Due to a bug, there are many duplicate folders in a file system. You are given a 2D array paths, where paths[i] is an array representing an absolute path to the ith folder in the file system.
- For example,
["one", "two", "three"]represents the path"/one/two/three".
Two folders (not necessarily on the same level) are identical if they contain the same non-empty set of identical subfolders and underlying subfolder structure. The folders do not need to be at the root level to be identical. If two or more folders are identical, then mark the folders as well as all their subfolders.
- For example, folders
"/a"and"/b"in the file structure below are identical. They (as well as their subfolders) should all be marked:<ul> <li><code>/a</code></li> <li><code>/a/x</code></li> <li><code>/a/x/y</code></li> <li><code>/a/z</code></li> <li><code>/b</code></li> <li><code>/b/x</code></li> <li><code>/b/x/y</code></li> <li><code>/b/z</code></li> </ul> </li> <li>However, if the file structure also included the path <code>"/b/w"</code>, then the folders <code>"/a"</code> and <code>"/b"</code> would not be identical. Note that <code>"/a/x"</code> and <code>"/b/x"</code> would still be considered identical even with the added folder.</li>
Once all the identical folders and their subfolders have been marked, the file system will delete all of them. The file system only runs the deletion once, so any folders that become identical after the initial deletion are not deleted.
Return the 2D array ans containing the paths of the remaining folders after deleting all the marked folders. The paths may be returned in any order.
Example 1:
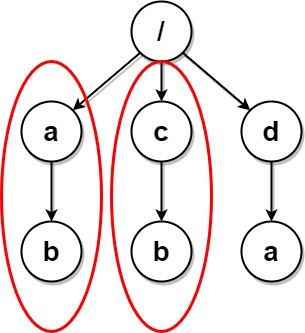
Input: paths = [["a"],["c"],["d"],["a","b"],["c","b"],["d","a"]] Output: [["d"],["d","a"]] Explanation: The file structure is as shown. Folders "/a" and "/c" (and their subfolders) are marked for deletion because they both contain an empty folder named "b".
Example 2:
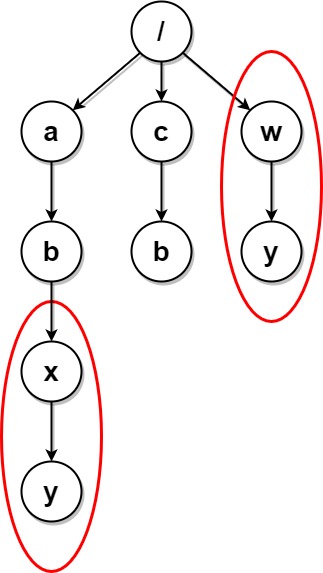
Input: paths = [["a"],["c"],["a","b"],["c","b"],["a","b","x"],["a","b","x","y"],["w"],["w","y"]] Output: [["c"],["c","b"],["a"],["a","b"]] Explanation: The file structure is as shown. Folders "/a/b/x" and "/w" (and their subfolders) are marked for deletion because they both contain an empty folder named "y". Note that folders "/a" and "/c" are identical after the deletion, but they are not deleted because they were not marked beforehand.
Example 3:
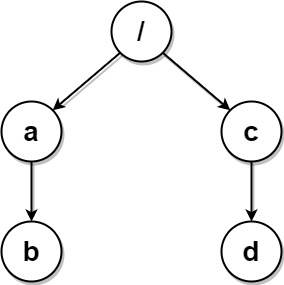
Input: paths = [["a","b"],["c","d"],["c"],["a"]] Output: [["c"],["c","d"],["a"],["a","b"]] Explanation: All folders are unique in the file system. Note that the returned array can be in a different order as the order does not matter.
Example 4:
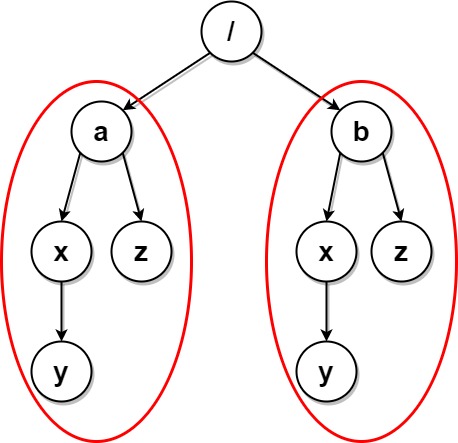
Input: paths = [["a"],["a","x"],["a","x","y"],["a","z"],["b"],["b","x"],["b","x","y"],["b","z"]] Output: [] Explanation: The file structure is as shown. Folders "/a/x" and "/b/x" (and their subfolders) are marked for deletion because they both contain an empty folder named "y". Folders "/a" and "/b" (and their subfolders) are marked for deletion because they both contain an empty folder "z" and the folder "x" described above.
Example 5:
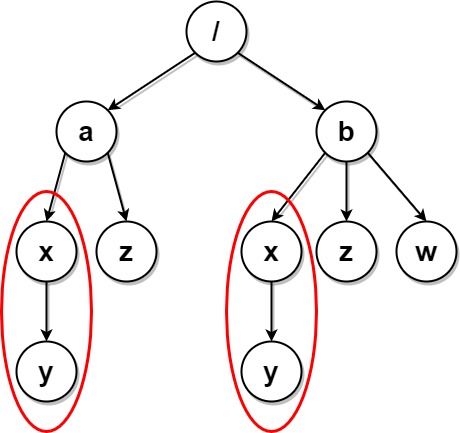
Input: paths = [["a"],["a","x"],["a","x","y"],["a","z"],["b"],["b","x"],["b","x","y"],["b","z"],["b","w"]] Output: [["b"],["b","w"],["b","z"],["a"],["a","z"]] Explanation: This has the same structure as the previous example, except with the added "/b/w". Folders "/a/x" and "/b/x" are still marked, but "/a" and "/b" are no longer marked because "/b" has the empty folder named "w" and "/a" does not. Note that "/a/z" and "/b/z" are not marked because the set of identical subfolders must be non-empty, but these folders are empty.
Constraints:
1 <= paths.length <= 2 * 1041 <= paths[i].length <= 5001 <= paths[i][j].length <= 101 <= sum(paths[i][j].length) <= 2 * 105path[i][j]consists of lowercase English letters.- No two paths lead to the same folder.
- For any folder not at the root level, its parent folder will also be in the input.
Similar Questions:
- Build Tree: Build a folder tree based on the
paths. The process is similar to the Trie building process. - Dedupe: Use post-order traversal to visit all the nodes. If we've seen the subfolder structure before, mark the node as deleted.
- Generate Paths: DFS to generate the output. We skip the nodes that have been deleted.
Note:
- To ensure we visit the subfolders in the same order, changed
Node::nexttounordered_maptomap. (Testcase:[["a"],["a","a"],["a","b"],["a","b","a"],["b"],["b","a"],["b","a","a"],["b","b"]].) - To ensure the subfolder structure string only map to a unique tree structure, changed the encoding to use parenthesis instead, e.g.
(root(firstChild)(secondChild)...). (Testcase:[["r","x"],["r","x", "b"],["r","x","b","a"],["r", "y"],["r","y", "a"],["r","y", "b"],["r"]].)
Complexity Analysis
Assume N is the number of folders, W is the maximum length of folder name, D is the deepest folder depth, and C is the maximum number of direct child folders.
- Build Tree: We need to add all the
Nfolders, each of which takesO(DWlogC)time. So overall it takesO(NDWlogC)time, andO(NW)space. - Dedupe: We traverse the
Nfolders in post-order. The maximum length ofsubfolderstructure string is roughlyO(NW), so each node visit needO(NW)time to check if it's a duplicate. The overall time complexity isO(N^2 * W)and the space complexity isO(N^2 * W). - Generate Paths: In the worst case we traverse the
Nnodes again. Each visit takesO(W)time to update the currentpathandO(DW)time to update the answer. So overall the time complexity isO(NDW)and space complexity isO(DW)for the temporarypath.
// OJ: https://leetcode.com/problems/delete-duplicate-folders-in-system/
// Author: github.com/lzl124631x
// Time: O(NDWlogC + N^2 * W) where `N` is the number of folders, `W` is the maximum length of folder name,
// `D` is the deepest folder depth, and `C` is the maximum number of direct child folders.
// Space: O(N^2 * W)
struct Node {
string name;
map<string, Node*> next; // mapping from folder name to the corresponding child node.
bool del = false; // whether this folder is deleted.
Node(string n = "") : name(n) {}
};
class Solution {
void addPath(Node *node, vector<string> &path) { // Given a path, add nodes to the folder tree. This is similar to the Trie build process.
for (auto &s : path) {
if (node->next.count(s) == 0) node->next[s] = new Node(s);
node = node->next[s];
}
}
unordered_map<string, Node*> seen; // mapping from subfolder structure string to the first occurrence node.
string dedupe(Node *node) { // post-order traversal to dedupe. If we've seen the subfolder structure before, mark it as deleted.
string subfolder;
for (auto &[name, next] : node->next) {
subfolder += dedupe(next);
}
if (subfolder.size()) { // leaf nodes should be ignored
if (seen.count(subfolder)) { // if we've seen this subfolder structure before, mark them as deleted.
seen[subfolder]->del = node->del = true;
} else {
seen[subfolder] = node; // otherwise, add the mapping
}
}
return "(" + node->name + subfolder + ")"; // return the folder structure string of this node.
}
vector<vector<string>> ans;
vector<string> path;
void getPath(Node *node) {
if (node->del) return; // if the current node is deleted, skip it.
path.push_back(node->name);
ans.push_back(path);
for (auto &[name, next] : node->next) {
getPath(next);
}
path.pop_back();
}
public:
vector<vector<string>> deleteDuplicateFolder(vector<vector<string>>& A) {
Node root;
for (auto &path : A) addPath(&root, path);
dedupe(&root);
for (auto &[name, next] : root.next) getPath(next);
return ans;
}
};