Scaling Local Self-Attention for Parameter Efficient Visual Backbones
Researchers from Google Research and UC Berkeley have developed a new model of self-attention that can outperform standard baseline models and even high-performance convolutional models.[1]
Blocked Self-Attention:The whole input image is divided into multiple blocks and self-attention is applied to each block.However, if only the information inside the block is considered each time, it will inevitably lead to the loss of information.Therefore, before calculating the SA, a haloing operation is performed on each block, i.e., outside of each block, the information of the original image is used to padding a circle, so that the sensory field of each block can be appropriately larger and focus on more information.
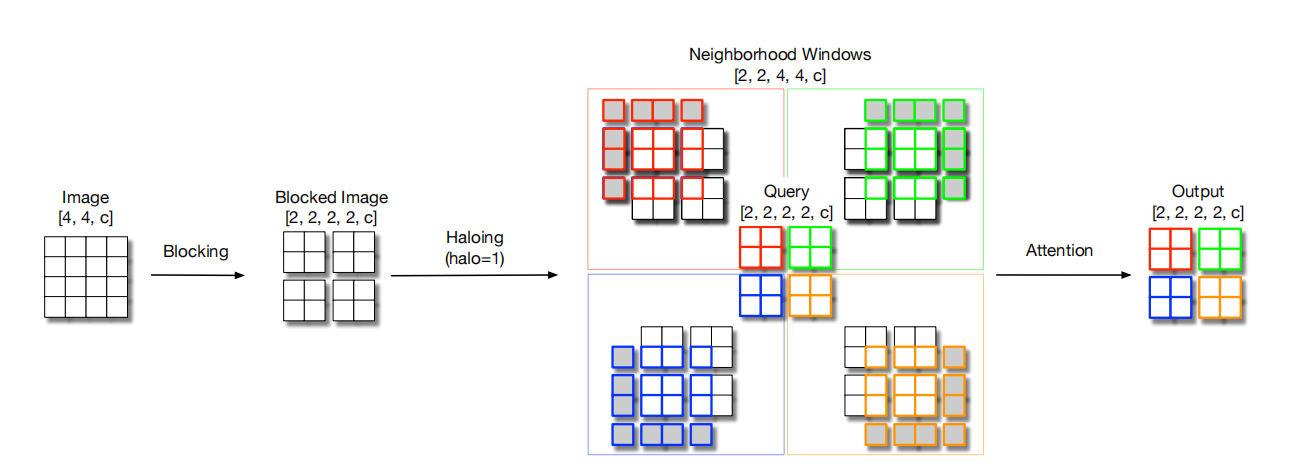
Figure 1. Architecture of Blocked Self-Attention [1]
Down Sampling:In order to reduce the amount of computation, each block is sampled separately, and then attentions are performed on this sampled information to reach the effect of down sampling.

Figure 2. Architecture of Down Sampling [1]
Our reproduced model performance on ImageNet-1K is reported as follows.
- ascend 910* with graph mode
coming soon
- ascend 910 with graph mode
| model | top-1 (%) | top-5 (%) | params (M) | batch size | cards | ms/step | jit_level | recipe | download |
|---|---|---|---|---|---|---|---|---|---|
| halonet_50t | 79.53 | 94.79 | 22.79 | 64 | 8 | 421.66 | O2 | yaml | weights |
- Top-1 and Top-5: Accuracy reported on the validation set of ImageNet-1K.
Please refer to the installation instruction in MindCV.
Please download the ImageNet-1K dataset for model training and validation.
- Distributed Training
It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple Ascend 910 devices, please run
# distributed training on multiple NPU devices
msrun --bind_core=True --worker_num 8 python train.py --config configs/halonet/halonet_50t_ascend.yaml --data_dir /path/to/imagenetFor detailed illustration of all hyper-parameters, please refer to config.py.
Note: As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
- Standalone Training
If you want to train or finetune the model on a smaller dataset without distributed training, please run:
# standalone training on single NPU device
python train.py --config configs/halonet/halonet_50t_ascend.yaml --data_dir /path/to/dataset --distribute FalseTo validate the accuracy of the trained model, you can use validate.py and parse the checkpoint path with --ckpt_path.
python validate.py -c configs/halonet/halonet_50t_ascend.yaml --data_dir /path/to/imagenet --ckpt_path /path/to/ckpt[1] Vaswani A, Ramachandran P, Srinivas A, et al. Scaling local self-attention for parameter efficient visual backbones[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 12894-12904.