From ff9c9da0156ab810039b4df48d130da730f57d61 Mon Sep 17 00:00:00 2001
From: Daoyuan Chen <67475544+yxdyc@users.noreply.github.com>
Date: Fri, 26 Jul 2024 16:06:47 +0800
Subject: [PATCH] update docs according to recently refactor and events (#366)
* update docs according to recently refactor and events
* update docs according to recently refactor and events
* update docs according to recently refactor and events
* minor fix according to yilun's comment
---
README.md | 59 +++++++++++++++++++++++++++++++++++++--
README_ZH.md | 43 +++++++++++++++++++++++++---
docs/DJ_SORA.md | 19 ++++++++-----
docs/DJ_SORA_ZH.md | 24 +++++++++-------
docs/DeveloperGuide.md | 8 ++++--
docs/DeveloperGuide_ZH.md | 8 ++++--
docs/Operators.md | 2 +-
docs/Operators_ZH.md | 2 +-
docs/awesome_llm_data.md | 2 +-
9 files changed, 134 insertions(+), 33 deletions(-)
diff --git a/README.md b/README.md
index 1b5c5131d..3e747e7c6 100644
--- a/README.md
+++ b/README.md
@@ -37,6 +37,7 @@ We welcome you to join us (via issues, PRs, [Slack](https://join.slack.com/t/dat
----
## News
+-  [2024-07-24] "Tianchi Better Synth Data Synthesis Competition for Multimodal Large Models" — Our 4th data-centric LLM competition has kicked off! Please visit the competition's [official website](https://tianchi.aliyun.com/competition/entrance/532251) for more information.
-  [2024-07-17] We utilized the Data-Juicer [Sandbox Laboratory Suite](https://github.com/modelscope/data-juicer/blob/main/docs/Sandbox.md) to systematically optimize data and models through an co-development workflow between data and models, achieving a new top spot on the [VBench](https://huggingface.co/spaces/Vchitect/VBench_Leaderboard) text-to-video leaderboard. The related achievements have been compiled and published in a [paper](http://arxiv.org/abs/2407.11784), and the model has been released on the [ModelScope](https://modelscope.cn/models/Data-Juicer/Data-Juicer-T2V) and [HuggingFace](https://huggingface.co/datajuicer/Data-Juicer-T2V) platforms.
-  [2024-07-12] Our *awesome list of MLLM-Data* has evolved into a systemic [survey](https://arxiv.org/abs/2407.08583) from model-data co-development perspective. Welcome to [explore](docs/awesome_llm_data.md) and contribute!
-  [2024-06-01] ModelScope-Sora "Data Directors" creative sprint—Our third data-centric LLM competition has kicked off! Please visit the competition's [official website](https://tianchi.aliyun.com/competition/entrance/532219) for more information.
@@ -96,8 +97,8 @@ Table of Contents
visualization, and multidimensional automatic evaluation, so that you can better understand and improve your data and models.
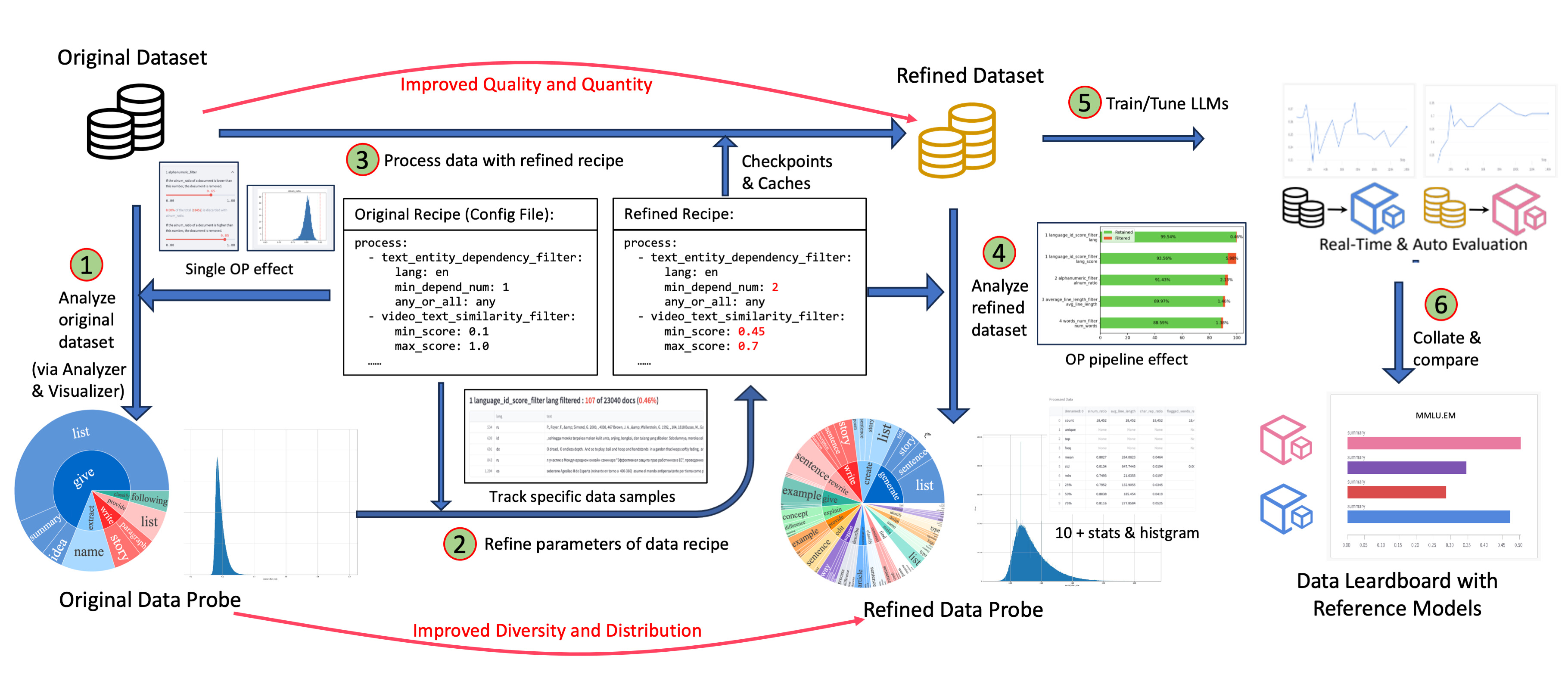
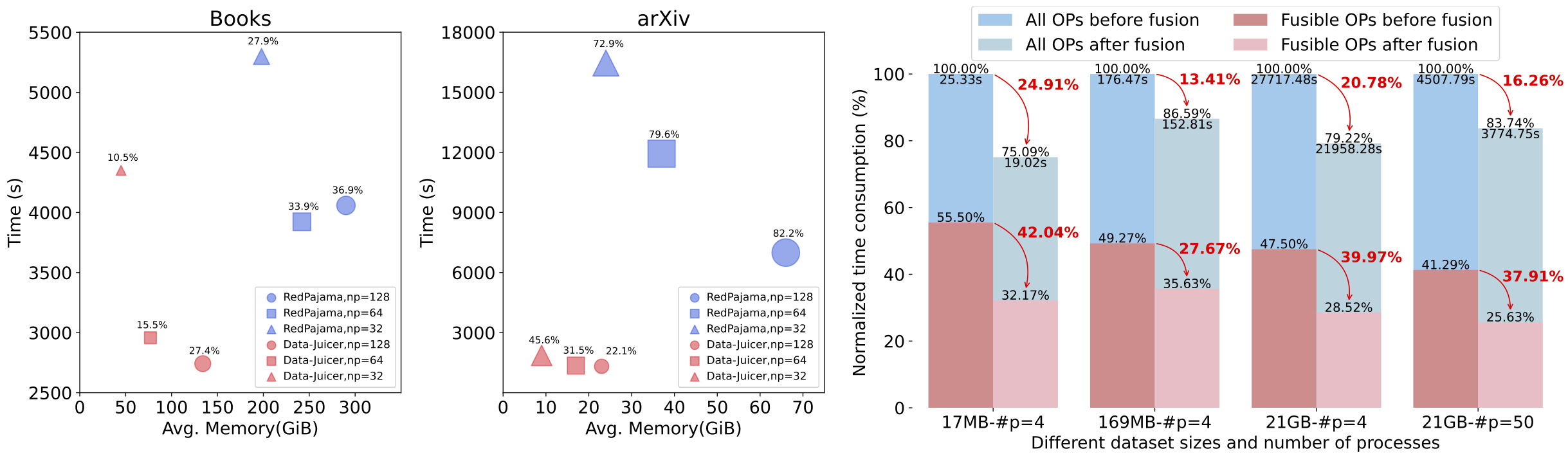
-- **Enhanced Efficiency**: Providing efficient and parallel data processing pipelines (Aliyun-PAI\Ray\Slurm\CUDA\OP Fusion)
- requiring less memory and CPU usage, optimized for maximum productivity.
+- **Towards production environment **: Providing efficient and parallel data processing pipelines (Aliyun-PAI\Ray\Slurm\CUDA\OP Fusion)
+ requiring less memory and CPU usage, optimized with automatic fault-toleration.
- **Comprehensive Data Processing Recipes**: Offering tens of [pre-built data
@@ -154,7 +155,7 @@ Table of Contents
## Installation
-### From Source
+### From Source
- Run the following commands to install the latest basic `data_juicer` version in
editable mode:
@@ -229,6 +230,15 @@ You can install FFmpeg using package managers(e.g. sudo apt install ffmpeg on De
Check if your environment path is set correctly by running the ffmpeg command from the terminal.
+
+
+
+
+[🔼 back to index](#documentation-index-)
+
+
+
+
## Quick Start
@@ -259,6 +269,20 @@ export DATA_JUICER_MODELS_CACHE="/path/to/another/directory/models"
export DATA_JUICER_ASSETS_CACHE="/path/to/another/directory/assets"
```
+#### Flexible Programming Interface
+We provide various simple interfaces for users to choose from as follows.
+```python
+#... init op & dataset ...
+
+# Chain call style, support single operator or operator list
+dataset = dataset.process(op)
+dataset = dataset.process([op1, op2])
+# Functional programming style for quick integration or script prototype iteration
+dataset = op(dataset)
+dataset = op.run(dataset)
+```
+
+
### Distributed Data Processing
We have now implemented multi-machine distributed data processing based on [RAY](https://www.ray.io/). The corresponding demos can be run using the following commands:
@@ -376,6 +400,14 @@ docker run -dit \ # run the container in the background
docker exec -it bash
```
+
+
+
+
+[🔼 back to index](#documentation-index-)
+
+
+
## Data Recipes
- [Recipes for data process in BLOOM](configs/reproduced_bloom/README.md)
- [Recipes for data process in RedPajama](configs/redpajama/README.md)
@@ -417,3 +449,24 @@ If you find our work useful for your research or development, please kindly cite
year={2024}
}
```
+
+
+ More related papers from Data-Juicer Team:
+
>
+
+- [Data-Juicer Sandbox: A Comprehensive Suite for Multimodal Data-Model Co-development](https://arxiv.org/abs/2407.11784)
+
+- [The Synergy between Data and Multi-Modal Large Language Models: A Survey from Co-Development Perspective](https://arxiv.org/abs/2407.08583)
+
+- [Data Mixing Made Efficient: A Bivariate Scaling Law for Language Model Pretraining](https://arxiv.org/abs/2402.11505)
+
+
+
+
+
+
+
+
+[🔼 back to index](#documentation-index-)
+
+
diff --git a/README_ZH.md b/README_ZH.md
index c8b1a4886..4b9880ce6 100644
--- a/README_ZH.md
+++ b/README_ZH.md
@@ -31,6 +31,7 @@ Data-Juicer正在积极更新和维护中,我们将定期强化和新增更多
----
## 新消息
+-  [2024-07-24] “天池 Better Synth 多模态大模型数据合成赛”——第四届Data-Juicer大模型数据挑战赛已经正式启动!立即访问[竞赛官网](https://tianchi.aliyun.com/competition/entrance/532251),了解赛事详情。
- [2024-07-17] 我们利用Data-Juicer[沙盒实验室套件](https://github.com/modelscope/data-juicer/blob/main/docs/Sandbox-ZH.md),通过数据与模型间的系统性研发工作流,调优数据和模型,在[VBench](https://huggingface.co/spaces/Vchitect/VBench_Leaderboard)文生视频排行榜取得了新的榜首。相关成果已经整理发表在[论文](http://arxiv.org/abs/2407.11784)中,并且模型已在[ModelScope](https://modelscope.cn/models/Data-Juicer/Data-Juicer-T2V)和[HuggingFace](https://huggingface.co/datajuicer/Data-Juicer-T2V)平台发布。
- [2024-07-12] 我们的MLLM-Data精选列表已经演化为一个模型-数据协同开发的角度系统性[综述](https://arxiv.org/abs/2407.08583)。欢迎[浏览](docs/awesome_llm_data.md)或参与贡献!
-  [2024-06-01] ModelScope-Sora“数据导演”创意竞速——第三届Data-Juicer大模型数据挑战赛已经正式启动!立即访问[竞赛官网](https://tianchi.aliyun.com/competition/entrance/532219),了解赛事详情。
@@ -82,7 +83,7 @@ Data-Juicer正在积极更新和维护中,我们将定期强化和新增更多
* **数据反馈回路 & 沙盒实验室**:支持一站式数据-模型协同开发,通过[沙盒实验室](docs/Sandbox-ZH.md)快速迭代,基于数据和模型反馈回路、可视化和多维度自动评估等功能,使您更了解和改进您的数据和模型。 
-* **效率增强**:提供高效并行化的数据处理流水线(Aliyun-PAI\Ray\Slurm\CUDA\算子融合),减少内存占用和CPU开销,提高生产力。 
+* **面向生产环境**:提供高效并行化的数据处理流水线(Aliyun-PAI\Ray\Slurm\CUDA\算子融合),减少内存占用和CPU开销,支持自动化处理容错。 
* **全面的数据处理菜谱**:为pre-training、fine-tuning、中英文等场景提供数十种[预构建的数据处理菜谱](configs/data_juicer_recipes/README_ZH.md)。 在LLaMA、LLaVA等模型上有效验证。 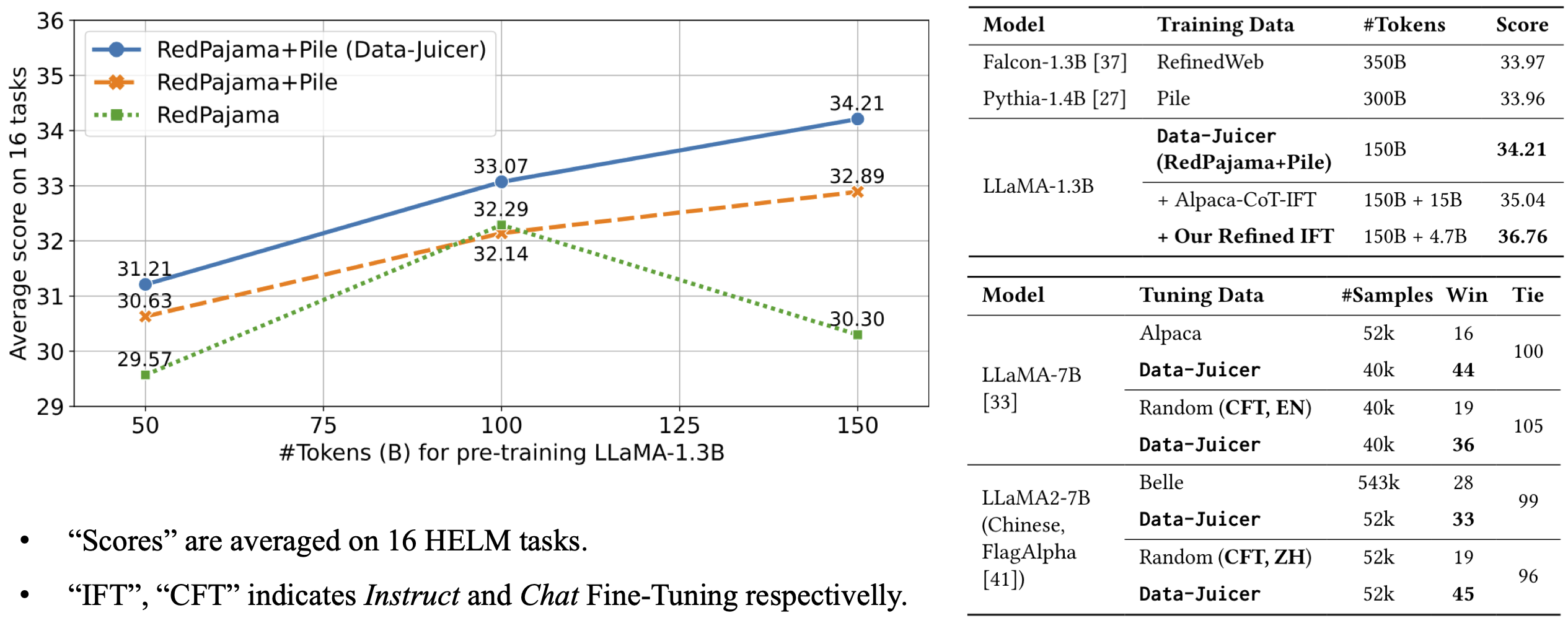
@@ -235,6 +236,19 @@ export DATA_JUICER_MODELS_CACHE="/path/to/another/directory/models"
export DATA_JUICER_ASSETS_CACHE="/path/to/another/directory/assets"
```
+#### 灵活的编程接口
+我们提供了各种层次的简单编程接口,以供用户选择:
+```python
+# ... init op & dataset ...
+
+# 链式调用风格,支持单算子或算子列表
+dataset = dataset.process(op)
+dataset = dataset.process([op1, op2])
+# 函数式编程风格,方便快速集成或脚本原型迭代
+dataset = op(dataset)
+dataset = op.run(dataset)
+```
+
### 分布式数据处理
Data-Juicer 现在基于[RAY](https://www.ray.io/)实现了多机分布式数据处理。
@@ -278,6 +292,9 @@ dj-analyze --config configs/demo/analyzer.yaml
streamlit run app.py
```
+
+
+
### 构建配置文件
* 配置文件包含一系列全局参数和用于数据处理的算子列表。您需要设置:
@@ -380,8 +397,6 @@ Data-Juicer 被各种 LLM产品和研究工作使用,包括来自阿里云-通
Data-Juicer 感谢并参考了社区开源项目:
[Huggingface-Datasets](https://github.com/huggingface/datasets), [Bloom](https://huggingface.co/bigscience/bloom), [RedPajama](https://github.com/togethercomputer/RedPajama-Data/tree/rp_v1), [Pile](https://huggingface.co/datasets/EleutherAI/pile), [Alpaca-Cot](https://huggingface.co/datasets/QingyiSi/Alpaca-CoT), [Megatron-LM](https://github.com/NVIDIA/Megatron-LM), [DeepSpeed](https://www.deepspeed.ai/), [Arrow](https://github.com/apache/arrow), [Ray](https://github.com/ray-project/ray), [Beam](https://github.com/apache/beam), [LM-Harness](https://github.com/EleutherAI/lm-evaluation-harness), [HELM](https://github.com/stanford-crfm/helm), ....
-
-
## 参考文献
如果您发现我们的工作对您的研发有帮助,请引用以下[论文](https://arxiv.org/abs/2309.02033) 。
@@ -392,4 +407,24 @@ Data-Juicer 感谢并参考了社区开源项目:
booktitle={International Conference on Management of Data},
year={2024}
}
-```
\ No newline at end of file
+```
+
+更多Data-Juicer团队相关论文:
+
>
+
+- [Data-Juicer Sandbox: A Comprehensive Suite for Multimodal Data-Model Co-development](https://arxiv.org/abs/2407.11784)
+
+- [The Synergy between Data and Multi-Modal Large Language Models: A Survey from Co-Development Perspective](https://arxiv.org/abs/2407.08583)
+
+- [Data Mixing Made Efficient: A Bivariate Scaling Law for Language Model Pretraining](https://arxiv.org/abs/2402.11505)
+
+
+
+
+
+
+
+
+[🔼 back to index](#documentation-index-a-namedocuments)
+
+
diff --git a/docs/DJ_SORA.md b/docs/DJ_SORA.md
index 4a228683b..2e5139b75 100644
--- a/docs/DJ_SORA.md
+++ b/docs/DJ_SORA.md
@@ -38,7 +38,8 @@ This project is being actively updated and maintained. We eagerly invite you to
- [✅] Ray based multi-machine distributed running
- [✅] Aliyun PAI-DLC & Slurm based multi-machine distributed running
- [✅] Distributed scheduling optimization (OP-aware, automated load balancing) --> Aliyun PAI-DLC
-- [ ] [WIP] Distributed storage optimization
+- [WIP] Low precision acceleration support for video related operators. (git tags: dj_op, dj_efficiency)
+- [WIP] SOTA model enhancement of existing video related operators. (git tags: dj_op, dj_sota_models)
## Basic Operators (video spatio-temporal dimension)
- Towards Data Quality
@@ -90,20 +91,24 @@ This project is being actively updated and maintained. We eagerly invite you to
- [✅] **Youku-mPLUG-CN**: 36TB video-caption data: `{}`
- [✅] **InternVid**: 234M data sample: `{}`
- [✅] **MSR-VTT**: 10K video-caption data: `{}`
- - [ ] [WIP] ModelScope's datasets integration
- - [ ] VideoInstruct-100K, Panda70M, ......
+ - [✅] ModelScope's datasets integration
+ - [✅] VideoInstruct-100K, Panda70M, ......
- [ ] Large-scale high-quality DJ-SORA dataset
- [✅] (Data sandbox) Building and optimizing multimodal data recipes with DJ-video operators (which are also being continuously extended and improved).
- - [ ] [WIP] Continuous expansion of data sources: open-datasets, Youku, web, ...
- - [ ] [WIP] Large-scale analysis, cleaning, and generation of high-quality multimodal datasets based on DJ recipes (OpenVideos, ...)
- - [ ] [WIP] Large-scale generation of 3DPatch datasets based on DJ recipes.
+ - [✅] Continuous expansion of data sources: open-datasets, Youku, web, ...
+ - [ ] Large-scale analysis, cleaning, and generation of high-quality multimodal datasets based on DJ recipes (OpenVideos, ...)
+ - [WIP] broad scenarios, high-dynamic
- ...
## DJ-SORA Data Validation and Model Training
- - [ ] [WIP] (DJ-Bench101) Exploring and refining the collaborative development of multimodal data and model, establishing benchmarks and insights.
+ - [ ] Exploring and refining the collaborative development of multimodal data and model, establishing benchmarks and insights. [paper](https://arxiv.org/abs/2407.11784)
- [ ] [WIP] Integration of SORA-like model training pipelines
- [EasyAnimate](https://github.com/aigc-apps/EasyAnimate)
+ - [✅] [T2V](https://t2v-turbo.github.io/)
+ - [✅] [V-Bench](https://vchitect.github.io/VBench-project/)
- ...
- [✅] (Model-Data sandbox) With relatively small models and the DJ-SORA dataset, exploring low-cost, transferable, and instructive data-model co-design, configurations and checkpoints.
- [ ] [WIP] Training SORA-like models with DJ-SORA data on larger scales and in more scenarios to improve model performance.
+ - [✅] Data-Juicer-T2v, [V-Bench Top1 model](https://huggingface.co/datajuicer/Data-Juicer-T2V)
+ - ...
- ...
diff --git a/docs/DJ_SORA_ZH.md b/docs/DJ_SORA_ZH.md
index 8e5dda301..9afe4e1bc 100644
--- a/docs/DJ_SORA_ZH.md
+++ b/docs/DJ_SORA_ZH.md
@@ -38,7 +38,8 @@ DJ-SORA将基于Data-Juicer(包含上百个专用的视频、图像、音频、
- [✅] Ray多机分布式
- [✅] 基于阿里云PAI-DLC和Slurm的多机分布式
- [✅] 分布式调度优化(OP-aware、自动化负载均衡)--> Aliyun PAI-DLC
-- [ ] [WIP] 分布式存储优化
+- [WIP] 视频相关算子的低精度加速支持, git tags: dj_op, dj_efficiency
+- [WIP] 现有视频相关算子的SOTA模型增强, git tags: dj_op, dj_sota_models
## 基础算子(视频时空维度)
- 面向数据质量
@@ -94,22 +95,25 @@ DJ-SORA将基于Data-Juicer(包含上百个专用的视频、图像、音频、
- [✅] **Youku-mPLUG-CN**: 36TB video-caption data:`{}`
- [✅] **InternVid**: 234M data sample:`{}`
- [✅] **MSR-VTT**: 10K video-caption data:`{}`
- - [ ] [WIP] ModelScope数据集集成
- - [ ] VideoInstruct-100K, Panda70M, ......
+ - [✅] ModelScope数据集集成
+ - [✅] VideoInstruct-100K, Panda70M, ......
- [ ] 大规模高质量DJ-SORA数据集
- [✅] (Data sandbox) 基于DJ-video算子构建和优化多模态数据菜谱 (算子同期持续完善)
- - [ ] [WIP] 数据源持续扩充:open-datasets, youku, web, ...
- - [ ] [WIP] 基于DJ菜谱规模化分析、清洗、生成高质量多模态数据集 (OpenVideo, ...)
- - [ ] [WIP] 基于DJ菜谱形成大规模3DPatch数仓
+ - [✅] 数据源持续扩充:open-datasets, youku, web, ...
+ - [ ] 基于DJ菜谱规模化分析、清洗、生成高质量多模态数据集
+ - [WIP] 多场景、高动态
- ...
## DJ-SORA数据验证及模型训练
- - [ ] [WIP] (DJ-Bench101) 探索及完善多模态数据和模型的协同开发,形成benchmark和insights
- - [ ] [WIP] 类SORA模型训练pipeline集成
- - [EasyAnimate](https://github.com/aigc-apps/EasyAnimate)
+ - [✅] 探索及完善多模态数据和模型的协同开发,形成benchmark和insights: [paper](https://arxiv.org/abs/2407.11784)
+ - [] [WIP] 类SORA模型训练pipeline集成
+ - [✅] [EasyAnimate](https://github.com/aigc-apps/EasyAnimate)
+ - [✅] [T2V](https://t2v-turbo.github.io/)
+ - [✅] [V-Bench](https://vchitect.github.io/VBench-project/)
- ...
- [✅] (Model-Data sandbox) 在相对小的模型和DJ-SORA数据集上,探索形成低开销、可迁移、有指导性的data-model co-design、配置及检查点
- [ ] [WIP] 更大规模、更多场景使用DJ-SORA数据训练类SORA模型,提高模型性能
- - ...
+ - [✅] Data-Juicer-T2v, [V-Bench Top1 model](https://huggingface.co/datajuicer/Data-Juicer-T2V)
+ - ...
diff --git a/docs/DeveloperGuide.md b/docs/DeveloperGuide.md
index 7940ed0c0..4bc80d1ae 100644
--- a/docs/DeveloperGuide.md
+++ b/docs/DeveloperGuide.md
@@ -11,7 +11,7 @@
## Coding Style
We define our styles in `.pre-commit-config.yaml`. Before committing,
-please install `pre-commit` tool to check and modify accordingly:
+please install `pre-commit` tool to automatically check and modify accordingly:
```shell
# ===========install pre-commit tool===========
@@ -104,20 +104,22 @@ class StatsKeys(object):
return False
```
- - If Hugging Face models are used within an operator, you might want to leverage GPU acceleration. To achieve this, declare `self._accelerator = 'cuda'` in the constructor, and ensure that `compute_stats` and `process` methods accept an additional positional argument `rank`.
+ - If Hugging Face models are used within an operator, you might want to leverage GPU acceleration. To achieve this, declare `_accelerator = 'cuda'` in the constructor, and ensure that `compute_stats` and `process` methods accept an additional positional argument `rank`.
```python
# ... (same as above)
@OPERATORS.register_module('text_length_filter')
class TextLengthFilter(Filter):
+
+ _accelerator = 'cuda'
+
def __init__(self,
min_len: PositiveInt = 10,
max_len: PositiveInt = sys.maxsize,
*args,
**kwargs):
# ... (same as above)
- self._accelerator = 'cuda'
def compute_stats(self, sample, rank=None):
# ... (same as above)
diff --git a/docs/DeveloperGuide_ZH.md b/docs/DeveloperGuide_ZH.md
index 9ec85a5ce..b3e424452 100644
--- a/docs/DeveloperGuide_ZH.md
+++ b/docs/DeveloperGuide_ZH.md
@@ -10,7 +10,7 @@
## 编码规范
-我们将编码规范定义在 `.pre-commit-config.yaml` 中。在向仓库贡献代码之前,请使用 `pre-commit` 工具对代码进行规范化。
+我们将编码规范定义在 `.pre-commit-config.yaml` 中。在向仓库贡献代码之前,请使用 `pre-commit` 工具对代码进行自动规范化。
```shell
# ===========install pre-commit tool===========
@@ -99,20 +99,22 @@ class StatsKeys(object):
return False
```
- - 如果在算子中使用了 Hugging Face 模型,您可能希望利用 GPU 加速。为了实现这一点,请在构造函数中声明 `self._accelerator = 'cuda'`,并确保 `compute_stats` 和 `process` 方法接受一个额外的位置参数 `rank`。
+ - 如果在算子中使用了 Hugging Face 模型,您可能希望利用 GPU 加速。为了实现这一点,请在构造函数中声明 `_accelerator = 'cuda'`,并确保 `compute_stats` 和 `process` 方法接受一个额外的位置参数 `rank`。
```python
# ... (same as above)
@OPERATORS.register_module('text_length_filter')
class TextLengthFilter(Filter):
+
+ _accelerator = 'cuda'
+
def __init__(self,
min_len: PositiveInt = 10,
max_len: PositiveInt = sys.maxsize,
*args,
**kwargs):
# ... (same as above)
- self._accelerator = 'cuda'
def compute_stats(self, sample, rank=None):
# ... (same as above)
diff --git a/docs/Operators.md b/docs/Operators.md
index 045bfd92c..6bc3599ba 100644
--- a/docs/Operators.md
+++ b/docs/Operators.md
@@ -2,7 +2,7 @@
Operators are a collection of basic processes that assist in data modification, cleaning, filtering, deduplication, etc. We support a wide range of data sources and file formats, and allow for flexible extension to custom datasets.
-This page offers a basic description of the operators (OPs) in Data-Juicer. Users can refer to the [API documentation](https://modelscope.github.io/data-juicer/) for the specific parameters of each operator. Users can refer to and run the unit tests for [examples of operator-wise usage](../tests/ops) as well as the effects of each operator when applied to built-in test data samples.
+This page offers a basic description of the operators (OPs) in Data-Juicer. Users can refer to the [API documentation](https://modelscope.github.io/data-juicer/) for the specific parameters of each operator. Users can refer to and run the unit tests (`tests/ops/...`) for [examples of operator-wise usage](../tests/ops) as well as the effects of each operator when applied to built-in test data samples.
## Overview
diff --git a/docs/Operators_ZH.md b/docs/Operators_ZH.md
index 5c32c4ee4..3ee94d381 100644
--- a/docs/Operators_ZH.md
+++ b/docs/Operators_ZH.md
@@ -2,7 +2,7 @@
算子 (Operator) 是协助数据修改、清理、过滤、去重等基本流程的集合。我们支持广泛的数据来源和文件格式,并支持对自定义数据集的灵活扩展。
-这个页面提供了OP的基本描述,用户可以参考[API文档](https://modelscope.github.io/data-juicer/)更细致了解每个OP的具体参数,并且可以查看、运行单元测试,来体验[各OP的用法示例](../tests/ops)以及每个OP作用于内置测试数据样本时的效果。
+这个页面提供了OP的基本描述,用户可以参考[API文档](https://modelscope.github.io/data-juicer/)更细致了解每个OP的具体参数,并且可以查看、运行单元测试 (`tests/ops/...`),来体验[各OP的用法示例](../tests/ops)以及每个OP作用于内置测试数据样本时的效果。
## 概览
diff --git a/docs/awesome_llm_data.md b/docs/awesome_llm_data.md
index 0392ab367..05d4e1c96 100644
--- a/docs/awesome_llm_data.md
+++ b/docs/awesome_llm_data.md
@@ -1,5 +1,5 @@
# Awesome Data-Model Co-Development of MLLMs [](https://awesome.re)
-Welcome to the "Awesome List" for data-model co-development of Multi-Modal Large Language Models (MLLMs), a continually updated resource tailored for the open-source community. This compilation features cutting-edge research, insightful articles focusing on improving MLLMs involving with the data-model co-development of MLLMs, and tagged based on the proposed **taxonomy** from data-model co-development, as illustrated below.
+Welcome to the "Awesome List" for data-model co-development of Multi-Modal Large Language Models (MLLMs), a continually updated resource tailored for the open-source community. This compilation features cutting-edge research, insightful articles focusing on improving MLLMs involving with the data-model co-development of MLLMs, and tagged based on the proposed **taxonomy** from our data-model co-development [survey](https://arxiv.org/abs/2407.08583), as illustrated below.

Soon we will provide a dynamic table of contents to help readers more easily navigate through the materials with features such as search, filter, and sort.