OpenGL的左下角是(0.0f, 0.0f),右上角是(1.0f, 1.0f)
GLSL可以把顶点着色器和片段着色器写到一个文件里来处理,参看这个项目,在其Shader.cpp中看它的一个函数void Shader::compileRaw(const char* rawSource),里面有具体实现。
learnOpenGL教程的地址,别人比较新的对应源码的项目。
OpenGL在linux下查看版本命令glxinfo | grep "OpenGL version",可能在xshell终端查询是报错的,然后再centos中安装的是mesa,即yum install mesa-libGL mesa-libGL-devel(带-devel的是另一个包)。
==像素着色器(Pixel Shader,Direct3D 中的叫法),常常又称为片断着色器,片元着色器(Fragment Shader,OpenGL 中的叫法),用于进行逐像素计算颜色的操作,让复杂的着色方程在每一个像素上执行==
OpenGL的错误代码,以及相关debug的教程。(这里面讲了像“RenderDoc”、“CodeXL”、“NVIDIA Nsight”等软件来做调试)(“RenderDoc”是可以打开".exr"格式文件(这是一种高动态范围(HDR)图像格式))
最初的介绍。
环境配置,这里:
-
GLFW:GLFW是一个专门针对OpenGL的C语言库,它提供了一些渲染物体所需的最低限度的接口。它允许用户创建OpenGL上下文、定义窗口参数以及处理用户输入。 同样的类似的还有一个名字为
glut的库,它跟glfw一样的作用,但不如glfw方便强大。-
添加头文件路径:D:\lib\for_vulkan\glfw-3.3.7.bin.WIN64\include
-
添加库文件路径:D:\lib\for_vulkan\glfw-3.3.7.bin.WIN64\lib-vc2017
-
添加动态库,一般用: glfw3.lib
-
-------linux下------
-
直接安装yum search all glfw, 然后 install:yum install glfw.x86_64 glfw-devel.x86_64
- 接着就有 /use/include/GLFW/glfw3.h /usr/lib64/libglfw.so
- 还有cmake路径:/usr/lib64/cmake/glfw3/glfw3Targets.cmake
----ubuntu下-------- 可以直接去这里下源码编译。
- 先安装依赖:apt-get install xorg-dev libglu1-mesa-dev
- 直接源码去cmake就可以了,然后设置它的cmake路径 export glfw3_ROOT=/opt/glfw-3.3.8/my_install/lib/cmake/glfw3
-
-
OpenGL库:
- windows:==opengl32.lib==已经包含在Microsoft SDK里了(所以直接添加到链接器的附加依赖项中),它在Visual Studio安装的时候就默认安装了。只需将opengl32.lib添加进连接器设置里就行了。值得注意的是,OpenGL库64位版本的文件名仍然是opengl32.lib(和32位版本一样)。
- linux:在Linux下你需要链接==libGL.so==库文件(一般有,在/usr/lib64/libGL.so),这需要添加
-lGL到你的链接器设置中。如果找不到这个库你可能需要安装Mesa; 对于用GCC编译的Linux用户建议使用这个命令行选项-lglfw3 -lGL -lX11 -lpthread -lXrandr -lXi -ldl。没有正确链接相应的库会产生 *undefined reference* (未定义的引用) 这个错误。
-
GLAD:因为OpenGL只是一个标准/规范,具体的实现是由驱动开发商针对特定显卡实现的(用它来替代==GLEW==扩展库的)。由于OpenGL驱动版本众多,它大多数函数的位置都无法在编译时确定下来,需要在运行时查询。所以任务就落在了开发者身上,开发者需要在运行时获取函数地址并将其保存在一个函数指针中供以后使用。取得地址的方法因平台而异,在Windows上会是类似这样:
// 定义函数原型 typedef void (*GL_GENBUFFERS) (GLsizei, GLuint*); // 找到正确的函数并赋值给函数指针 GL_GENBUFFERS glGenBuffers = (GL_GENBUFFERS)wglGetProcAddress("glGenBuffers"); // 现在函数可以被正常调用了 GLuint buffer; glGenBuffers(1, &buffer);
我们需要对每个可能使用的函数都要重复这个过程。幸运的是,有些库能简化此过程,其中GLAD是目前最新,也是最流行的库。 配置看这里。根据上面讲的,下好后
- 添加头文件路径:D:\lib\glad\include
- 解压后的src中的glad.c复制到main.cpp同级
以下代码用之前要把glad三方库配好,然后把glad.c复制到源码位置。
这里面包括了最开始的基础应用,更详细的解释在这里,下面不是很明白的函数就可以点进去看。
#include <iostream>
#include <glad/glad.h> // 特别注意:在包含GLFW的头文件之前包含了GLAD的头文件。GLAD的头文件包含了正确的OpenGL头文件(例如GL/gl.h),所以需要在其它依赖于OpenGL的头文件之前包含GLAD。
#include <GLFW/glfw3.h>
void framebuffer_size_callback(GLFWwindow* window, int width, int height);
void processInput(GLFWwindow* window);
int main() {
// 1、实例化GLFW窗口
glfwInit();
glfwWindowHint(GLFW_CONTEXT_VERSION_MAJOR, 3); // 说明opengl版本,方便glfw做调整
glfwWindowHint(GLFW_CONTEXT_VERSION_MINOR, 3);
glfwWindowHint(GLFW_OPENGL_PROFILE, GLFW_OPENGL_CORE_PROFILE); //告诉GLFW我们使用的是核心模式(Core-profile);明确告诉GLFW我们需要使用核心模式意味着我们只能使用OpenGL功能的一个子集(没有我们已不再需要的向后兼容特性)
#ifdef __APPLE__
glfwWindowHint(GLFW_OPENGL_FORWARD_COMPAT, GL_TRUE); // 针对苹果,上一行core-profile才生效
#endif
// 2、创建一个窗口对象
GLFWwindow* window = glfwCreateWindow(800, 600, "LearnOpenGL", NULL, NULL);
if (window == NULL) {
std::cout << "Failed to create GLFW window" << std::endl;
glfwTerminate();
return -1;
}
// 通知GLFW将我们窗口的上下文设置为当前线程的主上下文了
glfwMakeContextCurrent(window);
glfwSetFramebufferSizeCallback(window, framebuffer_size_callback);
// 3、初始化glad,GLAD是用来管理OpenGL的函数指针的,所以在调用任何OpenGL的函数之前我们需要初始化GLAD
if (!gladLoadGLLoader((GLADloadproc)glfwGetProcAddress)) {
std::cout << "Failed to initialize GLAD" << std::endl;
return -1;
} // 给GLAD传入了用来加载系统相关的OpenGL函数指针地址的函数
// 5、Render Loop
while (!glfwWindowShouldClose(window)) {
// 输入控制,事件来控制关闭与否
processInput(window);
// 渲染指令(核心功能代码就放这里,下面两行只是一个实例,)
glClearColor(0.2f, 0.3f, 0.3f, 1.0f);
glClear(GL_COLOR_BUFFER_BIT);
glfwSwapBuffers(window); // 函数会交换颜色缓冲(它是一个储存着GLFW窗口每一个像素颜色值的大缓冲),它在这一迭代中被用来绘制,并且将会作为输出显示在屏幕上。
glfwPollEvents(); // 函数检查有没有触发什么事件(比如键盘输入、鼠标移动等)、更新窗口状态,并调用对应的回调函数(可以通过回调方法手动设置)
}
// 释放所有资源
glfwTerminate();
return 0;
}
void framebuffer_size_callback(GLFWwindow* window, int width, int height) {
// 4、glViewport函数前两个参数控制窗口左下角的位置。第三个和第四个参数控制渲染窗口的宽度和高度(像素)(有更深含义的技术,看这些代码的链接解释)
glViewport(0, 0, width, height);
}
void processInput(GLFWwindow* window) {
// 按esc关闭窗口
if (glfwGetKey(window, GLFW_KEY_ESCAPE) == GLFW_PRESS)
glfwSetWindowShouldClose(window, true);
}源码讲解地址。然后附几个概念:
- 顶点数组对象:Vertex Array Object,VAO
- 顶点缓冲对象:Vertex Buffer Object,VBO
- 元素缓冲对象:Element Buffer Object,EBO 或 索引缓冲对象 Index Buffer Object,IBO
这里是没有用到EBO,仅用了glDrawArrays来绘制。
#include <glad/glad.h>
#include <GLFW/glfw3.h>
#include <iostream>
void framebuffer_size_callback(GLFWwindow* window, int width, int height);
void processInput(GLFWwindow *window);
// settings
const unsigned int SCR_WIDTH = 800;
const unsigned int SCR_HEIGHT = 600;
// gl_Position是GLSL中预定义的
const char *vertexShaderSource = "#version 330 core\n"
"layout (location = 0) in vec3 aPos;\n"
"void main()\n"
"{\n"
" gl_Position = vec4(aPos.x, aPos.y, aPos.z, 1.0);\n"
"}\0";
// 如果这里写的 -aPos.y 那就是所有的y坐标都加一个符号,三角形就会上下颠倒
// GLSL里的这个颜色决定了三角形的颜色
const char *fragmentShaderSource = "#version 330 core\n"
"out vec4 FragColor;\n"
"void main()\n"
"{\n"
" FragColor = vec4(1.0f, 0.5f, 0.2f, 1.0f);\n"
"}\n\0";
int main() {
// glfw: initialize and configure
// ------------------------------
glfwInit();
glfwWindowHint(GLFW_CONTEXT_VERSION_MAJOR, 3);
glfwWindowHint(GLFW_CONTEXT_VERSION_MINOR, 3);
glfwWindowHint(GLFW_OPENGL_PROFILE, GLFW_OPENGL_CORE_PROFILE);
#ifdef __APPLE__
glfwWindowHint(GLFW_OPENGL_FORWARD_COMPAT, GL_TRUE);
#endif
// glfw window creation
GLFWwindow* window = glfwCreateWindow(SCR_WIDTH, SCR_HEIGHT, "LearnOpenGL", NULL, NULL);
if (window == NULL) {
std::cout << "Failed to create GLFW window" << std::endl;
glfwTerminate();
return -1;
}
glfwMakeContextCurrent(window);
glfwSetFramebufferSizeCallback(window, framebuffer_size_callback);
// glad: load all OpenGL function pointers
if (!gladLoadGLLoader((GLADloadproc)glfwGetProcAddress)) {
std::cout << "Failed to initialize GLAD" << std::endl;
return -1;
}
// build and compile our shader program
// ------------------------------------
// 1、vertex shader(顶点着色器)
unsigned int vertexShader = glCreateShader(GL_VERTEX_SHADER);
glShaderSource(vertexShader, 1, &vertexShaderSource, NULL);
glCompileShader(vertexShader);
// check for shader compile errors
int success;
char infoLog[512];
glGetShaderiv(vertexShader, GL_COMPILE_STATUS, &success);
if (!success) {
glGetShaderInfoLog(vertexShader, 512, NULL, infoLog);
std::cout << "ERROR::SHADER::VERTEX::COMPILATION_FAILED\n" << infoLog << std::endl;
}
// 2、fragment shader(片段着色器)
unsigned int fragmentShader = glCreateShader(GL_FRAGMENT_SHADER);
glShaderSource(fragmentShader, 1, &fragmentShaderSource, NULL);
glCompileShader(fragmentShader);
// check for shader compile errors
glGetShaderiv(fragmentShader, GL_COMPILE_STATUS, &success);
if (!success) {
glGetShaderInfoLog(fragmentShader, 512, NULL, infoLog);
std::cout << "ERROR::SHADER::FRAGMENT::COMPILATION_FAILED\n" << infoLog << std::endl;
}
// 3、link shaders(把上面两个着色器链接为一个着色器程序对象)
unsigned int shaderProgram = glCreateProgram();
glAttachShader(shaderProgram, vertexShader);
glAttachShader(shaderProgram, fragmentShader);
glLinkProgram(shaderProgram);
// check for linking errors(注意和上面着色器检查使用的函数不同)
glGetProgramiv(shaderProgram, GL_LINK_STATUS, &success);
if (!success) {
glGetProgramInfoLog(shaderProgram, 512, NULL, infoLog);
std::cout << "ERROR::SHADER::PROGRAM::LINKING_FAILED\n" << infoLog << std::endl;
}
glDeleteShader(vertexShader); // 链接后就可以删除着色器对象了,后面用不到了
glDeleteShader(fragmentShader);
/* 以上是准备顶点、片段着色器,然后链接得到着色器程序,下面是绘画 */
// 三角形三个坐标,平面上深度Z轴为0
float vertices[] = {
-0.5f, -0.5f, 0.0f,
0.5f, -0.5f, 0.0f,
0.0f, 0.5f, 0.0f
};
// 一定是按照下面的顺序性
// (1)绑定VAO
unsigned int VAO; // 顶点数组对象(VAO)
glGenVertexArrays(1, &VAO);
glBindVertexArray(VAO);
// (2)把顶点数据复制到缓冲中供OpenGL使用
unsigned int VBO;
glGenBuffers(1, &VBO);
glBindBuffer(GL_ARRAY_BUFFER, VBO); // 注意这里类型是 GL_ARRAY_BUFFER
glBufferData(GL_ARRAY_BUFFER, sizeof(vertices), vertices, GL_STATIC_DRAW);
// (3)设置顶点属性指针
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(float), (void*)0);
glEnableVertexAttribArray(0);
// render loop
// -----------
while (!glfwWindowShouldClose(window)) {
processInput(window);
// render
// ------
glClearColor(0.2f, 0.3f, 0.3f, 1.0f); // 背景色
glClear(GL_COLOR_BUFFER_BIT);
// (4)绘制物体
glUseProgram(shaderProgram);
glBindVertexArray(VAO); // 当有多个VAO时,可通过来这种来切换到不同的VAO,当有多个VAO时
glDrawArrays(GL_TRIANGLES, 0, 3); // 如果有6个顶点,2个三角形,这里的3就改成6,vertices里也是6个值
glfwSwapBuffers(window);
glfwPollEvents();
}
// (5)释放资源
glDeleteVertexArrays(1, &VAO);
glDeleteBuffers(1, &VBO);
glDeleteProgram(shaderProgram);
glfwTerminate();
return 0;
}
void processInput(GLFWwindow *window) {
if (glfwGetKey(window, GLFW_KEY_ESCAPE) == GLFW_PRESS)
glfwSetWindowShouldClose(window, true);
}
void framebuffer_size_callback(GLFWwindow* window, int width, int height) {
glViewport(0, 0, width, height);
}==以上是画一个三角形的源码,但不具有普适性==,对不同的三角形,使用不同的VAO、VBO,
只写核心代码,这算是通用的,上面画一个三角形可以看作是长度为1的数组来处理。
下面的代码才应该是上面代码的核心(上面那种结合EBO,所有顶点都在一个vertex数组中,用比较合适,但用下面这种数组也无所谓)
// 三角形三个坐标,平面上深度Z轴为0
float firstTriangle[] = {
-0.9f, -0.5f, 0.0f, // left
-0.0f, -0.5f, 0.0f, // right
-0.45f, 0.5f, 0.0f, // top
};
float secondTriangle[] = {
0.0f, -0.5f, 0.0f, // left
0.9f, -0.5f, 0.0f, // right
0.45f, 0.5f, 0.0f // top
};
// 一定是按照下面的顺序性
// (1)绑定VAO
unsigned int VAOs[2]; // 顶点数组对象(VAO)
glGenVertexArrays(2, VAOs); // 2就是上组的长度,上面一个三角形,所以用的1
// (2)把顶点数据复制到缓冲中供OpenGL使用
unsigned int VBOs[2];
glGenBuffers(2, VBOs);
glBindVertexArray(VAOs[0]);
glBindBuffer(GL_ARRAY_BUFFER, VBOs[0]);
glBufferData(GL_ARRAY_BUFFER, sizeof(firstTriangle), firstTriangle, GL_STATIC_DRAW);
//(3)设置顶点属性指针
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(float), (void*)0);
glEnableVertexAttribArray(0);
/* 绑定顶点数组 以及 顶点数据时这个操作是上面、下面这样一样的,重复的 */
glBindVertexArray(VAOs[1]);
glBindBuffer(GL_ARRAY_BUFFER, VBOs[1]);
glBufferData(GL_ARRAY_BUFFER, sizeof(secondTriangle), secondTriangle, GL_STATIC_DRAW);
// (3)设置顶点属性指针
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(float), (void*)0);
glEnableVertexAttribArray(0); // 这里的0是代表索引,第一个属性
// 在while中绘图也是要几个画几个
while () {
// (4)绘制物体
glUseProgram(shaderProgram);
glBindVertexArray(VAOs[0]); // 用数组标识来代表画哪个三角形
glDrawArrays(GL_TRIANGLES, 0, 3);
// 要画几个,这里就要操作几个
glBindVertexArray(VAOs[1]);
glDrawArrays(GL_TRIANGLES, 0, 3);
}
// (5)释放资源
glDeleteVertexArrays(2, VAOs); // 释放资源的个数2,是VAOs数组的长度
glDeleteBuffers(2, VBOs);
glDeleteProgram(shaderProgram);下面开始把一些函数的意义及参数说明一下:
现代OpenGL需要我们至少设置一个顶点和一个片段着色器,
// 1、vertex shader(顶点着色器) && 2、fragment shader(片段着色器)
第一件事是用着色器语言GLSL(OpenGL Shading Language)编写顶点着色器,然后编译这个着色器,这样我们就可以在程序中使用它了,上面的const char *vertexShaderSource就是GLSL的源码,写成了C字符串的样式,具体解读看这个解释的网站吧,步骤都是:
- 先创建一个着色器对象;
- 着色器源码附加到着色器对象上,然后编译它;==glShaderSource==的第二参数指定了传递的源码字符串数量,这里只有一个,所以是1;
- 检查编译是是否出错。这里用的函数数是==glGetShaderiv==,用==glGetShaderInfoLog==获取报错信息
// 3、link shaders(把上面两个着色器链接为一个着色器程序对象)
- 先创建一个着色器程序:glCreateProgram();
- 把上面的两个着色器对象添加到这着色器程序,然后链接;
- 检查链接是否出错,用==glGetProgramiv==,用==glGetProgramInfoLog==获取报错信息(注意与着色器的函数名不同)。
----------- 以上做好了准备工作,下面就是准备点位进行数据的处理渲染 --------
首先先准备一个数组,包含了三角形的三个顶点坐标。(以下顺序很重要,不能乱了)
// (1)绑定VAO(顶点数组对象)
VAO可以像顶点缓冲对象那样被绑定,任何随后的顶点属性调用都会储存在这个VAO中。这样的好处就是,当配置顶点属性指针时,你只需要将那些调用执行一次,之后再绘制物体的时候只需要绑定相应的VAO就行了。这使在不同顶点数据和属性配置之间切换变得非常简单,只需要绑定不同的VAO就行了。刚刚设置的所有状态都将存储在VAO中。 下面的第(3)带你的内容都是跟这相关的
// (2)把顶点数据复制到缓冲中供OpenGL使用 (VBO:顶点缓冲对象)
- 顶点缓冲对象的缓冲类型是==GL_ARRAY_BUFFER==,使用==函数glBindBuffer==绑定;
- 再使用==函数glBufferData==把用户定义的数据复制到当前绑定缓冲,参数解释:
- 第一个参数是目标缓冲的类型:顶点缓冲对象当前绑定到GL_ARRAY_BUFFER目标上,
这一刻起,我们使用的任何(在GL_ARRAY_BUFFER目标上的)缓冲调用都会用来配置当前绑定的缓冲(VBO) - 第二个参数指定传输数据的大小(以字节为单位);用一个简单的
sizeof计算出顶点数据大小就行; - 第三个参数是我们希望发送的实际数据(也就是定义的三角形顶点);
- 第四个参数指定了我们希望显卡如何管理给定的数据。它有三种形式: GL_STATIC_DRAW :数据不会或几乎不会改变, GL_DYNAMIC_DRAW:数据会被改变很多, GL_STREAM_DRAW :数据每次绘制时都会改变。 说明:三角形的位置数据不会改变,每次渲染调用时都保持原样,所以它的使用类型最好是GL_STATIC_DRAW。如果,比如说一个缓冲中的数据将频繁被改变,那么使用的类型就是GL_DYNAMIC_DRAW或GL_STREAM_DRAW,这样就能确保显卡把数据放在能够高速写入的内存部分。
- 第一个参数是目标缓冲的类型:顶点缓冲对象当前绑定到GL_ARRAY_BUFFER目标上,
// (3)设置顶点属性指针
使用==glVertexAttribPointer函数==告诉OpenGL该如何解析顶点数据(应用到逐个顶点属性上),此函数的参数说明:
- 第一个参数指定我们要配置的顶点属性。还记得我们在顶点着色器中使用
layout(location = 0)定义了position顶点属性的位置值(Location)吗?它可以把顶点属性的位置值设置为0。因为我们希望把数据传递到这一个顶点属性中,所以这里我们传入0。 - 第二个参数指定顶点属性的大小。比如index为0的顶点属性是坐标,一个vec3,它由3个值组成,所以大小是3;然后index为1的顶点属性是纹理坐标,一个vec2,它由2个值组成,那这时就是2;
- 第三个参数指定数据的类型,这里是GL_FLOAT(GLSL中
vec*都是由浮点数值组成的)。 - 下个参数定义我们是否希望数据被标准化(Normalize)。如果我们设置为GL_TRUE,所有数据都会被映射到0(对于有符号型signed数据是-1)到1之间。我们把它设置为GL_FALSE。
- 第五个参数叫做步长(Stride),它告诉我们在连续的顶点属性组之间的间隔。由于下个点位置数据在3个
float之后,我们把步长设置为3 * sizeof(float)。要注意的是由于我们知道这个数组是紧密排列的(在两个顶点属性之间没有空隙)我们也可以设置为0来让OpenGL决定具体步长是多少(只有当数值是紧密排列时才可用)。 ==一旦我们有更多的顶点属性,比如下面的一个点的数据包含 顶点坐标3个值、顶点颜色3个值、纹理坐标2个值,那此时的stride就是3+3+2=8,即8*sizeof(float)==。 - 最后一个参数的类型是void*,所以需要我们进行这个奇怪的强制类型转换。它表示位置数据在缓冲中起始位置的偏移量(Offset)。由于位置数据在数组的开头,所以这里是0。 接着上条,指定索引为1的顶点颜色时,它前面有3个值的顶点坐标,所以就会是(void*)(3 * sizeof(float));同理纹理坐标就会是是(void*)(6 * sizeof(float))。
然后因为顶点属性是默认是禁用的,所以用==glEnableVertexAttribArray(0);==启动,# 这里面的0是代表属性的索引,这里是第一个,后面的纹理用到了3个属性,就会有0、1、2
// (4)绘制物体
- 调用==glUseProgram函数==以激活这个程序对象;
- ==glDrawArrays函数==,它使用当前激活的着色器,之前定义的顶点属性配置,和VBO的顶点数据(通过VAO间接绑定)来绘制图元,参数:
- 第一个参数是我们打算绘制的OpenGL图元的类型;
- 第二个参数指定了顶点数组的起始索引,我们这里填0;
- 最后一个参数指定我们打算绘制多少个顶点,这里是
3(我们只从我们的数据中渲染一个三角形,它只有3个顶点长)。
// (5)释放资源
直接用对应的delete函数释放就行了。
==元素缓冲对象(EBO)== 也叫作 ==索引缓冲对象(IBO)==
假设我们不再绘制一个三角形而是绘制一个矩形。我们可以绘制两个三角形来组成一个矩形(OpenGL主要处理三角形),这会生成下面的顶点的集合:
float vertices[] = {
// 第一个三角形
0.5f, 0.5f, 0.0f, // 右上角
0.5f, -0.5f, 0.0f, // 右下角
-0.5f, 0.5f, 0.0f, // 左上角
// 第二个三角形
0.5f, -0.5f, 0.0f, // 右下角
-0.5f, -0.5f, 0.0f, // 左下角
-0.5f, 0.5f, 0.0f // 左上角
}; 注:用这去替换上面代码,然后把glDrawArrays(GL_TRIANGLES, 0, 3);里面的3改成6是可以画出来这矩形的。
分析:
上面指定了右下角和左上角两次,一个矩形只有4个而不是6个顶点,这样就产生50%的额外开销,当三角形很多时,额外开销就很大了。只要储存4个顶点就能绘制矩形了,之后只要指定绘制的顺序就行了,元素缓冲区对象的工作方式正是如此。 EBO是一个缓冲区,就像一个顶点缓冲区对象一样,它存储 OpenGL 用来决定要绘制哪些顶点的索引。这种所谓的索引绘制(Indexed Drawing)正是我们问题的解决方案。
float vertices[] = {
0.5f, 0.5f, 0.0f, // 右上角
0.5f, -0.5f, 0.0f, // 右下角
-0.5f, -0.5f, 0.0f, // 左下角
-0.5f, 0.5f, 0.0f // 左上角
};
unsigned int indices[] = {
// 注意索引从0开始!
// 此例的索引(0,1,2,3)就是顶点数组vertices的下标,
// 这样可以由下标代表顶点组合成矩形
0, 1, 3, // 第一个三角形
1, 2, 3 // 第二个三角形
};-
加一个(2.5)顶点数组复制到一个顶点缓冲中,供OpenGL使用
unsigned int EBO; glGenBuffers(1, &EBO); glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, EBO); // 这里类型是 GL_ELEMENT_ARRAY_BUFFER glBufferData(GL_ELEMENT_ARRAY_BUFFER, sizeof(indices), indices, GL_STATIC_DRAW);
-
然后while中将用==glDrawElements==来替换glDrawArrays函数,表示我们要从索引缓冲区渲染三角形。使用glDrawElements时,我们会使用当前绑定的索引缓冲对象中的索引进行绘制,里面就成了
//glDrawArrays(GL_TRIANGLES, 0, 6); glDrawElements(GL_TRIANGLES, 6, GL_UNSIGNED_INT, 0); // glBindVertexArray(0); // no need to unbind it every time
- 第一个参数指定了我们绘制的模式;
- 第二个参数是我们打算绘制顶点的个数,这里是6个顶点;
- 第三个参数是索引的类型,这里是GL_UNSIGNED_INT;
- 最后一个参数里我们可以指定EBO中的偏移量(或者传递一个索引数组,但是这是当你不在使用索引缓冲对象的时候),但是我们会在这里填写0。
-
glBindVertexArray(0);是解除绑定,加了EBO后才有的这个,好像是有了EBO,目标是GL_ELEMENT_ARRAY_BUFFER,就可以解绑这个顶点数组了(我的理解),然后就把这一句加到while循环的前一句(不加也没报错)
线框模式(Wireframe Mode)
绘制出来的图的区域是填充的,可以只画边框线,在while之前加上: glPolygonMode(GL_FRONT_AND_BACK, GL_LINE); // 这一行是代表用线框模式,
glPolygonMode(GL_FRONT_AND_BACK, GL_FILL); // 这就是又设置回默认
下面的代码是画的三角形的,后面加了一些代码后:
#include <glad/glad.h>
#include <GLFW/glfw3.h>
#include <iostream>
void framebuffer_size_callback(GLFWwindow* window, int width, int height);
void processInput(GLFWwindow *window);
// settings
const unsigned int SCR_WIDTH = 800;
const unsigned int SCR_HEIGHT = 600;
const char *vertexShaderSource = "#version 330 core\n"
"layout (location = 0) in vec3 aPos;\n"
"void main()\n"
"{\n"
" gl_Position = vec4(aPos.x, aPos.y, aPos.z, 1.0);\n"
"}\0";
// GLSL里的这个颜色决定了三角形的颜色
const char *fragmentShaderSource = "#version 330 core\n"
"out vec4 FragColor;\n"
"void main()\n"
"{\n"
" FragColor = vec4(1.0f, 0.5f, 0.2f, 1.0f);\n"
"}\n\0";
int main() {
// glfw: initialize and configure
// ------------------------------
glfwInit();
glfwWindowHint(GLFW_CONTEXT_VERSION_MAJOR, 3);
glfwWindowHint(GLFW_CONTEXT_VERSION_MINOR, 3);
glfwWindowHint(GLFW_OPENGL_PROFILE, GLFW_OPENGL_CORE_PROFILE);
#ifdef __APPLE__
glfwWindowHint(GLFW_OPENGL_FORWARD_COMPAT, GL_TRUE);
#endif
// glfw window creation
GLFWwindow* window = glfwCreateWindow(SCR_WIDTH, SCR_HEIGHT, "LearnOpenGL", NULL, NULL);
if (window == NULL) {
std::cout << "Failed to create GLFW window" << std::endl;
glfwTerminate();
return -1;
}
glfwMakeContextCurrent(window);
glfwSetFramebufferSizeCallback(window, framebuffer_size_callback);
// glad: load all OpenGL function pointers
if (!gladLoadGLLoader((GLADloadproc)glfwGetProcAddress)) {
std::cout << "Failed to initialize GLAD" << std::endl;
return -1;
}
// build and compile our shader program
// ------------------------------------
// 1、vertex shader(顶点着色器)
unsigned int vertexShader = glCreateShader(GL_VERTEX_SHADER);
glShaderSource(vertexShader, 1, &vertexShaderSource, NULL);
glCompileShader(vertexShader);
// check for shader compile errors
int success;
char infoLog[512];
glGetShaderiv(vertexShader, GL_COMPILE_STATUS, &success);
if (!success) {
glGetShaderInfoLog(vertexShader, 512, NULL, infoLog);
std::cout << "ERROR::SHADER::VERTEX::COMPILATION_FAILED\n" << infoLog << std::endl;
}
// 2、fragment shader(片段着色器)
unsigned int fragmentShader = glCreateShader(GL_FRAGMENT_SHADER);
glShaderSource(fragmentShader, 1, &fragmentShaderSource, NULL);
glCompileShader(fragmentShader);
// check for shader compile errors
glGetShaderiv(fragmentShader, GL_COMPILE_STATUS, &success);
if (!success) {
glGetShaderInfoLog(fragmentShader, 512, NULL, infoLog);
std::cout << "ERROR::SHADER::FRAGMENT::COMPILATION_FAILED\n" << infoLog << std::endl;
}
// 3、link shaders(把上面两个着色器链接为一个着色器程序对象)
unsigned int shaderProgram = glCreateProgram();
glAttachShader(shaderProgram, vertexShader);
glAttachShader(shaderProgram, fragmentShader);
glLinkProgram(shaderProgram);
// check for linking errors(注意和上面着色器检查使用的函数不同)
glGetProgramiv(shaderProgram, GL_LINK_STATUS, &success);
if (!success) {
glGetProgramInfoLog(shaderProgram, 512, NULL, infoLog);
std::cout << "ERROR::SHADER::PROGRAM::LINKING_FAILED\n" << infoLog << std::endl;
}
glDeleteShader(vertexShader); // 链接后就可以删除着色器对象了,后面用不到了
glDeleteShader(fragmentShader);
/* 以上是准备顶点、片段着色器,然后链接得到着色器程序,下面是绘画 */
// 三角形三个坐标,平面上深度Z轴为0
float vertices[] = {
0.5f, 0.5f, 0.0f, // 右上角
0.5f, -0.5f, 0.0f, // 右下角
-0.5f, -0.5f, 0.0f, // 左下角
-0.5f, 0.5f, 0.0f // 左上角
};
unsigned int indices[] = {
// 注意索引从0开始!
// 此例的索引(0,1,2,3)就是顶点数组vertices的下标,
// 这样可以由下标代表顶点组合成矩形
0, 1, 3, // 第一个三角形
1, 2, 3 // 第二个三角形
};
// 一定是按照下面的顺序性
// (1)绑定VAO
unsigned int VAO; // 顶点数组对象(VAO)
glGenVertexArrays(1, &VAO);
glBindVertexArray(VAO);
// (2)把顶点数据复制到缓冲中供OpenGL使用
unsigned int VBO;
glGenBuffers(1, &VBO);
glBindBuffer(GL_ARRAY_BUFFER, VBO); // 注意这里类型是 GL_ARRAY_BUFFER
glBufferData(GL_ARRAY_BUFFER, sizeof(vertices), vertices, GL_STATIC_DRAW);
// (2.5)顶点数组复制到一个顶点缓冲中,供OpenGL使用
unsigned int EBO;
glGenBuffers(1, &EBO);
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, EBO); // 这里类型是 GL_ELEMENT_ARRAY_BUFFER
glBufferData(GL_ELEMENT_ARRAY_BUFFER, sizeof(indices), indices, GL_STATIC_DRAW);
// (3)设置顶点属性指针
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(float), (void*)0);
glEnableVertexAttribArray(0);
glBindVertexArray(0); // 加了EBO后才有的这个,好像是有了EBO,目标是GL_ELEMENT_ARRAY_BUFFER,就可以解绑这个顶点数组了(我的理解),如果不用EBO,而是用glDrawArrays,一定要把这行删了
glPolygonMode(GL_FRONT_AND_BACK, GL_LINE); // 这一行是代表用线框模式,可注释掉看效果
glPolygonMode(GL_FRONT_AND_BACK, GL_FILL);
// render loop
// -----------
while (!glfwWindowShouldClose(window)) {
processInput(window);
// render
// ------
glClearColor(0.2f, 0.3f, 0.3f, 1.0f); // 背景色
glClear(GL_COLOR_BUFFER_BIT);
// (4)绘制物体
glUseProgram(shaderProgram);
glBindVertexArray(VAO); // 当有多个VAO时,可通过来这种来切换到不同的VAO,当有多个VAO时
//glDrawArrays(GL_TRIANGLES, 0, 3);
glDrawElements(GL_TRIANGLES, 6, GL_UNSIGNED_INT, 0);
// glBindVertexArray(0); // no need to unbind it every time
glfwSwapBuffers(window);
glfwPollEvents();
}
// (5)释放资源
glDeleteVertexArrays(1, &VAO);
glDeleteBuffers(1, &VBO);
glDeleteBuffers(1, &EBO);
glDeleteProgram(shaderProgram);
glfwTerminate();
return 0;
}
void processInput(GLFWwindow *window) {
if (glfwGetKey(window, GLFW_KEY_ESCAPE) == GLFW_PRESS)
glfwSetWindowShouldClose(window, true);
}
void framebuffer_size_callback(GLFWwindow* window, int width, int height) {
glViewport(0, 0, width, height);
} 2.2.4中的代码块里的代码是完整的放上来的。
练习中新增的,==画两个三角形,一个为橘色,一个为黄色==;仅放核心代码
// 1、新增黄的的GLSL的源码
const char *fragmeYellowShaderSource = "#version 330 core\n"
"out vec4 FragColor;\n"
"void main()\n"
"{\n"
" FragColor = vec4(1.0f, 1.0f, 0.0f, 1.0f);\n"
"}\n\0";
int main() {
// 2、编译黄色fragme着色器
unsigned int fragmeYellowShader = glCreateShader(GL_FRAGMENT_SHADER);
glShaderSource(fragmeYellowShader, 1, &fragmeYellowShaderSource, NULL);
glCompileShader(fragmeYellowShader);
glGetShaderiv(fragmeYellowShader, GL_COMPILE_STATUS, &success);
if (!success) {
glGetShaderInfoLog(fragmeYellowShader, 512, NULL, infoLog);
std::cout << "ERROR::SHADER::FRAGMENT::COMPILATION_FAILED\n" << infoLog << std::endl;
}
// 3、新建一个着色器程序,输出一个黄色;
unsigned int shaderYellowProgram = glCreateProgram();
glAttachShader(shaderYellowProgram, vertexShader); // vertexShader顶点着色器就是用的原来的
glAttachShader(shaderYellowProgram, fragmeYellowShader);
glLinkProgram(shaderYellowProgram);
// link链接完着色器程序后可以删除了
glDeleteShader(fragmeYellowShader);
while () {
// 4、使用着色器程序画图
glUseProgram(shaderProgram); // 着色器
glBindVertexArray(VAOs[0]); // 第一个为橘色,
glDrawArrays(GL_TRIANGLES, 0, 3);
/* 一个三角形VAOs[n]只能使用一个shaderProgram,后续再次用的话,前面的就会被后面的效果覆盖,前面的代码也就没意义了 */
glUseProgram(shaderYellowProgram); //
glBindVertexArray(VAOs[1]); // 第二个为黄色
glDrawArrays(GL_TRIANGLES, 0, 3);
}
}原文地址,讲的非常详细。
着色器(Shader)是运行在GPU上的小程序,着色器是使用一种叫GLSL的类C语言写成的,OpenGL着色器语言(GLSL)。
着色器的开头总是要==声明版本==,接着是==输入和输出变量==、==uniform和main函数==。每个着色器的入口点都是main函数,在这个函数中我们处理所有的输入变量,并将结果输出到输出变量中。
一个典型的着色器有下面的结构:
#version version_number
in type in_variable_name;
in type in_variable_name;
out type out_variable_name;
uniform type uniform_name;
int main()
{
// 处理输入并进行一些图形操作
...
// 输出处理过的结果到输出变量
out_variable_name = weird_stuff_we_processed;
}-
数据类型:GLSL中包含C等其它语言大部分的默认基础数据类型:
int、float、double、uint和bool。GLSL也有两种容器类型,分别是向量(Vector)和矩阵(Matrix)。-
向量:GLSL中的向量是一个可以包含有2、3或者4个分量的容器,分量的类型可以是前面默认基础类型的任意一个。它们可以是下面的形式(
n代表分量的数量,如2、3、4这些):类型 含义 vecn包含 n个float分量的默认向量bvecn包含 n个bool分量的向量ivecn包含 n个int分量的向量uvecn包含 n个unsigned int分量的向量dvecn包含 n个double分量的向量大多数时候我们使用
vecn,因为float足够满足大多数要求了。 -
一个向量的分量可以通过
vec.x这种方式获取,这里x是指这个向量的第一个分量。你可以分别使用.x、.y、.z和.w来获取它们的第1、2、3、4个分量。GLSL也允许你对颜色使用rgba,或是对纹理坐标使用stpq访问相同的分量。 -
还可以==重组==:
vec2 someVec; vec4 differentVec = someVec.xyxx; vec3 anotherVec = differentVec.zyw; vec4 otherVec = someVec.xxxx + anotherVec.yxzy;
也可以把一个向量作为一个参数传给不同的向量构造函数,以减少需求参数的数量:
vec2 vect = vec2(0.5, 0.7); vec4 result = vec4(vect, 0.0, 0.0); vec4 otherResult = vec4(result.xyz, 1.0);
-
-
输入与输出:
-
在顶点着色器中,
gl_Position是预设变量名,可以直接使用,具体看网站里面讲解; -
关键字就是 out、in 来做交互,片段着色器中的颜色输出可以来自顶点着色器中的输入(如下面例子),不过不如直接写在片段着色器中。 顶点着色器:
#version 330 core layout (location = 0) in vec3 aPos; // 位置变量的属性位置值为0 out vec4 vertexColor; // 为片段着色器指定一个颜色输出 void main() { gl_Position = vec4(aPos, 1.0); // 注意我们如何把一个vec3作为vec4的构造器的参数 vertexColor = vec4(0.5, 0.0, 0.0, 1.0); // 把输出变量设置为暗红色 }
片段着色器:
#version 330 core out vec4 FragColor; in vec4 vertexColor; // 从顶点着色器传来的输入变量(名称相同、类型相同) void main() { FragColor = vertexColor; }
-
-
uniform:
-
Uniform是一种从CPU中的应用向GPU中的着色器发送数据的方式,但uniform和顶点属性有些不同。首先,==uniform是全局的(Global)==。全局意味着uniform变量必须在每个着色器程序对象中都是独一无二的,而且它可以被着色器程序的任意着色器在任意阶段访问。第二,无论你把uniform值设置成什么,uniform会一直保存它们的数据,直到它们被重置或更新。
-
例子:让一个三角形颜色随着时间变化:(仅关键代码,源码地址)
const char *fragmeShaderSource = "#version 330 core\n" "out vec4 FragColor;\n" "uniform vec4 outColor;\n" // 在OpenGL程序代码中设定这个变量 "void main()\n" "{\n" " FragColor = outColor;\n" "}\n\0"; int main() { glBindVertexArray(VAO); // 这个可以放在循环体外 while(!glfwWindowShouldClose(window)) { // 输入 processInput(window); // 渲染 // 清除颜色缓冲 glClearColor(0.2f, 0.3f, 0.3f, 1.0f); glClear(GL_COLOR_BUFFER_BIT); // 记得激活着色器 glUseProgram(shaderProgram); // uniform改值前一定要先执行这句,且这句可以拿到循环体外去 // 更新uniform颜色 float timeValue = glfwGetTime(); //获取运行的秒数 float greenValue = sin(timeValue) / 2.0f + 0.5f; // glGetUniformLocation查询uniform ourColor的位置值,返回的是-1就代表没有找到这个位置值 int vertexColorLocation = glGetUniformLocation(shaderProgram, "ourColor"); // 这里的名字一定要跟glsl中的uniform变量名一模一样 // glUniform4f函数设置uniform值 glUniform4f(vertexColorLocation, 0.0f, greenValue, 0.0f, 1.0f); // 绘制三角形 glBindVertexArray(VAO); glDrawArrays(GL_TRIANGLES, 0, 3); }
注: 查询uniform地址不要求你之前使用过着色器程序,但是
更新一个uniform之前你**必须**先使用程序(调用glUseProgram),因为它是在当前激活的着色器程序中设置uniform的。 glGetUniformfv函数可以用来获取这个uniform变量(float类型)的值,同理glGetUniformiv就是针对int类型的uniform变量。
-
-
顶点直接带颜色属性:
-
glsl的写法:(就是常用来展示的那个三角形,源码)
// 1、新的glsl格式 const char *vertexShaderSource = "#version 330 core\n" "layout (location = 0) in vec3 aPos;\n" // 位置变量的属性位置值为 0 "layout (location = 1) in vec3 aColor;\n" // 颜色变量的属性位置值为 1 "out vec3 outColor;\n" // 向片段着色器输出一个颜色 "void main() {\n" " gl_Position = vec4(aPos, 1.0);\n" " outColor = aColor;\n" // 将ourColor设置为我们从顶点数据那里得到的输入颜色 "}\0"; // GLSL里的这个颜色决定了三角形的颜色 const char *fragmentShaderSource = "#version 330 core\n" "out vec4 FragColor;\n" "in vec3 outColor;\n" // 不再使用uniform来传递片段的颜色了,现在使用ourColor输出变量 "void main() {\n" " FragColor = vec4(outColor, 1.0);\n" "}\n\0"; // 2、顶点坐标带了颜色 float vertices[] = { // 位置 // 颜色 -0.5f, -0.5f, 0.0f, 1.0f, 0.0f, 0.0f, 0.5f, -0.5f, 0.0f, 0.0f, 1.0f, 0.0f, 0.0f, 0.5f, 0.0f, 0.0f, 0.0f, 1.0f }; // 3、使用glVertexAttribPointer函数更新顶点格式 // 位置属性 // 要变成6,这是步长 glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 6 * sizeof(float), (void*)0); glEnableVertexAttribArray(0); // 这还是0 // 颜色属性 glVertexAttribPointer(1, 3, GL_FLOAT, GL_FALSE, 6 * sizeof(float), (void*)(3* sizeof(float))); // 最后一个参数是偏移量 glEnableVertexAttribArray(1); // 注意这里是1
glVertexAttribPointer参数说明: 现在有了两个顶点属性,我们不得不重新计算步长值。为获得数据队列中下一个属性值(比如位置向量的下个
x分量)我们必须向右移动6个float,其中3个是位置值,另外3个是颜色值。这使我们的步长值为6乘以float的字节数(=24字节)。 同样,这次我们必须指定一个偏移量。==对于每个顶点来说,位置顶点属性在前,所以它的偏移量是0。颜色属性紧随位置数据之后,所以偏移量就是3 * sizeof(float)==,用字节来计算就是12字节。
-
前面shader的顶点着色器、片段着色器、着色器程序都是固定的,可以将其写成一个类,然后把GLSL源码部分写到文件里(后期也比较好改),作为参数传入这个类,看着比较直观。
源码地址。如果真的要写,就建议按照这个来,不要全都写到main函数中去。
在cuda的samples中,看到它写shader的一个方式:
-
shaders.h # 注意,这里的 extern关键字是声明变量,不要显示的初始化变量。
extern const char *vertexShader; extern const char *spherePixelShader;
-
shaders.cpp # 直接通过定义宏来转换这个字符串
#define STRINGIFY(A) #A // vertex shader const char *vertexShader = STRINGIFY( uniform float pointRadius; // point size in world space uniform float pointScale; // scale to calculate size in pixels uniform float densityScale; uniform float densityOffset; void main() { // calculate window-space point size vec3 posEye = vec3(gl_ModelViewMatrix * vec4(gl_Vertex.xyz, 1.0)); float dist = length(posEye); gl_PointSize = pointRadius * (pointScale / dist); gl_TexCoord[0] = gl_MultiTexCoord0; gl_Position = gl_ModelViewProjectionMatrix * vec4(gl_Vertex.xyz, 1.0); gl_FrontColor = gl_Color; } ); // pixel shader for rendering points as shaded spheres const char *spherePixelShader = STRINGIFY( void main() { const vec3 lightDir = vec3(0.577, 0.577, 0.577); // calculate normal from texture coordinates vec3 N; N.xy = gl_TexCoord[0].xy*vec2(2.0, -2.0) + vec2(-1.0, 1.0); float mag = dot(N.xy, N.xy); if (mag > 1.0) discard; // kill pixels outside circle N.z = sqrt(1.0-mag); // calculate lighting float diffuse = max(0.0, dot(lightDir, N)); gl_FragColor = gl_Color * diffuse; } );
原文笔记地址,更多更清楚。
纹理环绕方式:==glTexParameteri==函数来设定
它与纹理坐标是相关的,纹理坐标的范围通常是从(0, 0)到(1, 1),纹理坐标设置在范围之外,OpenGL默认的行为是重复这个纹理图像,OpenGL提供了下表中更多的选择:
float vertices[] = {
// ---- 位置 ---- ---- 颜色 ---- - 纹理坐标 -
0.5f, 0.5f, 0.0f, 1.0f, 0.0f, 0.0f, 3.0f, 3.0f, // 右上
0.5f, -0.5f, 0.0f, 0.0f, 1.0f, 0.0f, 3.0f, 0.0f, // 右下
-0.5f, -0.5f, 0.0f, 0.0f, 0.0f, 1.0f, 0.0f, 0.0f, // 左下
-0.5f, 0.5f, 0.0f, 1.0f, 1.0f, 0.0f, 0.0f, 3.0f // 左上
};注:纹理坐标,一般给1.0f,整张图就1个笑脸,按上面给3.0f,就会有3*3=9,一张图就会分成9宫格,9个笑脸。如果把纹理坐标的y的3.0f给到2.0f,结果就是2行3列。
| 环绕方式 | 描述 |
|---|---|
| GL_REPEAT | 对纹理的默认行为。重复纹理图像。 |
| GL_MIRRORED_REPEAT | 和GL_REPEAT一样,但每次重复图片是镜像放置的。 |
| GL_CLAMP_TO_EDGE | 纹理坐标会被约束在0到1之间,超出的部分会重复纹理坐标的边缘,产生一种边缘被拉伸的效果。 |
| GL_CLAMP_TO_BORDER | 超出的坐标为用户指定的边缘颜色。 |
每个选项都可以使用glTexParameter*函数对单独的一个坐标轴设置(s、t(如果是使用3D纹理那么还有一个r)它们和x、y、z是等价的),如
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_MIRRORED_REPEAT);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_REPEAT);-
第一个参数指定了纹理目标;我们使用的是2D纹理,因此纹理目标是GL_TEXTURE_2D
-
第二个参数需要我们指定设置的选项与应用的纹理轴,打算配置的是
WRAP选项,并且指定S和T轴; 注:如果我们选择GL_CLAMP_TO_BORDER选项,我们还需要指定一个边缘的颜色。这需要使用glTexParameter函数的fv后缀形式,用GL_TEXTURE_BORDER_COLOR作为它的选项,并且传递一个float数组作为边缘的颜色值:float borderColor[] = { 1.0f, 1.0f, 0.0f, 1.0f }; glTexParameterfv(GL_TEXTURE_2D, GL_TEXTURE_BORDER_COLOR, borderColor);
-
最后一个参数需要我们传递一个环绕方式(Wrapping)。
纹理过滤:具体去看笔记吧(笔记里有效果区别),用处:当你有一个很大的物体但是纹理的分辨率很低的时候这就变得很重要了。OpenGL主要有2中形式: 也是通过使用glTexParameter*函数为放大和缩小指定过滤方式
-
GL_NEAREST(也叫邻近过滤,Nearest Neighbor Filtering)是OpenGL默认的纹理过滤方式,看起来像素更加具体;
-
和GL_LINEAR(也叫线性过滤,(Bi)linear Filtering)它会基于纹理坐标附近的纹理像素,计算出一个插值,会比较平滑。
-
// 如 glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_NEAREST); glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
-
注:==一般对一个texture做处理,上面的纹理环绕方式、纹理过滤这四行代码会放一起做处理==。
-
多级渐远纹理:
- OpenGL使用一种叫做多级渐远纹理(Mipmap)的概念来解决纹理远近的真实感。
- 看下面关于==glTexImage2D==函数的第二个参数的解释里面有写到。
直接上代码吧,源码地址。
关于顶点着色器的GLSL的修改:
// 调整顶点着色器使其能够接受顶点坐标为一个顶点属性,并把坐标传给片段着色器
#version 330 core
layout (location = 0) in vec3 aPos;
layout (location = 1) in vec3 aColor;
layout (location = 2) in vec2 aTexCoord; // 这个0、1、2和代码中设置顶点属性是对应的
out vec3 ourColor;
out vec2 TexCoord;
void main() {
gl_Position = vec4(aPos, 1.0);
ourColor = aColor;
TexCoord = aTexCoord;
}片段着色器应该接下来会把顶点着色器输出变量TexCoord作为输入变量。
#version 330 core
out vec4 FragColor;
in vec3 ourColor;
in vec2 TexCoord;
// GLSL有一个供纹理对象使用的内建数据类型,叫做采样器(Sampler),它以纹理类型作为后缀,比如sampler1D、sampler3D
uniform sampler2D ourTexture; // 记得一定要声明为uniform
void main() {
// GLSL内建的texture函数来采样纹理的颜色,它第一个参数是纹理采样器,第二个参数是对应的纹理坐标
FragColor = texture(ourTexture, TexCoord) * vec4(ourColor, 1.0f);
}还可以把得到的纹理颜色与顶点颜色混合得到有趣的结果: ==FragColor = texture(ourTexture, TexCoord) * vec4(ourColor, 1.0);==
下面是主要代码里的内容,编译着色器的那固定代码用的是上面的shader的自定义类。
#define STB_IMAGE_IMPLEMENTATION // 不加这个会得到外部链接无法解析的错误,且这一句一定要在导入之前添加。(很重要)
#include "stb_image.h"
int main() {
float vertices[] = { // 3个顶点属性
// ---- 位置 ---- ---- 颜色 ---- - 纹理坐标 -
0.5f, 0.5f, 0.0f, 1.0f, 0.0f, 0.0f, 1.0f, 1.0f, // 右上
0.5f, -0.5f, 0.0f, 0.0f, 1.0f, 0.0f, 1.0f, 0.0f, // 右下
-0.5f, -0.5f, 0.0f, 0.0f, 0.0f, 1.0f, 0.0f, 0.0f, // 左下
-0.5f, 0.5f, 0.0f, 1.0f, 1.0f, 0.0f, 0.0f, 1.0f // 左上
};
unsigned int indices[] = {
0, 1, 3, // first triangle
1, 2, 3 // second triangle
};
// VAO、VBO、EBO是固定的,
// (3)设置顶点属性指针
// (3.1)位置属性 // 要变成6,这是步长
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 8 * sizeof(float), (void*)0);
glEnableVertexAttribArray(0);
// (3.2)颜色信息
glVertexAttribPointer(1, 3, GL_FLOAT, GL_FALSE, 8 * sizeof(float), (void*)(3 * sizeof(float)));
glEnableVertexAttribArray(1); // 注意这里是1
// (3.3)纹理坐标信息 // 3、6就是代表开始的偏移量 *******
glVertexAttribPointer(2, 2, GL_FLOAT, GL_FALSE, 8 * sizeof(float), (void*)(6 * sizeof(float)));
glEnableVertexAttribArray(2); // 2代表的顶点属性的索引 *****
// 一个纹理的过程应该看起来像这样:
// 1、
unsigned int texture;
glGenTextures(1, &texture);
glBindTexture(GL_TEXTURE_2D, texture);
// 2、为当前绑定的纹理对象设置环绕、过滤方式
// set the texture wrapping parameters
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_REPEAT);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_REPEAT);
// set texture filtering parameters
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
// 3、加载图片并生成纹理
int width, height, nrChannels;
unsigned char* data = stbi_load("container.jpg", &width, &height, &nrChannels, 0);
if (data) {
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGB, width, height, 0, GL_RGB, GL_UNSIGNED_BYTE, data);
glGenerateMipmap(GL_TEXTURE_2D);
}
else {
std::cout << "Failed to load texture!" << std::endl;
}
stbi_image_free(data); // 4、释放图像内存
// 哪怕就一张纹理,也记得设置(下一小节,纹理单位有详说)
glUseProgram(ShaderProgramID); // 在设置uniform变量之一定激活着色器程序
// 教程里是把shader写成了类,封装了下,就是用 ourShader.use();
glUniform1i(glGetUniformLocation(ourShader.ID, "texture1"), 0);
// while 中绘制就是 glDrawElements(GL_TRIANGLES, 6, GL_UNSIGNED_INT, 0);
// 但是在这之前要记得激活绑定(下一小节有讲)
glActiveTexture(GL_TEXTURE0); // 在绑定纹理之前先激活纹理单元
glBindTexture(GL_TEXTURE_2D, texture);
}说明:(就用stb_image.h来加载图片,不要再用 SOIL.h 这个库了,很久没更新了,也找不到下载)
-
通过定义STB_IMAGE_IMPLEMENTATION,预处理器会修改头文件,让其只包含相关的函数定义源码,等于是将这个头文件变为一个 .cpp 文件了。
stb_image.h可以在这里下载。 -
纹理可以通过==glTexImage2D==来生成,参数说明:
- 第一个参数指定了纹理目标(Target)。设置为GL_TEXTURE_2D意味着会生成与当前绑定的纹理对象在同一个目标上的纹理(任何绑定到GL_TEXTURE_1D和GL_TEXTURE_3D的纹理不会受到影响)。
- 第二个参数为纹理指定多级渐远纹理的级别,如果你希望单独手动设置每个多级渐远纹理的级别的话。这里我们填0,也就是基本级别。 或者,直接在生成纹理之后调用==glGenerateMipmap==(上面代码就是)。这会为当前绑定的纹理自动生成所有需要的多级渐远纹理。
- 第三个参数告诉OpenGL我们希望把纹理储存为何种格式。我们的图像只有
RGB值(opencv读的BGR要先转成RGB才行),因此我们也把纹理储存为RGB值。 - 第四个和第五个参数设置最终的纹理的宽度和高度。我们之前加载图像的时候储存了它们,所以我们使用对应的变量。
- 下个参数应该总是被设为
0(历史遗留的问题)。 - 第七第八个参数定义了源图的格式和数据类型。我们使用RGB值加载这个图像,并把它们储存为
char(byte)数组,我们将会传入对应值。 - 最后一个参数是真正的图像数据。
-
2.4.1漫反射贴图把加载图片写成了一个函数
unsigned int loadTexture(const char* path) { unsigned int textureID; glGenTextures(1, &textureID); int width, height, nrComponents; unsigned char* data = stbi_load(path, &width, &height, &nrComponents, 0); if (data) { GLenum format; if (nrComponents == 1) format = GL_RED; else if (nrComponents == 3) format = GL_RGB; else if (nrComponents == 4) format = GL_RGBA; glBindTexture(GL_TEXTURE_2D, textureID); glTexImage2D(GL_TEXTURE_2D, 0, format, width, height, 0, format, GL_UNSIGNED_BYTE, data); glGenerateMipmap(GL_TEXTURE_2D); glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_REPEAT); glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_REPEAT); glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR_MIPMAP_LINEAR); glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR); } else { std::cout << "Texture failed to load at path: " << path << std::endl; } stbi_image_free(data); return textureID; }
==纹理单元==:(挺有意思的,整体源码)(把里面的awesomeface.png换个别的图就报错,不了解)
简单来说,就是一个图形上的纹理贴图可以有多个,一个纹理的位置值通常称为一个==纹理单元==(Texture Unit)。一个纹理的默认纹理单元是0,它是默认的激活纹理单元,所以前面部分我们没有分配一个位置值。
-
可以使用==glActiveTexture==激活纹理单元,传入我们需要使用的纹理单元:
glActiveTexture(GL_TEXTURE0); // 在绑定纹理之前先激活纹理单元 glBindTexture(GL_TEXTURE_2D, texture);
说明:OpenGL至少保证有16个纹理单元供你使用,也就是说你可以激活从GL_TEXTURE0到GL_TEXTRUE15。它们都是按顺序定义的,所以我们也可以通过GL_TEXTURE0 + 8的方式获得GL_TEXTURE8,这在当我们需要循环一些纹理单元的时候会很有用; 纹理单元GL_TEXTURE0默认总是被激活,可以直接使用。
-
那么着色器片段就需要接收另一个采样器:(最终输出颜色现在是两个纹理的结合)
#version 330 core in vec2 TexCoord; uniform sampler2D texture1; uniform sampler2D texture2; void main() { FragColor = mix(texture(texture1, TexCoord), texture(texture2, TexCoord), 0.2); }
-
GLSL内建的==mix函数==需要接受两个值作为参数,并对它们根据第三个参数进行线性插值。 如果第三个值是
0.0,它会返回第一个输入; 如果是1.0,会返回第二个输入值。0.2会返回80%的第一个输入颜色和20%的第二个输入颜色,即返回两个纹理的混合色。 -
改片段着色器就可以达到改笑脸图片的朝向、方向等,具体到时自己试:
// TexCoord的类型是vec2,这样去构造,然后横坐标是1.0-TexCoord.x,笑脸朝向就变了 FragColor = mix(texture(texture1, TexCoord), texture(texture2, vec2(1.0-TexCoord.x, TexCoord.y)), 0.2); // 这就是把笑脸上下翻转(去改y) FragColor = mix(texture(texture1, TexCoord), texture(texture2, vec2(TexCoord.x, 1.0-TexCoord.y)), 0.2);
注:==1.0 - TexCoord.y==和==-TexCoord.y==是等价的。
-
-
在主代码中还需要使用==glUniform1i==函数置每个采样器的方式告诉OpenGL每个着色器采样器属于哪个纹理单元,设只一次,放在循环渲染的前面:
glUseProgram(ShaderProgramID); // 在设置uniform变量之一定激活着色器程序 glUniform1i(glGetUniformLocation(ourShader.ID, "texture1"), 0); // “texture2”名字这些一定要和上面片段着色器的uniform变量的名字完全对上 glUniform1i(glGetUniformLocation(ourShader.ID, "texture2"), 1); // 0、1就是看作第一幅图、第二幅图的索引, glUniform1i的i代表int,所以设置的是0、1的int值
-
翻转一个图片纹理:OpenGL要求y轴
0.0坐标是在图片的底部的,但是图片的y轴0.0坐标通常在顶部,stb_image.h加载图片时默认就帮我们反转了,所以我们想看到它本来的就是上下翻转的图,就在家在图片前加一句: ==stbi_set_flip_vertically_on_load(false);== -
练习:将片段着色器mix函数的第3个参数改成uniform,通过按键上下来改变,而不是写定为0.2
解答很简单,直接上源码,需要注意一点,glfw的按键检查应该是一直在执行,不是想的按一下才执行一下,所以按一下上键,里面的代码会执行很多次,所以每次增加值时不能给大了,要根据硬件速度来,如
if (glfwGetKey(window, GLFW_KEY_UP) == GLFW_PRESS) { // change this value accordingly (might be too slow or too fast based on system hardware) transparentValue += 0.001f; // 按一下这里会执行很多很多次,给0.1就大了,就不妥。 if (transparentValue > 1.0f) transparentValue = 1.0f; } if (glfwGetKey(window, GLFW_KEY_DOWN) == GLFW_PRESS) { transparentValue -= 0.001f; if (transparentValue < 0.0f) transparentValue = 0.0f; }
GLM是OpenGL Mathematics的缩写,它是一个==只有头文件==的库,也就是说我们只需包含对应的头文件就行了(所以直接在inlcude里那种直接添加类似 D:\lib\glm 这样的路径就可以了),不用链接和编译。直接github这个项目里面去下载。
变换的理论就不细说了,B站图形学视频说了很多了,这是笔记的原地址,着重写一下。
-
顶点着色器中需要一个unifrom变量把变换矩阵传递进去
#version 330 core layout (location = 0) in vec3 aPos; layout (location = 1) in vec3 aColor; layout (location = 2) in vec2 aTexCoord; out vec2 TexCoord; uniform mat4 transform; // 变换矩阵,,mat4是glsl的内置类型 void main() { gl_Position = transform * vec4(aPos, 1.0); TexCoord = aTexCoord; }
-
在主函数中创建变换函数,通过==glUniformMatrix4fv==赋值uniform变量 里面有
glm库关于旋转、平移、缩放的代码#include <glm/glm.hpp> #include <glm/gtc/matrix_transform.hpp> // 矩阵变换需要 // 0.9.9及以上版本需要这样初始化单位矩阵, glm::mat4 trans(1.0f); // glm::mat4 trans;这种就默认全是0 // (1)旋转, 这里就是绕z轴,因为是二维平面嘛 trans = glm::rotate(trans, glm::radians(90.0f), glm::vec3(0.0, 0.0, 1.0)); // 旋转第二个参数给的角度是 弧度制 trans = glm::scale(trans, glm::vec3(0.5, 0.5, 0.5)); // (2)缩放 // 当三个维度缩放一样时可以直接写 glm::vec3(0.5) trans = glm::translate(trans, glm::vec3(1.0f, 1.0f, 0.0f)); // 平移 // 就需要把这个变换矩阵传递给顶点着色器中的uniform变量 unsigned int transformLoc = glGetUniformLocation(ourshader.ID, "transform"); glUniformMatrix4fv(transformLoc, 1, GL_FALSE, (GLfloat*)&trans);
glUniformMatrix4fv参数再次说明:
- 第一个参数是uniform的位置值;
- 第二个参数告诉OpenGL我们将要发送多少个矩阵,这里是1;
- 第三个参数询问我们是否希望对我们的矩阵进行转置(Transpose)。OpenGL开发者通常使用一种内部矩阵布局,叫做列主序(Column-major Ordering)布局。GLM的默认布局就是列主序,所以并不需要转置矩阵。
- 最后一个参数是传递的矩阵数据,教程写的是==glm::value_ptr(trans)==, // 这需要头文件#include <glm/gtc/type_ptr.hpp>。然后按照上面我写的这种类型转换也是可以的。
- 如果要让其绕某个点(好像是图片中心点)一直旋转的话,就把上面的代码放到while渲染中去,然后旋转代码需要跟时间挂钩:(主要是第二个参数变了)
==trans = glm::rotate(trans, (float)glfwGetTime(), glm::vec3(0.0, 0.0, 1.0));==
注:因为一直绕着正中心旋转的,所以可以图形先做平移还是先做旋转,效果完全不一样,自己酌情考虑。
#### 2.5.2 画两个箱子
**可以再次调用glDrawElements画出第二个箱子**
之前调用两次glDrawElements画,界面体现不出来,是因为都画的同一个地方,一模一样看不出来,现在在再次调用glDrawElements画之前,重新做一下变换,然后位置不一样就能看出来,以下代码是在while循环中:
```c++
glm::mat4 trans(1.0f);
trans = glm::translate(trans, glm::vec3(0.5, 0.5, 0.0));
trans = glm::rotate(trans, (float)glfwGetTime(), glm::vec3(0.0, 0.0, 1.0));
trans = glm::scale(trans, glm::vec3(0.5, 0.5, 0.5));
unsigned int transformLoc = glGetUniformLocation(ourshader.ID, "transform");
//glUniformMatrix4fv(transformLoc, 1, GL_FALSE, (GLfloat*)&trans);
glUniformMatrix4fv(transformLoc, 1, GL_FALSE, glm::value_ptr(trans));
// 绘制第一个箱子
glDrawElements(GL_TRIANGLES, 6, GL_UNSIGNED_INT, 0);
// 第二个箱子
trans = glm::mat4(1.0f);
trans = glm::translate(trans, glm::vec3(-0.5, -0.5, 0.0));
float scaleAmount = static_cast<float>(std::sin(glfwGetTime()));
trans = glm::scale(trans, glm::vec3(scaleAmount, scaleAmount, scaleAmount));
glUniformMatrix4fv(transformLoc, 1, GL_FALSE, &trans[0][0]);
// now with the uniform matrix being replaced with new transformations, draw it again.
glDrawElements(GL_TRIANGLES, 6, GL_UNSIGNED_INT, 0);
- 第二个箱子就达到了不断缩放的效果,使用三角函数,不过当三角函数为负值时,会导致物体被翻转,可以在sin外面再加一个abs绝对值解决。
- 看第二箱子的glUniformMatrix4fv中的最后一个参数,写的是
&trans[0][0],把trans这个矩阵看做二维数组,这样拿到的就是第一个数(float),再&取地址,就是首地址,所以效果跟前面的(GLfloat*)&trans一样(&trans就拿到了首地址,但是类型不对,再转换一下)。
这是文章原地址,不是很建议去通读了,下面写自己的理解。(也是按照这个顺序来变换)
- 第一个是模型矩阵,model本身的变换(旋转、平移这些);
- 第二个是观察矩阵,z轴负向的延伸就是离我们观察越来越远的点,观察矩阵就要向z轴负向平移translate来看到效果;
- 第三个是透视矩阵,简单说就是把远平面透视到近平面。
-
然后把这三个矩阵按这个顺序相乘到顶点坐标上,所以顶点着色器:
#version 330 core layout (location = 0) in vec3 aPos; layout (location = 1) in vec3 aColor; layout (location = 2) in vec2 aTexCoord; out vec2 TexCoord; uniform mat4 model; uniform mat4 view; // 都写成uniform方便传进来 uniform mat4 projection; void main() { // gl_Position = vec4(aPos, 1.0); // 这个顺序一定是这样的,不能变,从右往左读 gl_Position = projection * view * model * vec4(aPos, 1.0); TexCoord = aTexCoord; }
-
主程序中代码:(始终注意再给unifrom数据赋值前要先glUseProgram(shaderProgramID);)
// 初始化单位矩阵 glm::mat4 model = glm::mat4(1.0f); glm::mat4 view = glm::mat4(1.0f); glm::mat4 projection = glm::mat4(1.0f); model = glm::rotate(model, glm::radians(-55.0f), glm::vec3(1.0f, 0.0f, 0.0f)); view = glm::translate(view, glm::vec3(0.0f, 0.0f, -3.0f)); projection = glm::perspective(glm::radians(45.0f), (float)SCR_WIDTH/(float)SCR_HEIGHT, 0.1f, 100.0f); unsigned int modelLoc = glGetUniformLocation(ourshader.ID, "model"); unsigned int viewLoc = glGetUniformLocation(ourshader.ID, "view"); unsigned int projectionLoc = glGetUniformLocation(ourshader.ID, "projection"); // 下面最后一个参数,这3中写法一个意思,前面解释过 glUniformMatrix4fv(modelLoc, 1, GL_FALSE, glm::value_ptr(model)); glUniformMatrix4fv(viewLoc, 1, GL_FALSE, (GLfloat*)&view); glUniformMatrix4fv(projectionLoc, 1, GL_FALSE, &projection[0][0]);
解读:
-
model向着x轴旋转了(也可以加其它操作),像是躺在地面上,效果更加明显;
-
view观察矩阵,z轴取的值越小,看起来更远,不要为0或正值,一般x、y轴的偏移量去0.0f;
- 若在x、y轴上取值,就是观察者角度变了,某种程度上模型矩阵进行位移也能达到效果。
-
projection透视投影矩阵,==glm::perspective()函数==:
- 第一个参数定义了fov的值,它表示的是视野(Field of View),并且设置了观察空间的大小。==这个值越大,视场越大,相对应的一个物体看起来就越小==。 如果想要一个真实的观察效果,它的值通常设置为45.0f,但想要一个末日风格的结果你可以将其设置一个更大的值;
- 第二个参数aspect-ratio设置了宽高比,由视口的宽除以高所得;
-
第三zNear和第四个zFar参数设置了平截头体的近和远平面。我们通常设置近距离为0.1f,而远距离设为100.0f。所有在近平面和远平面内且处于平截头体内的顶点都会被渲染。
注:当你把透视矩阵的 近距离值(上一条的0.1g) 设置太大时(如10.0f),OpenGL会将靠近摄像机的坐标(在0.0f和10.0f之间)都裁剪掉,这会导致一个你在游戏中很熟悉的视觉效果:在太过靠近一个物体的时候你的视线会直接穿过去。
-
补充一个正投影:==glm::ortho(0.0f, 800.0f, 0.0f, 600.0f, 0.1f, 100.0f);== # 参数的话具体使用再说吧。(后面两个参数,一个是近平面,一个是远平面)
-
想渲染一个立方体,我们一共需要36个顶点(6个面 x 每个面有2个三角形组成 x 每个三角形有3个顶点),这36个顶点的位置你可以从这里获取。
为了有趣一点,我们将让立方体随着时间旋转:
model = glm::rotate(model, (float)glfwGetTime() * glm::radians(50.0f), glm::vec3(0.5f, 1.0f, 0.0f));
然后我们使用glDrawArrays来绘制立方体,但这一次总共有36个顶点。
glDrawArrays(GL_TRIANGLES, 0, 36);
注意:上面这36个点没再写对应的坐标点颜色属性,沿用上面的代码时,要去改glVertexAttribPointer(),要取消掉一个,同时顶点着色器中的layout (location = 1) in vec3 aColor;这个也要删除。
上面的3D信息看起来会很奇怪,进一步优化,OpenGL存储深度信息在一个叫做==Z缓冲==(Z-buffer)的缓冲中,也被称为==深度缓冲==(Depth Buffer),它允许OpenGL决定何时覆盖一个像素而何时不覆盖。
GLFW会自动为你生成这样一个缓冲(就像它也有一个颜色缓冲来存储输出图像的颜色)。深度值存储在每个片段里面(作为片段的z值),当片段想要输出它的颜色时,OpenGL会将它的深度值和z缓冲进行比较,如果当前的片段在其它片段之后,它将会被丢弃,否则将会覆盖。这个过程称为==深度测试==(Depth Testing),它是由OpenGL自动完成的。
==glEnable==和==glDisable==函数允许我们启用或禁用某个OpenGL功能。这个功能会一直保持启用/禁用状态,直到另一个调用来禁用/启用它。现在我们想启用深度测试,需要开启==GL_DEPTH_TEST==:
glEnable(GL_DEPTH_TEST); // 在while循环外开启就好了 因为我们使用了深度测试,我们也想要在每次渲染迭代之前清除深度缓冲(否则前一帧的深度信息仍然保存在缓冲中)。就像清除颜色缓冲一样,我们可以通过在glClear函数中指定DEPTH_BUFFER_BIT位来清除深度缓冲:
//glClear(GL_COLOR_BUFFER_BIT ); // 这是一开始的,要清除颜色缓冲
//glClear(GL_DEPTH_BUFFER_BIT); // 清除深度缓冲
// 这种写法跟上面两行是一个效果
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
深度测试函数:glDepthFunc(GL_ALWAYS);
这是深度测试的进阶,紧跟在glEnable(GL_DEPTH_TEST);之后,除了GL_ALWAYS之外还有别的深度函数:
| 函数 | 描述 |
|---|---|
| GL_ALWAYS | 永远通过深度测试 |
| GL_NEVER | 永远不通过深度测试 |
| GL_LESS | 在片段深度值小于缓冲的深度值时通过测试 |
| GL_EQUAL | 在片段深度值等于缓冲区的深度值时通过测试 |
| GL_LEQUAL | 在片段深度值小于等于缓冲区的深度值时通过测试 |
| GL_GREATER | 在片段深度值大于缓冲区的深度值时通过测试 |
| GL_NOTEQUAL | 在片段深度值不等于缓冲区的深度值时通过测试 |
| GL_GEQUAL | 在片段深度值大于等于缓冲区的深度值时通过测试 |
注:默认情况下使用的深度函数是GL_LESS,它将会丢弃深度值大于等于当前深度缓冲值的所有片段。像上面改成GL_ALWAYS,那么深度测试将会永远通过,所以最后绘制的片段将会总是会渲染在之前绘制片段的上面,即使之前绘制的片段本就应该渲染在最前面。
进一步:在图上画出来10个不同的箱子:源码。
-
首先为10个立方体定义一个translate位移向量来制定它在世界空间不同的位置,
glm::vec3 cubePositions[] = { glm::vec3( 0.0f, 0.0f, 0.0f), glm::vec3( 2.0f, 5.0f, -15.0f), glm::vec3(-1.5f, -2.2f, -2.5f), glm::vec3(-3.8f, -2.0f, -12.3f), glm::vec3( 2.4f, -0.4f, -3.5f), glm::vec3(-1.7f, 3.0f, -7.5f), glm::vec3( 1.3f, -2.0f, -2.5f), glm::vec3( 1.5f, 2.0f, -2.5f), glm::vec3( 1.5f, 0.2f, -1.5f), glm::vec3(-1.3f, 1.0f, -1.5f) }; -
while循环中,调用 glDrawArrays 10次,但需要渲染之前每次传入一个不同的模型矩阵到顶点着色器中:
// 视图矩阵、透视矩阵基本都是不变的,设置一次就好了 # 在while之外 glm::mat4 view = glm::mat4(1.0f); glm::mat4 projection = glm::mat4(1.0f); view = glm::translate(view, glm::vec3(0.0f, 0.0f, -3.0f)); projection = glm::perspective(glm::radians(45.0f), (float)SCR_WIDTH / (float)SCR_HEIGHT, 0.1f, 100.0f); unsigned int viewLoc = glGetUniformLocation(ourshader.ID, "view"); unsigned int projectionLoc = glGetUniformLocation(ourshader.ID, "projection"); glUniformMatrix4fv(viewLoc, 1, GL_FALSE, (GLfloat*)&view); glUniformMatrix4fv(projectionLoc, 1, GL_FALSE, &projection[0][0]); while () { for (unsigned int i = 0; i < sizeof(cubePositions) / sizeof(cubePositions[0]); i++) { // 模型矩阵 glm::mat4 model = glm::mat4(1.0f); // 模型位置移动到不同的地方 model = glm::translate(model, cubePositions[i]); float angle = 20.0f * i; //model = glm::rotate(model, glm::radians(angle), glm::vec3(1.0f, 0.3f, 0.5f)); // 这是上面那就是静态的 model = glm::rotate(model, (float)glfwGetTime() * glm::radians(50.0f), glm::vec3(1.0f, 0.3f, 0.5f)); // 这是动态的 unsigned int modelLoc = glGetUniformLocation(ourshader.ID, "model"); glUniformMatrix4fv(modelLoc, 1, GL_FALSE, glm::value_ptr(model)); glDrawArrays(GL_TRIANGLES, 0, 36); // 绘制 } }
这是原文理论的地址。只能说不求甚解了,主要还是API的理解。
说明:2.6都是视角固定,箱子在旋转,下面内容就是让箱子固定,视角(摄像机)位置来变动:
-
while循环外,只要透视矩阵就好了
glm::mat4 projection = glm::mat4(1.0f); projection = glm::perspective(glm::radians(45.0f), (float)SCR_WIDTH / (float)SCR_HEIGHT, 0.1f, 100.0f); unsigned int projectionLoc = glGetUniformLocation(ourshader.ID, "projection"); glUniformMatrix4fv(projectionLoc, 1, GL_FALSE, &projection[0][0]);
-
while循环中,创建LookAt矩阵,具体理论去看原文笔记吧 这里的效果是以x、z轴为平面绕着y轴环绕转动
glm::mat4 view = glm::mat4(1.0f); float radius = 10.0f; // 圆的半径 // 以下的sin、cos也是有讲究的,可以改变其顺序来改变旋转顺序 float camX = static_cast<float>(std::sin(glfwGetTime()) * radius); float camZ = static_cast<float>(std::cos(glfwGetTime()) * radius); view = glm::lookAt(glm::vec3(camX, 0.0f, camZ), glm::vec3(0.0f, 0.0f, 0.0f), glm::vec3(0.0f, 1.0f, 0.0f)); // 这就可以不需要了,这是2.6及以前移动视角的,加了也可以看看效果 // view = glm::translate(view, glm::vec3(0.0f, 0.0f, -3.0f)); unsigned int viewLoc = glGetUniformLocation(ourshader.ID, "view"); glUniformMatrix4fv(viewLoc, 1, GL_FALSE, (GLfloat*)&view);
==glm::LookAt函数==参数说明:(它会创建一个和在上一节使用的一样的观察矩阵)
- 第一个参数为摄像机的位置,这里的camX、camZ就是x、z平面上的圆的坐标,y轴上取0.0f就代表是正中间的位置; 在每次渲染迭代中使用GLFW的glfwGetTime函数重新创建观察矩阵,来扩大这个圆, # 这不是很懂,感觉也是需要一个不断增加变化的量去使得三角函数周期走起来。
- 第二个参数为摄像机的注视点,这里是保持在(0,0,0);
- 第三个参数为上向量(原理看原文),简单来说就是摄像机向上的方向,这里的理解是环绕轨迹平面的向上的法向量,这里理所当然是(0,1,0),一般都是这个值,世界坐标的向上就是这,这样就代表摄像机不允许俯仰角大于90度,这在需要考虑滚转角的时候就不能用了。
- 手动实现LookAt函数功能的代码。
- 设置模型位置,模型本身的旋转等,然后绘制出来,就是2.6中的while中的for循环代码。
-
自由移动:
上面的都是一直在自己转动,我们改成按键的形式让它动,一切都是在上面代码基础上:源码
// 1、搞三个全局变量 glm::vec3 cameraPos = glm::vec3(0.0f, 0.0f, 3.0f); glm::vec3 cameraFront = glm::vec3(0.0f, 0.0f, -1.0f); glm::vec3 cameraUp = glm::vec3(0.0f, 1.0f, 0.0f); // 2、LookAt函数现在成了:(将摄像机位置设置为之前定义的cameraPos。方向是当前的位置加上我们刚刚定义的方向向量。这样能保证无论我们怎么移动,摄像机都会注视着目标方向) view = glm::lookAt(cameraPos, cameraPos + cameraFront, cameraUp); // 3、按键 void processInput(GLFWwindow *window) { ... float cameraSpeed = 0.05f; // adjust accordingly if (glfwGetKey(window, GLFW_KEY_W) == GLFW_PRESS) cameraPos += cameraSpeed * cameraFront; if (glfwGetKey(window, GLFW_KEY_S) == GLFW_PRESS) cameraPos -= cameraSpeed * cameraFront; if (glfwGetKey(window, GLFW_KEY_A) == GLFW_PRESS) cameraPos -= glm::normalize(glm::cross(cameraFront, cameraUp)) * cameraSpeed; if (glfwGetKey(window, GLFW_KEY_D) == GLFW_PRESS) cameraPos += glm::normalize(glm::cross(cameraFront, cameraUp)) * cameraSpeed; } // 除了以上方式,还在最后的2D游戏实例中看到一种写法 // 一般先定义一个类的共有变量 GLboolean Keys[1024]; // 默认初始化都是0 // 再在类的函数用直接判定 if (this->Keys[GLFW_KEY_A]) { /* do something */ } // 按下后对应的值变为1 if (this->Keys[GLFW_KEY_D]) { /* do something */ }
说明:
- 向左右移动,我们使用叉乘来创建一个右向量,并标准化,保证移动时匀速的,但看这里的结果,应该是可以直接定义出来右向量为(1, 0, 0),跟叉乘出来的结果也是一样的。
- cameraSpeed移动速度和系统有关,可能需要根据机器调整,可以计算出两帧之间的时差,然后做出对应的自动调整,源码。
-
视角移动:
以上都是键盘的移动,主要是还不能转向,需要根据鼠标的输入改变cameraFront向量
这节的笔记中还讲到了欧拉角的原理,多的就不写了
-
鼠标输入: 把上面的视角移动和鼠标输入结合起来。
-
告诉GLFW,它应该隐藏光标,并捕捉(Capture)它,glfw调用这个函数设置后,无论怎么去移动鼠标,光标都不会显示了,它也不会离开窗口:
glfwSetInputMode(window, GLFW_CURSOR, GLFW_CURSOR_DISABLED); -
为了计算俯仰角和偏航角,需要GLFW监听鼠标移动事件,所以需要一个回调函数: xpos和ypos代表当前鼠标的位置,
void mouse_callback(GLFWwindow* window, double xpos, double ypos); -
用GLFW注册了回调函数之后,鼠标一移动mouse_callback函数就会被调用:
glfwSetCursorPosCallback(window, mouse_callback); -
具体函数,理论实现不写了,太多了,用到的时候再去看吧
-
-
缩放: 跟上面自由移动类似,自由移动中按W、S前进后退就是放大、缩小的效果,缩放就是用鼠标滑轮实现,一样使用回调函数
-
定义回调函数:当滚动鼠标滚轮的时候,yoffset值代表我们竖直滚动的大小。当scroll_callback函数被调用后,我们改变全局变量fov变量的内容。因为
45.0f是默认的视野值,我们将会把缩放级别(Zoom Level)限制在1.0f到45.0ffloat fov = 45.0f; // 把透视矩阵参数的flv定义为全局变量 void scroll_callback(GLFWwindow *window, double xoffset, double yoffset) { if(fov >= 1.0f && fov <= 45.0f) fov -= yoffset; if(fov <= 1.0f) fov = 1.0f; if(fov >= 45.0f) fov = 45.0f; } -
注册回调函数:
glfwSetScrollCallback(window, scroll_callback); -
每一帧都必须把透视投影矩阵上传到GPU,但现在使用fov变量作为它的视野,那么透视矩阵:
// fov就不是写死了的,写进循环中,每次传递进来 glm::mat4 projection = glm::perspective(glm::radians(fov), (float)SCR_WIDTH / (float)SCR_HEIGHT, 0.1f, 100.0f);
-
注意:注意使用欧拉角的摄像机系统并不完美。根据你的视角限制或者是配置,你仍然可能引入万向节死锁问题。最好的摄像机系统是使用四元数(Quaternions)的,但我们将会把这个留到后面讨论。(译注:[这里](https://github.com/cybercser/OpenGL_3_3_Tutorial_Translation/blob/master/Tutorial 17 Rotations.md)可以查看四元数摄像机的实现)
原文地址。
颜色理论:现实生活中看到某一物体的颜色并不是这个物体真正拥有的颜色,而是它所反射的(Reflected)颜色。所以当光源颜色跟物体颜色相乘就是我们看到的颜色。例如:
-
白色光源+珊瑚红(Coral)的物体=看到的就是珊瑚红的:
glm::vec3 lightColor(1.0f, 1.0f, 1.0f); // 白色光源 glm::vec3 toyColor(1.0f, 0.5f, 0.31f); // 珊瑚红物体 glm::vec3 result = lightColor * toyColor; // = (1.0f, 0.5f, 0.31f);
-
绿色光源的话:并没有红色和蓝色的光让我们的玩具来吸收或反射,这个玩具吸收了光线中一半的绿色值,但仍然也反射了一半的绿色值。玩具现在看上去是深绿色(Dark-greenish)的,那么就是一个珊瑚红的玩具突然变成了深绿色物体。
glm::vec3 lightColor(0.0f, 1.0f, 0.0f); // 绿色光源 glm::vec3 toyColor(1.0f, 0.5f, 0.31f); glm::vec3 result = lightColor * toyColor; // = (0.0f, 0.5f, 0.0f);
-
使用深橄榄绿色(Dark olive-green)的光源:就会出现意想不到的颜色
glm::vec3 lightColor(0.33f, 0.42f, 0.18f); // 橄榄绿色光源 glm::vec3 toyColor(1.0f, 0.5f, 0.31f); glm::vec3 result = lightColor * toyColor; // = (0.33f, 0.21f, 0.06f);
创建一个光照场景:
结合上面的颜色理论,给定一个光源立方体,再有一个颜色立方体来看效果,不算难,直接看这的理论和源码吧。(这里的源码运行起来后,下面的分节都是在这基础上进行的修改)
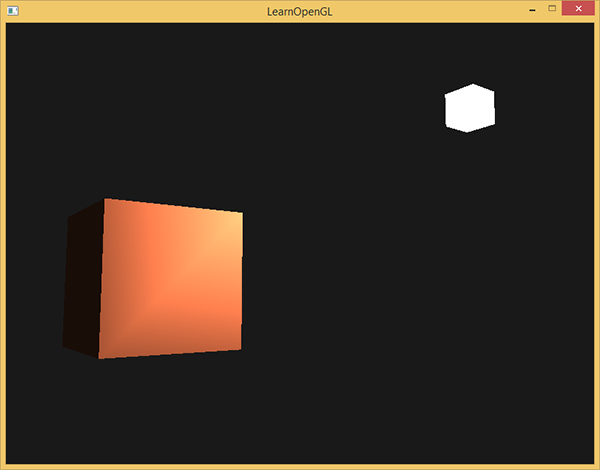
下面主要讲的是==冯氏光照模型(Phong Lighting Model)==。冯氏光照模型的主要结构由3个分量组成:环境(Ambient)、漫反射(Diffuse)和镜面(Specular)光照。原文地址。
- ==环境光照(Ambient Lighting)==:即使在黑暗的情况下,世界上通常也仍然有一些光亮(月亮、远处的光),所以物体几乎永远不会是完全黑暗的。为了模拟这个,我们会使用一个环境光照常量,它永远会给物体一些颜色。
- ==漫反射光照(Diffuse Lighting)==:物体的某一部分越是正对着光源,它就会越亮。
- ==镜面光照(Specular Lighting)==:模拟有光泽物体上面出现的亮点。镜面光照的颜色相比于物体的颜色会更倾向于光的颜色。
这是简化算法,使用一个很小的常量(光照)颜色,添加到物体片段的最终颜色中,这样子的话即便场景中没有直接的光源也能看起来存在有一些发散的光,把环境光照添加到场景里非常简单。 我们用光的颜色乘以一个很小的常量环境因子,再乘以物体的颜色,然后将最终结果作为片段的颜色:(对光源的==片段着色器==进行修改,可以参考上面创建一个光照场景对比)
#version 330 core
out vec4 FragColor;
uniform vec3 objectColor;
uniform vec3 lightColor;
void main() {
float ambientStrength = 0.1;
vec3 ambient = ambientStrength * lightColor;
vec3 result = ambient * objectColor;
// FragColor = vec4(lightColor * objectColor, 1.0f); // 上面的就这一行
FragColor = vec4(result, 1.0f);
}注:冯氏光照的第一个阶段已经应用到你的物体上了。这个物体非常暗,但由于应用了环境光照(注意光源立方体没受影响是因为我们对它使用了另一个着色器),也不是完全黑的。
原文地址。这里写的比较简单,方便检索,更多的细节还是看原文 以下改的都是针对 光源的顶点、片段着色器。
-
法向量
-
需要计算法向量,这里是直接将其写到顶点属性中,由于向顶点数组添加了额外的数据,所以应该更新==光照的顶点着色器 .vs==:(这里是对应的顶点坐标)
#version 330 core layout (location = 0) in vec3 aPos; layout (location = 1) in vec3 aNormal; // 法向量 out vec3 FragPos; out vec3 Normal; uniform mat4 model; uniform mat4 view; uniform mat4 projection; void main() { FragPos = vec3(model * vec4(aPos, 1.0)); // 位置也传递 Normal = aNormal; // 法向量传递给片段着色器 gl_Position = projection * view * vec4(FragPos, 1.0); }
-
更新顶点属性指针:注意,灯使用同样的顶点数组作为它的顶点数据,然而灯的着色器并没有使用新添加的法向量。我们不需要更新灯的着色器或者是属性的配置,但是我们必须至少修改一下 顶点属性指针来适应新的顶点数组的大小: 用来展示的物体属性设置:顶点属性有两个
// position attribute glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 6 * sizeof(float), (void*)0); glEnableVertexAttribArray(0); // normal attribute 法线属性 glVertexAttribPointer(1, 3, GL_FLOAT, GL_FALSE, 6 * sizeof(float), (void*)(3 * sizeof(float))); glEnableVertexAttribArray(1);
光源立方体的属性设置:光源用的是同一套顶点坐标,但是用不到法线属性,只需要修改一下步长,不用开启属性为1的顶点
// 把3改成6了 glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 6 * sizeof(float), (void*)0); glEnableVertexAttribArray(0);
-
-
计算漫反射光照
每个顶点都有了法向量,但是我们仍然需要光源的位置向量和片段的位置向量。由于光源的位置是一个静态变量,我们可以简单地在片段着色器中把它声明为uniform;然后在主代码中更新uniform。我们使用在前面声明的lightPos向量(一个主代码中的全局变量)作为光源位置。
结合1.中的顶点着色器的输出,看光源的片段着色器:
#version 330 core out vec4 FragColor; in vec3 Normal; in vec3 FragPos; // 这俩都是顶点着色器传进来的 uniform vec3 lightPos; uniform vec3 lightColor; uniform vec3 objectColor; void main() { // ambient(环境光照) float ambientStrength = 0.1; vec3 ambient = ambientStrength * lightColor; // diffuse (漫反射光照) vec3 norm = normalize(Normal); // 法向量。只关心方向,所以标准化 vec3 lightDir = normalize(lightPos - FragPos); // 两个向量作差得方向 float diff = max(dot(norm, lightDir), 0.0); vec3 diffuse = diff * lightColor; vec3 result = (ambient + diffuse) * objectColor; FragColor = vec4(result, 1.0); }
注:
- 第20行的dot点乘:两个标准向量点乘就会得到这两个向量之间的余弦值。 两个向量之间的角度越大,漫反射分量就会越小。
- 两个向量之间的角度大于90度,点乘的结果就会变成负数,这样会导致漫反射分量变为负数。为此,我们使用max函数返回两个参数之间较大的参数,从而保证漫反射分量不会变成负数。负数颜色的光照是没有定义的,所以最好避免它,除非你是那种古怪的艺术家。
- 有了环境光分量和漫反射分量,我们把它们相加,然后把结果乘以物体的颜色,来获得片段最后的输出颜色。
-
以上这一小节的源码。注意:如果进行了不等比例的缩放,是会破坏法线方向的,就需要用法线矩阵去修正,遇到再看这节的原文笔记的最后一件事吧。 然后光源的顶点着色器中要把==Normal = aNormal;==改成 ==Normal = mat3(transpose(inverse(model))) * aNormal;==
加上镜面光照后的==光源的片段着色器==:
#version 330 core
out vec4 FragColor;
in vec3 Normal;
in vec3 FragPos;
uniform vec3 lightPos;
uniform vec3 viewPos; // 镜面光照,相机位置传进来
uniform vec3 lightColor;
uniform vec3 objectColor;
void main()
{
// ambient
float ambientStrength = 0.1;
vec3 ambient = ambientStrength * lightColor;
// diffuse
vec3 norm = normalize(Normal);
vec3 lightDir = normalize(lightPos - FragPos);
float diff = max(dot(norm, lightDir), 0.0);
vec3 diffuse = diff * lightColor;
// specular (镜面光照)
float specularStrength = 0.5;
vec3 viewDir = normalize(viewPos - FragPos);
vec3 reflectDir = reflect(-lightDir, norm);
float spec = pow(max(dot(viewDir, reflectDir), 0.0), 32);
vec3 specular = specularStrength * spec * lightColor;
vec3 result = (ambient + diffuse + specular) * objectColor;
FragColor = vec4(result, 1.0);
}注:
- 25行:镜面强度(Specular Intensity)变量,
- 给镜面高光一个中等亮度颜色,让它不要产生过度的影响。如果设置为1.0f,会得到一个非常亮的镜面光分量。
- 27行:==reflect函数==
- 要求第一个向量是从光源指向片段位置的向量,但是lightDir当前正好相反,是从片段指向光源(由先前我们计算lightDir向量时,减法的顺序决定),为了确保正确,对
lightDir向量进行了取反。 - 第二个参数要求是一个法向量,所以我们提供的是已标准化的
norm向量。
- 要求第一个向量是从光源指向片段位置的向量,但是lightDir当前正好相反,是从片段指向光源(由先前我们计算lightDir向量时,减法的顺序决定),为了确保正确,对
- 28行:计算镜面分量
- 标准向量dot点乘得到方向,再max确保不是负值;
- pow函数代表取次幂,这里是32次幂。这个32是高光的==反光度(Shininess)==。一个物体的反光度越高,反射光的能力越强,散射得越少,高光点就会越小。原文去看取2~256之间的差别。
看原文里有解答。
-
光源是静止的,你可以尝试使用sin或cos函数让光源在场景中来回移动,主要就是改变lightPOs的值,写到while渲染循环中:
lightPos.x = 1.0f + sin(glfwGetTime()) * 2.0f; lightPos.y = sin(glfwGetTime() / 2.0f) * 1.0f;
-
尝试使用不同的环境光、漫反射和镜面强度,观察它们怎么是影响光照效果的。同样,尝试实验一下镜面光照的反光度因子(反光度)。
-
在观察空间(而不是世界空间)中计算冯氏光照:参考解答。
-
尝试实现一个Gouraud着色(而不是冯氏着色)。如果你做对了话,立方体的光照应该会看起来有些奇怪,尝试推理为什么它会看起来这么奇怪:参考解答。
{kind=link}
原文地址。
-
光源的顶点着色器还是一样的
#version 330 core layout (location = 0) in vec3 aPos; layout (location = 1) in vec3 aNormal; out vec3 FragPos; out vec3 Normal; uniform mat4 model; uniform mat4 view; uniform mat4 projection; void main() { FragPos = vec3(model * vec4(aPos, 1.0)); Normal = mat3(transpose(inverse(model))) * aNormal; gl_Position = projection * view * vec4(FragPos, 1.0); }
-
片段着色器.fs中,很重要:
#version 330 core out vec4 FragColor; struct Material { vec3 ambient; vec3 diffuse; vec3 specular; float shininess; }; struct Light { vec3 position; vec3 ambient; vec3 diffuse; vec3 specular; }; in vec3 FragPos; in vec3 Normal; uniform vec3 viewPos; uniform Material material; // 实例化,方便后续赋值,取用 uniform Light light; void main() { // ambient vec3 ambient = light.ambient * material.ambient; // diffuse vec3 norm = normalize(Normal); vec3 lightDir = normalize(light.position - FragPos); float diff = max(dot(norm, lightDir), 0.0); vec3 diffuse = light.diffuse * (diff * material.diffuse); // specular vec3 viewDir = normalize(viewPos - FragPos); vec3 reflectDir = reflect(-lightDir, norm); float spec = pow(max(dot(viewDir, reflectDir), 0.0), material.shininess); vec3 specular = light.specular * (spec * material.specular); vec3 result = ambient + diffuse + specular; FragColor = vec4(result, 1.0); }
-
设置材质:即定义一个材质颜色:环境光照(Ambient Lighting)、漫反射光照(Diffuse Lighting)和镜面光照(Specular Lighting),再添加一个反光度(Shininess)分量,写成一个struct结构体。主代码中赋值:
lightingShader.setVec3("material.ambient", 1.0f, 0.5f, 0.31f); lightingShader.setVec3("material.diffuse", 1.0f, 0.5f, 0.31f); lightingShader.setVec3("material.specular", 0.5f, 0.5f, 0.5f); lightingShader.setFloat("material.shininess", 32.0f);
-
光的属性:看上面结构体。然后在主代码中赋值时,一个光源对它的ambient、diffuse和specular光照分量有着不同的强度。环境光照通常被设置为一个比较低的强度,因为我们不希望环境光颜色太过主导。光源的漫反射分量通常被设置为我们希望光所具有的那个颜色,通常是一个比较明亮的白色。镜面光分量通常会保持为
vec3(1.0),以最大强度发光。lightingShader.setVec3("light.ambient", 0.2f, 0.2f, 0.2f); lightingShader.setVec3("light.diffuse", 0.5f, 0.5f, 0.5f); // 将光照调暗了一些以搭配场景 lightingShader.setVec3("light.specular", 1.0f, 1.0f, 1.0f);
-
前两个在主代码中某结构体中某个变量赋值就是 lightingShader.setVec3("material.ambient", 1.0f, 0.5f, 0.31f); 函数实现是 glUniform3f(glGetUniformLocation(shader.ID, "material.ambient", 1.0f, 0.5f, 0.31f); // 对应源码实现里还有 glUniform3fv 的方法,它赋值时传的是指针,了解。
-
不同的光源颜色
因为光源也在片段着色器中定义了struct结构体,可以轻松改变光源的颜色:在主代码中,利用sin和glfwGetTime函数改变光源的环境光和漫反射颜色,从而很容易地让光源的颜色随着时间变化
glm::vec3 lightColor;
lightColor.x = sin(glfwGetTime() * 2.0f);
lightColor.y = sin(glfwGetTime() * 0.7f);
lightColor.z = sin(glfwGetTime() * 1.3f);
glm::vec3 diffuseColor = lightColor * glm::vec3(0.5f); // 降低影响
glm::vec3 ambientColor = diffuseColor * glm::vec3(0.2f); // 很低的影响
lightingShader.setVec3("light.ambient", ambientColor);
lightingShader.setVec3("light.diffuse", diffuseColor);定义相应的材质来模拟现实世界的物体:
简单来说,无提示什么颜色就是什么样的显示,这样的话就要把光照强度都设置为vec3(1.0),这样才能得到一致的输出(因为光源颜色也会影响显示的颜色,这在2.1颜色中讲到过,两个是要相乘的),如青色塑料(Cyan Plastic)容器这种颜色:
// light properties
// note that all light colors are set at full intensity
lightingShader.setVec3("light.ambient", 1.0f, 1.0f, 1.0f);
lightingShader.setVec3("light.diffuse", 1.0f, 1.0f, 1.0f);
lightingShader.setVec3("light.specular", 1.0f, 1.0f, 1.0f);
// material properties
lightingShader.setVec3("material.ambient", 0.0f, 0.1f, 0.06f);
lightingShader.setVec3("material.diffuse", 0.0f, 0.50980392f, 0.50980392f);
lightingShader.setVec3("material.specular", 0.50196078f, 0.50196078f, 0.50196078f);
lightingShader.setFloat("material.shininess", 32.0f); 原文地址。
简单来说,上一节将整个物体的材质定义为一个整体,但现实世界中的物体通常并不只包含有一种材质,而是由多种材质所组成,需要拓展之前的系统,引入漫反射和镜面光贴图(Map)。这允许我们对物体的漫反射分量(以及间接地对环境光分量,它们几乎总是一样的)和镜面光分量有着更精确的控制。
通过某种方式对物体的每个片段单独设置漫反射颜色。有能够让我们根据片段在物体上的位置来获取颜色值的系统。这听起来很像在[之前](https://learnopengl-cn.github.io/01 Getting started/06 Textures/)教程中详细讨论过的纹理,而这基本就是这样:一个纹理。我们仅仅是对同样的原理使用了不同的名字:其实都是使用一张覆盖物体的图像,让我们能够逐片段索引其独立的颜色值。在光照场景中,它通常叫做一个==漫反射贴图(Diffuse Map)==,它是一个表现了物体所有的漫反射颜色的纹理图像。
-
新的光源的顶点着色器
-
更新后的顶点数据在这里。此刻有了纹理坐标,顶点数据现在包含了顶点位置、法向量和立方体顶点处的纹理坐标。让我们更新顶点着色器来以顶点属性的形式接受纹理坐标,并将它们传递到片段着色器中:那么相比2.3中,新增3行来说明纹理
#version 330 core layout (location = 0) in vec3 aPos; layout (location = 1) in vec3 aNormal; // 法向量 layout (location = 2) in vec2 aTexCoords; // 2.4.1新增 out vec3 FragPos; out vec3 Normal; out vec2 TexCoords; // 2.4.1新增 uniform mat4 model; uniform mat4 view; uniform mat4 projection; void main() { FragPos = vec3(model * vec4(aPos, 1.0)); Normal = mat3(transpose(inverse(model))) * aNormal; TexCoords = aTexCoords; // 2.4.1新增 gl_Position = projection * view * vec4(FragPos, 1.0); }
-
-
新的光源的片段着色器
#version 330 core out vec4 FragColor; struct Material { // vec3 ambient; //移除了环境光材质颜色向量 // vec3 diffuse; sampler2D diffuse; // 新增 vec3 specular; float shininess; }; struct Light { vec3 position; vec3 ambient; vec3 diffuse; vec3 specular; }; in vec3 FragPos; in vec3 Normal; in vec2 TexCoords; // 新增 uniform vec3 viewPos; uniform Material material; uniform Light light; void main() { // ambient // vec3 ambient = light.ambient * material.ambient; // 材质和纹理坐标结合起来了 vec3 ambient = light.ambient * texture(material.diffuse, TexCoords).rgb; // diffuse vec3 norm = normalize(Normal); vec3 lightDir = normalize(light.position - FragPos); float diff = max(dot(norm, lightDir), 0.0); // vec3 diffuse = light.diffuse * (diff * material.diffuse); // 同上 vec3 diffuse = light.diffuse * diff * texture(material.diffuse, TexCoords).rgb; // specular vec3 viewDir = normalize(viewPos - FragPos); vec3 reflectDir = reflect(-lightDir, norm); float spec = pow(max(dot(viewDir, reflectDir), 0.0), material.shininess); vec3 specular = light.specular * (spec * material.specular); vec3 result = ambient + diffuse + specular; FragColor = vec4(result, 1.0); }
说明:
- 对于struct Material,将纹理储存为Material结构体中的一个
sampler2D。我们将之前定义的vec3漫反射颜色向量替换为漫反射贴图; - 移除了环境光材质颜色向量,因为环境光颜色在几乎所有情况下都等于漫反射颜色,所以我们不需要将它们分开储存;
- 40行:片段着色器中再次需要纹理坐标,所以我们声明一个额外的输入变量。接下来我们只需要从纹理中采样片段的漫反射颜色值即可
- 32行:不要忘记将环境光的材质颜色设置为漫反射材质颜色同样的值。
- 对于struct Material,将纹理储存为Material结构体中的一个
-
主要代码:源码地址
没什么特别的,跟前面加载纹理图片,设置纹理过程差不多,几乎一样。
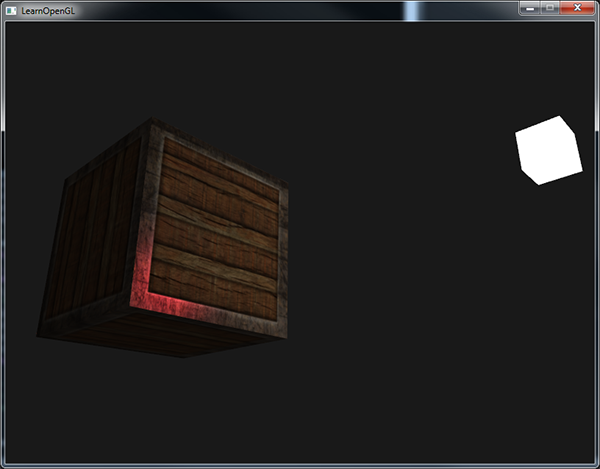
上面的做法有点问题,木头不应该有这么强的镜面高光的。我们可以将物体的镜面光材质设置为vec3(0.0)来解决这个问题,但这也意味着箱子钢制的边框将不再能够显示镜面高光了,我们知道钢铁应该是有一些镜面高光的。所以,我们想要让物体的某些部分以不同的强度显示镜面高光。
可以使用一个专门用于镜面高光的纹理贴图,即再加一张纹理图作为镜面光贴图(Specular Map),更多的理论用到看原文地址。
{kind=link}
-
相对2.4.1的片段着色器
#version 330 core out vec4 FragColor; struct Material { sampler2D diffuse; // vec3 specular; sampler2D specular; // 不再是vec3类型,而是纹理的sampler2D float shininess; }; struct Light { vec3 position; vec3 ambient; vec3 diffuse; vec3 specular; }; in vec3 FragPos; in vec3 Normal; in vec2 TexCoords; uniform vec3 viewPos; uniform Material material; uniform Light light; void main() { // ambient vec3 ambient = light.ambient * texture(material.diffuse, TexCoords).rgb; // diffuse vec3 norm = normalize(Normal); vec3 lightDir = normalize(light.position - FragPos); float diff = max(dot(norm, lightDir), 0.0); vec3 diffuse = light.diffuse * diff * texture(material.diffuse, TexCoords).rgb; // specular vec3 viewDir = normalize(viewPos - FragPos); vec3 reflectDir = reflect(-lightDir, norm); float spec = pow(max(dot(viewDir, reflectDir), 0.0), material.shininess); // vec3 specular = light.specular * (spec * material.specular); // 变的是这 vec3 specular = light.specular * spec * texture(material.specular, TexCoords).rgb; vec3 result = ambient + diffuse + specular; FragColor = vec4(result, 1.0); }
-
主代码中要把新的纹理图用stbi_load加载出来,然后激活绑定
// loadTexture是自定义函数,2.4.3中写到过 unsigned int diffuseMap = loadTexture("container2.png"); unsigned int specularMap = loadTexture("container2_specular.png"); // shader configuration // -------------------- lightingShader.use(); lightingShader.setInt("material.diffuse", 0); lightingShader.setInt("material.specular", 1); while (1) { /* ---- ---*/ // active and bind diffuse map glActiveTexture(GL_TEXTURE0); glBindTexture(GL_TEXTURE_2D, diffuseMap); // active and bind specular map glActiveTexture(GL_TEXTURE1); glBindTexture(GL_TEXTURE_2D, specularMap); }
- 调整光源的环境光、漫反射和镜面光向量,看看它们如何影响箱子的视觉输出。
- 尝试在片段着色器中反转镜面光贴图的颜色值,让木头显示镜面高光而钢制边缘不反光(由于钢制边缘中有一些裂缝,边缘仍会显示一些镜面高光,虽然强度会小很多):参考解答。
- 使用漫反射贴图创建一个彩色而不是黑白的镜面光贴图,看看结果看起来并不是那么真实了。如果你不会生成的话,可以使用这张彩色的镜面光贴图:最终效果。
- 添加一个叫做放射光贴图(Emission Map)的东西,它是一个储存了每个片段的发光值(Emission Value)的贴图。发光值是一个包含(假设)光源的物体发光(Emit)时可能显现的颜色,这样的话物体就能够忽略光照条件进行发光(Glow)。游戏中某个物体在发光的时候,你通常看到的就是放射光贴图(比如 机器人的眼,或是箱子上的灯带)。将这个纹理(作者为 creativesam)作为放射光贴图添加到箱子上,产生这些字母都在发光的效果:参考解答,最终效果。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
原文地址。
当一个光源处于很远的地方时,来自光源的每条光线就会近似于互相平行。不论物体和/或者观察者的位置,看起来好像所有的光都来自于同一个方向。当我们使用一个假设光源处于无限远处的模型时,它就被称为==定向光==,因为它的所有光线都有着相同的方向,它与光源的位置是没有关系的。如太阳光。
-
光源的片段着色器,基本和前面类似,就是需要定义一个光线方向向量而不是位置向量来模拟一个定向光。取反是因为人们更习惯定义定向光为一个从光源出发的全局方向。所以我们需要对全局光照方向向量取反来改变它的方向,它现在是一个指向光源的方向向量了
struct Light { // vec3 position; // 使用定向光就不再需要了 vec3 direction; vec3 ambient; vec3 diffuse; vec3 specular; }; ... void main() { vec3 lightDir = normalize(-light.direction); ... }
点光源就是一个能够配置位置和衰减的光源,多的看原文吧。
就是聚光灯的效果,用到时再深入吧,里面还涉及到了==平滑/软化边缘==(就是聚光的边缘)。
就是把上面几个光源全部组合在一起,主要修改的还是光源的片段着色器,全部写到片段着色器中,glsl语法中也能定义函数,跟C\C++的写法是一样的。原文地址。
常见的模型格式:(这俩网址要科学上网)
- Wavefront的.obj这样的模型格式,只包含了模型数据以及材质信息,像是模型颜色和漫反射/镜面光贴图;
- 以XML为基础的Collada文件格式则非常的丰富,包含模型、光照、多种材质、动画数据、摄像机、完整的场景信息等等。
- 还可以用它在fbx、obj格式之间转换。
一个非常流行的模型导入库是Assimp,它是==Open Asset Import Library==(开放的资产导入库)的缩写。Assimp能够导入很多种不同的模型文件格式(并也能够导出部分的格式),它会将所有的模型数据加载至Assimp的通用数据结构中。当Assimp加载完模型之后,我们就能够从Assimp的数据结构中提取我们所需的所有数据了。由于Assimp的数据结构保持不变,不论导入的是什么种类的文件格式,它都能够将我们从这些不同的文件格式中抽象出来,用同一种方式访问我们需要的数据。
当使用Assimp导入一个模型的时候,它通常会将整个模型加载进一个场景(Scene)对象,它会包含导入的模型/场景中的所有数据。Assimp会将场景载入为一系列的节点(Node),每个节点包含了场景对象中所储存数据的索引,每个节点都可以有任意数量的子节点。
安装:github下载源码,直接cmake编译出来,再添加路径就好了。
预处理指令offsetof(s, m),它的第一个参数是一个结构体,第二个参数是这个结构体中变量的名字。这个宏会返回那个变量距结构体头部的字节偏移量(Byte Offset)
库的加载的简单使用:
#include <assimp/Importer.hpp>
#include <assimp/scene.h>
#include <assimp/postprocess.h>
#include <assimp/Exporter.hpp>
int main() {
// 读取
Assimp::Importer importer;
const aiScene *scene = importer.ReadFile(path, aiProcess_Triangulate | aiProcess_GenSmoothNormals | aiProcess_FlipUVs | aiProcess_CalcTangentSpace);
// check for errors // if is Not Zero
if (!scene || scene->mFlags & AI_SCENE_FLAGS_INCOMPLETE || !scene->mRootNode) {
std::cout << "ERROR::ASSIMP:: " << importer.GetErrorString() << std::endl;
return;
}
// 格式转换的话:比如fbx转成obj(默认scene场景读的fbx格式)
Assimp::Exporter exporter;
exporter.Export(scene, "obj", "model.obj");
// 缩放,如果模型太大了需要缩放
float scale = 0.25f; // 指定缩放比例
// 缩放所有顶点
for (unsigned int i = 0; i < scene->mNumMeshes; i++) {
aiMesh *mesh = scene->mMeshes[i];
for (unsigned int j = 0; j < mesh->mNumVertices; j++) {
mesh->mVertices[j] *= scale; // 这里就是直接坐标缩放
// 核心是这里的代码,缩放因子那些没啥用,如绕x轴喜欢转180
// x坐标不变:mesh->mVertices[j].x
mesh->mVertices[j].y *= -1.0;
mesh->mVertices[j].z *= -1.0;
/* 这个值为啥是这样,是由下面的X轴旋转矩阵来的,其它的轴的看三维重建
[1 0 0 0] [x]
[0 cosα -sinα 0] × [y]
[0 sinα cosα 0] [z]
[0 0 0 1] [1]
(α取180带进去算出来就好了)
*/
}
}
/* // 更新缩放因子
//scene->mRootNode->mTransformation.a1 *= scale;
//scene->mRootNode->mTransformation.b2 *= scale;
//scene->mRootNode->mTransformation.c3 *= scale;
// 或者采用下面函数的方式
aiMatrix4x4::Scaling(aiVector3D(scale, scale, scale), scene->mRootNode->mTransformation);
*/
/*
// 打印更新后的缩放因子
aiVector3D scalingVector = aiVector3D(scene->mRootNode->mTransformation.a1, scene->mRootNode->mTransformation.b2, scene->mRootNode->mTransformation.c3);
std::cout << calingVector.x << scalingVector.y << scalingVector.z;
// 结果由一开始的1、1、1,现在成为了0.25、0.25、0.25
*/
}
/*使用OpenAI写的似乎更全面*/
int main() {
Assimp::Importer importer;
const aiScene* scene = importer.ReadFile("model.obj", aiProcess_Triangulate | aiProcess_FlipUVs);
if(!scene || scene->mFlags & AI_SCENE_FLAGS_INCOMPLETE || !scene->mRootNode) {
std::cout << "ERROR::ASSIMP::" << importer.GetErrorString() << std::endl;
return -1;
}
std::cout << "Mesh num: " << scene->mNumMeshes << std::endl;
for(unsigned int i = 0; i < scene->mNumMeshes; i++) {
aiMesh* mesh = scene->mMeshes[i];
std::cout << "Mesh " << i << " vertex num: " << mesh->mNumVertices << std::endl;
}
// 还写了一种
if (scene != nullptr) {
std::cout << "顶点数量:" << scene->mMeshes[0]->mNumVertices << std::endl;
for (unsigned int i = 0; i < scene->mMeshes[0]->mNumVertices; i++) {
const aiVector3D* pPos = &(scene->mMeshes[0]->mVertices[i]);
std::cout << "顶点:" << i << ":" << pPos->x << "," << pPos->y << "," << pPos->z << std::endl;
}
}
else {std::cout << "文件读取失败" << std::endl;}
return 0;
} 首先声明了Assimp命名空间内的一个Importer,之后调用了它的ReadFile函数。这个函数需要一个文件路径,它的第二个参数是一些后期处理(Post-processing)的选项。除了加载文件之外,Assimp允许我们设定一些选项来强制它对导入的数据做一些额外的计算或操作。通过设定aiProcess_Triangulate,我们告诉Assimp,如果模型不是(全部)由三角形组成,它需要将模型所有的图元形状变换为三角形。aiProcess_FlipUVs将在处理的时候翻转y轴的纹理坐标(你可能还记得我们在[纹理](https://learnopengl-cn.github.io/01 Getting started/06 Textures/)教程中说过,在OpenGL中大部分的图像的y轴都是反的,所以这个后期处理选项将会修复这个)。其它一些比较有用的选项有:
- aiProcess_GenNormals:如果模型不包含法向量的话,就为每个顶点创建法线。
- aiProcess_SplitLargeMeshes:将比较大的网格分割成更小的子网格,如果你的渲染有最大顶点数限制,只能渲染较小的网格,那么它会非常有用。
- aiProcess_OptimizeMeshes:和上个选项相反,它会将多个小网格拼接为一个大的网格,减少绘制调用从而进行优化。
Assimp提供了很多有用的后期处理指令,你可以在这里找到全部的指令。实际上使用Assimp加载模型是非常容易的(你也可以看到)。困难的是之后使用返回的场景对象将加载的数据转换到一个Mesh对象的数组。
写到最后,加载obj的完整代码,看这里。创建了一个自定义Mesh、Model的头文件,把功能都封装了。
然后注意源码里的一句==directory = path.substr(0, path.find_last_of('/'));==,因为它是linux的斜线,在win上记得换成, 不然一些贴图路径找不到,没有贴图整个模型就是黑的(这里是针对OpenGL那个加载巨人模型说的)
模型加载后,如果使用线框模式,又会得到不一样的结果
同样使用Assimp库来加载fbx模型,老一点格式的fbx这个就加载不了;
FBX模型一般用来存动画这些,用Assimp也可以加载,assimp加载骨骼动画网上有很详细的教程,地址:http://ogldev.org,tutorial38。
-
CMakeLists.txt
cmake_minimum_required(VERSION 3.1) project(fbx-sdk) # Enable C++11 set(CMAKE_CXX_STANDARD 11) set(CMAKE_CXX_STANDARD_REQUIRED TRUE) include_directories("D:/lib/assimp/include") link_directories("D:/lib/assimp/lib") add_executable(main main.cpp) target_link_libraries(main assimp-vc141-mtd)
-
main.cpp
#include <assimp/Importer.hpp> #include <assimp/scene.h> #include <assimp/postprocess.h> #include <iostream> int main() { // Create an assimp importer object. Assimp::Importer importer; // Specify the FBX file to load. const char* filename = "1322000501238833153.fbx"; // Load the FBX file. const aiScene* scene = importer.ReadFile(filename, aiProcess_Triangulate | aiProcess_GenSmoothNormals | aiProcess_FlipUVs); if (!scene) { std::cerr << importer.GetErrorString() << std::endl; return 1; } // Process the scene. aiNode* root = scene->mRootNode; if (root) { for (int i = 0; i < root->mNumChildren; i++) { aiNode* child = root->mChildren[i]; if (!child) continue; // Process the child node. // ... } } // Destroy the scene and other objects. importer.FreeScene(); std::cout << "hello world" << std::endl; return 0; }
Assimp库本身不支持动画的解析,但提供了加载骨骼和动画的接口。下面是一个基于Assimp库的模型动画控制的示例代码,主要通过对模型骨骼节点的变换来实现模型的动画效果:
#include <assimp/Importer.hpp> #include <assimp/scene.h> #include <assimp/postprocess.h> #include <iostream> int main() { // Create an assimp importer object. Assimp::Importer importer; // Specify the FBX file to load. const char* filename = "example.fbx"; // Load the FBX file. const aiScene* scene = importer.ReadFile(filename, aiProcess_Triangulate | aiProcess_GenSmoothNormals | aiProcess_FlipUVs); if (!scene) { std::cerr << importer.GetErrorString() << std::endl; return 1; } // Process the scene. aiNode* root = scene->mRootNode; if (root) { for (int i = 0; i < root->mNumChildren; i++) { aiNode* child = root->mChildren[i]; if (!child) continue; // Process the child node. // ... } } // Get the animation object. aiAnimation* animation = scene->mAnimations[0]; aiNode* rootNode = scene->mRootNode; // Find the animation node in the scene graph. aiNode* animationNode = rootNode->FindNode(animation->mName); if (!animationNode) return 1; // Create a transformation matrix for the animation. aiMatrix4x4 transform; aiVector3D position(0.0f, 0.0f, 0.0f), scaling(1.0f, 1.0f, 1.0f); aiQuaternion rotation(1.0f, 0.0f, 0.0f, 0.0f); // Find the keyframe at the current time. float time = 0.0f; aiNodeAnim* animationNodeAnim = NULL; for (int i = 0; i < animation->mNumChannels; i++) { aiNodeAnim* nodeAnim = animation->mChannels[i]; if (!nodeAnim) continue; if (strcmp(nodeAnim->mNodeName.data, animationNode->mName.data) == 0) { animationNodeAnim = nodeAnim; time = 0.0f; while (time < animationNodeAnim->mNumPositionKeys && time < animationNodeAnim->mNumScalingKeys && time < animationNodeAnim->mNumRotationKeys) { if (animationNodeAnim->mPositionKeys[time].mTime > animationNodeAnim->mScalingKeys[time].mTime && animationNodeAnim->mPositionKeys[time].mTime > animationNodeAnim->mRotationKeys[time].mTime) break; time += 0.01f; } break; } } // Interpolate the position, scaling, and rotation values for the current keyframe. if (animationNodeAnim) { if (time < animationNodeAnim->mNumPositionKeys && time < animationNodeAnim->mNumScalingKeys && time < animationNodeAnim->mNumRotationKeys) { position = animationNodeAnim->mPositionKeys[time].mValue; scaling = animationNodeAnim->mScalingKeys[time].mValue; rotation = animationNodeAnim->mRotationKeys[time].mValue; } } // Set the transformation matrix. transform = aiMatrix4x4::Translation(position) * aiMatrix4x4(rotation.GetMatrix()) * aiMatrix4x4::Scaling(scaling); // Apply the transformation to the animation node. aiMatrix4x4 parentTransform; if (animationNode->mParent) parentTransform = animationNode->mParent->mTransformation; animationNode->mTransformation = parentTransform * transform; // Destroy the scene and other objects. importer.FreeScene(); return 0; }
上面的代码演示了如何使用Assimp库加载FBX文件并实现骨骼动画控制。其中通过获取模型的动画对象和根节点,并通过遍历动画的关键帧实现模型动画的线性插值。用户可以根据骨骼动画的需要,对关键帧进行处理,并用变换矩阵来控制模型动画的效果。
网上说用这这个autodesk发布的FBX SDK更好用一些,下载地址。跨平台的,然后win下载后就是一个exe,点击安装就行,里面有很多samples,都是可以编译通过使用的。再放个博客参考一下。
这是chatgpt回答的用fbx-sdk加载fbx模型:测试已通过
加载一个FBX文件,创建一个场景对象,并遍历场景中的节点。在实际使用中,可以根据需要对不同类型的节点进行处理,例如获取节点的平移、旋转、缩放等参数,或者获取节点上的网格、材质、动画等属性。
-
CMakeLists.txt
cmake_minimum_required(VERSION 3.1) project(fbx-sdk) # Enable C++11 set(CMAKE_CXX_STANDARD 11) set(CMAKE_CXX_STANDARD_REQUIRED TRUE) include_directories("D:/lib/FBX SDK/2020.3.1/include") # 记得把这路径下的 libfbxsdk.dll 动态库复制到执行文件路径中 link_directories("D:/lib/FBX SDK/2020.3.1/lib/vs2017/x64/debug") add_executable(main main.cpp) target_link_libraries(main libfbxsdk)
-
main.cpp
#include <fbxsdk.h> #include <iostream> int main() { // Initialize the SDK manager. FbxManager* manager = FbxManager::Create(); std::cout << "7 line" << std::endl; if (!manager) { std::cerr << "Failed to initialize the FBX SDK manager." << std::endl; return 1; } // Create an IO settings object. FbxIOSettings* ioSettings = FbxIOSettings::Create(manager, IOSROOT); if (!ioSettings) { std::cerr << "Failed to create the IO settings object." << std::endl; manager->Destroy(); return 1; } manager->SetIOSettings(ioSettings); // Create an importer object. FbxImporter* importer = FbxImporter::Create(manager, ""); if (!importer) { std::cerr << "Failed to create the FBX importer object." << std::endl; ioSettings->Destroy(); manager->Destroy(); return 1; } // Specify the FBX file to import. const char* filename = "my_fbx_obj.fbx"; if (!importer->Initialize(filename, -1, manager->GetIOSettings())) { std::cerr << "Failed to initialize the FBX importer." << std::endl; importer->Destroy(); ioSettings->Destroy(); manager->Destroy(); return 1; } // Create a scene object. FbxScene* scene = FbxScene::Create(manager, "Scene"); if (!scene) { std::cerr << "Failed to create the FBX scene." << std::endl; importer->Destroy(); ioSettings->Destroy(); manager->Destroy(); return 1; } // Import the FBX file into the scene. if (!importer->Import(scene)) { std::cerr << "Failed to import the FBX file." << std::endl; importer->Destroy(); ioSettings->Destroy(); manager->Destroy(); return 1; } // Destroy the importer object. importer->Destroy(); // Process the scene. FbxNode* root = scene->GetRootNode(); if (root) { for (int i = 0; i < root->GetChildCount(); i++) { FbxNode* child = root->GetChild(i); if (!child) continue; // Process the child node. // ... } } // Destroy the scene and other objects. scene->Destroy(); ioSettings->Destroy(); manager->Destroy(); std::cout << "hello world" << std::endl; return 0; }
原文地址,里面还有涉及到==物体轮廓==。
用于写入颜色值的颜色缓冲、用于写入深度信息的深度缓冲和允许我们根据一些条件丢弃特定片段的模板缓冲。
原文地址,简单来说就是带颜色的窗户,涉及到的主要API有:
- 启用混合功能:glEnable(GL_BLEND);
- 混合方式:glBlendFunc(GLenum sfactor, GLenum dfactor);
- 以及:glBlendFuncSeparate(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA, GL_ONE, GL_ZERO);
原文地址,简单来说就是把观察者看不到的面直接不渲染,节省开销,涉及到的API有:
-
OpenGL启用面剔除:glEnable(GL_CULL_FACE);
-
glCullFace(GL_FRONT); glCullFace函数有三个可用的选项:
GL_BACK:只剔除背向面。GL_FRONT:只剔除正向面。GL_FRONT_AND_BACK:剔除正向面和背向面。
glCullFace的初始值是GL_BACK
原文地址。
到目前为止,我们已经使用了很多屏幕缓冲了:用于写入颜色值的颜色缓冲、用于写入深度信息的深度缓冲和允许我们根据一些条件丢弃特定片段的模板缓冲。这些缓冲结合起来叫做帧缓冲(Framebuffer),它被储存在内存中。OpenGL允许我们定义我们自己的帧缓冲,也就是说我们能够定义我们自己的颜色缓冲,甚至是深度缓冲和模板缓冲。
涉及到的一些API:
-
unsigned int fbo; glGenFramebuffers(1, &fbo); glBindFramebuffer(GL_FRAMEBUFFER, fbo); //检查帧缓冲是否完整 if(glCheckFramebufferStatus(GL_FRAMEBUFFER) == GL_FRAMEBUFFER_COMPLETE) -
创建好一个纹理了,要做的最后一件事就是将它附加到帧缓冲上了:(参数含义去看原文)
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0, GL_TEXTURE_2D, texture, 0);
可以通过帧缓冲对图像做一些后期处理,如==反相==、==灰度图==、核处理做出==模糊==、==边缘检测==的效果。
原文地址。
创建立方体贴图:整个源代码地址。
std::vector<std::string> faces{
"C:\\Users\\Administrator\\Pictures\\skybox\\right.jpg",
"C:\\Users\\Administrator\\Pictures\\skybox\\left.jpg",
"C:\\Users\\Administrator\\Pictures\\skybox\\top.jpg",
"C:\\Users\\Administrator\\Pictures\\skybox\\bottom.jpg",
"C:\\Users\\Administrator\\Pictures\\skybox\\front.jpg",
"C:\\Users\\Administrator\\Pictures\\skybox\\back.jpg"
}; // 一定要是这个顺序
// 将这个天空盒加载为一个立方体贴图了
unsigned int cubemapTexture = loadCubemap(faces);
// loads a cubemap texture from 6 individual texture faces
// order:
// +X (right)
// -X (left)
// +Y (top)
// -Y (bottom)
// +Z (front)
// -Z (back)
// -------------------------------------------------------
unsigned int loadCubemap(vector<std::string> faces) {
unsigned int textureID;
glGenTextures(1, &textureID);
// 注意这里的类型是 GL_TEXTURE_CUBE_MAP
glBindTexture(GL_TEXTURE_CUBE_MAP, textureID);
int width, height, nrChannels;
for (unsigned int i = 0; i < faces.size(); i++) {
unsigned char *data = stbi_load(faces[i].c_str(), &width, &height, &nrChannels, 0);
if (data) {
// 注意这里 GL_TEXTURE_CUBE_MAP_POSITIVE_X 是枚举值,按顺序递增的,
glTexImage2D(GL_TEXTURE_CUBE_MAP_POSITIVE_X + i, 0, GL_RGB, width, height, 0, GL_RGB, GL_UNSIGNED_BYTE, data);
stbi_image_free(data);
}
else {
std::cout << "Cubemap texture failed to load at path: " << faces[i] << std::endl;
stbi_image_free(data);
}
}
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_EDGE);
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_EDGE);
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_WRAP_R, GL_CLAMP_TO_EDGE);
return textureID;
}解读:
-
glBindTexture(GL_TEXTURE_CUBE_MAP, textureID); //类型是
GL_TEXTURE_CUBE_MAP -
因为立方体贴图包含有6个纹理,每个面一个,我们需要调用glTexImage2D函数6次。6个面,OpenGL给我们提供了6个特殊的纹理目标,专门对应立方体贴图的一个面
纹理目标 方位 GL_TEXTURE_CUBE_MAP_POSITIVE_X 右 GL_TEXTURE_CUBE_MAP_NEGATIVE_X 左 GL_TEXTURE_CUBE_MAP_POSITIVE_Y 上 GL_TEXTURE_CUBE_MAP_NEGATIVE_Y 下 GL_TEXTURE_CUBE_MAP_POSITIVE_Z 后 GL_TEXTURE_CUBE_MAP_NEGATIVE_Z 前 和OpenGL的很多枚举(Enum)一样,它们背后的int值是线性递增的,所以如果我们有一个纹理位置的数组或者vector,我们就可以从GL_TEXTURE_CUBE_MAP_POSITIVE_X开始遍历它们,在每个迭代中对枚举值加1,遍历了整个纹理目标(上面代码31行就是这样实现的,所以一定要注意faces这个vector的顺序要对应起来)。
-
GL_TEXTURE_WRAP_R仅仅是为纹理的R坐标设置了环绕方式,它对应的是纹理的第三个维度(和位置的z一样)。我们将环绕方式设置为GL_CLAMP_TO_EDGE,这是因为正好处于两个面之间的纹理坐标可能不能击中一个面(由于一些硬件限制),所以通过使用GL_CLAMP_TO_EDGE,OpenGL将在我们对两个面之间采样的时候,永远返回它们的边界值。
天空盒子的片段着色器中:
使用了GLSL中新的类型samplerCube: uniform samplerCube skybox;
简单来说就是让箱子能反射周围的环境。(这里没有完整的源码,要把机器人模型加载进行进去,需要子就去看模型加载那里的笔记,在这节代码上加上几行就可以了)
根据观察方向向量I和物体的法向量N,来计算反射向量R。我们可以使用GLSL内建的reflect函数来计算这个反射向量。最终的R¯R¯向量将会作为索引/采样立方体贴图的方向向量,返回环境的颜色值。最终的结果是物体看起来反射了天空盒。
箱子的==片段着色器==如下:
#version 330 core
out vec4 FragColor;
in vec3 Normal;
in vec3 Position;
uniform vec3 cameraPos;
uniform samplerCube skybox;
void main() {
vec3 I = normalize(Position - cameraPos);
vec3 R = reflect(I, normalize(Normal));
FragColor = vec4(texture(skybox, R).rgb, 1.0);
}先计算了观察/摄像机方向向量I,并使用它来计算反射向量R,之后我们将使用R来从天空盒立方体贴图中采样
现在又有了片段的插值Normal和Position变量,所以我们需要更新一下==顶点着色器==:
#version 330 core
layout (location = 0) in vec3 aPos;
layout (location = 1) in vec3 aNormal;
out vec3 Normal;
out vec3 Position;
uniform mat4 model;
uniform mat4 view;
uniform mat4 projection;
void main() {
Normal = mat3(transpose(inverse(model))) * aNormal;
Position = vec3(model * vec4(aPos, 1.0));
gl_Position = projection * view * model * vec4(aPos, 1.0);
} 现在使用了一个法向量,所以我们将再次使用法线矩阵(Normal Matrix)来变换它们。Position输出向量是一个世界空间的位置向量。顶点着色器的这个Position输出将用来在片段着色器内计算观察方向向量。
因为我们使用了法线,你还需要更新一下顶点数据,并更新属性指针。还要记得去设置cameraPos这个uniform。
还可以结合前面机器人模型的加载,得到一种整个套装都是使用铬做成的效果。但在现实中大部分的模型都不具有完全反射性。我们可以引入==反射贴图(Reflection Map)==,来给模型更多的细节。与漫反射和镜面光贴图一样,反射贴图也是可以采样的纹理图像,它决定这片段的反射性。通过使用反射贴图,我们可以知道模型的哪些部分该以什么强度显示反射。
与折射基本类似,就是要确定不同材质的折射率,一些最常见的折射率可以在下表中找到:
| 材质 | 折射率 |
|---|---|
| 空气 | 1.00 |
| 水 | 1.33 |
| 冰 | 1.309 |
| 玻璃 | 1.52 |
| 钻石 | 2.42 |
然后唯一要修改的就是立方体的片段着色器:GLSL的==refract==函数实现
#version 330 core
out vec4 FragColor;
in vec3 Normal;
in vec3 Position;
uniform vec3 cameraPos;
uniform samplerCube skybox;
void main() {
float ratio = 1.00 / 1.52; // 光线(视线)从空气进入玻璃
vec3 I = normalize(Position - cameraPos);
// vec3 R = reflect(I, normalize(Normal));
vec3 R = refract(I, normalize(Normal), ratio);
FragColor = vec4(texture(skybox, R).rgb, 1.0);
}原文地址。
分批顶点属性:
之前我们的顶点位置、法线、纹理坐标都是在一个数组里,然后使用glBufferData(GL_ARRAY_BUFFER, sizeof(cubeVertices), &cubeVertices, GL_STATIC_DRAW);这个函数来完成赋值,再使用glVertexAttribPointer来设置顶点属性。
然后还有一种别的处理方式,使用==glBufferSubData==函数实现:(方式不一样而已,用哪种都可以)
float positions[] = { ... };
float normals[] = { ... };
float tex[] = { ... };
// 填充缓冲
glBufferSubData(GL_ARRAY_BUFFER, 0, sizeof(positions), &positions);
glBufferSubData(GL_ARRAY_BUFFER, sizeof(positions), sizeof(normals), &normals);
glBufferSubData(GL_ARRAY_BUFFER, sizeof(positions) + sizeof(normals), sizeof(tex), &tex);原文地址。
GLSL里面有很多内置变量,前面遇到最多的就是==gl_Position==,片段着色器中有一个有意思的变量==gl_FragCoord==.
gl_FragCoord的x和y分量是片段的窗口空间(Window-space)坐标,其原点为窗口的左下角。我们已经使用glViewport设定了一个800x600的窗口了,所以片段窗口空间坐标的x分量将在0到800之间,y分量在0到600之间。
通过利用片段着色器,我们可以根据片段的窗口坐标,计算出不同的颜色。gl_FragCoord的一个常见用处是用于对比不同片段计算的视觉输出效果,这在技术演示中可以经常看到。比如说,我们能够将屏幕分成两部分,在窗口的左侧渲染一种输出,在窗口的右侧渲染另一种输出。下面这个例子片段着色器会根据窗口坐标输出不同的颜色:(其它的看原文吧)
void main() {
if(gl_FragCoord.x < 400)
FragColor = vec4(1.0, 0.0, 0.0, 1.0);
else
FragColor = vec4(0.0, 1.0, 0.0, 1.0);
}此外,还可以使用==Uniform块布局==,有点像结构体那种,传入数据赋值要比一个个的来更加方便,用到时再来看吧
原文地址。只写了皮毛,具体的使用、==法向量可视化==这些还是去看原文吧。
几何着色器,有些类似于顶点着色器和片段着色器,几何着色器也需要编译和链接,但这次在创建着色器时我们将会使用GL_GEOMETRY_SHADER作为着色器类型:
geometryShader = glCreateShader(GL_GEOMETRY_SHADER);
glShaderSource(geometryShader, 1, &gShaderCode, NULL);
glCompileShader(geometryShader);
...
glAttachShader(program, geometryShader);
glLinkProgram(program);再举例一个几何着色器的例子:
#version 330 core
layout (points) in;
layout (line_strip, max_vertices = 2) out;
void main() {
gl_Position = gl_in[0].gl_Position + vec4(-0.1, 0.0, 0.0, 0.0);
EmitVertex();
gl_Position = gl_in[0].gl_Position + vec4( 0.1, 0.0, 0.0, 0.0);
EmitVertex();
EndPrimitive();
}在几何着色器的顶部,我们需要声明从顶点着色器输入的图元类型。这需要在in关键字前声明一个布局修饰符(Layout Qualifier)。这个输入布局修饰符可以从顶点着色器接收下列任何一个图元值:
points:绘制GL_POINTS图元时(1)。lines:绘制GL_LINES或GL_LINE_STRIP时(2)lines_adjacency:GL_LINES_ADJACENCY或GL_LINE_STRIP_ADJACENCY(4)triangles:GL_TRIANGLES、GL_TRIANGLE_STRIP或GL_TRIANGLE_FAN(3)triangles_adjacency:GL_TRIANGLES_ADJACENCY或GL_TRIANGLE_STRIP_ADJACENCY(6)
以上是能提供给glDrawArrays渲染函数的几乎所有图元了。如果我们想要将顶点绘制为GL_TRIANGLES,我们就要将输入修饰符设置为triangles。括号内的数字表示的是一个图元所包含的最小顶点数。
接下来,我们还需要指定几何着色器输出的图元类型,这需要在out关键字前面加一个布局修饰符。和输入布局修饰符一样,输出布局修饰符也可以接受几个图元值:
pointsline_striptriangle_strip
有了这3个输出修饰符,我们就可以使用输入图元创建几乎任意的形状了。要生成一个三角形的话,我们将输出定义为triangle_strip,并输出3个顶点。
几何着色器同时希望我们设置一个它最大能够输出的顶点数量(如果你超过了这个值,OpenGL将不会绘制多出的顶点),这个也可以在out关键字的布局修饰符中设置。在这个例子中,我们将输出一个line_strip,并将最大顶点数设置为2个。
原文地址。这里面还讲了实例化,就不写了,直接上实例化数组。
要渲染远超过100个实例的时候(这其实非常普遍),我们最终会超过最大能够发送至着色器的uniform数据大小上限。它的一个代替方案是实例化数组(Instanced Array),它被定义为一个顶点属性(能够让我们储存更多的数据),仅在顶点着色器渲染一个新的实例时才会更新。
使用顶点属性时,顶点着色器的每次运行都会让GLSL获取新一组适用于当前顶点的属性。而当我们将顶点属性定义为一个实例化数组时,顶点着色器就只需要对每个实例,而不是每个顶点,更新顶点属性的内容了。这允许我们对逐顶点的数据使用普通的顶点属性,而对逐实例的数据使用实例化数组。
以下的总的源代码。
-
将偏移量uniform数组设置为一个实例化数组。我们需要在==顶点着色器==中再添加一个顶点属性:
#version 330 core layout (location = 0) in vec2 aPos; layout (location = 1) in vec3 aColor; layout (location = 2) in vec2 aOffset; // 加一个属性 out vec3 fColor; void main() { gl_Position = vec4(aPos + aOffset, 0.0, 1.0); fColor = aColor; }
-
不再使用gl_InstanceID,现在不需要索引一个uniform数组就能够直接使用offset属性了,因为实例化数组和position与color变量一样,都是顶点属性,我们还需要将它的内容存在顶点缓冲对象中,并且配置它的属性指针
// generate a list of 100 quad locations/translation-vectors glm::vec2 translations[100]; int index = 0; float offset = 0.1f; for (int y = -10; y < 10; y += 2) { for (int x = -10; x < 10; x += 2) { glm::vec2 translation; translation.x = (float)x / 10.0f + offset; translation.y = (float)y / 10.0f + offset; translations[index++] = translation; } } // store instance data in an array buffer unsigned int instanceVBO; glGenBuffers(1, &instanceVBO); glBindBuffer(GL_ARRAY_BUFFER, instanceVBO); glBufferData(GL_ARRAY_BUFFER, sizeof(glm::vec2) * 100, &translations[0], GL_STATIC_DRAW); glBindBuffer(GL_ARRAY_BUFFER, 0); // 这算是复原吧
-
之后我们还需要设置它的顶点属性指针,并启用顶点属性:
glEnableVertexAttribArray(2); // this attribute comes from a different vertex buffer glBindBuffer(GL_ARRAY_BUFFER, instanceVBO); glVertexAttribPointer(2, 2, GL_FLOAT, GL_FALSE, 2 * sizeof(float), (void*)0); glBindBuffer(GL_ARRAY_BUFFER, 0); // tell OpenGL this is an instanced vertex attribute. glVertexAttribDivisor(2, 1);
说明:调用了
glVertexAttribDivisor。这个函数告诉了OpenGL该什么时候更新顶点属性的内容至新一组数据。它的第一个参数是需要的顶点属性,第二个参数是属性除数(Attribute Divisor)。默认情况下,属性除数是0,告诉OpenGL我们需要在顶点着色器的每次迭代时更新顶点属性。将它设置为1时,我们告诉OpenGL我们希望在渲染一个新实例的时候更新顶点属性。而设置为2时,我们希望每2个实例更新一次属性,以此类推。我们将属性除数设置为1,是在告诉OpenGL,处于位置值2的顶点属性是一个实例化数组。 -
最终在while中调用
glDrawArraysInstanced进行绘制:glBindVertexArray(quadVAO); glDrawArraysInstanced(GL_TRIANGLES, 0, 6, 100); glBindVertexArray(0); // 相当于复原了吧
补充:GLSL中有一个内建变量gl_InstanceID,使用实例化渲染调用时,gl_InstanceID会从0开始,在每个实例被渲染时递增1。比如说,我们正在渲染第43个实例,那么顶点着色器中它的gl_InstanceID将会是42。因为每个实例都有唯一的ID,我们可以建立一个数组,将ID与位置值对应起来,将每个实例放置在世界的不同位置。
所以上面绘制的100个图案可以越来越小,改一下它的片段着色器:
#version 330 core
layout (location = 0) in vec2 aPos;
layout (location = 1) in vec3 aColor;
layout (location = 2) in vec2 aOffset;
out vec3 fColor;
void main() {
fColor = aColor;
// gl_InstanceID内建变量,随着实例增加值增加
vec2 pos = aPos * (gl_InstanceID / 100.0);
gl_Position = vec4(pos + aOffset, 0.0, 1.0);
}原文地址。要在这里面下载模型文件。
加载模型后,设置模型不同位置,源码。
以上有多少个小行星每帧就要多少次旋绕调用,当数量很大时,场景运行就会很不流畅,就要改进,尝试使用实例化渲染来渲染相同的场景。
-
首先对==顶点着色器==进行一点修改:不再使用模型uniform变量,改为一个mat4的顶点属性,让我们能够存储一个实例化数组的变换矩阵
#version 330 core layout (location = 0) in vec3 aPos; layout (location = 2) in vec2 aTexCoords; layout (location = 3) in mat4 instanceMatrix; // 新增的 out vec2 TexCoords; uniform mat4 projection; uniform mat4 view; // uniform mat4 model; // 取消掉的 void main() { TexCoords = aTexCoords; // gl_Position = projection * view * model * vec4(aPos, 1.0f); gl_Position = projection * view * instanceMatrix * vec4(aPos, 1.0f); }
-
然而,当我们顶点属性的类型大于vec4时,就要多进行一步处理了。顶点属性最大允许的数据大小等于一个vec4。因为一个mat4本质上是4个vec4,我们需要为这个矩阵预留4个顶点属性。因为我们将它的位置值设置为3,矩阵每一列的顶点属性位置值就是3、4、5和6。
// 顶点缓冲对象 unsigned int buffer; glGenBuffers(1, &buffer); glBindBuffer(GL_ARRAY_BUFFER, buffer); glBufferData(GL_ARRAY_BUFFER, amount * sizeof(glm::mat4), &modelMatrices[0], GL_STATIC_DRAW); for(unsigned int i = 0; i < rock.meshes.size(); i++) { unsigned int VAO = rock.meshes[i].VAO; glBindVertexArray(VAO); // 顶点属性 GLsizei vec4Size = sizeof(glm::vec4); glEnableVertexAttribArray(3); glVertexAttribPointer(3, 4, GL_FLOAT, GL_FALSE, 4 * vec4Size, (void*)0); glEnableVertexAttribArray(4); glVertexAttribPointer(4, 4, GL_FLOAT, GL_FALSE, 4 * vec4Size, (void*)(vec4Size)); glEnableVertexAttribArray(5); glVertexAttribPointer(5, 4, GL_FLOAT, GL_FALSE, 4 * vec4Size, (void*)(2 * vec4Size)); glEnableVertexAttribArray(6); glVertexAttribPointer(6, 4, GL_FLOAT, GL_FALSE, 4 * vec4Size, (void*)(3 * vec4Size)); glVertexAttribDivisor(3, 1); glVertexAttribDivisor(4, 1); glVertexAttribDivisor(5, 1); glVertexAttribDivisor(6, 1); glBindVertexArray(0); // 应该只是复原 }
注:这里将Mesh的VAO从私有变量改为了公有变量,让我们能够访问它的顶点数组对象。这并不是最好的解决方案,只是为了配合本小节的一个简单的改动。
-
再次使用网格的VAO,这一次使用
glDrawElementsInstanced进行绘制(注意和上一小节的实例绘制函数是不一样的):while循环中// draw meteorites asteroidShader.use(); asteroidShader.setInt("texture_diffuse1", 0); glActiveTexture(GL_TEXTURE0); glBindTexture(GL_TEXTURE_2D, rock.textures_loaded[0].id); // note: we also made the textures_loaded vector public (instead of private) from the model class. for (unsigned int i = 0; i < rock.meshes.size(); i++) { glBindVertexArray(rock.meshes[i].VAO); glDrawElementsInstanced(GL_TRIANGLES, static_cast<unsigned int>(rock.meshes[i].indices.size()), GL_UNSIGNED_INT, 0, amount); glBindVertexArray(0); }
注:这里,我们绘制与之前相同数量amount的小行星,但是使用的是实例渲染。结果应该是非常相似的,但如果你开始增加amount变量,你就能看见实例化渲染的效果了。没有实例化渲染的时候,我们只能流畅渲染1000到1500个小行星。而使用了实例化渲染之后,我们可以将这个值设置为100000,每个岩石模型有576个顶点,每帧加起来大概要绘制5700万个顶点,但性能却没有受到任何影响!
总结:在合适的环境下,实例化渲染能够大大增加显卡的渲染能力。正是出于这个原因,实例化渲染通常会用于渲染草、植被、粒子,以及上面这样的场景,基本上只要场景中有很多重复的形状,都能够使用实例化渲染来提高性能。总的源码地址。
原文地址。(还有其它抗锯齿的做法,可看书==《Real-Time Rendering 3rd》 提炼总结.pdf==)
要在OpenGL开启MSAA(多重采样抗锯齿),可以:
大多数的窗口系统都应该提供了一个多重采样缓冲,用以代替默认的颜色缓冲。GLFW同样给了我们这个功能,我们所要做的只是提示(Hint) GLFW,我们希望使用一个包含N个样本的多重采样缓冲。这可以在创建窗口之前调用glfwWindowHint来完成。
glfwWindowHint(GLFW_SAMPLES, 4);
现在再调用glfwCreateWindow创建渲染窗口时,每个屏幕坐标就会使用一个包含4个子采样点的颜色缓冲了。GLFW会自动创建一个每像素4个子采样点的深度和样本缓冲。这也意味着所有缓冲的大小都增长了4倍。
现在我们已经向GLFW请求了多重采样缓冲,我们还需要调用glEnable并启用GL_MULTISAMPLE,来启用多重采样。在大多数OpenGL的驱动上,多重采样都是默认启用的,所以这个调用可能会有点多余,但显式地调用一下会更保险一点。这样子不论是什么OpenGL的实现都能够正常启用多重采样了。
glEnable(GL_MULTISAMPLE);
多重采样的算法都在OpenGL驱动的光栅器中实现了,我们不需要再多做什么。
具体不再多写,为了方便检索,涉及到的API还有,
-
使用glTexImage2DMultisample来替代glTexImage2D,它的纹理目标是GL_TEXTURE_2D_MULTISAPLE。
glBindTexture(GL_TEXTURE_2D_MULTISAMPLE, tex); glTexImage2DMultisample(GL_TEXTURE_2D_MULTISAMPLE, samples, GL_RGB, width, height, GL_TRUE); glBindTexture(GL_TEXTURE_2D_MULTISAMPLE, 0); -
多重采样渲染缓冲对象:和纹理类似,创建一个多重采样渲染缓冲对象并不难。我们所要做的只是在指定(当前绑定的)渲染缓冲的内存存储时,将glRenderbufferStorage的调用改为glRenderbufferStorageMultisample就可以了
glRenderbufferStorageMultisample(GL_RENDERBUFFER, 4, GL_DEPTH24_STENCIL8, width, height);函数中,渲染缓冲对象后的参数我们将设定为样本的数量,在当前的例子中是4。
原文地址。
前面讲的都是冯氏光照,然后存在一点小问题,Blinn-Phong是另外一种算是一点改进的做法吧,然后主要是在片段着色器部分有一些对光照的处理,其它都一样(按B进行切换)
void main()
{
[...]
float spec = 0.0;
if(blinn)
{
vec3 halfwayDir = normalize(lightDir + viewDir);
spec = pow(max(dot(normal, halfwayDir), 0.0), 16.0);
}
else
{
vec3 reflectDir = reflect(-lightDir, normal);
spec = pow(max(dot(viewDir, reflectDir), 0.0), 8.0);
}注:但是源代码里没有地板的图片,然后换了其它的图片没运行起来,但感觉代码里的shader.setInt("texture1", 0);这句有问题,因为无论在片段着色器还是顶点着色器中都没有“texture1”这个uniform变量,改成对应的还是不行。
原文地址。伽玛校正。
简单理解:人类所感知的亮度恰好和CRT所显示出来相似的指数关系非常匹配。
Gamma校正(Gamma Correction)的思路是在最终的颜色输出上应用监视器Gamma的倒数。
来看另一个例子。还是那个暗红色(0.5,0.0,0.0)(0.5,0.0,0.0)。在将颜色显示到监视器之前,我们先对颜色应用Gamma校正曲线。线性的颜色显示在监视器上相当于降低了2.2次幂的亮度,所以倒数就是1/2.2次幂。Gamma校正后的暗红色就会成为(0.5,0.0,0.0)^1/2.2^=(0.5,0.0,0.0)^0.45^=(0.73,0.0,0.0)。校正后的颜色接着被发送给监视器,最终显示出来的颜色是(0.73,0.0,0.0)^2.2^=(0.5,0.0,0.0)。你会发现使用了Gamma校正,监视器最终会显示出我们在应用中设置的那种线性的颜色。
OpenGL中的两种场景应用gamma校正的方式:
-
使用OpenGL内建的sRGB帧缓冲,自己在像素着色器中进行gamma校正,sRGB这个颜色空间大致对应于gamma2.2
glEnable(GL_FRAMEBUFFER_SRGB); -
在每个相关像素着色器运行的最后应用gamma校正,所以在发送到帧缓冲前,颜色就被校正了
void main() { // do super fancy lighting [...] // apply gamma correction float gamma = 2.2; fragColor.rgb = pow(fragColor.rgb, vec3(1.0/gamma)); }
最后一行代码,将fragColor的每个颜色元素应用有一个1.0/gamma的幂运算,校正像素着色器的颜色输出。
这个更多的就没去深究了,看原文吧。
原文地址。
就是为了让砖这种平面看起来能凹凸不平,而不就是平的,更加真实。还涉及到的词==切线空间==,==TBN矩阵==。
每个fragment使用了自己的法线,我们就可以让光照相信一个表面由很多微小的(垂直于法线向量的)平面所组成,物体表面的细节将会得到极大提升。这种每个fragment使用各自的法线,替代一个面上所有fragment使用同一个法线的技术叫做==法线贴图(normal mapping)==或==凹凸贴图(bump mapping)==。更确切的说,法线贴图是凹凸贴图技术的一种应用。
原文地址。
视差贴图(Parallax Mapping)技术和法线贴图差不多,但它有着不同的原则。和法线贴图一样视差贴图能够极大提升表面细节,使之具有深度感。它也是利用了视错觉,然而对深度有着更好的表达,与法线贴图一起用能够产生难以置信的效果。视差贴图和光照无关,我在这里是作为法线贴图的技术延续来讨论它的。需要注意的是在开始学习视差贴图之前强烈建议先对法线贴图,特别是切线空间有较好的理解。
视差贴图属于位移贴图(Displacement Mapping)技术的一种,它对根据储存在纹理中的几何信息对顶点进行位移或偏移。一种实现的方式是比如有1000个顶点,根据纹理中的数据对平面特定区域的顶点的高度进行位移。这样的每个纹理像素包含了高度值纹理叫做高度贴图。
原文地址。
HDR(high dynamic range),简单来说在过亮时依然保持足够的细节。
还涉及到一些名词:==浮点帧缓冲==,一个帧缓冲的颜色缓冲的内部格式被设定成了GL_RGB16F, GL_RGBA16F, GL_RGB32F 或者GL_RGBA32F时,这些帧缓冲被叫做浮点帧缓冲(Floating Point Framebuffer),浮点帧缓冲可以存储超过0.0到1.0范围的浮点值,所以非常适合HDR渲染;
==色调映射==:色调映射(Tone Mapping)是一个损失很小的转换浮点颜色值至我们所需的LDR[0.0, 1.0]范围内的过程,通常会伴有特定的风格的色平衡(Stylistic Color Balance)。
原文地址。
简单来说就是给发光的光源添加一个光晕,过程是提取亮色、高斯模糊、再把两个纹理混合。
原文地址。
一些名词:正向渲染(Forward Rendering)或者正向着色法(Forward Shading);
延迟着色法(Deferred Shading),或者说是延迟渲染(Deferred Rendering)
**G缓冲(G-buffer)**是对所有用来储存光照相关的数据,并在最后的光照处理阶段中使用的所有纹理的总称。
原文地址。==屏幕空间环境光遮蔽(Screen-Space Ambient Occlusion, SSAO)==
简单来说,效果就是让拐角、角落、褶皱处更暗一些,不是都那么亮,更加真实。
PBR,或者用更通俗一些的称呼是指基于物理的渲染(Physically Based Rendering),它指的是一些在不同程度上都基于与现实世界的物理原理更相符的基本理论所构成的渲染技术的集合
原文地址:里面有更多的详细的使用,以后需要debug时再来深入。
使用==glGetError()==获取错误:GLenum glGetError();
当glGetError被调用时,它要么会返回错误标记之一,要么返回无错误。glGetError会返回的错误值如下:
| 标记 | 代号 | 描述 |
|---|---|---|
| GL_NO_ERROR | 0 | 自上次调用glGetError以来没有错误 |
| GL_INVALID_ENUM | 1280 | 枚举参数不合法 |
| GL_INVALID_VALUE | 1281 | 值参数不合法 |
| GL_INVALID_OPERATION | 1282 | 一个指令的状态对指令的参数不合法 |
| GL_STACK_OVERFLOW | 1283 | 压栈操作造成栈上溢(Overflow) |
| GL_STACK_UNDERFLOW | 1284 | 弹栈操作时栈在最低点(译注:即栈下溢(Underflow)) |
| GL_OUT_OF_MEMORY | 1285 | 内存调用操作无法调用(足够的)内存 |
| GL_INVALID_FRAMEBUFFER_OPERATION | 1286 | 读取或写入一个不完整的帧缓冲 |
写一个助手函数来简便地打印出错误字符串以及错误检测函数调用的位置:(注意这种写法)
GLenum glCheckError_(const char *file, int line) {
GLenum errorCode;
while ((errorCode = glGetError()) != GL_NO_ERROR) {
std::string error;
switch (errorCode) {
case GL_INVALID_ENUM: error = "INVALID_ENUM"; break;
case GL_INVALID_VALUE: error = "INVALID_VALUE"; break;
case GL_INVALID_OPERATION: error = "INVALID_OPERATION"; break;
case GL_STACK_OVERFLOW: error = "STACK_OVERFLOW"; break;
case GL_STACK_UNDERFLOW: error = "STACK_UNDERFLOW"; break;
case GL_OUT_OF_MEMORY: error = "OUT_OF_MEMORY"; break;
case GL_INVALID_FRAMEBUFFER_OPERATION: error = "INVALID_FRAMEBUFFER_OPERATION"; break;
}
std::cout << error << " | " << file << " (" << line << ")" << std::endl;
}
return errorCode;
}
#define glCheckError() glCheckError_(__FILE__, __LINE__) 注:__FILE__和__LINE__是两个预处理指令。
GLSL参考编译器、调试着色器输出等。在原文中是有的。
还有外部调试工具:(原文中有)
- gDebugger:是一个非常易用的跨平台OpenGL程序调试工具;
- RenderDoc:是另外一个很棒的(完全开源的)独立调试工具;
- CodeXL:是由AMD开发的一款GPU调试工具,它有独立版本也有Visual Studio插件版本。CodeXL可以给你非常多的信息,对于图形程序的性能测试也非常有用。CodeXL在NVidia与Intel的显卡上也能运行,不过会不支持OpenCL调试;
- NVIDIA Nsight:NVIDIA流行的Nsight GPU调试工具并不是一个独立程序,而是一个Visual Studio IDE或者Eclipse IDE的插件。Nsight插件对图形开发者来说非常容易使用,因为它给出了GPU用量,逐帧GPU状态大量运行时的统计数据。(如果是N卡,强烈建议使用)
用到时一定看原文,图文并茂很详细的。原文链接。
- 实战中的字体下载网站。
用了两个库:
-
FreeType:是一个能够用于加载字体并将他们渲染到位图以及提供多种字体相关的操作的跨平台软件开发库。FreeType可以在他们的官方网站中下载到,然后用cmake编译,然后设置好路径,freetype.lib添加到项目的链接库中,然后确认包含的头文件:
#include <ft2build.h> #include FT_FREETYPE_H // FT_FREETYPE_H 是库自己定义的宏,也是一个头文件路径
-
glew:官网下载它的binaries,直接使用,它的lib里有glew32.lib、glew32s.lib,使用glew32s.lib(有s代表静态库,不带s就还需要glew32.dll)(尽量不用)(linux中直接源码编译就是非常简单,它的README写得相当清楚) 注意:导入头文件时,要注意顺序,以及所有涉及到自己写的.h头文件(比如自己写的shader.h),都把里面的 #include <glad/glad.h> 给删除掉,不然会报头文件错误
xxxxxxxxxx9 1// GLEW 注意这导入的写法2#define GLEW_STATIC3#include <GL/glew.h>4// GLFW 这不再要 #include <glad/glad.h>5#include <GLFW/glfw3.h>67 // Initialize GLEW to setup the OpenGL Function pointers8 glewExperimental = GL_TRUE;9 glewInit();
glew、glad、glut、glfw 的一句话介绍 glew:是对底层 OpenGL 接口的封装,可以让你的代码跨平台 glad:和 glew 作用相同,glew 的升级版(更新说明:==尽量都用glad,用了glad就不要用glew了,会有冲突==) glut:处理 OpenGL 程式的工具库,负责处理和底层操作系统的呼叫以及I/O glfw:glut 的升级版
一、开始字体相关:
-
初始化FreeType库,加载一个TrueType字体文件arial.ttf:
FT_Library ft; if (FT_Init_FreeType(&ft)) std::cout << "ERROR::FREETYPE: Could not init FreeType Library" << std::endl; FT_Face face; if (FT_New_Face(ft, "fonts/arial.ttf", 0, &face)) std::cout << "ERROR::FREETYPE: Failed to load font" << std::endl;
注:这些FreeType函数在出现错误时将返回一个非零的整数值。
-
定义字体大小:
FT_Set_Pixel_Sizes(face, 0, 48);
注:48是字体高度,宽度值设为0表示要从字体面通过给定的高度中动态计算出字形的宽度。
-
一个FreeType面中包含了一个字形的集合。我们可以调用FT_Load_Char函数来将其中一个字形设置为激活字形:
if (FT_Load_Char(face, 'X', FT_LOAD_RENDER)) std::cout << "ERROR::FREETYTPE: Failed to load Glyph" << std::endl;
注:通过将FT_LOAD_RENDER设为加载标记之一,我们告诉FreeType去创建一个8位的灰度位图,我们可以通过
face->glyph->bitmap来访问这个位图。 -
定义一个非常方便的结构体,并将这些结构体存储在一个map中:
struct Character { GLuint TextureID; // 字形纹理的ID glm::ivec2 Size; // 字形大小 glm::ivec2 Bearing; // 从基准线到字形左部/顶部的偏移值 GLuint Advance; // 原点距下一个字形原点的距离 }; std::map<GLchar, Character> Characters;
注:有些度量值精确定义了摆放字形所需的每个字形距离基准线的偏移量,每个字形的大小,以及需要预留多少空间来渲染下一个字形(具体图片示意看原文链接,更好理解下标的描述)
属性 获取方式 生成位图描述 width face->glyph->bitmap.width 位图宽度(像素) height face->glyph->bitmap.rows 位图高度(像素) bearingX face->glyph->bitmap_left 水平距离,即位图相对于原点的水平位置(像素) beraingY face->glyph->bitmap_top 垂直距离,即位图相对于基准线的垂直位置(像素) advance face->glyph->advance.x 水平预留值,即原点到下一个字形原点的水平距离(单位:1/64像素) -
glPixelStorei(GL_UNPACK_ALIGNMENT, 1); //禁用字节对齐限制
-
清理FreeType的资源:
FT_Done_Face(face); FT_Done_FreeType(ft);
二、着色器
-
顶点着色器:
#version 330 core layout (location = 0) in vec4 vertex; // <vec2 pos, vec2 tex> out vec2 TexCoords; uniform mat4 projection; void main() { gl_Position = projection * vec4(vertex.xy, 0.0, 1.0); TexCoords = vertex.zw; }
-
片段着色器:将位置和纹理纹理坐标的数据合起来存在一个vec4中。这个顶点着色器将位置坐标与一个投影矩阵相乘,并将纹理坐标传递给片段着色器
#version 330 core in vec2 TexCoords; out vec4 color; uniform sampler2D text; uniform vec3 textColor; void main() { vec4 sampled = vec4(1.0, 1.0, 1.0, texture(text, TexCoords).r); color = vec4(textColor, 1.0) * sampled; }
注:片段着色器有两个uniform变量:一个是单颜色通道的字形位图纹理,另一个是颜色uniform,它可以用来调整文本的最终颜色。我们首先从位图纹理中采样颜色值,由于纹理数据中仅存储着红色分量,我们就采样纹理的==r==分量来作为取样的alpha值。通过变换颜色的alpha值,最终的颜色在字形背景颜色上会是透明的,而在真正的字符像素上是不透明的。我们也将RGB颜色与textColor这个uniform相乘,来变换文本颜色。当然我们需要启用[混合](https://learnopengl-cn.github.io/04 Advanced OpenGL/03 Blending/)才能让这一切行之有效:
glEnable(GL_BLEND); glBlendFunc(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA);
-
对于投影矩阵,我们将使用一个正射投影矩阵(Orthographic Projection Matrix)。对于文本渲染我们(通常)都不需要透视,使用正射投影同样允许我们在屏幕坐标系中设定所有的顶点坐标:
glm::mat4 projection = glm::ortho(0.0f, 800.0f, 0.0f, 600.0f);
注:置投影矩阵的底部参数为
0.0f,并将顶部参数设置为窗口的高度。这样做的结果是我们指定了y坐标的范围为屏幕底部(0.0f)至屏幕顶部(600.0f)。这意味着现在点(0.0, 0.0)对应左下角(译注:而不再是窗口正中间)
三、定义一个RenderText函数渲染一个字符串:
void RenderText(Shader &s, std::string text, GLfloat x, GLfloat y, GLfloat scale, glm::vec3 color) {
// 激活对应的渲染状态
s.use();
glUniform3f(glGetUniformLocation(s.Program, "textColor"), color.x, color.y, color.z);
glActiveTexture(GL_TEXTURE0);
glBindVertexArray(VAO);
// 遍历文本中所有的字符
std::string::const_iterator c;
for (c = text.begin(); c != text.end(); c++) {
Character ch = Characters[*c];
GLfloat xpos = x + ch.Bearing.x * scale;
// 这行代码要注意怎么算的,原文中有讲解。
GLfloat ypos = y - (ch.Size.y - ch.Bearing.y) * scale;
GLfloat w = ch.Size.x * scale;
GLfloat h = ch.Size.y * scale;
// 对每个字符更新VBO
GLfloat vertices[6][4] = {
{ xpos, ypos + h, 0.0, 0.0 },
{ xpos, ypos, 0.0, 1.0 },
{ xpos + w, ypos, 1.0, 1.0 },
{ xpos, ypos + h, 0.0, 0.0 },
{ xpos + w, ypos, 1.0, 1.0 },
{ xpos + w, ypos + h, 1.0, 0.0 }
};
// 在四边形上绘制字形纹理
glBindTexture(GL_TEXTURE_2D, ch.textureID);
// 更新VBO内存的内容
glBindBuffer(GL_ARRAY_BUFFER, VBO);
// be sure to use glBufferSubData and not glBufferData
glBufferSubData(GL_ARRAY_BUFFER, 0, sizeof(vertices), vertices);
glBindBuffer(GL_ARRAY_BUFFER, 0);
// 绘制四边形
glDrawArrays(GL_TRIANGLES, 0, 6);
// 更新位置到下一个字形的原点,注意单位是1/64像素
x += (ch.Advance >> 6) * scale; // 位偏移6个单位来获取单位为像素的值 (2^6 = 64)
}
glBindVertexArray(0);
glBindTexture(GL_TEXTURE_2D, 0);
}最后:整个总的源代码。(可以试着去关闭掉混合那几行代码,看看效果)
说明:OpenGL不提供关于音频的任何支持。我们不得不手动将音频加载为字节格式,处理并将其转化为音频流,并适当地管理多个音频流以供我们的游戏使用,可以手动加载来自多种扩展名的音频文件的音频流。然而,我们将使用被称为irrKlang的音频管理库。
- IrrKlang是一个可以播放WAV,MP3,OGG和FLAC文件的高级二维和三维(Windows,Mac OS X,Linux)声音引擎和音频库。它还有一些可以自由调整的音频效果,如混响、延迟和失真。 3D音频意味着音频源可以有一个3D位置,然后根据相机到音频源的位置衰减音量,使其在一个3D世界里显得自然(想想3D世界中的枪声,通常你可以从音效中听出它来自什么方向/位置)。
- irrKlang有一个有一定限制的证书:允许你将irrKlang用于非商业目的,但是如果你想使用irrKlang商业版,就必须支付购买他们的专业版。
使用说明:
- 需要引入了irrKlang的头文件,将他们的库文件(irrKlang.lib)添加到链接器设置中;
- 将他们的dll文件(irrKlang.dll)复制到适当的目录下(通常和.exe在同一目录下),或者将其所在的bin目录添加到环境变量中;
- 需要注意的是,如果==想要加载MP3文件,则还需要引入ikpMP3.dll文件==。