DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
DreamBooth is a method used to fine-tune existing Text-to-Image models, developed by researchers from Google Research and Boston University in 2022. It allows the model to generate contextualized images of the subject, e.g., a cute puppy of yours, in different scenes, poses, and views. DreamBooth can be used to fine-tune models such as Stable Diffusion2.
The following picture gives a high-level overview of the DreamBooth Method.
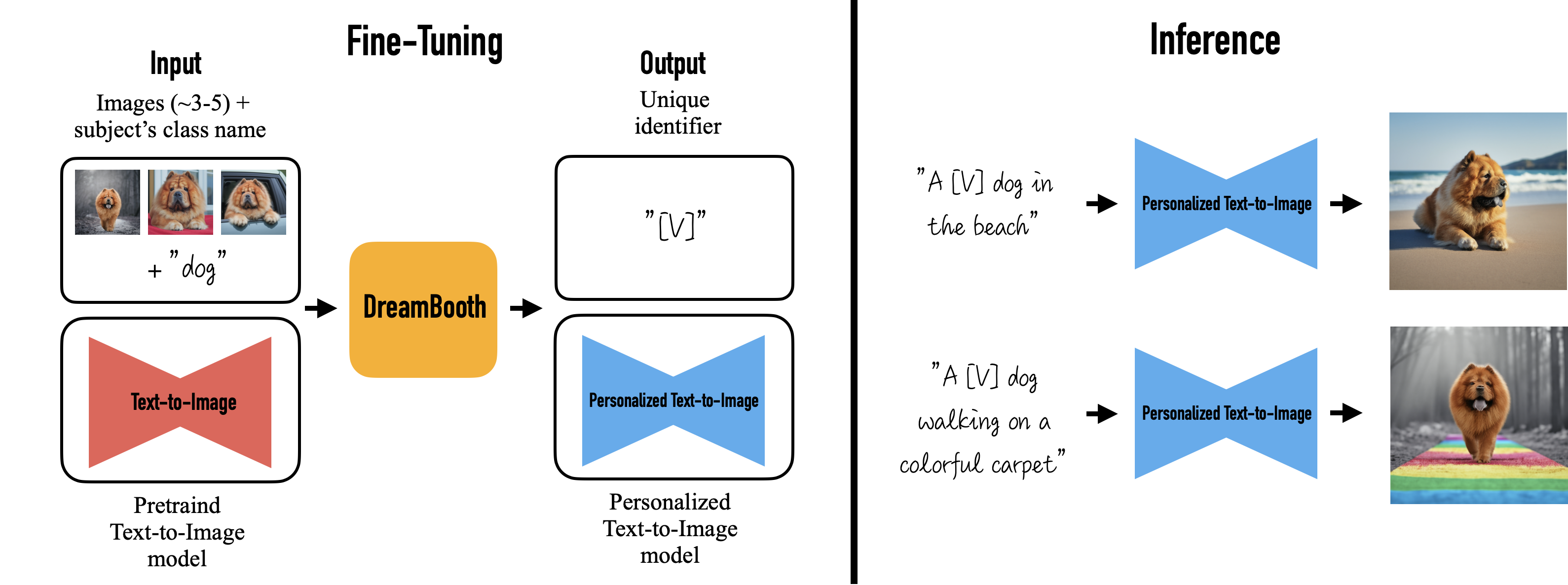
Figure 1. The Diagram of DreamBooth. [1]
DreamBooth only requires a pretrained Text-to-Image model and a few images (3-5) of a subject (more images are needed for a complex object) along with its name as a Unique Identifier. Unique Identifier prevents the Text-to-Image model from language drift [2]. Language Drift is a phenonomon that the model tends to associate the class name (e.g., "dog") with the specific instance (e.g., your dog). Because during finetuning, the model only sees the prompt "dog" and your dog's pictures, so that it gradually forgets other dogs' look. Therefore, we need a Unique Identifier ("sks") to differentiate your dog ("sks dog") and a general dog ("dog").
To do this, authors came up with a class-specific prior preservation loss:
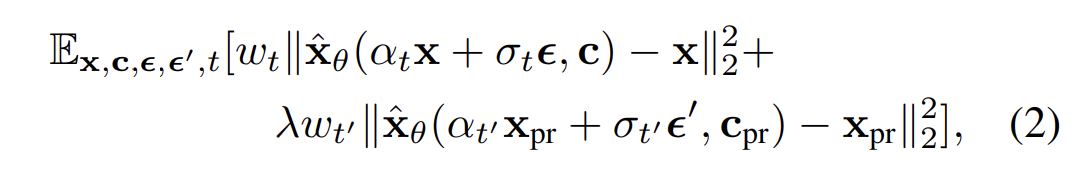
Equation 1. The class-specific prior preservation loss. [1]
Notes:
- Unlike LoRA, Dreambooth is a method that updates all the weights of the Latent Diffusion model. If needed, the text encoder of the CLIP model can also be updated. We find that finetuning text encoder and the Text-to-Image model yields better performance than finetuning the Text-to-Image model alone.
MindONE supports DreamBooth finetuning and inference for Stable Diffusion models based on MindSpore and Ascend platforms.
For finetuning experiment details, please refer to Section 2.
For inference with existing dreambooth models, please refer to Section 3.
Please refer to the Installation section.
Please download the pretrained SD2.0-base checkpoint and put it under stable_diffusion_v2/models folder.
The finetuning dataset should contain 3-5 images from the same subject under the same folder.
dir
├── img1.jpg
├── img2.jpg
├── img3.jpg
├── img4.jpg
└── img5.jpg
In Google/DreamBooth, there are many images from different classes. In this tutorial, we will use the five images from this dog. They are shown below:

Figure 2. The five images from the subject dog for finetuning.
Before starting to run the fine-tuning program, please modify the following experiment-related variables in the shell or
in the config file train_config_dreambooth_v2.yaml that may vary for different users:
--instance_data_dir=/path/to/data--class_data_dir=/path/to/class_image--output_path=/path/to/save/output_data--pretrained_model_path=/path/to/pretrained_model
Then, execute the script to launch finetuning:
python train_dreambooth.py \
--train_config "configs/train/train_config_dreambooth_v2.yaml" \
--instance_prompt "a photo of sks dog" \
--instance_data_dir "datasets/dog" \
--class_prompt "a photo of a dog" \
--class_data_dir "temp_class_images/dog" \
--output_path "output/dreambooth_dog/txt2img" \
--pretrained_model_path "models/sd_v2_base-57526ee4.ckpt"Please enable INFNAN mode by
export MS_ASCEND_CHECK_OVERFLOW_MODE="INFNAN_MODE"for Ascend 910* if overflow found.
To modify other important hyper-parameters, please refer to training config file train_config_dreambooth_v2.yaml.
Using the command above, we will start standalone training (use_parallel=False) with a constant learning rate (2e-6) for 4 epochs (800 steps).
The num_class_images in the arguments is 200 by default. It is the number of class images for prior preservation loss. If there are not enough images already present in class_data_dir, additional images will be sampled with class_prompt. We also resample the instance images by train_data_repeats times so that the numbers of class images and instance images are the same.
The finetuning process takes about 20 minutes.
Notes:
- Setting
train_text_encodertoTrueallows to finetune the stable diffusion model along with the CLIP text encoder. We recommend to set it to True, since it yields better performance thantrain_text_encoder=False.- If
train_text_encoderis set toFalsewhich saves some memory, we recommend you to change theepochsto 20 to achieve better performance.
Vanilla Finetuning is to finetune the network with the five dogs images directly, without applying the prior perservation loss.
To run Vanilla Finetuning, you can set the Experiment-Related Variables as 2.2.1. The training command for vanilla finetuning is:
python train_dreambooth.py \
--train_config "configs/train/train_config_dreambooth_vanilla_v2.yaml" \
--instance_prompt "a photo of sks dog" \
--instance_data_dir "datasets/dog" \
--output_path "output/dreambooth_vanilla_dog/txt2img" \
--pretrained_model_path "models/sd_v2_base-57526ee4.ckpt"Please enable INFNAN mode by
export MS_ASCEND_CHECK_OVERFLOW_MODE="INFNAN_MODE"for Ascend 910* if overflow found.
LoRA is a parameter-efficient finetuning method. Here, we combine DreamBooth with LoRA by injecting the LoRA parameters into the text encoder and the UNet of Text-to-Image model, and training with the prior preservation loss.
Please execute the training command below to launch finetuning:
python train_dreambooth.py \
--train_config "configs/train/train_config_dreambooth_lora_v2.yaml" \
--instance_prompt "a photo of sks dog" \
--instance_data_dir "datasets/dog" \
--class_prompt "a photo of a dog" \
--class_data_dir "temp_class_images/dog" \
--output_path "output/dreambooth_lora_dog/txt2img" \
--pretrained_model_path "models/sd_v2_base-57526ee4.ckpt"Please enable INFNAN mode by
export MS_ASCEND_CHECK_OVERFLOW_MODE="INFNAN_MODE"for Ascend 910* if overflow found.
Note that we train the LoRA parameters with a constant learning rate 5e-5, a weight decay 1e-4 for 4 epochs (800 steps). The rank of the LoRA parameter is 64.
The inference command generates images on a given prompt and save them to a given output directory. An example command is as follows:
python text_to_image.py \
--prompt "a sks dog swimming in a pool" \
--output_path vis/output/dir \
--config configs/train_dreambooth_sd_v2.yaml \
--ckpt_path path/to/checkpoint/fileWe can also change the prompt to other options to generate variant images with this subject. path/to/checkpoint/file specifies the checkpoint path after finetuing.
Here are some examples of generated images with the DreamBooth model using the three different prompts:
- "a sks dog swimming in a pool"
- "a sks dog on the hill"
- "a sks dog in Van Gogh painting style"

Figure 3. The generated images of the DreamBooth model using three different text prompts.
Some generated images with the vanilla finetuned model are shown below:

Figure 4. The generated images of the vanilla-finetuned model using three different text prompts.
Figure 3. and Figure 4. look similar. However, when we use other prompts with the "dog" class name, for example, "a dog in swimming pool", the DreamBooth model preserves the various looks of different dogs, while the vanilla-finetuned model forgets many dogs' looks except for the "sks dog", which is known as the "language drift" phenonomon.
Here are the three prompts we used with class name "dog":
- "a dog swimming in a pool"
- "a dog on the hill"
- "a dog in Van Gogh painting style"

Figure 5. The generated images of the DreamBooth model using three text prompts above.

Figure 6. The generated images of the vanilla-finetuned model using three text prompts above.
If using LoRA with DreamBooth, the inference command should be:
python text_to_image.py \
--prompt "a sks dog in Van Gogh painting style" \
--output_path vis/output/dir \
--config configs/train_dreambooth_sd_v2.yaml \
--ckpt_path models/sd_v2_base-57526ee4.ckpt \
--lora_ckpt_path path/to/checkpoint/file \
--use_lora True \
--lora_ft_unet True \
--lora_ft_text_encoder True

Figure 7. The generated images of the model finetuned with DreamBooth and LoRA.
The results in Figure 7. are very close to the results in Figure 3.
For evaluation, we consider two metrics:
- CLIP-T score: the cosine similarity between the text prompt and the image CLIP embedding.
- CLIP-I score: the cosine similarity between the CLIP embeddings of the real and the generated images.
By default, we use the pretrained clip_vit_base_patch16 model to extract the image/text embeddings and bpe_simple_vocab_16e6 as the text tokenizer. To download the two files, please refer to the guideline Clip Score Evaluation.
The command to evaluate the CLIP-T score is shown below:
python tools/eval/eval_clip_score.py \
--ckpt_path <path-to-clip-model> \
--image_path_or_dir <path-to-image> \
--prompt_or_path <string/path-to-txt>The command to evaluate the CLIP-I score is shown below:
python tools/eval/eval_clip_i_score.py \
--ckpt_path <path-to-clip-model> \
--gen_image_path_or_dir <path-to-generated-image> \
--real_image_path_or_dir <path-to-real-image>If you already have a pretrained DreamBooth model saved in mindspore checkpoint file format, you can easily run inference with text_to_image.py. For example:
SD_VERSION=1.5 # or 2.0 and 2.1 depending on the DreamBooth model version
python text_to_image.py --prompt 'A girl, cherry blossoms, pink flowers, spring season' -v $SD_VERSION --ckpt_path "ckpt-path-to-dreambooth-ms-ckpt"
The generated images will be saved in output/samples by default. You can set the output path by --output_path output/dir.
However, if you want to run inference with other existing DreamBooth models saved in Pytorch framework, you should first convert the pytorch checkpoint file into the mindspore checkpoint file, and then run inference using the command above.
Taking the ToonYou (beta3) DreamBooth model as an example, you can download the checkpoint from civitai.com using:
wget https://civitai.com/api/download/models/78755 -P models/ --content-disposition --no-check-certificate
It will save toonyou_beta3.safetensors under the folder models/.
Next, you can convert this checkpoint file into mindspore checkpoint file by using:
python tools/model_conversion/convert_weights.py --source models/toonyou_beta3.safetensors --target models/toonyou_beta3.ckpt --model sdv1 --source_version pt
The mindspore checkpoint file will be saved as models/toonyou_beta3.ckpt.
Now, set --ckpt_path as models/toonyou_beta3.ckpt and run text_to_image.py, you will get the generated images like below:

Figure 8. The generated images of the ToonYou (beta3) DreamBooth model using the prompt 'A girl, cherry blossoms, pink flowers, spring season'.
[1] Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, Kfir Aberman: DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation. CoRR abs/2208.12242 (2022)
[2]: Jason Lee, Kyunghyun Cho, Douwe Kiela: Countering Language Drift via Visual Grounding. CoRR abs/1909.04499 (2019)