The "fgrep problem" is to match a set of fixed strings in a corpus. The matching can be done "in parallel" by a DFA.
There are various methods to generate the DFA.
See the top of fixed-strings.sh for instructions on running these benchmarks.
Lobste.rs Discussion about Aho-Corasick Algorithm
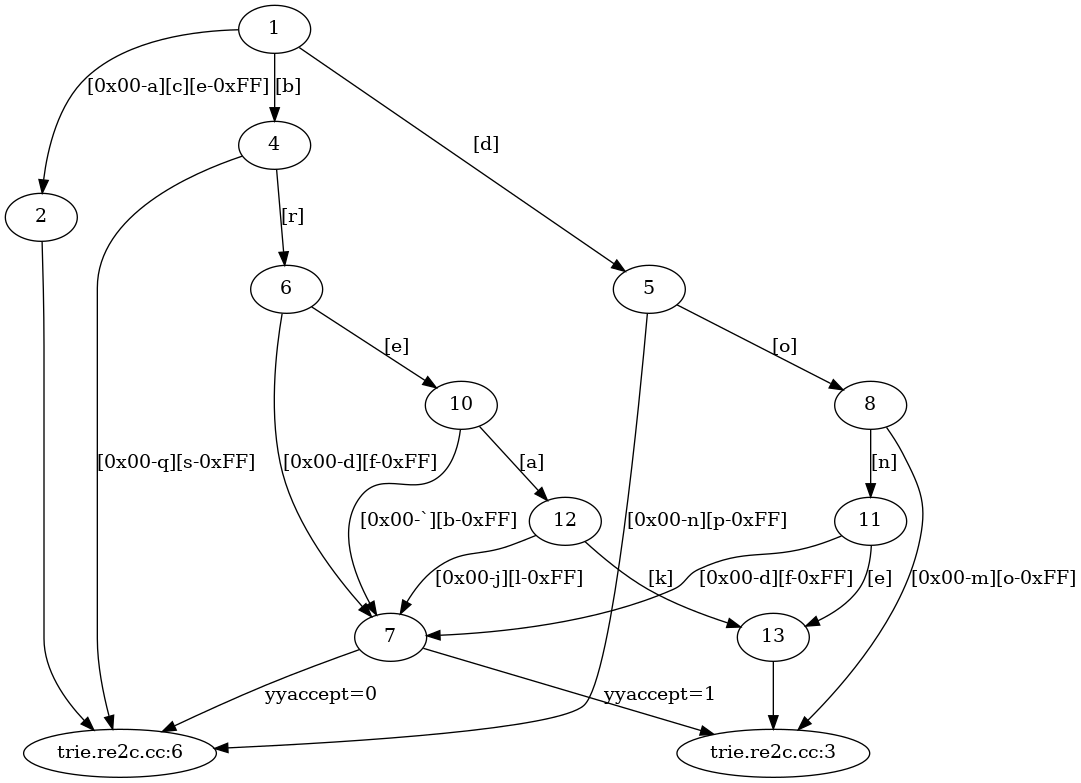
Simple DFA for "do" | "done" | "break". See below for the DFA for the bigger
benchmark problem.
Matching this file:
-rw-rw-r-- 1 andy andy 338M Nov 10 11:09 _tmp/all-10.txt
Against 13 keywords:
for while continue break if fi then else elif case esac do done
- DFA for fixed-strings.re2.cc
- Source generated by
re2c from fixed-strings.re2c.cc
Note that there are ~35 states
yy2-yy36. - Native code stats for
fixed-strings.re2c.cc.
GrepFixedStrings()is compiled to 791 bytes of native code. It has one or two variables, so all of them should fix in registers.
{kind=link}
| Benchmark | User Space Time (ms) | Real Time (ms) |
|---|---|---|
| cat | 0 | 46 |
| wc -l | 139 | 189 |
| fgrep | 1,368 | 1,432 |
| grep | 1,093 | 1,133 |
| ripgrep | 949 | 962 |
fixed-strings.cc read:count-lines (touch every byte in C++) |
49 | 186 |
fixed-strings.cc read:re2c-match (re2c compiler) |
1,211 | 1,347 |
re2_grep.cc (RE2 interpreter) |
1,906 | 2,055 |
| Python re | 5,781 | 5,946 |
NOTE: Each benchmarks matches the same set of strings, but the output is slightly different. I did enough experiments to convince myself that this doesn't matter. Aside from I/O, which we've accounted for, matching is the lion's share of the work, not say printing lines.
- grep is faster than native code! I think this is because doesn't touch every byte. It knows how to skip bytes in the fashion of Boyer-Moore. See links below.
- I think that Python is slower because it's a Perl-style backtracking
engine rather than an automata-based angine. However,
re.findall()must create a Python string object for every result (nearly 30 million of them), which is slow. So it might not be completely fair.
- Why GNU Grep is Fast (Discussions)
- ripgrep is faster than {grep, ag, git grep, ucg, pt, sift}
- ripgrep uses many strategies, including NFA, DFA, Aho-Corasick, and Teddy (SIMD)!
- aho-corasick library in Rust.
- Measure running time of other regex implementations on the same problem.
(Pull requests accepted.)
- Are all backtracking engines slower than automata-based engines?
- Compare Perl 5 vs. Python. Perl 5 is the "original" backtracking engine.
- Does interpreting vs. compiling make a difference?
grepis an interpreter but it beats a compiler, probably due to the strings it does not try to match. - Others like Go regex, which is based on re2?
- redgrep? Uses derivatives to construct automata. (I tried to build it but the dependencies seem out of date, and it doesn't have binaries.)
- Plot running time vs. number of strings. Right now we have a fixed set of 13 strings. It would be nice to do 2, 10, 20, 30, etc.