Officially supported AllenNLP models.
![]()


This repository contains the components - such as DatasetReader, Model, and Predictor classes - for applying AllenNLP to a wide variety of NLP tasks.
It also provides an easy way to download and use pre-trained models that were trained with these components.
This is an overview of the tasks supported by the AllenNLP Models library along with the corresponding components provided, organized by category. For a more comprehensive overview, see the AllenNLP Models documentation or the Paperswithcode page.
-
Classification tasks involve predicting one or more labels from a predefined set to assign to each input. Examples include Sentiment Analysis, where the labels might be
{"positive", "negative", "neutral"}, and Binary Question Answering, where the labels are{True, False}.🛠 Components provided: Dataset readers for various datasets, including BoolQ and SST, as well as a Biattentive Classification Network model.
-
Coreference resolution tasks require finding all of the expressions in a text that refer to common entities.
See nlp.stanford.edu/projects/coref for more details.
🛠 Components provided: A general Coref model and several dataset readers.
-
This is a broad category for tasks such as Summarization that involve generating unstructered and often variable-length text.
🛠 Components provided: Several Seq2Seq models such a Bart, CopyNet, and a general Composed Seq2Seq, along with corresponding dataset readers.
-
Language modeling tasks involve learning a probability distribution over sequences of tokens.
🛠 Components provided: Several language model implementations, such as a Masked LM and a Next Token LM.
-
Multiple choice tasks require selecting a correct choice among alternatives, where the set of choices may be different for each input. This differs from classification where the set of choices is predefined and fixed across all inputs.
🛠 Components provided: A transformer-based multiple choice model and a handful of dataset readers for specific datasets.
-
Pair classification is another broad category that contains tasks such as Textual Entailment, which is to determine whether, for a pair of sentences, the facts in the first sentence imply the facts in the second.
🛠 Components provided: Dataset readers for several datasets, including SNLI and Quora Paraphrase.
-
Reading comprehension tasks involve answering questions about a passage of text to show that the system understands the passage.
🛠 Components provided: Models such as BiDAF and a transformer-based QA model, as well as readers for datasets such as DROP, QuAC, and SQuAD.
-
Structured prediction includes tasks such as Semantic Role Labeling (SRL), which is for determining the latent predicate argument structure of a sentence and providing representations that can answer basic questions about sentence meaning, including who did what to whom, etc.
🛠 Components provided: Dataset readers for Penn Tree Bank, OntoNotes, etc., and several models including one for SRL and a very general graph parser.
-
Sequence tagging tasks include Named Entity Recognition (NER) and Fine-grained NER.
🛠 Components provided: A Conditional Random Field model and dataset readers for datasets such as CoNLL-2000, CoNLL-2003, CCGbank, and OntoNotes.
-
This is a catch-all category for any text + vision multi-modal tasks such Visual Question Answering (VQA), the task of generating a answer in response to a natural language question about the contents of an image.
🛠 Components provided: Several models such as a ViLBERT model for VQA and one for Visual Entailment, along with corresponding dataset readers.
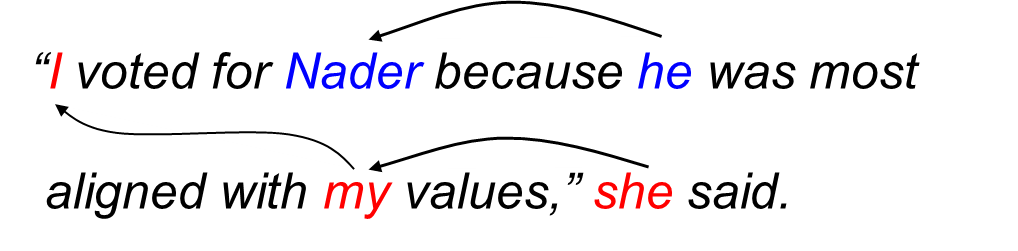
Every pretrained model in AllenNLP Models has a corresponding ModelCard in the allennlp_models/modelcards/ folder.
Many of these models are also hosted on the AllenNLP Demo and the AllenNLP Project Gallery.
To programmatically list the available models, you can run the following from a Python session:
>>> from allennlp_models import pretrained
>>> print(pretrained.get_pretrained_models())The output is a dictionary that maps the model IDs to their ModelCard:
{'structured-prediction-srl-bert': <allennlp.common.model_card.ModelCard object at 0x14a705a30>, ...}
You can load a Predictor for any of these models with the pretrained.load_predictor() helper.
For example:
>>> pretrained.load_predictor("mc-roberta-swag")Here is a list of pre-trained models currently available.
coref-spanbert- Higher-order coref with coarse-to-fine inference (with SpanBERT embeddings).evaluate_rc-lerc- A BERT model that scores candidate answers from 0 to 1.generation-bart- BART with a language model head for generation.glove-sst- LSTM binary classifier with GloVe embeddings.lm-masked-language-model- BERT-based masked language modellm-next-token-lm-gpt2- OpenAI's GPT-2 language model that generates the next token.mc-roberta-commonsenseqa- RoBERTa-based multiple choice model for CommonSenseQA.mc-roberta-piqa- RoBERTa-based multiple choice model for PIQA.mc-roberta-swag- RoBERTa-based multiple choice model for SWAG.nlvr2-vilbert- ViLBERT-based model for Visual Entailment.nlvr2-vilbert- ViLBERT-based model for Visual Entailment.pair-classification-adversarial-binary-gender-bias-mitigated-roberta-snli- RoBERTa finetuned on SNLI with adversarial binary gender bias mitigation.pair-classification-binary-gender-bias-mitigated-roberta-snli- RoBERTa finetuned on SNLI with binary gender bias mitigation.pair-classification-decomposable-attention-elmo- The decomposable attention model (Parikh et al, 2017) combined with ELMo embeddings trained on SNLI.pair-classification-esim- Enhanced LSTM trained on SNLI.pair-classification-roberta-mnli- RoBERTa finetuned on MNLI.pair-classification-roberta-rte- A pair classification model patterned after the proposed model in Devlin et al, fine-tuned on the SuperGLUE RTE corpuspair-classification-roberta-snli- RoBERTa finetuned on SNLI.rc-bidaf-elmo- BiDAF model with ELMo embeddings instead of GloVe.rc-bidaf- BiDAF model with GloVe embeddings.rc-naqanet- An augmented version of QANet that adds rudimentary numerical reasoning ability, trained on DROP (Dua et al., 2019), as published in the original DROP paper.rc-nmn- A neural module network trained on DROP.rc-transformer-qa- A reading comprehension model patterned after the proposed model in Devlin et al, with improvements borrowed from the SQuAD model in the transformers projectroberta-sst- RoBERTa-based binary classifier for Stanford Sentiment Treebanksemparse-nlvr- The model is a semantic parser trained on Cornell NLVR.semparse-text-to-sql- This model is an implementation of an encoder-decoder architecture with LSTMs and constrained type decoding trained on the ATIS dataset.semparse-wikitables- The model is a semantic parser trained on WikiTableQuestions.structured-prediction-biaffine-parser- A neural model for dependency parsing using biaffine classifiers on top of a bidirectional LSTM.structured-prediction-constituency-parser- Constituency parser with character-based ELMo embeddingsstructured-prediction-srl-bert- A BERT based model (Shi et al, 2019) with some modifications (no additional parameters apart from a linear classification layer)structured-prediction-srl- A reimplementation of a deep BiLSTM sequence prediction model (Stanovsky et al., 2018)tagging-elmo-crf-tagger- NER tagger using a Gated Recurrent Unit (GRU) character encoder as well as a GRU phrase encoder, with GloVe embeddings.tagging-fine-grained-crf-tagger- This model identifies a broad range of 16 semantic types in the input text. It is a reimplementation of Lample (2016) and uses a biLSTM with a CRF layer, character embeddings and ELMo embeddings.tagging-fine-grained-transformer-crf-tagger- Fine-grained NER modelve-vilbert- ViLBERT-based model for Visual Entailment.vgqa-vilbert- ViLBERT (short for Vision-and-Language BERT), is a model for learning task-agnostic joint representations of image content and natural language.vqa-vilbert- ViLBERT (short for Vision-and-Language BERT), is a model for learning task-agnostic joint representations of image content and natural language.
allennlp-models is available on PyPI. To install with pip, just run
pip install allennlp-modelsNote that the allennlp-models package is tied to the allennlp core package. Therefore when you install the models package you will get the corresponding version of allennlp (if you haven't already installed allennlp). For example,
pip install allennlp-models==2.2.0
pip freeze | grep allennlp
# > allennlp==2.2.0
# > allennlp-models==2.2.0If you intend to install the models package from source, then you probably also want to install allennlp from source.
Once you have allennlp installed, run the following within the same Python environment:
git clone https://github.com/allenai/allennlp-models.git
cd allennlp-models
ALLENNLP_VERSION_OVERRIDE='allennlp' pip install -e .
pip install -r dev-requirements.txtThe ALLENNLP_VERSION_OVERRIDE environment variable ensures that the allennlp dependency is unpinned so that your local install of allennlp will be sufficient. If, however, you haven't installed allennlp yet and don't want to manage a local install, just omit this environment variable and allennlp will be installed from the main branch on GitHub.
Both allennlp and allennlp-models are developed and tested side-by-side, so they should be kept up-to-date with each other. If you look at the GitHub Actions workflow for allennlp-models, it's always tested against the main branch of allennlp. Similarly, allennlp is always tested against the main branch of allennlp-models.
Docker provides a virtual machine with everything set up to run AllenNLP-- whether you will leverage a GPU or just run on a CPU. Docker provides more isolation and consistency, and also makes it easy to distribute your environment to a compute cluster.
Once you have installed Docker you can either use a prebuilt image from a release or build an image locally with any version of allennlp and allennlp-models.
If you have GPUs available, you also need to install the nvidia-docker runtime.
To build an image locally from a specific release, run
docker build \
--build-arg RELEASE=1.2.2 \
--build-arg CUDA=10.2 \
-t allennlp/models - < Dockerfile.releaseJust replace the RELEASE and CUDA build args with what you need. You can check the available tags
on Docker Hub to see which CUDA versions are available for a given RELEASE.
Alternatively, you can build against specific commits of allennlp and allennlp-models with
docker build \
--build-arg ALLENNLP_COMMIT=d823a2591e94912a6315e429d0fe0ee2efb4b3ee \
--build-arg ALLENNLP_MODELS_COMMIT=01bc777e0d89387f03037d398cd967390716daf1 \
--build-arg CUDA=10.2 \
-t allennlp/models - < Dockerfile.commitJust change the ALLENNLP_COMMIT / ALLENNLP_MODELS_COMMIT and CUDA build args to the desired commit SHAs and CUDA versions, respectively.
Once you've built your image, you can run it like this:
mkdir -p $HOME/.allennlp/
docker run --rm --gpus all -v $HOME/.allennlp:/root/.allennlp allennlp/modelsNote: the
--gpus allis only valid if you've installed the nvidia-docker runtime.