环境说明:
Python3.6Centos7.5Scrapy框架&简单py爬虫
已实现功能:
- 爬虫 Scrapy 爬取百度网盘搜索引擎数据
- 自动将百度网盘资源转存到自己网盘
- 支持无提取码 URL
- 支持有提取码 URL
待完成项:
- 优质代理 IP 池
- 百度网盘自动保存资源 提取码-验证码问题
- 暂不支持保存自己分享的资源
- 代码优化
文件说明:
- baiduyun_tools.py 自动转存百度云盘资料
- file 存放自动转存百度云盘 信息
- proxies_tools.py 自动生成代理文件
- Spiders 爬取百度网盘搜索引擎资源
- scrapy_mockplus_template Scrapy 爬虫,爬取 MockPlus 模板(待优化)
- Baiduyun
- 查询 网盘搜索引擎 上百度云盘资源
- 将云盘资源保存到百度网盘中
- MockPLus
- 自动获取 MockPlus 精美模板
scrapy startproject baidu
# 传递参数
scrapy crawl pansoso1 -a search_text=excel通用参数说明:
- mode 保存模式 append/override 建议 append
- search_text 搜索内容
- page 搜索页数
TODO override 存在 bug 后面覆盖前面的情况
网站资源一般,链接存在加密,存在访问过多时 IP 封锁.
网站链接: 网盘资源 www.pansoso.com
# 项目命令
scrapy crawl pansoso01 -a search_text=excel
scrapy crawl pansoso02
scrapy crawl pansoso03说明:
- 搜百度盘 网站简单,适合练手
- 但是资源基本(99%)都是无效资源,无过多反爬虫机制.
- 不建议使用此网站
# 项目命令
scrapy crawl sobaidupan01 -a search_text=excel -a page=1000
scrapy crawl sobaidupan02网站链接: 网盘资源 www.sobaidupan.com
说明:
- 大多资源有效,且网站存在资源校验机制.
- 资源分为无提取码和有提取码两种.
- 资源文件都较大,且命名不规范,或非实际所需文件
- 反爬虫机制
- 延迟加载(提取码 & 提取码是否有效)
- 解决方法: 使用 selenium(浏览器处理)
- 延迟加载(提取码 & 提取码是否有效)
网站链接: 网盘资源 www.dashengpan.com
# 项目命令
scrapy crawl dashengpan01 -a mode=append -a search_text=excel -a page=1
scrapy crawl dashengpan02 -a mode=append # 需要在有UI界面的地方执行项目详细说明:
- 支持功能
- 自动将 文件中 URL 保存到百度网盘中
- 支持有提取码和无提取码格式
- 对资源保存情况有整体说明等
- TODO 暂不支持
- 根据用户名称和密码自动登录获取 Cookie
- 部分资源有提取码时仍需要验证码,暂不支持
- 其他说明:
- 使用 Linux 测试,Windows 未测试
- 附件说明
file/badidu_result.txt存放百度云资料file/success.txt存放保存成功的资源file/failed.txt存放保存失败的资源
使用样例:
# 将网盘资源保存到百度网盘
python baiduyun_tools.py -filename xxxxx -cookie xxxxx -path xxxx
# 输出说明
success.txt 记录成功运行的 URL, 下次运行时不会在运行此中URL
failed.txt 记录失败的URL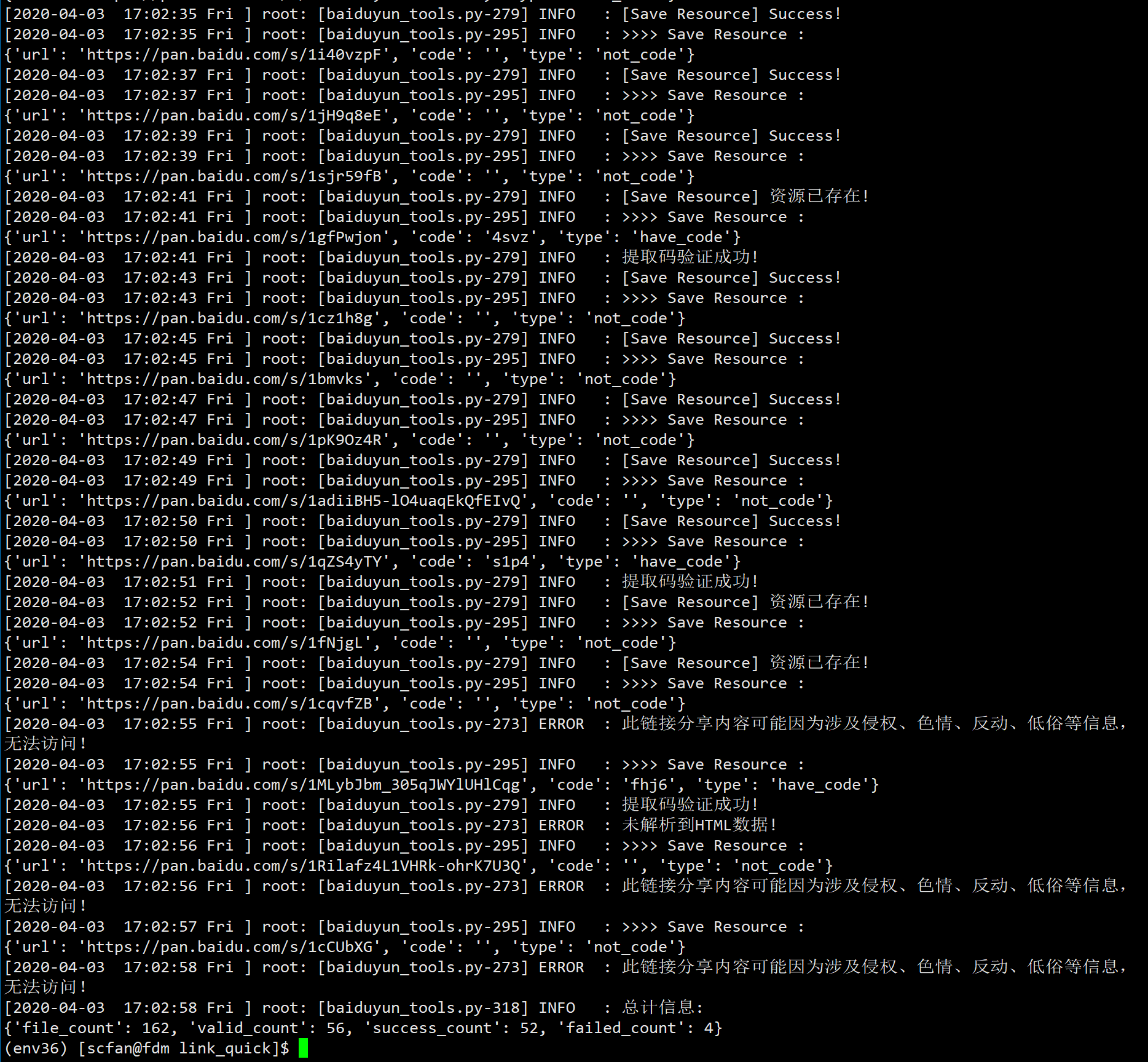
- 非商业用途.
- 如有侵犯您的合法权益或违法违规,请提供相关有效书面证明与侵权页面链接联系我们进行删除。感谢您的支持