- 1. Lý thuyết
- 2. Bài tập
- 3. Nguồn tham khảo
File desciptor (file desciptor) là một con số xác định một file đang mở trong hệ điều hành máy tính. Nó mô tả tài nguyên dữ liệu và cách để truy cập tài nguyên.
Khi chương trình yêu cầu mở một file hoặc tài nguyên khác (như network socket) - kernel của OS cấp quyền truy cập, tạo một entry trong global file table và cung cấp cho phần mềm vị trí của entry đó.
Descriptor được xác định bởi một số nguyên không âm duy nhất (như 0, 12 hoặc 567). Ít nhất một file desciptor tồn tại cho mỗi file đang mở trên hệ thống.

File descriptors được sử dụng lần đầu tiên là trong Unix, và được sử dụng bởi các OS hiện đại như Linux, macOS X và BSD. Trong MS Windows, file descriptors được gọi là file handles.
Khi một process thực hiện một request để mở file thành công, kernel trả về một file descriptor trỏ tới một entry trong global file table trong kernel. File table entry bao gồm các thông tin như inode của file, byte offset và quyền truy cập cho data stream (read-only, write-only,...).
Trên OS như Unix, mặc định 3 file desciptors là STDIN (standard input - 0), STDOUT (standard output - 1) và STDERR (standard error - 2).
File desciptors có thể được truy cập trực tiếp bằng bash, shell của Linux, macOS X và Windows Subsystem for Linux (Win 10).
Ví dụ: Khi dùng lệnh find thành công, output đưa ra stdout và error đưa ra stderr (cả 2 được hiển thị trên terminal output).
Everything is a file
Trong các hệ điều hành Unix, file descriptor (FD) là một công cụ dùng để quản lý truy cập file, các thao tác nhập xuất, network socket, library files, file thực thi chương trình, chuột, bàn phím,... Nói cho đơn giản thì toàn bộ mọi thứ trên Unix điều được biểu diễn dưới dạng file. Và FD là các số nguyên không âm đại diện cho những file này.
Khi ta mở hoặc tạo một file, kernel sẽ trả về giá trị file descriptor cho process tương ứng. Khi ta đóng file đó lại thì file descriptor này sẽ được giải phóng để cấp phát cho những lần mở file sau. Ví dụ. nếu người dùng A mở 10 tập tin để đọc thì sẽ có 10 FD tương ứng (có thể được đánh số lần lượt là 101, 102, 103,…, 110) và các giá trị này sẽ được lưu trong bảng danh sách chứa file descriptors.
Mỗi một process sẽ có một bảng danh sách file descriptor riêng do kernel quản lý, kernel sẽ chuyển danh sách này sang danh sách file table quản lý toàn bộ file được truy cập bởi tất cả các process. File table này sẽ lưu lại chế độ mà file đó đang được sử dụng (đọc, ghi, chèn). Và file table này sẽ được mapping qua một bảng thứ 3 là inode table thật sự quản lý các file nằm bên dưới. Khi một tiến trình muốn đọc hoặc ghi file, tiến trình này sẽ chuyển file descriptor cho kernel xử lý (bằng các lệnh system call) và kernel sẽ truy cập file này thay cho process. Process không thể truy cập trực tiếp các file hoặc inode table.

Regular files
Chúng là các file mà dữ liệu là text, data hoặc program instructions và chúng là loại tệp phổ biến nhất trong Linux system:
- Readable files
- Binary files
- Image files
- Compressed files ...
Special files
Block files
Chúng là các device file mà cung cấp buffered access cho các thành phần phần cứng hệ thống. Chúng cung cấp các phương pháp giao tiếp với device drivers thông qua file system.
Chúng có thể truyền một block data và information lớn tại một thời điểm nhất định.
Character files
Chúng cũng là các device file mà cung cấp unbuffered serial access tới thành phần phần cứng hệ thống. Chúng hoạt động bằng cách cung cấp cách giao tiếp với device thông qua truyền data one character tại một thời điểm.
Symbolic link files
Chúng là cách tham chiếu tới file khác trên hệ thống. Do đó, chúng là các file mà trỏ tới các file khác (các thư mục hoặc regular files).
VD: Tạo một file tên file1.txt trong /tmp sau đó dùng lệnh ln -s file1.txt /home/vuongnguyen/file1.txt để tạo symbolic link.
Pipes or Named pipes
Đây là các file cho phép giao tiếp process bằng cách kết nối output của một process tới input của process khác.
VD: Dùng mkfifo để tạo pipe: mkfifo pipe1, sau đó echo "This is named pipe1" > pipe1 sẽ pass data tới pipe1 từ echo command, sau đó dùng shell để chạy lệnh in ra để kiểm tra: while read line ;do echo "This was passed-'$line' "; done<pipe1.
Socket files
Đây là các file mà cung cấp sự giao tiếp giữa các process, nhưng chúng có thể truyền dữ liệu và thông tin giữa các process đang chạy trên các môi trường khác nhau.
VD: int socket_desc= socket(AF_INET, SOCK_STREAM, 0 ); trong C.
AF_INET là họ địa chỉ (IPv4) SOCK_STREAM là loại (kết nối được định hướng giao thức TCP) 0 là giao thức (Giao thức IP)
Directories
Chúng là các file đặc biệt mà lưu trữ cả regular files và special files, chúng được tổ chức trên Linux file system theo cấp bậc, bắt đầu từ thư mục root (/).

Process là chương trình đang hoạt động, tức là một chương trình mà được thực thi. Nó không chỉ là code, nó bao gồm program counter, process stack, register và program code...
Có thể lấy một ví dụ như sau, khi bạn click đúp chuột vào biểu tượng MS Word, một process chạy ứng dụng Word được khởi tạo. Thread là một bước điều hành bên trong một process. Một process dĩ nhiên có thể chứa nhiều thread bên trong nó. Khi chúng ta chạy ứng dụng Word, hệ điều hành tạo ra một process và bắt đầu chạy các thread chính của process đó.
Điểm quan trọng nhất cần chú ý là một thread có thể làm bất cứ nhiệm vụ gì một process có thể làm. Tuy nhiên, vì một process có thể chứa nhiều thread, mỗi thread có thể coi như là một process nhỏ. Vậy, điểm khác biệt mấu chốt giữa thread và process là công việc mỗi cái thường phải làm.
Một điểm khác biệt nữa đó là nhiều thread nằm trong cùng một process dùng một không gian bộ nhớ giống nhau, trong khi process thì không. Điều này cho phép các thread đọc và viết cùng một kiểu cấu trúc và dữ liệu, giao tiếp dễ dàng giữa các thread với nhau. Giao thức giữa các process, hay còn gọi là IPC (inter-process communication) thì tương đối phức tạp bởi các dữ liệu có tính tập trung sâu hơn.
Cấu trúc cơ bản của một chương trình C đang chạy trong bộ nhớ gồm:

Text Segment
Text segment hay còn gọi là Code segment là phần bộ nhớ chứa code đã được compile của chương trình, vùng nhớ này thường là read-only. Phần text segment này lấy từ text segment trong file thực thi excutable object. Thông thường text segment là sharable memory, nó chỉ tồn tại duy nhất một bản copy trên physic memory dùng chung cho tất cả các instance của chương trình. Ví dụ như chương trình soạn thảo văn bản, có thể mở nhiều instance cùng lúc, nhiều process được tạo ra, nhưng chỉ là trên địa chỉ ảo (virtual address) của process, còn thực tế thì chỉ có một bản copy duy nhất trên physic memory.

Data Segment
Initalized data segement
Initialized data segment (hay còn gọi là Data segment) là vùng nhớ này chứa các biến global, static hoặc extern được khởi tạo trực tiếp trong code bởi lập trình viên (hard-code). Vùng nhớ này có thể được chia làm 2 loại: read-only và read-write. Và có thể một số cấu trúc chia segment này ra thành 2 segment: .data(initialized data) và .rdata(read-only initialized data).
VD:
char s1[] = "Hello world";
char* s2 = "Hello world";
s1[0] = 'A'; //Not error
s2[0] = 'A'; //ERROR
- s1 là non-const array, nghĩa là một mảng chứa 12 character bao gồm cả \0 ở cuối được khởi tạo trong vùng nhớ read-write. Vì s1 là mảng nên địa chỉ của s1 với địa chỉ phần tử đầu tiên của s1 là như nhau(xuất log %p của s1 hay của &s1 đều như nhau). Data của s1 nằm trong vùng nhớ read-write nên được phép thay đổi giá trị.
- s2 là non-const pointer to const data, nghĩa là con trỏ trỏ tới một vùng data(trỏ tới character đầu tiên) và vùng data này nằm trong vùng read-only. s2 chỉ là con trỏ nên địa chỉ của s2 khác với địa chỉ của &s2(&s2 là lấy địa chỉ của địa chỉ hay con trỏ cấp 2). Data của s2 nằm trong vùng nhớ read-only nên không thể thay đổi giá trị.
- Cả 2 data này đều không thể thay đổi kích thước, chỉ có data trên stack và heap là thay đổi được kích thước.
char s1[] = "Hello world";
char* s2 = "Hello world";
s1[] = "Hello world 2"; //ERROR
s2 = "Hello world 2"; //Trỏ con trỏ sang vùng nhớ khác
//chứ không phải thay đổi data ở vùng nhớ củ
Uninitialized data segment
Uninitialized data segment (hay còn gọi là BSS segment) là vùng nhớ chứa các biến global, static hoặc extern chưa được khởi tạo trong code và sẽ được khởi tạo bằng 0 khi chương trình bắt đầu thực thi. Các biến này không chiếm bộ nhớ trên object file, mà nó chỉ là một place holder.
Stack
Stack là vùng nhớ được dùng để chứa các biến local, các biến được truyền đi (passing argument) khi thực thi một hàm và địa chỉ của giá trị trả về sau khi thực thi hàm. Các biến local chỉ tồn tại trong một block code mà nó được định nghĩa, khi ra khỏi block các biến này sẽ được xóa khỏi stack. Các giá trị được thêm vào stack theo nguyên tắc LIFO theo hướng từ địa chỉ cao xuống đia chỉ thấp(trên kiến trúc x86, có thể theo chiều ngược lại ở một số kiến trúc khác). Thanh nhớ stack pointer sẽ ghi nhớ lại đỉnh của stack mổi khi có giá trị thêm vào. Khi một bộ các giá trị được đẩy vào để thực thi một hàm ta gọi là một stack frame. Một stack frame có ít nhất một địa chỉ trả vể(chứa địa chỉ của giá trị trả về sau khi gọi hàm). Tất cả các hàm gọi lồng nhau được thêm vào stack thành nhiều stack frame.
Heap
Heap là vùng nhớ được cấp phát động bởi các lệnh malloc, realloc và free. Vùng nhớ heap được cấp phát mở rộng từ vùng nhớ thấp đến vùng nhớ cao (ngược lại với stack). Stack và heap mở rộng đến khi "đụng" nhau là lúc bộ nhớ cạn kiệt. Vùng nhớ heap là vùng nhớ share giữa các tất cả các shared library và dynamic library được load trong process (tiến trình).
Vùng nhớ của một tiến trình được quản lý bằng địa chỉ ảo (virtual address) nên sẽ liên tục nhau, nhưng thực tế sẽ được ánh xạ không liên tục trên RAM.
Thread
Thread là một process nhỏ có thể được quản lý độc lập bằng bộ điều phối. Nó cải thiện hiệu suất của ứng dụng bằng cách chạy song song. Một thread chia sẻ thông tin như data segment, code segment, files với các peer thread, nó bao gồm registers, stack, counter,...
POSIX thread
POSIX Threads thường gọi là pthreads là một mô hình thực thi tồn tại độc lập với ngôn ngữ lập trình, nó là mô hình thực thi song song. Nó cho phép một chưowng trình điều khiểm nhiều luồng công việc khác nhau tại cùng một thời điểm. Mỗi luồng công việc gọi là một thread, việc tạo và điều khiển luồng thực hiện bằng cách gọi đến POSIX Threads API.
pthread được giới thiệu là thư viện implement chuẩn POSIX đặc tả việc tạo nhiều luồng tính toán song song.
Hầu hết các implement của pthread là trên Linux. Ta hiểu POSIX miểu tả các API (tức là các tên hàm và chức năng của chúng). Khi viết các hàm đó, thì tùy mỗi nền tảng mà người ta sẽ có những các khác nhau để thực hiện được nhiệm vụ được miêu tả trong đặc tả của các hàm này.
Phân loại API của pthread
Dựa theo chức năng mà các API của pthread được chia làm 4 loại:
- Thread management: Là các hàm sử dụng để tạo, hủy, detached, join thread cũng như set/get các thuộc tính của thread nữa.
- Mutexes: Là các hàm sử dụng để tạo, hủy, unlocking, locking mutex (“mutual exclusion” : vùng tranh chấp), cũng như set/get các thuộc tính của mutex.
- Condition variables: Là các hàm để tạo, hủy, đợi hoặc phát tín hiệu dựa trên giá trị của một biến cụ thể.
- Synchronization: Là các hàm dùng để quản lý việc read/write lock và barriers.
API của pthread
- pthread_create: tạo mới một thread. Tham số đầu vào là một biến của thread thuộc kiểu pthread_t, một thuộc tính của thead thuộc kiểu pthread_attr_t, đặt là NULL nếu giữ thuộc tính thread mặc định, một thủ tục kiểu void và một con trỏ đối số cho hàm thuộc kiểu void.
- pthread_join được sử dụng để đợi cho việc kết thúc của một thread hoặc chờ để tái kết hợp với luồng chính của hàm main.
- pthread_mutex_init: tạo mutex
- pthread_mutex_destroy: hủy mutex
- pthread_mutex_lock: giữ khóa trên biến mutex chỉ định. Nếu mutex đã bị khoá bở một thread khác, lời gọi này sẽ bị giữ lại cho tới khi mutex này mở khoá.
- pthread_mutex_unlock: mở khoá biến mutex. Một lỗi trả về nếu mutex đã mở khoá hoặc được sở hữu của một thread khác.
- pthread_mutex_trylock: thử khoá một mutex hoặc sẽ trả về mã lỗi nếu bận. Hữu ích cho việc ngăn ngừa trường hợp khoá chết (deadlock).
Thread, dĩ nhiên cho phép chạy đa luồng. Minh hoạ dễ hiểu cho tính ưu việt của sự đa luồng là trình xử lý Word có thể vừa in tài liệu sử dụng một thread nền, vừa cùng lúc chạy một thread khác nhận dữ liệu vào từ người dùng để gõ một văn bản mới.
Nếu bạn đang làm việc với ứng dụng sử dụng một thread duy nhất, mà ứng dụng đó chỉ có thể làm một việc đơn lẻ vào một thời điểm – thì việc vừa in văn bản vừa tiếp nhận thông tin người dùng là bất khả thi trong ứng dụng đơn luồng này.
Mỗi một process có một vùng nhớ riêng của chúng, song các thread trong cùng một process thì dùng chung địa chỉ nhớ. Và các thread cũng dùng chung bất cứ tài nguyên nào nằm trong process đấy. Có nghĩa là rất dễ để chia sẻ dữ liệu giữa các thread, nhưng cũng rất dễ làm thread này nhảy sang thread khác, dẫn đến một số kết quả tồi tệ.
Các chương trình đa luồng cần được lập trình cẩn thận để tránh việc nhảy cóc như trên xảy ra. Đoạn mã lệnh thay đổi cấu trúc dữ liệu chia sẻ giữa các đa luồng này được gọi là những đoạn quan trọng. Khi một đoạn quan trọng đang chạy ở thread này, cần đảm bảo không thread khác nào được phép sử dụng đoạn quan trọng này. Đây là quy đình đồng bộ hoá, nhằm tránh không bị dừng chương trình một cách bất ngờ ở đây. Và đó cũng là lý do tại sao đa luồng đòi hỏi lập trình một cách rất cẩn thận.
Nhìn chung, môi trường chuyển đổi của các thread đỡ tốn kém hơn so với giữa các process. Đặt biệt là overhead (chi phí giao thức) giữa các thread đặc biệt thấp so với các process.
Các vấn đề với multi-thread:
-
Truy cập dữ liệu chia sẻ: Nếu 2 thread truy cập cùng 1 biến được chia sẻ mà không có bảo vệ nào, việc ghi biến đó có thể bị chồng chéo.
-
Việc lock có thể gây giảm hiệu suất
-
Độ phức tạp tăng
-
Khó xử lý đồng thời nhiều thread
-
Khó xác định lỗi
-
Có thể gặp các kết quả không mong muốn
Critical section (miền găng): đoạn mã nguồn đọc/ghi dữ liệu lên vùng nhớ chia sẻ.
Race condition (tranh đoạt quyền điều khiển): có tiềm năng bị xen kẻ lệnh giữa các tiểu trình khác nhau trong miền găng.
Mutual exclusion: cơ chế đồng bộ đảm bảo chỉ có một tiểu trình duy nhất được thực hiện trong miền găng tại một thời điểm
Ví dụ Race condition
Trong lĩnh vực lập trình Race condition là một tình huống xảy ra khi nhiều threads cùng truy cập và cùng lúc muốn thay đổi dữ liệu (có thể là 1 biến, 1 row trong database, 1 vùng shared data, memory , etc...). Vì thuật toán chuyển đổi việc thực thi giữa các threads có thể xảy ra bất cứ lúc nào nên không thể biết được thứ tự của các threads truy cập và thay đổi dữ liệu đó sẽ dẫn đến giá trị của data sẽ không như mong muốn. Kết quả sẽ phụ thuộc vào thuật toán thread scheduling của hệ điều hành.
VD: Bài toán rút tiền ngân hàng

Sau một thời gian hoạt động thì tài khoản của khách hàng này là số âm. Vậy lý do là gì? Race Condition là một lời giải đáp.
Với đoạn code ở trên, tình huống đặt ra là nếu có hai yêu cầu đến gần như cùng một lúc, thì chúng sẽ được thực thi cùng một lúc hoặc việc thực thi chúng sẽ bị xen kẽ. Kết quả là một vài các yêu cầu cuối cùng được xử lý như thế này:

Sau khi hai yêu cầu được xử lý, số dư là là 100$ – 10$ – 15$ =75$. Nhưng vì yêu cầu thứ 1 vẫn đang thực hiện, chưa hoàn tất việc cập nhật ví tiền thì yêu cầu thứ hai chen vào. Điều này là nguyên nhân dẫn đến dữ liệu bị sai. Và như ví dụ trên thì ví tiền chỉ bị trừ 10$
Có nhiều cách để xử lý race condition, nhưng ở đây ta sẽ sử dụng LOCK để giải quyết vấn đề.
Giải pháp là: Khi có thread truy cập vào để lấy dữ liệu, mình sẽ LOCK file lại, khi thread hoàn tất việc setBalance thì mình sẽ UNLOCK file. Mình sử dụng 1 file trung gian để kiểm tra việc Lock/Unlock
- Kiểm tra xem nếu file là UNLOCK thì mới cho phép đọc dữ liệu
- Thực hiện LOCK file và thực hiện các yêu cầu bên dưới
- Sau khi hoàn tất, UNLOCK file
Giải pháp tốt cho bài toán race condition
-
Tại một thời điểm, chỉ duy nhất một tiến trình được thực thi trong miền găng
-
Không được giả sử về tốc độ xử lý của CPU, hay số lượng CPU.
-
Không có tiến trình nào đang ở ngoài miền găng mà lại khóa không cho tiến trình khác vào miền găng
-
Không tiến trình nào phải chờ đợi mãi mãi để vào miền găng
Giải pháp ngăn chặn race condition
-
Busy Waiting: Các tiến trình bị khóa trước khi vào miền găng phải liên tục kiểm tra trạng thái để biết được mình hết bị khóa và có thể vào miền găng.
-
Sleep và Wakeup: semaphore, mutex (sẽ nói sau), ...
Deadlock
Deadlock là trạng thái xảy ra trong môi trường đa nhiệm (muti-threading) khi hai hoặc nhiều thread đi vào vòng lặp chờ tài nguyên mãi mãi.
VD: Thread 1 và 2 muốn lấy tài nguyên A và B, thread 1 chiếm tài nguyên A và chờ thread 2 bắt đầu chạy cho tới khi thread 2 đợi tài nguyên A giải phóng, thread 2 chiếm tài nguyên B và đợi tài nguyên A được giải phóng trong khi thread 1 cũng đang đợi tài nguyên B giải phóng.
Điều kiện xảy ra Deadlock
4 điều kiện thỏa mãn cùng lúc để xảy ra deadlock:
-
Độc quyền. Mỗi tài nguyên chỉ được cấp cho duy nhất một tiến trình tại một thời điểm, hoặc không cấp cho tiến trình nào hết.
-
Giữ và chờ. Tiến trình đang giữ tài nguyên và yêu cầu thêm tài nguyên mới.
-
Không thu hồi. Hệ thống không thể thu hồi tài nguyên cấp cho một tiến trình nào đó, trừ khi tiến trình này trả lại tài nguyên.
-
Vòng lặp chờ. Tồn tại một vòng lặp của các tiến trình, mỗi tiến trình chờ đợi tài nguyên của tiến trình kế tiếp trong vòng lặp.
Ngăn chặn Deadlock
Ngăn chặn xảy ra cùng lúc 4 điều kiện:
-
Điều kiện truy xuất độc quyền: Về lý thuyết, không thể ngăn chặn truy xuất độc quyền. Tuy nhiên, hệ thống thường hay sử dụng hạn chế tối đa việc cấp phát tài nguyên khi mà nó chưa thật sự cần thiết. Giảm thiểu tối đa số tiến trình đồng thời yêu cầu một tài nguyên.
-
Điều kiện giữ và yêu cầu tài nguyên mới: Hệ thống chỉ cần chờ cho tiến trình yêu cầu tất cả tài nguyên cần sử dụng trước khi thực thi thì cấp phát cho tiến trình thực thi. Tuy nhiên, thực tế nhiều tiến trình không biết nó cần bao nhiêu tài nguyên cho đến khi nó thực thi. => có vẻ khả thi.
-
Điều kiện không thu hồi tài nguyên: Ví dụ như máy in đang in nửa chừng phải tạm ngừng để chờ dữ liệu đầu vào từ máy scan. Nếu nó bị thu hồi máy in và cấp cho tiến hình khác thì kết quả in không đúng nữa. => có vẻ ít khả thi hơn.
-
Điều kiện vòng lặp chờ:
- Cách 1: Không cho phép tiến trình giữa 2 tài nguyên tại cùng một thời điểm. Nếu muốn được cấp tài nguyên thứ 2 thì tiến trình phải nhả tài nguyên đang nắm giữ.
- Cách 2: Đánh số thứ tự tất cả các tài nguyên. Tất cả tiến trình phải yêu cầu tài nguyên theo luật từ số nhỏ đến số lớn. Nếu muốn yêu cầu tài nguyên số nhỏ hơn các tài nguyên nó đang nắm giữ thì tiến trình phải trả lại tất cả tài nguyên có số lớn hơn.
Context switching time
- Process yêu cầu nhiều thời gian để context switch.
- Thread cần thời gian ít hơn để context switch bởi vì chúng
nhẹhơn process.
Memory sharing
- Process hoàn toàn độc lập và không chia sẻ bộ nhớ.
- Thread có thể chia sẻ bộ nhớ với peer thread khác.
Communication
- Giao tiếp giữa các process cần nhiều thời gian hơn so với thread.
- Giao tiếp giữa các thread cần ít thời gian hơn so với process.
Blocked
- Nếu một process bị chặn, các process còn lại có thể tiếp tục thực thi.
- Nếu một thread ở mức người dùng bị chặn, tất cả các peer thread khác cũng bị chặn.
Resource Consumption
- Process yêu cầu nhiều tài nguyên hơn thread.
- Thread thường yêu cầu ít tài nguyên hơn process.
Dependency
- Các process riêng lẻ thì độc lập với nhau.
- Các thread là một phần của process nên chúng phụ thuộc nhau.
Data and Code sharing
- Process có data và code segments độc lập.
- Thread chia sẻ data segment, code segment, files,... với các peer thread khác.
Treatment by OS
- Tất cả các process khác nhau được xử lý riêng biệt bởi OS.
- Tất cả các peer thread ở mức người dùng được xử lý như một tác vụ duy nhất của OS.
Time for creation
- Process yêu cầu nhiều thời gian để khởi tạo.
- Thread yêu cầu ít thời gian để khởi tạo.
Time for termination
- Process yêu cầu nhiều thời gian để chấm dứt.
- Thread yêu cầu ít thời gian để chấm dứt.
Semaphore là 1 biến có đặc tính sau:
-
Một giá trị nguyên dương e(s)
-
Một hàng đợi f(s) lưu danh sách các tiến trình đang bị khóa
-
Chỉ có 2 thao tác được định nghĩa trên semaphore:
-
Down(s): giảm giá trị của semaphore s đi 1 đơn vị nếu e(s) > 0, và tiếp tục xử lý. Nếu e(s) = 0, tiến trình phải chờ đến khi e(s) > 0.
-
Up(s): tăng giá trị của semaphore s lên 1 đơn vị, hệ thống sẽ chọn một trong các tiến trình bị khóa để tiếp tục thực thi.
-
Mutex là một phiên bản đặc biệt của semaphore, nó được dùng khi chức năng đếm của semaphore không cần thiết sử dụng.
Một mutex có thể một trong hai trạng thái: khóa hoặc mở. Thường biến mutex là kiểu int (dù chỉ cần 1 bit là đủ), giá trị 0 biểu diễn cho trạng thái mở và giá trị 1 biểu diễn trạng thái khóa.
Semaphore vs Mutex
Ví dụ như race condition thì mutex chỉ cho 1 thread vào, còn semaphore có thể giới hạn nhiều hơn 1 thread tại một thời điểm.
Reader Writer Problem liên quan đến một đối tượng (như file) được chia sẻ giữa nhiều tiến trình. Một vài tiến trình chỉ muốn đọc và một vài tiến trình chỉ muốn ghi.
Reader Writer Problem được sử dụng để quản lý đồng bộ hóa để không có vấn về nào xảy ra với dữ liệu. Ví dụ: Nếu 2 readers truy cập đối tượng cùng một thời điểm thì không có vấn đề gì nhưng nếu 2 writes hoặc 1 reader 1 writer truy cập đối tượng cùng một thời điểm thì sẽ phát sinh vấn đề.
Để giải quyết tình huống này, 1 writer nên có quyền truy cập độc quyền vào 1 đối tượng, tức là khi 1 writer truy cập đối tượng, không 1 reader hay writer nào có thể truy cập nó. Tuy nhiên, nhiều readers có thể truy cập đối tượng cùng một thời điểm.
Ta có thể implement cách trên bằng semaphore như sau:
Reader process
wait (mutex);
rc ++;
if (rc == 1)
wait (wrt);
signal(mutex);
.
. READ THE OBJECT
.
wait(mutex);
rc --;
if (rc == 0)
signal (wrt);
signal(mutex);
mutex và wrt là semaphores mà được khởi tạo là 1. Cũng như rc là biến khởi tạo bằng 0. Mutex semaphore đảm bảo mutual exclusion và wrt xử lý cơ chế ghi
Biến rc biểu thị số lượng reader truy cập đối tượng. Khi rc == 1, thao tác wait được sử dụng trên wrt. Nghĩa là 1 writer không thể truy cập đối tượng nữa. Sau khi thao tác đọc hoàn thành, rc giảm. Khi rc == 0, thao tác signal được sử dụng trên wrt. Vì thế, writer có thể truy cập đối tượng.
Writer process
wait(wrt);
.
. WRITE INTO THE OBJECT
.
signal(wrt);
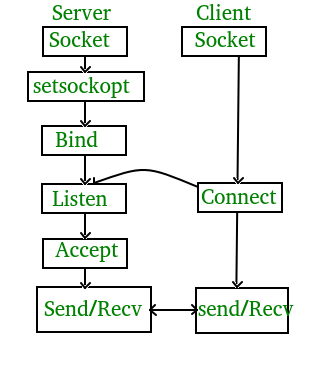
Socket TCP
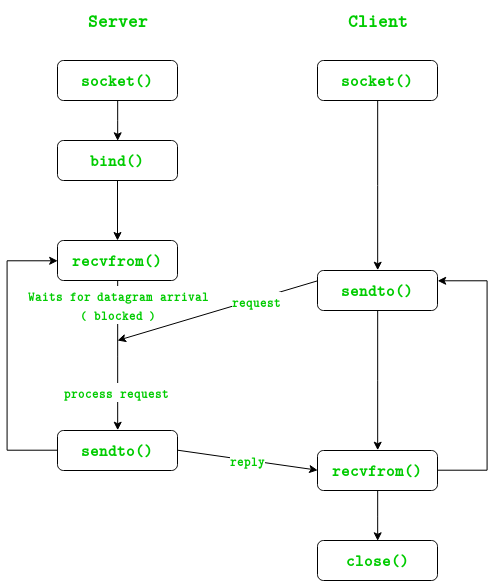
Socket UDP
So sánh
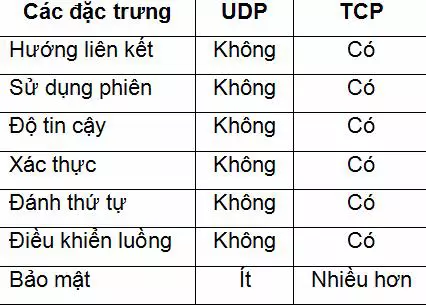
TCP (Transmission Control Protocol - "Giao thức điều khiển truyền vận") Là một trong các giao thức cốt lõi của bộ giao thức TCP/IP. Sử dụng TCP, các ứng dụng trên các máy chủ được nối mạng có thể tạo các "kết nối" với nhau, mà qua đó chúng có thể trao đổi dữ liệu hoặc các gói tin. Giao thức này đảm bảo chuyển giao dữ liệu tới nơi nhận một cách đáng tin cậy và đúng thứ tự. TCP còn phân biệt giữa dữ liệu của nhiều ứng dụng (chẳng hạn, dịch vụ Web và dịch vụ thư điện tử) đồng thời chạy trên cùng một máy chủ. UDP (User Datagram Protocol) Là một trong những giao thức cốt lõi của giao thức TCP/IP. Dùng UDP, chương trình trên mạng máy tính có thể gởi những dữ liệu ngắn được gọi là datagram tới máy khác. UDP không cung cấp sự tin cậy và thứ tự truyền nhận mà TCP làm, các gói dữ liệu có thể đến không đúng thứ tự hoặc bị mất mà không có thông báo. Tuy nhiên UDP nhanh và hiệu quả hơn đối với các mục tiêu như kích thước nhỏ và yêu cầu khắt khe về thời gian. Do bản chất không trạng thái của nó nên nó hữu dụng đối với việc trả lời các truy vấn nhỏ với số lượng lớn người yêu cầu.
Chúng ta có thể hiểu một cách đơn giản, nếu chương trình được thực hiện theo mô hình Blocking có nghĩa là các dòng lệnh được thực hiện một cách tuần tự. Khi một dòng lệnh ở phía trước chưa được hoàn thành thì các dòng lệnh phía sau sẽ chưa được thực hiện và phải đợi khi mà thao tác phía trước hoàn tất, và nếu như các dòng lệnh trước là các thao tác cần nhiều thời gian xử lý như liên quan đến I/O (input/output) hay mạng (networking) thì bản thân nó sẽ trở thành vật cản trở (blocker) cho các lệnh xử lý phía sau mặc dù theo logic thì có những việc ở phía sau ta có thể xử lý được luôn mà không cần phải đợi vì chúng không có liên quan gì đến nhau.
Trong mô hình Non-Blocking, các dòng lệnh không nhất thiết phải lúc nào cũng phải thực hiện một cách tuần tự (sequential) và đồng bộ (synchronous) với nhau. Ở mô hình này nếu như về mặt logic dòng lệnh phía sau không phụ thuộc vào kết quả của dòng lệnh phía trước, thì nó cũng có thể hoàn toàn được thực hiện ngay sau khi dòng lệnh phía trước được gọi mà không cần đợi cho tới khi kết quả được sinh ra. Những dòng lệnh phía trước miêu tả ở trên còn có thể gọi là được thực hiện theo cách không đồng bộ (Asynchronous), và đi theo mỗi dòng lệnh thường có một callback (lời gọi lại) là đoạn mã sẽ được thực hiện ngay sau khi có kết quả trả về từ dòng lệnh không đồng bộ. Để thực hiện mô hình Non-Blocking, người ta có những cách để thực hiện khác nhau, nhưng về cơ bản vẫn dựa vào việc dùng nhiều Thread (luồng) khác nhau trong cùng một Process (tiến trình), hay thậm chí nhiều Process khác nhau (inter-process communication – IPC) để thực hiện.

select() system call trong network socket là một dạng nonblocking
Debugger là một chương trình chạy các chương trình khác, cho phép người dùng kiểm soát các chương trình này và kiểm tra các biến khi có vấn đề phát sinh.
GNU Debugger (GDB) là debugger phổ biến nhất cho UNIX system để debug chương trình C/C++.
-
Kiểm tra đã cài đặt GDB chưa? -
gdb -help -
Cài đặt GDB -
sudo apt-get install libc6-dbg gdb valgrind
Hiểu các giá trị ouput của ls -l
-l là 1 tùy chọn của ls để hiển thị output dưới dạng danh sách dài
VD:
ls -l file1
-rw-rw-r--. 1 lilo lilo 0 Feb 26 07:08 file1
-rw-rw-r-: loạifilevà phân quyền của user, group, others1: số lượnglinked hard-linkslilo: owner của filelilo: file thuộc về group nào0: sizeFeb 26 07:08: thời gian sửa/tạo filefile1: tên file/thư mục
Tìm hiểu
-
opendir(): là hàm ở directory stream tương ứng với đường dẫn và trả về 1 con trỏDIRtrỏ tới directory stream đó -
readdir(): trả về 1 con trỏ tới cấu trúcdirentđại diện cho directory entry kế tiếp trong con trỏ DIR đã nói, nó trả về NULL thì đọc hết hoặc lỗi -
Cấu trúc
dirent:
struct dirent {
ino_t d_ino; /* Inode number */
off_t d_off; /* Not an offset; see below */
unsigned short d_reclen; /* Length of this record */
unsigned char d_type; /* Type of file; not supported
by all filesystem types */
char d_name[256]; /* Null-terminated filename */
};
- Trong này, tôi có dùng d_name để lấy tên nội dung bên trong thư mục đang trỏ
-
stat(): lấy thông tin củafileđược trỏ đến theo tên đường dẫn đưa vào cấu trúcstat -
Cấu trúc
stat:
struct stat {
dev_t st_dev; /* ID of device containing file */
ino_t st_ino; /* Inode number */
mode_t st_mode; /* File type and mode */
nlink_t st_nlink; /* Number of hard links */
uid_t st_uid; /* User ID of owner */
gid_t st_gid; /* Group ID of owner */
dev_t st_rdev; /* Device ID (if special file) */
off_t st_size; /* Total size, in bytes */
blksize_t st_blksize; /* Block size for filesystem I/O */
blkcnt_t st_blocks; /* Number of 512B blocks allocated */
/* Since Linux 2.6, the kernel supports nanosecond
precision for the following timestamp fields.
For the details before Linux 2.6, see NOTES. */
struct timespec st_atim; /* Time of last access */
struct timespec st_mtim; /* Time of last modification */
struct timespec st_ctim; /* Time of last status change */
#define st_atime st_atim.tv_sec /* Backward compatibility */
#define st_mtime st_mtim.tv_sec
#define st_ctime st_ctim.tv_sec
};
-
mode_t: dùng để kiểm tra cấp quyền truy cập của user, group, others- File type:
- S_IFMT - type of file
- S_IFBLK - block special
- S_IFCHR - character special
- S_IFIFO - FIFO special
- S_IFREG - regular
- S_IFDIR - directory
- S_IFLNK - symbolic link
- File mode bits:
- S_IRUSR - read permission, owner
- S_IWUSR - write permission, owner
- S_IXUSR - execute/search permission, owner
- S_IRGRP - read permission, group
- S_IWGRP - write permission, group
- S_IXGRP - execute/search permission, group
- S_IROTH - read permission, others
- S_IWOTH - write permission, others
- S_IXOTH - execute/search permission, others
- File type:
Cài đặt
For each directory that is listed, preface the files with a line `total BLOCKS', where BLOCKS is the total disk allocation for all files in that directory.
-
Vì lệnh ls có thể nhận đầu vào là danh sách file hoặc danh sách thư mục, tiến hành xử lý các đối số đầu vào để có đường dẫn thích hợp
-
Hàm
printf_info_file:-
Sử dụng cấu trúc stat để có thể lấy info của file
-
Tiến hành xử lý
mode_ttrả về để in ra loại file và phân quyền -
Từ
uidvàgiddùnggetpwuid_rvàgetgrgid_rđể lấy ra tên user và group -
Lấy size của file
-
In ra định dạng ngày tháng theo format
-
In ra tên
-
-
Hàm
print_info_dir:-
Dùng
opendir()vàreaddirđể mở directory stream -
Dùng cấu trúc
direntđể lấy tên các file và thư mục trong thư mục đang xét -
Dùng cấu trúc
statđể lấy được info của file và thư mục (như hàmprint_info_file) -
st_blocks: số lượng block được cấp phát, ta tiến hành cộng dồn. Sau khi đọc xong hết, chia cho 2 thì nó tương ứng vớiTotaltrong lệnhls -l
-
Tìm hiểu
-
API của pthread (đã nói ở phần lý thuyết)
-
Socket TCP (đã mô hình hóa ở phần lý thuyết)
Phía Server
-
Server liên tục lắng nghe và chấp nhận kết nối
-
Mỗi kết nối là 1 thread
-
Server sẽ khởi tạo 1 mảng giá trị trong đoạn [100-10000] với kích thước random trong đoạn [100-1000]
-
Số lượng client trong khoảng (2-10)
-
Sẽ có 1 mảng ClientInfo để lưu thông tin: isActive (client đó còn kết nối không), sum (tổng giá trị mà client gửi về server), thread (biết được thread mà nó đang xử lý) và socket (biết được socket của nó)
-
Sẽ có 1 biến countClients để đếm các client đang kết nối tới server
-
Tạo 1 thread chuyên để tính xếp hạng các client, thread này chờ mảng bị lấy hết phần tử rồi tiến hành join với các thread xử lý các client, chờ tất cả thread xử lý các client xong thì tiến hành xếp hạng và gửi file xếp hạng về mỗi client qua socket
-
Mỗi thread là 1 kết nối của client sẽ thực hiện các công việc sau:
-
Vào mutex lock, tiến hành đăng ký
IDcho mình từ mảng client_info,IDtương ứng với index của mảng này; biến countCLients tăng 1 -
Kiểm tra số client có vượt quá giới hạn hay không, nếu có gửi về thông điệp
Over clientscho client; biến countClients giảm 1 -
Ngược lại, server tiến hành gửi
IDvề cho client biết -
1 vòng lặp nhận thông điệp được mở ra:
-
Nếu thông điệp không phải
getthì bỏ qua -
Ngược lại, tiến hành truy cập mảng (dùng mutex lock) để lấy và gửi phần tử trong mảng cho client
-
Khi mảng hết phần tử, tiến hành nhận file data mà client gửi đến
-
Tính tổng giá trị trong file data
-
Thoát thread
-
Cần lưu ý giới hạn số client
-
-
Khi không nhận được thông điệp hoặc nhận fail thì mở mutex lock để cập nhập tình trạng và số lượng client, thoát thread
-
Phía Client
-
Tiến hành connect tới server
-
Thông điệp đầu tiên nó nhận được là
IDhoặc thông báo Over. Nếu Over thì tắt -
1 vòng lặp mở ra
-
Gửi thông điệp
getcho server -
Khi đó client sẽ nhận được data từ server và ghi data đó vào file (file có sắp xếp tăng dần)
-
Đến một lúc nào đó, server hết phần tử, tiến hành gửi file data cho server
-
Rồi thì client sẽ nhận được tổng kết xếp hạng của mình từ server
-