{kind=link}
DeciDiffusion 1.0 is a diffusion-based text-to-image generation model. While it maintains foundational architecture elements from Stable Diffusion, such as the Variational Autoencoder (VAE) and CLIP's pre-trained Text Encoder, DeciDiffusion introduces significant enhancements. The primary innovation is the substitution of U-Net with the more efficient U-Net-NAS, a design pioneered by Deci. This novel component streamlines the model by reducing the number of parameters, leading to superior computational efficiency.
The domain of text-to-image generation, with its transformative potential in design, art, and advertising, has captivated both experts and laypeople. This technology’s allure lies in its ability to effortlessly transform text into vivid images, marking a significant leap in AI capabilities. While Stable Diffusion’s open-source foundation has spurred many advancements, it grapples with practical deployment challenges due to its heavy computational needs. These challenges lead to notable latency and cost concerns in training and deployment. In contrast, DeciDiffusion stands out. Its superior computational efficiency ensures a smoother user experience and boasts an impressive reduction of nearly 66% in production costs.
More details about model can be found in blog post and model card.
In this tutorial we consider how to convert and run DeciDiffusion using OpenVINO, making text-to-image generative applications more accessible and feasible.
It considers two approaches of image generation using an AI method called diffusion:
Text-to-imagegeneration to create images from a text description as input.Text-guided Image-to-Imagegeneration to create an image, using text description and initial image semantic.
The complete pipeline of this demo is shown below.
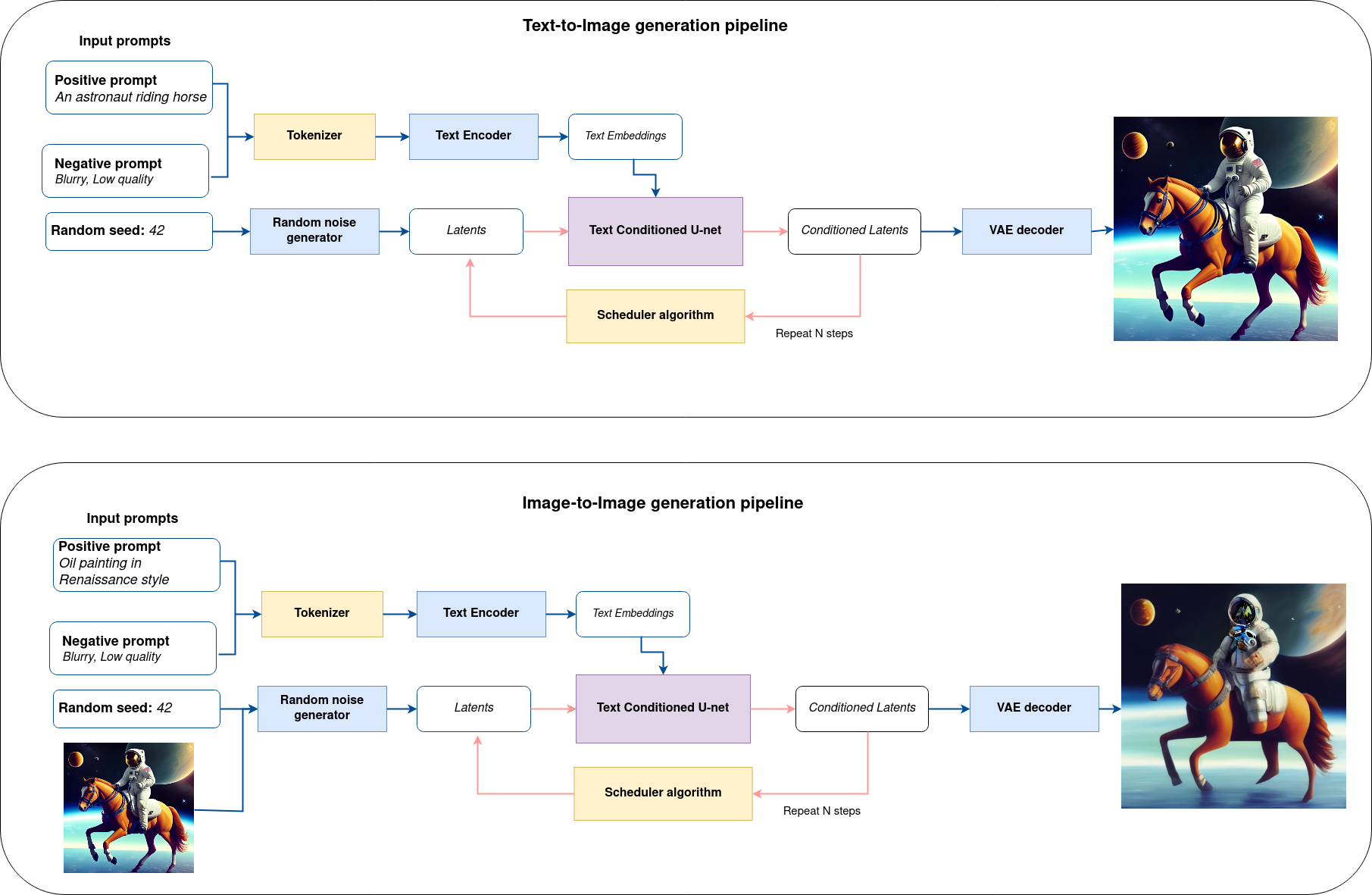
This is a demonstration in which you can type a text description (and provide input image in case of Image-to-Image generation) and the pipeline will generate an image that reflects the context of the input text. Step-by-step, the diffusion process will iteratively denoise latent image representation while being conditioned on the text embeddings provided by the text encoder.
The following image shows an example of the input sequence and corresponding predicted image.
Input text: Highly detailed realistic portrait of a grumpy small, adorable cat with round, expressive eyes

This notebook demonstrates how to convert and run DeciDiffusion using OpenVINO.
The notebook contains the following steps:
- Convert PyTorch models to OpenVINO Intermediate Representation using OpenVINO Converter Tool (OVC).
- Prepare Inference Pipeline.
- Run Inference pipeline with OpenVINO.
- Run Interactive demo for DeciDiffusion model
The notebook also provides interactive interface for image generation based on user input (text prompts and source image, if required).
Text-to-Image Generation Example

Image-to-Image Generation Example

This is a self-contained example that relies solely on its own code.
We recommend running the notebook in a virtual environment. You only need a Jupyter server to start.
For details, please refer to Installation Guide.