For a given query, find a correct execution plan that has the lowest "cost".
This is the part of a DBMS that is the hardest to implement well (proven to be ==NP-Complete==).
No optimizer truly produces the "optimal" plan:
- Use ==estimation techniques== to guess real plan cost.
- Use ==heuristics== to limit the search space.

Logical vs. Physical Plans
The optimizer generates a mapping of a ==logical algebra expression== to the ==optimal== ==equivalent== ==physical algebra expression==.
Physical operators define a specific execution strategy using an ==access path==.
- They can depend on the physical format of the data that they process (i.e., sorting, compression).
- Not always a 1:1 mapping from logical to physical.
关于 access path 的概念参考:Selinger, P. Griffiths, et al. "Access path selection in a relational database management system." Readings in Artificial Intelligence and Databases. Morgan Kaufmann, 1989. 511-522.
Relational Algebra Equivalent
Two relational algebra expressions are said to be equivalent if on every legal database instance the two expressions generate the same set of tuples.
Example: (A ⨝ (B ⨝ C)) = (B ⨝ (A ⨝ C))
Query planning for OLTP queries is easy because they are ==sargable== (Search Argument Able).
- It is usually picking the best index with simple heuristics.
- Joins are almost always on foreign key relationships with a small cardinality.
Cost Estimation
Generate an estimate of the cost of executing a plan for the current state of the database.
- Interactions with other work in DBMS
- Size of intermediate results
- Choices of algorithms, access methods
- Resource utilization (CPU, I/O, network)
- Data properties (skew, order, placement)
Choice #1: Single Query
- Much smaller search space.
- DBMS (usually) does not reuse results across queries.
- To account for resource contention, the cost model must consider what is currently running.
Choice #2: Multiple Queries
- More efficient if there are many similar queries.
- Search space is much larger.
- Useful for data / intermediate result sharing.
Choice #1: Static Optimization
- Select the best plan prior to execution.
- Plan quality is dependent on cost model accuracy.
- Can amortize over executions with prepared statements.
Choice #2: Dynamic Optimization
- Select operator plans on-the-fly as queries execute.
- Will have re-optimize for multiple executions.
- Difficult to implement/debug (non-deterministic)
Choice #3: Adaptive Optimization
- Compile using a static algorithm.
- If the estimate errors > threshold, change or re-optimize.

Choice #1: Reuse Last Plan
- Use the plan generated for the previous invocation.
Choice #2: Re-Optimize
- Rerun optimizer each time the query is invoked.
- Tricky to reuse existing plan as starting point.
Choice #3: Multiple Plans
- Generate multiple plans for different values of the parameters (e.g., buckets).
Choice #4: Average Plan
- Choose the average value for a parameter and use that for all invocations.
Choice #1: Hints
- Allow the DBA to provide hints to the optimizer.
Choice #2: Fixed Optimizer Versions
- Set the optimizer version number and migrate queries one-by-one to the new optimizer.
Choice #3: Backwards-Compatible Plans
- Save query plan from old version and provide it to the new DBMS.
Approach #1: Wall-clock Time
- Stop after the optimizer runs for some length of time.
Approach #2: Cost Threshold
- Stop when the optimizer finds a plan that has a lower cost than some threshold.
Approach #3: Exhaustion
- Stop when there are no more enumerations of the target plan. Usually done per group.
Define ==static rules== that transform logical operators to a physical plan.
- Perform most restrictive selection early
- Perform all selections before joins
- Predicate/Limit/Projection pushdowns
- Join ordering based on cardinality
Examples: INGRES and Oracle (until mid 1990s).
Advantages:
- Easy to implement and debug.
- Works reasonably well and is fast for simple queries.
Disadvantages:
- Relies on magic constants that predict the efficacy of a planning decision.
- Nearly impossible to generate good plans when operators have complex inter-dependencies.


Use static rules to perform initial optimization. Then use ==dynamic programming== to determine the best join order for tables.
- First cost-based query optimizer
- ==Bottom-up== planning (forward chaining) using a ==divide-and-conquer== search method
Examples: System R, early IBM DB2, most open-source DBMSs.
Advantages:
- Usually finds a reasonable plan without having to perform an exhaustive search.
Disadvantages:
- All the same problems as the heuristic-only approach.
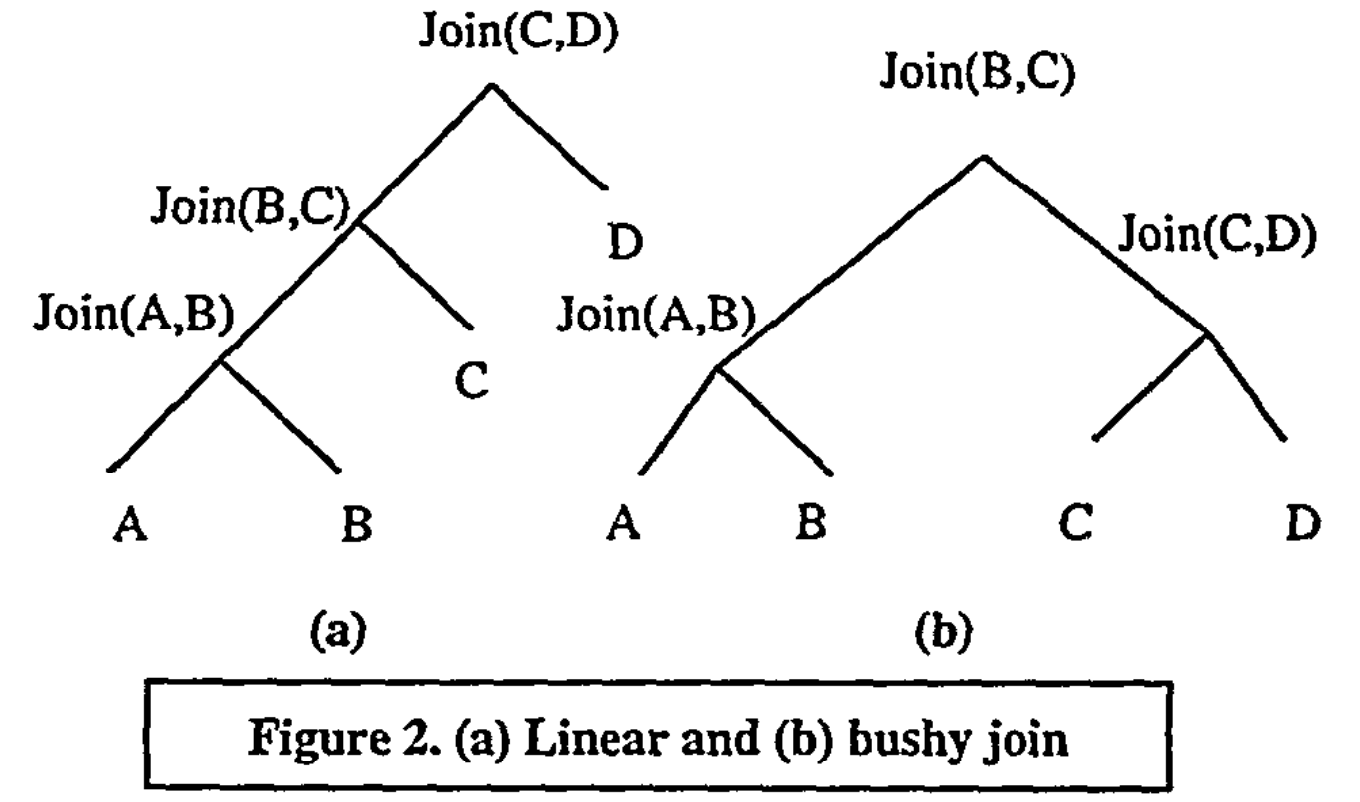
- Left-deep join trees are not always optimal.
- ==Must take in consideration the physical properties of data in the cost model (e.g., sort order).==
Top-down Optimization
- Start with the outcome that you want, and then work down the tree to find the optimal plan that gets you to that goal.
- Examples: Volcano, Cascades
Bottom-up Optimization
- Start with nothing and then build up the plan to get to the outcome that you want.
- Examples: System R, Starburst
- Break query up into blocks and generate the logical operators for each block.
- For each logical operator, generate a set of physical operators that implement it.
- All combinations of join algorithms and access paths
- Then iteratively construct a ==“left-deep” join tree== that minimizes the estimated amount of work to execute the plan.
Tips:
详细实现参考: Selinger, P. Griffiths, et al. "Access path selection in a relational database management system." Readings in Artificial Intelligence and Databases. Morgan Kaufmann, 1989. 511-522.
left-join tree and bushy-join tree 参考: Chaudhuri, Surajit. "An overview of query optimization in relational systems." Proceedings of the seventeenth ACM SIGACT-SIGMOD-SIGART symposium on Principles of database systems. 1998.

-
决定每个表的最优 access path
-
列出所有可能的 join 顺序
-
找出 2 表 join 的最优解:
-
Artist-Appears 和 Album-Appears 的 join 中,因为 hash-join 的 cost 比 sm-join 的 cost 更低,所以我们只保留 hash-join
-
Appears-Album 的 join 中,sm-join 的 cost 比 hash-join 更低,我们保留 sm-join
-


- 找出三表 join 的最优解:同理保留 cost 最低的结果

- 最后,选出所有 access path cost 最低的结果。

==But, the query has ORDER BY on ARTIST.ID but the logical plans do not contain sorting properties.== 因为在选择 cost 最低的 operator 的时候,并没有考虑 physical properties 即需要最终的结果按 ARTIST.ID 有序,如果在选择最优的 operator 的时候,保留了 artist 表的 sm-join,那么最终结果就是有序的了。
Perform a random walk over a solution space of all possible (valid) plans for a query.
Continue searching until a cost threshold is reached or the optimizer runs for a length of time.
Examples: Postgres’ genetic algorithm.
Advantages:
- Jumping around the search space randomly allows the optimizer to get out of local minimums.
- Low memory overhead (if no history is kept).
Disadvantages:
- Difficult to determine why the DBMS may have chosen a plan.
- Must do extra work to ensure that query plans are deterministic.
- Still must implement correctness rules.

Use a rule engine that allows transformations to modify the query plan operators. The physical properties of data is embedded with the operators themselves.
First rewrite the logical query plan using transformation rules.
- The engine checks whether the transformation is allowed before it can be applied.
- Cost is never considered in this step.
Then perform a cost-based search to map the logical plan to a physical plan.
Better implementation of the System R optimizer that uses declarative rules.
Stage #1: Query Rewrite
- Compute a SQL-block-level, relational calculus-like representation of queries.
Stage #2: Plan Optimization
- Execute a System R-style dynamic programming phase once query rewrite has completed.
Advantages:
- Works well in practice with fast performance.
Disadvantages:
- Difficult to assign priorities to transformations
- Some transformations are difficult to assess without computing multiple cost estimations.
- Rules maintenance is a huge pain.
Unify the notion of both logical -> logical and logical -> physical transformations. No need for separate stages because everything is transformations.
This approach generates many transformations, so it makes heavy use of memoization to reduce redundant work.
General purpose cost-based query optimizer, based on equivalence rules on algebras.
- Easily add new operations and equivalence rules.
- Treats physical properties of data as first-class entities during planning.
- ==Top-down== approach (backward chaining) using ==branch-and-bound== search.
-
枚举各种可能的 expression
-
从 top logical expression 开始,深度优先向下递归,考虑可能的 physical implementation rule,算子的不同物理实现会对下层的 logical expression 产生不同的 physical property 要求,在下图中,SM-JOIN 会对两个输入各自在 join key 上产生 order 属性,其输出可以产生 ARTIST.ID 的有序属性。
-
Hash-Join 因为输出不满足 artist.id 有序,不能直接使用
-
虽然 Hash-Join 不满足 order 属性,但是可以通过 Enforcer 加上一个 Quicksort 来解决,不过 Quicksort + Hash-Join 的 cost 大于 前面已经找到的 SM-Join 了,根据 ==branch-and-bound== 规则直接丢弃掉。




Advantages:
- Use declarative rules to generate transformations.
- Better extensibility with an efficient search engine. Reduce redundant estimations using memoization.
Disadvantages:
- All equivalence classes are completely expanded to generate all possible logical operators before the optimization search.
- Not easy to modify predicates.