Editors:
- Christian Chiarcos (Applied Computational Linguistics, University of Augsburg, Germany)
Contributors: (please add yourself)
- Besim Kabashi (Corpus and Computational Linguistics, Friedrich-Alexander-Universität Erlangen-Nürnberg, Germany)
- Fahad Khan (Istituto di Linguistica Computazionale <<A. Zampolli>>, Italy)
- Ciprian-Octavian Truică
- Katerina Gkirtzou
- John P. McCrae
- Sander Stolk
- Thierry Declerck+
- Jesse de Does
- Katrien Depuydt
- Elena-Simona Apostol
- Max Ionov (Institute for Digital Humanities, University of Cologne, Germany)
- ...
Copyright © 2023 the Contributors to the The Ontolex Module for Frequency, Attestation and Corpus Information Specification, published by Ontology Lexica under the W3C Community Contributor License Agreement (CLA). A human-readable summary is available.
This document describes the module for frequency, attestation and corpus information of the OntoLex Lexicon Model for Ontologies (OntoLex-Lemon) developed by the W3C Community Group Ontology-Lexica. The module is targeted at complementing dictionaries and other linguistic resources containing lexicographic data with a vocabulary to express
- corpus-derived information (frequency and cooccurrence information, collocation analysis, distributional similarity),
- pointers from lexical resources to corpora and other collections of text (attestations, examples),
- the linking of corpora and linguistic primary data with lexical information (dictionary linking), and
- distributional semantics (collocation vectors, word embeddings, sense embeddings, concept embeddings).
The module tackles use cases in corpus-based lexicography, corpus linguistics and natural language processing, and operates in combination with the OntoLex-Lemon core module (Lemon), as well as with other lemon modules.
This document is a working draft for a module for frequency, attestation and corpus data of the OntoLex specifications. It is not a W3C Standard nor is it on the W3C Standards Track.
Note: the following information is to be removed from the final report
There are a number of ways that one may participate in the development of this report:
* Mailing list: [[email protected]](http://lists.w3.org/Archives/Public/public-ontolex/)
* Wiki: [Main page](https://www.w3.org/community/ontolex/wiki/Main_Page)
* More information about meetings of the ONTOLEX group can be obtained [here](https://www.w3.org/community/ontolex/wiki/Main_Page#Meetings)
* [Source code](https://github.com/ontolex/frequency-attestation-corpus-information/) for this document can be found on Github.
Disclaimer: This draft follows closely the structure and design of The Ontolex Lexicography Module. Draft Community Group Report 28 October 2018, edited by Julia Bosque-Gil and Jorge Gracia. In particular, motivational and introductory text are partially adapted without being marked as quotes. This is to be replaced by original text before publication.
Note: HTML template to be applied
- Introduction
- Overview
- Observations and Observables
- Frequency
- Attestation
- Collocations
- Embeddings
- Similarity
- Corpus Annotation (non-normative)
back to (Table of Contents)
back to (Table of Contents)
OntoLex-Lemon provides a core vocabulary to represent linguistic information associated to ontology and vocabulary elements. The model follows the principle of semantics by reference in the sense that the semantics of a lexical entry is expressed by reference to an individual, class or property defined in an ontology. The OntoLex module for Frequency, Attestations and Corpus-Based Information (OntoLex-FrAC) complements OntoLex-Lemon with the capability of including information drawn from or found in corpora and linguistic primary data.
This builds on two primary motivations:
-
corpus-based lexicography: OntoLex-Lemon has been increasingly used to publish, exchange and create dictionaries and lexicographical data in a machine-readable way. This module is partially motivated by requirements of corpus-based lexicography (frequency, collocations, semantic similarity) and digital philology (linking lexical resources with attestations and corpus data) and complements the OntoLex module for lexicography in that regard.
-
natural language processing: With the rise of distributional semantics since the early 1990s, lexical semantics have been complemented by corpus-based co-occurrence statistics, collocation vectors (Schütze 1993), word embeddings (Collobert et al. 2012) and sense embeddings (Rothe and Schütze, 2017). With the proposed module and in addition to the requirements from corpus-based lexicography, OntoLex can serve as a community standard to encode, store and exchange numerical vector representations (embeddings) along with the lexical concepts, senses, lemmas, words or contexts (attestations) that they represent.
The added value of using linked data technologies to represent such information is an increased level of interoperability and integration between different types of lexical resources, the textual data they pertain to, as well as distributional representations of words, lexical senses and lexical concepts. Creating a designated module within OntoLex is a suitable means for establishing a vocabulary on a broad consensus that takes into account all use cases identified above in an adequate fashion. The OntoLex community is the natural forum to accomplish this for several reasons:
- The extended use of OntoLex-Lemon to support digital lexicography,
- the improved application and applicabiltiy of OntoLex-Lemon in natural language processing,
- the coming together of the lexicography, AI and human language technology communities, resp. resources, and
- the possibility of reusing already available mechanisms in OntoLex-Lemon, preventing researchers from "re-inventing the wheel",
back to (Table of Contents)
The goal of this module is to complement OntoLex-Lemon elements with a vocabulary layer to represent lexicographical and semantic information derived from or defined with reference to corpora and external resources in a way that (a) generalizes over use cases from digital lexicography, natural language processing, artificial intelligence, computational philology and corpus linguistics, that (b) facilitates exchange, storage and re-usability of such data along with lexical information, and that (c) minimizes information loss in comparison to other commonly used formalisms for such data.
The scope of the model is three-fold:
- complementing OntoLex-Lexicog with corpus information to support corpus-driven lexicography (results of statistical analyses) and the inclusion of corpus evidence (attestations),
- modelling existing lexical and distributional-semantic resources (corpus-based dictionaries, collocation dictionaries, embeddings) as linked data, to allow their conjoint publication and inter-operation by Semantic Web standards, and
- providing a conceptual / abstract model of relevant concepts in distributional semantics (embeddings, similarity metrics, collocations) that facilitates building linked data-based applications that consume and combine both lexical and distributional information.
Corpus as used throughout this document is understood in its traditional, broader sense as a structured data collection -- or material suitable for being included into such a collection, such as manuscripts or other works. We do not intend to limit the use of the term to corpora in a linguistic or NLP sense. Language resources of any kind (web documents, dictionaries, plain text, unannotated corpora, etc.) are considered "corpus data" and a collection of such information as a "corpus" in this sense. Any information drawn from or pertaining to such information is considered "corpus-based". Accordingly, we account for observations in any kind of resource (identified by a URI), but ask users to specify its specific type according to the Dublin Core standard.
back to (Table of Contents)
This is a list of relevant namespaces that will be used in the rest of this document:
OntoLex module for frequency, attestation and corpus information
@prefix frac: <http://www.w3.org/ns/lemon/frac#> .
OntoLex (core) model and other lemon modules:
@prefix ontolex: <http://www.w3.org/ns/lemon/ontolex#> .
@prefix synsem: <http://www.w3.org/ns/lemon/synsem#> .
@prefix decomp: <http://www.w3.org/ns/lemon/decomp#> .
@prefix vartrans: <http://www.w3.org/ns/lemon/vartrans#> .
@prefix lime: <http://www.w3.org/ns/lemon/lime#> .
@prefix lexicog: <http://www.w3.org/ns/lemon/lexicog#> .
Other models [TO REVIEW]:
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>.
@prefix owl: <http://www.w3.org/2002/07/owl#>.
@prefix xsd: <http://www.w3.org/2001/XMLSchema#>.
@prefix skos: <http://www.w3.org/2004/02/skos#>.
@prefix dbr: <http://dbpedia.org/resource/>.
@prefix dbo: <http://dbpedia.org/ontology/>.
@prefix void: <http://rdfs.org/ns/void#>.
@prefix lexinfo: <http://www.lexinfo.net/ontology/2.0/lexinfo#>.
@prefix dct: <http://purl.org/dc/terms/>.
@prefix provo: <http://www.w3.org/ns/prov#>.
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#>.
@prefix oa: <http://www.w3.org/ns/oa#>.
@prefix aat: <http://vocab.getty.edu/aat/>.
@prefix voaf: <http://purl.org/vocommons/voaf#>.
@prefix dcam: <http://purl.org/dc/dcam/> .
@prefix dcterms: <http://purl.org/dc/terms/> .
@prefix dcmitype: <http://purl.org/dc/dcmitype/>
Helper namespace (for monitoring revision status, remove from final):
@prefix vs: <http://www.w3.org/2003/06/sw-vocab-status/ns#> .
Necessary for bootstrapping Turtle from this file, keep in, but remove section before preparing the final report.
##########################
# vocabulary declaration #
##########################
<http://www.w3.org/ns/lemon/frac#>
a owl:Ontology, voaf:Vocabulary ;
# owl:imports <http://www.w3.org/ns/lemon/ontolex>
.
#########################
# imported vocabularies #
#########################
rdf:Bag
rdfs:subClassOf rdfs:Container .
rdf:Seq
rdfs:subClassOf rdfs:Container .
rdfs:member
a owl:ObjectProperty .
rdf:value
a owl:DatatypeProperty .
dct:extent
a owl:DatatypeProperty .
dct:description
a owl:DatatypeProperty .
back to (Table of Contents)
The following diagram depicts the OntoLex module for frequency, attestation and corpus information (OntoLex-FrAC). Boxes represent classes of the model. Arrows with filled heads represent object properties. Arrows with empty heads represent rdfs:subClassOf. Vocabulary elements introduced by this module are shaded grey (classes) or set in italics.
 Fig. 2 OntoLex Module for Frequency, Attestation and Corpus Information (FrAC), overview
Fig. 2 OntoLex Module for Frequency, Attestation and Corpus Information (FrAC), overview
Note: old diagram:

Please use [this link](https://service.tib.eu/webvowl/#opts=doc=1;cd=180;dd=220;filter_disjoint=false;filter_setOperator=true;mode_compact=true;#iri=https://github.com/ontolex/frequency-attestation-corpus-information/raw/master/owl/frac.ttl) to get a live view on [the ontology](owl/frac.ttl).
#####################
# top-level classes #
#####################
back to (Table of Contents)
OntoLex-FrAC provides the necessary vocabulary to express observations obtained from a language resource about any linguistic or conceptual entity that can be observed in a corpus ("observable"). By observable, we mean
- any lexical entity that can be described with OntoLex (including, but not limited to OntoLex core classes
ontolex:LexicalEntry,ontolex:Form,ontolex:LexicalSenseorontolex:LexicalConcept), as well as - any ontological entity from a knowledge graph (corresponding to the object of an
ontolex:denotes,ontolex:referenceorontolex:isConceptOfproperty).
The top-level concepts of OntoLex-FrAC are thus frac:Observable and frac:Observation, complemented by a designating where the observation has been frac:observedIn.
URI: http://www.w3.org/nl/lemon/frac#Observable Observable is an abstract superclass for any element of a lexical resource that frequency, attestation or corpus-derived information can be expressed about. This includes, among others,
ontolex:LexicalEntry,ontolex:LexicalSense,ontolex:Form, andontolex:LexicalConcept. Elements that FrAC properties apply to must be observable in a corpus or another linguistic data source.
frac:Observable
a owl:Class ;
# vs:term_status "stable" ;
skos:definition """Observable is an abstract superclass for any element of a lexical resource that frequency, attestation or corpus-derived information can be expressed about. This includes, among others, `ontolex:LexicalEntry`, `ontolex:LexicalSense`, `ontolex:Form`, and `ontolex:LexicalConcept`. Elements that FrAC properties apply to must be observable in a corpus or another linguistic data source."""@en;
rdfs:label "observable"@en.
ontolex:Form
rdfs:subClassOf frac:Observable ;
vs:term_status "stable" .
ontolex:LexicalConcept
rdfs:subClassOf frac:Observable ;
vs:term_status "stable" .
ontolex:LexicalEntry
rdfs:subClassOf frac:Observable ;
vs:term_status "stable" .
ontolex:LexicalSense
rdfs:subClassOf frac:Observable ;
vs:term_status "stable" .
 Fig. 1.
Fig. 1. frac:Observable as a superclass of ontolex:LexicalEntry, ontolex:Form, ontolex:LexicalSense and ontolex:LexicalConcept
For OntoLex, we assume that frequency, attestation and corpus information can be provided about every linguistic content element in the OntoLex-Lemon core model and in existing or forthcoming OntoLex modules. This includes ontolex:Form (for token frequency, etc.), ontolex:LexicalEntry (frequency of disambiguated lemmas), ontolex:LexicalSense (sense frequency), ontolex:LexicalConcept (e.g., synset frequency), lexicog:Entry (if used for representing homonyms: frequency of non-disambiguated lemmas), etc. (cf. Fig. 1).
In particular, we consider all these elements as being countable, annotatable/attestable and suitable for a numerical representation by means of an embedding. For this reason, we introduce frac:Observable as a top-level element within the FrAC module that is used to define the rdfs:domain of any properties that link lexical and corpus-derived information.
Note: The definition
frac:Observabledoes not posit an exhaustive list of possible observables. Instead, anything that can be observed in a corpus can be defined asfrac:Observable. This includes elements of OntoLex modules not listed here (e.g.,decomp:Component,synsem:SyntacticArgument, etc.) or future OntoLex vocabularies. Likewise, it can also include URIs which have no relation to OntoLex whatsoever, as these are foreseen as external elements that OntoLex-Lemon can provide information about, but only if they are based on or linked with corpus information, attested in a document, a text or its annotations.
URI: http://www.w3.org/nl/lemon/frac#Observation Observation is an abstract superclass for anything that can be observed in a corpus about an Observable. An observation MUST have at least one
rdf:valueto express its value, it SHOULD have exactly onefrac:observedInproperty that defines the data from which this information was drawn, and it SHOULD have adct:descriptionexplaining the methodolgy and/or extraction method by which the observation was obtained. rdfs:subclassOf 1frac:observedInrdfs:subclassOf min 1dct:descriptionrdfs:subClassOf 1 rdf:value
frac:Observation
a owl:Class;
rdfs:subClassOf [
a <http://www.w3.org/2002/07/owl#Restriction> ;
<http://www.w3.org/2002/07/owl#minCardinality> "1"^^<http://www.w3.org/2001/XMLSchema#nonNegativeInteger> ;
<http://www.w3.org/2002/07/owl#onProperty> rdf:value
] ;
rdfs:subClassOf [
a <http://www.w3.org/2002/07/owl#Restriction> ;
<http://www.w3.org/2002/07/owl#minCardinality> "1"^^<http://www.w3.org/2001/XMLSchema#nonNegativeInteger> ;
<http://www.w3.org/2002/07/owl#onProperty> frac:observedIn
] ;
# the following constraint is semantically empty
# it is supposed to express that there should be
# a human-readable description, but we don't enforce it
# in order not to break validation
rdfs:subClassOf [
a <http://www.w3.org/2002/07/owl#Restriction> ;
<http://www.w3.org/2002/07/owl#minCardinality> "0"^^<http://www.w3.org/2001/XMLSchema#nonNegativeInteger> ;
<http://www.w3.org/2002/07/owl#onProperty> dct:description
] ;
vs:term_status "tbc" .
Observations as understood here are empirical (quantitative) observations that are made against a corpus, a text, a document or another type of language data. Observations can be made in any kind of (collection or excerpt of) linguistic data at any scale, structured or unstructured, regardless of its physical materialization (as an electronic corpus, as a series of printed books, as a bibliographical database or as metadata record for a particular corpus).
For a
frac:Observation, the property observedIn defines the URI of the data source (or its metadata entry) that this particular observation was made in or derived from. This can be, for example, a corpus or a text represented by its access URL, a book represented by its bibliographical metadata, etc. As these data sources can have different characteristics, users SHOULD specify their respective type using the DCMI Type Vocabulary. Domain: frac:Observation Range: anyURI
frac:observedIn
a owl:ObjectProperty ;
rdfs:domain frac:Observation ;
rdfs:range [
a owl:Restriction ;
owl:onProperty rdf:type ;
owl:someValuesFrom [
a owl:Restriction ;
owl:onProperty dcam:memberOf ;
owl:hasValue dcterms:DCMIType ] ] ;
vs:term_status "tbc" ;
rdfs:comment """For an Observation, the property observedIn defines the URI of the data
source (or its metadata entry) that this particular observation was made in or derived from.
This can be, for example, a corpus or a text represented by its access URL, a book
represented by its bibliographical metadata, etc."""@en .
For machine-readable corpora that are/can be characterized by their size, data providers can provide overall size information using the property frac:total, see section on Frequency below.
We provide four examples for FrAC data sources below:
-
2012 English news subcorpus of the Leipzig Corpora collection, primarily used for computational lexicography. For
frac:total, see the frequency section. The data provider provides the total number of sentences, lemmas ("types") and words ("tokens"), as reflected by the units of thefrac:Frequency. The use of additional language resource metadata, e.g., language or publication year, is highly recommended, but not formally required.<http://corpora.uni-leipzig.de/en/res?corpusId=eng_news_2012> a dcmitype:Collection ; frac:total [ a frac:Frequency ; frac:measure "sentences" ; rdf:value "8,525,045" ] , [ a frac:Frequency ; frac:measure "tokens" ; rdf:value "177,363,729" ] , [ a frac:Frequency ; frac:measure "lemmas" ; rdf:value "1,126,551" ] ; dct:language <http://lexvo.org/id/iso639-3/eng> ; dct:date "2012" ; dct:description """Leipzig Corpora Collection: English news corpus based on material from 2012. Leipzig Corpora Collection. Dataset."""@en . -
Google Books NGrams, a collection of n-grams. This is not a corpus, but a table of tab-separated values with sequences of words, their frequency in the underlying corpus and the number of individual documents they occur in (document frequency) for individual languages and n-gram sizes. This is a multilingual resource, so we cannot provide a unique language code. Further, it does not provide a total.
<https://books.google.com/ngrams> a dcmitype:Dataset . -
The EPSD corpus, the data basis underlying the Electronic Penn Sumerian Dictionary. This is a multilingual corpus, consisting primarily of Sumerian, but also of Akkadian texts, hence it provides two language codes. The frequencies ("almost ...", "over ...") are provided in the same form as on the EPSD website for version 2.7. Note that
frac:Frequencycan be RDFS-inferred fromfrac:totalandfrac:measure, so that it can be left implicit.<http://oracc.museum.upenn.edu/epsd2> a dcmitype:Collection ; dct:language "sux", "akk" ; frac:total [ frac:measure "lexemes" ; rdf:value "almost 16,000" ] ; frac:total [ frac:measure "names" ; rdf:value "over 50,000" ] ; frac:total [ frac:measure "distinct forms" ; rdf:value "more than 225,000" ] ; frac:total [ frac:measure "texts" ; rdf:value "over 110,000" ] ; frac:total [ frac:measure "tokens" ; rdf:value "almost 3.4 million" ] . -
Yet another type of FrAC data sources are
dcmitype:Textobjects, including digitally edited text, edited text bundled with metadata about the original text, or digital metadata about a non-digital text. Also note that in this particular case, the only total provided by the original metadata / description (indirectly, though) is that this constitutes one letter.<https://www.dbnl.org/tekst/groo001brie04_01/groo001brie04_01_0003.php> a dcmitype:Text ; dct:language "nl" ; dct:date "1629-01-06" ; dct:author "N. van Reigersberch" ; rdfs:comment """Hugo de Groot, Briefwisseling van Hugo Grotius. Deel 4(1964), 1361. 1629 januari 6. Van N. van Reigersberch, Adres: (A Mon)sieur Monsieur Grotius à Paris. In dorso schreef Grotius: 6 Jan. 1629 N. Reigersberg."""@nl .Note: For anchoring individual attestations in documents, groups of documents, or their components, the property
frac:locuscan be used in addition tofrac:observedIn, see Attestation section below. Furthermore, it is recommended to employ specialized vocabularies for bibliographical references.
Implementation note: tbc. whether all example datasets used in text are listed here
Note that for FrAC data sources illustrated above, we use the original access URL as data source URI. As these will resolve only if the data providers themselves provide linked-data-compliant metadata, these URIs will not resolve at the moment. For providers of lexical data, a best practice recommendation for cases in which they are not in control of the access URL is to mint (and host) a distinct data source URI and define it to be
owl:sameAsthe access URL.
#############
# frequency #
#############
back to (Table of Contents)
Frequency information is a crucial component in human language technology. Corpus-based lexicography originates with Francis and Kucera (1958), and subsequently, the analysis of frequency distributions of word forms, lemmas and other linguistic elements has become a standard technique in lexicography and philology, and given rise to the field of corpus linguistics. At its core, this means that lexicographers use (corpus) frequency and distribution information while compiling lexical entries (also see the section on collocations and similarity below). As a qualitative assessment, frequency can be expressed with lexinfo:frequency, "[t]he relative commonness with which a term occurs". However, this is an object property with possible values lexinfo:commonlyUsed, lexinfo:infrequentlyUsed, lexinfo:rarelyUsed, while absolute counts over a particular resource (corpus) require novel vocabulary elements.
For modelling, we focus on absolute frequencies, as relative frequencies can be derived if absolute frequencies and totals are known. Absolute frequencies are used in computational lexicography (e.g., the Electronic Penn Sumerian Dictionary), and they are an essential piece of information for NLP and corpus linguistics. In order to avoid confusion with lexinfo:Frequency (which provides lexicographic assessments such as commonly used, infrequently used, etc.), this is defined with reference to a particular dataset, a corpus.
URI: http://www.w3.org/nl/lemon/frac#Frequency Frequency is a
frac:Observationof the absolute number of attestations (rdf:value) of a particularfrac:Observable(seefrac:frequency) that isfrac:observedInin a particular data source. Usingfrac:unit, frequency objects can also identify the (segmentation) unit that their counts are based on. SubClassOf:frac:ObservationSubClassOf:rdf:valueexactly 1 ,frac:observedInexactly 1
frac:Frequency
a owl:Class ;
rdfs:subClassOf frac:Observation ;
rdfs:subClassOf [
a owl:Restriction ;
owl:cardinality "1"^^xsd:nonNegativeInteger ;
owl:onDataRange xsd:int ;
owl:onProperty rdf:value
] ;
vs:term_status "stable" .
URI: http://www.w3.org/nl/lemon/frac#unit For a
frac:Frequencyobject, the property unit provides an identifier of the respective segmentation unit. rdfs:rangefrac:Frequency
Examples for frac:unit include string literals such as "tokens", "sentences", etc. If a future community standard provides reference URIs for such datatypes, frac:unit should be used as a datatype property. Until such a convention has been established, it is recommended to be used as a datatype property.
Note: One function of
frac:unitis to calculate relative frequencies from absolute values as provided by therdf:valueoffrac:Frequencyobjects. While these can be calculated by divingrdf:valueof a particular frequency object f by therdf:valueof itsfrac:observedIn/frac:total, this equation is restricted to frequency objects using the samefrac:unit.
Implementation note: check whether domain and range are always put right!
URI: http://www.w3.org/nl/lemon/frac#frequency The property frequency assigns a particular
frac:Observableafrac:Frequency. rdfs:domainfrac:Observablerdfs:rangefrac:Frequency
frac:frequency
a owl:ObjectProperty ;
rdfs:domain frac:Observable ;
rdfs:range frac:Frequency ;
vs:term_status "stable" .
If information from multiple language resources is aggregated (also cf. the section on embeddings below), these should be aggregated into a a single data source that can be referred to by
frac:observedIn, as there must be exactly onefrac:observedIn.
TODO: make sure that this unique cardinality constrain is respected in the examples here.
The definition above only applies to absolute frequencies. For expressing relative frequencies, we expect the associated data source (frac:observedIn) object to define a total of elements contained (frac:total). In many practical applications, it is necessary to provide relative counts, and in this way, these can be easily derived from the absolute (element) frequency provided by the Frequency class and the total defined by the underlying corpus. If the real absolute values are unknown and only relative scores are provided, data providers should use percentage values for both the Frequency rdf:value and for the frac:total (i.e., 100%) of the associated corpus.
The object property total assigns any potential FrAC data source (i.e.,
dct:Collection,dct:Dataset,dct:Textor any other member of DCMI Type) the total number of elements that it contains as afrac:Frequencyobject. Domain: class that is adcam:memberOfDCMI Type Range: frac:Frequency
Note: For
frac:total, users should provide both the frequency and the segmentation/unit over which this frequency is obtailed. For an observable, then, relative frequencies (for any given unit u) can then be calculated from the object values offrac:frequency/rdf:valueandfrac:frequency/frac:observedIn/frac:total/rdf:valueif (and only if) the correspondung units match.
frac:total
a owl:DatatypeProperty, owl:FunctionalProperty ;
rdfs:domain [
a owl:Restriction ;
owl:onProperty rdf:type ;
owl:someValuesFrom [
a owl:Restriction ;
owl:onProperty dcam:memberOf ;
owl:hasValue dcterms:DCMIType ] ] ;
rdfs:range xsd:int ;
rdfs:label "could be renamed to frac:tokens, as different kinds of totals as possible for multi-word expressions"@en ;
vs:term_status "tbc" .
The following example illustrates word and form frequencies for the Sumerian word a (n.) "water" from the Electronic Penn Sumerian Dictionary and the frequencies of the underlying corpus.
# word frequency, over all form variants
epsd:kalag_strong_v a ontolex:LexicalEntry;
frac:frequency [
a frac:Frequency;
rdf:value "2398"^^xsd:int;
frac:observedIn <http://oracc.museum.upenn.edu/epsd2/pager>
] .
# form frequency for individual orthographical variants
epsd:kalag_strong_v ontolex:canonicalForm [
ontolex:writtenRep "kal-ga"@sux-Latn;
frac:frequency [
a frac:Frequency;
rdf:value "2312"^^xsd:int;
frac:observedIn <http://oracc.museum.upenn.edu/epsd2/pager>
]
] .
epsd:kalag_strong_v ontolex:otherForm [
ontolex:writtenRep "kalag"@sux-Latn;
frac:frequency [
a frac:Frequency;
rdf:value "70"^^xsd:int;
frac:observedIn <http://oracc.museum.upenn.edu/epsd2/pager>
]
] .
The example shows orthographic variation (in the original writing system, Sumerian Cuneiform sux-Xsux, and its Latin transcription sux-Latn). It is slightly simplified insofar as the ePSD2 provides individual counts for different periods and that only three of six orthographical variants are given. Note that these are orthographical variants, not morphological variants (which are not given in the dictionary).
It is necessary to provide the link to the underlying corpus for every frequency assessment because the same element may receive different counts over different corpora. For data modelling, it is recommended to define a corpus- or collection-specific subclass of frac:Frequency with a fixed
frac:observedInobject. This leads to more compact data and avoids potential difficulties with the Open World Assumption (interpretability of incomplete data).
# Frequency in the EPSD corpus
:EPSDFrequency rdfs:subClassOf frac:Frequency.
:EPSDFrequency rdfs:subClassOf
[ a owl:Restriction ;
owl:onProperty frac:observedIn ;
owl:hasValue ] .
# frequency assessment
epsd:a_water_n frac:frequency [
a :EPSDFrequency;
rdf:value "4683"^^xsd:int ].`
frac:Frequency can be extended with additional filter conditions to define sub-corpora. For example, we can restrict the subcorpus to a particular time period, e.g., the Neo-Sumerian Ur III period:
# EPSD frequency for the Ur-III period (aat:300019910)
:EPSDFrequency_UrIII
rdfs:subClassOf :EPSDFrequency;
rdfs:subClassOf
[ a owl:Restriction ;
owl:onProperty dct:temporal ;
owl:hasValue aat:300019910 ] .
# frequency assessment for sub-corpus
epsd:a_water_n frac:frequency [
a :EPSDFrequency_UrIII;
rdf:value "2299"^^xsd:int ].`
###############
# attestation #
###############
back to (Table of Contents)
Attestations constitute a special form of citation that provide evidence for the existence of a certain lexical phenomena; they can elucidate meaning or illustrate various linguistic features.
In scholarly dictionaries, attestations are a representative selection from the occurrences of a headword in a textual corpus. These citations often consist of a quotation accompanied by a reference to the source. The quoted text usually contains the occurrence of the headword.
URI: http://www.w3.org/nl/lemon/frac#Attestation An Attestation is a
frac:Observationthat represents one exact or normalized quotation or excerpt from a source document that illustrates a particular form, sense, lexeme or features such as spelling variation, morphology, syntax, collocation, register. An attestation SHOULD have anrdf:value, it CAN have afrac:gloss, and it SHOULD have afrac:observedInorfrac:locusobject to identify the source of this material. For an attestation,rdf:valuerepresents the text of a quotation as represented in the original source. If that needs to be distinguished or is different from the way how it is represented in the dictionary, FrAC users should usefrac:glossfor the latter purpose. SubClassOf:rdf:valuemax 1 SubClassOf:frac:Observation
frac:Attestation
rdfs:subClassOf frac:Observation ;
vs:term_status "stable" .
The property frac:attestation associates an attestation to the frac:Observable. This is a subproperty of
frac:citationusing concrete data as evidence. Domain:ObservableRange:AttestationSubPropertyOf:citation
frac:attestation
a owl:ObjectProperty ;
rdfs:domain frac:Observable ;
rdfs:range frac:Attestation ;
rdfs:subPropertyOf frac:citation ;
vs:term_status "stable" .
The property frac:citation associates a citation to the
Observableciting it. Domain:Observable
frac:citation
a owl:ObjectProperty ;
rdfs:domain frac:Observable ;
vs:term_status "tbc" .
In general, the object of a citation represents the successful act of citing an entity which can be referred to by a standardised bibliographic reference, cf. Peroni (2012) \cite{peroni2012fabio}:
[a Citation is] ``a conceptual directional link from a citing entity to a cited entity, created by a human performative act of making a citation, typically instantiated by the inclusion of a bibliographic reference in the reference list of the citing entity, or by the inclusion within the citing entity of a link, in the form of an HTTP Uniform Resource Locator (URL), to a resource on the World Wide Web''.
However, note that FrAC does not formally define a general "Citation" class to define the range of citation, but only provides Attestation as one specific possibility. Beyond attestations, different vocabularies have been suggested for linking bibliographical information, and we advise users of FrAC to make a consistent choice among them, adequate for their respective needs and the conventions of their users community. frac:citation serves as an interface to these external vocabularies. If the CITO vocabulary is used in a particular resource, their FrAC Citations can be defined as the subclass of CITO citations having frac:Observable as citing entity and attestations would correspond to citations with the cito:hasCitationCharacterization value citesAsEvidence. Other relevant vocabularies include, for example, BIBFRAME, FRBR and FaBiO, but also, generic vocabularies such as schema.org.
The gloss of an attestation contains the text content of an attestation as represented within a dictionary. This property should not be used to provide direct quotations from the original data source, which should be represented by
rdf:value. Instead, its recommended use is for representations that are either enriched (e.g., by annotations and metadata), amended (e.g., by expanding ligatures or omissions), simplified (e.g., by omissions from the original context, e.g., of the lexeme under consideration) or otherwise differentiated from the plain text representation of the context. Domain:AttestationRange:xsd:String
frac:gloss
a owl:DatatypeProperty ;
rdfs:domain frac:Attestation ;
rdfs:range xsd:string ;
rdfs:comment "An attestation gloss is the representation of the attestation as provided in a lexical resource. This may contain, for example, amendments or additional comments. For the string as found in the original text, use rdf:value." ;
vs:term_status "tbc" .
Note: With
frac:glossandrdf:value,frac:Attestationprovides two different properties to represent the context of an observable in any particular data source.rdf:valueshould provide information as found in the underlying corpus, e.g., a plain text string. If the dictionary provides a different representation, or if the attestation as given in an underlying dictionary has not yet been confirmed to match the context in the underlying corpus, applications should usefrac:glossinstead ofrdf:value. In other words,rdf:valuecorresponds to the representation of the context in the underlying corpus,frac:glossto its representation in the underlying dictionary. If both are confirmed to be equal, userdf:value.
As an example, for Old English hwæt-hweganunges, Bosworth (2014) gives the example "Ða niétenu ðonne beóþ hwæthuguningas [MS. Cote. -hwugununges] .... In OntoLex-FrAC, this would be the frac:gloss because it contains additional information about spelling variation/normalized spelling not found found in the quoted source (MS. Cote.):
<https://bosworthtoller.com/20070> a ontolex:LexicalEntry;
frac:attestation [
a frac:Attestation;
rdf:value "Ða niétenu ðonne beóþ hwæthwugununges" ;
frac:gloss "Ða niétenu ðonne beóþ hwæthuguningas [MS. Cote. -hwugununges] ..."
# TODO: resolve literature pointers properly!
] .
Bosworth, Joseph. “hwæt-hweganunges.” In An Anglo-Saxon Dictionary Online, edited by Thomas Northcote Toller, Christ Sean, and Ondřej Tichy. Prague: Faculty of Arts, Charles University, 2014. https://bosworthtoller.com/20070. [REFORMAT]
In many applications, it is desirable to specify the location of the occurrence of a headword in the quoted text of an attestation, for example, by means of character offsets. Different conventions for referencing strings by character offsets do exist, representative solutions are string URIs as provided by RCF5147 (for plain text) and NIF (all mimetypes), As different vocabularies can be used to establish locus objects, the FrAC vocabulary is underspecified with respect to the exact nature of the locus object. Accordingly, the locus property that links an attestation with its source takes any URI as object.
frac:locus points to the location at which the relevant word(s) can be found. Domain:
Attestation
frac:locus
a owl:ObjectProperty ;
rdfs:domain frac:Attestation ;
vs:term_status "stable" ;
rdfs:comment """Points from an Observation to the exact location in the source material on where it is to be found. This can be, for example, a page in a book, the string URI of a passage in a text, a canonical reference to a passage in piece of literatur, or any Web Annotation selector. We have confirmed name, function and necessity of this property.
When the locus is provided, it is not necessary to also refer to the source material as a whole. The existence of such a reference is nevertheless implied."""@en .
Note: In humanities practice, locations (
frac:locusobjects) can be provided at different levels of granularity, e.g., referring to a particular text span within a text, to a verse, paragraph or chapter within which the text can be found, to a complete work, or a collection of works. Data providers should generally usefrac:observedInunless the the specific semantics require the use offrac:locus. In particular, if the location is a complete work (e.g.,dct:Text) or a corpus identifiable by a URI (i.e., adct:Collection), data providers should use thefrac:observedInproperty. For references within a work or to a collection without explicitly defined boundaries (e.g.,Platoto designate all of Plato's preserved works as well as any statement ascribed to him from an unpreserved work), data providers should usefrac:locus.
Implementation note: as the type of data source is now to indicated by
dct:DMCIType, we can mergefrac:locusandfrac:observedIn, again.
example: DiaMaNT (Diachroon seMAntisch lexicon van de Nederlandse Taal) is a diachronic semantic computational lexicon of Dutch, at its core formed by four scholarly historical dictionaries of Dutch covering a language period from ca. 500 – 1976. The example below illustrates the combination of FrAC attestations with the CITO and FRBR vocabularies, as well as with the NLP Interchange Format.
diamant:entry_WNT_M030758 a ontolex:LexicalEntry ;
ontolex:sense diamant:sense_WNT_M030758_bet_207 .
diamant:sense_WNT_M030758_bet_207 a ontolex:LexicalSense;
rdfs:label "V.-" ;
frac:attestation diamant:attestation_2108540 ;
skos:definition "Iemand een kat (of de kat) aan het been jagen...... iemand in moeilijkheden brengen." .
diamant:attestation_2108540 a frac:Attestation ;
cito:hasCitedEntity diamant:cited_document_WNT_332819 ;
cito:hasCitingEntity diamant:sense_WNT_M030758_bet_207;
frac:locus diamant:locus_2108540 ;
frac:quotation "... dat men licht yemant de cat aen het been kan werpen," .
diamant:locus_2108540 a diamant:Occurrence ;
nif:beginIndex 107 ;
nif:endIndex 110 .
diamant:cited_document_WNT_332819 a frbr:Manifestation ;
frbr:embodimentOf diamant:expression_WNT_332819 ;
diamant:witnessYearFrom 1621 ;
diamant:witnessYearTo 1621 .
diamant:expression_WNT_332819 a frbr:Expression ;
dcterms:creator "N. V. REIGERSB." ;
dcterms:title "Brieven van Nicolaes van Reigersberch aan Hugo de Groot" ;
frbr:embodiment diamant:quotation_WNT_332819 .
Note: In the example above, NIF is not correctly used: NIF requires string URIs for loci, including the identification of the source document within the base URI and the identification of a context (this is instead provided via hasCitedEntity). To be revised or replaced.
Note: Update example to https://www.dbnl.org/tekst/groo001brie04_01/groo001brie04_01_0003.php?q=dat%20men%20licht%20yemant%20de%20cat%20aen%20het%20been%20kan%20werpen;#hl1
###############
# collocation #
###############
back to (Table of Contents)
Collocation analysis is an important tool for lexicographical research and instrumental for modern NLP techniques. It has been the mainstay of 1990s corpus linguistics and continues to be an area of active research in computational philology and lexicography.
Collocations are usually defined on surface-oriented criteria, i.e., as a relation between forms or lemmas (lexical entries), not between senses, but they can be analyzed on the level of word senses (the sense that gave rise to the idiom or collocation). Indeed, collocations often contain a variable part, which can be represented by a ontolex:LexicalConcept.
Collocations can involve two or more words, they are thus modelled as an rdfs:Container of frac:Observabless. Collocations may have a fixed or a variable word order. Where fixed word order is required, the collocation must be defined as a sequence (rdf:Seq), otherwise, the default interpretation is as an ordered set (rdf:Bag).
Collocations obtained by quantitative methods are characterized by their method of creation (dct:description), their collocation strength (rdf:value), and the corpus or data source used to create them (frac:observedIn). Collocations share these characteristics with other frac:Observations and thus, these are inherited from the abstract frac:Observation class.
URI: http://www.w3.org/nl/lemon/frac#Collocation A Collocation is a frac:Observation that describes the co-occurrence of two or more frac:Observabless within the same context window and that can be characterized by their collocation score (or weight, frac:cScore) in a particular data source (frac:observedIn). Collocations are both observations and observables, and they are modelled as an aggregate (
rdfs:Container) of observables. SubClassOf: frac:Observation, rdfs:Container, frac:Observable rdfs:member: only frac:Observable SubClassOf:frac:headmax 1
frac:Collocation
rdfs:subClassOf rdfs:Container, frac:Observable, frac:Observation, [
a owl:Restriction ;
owl:minQualifiedCardinality "2"^^xsd:nonNegativeInteger ;
owl:onClass frac:Observable ;
owl:onProperty rdfs:member
] ,
[
a <http://www.w3.org/2002/07/owl#Restriction> ;
<http://www.w3.org/2002/07/owl#allValuesFrom> <http://www.w3.org/ns/lemon/frac#Observable> ;
<http://www.w3.org/2002/07/owl#onProperty> <http://www.w3.org/2000/01/rdf-schema#member>
] ;
vs:term_status "stable" .
Collocations are collections of frac:Observables, and formalized as rdfs:Container, i.e., rdf:Seq or rdf:Bag. The elements of any collocation can be accessed by rdfs:member. In addition, the elements of an ordered collocation (rdfs:subClassOf rdf:Seq) can be accessed by means of numerical indices (rdf:_1, rdf:_2, etc.).
By default, frac:Collocation is insensitive to word order. If a collocation is word order sensitive, it should be defined as rdfs:subClassOf rdf:Seq. Collocation analysis typically involves additional parameters such as the size of the context window considered. Such information can be provided in human-readable form in dct:description.
Collocations are frac:Observables, i.e., they can be ascribed frac:frequency, frac:attestation, frac:embedding, they can be described in terms of their (embedding) similarity, and they can be nested inside larger collocations.
Collocations can be described in terms of various collocation scores. If scores for multiple metrics are being provided, these should not use the generic rdf:value property, but a designated subproperty of frac:cScore:
URI: http://www.w3.org/nl/lemon/frac#Collocation Collocation score is a subproperty of
rdf:valuethat provides the value for one specific type of collocation score for a particular collocation in its respective corpus. Note that this property should not be used directly, but instead, its respective sub-properties for scores of a particular type. SubPropertyOf: rdf:value domain: frac:Collocation
frac:cScore
rdfs:subPropertyOf rdf:value ;
rdfs:domain frac:Collocation ;
vs:term_status "stable" .
FrAC defines a number of popular collocation metrics as sub-properties of frac:cScore:
frac:relFreq(relative frequency):(asymmetric, requires
frac:head)frac:relFreq rdfs:subPropertyOf frac:cScore .frac:pmi(pointwise mutual information, sometimes referred to as MI-score or association ratio, cf. Church and Hanks 1990, via Ewert 2005:frac:pmi rdfs:subPropertyOf frac:cScore .frac:pmi2(PMI²-score):frac:pmi2 rdfs:subPropertyOf frac:cScore .frac:pmi3(PMI³-score, cf. Daille 1994 in Ebert 2005, p.89):frac:pmi3 rdfs:subPropertyOf frac:cScore .frac:pmiLogFreq(PMI.log-f, salience, formerly default metric in SketchEngine):frac:pmiLogFreq rdfs:subPropertyOf frac:cScore .frac:dice(Dice coefficient):frac:dice rdfs:subPropertyOf frac:cScore .frac:logDice(default metric in SketchEngine, Rychly 2008):frac:logDice rdfs:subPropertyOf frac:cScore .frac:minSensitivity(minimum sensitivity, cf. Pedersen 1998):frac:minSensitivity rdfs:subPropertyOf frac:cScore .
with
the (head) word and its collocate
the number of occurrences of the word x
the number of occurrences of the word y
the number of co-occurrences of the words x and y
relative frequency of y
the total number of words in the corpus, this should be documented in
dct:description
In addition to collocation scores, also statistical independence tests are being employed as collocation scores:
frac:logLikelihood(log likelihood, G² Dunning 1993, via Ewer 2005)frac:logLikelihood rdfs:subPropertyOf frac:cScore .frac:tScore(Student's t test, T-score, cf. Church et al. 1991, via Ewert 2005, p.82 ):frac:tScore rdfs:subPropertyOf frac:cScore .frac:chi2(Person's Chi-square test Manning 1999 ):frac:chi2 rdfs:subPropertyOf frac:cScore .
with
-
-
-
-
In addition to classical collocation metrics as established in computational lexicography and corpus linguistics, related metrics can also be found in different disciplines and are represented here as subproperties of frac:cScore, as well. This includes metrics for association rule mining. In this context, an association rule (collocation) means that the existence of word x implies the existence of word y
frac:support(the support is an indication of how frequently the rule appears in the dataset):(with N the total number of collocations)
frac:support rdfs:subPropertyOf frac:cScore .frac:confidence(the confidence is an indication of how often the rule has been found to be true):frac:confidence rdfs:subPropertyOf frac:cScore .frac:lift(the lift or interest of a rule measures how many times more often x and y occur together than expected if they are statistically independent):frac:lift rdfs:subPropertyOf frac:cScore .frac:conviction(the conviction of a rule is interpreted as the ratio of the expected frequency that x occurs without y, i.e., the frequency that the rule makes an incorrect prediction, if x and y are independent divided by the observed frequency of incorrect predictions):frac:conviction rdfs:subPropertyOf frac:cScore .
Note: As OntoLex does not provide a generic inventory for grammatical relations, scores defined for grammatical relations are omitted (cf. https://www.sketchengine.eu/wp-content/uploads/ske-statistics.pdf). However, these may be defined by the user.
Many of these metrics are asymmetric and distinguish the lexical element they are about (the head) from its collocate(s). If such metrics are provided, a collocation should explicitly identify its head:
URI: http://www.w3.org/nl/lemon/frac#Collocation The head property identifies the element of a collocation that its scores are about. A collocation must not have more than one head. domain: frac:Collocation range: frac:Observable
frac:head
a owl:ObjectProperty ;
rdfs:domain frac:Collocation ;
rdfs:range frac:Observable ;
vs:term_status "stable" .
As an example, the relative frequency score is the number of occurrences of a collocation relative to the overall frequency of its head.
Note: The function of the property
frac:headis restricted to indicate the directionality of asymmetric collocation scores. It must not be confused with the notion of "head" in certain fields of linguistics, e.g., dependency syntax. Note:frac:headshould not be used to model the structure of collocation dictionaries, i.e., the selection of collocations to be displayed with a particular head word. For these functions, please resort to the *lexicog:` vocabulary.
The most elementary level of a collocation is an n-gram, as provided, for example, by Google Books, which provide n-gram frequencies per publication year as tab-separated values. For 2008, the 2012 edition provides the following statistics for the bigram kill + switch.
# form-form bigrams kill switch 2008 199 121 # form-lexeme bigrams kill switch_NOUN 2008 187 115 kill switch_VERB 2008 8 8 # lexeme-form bigrams kill_ADJ switch 2008 70 48 kill_NOUN switch 2008 89 64 kill_VERB switch 2008 40 30 # lexeme-lexeme bigrams kill_VERB switch_VERB 2008 2 2 kill_NOUN switch_NOUN 2008 83 61 kill_VERB switch_NOUN 2008 35 26 kill_ADJ switch_NOUN 2008 69 48 kill_NOUN switch_VERB 2008 6 6`
In this example, forms are string values (cf. ontolex:LexicalForm), lexemes are string values with parts-of-speech (cf. ontolex:LexicalEntry). A partial ontolex-frac representation is given below:
# kill (verb) :kill_v a ontolex:LexicalEntry; lexinfo:partOfSpeech lexinfo:verb; ontolex:canonicalForm :kill_cf. # kill (canonical form) :kill_cf ontolex:writtenRep "kill"@en. # switch (noun) :switch_n a ontolex:LexicalEntry; lexinfo:partOfSpeech lexinfo:noun; ontolex:canonicalForm :switch_cf. # switch (canonical form) :switch_cf ontolex:writtenRep "switch"@en. # form-form bigrams [ rdf:_1 :kill_cf; rdf:_2 :switch_cf ] a frac:Collocation, rdf:Seq ; rdf:value "199"; dct:description "2-grams, English Version 20120701, word frequency"; frac;observedIn ; dct:temporal "2008"^^xsd:date; lexinfo:termType lexinfo:idiom. [ rdf:_1 :kill_cf; rdf:_2 :switch_cf ] a frac:Collocation, rdf:Seq ; rdf:value "121"; dct:description "2-grams, English Version 20120701, document frequency"; frac:observedIn ; dct:temporal "2008"^^xsd:date; lexinfo:termType lexinfo:idiom. # form-lexeme bigrams [ rdf:_1 :kill_cf; rdf:_2 :switch_n ] a frac:Collocation, rdf:Seq ; rdf:value "187"; dct:description "2-grams, English Version 20120701, word frequency"; frac:observedIn ; dct:temporal "2008"^^xsd:date; lexinfo:termType lexinfo:idiom. [ rdf:_1 :kill_cf, rdf:_2 :switch_n ] a frac:Collocation, rdf:Seq ; rdf:value "115"; dct:description "2-grams, English Version 20120701, document frequency"; frac:observedIn ; dct:temporal "2008"^^xsd:date; lexinfo:termType lexinfo:idiom.`
The second example illustrates more complex types of collocation are provided as provided by the Wortschatz portal (scores and definitions as provided for beans, spill the beans, etc.
@prefix wsen: <http://corpora.uni-leipzig.de/en/res?corpusId=eng_news_2012&word=>
# selected lexical entries
# (we assume that every Wortschatz word is an independent lexical entry)
wsen:beans a ontolex:LexicalEntry;
ontolex:canonicalForm/ontolex:writtenRep "beans"@en.
wsen:spill a ontolex:LexicalEntry;
ontolex:canonicalForm/ontolex:writtenRep "spill"@en.
wsen:green a ontolex:LexicalEntry;
ontolex:canonicalForm/ontolex:writtenRep "green"@en.
wsen:about a ontolex:LexicalEntry;
ontolex:canonicalForm/ontolex:writtenRep "about"@en
# collocations, non-lexicalized
[ rdfs:member wsen:spill, wsen:beans ] a frac:Collocation;
rdf:value "182";
dct:description "cooccurrences in the same sentence, unordered";
frac:observedIn <http://corpora.uni-leipzig.de/en/res?corpusId=eng_news_2012>.
[ rdf:_1 wsen:green; rdf:_2 wsen:beans ] a frac:Collocation, rdf:Seq ;
rdf:value "778";
dct:description "left neighbor cooccurrence";
frac:observedIn <http://corpora.uni-leipzig.de/en/res?corpusId=eng_news_2012>;
lexinfo:termType lexinfo:idiom.
[ rdf:_1 wsen:beans; rdf:_2 wsen:about ] a frac:Collocation, rdf:Seq;
rdf:value "35";
dct:description "right neighbor cooccurrence";
frac:observedIn <http://corpora.uni-leipzig.de/en/res?corpusId=eng_news_2012>;
lexinfo:termType lexinfo:idiom.
# multi-word expression, lexicalized (!)
wsen:spill+the+beans a ontolex:MultiWordExpression;
ontolex:canonicalForm/ontolex:writtenRep "spill the beans"@en.
[ rdfs:member wsen:beans, wsen:spill+the+beans ] a frac:Collocation;
rdf:value "401";
dct:description "cooccurrences in the same sentence, unordered";
frac:obsevedIn <http://corpora.uni-leipzig.de/en/res?corpusId=eng_news_2012>.` </pre>
Again, it is recommended to define resource-specific subclasses of frac:Collocation with default values for dct:description, frac:obsevedIn, and (where applicable) lexinfo:termType.
#############
# embedding #
#############
back to (Table of Contents)
In distributional semantics, the contexts in which a word is attested are taken to define its meaning. Contextual similarity is thus a correlate of semantic similarity. Different representations of context are possible, the most prominent model to date is the form of a vector. A word vector can be created, for example, by means of a reference list of vocabulary items, where every reference word is associated with a fixed position, e.g., ship with position 1, ocean with 2, sky with 3, etc. Given a corpus (and a selection criterion for collocates, e.g., within the same sentence), every word in the corpus can be described by the frequency that a reference word occurred as a collocate in the corpus. Assume we want to define the meaning of frak, with (exactly) the following attestations in our sample corpus (random samples from wikiquote):
- It's in the frakking ship!
- Have you lost your frakkin' mind?
- Oh, for frak's sake, let me see if I can make heads or tails of it.
- It's a frakking Cylon.
- Our job isn't to be careful, it's to shoot Cylons out of the frakking sky!
With the following list of reference words: (ship, ocean, lose, find, brain, mind, head, sky, Cylon, ...), we obtain the vector (1,0,1,0,0,1,1,1,2,...) for the lemma (lexical entry) frak. For practical applications, these vectors are projected into lower-dimensional spaces, e.g., by means of statistical (Schütze 1993) or neural methods (Socher et al. 2011). The process of mapping a word to a numerical vector and its result are referred to as "word embedding". Aside from collocation counts, other methods for creating word embeddings do exist, but they are always defined relative to a corpus.
Embeddings have become a dominating paradigm in natural language processing and machine learning, but, if compiled from large corpora, they require long training periods and thus tend to be re-used. However, embedding distributions often use tool-specific binary formats (cf. Gensim), and thus a portability problem arises. CSV and related formats (cf. SENNA embeddings) are a better alternative, but their application to sense and concept embeddings (as provided, for example, by Rothe and Schütze 2017) is problematic if their distribution is detached from the definition of the underlying sense and concept definitions. With frac, Ontolex-lemon provides a vocabulary for the conjoint publication and sharing of embeddings and lexical information at all levels: non-lemmatized words (ontolex:Form), lemmatized words (ontolex:LexicalEntry), phrases (ontolex:MultiWordExpression), lexical senses (ontolex:LexicalSense) and lexical concepts (ontolex:LexicalConcept).
We focus on publishing and sharing embeddings, not on their processing by means of Semantic Web formalisms, and thus, embeddings are represented as untyped or string literals with whitespace-separated numbers. If necessary, more elaborate representations, e.g., using rdf:List, may subsequently be generated from these literals.
Lexicalized embeddings provide their data via rdf:value, and should be published together with their metadata, most importantly
- procedure/method (dct:description with free text, e.g., "CBOW", "SKIP-GRAM", "collocation counts")
- corpus (frac:observedIn)
- dimensionality (dct:extent)
URI: http://www.w3.org/nl/lemon/frac#Embedding An Embedding is a representation (of a given frac:Observable (see frac:embedding) in a numerical feature space. It is defined by the methodology used for creating it (dct:description), the URI of the corpus or language resource from which it was created (frac:observedIn). The literal value of an Embedding is provided by rdf:value). In OntoLex-FrAC, embeddings are
frac:Observations that are obtained from a particular corpus. SubClassOf: rdf:value exactly 1 xsd:string, frac:observedIn exactly 1, dct:description min 1 SubClassOf:frac:Observation
frac:Embedding
rdfs:subClassOf frac:Observation, [
a owl:Restriction ;
owl:onDataRange xsd:int ;
owl:onProperty dct:extent ;
owl:qualifiedCardinality "1"^^xsd:nonNegativeInteger
] ;
vs:term_status "stable" .
URI: http://www.w3.org/nl/lemon/frac#embedding The property embedding is a relation that maps a frac:Observable into a numerical feature space. An embedding is a structure-preserving mapping in the sense that it encodes and preserves contextual features of a particular frac:Observable (or, an aggregation over all its attestations) in a particular corpus. rdfs:range ontolex:Element rdfs:domain frac:Embedding
frac:embedding
a owl:ObjectProperty ;
rdfs:domain frac:Observable ;
rdfs:range frac:Embedding ;
vs:term_status "stable" .
split(/[^0-9\.,\-]+/, $value)
This means that doubles should be provided in the conventional format, not using the exponent notation.
Also note that different subclasses of frac:Embedding may have different encoding strategies.
URI: http://www.w3.org/nl/lemon/frac#FixedSizeVector A FixedSizeVector is the value of a frac:embedding into a fixed-size numerical feature space. The literal value (rdf:value) of a FixedSizeVector is a list of numbers. The dimensionality of the feature space should be encoded by dct:extent. SubClassOf: Embedding, dct:extent exactly 1
frac:FixedSizeVector
rdfs:subClassOf frac:Embedding ;
vs:term_status "stable" .
Word, sense or concept embeddings as conventionally used in language technology are fixed size vectors. The 50-dimensional GloVe 6B (Wikipedia 2014+Gigaword 5) embedding for frak is given below:
frak 0.015246 -0.30472 0.68107 -0.59727 -0.95368 -1.0931 0.58783 -0.19128 0.49108 0.61215 -0.14967 0.68197 0.22723 0.38514 -0.54721 -0.71187 0.21832 0.59857 0.1076 -0.23619 -0.86604 -0.91168 0.26087 -0.42067 0.60649 0.80644 -1.0477 0.67461 0.34154 -0.072511 -1.01 0.35331 -0.35636 0.9764 -0.62665 -0.29075 0.50797 -1.3538 0.18744 0.27852 -0.22557 -1.187 -0.11523 -0.078265 0.29849 0.22993 -0.12354 0.2829 1.0697 0.015366
As a lemma (LexicalEntry) embedding, this can be represented as follows:
:frak a ontolex:LexicalEntry;
ontolex:canonicalForm/ontolex:writtenRep "frak"@en;
frac:embedding [
a frac:FixedSizeVector;
rdf:value "[ 0.015246 , -0.30472 , 0.68107, ... ]"^^rdf:JSON;
frac:observedIn
<http://dumps.wikimedia.org/enwiki/20140102/>,
<https://catalog.ldc.upenn.edu/LDC2011T07>;
# note: two values for frac:obseredIn entails that these are owl:sameAs
dct:extent 50^^^xsd:int;
dct:description "GloVe v.1.1, documented in Jeffrey Pennington, Richard Socher, and Christopher D. Manning. 2014\. GloVe: Global Vectors for Word Representation, see https://nlp.stanford.edu/projects/glove/; uncased"@en. ].`
In this example, the rdf:value of the embedding is represented my a JSON array (abbreviated).
As with frac:Frequency, we recommend defining resource-specific subclasses of frac:Embedding in order to reduce redundancy in the data:
# resource-specific embedding class
:GloVe6BEmbedding_50d rdfs:subClassOf frac:FixedSizeVector;
rdfs:subClassOf
[ a owl:Restriction;
owl:onProperty frac:observedIn;
owl:hasValue
<http://dumps.wikimedia.org/enwiki/20140102/>,
<https://catalog.ldc.upenn.edu/LDC2011T07> ],
[ a owl:Restriction;
owl:onProperty rdf:value;
owl:allValuesFrom rdf:JSON ],
[ a owl:Restriction;
owl:onProperty dct:extent;
owl:hasValue 50^^xsd:int ],
[ a owl:Restriction;
owl:onProperty dct:description;
owl:hasValue "GloVe v.1.1, documented in Jeffrey Pennington, Richard Socher, and Christopher D. Manning. 2014\. GloVe: Global Vectors for Word Representation, see https://nlp.stanford.edu/projects/glove/; uncased"@en. ].
# embedding assignment
:frak a ontolex:LexicalEntry;
ontolex:canonicalForm/ontolex:writtenRep "frak"@en;
frac:embedding [
a :GloVe6BEmbedding_50d;
rdf:value "[ 0.015246 , -0.30472 , 0.68107 , ... ]"^^rdf:JSON.`
Examples for non-word embeddings:
- AutoExtend: (a method to build) synset and lexeme embeddings, data here
- SenseGram: sense embeddings, data here
- Vec2Synset: (a method to build) WordNet synset (= LexicalConcept) embeddings
- Character embeddings are probably beyond the scope of OntoLex, unless characters are regarded LexicalEntries. (Which they could, for languages such as Chinese or Sumerian certainly, but also for Western languages -- given the fact that character-level pseudo entries are sometimes used in dictionaries to describe the phonology and orthography of a language. This is the case, for example, for Grimm's Deutsches Wörterbuch.)
URI: http://www.w3.org/nl/lemon/frac#TimeSeries A TimeSeries is a sequence of observations represented as numerical values, e.g., sensor data. Every point in the sequence is represented by a fixed number of numerical values. The time series is the concatenation of these values. The obligatory attribute dct:extent defines the number of observations (dimensionality) for every individual point of time. SubClassOf: Embedding, dct:extent exactly 1
frac:TimeSeries
rdfs:subClassOf frac:Embedding ;
vs:term_status "stable" .
Note: name to be discussed. Maybe "Sequence". Example to be provided by Manolis and Sander. ...
Note: Other embeddings are usually obtained by aggregation over multiple attestations in a corpus. TimeSeries, however, can also encode a single observation that serves as a prototype.
Other examples of time series:
- a sequence of contextualized word embeddings to represent longer phrases, e.g., in attention-based neural architectures [REF: Bahdanau, D., Cho, K., & Bengio, Y. (2015, January). Neural machine translation by jointly learning to align and translate. In 3rd International Conference on Learning Representations, ICLR 2015. -- this ]
- formant analysis as provided in phonetic analysis by Praat [REF: Boersma, Paul; van Heuven, Vincent (2001). "Speak and unSpeak with Praat" (PDF). Glot International. 5 (9/10): 341–347.]
URI: http://www.w3.org/nl/lemon/frac#BagOfWords For any frac:Observable, a frac:BagOfWords represents the collocates it occurs with in a particular corpus. In a weighted bag of words, every collocate is stored together with a frequency, confidence score or association weight. A bag of words must not define a dct:extent.
SubClassOf: Embedding, dct:extent exactly 0
frac:BagOfWords
rdfs:subClassOf frac:Embedding ;
vs:term_status "stable" .
Bags of words can be compared to word embeddings (in languagte technology) in the sense that they represent infinite-dimensional, uncompressed frequency counts obtained from the aggregation over attestations in a corpus. The interpretability of their respective numerical dimensions, however, depends on the lexical provided along with it, so the normal data structure of a bag of words is not a vector, but a map (from collocates to weights, frequencies or association scores) or a set (of collocates, assuming each collocate is equally weighted). The encoding of the rdf:value must be specified in the dct:description. The example below uses an rdf:JSON literal representing a map.
Example taken from Wortschatz, collocations of frac (significant collocates in the same sentence), with frequency scores provided, filtered for significance (log-likelihood):
sand (508), mining (82), Chesterland-based (75), wells (73), DNR (73), Silica (53), fluid (52), category (51), spill (49), rigs (48), New Canaan (48), oil (47), drilling (46), County (45), shale (45), mine (43), Permian (41), tons (40), Canaan (39), gas (39), More (38), fracturing (38), Texas (37), Monroe (35), hydraulic (35), per (35), judge’s (35), plant (34), miner (34), fluids (34), Alpine (33), company (33), crews (30), producer (28), used (26), disposal (25), million (24), chemicals (23), premium (22), approximately (22), raw (21), coal (20), stages (20), review (20), permit (18), water (18), industry (18), industrial (17), fees (16), production (16), attorney (15), lines (14), active (13), Canadian (12), feet (12), demand (12), county (11), River (11), major (11), in (11)
:frac a ontolex:LexicalEntry;
ontolex:canonicalForm/ontolex:writtenRep "frac"@en;
frac:embedding [
a frac:BagOfWords;
dct:description "Cooccurrences of a word are those words that occur
noticeably often together with it. This may be the case as immediate
left neighbour, as immediate right neighbour, or in the same sentence.
The relevance of a cooccurrence is measured using a significance
measure; cooccurrences are ordered by their significance. At the
_Leipzig Corpora Collection_ the log-likelihood ratio is used as significance
measure and word pairs of little significance are removed.";
frac:observedIn <https://corpora.uni-leipzig.de/en/res?corpusId=eng_newscrawl-public_2018&word=frac>;
rdf:value " { \"sand\" : \"508\" , \"mining\" : \"82\" , ... }"^^rdf:JSON.`
Note: It is important to not confuse
frac:BagOfWordsandfrac:Collocation. Both represent words in their context, but they differ in their usage and interpretation. A bag of words is an aggregation over all contexts that a word occurs in. A collocation represents one specific context constellation and its likelihood to occur for the word.
The modelling described so far pertains to static (non-contextualized) embeddings.
Since 2018, static word and concept embeddings have been increasingly replaced by contextualized (dynamic) embeddings. For these, the embedding is not a property of the observable itself, but of the observable in a particular context (i.e., an attestation). This is modelled by means of frac:attestationEmbedding.
URI: http://www.w3.org/nl/lemon/frac#embedding The property attestation embedding is a relation that maps an attestation of a particular observable into a numerical feature space. The string representation of the attestation should represent the necessary context that the respective embedding is calculated from. rdfs:domain frac:Attestation rdfs:range frac:Embedding
frac:attestationEmbedding
a owl:ObjectProperty ;
rdfs:domain frac:Attestation ;
rdfs:range frac:Embedding ;
vs:term_status "stable" .
TODO: example attestation embedding
##############
# similarity #
##############
back to (Table of Contents)
Similarity is a paradigmatic relation between elements that can replace each other in the same context. In distributional semantics, a quantitative assessment of the similarity of two forms, lexemes, phrases, word senses or concepts is thus grounded in numerical representations of their respective contexts, i.e., their embeddings. In a broader sense of `embedding', also bags of words fall under the scope of frac:Embedding, see the usage note below.
Similarity is characterized by a similarity score (rdf:value), e.g., the number of shared dimensions/collocates (in a bag-of-word model) or the cosine distance between two word vectors (for fixed-size embeddings), the corpus used to generate this score (frac:observedIn), and the method used for calculating the score (dct:description).
Similarity is symmetric. The order of similes is irrelevant.
Like frac:Collocation, quantitative similarity relations are aggregates (containers, here rdfs:Bags) of Observables.
URI: http://www.w3.org/nl/lemon/frac#Similarity Similarity is a frac:Observation about the relatedness between two or more frac:Embeddings, and it is characterized by a similarity score (rdf:value) in a specific source corpus (frac:observedIn) and a dct:description that explains the method of comparison. SubClassOf: frac:Observation, rdfs:Bag rdfs:member: only frac:Embedding
frac:Similarity
rdfs:subClassOf rdf:Bag, frac:Observation, [
a owl:Restriction ;
owl:minCardinality "2"^^xsd:nonNegativeInteger ;
owl:onProperty rdfs:member
] ,
[
a <http://www.w3.org/2002/07/owl#Restriction> ;
<http://www.w3.org/2002/07/owl#allValuesFrom> <http://www.w3.org/ns/lemon/frac#Embedding> ;
<http://www.w3.org/2002/07/owl#onProperty> <http://www.w3.org/2000/01/rdf-schema#member>
] ;
vs:term_status "stable" .
frac:Similarity applies to two different use cases: The specific similarity between (exactly) two words, and similarity clusters (synonym groups obtained from clustering quantitatively obtained synonym candidates according to their distributional semantics in a particular corpus) that can contain an arbitrary number of words. Both differ in the semantics of rdf:value: Quantitatively obtained similarity relations normally provide a different score for every pair of similes. Within a similarity cluster, a generalization over these pair-wise scores must be provided. This could be the minimal similarity between all cluster members or a score produced by the clustering algorithm (e.g., depth or size of cluster). This must be explained in dct:description.
Similarity clusters are typical outcomes of Word Sense Induction techniques or unsupervised POS tagging. Classical sample data are Brown clusters, e.g., here or here.
Similarity is defined as a property of embeddings, not between ontolex:Elements. This excludes at least two important use cases:
- manual similarity assessments as used for evaluating similarity assessments, and as created, for example, as part of psycholinguistic association or priming experiments (also cf. WordNet synsets, which provide, however, detailed lexicographic information in addition to similarity, and which thus to be represented as ontolex:LexicalConcept),
- similarity assessments obtained by other means than embeddings, e.g., by means of a traditional bag of words.
In both (and similar) cases, the recommendation is to make use of (a resource-specific subclass of) frac:Embedding, nevertheless, and to document the specifics of the similarity relation and/or the embeddings in the dct:description of these embeddings. For the first use case, this approach can be justified by assuming that embeddings are correlated with a psycholinguistically `real' phenomenon. For the second use case, any bag of words can be interpreted as an infinite-size binary vector for which an embedding provides a fixed-size approximation.
As with frequency and embeddings, a resource-specific similarity type can be defined, analoguously. In particular, this is required if directed (asymmetric) similarity assessments are to be provided.
back to (Table of Contents)
The Ontolex Module for Frequency, Attestation and Corpus Information does not specify a vocabulary for annotating corpora or other data with lexical information, as this is being provided by the Web Annotation Vocabulary. The following description is non-normative as Web Annotation is defined in a separate W3C recommendation. The definitions below are reproduced, and refined only insofar as domain and range declarations have been refined to our usecase.
In Web Annotation terminology, the annotated element is the 'target', the content of the annotation is the `body', and the process and provenance of the annotation is expressed by properties of oa:Annotation.
IRI: http://www.w3.org/ns/oa#Annotation Required Predicates: oa:hasTarget, rdf:type, oa:hasBody Recommended Predicates: oa:motivatedBy, dcterms:creator, dcterms:created Other Predicates: oa:styledBy, dcterms:issued, as:generator
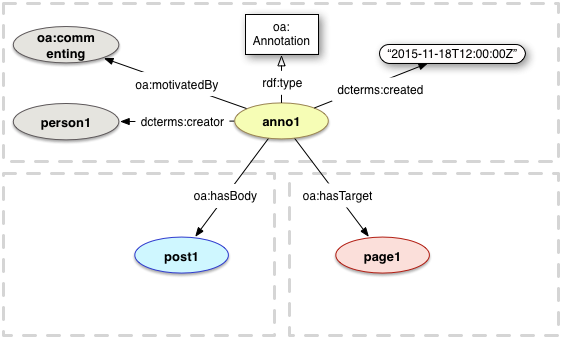
IRI: http://www.w3.org/ns/oa#hasBody The object of the relationship is a resource that is a body of the Annotation. In the context of lemon, the body is an ontolex:Element
IRI: http://www.w3.org/ns/oa#hasTarget The relationship between an Annotation and its Target. Domain: oa:Annotation
The Web Annotation Vocabulary supports different ways to define targets. This includes:
- plain URI: The target can be a URI defined within the corpus (e.g., if corpus data is provided as native RDF, or by means of the @about attribute in an HTML/XML+RDFa document, or by means of @xml:id in a TEI/XML document).
- string URI: String URIs provide the possibility to point directly to a text fragment in a web document, using the URI schemas as provided by RFC5147 (text files only) or NIF (all text-based formats).
- oa:TextPositionSelector: a range of text defined by the start and end positions of the selection in the stream
- oa:DataPositionSelector: a range of data by recording the start and end positions of the selection in the stream
- oa:TextQuoteSelector: The TextQuoteSelector describes a range of text by copying it. The TextQuoteSelector can include some of the text immediately before (a prefix) and after (a suffix) it to distinguish between multiple copies of the same sequence of characters. If this does suffice for disambiguation, all matching text fragments in the document are being annotated.
- oa:XPathSelector: select elements and content within a resource that supports the Document Object Model via a specified XPath value.
- oa:RangeSelector: identify the beginning and the end of the selection by using other Selectors.
oa:Annotation explicitly allows n:m relations between ontolex:Elements and elements in the annotated elements. It is thus sufficient for every ontolex:Element to appear in one oa:hasBody statement in order to produce a full annotation of the corpus.
As for frequency, embeddings, etc., resource-specific annotation classes can be defined by owl:Restriction so that modelling effort and verbosity are reduced. These should follow the same conventions.
back to (Table of Contents)
back to (Table of Contents)
As corpus-derived information requires provenance and other metadata, the frac module uses reification (class-based modelling) for concepts such as frequency or embeddings. In a data set, this information will be recurring, and for redundancy reduction, we recommend to provide resource-specific subclasses of frac concepts that provide metadata by means of owl:Restrictions that provide the value for the respective properties. This was illustrated above for the relevant frac classes.
As a rule of best practice, we recommend for such cases to provide (a copy of) the OWL definitions of resource-specific classes in the same graph (and file) as the data. Within the graph containing the data, the following SPARQL 1.1 query must return the full frac definition of all instances of, say, :EPSDFrequency (see examples above):
CONSTRUCT {
?data a ?class, ?sourceClass; ?property ?value.
} WHERE {
?data a ?sourceClass. # e.g., [] a :EPSDFrequency
?sourceClass (rdfs:subClassOf|owl:equivalentClass)* ?class.
FILTER(strstarts(str(?class),'http://www.w3.org/ns/lemon/frac#'))
# ?class: all superclasses of ?sourceClass which are in the frac namespace
{ # return all value restrictions
?class (rdfs:subClassOf|owl:equivalentClass)* ?restriction.
?restriction a owl:Restriction.
?restriction owl:onProperty ?property.
?restriction owl:hasValue ?value.
} UNION {
# return all directly expressed values
?data ?property ?value.
FILTER(?property in (frac:observedIn,rdf:value))
# TODO: update list of properties
}
}
This query can be used as a test for frac compliancy, and for property `inference'. Note that it does not support owl:intersection nor owl:join, nor owl:sameAs.
We use the OWL2/DL vocabulary for modelling restrictions. However, lemon is partially compatible with OWL2/DL only in that several modules use rdf:List -- which is a reserved construct in OWL2. Therefore, the primary means of accessing and manipulation lemon and ontolex-frac data is by means of SPARQL, resp., RDF- (rather than OWL-) technology. In particular, we do not guarantee nor require that OWL2/DL inferences can be used for validating or querying lemon and ontolex-frac data.
Note: TODO analoguous example for corpus-specific collocations
back to (Table of Contents)
Usually, numerical information drawn from corpora is distributed and shared as comma-separated values (CSV), e.g., ngram lists or embeddings. Ontolex-frac as an RDF vocabulary is agnostic about its serialization (RDF/TTL, RDF/XML, JSON-LD, etc.), but in particular, it is compliant with CSV and related tabular formats by means of W3C recommendations such as CSV2RDF, RDB Direct Mapping and the RDB to RDF Mapping Language. For corpus-derived lexical-semantic information which is typically distributed in CSV, the best practice is to continue to do so, but to provide a mapping to Ontolex-frac as this provides a vocabulary for their interpretation as Linked Data, and thus establishes an interoperability layer over the raw data without creating additional overhead.
Ontolex-frac is compliant with CSV formats, but its handling of structured information has an impact on the CSV format. In particular, individual dimensions of embeddings must not use comma as separator in order to be mapped to a single literal. For the example embedding of frak above, the first column (containing the word) should be comma-separated, the following columns (containing the embedding) should be white-space separated.
back to (Table of Contents)
TBC
back to (Table of Contents)
from lexicog, to be revised