

Contextualized Topic Models (CTM) are a family of topic models that use pre-trained representations of language (e.g., BERT) to support topic modeling. See the papers for details:
- Cross-lingual Contextualized Topic Models with Zero-shot Learning https://arxiv.org/pdf/2004.07737v1.pdf
- Pre-training is a Hot Topic: Contextualized Document Embeddings Improve Topic Coherence https://arxiv.org/pdf/2004.03974.pdf
![]()
Make sure you read the doc a bit. The cross-lingual topic modeling requires to use a ZeroShot model and it is trained only on ONE language; with the power of multilingual BERT it can then be used to predict the topics of documents in unseen languages. For more details you can read the two papers mentioned above.
| Name | Link |
|---|---|
| Zero-Shot Cross-lingual Topic Modeling (stable v1.7.0) | |
| CombinedTM for Wikipedia Documents (stable v1.7.0) | |
| CombinedTM with Preprocessing (stable v1.7.0) | |
| CombinedTM for Wikipedia Documents (v1.6.0) | |
| CombinedTM with Preprocessing (v1.6.0) |
- In CTMs we have two models. CombinedTM and ZeroShotTM, they have different use cases.
- CTMs work better when the size of the bag of words has been restricted to a number of terms that does not go over 2000 elements (this is because we have a neural model that reconstructs the input bag of word). We have a preprocessing pipeline that can help you in dealing with this.
- Check the BERT model you are using, the multilingual BERT model one used on English data might not give results that are as good as the pure English trained one.
- Preprocessing is key. If you give BERT preprocessed text, it might be difficult to get out a good representation. What we usually do is use the preprocessed text for the bag of word creating and use the NOT preprocessed text for BERT embeddings. Our preprocessing class can take care of this for you.
- Free software: MIT license
- Documentation: https://contextualized-topic-models.readthedocs.io.
- Super big shout-out to Stephen Carrow for creating the awesome https://github.com/estebandito22/PyTorchAVITM package from which we constructed the foundations of this package. We are happy to redistribute again this software under the MIT License.
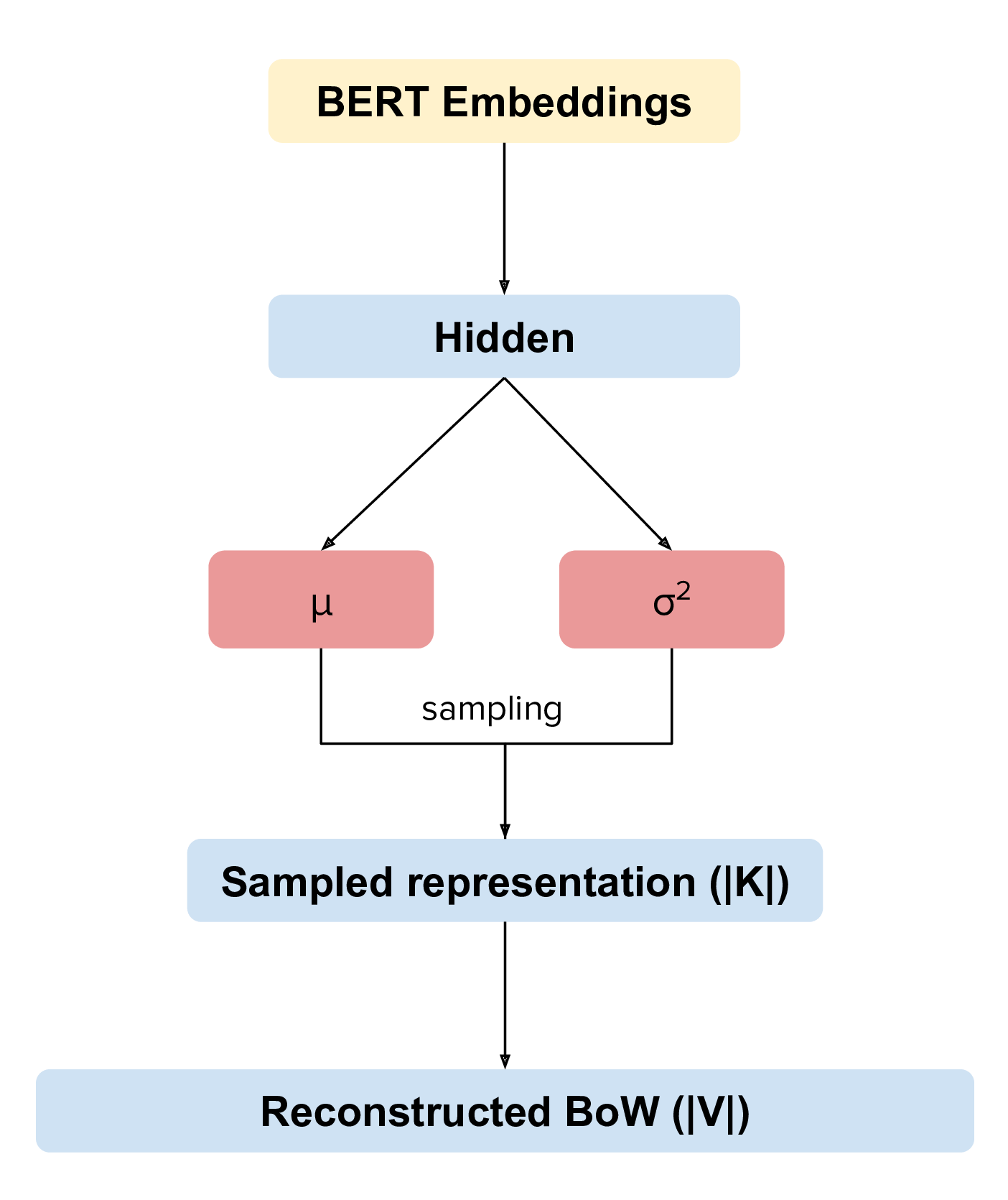
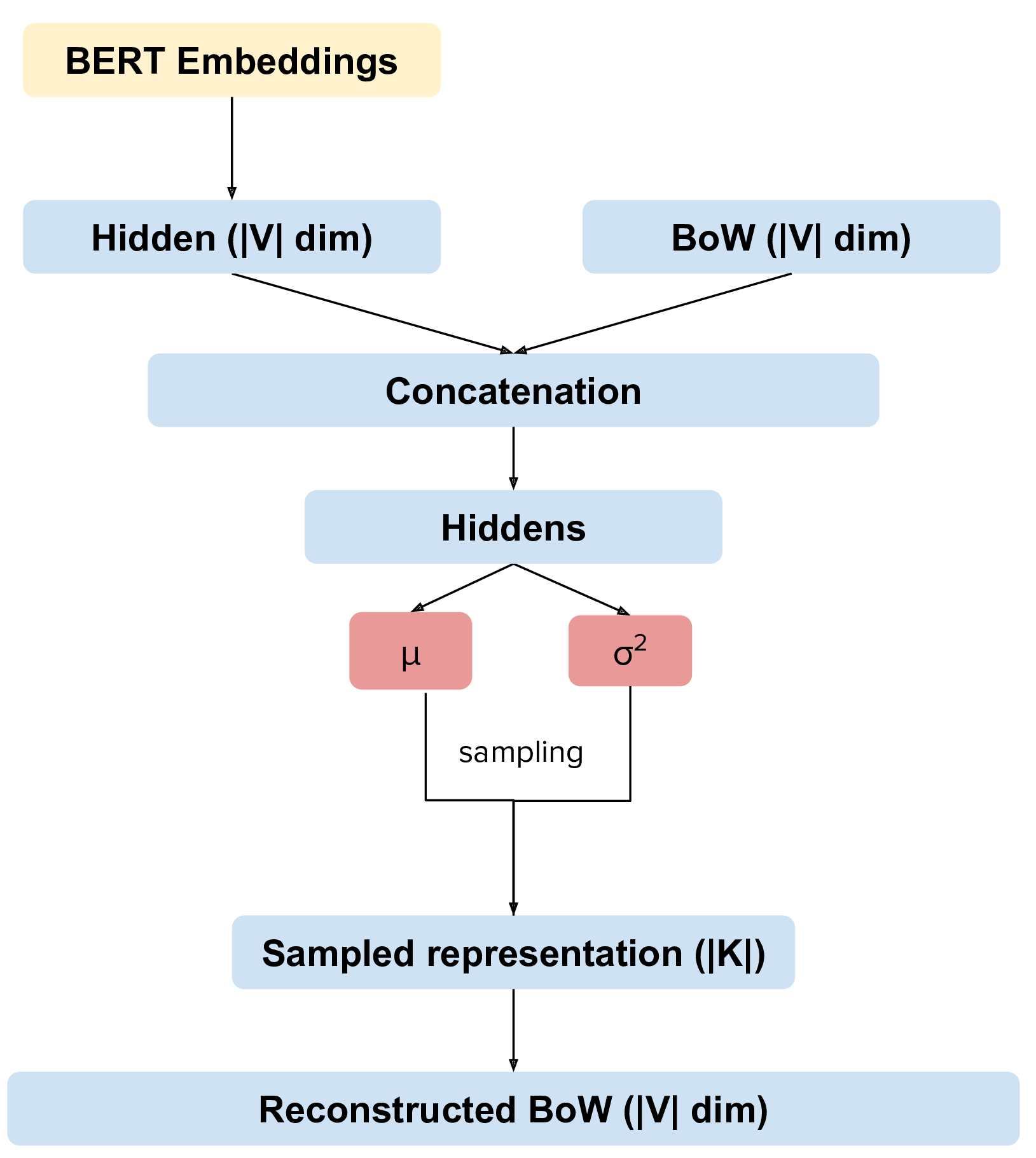
- Combines BERT and Neural Variational Topic Models
- Two different methodologies: Combined, where we combine BoW and BERT embeddings and ZeroShot, that uses only BERT embeddings
- Includes methods to create embedded representations and BoW
- Includes evaluation metrics
Important: If you want to use CUDA you need to install the correct version of the CUDA systems that matches your distribution, see pytorch.
Install the package using pip
pip install -U contextualized_topic_modelsContextual neural topic models can be easily instantiated using few parameters (although there is a wide range of parameters you can use to change the behaviour of the neural topic model). When you generate embeddings with BERT remember that there is a maximum length and for documents that are too long some words will be ignored.
An important aspect to take into account is which network you want to use: the one that combines BERT and the BoW or the one that just uses BERT. It's easy to swap from one to the other:
ZeroShotTM:
ZeroShotTM(input_size=len(qt.vocab), bert_input_size=embedding_dimension, n_components=number_of_topics)CombinedTM:
CombinedTM(input_size=len(qt.vocab), bert_input_size=embedding_dimension, n_components=number_of_topics)But remember that you can do zero-shot cross-lingual topic modeling only with the ZeroShotTM model. See cross-lingual-topic-modeling
All the examples below use a multilingual embedding model distiluse-base-multilingual-cased.
If you are doing topic modeling in English, you SHOULD use the English sentence-bert model, bert-base-nli-mean-tokens. In that case,
it's really easy to update the code to support mono-lingual English topic modeling.
qt = QuickText("bert-base-nli-mean-tokens",
text_for_bert=list_of_unpreprocessed_documents,
text_for_bow=list_of_preprocessed_documents)In general, our package should be able to support all the models described in the sentence transformer package. and in HuggingFace.
Our ZeroShotTM can be used for zero-shot topic modeling. It can handle words that are not used during the training phase. More interestingly, this model can be used for cross-lingual topic modeling! See the paper (https://arxiv.org/pdf/2004.07737v1.pdf)
from contextualized_topic_models.models.ctm import ZeroShotTM
from contextualized_topic_models.utils.data_preparation import QuickText
from contextualized_topic_models.utils.data_preparation import bert_embeddings_from_file
from contextualized_topic_models.datasets.dataset import CTMDataset
text_for_bert = [
"hello, this is unpreprocessed text you can give to the model",
"have fun with our topic model",
]
text_for_bow = [
"hello unpreprocessed give model",
"fun topic model",
]
qt = QuickText("distiluse-base-multilingual-cased",
text_for_bert=list_of_ENGLISH_unpreprocessed_documents,
text_for_bow=list_of_ENGLISH_preprocessed_documents)
training_dataset = qt.load_dataset()
ctm = ZeroShotTM(input_size=len(qt.vocab), bert_input_size=512, n_components=50)
ctm.fit(training_dataset) # run the model
ctm.get_topics()As you cann see, the high level API to handle the text is pretty easy to use; text_for_bert should be used to pass to the model a list of documents that are not preprocessed. Instead, to text_for_bow you should pass the pre-processed text used to build the BoW.
Advanced Notes: in this way, SBERT can use all the information in the text to generate the representations.
Once you have trained the cross-lingual topic model, you can use this simple pipeline to predict the topics for documents in a different language (as long as this language is covered by distiluse-base-multilingual-cased).
list_of_SPANISH_documents = [
"hola, bienvenido",
]
qt = QuickText("distiluse-base-multilingual-cased",
text_for_bert=list_of_SPANISH_documents,
text_for_bow=list_of_SPANISH_documents)
testing_dataset = qt.load_dataset()
# n_sample how many times to sample the distribution (see the doc)
ctm.get_thetas(testing_dataset, n_samples=20) # returns a (n_documents, n_topics) matrix with the topic distribution of each documentAdvanced Notes: the bag of words of the two languages will not be comparable! We are passing it to the model for compatibility reason, but you cannot get the output of the model (i.e., the predicted BoW of the trained language) and compare it with the testing language one.
You can also create a word cloud of the topic!
ctm.get_wordcloud(topic_id=47, n_words=15)
Here is how you can use the CombinedTM. This is a standard topic model that also uses BERT.
from contextualized_topic_models.models.ctm import CombinedTM
from contextualized_topic_models.utils.data_preparation import QuickText
from contextualized_topic_models.utils.data_preparation import bert_embeddings_from_file
from contextualized_topic_models.datasets.dataset import CTMDataset
qt = QuickText("bert-base-nli-mean-tokens",
text_for_bert=list_of_unpreprocessed_documents,
text_for_bow=list_of_preprocessed_documents)
training_dataset = qt.load_dataset()
ctm = CombinedTM(input_size=len(qt.vocab), bert_input_size=768, n_components=50)
ctm.fit(training_dataset) # run the model
ctm.get_topics()
#ctm.get_thetas(testing_dataset, n_samples=20) # returns a (n_documents, n_topics) matrix with the topic distribution of each documentAdvanced Notes: Combined TM combines the BoW with SBERT, a process that seems to increase the coherence of the predicted topics (https://arxiv.org/pdf/2004.03974.pdf).
We have also included some of the metrics normally used in the evaluation of topic models, for example you can compute the coherence of your topics using NPMI using our simple and high-level API.
from contextualized_topic_models.evaluation.measures import CoherenceNPMI
with open('preprocessed_documents.txt',"r") as fr:
texts = [doc.split() for doc in fr.read().splitlines()] # load text for NPMI
npmi = CoherenceNPMI(texts=texts, topics=ctm.get_topic_lists(10))
npmi.score()Do you need a quick script to run the preprocessing pipeline? we got you covered! Load your documents and then use our SimplePreprocessing class. It will automatically filter infrequent words and remove documents that are empty after training. The preprocess method will return the preprocessed and the unpreprocessed documents. We generally use the unpreprocessed for BERT and the preprocessed for the Bag Of Word.
from contextualized_topic_models.utils.preprocessing import WhiteSpacePreprocessing
documents = [line.strip() for line in open("unpreprocessed_documents.txt").readlines()]
sp = WhiteSpacePreprocessing(documents)
preprocessed_documents, unpreprocessed_documents, vocab = sp.preprocess()- Federico Bianchi <[email protected]> Bocconi University
- Silvia Terragni <[email protected]> University of Milan-Bicocca
- Dirk Hovy <[email protected]> Bocconi University
If you use this in a research work please cite these papers:
ZeroShotTM
@article{bianchi2020crosslingual,
title={Cross-lingual Contextualized Topic Models with Zero-shot Learning},
author={Federico Bianchi and Silvia Terragni and Dirk Hovy and Debora Nozza and Elisabetta Fersini},
year={2020},
journal={arXiv preprint arXiv:2004.07737},
}
CombinedTM
@article{bianchi2020pretraining,
title={Pre-training is a Hot Topic: Contextualized Document Embeddings Improve Topic Coherence},
author={Federico Bianchi and Silvia Terragni and Dirk Hovy},
year={2020},
journal={arXiv preprint arXiv:2004.03974},
}
This package was created with Cookiecutter and the audreyr/cookiecutter-pypackage project template. To ease the use of the library we have also included the rbo package, all the rights reserved to the author of that package.
Remember that this is a research tool :)