diff --git a/docs/_quarto.yml b/docs/_quarto.yml
index 816a442..aae7965 100644
--- a/docs/_quarto.yml
+++ b/docs/_quarto.yml
@@ -293,15 +293,33 @@ website:
href: notes/predictive-modeling/regression/ols.qmd
text: "Linear Regression w/ statsmodels"
- section:
- href: notes/predictive-modeling/regression/time-series-forecasting.qmd
- text: "Time Series Forecasting"
+ href: notes/predictive-modeling/regression/multiple-features.qmd
+ text: "Regression with Multiple Features"
+
+ - section:
+ href: notes/predictive-modeling/time-series-forecasting/index.qmd
+ text: "Regression for Time-series Forecasting"
+ contents:
- section:
- href: notes/predictive-modeling/regression/seasonality.qmd
+ href: notes/predictive-modeling/time-series-forecasting/polynomial.qmd
+ text: "Polynomial Features"
+ - section:
+ href: notes/predictive-modeling/time-series-forecasting/seasonality.qmd
text: "Seasonality Analysis"
- section:
- href: notes/predictive-modeling/regression/autoregressive-models.qmd
- text: "Autoregressive Models"
+ href: notes/predictive-modeling/autoregressive-models/index.qmd
+ text: "Autoregressive Models for Time-series Forecasting"
+ contents:
+ - section:
+ href: notes/predictive-modeling/autoregressive-models/stationarity.qmd
+ text: "Stationarity"
+ - section:
+ href: notes/predictive-modeling/autoregressive-models/autocorrelation.qmd
+ text: "Autocorrelation"
+ - section:
+ href: notes/predictive-modeling/autoregressive-models/arima.qmd
+ text: "Autoregressive Models w/ statsmodels"
- section:
href: notes/predictive-modeling/classification/index.qmd
@@ -356,6 +374,12 @@ website:
- section:
text: "Financial Data Sources"
contents:
+ - section:
+ href: notes/financial-data-sources/yfinance.qmd
+ text: "Y-Finance"
+ - section:
+ href: notes/financial-data-sources/yahooquery.qmd
+ text: "Yahoo Query"
- section:
href: notes/financial-data-sources/pandas-datareader.qmd
text: "Pandas Datareader"
diff --git a/docs/data/baseball_data.xlsx b/docs/data/baseball_data.xlsx
new file mode 100644
index 0000000..c11c336
Binary files /dev/null and b/docs/data/baseball_data.xlsx differ
diff --git a/docs/images/quadratic-equation.svg b/docs/images/quadratic-equation.svg
new file mode 100644
index 0000000..06bcf24
--- /dev/null
+++ b/docs/images/quadratic-equation.svg
@@ -0,0 +1 @@
+
\ No newline at end of file
diff --git a/docs/images/regression-formula.svg b/docs/images/regression-formula.svg
new file mode 100644
index 0000000..a159704
--- /dev/null
+++ b/docs/images/regression-formula.svg
@@ -0,0 +1 @@
+
\ No newline at end of file
diff --git a/docs/images/stationary-data-variance.webp b/docs/images/stationary-data-variance.webp
new file mode 100644
index 0000000..0c3474b
Binary files /dev/null and b/docs/images/stationary-data-variance.webp differ
diff --git a/docs/images/stationary-data.png b/docs/images/stationary-data.png
new file mode 100644
index 0000000..bf95782
Binary files /dev/null and b/docs/images/stationary-data.png differ
diff --git a/docs/notes/financial-data-sources/yahooquery.qmd b/docs/notes/financial-data-sources/yahooquery.qmd
new file mode 100644
index 0000000..b2c16e4
--- /dev/null
+++ b/docs/notes/financial-data-sources/yahooquery.qmd
@@ -0,0 +1 @@
+# The `yahooquery` Package
diff --git a/docs/notes/financial-data-sources/yfinance.qmd b/docs/notes/financial-data-sources/yfinance.qmd
new file mode 100644
index 0000000..1cb0152
--- /dev/null
+++ b/docs/notes/financial-data-sources/yfinance.qmd
@@ -0,0 +1,11 @@
+# The `yfinance` Pacakge
+
+Fetching data from Yahoo Finance:
+
+```{python}
+import yfinance as yf
+
+ticker = "NVDA"
+df = yf.download(ticker, start="2014-01-01", end="2024-01-01")
+df
+```
diff --git a/docs/notes/predictive-modeling/autoregressive-models/arima.qmd b/docs/notes/predictive-modeling/autoregressive-models/arima.qmd
new file mode 100644
index 0000000..721b900
--- /dev/null
+++ b/docs/notes/predictive-modeling/autoregressive-models/arima.qmd
@@ -0,0 +1,27 @@
+# Autocorrelation and Auto-Regressive Models
+
+Learning Objectives:
+
+ + Compute autocorrelation in Python using the statsmodels package
+ + Use autocorrelation to identify how many periods to use when training an ARMA model
+ + Train ARMA model in Python using the statsmodels package, to predict future values given past values.
+ + Understand the ARMA model assumption of stationary data.
+ + Remember that when making predictions using a trained ARMA model, the dates to predict have to match the format of the training dates. so if the model is trained on monthly data starting at the beginning of the month, we have to predict for dates at the beginning of future months. if the data is trained on quarterly data at the end of the quarter, we have to predict for dates at the end of future quarters.
+
+## Stationary Data
+
+what it means for data to be stationary - the mean does not move over time.
+
+
+for example:
+
+stock prices would probably not be stationary, however stock returns could be.
+
+gdp might not be stationary, however gdp growth could be.
+
+
+## Autocorrelation
+
+
+
+## Auto-Regressive Moving Average (ARMA)
diff --git a/docs/notes/predictive-modeling/autoregressive-models/autocorrelation.qmd b/docs/notes/predictive-modeling/autoregressive-models/autocorrelation.qmd
new file mode 100644
index 0000000..11e09ff
--- /dev/null
+++ b/docs/notes/predictive-modeling/autoregressive-models/autocorrelation.qmd
@@ -0,0 +1,29 @@
+# Autocorrelation
+
+**Autocorrelation** is a statistical concept that measures the relationship between a variable's current value and its past values over successive time intervals.
+
+In time series analysis, autocorrelation helps identify patterns and dependencies in data, particularly when dealing with sequences of observations over time, such as stock prices, temperature data, or sales figures. Autocorrelation analysis is helpful for detecting trends, periodicities, and other temporal patterns in the data, as well as for developing predictive models.
+
+## Interpreting Autocorrelation
+
+Similar to correlation, autocorrelation will range in values from -1 to 1. A positive autocorrelation indicates that a value tends to be similar to preceding values, while a negative autocorrelation suggests that a value is likely to differ from previous observations.
+
+ + **Strong Positive Autocorrelation**: A high positive autocorrelation at a particular lag (close to +1) indicates that past values strongly influence future values at that lag. This could mean that the series has a strong trend or persistent behavior, where high values are followed by high values and low values by low ones.
+
+ + **Strong Negative Autocorrelation**: A strong negative autocorrelation (close to -1) suggests an oscillatory pattern, where high values tend to be followed by low values and vice versa.
+
+ + **Weak Autocorrelation**: If the ACF value is close to zero for a particular lag, it suggests that the time series does not exhibit a strong linear relationship with its past values at that lag. This can indicate that the observations at that lag are not predictive of future values.
+
+## Uses for Predictive Modeling
+
+In predictive modeling, especially for time series forecasting, autocorrelation is essential for selecting the number of lagged observations (or lags) to use in autoregressive models. By calculating the autocorrelation for different lag intervals, it is possible to determine how much influence past values have on future ones. This process helps us choose the optimal lag length, which in turn can improve the accuracy of forecasts.
+
+## Calculating Autocorrelation in Python
+
+In Python, we can calculate autocorrelation using the [`acf` function](https://www.statsmodels.org/stable/generated/statsmodels.tsa.stattools.acf.html) from `statsmodels. The autocorrelation function (ACF) calculates the correlation of a time series with its lagged values, providing a guide to the structure of dependencies within the data.
+
+## Examples of Autocorrelation
+
+### Autocorrelation of Random Data
+
+### Autocorrelation of Baseball Team Performance
diff --git a/docs/notes/predictive-modeling/autoregressive-models/index.qmd b/docs/notes/predictive-modeling/autoregressive-models/index.qmd
new file mode 100644
index 0000000..2f4257f
--- /dev/null
+++ b/docs/notes/predictive-modeling/autoregressive-models/index.qmd
@@ -0,0 +1 @@
+# Autoregressive Models
diff --git a/docs/notes/predictive-modeling/autoregressive-models/stationarity.qmd b/docs/notes/predictive-modeling/autoregressive-models/stationarity.qmd
new file mode 100644
index 0000000..5537680
--- /dev/null
+++ b/docs/notes/predictive-modeling/autoregressive-models/stationarity.qmd
@@ -0,0 +1,78 @@
+# Stationarity in Time Series Data
+
+
+A **stationary** time series is one whose statistical properties, such as mean, variance, and autocorrelation, do not change over time. In other words, the data fluctuates around a constant mean and has constant variance.
+
+Stationarity ensures that the underlying process generating the data remains stable over time, which is crucial for building predictive models on time series data.
+
+## Types of Stationarity
+
+
+1. **Strict Stationarity**: The distribution of the time series does not change over time. This is quite strict, and rarely occurs in real-world data.
+2. **Weak Stationarity (or Second-Order Stationarity)**: This is the most common type and only requires the mean, variance, and autocorrelation to be constant over time.
+
+
+
+In the first example, we examine whether the mean is stationary:
+
+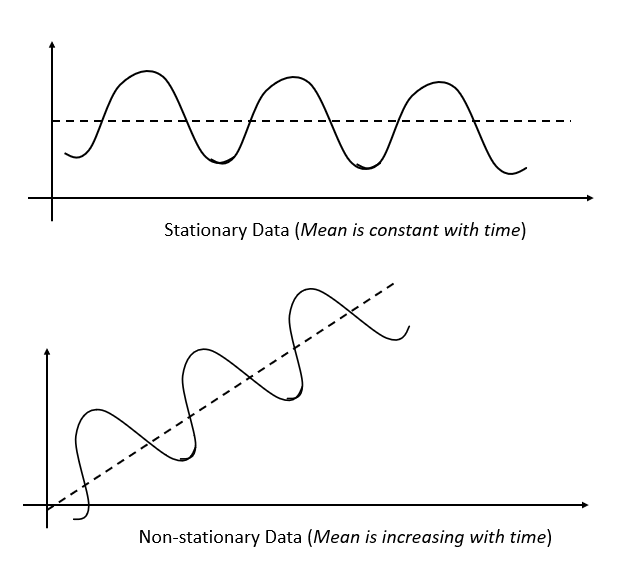.](../../../images/stationary-data.png)
+
+In the second example, we examine whether the standard deviation is stationary:
+
+.](../../../images/stationary-data-variance.webp)
+
+
+
+
+## Why Does Stationarity Matter?
+
+In time series analysis, stationarity is a key assumption that greatly influences our choice of which models to use.
+
+ + For **Linear Regression** models: while linear regression does not explicitly require stationarity in the data, regression models generally work better with stationary data, particularly if the relationship between the features and the target is assumed to be stable over time.
+
+ + For **ARIMA (Autoregressive Integrated Moving Average)** modesl: ARIMA models require the data to be stationary. If the time series is not stationary, the model's assumptions break down, and it will not perform well. The "Integrated (I)" part specifically deals with non-stationarity by differencing the data (i.e. subtracting the previous observation from the current one) to make it stationary.
+
+## Testing for Stationarity
+
+Here are some common ways to test for stationarity in time series data:
+
+1. **Visual Inspection**: Plot the Data: Plotting the time series can often give a good idea of whether the data is stationary. Look for consistent variance, a constant mean, and no obvious trend or seasonality over time.
+
+2. **Augmented Dickey-Fuller (ADF) Test**: The ADF test is a statistical test where the null hypothesis is that the data has a unit root (i.e. is non-stationary). If the p-value is below a certain threshold (e.g. 0.05), we can reject the null hypothesis, indicating that the series is stationary.
+
+```python
+from statsmodels.tsa.stattools import adfuller
+
+result = adfuller(time_series)
+print(f"ADF Statistic: {result[0]}")
+print(f"P-value: {result[1]}")
+```
+
+3. **KPSS Test** (Kwiatkowski-Phillips-Schmidt-Shin): the KPSS test is another test for stationarity, but its null hypothesis is the opposite of the ADF test. In KPSS, the null hypothesis is that the series is stationary. A low p-value indicates non-stationarity.
+
+```python
+from statsmodels.tsa.stattools import kpss
+
+result = kpss(time_series)
+print(f"KPSS Statistic: {result[0]}")
+print(f"P-value: {result[1]}")
+```
+
+4. **Rolling Statistics**: another simple method is to calculate the rolling mean and variance over time. If these values change significantly over time, the series is likely non-stationary.
+
+```python
+rolling_mean = time_series.rolling(window=12).mean()
+rolling_std = time_series.rolling(window=12).std()
+```
+
+### Transformations to Achieve Stationarity
+
+If your data is non-stationary, here are a few common techniques to make it stationary:
+
+1. **Differencing**: Subtracting the previous value from the current value to remove trends.
+
+2. **Logarithmic Transformation**: Taking the logarithm of the data can help stabilize variance.
+
+3. **De-trending**: Remove trends either by subtracting a moving average, or fitting a regression model and subtracting the predicted trend.
+
+4. **Seasonal Decomposition**: If there's seasonality, we can decompose the time series into trend, seasonality, and residual components and work with the residuals.
diff --git a/docs/notes/predictive-modeling/ml-foundations/generalization.ipynb b/docs/notes/predictive-modeling/ml-foundations/generalization.ipynb
index f6b27d8..98cc8f1 100644
--- a/docs/notes/predictive-modeling/ml-foundations/generalization.ipynb
+++ b/docs/notes/predictive-modeling/ml-foundations/generalization.ipynb
@@ -23,7 +23,7 @@
"\n",
"Common causes of overfitting include:\n",
"\n",
- " + Using a model that is too complex for the given data (e.g., deep neural networks on small datasets).\n",
+ " + Using a model that is too complex for the given data (e.g. deep neural networks on small datasets).\n",
" + Training the model for too long without proper regularization.\n",
" + Using too many features or irrelevant features.\n",
"\n",
@@ -41,7 +41,7 @@
"\n",
"Common causes of underfitting include:\n",
"\n",
- " + Using a model that is too simple for the task at hand (e.g., linear regression for non-linear data).\n",
+ " + Using a model that is too simple for the task at hand (e.g. linear regression for non-linear data).\n",
" + Not training the model long enough or with sufficient data.\n",
" + Using too few features or ignoring important features.\n",
"\n",
@@ -103,7 +103,7 @@
".](../../../images/k-fold-cross-validation.png)\n",
"\n",
"\n",
- "The dataset is divided into several folds (commonly called **K-fold cross-validation**), and the model is trained and validated on different subsets of the data in each iteration. This provides a more comprehensive understanding of the model’s performance across various data splits, making it less sensitive to any specific partitioning.\n",
+ "The dataset is divided into several folds (commonly called **K-fold cross-validation**), and the model is trained and validated on different subsets of the data in each iteration. This provides a more comprehensive understanding of the model's performance across various data splits, making it less sensitive to any specific partitioning.\n",
"\n",
"\n",
"Cross validation is especially valuable when fine-tuning model hyperparameters, as it prevents overfitting to a specific validation set or the test set by providing a more generalized evaluation before the final test set assessment.\n",
@@ -151,7 +151,7 @@
"\n",
" + **Unreliable Performance Metrics**: If the model is trained on future data, performance metrics like accuracy or RMSE will be unrealistically high, but once deployed, the model's performance will significantly degrade as it won't have access to future data in a real-time scenario.\n",
"\n",
- "In short, shuffling time series data before splitting leads to unrealistic results and invalidates the model's ability to generalize properly. The correct approach is to split based on time (e.g., using methods like time-based cross-validation or time series splits), ensuring that the training set only contains past data relative to the test set.\n"
+ "In short, shuffling time series data before splitting leads to unrealistic results and invalidates the model's ability to generalize properly. The correct approach is to split based on time (e.g. using methods like time-based cross-validation or time series splits), ensuring that the training set only contains past data relative to the test set.\n"
],
"id": "b1afba72"
},
@@ -186,4 +186,4 @@
},
"nbformat": 4,
"nbformat_minor": 5
-}
\ No newline at end of file
+}
diff --git a/docs/notes/predictive-modeling/ml-foundations/generalization.qmd b/docs/notes/predictive-modeling/ml-foundations/generalization.qmd
index 2b6cdf9..8d47bdb 100644
--- a/docs/notes/predictive-modeling/ml-foundations/generalization.qmd
+++ b/docs/notes/predictive-modeling/ml-foundations/generalization.qmd
@@ -106,7 +106,7 @@ With **cross validation**, instead of relying on a single training or validation
.](../../../images/k-fold-cross-validation.png)
-The dataset is divided into several folds (commonly called **K-fold cross-validation**), and the model is trained and validated on different subsets of the data in each iteration. This provides a more comprehensive understanding of the model’s performance across various data splits, making it less sensitive to any specific partitioning.
+The dataset is divided into several folds (commonly called **K-fold cross-validation**), and the model is trained and validated on different subsets of the data in each iteration. This provides a more comprehensive understanding of the model's performance across various data splits, making it less sensitive to any specific partitioning.
Cross validation is especially valuable when fine-tuning model hyperparameters, as it prevents overfitting to a specific validation set or the test set by providing a more generalized evaluation before the final test set assessment.
@@ -163,16 +163,57 @@ Instead of shuffling, we can split based on time, using methods like time series
To implement a sequential split, assuming your data is sorted by date in ascending order, pick a cutoff date, and use all samples before the cutoff in the training set, and samples after the cutoff date in the test set. This ensures the model can't rely on data from the future when making predictions for the test set.
```python
-print(len(df))
-
training_size = round(len(df) * .8)
-print(training_size)
x_train = x.iloc[:training_size] # all before cutoff
y_train = y.iloc[:training_size] # all before cutoff
x_test = x.iloc[training_size:] # all after cutoff
y_test = y.iloc[training_size:] # all after cutoff
-print("TRAIN:", x_train.shape)
-print("TEST:", x_test.shape)
+
+print("TRAIN:", x_train.shape, y_train.shape)
+print("TEST:", x_test.shape, y_test.shape)
+```
+
+Helper function:
+
+```python
+def sequential_split(df, training_size=0.8, test_size=None):
+ """Splits x and y sequentially, for time-series data.
+ Assumes data is already sorted by date in ascending order.
+ Assumes x is same size as y.
+ Calculates a cutoff based on the desired training or test size.
+ Gives training set as all datapoints before the cutoff,
+ and test set as all datapoints after the cutoff.
+
+ Args:
+ x (DataFrame): X values to be split.
+
+ y (Series): Y values to be split.
+
+ training_size (float, optional): The proportion of the data to use for training.
+ Defaults to 0.8.
+
+ test_size (float, optional): The proportion of the data to use for testing.
+ If provided, it overrides `training_size`. Should be between 0 and 1.
+
+ """
+ if test_size:
+ training_size = 1 - test_size
+
+ assert len(x) == len(y)
+ cutoff = round(len(x) * training_size)
+
+ x_train = x.iloc[:cutoff] # all before cutoff
+ y_train = y.iloc[:cutoff] # all before cutoff
+
+ x_test = x.iloc[cutoff:] # all after cutoff
+ y_test = y.iloc[cutoff:] # all after cutoff
+
+ return x_train, x_test, y_train, y_test
+
+
+x_train, x_test, y_train, y_test = sequential_split(x, y, test_size=.2)
+print("TRAIN:", x_train.shape, y_train.shape)
+print("TEST:", x_test.shape, y_test.shape)
```
diff --git a/docs/notes/predictive-modeling/ml-foundations/index.qmd b/docs/notes/predictive-modeling/ml-foundations/index.qmd
index 32933b2..0841d2e 100644
--- a/docs/notes/predictive-modeling/ml-foundations/index.qmd
+++ b/docs/notes/predictive-modeling/ml-foundations/index.qmd
@@ -72,7 +72,7 @@ Machine learning problem formulation refers to the process of clearly defining t
+ Identifying Features and Labels: Specifying the input variables (features) that the model will use to make predictions and, in the case of supervised learning, the corresponding output or target variable (label) that the model should predict.
- + Data Availability and Quality: Assessing what data is available, its format, and whether it’s sufficient for training a model. Good data is key, as noisy or incomplete data can lead to poor model performance.
+ + Data Availability and Quality: Assessing what data is available, its format, and whether it's sufficient for training a model. Good data is key, as noisy or incomplete data can lead to poor model performance.
+ Evaluation Metrics: Establishing how the model's success will be measured. This could involve metrics like accuracy, precision, recall for classification problems, or r-squared or mean squared error for regression problems.
diff --git a/docs/notes/predictive-modeling/model-management/deploying.qmd b/docs/notes/predictive-modeling/model-management/deploying.qmd
index b9b6524..25fefa2 100644
--- a/docs/notes/predictive-modeling/model-management/deploying.qmd
+++ b/docs/notes/predictive-modeling/model-management/deploying.qmd
@@ -55,7 +55,7 @@ In these situations where saving it locally may consume significant disk space,
- Cloud storage requires a stable internet connection. If connectivity is slow or unreliable, accessing or saving the model could be problematic.
4. **Security Risks**:
- - While cloud providers offer strong security features, there is always a risk of data breaches or misconfigurations (e.g., incorrect access permissions), potentially exposing sensitive models.
+ - While cloud providers offer strong security features, there is always a risk of data breaches or misconfigurations (e.g. incorrect access permissions), potentially exposing sensitive models.
### When to Use Cloud Storage
diff --git a/docs/notes/predictive-modeling/regression/autoregressive-models.qmd b/docs/notes/predictive-modeling/regression/autoregressive-models.qmd
deleted file mode 100644
index 7f45a80..0000000
--- a/docs/notes/predictive-modeling/regression/autoregressive-models.qmd
+++ /dev/null
@@ -1,5 +0,0 @@
-# Autocorrelation and Auto-Regressive Models
-
-## Autocorrelation
-
-## Auto-Regressive Models
diff --git a/docs/notes/predictive-modeling/regression/multiple-features.qmd b/docs/notes/predictive-modeling/regression/multiple-features.qmd
new file mode 100644
index 0000000..606d1ac
--- /dev/null
+++ b/docs/notes/predictive-modeling/regression/multiple-features.qmd
@@ -0,0 +1 @@
+# Regression with Multiple Features
diff --git a/docs/notes/predictive-modeling/regression/ols.qmd b/docs/notes/predictive-modeling/regression/ols.qmd
index 1cbba1f..0cbe001 100644
--- a/docs/notes/predictive-modeling/regression/ols.qmd
+++ b/docs/notes/predictive-modeling/regression/ols.qmd
@@ -220,8 +220,8 @@ When we use the `summary_frame` method on prediction results, it returns a `Data
What's the difference between confidence and prediction intervals?
-- **Confidence Interval** (`mean_ci_lower` and `mean_ci_upper`): Represents the range in which the true mean prediction is likely to lie. For predicting the *average* value (e.g., "the average apple weight is between 140 and 160 grams").
-- **Prediction Interval** (`obs_ci_lower` and `obs_ci_upper`): Represents the range in which an individual new observation is likely to lie. For predicting the range where *individual* values could fall (e.g., "an individual apple might weigh between 120 and 180 grams").
+- **Confidence Interval** (`mean_ci_lower` and `mean_ci_upper`): Represents the range in which the true mean prediction is likely to lie. For predicting the *average* value (e.g. "the average apple weight is between 140 and 160 grams").
+- **Prediction Interval** (`obs_ci_lower` and `obs_ci_upper`): Represents the range in which an individual new observation is likely to lie. For predicting the range where *individual* values could fall (e.g. "an individual apple might weigh between 120 and 180 grams").
diff --git a/docs/notes/predictive-modeling/supervised-learning.qmd b/docs/notes/predictive-modeling/supervised-learning.qmd
index 163fe16..ed4db84 100644
--- a/docs/notes/predictive-modeling/supervised-learning.qmd
+++ b/docs/notes/predictive-modeling/supervised-learning.qmd
@@ -4,7 +4,7 @@
## Supervised Learning Tasks
-**Regression**: Used when the target variable is continuous (e.g., predicting house prices or stock market returns).
+**Regression**: Used when the target variable is continuous (e.g. predicting house prices or stock market returns).
**Regression**: when the target variable we wish to predict is continuous - usually numeric.
@@ -16,7 +16,7 @@ Examples:
+ Distance to the Nearest Galaxy (in light years)
-**Classification**: Used when the target variable is categorical (e.g., determining whether a transaction is fraudulent or not).
+**Classification**: Used when the target variable is categorical (e.g. determining whether a transaction is fraudulent or not).
**Classification**: when the target variable we wish to predict is discrete - usually binary or categorical.
diff --git a/docs/notes/predictive-modeling/regression/time-series-forecasting.qmd b/docs/notes/predictive-modeling/time-series-forecasting/index.qmd
similarity index 99%
rename from docs/notes/predictive-modeling/regression/time-series-forecasting.qmd
rename to docs/notes/predictive-modeling/time-series-forecasting/index.qmd
index 29bfd8d..c45bd45 100644
--- a/docs/notes/predictive-modeling/regression/time-series-forecasting.qmd
+++ b/docs/notes/predictive-modeling/time-series-forecasting/index.qmd
@@ -1,6 +1,5 @@
# Regression for Time Series Forecasting (with `sklearn`)
-
Let's explore an example of how to use regression to perform trend analysis with time series data.
```{python}
@@ -104,7 +103,7 @@ Splitting into training vs testing datasets:
#print("TEST:", x_test.shape, y_test.shape)
```
-Splitting data sequentially where earlier data is used in training and recent data is use for testing:
+Splitting data sequentially where earlier data is used in training and recent data is used for testing:
```{python}
print(len(df))
diff --git a/docs/notes/predictive-modeling/time-series-forecasting/polynomial.qmd b/docs/notes/predictive-modeling/time-series-forecasting/polynomial.qmd
new file mode 100644
index 0000000..daaa085
--- /dev/null
+++ b/docs/notes/predictive-modeling/time-series-forecasting/polynomial.qmd
@@ -0,0 +1,20 @@
+# Regression with Polynomial Features for Time Series Forecasting
+
+
+
+## Linear Regression
+
+
+
+
+Results and Interpretation:
+
+Train R-squared: 0.85
+
+This indicates that the linear regression model explains about 85% of the variance in the GDP data during the training period. It suggests that the model fits the training data reasonably well.
+
+A negative R-squared score on the test set means that the model performs poorly on future data, doing worse than a simple horizontal line (mean prediction). This is a clear indication that the linear regression model is not capturing the temporal patterns in the GDP data and fails to generalize beyond the training period.
+
+
+
+## Polynomial
diff --git a/docs/notes/predictive-modeling/regression/seasonality.qmd b/docs/notes/predictive-modeling/time-series-forecasting/seasonality.qmd
similarity index 100%
rename from docs/notes/predictive-modeling/regression/seasonality.qmd
rename to docs/notes/predictive-modeling/time-series-forecasting/seasonality.qmd
diff --git a/docs/references.bib b/docs/references.bib
new file mode 100644
index 0000000..5b38a7b
--- /dev/null
+++ b/docs/references.bib
@@ -0,0 +1,90 @@
+
+
+
+#
+# STATIONARY DATA
+#
+
+# Forecasting: Principles and Practice (2nd ed)
+# Rob J Hyndman and George Athanasopoulos
+# 2018
+# https://otexts.com/fpp2/
+
+# Statistical forecasting: notes on regression and time series analysis
+# Robert Nau
+# 2020
+# https://people.duke.edu/~rnau/411home.htm
+
+# A proposed novel adaptive DC technique for non-stationary data removal
+# Hmeda Musbah, Hamed H. Aly, Timothy A. Little
+# 2023
+# https://www.sciencedirect.com/science/article/pii/S2405844023011106
+
+# Time Series Analysis
+# Robert Shumway, David Stoffer
+# 2019
+# http://www-stat.wharton.upenn.edu/~stine/stat910/
+# https://www.stat.pitt.edu/stoffer/tsda/
+# https://www.routledge.com/Time-Series-A-Data-Analysis-Approach-Using-R/Shumway-Stoffer/p/book/9780367221096
+
+
+#
+# AUTOCORRELATION
+#
+
+# An Introductory Study on Time Series Modeling and Forecasting
+# Ratnadip Adhikari and R.K. Agrawal.
+# 2013
+# https://arxiv.org/abs/1302.6613
+# This paper discusses various time series models, including ARMA and ARIMA, and explains the role of autocorrelation in determining the model's structure.
+# The autocorrelation function (ACF) is highlighted as a key tool for identifying lagged relationships in time series data(
+
+
+# Autocorrelation and Time Series Analysis
+# H.C. Smit.
+#
+# https://link.springer.com/chapter/10.1007/978-94-017-1026-8_6
+# This chapter delves into the role of autocorrelation in the context of time series modeling, providing a mathematical framework and practical applications.
+# It offers a rigorous discussion of how autocorrelation functions are used to identify dependencies in time series data(
+@Inbook{Smit1984,
+ author="Smit, H. C.",
+ editor="Kowalski, Bruce R.",
+ title="Autocorrelation and Time Series Analysis",
+ bookTitle="Chemometrics: Mathematics and Statistics in Chemistry",
+ year="1984",
+ publisher="Springer Netherlands",
+ address="Dordrecht",
+ pages="157--176",
+ abstract="In several disciplines time series analysis is of increasing importance. It is used (1) in a number of applications:Optimal forecast, i.e. the estimation of future values of the known current and past values of the series up to the present time.Parameter estimation, i.e. the estimation of system parameters from time series (signals) generated during a measurement procedure.Transfer function estimation. A transfer function typifies the inertial characteristics of a linear system.Information extraction, i.e. the extraction of relevant information from time series containing much more but not relevant information. The separation of signal and noise (noise reduction, filtering, signal estimation) belongs to this category.Optimal control. A time series of (analytical) results can be used for optimum process control.",
+ isbn="978-94-017-1026-8",
+ doi="10.1007/978-94-017-1026-8_6",
+ url="https://doi.org/10.1007/978-94-017-1026-8_6"
+}
+
+# ARIMA Modelling and Forecasting
+# Timina Liu and Shuangzhe Liu
+# https://link.springer.com/chapter/10.1007/978-981-15-0321-4_4
+# This book chapter provides a comprehensive guide to ARIMA modeling, where autocorrelation plays a vital role in determining the parameters of the model.
+# The authors describe the process of model identification using ACF and PACF, essential for selecting appropriate lag orders
+@Inbook{Liu2020,
+ author="Liu, Timina and Liu, Shuangzhe and Shi, Lei",
+ title="ARIMA Modelling and Forecasting",
+ bookTitle="Time Series Analysis Using SAS Enterprise Guide",
+ year="2020",
+ publisher="Springer Singapore",
+ address="Singapore",
+ pages="61--85",
+ abstract="The Auto-Regressive Integrated Moving Average (ARIMA) model is the general class of models for modelling and forecasting a time series. It consists of the AR, MA and ARMA models. In this chapter, we will discuss each of these models in turn before summarising the steps for ARIMA modelling. We conclude this chapter with a numerical example.",
+ isbn="978-981-15-0321-4",
+ doi="10.1007/978-981-15-0321-4_4",
+ url="https://doi.org/10.1007/978-981-15-0321-4_4"
+}
+
+
+# Autoregressive Models in Environmental Forecasting Time Series
+# Jatinder Kaur, Kulwinder Singh Parmar & Sarbjit Singh
+# 2023
+# https://link.springer.com/article/10.1007/s11356-023-25148-9
+# Environmental Science and Pollution Research
+# This paper provides a review of autoregressive models in time series forecasting, emphasizing the importance of autocorrelation for identifying temporal dependencies and improving model accuracy.
+# Kaur, J., Parmar, K.S. & Singh, S. Autoregressive models in environmental forecasting time series: a theoretical and application review. Environ Sci Pollut Res 30, 19617–19641 (2023). https://doi.org/10.1007/s11356-023-25148-9
diff --git a/docs/requirements.txt b/docs/requirements.txt
index 00df8b4..6ca7481 100644
--- a/docs/requirements.txt
+++ b/docs/requirements.txt
@@ -25,6 +25,8 @@ scipy
pandas_datareader
+yahooquery
+yfinance
# predictive modeling:
@@ -34,4 +36,5 @@ ucimlrepo
+
#gspread==6.0.2