| title | since |
|---|---|
Journal |
2021-11-30 |
- tableau de bord
- workspace vs équipe
- unification du vocabulaire
1 seule interface:
- avoir un tableau générique qui permet de travailler dans les données et pas multiplier et les interfaces
- requiert un lieu pour administrer les comptes
- est-ce qu'une même vue permet de gérer le siloter les données?
test use case:
chaque personne voit "tout" ce à quoi elle a accès utilise ou crée des entités à partir de ce qu'elle voit définir que les entités sont accessibles à tou·te·s, mais pas les liens entre les ressources? permet de montrer les sources bibliographiques, les expositions
Seule la personne qui a créé l'entité peut la modifier. Si besoin, contacter la personne qui a créé la ressource.
- avoir plusieurs manifestations pour les entités? très complexe à mettre en œuvre
est-ce qu'une liste de ressources (ex liste d'exposition) doit être protégée? particulièrement pour le travail des étudiant·e·s Question à soummettre aux responsables d'axes?
Archives numérisées, principalement en pdf, et si les image sont à publier alors on en fait des images IIIF etc.
workspaces
- cohérence?
- ex: superadmin → question des liens
Reprendre travail dans le cahier des charges (p13)
- images: ajouter liens entre Image et les autres entités (1 to many)
- interface de validation & validation en batch (tableau)
décrire les opérations et sortir les questions d'interface dans la section interface
affichage/interface
- affichage de chaque entité par entité tabulaire ou par liste (développer les listes par notice)
- vue tabulaire: voir(choisir) les colonnes qu'on affiche
publication des données
-
sur le site cieco?
-
environnement de consultation (common) mais version non éditable
-
champs pour indiquer définir et gérer les métadonnées
signalement: la description des ressources ne devrait jamais être protégé
- Vocabulaires contrôlés
- Versionnement des contenus (versionnement pour une éventuelle version logicielle asynchrone)
- qui a fait la modif
- est-ce qu'on stocke la modif
Paul Morel: developpeur et designer d'interface
- a-t-on vraiment besoin d'inscrire l'uri des métadonnées stockées dans la base de common à l'intérieur de l'image (metadonnées xmp) ?
- comment accéder à distance au fs de cantaloupe ? (ssh ?)
Où est-ce qu'on stocke les informations?
métadonnées des images / info.json
- exemple de manifeste Gallica
- exemple bac à sable
Cantaloupe requiert un générateur de manifeste
-> ajouter un seeAlso au info.json avec les infos oai ou de notre api
-> voir les autres informations nécessaires pour faire ça proprement cf. doc IIIF #58
-> prendre en compte la possibilité d’utiliser partof car nous aurons probablement des collections
-> spécifier le fonctionnement du serveur d’images pour le traitement des documents multipages (gestion des identifiants uniques)
Processus imaginé
- connexion au client
- verser l'image
- envoi du fichier au serveur
- récupère le id du serveur
serveur de fichiers
- vérifier que l'id est unique
- éventuellement un ark
- doit gérer les documents multiparties
Pas de dépendances pour générer un manifest.json
pdf d'archive
Document ID : 10.34847/nkl.b5d9ehd5 Image 1 : https://api.nakala.fr/data/10.34847/nkl.b5d9ehd5/90ba0b4b6f911361977f5f3638a27490090e9152 Image 1 : https://api.nakala.fr/data/10.34847/nkl.b5d9ehd5/fe5d66d58205da01bfde43223f3b5f245b2f66e6
relire ER et voir si on a des idées pour ajouter des propriétés
- penser à comment on gère l'ajout de propriétés : quelle stratégie d'accompagnement
- ajout de propriété (est-ce qu'on le permet, quand serait-ce nécessaire?)
- utiliser les tags
- quelles métadonnées standard?
Lena: interface
william ajoute les éléments d'interface dans CRUD en laissant des liens vers les sections
Document de cahier des charges
- Présentation du projet
- Analyse des besoins (provisoire)
- Explication du fonctionnement actuel
- Authentification et gestion des droits
- Références bibliographiques (gain pour la saisie normalisée des données)
- Documents d’archives scannés (gain pour le stockage et le partage de fichiers)
Zotero doit-il gérer les œuvres ? car Zotero n’est pas très bon pour gérer les œuvres. Les musées sont mieux placés pour les décrire mais celles-ci ne sont pas nécessairement disponibles. Comme on peut avoir besoin de décrire sommairement des œuvres, il pourrait être nécessaire de créer des œuvres.
hésitation: catégorie 'œuvre'
manques:
- événements
- œuvres: ne correspond pas aux exigences des historien·ne·s de l'art (mais litigieux)
- personnes
- lieux
Zotero = contenus description structurée Common = Hiérarchisation, entités, expression explicite des relations
Dans Zotéro les contenus sont structurés à plat, il est seulement possible de structurer les contenus en collections ou avec des tags. L’application permet de créer du lien entre les ressources, de donner de la profondeur aux données.
Dans Zotero on a la documentation, les sources, les entités historiques sont gérées dans l’application.
On référence les sources et la documentation par un lien à l’ItemKey de Zotero. Il est possible de chercher par itemKey même si on ne peut pas afficher les itemKeys dans l'interface du logiciel.
Les utilisateur·rice·s de Zotero développent des stratégies palliatives pour compenser l'absence d’expression explicite des relations. Par exemple, pour regrouper des documents par exposition, etc.
En gardant Zotero au centre du dispositif, prévoir une fonctionnalité qui permette de récupérer les données de collections pour les transformer en entités.
Sinon, a minima, se poser la question du statut des collections et des tags dans l’application.
La gestion des droits est gouvernée par l’organisation des groupes bibliographiques.
@todo Vérifier s’il est possible d’utiliser l’authentification de l’API Zotero & à tester
rôle:
- superadmin: ouvroir (adminsitre toutes les ressources)
- admin - réviseur: validation des ressources (révision des ressources d'un groupe)
- éditeur
- lecteur
création d'un groupe: vient du prof ou d’un autre éditeur
profs = droit de révision des contenus
- voir les dernières choses modifiées
- réviser/valider
le prestataire ne devrait pas faire le serveur IIIF (c'est du java)
comment planifier l'interaction avec un serveur IIIF
- quel est le niveau de description de l'API (@todo: trouver si la procédure cantaloupe est suffisamment bien détaillée?)
- quel est le niveau de description des images qu'on veut prendre en charge? les métadonnées de IIIF sont pauvres
- moyen pour les exposer? OAI PMH
- dans manifeste: forme clé-valeur
- métadonnées dans Common, liées à l'identifiant IIIF du serveur
Nous n’avons pas besoin d’éditer des manifestes.
Il faut pouvoir disposer d’un serveur de test accessible pour le développeur.
@william tester cantaloupe local et explorer la question des métadonnées @todo trouver comment ajouter un lien vers les métadonnées de l'image lors de l’ajout d’une ressource dans un serveur IIIF?
- formats d'image,
- renommer l'image ?
- différents paramètres de traitement ? (images pyramidales jpeg2000)
- dépôt d'images en batch ?
- utilisation du filesystem ?
Pas besoin de stocker les métadonnées bibliographiques déjà stockées sur Zotero
Ajouter une table image avec description à deux niveaux.
À tester :
- temps pour requeter une collection Zotero, documents
geonames
importation générale vs API gSheets
- importer csv
- contraintes au besoin pour limiter les coûts
- est-ce que l'importation des données muséales doit être comprise dans common ou est-ce que ce ne serait pas logique de les traiter nous-mêmes
- avantage gDrive:
- travail collaboratif sur le tableur
- priorité basse: utilisation API google drive
- problématique pour alignement des données à terme, on s'entend pour éviter le travail avec googleDrive
quantité de modifs admin-ouvroir faisables?
- plus on reste sur ce qu'on connaît, plus ça peut tenir (svelte, baseX)
- garder le modèle de données en interne, externaliser seulement le client (modèle à partir de ce qu'Emmanuel fait avec Jocelyn)
vocabulaire:
- gestion interne: choix de termes prédéfinis → séance de travail sur la terminologie (fait partie de la recherche)
- interface pour gérer les termes du système (sont associés à des uri)
- gestion externe Getty API
tags suffisants pour la catégorisation/typologie?
- tags: mot-clefs liste ouverte
- catégories: catégories disjointes = typage? liste fermée
penser les entités en fiche, comme Notion
voc Ministère culture FR ou getty
modélisation orientée événement
Événement E5 → activité E7 → acquisition E8
Événement E5 → activité E7 → Création E65 → E83 Type Création ?
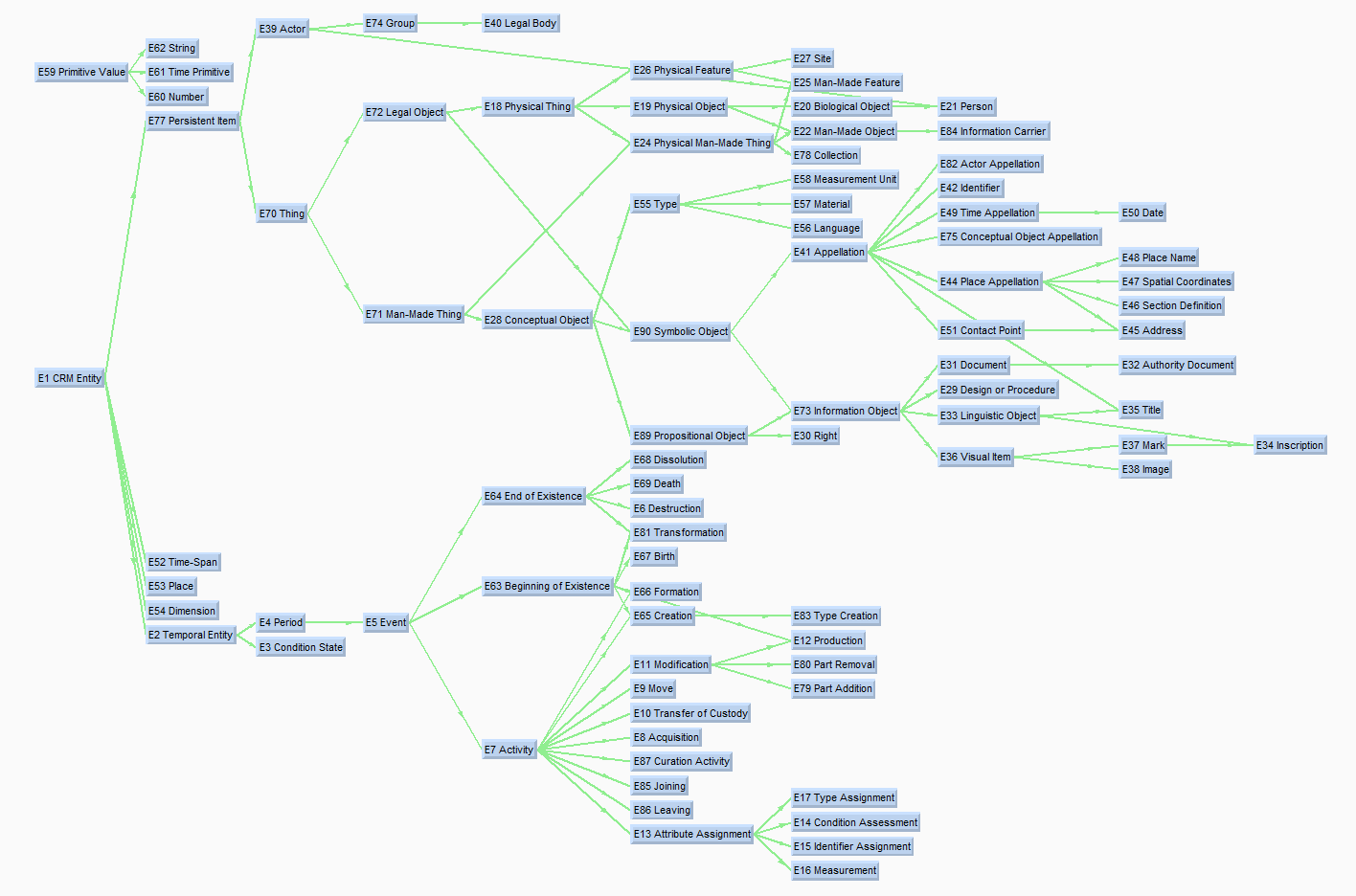
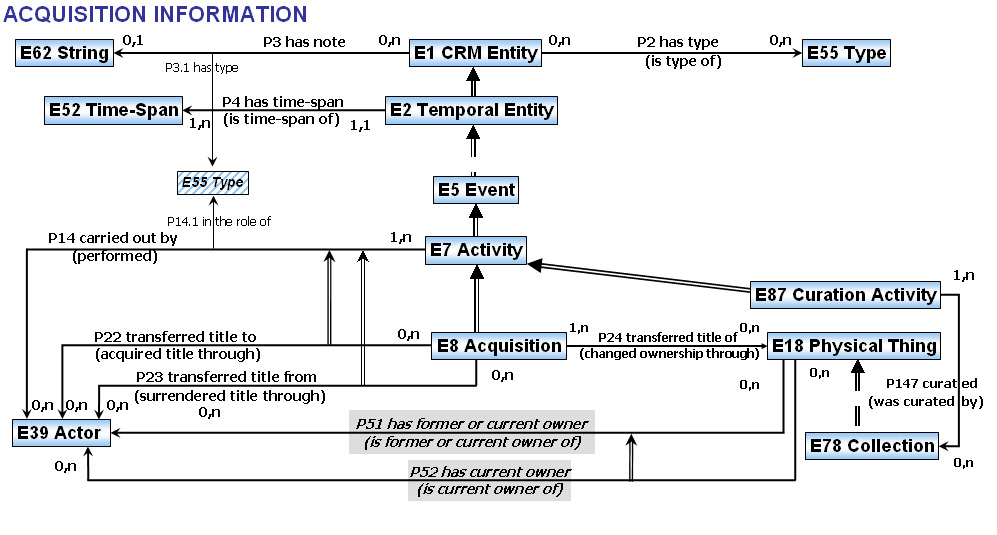
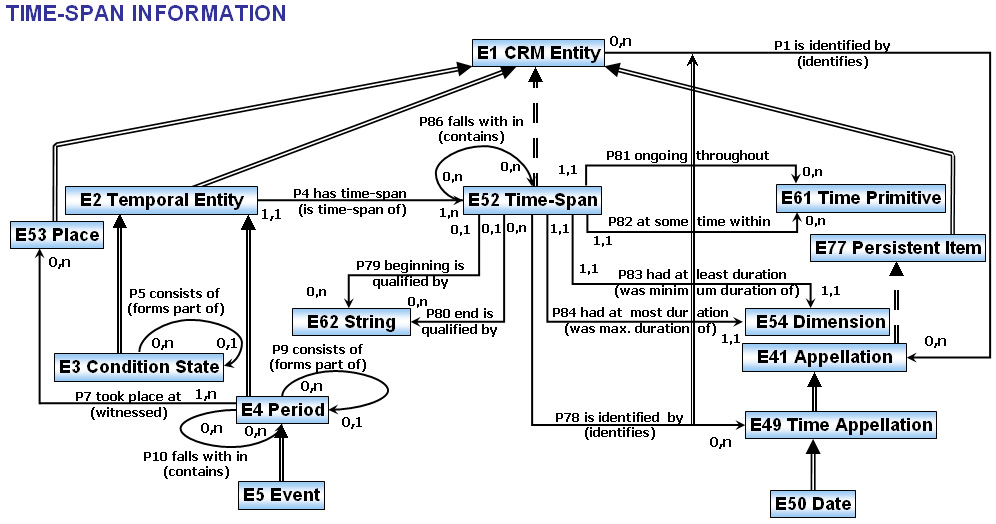
{kind=link}
Pseudo code pour une exposition:
Fichier A.jsonld // Documenta14 expo hasId "Documenta14" expo isTypeOf E-Event expo hasPeriod p expo hasLabel 'Documenta14'
p hasId "documenta14-period" hasBeginDate 2017-05-01 hasEndDate 2017-09-01
// mentionner les événements fils ?
Fichier B.jsonld part isTypeOf E-Event part isPartOf aa-bb expo hasPeriod p
p isPartOf "documenta14-period" hasBeginDate 2017-05-01 hasEndDate 2017-08-01
part hasArtworks [ 'art-id01' 'art-id02', 'art-id03' ]
Fichier C.jsonld part isTypeOf E-Event part isPartOf aa-bb expo hasPeriod p
p isPartOf "documenta14-period" hasBeginDate 2017-08-01 hasEndDate 2017-09-01
part hasArtworks [ 'art-id01' 'art-id04', 'art-id05' ]
décrire une exposition
grande échelle (histoire des expositions de collection)
Actuellement: données tabulaires
- Titre de l'exposition (fr)
- Titre de l'exposition (en)
- Sous-titre de l'exposition
- Date de début
- Date de fin
- Salles
- Lieux
- Catégorie
- Titre série
- Typologie
- Tag
- Commissaires
- Observations
Quelles possibilités d'avoir un événement dans un événement? forms part of récursivité
Table de mapping vers CIDOC { 'titre': 'label' }
variablilité: changements dans une exposition → FRBROO manifestation contient des items particuliers
- s'applique particulièrement bien pour les expositions itinérantes
Acquisition
Initiative - citoyenne - numérique
Objectifs en sortie: quel est le format qu'on veut avoir en sortie?
- pouvoir exprimer les concepts en CIDOC CRM
- comprendre comment lier les entités
tester si l'alignement d'ontologie peut se faire
- quand se fait-il et par qui?
Format en interne? base de données interne: structure définie par les cas d'utiliations
- doit être structurée de manière efficace
<db>
<exposition xml:id='expo-001'>
<dateDeb></dateDeb>
<dateDeb></dateDeb>
<title fr="documenta14" en="documenta" />
<subtitle/>
<titreSerie/>
<location/> //id d'un musée?
<category/>
<actors>
<pers>
<name/> //id ?
<role/>
</pers>
</actors>
</exposition>
</db>wikiData? beaucoup d'utilisation en DH
gestion admin:
- module pour 'ajouter des colonnes / propriétés'
- contrôle de type
interface:
- vue en données tabulaires
- entrée de données en formulaire contrôlé/validé
penser aux fonctionnalités analytiques/visualisation en sortie → source de motivation pour entrer les données correctement
- chronologies → quels paramètres sur y
validation
- vérifier ";()[]" ...
TODO: schéma bd complète
- entités
- voc / thesauri
- utilisateurs
- droits
- actions
TODO: lister les opérations qui impliquent la manipulation de données TODO: figma ou autre débuts d'interface
- outil de dépôt/importation et stockage+consultation de données tabulaire
- droits sur l'interface selon les rôles
- avoir une API pour récupérer les données
- prototypes développés autour des données doivent être intégrés à l'interface
22 juin 2022
En rédaction de thèse (et sur le comité de la recherche CIÉCO)
- façon dont le vivant change les pratiques muséales (animal, végétal)
- 9 chapitres, 3 grosses parties
- normalement pas trop de répétitions dans les œuvres entre les chapitres
beaucoup d'images
- organisation par chapitre?
- œuvres: évolution à travers le temps, plusieurs images
- vérifier infos manquantes
solution pour mettre: image, source, crédits
Marilie fait un excel pour mettre ses infos
corpus > par nom d'artiste > captures d'écran / images si téléchargement semble nécessaire
Zotero Tropy Endnote
Thèses et mémoires: pas forcément liés pour la documentation/archivage CIÉCO
DIA 1
Projet initial : base de données documentaire
La base de données documentaire du Partenariat CIÉCO est destinée à rassembler et décrire avec des métadonnées appropriées toutes les sources mobilisées et les contenus documentaires produits dans le cadre du partenariat (métadonnées sur les accrochages de collections, dépouillements d’archives, et sources visuelles et audiovisuelles).
C’est un système de gestion documentaire multi-utilisateurs qui permet l’archivage, le signalement et le partage des ressources avec des métadonnées appropriées. La base de données sera produite en utilisant le Gestionnaire de contenus libre et open source Omeka-S qui offre les fonctionnalités nécessaires pour la description des ressources avec des modèles de métadonnées métiers appropriés (Dublin Core qualifié, BIBO, LIDO, BIO-CRM, utilisation de vocabulaires SKOS [fonctionnalités offertes par défaut par Omeka-S]) tout en présentant des interfaces collaboratives facile d’emploi pour les chercheurs du projet et les auxiliaires de recherche.
Ce n’est pas finalement ce que nous allons faire [rayer la diapo ?]
DIA 2
Phase de recueil des besoins
Rappel sur les différentes rencontres qui ont eu lieu :
- 1 rencontre collective
- 3 rencontres avec Marie sur Expots
- 1 rencontre avec Mélanie
- résumé des activités de l'axe 4
Synthèse sur l’expression des besoins a
DIA 3 Projet révisé : Portail documentaire du CIÉCO
Privilégier un modèle basé sur des outils très liés aux pratiques quotidiennent des chercheuses et l’utilisation d’APIs. Sorte de tableau de bord qui permet d’agréger des contenus de différents endroits et de créer les entités dont nous avons besoin en lien avec ce contenu. Système modulaire qui permet la création de nouveaux formulaires en fonction des besoins.
- modèle no-code (facile d’accès)
- flexibilité (adaptable en fonction de l’évolution des besoins)
- visualisation (vues d'ensemble)
titre:
- common (sonne anglais)
- portail
- plateforme
Aproche
Production d’un dashboard qui inteargi avec les
Zotero pour stocker la biblio Possibilité abonnement Lab
Un environnement de travail
- unifié (mêmes techno : front-end site CIÉCO / Commons / Expots, etc.)
- modulaire et extensible (capitalisation possible sur les composants : ex. gestion de l’identification)
Un écosystème basé sur l’utilisation d’API
- importations automatisée de données externes (données muséales, feuilles de calcul, etc.)
- délégation de certaines fonctionnalités à des services tiers (Zotero pour la gestion de références bibliographiques)
- remplacement possible des composants
plus grande fluidité dans les étapes de travail
Stack:
@lenamk:
- présentation 3 mai
- décrire les fonctionnalités (énoncé des besoins) : 3xdemi-journées
- spécifier les techs auxquelles il faut répondre
Tests implémentations - quelle marge de négociation avec le(s) dev(s)
- BaseX
- CouchDB and its standard API
- CouchDB+GraphQL
- Deno + couchDB?
- Zotero
- métadonnées sur les documents
- PDF à partir des archives
- biblio
- thesauri?
- cantaloupe
- dépôt
- stockage
- service des images en IIIF
- [HSS common]
modules:
- users
- authentification
Fiches:
- things
- œuvre
- lieux
- actors
- personnes
- groupes/institutions
- events
- expo
- acquisitions
- base de données (contient des fichiers json ou xml)
- langage de manipulation de données: n'existe pas en json (excepté jsonIQ), xml ou graphql permettent ça
Afficher les ressources stockées dans Zotero (définir la liste ciblée)
- livres
- rapports
- thèses
- articles de revue
- articles de conférences
- documents (archives)
- photos
- presse
- page web
- video
Saisir et modifier des images (+leurs métadonnées)
Afficher les images stockées dans Cantaloupe
Composants
Implémentation et mise en œuvre
- 3 mai 2022, rencontre
- validation du plan
- mise en place du Zotero après la rencontre ($)
- 20 mai 2022, forum étudiant CIÉCO
- introduction de common et annonce des ateliers Zotero
- 20 juin 2022, cahier des charges
- modules
- API Zotero
- données type événements
- modules
- été 2022, recherche de prestataire + ateliers Zotero
- septembre --> décembre livraisons
- septembre --> octobre, réunions utilisateurs
Take away
- Validation des orientations
- Abonnement Zotero + ateliers les groupes de chercheur.se.s
- validation du calendrier
- choisir si on crée un compte institutionnel pour le labo/Partenariat (pour le moment)
- tester l'annotation collaborative pour les groupes (& l'ajout de fichiers)
Choix d'interlocuteurs
utilisation de Zotero pour les pdfs et archives
architecture client-serveur basée sur la consommation d'API qui permet de gérer des ressources avec Zotero, des images avec IIIF et un entrepot IIIF. On investit l'argent sur la construction d'une infrastructure qui serait un client web (associé à une base de données) qui permet de gérer un tableau de bord, d'entrer des données qui ne sont pas gérables par Zotero (événements historiques) et de les mettre en lien avec les ressources documentaires stockées dans Zotero et autres services web (serveur d'images cantaloupe)
peut-on faire un moteur de recherche avec des documents stockés en pdf?
- restocker les documents
- héberger zotero: faire notre propre zotero, permet de raffiner l'autentification?
- auto-héberger l'API Zotero?
auto-hébergement semble difficile faute de documentation, à vérifier en contactant Sean Takats ([email protected])
Cher Sean,
Nous travaillons actuellement sur un projet de recherche pour lequel nous envisageons une utilisation plutôt intensive de Zotero au sein de l’équipe de recherche. Pour certaines fonctionnalités, nous nous demandons s’il ne pourrait pas être intéressant d’auto-héberger un serveur Zotero et éventuellement d’en augmenter les fonctionnalités.
Pourrais-tu, s’il te plaît, m’indiquer quelle est votre roadmap actuelle sur cet aspect du projet ? Avez-vous prévu à court ou moyen terme des évolutions de cette partie du logiciel dont il faudrait tenir compte ? Serait-il possible de contribuer utilement au logiciel d’une manière ou d’une autre ?
D’après la recherche préliminaire que nous avons faites dans le forum et la documentation, voici les ressources identifies.
Est-ce que c’est bien toujours ce repo qu’il faut utiliser
https://github.com/zotero/dataserver
Il était question d’une distribution Docker, où se trouve-t-elle ?
https://github.com/gfacciol/zotero_dataserver-docker
Nous avons-vu que la synchronisation des fichiers impliquait un serveur WebDAV sur Amazon.
La documentation est assez sommaire sur Github. Existe
développeurs?
-
conjoint de Marina
-
envoyer une demande sur Astro
- utiliser l'API, semble fonctionner de façon complète (toutes les fonctionnalités logicielles)
- créer une couche par dessus pour ce qu'il manque (événements)
Svelte: permettrait de tweaker l'API Zotero
- utiliser svelte pour requêter l'API (js / graphql)
Trouver un composant de base de données qui serait "directement pluggable"
avantage: options hors ligne inconvénient: SQL (ne fait pas de json)
- requis pour l'édition numérique
Création d'un projet et ajout de ressources externes
- lien vers le drive: difficulté à paramétrer
- seule option = current directory...
- github: ne fonctionne pas... (404 pour https://github.com/ouvroir/labouvroir)
Todo: old school mais fonctionnel
Notes: versionnement + commentaires, éditeur wiki markup, tags
Je me sens décidemment surveillée dans l'onglet Updates...
Proposition de rencontre le 17 mars, préparer une liste de questions d'ici là
- Client API javascript
- requêtes de base très facile
- on peut prendre un document et "publish to the web" mais ce serait public
- pour créer une API → Google Cloud Project
- Google Cloud : 300$ free credits to explore and conduct an assessment of Google cloud platform
- 20+ free products, up to monthly limits: details and full program
- enable GoogleSheets API
- create credentials
- Are you planning to use this API with Compute Engine, Kubernetes Engine, App Engine, or Cloud Functions? Applications running on GCE, GKE, GAE, and GCF can use Application Default Credentials and don't require that you create a credential.
todo
Penser malin, ne pas chercher nécessairement une solution qui fait tout.
- Quid des logiciels identifiés ? (bilan sur les recherches déjà faites)
- Quid des besoins exprimés par l’équipe ?
- très changeants
- De quoi pourraient-ils avoir besoin auxquels ils ne pensent pas ?
- Comment se positionner en support à nos chercheurs ?
- Quels scénarios (Zotero) ?
Il existe plusieurs solutions logicielles dédiées pour le partage de documents ou de contenus en contexte de recherche.
- Islandora (drupal)
- HSS Commons (HubZéro)
- Omeka-S
Ce sont des solutions libres développées en contexte académique qui présentent donc un certain nombre de caractéristiques intéressantes pour le travail que nous voulons mener :
- utilisation de standards de métadonnées descriptives
- exposition des données OAI-PMH
- orientation préservation et archivage à long terme
- compatibilité avec certains services d’identité numérique (ORCID, etc.)
- compatibilité avec certains outils de travail des chercheurs (Zotero)
Dans le cas d’Islandora et de HSS Commons, il s’agit de suites logicielles relativement complexes qui présentent plusieurs dépendances logicielles. L’utilisation des logiciels est plus ou moins ergonomique et nécessite sans doute un apprentissage important (tout particulièrement Islandora). Le modèle de plateforme pour les chercheurs développé par HSS Commons autour de HubZéro permet de disposer gratuitement des fonctionnalités administrées par un établissement de recherche au Canada. Toutefois HubZéro est surtout centré sur le partage de l’information scientifique et la création de communauté et est moins adapté qu’Islandora pour le travail sur la documentation figurée et les documents d’archives. Les fonctionnalités de gestion de fichiers restent très limités dans HubZéro qui mise plus sur le dialogue scientifique.
Omeka-S est un système de gestion de contenu (CMS) particulièrement flexible qui permet l’utilisation de standards de description de métadonnées et offre une compatibilité avec Zotero et une API. Mais ses interfaces génériques sont peu ergonomiques à moins d’un investissement important dans le design d’interfaces. Les retours d’utilisateurs de plusieurs collègues utilisant le logiciel sont contrastés. Le logiciel repose sur une conception web relativement ancienne, et la nouvelle version ne bénéficie pas de développement très actifs depuis quelques années. Nombre de plugins initialement disponibles pour Omeka n’ont pas été portés dans Omeka-S.
Les trois solutions offrent une gestion fine des droits d’utilisateurs. L’interface d’administration d’Omeka ne permet pas de contrôler l’accès aux ressources qui restent visibles pour tous les utilisateurs.
Aucune des solutions passées en revue n’est réellement satisfaisante pour une approche visuelle des contenus. Les fonctionnalités d’affichage restent largement déterminées par l’outil ou le cadre technique utilisé par le logiciel.
- Islandora est une solution trop lourde à mettre en œuvre pour nos besoins et qui risque de présenter des difficultés importantes d’adoption. L’infrastructure repose sur Drupal et plusieurs dépendances.
- HSS Commons, ne constitue pas en soi une solution entièrement satisfaisante pour la gestion des fichiers et particulièrement des images mais ses fonctionnalités de communautés de recherche pourraient être mises à profit pour le projet. Il n’est pas très clair si le projet canadien dispose déjà d’une API. Les métadonnées sont très limités.
- Omeka-S présente un réel intérêt en raison de sa flexibilité et de sa compatibilité avec Zotero. La gestion des droits restent limité et plusieurs retours utilisateurs nous alertent sur les limites du logiciel. L’API utilise JSONLD mais avec des fonctionnalités très limitées.
version alimentée par une API
- cantaloupe est le serveur d'image
- webDav pour les fichiers
- client web qui fait toutes les interactions (en svelte ou react)
- authentification (module à réutiliser pour tout le partenariat)
version parasite Bernard l'hermitte
- on squatte des services web (qui propose une API) et on se crée un client pour s'y connecter
- outils low tech orchestrés par notre client
Ne pas démultiplier les recours aux prestataires de services pour éviter la surcharge. Pb rédaction cahier des charges.
Exemple de Carbon Design System
Trouver une personne qui serait capable de créer des composants ou faire un thème à partir du système existant. Faire appel à William pour faire l'intégration à l'interne. Créer l'API est léger.
Inconvénients
- interface pas très commode,
- gestion de format pdf
utiliser l'API pour récupérer les données dans le tableur
Utilisation de IIF pour toutes les images? Que faire des images de mauvaises qualités et des numérisation directement en PDF? PDF sur Zotero
Outil de gestion des documents interne
- tableau de bord et dataviz (aiderait beaucoup à l'adoption)
- créer soi-même formulaire de saisies (fiches signalétiques)
- Zotero servirait pour le stockage des PDFs et les références bibliographiques
- gérer les interactions avec les APIs
- IIIF: visionneuse , annotations
- signalement des ressources
- authentification
- sécuriser le tout
- option en ligne/hors-ligne avec un client web qui peut être déployé comme une application avec Electron (multiplateforme), se connecte à une BD locale (compatible hors-ligne).
Avantage:
- facilité pour Emmanuel pour faire des modifs Inconvénient:
- difficulté à trouver un dev
Avantages:
- BD orientée document, en JSON
- facile d'utilisation
- crée des GraphQL Inconvénients:
- requiert langage intermédiaire SQL
HSS commons comme outil de communication
d'ici fin mars
-
cahier des charges
-
justifier les choix
-
explorer API Zotero
-
lire la doc cantaloupe
-
session installation locale de Cantaloupe (15 mars?) attention: config Java ou sinon, Docker
Cas d’utilisations et sondage des fonctionnalités
Les besoins de gestion de fichiers sont très divers et incluent des fichiers bureautiques, des images.
- PNG, JPG, TIF
- MSWord et Excel
- liens (renvois vers d’autres archives type radio-canada ou CCA)
- 3D (sketchUp)
- fichiers audio et vidéo
- Markdown
Les fichiers 3D et vidéos doivent être pris en charge optionnellement car ils peuvent être mieux gérés sur des applications dédiées.
Les chercheur·se·s du projet manipulent abondamment des contenus visuels. Le travail sur ce matériau réclame des outils spécifiques pour travailler de manière commode.
- régularité - uniformité
- prévoir l'uniformisation et le traitement minimal des images (bonnes pratiques pour scanner avec le téléphone)
- annotation des images : tout le monde y est favorable. À quel niveau peut-on l’implémenter ? Faire une recherche des plugins/outils libres
Se concentrer sur le signalement?
- gestion des structures arborescentes
- chronologique, avec tags visibles
Importance d'expérimenter avec des mots-clés, la catégorisation, la création de concepts ou de notion. Permettre l'édition en batch pour attribuer ou enlever des tags?
Pour analyse comparative:
- prévoir la possibilité de visualiser deux ressources côte-à-côte pour les comparer (divise l'écran divisé en 2 fenêtres)
- sélection de ressources en une sous-collection
Est-ce une arborescence? Un document doit pouvoir être rattaché à plusieurs institutions/projets/événements tout comme à aucun (événement annulé ou qui n'a pas lieu. Document hors norme)
Axe de recherche
Institution/établissement:
- projet ? (exposition/médiation-initiative/acquisition/projet numérique...)
- document
- événement
- œuvre
Si on pense cartographie, il faut penser le degré de description de l'emplacement de chaque entité
Liens avec de la bibliographie: par entité? (= un sous-dossier Zotero?)
Métriques (indicateurs) pour chaque entité? (utile pour les rapports CRSH notamment, mais aussi pour avoir un retour sur l'emploi de la recherche primaire par la recherche secondaire)
Comment permettre la répartition des tâches, simplifier/aider à déléguer?
Importance de la confidentialité des documents: préciser les droits (accès, édition, partage...). Identifier les stratégies (qui, combien de temps, quelle utilisation, qui a le droit de publier en premier...)
Travail collaboratif - mode hors ligne: à discuter/réfléchir d'avantage
- consulter une page/entité en même temps? toujours possible. La modifier en même temps? non si ce n'est pas de la colalboration en temps réel, git permettrait de gérer une partie mais pas tout
- veut-on des feuilles de calcul et des tableaux directement dans la BDD? Si oui, préférable d'avoir la collaboration en temps réel puisque plusieurs personnes peuvent vouloir travailler dessus en même temps
Versionnement du travail
Annotations type Hypothesis
Saisie: champs structurés et typés
Discussion de solutions possibles avec Svelte ou Islandora évaluation de la solution Svelte
évaluation d'Islandora
Library (NYTimes) GoogleDrive CMS Google Drive for Developers OSF HSS Commons
Rôles
- admin
- multiutilisateur
- groupes d’utilisateurs
- droits différentiés selon les répertoires
- Identité fédérée
- arborescence de dossiers
- gestion des droits
- versionner (??)
- historique des interventions
Types de fichiers supportés
- fichiers images : jpg, svg, png, tiff, etc.
- vidéos, sons (optionnel)
- documents bureautiques (docx, odt, csv, md)
- fichiers pdf
Fonctionnalités d’importation
- glissé-déposé
- importation par lot
- API ou consommation d’API
- renseignement mandataire des métadonnées
- formulaires personnalisés selon les types de ressources
- exposition des métadonnées (DC, autres formats, OAI-PMH)
- Annotation des contenus et commentaires
- Discussions, etc.
- Importation des documents dans Zotero
- Exposition par l’intermédiaire d’API (Rest, graphql)
- compatibilité IIIF
- API pour populer
Se contenter de définir des règles de nommage qui ne seront pas suivies
Une interface compliquée qui créée plus d’embuches que de faciliter le travail
« Une base de données »
Redocumenter les collections muséales (charger les documents individuellement et refaire des notices)
Incorporer les processus dans l’interface
Accompagner les besoins
Faciliter la découverte, le classement et le partage des documents
Faciliter l’adoption de la solution présentée à partir de démonstration de fonctionnalités utiles
- Google Drive
- OneDrive / Sharedocs / Dropbox = WebDAV Web Distributed Authoring and Versioning
- Strapi
- Zotero/Tropy/Omeka
- Bdd relationnelle personnalisée
- Bdd XML native
- Solid