我们提出mesos, 一个能在多种不同集群计算框架(例如hadoop,mpi等)之间共享集群的平台.共享改善了集群的资源利用,避免了每框架应用数据的复制. mesos能以细粒度方式分享资源, 允许框架通过轮流读取每个机器上的数据,来完成数据局部性.为了支持当今框架使用日益复杂的调度器, mesos 引入了叫做resource offers的分布式双层调度机制. mesos来决定供给每个框架多少资源,与此同时框架可以决定接受哪些资源,哪些计算运行在其上. 我们的测试结果显示,在多个计算框架之间共享集群, mesos能达到接近最优的数据局部性,能延伸到50,000模拟节点.
使用日常的服务器搭建的集群,已经变成主流计算平台, 驱动着大型因特网服务和逐渐增长的数据密集型科学计算应用. 在这些应用的驱使下,学界和业界开发了多种集群计算框架,简化集群上的编程任务.典型的代表,包括MapReduce, Dryad, MapReduce Online, Pregel等等.
显而易见,未来将会浮现更多的集群计算框架,没有任何框架能成为所有应用的最佳选择. 因此,组织机构常常在同一个集群上,部署多个应用框架,为每个应用选取最佳的框架. 在多个框架之间共享集群,提高资源利用率,允许应用共享访问那些拷贝代价高昂大数据集.
目前共享集群的解决方案,要么采用分区方式,每分区部署一个框架,或者分配一堆虚拟机供给每个框架. 不幸的是,这些解决方案既没有完成高效资源利用,也不能高效地数据共享.主要问题是这些解决方案的资源分配粒度和存在框架之间的失配. 许多框架,如Hadoop,Dryada,采用了细粒度共享模型:节点被分割成槽(slots), 作业(jobs)由匹配相应槽的短时任务(tasks)构成. 短时任务和能够在每个节点上运行多个这样的任务,使得作业完成了高效的数据局部性,每个作业很快获得机会,运行在存储输入数据的节点上. 短时任务同样使得框架完成高效资源利用,因为作业能快速延伸到新的可用节点. 不幸的是, 由于这些框架是单独开发, 没办法执行跨框架的细粒度共享,这样以来,框架之间高效共享集群及数据,变得特别困难.
在这篇论文中,我们倡议使用mesos, 一个能跨多种集群框架,通过提供公用接口访问集群资源,提供细粒度资源共享的瘦资源共享层.
mesos必须解决的主要设计问题是怎么在任务之间匹配资源.多个因素,这个问题变得极具挑战性. 首先, 方案需要能支持范围广泛的当前及将来的框架, 基于它们自身的编程模型,通讯模式,任务依赖性, 数据存放, 每个都有自己的调度需求. 其次,方案必须具有高度伸缩性,因为现代集群包含数以万计的节点,数以百计的作业,数百万的任务同时激活. 再次,调度系统必须是容错高可用的,因为,集群中所有应用依赖于它.
对于mesos, 方案之一是实现一个中心调度器,它把框架约束,资源可用度,组织策略作为输入,为所有任务做全局的计算调度.尽管这种方法可以实施跨框架的调度优化,也面临多种挑战. 首先,就是复杂度, 调度器将要提供有充分表达性的api, 来捕获所有框架的约束, 同时要解决百万任务的在线优化问题.即使这样一个调度器是可行的,这种复杂度也会给它的伸缩性及弹性带来负面影响. 其次, 随着不断新的框架,针对当前框架的新调度策略, 被开发, 目前也 没有一个完整的框架约束规范. 再次, 众多当前框架实现了自己的精巧调度策略,移动此项功能进全局调度器,要求昂贵的重构工作.
mesos采用了另一种方法: 由一种叫做resource offer的抽象, 代理调度控制到框架.resource offer封装了一堆计算资源,框架可以获取用来运行任务. 基于类似公平分享的组织策略, mesos来决定供给每个框架多少资源, 同时框架决定接受哪些资源, 哪些任务在其上运行. 尽管,这种去中心化化的调度模型并不总是导致全局最优调度, 我们发现在实践上它执行的相当良好,允许框架几乎完美地达到如数据局部性这样的目标. 此外,资源供给简单有效的实现,允许mesos 具有高度伸缩性和健壮性.
mesos灵活的细粒度共享模型有着其他一些优势. 首先, 即使组织仅运行一个框架,可以使用mesos, 在一个集群上运行此框架的多个实例, 或者多个版本.我们在yahoo,facebook的联系人, 指出这是一种很好的方式, 用来隔离生产环境和试验环境的工作负载,展开新版本的hadoop部署. 其次,通过提供跨框架的共享资源的方法, mesos允许开发者构建针对特定应用领域的框架,而非一个万能的通用框架.如此, 框架能够演化的更快,为特定的问题域提供更好的支持.
我们用了10,000行c++ 实现mesos.系统延伸到50,000模拟节点,使用zookeeper做容错处理. 为了评估mesos,我们移植了三个集群计算系统: hadoop,mpi,torque batch scheduler.为了验证我们关于特定的框架比通用框架更有价值的假设,我们在mesos之上开发了名为spark的框架, spark特别为数据集被众多并行操作重用的迭代作业优化, 结果显示spark在迭代机器学习方面胜过hadoop 10倍.
本论文按如下方式组织,第二节描述了设计mesos所针对的数据中心环境,第三节呈现mesos架构,第四节分析我们的分布式调度模型,描述mesos在哪些环境下工作良好,第五节给出mesos的实现描述,第六节做一些评估, 第七节考察以下相关的工作, 最后我们在第八节给出总结.
作为一个我们支持的工作负载例子,考虑facebook的hadoop 数据仓库, facebook从它的web service 加载日志到1200个节点的hadoop集群, 它们被用于商业智能, 垃圾邮件检测,广告优化. 除了那些周期运行的生产作业, 集群也被用于许多试验作业, 范围从多小时的机器学习计算到经由名叫hive的hadoop SQL 接口提交的1-2 小时临时查询. 大部分作业都是短时的(平均84秒), 作业由细粒度的map,reduce 任务构成(平均23s).如图1所示.
为了满足这些作业的性能要求,facebook为hadoop使用了公平调度器, 它利用了工作负载细粒度属性, 在map-reduce 任务级别,做调度决策,优化数据局部性. 不幸的是, 这意味着集群只能运行hadoop 作业.如果用户希望使用MPI 代替MapReduce, 编写新的广告定位算法, 可能因为MPI的通讯模式更加高效, 用户不得不使用新的集群,往里导入数以太字节的数据.mesos 旨在为多种集群框架提供细粒度共享,同时给框架足够的控制来完成如数据局部化这样的既定目标.
我们以讨论我们的设计理念开始描述mesos.然后,描述mesos 组件,资源分配机制,mesos怎么完成隔离,伸缩,容错.
mesos旨在为多种框架有效共享集群提供可伸缩,有弹性的核心.由于集群框架差异巨大,快速演化,我们主导设计理念是:定义一个有效跨框架共享的最小接口, 否则把任务调度及执行推到框架处理. 将控制权推给框架有两个优势:首先,这允许框架为不同的问题域采用不同的方法,解决方案可以单独演化.其次,这使得mesos简单,最小化系统需求的改动速度,使得mesos更容易保持伸缩健壮性. 尽管mesos提供了低级别接口,我们期待构建在mesos之上,实现常见的功能高级别的库.这些库类似于外内核中库操作系统. 把这些功能放进库,而非mesos,使得mesos小而灵活,库可以单独演化.
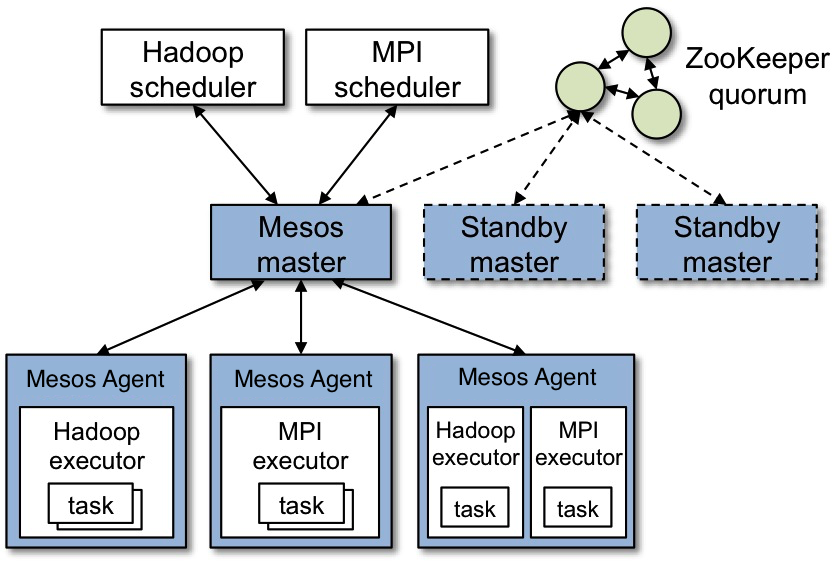
架构图显示了mesos主要组件.mesos 由master进程,slave 守护进程,框架构成.master管理集群节点上的slave 进程, 框架安排任务在salve上运行. master 使用resource offers 实现细粒度跨框架资源共享. 每个资源供给包含由多个slave可用资源构成的列表. master根据给定的组织策略(如公平分享,严格优先级),决定供给每个框架多少资源. 为了支持多种策略,master 采用模块化架构,使得经由插件添加新的分配模块变得容易. 为了让master容错,我们使用zookeeper实现故障转移机制.
运行在mesos之上的框架由两个组件构成:一个注册到master上,接受资源供给的调度器, 一个在slave节点上启动,运行框架任务的executor进程. 虽然master决定供给每个框架多少资源,框架的调度器来选择自己使用哪些供给. 当框架接受供给后,它传递给mesos一份想要在mesos上运行任务的描述,接着,mesos 在slave上启动相应的的任务.
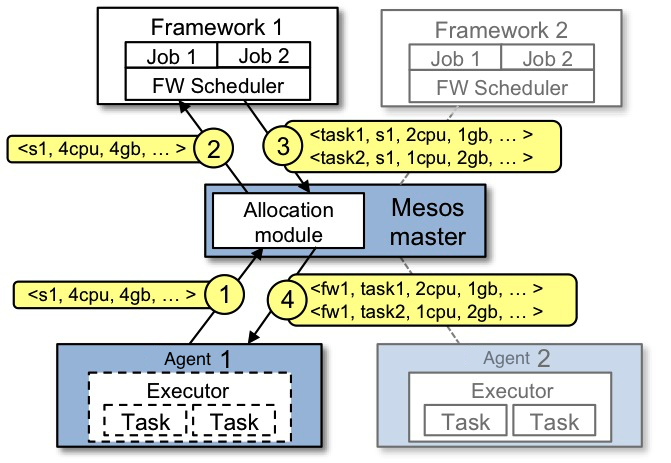
资源供给图展示了一个框架怎样被调度来运行一个任务.在步骤(1), salve 1 向master报告它有4个cpu,4GB可用内存, master 调用分配策略模块, 分配模块告知master, 向框架1供给所有可用资源. 在步骤(2),master给框架1发送一份可以在salve 1上使用的资源描述. 步骤(3), 框架调度器回应给master两个运行任务, 第一个任务使用<2cpu, 1G ram>, 第二个使用<1cpu,2G ram>. 最后,步骤(4), master 向slave发送任务,slave为框架executor分配相应的资源,executor启动两个任务.剩下的1cpu,1Gb内存仍然未分配, 可能会被供给框架2. 另外,当任务完成,有新的可用资源,资源供给过程会继续运作.
虽然mesos提供的瘦接口易于伸缩,允许框架单独演化.仍然还有一个问题:mesos 不了解框架约束情况下,怎么满足它们的约束?比如,在mesos不了解哪个节点存储了框架想要的数据情况下, 框架怎么完成数据局部性?mesos仅仅通过给予框架拒绝供给的能力,回答上述问题. 框架将会拒绝那些不能满足它的供给,接受哪些可以满足的.特别,我们发现一种叫做延迟调度的简单策略,框架会为获取存储输入数据的节点,等待一段受限时间, 结果,产出了几乎最优的数据局部化.
mesos 代理分配决策到一个可插拔的分配模块, 如此组织可以根据自己的需求定制分配策略. 在一般的运作情况下,mesos 利用了大部分任务是短时这个事实,当任务完成后,重新分配资源. 这种情况一般发生比较频繁,这样新的框架就能更快地获取资源份额. 比如,一个框架的份额是集群的10%, 他需要等待10% 的平均任务长度,获得资源份额. 如果资源供给不能足够快,分配模块也具备撤销(杀死)任务的能力. 目前,我们已经实现了两种简单分配模块:一个执行公平分享,一个实现严格优先级.hadoop,dryad当前也使用了类似的方法.
由于mesos管理每个slave上多个资源(cpu,内存,网络带宽等). 自然浮现这样疑问:当不同的框架偏向的资源不同时,什么构成了公平分配. 我们对合理公平属性和可能的公平定义做了详尽的研究(drf 论文). 我们归结大部分其他的公平定义有着不太合理的属性.比如,来自均等收入的竞争均衡, 微观经济学里的偏好公平等,都存在资源的释放可能会已经分配的用户造成伤害的缺点. 类似的其他一些公平理念,违反了如免嫉妒这样的合理属性, 可能导致用户囤积自己不需要的资源,欺骗系统. 此处结尾,我们设计了一种叫做主导资源公平(DRF)的公平策略.它试图均等每个框架的主导资源所占份额.即是,框架需求资源中占比率最大的那个.比如,一个集群拥有100个cpu, 100GB内存,框架F1每任务需要4 cpu, 1GB内存,框架F2每任务需要1cpu,8GB 内存,DRF 会给f1分配20个任务(80 cpu 和 20gb), 给f2分配10个任务(10 cpu,80gb). 这就使得f1的cpu 份额等于f2的内存份额,同时完全使用了内存这项资源. DRF是最大最小公平的自然泛化.drf满足上面提到的所有属性,能在O(logn)时间调度n个框架.
假设系统有9个cpu,18GB内存,有两个用户(框架), 用户A请求任务所需资源<1 cpu, 4GB 内存>, 用户B 请求任务所需资源<3 cpu, 1GB 内存>. 在这种情况下,用户A的任务消耗了1/9 cpu, 2/9 mem, 用户B的任务消耗了1/3 cpu, 1/18 mem.用户A的主导资源是mem,用户B主要资源是cpu.drf 试图均等用户的主导资源,最终系统分配了3 个用户A的任务,总消耗<3 cpu, 12GB>, 2 个用户B的任务,总消耗<6 cpu, 2GB>.

drf实现(假设用户寻求向量长度为1, 分配后无任务回收):
package main
import (
"container/heap"
"fmt"
"math"
)
type userShare struct {
user string //user name
share float64 //dominant resource share
}
//记录系统的全部资源容量
var resourceCapacity = map[string]uint{
"cpu": 9,
"mem": 18,
}
//记录每种资源的消费情况
var resourceConsumed = map[string]uint{
"cpu": 0,
"mem": 0,
}
//跟踪每个用户当前主导资源比例
var drs = map[string]userShare{
"user b": userShare{user: "user b", share: 0.0},
"user a": userShare{user: "user a", share: 0.0},
}
//记录每个用户当前累计获得的资源分配
var UserAlloc = map[string]*Task{}
//用户的资源分配请求
type Task struct {
cpu uint
mem uint
}
//假设用户每次请求资源相同,即 demand vector 里面元素相同
var UserTasks = map[string][]Task{
"user a": []Task{{cpu: 1, mem: 4}},
"user b": []Task{{cpu: 3, mem: 1}},
}
type minHeap []userShare
func (mh minHeap) Len() int { return len(mh) }
func (mh minHeap) Less(i, j int) bool { return mh[i].share < mh[j].share }
func (mh minHeap) Swap(i, j int) { mh[i], mh[j] = mh[j], mh[i] }
func (mh *minHeap) Push(x interface{}) {
*mh = append(*mh, x.(userShare))
}
func (mh *minHeap) Pop() interface{} {
old := *mh
n := len(old)
x := old[n-1]
*mh = old[0 : n-1]
return x
}
func drf() {
for {
ds := &minHeap{}
for _, e := range drs {
*ds = append(*ds, e)
}
heap.Init(ds)
min := heap.Pop(ds).(userShare)
t := UserTasks[min.user][0]
if resourceConsumed["cpu"]+t.cpu <= resourceCapacity["cpu"] &&
resourceConsumed["mem"]+t.mem <= resourceCapacity["mem"] {
fmt.Printf("system will allocate task <%d cpu ,%d mem> for %s\n",
t.cpu, t.mem, min.user)
resourceConsumed["cpu"] += t.cpu
resourceConsumed["mem"] += t.mem
if _, ok := UserAlloc[min.user]; !ok {
UserAlloc[min.user] = &Task{}
}
UserAlloc[min.user].cpu += t.cpu
UserAlloc[min.user].mem += t.mem
cpuShare := float64(UserAlloc[min.user].cpu) / float64(resourceCapacity["cpu"])
memShare := float64(UserAlloc[min.user].mem) / float64(resourceCapacity["mem"])
drs[min.user] = userShare{min.user, math.Max(cpuShare, memShare)}
} else {
fmt.Printf("system full\n")
fmt.Printf("total resource consumed %v \n", resourceConsumed)
for user, usage := range UserAlloc {
fmt.Printf("%s , cpu: %d , mem: %d\n", user, usage.cpu, usage.mem)
}
return
}
}
}
func main() {
drf()
}
除了包含短任务的细粒度工作量,mesos也能支持包含像web service ,mpi 程序这样长任务的框架. 这是通过在长短任务间共享节点空间完成:比如,4 core 节点上,其中两个核心上运行mpi,同时也会运行访问本地节点的mapreduce任务. 如果在集群里肆意安排长任务,某些节点会被长任务占据掉,阻止了其他框架访问本地数据. 为了解决这一问题,mesos 允许分配模块在每个运行长任务的节点上绑定全部资源. 在资源供给过程中,报告给框架的节点上,长任务的资源仍然可用. 当框架启动任务时,它标记任务是长或者短,短任务可以使用任何资源,但是长任务最多能使用资源供给的指定额度. 当然,框架可以不做标记地启动一个长任务,这种情况下,mesos 最终会撤销它.
如同之前描述,在一个细粒度任务环境中,mesos能通过仅仅等待任务完成,快速重新分配资源. 然而,如果集群被长任务占据,比如,由于缺陷的作业,贪心的框架, mesos可以撤销任务. 杀掉任务前,mesos 给框架一个合理时间段,清理自身.mesos会要求相应的executor 杀掉任务,如果它不响应请求,mesos 杀掉整个executor及其中所有任务. 我们将撤销任务策略留给分配模块去实现,这里我们描述两个相关的机制. 首先,尽管杀掉任务对大部分框架有较低的影响(如,MapReduce,无状态的web服务),但是对那些有着相互依赖任务的框架构成伤害.(如,MPI).通过让分配模块向框架提供保障分配(大量框架可以持有的资源,而不用担心任务丢失),我们允许框架的任务避免被杀死. 框架通过调用api获取保障分配.分配模块负责确保自己可以并发提供保障分配. 当前我们让保障分配有着简单的语义:如果框架低于保障分配,它的任何任务都不应该被杀掉,如果高于保障分配,它的任何任务都有可能被杀掉. 然而,如果用户觉得此模型太过简单,也可让框架为它们的任务指定优先级,如此,分配模块会试图杀掉低优先级的任务. 其次,为了决定什么时候触发撤销,分配模块必须了解哪些框架将会使用更多的资源. 框架通过api调用来表明自己对资源供给的兴趣.
mesos利用操作系统已有的隔离机制,实现相同slave上不同框架executor之间的性能隔离. 由于这些隔离机制依赖特定平台,我们通过可插拔的隔离模块支持多种隔离机制. 当前的实现中,我们使用了操作系统的容器技术达到隔离效果.这些技术可以限制一颗进程树的cpu,物理内存,虚存,网络带宽,磁盘io带宽(新版linux内核). 另外,它们支持动态重配置容器的资源限制.这为mesos能在executor中启动关闭任务时,添加删除资源提供了必要的手段. 将来,如果能像使用容器一样使用虚拟机提供隔离,也是很有吸引力的方案. 但是,目前的虚拟化技术对数据密集型工作有着显著的开销,而且对动态重配置支持有限,我们没有实现这种方案.
由于mesos的任务调度是一个分布式过程, 其中会发生master与框架调度器的通讯,这一过程务必是高效健壮的.mesos包括三种机制来达到此目的. 首先,某些框架总是拒绝一些资源,mesos在master上布置过滤器,消除这一拒绝过程,避免不必要的通讯发生.我们提供了两种类型的过滤器: "仅供给来自列表L的节点" 和 "仅供给拥有至少R个可用资源的节点". 一个不能满足过滤器条件的资源被当做被拒绝的资源.默认,会在被拒绝的资源上布置一个五秒的临时过滤器,减轻那些不想手动设置过滤器的开发人员负担. 其次,由于框架可能花费一定时间响应资源供给,mesos把提供给框架的资源份额算入框架在集群上使用资源份额.这会给框架很强的动力,快速回应资源供给,过滤掉那些不能使用的资源供给,如此, 它们可以更快地获取合适的资源. 再次,如果一个框架长时间未响应供给,mesos会废除供给,重新提供给其它框架. 我们也注意到即使没有使用过滤器, mesos也能做出每秒数以万计的资源供给,因为它执行的调度算法是相当高效(公平分享).
由于master在我们的架构中处于中心位置, 我们已经通过把状态推向salve和调度器, master维持尽量少的状态,以此达到容错的目的. 有多个master同时运行,但只有一个能作为领导者.其它的master作为随从,随时准备替代失败的领导者. zookeeper被用于在master之间选举领导者.调度器和slaves可以通过zookeeper找到当前的领导者.在master失败的时候, salves和调度器连接新选举的领导者,辅助恢复自己的状态. 通过使用带有序列号和重传机制的瘦通讯层, 我们确保那些已经发送给失败的master的消息被重传到新的master.除了处理master的失败,mesos同样向框架的调度器报告失败的任务,slave,executor.框架可以选择它们自己的策略回应失败. 最后,为了处理调度器的失败,mesos可被拓展,允许一个框架注册多个调度器,其中一个失败,mesos master通知另一个去接管.框架必须提供自己的调度器间共享机制.