diff --git a/colossalai/shardformer/README.md b/colossalai/shardformer/README.md
index 5489f97e4d19..5d00e606dc94 100644
--- a/colossalai/shardformer/README.md
+++ b/colossalai/shardformer/README.md
@@ -30,7 +30,7 @@
### Quick Start
-The sample API usage is given below:
+The sample API usage is given below(If you enable the use of flash attention, please install xformers.):
```python
from colossalai.shardformer import ShardConfig, Shard
@@ -106,6 +106,20 @@ We will follow this roadmap to develop Shardformer:
- [ ] Multi-modal
- [x] SAM
- [x] BLIP-2
+- [ ] Flash Attention Support
+ - [ ] NLP
+ - [x] BERT
+ - [x] T5
+ - [x] LlaMa
+ - [x] GPT2
+ - [x] OPT
+ - [x] BLOOM
+ - [ ] GLM
+ - [ ] RoBERTa
+ - [ ] ALBERT
+ - [ ] ERNIE
+ - [ ] GPT Neo
+ - [ ] GPT-J
## 💡 API Design
@@ -373,11 +387,49 @@ pytest tests/test_shardformer
### System Performance
-To be added.
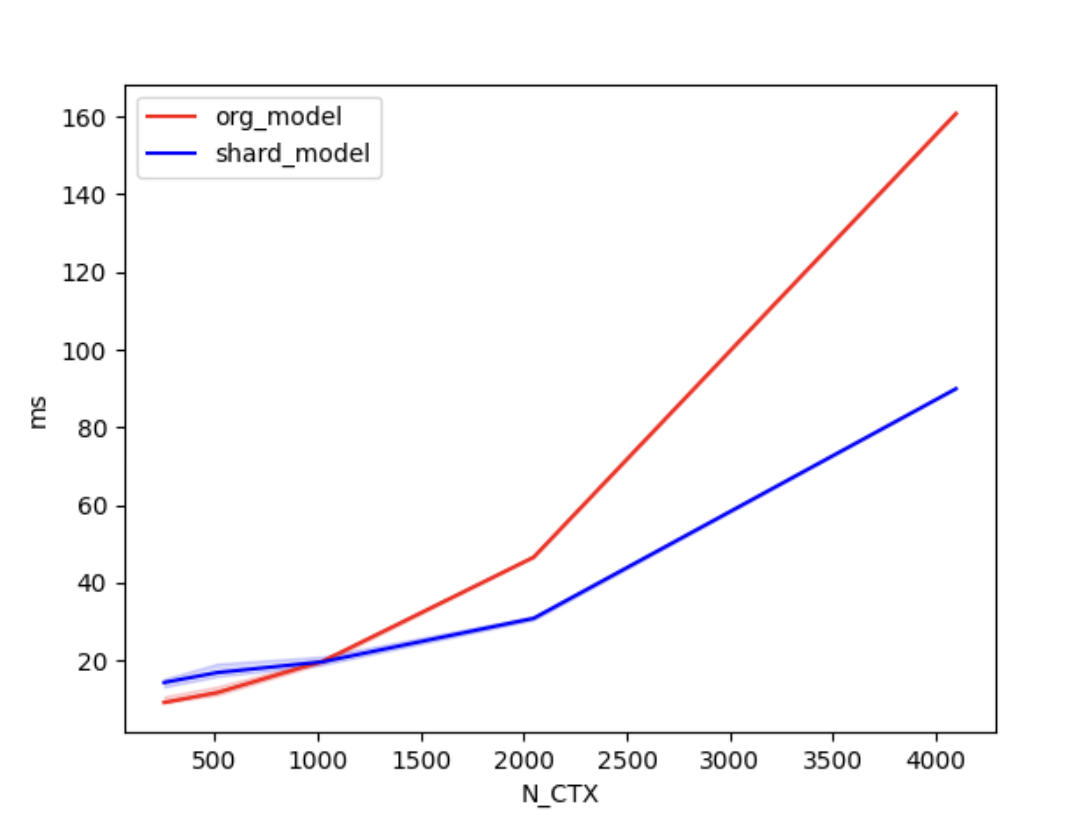
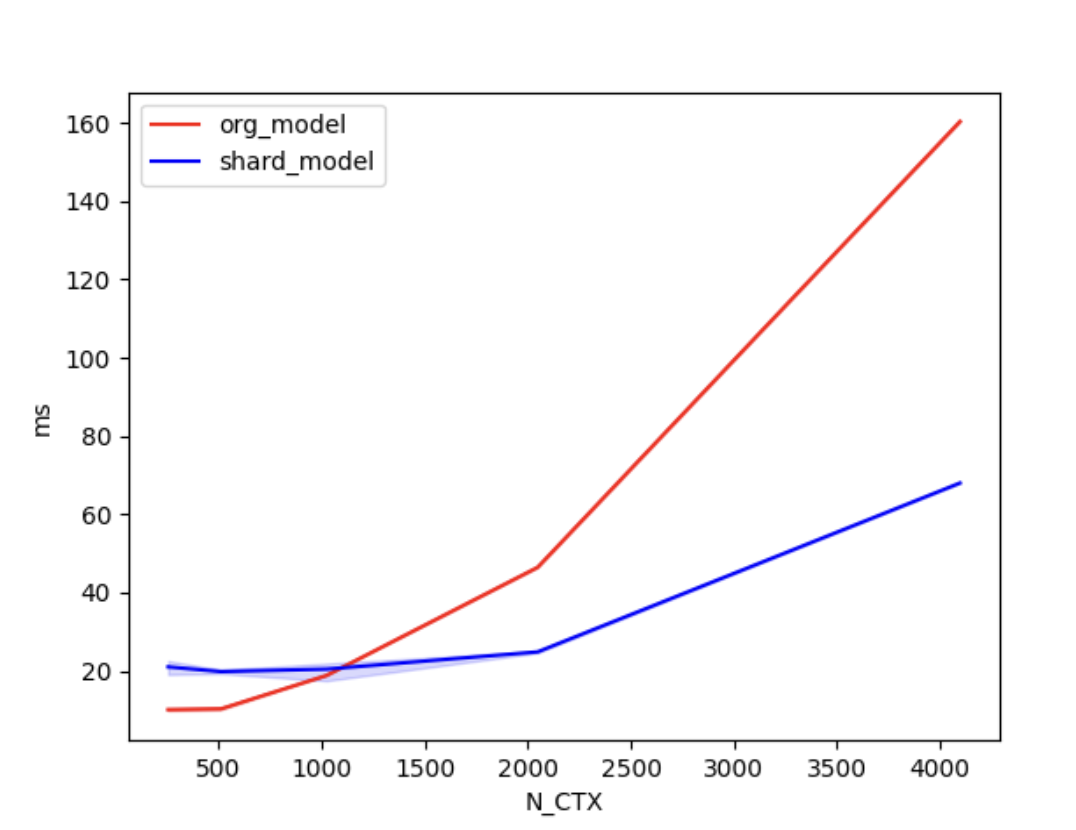
+We conducted [benchmark tests](./examples/performance_benchmark.py) to evaluate the performance improvement of Shardformer. We compared the training time between the original model and the shard model.
+
+We set the batch size to 4, the number of attention heads to 8, and the head dimension to 64. 'N_CTX' refers to the sequence length.
+
+In the case of using 2 GPUs, the training times are as follows.
+| N_CTX | org_model | shard_model |
+| :------: | :-----: | :-----: |
+| 256 | 11.2ms | 17.2ms |
+| 512 | 9.8ms | 19.5ms |
+| 1024 | 19.6ms | 18.9ms |
+| 2048 | 46.6ms | 30.8ms |
+| 4096 | 160.5ms | 90.4ms |
+
+
+
+  +
+
+
+
+In the case of using 4 GPUs, the training times are as follows.
+
+| N_CTX | org_model | shard_model |
+| :------: | :-----: | :-----: |
+| 256 | 10.0ms | 21.1ms |
+| 512 | 11.5ms | 20.2ms |
+| 1024 | 22.1ms | 20.6ms |
+| 2048 | 46.9ms | 24.8ms |
+| 4096 | 160.4ms | 68.0ms |
+
+
+
+
+  +
+
+
+
+
+As shown in the figures above, when the sequence length is around 1000 or greater, the parallel optimization of Shardformer for long sequences starts to become evident.
### Convergence
-To validate that training the model using shardformers does not impact its convergence. We [fine-tuned the BERT model](./examples/shardformer_benchmark.py) using both shardformer and non-shardformer approaches. We compared the accuracy, loss, F1 score of the training results.
+
+To validate that training the model using shardformers does not impact its convergence. We [fine-tuned the BERT model](./examples/convergence_benchmark.py) using both shardformer and non-shardformer approaches. We compared the accuracy, loss, F1 score of the training results.
| accuracy | f1 | loss | GPU number | model shard |
| :------: | :-----: | :-----: | :--------: | :---------: |
diff --git a/colossalai/shardformer/examples/shardformer_benchmark.py b/colossalai/shardformer/examples/convergence_benchmark.py
similarity index 100%
rename from colossalai/shardformer/examples/shardformer_benchmark.py
rename to colossalai/shardformer/examples/convergence_benchmark.py
diff --git a/colossalai/shardformer/examples/shardformer_benchmark.sh b/colossalai/shardformer/examples/convergence_benchmark.sh
similarity index 76%
rename from colossalai/shardformer/examples/shardformer_benchmark.sh
rename to colossalai/shardformer/examples/convergence_benchmark.sh
index f42b19a32d35..1c281abcda6d 100644
--- a/colossalai/shardformer/examples/shardformer_benchmark.sh
+++ b/colossalai/shardformer/examples/convergence_benchmark.sh
@@ -1,4 +1,4 @@
-torchrun --standalone --nproc_per_node=4 shardformer_benchmark.py \
+torchrun --standalone --nproc_per_node=4 convergence_benchmark.py \
--model "bert" \
--pretrain "bert-base-uncased" \
--max_epochs 1 \
diff --git a/colossalai/shardformer/examples/performance_benchmark.py b/colossalai/shardformer/examples/performance_benchmark.py
new file mode 100644
index 000000000000..9c7b76bcf0a6
--- /dev/null
+++ b/colossalai/shardformer/examples/performance_benchmark.py
@@ -0,0 +1,86 @@
+"""
+Shardformer Benchmark
+"""
+import torch
+import torch.distributed as dist
+import transformers
+import triton
+
+import colossalai
+from colossalai.shardformer import ShardConfig, ShardFormer
+
+
+def data_gen(batch_size, seq_length):
+ input_ids = torch.randint(0, seq_length, (batch_size, seq_length), dtype=torch.long)
+ attention_mask = torch.ones((batch_size, seq_length), dtype=torch.long)
+ return dict(input_ids=input_ids, attention_mask=attention_mask)
+
+
+def data_gen_for_sequence_classification(batch_size, seq_length):
+ # LM data gen
+ # the `labels` of LM is the token of the output, cause no padding, use `input_ids` as `labels`
+ data = data_gen(batch_size, seq_length)
+ data['labels'] = torch.ones((batch_size), dtype=torch.long)
+ return data
+
+
+MODEL_CONFIG = transformers.LlamaConfig(num_hidden_layers=4,
+ hidden_size=128,
+ intermediate_size=256,
+ num_attention_heads=4,
+ max_position_embeddings=128,
+ num_labels=16)
+BATCH, N_HEADS, N_CTX, D_HEAD = 4, 8, 4096, 64
+model_func = lambda: transformers.LlamaForSequenceClassification(MODEL_CONFIG)
+
+# vary seq length for fixed head and batch=4
+configs = [
+ triton.testing.Benchmark(x_names=['N_CTX'],
+ x_vals=[2**i for i in range(8, 13)],
+ line_arg='provider',
+ line_vals=['org_model', 'shard_model'],
+ line_names=['org_model', 'shard_model'],
+ styles=[('red', '-'), ('blue', '-')],
+ ylabel='ms',
+ plot_name=f'lama_for_sequence_classification-batch-{BATCH}',
+ args={
+ 'BATCH': BATCH,
+ 'dtype': torch.float16,
+ 'model_func': model_func
+ })
+]
+
+
+def train(model, data):
+ output = model(**data)
+ loss = output.logits.mean()
+ loss.backward()
+
+
+@triton.testing.perf_report(configs)
+def bench_shardformer(BATCH, N_CTX, provider, model_func, dtype=torch.float32, device="cuda"):
+ warmup = 10
+ rep = 100
+ # prepare data
+ data = data_gen_for_sequence_classification(BATCH, N_CTX)
+ data = {k: v.cuda() for k, v in data.items()}
+ model = model_func().to(device)
+ model.train()
+ if provider == "org_model":
+ fn = lambda: train(model, data)
+ ms = triton.testing.do_bench(fn, warmup=warmup, rep=rep)
+ return ms
+ if provider == "shard_model":
+ shard_config = ShardConfig(enable_fused_normalization=True, enable_tensor_parallelism=True)
+ shard_former = ShardFormer(shard_config=shard_config)
+ sharded_model = shard_former.optimize(model).cuda()
+ fn = lambda: train(sharded_model, data)
+ ms = triton.testing.do_bench(fn, warmup=warmup, rep=rep)
+ return ms
+
+
+# start benchmark, command:
+# torchrun --standalone --nproc_per_node=2 performance_benchmark.py
+if __name__ == "__main__":
+ colossalai.launch_from_torch({})
+ bench_shardformer.run(save_path='.', print_data=dist.get_rank() == 0)
diff --git a/colossalai/shardformer/modeling/bert.py b/colossalai/shardformer/modeling/bert.py
index 1b3c14d9d1c9..b9d4b5fda7af 100644
--- a/colossalai/shardformer/modeling/bert.py
+++ b/colossalai/shardformer/modeling/bert.py
@@ -1,5 +1,6 @@
+import math
import warnings
-from typing import Any, Dict, List, Optional, Tuple
+from typing import Dict, List, Optional, Tuple
import torch
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
@@ -962,3 +963,138 @@ def bert_for_question_answering_forward(
else:
hidden_states = outputs.get('hidden_states')
return {'hidden_states': hidden_states}
+
+
+def get_bert_flash_attention_forward():
+
+ try:
+ from xformers.ops import memory_efficient_attention as me_attention
+ except:
+ raise ImportError("Error: xformers module is not installed. Please install it to use flash attention.")
+ from transformers.models.bert.modeling_bert import BertAttention
+
+ def forward(
+ self: BertAttention,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.FloatTensor] = None,
+ encoder_attention_mask: Optional[torch.FloatTensor] = None,
+ past_key_value: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.Tensor]:
+ mixed_query_layer = self.query(hidden_states)
+
+ # If this is instantiated as a cross-attention module, the keys
+ # and values come from an encoder; the attention mask needs to be
+ # such that the encoder's padding tokens are not attended to.
+ is_cross_attention = encoder_hidden_states is not None
+
+ if is_cross_attention and past_key_value is not None:
+ # reuse k,v, cross_attentions
+ key_layer = past_key_value[0]
+ value_layer = past_key_value[1]
+ attention_mask = encoder_attention_mask
+ elif is_cross_attention:
+ key_layer = self.transpose_for_scores(self.key(encoder_hidden_states))
+ value_layer = self.transpose_for_scores(self.value(encoder_hidden_states))
+ attention_mask = encoder_attention_mask
+ elif past_key_value is not None:
+ key_layer = self.transpose_for_scores(self.key(hidden_states))
+ value_layer = self.transpose_for_scores(self.value(hidden_states))
+ key_layer = torch.cat([past_key_value[0], key_layer], dim=2)
+ value_layer = torch.cat([past_key_value[1], value_layer], dim=2)
+ else:
+ key_layer = self.transpose_for_scores(self.key(hidden_states))
+ value_layer = self.transpose_for_scores(self.value(hidden_states))
+
+ query_layer = self.transpose_for_scores(mixed_query_layer)
+
+ use_cache = past_key_value is not None
+ if self.is_decoder:
+ # if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
+ # Further calls to cross_attention layer can then reuse all cross-attention
+ # key/value_states (first "if" case)
+ # if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
+ # all previous decoder key/value_states. Further calls to uni-directional self-attention
+ # can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
+ # if encoder bi-directional self-attention `past_key_value` is always `None`
+ past_key_value = (key_layer, value_layer)
+
+ final_attention_mask = None
+ if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
+ query_length, key_length = query_layer.shape[2], key_layer.shape[2]
+ if use_cache:
+ position_ids_l = torch.tensor(key_length - 1, dtype=torch.long, device=hidden_states.device).view(-1, 1)
+ else:
+ position_ids_l = torch.arange(query_length, dtype=torch.long, device=hidden_states.device).view(-1, 1)
+ position_ids_r = torch.arange(key_length, dtype=torch.long, device=hidden_states.device).view(1, -1)
+ distance = position_ids_l - position_ids_r
+
+ positional_embedding = self.distance_embedding(distance + self.max_position_embeddings - 1)
+ positional_embedding = positional_embedding.to(dtype=query_layer.dtype) # fp16 compatibility
+
+ if self.position_embedding_type == "relative_key":
+ relative_position_scores = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
+ final_attention_mask = relative_position_scores
+ elif self.position_embedding_type == "relative_key_query":
+ relative_position_scores_query = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
+ relative_position_scores_key = torch.einsum("bhrd,lrd->bhlr", key_layer, positional_embedding)
+ final_attention_mask = relative_position_scores_query + relative_position_scores_key
+
+ scale = 1 / math.sqrt(self.attention_head_size)
+ if attention_mask is not None:
+ if final_attention_mask != None:
+ final_attention_mask = final_attention_mask * scale + attention_mask
+ else:
+ final_attention_mask = attention_mask
+ batch_size, src_len = query_layer.size()[0], query_layer.size()[2]
+ tgt_len = key_layer.size()[2]
+ final_attention_mask = final_attention_mask.expand(batch_size, self.num_attention_heads, src_len, tgt_len)
+
+ query_layer = query_layer.permute(0, 2, 1, 3).contiguous()
+ key_layer = key_layer.permute(0, 2, 1, 3).contiguous()
+ value_layer = value_layer.permute(0, 2, 1, 3).contiguous()
+
+ context_layer = me_attention(query_layer,
+ key_layer,
+ value_layer,
+ attn_bias=final_attention_mask,
+ p=self.dropout.p,
+ scale=scale)
+ new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
+ context_layer = context_layer.view(new_context_layer_shape)
+
+ outputs = (context_layer, None)
+
+ if self.is_decoder:
+ outputs = outputs + (past_key_value,)
+ return outputs
+
+ return forward
+
+
+def get_jit_fused_bert_self_output_forward():
+
+ from transformers.models.bert.modeling_bert import BertSelfOutput
+
+ def forward(self: BertSelfOutput, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout_add(hidden_states, input_tensor, self.dropout.p, self.dropout.training)
+ hidden_states = self.LayerNorm(hidden_states)
+ return hidden_states
+
+ return forward
+
+
+def get_jit_fused_bert_output_forward():
+
+ from transformers.models.bert.modeling_bert import BertOutput
+
+ def forward(self: BertOutput, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout_add(hidden_states, input_tensor, self.dropout.p, self.dropout.training)
+ hidden_states = self.LayerNorm(hidden_states)
+ return hidden_states
+
+ return forward
diff --git a/colossalai/shardformer/modeling/blip2.py b/colossalai/shardformer/modeling/blip2.py
index b7945423ae83..c5c6b14ba993 100644
--- a/colossalai/shardformer/modeling/blip2.py
+++ b/colossalai/shardformer/modeling/blip2.py
@@ -1,3 +1,4 @@
+import math
from typing import Optional, Tuple, Union
import torch
@@ -58,3 +59,62 @@ def forward(
return outputs
return forward
+
+
+def get_blip2_flash_attention_forward():
+
+ from transformers.models.blip_2.modeling_blip_2 import Blip2Attention
+
+ from colossalai.kernel.cuda_native.flash_attention import AttnMaskType, ColoAttention
+
+ def forward(
+ self: Blip2Attention,
+ hidden_states: torch.Tensor,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ """Input shape: Batch x Time x Channel"""
+
+ bsz, tgt_len, embed_dim = hidden_states.size()
+ mixed_qkv = self.qkv(hidden_states)
+ mixed_qkv = mixed_qkv.reshape(bsz, tgt_len, 3, self.num_heads, -1).permute(2, 0, 1, 3, 4)
+ query_states, key_states, value_states = mixed_qkv[0], mixed_qkv[1], mixed_qkv[2]
+
+ attention = ColoAttention(embed_dim=self.embed_dim,
+ num_heads=self.num_heads,
+ dropout=self.dropout.p,
+ scale=self.scale)
+ context_layer = attention(query_states, key_states, value_states)
+
+ output = self.projection(context_layer)
+ outputs = (output, None)
+
+ return outputs
+
+ return forward
+
+
+def get_jit_fused_blip2_QFormer_self_output_forward():
+
+ from transformers.models.blip_2.modeling_blip_2 import Blip2QFormerSelfOutput
+
+ def forward(self: Blip2QFormerSelfOutput, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout_add(hidden_states, input_tensor, self.dropout.p, self.dropout.training)
+ hidden_states = self.LayerNorm(hidden_states)
+ return hidden_states
+
+ return forward
+
+
+def get_jit_fused_blip2_QFormer_output_forward():
+
+ from transformers.models.blip_2.modeling_blip_2 import Blip2QFormerOutput
+
+ def forward(self: Blip2QFormerOutput, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout_add(hidden_states, input_tensor, self.dropout.p, self.dropout.training)
+ hidden_states = self.LayerNorm(hidden_states)
+ return hidden_states
+
+ return forward
diff --git a/colossalai/shardformer/modeling/bloom.py b/colossalai/shardformer/modeling/bloom.py
index 76948fc70439..57c45bc6adfa 100644
--- a/colossalai/shardformer/modeling/bloom.py
+++ b/colossalai/shardformer/modeling/bloom.py
@@ -5,6 +5,7 @@
import torch.distributed as dist
from torch.distributed import ProcessGroup
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
+from torch.nn import functional as F
from transformers.modeling_outputs import (
BaseModelOutputWithPastAndCrossAttentions,
CausalLMOutputWithCrossAttentions,
@@ -675,3 +676,223 @@ def bloom_for_question_answering_forward(
else:
hidden_states = outputs.get('hidden_states')
return {'hidden_states': hidden_states}
+
+
+def get_bloom_flash_attention_forward(enabel_jit_fused=False):
+
+ try:
+ from xformers.ops import memory_efficient_attention as me_attention
+ except:
+ raise ImportError("Error: xformers module is not installed. Please install it to use flash attention.")
+ from transformers.models.bloom.modeling_bloom import BloomAttention
+
+ def forward(
+ self: BloomAttention,
+ hidden_states: torch.Tensor,
+ residual: torch.Tensor,
+ alibi: torch.Tensor,
+ attention_mask: torch.Tensor,
+ layer_past: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ use_cache: bool = False,
+ output_attentions: bool = False,
+ ):
+
+ fused_qkv = self.query_key_value(hidden_states)
+ (query_layer, key_layer, value_layer) = self._split_heads(fused_qkv)
+ batch_size, tgt_len, _ = hidden_states.size()
+ assert tgt_len % 4 == 0, "Flash Attention Error: The sequence length should be a multiple of 4."
+
+ _, kv_length, _, _ = key_layer.size()
+
+ proj_shape = (batch_size, tgt_len, self.num_heads, self.head_dim)
+ query_layer = query_layer.contiguous().view(*proj_shape)
+ key_layer = key_layer.contiguous().view(*proj_shape)
+ value_layer = value_layer.contiguous().view(*proj_shape)
+
+ if layer_past is not None:
+ past_key, past_value = layer_past
+ # concatenate along seq_length dimension:
+ # - key: [batch_size * self.num_heads, head_dim, kv_length]
+ # - value: [batch_size * self.num_heads, kv_length, head_dim]
+ key_layer = torch.cat((past_key, key_layer), dim=1)
+ value_layer = torch.cat((past_value, value_layer), dim=1)
+
+ if use_cache is True:
+ present = (key_layer, value_layer)
+ else:
+ present = None
+
+ tgt_len = key_layer.size()[1]
+
+ attention_numerical_mask = torch.zeros((batch_size, self.num_heads, tgt_len, kv_length),
+ dtype=torch.float32,
+ device=query_layer.device,
+ requires_grad=True)
+ attention_numerical_mask = attention_numerical_mask + alibi.view(batch_size, self.num_heads, 1,
+ kv_length) * self.beta
+ attention_numerical_mask = torch.masked_fill(attention_numerical_mask, attention_mask,
+ torch.finfo(torch.float32).min)
+
+ context_layer = me_attention(query_layer,
+ key_layer,
+ value_layer,
+ attn_bias=attention_numerical_mask,
+ scale=self.inv_norm_factor,
+ p=self.attention_dropout.p)
+ context_layer = context_layer.reshape(-1, kv_length, self.hidden_size)
+ if self.pretraining_tp > 1 and self.slow_but_exact:
+ slices = self.hidden_size / self.pretraining_tp
+ output_tensor = torch.zeros_like(context_layer)
+ for i in range(self.pretraining_tp):
+ output_tensor = output_tensor + F.linear(
+ context_layer[:, :, int(i * slices):int((i + 1) * slices)],
+ self.dense.weight[:, int(i * slices):int((i + 1) * slices)],
+ )
+ else:
+ output_tensor = self.dense(context_layer)
+
+ # TODO to replace with the bias_dropout_add function in jit
+ output_tensor = self.dropout_add(output_tensor, residual, self.hidden_dropout, self.training)
+ outputs = (output_tensor, present, None)
+
+ return outputs
+
+ return forward
+
+
+def get_jit_fused_bloom_attention_forward():
+
+ from transformers.models.bloom.modeling_bloom import BloomAttention
+
+ def forward(
+ self: BloomAttention,
+ hidden_states: torch.Tensor,
+ residual: torch.Tensor,
+ alibi: torch.Tensor,
+ attention_mask: torch.Tensor,
+ layer_past: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
+ head_mask: Optional[torch.Tensor] = None,
+ use_cache: bool = False,
+ output_attentions: bool = False,
+ ):
+ fused_qkv = self.query_key_value(hidden_states) # [batch_size, seq_length, 3 x hidden_size]
+
+ # 3 x [batch_size, seq_length, num_heads, head_dim]
+ (query_layer, key_layer, value_layer) = self._split_heads(fused_qkv)
+
+ batch_size, q_length, _, _ = query_layer.shape
+
+ query_layer = query_layer.transpose(1, 2).reshape(batch_size * self.num_heads, q_length, self.head_dim)
+ key_layer = key_layer.permute(0, 2, 3, 1).reshape(batch_size * self.num_heads, self.head_dim, q_length)
+ value_layer = value_layer.transpose(1, 2).reshape(batch_size * self.num_heads, q_length, self.head_dim)
+ if layer_past is not None:
+ past_key, past_value = layer_past
+ # concatenate along seq_length dimension:
+ # - key: [batch_size * self.num_heads, head_dim, kv_length]
+ # - value: [batch_size * self.num_heads, kv_length, head_dim]
+ key_layer = torch.cat((past_key, key_layer), dim=2)
+ value_layer = torch.cat((past_value, value_layer), dim=1)
+
+ _, _, kv_length = key_layer.shape
+
+ if use_cache is True:
+ present = (key_layer, value_layer)
+ else:
+ present = None
+
+ # [batch_size * num_heads, q_length, kv_length]
+ # we use `torch.Tensor.baddbmm` instead of `torch.baddbmm` as the latter isn't supported by TorchScript v1.11
+ matmul_result = alibi.baddbmm(
+ batch1=query_layer,
+ batch2=key_layer,
+ beta=self.beta,
+ alpha=self.inv_norm_factor,
+ )
+
+ # change view to [batch_size, num_heads, q_length, kv_length]
+ attention_scores = matmul_result.view(batch_size, self.num_heads, q_length, kv_length)
+
+ # cast attention scores to fp32, compute scaled softmax and cast back to initial dtype - [batch_size, num_heads, q_length, kv_length]
+ input_dtype = attention_scores.dtype
+ # `float16` has a minimum value of -65504.0, whereas `bfloat16` and `float32` have a minimum value of `-3.4e+38`
+ if input_dtype == torch.float16:
+ attention_scores = attention_scores.to(torch.float)
+ attn_weights = torch.masked_fill(attention_scores, attention_mask, torch.finfo(attention_scores.dtype).min)
+ attention_probs = F.softmax(attn_weights, dim=-1, dtype=torch.float32).to(input_dtype)
+
+ # [batch_size, num_heads, q_length, kv_length]
+ attention_probs = self.attention_dropout(attention_probs)
+
+ if head_mask is not None:
+ attention_probs = attention_probs * head_mask
+
+ # change view [batch_size x num_heads, q_length, kv_length]
+ attention_probs_reshaped = attention_probs.view(batch_size * self.num_heads, q_length, kv_length)
+
+ # matmul: [batch_size * num_heads, q_length, head_dim]
+ context_layer = torch.bmm(attention_probs_reshaped, value_layer)
+
+ # change view [batch_size, num_heads, q_length, head_dim]
+ context_layer = self._merge_heads(context_layer)
+
+ # aggregate results across tp ranks. See here: https://github.com/pytorch/pytorch/issues/76232
+ if self.pretraining_tp > 1 and self.slow_but_exact:
+ slices = self.hidden_size / self.pretraining_tp
+ output_tensor = torch.zeros_like(context_layer)
+ for i in range(self.pretraining_tp):
+ output_tensor = output_tensor + F.linear(
+ context_layer[:, :, int(i * slices):int((i + 1) * slices)],
+ self.dense.weight[:, int(i * slices):int((i + 1) * slices)],
+ )
+ else:
+ output_tensor = self.dense(context_layer)
+
+ output_tensor = self.dropout_add(output_tensor, residual, self.hidden_dropout, self.training)
+
+ outputs = (output_tensor, present)
+ if output_attentions:
+ outputs += (attention_probs,)
+
+ return outputs
+
+ return forward
+
+
+def get_jit_fused_bloom_mlp_forward():
+
+ from transformers.models.bloom.modeling_bloom import BloomMLP
+
+ def forward(self: BloomMLP, hidden_states: torch.Tensor, residual: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.gelu_impl(self.dense_h_to_4h(hidden_states))
+
+ if self.pretraining_tp > 1 and self.slow_but_exact:
+ intermediate_output = torch.zeros_like(residual)
+ slices = self.dense_4h_to_h.weight.shape[-1] / self.pretraining_tp
+ for i in range(self.pretraining_tp):
+ intermediate_output = intermediate_output + F.linear(
+ hidden_states[:, :, int(i * slices):int((i + 1) * slices)],
+ self.dense_4h_to_h.weight[:, int(i * slices):int((i + 1) * slices)],
+ )
+ else:
+ intermediate_output = self.dense_4h_to_h(hidden_states)
+ output = self.dropout_add(intermediate_output, residual, self.hidden_dropout, self.training)
+ return output
+
+ return forward
+
+
+def get_jit_fused_bloom_gelu_forward():
+
+ from transformers.models.bloom.modeling_bloom import BloomGelu
+
+ from colossalai.kernel.jit.bias_gelu import GeLUFunction as JitGeLUFunction
+
+ def forward(self: BloomGelu, x: torch.Tensor) -> torch.Tensor:
+ bias = torch.zeros_like(x)
+ if self.training:
+ return JitGeLUFunction.apply(x, bias)
+ else:
+ return self.bloom_gelu_forward(x, bias)
+
+ return forward
diff --git a/colossalai/shardformer/modeling/chatglm.py b/colossalai/shardformer/modeling/chatglm.py
index 0bb8bdc58218..3d453c3bd6db 100644
--- a/colossalai/shardformer/modeling/chatglm.py
+++ b/colossalai/shardformer/modeling/chatglm.py
@@ -17,6 +17,116 @@
)
+def get_flash_core_attention_forward():
+
+ from colossalai.kernel.cuda_native.flash_attention import AttnMaskType, ColoAttention
+
+ from .chatglm2_6b.modeling_chatglm import CoreAttention
+
+ def forward(self: CoreAttention, query_layer, key_layer, value_layer, attention_mask):
+ pytorch_major_version = int(torch.__version__.split(".")[0])
+ if pytorch_major_version >= 2:
+ query_layer, key_layer, value_layer = [k.permute(1, 2, 0, 3) for k in [query_layer, key_layer, value_layer]]
+ if attention_mask is None and query_layer.shape[2] == key_layer.shape[2]:
+ context_layer = torch.nn.functional.scaled_dot_product_attention(query_layer,
+ key_layer,
+ value_layer,
+ is_causal=True)
+ else:
+ if attention_mask is not None:
+ attention_mask = ~attention_mask
+ context_layer = torch.nn.functional.scaled_dot_product_attention(query_layer, key_layer, value_layer,
+ attention_mask)
+ context_layer = context_layer.permute(2, 0, 1, 3)
+ new_context_layer_shape = context_layer.size()[:-2] + (self.hidden_size_per_partition,)
+ context_layer = context_layer.reshape(*new_context_layer_shape)
+ else:
+ # Raw attention scores
+ query_layer = query_layer.permute(1, 0, 2, 3).contiguous()
+ key_layer = key_layer.permute(1, 0, 2, 3).contiguous()
+ value_layer = value_layer.permute(1, 0, 2, 3).contiguous()
+
+ scale = 1.0 / self.norm_factor
+ if self.coeff is not None:
+ scale = scale * self.coeff
+
+ flash_attention_mask = None
+ attn_mask_type = None
+ if attention_mask is None:
+ attn_mask_type = AttnMaskType.causal
+ else:
+ flash_attention_mask = ~(attention_mask[:, :, -1].squeeze(1).to(torch.bool)).contiguous()
+ attn_mask_type = AttnMaskType.paddedcausal
+
+ attention = ColoAttention(embed_dim=self.hidden_size_per_partition,
+ num_heads=self.num_attention_heads_per_partition,
+ dropout=self.attention_dropout.p,
+ scale=scale)
+ context_layer = attention(query_layer,
+ key_layer,
+ value_layer,
+ attn_mask=flash_attention_mask,
+ attn_mask_type=attn_mask_type)
+
+ context_layer = context_layer.permute(1, 0, -1).contiguous()
+
+ return context_layer
+
+ return forward
+
+
+def get_jit_fused_glm_block_forward():
+
+ from .chatglm2_6b.modeling_chatglm import GLMBlock
+
+ def forward(
+ self: GLMBlock,
+ hidden_states,
+ attention_mask,
+ rotary_pos_emb,
+ kv_cache=None,
+ use_cache=True,
+ ):
+ # hidden_states: [s, b, h]
+ # Layer norm at the beginning of the transformer layer.
+ layernorm_output = self.input_layernorm(hidden_states)
+ # Self attention.
+ attention_output, kv_cache = self.self_attention(
+ layernorm_output,
+ attention_mask,
+ rotary_pos_emb,
+ kv_cache=kv_cache,
+ use_cache=use_cache,
+ )
+
+ # Residual connection.
+ if self.apply_residual_connection_post_layernorm:
+ residual = layernorm_output
+ else:
+ residual = hidden_states
+
+ layernorm_input = self.dropout_add(attention_output, residual, self.hidden_dropout, self.training)
+
+ # Layer norm post the self attention.
+ layernorm_output = self.post_attention_layernorm(layernorm_input)
+
+ # MLP.
+ mlp_output = self.mlp(layernorm_output)
+
+ # Second residual connection.
+ if self.apply_residual_connection_post_layernorm:
+ residual = layernorm_output
+ else:
+ residual = layernorm_input
+
+ output = self.dropout_add(mlp_output, residual, self.hidden_dropout, self.training)
+
+ return output, kv_cache
+
+ return forward
+
+
+
class ChatGLMPipelineForwards:
'''
This class serves as a micro library for ChatGLM model forwards under pipeline parallelism.
diff --git a/colossalai/shardformer/modeling/gpt2.py b/colossalai/shardformer/modeling/gpt2.py
index dc5a81dc912b..e02581fbaa9b 100644
--- a/colossalai/shardformer/modeling/gpt2.py
+++ b/colossalai/shardformer/modeling/gpt2.py
@@ -668,3 +668,88 @@ def gpt2_for_sequence_classification_forward(
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
+
+
+def get_gpt2_flash_attention_forward():
+
+ from transformers.models.gpt2.modeling_gpt2 import GPT2Attention
+
+ from colossalai.kernel.cuda_native.flash_attention import AttnMaskType, ColoAttention
+
+ def split_heads(tensor, num_heads, attn_head_size):
+ """
+ Splits hidden_size dim into attn_head_size and num_heads
+ """
+ new_shape = tensor.size()[:-1] + (num_heads, attn_head_size)
+ tensor = tensor.view(new_shape)
+ return tensor
+
+ def forward(
+ self: GPT2Attention,
+ hidden_states: Optional[Tuple[torch.FloatTensor]],
+ layer_past: Optional[Tuple[torch.Tensor]] = None,
+ attention_mask: Optional[torch.FloatTensor] = None,
+ head_mask: Optional[torch.FloatTensor] = None,
+ encoder_hidden_states: Optional[torch.Tensor] = None,
+ encoder_attention_mask: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = False,
+ output_attentions: Optional[bool] = False,
+ ) -> Tuple[Union[torch.Tensor, Tuple[torch.Tensor]], ...]:
+ _, tgt_len, _ = hidden_states.size()
+ assert tgt_len % 4 == 0, "Flash Attention Error: The sequence length should be a multiple of 4."
+
+ if encoder_hidden_states is not None:
+ if not hasattr(self, "q_attn"):
+ raise ValueError(
+ "If class is used as cross attention, the weights `q_attn` have to be defined. "
+ "Please make sure to instantiate class with `GPT2Attention(..., is_cross_attention=True)`.")
+
+ query = self.q_attn(hidden_states)
+ key, value = self.c_attn(encoder_hidden_states).split(self.split_size, dim=2)
+ attention_mask = encoder_attention_mask
+ else:
+ query, key, value = self.c_attn(hidden_states).split(self.split_size, dim=2)
+
+ query = split_heads(query, self.num_heads, self.head_dim)
+ key = split_heads(key, self.num_heads, self.head_dim)
+ value = split_heads(value, self.num_heads, self.head_dim)
+
+ if layer_past is not None:
+ past_key, past_value = layer_past
+ key = torch.cat((past_key, key), dim=1)
+ value = torch.cat((past_value, value), dim=1)
+
+ if use_cache is True:
+ present = (key, value)
+ else:
+ present = None
+
+ if not self.is_cross_attention:
+ attn_mask_type = AttnMaskType.causal
+ flash_attention_mask = None
+ if attention_mask != None:
+ if attn_mask_type == AttnMaskType.causal:
+ attn_mask_type == AttnMaskType.paddedcausal
+ else:
+ attn_mask_type = AttnMaskType.padding
+ flash_attention_mask = ~(attention_mask[:, :, -1].squeeze(1).to(torch.bool)).contiguous()
+
+ scale = value.size(-1)**-0.5
+ if self.scale_attn_by_inverse_layer_idx:
+ scale = scale * (1 / float(self.layer_idx + 1))
+
+ # use coloattention
+ attention = ColoAttention(embed_dim=self.embed_dim,
+ num_heads=self.num_heads,
+ dropout=self.attn_dropout.p,
+ scale=scale)
+
+ attn_output = attention(query, key, value, attn_mask=flash_attention_mask, attn_mask_type=attn_mask_type)
+
+ attn_output = self.c_proj(attn_output)
+ attn_output = self.resid_dropout(attn_output)
+ outputs = (attn_output, present, None)
+
+ return outputs
+
+ return forward
diff --git a/colossalai/shardformer/modeling/jit.py b/colossalai/shardformer/modeling/jit.py
new file mode 100644
index 000000000000..6434348ef823
--- /dev/null
+++ b/colossalai/shardformer/modeling/jit.py
@@ -0,0 +1,34 @@
+import torch
+
+
+def get_dropout_add_func():
+
+ from transformers.models.bloom.modeling_bloom import dropout_add
+
+ def self_dropout_add(self, x: torch.Tensor, residual: torch.Tensor, prob: float, training: bool) -> torch.Tensor:
+ return dropout_add(x, residual, prob, training)
+
+ return self_dropout_add
+
+
+def get_jit_fused_dropout_add_func():
+
+ from colossalai.kernel.jit import bias_dropout_add_fused_inference, bias_dropout_add_fused_train
+
+ def self_dropout_add(self, x: torch.Tensor, residual: torch.Tensor, prob: float, training: bool) -> torch.Tensor:
+ bias = torch.zeros_like(x)
+ if training:
+ return bias_dropout_add_fused_train(x, bias, residual, prob)
+ return bias_dropout_add_fused_inference(x, bias, residual, prob)
+
+ return self_dropout_add
+
+
+def get_jit_fused_gelu_forward_func():
+
+ from colossalai.kernel.jit.bias_gelu import bias_gelu
+
+ def bloom_gelu_forward(x: torch.Tensor, bias: torch.Tensor) -> torch.Tensor:
+ return bias_gelu(bias, x)
+
+ return bloom_gelu_forward
diff --git a/colossalai/shardformer/modeling/llama.py b/colossalai/shardformer/modeling/llama.py
index e1ed5f64665c..9d6335503b36 100644
--- a/colossalai/shardformer/modeling/llama.py
+++ b/colossalai/shardformer/modeling/llama.py
@@ -1,4 +1,4 @@
-from typing import Callable, List, Optional
+from typing import Callable, List, Optional, Tuple
import torch
from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
@@ -386,3 +386,67 @@ def llama_for_sequence_classification_forward(
else:
hidden_states = transformer_outputs.get('hidden_states')
return {'hidden_states': hidden_states}
+
+
+def get_llama_flash_attention_forward():
+
+ from transformers.models.llama.modeling_llama import LlamaAttention, apply_rotary_pos_emb
+
+ from colossalai.kernel.cuda_native.flash_attention import AttnMaskType, ColoAttention
+
+ def forward(
+ self: LlamaAttention,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ bsz, q_len, _ = hidden_states.size()
+ assert q_len % 4 == 0, "Flash Attention Error: The sequence length should be a multiple of 4."
+
+ query_states = self.q_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
+ key_states = self.k_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
+ value_states = self.v_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ kv_seq_len += past_key_value[0].shape[-2]
+
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
+
+ if past_key_value is not None:
+ # reuse k, v, self_attention
+ key_states = torch.cat([past_key_value[0], key_states], dim=2)
+ value_states = torch.cat([past_key_value[1], value_states], dim=2)
+
+ past_key_value = (key_states, value_states) if use_cache else None
+
+ me_input_shape = (bsz, q_len, self.num_heads, self.head_dim)
+ query_states = query_states.transpose(1, 2).contiguous().view(*me_input_shape)
+ key_states = key_states.transpose(1, 2).contiguous().view(*me_input_shape)
+ value_states = value_states.transpose(1, 2).contiguous().view(*me_input_shape)
+
+ flash_attention_mask = None
+ attn_mask_type = AttnMaskType.causal
+ if attention_mask != None:
+ if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):
+ raise ValueError(
+ f"Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}")
+ flash_attention_mask = ~(attention_mask[:, :, -1].squeeze(1).to(torch.bool)).contiguous()
+ attn_mask_type = AttnMaskType.paddedcausal
+
+ attention = ColoAttention(embed_dim=self.hidden_size, num_heads=self.num_heads)
+ attn_output = attention(query_states,
+ key_states,
+ value_states,
+ attn_mask=flash_attention_mask,
+ attn_mask_type=attn_mask_type)
+
+ attn_output = self.o_proj(attn_output)
+
+ return attn_output, None, past_key_value
+
+ return forward
diff --git a/colossalai/shardformer/modeling/opt.py b/colossalai/shardformer/modeling/opt.py
new file mode 100644
index 000000000000..299dfb5562f3
--- /dev/null
+++ b/colossalai/shardformer/modeling/opt.py
@@ -0,0 +1,174 @@
+from typing import Optional, Tuple
+
+import torch
+from torch import nn
+
+
+def get_opt_flash_attention_forward():
+
+ from transformers.models.opt.modeling_opt import OPTAttention
+
+ from colossalai.kernel.cuda_native.flash_attention import AttnMaskType, ColoAttention
+
+ def forward(
+ self: OPTAttention,
+ hidden_states: torch.Tensor,
+ key_value_states: Optional[torch.Tensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ layer_head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ """Input shape: Batch x Time x Channel"""
+
+ # if key_value_states are provided this layer is used as a cross-attention layer
+ # for the decoder
+ is_cross_attention = key_value_states is not None
+ bsz, tgt_len, _ = hidden_states.size()
+ assert tgt_len % 4 == 0, "Flash Attention Error: The sequence length should be a multiple of 4."
+
+ attention_input_shape = (bsz, -1, self.num_heads, self.head_dim)
+ # get query proj
+ query_states = self.q_proj(hidden_states).view(*attention_input_shape)
+ # get key, value proj
+ if is_cross_attention and past_key_value is not None:
+ # reuse k, v, cross_attentions
+ key_states = past_key_value[0].transpose(1, 2).contiguous().view(*attention_input_shape)
+ value_states = past_key_value[1].transpose(1, 2).contiguous().view(*attention_input_shape)
+ elif is_cross_attention:
+ # cross_attentions
+ key_states = self.k_proj(key_value_states).view(*attention_input_shape)
+ value_states = self.v_proj(key_value_states).view(*attention_input_shape)
+ elif past_key_value is not None:
+ # reuse k, v, self_attention
+ key_states = self.k_proj(hidden_states).view(*attention_input_shape)
+ value_states = self.v_proj(hidden_states).view(*attention_input_shape)
+ key_states = torch.cat([past_key_value[0], key_states], dim=1)
+ value_states = torch.cat([past_key_value[1], value_states], dim=1)
+ else:
+ # self_attention
+ key_states = self.k_proj(hidden_states).view(*attention_input_shape)
+ value_states = self.v_proj(hidden_states).view(*attention_input_shape)
+
+ if self.is_decoder:
+ # if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
+ # Further calls to cross_attention layer can then reuse all cross-attention
+ # key/value_states (first "if" case)
+ # if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
+ # all previous decoder key/value_states. Further calls to uni-directional self-attention
+ # can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
+ # if encoder bi-directional self-attention `past_key_value` is always `None`
+ past_key_value = (key_states, value_states)
+
+ src_len = key_states.size(1)
+ if layer_head_mask != None:
+ if layer_head_mask.size() != (self.num_heads,):
+ raise ValueError(f"Head mask for a single layer should be of size {(self.num_heads,)}, but is"
+ f" {layer_head_mask.size()}")
+
+ flash_attention_mask = None
+ attn_mask_type = AttnMaskType.causal
+ if attention_mask != None:
+ if attention_mask.size() != (bsz, 1, tgt_len, src_len):
+ raise ValueError(
+ f"Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is {attention_mask.size()}")
+ flash_attention_mask = ~(attention_mask[:, :, -1].squeeze(1).to(torch.bool)).contiguous()
+ attn_mask_type = AttnMaskType.paddedcausal
+
+ attention = ColoAttention(embed_dim=self.embed_dim,
+ num_heads=self.num_heads,
+ dropout=self.dropout,
+ scale=self.scaling)
+ attn_output = attention(query_states,
+ key_states,
+ value_states,
+ attn_mask=flash_attention_mask,
+ attn_mask_type=attn_mask_type)
+
+ attn_output = self.out_proj(attn_output)
+ return attn_output, None, past_key_value
+
+ return forward
+
+
+def get_jit_fused_opt_decoder_layer_forward():
+
+ from transformers.models.opt.modeling_opt import OPTDecoderLayer
+
+ def forward(
+ self: OPTDecoderLayer,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ layer_head_mask: Optional[torch.Tensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: Optional[bool] = False,
+ use_cache: Optional[bool] = False,
+ ) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
+ attention_mask (`torch.FloatTensor`, *optional*): attention mask of size
+ `(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
+ layer_head_mask (`torch.FloatTensor`, *optional*): mask for attention heads in a given layer of size
+ `(encoder_attention_heads,)`.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
+ (see `past_key_values`).
+ past_key_value (`Tuple(torch.FloatTensor)`, *optional*): cached past key and value projection states
+ """
+
+ residual = hidden_states
+
+ # 125m, 1.7B, ..., 175B applies layer norm BEFORE attention
+ if self.do_layer_norm_before:
+ hidden_states = self.self_attn_layer_norm(hidden_states)
+
+ # Self Attention
+ hidden_states, self_attn_weights, present_key_value = self.self_attn(
+ hidden_states=hidden_states,
+ past_key_value=past_key_value,
+ attention_mask=attention_mask,
+ layer_head_mask=layer_head_mask,
+ output_attentions=output_attentions,
+ )
+
+ hidden_states = self.dropout_add(hidden_states, residual, self.dropout, self.training)
+
+ # 350m applies layer norm AFTER attention
+ if not self.do_layer_norm_before:
+ hidden_states = self.self_attn_layer_norm(hidden_states)
+
+ # Fully Connected
+ hidden_states_shape = hidden_states.shape
+ hidden_states = hidden_states.reshape(-1, hidden_states.size(-1))
+ residual = hidden_states
+
+ # 125m, 1.7B, ..., 175B applies layer norm BEFORE attention
+ if self.do_layer_norm_before:
+ hidden_states = self.final_layer_norm(hidden_states)
+
+ hidden_states = self.fc1(hidden_states)
+ hidden_states = self.activation_fn(hidden_states)
+
+ hidden_states = self.fc2(hidden_states)
+
+ hidden_states = self.dropout_add(hidden_states, residual, self.dropout, self.training).view(hidden_states_shape)
+
+ # 350m applies layer norm AFTER attention
+ if not self.do_layer_norm_before:
+ hidden_states = self.final_layer_norm(hidden_states)
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (self_attn_weights,)
+
+ if use_cache:
+ outputs += (present_key_value,)
+
+ return outputs
+
+ return forward
diff --git a/colossalai/shardformer/modeling/sam.py b/colossalai/shardformer/modeling/sam.py
index 63ebfe89d5fa..c40c02ec411a 100644
--- a/colossalai/shardformer/modeling/sam.py
+++ b/colossalai/shardformer/modeling/sam.py
@@ -1,4 +1,9 @@
+import math
+from typing import Tuple
+
import torch
+import torch.nn.functional as F
+from torch import Tensor
def forward_fn():
@@ -37,3 +42,162 @@ def forward(self, hidden_states: torch.Tensor, output_attentions=False) -> torch
return outputs
return forward
+
+
+def get_sam_flash_attention_forward():
+
+ from transformers.models.sam.modeling_sam import SamAttention
+ try:
+ from xformers.ops import memory_efficient_attention as me_attention
+ except:
+ raise ImportError("Error: xformers module is not installed. Please install it to use flash attention.")
+
+ def _separate_heads(hidden_states: Tensor, num_attention_heads: int) -> Tensor:
+ batch, point_batch_size, n_tokens, channel = hidden_states.shape
+ c_per_head = channel // num_attention_heads
+ hidden_states = hidden_states.reshape(batch * point_batch_size, n_tokens, num_attention_heads, c_per_head)
+ return hidden_states
+
+ def _recombine_heads(hidden_states: Tensor, point_batch_size: int) -> Tensor:
+ batch, n_tokens, n_heads, c_per_head = hidden_states.shape
+ return hidden_states.reshape(batch // point_batch_size, point_batch_size, n_tokens, n_heads * c_per_head)
+
+ def forward(self: SamAttention,
+ query: Tensor,
+ key: Tensor,
+ value: Tensor,
+ attention_similarity: Tensor = None) -> Tensor:
+ # Input projections
+ query = self.q_proj(query)
+ key = self.k_proj(key)
+ value = self.v_proj(value)
+
+ point_batch_size = query.shape[1]
+ # Separate into heads
+ query = _separate_heads(query, self.num_attention_heads)
+ key = _separate_heads(key, self.num_attention_heads)
+ value = _separate_heads(value, self.num_attention_heads)
+
+ # SamAttention
+ _, _, _, c_per_head = query.shape
+ bias = None
+ if attention_similarity is not None:
+ bias = attention_similarity
+
+ scale = 1.0 / math.sqrt(c_per_head)
+ out = me_attention(query, key, value, attn_bias=bias, scale=scale)
+
+ out = _recombine_heads(out, point_batch_size)
+ out = self.out_proj(out)
+
+ return out
+
+ return forward
+
+
+def get_sam_vision_flash_attention_forward():
+
+ from transformers.models.sam.modeling_sam import SamVisionAttention
+ try:
+ from xformers.ops import memory_efficient_attention as me_attention
+ except:
+ raise ImportError("Error: xformers module is not installed. Please install it to use flash attention.")
+
+ def add_decomposed_rel_pos(
+ query: torch.Tensor,
+ rel_pos_h: torch.Tensor,
+ rel_pos_w: torch.Tensor,
+ q_size: Tuple[int, int],
+ k_size: Tuple[int, int],
+ ) -> torch.Tensor:
+ """
+ Calculate decomposed Relative Positional Embeddings from :paper:`mvitv2`.
+ https://github.com/facebookresearch/mvit/blob/19786631e330df9f3622e5402b4a419a263a2c80/mvit/models/attention.py
+
+ Args:
+ attn (`torch.Tensor`):
+ attention map.
+ query (`torch.Tensor`):
+ query q in the attention layer with shape (batch_size, query_height * query_width, channel).
+ rel_pos_h (`torch.Tensor`):
+ relative position embeddings (Lh, channel) for height axis.
+ rel_pos_w (`torch.Tensor`):
+ relative position embeddings (Lw, channel) for width axis.
+ q_size (tuple):
+ spatial sequence size of query q with (query_height, query_width).
+ k_size (tuple):
+ spatial sequence size of key k with (key_height, key_width).
+
+ Returns:
+ attn (`torch.Tensor`):
+ attention map with added relative positional embeddings.
+ """
+
+ query_height, query_width = q_size
+ key_height, key_width = k_size
+ relative_position_height = get_rel_pos(query_height, key_height, rel_pos_h)
+ relative_position_width = get_rel_pos(query_width, key_width, rel_pos_w)
+
+ batch_size, _, nHead, dim = query.shape
+ reshaped_query = query.transpose(1, 2).reshape(batch_size * nHead, query_height, query_width, dim)
+ rel_h = torch.einsum("bhwc,hkc->bhwk", reshaped_query, relative_position_height)
+ rel_w = torch.einsum("bhwc,wkc->bhwk", reshaped_query, relative_position_width)
+ rel_pos = rel_h[:, :, :, :, None] + rel_w[:, :, :, None, :]
+ rel_pos = rel_pos.reshape(batch_size, nHead, query_height * query_width, key_height * key_width)
+ return rel_pos
+
+ def get_rel_pos(q_size: int, k_size: int, rel_pos: torch.Tensor) -> torch.Tensor:
+ """
+ Get relative positional embeddings according to the relative positions of
+ query and key sizes.
+
+ Args:
+ q_size (int):
+ size of the query.
+ k_size (int):
+ size of key k.
+ rel_pos (`torch.Tensor`):
+ relative position embeddings (L, channel).
+
+ Returns:
+ Extracted positional embeddings according to relative positions.
+ """
+ max_rel_dist = int(2 * max(q_size, k_size) - 1)
+ # Interpolate rel pos.
+ rel_pos_resized = F.interpolate(
+ rel_pos.reshape(1, rel_pos.shape[0], -1).permute(0, 2, 1),
+ size=max_rel_dist,
+ mode="linear",
+ )
+ rel_pos_resized = rel_pos_resized.reshape(-1, max_rel_dist).permute(1, 0)
+
+ # Scale the coords with short length if shapes for q and k are different.
+ q_coords = torch.arange(q_size)[:, None] * max(k_size / q_size, 1.0)
+ k_coords = torch.arange(k_size)[None, :] * max(q_size / k_size, 1.0)
+ relative_coords = (q_coords - k_coords) + (k_size - 1) * max(q_size / k_size, 1.0)
+
+ return rel_pos_resized[relative_coords.long()]
+
+ def forward(self: SamVisionAttention, hidden_states: torch.Tensor, output_attentions=False) -> torch.Tensor:
+ batch_size, height, width, _ = hidden_states.shape
+ # qkv with shape (3, batch_size, nHead, height * width, channel)
+ qkv = (self.qkv(hidden_states).reshape(batch_size, height * width, 3, self.num_attention_heads,
+ -1).permute(2, 0, 1, 3, 4))
+
+ query, key, value = qkv.reshape(3, batch_size, height * width, self.num_attention_heads, -1).unbind(0)
+
+ rel_pos = None
+ if self.use_rel_pos:
+ rel_pos = add_decomposed_rel_pos(query, self.rel_pos_h, self.rel_pos_w, (height, width), (height, width))
+
+ attn_output = me_attention(query, key, value, attn_bias=rel_pos, p=self.dropout, scale=self.scale)
+
+ attn_output = attn_output.reshape(batch_size, height, width, -1)
+
+ attn_output = self.proj(attn_output)
+
+ outputs = (attn_output, None)
+
+ return outputs
+
+ return forward
diff --git a/colossalai/shardformer/modeling/t5.py b/colossalai/shardformer/modeling/t5.py
index 7eb4d17928d6..0b3486e87c7e 100644
--- a/colossalai/shardformer/modeling/t5.py
+++ b/colossalai/shardformer/modeling/t5.py
@@ -587,3 +587,209 @@ def t5_encoder_model_forward(
decoder_starting_stage=decoder_starting_stage)
return outputs
+
+
+def get_t5_flash_attention_forward():
+
+ try:
+ from xformers.ops import memory_efficient_attention as me_attention
+ except:
+ raise ImportError("Error: xformers module is not installed. Please install it to use flash attention.")
+ from transformers.models.t5.modeling_t5 import T5Attention
+
+ def forward(
+ self: T5Attention,
+ hidden_states: torch.Tensor,
+ mask: Optional[torch.Tensor] = None,
+ key_value_states: Optional[torch.Tensor] = None,
+ position_bias: Optional[torch.Tensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ layer_head_mask: Optional[torch.Tensor] = None,
+ query_length: Optional[int] = None,
+ use_cache: bool = False,
+ output_attentions: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[torch.Tensor]]:
+ """
+ Self-attention (if key_value_states is None) or attention over source sentence (provided by key_value_states).
+ """
+ # Input is (batch_size, seq_length, dim)
+ # Mask is (batch_size, key_length) (non-causal) or (batch_size, key_length, key_length)
+ # past_key_value[0] is (batch_size, n_heads, q_len - 1, dim_per_head)
+ batch_size, seq_length = hidden_states.shape[:2]
+
+ real_seq_length = seq_length
+
+ if past_key_value is not None:
+ if len(past_key_value) != 2:
+ raise ValueError(
+ f"past_key_value should have 2 past states: keys and values. Got { len(past_key_value)} past states"
+ )
+ real_seq_length += past_key_value[0].shape[2] if query_length is None else query_length
+
+ key_length = real_seq_length if key_value_states is None else key_value_states.shape[1]
+
+ def shape(states):
+ """projection"""
+ return states.view(batch_size, -1, self.n_heads, self.key_value_proj_dim)
+
+ def unshape(states):
+ """reshape"""
+ return states.view(batch_size, -1, self.inner_dim)
+
+ def project(hidden_states, proj_layer, key_value_states, past_key_value):
+ """projects hidden states correctly to key/query states"""
+ if key_value_states is None:
+ # self-attn
+ # (batch_size, n_heads, seq_length, dim_per_head)
+ hidden_states = shape(proj_layer(hidden_states))
+ elif past_key_value is None:
+ # cross-attn
+ # (batch_size, n_heads, seq_length, dim_per_head)
+ hidden_states = shape(proj_layer(key_value_states))
+
+ if past_key_value is not None:
+ if key_value_states is None:
+ # self-attn
+ # (batch_size, n_heads, key_length, dim_per_head)
+ hidden_states = torch.cat([past_key_value, hidden_states], dim=1)
+ elif past_key_value.shape[1] != key_value_states.shape[1]:
+ # checking that the `sequence_length` of the `past_key_value` is the same as
+ # the provided `key_value_states` to support prefix tuning
+ # cross-attn
+ # (batch_size, n_heads, seq_length, dim_per_head)
+ hidden_states = shape(proj_layer(key_value_states))
+ else:
+ # cross-attn
+ hidden_states = past_key_value
+ return hidden_states
+
+ # get query states
+ query_states = shape(self.q(hidden_states)) # (batch_size, n_heads, seq_length, dim_per_head)
+
+ # get key/value states
+ key_states = project(hidden_states, self.k, key_value_states,
+ past_key_value[0] if past_key_value is not None else None)
+ value_states = project(hidden_states, self.v, key_value_states,
+ past_key_value[1] if past_key_value is not None else None)
+
+ if position_bias is None:
+ if not self.has_relative_attention_bias:
+ position_bias = torch.zeros((1, self.n_heads, real_seq_length, key_length),
+ device=query_states.device,
+ dtype=query_states.dtype)
+ if self.gradient_checkpointing and self.training:
+ position_bias.requires_grad = True
+ else:
+ position_bias = self.compute_bias(real_seq_length, key_length, device=query_states.device)
+
+ # if key and values are already calculated
+ # we want only the last query position bias
+ if past_key_value is not None:
+ position_bias = position_bias[:, :, -hidden_states.size(1):, :]
+
+ if mask is not None:
+ position_bias = position_bias + mask # (batch_size, n_heads, seq_length, key_length)
+
+ if self.pruned_heads:
+ mask = torch.ones(position_bias.shape[1])
+ mask[list(self.pruned_heads)] = 0
+ position_bias_masked = position_bias[:, mask.bool()]
+ else:
+ position_bias_masked = position_bias
+
+ position_bias_masked = position_bias_masked.contiguous()
+ attn_output = me_attention(query_states,
+ key_states,
+ value_states,
+ attn_bias=position_bias_masked,
+ p=self.dropout,
+ scale=1.0)
+ attn_output = unshape(attn_output)
+ attn_output = self.o(attn_output)
+
+ present_key_value_state = (key_states, value_states) if (self.is_decoder and use_cache) else None
+
+ outputs = (attn_output,) + (present_key_value_state,) + (position_bias,)
+
+ return outputs
+
+ return forward
+
+
+def get_jit_fused_T5_layer_ff_forward():
+
+ from transformers.models.t5.modeling_t5 import T5LayerFF
+
+ def forward(self: T5LayerFF, hidden_states: torch.Tensor) -> torch.Tensor:
+ forwarded_states = self.layer_norm(hidden_states)
+ forwarded_states = self.DenseReluDense(forwarded_states)
+ hidden_states = self.dropout_add(forwarded_states, hidden_states, self.dropout.p, self.dropout.training)
+ return hidden_states
+
+ return forward
+
+
+def get_T5_layer_self_attention_forward():
+
+ from transformers.models.t5.modeling_t5 import T5LayerSelfAttention
+
+ def forward(
+ self: T5LayerSelfAttention,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_bias: Optional[torch.Tensor] = None,
+ layer_head_mask: Optional[torch.Tensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ use_cache: bool = False,
+ output_attentions: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[torch.Tensor]]:
+ normed_hidden_states = self.layer_norm(hidden_states)
+ attention_output = self.SelfAttention(
+ normed_hidden_states,
+ mask=attention_mask,
+ position_bias=position_bias,
+ layer_head_mask=layer_head_mask,
+ past_key_value=past_key_value,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ )
+ hidden_states = self.dropout_add(attention_output[0], hidden_states, self.dropout.p, self.dropout.training)
+ outputs = (hidden_states,) + attention_output[1:] # add attentions if we output them
+ return outputs
+
+ return forward
+
+
+def get_T5_layer_cross_attention_forward():
+
+ from transformers.models.t5.modeling_t5 import T5LayerCrossAttention
+
+ def forward(
+ self: T5LayerCrossAttention,
+ hidden_states: torch.Tensor,
+ key_value_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_bias: Optional[torch.Tensor] = None,
+ layer_head_mask: Optional[torch.Tensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ use_cache: bool = False,
+ query_length: Optional[int] = None,
+ output_attentions: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[torch.Tensor]]:
+ normed_hidden_states = self.layer_norm(hidden_states)
+ attention_output = self.EncDecAttention(
+ normed_hidden_states,
+ mask=attention_mask,
+ key_value_states=key_value_states,
+ position_bias=position_bias,
+ layer_head_mask=layer_head_mask,
+ past_key_value=past_key_value,
+ use_cache=use_cache,
+ query_length=query_length,
+ output_attentions=output_attentions,
+ )
+ layer_output = self.dropout_add(attention_output[0], hidden_states, self.dropout.p, self.dropout.training)
+ outputs = (layer_output,) + attention_output[1:] # add attentions if we output them
+ return outputs
+
+ return forward
diff --git a/colossalai/shardformer/modeling/vit.py b/colossalai/shardformer/modeling/vit.py
index f28c13ad0aa2..22c4dd998cac 100644
--- a/colossalai/shardformer/modeling/vit.py
+++ b/colossalai/shardformer/modeling/vit.py
@@ -1,4 +1,5 @@
import logging
+import math
from typing import Dict, List, Optional, Set, Tuple, Union
import torch
@@ -335,3 +336,51 @@ def pp_forward(
)
return pp_forward
+
+
+def get_vit_flash_self_attention_forward():
+
+ from transformers.models.vit.modeling_vit import ViTSelfAttention
+
+ from colossalai.kernel.cuda_native.flash_attention import ColoAttention
+
+ def transpose_for_scores(x: torch.Tensor, num_attention_heads, attention_head_size) -> torch.Tensor:
+ new_x_shape = x.size()[:-1] + (num_attention_heads, attention_head_size)
+ x = x.view(new_x_shape)
+ return x
+
+ def forward(self: ViTSelfAttention,
+ hidden_states: torch.Tensor,
+ head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
+ mixed_query_layer = self.query(hidden_states)
+
+ key_layer = transpose_for_scores(self.key(hidden_states), self.num_attention_heads, self.attention_head_size)
+ value_layer = transpose_for_scores(self.value(hidden_states), self.num_attention_heads,
+ self.attention_head_size)
+ query_layer = transpose_for_scores(mixed_query_layer, self.num_attention_heads, self.attention_head_size)
+
+ scale = 1.0 / math.sqrt(self.attention_head_size)
+ attention = ColoAttention(embed_dim=self.all_head_size,
+ num_heads=self.num_attention_heads,
+ dropout=self.dropout.p,
+ scale=scale)
+ context_layer = attention(query_layer, key_layer, value_layer)
+
+ outputs = (context_layer,)
+
+ return outputs
+
+ return forward
+
+
+def get_jit_fused_vit_output_forward():
+
+ from transformers.models.vit.modeling_vit import ViTOutput
+
+ def forward(self: ViTOutput, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout_add(hidden_states, input_tensor, self.dropout.p, self.dropout.training)
+ return hidden_states
+
+ return forward
diff --git a/colossalai/shardformer/modeling/whisper.py b/colossalai/shardformer/modeling/whisper.py
new file mode 100644
index 000000000000..6bc387ac8974
--- /dev/null
+++ b/colossalai/shardformer/modeling/whisper.py
@@ -0,0 +1,249 @@
+from typing import Optional, Tuple
+
+import torch
+from torch import nn
+
+
+def get_whisper_flash_attention_forward():
+
+ from transformers.models.whisper.modeling_whisper import WhisperAttention
+
+ from colossalai.kernel.cuda_native.flash_attention import AttnMaskType, ColoAttention
+
+ def shape(tensor: torch.Tensor, seq_len: int, bsz: int, num_heads: int, head_dim: int):
+ return tensor.view(bsz, seq_len, num_heads, head_dim).contiguous()
+
+ def forward(
+ self: WhisperAttention,
+ hidden_states: torch.Tensor,
+ key_value_states: Optional[torch.Tensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ layer_head_mask: Optional[torch.Tensor] = None,
+ output_attentions: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ """Input shape: Batch x Time x Channel"""
+
+ # if key_value_states are provided this layer is used as a cross-attention layer
+ # for the decoder
+ is_cross_attention = key_value_states is not None
+
+ bsz, tgt_len, _ = hidden_states.size()
+
+ # get key, value proj
+ # `past_key_value[0].shape[2] == key_value_states.shape[1]`
+ # is checking that the `sequence_length` of the `past_key_value` is the same as
+ # the provided `key_value_states` to support prefix tuning
+ if (is_cross_attention and past_key_value is not None
+ and past_key_value[0].shape[1] == key_value_states.shape[1]):
+ # reuse k,v, cross_attentions
+ key_states = past_key_value[0]
+ value_states = past_key_value[1]
+ elif is_cross_attention:
+ # cross_attentions
+ key_states = shape(self.k_proj(key_value_states), -1, bsz, self.num_heads, self.head_dim)
+ value_states = shape(self.v_proj(key_value_states), -1, bsz, self.num_heads, self.head_dim)
+ elif past_key_value is not None:
+ # reuse k, v, self_attention
+ key_states = shape(self.k_proj(hidden_states), -1, bsz, self.num_heads, self.head_dim)
+ value_states = shape(self.v_proj(hidden_states), -1, bsz, self.num_heads, self.head_dim)
+ key_states = torch.cat([past_key_value[0], key_states], dim=1)
+ value_states = torch.cat([past_key_value[1], value_states], dim=1)
+ else:
+ # self_attention
+ key_states = shape(self.k_proj(hidden_states), -1, bsz, self.num_heads, self.head_dim)
+ value_states = shape(self.v_proj(hidden_states), -1, bsz, self.num_heads, self.head_dim)
+
+ if self.is_decoder:
+ # if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
+ # Further calls to cross_attention layer can then reuse all cross-attention
+ # key/value_states (first "if" case)
+ # if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
+ # all previous decoder key/value_states. Further calls to uni-directional self-attention
+ # can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
+ # if encoder bi-directional self-attention `past_key_value` is always `None`
+ past_key_value = (key_states, value_states)
+
+ # get query proj
+ query_states = shape(self.q_proj(hidden_states), tgt_len, bsz, self.num_heads, self.head_dim)
+
+ src_len = key_states.size(1)
+ if layer_head_mask is not None:
+ if layer_head_mask.size() != (self.num_heads,):
+ raise ValueError(f"Head mask for a single layer should be of size {(self.num_heads,)}, but is"
+ f" {layer_head_mask.size()}")
+
+ attn_type = None
+ flash_attention_mask = None
+
+ if self.is_decoder:
+ if attention_mask is not None:
+ if attention_mask.size() != (bsz, 1, tgt_len, src_len):
+ raise ValueError(
+ f"Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is {attention_mask.size()}"
+ )
+ flash_attention_mask = ~(attention_mask[:, :, -1].squeeze(1).to(torch.bool).contiguous())
+ attn_type = AttnMaskType.paddedcausal
+
+ attention = ColoAttention(embed_dim=self.embed_dim,
+ num_heads=self.num_heads,
+ dropout=self.dropout,
+ scale=self.scaling)
+ attn_output = attention(query_states,
+ key_states,
+ value_states,
+ attn_mask=flash_attention_mask,
+ attn_mask_type=attn_type)
+
+ attn_output = self.out_proj(attn_output)
+
+ return attn_output, None, past_key_value
+
+ return forward
+
+
+def get_jit_fused_whisper_encoder_layer_forward():
+
+ from transformers.models.whisper.modeling_whisper import WhisperEncoderLayer
+
+ def forward(
+ self: WhisperEncoderLayer,
+ hidden_states: torch.Tensor,
+ attention_mask: torch.Tensor,
+ layer_head_mask: torch.Tensor,
+ output_attentions: bool = False,
+ ) -> torch.Tensor:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
+ attention_mask (`torch.FloatTensor`): attention mask of size
+ `(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
+ layer_head_mask (`torch.FloatTensor`): mask for attention heads in a given layer of size
+ `(encoder_attention_heads,)`.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ """
+ residual = hidden_states
+ hidden_states = self.self_attn_layer_norm(hidden_states)
+ hidden_states, attn_weights, _ = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ layer_head_mask=layer_head_mask,
+ output_attentions=output_attentions,
+ )
+ hidden_states = self.dropout_add(hidden_states, residual, self.dropout, self.training)
+
+ residual = hidden_states
+ hidden_states = self.final_layer_norm(hidden_states)
+ hidden_states = self.activation_fn(self.fc1(hidden_states))
+ hidden_states = nn.functional.dropout(hidden_states, p=self.activation_dropout, training=self.training)
+ hidden_states = self.fc2(hidden_states)
+ hidden_states = self.dropout_add(hidden_states, residual, self.dropout, self.training)
+
+ if hidden_states.dtype == torch.float16 and (torch.isinf(hidden_states).any()
+ or torch.isnan(hidden_states).any()):
+ clamp_value = torch.finfo(hidden_states.dtype).max - 1000
+ hidden_states = torch.clamp(hidden_states, min=-clamp_value, max=clamp_value)
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (attn_weights,)
+
+ return outputs
+
+ return forward
+
+
+def get_jit_fused_whisper_decoder_layer_forward():
+
+ from transformers.models.whisper.modeling_whisper import WhisperDecoderLayer
+
+ def forward(
+ self: WhisperDecoderLayer,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ encoder_hidden_states: Optional[torch.Tensor] = None,
+ encoder_attention_mask: Optional[torch.Tensor] = None,
+ layer_head_mask: Optional[torch.Tensor] = None,
+ cross_attn_layer_head_mask: Optional[torch.Tensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: Optional[bool] = False,
+ use_cache: Optional[bool] = True,
+ ) -> torch.Tensor:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
+ attention_mask (`torch.FloatTensor`): attention mask of size
+ `(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
+ encoder_hidden_states (`torch.FloatTensor`):
+ cross attention input to the layer of shape `(batch, seq_len, embed_dim)`
+ encoder_attention_mask (`torch.FloatTensor`): encoder attention mask of size
+ `(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
+ layer_head_mask (`torch.FloatTensor`): mask for attention heads in a given layer of size
+ `(encoder_attention_heads,)`.
+ cross_attn_layer_head_mask (`torch.FloatTensor`): mask for cross-attention heads in a given layer of
+ size `(decoder_attention_heads,)`.
+ past_key_value (`Tuple(torch.FloatTensor)`): cached past key and value projection states
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ """
+ residual = hidden_states
+ hidden_states = self.self_attn_layer_norm(hidden_states)
+
+ # Self Attention
+ # decoder uni-directional self-attention cached key/values tuple is at positions 1,2
+ self_attn_past_key_value = past_key_value[:2] if past_key_value is not None else None
+ # add present self-attn cache to positions 1,2 of present_key_value tuple
+ hidden_states, self_attn_weights, present_key_value = self.self_attn(
+ hidden_states=hidden_states,
+ past_key_value=self_attn_past_key_value,
+ attention_mask=attention_mask,
+ layer_head_mask=layer_head_mask,
+ output_attentions=output_attentions,
+ )
+ hidden_states = self.dropout_add(hidden_states, residual, self.dropout, self.training)
+
+ # Cross-Attention Block
+ cross_attn_present_key_value = None
+ cross_attn_weights = None
+ if encoder_hidden_states is not None:
+ residual = hidden_states
+ hidden_states = self.encoder_attn_layer_norm(hidden_states)
+
+ # cross_attn cached key/values tuple is at positions 3,4 of present_key_value tuple
+ cross_attn_past_key_value = past_key_value[-2:] if past_key_value is not None else None
+ hidden_states, cross_attn_weights, cross_attn_present_key_value = self.encoder_attn(
+ hidden_states=hidden_states,
+ key_value_states=encoder_hidden_states,
+ attention_mask=encoder_attention_mask,
+ layer_head_mask=cross_attn_layer_head_mask,
+ past_key_value=cross_attn_past_key_value,
+ output_attentions=output_attentions,
+ )
+ hidden_states = self.dropout_add(hidden_states, residual, self.dropout, self.training)
+
+ # add cross-attn to positions 3,4 of present_key_value tuple
+ present_key_value = present_key_value + cross_attn_present_key_value
+
+ # Fully Connected
+ residual = hidden_states
+ hidden_states = self.final_layer_norm(hidden_states)
+ hidden_states = self.activation_fn(self.fc1(hidden_states))
+ hidden_states = nn.functional.dropout(hidden_states, p=self.activation_dropout, training=self.training)
+ hidden_states = self.fc2(hidden_states)
+ hidden_states = self.dropout_add(hidden_states, residual, self.dropout, self.training)
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (self_attn_weights, cross_attn_weights)
+
+ if use_cache:
+ outputs += (present_key_value,)
+
+ return outputs
+
+ return forward
diff --git a/colossalai/shardformer/policies/bert.py b/colossalai/shardformer/policies/bert.py
index 6f86de232fad..ace9ada3904f 100644
--- a/colossalai/shardformer/policies/bert.py
+++ b/colossalai/shardformer/policies/bert.py
@@ -7,7 +7,14 @@
import colossalai.shardformer.layer as col_nn
-from ..modeling.bert import BertPipelineForwards
+from .._utils import getattr_, setattr_
+from ..modeling.bert import (
+ BertPipelineForwards,
+ get_bert_flash_attention_forward,
+ get_jit_fused_bert_output_forward,
+ get_jit_fused_bert_self_output_forward,
+)
+from ..modeling.jit import get_jit_fused_dropout_add_func
from .base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
__all__ = [
@@ -37,7 +44,13 @@ def preprocess(self):
return self.model
def module_policy(self):
- from transformers.models.bert.modeling_bert import BertEmbeddings, BertLayer
+ from transformers.models.bert.modeling_bert import (
+ BertEmbeddings,
+ BertLayer,
+ BertOutput,
+ BertSelfAttention,
+ BertSelfOutput,
+ )
policy = {}
@@ -126,6 +139,23 @@ def module_policy(self):
policy=policy,
target_key=BertEmbeddings)
+ # use flash attention
+ if self.shard_config.enable_flash_attention:
+ policy[BertSelfAttention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_bert_flash_attention_forward(),
+ })
+
+ # use jit operator
+ if self.shard_config.enable_jit_fused:
+ policy[BertSelfOutput] = ModulePolicyDescription(method_replacement={
+ 'forward': get_jit_fused_bert_self_output_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
+ policy[BertOutput] = ModulePolicyDescription(method_replacement={
+ 'forward': get_jit_fused_bert_output_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
+
return policy
def add_lm_head_policy(self, base_policy):
diff --git a/colossalai/shardformer/policies/blip2.py b/colossalai/shardformer/policies/blip2.py
index a244d70b56f5..50356302e93e 100644
--- a/colossalai/shardformer/policies/blip2.py
+++ b/colossalai/shardformer/policies/blip2.py
@@ -3,7 +3,13 @@
import colossalai.shardformer.layer as col_nn
from .._utils import getattr_, setattr_
-from ..modeling.blip2 import forward_fn
+from ..modeling.blip2 import (
+ forward_fn,
+ get_blip2_flash_attention_forward,
+ get_jit_fused_blip2_QFormer_output_forward,
+ get_jit_fused_blip2_QFormer_self_output_forward,
+)
+from ..modeling.jit import get_jit_fused_dropout_add_func
from .base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
__all__ = ['BlipPolicy', 'BlipModelPolicy']
@@ -33,6 +39,8 @@ def module_policy(self):
Blip2EncoderLayer,
Blip2QFormerLayer,
Blip2QFormerModel,
+ Blip2QFormerOutput,
+ Blip2QFormerSelfOutput,
Blip2VisionModel,
)
from transformers.models.opt.modeling_opt import OPTDecoderLayer, OPTForCausalLM
@@ -275,6 +283,24 @@ def module_policy(self):
policy=policy,
target_key=OPTDecoderLayer)
+ # use flash attention
+ if self.shard_config.enable_flash_attention:
+ policy[Blip2Attention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_blip2_flash_attention_forward(),
+ })
+
+ # use jit operator
+ if self.shard_config.enable_jit_fused:
+ policy[Blip2QFormerSelfOutput] = ModulePolicyDescription(
+ method_replacement={
+ 'forward': get_jit_fused_blip2_QFormer_self_output_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
+ policy[Blip2QFormerOutput] = ModulePolicyDescription(method_replacement={
+ 'forward': get_jit_fused_blip2_QFormer_output_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
+
return policy
def postprocess(self):
diff --git a/colossalai/shardformer/policies/bloom.py b/colossalai/shardformer/policies/bloom.py
index 15bae2f4a959..b35764db3870 100644
--- a/colossalai/shardformer/policies/bloom.py
+++ b/colossalai/shardformer/policies/bloom.py
@@ -7,7 +7,16 @@
import colossalai.shardformer.layer as col_nn
-from ..modeling.bloom import BloomPipelineForwards, build_bloom_alibi_tensor_fn
+from .._utils import getattr_, setattr_
+from ..modeling.bloom import (
+ BloomPipelineForwards,
+ build_bloom_alibi_tensor_fn,
+ get_bloom_flash_attention_forward,
+ get_jit_fused_bloom_attention_forward,
+ get_jit_fused_bloom_gelu_forward,
+ get_jit_fused_bloom_mlp_forward,
+)
+from ..modeling.jit import get_dropout_add_func, get_jit_fused_dropout_add_func, get_jit_fused_gelu_forward_func
from .base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
@@ -30,7 +39,7 @@ def preprocess(self):
return self.model
def module_policy(self):
- from transformers.models.bloom.modeling_bloom import BloomBlock, BloomModel
+ from transformers.models.bloom.modeling_bloom import BloomAttention, BloomBlock, BloomGelu, BloomMLP, BloomModel
policy = {}
@@ -107,6 +116,27 @@ def module_policy(self):
policy=policy,
target_key=BloomBlock)
+ if self.shard_config.enable_flash_attention:
+ policy[BloomAttention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_bloom_flash_attention_forward(),
+ 'dropout_add': get_dropout_add_func()
+ })
+
+ # enable jit fused operator
+ if self.shard_config.enable_jit_fused:
+ policy[BloomAttention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_jit_fused_bloom_attention_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
+ policy[BloomMLP] = ModulePolicyDescription(method_replacement={
+ 'forward': get_jit_fused_bloom_mlp_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
+ policy[BloomGelu] = ModulePolicyDescription(method_replacement={
+ 'forward': get_jit_fused_bloom_gelu_forward(),
+ 'bloom_gelu_forward': get_jit_fused_gelu_forward_func(),
+ })
+
return policy
def postprocess(self):
diff --git a/colossalai/shardformer/policies/chatglm.py b/colossalai/shardformer/policies/chatglm.py
index 9cc651caddc1..e6b458936637 100644
--- a/colossalai/shardformer/policies/chatglm.py
+++ b/colossalai/shardformer/policies/chatglm.py
@@ -15,6 +15,8 @@
GLMBlock,
)
+from ..modeling.chatglm import get_flash_core_attention_forward, get_jit_fused_glm_block_forward
+from ..modeling.jit import get_jit_fused_dropout_add_func
from .base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
__all__ = ['ChatGLMPolicy', 'ChatGLMModelPolicy', 'ChatGLMForConditionalGenerationPolicy']
@@ -35,12 +37,11 @@ def preprocess(self):
new_vocab_size = vocab_size + world_size - vocab_size % world_size
self.model.resize_token_embeddings(new_vocab_size)
-
return self.model
def module_policy(self) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
- from colossalai.shardformer.modeling.chatglm2_6b.modeling_chatglm import ChatGLMModel, GLMBlock
+ from colossalai.shardformer.modeling.chatglm2_6b.modeling_chatglm import ChatGLMModel, CoreAttention, GLMBlock
policy = {}
@@ -121,6 +122,19 @@ def module_policy(self) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
policy=policy,
target_key=ChatGLMModel)
+ # use flash attention
+ if self.shard_config.enable_flash_attention:
+ policy[CoreAttention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_flash_core_attention_forward(),
+ })
+
+ # use jit fused operator
+ if self.shard_config.enable_jit_fused:
+ policy[GLMBlock] = ModulePolicyDescription(method_replacement={
+ 'forward': get_jit_fused_glm_block_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
+
return policy
def postprocess(self):
@@ -192,7 +206,6 @@ def get_shared_params(self) -> List[Dict[int, Tensor]]:
return []
-
class ChatGLMForConditionalGenerationPolicy(ChatGLMModelPolicy):
def module_policy(self):
@@ -213,4 +226,3 @@ def get_held_layers(self) -> List[nn.Module]:
def get_shared_params(self) -> List[Dict[int, Tensor]]:
"""No shared params in ChatGLMForConditionalGenerationModel."""
return []
-
diff --git a/colossalai/shardformer/policies/gpt2.py b/colossalai/shardformer/policies/gpt2.py
index 6d734b063036..20e5fa372c8f 100644
--- a/colossalai/shardformer/policies/gpt2.py
+++ b/colossalai/shardformer/policies/gpt2.py
@@ -5,7 +5,8 @@
import colossalai.shardformer.layer as col_nn
-from ..modeling.gpt2 import GPT2PipelineForwards
+from .._utils import getattr_, setattr_
+from ..modeling.gpt2 import GPT2PipelineForwards, get_gpt2_flash_attention_forward
from .base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
__all__ = [
@@ -33,7 +34,7 @@ def preprocess(self):
return self.model
def module_policy(self):
- from transformers.models.gpt2.modeling_gpt2 import GPT2Block, GPT2Model
+ from transformers.models.gpt2.modeling_gpt2 import GPT2Attention, GPT2Block, GPT2Model
policy = {}
@@ -53,42 +54,42 @@ def module_policy(self):
"attn.split_size": self.model.config.hidden_size // self.shard_config.tensor_parallel_size,
"attn.num_heads": self.model.config.num_attention_heads // self.shard_config.tensor_parallel_size,
},
- sub_module_replacement=[
- SubModuleReplacementDescription(
- suffix="attn.c_attn",
- target_module=col_nn.GPT2FusedLinearConv1D_Col,
- kwargs={
- "n_fused": 3,
- },
- ),
- SubModuleReplacementDescription(
- suffix="attn.c_proj",
- target_module=col_nn.GPT2FusedLinearConv1D_Row,
- ),
- SubModuleReplacementDescription(
- suffix="mlp.c_fc",
- target_module=col_nn.GPT2FusedLinearConv1D_Col,
- kwargs={
- "n_fused": 1,
- },
- ),
- SubModuleReplacementDescription(
- suffix="mlp.c_proj",
- target_module=col_nn.GPT2FusedLinearConv1D_Row,
- ),
- SubModuleReplacementDescription(
- suffix="attn.attn_dropout",
- target_module=col_nn.DropoutForParallelInput,
- ),
- SubModuleReplacementDescription(
- suffix="attn.resid_dropout",
- target_module=col_nn.DropoutForParallelInput,
- ),
- SubModuleReplacementDescription(
- suffix="mlp.dropout",
- target_module=col_nn.DropoutForParallelInput,
- ),
- ])
+ sub_module_replacement=[
+ SubModuleReplacementDescription(
+ suffix="attn.c_attn",
+ target_module=col_nn.GPT2FusedLinearConv1D_Col,
+ kwargs={
+ "n_fused": 3,
+ },
+ ),
+ SubModuleReplacementDescription(
+ suffix="attn.c_proj",
+ target_module=col_nn.GPT2FusedLinearConv1D_Row,
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.c_fc",
+ target_module=col_nn.GPT2FusedLinearConv1D_Col,
+ kwargs={
+ "n_fused": 1,
+ },
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.c_proj",
+ target_module=col_nn.GPT2FusedLinearConv1D_Row,
+ ),
+ SubModuleReplacementDescription(
+ suffix="attn.attn_dropout",
+ target_module=col_nn.DropoutForParallelInput,
+ ),
+ SubModuleReplacementDescription(
+ suffix="attn.resid_dropout",
+ target_module=col_nn.DropoutForParallelInput,
+ ),
+ SubModuleReplacementDescription(
+ suffix="mlp.dropout",
+ target_module=col_nn.DropoutForParallelInput,
+ ),
+ ])
# optimization configuration
if self.shard_config.enable_fused_normalization:
@@ -96,8 +97,8 @@ def module_policy(self):
suffix="ln_f",
target_module=col_nn.FusedLayerNorm,
),
- policy=policy,
- target_key=GPT2Model)
+ policy=policy,
+ target_key=GPT2Model)
self.append_or_create_submodule_replacement(description=[
SubModuleReplacementDescription(
@@ -112,8 +113,13 @@ def module_policy(self):
target_module=col_nn.FusedLayerNorm,
ignore_if_not_exist=True)
],
- policy=policy,
- target_key=GPT2Block)
+ policy=policy,
+ target_key=GPT2Block)
+
+ if self.shard_config.enable_flash_attention:
+ policy[GPT2Attention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_gpt2_flash_attention_forward(),
+ })
return policy
def postprocess(self):
diff --git a/colossalai/shardformer/policies/llama.py b/colossalai/shardformer/policies/llama.py
index 5988366ed57b..5ee95f3be8fa 100644
--- a/colossalai/shardformer/policies/llama.py
+++ b/colossalai/shardformer/policies/llama.py
@@ -7,7 +7,7 @@
from colossalai.shardformer.layer import FusedRMSNorm, Linear1D_Col, Linear1D_Row, VocabParallelEmbedding1D
-from ..modeling.llama import LlamaPipelineForwards
+from ..modeling.llama import LlamaPipelineForwards, get_llama_flash_attention_forward
from .base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
__all__ = ['LlamaPolicy', 'LlamaForCausalLMPolicy', 'LlamaForSequenceClassificationPolicy']
@@ -31,7 +31,7 @@ def preprocess(self):
return self.model
def module_policy(self) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
- from transformers.models.llama.modeling_llama import LlamaDecoderLayer, LlamaModel
+ from transformers.models.llama.modeling_llama import LlamaAttention, LlamaDecoderLayer, LlamaModel
policy = {}
@@ -104,6 +104,11 @@ def module_policy(self) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
policy=policy,
target_key=LlamaModel)
+ if self.shard_config.enable_flash_attention:
+ policy[LlamaAttention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_llama_flash_attention_forward(),
+ })
+
return policy
def postprocess(self):
diff --git a/colossalai/shardformer/policies/opt.py b/colossalai/shardformer/policies/opt.py
index 6fc3a2d31f4d..88ecd8565091 100644
--- a/colossalai/shardformer/policies/opt.py
+++ b/colossalai/shardformer/policies/opt.py
@@ -25,6 +25,8 @@
from colossalai.shardformer.layer import FusedLayerNorm, Linear1D_Col, Linear1D_Row, VocabParallelEmbedding1D
from .._utils import getattr_, setattr_
+from ..modeling.jit import get_jit_fused_dropout_add_func
+from ..modeling.opt import get_jit_fused_opt_decoder_layer_forward, get_opt_flash_attention_forward
from .base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
__all__ = [
@@ -114,6 +116,19 @@ def module_policy(self):
policy=policy,
target_key=OPTDecoderLayer)
+ # use flash attention
+ if self.shard_config.enable_flash_attention:
+ policy[OPTAttention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_opt_flash_attention_forward(),
+ })
+
+ # use jit fused operator
+ if self.shard_config.enable_jit_fused:
+ policy[OPTDecoderLayer] = ModulePolicyDescription(method_replacement={
+ 'forward': get_jit_fused_opt_decoder_layer_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
+
return policy
def postprocess(self):
@@ -189,13 +204,11 @@ def module_policy(self):
from transformers.models.opt.modeling_opt import OPTForCausalLM
policy = super().module_policy()
-
if self.shard_config.enable_tensor_parallelism:
self.append_or_create_submodule_replacement(description=SubModuleReplacementDescription(
suffix="lm_head", target_module=Linear1D_Col, kwargs=dict(gather_output=True)),
policy=policy,
target_key=OPTForCausalLM)
-
if self.pipeline_stage_manager:
self.set_pipeline_forward(model_cls=OPTForCausalLM,
new_forward=OPTPipelineForwards.opt_for_causal_lm_forward,
diff --git a/colossalai/shardformer/policies/sam.py b/colossalai/shardformer/policies/sam.py
index ca20fff715f2..b1eba0432b49 100644
--- a/colossalai/shardformer/policies/sam.py
+++ b/colossalai/shardformer/policies/sam.py
@@ -3,7 +3,7 @@
import colossalai.shardformer.layer as col_nn
from .._utils import getattr_, setattr_
-from ..modeling.sam import forward_fn
+from ..modeling.sam import forward_fn, get_sam_flash_attention_forward, get_sam_vision_flash_attention_forward
from .base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
__all__ = ['SamPolicy', 'SamModelPolicy']
@@ -19,6 +19,7 @@ def preprocess(self):
def module_policy(self):
from transformers.models.sam.modeling_sam import (
+ SamAttention,
SamFeedForward,
SamTwoWayAttentionBlock,
SamTwoWayTransformer,
@@ -196,6 +197,15 @@ def module_policy(self):
policy=policy,
target_key=SamTwoWayTransformer)
+ # use flash attention
+ if self.shard_config.enable_flash_attention:
+ policy[SamAttention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_sam_flash_attention_forward(),
+ })
+ policy[SamVisionAttention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_sam_vision_flash_attention_forward(),
+ })
+
return policy
def postprocess(self):
diff --git a/colossalai/shardformer/policies/t5.py b/colossalai/shardformer/policies/t5.py
index 0ee18d6c4940..5e78ae9093fa 100644
--- a/colossalai/shardformer/policies/t5.py
+++ b/colossalai/shardformer/policies/t5.py
@@ -14,7 +14,14 @@
from colossalai.shardformer.policies.base_policy import ModulePolicyDescription
from .._utils import getattr_, setattr_
-from ..modeling.t5 import T5PipelineForwards
+from ..modeling.jit import get_jit_fused_dropout_add_func
+from ..modeling.t5 import (
+ T5PipelineForwards,
+ get_jit_fused_T5_layer_ff_forward,
+ get_t5_flash_attention_forward,
+ get_T5_layer_cross_attention_forward,
+ get_T5_layer_self_attention_forward,
+)
from .base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
__all__ = ["distribute_t5_layers", "T5ModelPolicy", "T5ForConditionalGenerationPolicy", "T5EncoderPolicy"]
@@ -168,6 +175,27 @@ def module_policy(self):
suffix="final_layer_norm", target_module=FusedRMSNorm),
policy=policy,
target_key=T5Stack)
+
+ # use flash attention
+ if self.shard_config.enable_flash_attention:
+ policy[T5Attention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_t5_flash_attention_forward(),
+ })
+
+ # use jit operator
+ if self.shard_config.enable_jit_fused:
+ policy[T5LayerFF] = ModulePolicyDescription(method_replacement={
+ 'forward': get_jit_fused_T5_layer_ff_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
+ policy[T5LayerSelfAttention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_T5_layer_self_attention_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
+ policy[T5LayerCrossAttention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_T5_layer_cross_attention_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
return policy
def postprocess(self):
diff --git a/colossalai/shardformer/policies/vit.py b/colossalai/shardformer/policies/vit.py
index 1feb11ffcf24..26fcb6e77d35 100644
--- a/colossalai/shardformer/policies/vit.py
+++ b/colossalai/shardformer/policies/vit.py
@@ -3,11 +3,15 @@
import torch.nn as nn
import colossalai.shardformer.layer as col_nn
+from colossalai.shardformer.layer import DropoutForReplicatedInput, Linear1D_Col
+from ..modeling.jit import get_jit_fused_dropout_add_func
from ..modeling.vit import (
ViTForImageClassification_pipeline_forward,
ViTForMaskedImageModeling_pipeline_forward,
ViTModel_pipeline_forward,
+ get_jit_fused_vit_output_forward,
+ get_vit_flash_self_attention_forward,
)
from .base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
@@ -23,7 +27,8 @@ def preprocess(self):
return self.model
def module_policy(self) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
- from transformers.models.vit.modeling_vit import ViTEmbeddings, ViTLayer, ViTModel
+
+ from transformers.models.vit.modeling_vit import ViTEmbeddings, ViTLayer, ViTModel, ViTOutput, ViTSelfAttention
policy = {}
@@ -33,7 +38,7 @@ def module_policy(self) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
sub_module_replacement=[
SubModuleReplacementDescription(
suffix="dropout",
- target_module=col_nn.DropoutForReplicatedInput,
+ target_module=DropoutForReplicatedInput,
)
])
@@ -83,8 +88,18 @@ def module_policy(self) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
),
])
- return policy
-
+ # use flash attention
+ if self.shard_config.enable_flash_attention:
+ policy[ViTSelfAttention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_vit_flash_self_attention_forward(),
+ })
+
+ # use jit fused operator
+ if self.shard_config.enable_jit_fused:
+ policy[ViTOutput] = ModulePolicyDescription(method_replacement={
+ 'forward': get_jit_fused_vit_output_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
return policy
def new_model_class(self):
@@ -167,7 +182,7 @@ def module_policy(self):
ViTForImageClassification:
ModulePolicyDescription(sub_module_replacement=[
SubModuleReplacementDescription(
- suffix="classifier", target_module=col_nn.Linear1D_Col, kwargs=dict(gather_output=True))
+ suffix="classifier", target_module=Linear1D_Col, kwargs=dict(gather_output=True))
])
}
policy.update(new_item)
diff --git a/colossalai/shardformer/policies/whisper.py b/colossalai/shardformer/policies/whisper.py
index 2f3565bdaa96..2ac7a49fd27b 100644
--- a/colossalai/shardformer/policies/whisper.py
+++ b/colossalai/shardformer/policies/whisper.py
@@ -3,6 +3,12 @@
import colossalai.shardformer.layer as col_nn
from .._utils import getattr_, setattr_
+from ..modeling.jit import get_jit_fused_dropout_add_func
+from ..modeling.whisper import (
+ get_jit_fused_whisper_decoder_layer_forward,
+ get_jit_fused_whisper_encoder_layer_forward,
+ get_whisper_flash_attention_forward,
+)
from .base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
__all__ = [
@@ -30,6 +36,7 @@ def preprocess(self):
def module_policy(self):
from transformers.models.whisper.modeling_whisper import (
+ WhisperAttention,
WhisperDecoder,
WhisperDecoderLayer,
WhisperEncoder,
@@ -181,6 +188,24 @@ def module_policy(self):
],
policy=policy,
target_key=WhisperDecoder)
+
+ # enable flash attention
+ if self.shard_config.enable_flash_attention:
+ policy[WhisperAttention] = ModulePolicyDescription(method_replacement={
+ 'forward': get_whisper_flash_attention_forward(),
+ })
+
+ # use jit fused operator
+ if self.shard_config.enable_jit_fused:
+ policy[WhisperEncoderLayer] = ModulePolicyDescription(method_replacement={
+ 'forward': get_jit_fused_whisper_encoder_layer_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
+ policy[WhisperDecoderLayer] = ModulePolicyDescription(method_replacement={
+ 'forward': get_jit_fused_whisper_decoder_layer_forward(),
+ 'dropout_add': get_jit_fused_dropout_add_func(),
+ })
+
return policy
def add_lm_head_policy(self, base_policy):
diff --git a/colossalai/shardformer/shard/shard_config.py b/colossalai/shardformer/shard/shard_config.py
index 75fad4eb7431..ec6e0cd0d4be 100644
--- a/colossalai/shardformer/shard/shard_config.py
+++ b/colossalai/shardformer/shard/shard_config.py
@@ -26,6 +26,8 @@ class ShardConfig:
enable_tensor_parallelism: bool = True
enable_fused_normalization: bool = False
enable_all_optimization: bool = False
+ enable_flash_attention: bool = False
+ enable_jit_fused: bool = False
# TODO: add support for tensor parallel
# pipeline_parallel_size: int
@@ -44,7 +46,6 @@ def __post_init__(self):
else:
# get the parallel size
self._tensor_parallel_size = dist.get_world_size(self.tensor_parallel_process_group)
-
# turn on all optimization if all_optimization is set to True
if self.enable_all_optimization:
self._turn_on_all_optimization()
@@ -55,3 +56,5 @@ def _turn_on_all_optimization(self):
"""
# you can add all the optimization flag here
self.enable_fused_normalization = True
+ self.enable_flash_attention = True
+ self.enable_jit_fused = True
diff --git a/requirements/requirements-test.txt b/requirements/requirements-test.txt
index 2dae645f7eb9..510af5f3c7ff 100644
--- a/requirements/requirements-test.txt
+++ b/requirements/requirements-test.txt
@@ -18,3 +18,5 @@ SentencePiece
ninja
flash_attn>=2.0
datasets
+ninja
+flash-attn
diff --git a/tests/kit/model_zoo/transformers/bert.py b/tests/kit/model_zoo/transformers/bert.py
index d17b8fda425a..9834f5425027 100644
--- a/tests/kit/model_zoo/transformers/bert.py
+++ b/tests/kit/model_zoo/transformers/bert.py
@@ -20,7 +20,7 @@ def data_gen():
# token_type_ids = tokenized_input['token_type_ids']
input_ids = torch.tensor([[101, 7592, 1010, 2026, 3899, 2003, 10140, 102]], dtype=torch.int64)
token_type_ids = torch.tensor([[0, 0, 0, 0, 0, 0, 0, 0]], dtype=torch.int64)
- attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1, 1, 1]], dtype=torch.int64)
+ attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1, 1, 0]], dtype=torch.int64)
return dict(input_ids=input_ids, token_type_ids=token_type_ids, attention_mask=attention_mask)
@@ -69,19 +69,21 @@ def data_gen_for_mcq():
# data['labels'] = torch.tensor([0], dtype=torch.int64)
input_ids = torch.tensor([[[
101, 1999, 3304, 1010, 10733, 2366, 1999, 5337, 10906, 1010, 2107, 2004, 2012, 1037, 4825, 1010, 2003, 3591,
- 4895, 14540, 6610, 2094, 1012, 102, 2009, 2003, 8828, 2007, 1037, 9292, 1998, 1037, 5442, 1012, 102
+ 4895, 14540, 6610, 2094, 1012, 102, 2009, 2003, 8828, 2007, 1037, 9292, 1998, 1037, 5442, 1012, 102, 102
],
[
101, 1999, 3304, 1010, 10733, 2366, 1999, 5337, 10906, 1010, 2107, 2004, 2012, 1037,
4825, 1010, 2003, 3591, 4895, 14540, 6610, 2094, 1012, 102, 2009, 2003, 8828, 2096,
- 2218, 1999, 1996, 2192, 1012, 102, 0
+ 2218, 1999, 1996, 2192, 1012, 102, 0, 0
]]])
token_type_ids = torch.tensor(
- [[[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
- [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0]]])
+ [[[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
+ [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0,
+ 0]]])
attention_mask = torch.tensor(
- [[[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
- [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0]]])
+ [[[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
+ [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0,
+ 0]]])
labels = torch.tensor([0], dtype=torch.int64)
return dict(input_ids=input_ids, token_type_ids=token_type_ids, attention_mask=attention_mask, labels=labels)
diff --git a/tests/kit/model_zoo/transformers/blip2.py b/tests/kit/model_zoo/transformers/blip2.py
index 7338f740be7f..984a6ffa920d 100644
--- a/tests/kit/model_zoo/transformers/blip2.py
+++ b/tests/kit/model_zoo/transformers/blip2.py
@@ -38,6 +38,7 @@ def data_gen():
loss_fn_blip2_model = lambda x: x.loss
config = transformers.Blip2Config()
+config.vision_config.patch_size = 14
config.text_config.num_hidden_layers = 1
config.qformer_config.num_hidden_layers = 1
config.vision_config.num_hidden_layers = 1
diff --git a/tests/kit/model_zoo/transformers/bloom.py b/tests/kit/model_zoo/transformers/bloom.py
index 5d195db2c68d..177edbef8935 100644
--- a/tests/kit/model_zoo/transformers/bloom.py
+++ b/tests/kit/model_zoo/transformers/bloom.py
@@ -16,8 +16,8 @@ def data_gen():
# tokenized_input = tokenizer(input, return_tensors='pt')
# input_ids = tokenized_input['input_ids']
# attention_mask = tokenized_input['attention_mask']
- input_ids = torch.tensor([[59414, 15, 2670, 35433, 632, 207595]], dtype=torch.int64)
- attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1]], dtype=torch.int64)
+ input_ids = torch.tensor([[59414, 15, 2670, 35433, 632, 207595, 632, 207595]], dtype=torch.int64)
+ attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1, 1, 1]], dtype=torch.int64)
return dict(input_ids=input_ids, attention_mask=attention_mask)
@@ -33,7 +33,7 @@ def data_gen_for_token_classification():
# token classification data gen
# `labels` is the type not the token id for token classification, 0 or 1
data = data_gen()
- data['labels'] = torch.tensor([[0, 0, 0, 0, 0, 0]], dtype=torch.int64)
+ data['labels'] = torch.tensor([[0, 0, 0, 0, 0, 0, 0, 0]], dtype=torch.int64)
return data
@@ -53,8 +53,8 @@ def data_gen_for_question_answering():
# inputs = tokenizer(question, text, return_tensors="pt")
input_ids = torch.tensor(
- [[57647, 1620, 23967, 620, 107373, 34, 91514, 620, 107373, 1620, 267, 35378, 48946, 18161]], dtype=torch.int64)
- attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]], dtype=torch.int64)
+ [[57647, 1620, 23967, 620, 107373, 34, 91514, 620, 107373, 1620, 267, 35378, 48946, 18161, 48946, 18161]], dtype=torch.int64)
+ attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]], dtype=torch.int64)
start_positions = torch.tensor([1], dtype=torch.int64)
end_positions = torch.tensor([10], dtype=torch.int64)
return dict(input_ids=input_ids,
diff --git a/tests/kit/model_zoo/transformers/chatglm.py b/tests/kit/model_zoo/transformers/chatglm.py
index 056c910a8dfe..90bb70bc7f79 100644
--- a/tests/kit/model_zoo/transformers/chatglm.py
+++ b/tests/kit/model_zoo/transformers/chatglm.py
@@ -6,7 +6,6 @@
from ..registry import ModelAttribute, model_zoo
-
# ================================
# Register single-sentence ChatGLM
# ================================
diff --git a/tests/kit/model_zoo/transformers/chatglm2_6b/configuration_chatglm.py b/tests/kit/model_zoo/transformers/chatglm2_6b/configuration_chatglm.py
deleted file mode 100644
index 3e78732be2da..000000000000
--- a/tests/kit/model_zoo/transformers/chatglm2_6b/configuration_chatglm.py
+++ /dev/null
@@ -1,58 +0,0 @@
-from transformers import PretrainedConfig
-
-
-class ChatGLMConfig(PretrainedConfig):
- model_type = "chatglm"
-
- def __init__(self,
- num_layers=28,
- padded_vocab_size=65024,
- hidden_size=4096,
- ffn_hidden_size=13696,
- kv_channels=128,
- num_attention_heads=32,
- seq_length=2048,
- hidden_dropout=0.0,
- attention_dropout=0.0,
- layernorm_epsilon=1e-5,
- rmsnorm=True,
- apply_residual_connection_post_layernorm=False,
- post_layer_norm=True,
- add_bias_linear=False,
- add_qkv_bias=False,
- bias_dropout_fusion=True,
- multi_query_attention=False,
- multi_query_group_num=1,
- apply_query_key_layer_scaling=True,
- attention_softmax_in_fp32=True,
- fp32_residual_connection=False,
- quantization_bit=0,
- pre_seq_len=None,
- prefix_projection=False,
- **kwargs):
- self.num_layers = num_layers
- self.vocab_size = padded_vocab_size
- self.padded_vocab_size = padded_vocab_size
- self.hidden_size = hidden_size
- self.ffn_hidden_size = ffn_hidden_size
- self.kv_channels = kv_channels
- self.num_attention_heads = num_attention_heads
- self.seq_length = seq_length
- self.hidden_dropout = hidden_dropout
- self.attention_dropout = attention_dropout
- self.layernorm_epsilon = layernorm_epsilon
- self.rmsnorm = rmsnorm
- self.apply_residual_connection_post_layernorm = apply_residual_connection_post_layernorm
- self.post_layer_norm = post_layer_norm
- self.add_bias_linear = add_bias_linear
- self.add_qkv_bias = add_qkv_bias
- self.bias_dropout_fusion = bias_dropout_fusion
- self.multi_query_attention = multi_query_attention
- self.multi_query_group_num = multi_query_group_num
- self.apply_query_key_layer_scaling = apply_query_key_layer_scaling
- self.attention_softmax_in_fp32 = attention_softmax_in_fp32
- self.fp32_residual_connection = fp32_residual_connection
- self.quantization_bit = quantization_bit
- self.pre_seq_len = pre_seq_len
- self.prefix_projection = prefix_projection
- super().__init__(**kwargs)
diff --git a/tests/kit/model_zoo/transformers/chatglm2_6b/modeling_chatglm.py b/tests/kit/model_zoo/transformers/chatglm2_6b/modeling_chatglm.py
deleted file mode 100644
index bae6d425878d..000000000000
--- a/tests/kit/model_zoo/transformers/chatglm2_6b/modeling_chatglm.py
+++ /dev/null
@@ -1,1372 +0,0 @@
-"""
-The ChatGLM2-6B License
-
-1. Definitions
-
-“Licensor” means the ChatGLM2-6B Model Team that distributes its Software.
-
-“Software” means the ChatGLM2-6B model parameters made available under this license.
-
-2. License Grant
-
-Subject to the terms and conditions of this License, the Licensor hereby grants to you a non-exclusive, worldwide, non-transferable, non-sublicensable, revocable, royalty-free copyright license to use the Software solely for your non-commercial research purposes.
-
-The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
-
-3. Restriction
-
-You will not use, copy, modify, merge, publish, distribute, reproduce, or create derivative works of the Software, in whole or in part, for any commercial, military, or illegal purposes.
-
-You will not use the Software for any act that may undermine China's national security and national unity, harm the public interest of society, or infringe upon the rights and interests of human beings.
-
-4. Disclaimer
-
-THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
-
-5. Limitation of Liability
-
-EXCEPT TO THE EXTENT PROHIBITED BY APPLICABLE LAW, IN NO EVENT AND UNDER NO LEGAL THEORY, WHETHER BASED IN TORT, NEGLIGENCE, CONTRACT, LIABILITY, OR OTHERWISE WILL ANY LICENSOR BE LIABLE TO YOU FOR ANY DIRECT, INDIRECT, SPECIAL, INCIDENTAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES, OR ANY OTHER COMMERCIAL LOSSES, EVEN IF THE LICENSOR HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
-
-6. Dispute Resolution
-
-This license shall be governed and construed in accordance with the laws of People’s Republic of China. Any dispute arising from or in connection with this License shall be submitted to Haidian District People's Court in Beijing.
-
-Note that the license is subject to update to a more comprehensive version. For any questions related to the license and copyright, please contact us at glm-130b@googlegroups.com.
-"""
-""" PyTorch ChatGLM model. """
-
-import copy
-import math
-import re
-import sys
-import warnings
-from typing import Any, Callable, Dict, List, Optional, Tuple, Union
-
-import torch
-import torch.nn.functional as F
-import torch.utils.checkpoint
-from torch import nn
-from torch.nn import CrossEntropyLoss, LayerNorm
-from torch.nn.utils import skip_init
-from transformers.generation.logits_process import LogitsProcessor
-from transformers.generation.utils import GenerationConfig, LogitsProcessorList, ModelOutput, StoppingCriteriaList
-from transformers.modeling_outputs import BaseModelOutputWithPast, CausalLMOutputWithPast
-from transformers.modeling_utils import PreTrainedModel
-from transformers.utils import logging
-
-from .configuration_chatglm import ChatGLMConfig
-
-# flags required to enable jit fusion kernels
-
-if sys.platform != "darwin":
- torch._C._jit_set_profiling_mode(False)
- torch._C._jit_set_profiling_executor(False)
- torch._C._jit_override_can_fuse_on_cpu(True)
- torch._C._jit_override_can_fuse_on_gpu(True)
-
-logger = logging.get_logger(__name__)
-
-_CHECKPOINT_FOR_DOC = "THUDM/ChatGLM2-6B"
-_CONFIG_FOR_DOC = "ChatGLM6BConfig"
-
-CHATGLM_6B_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "THUDM/chatglm2-6b",
- # See all ChatGLM models at https://huggingface.co/models?filter=chatglm
-]
-
-
-def default_init(cls, *args, **kwargs):
- return cls(*args, **kwargs)
-
-
-class InvalidScoreLogitsProcessor(LogitsProcessor):
-
- def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
- if torch.isnan(scores).any() or torch.isinf(scores).any():
- scores.zero_()
- scores[..., 5] = 5e4
- return scores
-
-
-class PrefixEncoder(torch.nn.Module):
- """
- The torch.nn model to encode the prefix
- Input shape: (batch-size, prefix-length)
- Output shape: (batch-size, prefix-length, 2*layers*hidden)
- """
-
- def __init__(self, config: ChatGLMConfig):
- super().__init__()
- self.prefix_projection = config.prefix_projection
- if self.prefix_projection:
- # Use a two-layer MLP to encode the prefix
- kv_size = (config.num_layers * config.kv_channels * config.multi_query_group_num * 2)
- self.embedding = torch.nn.Embedding(config.pre_seq_len, kv_size)
- self.trans = torch.nn.Sequential(
- torch.nn.Linear(kv_size, config.hidden_size),
- torch.nn.Tanh(),
- torch.nn.Linear(config.hidden_size, kv_size),
- )
- else:
- self.embedding = torch.nn.Embedding(
- config.pre_seq_len,
- config.num_layers * config.kv_channels * config.multi_query_group_num * 2,
- )
-
- def forward(self, prefix: torch.Tensor):
- if self.prefix_projection:
- prefix_tokens = self.embedding(prefix)
- past_key_values = self.trans(prefix_tokens)
- else:
- past_key_values = self.embedding(prefix)
- return past_key_values
-
-
-def split_tensor_along_last_dim(
- tensor: torch.Tensor,
- num_partitions: int,
- contiguous_split_chunks: bool = False,
-) -> List[torch.Tensor]:
- """Split a tensor along its last dimension.
-
- Arguments:
- tensor: input tensor.
- num_partitions: number of partitions to split the tensor
- contiguous_split_chunks: If True, make each chunk contiguous
- in memory.
-
- Returns:
- A list of Tensors
- """
- # Get the size and dimension.
- last_dim = tensor.dim() - 1
- last_dim_size = tensor.size()[last_dim] // num_partitions
- # Split.
- tensor_list = torch.split(tensor, last_dim_size, dim=last_dim)
- # Note: torch.split does not create contiguous tensors by default.
- if contiguous_split_chunks:
- return tuple(chunk.contiguous() for chunk in tensor_list)
-
- return tensor_list
-
-
-class RotaryEmbedding(nn.Module):
-
- def __init__(self, dim, original_impl=False, device=None, dtype=None):
- super().__init__()
- inv_freq = 1.0 / (10000**(torch.arange(0, dim, 2, device=device).to(dtype=dtype) / dim))
- self.register_buffer("inv_freq", inv_freq)
- self.dim = dim
- self.original_impl = original_impl
-
- def forward_impl(
- self,
- seq_len: int,
- n_elem: int,
- dtype: torch.dtype,
- device: torch.device,
- base: int = 10000,
- ):
- """Enhanced Transformer with Rotary Position Embedding.
-
- Derived from: https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/master/labml_nn/
- transformers/rope/__init__.py. MIT License:
- https://github.com/labmlai/annotated_deep_learning_paper_implementations/blob/master/license.
- """
- # $\Theta = {\theta_i = 10000^{\frac{2(i-1)}{d}}, i \in [1, 2, ..., \frac{d}{2}]}$
- theta = 1.0 / (base**(torch.arange(0, n_elem, 2, dtype=dtype, device=device) / n_elem))
-
- # Create position indexes `[0, 1, ..., seq_len - 1]`
- seq_idx = torch.arange(seq_len, dtype=dtype, device=device)
-
- # Calculate the product of position index and $\theta_i$
- idx_theta = torch.outer(seq_idx, theta).float()
-
- cache = torch.stack([torch.cos(idx_theta), torch.sin(idx_theta)], dim=-1)
-
- # this is to mimic the behaviour of complex32, else we will get different results
- if dtype in (torch.float16, torch.bfloat16, torch.int8):
- cache = cache.bfloat16() if dtype == torch.bfloat16 else cache.half()
- return cache
-
- def forward(self, max_seq_len, offset=0):
- return self.forward_impl(
- max_seq_len,
- self.dim,
- dtype=self.inv_freq.dtype,
- device=self.inv_freq.device,
- )
-
-
-@torch.jit.script
-def apply_rotary_pos_emb(x: torch.Tensor, rope_cache: torch.Tensor) -> torch.Tensor:
- # x: [sq, b, np, hn]
- sq, b, np, hn = x.size(0), x.size(1), x.size(2), x.size(3)
- rot_dim = rope_cache.shape[-2] * 2
- x, x_pass = x[..., :rot_dim], x[..., rot_dim:]
- # truncate to support variable sizes
- rope_cache = rope_cache[:sq]
- xshaped = x.reshape(sq, -1, np, rot_dim // 2, 2)
- rope_cache = rope_cache.view(sq, -1, 1, xshaped.size(3), 2)
- x_out2 = torch.stack(
- [
- xshaped[..., 0] * rope_cache[..., 0] - xshaped[..., 1] * rope_cache[..., 1],
- xshaped[..., 1] * rope_cache[..., 0] + xshaped[..., 0] * rope_cache[..., 1],
- ],
- -1,
- )
- x_out2 = x_out2.flatten(3)
- return torch.cat((x_out2, x_pass), dim=-1)
-
-
-class RMSNorm(torch.nn.Module):
-
- def __init__(self, normalized_shape, eps=1e-5, device=None, dtype=None, **kwargs):
- super().__init__()
- self.weight = torch.nn.Parameter(torch.empty(normalized_shape, device=device, dtype=dtype))
- self.eps = eps
-
- def forward(self, hidden_states: torch.Tensor):
- input_dtype = hidden_states.dtype
- variance = hidden_states.to(torch.float32).pow(2).mean(-1, keepdim=True)
- hidden_states = hidden_states * torch.rsqrt(variance + self.eps)
-
- return (self.weight * hidden_states).to(input_dtype)
-
-
-class CoreAttention(torch.nn.Module):
-
- def __init__(self, config: ChatGLMConfig, layer_number):
- super(CoreAttention, self).__init__()
-
- self.apply_query_key_layer_scaling = config.apply_query_key_layer_scaling
- self.attention_softmax_in_fp32 = config.attention_softmax_in_fp32
- if self.apply_query_key_layer_scaling:
- self.attention_softmax_in_fp32 = True
- self.layer_number = max(1, layer_number)
-
- projection_size = config.kv_channels * config.num_attention_heads
-
- # Per attention head and per partition values.
- self.hidden_size_per_partition = projection_size
- self.hidden_size_per_attention_head = (projection_size // config.num_attention_heads)
- self.num_attention_heads_per_partition = config.num_attention_heads
-
- coeff = None
- self.norm_factor = math.sqrt(self.hidden_size_per_attention_head)
- if self.apply_query_key_layer_scaling:
- coeff = self.layer_number
- self.norm_factor *= coeff
- self.coeff = coeff
-
- self.attention_dropout = torch.nn.Dropout(config.attention_dropout)
-
- def forward(self, query_layer, key_layer, value_layer, attention_mask):
- pytorch_major_version = int(torch.__version__.split(".")[0])
- if pytorch_major_version >= 2:
- query_layer, key_layer, value_layer = [k.permute(1, 2, 0, 3) for k in [query_layer, key_layer, value_layer]]
- if attention_mask is None and query_layer.shape[2] == key_layer.shape[2]:
- context_layer = torch.nn.functional.scaled_dot_product_attention(query_layer,
- key_layer,
- value_layer,
- is_causal=True)
- else:
- if attention_mask is not None:
- attention_mask = ~attention_mask
- context_layer = torch.nn.functional.scaled_dot_product_attention(query_layer, key_layer, value_layer,
- attention_mask)
- context_layer = context_layer.permute(2, 0, 1, 3)
- new_context_layer_shape = context_layer.size()[:-2] + (self.hidden_size_per_partition,)
- context_layer = context_layer.reshape(*new_context_layer_shape)
- else:
- # Raw attention scores
-
- # [b, np, sq, sk]
- output_size = (
- query_layer.size(1),
- query_layer.size(2),
- query_layer.size(0),
- key_layer.size(0),
- )
-
- # [sq, b, np, hn] -> [sq, b * np, hn]
- query_layer = query_layer.view(output_size[2], output_size[0] * output_size[1], -1)
- # [sk, b, np, hn] -> [sk, b * np, hn]
- key_layer = key_layer.view(output_size[3], output_size[0] * output_size[1], -1)
-
- # preallocting input tensor: [b * np, sq, sk]
- matmul_input_buffer = torch.empty(
- output_size[0] * output_size[1],
- output_size[2],
- output_size[3],
- dtype=query_layer.dtype,
- device=query_layer.device,
- )
-
- # Raw attention scores. [b * np, sq, sk]
- matmul_result = torch.baddbmm(
- matmul_input_buffer,
- query_layer.transpose(0, 1), # [b * np, sq, hn]
- key_layer.transpose(0, 1).transpose(1, 2), # [b * np, hn, sk]
- beta=0.0,
- alpha=(1.0 / self.norm_factor),
- )
-
- # change view to [b, np, sq, sk]
- attention_scores = matmul_result.view(*output_size)
-
- # ===========================
- # Attention probs and dropout
- # ===========================
-
- # attention scores and attention mask [b, np, sq, sk]
- if self.attention_softmax_in_fp32:
- attention_scores = attention_scores.float()
- if self.coeff is not None:
- attention_scores = attention_scores * self.coeff
- if (attention_mask is None and attention_scores.shape[2] == attention_scores.shape[3]):
- attention_mask = torch.ones(
- output_size[0],
- 1,
- output_size[2],
- output_size[3],
- device=attention_scores.device,
- dtype=torch.bool,
- )
- attention_mask.tril_()
- attention_mask = ~attention_mask
- if attention_mask is not None:
- attention_scores = attention_scores.masked_fill(attention_mask, float("-inf"))
- attention_probs = F.softmax(attention_scores, dim=-1)
- attention_probs = attention_probs.type_as(value_layer)
-
- # This is actually dropping out entire tokens to attend to, which might
- # seem a bit unusual, but is taken from the original Transformer paper.
- attention_probs = self.attention_dropout(attention_probs)
- # =========================
- # Context layer. [sq, b, hp]
- # =========================
-
- # value_layer -> context layer.
- # [sk, b, np, hn] --> [b, np, sq, hn]
-
- # context layer shape: [b, np, sq, hn]
- output_size = (
- value_layer.size(1),
- value_layer.size(2),
- query_layer.size(0),
- value_layer.size(3),
- )
- # change view [sk, b * np, hn]
- value_layer = value_layer.view(value_layer.size(0), output_size[0] * output_size[1], -1)
- # change view [b * np, sq, sk]
- attention_probs = attention_probs.view(output_size[0] * output_size[1], output_size[2], -1)
- # matmul: [b * np, sq, hn]
- context_layer = torch.bmm(attention_probs, value_layer.transpose(0, 1))
- # change view [b, np, sq, hn]
- context_layer = context_layer.view(*output_size)
- # [b, np, sq, hn] --> [sq, b, np, hn]
- context_layer = context_layer.permute(2, 0, 1, 3).contiguous()
- # [sq, b, np, hn] --> [sq, b, hp]
- new_context_layer_shape = context_layer.size()[:-2] + (self.hidden_size_per_partition,)
- context_layer = context_layer.view(*new_context_layer_shape)
-
- return context_layer
-
-
-class SelfAttention(torch.nn.Module):
- """Parallel self-attention layer abstract class.
-
- Self-attention layer takes input with size [s, b, h]
- and returns output of the same size.
- """
-
- def __init__(self, config: ChatGLMConfig, layer_number, device=None):
- super(SelfAttention, self).__init__()
- self.layer_number = max(1, layer_number)
-
- self.projection_size = config.kv_channels * config.num_attention_heads
- # Per attention head and per partition values.
- self.hidden_size_per_attention_head = (self.projection_size // config.num_attention_heads)
- self.num_attention_heads_per_partition = config.num_attention_heads
-
- self.multi_query_attention = config.multi_query_attention
- self.qkv_hidden_size = 3 * self.projection_size
- if self.multi_query_attention:
- self.num_multi_query_groups_per_partition = config.multi_query_group_num
- self.qkv_hidden_size = (self.projection_size +
- 2 * self.hidden_size_per_attention_head * config.multi_query_group_num)
- self.query_key_value = nn.Linear(
- config.hidden_size,
- self.qkv_hidden_size,
- bias=config.add_bias_linear or config.add_qkv_bias,
- device=device,
- **_config_to_kwargs(config),
- )
-
- self.core_attention = CoreAttention(config, self.layer_number)
-
- # Output.
- self.dense = nn.Linear(
- self.projection_size,
- config.hidden_size,
- bias=config.add_bias_linear,
- device=device,
- **_config_to_kwargs(config),
- )
-
- def _allocate_memory(self, inference_max_sequence_len, batch_size, device=None, dtype=None):
- if self.multi_query_attention:
- num_attention_heads = self.num_multi_query_groups_per_partition
- else:
- num_attention_heads = self.num_attention_heads_per_partition
- return torch.empty(
- inference_max_sequence_len,
- batch_size,
- num_attention_heads,
- self.hidden_size_per_attention_head,
- dtype=dtype,
- device=device,
- )
-
- def forward(
- self,
- hidden_states,
- attention_mask,
- rotary_pos_emb,
- kv_cache=None,
- use_cache=True,
- ):
- # hidden_states: [sq, b, h]
-
- # =================================================
- # Pre-allocate memory for key-values for inference.
- # =================================================
- # =====================
- # Query, Key, and Value
- # =====================
-
- # Attention heads [sq, b, h] --> [sq, b, (np * 3 * hn)]
- mixed_x_layer = self.query_key_value(hidden_states)
-
- if self.multi_query_attention:
- (query_layer, key_layer, value_layer) = mixed_x_layer.split(
- [
- self.num_attention_heads_per_partition * self.hidden_size_per_attention_head,
- self.num_multi_query_groups_per_partition * self.hidden_size_per_attention_head,
- self.num_multi_query_groups_per_partition * self.hidden_size_per_attention_head,
- ],
- dim=-1,
- )
- query_layer = query_layer.view(query_layer.size()[:-1] + (
- self.num_attention_heads_per_partition,
- self.hidden_size_per_attention_head,
- ))
- key_layer = key_layer.view(key_layer.size()[:-1] + (
- self.num_multi_query_groups_per_partition,
- self.hidden_size_per_attention_head,
- ))
- value_layer = value_layer.view(value_layer.size()[:-1] + (
- self.num_multi_query_groups_per_partition,
- self.hidden_size_per_attention_head,
- ))
- else:
- new_tensor_shape = mixed_x_layer.size()[:-1] + (
- self.num_attention_heads_per_partition,
- 3 * self.hidden_size_per_attention_head,
- )
- mixed_x_layer = mixed_x_layer.view(*new_tensor_shape)
- # [sq, b, np, 3 * hn] --> 3 [sq, b, np, hn]
- (query_layer, key_layer, value_layer) = split_tensor_along_last_dim(mixed_x_layer, 3)
-
- # apply relative positional encoding (rotary embedding)
- if rotary_pos_emb is not None:
- query_layer = apply_rotary_pos_emb(query_layer, rotary_pos_emb)
- key_layer = apply_rotary_pos_emb(key_layer, rotary_pos_emb)
-
- # adjust key and value for inference
- if kv_cache is not None:
- cache_k, cache_v = kv_cache
- key_layer = torch.cat((cache_k, key_layer), dim=0)
- value_layer = torch.cat((cache_v, value_layer), dim=0)
- if use_cache:
- kv_cache = (key_layer, value_layer)
- else:
- kv_cache = None
-
- if self.multi_query_attention:
- key_layer = key_layer.unsqueeze(-2)
- key_layer = key_layer.expand(
- -1,
- -1,
- -1,
- self.num_attention_heads_per_partition // self.num_multi_query_groups_per_partition,
- -1,
- )
- key_layer = key_layer.contiguous().view(key_layer.size()[:2] + (
- self.num_attention_heads_per_partition,
- self.hidden_size_per_attention_head,
- ))
- value_layer = value_layer.unsqueeze(-2)
- value_layer = value_layer.expand(
- -1,
- -1,
- -1,
- self.num_attention_heads_per_partition // self.num_multi_query_groups_per_partition,
- -1,
- )
- value_layer = value_layer.contiguous().view(value_layer.size()[:2] + (
- self.num_attention_heads_per_partition,
- self.hidden_size_per_attention_head,
- ))
-
- # ==================================
- # core attention computation
- # ==================================
-
- context_layer = self.core_attention(query_layer, key_layer, value_layer, attention_mask)
-
- # =================
- # Output. [sq, b, h]
- # =================
-
- output = self.dense(context_layer)
-
- return output, kv_cache
-
-
-def _config_to_kwargs(args):
- common_kwargs = {
- "dtype": args.torch_dtype,
- }
- return common_kwargs
-
-
-class MLP(torch.nn.Module):
- """MLP.
-
- MLP will take the input with h hidden state, project it to 4*h
- hidden dimension, perform nonlinear transformation, and project the
- state back into h hidden dimension.
- """
-
- def __init__(self, config: ChatGLMConfig, device=None):
- super(MLP, self).__init__()
-
- self.add_bias = config.add_bias_linear
-
- # Project to 4h. If using swiglu double the output width, see https://arxiv.org/pdf/2002.05202.pdf
- self.dense_h_to_4h = nn.Linear(
- config.hidden_size,
- config.ffn_hidden_size * 2,
- bias=self.add_bias,
- device=device,
- **_config_to_kwargs(config),
- )
-
- def swiglu(x):
- x = torch.chunk(x, 2, dim=-1)
- return F.silu(x[0]) * x[1]
-
- self.activation_func = swiglu
-
- # Project back to h.
- self.dense_4h_to_h = nn.Linear(
- config.ffn_hidden_size,
- config.hidden_size,
- bias=self.add_bias,
- device=device,
- **_config_to_kwargs(config),
- )
-
- def forward(self, hidden_states):
- # [s, b, 4hp]
- intermediate_parallel = self.dense_h_to_4h(hidden_states)
- intermediate_parallel = self.activation_func(intermediate_parallel)
- # [s, b, h]
- output = self.dense_4h_to_h(intermediate_parallel)
- return output
-
-
-class GLMBlock(torch.nn.Module):
- """A single transformer layer.
-
- Transformer layer takes input with size [s, b, h] and returns an
- output of the same size.
- """
-
- def __init__(self, config: ChatGLMConfig, layer_number, device=None):
- super(GLMBlock, self).__init__()
- self.layer_number = layer_number
-
- self.apply_residual_connection_post_layernorm = (config.apply_residual_connection_post_layernorm)
-
- self.fp32_residual_connection = config.fp32_residual_connection
-
- LayerNormFunc = RMSNorm if config.rmsnorm else LayerNorm
- # Layernorm on the input data.
- self.input_layernorm = LayerNormFunc(
- config.hidden_size,
- eps=config.layernorm_epsilon,
- device=device,
- dtype=config.torch_dtype,
- )
-
- # Self attention.
- self.self_attention = SelfAttention(config, layer_number, device=device)
- self.hidden_dropout = config.hidden_dropout
-
- # Layernorm on the attention output
- self.post_attention_layernorm = LayerNormFunc(
- config.hidden_size,
- eps=config.layernorm_epsilon,
- device=device,
- dtype=config.torch_dtype,
- )
-
- # MLP
- self.mlp = MLP(config, device=device)
-
- def forward(
- self,
- hidden_states,
- attention_mask,
- rotary_pos_emb,
- kv_cache=None,
- use_cache=True,
- ):
- # hidden_states: [s, b, h]
-
- # Layer norm at the beginning of the transformer layer.
- layernorm_output = self.input_layernorm(hidden_states)
- # Self attention.
- attention_output, kv_cache = self.self_attention(
- layernorm_output,
- attention_mask,
- rotary_pos_emb,
- kv_cache=kv_cache,
- use_cache=use_cache,
- )
-
- # Residual connection.
- if self.apply_residual_connection_post_layernorm:
- residual = layernorm_output
- else:
- residual = hidden_states
-
- layernorm_input = torch.nn.functional.dropout(attention_output, p=self.hidden_dropout, training=self.training)
- layernorm_input = residual + layernorm_input
-
- # Layer norm post the self attention.
- layernorm_output = self.post_attention_layernorm(layernorm_input)
-
- # MLP.
- mlp_output = self.mlp(layernorm_output)
-
- # Second residual connection.
- if self.apply_residual_connection_post_layernorm:
- residual = layernorm_output
- else:
- residual = layernorm_input
-
- output = torch.nn.functional.dropout(mlp_output, p=self.hidden_dropout, training=self.training)
- output = residual + output
-
- return output, kv_cache
-
-
-class GLMTransformer(torch.nn.Module):
- """Transformer class."""
-
- def __init__(self, config: ChatGLMConfig, device=None):
- super(GLMTransformer, self).__init__()
-
- self.fp32_residual_connection = config.fp32_residual_connection
- self.post_layer_norm = config.post_layer_norm
-
- # Number of layers.
- self.num_layers = config.num_layers
-
- # Transformer layers.
- def build_layer(layer_number):
- return GLMBlock(config, layer_number, device=device)
-
- self.layers = torch.nn.ModuleList([build_layer(i + 1) for i in range(self.num_layers)])
-
- if self.post_layer_norm:
- LayerNormFunc = RMSNorm if config.rmsnorm else LayerNorm
- # Final layer norm before output.
- self.final_layernorm = LayerNormFunc(
- config.hidden_size,
- eps=config.layernorm_epsilon,
- device=device,
- dtype=config.torch_dtype,
- )
-
- self.gradient_checkpointing = False
-
- def _get_layer(self, layer_number):
- return self.layers[layer_number]
-
- def forward(
- self,
- hidden_states,
- attention_mask,
- rotary_pos_emb,
- kv_caches=None,
- use_cache: Optional[bool] = True,
- output_hidden_states: Optional[bool] = False,
- ):
- if not kv_caches:
- kv_caches = [None for _ in range(self.num_layers)]
- presents = () if use_cache else None
- if self.gradient_checkpointing and self.training:
- if use_cache:
- logger.warning_once(
- "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`...")
- use_cache = False
-
- all_self_attentions = None
- all_hidden_states = () if output_hidden_states else None
- for index in range(self.num_layers):
- if output_hidden_states:
- all_hidden_states = all_hidden_states + (hidden_states,)
-
- layer = self._get_layer(index)
- if self.gradient_checkpointing and self.training:
- layer_ret = torch.utils.checkpoint.checkpoint(
- layer,
- hidden_states,
- attention_mask,
- rotary_pos_emb,
- kv_caches[index],
- use_cache,
- )
- else:
- layer_ret = layer(
- hidden_states,
- attention_mask,
- rotary_pos_emb,
- kv_cache=kv_caches[index],
- use_cache=use_cache,
- )
- hidden_states, kv_cache = layer_ret
- if use_cache:
- presents = presents + (kv_cache,)
-
- if output_hidden_states:
- all_hidden_states = all_hidden_states + (hidden_states,)
-
- # Final layer norm.
- if self.post_layer_norm:
- hidden_states = self.final_layernorm(hidden_states)
-
- return hidden_states, presents, all_hidden_states, all_self_attentions
-
-
-class ChatGLMPreTrainedModel(PreTrainedModel):
- """
- An abstract class to handle weights initialization and
- a simple interface for downloading and loading pretrained models.
- """
-
- is_parallelizable = False
- supports_gradient_checkpointing = True
- config_class = ChatGLMConfig
- base_model_prefix = "transformer"
- _no_split_modules = ["GLMBlock"]
-
- def _init_weights(self, module: nn.Module):
- """Initialize the weights."""
- return
-
- def get_masks(self, input_ids, past_key_values, padding_mask=None):
- batch_size, seq_length = input_ids.shape
- full_attention_mask = torch.ones(batch_size, seq_length, seq_length, device=input_ids.device)
- full_attention_mask.tril_()
- past_length = 0
- if past_key_values:
- past_length = past_key_values[0][0].shape[0]
- if past_length:
- full_attention_mask = torch.cat(
- (
- torch.ones(batch_size, seq_length, past_length, device=input_ids.device),
- full_attention_mask,
- ),
- dim=-1,
- )
- if padding_mask is not None:
- full_attention_mask = full_attention_mask * padding_mask.unsqueeze(1)
- if not past_length and padding_mask is not None:
- full_attention_mask -= padding_mask.unsqueeze(-1) - 1
- full_attention_mask = (full_attention_mask < 0.5).bool()
- full_attention_mask.unsqueeze_(1)
- return full_attention_mask
-
- def get_position_ids(self, input_ids, device):
- batch_size, seq_length = input_ids.shape
- position_ids = (torch.arange(seq_length, dtype=torch.long, device=device).unsqueeze(0).repeat(batch_size, 1))
- return position_ids
-
- def _set_gradient_checkpointing(self, module, value=False):
- if isinstance(module, GLMTransformer):
- module.gradient_checkpointing = value
-
-
-class Embedding(torch.nn.Module):
- """Language model embeddings."""
-
- def __init__(self, config: ChatGLMConfig, device=None):
- super(Embedding, self).__init__()
-
- self.hidden_size = config.hidden_size
- # Word embeddings (parallel).
- self.word_embeddings = nn.Embedding(
- config.padded_vocab_size,
- self.hidden_size,
- dtype=config.torch_dtype,
- device=device,
- )
- self.fp32_residual_connection = config.fp32_residual_connection
-
- def forward(self, input_ids):
- # Embeddings.
- words_embeddings = self.word_embeddings(input_ids)
- embeddings = words_embeddings
- # Data format change to avoid explicit tranposes : [b s h] --> [s b h].
- embeddings = embeddings.transpose(0, 1).contiguous()
- # If the input flag for fp32 residual connection is set, convert for float.
- if self.fp32_residual_connection:
- embeddings = embeddings.float()
- return embeddings
-
-
-class ChatGLMModel(ChatGLMPreTrainedModel):
-
- def __init__(self, config: ChatGLMConfig, device=None, empty_init=True):
- super().__init__(config)
- if empty_init:
- init_method = skip_init
- else:
- init_method = default_init
- init_kwargs = {}
- if device is not None:
- init_kwargs["device"] = device
- self.embedding = init_method(Embedding, config, **init_kwargs)
- self.num_layers = config.num_layers
- self.multi_query_group_num = config.multi_query_group_num
- self.kv_channels = config.kv_channels
-
- # Rotary positional embeddings
- self.seq_length = config.seq_length
- rotary_dim = (config.hidden_size //
- config.num_attention_heads if config.kv_channels is None else config.kv_channels)
-
- self.rotary_pos_emb = RotaryEmbedding(
- rotary_dim // 2,
- original_impl=config.original_rope,
- device=device,
- dtype=config.torch_dtype,
- )
- self.encoder = init_method(GLMTransformer, config, **init_kwargs)
- self.output_layer = init_method(
- nn.Linear,
- config.hidden_size,
- config.padded_vocab_size,
- bias=False,
- dtype=config.torch_dtype,
- **init_kwargs,
- )
- self.pre_seq_len = config.pre_seq_len
- self.prefix_projection = config.prefix_projection
- if self.pre_seq_len is not None:
- for param in self.parameters():
- param.requires_grad = False
- self.prefix_tokens = torch.arange(self.pre_seq_len).long()
- self.prefix_encoder = PrefixEncoder(config)
- self.dropout = torch.nn.Dropout(0.1)
-
- def get_input_embeddings(self):
- return self.embedding.word_embeddings
-
- def get_prompt(self, batch_size, device, dtype=torch.half):
- prefix_tokens = (self.prefix_tokens.unsqueeze(0).expand(batch_size, -1).to(device))
- past_key_values = self.prefix_encoder(prefix_tokens).type(dtype)
- past_key_values = past_key_values.view(
- batch_size,
- self.pre_seq_len,
- self.num_layers * 2,
- self.multi_query_group_num,
- self.kv_channels,
- )
- # seq_len, b, nh, hidden_size
- past_key_values = self.dropout(past_key_values)
- past_key_values = past_key_values.permute([2, 1, 0, 3, 4]).split(2)
- return past_key_values
-
- def forward(
- self,
- input_ids,
- position_ids: Optional[torch.Tensor] = None,
- attention_mask: Optional[torch.BoolTensor] = None,
- full_attention_mask: Optional[torch.BoolTensor] = None,
- past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
- inputs_embeds: Optional[torch.Tensor] = None,
- use_cache: Optional[bool] = None,
- output_hidden_states: Optional[bool] = None,
- return_dict: Optional[bool] = None,
- ):
- output_hidden_states = (output_hidden_states
- if output_hidden_states is not None else self.config.output_hidden_states)
- use_cache = use_cache if use_cache is not None else self.config.use_cache
- return_dict = (return_dict if return_dict is not None else self.config.use_return_dict)
-
- batch_size, seq_length = input_ids.shape
-
- if inputs_embeds is None:
- inputs_embeds = self.embedding(input_ids)
-
- if self.pre_seq_len is not None:
- if past_key_values is None:
- past_key_values = self.get_prompt(
- batch_size=batch_size,
- device=input_ids.device,
- dtype=inputs_embeds.dtype,
- )
- if attention_mask is not None:
- attention_mask = torch.cat(
- [
- attention_mask.new_ones((batch_size, self.pre_seq_len)),
- attention_mask,
- ],
- dim=-1,
- )
-
- if full_attention_mask is None:
- if (attention_mask is not None and not attention_mask.all()) or (past_key_values and seq_length != 1):
- full_attention_mask = self.get_masks(input_ids, past_key_values, padding_mask=attention_mask)
-
- # Rotary positional embeddings
- rotary_pos_emb = self.rotary_pos_emb(self.seq_length)
- if position_ids is not None:
- rotary_pos_emb = rotary_pos_emb[position_ids]
- else:
- rotary_pos_emb = rotary_pos_emb[None, :seq_length]
- rotary_pos_emb = rotary_pos_emb.transpose(0, 1).contiguous()
-
- # Run encoder.
- hidden_states, presents, all_hidden_states, all_self_attentions = self.encoder(
- inputs_embeds,
- full_attention_mask,
- rotary_pos_emb=rotary_pos_emb,
- kv_caches=past_key_values,
- use_cache=use_cache,
- output_hidden_states=output_hidden_states,
- )
-
- if not return_dict:
- return tuple(v for v in [
- hidden_states,
- presents,
- all_hidden_states,
- all_self_attentions,
- ] if v is not None)
-
- return BaseModelOutputWithPast(
- last_hidden_state=hidden_states,
- past_key_values=presents,
- hidden_states=all_hidden_states,
- attentions=all_self_attentions,
- )
-
- def quantize(self, weight_bit_width: int):
- from .quantization import quantize
-
- quantize(self.encoder, weight_bit_width)
- return self
-
-
-class ChatGLMForConditionalGeneration(ChatGLMPreTrainedModel):
-
- def __init__(self, config: ChatGLMConfig, empty_init=True, device=None):
- super().__init__(config)
-
- self.max_sequence_length = config.max_length
- self.transformer = ChatGLMModel(config, empty_init=empty_init, device=device)
- self.config = config
- self.quantized = False
-
- if self.config.quantization_bit:
- self.quantize(self.config.quantization_bit, empty_init=True)
-
- def _update_model_kwargs_for_generation(
- self,
- outputs: ModelOutput,
- model_kwargs: Dict[str, Any],
- is_encoder_decoder: bool = False,
- standardize_cache_format: bool = False,
- ) -> Dict[str, Any]:
- # update past_key_values
- model_kwargs["past_key_values"] = self._extract_past_from_model_output(
- outputs, standardize_cache_format=standardize_cache_format)
-
- # update attention mask
- if "attention_mask" in model_kwargs:
- attention_mask = model_kwargs["attention_mask"]
- model_kwargs["attention_mask"] = torch.cat(
- [attention_mask, attention_mask.new_ones((attention_mask.shape[0], 1))],
- dim=-1,
- )
-
- # update position ids
- if "position_ids" in model_kwargs:
- position_ids = model_kwargs["position_ids"]
- new_position_id = position_ids[..., -1:].clone()
- new_position_id += 1
- model_kwargs["position_ids"] = torch.cat([position_ids, new_position_id], dim=-1)
-
- model_kwargs["is_first_forward"] = False
- return model_kwargs
-
- def prepare_inputs_for_generation(
- self,
- input_ids: torch.LongTensor,
- past_key_values: Optional[torch.Tensor] = None,
- attention_mask: Optional[torch.Tensor] = None,
- position_ids: Optional[torch.Tensor] = None,
- is_first_forward: bool = True,
- **kwargs,
- ) -> dict:
- # only last token for input_ids if past is not None
- if position_ids is None:
- position_ids = self.get_position_ids(input_ids, device=input_ids.device)
- if not is_first_forward:
- position_ids = position_ids[..., -1:]
- input_ids = input_ids[:, -1:]
- return {
- "input_ids": input_ids,
- "past_key_values": past_key_values,
- "position_ids": position_ids,
- "attention_mask": attention_mask,
- "return_last_logit": True,
- }
-
- def forward(
- self,
- input_ids: Optional[torch.Tensor] = None,
- position_ids: Optional[torch.Tensor] = None,
- attention_mask: Optional[torch.Tensor] = None,
- past_key_values: Optional[Tuple[torch.FloatTensor]] = None,
- inputs_embeds: Optional[torch.Tensor] = None,
- labels: Optional[torch.Tensor] = None,
- use_cache: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- output_hidden_states: Optional[bool] = None,
- return_dict: Optional[bool] = None,
- return_last_logit: Optional[bool] = False,
- ):
- use_cache = use_cache if use_cache is not None else self.config.use_cache
- return_dict = (return_dict if return_dict is not None else self.config.use_return_dict)
-
- transformer_outputs = self.transformer(
- input_ids=input_ids,
- position_ids=position_ids,
- attention_mask=attention_mask,
- past_key_values=past_key_values,
- inputs_embeds=inputs_embeds,
- use_cache=use_cache,
- output_hidden_states=output_hidden_states,
- return_dict=return_dict,
- )
-
- hidden_states = transformer_outputs[0]
- if return_last_logit:
- hidden_states = hidden_states[-1:]
- lm_logits = self.transformer.output_layer(hidden_states)
- lm_logits = lm_logits.transpose(0, 1).contiguous()
-
- loss = None
- if labels is not None:
- lm_logits = lm_logits.to(torch.float32)
-
- # Shift so that tokens < n predict n
- shift_logits = lm_logits[..., :-1, :].contiguous()
- shift_labels = labels[..., 1:].contiguous()
- # Flatten the tokens
- loss_fct = CrossEntropyLoss(ignore_index=-100)
- loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
-
- lm_logits = lm_logits.to(hidden_states.dtype)
- loss = loss.to(hidden_states.dtype)
-
- if not return_dict:
- output = (lm_logits,) + transformer_outputs[1:]
- return ((loss,) + output) if loss is not None else output
-
- return CausalLMOutputWithPast(
- loss=loss,
- logits=lm_logits,
- past_key_values=transformer_outputs.past_key_values,
- hidden_states=transformer_outputs.hidden_states,
- attentions=transformer_outputs.attentions,
- )
-
- @staticmethod
- def _reorder_cache(past: Tuple[Tuple[torch.Tensor, torch.Tensor], ...],
- beam_idx: torch.LongTensor) -> Tuple[Tuple[torch.Tensor, torch.Tensor], ...]:
- """
- This function is used to re-order the `past_key_values` cache if [`~PreTrainedModel.beam_search`] or
- [`~PreTrainedModel.beam_sample`] is called. This is required to match `past_key_values` with the correct
- beam_idx at every generation step.
-
- Output shares the same memory storage as `past`.
- """
- return tuple((
- layer_past[0].index_select(1, beam_idx.to(layer_past[0].device)),
- layer_past[1].index_select(1, beam_idx.to(layer_past[1].device)),
- ) for layer_past in past)
-
- def process_response(self, response):
- response = response.strip()
- response = response.replace("[[训练时间]]", "2023年")
- return response
-
- def build_inputs(self, tokenizer, query: str, history: List[Tuple[str, str]] = None):
- prompt = tokenizer.build_prompt(query, history=history)
- inputs = tokenizer([prompt], return_tensors="pt")
- inputs = inputs.to(self.device)
- return inputs
-
- def build_stream_inputs(self, tokenizer, query: str, history: List[Tuple[str, str]] = None):
- if history:
- prompt = "\n\n[Round {}]\n\n问:{}\n\n答:".format(len(history) + 1, query)
- input_ids = tokenizer.encode(prompt, add_special_tokens=False)
- input_ids = input_ids[1:]
- inputs = tokenizer.batch_encode_plus([(input_ids, None)], return_tensors="pt", add_special_tokens=False)
- else:
- prompt = "[Round {}]\n\n问:{}\n\n答:".format(len(history) + 1, query)
- inputs = tokenizer([prompt], return_tensors="pt")
- inputs = inputs.to(self.device)
- return inputs
-
- @torch.no_grad()
- def chat(
- self,
- tokenizer,
- query: str,
- history: List[Tuple[str, str]] = None,
- max_length: int = 8192,
- num_beams=1,
- do_sample=True,
- top_p=0.8,
- temperature=0.8,
- logits_processor=None,
- **kwargs,
- ):
- if history is None:
- history = []
- if logits_processor is None:
- logits_processor = LogitsProcessorList()
- logits_processor.append(InvalidScoreLogitsProcessor())
- gen_kwargs = {
- "max_length": max_length,
- "num_beams": num_beams,
- "do_sample": do_sample,
- "top_p": top_p,
- "temperature": temperature,
- "logits_processor": logits_processor,
- **kwargs,
- }
- inputs = self.build_inputs(tokenizer, query, history=history)
- outputs = self.generate(**inputs, **gen_kwargs)
- outputs = outputs.tolist()[0][len(inputs["input_ids"][0]):]
- response = tokenizer.decode(outputs)
- response = self.process_response(response)
- history = history + [(query, response)]
- return response, history
-
- @torch.no_grad()
- def stream_chat(
- self,
- tokenizer,
- query: str,
- history: List[Tuple[str, str]] = None,
- past_key_values=None,
- max_length: int = 8192,
- do_sample=True,
- top_p=0.8,
- temperature=0.8,
- logits_processor=None,
- return_past_key_values=False,
- **kwargs,
- ):
- if history is None:
- history = []
- if logits_processor is None:
- logits_processor = LogitsProcessorList()
- logits_processor.append(InvalidScoreLogitsProcessor())
- gen_kwargs = {
- "max_length": max_length,
- "do_sample": do_sample,
- "top_p": top_p,
- "temperature": temperature,
- "logits_processor": logits_processor,
- **kwargs,
- }
- if past_key_values is None and not return_past_key_values:
- inputs = self.build_inputs(tokenizer, query, history=history)
- else:
- inputs = self.build_stream_inputs(tokenizer, query, history=history)
- if past_key_values is not None:
- past_length = past_key_values[0][0].shape[0]
- if self.transformer.pre_seq_len is not None:
- past_length -= self.transformer.pre_seq_len
- inputs.position_ids += past_length
- attention_mask = inputs.attention_mask
- attention_mask = torch.cat((attention_mask.new_ones(1, past_length), attention_mask), dim=1)
- inputs["attention_mask"] = attention_mask
- for outputs in self.stream_generate(
- **inputs,
- past_key_values=past_key_values,
- return_past_key_values=return_past_key_values,
- **gen_kwargs,
- ):
- if return_past_key_values:
- outputs, past_key_values = outputs
- outputs = outputs.tolist()[0][len(inputs["input_ids"][0]):]
- response = tokenizer.decode(outputs)
- if response and response[-1] != "�":
- response = self.process_response(response)
- new_history = history + [(query, response)]
- if return_past_key_values:
- yield response, new_history, past_key_values
- else:
- yield response, new_history
-
- @torch.no_grad()
- def stream_generate(
- self,
- input_ids,
- generation_config: Optional[GenerationConfig] = None,
- logits_processor: Optional[LogitsProcessorList] = None,
- stopping_criteria: Optional[StoppingCriteriaList] = None,
- prefix_allowed_tokens_fn: Optional[Callable[[int, torch.Tensor], List[int]]] = None,
- return_past_key_values=False,
- **kwargs,
- ):
- batch_size, input_ids_seq_length = input_ids.shape[0], input_ids.shape[-1]
-
- if generation_config is None:
- generation_config = self.generation_config
- generation_config = copy.deepcopy(generation_config)
- model_kwargs = generation_config.update(**kwargs)
- bos_token_id, eos_token_id = (
- generation_config.bos_token_id,
- generation_config.eos_token_id,
- )
-
- if isinstance(eos_token_id, int):
- eos_token_id = [eos_token_id]
-
- has_default_max_length = (kwargs.get("max_length") is None and generation_config.max_length is not None)
- if has_default_max_length and generation_config.max_new_tokens is None:
- warnings.warn(
- f"Using `max_length`'s default ({generation_config.max_length}) to control the generation length. "
- "This behaviour is deprecated and will be removed from the config in v5 of Transformers -- we"
- " recommend using `max_new_tokens` to control the maximum length of the generation.",
- UserWarning,
- )
- elif generation_config.max_new_tokens is not None:
- generation_config.max_length = (generation_config.max_new_tokens + input_ids_seq_length)
- if not has_default_max_length:
- logger.warn(
- f"Both `max_new_tokens` (={generation_config.max_new_tokens}) and `max_length`(="
- f"{generation_config.max_length}) seem to have been set. `max_new_tokens` will take precedence. "
- "Please refer to the documentation for more information. "
- "(https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)",
- UserWarning,
- )
-
- if input_ids_seq_length >= generation_config.max_length:
- input_ids_string = ("decoder_input_ids" if self.config.is_encoder_decoder else "input_ids")
- logger.warning(f"Input length of {input_ids_string} is {input_ids_seq_length}, but `max_length` is set to"
- f" {generation_config.max_length}. This can lead to unexpected behavior. You should consider"
- " increasing `max_new_tokens`.")
-
- # 2. Set generation parameters if not already defined
- logits_processor = (logits_processor if logits_processor is not None else LogitsProcessorList())
- stopping_criteria = (stopping_criteria if stopping_criteria is not None else StoppingCriteriaList())
-
- logits_processor = self._get_logits_processor(
- generation_config=generation_config,
- input_ids_seq_length=input_ids_seq_length,
- encoder_input_ids=input_ids,
- prefix_allowed_tokens_fn=prefix_allowed_tokens_fn,
- logits_processor=logits_processor,
- )
-
- stopping_criteria = self._get_stopping_criteria(generation_config=generation_config,
- stopping_criteria=stopping_criteria)
- logits_warper = self._get_logits_warper(generation_config)
-
- unfinished_sequences = input_ids.new(input_ids.shape[0]).fill_(1)
- scores = None
- while True:
- model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)
- # forward pass to get next token
- outputs = self(
- **model_inputs,
- return_dict=True,
- output_attentions=False,
- output_hidden_states=False,
- )
-
- next_token_logits = outputs.logits[:, -1, :]
-
- # pre-process distribution
- next_token_scores = logits_processor(input_ids, next_token_logits)
- next_token_scores = logits_warper(input_ids, next_token_scores)
-
- # sample
- probs = nn.functional.softmax(next_token_scores, dim=-1)
- if generation_config.do_sample:
- next_tokens = torch.multinomial(probs, num_samples=1).squeeze(1)
- else:
- next_tokens = torch.argmax(probs, dim=-1)
-
- # update generated ids, model inputs, and length for next step
- input_ids = torch.cat([input_ids, next_tokens[:, None]], dim=-1)
- model_kwargs = self._update_model_kwargs_for_generation(outputs,
- model_kwargs,
- is_encoder_decoder=self.config.is_encoder_decoder)
- unfinished_sequences = unfinished_sequences.mul((sum(next_tokens != i for i in eos_token_id)).long())
- if return_past_key_values:
- yield input_ids, outputs.past_key_values
- else:
- yield input_ids
- # stop when each sentence is finished, or if we exceed the maximum length
- if unfinished_sequences.max() == 0 or stopping_criteria(input_ids, scores):
- break
-
- def quantize(self, bits: int, empty_init=False, device=None, **kwargs):
- if bits == 0:
- return
-
- from .quantization import quantize
-
- if self.quantized:
- logger.info("Already quantized.")
- return self
-
- self.quantized = True
-
- self.config.quantization_bit = bits
-
- self.transformer.encoder = quantize(
- self.transformer.encoder,
- bits,
- empty_init=empty_init,
- device=device,
- **kwargs,
- )
- return self
diff --git a/tests/kit/model_zoo/transformers/gpt.py b/tests/kit/model_zoo/transformers/gpt.py
index 73c210221e61..5c3eb4438bc8 100644
--- a/tests/kit/model_zoo/transformers/gpt.py
+++ b/tests/kit/model_zoo/transformers/gpt.py
@@ -18,8 +18,8 @@ def data_gen():
# tokenized_input = tokenizer(input, return_tensors='pt')
# input_ids = tokenized_input['input_ids']
# attention_mask = tokenized_input['attention_mask']
- input_ids = torch.tensor([[15496, 11, 616, 3290, 318, 13779]], dtype=torch.int64)
- attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1]], dtype=torch.int64)
+ input_ids = torch.tensor([[15496, 11, 616, 3290, 318, 13779, 318, 13779]], dtype=torch.int64)
+ attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1, 1, 1]], dtype=torch.int64)
return dict(input_ids=input_ids, attention_mask=attention_mask)
@@ -46,7 +46,7 @@ def data_gen_for_token_classification():
# token classification data gen
# `labels` is the type not the token id for token classification, 0 or 1
data = data_gen()
- data['labels'] = torch.tensor([[0, 0, 0, 0, 0, 1]], dtype=torch.int64)
+ data['labels'] = torch.tensor([[0, 0, 0, 0, 0, 0, 0, 1]], dtype=torch.int64)
return data
diff --git a/tests/kit/model_zoo/transformers/t5.py b/tests/kit/model_zoo/transformers/t5.py
index 689db2c40abb..435cb6f46937 100644
--- a/tests/kit/model_zoo/transformers/t5.py
+++ b/tests/kit/model_zoo/transformers/t5.py
@@ -16,8 +16,9 @@ def data_gen_for_encoder_only():
# config = T5Config(decoder_start_token_id=0)
# tokenizer = T5Tokenizer.from_pretrained("t5-small")
# input_ids = tokenizer("translate English to German: The house is wonderful.", return_tensors="pt").input_ids
- input_ids = torch.Tensor([[13959, 1566, 12, 2968, 10, 37, 629, 19, 1627, 5, 1]]).long()
- return dict(input_ids=input_ids)
+ input_ids = torch.Tensor([[13959, 1566, 12, 2968, 10, 37, 629, 19, 1627, 5, 1, 12]]).long()
+ attention_mask = torch.Tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0]]).long()
+ return dict(input_ids=input_ids, attention_mask=attention_mask)
def data_gen_for_conditional_generation():
@@ -25,17 +26,16 @@ def data_gen_for_conditional_generation():
#
# labels = tokenizer("Das Haus ist wunderbar.", return_tensors="pt").input_ids
data = data_gen_for_encoder_only()
- labels = torch.Tensor([[644, 4598, 229, 19250, 5, 1]]).long()
+ labels = torch.Tensor([[644, 4598, 229, 19250, 5, 1, 644, 4598, 229, 19250, 5, 1]]).long()
data['labels'] = labels
return data
def data_gen_for_t5_model():
# decoder_inputs_ids is obtained with the following code
- #
# decoder_input_ids = model._shift_right(input_ids)
data = data_gen_for_encoder_only()
- decoder_input_ids = torch.Tensor([[0, 13959, 1566, 12, 2968, 10, 37, 629, 19, 1627, 5]]).long()
+ decoder_input_ids = torch.Tensor([[0, 13959, 1566, 12, 2968, 10, 37, 629, 19, 1627, 5, 5]]).long()
data['decoder_input_ids'] = decoder_input_ids
return data
diff --git a/tests/kit/model_zoo/transformers/whisper.py b/tests/kit/model_zoo/transformers/whisper.py
index 40c96a5777ab..f7cdc052aaf0 100644
--- a/tests/kit/model_zoo/transformers/whisper.py
+++ b/tests/kit/model_zoo/transformers/whisper.py
@@ -76,14 +76,14 @@ def data_gen_for_audio_classification():
loss_fn=loss_fn,
model_attribute=ModelAttribute(has_control_flow=True))
-model_zoo.register(name='transformers_whisperForConditionalGeneration',
+model_zoo.register(name='transformers_whisper_for_conditional_generation',
model_fn=lambda: transformers.WhisperForConditionalGeneration(config),
data_gen_fn=data_gen_for_conditional_generation,
output_transform_fn=output_transform_fn,
loss_fn=loss_fn_attr,
model_attribute=ModelAttribute(has_control_flow=True))
-model_zoo.register(name='transformers_whisperWhisperForAudioClassification',
+model_zoo.register(name='transformers_whisper_for_audio_classification',
model_fn=lambda: transformers.WhisperForAudioClassification(config),
data_gen_fn=data_gen_for_audio_classification,
output_transform_fn=output_transform_fn,
diff --git a/tests/test_booster/test_plugin/test_gemini_plugin.py b/tests/test_booster/test_plugin/test_gemini_plugin.py
index a06b2c963bfe..fee153baf1ac 100644
--- a/tests/test_booster/test_plugin/test_gemini_plugin.py
+++ b/tests/test_booster/test_plugin/test_gemini_plugin.py
@@ -93,7 +93,7 @@ def check_gemini_plugin(init_method: str = 'none', early_stop: bool = True):
'transformers_vit_for_image_classification', 'transformers_chatglm',
'transformers_chatglm_for_conditional_generation', 'transformers_blip2',
'transformers_blip2_conditional_gerneration', 'transformers_sam', 'transformers_whisper',
- 'transformers_whisperForConditionalGeneration', 'transformers_whisperWhisperForAudioClassification'
+ 'transformers_whisper_for_conditional_generation', 'transformers_whisper_for_audio_classification'
]:
continue
diff --git a/tests/test_shardformer/test_model/_utils.py b/tests/test_shardformer/test_model/_utils.py
index 0e5cb8144ef3..98cdc5a4b95b 100644
--- a/tests/test_shardformer/test_model/_utils.py
+++ b/tests/test_shardformer/test_model/_utils.py
@@ -21,7 +21,13 @@
from colossalai.tensor.d_tensor.api import is_customized_distributed_tensor, is_distributed_tensor
-def build_model(model_fn, enable_fused_normalization=True, enable_tensor_parallelism=True, use_lazy_init: bool = False):
+def build_model(model_fn,
+ enable_fused_normalization=True,
+ enable_tensor_parallelism=True,
+ enable_flash_attention=False,
+ enable_jit_fused=False,
+ use_lazy_init: bool = False):
+ # create new model
ctx = LazyInitContext() if use_lazy_init else nullcontext()
with ctx:
# create new model
@@ -31,7 +37,10 @@ def build_model(model_fn, enable_fused_normalization=True, enable_tensor_paralle
ctx.materialize(org_model)
# shard model
shard_config = ShardConfig(enable_fused_normalization=enable_fused_normalization,
- enable_tensor_parallelism=enable_tensor_parallelism)
+ enable_tensor_parallelism=enable_tensor_parallelism,
+ enable_flash_attention=enable_flash_attention,
+ enable_jit_fused=enable_jit_fused)
+ model_copy = copy.deepcopy(org_model)
shard_former = ShardFormer(shard_config=shard_config)
sharded_model, shared_params = shard_former.optimize(model_copy)
return org_model.cuda(), sharded_model.cuda()
diff --git a/tests/test_shardformer/test_model/test_shard_bert.py b/tests/test_shardformer/test_model/test_shard_bert.py
index 1d42f1c4703e..afc1507e8b24 100644
--- a/tests/test_shardformer/test_model/test_shard_bert.py
+++ b/tests/test_shardformer/test_model/test_shard_bert.py
@@ -46,14 +46,17 @@ def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transfo
check_grad(bert, sharded_bert, row_layer_for_check, atol=1e-7, rtol=1e-3, dim=1, verbose=False)
-@parameterize('enable_fused_normalization', [False, True])
-@parameterize('enable_tensor_parallelism', [False, True])
+@parameterize('enable_fused_normalization', [True, False])
+@parameterize('enable_tensor_parallelism', [True, False])
+@parameterize('enable_flash_attention', [True, False])
+@parameterize('enable_jit_fused', [True, False])
@parameterize('use_lazy_init', [False, True])
-def run_bert_test(enable_fused_normalization, enable_tensor_parallelism, use_lazy_init):
+def run_bert_test(enable_fused_normalization, enable_tensor_parallelism, enable_flash_attention, enable_jit_fused,
+ use_lazy_init):
sub_model_zoo = model_zoo.get_sub_registry('transformers_bert')
for name, (model_fn, data_gen_fn, output_transform_fn, loss_fn, _) in sub_model_zoo.items():
org_model, sharded_model = build_model(model_fn, enable_fused_normalization, enable_tensor_parallelism,
- use_lazy_init)
+ enable_flash_attention, enable_jit_fused, use_lazy_init)
check_state_dict(org_model, sharded_model, name=name)
check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn)
diff --git a/tests/test_shardformer/test_model/test_shard_blip2.py b/tests/test_shardformer/test_model/test_shard_blip2.py
index cb9725f4de7f..cd034d0c139a 100644
--- a/tests/test_shardformer/test_model/test_shard_blip2.py
+++ b/tests/test_shardformer/test_model/test_shard_blip2.py
@@ -47,10 +47,13 @@ def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transfo
@parameterize('enable_fused_normalization', [True, False])
@parameterize('enable_tensor_parallelism', [True, False])
-def run_blip2_test(enable_fused_normalization, enable_tensor_parallelism):
+@parameterize('enable_flash_attention', [True, False])
+@parameterize('enable_jit_fused', [True, False])
+def run_blip2_test(enable_fused_normalization, enable_tensor_parallelism, enable_flash_attention, enable_jit_fused):
sub_model_zoo = model_zoo.get_sub_registry('transformers_blip2')
for name, (model_fn, data_gen_fn, output_transform_fn, loss_fn, _) in sub_model_zoo.items():
- org_model, sharded_model = build_model(model_fn, enable_fused_normalization, enable_tensor_parallelism)
+ org_model, sharded_model = build_model(model_fn, enable_fused_normalization, enable_tensor_parallelism,
+ enable_flash_attention, enable_jit_fused)
check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn)
torch.cuda.empty_cache()
diff --git a/tests/test_shardformer/test_model/test_shard_bloom.py b/tests/test_shardformer/test_model/test_shard_bloom.py
index c13596fe8db3..e11bcf92ea3c 100644
--- a/tests/test_shardformer/test_model/test_shard_bloom.py
+++ b/tests/test_shardformer/test_model/test_shard_bloom.py
@@ -44,13 +44,15 @@ def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transfo
@parameterize('enable_fused_normalization', [True, False])
@parameterize('enable_tensor_parallelism', [True, False])
+@parameterize('enable_flash_attention', [True, False])
+@parameterize('enable_jit_fused', [True, False])
@parameterize('use_lazy_init', [False, True])
-def run_bloom_test(enable_fused_normalization, enable_tensor_parallelism, use_lazy_init):
+def run_bloom_test(enable_fused_normalization, enable_tensor_parallelism, enable_flash_attention, enable_jit_fused,
+ use_lazy_init):
sub_model_zoo = model_zoo.get_sub_registry('transformers_bloom')
for name, (model_fn, data_gen_fn, output_transform_fn, loss_fn, _) in sub_model_zoo.items():
org_model, sharded_model = build_model(model_fn, enable_fused_normalization, enable_tensor_parallelism,
- use_lazy_init)
- check_state_dict(org_model, sharded_model, name=name)
+ enable_flash_attention, enable_jit_fused, use_lazy_init)
check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn)
torch.cuda.empty_cache()
diff --git a/tests/test_shardformer/test_model/test_shard_chatglm.py b/tests/test_shardformer/test_model/test_shard_chatglm.py
index 005223fb8ae4..c455a99d26ce 100644
--- a/tests/test_shardformer/test_model/test_shard_chatglm.py
+++ b/tests/test_shardformer/test_model/test_shard_chatglm.py
@@ -72,7 +72,9 @@ def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transfo
@parameterize('enable_fused_normalization', [True, False])
@parameterize('enable_tensor_parallelism', [True, False])
-def run_chatglm_test(enable_fused_normalization, enable_tensor_parallelism):
+@parameterize('enable_flash_attention', [True, False])
+@parameterize('enable_jit_fused', [True, False])
+def run_chatglm_test(enable_fused_normalization, enable_tensor_parallelism, enable_flash_attention, enable_jit_fused):
sub_model_zoo = model_zoo.get_sub_registry('transformers_chatglm')
for name, (model_fn, data_gen_fn, output_transform_fn, loss_fn, _) in sub_model_zoo.items():
# create new model
@@ -80,7 +82,9 @@ def run_chatglm_test(enable_fused_normalization, enable_tensor_parallelism):
# shard model
shard_config = ShardConfig(enable_fused_normalization=enable_fused_normalization,
- enable_tensor_parallelism=enable_tensor_parallelism)
+ enable_tensor_parallelism=enable_tensor_parallelism,
+ enable_flash_attention=enable_flash_attention,
+ enable_jit_fused=enable_jit_fused)
model_copy = copy.deepcopy(org_model)
shard_former = ShardFormer(shard_config=shard_config)
if name == "transformers_chatglm":
diff --git a/tests/test_shardformer/test_model/test_shard_gpt2.py b/tests/test_shardformer/test_model/test_shard_gpt2.py
index cebb40bd16fe..f7213d8c50b4 100644
--- a/tests/test_shardformer/test_model/test_shard_gpt2.py
+++ b/tests/test_shardformer/test_model/test_shard_gpt2.py
@@ -68,7 +68,6 @@ def check_forward_backward(model_fn, data_gen_fn, output_transform_fn, loss_fn,
torch.cuda.empty_cache()
-
@parameterize('test_config', [{
'tp_size': 1,
'pp_size': 2,
diff --git a/tests/test_shardformer/test_model/test_shard_llama.py b/tests/test_shardformer/test_model/test_shard_llama.py
index 2cfc172c8df6..ead14ab111e6 100644
--- a/tests/test_shardformer/test_model/test_shard_llama.py
+++ b/tests/test_shardformer/test_model/test_shard_llama.py
@@ -49,12 +49,13 @@ def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transfo
@parameterize('enable_fused_normalization', [True, False])
@parameterize('enable_tensor_parallelism', [True, False])
+@parameterize('enable_flash_attention', [True, False])
@parameterize('use_lazy_init', [False, True])
-def run_gpt2_llama(enable_fused_normalization, enable_tensor_parallelism, use_lazy_init):
+def run_gpt2_llama(enable_fused_normalization, enable_tensor_parallelism, enable_flash_attention, use_lazy_init):
sub_model_zoo = model_zoo.get_sub_registry('transformers_llama')
for name, (model_fn, data_gen_fn, output_transform_fn, loss_fn, _) in sub_model_zoo.items():
org_model, sharded_model = build_model(model_fn, enable_fused_normalization, enable_tensor_parallelism,
- use_lazy_init)
+ enable_flash_attention, use_lazy_init)
check_state_dict(org_model, sharded_model, name=name)
check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn)
torch.cuda.empty_cache()
diff --git a/tests/test_shardformer/test_model/test_shard_opt.py b/tests/test_shardformer/test_model/test_shard_opt.py
index 4684bacb4788..99a278d4303a 100644
--- a/tests/test_shardformer/test_model/test_shard_opt.py
+++ b/tests/test_shardformer/test_model/test_shard_opt.py
@@ -42,18 +42,21 @@ def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transfo
# check grad
col_layer_for_check = ['decoder.layers[0].self_attn.q_proj', 'decoder.embed_tokens']
row_layer_for_check = ['decoder.layers[0].self_attn.out_proj']
- check_grad(opt_model, shard_opt_model, col_layer_for_check, atol=1e-7, rtol=1e-3, dim=0, verbose=False)
- check_grad(opt_model, shard_opt_model, row_layer_for_check, atol=1e-7, rtol=1e-3, dim=1, verbose=False)
+ check_grad(opt_model, shard_opt_model, col_layer_for_check, atol=1e-6, rtol=1e-3, dim=0, verbose=False)
+ check_grad(opt_model, shard_opt_model, row_layer_for_check, atol=1e-6, rtol=1e-3, dim=1, verbose=False)
+@parameterize('use_lazy_init', [False, True])
@parameterize('enable_fused_normalization', [True, False])
@parameterize('enable_tensor_parallelism', [True, False])
-@parameterize('use_lazy_init', [False, True])
-def run_t5_test(enable_fused_normalization, enable_tensor_parallelism, use_lazy_init):
+@parameterize('enable_flash_attention', [True, False])
+@parameterize('enable_jit_fused', [True, False])
+def run_opt_test(use_lazy_init, enable_fused_normalization, enable_tensor_parallelism, enable_flash_attention,
+ enable_jit_fused):
sub_model_zoo = model_zoo.get_sub_registry('transformers_opt')
for name, (model_fn, data_gen_fn, output_transform_fn, loss_fn, _) in sub_model_zoo.items():
org_model, sharded_model = build_model(model_fn, enable_fused_normalization, enable_tensor_parallelism,
- use_lazy_init)
+ enable_flash_attention, enable_jit_fused, use_lazy_init)
check_state_dict(org_model, sharded_model, name=name)
check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn)
torch.cuda.empty_cache()
@@ -62,7 +65,7 @@ def run_t5_test(enable_fused_normalization, enable_tensor_parallelism, use_lazy_
def check_OPTModel(rank, world_size, port):
disable_existing_loggers()
colossalai.launch(config={}, rank=rank, world_size=world_size, host='localhost', port=port, backend='nccl')
- run_t5_test()
+ run_opt_test()
@pytest.mark.dist
diff --git a/tests/test_shardformer/test_model/test_shard_sam.py b/tests/test_shardformer/test_model/test_shard_sam.py
index e7748cfd189d..616104cd7828 100644
--- a/tests/test_shardformer/test_model/test_shard_sam.py
+++ b/tests/test_shardformer/test_model/test_shard_sam.py
@@ -41,10 +41,12 @@ def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transfo
@parameterize('enable_fused_normalization', [True, False])
@parameterize('enable_tensor_parallelism', [True, False])
-def run_sam_test(enable_fused_normalization, enable_tensor_parallelism):
+@parameterize('enable_flash_attention', [True, False])
+def run_sam_test(enable_fused_normalization, enable_tensor_parallelism, enable_flash_attention):
sub_model_zoo = model_zoo.get_sub_registry('transformers_sam')
for name, (model_fn, data_gen_fn, output_transform_fn, loss_fn, _) in sub_model_zoo.items():
- org_model, sharded_model = build_model(model_fn, enable_fused_normalization, enable_tensor_parallelism)
+ org_model, sharded_model = build_model(model_fn, enable_fused_normalization, enable_tensor_parallelism,
+ enable_flash_attention)
check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn)
torch.cuda.empty_cache()
diff --git a/tests/test_shardformer/test_model/test_shard_t5.py b/tests/test_shardformer/test_model/test_shard_t5.py
index 024c5016b0c1..22f04c879879 100644
--- a/tests/test_shardformer/test_model/test_shard_t5.py
+++ b/tests/test_shardformer/test_model/test_shard_t5.py
@@ -33,8 +33,8 @@ def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transfo
# check grad
col_layer_for_check = ['encoder.block[0].layer[0].SelfAttention.q', 'shared']
row_layer_for_check = ['encoder.block[0].layer[0].SelfAttention.relative_attention_bias']
- check_grad(org_model, sharded_model, col_layer_for_check, atol=1e-7, rtol=1e-5, dim=0, verbose=False)
- check_grad(org_model, sharded_model, row_layer_for_check, atol=1e-7, rtol=1e-5, dim=1, verbose=False)
+ check_grad(org_model, sharded_model, col_layer_for_check, atol=1e-6, rtol=1e-5, dim=0, verbose=False)
+ check_grad(org_model, sharded_model, row_layer_for_check, atol=1e-6, rtol=1e-5, dim=1, verbose=False)
# check weights are tied
if hasattr(org_model, 'lm_head'):
@@ -45,11 +45,14 @@ def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transfo
@parameterize('enable_fused_normalization', [True, False])
@parameterize('enable_tensor_parallelism', [True, False])
@parameterize('use_lazy_init', [False, True])
-def run_t5_test(enable_fused_normalization, enable_tensor_parallelism, use_lazy_init):
+@parameterize('enable_flash_attention', [True, False])
+@parameterize('enable_jit_fused', [True, False])
+def run_t5_test(enable_fused_normalization, enable_tensor_parallelism, use_lazy_init, enable_flash_attention,
+ enable_jit_fused):
sub_model_zoo = model_zoo.get_sub_registry('transformers_t5')
for name, (model_fn, data_gen_fn, output_transform_fn, loss_fn, _) in sub_model_zoo.items():
org_model, sharded_model = build_model(model_fn, enable_fused_normalization, enable_tensor_parallelism,
- use_lazy_init)
+ enable_flash_attention, enable_jit_fused, use_lazy_init)
check_state_dict(org_model, sharded_model, name=name)
check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn)
torch.cuda.empty_cache()
diff --git a/tests/test_shardformer/test_model/test_shard_vit.py b/tests/test_shardformer/test_model/test_shard_vit.py
index 7833ab70275d..d179c8a8ee32 100644
--- a/tests/test_shardformer/test_model/test_shard_vit.py
+++ b/tests/test_shardformer/test_model/test_shard_vit.py
@@ -20,7 +20,9 @@ def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transfo
# check forward
org_output, org_loss, shard_output, shard_loss = run_forward(org_model, sharded_model, data_gen_fn,
output_transform_fn, loss_fn)
+
assert_hf_output_close(org_output, shard_output, atol=1e-3, rtol=1e-3)
+
# do backward
org_loss.backward()
shard_loss.backward()
@@ -45,10 +47,13 @@ def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transfo
@parameterize('enable_fused_normalization', [True, False])
@parameterize('enable_tensor_parallelism', [True, False])
-def run_vit_test(enable_fused_normalization, enable_tensor_parallelism):
+@parameterize('enable_flash_attention', [True, False])
+@parameterize('enable_jit_fused', [True, False])
+def run_vit_test(enable_fused_normalization, enable_tensor_parallelism, enable_flash_attention, enable_jit_fused):
sub_model_zoo = model_zoo.get_sub_registry('transformers_vit')
for name, (model_fn, data_gen_fn, output_transform_fn, loss_fn, _) in sub_model_zoo.items():
- org_model, sharded_model = build_model(model_fn, enable_fused_normalization, enable_tensor_parallelism)
+ org_model, sharded_model = build_model(model_fn, enable_fused_normalization, enable_tensor_parallelism,
+ enable_flash_attention, enable_jit_fused)
check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn)
torch.cuda.empty_cache()
diff --git a/tests/test_shardformer/test_model/test_shard_whisper.py b/tests/test_shardformer/test_model/test_shard_whisper.py
index a271bbdf1223..9b38ae07b1d6 100644
--- a/tests/test_shardformer/test_model/test_shard_whisper.py
+++ b/tests/test_shardformer/test_model/test_shard_whisper.py
@@ -48,12 +48,16 @@ def check_forward_backward(org_model, sharded_model, data_gen_fn, output_transfo
@parameterize('enable_fused_normalization', [True, False])
@parameterize('enable_tensor_parallelism', [True, False])
-def run_whisper_test(enable_fused_normalization, enable_tensor_parallelism):
+@parameterize('enable_flash_attention', [True, False])
+@parameterize('enable_jit_fused', [True, False])
+def run_whisper_test(enable_fused_normalization, enable_tensor_parallelism, enable_flash_attention, enable_jit_fused):
sub_model_zoo = model_zoo.get_sub_registry('transformers_whisper')
for name, (model_fn, data_gen_fn, output_transform_fn, loss_fn, _) in sub_model_zoo.items():
org_model, sharded_model = build_model(model_fn,
enable_fused_normalization=enable_fused_normalization,
- enable_tensor_parallelism=enable_tensor_parallelism)
+ enable_tensor_parallelism=enable_tensor_parallelism,
+ enable_flash_attention=enable_flash_attention,
+ enable_jit_fused=enable_jit_fused)
check_forward_backward(org_model, sharded_model, data_gen_fn, output_transform_fn, loss_fn)
torch.cuda.empty_cache()
diff --git a/tests/test_utils/test_flash_attention.py b/tests/test_utils/test_flash_attention.py
index e1c7446f40db..28369d4c9fdb 100644
--- a/tests/test_utils/test_flash_attention.py
+++ b/tests/test_utils/test_flash_attention.py
@@ -167,4 +167,4 @@ def test_cross_attention(proj_shape, dtype, dropout):
torch.allclose(y, out_ref, atol=1e-18), f"{(y - out_ref).abs().max()}"
torch.allclose(grad_q, grad_ref_q, atol=1e-7), f"{(grad_q - grad_ref_q).abs().max()}"
torch.allclose(grad_k, grad_ref_k, atol=1e-7), f"{(grad_k - grad_ref_k).abs().max()}"
- torch.allclose(grad_v, grad_ref_v, atol=1e-7), f"{(grad_v - grad_ref_v).abs().max()}"
\ No newline at end of file
+ torch.allclose(grad_v, grad_ref_v, atol=1e-7), f"{(grad_v - grad_ref_v).abs().max()}"