In Practical Methodology chapter the author is talking about the methodologies needed to debug, optimize the model,as well as analyse the model's performance.
To analyse your model's performance, you can't use the cost function because it is not interpratable, additionally the accuracy rate is not enough.
We need an advanced matrics to check our model performance.
The next 2 examples will show the differance between accuracy rate anad adavanced metrics.
System has 2 kinds of mistakes:
- Classifying legitimate message as a spam (False Positive).
- Allow spam message to appear in the inbox (False Negative).
In case of performance evaluation the first mistake is catastrophic and needed much more to be prevented than the second one; because the harmful of missing an important email (e.g work's meeting invitation) - because it is detected as a spam message - is much more than showing a spam message in the inbox.
Our classifier is a binary classifier for a rare disease that happens once in a million people.
Our classifier can achieve accuracy of 99.9999%, by hard-coding the output to be non-patient for all input cases (False Negative).
Although the classifier doesn’t achieve the expected goal, it is able to pass the accuracy rate check.
so we need an advanced metrics that prevent such a problem.
To avoid the problems mentioned in the previous examples we need at the beggining to exaplain the confusion metrics concept.
| | | | ------------- |:-------------:| | True Positive | False Positive| | False Negative| True Negative |
- True Positive: a truely detected/classified output (as the expected value).
- False Positive: a wrongly detected/classified output (the expected value should be non-detected).
- False Negative: a wrongly non-detected/non-classified output (the expected value should be detected).
- True Negatie: a truely non-detected/non-classified output (as the expected value).
Note: The confusion matrix can be extended to multi-label classification as well.
There is a list of performance matrics that you can choose one of them to achieve your model's goal.
- FPR
- FNR
- Recall
- Precision
- Mean Absolute Error(MAE)
- Mean Squared Error(MSE)
- Root Mean Squared Error(RMSE)
False Positive Rate Matrics is a Performance Matrics that compute the rate of the falsely detected cases in your model.
To achieve the goal in our Spam Detection System, we should compute the rate of the False Positive output(the cases where the important emails were wrongly detected as a spam).
Precision is a Performance Matrics that checks how many of the detected values were right.
Recall is a Performance Matrics that checks how many true events were detected.
There is always a tradeoff between Precision and Recall Matrics (inversely proportional relationship). For example in our Rare Disease Classifier, the hard-coded solution of all the output is non-patient will get a good precision but zero recall. On the other hand, a hard-coded solution of all the output is patient will get a good recall but zero precision.
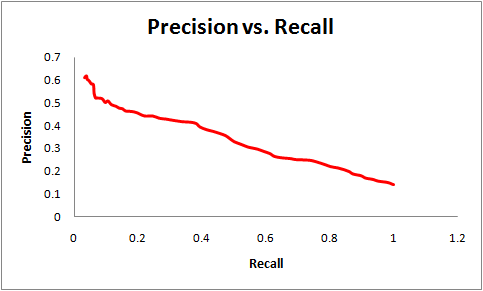
[source cb.csail.mit.edu]
To get a Performance Matrics that include both Precision and Recall Matrics in the same time, then you should compute the F1 score. F1 score is the harmonic mean of the Precision and Recall Matrics.
To have an end to end system you need to start with a default baseline model and then increment it when is needed.

End-to-end System fig.1

End-to-end System fig. 2

End-to-end System fig. 3
Steps to create a default baseline model:
- In case the problem is not AI-Complete, It is preferred to implement machine learning solution (e.g Logistic Regression, SVM, etc.), that can solve the given problem and need less effort and less time for Trianing, validating, debugging, and testing. However, in case of AI-Complete problems, Deep Learning solution is needed.
- Choose your model based on the given problem category and the input type ( FCN for fixed-sized data, CNN for images or RNN for sequence data).
- Choose your optimization algorithm
- Constant Learning Rate algorithm ( SGD, SGD + Momentum)
- Decaying Learning Rate algorithm with decaying schedule scheme ( Linearly, fixed minimum , factor 2-10).
- Separate Learning Rate algorithm ( AdaGrad, RMSProp, ADAM).
- At the begininning try to train your model without Batch Normalization to save the computation effort needed for it. However, in case that your model struggle to converge, than add Batch Normalization to your model.
- If your dataset is not enough and you are facing underfitting in the training phase, then use Transfer Learning, Data Augmentation Techniques, and Regularizer.
- If the trianing goes well, then validate your model with the validation dataset and tune your hyper parameters.
When your model has bad preformance it is better to debug the model in systematic way before you decide to gather more data; as gathering more data is very expensive and time consuming. In some cases it is also not easy to gather more data specially with medical models for Rare diseases classification.
The authors suggested a systematic way that might help you to debug your model ( but any extra ideas for dubugging can be done as well).

Wether to gather data fig. 1

Wether to gather data fig. 2
- If the training performance is bad (underfitting):
- Analyse your training implementation code.
- Use larger network, and/or switch to Adam Optimizer (as it has more convergance advantages).
- As suggested by the authors, in case of still having bad trianing performance, then you need to gather more data.
- During Evaluationg your model, if the validation performance is bad (overfitting):
- Hyper-tuning your model.
- Add Regularizer to your model.
- As suggested by the authors, in case of still having bad validation performance, then you need to gather more data.
- During Testing your model, as suggested by the authors, in case of bad testing performance, then you need to gather more data.
Sometimes it is hard to find the source of your model's problem; as the Deep Learning's models are composed of adaptive parts, if one went wrong the other parts can adapt and achieve roughly acceptable performance.
- Visualize/listen to the model output in action: as it helps to trigger the model's problem trather than only supervising the accuracy rate.
- Visualize the worst mistakes: as - in classifiers that output probability for each class - tracking the expected outputs with least probability, gives you an idea why the model went wrong.
- Fit a tiny dataset: as doing intended overfitting by training the model with small number of samples, will let you check the ability of the model to learn already.
- Compare back-propagated derivatives to numerical derivatives.
- Mintor histograms of activations and gradient.
Hyperparameters control how the training algorithm of our model behaves, and also how the model behaves during inference. We can break them up into two categories:
-
Hyperparameters which control time and memory costs of the optimization algorithm and the model inference. One such example is batch size, which drives up both time and memory costs of the optimization. Another is number of units, which additionally also affects the runtime during inference.
-
Hyperparameters that control the quality and the performance of the optimization, and of the inference. The learning rate, for instance, influences the size of our gradients and therefore how our model learns. Similarly, the batch size affects our gradients as well: it practically determines how "smooth" they become as it averages them over more than one data point.
Knowing about how hyperparameters work is benefetial: we want to keep time and memory requirements low while at the same time achieve high performances with our model. This is almost always a trade-off because our resources are limited.
Our goal is to find the optimal solution for this trade-off. Specifically, we want to find hyperparameter values that minimize the generalization error. The secondary condition is that the values can not exceed our runtime and memory requirements.
If we want to tune our hyperparameters manually, we need to understand how they work. So what exactly do all hyperparameters control in one way or another? This concept is called model capacity, and hyperparameters either increase or decrease it depending on its value. Model capacity consists of representational capacity, cost function capacity, and regularization capacity:
-
Representation capacity determines what types of functions our model can represent. Can we even learn the XOR function if our network is only a perceptron? Can we even learn to detect dogs in our input image or do we need to improve our encoder-decoder architecture so that this task is actually learnable?
-
Cost function capacity: is our learning algorithm even capable to minimize the cost or loss function we have set up? The learning algorithm needs to be able to discover functions that minimize our training cost.
-
Regularization capacity: parameters such as weight decay could block the optimization from reaching some of the functions that minimize the training cost. It would forbid our model to learn the optimal model parameters.
-
A low capacity leads the model to underfit our problem, we can see this zone to the left of the red line. On the extreme end near 0, training error can be so high that it does not matter what our generalization error is. The capacity is too low to properly fit the problem even on the training set.
-
A very high capacity leads the model to overfit our problem, this zone is on the right of the red line. With growing capacity, training error decreases more and more, but in the process the generalization error moves away from us. This growing generalization error in light of low training error is called generalization gap. Our model works perfectly well on the training set, but can not generalize to unseen data.
-
Our model capacity should not be low or high, but rather optimal. It lies on exactly that spot where generalization error is lowest. However (!), it should be noted that some modern deep neural networks achieve remarkable results even with enormous model capacity. The key here is to have enormous amounts of data as well.
So, our more specific goal with hyperparameter tuning is to choose parameters in such a way that the model capacity is optimal. There are different kinds of hyperparameters that do it in different ways.
Hyperparameters can appear in various forms or data types.
-
A hyperparameter is either discrete or continuous. Discrete hyperparameters can only have values at specific intervals, while continuous hyperparameters of course can have any value on a given interval. Depending on the actual hyperparameter in question, a small value either has the tendency to under- or to overfit the model, and the same goes for large values.
-
Binary hyperparameters only have two states: one state has the tendency to overfit and one state has the tendency to overfit. By using this switch, we can either push the model in the direction of the underfitting or to the overfitting zone.
-
There are also hyperparameters that can only decrease model capacity, for example weight decay. The value can only be 0 or positive, which means we can only use it to push the model more to the underfitting side.
Examples of hyperparameters that, when made larger, can only increase model capacity:
- Number of units.
- Kernel size.
- Implicit zero padding.
Examples of hyperparameters that, when made larger, can only decrease model capacity:
- Weight decay coefficient.
- Dropout rate.
Examples of hyperparameters that need to be optimal to increase model capacity:
- Learning rate.
The learning rate is arguably the most important hyperparameter. When adjusting it, you should not think about it in terms of "larger is worse" and "lower is better" or vice-versa, you should think about it in terms of "too large or too low is bad, find the optimal value". Because it directly influences how big the gradient will be, always tune it first if you have not much time.
A large training error indicates that our training algorithm is not able to find the function we want to learn, or that the model can not represent this function in the first place. We should increase the model capacity. If we are using regularization, we can use it less. Maybe our optimization algorithm does not work correctly or we feed the wrong target values into the cost function. In this case, we need to fix it. Maybe our model is simply too small to fit the target function, in this case we can add layers, units, increase kernel size, or make the model larger in another way.
A large test error, but small training error, is known as a large generalization gap. By adjusting our hyperparameters, we need to reduce this gap faster than the training error increases due to the very same adjustments (again, this is a trade-off). We can do this by increasing weight decay, the dropout rate or simply gathering more data.
Using automatic tuning, we do not need to know exactly how hyperparameters work because an algorithm will find the values that meet our goal: minimizing the validation error.
Using grid search, we first select a small finite set of hyperparameter values to explore. Then, grid search trains the model for every combination of these hyperparameter values. It then looks at the validation error to see what combination worked best. Grid search is suited for three or fewer hyperparameters, as the number of combinations can grow very large otherwise.
The exploration set (or "grid") has to be set by the developer. Usually, we choose possible values on a logarithmic scale to maximize our search space. For the learning rate, a possible set could be
Random search however is not aligned on a grid of hand-selected values, the values are instead chosen automatically in a randomized way. What we can choose is:
• What hyperparameters do we want to find the best value for and
• What random distribution should each hyperparameter be selected from.
A big advantage is that, practically, we can use it for more than three hyperparameters since not every combination is tried out. And we do not have to try every combination because more of the parameter space can be explored, as we do not pre-define possible values.
Another reason it is more efficient is also that it is faster in reducing the validation error if you look at the number of trials: we do not "waste" trials.
For example, let’s say we have the hyperparameters "number of units", "learning rate" and "kernel size". We look at two specific combinations on the grid to illustrate wasted trials. Here, changing the number of units does not have an effect on the generalization error. But we tried it anyway, so in some sense this trial was wasted. In random search however, in the meantime we have also randomly adjusted the learning rate and the kernel size. We are not restricted to our pre-defined grid after all. This way we have found two configurations that are even better than 0.81.
This comes at the cost of not knowing what hyperparameter is more responsible for this reduced error.
Grid search trials:
| Units | LR | Kernel Size | Error |
|---|---|---|---|
| 50 | 0.01 | 5 | 0.81 |
| 100 | 0.01 | 5 | 0.81 |
Random search trials:
| Units | LR | Kernel Size | Error |
|---|---|---|---|
| 50 | 0.009 | 3 | 0.42 |
| 100 | 0.012 | 5 | 0.69 |
Hyperparameter tuning is in essence an optimization problem itself. Therefore, to find the best hyperparameter values, one can also train a model to do so. Assuming the gradient
Bayesian optimization works by looking at past evaluations of the model, and then based on these observations it chooses the hyperparameter values to evaluate next. It does this by trying to predict the accuracy (or probability of receiving a good accuracy) based on hyperparameter values,
A popular library is Hyperopt, which uses the Tree Parzen Estimator (TPE), an estimator that implements Bayesian optimization.
The knowledge outlined in the previous sections is put to test using a real-life example from Goodfellow et al.

Here, we have a subproject of Google Street View, where each house needed to be assigned a street number. A model is trained to predict a street number, given an image patch that contains one or more digits. We go through each step outlined in this chapter to show their application in this Street View example.
The goal is to assign each image patch containing street numbers its corresponding digits. The model that was used gave a confidence
However, for this project it was important that the accuracy was very high, i.e. that at least 98% of houses were labeled correctly. For this reason, a restriction of this transcription system was to only label houses if the model was very confident that the predicted labels were correct. A wrong prediction taints the accuracy, making no prediction taints the coverage metric.
The intuition is that users want very high accuracy because it is frustrating to be led to the wrong direction. However, it is acceptable that not every house is labeled. This is therefore a trade-off where coverage is sacrificed, because it can always be improved later. So this project used coverage as the metric to meet the threshold more often, so that the system is both very accurate and has high coverage.
The performance metric is therefore the percentage of patches where
The baseline model is the model that should be improved on or subsequently compared to. In this case, the default model had
At this stage, the coverage was far below 90% and the goal therefore not met. The authors needed to debug the model.

Training and test error were nearly identical, which indicated that the problem was underfitting or that training data itself showed issues. They visualized the worst mistakes the model did (wrong examples with highest confidence) and found out that some patches were cropped too tightly in the processing step before. A safety margin around the crops was added, which resulted in a coverage boost of +10%.
Now, training and test error were still similar, which again indicated underfitting. Since the training data was already inspected and fixed, the only other option was adjusting the hyperparameters. The solution was to add the number of units to make the model larger. At the end, a coverage of 95.64% was achieved at an accuracy of 98% on the Street View House Numbers (SVHN) dataset.
For real-life tasks, it's impossible to achieve absolute zero error because of the so called Bayes error. How is Bayes error defined and how can it be estimated?
Bayes error is the minimum error that is possible to achieve and is analogous to the irreducible error. We can use human-level error as a proxy for estimating the Bayes error. For example the performance of a team of specialists could serve as the human-level error for the specific task.
What techniques can be used to improve a model in case we have a large gap between the human-level error and our training error?
We could use bias reduction techniques, e.g. increasing model capacity, decreasing regularization, or if our model is already complex enough but still poorly performing, then we should consider collecting a larger and richer dataset.
Consider a network outputting the probability of an event to be positive (e.g. with a single sigmoid output unit). Then we can take a threshold in range (0,1) and report a detection only when the probability is above this threshold. How does the choice of this threshold control the model's Precision and Recall metrics?
The smaller the threshold, the more likely we are to output false positives and less likely to miss detecting a positive event. Thus, the smaller Precision and the higher Recall will be. And vice versa, the bigger the threshold is, the smaller Recall and the higher Precision will be.
Often we have lack of labeled training data but have plenty of unlabeled data. Obviously, pure supervised approach might not give satisfactory results. In this case, we could e.g. train an Autoencoder model in unsupervised way on the large dataset available, thus extracting useful feature representations. The encoder part can then be extended with some additional layers (e.g. a fully-connected layer yielding the output class scores) and further trained on the smaller labeled dataset in supervised manner.
The authors mentioned that the neural networks research progresses rapidly and that some of the default algorithms in the book would be replaced by others soon. Now, after 5 years of publishing this book, can you prove this statement by some examples? Are the default optimization techniques mentioned in the book still the same in 2021?
Neural Networks
- For Computer Vision/Topological structure, Graph Neural Networks and Capsule Neural Networks are used nowadays to overcome the limitations of CNN.
- For sequence based input/output, Transformers/AttentionNeuralNetworks (2017), on which BERT and XLNet are based, have been successfully used. In addition, Momentum LSTM is a new technique proposed in 2020.
Optimization Algorithms
- Basically, the optimization techniques, e.g. SGD with momentum, Adam and batch normalization, are still widely applied nowadays. In addition, there is progress to help apply Newton’s method.
- In general, almost every task proposes its own neural network and its own optimization and regularization techniques to achieve the intended results. Therefore, novel neural networks and optimization strategies regularly appear in the research field.
What is the difference between primary and secondary hyperparameters in the context of automatic hyperparameter tuning?
Hyperparameter optimization algorithms have their own parameters that can be called "secondary" hyperparameters, e.g. the range of values (and the step) to be explored for each hyperparameter. So in this context, we have primary hyperparameters of the learning algorithm automatically tuned by the hyperparameter optimization algorithm, and secondary hyperparameters which should be tuned manually.
On slide 26, a U-shaped curve shows how the generalization error behaves with respect to the training error. It is feasible to draw this shape like this because the hyperparameter examined is continuous. How does the U-shaped curve change if the hyperparameter is discrete? What if the hyperparameter is binary?
- If the hyperparameter is discrete, e.g. number of units in a layer, it is only possible to plot some points along the U-shaped curve.
- If the hyperparameter is binary, it is only possible to explore two points on the U-shaped curve.
We can depict the relationship between the training error and the learning rate by a U-shaped curve.
- The training error is high if the learning rate is very low or very large.
- The training error is low if the choice learning rate is appropriate, i.e. the learning error rate is between low and high.
In general, the training error strongly depends on the problem we are trying to solve, the model’s architecture and other hyperparameters beside the learning rate.
What is the benefit of randomSearch over model-based hyperparameter optimization? What has been a mitigation technique for it?
Hyperparameter optimization algorithms must completely run a training experiment in order to extract any information from the experiment, unlike random search that have the opportunity to only experiment with promising hyperparameters. The proposed algorithm for mitigation can choose to begin a new experiment, freeze a running experiment that appears not so important/promising or to unfreeze/thaw a previously frozen experiment.
Bayesian optimization, in contrast to Random search and Grid search, keeps track of the previous evaluation results which are used to form a probabilistic model from hyperparameter values to a probability of achieving certain scores for the objective function.
- One reason is that we have no idea on how the algorithm should behave.
- Another reason is that the parts of machine learning models are adaptive and depend on each other during training. For instance, the loss function, the weighting process and adjusting hyperparameters are adaptive parts that depend on each other. If a part failed, others part do not stop, instead, they continue their calculations with false measurements.
In the example project of Street View transcription system, people used a CNN with multiple output softmax units to predict a sequence of n characters. But this assumes predicting a fixed number of maximum digits in the image. Wouldn’t it be more suitable to use an RNN instead of a CNN in this case?
They could probably also use a CNN in combination with an RNN in this project. For example, a CNN encoder to get a useful feature representation, followed by an RNN decoder to output the sequence of digits. But the reason for not considering more complex models could be that the achieved performance was already acceptable enough.