大部分开发者都知道加索引会快。但实际过程中,我们常碰到一些疑问&困难:
- 我们查询的字段会各种case都有,是不是各个涉及查询的字段都要加索引?
- 复合索引和单字段怎么选择,都加还是每一个的单个字段就好了?
- 加索引有没有副作用?
- 索引都加了,但还是不够快?怎么办?
本文尝试去解释索引的基本知识&解答上述的疑问。
大部分开发者接触索引,大概知道索引类似书的目录,你要找到想要的内容,通过目录找到限定的关键字,进而找到对应的章节的pageno,再找到具体的内容。 在数据结构里面,最简单的索引实现类似hashmap,通过关键字key,映射到具体的位置,找到具体的内容。但除了hash的方式,还有多种的方式实现索引。
hash / b-tree / b+-tree redis HSET / MongoDB&PostgreSQL / MySQL
hashmap

一图见b-tree & b+-tree 差别

- b+-tree 叶子存数据,非叶子存索引,不存数据,叶子间有link
- b-tree 非叶子可存数据
算法查找复杂度上来说
hash 接近O(1)
b-tree O(1)~ O(Log(n))更快的平均查找时间,不稳定的查询时间
b+ tree O(Log(n)) 连续数据, 查询的稳定性
至于为何MongoDB 的实现选择b-tree 而非 b+-tree ? 网上多篇文章有阐述,非本文重点。
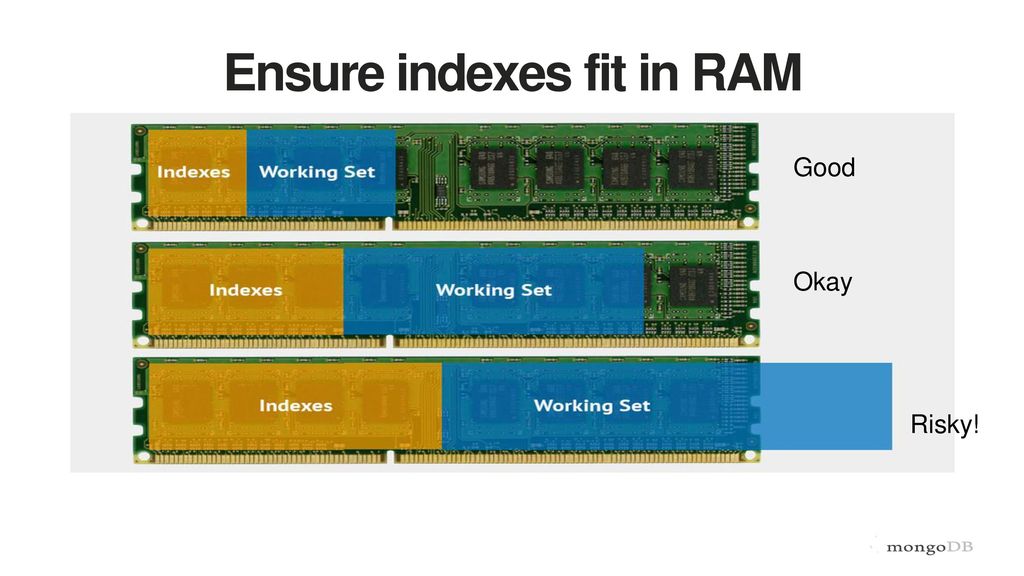
insert/update/delete 会触发rebalance tree -- 所以,增删改数据,索引会触发修改,性能会有损耗 索引不是越多越好 既然如此,选择哪些字段作为索引呢?当查询用到这些条件,怎么办? 拿一个最简单的hashmap来讲,为什么复杂度不是O(1),而是所谓接近 O(1)。因为有key 冲突/重复啊~。DB 去找的时候,key 冲突的数据一大堆的话,还是得轮着继续找。 上面的b-tree 看键(key)的选择也是如此。 因此一个大部分开发经常犯的错就是对没有区分度的key 建索引。 例如:很多就只有集中类别的 type/status 的 documents count 达几十万以上的collection --- 通常这种索引没什么帮助。
复合索引不是越多越好 如果不想多建多余的索引,开发的同事在复合 & 单个字段 有时选择上挺纠结的。
根据典型碰到的场景,来做几个实验: 这里创建了个loans collection。简化只有100条数据。这个是借贷的表有 _id, userId, status(借贷状态), amount(金额).
看完 这个实验, 明白了 {userId:1, status:1}, vs {status:1,userId:1} 的差别了吗?
PS:这个case 里面其实status 区分度不高,不应该建立的,这里只是作为实例展示。
总结:
- 注意使用上 使用频率上 区分高的/常用的在前面
- 如果需要减少索引以节省memory/提高修改数据的性能的话,可以保留区分度高,常用的,去除区分度不高,不常用的索引。
DB 一般都有执行器优化的分析,MySQL & MongoDB 都是 用explain 来做分析。 语法上MySQL :
explain your_sql
MongoDB:
yoursql.explain()
至于怎么看,这里不展开,网上可以搜到各种文章。
结合explain 的指标,他们通常是多个的混合
- IXSCAN : 索引命中
- Limit : 带limit
- Projection : 相当于非 select *
- Docs Size less is better
- Docs Examined less is better
- nReturned=totalDocsExamined=totalKeysExamined
- SORT in index :sort 也是命中索引,否则,需要拿到数据后,再执行一遍排序
- Limit Array elements : 限定数组返回的条数,数组也不应该太多数据,否则schema 设计不合理
文末,还有一个最开头一个问题没回答,如果我的索引该加的都加了,还不够快。怎么办?留个悬念,之后再写一篇。
PS:这个case 里面其实status 区分度不高,不应该建立的,这里只是作为实例展示。
总结:
- 注意使用上 使用频率上 区分高的/常用的在前面
- 如果需要减少索引以节省memory/提高修改数据的性能的话,可以保留区分度高,常用的,去除区分度不高,不常用的索引。
DB 一般都有执行器优化的分析,MySQL & MongoDB 都是 用explain 来做分析。 语法上MySQL :
explain your_sql
MongoDB:
yoursql.explain()
至于怎么看,这里不展开,网上可以搜到各种文章。
结合explain 的指标,他们通常是多个的混合
- IXSCAN : 索引命中
- Limit : 带limit
- Projection : 相当于非 select *
- Docs Size less is better
- Docs Examined less is better
- nReturned=totalDocsExamined=totalKeysExamined
- SORT in index :sort 也是命中索引,否则,需要拿到数据后,再执行一遍排序
- Limit Array elements : 限定数组返回的条数,数组也不应该太多数据,否则schema 设计不合理
文末,还有一个最开头一个问题没回答,如果我的索引改加的都加了,还不够快。怎么办?留个悬念,之后再写一篇。