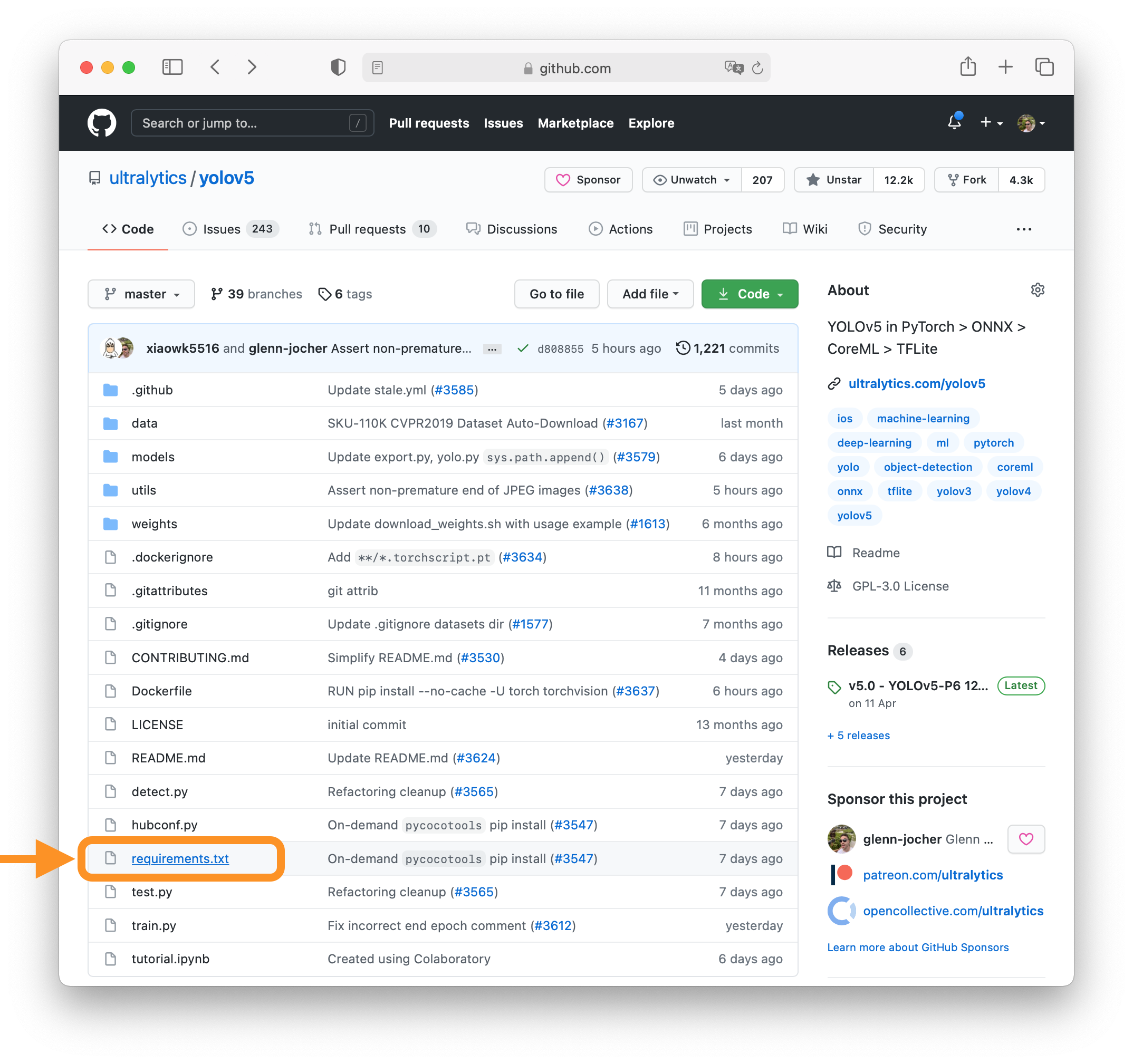
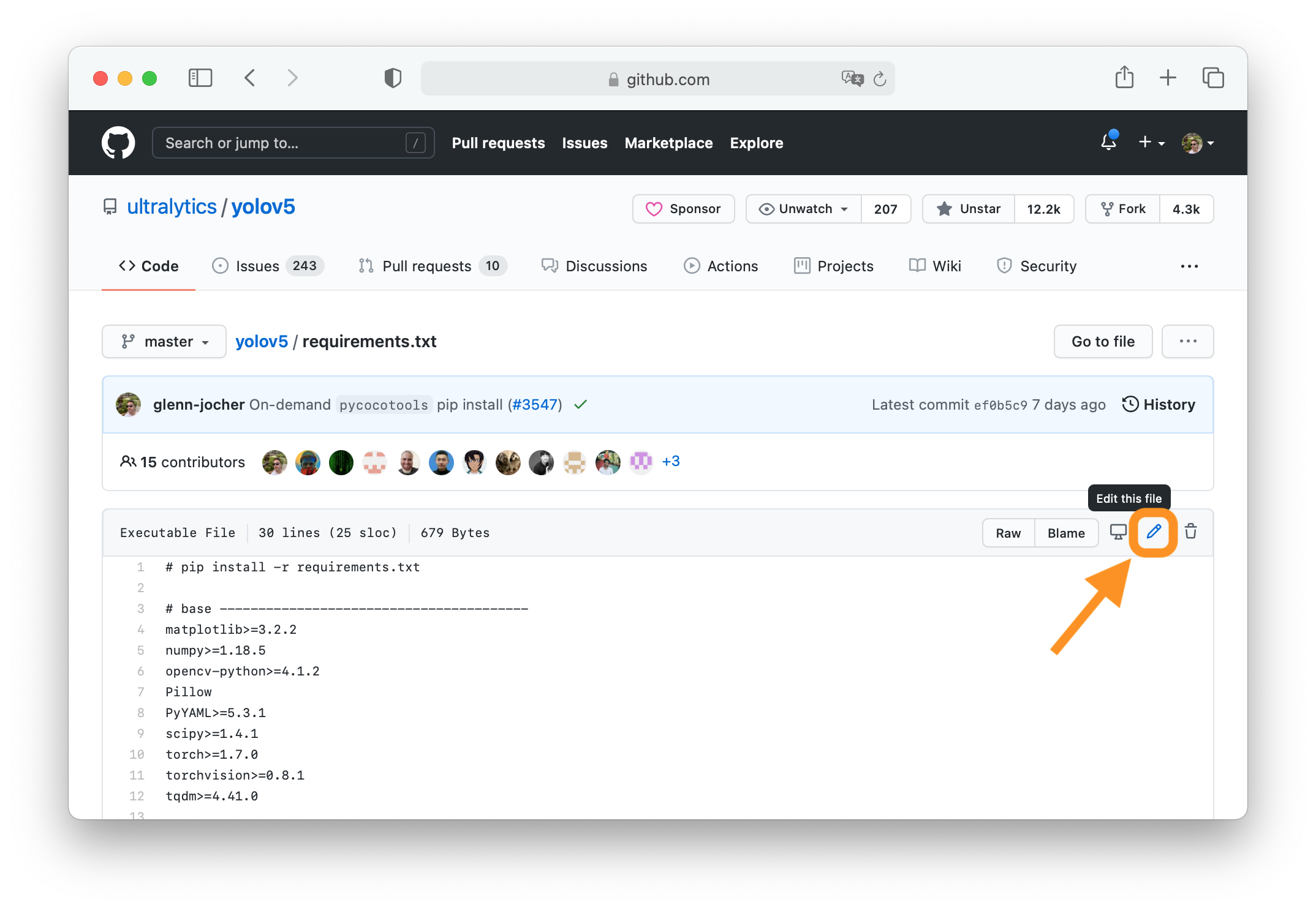
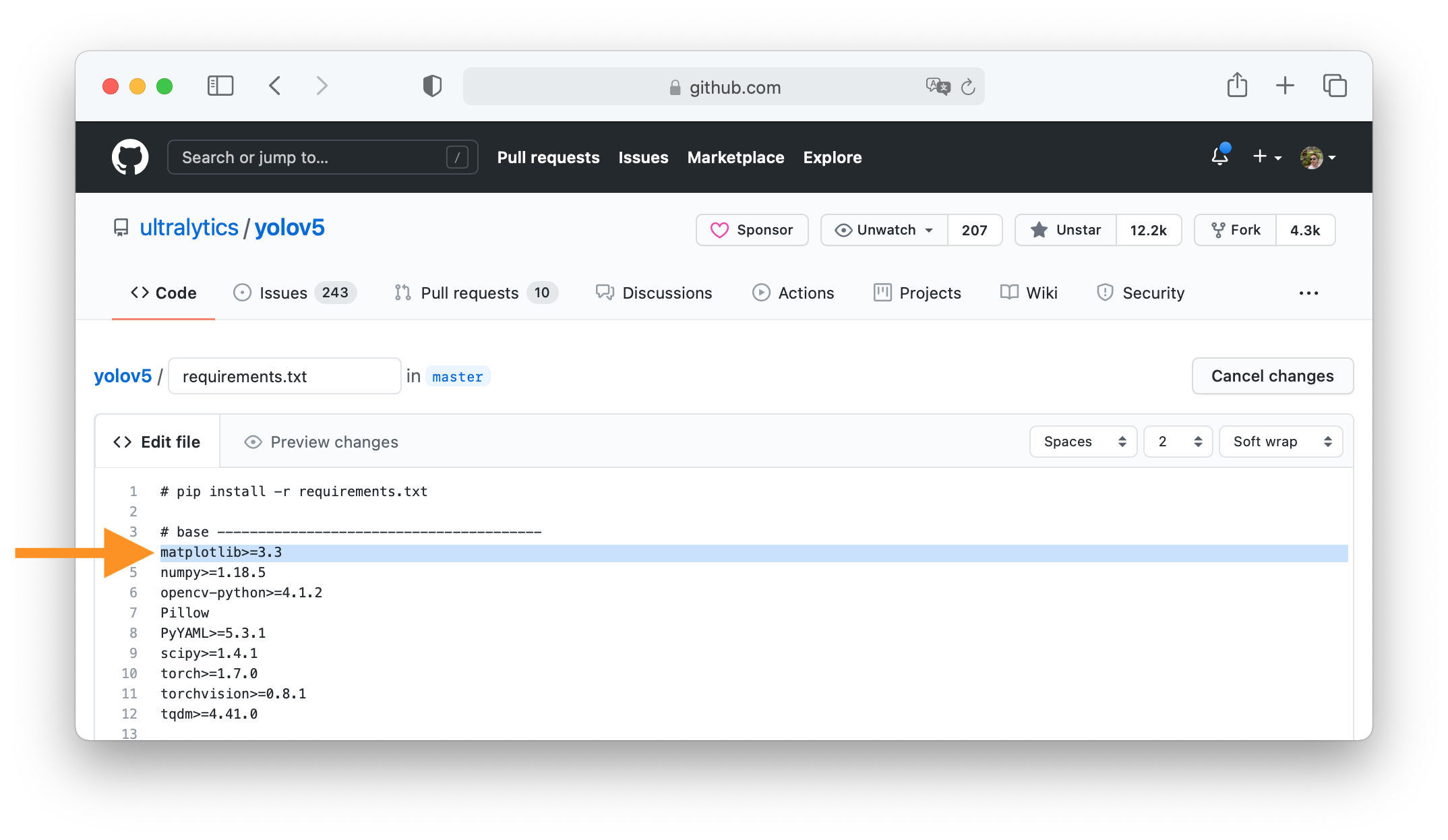
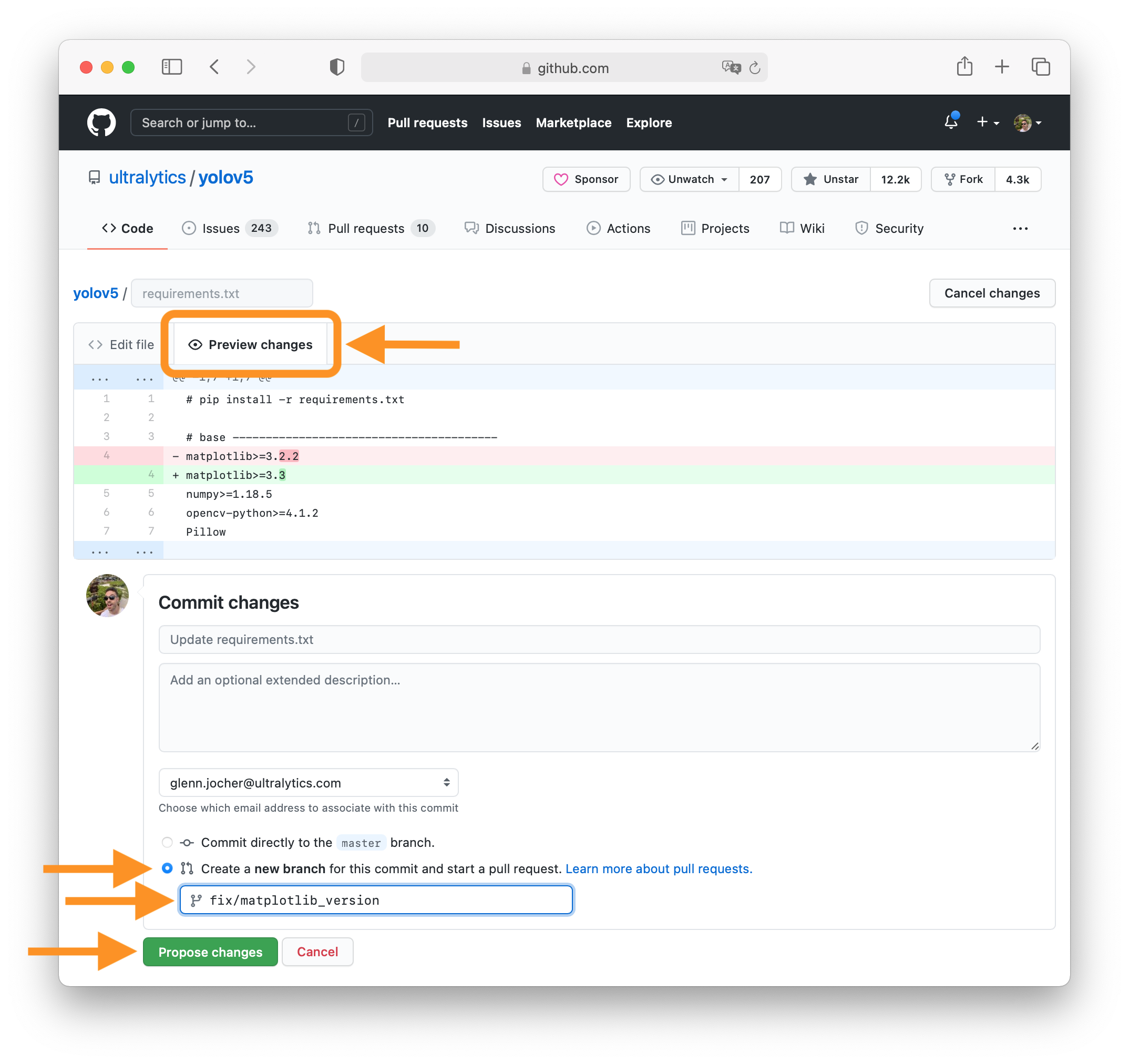

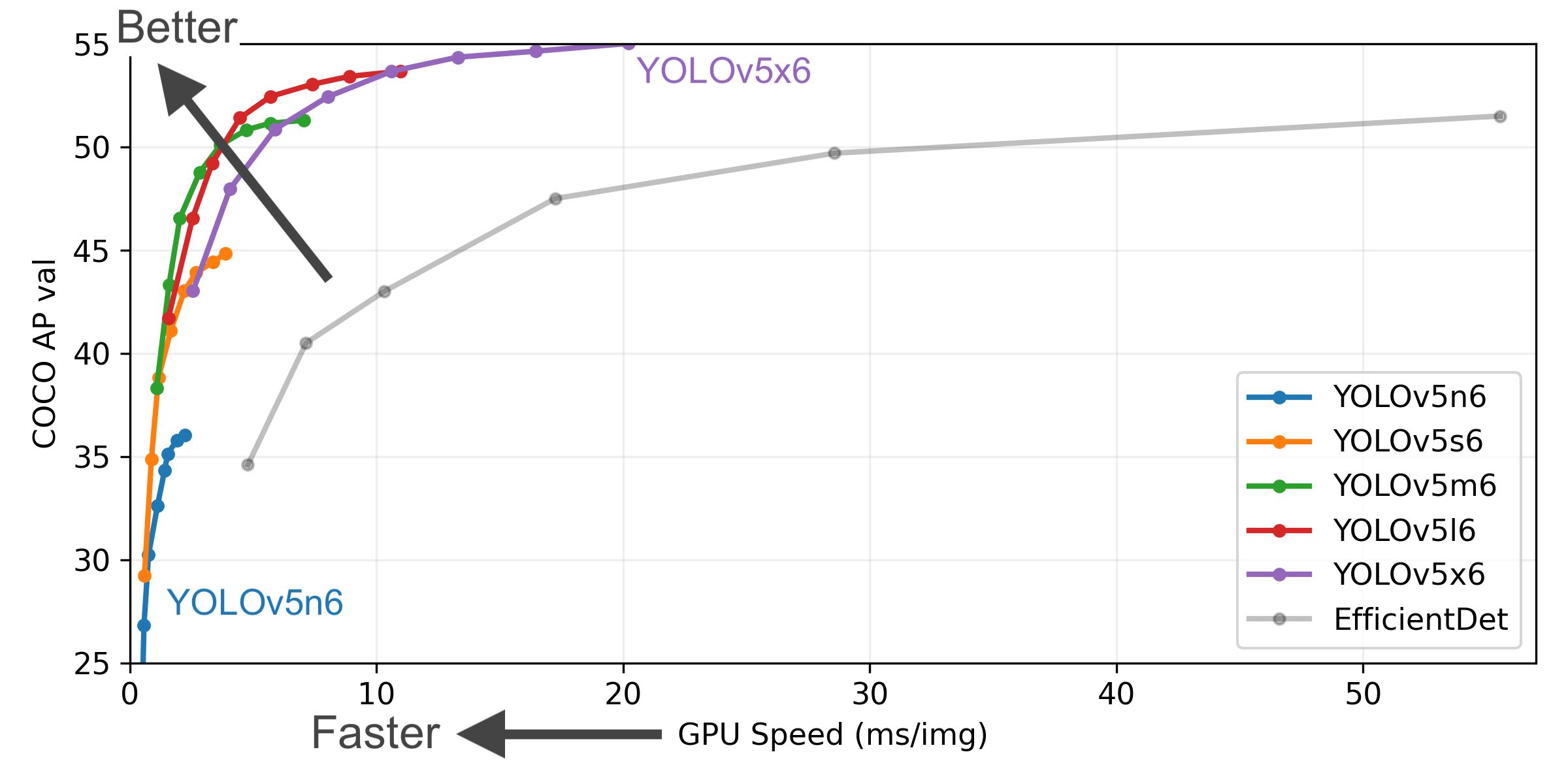
+
+  +
+
 +
+  +
+  +
+ +
+
+
+ +
+ +
+##
+
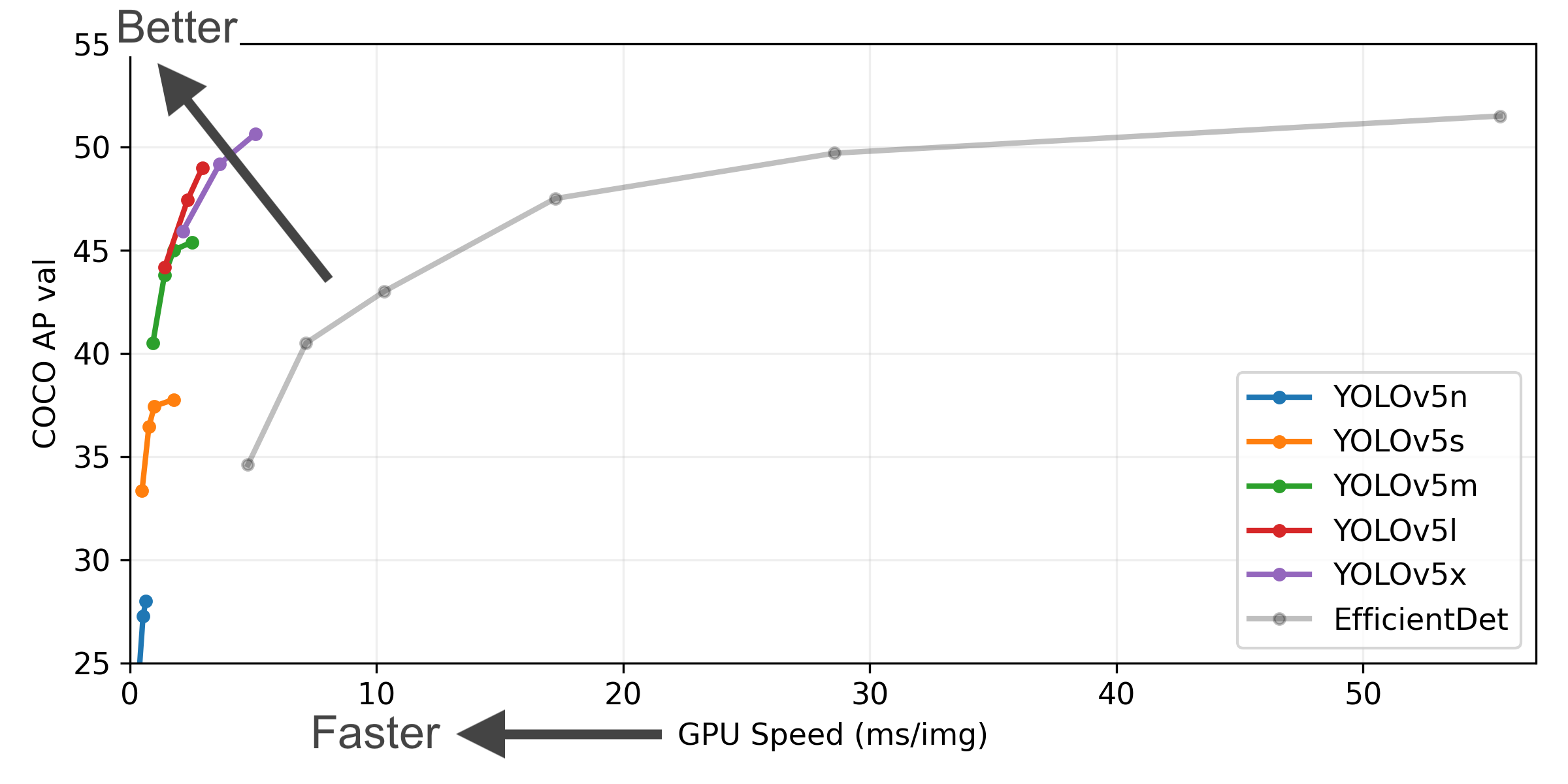
+## 
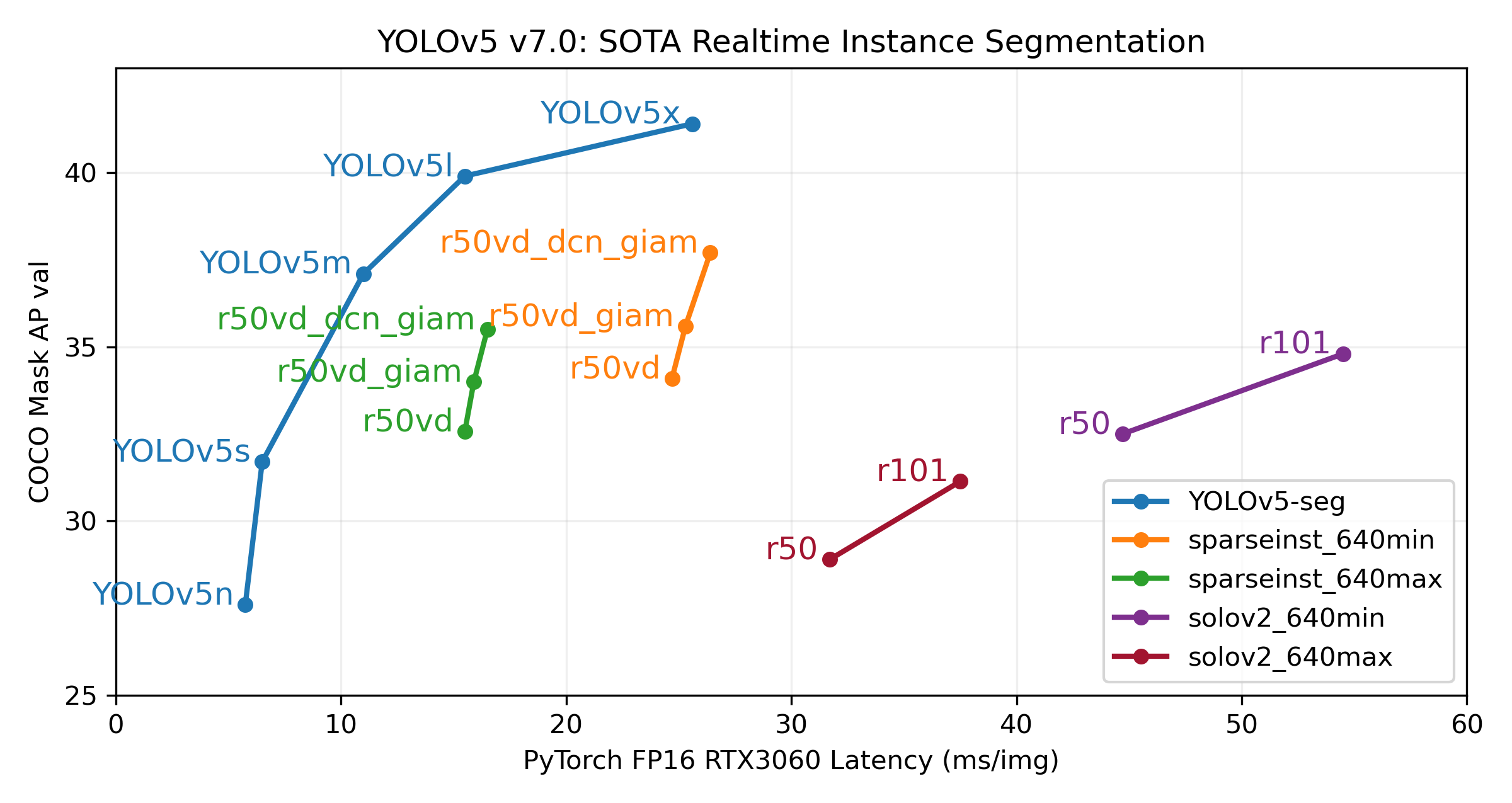 +
+ +
+##
+
+##
+
+
+
+
+
+
+
+
+
+
+##
+
+
+##  \n",
+ "\n",
+ "\n",
+ "
\n",
+ "\n",
+ "\n",
+ " \n",
+ "
\n",
+ " "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "0eq1SMWl6Sfn"
+ },
+ "source": [
+ "# 2. Validate\n",
+ "Validate a model's accuracy on the [COCO](https://cocodataset.org/#home) dataset's `val` or `test` splits. Models are downloaded automatically from the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases). To show results by class use the `--verbose` flag."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "WQPtK1QYVaD_",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "outputId": "cf7d52f0-281c-4c96-a488-79f5908f8426"
+ },
+ "source": [
+ "# Download COCO val\n",
+ "torch.hub.download_url_to_file('https://ultralytics.com/assets/coco2017val.zip', 'tmp.zip') # download (780M - 5000 images)\n",
+ "!unzip -q tmp.zip -d ../datasets && rm tmp.zip # unzip"
+ ],
+ "execution_count": 3,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stderr",
+ "text": [
+ "100%|██████████| 780M/780M [00:12<00:00, 66.6MB/s]\n"
+ ]
+ }
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "X58w8JLpMnjH",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "outputId": "3e234e05-ee8b-4ad1-b1a4-f6a55d5e4f3d"
+ },
+ "source": [
+ "# Validate YOLOv5s on COCO val\n",
+ "!python val.py --weights yolov5s.pt --data coco.yaml --img 640 --half"
+ ],
+ "execution_count": 4,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "\u001b[34m\u001b[1mval: \u001b[0mdata=/content/yolov5/data/coco.yaml, weights=['yolov5s.pt'], batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.6, max_det=300, task=val, device=, workers=8, single_cls=False, augment=False, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=True, project=runs/val, name=exp, exist_ok=False, half=True, dnn=False\n",
+ "YOLOv5 🚀 v7.0-136-g71244ae Python-3.9.16 torch-2.0.0+cu118 CUDA:0 (Tesla T4, 15102MiB)\n",
+ "\n",
+ "Fusing layers... \n",
+ "YOLOv5s summary: 213 layers, 7225885 parameters, 0 gradients\n",
+ "\u001b[34m\u001b[1mval: \u001b[0mScanning /content/datasets/coco/val2017... 4952 images, 48 backgrounds, 0 corrupt: 100% 5000/5000 [00:02<00:00, 2024.59it/s]\n",
+ "\u001b[34m\u001b[1mval: \u001b[0mNew cache created: /content/datasets/coco/val2017.cache\n",
+ " Class Images Instances P R mAP50 mAP50-95: 100% 157/157 [01:25<00:00, 1.84it/s]\n",
+ " all 5000 36335 0.671 0.519 0.566 0.371\n",
+ "Speed: 0.1ms pre-process, 3.1ms inference, 2.3ms NMS per image at shape (32, 3, 640, 640)\n",
+ "\n",
+ "Evaluating pycocotools mAP... saving runs/val/exp/yolov5s_predictions.json...\n",
+ "loading annotations into memory...\n",
+ "Done (t=0.43s)\n",
+ "creating index...\n",
+ "index created!\n",
+ "Loading and preparing results...\n",
+ "DONE (t=5.32s)\n",
+ "creating index...\n",
+ "index created!\n",
+ "Running per image evaluation...\n",
+ "Evaluate annotation type *bbox*\n",
+ "DONE (t=78.89s).\n",
+ "Accumulating evaluation results...\n",
+ "DONE (t=14.51s).\n",
+ " Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.374\n",
+ " Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.572\n",
+ " Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.402\n",
+ " Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.211\n",
+ " Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.423\n",
+ " Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.489\n",
+ " Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.311\n",
+ " Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.516\n",
+ " Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.566\n",
+ " Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.378\n",
+ " Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.625\n",
+ " Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.722\n",
+ "Results saved to \u001b[1mruns/val/exp\u001b[0m\n"
+ ]
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ZY2VXXXu74w5"
+ },
+ "source": [
+ "# 3. Train\n",
+ "\n",
+ "
"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "0eq1SMWl6Sfn"
+ },
+ "source": [
+ "# 2. Validate\n",
+ "Validate a model's accuracy on the [COCO](https://cocodataset.org/#home) dataset's `val` or `test` splits. Models are downloaded automatically from the [latest YOLOv5 release](https://github.com/ultralytics/yolov5/releases). To show results by class use the `--verbose` flag."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "WQPtK1QYVaD_",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "outputId": "cf7d52f0-281c-4c96-a488-79f5908f8426"
+ },
+ "source": [
+ "# Download COCO val\n",
+ "torch.hub.download_url_to_file('https://ultralytics.com/assets/coco2017val.zip', 'tmp.zip') # download (780M - 5000 images)\n",
+ "!unzip -q tmp.zip -d ../datasets && rm tmp.zip # unzip"
+ ],
+ "execution_count": 3,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stderr",
+ "text": [
+ "100%|██████████| 780M/780M [00:12<00:00, 66.6MB/s]\n"
+ ]
+ }
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "X58w8JLpMnjH",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "outputId": "3e234e05-ee8b-4ad1-b1a4-f6a55d5e4f3d"
+ },
+ "source": [
+ "# Validate YOLOv5s on COCO val\n",
+ "!python val.py --weights yolov5s.pt --data coco.yaml --img 640 --half"
+ ],
+ "execution_count": 4,
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "\u001b[34m\u001b[1mval: \u001b[0mdata=/content/yolov5/data/coco.yaml, weights=['yolov5s.pt'], batch_size=32, imgsz=640, conf_thres=0.001, iou_thres=0.6, max_det=300, task=val, device=, workers=8, single_cls=False, augment=False, verbose=False, save_txt=False, save_hybrid=False, save_conf=False, save_json=True, project=runs/val, name=exp, exist_ok=False, half=True, dnn=False\n",
+ "YOLOv5 🚀 v7.0-136-g71244ae Python-3.9.16 torch-2.0.0+cu118 CUDA:0 (Tesla T4, 15102MiB)\n",
+ "\n",
+ "Fusing layers... \n",
+ "YOLOv5s summary: 213 layers, 7225885 parameters, 0 gradients\n",
+ "\u001b[34m\u001b[1mval: \u001b[0mScanning /content/datasets/coco/val2017... 4952 images, 48 backgrounds, 0 corrupt: 100% 5000/5000 [00:02<00:00, 2024.59it/s]\n",
+ "\u001b[34m\u001b[1mval: \u001b[0mNew cache created: /content/datasets/coco/val2017.cache\n",
+ " Class Images Instances P R mAP50 mAP50-95: 100% 157/157 [01:25<00:00, 1.84it/s]\n",
+ " all 5000 36335 0.671 0.519 0.566 0.371\n",
+ "Speed: 0.1ms pre-process, 3.1ms inference, 2.3ms NMS per image at shape (32, 3, 640, 640)\n",
+ "\n",
+ "Evaluating pycocotools mAP... saving runs/val/exp/yolov5s_predictions.json...\n",
+ "loading annotations into memory...\n",
+ "Done (t=0.43s)\n",
+ "creating index...\n",
+ "index created!\n",
+ "Loading and preparing results...\n",
+ "DONE (t=5.32s)\n",
+ "creating index...\n",
+ "index created!\n",
+ "Running per image evaluation...\n",
+ "Evaluate annotation type *bbox*\n",
+ "DONE (t=78.89s).\n",
+ "Accumulating evaluation results...\n",
+ "DONE (t=14.51s).\n",
+ " Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.374\n",
+ " Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.572\n",
+ " Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.402\n",
+ " Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.211\n",
+ " Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.423\n",
+ " Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.489\n",
+ " Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.311\n",
+ " Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.516\n",
+ " Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.566\n",
+ " Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.378\n",
+ " Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.625\n",
+ " Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.722\n",
+ "Results saved to \u001b[1mruns/val/exp\u001b[0m\n"
+ ]
+ }
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ZY2VXXXu74w5"
+ },
+ "source": [
+ "# 3. Train\n",
+ "\n",
+ "
 "
+ ],
+ "metadata": {
+ "id": "nWOsI5wJR1o3"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## ClearML Logging and Automation 🌟 NEW\n",
+ "\n",
+ "[ClearML](https://cutt.ly/yolov5-notebook-clearml) is completely integrated into YOLOv5 to track your experimentation, manage dataset versions and even remotely execute training runs. To enable ClearML (check cells above):\n",
+ "\n",
+ "- `pip install clearml`\n",
+ "- run `clearml-init` to connect to a ClearML server (**deploy your own [open-source server](https://github.com/allegroai/clearml-server)**, or use our [free hosted server](https://cutt.ly/yolov5-notebook-clearml))\n",
+ "\n",
+ "You'll get all the great expected features from an experiment manager: live updates, model upload, experiment comparison etc. but ClearML also tracks uncommitted changes and installed packages for example. Thanks to that ClearML Tasks (which is what we call experiments) are also reproducible on different machines! With only 1 extra line, we can schedule a YOLOv5 training task on a queue to be executed by any number of ClearML Agents (workers).\n",
+ "\n",
+ "You can use ClearML Data to version your dataset and then pass it to YOLOv5 simply using its unique ID. This will help you keep track of your data without adding extra hassle. Explore the [ClearML Tutorial](https://docs.ultralytics.com/yolov5/tutorials/clearml_logging_integration) for details!\n",
+ "\n",
+ "\n",
+ "
"
+ ],
+ "metadata": {
+ "id": "nWOsI5wJR1o3"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "source": [
+ "## ClearML Logging and Automation 🌟 NEW\n",
+ "\n",
+ "[ClearML](https://cutt.ly/yolov5-notebook-clearml) is completely integrated into YOLOv5 to track your experimentation, manage dataset versions and even remotely execute training runs. To enable ClearML (check cells above):\n",
+ "\n",
+ "- `pip install clearml`\n",
+ "- run `clearml-init` to connect to a ClearML server (**deploy your own [open-source server](https://github.com/allegroai/clearml-server)**, or use our [free hosted server](https://cutt.ly/yolov5-notebook-clearml))\n",
+ "\n",
+ "You'll get all the great expected features from an experiment manager: live updates, model upload, experiment comparison etc. but ClearML also tracks uncommitted changes and installed packages for example. Thanks to that ClearML Tasks (which is what we call experiments) are also reproducible on different machines! With only 1 extra line, we can schedule a YOLOv5 training task on a queue to be executed by any number of ClearML Agents (workers).\n",
+ "\n",
+ "You can use ClearML Data to version your dataset and then pass it to YOLOv5 simply using its unique ID. This will help you keep track of your data without adding extra hassle. Explore the [ClearML Tutorial](https://docs.ultralytics.com/yolov5/tutorials/clearml_logging_integration) for details!\n",
+ "\n",
+ "\n",
+ " "
+ ],
+ "metadata": {
+ "id": "Lay2WsTjNJzP"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "-WPvRbS5Swl6"
+ },
+ "source": [
+ "## Local Logging\n",
+ "\n",
+ "Training results are automatically logged with [Tensorboard](https://www.tensorflow.org/tensorboard) and [CSV](https://github.com/ultralytics/yolov5/pull/4148) loggers to `runs/train`, with a new experiment directory created for each new training as `runs/train/exp2`, `runs/train/exp3`, etc.\n",
+ "\n",
+ "This directory contains train and val statistics, mosaics, labels, predictions and augmentated mosaics, as well as metrics and charts including precision-recall (PR) curves and confusion matrices. \n",
+ "\n",
+ "
"
+ ],
+ "metadata": {
+ "id": "Lay2WsTjNJzP"
+ }
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "-WPvRbS5Swl6"
+ },
+ "source": [
+ "## Local Logging\n",
+ "\n",
+ "Training results are automatically logged with [Tensorboard](https://www.tensorflow.org/tensorboard) and [CSV](https://github.com/ultralytics/yolov5/pull/4148) loggers to `runs/train`, with a new experiment directory created for each new training as `runs/train/exp2`, `runs/train/exp3`, etc.\n",
+ "\n",
+ "This directory contains train and val statistics, mosaics, labels, predictions and augmentated mosaics, as well as metrics and charts including precision-recall (PR) curves and confusion matrices. \n",
+ "\n",
+ " \n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Zelyeqbyt3GD"
+ },
+ "source": [
+ "# Environments\n",
+ "\n",
+ "YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):\n",
+ "\n",
+ "- **Notebooks** with free GPU: \n",
+ "- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)\n",
+ "- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)\n",
+ "- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/)
\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "Zelyeqbyt3GD"
+ },
+ "source": [
+ "# Environments\n",
+ "\n",
+ "YOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including [CUDA](https://developer.nvidia.com/cuda)/[CUDNN](https://developer.nvidia.com/cudnn), [Python](https://www.python.org/) and [PyTorch](https://pytorch.org/) preinstalled):\n",
+ "\n",
+ "- **Notebooks** with free GPU: \n",
+ "- **Google Cloud** Deep Learning VM. See [GCP Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/)\n",
+ "- **Amazon** Deep Learning AMI. See [AWS Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/)\n",
+ "- **Docker Image**. See [Docker Quickstart Guide](https://docs.ultralytics.com/yolov5/environments/docker_image_quickstart_tutorial/)  \n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "6Qu7Iesl0p54"
+ },
+ "source": [
+ "# Status\n",
+ "\n",
+ "\n",
+ "\n",
+ "If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training ([train.py](https://github.com/ultralytics/yolov5/blob/master/train.py)), testing ([val.py](https://github.com/ultralytics/yolov5/blob/master/val.py)), inference ([detect.py](https://github.com/ultralytics/yolov5/blob/master/detect.py)) and export ([export.py](https://github.com/ultralytics/yolov5/blob/master/export.py)) on macOS, Windows, and Ubuntu every 24 hours and on every commit.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "IEijrePND_2I"
+ },
+ "source": [
+ "# Appendix\n",
+ "\n",
+ "Additional content below."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "GMusP4OAxFu6"
+ },
+ "source": [
+ "# YOLOv5 PyTorch HUB Inference (DetectionModels only)\n",
+ "import torch\n",
+ "\n",
+ "model = torch.hub.load('ultralytics/yolov5', 'yolov5s', force_reload=True) # yolov5n - yolov5x6 or custom\n",
+ "im = 'https://ultralytics.com/images/zidane.jpg' # file, Path, PIL.Image, OpenCV, nparray, list\n",
+ "results = model(im) # inference\n",
+ "results.print() # or .show(), .save(), .crop(), .pandas(), etc."
+ ],
+ "execution_count": null,
+ "outputs": []
+ }
+ ]
+}
diff --git a/val.py b/val.py
new file mode 100644
index 0000000..522e33f
--- /dev/null
+++ b/val.py
@@ -0,0 +1,409 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Validate a trained YOLOv5 detection model on a detection dataset
+
+Usage:
+ $ python val.py --weights yolov5s.pt --data coco128.yaml --img 640
+
+Usage - formats:
+ $ python val.py --weights yolov5s.pt # PyTorch
+ yolov5s.torchscript # TorchScript
+ yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn
+ yolov5s_openvino_model # OpenVINO
+ yolov5s.engine # TensorRT
+ yolov5s.mlmodel # CoreML (macOS-only)
+ yolov5s_saved_model # TensorFlow SavedModel
+ yolov5s.pb # TensorFlow GraphDef
+ yolov5s.tflite # TensorFlow Lite
+ yolov5s_edgetpu.tflite # TensorFlow Edge TPU
+ yolov5s_paddle_model # PaddlePaddle
+"""
+
+import argparse
+import json
+import os
+import subprocess
+import sys
+from pathlib import Path
+
+import numpy as np
+import torch
+from tqdm import tqdm
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[0] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+from models.common import DetectMultiBackend
+from utils.callbacks import Callbacks
+from utils.dataloaders import create_dataloader
+from utils.general import (LOGGER, TQDM_BAR_FORMAT, Profile, check_dataset, check_img_size, check_requirements,
+ check_yaml, coco80_to_coco91_class, colorstr, increment_path, non_max_suppression,
+ print_args, scale_boxes, xywh2xyxy, xyxy2xywh)
+from utils.metrics import ConfusionMatrix, ap_per_class, box_iou
+from utils.plots import output_to_target, plot_images, plot_val_study
+from utils.torch_utils import select_device, smart_inference_mode
+
+
+def save_one_txt(predn, save_conf, shape, file):
+ # Save one txt result
+ gn = torch.tensor(shape)[[1, 0, 1, 0]] # normalization gain whwh
+ for *xyxy, conf, cls in predn.tolist():
+ xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
+ line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
+ with open(file, 'a') as f:
+ f.write(('%g ' * len(line)).rstrip() % line + '\n')
+
+
+def save_one_json(predn, jdict, path, class_map):
+ # Save one JSON result {"image_id": 42, "category_id": 18, "bbox": [258.15, 41.29, 348.26, 243.78], "score": 0.236}
+ image_id = int(path.stem) if path.stem.isnumeric() else path.stem
+ box = xyxy2xywh(predn[:, :4]) # xywh
+ box[:, :2] -= box[:, 2:] / 2 # xy center to top-left corner
+ for p, b in zip(predn.tolist(), box.tolist()):
+ jdict.append({
+ 'image_id': image_id,
+ 'category_id': class_map[int(p[5])],
+ 'bbox': [round(x, 3) for x in b],
+ 'score': round(p[4], 5)})
+
+
+def process_batch(detections, labels, iouv):
+ """
+ Return correct prediction matrix
+ Arguments:
+ detections (array[N, 6]), x1, y1, x2, y2, conf, class
+ labels (array[M, 5]), class, x1, y1, x2, y2
+ Returns:
+ correct (array[N, 10]), for 10 IoU levels
+ """
+ correct = np.zeros((detections.shape[0], iouv.shape[0])).astype(bool)
+ iou = box_iou(labels[:, 1:], detections[:, :4])
+ correct_class = labels[:, 0:1] == detections[:, 5]
+ for i in range(len(iouv)):
+ x = torch.where((iou >= iouv[i]) & correct_class) # IoU > threshold and classes match
+ if x[0].shape[0]:
+ matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy() # [label, detect, iou]
+ if x[0].shape[0] > 1:
+ matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 1], return_index=True)[1]]
+ # matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 0], return_index=True)[1]]
+ correct[matches[:, 1].astype(int), i] = True
+ return torch.tensor(correct, dtype=torch.bool, device=iouv.device)
+
+
+@smart_inference_mode()
+def run(
+ data,
+ weights=None, # model.pt path(s)
+ batch_size=32, # batch size
+ imgsz=640, # inference size (pixels)
+ conf_thres=0.001, # confidence threshold
+ iou_thres=0.6, # NMS IoU threshold
+ max_det=300, # maximum detections per image
+ task='val', # train, val, test, speed or study
+ device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
+ workers=8, # max dataloader workers (per RANK in DDP mode)
+ single_cls=False, # treat as single-class dataset
+ augment=False, # augmented inference
+ verbose=False, # verbose output
+ save_txt=False, # save results to *.txt
+ save_hybrid=False, # save label+prediction hybrid results to *.txt
+ save_conf=False, # save confidences in --save-txt labels
+ save_json=False, # save a COCO-JSON results file
+ project=ROOT / 'runs/val', # save to project/name
+ name='exp', # save to project/name
+ exist_ok=False, # existing project/name ok, do not increment
+ half=True, # use FP16 half-precision inference
+ dnn=False, # use OpenCV DNN for ONNX inference
+ model=None,
+ dataloader=None,
+ save_dir=Path(''),
+ plots=True,
+ callbacks=Callbacks(),
+ compute_loss=None,
+):
+ # Initialize/load model and set device
+ training = model is not None
+ if training: # called by train.py
+ device, pt, jit, engine = next(model.parameters()).device, True, False, False # get model device, PyTorch model
+ half &= device.type != 'cpu' # half precision only supported on CUDA
+ model.half() if half else model.float()
+ else: # called directly
+ device = select_device(device, batch_size=batch_size)
+
+ # Directories
+ save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
+ (save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
+
+ # Load model
+ model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)
+ stride, pt, jit, engine = model.stride, model.pt, model.jit, model.engine
+ imgsz = check_img_size(imgsz, s=stride) # check image size
+ half = model.fp16 # FP16 supported on limited backends with CUDA
+ if engine:
+ batch_size = model.batch_size
+ else:
+ device = model.device
+ if not (pt or jit):
+ batch_size = 1 # export.py models default to batch-size 1
+ LOGGER.info(f'Forcing --batch-size 1 square inference (1,3,{imgsz},{imgsz}) for non-PyTorch models')
+
+ # Data
+ data = check_dataset(data) # check
+
+ # Configure
+ model.eval()
+ cuda = device.type != 'cpu'
+ is_coco = isinstance(data.get('val'), str) and data['val'].endswith(f'coco{os.sep}val2017.txt') # COCO dataset
+ nc = 1 if single_cls else int(data['nc']) # number of classes
+ iouv = torch.linspace(0.5, 0.95, 10, device=device) # iou vector for mAP@0.5:0.95
+ niou = iouv.numel()
+
+ # Dataloader
+ if not training:
+ if pt and not single_cls: # check --weights are trained on --data
+ ncm = model.model.nc
+ assert ncm == nc, f'{weights} ({ncm} classes) trained on different --data than what you passed ({nc} ' \
+ f'classes). Pass correct combination of --weights and --data that are trained together.'
+ model.warmup(imgsz=(1 if pt else batch_size, 3, imgsz, imgsz)) # warmup
+ pad, rect = (0.0, False) if task == 'speed' else (0.5, pt) # square inference for benchmarks
+ task = task if task in ('train', 'val', 'test') else 'val' # path to train/val/test images
+ dataloader = create_dataloader(data[task],
+ imgsz,
+ batch_size,
+ stride,
+ single_cls,
+ pad=pad,
+ rect=rect,
+ workers=workers,
+ prefix=colorstr(f'{task}: '))[0]
+
+ seen = 0
+ confusion_matrix = ConfusionMatrix(nc=nc)
+ names = model.names if hasattr(model, 'names') else model.module.names # get class names
+ if isinstance(names, (list, tuple)): # old format
+ names = dict(enumerate(names))
+ class_map = coco80_to_coco91_class() if is_coco else list(range(1000))
+ s = ('%22s' + '%11s' * 6) % ('Class', 'Images', 'Instances', 'P', 'R', 'mAP50', 'mAP50-95')
+ tp, fp, p, r, f1, mp, mr, map50, ap50, map = 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0
+ dt = Profile(), Profile(), Profile() # profiling times
+ loss = torch.zeros(3, device=device)
+ jdict, stats, ap, ap_class = [], [], [], []
+ callbacks.run('on_val_start')
+ pbar = tqdm(dataloader, desc=s, bar_format=TQDM_BAR_FORMAT) # progress bar
+ for batch_i, (im, targets, paths, shapes) in enumerate(pbar):
+ callbacks.run('on_val_batch_start')
+ with dt[0]:
+ if cuda:
+ im = im.to(device, non_blocking=True)
+ targets = targets.to(device)
+ im = im.half() if half else im.float() # uint8 to fp16/32
+ im /= 255 # 0 - 255 to 0.0 - 1.0
+ nb, _, height, width = im.shape # batch size, channels, height, width
+
+ # Inference
+ with dt[1]:
+ preds, train_out = model(im) if compute_loss else (model(im, augment=augment), None)
+
+ # Loss
+ if compute_loss:
+ loss += compute_loss(train_out, targets)[1] # box, obj, cls
+
+ # NMS
+ targets[:, 2:] *= torch.tensor((width, height, width, height), device=device) # to pixels
+ lb = [targets[targets[:, 0] == i, 1:] for i in range(nb)] if save_hybrid else [] # for autolabelling
+ with dt[2]:
+ preds = non_max_suppression(preds,
+ conf_thres,
+ iou_thres,
+ labels=lb,
+ multi_label=True,
+ agnostic=single_cls,
+ max_det=max_det)
+
+ # Metrics
+ for si, pred in enumerate(preds):
+ labels = targets[targets[:, 0] == si, 1:]
+ nl, npr = labels.shape[0], pred.shape[0] # number of labels, predictions
+ path, shape = Path(paths[si]), shapes[si][0]
+ correct = torch.zeros(npr, niou, dtype=torch.bool, device=device) # init
+ seen += 1
+
+ if npr == 0:
+ if nl:
+ stats.append((correct, *torch.zeros((2, 0), device=device), labels[:, 0]))
+ if plots:
+ confusion_matrix.process_batch(detections=None, labels=labels[:, 0])
+ continue
+
+ # Predictions
+ if single_cls:
+ pred[:, 5] = 0
+ predn = pred.clone()
+ scale_boxes(im[si].shape[1:], predn[:, :4], shape, shapes[si][1]) # native-space pred
+
+ # Evaluate
+ if nl:
+ tbox = xywh2xyxy(labels[:, 1:5]) # target boxes
+ scale_boxes(im[si].shape[1:], tbox, shape, shapes[si][1]) # native-space labels
+ labelsn = torch.cat((labels[:, 0:1], tbox), 1) # native-space labels
+ correct = process_batch(predn, labelsn, iouv)
+ if plots:
+ confusion_matrix.process_batch(predn, labelsn)
+ stats.append((correct, pred[:, 4], pred[:, 5], labels[:, 0])) # (correct, conf, pcls, tcls)
+
+ # Save/log
+ if save_txt:
+ save_one_txt(predn, save_conf, shape, file=save_dir / 'labels' / f'{path.stem}.txt')
+ if save_json:
+ save_one_json(predn, jdict, path, class_map) # append to COCO-JSON dictionary
+ callbacks.run('on_val_image_end', pred, predn, path, names, im[si])
+
+ # Plot images
+ if plots and batch_i < 3:
+ plot_images(im, targets, paths, save_dir / f'val_batch{batch_i}_labels.jpg', names) # labels
+ plot_images(im, output_to_target(preds), paths, save_dir / f'val_batch{batch_i}_pred.jpg', names) # pred
+
+ callbacks.run('on_val_batch_end', batch_i, im, targets, paths, shapes, preds)
+
+ # Compute metrics
+ stats = [torch.cat(x, 0).cpu().numpy() for x in zip(*stats)] # to numpy
+ if len(stats) and stats[0].any():
+ tp, fp, p, r, f1, ap, ap_class = ap_per_class(*stats, plot=plots, save_dir=save_dir, names=names)
+ ap50, ap = ap[:, 0], ap.mean(1) # AP@0.5, AP@0.5:0.95
+ mp, mr, map50, map = p.mean(), r.mean(), ap50.mean(), ap.mean()
+ nt = np.bincount(stats[3].astype(int), minlength=nc) # number of targets per class
+
+ # Print results
+ pf = '%22s' + '%11i' * 2 + '%11.3g' * 4 # print format
+ LOGGER.info(pf % ('all', seen, nt.sum(), mp, mr, map50, map))
+ if nt.sum() == 0:
+ LOGGER.warning(f'WARNING ⚠️ no labels found in {task} set, can not compute metrics without labels')
+
+ # Print results per class
+ if (verbose or (nc < 50 and not training)) and nc > 1 and len(stats):
+ for i, c in enumerate(ap_class):
+ LOGGER.info(pf % (names[c], seen, nt[c], p[i], r[i], ap50[i], ap[i]))
+
+ # Print speeds
+ t = tuple(x.t / seen * 1E3 for x in dt) # speeds per image
+ if not training:
+ shape = (batch_size, 3, imgsz, imgsz)
+ LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {shape}' % t)
+
+ # Plots
+ if plots:
+ confusion_matrix.plot(save_dir=save_dir, names=list(names.values()))
+ callbacks.run('on_val_end', nt, tp, fp, p, r, f1, ap, ap50, ap_class, confusion_matrix)
+
+ # Save JSON
+ if save_json and len(jdict):
+ w = Path(weights[0] if isinstance(weights, list) else weights).stem if weights is not None else '' # weights
+ anno_json = str(Path('../datasets/coco/annotations/instances_val2017.json')) # annotations
+ pred_json = str(save_dir / f'{w}_predictions.json') # predictions
+ LOGGER.info(f'\nEvaluating pycocotools mAP... saving {pred_json}...')
+ with open(pred_json, 'w') as f:
+ json.dump(jdict, f)
+
+ try: # https://github.com/cocodataset/cocoapi/blob/master/PythonAPI/pycocoEvalDemo.ipynb
+ check_requirements('pycocotools>=2.0.6')
+ from pycocotools.coco import COCO
+ from pycocotools.cocoeval import COCOeval
+
+ anno = COCO(anno_json) # init annotations api
+ pred = anno.loadRes(pred_json) # init predictions api
+ eval = COCOeval(anno, pred, 'bbox')
+ if is_coco:
+ eval.params.imgIds = [int(Path(x).stem) for x in dataloader.dataset.im_files] # image IDs to evaluate
+ eval.evaluate()
+ eval.accumulate()
+ eval.summarize()
+ map, map50 = eval.stats[:2] # update results (mAP@0.5:0.95, mAP@0.5)
+ except Exception as e:
+ LOGGER.info(f'pycocotools unable to run: {e}')
+
+ # Return results
+ model.float() # for training
+ if not training:
+ s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
+ LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}{s}")
+ maps = np.zeros(nc) + map
+ for i, c in enumerate(ap_class):
+ maps[c] = ap[i]
+ return (mp, mr, map50, map, *(loss.cpu() / len(dataloader)).tolist()), maps, t
+
+
+def parse_opt():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
+ parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model path(s)')
+ parser.add_argument('--batch-size', type=int, default=32, help='batch size')
+ parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='inference size (pixels)')
+ parser.add_argument('--conf-thres', type=float, default=0.001, help='confidence threshold')
+ parser.add_argument('--iou-thres', type=float, default=0.6, help='NMS IoU threshold')
+ parser.add_argument('--max-det', type=int, default=300, help='maximum detections per image')
+ parser.add_argument('--task', default='val', help='train, val, test, speed or study')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
+ parser.add_argument('--single-cls', action='store_true', help='treat as single-class dataset')
+ parser.add_argument('--augment', action='store_true', help='augmented inference')
+ parser.add_argument('--verbose', action='store_true', help='report mAP by class')
+ parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
+ parser.add_argument('--save-hybrid', action='store_true', help='save label+prediction hybrid results to *.txt')
+ parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
+ parser.add_argument('--save-json', action='store_true', help='save a COCO-JSON results file')
+ parser.add_argument('--project', default=ROOT / 'runs/val', help='save to project/name')
+ parser.add_argument('--name', default='exp', help='save to project/name')
+ parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
+ parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
+ parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
+ opt = parser.parse_args()
+ opt.data = check_yaml(opt.data) # check YAML
+ opt.save_json |= opt.data.endswith('coco.yaml')
+ opt.save_txt |= opt.save_hybrid
+ print_args(vars(opt))
+ return opt
+
+
+def main(opt):
+ check_requirements(ROOT / 'requirements.txt', exclude=('tensorboard', 'thop'))
+
+ if opt.task in ('train', 'val', 'test'): # run normally
+ if opt.conf_thres > 0.001: # https://github.com/ultralytics/yolov5/issues/1466
+ LOGGER.info(f'WARNING ⚠️ confidence threshold {opt.conf_thres} > 0.001 produces invalid results')
+ if opt.save_hybrid:
+ LOGGER.info('WARNING ⚠️ --save-hybrid will return high mAP from hybrid labels, not from predictions alone')
+ run(**vars(opt))
+
+ else:
+ weights = opt.weights if isinstance(opt.weights, list) else [opt.weights]
+ opt.half = torch.cuda.is_available() and opt.device != 'cpu' # FP16 for fastest results
+ if opt.task == 'speed': # speed benchmarks
+ # python val.py --task speed --data coco.yaml --batch 1 --weights yolov5n.pt yolov5s.pt...
+ opt.conf_thres, opt.iou_thres, opt.save_json = 0.25, 0.45, False
+ for opt.weights in weights:
+ run(**vars(opt), plots=False)
+
+ elif opt.task == 'study': # speed vs mAP benchmarks
+ # python val.py --task study --data coco.yaml --iou 0.7 --weights yolov5n.pt yolov5s.pt...
+ for opt.weights in weights:
+ f = f'study_{Path(opt.data).stem}_{Path(opt.weights).stem}.txt' # filename to save to
+ x, y = list(range(256, 1536 + 128, 128)), [] # x axis (image sizes), y axis
+ for opt.imgsz in x: # img-size
+ LOGGER.info(f'\nRunning {f} --imgsz {opt.imgsz}...')
+ r, _, t = run(**vars(opt), plots=False)
+ y.append(r + t) # results and times
+ np.savetxt(f, y, fmt='%10.4g') # save
+ subprocess.run(['zip', '-r', 'study.zip', 'study_*.txt'])
+ plot_val_study(x=x) # plot
+ else:
+ raise NotImplementedError(f'--task {opt.task} not in ("train", "val", "test", "speed", "study")')
+
+
+if __name__ == '__main__':
+ opt = parse_opt()
+ main(opt)
\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "6Qu7Iesl0p54"
+ },
+ "source": [
+ "# Status\n",
+ "\n",
+ "\n",
+ "\n",
+ "If this badge is green, all [YOLOv5 GitHub Actions](https://github.com/ultralytics/yolov5/actions) Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training ([train.py](https://github.com/ultralytics/yolov5/blob/master/train.py)), testing ([val.py](https://github.com/ultralytics/yolov5/blob/master/val.py)), inference ([detect.py](https://github.com/ultralytics/yolov5/blob/master/detect.py)) and export ([export.py](https://github.com/ultralytics/yolov5/blob/master/export.py)) on macOS, Windows, and Ubuntu every 24 hours and on every commit.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "IEijrePND_2I"
+ },
+ "source": [
+ "# Appendix\n",
+ "\n",
+ "Additional content below."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "metadata": {
+ "id": "GMusP4OAxFu6"
+ },
+ "source": [
+ "# YOLOv5 PyTorch HUB Inference (DetectionModels only)\n",
+ "import torch\n",
+ "\n",
+ "model = torch.hub.load('ultralytics/yolov5', 'yolov5s', force_reload=True) # yolov5n - yolov5x6 or custom\n",
+ "im = 'https://ultralytics.com/images/zidane.jpg' # file, Path, PIL.Image, OpenCV, nparray, list\n",
+ "results = model(im) # inference\n",
+ "results.print() # or .show(), .save(), .crop(), .pandas(), etc."
+ ],
+ "execution_count": null,
+ "outputs": []
+ }
+ ]
+}
diff --git a/val.py b/val.py
new file mode 100644
index 0000000..522e33f
--- /dev/null
+++ b/val.py
@@ -0,0 +1,409 @@
+# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
+"""
+Validate a trained YOLOv5 detection model on a detection dataset
+
+Usage:
+ $ python val.py --weights yolov5s.pt --data coco128.yaml --img 640
+
+Usage - formats:
+ $ python val.py --weights yolov5s.pt # PyTorch
+ yolov5s.torchscript # TorchScript
+ yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn
+ yolov5s_openvino_model # OpenVINO
+ yolov5s.engine # TensorRT
+ yolov5s.mlmodel # CoreML (macOS-only)
+ yolov5s_saved_model # TensorFlow SavedModel
+ yolov5s.pb # TensorFlow GraphDef
+ yolov5s.tflite # TensorFlow Lite
+ yolov5s_edgetpu.tflite # TensorFlow Edge TPU
+ yolov5s_paddle_model # PaddlePaddle
+"""
+
+import argparse
+import json
+import os
+import subprocess
+import sys
+from pathlib import Path
+
+import numpy as np
+import torch
+from tqdm import tqdm
+
+FILE = Path(__file__).resolve()
+ROOT = FILE.parents[0] # YOLOv5 root directory
+if str(ROOT) not in sys.path:
+ sys.path.append(str(ROOT)) # add ROOT to PATH
+ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
+
+from models.common import DetectMultiBackend
+from utils.callbacks import Callbacks
+from utils.dataloaders import create_dataloader
+from utils.general import (LOGGER, TQDM_BAR_FORMAT, Profile, check_dataset, check_img_size, check_requirements,
+ check_yaml, coco80_to_coco91_class, colorstr, increment_path, non_max_suppression,
+ print_args, scale_boxes, xywh2xyxy, xyxy2xywh)
+from utils.metrics import ConfusionMatrix, ap_per_class, box_iou
+from utils.plots import output_to_target, plot_images, plot_val_study
+from utils.torch_utils import select_device, smart_inference_mode
+
+
+def save_one_txt(predn, save_conf, shape, file):
+ # Save one txt result
+ gn = torch.tensor(shape)[[1, 0, 1, 0]] # normalization gain whwh
+ for *xyxy, conf, cls in predn.tolist():
+ xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
+ line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
+ with open(file, 'a') as f:
+ f.write(('%g ' * len(line)).rstrip() % line + '\n')
+
+
+def save_one_json(predn, jdict, path, class_map):
+ # Save one JSON result {"image_id": 42, "category_id": 18, "bbox": [258.15, 41.29, 348.26, 243.78], "score": 0.236}
+ image_id = int(path.stem) if path.stem.isnumeric() else path.stem
+ box = xyxy2xywh(predn[:, :4]) # xywh
+ box[:, :2] -= box[:, 2:] / 2 # xy center to top-left corner
+ for p, b in zip(predn.tolist(), box.tolist()):
+ jdict.append({
+ 'image_id': image_id,
+ 'category_id': class_map[int(p[5])],
+ 'bbox': [round(x, 3) for x in b],
+ 'score': round(p[4], 5)})
+
+
+def process_batch(detections, labels, iouv):
+ """
+ Return correct prediction matrix
+ Arguments:
+ detections (array[N, 6]), x1, y1, x2, y2, conf, class
+ labels (array[M, 5]), class, x1, y1, x2, y2
+ Returns:
+ correct (array[N, 10]), for 10 IoU levels
+ """
+ correct = np.zeros((detections.shape[0], iouv.shape[0])).astype(bool)
+ iou = box_iou(labels[:, 1:], detections[:, :4])
+ correct_class = labels[:, 0:1] == detections[:, 5]
+ for i in range(len(iouv)):
+ x = torch.where((iou >= iouv[i]) & correct_class) # IoU > threshold and classes match
+ if x[0].shape[0]:
+ matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy() # [label, detect, iou]
+ if x[0].shape[0] > 1:
+ matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 1], return_index=True)[1]]
+ # matches = matches[matches[:, 2].argsort()[::-1]]
+ matches = matches[np.unique(matches[:, 0], return_index=True)[1]]
+ correct[matches[:, 1].astype(int), i] = True
+ return torch.tensor(correct, dtype=torch.bool, device=iouv.device)
+
+
+@smart_inference_mode()
+def run(
+ data,
+ weights=None, # model.pt path(s)
+ batch_size=32, # batch size
+ imgsz=640, # inference size (pixels)
+ conf_thres=0.001, # confidence threshold
+ iou_thres=0.6, # NMS IoU threshold
+ max_det=300, # maximum detections per image
+ task='val', # train, val, test, speed or study
+ device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
+ workers=8, # max dataloader workers (per RANK in DDP mode)
+ single_cls=False, # treat as single-class dataset
+ augment=False, # augmented inference
+ verbose=False, # verbose output
+ save_txt=False, # save results to *.txt
+ save_hybrid=False, # save label+prediction hybrid results to *.txt
+ save_conf=False, # save confidences in --save-txt labels
+ save_json=False, # save a COCO-JSON results file
+ project=ROOT / 'runs/val', # save to project/name
+ name='exp', # save to project/name
+ exist_ok=False, # existing project/name ok, do not increment
+ half=True, # use FP16 half-precision inference
+ dnn=False, # use OpenCV DNN for ONNX inference
+ model=None,
+ dataloader=None,
+ save_dir=Path(''),
+ plots=True,
+ callbacks=Callbacks(),
+ compute_loss=None,
+):
+ # Initialize/load model and set device
+ training = model is not None
+ if training: # called by train.py
+ device, pt, jit, engine = next(model.parameters()).device, True, False, False # get model device, PyTorch model
+ half &= device.type != 'cpu' # half precision only supported on CUDA
+ model.half() if half else model.float()
+ else: # called directly
+ device = select_device(device, batch_size=batch_size)
+
+ # Directories
+ save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
+ (save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
+
+ # Load model
+ model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)
+ stride, pt, jit, engine = model.stride, model.pt, model.jit, model.engine
+ imgsz = check_img_size(imgsz, s=stride) # check image size
+ half = model.fp16 # FP16 supported on limited backends with CUDA
+ if engine:
+ batch_size = model.batch_size
+ else:
+ device = model.device
+ if not (pt or jit):
+ batch_size = 1 # export.py models default to batch-size 1
+ LOGGER.info(f'Forcing --batch-size 1 square inference (1,3,{imgsz},{imgsz}) for non-PyTorch models')
+
+ # Data
+ data = check_dataset(data) # check
+
+ # Configure
+ model.eval()
+ cuda = device.type != 'cpu'
+ is_coco = isinstance(data.get('val'), str) and data['val'].endswith(f'coco{os.sep}val2017.txt') # COCO dataset
+ nc = 1 if single_cls else int(data['nc']) # number of classes
+ iouv = torch.linspace(0.5, 0.95, 10, device=device) # iou vector for mAP@0.5:0.95
+ niou = iouv.numel()
+
+ # Dataloader
+ if not training:
+ if pt and not single_cls: # check --weights are trained on --data
+ ncm = model.model.nc
+ assert ncm == nc, f'{weights} ({ncm} classes) trained on different --data than what you passed ({nc} ' \
+ f'classes). Pass correct combination of --weights and --data that are trained together.'
+ model.warmup(imgsz=(1 if pt else batch_size, 3, imgsz, imgsz)) # warmup
+ pad, rect = (0.0, False) if task == 'speed' else (0.5, pt) # square inference for benchmarks
+ task = task if task in ('train', 'val', 'test') else 'val' # path to train/val/test images
+ dataloader = create_dataloader(data[task],
+ imgsz,
+ batch_size,
+ stride,
+ single_cls,
+ pad=pad,
+ rect=rect,
+ workers=workers,
+ prefix=colorstr(f'{task}: '))[0]
+
+ seen = 0
+ confusion_matrix = ConfusionMatrix(nc=nc)
+ names = model.names if hasattr(model, 'names') else model.module.names # get class names
+ if isinstance(names, (list, tuple)): # old format
+ names = dict(enumerate(names))
+ class_map = coco80_to_coco91_class() if is_coco else list(range(1000))
+ s = ('%22s' + '%11s' * 6) % ('Class', 'Images', 'Instances', 'P', 'R', 'mAP50', 'mAP50-95')
+ tp, fp, p, r, f1, mp, mr, map50, ap50, map = 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0
+ dt = Profile(), Profile(), Profile() # profiling times
+ loss = torch.zeros(3, device=device)
+ jdict, stats, ap, ap_class = [], [], [], []
+ callbacks.run('on_val_start')
+ pbar = tqdm(dataloader, desc=s, bar_format=TQDM_BAR_FORMAT) # progress bar
+ for batch_i, (im, targets, paths, shapes) in enumerate(pbar):
+ callbacks.run('on_val_batch_start')
+ with dt[0]:
+ if cuda:
+ im = im.to(device, non_blocking=True)
+ targets = targets.to(device)
+ im = im.half() if half else im.float() # uint8 to fp16/32
+ im /= 255 # 0 - 255 to 0.0 - 1.0
+ nb, _, height, width = im.shape # batch size, channels, height, width
+
+ # Inference
+ with dt[1]:
+ preds, train_out = model(im) if compute_loss else (model(im, augment=augment), None)
+
+ # Loss
+ if compute_loss:
+ loss += compute_loss(train_out, targets)[1] # box, obj, cls
+
+ # NMS
+ targets[:, 2:] *= torch.tensor((width, height, width, height), device=device) # to pixels
+ lb = [targets[targets[:, 0] == i, 1:] for i in range(nb)] if save_hybrid else [] # for autolabelling
+ with dt[2]:
+ preds = non_max_suppression(preds,
+ conf_thres,
+ iou_thres,
+ labels=lb,
+ multi_label=True,
+ agnostic=single_cls,
+ max_det=max_det)
+
+ # Metrics
+ for si, pred in enumerate(preds):
+ labels = targets[targets[:, 0] == si, 1:]
+ nl, npr = labels.shape[0], pred.shape[0] # number of labels, predictions
+ path, shape = Path(paths[si]), shapes[si][0]
+ correct = torch.zeros(npr, niou, dtype=torch.bool, device=device) # init
+ seen += 1
+
+ if npr == 0:
+ if nl:
+ stats.append((correct, *torch.zeros((2, 0), device=device), labels[:, 0]))
+ if plots:
+ confusion_matrix.process_batch(detections=None, labels=labels[:, 0])
+ continue
+
+ # Predictions
+ if single_cls:
+ pred[:, 5] = 0
+ predn = pred.clone()
+ scale_boxes(im[si].shape[1:], predn[:, :4], shape, shapes[si][1]) # native-space pred
+
+ # Evaluate
+ if nl:
+ tbox = xywh2xyxy(labels[:, 1:5]) # target boxes
+ scale_boxes(im[si].shape[1:], tbox, shape, shapes[si][1]) # native-space labels
+ labelsn = torch.cat((labels[:, 0:1], tbox), 1) # native-space labels
+ correct = process_batch(predn, labelsn, iouv)
+ if plots:
+ confusion_matrix.process_batch(predn, labelsn)
+ stats.append((correct, pred[:, 4], pred[:, 5], labels[:, 0])) # (correct, conf, pcls, tcls)
+
+ # Save/log
+ if save_txt:
+ save_one_txt(predn, save_conf, shape, file=save_dir / 'labels' / f'{path.stem}.txt')
+ if save_json:
+ save_one_json(predn, jdict, path, class_map) # append to COCO-JSON dictionary
+ callbacks.run('on_val_image_end', pred, predn, path, names, im[si])
+
+ # Plot images
+ if plots and batch_i < 3:
+ plot_images(im, targets, paths, save_dir / f'val_batch{batch_i}_labels.jpg', names) # labels
+ plot_images(im, output_to_target(preds), paths, save_dir / f'val_batch{batch_i}_pred.jpg', names) # pred
+
+ callbacks.run('on_val_batch_end', batch_i, im, targets, paths, shapes, preds)
+
+ # Compute metrics
+ stats = [torch.cat(x, 0).cpu().numpy() for x in zip(*stats)] # to numpy
+ if len(stats) and stats[0].any():
+ tp, fp, p, r, f1, ap, ap_class = ap_per_class(*stats, plot=plots, save_dir=save_dir, names=names)
+ ap50, ap = ap[:, 0], ap.mean(1) # AP@0.5, AP@0.5:0.95
+ mp, mr, map50, map = p.mean(), r.mean(), ap50.mean(), ap.mean()
+ nt = np.bincount(stats[3].astype(int), minlength=nc) # number of targets per class
+
+ # Print results
+ pf = '%22s' + '%11i' * 2 + '%11.3g' * 4 # print format
+ LOGGER.info(pf % ('all', seen, nt.sum(), mp, mr, map50, map))
+ if nt.sum() == 0:
+ LOGGER.warning(f'WARNING ⚠️ no labels found in {task} set, can not compute metrics without labels')
+
+ # Print results per class
+ if (verbose or (nc < 50 and not training)) and nc > 1 and len(stats):
+ for i, c in enumerate(ap_class):
+ LOGGER.info(pf % (names[c], seen, nt[c], p[i], r[i], ap50[i], ap[i]))
+
+ # Print speeds
+ t = tuple(x.t / seen * 1E3 for x in dt) # speeds per image
+ if not training:
+ shape = (batch_size, 3, imgsz, imgsz)
+ LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {shape}' % t)
+
+ # Plots
+ if plots:
+ confusion_matrix.plot(save_dir=save_dir, names=list(names.values()))
+ callbacks.run('on_val_end', nt, tp, fp, p, r, f1, ap, ap50, ap_class, confusion_matrix)
+
+ # Save JSON
+ if save_json and len(jdict):
+ w = Path(weights[0] if isinstance(weights, list) else weights).stem if weights is not None else '' # weights
+ anno_json = str(Path('../datasets/coco/annotations/instances_val2017.json')) # annotations
+ pred_json = str(save_dir / f'{w}_predictions.json') # predictions
+ LOGGER.info(f'\nEvaluating pycocotools mAP... saving {pred_json}...')
+ with open(pred_json, 'w') as f:
+ json.dump(jdict, f)
+
+ try: # https://github.com/cocodataset/cocoapi/blob/master/PythonAPI/pycocoEvalDemo.ipynb
+ check_requirements('pycocotools>=2.0.6')
+ from pycocotools.coco import COCO
+ from pycocotools.cocoeval import COCOeval
+
+ anno = COCO(anno_json) # init annotations api
+ pred = anno.loadRes(pred_json) # init predictions api
+ eval = COCOeval(anno, pred, 'bbox')
+ if is_coco:
+ eval.params.imgIds = [int(Path(x).stem) for x in dataloader.dataset.im_files] # image IDs to evaluate
+ eval.evaluate()
+ eval.accumulate()
+ eval.summarize()
+ map, map50 = eval.stats[:2] # update results (mAP@0.5:0.95, mAP@0.5)
+ except Exception as e:
+ LOGGER.info(f'pycocotools unable to run: {e}')
+
+ # Return results
+ model.float() # for training
+ if not training:
+ s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
+ LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}{s}")
+ maps = np.zeros(nc) + map
+ for i, c in enumerate(ap_class):
+ maps[c] = ap[i]
+ return (mp, mr, map50, map, *(loss.cpu() / len(dataloader)).tolist()), maps, t
+
+
+def parse_opt():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
+ parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model path(s)')
+ parser.add_argument('--batch-size', type=int, default=32, help='batch size')
+ parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='inference size (pixels)')
+ parser.add_argument('--conf-thres', type=float, default=0.001, help='confidence threshold')
+ parser.add_argument('--iou-thres', type=float, default=0.6, help='NMS IoU threshold')
+ parser.add_argument('--max-det', type=int, default=300, help='maximum detections per image')
+ parser.add_argument('--task', default='val', help='train, val, test, speed or study')
+ parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
+ parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
+ parser.add_argument('--single-cls', action='store_true', help='treat as single-class dataset')
+ parser.add_argument('--augment', action='store_true', help='augmented inference')
+ parser.add_argument('--verbose', action='store_true', help='report mAP by class')
+ parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
+ parser.add_argument('--save-hybrid', action='store_true', help='save label+prediction hybrid results to *.txt')
+ parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
+ parser.add_argument('--save-json', action='store_true', help='save a COCO-JSON results file')
+ parser.add_argument('--project', default=ROOT / 'runs/val', help='save to project/name')
+ parser.add_argument('--name', default='exp', help='save to project/name')
+ parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
+ parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
+ parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
+ opt = parser.parse_args()
+ opt.data = check_yaml(opt.data) # check YAML
+ opt.save_json |= opt.data.endswith('coco.yaml')
+ opt.save_txt |= opt.save_hybrid
+ print_args(vars(opt))
+ return opt
+
+
+def main(opt):
+ check_requirements(ROOT / 'requirements.txt', exclude=('tensorboard', 'thop'))
+
+ if opt.task in ('train', 'val', 'test'): # run normally
+ if opt.conf_thres > 0.001: # https://github.com/ultralytics/yolov5/issues/1466
+ LOGGER.info(f'WARNING ⚠️ confidence threshold {opt.conf_thres} > 0.001 produces invalid results')
+ if opt.save_hybrid:
+ LOGGER.info('WARNING ⚠️ --save-hybrid will return high mAP from hybrid labels, not from predictions alone')
+ run(**vars(opt))
+
+ else:
+ weights = opt.weights if isinstance(opt.weights, list) else [opt.weights]
+ opt.half = torch.cuda.is_available() and opt.device != 'cpu' # FP16 for fastest results
+ if opt.task == 'speed': # speed benchmarks
+ # python val.py --task speed --data coco.yaml --batch 1 --weights yolov5n.pt yolov5s.pt...
+ opt.conf_thres, opt.iou_thres, opt.save_json = 0.25, 0.45, False
+ for opt.weights in weights:
+ run(**vars(opt), plots=False)
+
+ elif opt.task == 'study': # speed vs mAP benchmarks
+ # python val.py --task study --data coco.yaml --iou 0.7 --weights yolov5n.pt yolov5s.pt...
+ for opt.weights in weights:
+ f = f'study_{Path(opt.data).stem}_{Path(opt.weights).stem}.txt' # filename to save to
+ x, y = list(range(256, 1536 + 128, 128)), [] # x axis (image sizes), y axis
+ for opt.imgsz in x: # img-size
+ LOGGER.info(f'\nRunning {f} --imgsz {opt.imgsz}...')
+ r, _, t = run(**vars(opt), plots=False)
+ y.append(r + t) # results and times
+ np.savetxt(f, y, fmt='%10.4g') # save
+ subprocess.run(['zip', '-r', 'study.zip', 'study_*.txt'])
+ plot_val_study(x=x) # plot
+ else:
+ raise NotImplementedError(f'--task {opt.task} not in ("train", "val", "test", "speed", "study")')
+
+
+if __name__ == '__main__':
+ opt = parse_opt()
+ main(opt)