设计目的:
-
分布式水平扩展
Allowing the log to scale beyond a size that will fit on a single server. Each individual partition must fit on the servers that host it, but a topic may have many partitions so it can handle an arbitrary amount of data.
-
提高消息处理的并行度
Act as the unit of parallelism—more on that in a bit.

ConsumerGroup用于标注一组消费者属于同一个组,对应Paritition的设计理念2,提高消息处理的并行度。
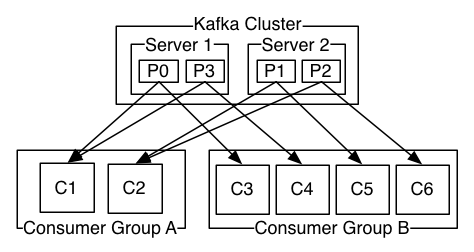
这种设计有几个特性
If all the consumer instances have the same consumer group, then the records will effectively be load balanced over the consumer instances.If all the consumer instances have different consumer groups, then each record will be broadcast to all the consumer processes.如果一个消费者组下的consumer多于partition的数量,意味着有一些consumer将无法消费到消息
Kafka的Offset管理在kafka名字为__offset_consumer的topic中,每一个消费者组对应的partition是固定的,会记录在${"consumerGroup.id".hashCode%50}的partition中,可以使用kafka-simple-consumer-shell.sh查看Offset的提交记录。

- CurrentOffset(保存在Consumer中,Consumer可以自行维护该Offset,以便下次从自行寻找offset进行消费)
- CommitedOffset(保存在kafka的broker上,记录Consumer下次开始消费的位置)
当一个ConsumerGroup开始消费kafka时,将从上次提交的位置开始继续消费,如果该ConsumerGroup没有初始的offset或者提交的offset不在kafka的留存范围内,auto.offset.reset(earliest/latest[Default])将决定开始消费的位置
-
Kafka消费者默认每5秒提交一次offset(
auto.commit.interval.ms默认为5000ms)可以通过设置enable.auto.commit为false禁止默认提交行为 -
此外,用户可以显示的调用
consumer.commitSync()提交offset,也可以指定Topic和Partition和offset进行提交public void commitSync(final Map<TopicPartition, OffsetAndMetadata> offsets) { coordinator.commitOffsetsSync(new HashMap<>(offsets), Long.MAX_VALUE); } public boolean commitOffsetsSync(Map<TopicPartition, OffsetAndMetadata> offsets, long timeoutMs) { ... } public void commitOffsetsAsync(final Map<TopicPartition, OffsetAndMetadata> offsets, final OffsetCommitCallback callback) { }
一个partition都会有一个leader和若干ISR(In-Sync Replicas),该列表维护在leader-partition端,leader有权剔除落后过多或者宕掉的ISR
- 同步过程如图


- 同步延迟(Last End Offset)

- HW(HighWatermark)

消息传递保证
通过producer的ack参数可以实现at-most-once和at-least-once的语义保证
acks=0If set to zero then the producer will not wait for any acknowledgment from the server at all. The record will be immediately added to the socket buffer and considered sent. No guarantee can be made that the server has received the record in this case, and theretriesconfiguration will not take effect (as the client won't generally know of any failures). The offset given back for each record will always be set to -1.acks=1This will mean the leader will write the record to its local log but will respond without awaiting full acknowledgement from all followers. In this case should the leader fail immediately after acknowledging the record but before the followers have replicated it then the record will be lost.acks=allThis means the leader will wait for the full set of in-sync replicas to acknowledge the record. This guarantees that the record will not be lost as long as at least one in-sync replica remains alive. This is the strongest available guarantee. This is equivalent to the acks=-1 setting.- 默认值:1
-
At-most-once
- 设置ack为0,消息发送之后不在理会broker是否收到
-
At-least-once
- 设置ack为1或者all,每次发送消息都需要收到broker的应答才算该条消息发送成功,但如果消息成功发送,但broker的ack受阻,可能会导致消息重发
- 如果ack为1时,leader-partition收到消息之后就给与应答,但在其他isr同步到消息之前,如果leader-crush,该条消息可能丢失
Kafka提供enable.idempotence配置提供对消费者发送消息的幂等处理
When set to 'true', the producer will ensure that exactly one copy of each message is written in the stream. If 'false', producer retries due to broker failures, etc., may write duplicates of the retried message in the stream. Note that enabling idempotence requires
max.in.flight.requests.per.connectionto be less than or equal to 5,retriesto be greater than 0 andacksmust be 'all'. If these values are not explicitly set by the user, suitable values will be chosen. If incompatible values are set, aConfigExceptionwill be thrown.
而at-lesast-once + idempotence = exactly-once
思路:
对于消息来讲,处理幂等性的一般方式为为消息添加唯一性的ID,消息处理方判断该ID是否处理过实现幂等(这种思想早在TCP/IP协议就已被采用)
实现方式:
- 每个 Producer 在初始化时都会被分配一个唯一的 PID,这个 PID 对应用是透明的,用来标识每个 producer client。
- sequence numbers,client 发送的每条消息都会带相应的 sequence number,每次对其加1,Server 端就是根据这个值来判断数据是否重复。
但这种幂等是有条件的
- 只能保证 Producer 在单个会话内不丟不重,如果 Producer 出现意外挂掉再重启是无法保证的(幂等性情况下,是无法获取之前的状态信息,因此是无法做到跨会话级别的不丢不重)。
- 幂等性不能跨多个 Topic-Partition,只能保证单个 partition 内的幂等性,当涉及多个 Topic-Partition 时,这中间的状态并没有同步。
原因在于一旦Producer挂掉之后,PID的状态就追踪不到了,因此需要一个始终如一的PID来保证会话的状态,Kafka允许用户自定义TransactionnalId实现事务
The TransactionalId to use for transactional delivery. This enables reliability semantics which span multiple producer sessions since it allows the client to guarantee that transactions using the same TransactionalId have been completed prior to starting any new transactions. If no TransactionalId is provided, then the producer is limited to idempotent delivery. Note that
enable.idempotencemust be enabled if a TransactionalId is configured. The default isnull, which means transactions cannot be used. Note that, by default, transactions require a cluster of at least three brokers which is the recommended setting for production; for development you can change this, by adjusting broker settingtransaction.state.log.replication.factor.
代码示例:
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("transactional.id", "test-transactional");
props.put("acks", "all");
KafkaProducer producer = new KafkaProducer(props);
producer.initTransactions();
try {
String msg = "matt test";
producer.beginTransaction();
producer.send(new ProducerRecord(topic, "0", msg.toString()));
producer.commitTransaction();
} catch (ProducerFencedException e1) {
producer.close();
} catch (KafkaException e2) {
producer.abortTransaction();
}
producer.close();语义保证
-
At least once
如果在消息处理之前就提交Offset,即
At Most Once语义,可能造成数据没有被处理就已提交。 -
At most once
如果在消息完全处理完毕之后再提交Offset,即
At Least Once语义,可能造成数据被重复消费。
在处理消息的同时完成Kafa的提交,可以抽象为保证两个系统操作的原子性,因为两个系统必然涉及到消息的传递,这是一个无解的过程。
因为完成这种类分布式事务的问题的一般解决办法都是将其转换为本地事务,在采用消息应答的方式实现消息的最终一致。
由于Kafka的Offset可以完全由Consumer去控制,所以Consumer可以完全控制消费消息的位置,从而自身实现exactly-once的语义保证。
以下摘自Kafka权威指南
Kafka API还允许你定位到指定的位置(在谈到提交时我们会说提交偏移量,在谈到定位时我们会说位置,位置这个概念用在现实生活中表示要到哪个地方,而偏移量更多表示的是处于一种什么状态,提交时主要关注的是状态数据,当然你不需要纠结这么多,位置和偏移量其实是相同的概念)。这种特性可以用在很多地方,比如回退几个消息重新处理,或者跳过一些消息(也许是一个时间敏感的应用程序,如果数据处理的进度落后太多时,你会想跳到最近的时间点,因为这些消息更能表示相关的当前状态)。但这种特性最令人兴奋的一个用例是:将偏移量存储到其他系统而不是Kafka中。
while (true) { ConsumerRecords<String, String> records = consumer.poll(100); for (ConsumerRecord<String, String> record : records) { currentOffsets.put( new TopicPartition(record.topic(), record.partition()), record.offset()); processRecord(record); //处理每一条记录 storeRecordInDB(record); //存储记录到数据库、NoSQL或Hadoop consumer.commitAsync(currentOffsets); //提交偏移量 } }请注意,我们非常偏执,在处理完每条记录都执行一次提交偏移量的动作。但是即使如此,应用程序仍然有可能会在存储到数据库之后,并且在提交偏移量之前挂掉,从而导致记录会被重新处理,最终数据库中的记录仍然会有重复的。
如果存在一种方式只有以原子操作的方式同时存储记录和偏移量,就可以避免上面的问题了。原子的意思是:记录和偏移量要么同时都提交了,要么都没有提交。只要是记录写到数据库,而偏移量写到Kafka中,这就不可能做到原子操作(毕竟写两个不同的存储系统是没有事务保证的)。
但如果我们在一个事务中同时写入记录和偏移量到数据库中呢?那么我们就会知道要么我们处理完了这条记录并且偏移量也成功提交了,要么这两个操作都没有发生,后者就会重新处理记录(因为记录和偏移量都没有成功存储,所以重复处理并不会使得存储系统有重复的数据)。
现在问题只有一个了:如果将记录存储在数据库而不是Kafka,我们的应用程序怎么知道要从分配分区的哪里开始读取?这就是
seek()方法发挥作用的地方。当消费者启动或者分配到新的分区,可以先去数据库中查询分区的最近偏移量,然后通过seek()方法定位到这个位置。
参考:http://kafka.apache.org/documentation/#semantics
具体的 group,是根据其 group 名进行 hash 并计算得到其具对应的 partition 值,该 partition leader 所在 Broker 即为该 Group 所对应的 GroupCoordinator,GroupCoordinator 会存储与该 group 相关的所有的 Meta 信息。
在 Broker 启动时,每个 Broker 都会启动一个 GroupCoordinator 服务,但只有 __consumer_offsets的 partition 的 leader 才会直接与 Consumer Client 进行交互,也就是其 group 的 GroupCoordinator,其他的 GroupCoordinator 只是作为备份,一旦作为 leader 的 Broker 挂掉之后及时进行替代。
- Empty:Group 没有任何成员,如果所有的 offsets 都过期的话就会变成 Dead,一般当 Group 新创建时是这个状态,也有可能这个 Group 仅仅用于 offset commits 并没有任何成员(Group has no more members, but lingers until all offsets have expired. This state also represents groups which use Kafka only for offset commits and have no members.);
- PreparingRebalance:Group 正在准备进行 Rebalance(Group is preparing to rebalance);
- AwaitingSync:Group 正在等待来 group leader 的 assignment(Group is awaiting state assignment from the leader);
- Stable:稳定的状态(Group is stable);
- Dead:Group 内已经没有成员,并且它的 Meta 已经被移除(Group has no more members and its metadata is being removed)。
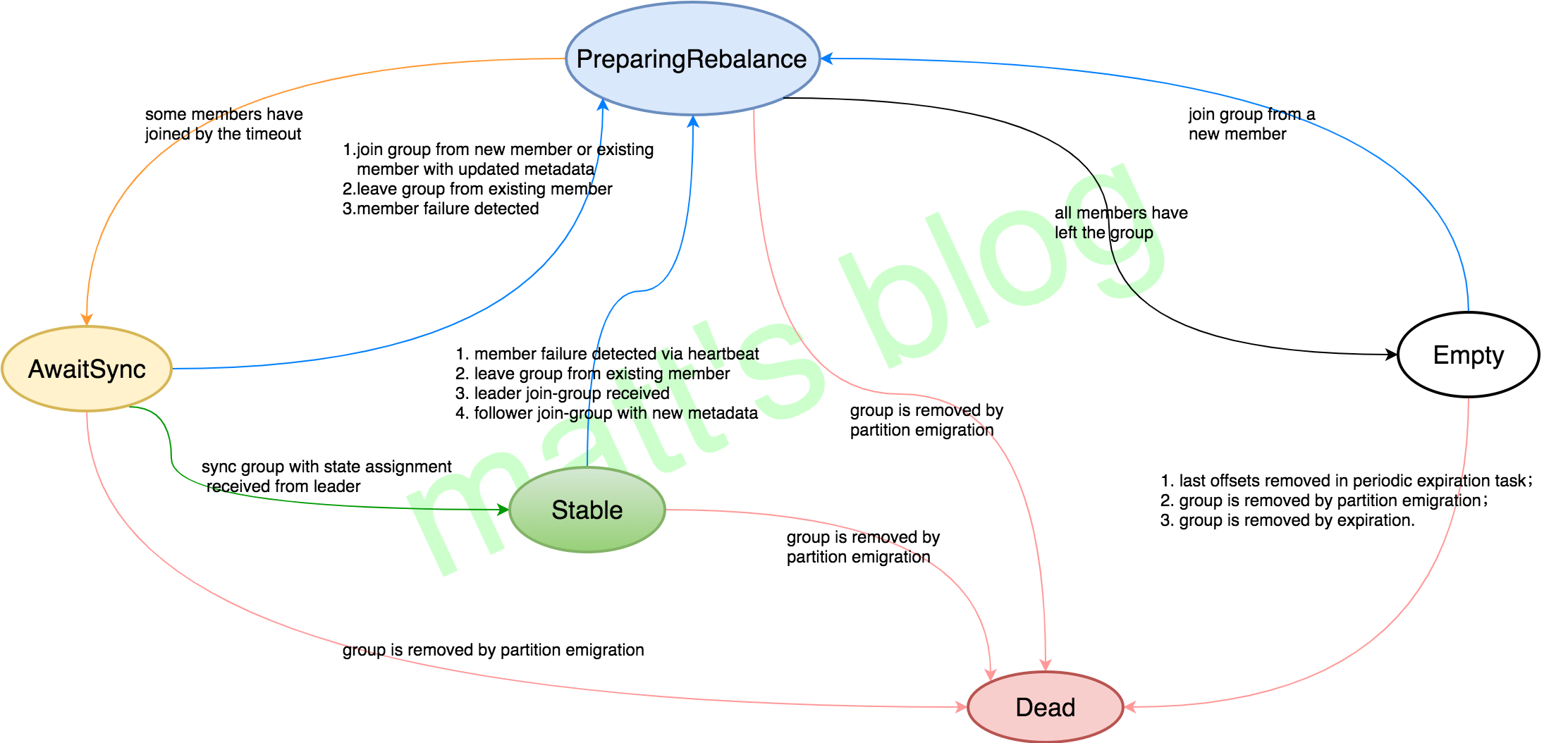
consumer消费的kafka-topic-partition发生了变化,称之为你consumer-rebalance
- ApcacheKafka Wiki:https://cwiki.apache.org/confluence/display/KAFKA/System+Tools
- 查看Kafka的某个ConsumerGroup的offset情况
kafka-consumer-groups.sh --bootstrap-server node1:9092 --group flink_group_id --describe - 通过
kafka-consumer-groups.sh手动设置offset: https://gist.github.com/marwei/cd40657c481f94ebe273ecc16601674b - 获取topic中各个partition当前的offset:
kafka-run-class.sh kafka.tools.GetOffsetShell - 查看kafka-log中的内容:
kafka-run-class.sh kafka.tools.DumpLogSegments - 查看offset_consumer中的内容:
kafka-simple-consumer-shell.sh --topic __consumer_offsets --partition 38 --broker-list node1:9092 --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter"
- Kafka-In-Deep:http://www.jasongj.com/tags/Kafka/
- Kafka源码解析:http://matt33.com/tags/kafka/
0-8保存在zookeeper中(Kafka的起始位置与auto.offset.reset的语义一致)
This new receiver-less “direct” approach has been introduced in Spark 1.3 to ensure stronger end-to-end guarantees. Instead of using receivers to receive data, this approach periodically queries Kafka for the latest offsets in each topic+partition, and accordingly defines the offset ranges to process in each batch. When the jobs to process the data are launched, Kafka’s simple consumer API is used to read the defined ranges of offsets from Kafka
0-8的Kafka需要自己管理Offset,你可以将Offset管理到任何位置(dm-strategy目前采用的方式)
// Hold a reference to the current offset ranges, so it can be used downstream
var offsetRanges = Array[OffsetRange]()
directKafkaStream.transform { rdd =>
offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd
}.map {
...
}.foreachRDD { rdd =>
for (o <- offsetRanges) {
println(s"${o.topic} ${o.partition} ${o.fromOffset} ${o.untilOffset}")
}
...
}Note: that the typecast to HasOffsetRanges will only succeed if it is done in the first method called on the directKafkaStream, not later down a chain of methods. You can use transform() instead of foreachRDD() as your first method call in order to access offsets, then call further Spark methods.
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "localhost:9092,anotherhost:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "use_a_separate_group_id_for_each_stream",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topics = Array("topicA", "topicB")
val stream = KafkaUtils.createDirectStream[String, String](
streamingContext,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
stream.map(record => (record.key, record.value))!Note:If your Spark batch duration is larger than the default Kafka heartbeat session timeout (30 seconds), increase heartbeat.interval.ms and session.timeout.ms appropriately. For batches larger than 5 minutes, this will require changing group.max.session.timeout.ms on the broker.
If you enable Spark checkpointing, offsets will be stored in the checkpoint. This is easy to enable, but there are drawbacks. Your output operation must be idempotent, since you will get repeated outputs; transactions are not an option. Furthermore, you cannot recover from a checkpoint if your application code has changed
通过Kafka本身的auto.commit参数存储Offset
代码示例:
stream.foreachRDD { rdd =>
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
// some time later, after outputs have completed
stream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
}As with HasOffsetRanges, the cast to CanCommitOffsets will only succeed if called on the result of createDirectStream, not after transformations. The commitAsync call is threadsafe, but must occur after outputs if you want meaningful semantics.
详见dm-strategy的处理方式
Apache Flink 中实现的 Kafka 消费者是一个有状态的算子(operator),它集成了 Flink 的检查点机制,它的状态是所有 Kafka 分区的读取偏移量。当一个检查点被触发时,每一个分区的偏移量都被存到了这个检查点中。Flink 的检查点机制保证了所有 operator task 的存储状态都是一致的。这里的“一致的”是什么意思呢?意思是它们存储的状态都是基于相同的输入数据。当所有的 operator task 成功存储了它们的状态,一个检查点才算完成。
Flink对Kafka的ConumerAPI和ProducerAPI与自身的CheckPoint进行了整合,Flink在每次CheckPoint持久化的同时会提交Kafka的Offset,Flink通过这种方式保证消息在Flink的处理过程中不会有任何一条Record在CheckPoint之前