+# MapReader
+> [!IMPORTANT] A computer vision pipeline for exploring and analyzing images at scale
-## What is MapReader?
+
+[](#contributors)
+
-
-
-
-
-
+
+
+
+
+
+
+## Table of Contents
+
+- [MapReader](#mapreader)
+ - [Table of Contents](#table-of-contents)
+ - [What is MapReader?](#what-is-mapreader)
+ - [Overview](#overview)
+ - [MapReader pipeline](#mapreader-pipeline)
+ - [Documentation](#documentation)
+ - [What is included in this repo?](#what-is-included-in-this-repo)
+ - [How to cite MapReader](#how-to-cite-mapreader)
+ - [Acknowledgements](#acknowledgements)
+ - [Contributors](#contributors)
+
+---
+
+
+## What is MapReader?
MapReader is an end-to-end computer vision (CV) pipeline for exploring and analyzing images at scale.
+
+
+
+
MapReader was developed in the [Living with Machines](https://livingwithmachines.ac.uk/) project to analyze large collections of historical maps but is a _**generalizable**_ computer vision pipeline which can be applied to _**any images**_ in a wide variety of domains.
## Overview
@@ -44,30 +46,28 @@ MapReader is a groundbreaking interdisciplinary tool that emerged from a specifi
### MapReader pipeline
-
-
-
+
-
-
-
-The MapReader pipeline consists of a linear sequence of tasks which, together, can be used to train a computer vision (CV) classifier to recognize visual features within maps and identify patches containing these features across entire map collections.
+
-See our [About MapReader](https://mapreader.readthedocs.io/en/latest/About.html) page to learn more.
+See our [Introduction to MapReader](https://mapreader.readthedocs.io/en/latest/introduction-to-mapreader/) page to learn more.
## Documentation
-The MapReader documentation can be found at https://mapreader.readthedocs.io/en/latest/index.html.
+The MapReader documentation can be found at https://mapreader.readthedocs.io/en/latest/.
-**New users** should refer to the [Installation instructions](https://mapreader.readthedocs.io/en/latest/Install.html) and [Input guidance](https://mapreader.readthedocs.io/en/latest/Input-guidance.html) for help with the initial set up of MapReader.
+**New users** should refer to the [Installation instructions](https://mapreader.readthedocs.io/en/latest/getting-started/installation-instructions/index.html) and [Input guidance](https://mapreader.readthedocs.io/en/latest/using-mapreader/input-guidance/) for help with the initial set up of MapReader.
-**All users** should refer to our [User Guide](https://mapreader.readthedocs.io/en/latest/User-guide/User-guide.html) for guidance on how to use MapReader. This contains end-to-end instructions on how to use the MapReader pipeline, plus a number of worked examples illustrating use cases such as:
+**All users** should refer to our [User Guide](https://mapreader.readthedocs.io/en/latest/using-mapreader/) for guidance on how to use MapReader. This contains end-to-end instructions on how to use the MapReader pipeline, plus a number of worked examples illustrating use cases such as:
- Geospatial images (i.e. maps)
- Non-geospatial images
- **Developers and contributors** may also want to refer to the [API documentation](https://mapreader.readthedocs.io/en/latest/api/index.html) and [Contribution guide](https://mapreader.readthedocs.io/en/latest/Contribution-guide/Contribution-guide.html) for guidance on how to contribute to the MapReader package.
+ **Developers and contributors** may also want to refer to the [API documentation](https://mapreader.readthedocs.io/en/latest/in-depth-resources/api/mapreader/) and [Contribution guide](https://mapreader.readthedocs.io/en/latest/community-and-contributions/contribution-guide/) for guidance on how to contribute to the MapReader package.
**Join our Slack workspace!**
Please fill out [this form](https://forms.gle/dXjECHZQkwrZ3Xpt9) to receive an invitation to the Slack workspace.
@@ -95,7 +95,6 @@ If you use MapReader in your work, please cite both the MapReader repo and [our
- Kasra Hosseini, Daniel C. S. Wilson, Kaspar Beelen, and Katherine McDonough. 2022. MapReader: a computer vision pipeline for the semantic exploration of maps at scale. In Proceedings of the 6th ACM SIGSPATIAL International Workshop on Geospatial Humanities (GeoHumanities '22). Association for Computing Machinery, New York, NY, USA, 8–19. https://doi.org/10.1145/3557919.3565812
- Kasra Hosseini, Rosie Wood, Andy Smith, Katie McDonough, Daniel C.S. Wilson, Christina Last, Kalle Westerling, and Evangeline Mae Corcoran. “Living-with-machines/mapreader: End of Lwm”. Zenodo, July 27, 2023. https://doi.org/10.5281/zenodo.8189653.
-
## Acknowledgements
This work was supported by Living with Machines (AHRC grant AH/S01179X/1) and The Alan Turing Institute (EPSRC grant EP/N510129/1).
@@ -106,10 +105,6 @@ Maps above reproduced with the permission of the National Library of Scotland ht
## Contributors
-
-[](#contributors-)
-
-
diff --git a/docs/source/About.rst b/docs/source/About.rst
deleted file mode 100644
index 6c267a17..00000000
--- a/docs/source/About.rst
+++ /dev/null
@@ -1,87 +0,0 @@
-About MapReader
-================
-
-What is MapReader?
--------------------
-
-MapReader is an end-to-end computer vision (CV) pipeline for exploring and analyzing images at scale.
-
-What is unique about MapReader?
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-MapReader is based on the 'patchwork method' in which whole map images are sliced into a grid of squares or 'patches':
-
-.. image:: figures/patchify.png
-
-This unique way of pre-processing map images enables the use of image classification to identify visual features within maps, in order to answer important research questions.
-
-What is 'the MapReader pipeline'?
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-The MapReader pipeline consists of a linear sequence of tasks:
-
-.. image:: figures/pipeline_explained.png
-
-Together, these tasks can be used to train a computer vision (CV) classifier to recognize visual features within maps and identify patches containing these features across entire map collections.
-
-What kind of visual features can MapReader help me identify?
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-In order to train a CV classifier to recognize visual features within your maps, your features must have a homogeneous visual signal across your map collection (i.e. always be represented in the same way).
-
-Why use MapReader?
--------------------
-
-MapReader becomes useful when the number of maps you wish to analyze exceeds the number which you (or your team) are willing to/capable of annotating manually.
-
-This exact number will vary depending on:
-
-- the size of your maps,
-- the features you want to find,
-- the skills you (or your team) have,
-- the amount of time at your disposal.
-
-Deciding to use MapReader, which uses deep learning computer vision (CV) models to predict the class of content on patches across many sheets, means weighing the pros and cons of working with the data output that is inferred by the model.
-Inferred data can be evaluated against expert-annotated data to understand its general quality (are all instances of a feature of interest identified by the model? does the model apply the correct label to that feature?), but in the full dataset there *will necessarily be* some percentage of error.
-
-MapReader creates output that you can link and analyze in relation to other geospatial datasets (e.g. census, gazetteers, toponyms in text corpora).
-
-Who might be interested in using MapReader?
---------------------------------------------
-
-MapReader might be useful to you if:
-
-- You have access to a large collection of maps and want to identify visual features within them without having to manually annotating each map.
-- You want to quickly test different labels to help refine a research question that depends on identifying visual features within maps before/without committing to manual vector data creation.
-- Your maps were created before surveying accuracy reached modern standards, and therefore you do not want to create overly precise geolocated data based on the content of those maps.
-
-What skills/knowledge will I need to use MapReader?
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-* Understanding of your map collection and knowledge of visual features you would like to identify within your maps
-* Basic understanding of how to use your terminal
-* Basic python
-* Basic understanding of machine learning and computer vision (CV) methodology
-
-What are the inputs and outputs of each stage in the MapReader pipeline?
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-Download
-^^^^^^^^^
-.. image:: figures/in_out_download.png
- :width: 600px
-
-Load
-^^^^^
-.. image:: figures/in_out_load.png
- :width: 600px
-
-Annotate
-^^^^^^^^^
-.. image:: figures/in_out_annotate.png
- :width: 600px
-
-Classify (Train and Predict)
-^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
-.. image:: figures/in_out_classify.png
- :width: 600px
diff --git a/docs/source/Input-guidance.rst b/docs/source/Input-guidance.rst
deleted file mode 100644
index d6d72218..00000000
--- a/docs/source/Input-guidance.rst
+++ /dev/null
@@ -1,187 +0,0 @@
-Input Guidance
-===============
-
-.. contents:: Table of Contents
- :depth: 2
- :local:
-
-Input options
---------------
-
-The MapReader pipeline is explained in detail :doc:`here `.
-The inputs you will need for MapReader will depend on where you begin within the pipeline.
-
-Option 1 - If the map(s) you want have been georeferenced and made available via a Tile Server
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-Some GLAM institutions or other services make digitized, georeferenced maps available via tile servers, for example as raster (XYZ, or 'slippy map') tiles.
-
-Instructions for accessing tile layers from one example collection is below:
-
-- National Library of Scotland tile layers
-
-If you want to download maps from a TileServer using MapReader's ``Download`` subpackage, you will need to begin with the 'Download' task.
-For this, you will need:
-
-* A ``json`` file containing metadata for each map sheet you would like to query/download.
-* The URL of the XYZ tile layer which you would like to access.
-
-At a minimum, for each map sheet, your ``json`` file should contain information on:
-
-- the name and URL of an individual sheet that is contained in the composite layer
-- the geometry of the sheet (i.e. its coordinates), so that, where applicable, individual sheets can be isolated from the whole layer
-- the coordinate reference system (CRS) used
-
-These should be saved in a format that looks something like this:
-
-.. code-block:: javascript
-
- {
- "type": "FeatureCollection",
- "features": [{
- "type": "Feature",
- "geometry": {
- "geometry_name": "the_geom",
- "coordinates": [...]
- },
- "properties": {
- "IMAGE": "...",
- "WFS_TITLE": "..."
- "IMAGEURL": "..."
- },
- }],
- "crs": {
- "name": "EPSG:4326"
- },
- }
-
-.. Check these links are still valid
-
-Some example metadata files, corresponding to the `OS one-inch 2nd edition maps `_ and `OS six-inch 1st edition maps for Scotland `_, are provided in ``MapReader/worked_examples/persistent_data``.
-
-Option 2 - If your files are already saved locally
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-If you already have your maps saved locally, you can skip the 'Download' task and move straight to 'Load'.
-
-If you would like to work with georeferenced maps, you will need either:
-
-* Your map images saved as standard, non-georeferenced, image files (e.g. JPEG, PNG or TIFF) along with a separate file containing georeferencing metadata you wish to associate to these map images **OR**
-* You map images saved as georeferenced image files (e.g. geoTIFF).
-
-Alternatively, if you would like to work with non-georeferenced maps/images, you will need:
-
-* Your images saved as standard image files (e.g. JPEG, PNG or TIFF).
-
-.. note:: It is possible to use non-georeferenced maps in MapReader, however none of the functionality around plotting patches based on geospatial coordinates will be possible. In this case, patches can be analyzed as regions within a map sheet, where the sheet itself may have some geospatial information associated with it (e.g. the geospatial coordinates for its center point, or the place name in its title).
-
-Recommended directory structure
---------------------------------
-
-If you are using non-georeferenced image files (e.g. PNG files) plus a separate metadata file, we recommend setting these up in the following directory structure:
-
-::
-
- project
- ├──your_notebook.ipynb
- └──maps
- ├── map1.png
- ├── map2.png
- ├── map3.png
- ├── ...
- └── metadata.csv
-
-This is the directory structure created by default when downloading maps using MapReader's ``Download`` subpackage.
-
-Alternatively, if you are using geo-referenced image files (eg. geoTIFF files), your will not need a metadata file, and so your files can be set up as follows:
-
-::
-
- project
- ├──your_notebook.ipynb
- └──maps
- ├── map1.tif
- ├── map2.tif
- ├── map3.tif
- └── ...
-
-
-.. note:: Your map images should be stored in a flat directory. They **cannot be nested** (e.g. if you have states within a nation, or some other hierarchy or division).
-
-.. note:: Additionally, map images should be available locally or you should set up access via cloud storage. If you are working with a very large corpus of maps, you should consider running MapReader in a Virtual Machine with adequate storage.
-
-Preparing your metadata
-------------------------
-
-MapReader uses the file names of your map images as unique identifiers (``image_id`` s).
-Therefore, if you would like to associate metadata to your map images, then, **at minimum**, your metadata must contain a column/header named ``image_id`` or ``name`` whose content is the file name of each map image.
-
-To load metadata (e.g. georeferencing information, publication dates or any other information about your images) into MapReader, your metadata must be in a `pandas readable file format `_.
-
-.. note:: Many map collections do not have item-level metadata, however even the minimal requirements here (a filename, geospatial coordinates, and CRS) will suffice for using MapReader. It is always a good idea to talk to the curators of the map collections you wish to use with MapReader to see if there are metadata files that can be shared for research purposes.
-
-
-Option 1 - Using a ``csv``, ``xls`` or ``xlsx`` file
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-The simplest option is to save your metadata as a ``csv``, ``xls`` or ``xlsx`` file and load it directly into MapReader.
-
-.. note:: If you are using a ``csv`` file but the contents of you metadata contains commas, you will need to use another delimiter. We recommend using a pipe (``|``).
-
-If you are loading metadata from a ``csv``, ``xls`` or ``xlsx`` file, your file should be structures as follows:
-
-+-----------+-----------------------------+------------------------+--------------+
-| image_id | column1 (e.g. coords) | column2 (e.g. region) | column3 |
-+===========+=============================+========================+==============+
-| map1.png | (-4.8, 55.8, -4.2, 56.4) | Glasgow | ... |
-+-----------+-----------------------------+------------------------+--------------+
-| map2.png | (-2.2, 53.2, -1.6, 53.8) | Manchester | ... |
-+-----------+-----------------------------+------------------------+--------------+
-| map3.png | (-3.6, 50.1, -3.0, 50.8) | Dorset | ... |
-+-----------+-----------------------------+------------------------+--------------+
-| ... | ... | ... | ... |
-+-----------+-----------------------------+------------------------+--------------+
-
-Your file can contain as many columns/rows as you like, so long as it contains at least one named ``image_id`` or ``name``.
-
-.. Add comment about nature of coordinates as supplied by NLS vs what they might be for other collections
-
-Option 2 - Loading metadata from other file formats
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-As pandas is able to read `a number of different file formats `_, you may still be able to use your metadata even if it is saved in a different file format.
-
-To do this, you will need to use python to:
-
-1. Read your file using one of pandas ``read_xxx`` methods and create a dataframe from it.
-2. Ensure there is an ``image_ID`` column to your dataframe (and add one if there is not).
-3. Pass your dataframe to MapReader.
-
-Depending on the structure/format of your metadata, this may end up being a fairly complex task and so is not recommended unless absolutely necessary.
-A conversation with the collection curator is always a good idea to check what formats metadata may already be available in/or easily made available in using existing workflows.
-
-Accessing maps via TileServers
-------------------------------
-
-National Library of Scotland
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-It is possible to bring in any other georeferenced layers from the National Library of Scotland into MapReader.
-To do this, you would need to create a TileServer object and specify the metadata_path (the path to your metadata.json file) and the download_url (the WMTS or XYZ URL for your tileset) for your chosen tilelayer.
-
-`This page `__ lists some of the NLS's most popular georeferenced layers and provides links to their WMTS and XYZ URLs.
-If, for example, you wanted to use the "Ordnance Survey - 10 mile, General, 1955 - 1:633,600" in MapReader, you would need to look up its XYZ URL (https://mapseries-tilesets.s3.amazonaws.com/ten_mile/general/{z}/{x}/{y}.png) and insert it your MapReader code as shown below:
-
-.. code-block:: python
-
- from mapreader import TileServer
-
- my_ts = TileServer(
- metadata_path="path/to/metadata.json",
- download_url="https://mapseries-tilesets.s3.amazonaws.com/ten_mile/general/{z}/{x}/{y}.png",
- )
-
-.. note:: You would need to generate the corresponding `metadata.json` before running this code.
-
-More information about using NLS georeferenced layers is available `here `__, including details about accessing metadata for each layer.
-Please note the Re-use terms for each layer, as these vary.
diff --git a/docs/source/Install.rst b/docs/source/Install.rst
deleted file mode 100644
index 4721df89..00000000
--- a/docs/source/Install.rst
+++ /dev/null
@@ -1,192 +0,0 @@
-Installation Instructions
-=========================
-
-.. note:: Run these commands from your terminal.
-
-There are three steps to setting up MapReader.
-You should choose one method within each step and follow the instructions for that method.
-
-.. note:: You do not need to use the same method between steps. i.e. It is completely fine to follow Method 1 for Step 1 and Method 2 for Step 2.
-
-.. contents:: Table of Contents
- :depth: 2
- :local:
-
-.. todo:: Add comments about how to get to conda in Windows
-
-Step 1: Set up a virtual python environment
-----------------------------------------------
-
-The most recent version of MapReader supports python versions 3.9+.
-
-Method 1: Using conda (recommended)
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-We recommend installing MapReader using either Anaconda (`installation instructions here `__) or miniconda (`installation instructions here `__).
-A discussion of which of these to choose can be found `here `__.
-
-Once you have installed either Ananconda or miniconda, open your terminal and use the following commands to set up your virtual python environment:
-
-- Create a new conda environment for ``mapreader`` (you can call this whatever you like, we use ``mapreader``):
-
- .. code-block:: bash
-
- conda create -n mapreader python=3.10
-
- This will create a conda enviroment for you to install MapReader and its dependencies into.
-
-- Activate your conda environment:
-
- .. code-block:: bash
-
- conda activate mapreader
-
-Method 2: Using venv or other
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-If you would like not to use conda, you are more than welcome to set up a virtual python environment using other methods.
-
-For example, if you would like to use venv, open your terminal and use the following commands to set up your virtual python environment:
-
-- First, importantly, check which version of python your system is using:
-
- .. code-block:: bash
-
- python3 --version
-
- If this returns a version below 3.9, you will need download an updated python version.
- You can do this by downloading from `here `__ (make sure you download the right one for your operating system).
-
- You should then run the above command again to check your python version has updated.
-
-- Create a new virtual python environment for ``mapreader`` (you can call this whatever you like, we use ``mapreader``):
-
- .. code-block:: bash
-
- python3 -m venv mapreader
-
-- Activate your virtual environment:
-
- .. code-block:: bash
-
- source mapreader/bin/activate
-
-Step 2: Install MapReader
---------------------------
-
-Method 1: Install from `PyPI `_
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-If you want to use the latest stable release of MapReader and do not want/need access to the worked examples or MapReader code, we recommend installing from PyPI.
-This is probably the easiest way to install MapReader.
-
-- Install ``mapreader``:
-
- .. code-block:: bash
-
- pip install mapreader
-
-.. note:: To install the dev dependencies too use ``pip install "mapreader[dev]"`` instead.
-
-Method 2: Install from source
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-If you want to keep up with the latest changes to MapReader, or want/need easy access to the worked examples or MapReader code, we reccommend installing from source.
-This method will create a ``MapReader`` directory on your machine which will contain all the MapReader code, docs and worked examples.
-
-.. note:: You will need to have `git `__ installed to use this method. If you are using conda, this can be done by running ``conda install git``. Otherwise, you should install git by following the instructions on `their website `__.
-
-- Clone the ``mapreader`` source code from the `MapReader GitHub repository `_:
-
- .. code-block:: bash
-
- git clone https://github.com/Living-with-machines/MapReader.git
-
-- Install ``mapreader``:
-
- .. code-block:: bash
-
- cd MapReader
- pip install -v -e .
-
-.. note:: To install the dev dependencies too use ``pip install -v -e ".[dev]"`` instead.
-
-..
- Method 3: Install via conda (**EXPERIMENTAL**)
- ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
- If neither of the above methods work, you can try installing MapReader using conda.
- This method is still in development so should be avoided for now.
-
- - Install MapReader directly from the conda package:
-
- .. code:: bash
-
- conda install -c anothersmith -c conda-forge -c defaults --override-channels --strict-channel-priority mapreader
-
- .. note:: The conda package seems to be sensitive to the precise priority of the conda channels, hence the use of the `--override-channels --strict-channel-priority` switches is required for this to work. Until this is resolve this installation method will be marked "experimental".
-
-Step 3: Add virtual python environment to notebooks
-------------------------------------------------------
-
-- To allow the newly created python virtual environment to show up in jupyter notebooks, run the following command:
-
-.. code-block:: bash
-
- python -m ipykernel install --user --name mapreader --display-name "Python (mr_py)"
-
-.. note:: if you have used a different name for your python virtual environment replace the ``mapreader`` with whatever name you have used.
-
-
-Running tests
--------------
-
-To run the tests for MapReader, you will need to have installed the **dev dependencies** as described above.
-
-Also, if you have followed the "Install from PyPI" instructions, you will need to clone the MapReader repository to access the tests. i.e.:
-
-.. code-block:: bash
-
- git clone https://github.com/Living-with-machines/MapReader.git
-
-You can then run the tests using from the root of the MapReader directory using the following commands:
-
-.. code-block:: bash
-
- cd path/to/MapReader # change this to your path, e.g. cd ~/MapReader
- conda activate mapreader
- python -m pytest -v
-
-If all tests pass, this means that MapReader has been installed and is working as expected.
-
-
-Troubleshooting
-----------------
-
-M1 mac
-~~~~~~~
-
-If you are using an M1 mac and are having issues installing MapReader due to an error when installing numpy or scikit-image:
-
-- Try separately installing the problem packages (edit as needed) and then installing MapReader:
-
- .. code-block:: bash
-
- pip install numpy==1.21.5
- pip install scikit-image==0.18.3
- pip install mapreader
-
-- Try using conda to install the problem packages (edit as needed) and then pip to install MapReader:
-
- .. code-block:: bash
-
- conda install numpy==1.21.5
- conda install scikit-image==0.18.3
- pip install mapreader
-
-- Alternatively, you can try using a different version of openBLAS when installing:
-
- .. code-block:: bash
-
- brew install openblas
- OPENBLAS="$(brew --prefix openblas)" pip install mapreader
diff --git a/docs/source/figures/IoA.png b/docs/source/_static/IoA.png
similarity index 100%
rename from docs/source/figures/IoA.png
rename to docs/source/_static/IoA.png
diff --git a/docs/source/figures/IoA_0.9.png b/docs/source/_static/IoA_0.9.png
similarity index 100%
rename from docs/source/figures/IoA_0.9.png
rename to docs/source/_static/IoA_0.9.png
diff --git a/docs/source/figures/annotate.png b/docs/source/_static/annotate.png
similarity index 100%
rename from docs/source/figures/annotate.png
rename to docs/source/_static/annotate.png
diff --git a/docs/source/figures/annotate_context.png b/docs/source/_static/annotate_context.png
similarity index 100%
rename from docs/source/figures/annotate_context.png
rename to docs/source/_static/annotate_context.png
diff --git a/docs/source/figures/hist_published_dates.png b/docs/source/_static/hist_published_dates.png
similarity index 100%
rename from docs/source/figures/hist_published_dates.png
rename to docs/source/_static/hist_published_dates.png
diff --git a/docs/source/figures/in_out_annotate.png b/docs/source/_static/in_out_annotate.png
similarity index 100%
rename from docs/source/figures/in_out_annotate.png
rename to docs/source/_static/in_out_annotate.png
diff --git a/docs/source/figures/in_out_classify.png b/docs/source/_static/in_out_classify.png
similarity index 100%
rename from docs/source/figures/in_out_classify.png
rename to docs/source/_static/in_out_classify.png
diff --git a/docs/source/figures/in_out_download.png b/docs/source/_static/in_out_download.png
similarity index 100%
rename from docs/source/figures/in_out_download.png
rename to docs/source/_static/in_out_download.png
diff --git a/docs/source/figures/in_out_load.png b/docs/source/_static/in_out_load.png
similarity index 100%
rename from docs/source/figures/in_out_load.png
rename to docs/source/_static/in_out_load.png
diff --git a/docs/source/figures/inference_sample_results.png b/docs/source/_static/inference_sample_results.png
similarity index 100%
rename from docs/source/figures/inference_sample_results.png
rename to docs/source/_static/inference_sample_results.png
diff --git a/docs/source/figures/loss.png b/docs/source/_static/loss.png
similarity index 100%
rename from docs/source/figures/loss.png
rename to docs/source/_static/loss.png
diff --git a/docs/source/figures/patchify.png b/docs/source/_static/patchify.png
similarity index 100%
rename from docs/source/figures/patchify.png
rename to docs/source/_static/patchify.png
diff --git a/docs/source/figures/pipeline_explained.png b/docs/source/_static/pipeline_explained.png
similarity index 100%
rename from docs/source/figures/pipeline_explained.png
rename to docs/source/_static/pipeline_explained.png
diff --git a/docs/source/figures/plot_metadata_on_map.png b/docs/source/_static/plot_metadata_on_map.png
similarity index 100%
rename from docs/source/figures/plot_metadata_on_map.png
rename to docs/source/_static/plot_metadata_on_map.png
diff --git a/docs/source/figures/review_labels.png b/docs/source/_static/review_labels.png
similarity index 100%
rename from docs/source/figures/review_labels.png
rename to docs/source/_static/review_labels.png
diff --git a/figs/river_banner_8bit.png b/docs/source/_static/river_banner_8bit.png
similarity index 100%
rename from figs/river_banner_8bit.png
rename to docs/source/_static/river_banner_8bit.png
diff --git a/docs/source/figures/show.png b/docs/source/_static/show.png
similarity index 100%
rename from docs/source/figures/show.png
rename to docs/source/_static/show.png
diff --git a/docs/source/figures/show_image.png b/docs/source/_static/show_image.png
similarity index 100%
rename from docs/source/figures/show_image.png
rename to docs/source/_static/show_image.png
diff --git a/docs/source/figures/show_image_labels_10.png b/docs/source/_static/show_image_labels_10.png
similarity index 100%
rename from docs/source/figures/show_image_labels_10.png
rename to docs/source/_static/show_image_labels_10.png
diff --git a/docs/source/figures/show_list.png b/docs/source/_static/show_list.png
similarity index 100%
rename from docs/source/figures/show_list.png
rename to docs/source/_static/show_list.png
diff --git a/docs/source/figures/show_par.png b/docs/source/_static/show_par.png
similarity index 100%
rename from docs/source/figures/show_par.png
rename to docs/source/_static/show_par.png
diff --git a/docs/source/figures/show_par_RGB.png b/docs/source/_static/show_par_RGB.png
similarity index 100%
rename from docs/source/figures/show_par_RGB.png
rename to docs/source/_static/show_par_RGB.png
diff --git a/docs/source/figures/show_par_RGB_0.5.png b/docs/source/_static/show_par_RGB_0.5.png
similarity index 100%
rename from docs/source/figures/show_par_RGB_0.5.png
rename to docs/source/_static/show_par_RGB_0.5.png
diff --git a/docs/source/figures/show_sample_child.png b/docs/source/_static/show_sample_child.png
similarity index 100%
rename from docs/source/figures/show_sample_child.png
rename to docs/source/_static/show_sample_child.png
diff --git a/docs/source/figures/show_sample_parent.png b/docs/source/_static/show_sample_parent.png
similarity index 100%
rename from docs/source/figures/show_sample_parent.png
rename to docs/source/_static/show_sample_parent.png
diff --git a/docs/source/figures/show_sample_train_8.png b/docs/source/_static/show_sample_train_8.png
similarity index 100%
rename from docs/source/figures/show_sample_train_8.png
rename to docs/source/_static/show_sample_train_8.png
diff --git a/docs/source/figures/show_sample_val_8.png b/docs/source/_static/show_sample_val_8.png
similarity index 100%
rename from docs/source/figures/show_sample_val_8.png
rename to docs/source/_static/show_sample_val_8.png
diff --git a/figs/tutorial_classification_mnist.png b/docs/source/_static/tutorial_classification_mnist.png
similarity index 100%
rename from figs/tutorial_classification_mnist.png
rename to docs/source/_static/tutorial_classification_mnist.png
diff --git a/figs/tutorial_classification_one_inch_maps_001.png b/docs/source/_static/tutorial_classification_one_inch_maps_001.png
similarity index 100%
rename from figs/tutorial_classification_one_inch_maps_001.png
rename to docs/source/_static/tutorial_classification_one_inch_maps_001.png
diff --git a/figs/tutorial_classification_plant_phenotype.png b/docs/source/_static/tutorial_classification_plant_phenotype.png
similarity index 100%
rename from figs/tutorial_classification_plant_phenotype.png
rename to docs/source/_static/tutorial_classification_plant_phenotype.png
diff --git a/docs/source/Coc.rst b/docs/source/community-and-contributions/code-of-conduct-and-inclusivity.rst
similarity index 100%
rename from docs/source/Coc.rst
rename to docs/source/community-and-contributions/code-of-conduct-and-inclusivity.rst
diff --git a/docs/source/Developers-guide.rst b/docs/source/community-and-contributions/contribution-guide/developers-corner/building-conda-package.rst
similarity index 55%
rename from docs/source/Developers-guide.rst
rename to docs/source/community-and-contributions/contribution-guide/developers-corner/building-conda-package.rst
index 8c4cb126..a463297e 100644
--- a/docs/source/Developers-guide.rst
+++ b/docs/source/community-and-contributions/contribution-guide/developers-corner/building-conda-package.rst
@@ -1,35 +1,5 @@
-Developer's Guide
-=================
-
-Installing and using pre-commit
---------------------------------
-
-MapReader uses `pre-commit `_ to enforce code style and quality. To install pre-commit, run the following commands:
-
-.. code-block:: bash
-
- pip install pre-commit
- pre-commit install
-
-This will install the pre-commit hooks in the repository. The hooks will run automatically when you commit code. If the hooks fail, the commit will be aborted.
-
-Managing version numbers
-------------------------
-
-To assign meaning to the version number, we use `semantic versioning `_.
-Technically we use the package `versioneer `_ to increment the version number. To update the version number, run the following commands:
-
-.. code-block:: bash
-
- git checkout main
- git tag -a v1.2.3 -m "mapreader-1.2.3"
- git push --tags
-
-All intermediate development version numbers are automatically generated by versioneer.
-
-
Building the Conda package
---------------------------
+===========================
The overall challenge with installing MapReader is that it some of its dependencies are only available on PyPI, whilst others are only available on conda-forge.
diff --git a/docs/source/community-and-contributions/contribution-guide/developers-corner/index.rst b/docs/source/community-and-contributions/contribution-guide/developers-corner/index.rst
new file mode 100644
index 00000000..9fd9675e
--- /dev/null
+++ b/docs/source/community-and-contributions/contribution-guide/developers-corner/index.rst
@@ -0,0 +1,13 @@
+Developer's Corner
+===================
+
+..
+ TODO: Write intro to developer's corner here.
+
+.. toctree::
+ :maxdepth: 1
+
+ installing-using-precommit
+ running-tests
+ managing-version-numbers
+ building-conda-package
diff --git a/docs/source/community-and-contributions/contribution-guide/developers-corner/installing-using-precommit.rst b/docs/source/community-and-contributions/contribution-guide/developers-corner/installing-using-precommit.rst
new file mode 100644
index 00000000..360f1d6e
--- /dev/null
+++ b/docs/source/community-and-contributions/contribution-guide/developers-corner/installing-using-precommit.rst
@@ -0,0 +1,11 @@
+Installing and using pre-commit
+--------------------------------
+
+MapReader uses `pre-commit `_ to enforce code style and quality. To install pre-commit, run the following commands:
+
+.. code-block:: bash
+
+ pip install pre-commit
+ pre-commit install
+
+This will install the pre-commit hooks in the repository. The hooks will run automatically when you commit code. If the hooks fail, the commit will be aborted.
diff --git a/docs/source/community-and-contributions/contribution-guide/developers-corner/managing-version-numbers.rst b/docs/source/community-and-contributions/contribution-guide/developers-corner/managing-version-numbers.rst
new file mode 100644
index 00000000..3e6b5cf4
--- /dev/null
+++ b/docs/source/community-and-contributions/contribution-guide/developers-corner/managing-version-numbers.rst
@@ -0,0 +1,13 @@
+Managing version numbers
+========================
+
+To assign meaning to the version number, we use `semantic versioning `_.
+Technically we use the package `versioneer `_ to increment the version number. To update the version number, run the following commands:
+
+.. code-block:: bash
+
+ git checkout main
+ git tag -a v1.2.3 -m "mapreader-1.2.3"
+ git push --tags
+
+All intermediate development version numbers are automatically generated by versioneer.
diff --git a/docs/source/community-and-contributions/contribution-guide/developers-corner/running-tests.rst b/docs/source/community-and-contributions/contribution-guide/developers-corner/running-tests.rst
new file mode 100644
index 00000000..db20c10a
--- /dev/null
+++ b/docs/source/community-and-contributions/contribution-guide/developers-corner/running-tests.rst
@@ -0,0 +1,20 @@
+Running tests
+=============
+
+To run the tests for MapReader, you will need to have installed the **dev dependencies** as described above.
+
+Also, if you have followed the "Install from PyPI" instructions, you will need to clone the MapReader repository to access the tests. i.e.:
+
+.. code-block:: bash
+
+ git clone https://github.com/Living-with-machines/MapReader.git
+
+You can then run the tests using from the root of the MapReader directory using the following commands:
+
+.. code-block:: bash
+
+ cd path/to/MapReader # change this to your path, e.g. cd ~/MapReader
+ conda activate mapreader
+ python -m pytest -v
+
+If all tests pass, this means that MapReader has been installed and is working as expected.
diff --git a/docs/source/Contribution-guide/Code.rst b/docs/source/community-and-contributions/contribution-guide/getting-started-with-contributions/add-or-update-code.rst
similarity index 97%
rename from docs/source/Contribution-guide/Code.rst
rename to docs/source/community-and-contributions/contribution-guide/getting-started-with-contributions/add-or-update-code.rst
index ae3fb343..a484f677 100644
--- a/docs/source/Contribution-guide/Code.rst
+++ b/docs/source/community-and-contributions/contribution-guide/getting-started-with-contributions/add-or-update-code.rst
@@ -37,7 +37,7 @@ Style guide
When making your changes, please:
-- Try to align to the `PEP 8 style guide for python code `.
+- Try to align to the `PEP 8 style guide for Python code `.
- Try to use the numpy-style docstrings (as per `this link _`).
- Ensure all docstrings are kept up to date and reflect any changes to code functionality you have made.
- Add and run tests for your code.
diff --git a/docs/source/Contribution-guide/Documentation.rst b/docs/source/community-and-contributions/contribution-guide/getting-started-with-contributions/add-or-update-documentation.rst
similarity index 91%
rename from docs/source/Contribution-guide/Documentation.rst
rename to docs/source/community-and-contributions/contribution-guide/getting-started-with-contributions/add-or-update-documentation.rst
index b7929291..f5b33d36 100644
--- a/docs/source/Contribution-guide/Documentation.rst
+++ b/docs/source/community-and-contributions/contribution-guide/getting-started-with-contributions/add-or-update-documentation.rst
@@ -13,7 +13,7 @@ Documentation dependencies
If you would like to edit or add to the MapReader documentation, you will need to install ``sphinx`` along with the packages detailed in ``MapReader/docs/requirements.txt``.
-To do this (assuming you have installed MapReader from source, as per our :doc:`Installation instructions `), use:
+To do this (assuming you have installed MapReader from source, as per our :doc:`Installation instructions `), use:
.. code-block:: bash
@@ -43,7 +43,7 @@ You will then need to fork the `MapReader repository ` if you would like to have a go at this, or, if you feel hesitant about making code changes, create an issue detailing the changes you think need making.
+Head to our :doc:`guide to updating the MapReader code ` if you would like to have a go at this, or, if you feel hesitant about making code changes, create an issue detailing the changes you think need making.
Style guide
-----------
@@ -61,7 +61,7 @@ Style guide
Four
^^^^
-- Use ``.. code-block:: `` to create code blocks formatted as per your given langauge (replace ```` with the language you will be writing in). e.g. ``.. code-block:: python`` will create a code block with python formatting.
+- Use ``.. code-block:: `` to create code blocks formatted as per your given langauge (replace ```` with the language you will be writing in). e.g. ``.. code-block:: python`` will create a code block with Python formatting.
- Use ``Link title `__`` to link to external pages.
- Use ``.. contents::`` to automatically generate a table of contents detailing sections within the current page. e.g.
diff --git a/docs/source/community-and-contributions/contribution-guide/getting-started-with-contributions/index.rst b/docs/source/community-and-contributions/contribution-guide/getting-started-with-contributions/index.rst
new file mode 100644
index 00000000..5423b206
--- /dev/null
+++ b/docs/source/community-and-contributions/contribution-guide/getting-started-with-contributions/index.rst
@@ -0,0 +1,12 @@
+Getting started with contributions
+==================================
+
+..
+ TODO: Add an intro here...
+
+.. toctree::
+ :maxdepth: 1
+
+ write-tutorial-or-worked-example
+ add-or-update-documentation
+ add-or-update-code
diff --git a/docs/source/Contribution-guide/Worked-examples.rst b/docs/source/community-and-contributions/contribution-guide/getting-started-with-contributions/write-tutorial-or-worked-example.rst
similarity index 86%
rename from docs/source/Contribution-guide/Worked-examples.rst
rename to docs/source/community-and-contributions/contribution-guide/getting-started-with-contributions/write-tutorial-or-worked-example.rst
index ef1ab44a..5b7aed66 100644
--- a/docs/source/Contribution-guide/Worked-examples.rst
+++ b/docs/source/community-and-contributions/contribution-guide/getting-started-with-contributions/write-tutorial-or-worked-example.rst
@@ -6,7 +6,7 @@ If you are using MapReader in your own work, we would love for you to showcase a
Before you begin
----------------
-If you are currently unfamiliar with using GitHub for collaboration, remember to take a look at our :doc:`GitHub guide `.
+If you are currently unfamiliar with using GitHub for collaboration, remember to take a look at our :doc:`GitHub guide `.
Before you begin writing your tutorial, you should ensure your tutorial/worked example has a corresponding issue on the `MapReader repository `_ (or create one if needed).
You should then either assign yourself to the issue or comment on it saying you will be working on making this tutorial.
@@ -18,9 +18,9 @@ Writing your tutorial or worked example
----------------------------------------
You can write your tutorial/worked example in any way you like but should save it in the ``worked_examples`` folder.
-We suggest using a `jupyter notebook `_.
+We suggest using a `Jupyter notebook `_.
-Take a look through our current :doc:`worked examples ` for inspiration.
+Take a look through our current :doc:`worked examples ` for inspiration.
When you are finished
---------------------
diff --git a/docs/source/community-and-contributions/contribution-guide/how-to-add-yourself-as-a-contributor.rst b/docs/source/community-and-contributions/contribution-guide/how-to-add-yourself-as-a-contributor.rst
new file mode 100644
index 00000000..cbdf32aa
--- /dev/null
+++ b/docs/source/community-and-contributions/contribution-guide/how-to-add-yourself-as-a-contributor.rst
@@ -0,0 +1,60 @@
+How to add yourself as a contributor
+====================================
+
+We use the `all-contributors `__ bot to keep a record of contributors to the MapReader repo.
+To add yourself as a contributor to MapReader, comment on your issue or PR with the following:
+
+``@all-contributors please add @your_username_here for A, B, C``
+
+.. note:: Remember to change this to your GitHub username!
+
+for example, to add Katie McDonough for research, ideas and docs, you would write:
+
+``@all-contributors please add @kmcdono2 for research, ideas, docs``
+
+Types of contribution
+~~~~~~~~~~~~~~~~~~~~~
+
+.. list-table::
+ :widths: 30 30 40
+ :header-rows: 1
+
+ * - Emoji/Type
+ - Represents
+ - Comments
+ * - 💻 ``code``
+ - Code
+ -
+ * - 🔣 ``data``
+ - Data
+ -
+ * - 📖 ``doc``
+ - Documentation
+ - e.g. ReadtheDocs, Wiki, or other source of documentation
+ * - 🤔 ``ideas``
+ - Ideas & Planning
+ -
+ * - 🚧 ``maintenance``
+ - Maintenance
+ - People who are actively maintaining the repo
+ * - 🧑🏫 ``mentoring``
+ - Mentoring
+ - People who mentor new contributors
+ * - 📆 ``projectManagement``
+ - Project Management
+ -
+ * - 🔬 ``research``
+ - Research
+ -
+ * - 👀 ``review``
+ - Reviewed Pull Requests
+ -
+ * - 🌍 ``translation``
+ - Translation
+ -
+ * - ✅ ``tutorial``
+ - Tutorials
+ - e.g. ``worked_examples`` or external tutorials.
+ * - 📢 ``talk``
+ - Talks
+ -
diff --git a/docs/source/community-and-contributions/contribution-guide/index.rst b/docs/source/community-and-contributions/contribution-guide/index.rst
new file mode 100644
index 00000000..e013a5c8
--- /dev/null
+++ b/docs/source/community-and-contributions/contribution-guide/index.rst
@@ -0,0 +1,34 @@
+Contribution Guide
+===================
+
+Welcome! We are pleased to know that you're interested in contributing to MapReader!
+
+MapReader is a collaborative project, now expanding its community beyond the initial group in the `Living with Machines `_ project (The Alan Turing Institute).
+We welcome all contributions but **please** follow these guidelines to make sure your contributions can be easily integrated into the project.
+
+Pre-requisites
+--------------
+
+Regardless of how you will be contributing to MapReader, you will need to:
+
+1. Ensure you have a `GitHub account `_ set up.
+2. Be able to use GitHub issues and pull requests - if you are unfamiliar with these, please look at our :doc:`GitHub guide ` before continuing.
+3. Set up a virtual Python environment and install MapReader (as per our :doc:`Installation instructions `).
+4. Have read this guide.
+
+Ways to contribute
+------------------
+
+We welcome contributions from community members of all skill levels and so have written three different guides for different types of contributions:
+
+- :doc:`Write a tutorial or worked example ` - For those who are familiar with using MapReader and would like to showcase an example of how to use it, but are not comfortable with using Sphinx to write documentation or writing code.
+- :doc:`Add to or update the MapReader documentation ` - For those who are familiar with using MapReader and either already comfortable with using Sphinx to write documentation or feel able to have a go at to learning it.
+- :doc:`Add to or update the MapReader code ` - For those who are familiar with using MapReader and either already comfortable with writing code in Python or feel able to have a go at learning it.
+
+.. toctree::
+ :maxdepth: 2
+
+ ways-of-working
+ how-to-add-yourself-as-a-contributor
+ getting-started-with-contributions/index
+ developers-corner/index
diff --git a/docs/source/ways-of-working.rst b/docs/source/community-and-contributions/contribution-guide/ways-of-working.rst
similarity index 100%
rename from docs/source/ways-of-working.rst
rename to docs/source/community-and-contributions/contribution-guide/ways-of-working.rst
diff --git a/docs/source/Events.rst b/docs/source/community-and-contributions/events.rst
similarity index 97%
rename from docs/source/Events.rst
rename to docs/source/community-and-contributions/events.rst
index 263c8aef..f5e6e6fb 100644
--- a/docs/source/Events.rst
+++ b/docs/source/community-and-contributions/events.rst
@@ -62,17 +62,17 @@ workshops to support a growing user community around MapReader during 2024.
* - Sept 25, 2024
- MapReader Workshop
-
+
at Spatial Humanities 2024
- 1/2 day workshop co-located with the Spatial Humanities conference.
- `More details `_
* - Sept 30-Oct 2, 2024
- Fall Data/Culture Workshop:
-
+
MapReader + Newspapers
- At The Alan Turing Institute, London, UK
-
+
(and partially online/hybrid)
- Website coming soon
@@ -89,25 +89,25 @@ workshops to support a growing user community around MapReader during 2024.
* - Jun 5-7, 2024
- Summer Data/Culture Workshop:
-
+
MapReader + Newspapers
- 3-day workshop for historians and other historically-inclined researchers
-
+
about learning to use MapReader (2 days) paired with an introduction to
-
+
tools and data from Living with Machines related to digitized British
-
+
newspaper collections. Co-sponsored by the N8. Bursaries available.
-
+
- `Summer Data/Culture Workshop webpage `_
* - Apr 30-May 1, 2024
- Spring Data/Culture Workshop:
-
+
MapReader
- 2-day workshop for historians and other historically-inclined researchers
-
+
about learning to use MapReader.
-
+
Bursaries available.
- `Spring Data/Culture Workshop webpage `_
diff --git a/docs/source/community-and-contributions/index.rst b/docs/source/community-and-contributions/index.rst
new file mode 100644
index 00000000..14a981ee
--- /dev/null
+++ b/docs/source/community-and-contributions/index.rst
@@ -0,0 +1,14 @@
+Community and contributions
+===========================
+
+..
+ TODO: Write an intro to community and contributions here.
+
+.. toctree::
+ :maxdepth: 2
+
+ joining-the-community
+ events
+ share-your-story
+ contribution-guide/index
+ code-of-conduct-and-inclusivity
diff --git a/docs/source/community-and-contributions/joining-the-community.rst b/docs/source/community-and-contributions/joining-the-community.rst
new file mode 100644
index 00000000..0216f967
--- /dev/null
+++ b/docs/source/community-and-contributions/joining-the-community.rst
@@ -0,0 +1,14 @@
+Joining the community
+=====================
+
+Before you begin contributing to MapReader, we would love for you to join our community and there are many ways to do this:
+
+- Star the `MapReader GitHub repository `_.
+- Start creating Github issues and/or pull requests on our repository.
+- Join our `Slack workspace `_.
+
+You can also get in touch with the MapReader team personally by:
+
+- Tagging us on Github (find our Github handles `here `__).
+- Messaging us on Slack.
+- Emailing Katie McDonough at k.mcdonough@lancaster.ac.uk.
diff --git a/docs/source/community-and-contributions/share-your-story.rst b/docs/source/community-and-contributions/share-your-story.rst
new file mode 100644
index 00000000..0f6f9b57
--- /dev/null
+++ b/docs/source/community-and-contributions/share-your-story.rst
@@ -0,0 +1,69 @@
+Share Your MapReader Story
+==========================
+
+Are you using MapReader in your research or projects? We are excited to learn
+about the diverse ways our tool is being put to use across different fields and
+applications. Your experiences can inspire and inform others, and we would love
+to feature your work in our case studies, presentations, and community calls.
+
+Why Share Your Story?
+---------------------
+
+**Highlight Your Work**: Gain visibility for your research or project by being
+featured in our case studies and community calls.
+
+**Inspire Others**: Help other users see the potential of MapReader through
+real-world applications.
+
+**Contribute to the Community**: Your insights can help improve MapReader and
+guide its future development.
+
+How to Share Your Story
+------------------------
+We've made it easy for you to share your MapReader experience. Here's how you
+can do it:
+
+1. **Prepare Your Story:**
+
+ *Description*: Provide a brief description of your project and how you are
+ using MapReader.
+
+ *Impact*: Explain the impact MapReader has had on your work.
+
+ *Visuals*: Include any relevant images, screenshots, or visualisations.
+
+ *Contact Information*: Let us know how we can get in touch with you for further details.
+
+2. **Submit Your Story:**
+
+ *Email*: Send your story to our Research Application Manager, `Kalle
+ Westerling `_ with the subject line
+ "MapReader Case Study".
+
+ *GitHub*: Open an issue in our GitHub repository with the label "Case
+ Study".
+
+3. **Review and Feature**
+
+ Once we receive your story, we will review it and get in touch with you for
+ any additional information. We will then feature your work in our case
+ studies, presentations, and community calls.
+
+We look forward to hearing from you and sharing your MapReader story with the
+rest of the community!
+
+Examples of User Stories
+-------------------------
+
+Here are a few examples of what a case study on MapReader could look like:
+
+**Historical Research**: Dr. Jane Doe used MapReader to analyze historical
+maps, uncovering new insights into urban development in the 19th century.
+
+**Education**: Prof. Jane Doe integrated MapReader into her digital humanities
+course, allowing students to engage with primary sources in new ways.
+
+.. We will want to update this section with real user stories once we start
+ receiving submissions. I think we want to make sure that the user stories
+ are not just about research but also about projects, teaching, etc. so that
+ we can show the diversity of use cases. - Kalle
diff --git a/docs/source/conf.py b/docs/source/conf.py
index f40875ba..e8990d7f 100644
--- a/docs/source/conf.py
+++ b/docs/source/conf.py
@@ -32,7 +32,7 @@
"sphinx.ext.napoleon",
"sphinx.ext.todo",
"sphinx_togglebutton",
- 'sphinxemoji.sphinxemoji',
+ "sphinxemoji.sphinxemoji",
]
templates_path = ["_templates"]
@@ -43,11 +43,13 @@
".md": "markdown",
}
+suppress_warnings = ["myst.header"]
+
# -- autoapi configuration -----
autoapi_dirs = ["../../mapreader"]
autoapi_type = "python"
-autoapi_root = "api"
+autoapi_root = "in-depth-resources/api"
autoapi_options = [
"members",
diff --git a/docs/source/getting-started/index.rst b/docs/source/getting-started/index.rst
new file mode 100644
index 00000000..dbd20c9d
--- /dev/null
+++ b/docs/source/getting-started/index.rst
@@ -0,0 +1,12 @@
+Getting Started
+===============
+
+..
+ TODO: Add intro to getting started
+
+
+.. toctree::
+ :maxdepth: 2
+
+ installation-instructions/index
+ troubleshooting-problems
diff --git a/docs/source/getting-started/installation-instructions/1-set-up-virtual-environment.rst b/docs/source/getting-started/installation-instructions/1-set-up-virtual-environment.rst
new file mode 100644
index 00000000..1b1c358f
--- /dev/null
+++ b/docs/source/getting-started/installation-instructions/1-set-up-virtual-environment.rst
@@ -0,0 +1,58 @@
+Step 1: Set up a virtual Python environment
+===========================================
+
+.. todo:: Add comments about how to get to conda in Windows
+
+The most recent version of MapReader supports Python versions 3.9+.
+
+Method 1: Using conda (recommended)
+------------------------------------
+
+We recommend installing MapReader using either Anaconda (`installation instructions here `__) or miniconda (`installation instructions here `__).
+A discussion of which of these to choose can be found `here `__.
+
+Once you have installed either Ananconda or miniconda, open your terminal and use the following commands to set up your virtual Python environment:
+
+- Create a new conda environment for ``mapreader`` (you can call this whatever you like, we use ``mapreader``):
+
+ .. code-block:: bash
+
+ conda create -n mapreader python=3.10
+
+ This will create a conda enviroment for you to install MapReader and its dependencies into.
+
+- Activate your conda environment:
+
+ .. code-block:: bash
+
+ conda activate mapreader
+
+Method 2: Using venv or other
+-----------------------------
+
+If you would like not to use conda, you are more than welcome to set up a virtual Python environment using other methods.
+
+For example, if you would like to use venv, open your terminal and use the following commands to set up your virtual Python environment:
+
+- First, importantly, check which version of Python your system is using:
+
+ .. code-block:: bash
+
+ python3 --version
+
+ If this returns a version below 3.9, you will need download an updated Python version.
+ You can do this by downloading from `here `__ (make sure you download the right one for your operating system).
+
+ You should then run the above command again to check your Python version has updated.
+
+- Create a new virtual Python environment for ``mapreader`` (you can call this whatever you like, we use ``mapreader``):
+
+ .. code-block:: bash
+
+ python3 -m venv mapreader
+
+- Activate your virtual environment:
+
+ .. code-block:: bash
+
+ source mapreader/bin/activate
diff --git a/docs/source/getting-started/installation-instructions/2-install-mapreader.rst b/docs/source/getting-started/installation-instructions/2-install-mapreader.rst
new file mode 100644
index 00000000..2c344b1f
--- /dev/null
+++ b/docs/source/getting-started/installation-instructions/2-install-mapreader.rst
@@ -0,0 +1,54 @@
+Step 2: Install MapReader
+==========================
+
+Method 1: Install from `PyPI `_
+--------------------------------------------------------------------
+
+If you want to use the latest stable release of MapReader and do not want/need access to the worked examples or MapReader code, we recommend installing from PyPI.
+This is probably the easiest way to install MapReader.
+
+- Install ``mapreader``:
+
+ .. code-block:: bash
+
+ pip install mapreader
+
+.. note:: To install the dev dependencies too use ``pip install "mapreader[dev]"`` instead.
+
+Method 2: Install from source
+-----------------------------
+
+If you want to keep up with the latest changes to MapReader, or want/need easy access to the worked examples or MapReader code, we reccommend installing from source.
+This method will create a ``MapReader`` directory on your machine which will contain all the MapReader code, docs and worked examples.
+
+.. note:: You will need to have `git `__ installed to use this method. If you are using conda, this can be done by running ``conda install git``. Otherwise, you should install git by following the instructions on `their website `__.
+
+- Clone the ``mapreader`` source code from the `MapReader GitHub repository `_:
+
+ .. code-block:: bash
+
+ git clone https://github.com/Living-with-machines/MapReader.git
+
+- Install ``mapreader``:
+
+ .. code-block:: bash
+
+ cd MapReader
+ pip install -v -e .
+
+.. note:: To install the dev dependencies too use ``pip install -v -e ".[dev]"`` instead.
+
+..
+ Method 3: Install via conda (**EXPERIMENTAL**)
+ ----------------------------------------------
+
+ If neither of the above methods work, you can try installing MapReader using conda.
+ This method is still in development so should be avoided for now.
+
+ - Install MapReader directly from the conda package:
+
+ .. code:: bash
+
+ conda install -c anothersmith -c conda-forge -c defaults --override-channels --strict-channel-priority mapreader
+
+ .. note:: The conda package seems to be sensitive to the precise priority of the conda channels, hence the use of the `--override-channels --strict-channel-priority` switches is required for this to work. Until this is resolve this installation method will be marked "experimental".
diff --git a/docs/source/getting-started/installation-instructions/3-add-virtual-environment-to-notebooks.rst b/docs/source/getting-started/installation-instructions/3-add-virtual-environment-to-notebooks.rst
new file mode 100644
index 00000000..b10051be
--- /dev/null
+++ b/docs/source/getting-started/installation-instructions/3-add-virtual-environment-to-notebooks.rst
@@ -0,0 +1,10 @@
+Step 3: Add virtual Python environment to notebooks
+===================================================
+
+- To allow the newly created Python virtual environment to show up in Jupyter notebooks, run the following command:
+
+.. code-block:: bash
+
+ python -m ipykernel install --user --name mapreader --display-name "Python (mr_py)"
+
+.. note:: if you have used a different name for your Python virtual environment replace the ``mapreader`` with whatever name you have used.
diff --git a/docs/source/getting-started/installation-instructions/index.rst b/docs/source/getting-started/installation-instructions/index.rst
new file mode 100644
index 00000000..69d697ff
--- /dev/null
+++ b/docs/source/getting-started/installation-instructions/index.rst
@@ -0,0 +1,16 @@
+Installation Instructions
+=========================
+
+.. note:: Run these commands from your terminal.
+
+There are three steps to setting up MapReader.
+You should choose one method within each step and follow the instructions for that method.
+
+.. note:: You do not need to use the same method between steps. i.e. It is completely fine to follow Method 1 for Step 1 and Method 2 for Step 2.
+
+.. toctree::
+ :maxdepth: 2
+
+ 1-set-up-virtual-environment
+ 2-install-mapreader
+ 3-add-virtual-environment-to-notebooks
diff --git a/docs/source/getting-started/troubleshooting-problems.rst b/docs/source/getting-started/troubleshooting-problems.rst
new file mode 100644
index 00000000..120ab8aa
--- /dev/null
+++ b/docs/source/getting-started/troubleshooting-problems.rst
@@ -0,0 +1,30 @@
+Troubleshooting
+===============
+
+M1 mac
+------
+
+If you are using an M1 mac and are having issues installing MapReader due to an error when installing numpy or scikit-image:
+
+- Try separately installing the problem packages (edit as needed) and then installing MapReader:
+
+ .. code-block:: bash
+
+ pip install numpy==1.21.5
+ pip install scikit-image==0.18.3
+ pip install mapreader
+
+- Try using conda to install the problem packages (edit as needed) and then pip to install MapReader:
+
+ .. code-block:: bash
+
+ conda install numpy==1.21.5
+ conda install scikit-image==0.18.3
+ pip install mapreader
+
+- Alternatively, you can try using a different version of openBLAS when installing:
+
+ .. code-block:: bash
+
+ brew install openblas
+ OPENBLAS="$(brew --prefix openblas)" pip install mapreader
diff --git a/docs/source/api/index.rst b/docs/source/in-depth-resources/api/index.rst
similarity index 90%
rename from docs/source/api/index.rst
rename to docs/source/in-depth-resources/api/index.rst
index 60ddceaa..57f327e0 100644
--- a/docs/source/api/index.rst
+++ b/docs/source/in-depth-resources/api/index.rst
@@ -6,6 +6,6 @@ This page contains auto-generated API reference documentation [#f1]_.
.. toctree::
:titlesonly:
- /api/mapreader/index
+ mapreader/index
.. [#f1] Created with `sphinx-autoapi `_
diff --git a/docs/source/in-depth-resources/coding-basics/index.rst b/docs/source/in-depth-resources/coding-basics/index.rst
new file mode 100644
index 00000000..9199d4bf
--- /dev/null
+++ b/docs/source/in-depth-resources/coding-basics/index.rst
@@ -0,0 +1,13 @@
+Coding Basics
+==============
+
+This section contains information on the basics of coding, including how to use the terminal, how to install Python packages, how to create virtual environments, and how to use Jupyter Notebooks.
+It is intended for users who are new to coding or who need a refresher on some of the basics.
+
+.. toctree::
+ :maxdepth: 1
+
+ terminal
+ python-packages
+ virtual-environments
+ jupyter-notebooks
diff --git a/docs/source/in-depth-resources/coding-basics/jupyter-notebooks.rst b/docs/source/in-depth-resources/coding-basics/jupyter-notebooks.rst
new file mode 100644
index 00000000..e9f8bcf5
--- /dev/null
+++ b/docs/source/in-depth-resources/coding-basics/jupyter-notebooks.rst
@@ -0,0 +1,60 @@
+Jupyter notebooks
+=================
+
+A Jupyter notebook is an interactive computational environment that allows you to write and run code, visualize data, and write narrative text all in the same place.
+It's a popular tool among data scientists and is commonly used for data analysis, machine learning, and scientific computing.
+Jupyter notebooks support multiple programming languages, but the most common language used is Python.
+You will notice that many of our "worked examples" are built in Jupyter notebooks so you can test run some of this code as soon as you have understood what the notebooks are, how to set them up on your computer, and how to run code in them.
+
+Key features of Jupyter notebooks include:
+
+- **Code execution**: You can write and run code in the notebook, and see the output immediately.
+- **Markdown cells**: You can write text in Markdown format to provide explanations, documentation, or commentary on your code.
+- **Rich output**: You can display images, plots, and other media directly in the notebook.
+- **Reproducibility**: Notebooks are a great way to document your code and analysis in a way that is easy to share and reproduce.
+- **Interactive widgets**: You can create interactive elements like sliders, buttons, and dropdowns to explore your data or control your code.
+
+Installing Jupyter notebooks
+----------------------------
+
+To install Jupyter notebooks, you can use the ``pip`` package manager, which comes pre-installed with Python.
+To install Jupyter, you can use the following command:
+
+.. code-block:: bash
+
+ pip install jupyter
+
+This will install the Jupyter package and all its dependencies.
+
+Running Jupyter notebooks
+-------------------------
+
+Once you have installed Jupyter, you can start the Jupyter notebook server by running the following command in your terminal:
+
+.. code-block:: bash
+
+ jupyter notebook
+
+This will open a new tab in your web browser with the Jupyter notebook interface.
+From there, you can create a new notebook, open an existing one, or run code in the notebook cells.
+
+Basic usage of Jupyter notebooks
+--------------------------------
+
+Once you have opened a Jupyter notebook, you can start writing and running code in the code cells.
+To run a cell, you can press ``Shift + Enter`` or click the "Run" button in the toolbar.
+
+You can also add new cells by clicking the "+" button in the toolbar, and you can change the cell type from code to Markdown by selecting the cell type from the dropdown menu.
+
+Notebooks are automatically saved as you work.
+You can also save them manually by clicking the "Save" button in the toolbar or pressing ``Ctrl + S``.
+
+Additional Resources
+--------------------
+
+If you're new to Jupyter notebooks, here are some great places to start:
+
+- `Introduction to Jupyter Notebooks `__
+- `How to use Jupyter Notebooks: A beginner's tutorial `__
+
+.. more??
diff --git a/docs/source/in-depth-resources/coding-basics/python-packages.rst b/docs/source/in-depth-resources/coding-basics/python-packages.rst
new file mode 100644
index 00000000..27dae2c5
--- /dev/null
+++ b/docs/source/in-depth-resources/coding-basics/python-packages.rst
@@ -0,0 +1,56 @@
+Python packages
+===============
+
+A Python package is a collection of modules bundled together, which can be reused across various projects.
+Unlike programs or apps that you can click and find in your start page or launch pad, Python packages are typically used within your code and usually do not have a graphical user interface (GUI).
+
+Common Uses of Python Packages
+------------------------------
+
+Python packages are used for a variety of purposes, including:
+
+- **Data analysis**: Packages like ``pandas`` and ``numpy`` are commonly used for data analysis and manipulation.
+- **Web development**: Packages like ``flask`` and ``django`` are used for building web applications.
+- **Machine learning**: Packages like ``scikit-learn`` and ``tensorflow`` are used for machine learning and artificial intelligence.
+- **Scientific computing**: Packages like ``scipy`` and ``matplotlib`` are used for scientific computing and data visualization.
+- **Utilities**: Packages like ``requests`` and ``beautifulsoup4`` are used for web scraping and interacting with web APIs.
+- ...and more!
+
+Installing Python Packages
+--------------------------
+
+Python packages can be installed using the ``pip`` package manager, which comes pre-installed with Python.
+To install a package, you can use the following command:
+
+.. code-block:: bash
+
+ pip install
+
+For instance, to install the ``pandas`` package, you can run:
+
+.. code-block:: bash
+
+ pip install pandas
+
+You can also install multiple packages at once by separating them with spaces:
+
+.. code-block:: bash
+
+ pip install pandas numpy matplotlib
+
+For more information on using ``pip``, you can refer to the `official documentation `_.
+Once a package is installed, you can import it into your Python code using the `import` statement:
+
+.. code-block:: python
+
+ import pandas
+
+This will allow you to use the functions and classes provided by the package in
+your code.
+
+Additional Resources
+--------------------
+
+- `Python Package Documentation `_: A tutorial on installing Python packages.
+- `Python Package Index (PyPI) `_: The official repository for Python packages.
+- `Python Packaging User Guide `_: A comprehensive guide to packaging and distributing Python packages.
diff --git a/docs/source/in-depth-resources/coding-basics/terminal.rst b/docs/source/in-depth-resources/coding-basics/terminal.rst
new file mode 100644
index 00000000..50917d93
--- /dev/null
+++ b/docs/source/in-depth-resources/coding-basics/terminal.rst
@@ -0,0 +1,65 @@
+Using the terminal
+==================
+
+A terminal is a command-line interface where you can type in commands and interact with your computer's operating system.
+It can be a powerful tool for programmers, allowing them to execute complex tasks with just a few keystrokes.
+However, it can also be intimidating for beginners who are not familiar with using it.
+
+What is a Terminal?
+-------------------
+
+A terminal is a text-based interface that allows you to interact with your computer's operating system.
+It provides a way to execute commands and run programs without using a graphical user interface (GUI).
+The terminal is also known bu different names, depending on the operating system you are using.
+
+- **Windows**: The terminal is typically called Command Prompt or PowerShell.
+- **macOS**: The terminal is simply called Terminal, and it uses a shell called Bash or Zsh.
+- **Linux**: The terminal is also called Terminal, and it commonly uses Bash.
+
+Why use the terminal?
+---------------------
+
+The terminal can be a powerful tool for programmers and developers.
+Here are some reasons why you might want to use the terminal:
+
+- **Efficiency**: The terminal allows you to execute commands quickly and efficiently, without having to navigate through menus and windows.
+- **Automation**: You can write scripts and automate repetitive tasks using the terminal.
+- **Remote access**: The terminal can be used to connect to remote servers and run commands on them.
+- **Development**: Many development tools and libraries are designed to be used from the terminal.
+
+Getting started with the terminal
+---------------------------------
+
+If you're new to using the terminal, it can be helpful to start with some basic commands and concepts.
+
+- **Navigating directories**:
+
+ - List files and directories: ``ls`` (macOS/Linux) or ``dir`` (Windows)
+ - Change directory: ``cd ``
+ - Show the current directory: ``pwd`` (macOS/Linux) or ``cd`` (Windows)
+
+- **Working with files**:
+
+ - Create a file: ``touch ``
+ - Create a new directory: ``mkdir ``
+ - Remove a file: ``rm ``
+ - Remove a directory: ``rm -r ``
+ - Copy a file: ``cp ``
+ - Move a file: ``mv ``
+ - View the contents of a file: ``cat `` (macOS/Linux) or ``type `` (Windows)
+
+- **Miscellaneous**:
+
+ - Display a line of text: ``echo ``
+ - Clear the terminal screen: ``clear`` (macOS/Linux) or ``cls`` (Windows)
+ - Exit the terminal: ``exit``
+
+Additional Resources
+--------------------
+
+Here are some resources to help you get started with using the terminal on your computer:
+
+- `Introduction to the command line `__
+- `Introduction to the bash command line `__
+- `Introduction to the Windows command line with PowerShell `__
+- `The Unix shell `__
diff --git a/docs/source/in-depth-resources/coding-basics/virtual-environments.rst b/docs/source/in-depth-resources/coding-basics/virtual-environments.rst
new file mode 100644
index 00000000..46ff4596
--- /dev/null
+++ b/docs/source/in-depth-resources/coding-basics/virtual-environments.rst
@@ -0,0 +1,84 @@
+Conda and python virtual environments
+======================================
+
+A virtual environment is a way to create an isolated environment in which you can install specific versions of packages and dependencies for your Python projects.
+This is useful because it allows you to avoid conflicts between different projects that may require different versions of the same package.
+In the installation instructions provided, there are two methods for setting up a virtual environment for MapReader: using Anaconda (also known as conda) or using venv, which is Python's native way of handling virtual environments.
+
+Benefits of using virtual environments
+--------------------------------------
+
+- **Isolation**: Each virtual environment is isolated from the system Python installation and other virtual environments, so you can have different versions of packages in each environment.
+- **Dependency management**: You can specify the exact versions of packages that your project depends on, making it easier to reproduce your environment on different machines.
+- **Sandboxing**: Virtual environments provide a sandboxed environment for your project, so you can experiment with different packages and configurations without affecting your system Python installation.
+- **Reproducibility**: By using virtual environments, you can ensure that your project will run the same way on different machines, regardless of the system Python installation or other dependencies.
+
+Creating a virtual environment with conda
+------------------------------------------
+
+Conda is a package manager that is commonly used for data science and scientific computing projects.
+It also includes a virtual environment manager that allows you to create and manage virtual environments for your Python projects.
+
+To create a virtual environment with conda, you can use the following command:
+
+.. code-block:: bash
+
+ conda create --name myenv
+
+This will create a new virtual environment named ``myenv``.
+
+To activate the virtual environment, you can use the following command:
+
+.. code-block:: bash
+
+ conda activate myenv
+
+Once the virtual environment is activated, you can install packages using ``conda`` or ``pip``, and they will be installed in the virtual environment rather than the system Python installation.
+
+To deactivate the virtual environment, you can use the following command:
+
+.. code-block:: bash
+
+ conda deactivate
+
+For more information on using conda and virtual environments, you can refer to the `official documentation `_.
+
+Creating a virtual environment with venv
+-----------------------------------------
+
+If you prefer to use Python's native virtual environment manager, you can use the ``venv`` module to create a virtual environment for your project.
+
+To create a virtual environment with ``venv``, you can use the following command:
+
+.. code-block:: bash
+
+ python -m venv myenv
+
+This will create a new virtual environment named ``myenv``.
+
+To activate the virtual environment, you can use the following command:
+
+.. code-block:: bash
+
+ source myenv/bin/activate
+
+Once the virtual environment is activated, you can install packages using ``pip``, and they will be installed in the virtual environment rather than the system Python installation.
+
+To deactivate the virtual environment, you can use the following command:
+
+.. code-block:: bash
+
+ deactivate
+
+For more information on using virtual environments in Python, you can refer to the `official documentation `_.
+
+Additional Resources
+--------------------
+
+Here are some resources to help you get started with virtual environments and Anaconda:
+
+- `Getting started with python environments (using conda) `__
+- `Why you need python environments and how to manage them with conda `__
+- `Virtual environments and packages `__
+
+.. more??
diff --git a/docs/source/Contribution-guide/GitHub-guide.rst b/docs/source/in-depth-resources/github-basics.rst
similarity index 100%
rename from docs/source/Contribution-guide/GitHub-guide.rst
rename to docs/source/in-depth-resources/github-basics.rst
diff --git a/docs/source/in-depth-resources/index.rst b/docs/source/in-depth-resources/index.rst
new file mode 100644
index 00000000..22a54302
--- /dev/null
+++ b/docs/source/in-depth-resources/index.rst
@@ -0,0 +1,13 @@
+In-Depth Resources
+==================
+
+..
+ TODO: Write intro to in-depth resources section
+
+.. toctree::
+ :maxdepth: 2
+
+ coding-basics/index
+ github-basics
+ worked-examples/index
+ api/index
diff --git a/docs/source/Worked-examples/Worked-examples.rst b/docs/source/in-depth-resources/worked-examples/geospatial-images.rst
similarity index 52%
rename from docs/source/Worked-examples/Worked-examples.rst
rename to docs/source/in-depth-resources/worked-examples/geospatial-images.rst
index b31c5598..2b981421 100644
--- a/docs/source/Worked-examples/Worked-examples.rst
+++ b/docs/source/in-depth-resources/worked-examples/geospatial-images.rst
@@ -1,30 +1,15 @@
-Worked Examples
-================
-
-We have provided a number of worked examples to demonstrate how to use MapReader.
-These examples can be found in the `worked_examples `_ directory of the repository.
-
-To run these, you will need to clone the MapReader repository and open the notebooks located in the `worked_examples` directory.
-This can be done by running the following commands in your terminal:
-
-.. code-block:: bash
-
- git clone https://github.com/Living-with-machines/MapReader.git
- cd MapReader/worked_examples/
- jupyter notebook
-
-.. note:: Make sure you set your notebook kernel to use your MapReader environment!
-
-
Geospatial images: Maps and earth observation imagery
------------------------------------------------------
+=====================================================
MapReader was developed for maps and geospatial images.
+..
+ TODO: Add a note here that says that you should look through step-by-step guidance before engaging with the worked examples to understand the workflow.
+
Classification of one-inch OS maps
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+----------------------------------
-.. image:: https://raw.githubusercontent.com/Living-with-machines/MapReader/main/figs/tutorial_classification_one_inch_maps_001.png
+.. image:: /_static/tutorial_classification_one_inch_maps_001.png
:width: 400px
:target: https://github.com/Living-with-machines/MapReader/tree/main/worked_examples/geospatial
@@ -41,7 +26,7 @@ It can be found `here `__.
-
-Classification of MNIST digits
-~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
-
-.. image:: https://raw.githubusercontent.com/Living-with-machines/MapReader/main/figs/tutorial_classification_mnist.png
- :width: 400px
- :target: https://github.com/Living-with-machines/MapReader/blob/main/worked_examples/non-geospatial/classification_mnist/Pipeline.ipynb
-
-In our ``classification_mnist`` example, we demonstrate how to use MapReader to classify MNIST digits.
-Importantly, this example demonstrates how to use MapReader to classify whole images instead of patches and therefore how MapReader can generalize to much broader use cases.
-It can be found `here `__.
diff --git a/docs/source/in-depth-resources/worked-examples/index.rst b/docs/source/in-depth-resources/worked-examples/index.rst
new file mode 100644
index 00000000..dbce9ffc
--- /dev/null
+++ b/docs/source/in-depth-resources/worked-examples/index.rst
@@ -0,0 +1,25 @@
+Worked Examples
+===============
+
+We have provided a number of worked examples to demonstrate how to use MapReader.
+These examples can be found in the `worked_examples `_ directory of the repository.
+
+To run these, you will need to clone the MapReader repository and open the notebooks located in the `worked_examples` directory.
+This can be done by running the following commands in your terminal:
+
+.. code-block:: bash
+
+ git clone https://github.com/Living-with-machines/MapReader.git
+ cd MapReader/worked_examples/
+ jupyter notebook
+
+.. note:: Make sure you set your notebook kernel to use your MapReader environment!
+
+..
+ TODO: Add a note here that says that you should look through step-by-step guidance before engaging with the worked examples to understand the workflow.
+
+.. toctree::
+ :maxdepth: 1
+
+ geospatial-images
+ non-geospatial-images
diff --git a/docs/source/in-depth-resources/worked-examples/non-geospatial-images.rst b/docs/source/in-depth-resources/worked-examples/non-geospatial-images.rst
new file mode 100644
index 00000000..c2a72dfe
--- /dev/null
+++ b/docs/source/in-depth-resources/worked-examples/non-geospatial-images.rst
@@ -0,0 +1,30 @@
+Non-geospatial images
+======================
+
+..
+ TODO: Add a note here that says that you should look through step-by-step guidance before engaging with the worked examples to understand the workflow.
+
+While MapReader was developed for maps and geospatial images, the package can also be used for non-geospatial images.
+We have provided two examples of this.
+
+Classification of plant phenotypes
+----------------------------------
+
+.. image:: /_static/tutorial_classification_plant_phenotype.png
+ :width: 400px
+ :target: https://github.com/Living-with-machines/MapReader/blob/main/worked_examples/non-geospatial/classification_plant_phenotype/Pipeline.ipynb
+
+In our ``classification_plant_phenotype`` example, we demonstrate how to use MapReader to classify plant phenotypes in images of plants.
+Importantly, this worked example demonstrates how to use MapReader with non-georeferenced images (e.g. non-georeferenced map images).
+It can be found `here `__.
+
+Classification of MNIST digits
+------------------------------
+
+.. image:: /_static/tutorial_classification_mnist.png
+ :width: 400px
+ :target: https://github.com/Living-with-machines/MapReader/blob/main/worked_examples/non-geospatial/classification_mnist/Pipeline.ipynb
+
+In our ``classification_mnist`` example, we demonstrate how to use MapReader to classify MNIST digits.
+Importantly, this example demonstrates how to use MapReader to classify whole images instead of patches and therefore how MapReader can generalize to much broader use cases.
+It can be found `here `__.
diff --git a/docs/source/index.rst b/docs/source/index.rst
index a77c2403..80ab9b57 100644
--- a/docs/source/index.rst
+++ b/docs/source/index.rst
@@ -1,41 +1,24 @@
MapReader
=========
-**A computer vision pipeline for exploring and analyzing images at scale**
+.. include:: ../../README.md
+ :parser: myst_parser.sphinx_
+ :start-after:
.. toctree::
:hidden:
:maxdepth: 2
- About
- Events
- Project-cv
- coding-basics/index
- Install
- Input-guidance
- User-guide/User-guide
- Worked-examples/Worked-examples
- api/index
- Coc
- Contribution-guide/Contribution-guide
- Developers-guide
- ways-of-working
-
-------------
-
-.. include:: ../../README.md
- :parser: myst_parser.sphinx_
-
--------------
-
-.. admonition:: To do list
- :class: dropdown
-
- .. todolist::
+ introduction-to-mapreader/index
+ getting-started/index
+ using-mapreader/index
+ in-depth-resources/index
+ community-and-contributions/index
-Indices and tables
-==================
+..
+ Indices and tables
+ ==================
-* :ref:`genindex`
-* :ref:`modindex`
-* :ref:`search`
+ * :ref:`genindex`
+ * :ref:`modindex`
+ * :ref:`search`
diff --git a/docs/source/introduction-to-mapreader/index.rst b/docs/source/introduction-to-mapreader/index.rst
new file mode 100644
index 00000000..85e7543c
--- /dev/null
+++ b/docs/source/introduction-to-mapreader/index.rst
@@ -0,0 +1,14 @@
+Introduction to MapReader
+=========================
+
+..
+ TODO: Add something here as a super high-level intro
+
+.. toctree::
+ :maxdepth: 1
+
+ what-is-mapreader
+ why-should-you-use-mapreader
+ who-might-be-interested-in-mapreader
+ what-skills-do-i-need-to-use-mapreader
+ project-curriculum-vitae
diff --git a/docs/source/Project-cv.rst b/docs/source/introduction-to-mapreader/project-curriculum-vitae.rst
similarity index 96%
rename from docs/source/Project-cv.rst
rename to docs/source/introduction-to-mapreader/project-curriculum-vitae.rst
index 62024593..535cd0a3 100644
--- a/docs/source/Project-cv.rst
+++ b/docs/source/introduction-to-mapreader/project-curriculum-vitae.rst
@@ -1,10 +1,12 @@
Project Curriculum Vitae
=========================
-.. Notes to editors:
-.. 1. Add links to slides/videos (always add slides to mapreader.team@gmail.com drive)
-.. 2. Use Chicago style format for citations
-.. 3. entries requiring more info left commented out for now
+..
+ Notes to editors:
+
+ 1. Add links to slides/videos (always add slides to mapreader.team@gmail.com drive)
+ 2. Use Chicago style format for citations
+ 3. entries requiring more info left commented out for now
Peer-reviewed publications
---------------------------
diff --git a/docs/source/introduction-to-mapreader/what-is-mapreader.rst b/docs/source/introduction-to-mapreader/what-is-mapreader.rst
new file mode 100644
index 00000000..303a3996
--- /dev/null
+++ b/docs/source/introduction-to-mapreader/what-is-mapreader.rst
@@ -0,0 +1,50 @@
+What is MapReader?
+===================
+
+MapReader is an end-to-end computer vision (CV) pipeline for exploring and analyzing images at scale.
+
+What is unique about MapReader?
+--------------------------------
+
+MapReader is based on the 'patchwork method' in which whole map images are sliced into a grid of squares or 'patches':
+
+.. image:: /_static/patchify.png
+
+This unique way of pre-processing map images enables the use of image classification to identify visual features within maps, in order to answer important research questions.
+
+What is 'the MapReader pipeline'?
+---------------------------------
+
+The MapReader pipeline consists of a linear sequence of tasks:
+
+.. image:: /_static/pipeline_explained.png
+
+Together, these tasks can be used to train a computer vision (CV) classifier to recognize visual features within maps and identify patches containing these features across entire map collections.
+
+What kind of visual features can MapReader help me identify?
+------------------------------------------------------------
+
+In order to train a CV classifier to recognize visual features within your maps, your features must have a homogeneous visual signal across your map collection (i.e. always be represented in the same way).
+
+What are the inputs and outputs of each stage in the MapReader pipeline?
+------------------------------------------------------------------------
+
+Download
+~~~~~~~~
+.. image:: /_static/in_out_download.png
+ :width: 600px
+
+Load
+~~~~
+.. image:: /_static/in_out_load.png
+ :width: 600px
+
+Annotate
+~~~~~~~~
+.. image:: /_static/in_out_annotate.png
+ :width: 600px
+
+Classify (Train and Predict)
+~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+.. image:: /_static/in_out_classify.png
+ :width: 600px
diff --git a/docs/source/introduction-to-mapreader/what-skills-do-i-need-to-use-mapreader.rst b/docs/source/introduction-to-mapreader/what-skills-do-i-need-to-use-mapreader.rst
new file mode 100644
index 00000000..33719591
--- /dev/null
+++ b/docs/source/introduction-to-mapreader/what-skills-do-i-need-to-use-mapreader.rst
@@ -0,0 +1,10 @@
+What skills/knowledge do I need to use MapReader?
+=================================================
+
+- Understanding of your map collection and knowledge of visual features you would like to identify within your maps
+- Basic understanding of how to use your terminal
+- Basic Python
+- Basic understanding of machine learning and computer vision (CV) methodology
+
+..
+ Add something here about how we have resources for you to learn these skills.
diff --git a/docs/source/introduction-to-mapreader/who-might-be-interested-in-mapreader.rst b/docs/source/introduction-to-mapreader/who-might-be-interested-in-mapreader.rst
new file mode 100644
index 00000000..e34c67b2
--- /dev/null
+++ b/docs/source/introduction-to-mapreader/who-might-be-interested-in-mapreader.rst
@@ -0,0 +1,8 @@
+Who might be interested in using MapReader?
+===========================================
+
+MapReader might be useful to you if:
+
+- You have access to a large collection of maps and want to identify visual features within them without having to manually annotating each map.
+- You want to quickly test different labels to help refine a research question that depends on identifying visual features within maps before/without committing to manual vector data creation.
+- Your maps were created before surveying accuracy reached modern standards, and therefore you do not want to create overly precise geolocated data based on the content of those maps.
diff --git a/docs/source/introduction-to-mapreader/why-should-you-use-mapreader.rst b/docs/source/introduction-to-mapreader/why-should-you-use-mapreader.rst
new file mode 100644
index 00000000..79a5f5d5
--- /dev/null
+++ b/docs/source/introduction-to-mapreader/why-should-you-use-mapreader.rst
@@ -0,0 +1,16 @@
+Why should you use MapReader?
+=============================
+
+MapReader becomes useful when the number of maps you wish to analyze exceeds the number which you (or your team) are willing to/capable of annotating manually.
+
+This exact number will vary depending on:
+
+- the size of your maps,
+- the features you want to find,
+- the skills you (or your team) have,
+- the amount of time at your disposal.
+
+Deciding to use MapReader, which uses deep learning computer vision (CV) models to predict the class of content on patches across many sheets, means weighing the pros and cons of working with the data output that is inferred by the model.
+Inferred data can be evaluated against expert-annotated data to understand its general quality (are all instances of a feature of interest identified by the model? does the model apply the correct label to that feature?), but in the full dataset there *will necessarily be* some percentage of error.
+
+MapReader creates output that you can link and analyze in relation to other geospatial datasets (e.g. census, gazetteers, toponyms in text corpora).
diff --git a/docs/source/User-guide/User-guide.rst b/docs/source/using-mapreader/index.rst
similarity index 52%
rename from docs/source/User-guide/User-guide.rst
rename to docs/source/using-mapreader/index.rst
index eb420ada..3fedc4b7 100644
--- a/docs/source/User-guide/User-guide.rst
+++ b/docs/source/using-mapreader/index.rst
@@ -1,23 +1,19 @@
-User Guide
-===========
+Using MapReader
+===============
.. todo:: Add a bit of text explaining format of user guide.
.. todo:: Explain what the user guide is for vs worked examples
-This User Guide provides guidance to all users of MapReader on how to use the MapReader package.
-We have tried to split our guide logically, into smaller sub-tasks, which may be used as part of an end-to-end run of the MapReader pipeline (detailed :doc:`here `).
+This user guide provides guidance to all users of MapReader on how to use the MapReader package.
+We have tried to split our guide logically, into smaller sub-tasks, which may be used as part of an end-to-end run of the MapReader pipeline (detailed :doc:`here `).
-Throughout this User Guide, we will use OS maps as examples.
+Throughout this user guide, we will use OS maps as examples.
**These are provided for illustrative purposes only.**
-Please read this User Guide **before** looking through the worked examples.
+Please read this user guide **before** looking through the worked examples.
.. toctree::
:maxdepth: 1
- Download
- Load
- Annotate
- Classify/Classify
- Post-process
- Spot-text
+ step-by-step-guide/index
+ input-guidance/index
diff --git a/docs/source/using-mapreader/input-guidance/accessing-maps-via-tileservers.rst b/docs/source/using-mapreader/input-guidance/accessing-maps-via-tileservers.rst
new file mode 100644
index 00000000..343b5e5d
--- /dev/null
+++ b/docs/source/using-mapreader/input-guidance/accessing-maps-via-tileservers.rst
@@ -0,0 +1,25 @@
+Accessing maps via TileServers
+==============================
+
+National Library of Scotland
+----------------------------
+
+It is possible to bring in any other georeferenced layers from the National Library of Scotland into MapReader.
+To do this, you would need to create a TileServer object and specify the metadata_path (the path to your metadata.json file) and the download_url (the WMTS or XYZ URL for your tileset) for your chosen tilelayer.
+
+`This page `__ lists some of the NLS's most popular georeferenced layers and provides links to their WMTS and XYZ URLs.
+If, for example, you wanted to use the "Ordnance Survey - 10 mile, General, 1955 - 1:633,600" in MapReader, you would need to look up its XYZ URL (``https://mapseries-tilesets.s3.amazonaws.com/ten_mile/general/{z}/{x}/{y}.png``) and insert it your MapReader code as shown below:
+
+.. code-block:: python
+
+ from mapreader import TileServer
+
+ my_ts = TileServer(
+ metadata_path="path/to/metadata.json",
+ download_url="https://mapseries-tilesets.s3.amazonaws.com/ten_mile/general/{z}/{x}/{y}.png",
+ )
+
+.. note:: You would need to generate the corresponding `metadata.json` before running this code.
+
+More information about using NLS georeferenced layers is available `here `__, including details about accessing metadata for each layer.
+Please note the Re-use terms for each layer, as these vary.
diff --git a/docs/source/using-mapreader/input-guidance/file-map-options.rst b/docs/source/using-mapreader/input-guidance/file-map-options.rst
new file mode 100644
index 00000000..bc3e1bec
--- /dev/null
+++ b/docs/source/using-mapreader/input-guidance/file-map-options.rst
@@ -0,0 +1,69 @@
+File/Map Options
+================
+
+The MapReader pipeline is explained in detail :doc:`here `.
+The inputs you will need for MapReader will depend on where you begin within the pipeline.
+
+Option 1 - If the map(s) you want have been georeferenced and made available via a Tile Server
+------------------------------------------------------------------------------------------------
+
+Some GLAM institutions or other services make digitized, georeferenced maps available via tile servers, for example as raster (XYZ, or 'slippy map') tiles.
+
+Instructions for accessing tile layers from one example collection is below:
+
+- National Library of Scotland tile layers
+
+If you want to download maps from a TileServer using MapReader's ``Download`` subpackage, you will need to begin with the 'Download' task.
+For this, you will need:
+
+* A ``json`` file containing metadata for each map sheet you would like to query/download.
+* The URL of the XYZ tile layer which you would like to access.
+
+At a minimum, for each map sheet, your ``json`` file should contain information on:
+
+- the name and URL of an individual sheet that is contained in the composite layer
+- the geometry of the sheet (i.e. its coordinates), so that, where applicable, individual sheets can be isolated from the whole layer
+- the coordinate reference system (CRS) used
+
+These should be saved in a format that looks something like this:
+
+.. code-block:: javascript
+
+ {
+ "type": "FeatureCollection",
+ "features": [{
+ "type": "Feature",
+ "geometry": {
+ "geometry_name": "the_geom",
+ "coordinates": [...]
+ },
+ "properties": {
+ "IMAGE": "...",
+ "WFS_TITLE": "..."
+ "IMAGEURL": "..."
+ },
+ }],
+ "crs": {
+ "name": "EPSG:4326"
+ },
+ }
+
+.. Check these links are still valid
+
+Some example metadata files, corresponding to the `OS one-inch 2nd edition maps `_ and `OS six-inch 1st edition maps for Scotland `_, are provided in ``MapReader/worked_examples/persistent_data``.
+
+Option 2 - If your files are already saved locally
+--------------------------------------------------
+
+If you already have your maps saved locally, you can skip the 'Download' task and move straight to 'Load'.
+
+If you would like to work with georeferenced maps, you will need either:
+
+* Your map images saved as standard, non-georeferenced, image files (e.g. JPEG, PNG or TIFF) along with a separate file containing georeferencing metadata you wish to associate to these map images **OR**
+* You map images saved as georeferenced image files (e.g. geoTIFF).
+
+Alternatively, if you would like to work with non-georeferenced maps/images, you will need:
+
+* Your images saved as standard image files (e.g. JPEG, PNG or TIFF).
+
+.. note:: It is possible to use non-georeferenced maps in MapReader, however none of the functionality around plotting patches based on geospatial coordinates will be possible. In this case, patches can be analyzed as regions within a map sheet, where the sheet itself may have some geospatial information associated with it (e.g. the geospatial coordinates for its center point, or the place name in its title).
diff --git a/docs/source/using-mapreader/input-guidance/index.rst b/docs/source/using-mapreader/input-guidance/index.rst
new file mode 100644
index 00000000..bc72ecbd
--- /dev/null
+++ b/docs/source/using-mapreader/input-guidance/index.rst
@@ -0,0 +1,14 @@
+Input Guidance
+==============
+
+..
+ Write intro to input guidance here.
+
+
+.. toctree::
+ :maxdepth: 1
+
+ file-map-options
+ accessing-maps-via-tileservers
+ preparing-metadata
+ recommended-directory-structure
diff --git a/docs/source/using-mapreader/input-guidance/preparing-metadata.rst b/docs/source/using-mapreader/input-guidance/preparing-metadata.rst
new file mode 100644
index 00000000..84ed07c1
--- /dev/null
+++ b/docs/source/using-mapreader/input-guidance/preparing-metadata.rst
@@ -0,0 +1,49 @@
+Preparing your metadata
+=======================
+
+MapReader uses the file names of your map images as unique identifiers (``image_id`` s).
+Therefore, if you would like to associate metadata to your map images, then, **at minimum**, your metadata must contain a column/header named ``image_id`` or ``name`` whose content is the file name of each map image.
+
+To load metadata (e.g. georeferencing information, publication dates or any other information about your images) into MapReader, your metadata must be in a `file format readable by Pandas `_.
+
+.. note:: Many map collections do not have item-level metadata, however even the minimal requirements here (a filename, geospatial coordinates, and CRS) will suffice for using MapReader. It is always a good idea to talk to the curators of the map collections you wish to use with MapReader to see if there are metadata files that can be shared for research purposes.
+
+
+Option 1 - Using a ``csv``, ``xls`` or ``xlsx`` file
+-----------------------------------------------------
+
+The simplest option is to save your metadata as a ``csv``, ``xls`` or ``xlsx`` file and load it directly into MapReader.
+
+.. note:: If you are using a ``csv`` file but the contents of you metadata contains commas, you will need to use another delimiter. We recommend using a pipe (``|``).
+
+If you are loading metadata from a ``csv``, ``xls`` or ``xlsx`` file, your file should be structures as follows:
+
++-----------+-----------------------------+------------------------+--------------+
+| image_id | column1 (e.g. coords) | column2 (e.g. region) | column3 |
++===========+=============================+========================+==============+
+| map1.png | (-4.8, 55.8, -4.2, 56.4) | Glasgow | ... |
++-----------+-----------------------------+------------------------+--------------+
+| map2.png | (-2.2, 53.2, -1.6, 53.8) | Manchester | ... |
++-----------+-----------------------------+------------------------+--------------+
+| map3.png | (-3.6, 50.1, -3.0, 50.8) | Dorset | ... |
++-----------+-----------------------------+------------------------+--------------+
+| ... | ... | ... | ... |
++-----------+-----------------------------+------------------------+--------------+
+
+Your file can contain as many columns/rows as you like, so long as it contains at least one named ``image_id`` or ``name``.
+
+.. Add comment about nature of coordinates as supplied by NLS vs what they might be for other collections
+
+Option 2 - Loading metadata from other file formats
+---------------------------------------------------
+
+As Pandas is able to read `a number of different file formats `_, you may still be able to use your metadata even if it is saved in a different file format.
+
+To do this, you will need to use Python to:
+
+1. Read your file using one of Pandas ``read_xxx`` methods and create a dataframe from it.
+2. Ensure there is an ``image_ID`` column to your dataframe (and add one if there is not).
+3. Pass your dataframe to MapReader.
+
+Depending on the structure/format of your metadata, this may end up being a fairly complex task and so is not recommended unless absolutely necessary.
+A conversation with the collection curator is always a good idea to check what formats metadata may already be available in/or easily made available in using existing workflows.
diff --git a/docs/source/using-mapreader/input-guidance/recommended-directory-structure.rst b/docs/source/using-mapreader/input-guidance/recommended-directory-structure.rst
new file mode 100644
index 00000000..e5d46734
--- /dev/null
+++ b/docs/source/using-mapreader/input-guidance/recommended-directory-structure.rst
@@ -0,0 +1,34 @@
+Recommended directory structure
+===============================
+
+If you are using non-georeferenced image files (e.g. PNG files) plus a separate metadata file, we recommend setting these up in the following directory structure:
+
+::
+
+ project
+ ├──your_notebook.ipynb
+ └──maps
+ ├── map1.png
+ ├── map2.png
+ ├── map3.png
+ ├── ...
+ └── metadata.csv
+
+This is the directory structure created by default when downloading maps using MapReader's ``Download`` subpackage.
+
+Alternatively, if you are using geo-referenced image files (eg. geoTIFF files), your will not need a metadata file, and so your files can be set up as follows:
+
+::
+
+ project
+ ├──your_notebook.ipynb
+ └──maps
+ ├── map1.tif
+ ├── map2.tif
+ ├── map3.tif
+ └── ...
+
+
+.. note:: Your map images should be stored in a flat directory. They **cannot be nested** (e.g. if you have states within a nation, or some other hierarchy or division).
+
+.. note:: Additionally, map images should be available locally or you should set up access via cloud storage. If you are working with a very large corpus of maps, you should consider running MapReader in a Virtual Machine with adequate storage.
diff --git a/docs/source/User-guide/Download.rst b/docs/source/using-mapreader/step-by-step-guide/1-download.rst
similarity index 96%
rename from docs/source/User-guide/Download.rst
rename to docs/source/using-mapreader/step-by-step-guide/1-download.rst
index 55af1b1f..47b22918 100644
--- a/docs/source/User-guide/Download.rst
+++ b/docs/source/using-mapreader/step-by-step-guide/1-download.rst
@@ -4,11 +4,11 @@ Download
.. todo:: Add comment saying navigate in your terminal to your working directory and then open a notebook from there. Shift right click on a folder in windows to copy path name.
.. todo:: Add instruction to create a new notebook.
-.. note:: Run these commands in a Jupyter notebook (or other IDE), ensuring you are in your `mapreader` python environment.
+.. note:: Run these commands in a Jupyter notebook (or other IDE), ensuring you are in your ``mapreader`` Python environment.
.. note:: You will need to update file paths to reflect your own machines directory structure.
-.. note:: If you already have your maps stored locally, you can skip this section and proceed on to the :doc:`Load ` part of the User Guide.
+.. note:: If you already have your maps stored locally, you can skip this section and proceed on to the :doc:`Load ` part of the User Guide.
MapReader's ``Download`` subpackage is used to download maps stored on as XYZ tile layers on a tile server.
It contains two classes for downloading maps:
@@ -29,7 +29,7 @@ SheetDownloader
---------------
To download map sheets, you must provide MapReader with a metadata file (usually a ``json`` file), which contains information about your map sheets.
-Guidance on what this metadata ``json`` should contain can be found in our :doc:`Input Guidance `.
+Guidance on what this metadata ``json`` should contain can be found in our :doc:`Input Guidance `.
An example is shown below:
.. code-block:: javascript
@@ -84,7 +84,7 @@ To help you visualize your metadata, the boundaries of the map sheets included i
my_ts.plot_all_metadata_on_map()
-.. image:: ../figures/plot_metadata_on_map.png
+.. image:: /_static/plot_metadata_on_map.png
:width: 400px
:align: center
@@ -178,17 +178,15 @@ If you would like to use a different zoom level, use the ``zoom_level`` argument
.. code-block:: python
- my_ts.get_grid_bb(zoom_level=16)
-
-.. note:: The higher the zoom level, the more detailed your maps will be (and so the larger the file size). MapReader will raise a warning if you are downloading more than 100MB of data, to bypass this you will need to add ``force=True`` when calling the function to download your maps.
+ my_ts.get_grid_bb(zoom_level=10)
For all download methods, you should also be aware of the following arguments:
- ``path_save`` - By default, this is set to ``maps`` so that your map images and metadata are saved in a directory called "maps". You can change this to save your map images and metadata in a different directory (e.g. ``path_save="my_maps_directory"``).
- ``metadata_fname`` - By default, this is set to ``metadata.csv``. You can change this to save your metadata with a different file name (e.g. ``metadata_fname="my_maps_metadata.csv"``).
- ``overwrite`` - By default, this is set to ``False`` and so if a map image exists already, the download is skipped and map images are not overwritten. Setting it to ``True`` (i.e. by specifying ``overwrite=True``) will result in existing map images being overwritten.
-- ``date_col`` - The key(s) to use when extracting the publication dates from your metadata.json.
-- ``metadata_to_save`` - A dictionary containing information about the metadata you'd like to transfer from your metadata.json to your metadata.csv. See below for further details.
+- ``date_col`` - The key(s) to use when extracting the publication dates from your ``metadata.json``.
+- ``metadata_to_save`` - A dictionary containing information about the metadata you'd like to transfer from your ``metadata.json`` to your ``metadata.csv``. See below for further details.
- ``force`` - If you are downloading more than 100MB of data, you will need to confirm that you would like to download this data by setting ``force=True``.
Using the default ``path_save`` and ``metadata_fname`` arguments will result in the following directory structure:
diff --git a/docs/source/User-guide/Load.rst b/docs/source/using-mapreader/step-by-step-guide/2-load.rst
similarity index 94%
rename from docs/source/User-guide/Load.rst
rename to docs/source/using-mapreader/step-by-step-guide/2-load.rst
index 66c0c0cb..45174123 100644
--- a/docs/source/User-guide/Load.rst
+++ b/docs/source/using-mapreader/step-by-step-guide/2-load.rst
@@ -1,7 +1,7 @@
Load
=====
-.. note:: Run these commands in a Jupyter notebook (or other IDE), ensuring you are in your `mr_py38` python environment.
+.. note:: Run these commands in a Jupyter notebook (or other IDE), ensuring you are in your ``mr_py38`` Python environment.
.. note:: You will need to update file paths to reflect your own machines directory structure.
@@ -28,7 +28,7 @@ or
my_files = loader("./path/to/files/", file_ext="png")
-For example, if you have downloaded your maps using the default settings of our ``Download`` subpackage or have set up your directory as recommended in our :doc:`Input Guidance `:
+For example, if you have downloaded your maps using the default settings of our ``Download`` subpackage or have set up your directory as recommended in our :doc:`Input Guidance `:
.. code-block:: python
@@ -59,15 +59,15 @@ If your image files are georeferenced and already contain metadata (e.g. geoTIFF
.. note:: This function will reproject your coordinates into "EPSG:4326". To change this specify ``target_crs``.
-Or, if you have separate metadata (e.g. a ``csv``, ``xls`` or ``xlsx`` file or, a pandas dataframe), use:
+Or, if you have separate metadata (e.g. a ``csv``, ``xls`` or ``xlsx`` file or, a Pandas dataframe), use:
.. code-block:: python
my_files.add_metadata(metadata="./path/to/metadata.csv")
-.. note:: Specific guidance on preparing your metadata file/dataframe can be found on our :doc:`Input Guidance ` page.
+.. note:: Specific guidance on preparing your metadata file/dataframe can be found on our :doc:`Input Guidance ` page.
-For example, if you have downloaded your maps using the default settings of our ``Download`` subpackage or have set up your directory as recommended in our `Input Guidance `:
+For example, if you have downloaded your maps using the default settings of our ``Download`` subpackage or have set up your directory as recommended in our `Input Guidance `:
.. code-block:: python
@@ -79,10 +79,10 @@ For example, if you have downloaded your maps using the default settings of our
Other arguments you may want to specify when adding metadata to your images include:
- - ``index_col`` - By default, this is set to ``0`` so the first column of your csv/excel spreadsheet will be used as the index column when creating a pandas dataframe. If you would like to use a different column you can specify ``index_col``.
+ - ``index_col`` - By default, this is set to ``0`` so the first column of your ``csv``/Excel spreadsheet will be used as the index column when creating a Pandas dataframe. If you would like to use a different column you can specify ``index_col``.
- ``columns`` - By default, the ``add_metadata()`` method will add all the columns in your metadata to your ``MapImages`` object. If you would like to add only specific columns, you can pass a list of these as the ``columns``\s argument (e.g. ``columns=[`name`, `coordinates`, `region`]``) to add only these columns to your ``MapImages`` object.
- ``ignore_mismatch``- By default, this is set to ``False`` so that an error is given if the images in your ``MapImages`` object are mismatched to your metadata. Setting ``ignore_mismatch`` to ``True`` (by specifying ``ignore_mismatch=True``) will allow you to bypass this error and add mismatched metadata. Only metadata corresponding to images in your ``MapImages`` object will be added.
- - ``delimiter`` - By default, this is set to ``|``. If your csv file is delimited using a different delimiter you should specify the delimiter argument.
+ - ``delimiter`` - By default, this is set to ``|``. If your ``csv`` file is delimited using a different delimiter you should specify the delimiter argument.
.. note:: In MapReader versions < 1.0.7, coordinates were miscalculated. To correct this, use the ``add_coords_from_grid_bb()`` method to calculate new, correct coordinates.
@@ -90,7 +90,7 @@ For example, if you have downloaded your maps using the default settings of our
Patchify
----------
-Once you've loaded in all your data, you'll then need to :doc:`'patchify' ` your images.
+Once you've loaded in all your data, you'll then need to :doc:`'patchify' ` your images.
Creating patches from your parent images is a core intellectual and technical task within MapReader.
Choosing the size of your patches (and whether you want to measure them in pixels or in meters) is an important decision and will depend upon the research question you are trying to answer:
@@ -283,7 +283,7 @@ To view a random sample of your images, use:
my_files.show_sample(num_samples=3)
-.. image:: ../figures/show_sample_parent.png
+.. image:: /_static/show_sample_parent.png
:width: 400px
@@ -295,7 +295,7 @@ If, however, you want to see a random sample of your patches use the ``tree_leve
my_files.show_sample(num_samples=3, tree_level="patch")
-.. image:: ../figures/show_sample_child.png
+.. image:: /_static/show_sample_child.png
:width: 400px
@@ -310,7 +310,7 @@ e.g. :
patch_list = my_files.list_patches()
my_files.show(patch_list[250:300])
-.. image:: ../figures/show.png
+.. image:: /_static/show.png
:width: 400px
@@ -323,7 +323,7 @@ or
files_to_show = [patch_list[0], patch_list[350], patch_list[400]]
my_files.show(files_to_show)
-.. image:: ../figures/show_list.png
+.. image:: /_static/show_list.png
:width: 400px
@@ -343,7 +343,7 @@ This can be done using:
parent_list = my_files.list_parents()
my_files.show_parent(parent_list[0])
-.. image:: ../figures/show_par.png
+.. image:: /_static/show_par.png
:width: 400px
@@ -397,7 +397,7 @@ e.g. to view "mean_pixel_R" on your patches:
parent_list = my_files.list_parents()
my_files.show_parent(parent_list[0], column_to_plot="mean_pixel_R")
-.. image:: ../figures/show_par_RGB.png
+.. image:: /_static/show_par_RGB.png
:width: 400px
If you want to see your image underneath, you can specify the ``alpha`` argument, which sets the transparency of your plotted values.
@@ -411,7 +411,7 @@ e.g. to view "mean_pixel_R" on your patches:
parent_list = my_files.list_parents()
my_files.show_parent(parent_list[0], column_to_plot="mean_pixel_R", alpha=0.5)
-.. image:: ../figures/show_par_RGB_0.5.png
+.. image:: /_static/show_par_RGB_0.5.png
:width: 400px
.. note:: The ``column_to_plot`` argument can also be used with the ``show()`` method.
diff --git a/docs/source/User-guide/Annotate.rst b/docs/source/using-mapreader/step-by-step-guide/3-annotate.rst
similarity index 96%
rename from docs/source/User-guide/Annotate.rst
rename to docs/source/using-mapreader/step-by-step-guide/3-annotate.rst
index b079c108..89df007f 100644
--- a/docs/source/User-guide/Annotate.rst
+++ b/docs/source/using-mapreader/step-by-step-guide/3-annotate.rst
@@ -10,7 +10,7 @@ MapReader's ``Annotate`` subpackage is used to interactively annotate images (e.
Annotate your images
----------------------
-.. note:: Run these commands in a Jupyter notebook (or other IDE), ensuring you are in your `mr_py38` python environment.
+.. note:: Run these commands in a Jupyter notebook (or other IDE), ensuring you are in your `mr_py38` Python environment.
To prepare your annotations, you must specify a number of parameters when initializing the Annotator class.
@@ -51,7 +51,7 @@ e.g. :
username="rosie",
)
-.. note:: You can pass either a pandas DataFrame or the path to a csv file as the ``patch_df`` and ``parent_df`` arguments.
+.. note:: You can pass either a Pandas DataFrame or the path to a ``csv`` file as the ``patch_df`` and ``parent_df`` arguments.
In the above examples, the following parameters are also specified:
@@ -230,7 +230,7 @@ If you need to know the name of the annotations file, you may refer to a propert
The file will be located in the ``annotations_dir`` that you may have passed as a keyword argument when you set up the ``Annotator`` instance.
If you didn't provide a keyword argument, it will be in the ``./annotations`` directory.
-For example, if you have downloaded your maps using the default settings of our ``Download`` subpackage or have set up your directory as recommended in our :doc:`Input Guidance `, and then saved your patches using the default settings:
+For example, if you have downloaded your maps using the default settings of our ``Download`` subpackage or have set up your directory as recommended in our :doc:`Input Guidance `, and then saved your patches using the default settings:
::
diff --git a/docs/source/User-guide/Classify/Classify.rst b/docs/source/using-mapreader/step-by-step-guide/4-classify/index.rst
similarity index 79%
rename from docs/source/User-guide/Classify/Classify.rst
rename to docs/source/using-mapreader/step-by-step-guide/4-classify/index.rst
index df68ce6b..64144df7 100644
--- a/docs/source/User-guide/Classify/Classify.rst
+++ b/docs/source/using-mapreader/step-by-step-guide/4-classify/index.rst
@@ -1,7 +1,7 @@
Classify (Train and Infer)
==========================
-.. note:: Run these commands in a Jupyter notebook (or other IDE), ensuring you are in your `mapreader` python environment.
+.. note:: Run these commands in a Jupyter notebook (or other IDE), ensuring you are in your ``mapreader`` Python environment.
.. note:: You will need to update file paths to reflect your own machines directory structure.
@@ -20,12 +20,12 @@ This is all done within MapReader's ``ClassifierContainer()`` class, which is us
- Predict labels of unannotated images (model inference).
- Visualize datasets and predictions.
-If you already have a fine-tuned model, you can skip to the :doc:`Infer labels using a fine-tuned model ` page.
+If you already have a fine-tuned model, you can skip to the :doc:`Infer labels using a fine-tuned model ` page.
-If not, you should proceed to the :doc:`Train/fine-tune a classifier ` page.
+If not, you should proceed to the :doc:`Train/fine-tune a classifier ` page.
.. toctree::
:maxdepth: 1
- Train
- Infer
+ train
+ infer
diff --git a/docs/source/User-guide/Classify/Infer.rst b/docs/source/using-mapreader/step-by-step-guide/4-classify/infer.rst
similarity index 96%
rename from docs/source/User-guide/Classify/Infer.rst
rename to docs/source/using-mapreader/step-by-step-guide/4-classify/infer.rst
index cdfaa6c5..ccabee35 100644
--- a/docs/source/User-guide/Classify/Infer.rst
+++ b/docs/source/using-mapreader/step-by-step-guide/4-classify/infer.rst
@@ -102,7 +102,7 @@ This can be done by loading a dataframe containing the paths to your patches:
infer = PatchDataset("./patch_df.csv", delimiter=",", transform="test")
-.. note:: You can create this ``.csv`` file using the ``.convert_image(save=True)`` method on your ``MapImages`` object (follow instructions in the :doc:`Load ` user guidance).
+.. note:: You can create this ``.csv`` file using the ``.convert_image(save=True)`` method on your ``MapImages`` object (follow instructions in the :doc:`Load ` user guidance).
The ``transform`` argument is used to specify which `image transforms `__ to use on your patch images.
See :ref:`this section` for more information on transforms.
@@ -172,7 +172,7 @@ For example, to load the predictions for the "infer" dataset:
#EXAMPLE
my_maps.add_metadata("./infer_predictions_patch_df.csv", tree_level='patch')
-From here, you can use the ``.show_parent()`` method to visualize your predictions on the parent images as shown in the :doc:`Load ` user guide:
+From here, you can use the ``.show_parent()`` method to visualize your predictions on the parent images as shown in the :doc:`Load ` user guide:
.. code-block:: python
@@ -181,4 +181,4 @@ From here, you can use the ``.show_parent()`` method to visualize your predictio
parent_list = my_maps.list_parents()
my_maps.show_parent(parent_list[0], column_to_plot="conf", vmin=0, vmax=1, alpha=0.5, patch_border=False)
-Refer to the :doc:`Load ` user guidance for further details on how these methods work.
+Refer to the :doc:`Load ` user guidance for further details on how these methods work.
diff --git a/docs/source/User-guide/Classify/Train.rst b/docs/source/using-mapreader/step-by-step-guide/4-classify/train.rst
similarity index 98%
rename from docs/source/User-guide/Classify/Train.rst
rename to docs/source/using-mapreader/step-by-step-guide/4-classify/train.rst
index 5aa6734a..dd1a4ae3 100644
--- a/docs/source/User-guide/Classify/Train.rst
+++ b/docs/source/using-mapreader/step-by-step-guide/4-classify/train.rst
@@ -19,7 +19,7 @@ First, load in your annotations using:
annotated_images = AnnotationsLoader()
annotated_images.load(annotations = "./path/to/annotations.csv")
-For example, if you have set up your directory as recommended in our :doc:`Input Guidance `, and then saved your patches and annotations using the default settings:
+For example, if you have set up your directory as recommended in our :doc:`Input Guidance `, and then saved your patches and annotations using the default settings:
.. code-block:: python
@@ -65,7 +65,7 @@ For example, to show your "railspace" label:
.. todo:: update this pic
-.. image:: ../../figures/show_image_labels_10.png
+.. image:: /_static/show_image_labels_10.png
:width: 400px
@@ -78,7 +78,7 @@ The ``.review_labels()`` method, which returns an interactive tool for adjusting
annotated_images.review_labels()
-.. image:: ../../figures/review_labels.png
+.. image:: /_static/review_labels.png
:width: 400px
@@ -515,7 +515,7 @@ e.g. to plot the loss during each epoch of training and validation:
legends=["Train", "Valid"],
)
-.. image:: ../../figures/loss.png
+.. image:: /_static/loss.png
:width: 400px
@@ -535,7 +535,7 @@ To see a sample of your predictions, use:
my_classifier.show_inference_sample_results(label="railspace")
-.. image:: ../../figures/inference_sample_results.png
+.. image:: /_static/inference_sample_results.png
:width: 400px
@@ -587,6 +587,7 @@ e.g. to view the `Area Under the Receiver Operating Characteristic Curve (ROC AU
e.g. to view f-scores per class for each class in your labels map:
.. code-block:: python
+
for label_id, label_name in annotated_images.labels_map.items():
print(label_name, my_classifier.metrics['epoch_fscore_'+str(label_id)+'_test'])
@@ -626,7 +627,7 @@ To do this, you will need to create a new dataset containing your patches:
infer = PatchDataset("./patch_df.csv", delimiter=",", transform="test")
-.. note:: You should have created this ``.csv`` file using the ``.convert_image(save=True)`` method on your ``MapImages`` object (follow instructions in the :doc:`Load ` user guidance).
+.. note:: You should have created this ``.csv`` file using the ``.convert_image(save=True)`` method on your ``MapImages`` object (follow instructions in the :doc:`Load ` user guidance).
The ``transform`` argument is used to specify which `image transforms `__ to use on your patch images.
See :ref:`this section` for more information on transforms.
@@ -692,7 +693,7 @@ For example, to load the predictions for the "infer" dataset:
#EXAMPLE
my_maps.add_metadata("./infer_predictions_patch_df.csv", tree_level='patch')
-From here, you can use the ``.show_parent()`` method to visualize your predictions on the parent images as shown in the :doc:`Load ` user guide:
+From here, you can use the ``.show_parent()`` method to visualize your predictions on the parent images as shown in the :doc:`Load ` user guide:
.. code-block:: python
@@ -701,4 +702,4 @@ From here, you can use the ``.show_parent()`` method to visualize your predictio
parent_list = my_maps.list_parents()
my_maps.show_parent(parent_list[0], column_to_plot="conf", vmin=0, vmax=1, alpha=0.5, patch_border=False)
-Refer to the :doc:`Load ` user guidance for further details on how these methods work.
+Refer to the :doc:`Load ` user guidance for further details on how these methods work.
diff --git a/docs/source/User-guide/Post-process.rst b/docs/source/using-mapreader/step-by-step-guide/5-post-process.rst
similarity index 95%
rename from docs/source/User-guide/Post-process.rst
rename to docs/source/using-mapreader/step-by-step-guide/5-post-process.rst
index 594466a5..6afd916a 100644
--- a/docs/source/User-guide/Post-process.rst
+++ b/docs/source/using-mapreader/step-by-step-guide/5-post-process.rst
@@ -8,9 +8,9 @@ To implement this, for a given patch, the code checks whether any of the 8 surro
The user can then choose how to relabel the patch (e.g. 'railspace' -> 'no').
To run the post-processing code, you will need to have saved the predictions from your model in the format expected for the post-processing code.
-See the :doc:`/User-guide/Classify/Classify` docs for more on this.
+See the :doc:`/using-mapreader/step-by-step-guide/4-classify/index` docs for more on this.
-If you have your predictions saved in a csv file, you will first need to load them into a pandas DataFrame:
+If you have your predictions saved in a ``csv`` file, you will first need to load them into a Pandas DataFrame:
.. code-block:: python
diff --git a/docs/source/User-guide/Spot-text.rst b/docs/source/using-mapreader/step-by-step-guide/6-spot-text.rst
similarity index 95%
rename from docs/source/User-guide/Spot-text.rst
rename to docs/source/using-mapreader/step-by-step-guide/6-spot-text.rst
index 20779b7a..71659c9c 100644
--- a/docs/source/User-guide/Spot-text.rst
+++ b/docs/source/using-mapreader/step-by-step-guide/6-spot-text.rst
@@ -85,7 +85,7 @@ You will need to experiment with the amount of overlap to find the best results
.. note::
Greater overlaps will create more patches and result in greater computational costs when running.
-See the :doc:`Load ` user guide for more information on how to create patches.
+See the :doc:`Load ` user guide for more information on how to create patches.
Set-up the runner
-----------------
@@ -102,7 +102,7 @@ e.g. for the ``DPTextDETRRunner``, if you choose the "ArT/R_50_poly.yaml", you s
e.g. for the ``DeepSoloRunner``, if you choose the "R_50/IC15/finetune_150k_tt_mlt_13_15_textocr.yaml", you should download the "ic15_res50_finetune_synth-tt-mlt-13-15-textocr.pth" model weights file from the DeepSolo repo.
You will also need to load your patch and parent dataframes.
-Assuming you have saved them, as shown in the :doc:`Load ` user guide, you can load them like so:
+Assuming you have saved them, as shown in the :doc:`Load ` user guide, you can load them like so:
.. code-block:: python
@@ -162,10 +162,10 @@ If two polygons overlap with intersection over area greater than the minimum IoA
Below are two examples of this:
-.. image:: ../figures/IoA.png
+.. image:: /_static/IoA.png
:width: 400px
-.. image:: ../figures/IoA_0.9.png
+.. image:: /_static/IoA_0.9.png
:width: 400px
By default, the minimum IoA is set to 0.7 so the deduplication algorithm will only remove the smaller polygon in the second example.
@@ -176,7 +176,7 @@ You can adjust the minimum IoA by setting the ``min_ioa`` argument:
patch_preds_df = my_runner.run_all(return_dataframe=True, min_ioa=0.9)
-Higher ``min_ioa``values will mean a tighter threshold for identifying two polygons as duplicates.
+Higher ``min_ioa`` values will mean a tighter threshold for identifying two polygons as duplicates.
If you'd like to run the runner on a single patch, you can also just run on one image:
@@ -257,7 +257,7 @@ As above, use the ``border_color``, ``text_color`` and ``figsize`` arguments to
)
-You can then save these predictions to a csv file:
+You can then save these predictions to a ``csv`` file:
.. code-block:: python
diff --git a/docs/source/using-mapreader/step-by-step-guide/index.rst b/docs/source/using-mapreader/step-by-step-guide/index.rst
new file mode 100644
index 00000000..8f6634ec
--- /dev/null
+++ b/docs/source/using-mapreader/step-by-step-guide/index.rst
@@ -0,0 +1,14 @@
+Step-by-step Guide to Using MapReader
+======================================
+
+This guide will walk you through the steps to use MapReader to read and process a map.
+
+.. toctree::
+ :maxdepth: 2
+
+ 1-download
+ 2-load
+ 3-annotate
+ 4-classify/index
+ 5-post-process
+ 6-spot-text
diff --git a/figs/MapReader_pipeline.png b/figs/MapReader_pipeline.png
deleted file mode 100644
index 6beab518..00000000
Binary files a/figs/MapReader_pipeline.png and /dev/null differ
diff --git a/figs/mapreader_paper.png b/figs/mapreader_paper.png
deleted file mode 100644
index e00dc58d..00000000
Binary files a/figs/mapreader_paper.png and /dev/null differ
diff --git a/mapreader/__init__.py b/mapreader/__init__.py
index fba33175..224dd264 100644
--- a/mapreader/__init__.py
+++ b/mapreader/__init__.py
@@ -34,5 +34,7 @@
import mapreader
+
def print_version():
+ """Print the current version of mapreader."""
print(mapreader.__version__)
diff --git a/mapreader/annotate/annotator.py b/mapreader/annotate/annotator.py
index f04251ea..dce7f92a 100644
--- a/mapreader/annotate/annotator.py
+++ b/mapreader/annotate/annotator.py
@@ -680,7 +680,8 @@ def annotate(
Notes
-----
- This method is a wrapper for the ``_annotate`` method.
+ This method is a wrapper for the
+ :meth:`~.annotate.annotator.Annotate._annotate` method.
"""
if sortby is not None:
self._sortby = sortby
diff --git a/mapreader/classify/classifier.py b/mapreader/classify/classifier.py
index e8d1af8e..4a15aa85 100644
--- a/mapreader/classify/classifier.py
+++ b/mapreader/classify/classifier.py
@@ -31,6 +31,77 @@
class ClassifierContainer:
+ """
+ A class to store and train a PyTorch model.
+
+ Parameters
+ ----------
+ model : str, nn.Module or None
+ The PyTorch model to add to the object.
+
+ - If passed as a string, will run ``_initialize_model(model, **kwargs)``. See https://pytorch.org/vision/0.8/models.html for options.
+ - Must be ``None`` if ``load_path`` is specified as model will be loaded from file.
+
+ labels_map: Dict or None
+ A dictionary containing the mapping of each label index to its label, with indices as keys and labels as values (i.e. idx: label).
+ Can only be ``None`` if ``load_path`` is specified as labels_map will be loaded from file.
+ dataloaders: Dict or None
+ A dictionary containing set names as keys and dataloaders as values (i.e. set_name: dataloader).
+ device : str, optional
+ The device to be used for training and storing models.
+ Can be set to "default", "cpu", "cuda:0", etc. By default, "default".
+ input_size : int, optional
+ The expected input size of the model. Default is ``(224,224)``.
+ is_inception : bool, optional
+ Whether the model is an Inception-style model.
+ Default is ``False``.
+ load_path : str, optional
+ The path to an ``.obj`` file containing a
+ force_device : bool, optional
+ Whether to force the use of a specific device.
+ If set to ``True``, the default device is used.
+ Defaults to ``False``.
+ kwargs : Dict
+ Keyword arguments to pass to the
+ :meth:`~.classify.classifier.ClassifierContainer._initialize_model`
+ method (if passing ``model`` as a string).
+
+ Attributes
+ ----------
+ device : torch.device
+ The device being used for training and storing models.
+ dataloaders : dict
+ A dictionary to store dataloaders for the model.
+ labels_map : dict
+ A dictionary mapping label indices to their labels.
+ dataset_sizes : dict
+ A dictionary to store sizes of datasets for the model.
+ model : torch.nn.Module
+ The model.
+ input_size : None or tuple of int
+ The size of the input to the model.
+ is_inception : bool
+ A flag indicating if the model is an Inception model.
+ optimizer : None or torch.optim.Optimizer
+ The optimizer being used for training the model.
+ scheduler : None or torch.optim.lr_scheduler._LRScheduler
+ The learning rate scheduler being used for training the model.
+ criterion : None or nn.modules.loss._Loss
+ The criterion to use for training the model.
+ metrics : dict
+ A dictionary to store the metrics computed during training.
+ last_epoch : int
+ The last epoch number completed during training.
+ best_loss : torch.Tensor
+ The best validation loss achieved during training.
+ best_epoch : int
+ The epoch in which the best validation loss was achieved during
+ training.
+ tmp_save_filename : str
+ A temporary file name to save checkpoints during training and
+ validation.
+ """
+
def __init__(
self,
model: str | nn.Module | None,
@@ -43,75 +114,6 @@ def __init__(
force_device: bool | None = False,
**kwargs,
):
- """
- Initialize an ClassifierContainer object.
-
- Parameters
- ----------
- model : str, nn.Module or None
- The PyTorch model to add to the object.
-
- - If passed as a string, will run ``_initialize_model(model, **kwargs)``. See https://pytorch.org/vision/0.8/models.html for options.
- - Must be ``None`` if ``load_path`` is specified as model will be loaded from file.
-
- labels_map: Dict or None
- A dictionary containing the mapping of each label index to its label, with indices as keys and labels as values (i.e. idx: label).
- Can only be ``None`` if ``load_path`` is specified as labels_map will be loaded from file.
- dataloaders: Dict or None
- A dictionary containing set names as keys and dataloaders as values (i.e. set_name: dataloader).
- device : str, optional
- The device to be used for training and storing models.
- Can be set to "default", "cpu", "cuda:0", etc. By default, "default".
- input_size : int, optional
- The expected input size of the model. Default is ``(224,224)``.
- is_inception : bool, optional
- Whether the model is an Inception-style model.
- Default is ``False``.
- load_path : str, optional
- The path to an ``.obj`` file containing a
- force_device : bool, optional
- Whether to force the use of a specific device.
- If set to ``True``, the default device is used.
- Defaults to ``False``.
- kwargs : Dict
- Keyword arguments to pass to the ``_initialize_model()`` method (if passing ``model`` as a string).
-
- Attributes
- ----------
- device : torch.device
- The device being used for training and storing models.
- dataloaders : dict
- A dictionary to store dataloaders for the model.
- labels_map : dict
- A dictionary mapping label indices to their labels.
- dataset_sizes : dict
- A dictionary to store sizes of datasets for the model.
- model : torch.nn.Module
- The model.
- input_size : None or tuple of int
- The size of the input to the model.
- is_inception : bool
- A flag indicating if the model is an Inception model.
- optimizer : None or torch.optim.Optimizer
- The optimizer being used for training the model.
- scheduler : None or torch.optim.lr_scheduler._LRScheduler
- The learning rate scheduler being used for training the model.
- criterion : None or nn.modules.loss._Loss
- The criterion to use for training the model.
- metrics : dict
- A dictionary to store the metrics computed during training.
- last_epoch : int
- The last epoch number completed during training.
- best_loss : torch.Tensor
- The best validation loss achieved during training.
- best_epoch : int
- The epoch in which the best validation loss was achieved during
- training.
- tmp_save_filename : str
- A temporary file name to save checkpoints during training and
- validation.
- """
-
# set up device
if device in ["default", None]:
self.device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
@@ -624,7 +626,7 @@ def inference(
Notes
-----
This method calls the
- :meth:`mapreader.train.classifier.classifier.train` method with the
+ :meth:`~.train.classifier.classifier.train` method with the
``num_epochs`` set to ``1`` and all the other parameters specified in
the function arguments.
"""
@@ -674,7 +676,7 @@ def train(
Train the model on the specified phases for a given number of epochs.
Wrapper function for
- :meth:`mapreader.train.classifier.classifier.train_core` method to
+ :meth:`~.train.classifier.classifier.train_core` method to
capture exceptions (``KeyboardInterrupt`` is the only supported
exception currently).
@@ -716,7 +718,7 @@ def train(
Notes
-----
Refer to the documentation of
- :meth:`mapreader.train.classifier.classifier.train_core` for more
+ :meth:`~.train.classifier.classifier.train_core` for more
information.
"""
@@ -781,16 +783,19 @@ def train_core(
Raises
------
ValueError
- If the criterion is not set. Use the ``add_criterion`` method to
- set the criterion.
+ If the criterion is not set. Use the
+ :meth:`~.classify.classifier.ClassifierContainer.add_criterion`
+ method to set the criterion.
If the optimizer is not set and the phase is "train". Use the
- ``initialize_optimizer`` or ``add_optimizer`` method to set the
- optimizer.
+ :meth:`~.classify.classifier.ClassifierContainer.initialize_optimizer`
+ or :meth:`~.classify.classifier.ClassifierContainer.add_optimizer`
+ method to set the optimizer.
KeyError
If the specified phase cannot be found in the keys of the object's
- ``dataloaders`` dictionary property.
+ :attr:`~.classify.classifier.ClassifierContainer.dataloaders`
+ dictionary property.
Returns
-------
@@ -1102,11 +1107,11 @@ def calculate_add_metrics(
Notes
-----
This method uses both the
- ``sklearn.metrics.precision_recall_fscore_support`` and
- ``sklearn.metrics.roc_auc_score`` functions from ``scikit-learn`` to
- calculate the metrics for each average type (``"micro"``, ``"macro"``
- and ``"weighted"``). The results are then added to the ``metrics``
- dictionary. It also writes the metrics to the TensorBoard
+ :func:`sklearn.metrics.precision_recall_fscore_support` and
+ :func:`sklearn.metrics.roc_auc_score` functions from ``scikit-learn``
+ to calculate the metrics for each average type (``"micro"``,
+ ``"macro"`` and ``"weighted"``). The results are then added to the
+ ``metrics`` dictionary. It also writes the metrics to the TensorBoard
SummaryWriter, if ``tboard_writer`` is not None.
"""
# convert y_score to a numpy array:
@@ -1501,9 +1506,9 @@ def show_sample(
Notes
-----
This method uses the dataloader of the ``ImageClassifierData`` class
- and the ``torchvision.utils.make_grid`` function to display the sample
- data in a grid format. It also calls the ``_imshow`` method of the
- ``ImageClassifierData`` class to show the sample data.
+ and the :func:`torchvision.utils.make_grid` function to display the
+ sample data in a grid format. It also calls the ``_imshow`` method of
+ the ``ImageClassifierData`` class to show the sample data.
"""
if set_name not in self.dataloaders.keys():
raise ValueError(
diff --git a/mapreader/classify/datasets.py b/mapreader/classify/datasets.py
index 9535bcf6..85ab6138 100644
--- a/mapreader/classify/datasets.py
+++ b/mapreader/classify/datasets.py
@@ -26,6 +26,69 @@
class PatchDataset(Dataset):
+ """A PyTorch Dataset class for loading image patches from a DataFrame.
+
+ Parameters
+ ----------
+ patch_df : pandas.DataFrame or str
+ DataFrame or path to csv file containing the paths to image patches and their labels.
+ transform : Union[str, transforms.Compose, Callable]
+ The transform to use on the image.
+ A string can be used to call default transforms - options are "train", "test" or "val".
+ Alternatively, a callable object (e.g. a torchvision transform or torchvision.transforms.Compose) that takes in an image
+ and performs image transformations can be used.
+ At minimum, transform should be ``torchvision.transforms.ToTensor()``.
+ delimiter : str, optional
+ The delimiter to use when reading the dataframe. By default ``","``.
+ patch_paths_col : str, optional
+ The name of the column in the DataFrame containing the image paths. Default is "image_path".
+ label_col : str, optional
+ The name of the column containing the image labels. Default is None.
+ label_index_col : str, optional
+ The name of the column containing the indices of the image labels. Default is None.
+ image_mode : str, optional
+ The color format to convert the image to. Default is "RGB".
+
+ Attributes
+ ----------
+ patch_df : pandas.DataFrame
+ DataFrame containing the paths to image patches and their labels.
+ label_col : str
+ The name of the column containing the image labels.
+ label_index_col : str
+ The name of the column containing the labels indices.
+ patch_paths_col : str
+ The name of the column in the DataFrame containing the image
+ paths.
+ image_mode : str
+ The color format to convert the image to.
+ unique_labels : list
+ The unique labels in the label column of the patch_df DataFrame.
+ transform : callable
+ A callable object (a torchvision transform) that takes in an image
+ and performs image transformations.
+
+ Methods
+ -------
+ __len__()
+ Returns the length of the dataset.
+ __getitem__(idx)
+ Retrieves the image, its label and the index of that label at the given index in the dataset.
+ return_orig_image(idx)
+ Retrieves the original image at the given index in the dataset.
+ _default_transform(t_type, resize2)
+ Returns a transforms.Compose containing the default image transformations for the train and validation sets.
+
+ Raises
+ ------
+ ValueError
+ If ``label_col`` not in ``patch_df``.
+ ValueError
+ If ``label_index_col`` not in ``patch_df``.
+ ValueError
+ If ``transform`` passed as a string, but not one of "train", "test" or "val".
+ """
+
def __init__(
self,
patch_df: pd.DataFrame | str,
@@ -36,69 +99,6 @@ def __init__(
label_index_col: str | None = None,
image_mode: str | None = "RGB",
):
- """A PyTorch Dataset class for loading image patches from a DataFrame.
-
- Parameters
- ----------
- patch_df : pandas.DataFrame or str
- DataFrame or path to csv file containing the paths to image patches and their labels.
- transform : Union[str, transforms.Compose, Callable]
- The transform to use on the image.
- A string can be used to call default transforms - options are "train", "test" or "val".
- Alternatively, a callable object (e.g. a torchvision transform or torchvision.transforms.Compose) that takes in an image
- and performs image transformations can be used.
- At minimum, transform should be ``torchvision.transforms.ToTensor()``.
- delimiter : str, optional
- The delimiter to use when reading the dataframe. By default ``","``.
- patch_paths_col : str, optional
- The name of the column in the DataFrame containing the image paths. Default is "image_path".
- label_col : str, optional
- The name of the column containing the image labels. Default is None.
- label_index_col : str, optional
- The name of the column containing the indices of the image labels. Default is None.
- image_mode : str, optional
- The color format to convert the image to. Default is "RGB".
-
- Attributes
- ----------
- patch_df : pandas.DataFrame
- DataFrame containing the paths to image patches and their labels.
- label_col : str
- The name of the column containing the image labels.
- label_index_col : str
- The name of the column containing the labels indices.
- patch_paths_col : str
- The name of the column in the DataFrame containing the image
- paths.
- image_mode : str
- The color format to convert the image to.
- unique_labels : list
- The unique labels in the label column of the patch_df DataFrame.
- transform : callable
- A callable object (a torchvision transform) that takes in an image
- and performs image transformations.
-
- Methods
- -------
- __len__()
- Returns the length of the dataset.
- __getitem__(idx)
- Retrieves the image, its label and the index of that label at the given index in the dataset.
- return_orig_image(idx)
- Retrieves the original image at the given index in the dataset.
- _default_transform(t_type, resize2)
- Returns a transforms.Compose containing the default image transformations for the train and validation sets.
-
- Raises
- ------
- ValueError
- If ``label_col`` not in ``patch_df``.
- ValueError
- If ``label_index_col`` not in ``patch_df``.
- ValueError
- If ``transform`` passed as a string, but not one of "train", "test" or "val".
- """
-
if isinstance(patch_df, pd.DataFrame):
self.patch_df = patch_df
@@ -250,7 +250,7 @@ def return_orig_image(self, idx: int | torch.Tensor) -> Image:
``patch_paths_col`` column of the ``patch_df`` DataFrame at the given
index. The loaded image is then converted to the format specified by
the ``image_mode`` attribute of the object. The resulting
- ``PIL.Image.Image`` object is returned.
+ :class:`PIL.Image.Image` object is returned.
"""
if torch.is_tensor(idx):
idx = idx.tolist()
@@ -387,6 +387,62 @@ def create_dataloaders(
# --- Dataset that returns an image, its context and its label
class PatchContextDataset(PatchDataset):
+ """
+ A PyTorch Dataset class for loading contextual information about image
+ patches from a DataFrame.
+
+ Parameters
+ ----------
+ patch_df : pandas.DataFrame or str
+ DataFrame or path to csv file containing the paths to image patches and their labels.
+ total_df : pandas.DataFrame or str
+ DataFrame or path to csv file containing the paths to all images and their labels.
+ transform : str
+ Torchvision transform to be applied to context images.
+ Either "train" or "val".
+ delimiter : str
+ The delimiter to use when reading the csv file. By default ``","``.
+ patch_paths_col : str, optional
+ The name of the column in the DataFrame containing the image paths. Default is "image_path".
+ label_col : str, optional
+ The name of the column containing the image labels. Default is None.
+ label_index_col : str, optional
+ The name of the column containing the indices of the image labels. Default is None.
+ image_mode : str, optional
+ The color space of the images. Default is "RGB".
+ context_dir : str, optional
+ The path to context maps (or, where to save context if not created yet).
+ Default is "./maps/maps_context".
+ create_context : bool, optional
+ Whether or not to create context maps. Default is False.
+ parent_path : str, optional
+ The path to the directory containing parent images. Default is
+ "./maps".
+
+ Attributes
+ ----------
+ patch_df : pandas.DataFrame
+ A pandas DataFrame with columns representing image paths, labels,
+ and object bounding boxes.
+ label_col : str
+ The name of the column containing the image labels.
+ label_index_col : str
+ The name of the column containing the labels indices.
+ patch_paths_col : str
+ The name of the column in the DataFrame containing the image
+ paths.
+ image_mode : str
+ The color space of the images.
+ parent_path : str
+ The path to the directory containing parent images.
+ create_context : bool
+ Whether or not to create context maps.
+ context_dir : str
+ The path to context maps.
+ unique_labels : list or str
+ The unique labels in ``label_col``.
+ """
+
def __init__(
self,
patch_df: pd.DataFrame | str,
@@ -401,62 +457,6 @@ def __init__(
create_context: bool = False,
parent_path: str | None = "./maps",
):
- """
- A PyTorch Dataset class for loading contextual information about image
- patches from a DataFrame.
-
- Parameters
- ----------
- patch_df : pandas.DataFrame or str
- DataFrame or path to csv file containing the paths to image patches and their labels.
- total_df : pandas.DataFrame or str
- DataFrame or path to csv file containing the paths to all images and their labels.
- transform : str
- Torchvision transform to be applied to context images.
- Either "train" or "val".
- delimiter : str
- The delimiter to use when reading the csv file. By default ``","``.
- patch_paths_col : str, optional
- The name of the column in the DataFrame containing the image paths. Default is "image_path".
- label_col : str, optional
- The name of the column containing the image labels. Default is None.
- label_index_col : str, optional
- The name of the column containing the indices of the image labels. Default is None.
- image_mode : str, optional
- The color space of the images. Default is "RGB".
- context_dir : str, optional
- The path to context maps (or, where to save context if not created yet).
- Default is "./maps/maps_context".
- create_context : bool, optional
- Whether or not to create context maps. Default is False.
- parent_path : str, optional
- The path to the directory containing parent images. Default is
- "./maps".
-
- Attributes
- ----------
- patch_df : pandas.DataFrame
- A pandas DataFrame with columns representing image paths, labels,
- and object bounding boxes.
- label_col : str
- The name of the column containing the image labels.
- label_index_col : str
- The name of the column containing the labels indices.
- patch_paths_col : str
- The name of the column in the DataFrame containing the image
- paths.
- image_mode : str
- The color space of the images.
- parent_path : str
- The path to the directory containing parent images.
- create_context : bool
- Whether or not to create context maps.
- context_dir : str
- The path to context maps.
- unique_labels : list or str
- The unique labels in ``label_col``.
- """
-
if isinstance(patch_df, pd.DataFrame):
self.patch_df = patch_df
diff --git a/mapreader/classify/load_annotations.py b/mapreader/classify/load_annotations.py
index 6292b211..d7897e8c 100644
--- a/mapreader/classify/load_annotations.py
+++ b/mapreader/classify/load_annotations.py
@@ -18,10 +18,12 @@
class AnnotationsLoader:
+ """
+ A class for loading annotations and preparing datasets and dataloaders for
+ use in training/validation of a model.
+ """
+
def __init__(self):
- """
- A Class for loading annotations and preparing datasets and dataloaders for use in training/validation of a model.
- """
self.annotations = pd.DataFrame()
self.reviewed = pd.DataFrame()
self.patch_paths_col = None
@@ -41,7 +43,9 @@ def load(
scramble_frame: bool | None = False,
reset_index: bool | None = False,
):
- """Loads annotations from a csv file or dataframe and can be used to set the ``patch_paths_col`` and ``label_col`` attributes.
+ """
+ Loads annotations from a csv file or dataframe and can be used to set
+ the ``patch_paths_col`` and ``label_col`` attributes.
Parameters
----------
@@ -329,10 +333,18 @@ def review_labels(
This method reviews images with their corresponding labels and allows
the user to change the label for each image.
- Updated labels are saved in ``self.annotations`` and in a newly created ``self.reviewed`` DataFrame.
+ Updated labels are saved in
+ :attr:`~.classify.load_annotations.AnnotationsLoader.annotations`
+ and in a newly created
+ :attr:`~.classify.load_annotations.AnnotationsLoader.reviewed`
+ DataFrame.
+
If ``exclude_df`` is provided, images found in this df are skipped in the review process.
+
If ``include_df`` is provided, only images found in this df are reviewed.
- The ``self.reviewed`` DataFrame is deduplicated based on the ``deduplicate_col``.
+
+ The :attr:`~.classify.load_annotations.AnnotationsLoader.reviewed`
+ DataFrame is deduplicated based on the ``deduplicate_col``.
"""
if len(self.annotations) == 0:
raise ValueError("[ERROR] No annotations loaded.")
diff --git a/mapreader/download/sheet_downloader.py b/mapreader/download/sheet_downloader.py
index 3a852bba..44c1d028 100644
--- a/mapreader/download/sheet_downloader.py
+++ b/mapreader/download/sheet_downloader.py
@@ -651,7 +651,9 @@ def _save_metadata(
e.g. ``{"county": ["properties", "COUNTY"], "id": "id"}``
**kwargs: dict, optional
- Keyword arguments to pass to the ``extract_published_dates()`` method.
+ Keyword arguments to pass to the
+ :meth:`~.download.sheet_downloader.SheetDownloader.extract_published_dates`
+ method.
Returns
-------
@@ -660,8 +662,9 @@ def _save_metadata(
Notes
-----
- Default metadata items are: name, url, coordinates, crs, published_date, grid_bb.
- Additional items can be added using ``metadata_to_save``.
+ Default metadata items are: ``name``, ``url``, ``coordinates``,
+ ``crs``, ``published_date``, ``grid_bb``. Additional items can be
+ added using the ``metadata_to_save`` argument.
"""
metadata_cols = [
"name",
@@ -747,7 +750,9 @@ def _download_map_sheets(
force : bool, optional
Whether to force the download or ask for confirmation, by default ``False``.
**kwargs : dict, optional
- Keyword arguments to pass to the ``_save_metadata()`` method.
+ Keyword arguments to pass to the
+ :meth:`~.download.sheet_downloader.SheetDownloader._save_metadata`
+ method.
"""
try:
# get url for single tile to estimate size
@@ -826,7 +831,9 @@ def download_all_map_sheets(
download_in_parallel : bool, optional
Whether to download tiles in parallel, by default ``True``.
**kwargs : dict, optional
- Keyword arguments to pass to the ``_download_map_sheets()`` method.
+ Keyword arguments to pass to the
+ :meth:`~.download.sheet_downloader.SheetDownloader._download_map_sheets`
+ method.
"""
if not self.grid_bbs:
raise ValueError("[ERROR] Please first run ``get_grid_bb()``")
@@ -869,7 +876,9 @@ def download_map_sheets_by_wfs_ids(
download_in_parallel : bool, optional
Whether to download tiles in parallel, by default ``True``.
**kwargs : dict, optional
- Keyword arguments to pass to the ``_download_map_sheets()`` method.
+ Keyword arguments to pass to the
+ :meth:`~.download.sheet_downloader.SheetDownloader._download_map_sheets`
+ method.
"""
if not self.wfs_id_nos:
@@ -938,7 +947,9 @@ def download_map_sheets_by_polygon(
download_in_parallel : bool, optional
Whether to download tiles in parallel, by default ``True``.
**kwargs : dict, optional
- Keyword arguments to pass to the ``_download_map_sheets()`` method.
+ Keyword arguments to pass to the
+ :meth:`~.download.sheet_downloader.SheetDownloader._download_map_sheets`
+ method.
Notes
-----
@@ -1016,7 +1027,9 @@ def download_map_sheets_by_coordinates(
download_in_parallel : bool, optional
Whether to download tiles in parallel, by default ``True``.
**kwargs : dict, optional
- Keyword arguments to pass to the ``_download_map_sheets()`` method.
+ Keyword arguments to pass to the
+ :meth:`~.download.sheet_downloader.SheetDownloader._download_map_sheets`
+ method.
"""
if not isinstance(coords, tuple):
@@ -1076,7 +1089,9 @@ def download_map_sheets_by_line(
download_in_parallel : bool, optional
Whether to download tiles in parallel, by default ``True``.
**kwargs : dict, optional
- Keyword arguments to pass to the ``_download_map_sheets()`` method.
+ Keyword arguments to pass to the
+ :meth:`~.download.sheet_downloader.SheetDownloader._download_map_sheets`
+ method.
Notes
-----
@@ -1151,7 +1166,9 @@ def download_map_sheets_by_string(
download_in_parallel : bool, optional
Whether to download tiles in parallel, by default ``True``.
**kwargs : dict, optional
- Keyword arguments to pass to the ``_download_map_sheets()`` method.
+ Keyword arguments to pass to the
+ :meth:`~.download.sheet_downloader.SheetDownloader._download_map_sheets`
+ method.
Notes
-----
@@ -1220,7 +1237,9 @@ def download_map_sheets_by_queries(
download_in_parallel : bool, optional
Whether to download tiles in parallel, by default ``True``.
**kwargs : dict, optional
- Keyword arguments to pass to the ``_download_map_sheets()`` method.
+ Keyword arguments to pass to the
+ :meth:`~.download.sheet_downloader.SheetDownloader._download_map_sheets`
+ method.
"""
if not self.grid_bbs:
raise ValueError("[ERROR] Please first run ``get_grid_bb()``")
diff --git a/mapreader/load/images.py b/mapreader/load/images.py
index 513db9d1..3d62acee 100644
--- a/mapreader/load/images.py
+++ b/mapreader/load/images.py
@@ -56,8 +56,8 @@ class MapImages:
parent_path : str, optional
Path to parent images (if applicable), by default ``None``.
**kwargs : dict, optional
- Additional keyword arguments to be passed to the ``_images_constructor``
- method.
+ Keyword arguments to pass to the
+ :meth:`~.load.images.MapImages._images_constructor` method.
Attributes
----------
@@ -160,7 +160,9 @@ def _images_constructor(
**kwargs: dict,
) -> None:
"""
- Constructs image data from the given image path and parent path and adds it to the ``MapImages`` instance's ``images`` attribute.
+ Constructs image data from the given image path and parent path and
+ adds it to the :class:`~.load.images.MapImages` instance's ``images``
+ attribute.
Parameters
----------
@@ -186,7 +188,11 @@ def _images_constructor(
Notes
-----
- This method assumes that the ``images`` attribute has been initialized on the MapImages instance as a dictionary with two levels of hierarchy, ``"parent"`` and ``"patch"``. The image data is added to the corresponding level based on the value of ``tree_level``.
+ This method assumes that the ``images`` attribute has been initialized
+ on the :class:`~.load.images.MapImages` instance as a dictionary with
+ two levels of hierarchy, ``"parent"`` and ``"patch"``. The image data
+ is added to the corresponding level based on the value of
+ ``tree_level``.
"""
if tree_level not in ["parent", "patch"]:
@@ -256,7 +262,8 @@ def _check_image_mode(image_path):
@staticmethod
def _convert_image_path(inp_path: str) -> tuple[str, str, str]:
"""
- Convert an image path into an absolute path and find basename and directory name.
+ Convert an image path into an absolute path and find basename and
+ directory name.
Parameters
----------
@@ -283,7 +290,7 @@ def add_metadata(
ignore_mismatch: bool | None = False,
) -> None:
"""
- Add metadata information to the images dictionary.
+ Add metadata information to the ``images`` dictionary property.
Parameters
----------
@@ -325,10 +332,13 @@ def add_metadata(
Notes
------
- Your metadata file must contain an column which contains the image IDs (filenames) of your images.
- This should have a column name of either ``name`` or ``image_id``.
+ Your metadata file must contain an column which contains the image IDs
+ (filenames) of your images. This should have a column name of either
+ ``name`` or ``image_id``.
- Existing information in your ``MapImages`` object will be overwritten if there are overlapping column headings in your metadata file/dataframe.
+ Existing information in your :class:`~.load.images.MapImages` object
+ will be overwritten if there are overlapping column headings in your
+ metadata file/dataframe.
"""
if isinstance(metadata, pd.DataFrame):
@@ -508,7 +518,7 @@ def add_shape(self, tree_level: str | None = "parent") -> None:
Notes
-----
- The method runs :meth:`mapreader.load.images.MapImages._add_shape_id`
+ The method runs :meth:`~.load.images.MapImages._add_shape_id`
for each image present at the ``tree_level`` provided.
"""
print(f"[INFO] Add shape, tree level: {tree_level}")
@@ -547,7 +557,7 @@ def add_coord_increments(self, verbose: bool | None = False) -> None:
Notes
-----
The method runs
- :meth:`mapreader.load.images.MapImages._add_coord_increments_id`
+ :meth:`~.load.images.MapImages._add_coord_increments_id`
for each image present at the parent level, which calculates
pixel-wise delta longitude (``dlon``) and delta latitude (``dlat``)
for the image and adds the data to it.
@@ -614,7 +624,7 @@ def add_center_coord(
Notes
-----
The method runs
- :meth:`mapreader.load.images.MapImages._add_center_coord_id`
+ :meth:`~.load.images.MapImages._add_center_coord_id`
for each image present at the ``tree_level`` provided, which calculates
central longitude and latitude (``center_lon`` and ``center_lat``) for
the image and adds the data to it.
@@ -742,19 +752,19 @@ def _add_coord_increments_id(
dlat = abs(lat_max - lat_min) / image_height
dlon = abs(lon_max - lon_min) / image_width
- ``lon_min``, ``lat_min``, ``lon_max`` and ``lat_max`` are the coordinate
- bounds of the image, and ``image_height`` and ``image_width`` are the
- height and width of the image in pixels respectively.
+ ``lon_min``, ``lat_min``, ``lon_max`` and ``lat_max`` are the
+ coordinate bounds of the image, and ``image_height`` and
+ ``image_width`` are the height and width of the image in pixels
+ respectively.
- This method assumes that the coordinate and shape metadata of the
- image have already been added to the metadata.
+ This method assumes that the coordinate and shape metadata of the image
+ have already been added to the metadata.
If the coordinate metadata cannot be found, a warning message will be
printed if ``verbose=True``.
If the shape metadata cannot be found, this method will call the
- :meth:`mapreader.load.images.MapImages._add_shape_id` method to add
- it.
+ :meth:`~.load.images.MapImages._add_shape_id` method to add it.
"""
if "coordinates" not in self.parents[image_id].keys():
@@ -924,8 +934,8 @@ def _calc_pixel_height_width(
Notes
-----
This method requires the parent image to have location metadata added
- with either the :meth:`mapreader.load.images.MapImages.add_metadata`
- or :meth:`mapreader.load.images.MapImages.add_geo_info` methods.
+ with either the :meth:`~.load.images.MapImages.add_metadata`
+ or :meth:`~.load.images.MapImages.add_geo_info` methods.
The calculations are performed using the ``geopy.distance.geodesic``
and ``geopy.distance.great_circle`` methods. Thus, the method requires
@@ -1438,8 +1448,8 @@ def convert_images(
delimiter: str | None = ",",
) -> tuple[pd.DataFrame, pd.DataFrame]:
"""
- Convert the ``MapImages`` instance's ``images`` dictionary into pandas
- DataFrames for easy manipulation.
+ Convert the :class:`~.load.images.MapImages` instance's ``images``
+ dictionary into pandas DataFrames for easy manipulation.
Parameters
----------
@@ -1491,8 +1501,8 @@ def show_parent(
**kwargs: dict,
) -> None:
"""
- A wrapper method for `.show()` which plots all patches of a
- specified parent (`parent_id`).
+ A wrapper method for :meth:`~.load.images.MapImages.show` which plots
+ all patches of a specified parent (`parent_id`).
Parameters
----------
@@ -1501,8 +1511,9 @@ def show_parent(
column_to_plot : str, optional
Column whose values will be plotted on patches, by default ``None``.
**kwargs: Dict
- Key words to pass to ``show`` method.
- See help text for ``show`` for more information.
+ Key words to pass to :meth:`~.load.images.MapImages.show` method.
+ See help text for :meth:`~.load.images.MapImages.show` for more
+ information.
Returns
-------
@@ -1512,7 +1523,7 @@ def show_parent(
Notes
-----
This is a wrapper method. See the documentation of the
- :meth:`mapreader.load.images.MapImages.show` method for more detail.
+ :meth:`~.load.images.MapImages.show` method for more detail.
"""
patch_ids = self.parents[parent_id]["patches"]
figures = self.show(patch_ids, column_to_plot=column_to_plot, **kwargs)
@@ -1538,7 +1549,7 @@ def show(
kml_dpi_image: int | None = None,
) -> None:
"""
- Plot images from a list of `image_ids`.
+ Plot images from a list of ``image_ids``.
Parameters
----------
@@ -1849,7 +1860,7 @@ def load_patches(
) -> None:
"""
Loads patch images from the given paths and adds them to the ``images``
- dictionary in the ``MapImages`` instance.
+ dictionary in the :class:`~.load.images.MapImages` instance.
Parameters
----------
@@ -2060,7 +2071,8 @@ def load_df(
clear_images: bool | None = True,
) -> None:
"""
- Create ``MapImages`` instance by loading data from pandas DataFrame(s).
+ Create :class:`~.load.images.MapImages` instance by loading data from
+ pandas DataFrame(s).
Parameters
----------
@@ -2101,8 +2113,8 @@ def load_csv(
) -> None:
"""
Load CSV files containing information about parent and patches,
- and update the ``images`` attribute of the ``MapImages`` instance with
- the loaded data.
+ and update the ``images`` attribute of the
+ :class:`~.load.images.MapImages` instance with the loaded data.
Parameters
----------
@@ -2263,7 +2275,9 @@ def save_parents_as_geotiffs(
verbose: bool = False,
crs: str | None = None,
) -> None:
- """Save all parents in MapImages instance as geotiffs.
+ """
+ Save all parents in :class:`~.load.images.MapImages` instance as
+ geotiffs.
Parameters
----------
@@ -2373,7 +2387,9 @@ def save_patches_as_geotiffs(
verbose: bool | None = False,
crs: str | None = None,
) -> None:
- """Save all patches in MapImages instance as geotiffs.
+ """
+ Save all patches in :class:`~.load.images.MapImages` instance as
+ geotiffs.
Parameters
----------
diff --git a/mapreader/load/loader.py b/mapreader/load/loader.py
index 77838fde..93dd8999 100644
--- a/mapreader/load/loader.py
+++ b/mapreader/load/loader.py
@@ -11,7 +11,7 @@ def loader(
**kwargs: dict,
) -> MapImages:
"""
- Creates a ``MapImages`` class to manage a collection of image paths and
+ Creates a :class:`~.load.images.MapImages` class to manage a collection of image paths and
construct image objects.
Parameters
@@ -31,13 +31,13 @@ def loader(
Returns
-------
MapImages
- The ``MapImages`` class which can manage a collection of image paths
- and construct image objects.
+ The :class:`~.load.images.MapImages` class which can manage a
+ collection of image paths and construct image objects.
Notes
-----
This is a wrapper method. See the documentation of the
- :class:`mapreader.load.images.MapImages` class for more detail.
+ :class:`~.load.images.MapImages` class for more detail.
"""
img = MapImages(
path_images=path_images,
@@ -57,9 +57,10 @@ def load_patches(
clear_images: bool | None = False,
) -> MapImages:
"""
- Creates a ``MapImages`` class to manage a collection of image paths and
- construct image objects. Then loads patch images from the given paths and
- adds them to the ``images`` dictionary in the ``MapImages`` instance.
+ Creates a :class:`~.load.images.MapImages` class to manage a collection of
+ image paths and construct image objects. Then loads patch images from the
+ given paths and adds them to the ``images`` dictionary in the
+ :class:`~.load.images.MapImages` instance.
Parameters
----------
@@ -68,7 +69,8 @@ def load_patches(
*Note: The ``patch_paths`` parameter accepts wildcards.*
patch_file_ext : str or bool, optional
- The file extension of the patches, ignored if file extensions are specified in ``patch_paths`` (e.g. with ``"./path/to/dir/*png"``)
+ The file extension of the patches, ignored if file extensions are
+ specified in ``patch_paths`` (e.g. with ``"./path/to/dir/*png"``)
By default ``False``.
parent_paths : str or bool, optional
The file path of the parent images to be loaded. If set to
@@ -76,7 +78,8 @@ def load_patches(
*Note: The ``parent_paths`` parameter accepts wildcards.*
parent_file_ext : str or bool, optional
- The file extension of the parent images, ignored if file extensions are specified in ``parent_paths`` (e.g. with ``"./path/to/dir/*png"``)
+ The file extension of the parent images, ignored if file extensions
+ are specified in ``parent_paths`` (e.g. with ``"./path/to/dir/*png"``)
By default ``False``.
add_geo_info : bool, optional
If ``True``, adds geographic information to the parent image.
@@ -88,16 +91,16 @@ def load_patches(
Returns
-------
MapImages
- The ``MapImages`` class which can manage a collection of image paths
- and construct image objects.
+ The :class:`~.load.images.MapImages` class which can manage a
+ collection of image paths and construct image objects.
Notes
-----
This is a wrapper method. See the documentation of the
- :class:`mapreader.load.images.MapImages` class for more detail.
+ :class:`~.load.images.MapImages` class for more detail.
This function in particular, also calls the
- :meth:`mapreader.load.images.MapImages.loadPatches` method. Please see
+ :meth:`~.load.images.MapImages.load_patches` method. Please see
the documentation for that method for more information as well.
"""
img = MapImages()
 -
-
-
-
-
- 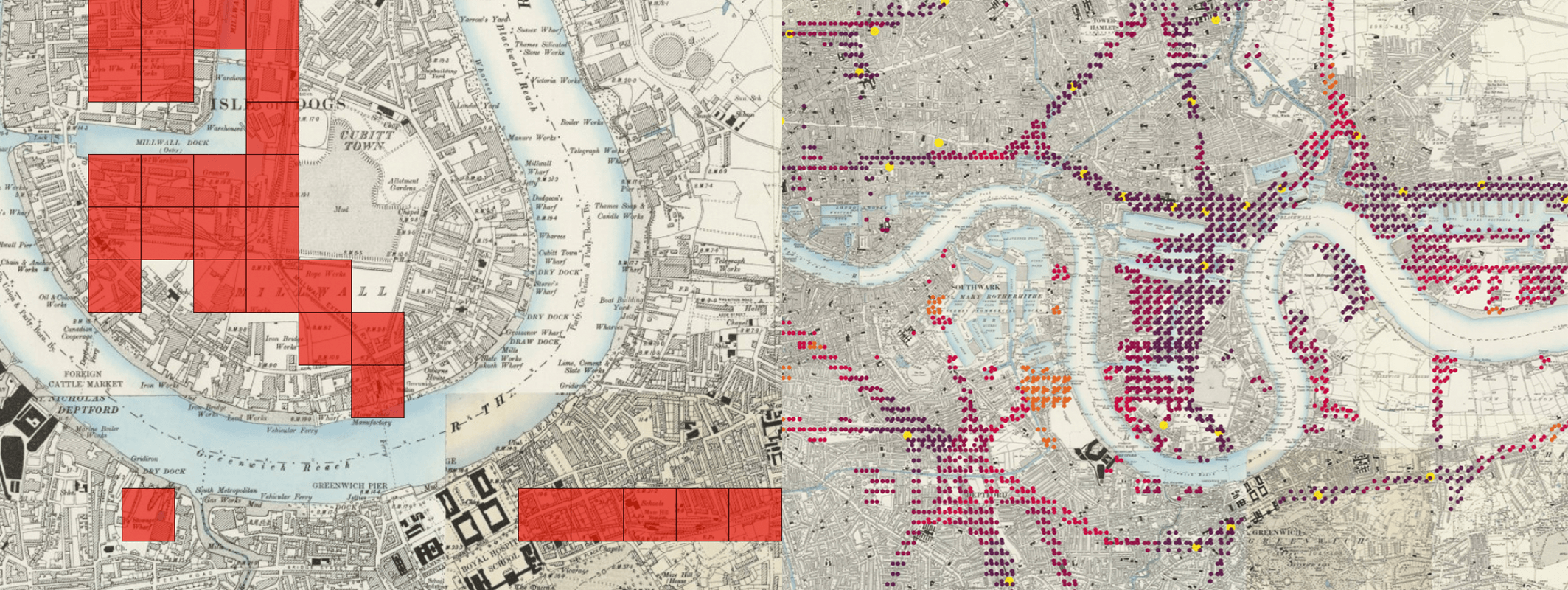 -
- 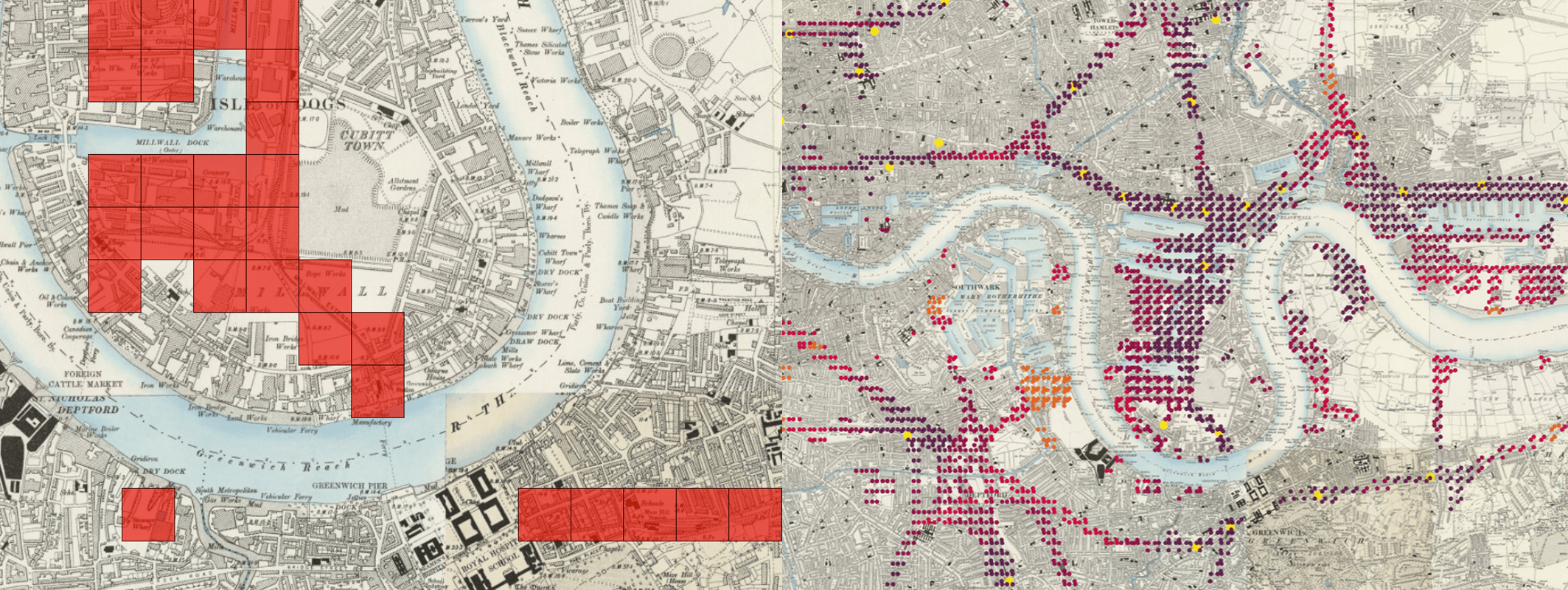 +
+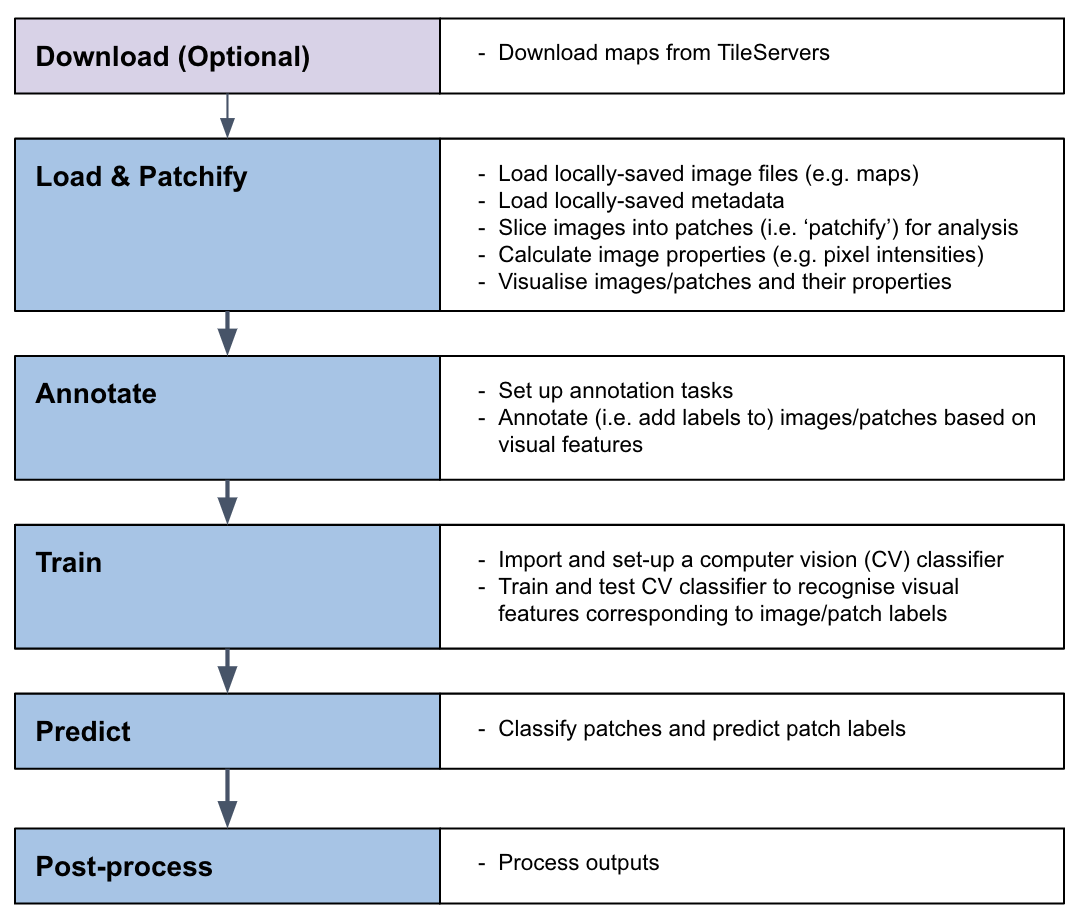 +
+ 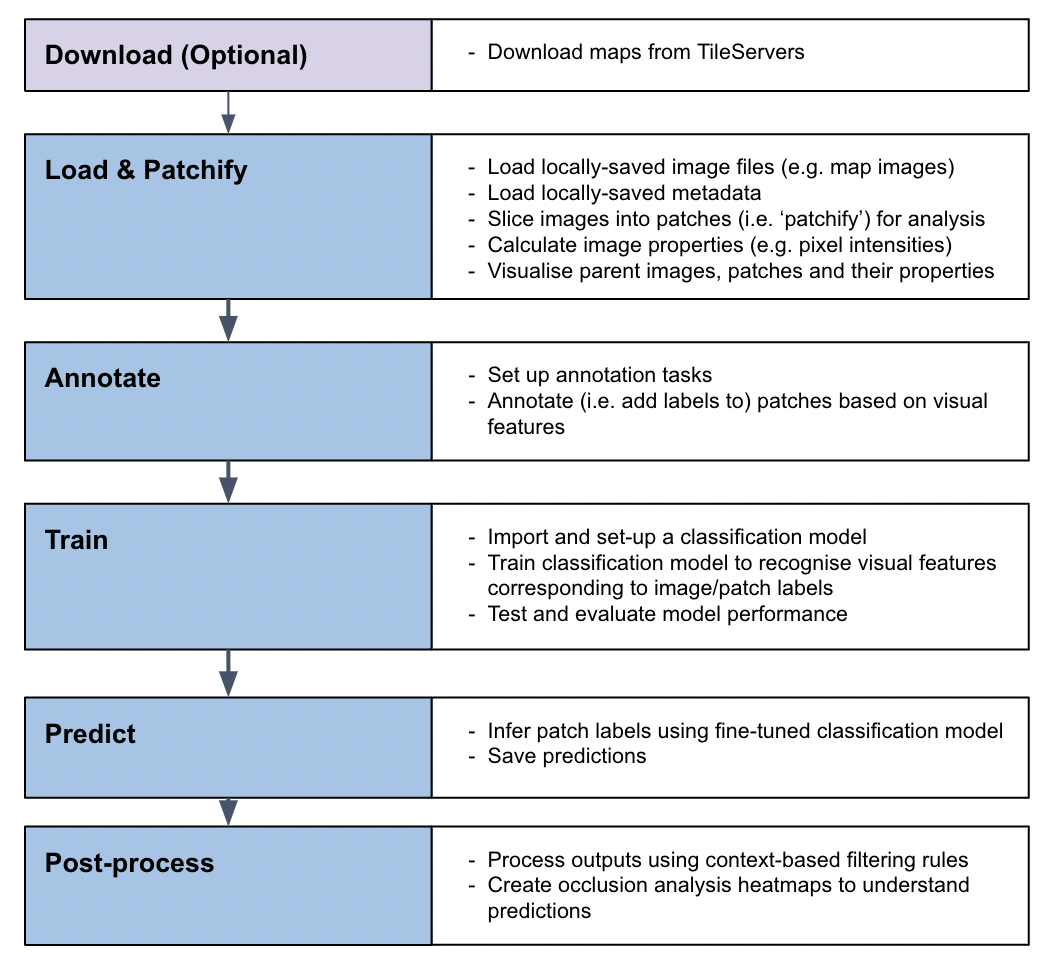 -
-