(amazing) embeddings from the ground up singlelunch
- Faiss - a library for efficient similarity search
- Benchmarking - complete with almost everything imaginable
- Singlestore
- Elastic search - dense vector
- Google cloud vertex matching engine NN search
- search
- Recommendation engines
- Search engines
- Ad targeting systems
- Image classification or image search
- Text classification
- Question answering
- Chat bots
- Features
- Low latency
- High recall
- managed
- Filtering
- scale
- search
- Pinecone - managed vector similarity search - Pinecone is a fully managed vector database that makes it easy to add vector search to production applications. No more hassles of benchmarking and tuning algorithms or building and maintaining infrastructure for vector search.
- Nmslib (benchmarked - Benchmarks of approximate nearest neighbor libraries in Python) is a Non-Metric Space Library (NMSLIB): An efficient similarity search library and a toolkit for evaluation of k-NN methods for generic non-metric spaces.
- scann,
- Vespa.ai - Make AI-driven decisions using your data, in real time. At any scale, with unbeatable performance
- Weaviate - Weaviate is an open source vector search engine and vector database. Weaviate uses machine learning to vectorize and store data, and to find answers to natural language queries, or any other media type.
- Neural Search with BERT and Solr - Indexing BERT vector data in Solr and searching with full traversal
- Fun With Apache Lucene and BERT Embeddings - This post goes much deeper -- to the similarity search algorithm on Apache Lucene level. It upgrades the code from 6.6 to 8.0
- Speeding up BERT Search in Elasticsearch - Neural Search in Elasticsearch: from vanilla to KNN to hardware acceleration
- Ask Me Anything about Vector Search - In the Ask Me Anything: Vector Search! session Max Irwin and Dmitry Kan discussed major topics of vector search, ranging from its areas of applicability to comparing it to good ol’ sparse search (TF-IDF/BM25), to its readiness for prime time and what specific engineering elements need further tuning before offering this to users.
- Search with BERT vectors in Solr and Elasticsearch - GitHub repository used for experiments with Solr and Elasticsearch using DBPedia abstracts comparing Solr, vanilla Elasticsearch, elastiknn enhanced Elasticsearch, OpenSearch, and GSI APU
- Not All Vector Databases Are Made Equal - A detailed comparison of Milvus, Pinecone, Vespa, Weaviate, Vald, GSI and Qdrant
- Vector Podcast - Podcast hosted by Dmitry Kan, interviewing the makers in the Vector / Neural Search industry. Available on YouTube, Spotify, Apple Podcasts and RSS
- Players in Vector Search: Video -Video recording and slides of the talk presented on London IR Meetup on the topic of players, algorithms, software and use cases in Vector Search
- (paper) Hybrid retrieval using search and semantic search
- Name-Entity Recognition (NER): It can recognise whether a word represents a person, location or names in the text.
- Parts-of-Speech Tagging (PoS): Tags all the words in the given text as to which “part of speech” they belong to.
- Text Classification: Classifying text based on the criteria (labels)
- Training Custom Models: Making our own custom models.
- It comprises of popular and state-of-the-art word embeddings, such as GloVe, BERT, ELMo, Character Embeddings, etc. There are very easy to use thanks to the Flair API
- Flair’s interface allows us to combine different word embeddings and use them to embed documents. This in turn leads to a significant uptick in results
- ‘Flair Embedding’ is the signature embedding provided within the Flair library. It is powered by contextual string embeddings. We’ll understand this concept in detail in the next section
- Flair supports a number of languages – and is always looking to add new ones
- Git
- Hugging face nlp pretrained
- hugging face on emotions
- how to make a custom pyTorch LSTM with custom activation functions,
- how the PackedSequence object works and is built,
- how to convert an attention layer from Keras to pyTorch,
- how to load your data in pyTorch: DataSets and smart Batching,
- how to reproduce Keras weights initialization in pyTorch.
- A thorough tutorial on bert, fine tuning using hugging face transformers package. Code

- Google’s intro to transformers and multi-head self attention
- How self attention and relative positioning work (great!)
- Rnns are sequential, same word in diff position will have diff encoding due to the input from the previous word, which is inherently different.
- Attention without positional! Will have distinct (Same) encoding.
- Relative look at a window around each word and adds a distance vector in terms of how many words are before and after, which fixes the problem.
- The authors hypothesized that precise relative position information is not useful beyond a certain distance.
- Clipping the maximum distance enables the model to generalize to sequence lengths not seen during training.
- From bert to albert
- All the latest buzz algos
- A Summary of them
- 8 pretrained language embeddings
- Hugging face pytorch transformers
- Hugging face nlp pretrained


- Medium on Introduction into word embeddings, sentence embeddings, trends in the field. The Indian guy, git notebook, his git,
- Baseline Averaged Sentence Embeddings
- Doc2Vec
- Neural-Net Language Models (Hands-on Demo!)
- Skip-Thought Vectors
- Quick-Thought Vectors
- InferSent
- Universal Sentence Encoder
- Shay palachy on word embedding covering everything from bow to word/doc/sent/phrase.
- Another intro, not as good as the one above
- Using sklearn vectorizer to create custom ones, i.e. a vectorizer that does preprocessing and tfidf and other things.
- TFIDF - n-gram based top weighted tfidf words
- Gensim bi-gram phraser/phrases analyser/converter
- Countvectorizer, stemmer, lemmatization code tutorial
- Current 2018 best universal word and sentence embeddings -> elmo
- 5-part series on word embeddings, part 2, 3, 4 - cross lingual review, 5-future trends
- Word embedding posts
- Facebook github for embedings called starspace
- Medium on Fast text / elmo etc
- Ruder on language modelling as the next imagenet - Language modelling, the last approach mentioned, has been shown to capture many facets of language relevant for downstream tasks, such as long-term dependencies , hierarchical relations , and sentiment . Compared to related unsupervised tasks such as skip-thoughts and autoencoding, language modelling performs better on syntactic tasks even with less training data.
- A tutorial about w2v skipthought - with code!, specifically language modelling here is important - Our second method is training a language model to represent our sentences. A language model describes the probability of a text existing in a language. For example, the sentence “I like eating bananas” would be more probable than “I like eating convolutions.” We train a language model by slicing windows of n words and predicting what the next word will be in the text
- Unread - universal language model fine tuning for text-classification
- ELMO - medium
- Bert **[python git](https://github.com/CyberZHG/keras-bert)- We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional representations by jointly conditioning on both left and right context in all layers. As a result, the pre-trained BERT representations can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial task-specific architecture modifications. BERT is conceptually simple and empirically powerful. It obtains new state-of-the-art results on eleven natural language processing tasks.**
- Open.ai on language modelling - We’ve obtained state-of-the-art results on a suite of diverse language tasks with a scalable, task-agnostic system, which we’re also releasing. Our approach is a combination of two existing ideas: transformers and unsupervised pre-training. READ PAPER, VIEW CODE.
- Scikit-learn inspired model finetuning for natural language processing.

finetune ships with a pre-trained language model from “Improving Language Understanding by Generative Pre-Training” and builds off the OpenAI/finetune-language-model repository.
- Did not read - The annotated Transformer - jupyter on transformer with annotation
- Medium on Dissecting Bert, appendix
- Medium on distilling 6 patterns from bert
- A good overview of sentence embedding methods - w2v ft s2v skip, d2v
- A very good overview of word embeddings
- Intro to word embeddings - lots of images
- A very long and extensive thesis about embeddings
- Sent2vec by gensim - sentence embedding is defined as the average of the source word embeddings of its constituent words. This model is furthermore augmented by also learning source embeddings for not only unigrams but also n-grams of words present in each sentence, and averaging the n-gram embeddings along with the words
- Sent2vec vs fasttext - with info about s2v parameters
- Wordrank vs fasttext vs w2v comparison - the better word similarity algorithm
- W2v vs glove vs sppmi vs svd by gensim
- Medium on a gentle intro to d2v
- Doc2vec tutorial by gensim - Doc2vec (aka paragraph2vec, aka sentence embeddings) modifies the word2vec algorithm to unsupervised learning of continuous representations for larger blocks of text, such as sentences, paragraphs or entire documents. - Most importantly this tutorial has crucial information about the implementation parameters that should be read before using it.
- Lbl2Vec, medium, is an algorithm for unsupervised document classification and unsupervised document retrieval. It automatically generates jointly embedded label, document and word vectors and returns documents of categories modeled by manually predefined keywords.
- Git for word embeddings - taken from mastery’s nlp course
- Skip-thought - **[git](https://github.com/ryankiros/skip-thoughts)- Where word2vec attempts to predict surrounding words from certain words in a sentence, skip-thought vector extends this idea to sentences: it predicts surrounding sentences from a given sentence. NOTE: Unlike the other methods, skip-thought vectors require the sentences to be ordered in a semantically meaningful way. This makes this method difficult to use for domains such as social media text, where each snippet of text exists in isolation.**
- Fastsent - Skip-thought vectors are slow to train. FastSent attempts to remedy this inefficiency while expanding on the core idea of skip-thought: that predicting surrounding sentences is a powerful way to obtain distributed representations. Formally, FastSent represents sentences as the simple sum of its word embeddings, making training efficient. The word embeddings are learned so that the inner product between the sentence embedding and the word embeddings of surrounding sentences is maximized. NOTE: FastSent sacrifices word order for the sake of efficiency, which can be a large disadvantage depending on the use-case.
- Weighted sum of words - In this method, each word vector is weighted by the factor
where
is a hyperparameter and
is the (estimated) word frequency. This is similar to tf-idf weighting, where more frequent terms are weighted downNOTE: Word order and surrounding sentences are ignored as well, limiting the information that is encoded.
- Infersent by facebook - paper InferSent is a sentence embeddings method that provides semantic representations for English sentences. It is trained on natural language inference data and generalizes well to many different tasks. ABSTRACT: we show how universal sentence representations trained using the supervised data of the Stanford Natural Language Inference datasets can consistently outperform unsupervised methods like SkipThought vectors on a wide range of transfer tasks. Much like how computer vision uses ImageNet to obtain features, which can then be transferred to other tasks, our work tends to indicate the suitability of natural language inference for transfer learning to other NLP tasks.
- Universal sentence encoder - google - notebook, git The Universal Sentence Encoder encodes text into high dimensional vectors that can be used for text classification, semantic similarity, clustering and other natural language tasks. The model is trained and optimized for greater-than-word length text, such as sentences, phrases or short paragraphs. It is trained on a variety of data sources and a variety of tasks with the aim of dynamically accommodating a wide variety of natural language understanding tasks. The input is variable length English text and the output is a 512 dimensional vector. We apply this model to the STS benchmark for semantic similarity, and the results can be seen in the example notebook made available. The universal-sentence-encoder model is trained with a deep averaging network (DAN) encoder.
- Multi language universal sentence encoder - no hebrew
- Pair2vec - paper - paper proposes new methods for learning and using embeddings of word pairs that implicitly represent background knowledge about such relationships. I.e., using p2v information with existing models to increase performance. Experiments show that our pair embeddings can complement individual word embeddings, and that they are perhaps capturing information that eludes the traditional interpretation of the Distributional Hypothesis
- Fast text python tutorial

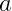

- Part1: Label encoder/ ordinal, One hot, one hot with a rare bucket, hash
- Part2: cat2vec using w2v, and entity embeddings for categorical data

- Star - General purpose embedding paper with code somewhere
- Using embeddings on tabular data, specifically categorical - introduction, using fastai without limiting ourselves to pytorch - the material from this post is covered in much more detail starting around 1:59:45 in the Lesson 3 video and continuing in Lesson 4 of our free, online Practical Deep Learning for Coders course. To see example code of how this approach can be used in practice, check out our Lesson 3 jupyter notebook. Perhaps Saturday and Sunday have similar behavior, and maybe Friday behaves like an average of a weekend and a weekday. Similarly, for zip codes, there may be patterns for zip codes that are geographically near each other, and for zip codes that are of similar socio-economic status. The jupyter notebook doesn't seem to have the embedding example they are talking about.
- Rossman on kaggle, used entity-embeddings, here, github, paper
- Medium on rossman - good
- Embedder - git code for a simplified entity embedding above.
- Finally what they do is label encode each feature using labelEncoder into an int-based feature, then push each feature into its own embedding layer of size 1 with an embedding size defined by a rule of thumb (so it seems), merge all layers, train a synthetic regression/classification and grab the weights of the corresponding embedding layer.
- Entity2vec
- Categorical using keras
- ALL ???-2-VEC ideas
- Fast.ai post regarding embedding for tabular data, i.e., cont and categorical data
- Entity embedding for categorical data + notebook
- Kaggle taxi competition + code
- Ross man competition - entity embeddings, code missing +alternative code
- CODE TO CREATE EMBEDDINGS straight away, based onthe ideas by cheng guo in keras
- PIN2VEC - pinterest embeddings using the same idea
- Tweet2Vec - code in theano, paper.
- Clustering of tweet2vec, paper
- Paper: Character neural embeddings for tweet clustering
- Diff2vec - might be useful on social network graphs, paper, code
- emoji 2vec (below)
- Char2vec **[Git](https://github.com/IntuitionEngineeringTeam/chars2vec), similarity measure for words with types. [ **](https://arxiv.org/abs/1708.00524)
EMOJIS
- 1. Deepmoji,
- hugging face on emotions
- how to make a custom pyTorch LSTM with custom activation functions,
- how the PackedSequence object works and is built,
- how to convert an attention layer from Keras to pyTorch,
- how to load your data in pyTorch: DataSets and smart Batching,
- how to reproduce Keras weights initialization in pyTorch.
- Another great emoji paper, how to get vector representations from
- 3. What can we learn from emojis (deep moji)
- Learning millions of for emoji, sentiment, sarcasm, medium
- EMOJI2VEC - medium article with keras code, another paper on classifying tweets using emojis
- Group2vec git and medium, which is a multi input embedding network using a-f below. plus two other methods that involve groupby and applying entropy and join/countvec per class. Really interesting
- Initialize embedding layers for each categorical input;
- For each category, compute dot-products among other embedding representations. These are our ‘groups’ at the categorical level;
- Summarize each ‘group’ adopting an average pooling;
- Concatenate ‘group’ averages;
- Apply regularization techniques such as BatchNormalization or Dropout;
- Output probabilities.
- Monitor train loss using callbacks for word2vec
- Cleaning datasets using weighted w2v sentence encoding, then pca and isolation forest to remove outlier sentences.
- Removing ‘gender bias using pair mean pca
- KPCA w2v approach on a very small dataset, similar git for correspondence analysis, paper
- The best w2v/tfidf/bow/ embeddings post ever
- Chris mccormick ml on w2v, **[post #2](http://mccormickml.com/2017/01/11/word2vec-tutorial-part-2-negative-sampling/) - negative sampling “Negative sampling addresses this by having each training sample only modify a small percentage of the weights, rather than all of them. With negative sampling, we are instead going to randomly select just a small number of “negative” words (let’s say 5) to update the weights for. (In this context, a “negative” word is one for which we want the network to output a 0 for). We will also still update the weights for our “positive” word (which is the word “quick” in our current example). The “negative samples” (that is, the 5 output words that we’ll train to output 0) are chosen using a “unigram distribution”. Essentially, the probability for selecting a word as a negative sample is related to its frequency, with more frequent words being more likely to be selected as negative samples.**
- Chris mccormick on negative sampling and hierarchical soft max training, i.e., huffman binary tree for the vocabulary, learning internal tree nodes ie.,, the path as the probability vector instead of having len(vocabulary) neurons.
- Great W2V tutorial
- Another gensim-based w2v tutorial, with starter code and some usage examples of similarity
- Clustering using gensim word2vec
- Yet another w2v medium explanation
- Mean w2v
- Sequential w2v embeddings.
- Negative sampling, why does it work in w2v - didnt read
- Semantic contract using w2v/ft - he chose a good food category and selected words that worked best in order to find similar words to good bad etc. lior magen
- Semantic contract, syn-antonym DS, using w2v, a paper that i havent read yet but looks promising
- Amazing w2v most similar tutorial, examples for vectors, misspellings, semantic contrast and relations that may or may not be captured in the network.
- Followup tutorial about genderfying words using ‘he’ ‘she’ similarity
- W2v Analogies using predefined anthologies of the form x:y:
🅰️ b, plus code, plus insights of why it works and doesn't. presence : absence :: happy : unhappy absence : presence :: happy : proud abundant : scarce :: happy : glad refuse : accept :: happy : satisfied accurate : inaccurate :: happy : disappointed admit : deny :: happy : delighted never : always :: happy : Said_Hirschbeck modern : ancient :: happy : ecstatic - Nlpforhackers on bow, w2v embeddings with code on how to use
- Hebrew word embeddings with w2v, ron shemesh, on wiki/twitter
GLOVE
- W2v vs glove vs fasttext, in terms of overfitting and what is the idea behind
- W2v against glove performance comparison - glove wins in % and time.
- How glove and w2v work, but the following has a very good description - “GloVe takes a different approach. Instead of extracting the embeddings from a neural network that is designed to perform a surrogate task (predicting neighbouring words), the embeddings are optimized directly so that the dot product of two word vectors equals the log of the number of times the two words will occur near each other (within 5 words for example). For example if "dog" and "cat" occur near each other 10 times in a corpus, then vec(dog) dot vec(cat) = log(10). This forces the vectors to somehow encode the frequency distribution of which words occur near them.”
- Glove vs w2v, concise explanation
- Fasttext - using fast text and upsampling/oversapmling on twitter data
- A great youtube lecture 9m about ft, rarity, loss, class tree speedup **
- A thorough tutorial about what is FT and how to use it, performance, pros and cons.
- Docs
- Medium: word embeddings with w2v and fast text in gensim , data cleaning and word similarity
- Gensim - fasttext docs, similarity, analogies
- Alternative to gensim - promises speed and out of the box support for many embeddings.
- Comparison of usage w2v fasttext
- Using gensim fast text - recommendation against using the fb version
- A comparison of w2v vs ft using gensim - “Word2Vec embeddings seem to be slightly better than fastText embeddings at the semantic tasks, while the fastText embeddings do significantly better on the syntactic analogies. Makes sense, since fastText embeddings are trained for understanding morphological nuances, and most of the syntactic analogies are morphology based.
- Syntactic means syntax, as in tasks that have to do with the structure of the sentence, these include tree parsing, POS tagging, usually they need less context and a shallower understanding of world knowledge
- Semantic tasks mean meaning related, a higher level of the language tree, these also typically involve a higher level understanding of the text and might involve tasks s.a. question answering, sentiment analysis, etc...
- As for analogies, he is referring to the mathematical operator like properties exhibited by word embedding, in this context a syntactic analogy would be related to plurals, tense or gender, those sort of things, and semantic analogy would be word meaning relationships s.a. man + queen = king, etc... See for instance this article (and many others)
- Skip gram vs CBOW

- Paper on fasttext vs glove vs w2v on a single DS, performance comparison. Ft wins by a small margin
- Medium on w2v/fast text ‘most similar’ words with code
- keras/tf code for a fast text implementation
- Medium on fast text and imbalance data
- Medium on universal Sentence encoder, w2v, Fast text for sentiment with code.
- Blog, github: Using spacy or not, with w2v using POS/ENTITY TAGS to find similarities.based on reddit. “We follow Trask et al in adding part-of-speech tags and named entity labels to the tokens. Additionally, we merge named entities and base noun phrases into single tokens, so that they receive a single vector.”
- >>> model.similarity('fair_game|NOUN', 'game|NOUN') 0.034977455677555599 >>> model.similarity('multiplayer_game|NOUN', 'game|NOUN') 0.54464530644393849
- Gensim implementation of sent2vec - usage examples, parallel training, a detailed comparison against gensim doc2vec
- Git implementation
- Another git - worked
- Shuffle before training each epoch in d2v in order to fight overfitting