Add Exponential Smoothing Plot #20
Comments
|
Yes, that makes a lot of sense! |
|
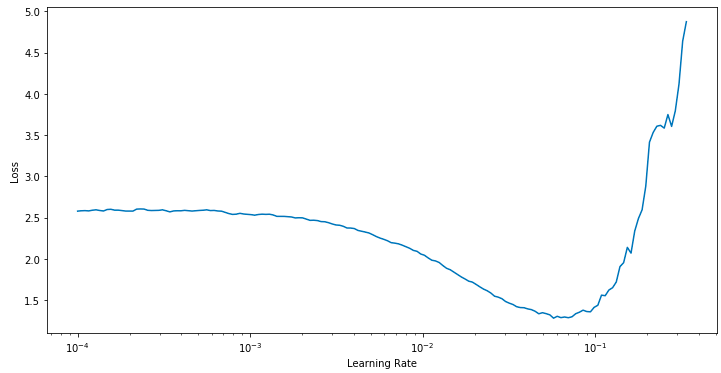
This repo implements exponential smoothing: https://github.com/WittmannF/LRFinder
|
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
After reading this blog post: https://sgugger.github.io/how-do-you-find-a-good-learning-rate.html
It seems that you can get better smoothing by using an exponential weighting. Could this potentially provide better a learning rate?
I'll make a pull request but my code currently looks like this:
The text was updated successfully, but these errors were encountered: