Un cadre le système crawler agil, puissant, autonome et distribué.
L'objectif de SeimiCrawler est de devenir le cadre le système crawler le plus utile et pratique dans le monde Java.
SeimiCrawler est un cadre le système crawler agile, déployable de manière autonome et supportant le déploiement distribué en Java. L'objectif est de réduire au maximum le seuil d'entrée pour les nouveaux développeurs afin qu'ils puissent créer un système de爬虫 performant et utilisable, tout en améliorant l'efficacité de développement de ces systèmes. Dans l'univers de SeimiCrawler, la plupart des utilisateurs n'ont besoin de se concentrer que sur la logique d'achat. Tout le reste est géré par Seimi. L'architecture de SeimiCrawler a été inspirée par le cadre de爬虫 Python, Scrapy, et a fusionné les caractéristiques propres au langage Java ainsi que les caractéristiques de Spring. Il vise à rendre l'utilisation plus efficace et plus répandue de XPath pour analyser HTML en Chine, c'est pourquoi l'analyseur HTML par défaut de SeimiCrawler est JsoupXpath (un projet d'extension indépendant, non inclus dans jsoup par défaut). Par défaut, toutes les opérations d'analyse et d'extraction de données HTML utilisent XPath (bien sûr, d'autres analyseurs peuvent également être choisis pour le traitement des données). En combinaison avec SeimiAgent, il résout parfaitement le problème de rendu de pages dynamiques complexes. Il supporte parfaitement SpringBoot, permettant une utilisation maximale de l'imagination et de la créativité.
JDK1.8+
<dependency>
<groupId>cn.wanghaomiao</groupId>
<artifactId>SeimiCrawler</artifactId>
<version>Consultez la dernière version sur Github</version>
</dependency>
Liste des versions Github Liste des versions Maven
Créez un projet SpringBoot standard et ajoutez des règles de爬虫 dans le package crawlers, par exemple :
@Crawler(name = "basic")
public class Basic extends BaseSeimiCrawler {
@Override
public String[] startUrls() {
// Deux pour tester la déduplication
return new String[]{"http://www.cnblogs.com/","http://www.cnblogs.com/"};
}
@Override
public void start(Response response) {
JXDocument doc = response.document();
try {
List<Object> urls = doc.sel("//a[@class='titlelnk']/@href");
logger.info("{}", urls.size());
for (Object s:urls){
push(Request.build(s.toString(),Basic::getTitle));
}
} catch (Exception e) {
e.printStackTrace();
}
}
public void getTitle(Response response){
JXDocument doc = response.document();
try {
logger.info("url:{} {}", response.getUrl(), doc.sel("//h1[@class='postTitle']/a/text()|//a[@id='cb_post_title_url']/text()"));
// Faire quelque chose
} catch (Exception e) {
e.printStackTrace();
}
}
}
Configurez application.properties
# Démarrer SeimiCrawler
seimi.crawler.enabled=true
seimi.crawler.names=basic
Lancement standard de SpringBoot
@SpringBootApplication
public class SeimiCrawlerApplication {
public static void main(String[] args) {
SpringApplication.run(SeimiCrawlerApplication.class, args);
}
}Des utilisations plus complexes peuvent être consultées dans la documentation plus détaillée ou dans l'exemple sur Github.
Créez un projet Maven standard, ajoutez les règles de crawler dans le package crawlers, par exemple :
@Crawler(name = "basic")
public class Basic extends BaseSeimiCrawler {
@Override
public String[] startUrls() {
// Deux URLs pour tester la déduplication
return new String[]{"http://www.cnblogs.com/","http://www.cnblogs.com/"};
}
@Override
public void start(Response response) {
JXDocument doc = response.document();
try {
List<Object> urls = doc.sel("//a[@class='titlelnk']/@href");
logger.info("{}", urls.size());
for (Object s : urls) {
push(Request.build(s.toString(), Basic::getTitle));
}
} catch (Exception e) {
e.printStackTrace();
}
}
public void getTitle(Response response) {
JXDocument doc = response.document();
try {
logger.info("url:{} {}", response.getUrl(), doc.sel("//h1[@class='postTitle']/a/text()|//a[@id='cb_post_title_url']/text()"));
// Faire quelque chose
} catch (Exception e) {
e.printStackTrace();
}
}
}Ajoutez ensuite une fonction main dans n'importe quel package pour démarrer SeimiCrawler :
public class Boot {
public static void main(String[] args) {
Seimi s = new Seimi();
s.start("basic");
}
}Ceci est le processus de développement le plus simple pour un système de crawler.
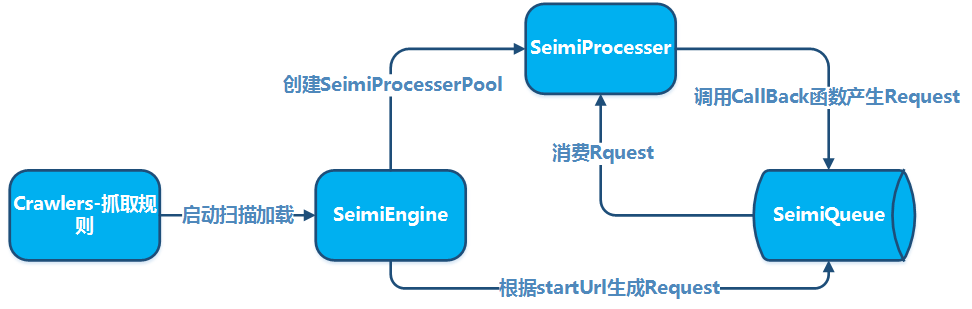
Les conventions sont mises en place principalement pour rendre le code source des systèmes de crawler développés avec SeimiCrawler plus normé et lisible. Si tout le monde respecte les mêmes conventions, le code des projets d'entreprise sera plus facile à lire et à modifier par les membres de l'équipe, évitant ainsi des situations où il est difficile de trouver la classe développée par quelqu'un d'autre. Nous voulons un outil puissant, simple et facile à utiliser. Les conventions ne signifient pas que SeimiCrawler n'est pas flexible.
- Étant donné que le contexte de SeimiCrawler est basé sur Spring, il prend en charge presque tous les formats de fichiers de configuration de Spring et les utilisations standards de Spring. SeimiCrawler scannera tous les fichiers de configuration XML sous le classpath de l'application, mais seuls les fichiers XML dont le nom commence par
seimiseront reconnus et chargés par SeimiCrawler. - Le journal de SeimiCrawler utilise slf4j, dont l'implémentation spécifique peut être configurée selon vos besoins.
- Les conventions à suivre lors du développement avec SeimiCrawler seront détaillées dans les points clés du développement ci-dessous.
La classe de règle de爬虫 est la partie la plus importante pour développer des爬虫 avec SeimiCrawler. La classe Basic dans le guide de démarrage rapide est une classe de爬虫 de base. Pour écrire un crawler, il faut prêter attention aux points suivants :
- Il faut hériter de
BaseSeimiCrawler - Il faut utiliser l'annotation
@Crawler. L'attributnamede l'annotation est optionnel. Si il est défini, le crawler sera nommé selon le nom que vous avez défini, sinon, il utilisera par défaut le nom de la classe que vous avez créée. - Tous les crawlers que vous souhaitez que SeimiCrawler scanne doivent être placés dans le package
crawlers, par exemple :cn.wanghaomiao.xxx.crawlers, vous pouvez aussi vous référer à l'ingénierie de démonstration fournie avec le projet. Après avoirinitialisé le Crawler, vous devez implémenter deux méthodes de base :public String[] startUrls();etpublic void start(Response response). Une fois ces méthodes mises en œuvre, un simple爬虫 sera prêt.
Actuellement, l'annotation @Crawler possède les attributs suivants :
nameNom personnalisé d'une règle de爬虫, il ne doit pas y avoir de doublon dans le projet que SeimiCrawler peut scanner. Par défaut, le nom de la classe est utilisé.proxyIndique à Seimi si le爬虫 doit utiliser un proxy, et quel type de proxy doit être utilisé. Trois formats sont actuellement supportés :http|https|socket://host:port. Cette version ne supporte pas encore les proxies avec nom d'utilisateur et mot de passe.useCookieIndique si les cookies doivent être activés. Si activés, cela permet de maintenir l'état de la requête comme dans un navigateur, mais cela peut aussi entraîner un suivi.queueSpécifie la file d'attente de données à utiliser pour ce爬虫. La file d'attente par défaut est une implémentation localeDefaultLocalQueue.class. Vous pouvez également configurer pour utiliser l'implémentation par défaut Redis ou une implémentation basée sur un autre système de file d'attente. Une introduction plus détaillée sera fournie ultérieurement.delayDéfinit l'intervalle de temps en secondes entre les requêtes d'extraction. Par défaut, c'est 0, ce qui signifie qu'il n'y a pas d'intervalle.httpTypeType d'implémentation du téléchargeur, l'implémentation par défaut est Apache Httpclient, mais vous pouvez la modifier pour utiliser OkHttp3.httpTimeOutSupporte la définition d'un temps de timeout personnalisé, unité en millisecondes, par défaut 15000ms.
C'est l'entrée du爬虫, la valeur de retour est un tableau d'URLs. Par défaut, le startURL est traité par une requête GET. Si dans des cas spéciaux, vous avez besoin que Seimi traite votre startURL avec la méthode POST, vous pouvez ajouter ##post à la fin de cette URL, par exemple http://passport.cnblogs.com/user/signin?ReturnUrl=http%3a%2f%2fi.cnblogs.com%2f##post. Cette règle n'est pas sensible à la casse. Cette règle s'applique uniquement au traitement des startURLs.
Cette méthode est la fonction de rappel pour le startURL, c'est-à-dire qu'elle indique à Seimi comment traiter les données renvoyées par la requête du startURL.
- Résultats textuels
Seimi recommande par défaut d'utiliser XPath pour extraire des données HTML. Bien que l'apprentissage initial de XPath puisse présenter un certain coût en termes de compréhension, le gain en efficacité de développement qu'il offre une fois que vous le maîtrisez est bien plus important.
JXDocument doc = response.document();vous permet d'obtenir unJXDocument(l'objet de document JsoupXpath), et vous pouvez alors extraire n'importe quelles données avecdoc.sel("xpath"). Généralement, une seule instruction XPath suffit pour extraire n'importe quelles données. Pour une meilleure compréhension du parseur de syntaxe XPath utilisé par Seimi, ou pour approfondir vos connaissances en XPath, veuillez vous rendre sur JsoupXpath. Si vous n'êtes vraiment pas à l'aise avec XPath, vous avez toujours la possibilité d'utiliser d'autres analyseurs de données sur les résultats de la requête brute. - Résultats de type fichier
Si la réponse est un fichier, vous pouvez l'enregistrer avec
reponse.saveTo(File targetFile), ou manipuler le flux de bytes du fichier avecbyte[] getData().
private BodyType bodyType;
private Request request;
private String charset;
private String referer;
private byte[] data;
private String content;
/**
* Cet attribut est principalement utilisé pour stocker des données personnalisées transmises par le processus en amont
*/
private Map<String, String> meta;
private String url;
private Map<String, String> params;
/**
* L'adresse source réelle du contenu web
*/
private String realUrl;
/**
* Le type de gestionnaire HTTP de la réponse à cette requête
*/
private SeimiHttpType seimiHttpType;
L'utilisation d'une fonction de rappel par défaut ne répondra vraisemblablement pas à vos besoins. Si vous souhaitez extraire certaines URL de la page startURL, les requêter et traiter les données obtenues, vous devrez définir votre propre fonction de rappel. Points importants à noter :
- À partir de la version 2.0, Seimi支持方法引用, making the setting of callback functions more intuitive, such as:
Basic::getTitle. - The
Requestgenerated within the callback function can specify another callback function or itself as the callback. - The callback function must adhere to the format:
public void callbackName(Response response); the method must be public, have exactly oneResponseparameter, and have no return value. - To set a callback function for a
Request, you only need to provide the name of the callback function as aString, for example,getTitlefrom the quick start guide. - Crawlers that inherit from
BaseSeimiCrawlercan directly call the parent class’spush(Request request)method within the callback to enqueue new requests. - You can create a
RequestthroughRequest.build().
public class Request {
public static Request build(String url, String callBack, HttpMethod httpMethod, Map<String, String> params, Map<String, String> meta);
public static Request build(String url, String callBack, HttpMethod httpMethod, Map<String, String> params, Map<String, String> meta,int maxReqcount);
public static Request build(String url, String callBack);
public static Request build(String url, String callBack, int maxReqCount);
@NotNull
private String crawlerName;
/**
* L'URL à requêter
*/
@NotNull
private String url;
/**
* Le type de méthode de requête get, post, put...
*/
private HttpMethod httpMethod;
/**
* Si des paramètres sont nécessaires pour la requête, ils sont placés ici
*/
private Map<String,String> params;
/**
* Cet attribut est principalement utilisé pour stocker des données personnalisées à transmettre aux fonctions de rappel inférieures
*/
private Map<String,Object> meta;
/**
* Le nom de la méthode de la fonction de rappel
*/
@NotNull
private String callBack;
/**
* Indique si la fonction de rappel est une expression lambda
*/
private transient boolean lambdaCb = false;
/**
* Fonction de rappel
*/
private transient SeimiCallbackFunc callBackFunc;
/**
* Signal d'arrêt, le thread de traitement se terminera lorsqu'il reçoit ce signal
*/
private boolean stop = false;
/**
* Nombre maximal de re-demandes autorisées
*/
private int maxReqCount = 3;
/**
* Utilisé pour enregistrer le nombre de fois où la demande actuelle a été exécutée
*/
private int currentReqCount = 0;
/**
* Utilisé pour indiquer si une demande doit passer par le filtre de duplication
*/
private boolean skipDuplicateFilter = false;
/**
* Indique si SeimiAgent doit être activé pour cette demande
*/
private boolean useSeimiAgent = false;
/**
* En-têtes de protocole HTTP personnalisées
*/
private Map<String, String> header;
/**
* Définit le temps de rendu de SeimiAgent, en millisecondes
*/
private long seimiAgentRenderTime = 0;
/**
* Utilisé pour exécuter des scripts JavaScript spécifiés sur SeimiAgent
*/
private String seimiAgentScript;
/**
* Indique si les demandes soumises à SeimiAgent doivent utiliser des cookies
*/
private Boolean seimiAgentUseCookie;
/**
* Indique à SeimiAgent le format dans lequel les résultats doivent être rendus, par défaut HTML
*/
private SeimiAgentContentType seimiAgentContentType = SeimiAgentContentType.HTML;
/**
* Permet d'ajouter des cookies personnalisés
*/
private List<SeimiCookie> seimiCookies;
/**
* Ajoute le support du corps de la demande JSON
*/
private String jsonBody;
}
L'UA par défaut de SeimiCrawler est SeimiCrawler/JsoupXpath. Si vous souhaitez personnaliser l'Agent Utilisateur, vous pouvez redéfinir la méthode public String getUserAgent() de BaseSeimiCrawler. Lors de chaque traitement de demande, SeimiCrawler récupère une fois l'Agent Utilisateur. Si vous souhaitez simuler un Agent Utilisateur, vous pouvez implémenter une bibliothèque d'UA qui retourne un Agent Utilisateur aléatoire à chaque fois.
Cela a déjà été expliqué lors de la présentation de l'annotation @Crawler. Cette section est répétée pour faciliter une navigation rapide à travers ces fonctionnalités de base. L'activation des cookies est configurée via la propriété useCookie de l'annotation @Crawler. Vous pouvez également utiliser Request.setSeimiCookies(List<SeimiCookie> seimiCookies) ou Request.setHeader(Map<String, String> header) pour des paramètres personnalisés. L'objet Request permet de nombreuses personnalisations, vous pouvez explorer l'objet Request pour en apprendre davantage et ouvrir de nouvelles perspectives.
Cela est configuré via la propriété proxy de l'annotation @Crawler. Veuillez consulter la présentation de @Crawler pour plus de détails. Si vous souhaitez spécifier un proxy dynamiquement, veuillez consulter la section suivante sur "La configuration du proxy dynamique". Actuellement, trois formats sont pris en charge : http|https|socket://host:port.
Cela est configuré via la propriété delay de l'annotation @Crawler. Le délai entre les requêtes d'霤ction est défini en secondes, par défaut il est de 0, ce qui signifie qu'il n'y a pas de délai. Dans de nombreux cas, le fournisseur de contenu impose des restrictions sur la fréquence des requêtes pour contrer les robots, il est donc possible d'ajuster ce paramètre pour obtenir de meilleurs résultats de récolte.
En surchargeant public String[] allowRules() de BaseSeimiCrawler, vous pouvez définir les règles de la liste blanche des URL de requête. Ces règles sont des expressions régulières, et si une URL correspond à l'une d'entre elles, la requête est autorisée.
En surchargeant public String[] denyRules() de BaseSeimiCrawler, vous pouvez définir les règles de la liste noire des URL de requête. Ces règles sont des expressions régulières, et si une URL correspond à l'une d'entre elles, la requête est bloquée.
En surchargeant public String proxy() de BaseSeimiCrawler, vous pouvez indiquer à Seimi quel proxy utiliser pour une requête donnée. Vous pouvez choisir un proxy de manière séquentielle ou aléatoire à partir d'une base de proxies existante. Si l'adresse du proxy n'est pas vide, les paramètres de proxy définis dans l'annotation @Crawler sont ignorés. Actuellement, trois formats sont supportés : http|https|socket://host:port.
Vous pouvez contrôler l'activation ou la désactivation de la déduplication du système via la propriété useUnrepeated de l'annotation @Crawler. Par défaut, la déduplication est activée.
Actuellement, SeimiCrawler supporte les redirections 301, 302 et les redirections meta refresh. Pour ces types de redirections, vous pouvez obtenir l'URL finale après la redirection en utilisant la méthode getRealUrl() de l'objet Response.
Si une requête génère une erreur lors de son traitement, elle a trois chances d'être reprise dans la file d'attente de traitement. Si elle échoue finalement, le système appelle la méthode public void handleErrorRequest(Request request) du crawler pour gérer cette requête. Par défaut, cette méthode enregistre l'erreur dans les logs, mais les développeurs peuvent surcharger cette méthode pour implémenter leur propre gestion des erreurs.
Il est important de souligner ce point. Les étudiants qui ne connaissent pas encore SeimiAgent peuvent consulter la page d'accueil du projet SeimiAgent. En résumé, SeimiAgent est un noyau de navigateur qui s'exécute sur le serveur, développé à partir de QtWebkit, et qui propose des services via une interface HTTP standard. Il est spécialement conçu pour résoudre des problèmes complexes liés au rendu de pages web dynamiques, à la capture de snapshots, et à la surveillance. En termes simples, le traitement des pages par SeimiAgent est au niveau d'un navigateur standard, vous pouvez obtenir toutes les informations que vous pourriez obtenir avec un navigateur.
Pour que SeimiCrawler puisse utiliser SeimiAgent, il faut d'abord configurer l'adresse du service SeimiAgent.
Via la configuration SeimiConfig, par exemple :
SeimiConfig config = new SeimiConfig();
config.setSeimiAgentHost("127.0.0.1");
Seimi s = new Seimi(config);
s.goRun("basic");
Dans le fichier application.properties :
seimi.crawler.seimi-agent-host=xx
seimi.crawler.seimi-agent-port=xx
Décider quels requêtes soumettre à SeimiAgent pour leur traitement et spécifier comment SeimiAgent doit les traiter. C'est au niveau de la requête.
Request.useSeimiAgent()Indique à SeimiCrawler que cette requête doit être soumise à SeimiAgent.Request.setSeimiAgentRenderTime(long seimiAgentRenderTime)Définit le temps de rendu de SeimiAgent (temps accordé à SeimiAgent pour exécuter les scripts JavaScript et d'autres ressources après que toutes les ressources aient été chargées), l'unité de temps est en millisecondes.Request.setSeimiAgentUseCookie(Boolean seimiAgentUseCookie)Indique à SeimiAgent s'il doit utiliser des cookies. Si ce paramètre n'est pas défini, le paramètre de cookie global de seimiCrawler est utilisé.- Autres Si votre Crawler utilise un proxy, seimiCrawler l'utilisera également automatiquement lorsque cette requête sera transférée à SeimiAgent.
- Démonstration Pour une utilisation pratique, vous pouvez vous référer au démonstration dans le dépôt
Configuration dans application.properties
seimi.crawler.enabled=true
# Spécifiez le nom du crawler pour lequel une requête de démarrage doit être lancée
seimi.crawler.names=basic,test
Ensuite, il suffit de démarrer SpringBoot de manière standard
@SpringBootApplication
public class SeimiCrawlerApplication {
public static void main(String[] args) {
SpringApplication.run(SeimiCrawlerApplication.class, args);
}
}
Ajoutez une fonction main dans une classe de démarrage indépendante, comme dans l'exemple du projet. Dans la fonction main, initialisez l'objet Seimi et vous pouvez configurer certains paramètres spécifiques via SeimiConfig, tels que les informations de cluster Redis nécessaires pour la file d'attente distribuée, ou les informations host de seimiAgent si nécessaire. SeimiConfig est optionnel. Par exemple :
public class Boot {
public static void main(String[] args){
SeimiConfig config = new SeimiConfig();
// config.setSeimiAgentHost("127.0.0.1");
// config.redisSingleServer().setAddress("redis://127.0.0.1:6379");
Seimi s = new Seimi(config);
s.goRun("basic");
}
}
Seimi dispose des fonctions de démarrage suivantes :
public void start(String... crawlerNames): Démarre l'exécution d'un ou plusieurs Crawler spécifiés.public void startAll(): Démarre tous les Crawler chargés.public void startWithHttpd(int port, String... crawlerNames): Démarre l'exécution d'un Crawler spécifié et lance un service HTTP sur un port spécifié. Vous pouvez envoyer une requête de crawling à un Crawler spécifique via/push/crawlerName, avec le paramètrereq, supportant POST et GET.public void startWorkers(): Initialise tous les Crawler chargés et écoute les requêtes de crawling. Cette fonction de démarrage est principalement utilisée pour démarrer un ou plusieurs systèmes de travail simple dans le cas d'une installation distribuée, ce qui sera détaillé ultérieurement dans la section consacrée à la mise en place et au support de l'installation distribuée.
Dans le cadre du projet, exécutez la commande suivante pour empaqueter et sortir l'ensemble du projet,
Sous Windows, pour éviter les problèmes de caractères incorrects dans la console Windows, modifiez le format de sortie de la console dans le fichier de configuration logback en
GBK, par défautUTF-8.
mvn clean package&&mvn -U compile dependency:copy-dependencies -DoutputDirectory=./target/seimi/&&cp ./target/*.jar ./target/seimi/
À ce moment, dans le répertoire target du projet, il y aura un répertoire appelé seimi, qui est le projet compilé et prêt à être déployé. Ensuite, exécutez la commande suivante pour le démarrer,
Sous Windows :
java -cp .;./target/seimi/* cn.wanghaomiao.main.Boot
Sous Linux :
java -cp .:./target/seimi/* cn.wanghaomiao.main.Boot
Les commandes ci-dessus peuvent être intégrées dans des scripts, et les répertoires peuvent être ajustés en fonction de vos besoins. Ce qui précède ne concerne qu'un exemple pour un projet de démonstration. Pour des scénarios de déploiement réels, vous pouvez utiliser l'outil de packaging dédié maven-seimicrawler-plugin pour SeimiCrawler afin de packager et déployer le projet. La section suivante Packaging et déploiement du projet donnera plus de détails.
Il est recommandé d'utiliser Spring Boot pour construire le projet, ce qui permet d'exploiter l'écosystème existant de Spring Boot pour de nombreuses fonctionnalités inattendues. Pour empaqueter un projet Spring Boot, vous pouvez suivre la méthode standard de packaging décrite sur le site officiel de Spring Boot.
mvn package
La méthode décrite ci-dessus est pratique pour le développement ou le débogage, et peut également être utilisée comme une méthode de démarrage dans un environnement de production. Cependant, pour faciliter le déploiement et la distribution du projet, SeimiCrawler fournit un plugin de packaging dédié pour empaqueter les projets SeimiCrawler. Une fois le package prêt, il peut être directement distribué et déployé. Voici ce que vous devez faire :
Ajoutez le plugin dans le pom.xml
<plugin>
<groupId>cn.wanghaomiao</groupId>
<artifactId>maven-seimicrawler-plugin</artifactId>
<version>1.0.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>build</goal>
</goals>
</execution>
</executions>
</plugin>
Exécutez mvn clean package, et la structure du répertoire empaqueté sera la suivante :
.
├── bin # Les scripts correspondants contiennent également des explications des paramètres de démarrage, donc je ne vais pas les répéter ici
│ ├── run.bat # Script de démarrage pour Windows
│ └── run.sh # Script de démarrage pour Linux
└── seimi
├── classes # Répertoire des classes d'affaires du projet Crawler et des fichiers de configuration associés
└── lib # Répertoire des bibliothèques de dépendance du projet
Vous pouvez maintenant directement utiliser ces fichiers pour la distribution et le déploiement.
La planification personnalisée de SeimiCrawler peut être directement réalisée en utilisant l'annotation @Scheduled de Spring, sans besoin de configuration supplémentaire. Par exemple, une définition directement dans le fichier de règles du Crawler peut ressembler à ce qui suit :
@Scheduled(cron = "0/5 * * * * ?")
public void callByCron(){
logger.info("Je suis un planificateur exécuté selon une expression cron, toutes les 5 secondes");
// On peut envoyer une requête périodiquement
// push(Request.build(startUrls()[0],"start").setSkipDuplicateFilter(true));
}
Si vous souhaitez définir un service indépendant, il suffit de s'assurer que cette classe de service soit scannable. Pour en savoir plus sur @Scheduled, les développeurs peuvent se référer à la documentation Spring pour comprendre les détails de ses paramètres, ou consulter les exemples de démonstration de SeimiCrawler sur GitHub.
Si vous souhaitez définir un Bean, SeimiCrawler peut automatiquement extraire les données selon vos règles et les injecter dans les champs correspondants. Cette fonctionnalité est alors nécessaire.
Examinons un exemple :
public class BlogContent {
@Xpath("//h1[@class='postTitle']/a/text()|//a[@id='cb_post_title_url']/text()")
private String title;
// On peut aussi écrire @Xpath("//div[@id='cnblogs_post_body']//text()")
@Xpath("//div[@id='cnblogs_post_body']/allText()")
private String content;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}
La classe BlogContent est un Bean cible que vous avez défini. L'annotation @Xpath doit être placée sur les champs vers lesquels vous souhaitez injecter des données, en y configurant une règle d'extraction XPath. Les champs peuvent être privés ou publics, et il n'est pas nécessaire qu'ils aient des méthodes getter et setter.
Une fois que le Bean est prêt, vous pouvez utiliser la méthode intégrée de Response public <T> T render(Class<T> bean) dans la fonction de rappel pour obtenir un objet Bean avec des données injectées.
SeimiCrawler prend également en charge l'ajout d'intercepteurs à des fonctions de rappel spécifiques ou à toutes. Pour implementer un intercepteur, veuillez noter les points suivants :
- L'annotation
@Interceptordoit être utilisée - L'interface
SeimiInterceptordoit être implémentée - Tous les intercepteurs que vous souhaitez activer doivent être placés dans le package interceptors, par exemple
cn.wanghaomiao.xxx.interceptors, des exemples sont également disponibles dans l'ingénierie démo. - Une annotation personnalisée doit être définie pour marquer les fonctions qui doivent être interceptées, ou pour l'interception de toutes les fonctions.
Cette annotation indique à Seimi qu'une classe annotée pourrait être un intercepteur (car pour qu'un intercepteur Seimi soit véritable, il doit également satisfaire d'autres conventions mentionnées ci-dessus). Elle possède une propriété,
everyMethodpar défaut false, qui indique à Seimi si cet intercepteur doit intercepter toutes les fonctions de rappel.
Voici l'interface :
public interface SeimiInterceptor {
/**
* Obtient l'annotation qui doit être marquée sur la méthode cible
* @return Annotation
*/
public Class<? extends Annotation> getTargetAnnotationClass();
/**
* Lorsqu'il est nécessaire de contrôler l'ordre d'exécution de plusieurs intercepteurs, cette méthode peut être surchargée
* @return Poids, plus le poids est grand, plus il se trouve à l'extérieur, et est intercepté en priorité
*/
public int getWeight();
/**
* Permet de définir certaines logiques de traitement avant l'exécution de la méthode cible
*/
public void before(Method method, Response response);
/**
* Permet de définir certaines logiques de traitement après l'exécution de la méthode cible
*/
public void after(Method method, Response response);
}
Les commentaires expliquent déjà tout en détail, donc je ne vais pas répéter ici.
Référez-vous à DemoInterceptor dans l'application démo, adresse GitHub directe
SeimiQueue est la seule voie de transfert de données et de communication interne et entre systèmes dans SeimiCrawler. Par défaut, SeimiQueue est une implémentation basée sur une file d'attente bloquante thread-safe locale. SeimiCrawler prend également en charge une implémentation de SeimiQueue basée sur Redis--DefaultRedisQueue, bien sûr, vous pouvez également implémenter votre propre SeimiQueue conforme aux conventions de Seimi. Lors de l'utilisation, vous pouvez spécifier quelle implémentation utiliser pour un Crawler à travers l'attribut queue de l'annotation @Crawler.
Définissez l'annotation du Crawler comme @Crawler(name = "xx", queue = DefaultRedisQueue.class)
SeimiConfig config = new SeimiConfig();
config.setSeimiAgentHost("127.0.0.1");
config.redisSingleServer().setAddress("redis://127.0.0.1:6379");
Seimi s = new Seimi(config);
s.goRun("basic");
Généralement, les deux implémentations fournies par SeimiCrawler suffisent pour la majorité des utilisations. Cependant, si ces implémentations ne conviennent pas, vous pouvez implémenter votre propre SeimiQueue et la configurer pour l'utilisation. Voici les points à considérer lors de l'implémentation personnalisée :
- Vous devez annoter la classe avec
@Queuepour indiquer à Seimi que cette classe peut être un SeimiQueue (d'autres conditions doivent également être satisfaites). - Vous devez implémenter l'interface
SeimiQueue, comme suit :
/**
* Définit l'interface de base de la file d'attente du système. Vous êtes libre de choisir l'implémentation, tant qu'elle respecte les spécifications.
* @author 汪浩淼 [email protected]
* @since 2015/6/2.
*/
public interface SeimiQueue extends Serializable {
/**
* Défile un(avance la tête de la file pour récupérer) une requête de manière bloquante
* @param crawlerName nom du crawler
* @return la requête
*/
Request bPop(String crawlerName);
/**
* Ajoute une requête à la file d'attente
* @param req la requête
* @return --
*/
boolean push(Request req);
/**
* Renvoie la longueur restante de la file d'attente des tâches
* @param crawlerName nom du crawler
* @return nombre
*/
long len(String crawlerName);
/**
* Vérifie si une URL a déjà été traitée
* @param req la requête
* @return true si elle a été traitée, false sinon
*/
boolean isProcessed(Request req);
/**
* Enregistre une requête traitée
* @param req la requête
*/
void addProcessed(Request req);
/**
* Renvoie le nombre total de pages crawlées
* @param crawlerName nom du crawler
* @return nombre
*/
long totalCrawled(String crawlerName);
/**
* Efface les enregistrements de crawl
* @param crawlerName nom du crawler
*/
void clearRecord(String crawlerName);
}
- Toutes les classes SeimiQueue que vous souhaitez utiliser doivent être placées dans le package
queues, par exemplecn.wanghaomiao.xxx.queues. Vous pouvez également consulter des exemples dans le projet demo. Une fois ces exigences satisfaites, après avoir écrit votre propre SeimiQueue, vous pouvez la configurer et l'utiliser en utilisant l'annotation@Crawler(name = "xx", queue = YourSelfRedisQueueImpl.class).
Référez-vous à DefaultRedisQueueEG dans le projet demo (lien direct GitHub)
Comme SeimiCrawler utilise Spring pour gérer les beans et effectuer l'injection de dépendances, il est facile d'intégrer les solutions de persistance de données courantes, telles que Mybatis, Hibernate, Paoding-jade, etc. Ici, nous utilisons Mybatis.
Ajoutez les dépendances de Mybatis et de la connexion à la base de données :
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-spring</artifactId>
<version>1.3.0</version>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.4.1</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-dbcp2</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.4.2</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.37</version>
</dependency>Ajoutez un fichier de configuration XML seimi-mybatis.xml (n'oubliez pas que les fichiers de configuration doivent toujours commencer par seimi, d'accord ?)
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="propertyConfigurer" class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer">
<property name="locations">
<list>
<value>classpath:**/*.properties</value>
</list>
</property>
</bean>
<bean id="mybatisDataSource" class="org.apache.commons.dbcp2.BasicDataSource">
<property name="driverClassName" value="${database.driverClassName}"/>
<property name="url" value="${database.url}"/>
<property name="username" value="${database.username}"/>
<property name="password" value="${database.password}"/>
</bean>
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean" abstract="true">
<property name="configLocation" value="classpath:mybatis-config.xml"/>
</bean>
<bean id="seimiSqlSessionFactory" parent="sqlSessionFactory">
<property name="dataSource" ref="mybatisDataSource"/>
</bean>
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="cn.wanghaomiao.dao.mybatis"/>
<property name="sqlSessionFactoryBeanName" value="seimiSqlSessionFactory"/>
</bean>
</beans>Comme le projet de démonstration contient un fichier de configuration unique seimi.properties, les informations de connexion à la base de données sont également injectées via les propriétés. Bien sûr, vous pouvez également les écrire directement. Voici la configuration des propriétés :
database.driverClassName=com.mysql.jdbc.Driver
database.url=jdbc:mysql://127.0.0.1:3306/xiaohuo?useUnicode=true&characterEncoding=UTF8&autoReconnect=true&autoReconnectForPools=true&zeroDateTimeBehavior=convertToNull
database.username=xiaohuo
database.password=xiaohuo
À ce stade, le projet est prêt. Il ne vous reste plus qu'à créer une base de données et une table pour stocker les informations de l'expérience. La structure de la table est fournie dans le projet de démonstration, vous pouvez ajuster le nom de la base de données selon vos besoins :
CREATE TABLE `blog` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(300) DEFAULT NULL,
`content` text,
`update_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
Créez un fichier DAO de Mybatis :
public interface MybatisStoreDAO {
@Insert("insert into blog (title,content,update_time) values (#{blog.title},#{blog.content},now())")
@Options(useGeneratedKeys = true, keyProperty = "blog.id")
int save(@Param("blog") BlogContent blog);
}
La configuration de Mybatis devrait être familière, je n'entrerai pas dans les détails. Pour en savoir plus, consultez le projet de démonstration ou la documentation officielle de Mybatis.
Injectez directement dans le Crawler correspondant, par exemple :
@Crawler(name = "mybatis")
public class DatabaseMybatisDemo extends BaseSeimiCrawler {
@Autowired
private MybatisStoreDAO storeToDbDAO;
@Override
public String[] startUrls() {
return new String[]{"http://www.cnblogs.com/"};
}
@Override
public void start(Response response) {
JXDocument doc = response.document();
try {
List<Object> urls = doc.sel("//a[@class='titlelnk']/@href");
logger.info("{}", urls.size());
for (Object s : urls) {
push(Request.build(s.toString(), DatabaseMybatisDemo::renderBean));
}
} catch (Exception e) {
e.printStackTrace();
}
}
public void renderBean(Response response) {
try {
BlogContent blog = response.render(BlogContent.class);
logger.info("bean resolve res={},url={}", blog, response.getUrl());
// Utiliser l'outil paoding-jade pour stocker dans la base de données
int changeNum = storeToDbDAO.save(blog);
int blogId = blog.getId();
logger.info("store success,blogId = {},changeNum={}", blogId, changeNum);
} catch (Exception e) {
e.printStackTrace();
}
}
}
Bien sûr, si les besoins de l'entreprise sont complexes, il est recommandé de créer une couche de service supplémentaire et d'injecter ce service dans le Crawler.
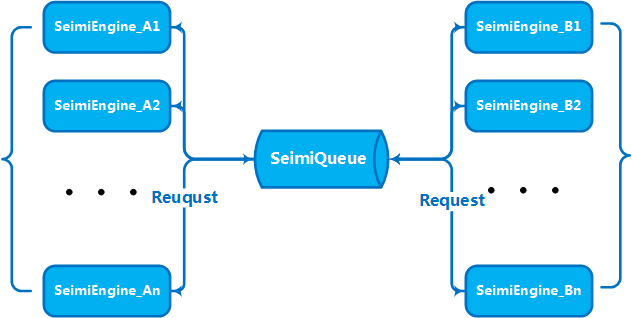
Lorsque le volume d'affaires et la quantité de données atteignent un certain niveau, il est naturel d'établir un service en cluster en élargissant horizontalement plusieurs machines pour améliorer les capacités de traitement. C'est un problème que SeimiCrawler a pris en compte dès sa conception. Ainsi, SeimiCrawler prend en charge la distribution dès le départ. Avec le SeimiQueue introduit précédemment, l'ingénieux lecteur a sans doute deviné comment procéder à la distribution. Pour mettre en place la distribution avec SeimiCrawler, il faut activer DefaultRedisQueue comme SeimiQueue par défaut et configurer les informations de connexion Redis identiques sur chaque machine à déployer. Cela a été expliqué en détail précédemment. Une fois DefaultRedisQueue activé, initialisez le processeur Seimi sur les machines de worker avec new Seimi().startWorkers(). Le processus worker de Seimi commencera alors à écouter la file de messages. Lorsque le service principal émet une demande de collecte, le cluster entier communique via la file de messages, divisant le travail et travaillant activement ensemble. À partir de la version 2.0, la file de messages distribuée par défaut est mise en œuvre avec Redisson et intègre un BloomFilter.
Si vous souhaitez envoyer des requêtes de collecte personnalisées à Seimicrawler, la requête doit inclure les paramètres suivants :
url: l'adresse à collectercrawlerName: le nom de la règlecallBack: la fonction de rappel
Vous pouvez tout à fait créer un projet SpringBoot et écrire vous-même un contrôleur Spring MVC pour gérer ce type de demande. Voici un exemple simple, sur lequel vous pouvez vous appuyer pour faire beaucoup plus de choses intéressantes.
Si vous ne souhaitez pas exécuter le projet sous forme de SpringBoot, vous pouvez utiliser l'interface interne. SeimiCrawler peut démarrer un service HTTP intégré à un port spécifique pour recevoir des requêtes de collecte via HTTP API ou pour vérifier l'état de collecte d'un Crawler spécifique.
Envoyez une requête Request au format JSON à SeimiCrawler via l'interface HTTP. Après réception de la requête de collecte et sa validation, l'interface HTTP la traitera avec les autres requêtes générées par les règles de traitement.
- URL de la requête: http://host:port/push/${YourCrawlerName}
- Méthode d'appel: GET/POST
- Paramètres d'entrée:
| Nom du paramètre | Obligatoire | Type de paramètre | Description du paramètre |
|---|---|---|---|
| req | true | str | Contenu sous forme json de la requête Request, unique ou sous forme de tableau json |
- Exemple de structure de paramètres:
{
"callBack": "start",
"maxReqCount": 3,
"meta": {
"listPageSomeKey": "xpxp"
},
"params": {
"paramName": "xxxxx"
},
"stop": false,
"url": "http://www.github.com"
}
ou
[
{
"callBack": "start",
"maxReqCount": 3,
"meta": {
"listPageSomeKey": "xpxp"
},
"params": {
"paramName": "xxxxx"
},
"stop": false,
"url": "http://www.github.com"
},
{
"callBack": "start",
"maxReqCount": 3,
"meta": {
"listPageSomeKey": "xpxp"
},
"params": {
"paramName": "xxxxx"
},
"stop": false,
"url": "http://www.github.com"
}
]
Explication des champs de structure :
| Champ JSON | Obligatoire | Type de champ | Description du champ |
|---|---|---|---|
| url | vrai | str | Adresse de la requête |
| callBack | vrai | str | Fonction de rappel pour le résultat de la requête |
| meta | faux | map | Données personnalisées optionnelles à passer au contexte suivant |
| params | faux | map | Paramètres de requête nécessaires pour la requête actuelle |
| stop | faux | bool | Si true, le thread de travail recevant la requête arrêtera son travail |
| maxReqCount | faux | int | Nombre maximal de retraitements autorisés si le traitement de la requête échoue |
Adresse de la demande : /status/${YourCrawlerName} pour afficher l'état d'analyse actuel du Crawler spécifié, le format des données est JSON.
Voir 5.2.13. Configurer un proxy dynamique
Voir 5.2.8. Activer les cookies (optionnel)
- Les Crawler de même nom dans différentes instances de SeimiCrawler travailleront de manière collaborative via le même Redis (partageant la même file de production et de consommation)
- Assurez-vous que la machine sur laquelle SeimiCrawler est lancé est correctement connectée au Redis
- Dans l'exemple, un mot de passe Redis est configuré, mais si votre Redis n'en nécessite pas, ne configurez pas de mot de passe
- De nombreux utilisateurs rencontrent des problèmes de réseau, ce qui signifie qu'il est nécessaire de vérifier la situation de son réseau. SeimiCrawler utilise une bibliothèque réseau mature, donc si des problèmes de réseau apparaissent, il est certain que c'est dû à des problèmes de réseau. Il faut notamment vérifier si le site cible a pris des mesures spécifiques pour bloquer l'accès, si la connexion au proxy est fluide, si le proxy est bloqué, si le proxy a la capacité d'accéder à Internet, et si la machine sur laquelle vous vous trouvez a une connexion Internet fluide.
Réécrire l'implémentation public List<Request> startRequests(), ici vous pouvez définir librement des requêtes de départ complexes. Si cela est réalisé, public String[] startUrls() peut retourner null. Un exemple est le suivant :
@Crawler(name = "usecookie", useCookie = true)
public class UseCookie extends BaseSeimiCrawler {
@Override
public String[] startUrls() {
return null;
}
@Override
public List<Request> startRequests() {
List<Request> requests = new LinkedList<>();
Request start = Request.build("https://www.oschina.net/action/user/hash_login", "start");
Map<String, String> params = new HashMap<>();
params.put("email", "[email protected]");
params.put("pwd", "xxxxxxxxxxxxxxxxxxx");
params.put("save_login", "1");
params.put("verifyCode", "");
start.setHttpMethod(HttpMethod.POST);
start.setParams(params);
requests.add(start);
return requests;
}
@Override
public void start(Response response) {
logger.info(response.getContent());
push(Request.build("http://www.oschina.net/home/go?page=blog", "minePage"));
}
public void minePage(Response response) {
JXDocument doc = response.document();
try {
logger.info("uname:{}", StringUtils.join(doc.sel("//div[@class='name']/a/text()"), ""));
logger.info("httpType:{}", response.getSeimiHttpType());
} catch (XpathSyntaxErrorException e) {
logger.debug(e.getMessage(), e);
}
}
}
<dependency>
<groupId>cn.wanghaomiao</groupId>
<artifactId>SeimiCrawler</artifactId>
<version>2.1.2</version>
</dependency>
Veuillez vous assurer que vous utilisez la version 2.1.2 ou une version ultérieure, qui prend en charge la configuration de la propriété jsonBody dans Request pour lancer une requête avec un corps JSON.
Vous pouvez maintenant choisir de discuter par le biais de la liste de diffusion suivante pour toute question ou suggestion. Avant de poster, vous devez vous abonner et attendre l'approbation (principalement pour filtrer la publicité, etc., afin de créer un bon environnement de discussion).
- Abonnement : envoyez un email à
[email protected] - Publication : envoyez un email à
[email protected] - Désabonnement : envoyez un email à
[email protected]
AU FaIT : N'hésitez pas à mettre une étoile sur Github ^_^