login","1");
params.put("verifyCode","");
start.setHttpMethod(HttpMethod.POST);
start.setParams(params);
requests.add(start);
return requests;
}
@Override
public void start(Response response) {
logger.info(response.getContent());
push(Request.build("http://www.oschina.net/home/go?page=blog","minePage"));
}
public void minePage(Response response){
JXDocument doc = response.document();
try {
logger.info("uname:{}", StringUtils.join(doc.sel("//div[@class='name']/a/text()"),""));
logger.info("httpType:{}",response.getSeimiHttpType());
} catch (XpathSyntaxErrorException e) {
logger.debug(e.getMessage(),e);
}
}
}
<dependency>
<groupId>cn.wanghaomiao</groupId>
<artifactId>SeimiCrawler</artifactId>
<version>2.1.2</version>
</dependency>
使用しているバージョンが2.1.2以上であることを確認してください。RequestでjsonBodyプロパティを設定し、JSON形式のリクエストボディを送信することができます。
皆さんの質問や提案は、以下のメーリングリストを通じて議論することをお勧めします。最初の投稿の前に、購読を申請し、承認を待つ必要があります(主に広告などを排除し、健全な議論環境を提供するため)。
- 購読:
[email protected]にメールを送ってください - 投稿:
[email protected]にメールを送ってください - 退訂:
[email protected]にメールを送ってください
BTW: GitHubで
starしていただけると嬉しいです ^_^