Math类定义了一个简单的方法我们从这里开始
package com.jvm.memory.testStack;
import com.jvm.memory.controller.User;
public class Math {
public static int initData = 666 ;
public static User user = new User();
//每一个方法对应一块单独的栈针内存区域
public int compute(){
int a=1;
int b=1;
int c = (a+b) *10;
return c;
}
//比如main 方法执行的时候就会单独为main方法开辟出一块内存区域
public static void main(String[] args) {
Math math = new Math();
math.compute();
}
}
用javap -c math.class 反编译成我们可以看懂的语言
Compiled from "Math.java"
public class com.jvm.memory.testStack.Math {
public static int initData;
public static com.jvm.memory.controller.User user;
public com.jvm.memory.testStack.Math();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
public int compute();
Code:
行号 0: iconst_1 //讲int 类型的常量1 压入操作数栈
1: istore_1 //将int 类型的值存入局部变量1
2: iconst_1
3: istore_2
4: iload_1 //从局部变量1中装载int 类型的值
5: iload_2
6: iadd
7: bipush 10
9: imul 乘法
10: istore_3
11: iload_3
12: ireturn
public static void main(java.lang.String[]);
Code:
0: new #2 // class com/jvm/memory/testStack/Math
3: dup
4: invokespecial #3 // Method "<init>":()V
7: astore_1
8: aload_1
9: invokevirtual #4 // Method compute:()I
12: pop
13: return
static {};
Code:
0: sipush 666
3: putstatic #5 // Field initData:I
6: new #6 // class com/jvm/memory/controller/User
9: dup
10: invokespecial #7 // Method com/jvm/memory/controller/User."<init>":()V
13: putstatic #8 // Field user:Lcom/jvm/memory/controller/User;
16: return
}
这个就是反编后程序的栈运行机制
大致流程如下:

类元信息 ---- 类的组成部分
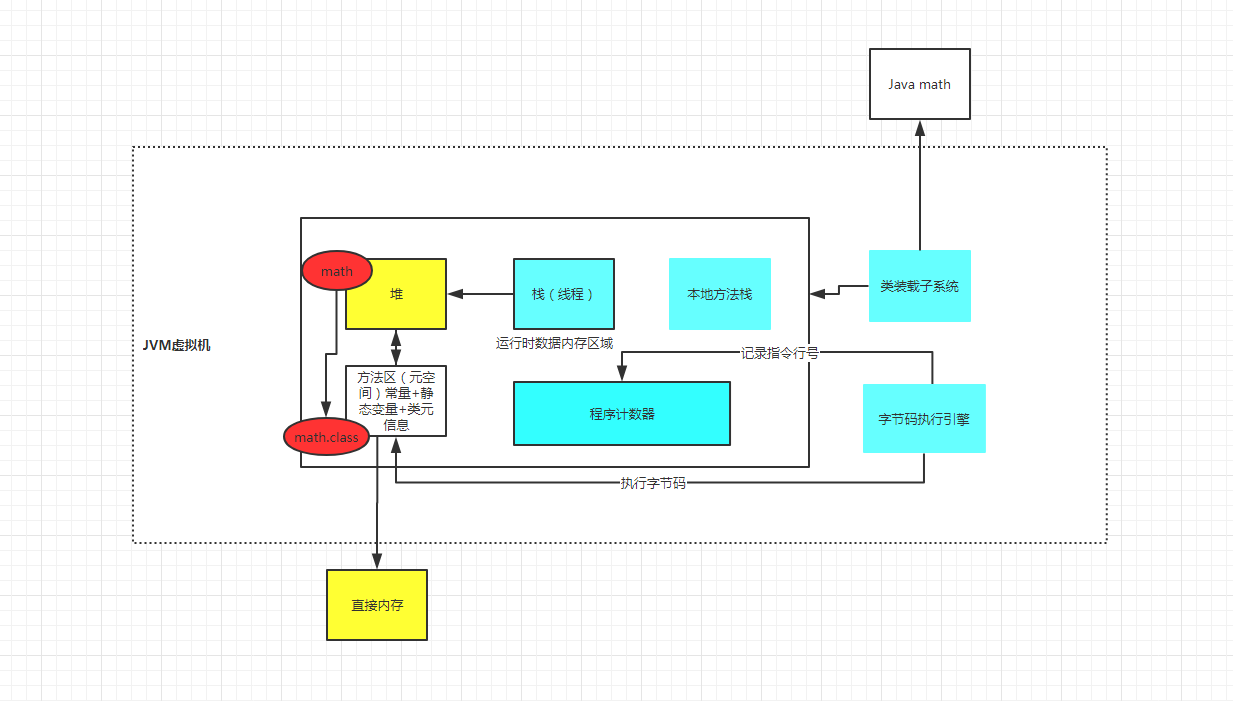
整体结构如下都属于jvm虚拟机范畴 如果静态变量是一个对象那么就需要一个指针指向堆
JVM -Xss 128k -Xss默认1M
StackOverFlowTest 模拟了栈内存溢出问题
这个适合你设置的分配内存有关系 -Xss设置越小count值越小,说明一个线程栈里能分配的栈帧就越少,但是对JVM整体来说能开启的线程数会更多 循环的次数变为栈的深度大概是多少
类的组成部分(比如方法头 (), 变量等等)你都可以把它当作符号 在类装载的时候有一个把符号引用转变成直接引用 最开始的时候是把这些符号都放在了常量池里面 可以用javap -v math.class 观察 动态链接就是在程序运行期间解析你调用的方法将符号引用替换为直接引用
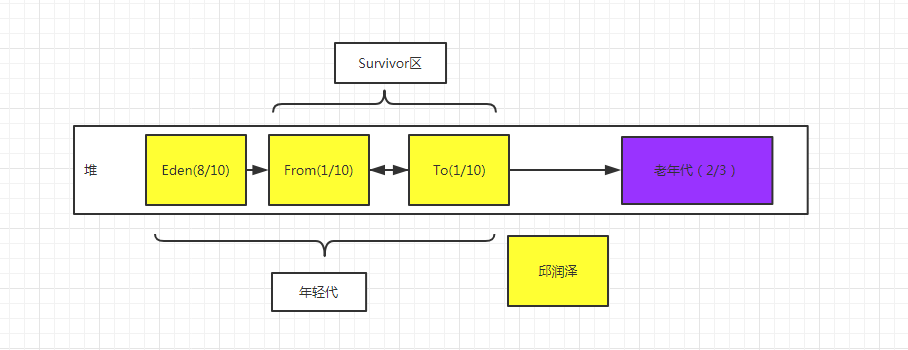
我们给堆初始化的大小为600M 那么我们我们就会大概给老年代分配400m 那么给年轻代就会分配200m
200m 就会 变为 eden 为 160m survivor 为 40m 当eden区放满了的时候就会从出发一次
yong gc 回收没有引用的对象那么 剩余存活的对象就会 跑到 survivor 区域 继续new 对象出来
当eden 区域继续放慢又会出发yonggc 那么这次我们的yonggc 就会把from 区域一起回收
最后把无效的对象收集完那么就会把剩余的放到To区域里面 当eden 再次放满那么这次回收的是
eden + To区域 之后把 存活的对象放在 from 区域 这个循环的过程 分代年龄经过15次还没被回收那么就会
放在老年代 当老年代放满就会full gc 当老年代放满 但是对象都没法回收 那么只能发生oom内存溢出
JVM对象运行模式一般来说有三种:
1.解释模式:只使用解释器(-Xint 强制JVM使用解释模式) 执行一行JVM字节码就编译一行机器码
2.变异模式:只使用编译器(-Xcomp jvm使用编译模式)现将所有的JVM字节码一次编译为机器码然后一次性执行所有机器码
3.混合模式:依然使用解释模式执行代码 但是对于一些热点的代码采用编译模式执行 JVM一般采用混合模式执行代码
解释模式启动快,对于只需要执行部分代码,并且大多数代码只会执行一次的情况比较适合;编译模式启动慢,但是后期执行速度快,而
且比较占用内存,因为机器码的数量至少是JVM字节码的十倍以上,这种模式适合代码可能会被反复执行的场景;混合模式是JVM默认采
用的执行代码方式,一开始还是解释执行,但是对于少部分 “热点 ”代码会采用编译模式执行,这些热点代码对应的机器码会被缓存起
来,下次再执行无需再编译,这就是我们常见的JIT(Just In Time Compiler)即时编译技术。
在即时编译过程中JVM可能会对我们的代码最一些优化,比如对象逃逸分析等
对象逃逸分析:就是分析对象动态作用域,当一个对象在方法中被定义后,它可能被外部方法所引用,例如作为调用参数传递到其他地方中
public User test1() {
User user = new User();
user.setId(1);
user.setName("zhuge");
//TODO 保存到数据库
return user;
}
public void test2() {
User user = new User();
user.setId(1);
user.setName("zhuge");
//TODO 保存到数据库
}
很显然test1方法中的user对象被返回了,这个对象的作用域范围不确定,test2方法中的user对象我们可以确定当方法结束这个对象就可
以认为是无效对象了,对于这样的对象我们其实可以将其分配的栈内存里,让其在方法结束时跟随栈内存一起被回收掉。
JVM对于这种情况可以通过开启逃逸分析参数(-XX:+DoEscapeAnalysis)来优化对象内存分配位置,JDK7之后默认开启逃逸分析,如果要
关闭使用参数(-XX:-DoEscapeAnalysis)