
K510 nncase Ontwikkelaarshandleiding
Document versie: V1.0.1
Publicatiedatum: 2022-05-10
Disclaimer De producten, diensten of functies die u koopt, zijn onderworpen aan de commerciële contracten en voorwaarden van Beijing Canaan Jiesi Information Technology Co., Ltd. ("het Bedrijf", hierna hetzelfde), en alle of een deel van de producten, diensten of functies die in dit document worden beschreven, vallen mogelijk niet binnen het bereik van uw aankoop of gebruik. Tenzij anders overeengekomen in het contract, wijst het bedrijf alle verklaringen of garanties af, expliciet of impliciet, met betrekking tot de nauwkeurigheid, betrouwbaarheid, volledigheid, marketing, specifiek doel en niet-agressie van verklaringen, informatie of inhoud van dit document. Tenzij anders overeengekomen, wordt dit document uitsluitend verstrekt als leidraad voor gebruik. Vanwege upgrades van de productversie of andere redenen kan de inhoud van dit document van tijd tot tijd zonder enige kennisgeving worden bijgewerkt of gewijzigd.
Handelsmerkkennisgevingen
""
Copyright ©2022 Beijing Canaan Jiesi Information Technology Co, Ltd Dit document is alleen van toepassing op de ontwikkeling en het ontwerp van het K510-platform, zonder de schriftelijke toestemming van het bedrijf mag geen enkele eenheid of persoon een deel of de inhoud van dit document in welke vorm dan ook verspreiden.
Beijing Canaan Jiesi Information Technology Co, Ltd URL: canaan-creative.com Zakelijke vragen: [email protected]
# inleiding **Doel van het document** Dit document is een beschrijvingsdocument voor het gebruik van de nncase/K510-compiler, waarin gebruikers worden geboden hoe ze nncase kunnen installeren, hoe ze de compiler-API's kunnen aanroepen om neurale netwerkmodellen te compileren en runtime-API's om AI-inferentieprogramma's te schrijvenReader Objecten
De belangrijkste personen op wie dit document (deze gids) van toepassing is:
- Softwareontwikkelaars
- Technisch ondersteunend personeel
Termen en acroniemen
| term | Toelichting/volledige naam |
|---|---|
| Ptq | Kwantisatie na de training, kwantisatie na de training |
| MSE | gemiddelde-kwadraatfout, gemiddelde kwadraatfout |
Revisiegeschiedenis De revisiegeschiedenis bevat een beschrijving van elke documentupdate. De nieuwste versie van het document bevat updates voor alle voorgaande versies.
| Het versienummer | Gewijzigd door | Datum van herziening | Opmerkingen bij herziening |
|---|---|---|---|
| V1.0.1 | Reclame | 2022-05-10 | nncase_v1.6.1. |
| V1.0.0 | Zhang Yang/Zhang Jizhao/Yang Haoqi | 2022-05-06 | nncase_v1.6.0 |
| V0.9.0 | Reclame | 2022-04-01 | nncase_v1.5.0 |
| V0.8.0 | Zhang Yang/Zhang Jizhao | 2022-03-03 | nncase_v1.4.0 |
| V0.7.0 | Reclame | 2022-01-28 | nncase_v1.3.0 |
| V0.6.0 | Reclame | 2021-12-31 | nncase_v1.2.0 |
| V0.5.0 | Reclame | 2021-12-03 | nncase_v1.1.0 |
| V0.4.0 | Zhang Yang / Haoqi Yang / Zheng Qihang | 2021-10-29 | nncase_v1.0.0 |
| V0.3.0 | Zhang Yang / Yang Haoqi | 2021-09-28 | nncase_v1.0.0_rc1 |
| V0.2.0 | Zhang Yang / Yang Haoqi | 2021-09-02 | nncase_v1.0.0_beta2 |
| V0.1.0 | Zhang Yang / Yang Haoqi | 2021-08-31 | nncase_v1.0.0_beta1 |
[INHOUDSOPGAVE]
- Ubuntu 18.04 / 20.04
De vereisten voor de softwareomgeving worden weergegeven in de volgende tabel:
| serienummer | Softwarebronnen | illustreren |
|---|---|---|
| 1 | Python | Python 3.6/3.7/3.8/3.9/3.10 |
| 2 | Pip3 | pip3 versie > = 20.3 |
| 3 | Onnx | De onnx versie is 1.9.0 |
| 4 | onnx-vereenvoudigen | De onnx-simplifier versie is 0.3.6 |
| 5 | onnxoptimizer |
De vereisten voor de hardwareomgeving worden weergegeven in de volgende tabel:
| serienummer | Hardwarebronnen | illustreren |
|---|---|---|
| 1 | K510 CRB | |
| 2 | SD-kaart en kaartlezer |
nncase is een neurale netwerkcompiler die is ontworpen voor AI-versnellers en ondersteunt momenteel doelen zoals CPU / K210 / K510
Functies van nncase
- Ondersteuning van meerdere input en meerdere output netwerken, ondersteuning multi-branch structuur
- Toewijzing van statisch geheugen, geen heap-geheugen vereist
- Operator samenvoegen en optimaliseren
- Ondersteunt float en uint8/int8 kwantisatie-inferentie
- Ondersteunt kwantisatie na de training, met behulp van floating-point modellen en kwantisatie kalibratie sets
- Plat model zonder ondersteuning voor het laden van kopieën
Neuraal netwerkframework ondersteund door nncase
- Tflite
- Onnx
- Caffe
-
Eenvoudige end-to-end implementatie
Verminder het aantal interacties met gebruikers. Implementatie op KPI's kan worden bereikt door dezelfde hulpprogramma's en processen te gebruiken en te implementeren voor de CPU- en GPU-modellen. Het is niet nodig om complexe parameters in te stellen, de gebruiksdrempel te verlagen en de iteratiecyclus van AI-algoritmen te versnellen.
-
Maak optimaal gebruik van het bestaande AI-ecosysteem
Gehecht aan een raamwerk dat veel wordt gebruikt in de industrie. Aan de ene kant kan het zijn zichtbaarheid verbeteren en genieten van de dividenden van een volwassen ecologie. Aan de andere kant kunnen de ontwikkelingskosten van kleine en middelgrote ontwikkelaars worden verlaagd en kunnen de volwassen modellen en algoritmen in de industrie direct worden ingezet.
-
Haal het meeste uit uw hardware
Het voordeel van NPU is dat de prestaties hoger zijn dan die van CPU en GPU, en de DL Compiler moet de prestaties van de hardware volledig kunnen benutten. Compiler moet ook de prestaties voor de nieuwe modelstructuur adaptief optimaliseren, dus naast handmatige optimalisatie moet een nieuwe automatische optimalisatietechniek worden onderzocht.
-
Schaalbaarheid en onderhoudbaarheid
Mogelijkheid om AI-modelimplementaties voor K210, K510 en toekomstige chips te ondersteunen. Enige schaalbaarheid moet worden geboden op architectonisch niveau. Het toevoegen van een nieuwe Target is minder duur en stelt u in staat om zoveel mogelijk modules opnieuw te gebruiken. Versnel de ontwikkeling van nieuwe producten om de technologische accumulatie van DL Compiler te bereiken.
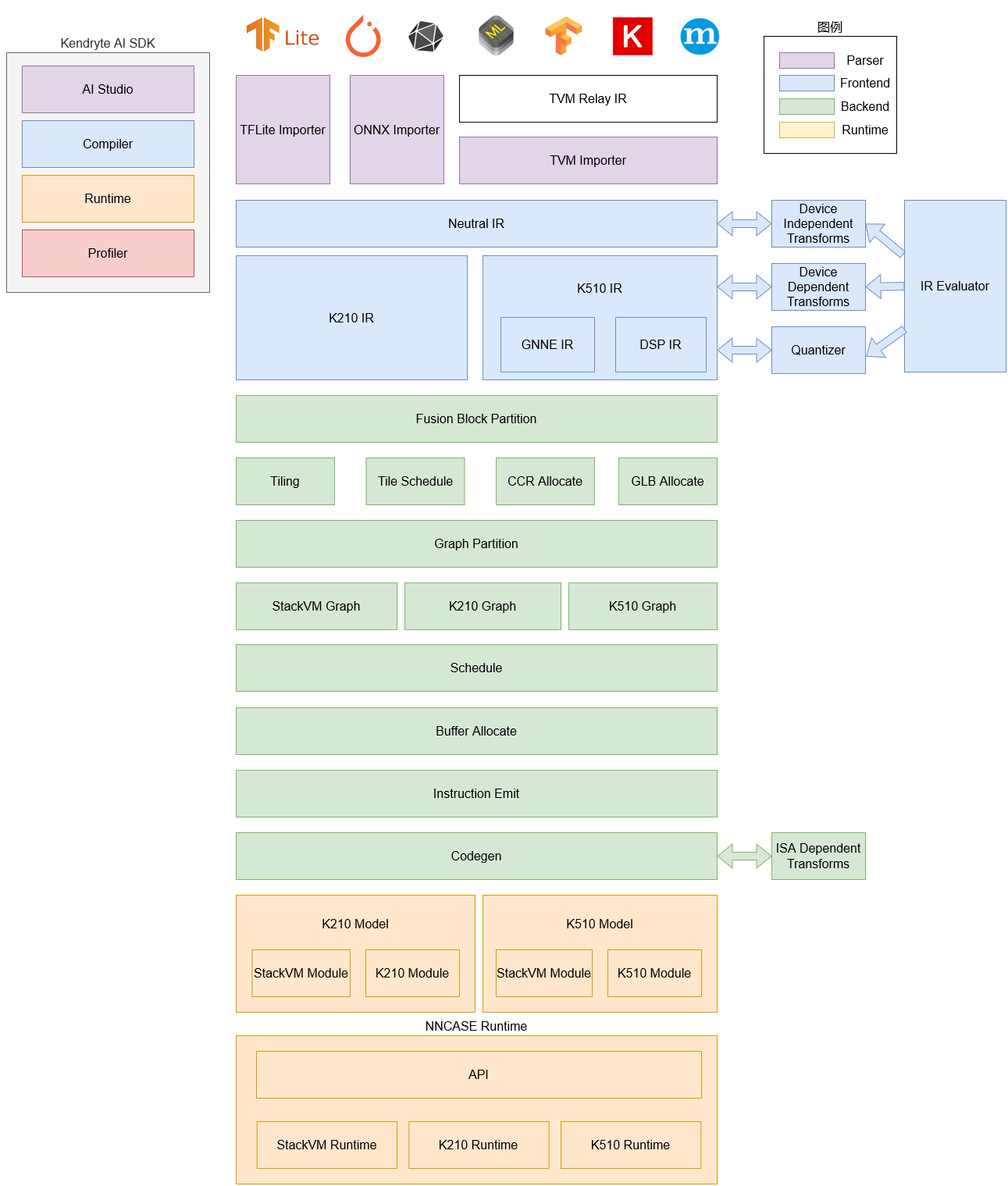
De nnncase software stack bestaat momenteel uit twee delen: compiler en runtime.
Compiler: Wordt gebruikt om neurale netwerkmodellen op een pc te compileren en uiteindelijk een kmodel-bestand te genereren. Het omvat voornamelijk importeur, IR, Evaluator, Quantize, Transform optimalisatie, Tiling, Partition, Schedule, Codegen en andere modules.
- Importeur: importeert modellen uit andere neurale netwerkframeworks in nncase
- IR: Middelste representatie, verdeeld in door de importeur geïmporteerde Neutrale IR (apparaatonafhankelijk) en Nutral IR gegenereerd door het verlagen van conversie Doel IR (apparaatafhankelijk)
- Evaluator: Evaluator biedt interpretatieve uitvoering van IR en wordt vaak gebruikt in scenario's zoals Constant Folding/PTQ Kalibratie
- Transform: Voor IR-transformatie en graph traversal optimalisatie, etc
- Kwantificeren: Kwantificeren na training, kwantisatiemarkers toevoegen aan de te kwantificeren tensor, Evaluator aanroepen voor interpretatie-uitvoering volgens de invoercorrectieset, tensorgegevensbereik verzamelen, kwantisatie- / dequantisatieknooppunten invoegen en ten slotte optimaliseren om onnodige kwantisatie- / dequantisatieknooppunten te elimineren, enz
- Tiling: Beperkt door de lagere geheugencapaciteit van de NPU, moeten grote stukken berekening worden gesplitst. Bovendien heeft het selecteren van de parameter Tilling wanneer er een grote hoeveelheid gegevensmultiplexing in de berekening is, invloed op de latentie en bandbreedte
- Partitie: Deel de grafiek door ModuleType, elke subgraaf na het splitsen komt overeen met RuntimeModule, verschillende soorten RuntimeModule komen overeen met verschillende apparaten (cpu / K510)
- Planning: genereert een berekeningsvolgorde en wijst buffers toe op basis van de gegevensafhankelijkheden in de geoptimaliseerde grafiek
- Codegen: Roep voor elke subgraaf het codegen aan dat overeenkomt met ModuleType om RuntimeModule te genereren
Runtime: Geïntegreerd in de gebruikersapp, biedt het functies zoals het laden van kmodel / het instellen van invoergegevens, KPU-uitvoering en het verkrijgen van uitvoergegevens
Het compilergedeelte van de nncase-toolchain bevat nncase en K510-compiler, die beide het bijbehorende wielpakket moeten installeren.
- Het nncase wheel-pakket isuitgebracht op nncase githuben ondersteunt Python 3.6 / 3.7 / 3.8 / 3.9 / 3.10, gebruikers kunnen de bijbehorende versie kiezen om te downloaden op basis van het besturingssysteem en Python
- Het K510 compilerwielpakket bevindt zich in de map x86_64 van de nncase SDK, is niet afhankelijk van de Python-versie en kan direct worden geïnstalleerd
Als u geen Ubuntu-omgeving hebt, kunt unncase docker(Ubuntu 20.04 + Python 3.8) gebruiken.
cd /path/to/nncase_sdk
docker pull registry.cn-hangzhou.aliyuncs.com/kendryte/nncase:latest
docker run -it --rm -v `pwd`:/mnt -w /mnt registry.cn-hangzhou.aliyuncs.com/kendryte/nncase:latest /bin/bash -c "/bin/bash"Het volgende neemt Ubuntu 20.04 + Python 3.8 installatie van nncase als voorbeeld
wget -P x86_64 https://github.com/kendryte/nncase/releases/download/v1.6.0/nncase-1.6.0.20220505-cp38-cp38-manylinux_2_24_x86_64.whl
pip3 install x86_64/*.whlnncase biedtPython APIvoor het compileren/afleiden van deep learning modellen op een pc
| Bediener | Wordt ondersteund |
|---|---|
| ABS | ✅ |
| TOEVOEGEN | ✅ |
| ARG_MAX | ✅ |
| ARG_MIN | ✅ |
| AVERAGE_POOL_2D | ✅ |
| BATCH_MATMUL | ✅ |
| GIETEN | ✅ |
| Ceil | ✅ |
| AANEENSCHAKELING | ✅ |
| CONV_2D | ✅ |
| LICHAAM | ✅ |
| GEWOONTE | ✅ |
| DEPTHWISE_CONV_2D | ✅ |
| DIV | ✅ |
| GELIJK | ✅ |
| EXP | ✅ |
| EXPAND_DIMS | ✅ |
| VLOER | ✅ |
| FLOOR_DIV | ✅ |
| FLOOR_MOD | ✅ |
| FULLY_CONNECTED | ✅ |
| GROTER | ✅ |
| GREATER_EQUAL | ✅ |
| L2_NORMALIZATION | ✅ |
| LEAKY_RELU | ✅ |
| MINDER | ✅ |
| LESS_EQUAL | ✅ |
| LOG | ✅ |
| LOGISTIEK | ✅ |
| MAX_POOL_2D | ✅ |
| MAXIMUM | ✅ |
| BEDOELEN | ✅ |
| MINIMUM | ✅ |
| Ik | ✅ |
| NEG | ✅ |
| NOT_EQUAL | ✅ |
| OPVULLEN | ✅ |
| Padv2 | ✅ |
| MIRROR_PAD | ✅ |
| INPAKKEN | ✅ |
| KRIJGSGEVANGENE | ✅ |
| REDUCE_MAX | ✅ |
| REDUCE_MIN | ✅ |
| REDUCE_PROD | ✅ |
| Relu | ✅ |
| PRELU | ✅ |
| Relu6 | ✅ |
| OMVORMEN | ✅ |
| RESIZE_BILINEAR | ✅ |
| RESIZE_NEAREST_NEIGHBOR | ✅ |
| ROND | ✅ |
| Rsqrt | ✅ |
| VORM | ✅ |
| ZONDER | ✅ |
| PLAK | ✅ |
| Softmax | ✅ |
| SPACE_TO_BATCH_ND | ✅ |
| DRUKKEN | ✅ |
| BATCH_TO_SPACE_ND | ✅ |
| STRIDED_SLICE | ✅ |
| SQRT | ✅ |
| VIERKANT | ✅ |
| SUB | ✅ |
| SOM | ✅ |
| VERDACHT | ✅ |
| TEGEL | ✅ |
| TRANSPONEREN | ✅ |
| TRANSPOSE_CONV | ✅ |
| QUANTIZE | ✅ |
| FAKE_QUANT | ✅ |
| DEQUANTISEREN | ✅ |
| VERZAMELEN | ✅ |
| GATHER_ND | ✅ |
| ONE_HOT | ✅ |
| SQUARED_DIFFERENCE | ✅ |
| LOG_SOFTMAX | ✅ |
| SPLIJTEN | ✅ |
| HARD_SWISH | ✅ |
| Bediener | Wordt ondersteund |
|---|---|
| ABS | ✅ |
| Ac's | ✅ |
| Acosh · | ✅ |
| En | ✅ |
| Argmax | ✅ |
| Argmin | ✅ |
| Zout | ✅ |
| Asinh | ✅ |
| Toevoegen | ✅ |
| GemiddeldPoolen | ✅ |
| Batchnormalisatie | ✅ |
| Gieten | ✅ |
| Ceil · | ✅ |
| Aan | ✅ |
| Knippen | ✅ |
| Concat | ✅ |
| Constant | ✅ |
| ConstantOfShape | ✅ |
| Conv | ✅ |
| ConvTranspose | ✅ |
| Lichaam | ✅ |
| Ploertendoder | ✅ |
| CumSum | ✅ |
| DiepteToSpace | ✅ |
| DequantizeLinear | ✅ |
| Div | ✅ |
| Voortijdig schoolverlaten | ✅ |
| Leven | ✅ |
| Exp | ✅ |
| Uitbreiden | ✅ |
| Gelijk | ✅ |
| Pletten | ✅ |
| Vloer | ✅ |
| Verzamelen | ✅ |
| GatherND | ✅ |
| Gemm | ✅ |
| GlobalAveragePool | ✅ |
| GlobalMaxPool | ✅ |
| Groter | ✅ |
| GreaterOrEqual | ✅ |
| Hardmax | ✅ |
| HardSigmoid | ✅ |
| HardSwish | ✅ |
| Identiteit | ✅ |
| InstanceNormalisatie | ✅ |
| LpNormalisatie | ✅ |
| LeakyRelu | ✅ |
| Minder | ✅ |
| LessOrEqual | ✅ |
| Log | ✅ |
| LogSoftmax | ✅ |
| LRN | ✅ |
| LSTM | ✅ |
| Matmul | ✅ |
| MaxPool | ✅ |
| Max | ✅ |
| Min | ✅ |
| Ik | ✅ |
| Neg | ✅ |
| Niet | ✅ |
| OneHot | ✅ |
| Opvullen | ✅ |
| Krijgsgevangene | ✅ |
| PRelu | ✅ |
| QuantizeLinear | ✅ |
| RandomNormaal | ✅ |
| RandomNormalLike | ✅ |
| RandomUniform | ✅ |
| RandomUniformAchtig | ✅ |
| ReduceL1 | ✅ |
| ReduceL2 | ✅ |
| ReduceLogSum | ✅ |
| ReduceLogSumexp | ✅ |
| ReduceMax | ✅ |
| ReduceMean | ✅ |
| ReduceMin | ✅ |
| ReduceProd | ✅ |
| ReduceSum | ✅ |
| ReduceSumSquare | ✅ |
| Relu | ✅ |
| Omvormen | ✅ |
| Formaat | ✅ |
| Omgekeerdequence | ✅ |
| RoiAlign | ✅ |
| Rond | ✅ |
| Dorp | ✅ |
| Vorm | ✅ |
| Teken | ✅ |
| Zonder | ✅ |
| Geboorte | ✅ |
| Sigmoid | ✅ |
| Grootte | ✅ |
| Plak | ✅ |
| Softmax | ✅ |
| Softplus | ✅ |
| Softsign | ✅ |
| SpaceToDepth | ✅ |
| Splijten | ✅ |
| Sqrt | ✅ |
| Drukken | ✅ |
| Sub | ✅ |
| Som | ✅ |
| Verdacht | ✅ |
| Tegel | ✅ |
| TopK | ✅ |
| Transponeren | ✅ |
| Trilu · | ✅ |
| Upsampple | ✅ |
| Uitkleden | ✅ |
| Waar | ✅ |
| Bediener | Wordt ondersteund |
|---|---|
| Invoer | ✅ |
| Concat | ✅ |
| Convolutie | ✅ |
| Eltwise | ✅ |
| Inruil | ✅ |
| Relu | ✅ |
| Omvormen | ✅ |
| Plak | ✅ |
| Softmax | ✅ |
| Splijten | ✅ |
| Vervolgindicator | ✅ |
| Bundeling | ✅ |
| Batchnorm | ✅ |
| Schub | ✅ |
| Omkeren | ✅ |
| LSTM | ✅ |
| Innerproduct | ✅ |
Op dit moment ondersteunt de compilatiemodel API deep learning frameworks zoals tflite/onnx/caffe.
Functiebeschrijving
Klasse CompileOptions voor het configureren van nncase-compilatieopties
Klassendefinitie
py::class_<compile_options>(m, "CompileOptions")
.def(py::init())
.def_readwrite("target", &compile_options::target)
.def_readwrite("quant_type", &compile_options::quant_type)
.def_readwrite("w_quant_type", &compile_options::w_quant_type)
.def_readwrite("use_mse_quant_w", &compile_options::use_mse_quant_w)
.def_readwrite("split_w_to_act", &compile_options::split_w_to_act)
.def_readwrite("preprocess", &compile_options::preprocess)
.def_readwrite("swapRB", &compile_options::swapRB)
.def_readwrite("mean", &compile_options::mean)
.def_readwrite("std", &compile_options::std)
.def_readwrite("input_range", &compile_options::input_range)
.def_readwrite("output_range", &compile_options::output_range)
.def_readwrite("input_shape", &compile_options::input_shape)
.def_readwrite("letterbox_value", &compile_options::letterbox_value)
.def_readwrite("input_type", &compile_options::input_type)
.def_readwrite("output_type", &compile_options::output_type)
.def_readwrite("input_layout", &compile_options::input_layout)
.def_readwrite("output_layout", &compile_options::output_layout)
.def_readwrite("model_layout", &compile_options::model_layout)
.def_readwrite("is_fpga", &compile_options::is_fpga)
.def_readwrite("dump_ir", &compile_options::dump_ir)
.def_readwrite("dump_asm", &compile_options::dump_asm)
.def_readwrite("dump_quant_error", &compile_options::dump_quant_error)
.def_readwrite("dump_dir", &compile_options::dump_dir)
.def_readwrite("benchmark_only", &compile_options::benchmark_only);Elke woning wordt hieronder beschreven
| Naam van de woning | type | Ja of nee | beschrijving |
|---|---|---|---|
| doel | snaar | zijn | Geef het compilatiedoel op, zoals 'k210', 'k510' |
| quant_type | snaar | niet | Geef het gegevenskwantisatietype op, zoals 'uint8', 'int8' |
| w_quant_type | snaar | niet | Geef het gewichtskwantisatietype op, zoals 'uint8', 'int8', standaard 'uint8' |
| use_mse_quant_w | Bool | niet | Hiermee geeft u op of het MSE-algoritme (mean-square error) moet worden gebruikt om de kwantisatieparameters te optimaliseren bij het kwantificeren van gewichten |
| split_w_to_act | Bool | niet | Hiermee geeft u op of gedeeltelijke gewichtsgegevens moeten worden gebalanceerd in actieve gegevens |
| voorbewerking | Bool | niet | Of voorbewerking nu is ingeschakeld of niet, de standaardwaarde is False |
| swapRB | Bool | niet | Of u nu RGB-invoergegevens wilt uitwisselen tussen de rode en blauwe kanalen (RGB- > BGR of BGR->RGB), de standaardwaarde is False |
| bedoelen | lijst | niet | Voorbewerking normaliseert het parametergemiddelde, dat standaard wordt ingesteld op[0, 0, 0] |
| Geslachtsziekte | lijst | niet | Voorbewerking normaliseert de parametervariantie, die standaard is ingesteld op[1, 1, 1] |
| input_range | lijst | niet | Het bereik van getallen met drijvende komma na dequantisatie van de invoergegevens, dat standaard is ingesteld op[0, 1] |
| output_range | lijst | niet | Het bereik van getallen met drijvende komma voordat de gegevens met vast punt worden uitgevoerd, dat standaard leeg is |
| input_shape | lijst | niet | Geef de vorm van de invoergegevens op, de lay-out van de input_shape moet consistent zijn met de invoerlay-out en de input_shape van de invoergegevens is inconsistent met de invoervorm van het model en de bitboxbewerking (formaat wijzigen /pad, enz.) wordt uitgevoerd. |
| letterbox_value | drijven | niet | Hiermee geeft u de opvulwaarde op van het fetchbox voorbewerking |
| input_type | snaar | niet | Hiermee geeft u het type invoergegevens op, standaard 'float32' |
| output_type | snaar | niet | Hiermee geeft u het type uitvoergegevens op, zoals 'float32', 'uint8' (alleen voor opgegeven kwantisatie), standaard 'float32' |
| input_layout | snaar | niet | Geef de lay-out van de invoergegevens op, zoals 'NCHW', 'NHWC'. Als de lay-out van de invoergegevens verschilt van het model zelf, worden nncase-inserts omgezet voor conversie |
| output_layout | snaar | niet | Geef de uitvoergegevens voor de lay-out op, zoals 'NCHW', 'NHWC'. Als de lay-out van de uitvoergegevens verschilt van het model zelf, zal nncase transpose invoegen voor conversie |
| model_layout | snaar | niet | Geef de lay-out van het model op, die standaard leeg is, en geef aan wanneer de tflite-modellay-out 'NCHW' is en de Onnx- en Caffe-modellen 'NHWC' |
| is_fpga | Bool | niet | Hiermee geeft u op of kmodel wordt gebruikt voor FPGA's, die standaard false gebruiken |
| dump_ir | Bool | niet | Hiermee geeft u op of IR dumpen standaard false is |
| dump_asm | Bool | niet | Hiermee geeft u op of het dump-asm-assemblybestand standaard false is |
| dump_quant_error | Bool | niet | Hiermee geeft u op of dump de modelfout voor en na kwantificeert |
| dump_dir | snaar | niet | Nadat u eerder de dump_ir en andere schakelopties hebt opgegeven, geeft u hier de map met dump op, die standaard een lege tekenreeks bevat |
| benchmark_only | Bool | niet | Hiermee geeft u op of kmodel alleen wordt gebruikt voor benchmark, die standaard false is |
- Invoerbereik is het bereik van drijvende-kommagetallen, dat wil zeggen, als het invoergegevenstype uint8 is, dan is het invoerbereik het bereik na dequantisatie tot drijvende komma (kan niet 0 ~ 1 zijn), dat vrij kan worden opgegeven.
- input_shape moeten worden gespecificeerd volgens de input_layout, [1,224,224,3]bijvoorbeeld als de input_layout NCHW is, moet de input_shape worden gespecificeerd als[1,3,224,224]; input_layout NHWC is, moet de input_shape worden gespecificeerd als[1,224,224,3];
- gemiddelde en std zijn parameters voor het normaliseren van drijvende-kommagetallen, die de gebruiker vrij kan opgeven;
- Wanneer u de brievenbusfunctie gebruikt, moet u de invoergrootte beperken tot 1,5 MB en de grootte van een enkel kanaal is binnen 0,75 MB;
Bijvoorbeeld:
- Het invoergegevenstype is ingesteld op uint8, input_range ingesteld op[0,255], de rol van dequantisatie is alleen om het type te converteren, de gegevens van uint8 naar float32 te converteren en de gemiddelde en std-parameters kunnen nog steeds worden opgegeven volgens de gegevens van 0 ~ 255
- Het invoergegevenstype is ingesteld op uint8, input_range ingesteld op[0,1], wordt het vastepuntnummer gekwantificeerd tot een [0,1]drijvende-kommagetal in het bereik en moeten het gemiddelde en de std worden opgegeven volgens het nieuwe drijvende-kommagetalbereik.
Het voorbewerkingsproces is als volgt (de groene knooppunten in de afbeelding zijn optioneel):
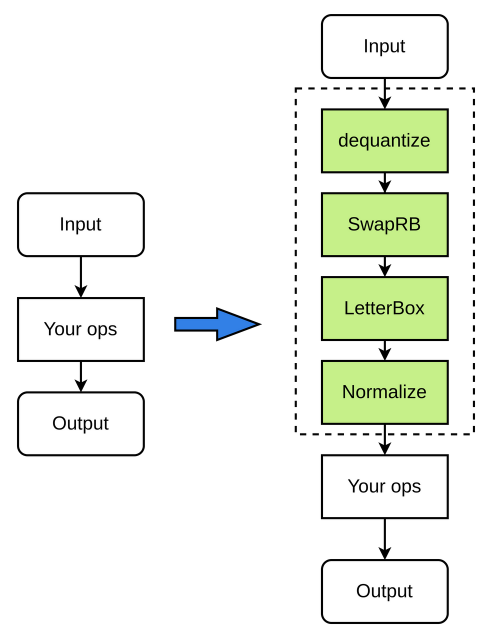
Codevoorbeeld
Instantiate CompileOptions, configureer de waarden van elke eigenschap
# compile_options
compile_options = nncase.CompileOptions()
compile_options.target = target
compile_options.input_type = 'float32' # or 'uint8' 'int8'
compile_options.output_type = 'float32' # or 'uint8' 'int8'. Only work in PTQ
compile_options.output_range = [] # Only work in PTQ and output type is not "float32"
compile_options.preprocess = True # if False, the args below will unworked
compile_options.swapRB = True
compile_options.input_shape = [1,224,224,3] # keep layout same as input layout
compile_options.input_layout = 'NHWC'
compile_options.output_layout = 'NHWC'
compile_options.model_layout = '' # Specific it when tflite model with "NCHW" layout and Onnx(Caffe) model with "NHWC" layout
compile_options.mean = [0,0,0]
compile_options.std = [1,1,1]
compile_options.input_range = [0,1]
compile_options.letterbox_value = 114. # pad what you want
compile_options.dump_ir = True
compile_options.dump_asm = True
compile_options.dump_dir = 'tmp'Functiebeschrijving
Klasse ImportOptions voor het configureren van importopties voor nncases
Klassendefinitie
py::class_<import_options>(m, "ImportOptions")
.def(py::init())
.def_readwrite("output_arrays", &import_options::output_arrays);Elke woning wordt hieronder beschreven
| Naam van de woning | type | Ja of nee | beschrijving |
|---|---|---|---|
| output_arrays | snaar | niet | Uitvoernaam |
Codevoorbeeld
Instantiate ImageOptions, configureer de waarden van elke eigenschap
# import_options
import_options = nncase.ImportOptions()
import_options.output_arrays = 'output' # Your output node nameFunctiebeschrijving
PTQTensorOptions klasse voor het configureren van nncase PTQ opties
Klassendefinitie
py::class_<ptq_tensor_options>(m, "PTQTensorOptions")
.def(py::init())
.def_readwrite("calibrate_method", &ptq_tensor_options::calibrate_method)
.def_readwrite("samples_count", &ptq_tensor_options::samples_count)
.def("set_tensor_data", [](ptq_tensor_options &o, py::bytes bytes) {
uint8_t *buffer;
py::ssize_t length;
if (PyBytes_AsStringAndSize(bytes.ptr(), reinterpret_cast<char **>(&buffer), &length))
throw std::invalid_argument("Invalid bytes");
o.tensor_data.assign(buffer, buffer + length);
});Elke woning wordt hieronder beschreven
| De veldnaam | type | Ja of nee | beschrijving |
|---|---|---|---|
| calibrate_method | snaar | niet | Kalibratiemethode, ondersteunt 'no_clip', 'l2', 'kld_m0', 'kld_m1', 'kld_m2', 'cdf', standaard is 'no_clip' |
| samples_count | Int | niet | Het aantal monsters |
Functiebeschrijving
De correctiegegevens instellen
Interface definitie
set_tensor_data(calib_data)Invoerparameters
| Parameternaam | type | Ja of nee | beschrijving |
|---|---|---|---|
| calib_data | byte[] | zijn | Corrigeer de gegevens |
De retourwaarde
N.V.T
Codevoorbeeld
# ptq_options
ptq_options = nncase.PTQTensorOptions()
ptq_options.samples_count = cfg.generate_calibs.batch_size
ptq_options.set_tensor_data(np.asarray([sample['data'] for sample in self.calibs]).tobytes())Functiebeschrijving
Compilerklasse voor het compileren van neurale netwerkmodellen
Klassendefinitie
py::class_<compiler>(m, "Compiler")
.def(py::init(&compiler::create))
.def("import_tflite", &compiler::import_tflite)
.def("import_onnx", &compiler::import_onnx)
.def("import_caffe", &compiler::import_caffe)
.def("compile", &compiler::compile)
.def("use_ptq", py::overload_cast<ptq_tensor_options>(&compiler::use_ptq))
.def("gencode", [](compiler &c, std::ostream &stream) { c.gencode(stream); })
.def("gencode_tobytes", [](compiler &c) {
std::stringstream ss;
c.gencode(ss);
return py::bytes(ss.str());
})
.def("create_evaluator", [](compiler &c, uint32_t stage) {
auto &graph = c.graph(stage);
return std::make_unique<graph_evaluator>(c.target(), graph);
});Codevoorbeeld
compiler = nncase.Compiler(compile_options)Functiebeschrijving
Importeer het tflite-model
Interface definitie
import_tflite(model_content, import_options)Invoerparameters
| Parameternaam | type | Ja of nee | beschrijving |
|---|---|---|---|
| model_content | byte[] | zijn | Lees de inhoud van het model |
| import_options | ImportOpties | zijn | Opties importeren |
De retourwaarde
N.V.T
Codevoorbeeld
model_content = read_model_file(model)
compiler.import_tflite(model_content, import_options)Functiebeschrijving
Het onnx-model importeren
Interface definitie
import_onnx(model_content, import_options)Invoerparameters
| Parameternaam | type | Ja of nee | beschrijving |
|---|---|---|---|
| model_content | byte[] | zijn | Lees de inhoud van het model |
| import_options | ImportOpties | zijn | Opties importeren |
De retourwaarde
N.V.T
Codevoorbeeld
model_content = read_model_file(model)
compiler.import_onnx(model_content, import_options)Functiebeschrijving
Het caffe-model importeren
Gebruikers moeten caffe compileren/installeren op de lokale computer.
Interface definitie
import_caffe(caffemodel, prototxt)Invoerparameters
| Parameternaam | type | Ja of nee | beschrijving |
|---|---|---|---|
| Caffemodel | byte[] | zijn | Lees de caffemodel inhoud |
| Prototxt | byte[] | zijn | Lees de prototxt inhoud |
De retourwaarde
N.V.T
Codevoorbeeld
# import
caffemodel = read_model_file('test.caffemodel')
prototxt = read_model_file('test.prototxt')
compiler.import_caffe(caffemodel, prototxt)Functiebeschrijving
PTQ-configuratieopties instellen
Interface definitie
use_ptq(ptq_options)Invoerparameters
| Parameternaam | type | Ja of nee | beschrijving |
|---|---|---|---|
| ptq_options | PTQTensorOptie | zijn | PTQ-configuratieopties |
De retourwaarde
N.V.T
Codevoorbeeld
compiler.use_ptq(ptq_options)Functiebeschrijving
Het neurale netwerkmodel compileren
Interface definitie
compile()Invoerparameters
N.V.T
De retourwaarde
N.V.T
Codevoorbeeld
compiler.compile()Functiebeschrijving
Genereert een stroom codebytes
Interface definitie
gencode_tobytes()Invoerparameters
N.V.T
De retourwaarde
Bytes[]
Codevoorbeeld
kmodel = compiler.gencode_tobytes()
with open(os.path.join(infer_dir, 'test.kmodel'), 'wb') as f:
f.write(kmodel)In het volgende voorbeeld worden het model en het python-compilatiescript gebruikt
- Het model bevindt zich in de submap /path/to/nncase_sdk/examples/models/
- Het python-compilatiescript bevindt zich in de submap /path/to/nncase_sdk/examples/scripts
- Mobilenetv2_tflite_fp32_image.py script is als volgt
import nncase
import os
import argparse
def read_model_file(model_file):
with open(model_file, 'rb') as f:
model_content = f.read()
return model_content
def main():
parser = argparse.ArgumentParser(prog="nncase")
parser.add_argument("--target", type=str, help='target to run')
parser.add_argument("--model", type=str, help='model file')
args = parser.parse_args()
# compile_options
dump_dir = 'tmp/mobilenetv2_tflite_fp32_image'
compile_options = nncase.CompileOptions()
compile_options.target = args.target
compile_options.dump_ir = True
compile_options.dump_asm = True
compile_options.dump_dir = dump_dir
# compiler
compiler = nncase.Compiler(compile_options)
# import_options
import_options = nncase.ImportOptions()
# import
model_content = read_model_file(args.model)
compiler.import_tflite(model_content, import_options)
# compile
compiler.compile()
# kmodel
kmodel = compiler.gencode_tobytes()
with open(os.path.join(dump_dir, 'test.kmodel'), 'wb') as f:
f.write(kmodel)
if __name__ == '__main__':
main()- Voer de volgende opdracht uit om het tflite-model van mobiletv2, target k510 te compileren
cd /path/to/nncase_sdk/examples
python3 scripts/mobilenetv2_tflite_fp32_image.py --target k510 --model models/mobilenet_v2_1.0_224.tflite- Voor onnx-modellen wordt aanbevolen om het gebruik vanONNX Simplifier te vereenvoudigenvoordat u compileert met nncase
- mobilenetv2_onnx_fp32_image.py script is als volgt
import os
import onnxsim
import onnx
import nncase
import argparse
def parse_model_input_output(model_file):
onnx_model = onnx.load(model_file)
input_all = [node.name for node in onnx_model.graph.input]
input_initializer = [node.name for node in onnx_model.graph.initializer]
input_names = list(set(input_all) - set(input_initializer))
input_tensors = [node for node in onnx_model.graph.input if node.name in input_names]
# input
inputs= []
for _, e in enumerate(input_tensors):
onnx_type = e.type.tensor_type
input_dict = {}
input_dict['name'] = e.name
input_dict['dtype'] = onnx.mapping.TENSOR_TYPE_TO_NP_TYPE[onnx_type.elem_type]
input_dict['shape'] = [(i.dim_value if i.dim_value != 0 else d) for i, d in zip(
onnx_type.shape.dim, [1, 3, 224, 224])]
inputs.append(input_dict)
return onnx_model, inputs
def onnx_simplify(model_file, dump_dir):
onnx_model, inputs = parse_model_input_output(model_file)
onnx_model = onnx.shape_inference.infer_shapes(onnx_model)
input_shapes = {}
for input in inputs:
input_shapes[input['name']] = input['shape']
onnx_model, check = onnxsim.simplify(onnx_model, input_shapes=input_shapes)
assert check, "Simplified ONNX model could not be validated"
model_file = os.path.join(dump_dir, 'simplified.onnx')
onnx.save_model(onnx_model, model_file)
return model_file
def read_model_file(model_file):
with open(model_file, 'rb') as f:
model_content = f.read()
return model_content
def main():
parser = argparse.ArgumentParser(prog="nncase")
parser.add_argument("--target", type=str, help='target to run')
parser.add_argument("--model", type=str, help='model file')
args = parser.parse_args()
dump_dir = 'tmp/mobilenetv2_onnx_fp32_image'
if not os.path.exists(dump_dir):
os.makedirs(dump_dir)
# onnx simplify
model_file = onnx_simplify(args.model, dump_dir)
# compile_options
compile_options = nncase.CompileOptions()
compile_options.target = args.target
compile_options.dump_ir = True
compile_options.dump_asm = True
compile_options.dump_dir = dump_dir
# compiler
compiler = nncase.Compiler(compile_options)
# import_options
import_options = nncase.ImportOptions()
# import
model_content = read_model_file(model_file)
compiler.import_onnx(model_content, import_options)
# compile
compiler.compile()
# kmodel
kmodel = compiler.gencode_tobytes()
with open(os.path.join(dump_dir, 'test.kmodel'), 'wb') as f:
f.write(kmodel)
if __name__ == '__main__':
main()- Voer de volgende opdracht uit om het onnx-model van mobiletv2 te compileren, target k510
cd /path/to/nncase_sdk/examples
python3 scripts/mobilenetv2_onnx_fp32_image.py --target k510 --model models/mobilenetv2-7.onnx- Het caffe wielpakket isafkomstig vankendryte caffe
- conv2d_caffe_fp32.py script is als volgt
import nncase
import os
import argparse
def read_model_file(model_file):
with open(model_file, 'rb') as f:
model_content = f.read()
return model_content
def main():
parser = argparse.ArgumentParser(prog="nncase")
parser.add_argument("--target", type=str, help='target to run')
parser.add_argument("--caffemodel", type=str, help='caffemodel file')
parser.add_argument("--prototxt", type=str, help='prototxt file')
args = parser.parse_args()
# compile_options
dump_dir = 'tmp/conv2d_caffe_fp32'
compile_options = nncase.CompileOptions()
compile_options.target = args.target
compile_options.dump_ir = True
compile_options.dump_asm = True
compile_options.dump_dir = dump_dir
# compiler
compiler = nncase.Compiler(compile_options)
# import_options
import_options = nncase.ImportOptions()
# import
caffemodel = read_model_file(args.caffemodel)
prototxt = read_model_file(args.prototxt)
compiler.import_caffe(caffemodel, prototxt)
# compile
compiler.compile()
# kmodel
kmodel = compiler.gencode_tobytes()
with open(os.path.join(dump_dir, 'test.kmodel'), 'wb') as f:
f.write(kmodel)
if __name__ == '__main__':
main()- Voer de volgende opdracht uit om het caffe-model van conv2d te compileren, met het doel k510
cd /path/to/nncase_sdk/examples
python3 scripts/conv2d_caffe_fp32.py --target k510 --caffemodel models/test.caffemodel --prototxt models/test.prototxt- Voor onnx-modellen wordt aanbevolen om het gebruik vanONNX Simplifier te vereenvoudigenvoordat u compileert met nncase
- Mobilenetv2_onnx_fp32_preprocess.py script is als volgt
import os
import onnxsim
import onnx
import nncase
import argparse
def parse_model_input_output(model_file):
onnx_model = onnx.load(model_file)
input_all = [node.name for node in onnx_model.graph.input]
input_initializer = [node.name for node in onnx_model.graph.initializer]
input_names = list(set(input_all) - set(input_initializer))
input_tensors = [node for node in onnx_model.graph.input if node.name in input_names]
# input
inputs= []
for _, e in enumerate(input_tensors):
onnx_type = e.type.tensor_type
input_dict = {}
input_dict['name'] = e.name
input_dict['dtype'] = onnx.mapping.TENSOR_TYPE_TO_NP_TYPE[onnx_type.elem_type]
input_dict['shape'] = [(i.dim_value if i.dim_value != 0 else d) for i, d in zip(
onnx_type.shape.dim, [1, 3, 224, 224])]
inputs.append(input_dict)
return onnx_model, inputs
def onnx_simplify(model_file, dump_dir):
onnx_model, inputs = parse_model_input_output(model_file)
onnx_model = onnx.shape_inference.infer_shapes(onnx_model)
input_shapes = {}
for input in inputs:
input_shapes[input['name']] = input['shape']
onnx_model, check = onnxsim.simplify(onnx_model, input_shapes=input_shapes)
assert check, "Simplified ONNX model could not be validated"
model_file = os.path.join(dump_dir, 'simplified.onnx')
onnx.save_model(onnx_model, model_file)
return model_file
def read_model_file(model_file):
with open(model_file, 'rb') as f:
model_content = f.read()
return model_content
def main():
parser = argparse.ArgumentParser(prog="nncase")
parser.add_argument("--target", type=str, help='target to run')
parser.add_argument("--model", type=str, help='model file')
args = parser.parse_args()
dump_dir = 'tmp/mobilenetv2_onnx_fp32_preprocess'
if not os.path.exists(dump_dir):
os.makedirs(dump_dir)
# onnx simplify
model_file = onnx_simplify(args.model, dump_dir)
# compile_options
compile_options = nncase.CompileOptions()
compile_options.target = args.target
compile_options.input_type = 'uint8'
compile_options.preprocess = True
compile_options.swapRB = True
compile_options.input_layout = 'NHWC'
compile_options.output_layout = 'NCHW'
compile_options.input_shape = [1, 256, 256, 3]
compile_options.mean = [0.485, 0.456, 0.406]
compile_options.std = [0.229, 0.224, 0.225]
compile_options.input_range = [0, 1]
compile_options.dump_ir = True
compile_options.dump_asm = True
compile_options.dump_dir = dump_dir
# compiler
compiler = nncase.Compiler(compile_options)
# import_options
import_options = nncase.ImportOptions()
# import
model_content = read_model_file(model_file)
compiler.import_onnx(model_content, import_options)
# compile
compiler.compile()
# kmodel
kmodel = compiler.gencode_tobytes()
with open(os.path.join(dump_dir, 'test.kmodel'), 'wb') as f:
f.write(kmodel)
if __name__ == '__main__':
main()- Voer de volgende opdracht uit om het onnx-model van mobiletv2 te compileren met het doel k510
cd /path/to/nncase_sdk/examples
python3 scripts/mobilenetv2_onnx_fp32_preprocess.py --target k510 --model models/mobilenetv2-7.onnx- Mobilenetv2_tflite_uint8_image.py script is als volgt
import nncase
import os
import argparse
import numpy as np
def read_model_file(model_file):
with open(model_file, 'rb') as f:
model_content = f.read()
return model_content
def generate_data(shape, batch):
shape[0] *= batch
data = np.random.rand(*shape).astype(np.float32)
return data
def main():
parser = argparse.ArgumentParser(prog="nncase")
parser.add_argument("--target", type=str, help='target to run')
parser.add_argument("--model", type=str, help='model file')
args = parser.parse_args()
input_shape = [1, 224, 224, 3]
# compile_options
dump_dir = 'tmp/mobilenetv2_tflite_uint8_image'
compile_options = nncase.CompileOptions()
compile_options.target = args.target
compile_options.input_type = 'float32'
compile_options.input_layout = 'NHWC'
compile_options.output_layout = 'NHWC'
compile_options.dump_ir = True
compile_options.dump_asm = True
compile_options.dump_dir = dump_dir
# compiler
compiler = nncase.Compiler(compile_options)
# import_options
import_options = nncase.ImportOptions()
# quantize model
compile_options.quant_type = 'uint8'
# ptq_options
ptq_options = nncase.PTQTensorOptions()
ptq_options.samples_count = 10
ptq_options.set_tensor_data(generate_data(input_shape, ptq_options.samples_count).tobytes())
# import
model_content = read_model_file(args.model)
compiler.import_tflite(model_content, import_options)
# compile
compiler.use_ptq(ptq_options)
compiler.compile()
# kmodel
kmodel = compiler.gencode_tobytes()
with open(os.path.join(dump_dir, 'test.kmodel'), 'wb') as f:
f.write(kmodel)
if __name__ == '__main__':
main()- Voer de volgende opdracht uit om het tflite-model van uint8 gekwantificeerde mobiletv2, target k510 te compileren
cd /path/to/nncase_sdk/examples
python3 scripts/mobilenetv2_tflite_uint8_image.py --target k510 --model models/mobilenet_v2_1.0_224.tfliteNaast de AP's van het gecompileerde model levert nncase ook de API's van het inferentiemodel, die op de pc kunnen worden afgeleid vóór de compilatie van het kmodel, dat wordt gebruikt om te verifiëren of de nncase-inferentieresultaten en de runtime-resultaten van het bijbehorende deep learning-framework consistent zijn.
Functiebeschrijving
De klasse MemoryRange, die wordt gebruikt om een geheugenbereik weer te geven
Klassendefinitie
py::class_<memory_range>(m, "MemoryRange")
.def_readwrite("location", &memory_range::memory_location)
.def_property(
"dtype", [](const memory_range &range) { return to_dtype(range.datatype); },
[](memory_range &range, py::object dtype) { range.datatype = from_dtype(py::dtype::from_args(dtype)); })
.def_readwrite("start", &memory_range::start)
.def_readwrite("size", &memory_range::size);Elke woning wordt hieronder beschreven
| Naam van de woning | type | Ja of nee | beschrijving |
|---|---|---|---|
| plaats | Int | niet | Geheugenpositie, 0 voor invoer, 1 voor uitvoer, 2 voor rdata, 3 voor gegevens, 4 voor shared_data |
| dtype | Gegevenstype Python | niet | gegevenstype |
| beginnen | Int | niet | Geheugen startadres |
| grootte | Int | niet | Geheugengrootte |
Codevoorbeeld
Instantiate MemoryRange
mr = nncase.MemoryRange()Functiebeschrijving
De klasse RuntimeTensor, die de runtime-tensor vertegenwoordigt
Klassendefinitie
py::class_<runtime_tensor>(m, "RuntimeTensor")
.def_static("from_numpy", [](py::array arr) {
auto src_buffer = arr.request();
auto datatype = from_dtype(arr.dtype());
auto tensor = host_runtime_tensor::create(
datatype,
to_rt_shape(src_buffer.shape),
to_rt_strides(src_buffer.itemsize, src_buffer.strides),
gsl::make_span(reinterpret_cast<gsl::byte *>(src_buffer.ptr), src_buffer.size * src_buffer.itemsize),
[=](gsl::byte *) { arr.dec_ref(); })
.unwrap_or_throw();
arr.inc_ref();
return tensor;
})
.def("copy_to", [](runtime_tensor &from, runtime_tensor &to) {
from.copy_to(to).unwrap_or_throw();
})
.def("to_numpy", [](runtime_tensor &tensor) {
auto host = tensor.as_host().unwrap_or_throw();
auto src_map = std::move(hrt::map(host, hrt::map_read).unwrap_or_throw());
auto src_buffer = src_map.buffer();
return py::array(
to_dtype(tensor.datatype()),
tensor.shape(),
to_py_strides(runtime::get_bytes(tensor.datatype()), tensor.strides()),
src_buffer.data());
})
.def_property_readonly("dtype", [](runtime_tensor &tensor) {
return to_dtype(tensor.datatype());
})
.def_property_readonly("shape", [](runtime_tensor &tensor) {
return to_py_shape(tensor.shape());
});Elke woning wordt hieronder beschreven
| Naam van de woning | type | Ja of nee | beschrijving |
|---|---|---|---|
| dtype | Int | niet | Gegevenstype tensor |
| vorm | lijst | niet | De vorm van de tensor |
Functiebeschrijving
Het object RuntimeTensor maken op basis van numpy.ndarray
Interface definitie
from_numpy(py::array arr)Invoerparameters
| Parameternaam | type | Ja of nee | beschrijving |
|---|---|---|---|
| Arr | numpy.ndarray | zijn | numpy.ndarray, object |
De retourwaarde
RuntimeTensor
Codevoorbeeld
tensor = nncase.RuntimeTensor.from_numpy(self.inputs[i]['data'])Functiebeschrijving
Copy Runtime Tensor
Interface definitie
copy_to(RuntimeTensor to)Invoerparameters
| Parameternaam | type | Ja of nee | beschrijving |
|---|---|---|---|
| Aan | RuntimeTensor | zijn | RuntimeTensor-object |
De retourwaarde
N.V.T
Codevoorbeeld
sim.get_output_tensor(i).copy_to(to)Functiebeschrijving
RuntimeTensor converteren naar een numpy.ndarray-object
Interface definitie
to_numpy()Invoerparameters
N.V.T
De retourwaarde
numpy.ndarray, object
Codevoorbeeld
arr = sim.get_output_tensor(i).to_numpy()Functiebeschrijving
Simulatorklasse voor inferentie kmodel op pc
Klassendefinitie
py::class_<interpreter>(m, "Simulator")
.def(py::init())
.def("load_model", [](interpreter &interp, gsl::span<const gsl::byte> buffer) { interp.load_model(buffer).unwrap_or_throw(); })
.def_property_readonly("inputs_size", &interpreter::inputs_size)
.def_property_readonly("outputs_size", &interpreter::outputs_size)
.def("get_input_desc", &interpreter::input_desc)
.def("get_output_desc", &interpreter::output_desc)
.def("get_input_tensor", [](interpreter &interp, size_t index) { return interp.input_tensor(index).unwrap_or_throw(); })
.def("set_input_tensor", [](interpreter &interp, size_t index, runtime_tensor tensor) { return interp.input_tensor(index, tensor).unwrap_or_throw(); })
.def("get_output_tensor", [](interpreter &interp, size_t index) { return interp.output_tensor(index).unwrap_or_throw(); })
.def("set_output_tensor", [](interpreter &interp, size_t index, runtime_tensor tensor) { return interp.output_tensor(index, tensor).unwrap_or_throw(); })
.def("run", [](interpreter &interp) { interp.run().unwrap_or_throw(); });Elke woning wordt hieronder beschreven
| Naam van de woning | type | Ja of nee | beschrijving |
|---|---|---|---|
| inputs_size | Int | niet | Voer het aantal in |
| outputs_size | Int | niet | Het aantal uitgangen |
Codevoorbeeld
Instantiate de Simulator
sim = nncase.Simulator()Functiebeschrijving
Laad het kmodel
Interface definitie
load_model(model_content)Invoerparameters
| Parameternaam | type | Ja of nee | beschrijving |
|---|---|---|---|
| model_content | byte[] | zijn | Kmodel byte stream |
De retourwaarde
N.V.T
Codevoorbeeld
sim.load_model(kmodel)Functiebeschrijving
Hiermee wordt de beschrijving van de invoer voor de opgegeven index opgehaald
Interface definitie
get_input_desc(index)Invoerparameters
| Parameternaam | type | Ja of nee | beschrijving |
|---|---|---|---|
| index | Int | zijn | De index van de invoer |
De retourwaarde
Geheugenbereik
Codevoorbeeld
input_desc_0 = sim.get_input_desc(0)Functiebeschrijving
Krijgt de beschrijving van de uitvoer van de opgegeven index
Interface definitie
get_output_desc(index)Invoerparameters
| Parameternaam | type | Ja of nee | beschrijving |
|---|---|---|---|
| index | Int | zijn | De index van de output |
De retourwaarde
Geheugenbereik
Codevoorbeeld
output_desc_0 = sim.get_output_desc(0)Functiebeschrijving
Haalt de RuntimeTensor op voor de invoer voor de opgegeven index
Interface definitie
get_input_tensor(index)Invoerparameters
| Parameternaam | type | Ja of nee | beschrijving |
|---|---|---|---|
| index | Int | zijn | Voer de index van de tensor in |
De retourwaarde
RuntimeTensor
Codevoorbeeld
input_tensor_0 = sim.get_input_tensor(0)Functiebeschrijving
Hiermee stelt u de Runtime Tensor in voor de invoer van de opgegeven index
Interface definitie
set_input_tensor(index, tensor)Invoerparameters
| Parameternaam | type | Ja of nee | beschrijving |
|---|---|---|---|
| index | Int | zijn | Voer de index van RuntimeTensor in |
| tensor | RuntimeTensor | zijn | RuntimeTensor invoeren |
De retourwaarde
N.V.T
Codevoorbeeld
sim.set_input_tensor(0, nncase.RuntimeTensor.from_numpy(self.inputs[0]['data']))Functiebeschrijving
Hiermee wordt de Runtime Tensor opgehaald voor de uitvoer van de opgegeven index
Interface definitie
get_output_tensor(index)Invoerparameters
| Parameternaam | type | Ja of nee | beschrijving |
|---|---|---|---|
| index | Int | zijn | Voert de index van de RuntimeTensor uit |
De retourwaarde
RuntimeTensor
Codevoorbeeld
output_arr_0 = sim.get_output_tensor(0).to_numpy()Functiebeschrijving
Stelt de RuntimeTensor in voor de uitvoer van de opgegeven index
Interface definitie
set_output_tensor(index, tensor)Invoerparameters
| Parameternaam | type | Ja of nee | beschrijving |
|---|---|---|---|
| index | Int | zijn | Voert de index van de RuntimeTensor uit |
| tensor | RuntimeTensor | zijn | Uitvoer Runtime Tensor |
De retourwaarde
N.V.T
Codevoorbeeld
sim.set_output_tensor(0, tensor)Functiebeschrijving
Kmodel-inferentie uitvoeren
Interface definitie
run()Invoerparameters
N.V.T
De retourwaarde
N.V.T
Codevoorbeeld
sim.run()**Voorwaarde:**mobilenetv2_onnx_fp32_image.py script is gecompileerd met het mobiletv2-7.onnx model
mobilenetv2_onnx_simu.py bevindt zich in de submap /path/to/nncase_sdk/examples/scripts, die als volgt luidt
import os
import copy
import argparse
import numpy as np
import onnxruntime as ort
import nncase
def read_model_file(model_file):
with open(model_file, 'rb') as f:
model_content = f.read()
return model_content
def cosine(gt, pred):
return (gt @ pred) / (np.linalg.norm(gt, 2) * np.linalg.norm(pred, 2))
def main():
parser = argparse.ArgumentParser(prog="nncase")
parser.add_argument("--model_file", type=str, help='original model file')
parser.add_argument("--kmodel_file", type=str, help='kmodel file')
parser.add_argument("--input_file", type=str, help='input bin file for kmodel')
args = parser.parse_args()
# create simulator
sim = nncase.Simulator()
# read kmodel
kmodel = read_model_file(args.kmodel_file)
# load kmodel
sim.load_model(kmodel)
# read input.bin
input_tensor=sim.get_input_tensor(0).to_numpy()
input = np.fromfile(args.input_file, input_tensor.dtype).reshape(input_tensor.shape)
# set input for simulator
sim.set_input_tensor(0, nncase.RuntimeTensor.from_numpy(input))
# simulator inference
nncase_results = []
sim.run()
for i in range(sim.outputs_size):
nncase_result = sim.get_output_tensor(i).to_numpy()
nncase_results.append(copy.deepcopy(nncase_result))
# cpu inference
cpu_results = []
ort_session = ort.InferenceSession(args.model_file)
input_name = ort_session.get_inputs()[0].name
output_name = ort_session.get_outputs()[0].name
cpu_results = ort_session.run([output_name], { input_name : input })
# compare
for i in range(sim.outputs_size):
cos = cosine(np.reshape(nncase_results[i], (-1)), np.reshape(cpu_results[i], (-1)))
print('output {0} cosine similarity : {1}'.format(i, cos))
if __name__ == '__main__':
main()Het inferentiescript uitvoeren
cd /path/to/nncase_sdk/examples
python3 scripts/mobilenetv2_onnx_simu.py --model_file models/mobilenetv2-7.onnx --kmodel_file tmp/mobilenetv2_onnx_fp32_image/test.kmodel --input_file mobilenetv2_onnx_fp32_image/data/input_0_0.binDe vergelijking van nncase simulator en CPU inferentie resultaten is als volgt
... ...
output 0 cosine similarity : 0.9992437958717346nncase runtime wordt gebruikt om kmodel op AI-apparaten te laden / invoergegevens in te stellen / KPU-berekeningen uit te voeren / uitvoergegevens te verkrijgen, enz.
Momenteel zijn alleende C++ versievan API's, gerelateerde headerbestanden en statische bibliotheken beschikbaar in de map nncase sdk/riscv64
$ tree -L 3 riscv64/
riscv64/
├── include
│ ├── gsl
│ │ └── gsl-lite.hpp
│ ├── gsl-lite
│ │ └── gsl-lite.hpp
│ ├── mpark
│ │ ├── config.hpp
│ │ ├── in_place.hpp
│ │ ├── lib.hpp
│ │ └── variant.hpp
│ └── nncase
│ ├── functional
│ ├── kernels
│ ├── runtime
│ └── version.h
└── lib
├── cmake
│ ├── nncasefunctional
│ ├── nncase_rt_modules_k510
│ └── nncaseruntime
├── libnncase.functional.a
├── libnncase.rt_modules.k510.a
└── libnncase.runtime.a
13 directories, 10 filesTensor gebruikt om modelinvoer- / uitvoergegevens op te slaan
Functiebeschrijving
Een runtime_tensor maken
Interface definitie
(1) NNCASE_API result<runtime_tensor> create(datatype_t datatype, runtime_shape_t shape, memory_pool_t pool = pool_cpu_only, uintptr_t physical_address = 0) noexcept;
(2) NNCASE_API result<runtime_tensor> create(datatype_t datatype, runtime_shape_t shape, gsl::span<gsl::byte> data, bool copy, memory_pool_t pool = pool_cpu_only, uintptr_t physical_address = 0) noexcept;Invoerparameters
| Parameternaam | type | Ja of nee | beschrijving |
|---|---|---|---|
| Datatype | datatype_t | zijn | Gegevenstype, zoals dt_float32 |
| vorm | runtime_shape_t | zijn | De vorm van de tensor |
| gegevens | gsl::span<gsl::byte> | zijn | Gegevensbuffer met gebruikersstatus |
| kopiëren | Bool | zijn | Of te kopiëren |
| poel | memory_pool_t | niet | Type geheugenpool, standaardwaarde is pool_cpu_only |
| physical_address | uintptr_t | niet | Fysiek adres, standaardwaarde is 0 |
De retourwaarde
resultaat<runtime_tensor>
Codevoorbeeld
// create input
auto in_shape = interp.input_shape(0);
auto input_tensor = host_runtime_tensor::create(dt_float32, in_shape,
{(gsl::byte *)mat.data, mat.cols * mat.rows * mat.elemSize()},
true, hrt::pool_shared).expect("cannot create input tensor");Interpreter is een actieve instantie van de nncase-runtime, die functionele kernfuncties biedt, zoals load_model()/run()/input_tensor()/output_tensor().
Functiebeschrijving
Laad het kmodel model
Interface definitie
NNCASE_NODISCARD result<void> load_model(gsl::span<const gsl::byte> buffer) noexcept;Invoerparameters
| Parameternaam | type | Ja of nee | beschrijving |
|---|---|---|---|
| buffer | gsl::span <const gsl::byte> |
zijn | kmodel buffer |
De retourwaarde
resultaat <void>
Codevoorbeeld
template <class T>
std::vector<T>read_binary_file(const char *file_name)
{
std::ifstream ifs(file_name, std::ios::binary);
ifs.seekg(0, ifs.end);
size_t len = ifs.tellg();
std::vector<T> vec(len / sizeof(T), 0);
ifs.seekg(0, ifs.beg);
ifs.read(reinterpret_cast<char*>(vec.data()), len);
ifs.close();
return vec;
}
interpreter interp;
auto model = read_binary_file<unsigned char>(kmodel);
interp.load_model({(const gsl::byte *)model.data(), model.size()}).expect("cannot load model.");Functiebeschrijving
Haalt het aantal modelingangen op
Interface definitie
size_t inputs_size() const noexcept;Invoerparameters
N.V.T
De retourwaarde
size_t
Codevoorbeeld
auto inputs_size = interp.inputs_size();Functiebeschrijving
Haalt het aantal modeluitgangen op
Interface definitie
size_t outputs_size() const noexcept;Invoerparameters
N.V.T
De retourwaarde
size_t
Codevoorbeeld
auto outputs_size = interp.outputs_size();Functiebeschrijving
Hiermee wordt de vorm van de opgegeven modelinvoer opgehaald
Interface definitie
const runtime_shape_t &input_shape(size_t index) const noexcept;Invoerparameters
| Parameternaam | type | Ja of nee | beschrijving |
|---|---|---|---|
| index | size_t | zijn | De index van de invoer |
De retourwaarde
runtime_shape_t
Codevoorbeeld
auto in_shape = interp.input_shape(0);Functiebeschrijving
Hiermee wordt de vorm van de opgegeven uitvoer van het model opgehaald
Interface definitie
const runtime_shape_t &output_shape(size_t index) const noexcept;Invoerparameters
| Parameternaam | type | Ja of nee | beschrijving |
|---|---|---|---|
| index | size_t | zijn | De index van de output |
De retourwaarde
runtime_shape_t
Codevoorbeeld
auto out_shape = interp.output_shape(0);Functiebeschrijving
Haalt/stelt de ingangstensor voor de opgegeven index in
Interface definitie
(1) result<runtime_tensor> input_tensor(size_t index) noexcept;
(2) result<void> input_tensor(size_t index, runtime_tensor tensor) noexcept;Invoerparameters
| Parameternaam | type | Ja of nee | beschrijving |
|---|---|---|---|
| index | size_t | zijn | kmodel buffer |
| tensor | runtime_tensor | zijn | Voer de bijbehorende runtime-tensor in |
De retourwaarde
(1) Geeft als resultaat de resultaten<runtime_tensor>
(2) Geeft als resultaat de resultaten <void>
Codevoorbeeld
// set input
interp.input_tensor(0, input_tensor).expect("cannot set input tensor");Functiebeschrijving
Gets/stelt de uitgaande tensor voor de opgegeven index in
Interface definitie
(1) result<runtime_tensor> output_tensor(size_t index) noexcept;
(2) result<void> output_tensor(size_t index, runtime_tensor tensor) noexcept;Invoerparameters
| Parameternaam | type | Ja of nee | beschrijving |
|---|---|---|---|
| index | size_t | zijn | |
| tensor | runtime_tensor | zijn | Voer de bijbehorende runtime-tensor in |
De retourwaarde
(1) Geeft als resultaat de resultaten<runtime_tensor>
(2) Geeft als resultaat de resultaten <void>
Codevoorbeeld
// get output
auto output_tensor = interp.output_tensor(0).expect("cannot get output tensor");
auto mapped_buf = std::move(hrt::map(output_tensor, hrt::map_read).unwrap_or_throw());
float *output_data = reinterpret_cast<float *>(mapped_buf.buffer().data());
auto out_shape = interp.output_shape(0);
auto it = std::max_element(output_data, output_data + compute_size(out_shape));
size_t idx = it - output_data;
std::cout << "image classification result: " << labels[idx] << "(" << *it << ")" << std::endl;Functiebeschrijving
KPU-berekeningen uitvoeren
Interface definitie
result<void> run() noexcept;Invoerparameters
N.V.T
De retourwaarde
resultaat <void>
Codevoorbeeld
// run
interp.run().expect("error occurred in running model");De voorbeeldcode bevindt zich op /path/to/nncase_sdk/examples/mobilenetv2_onnx_fp32_image
Voorwaarde voor voorvoegsel
- mobilenetv2_onnx_fp32_image.py script heeft gecompileerd de mobiletv2-7.onnx model
- Aangezien het voorbeeld afhankelijk is van de OpenCV-bibliotheek, moet u het pad naar OpenCV opgeven in de CMakeLists .txt van het voorbeeld.
Apps cross-compileren
cd /path/to/nncase_sdk/examples
./build.shGenereer ten slotte de mobilenetv2_onnx_fp32_image in de map out / bin
De k510 EVB opereert op het bord
Kopieer de volgende bestanden naar de K510 EVB board
| bestand | opmerking |
|---|---|
| mobilenetv2_onnx_fp32_image | Voorbeelden van cross-compileren worden gegenereerd |
| test.kmodel | Gebruik mobilenetv2_onnx_fp32_image.py compileer de mobiletv2-7.onnx build |
| Katten .png en labels_1000.txt | Onder de submap /path/to/nncase_sdk/examples/mobilenetv2_onnx_fp32_image/data/ |
$ export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/mnt/zhangyang/nncase_check/lib/gomp:/mnt/zhangyang/nncase_check/lib/opencv
$ ./mobilenetv2_onnx_fp32_image test.kmodel cat.png labels_1000.txt
case ./mobilenetv2_onnx_fp32_image build at Mar 1 2022 16:31:29
interp.run() duration: 12.6642 ms
image classification result: tiger cat(9.25)nncase Functional wordt gebruikt om het gebruiksgemak te verbeteren bij gebruikers pre- en post-process modellen
Momenteel is alleen de C++-versie van API's beschikbaar en bevinden de bijbehorende headerbestanden en bibliotheken zich in de map riscv64 van de nncase sdk.
Functiebeschrijving
Bereken het kwadraat, momenteel ondersteuning input uint8/int8, output is ook uint8/int8, merk op dat de input een vast punt is en de output floating point nodig is om de kwantisatieparameters in te stellen.
Interface definitie
public inline NNCASE_APIresult< runtime::runtime_tensor >square(runtime::runtime_tensor & input,datatype_t dtype) noexcept
Invoerparameters
| Parameternaam | type | Ja of nee | beschrijving |
|---|---|---|---|
input |
runtime_tensor | zijn | invoer |
dtype |
datatype_t | zijn | Gegevenstype uitvoertensor |
De retourwaarde
result<runtime_tensor>
Codevoorbeeld
if ((input_type == dt_uint8 or input_type == dt_int8) and (output_type == dt_float32 or output_type == dt_bfloat16))
{
input.quant_param(xxx);
}
auto squared = F::square(input, output_type).unwrap_or_throw();Functiebeschrijving
Bereken de waarde van het rootnummer, momenteel ondersteuning voor input uint8/int8, output is ook uint8/int8, merk op dat de input een vast punt is en dat de output floating point is om de kwantisatieparameters in te stellen.
Interface definitie
public inline NNCASE_APIresult< runtime::runtime_tensor >sqrt(runtime::runtime_tensor & input,datatype_t dtype) noexcept
Invoerparameters
| Parameternaam | type | Ja of nee | beschrijving |
|---|---|---|---|
input |
runtime_tensor | zijn | invoer |
dtype |
datatype_t | zijn | Gegevenstype uitvoertensor |
De retourwaarde
result<runtime_tensor>
Codevoorbeeld
if ((input_type == dt_uint8 or input_type == dt_int8) and (output_type == dt_float32 or output_type == dt_bfloat16))
{
input.quant_param(xxx);
}
auto output = F::sqrt(input, output_type).unwrap_or_throw();Functiebeschrijving
Bereken de logwaarde, het negatieve aantal invoer wordt geconverteerd naar Nan, ondersteunt momenteel input uint8 / int8, output is ook uint8 / int8, merk op dat de invoer een vast punt is en dat de uitvoer drijvende komma is om de kwantisatieparameter in te stellen.
Interface definitie
public inline NNCASE_APIresult< runtime::runtime_tensor >log(runtime::runtime_tensor & input,datatype_t dtype) noexcept
Invoerparameters
| Parameternaam | type | Ja of nee | beschrijving |
|---|---|---|---|
input |
runtime_tensor | zijn | invoer |
dtype |
datatype_t | zijn | Gegevenstype uitvoertensor |
De retourwaarde
result<runtime_tensor>
Codevoorbeeld
if ((input_type == dt_uint8 or input_type == dt_int8) and (output_type == dt_float32 or output_type == dt_bfloat16))
{
input.quant_param(xxx);
}
auto output = F::log(input, output_type).unwrap_or_throw();Functiebeschrijving
Bereken de exp-waarde, momenteel ondersteuning voor input uint8/int8, output is ook uint8/int8, merk op dat de input een vast punt is en dat de output floating point is en dat de kwantisatieparameters moeten worden ingesteld.
Interface definitie
public inline NNCASE_APIresult< runtime::runtime_tensor >exp(runtime::runtime_tensor & input,datatype_t dtype) noexcept
Invoerparameters
| Parameternaam | type | Ja of nee | beschrijving |
|---|---|---|---|
input |
runtime_tensor | zijn | invoer |
dtype |
datatype_t | zijn | Gegevenstype uitvoertensor |
De retourwaarde
result<runtime_tensor>
Codevoorbeeld
if ((input_type == dt_uint8 or input_type == dt_int8) and (output_type == dt_float32 or output_type == dt_bfloat16))
{
input.quant_param(xxx);
}
auto output = F::exp(input, output_type).unwrap_or_throw();Functiebeschrijving
Om de zondewaarde te berekenen, wordt de invoer uint8/int8 momenteel ondersteund en de uitvoer is ook uint8/int8, merk op dat de kwantisatieparameters moeten worden ingesteld wanneer de invoer een vast punt is en de uitvoer drijvende komma.
Interface definitie
public inline NNCASE_APIresult< runtime::runtime_tensor >sin(runtime::runtime_tensor & input,datatype_t dtype) noexcept
Invoerparameters
| Parameternaam | type | Ja of nee | beschrijving |
|---|---|---|---|
input |
runtime_tensor | zijn | invoer |
dtype |
datatype_t | zijn | Gegevenstype uitvoertensor |
De retourwaarde
result<runtime_tensor>
Code voorbeelden
if ((input_type == dt_uint8 or input_type == dt_int8) and (output_type == dt_float32 or output_type == dt_bfloat16))
{
input.quant_param(xxx);
}
auto output = F::sin(input, output_type).unwrap_or_throw();Functiebeschrijving
Bereken de cos-waarde, momenteel ondersteuning voor input uint8/ int8, output is ook uint8 / int8, merk op dat de invoer een vast punt is en dat de uitvoer drijvende komma is om de kwantisatieparameter in te stellen.
Interface definitie
public inline NNCASE_APIresult< runtime::runtime_tensor >cos(runtime::runtime_tensor & input,datatype_t dtype) noexcept
Invoerparameters
| Parameternaam | type | Ja of nee | beschrijving |
|---|---|---|---|
input |
runtime_tensor | zijn | invoer |
dtype |
datatype_t | zijn | Gegevenstype uitvoertensor |
De retourwaarde
result<runtime_tensor>
Code voorbeelden
if ((input_type == dt_uint8 or input_type == dt_int8) and (output_type == dt_float32 or output_type == dt_bfloat16))
{
input.quant_param(xxx);
}
auto output = F::cos(input, output_type).unwrap_or_throw();Functiebeschrijving
Om de ronde waarde te berekenen, wordt de input uint8/int8 momenteel ondersteund en de output is ook uint8/int8, merk op dat de kwantisatieparameter moet worden ingesteld wanneer de input een vast punt is en de output floating point is.
Interface definitie
public inline NNCASE_APIresult< runtime::runtime_tensor >round(runtime::runtime_tensor & input,datatype_t dtype) noexcept
Invoerparameters
| Parameternaam | type | Ja of nee | beschrijving |
|---|---|---|---|
input |
runtime_tensor | zijn | invoer |
dtype |
datatype_t | zijn | Gegevenstype uitvoertensor |
De retourwaarde
result<runtime_tensor>
Code voorbeelden
if ((input_type == dt_uint8 or input_type == dt_int8) and (output_type == dt_float32 or output_type == dt_bfloat16))
{
input.quant_param(xxx);
}
auto output = F::round(input, output_type).unwrap_or_throw();Functiebeschrijving
Bereken de vorstwaarde, momenteel ondersteuning voor input uint8/ int8, output is ook uint8 / int8, merk op dat de invoer een vast punt is en de output een zwevend punt is om de kwantisatieparameters in te stellen.
Interface definitie
public inline NNCASE_APIresult< runtime::runtime_tensor >floor(runtime::runtime_tensor & input,datatype_t dtype) noexcept
Invoerparameters
| Parameternaam | type | Ja of nee | beschrijving |
|---|---|---|---|
input |
runtime_tensor | zijn | invoer |
dtype |
datatype_t | zijn | Gegevenstype uitvoertensor |
De retourwaarde
result<runtime_tensor>
Code voorbeelden
if ((input_type == dt_uint8 or input_type == dt_int8) and (output_type == dt_float32 or output_type == dt_bfloat16))
{
input.quant_param(xxx);
}
auto output = F::floor(input, output_type).unwrap_or_throw();Functiebeschrijving
Bereken de ceil-waarde, momenteel ondersteuning voor input uint8/ int8, output is ook uint8 / int8, merk op dat de invoer een vast punt is en dat de output drijvende komma is om de kwantisatieparameters in te stellen.
Interface definitie
public inline NNCASE_APIresult< runtime::runtime_tensor >ceil(runtime::runtime_tensor & input,datatype_t dtype) noexcept
Invoerparameters
| Parameternaam | type | Ja of nee | beschrijving |
|---|---|---|---|
input |
runtime_tensor | zijn | invoer |
dtype |
datatype_t | zijn | Gegevenstype uitvoertensor |
De retourwaarde
result<runtime_tensor>
Code voorbeelden
if ((input_type == dt_uint8 or input_type == dt_int8) and (output_type == dt_float32 or output_type == dt_bfloat16))
{
input.quant_param(xxx);
}
auto output = F::ceil(input, output_type).unwrap_or_throw();Functiebeschrijving
Bereken de abs-waarde, momenteel ondersteuning voor input uint8 / int8, output is ook uint8 / int8, merk op dat de ingang een vast punt is en dat de output zwevend punt is, moet de kwantisatieparameters instellen.
Interface definitie
public inline NNCASE_APIresult< runtime::runtime_tensor >abs(runtime::runtime_tensor & input,datatype_t dtype) noexcept
Invoerparameters
| Parameternaam | type | Ja of nee | beschrijving |
|---|---|---|---|
input |
runtime_tensor | zijn | invoer |
dtype |
datatype_t | zijn | Gegevenstype uitvoertensor |
De retourwaarde
result<runtime_tensor>
Code voorbeelden
if ((input_type == dt_uint8 or input_type == dt_int8) and (output_type == dt_float32 or output_type == dt_bfloat16))
{
input.quant_param(xxx);
}
auto output = F::abs(input, output_type).unwrap_or_throw();Functiebeschrijving
Bereken de waarde van neg, momenteel ondersteuning input uint8/int8, output is ook uint8/int8, merk op dat de input een vast punt is en dat de output floating point is, moet de kwantisatieparameters instellen.
Interface definitie
public inline NNCASE_APIresult< runtime::runtime_tensor >neg(runtime::runtime_tensor & input,datatype_t dtype) noexcept
Invoerparameters
| Parameternaam | type | Ja of nee | beschrijving |
|---|---|---|---|
input |
runtime_tensor | zijn | invoer |
dtype |
datatype_t | zijn | Gegevenstype uitvoertensor |
De retourwaarde
result<runtime_tensor>
Code voorbeelden
if ((input_type == dt_uint8 or input_type == dt_int8) and (output_type == dt_float32 or output_type == dt_bfloat16))
{
input.quant_param(xxx);
}
auto output = F::neg(input, output_type).unwrap_or_throw();Functiebeschrijving
Invoer dt_bfloat16, dt_float32 gegevens, uitvoer dt_int8 of dt_uint8 uitvoer
Interface definitie
public inline NNCASE_APIresult< runtime::runtime_tensor >quantize(runtime::runtime_tensor & input,datatype_t dtype) noexcept
Invoerparameters
| Parameternaam | type | Ja of nee | beschrijving |
|---|---|---|---|
input |
runtime_tensor | zijn | Ingang, type moet float32 of bfloat16 zijn |
dtype |
datatype_t | zijn | Gegevenstype uitvoertensor |
De retourwaarde
result<runtime_tensor>
Code voorbeelden
auto quantized = F::quantize(input, dt_int8).unwrap_or_throw();Functiebeschrijving
Voer uint8- of int8-invoer in, converteer naar float- of bfloat-gegevens. Merk op dat de gebruiker vooraf de juiste kwantisatieparameters voor de gegevens moet instellen voor dequantisatie.
Interface definitie
public inline NNCASE_APIresult< runtime::runtime_tensor >dequantize(runtime::runtime_tensor & input,datatype_t dtype) noexcept
Invoerparameters
| Parameternaam | type | Ja of nee | beschrijving |
|---|---|---|---|
input |
runtime_tensor | zijn | invoer |
dtype |
datatype_t | zijn | Gegevenstype uitvoertensor |
De retourwaarde
result<runtime_tensor>
Code voorbeelden
input.quant_param({ 0, 1 });
auto dequantized = F::dequantize(input, output_type).unwrap_or_throw();Functiebeschrijving
Gegeven bboxes, bijgesneden van de oorspronkelijke tensor en resize output in de nieuwe tensor. Accepteer dt_bfloat16, dt_float32, dt_int8, dt_uint8 type uitvoer, uitvoer van hetzelfde type.
Interface definitie
NNCASE_API inline result<runtime::runtime_tensor> crop(runtime::runtime_tensor &input, runtime::runtime_tensor &bbox, size_t out_h, size_t out_w, image_resize_mode_t resize_mode, bool align_corners, bool half_pixel_centers) noexcept
Invoerparameters
| Parameternaam | type | Ja of nee | beschrijving |
|---|---|---|---|
| invoer | runtime_tensor | zijn | Voer de gegevens in, moet [n,c,h,w] de lay-out opmaken, als de gegevens uint8 of int8 zijn, zorg dan voor de juistheid van de gegevenskwantisatieparameters |
| bbox | runtime_tensor | zijn | Voer de bbox-gegevens in, moet [1,1,m,4] de lay-out opmaken, de interne gegevens zijn[y0,x0,y1,x1], het type is[float32, bfloat16] |
| out_h | size_t | zijn | Hoogte van de uitvoergegevens |
| out_w | size_t | zijn | Voer de gegevensbreedte in |
| resize_mode | image_resize_mode_t | zijn | Formaat van methodepatroon wijzigen |
| align_corners | Bool | zijn | Het formaat wijzigen of align_corners |
| half_pixel_centers | Bool | zijn | Formaat wijzigen als de pixel in het midden is uitgelijnd |
De retourwaarde
result<runtime_tensor>
Code voorbeelden
auto bbox = get_rand_bbox(input_shape, roi_amount);
auto &&[out_h, out_w] = get_rand_out_hw();
auto output_opt = F::crop(input, bbox, out_h, out_w, resize_mode).unwrap_or_throw();Functiebeschrijving
Gezien de breedte van de uitvoerhoogte, plaatst u het formaat van de ingangstensor naar de nieuwe grootte. Accepteer dt_bfloat16, dt_float32, dt_int8, dt_uint8 type uitvoer, uitvoer van hetzelfde type.
Interface definitie
NNCASE_API inline result<runtime::runtime_tensor> resize(runtime::runtime_tensor &input, size_t out_h, size_t out_w, image_resize_mode_t resize_mode, bool align_corners, bool half_pixel_centers) noexcept
Invoerparameters
| Parameternaam | type | Ja of nee | beschrijving |
|---|---|---|---|
| invoer | runtime_tensor | zijn | Voer de gegevens in, moet worden [n,c,h,w] opgemaakt, als de gegevens uint8 of int8 zijn, zorg dan voor de juistheid van de gegevenskwantisatieparameters |
| out_h | size_t | zijn | Hoogte van de uitvoergegevens |
| out_w | size_t | zijn | Voer de gegevensbreedte in |
| resize_mode | image_resize_mode_t | zijn | Formaat van methodepatroon wijzigen |
| align_corners | Bool | zijn | Het formaat wijzigen of align_corners |
| half_pixel_centers | Bool | zijn | Formaat wijzigen als de pixel in het midden is uitgelijnd |
De retourwaarde
result<runtime_tensor>
Code voorbeelden
auto &&[out_h, out_w] = get_rand_out_hw();
auto output_opt = F::resize(input, out_h, out_w, resize_mode, false, false).unwrap_or_throw();Functiebeschrijving
Opvulgegevens over elke dimensie accepteren uitvoer en uitvoer van hetzelfde type dt_bfloat16, dt_float32, dt_int8 dt_uint8 type.
Interface definitie
NNCASE_API inline result<runtime::runtime_tensor> pad(runtime::runtime_tensor &input, runtime_paddings_t &paddings, pad_mode_t pad_mode, float fill_v)
Invoerparameters
| Parameternaam | type | Ja of nee | beschrijving |
|---|---|---|---|
| invoer | runtime_tensor | zijn | Voer de gegevens in, als de gegevens uint8 of int8 Zijn, zorg voor de juistheid van de gegevenskwantisatieparameters |
| vulling | runtime_paddings_t | zijn | De opvulwaarde wordt bijvoorbeeld [ {2,3}, {1,3} ]aangegeven voor pad 2 in de laatste dimensie, gevolgd door pad 3. De voorlaatste dimensie wordt voorafgegaan door pad 1, gevolgd door pad 2 |
| pad_mode | pad_mode_t | zijn | Momenteel wordt alleen de const-modus ondersteund |
| fill_v | drijven | zijn | Vul de waarden in |
De retourwaarde
result<runtime_tensor>
Code voorbeelden
runtime_paddings_t paddings{ { 0, 0 }, { 0, 0 }, { 0, 0 }, { 1, 2 } };
auto output = F::pad(input, paddings, pad_constant, pad_value).unwrap_or_throw();| Classificatiemodel | CPU-precisie (Top-1) | Floating-point nauwkeurigheid (Top-1) | uint8 precisie (Top-1) | int8 Precisie (Top-1) |
|---|---|---|---|---|
| Alexnet | 0.531 | 0.53 | N.V.T | 0.52 |
| Densenet 121 | 0.732 | 0.732 | 0.723 | N.V.T |
| Inception v3 | 0.766 | 0.765 | 0.773 | 0.77 |
| Inception v4 | 0.789 | 0.789 | 0.793 | 0.792 |
| MobileNet v1 | 0.731 | 0.73 | 0.723 | 0.718 |
| MobileNet v2 | 0.713 | 0.715 | 0.713 | 0.719 |
| resnet50 v2 | 0.747 | 0.74 | 0.748 | 0.749 |
| VGG 16 | 0.689 | 0.687 | 0.690 | 0.689 |
Deze tabel is voornamelijk bedoeld om de prestaties van kwantisatie te vergelijken, de CPU-precisie is de volledige ImageNet-validatiesetgegevens en de floating-point en kwantisatienauwkeurigheid is het resultaat van de gegevenssubsettest voor de eerste afbeelding van de 1000 klassen in de validatieset volgens het ordinale getal.
De testresultaten van Alexnet en SenseNet zijn oude gegevens, die beide testresultaten zijn van de eerste 1000 afbeeldingen van de verificatieset als een subset van de gegevens, en N / A is dat de subset van testgegevens op dat moment verschilt van de CPU, dus het wordt niet gebruikt als een vergelijking.
Omdat het geselecteerde netwerk niet noodzakelijkerwijs afkomstig is van de ambtenaar of er verschillen zijn in de voorbewerking, enz., Kan het afwijken van de officiële prestaties.
-
Yolov3
COCOAPI Officiële resultaten CPU floating-point precisie gnne floating-point precisie uint8 precisie int8 precisie Gemiddelde precisie (AP) @ [IoU = 0.50:0.95| oppervlakte = alle | maxDets = 100] 0.314 0.307 0.306 0.295 0.288 Gemiddelde precisie (AP) @ [IoU = 0,50| oppervlakte = alle | maxDets = 100] 0.559 0.555 0.554 0.555 0.554 Gemiddelde precisie (AP) @ [IoU = 0,75| oppervlakte = alle | maxDets = 100] 0.318 0.308 0.307 0.287 0.275 Gemiddelde precisie (AP) @ [IoU = 0.50:0.95| oppervlakte = klein | maxDets = 100] 0.142 0.150 0.149 0.147 0.144 Gemiddelde precisie (AP) @ [IoU = 0.50:0.95 \ oppervlakte = medium | maxDets = 100] 0.341 0.332 0.332 0.322 Gemiddelde precisie (AP) @ [IoU = 0.50:0.95| oppervlakte = groot | maxDets = 100] 0.464 0.437 0.437 0.414 0.404 Gemiddelde recall (AR) @ [IoU = 0.50:0.95 \ oppervlakte = alle | maxDets = 1] 0.278 0.270 0.271 0.262 Gemiddelde recall (AR) @ [IoU = 0.50:0.95 \ oppervlakte = alle | maxDets = 10] 0.419 0.412 0.412 0.399 Gemiddelde recall (AR) @ [IoU = 0.50:0.95| oppervlakte = alle | maxDets = 100] 0.442 0.433 0.433 0.421 0.414 Gemiddelde recall (AR) @ [IoU = 0.50:0.95| oppervlakte = klein | maxDets = 100] 0.239 0.251 0.251 0.248 0.246 Gemiddelde recall (AR) @ [IoU = 0.50:0.95 \ oppervlakte = medium | maxDets = 100] 0.482 0.462 0.463 0.451 Gemiddelde recall (AR) @ [IoU = 0.50:0.95| oppervlakte = groot | maxDets = 100] 0.611 0.586 0.585 0.559 0.550 -
SSD-Mobilenetv1
COCOAPI Officiële resultaten CPU floating-point precisie gnne floating-point precisie uint8 precisie int8 precisie Gemiddelde precisie (AP) @ [IoU = 0.50:0.95| oppervlakte = alle | maxDets = 100] 0.184 0.184 0.184 0.183 0.183 Gemiddelde precisie (AP) @ [IoU = 0,50| oppervlakte = alle | maxDets = 100] 0.306 0.307 0.306 0.305 0.306 Gemiddelde precisie (AP) @ [IoU = 0,75| oppervlakte = alle | maxDets = 100] 0.191 0.192 0.190 0.189 0.190 Gemiddelde precisie (AP) @ [IoU = 0.50:0.95| oppervlakte = klein | maxDets = 100] 0.017 0.017 0.017 0.017 0.017 Gemiddelde precisie (AP) @ [IoU = 0.50:0.95 \ oppervlakte = medium | maxDets = 100] 0.157 0.157 0.157 0.156 Gemiddelde precisie (AP) @ [IoU = 0.50:0.95| oppervlakte = groot | maxDets = 100] 0.371 0.372 0.371 0.370 0.369 Gemiddelde terugroepactie (AR) @ [IoU = 0.50:0.95 \ oppervlakte = alle | maxDets = 1] 0.180 0.180 0.180 0.181 Gemiddelde terugroepactie (AR) @ [IoU = 0.50:0.95 \ oppervlakte = alle | maxDets = 10] 0.242 0.242 0.242 0.243 Gemiddelde terugroepactie (AR) @ [IoU = 0.50:0.95| oppervlakte = alle | maxDets = 100] 0.242 0.242 0.242 0.243 0.243 Gemiddelde terugroepactie (AR) @ [IoU = 0.50:0.95| oppervlakte = klein | maxDets = 100] 0.026 0.026 0.026 0.026 0.026 Gemiddelde terugroepactie (AR) @ [IoU = 0.50:0.95 \ oppervlakte = medium | maxDets = 100] 0.206 0.206 0.206 0.206 Gemiddelde terugroepactie (AR) @ [IoU = 0.50:0.95| oppervlakte = groot | maxDets = 100] 0.489 0.491 0.490 0.490 0.491 -
Yolov5s
COCOAPI Officiële resultaten CPU floating-point precisie gnne floating-point precisie uint8 precisie int8 precisie Gemiddelde precisie (AP) @ [IoU = 0.50:0.95| oppervlakte = alle | maxDets = 100] 0.367 0.365 0.335 0.334 0.335 Gemiddelde precisie (AP) @ [IoU = 0,50| oppervlakte = alle | maxDets = 100] 0.555 0.552 0.518 0.518 0.518 Gemiddelde precisie (AP) @ [IoU = 0,75| oppervlakte = alle | maxDets = 100] 0.398 0.395 0.364 0.363 0.362 Gemiddelde precisie (AP) @ [IoU = 0.50:0.95| oppervlakte = klein | maxDets = 100] 0.223 0.220 0.199 0.199 0.197 Gemiddelde precisie (AP) @ [IoU = 0.50:0.95 \ oppervlakte = medium | maxDets = 100] 0.419 0.418 0.387 0.386 Gemiddelde precisie (AP) @ [IoU = 0.50:0.95| oppervlakte = groot | maxDets = 100] 0.463 0.459 0.423 0.422 0.423 Gemiddelde terugroepactie (AR) @ [IoU = 0.50:0.95 \ oppervlakte = alle | maxDets = 1] 0.306 0.306 0.288 0.287 Gemiddelde terugroepactie (AR) @ [IoU = 0.50:0.95 \ oppervlakte = alle | maxDets = 10] 0.518 0.518 0.487 0.486 Gemiddelde terugroepactie (AR) @ [IoU = 0.50:0.95| oppervlakte = alle | maxDets = 100] 0.576 0.576 0.540 0.539 0.540 Gemiddelde terugroepactie (AR) @ [IoU = 0.50:0.95| oppervlakte = klein | maxDets = 100] 0.391 0.399 0.350 0.350 0.347 Gemiddelde terugroepactie (AR) @ [IoU = 0.50:0.95 \ oppervlakte = medium | maxDets = 100] 0.641 0.640 0.606 0.605 Gemiddelde terugroepactie (AR) @ [IoU = 0.50:0.95| oppervlakte = groot | maxDets = 100] 0.716 0.710 0.680 0.683 0.685
-
安装wheel时报错: "xxx.whl is geen ondersteund wiel op dit platform." **
Q: 安装ncase wheel包, 出现ERROR: nncase-1.0.0.20210830-cp37-cp37m-manylinux_2_24_x86_64.whl is geen ondersteund wiel op dit platform.
A: Upgrade pip > = 20.3
sudo pip3 install --upgrade pip
-
Wanneer de CRB het App-inferentieprogramma uitvoert, meldt het de fout "std::bad_alloc"
V: Voer het app-inferentieprogramma uit op de CRB en gooi een "std::bad_alloc"-uitzondering
$ ./cpp.sh case ./yolov3_bfloat16 build at Sep 16 2021 18:12:03 terminate called after throwing an instance of 'std::bad_alloc' what(): std::bad_alloc
A: std::bad_alloc uitzonderingen worden meestal veroorzaakt door geheugentoewijzingsfouten, die als volgt kunnen worden gecontroleerd.
- Controleer of het gegenereerde kmodel het huidige beschikbare geheugen van het systeem overschrijdt (zoals yolov3 bfloat16 kmodel grootte is 121MB, het huidige Linux beschikbare geheugen is slechts 70MB, de uitzondering zal worden gegooid). Als het overschrijdt, probeer dan na de training kwantisatie te gebruiken om de kmodelgrootte te verkleinen.
- Controleer de app op geheugenlekken
-
Bij het uitvoeren van het App inference programma[.. t_runtime_tensor.cpp:310 (maken)] data.size_bytes() == size = false (bool).
V: Simulator voert het app-inferentieprogramma uit en genereert een uitzondering "[.. t_runtime_tensor.cpp:310 (maken)] data.size_bytes() == size = false (bool)"
A: Controleer de invoertensorinformatie voor de instellingen, met de nadruk op de invoervorm en het aantal bytes dat door elk element wordt ingenomen (fp32/uint8)
Vertaling Disclaimer
Voor het gemak van klanten gebruikt Canaan een AI-vertaler om tekst in meerdere talen te vertalen, wat fouten kan bevatten. Wij garanderen niet de nauwkeurigheid, betrouwbaarheid of tijdigheid van de geleverde vertalingen. Canaan is niet aansprakelijk voor enig verlies of schade veroorzaakt door het vertrouwen op de nauwkeurigheid of betrouwbaarheid van de vertaalde informatie. Als er een inhoudelijk verschil is tussen de vertalingen in verschillende talen, prevaleert de vereenvoudigd Chinese versie.
Als u een vertaalfout of onnauwkeurigheid wilt melden, neem dan gerust contact met ons op via e-mail.