Un framework web crawler agile, potente, standalone e distribuito.
L'obiettivo di SeimiCrawler è diventare il framework di crawling più facile da usare e pratico nel mondo Java.
SeimiCrawler è un framework Java per web crawling agile, indipendente e supportato in modo distribuito. Il suo scopo è abbassare al minimo la soglia di accesso per i principianti che desiderano sviluppare un sistema di crawling efficiente e performante, migliorando allo stesso tempo l'efficienza dello sviluppo di tali sistemi. In SeimiCrawler, la maggior parte delle persone deve preoccuparsi solo della logica di business di estrazione dei dati, il resto è gestito da Seimi. Dal punto di vista della progettazione, SeimiCrawler si ispira al framework Python Scrapy, integrando le caratteristiche del linguaggio Java e le funzionalità di Spring. Si mira a facilitare l'uso di XPath per analizzare HTML in modo più efficiente in China, pertanto l'analizzatore HTML predefinito di SeimiCrawler è JsoupXpath (un progetto di estensione indipendente, non incluso in jsoup). L'estrazione di dati HTML predefinita viene eseguita utilizzando XPath (naturalmente, è possibile scegliere altri parser per il trattamento dei dati). In combinazione con SeimiAgent, si risolve in modo perfetto il problema di rendering e estrazione di pagine dinamiche complesse. Supporta in modo perfetto SpringBoot, permettendo di spingere al massimo l'immaginazione e la creatività.
JDK1.8+
<dependency>
<groupId>cn.wanghaomiao</groupId>
<artifactId>SeimiCrawler</artifactId>
<version>vedi la versione più recente su github</version>
</dependency>
Lista delle versioni su Github Lista delle versioni su Maven
Crea un progetto SpringBoot standard e aggiungi le regole del crawler nel pacchetto crawlers, ad esempio:
@Crawler(name = "basic")
public class Basic extends BaseSeimiCrawler {
@Override
public String[] startUrls() {
// Due URL per testare l'eliminazione dei duplicati
return new String[]{"http://www.cnblogs.com/","http://www.cnblogs.com/"};
}
@Override
public void start(Response response) {
JXDocument doc = response.document();
try {
List<Object> urls = doc.sel("//a[@class='titlelnk']/@href");
logger.info("{}", urls.size());
for (Object s:urls) {
push(Request.build(s.toString(), Basic::getTitle));
}
} catch (Exception e) {
e.printStackTrace();
}
}
public void getTitle(Response response) {
JXDocument doc = response.document();
try {
logger.info("url:{} {}", response.getUrl(), doc.sel("//h1[@class='postTitle']/a/text()|//a[@id='cb_post_title_url']/text()"));
// Fai qualcosa
} catch (Exception e) {
e.printStackTrace();
}
}
}
Configura application.properties
# Avvia SeimiCrawler
seimi.crawler.enabled=true
seimi.crawler.names=basic
Avvio standard di SpringBoot
@SpringBootApplication
public class SeimiCrawlerApplication {
public static void main(String[] args) {
SpringApplication.run(SeimiCrawlerApplication.class, args);
}
}Per utilizzi più complessi, è possibile consultare le documentazioni più dettagliate o il demo su Github.
Creare un progetto Maven standard e aggiungere le regole di crawling nel pacchetto crawlers, ad esempio:
@Crawler(name = "basic")
public class Basic extends BaseSeimiCrawler {
@Override
public String[] startUrls() {
// Due URL per testare la rimozione dei duplicati
return new String[]{"http://www.cnblogs.com/","http://www.cnblogs.com/"};
}
@Override
public void start(Response response) {
JXDocument doc = response.document();
try {
List<Object> urls = doc.sel("//a[@class='titlelnk']/@href");
logger.info("{}", urls.size());
for (Object s : urls) {
push(Request.build(s.toString(), Basic::getTitle));
}
} catch (Exception e) {
e.printStackTrace();
}
}
public void getTitle(Response response) {
JXDocument doc = response.document();
try {
logger.info("url:{} {}", response.getUrl(), doc.sel("//h1[@class='postTitle']/a/text()|//a[@id='cb_post_title_url']/text()"));
// Fai qualcosa
} catch (Exception e) {
e.printStackTrace();
}
}
}Quindi, aggiungi una funzione main in qualsiasi pacchetto per avviare SeimiCrawler:
public class Boot {
public static void main(String[] args) {
Seimi s = new Seimi();
s.start("basic");
}
}Questo è il flusso di sviluppo più semplice di un sistema di crawling.
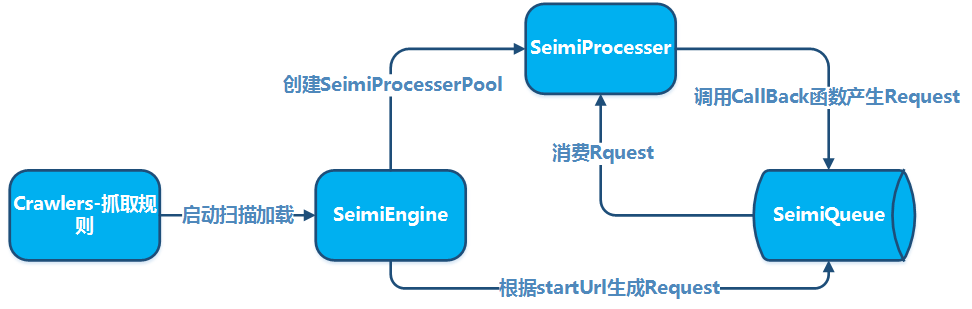
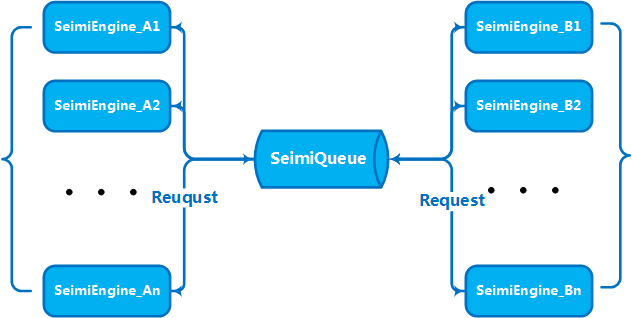
Le convenzioni sono necessarie principalmente per rendere il codice sorgente di un sistema di crawling sviluppato con SeimiCrawler più standardizzato e leggibile. Se tutti seguono le stesse convenzioni, il codice dei progetti di business sarà più facile da leggere e modificare tra i membri del team. Non vogliamo che una persona sviluppi una logica di business e un'altra che la eredita abbia difficoltà a trovare le classi. Noi vogliamo che SeimiCrawler sia potente, semplice e utile. Infine, la presenza di convenzioni non significa che SeimiCrawler non sia flessibile.
- Poiché il contesto di SeimiCrawler è basato su spring, supporta quasi tutti i formati di file di configurazione spring e le pratiche comuni di spring. SeimiCrawler scannerà tutti i file di configurazione XML nel classpath dell'ingegneria, ma solo i file XML che iniziano con
seimisaranno riconosciuti e caricati da SeimiCrawler. - SeimiCrawler utilizza slf4j per i log, e può essere configurato con implementazioni specifiche.
- Le convenzioni da rispettare durante lo sviluppo di SeimiCrawler verranno illustrate dettagliatamente nei punti di sviluppo successivi.
La classe di regola del crawler è la parte più importante per sviluppare un crawler utilizzando SeimiCrawler, la classe Basic del rapido inizio è una classe di crawler di base. Per scrivere un crawler, fa' attenzione ai seguenti punti:
- Devi ereditare da
BaseSeimiCrawler - Devi usare l'annotazione
@Crawler, l'attributonamedell'annotazione è opzionale. Se è impostato, il crawler verrà denominato con il nome che hai definito, altrimenti verrà usato il nome della classe che hai creato. - Tutti i crawler che desideri far scansionare da SeimiCrawler devono essere posizionati nel pacchetto crawlers, ad esempio:
cn.wanghaomiao.xxx.crawlers, puoi anche consultare l'ingegneria demo inclusa nel progetto. Dopo aver inizializzato il Crawler, devi implementare due metodi basilaripublic String[] startUrls();epublic void start(Response response), dopo l'implementazione, un semplice crawler sarà considerato completato.
Attualmente l'annotazione @Crawler ha le seguenti proprietà:
nameper definire un nome personalizzato per la regola del crawler, non possono esserci nomi duplicati all'interno del progetto a portata di scansione di un SeimiCrawler. L'impostazione predefinita è il nome della classe.proxyper informare Seimi se il crawler deve utilizzare un proxy e, se sì, quale tipo di proxy. Al momento sono supportati tre formatihttp|https|socket://host:port, questa versione non supporta proxy con nome utente e password.useCookieper abilitare o meno i cookie, una volta abilitato, statti comporterà come un browser mantenendo lo stato delle tue richieste, con il rischio di essere tracciato.queueper specificare la coda di dati da utilizzare per questo crawler, l'impostazione predefinita èDefaultLocalQueue.class, puoi configurarla per utilizzare l'implementazione Redis di default o implementare un tua coda basata su altri sistemi, questo verrà introdotto in dettaglio più avanti.delayper impostare l'intervallo di tempo in secondi tra le richieste di estrazione, il valore predefinito è 0, ovvero nessun intervallo.httpTypeper specificare il tipo di implementazione dello scaricatore, l'implementazione predefinita del Downloader è Apache Httpclient, puoi modificarla per utilizzare OkHttp3.httpTimeOutper specificare un timeout personalizzato, espresso in millisecondi, il valore predefinito è 15000ms.
Questa è l'entrata del crawler, restituisce un array di URL. Di default, lo startURL verrà trattato come richiesta GET, se in alcuni casi speciali desideri che Seimi tratti il tuo startURL con il metodo POST, basta aggiungere ##post alla fine dell'URL, ad esempio http://passport.cnblogs.com/user/signin?ReturnUrl=http%3a%2f%2fi.cnblogs.com%2f##post, questa specifica non distingue tra maiuscole e minuscole. Questa regola si applica solo al trattamento dello startURL.
Questo metodo è il callback per lo startURL, ovvero indica a Seimi come gestire i dati restituiti dalla richiesta dello startURL.
- Risultati testuali
Seimi consiglia di utilizzare XPath per estrarre dati HTML, anche se l'apprendimento iniziale di XPath può comportare una piccola curva di apprendimento, ciò che ottieni in termini di efficienza di sviluppo una volta che lo conosci è davvero insignificante in confronto.
JXDocument doc = response.document();permette di ottenereJXDocument(l'oggetto documento di JsoupXpath), dopodiché è possibile estrarre qualsiasi dato desiderato attraversodoc.sel("xpath"). L'estrazione di qualsiasi dato dovrebbe essere gestita da una singola espressione XPath. Per chi desidera approfondire l'interprete di sintassi XPath utilizzato da Seimi o per saperne di più su XPath, si prega di visitare JsoupXpath. Naturalmente, se XPath non è della vostra predilezione, è possibile utilizzare gli altri analizzatori di dati sulla risposta originale contenuta inresponse. - Risultati file
Se il risultato è un file, è possibile utilizzare
reponse.saveTo(File targetFile)per salvarlo, o ottenere un flusso di bytebyte[] getData()per effettuare altre operazioni.
private BodyType bodyType;
private Request request;
private String charset;
private String referer;
private byte[] data;
private String content;
/**
* Questo viene utilizzato principalmente per memorizzare dati personalizzati trasmessi dall'upstream
*/
private Map<String, String> meta;
private String url;
private Map<String, String> params;
/**
* Indirizzo sorgente reale del contenuto web
*/
private String realUrl;
/**
* Tipo di gestore HTTP del risultato della richiesta
*/
private SeimiHttpType seimiHttpType;
L'uso di una funzione di callback predefinita è ovviamente insufficiente per le tue esigenze, se vuoi estrarre determinati URL dalla pagina startURL e richiedere dati per il loro trattamento, dovrai definire funzioni di callback personalizzate. Ecco alcuni punti da tenere a mente:
- Dalla versione 2.0 è supportata la sintassi di riferimento ai metodi, la configurazione di funzioni di callback è più naturale, come
Basic::getTitle. - Le
Requestgenerate all'interno di una funzione di callback possono specificare altre funzioni di callback o se stesse come callback. - Una funzione di callback deve avere questo formato:
public void callbackName(Response response), ovvero il metodo deve essere pubblico, avere un solo parametroResponsee non avere un valore di ritorno. - Per impostare una funzione di callback su una
Request, basta fornire il nome della funzione di callback come stringa, come ad esempiogetTitlenel rapido inizio. - Un Crawler che eredita da
BaseSeimiCrawlerpuò inviare nuove richieste di estrazione alla coda delle richieste chiamando direttamentepush(Request request)all'interno della funzione di callback. - È possibile creare una
RequestattraversoRequest.build().
public class Request {
public static Request build(String url, String callBack, HttpMethod httpMethod, Map<String, String> params, Map<String, String> meta);
public static Request build(String url, String callBack, HttpMethod httpMethod, Map<String, String> params, Map<String, String> meta,int maxReqcount);
public static Request build(String url, String callBack);
public static Request build(String url, String callBack, int maxReqCount);
@NotNull
private String crawlerName;
/**
* URL da richiedere
*/
@NotNull
private String url;
/**
* Tipo di metodo da richiedere get, post, put...
*/
private HttpMethod httpMethod;
/**
* Se la richiesta richiede parametri, questi vengono memorizzati qui
*/
private Map<String,String> params;
/**
* Questo viene utilizzato principalmente per memorizzare dati personalizzati da trasmettere alla funzione di callback successiva
*/
private Map<String,Object> meta;
/**
* Nome del metodo di callback
*/
@NotNull
private String callBack;
/**
* Indica se la funzione di callback è un'espressione lambda
*/
private transient boolean lambdaCb = false;
/**
* Funzione di callback
*/
private transient SeimiCallbackFunc callBackFunc;
/**
* Segnale di arresto, i thread di elaborazione che ricevono questo segnale si interrompent
*/
private boolean stop = false;
/**
* Numero massimo di richieste consentite
*/
private int maxReqCount = 3;
/**
* Utilizzato per registrare il numero di volte in cui la richiesta è stata eseguita
*/
private int currentReqCount = 0;
/**
* Specifica se una richiesta deve passare attraverso il meccanismo di deduplicazione
*/
private boolean skipDuplicateFilter = false;
/**
* Indica se per la richiesta deve essere abilitato SeimiAgent
*/
private boolean useSeimiAgent = false;
/**
* Intestazioni di protocollo HTTP personalizzate
*/
private Map<String,String> header;
/**
* Definisce il tempo di rendering di SeimiAgent, espresso in millisecondi
*/
private long seimiAgentRenderTime = 0;
/**
* Utilizzato per eseguire script JavaScript specifici su SeimiAgent
*/
private String seimiAgentScript;
/**
* Specifica se le richieste inviate a SeimiAgent devono utilizzare i cookie
*/
private Boolean seimiAgentUseCookie;
/**
* Indica a SeimiAgent in quale formato restituire i risultati, HTML di default
*/
private SeimiAgentContentType seimiAgentContentType = SeimiAgentContentType.HTML;
/**
* Supporta l'aggiunta di cookie personalizzati
*/
private List<SeimiCookie> seimiCookies;
/**
* Supporta l'aggiunta di un body della richiesta in formato JSON
*/
private String jsonBody;
}
L'User-Agent predefinito di SeimiCrawler è SeimiCrawler/JsoupXpath, se si desidera personalizzare l'User-Agent, è possibile sovrascrivere public String getUserAgent() in BaseSeimiCrawler. SeimiCrawler richiede l'User-Agent ogni volta che elabora una richiesta, quindi se si vuole mimetizzare l'User-Agent, è possibile implementare una libreria UA che restituisce un valore casuale ogni volta.
Il concetto è stato introdotto nella sezione di presentazione dell'annotazione @Crawler, qui viene ripetuto per facilitare una rapida consultazione di queste funzionalità di base. L'abilitazione dei cookies viene configurata tramite l'attributo useCookie dell'annotazione @Crawler. In alternativa, è possibile utilizzare Request.setSeimiCookies(List<SeimiCookie> seimiCookies) o Request.setHeader(Map<String, String> header) per impostazioni personalizzate. Il metodo Request permette molte personalizzazioni, si consiglia di esaminare l'oggetto Request per un utilizzo più efficiente e per dare spazio a nuove idee.
La configurazione avviene tramite l'attributo proxy dell'annotazione @Crawler, per ulteriori dettagli consultare la sezione @Crawler. Se si desidera specificare dinamicamente il proxy, consultare la sezione successiva "Configurazione di un proxy dinamico". Attualmente sono supportate tre formattazioni: http|https|socket://host:port.
La configurazione avviene tramite l'attributo delay dell'annotazione @Crawler, l'intervallo di tempo tra le richieste è espresso in secondi, con un valore predefinito di 0 (nessun intervallo). In molti casi, il contenitore limita la frequenza delle richieste per prevenire i web scraper, quindi è possibile regolare questo parametro per ottenere risultati di crawling più efficaci.
Impostare le regole della whitelist degli URL delle richieste attraverso l'override del metodo public String[] allowRules() di BaseSeimiCrawler. Le regole sono espressioni regolari, e l'abbinamento a qualsiasi una di queste permette la richiesta.
Impostare le regole della blacklist degli URL delle richieste attraverso l'override del metodo public String[] denyRules() di BaseSeimiCrawler. Le regole sono espressioni regolari, e l'abbinamento a qualsiasi una di queste blocca la richiesta.
Impostare il proxy da utilizzare per una singola richiesta attraverso l'override del metodo public String proxy() di BaseSeimiCrawler. Qui puoi scegliere un proxy dal tuo pool di proxy in modo sequenziale o casuale. Se l'indirizzo del proxy non è vuoto, l'impostazione della proprietà proxy nel @Crawler diventa inefficace. Attualmente vengono supportati tre formati: http|https|socket://host:port.
Controllare se attivare la rimozione dei duplicati dal sistema tramite la proprietà useUnrepeated dell'annotazione @Crawler, che è attiva per impostazione predefinita.
Attualmente SeimiCrawler supporta i reindirizzamenti 301, 302 e meta refresh. Per ottenere l'URL reindirizzato o rediretto effettivo, utilizza il metodo getRealUrl() dell'oggetto Response.
Se una richiesta causa un errore durante il suo processo, viene posta nuovamente nella coda delle richieste per un totale di tre tentativi. Se tuttavia l'errore persiste, il sistema chiamerà il metodo public void handleErrorRequest(Request request) del crawler per gestire la richiesta problematica. L'implementazione predefinita registra l'errore tramite log, ma gli sviluppatori possono ridefinire questo metodo per aggiungere la propria logica di gestione.
Questo merita una spiegazione dettagliata. Gli utenti che non conoscono bene SeimiAgent possono visitare la pagina principale del progetto SeimiAgent per maggiori informazioni. In breve, SeimiAgent è un motore del browser che viene eseguito sul lato server, sviluppato su QtWebkit e che offre servizi tramite una standard HTTP API. È ideale per la gestione di pagine web dinamiche complesse, inclusa la resa, lo screenshot e la sorveglianza. In pratica, consente di ottenere qualsiasi informazione che sarebbe disponibile in un browser standard.
Per far sì che SeimiCrawler supporti SeimiAgent, è necessario specificare l'indirizzo del servizio SeimiAgent.
Configurare tramite SeimiConfig, ad esempio
SeimiConfig config = new SeimiConfig();
config.setSeimiAgentHost("127.0.0.1");
Seimi s = new Seimi(config);
s.goRun("basic");
Configurare in application.properties
seimi.crawler.seimi-agent-host=xx
seimi.crawler.seimi-agent-port=xx
Determinare quali richieste siano sottoposte a SeimiAgent per il trattamento e specificare come SeimiAgent debba trattarle. Questo avviene a livello di richiesta.
Request.useSeimiAgent()Indica a SeimiCrawler che la richiesta deve essere sottoposta a SeimiAgent.Request.setSeimiAgentRenderTime(long seimiAgentRenderTime)Imposta il tempo di rendering di SeimiAgent (il tempo assegnato a SeimiAgent per eseguire gli script JavaScript nelle risorse dopo il caricamento di tutte le risorse), espresso in millisecondi.Request.setSeimiAgentUseCookie(Boolean seimiAgentUseCookie)Indica a SeimiAgent se utilizzare i cookie. Se non è specificato, verrà utilizzata l'impostazione globale di seimiCrawler.- Altri Se il tuo Crawler è configurato con un proxy, allora quando la richiesta viene trasferita a SeimiAgent, seimiCrawler configurerà automaticamente SeimiAgent per utilizzare lo stesso proxy.
- Demo Per un esempio pratico, puoi consultare il demo nel repository.
Configurazione in application.properties
seimi.crawler.enabled=true
# Specifica i nomi dei crawler per i quali avviare le richieste di inizio
seimi.crawler.names=basic,test
Poi è sufficiente avviare SpringBoot standard
@SpringBootApplication
public class SeimiCrawlerApplication {
public static void main(String[] args) {
SpringApplication.run(SeimiCrawlerApplication.class, args);
}
}
Aggiungere una funzione main, preferibilmente in una classe di avvio separata, come mostrato nell'esempio del progetto. Nella funzione main, inizializzare l'oggetto Seimi e configurare alcuni parametri specifici attraverso SeimiConfig, come l'informazione del cluster Redis necessaria per le code distribuite o le informazioni host necessarie se si utilizza seimiAgent, anche se SeimiConfig è opzionale. Ad esempio:
public class Boot {
public static void main(String[] args){
SeimiConfig config = new SeimiConfig();
// config.setSeimiAgentHost("127.0.0.1");
// config.redisSingleServer().setAddress("redis://127.0.0.1:6379");
Seimi s = new Seimi(config);
s.goRun("basic");
}
}
Seimi comprende le seguenti funzioni di avvio:
public void start(String... crawlerNames)avvia l'esecuzione di uno o più Crawler specificati.public void startAll()avvia tutti i Crawler caricati.public void startWithHttpd(int port, String... crawlerNames)avvia l'esecuzione di un Crawler specificato e avvia un servizio HTTP su una porta specificata, consentendo di inviare una richiesta di crawling a un Crawler specifico tramite/push/crawlerName. Il parametro accettato èreq, supportato in POST e GET.public void startWorkers()inizializza tutti i Crawler caricati e ascolta le richieste di crawling. Questa funzione di avvio è principalmente utilizzata per avviare uno o più sistemi worker puri in un'architettura distribuita, e verrà descritta più dettagliatamente successivamente nella sezione dedicata alla distribuzione.
Esegui i seguenti comandi sotto il progetto per creare e output l'intero progetto,
Sotto Windows, per evitare che i log vengano visualizzati in modo errato nella console di Windows, modifica manualmente il formato di output della console nel file di configurazione logback a
GBK, predefinitoUTF-8.
mvn clean package&&mvn -U compile dependency:copy-dependencies -DoutputDirectory=./target/seimi/&&cp ./target/*.jar ./target/seimi/
A questo punto, nella directory target del progetto, ci sarà una directory chiamata seimi, questa directory contiene il progetto compilato e pronto per la distribuzione. Quindi, esegui il comando seguente per avviare il progetto,
Sotto Windows:
java -cp .;./target/seimi/* cn.wanghaomiao.main.Boot
Sotto Linux:
java -cp .:./target/seimi/* cn.wanghaomiao.main.Boot
Puoi scrivere tu stesso gli script e regolare le directory come preferisci; l'esempio sopra è solo relativo a un progetto demo. In una vera situazione di distribuzione, puoi utilizzare lo strumento di packaging specifico per SeimiCrawler, il plugin maven-seimicrawler-plugin, per il packaging e la distribuzione. Nella sezione successiva, "Packaging e distribuzione", verrà fornita una descrizione dettagliata.
Si consiglia di costruire il progetto utilizzando Spring Boot, in questo modo è possibile sfruttare l'ecosistema esistente di Spring Boot, che offre numerose possibilità. Il packaging di un progetto Spring Boot può essere eseguito seguendo la procedura standard descritta nel sito ufficiale di Spring Boot
mvn package
Il metodo descritto sopra può essere utilizzato comodamente per lo sviluppo o il debug, e può anche diventare un modo per avviare il progetto in un ambiente di produzione. Tuttavia, per facilitare il packaging e la distribuzione, SeimiCrawler fornisce un plugin di packaging dedicato per creare un pacchetto del progetto SeimiCrawler pronto per la distribuzione e l'esecuzione. Devi solo fare le seguenti cose:
Aggiungi il plugin nel file pom
<plugin>
<groupId>cn.wanghaomiao</groupId>
<artifactId>maven-seimicrawler-plugin</artifactId>
<version>1.0.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>build</goal>
</goals>
</execution>
</executions>
</plugin>
Esegui mvn clean package, la struttura della directory del pacchetto sarà come segue:
.
├── bin # Nelle rispettive script sono presenti anche dettagli sui parametri di avvio, non verranno ripetuti qui
│ ├── run.bat # Script di avvio per Windows
│ └── run.sh # Script di avvio per Linux
└── seimi
├── classes # Directory delle classi dell'applicazione Crawler e file di configurazione associati
└── lib # Directory dei pacchetti di dipendenza del progetto
A questo punto, il pacchetto è pronto per essere distribuito e implementato.
La pianificazione personalizzata di SeimiCrawler può essere implementata direttamente utilizzando l'annotazione @Scheduled di Spring, senza ulteriori configurazioni. Ad esempio, è sufficiente definire nel file delle regole Crawler come mostrato di seguito:
@Scheduled(cron = "0/5 * * * * ?")
public void callByCron(){
logger.info("Sono un pianificatore eseguito in base all'espressione cron, ogni 5 secondi");
// È possibile inviare una richiesta in modo programmato
// push(Request.build(startUrls()[0],"start").setSkipDuplicateFilter(true));
}
Se si desidera definire un servizio indipendente, è necessario assicurarsi che tale classe di servizio possa essere individuata. Per quanto riguarda @Scheduled, gli sviluppatori possono consultare autonomamente i materiali Spring per conoscere i dettagli dei parametri, oppure fare riferimento al demo esemplificativo di SeimiCrawler su GitHub.
Se si desidera definire un Bean, SeimiCrawler può estrazione i dati automaticamente in base alle regole definite e iniettarli nei campi corrispondenti, in questo caso è necessario utilizzare questa funzionalità.
Consideriamo un esempio:
public class BlogContent {
@Xpath("//h1[@class='postTitle']/a/text()|//a[@id='cb_post_title_url']/text()")
private String title;
// Può anche essere scritto come @Xpath("//div[@id='cnblogs_post_body']//text()")
@Xpath("//div[@id='cnblogs_post_body']/allText()")
private String content;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}
La classe BlogContent è un Bean target che hai definito. L'annotazione @Xpath deve essere applicata ai campi in cui desideri iniettare dati e dovrebbe essere configurata con una regola di estrazione XPath. Non è richiesto che i campi siano privati o pubblici, né che esistano getter e setter.
Dopo aver preparato il Bean, nel metodo di callback è possibile utilizzare la funzione incorporata public <T> T render(Class<T> bean) di Response per ottenere un'istanza del Bean con i dati già iniettati.
SeimiCrawler supporta anche l'aggiunta di intercettori a funzioni di callback specifiche o a tutte. Per implementare un intercettore, è necessario tenere a mente i punti seguenti:
- Deve essere annotato con
@Interceptor - Deve implementare l'interfaccia
SeimiInterceptor - Tutti gli intercettori che si desidera attivare devono essere piazzati nella cartella
interceptors, comecn.wanghaomiao.xxx.interceptors, esempi sono disponibili anche nel progetto demo. - È necessario definire un'annotazione personalizzata per indicare quali funzioni devono essere intercettate o se deve essere intercettato tutto.
Questa annotazione comunica a Seimi che la classe annotata potrebbe essere un intercettore (poiché per essere un vero intercettore Seimi è necessario soddisfare anche gli altri requisiti menzionati). Essa ha una proprietà,
everyMethodpredefinito afalse, per indicare a Seimi se questo intercettore deve intercettare tutte le funzioni di callback.
Procediamo direttamente con l'interfaccia:
public interface SeimiInterceptor {
/**
* Ottiene l'annotazione che il metodo di destinazione deve contrassegnare
* @return Annotation
*/
public Class<? extends Annotation> getTargetAnnotationClass();
/**
* Quando è necessario controllare l'ordine di esecuzione di più interceptors, è possibile sovrascrivere questo metodo
* @return Il peso, maggiore è il peso, più esterno è il livello, con priorità di intercettazione
*/
public int getWeight();
/**
* È possibile definire alcune logiche di elaborazione prima dell'esecuzione del metodo di destinazione
*/
public void before(Method method, Response response);
/**
* È possibile definire alcune logiche di elaborazione dopo l'esecuzione del metodo di destinazione
*/
public void after(Method method, Response response);
}
Le note già spiegano tutto chiaramente, quindi non entrerò in ulteriori dettagli.
Fate riferimento a DemoInterceptor nel progetto demo, collegamento diretto a GitHub
SeimiQueue è l'unico canale utilizzato da SeimiCrawler per la trasferimento di dati e la comunicazione interna e inter-sistemi. Il sistema usa per default una SeimiQueue basata su un'implementazione di coda bloccante thread-safe locale. SeimiCrawler supporta inoltre un'implementazione di SeimiQueue basata su Redis, ovvero DefaultRedisQueue; è inoltre possibile implementare una SeimiQueue conforme alle convenzioni di Seimi, e specificare quale implementazione utilizzare tramite la proprietà queue dell'annotazione @Crawler.
Impostate l'annotazione del Crawler come @Crawler(name = "xx", queue = DefaultRedisQueue.class)
SeimiConfig config = new SeimiConfig();
config.setSeimiAgentHost("127.0.0.1");
config.redisSingleServer().setAddress("redis://127.0.0.1:6379");
Seimi s = new Seimi(config);
s.goRun("basic");
In genere, le due implementazioni predefinite di SeimiCrawler sono sufficienti per la maggior parte delle situazioni di utilizzo, ma se si incontrano casi particolari, è possibile implementare autonomamente SeimiQueue e configurarla per l'uso. Gli aspetti da considerare per un'implementazione personalizzata sono:
- Devi applicare l'annotazione
@Queue, per indicare a Seimi che la classe annotata potrebbe essere una SeimiQueue (per diventare effettivamente una SeimiQueue, la classe deve soddisfare altre condizioni). - Devi implementare l'interfaccia
SeimiQueue, come segue:
/**
* Definisce l'interfaccia di base della coda di sistema, può essere implementata liberamente a patto di rispettare le specifiche.
* @author 汪浩淼 [email protected]
* @since 2015/6/2.
*/
public interface SeimiQueue extends Serializable {
/**
* Estrae in modo bloccante una richiesta dalla coda
* @param crawlerName --
* @return --
*/
Request bPop(String crawlerName);
/**
* Inserisce una richiesta nella coda
* @param req Richiesta
* @return --
*/
boolean push(Request req);
/**
* Lunghezza residua della coda delle richieste
* @param crawlerName --
* @return Numero
*/
long len(String crawlerName);
/**
* Verifica se un URL è già stato elaborato
* @param req --
* @return --
*/
boolean isProcessed(Request req);
/**
* Registra una richiesta già elaborata
* @param req --
*/
void addProcessed(Request req);
/**
* Numero totale di estrazioni attuali
* @param crawlerName --
* @return Numero
*/
long totalCrawled(String crawlerName);
/**
* Elimina i record di estrazione
* @param crawlerName --
*/
void clearRecord(String crawlerName);
}
- Tutte le SeimiQueue che si desidera far rilevare e attivare devono essere collocate nel pacchetto
queues, ad esempiocn.wanghaomiao.xxx.queues, con esempi presenti anche nel progetto demo. Fatto ciò, una volta scritta la propria SeimiQueue, si può configurare il suo utilizzo tramite l'annotazione@Crawler(name = "xx", queue = YourSelfRedisQueueImpl.class).
Rifarsi all'esempio DefaultRedisQueueEG nel progetto demo (link diretto su GitHub)
Poiché SeimiCrawler utilizza Spring per la gestione dei bean e l'inserimento delle dipendenze, è abbastanza semplice integrare soluzioni di persistenza dati mainstream come Mybatis, Hibernate, Paoding-jade, ecc. In questo caso, si utilizza Mybatis.
Aggiungere le dipendenze necessarie per Mybatis e la connessione al database:
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-spring</artifactId>
<version>1.3.0</version>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.4.1</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-dbcp2</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.4.2</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.37</version>
</dependency>Aggiungere un file di configurazione XML seimi-mybatis.xml (ricorda, i file di configurazione devono iniziare con "seimi")
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="propertyConfigurer" class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer">
<property name="locations">
<list>
<value>classpath:**/*.properties</value>
</list>
</property>
</bean>
<bean id="mybatisDataSource" class="org.apache.commons.dbcp2.BasicDataSource">
<property name="driverClassName" value="${database.driverClassName}"/>
<property name="url" value="${database.url}"/>
<property name="username" value="${database.username}"/>
<property name="password" value="${database.password}"/>
</bean>
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean" abstract="true">
<property name="configLocation" value="classpath:mybatis-config.xml"/>
</bean>
<bean id="seimiSqlSessionFactory" parent="sqlSessionFactory">
<property name="dataSource" ref="mybatisDataSource"/>
</bean>
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="cn.wanghaomiao.dao.mybatis"/>
<property name="sqlSessionFactoryBeanName" value="seimiSqlSessionFactory"/>
</bean>
</beans>Poiché nel progetto demo esiste un file di configurazione unificato seimi.properties, le informazioni di connessione del database vengono iniettate tramite properties, naturalmente qui puoi anche scriverle direttamente. La configurazione properties è la seguente:
database.driverClassName=com.mysql.jdbc.Driver
database.url=jdbc:mysql://127.0.0.1:3306/xiaohuo?useUnicode=true&characterEncoding=UTF8&autoReconnect=true&autoReconnectForPools=true&zeroDateTimeBehavior=convertToNull
database.username=xiaohuo
database.password=xiaohuo
Il progetto fin qui è pronto, rimane da creare un database e una tabella per memorizzare le informazioni sperimentali. Il progetto demo fornisce la struttura della tabella, il nome del database può essere personalizzato:
CREATE TABLE `blog` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(300) DEFAULT NULL,
`content` text,
`update_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
Creare un file DAO di Mybatis:
public interface MybatisStoreDAO {
@Insert("insert into blog (title,content,update_time) values (#{blog.title},#{blog.content},now())")
@Options(useGeneratedKeys = true, keyProperty = "blog.id")
int save(@Param("blog") BlogContent blog);
}
Si presuppone che si conosca la configurazione di Mybatis, quindi non entreremo nei dettagli. Per maggiori informazioni, è possibile consultare il progetto demo o la documentazione ufficiale di Mybatis.
È sufficiente iniettare il DAO nel corrispondente Crawler come nell'esempio seguente:
@Crawler(name = "mybatis")
public class DatabaseMybatisDemo extends BaseSeimiCrawler {
@Autowired
private MybatisStoreDAO storeToDbDAO;
@Override
public String[] startUrls() {
return new String[]{"http://www.cnblogs.com/"};
}
@Override
public void start(Response response) {
JXDocument doc = response.document();
try {
List<Object> urls = doc.sel("//a[@class='titlelnk']/@href");
logger.info("{}", urls.size());
for (Object s : urls) {
push(Request.build(s.toString(), DatabaseMybatisDemo::renderBean));
}
} catch (Exception e) {
e.printStackTrace();
}
}
public void renderBean(Response response) {
try {
BlogContent blog = response.render(BlogContent.class);
logger.info("bean resolve res={},url={}", blog, response.getUrl());
// Utilizza paoding-jade per salvare sui DB
int changeNum = storeToDbDAO.save(blog);
int blogId = blog.getId();
logger.info("store success,blogId = {},changeNum={}", blogId, changeNum);
} catch (Exception e) {
e.printStackTrace();
}
}
}
Naturalmente, se le operazioni sono complesse, si consiglia di creare un ulteriore strato di service e di iniettarlo nel Crawler.
Quando il volume di attività e i dati raggiungono una certa scala, è necessario espandere orizzontalmente con più macchine per creare un servizio cluster per migliorare le capacità di elaborazione, problema preso in considerazione sin dall'inizio nella progettazione di SeimiCrawler. Pertanto, SeimiCrawler supporta nativamente la distribuzione. Come descritto nel paragrafo precedente su SeimiQueue, la distribuzione può essere configurata utilizzando DefaultRedisQueue come SeimiQueue predefinita e configurando le stesse informazioni di connessione Redis su ogni macchina da distribuire. Dopo aver attivato DefaultRedisQueue, su ogni macchina worker si può inizializzare il processore di Seimi con new Seimi().startWorkers(), il processo worker di Seimi inizierà a monitorare la coda dei messaggi. Quando il servizio principale emette una richiesta di crawling, l'intero cluster inizia a comunicare attraverso la coda dei messaggi, collaborando efficacemente. Dalla versione 2.0, la coda distribuita predefinita utilizza Redisson e introduce BloomFilter.
Se si desidera inviare una richiesta di crawling personalizzata a Seimicrawler, la richiesta deve includere i seguenti parametri:
urll'URL da crawlingcrawlerNameil nome della regolacallBackfunzione di callback
È possibile creare un progetto SpringBoot e scrivere un controller Spring MVC per gestire tali richieste. Ecco un semplice DEMO, che può servire come base per realizzare altre funzionalità interessanti.
Se non si desidera eseguire il progetto in formato SpringBoot, è possibile utilizzare le interfacce interne. SeimiCrawler può iniziare un servizio HTTP integrato su una porta specifica per ricevere richieste di crawling tramite HTTP API o per visualizzare lo stato del Crawler.
Le richieste Request in formato JSON vengono inviate a SeimiCrawler tramite l'interfaccia HTTP. Dopo la ricezione e la verifica base, la richiesta di crawling verrà elaborata insieme alle altre richieste generate dalle regole.
- URL: http://host:port/push/${YourCrawlerName}
- Metodo: GET/POST
- Parametri di input:
| Nome del parametro | Obbligatorio | Tipo di parametro | Descrizione del parametro |
|---|---|---|---|
| req | true | str | Il contenuto è la forma JSON di una richiesta Request, singola o array JSON |
- Esempio di struttura del parametro:
{
"callBack": "start",
"maxReqCount": 3,
"meta": {
"listPageSomeKey": "xpxp"
},
"params": {
"paramName": "xxxxx"
},
"stop": false,
"url": "http://www.github.com"
}
o
[
{
"callBack": "start",
"maxReqCount": 3,
"meta": {
"listPageSomeKey": "xpxp"
},
"params": {
"paramName": "xxxxx"
},
"stop": false,
"url": "http://www.github.com"
},
{
"callBack": "start",
"maxReqCount": 3,
"meta": {
"listPageSomeKey": "xpxp"
},
"params": {
"paramName": "xxxxx"
},
"stop": false,
"url": "http://www.github.com"
}
]
Spiegazione dei campi della struttura:
| Campo Json | Obbligatorio | Tipo di campo | Descrizione del campo |
|---|---|---|---|
| url | true | str | Indirizzo di destinazione della richiesta |
| callBack | true | str | Funzione di callback per i risultati della richiesta corrispondente |
| meta | false | map | Dati personalizzati opzionali da passare al contesto |
| params | false | map | Parametri di richiesta necessari per la richiesta corrente |
| stop | false | bool | Se true, il thread di lavoro che riceve la richiesta smetterà di funzionare |
| maxReqCount | false | int | Numero massimo di reinoltramenti consentiti se il processo della richiesta è anormale |
Indirizzo della richiesta: /status/${YourCrawlerName} per visualizzare lo stato attuale di raccolta di base del Crawler specificato nei dati con formato Json.
Vedere 5.2.13. Impostazione del proxy dinamico
Vedere 5.2.8. Abilitazione dei cookies (facoltativo)
- I Crawler omonimi in istanze diverse di SeimiCrawler collaboreranno attraverso lo stesso Redis (condividendo la stessa coda di produzione e consumo)
- Assicurarsi che le macchine su cui viene avviato SeimiCrawler possano comunicare correttamente con Redis
- Nella demo è configurata una password per Redis, ma se il tuo Redis non richiede una password, non configurare la password
- Molti utenti hanno riscontrato problemi di rete, ciò indica che è necessario verificare la propria situazione di rete. La libreria di rete utilizzata da SeimiCrawler è matura, se si verificano problemi di rete, è sicuramente un problema di rete. Inclusi, ma non limitati a, verifiche su: se il sito di destinazione ha bloccato mirato, se il proxy è accessibile, se il proxy è stato bloccato, se il proxy ha la capacità di accedere a Internet, se la macchina su cui si trova il crawler può accedere a Internet, ecc.
Riscrivi l'implementazione di public List<Request> startRequests(), qui puoi definire liberamente richieste di avvio complesse. In questo caso, public String[] startUrls() può restituire null. Un esempio:
@Crawler(name = "usecookie",useCookie = true)
public class UseCookie extends BaseSeimiCrawler {
@Override
public String[] startUrls() {
return null;
}
@Override
public List<Request> startRequests() {
List<Request> requests = new LinkedList<>();
Request start = Request.build("https://www.oschina.net/action/user/hash_login","start");
Map<String,String> params = new HashMap<>();
params.put("email","[email protected]");
params.put("pwd","xxxxxxxxxxxxxxxxxxx");
params.put("save_login","1");
params.put("verifyCode","");
start.setHttpMethod(HttpMethod.POST);
start.setParams(params);
requests.add(start);
return requests;
}
@Override
public void start(Response response) {
logger.info(response.getContent());
push(Request.build("http://www.oschina.net/home/go?page=blog","minePage"));
}
public void minePage(Response response){
JXDocument doc = response.document();
try {
logger.info("uname:{}", StringUtils.join(doc.sel("//div[@class='name']/a/text()"),""));
logger.info("httpType:{}",response.getSeimiHttpType());
} catch (XpathSyntaxErrorException e) {
logger.debug(e.getMessage(),e);
}
}
}
<dependency>
<groupId>cn.wanghaomiao</groupId>
<artifactId>SeimiCrawler</artifactId>
<version>2.1.2</version>
</dependency>
Assicurati di utilizzare la versione 2.1.2 o superiore, che supporta l'impostazione della proprietà jsonBody in Request per inviare una richiesta con un corpo JSON.
Qualsiasi domanda o suggerimento ora può essere discusso attraverso la seguente lista di distribuzione email. Prima di inviare un messaggio, è necessario iscriversi e attendere il completamento della revisione (principalmente per filtrare la pubblicità e creare un ambiente di discussione piacevole).
- Iscrizione: invia un'email a
[email protected] - Discussione: invia un'email a
[email protected] - Annullamento iscrizione: invia un'email a
[email protected]
PER INCISO: Siete invitati a dare un
starsu Github ^_^