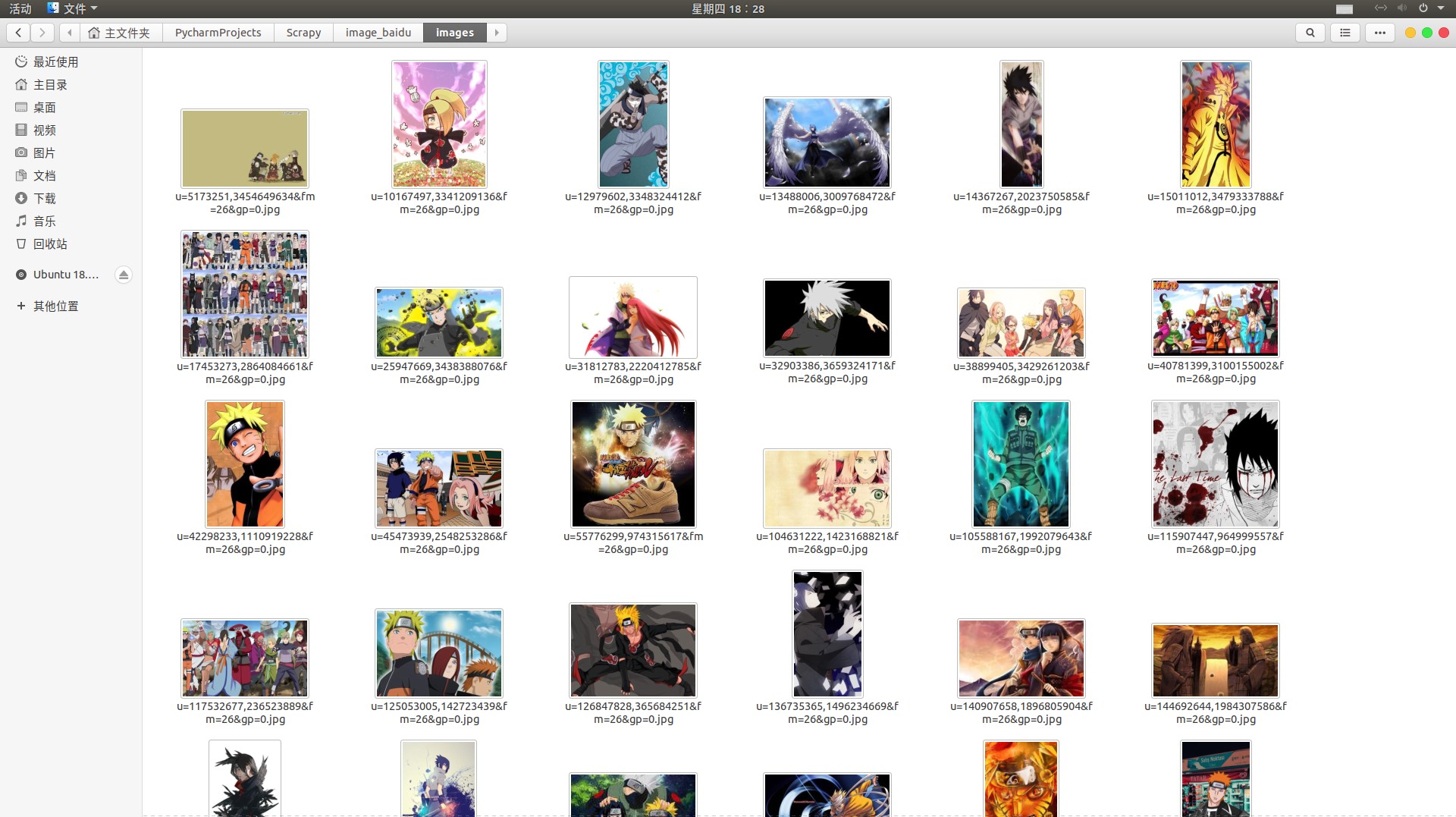
我们首先在百度图片中输入:火影忍者壁纸,可以看出来页面输入Ajax请求,打开谷歌开发者工具,查看f12,得到如下结果:
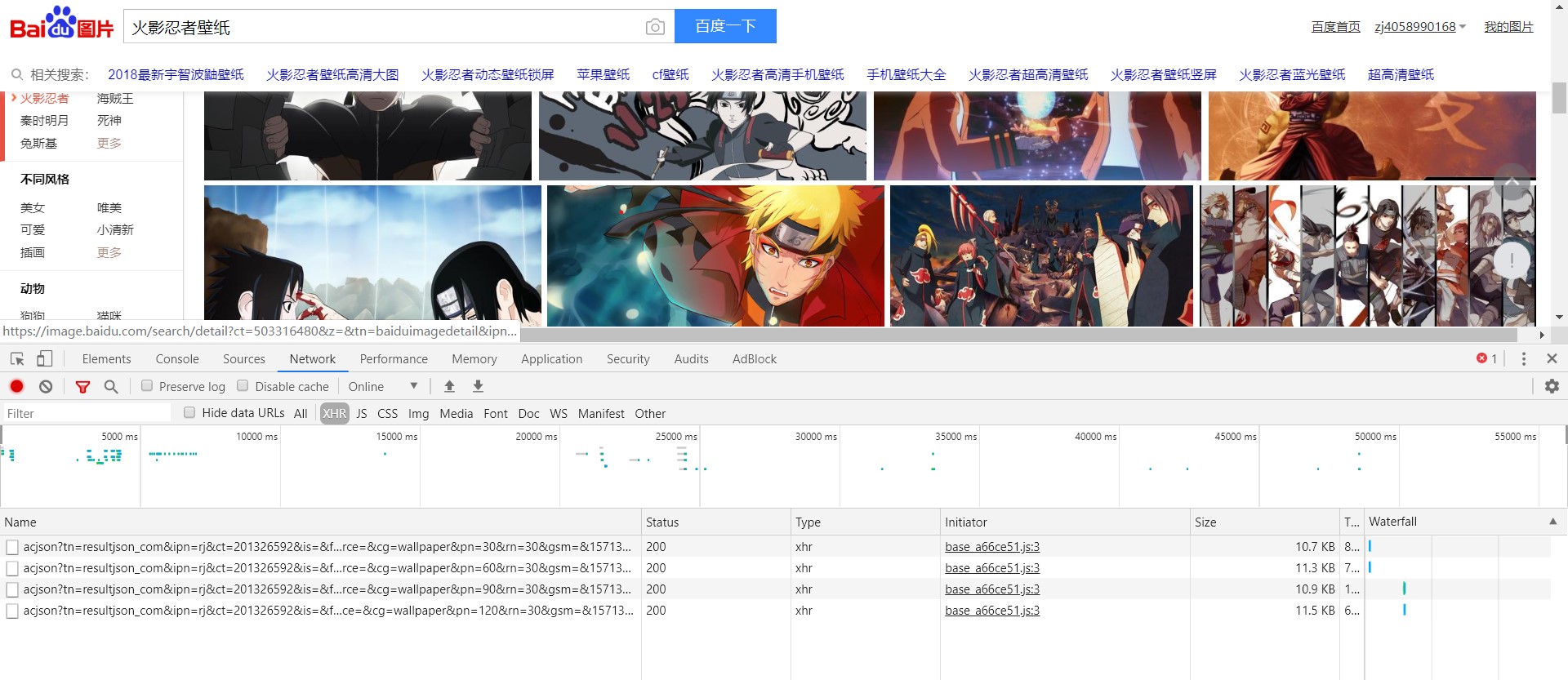
我们可以发现其实只有最后的pn参数发生了变化,所以我们只需要对pn进行更新即可。
然后我们再看每个url下的json数据长什么样:
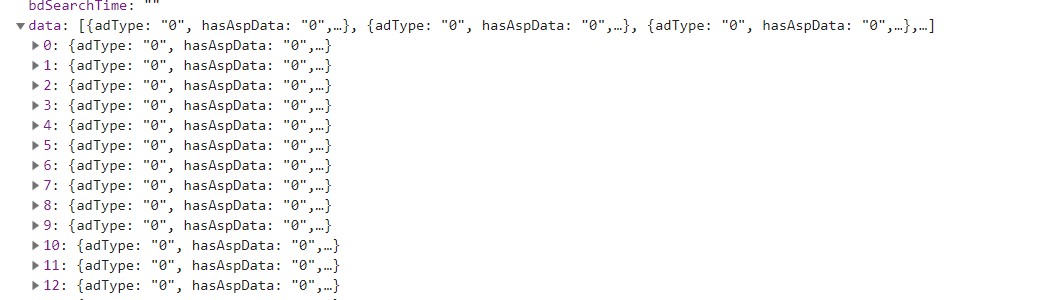
可以发现每个图片的信息都存放在这些data中,然后我们打开看一下我们需要的数据在哪里:

可以发现我们要爬取的标题和图片链接在键名为fromPageTitleEnc和hoverURL中
于是我们就可以开始我们的抓取工作了。
首先需要新建一个项目,这里不再赘述。
具体代码spiders中的images.py中。
这里需要现在settings创建MAX_PAGE,即爬取页数。其中需要将ROBOTISTXT_OBEY修改为False,不然无法抓取。
具体代码在item中。
在pipelines.py中实现保存数据到mongo。
需要重写ImagePipline类,之后就可以爬取了。
展示一下结果: