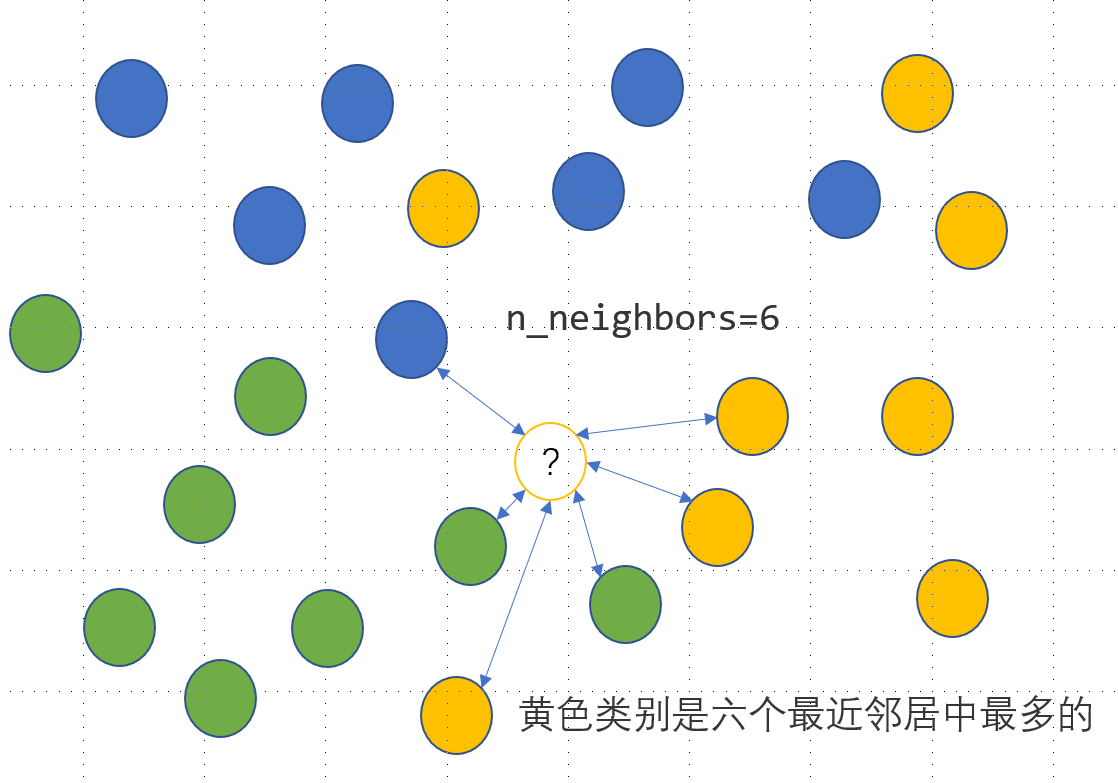
数值数据表示的三要素:
1.进位计数制
2.定点、浮点表示
3.如何用二进制编码
即:要确定一个数值数据的值必须先确定这三个要素。
例如机器数 01011001的值是多少?答案是不知道
原码
原码范围:-127~+127
- -[+127]=01111111
[-127]=11111111
0有两种:
[+0]=00000000
[-0]=10000000
原码
原码范围:-127~+127
[+127]=01111111
[-127]=11111111
0有两种:
[+0]=00000000
[-0]=10000000
反码
$X原->X反$
正数:X反=X原
负数: X原符号位为1,数值为按位取反
反码范围:-127~+127
[+127]=01111111
[-127]=10000000
0有两种:
[+0]=00000000
[-0]=11111111
补码
$X原->X补$
正数:X补=X原
负数:符号位为1,数值为按位取反,末尾加1
补码范围:**-128~+127**
[+127]=01111111
[-128]=10000000
[-1] = 11111111
0只有一种表示[+0]补=[-0]补=00000000
移码
移码通常表示浮点数的阶码
移码一般为整数,故移码通常只用于表示整数
对定点正数,阶码为n,他的移码是:
$$X_移=2^{n-1}+X_原$$
0的移码和补码一样
$X原->X移$
正数:将原码符号位一起变反
负数:将原码连同符号位一起变反,末尾再加1
$X补->X移$
符号相反,数值位相同
移码的表示范围与补码一致:-128~+127
补码
$X原->X补$
正数:X补=X原
负数:符号位为1,数值为按位取反,末尾加1
补码范围:-128~+127
[+127]=01111111
[-128]=10000000
[-1] = 11111111
0只有一种表示[+0]补=[-0]补=00000000
移码
移码通常表示浮点数的阶码
移码一般为整数,故移码通常只用于表示整数
对定点正数,阶码为n,他的移码是:
0的移码和补码一样
$X原->X移$
正数:将原码符号位一起变反
负数:将原码连同符号位一起变反,末尾再加1
$X补->X移$
符号相反,数值位相同
移码的表示范围与补码一致:-128~+127
定点数
数的小数点固定在同一位置不变
1.带符号的定点小数
约定所有数的小数点的位置,固定在符号位之后
符号位+“.”+数值位
字长n+1位时,表示范围是$-(1-2^{-n})=>(1-2^{-n})$
2.带符号的定点整数
小数点固定在最低数值位之后
符号位+数值位+“.”
- 编译原理 + 数据库系统
- Hexo + 编译原理
- Hexo博客搭建
鸽了半年的hexo博客搭建,阿里云都快过了半年了,把自己的一些踩坑和修改写一下吧,首先放一下我hexo博客搭建的时候的一些参考吧,这几个链接应该按道理没有很多踩坑的地方,我使用的主题是yilia主题所以说下面几个链接主要是关于yilia的,不过其实hexo博客框架的那个js和css名字都一样,配置文件的语法和格式也是一致的,所以说还是可以提供到一些帮助的,而且我自己在搭建一些操作的时候也学习了其他主题的一些方法。
从0开始搭建一个hexo博客无坑教程,是真的无坑版本,一切顺利(这里需要感谢一位b站的良心up主codesheep,他其他的视频也不错哦):
手把手教你从0开始搭建自己的个人博客 |无坑版视频教程| hexo
美化相关链接:
+ Hexo博客搭建
鸽了半年的hexo博客搭建,阿里云都快过了半年了,把自己的一些踩坑和修改写一下吧,首先放一下我hexo博客搭建的时候的一些参考吧,这几个链接应该按道理没有很多踩坑的地方,我使用的主题是yilia主题所以说下面几个链接主要是关于yilia的,不过其实hexo博客框架的那个js和css名字都一样,配置文件的语法和格式也是一致的,所以说还是可以提供到一些帮助的,而且我自己在搭建一些操作的时候也学习了其他主题的一些方法。
从0开始搭建一个hexo博客无坑教程,是真的无坑版本,一切顺利(这里需要感谢一位b站的良心up主codesheep,他其他的视频也不错哦):
手把手教你从0开始搭建自己的个人博客 |无坑版视频教程| hexo
美化相关链接:
- 参考链接1
- 参考链接2
@@ -226,18 +226,10 @@
安装git,nodejs
安装git和nodejs这个我就不过多介绍了,大家去csdn找找最新的相关安装教程就行了,在codesheep的视频里面也有教大家怎么做,记得切换一下node源到淘宝镜像cnpm,有的时候npm下载特别慢或者是报错。2024-10-9更新:安装node现在最好使用nvm安装管理node版本,再来通过npm装hexo
-官网下载hexo博客框架
hexo官网,如果在hexo的使用过程有什么问题也可以去看hexo的官方文档
在git或者cmd下面都可以使用该命令完成hexo博客的安装
-npm install -g hexo-cli#建议用这个全局安装
-高级用户可能更喜欢安装和使用hexo软件包。
-npm install hexo
-初始化hexo博客
安装Hexo后,输入以下命令以创建一个新文件夹初始化Hexo,注意这个文件夹就是我们的以后存放博客等各种主题等配置文件的文件夹了,如果配置过程博客出了问题,重新建一个新文件夹就行了,问题不大,注意信息备份。
-hexo init <folder>
cd <folder>
npm install
-npm instal以后目录中会出现这些文件
+官网下载hexo博客框架
hexo官网,如果在hexo的使用过程有什么问题也可以去看hexo的官方文档
在git或者cmd下面都可以使用该命令完成hexo博客的安装
npm install -g hexo-cli#建议用这个全局安装
高级用户可能更喜欢安装和使用hexo软件包。
npm install hexo
+初始化hexo博客
安装Hexo后,输入以下命令以创建一个新文件夹初始化Hexo,注意这个文件夹就是我们的以后存放博客等各种主题等配置文件的文件夹了,如果配置过程博客出了问题,重新建一个新文件夹就行了,问题不大,注意信息备份。
hexo init <folder>
cd <folder>
npm install
npm instal以后目录中会出现这些文件
├── _config.yml 最重要的配置文件
├── package.json
├── scaffolds
├── source 这里会存放你的博客文件
| ├── _drafts
| └── _posts
└── themes 这里存放各种主题
-
-这样完了以后其实我们的博客就已经搭建完成了,你可以在你初始化后的博客目录下输入一下命令,然后就会开启hexo服务,在浏览器输入http://localhost:4000
就可以看到你生成的博客了,默认情况下hexo博客主题是landspace
-hexo s
-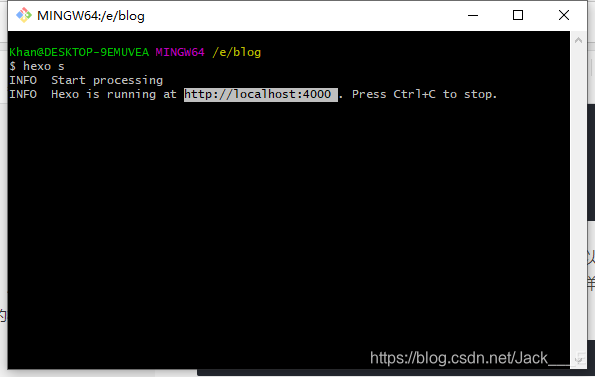
+这样完了以后其实我们的博客就已经搭建完成了,你可以在你初始化后的博客目录下输入一下命令,然后就会开启hexo服务,在浏览器输入http://localhost:4000
就可以看到你生成的博客了,默认情况下hexo博客主题是landspace
hexo s
github部署
对于github上进行部署的话我们首先需要新建一个repo,并且必须命名为:你的github账户名.github.io,建议大家最好配置好ssh这样就不用每次输入密码了
然后我们需要在博客根目录下npm一个用于部署的模块deploy-git
npm install hexo-deployer-git --save
github对于hexo博客的部署是非常方便的,只需要在主配置文件_config.yml下添加一项配置就可以了,配置到服务器上也是如此
这里我直接将github和服务器都配置好了提交,你如果没有服务器端的配置就直接删掉那一行就行。
@@ -245,9 +237,7 @@
#建议每次提交都执行这三个命令,
#当然了你也可以在直接写成bat文件或者sh文件,就不用每次自己手动输入了
hexo clean
hexo g
hexo d
他就会自动将我们所写的博客和所需要展示的内容转成htmlcssjs等文件push到我们的github上去,所以说大家如果有配置和修改自己选择的主题的话,可能你需要备份一下,不然到时候就没了,在部署的网页上这些npmmodules和你修改的样式都是直接打包好了的,你的源代码是不会提交上去的。
-常用操作
好了其实到这里我们的博客搭建就已经完成了,这里我们介绍几个常用的命令和操作吧,
-hexo clean 清除生成的文件
hexo g 重新生成博客的文件
hexo s 开启hexo服务,我们可以预览自己新写的博客在网页上的样子
hexo d 提交部署到服务器上包括github
hexo new "my first blog" 新建一个名为my first blog的博客,会显示在你的博客根目录的`source/_posts`下面
-
大家可能会注意到我这里好像不仅生成了文件还生成了一个同名的文件夹,这个文件夹是用于引入同名博客的图片的。
当然了其实我建议最好在csdn上写好自己的博客发表以后就变成网图了,然后直接复制csdn的博文在commit到hexo上面这样就不用存图片啥的,不过这里还是介绍一下本地图片引入吧
+常用操作
好了其实到这里我们的博客搭建就已经完成了,这里我们介绍几个常用的命令和操作吧,
hexo clean 清除生成的文件
hexo g 重新生成博客的文件
hexo s 开启hexo服务,我们可以预览自己新写的博客在网页上的样子
hexo d 提交部署到服务器上包括github
hexo new "my first blog" 新建一个名为my first blog的博客,会显示在你的博客根目录的`source/_posts`下面
大家可能会注意到我这里好像不仅生成了文件还生成了一个同名的文件夹,这个文件夹是用于引入同名博客的图片的。
当然了其实我建议最好在csdn上写好自己的博客发表以后就变成网图了,然后直接复制csdn的博文在commit到hexo上面这样就不用存图片啥的,不过这里还是介绍一下本地图片引入吧
- 把主页配置文件
_config.yml 里的post_asset_folder:这个选项设置为true
- 在你的hexo目录下执行这样一句话
npm install hexo-asset-image --save,这是下载安装一个可以上传本地图片的插件
@@ -561,7 +551,7 @@
- 编译原理
+ 数据库系统
-
diff --git "a/2020/07/12/python\345\256\236\347\216\260\351\201\227\344\274\240\347\256\227\346\263\225/index.html" "b/2020/07/12/python\345\256\236\347\216\260\351\201\227\344\274\240\347\256\227\346\263\225/index.html"
index 740163f2..9afc76b8 100644
--- "a/2020/07/12/python\345\256\236\347\216\260\351\201\227\344\274\240\347\256\227\346\263\225/index.html"
+++ "b/2020/07/12/python\345\256\236\347\216\260\351\201\227\344\274\240\347\256\227\346\263\225/index.html"
@@ -214,8 +214,7 @@
- 今天研究了一下遗传算法,发现原理还是很好懂的,不过在应用层面上还是有很多要学习的方法,如何定义编码解码的过程,如何进行选择和交叉变异,这都是我们需要解决的事情,估计还是要多学多用才能学会,当然了如果大家对我写的这些内容如果有什么不同的看法的话也建议大家提出,毕竟算法小白一个。
-
+ 今天研究了一下遗传算法,发现原理还是很好懂的,不过在应用层面上还是有很多要学习的方法,如何定义编码解码的过程,如何进行选择和交叉变异,这都是我们需要解决的事情,估计还是要多学多用才能学会,当然了如果大家对我写的这些内容如果有什么不同的看法的话也建议大家提出,毕竟算法小白一个。
遗传算法介绍
所谓遗传算法其实就是一种仿生算法,一种仿生全局优化算法模仿生物的遗传进化原理,通过自然选择(selection)、交叉(crossover)与变异(mutation)等操作机制,逐步淘汰掉适应度不够高的个体,使种群中个体的适应性(fitness)不断提高。
核心思想:物竞天择,适者生存

主要的一些应用领域主要是在
- 函数优化,求函数极值类
@@ -230,20 +229,16 @@ 解码 :解码主要是能够解析我们编码后的DNA序列,然后讲其表示的信息还原出来,然后进行适应度的计算。
- 自然选择 :自然选择主要是依据个体适应度的大小转化成被选择的概率,利用轮盘赌的方式——将数据按照指定的概率分布方式提取出来,从而实现了物竞天择适者生存的原理,适应度大的个体被留下来的概率会逐步增大。
- 变异 :随机修改某一位基因序列,从而改变他的适应度
-- 交叉重组 :种群中随机选取两个个体,交互若干的DNA片段,从而改变他的适应度,生成新的子代
+- 交叉重组 :种群中随机选取两个个体,交互若干的DNA片段,从而改变他的适应度,生成新的子代
这里我们要明白的一点就是,遗传算法只是提供了一个迭代的模板,具体的适应度函数也就是我们选择优化的相关指标和他的表示都是需要根据题目里面的问题来建模,然后编码解码的方式说白了其实就是如何表示我们要的可行解,比如说求一个函数的极值且精确到多少位那么他的可行解就是自变量,这里我们通常采用二进制编码,如果是TSP问题,那么可行解就可以表示成为各个配送点编号构成的一个数组,进行实数数组序列的方式编码,自然而然解码的方法和含义我们也都清楚了求函数极值的问题
这里是我根据网上莫烦的python视频教程,来写的一个算法,这里我们要做的问题是求出$f(x)=sin(10x)×x+cos(2x)×x$的极大值。
-这里我们要明白的一点就是,遗传算法只是提供了一个迭代的模板,具体的适应度函数也就是我们选择优化的相关指标和他的表示都是需要根据题目里面的问题来建模,然后编码解码的方式说白了其实就是如何表示我们要的可行解,比如说求一个函数的极值且精确到多少位那么他的可行解就是自变量,这里我们通常采用二进制编码,如果是TSP问题,那么可行解就可以表示成为各个配送点编号构成的一个数组,进行实数数组序列的方式编码,自然而然解码的方法和含义我们也都清楚了
-求函数极值的问题
这里是我根据网上莫烦的python视频教程,来写的一个算法,这里我们要做的问题是求出$f(x)=sin(10x)×x+cos(2x)×x$的极大值。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
DNA_SIZE=10 #编码DNA的长度
POP_SIZE=100 #初始化种群的大小
CROSS_RATE=0.8 #DNA交叉概率
MUTATION_RATE=0.003 #DNA变异概率
N_GENERATIONS=200 #迭代次数
X_BOUND=[0,5] #x upper and lower bounds x的区间
def F(x):
return np.sin(10*x)*x+np.cos(2*x)*x
def get_fitness(pred):
return pred+1e-3-np.min(pred)
#获得适应值,这里是与min比较,越大则适应度越大,便于我们寻找最大值,为了防止结果为0特意加了一个较小的数来作为偏正
def translateDNA(pop):#DNA的二进制序列映射到x范围内
return pop.dot(2 ** np.arange(DNA_SIZE)[::-1]) / float(2**DNA_SIZE-1) * (X_BOUND[1]-X_BOUND[0])
def select(pop,fitness):
idx = np.random.choice(np.arange(POP_SIZE), size=POP_SIZE, replace=True,p=fitness / fitness.sum())
#我们只要按照适应程度 fitness 来选 pop 中的 parent 就好. fitness 越大, 越有可能被选到.
return pop[idx]
#交叉
def crossover(parent,pop):
if np.random.rand() < CROSS_RATE:
i_ = np.random.randint(0, POP_SIZE, size=1) # 选择一个母本的index
print("i_:",i_)
print("i_.size:",i_.size)
cross_points = np.random.randint(0, 2, size=DNA_SIZE).astype(np.bool) # choose crossover points
print("cross_point",cross_points)
print("corsssize:",cross_points.size)
print(parent[cross_points])
print(pop[i_, cross_points])
parent[cross_points] = pop[i_, cross_points] # mating and produce one child
print(parent[cross_points])
return parent
#变异
def mutate(child):
for point in range(DNA_SIZE):
if np.random.rand() < MUTATION_RATE:
child[point] = 1 if child[point] == 0 else 0
return child
pop = np.random.randint(2, size=(POP_SIZE, DNA_SIZE)) # initialize the pop DNA
plt.ion() # something about plotting
x = np.linspace(*X_BOUND, 200)
plt.plot(x, F(x))
for _ in range(N_GENERATIONS):
F_values = F(translateDNA(pop)) # compute function value by extracting DNA
# something about plotting
# if 'sca' in globals():
# sca.remove()
# sca = plt.scatter(translateDNA(pop), F_values, s=200, lw=0, c='red', alpha=0.5)
# plt.pause(0.05)
# GA part (evolution)
fitness = get_fitness(F_values)
print("Most fitted DNA: ", pop[np.argmax(fitness), :])
pop = select(pop, fitness)
pop_copy = pop.copy()
for parent in pop:
child = crossover(parent, pop_copy)
child = mutate(child)
parent[:] = child # parent is replaced by its child
plt.scatter(translateDNA(pop), F_values, s=200, lw=0, c='red', alpha=0.5)
print("x:",translateDNA(pop))
print(type(translateDNA(pop)))
print(len(translateDNA(pop)))
print("max:",F_values)
plt.ioff()
plt.show()
-最后我们可以展示一个结果,注意这个看似只有一个红点,其实这是100个种群个体集中得到的结果。,所以你最后打印的时候是一个100个解构成的1×100的解向量,最终都集中到了这个极值附近。

轮盘赌说的很复杂其实在python的random函数里可以说是封装好了,这里我们可以着重看看这个choice函数
-np.random.choice(a, size=None, replace=True, p=None)
-a表示我们需要选取的数组。
size表示我们需要提取的数据个数。
replace 代表的意思是抽样之后还放不放回去,如果是False的话,抽取不放回,如果是True的话, 抽取放回。
p表示的就是概率数组,代表每一个数被抽取出来的概率。
在我们代码中是写的
+最后我们可以展示一个结果,注意这个看似只有一个红点,其实这是100个种群个体集中得到的结果。,所以你最后打印的时候是一个100个解构成的1×100的解向量,最终都集中到了这个极值附近。
轮盘赌说的很复杂其实在python的random函数里可以说是封装好了,这里我们可以着重看看这个choice函数
np.random.choice(a, size=None, replace=True, p=None)
a表示我们需要选取的数组。
size表示我们需要提取的数据个数。
replace 代表的意思是抽样之后还放不放回去,如果是False的话,抽取不放回,如果是True的话, 抽取放回。
p表示的就是概率数组,代表每一个数被抽取出来的概率。
在我们代码中是写的
idx = np.random.choice(np.arange(POP_SIZE), size=POP_SIZE, replace=True,p=fitness / fitness.sum())
-直接就抽取出了种群pop中每个个体的下标编号,这里我们的概率数组是使用的按照比例的适应度分配比例方法提取,而概率是以这种方式来建模计算的。
$$P_{i}=\frac{fitness(i)}{\sum_{i=0}^{n}{fitness(i)}}$$

+直接就抽取出了种群pop中每个个体的下标编号,这里我们的概率数组是使用的按照比例的适应度分配比例方法提取,而概率是以这种方式来建模计算的。
+
求解TSP最短路的问题
tsp问题主要就是用户从某一起点出发然后经过所有的点一次并回到起点的最短路径,同时约定任意两点之前是互通可达的,我们要注意的是,可能两点之间的距离有时候是欧式距离,有的时候可能是哈密顿距离,自己要根据题意去判断。
这里我们主要讲解一下他的fitness函数主要是最短路径的总距离,编码序列则是最短路的编号,然后我们要注意这个问题在交叉变异的时候,我们一定要保证他首先是一条正确的可行解!不要出现有顶点重合或缺失的情况。
这里我们在解决交叉的时候是先随机选取一部分父类的基因编号,然后再从母本的DNA序列里面选出子类中缺少的基因,从而获得基因重组。
而变异的时候也不同于例1里面的修改二进制编码,而是采用的调换两个基因序号来完成,从而保证我们的结果一定是一条规范正确的回路。
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
N_CITIES = 20 # 城市数量
CROSS_RATE = 0.1 #交叉概率
MUTATE_RATE = 0.02 #变异概率
POP_SIZE = 500 #种群概率
N_GENERATIONS = 500 #迭代次数
class GA(object):
def __init__(self, DNA_size, cross_rate, mutation_rate, pop_size, ):
self.DNA_size = DNA_size
self.cross_rate = cross_rate
self.mutate_rate = mutation_rate
self.pop_size = pop_size
self.pop = np.vstack([np.random.permutation(DNA_size) for _ in range(pop_size)])
def translateDNA(self, DNA, city_position): # get cities' coord in order
line_x = np.empty_like(DNA, dtype=np.float64)
line_y = np.empty_like(DNA, dtype=np.float64)
for i, d in enumerate(DNA):
city_coord = city_position[d]
line_x[i, :] = city_coord[:, 0]
line_y[i, :] = city_coord[:, 1]
return line_x, line_y
def get_fitness(self, line_x, line_y):
total_distance = np.empty((line_x.shape[0],), dtype=np.float64)
for i, (xs, ys) in enumerate(zip(line_x, line_y)):
total_distance[i] = np.sum(np.sqrt(np.square(np.diff(xs)) + np.square(np.diff(ys))))
fitness = np.exp(self.DNA_size * 2 / total_distance)#把欧氏距离的影响扩大化
return fitness, total_distance
def select(self, fitness):
idx = np.random.choice(np.arange(self.pop_size), size=self.pop_size, replace=True, p=fitness / fitness.sum())
return self.pop[idx]
def crossover(self, parent, pop):
if np.random.rand() < self.cross_rate:
i_ = np.random.randint(0, self.pop_size, size=1) # select another individual from pop
cross_points = np.random.randint(0, 2, self.DNA_size).astype(np.bool) # choose crossover points
keep_city = parent[~cross_points] # find the city number
swap_city = pop[i_, np.isin(pop[i_].ravel(), keep_city, invert=True)]
parent[:] = np.concatenate((keep_city, swap_city))
return parent
def mutate(self, child):
for point in range(self.DNA_size):
if np.random.rand() < self.mutate_rate:
swap_point = np.random.randint(0, self.DNA_size)
swapA, swapB = child[point], child[swap_point]
child[point], child[swap_point] = swapB, swapA
return child
def evolve(self, fitness):
pop = self.select(fitness)
pop_copy = pop.copy()
for parent in pop: # for every parent
child = self.crossover(parent, pop_copy)
child = self.mutate(child)
parent[:] = child
self.pop = pop
class TravelSalesPerson(object):
def __init__(self, n_cities):
self.city_position = np.random.rand(n_cities, 2)
plt.ion()
def plotting(self, lx, ly, total_d):
plt.cla()
plt.scatter(self.city_position[:, 0].T, self.city_position[:, 1].T, s=100, c='k')
plt.plot(lx.T, ly.T, 'r-')
plt.text(-0.05, -0.05, "Total distance=%.2f" % total_d, fontdict={'size': 20, 'color': 'red'})
plt.xlim((-0.1, 1.1))
plt.ylim((-0.1, 1.1))
plt.pause(0.01)
ga = GA(DNA_size=N_CITIES, cross_rate=CROSS_RATE, mutation_rate=MUTATE_RATE, pop_size=POP_SIZE)
env = TravelSalesPerson(N_CITIES)
for generation in range(N_GENERATIONS):
lx, ly = ga.translateDNA(ga.pop, env.city_position)#city_position(x,y)
fitness, total_distance = ga.get_fitness(lx, ly)#根据获得的路径计算路程
ga.evolve(fitness)
best_idx = np.argmax(fitness)
print('Gen:', generation, '| best fit: %.2f' % fitness[best_idx],)
# env.plotting(lx[best_idx], ly[best_idx], total_distance[best_idx])
env.plotting(lx[best_idx], ly[best_idx], total_distance[best_idx])
plt.ioff()
plt.show()
-
-
在最后我附上我学习的这个视频教程吧,多看看知乎csdn还有很多解释。明天我的京东快递《matlab智能算法30个案例分析》就要到了,真的是本好书,顺带一提学校培训真累啊,还啥都不会。
莫烦python遗传算法
+
在最后我附上我学习的这个视频教程吧,多看看知乎csdn还有很多解释。明天我的京东快递《matlab智能算法30个案例分析》就要到了,真的是本好书,顺带一提学校培训真累啊,还啥都不会。
莫烦python遗传算法
@@ -548,7 +543,7 @@
-
@@ -556,15 +551,15 @@
-
diff --git "a/2020/07/15/\346\250\241\346\213\237\351\200\200\347\201\253matlab\345\256\236\347\216\260\357\274\210TSP\344\270\272\344\276\213\357\274\211/index.html" "b/2020/07/15/\346\250\241\346\213\237\351\200\200\347\201\253matlab\345\256\236\347\216\260\357\274\210TSP\344\270\272\344\276\213\357\274\211/index.html"
index 27d5f0a0..2077abc4 100644
--- "a/2020/07/15/\346\250\241\346\213\237\351\200\200\347\201\253matlab\345\256\236\347\216\260\357\274\210TSP\344\270\272\344\276\213\357\274\211/index.html"
+++ "b/2020/07/15/\346\250\241\346\213\237\351\200\200\347\201\253matlab\345\256\236\347\216\260\357\274\210TSP\344\270\272\344\276\213\357\274\211/index.html"
@@ -213,41 +213,28 @@
最近学习了模拟退火智能算法,顺便学习了一下matlab,顺带一提matlba真香,对矩阵的操作会比python的numpy操作要更加方便,这里我们是以TSP问题为例子,因为比较好理解。
-模拟退火介绍
模拟退火总的来说还是一种优化算法,他模拟的是淬火冶炼的一个过程,通过升温增强分子的热运动,然后再慢慢降温,使其达到稳定的状态。
-
-
初始解
通常是以一个随机解作为初始解. 并保证理论上能够生成解空间中任意的解,也可以是一个经挑选过的较好的解,初始解不宜“太好”, 否则很难从这个解的邻域跳出,针对问题去分析。
扰动邻解
邻解生成函数应尽可能保证产生的侯选解能够遍布解空间,邻域应尽可能的小,能够在少量循环步中允分探测.,但每次的改变不应该引起太大的变化。
初始温度
+模拟退火介绍
模拟退火总的来说还是一种优化算法,他模拟的是淬火冶炼的一个过程,通过升温增强分子的热运动,然后再慢慢降温,使其达到稳定的状态。
初始解
通常是以一个随机解作为初始解. 并保证理论上能够生成解空间中任意的解,也可以是一个经挑选过的较好的解,初始解不宜“太好”, 否则很难从这个解的邻域跳出,针对问题去分析。
扰动邻解
邻解生成函数应尽可能保证产生的侯选解能够遍布解空间,邻域应尽可能的小,能够在少量循环步中允分探测.,但每次的改变不应该引起太大的变化。
初始温度
- 初始温度应该设置的尽可能的高, 以确保最终解不受初始解
影响. 但过高又会增加计算时间.
- 均匀抽样一组状态,以各状态目标值的方差为初温.
-- 如果能确定邻解间目标函数(COST 函数) 的最大差值, 就可以确定出初始温度$T_{0}$,以使初始接受概率$P=e^{-|\Delta C|_{max}/T}$足够大。$|\Delta C|_{max}$ 可由随机产生一组状态的最大目标值差来替代.
+- 如果能确定邻解间目标函数(COST 函数) 的最大差值, 就可以确定出初始温度$T{0}$,以使初始接受概率$P=e^{-|\Delta C|\{max}/T}$足够大。$|\Delta C|_{max}$ 可由随机产生一组状态的最大目标值差来替代.
- 在正式开始退火算法前, 可进行一个升温过程确定初始温度:逐渐增加温度, 直到所有的尝试尝试运动都被接受, 将此时的温度设置为初始温度.
-- 由经验给出, 或通过尝试找到较好的初始温度.
-
-等温步数
-
+- 由经验给出, 或通过尝试找到较好的初始温度.
等温步数
- 等温步数也称Metropolis 抽样稳定准则, 用于决定在各温度下产生候选解的数目. 通常取决于解空间和邻域的大小.
- 等温过程是为了让系统达到平衡, 因此可通过检验目标函数的均值是否稳定(或连续若干步的目标值变化较小) 来确定等温步数.
- 等温步数受温度的影响. 高温时, 等温步数可以较小, 温度较小时, 等温步数要大. 随着温度的降低, 增加等温步数.
-- 有时为了考虑方便, 也可直接按一定的步数抽样。
+- 有时为了考虑方便, 也可直接按一定的步数抽样。
Metropolis法则
Metropolis法则是SA接受新解的概率。 $x$是表示当前解,$x’$是新解,其实这也是模拟退火区别于贪心的一点,我们在更新新解的时候对于不满足条件的情况,我们也有一定的概率来进行选取,从而可以使得退火模拟可以跳出局部最优解。
-Metropolis法则
Metropolis法则是SA接受新解的概率。
$$P(x=>x’)=
\begin{cases}
1 &\text{$,f(x’)<f(x)$} \\
e^{-\frac{f(x’)-f(x)}{T}} & \text{$,f(x’)>f(x)$}\
\end{cases}
$$
$x$是表示当前解,$x’$是新解,其实这也是模拟退火区别于贪心的一点,我们在更新新解的时候对于不满足条件的情况,我们也有一定的概率来进行选取,从而可以使得退火模拟可以跳出局部最优解。
-降温公式
经典模拟退火算法的降温方式:
$$T(t)=\frac{T_0}{log(1+t)}$$
快速模拟退火算法的降温方式:
$$T(t)=\frac{T_0}{1+t}$$
常用的模拟退火算法的降温方式还有(通常$0.8<\alpha<0.99$)
$$T(t+\Delta t)=\alpha T(t)$$
终止条件自己设定阈值即可。
花费函数COST
这个基本就是分析题目,一般设置为我们需要求解的目标函数最值。
-TSP问题
已知中国34 个省会城市(包括直辖市) 的经纬度, 要求从北京出发, 游遍34 个城市, 最后回到北京. 用模拟退火算法求最短路径。
1.main.m
主函数
-clc
clear;
%%
load('china.mat');
plotcities(province, border, city);%画出地图
cityaccount=length(city);%城市数量
dis=distancematrix(city)%距离矩阵
route =randperm(cityaccount);%路径格式
temperature=1000;%初始化温度
cooling_rate=0.95;%温度下降比率
item=1;%用来控制降温的循环记录次数
distance=totaldistance(route,dis);%计算路径总长度
temperature_iterations = 1;
% This is a flag used to plot the current route after 200 iterations
plot_iterations = 1;
plotroute(city, route, distance,temperature);%画出路线
%%
while temperature>1.0 %循环条件
temp_route=change(route,'reverse');%产生扰动。分子序列变化
% fprintf("%d\n",temp_route(1));
temp_distance=totaldistance(temp_route,dis);%产生变化后的长度
dist=temp_distance-distance;%两个路径的差距
if(dist<0)||(rand < exp(-dist/(temperature)))
route=temp_route;
distance=temp_distance;
item=item+1;
temperature_iterations=temperature_iterations+1;
plot_iterations=plot_iterations+1;
end
if temperature_iterations>=10
temperature=cooling_rate*temperature;
temperature_iterations=0;
end
if plot_iterations >= 20
plotroute(city, route, distance,temperature);%画出路线
plot_iterations = 0;
end
% fprintf("it=%d",item);
end
-2.distance.m
计算两点之间的距离
-function d = distance(lat1, long1, lat2, long2, R)
% DISTANCE
% d = DISTANCE(lat1, long1, lat2, long2, R) compute distance between points
% on sphere with radians R.
%
% Latitude/Longitude Distance Calculation:
% http://www.mathforum.com/library/drmath/view/51711.html
y1 = lat1/180*pi; x1 = long1/180*pi;
y2 = lat2/180*pi; x2 = long2/180*pi;
dy = y1-y2; dx = x1-x2;
d = 2*R*asin(sqrt(sin(dy/2)^2+sin(dx/2)^2*cos(y1)*cos(y2)));
end
-3.totaldistance.m
一条route路线的总路程,也是我们需要优化的目标函数
-function totaldis = totaldistance(route,dis)%传入距离矩阵和当前路线
%TOTALDISTANCE 此处显示有关此函数的摘要
% 此处显示详细说明
% fprintf("%d\n",route(1));
totaldis=dis(route(end),route(1));
% totaldis=dis(route(end),route(1));
for k=1:length(route)-1
totaldis=totaldis+dis(route(k),route(k+1));%直接加两个点之间的距离
end
-4.distancematrix.m
任意两点之间的距离矩阵
-function dis = distancematrix(city)
%DISTANCEMATRIX 此处显示有关此函数的摘要
% 此处显示详细说明
cityacount=length(city);
R=6378.137;%地球半径用于求两个城市的球面距离
for i = 1:cityacount
for j = i+1:cityacount
dis(i,j)=distance(city(i).lat,city(i).long,...
city(j).lat,city(j).long,R);%distance函数原来是设计来计算球面上距离的
dis(j,i)=dis(i,j);%对称,无向图
end
end
end
-
-5.change.m
产生分子扰动,求当前解的邻解
-function route = change(pre_route,method)
%CHANGE 此处显示有关此函数的摘要
% 此处显示详细说明
route=pre_route;
cityaccount=length(route);
%随机取数,相当于把0-34个城市映射到0-1的等概率抽取上,再取整
city1=ceil(cityaccount*rand); % [1, 2, ..., n-1, n]
city2=ceil(cityaccount*rand); % 1<=city1, city2<=n
switch method
case 'reverse' %[1 2 3 4 5 6] -> [1 5 4 3 2 6]
cmin = min(city1,city2);
cmax = max(city1,city2);
route(cmin:cmax) = route(cmax:-1:cmin);%反转某一段
case 'swap' %[1 2 3 4 5 6] -> [1 5 3 4 2 6]
route([city1, city2]) = route([city2, city1]);
end
-6.plotcities.m
画出city
-function h = plotcities(province, border, city)
% PLOTCITIES
% h = PLOTCITIES(province, border, city) draw the map of China, and return
% the route handle.
global h;
% draw the map of China
plot(province.long, province.lat, 'color', [0.7,0.7,0.7])
hold on
plot(border.long , border.lat , 'color', [0.5,0.5,0.5], 'linewidth', 1.5);
% plot a NaN route, and global the handle h.
h = plot(NaN, NaN, 'b-', 'linewidth', 1);
% plot cities as green dots
plot([city(2:end).long], [city(2:end).lat], 'o', 'markersize', 3, ...
'MarkerEdgeColor','b','MarkerFaceColor','g');
% plot Beijing as a red pentagram
plot([city(1).long],[city(1).lat],'p','markersize',5, ...
'MarkerEdgeColor','r','MarkerFaceColor','g');
axis([70 140 15 55]);
-7.plotroute.m
画出路线
-function plotroute(city, route, current_distance, temperature)
% PLOTROUTE
% PLOTROUTE(city, route, current_distance, temperature) plots the route and
% display current temperautre and distance.
global h;
cycle = route([1:end, 1]);
% update route
set(h,'Xdata',[city(cycle).long],'Ydata',[city(cycle).lat]);
% display current temperature and total distance
xlabel(sprintf('T = %6.1f Total Distance = %6.1f', ...
temperature, current_distance));
drawnow
-一开始的路径

最后运行出来的最优化路径

有需要的朋友可以下载相关的数据集下载链接
+降温公式
经典模拟退火算法的降温方式:
+快速模拟退火算法的降温方式:
+常用的模拟退火算法的降温方式还有(通常$0.8<\alpha<0.99$)
+终止条件自己设定阈值即可。
花费函数COST
这个基本就是分析题目,一般设置为我们需要求解的目标函数最值。
+TSP问题
已知中国34 个省会城市(包括直辖市) 的经纬度, 要求从北京出发, 游遍34 个城市, 最后回到北京. 用模拟退火算法求最短路径。
1.main.m
主函数
clc
clear;
%%
load('china.mat');
plotcities(province, border, city);%画出地图
cityaccount=length(city);%城市数量
dis=distancematrix(city)%距离矩阵
route =randperm(cityaccount);%路径格式
temperature=1000;%初始化温度
cooling_rate=0.95;%温度下降比率
item=1;%用来控制降温的循环记录次数
distance=totaldistance(route,dis);%计算路径总长度
temperature_iterations = 1;
% This is a flag used to plot the current route after 200 iterations
plot_iterations = 1;
plotroute(city, route, distance,temperature);%画出路线
%%
while temperature>1.0 %循环条件
temp_route=change(route,'reverse');%产生扰动。分子序列变化
% fprintf("%d\n",temp_route(1));
temp_distance=totaldistance(temp_route,dis);%产生变化后的长度
dist=temp_distance-distance;%两个路径的差距
if(dist<0)||(rand < exp(-dist/(temperature)))
route=temp_route;
distance=temp_distance;
item=item+1;
temperature_iterations=temperature_iterations+1;
plot_iterations=plot_iterations+1;
end
if temperature_iterations>=10
temperature=cooling_rate*temperature;
temperature_iterations=0;
end
if plot_iterations >= 20
plotroute(city, route, distance,temperature);%画出路线
plot_iterations = 0;
end
% fprintf("it=%d",item);
end
2.distance.m
计算两点之间的距离
function d = distance(lat1, long1, lat2, long2, R)
% DISTANCE
% d = DISTANCE(lat1, long1, lat2, long2, R) compute distance between points
% on sphere with radians R.
%
% Latitude/Longitude Distance Calculation:
% http://www.mathforum.com/library/drmath/view/51711.html
y1 = lat1/180*pi; x1 = long1/180*pi;
y2 = lat2/180*pi; x2 = long2/180*pi;
dy = y1-y2; dx = x1-x2;
d = 2*R*asin(sqrt(sin(dy/2)^2+sin(dx/2)^2*cos(y1)*cos(y2)));
end
3.totaldistance.m
一条route路线的总路程,也是我们需要优化的目标函数
function totaldis = totaldistance(route,dis)%传入距离矩阵和当前路线
%TOTALDISTANCE 此处显示有关此函数的摘要
% 此处显示详细说明
% fprintf("%d\n",route(1));
totaldis=dis(route(end),route(1));
% totaldis=dis(route(end),route(1));
for k=1:length(route)-1
totaldis=totaldis+dis(route(k),route(k+1));%直接加两个点之间的距离
end
4.distancematrix.m
任意两点之间的距离矩阵
function dis = distancematrix(city)
%DISTANCEMATRIX 此处显示有关此函数的摘要
% 此处显示详细说明
cityacount=length(city);
R=6378.137;%地球半径用于求两个城市的球面距离
for i = 1:cityacount
for j = i+1:cityacount
dis(i,j)=distance(city(i).lat,city(i).long,...
city(j).lat,city(j).long,R);%distance函数原来是设计来计算球面上距离的
dis(j,i)=dis(i,j);%对称,无向图
end
end
end
+5.change.m
产生分子扰动,求当前解的邻解
function route = change(pre_route,method)
%CHANGE 此处显示有关此函数的摘要
% 此处显示详细说明
route=pre_route;
cityaccount=length(route);
%随机取数,相当于把0-34个城市映射到0-1的等概率抽取上,再取整
city1=ceil(cityaccount*rand); % [1, 2, ..., n-1, n]
city2=ceil(cityaccount*rand); % 1<=city1, city2<=n
switch method
case 'reverse' %[1 2 3 4 5 6] -> [1 5 4 3 2 6]
cmin = min(city1,city2);
cmax = max(city1,city2);
route(cmin:cmax) = route(cmax:-1:cmin);%反转某一段
case 'swap' %[1 2 3 4 5 6] -> [1 5 3 4 2 6]
route([city1, city2]) = route([city2, city1]);
end
6.plotcities.m
画出city
function h = plotcities(province, border, city)
% PLOTCITIES
% h = PLOTCITIES(province, border, city) draw the map of China, and return
% the route handle.
global h;
% draw the map of China
plot(province.long, province.lat, 'color', [0.7,0.7,0.7])
hold on
plot(border.long , border.lat , 'color', [0.5,0.5,0.5], 'linewidth', 1.5);
% plot a NaN route, and global the handle h.
h = plot(NaN, NaN, 'b-', 'linewidth', 1);
% plot cities as green dots
plot([city(2:end).long], [city(2:end).lat], 'o', 'markersize', 3, ...
'MarkerEdgeColor','b','MarkerFaceColor','g');
% plot Beijing as a red pentagram
plot([city(1).long],[city(1).lat],'p','markersize',5, ...
'MarkerEdgeColor','r','MarkerFaceColor','g');
axis([70 140 15 55]);
7.plotroute.m
画出路线
function plotroute(city, route, current_distance, temperature)
% PLOTROUTE
% PLOTROUTE(city, route, current_distance, temperature) plots the route and
% display current temperautre and distance.
global h;
cycle = route([1:end, 1]);
% update route
set(h,'Xdata',[city(cycle).long],'Ydata',[city(cycle).lat]);
% display current temperature and total distance
xlabel(sprintf('T = %6.1f Total Distance = %6.1f', ...
temperature, current_distance));
drawnow
一开始的路径
最后运行出来的最优化路径
有需要的朋友可以下载相关的数据集下载链接
@@ -552,7 +539,7 @@
-
diff --git "a/2020/07/16/matlab\347\256\200\345\215\225\345\276\256\345\210\206\346\226\271\347\250\213\346\261\202\350\247\243/index.html" "b/2020/07/16/matlab\347\256\200\345\215\225\345\276\256\345\210\206\346\226\271\347\250\213\346\261\202\350\247\243/index.html"
index 043e24a4..51e759ea 100644
--- "a/2020/07/16/matlab\347\256\200\345\215\225\345\276\256\345\210\206\346\226\271\347\250\213\346\261\202\350\247\243/index.html"
+++ "b/2020/07/16/matlab\347\256\200\345\215\225\345\276\256\345\210\206\346\226\271\347\250\213\346\261\202\350\247\243/index.html"
@@ -221,22 +221,13 @@
- 时隔半年,我又重回微分方程的学习了,现在学确实挺难搞的,很多知识和理论思路都忘了,数学还是很重要啊,其实一个蛮简单的东西我看了很久很久才慢慢的又懂了,话不多说,直接写文。
首先要明确的一点就是,我们求微分方程的时候,要注意有解析解和数值解,解析解又有通解和特解,这在我们编写代码的时候可以通过初始点的值来获得特解。其实今天老师讲的还挺不错的,举出了很多的例子,基本上与物理有关,其实要说这一个模块最稳妥的办法其实是如果能够求出通解,一般最好手动进行微分方程的求解,然后用计算机检验,用计算机求微分方程的情况大多数是求数值解。所以说这一部分的话,其实对建模的要求更高,求解我们到时候可以看到matlab调用函数就可以了
-
+ 时隔半年,我又重回微分方程的学习了,现在学确实挺难搞的,很多知识和理论思路都忘了,数学还是很重要啊,其实一个蛮简单的东西我看了很久很久才慢慢的又懂了,话不多说,直接写文。
首先要明确的一点就是,我们求微分方程的时候,要注意有解析解和数值解,解析解又有通解和特解,这在我们编写代码的时候可以通过初始点的值来获得特解。其实今天老师讲的还挺不错的,举出了很多的例子,基本上与物理有关,其实要说这一个模块最稳妥的办法其实是如果能够求出通解,一般最好手动进行微分方程的求解,然后用计算机检验,用计算机求微分方程的情况大多数是求数值解。所以说这一部分的话,其实对建模的要求更高,求解我们到时候可以看到matlab调用函数就可以了
dsolve函数的妙用


-求解常微分方程通解
$求微分方程\frac{du}{dx}=1+u^2和x^2+y+(x-2y)y’的通解$
-dsolve('Du=1+u^2','t');
dsolve('x^2+y+(x-2*y)*Dy=0','x');
-求解常微分方程特解
$求y’’’-y’’=x,y(1)=8,y’(1)=7,y’’(2)=4的特解$
-y=dsolve('D3y-D2y=x','y(1)=8','Dy(1)=7','D2y(2)=4','x');
-```
#### 求解微分方程组

```matlab
[x,y,z]=dsolve('Dx=2*x-3*y+3*z','Dy=4*x-5*y+3*z','Dz=4*x-4*y+2*z','t');
x=simplify(x);%化简
y=simplify(y);
z=simplify(z);
-
+求解常微分方程通解
$求微分方程\frac{du}{dx}=1+u^2和x^2+y+(x-2y)y’的通解$
dsolve('Du=1+u^2','t');
dsolve('x^2+y+(x-2*y)*Dy=0','x');
+求解常微分方程特解
$求y’’’-y’’=x,y(1)=8,y’(1)=7,y’’(2)=4的特解$
y=dsolve('D3y-D2y=x','y(1)=8','Dy(1)=7','D2y(2)=4','x');
```
#### 求解微分方程组

```matlab
[x,y,z]=dsolve('Dx=2*x-3*y+3*z','Dy=4*x-5*y+3*z','Dz=4*x-4*y+2*z','t');
x=simplify(x);%化简
y=simplify(y);
z=simplify(z);
equ1='D2f+3*g=sin(x)';
equ2='Dg+Df=cos(x)';
[general_f,general_g]=dsolve(equ1,equ2,'x'); %通解
[f,g]=dsolve(equ1,equ2,'Df(2)=0,f(3)=3,g(5)=1','x');
龙哥库塔求数值解
在介绍龙哥库塔求数值解的时候,我们先要介绍一下这个刚性方程组的定义

然后matlab里面提供了几个非常好的解刚性常微分方程的功能函数如ode15s,ode45,ode113,ode23,ode23s,ode23t,ode23tb,

然后在介绍求解的知识之前,我需要先让你对这个过程做一个了解,以至于你写的时候不会觉得很晕,其实很简单的,估计我是忘了老师怎么教的了,看了半天我才慢慢明白。
其实他的思路就是,用当前可以得到的函数值和自变量来导出我们所需要的求得微分变量,如果出现了高阶得情况,则将每一个高阶都逐一替换成导数用函数值表示的公式,前几阶导数完全可以嵌套定义表示出来,可能你还是没用很懂,不过等你看到我下面的分析的时候,你应该就懂了,而且通过我的发现,基本上告诉你几个初始值,一般你就要求多少阶的导数。
-简单的一阶方程初值问题


F2.m
-function dy = F2(t,y)
%F2 此处显示有关此函数的摘要
% 此处显示详细说明
dy=-2*y+2*t^2+2*t;
end
-main.m
-[T,Y]=ode45('F2',[0,500],[1]);
plot(T,Y(:,1),'-');
-
+简单的一阶方程初值问题
F2.m
function dy = F2(t,y)
%F2 此处显示有关此函数的摘要
% 此处显示详细说明
dy=-2*y+2*t^2+2*t;
end
main.m
[T,Y]=ode45('F2',[0,500],[1]);
plot(T,Y(:,1),'-');
高阶微分方程
做变量替换,转化成多个一阶微分方程

F.m
%y1=y
%y2=y1'=y'
%y2'=y''
%y0=2,y1=0
function dy=F(t,y)%虽然这里我们没用上自变量但是这个参数还是要加,毕竟是调库函数所以说还是得按他的规矩
dy=zeros(2,1);
dy(1)=y(2);
dy(2)=1000*(1-y(1)^2)*y(2)-y(1);
main.m
@@ -546,7 +537,7 @@
-
@@ -554,15 +545,15 @@
-
diff --git "a/2020/09/09/java\347\232\204String\345\270\270\347\224\250\346\223\215\344\275\234/index.html" "b/2020/09/09/java\347\232\204String\345\270\270\347\224\250\346\223\215\344\275\234/index.html"
index 9fa98b7d..845c7b77 100644
--- "a/2020/09/09/java\347\232\204String\345\270\270\347\224\250\346\223\215\344\275\234/index.html"
+++ "b/2020/09/09/java\347\232\204String\345\270\270\347\224\250\346\223\215\344\275\234/index.html"
@@ -209,17 +209,11 @@
java的String类常用操作
最近在准备蓝桥杯,补题目,顺便也是稍微缓一下暑假自闭,主要还是不想浪费300,顺便回顾一下java的基本语法,java的String类这一块感觉还是挺多操作的,字符串的不可变性也使得其操作和c++存在一些差别。这里需要推荐一个十分好的博客就是廖雪峰的java教程,其实菜鸟教程也不错的。
-Java字符串的一个重要特点就是字符串不可变。这种不可变性是通过内部的private final char[]字段,以及没有任何修改char[]的方法实现的。
-
-创建字符串
创建字符串主要是两种常用方法吧,一个是new还有一个就是直接定义,毕竟已经是一个关键字了。
-
public class Main {
public static void main(String[] args) {
String a="hello";
a+="121";//Strin的+操作
char[] helloArray = { 'r', 'u', 'n', 'o', 'o', 'b'};
String helloString = new String(helloArray);
System.out.println(a);
System.out.println(helloString);
}
}
-当然如果需要对字符串转换成char数组的话也是封装好了函数的toCharArray()
-public class Main {
public static void main(String[] args) {
str="Hello";
char[] lisc = str.toCharArray();
String s = new String(lisc);
System.out.println(s);
}
}
+Java字符串的一个重要特点就是字符串不可变。这种不可变性是通过内部的private final char[]字段,以及没有任何修改char[]的方法实现的。
+创建字符串
创建字符串主要是两种常用方法吧,一个是new还有一个就是直接定义,毕竟已经是一个关键字了。
public class Main {
public static void main(String[] args) {
String a="hello";
a+="121";//Strin的+操作
char[] helloArray = { 'r', 'u', 'n', 'o', 'o', 'b'};
String helloString = new String(helloArray);
System.out.println(a);
System.out.println(helloString);
}
}
当然如果需要对字符串转换成char数组的话也是封装好了函数的toCharArray()
public class Main {
public static void main(String[] args) {
str="Hello";
char[] lisc = str.toCharArray();
String s = new String(lisc);
System.out.println(s);
}
}
String的长度——length()
public class Main {
public static void main(String[] args) {
String str = "abcde";
int len = str.length();
System.out.println("len="+len);
}
}
-
字符串比较
当我们想要比较两个字符串是否相同时,要特别注意,我们实际上是想比较字符串的内容是否相同。必须使用equals()方法而不能用==。==比较的是两个变量是否指向同一个字符串对象。可以看一下下面两个结果,有什么不同。
public class Main {
public static void main(String[] args) {
String s1 = "hello";
String s2 = "HELLO".toLowerCase();
System.out.println(s1 == s2);
System.out.println(s1.equals(s2));
}
}
-
这里还有一个用于比较java的字符串方法的compareTo()方法
compareTo()方法用于两种方式的比较:
@@ -233,16 +227,10 @@
int compareTo(Object o)
int compareTo(String anotherString)
-
-下面是一个demo
-public class Test {
public static void main(String args[]) {
System.out.println("Hello World!");
String str1 = "Strings";
String str2 = "Strings";
String str3 = "Strin1212";
String str4 = "Stringr";
int result = str1.compareTo( str2 );
System.out.println(result);
result = str2.compareTo( str3 );
System.out.println(result);
result = str3.compareTo( str1 );
System.out.println(result);
}
}
-
+下面是一个demo
public class Test {
public static void main(String args[]) {
System.out.println("Hello World!");
String str1 = "Strings";
String str2 = "Strings";
String str3 = "Strin1212";
String str4 = "Stringr";
int result = str1.compareTo( str2 );
System.out.println(result);
result = str2.compareTo( str3 );
System.out.println(result);
result = str3.compareTo( str1 );
System.out.println(result);
}
}
String遍历——charAt() 方法
charAt() 方法用于返回指定索引处的字符。索引范围为从 0 到 length() - 1。
public class Test {
public static void main(String args[]) {
String first="hello";
for(int i=0;i<len1;i++)
{
char c1 = first.charAt(i);
}
}
}
-
-如果已经变成了char[]了,不同于普通循环,你还能使用for each来循环,类似python的操作。
-char[] charlist={'a','b','c'};
for(char c: charlist)
{
System.out.println(c);
}
-
+如果已经变成了char[]了,不同于普通循环,你还能使用for each来循环,类似python的操作。
char[] charlist={'a','b','c'};
for(char c: charlist)
{
System.out.println(c);
}
去除首尾空白字符
其实用的不太多,具体可以看廖雪峰的教程,一般就是trim()方法,截去字符串两端的空格,但对于中间的空格不处理。
查找indexOf()
这个菜鸟教程讲的挺细的可以看看。indexOf() 方法有以下四种形式:
@@ -256,24 +244,14 @@
public int indexOf(int ch )
public int indexOf(int ch, int fromIndex)
int indexOf(String str)
int indexOf(String str, int fromIndex)
-
-
-
lastIndexOf() 则差不多,进行反向搜索
还有startsWith(),endsWith()
字串提取
contains()可以判断给定字串是否存在于原string当中
String str = "abcde";
int index = str.indexOf(“bcd”);
//判断是否包含指定字符串,包含则返回第一次出现该字符串的索引,不包含则返回-1
boolean b2 = str.contains("bcd");
//判断是否包含指定字符串,包含返回true,不包含返回false
-
-substring()方法,索引从 0 开始。返回一个新字符串。
-public String substring(int beginIndex)
public String substring(int beginIndex, int endIndex)
-
+substring()方法,索引从 0 开始。返回一个新字符串。
public String substring(int beginIndex)
public String substring(int beginIndex, int endIndex)
public class Test {
public static void main(String args[]) {
String Str = new String("12345678908868");
System.out.print("返回值 :" );
System.out.println(Str.substring(4) );
System.out.print("返回值 :" );
System.out.println(Str.substring(4, 10) );
}
}
-
-替换子串replace()
要在字符串中替换子串,有两种方法即根据字符或字符串替换replace()
-String s = "hello";
s.replace('l', 'w');
s.replace("ll", "~~");
-
+替换子串replace()
要在字符串中替换子串,有两种方法即根据字符或字符串替换replace()
String s = "hello";
s.replace('l', 'w');
s.replace("ll", "~~");
分割字符串split()
split()方法,里面可以用正则表达式
String s = "A,B,C,D";
String[] ss = s.split("\\,");
-
valueOf()
做题的话感觉,主要用于char[],其他数字类型的转换,当让也能用之前new的方法操作。
public class Test {
public static void main(String args[]) {
double d = 1100.00;
boolean b = true;
long l = 1234567890;
char[] arr = {'r', 'u', 'n', 'o', 'o', 'b' };
System.out.println("返回值 : " + String.valueOf(d) );
System.out.println("返回值 : " + String.valueOf(b) );
System.out.println("返回值 : " + String.valueOf(l) );
System.out.println("返回值 : " + String.valueOf(arr) );
}
}
@@ -579,7 +557,7 @@
-
@@ -587,15 +565,15 @@
-
diff --git "a/2020/09/11/\345\271\266\345\217\221\346\216\247\345\210\266\346\234\272\345\210\266\347\232\204\345\277\205\350\246\201\346\200\247/index.html" "b/2020/09/11/\345\271\266\345\217\221\346\216\247\345\210\266\346\234\272\345\210\266\347\232\204\345\277\205\350\246\201\346\200\247/index.html"
index 792669de..907802c4 100644
--- "a/2020/09/11/\345\271\266\345\217\221\346\216\247\345\210\266\346\234\272\345\210\266\347\232\204\345\277\205\350\246\201\346\200\247/index.html"
+++ "b/2020/09/11/\345\271\266\345\217\221\346\216\247\345\210\266\346\234\272\345\210\266\347\232\204\345\277\205\350\246\201\346\200\247/index.html"
@@ -208,9 +208,7 @@
- Concurrency-control mechanisms并发控制机制的必要性
事务是并发控制的基本单位,保证事务的ACID特性是事务处理的重要任务,而事务的 ACID 特性可能遭到破坏的原因之一是多个事务对数据库的并发操作造成的。为了保证事务的隔离性和一致性,数据库管理系统需要对并发操作进行正确。并发操作带来的数据不一致性包括丢失修改、不可重复读和读“脏”数据。
-
-1. 丢失修改(lost update)
两个事务T1和T2,读入同一数据并修改,T2,提交的结果破坏了T1提交的结果,导致T的修改被丢失。
2. 不可重复读(non-repeatable read)
不可重复读是指事务T读取数据后,事务T执行更新操作,使T无法再现前一次读取结果。
具体地讲,不可重复读包括三种情况:
+ Concurrency-control mechanisms并发控制机制的必要性
事务是并发控制的基本单位,保证事务的ACID特性是事务处理的重要任务,而事务的 ACID 特性可能遭到破坏的原因之一是多个事务对数据库的并发操作造成的。为了保证事务的隔离性和一致性,数据库管理系统需要对并发操作进行正确。并发操作带来的数据不一致性包括丢失修改、不可重复读和读“脏”数据。
1. 丢失修改(lost update)
两个事务T1和T2,读入同一数据并修改,T2,提交的结果破坏了T1提交的结果,导致T的修改被丢失。
2. 不可重复读(non-repeatable read)
不可重复读是指事务T读取数据后,事务T执行更新操作,使T无法再现前一次读取结果。
具体地讲,不可重复读包括三种情况:
- 事务T1读取某一数据后,事务T2对其进行了修改,当事务T1再次读该数据时,得到与前一次不同的值。
- 事务T1按一定条件从数据库中读取了某些数据记录后,事务T2删除了其中部分记录,当T1再次按相同条件读取数据时,发现某些记录神秘地消失了。
@@ -522,7 +520,7 @@
- 编译原理
+ 数据库系统
-
diff --git "a/2020/09/13/Business-Intelligence-BI-System\344\273\213\347\273\215/index.html" "b/2020/09/13/Business-Intelligence-BI-System\344\273\213\347\273\215/index.html"
index 17ef25be..01b85d85 100644
--- "a/2020/09/13/Business-Intelligence-BI-System\344\273\213\347\273\215/index.html"
+++ "b/2020/09/13/Business-Intelligence-BI-System\344\273\213\347\273\215/index.html"
@@ -214,8 +214,7 @@
- Business Intelligence(BI) System介绍
本文内容笔记摘录自王珊和萨师煊的《数据库系统概论》以及网上写的比较好的博客Business Intelligence,商务智能系统的组成,以及百度百科。
-
+ Business Intelligence(BI) System介绍
本文内容笔记摘录自王珊和萨师煊的《数据库系统概论》以及网上写的比较好的博客Business Intelligence,商务智能系统的组成,以及百度百科。
Business Intelligence System
BI是Business Intelligence的英文缩写,中文解释为商务智能,用来帮助企业更好地利用数据提高决策质量的技术集合,是从大量的数据中钻取信息与知识的过程。

这样不难看出,传统的交易系统完成的是Business到Data的过程,而BI要做的事情是在Data的基础上,让Data产生价值,这个产生价值的过程就是Business Intelligence analyse的过程。

它以数据仓库(Data Warehousing)、在线分析处理(OLAP)、数据挖掘(Data Mining) 3种技术的整合为基础,建立企业数据中心和业务分析模型,以提高企业获取经营分析信息的能力,从而提高企业经营和决策的质量与速度。
简单的说就是把交易系统已经发生过的数据,通过ETL工具抽取到主题明确的数据仓库中,OLAP后生成Cube或报表,透过Portal展现给用户,用户利用这些经过分类、聚集、描述和可视化的数据,支持业务决策。
BI不能产生决策,而是利用BI过程处理后的数据来支持决策。那么BI所谓的智能到底是什么呢? BI最终展现给用户的信息就是报表或图视,但它不同于传统的静态报表或图视,它颠覆了传统报表或图视的提供与阅读的方式,有力的保障了用户分析数据时操作的简单性、报表或图视直观性及思维的连惯性。
@@ -542,7 +541,7 @@
-
diff --git "a/2020/09/21/\350\277\233\347\250\213/index.html" "b/2020/09/21/\350\277\233\347\250\213/index.html"
index cfbf5f1c..562a89eb 100644
--- "a/2020/09/21/\350\277\233\347\250\213/index.html"
+++ "b/2020/09/21/\350\277\233\347\250\213/index.html"
@@ -216,8 +216,7 @@
- 进程是支持程序执行的机制,可以理解为程序对数据或请求的处理过程,是一个独立功能的程序关于数据集合的一次运动活动,是操作系统进行资源分配的一个单位。在介绍相关知识之前,首先我们需要了解几个重要概念。
进程实体主要包含PCB,程序段,数据段三个部分构成进程实体又称进程映像。
PCB是指系统为每个运行的程序分配了一个数据结构被称为进程控制块。PCB是进程存在的唯一标志,创建进程和撤销进程实质上都是创建和撤销PCB。
进程实体是静态的指进程三要素存放的数据,而进程是一个动态执行的过程,一般我们不区分进程和进程实体的概念,所以也可以说进程是由PCB,程序段,数据段组成。
-
+ 进程是支持程序执行的机制,可以理解为程序对数据或请求的处理过程,是一个独立功能的程序关于数据集合的一次运动活动,是操作系统进行资源分配的一个单位。在介绍相关知识之前,首先我们需要了解几个重要概念。
进程实体主要包含PCB,程序段,数据段三个部分构成进程实体又称进程映像。
PCB是指系统为每个运行的程序分配了一个数据结构被称为进程控制块。PCB是进程存在的唯一标志,创建进程和撤销进程实质上都是创建和撤销PCB。
进程实体是静态的指进程三要素存放的数据,而进程是一个动态执行的过程,一般我们不区分进程和进程实体的概念,所以也可以说进程是由PCB,程序段,数据段组成。
进程状态和控制切换


进程通信
进程通信顾名思义是指进程之间的信息交换,有三种方式,共享存储,消息传递,管道通信。各进程拥有的内存地址空间是独立的,为了保证安全,一个进程是不能直接访问另外一个进程的内存地址的。
@@ -532,7 +531,7 @@
- 编译原理
+ 数据库系统
-
diff --git "a/2020/09/24/htmlcss\345\233\236\351\241\276/index.html" "b/2020/09/24/htmlcss\345\233\236\351\241\276/index.html"
index 4cbeff92..aa50ad28 100644
--- "a/2020/09/24/htmlcss\345\233\236\351\241\276/index.html"
+++ "b/2020/09/24/htmlcss\345\233\236\351\241\276/index.html"
@@ -219,50 +219,51 @@
html回顾
重回前端,文章是记录的MDN Web Doc和绿叶学习网的相关内容笔记。这里不会把基础知识列出来,这里主要是记录一些自己有新体会的东西。
-
HTML 不是一门编程语言,而是一种用于定义内容结构的标记语言,超文本标记语言 (英语:Hypertext Markup Language,简称:HTML ) 是一种用来结构化 Web 网页及其内容的标记语言。
浏览器的同源策略
同源策略是一个重要的安全策略,它用于限制一个origin的文档或者它加载的脚本如何能与另一个源的资源进行交互。它能帮助阻隔恶意文档,减少可能被攻击的媒介。
如果两个 URL 的 protocol、port (如果有指定的话)和 host 都相同的话,则这两个 URL 是同源。这个方案也被称为“协议/主机/端口元组”,或者直接是 “元组”。(“元组” 是指一组项目构成的整体,双重/三重/四重/五重/等的通用形式)。
下表给出了与 URL http://store.company.com/dir/page.html 的源进行对比的示例:
+
-URL
-结果
-原因
+URL
+结果
+原因
-
-http://store.company.com/dir2/other.html同源
-只有路径不同
+
+
+http://store.company.com/dir2/other.html同源
+只有路径不同
-http://store.company.com/dir/inner/another.html 同源
-只有路径不同
+http://store.company.com/dir/inner/another.html同源
+只有路径不同
-https://store.company.com/secure.html失败
-协议不同
+https://store.company.com/secure.html失败
+协议不同
-http://store.company.com:81/dir/etc.html失败
-端口不同 ( http:// 默认端口是80)
+http://store.company.com:81/dir/etc.html失败
+端口不同 ( http:// 默认端口是80)
-http://news.company.com/dir/other.html失败
-主机不同
+http://news.company.com/dir/other.html失败
+主机不同
-
+
+
+
插入图片不推荐方式
<img src="https://www.example.com/images/dinosaur.jpg">
这种方式是不被推荐的,这样做只会使浏览器做更多的工作,例如重新通过 DNS 再去寻找 IP 地址。通常我们都会把图片和 HTML 放在同一个服务器上。
-有一个更好的做法是使用 HTML5 的<figure>和 <figcaption> 元素,它正是为此而被创造出来的:为图片提供一个语义容器,在标题和图片之间建立清晰的关联。我们之前的例子可以重写为:
-<figure>
<img src="https://raw.githubusercontent.com/mdn/learning-area/master/html/multimedia-and-embedding/images-in-html/dinosaur_small.jpg"
alt="一只恐龙头部和躯干的骨架,它有一个巨大的头,长着锋利的牙齿。"
width="400"
height="341">
<figcaption>曼彻斯特大学博物馆展出的一只霸王龙的化石</figcaption>
</figure>
-
+有一个更好的做法是使用 HTML5 的<figure>和 <figcaption> 元素,它正是为此而被创造出来的:为图片提供一个语义容器,在标题和图片之间建立清晰的关联。我们之前的例子可以重写为:
<figure>
<img src="https://raw.githubusercontent.com/mdn/learning-area/master/html/multimedia-and-embedding/images-in-html/dinosaur_small.jpg"
alt="一只恐龙头部和躯干的骨架,它有一个巨大的头,长着锋利的牙齿。"
width="400"
height="341">
<figcaption>曼彻斯特大学博物馆展出的一只霸王龙的化石</figcaption>
</figure>
<input>
formenctype属性
由于input元素是一个提交按钮,因此该formenctype属性指定用于向服务器提交表单的内容类型。可能的值为:
- application/x-www-form-urlencoded:如果未指定属性,则为默认值。
@@ -277,148 +278,155 @@ 元素的id和class元素的id属性
id属性被赋予了标识页面元素的唯一身份。如果一个页面出现了多个相同id属性取值,CSS选择器或者JavaScript就会因为无法分辨要控制的元素而最终报错。
元素的class属性
如果你要为两个元素或者两个以上元素定义相同的样式,建议使用class属性。
(1)一个标签可以同时定义多个class;
(2)id也可以写成name,区别在于name是HTML中的标准,而id是XHTML中的标准,现在网页的标准都是使用id,所以大家尽量不要用name属性;
-选择器
1.元素选择器

2.id选择器

3.class选择器

4.子元素选择器
子元素选择器,就是选中某个元素下的子元素,然后对该子元素设置CSS样式。

5.相邻选择器
相邻选择器,就是选中该元素的下一个兄弟元素,在这里注意一点,相邻选择器的操作对象是该元素的同级元素。

6.群组选择器
群组选择器,就是同时对几个选择器进行相同的操作。

7.全局选择器
全局选择器,是由一个星号(*)代指的,它选中了文档中的所有内容(或者是父元素中的所有内容,比如,它紧随在其他元素以及邻代运算符之后的时候)下面的示例中,我们已经用全局选择器,移去了所有元素上的外边距
-* {
margin: 0;
}
-一些新用法


+选择器
1.元素选择器
2.id选择器
3.class选择器
4.子元素选择器
子元素选择器,就是选中某个元素下的子元素,然后对该子元素设置CSS样式。
5.相邻选择器
相邻选择器,就是选中该元素的下一个兄弟元素,在这里注意一点,相邻选择器的操作对象是该元素的同级元素。
6.群组选择器
群组选择器,就是同时对几个选择器进行相同的操作。
7.全局选择器
全局选择器,是由一个星号(*)代指的,它选中了文档中的所有内容(或者是父元素中的所有内容,比如,它紧随在其他元素以及邻代运算符之后的时候)下面的示例中,我们已经用全局选择器,移去了所有元素上的外边距
* {
margin: 0;
}
一些新用法
::before和::after
::before和::after伪元素与content属性的共同使用,在CSS中被叫做“生成内容”
text-align属性
在CSS中,使用text-align属性控制文本的水平方向的对齐方式:左对齐、居中对齐、右对齐。
text-align属性不仅对文本文字有效,对img标签也有效,但是对其他标签无效。
+
-text-align属性值
-说明
+text-align属性值
+说明
-
-left
-默认值,左对齐
+
+
+left
+默认值,左对齐
-center
-居中对齐
+center
+居中对齐
-right
-右对齐
+right
+右对齐
-
+
+
+
块元素和行内元素
1、HTML元素根据浏览器表现形式分为两类:块元素,行内元素;
2、块元素特点:
- 独占一行,排斥其他元素跟其位于同一行,包括块元素和行内元素;
- 块元素内部可以容纳其他块元素或行元素;
+
-块元素
-说明
+块元素
+说明
-
-div
-div层
-
+
-h1~h6
-1到6级标题
+div
+div层
-p 段落
-会自动在其前后创建一些空白
+h1~h6
+1到6级标题
-hr
-分割线
+p 段落
+会自动在其前后创建一些空白
-ol
-有序列表
+hr
+分割线
-ul
-无序列表
+ol
+有序列表
-3、行内元素特点:
-ul
+无序列表
-
+
+
+
+3、行内元素特点:
- 可以与其他行内元素位于同一行;
- 行内内部可以容纳其他行内元素,但不可以容纳块元素,不然会出现无法预知的效果;
+
-行内元素
-说明
+行内元素
+说明
-
-strong
-加粗强调
+
+
+strong
+加粗强调
-em
-斜体强调
+em
+斜体强调
-s
-删除线
+s
+删除线
-u
-下划线
+u
+下划线
-a
-超链接
+a
+超链接
-span
-常用行级,可定义文档中的行内元素
+span
+常用行级,可定义文档中的行内元素
-img
-图片
+img
+图片
-input
-表单
+input
+表单
-
-CSS边框(border)
任何块元素和行内元素都可以设置边框属性。
设置一个元素的边框必须要同时设置border-width、border-style、border-color这三个属性,这个元素的边框才能在浏览器显示出来。
-border-width:1px;
border-style:solid;
border-color:Red;
/*简介写法*/
border: 1px solid Red;
-在CSS中,我们可以分别针对上下左右四条边框设置单独的样式。
-border-top-width:1px;
border-top-style:solid;
border-top-color:red;
/*简介写法*/
border-top: 1px solid Red;
border-bottom: 1px solid Red;
border-left: 1px solid Red;
border-right: 1px solid Red;
/*去除边框的两种方法*/
border-bottom:0px /*去除边框就不需要写颜色和样式了*/
border-bottom:none
-
+
+
+
+CSS边框(border)
任何块元素和行内元素都可以设置边框属性。
设置一个元素的边框必须要同时设置border-width、border-style、border-color这三个属性,这个元素的边框才能在浏览器显示出来。
border-width:1px;
border-style:solid;
border-color:Red;
/*简介写法*/
border: 1px solid Red;
在CSS中,我们可以分别针对上下左右四条边框设置单独的样式。
border-top-width:1px;
border-top-style:solid;
border-top-color:red;
/*简介写法*/
border-top: 1px solid Red;
border-bottom: 1px solid Red;
border-left: 1px solid Red;
border-right: 1px solid Red;
/*去除边框的两种方法*/
border-bottom:0px /*去除边框就不需要写颜色和样式了*/
border-bottom:none
css背景样式background
目前,不要再使用HTML的bgcolor之类的属性了,现在几乎全部都是使用CSS的background属性来控制元素的背景颜色和背景图像。
1.背景颜色
使用css的background-color属性
2.背景图像
+
-属性
-说明
+属性
+说明
-
-background-image
-定义背景图像的路径,这样图片才能显示
+
+
+background-image
+定义背景图像的路径,这样图片才能显示
-background-repeat
-定义背景图像显示方式,例如纵向平铺、横向平铺
+background-repeat
+定义背景图像显示方式,例如纵向平铺、横向平铺
-background-position
-定义背景图像在元素哪个位置
+background-position
+定义背景图像在元素哪个位置
-background-attachment
-定义背景图像是否随内容而滚动
+background-attachment
+定义背景图像是否随内容而滚动
-
+
+
+
img适合框大小
object-fit属性可以在这里帮助你。当使用object-fit时,替换元素可以以多种方式被调整到合乎盒子的大小。
布局样式
主要是通过display属性来操作,一般有block,inline,inline-block,grid,flex,none这几种操作,具体的使用还是需要多练习才能明白。
@@ -725,7 +733,7 @@
- 编译原理
+ 数据库系统
-
diff --git "a/2020/09/26/js\345\237\272\347\241\200\342\200\224\342\200\224\346\225\260\346\215\256\347\261\273\345\236\213\344\270\216\345\237\272\346\234\254\351\200\273\350\276\221\350\257\255\345\217\245/index.html" "b/2020/09/26/js\345\237\272\347\241\200\342\200\224\342\200\224\346\225\260\346\215\256\347\261\273\345\236\213\344\270\216\345\237\272\346\234\254\351\200\273\350\276\221\350\257\255\345\217\245/index.html"
index d4629722..532985c5 100644
--- "a/2020/09/26/js\345\237\272\347\241\200\342\200\224\342\200\224\346\225\260\346\215\256\347\261\273\345\236\213\344\270\216\345\237\272\346\234\254\351\200\273\350\276\221\350\257\255\345\217\245/index.html"
+++ "b/2020/09/26/js\345\237\272\347\241\200\342\200\224\342\200\224\346\225\260\346\215\256\347\261\273\345\236\213\344\270\216\345\237\272\346\234\254\351\200\273\350\276\221\350\257\255\345\217\245/index.html"
@@ -213,8 +213,7 @@
- 本文将记录学习JavaScript(包含有ES)语法基础,主要来自MDN的官方文档
-
+ 本文将记录学习JavaScript(包含有ES)语法基础,主要来自MDN的官方文档
语法和数据类型
最新的 ECMAScript 标准定义了8种数据类型:
- 七种基本数据类型:
@@ -231,44 +230,26 @@ 运算细节
你可以使用 undefined 来判断一个变量是否已赋值
-var input;
if(input === undefined){
doThis();
} else {
doThat();
}
-undefined 值在布尔类型环境中会被当作 false
+运算细节
你可以使用 undefined 来判断一个变量是否已赋值
var input;
if(input === undefined){
doThis();
} else {
doThat();
}
undefined 值在布尔类型环境中会被当作 false
数值类型环境中 undefined 值会被转换为 NaN
当你对一个 null 变量求值时,空值 null 在数值类型环境中会被当作0来对待,而布尔类型环境中会被当作 false
-在包含的数字和字符串的表达式中使用加法运算符(+),JavaScript 会把数字转换成字符串
-x = "The answer is " + 42 // "The answer is 42"
y = 42 + " is the answer" // "42 is the answer"
-在涉及其它运算符(译注:如下面的减号’-‘)时,JavaScript语言不会把数字变为字符串
-"37" - 7 // 30
"37" + 7 // "377"
-
-
-
+在包含的数字和字符串的表达式中使用加法运算符(+),JavaScript 会把数字转换成字符串
x = "The answer is " + 42 // "The answer is 42"
y = 42 + " is the answer" // "42 is the answer"
在涉及其它运算符(译注:如下面的减号’-‘)时,JavaScript语言不会把数字变为字符串
"37" - 7 // 30
"37" + 7 // "377"
对象字面量
对象字面值是封闭在花括号对({})中的一个对象的零个或多个”属性名-值”对的(元素)列表。
-对象属性名字可以是任意字符串,包括空串。如果对象属性名字不是合法的javascript标识符,它必须用””包裹。属性的名字不合法,那么便不能用.访问属性值,而是通过类数组标记(“[]”)访问和赋值。
-var unusualPropertyNames = {
"": "An empty string",
"!": "Bang!"
}
console.log(unusualPropertyNames.""); // 语法错误: Unexpected string
console.log(unusualPropertyNames[""]); // An empty string
console.log(unusualPropertyNames.!); // 语法错误: Unexpected token !
console.log(unusualPropertyNames["!"]); // Bang!
-
+对象属性名字可以是任意字符串,包括空串。如果对象属性名字不是合法的javascript标识符,它必须用””包裹。属性的名字不合法,那么便不能用.访问属性值,而是通过类数组标记(“[]”)访问和赋值。
var unusualPropertyNames = {
"": "An empty string",
"!": "Bang!"
}
console.log(unusualPropertyNames.""); // 语法错误: Unexpected string
console.log(unusualPropertyNames[""]); // An empty string
console.log(unusualPropertyNames.!); // 语法错误: Unexpected token !
console.log(unusualPropertyNames["!"]); // Bang!
var foo = {a: "alpha", 2: "two"};
console.log(foo.a); // alpha
console.log(foo[2]); // two
//console.log(foo.2); // SyntaxError: missing ) after argument list
//console.log(foo[a]); // ReferenceError: a is not defined
console.log(foo["a"]); // alpha
console.log(foo["2"]); // two
-
-ES2015新增模板字面量,直接打印出多行字符串。
-console.log(`Roses are red,
Violets are blue.
Sugar is sweet,
and so is foo.`)
+ES2015新增模板字面量,直接打印出多行字符串。
console.log(`Roses are red,
Violets are blue.
Sugar is sweet,
and so is foo.`)
流程控制与错误处理
判断语句的小细节
其值不是undefined或null的任何对象(包括其值为false的布尔对象)在传递给条件语句时都将计算为true
这里我们以Boolean对象为例子:
如果需要,作为第一个参数传递的值将转换为布尔值。如果省略或值0,-0,null,false,NaN,undefined,或空字符串(""),该对象具有的初始值false。所有其他值,包括任何对象,空数组([])或字符串"false",都会创建一个初始值为的对象true。
注意不要将基本类型中的布尔值 true 和 false 与值为 true 和 false 的 Boolean 对象弄混了,不要在应该使用基本类型布尔值的地方使用 Boolean 对象。
let un;
//undifined
if (un){
//这里的代码不会被执行
console.log(un);
}
un=null;
//null
if (un){
//这里的代码不会被执行
console.log(un);
}
let b = new Boolean(false);
if (b){
//这里的代码会被执行
console.log(b.toString());
}
let a= new Boolean("false");
if(a){
//这里的代码会被执行
console.log(a.toString());//会打印出false
}
let x = false;
if (x) {
// 这里的代码不会执行
console.log("false");
}
-正确使用途径
不要用创建 Boolean 对象的方式将一个非布尔值转化成布尔值,直接将 Boolean 当做转换函数来使用即可,或者使用双重非(!!)运算符:
-var x = Boolean(expression); // 推荐
var x = !!(expression); // 推荐
var x = new Boolean(expression); // 不太好
-
+正确使用途径
不要用创建 Boolean 对象的方式将一个非布尔值转化成布尔值,直接将 Boolean 当做转换函数来使用即可,或者使用双重非(!!)运算符:
var x = Boolean(expression); // 推荐
var x = !!(expression); // 推荐
var x = new Boolean(expression); // 不太好
switch 语句
同java,c++
异常处理语句
你可以用 throw 语句抛出一个异常并且用 try...catch 语句捕获处理它。同Java语法差不多。
-循环与迭代
forEach
foreach里面不支持break,continue,
-const array1 = ['a', 'b', 'c'];//数组的类型其实也是对象
array1.forEach((element,index) => console.log(element,index));
-
+循环与迭代
forEach
foreach里面不支持break,continue,
const array1 = ['a', 'b', 'c'];//数组的类型其实也是对象
array1.forEach((element,index) => console.log(element,index));
for…in
for…in 语句循环一个指定的变量来循环一个对象所有可枚举的属性。JavaScript 会为每一个不同的属性执行指定的语句。
-for…of
for…of 语句在可迭代对象(包括Array、Map、Set、arguments 等等)上创建了一个循环,对值的每一个独特属性调用一次迭代,对象属于object,不可迭代。

所以for of 则无法迭代js的object属性值
-let arr = [3, 5, 7];
arr.foo = "hello";
for (let i in arr) {
console.log(i,arr[i]);
// 输出 "0 3", "1 5", "2 7", "foo hello"
}
for (let i of arr) {
console.log(i); // 输出 "3", "5", "7"
}
// 注意 for...of 的输出没有出现 "hello"
-
for … in循环将把foo包括在内了,但Array的length属性却不包括在内,所以length还是3.
+for…of
for…of 语句在可迭代对象(包括Array、Map、Set、arguments 等等)上创建了一个循环,对值的每一个独特属性调用一次迭代,对象属于object,不可迭代。
所以for of 则无法迭代js的object属性值
let arr = [3, 5, 7];
arr.foo = "hello";
for (let i in arr) {
console.log(i,arr[i]);
// 输出 "0 3", "1 5", "2 7", "foo hello"
}
for (let i of arr) {
console.log(i); // 输出 "3", "5", "7"
}
// 注意 for...of 的输出没有出现 "hello"
for … in循环将把foo包括在内了,但Array的length属性却不包括在内,所以length还是3.

这是MDN官方文档的解释,多看几遍就能理解,其实for in会把array作为一个对象来打迎打所有的属性,而for of则只对可迭代的对象进行遍历,也就是这里面的array了,这也能解释为什么foreach也只能打印数组元素了。
-两者区别参考了博客for…in和for…of的用法与区别1和for…in和for…of的用法与区别2
+两者区别参考了博客for…in和for…of的用法与区别1和for…in和for…of的用法与区别2
@@ -577,7 +558,7 @@ fo
-
diff --git "a/2020/09/27/js\345\237\272\347\241\200\342\200\224\342\200\224\345\207\275\346\225\260/index.html" "b/2020/09/27/js\345\237\272\347\241\200\342\200\224\342\200\224\345\207\275\346\225\260/index.html"
index bee75e2a..a603a6ab 100644
--- "a/2020/09/27/js\345\237\272\347\241\200\342\200\224\342\200\224\345\207\275\346\225\260/index.html"
+++ "b/2020/09/27/js\345\237\272\347\241\200\342\200\224\342\200\224\345\207\275\346\225\260/index.html"
@@ -209,17 +209,14 @@
- 这一块关于闭包和箭头函数理解还不够,先提交一点记录一下,后期再补
-
+ 这一块关于闭包和箭头函数理解还不够,先提交一点记录一下,后期再补
函数声明
一个函数定义(也称为函数声明,或函数语句)由一系列的function关键字组成,依次为:
- 函数的名称。
- 函数参数列表,包围在括号中并由逗号分隔。
- 定义函数的 JavaScript 语句,用大括号
{}括起来。
-当函数参数为基本类型时,则会采用值传递的方式,不会改变变量本身,而当你传递的是一个对象(即一个非原始值,例如Array或用户自定义的对象)作为参数的时候,而函数改变了这个对象的属性,这样的改变对函数外部是可见的
-function myFunc(theObject) {
theObject.make = "Toyota";
}
var mycar = {make: "Honda", model: "Accord", year: 1998};
var x, y;
x = mycar.make; // x获取的值为 "Honda"
myFunc(mycar);
y = mycar.make;
-
+当函数参数为基本类型时,则会采用值传递的方式,不会改变变量本身,而当你传递的是一个对象(即一个非原始值,例如Array或用户自定义的对象)作为参数的时候,而函数改变了这个对象的属性,这样的改变对函数外部是可见的
function myFunc(theObject) {
theObject.make = "Toyota";
}
var mycar = {make: "Honda", model: "Accord", year: 1998};
var x, y;
x = mycar.make; // x获取的值为 "Honda"
myFunc(mycar);
y = mycar.make;
函数表达式——Function expressions
根据MDN的文档描述我大致理解了他所说的函数表达式用法和意义了,其实类似于c语言的函数指针和java匿名函数相结合的这种用法,这种用法的最大好处就是能够将函数作为一个参数或者变量,将其传递给其他的函数使用
箭头函数
箭头函数主要利用的是箭头表达式,箭头函数表达式的语法比函数表达式更简洁,箭头函数表达式更适用于那些本来需要匿名函数的地方,并且它不能用作构造函数。箭头函数两大特点:更简短的函数并且不绑定this。
箭头函数真的很灵活,我暂时还没法完全参透只是了解了一个大概,具体的用法可以去MDN上看官方文档箭头函数
闭包
闭包是 JavaScript 中最强大的特性之一。JavaScript 允许函数嵌套,并且内部函数可以访问定义在外部函数中的所有变量和函数,以及外部函数能访问的所有变量和函数。
@@ -531,7 +528,7 @@ 闭包
-
diff --git "a/2020/09/29/SQL\350\257\255\345\217\245\342\200\224\342\200\224\342\200\224\342\200\224\346\225\260\346\215\256\345\256\232\344\271\211/index.html" "b/2020/09/29/SQL\350\257\255\345\217\245\342\200\224\342\200\224\342\200\224\342\200\224\346\225\260\346\215\256\345\256\232\344\271\211/index.html"
index 840efb3a..cdb541a8 100644
--- "a/2020/09/29/SQL\350\257\255\345\217\245\342\200\224\342\200\224\342\200\224\342\200\224\346\225\260\346\215\256\345\256\232\344\271\211/index.html"
+++ "b/2020/09/29/SQL\350\257\255\345\217\245\342\200\224\342\200\224\342\200\224\342\200\224\346\225\260\346\215\256\345\256\232\344\271\211/index.html"
@@ -208,11 +208,8 @@
- SQL又称结构化查询语句(Structed Query Language)是关系数据库的标准语言,也是一个通用的,功能极强的关系数据库语言。
SQL集数据查询、数据操纵、数据定义、数据控制功能于一体。
目前没有一个数据库系统能支持SQL标准的所有概念和特性。但同时许多软件厂商对SQL基本命令集还进行了不同程度的扩充和修改,又可以支持标准以外的一些功能特性。
-
-定义模式
在SQL中,模式定义语句如下:
-CREATE SCHEMA <模式名> AUTHORIZATION <用户名>
-如果没有指定<模式名>,那么<模式名>隐含为<用户名>
要创建模式,调用该命令的用户名必需拥有数据库管理员权限,或者获得了数据库管理员授权的CREATE SCHEMA的权限。
+ SQL又称结构化查询语句(Structed Query Language)是关系数据库的标准语言,也是一个通用的,功能极强的关系数据库语言。
SQL集数据查询、数据操纵、数据定义、数据控制功能于一体。
目前没有一个数据库系统能支持SQL标准的所有概念和特性。但同时许多软件厂商对SQL基本命令集还进行了不同程度的扩充和修改,又可以支持标准以外的一些功能特性。
+定义模式
在SQL中,模式定义语句如下:
CREATE SCHEMA <模式名> AUTHORIZATION <用户名>
如果没有指定<模式名>,那么<模式名>隐含为<用户名>
要创建模式,调用该命令的用户名必需拥有数据库管理员权限,或者获得了数据库管理员授权的CREATE SCHEMA的权限。
删除模式
DROP SCHEMA <模式名> <CASCADE|RESTRICT>
其中CASCADE|RESTRICT必须二选一,两者有不同的作用。
@@ -220,10 +217,7 @@ 基本表的定义与创建
CREATE TABLE <表名>(
<列名><数据类型>,[列级完整性约束条件],
<列名><数据类型>,[列级完整性约束条件],
<列名><数据类型>,[列级完整性约束条件],
...
);
-
-修改基本表
修改语句主要是通过ALERT TABLE来操作
-ALTER TABLE <表名>
[ADD [COLUMN] <新列名><数据类型> [完整性约束]]
[ADD <表级完整性约束>]
[DROP [COLUMN] <列名> [CASCADE|RESTRICT] ]
[DROP CONSTRAINT <完整性约束名> [CASCADE|RESTRICT]]
[ALER COLUMN<列名><数据类型>];
-
+修改基本表
修改语句主要是通过ALERT TABLE来操作
ALTER TABLE <表名>
[ADD [COLUMN] <新列名><数据类型> [完整性约束]]
[ADD <表级完整性约束>]
[DROP [COLUMN] <列名> [CASCADE|RESTRICT] ]
[DROP CONSTRAINT <完整性约束名> [CASCADE|RESTRICT]]
[ALER COLUMN<列名><数据类型>];
删除表
DROP TABLE <表名> [RESTRICT|CASCADE]
@@ -529,7 +523,7 @@
-
diff --git "a/2020/09/29/js\345\237\272\347\241\200\342\200\224\342\200\224\346\225\260\347\273\204\345\257\271\350\261\241-Array-object/index.html" "b/2020/09/29/js\345\237\272\347\241\200\342\200\224\342\200\224\346\225\260\347\273\204\345\257\271\350\261\241-Array-object/index.html"
index 4de4aac2..9c007ca5 100644
--- "a/2020/09/29/js\345\237\272\347\241\200\342\200\224\342\200\224\346\225\260\347\273\204\345\257\271\350\261\241-Array-object/index.html"
+++ "b/2020/09/29/js\345\237\272\347\241\200\342\200\224\342\200\224\346\225\260\347\273\204\345\257\271\350\261\241-Array-object/index.html"
@@ -211,43 +211,22 @@
- 这次要介绍的是js的数组对象,其实在js里面他本质上是一种object对象(他的原型),创建和使用方法和python有点类似,最重要的一点数组里面的数据类型可以是各种类型。
-
-创建数组对象
使用Array()的方式或者直接用[]来创建一个数组。
-var arr = new Array(element0, element1, ..., elementN);
var arr = Array(element0, element1, ..., elementN);
var arr = [element0, element1, ..., elementN];
// 译者注: var arr=[4] 和 var arr=new Array(4)是不等效的,
// 后者4指数组长度,所以使用字面值(literal)的方式应该不仅仅是便捷,同时也不易踩坑
-
-为了创建一个长度不为0,但是又没有任何元素的数组,可选以下任何一种方式:
-var arr = new Array(arrayLength);
var arr = Array(arrayLength);
// 这样有同样的效果
var arr = [];
arr.length = arrayLength;
-
-这里还有一些特殊情况需要进行说明
-let a=[,"12",,3];//这样的数组也是成立的,这种逗号法省略的部分为undefined
let b=[1,2,,];//这里数组最后一个逗号是忽略的,也就是这里只有一个undefined
-结果测试:

-填充数组
可以使用类似赋值操作的方法来填充元素,如果你在以上代码中给数组操作符的是一个非整形数值,那么将作为一个代表数组的对象的属性(property)创建,而非作为数组的元素。
-var emp = [];
emp[0] = "Casey Jones";
emp[1] = "Phil Lesh";
emp[2] = "August West";
-
+ 这次要介绍的是js的数组对象,其实在js里面他本质上是一种object对象(他的原型),创建和使用方法和python有点类似,最重要的一点数组里面的数据类型可以是各种类型。
+创建数组对象
使用Array()的方式或者直接用[]来创建一个数组。
var arr = new Array(element0, element1, ..., elementN);
var arr = Array(element0, element1, ..., elementN);
var arr = [element0, element1, ..., elementN];
// 译者注: var arr=[4] 和 var arr=new Array(4)是不等效的,
// 后者4指数组长度,所以使用字面值(literal)的方式应该不仅仅是便捷,同时也不易踩坑
+为了创建一个长度不为0,但是又没有任何元素的数组,可选以下任何一种方式:
var arr = new Array(arrayLength);
var arr = Array(arrayLength);
// 这样有同样的效果
var arr = [];
arr.length = arrayLength;
+这里还有一些特殊情况需要进行说明
let a=[,"12",,3];//这样的数组也是成立的,这种逗号法省略的部分为undefined
let b=[1,2,,];//这里数组最后一个逗号是忽略的,也就是这里只有一个undefined
结果测试:
+填充数组
可以使用类似赋值操作的方法来填充元素,如果你在以上代码中给数组操作符的是一个非整形数值,那么将作为一个代表数组的对象的属性(property)创建,而非作为数组的元素。
var emp = [];
emp[0] = "Casey Jones";
emp[1] = "Phil Lesh";
emp[2] = "August West";
数组方法
关于数组的方法其实很多,这里我们不会一一详细介绍,大概就给一些常用的函数。
concat() 连接两个数组并返回一个新的数组。
join(deliminator = ',') 将数组的所有元素连接成一个字符串。
push() 在数组末尾添加一个或多个元素,并返回数组操作后的长度。
sort() 给数组元素排序。
pop() 从数组移出最后一个元素,并返回该元素。
slice(start_index, upto_index) 从数组提取一个片段,并作为一个新数组返回。
-map(callback[, thisObject]) 在数组的每个单元项上执行callback函数,并把返回包含回调函数返回值的新数组(译者注:也就是遍历数组,并通过callback对数组元素进行操作,并将所有操作结果放入数组中并返回该数组)。
-var a1 = ['a', 'b', 'c'];
var a2 = a1.map(function(item) { return item.toUpperCase(); });
console.log(a2); // logs A,B,C
-
-
-filter(callback[, thisObject]) 返回一个包含所有在回调函数上返回为true的元素的新数组(译者注:callback在这里担任的是过滤器的角色,当元素符合条件,过滤器就返回true,而filter则会返回所有符合过滤条件的元素)。
-var a1 = ['a', 10, 'b', 20, 'c', 30];
var a2 = a1.filter(function(item) { return typeof item == 'number'; });
console.log(a2); // logs 10,20,30
-
-
-every(callback[, thisObject]) 当数组中每一个元素在callback上被返回true时就返回true(译者注:同上,every其实类似filter,只不过它的功能是判断是不是数组中的所有元素都符合条件,并且返回的是布尔值)。
-function isNumber(value){
return typeof value == 'number';
}
var a1 = [1, 2, 3];
console.log(a1.every(isNumber)); // logs true
var a2 = [1, '2', 3];
console.log(a2.every(isNumber)); // logs false
-
-some(callback[, thisObject]) 只要数组中有一项在callback上被返回true,就返回true(译者注:同上,类似every,不过前者要求都符合筛选条件才返回true,后者只要有符合条件的就返回true)。
-function isNumber(value){
return typeof value == 'number';
}
var a1 = [1, 2, 3];
console.log(a1.some(isNumber)); // logs true
var a2 = [1, '2', 3];
console.log(a2.some(isNumber)); // logs true
var a3 = ['1', '2', '3'];
console.log(a3.some(isNumber)); // logs false
-
+map(callback[, thisObject]) 在数组的每个单元项上执行callback函数,并把返回包含回调函数返回值的新数组(译者注:也就是遍历数组,并通过callback对数组元素进行操作,并将所有操作结果放入数组中并返回该数组)。
var a1 = ['a', 'b', 'c'];
var a2 = a1.map(function(item) { return item.toUpperCase(); });
console.log(a2); // logs A,B,C
+filter(callback[, thisObject]) 返回一个包含所有在回调函数上返回为true的元素的新数组(译者注:callback在这里担任的是过滤器的角色,当元素符合条件,过滤器就返回true,而filter则会返回所有符合过滤条件的元素)。
var a1 = ['a', 10, 'b', 20, 'c', 30];
var a2 = a1.filter(function(item) { return typeof item == 'number'; });
console.log(a2); // logs 10,20,30
+every(callback[, thisObject]) 当数组中每一个元素在callback上被返回true时就返回true(译者注:同上,every其实类似filter,只不过它的功能是判断是不是数组中的所有元素都符合条件,并且返回的是布尔值)。
function isNumber(value){
return typeof value == 'number';
}
var a1 = [1, 2, 3];
console.log(a1.every(isNumber)); // logs true
var a2 = [1, '2', 3];
console.log(a2.every(isNumber)); // logs false
+some(callback[, thisObject]) 只要数组中有一项在callback上被返回true,就返回true(译者注:同上,类似every,不过前者要求都符合筛选条件才返回true,后者只要有符合条件的就返回true)。
function isNumber(value){
return typeof value == 'number';
}
var a1 = [1, 2, 3];
console.log(a1.some(isNumber)); // logs true
var a2 = [1, '2', 3];
console.log(a2.some(isNumber)); // logs true
var a3 = ['1', '2', '3'];
console.log(a3.some(isNumber)); // logs false
数组推导式
这个其实有点类似于python里面的列表推导式或者列表条件筛选操作,主要还是对上面的map()和filter()做了一些改进吧,让他的使用更方便了。
var numbers = [1, 2, 3, 4];
var doubled = [for (i of numbers) i * 2];
console.log(doubled); // logs 2,4,6,8
-这种方法等价于map函数
-var doubled = numbers.map(fuction(i){return i*2};);
-
+这种方法等价于map函数
var doubled = numbers.map(fuction(i){return i*2};);
var numbers = [1, 2, 3, 21, 22, 30];
var evens = [i for (i of numbers) if (i % 2 === 0)];
console.log(evens); // logs 2,22,30
-这种方法等价于filter函数
-var events=numbers.filter(fuction(i){return i%2==0;});
+这种方法等价于filter函数
var events=numbers.filter(fuction(i){return i%2==0;});
+
@@ -555,7 +534,7 @@
- 编译原理
+ 数据库系统
-
diff --git "a/2020/10/02/js\345\237\272\347\241\200\342\200\224\342\200\224\345\205\263\344\272\216\345\257\271\350\261\241/index.html" "b/2020/10/02/js\345\237\272\347\241\200\342\200\224\342\200\224\345\205\263\344\272\216\345\257\271\350\261\241/index.html"
index a3c30249..3599d705 100644
--- "a/2020/10/02/js\345\237\272\347\241\200\342\200\224\342\200\224\345\205\263\344\272\216\345\257\271\350\261\241/index.html"
+++ "b/2020/10/02/js\345\237\272\347\241\200\342\200\224\342\200\224\345\205\263\344\272\216\345\257\271\350\261\241/index.html"
@@ -209,9 +209,7 @@
- 对象与属性
同其他语言里面所描述的对象一样,在js里,一个对象就是一系列属性的集合,一个属性包含一个名和一个值。一个属性的值可以是函数,这种情况下属性也被称为方法。一个对象的属性可以被解释成一个附加到对象上的变量。对象有时也被叫作关联数组, 因为每个属性都有一个用于访问它的字符串值。
-
-属性的访问设置与修改主要是通过两种手段实现,一种是通过点号对变量进行调用,一种是通过方括号的方式访问,其中通过方括号的方式是一种动态判定法(属性名只有到运行时才能判定)。
+ 对象与属性
同其他语言里面所描述的对象一样,在js里,一个对象就是一系列属性的集合,一个属性包含一个名和一个值。一个属性的值可以是函数,这种情况下属性也被称为方法。一个对象的属性可以被解释成一个附加到对象上的变量。对象有时也被叫作关联数组, 因为每个属性都有一个用于访问它的字符串值。
属性的访问设置与修改主要是通过两种手段实现,一种是通过点号对变量进行调用,一种是通过方括号的方式访问,其中通过方括号的方式是一种动态判定法(属性名只有到运行时才能判定)。
一个对象的属性名可以是任何有效的 JavaScript 字符串,或者可以被转换为字符串的任何类型,包括空字符串。然而,一个属性的名称如果不是一个有效的 JavaScript 标识符(例如,一个由空格或连字符,或者以数字开头的属性名),就只能通过方括号标记访问。
方括号中的所有键都将转换为字符串类型,因为JavaScript中的对象只能使用String类型作为键类型,如果是object类型的话,也可以通过方括号直接添加属性,不过他添加属性的时候会调用toString()方法,并将其作为新的key值。
你可以在for...in语句中使用方括号标记以枚举一个对象的所有属性
@@ -222,30 +220,18 @@ 创建新对象
JavaScript 拥有一系列预定义的对象,当然我们也可以自己创建对象,从 JavaScript 1.2 之后,你可以通过对象初始化器(Object Initializer)创建对象。或者你可以创建一个构造函数并使用该函数和new操作符初始化对象。
-使用对象初始化器
使用对象初始化器也被称作通过字面值创建对象,通过对象初始化器创建对象的语法如下:
-var obj = { property_1: value_1, // property_# 可以是一个标识符...
2: value_2, // 或一个数字...
["property" +3]: value_3, // 或一个可计算的key名...
// ...,
"property n": value_n }; // 或一个字符串
-这里 obj是新对象的名称,每一个 property_i 是一个标识符(可以是一个名称、数字或字符串字面量),并且每个 value_i 是一个其值将被赋予 property_i 的表达式。obj 与赋值是可选的;
-var myHonda = {color: "red", wheels: 4, engine: {cylinders: 4, size: 2.2}};//这里面的engine也是一个对象
-
+使用对象初始化器
使用对象初始化器也被称作通过字面值创建对象,通过对象初始化器创建对象的语法如下:
var obj = { property_1: value_1, // property_# 可以是一个标识符...
2: value_2, // 或一个数字...
["property" +3]: value_3, // 或一个可计算的key名...
// ...,
"property n": value_n }; // 或一个字符串
这里 obj是新对象的名称,每一个 property_i 是一个标识符(可以是一个名称、数字或字符串字面量),并且每个 value_i 是一个其值将被赋予 property_i 的表达式。obj 与赋值是可选的;
var myHonda = {color: "red", wheels: 4, engine: {cylinders: 4, size: 2.2}};//这里面的engine也是一个对象
使用构造函数
使用构造函数实例化对象的过程分为两步:
- 通过创建一个构造函数来定义对象的类型。首字母大写是非常普遍而且很恰当的惯用法。
- 通过
new 创建对象实例。
-使用 Object.create 方法
对象也可以用 Object.create() 方法创建。该方法非常有用,因为它允许你为创建的对象选择一个原型对象,而不用定义构造函数。
-// Animal properties and method encapsulation
var Animal = {
type: "Invertebrates", // 属性默认值
displayType : function() { // 用于显示type属性的方法
console.log(this.type);
}
}
// 创建一种新的动物——animal1
var animal1 = Object.create(Animal);
animal1.displayType(); // Output:Invertebrates
// 创建一种新的动物——Fishes
var fish = Object.create(Animal);
fish.type = "Fishes";
fish.displayType(); // Output:Fishes
-
+使用 Object.create 方法
对象也可以用 Object.create() 方法创建。该方法非常有用,因为它允许你为创建的对象选择一个原型对象,而不用定义构造函数。
// Animal properties and method encapsulation
var Animal = {
type: "Invertebrates", // 属性默认值
displayType : function() { // 用于显示type属性的方法
console.log(this.type);
}
}
// 创建一种新的动物——animal1
var animal1 = Object.create(Animal);
animal1.displayType(); // Output:Invertebrates
// 创建一种新的动物——Fishes
var fish = Object.create(Animal);
fish.type = "Fishes";
fish.displayType(); // Output:Fishes
继承
所有的 JavaScript 对象至少继承于一个对象。被继承的对象被称作原型,并且继承的属性可通过构造函数的prototype对象找到。
-为对象类型定义属性
你可以通过 prototype 属性为之前定义的对象类型增加属性。这为该类型的所有对象,而不是仅仅一个对象增加了一个属性。下面的代码为所有类型为 car 的对象增加了 color 属性,然后为对象 car1 的 color 属性赋值:
-Car.prototype.color = null;
car1.color = "black";
-
+为对象类型定义属性
你可以通过 prototype 属性为之前定义的对象类型增加属性。这为该类型的所有对象,而不是仅仅一个对象增加了一个属性。下面的代码为所有类型为 car 的对象增加了 color 属性,然后为对象 car1 的 color 属性赋值:
Car.prototype.color = null;
car1.color = "black";
通过 this 引用对象
avaScript 有一个特殊的关键字 this,它可以在方法中使用以指代当前对象。
-删除属性
你可以用delete操作符删除一个不是继承而来的属性。下面的例子说明如何删除一个属性:
-//Creates a new object, myobj, with two properties, a and b.
var myobj = new Object;
myobj.a = 5;
myobj.b = 12;
//Removes the a property, leaving myobj with only the b property.
delete myobj.a;
-
-比较对象
在 JavaScript 中 objects 是一种引用类型。两个独立声明的对象永远也不会相等,即使他们有相同的属性,只有在比较一个对象和这个对象的引用时,才会返回true.
这边是官方给出的例子
-// 两个变量, 两个具有同样的属性、但不相同的对象
var fruit = {name: "apple"};
var fruitbear = {name: "apple"};
fruit == fruitbear // return false
fruit === fruitbear // return false
-// 两个变量, 同一个对象
var fruit = {name: "apple"};
var fruitbear = fruit; // 将fruit的对象引用(reference)赋值给 fruitbear
// 也称为将fruitbear“指向”fruit对象
// fruit与fruitbear都指向同样的对象
fruit == fruitbear // return true
fruit === fruitbear // return true
+删除属性
你可以用delete操作符删除一个不是继承而来的属性。下面的例子说明如何删除一个属性:
//Creates a new object, myobj, with two properties, a and b.
var myobj = new Object;
myobj.a = 5;
myobj.b = 12;
//Removes the a property, leaving myobj with only the b property.
delete myobj.a;
+比较对象
在 JavaScript 中 objects 是一种引用类型。两个独立声明的对象永远也不会相等,即使他们有相同的属性,只有在比较一个对象和这个对象的引用时,才会返回true.
这边是官方给出的例子
// 两个变量, 两个具有同样的属性、但不相同的对象
var fruit = {name: "apple"};
var fruitbear = {name: "apple"};
fruit == fruitbear // return false
fruit === fruitbear // return false
// 两个变量, 同一个对象
var fruit = {name: "apple"};
var fruitbear = fruit; // 将fruit的对象引用(reference)赋值给 fruitbear
// 也称为将fruitbear“指向”fruit对象
// fruit与fruitbear都指向同样的对象
fruit == fruitbear // return true
fruit === fruitbear // return true
@@ -554,7 +540,7 @@
- 编译原理
+ 数据库系统
-
diff --git "a/2020/10/02/\347\274\226\350\257\221\345\216\237\347\220\206\347\254\254\344\272\214\347\253\240\342\200\224\342\200\224\346\226\207\346\263\225\345\210\206\347\261\273/index.html" "b/2020/10/02/\347\274\226\350\257\221\345\216\237\347\220\206\347\254\254\344\272\214\347\253\240\342\200\224\342\200\224\346\226\207\346\263\225\345\210\206\347\261\273/index.html"
index 21e69d60..702d9052 100644
--- "a/2020/10/02/\347\274\226\350\257\221\345\216\237\347\220\206\347\254\254\344\272\214\347\253\240\342\200\224\342\200\224\346\226\207\346\263\225\345\210\206\347\261\273/index.html"
+++ "b/2020/10/02/\347\274\226\350\257\221\345\216\237\347\220\206\347\254\254\344\272\214\347\253\240\342\200\224\342\200\224\346\226\207\346\263\225\345\210\206\347\261\273/index.html"
@@ -218,9 +218,7 @@
语言和文法
编译原理第二章文法分类,紫书内容和mooc知识总结,重新回顾了4种文法的知识。
文法分类
乔姆斯基把语言文法分成4类,0型,1型,2型,3型,这几类文法的差别主要在于对产生式的限制不同,等级越高,限制越严格。
-0型文法
0型文法是文法限制最弱的一种类型,0型文法的能力又被相当于图灵机模型,或者说任何0型文法都是递归可枚举的,反之,递归可枚举的一定是一个0型语言。
-
-定义:
设$G=(V_N,V_T,P,S)$,如果$P$中的每一个产生式$\alpha$->$\beta$满足条件:
+0型文法
0型文法是文法限制最弱的一种类型,0型文法的能力又被相当于图灵机模型,或者说任何0型文法都是递归可枚举的,反之,递归可枚举的一定是一个0型语言。
定义:
设$G=(V_N,V_T,P,S)$,如果$P$中的每一个产生式$\alpha$->$\beta$满足条件:
- $\alpha \in (V_N \cup V_T)^*$且至少含有一个非终结符。
- $\beta \in (V_N \cup V_T)^*$
@@ -543,7 +541,7 @@
-
@@ -551,15 +549,15 @@
-
diff --git "a/2020/10/03/\344\270\255\346\226\255\345\274\202\345\270\270\344\270\216\347\263\273\347\273\237\350\260\203\347\224\250/index.html" "b/2020/10/03/\344\270\255\346\226\255\345\274\202\345\270\270\344\270\216\347\263\273\347\273\237\350\260\203\347\224\250/index.html"
index 2c5968ad..dd8b744c 100644
--- "a/2020/10/03/\344\270\255\346\226\255\345\274\202\345\270\270\344\270\216\347\263\273\347\273\237\350\260\203\347\224\250/index.html"
+++ "b/2020/10/03/\344\270\255\346\226\255\345\274\202\345\270\270\344\270\216\347\263\273\347\273\237\350\260\203\347\224\250/index.html"
@@ -215,9 +215,7 @@
通常操作系统提供的主要功能都是由内核程序实现的,处理机在运行上层程序时,能进入操作系统内核运行的唯一途径就是中断或者异常。
-中断和异常基本概念
中断(Interruption):也称外中断,指来自处理机执行指令以外的事件发生。
异常(Exception):也称内中断、例外、自陷(trap),指源自处理机执行指令内部的事件。
-
-常见中断类型:
中断:I/O中断,时钟中断。
异常:系统调用(具体指系统调用当中的自陷指令),缺页异常,断点指令,其他程序性异常(如:算术溢出)
+中断和异常基本概念
中断(Interruption):也称外中断,指来自处理机执行指令以外的事件发生。
异常(Exception):也称内中断、例外、自陷(trap),指源自处理机执行指令内部的事件。
常见中断类型:
中断:I/O中断,时钟中断。
异常:系统调用(具体指系统调用当中的自陷指令),缺页异常,断点指令,其他程序性异常(如:算术溢出)
中断: 与正执行指令无关,可以屏蔽;
异常: 与正执行指令有关,不可屏蔽
中断屏蔽:指禁止处理机响应中断或禁止中断出现.
中断屏蔽有两种方法:
1.硬件实现(由软件置处理机优先级,硬件按系统设计时的约定,屏蔽那些低优先级中断);
2.软件实现(由软件按操作系统优先级约定,设置屏蔽寄存器)。


@@ -545,7 +543,7 @@
- 编译原理
+ 数据库系统
-
diff --git "a/2020/10/03/\346\223\215\344\275\234\347\263\273\347\273\237\347\232\204\350\277\220\350\241\214\346\234\272\345\210\266\345\222\214\344\275\223\347\263\273\347\273\223\346\236\204/index.html" "b/2020/10/03/\346\223\215\344\275\234\347\263\273\347\273\237\347\232\204\350\277\220\350\241\214\346\234\272\345\210\266\345\222\214\344\275\223\347\263\273\347\273\223\346\236\204/index.html"
index 2a6329d4..9bf2950e 100644
--- "a/2020/10/03/\346\223\215\344\275\234\347\263\273\347\273\237\347\232\204\350\277\220\350\241\214\346\234\272\345\210\266\345\222\214\344\275\223\347\263\273\347\273\223\346\236\204/index.html"
+++ "b/2020/10/03/\346\223\215\344\275\234\347\263\273\347\273\237\347\232\204\350\277\220\350\241\214\346\234\272\345\210\266\345\222\214\344\275\223\347\263\273\347\273\223\346\236\204/index.html"
@@ -214,8 +214,7 @@
- 操作系统比较硬核,不过最近发现了王道考研这个比较好的课程。这里是一些学习笔记总结。
-
+ 操作系统比较硬核,不过最近发现了王道考研这个比较好的课程。这里是一些学习笔记总结。
主要功能模块
操作系统核心的主要功能模块介绍如下:
系统初始化模块:准备系统运行环境,最后为每个终端创建一个进程,运行命令解释程序。
进程管理模块:处理进程类系统调用(如进程创建/结束等)和进程调度。
存储管理模块:配合进程管理,分配进程空间;处理存储类系统调用(如动态增加进程空间);在虚存系统缺页异常时调入页面进行处理。
@@ -232,26 +231,30 @@ 两种程序

操作系统的内核
内核是计算机上配置的底层软件,是操作系统最基本、最核心的部分。实现操作系统内核功能的那些程序就是内核程序。
这里其实还确实了一种,我们常说的操作系统四大模块是指,进程管理,存储管理,设备管理和文件系统管理。

由此引出了我们操作系统的两种内核:大内核和微内核。
+
-大内核
-微内核
+大内核
+微内核
-
-将操作系统的主要功能都作为系统内核,运行在核心态
-只把最基本的功能保留
+
+
+将操作系统的主要功能都作为系统内核,运行在核心态
+只把最基本的功能保留
-优点:高性能
-优点:内核功能少,结构清晰,方便维护
+优点:高性能
+优点:内核功能少,结构清晰,方便维护
-缺点:内核代码庞大,结构混乱,难以维护
-缺点:需要频繁地在用户态和核心态之间切换,性能低
+缺点:内核代码庞大,结构混乱,难以维护
+缺点:需要频繁地在用户态和核心态之间切换,性能低
-
+
+
+

@@ -557,7 +560,7 @@
- 编译原理
+ 数据库系统
-
diff --git "a/2020/10/13/\344\272\272\344\272\272\351\203\275\346\230\257\344\272\247\345\223\201\347\273\217\347\220\206\350\257\273\345\220\216\346\204\237/index.html" "b/2020/10/13/\344\272\272\344\272\272\351\203\275\346\230\257\344\272\247\345\223\201\347\273\217\347\220\206\350\257\273\345\220\216\346\204\237/index.html"
index b0914e7a..9553490a 100644
--- "a/2020/10/13/\344\272\272\344\272\272\351\203\275\346\230\257\344\272\247\345\223\201\347\273\217\347\220\206\350\257\273\345\220\216\346\204\237/index.html"
+++ "b/2020/10/13/\344\272\272\344\272\272\351\203\275\346\230\257\344\272\247\345\223\201\347\273\217\347\220\206\350\257\273\345\220\216\346\204\237/index.html"
@@ -530,7 +530,7 @@
-
@@ -538,15 +538,15 @@
-
diff --git "a/2020/11/01/\346\225\260\346\215\256\345\272\223\345\244\215\344\271\240\351\242\230/index.html" "b/2020/11/01/\346\225\260\346\215\256\345\272\223\345\244\215\344\271\240\351\242\230/index.html"
index 2219b559..fad586a0 100644
--- "a/2020/11/01/\346\225\260\346\215\256\345\272\223\345\244\215\344\271\240\351\242\230/index.html"
+++ "b/2020/11/01/\346\225\260\346\215\256\345\272\223\345\244\215\344\271\240\351\242\230/index.html"
@@ -208,55 +208,22 @@
- 复习题
Use only the INVENTORY table to answer Review Questions 2.17 through 2.40:
-
-2.17 Write an SQL statement to display SKU and SKU_Description.
-SELECT SKU,SKU_Description FROM INVENTORY;
-2.18 Write an SQL statement to display SKU_Description and SKU.
-SELECT SKU_Description,SKU FROM INVENTORY;
-
-2.19 Write an SQL statement to display WarehouseID.
-SELECT WarehouseID FROM INVENTORY;
-
-
-2.20 Write an SQL statement to display unique WarehouseIDs.
-SELECT DISTINCT WarehouseID FROM INVENTORY;
-
-2.26 Write an SQL statement to display the SKU, SKU_Description, and WarehouseID for products that have a QuantityOnHand greater than 0. Sort the results in descending order by WarehouseID and in ascending order by SKU.
-SELECT SKU, SKU_Description, WarehouseID
FROM INVENTORY
WHERE QuantityOnHand>0
ORDER BY WarehouseID DESC, SKU ASC;
-
-2.29 Write an SQL statement to display the SKU, SKU_Description, WarehouseID, and QuantityOnHand for all products having a QuantityOnHand greater than 1 and less than 10. Do not use the BETWEEN keyword.
-SELECT SKU, SKU_Description, WarehouseID, QuantityOnHand
FROM INVENTORY
WHERE QuantityOnHand>1 AND QuantityOnOrder<10;
-
-2.36 Write an SQL statement to display the WarehouseID and the sum of QuantityOnHand,grouped by WarehouseID. Name the sum TotalItemsOnHand and display the results in descending order of TotalItemsOnHand.
-SELECT WarehouseID , SUM (QuantityOnHand) AS TotalItamsOnHand
FROM INVENTORY
GROUP BY WarehouseID
ORDER BY TotalItemsOnHand DESC;
-
-2.37 Write an SQL statement to display the WarehouseID and the sum of QuantityOnHand, grouped by WarehouseID. Omit all SKU items that have 3 or more items on hand from the sum, and name the sum TotalItemsOnHandLT3 and display the results in descending order of TotalItemsOnHandLT3.
-SELECT WarehouseID , SUM (QuantityOnHand) AS TotalItamsOnHandLT3
FROM INVENTORY
WHERE QuantityOnHand<3
GROUP BY WarehouseID
ORDER BY TotalItemsOnHandLT3 DESC;
-
+ 复习题
Use only the INVENTORY table to answer Review Questions 2.17 through 2.40:
2.17 Write an SQL statement to display SKU and SKU_Description.
SELECT SKU,SKU_Description FROM INVENTORY;
2.18 Write an SQL statement to display SKU_Description and SKU.
SELECT SKU_Description,SKU FROM INVENTORY;
+2.19 Write an SQL statement to display WarehouseID.
SELECT WarehouseID FROM INVENTORY;
+2.20 Write an SQL statement to display unique WarehouseIDs.
SELECT DISTINCT WarehouseID FROM INVENTORY;
+2.26 Write an SQL statement to display the SKU, SKU_Description, and WarehouseID for products that have a QuantityOnHand greater than 0. Sort the results in descending order by WarehouseID and in ascending order by SKU.
SELECT SKU, SKU_Description, WarehouseID
FROM INVENTORY
WHERE QuantityOnHand>0
ORDER BY WarehouseID DESC, SKU ASC;
+2.29 Write an SQL statement to display the SKU, SKU_Description, WarehouseID, and QuantityOnHand for all products having a QuantityOnHand greater than 1 and less than 10. Do not use the BETWEEN keyword.
SELECT SKU, SKU_Description, WarehouseID, QuantityOnHand
FROM INVENTORY
WHERE QuantityOnHand>1 AND QuantityOnOrder<10;
+2.36 Write an SQL statement to display the WarehouseID and the sum of QuantityOnHand,grouped by WarehouseID. Name the sum TotalItemsOnHand and display the results in descending order of TotalItemsOnHand.
SELECT WarehouseID , SUM (QuantityOnHand) AS TotalItamsOnHand
FROM INVENTORY
GROUP BY WarehouseID
ORDER BY TotalItemsOnHand DESC;
+2.37 Write an SQL statement to display the WarehouseID and the sum of QuantityOnHand, grouped by WarehouseID. Omit all SKU items that have 3 or more items on hand from the sum, and name the sum TotalItemsOnHandLT3 and display the results in descending order of TotalItemsOnHandLT3.
SELECT WarehouseID , SUM (QuantityOnHand) AS TotalItamsOnHandLT3
FROM INVENTORY
WHERE QuantityOnHand<3
GROUP BY WarehouseID
ORDER BY TotalItemsOnHandLT3 DESC;
2.38 Write an SQL statement to display the WarehouseID and the sum of QuantityOnHand grouped by WarehouseID. Omit all SKU items that have 3 or more items on hand from the sum, and name the sum TotalItemsOnHandLT3. Show WarehouseID only for warehouses having fewer than 2 SKUs in their TotalItemesOnHandLT3 and display the results in descending order of TotalItemsOnHandLT3.
SELECT WarehouseID , SUM (QuantityOnHand) AS TotalItamsOnHandLT3,
FROM INVENTORY
WHERE QuantityOnHand <3
GROUP BY WarehouseID
HAVING COUNT(*)<2
ORDER BY TotalItemsOnHandLT3 DESC;
-
Use both the INVENTORY and WAREHOUSE tables to answer Review Questions 2.40 through 2.52:
-2.42 Write an SQL statement to display the SKU, SKU_Description, WarehouseID, Ware-houseCity, and WarehouseState of all items not stored in the Atlanta, Bangor, or Chicago warehouse. Do not use the NOT IN keyword.
-SELECT SKU, SKU_Description, INVENTORY.WarehouseID, WarehouseCity, WarehouseState
FROM INVENTORY, WAREHOUSE
WHERE INVENTORY.WarehouseID=WAREHOUSE.WarehouseID AND WarehouseCity!='Atlanta' AND WarehouseCity!='Chicago' AND WarehouseCity!='Bangor';
-
-2.44 Write an SQL statement to produce a single column called ItemLocation that combines the SKU_Description, the phrase “is in a warehouse in”, and WarehouseCity. Do not be concerned with removing leading or trailing blanks.
-SELECT DISTINCT RTRIM(SKU_Description)+ 'is in a warehouse' + RTRIM(WarehouseCity) AS ItemLocation
FROM INVENTORY, WAREHOUSE WHERE INVENTORY.WarehouseID=WAREHOUSE.WarehouseID;
-
-2.45 Write an SQL statement to show the SKU, SKU_Description, WarehouseID for all items stored in a warehouse managed by ‘Lucille Smith’. Use a subquery.
-SELECT SKU, SKU_Description, WarehouseID
FROM INVENTORY
WHERE WarehouseID IN (SELECT WarehouseID
FROM WAREHOUSE WHERE Manager='Lucille Smith');
-
-2.46 Write an SQL statement to show the SKU, SKU_Description, WarehouseID for all items stored in a warehouse managed by ‘Lucille Smith’. Use a join.
-SELECT SKU, SKU_Description, INVENTORY.WarehouseID
FROM INVENTORY, WAREHOUSE
WHERE INVENTORY.WarehouseID=WAREHOUSE.WarehouseID AND WAREHOUSE.Manager= 'Lucille Smith';
-
-2.50 Write an SQL statement to show the WarehouseID and average QuantityOnHand of all items stored in a warehouse managed by ‘Lucille Smith’. Use a join using JOIN ON syntax.
-SELECT INVENTORY.WarehouseID, AVG(QuantityOnHand)
FROM INVENTORY JOIN WAREHOUSE
ON INVENTORY.WarehouseID=WAREHOUSE.WarehouseID
WHERE WAREHOUSE.Manager='Lucille Smith';
-
-2.55 Write an SQL statement to join WAREHOUSE and INVENTORY and include all rows of WAREHOUSE in your answer, regardless of whether they have any INVENTORY. Run this statement.
-SELECT *
FROM WAREHOUSE LEFT OUTER JOIN INWENTORY
ON INVENTORY.WarehouseID=WAREHOUSE.WarehouseID;
-
-
+2.42 Write an SQL statement to display the SKU, SKU_Description, WarehouseID, Ware-houseCity, and WarehouseState of all items not stored in the Atlanta, Bangor, or Chicago warehouse. Do not use the NOT IN keyword.
SELECT SKU, SKU_Description, INVENTORY.WarehouseID, WarehouseCity, WarehouseState
FROM INVENTORY, WAREHOUSE
WHERE INVENTORY.WarehouseID=WAREHOUSE.WarehouseID AND WarehouseCity!='Atlanta' AND WarehouseCity!='Chicago' AND WarehouseCity!='Bangor';
+2.44 Write an SQL statement to produce a single column called ItemLocation that combines the SKU_Description, the phrase “is in a warehouse in”, and WarehouseCity. Do not be concerned with removing leading or trailing blanks.
SELECT DISTINCT RTRIM(SKU_Description)+ 'is in a warehouse' + RTRIM(WarehouseCity) AS ItemLocation
FROM INVENTORY, WAREHOUSE WHERE INVENTORY.WarehouseID=WAREHOUSE.WarehouseID;
+2.45 Write an SQL statement to show the SKU, SKU_Description, WarehouseID for all items stored in a warehouse managed by ‘Lucille Smith’. Use a subquery.
SELECT SKU, SKU_Description, WarehouseID
FROM INVENTORY
WHERE WarehouseID IN (SELECT WarehouseID
FROM WAREHOUSE WHERE Manager='Lucille Smith');
+2.46 Write an SQL statement to show the SKU, SKU_Description, WarehouseID for all items stored in a warehouse managed by ‘Lucille Smith’. Use a join.
SELECT SKU, SKU_Description, INVENTORY.WarehouseID
FROM INVENTORY, WAREHOUSE
WHERE INVENTORY.WarehouseID=WAREHOUSE.WarehouseID AND WAREHOUSE.Manager= 'Lucille Smith';
+2.50 Write an SQL statement to show the WarehouseID and average QuantityOnHand of all items stored in a warehouse managed by ‘Lucille Smith’. Use a join using JOIN ON syntax.
SELECT INVENTORY.WarehouseID, AVG(QuantityOnHand)
FROM INVENTORY JOIN WAREHOUSE
ON INVENTORY.WarehouseID=WAREHOUSE.WarehouseID
WHERE WAREHOUSE.Manager='Lucille Smith';
+2.55 Write an SQL statement to join WAREHOUSE and INVENTORY and include all rows of WAREHOUSE in your answer, regardless of whether they have any INVENTORY. Run this statement.
SELECT *
FROM WAREHOUSE LEFT OUTER JOIN INWENTORY
ON INVENTORY.WarehouseID=WAREHOUSE.WarehouseID;
@@ -561,7 +528,7 @@
-
diff --git "a/2020/11/06/\344\277\241\345\217\267\351\207\217\346\234\272\345\210\266\347\273\217\345\205\270\344\276\213\345\255\220/index.html" "b/2020/11/06/\344\277\241\345\217\267\351\207\217\346\234\272\345\210\266\347\273\217\345\205\270\344\276\213\345\255\220/index.html"
index fa343909..e3f83bd7 100644
--- "a/2020/11/06/\344\277\241\345\217\267\351\207\217\346\234\272\345\210\266\347\273\217\345\205\270\344\276\213\345\255\220/index.html"
+++ "b/2020/11/06/\344\277\241\345\217\267\351\207\217\346\234\272\345\210\266\347\273\217\345\205\270\344\276\213\345\255\220/index.html"
@@ -208,14 +208,9 @@
- 理发师问题
7.8 The Sleeping-Barber Problem. A barbershop consists of a waiting room with n chairs and the barber room containing the barber chair. If there are no customers to be served,the barber goes to sleep. If a customer enters the barbershop and all chairs are occupied, then the customer leaves the shop.If the barber is busy but chairs are available, then the customer sits in one of the free chairs. If the barber is asleep, the customer wakes up the barber. Write a program to coordinate the barber and the customers.
-
-semaphore:
full:=0,empty:=n,mutex:=1;//刘军的写法
/*
*full表示当前需要理发的人数
*empty表示当前还剩下多少空椅子
*mutex进程互斥控制量,理发师一次只能给一个人理发
*/
Parbegin:
customer: repeat
if empty=0:
customer leaves the shop//没有空位置则离开
P(empty);
P(mutex);
add a customer to chair
V(mutex);
V(full);
until false;
barber: repeat
if full=0:
barber sleep;//没有人需要理发则睡觉
P(full);
P(mutex);
cutting hair
V(mutex);
V(empty);
until false;
Parend;
-
+ 理发师问题
7.8 The Sleeping-Barber Problem. A barbershop consists of a waiting room with n chairs and the barber room containing the barber chair. If there are no customers to be served,the barber goes to sleep. If a customer enters the barbershop and all chairs are occupied, then the customer leaves the shop.If the barber is busy but chairs are available, then the customer sits in one of the free chairs. If the barber is asleep, the customer wakes up the barber. Write a program to coordinate the barber and the customers.
semaphore:
full:=0,empty:=n,mutex:=1;//刘军的写法
/*
*full表示当前需要理发的人数
*empty表示当前还剩下多少空椅子
*mutex进程互斥控制量,理发师一次只能给一个人理发
*/
Parbegin:
customer: repeat
if empty=0:
customer leaves the shop//没有空位置则离开
P(empty);
P(mutex);
add a customer to chair
V(mutex);
V(full);
until false;
barber: repeat
if full=0:
barber sleep;//没有人需要理发则睡觉
P(full);
P(mutex);
cutting hair
V(mutex);
V(empty);
until false;
Parend;
生产者消费者
type item=...;
var buffer=...;
full,empty,mutex:semaphore;
nextp,nextc:item;
begin:
full:=0;empty:=n;mutex:=1;
Parbegin:
producer:repeat
...
produce an item in nextp;
...
p(empty);
p(mutex);
add nextp to buffer;
V(mutex);
V(full);
until false;
consumer:repeat
...
p(full);
p(mutex);
remove an item from buffer to nextc;
释放缓冲区
V(mutex);
P(empty);
...
consume the item in nextc;
...
until false;
Parend
-
读者写者
semaphore mutex:=1,wrt:=1;
int readcount:=0;
Parbegin:
Writer:repeat
P(wrt);
写数据
V(wrt);
Reader:repeat
P(mutex);
readcount:=readcount+1;
if readcount:=1 then P(wrt);
V(mutex);
读数据
P(mutex);
readcount:=readcount-1;
if readcount=0 then V(wrt);
V(mutex);
Parend
-
哲学家问题
semaphore chopstick[5];//初始信号量都为1
第i个进程描述为(i=0,… ,4)
repeat
P(chopstick[i]);
P(chopstick[(i+1) mod 5]);
吃
V(chopstick[i]);
V(Chopstick[(i+1) mod 5];
思考
until false;
@@ -520,7 +515,7 @@
- 编译原理
+ 数据库系统
-
diff --git "a/2020/12/21/datawhale-pandas\346\225\260\346\215\256\345\210\206\346\236\220\351\242\204\345\244\207/index.html" "b/2020/12/21/datawhale-pandas\346\225\260\346\215\256\345\210\206\346\236\220\351\242\204\345\244\207/index.html"
index a0ec3ce5..3a28268a 100644
--- "a/2020/12/21/datawhale-pandas\346\225\260\346\215\256\345\210\206\346\236\220\351\242\204\345\244\207/index.html"
+++ "b/2020/12/21/datawhale-pandas\346\225\260\346\215\256\345\210\206\346\236\220\351\242\204\345\244\207/index.html"
@@ -8,12 +8,12 @@
datawhale-pandas数据分析预备 | khan's blog
-
+
-
+
@@ -214,31 +214,22 @@
datawhale-pandas数据分析预备
列表推导式
def my_func(x):
return 2*x
-
-[* for i in *]
其中,第一个 * 为映射函数,其输入为后面 i 指代的内容,第二个 * 表示迭代的对象。
-
-
+[ for i in ]
其中,第一个 为映射函数,其输入为后面 i 指代的内容,第二个 表示迭代的对象。
[my_func(i) for i in range(5)]
out:[0, 2, 4, 6, 8]
列表表达式支持多层嵌套
[m+'_'+n for m in['a','b'] for n in['c','d']]
out:[‘a_c’, ‘a_d’, ‘b_c’, ‘b_d’]
条件赋值
value = a if condition else b :
value = 'cat' if 2>1 else 'dog'
-
-
value
out:’cat’
下面举一个例子,截断列表中超过5的元素,即超过5的用5代替,小于5的保留原来的值:
L=[1,2,3,4,5,6,7]
[i if i<=5 else 5 for i in L]
out:[1, 2, 3, 4, 5, 5, 5]
lambda
my_func=lambda x:2*x
-
-
my_func(2)
out:4
f2=lambda a,b:a+b
-
-
f2(1,2)
out:3
[ (lambda i:2*i)(x) for x in range(5)]
@@ -251,8 +242,6 @@ lambda [‘0_a’, ‘1_b’, ‘2_c’, ‘3_d’, ‘4_e’]
zip
zip函数能够把多个可迭代对象打包成一个元组构成的可迭代对象,它返回了一个 zip 对象,通过 tuple, list 可以得到相应的打包结果:
L1, L2, L3 = list('abc'), list('def'), list('hij')
-
-
list(zip(L1, L2, L3))
[(‘a’, ‘d’, ‘h’), (‘b’, ‘e’, ‘i’), (‘c’, ‘f’, ‘j’)]
tuple(zip(L1, L2, L3))
@@ -261,8 +250,6 @@ zip
zip函
a d h
b e i
c f j
enumerate
enumerate 是一种特殊的打包,它可以在迭代时绑定迭代元素的遍历序号:
L = list('abcd')
-
-
for index, value in enumerate(L):
print(index, value)
0 a
1 b
2 c
3 d
用zip实现这个功能
@@ -274,15 +261,11 @@
dict(zip(L1,L2))
{‘a’: ‘d’, ‘b’: ‘e’, ‘c’: ‘f’}
zipped = list(zip(L1, L2, L3))
-
-
zipped
[(‘a’, ‘d’, ‘h’), (‘b’, ‘e’, ‘i’), (‘c’, ‘f’, ‘j’)]
list(zip(*zipped))
-
[(‘a’, ‘b’, ‘c’), (‘d’, ‘e’, ‘f’), (‘h’, ‘i’, ‘j’)]
numpy回顾
1. np数组的构造
import numpy as np
-
最一般的方法是通过 array 来构造:
np.array([1,2,3])
array([1, 2, 3])
@@ -307,6 +290,7 @@
np.full((2,3), [1,2,3]) # 每行填入相同的列表
array([[1, 2, 3],
[1, 2, 3]])
随机矩阵: np.random
+
代码实现
def iou_score(output, target):
'''计算IoU指标'''
intersection = np.logical_and(target, output)
union = np.logical_or(target, output)
return np.sum(intersection) / np.sum(union)
# 生成随机两个矩阵测试
target = np.random.randint(0, 2, (3, 3))
output = np.random.randint(0, 2, (3, 3))
d = iou_score(output, target)
# ----------------------------
target = array([[1, 0, 0],
[0, 1, 1],
[0, 0, 1]])
output = array([[1, 0, 1],
[0, 1, 0],
[0, 0, 0]])
d = 0.4
-
-4.5 BCE损失函数
BCE损失函数(Binary Cross-Entropy Loss)是交叉熵损失函数(Cross-Entropy Loss)的一种特例,BCE Loss只应用在二分类任务中。针对分类问题,单样本的交叉熵损失为:
$$
l(\pmb y, \pmb{\hat y})=- \sum_{i=1}^{c}y_i \cdot log\hat y_i
$$
式中,$\pmb{y}={y_1,y_2,…,y_c,}$,其中$y_i$是非0即1的数字,代表了是否属于第$i$类,为真实值;$\hat y_i$代表属于第i类的概率,为预测值。可以看出,交叉熵损失考虑了多类别情况,针对每一种类别都求了损失。针对二分类问题,上述公式可以改写为:
$$
l(y,\hat y)=-[y \cdot log\hat y +(1-y)\cdot log (1-\hat y)]
$$
式中,$y$为真实值,非1即0;$\hat y$为所属此类的概率值,为预测值。这个公式也就是BCE损失函数,即二分类任务时的交叉熵损失。值得强调的是,公式中的$\hat y$为概率分布形式,因此在使用BCE损失前,都应该将预测出来的结果转变成概率值,一般为sigmoid激活之后的输出。
+4.5 BCE损失函数
BCE损失函数(Binary Cross-Entropy Loss)是交叉熵损失函数(Cross-Entropy Loss)的一种特例,BCE Loss只应用在二分类任务中。针对分类问题,单样本的交叉熵损失为:
+式中,$\pmb{y}={y_1,y_2,…,y_c,}$,其中$y_i$是非0即1的数字,代表了是否属于第$i$类,为真实值;$\hat y_i$代表属于第i类的概率,为预测值。可以看出,交叉熵损失考虑了多类别情况,针对每一种类别都求了损失。针对二分类问题,上述公式可以改写为:
+式中,$y$为真实值,非1即0;$\hat y$为所属此类的概率值,为预测值。这个公式也就是BCE损失函数,即二分类任务时的交叉熵损失。值得强调的是,公式中的$\hat y$为概率分布形式,因此在使用BCE损失前,都应该将预测出来的结果转变成概率值,一般为sigmoid激活之后的输出。
代码实现
在pytorch中,官方已经给出了BCE损失函数的API,免去了自己编写函数的痛苦:
-torch.nn.BCELoss(weight: Optional[torch.Tensor] = None, size_average=None, reduce=None, reduction: str = 'mean')
$$
ℓ(y,\hat y)=L={l_1,…,l_N }^⊤,\ \ \ l_n=-w_n[y_n \cdot log\hat y_n +(1-y_n)\cdot log (1-\hat y_n)]
$$
参数:
weight(Tensor)- 为每一批量下的loss添加一个权重,很少使用
size_average(bool)- 弃用中
reduce(bool)- 弃用中
reduction(str) - ‘none’ | ‘mean’ | ‘sum’:为代替上面的size_average和reduce而生。——为mean时返回的该批量样本loss的平均值;为sum时,返回的该批量样本loss之和
+torch.nn.BCELoss(weight: Optional[torch.Tensor] = None, size_average=None, reduce=None, reduction: str = 'mean')
+参数:
weight(Tensor)- 为每一批量下的loss添加一个权重,很少使用
size_average(bool)- 弃用中
reduce(bool)- 弃用中
reduction(str) - ‘none’ | ‘mean’ | ‘sum’:为代替上面的size_average和reduce而生。——为mean时返回的该批量样本loss的平均值;为sum时,返回的该批量样本loss之和
同时,pytorch还提供了已经结合了Sigmoid函数的BCE损失:torch.nn.BCEWithLogitsLoss(),相当于免去了实现进行Sigmoid激活的操作。
import torch
import torch.nn as nn
bce = nn.BCELoss()
bce_sig = nn.BCEWithLogitsLoss()
input = torch.randn(5, 1, requires_grad=True)
target = torch.empty(5, 1).random_(2)
pre = nn.Sigmoid()(input)
loss_bce = bce(pre, target)
loss_bce_sig = bce_sig(input, target)
# ------------------------
input = tensor([[-0.2296],
[-0.6389],
[-0.2405],
[ 1.3451],
[ 0.7580]], requires_grad=True)
output = tensor([[1.],
[0.],
[0.],
[1.],
[1.]])
pre = tensor([[0.4428],
[0.3455],
[0.4402],
[0.7933],
[0.6809]], grad_fn=<SigmoidBackward>)
print(loss_bce)
tensor(0.4869, grad_fn=<BinaryCrossEntropyBackward>)
print(loss_bce_sig)
tensor(0.4869, grad_fn=<BinaryCrossEntropyWithLogitsBackward>)
-
4.6 Focal Loss
Focal loss最初是出现在目标检测领域,主要是为了解决正负样本比例失调的问题。那么对于分割任务来说,如果存在数据不均衡的情况,也可以借用focal loss来进行缓解。Focal loss函数公式如下所示:
-$$
loss = -\frac{1}{N} \sum_{i=1}^{N}\left(\alpha y_{i}\left(1-p_{i}\right)^{\gamma} \log p_{i}+(1-\alpha)\left(1-y_{i}\right) p_{i}^{\gamma} \log \left(1-p_{i}\right)\right)
$$
仔细观察就不难发现,它其实是BCE扩展而来,对比BCE其实就多了个
$$
\alpha(1-p_{i})^{\gamma}和(1-\alpha)p_{i}^{\gamma}
$$
为什么多了这个就能缓解正负样本不均衡的问题呢?见下图:
+仔细观察就不难发现,它其实是BCE扩展而来,对比BCE其实就多了个
+为什么多了这个就能缓解正负样本不均衡的问题呢?见下图:

简单来说:$α$解决样本不平衡问题,$γ$解决样本难易问题。
也就是说,当数据不均衡时,可以根据比例设置合适的$α$,这个很好理解,为了能够使得正负样本得到的损失能够均衡,因此对loss前面加上一定的权重,其中负样本数量多,因此占用的权重可以设置的小一点;正样本数量少,就对正样本产生的损失的权重设的高一点。
那γ具体怎么起作用呢?以图中$γ=5$曲线为例,假设$gt$类别为1,当模型预测结果为1的概率$p_t$比较大时,我们认为模型预测的比较准确,也就是说这个样本比较简单。而对于比较简单的样本,我们希望提供的loss小一些而让模型主要学习难一些的样本,也就是$p_t→ 1$则loss接近于0,既不用再特别学习;当分类错误时,$p_t → 0$则loss正常产生,继续学习。对比图中蓝色和绿色曲线,可以看到,γ值越大,当模型预测结果比较准确的时候能提供更小的loss,符合我们为简单样本降低loss的预期。
代码实现:
import torch.nn as nn
import torch
import torch.nn.functional as F
class FocalLoss(nn.Module):
def __init__(self, alpha=1, gamma=2, logits=False, reduce=True):
super(FocalLoss, self).__init__()
self.alpha = alpha
self.gamma = gamma
self.logits = logits # 如果BEC带logits则损失函数在计算BECloss之前会自动计算softmax/sigmoid将其映射到[0,1]
self.reduce = reduce
def forward(self, inputs, targets):
if self.logits:
BCE_loss = F.binary_cross_entropy_with_logits(inputs, targets, reduce=False)
else:
BCE_loss = F.binary_cross_entropy(inputs, targets, reduce=False)
pt = torch.exp(-BCE_loss)
F_loss = self.alpha * (1-pt)**self.gamma * BCE_loss
if self.reduce:
return torch.mean(F_loss)
else:
return F_loss
# ------------------------
FL1 = FocalLoss(logits=False)
FL2 = FocalLoss(logits=True)
inputs = torch.randn(5, 1, requires_grad=True)
targets = torch.empty(5, 1).random_(2)
pre = nn.Sigmoid()(inputs)
f_loss_1 = FL1(pre, targets)
f_loss_2 = FL2(inputs, targets)
# ------------------------
print('inputs:', inputs)
inputs: tensor([[-1.3521],
[ 0.4975],
[-1.0178],
[-0.3859],
[-0.2923]], requires_grad=True)
print('targets:', targets)
targets: tensor([[1.],
[1.],
[0.],
[1.],
[1.]])
print('pre:', pre)
pre: tensor([[0.2055],
[0.6219],
[0.2655],
[0.4047],
[0.4274]], grad_fn=<SigmoidBackward>)
print('f_loss_1:', f_loss_1)
f_loss_1: tensor(0.3375, grad_fn=<MeanBackward0>)
print('f_loss_2', f_loss_2)
f_loss_2 tensor(0.3375, grad_fn=<MeanBackward0>)
-
4.7 Lovász-Softmax
IoU是评价分割模型分割结果质量的重要指标,因此很自然想到能否用$1-IoU$(即Jaccard loss)来做损失函数,但是它是一个离散的loss,不能直接求导,所以无法直接用来作为损失函数。为了克服这个离散的问题,可以采用lLovász extension将离散的Jaccard loss 变得连续,从而可以直接求导,使得其作为分割网络的loss function。Lovász-Softmax相比于交叉熵函数具有更好的效果。
论文地址:
paper on CVF open access
arxiv paper
首先明确定义,在语义分割任务中,给定真实像素标签向量$\pmb{y^*}$和预测像素标签$\pmb{\hat{y} }$,则所属类别$c$的IoU(也称为Jaccard index)如下,其取值范围为$[0,1]$,并规定$0/0=1$:
-$$J_c(\pmb{y^*},\pmb{\hat{y} })=\frac{|{\pmb{y^*}=c} \cap {\pmb{\hat{y} }=c}|}{|{\pmb{y^*}=c} \cup {\pmb{\hat{y} }=c}|}
$$
-则Jaccard loss为:
$$\Delta_{J_c}(\pmb{y^*},\pmb{\hat{y} }) =1-J_c(\pmb{y^*},\pmb{\hat{y} })
$$
-针对类别$c$,所有未被正确预测的像素集合定义为:
-$$
M_c(\pmb{y^*},\pmb{\hat{y} })={ \pmb{y^*}=c, \pmb{\hat{y} } \neq c} \cup { \pmb{y^*}\neq c, \pmb{\hat{y} } = c }
$$
-则可将Jaccard loss改写为关于$M_c$的子模集合函数(submodular set functions):
$$\Delta_{J_c}:M_c \in {0,1}^{p} \mapsto \frac{|M_c|}{|{\pmb{y^*}=c}\cup M_c|}
$$
-方便理解,此处可以把${0,1}^p$理解成如图像mask展开成离散一维向量的形式。
-Lovász extension可以求解子模最小化问题,并且子模的Lovász extension是凸函数,可以高效实现最小化。在论文中作者对$\Delta$(集合函数)和$\overline{\Delta}$(集合函数的Lovász extension)进行了定义,为不涉及过多概念以方便理解,此处不再过多讨论。我们可以将$\overline{\Delta}$理解为一个线性插值函数,可以将${0,1}^p$这种离散向量连续化,主要是为了方便后续反向传播、求梯度等等。因此我们可以通过这个线性插值函数得到$\Delta_{J_c}$的Lovász extension$\overline{\Delta_{J_c} }$。
-在具有$c(c>2)$个类别的语义分割任务中,我们使用Softmax函数将模型的输出映射到概率分布形式,类似传统交叉熵损失函数所进行的操作:
$$p_i(c)=\frac{e^{F_i(c)} }{\sum_{c^{‘}\in C}e^{F_i(c^{‘})} } \forall i \in [1,p],\forall c \in C
$$
式中,$p_i(c)$表示了像素$i$所属类别$c$的概率。通过上式可以构建每个像素产生的误差$m(c)$:
-$$m_i(c)=\left {
\begin{array}{c}
1-p_i(c),\ \ if \ \ c=y^{*}_{i} \
p_i(c),\ \ \ \ \ \ \ otherwise
\end{array}
\right.
$$
-可知,对于一张图像中所有像素则误差向量为$m(c)\in {0, 1}^p$,则可以建立关于$\Delta_{J_c}$的代理损失函数:
$$
loss(p(c))=\overline{\Delta_{J_c} }(m(c))
$$
当我们考虑整个数据集是,一般会使用mIoU进行度量,因此我们对上述损失也进行平均化处理,则定义的Lovász-Softmax损失函数为:
$$
loss(\pmb{p})=\frac{1}{|C|}\sum_{c\in C}\overline{\Delta_{J_c} }(m(c))
$$
-代码实现
+则Jaccard loss为:
+针对类别$c$,所有未被正确预测的像素集合定义为:
+则可将Jaccard loss改写为关于$M_c$的子模集合函数(submodular set functions):
+方便理解,此处可以把${0,1}^p$理解成如图像mask展开成离散一维向量的形式。
+Lovász extension可以求解子模最小化问题,并且子模的Lovász extension是凸函数,可以高效实现最小化。在论文中作者对$\Delta$(集合函数)和$\overline{\Delta}$(集合函数的Lovász extension)进行了定义,为不涉及过多概念以方便理解,此处不再过多讨论。我们可以将$\overline{\Delta}$理解为一个线性插值函数,可以将${0,1}^p$这种离散向量连续化,主要是为了方便后续反向传播、求梯度等等。因此我们可以通过这个线性插值函数得到$\Delta{J_c}$的Lovász extension$\overline{\Delta{J_c} }$。
+在具有$c(c>2)$个类别的语义分割任务中,我们使用Softmax函数将模型的输出映射到概率分布形式,类似传统交叉熵损失函数所进行的操作:
+式中,$p_i(c)$表示了像素$i$所属类别$c$的概率。通过上式可以构建每个像素产生的误差$m(c)$:
+可知,对于一张图像中所有像素则误差向量为$m(c)\in {0, 1}^p$,则可以建立关于$\Delta_{J_c}$的代理损失函数:
+当我们考虑整个数据集是,一般会使用mIoU进行度量,因此我们对上述损失也进行平均化处理,则定义的Lovász-Softmax损失函数为:
+代码实现
论文作者已经给出了Lovász-Softmax实现代码,并且有pytorch和tensorflow两种版本,并提供了使用demo。此处将针对多分类任务的Lovász-Softmax源码进行展示。
import torch
from torch.autograd import Variable
import torch.nn.functional as F
import numpy as np
try:
from itertools import ifilterfalse
except ImportError: # py3k
from itertools import filterfalse as ifilterfalse
# --------------------------- MULTICLASS LOSSES ---------------------------
def lovasz_softmax(probas, labels, classes='present', per_image=False, ignore=None):
"""
Multi-class Lovasz-Softmax loss
probas: [B, C, H, W] Variable, class probabilities at each prediction (between 0 and 1).
Interpreted as binary (sigmoid) output with outputs of size [B, H, W].
labels: [B, H, W] Tensor, ground truth labels (between 0 and C - 1)
classes: 'all' for all, 'present' for classes present in labels, or a list of classes to average.
per_image: compute the loss per image instead of per batch
ignore: void class labels
"""
if per_image:
loss = mean(lovasz_softmax_flat(*flatten_probas(prob.unsqueeze(0), lab.unsqueeze(0), ignore), classes=classes)
for prob, lab in zip(probas, labels))
else:
loss = lovasz_softmax_flat(*flatten_probas(probas, labels, ignore), classes=classes)
return loss
def lovasz_softmax_flat(probas, labels, classes='present'):
"""
Multi-class Lovasz-Softmax loss
probas: [P, C] Variable, class probabilities at each prediction (between 0 and 1)
labels: [P] Tensor, ground truth labels (between 0 and C - 1)
classes: 'all' for all, 'present' for classes present in labels, or a list of classes to average.
"""
if probas.numel() == 0:
# only void pixels, the gradients should be 0
return probas * 0.
C = probas.size(1)
losses = []
class_to_sum = list(range(C)) if classes in ['all', 'present'] else classes
for c in class_to_sum:
fg = (labels == c).float() # foreground for class c
if (classes is 'present' and fg.sum() == 0):
continue
if C == 1:
if len(classes) > 1:
raise ValueError('Sigmoid output possible only with 1 class')
class_pred = probas[:, 0]
else:
class_pred = probas[:, c]
errors = (Variable(fg) - class_pred).abs()
errors_sorted, perm = torch.sort(errors, 0, descending=True)
perm = perm.data
fg_sorted = fg[perm]
losses.append(torch.dot(errors_sorted, Variable(lovasz_grad(fg_sorted))))
return mean(losses)
def flatten_probas(probas, labels, ignore=None):
"""
Flattens predictions in the batch
"""
if probas.dim() == 3:
# assumes output of a sigmoid layer
B, H, W = probas.size()
probas = probas.view(B, 1, H, W)
B, C, H, W = probas.size()
probas = probas.permute(0, 2, 3, 1).contiguous().view(-1, C) # B * H * W, C = P, C
labels = labels.view(-1)
if ignore is None:
return probas, labels
valid = (labels != ignore)
vprobas = probas[valid.nonzero().squeeze()]
vlabels = labels[valid]
return vprobas, vlabels
def xloss(logits, labels, ignore=None):
"""
Cross entropy loss
"""
return F.cross_entropy(logits, Variable(labels), ignore_index=255)
# --------------------------- HELPER FUNCTIONS ---------------------------
def isnan(x):
return x != x
def mean(l, ignore_nan=False, empty=0):
"""
nanmean compatible with generators.
"""
l = iter(l)
if ignore_nan:
l = ifilterfalse(isnan, l)
try:
n = 1
acc = next(l)
except StopIteration:
if empty == 'raise':
raise ValueError('Empty mean')
return empty
for n, v in enumerate(l, 2):
acc += v
if n == 1:
return acc
return acc / n
-
4.8 参考链接
What is “Dice loss” for image segmentation?
@@ -638,7 +693,7 @@
- 编译原理
+ 数据库系统
-
diff --git "a/2021/02/24/docker\345\256\211\350\243\205\345\222\214\347\256\200\346\230\223\345\216\237\347\220\206/index.html" "b/2021/02/24/docker\345\256\211\350\243\205\345\222\214\347\256\200\346\230\223\345\216\237\347\220\206/index.html"
index cafca1dc..2eb9ac32 100644
--- "a/2021/02/24/docker\345\256\211\350\243\205\345\222\214\347\256\200\346\230\223\345\216\237\347\220\206/index.html"
+++ "b/2021/02/24/docker\345\256\211\350\243\205\345\222\214\347\256\200\346\230\223\345\216\237\347\220\206/index.html"
@@ -222,14 +222,11 @@
docker安装和简易原理
最近参加了阿里云datawhale天池的一个比赛里面需要用docker进行提交,所以借此机会学习了一下docker,b站上有个很好的视频【狂神说Java】Docker最新超详细版教程通俗易懂
docker基本组成

-

docker安装
centos7安装
先查看centos版本,新版本的docker都只支持centos7以上
(base) [root@iZuf69rye0flkbn4kbxrobZ ~]# cat /etc/os-release
NAME="CentOS Linux"
VERSION="7 (Core)"
ID="centos"
ID_LIKE="rhel fedora"
VERSION_ID="7"
PRETTY_NAME="CentOS Linux 7 (Core)"
ANSI_COLOR="0;31"
CPE_NAME="cpe:/o:centos:centos:7"
HOME_URL="https://www.centos.org/"
BUG_REPORT_URL="https://bugs.centos.org/"
CENTOS_MANTISBT_PROJECT="CentOS-7"
CENTOS_MANTISBT_PROJECT_VERSION="7"
REDHAT_SUPPORT_PRODUCT="centos"
REDHAT_SUPPORT_PRODUCT_VERSION="7"
-
然后我们的操作均按照帮助文档进行操作即可
dockerCentos安装
# 卸载旧版本
sudo yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
# 安装
sudo yum install -y yum-utils
#配置镜像,官方是国外的很慢,这里我们使用阿里云镜像
sudo yum-config-manager \
--add-repo \
https://download.docker.com/linux/centos/docker-ce.repo
# 推荐使用这个
sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
#更新yum
yum makecache fast
# 安装相关的包
sudo yum install docker-ce docker-ce-cli containerd.io
-
Start Docker
sudo systemctl start docker
使用docker version查看是否安装成功

sudo docker run hello-world
使用docker images 查看所安装的所有镜像

@@ -237,10 +234,8 @@
sudo yum remove docker-ce docker-ce-cli containerd.io
2.删除默认工作目录和资源
$ sudo rm -rf /var/lib/docker
-
阿里云镜像加速器
这一块的话推荐天池的一个docker学习赛
登录阿里云找到容器服务,并创建新容器,然后找到里面的镜像加速器对centos进行配置。

sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://fdm7vcvf.mirror.aliyuncs.com"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
-
回归Hello World镜像的运行过程

底层原理
Docker是什么工作的?
Docker是一个Client - Server结构的系统,Docker的守护进行运行在主机上。通过Socket从客户端访问!DockerServer接收到Docker-Client的指令,就会执行这个命令!

docker为什么比虚拟机快?
参考链接


@@ -548,7 +543,7 @@
- 编译原理
+ 数据库系统
-
diff --git "a/2021/02/24/docker\345\270\270\347\224\250\345\221\275\344\273\244/index.html" "b/2021/02/24/docker\345\270\270\347\224\250\345\221\275\344\273\244/index.html"
index de6f2e8b..1eef5075 100644
--- "a/2021/02/24/docker\345\270\270\347\224\250\345\221\275\344\273\244/index.html"
+++ "b/2021/02/24/docker\345\270\270\347\224\250\345\221\275\344\273\244/index.html"
@@ -8,12 +8,12 @@
docker常用命令 | khan's blog
-
+
-
+
@@ -232,65 +232,61 @@
Docker 常用命令
帮助命令
docker version #显示docker版本信息
docker info #显示docker的系统信息,包括镜像和容器的数量
docker 命令 --help # 帮助命令
-
镜像命令
1.docker images查看所有本地的主机镜像
+
-docker images显示字段
-解释
+docker images显示字段
+解释
-
-REPOSITORY
-镜像的仓库源
+
+
+REPOSITORY
+镜像的仓库源
-TAG
-镜像的标签
+TAG
+镜像的标签
-IMAGE ID
-镜像的id
+IMAGE ID
+镜像的id
-CREATED
-镜像的创建时间
+CREATED
+镜像的创建时间
-SIZE
-镜像的大小
+SIZE
+镜像的大小
-
+
+
+
(base) [root@iZuf69rye0flkbn4kbxrobZ ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
hello-world latest bf756fb1ae65 13 months ago 13.3kB
(base) [root@iZuf69rye0flkbn4kbxrobZ ~]# docker images --help
Usage: docker images [OPTIONS] [REPOSITORY[:TAG]]
List images
Options:
-a, --all Show all images
-q, --quiet Only show image IDs
-

2.docker search命令搜索镜像
搜索镜像可以去docker hub网站上直接搜索,也可以通过命令行来搜索,通过万能帮助命令能更快的看到他的一些用法,这两种方法结果是一样的


我们也可以通过--filter来进行条件筛选
比如docker search mysql --filter=STARS=3000
(base) [root@iZuf69rye0flkbn4kbxrobZ ~]# docker search mysql --filter=STARS=3000
NAME DESCRIPTION STARS OFFICIAL AUTOMATED
mysql MySQL is a widely used, open-source relation… 10538 [OK]
mariadb MariaDB is a community-developed fork of MyS… 3935 [OK]
-
3.docker pull下载镜像
这个命令其实信息量很大,这也是docker高明的地方,关于指定版本下载一定要是docker hub官网上面支持和提供的版本

我这里使用了
docker pull mysql
docker pull mysql:5.7
-

4.docker rmi删除镜像
删除可以通过REPOSITORY来删,也可以通过IMAGE ID来删除

-容器命令
说明:我们有了镜像才可以创建容器,linux,下载一个centos镜像来测试学习
-docker pull centos
-1.新建容器并启动
通过docker run命令进入下载的centos容器里面后我们可以发现的是,我们的rootname不一样了


+容器命令
说明:我们有了镜像才可以创建容器,linux,下载一个centos镜像来测试学习
docker pull centos
1.新建容器并启动
通过docker run命令进入下载的centos容器里面后我们可以发现的是,我们的rootname不一样了
2.列出所有运行的容器
docker ps命令

3.exit退出命令
exit #直接容器停止并退出
Ctrl + P + Q #容器不停止并退出
在执行exit命令后,我们看到rootname又变回来了
4.删除容器
docker rm 容器id #删除指定的容器,不能删除正在运行的容器,如果要强制删除,需要使用 rm -f
docker rm $(docker ps -aq) #删除全部的容器
docker ps -a -q|xargs docker rm #删除全部容器
5.启动和停止容器
-日志元数据进程查看


1.docker top 容器id查看容器中的进程
+日志元数据进程查看
1.docker top 容器id查看容器中的进程

2.docker inspect 容器id查看元数据
3.进入当前正在运行的容器
-方式1: docker exec -it 容器id bashshell并可通过ps -ef查看容器当中的进程

+方式1: docker exec -it 容器id bashshell并可通过ps -ef查看容器当中的进程
方式2:docker attach 容器id进入容器,如果当前有正在执行的容器则会直接进入到当前正在执行的进程当中

-从容器内拷贝到主机上
即使容器已经停止也是可以进行拷贝的
-docker cp 容器id:容器内路径 目的主机路径
-
+从容器内拷贝到主机上
即使容器已经停止也是可以进行拷贝的
docker cp 容器id:容器内路径 目的主机路径
docker部署nginx
$ docker search nginx
$ docker pull nginx
$ docker run -d --name nginx01 -p 8083:80 nginx
$ docker ps
$ curl localhost:8083
docker stop 后则无法再访问



portainer可视化管理
docker run -d -p 8088:9000 --restart=always -v /var/run/docker.sock:/var/run/docker.sock --privileged=true portainer/portainer
@@ -599,7 +595,7 @@
- 编译原理
+ 数据库系统
-
diff --git "a/2021/02/25/docker\351\225\234\345\203\217\346\223\215\344\275\234/index.html" "b/2021/02/25/docker\351\225\234\345\203\217\346\223\215\344\275\234/index.html"
index 01a014c4..71b553fa 100644
--- "a/2021/02/25/docker\351\225\234\345\203\217\346\223\215\344\275\234/index.html"
+++ "b/2021/02/25/docker\351\225\234\345\203\217\346\223\215\344\275\234/index.html"
@@ -8,12 +8,12 @@
docker镜像操作 | khan's blog
-
+
-
+
@@ -233,41 +233,35 @@
commit镜像

-数据卷操作实战:mysql同步
mysql运行容器,需要做数据挂载,安装启动mysql是需要配置密码的这一点要注意,所以要去docker hub官方文档上面去看官方配置
-docker pull mysql:5.7
-
+数据卷操作实战:mysql同步
mysql运行容器,需要做数据挂载,安装启动mysql是需要配置密码的这一点要注意,所以要去docker hub官方文档上面去看官方配置
docker pull mysql:5.7
docker运行,docker run的常用参数这里我们再次回顾一下
-d 后台运行
-p 端口映射
-v 卷挂载
-e 环境配置
--name 环境名字
-
通过docker hub我们找到了官方的命令:docker run --name some-mysql -e MYSQL_ROOT_PASSWORD=my-secret-pw -d mysql:tag,在修改一下得到我们最终的输入命令
docker run -d -p 3310:3306 -v /home/mysql/conf:/etc/mysql/conf.d -v /home/mysql/data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=12345678 --name mysql01 mysql:5.7
-
CREATE DATABASE test_db;
-


删除这个镜像后数据则依旧保存下来了

具名/匿名挂载



大多数情况下,为了方便,我们会使用具名挂载

Dockerfile
Dockerfile就是用来构建docker镜像的文件,命令脚本,通过这个脚本可以生成镜像。
构建步骤
-编写一个Dockerfile
-docker build 构建成为一个镜像
-docker run 运行镜像
-- 编写一个Dockerfile
+- docker build 构建成为一个镜像
+- docker run 运行镜像
docker push 发布镜像(DockerHub,阿里云镜像)
这里我们可以先看看Docker Hub官方是怎么做的


官方镜像是比较基础的,有很多命令和功能都省去了,所以我们通常需要在基础的镜像上来构建我们自己的镜像

-Dockerfile命令
+Dockerfile命令
+
常用命令
用法
-
+
+
FROM
基础镜像,一切从这开始构建
@@ -311,7 +305,9 @@
创建一个自己的centos
Dockerfile中99%的镜像都来自于这个scratch镜像,然后配置需要的软件和配置来进行构建。
mkdir dockerfile
cd dockerfile
vim mydockerfile-centos
@@ -319,13 +315,9 @@
FROM centos
MAINTAINER khan<khany@foxmail.com>
ENV MYPATH /usr/local
WORKDIR $MYPATH
RUN yum -y install vim
RUN yum -y install net-tools
EXPOSE 80
CMD echo $MYPATH
CMD echo "---end---"
CMD /bin/bash
然后我们进入docker build,注意后面一定要有一个.号
docker build -f mydockerfile-centos -t mycentos:1.0 .
-然后我们通过docker run -it mycentos:1.0 命令进入我们自己创建的镜像测试运行我们新安装的包和命令是否能正常运行。

我们可以通过 docker history +容器名称/容器id看到这个容器的构建过程。

+然后我们通过docker run -it mycentos:1.0命令进入我们自己创建的镜像测试运行我们新安装的包和命令是否能正常运行。
我们可以通过 docker history +容器名称/容器id看到这个容器的构建过程。
CMD和ENTRYPOINT区别

-dockerfile-cmd-test:
-FROM centos
CMD ["ls","-a"]
-dockerfile-entrypoint-test:
-FROM centos
ENTRYPOINT ["ls","-a"]
-执行命令 docker run 容器名称 -l在CMD下会报错,命令会被后面追加的-l替代,而-l并不是有效的linux命令,所以报错,而ENTRYPOINT则是可以追加的则该命令会变为ls -al

+dockerfile-cmd-test:
FROM centos
CMD ["ls","-a"]
dockerfile-entrypoint-test:
FROM centos
ENTRYPOINT ["ls","-a"]
执行命令docker run 容器名称 -l在CMD下会报错,命令会被后面追加的-l替代,而-l并不是有效的linux命令,所以报错,而ENTRYPOINT则是可以追加的则该命令会变为ls -al
发布镜像
发布到Docker Hub
@@ -333,9 +325,8 @@ https://hub.docker.com/ 注册自己的账号
- 确定这个账号可以登录
- 在我们服务器上提交自己的镜像
-- 登录成功,通过
push命令提交镜像,记得注意添加版本号

这里出了一点小问题:
+- 登录成功,通过
push命令提交镜像,记得注意添加版本号
这里出了一点小问题:
在build自己的镜像的时候添加tag时必须在前面加上自己的dockerhub的username,然后再push就可以了

-在build自己的镜像的时候添加tag时必须在前面加上自己的dockerhub的username,然后再push就可以了
docker tag 镜像id YOUR_DOCKERHUB_NAME/firstimage
docker push YOUR_DOCKERHUB_NAME/firstimage

提交成功,可以在docker hub上找到你提交的镜像

@@ -344,7 +335,7 @@
Docker镜像操作过程总结


-
+
@@ -650,7 +641,7 @@
- 编译原理
+ 数据库系统
简介
人脸检测和脸部校准任务对于很多面部任务和应用来说都是十分重要的,比如说人脸识别,人脸表情分析。不过在现实生活当中,面部特征时常会因为一些遮挡物,强烈的光照对比,复杂的姿势发生很大的变化,这使得这些任务变得具有很大挑战性。Viola和Jones 提出的级联人脸检测器利用Haar特征和AdaBoost训练级联分类器,实现了具有实时效率的良好性能。 然而,也有相当一部分的工作表明,这种分类器可能在现实生活的应用中效果显着降低,即使具有更高级的特征和分类器。,之后人们又提出了DPM的方式,这些年来基于CNN的一些解决方案也层出不穷,基于CNN的方案主要是为了识别出面部的一些特征来实现。作者认为这种方式其实是需要花费更多的时间来对面部进行校准来训练同时还忽略了面部的重要特征点位置和边框问题。
对于人脸校准的话目前也有大致的两个方向:一个是基于回归的方法还有一个就是基于模板拟合的方式进行,主要是对特征识别起到一个辅助的工作。
作者认为关于人脸识别和面部对准这两个任务其实是有内在关联的,而目前大多数的方法则忽略了这一点,所以本文所提出的方案就是将这两者都结合起来,构建出一个三阶段的模型实现一个端到端的人脸检测并校准面部特征点的过程。
第一阶段:通过浅层CNN快速生成候选窗口。
第二阶段:通过more complex的CNN拒绝大量非面部窗口来细化窗口。
第三阶段:使用more powerful的CNN再次细化结果并输出五个面部标志位置。
-方法
Image pyramid图像金字塔
在进入stage-1之前,作者先构建了一组多尺度的图像金字塔缩放,这一块要理解起来还是有一点费力的,这里我们需要了解的是在训练网络的过程当中,作者都是把WIDER FACE的图片随机剪切成12x12size的大小进行单尺度训练的,不能满足任意大小的人脸检测,所以为了检测到不同尺寸的人脸,所以在推理时需要先生成图像金字塔生成一组不同scale的图像输入P-net进行来实现人脸的检测,同时也这是为什么P-net要使用FCN的原因。

-def calculateScales(img):
min_face_size = 20 # 最小的人脸尺寸
width, height = img.size
min_length = min(height, width)
min_detection_size = 12
factor = 0.707 # sqrt(0.5)
scales = []
m = min_detection_size / min_face_size
min_length *= m
factor_count = 0
# 图像尺寸缩小到不大于min_detection_size
while min_length > min_detection_size:
scales.append(m * factor ** factor_count)
min_length *= factor
factor_count += 1
-$$\text{length} =\text{length} \times (\frac{\text{min detection size}}{\text{min face size}} )\times factor^{count} $$
$\text{here we define in our code:} factor=\frac{1}{\sqrt{2}}, \text{min face size}=20,\text{min detection size}=12$
+方法
Image pyramid图像金字塔
在进入stage-1之前,作者先构建了一组多尺度的图像金字塔缩放,这一块要理解起来还是有一点费力的,这里我们需要了解的是在训练网络的过程当中,作者都是把WIDER FACE的图片随机剪切成12x12size的大小进行单尺度训练的,不能满足任意大小的人脸检测,所以为了检测到不同尺寸的人脸,所以在推理时需要先生成图像金字塔生成一组不同scale的图像输入P-net进行来实现人脸的检测,同时也这是为什么P-net要使用FCN的原因。
def calculateScales(img):
min_face_size = 20 # 最小的人脸尺寸
width, height = img.size
min_length = min(height, width)
min_detection_size = 12
factor = 0.707 # sqrt(0.5)
scales = []
m = min_detection_size / min_face_size
min_length *= m
factor_count = 0
# 图像尺寸缩小到不大于min_detection_size
while min_length > min_detection_size:
scales.append(m * factor ** factor_count)
min_length *= factor
factor_count += 1
+$\text{here we define in our code:} factor=\frac{1}{\sqrt{2}}, \text{min face size}=20,\text{min detection size}=12$
min_face_size和factor对推理过程会产生什么样的影响?
min_face_size越大,factor越小,图像最短边就越快缩放到接近min_detect_size,从而生成图像金字塔的耗时就越短,同时各尺度的跨度也更大。因此,加大min_face_size、减小factor能加速图像金字塔的生成,但同时也更易造成漏检。
Stage 1 P-Net(Proposal Network)
这是一个全卷积网络,也就是说这个网络可以兼容任意大小的输入,他的整个网络其实十分简单,该层的作用主要是为了获得人脸检测的大量候选框,这一层我们最大的作用就是要尽可能的提升recall,然后在获得许多候选框后再使用非极大抑制的方法合并高度重叠的候选区域。

P-Net的示意图当中我们也可以看到的是作者输入12x12大小最终的output为一个1x1x2的face label classification概率和一个1x1x4的boudingbox(左上角和右下角的坐标)以及一个1x1x10的landmark(双眼,鼻子,左右嘴角的坐标)
注意虽然这里作者举例是12x12的图片大小,但是他的意思并不是说这个P-Net的图片输入大小必须是12,我们可以知道这个网络是FCN,这就意味着不同输入的大小都是可以输入其中的,最后我们所得到的featuremap$[m \times n \times (2+4+10) ]$每一个小像素点映射到输入图像所在的12x12区域是否包含人脸的分类结果,候选框左上和右下基准点以及landmark,然后根据图像金字塔的我们再根据scale和resize的逆过程将其映射到原图像上
-P-net structure
-class P_Net(nn.Module):
def __init__(self):
super(P_Net, self).__init__()
self.pre_layer = nn.Sequential(
# 12x12x3
nn.Conv2d(3, 10, kernel_size=3, stride=1), # conv1
nn.PReLU(), # PReLU1
# 10x10x10
nn.MaxPool2d(kernel_size=2, stride=2), # pool1
# 5x5x10
nn.Conv2d(10, 16, kernel_size=3, stride=1), # conv2
# 3x3x16
nn.PReLU(), # PReLU2
nn.Conv2d(16, 32, kernel_size=3, stride=1), # conv3
# 1x1x32
nn.PReLU() # PReLU3
)
# detection
self.conv4_1 = nn.Conv2d(32, 1, kernel_size=1, stride=1)
# bounding box regresion
self.conv4_2 = nn.Conv2d(32, 4, kernel_size=1, stride=1)
# landmark localization
self.conv4_3 = nn.Conv2d(32, 10, kernel_size=1, stride=1)
# weight initiation with xavier
self.apply(weights_init)
def forward(self, x):
x = self.pre_layer(x)
det = torch.sigmoid(self.conv4_1(x))
box = self.conv4_2(x)
landmark = self.conv4_3(x)
# det:[,2,1,1], box:[,4,1,1], landmark:[,10,1,1]
return det, box, landmark
-这里要提一下nn.PReLU(),有点类似Leaky ReLU,可以看下面的博客深入了解一下

+P-net structure
class P_Net(nn.Module):
def __init__(self):
super(P_Net, self).__init__()
self.pre_layer = nn.Sequential(
# 12x12x3
nn.Conv2d(3, 10, kernel_size=3, stride=1), # conv1
nn.PReLU(), # PReLU1
# 10x10x10
nn.MaxPool2d(kernel_size=2, stride=2), # pool1
# 5x5x10
nn.Conv2d(10, 16, kernel_size=3, stride=1), # conv2
# 3x3x16
nn.PReLU(), # PReLU2
nn.Conv2d(16, 32, kernel_size=3, stride=1), # conv3
# 1x1x32
nn.PReLU() # PReLU3
)
# detection
self.conv4_1 = nn.Conv2d(32, 1, kernel_size=1, stride=1)
# bounding box regresion
self.conv4_2 = nn.Conv2d(32, 4, kernel_size=1, stride=1)
# landmark localization
self.conv4_3 = nn.Conv2d(32, 10, kernel_size=1, stride=1)
# weight initiation with xavier
self.apply(weights_init)
def forward(self, x):
x = self.pre_layer(x)
det = torch.sigmoid(self.conv4_1(x))
box = self.conv4_2(x)
landmark = self.conv4_3(x)
# det:[,2,1,1], box:[,4,1,1], landmark:[,10,1,1]
return det, box, landmark
这里要提一下nn.PReLU(),有点类似Leaky ReLU,可以看下面的博客深入了解一下
https://blog.csdn.net/qq_23304241/article/details/80300149
https://blog.csdn.net/shuzfan/article/details/51345832
然后在P-Net之后我们通过非极大抑制的方法和将所有的boudingbox都修正为框的最长边为边长的正方形框,主要是避免后面的Rnet在resize的时候因为尺寸原因出现信息的损失。

-Non-Maximum Suppression非极大抑制
其实关于非极大抑制这个trick最初是在目标检测任务当中提出的来的,其思想是搜素局部最大值,抑制极大值,主要用在目标检测当中,最传统的非极大抑制所采用的评价指标就是交并比IoU(intersection-over-union)即两个groud truth和bounding box的交集部分除以它们的并集.

$$IoU = \frac{area(C) \cap area(G)}{area(C) \cup area(G)}$$
-def IoU(box, boxes):
"""Compute IoU between detect box and gt boxes
Parameters:
----------
box: numpy array , shape (5, ): x1, y1, x2, y2, score
input box
boxes: numpy array, shape (n, 4): x1, y1, x2, y2
input ground truth boxes
Returns:
-------
ovr: numpy.array, shape (n, )
IoU
"""
box_area = (box[2] - box[0] + 1) * (box[3] - box[1] + 1)
area = (boxes[:, 2] - boxes[:, 0] + 1) * (boxes[:, 3] - boxes[:, 1] + 1)
xx1 = np.maximum(box[0], boxes[:, 0])
xx2 = np.minimum(box[2], boxes[:, 2])
yy1 = np.maximum(box[1], boxes[:, 1])
yy2 = np.minimum(box[3], boxes[:, 3])
# compute the width and height of the bounding box
w = np.maximum(0, xx2 - xx1 + 1)
h = np.maximum(0, yy2 - yy1 + 1)
inter = w * h
ovr = np.true_divide(inter,(box_area + area - inter))
#ovr = inter / (box_area + area - inter)
return ovr
-
+Non-Maximum Suppression非极大抑制
其实关于非极大抑制这个trick最初是在目标检测任务当中提出的来的,其思想是搜素局部最大值,抑制极大值,主要用在目标检测当中,最传统的非极大抑制所采用的评价指标就是交并比IoU(intersection-over-union)即两个groud truth和bounding box的交集部分除以它们的并集.
+def IoU(box, boxes):
"""Compute IoU between detect box and gt boxes
Parameters:
----------
box: numpy array , shape (5, ): x1, y1, x2, y2, score
input box
boxes: numpy array, shape (n, 4): x1, y1, x2, y2
input ground truth boxes
Returns:
-------
ovr: numpy.array, shape (n, )
IoU
"""
box_area = (box[2] - box[0] + 1) * (box[3] - box[1] + 1)
area = (boxes[:, 2] - boxes[:, 0] + 1) * (boxes[:, 3] - boxes[:, 1] + 1)
xx1 = np.maximum(box[0], boxes[:, 0])
xx2 = np.minimum(box[2], boxes[:, 2])
yy1 = np.maximum(box[1], boxes[:, 1])
yy2 = np.minimum(box[3], boxes[:, 3])
# compute the width and height of the bounding box
w = np.maximum(0, xx2 - xx1 + 1)
h = np.maximum(0, yy2 - yy1 + 1)
inter = w * h
ovr = np.true_divide(inter,(box_area + area - inter))
#ovr = inter / (box_area + area - inter)
return ovr
使用非极大抑制的前提是,我们已经得到了一组候选框和对应label的置信分数,以及groud truth的信息,通过设定阈值来删除重合度较高的候选框。
算法流程如下:
- 根据置信度得分进行排序
@@ -257,27 +253,25 @@
def nms(dets,threshod,mode="Union"):
"""
greedily select boxes with high confidence
keep boxes overlap <= thresh
rule out overlap > thresh
:param dets: [[x1, y1, x2, y2 score]]
:param threshod: retain overlap <= thresh
:return: indexes to keep
"""
x1 = dets[:,0]
y1 = dets[;,1]
x2 = dets[:,2]
y2 = dets[:,3]
scores = dets[:,4]
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
order = areas.argsort()[::-1] # reverse
keep=[]
while order.size()>0:
i = order[0]
keep.append(i)
# A & B left top position
xx1 = np.maximun(x1[i],x1[order[1,:]])
yy1 = np.maximun(y1[i],y1[order[1,:]])
# A & B right down position
xx2 = np.minimum(x2[i],x2[order[1,:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
# cacaulate the IOU between box which have largest score with other boxes
if mode == "Union":
# area[i]: the area of largest score
ovr = inter / (areas[i] + areas[order[1:]] - inter)
elif mode == "Minimum":
ovr = inter / np.minimum(areas[i], areas[order[1:]])
# delete the IoU that higher than threshod
inds = np.where(ovr <= threshod)[0]
order = order[inds + 1] # +1: eliminates the first element in order
return keep
-边框修正
以最大边作为边长将矩形修正为正方形,同时包含的信息也更多,以免在后面resize输入下一个网络时减少信息的损失。
-def convert_to_square(bboxes):
"""
Convert bounding boxes to a square form.
"""
# 将矩形对称扩大为正方形
square_bboxes = np.zeros_like(bboxes)
x1, y1, x2, y2 = [bboxes[:, i] for i in range(4)]
h = y2 - y1 + 1.0
w = x2 - x1 + 1.0
max_side = np.maximum(h, w)
square_bboxes[:, 0] = x1 + w * 0.5 - max_side * 0.5
square_bboxes[:, 1] = y1 + h * 0.5 - max_side * 0.5
square_bboxes[:, 2] = square_bboxes[:, 0] + max_side - 1.0
square_bboxes[:, 3] = square_bboxes[:, 1] + max_side - 1.0
return square_bboxes
-
+边框修正
以最大边作为边长将矩形修正为正方形,同时包含的信息也更多,以免在后面resize输入下一个网络时减少信息的损失。
def convert_to_square(bboxes):
"""
Convert bounding boxes to a square form.
"""
# 将矩形对称扩大为正方形
square_bboxes = np.zeros_like(bboxes)
x1, y1, x2, y2 = [bboxes[:, i] for i in range(4)]
h = y2 - y1 + 1.0
w = x2 - x1 + 1.0
max_side = np.maximum(h, w)
square_bboxes[:, 0] = x1 + w * 0.5 - max_side * 0.5
square_bboxes[:, 1] = y1 + h * 0.5 - max_side * 0.5
square_bboxes[:, 2] = square_bboxes[:, 0] + max_side - 1.0
square_bboxes[:, 3] = square_bboxes[:, 1] + max_side - 1.0
return square_bboxes
Stage 2 R-Net(Refine Network)
R-net的输入是固定的,必须是24x24,所以对于P-net产生的大量boundingbox我们需要先进行resize然后再输入R-Net,在论文中我们了解到该网络层的作用主要是对大量的boundingbox进行有效过滤,获得更加精细的候选框。

-R-net structure
-class R_Net(nn.Module):
def __init__(self):
super(R_Net, self).__init__()
self.pre_layer = nn.Sequential(
# 24x24x3
nn.Conv2d(3, 28, kernel_size=3, stride=1), # conv1
nn.PReLU(), # prelu1
# 22x22x28
nn.MaxPool2d(kernel_size=3, stride=2), # pool1
# 10x10x28
nn.Conv2d(28, 48, kernel_size=3, stride=1), # conv2
nn.PReLU(), # prelu2
# 8x8x48
nn.MaxPool2d(kernel_size=3, stride=2), # pool2
# 3x3x48
nn.Conv2d(48, 64, kernel_size=2, stride=1), # conv3
# 2x2x64
nn.PReLU() # prelu3
)
# 2x2x64
self.conv4 = nn.Linear(64 * 2 * 2, 128) # conv4
# 128
self.prelu4 = nn.PReLU() # prelu4
# detection
self.conv5_1 = nn.Linear(128, 1)
# bounding box regression
self.conv5_2 = nn.Linear(128, 4)
# lanbmark localization
self.conv5_3 = nn.Linear(128, 10)
# weight initiation weih xavier
self.apply(weights_init)
def forward(self, x):
x = self.pre_layer(x)
x = x.view(x.size(0), -1)
x = self.conv4(x)
x = self.prelu4(x)
det = torch.sigmoid(self.conv5_1(x))
box = self.conv5_2(x)
landmark = self.conv5_3(x)
return det, box, landmark
-
+R-net structure
class R_Net(nn.Module):
def __init__(self):
super(R_Net, self).__init__()
self.pre_layer = nn.Sequential(
# 24x24x3
nn.Conv2d(3, 28, kernel_size=3, stride=1), # conv1
nn.PReLU(), # prelu1
# 22x22x28
nn.MaxPool2d(kernel_size=3, stride=2), # pool1
# 10x10x28
nn.Conv2d(28, 48, kernel_size=3, stride=1), # conv2
nn.PReLU(), # prelu2
# 8x8x48
nn.MaxPool2d(kernel_size=3, stride=2), # pool2
# 3x3x48
nn.Conv2d(48, 64, kernel_size=2, stride=1), # conv3
# 2x2x64
nn.PReLU() # prelu3
)
# 2x2x64
self.conv4 = nn.Linear(64 * 2 * 2, 128) # conv4
# 128
self.prelu4 = nn.PReLU() # prelu4
# detection
self.conv5_1 = nn.Linear(128, 1)
# bounding box regression
self.conv5_2 = nn.Linear(128, 4)
# lanbmark localization
self.conv5_3 = nn.Linear(128, 10)
# weight initiation weih xavier
self.apply(weights_init)
def forward(self, x):
x = self.pre_layer(x)
x = x.view(x.size(0), -1)
x = self.conv4(x)
x = self.prelu4(x)
det = torch.sigmoid(self.conv5_1(x))
box = self.conv5_2(x)
landmark = self.conv5_3(x)
return det, box, landmark
然后在P-Net之后我们通过非极大抑制的方法和将所有的boudingbox都修正为框的最长边为边长的正方形框,也是避免后面的Onet在resize的时候出现因为尺寸原因出现信息的损失。

-Stage 3 O-Net(Output?[作者未指出命名] Network)

Onet与Rnet工作流程类似。只不过输入的尺寸变成了48x48,对于R-net当中的框再次进行处理,得到的网络结构的输出则是最终的label classfication,boundingbox,landmark。
O-net structure
-class O_Net(nn.Module):
def __init__(self):
super(O_Net, self).__init__()
self.pre_layer = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, stride=1), # conv1
nn.PReLU(), # prelu1
nn.MaxPool2d(kernel_size=3, stride=2), # pool1
nn.Conv2d(32, 64, kernel_size=3, stride=1), # conv2
nn.PReLU(), # prelu2
nn.MaxPool2d(kernel_size=3, stride=2), # pool2
nn.Conv2d(64, 64, kernel_size=3, stride=1), # conv3
nn.PReLU(), # prelu3
nn.MaxPool2d(kernel_size=2, stride=2), # pool3
nn.Conv2d(64, 128, kernel_size=2, stride=1), # conv4
nn.PReLU() # prelu4
)
self.conv5 = nn.Linear(128 * 2 * 2, 256) # conv5
self.prelu5 = nn.PReLU() # prelu5
# detection
self.conv6_1 = nn.Linear(256, 1)
# bounding box regression
self.conv6_2 = nn.Linear(256, 4)
# lanbmark localization
self.conv6_3 = nn.Linear(256, 10)
# weight initiation weih xavier
self.apply(weights_init)
def forward(self, x):
x = self.pre_layer(x)
x = x.view(x.size(0), -1)
x = self.conv5(x)
x = self.prelu5(x)
# detection
det = torch.sigmoid(self.conv6_1(x))
box = self.conv6_2(x)
landmark = self.conv6_3(x)
return det, box, landmark
-
注意,其实在之前的两个网络当中我们也预测了landmark的位置,只是在论文的图示当中没有展示而已,从作者描述的网络结构图的输出当中是详细指出了landmarkposition的卷积块的
+Stage 3 O-Net(Output?[作者未指出命名] Network)
Onet与Rnet工作流程类似。只不过输入的尺寸变成了48x48,对于R-net当中的框再次进行处理,得到的网络结构的输出则是最终的label classfication,boundingbox,landmark。
O-net structure
class O_Net(nn.Module):
def __init__(self):
super(O_Net, self).__init__()
self.pre_layer = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, stride=1), # conv1
nn.PReLU(), # prelu1
nn.MaxPool2d(kernel_size=3, stride=2), # pool1
nn.Conv2d(32, 64, kernel_size=3, stride=1), # conv2
nn.PReLU(), # prelu2
nn.MaxPool2d(kernel_size=3, stride=2), # pool2
nn.Conv2d(64, 64, kernel_size=3, stride=1), # conv3
nn.PReLU(), # prelu3
nn.MaxPool2d(kernel_size=2, stride=2), # pool3
nn.Conv2d(64, 128, kernel_size=2, stride=1), # conv4
nn.PReLU() # prelu4
)
self.conv5 = nn.Linear(128 * 2 * 2, 256) # conv5
self.prelu5 = nn.PReLU() # prelu5
# detection
self.conv6_1 = nn.Linear(256, 1)
# bounding box regression
self.conv6_2 = nn.Linear(256, 4)
# lanbmark localization
self.conv6_3 = nn.Linear(256, 10)
# weight initiation weih xavier
self.apply(weights_init)
def forward(self, x):
x = self.pre_layer(x)
x = x.view(x.size(0), -1)
x = self.conv5(x)
x = self.prelu5(x)
# detection
det = torch.sigmoid(self.conv6_1(x))
box = self.conv6_2(x)
landmark = self.conv6_3(x)
return det, box, landmark
注意,其实在之前的两个网络当中我们也预测了landmark的位置,只是在论文的图示当中没有展示而已,从作者描述的网络结构图的输出当中是详细指出了landmarkposition的卷积块的
损失函数
在研究完网络结构以后我们可以来看看这个mtcnn模型的一个损失函数,作者将损失函数分为了3个部分:Face classification、Bounding box regression、Facial landmark localization。
-Face classification
对于第一部分的损失就是用的是最常用的交叉熵损失函数,就本质上来说人脸识别还是一个二分类问题,这里就使用Cross Entropy是最简单也是最合适的选择。
$$L_i^{det} = -(y_i^{det} \log(p_i) + (1-y_i^det)(1-\log(p_i)))$$
$p_i$是预测为face的可能性,$y_i^{det}$指的是真实标签也就是groud truth label
-Bounding box regression
对于目标边界框的损失来说,对于每一个候选框我们都需要对与他最接近的真实目标边界框进行比较,the bounding box$(left, top, height, and width)$
$$L_i^{box} = ||y_j^{box}-y_i^{box} ||_2^2$$
-Facial landmark localization
而对于boundingbox和landmark来说整个框的调整过程其实可以看作是一个连续的变化过程,固使用的是欧氏距离回归损失计算方法。比较的是各个点的坐标与真实面部关键点坐标的差异。
$$L_i^{landmark} = ||y_j^{landmark}-y_i^{landmark} ||_2^2$$
-total loss
最终我们得到的损失函数是有上述这三部分加权而成
$$\min{\sum_{i=1}^{N}{\sum_{j \in {det,box,landmark}} \alpha_j \beta_i^j L_i^j}}$$
其中$\alpha_j$表示权重,$\beta_i^j$表示第i个样本的类型,也可以说是第i个样本在任务j中是否需要贡献loss,如果不存在人脸即label为0时则无需计算loss。
对于不同的网络我们所设置的权重是不一样的
in P-net & R-net(在这两层我们更注重classification的识别)
$$alpha_{det}=1, alpha_{box}=0.5,alpha_{landmark}=0.5$$
in O-net(在这层我们提高了对于注意关键点的预测精度)
$$alpha_{det}=1, alpha_{box}=0.5,alpha_{landmark}=1 $$
文中也有提到,采用的是随机梯度下降优化器进行的训练。
+Face classification
对于第一部分的损失就是用的是最常用的交叉熵损失函数,就本质上来说人脸识别还是一个二分类问题,这里就使用Cross Entropy是最简单也是最合适的选择。
+$p_i$是预测为face的可能性,$y_i^{det}$指的是真实标签也就是groud truth label
+Bounding box regression
对于目标边界框的损失来说,对于每一个候选框我们都需要对与他最接近的真实目标边界框进行比较,the bounding box$(left, top, height, and width)$
+Facial landmark localization
而对于boundingbox和landmark来说整个框的调整过程其实可以看作是一个连续的变化过程,固使用的是欧氏距离回归损失计算方法。比较的是各个点的坐标与真实面部关键点坐标的差异。
+total loss
最终我们得到的损失函数是有上述这三部分加权而成
+其中$\alpha_j$表示权重,$\beta_i^j$表示第i个样本的类型,也可以说是第i个样本在任务j中是否需要贡献loss,如果不存在人脸即label为0时则无需计算loss。
对于不同的网络我们所设置的权重是不一样的
in P-net & R-net(在这两层我们更注重classification的识别)
+in O-net(在这层我们提高了对于注意关键点的预测精度)
+文中也有提到,采用的是随机梯度下降优化器进行的训练。
OHEM(Online Hard Example Mining)
作者对于困难样本的在线预测所做的trick也比较简单,就是挑选损失最大的前70%作为困难样本,在反向传播时仅使用这70%困难样本产生的损失,这样就剔除了很容易预测的easy sample对训练结果的影响,不过在我参考的这两个版本的代码里面似乎没有这么做。
实验
实验这块的话也比较充分,验证了每个修改部分对于实验结果的有效性验证,主要是讲述了实验过程对于训练数据集的处理和划分,验证了在线硬样本挖掘的有效性,联合检测和校准的有效性,分别评估了face detection和lanmark的贡献,面部检测评估,面部校准评估以及与SOTA的对比,这一块的话就没有细看了,分享的网站也有详细解释,论文原文也写了。


总结
这篇论文是中科院深圳先进技术研究院的乔宇老师团队所作,2016ECCV,看完这篇文章的话给我的感觉的话就是idea和实现过程包括实验都是很充分的,创新点这块的话主要是挖掘了人脸特征关键点和目标检测的一些联系,结合了人脸检测和对准两个任务来进行人脸检测,相比其他经典的目标检测网络如yolov3,R-CNN系列,在网络和损失函数上的创新确实略有不足,但是也让我收到了一些启发,看似几个简单的model和常见的loss联合,在对数据进行有效处理的基础上也是可以实现达到十分不错的效果的,不过这个方案的话在训练的时候其实是很花费时间的,毕竟需要对于不同scale的图片都进行输入训练,然后就是这种输入输出的结构其实还是存在一些局限性的,对于图像检测框和关键点的映射我个人觉得也比较繁杂或者说浪费了一些时间,毕竟是一篇2016年的论文之后应该会有更好的实现方式。
参考资料
-参考链接: https://zhuanlan.zhihu.com/p/337690783
参考链接:https://zhuanlan.zhihu.com/p/60199964?utm_source=qq&utm_medium=social&utm_oi=1221207556791963648
参考链接: https://blog.csdn.net/weixin_44791964/article/details/103530206
参考链接:https://blog.csdn.net/qq_34714751/article/details/85536669
参考链接:https://www.bilibili.com/video/BV1fJ411C7AJ?from=search&seid=2691296178499711503
+参考链接: https://zhuanlan.zhihu.com/p/337690783
参考链接:https://zhuanlan.zhihu.com/p/60199964?utm_source=qq&utm_medium=social&utm_oi=1221207556791963648
参考链接: https://blog.csdn.net/weixin_44791964/article/details/103530206
参考链接:https://blog.csdn.net/qq_34714751/article/details/85536669
参考链接:https://www.bilibili.com/video/BV1fJ411C7AJ?from=search&seid=2691296178499711503
@@ -583,7 +577,7 @@
- 编译原理
+ 数据库系统
-
diff --git "a/2021/04/22/yolov1-3\350\256\272\346\226\207\350\247\243\346\236\220/index.html" "b/2021/04/22/yolov1-3\350\256\272\346\226\207\350\247\243\346\236\220/index.html"
index d45d9593..c0ef5534 100644
--- "a/2021/04/22/yolov1-3\350\256\272\346\226\207\350\247\243\346\236\220/index.html"
+++ "b/2021/04/22/yolov1-3\350\256\272\346\226\207\350\247\243\346\236\220/index.html"
@@ -224,53 +224,102 @@
- yolov1-3论文解析
最近在看经典目标检测算法yolo的思想,为了更好的了解yolo系列的相关文章,我从最初版本的论文思想开始看的,之后有时间会把yolov4和yolov5再认真看看,目前来说yolov3的spp版本是使用得最为广泛的一种,整体上来说yolo的设计思想还是很有创造性的数学也比较严谨。
-
+ yolov1-3论文解析
最近在看经典目标检测算法yolo的思想,为了更好的了解yolo系列的相关文章,我从最初版本的论文思想开始看的,之后有时间会把yolov4和yolov5再认真看看,目前来说yolov3的spp版本是使用得最为广泛的一种,整体上来说yolo的设计思想还是很有创造性的数学也比较严谨。
yolov1论文思想
物体检测主流的算法框架大致分为one-stage与two-stage。two-stage算法代表有R-CNN系列,one-stage算法代表有Yolo系列。按笔者理解,two-stage算法将步骤一与步骤二分开执行,输入图像先经过候选框生成网络(例如faster rcnn中的RPN网络),再经过分类网络;one-stage算法将步骤一与步骤二同时执行,输入图像只经过一个网络,生成的结果中同时包含位置与类别信息。two-stage与one-stage相比,精度高,但是计算量更大,所以运算较慢。
We present YOLO, a new approach to object detection. Prior work on object detection repurposes classifiers to perform detection. Instead, we frame object detection as a regression problem to spatially separated bounding boxes and associated class probabilities.
yolo相比其他R-CNN等方法最大的一个不同就是他将这个识别和定位的过程转化成了一个空间定位并分类的回归问题,这也是他为什么能够利用网络进行端到端直接同时预测的重要原因。
yolo的特点
1.YOLO速度非常快。由于我们的检测是当做一个回归问题,不需要很复杂的流程。在测试的时候我们只需将一个新的图片输入网络来检测物体。
First, YOLO is extremely fast. Since we frame detection as a regression problem we don’t need a complex pipeline
2.Yolo会基于整张图片信息进行预测,与基于滑动窗口和候选区域的方法不同,在训练和测试期间YOLO可以看到整个图像,所以它隐式地记录了分类类别的上下文信息及它的全貌
Second, YOLO reasons globally about the image when making predictions Unlike sliding window and region proposal-based techniques, YOLO sees the entire image during training and test time so it implicitly encodes contextual information about classes as well as their appearance
3.第三,YOLO能学习到目标的泛化表征。作者尝试了用自然图片数据集进行训练,用艺术画作品进行预测,Yolo的检测效果更佳。
Third, YOLO learns generalizable representations of objects. Since YOLO is highly generalizable it is less likely to break down when applied to new domains or unexpected inputs
-backbone-darknet

yolov1这块的话,由于是比较早期的网络所以在设计时没有使用batchnormal,激活函数上采用leaky relu,输入图像大小为448x448,经过许多卷积层与池化层,变为7x7x1024张量,最后经过两层全连接层,输出张量维度为7x7x30。除了最后一层的输出使用了线性激活函数,其他层全部使用Leaky Relu激活函数。
$$\phi(x)= \begin{cases}
x,& \text{if x>0} \
0.1x,& \text{otherwise}
\end{cases}$$
-输出维度
yolov1最精髓的地方应该就是他的输出维度,论文当中有放出这样一张图片,看完以后我们能对yolo算法的特点有更加深刻的理解。在上图的backbone当中我们可以看到的是
 yolo的输出相当于把原图片分割成了$S \times S$个区域,然后对预测目标标定他的boundingbox,boundingbox由中心点的坐标,长宽以及物体的置信分数组成$x,y,w,h,confidence$,图中的$B$表示的是boundingbox的个数。置信分数在yolo当中是这样定义的:$Pr(Object)IOU_{pred}^{truth}$对于$Pr(Object)=1 \text{ if detect object else 0}$,其实置信分数就是boudingbox与groundtruth之间的IOU,并对每个小网格对应的$C$个类别都预测出他的条件概率:$Pr(Class_i|Object)$。
yolo的输出相当于把原图片分割成了$S \times S$个区域,然后对预测目标标定他的boundingbox,boundingbox由中心点的坐标,长宽以及物体的置信分数组成$x,y,w,h,confidence$,图中的$B$表示的是boundingbox的个数。置信分数在yolo当中是这样定义的:$Pr(Object)IOU_{pred}^{truth}$对于$Pr(Object)=1 \text{ if detect object else 0}$,其实置信分数就是boudingbox与groundtruth之间的IOU,并对每个小网格对应的$C$个类别都预测出他的条件概率:$Pr(Class_i|Object)$。
在推理时,我们可以得到当前网格对于每个类别的预测置信分数:$$Pr(Class_i)*IOU_{pred}^{truth} = Pr(Class_i|Object)*Pr(Object)*IOU_{pred}^{truth}$$
这样一种严谨的条件概率的方式得到我们的最终概率是十分可行和合适的。
YOLO imposes strong spatial constraints on bounding box predictions since each grid cell only predicts two boxes and can only have one class. This spatial constraint limits the number of nearby objects that our model can predict. Our model struggles with small objects that appear in groups, such as flocks of birds.
*不过在原论文当中也有提到的一点是:YOLO给边界框预测强加空间约束,因为每个网格单元只预测两个框和只能有一个类别。这个空间约束限制了我们的模型可以预测的邻近目标的数量。我们的模型难以预测群组中出现的小物体(比如鸟群)。**
+backbone-darknet
yolov1这块的话,由于是比较早期的网络所以在设计时没有使用batchnormal,激活函数上采用leaky relu,输入图像大小为448x448,经过许多卷积层与池化层,变为7x7x1024张量,最后经过两层全连接层,输出张量维度为7x7x30。除了最后一层的输出使用了线性激活函数,其他层全部使用Leaky Relu激活函数。
+输出维度
yolov1最精髓的地方应该就是他的输出维度,论文当中有放出这样一张图片,看完以后我们能对yolo算法的特点有更加深刻的理解。在上图的backbone当中我们可以看到的是
yolo的输出相当于把原图片分割成了$S \times S$个区域,然后对预测目标标定他的boundingbox,boundingbox由中心点的坐标,长宽以及物体的置信分数组成$x,y,w,h,confidence$,图中的$B$表示的是boundingbox的个数。置信分数在yolo当中是这样定义的:$Pr(Object)IOU_{pred}^{truth}$对于$Pr(Object)=1 \text{ if detect object else 0}$,其实置信分数就是boudingbox与groundtruth之间的IOU,并对每个小网格对应的$C$个类别都预测出他的条件概率:$Pr(Class_i|Object)$。
在推理时,我们可以得到当前网格对于每个类别的预测置信分数:$$Pr(Class_i)IOU{pred}^{truth} = Pr(Class_i|Object)Pr(Object)IOU{pred}^{truth}$$
这样一种严谨的条件概率的方式得到我们的最终概率是十分可行和合适的。
YOLO imposes strong spatial constraints on bounding box predictions since each grid cell only predicts two boxes and can only have one class. This spatial constraint limits the number of nearby objects that our model can predict. Our model struggles with small objects that appear in groups, such as flocks of birds.
不过在原论文当中也有提到的一点是:YOLO给边界框预测强加空间约束,因为每个网格单元只预测两个框和只能有一个类别。这个空间约束限制了我们的模型可以预测的邻近目标的数量。我们的模型难以预测群组中出现的小物体(比如鸟群)。
损失函数
在损失函数方面,由于公式比较长所以就直接截图过来了,损失函数的设计放方面作者也考虑的比较周全,

预测框的中心点$(x,y)$。预测框的宽高$w,h$,其中$\mathbb{1}_{i j}^{\text {obj }}$为控制函数,在标签中包含物体的那些格点处,该值为 1 ,若格点不含有物体,该值为 0
在计算损失函数的时候作者最开始使用的是最简单的平方损失函数来计算检测,因为它是计算简单且容易优化的,但是它并不完全符合我们最大化平均精度的目标,原因如下:
It weights localization error equally with classification error which may not be ideal.
1.它对定位错误的权重与分类错误的权重相等,这可能不是理想的选择。
Also, in every image many grid cells do not contain any object. This pushes the “confidence” scores of those cells towards zero, often overpowering the gradient from cells that do contain objects. This can lead to model instability, causing training to diverge early on.
而且,在每个图像中,许多网格单元不包含任何对象。这就把这些网格的置信度分数推到零,往往超过了包含对象的网格的梯度。2.这可能导致模型不稳定,导致训练早期发散难以训练。
-解决方案:增加边界框坐标预测的损失,并且减少了不包含对象的框的置信度预测的损失。我们使用两个参数来实现这一点。$\lambda_{coord}=5,\lambda_{noobj}=0.5$,其实这也是yolo面临的一个样本数目不均衡的典型例子。主要目的是让含有物体的格点,在损失函数中的权重更大,让模型更加注重含有物体的格点所造成的损失。
我们的损失函数则只会对那些有真实物体所属的格点进行损失计算,若该格点不包含物体,那么预测数值不对损失函数造成影响。
+解决方案:增加边界框坐标预测的损失,并且减少了不包含对象的框的置信度预测的损失。我们使用两个参数来实现这一点。$\lambda{coord}=5,\lambda{noobj}=0.5$,其实这也是yolo面临的一个样本数目不均衡的典型例子。主要目的是让含有物体的格点,在损失函数中的权重更大,让模型更加注重含有物体的格点所造成的损失。
我们的损失函数则只会对那些有真实物体所属的格点进行损失计算,若该格点不包含物体,那么预测数值不对损失函数造成影响。
这里对$w,h$在损失函数中的处理分别取了根号,原因在于,如果不取根号,损失函数往往更倾向于调整尺寸比较大的预测框。例如,20个像素点的偏差,对于800x600的预测框几乎没有影响,此时的IOU数值还是很大,但是对于30x40的预测框影响就很大。取根号是为了尽可能的消除大尺寸框与小尺寸框之间的差异。
预测框的置信度$C_i$。当该格点不含有物体时,该置信度的标签为0;若含有物体时,该置信度的标签为预测框与真实物体框的IOU数值(。
物体类别概率$P_i$,对应的类别位置,该标签数值为1,其余位置为0,与分类网络相同。
yolov2:Better, Faster, Stronger
yolov2的论文里面其实更多的是对训练数据集的组合和扩充,然后再添加了很多计算机视觉方面新出的trick,然后达到了性能的提升。同时yolov2方面所使用的trick也是现在计算机视觉常用的方法,我认为这些都是我们需要好好掌握的,同时也是面试和kaggle上都经常使用的一些方法。
Batch Normalization
BN是由Google于2015年提出,论文是《Batch Normalization_ Accelerating Deep Network Training by Reducing Internal Covariate Shift》,这是一个深度神经网络训练的技巧,主要是让数据的分布变得一致,从而使得训练深层网络模型更加容易和稳定。
这里有一些相关的链接可以参考一下
-https://www.cnblogs.com/itmorn/p/11241236.html
https://zhuanlan.zhihu.com/p/24810318
https://zhuanlan.zhihu.com/p/93643523
莫烦python
李宏毅yyds
+https://www.cnblogs.com/itmorn/p/11241236.html
https://zhuanlan.zhihu.com/p/24810318
https://zhuanlan.zhihu.com/p/93643523
莫烦python
李宏毅yyds
算法具体过程:

这里要提一下这个$\gamma和\beta$是可训练参数,维度等于张量的通道数,主要是为了在反向传播更新网络时使得标准化后的数据分布与原始数据尽可能保持一直,从而很好的抽象和保留整个batch的数据分布。
Batch Normalization的作用:
将这些输入值或卷积网络的张量在batch维度上进行类似标准化的操作,将其放缩到合适的范围,加快模型训练时的收敛速度,使得模型训练过程更加稳定,避免梯度爆炸或者梯度消失,并且起到一定的正则化作用。
High Resolution Classifier
在Yolov1中,网络的backbone部分会在ImageNet数据集上进行预训练,训练时网络输入图像的分辨率为224x224。在v2中,将分类网络在输入图片分辨率为448x448的ImageNet数据集上训练10个epoch,再使用检测数据集(例如coco)进行微调。高分辨率预训练使mAP提高了大约4%。
Convolutional With Anchor Boxes
predicts these offsets at every location in a feature map
Predicting offsets instead of coordinates simplifies the problem and makes it easier for the network to learn.
第一篇解读v1时提到,每个格点预测两个矩形框,在计算loss时,只让与ground truth最接近的框产生loss数值,而另一个框不做修正。这样规定之后,作者发现两个框在物体的大小、长宽比、类别上逐渐有了分工。在v2中,神经网络不对预测矩形框的宽高的绝对值进行预测,而是预测与Anchor框的偏差(offset),每个格点指定n个Anchor框。在训练时,最接近ground truth的框产生loss,其余框不产生loss。在引入Anchor Box操作后,mAP由69.5下降至69.2,原因在于,每个格点预测的物体变多之后,召回率大幅上升,准确率有所下降,总体mAP略有下降。
-Dimension Clusters
Instead of choosing priors by hand, we run k-means clustering on the training set bounding boxes to automatically find good priors.
这里算是作者数据处理上的一个创新点,这里作者提到之前的工作当中先Anchor Box都是认为设定的比例和大小,而这里作者时采用无监督的方式将训练数据集中的矩形框全部拿出来,用kmeans聚类得到先验框的宽和高。使用(1-IOU)数值作为两个矩形框的的距离函数,这个处理也十分的聪明。
$$
d(\text { box }, \text { centroid })=1-\operatorname{IOU}(\text { box }, \text { centroid })
$$

-Direct location prediction
Yolo中的位置预测方法是预测的左上角的格点坐标预测偏移量。网络预测输出要素图中每个单元格的5个边界框。网络为每个边界框预测$t_x,t_y,t_h,t_w和t_o$这5个坐标。如果单元格从图像的左上角偏移了$(c_x,c_y)$并且先验边界框的宽度和高度为$p_w,p_h$,则预测对应于:
$$
\begin{array}{l}
x=\left(t_{x} * w_{a}\right)-x_{a} \
y=\left(t_{y} * h_{a}\right)-y_{a}
\end{array}
$$

$$
\begin{aligned}
b_{x} &=\sigma\left(t_{x}\right)+c_{x} \
b_{y} &=\sigma\left(t_{y}\right)+c_{y} \
b_{w} &=p_{w} e^{t_{w}} \
b_{h} &=p_{h} e^{t_{h}} \
\operatorname{Pr}(\text { object }) * I O U(b, \text { object }) &=\sigma\left(t_{o}\right)
\end{aligned}
$$
由于我们约束位置预测,参数化更容易学习,使得网络更稳定使用维度集群以及直接预测边界框中心位置使YOLO比具有anchor box的版本提高了近5%的mAP。
+Dimension Clusters
Instead of choosing priors by hand, we run k-means clustering on the training set bounding boxes to automatically find good priors.
这里算是作者数据处理上的一个创新点,这里作者提到之前的工作当中先Anchor Box都是认为设定的比例和大小,而这里作者时采用无监督的方式将训练数据集中的矩形框全部拿出来,用kmeans聚类得到先验框的宽和高。使用(1-IOU)数值作为两个矩形框的的距离函数,这个处理也十分的聪明。
+
+Direct location prediction
Yolo中的位置预测方法是预测的左上角的格点坐标预测偏移量。网络预测输出要素图中每个单元格的5个边界框。网络为每个边界框预测$t_x,t_y,t_h,t_w和t_o$这5个坐标。如果单元格从图像的左上角偏移了$(c_x,c_y)$并且先验边界框的宽度和高度为$p_w,p_h$,则预测对应于:
+
+由于我们约束位置预测,参数化更容易学习,使得网络更稳定使用维度集群以及直接预测边界框中心位置使YOLO比具有anchor box的版本提高了近5%的mAP。
Fine-Grained Features
在2626的特征图,经过卷积层等,变为1313的特征图后,作者认为损失了很多细粒度的特征,导致小尺寸物体的识别效果不佳,所以在此加入了passthrough层。
传递层通过将相邻特征堆叠到不同的通道而不是堆叠到空间位置,将较高分辨率特征与低分辨率特征相连,类似于ResNet中的标识映射。这将26×26×512特征映射转换为13×13×2048特征映射,其可以与原始特征连接。

-Multi-Scale Training
我觉得这个也是yolo为什么性能提升的一个很重要的点,解决了yolo1当中对于多个小物体检测的问题。
原始的YOLO使用448×448的输入分辨率。添加anchor box后,我们将分辨率更改为416×416。然而,由于我们的模型只使用卷积层和池化层,相比yolo1删除了全连接层,它可以在运行中调整大小(应该是使用了1x1卷积不过我没看代码)。我们希望YOLOv2能够在不同大小的图像上运行,因此我们将其训练到模型中。
instead of fixing the input image size we change the network every few iterations. Every 10 batches our network randomly chooses a new image dimension size.
不固定输入图像的大小,我们每隔几次迭代就更改网络。在每10个batch之后,我们的网络就会随机resize成{320, 352, …, 608}中的一种。不同的输入,最后产生的格点数不同,比如输入图片是320320,那么输出格点是1010,如果每个格点的先验框个数设置为5,那么总共输出500个预测结果;如果输入图片大小是608608,输出格点就是1919,共1805个预测结果。
YOLO’s convolutional layers downsample the image by a factor of 32 so by using an input image of 416 we get an output feature map of 13 × 13.
We do this because we want an odd number of locations in our feature map so there is a single center cell.
关于416×416也是有说法的,主要是下采样是32的倍数,而且最后的输出是13x13是奇数然后会有一个中心点更加易于目标检测。
这种训练方法迫使网络学习在各种输入维度上很好地预测。这意味着相同的网络可以预测不同分辨率的检测。
关于yolov2最大的一个提升还有一个原因就是WordTree组合数据集的训练方法,不过这里我就不再赘述,可以看参考资料有详细介绍,这里主要讲网络和思路
+Multi-Scale Training
我觉得这个也是yolo为什么性能提升的一个很重要的点,解决了yolo1当中对于多个小物体检测的问题。
原始的YOLO使用448×448的输入分辨率。添加anchor box后,我们将分辨率更改为416×416。然而,由于我们的模型只使用卷积层和池化层,相比yolo1删除了全连接层,它可以在运行中调整大小(应该是使用了1x1卷积不过我没看代码)。我们希望YOLOv2能够在不同大小的图像上运行,因此我们将其训练到模型中。
instead of fixing the input image size we change the network every few iterations. Every 10 batches our network randomly chooses a new image dimension size.
不固定输入图像的大小,我们每隔几次迭代就更改网络。在每10个batch之后,我们的网络就会随机resize成{320, 352, …, 608}中的一种。不同的输入,最后产生的格点数不同,比如输入图片是320320,那么输出格点是1010,如果每个格点的先验框个数设置为5,那么总共输出500个预测结果;如果输入图片大小是608608,输出格点就是1919,共1805个预测结果。
YOLO’s convolutional layers downsample the image by a factor of 32 so by using an input image of 416 we get an output feature map of 13 × 13.
We do this because we want an odd number of locations in our feature map so there is a single center cell.
关于416×416也是有说法的,主要是下采样是32的倍数,而且最后的输出是13x13是奇数然后会有一个中心点更加易于目标检测。
这种训练方法迫使网络学习在各种输入维度上很好地预测。这意味着相同的网络可以预测不同分辨率的检测。
关于yolov2最大的一个提升还有一个原因就是WordTree组合数据集的训练方法,不过这里我就不再赘述,可以看参考资料有详细介绍,这里主要讲网络和思路
yolov3论文改进
yolov3的论文改进就有很多方面了,而且yolov3-spp的网络效果很不错,和yolov4,yolov5的效果差别也不是特别大,这也是为什么yolov3网络被广泛应用的原因之一。
backbone:Darknet-53
相比yolov1的网络,在网络上有了很大的改进,借鉴了Resnet、Densenet、FPN的做法结合了当前网络中十分有效的

1.Yolov3中,全卷积,对于输入图片尺寸没有特别限制,可通过调节卷积步长控制输出特征图的尺寸。
2.Yolov3借鉴了金字塔特征图思想,小尺寸特征图用于检测大尺寸物体,而大尺寸特征图检测小尺寸物体。特征图的输出维度为$N \times N \times (3 \times (4+1+80))$, NxN为输出特征图格点数,一共3个Anchor框,每个框有4维预测框数值 $t_x,t_y,t_w,t_h$ ,1维预测框置信度,80维物体类别数。所以第一层特征图的输出维度为8x8x255
3.Yolov3总共输出3个特征图,第一个特征图下采样32倍,第二个特征图下采样16倍,第三个下采样8倍。每个特征图进行一次3X3、步长为2的卷积,然后保存该卷积layer,再进行一次1X1的卷积和一次3X3的卷积,并把这个结果加上layer作为最后的结果。三个特征层进行5次卷积处理,处理完后一部分用于输出该特征层对应的预测结果,一部分用于进行反卷积UmSampling2d后与其它特征层进行结合。
4.concat和resiual加操作,借鉴DenseNet将特征图按照通道维度直接进行拼接,借鉴Resnet添加残差边,缓解了在深度神经网络中增加深度带来的梯度消失问题。
5.上采样层(upsample):作用是将小尺寸特征图通过插值等方法,生成大尺寸图像。例如使用最近邻插值算法,将88的图像变换为1616。上采样层不改变特征图的通道数。
对于yolo3的模型来说,网络最后输出的内容就是三个特征层每个网格点对应的预测框及其种类,即三个特征层分别对应着图片被分为不同size的网格后,每个网格点上三个先验框对应的位置、置信度及其种类。然后对输出进行解码,解码过程也就是yolov2上面的Direct location prediction方法一样,每个网格点加上它对应的x_offset和y_offset,加完后的结果就是预测框的中心,然后再利用 先验框和h、w结合 计算出预测框的长和宽。这样就能得到整个预测框的位置了。
-CIoU loss
在yolov3当中我们使用的不再是传统的IoU loss,而是一个非常优秀的loss设计,整个发展过程也可以多了解了解IoU->GIoU->DIoU->CIoU,完整的考虑了重合面积,中心点距离,长宽比。
$$CIoU=IoU-(\frac{\rho(b,b^{gt}}{c^2}+\alpha v))$$
$$v=\frac{4}{\pi^2}(\arctan\frac{w^{gt}}{h^{gt}}-\arctan\frac{w}{h})^2$$
$$\alpha = \frac{v}{(1-IoU)+v}$$
其中, $b$ , $b^{gt}$ 分别代表了预测框和真实框的中心点,且 $\rho$代表的是计算两个中心点间的欧式距离。 [公式] 代表的是能够同时包含预测框和真实框的最小闭包区域的对角线距离。
在介绍CIoU之前,我们可以先介绍一下DIoU loss

其实这两项就是我们的DIoU
$$DIoU = IoU-(\frac{\rho(b,b^{gt}}{c^2})$$
则我们可以提出DIoU loss函数
$$
L_{\text {DIoU }}=1-D I o U \
0 \leq L_{\text {DloU}} \leq 2
$$
DloU损失能够直接最小化两个boxes之间的距离,因此收敛速度更快。
而我们的CIoU则比DIoU考虑更多的东西,也就是长宽比即最后一项。而$v$用来度量长宽比的相似性,$\alpha$是权重
在损失函数这块,有知乎大佬写了一下,其实就是对yolov1上的损失函数进行了一下变形。

+CIoU loss
在yolov3当中我们使用的不再是传统的IoU loss,而是一个非常优秀的loss设计,整个发展过程也可以多了解了解IoU->GIoU->DIoU->CIoU,完整的考虑了重合面积,中心点距离,长宽比。
+其中, $b$ , $b^{gt}$ 分别代表了预测框和真实框的中心点,且 $\rho$代表的是计算两个中心点间的欧式距离。 [公式] 代表的是能够同时包含预测框和真实框的最小闭包区域的对角线距离。
在介绍CIoU之前,我们可以先介绍一下DIoU loss
其实这两项就是我们的DIoU
+则我们可以提出DIoU loss函数
+DloU损失能够直接最小化两个boxes之间的距离,因此收敛速度更快。
而我们的CIoU则比DIoU考虑更多的东西,也就是长宽比即最后一项。而$v$用来度量长宽比的相似性,$\alpha$是权重
在损失函数这块,有知乎大佬写了一下,其实就是对yolov1上的损失函数进行了一下变形。
Spatial Pyramid Pooling
在yolov3的spp版本中使用了spp模块,实现了不同尺度的特征融合,spp模块最初来源于何凯明大神的论文SPP-net,主要用来解决输入图像尺寸不统一的问题,而目前的图像预处理操作中,resize,crop等都会造成一定程度的图像失真,因此影响了最终的精度。SPP模块,使用固定分块的池化操作,可以对不同尺寸的输入实现相同大小的输出,因此能够避免这一问题。
同时SPP模块中不同大小特征的融合,有利于待检测图像中目标大小差异较大的情况,也相当于增大了多重感受野吧,尤其是对于yolov3一般针对的复杂多目标图像。
在yolov3的darknet53输出到第一个特征图计算之前我们插入了一个spp模块。

SPP的这几个模块stride=1,而且会对外补padding,所以最后的输出特征图大小是一致的,然后在深度方向上进行concatenate,使得深度增大了4倍。


可以看出随着输入网络尺度的增大,spp的效果会更好。多个spp的效果增大也就是spp3和spp1的效果是差不多的,为了保证推理速度就只使用了一个spp
Mosaic图像增强
在yolov3-spp包括yolov4当中我们都使用了mosaic数据增强,有点类似cutmix。cutmix是合并两张图片进行预测,mosaic数据增强利用了四张图片,对四张图片进行拼接,每一张图片都有其对应的框框,将四张图片拼接之后就获得一张新的图片,同时也获得这张图片对应的框框,然后我们将这样一张新的图片传入到神经网络当中去学习,相当于一下子传入四张图片进行学习了。论文中说这极大丰富了检测物体的背景,且在标准化BN计算的时候一下子会计算四张图片的数据。

作用:增加数据的多样性,增加目标个数,BN能一次性归一化多张图片组合的分布,会更加接近原数据的分布。
-focal loss
最后我们提一下focal loss,虽然在原论文当中作者说focal loss效果反而下降了,但是我认为还是有必要了解一下何凯明的这篇bestpaper。作者提出focal loss的出发点也是希望one-stage detector可以达到two-stage detector的准确率,同时不影响原有的速度。作者认为造成这种情况的原因是样本的类别不均衡导致的。
对于二分类的CrossEntropy,我们有如下表示方法:
$$
\mathrm{CE}(p, y)=\left{\begin{array}{ll}
-\log (p) & \text { if } y=1 \
-\log (1-p) & \text { otherwise. }
\end{array}\right.
$$
我们定义$p_t$:
$$
p_{\mathrm{t}}=\left{\begin{array}{ll}
p & \text { if } y=1 \
1-p & \text { otherwise }
\end{array}\right.
$$
则重写交叉熵
$$
\operatorname{CE}(n, y)=C E(p_t)=-\log (p_t)
$$
接着我们提出改进思路就是在计算CE时添加了一个平衡因子,是一个可训练的参数
$$
\mathrm{CE}\left(p_{\mathrm{t}}\right)=-\alpha_{\mathrm{t}} \log \left(p_{\mathrm{t}}\right)
$$
其中
$$
\alpha_{\mathrm{t}}=\left{\begin{array}{ll}
\alpha_{\mathrm{t}} & \text { if } y=1 \
1-\alpha_{\mathrm{t}} & \text { otherwise }
\end{array}\right.
$$
相当于给正负样本加上权重,负样本出现的频次多,那么就降低负样本的权重,正样本数量少,就相对提高正样本的权重。因此可以通过设定a的值来控制正负样本对总的loss的共享权重。a取比较小的值来降低负样本(多的那类样本)的权重。
但是何凯明认为这个还是不能完全解决样本不平衡的问题,虽然这个平衡因子可以控制正负样本的权重,但是没法控制容易分类和难分类样本的权重
+focal loss
最后我们提一下focal loss,虽然在原论文当中作者说focal loss效果反而下降了,但是我认为还是有必要了解一下何凯明的这篇bestpaper。作者提出focal loss的出发点也是希望one-stage detector可以达到two-stage detector的准确率,同时不影响原有的速度。作者认为造成这种情况的原因是样本的类别不均衡导致的。
对于二分类的CrossEntropy,我们有如下表示方法:
+我们定义$p_t$:
+则重写交叉熵
+接着我们提出改进思路就是在计算CE时添加了一个平衡因子,是一个可训练的参数
+其中
+相当于给正负样本加上权重,负样本出现的频次多,那么就降低负样本的权重,正样本数量少,就相对提高正样本的权重。因此可以通过设定a的值来控制正负样本对总的loss的共享权重。a取比较小的值来降低负样本(多的那类样本)的权重。
但是何凯明认为这个还是不能完全解决样本不平衡的问题,虽然这个平衡因子可以控制正负样本的权重,但是没法控制容易分类和难分类样本的权重
As our experiments will show, the large class imbalance encountered during training of dense detectors overwhelms the cross entropy loss. Easily classified negatives comprise the majority of the loss and dominate the gradient. While
α balances the importance of positive/negative examples, it does not differentiate between easy/hard examples. Instead, we propose to reshape the loss function to down-weight easy examples and thus focus training on hard negatives
-于是提出了一种新的损失函数Focal Loss
$$
\mathrm{FL}\left(p_{\mathrm{t}}\right)=-\left(1-p_{\mathrm{t}}\right)^{\gamma} \log \left(p_{\mathrm{t}}\right)
$$

+于是提出了一种新的损失函数Focal Loss
+
focal loss的两个重要性质
1、当一个样本被分错的时候,pt是很小的,那么调制因子(1-Pt)接近1,损失不被影响;当Pt→1,因子(1-Pt)接近0,那么分的比较好的(well-classified)样本的权值就被调低了。因此调制系数就趋于1,也就是说相比原来的loss是没有什么大的改变的。当pt趋于1的时候(此时分类正确而且是易分类样本),调制系数趋于0,也就是对于总的loss的贡献很小。
2、当γ=0的时候,focal loss就是传统的交叉熵损失,当γ增加的时候,调制系数也会增加。 专注参数γ平滑地调节了易分样本调低权值的比例。γ增大能增强调制因子的影响,实验发现γ取2最好。直觉上来说,调制因子减少了易分样本的损失贡献,拓宽了样例接收到低损失的范围。当γ一定的时候,比如等于2,一样easy example(pt=0.9)的loss要比标准的交叉熵loss小100+倍,当pt=0.968时,要小1000+倍,但是对于hard example(pt < 0.5),loss最多小了4倍。这样的话hard example的权重相对就提升了很多。这样就增加了那些误分类的重要性
focal loss的两个性质算是核心,其实就是用一个合适的函数去度量难分类和易分类样本对总的损失的贡献。
-然后作者又提出了最终的focal loss形式
$$
\mathrm{FL}\left(p_{\mathrm{t}}\right)=-\alpha_{\mathrm{t}}\left(1-p_{\mathrm{t}}\right)^{\gamma} \log \left(p_{\mathrm{t}}\right)
$$
$$
F L(p)\left{\begin{array}{ll}
-\alpha(1-p)^{\gamma} \log (p) & \text { if } y=1 \
-(1-\alpha) p^{\gamma} \log (1-p) & \text { otherwise }
\end{array}\right.
$$
这样既能调整正负样本的权重,又能控制难易分类样本的权重
在实验中a的选择范围也很广,一般而言当γ增加的时候,a需要减小一点(实验中γ=2,a=0.25的效果最好)
+然后作者又提出了最终的focal loss形式
+这样既能调整正负样本的权重,又能控制难易分类样本的权重
在实验中a的选择范围也很广,一般而言当γ增加的时候,a需要减小一点(实验中γ=2,a=0.25的效果最好)
总结
yolo和yolov2的严谨数学推理和网络相结合的做法令人十分惊艳,而yolov3相比之前的两个版本不管是在数据处理还是网络性质上都有很大的改变,也使用了很多流行的tirck来实现目标检测,基本上结合了很多cv领域的精髓,博客中有很多部分由于时间关系没有太细讲,其实每个部分都可以去原论文中找到很多可以学习的地方,之后有时候会补上yolov4和yolov5的讲解,后面的网络添加了注意力机制模块效果应该是更加work的。
参考文献
-yolov3-spp
focal loss
batch normal
IoU系列
yolov1论文翻译
yolo1-3三部曲
Bubbliiiing的教程里
还有很多但是没找到之后会补上的
+yolov3-spp
focal loss
batch normal
IoU系列
yolov1论文翻译
yolo1-3三部曲
Bubbliiiing的教程里
还有很多但是没找到之后会补上的
@@ -576,7 +625,7 @@
- 编译原理
+ 数据库系统
-
diff --git "a/2021/05/09/EfficientNet\350\256\272\346\226\207\350\247\243\350\257\273\345\222\214pytorch\344\273\243\347\240\201\345\256\236\347\216\260/index.html" "b/2021/05/09/EfficientNet\350\256\272\346\226\207\350\247\243\350\257\273\345\222\214pytorch\344\273\243\347\240\201\345\256\236\347\216\260/index.html"
index aa12c257..34385509 100644
--- "a/2021/05/09/EfficientNet\350\256\272\346\226\207\350\247\243\350\257\273\345\222\214pytorch\344\273\243\347\240\201\345\256\236\347\216\260/index.html"
+++ "b/2021/05/09/EfficientNet\350\256\272\346\226\207\350\247\243\350\257\273\345\222\214pytorch\344\273\243\347\240\201\345\256\236\347\216\260/index.html"
@@ -221,41 +221,34 @@
EfficientNet论文解读和pytorch代码实现
传送门
论文地址:https://arxiv.org/pdf/1905.11946.pdf
官方github:https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
github参考:https://github.com/qubvel/efficientnet
github参考:https://github.com/lukemelas/EfficientNet-PyTorch
-摘要
谷歌的文章总是能让我印象深刻,不管从实验上还是论文的书写上都让人十分的佩服,不得不说这确实是一个非常creative的公司!
Convolutional Neural Networks (ConvNets) are commonly developed at a fixed resource budget, and then scaled up for better accuracy if more resources are available. In this paper, we systematically study model scaling and identify that carefully balancing network depth, width, and resolution can lead to better performance. Based on this observation, we propose a new scaling method that uniformly scales all dimensions of depth/width/resolution using a simple yet highly effective compound coefficient. We demonstrate the effectiveness of this method on scaling up MobileNets and ResNet.
卷积神经网络通常是在固定的资源预算下进行计算和发展的,如果有更多可用的资源,模型能通过缩放和扩展获得更好的效果,本文系统研究(工作量很充足)了模型缩放,并且证明了细致地平衡网络的深度,宽度,和分辨率能够得到更好的效果,基于这个观点,我们提出了一个新的尺度缩放的方法,我们提出了一个新的尺度缩放的方法即:使用一个简单且高效的复合系数统一地缩放所有网络层的深度/宽度/分辨率的维度。我们证明了该方法在扩大MobileNets和ResNet方面的有效性。
-
-
+摘要
谷歌的文章总是能让我印象深刻,不管从实验上还是论文的书写上都让人十分的佩服,不得不说这确实是一个非常creative的公司!
Convolutional Neural Networks (ConvNets) are commonly developed at a fixed resource budget, and then scaled up for better accuracy if more resources are available. In this paper, we systematically study model scaling and identify that carefully balancing network depth, width, and resolution can lead to better performance. Based on this observation, we propose a new scaling method that uniformly scales all dimensions of depth/width/resolution using a simple yet highly effective compound coefficient. We demonstrate the effectiveness of this method on scaling up MobileNets and ResNet.
卷积神经网络通常是在固定的资源预算下进行计算和发展的,如果有更多可用的资源,模型能通过缩放和扩展获得更好的效果,本文系统研究(工作量很充足)了模型缩放,并且证明了细致地平衡网络的深度,宽度,和分辨率能够得到更好的效果,基于这个观点,我们提出了一个新的尺度缩放的方法,我们提出了一个新的尺度缩放的方法即:使用一个简单且高效的复合系数统一地缩放所有网络层的深度/宽度/分辨率的维度。我们证明了该方法在扩大MobileNets和ResNet方面的有效性。
To go even further, we use neural architecture search to design a new baseline network and scale it up to obtain a family of models, called EfficientNets, which achieve much better accuracy and efficiency than previous ConvNets. In particular, our EfficientNet-B7 achieves state-of-the-art 84.3% top-1 accuracy on ImageNet, while being 8.4x smaller and 6.1x faster on inference than the best existing ConvNet. Our EfficientNets also transfer well and achieve state-of-the-art accuracy on CIFAR-100 (91.7%), Flowers (98.8%), and 3 other transfer learning datasets, with an order of magnitude fewer parameters. Source code is athttps://github.com/tensorflow/tpu/tree/
master/models/official/efficientnet.
更进一步,我们使用神经网络结构搜索设计了一个新的baseline网络架构并且对其进行缩放得到了一组模型,我们把他叫做EfficientNets。EfficientNets相比之前的ConvNets,有着更好的准确率和更高的效率。在ImageNet上达到了最好的水平即top-1准确率84.4%/top-5准确率97.1%,然而却比已有的最好的ConvNet模型小了8.4倍并且推理时间快了6.1倍。我们的EfficientNet迁移学习的效果也好,达到了最好的准确率水平CIFAR-100(91.7%),Flowers(98.8%),和其他3个迁移学习数据集合,参数少了一个数量级(with an order of magnitude fewer parameters)。
论文思想
在之前的一些工作当中,我们可以看到,有的会通过增加网络的width即增加卷积核的个数(从而增大channels)来提升网络的性能,有的会通过增加网络的深度即使用更多的层结构来提升网络的性能,有的会通过增加输入网络的分辨率来提升网络的性能。而在Efficientnet当中则重新探究了这个问题,并提出了一种组合条件这三者的网络结构,同时量化了这三者的指标。

The intuition is that deeper ConvNet can capture richer and more complex features, and generalize well on new tasks. However, deeper networks are also more difficult to train due to the vanishing gradient problem
增加网络的深度depth能够得到更加丰富、复杂的特征并且能够在其他新任务中很好的泛化性能。但是,由于逐渐消失的梯度问题,更深层的网络也更难以训练。
wider networks tend to be able to capture more fine-grained features and are easier to train. However, extremely wide but shallow networks tend to have difficulties in capturing higher level features
with更广的网络往往能够捕获更多细粒度的功能,并且更易于训练。但是,极其宽泛但较浅的网络在捕获更高级别的特征时往往会遇到困难
With higher resolution input images, ConvNets can potentially capture more fine-grained pattern,but the accuracy gain diminishes for very high resolutions
使用更高分辨率的输入图像,ConvNets可以捕获更细粒度的图案,但对于非常高分辨率的图片,准确度会降低。
-作者在论文中对整个网络的运算过程和复合扩展方法进行了抽象:
首先定义了每一层卷积网络为$\mathcal{F}{i}\left(X{i}\right)$,而$X_i$是输入张量,$Y_i$是输出张量,而tensor的形状是$<H_i,W_i,C_i>$
整个卷积网络由 k 个卷积层组成,可以表示为$\mathcal{N}=\mathcal{F}{k} \odot \ldots \odot \mathcal{F}{2} \odot \mathcal{F}{1}\left(X{1}\right)=\bigodot_{j=1 \ldots k} \mathcal{F}{j}\left(X{1}\right)$
从而得到我们的整个卷积网络:
$$
\mathcal{N}=\bigodot_{i=1 \ldots s} \mathcal{F}{i}^{L{i}}\left(X_{\left\langle H_{i}, W_{i}, C_{i}\right\rangle}\right)
$$
-下标 i(从 1 到 s) 表示的是 stage 的序号,$\mathcal{F}{i}^{L{i}}$表示第 i 个 stage ,它表示卷积层 $\mathcal{F}{i}$重复了${L{i}}$ 次。
+作者在论文中对整个网络的运算过程和复合扩展方法进行了抽象:
首先定义了每一层卷积网络为$\mathcal{F}{i}\left(X{i}\right)$,而$Xi$是输入张量,$Y_i$是输出张量,而tensor的形状是$$
整个卷积网络由 k 个卷积层组成,可以表示为$\mathcal{N}=\mathcal{F} {k} \odot \ldots \odot \mathcal{F}{2} \odot \mathcal{F}{1}\left(X{1}\right)=\bigodot{j=1 \ldots k} \mathcal{F}{j}\left(X{1}\right)$
从而得到我们的整个卷积网络:
+下标 i(从 1 到 s) 表示的是 stage 的序号,$\mathcal{F}{i}^{L{i}}$表示第 i 个 stage ,它表示卷积层 $\mathcal{F}{i}$重复了${L{i}}$ 次。
为了探究$d , r , w$这三个因子对最终准确率的影响,则将$d , r , w$加入到公式中,我们可以得到抽象化后的优化问题(在指定资源限制下),其中$s.t.$代表限制条件:

- $d$用来缩放深度$\widehat{L}_i $。
- $r$用来缩放分辨率即影响$\widehat{H}_i$以及$\widehat{W}_i$。
- $w$就是用来缩放特征矩阵的channels即 $\widehat{C}_i$。
- target_memory为memory限制
-- target_flops为FLOPs限制

Bigger networks with larger width, depth, or resolution tend to achieve higher accuracy, but the accuracy gain quickly saturate after reaching 80%, demonstrating the limitation of single dimension scaling
具有较大宽度,深度或分辨率的较大网络往往会实现较高的精度,但是精度增益在达到80%后会迅速饱和,这表明了单维缩放的局限性。compound scaling method
In this paper, we propose a new compound scaling method, which use a compound coefficient φ to uniformly scales network width, depth, and resolution in a principled way:
在本文中,我们提出了一种新的复合缩放方法,该方法使用一个统一的复合系数$\phi$对网络的宽度,深度和分辨率进行均匀缩放。

其中$\alpha,\beta,\gamma$是通过一个小格子搜索的方法决定的常量。通常来说,$\phi$是一个用户指定的系数来控制有多少的额外资源能够用于模型的缩放,$\alpha,\beta,\gamma$指明了怎么支配这些额外的资源分别到网络的宽度,深度,和分辨率上。尤其是,一个标准卷积操作的运算量的比例是$d,w^2,r^2$双倍的网络深度将带来双倍的运算量,但是双倍的网络宽度或分辨率将会增加运算为4倍。因为卷积操作通常在ConvNets中占据绝大部分计算量,通过3式来缩放ConvNet大约将增加$(\alpha,\beta^2,\gamma^2)$运算量。
+- target_flops为FLOPs限制
Bigger networks with larger width, depth, or resolution tend to achieve higher accuracy, but the accuracy gain quickly saturate after reaching 80%, demonstrating the limitation of single dimension scaling
具有较大宽度,深度或分辨率的较大网络往往会实现较高的精度,但是精度增益在达到80%后会迅速饱和,这表明了单维缩放的局限性。compound scaling method
In this paper, we propose a new compound scaling method, which use a compound coefficient φ to uniformly scales network width, depth, and resolution in a principled way:
在本文中,我们提出了一种新的复合缩放方法,该方法使用一个统一的复合系数$\phi$对网络的宽度,深度和分辨率进行均匀缩放。
其中$\alpha,\beta,\gamma$是通过一个小格子搜索的方法决定的常量。通常来说,$\phi$是一个用户指定的系数来控制有多少的额外资源能够用于模型的缩放,$\alpha,\beta,\gamma$指明了怎么支配这些额外的资源分别到网络的宽度,深度,和分辨率上。尤其是,一个标准卷积操作的运算量的比例是$d,w^2,r^2$双倍的网络深度将带来双倍的运算量,但是双倍的网络宽度或分辨率将会增加运算为4倍。因为卷积操作通常在ConvNets中占据绝大部分计算量,通过3式来缩放ConvNet大约将增加$(\alpha,\beta^2,\gamma^2)$运算量。
我们限制$\alpha \cdot \beta^{2} \cdot \gamma^{2} \approx 2$所以对于任意给定的$\phi$值,我们总共的运算量将大约增加$2^{\phi}$
-我们限制$\alpha \cdot \beta^{2} \cdot \gamma^{2} \approx 2$所以对于任意给定的$\phi$值,我们总共的运算量将大约增加$2^{\phi}$
网络结构
文中给出了Efficientnet-B0的基准框架,在Efficientnet当中,我们所使用的激活函数是swish激活函数,整个网络分为了9个stage,在第2到第8stage是一直在堆叠MBConv结构,表格当中MBConv结构后面的数字(1或6)表示的就是MBConv中第一个1x1的卷积层会将输入特征矩阵的channels扩充为n倍。Channels表示通过该Stage后输出特征矩阵的Channels。

-MBConv结构
MBConv的结构相对来说还是十分好理解的,这里是我自己画的一张结构图。

MBConv结构主要由一个1x1的expand conv(升维作用,包含BN和Swish激活函数)提升维度的倍率正是之前网络结构中看到的1和6,一个KxK的卷积深度可分离卷积Depthwise Conv(包含BN和Swish)k的具体值可看EfficientNet-B0的网络框架主要有3x3和5x5两种情况,一个SE模块,一个1x1的pointer conv降维作用,包含BN),一个Droupout层构成,一般情况下都添加上了残差边模块Shortcut,从而得到输出特征矩阵。
首先关于深度可分离卷积的概念是是我们需要了解的,相当于将卷积的过程拆成运算和合并两个过程,分别对应depthwise和point两个过程,这里给一个参考连接给大家就不在详细描述了Depthwise卷积与Pointwise卷积

1.由于该模块最初是用tensorflow来实现的与pytorch有一些小差别,所以在使用pytorch实现的时候我们最好将tensorflow当中的samepadding操作重新实现一下
2.在batchnormal时候的动量设置也是有一些不一样的,论文当中设置的batch_norm_momentum=0.99,在pytorch当中需要先执行1-momentum再设为参数与tensorflow不同。
-# Batch norm parameters
momentum= 1 - batch_norm_momentum # pytorch's difference from tensorflow
eps= batch_norm_epsilon
nn.BatchNorm2d(num_features=out_channels, momentum=momentum, eps=eps)
-
+MBConv结构
MBConv的结构相对来说还是十分好理解的,这里是我自己画的一张结构图。
MBConv结构主要由一个1x1的expand conv(升维作用,包含BN和Swish激活函数)提升维度的倍率正是之前网络结构中看到的1和6,一个KxK的卷积深度可分离卷积Depthwise Conv(包含BN和Swish)k的具体值可看EfficientNet-B0的网络框架主要有3x3和5x5两种情况,一个SE模块,一个1x1的pointer conv降维作用,包含BN),一个Droupout层构成,一般情况下都添加上了残差边模块Shortcut,从而得到输出特征矩阵。
首先关于深度可分离卷积的概念是是我们需要了解的,相当于将卷积的过程拆成运算和合并两个过程,分别对应depthwise和point两个过程,这里给一个参考连接给大家就不在详细描述了Depthwise卷积与Pointwise卷积
1.由于该模块最初是用tensorflow来实现的与pytorch有一些小差别,所以在使用pytorch实现的时候我们最好将tensorflow当中的samepadding操作重新实现一下
2.在batchnormal时候的动量设置也是有一些不一样的,论文当中设置的batch_norm_momentum=0.99,在pytorch当中需要先执行1-momentum再设为参数与tensorflow不同。
# Batch norm parameters
momentum= 1 - batch_norm_momentum # pytorch's difference from tensorflow
eps= batch_norm_epsilon
nn.BatchNorm2d(num_features=out_channels, momentum=momentum, eps=eps)
class Conv2dSamePadding(nn.Conv2d):
"""2D Convolutions like TensorFlow, for a dynamic image size.
The padding is operated in forward function by calculating dynamically.
"""
# Tips for 'SAME' mode padding.
# Given the following:
# i: width or height
# s: stride
# k: kernel size
# d: dilation
# p: padding
# Output after Conv2d:
# o = floor((i+p-((k-1)*d+1))/s+1)
# If o equals i, i = floor((i+p-((k-1)*d+1))/s+1),
# => p = (i-1)*s+((k-1)*d+1)-i
def __init__(self, in_channels, out_channels, kernel_size,padding=0, stride=1, dilation=1,
groups=1, bias=True, padding_mode = 'zeros'):
super().__init__(in_channels, out_channels, kernel_size, stride, padding, dilation, groups, bias)
self.stride = self.stride if len(self.stride) == 2 else [self.stride[0]] * 2
def forward(self, x):
ih, iw = x.size()[-2:] # input
kh, kw = self.weight.size()[-2:] # because kernel size equals to weight size
sh, sw = self.stride # stride
# change the output size according to stride
oh, ow = math.ceil(ih/sh), math.ceil(iw/sw) # output
"""
kernel effective receptive field size: (kernel_size-1) x dilation + 1
"""
pad_h = max((oh - 1) * self.stride[0] + (kh - 1) * self.dilation[0] + 1 - ih, 0)
pad_w = max((ow - 1) * self.stride[1] + (kw - 1) * self.dilation[1] + 1 - iw, 0)
if pad_h > 0 or pad_w > 0:
x = F.pad(x, [pad_w // 2, pad_w - pad_w // 2, pad_h // 2, pad_h - pad_h // 2])
return F.conv2d(x, self.weight, self.bias, self.stride, self.padding, self.dilation, self.groups)
-
MBConvBlock模块结构
class ConvBNActivation(nn.Module):
"""Convolution BN Activation"""
def __init__(self,in_channels,out_channels,kernel_size,stride=1,groups=1,
bias=False,momentum=0.01,eps=1e-3,active=False):
super().__init__()
self.layer=nn.Sequential(
Conv2dSamePadding(in_channels,out_channels,kernel_size=kernel_size,
stride=stride,groups=groups, bias=bias),
nn.BatchNorm2d(num_features=out_channels, momentum=momentum, eps=eps)
)
self.active=active
self.swish = Swish()
def forward(self, x):
x = self.layer(x)
if self.active:
x=self.swish(x)
return x
class MBConvBlock(nn.Module):
def __init__(self,in_channels,out_channels,kernel_size,stride,
expand_ratio=1, momentum=0.01,eps=1e-3,
drop_connect_ratio=0.2,training=True,
se_ratio=0.25,skip=True, image_size=None):
super().__init__()
self.expand_ratio = expand_ratio
self.se_ratio = se_ratio
self.has_se = (se_ratio is not None) and (0 < se_ratio <= 1)
self.skip = skip and stride == 1 and in_channels == out_channels
# 1x1 convolution channels expansion phase
expand_channels = in_channels * self.expand_ratio # number of output channels
if self.expand_ratio != 1:
self.expand_conv = ConvBNActivation(in_channels=in_channels,out_channels=expand_channels,
momentum=momentum,eps=eps,
kernel_size=1,bias=False,active=False)
# Depthwise convolution phase
self.depthwise_conv = ConvBNActivation(in_channels=expand_channels,out_channels=expand_channels,
momentum=momentum,eps=eps,
kernel_size=kernel_size,stride=stride,groups=expand_channels,bias=False,active=False)
# Squeeze and Excitation module
if self.has_se:
sequeeze_channels = max(1,int(expand_channels*self.se_ratio))
self.se = SEModule(expand_channels,sequeeze_channels)
# Pointwise convolution phase
self.project_conv = ConvBNActivation(expand_channels,out_channels,momentum=momentum,eps=eps,
kernel_size=1,bias=False,active=True)
self.drop_connect = DropConnect(drop_connect_ratio,training)
def forward(self,x):
input_x = x
if self.expand_ratio != 1:
x = self.expand_conv(x)
x = self.depthwise_conv(x)
if self.has_se:
x = self.se(x)
x = self.project_conv(x)
if self.skip:
x = self.drop_connect(x)
x = x + input_x
return x
-
SE模块
SE模块是通道注意力模块,该模块能够关注channel之间的关系,可以让模型自主学习到不同channel特征的重要程度。由一个全局平均池化,两个全连接层组成。第一个全连接层的节点个数是输入该MBConv特征矩阵channels的1/4 ,且使用Swish激活函数。第二个全连接层的节点个数等于Depthwise Conv层输出的特征矩阵channels,且使用Sigmoid激活函数,这里引用一下别人画好的示意图。


class SEModule(nn.Module):
"""Squeeze and Excitation module for channel attention"""
def __init__(self,in_channels,squeezed_channels):
super().__init__()
self.global_avg_pool = nn.AdaptiveAvgPool2d(1)
self.sequential = nn.Sequential(
nn.Conv2d(in_channels,squeezed_channels,1), # use 1x1 convolution instead of linear
Swish(),
nn.Conv2d(squeezed_channels,in_channels,1),
nn.Sigmoid()
)
def forward(self,x):
x= self.global_avg_pool(x)
y = self.sequential(x)
return x * y
-
-swish激活函数
Swish是Google提出的一种新型激活函数,其原始公式为:f(x)=x * sigmod(x),变形Swish-B激活函数的公式则为f(x)=x * sigmod(b * x),其拥有不饱和,光滑,非单调性的特征,Google在论文中的多项测试表明Swish以及Swish-B激活函数的性能即佳,在不同的数据集上都表现出了要优于当前最佳激活函数的性能。
$$f(x)=x \cdot \operatorname{sigmoid}(\beta x)$$
其中$\beta$是个常数或可训练的参数,Swish 具备无上界有下界、平滑、非单调的特性。
+swish激活函数
Swish是Google提出的一种新型激活函数,其原始公式为:f(x)=x sigmod(x),变形Swish-B激活函数的公式则为f(x)=x sigmod(b * x),其拥有不饱和,光滑,非单调性的特征,Google在论文中的多项测试表明Swish以及Swish-B激活函数的性能即佳,在不同的数据集上都表现出了要优于当前最佳激活函数的性能。
+其中$\beta$是个常数或可训练的参数,Swish 具备无上界有下界、平滑、非单调的特性。
class Swish(nn.Module):
""" swish activation function"""
def forward(self,x):
return x * torch.sigmoid(x)
droupout代码实现
class DropConnect(nn.Module):
"""Drop Connection"""
def __init__(self,ratio,training):
super().__init__()
assert 0 <= ratio <= 1
self.keep_prob = 1 - ratio
self.training=training
def forward(self,x):
if not self.training:
return x
batch_size = x.shape[0]
random_tensor = self.keep_prob
random_tensor += torch.rand([batch_size,1,1,1],dtype=x.dtype,device=x.device)
# generate binary_tensor mask according to probability (p for 0, 1-p for 1)
binary_tensor = torch.floor(random_tensor)
output = x / self.keep_prob * binary_tensor
return output
-
总结
这里我们只给出了b0结构的代码实现,对于其他结构的实现过程就是在b0的基础上对wdith,depth,resolution都通过倍率因子统一缩放,这个部分在这个博客里面有详细的介绍EfficientNet(B0-B7)参数设置。
在本文中,我们系统地研究了ConvNet的缩放比例,分析了各因素对网络结构的影响,并确定仔细平衡网络的宽度,深度和分辨率,这是目前网络训练最重要但缺乏研究的部分,也是我们无法获得更好的准确性和效率忽略的一个部分。为解决此问题,本文作者提出了一种简单而高效的复合缩放方法,通过一个倍率因子统一缩放各部分比例并添加上通道注意力机制和残差模块,从而改善网络架构得到SOTA的效果,同时对模型各成分因子进行量化十分具有创新性。
参考连接
EfficientNet网络详解
神经网络学习小记录50——Pytorch EfficientNet模型的复现详解
论文翻译
令人拍案叫绝的EfficientNet和EfficientDet
swish激活函数
Depthwise卷积与Pointwise卷积
CV领域常用的注意力机制模块(SE、CBAM)
Global Average Pooling
@@ -564,7 +557,7 @@ 总结
-
diff --git "a/2021/06/06/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225\345\237\272\347\241\200\342\200\224\342\200\224\345\277\253\351\200\237\346\216\222\345\272\217\344\270\216\345\275\222\345\271\266\346\216\222\345\272\217/index.html" "b/2021/06/06/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225\345\237\272\347\241\200\342\200\224\342\200\224\345\277\253\351\200\237\346\216\222\345\272\217\344\270\216\345\275\222\345\271\266\346\216\222\345\272\217/index.html"
index 7d4ef3be..e5972bde 100644
--- "a/2021/06/06/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225\345\237\272\347\241\200\342\200\224\342\200\224\345\277\253\351\200\237\346\216\222\345\272\217\344\270\216\345\275\222\345\271\266\346\216\222\345\272\217/index.html"
+++ "b/2021/06/06/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225\345\237\272\347\241\200\342\200\224\342\200\224\345\277\253\351\200\237\346\216\222\345\272\217\344\270\216\345\275\222\345\271\266\346\216\222\345\272\217/index.html"
@@ -211,15 +211,16 @@
- 前言
最近在复习数据结构,顺便整理之前刷题的一些模板和技巧,希望对大家都有帮助,博客会侧重讲解的是OJ代码实现,理论部分偏少但也会写一些自己的理解。
在之前大二上数据结构的时候我也有写过一个关于排序的专题介绍数据结构复习——内部排序
-
+ 前言
最近在复习数据结构,顺便整理之前刷题的一些模板和技巧,希望对大家都有帮助,博客会侧重讲解的是OJ代码实现,理论部分偏少但也会写一些自己的理解。
在之前大二上数据结构的时候我也有写过一个关于排序的专题介绍数据结构复习——内部排序
快速排序
快速排序主要就是通过选取一个基准点,将一个区间内的数分成大于和小于两个部分,然后对左右区间再进行上述操作,直到子区间的长度为空为止。快速排序是不稳定的排序,如果需要变成稳定排序通过双关键字排序即可,通过下标控制绝对大小就能得到稳定的排序结果。
快速排序分三步走:
- 确定分界点
- 调整左右区间
- 递归处理左右子区间
-在代码实现当中,我们一般选取中间分位点会比较好,这样划分的区间比较平均。在遍历的过程当中每次调整区间的时间是$O(n)$,而区间递归的深度类似二叉树是$O(logn)$
在最好情况下,对于递归型的算法,我们利用主定理公式来计算快速排序时间复杂度得到$O(nlogn)$
$$
T(n) = 2 T\left(\frac{n}{2}\right)+\Theta(n)
$$
当然在最坏情况下,也就是数组是有序或者逆序的情况下,我们如果选择左右端点作为基准点,那么整个算法就相当于冒泡排序,递归的层数也就变成了$n$,则最坏时间复杂度为$O(n^2)$
+在代码实现当中,我们一般选取中间分位点会比较好,这样划分的区间比较平均。在遍历的过程当中每次调整区间的时间是$O(n)$,而区间递归的深度类似二叉树是$O(logn)$
在最好情况下,对于递归型的算法,我们利用主定理公式来计算快速排序时间复杂度得到$O(nlogn)$
+当然在最坏情况下,也就是数组是有序或者逆序的情况下,我们如果选择左右端点作为基准点,那么整个算法就相当于冒泡排序,递归的层数也就变成了$n$,则最坏时间复杂度为$O(n^2)$
代码实现
void quick_sort(int[] q,int l,int r)
{
if(l>=r) return;
// 1.确定分界点
int i = l - 1, j = r + 1, mid = q[l + r >> 1];
// 2.调整左右区间
while(i<j)
{
do i++; while(q[i]<mid);
do j--; while(q[j]>mid);
if(i<j) swap(q[i],q[j]);
}
//3.递归处理左右子区间
quick_sort(l,j);
quick_sort(j+1,r);
}
经典例题
归并排序
归并排序也是基于分治的思想,每次将区间对半分,逐步递归合并有序化子区间,最终实现所有的左右区间的有序归并,但是跟快速排序不同的是,我们需要开一个辅助数组来存储有序的部分,所以时间复杂度为$O(nlogn)$。归并排序是稳定的排序,在元素相等情况下我们总是放入数组下标较小的元素。
归并排序分三步走:
@@ -536,7 +537,7 @@
- 编译原理
+ 数据库系统
-
diff --git "a/2021/06/13/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\345\210\267\351\242\230\342\200\224\342\200\224\351\223\276\350\241\250/index.html" "b/2021/06/13/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\345\210\267\351\242\230\342\200\224\342\200\224\351\223\276\350\241\250/index.html"
index be144b28..79187439 100644
--- "a/2021/06/13/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\345\210\267\351\242\230\342\200\224\342\200\224\351\223\276\350\241\250/index.html"
+++ "b/2021/06/13/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\345\210\267\351\242\230\342\200\224\342\200\224\351\223\276\350\241\250/index.html"
@@ -216,12 +216,9 @@
- 数据结构与刷题——链表
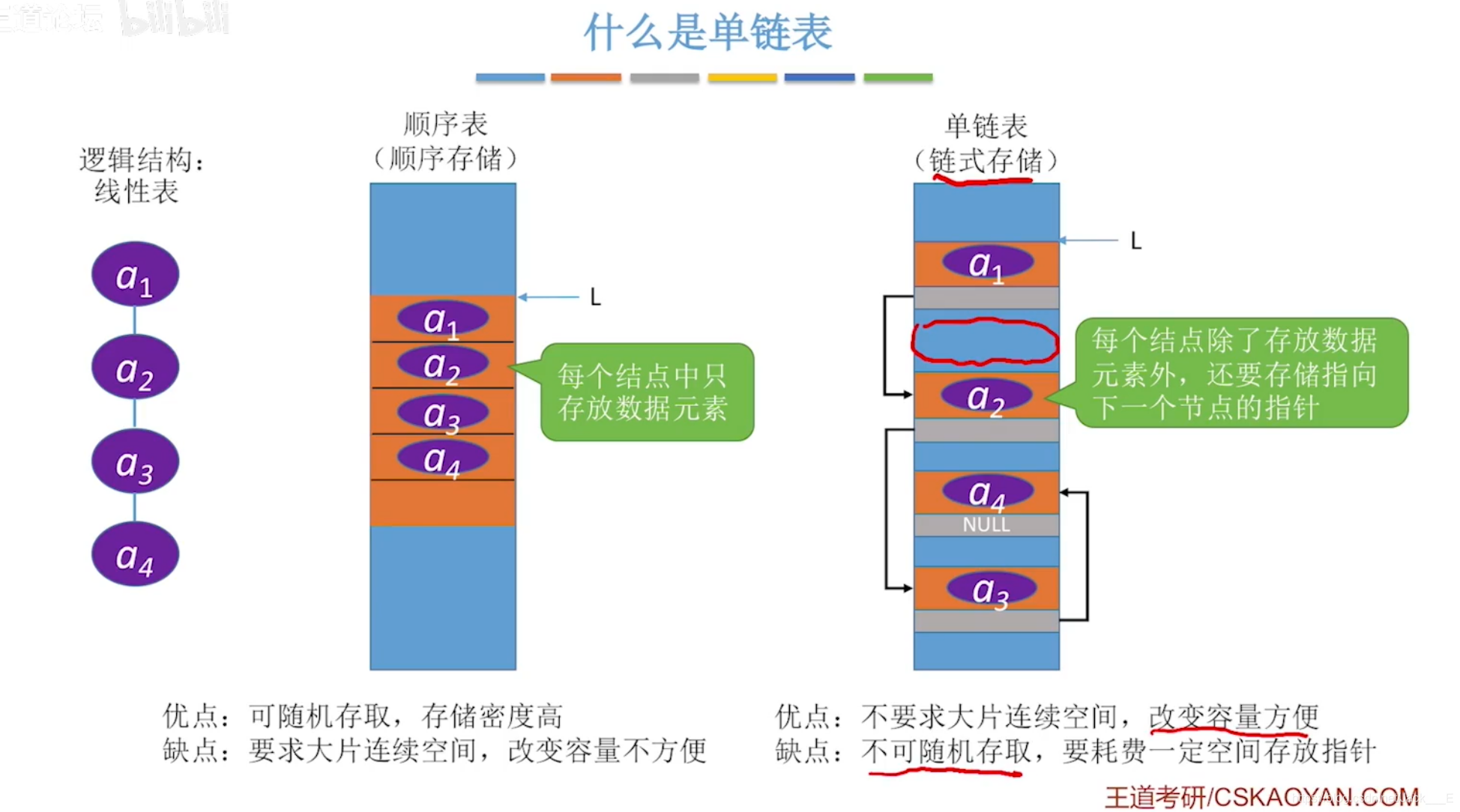
-
-
+ 数据结构与刷题——链表
单链表代码模板
代码实现单链表的方法有很多种,但是对于acm刷题来说,我们通常使用的是静态链表的方式,这样代码运行速度更快,防止被卡时间。
const int N = 100010;
int head; // 头指针
int e[N]; // e[i]表示第i个节点的
int ne[N];// 第i个节点的next指针,表示当前节点的直接后继的节点编号
int idx;//记录已经存储了多少个节点
void init()
{
head = -1;//用-1表示空节点
idx = 0;
}
//在第k个节点后面插入一个新节点,节点的值为x
void insert(int k,int x)
{
e[idx] = x;
ne[idx] = ne[k];
ne[k] = idx++;
}
// 删除第k+1个节点,即将将该节点的指针指向他的下一个元素
void delete_node(int k)
{
ne[k] = ne[ne[k]];
}
void delete_head()
{
head = ne[head];
}
//遍历过程
for(int i = head; i!=-1;i = ne[i])
{
cout<<e[i]<<endl;
}
-
双链表
在实际的代码编写过程当中,我们也是直接使用静态链表来设置双链表,我们首先设置0号点和1号点为左右边界head,tail。之后我们就只需要在这两者之间插入节点构造双链表。



const int N = 100010;
int e[N];
int l[N];
int r[N];
int idx;
//初始化直接初始化出左右端点的下标,从而避免边界问题
void init()
{
//初始化的左右别搞反了
r[0] = 1;
l[1] = 0;
idx =2;
}
// 在k节点的右侧插入一个x,其实也相当于左侧插入节点
void add(int k,int x)
{
e[idx] = x;
//操作新节点的左右指针
r[idx] = r[k];
l[idx] = k;
//再操作原数组的节点
l[r[k]] = idx;
r[k] = idx++;
}
void remove(int k)
{
l[r[k]] = l[k]; //右节点的左侧,指向左节点
r[l[k]] = r[k]; //左节点的右侧,指向右节点
}
@@ -530,7 +527,7 @@
- 编译原理
+ 数据库系统
-
diff --git "a/2021/06/15/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225\342\200\224\342\200\224\344\272\214\345\210\206/index.html" "b/2021/06/15/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225\342\200\224\342\200\224\344\272\214\345\210\206/index.html"
index 7e8f1552..4c453a2d 100644
--- "a/2021/06/15/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225\342\200\224\342\200\224\344\272\214\345\210\206/index.html"
+++ "b/2021/06/15/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225\342\200\224\342\200\224\344\272\214\345\210\206/index.html"
@@ -213,35 +213,16 @@
- 数据结构与算法——二分
最近leetcode每日一题经常出二分的题目,正好对前段时间学过的二分进行一些总结,首先这里要明确的一点是,二分的本质并不是单调性,而是通过某种条件将整个区间划分成满足条件和不满足条件的两端即可进行二分查找。
在二分这个专题,主要有两种类型的划分方式,一种是整数划分,一种是浮点数划分,前一种一般是我们最熟悉的二分查找的题型,也是出题比较灵活考的比较多的一种,后一种主要是为控制实数精度而设置的浮点数二分法(建议用double,float有时候会出现精度丢失)。
-
+ 数据结构与算法——二分
最近leetcode每日一题经常出二分的题目,正好对前段时间学过的二分进行一些总结,首先这里要明确的一点是,二分的本质并不是单调性,而是通过某种条件将整个区间划分成满足条件和不满足条件的两端即可进行二分查找。
在二分这个专题,主要有两种类型的划分方式,一种是整数划分,一种是浮点数划分,前一种一般是我们最熟悉的二分查找的题型,也是出题比较灵活考的比较多的一种,后一种主要是为控制实数精度而设置的浮点数二分法(建议用double,float有时候会出现精度丢失)。
整数二分
这里我们拿一道经典例题来给出我们二分的两个十分精妙的模板。AcWing789. 数的范围
bool check(int x) {/* ... */} // 检查x是否满足某种性质
// 区间[l, r]被划分成[l, mid]和[mid + 1, r]时使用:
int bsearch_1(int l, int r)
{
while(l < r)
{
int mid = l + r >> 1; // 如果写r=mid则这里不需要+1
if(check(mid)) r = mid; // check()判断mid是否满足性质
else l = mid + 1;
}
return l; //退出时 l与r相等
}
// 区间[l, r]被划分成[l, mid - 1]和[mid, r]时使用:
int bsearch_2(int l, int r)
{
while(l < r)
{
int mid = l + r + 1 >> 1;
if(check(mid)) l = mid;
else r = mid - 1;
}
return l;
}
-
浮点数二分
浮点数二分考的比较少,主要是实现对于高精度答案的控制。AcWing 790. 数的三次方根
这里有个小bug需要提醒一下,我们以求二次方根为例,我们可以知道,$x=0.01$时,$\sqrt{x}=0.1>x$,所以当我们把二分的区间设置成$[0,x]$时,我们则无法找到答案,所以设置区间的时候我们最好可以设置大一点的区间,或者设置成$[0,\max(1,x)]$

bool check(double x) {/* ... */} // 检查x是否满足某种性质
double bsearch_3(double l, double r)
{
const double eps = 1e-8; // eps 表示精度,取决于题目对精度的要求
while(r - l > eps)
{
double mid = (l + r) / 2; // 对于浮点数二分则不需要考虑+1的问题
if(check(mid)) r = mid;
else l = mid;
}
return l;
}
-
-STL
做题当中手写二分的题其实比较少,基本上记忆上述模板就能解决所以的问题,同时我们在日常做题的时候,为了方便,我们通常是使用STL当中的函数来实现二分,且支持vector,map,set等操作,还有结构体大小比较,这里就有三个一定要记住的API。头文件引入:#include<algorithm>
binary_search
功能:二分查找某个元素是否出现。
返回值:在数组中以二分法检索的方式查找,若在数组(要求数组元素非递减)中查找到indx元素则真,若查找不到则返回值为假。
用法实例:
a.数组用法
-int a[100]= {4,10,11,30,69,70,96,100};
int b=binary_search(a,a+9,4);//查找成功,返回1
cout<<"在数组中查找元素4,结果为:"<<b<<endl;
-b.vector用法
-vector<int> res = {1,2,3};
cout<<binary_search(res.begin(),res.end(),3)<<endl;
-lower_bound
功能:查找非递减序列[first,last) 内第一个大于或等于某个元素的位置。
返回值:如果找到返回找到元素的地址否则返回数组边界的下一个元素的地址。(这样不注意的话会越界,小心)
用法实例:
-int a[100]= {4,10,11,30,69,70,96,100};
int d=lower_bound(a,a+9,10)-a;
cout<<"在数组中查找第一个大于等于10的元素位置,结果为:"<<d<<endl;
int e=lower_bound(a,a+9,101)-a;
cout<<"在数组中查找第一个大于等于101的元素位置,结果为:"<<e<<endl;
-b.vector用法
-vector<int> res = {1,2,3};
vector<int>::iterator it = lower_bound(res.begin(),res.end(),3);//返回迭代器的位置
//如果不存在,迭代器的位置会返回res.end()
if(it==res.end()) cout<<"不存在"<<endl;
else cout<<"求出下标:"<<(it - res.begin())<<endl;
//也可以添加偏移量
vector<int>::iterator it = lower_bound(res.begin()+1,res.end(),3);
-
+STL
做题当中手写二分的题其实比较少,基本上记忆上述模板就能解决所以的问题,同时我们在日常做题的时候,为了方便,我们通常是使用STL当中的函数来实现二分,且支持vector,map,set等操作,还有结构体大小比较,这里就有三个一定要记住的API。头文件引入:#include<algorithm>
binary_search
功能:二分查找某个元素是否出现。
返回值:在数组中以二分法检索的方式查找,若在数组(要求数组元素非递减)中查找到indx元素则真,若查找不到则返回值为假。
用法实例:
a.数组用法
int a[100]= {4,10,11,30,69,70,96,100};
int b=binary_search(a,a+9,4);//查找成功,返回1
cout<<"在数组中查找元素4,结果为:"<<b<<endl;
b.vector用法
vector<int> res = {1,2,3};
cout<<binary_search(res.begin(),res.end(),3)<<endl;
lower_bound
功能:查找非递减序列[first,last) 内第一个大于或等于某个元素的位置。
返回值:如果找到返回找到元素的地址否则返回数组边界的下一个元素的地址。(这样不注意的话会越界,小心)
用法实例:
int a[100]= {4,10,11,30,69,70,96,100};
int d=lower_bound(a,a+9,10)-a;
cout<<"在数组中查找第一个大于等于10的元素位置,结果为:"<<d<<endl;
int e=lower_bound(a,a+9,101)-a;
cout<<"在数组中查找第一个大于等于101的元素位置,结果为:"<<e<<endl;
b.vector用法
vector<int> res = {1,2,3};
vector<int>::iterator it = lower_bound(res.begin(),res.end(),3);//返回迭代器的位置
//如果不存在,迭代器的位置会返回res.end()
if(it==res.end()) cout<<"不存在"<<endl;
else cout<<"求出下标:"<<(it - res.begin())<<endl;
//也可以添加偏移量
vector<int>::iterator it = lower_bound(res.begin()+1,res.end(),3);
upper_bound
功能:查找非递减序列[first,last) 内第一个大于某个元素的位置。
-返回值:如果找到返回找到元素的地址,否则返回数组边界的下一个元素的地址。(同样这样不注意的话会越界,小心)
用法实例:
-int a[100]= {4,10,11,30,69,70,96,100};
int d=upper_bound(a,a+9,10)-a;
cout<<"在数组中查找第一个大于等于10的元素位置,结果为:"<<d<<endl;
int e=upper_bound(a,a+9,101)-a;
cout<<"在数组中查找第一个大于等于101的元素位置,结果为:"<<e<<endl;
-b.vector用法
-vector<int> res = {1,2,3};
vector<int>::iterator it = upper_bound(res.begin(),res.end(),3);//返回迭代器的位置
//如果不存在,迭代器的位置会返回res.end()
if(it==res.end()) cout<<"不存在"<<endl;
else cout<<"求出下标:"<<(it - res.begin())<<endl;
//也可以添加偏移量
vector<int>::iterator it = upper_bound(res.begin()+1,res.end(),3);
-
-经典例题
这里我顺便给出这两天的每日一题的解题方案,里面还涉及到了一个防止溢出的二分处理trick。
猜数字大小

-/**
* Forward declaration of guess API.
* @param num your guess
* @return -1 if num is lower than the guess number
* 1 if num is higher than the guess number
* otherwise return 0
* int guess(int num);
*/
class Solution {
public:
int guessNumber(int n) {
int l = 1;
int r = n;
while(l<r)
{
int mid = l + (r - l >> 1);//防止溢出
if(guess(mid)<=0)
r = mid;
else
l = mid + 1;
}
return r;
}
};
-
-class Solution {
public:
int peakIndexInMountainArray(vector<int>& arr) {
int l = 0;
int r = arr.size() - 1;
while(l<r)
{
int mid = l + r >> 1;
if(arr[mid]>arr[mid+1]) r = mid;
else l = mid+1;
}
return l;
}
};
-这是三叶姐姐的二分经典题型汇总,大家也可以参考一下。

+返回值:如果找到返回找到元素的地址,否则返回数组边界的下一个元素的地址。(同样这样不注意的话会越界,小心)
用法实例:
int a[100]= {4,10,11,30,69,70,96,100};
int d=upper_bound(a,a+9,10)-a;
cout<<"在数组中查找第一个大于等于10的元素位置,结果为:"<<d<<endl;
int e=upper_bound(a,a+9,101)-a;
cout<<"在数组中查找第一个大于等于101的元素位置,结果为:"<<e<<endl;
b.vector用法
vector<int> res = {1,2,3};
vector<int>::iterator it = upper_bound(res.begin(),res.end(),3);//返回迭代器的位置
//如果不存在,迭代器的位置会返回res.end()
if(it==res.end()) cout<<"不存在"<<endl;
else cout<<"求出下标:"<<(it - res.begin())<<endl;
//也可以添加偏移量
vector<int>::iterator it = upper_bound(res.begin()+1,res.end(),3);
+经典例题
这里我顺便给出这两天的每日一题的解题方案,里面还涉及到了一个防止溢出的二分处理trick。
猜数字大小
/**
* Forward declaration of guess API.
* @param num your guess
* @return -1 if num is lower than the guess number
* 1 if num is higher than the guess number
* otherwise return 0
* int guess(int num);
*/
class Solution {
public:
int guessNumber(int n) {
int l = 1;
int r = n;
while(l<r)
{
int mid = l + (r - l >> 1);//防止溢出
if(guess(mid)<=0)
r = mid;
else
l = mid + 1;
}
return r;
}
};
山脉数组的峰顶索引

class Solution {
public:
int peakIndexInMountainArray(vector<int>& arr) {
int l = 0;
int r = arr.size() - 1;
while(l<r)
{
int mid = l + r >> 1;
if(arr[mid]>arr[mid+1]) r = mid;
else l = mid+1;
}
return l;
}
};
这是三叶姐姐的二分经典题型汇总,大家也可以参考一下。
@@ -546,7 +527,7 @@
- 编译原理
+ 数据库系统
-
diff --git "a/2021/06/16/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224voting-bagging/index.html" "b/2021/06/16/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224voting-bagging/index.html"
index 16b2e732..45428e69 100644
--- "a/2021/06/16/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224voting-bagging/index.html"
+++ "b/2021/06/16/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224voting-bagging/index.html"
@@ -217,8 +217,7 @@
10101100100111001011011011011
这导致的结果可能是致命的。一个常用的纠错方法是重复多次发送数据,并以少数服从多数的方法确定正确的传输数据。一般情况下,错误总是发生在局部,因此融合多个数据是降低误差的一个好方法,这就是投票法的基本思路。
对于回归模型来说,投票法最终的预测结果是多个其他回归模型预测结果的平均值。
-对于分类模型,硬投票法的预测结果是多个模型预测结果中出现次数最多的类别,软投票对各类预测结果的概率进行求和,最终选取概率之和最大的类标签。
-
+
对于分类模型,硬投票法的预测结果是多个模型预测结果中出现次数最多的类别,软投票对各类预测结果的概率进行求和,最终选取概率之和最大的类标签。
投票法的原理分析
投票法是一种遵循少数服从多数原则的集成学习模型,通过多个模型的集成降低方差,从而提高模型的鲁棒性。在理想情况下,投票法的预测效果应当优于任何一个基模型的预测效果。
投票法在回归模型与分类模型上均可使用:
@@ -257,32 +256,23 @@ 投票法的案例分析(基于sklearn,介绍pipe管道的使用以及voting的使用)
Sklearn中提供了 VotingRegressor 与 VotingClassifier 两个投票方法。 这两种模型的操作方式相同,并采用相同的参数。使用模型需要提供一个模型列表,列表中每个模型采用Tuple的结构表示,第一个元素代表名称,第二个元素代表模型,需要保证每个模型必须拥有唯一的名称。
例如这里,我们定义两个模型:
models = [('lr',LogisticRegression()),('svm',SVC())]
ensemble = VotingClassifier(estimators=models)
-
有时某些模型需要一些预处理操作,我们可以为他们定义Pipeline完成模型预处理工作:
models = [('lr',LogisticRegression()),('svm',make_pipeline(StandardScaler(),SVC()))]
ensemble = VotingClassifier(estimators=models)
-
模型还提供了voting参数让我们选择软投票或者硬投票:
models = [('lr',LogisticRegression()),('svm',SVC())]
ensemble = VotingClassifier(estimators=models, voting='soft')
-
下面我们使用一个完整的例子演示投票法的使用:
首先我们创建一个1000个样本,20个特征的随机数据集:
# test classification dataset
from sklearn.datasets import make_classification
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=2)
# summarize the dataset
print(X.shape, y.shape)
-
我们使用多个KNN模型作为基模型演示投票法,其中每个模型采用不同的邻居值K参数:
# get a voting ensemble of models
def get_voting():
# define the base models
models = list()
models.append(('knn1', KNeighborsClassifier(n_neighbors=1)))
models.append(('knn3', KNeighborsClassifier(n_neighbors=3)))
models.append(('knn5', KNeighborsClassifier(n_neighbors=5)))
models.append(('knn7', KNeighborsClassifier(n_neighbors=7)))
models.append(('knn9', KNeighborsClassifier(n_neighbors=9)))
# define the voting ensemble
ensemble = VotingClassifier(estimators=models, voting='hard')
return ensemble
-
然后,我们可以创建一个模型列表来评估投票带来的提升,包括KNN模型配置的每个独立版本和硬投票模型。下面的get_models()函数可以为我们创建模型列表进行评估。
# get a list of models to evaluate
def get_models():
models = dict()
models['knn1'] = KNeighborsClassifier(n_neighbors=1)
models['knn3'] = KNeighborsClassifier(n_neighbors=3)
models['knn5'] = KNeighborsClassifier(n_neighbors=5)
models['knn7'] = KNeighborsClassifier(n_neighbors=7)
models['knn9'] = KNeighborsClassifier(n_neighbors=9)
models['hard_voting'] = get_voting()
return models
-
下面的evaluate_model()函数接收一个模型实例,并以分层10倍交叉验证三次重复的分数列表的形式返回。
# evaluate a give model using cross-validation
def evaluate_model(model, X, y):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise')
return scores
-
然后,我们可以报告每个算法的平均性能,还可以创建一个箱形图和须状图来比较每个算法的精度分数分布。
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model, X, y)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()
-
我们得到的结果如下:
>knn1 0.873 (0.030)
>knn3 0.889 (0.038)
>knn5 0.895 (0.031)
>knn7 0.899 (0.035)
>knn9 0.900 (0.033)
>hard_voting 0.902 (0.034)
-
显然投票的效果略大于任何一个基模型。
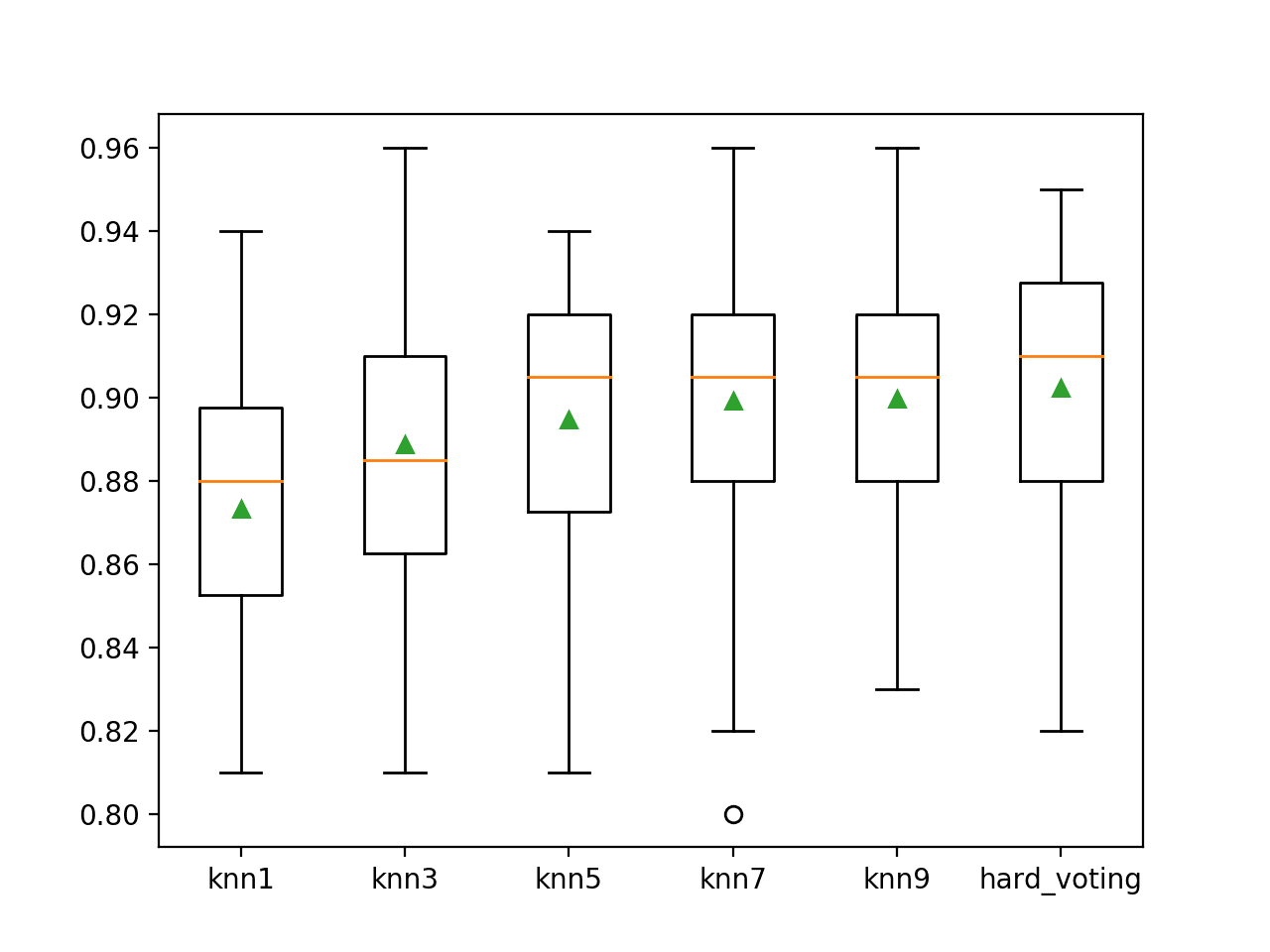
通过箱形图我们可以看到硬投票方法对交叉验证整体预测结果分布带来的提升。
@@ -294,10 +284,8 @@ bagging的案例分析(基于sklearn,介绍随机森林的相关理论以及实例)
Sklearn为我们提供了 BaggingRegressor 与 BaggingClassifier 两种Bagging方法的API,我们在这里通过一个完整的例子演示Bagging在分类问题上的具体应用。这里两种方法的默认基模型是树模型。
我们创建一个含有1000个样本20维特征的随机分类数据集:
# test classification dataset
from sklearn.datasets import make_classification
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=5)
# summarize the dataset
print(X.shape, y.shape)
-
我们将使用重复的分层k-fold交叉验证来评估该模型,一共重复3次,每次有10个fold。我们将评估该模型在所有重复交叉验证中性能的平均值和标准差。
# evaluate bagging algorithm for classification
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.ensemble import BaggingClassifier
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=5)
# define the model
model = BaggingClassifier()
# evaluate the model
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise')
# report performance
print('Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))
-
最终模型的效果是Accuracy: 0.856 标准差0.037
@@ -607,7 +595,7 @@
- 编译原理
+ 数据库系统
-
diff --git "a/2021/06/17/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224GBDT/index.html" "b/2021/06/17/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224GBDT/index.html"
index c9b411d9..326193c9 100644
--- "a/2021/06/17/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224GBDT/index.html"
+++ "b/2021/06/17/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224GBDT/index.html"
@@ -223,51 +223,79 @@
- 梯度提升决策树(GBDT)
(1) 基于残差学习的提升树算法:
在前面的学习过程中,我们一直讨论的都是分类树,比如Adaboost算法,并没有涉及回归的例子。在上一小节我们提到了一个加法模型+前向分步算法的框架,那能否使用这个框架解决回归的例子呢?答案是肯定的。接下来我们来探讨下如何使用加法模型+前向分步算法的框架实现回归问题。
在使用加法模型+前向分步算法的框架解决问题之前,我们需要首先确定框架内使用的基函数是什么,在这里我们使用决策树分类器。前面第二章我们已经学过了回归树的基本原理,树算法最重要是寻找最佳的划分点,分类树用纯度来判断最佳划分点使用信息增益(ID3算法),信息增益比(C4.5算法),基尼系数(CART分类树)。但是在回归树中的样本标签是连续数值,可划分点包含了所有特征的所有可取的值。所以再使用熵之类的指标不再合适,取而代之的是平方误差,它能很好的评判拟合程度。 基函数确定了以后,我们需要确定每次提升的标准是什么。回想Adaboost算法,在Adaboost算法内使用了分类错误率修正样本权重以及计算每个基本分类器的权重,那回归问题没有分类错误率可言,也就没办法在这里的回归问题使用了,因此我们需要另辟蹊径。模仿分类错误率,我们用每个样本的残差表示每次使用基函数预测时没有解决的那部分问题。因此,我们可以得出如下算法:
-
-输入数据集$T=\left{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \cdots,\left(x_{N}, y_{N}\right)\right}, x_{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}, y_{i} \in \mathcal{Y} \subseteq \mathbf{R}$,输出最终的提升树$f_{M}(x)$
+ 梯度提升决策树(GBDT)
(1) 基于残差学习的提升树算法:
在前面的学习过程中,我们一直讨论的都是分类树,比如Adaboost算法,并没有涉及回归的例子。在上一小节我们提到了一个加法模型+前向分步算法的框架,那能否使用这个框架解决回归的例子呢?答案是肯定的。接下来我们来探讨下如何使用加法模型+前向分步算法的框架实现回归问题。
在使用加法模型+前向分步算法的框架解决问题之前,我们需要首先确定框架内使用的基函数是什么,在这里我们使用决策树分类器。前面第二章我们已经学过了回归树的基本原理,树算法最重要是寻找最佳的划分点,分类树用纯度来判断最佳划分点使用信息增益(ID3算法),信息增益比(C4.5算法),基尼系数(CART分类树)。但是在回归树中的样本标签是连续数值,可划分点包含了所有特征的所有可取的值。所以再使用熵之类的指标不再合适,取而代之的是平方误差,它能很好的评判拟合程度。 基函数确定了以后,我们需要确定每次提升的标准是什么。回想Adaboost算法,在Adaboost算法内使用了分类错误率修正样本权重以及计算每个基本分类器的权重,那回归问题没有分类错误率可言,也就没办法在这里的回归问题使用了,因此我们需要另辟蹊径。模仿分类错误率,我们用每个样本的残差表示每次使用基函数预测时没有解决的那部分问题。因此,我们可以得出如下算法:
输入数据集$T=\left{\left(x{1}, y{1}\right),\left(x{2}, y{2}\right), \cdots,\left(x{N}, y{N}\right)\right}, x{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}, y{i} \in \mathcal{Y} \subseteq \mathbf{R}$,输出最终的提升树$f_{M}(x)$
- 初始化$f_0(x) = 0$
- 对m = 1,2,…,M:
-- 计算每个样本的残差:$r_{m i}=y_{i}-f_{m-1}\left(x_{i}\right), \quad i=1,2, \cdots, N$
-- 拟合残差$r_{mi}$学习一棵回归树,得到$T\left(x ; \Theta_{m}\right)$
-- 更新$f_{m}(x)=f_{m-1}(x)+T\left(x ; \Theta_{m}\right)$
+- 计算每个样本的残差:$r{m i}=y{i}-f{m-1}\left(x{i}\right), \quad i=1,2, \cdots, N$
+- 拟合残差$r{mi}$学习一棵回归树,得到$T\left(x ; \Theta{m}\right)$
+- 更新$f{m}(x)=f{m-1}(x)+T\left(x ; \Theta_{m}\right)$
-- 得到最终的回归问题的提升树:$f_{M}(x)=\sum_{m=1}^{M} T\left(x ; \Theta_{m}\right)$
+- 得到最终的回归问题的提升树:$f{M}(x)=\sum{m=1}^{M} T\left(x ; \Theta_{m}\right)$
-下面我们用一个实际的案例来使用这个算法:(案例来源:李航老师《统计学习方法》)
训练数据如下表,学习这个回归问题的提升树模型,考虑只用树桩作为基函数。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6RIHgryn-1623945003185)(./1.png)]](https://img-blog.csdnimg.cn/20210617235042845.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0phY2tfX19F,size_16,color_FFFFFF,t_70)




-至此,我们已经能够建立起依靠加法模型+前向分步算法的框架解决回归问题的算法,叫提升树算法。那么,这个算法还是否有提升的空间呢?
(2) 梯度提升决策树算法(GBDT):
提升树利用加法模型和前向分步算法实现学习的过程,当损失函数为平方损失和指数损失时,每一步优化是相当简单的,也就是我们前面探讨的提升树算法和Adaboost算法。但是对于一般的损失函数而言,往往每一步的优化不是那么容易,针对这一问题,我们得分析问题的本质,也就是是什么导致了在一般损失函数条件下的学习困难。对比以下损失函数:
$$
\begin{array}{l|l|l}
\hline \text { Setting } & \text { Loss Function } & -\partial L\left(y_{i}, f\left(x_{i}\right)\right) / \partial f\left(x_{i}\right) \
\hline \text { Regression } & \frac{1}{2}\left[y_{i}-f\left(x_{i}\right)\right]^{2} & y_{i}-f\left(x_{i}\right) \
\hline \text { Regression } & \left|y_{i}-f\left(x_{i}\right)\right| & \operatorname{sign}\left[y_{i}-f\left(x_{i}\right)\right] \
\hline \text { Regression } & \text { Huber } & y_{i}-f\left(x_{i}\right) \text { for }\left|y_{i}-f\left(x_{i}\right)\right| \leq \delta_{m} \
& & \delta_{m} \operatorname{sign}\left[y_{i}-f\left(x_{i}\right)\right] \text { for }\left|y_{i}-f\left(x_{i}\right)\right|>\delta_{m} \
& & \text { where } \delta_{m}=\alpha \text { th-quantile }\left{\left|y_{i}-f\left(x_{i}\right)\right|\right} \
\hline \text { Classification } & \text { Deviance } & k \text { th component: } I\left(y_{i}=\mathcal{G}{k}\right)-p{k}\left(x_{i}\right) \
\hline
\end{array}
$$
观察Huber损失函数:
$$
L_{\delta}(y, f(x))=\left{\begin{array}{ll}
\frac{1}{2}(y-f(x))^{2} & \text { for }|y-f(x)| \leq \delta \
\delta|y-f(x)|-\frac{1}{2} \delta^{2} & \text { otherwise }
\end{array}\right.
$$
针对上面的问题,Freidman提出了梯度提升算法(gradient boosting),这是利用最速下降法的近似方法,利用损失函数的负梯度在当前模型的值$-\left[\frac{\partial L\left(y, f\left(x_{i}\right)\right)}{\partial f\left(x_{i}\right)}\right]{f(x)=f{m-1}(x)}$作为回归问题提升树算法中的残差的近似值,拟合回归树。与其说负梯度作为残差的近似值,不如说残差是负梯度的一种特例。
以下开始具体介绍梯度提升算法:
输入训练数据集$T=\left{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \cdots,\left(x_{N}, y_{N}\right)\right}, x_{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}, y_{i} \in \mathcal{Y} \subseteq \mathbf{R}$和损失函数$L(y, f(x))$,输出回归树$\hat{f}(x)$
+下面我们用一个实际的案例来使用这个算法:(案例来源:李航老师《统计学习方法》)
训练数据如下表,学习这个回归问题的提升树模型,考虑只用树桩作为基函数。
+至此,我们已经能够建立起依靠加法模型+前向分步算法的框架解决回归问题的算法,叫提升树算法。那么,这个算法还是否有提升的空间呢?
(2) 梯度提升决策树算法(GBDT):
提升树利用加法模型和前向分步算法实现学习的过程,当损失函数为平方损失和指数损失时,每一步优化是相当简单的,也就是我们前面探讨的提升树算法和Adaboost算法。但是对于一般的损失函数而言,往往每一步的优化不是那么容易,针对这一问题,我们得分析问题的本质,也就是是什么导致了在一般损失函数条件下的学习困难。对比以下损失函数:
+观察Huber损失函数:
+针对上面的问题,Freidman提出了梯度提升算法(gradient boosting),这是利用最速下降法的近似方法,利用损失函数的负梯度在当前模型的值$-\left[\frac{\partial L\left(y, f\left(x{i}\right)\right)}{\partial f\left(x{i}\right)}\right]{f(x)=f{m-1}(x)}$作为回归问题提升树算法中的残差的近似值,拟合回归树。与其说负梯度作为残差的近似值,不如说残差是负梯度的一种特例。
以下开始具体介绍梯度提升算法:
输入训练数据集$T=\left{\left(x{1}, y{1}\right),\left(x{2}, y{2}\right), \cdots,\left(x{N}, y{N}\right)\right}, x{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}, y{i} \in \mathcal{Y} \subseteq \mathbf{R}$和损失函数$L(y, f(x))$,输出回归树$\hat{f}(x)$
-- 初始化$f_{0}(x)=\arg \min {c} \sum{i=1}^{N} L\left(y_{i}, c\right)$
+- 初始化$f{0}(x)=\arg \min {c} \sum{i=1}^{N} L\left(y{i}, c\right)$
- 对于m=1,2,…,M:
-- 对i = 1,2,…,N计算:$r_{m i}=-\left[\frac{\partial L\left(y_{i}, f\left(x_{i}\right)\right)}{\partial f\left(x_{i}\right)}\right]{f(x)=f{m-1}(x)}$
-- 对$r_{mi}$拟合一个回归树,得到第m棵树的叶结点区域$R_{m j}, j=1,2, \cdots, J$
-- 对j=1,2,…J,计算:$c_{m j}=\arg \min {c} \sum{x_{i} \in R_{m j}} L\left(y_{i}, f_{m-1}\left(x_{i}\right)+c\right)$
-- 更新$f_{m}(x)=f_{m-1}(x)+\sum_{j=1}^{J} c_{m j} I\left(x \in R_{m j}\right)$
+- 对i = 1,2,…,N计算:$r{m i}=-\left[\frac{\partial L\left(y{i}, f\left(x{i}\right)\right)}{\partial f\left(x{i}\right)}\right]{f(x)=f{m-1}(x)}$
+- 对$r{mi}$拟合一个回归树,得到第m棵树的叶结点区域$R{m j}, j=1,2, \cdots, J$
+- 对j=1,2,…J,计算:$c{m j}=\arg \min {c} \sum{x{i} \in R{m j}} L\left(y{i}, f{m-1}\left(x{i}\right)+c\right)$
+- 更新$f{m}(x)=f{m-1}(x)+\sum{j=1}^{J} c{m j} I\left(x \in R_{m j}\right)$
-- 得到回归树:$\hat{f}(x)=f_{M}(x)=\sum_{m=1}^{M} \sum_{j=1}^{J} c_{m j} I\left(x \in R_{m j}\right)$
+- 得到回归树:$\hat{f}(x)=f{M}(x)=\sum{m=1}^{M} \sum{j=1}^{J} c{m j} I\left(x \in R_{m j}\right)$
下面,我们来使用一个具体的案例来说明GBDT是如何运作的(案例来源:https://blog.csdn.net/zpalyq110/article/details/79527653 ):
下面的表格是数据:

-学习率:learning_rate=0.1,迭代次数:n_trees=5,树的深度:max_depth=3
平方损失的负梯度为:
$$
-\left[\frac{\left.\partial L\left(y, f\left(x_{i}\right)\right)\right)}{\partial f\left(x_{i}\right)}\right]{f(x)=f{t-1}(x)}=y-f\left(x_{i}\right)
$$
$c=(1.1+1.3+1.7+1.8)/4=1.475,f_{0}(x)=c=1.475$

+学习率:learning_rate=0.1,迭代次数:n_trees=5,树的深度:max_depth=3
平方损失的负梯度为:
+$c=(1.1+1.3+1.7+1.8)/4=1.475,f_{0}(x)=c=1.475$
学习决策树,分裂结点:


对于左节点,只有0,1两个样本,那么根据下表我们选择年龄7进行划分:

对于右节点,只有2,3两个样本,那么根据下表我们选择年龄30进行划分:


-因此根据$\Upsilon_{j 1}=\underbrace{\arg \min }{\Upsilon} \sum{x_{i} \in R_{j 1}} L\left(y_{i}, f_{0}\left(x_{i}\right)+\Upsilon\right)$:
$$
\begin{array}{l}
\left(x_{0} \in R_{11}\right), \quad \Upsilon_{11}=-0.375 \
\left(x_{1} \in R_{21}\right), \quad \Upsilon_{21}=-0.175 \
\left(x_{2} \in R_{31}\right), \quad \Upsilon_{31}=0.225 \
\left(x_{3} \in R_{41}\right), \quad \Upsilon_{41}=0.325
\end{array}
$$
这里其实和上面初始化学习器是一个道理,平方损失,求导,令导数等于零,化简之后得到每个叶子节点的参数$\Upsilon$,其实就是标签值的均值。
最后得到五轮迭代:

-最后的强学习器为:$f(x)=f_{5}(x)=f_{0}(x)+\sum_{m=1}^{5} \sum_{j=1}^{4} \Upsilon_{j m} I\left(x \in R_{j m}\right)$。
其中:
$$
\begin{array}{ll}
f_{0}(x)=1.475 & f_{2}(x)=0.0205 \
f_{3}(x)=0.1823 & f_{4}(x)=0.1640 \
f_{5}(x)=0.1476
\end{array}
$$
预测结果为:
$$
f(x)=1.475+0.1 *(0.2250+0.2025+0.1823+0.164+0.1476)=1.56714
$$
为什么要用学习率呢?这是Shrinkage的思想,如果每次都全部加上(学习率为1)很容易一步学到位导致过拟合。
+因此根据$\Upsilon{j 1}=\underbrace{\arg \min }{\Upsilon} \sum{x{i} \in R{j 1}} L\left(y{i}, f{0}\left(x{i}\right)+\Upsilon\right)$:
+这里其实和上面初始化学习器是一个道理,平方损失,求导,令导数等于零,化简之后得到每个叶子节点的参数$\Upsilon$,其实就是标签值的均值。
最后得到五轮迭代:
+最后的强学习器为:$f(x)=f{5}(x)=f{0}(x)+\sum{m=1}^{5} \sum{j=1}^{4} \Upsilon{j m} I\left(x \in R{j m}\right)$。
其中:
+预测结果为:
+为什么要用学习率呢?这是Shrinkage的思想,如果每次都全部加上(学习率为1)很容易一步学到位导致过拟合。
下面我们来使用sklearn来使用GBDT:
- https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingRegressor.html#sklearn.ensemble.GradientBoostingRegressor
- https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingClassifier.html?highlight=gra#sklearn.ensemble.GradientBoostingClassifier
from sklearn.metrics import mean_squared_error
from sklearn.datasets import make_friedman1
from sklearn.ensemble import GradientBoostingRegressor
'''
GradientBoostingRegressor参数解释:
loss:{‘ls’, ‘lad’, ‘huber’, ‘quantile’}, default=’ls’:‘ls’ 指最小二乘回归. ‘lad’ (最小绝对偏差) 是仅基于输入变量的顺序信息的高度鲁棒的损失函数。. ‘huber’ 是两者的结合. ‘quantile’允许分位数回归(用于alpha指定分位数)
learning_rate:学习率缩小了每棵树的贡献learning_rate。在learning_rate和n_estimators之间需要权衡。
n_estimators:要执行的提升次数。
subsample:用于拟合各个基础学习者的样本比例。如果小于1.0,则将导致随机梯度增强。subsample与参数n_estimators。选择会导致方差减少和偏差增加。subsample < 1.0
criterion:{'friedman_mse','mse','mae'},默认='friedman_mse':“ mse”是均方误差,“ mae”是平均绝对误差。默认值“ friedman_mse”通常是最好的,因为在某些情况下它可以提供更好的近似值。
min_samples_split:拆分内部节点所需的最少样本数
min_samples_leaf:在叶节点处需要的最小样本数。
min_weight_fraction_leaf:在所有叶节点处(所有输入样本)的权重总和中的最小加权分数。如果未提供sample_weight,则样本的权重相等。
max_depth:各个回归模型的最大深度。最大深度限制了树中节点的数量。调整此参数以获得最佳性能;最佳值取决于输入变量的相互作用。
min_impurity_decrease:如果节点分裂会导致杂质的减少大于或等于该值,则该节点将被分裂。
min_impurity_split:提前停止树木生长的阈值。如果节点的杂质高于阈值,则该节点将分裂
max_features{‘auto’, ‘sqrt’, ‘log2’},int或float:寻找最佳分割时要考虑的功能数量:
如果为int,则max_features在每个分割处考虑特征。
如果为float,max_features则为小数,并在每次拆分时考虑要素。int(max_features * n_features)
如果“auto”,则max_features=n_features。
如果是“ sqrt”,则max_features=sqrt(n_features)。
如果为“ log2”,则为max_features=log2(n_features)。
如果没有,则max_features=n_features。
'''
X, y = make_friedman1(n_samples=1200, random_state=0, noise=1.0)
X_train, X_test = X[:200], X[200:]
y_train, y_test = y[:200], y[200:]
reg = GradientBoostingRegressor(n_estimators=100,
learning_rate=0.1,max_depth=1, random_state=0, loss='ls')
est = reg.fit(X_train, y_train)
mean_squared_error(y_test, est.predict(X_test))
-
from sklearn.datasets import make_regression
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.model_selection import train_test_split
X, y = make_regression(random_state=0)
X_train, X_test, y_train, y_test = train_test_split(
X, y, random_state=0)
reg = GradientBoostingRegressor(random_state=0)
reg.fit(X_train, y_train)
reg.score(X_test, y_test)
-
-
GradientBoostingRegressor与GradientBoostingClassifier函数的各个参数的参考文档:
- https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingRegressor.html#sklearn.ensemble.GradientBoostingRegressor
@@ -581,7 +609,7 @@
-
@@ -589,15 +617,15 @@
-
diff --git "a/2021/06/17/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224adaboost\345\216\237\347\220\206\345\222\214sklearn\345\256\236\347\216\260/index.html" "b/2021/06/17/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224adaboost\345\216\237\347\220\206\345\222\214sklearn\345\256\236\347\216\260/index.html"
index 779a7549..0081ed3a 100644
--- "a/2021/06/17/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224adaboost\345\216\237\347\220\206\345\222\214sklearn\345\256\236\347\216\260/index.html"
+++ "b/2021/06/17/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224adaboost\345\216\237\347\220\206\345\222\214sklearn\345\256\236\347\216\260/index.html"
@@ -211,72 +211,108 @@
- 1. 导论
在前面的学习中,我们探讨了一系列简单而实用的回归和分类模型,同时也探讨了如何使用集成学习家族中的Bagging思想去优化最终的模型。Bagging思想的实质是:通过Bootstrap 的方式对全样本数据集进行抽样得到抽样子集,对不同的子集使用同一种基本模型进行拟合,然后投票得出最终的预测。我们也从前面的探讨知道:Bagging主要通过降低方差的方式减少预测误差。那么,本章介绍的Boosting是与Bagging截然不同的思想,Boosting方法是使用同一组数据集进行反复学习,得到一系列简单模型,然后组合这些模型构成一个预测性能十分强大的机器学习模型。 显然,Boosting思想提高最终的预测效果是通过不断减少偏差的形式,与Bagging有着本质的不同。在Boosting这一大类方法中,笔者主要介绍两类常用的Boosting方式:Adaptive Boosting 和 Gradient Boosting 以及它们的变体Xgboost、LightGBM以及Catboost。
-
+ 1. 导论
在前面的学习中,我们探讨了一系列简单而实用的回归和分类模型,同时也探讨了如何使用集成学习家族中的Bagging思想去优化最终的模型。Bagging思想的实质是:通过Bootstrap 的方式对全样本数据集进行抽样得到抽样子集,对不同的子集使用同一种基本模型进行拟合,然后投票得出最终的预测。我们也从前面的探讨知道:Bagging主要通过降低方差的方式减少预测误差。那么,本章介绍的Boosting是与Bagging截然不同的思想,Boosting方法是使用同一组数据集进行反复学习,得到一系列简单模型,然后组合这些模型构成一个预测性能十分强大的机器学习模型。 显然,Boosting思想提高最终的预测效果是通过不断减少偏差的形式,与Bagging有着本质的不同。在Boosting这一大类方法中,笔者主要介绍两类常用的Boosting方式:Adaptive Boosting 和 Gradient Boosting 以及它们的变体Xgboost、LightGBM以及Catboost。
2. Boosting方法的基本思路
在正式介绍Boosting思想之前,我想先介绍两个例子:
第一个例子:不知道大家有没有做过错题本,我们将每次测验的错的题目记录在错题本上,不停的翻阅,直到我们完全掌握(也就是能够在考试中能够举一反三)。
第二个例子:对于一个复杂任务来说,将多个专家的判断进行适当的综合所作出的判断,要比其中任何一个专家单独判断要好。实际上这是一种“三个臭皮匠顶个诸葛亮的道理”。
这两个例子都说明Boosting的道理,也就是不错地重复学习达到最终的要求。
Boosting的提出与发展离不开Valiant和 Kearns的努力,历史上正是Valiant和 Kearns提出了”强可学习”和”弱可学习”的概念。那什么是”强可学习”和”弱可学习”呢?在概率近似正确PAC学习的框架下:
- 弱学习:识别错误率小于1/2(即准确率仅比随机猜测略高的学习算法)
- 强学习:识别准确率很高并能在多项式时间内完成的学习算法
-非常有趣的是,在PAC 学习的框架下,强可学习和弱可学习是等价的,也就是说一个概念是强可学习的充分必要条件是这个概念是弱可学习的。这样一来,问题便是:在学习中,如果已经发现了弱可学习算法,能否将他提升至强可学习算法。因为,弱可学习算法比强可学习算法容易得多。提升方法就是从弱学习算法出发,反复学习,得到一系列弱分类器(又称为基本分类器),然后通过一定的形式去组合这些弱分类器构成一个强分类器。大多数的Boosting方法都是通过改变训练数据集的概率分布(训练数据不同样本的权值),针对不同概率分布的数据调用弱分类算法学习一系列的弱分类器。
对于Boosting方法来说,有两个问题需要给出答案:第一个是每一轮学习应该如何改变数据的概率分布,第二个是如何将各个弱分类器组合起来。关于这两个问题,不同的Boosting算法会有不同的答案,我们接下来介绍一种最经典的Boosting算法—-Adaboost,我们需要理解Adaboost是怎么处理这两个问题以及为什么这么处理的。
+非常有趣的是,在PAC 学习的框架下,强可学习和弱可学习是等价的,也就是说一个概念是强可学习的充分必要条件是这个概念是弱可学习的。这样一来,问题便是:在学习中,如果已经发现了弱可学习算法,能否将他提升至强可学习算法。因为,弱可学习算法比强可学习算法容易得多。提升方法就是从弱学习算法出发,反复学习,得到一系列弱分类器(又称为基本分类器),然后通过一定的形式去组合这些弱分类器构成一个强分类器。大多数的Boosting方法都是通过改变训练数据集的概率分布(训练数据不同样本的权值),针对不同概率分布的数据调用弱分类算法学习一系列的弱分类器。
对于Boosting方法来说,有两个问题需要给出答案:第一个是每一轮学习应该如何改变数据的概率分布,第二个是如何将各个弱分类器组合起来。关于这两个问题,不同的Boosting算法会有不同的答案,我们接下来介绍一种最经典的Boosting算法——Adaboost,我们需要理解Adaboost是怎么处理这两个问题以及为什么这么处理的。
3. Adaboost算法
Adaboost的基本原理
对于Adaboost来说,解决上述的两个问题的方式是:
- 提高那些被前一轮分类器错误分类的样本的权重,而降低那些被正确分类的样本的权重。这样一来,那些在上一轮分类器中没有得到正确分类的样本,由于其权重的增大而在后一轮的训练中“备受关注”。
- 各个弱分类器的组合是通过采取加权多数表决的方式,具体来说,加大分类错误率低的弱分类器的权重,因为这些分类器能更好地完成分类任务,而减小分类错误率较大的弱分类器的权重,使其在表决中起较小的作用。
-现在,我们来具体介绍Adaboost算法:(参考李航老师的《统计学习方法》)
假设给定一个二分类的训练数据集:$T=\left{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \cdots,\left(x_{N}, y_{N}\right)\right}$ ,其中每个样本点由特征与类别组成。特征$x_{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}$,类别$y_{i} \in \mathcal{Y}={-1,+1}$,$\mathcal{X}$是特征空间,$ \mathcal{Y}$是类别集合,输出最终分类器$G(x)$。Adaboost算法如下:
(1) 初始化训练数据的分布:$D_{1}=\left(w_{11}, \cdots, w_{1 i}, \cdots, w_{1 N}\right), \quad w_{1 i}=\frac{1}{N}, \quad i=1,2, \cdots, N$
(2) 对于m=1,2,…,M
+现在,我们来具体介绍Adaboost算法:(参考李航老师的《统计学习方法》)
假设给定一个二分类的训练数据集:$T=\left{\left(x{1}, y{1}\right),\left(x{2}, y{2}\right), \cdots,\left(x{N}, y{N}\right)\right}$ ,其中每个样本点由特征与类别组成。特征$x{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}$,类别$y{i} \in \mathcal{Y}={-1,+1}$,$\mathcal{X}$是特征空间,$ \mathcal{Y}$是类别集合,输出最终分类器$G(x)$。Adaboost算法如下:
(1) 初始化训练数据的分布:$D{1}=\left(w{11}, \cdots, w{1 i}, \cdots, w{1 N}\right), \quad w_{1 i}=\frac{1}{N}, \quad i=1,2, \cdots, N$
(2) 对于m=1,2,…,M
-使用具有权值分布$D_m$的训练数据集进行学习,得到基本分类器:$G_{m}(x): \mathcal{X} \rightarrow{-1,+1}$
-计算$G_m(x)$在训练集上的分类误差率$e_{m}=\sum_{i=1}^{N} P\left(G_{m}\left(x_{i}\right) \neq y_{i}\right)=\sum_{i=1}^{N} w_{m i} I\left(G_{m}\left(x_{i}\right) \neq y_{i}\right)$
-计算$G_m(x)$的系数$\alpha_{m}=\frac{1}{2} \log \frac{1-e_{m}}{e_{m}}$,这里的log是自然对数ln
-更新训练数据集的权重分布
$$
\begin{array}{c}
D_{m+1}=\left(w_{m+1,1}, \cdots, w_{m+1, i}, \cdots, w_{m+1, N}\right) \
w_{m+1, i}=\frac{w_{m i}}{Z_{m}} \exp \left(-\alpha_{m} y_{i} G_{m}\left(x_{i}\right)\right), \quad i=1,2, \cdots, N
\end{array}
$$
-这里的$Z_m$是规范化因子,使得$D_{m+1}$称为概率分布,$Z_{m}=\sum_{i=1}^{N} w_{m i} \exp \left(-\alpha_{m} y_{i} G_{m}\left(x_{i}\right)\right)$
+- 使用具有权值分布$Dm$的训练数据集进行学习,得到基本分类器:$G{m}(x): \mathcal{X} \rightarrow{-1,+1}$
+- 计算$Gm(x)$在训练集上的分类误差率$e{m}=\sum{i=1}^{N} P\left(G{m}\left(x{i}\right) \neq y{i}\right)=\sum{i=1}^{N} w{m i} I\left(G{m}\left(x{i}\right) \neq y_{i}\right)$
+- 计算$Gm(x)$的系数$\alpha{m}=\frac{1}{2} \log \frac{1-e{m}}{e{m}}$,这里的log是自然对数ln
+更新训练数据集的权重分布
+这里的$Zm$是规范化因子,使得$D{m+1}$称为概率分布,$Z{m}=\sum{i=1}^{N} w{m i} \exp \left(-\alpha{m} y{i} G{m}\left(x_{i}\right)\right)$
-(3) 构建基本分类器的线性组合$f(x)=\sum_{m=1}^{M} \alpha_{m} G_{m}(x)$,得到最终的分类器
-$$
\begin{aligned}
G(x) &=\operatorname{sign}(f(x)) \
&=\operatorname{sign}\left(\sum_{m=1}^{M} \alpha_{m} G_{m}(x)\right)
\end{aligned}
$$
-下面对Adaboost算法做如下说明:
对于步骤(1),假设训练数据的权值分布是均匀分布,是为了使得第一次没有先验信息的条件下每个样本在基本分类器的学习中作用一样。
对于步骤(2),每一次迭代产生的基本分类器$G_m(x)$在加权训练数据集上的分类错误率$\begin{aligned}e_{m} &=\sum_{i=1}^{N} P\left(G_{m}\left(x_{i}\right) \neq y_{i}\right) =\sum_{G_{m}\left(x_{i}\right) \neq y_{i}} w_{m i}\end{aligned}$代表了在$G_m(x)$中分类错误的样本权重和,这点直接说明了权重分布$D_m$与$G_m(x)$的分类错误率$e_m$有直接关系。同时,在步骤(2)中,计算基本分类器$G_m(x)$的系数$\alpha_m$,$\alpha_{m}=\frac{1}{2} \log \frac{1-e_{m}}{e_{m}}$,它表示了$G_m(x)$在最终分类器的重要性程度,$\alpha_m$的取值由基本分类器$G_m(x)$的分类错误率有直接关系,当$e_{m} \leqslant \frac{1}{2}$时,$\alpha_{m} \geqslant 0$,并且$\alpha_m$随着$e_m$的减少而增大,因此分类错误率越小的基本分类器在最终分类器的作用越大!
**最重要的,对于步骤(2)中的样本权重的更新: **
$$
w_{m+1, i}=\left{\begin{array}{ll}
\frac{w_{m i}}{Z_{m}} \mathrm{e}^{-\alpha_{m}}, & G_{m}\left(x_{i}\right)=y_{i} \
\frac{w_{m i}}{Z_{m}} \mathrm{e}^{\alpha_{m}}, & G_{m}\left(x_{i}\right) \neq y_{i}
\end{array}\right.
$$
因此,从上式可以看到:被基本分类器$G_m(x)$错误分类的样本的权重扩大,被正确分类的样本权重减少,二者相比相差$\mathrm{e}^{2 \alpha_{m}}=\frac{1-e_{m}}{e_{m}}$倍。
对于步骤(3),线性组合$f(x)$实现了将M个基本分类器的加权表决,系数$\alpha_m$标志了基本分类器$G_m(x)$的重要性,值得注意的是:所有的$\alpha_m$之和不为1。$f(x)$的符号决定了样本x属于哪一类。
-下面,我们使用一组简单的数据来手动计算Adaboost算法的过程:(例子来源:http://www.csie.edu.tw)
-训练数据如下表,假设基本分类器的形式是一个分割$x<v$或$x>v$表示,阈值v由该基本分类器在训练数据集上分类错误率$e_m$最低确定。
$$
\begin{array}{ccccccccccc}
\hline \text { 序号 } & 1 & 2 & 3 & 4 & 5 & 6 & 7 & 8 & 9 & 10 \
\hline x & 0 & 1 & 2 & 3 & 4 & 5 & 6 & 7 & 8 & 9 \
y & 1 & 1 & 1 & -1 & -1 & -1 & 1 & 1 & 1 & -1 \
\hline
\end{array}
$$
解:
初始化样本权值分布
$$
\begin{aligned}
D_{1} &=\left(w_{11}, w_{12}, \cdots, w_{110}\right) \
w_{1 i} &=0.1, \quad i=1,2, \cdots, 10
\end{aligned}
$$
对m=1:
+(3) 构建基本分类器的线性组合$f(x)=\sum{m=1}^{M} \alpha{m} G_{m}(x)$,得到最终的分类器
+下面对Adaboost算法做如下说明:
对于步骤(1),假设训练数据的权值分布是均匀分布,是为了使得第一次没有先验信息的条件下每个样本在基本分类器的学习中作用一样。
对于步骤(2),每一次迭代产生的基本分类器$Gm(x)$在加权训练数据集上的分类错误率$\begin{aligned}e{m} &=\sum{i=1}^{N} P\left(G{m}\left(x{i}\right) \neq y{i}\right) =\sum{G{m}\left(x{i}\right) \neq y{i}} w{m i}\end{aligned}$代表了在$G_m(x)$中分类错误的样本权重和,这点直接说明了权重分布$D_m$与$G_m(x)$的分类错误率$e_m$有直接关系。同时,在步骤(2)中,计算基本分类器$G_m(x)$的系数$\alpha_m$,$\alpha{m}=\frac{1}{2} \log \frac{1-e{m}}{e{m}}$,它表示了$Gm(x)$在最终分类器的重要性程度,$\alpha_m$的取值由基本分类器$G_m(x)$的分类错误率有直接关系,当$e{m} \leqslant \frac{1}{2}$时,$\alpha_{m} \geqslant 0$,并且$\alpha_m$随着$e_m$的减少而增大,因此分类错误率越小的基本分类器在最终分类器的作用越大!
最重要的,对于步骤(2)中的样本权重的更新:
+因此,从上式可以看到:被基本分类器$Gm(x)$错误分类的样本的权重扩大,被正确分类的样本权重减少,二者相比相差$\mathrm{e}^{2 \alpha{m}}=\frac{1-e{m}}{e{m}}$倍。
对于步骤(3),线性组合$f(x)$实现了将M个基本分类器的加权表决,系数$\alpha_m$标志了基本分类器$G_m(x)$的重要性,值得注意的是:所有的$\alpha_m$之和不为1。$f(x)$的符号决定了样本x属于哪一类。
+下面,我们使用一组简单的数据来手动计算Adaboost算法的过程:(例子来源:http://www.csie.edu.tw)
+训练数据如下表,假设基本分类器的形式是一个分割$xv$表示,阈值v由该基本分类器在训练数据集上分类错误率$e_m$最低确定。
+解:
初始化样本权值分布
+对m=1:
-- 在权值分布$D_1$的训练数据集上,遍历每个结点并计算分类误差率$e_m$,阈值取v=2.5时分类误差率最低,那么基本分类器为:
$$
G_{1}(x)=\left{\begin{array}{ll}
1, & x<2.5 \
-- 1, & x>2.5
\end{array}\right.
$$
-- $G_1(x)$在训练数据集上的误差率为$e_{1}=P\left(G_{1}\left(x_{i}\right) \neq y_{i}\right)=0.3$。
-- 计算$G_1(x)$的系数:$\alpha_{1}=\frac{1}{2} \log \frac{1-e_{1}}{e_{1}}=0.4236$
-- 更新训练数据的权值分布:
$$
\begin{aligned}
D_{2}=&\left(w_{21}, \cdots, w_{2 i}, \cdots, w_{210}\right) \
w_{2 i}=& \frac{w_{1 i}}{Z_{1}} \exp \left(-\alpha_{1} y_{i} G_{1}\left(x_{i}\right)\right), \quad i=1,2, \cdots, 10 \
D_{2}=&(0.07143,0.07143,0.07143,0.07143,0.07143,0.07143,\
&0.16667,0.16667,0.16667,0.07143) \
f_{1}(x) &=0.4236 G_{1}(x)
\end{aligned}
$$
+- 在权值分布$D_1$的训练数据集上,遍历每个结点并计算分类误差率$e_m$,阈值取v=2.5时分类误差率最低,那么基本分类器为:
+- $G1(x)$在训练数据集上的误差率为$e{1}=P\left(G{1}\left(x{i}\right) \neq y_{i}\right)=0.3$。
+- 计算$G1(x)$的系数:$\alpha{1}=\frac{1}{2} \log \frac{1-e{1}}{e{1}}=0.4236$
+- 更新训练数据的权值分布:
对于m=2:
-- 在权值分布$D_2$的训练数据集上,遍历每个结点并计算分类误差率$e_m$,阈值取v=8.5时分类误差率最低,那么基本分类器为:
$$
G_{2}(x)=\left{\begin{array}{ll}
1, & x<8.5 \
-- 1, & x>8.5
\end{array}\right.
$$
+- 在权值分布$D_2$的训练数据集上,遍历每个结点并计算分类误差率$e_m$,阈值取v=8.5时分类误差率最低,那么基本分类器为:
- $G_2(x)$在训练数据集上的误差率为$e_2 = 0.2143$
- 计算$G_2(x)$的系数:$\alpha_2 = 0.6496$
-- 更新训练数据的权值分布:
$$
\begin{aligned}
D_{3}=&(0.0455,0.0455,0.0455,0.1667,0.1667,0.1667\
&0.1060,0.1060,0.1060,0.0455) \
f_{2}(x) &=0.4236 G_{1}(x)+0.6496 G_{2}(x)
\end{aligned}
$$
+- 更新训练数据的权值分布:
对m=3:
-- 在权值分布$D_3$的训练数据集上,遍历每个结点并计算分类误差率$e_m$,阈值取v=5.5时分类误差率最低,那么基本分类器为:
$$
G_{3}(x)=\left{\begin{array}{ll}
1, & x>5.5 \
-- 1, & x<5.5
\end{array}\right.
$$
+- 在权值分布$D_3$的训练数据集上,遍历每个结点并计算分类误差率$e_m$,阈值取v=5.5时分类误差率最低,那么基本分类器为:
- $G_3(x)$在训练数据集上的误差率为$e_3 = 0.1820$
- 计算$G_3(x)$的系数:$\alpha_3 = 0.7514$
-- 更新训练数据的权值分布:
$$
D_{4}=(0.125,0.125,0.125,0.102,0.102,0.102,0.065,0.065,0.065,0.125)
$$
+- 更新训练数据的权值分布:
-于是得到:$f_{3}(x)=0.4236 G_{1}(x)+0.6496 G_{2}(x)+0.7514 G_{3}(x)$,分类器$\operatorname{sign}\left[f_{3}(x)\right]$在训练数据集上的误分类点的个数为0。
于是得到最终分类器为:$G(x)=\operatorname{sign}\left[f_{3}(x)\right]=\operatorname{sign}\left[0.4236 G_{1}(x)+0.6496 G_{2}(x)+0.7514 G_{3}(x)\right]$
+于是得到:$f{3}(x)=0.4236 G{1}(x)+0.6496 G{2}(x)+0.7514 G{3}(x)$,分类器$\operatorname{sign}\left[f{3}(x)\right]$在训练数据集上的误分类点的个数为0。
于是得到最终分类器为:$G(x)=\operatorname{sign}\left[f{3}(x)\right]=\operatorname{sign}\left[0.4236 G{1}(x)+0.6496 G{2}(x)+0.7514 G_{3}(x)\right]$
下面,我们使用sklearn对Adaboost算法进行建模:
本次案例我们使用一份UCI的机器学习库里的开源数据集:葡萄酒数据集,该数据集可以在 ( https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data )上获得。该数据集包含了178个样本和13个特征,从不同的角度对不同的化学特性进行描述,我们的任务是根据这些数据预测红酒属于哪一个类别。(案例来源《python机器学习(第二版》)
# 引入数据科学相关工具包:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use("ggplot")
%matplotlib inline
import seaborn as sns
-
-
# 加载训练数据:
wine = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data",header=None)
wine.columns = ['Class label', 'Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash','Magnesium', 'Total phenols','Flavanoids', 'Nonflavanoid phenols',
'Proanthocyanins','Color intensity', 'Hue','OD280/OD315 of diluted wines','Proline']
-
-
# 数据查看:
print("Class labels",np.unique(wine["Class label"]))
wine.head()
-
-
下面对数据做简单解读:
- Class label:分类标签
@@ -295,35 +331,31 @@
# 数据预处理
# 仅仅考虑2,3类葡萄酒,去除1类
wine = wine[wine['Class label']!=1]
y = wine['Class label'].values
X = wine[['Alcohol','OD280/OD315 of diluted wines']].values
-
-
# 将分类标签变成二进制编码:
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y = le.fit_transform(y)
# 按8:2分割训练集和测试集
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=1,stratify=y) # stratify参数代表了按照y的类别等比例抽样
-
使用单一决策树建模
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier(criterion='entropy',random_state=1,max_depth=1)
from sklearn.metrics import accuracy_score
tree = tree.fit(X_train,y_train)
y_train_pred = tree.predict(X_train)
y_test_pred = tree.predict(X_test)
tree_train = accuracy_score(y_train,y_train_pred)
tree_test = accuracy_score(y_test,y_test_pred)
print('Decision tree train/test accuracies %.3f/%.3f' % (tree_train,tree_test))
-
-
-
使用sklearn实现Adaboost(基分类器为决策树)
# 使用sklearn实现Adaboost(基分类器为决策树)
'''
AdaBoostClassifier相关参数:
base_estimator:基本分类器,默认为DecisionTreeClassifier(max_depth=1)
n_estimators:终止迭代的次数
learning_rate:学习率
algorithm:训练的相关算法,{'SAMME','SAMME.R'},默认='SAMME.R'
random_state:随机种子
'''
from sklearn.ensemble import AdaBoostClassifier
adaboost = AdaBoostClassifier(base_estimator=tree,n_estimators=500,learning_rate=0.1,random_state=1)
adaboost = adaboost.fit(X_train,y_train)
y_train_pred = adaboost.predict(X_train)
y_test_pred = adaboost.predict(X_test)
ada_train = accuracy_score(y_train,y_train_pred)
ada_test = accuracy_score(y_test,y_test_pred)
print('Adaboost train/test accuracies %.3f/%.3f' % (ada_train,ada_test))
-
-
-
-
结果分析:单层决策树似乎对训练数据欠拟合,而Adaboost模型正确地预测了训练数据的所有分类标签,而且与单层决策树相比,Adaboost的测试性能也略有提高。然而,为什么模型在训练集和测试集的性能相差这么大呢?我们使用图像来简单说明下这个道理!
# 画出单层决策树与Adaboost的决策边界:
x_min = X_train[:, 0].min() - 1
x_max = X_train[:, 0].max() + 1
y_min = X_train[:, 1].min() - 1
y_max = X_train[:, 1].max() + 1
# 生成网格矩阵
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),np.arange(y_min, y_max, 0.1))
f, axarr = plt.subplots(nrows=1, ncols=2,sharex='col',sharey='row',figsize=(12, 6))
for idx, clf, tt in zip([0, 1],[tree, adaboost],['Decision tree', 'Adaboost']):
clf.fit(X_train, y_train)
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
axarr[idx].contourf(xx, yy, Z, alpha=0.3)
axarr[idx].scatter(X_train[y_train==0, 0],X_train[y_train==0, 1],c='blue', marker='^')
axarr[idx].scatter(X_train[y_train==1, 0],X_train[y_train==1, 1],c='red', marker='o')
axarr[idx].set_title(tt)
-

从上面的决策边界图可以看到:Adaboost模型的决策边界比单层决策树的决策边界要复杂的多。也就是说,Adaboost试图用增加模型复杂度而降低偏差的方式去减少总误差,但是过程中引入了方差,可能出现过拟合,因此在训练集和测试集之间的性能存在较大的差距,这就简单地回答的刚刚问题。
值的注意的是:与单个分类器相比,Adaboost等Boosting模型增加了计算的复杂度,在实践中需要仔细思考是否愿意为预测性能的相对改善而增加计算成本,而且Boosting方式无法做到现在流行的并行计算的方式进行训练,因为每一步迭代都要基于上一部的基本分类器。
-4. 前向分步算法
回看Adaboost的算法内容,我们需要通过计算M个基本分类器,每个分类器的错误率、样本权重以及模型权重。我们可以认为:Adaboost每次学习单一分类器以及单一分类器的参数(权重)。接下来,我们抽象出Adaboost算法的整体框架逻辑,构建集成学习的一个非常重要的框架—-前向分步算法,有了这个框架,我们不仅可以解决分类问题,也可以解决回归问题。
(1) 加法模型:
在Adaboost模型中,我们把每个基本分类器合成一个复杂分类器的方法是每个基本分类器的加权和,即:$f(x)=\sum_{m=1}^{M} \beta_{m} b\left(x ; \gamma_{m}\right)$,其中,$b\left(x ; \gamma_{m}\right)$为即基本分类器,$\gamma_{m}$为基本分类器的参数,$\beta_m$为基本分类器的权重,显然这与第二章所学的加法模型。为什么这么说呢?大家把$b(x ; \gamma_{m})$看成是即函数即可。
在给定训练数据以及损失函数$L(y, f(x))$的条件下,学习加法模型$f(x)$就是:
$$
\min {\beta{m}, \gamma_{m}} \sum_{i=1}^{N} L\left(y_{i}, \sum_{m=1}^{M} \beta_{m} b\left(x_{i} ; \gamma_{m}\right)\right)
$$
通常这是一个复杂的优化问题,很难通过简单的凸优化的相关知识进行解决。前向分步算法可以用来求解这种方式的问题,它的基本思路是:因为学习的是加法模型,如果从前向后,每一步只优化一个基函数及其系数,逐步逼近目标函数,那么就可以降低优化的复杂度。具体而言,每一步只需要优化:
$$
\min {\beta, \gamma} \sum{i=1}^{N} L\left(y_{i}, \beta b\left(x_{i} ; \gamma\right)\right)
$$
(2) 前向分步算法:
给定数据集$T=\left{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \cdots,\left(x_{N}, y_{N}\right)\right}$,$x_{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}$,$y_{i} \in \mathcal{Y}={+1,-1}$。损失函数$L(y, f(x))$,基函数集合${b(x ; \gamma)}$,我们需要输出加法模型$f(x)$。
+4. 前向分步算法
回看Adaboost的算法内容,我们需要通过计算M个基本分类器,每个分类器的错误率、样本权重以及模型权重。我们可以认为:Adaboost每次学习单一分类器以及单一分类器的参数(权重)。接下来,我们抽象出Adaboost算法的整体框架逻辑,构建集成学习的一个非常重要的框架——前向分步算法,有了这个框架,我们不仅可以解决分类问题,也可以解决回归问题。
(1) 加法模型:
在Adaboost模型中,我们把每个基本分类器合成一个复杂分类器的方法是每个基本分类器的加权和,即:$f(x)=\sum{m=1}^{M} \beta{m} b\left(x ; \gamma{m}\right)$,其中,$b\left(x ; \gamma{m}\right)$为即基本分类器,$\gamma{m}$为基本分类器的参数,$\beta_m$为基本分类器的权重,显然这与第二章所学的加法模型。为什么这么说呢?大家把$b(x ; \gamma{m})$看成是即函数即可。
在给定训练数据以及损失函数$L(y, f(x))$的条件下,学习加法模型$f(x)$就是:
+通常这是一个复杂的优化问题,很难通过简单的凸优化的相关知识进行解决。前向分步算法可以用来求解这种方式的问题,它的基本思路是:因为学习的是加法模型,如果从前向后,每一步只优化一个基函数及其系数,逐步逼近目标函数,那么就可以降低优化的复杂度。具体而言,每一步只需要优化:
+(2) 前向分步算法:
给定数据集$T=\left{\left(x{1}, y{1}\right),\left(x{2}, y{2}\right), \cdots,\left(x{N}, y{N}\right)\right}$,$x{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}$,$y{i} \in \mathcal{Y}={+1,-1}$。损失函数$L(y, f(x))$,基函数集合${b(x ; \gamma)}$,我们需要输出加法模型$f(x)$。
- 初始化:$f_{0}(x)=0$
- 对m = 1,2,…,M:
-- (a) 极小化损失函数:
$$
\left(\beta_{m}, \gamma_{m}\right)=\arg \min {\beta, \gamma} \sum{i=1}^{N} L\left(y_{i}, f_{m-1}\left(x_{i}\right)+\beta b\left(x_{i} ; \gamma\right)\right)
$$
得到参数$\beta_{m}$与$\gamma_{m}$
-- (b) 更新:
$$
f_{m}(x)=f_{m-1}(x)+\beta_{m} b\left(x ; \gamma_{m}\right)
$$
+- (a) 极小化损失函数:得到参数$\beta{m}$与$\gamma{m}$
+- (b) 更新:
-- 得到加法模型:
$$
f(x)=f_{M}(x)=\sum_{m=1}^{M} \beta_{m} b\left(x ; \gamma_{m}\right)
$$
+- 得到加法模型:
-这样,前向分步算法将同时求解从m=1到M的所有参数$\beta_{m}$,$\gamma_{m}$的优化问题简化为逐次求解各个$\beta_{m}$,$\gamma_{m}$的问题。
(3) 前向分步算法与Adaboost的关系:
由于这里不是我们的重点,我们主要阐述这里的结论,不做相关证明,具体的证明见李航老师的《统计学习方法》第八章的3.2节。Adaboost算法是前向分步算法的特例,Adaboost算法是由基本分类器组成的加法模型,损失函数为指数损失函数。
+这样,前向分步算法将同时求解从m=1到M的所有参数$\beta{m}$,$\gamma{m}$的优化问题简化为逐次求解各个$\beta{m}$,$\gamma{m}$的问题。
(3) 前向分步算法与Adaboost的关系:
由于这里不是我们的重点,我们主要阐述这里的结论,不做相关证明,具体的证明见李航老师的《统计学习方法》第八章的3.2节。Adaboost算法是前向分步算法的特例,Adaboost算法是由基本分类器组成的加法模型,损失函数为指数损失函数。
@@ -632,7 +664,7 @@
-
@@ -640,15 +672,15 @@
-
diff --git "a/2021/06/18/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224Xgboost-LightGBM/index.html" "b/2021/06/18/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224Xgboost-LightGBM/index.html"
index d5f26def..bda69fc1 100644
--- "a/2021/06/18/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224Xgboost-LightGBM/index.html"
+++ "b/2021/06/18/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224Xgboost-LightGBM/index.html"
@@ -213,25 +213,48 @@
- XGBoost算法
XGBoost是陈天奇等人开发的一个开源机器学习项目,高效地实现了GBDT算法并进行了算法和工程上的许多改进,被广泛应用在Kaggle竞赛及其他许多机器学习竞赛中并取得了不错的成绩。XGBoost本质上还是一个GBDT,但是力争把速度和效率发挥到极致,所以叫X (Extreme) GBoosted, 包括前面说过,两者都是boosting方法。XGBoost是一个优化的分布式梯度增强库,旨在实现高效,灵活和便携。 它在Gradient Boosting框架下实现机器学习算法。 XGBoost提供了并行树提升(也称为GBDT,GBM),可以快速准确地解决许多数据科学问题。 相同的代码在主要的分布式环境(Hadoop,SGE,MPI)上运行,并且可以解决超过数十亿个样例的问题。XGBoost利用了核外计算并且能够使数据科学家在一个主机上处理数亿的样本数据。最终,将这些技术进行结合来做一个端到端的系统以最少的集群系统来扩展到更大的数据集上。Xgboost以CART决策树为子模型,通过Gradient Tree Boosting实现多棵CART树的集成学习,得到最终模型。下面我们来看看XGBoost的最终模型构建:
-
-引用陈天奇的论文,我们的数据为:$\mathcal{D}=\left{\left(\mathbf{x}{i}, y{i}\right)\right}\left(|\mathcal{D}|=n, \mathbf{x}{i} \in \mathbb{R}^{m}, y{i} \in \mathbb{R}\right)$
(1) 构造目标函数:
假设有K棵树,则第i个样本的输出为$\hat{y}{i}=\phi\left(\mathrm{x}{i}\right)=\sum_{k=1}^{K} f_{k}\left(\mathrm{x}{i}\right), \quad f{k} \in \mathcal{F}$,其中,$\mathcal{F}=\left{f(\mathbf{x})=w_{q(\mathbf{x})}\right}\left(q: \mathbb{R}^{m} \rightarrow T, w \in \mathbb{R}^{T}\right)$
因此,目标函数的构建为:
$$
\mathcal{L}(\phi)=\sum_{i} l\left(\hat{y}{i}, y{i}\right)+\sum_{k} \Omega\left(f_{k}\right)
$$
其中,$\sum_{i} l\left(\hat{y}{i}, y{i}\right)$为loss function,$\sum_{k} \Omega\left(f_{k}\right)$为正则化项。
(2) 叠加式的训练(Additive Training):
给定样本$x_i$,$\hat{y}i^{(0)} = 0$(初始预测),$\hat{y}_i^{(1)} = \hat{y}_i^{(0)} + f_1(x_i)$,$\hat{y}_i^{(2)} = \hat{y}_i^{(0)} + f_1(x_i) + f_2(x_i) = \hat{y}_i^{(1)} + f_2(x_i)$…….以此类推,可以得到:$ \hat{y}_i^{(K)} = \hat{y}_i^{(K-1)} + f_K(x_i)$ ,其中,$ \hat{y}_i^{(K-1)} $ 为前K-1棵树的预测结果,$ f_K(x_i)$ 为第K棵树的预测结果。
因此,目标函数可以分解为:
$$
\mathcal{L}^{(K)}=\sum{i=1}^{n} l\left(y_{i}, \hat{y}{i}^{(K-1)}+f{K}\left(\mathrm{x}{i}\right)\right)+\sum{k} \Omega\left(f_{k}\right)
$$
由于正则化项也可以分解为前K-1棵树的复杂度加第K棵树的复杂度,因此:$\mathcal{L}^{(K)}=\sum_{i=1}^{n} l\left(y_{i}, \hat{y}{i}^{(K-1)}+f{K}\left(\mathrm{x}{i}\right)\right)+\sum{k=1} ^{K-1}\Omega\left(f_{k}\right)+\Omega\left(f_{K}\right)$,由于$\sum_{k=1} ^{K-1}\Omega\left(f_{k}\right)$在模型构建到第K棵树的时候已经固定,无法改变,因此是一个已知的常数,可以在最优化的时候省去,故:
$$
\mathcal{L}^{(K)}=\sum_{i=1}^{n} l\left(y_{i}, \hat{y}{i}^{(K-1)}+f{K}\left(\mathrm{x}{i}\right)\right)+\Omega\left(f{K}\right)
$$
(3) 使用泰勒级数近似目标函数:
$$
\mathcal{L}^{(K)} \simeq \sum_{i=1}^{n}\left[l\left(y_{i}, \hat{y}^{(K-1)}\right)+g_{i} f_{K}\left(\mathrm{x}{i}\right)+\frac{1}{2} h{i} f_{K}^{2}\left(\mathrm{x}{i}\right)\right]+\Omega\left(f{K}\right)
$$
其中,$g_{i}=\partial_{\hat{y}(t-1)} l\left(y_{i}, \hat{y}^{(t-1)}\right)$和$h_{i}=\partial_{\hat{y}^{(t-1)}}^{2} l\left(y_{i}, \hat{y}^{(t-1)}\right)$
在这里,我们补充下泰勒级数的相关知识:
在数学中,泰勒级数(英语:Taylor series)用无限项连加式——级数来表示一个函数,这些相加的项由函数在某一点的导数求得。具体的形式如下:
$$
f(x)=\frac{f\left(x_{0}\right)}{0 !}+\frac{f^{\prime}\left(x_{0}\right)}{1 !}\left(x-x_{0}\right)+\frac{f^{\prime \prime}\left(x_{0}\right)}{2 !}\left(x-x_{0}\right)^{2}+\ldots+\frac{f^{(n)}\left(x_{0}\right)}{n !}\left(x-x_{0}\right)^{n}+……
$$
由于$\sum_{i=1}^{n}l\left(y_{i}, \hat{y}^{(K-1)}\right)$在模型构建到第K棵树的时候已经固定,无法改变,因此是一个已知的常数,可以在最优化的时候省去,故:
$$
\tilde{\mathcal{L}}^{(K)}=\sum_{i=1}^{n}\left[g_{i} f_{K}\left(\mathbf{x}{i}\right)+\frac{1}{2} h{i} f_{K}^{2}\left(\mathbf{x}{i}\right)\right]+\Omega\left(f{K}\right)
$$
(4) 如何定义一棵树:
为了说明如何定义一棵树的问题,我们需要定义几个概念:第一个概念是样本所在的节点位置$q(x)$,第二个概念是有哪些样本落在节点j上$I_{j}=\left{i \mid q\left(\mathbf{x}{i}\right)=j\right}$,第三个概念是每个结点的预测值$w{q(x)}$,第四个概念是模型复杂度$\Omega\left(f_{K}\right)$,它可以由叶子节点的个数以及节点函数值来构建,则:$\Omega\left(f_{K}\right) = \gamma T+\frac{1}{2} \lambda \sum_{j=1}^{T} w_{j}^{2}$。如下图的例子:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-t1tei3pE-1623946035306)(./16.png)]
$q(x_1) = 1,q(x_2) = 3,q(x_3) = 1,q(x_4) = 2,q(x_5) = 3$,$I_1 = {1,3},I_2 = {4},I_3 = {2,5}$,$w = (15,12,20)$
因此,目标函数用以上符号替代后:
$$
\begin{aligned}
\tilde{\mathcal{L}}^{(K)} &=\sum_{i=1}^{n}\left[g_{i} f_{K}\left(\mathrm{x}{i}\right)+\frac{1}{2} h{i} f_{K}^{2}\left(\mathrm{x}{i}\right)\right]+\gamma T+\frac{1}{2} \lambda \sum{j=1}^{T} w_{j}^{2} \
&=\sum_{j=1}^{T}\left[\left(\sum_{i \in I_{j}} g_{i}\right) w_{j}+\frac{1}{2}\left(\sum_{i \in I_{j}} h_{i}+\lambda\right) w_{j}^{2}\right]+\gamma T
\end{aligned}
$$
由于我们的目标就是最小化目标函数,现在的目标函数化简为一个关于w的二次函数:$\tilde{\mathcal{L}}^{(K)}=\sum_{j=1}^{T}\left[\left(\sum_{i \in I_{j}} g_{i}\right) w_{j}+\frac{1}{2}\left(\sum_{i \in I_{j}} h_{i}+\lambda\right) w_{j}^{2}\right]+\gamma T$,根据二次函数求极值的公式:$y=ax^2 bx c$求极值,对称轴在$x=-\frac{b}{2 a}$,极值为$y=\frac{4 a c-b^{2}}{4 a}$,因此:
$$
w_{j}^{*}=-\frac{\sum_{i \in I_{j}} g_{i}}{\sum_{i \in I_{j}} h_{i}+\lambda}
$$
以及
$$
\tilde{\mathcal{L}}^{(K)}(q)=-\frac{1}{2} \sum_{j=1}^{T} \frac{\left(\sum_{i \in I_{j}} g_{i}\right)^{2}}{\sum_{i \in I_{j}} h_{i}+\lambda}+\gamma T
$$
(5) 如何寻找树的形状:
不难发现,刚刚的讨论都是基于树的形状已经确定了计算$w$和$L$,但是实际上我们需要像学习决策树一样找到树的形状。因此,我们借助决策树学习的方式,使用目标函数的变化来作为分裂节点的标准。我们使用一个例子来说明:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nCrhWA4S-1623946035310)(./17.png)]
例子中有8个样本,分裂方式如下,因此:
$$
\tilde{\mathcal{L}}^{(old)} = -\frac{1}{2}[\frac{(g_7 + g_8)^2}{H_7+H_8 + \lambda} + \frac{(g_1 +…+ g_6)^2}{H_1+…+H_6 + \lambda}] + 2\gamma \
\tilde{\mathcal{L}}^{(new)} = -\frac{1}{2}[\frac{(g_7 + g_8)^2}{H_7+H_8 + \lambda} + \frac{(g_1 +…+ g_3)^2}{H_1+…+H_3 + \lambda} + \frac{(g_4 +…+ g_6)^2}{H_4+…+H_6 + \lambda}] + 3\gamma\
\tilde{\mathcal{L}}^{(old)} - \tilde{\mathcal{L}}^{(new)} = \frac{1}{2}[ \frac{(g_1 +…+ g_3)^2}{H_1+…+H_3 + \lambda} + \frac{(g_4 +…+ g_6)^2}{H_4+…+H_6 + \lambda} - \frac{(g_1+…+g_6)^2}{h_1+…+h_6+\lambda}] - \gamma
$$
因此,从上面的例子看出:分割节点的标准为$max{\tilde{\mathcal{L}}^{(old)} - \tilde{\mathcal{L}}^{(new)} }$,即:
$$
\mathcal{L}{\text {split }}=\frac{1}{2}\left[\frac{\left(\sum{i \in I_{L}} g_{i}\right)^{2}}{\sum_{i \in I_{L}} h_{i}+\lambda}+\frac{\left(\sum_{i \in I_{R}} g_{i}\right)^{2}}{\sum_{i \in I_{R}} h_{i}+\lambda}-\frac{\left(\sum_{i \in I} g_{i}\right)^{2}}{\sum_{i \in I} h_{i}+\lambda}\right]-\gamma
$$
(6.1) 精确贪心分裂算法:
XGBoost在生成新树的过程中,最基本的操作是节点分裂。节点分裂中最重 要的环节是找到最优特征及最优切分点, 然后将叶子节点按照最优特征和最优切 分点进行分裂。选取最优特征和最优切分点的一种思路如下:首先找到所有的候 选特征及所有的候选切分点, 一一求得其 $\mathcal{L}{\text {split }}$, 然后选择$\mathcal{L}{\mathrm{split}}$ 最大的特征及 对应切分点作为最优特征和最优切分点。我们称此种方法为精确贪心算法。该算法是一种启发式算法, 因为在节点分裂时只选择当前最优的分裂策略, 而非全局最优的分裂策略。精确贪心算法的计算过程如下所示:
+ XGBoost算法
XGBoost是陈天奇等人开发的一个开源机器学习项目,高效地实现了GBDT算法并进行了算法和工程上的许多改进,被广泛应用在Kaggle竞赛及其他许多机器学习竞赛中并取得了不错的成绩。XGBoost本质上还是一个GBDT,但是力争把速度和效率发挥到极致,所以叫X (Extreme) GBoosted, 包括前面说过,两者都是boosting方法。XGBoost是一个优化的分布式梯度增强库,旨在实现高效,灵活和便携。 它在Gradient Boosting框架下实现机器学习算法。 XGBoost提供了并行树提升(也称为GBDT,GBM),可以快速准确地解决许多数据科学问题。 相同的代码在主要的分布式环境(Hadoop,SGE,MPI)上运行,并且可以解决超过数十亿个样例的问题。XGBoost利用了核外计算并且能够使数据科学家在一个主机上处理数亿的样本数据。最终,将这些技术进行结合来做一个端到端的系统以最少的集群系统来扩展到更大的数据集上。Xgboost以CART决策树为子模型,通过Gradient Tree Boosting实现多棵CART树的集成学习,得到最终模型。下面我们来看看XGBoost的最终模型构建:
引用陈天奇的论文,我们的数据为:$\mathcal{D}=\left{\left(\mathbf{x}{i}, y{i}\right)\right}\left(|\mathcal{D}|=n, \mathbf{x}{i} \in \mathbb{R}^{m}, y{i} \in \mathbb{R}\right)$
(1) 构造目标函数:
假设有K棵树,则第i个样本的输出为$\hat{y}{i}=\phi\left(\mathrm{x}{i}\right)=\sum{k=1}^{K} f{k}\left(\mathrm{x}{i}\right), \quad f{k} \in \mathcal{F}$,其中,$\mathcal{F}=\left{f(\mathbf{x})=w_{q(\mathbf{x})}\right}\left(q: \mathbb{R}^{m} \rightarrow T, w \in \mathbb{R}^{T}\right)$
因此,目标函数的构建为:
+其中,$\sum{i} l\left(\hat{y}{i}, y{i}\right)$为loss function,$\sum{k} \Omega\left(f_{k}\right)$为正则化项。
(2) 叠加式的训练(Additive Training):
给定样本$x_i$,$\hat{y}_i^{(0)} = 0$(初始预测),$\hat{y}_i^{(1)} = \hat{y}_i^{(0)} + f_1(x_i)$,$\hat{y}_i^{(2)} = \hat{y}_i^{(0)} + f_1(x_i) + f_2(x_i) = \hat{y}_i^{(1)} + f_2(x_i)$…….以此类推,可以得到:$ \hat{y}_i^{(K)} = \hat{y}_i^{(K-1)} + f_K(x_i)$ ,其中,$ \hat{y}_i^{(K-1)} $ 为前K-1棵树的预测结果,$ f_K(x_i)$ 为第K棵树的预测结果。
因此,目标函数可以分解为:
+由于正则化项也可以分解为前K-1棵树的复杂度加第K棵树的复杂度,因此:$\mathcal{L}^{(K)}=\sum{i=1}^{n} l\left(y{i}, \hat{y}{i}^{(K-1)}+f{K}\left(\mathrm{x}{i}\right)\right)+\sum{k=1} ^{K-1}\Omega\left(f{k}\right)+\Omega\left(f{K}\right)$,由于$\sum{k=1} ^{K-1}\Omega\left(f{k}\right)$在模型构建到第K棵树的时候已经固定,无法改变,因此是一个已知的常数,可以在最优化的时候省去,故:
+(3) 使用泰勒级数近似目标函数:
+其中,$g{i}=\partial{\hat{y}(t-1)} l\left(y{i}, \hat{y}^{(t-1)}\right)$和$h{i}=\partial{\hat{y}^{(t-1)}}^{2} l\left(y{i}, \hat{y}^{(t-1)}\right)$
在这里,我们补充下泰勒级数的相关知识:
在数学中,泰勒级数(英语:Taylor series)用无限项连加式——级数来表示一个函数,这些相加的项由函数在某一点的导数求得。具体的形式如下:
+由于$\sum{i=1}^{n}l\left(y{i}, \hat{y}^{(K-1)}\right)$在模型构建到第K棵树的时候已经固定,无法改变,因此是一个已知的常数,可以在最优化的时候省去,故:
+(4) 如何定义一棵树:
为了说明如何定义一棵树的问题,我们需要定义几个概念:第一个概念是样本所在的节点位置$q(x)$,第二个概念是有哪些样本落在节点j上$I{j}=\left{i \mid q\left(\mathbf{x}{i}\right)=j\right}$,第三个概念是每个结点的预测值$w{q(x)}$,第四个概念是模型复杂度$\Omega\left(f{K}\right)$,它可以由叶子节点的个数以及节点函数值来构建,则:$\Omega\left(f{K}\right) = \gamma T+\frac{1}{2} \lambda \sum{j=1}^{T} w_{j}^{2}$。如下图的例子:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-t1tei3pE-1623946035306)(./16.png)]
$q(x_1) = 1,q(x_2) = 3,q(x_3) = 1,q(x_4) = 2,q(x_5) = 3$,$I_1 = {1,3},I_2 = {4},I_3 = {2,5}$,$w = (15,12,20)$
因此,目标函数用以上符号替代后:
+由于我们的目标就是最小化目标函数,现在的目标函数化简为一个关于w的二次函数:$\tilde{\mathcal{L}}^{(K)}=\sum{j=1}^{T}\left[\left(\sum{i \in I{j}} g{i}\right) w{j}+\frac{1}{2}\left(\sum{i \in I{j}} h{i}+\lambda\right) w_{j}^{2}\right]+\gamma T$,根据二次函数求极值的公式:$y=ax^2 bx c$求极值,对称轴在$x=-\frac{b}{2 a}$,极值为$y=\frac{4 a c-b^{2}}{4 a}$,因此:
+以及
+(5) 如何寻找树的形状:
不难发现,刚刚的讨论都是基于树的形状已经确定了计算$w$和$L$,但是实际上我们需要像学习决策树一样找到树的形状。因此,我们借助决策树学习的方式,使用目标函数的变化来作为分裂节点的标准。我们使用一个例子来说明:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nCrhWA4S-1623946035310)(./17.png)]
例子中有8个样本,分裂方式如下,因此:
+因此,从上面的例子看出:分割节点的标准为$max{\tilde{\mathcal{L}}^{(old)} - \tilde{\mathcal{L}}^{(new)} }$,即:
+(6.1) 精确贪心分裂算法:
XGBoost在生成新树的过程中,最基本的操作是节点分裂。节点分裂中最重 要的环节是找到最优特征及最优切分点, 然后将叶子节点按照最优特征和最优切 分点进行分裂。选取最优特征和最优切分点的一种思路如下:首先找到所有的候 选特征及所有的候选切分点, 一一求得其 $\mathcal{L}{\text {split }}$, 然后选择$\mathcal{L}{\mathrm{split}}$ 最大的特征及 对应切分点作为最优特征和最优切分点。我们称此种方法为精确贪心算法。该算法是一种启发式算法, 因为在节点分裂时只选择当前最优的分裂策略, 而非全局最优的分裂策略。精确贪心算法的计算过程如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HRrbM0fp-1623946035312)(./18.png)]
-(6.2) 基于直方图的近似算法:
精确贪心算法在选择最优特征和最优切分点时是一种十分有效的方法。它计算了所有特征、所有切分点的收益, 并从中选择了最优的, 从而保证模型能比较好地拟合了训练数据。但是当数据不能完全加载到内存时,精确贪心算法会变得 非常低效,算法在计算过程中需要不断在内存与磁盘之间进行数据交换,这是个非常耗时的过程, 并且在分布式环境中面临同样的问题。为了能够更高效地选 择最优特征及切分点, XGBoost提出一种近似算法来解决该问题。 基于直方图的近似算法的主要思想是:对某一特征寻找最优切分点时,首先对该特征的所有切分点按分位数 (如百分位) 分桶, 得到一个候选切分点集。特征的每一个切分点都可以分到对应的分桶; 然后,对每个桶计算特征统计G和H得到直方图, G为该桶内所有样本一阶特征统计g之和, H为该桶内所有样本二阶特征统计h之和; 最后,选择所有候选特征及候选切分点中对应桶的特征统计收益最大的作为最优特征及最优切分点。基于直方图的近似算法的计算过程如下所示:
-
-- 对于每个特征 $k=1,2, \cdots, m,$ 按分位数对特征 $k$ 分桶 $\Theta,$ 可得候选切分点, $S_{k}=\left{S_{k 1}, S_{k 2}, \cdots, S_{k l}\right}^{1}$
-- 对于每个特征 $k=1,2, \cdots, m,$ 有:
$$
\begin{array}{l}
G_{k v} \leftarrow=\sum_{j \in\left{j \mid s_{k, v} \geq \mathbf{x}{j k}>s{k, v-1;}\right}} g_{j} \
H_{k v} \leftarrow=\sum_{j \in\left{j \mid s_{k, v} \geq \mathbf{x}{j k}>s{k, v-1;}\right}} h_{j}
\end{array}
$$
-- 类似精确贪心算法,依据梯度统计找到最大增益的候选切分点。
下面用一个例子说明基于直方图的近似算法:
假设有一个年龄特征,其特征的取值为18、19、21、31、36、37、55、57,我们需要使用近似算法找到年龄这个特征的最佳分裂点:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MKLD2poX-1623946035314)(./19.png)]
-
+(6.2) 基于直方图的近似算法:
精确贪心算法在选择最优特征和最优切分点时是一种十分有效的方法。它计算了所有特征、所有切分点的收益, 并从中选择了最优的, 从而保证模型能比较好地拟合了训练数据。但是当数据不能完全加载到内存时,精确贪心算法会变得 非常低效,算法在计算过程中需要不断在内存与磁盘之间进行数据交换,这是个非常耗时的过程, 并且在分布式环境中面临同样的问题。为了能够更高效地选 择最优特征及切分点, XGBoost提出一种近似算法来解决该问题。 基于直方图的近似算法的主要思想是:对某一特征寻找最优切分点时,首先对该特征的所有切分点按分位数 (如百分位) 分桶, 得到一个候选切分点集。特征的每一个切分点都可以分到对应的分桶; 然后,对每个桶计算特征统计G和H得到直方图, G为该桶内所有样本一阶特征统计g之和, H为该桶内所有样本二阶特征统计h之和; 最后,选择所有候选特征及候选切分点中对应桶的特征统计收益最大的作为最优特征及最优切分点。基于直方图的近似算法的计算过程如下所示:
1) 对于每个特征 $k=1,2, \cdots, m,$ 按分位数对特征 $k$ 分桶 $\Theta,$ 可得候选切分点, $S{k}=\left{S{k 1}, S{k 2}, \cdots, S{k l}\right}^{1}$
2) 对于每个特征 $k=1,2, \cdots, m,$ 有:
+3) 类似精确贪心算法,依据梯度统计找到最大增益的候选切分点。
下面用一个例子说明基于直方图的近似算法:
假设有一个年龄特征,其特征的取值为18、19、21、31、36、37、55、57,我们需要使用近似算法找到年龄这个特征的最佳分裂点:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MKLD2poX-1623946035314)(./19.png)]
近似算法实现了两种候选切分点的构建策略:全局策略和本地策略。全局策略是在树构建的初始阶段对每一个特征确定一个候选切分点的集合, 并在该树每一层的节点分裂中均采用此集合计算收益, 整个过程候选切分点集合不改变。本地策略则是在每一次节点分裂时均重新确定候选切分点。全局策略需要更细的分桶才能达到本地策略的精确度, 但全局策略在选取候选切分点集合时比本地策略更简单。在XGBoost系统中, 用户可以根据需求自由选择使用精确贪心算法、近似算法全局策略、近似算法本地策略, 算法均可通过参数进行配置。
以上是XGBoost的理论部分,下面我们对XGBoost系统进行详细的讲解:
官方文档:https://xgboost.readthedocs.io/en/latest/python/python_intro.html
知乎总结:https://zhuanlan.zhihu.com/p/143009353
# XGBoost原生工具库的上手:
import xgboost as xgb # 引入工具库
# read in data
dtrain = xgb.DMatrix('demo/data/agaricus.txt.train') # XGBoost的专属数据格式,但是也可以用dataframe或者ndarray
dtest = xgb.DMatrix('demo/data/agaricus.txt.test') # # XGBoost的专属数据格式,但是也可以用dataframe或者ndarray
# specify parameters via map
param = {'max_depth':2, 'eta':1, 'objective':'binary:logistic' } # 设置XGB的参数,使用字典形式传入
num_round = 2 # 使用线程数
bst = xgb.train(param, dtrain, num_round) # 训练
# make prediction
preds = bst.predict(dtest) # 预测
-
-XGBoost的参数设置(括号内的名称为sklearn接口对应的参数名字):
推荐博客:https://link.zhihu.com/?target=https%3A//blog.csdn.net/luanpeng825485697/article/details/79907149
推荐官方文档:https://link.zhihu.com/?target=https%3A//xgboost.readthedocs.io/en/latest/parameter.html
+XGBoost的参数设置(括号内的名称为sklearn接口对应的参数名字):
推荐博客:https://link.zhihu.com/?target=https%3A//blog.csdn.net/luanpeng825485697/article/details/79907149
推荐官方文档:https://link.zhihu.com/?target=https%3A//xgboost.readthedocs.io/en/latest/parameter.html
XGBoost的参数分为三种:
-通用参数:(两种类型的booster,因为tree的性能比线性回归好得多,因此我们很少用线性回归。)
-
+- 通用参数:(两种类型的booster,因为tree的性能比线性回归好得多,因此我们很少用线性回归。)
- booster:使用哪个弱学习器训练,默认gbtree,可选gbtree,gblinear 或dart
- nthread:用于运行XGBoost的并行线程数,默认为最大可用线程数
- verbosity:打印消息的详细程度。有效值为0(静默),1(警告),2(信息),3(调试)。
@@ -324,7 +347,6 @@
from IPython.display import IFrame
IFrame('https://xgboost.readthedocs.io/en/latest/parameter.html', width=1400, height=800)
-
XGBoost的调参说明:
参数调优的一般步骤
@@ -332,23 +354,23 @@
+
- max_depth 和 min_child_weight 参数调优
+
- gamma参数调优
+
- subsample 和 colsample_bytree 参数优
+
- 正则化参数alpha调优
+
- 降低学习速率和使用更多的决策树
# 1.LibSVM文本格式文件
dtrain = xgb.DMatrix('train.svm.txt')
dtest = xgb.DMatrix('test.svm.buffer')
# 2.CSV文件(不能含类别文本变量,如果存在文本变量请做特征处理如one-hot)
dtrain = xgb.DMatrix('train.csv?format=csv&label_column=0')
dtest = xgb.DMatrix('test.csv?format=csv&label_column=0')
# 3.NumPy数组
data = np.random.rand(5, 10) # 5 entities, each contains 10 features
label = np.random.randint(2, size=5) # binary target
dtrain = xgb.DMatrix(data, label=label)
# 4.scipy.sparse数组
csr = scipy.sparse.csr_matrix((dat, (row, col)))
dtrain = xgb.DMatrix(csr)
# pandas数据框dataframe
data = pandas.DataFrame(np.arange(12).reshape((4,3)), columns=['a', 'b', 'c'])
label = pandas.DataFrame(np.random.randint(2, size=4))
dtrain = xgb.DMatrix(data, label=label)
-
笔者推荐:先保存到XGBoost二进制文件中将使加载速度更快,然后再加载进来
# 1.保存DMatrix到XGBoost二进制文件中
dtrain = xgb.DMatrix('train.svm.txt')
dtrain.save_binary('train.buffer')
# 2. 缺少的值可以用DMatrix构造函数中的默认值替换:
dtrain = xgb.DMatrix(data, label=label, missing=-999.0)
# 3.可以在需要时设置权重:
w = np.random.rand(5, 1)
dtrain = xgb.DMatrix(data, label=label, missing=-999.0, weight=w)
-
参数的设置方式:
import pandas as pd
# 加载并处理数据
df_wine = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data',header=None)
df_wine.columns = ['Class label', 'Alcohol','Malic acid', 'Ash','Alcalinity of ash','Magnesium', 'Total phenols',
'Flavanoids', 'Nonflavanoid phenols','Proanthocyanins','Color intensity', 'Hue','OD280/OD315 of diluted wines','Proline']
df_wine = df_wine[df_wine['Class label'] != 1] # drop 1 class
y = df_wine['Class label'].values
X = df_wine[['Alcohol','OD280/OD315 of diluted wines']].values
from sklearn.model_selection import train_test_split # 切分训练集与测试集
from sklearn.preprocessing import LabelEncoder # 标签化分类变量
le = LabelEncoder()
y = le.fit_transform(y)
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=1,stratify=y)
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test)
# 1.Booster 参数
params = {
'booster': 'gbtree',
'objective': 'multi:softmax', # 多分类的问题
'num_class': 10, # 类别数,与 multisoftmax 并用
'gamma': 0.1, # 用于控制是否后剪枝的参数,越大越保守,一般0.1、0.2这样子。
'max_depth': 12, # 构建树的深度,越大越容易过拟合
'lambda': 2, # 控制模型复杂度的权重值的L2正则化项参数,参数越大,模型越不容易过拟合。
'subsample': 0.7, # 随机采样训练样本
'colsample_bytree': 0.7, # 生成树时进行的列采样
'min_child_weight': 3,
'silent': 1, # 设置成1则没有运行信息输出,最好是设置为0.
'eta': 0.007, # 如同学习率
'seed': 1000,
'nthread': 4, # cpu 线程数
'eval_metric':'auc'
}
plst = list(params.items())
# evallist = [(dtest, 'eval'), (dtrain, 'train')] # 指定验证集
-
训练:
# 2.训练
num_round = 10
bst = xgb.train(plst, dtrain, num_round)
#bst = xgb.train( plst, dtrain, num_round, evallist )
-
保存模型:
# 3.保存模型
bst.save_model('0001.model')
# dump model
bst.dump_model('dump.raw.txt')
# dump model with feature map
#bst.dump_model('dump.raw.txt', 'featmap.txt')
-
加载保存的模型:
# 4.加载保存的模型:
bst = xgb.Booster({'nthread': 4}) # init model
bst.load_model('0001.model') # load data
-
设置早停机制:
# 5.也可以设置早停机制(需要设置验证集)
train(..., evals=evals, early_stopping_rounds=10)
-
预测:
# 6.预测
ypred = bst.predict(dtest)
-
绘制重要性特征图:
# 1.绘制重要性
xgb.plot_importance(bst)
# 2.绘制输出树
#xgb.plot_tree(bst, num_trees=2)
# 3.使用xgboost.to_graphviz()将目标树转换为graphviz
#xgb.to_graphviz(bst, num_trees=2)
-![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ir9Nm1ZN-1623946035316)(output_27_1.png)]](https://img-blog.csdnimg.cn/2021061800081388.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0phY2tfX19F,size_16,color_FFFFFF,t_70)
+
7. Xgboost算法案例
分类案例
from sklearn.datasets import load_iris
import xgboost as xgb
from xgboost import plot_importance
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score # 准确率
# 加载样本数据集
iris = load_iris()
X,y = iris.data,iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1234565) # 数据集分割
params = {
'booster' : 'gbtree',
'objective': 'multi:softmax', # 多分类的问题
'num_class': 3,
'gamma': 0.1, # 默认= 0,分裂节点时,损失函数减小值只有大于等于gamma节点才分裂,gamma值越大,算法越保守,越不容易过拟合,但性能就不一定能保证,需要平衡。
'max_depth': 12, # 树的最大深度
'lambda': 2, # 控制模型复杂度的权重值的L2正则化项参数,参数越大,模型越不容易过拟合。
'subsample': 0.7, # 随机采样训练样本
'colsample_bytree': 0.7, # 生成树时进行的列采样,列采样率,也就是特征采样率
'min_child_weight': 3,
'silent': 0,
'eta': 0.1,
'seed': 1,
'nthread': 4,
}
plst = list(params.items())
dtrain = xgb.DMatrix(X_train,y_train)
num_rounds = 500
model = xgb.train(plst,dtrain,num_rounds) # xgboost模型训练
# 对测试集进行预测
dtest = xgb.DMatrix(X_test)
y_pred = model.predict(dtest)
# 计算准确率
accuracy = accuracy_score(y_test,y_pred)
print("accuarcy: %.2f%%" % (accuracy*100.0))
# 显示重要特征
plot_importance(model)
plt.show()
-![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8vD1cJWm-1623946035317)(output_30_1.png)]](https://img-blog.csdnimg.cn/20210618000838223.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0phY2tfX19F,size_16,color_FFFFFF,t_70)
+
回归案例
import xgboost as xgb
from xgboost import plot_importance
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_boston
from sklearn.metrics import mean_squared_error
# 加载数据集
boston = load_boston()
X,y = boston.data,boston.target
# XGBoost训练过程
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
params = {
'booster': 'gbtree',
'objective': 'reg:squarederror',
'gamma': 0.1,
'max_depth': 5,
'lambda': 3,
'subsample': 0.7,
'colsample_bytree': 0.7,
'min_child_weight': 3,
'silent': 1,
'eta': 0.1,
'seed': 1000,
'nthread': 4,
}
dtrain = xgb.DMatrix(X_train, y_train)
num_rounds = 300
plst = list(params.items())
model = xgb.train(plst, dtrain, num_rounds)
# 对测试集进行预测
dtest = xgb.DMatrix(X_test)
ans = model.predict(dtest)
# 显示重要特征
plot_importance(model)
plt.show()
-![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8Zu2NWnA-1623946035318)(output_32_1.png)]](https://img-blog.csdnimg.cn/20210618000856713.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0phY2tfX19F,size_16,color_FFFFFF,t_70)
+
XGBoost调参(结合sklearn网格搜索)
代码参考:https://www.jianshu.com/p/1100e333fcab
import xgboost as xgb
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import roc_auc_score
iris = load_iris()
X,y = iris.data,iris.target
col = iris.target_names
train_x, valid_x, train_y, valid_y = train_test_split(X, y, test_size=0.3, random_state=1) # 分训练集和验证集
parameters = {
'max_depth': [5, 10, 15, 20, 25],
'learning_rate': [0.01, 0.02, 0.05, 0.1, 0.15],
'n_estimators': [500, 1000, 2000, 3000, 5000],
'min_child_weight': [0, 2, 5, 10, 20],
'max_delta_step': [0, 0.2, 0.6, 1, 2],
'subsample': [0.6, 0.7, 0.8, 0.85, 0.95],
'colsample_bytree': [0.5, 0.6, 0.7, 0.8, 0.9],
'reg_alpha': [0, 0.25, 0.5, 0.75, 1],
'reg_lambda': [0.2, 0.4, 0.6, 0.8, 1],
'scale_pos_weight': [0.2, 0.4, 0.6, 0.8, 1]
}
xlf = xgb.XGBClassifier(max_depth=10,
learning_rate=0.01,
n_estimators=2000,
silent=True,
objective='multi:softmax',
num_class=3 ,
nthread=-1,
gamma=0,
min_child_weight=1,
max_delta_step=0,
subsample=0.85,
colsample_bytree=0.7,
colsample_bylevel=1,
reg_alpha=0,
reg_lambda=1,
scale_pos_weight=1,
seed=0,
missing=None)
gs = GridSearchCV(xlf, param_grid=parameters, scoring='accuracy', cv=3)
gs.fit(train_x, train_y)
print("Best score: %0.3f" % gs.best_score_)
print("Best parameters set: %s" % gs.best_params_ )
-
Best score: 0.933
Best parameters set: {‘max_depth’: 5}
8. LightGBM算法
LightGBM也是像XGBoost一样,是一类集成算法,他跟XGBoost总体来说是一样的,算法本质上与Xgboost没有出入,只是在XGBoost的基础上进行了优化,因此就不对原理进行重复介绍,在这里我们来看看几种算法的差别:
@@ -433,7 +446,7 @@ https://blog.csdn.net/u012735708/article/details/83749703
import lightgbm as lgb
from sklearn import metrics
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
canceData=load_breast_cancer()
X=canceData.data
y=canceData.target
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=0,test_size=0.2)
### 数据转换
print('数据转换')
lgb_train = lgb.Dataset(X_train, y_train, free_raw_data=False)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train,free_raw_data=False)
### 设置初始参数--不含交叉验证参数
print('设置参数')
params = {
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': 'auc',
'nthread':4,
'learning_rate':0.1
}
### 交叉验证(调参)
print('交叉验证')
max_auc = float('0')
best_params = {}
# 准确率
print("调参1:提高准确率")
for num_leaves in range(5,100,5):
for max_depth in range(3,8,1):
params['num_leaves'] = num_leaves
params['max_depth'] = max_depth
cv_results = lgb.cv(
params,
lgb_train,
seed=1,
nfold=5,
metrics=['auc'],
early_stopping_rounds=10,
verbose_eval=True
)
mean_auc = pd.Series(cv_results['auc-mean']).max()
boost_rounds = pd.Series(cv_results['auc-mean']).idxmax()
if mean_auc >= max_auc:
max_auc = mean_auc
best_params['num_leaves'] = num_leaves
best_params['max_depth'] = max_depth
if 'num_leaves' and 'max_depth' in best_params.keys():
params['num_leaves'] = best_params['num_leaves']
params['max_depth'] = best_params['max_depth']
# 过拟合
print("调参2:降低过拟合")
for max_bin in range(5,256,10):
for min_data_in_leaf in range(1,102,10):
params['max_bin'] = max_bin
params['min_data_in_leaf'] = min_data_in_leaf
cv_results = lgb.cv(
params,
lgb_train,
seed=1,
nfold=5,
metrics=['auc'],
early_stopping_rounds=10,
verbose_eval=True
)
mean_auc = pd.Series(cv_results['auc-mean']).max()
boost_rounds = pd.Series(cv_results['auc-mean']).idxmax()
if mean_auc >= max_auc:
max_auc = mean_auc
best_params['max_bin']= max_bin
best_params['min_data_in_leaf'] = min_data_in_leaf
if 'max_bin' and 'min_data_in_leaf' in best_params.keys():
params['min_data_in_leaf'] = best_params['min_data_in_leaf']
params['max_bin'] = best_params['max_bin']
print("调参3:降低过拟合")
for feature_fraction in [0.6,0.7,0.8,0.9,1.0]:
for bagging_fraction in [0.6,0.7,0.8,0.9,1.0]:
for bagging_freq in range(0,50,5):
params['feature_fraction'] = feature_fraction
params['bagging_fraction'] = bagging_fraction
params['bagging_freq'] = bagging_freq
cv_results = lgb.cv(
params,
lgb_train,
seed=1,
nfold=5,
metrics=['auc'],
early_stopping_rounds=10,
verbose_eval=True
)
mean_auc = pd.Series(cv_results['auc-mean']).max()
boost_rounds = pd.Series(cv_results['auc-mean']).idxmax()
if mean_auc >= max_auc:
max_auc=mean_auc
best_params['feature_fraction'] = feature_fraction
best_params['bagging_fraction'] = bagging_fraction
best_params['bagging_freq'] = bagging_freq
if 'feature_fraction' and 'bagging_fraction' and 'bagging_freq' in best_params.keys():
params['feature_fraction'] = best_params['feature_fraction']
params['bagging_fraction'] = best_params['bagging_fraction']
params['bagging_freq'] = best_params['bagging_freq']
print("调参4:降低过拟合")
for lambda_l1 in [1e-5,1e-3,1e-1,0.0,0.1,0.3,0.5,0.7,0.9,1.0]:
for lambda_l2 in [1e-5,1e-3,1e-1,0.0,0.1,0.4,0.6,0.7,0.9,1.0]:
params['lambda_l1'] = lambda_l1
params['lambda_l2'] = lambda_l2
cv_results = lgb.cv(
params,
lgb_train,
seed=1,
nfold=5,
metrics=['auc'],
early_stopping_rounds=10,
verbose_eval=True
)
mean_auc = pd.Series(cv_results['auc-mean']).max()
boost_rounds = pd.Series(cv_results['auc-mean']).idxmax()
if mean_auc >= max_auc:
max_auc=mean_auc
best_params['lambda_l1'] = lambda_l1
best_params['lambda_l2'] = lambda_l2
if 'lambda_l1' and 'lambda_l2' in best_params.keys():
params['lambda_l1'] = best_params['lambda_l1']
params['lambda_l2'] = best_params['lambda_l2']
print("调参5:降低过拟合2")
for min_split_gain in [0.0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0]:
params['min_split_gain'] = min_split_gain
cv_results = lgb.cv(
params,
lgb_train,
seed=1,
nfold=5,
metrics=['auc'],
early_stopping_rounds=10,
verbose_eval=True
)
mean_auc = pd.Series(cv_results['auc-mean']).max()
boost_rounds = pd.Series(cv_results['auc-mean']).idxmax()
if mean_auc >= max_auc:
max_auc=mean_auc
best_params['min_split_gain'] = min_split_gain
if 'min_split_gain' in best_params.keys():
params['min_split_gain'] = best_params['min_split_gain']
print(best_params)
-
{‘bagging_fraction’: 0.7,
‘bagging_freq’: 30,
‘feature_fraction’: 0.8,
‘lambda_l1’: 0.1,
‘lambda_l2’: 0.0,
‘max_bin’: 255,
‘max_depth’: 4,
‘min_data_in_leaf’: 81,
‘min_split_gain’: 0.1,
‘num_leaves’: 10}
9. 结语
本章中,我们主要探讨了基于Boosting方式的集成方法,其中主要讲解了基于错误率驱动的Adaboost,基于残差改进的提升树,基于梯度提升的GBDT,基于泰勒二阶近似的Xgboost以及LightGBM。在实际的比赛或者工程中,基于Boosting的集成学习方式是非常有效且应用非常广泛的。更多的学习有待读者更深入阅读文献,包括原作者论文以及论文复现等。下一章我们即将探讨另一种集成学习方式:Stacking集成学习方式,这种集成方式虽然没有Boosting应用广泛,但是在比赛中或许能让你的模型更加出众。
本章作业:
本章在最后介绍LightGBM的时候并没有详细介绍它的原理以及它与XGBoost的不一样的地方,希望读者好好看看别的文章分享,总结LigntGBM与XGBoost的不同,然后使用一个具体的案例体现两者的不同。
参考链接: https://blog.csdn.net/weixin_30279315/article/details/95504220
@@ -826,7 +838,7 @@ 9
-
高精度
typedef long long LL;
LL get(char c)
{
if(c<='9') return c-'0';
else return c-'a' + 10;
}
LL getnum(string a,LL r)
{
LL res=0;
for(int i=0;i<a.size();i++)
{
res = res * r + get(a[i]);
}
return res;
}
-
- 十进制转其他进制的方法,使用带余除法

int get(char c)
{
if(c<='9') return c-'0';
else return c-'a' + 10;
}
char tochar(int c)
{
if(c<=9) return c+'0';
else return 'a' + c - 10;
}
//一个r进制数num转10进制
int numr_to10(string num,int r)
{
int res = 0;
for(int i=0;i<num.size();i++)
{
res = res * r + get(num[i]);
}
return res;
}
//一个10进制数num转r进制
string num10_tor(string num,int r)
{
string res;
int n = numr_to10(num,10); //先转成10进制整型
while(n)
{
// cout<<tochar(n % r)<<endl;
res = tochar(n % r) + res;
n /= r;
}
return res;
}
// cout<<numr_to10("6a",16)<<" "<<num10_tor("15",16)<<endl;
-
判断质数
//判断一个数是否为质数
bool is_prime(int n)
{
if (n < 2) return false; // 1和0不是质数
for(int i=2;i*i<=n;i++)
{
if(n % i == 0) return false;
}
return true;
}
手写堆排序
堆是一个完全二叉树的结构,分为小根堆和大根堆两种结构。
- 小根堆的递归定义:小根堆的每个节点都小于他的左右孩子节点的值,树的根节点为最小值。
- 大根堆的递归定义:大根堆的每个节点都大于他的左右孩子节点的值,树的根节点为最大值。
在STL当中可以使用prioirty_queue来轻松实现大根堆和小根堆,但是只能实现前3个功能,有时候我们不得不自己实现一个手写的堆,同时这样也能让我们更理解堆排序的过程。

-在AcWing基础课当中有两道经典例题,AcWing 839. 模拟堆(这个复杂一点),AcWing 838. 堆排序
这里给出堆排序的模板级代码
-#include <iostream>
using namespace std;
const int N = 100010;
int heap[N],heapsize=0;
void down(int x)// 参数下标
{
int p =x;
if(2*x<=heapsize && heap[2*x]<heap[p]) p = 2*x;//左子树
if(2*x+1<=heapsize && heap[2*x+1]<heap[p]) p=2*x+1;//右子树
if(p!=x)
{
swap(heap[p],heap[x]); //说明存在比父节点小的孩子节点
down(p); //继续向下递归down
}
}
void up(int x)// 参数下标
{
while(x / 2 && heap[x] < heap[x/2]) //父节点比子节点大则交换
{
swap(heap[x],heap[x/2]);
x >>= 1; // x = x/2
}
}
int main()
{
int n,m;
scanf("%d%d", &n, &m);
for (int i = 1; i <= n; i ++ ) scanf("%d", &heap[i]);
heapsize=n;
// O(n)建堆
for (int i = n / 2; i; i -- ) down(i);
while (m -- )
{
printf("%d ",heap[1]); //最小值是小根堆的堆顶
// 删除最小值,并重新建堆排序,从而获得倒数第二小的元素
heap[1] = heap[heapsize];
heapsize--;
down(1);
}
return 0;
}
-STL写法:priority_queue默认是大根堆,less<int>是对第一个参数的比较类,表示数字大的优先级越大,而greater<int>表示数字小的优先级越大,可以实现结构体运算符重载。
首先要引入头文件:#include<queue>
大根堆:
-priority_queue<int> q;
priority_queue<int, vector<int>, less<int> >q;
-小根堆:
+在AcWing基础课当中有两道经典例题,AcWing 839. 模拟堆(这个复杂一点),AcWing 838. 堆排序
这里给出堆排序的模板级代码
#include <iostream>
using namespace std;
const int N = 100010;
int heap[N],heapsize=0;
void down(int x)// 参数下标
{
int p =x;
if(2*x<=heapsize && heap[2*x]<heap[p]) p = 2*x;//左子树
if(2*x+1<=heapsize && heap[2*x+1]<heap[p]) p=2*x+1;//右子树
if(p!=x)
{
swap(heap[p],heap[x]); //说明存在比父节点小的孩子节点
down(p); //继续向下递归down
}
}
void up(int x)// 参数下标
{
while(x / 2 && heap[x] < heap[x/2]) //父节点比子节点大则交换
{
swap(heap[x],heap[x/2]);
x >>= 1; // x = x/2
}
}
int main()
{
int n,m;
scanf("%d%d", &n, &m);
for (int i = 1; i <= n; i ++ ) scanf("%d", &heap[i]);
heapsize=n;
// O(n)建堆
for (int i = n / 2; i; i -- ) down(i);
while (m -- )
{
printf("%d ",heap[1]); //最小值是小根堆的堆顶
// 删除最小值,并重新建堆排序,从而获得倒数第二小的元素
heap[1] = heap[heapsize];
heapsize--;
down(1);
}
return 0;
}
STL写法:priority_queue默认是大根堆,less<int>是对第一个参数的比较类,表示数字大的优先级越大,而greater<int>表示数字小的优先级越大,可以实现结构体运算符重载。
首先要引入头文件:#include<queue>
大根堆:
priority_queue<int> q;
priority_queue<int, vector<int>, less<int> >q;
小根堆:
priority_queue < int, vector<int>, greater<int> > q;
-
树
树是一种特殊的数据结构形式,在做题的过程当中,根据我的经验当题目需要使用树结构的时候主要有以下几种模式。
- 二叉树形式,在二叉树模型下,我们可以根据题目建立出静态的树形结构,构建每个节点左右孩子索引表来建立树的结构同时实现对树的遍历。如果已知或可以求得节点之间的关系,可以通过节点的度数或者访问标记找到根节点。,当然也是可以通过邻接表的方式创建二叉树。
- 多叉树形式,多叉树形式其实又类似于无向连通图的概念,常通过创建邻接表或者临接矩阵的方式建立树,并实现进行树的遍历,也是可以根据节点关系求出根节点的。注意在临接表当中,边的数量一般大于节点数量的两倍即我们需要开票邻接表的边数空间为$M = 2 \times N + d$
- 森林,多连通块的方式,这种也是利用无向图的方式,以邻接表或者临接矩阵的方式构建树的结构,同时我们可以利用并查集的方式得到当前无向图中含有的连通块数量并找到根节点。
-二叉树左右孩子索引表模型
-const int N = 100010;
int l[N],r[N]// 第i个节点的左孩子和右孩子的索引
bool has_father[N]; //建立树的时候判断一下当前节点有没有父节点,可用于寻找根节点
//初始化,-1表示子节点为空
memset(l,-1,sizeof l);
memset(r,-1,sizeof r);
// 查找根节点的过程
if(l[i]>=0) has_father[l[i]]=true;
if(r[i]>=0) has_father[r[i]]=true;
//查找根节点
int root = 0;
while(has_father[root]) root++;
-
-二叉树的遍历过程(以先序遍历为例子)
-void dfs(int root)
{
if(root==-1) return;
cout<<root<<endl;
if(l[root]>=0) dfs(l[root]);
if(r[root]>=0) dfs(r[root]);
}
-
-临接表模型
-const int N = 100010;
const int M = 2 * N + 10;
int h[N];//邻接表的N个节点头指针,h[i]表示以i为起点的,最新的一条边的编号
int e[M];// e[i] 表示第i条边的所指向的终点
int ne[M];// ne[i]表示与第i条边起点相同的下一条边的编号
int idx;// idx表示边的编号,每增加一条边就++
// 添加一条从a到b的边,如果是无向图,每次添加时要add(a,b)和add(b,a)
void add(int a,int b)
{
e[idx] = b; // 第idx条边的终点为b
ne[idx] = h[a]; // h[a] 和 第idx都是以a为起点的边,通过ne[idx]串联起来,找到上一条以a为起点的边h[a]
h[a] = idx ++; // 更新当前以a为起点的边的最新编号
}
//初始化,-1表示节点为空
memset(h,-1,sizeof h);
-
-临接表遍历过程方法1
-// x为起点,father为x的来源,防止节点遍历走回头路导致死循环
void dfs(int x,int father)
{
cout<<x<<endl;
for(int i = h[x];~i;i=ne[i]) // ~i就是i!=-1的意思
{
int to = e[i];
if(to==father) continue;
dfs(to,x);
}
}
dfs(x,-1);
-
-临接表遍历过程方法2
-const int N = 100010;
bool isvisited[N];
void dfs(int x)
{
isvisited[x]=true;
cout<<x<<endl;
for(int i = h[x];~i;i=ne[i])
{
int to = e[i];
if(isvisited[to]) continue;
dfs(to);
}
}
dfs(x);
-树的深度
临接表模型:AcWing1498. 最深的根
-int getdepth(int x,int father)
{
// cout<<"father"<<father<<" node"<<x<<endl;
int depth = 0;
for(int i = h[x];~i;i=ne[i])
{
int to = e[i];
if(to==father) continue;
depth = max(depth,getdepth(to,x)+1);
}
return depth;
}
-二叉树模型:剑指 Offer 55 - I. 二叉树的深度
-/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
int maxDepth(TreeNode* root) {
if(root==NULL) return 0;
return max(maxDepth(root->left),maxDepth(root->right))+1;
}
};
-多叉树模型(该题也是求叶子节点个数的经典写法):AcWing 1476. 数叶子结点
-const int N = 100010;
int max_depth = 0;
int cnt[N];
void dfs(int x,int depth)
{
//说明是叶子节点
if(h[x]==-1)
{
cnt[depth]++;
max_depth = max(max_depth,depth);
return;
}
for(int i=h[x];~i;i=ne[i])
{
dfs(e[i],depth+1);
}
}
dfs(root,0)
//输出每一层的叶子个数
for(int i=0;i<=max_depth;i++) cout<<" "<<cnt[i];
-
+二叉树左右孩子索引表模型
const int N = 100010;
int l[N],r[N]// 第i个节点的左孩子和右孩子的索引
bool has_father[N]; //建立树的时候判断一下当前节点有没有父节点,可用于寻找根节点
//初始化,-1表示子节点为空
memset(l,-1,sizeof l);
memset(r,-1,sizeof r);
// 查找根节点的过程
if(l[i]>=0) has_father[l[i]]=true;
if(r[i]>=0) has_father[r[i]]=true;
//查找根节点
int root = 0;
while(has_father[root]) root++;
+二叉树的遍历过程(以先序遍历为例子)
void dfs(int root)
{
if(root==-1) return;
cout<<root<<endl;
if(l[root]>=0) dfs(l[root]);
if(r[root]>=0) dfs(r[root]);
}
+临接表模型
const int N = 100010;
const int M = 2 * N + 10;
int h[N];//邻接表的N个节点头指针,h[i]表示以i为起点的,最新的一条边的编号
int e[M];// e[i] 表示第i条边的所指向的终点
int ne[M];// ne[i]表示与第i条边起点相同的下一条边的编号
int idx;// idx表示边的编号,每增加一条边就++
// 添加一条从a到b的边,如果是无向图,每次添加时要add(a,b)和add(b,a)
void add(int a,int b)
{
e[idx] = b; // 第idx条边的终点为b
ne[idx] = h[a]; // h[a] 和 第idx都是以a为起点的边,通过ne[idx]串联起来,找到上一条以a为起点的边h[a]
h[a] = idx ++; // 更新当前以a为起点的边的最新编号
}
//初始化,-1表示节点为空
memset(h,-1,sizeof h);
+临接表遍历过程方法1
// x为起点,father为x的来源,防止节点遍历走回头路导致死循环
void dfs(int x,int father)
{
cout<<x<<endl;
for(int i = h[x];~i;i=ne[i]) // ~i就是i!=-1的意思
{
int to = e[i];
if(to==father) continue;
dfs(to,x);
}
}
dfs(x,-1);
+临接表遍历过程方法2
const int N = 100010;
bool isvisited[N];
void dfs(int x)
{
isvisited[x]=true;
cout<<x<<endl;
for(int i = h[x];~i;i=ne[i])
{
int to = e[i];
if(isvisited[to]) continue;
dfs(to);
}
}
dfs(x);
+树的深度
临接表模型:AcWing1498. 最深的根
int getdepth(int x,int father)
{
// cout<<"father"<<father<<" node"<<x<<endl;
int depth = 0;
for(int i = h[x];~i;i=ne[i])
{
int to = e[i];
if(to==father) continue;
depth = max(depth,getdepth(to,x)+1);
}
return depth;
}
二叉树模型:剑指 Offer 55 - I. 二叉树的深度
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
int maxDepth(TreeNode* root) {
if(root==NULL) return 0;
return max(maxDepth(root->left),maxDepth(root->right))+1;
}
};
多叉树模型(该题也是求叶子节点个数的经典写法):AcWing 1476. 数叶子结点
const int N = 100010;
int max_depth = 0;
int cnt[N];
void dfs(int x,int depth)
{
//说明是叶子节点
if(h[x]==-1)
{
cnt[depth]++;
max_depth = max(max_depth,depth);
return;
}
for(int i=h[x];~i;i=ne[i])
{
dfs(e[i],depth+1);
}
}
dfs(root,0)
//输出每一层的叶子个数
for(int i=0;i<=max_depth;i++) cout<<" "<<cnt[i];
二叉搜索树
二叉搜索树 (BST) 递归定义为具有以下属性的二叉树:
- 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值
@@ -289,9 +266,7 @@ 完全二叉树
完全二叉树 (CBT) 定义为除最深层外的其他层的结点数都达到最大个数,最深层的所有结点都连续集中在最左边的二叉树。
构造完全二叉树的方法,可以直接开辟一个一维数组利用左右孩子与根节点的下标映射关系。如果通过中序遍历的方式以单调递增的方式来赋值则构造出了一颗完全二叉搜索树。

完全二叉树的赋值填充和构造过程(这里我们以中序遍历为例子):
例题:AcWing 1550. 完全二叉搜索树
-//中序遍历填充数据
int cnt; //记录已经赋值的节点下标
void dfs(int x) // 根节点为1-n
{
if(2*x <=n) dfs(2*x);
h[x] = a[cnt++];
if(2*x+1<=n) dfs(2*x+1);
}
void dfs(int u, int& k) // 中序遍历,k引用实现下标迁移
{
if (u * 2 <= n) dfs(u * 2, k);
tr[u] = w[k ++ ];
if (u * 2 + 1 <= n) dfs(u * 2 + 1, k);
}
-完全二叉树的节点个数规律:
+完全二叉树
完全二叉树 (CBT) 定义为除最深层外的其他层的结点数都达到最大个数,最深层的所有结点都连续集中在最左边的二叉树。
构造完全二叉树的方法,可以直接开辟一个一维数组利用左右孩子与根节点的下标映射关系。如果通过中序遍历的方式以单调递增的方式来赋值则构造出了一颗完全二叉搜索树。
完全二叉树的赋值填充和构造过程(这里我们以中序遍历为例子):
例题:AcWing 1550. 完全二叉搜索树
//中序遍历填充数据
int cnt; //记录已经赋值的节点下标
void dfs(int x) // 根节点为1-n
{
if(2*x <=n) dfs(2*x);
h[x] = a[cnt++];
if(2*x+1<=n) dfs(2*x+1);
}
void dfs(int u, int& k) // 中序遍历,k引用实现下标迁移
{
if (u * 2 <= n) dfs(u * 2, k);
tr[u] = w[k ++ ];
if (u * 2 + 1 <= n) dfs(u * 2 + 1, k);
}
完全二叉树的节点个数规律:
- 具有n个结点的完全二叉树的深度为$\lfloor log_2{n} \rfloor+ 1$
- 完全二叉树如果为满二叉树,且深度为$k$则总节点个数为$2^{k}-1$
@@ -302,9 +277,7 @@ leetcode 完全二叉树的节点个数
-/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public int countNodes(TreeNode root) {
return root==null ? 0:countNodes(root.left)+countNodes(root.right)+1;
}
}
-
+
例题(递归解法):leetcode 完全二叉树的节点个数
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public int countNodes(TreeNode root) {
return root==null ? 0:countNodes(root.left)+countNodes(root.right)+1;
}
}
完全二叉树
二叉平衡树
AVL树
- AVL树是一种自平衡二叉搜索树。
@@ -328,17 +301,13 @@ 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。

图论相关
并查集
经典例题:AcWing 836. 合并集合
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 100010;
int p[N];
int find(int x) // 查找x的祖先节点,并在回溯的过程当中进行路径压缩,将各节点直接指向根节点
{
if(x!=p[x]) p[x] = find(p[x]); // x和p[x]不相等,则继续向上找父节点的父节点
return p[x];
}
int main()
{
int n;
int m;
scanf("%d%d", &n, &m);
for(int i=1;i<=n;i++)
p[i]=i;
while (m -- )
{
char op[2];
int a,b;
scanf("%s%d%d", op,&a,&b);
int roota = find(a);
int rootb = find(b);
if(op[0]=='M')
{
if(roota == rootb) continue;
p[roota] = rootb; // root merge
}
else
{
cout<< (roota==rootb ? "Yes":"No")<<endl;
}
}
return 0;
}
-
dijstra算法
- 临接矩阵形式,适用于点的数量$N < 1000$的情形,朴素算法即可解决
- 邻接表形式,当$N>10000$,需要添加堆优化
一般来说堆优化版本的考试用的不多,这里就只介绍了朴素版本。
Dijkstra求最短路 I
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 510;
const int inf = 0x3f3f3f3f;
int n,m;
int g[N][N]; // 稠密图使用邻接矩阵
int dist[N]; // 存储距离
bool vis[N]; // 标志到该节点的距离是否已经被规整为最短距离
void dijkstra(int x)
{
memset(dist, inf, sizeof dist);
dist[x] = 0;
for(int i=0;i<n;i++)//外层循环n次遍历每个节点
{
int t= -1;
for(int j=1;j<=n;j++)
{
if(!vis[j]&&(t==-1 || dist[t]>dist[j])) t =j;
}
if(t==-1) break;
vis[t]=true;
for(int j=1;j<=n;j++)
{
if(!vis[j])
{
dist[j] = min(dist[j],dist[t]+g[t][j]);
}
}
}
if(dist[n]==inf) puts("-1");
else cout<<dist[n]<<endl;
}
int main()
{
scanf("%d%d", &n, &m);
memset(g, inf, sizeof g);
for(int i=0;i<m;i++)
{
int x,y,z;
scanf("%d%d%d", &x, &y,&z);
if(x==y) g[x][y]=0; // 自环
g[x][y] = min(g[x][y],z); // 重边仅记录最小的边
}
dijkstra(1);
return 0;
}
-
-最小生成树Prime
-//这里填你的代码^^
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 510, INF = 0x3f3f3f3f;
int n,m;
int g[N][N]; //稠密图使用prim和邻接矩阵
int dist[N];
bool isvisited[N];
int prime(int x)
{
memset(dist, 0x3f, sizeof dist);
int res = 0;
dist[x]=0;
for(int i=0;i<n;i++)
{
int t=-1;
for(int j=1;j<=n;j++)
if(!isvisited[j] && (t==-1 || dist[t] > dist[j]))
t= j;
if(dist[t] == INF) return -1;
//标记访问
res += dist[t];
isvisited[t]=true;
//更新dist
for(int j=1;j<=n;j++)
{
dist[j] = min(dist[j],g[t][j]);
}
}
return res;
}
int main()
{
scanf("%d%d", &n, &m);
memset(g, 0x3f, sizeof g);
while (m -- )
{
int a,b,c;
scanf("%d%d%d", &a, &b,&c);
g[a][b] = g[b][a] = min(g[a][b],c); //无向图
}
int t = prime(1);
if(t==-1)
cout<<"impossible"<<endl;
else
cout<<t<<endl;
return 0;
}
-最小生成树Kruskal
-#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 100010, INF =0x3f3f3f3f;
const int M = 2*N;
int n,m;
struct Edge
{
int x;
int y;
int w;
bool operator < (const Edge & E) const
{
return w < E.w;
}
}edge[M];
int p[N]; //并查集
int find(int x)//找祖宗节点
{
if(x!=p[x]) p[x] = find(p[x]);
return p[x];
}
int kruskal()
{
int res = 0;
int cnt=0;
sort(edge,edge+m);
for(int i=1;i<=n;i++) p[i]=i;//初始化并查集
for(int i=0;i<m;i++)
{
int x = edge[i].x, y = edge[i].y, w = edge[i].w;
int a = find(x);
int b = find(y);
//不是连通的
if(a!=b)
{
p[b] = a;
res += w;
cnt++;
}
}
//路径数量<n-1说明不连通
if (cnt<n-1) return INF;
return res;
}
int main()
{
scanf("%d%d", &n, &m);
for (int i = 0; i < m; i ++ )
{
scanf("%d%d%d", &edge[i].x, &edge[i].y, &edge[i].w);
}
int t = kruskal();
if(t == INF) cout<< "impossible"<<endl;
else cout<<t<<endl;
return 0;
}
+最小生成树Prime
AcWing 858.Prime算法求最小生成树
//这里填你的代码^^
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 510, INF = 0x3f3f3f3f;
int n,m;
int g[N][N]; //稠密图使用prim和邻接矩阵
int dist[N];
bool isvisited[N];
int prime(int x)
{
memset(dist, 0x3f, sizeof dist);
int res = 0;
dist[x]=0;
for(int i=0;i<n;i++)
{
int t=-1;
for(int j=1;j<=n;j++)
if(!isvisited[j] && (t==-1 || dist[t] > dist[j]))
t= j;
if(dist[t] == INF) return -1;
//标记访问
res += dist[t];
isvisited[t]=true;
//更新dist
for(int j=1;j<=n;j++)
{
dist[j] = min(dist[j],g[t][j]);
}
}
return res;
}
int main()
{
scanf("%d%d", &n, &m);
memset(g, 0x3f, sizeof g);
while (m -- )
{
int a,b,c;
scanf("%d%d%d", &a, &b,&c);
g[a][b] = g[b][a] = min(g[a][b],c); //无向图
}
int t = prime(1);
if(t==-1)
cout<<"impossible"<<endl;
else
cout<<t<<endl;
return 0;
}
+最小生成树Kruskal
AcWing859.Kruskal算法求最小生成树
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 100010, INF =0x3f3f3f3f;
const int M = 2*N;
int n,m;
struct Edge
{
int x;
int y;
int w;
bool operator < (const Edge & E) const
{
return w < E.w;
}
}edge[M];
int p[N]; //并查集
int find(int x)//找祖宗节点
{
if(x!=p[x]) p[x] = find(p[x]);
return p[x];
}
int kruskal()
{
int res = 0;
int cnt=0;
sort(edge,edge+m);
for(int i=1;i<=n;i++) p[i]=i;//初始化并查集
for(int i=0;i<m;i++)
{
int x = edge[i].x, y = edge[i].y, w = edge[i].w;
int a = find(x);
int b = find(y);
//不是连通的
if(a!=b)
{
p[b] = a;
res += w;
cnt++;
}
}
//路径数量<n-1说明不连通
if (cnt<n-1) return INF;
return res;
}
int main()
{
scanf("%d%d", &n, &m);
for (int i = 0; i < m; i ++ )
{
scanf("%d%d%d", &edge[i].x, &edge[i].y, &edge[i].w);
}
int t = kruskal();
if(t == INF) cout<< "impossible"<<endl;
else cout<<t<<endl;
return 0;
}
哈密顿图
- 通过图中所有顶点一次且仅一次的通路称为哈密顿通路。
- 通过图中所有顶点一次且仅一次的回路称为哈密顿回路。
@@ -359,8 +328,8 @@
给定一个数字 N,请你计算 1∼N 中一共出现了多少个数字 1。
例如,N=12 时,一共出现了 5 个数字 1,分别出现在 1,10,11,12 中。
-解题思路:相关视频链接

-class Solution {
public:
int countDigitOne(int n) {
vector<int> num;
while(n) num.push_back(n%10), n/=10;
int res = 0;
for(int i=num.size()-1;i>=0;i--)
{
int d = num[i];
int left=0,right=0,power=1;
for(int j=num.size()-1;j>i;j--) left = left * 10 + num[j];
for(int j=i-1;j>=0;j--) right = right * 10 + num[j], power*=10;
if(d==0) res += left*power;
else if(d==1) res += left*power + right + 1;
else res += (left+1) * power;
}
return res;
}
};
+解题思路:相关视频链接
class Solution {
public:
int countDigitOne(int n) {
vector<int> num;
while(n) num.push_back(n%10), n/=10;
int res = 0;
for(int i=num.size()-1;i>=0;i--)
{
int d = num[i];
int left=0,right=0,power=1;
for(int j=num.size()-1;j>i;j--) left = left * 10 + num[j];
for(int j=i-1;j>=0;j--) right = right * 10 + num[j], power*=10;
if(d==0) res += left*power;
else if(d==1) res += left*power + right + 1;
else res += (left+1) * power;
}
return res;
}
};
+
@@ -664,7 +633,7 @@
-
@@ -672,15 +641,15 @@
-
diff --git "a/2022/01/08/\345\233\236\351\246\226\345\220\221\346\235\245\350\220\247\347\221\237\345\244\204\357\274\214\345\275\222\345\216\273\357\274\214\344\271\237\346\227\240\351\243\216\351\233\250\344\271\237\346\227\240\346\231\264\357\275\2342021\345\271\264\347\273\210\346\200\273\347\273\223/index.html" "b/2022/01/08/\345\233\236\351\246\226\345\220\221\346\235\245\350\220\247\347\221\237\345\244\204\357\274\214\345\275\222\345\216\273\357\274\214\344\271\237\346\227\240\351\243\216\351\233\250\344\271\237\346\227\240\346\231\264\357\275\2342021\345\271\264\347\273\210\346\200\273\347\273\223/index.html"
index 6b160ea5..09070b1c 100644
--- "a/2022/01/08/\345\233\236\351\246\226\345\220\221\346\235\245\350\220\247\347\221\237\345\244\204\357\274\214\345\275\222\345\216\273\357\274\214\344\271\237\346\227\240\351\243\216\351\233\250\344\271\237\346\227\240\346\231\264\357\275\2342021\345\271\264\347\273\210\346\200\273\347\273\223/index.html"
+++ "b/2022/01/08/\345\233\236\351\246\226\345\220\221\346\235\245\350\220\247\347\221\237\345\244\204\357\274\214\345\275\222\345\216\273\357\274\214\344\271\237\346\227\240\351\243\216\351\233\250\344\271\237\346\227\240\346\231\264\357\275\2342021\345\271\264\347\273\210\346\200\273\347\273\223/index.html"
@@ -244,50 +244,49 @@
-
读研or就业的思考
这个问题其实在2年前就有在思考这件事情,虽然学生思维存在着一些局限性,但是你不得不承认这件事情确实是你需要尽早想清楚的事情,话是这么说其实还是当局者迷,旁观者清,尽管有一些我认识的人给过我他们的思考,我自己也没在最需要想清楚的时候想清楚这件事情,可能很多感受只有触碰到结果了才真正明白吧。
这个问题抛出来,我写起来还是不知从何说起,没有正确答案,未来都是未知的,害怕失去现有的一切,凭我的经验来看,还是要多遵从自己的内心,不要完全理性的去权衡利弊,失去如果每个选择都会后悔,就不要选让自己更后悔的那个。还是说一下自己当时思考的几件事情:
- 读研是为了什么,去企业又是为了什么
- 对于未来到底想做什么
- 抛开家长和他人的观点,你对自己的性格和能力是否足够了解,是否足够自信
- 都是最坏的情况,更能接受哪个选择
-- 如何承受选择带来的代价和自我和解之道
去黄鹤楼,看樱花
3月樱花又开了,大一没来得及看樱花,大二由于疫情影响也没能去成,大三正好有朋友过来武汉找我玩,就带着去黄鹤楼,隔壁学校赏樱花,那几天每天晚上和朋友们聊天一整夜,太久没一块说话了吧,我和他约定好考完研再来武汉陪我过生日。

春招面网易
4月有好友正好在做网易的春招宣传,内推了我一手,抱着涨点面试经验的心态,面了一下网易的算法岗,匆忙改了一版简历,笔试比较简单过了2/3,面试还行但还是没过,后面准备夏令营啥的也没有再投了。茶颜悦色&湖南师大&湖南大学
在湖南呆了这么久,这是第一次喝茶颜悦色,leo点的幽兰拿铁,晚上吃了一顿火锅直接拉肚子到凌晨2点,去了当初高二数学竞赛培训的湖师大,看了看那些当时买礼物的精品店和饭店,后面去了湖南大学找同学吃饭,湖南大学的建筑风格很不错,嘿嘿,不愧是湖大!有幸与神三元吃饭
毕业季,神三元学长也要毕业了,在学校一直听着他的江湖神话,终于有朝一日能见上一面了,迫不及待和朋友一起跑到另一个校区追星。见面一看确实是一表人才,吃饭紧张到有点不知道说话。不过听大佬聊技术趋势和工作思考,还是有很多不一样的体会。
+- 如何承受选择带来的代价和自我和解之道
去黄鹤楼,看樱花
3月樱花又开了,大一没来得及看樱花,大二由于疫情影响也没能去成,大三正好有朋友过来武汉找我玩,就带着去黄鹤楼,隔壁学校赏樱花,那几天每天晚上和朋友们聊天一整夜,太久没一块说话了吧,我和他约定好考完研再来武汉陪我过生日。

春招面网易
4月有好友正好在做网易的春招宣传,内推了我一手,抱着涨点面试经验的心态,面了一下网易的算法岗,匆忙改了一版简历,笔试比较简单过了2/3,面试还行但还是没过,后面准备夏令营啥的也没有再投了。茶颜悦色&湖南师大&湖南大学
在湖南呆了这么久,这是第一次喝茶颜悦色,leo点的幽兰拿铁,晚上吃了一顿火锅直接拉肚子到凌晨2点,去了当初高二数学竞赛培训的湖师大,看了看那些当时买礼物的精品店和饭店,后面去了湖南大学找同学吃饭,湖南大学的建筑风格很不错,嘿嘿,不愧是湖大!有幸与神三元吃饭
毕业季,神三元学长也要毕业了,在学校一直听着他的江湖神话,终于有朝一日能见上一面了,迫不及待和朋友一起跑到另一个校区追星。见面一看确实是一表人才,吃饭紧张到有点不知道说话。不过听大佬聊技术趋势和工作思考,还是有很多不一样的体会。

bytecamp再送人头
去年暑假参加了一次bytecamp的笔试,感觉挺有意思的,虽然当时也没过,今年再参加编程又爆0了,第一题是树形dp模版题,但是我当时忘了,后面两个就更难了不会。
-滚滚长江东逝水——再会江滩
暑假放假回家前,去了一次江滩,之前带朋友去的是汉口江滩,这次去武昌江滩看的,也算是两岸都看过了,虽然武汉夏天很热,但是长江的风吹过来还是很舒服的。

-
-魔都体验卡
有幸参加SIST的夏令营,体验了3天公费旅游的感觉,还吃了西餐,和朋友去了上海外滩和金融中心,半夜两点给健哥写前端。听说上海的天空很低!

-
+滚滚长江东逝水——再会江滩
暑假放假回家前,去了一次江滩,之前带朋友去的是汉口江滩,这次去武昌江滩看的,也算是两岸都看过了,虽然武汉夏天很热,但是长江的风吹过来还是很舒服的。

+
+魔都体验卡
有幸参加SIST的夏令营,体验了3天公费旅游的感觉,还吃了西餐,和朋友去了上海外滩和金融中心,半夜两点给健哥写前端。听说上海的天空很低!

+
梦碎了
9月差一点点,最后还是没能去到自己最想去的地方,感觉自己的学生时代已经结束了,梦碎了,不展开了,容易晚上emo😭
4年后再来南山区
18年国庆来深圳,只觉得繁华,人上人,4年后再来觉得这里还是缺少了一些文化感和年代感的东西,感谢朋友们的盛情招待,看海没赶上好时候,跟小w发我的照片完全不一样😔,第一次吃椰子鸡,去了SUST看夕阳,感受了朋友在字节跳动的“快乐”生活(我永远喜欢bytedance),遇到了突然其来的台风和大暴雨,沿着大沙河逛THU和PKU
-
-
-
+
+
+
最爱东湖与武大
在武汉,我独爱东湖,这次有幸还坐船浏览了对岸,去了磨山,一路听着粤语歌在东湖漫步,会有很多很多想法。逛完东湖与武大同学小歇畅聊,有幸参观了周恩来和闻一多先生的居所,一起吃饭听说他搞家教日薪1k+我羡慕。
-
-
-
-
-
+
+
+
+
+
摆烂的大四软测
大四一学期没听课,软测临时抱佛脚,卷了3年才知道整张试卷瞎写的感觉原来这么爽,还好没挂。
-CLANNAD
看了一直没看的CLANNAD,不得不说这个剧表达的东西很深刻,给了我很多生活的思考,我觉得是我心中看过的最好的动漫之一了,以后可以再看一遍,好像要一个团子啊🥺!

-科目二的败北
和朋友天天早出晚归跑去练科目二,到了考场发现自己学的东西都白学了,侧方直接挂,然后倒库紧张又挂了。。。坡上两只狗

+CLANNAD
看了一直没看的CLANNAD,不得不说这个剧表达的东西很深刻,给了我很多生活的思考,我觉得是我心中看过的最好的动漫之一了,以后可以再看一遍,好像要一个团子啊🥺!

+科目二的败北
和朋友天天早出晚归跑去练科目二,到了考场发现自己学的东西都白学了,侧方直接挂,然后倒库紧张又挂了。。。坡上两只狗

12月所思
12月陷入了一段特别迷茫的时间,他们说我所担心的并不能约束你,只能促进你,不要老是患得患失,后面拿了实习offer后开心了一些,等考研的朋友考完一起舒服了几天,后面的实训课继续摆烂,可惜说好来武汉陪我过生日的同学最后还是没来,那天写实训代码写到1点才睡,不过随着一年又一年,我倒是觉得就当平常日挺好的,也不用刻意去记,能想起来就想起来吧。
回家的所闻所见
纠结了很长时间关于寒假外出实习的事情,最后还是觉得去体验一下比较好,害怕过年回家待不了太久,所以提前跑路回家了几天,比较难受的是遇到了一些不好的事情,还是要常回家看看🙏
-啃了一些原理+Leetcode400题
今年感觉自己花在学习上的时间没有特别多,更多的时间被虚无的思考给浪费掉了,除了一些kaggle和工程代码之外,今年做了一些不一样的事情主要就是手推了《统计学习方法》当中一些基本算法,西瓜书也看了一些,leetocde不知不觉突破400题了! 还是很菜,只不过把刷题当成习惯了。
+啃了一些原理+Leetcode400题
今年感觉自己花在学习上的时间没有特别多,更多的时间被虚无的思考给浪费掉了,除了一些kaggle和工程代码之外,今年做了一些不一样的事情主要就是手推了《统计学习方法》当中一些基本算法,西瓜书也看了一些,leetocde不知不觉突破400题了! 还是很菜,只不过把刷题当成习惯了。

关于十年后再来北京这件事
今年跨年有些不一样,12.31飞北京跨年,下午处理好了租房的问题,人生地不熟,接下来元旦几天都是被朋友带着玩哈哈哈。
-Dr.Pepper & Sky
在旅店晚上喝了一杯命运石之门的Dr.Pepper,有一种穿越时空的味道 上次坐飞机还是10多年前,再一次飞上蓝天还是很激动!


+Dr.Pepper & Sky
在旅店晚上喝了一杯命运石之门的Dr.Pepper,有一种穿越时空的味道 上次坐飞机还是10多年前,再一次飞上蓝天还是很激动!


清华五道口
十年前曾踏过清华的大门,十年后还是没能跨进你的大门,来生请等我。
-单车刷夜去天安门和祖国母亲一起跨年
作为一名预备党员,元旦必然要在天安门通宵等升旗,被北方的寒风给冻傻了,和祖国母亲一起放飞和平鸽!

-
+单车刷夜去天安门和祖国母亲一起跨年
作为一名预备党员,元旦必然要在天安门通宵等升旗,被北方的寒风给冻傻了,和祖国母亲一起放飞和平鸽!

+
海底捞被朋友抓去过生日
虽然生日过了,但是他们想在北京陪我过一次,店里送了相框,正好一起拍照留作纪念,摆在新家当饰品,第一次在海底捞过生日社死。

-四季民福故宫店北京烤鸭南锣鼓巷中关村中科院
吃了很离谱的豆汁和正宗北京烤鸭


+四季民福故宫店北京烤鸭南锣鼓巷中关村中科院
吃了很离谱的豆汁和正宗北京烤鸭

环球影城,我要上魔法学院!
在环球影城玩了一天,看过的电影不多,环球影城的这几个设施特别还原,喝了魔法黄油啤酒,买了小黄人的盲盒。
-
-
-
-美团实习ing
太菜了只会摸鱼,要开始新的生活了

+
+
+
+美团实习ing
太菜了只会摸鱼,要开始新的生活了

To 2022
- 请你继续保持对技术的热情,脚踏实地,努力学习,祝你好运
- 好好体验实习,工作,一个人独立生活的感觉
@@ -299,7 +298,7 @@ To 20
- 还有不能忘记的音乐梦!
- 希望未来以后有机会当一个speaker
-「掘金链接:回首向来萧瑟处,归去,也无风雨也无晴|2021年终总结」
+「掘金链接:回首向来萧瑟处,归去,也无风雨也无晴|2021年终总结」
@@ -604,7 +603,7 @@ To 20
手写IoU
import numpy as np
def IoU(bounding_box,ground_truth):
"""
:param bounding_box: [[x1,y1,x2,y2,score]]
:param ground_truth: [x1,y1,x2,y2]
:return:
"""
x1 = bounding_box[:,0]
y1 = bounding_box[:,1]
x2 = bounding_box[:,2]
y2 = bounding_box[:,3]
score = bounding_box[:,4]
areas = (x2-x1) * (y2-y1)
gt_area = (ground_truth[2] - ground_truth[0]) * (ground_truth[3] - ground_truth[1])
xx1 = np.maximum(x1,ground_truth[0])
yy1 = np.maximum(y1,ground_truth[1])
xx2 = np.minimum(x2,ground_truth[2])
yy2 = np.minimum(y2,ground_truth[3])
h = np.maximum(0,yy2-yy1)
w = np.maximum(0,xx2-xx1)
inter = w * h
ovr = inter / (gt_area + areas - inter) # np.true_divide(inter, (gt_area + areas - inter))
return ovr
-
旋转矩阵
class Solution {
public:
void rotate(vector<vector<int>>& matrix) {
int n = matrix.size();
for(int i=0;i<n/2;i++)
{
for(int j=0;j<(n+1)/2;j++)
{
// (i,j) (j,n-i-1) (n-j-1,i) (n-i-1,n-j-1)
swap(matrix[i][j],matrix[n-i-1][n-j-1]);
swap(matrix[i][j],matrix[n-j-1][i]);
swap(matrix[j][n-i-1],matrix[n-i-1][n-j-1]);
}
}
}
};
小米
小米面试其实是当时最好的选择,因为就在武汉本地,也不用外出,但是当时面试确实不太好,面试官对我其中一个项目比较感兴趣,被疯狂怼着追问细节。
@@ -299,25 +297,21 @@ 剑指 Offer 39. 数组中出现次数超过一半的数字 第二题直接限制时间复杂度$O(n)$,空间复杂度$O(1)$,我只会哈希方法,然后和面试官说了一下最优解方法我只记得叫摩尔投票,然后具体忘了。
栈的压入、弹出序列
class Solution {
public:
bool validateStackSequences(vector<int>& pushed, vector<int>& popped) {
stack<int> stk;
int n = popped.size();
int m = pushed.size();
int j = 0;
for(int i=0;i<m;i++)
{
stk.push(pushed[i]);
while(stk.size()&&stk.top()==popped[j])
{
j++;
stk.pop();
}
}
return stk.empty();
}
};
-
其他
还有一些感觉比较重要,但是没有被问道的东西,包括各种评价指标的含义等等,包括数学基础等等。
经典教程推荐:cs231n,吴恩达,李宏毅,动手学深度学习,《统计学习方法》
关于八股文方面这里推荐一个DeepLearning-500-questions
手写非极大抑制
使用非极大抑制的前提是,我们已经得到了一组候选框和对应label的置信分数,以及groud truth的信息,通过设定阈值来删除重合度较高的候选框。
算法流程如下:
-- 根据置信度得分进行排序
-- 选择置信度最高的比边界框添加到最终输出列表中,将其从边界框列表中删除
-- 计算所有边界框的面积
-- 计算置信度最高的边界框与其它候选框的IoU。
-- 删除IoU大于阈值的边界框
-- 重复上述过程,直至边界框列表为空。
+- 根据置信度得分进行排序
+- 选择置信度最高的比边界框添加到最终输出列表中,将其从边界框列表中删除
+- 计算所有边界框的面积
+- 计算置信度最高的边界框与其它候选框的IoU。
+- 删除IoU大于阈值的边界框
+- 重复上述过程,直至边界框列表为空。
import numpy as np
def nms(dets, threshod, mode="Union"):
"""
greedily select boxes with high confidence
keep boxes overlap <= thresh
rule out overlap > thresh
:param dets: [[x1, y1, x2, y2 score]]
:param threshod: retain overlap <= thresh
:return: indexes to keep
"""
x1 = dets[:, 0]
y1 = dets[:, 1]
x2 = dets[:, 2]
y2 = dets[:, 3]
scores = dets[:, 4]
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
order = scores.argsort()[::-1] # reverse
keep = []
while order.size() > 0:
i = order[0]
keep.append(i)
# A & B left top position
xx1 = np.maximun(x1[i], x1[order[1, :]])
yy1 = np.maximun(y1[i], y1[order[1, :]])
# A & B right down position
xx2 = np.minimum(x2[i], x2[order[1, :]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
# cacaulate the IOU between box which have largest score with other boxes
if mode == "Union":
# area[i]: the area of largest score
ovr = inter / (areas[i] + areas[order[1:]] - inter)
elif mode == "Minimum":
ovr = inter / np.minimum(areas[i], areas[order[1:]])
# delete the IoU that higher than threshod
inds = np.where(ovr <= threshod)[0]
order = order[inds + 1] # +1: eliminates the first element in order
return keep
-
手写Kmeans方法
-这个版本不是最佳写法,某些处理有点暴力,可以用矩阵和numpy相关的操作会更简洁,但是退出迭代的条件写的很全的,有达到迭代次数,中心点集不变,中心点变化范围小于$\delta$
-import numpy as np
import matplotlib.pyplot as plt
n = 100
a = np.random.randn(0,50,n)
b = np.random.rand(0,50,n)
x = np.random.randint(0,50,n)
y = np.random.randint(0,50,n)
points = np.array(list(zip(x,y)))
def distance(x,y):
return np.sqrt(np.sum((x-y)**2))
def k_means(points,k=5,epochs=500,delta=1e-3):
# 初始化聚类中心
center_ids = np.random.randint(0,n,k)
centers = points[center_ids]
# 聚类集合初始化
results = []
for i in range(k):
results.append([])
step = 1
flag = True
# 计算各点到中心的距离
while flag and step < epochs:
# 重新迭代
for i in range(k):
results[i] = []
# 计算每个点到距离中心的距离
for i in range(len(points)):
point = points[i]
min_dis = np.inf
min_id = 0
for idx, center in enumerate(centers):
dis = distance(center,point)
if min_dis > dis:
min_dis = dis
min_id = idx
results[min_id].append(point)
# 更新聚类中心
for idx, old_center in enumerate(centers):
new_center = np.array(results[idx]).mean(axis=0)
if distance(center, new_center) > delta:
centers[idx] = new_center
flag = False
# flag=True说明聚类中心已经不变了则可以退出了
if flag:
break
else:
flag = True
step += 1
return results,centers
plt.plot(x,y,'ro')
results,centers=k_means(points,k=5)
color=['ko','go','bo','yo','co']
for i in range(len(results)):
result=results[i]
plt.plot([res[0] for res in result],[res[1] for res in result],color[i])
plt.plot([res[0] for res in centers],[res[1] for res in centers],'ro')
plt.show()
-
+这个版本不是最佳写法,某些处理有点暴力,可以用矩阵和numpy相关的操作会更简洁,但是退出迭代的条件写的很全的,有达到迭代次数,中心点集不变,中心点变化范围小于$\delta$
import numpy as np
import matplotlib.pyplot as plt
n = 100
a = np.random.randn(0,50,n)
b = np.random.rand(0,50,n)
x = np.random.randint(0,50,n)
y = np.random.randint(0,50,n)
points = np.array(list(zip(x,y)))
def distance(x,y):
return np.sqrt(np.sum((x-y)**2))
def k_means(points,k=5,epochs=500,delta=1e-3):
# 初始化聚类中心
center_ids = np.random.randint(0,n,k)
centers = points[center_ids]
# 聚类集合初始化
results = []
for i in range(k):
results.append([])
step = 1
flag = True
# 计算各点到中心的距离
while flag and step < epochs:
# 重新迭代
for i in range(k):
results[i] = []
# 计算每个点到距离中心的距离
for i in range(len(points)):
point = points[i]
min_dis = np.inf
min_id = 0
for idx, center in enumerate(centers):
dis = distance(center,point)
if min_dis > dis:
min_dis = dis
min_id = idx
results[min_id].append(point)
# 更新聚类中心
for idx, old_center in enumerate(centers):
new_center = np.array(results[idx]).mean(axis=0)
if distance(center, new_center) > delta:
centers[idx] = new_center
flag = False
# flag=True说明聚类中心已经不变了则可以退出了
if flag:
break
else:
flag = True
step += 1
return results,centers
plt.plot(x,y,'ro')
results,centers=k_means(points,k=5)
color=['ko','go','bo','yo','co']
for i in range(len(results)):
result=results[i]
plt.plot([res[0] for res in result],[res[1] for res in result],color[i])
plt.plot([res[0] for res in centers],[res[1] for res in centers],'ro')
plt.show()
总结
本人能力有限,如果上述回答有任何错误,还请各位大佬及时指出
@@ -328,7 +322,7 @@ 总结不用害怕,尽量多交流,避免场面陷入尴尬。
- 反问环节我一般问的是来这边的工作内容,学习的建议和评价,培养和安排之类的。
-「掘金链接:菜鸡的算法岗日常实习面经总结」
+「掘金链接:菜鸡的算法岗日常实习面经总结」
@@ -637,7 +631,7 @@ 总结
-
diff --git "a/2022/03/31/\346\227\242\345\276\200\344\270\215\346\201\213\357\274\214\347\272\265\346\203\205\345\220\221\345\211\215\357\274\214\346\261\237\346\271\226\345\206\215\350\247\201\342\200\224\342\200\22422\345\262\201\351\202\243\345\271\264\357\274\214\345\234\250\345\214\227\344\272\254\347\232\204\346\227\245\345\255\220/index.html" "b/2022/03/31/\346\227\242\345\276\200\344\270\215\346\201\213\357\274\214\347\272\265\346\203\205\345\220\221\345\211\215\357\274\214\346\261\237\346\271\226\345\206\215\350\247\201\342\200\224\342\200\22422\345\262\201\351\202\243\345\271\264\357\274\214\345\234\250\345\214\227\344\272\254\347\232\204\346\227\245\345\255\220/index.html"
index 344d40d7..f0a29343 100644
--- "a/2022/03/31/\346\227\242\345\276\200\344\270\215\346\201\213\357\274\214\347\272\265\346\203\205\345\220\221\345\211\215\357\274\214\346\261\237\346\271\226\345\206\215\350\247\201\342\200\224\342\200\22422\345\262\201\351\202\243\345\271\264\357\274\214\345\234\250\345\214\227\344\272\254\347\232\204\346\227\245\345\255\220/index.html"
+++ "b/2022/03/31/\346\227\242\345\276\200\344\270\215\346\201\213\357\274\214\347\272\265\346\203\205\345\220\221\345\211\215\357\274\214\346\261\237\346\271\226\345\206\215\350\247\201\342\200\224\342\200\22422\345\262\201\351\202\243\345\271\264\357\274\214\345\234\250\345\214\227\344\272\254\347\232\204\346\227\245\345\255\220/index.html"
@@ -210,8 +210,7 @@
既往不恋,纵情向前,江湖再见——22岁那年,在北京的日子
2022年3月31日0:52,睡不着,日常拖延症+强迫症导致清东西到现在,等会还想清扫一下弄脏的地板。
莲竹花园甲2号楼一门101,从今天起,这里将不再是我的家,本来是昨天的机票,天气不似预期,不打算买高铁,还想再飞上一次云霄,所以倔强的又改签了机票,不过正好也让我多看一眼这里吧,最近东航事件其实让我也有一点小慌,希望能平安到达吧。
-不出所料,我对这个城市并没有什么留恋,每天晚上我都会思考很多,有天夜里我的脑海里突然冒出来了那句:劝君更进一杯酒,西出阳关无故人。 这一刻我才真正明白什么是独在异乡为异客的感觉,什么才是我心里最想要的。
-
+不出所料,我对这个城市并没有什么留恋,每天晚上我都会思考很多,有天夜里我的脑海里突然冒出来了那句:劝君更进一杯酒,西出阳关无故人。 这一刻我才真正明白什么是独在异乡为异客的感觉,什么才是我心里最想要的。
从南山南到北海北
作为一个一直生活在南方的人,第一次在北京生活,拥挤的早晚高峰,寒风和冰雪的夜晚,疫情形势也不断变化,恰逢过年,回家的日子也迟迟不敢定下来,奇怪,你可能会好奇,在大厂工作我竟然并没有提到工作的压力,仔细想来,其实美团的作息是相对舒服的10-8-5,尽管工作和技术基础我有许多不足,但mentor比较照顾我,不会刻意去push进度,更多的是希望让我自己去探索和思考,所以更多的工作压力还是来自于我自己一贯所坚持的负责和标准。这是一件好事,说明我做事情有自己的原则和态度,但有时候也会让自己比较心累,毕竟作为一个新人,从0-1去启动项目,虽然我是个自信的人,即使遇到问题也会尽可能自己去想办法,但我也深知自己的代码习惯和知识结构存在很多不足,害怕的不是做不好做不成,而是做事的效率和维护性,其实这也是我应该要从这些前辈身上要学到的经验。
年前一周,我申请了远程实习提前坐飞机回家了,到家的一刻才明白,这种人间烟火气才真的是生活,说来有愧,从回家到过年收假的时间,工作上我确实有点摆烂了哈哈哈,我知道这应该最后一个这么长时间的寒假了,经过将近1个月的在外实习也格外体会到了这种归家的温暖,去学一学切菜炒菜,陪一陪老年人,约一场球,见想见的人,街头漫步,吃点臭干子,米粉,麻辣烫,和朋友分享一些见闻,借酒消愁,确实愁更愁。
时间很快,大年初五的下午,我就启程返工了,毕竟现在的身份是打工人而不是大学生。和我一同去北京的还有广平,也在美团,我们都不打算实习很久,刚好我房子够住2个人,就一起住了一个月,不得不说多了一个人生活确实没有这么孤单了,尽管工作和拥挤依旧麻烦,但至少回家轻松快活一些,虽然有时候会有一些赌气和争吵,睡眠问题,但不管怎么说,互相都分担了一些对未来的焦虑和思考,一块出去玩,打游戏开黑,去什刹海,天安门,吃各种小吃,也算是度过一段不那么枯燥的时间。
@@ -527,7 +526,7 @@
-
@@ -535,15 +534,15 @@
-官方源码链路思想
Protobuf 源码链路过程主要涉及三类数据类型之间的转换,以 Message 对象进行管理,自定义 Value 类实现反射和底层存储,用 Message 对象能有效地进行管理和迁移,但也带来了许多反射和序列化开销。

+官方源码链路思想
Protobuf 源码链路过程主要涉及三类数据类型之间的转换,以 Message 对象进行管理,自定义 Value 类实现反射和底层存储,用 Message 对象能有效地进行管理和迁移,但也带来了许多反射和序列化开销。
Protobuf编码格式
Protobuf 编码字段格式大体上遵循 TLV(Tag,Length,Value) 的结构,但针对具体的类型存在一些编码差异,这里我们将较为全面的给出常见类型的编码模式。
-Message Field
Protobuf 的接口必定包裹在一个 Message 类型下,因此无论是 request 还是 response 最终都会包裹成一个 Message 对象,那么 Field 则是 Message 的一个基本单元,任何类型的字段都遵循这样的 TLV 结构:

+Message Field
Protobuf 的接口必定包裹在一个 Message 类型下,因此无论是 request 还是 response 最终都会包裹成一个 Message 对象,那么 Field 则是 Message 的一个基本单元,任何类型的字段都遵循这样的 TLV 结构:
- Tag 由字段编号 Field_number 和 wiretype 两部分决定,对位运算后的结果进行 varint 压缩,得到压缩后的字节数组作为字段的 Tag。
- wiretype 的值则表示的是 value 部分的编码方式,可以帮助我们清楚如何对 value 的读取和写入。到目前为止,wiretype只有 VarintType,Fixed32Type,Fixed64Type,BytesType 四类编码方式。其中VarintType 类型会被压缩后再编码,属于 Fixed32Type 和 Fixed64Typ 固定长度类型则分别占用4字节和8字节,而属于不定长编码类型 BytesType 的则会编码计算 value 部分的 ByteLen 再拼接 value 。
@@ -247,13 +247,13 @@ List
li
- Packed List Mode
如果list的元素本身属于 VarintType/Fixed32Type/Fixed64Type 编码格式,那么将采用 packed 模式编码整个 List ,在这种模式下的 list 是有 bytelen 的。Protobuf3 默认对这些类型启用 packed。
-
+
- UnPacked List Mode
当 list 元素属于 BytesType 编码格式时,list 将使用 unpacked 模式,直接编码每一个元素的 TLV,这里的 V 可能是嵌套的如List模式,那么 unpacked 模式下所有元素的 tag 都是相同的,list 字段的结束标志为与下一个 TLV 字段编码不同或者到达 buf 末尾。
-
+
Map
Map 编码模式与 unpacked list 相同,根据官方设计思想,Map 的每个 KV 键值对其实本质上就是一个 Message,固定 key 的 Field_number 是1,value 的 Field_number 是2,那么 Map 的编码模式就和 List<Message> 一致了。
-
+
源码 Descriptor 细节
这里主要介绍一下源码的 descriptor 设计上的一些需要注意的细节。
- Service 接口由 ServiceDescriptor 来描述,ServiceDescriptor 当中可以拿到每个 rpc 函数的 MethodDescriptor。
@@ -261,14 +261,14 @@
+
动态反射
针对 Protobuf 的反射使用场景,我们归纳出以下需求:
- 具有完整的结构自描述和具体类型反射功能,兼容 scalar 类型以及复杂嵌套的 MESSAGE/LIST/MAP 结构。
- 支持字节流模式下的对任意局部进行动态数据修改与遍历。
- 保证数据可并发读。
这里我们借助 Go reflect 的设计思想,把通过 IDL 解析得到的准静态类型描述(只需跟随 IDL 更新一次)TypeDescriptor 和 原始数据单元 Node 打包成一个完全自描述的结构—— Value,提供一套完整的反射 API。
-
+
IDL 静态文件 parse 过程:
为了提供文件流和内存字符串 io 流的 idl 文件解析,同时保证保证 go 版本兼容性,我们利用protoreflect@v1.8.2解析结果完成按需构造。从实现原理上来看,与高版本 protoreflect 利用protocompile对原始链路再 make 出源码的 warp 版本一致,更好的实现或许是处理利用 protoreflect 中的 ast 语法树构造。
Descriptor设计
Descriptor 的设计原理基本尽可能与源码保持一致,但为了更好的自反射性,我们抽象了一个 TypeDescriptor 来表示更细粒度的类型。
FieldDescriptor
type FieldDescriptor struct {
kind ProtoKind // the same value with protobuf descriptor
id FieldNumber
name string
jsonName string
typ *TypeDescriptor
}
@@ -277,7 +277,6 @@ TypeDescriptor
type TypeDescriptor struct {
baseId FieldNumber // for LIST/MAP to write field tag by baseId
typ Type
name string
key *TypeDescriptor
elem *TypeDescriptor
msg *MessageDescriptor // for message, list+message element and map key-value entry
}
-
baseId:因为对于 LIST/MAP 类型的编码特殊性,如在 unpack 模式下,每一个元素都需要编写 Tag,我们必须在构造时针对 LIST/MAP 提供 fieldnumber,来保证读取和写入的自反射性。msg:这里的 msg 不是仅 Message 类型独有,主要是方便 J2P 部分对于 List 和裁剪场景中 map 获取可能存在 value 内部字段缺失的 MapEntry 的 MassageDescriptor(在源码的设计理念当中 MAP 的元素被认为是一个含有 key 和 value 两个字段的 message )的时候能直接利用 TypeDescriptor 进入下一层嵌套。
数据存储设计
从协议本身的 TLV 嵌套思想出发,我们利用字节流的编码格式,建立健壮的自反射性结构体处理任意类型的解析。
Node结构
type Node struct {
t proto.Type // node type
et proto.Type // for map value or list element type
kt proto.Type // for map key type
v unsafe.Pointer
l int // ptr len
size int // only for MAP/LIST element counts
}
-
具体的存储规则如下:
- 基本类型 Node 表示:指针 v 的起始位置不包含 tag,指向 (L)V,t = 具体类型。
@@ -300,13 +298,10 @@
- ERROR类型Node表示:在 setnotfound 中,若片段设计与上述规则一致则可正确构造插入节点。
虽然 MAP/LIST 的父级 Node 存储有些变化,但是其子元素节点都是基本类型 / MESSAGE,所以叶子节点存储格式都是基本的 (L)V,这也便于序列化和数据基本单位的原子操作。
-Value结构
value 的结构本身是对 Node 的封装,将 Node 与相应的 descriptor 封装起来,但不同于 thrift,在 Protobuf 当中由于片段无法完全自解析出具体类型,之后的涉及到具体编码的部分操作不能脱离 descriptor,部分 API 实现只能 Value 类作为调用单位。
-type Value struct {
Node
Desc *proto.TypeDescriptor
IsRoot bool
}
-
+Value结构
value 的结构本身是对 Node 的封装,将 Node 与相应的 descriptor 封装起来,但不同于 thrift,在 Protobuf 当中由于片段无法完全自解析出具体类型,之后的涉及到具体编码的部分操作不能脱离 descriptor,部分 API 实现只能 Value 类作为调用单位。
type Value struct {
Node
Desc *proto.TypeDescriptor
IsRoot bool
}
由于从 rpc 接口解析后我们直接得到了对应的 TypeDescriptor,再加上 root 节点本身没有前缀TL的独特编码结构,我们通过设置IsRoot标记来区分 root 节点和其余节点,实现 Value 结构的 Descriptor 统一。
数据编排
不同于源码 Message 对象数据动态管理的思想,我们设计了更高效的动态管理方式。我们借助 DOM (Document Object Model)思想,将原始字节流数据层层包裹的结构,抽象成多层嵌套的 BTree 结构,实现对数据的定位,切分,裁剪等操作的 inplace 处理。
-Path与PathNode
为了准确描述 DOM 中数据节点之间的嵌套关系,我们设计了 Path 结构,在 Path 的基础上,我们组合对应的数据单元 Node,然后再通过一个 Next 数组动态存储子节点,便可以组装成一个类似于 BTree 的泛型单元结构。
-// Path represents the relative position of a sub node in a complex parent node
type Path struct {
t PathType // 类似div标签的类型,用来区分field,map,list元素,帮助判定父级嵌套属于什么类型结构
v unsafe.Pointer // PathStrKey, PathFieldName类型,存储的是Key/FieldName的字符串指针
l int
// PathIndex类型,表示LIST的下标
// PathIntKey类型,表示MAPKey的数值
// PathFieldId类型,表示字段的id
}
pathes []Path : 合理正确的Path数组,可以定位到嵌套复杂类型里具体的key/index的位置
type PathNode struct {
Path // DOM tree中用于定位当前Node的位置,并包含FieldId/FieldName/Key/index信息
Node // 存储了复杂嵌套关系中该位置对应的具体bytes片段
Next []PathNode // 下层嵌套的Node节点,基本类型下层Next为空
}
+Path与PathNode
为了准确描述 DOM 中数据节点之间的嵌套关系,我们设计了 Path 结构,在 Path 的基础上,我们组合对应的数据单元 Node,然后再通过一个 Next 数组动态存储子节点,便可以组装成一个类似于 BTree 的泛型单元结构。
// Path represents the relative position of a sub node in a complex parent node
type Path struct {
t PathType // 类似div标签的类型,用来区分field,map,list元素,帮助判定父级嵌套属于什么类型结构
v unsafe.Pointer // PathStrKey, PathFieldName类型,存储的是Key/FieldName的字符串指针
l int
// PathIndex类型,表示LIST的下标
// PathIntKey类型,表示MAPKey的数值
// PathFieldId类型,表示字段的id
}
pathes []Path : 合理正确的Path数组,可以定位到嵌套复杂类型里具体的key/index的位置
type PathNode struct {
Path // DOM tree中用于定位当前Node的位置,并包含FieldId/FieldName/Key/index信息
Node // 存储了复杂嵌套关系中该位置对应的具体bytes片段
Next []PathNode // 下层嵌套的Node节点,基本类型下层Next为空
}
构建DOM Tree
构建 DOM 支持懒加载和全加载,在懒加载模式下 LIST/MAP 的 Node 当中 size 不会同步计算,而全加载在构造叶子节点的同时顺便更新了 size,构造后的节点都将遵循上述存储规则,具有自反射性和结构完整性。
查找字段
支持任意Node查找,查找函数设计了三个外部API:GetByPath,GetByPathWithAddress,GetMany。
- 指针向前移动到下一个 path 和 address。
-
+
DOM序列化
- Marshal:建好 PathNode 后,可遍历拼接 DOM 的所有叶子节点片段,Tag 部分会通过 Path 类型和 Node 类型进行补全,bytelen 根据实际遍历节点进行更新。
- MarshalTo:针对数据裁剪场景,该设计方案具有很好的扩展性,可直接比对新旧 descriptor 中共有的字段 id,对字节流一次性拼接写入,无需依赖中间结构体,可支持多层嵌套字段缺失以及 LIST/MAP 内部元素字段缺失。
-
+
协议转换
ProtoBuf——>JSON
Protobuf->JSON 协议转换的过程可以理解为逐字节解析 ProtoBuf,并结合 Descriptor 类型编码为 JSON 到输出字节流,整个过程是 in-place 进行的,并且结合内存池技术,仅需为输出字节流分配一次内存即可。
-
+
ProtoBuf——>JSON 的转换过程如下:
- 根据输入的 Descriptor 指针类型区分,若为 Singular(string/number/bool/Enum) 类型,跳转到第5步开始编码;
@@ -347,17 +342,15 @@ JSON——>ProtoBuf
协议转换过程中借助 JSON 状态机原理和 sonic 思想,设计 UserNodeStack 实现了接口 Onxxx(OnBool、OnString、OnInt64….)方法达到编码 ProtoBuf 的目标,实现 in-place 遍历 JSON 转换。
-
-VisitorUserNode 结构
因为在编码 Protobuf 格式的 Mesage/UnpackedList/Map 类型时需要对字段总长度回写,并且在解析复杂类型(Message/Map/List)的子元素时需要依赖复杂类型 Descriptor 来获取子元素 Descriptor,所以需要 VisitorUserNode 结构来保存解析 json 时的中间数据。
-type VisitorUserNode struct {
stk []VisitorUserNodeStack
sp uint8
p *binary.BinaryProtocol
globalFieldDesc *proto.FieldDescriptor
}
+
+VisitorUserNode 结构
因为在编码 Protobuf 格式的 Mesage/UnpackedList/Map 类型时需要对字段总长度回写,并且在解析复杂类型(Message/Map/List)的子元素时需要依赖复杂类型 Descriptor 来获取子元素 Descriptor,所以需要 VisitorUserNode 结构来保存解析 json 时的中间数据。
type VisitorUserNode struct {
stk []VisitorUserNodeStack
sp uint8
p *binary.BinaryProtocol
globalFieldDesc *proto.FieldDescriptor
}
- stk:记录解析时中间变量的栈结构,在解析 Message 类型时记录 MessageDescriptor、PrefixLen;在解析 Map 类型时记录 FieldDescriptor、PairPrefixLen;在解析 List 类型时记录 FieldDescriptor、PrefixListLen;
- sp:当前所处栈的层级;
- p:输出字节流;
- globalFieldDesc:每当解析完 MessageField 的 jsonKey 值,保存该字段 Descriptor 值;
-VisitorUserNodeStack 结构
记录解析时字段 Descriptor、回写长度的起始地址 PrefixLenPos 的栈结构。
-type VisitorUserNodeStack struct {
typ uint8
state visitorUserNodeState
}
+VisitorUserNodeStack 结构
记录解析时字段 Descriptor、回写长度的起始地址 PrefixLenPos 的栈结构。
type VisitorUserNodeStack struct {
typ uint8
state visitorUserNodeState
}
- typ:当前字段的类型,取值有对象类型(objStkType)、数组类型(arrStkType)、哈希类型(mapStkType);
- state:存储详细的数据值;
@@ -371,23 +364,19 @@ 协议转换过程
JSON——>ProtoBuf 的转换过程如下:
- 从输入字节流中读取一个 json 值,并判断其具体类型(
object/array/string/float/int/bool/null);
-- 如果是 object 类型,可能对应 ProtoBuf MapType/MessageType,sonic 会按照
OnObjectBegin()->OnObjectKey()->decodeValue()... 顺序处理输入字节流
-
-
+- 如果是 object 类型,可能对应 ProtoBuf MapType/MessageType,sonic 会按照
OnObjectBegin()->OnObjectKey()->decodeValue()... 顺序处理输入字节流
OnObjectBegin()阶段解析具体的动态类型描述 FieldDescriptor 并压栈;OnObjectKey() 阶段解析 jsonKey 并以 ProtoBuf 格式编码 Tag、Length 到输出字节流;decodeValue()阶段递归解析子元素并以 ProtoBuf 格式编码 Value 部分到输出字节流,若子类型为复杂类型(Message/Map),会递归执行第 2 步;若子类型为复杂类型(List),会递归执行第 3 步。
-
-- 如果是 array 类型,对应 ProtoBuf PackedList/UnpackedList,sonic 会按照
OnObjectBegin()->OnObjectKey()->OnArrayBegin()->decodeValue()->OnArrayEnd()... 顺序处理输入字节流
-
-
+
+- 如果是 array 类型,对应 ProtoBuf PackedList/UnpackedList,sonic 会按照
OnObjectBegin()->OnObjectKey()->OnArrayBegin()->decodeValue()->OnArrayEnd()... 顺序处理输入字节流
OnObjectBegin()阶段处理解析 List 字段对应动态类型描述 FieldDescriptor 并压栈;OnObjectKey()阶段解析 List 下子元素的动态类型描述 FieldDescriptor 并压栈;OnArrayBegin()阶段将 PackedList 类型的 Tag、Length 编码到输出字节流;decodeValue()阶段循环处理子元素,按照子元素类型编码到输出流,若子元素为复杂类型(Message),会跳转到第 2 步递归执行。
-
+
- 在结束处理某字段数据后执行
onValueEnd()、OnArrayEnd()、OnObjectEnd(),获取栈顶 lenPos 数据,对字段长度部分回写并退栈。
- 更新输入和输出字节流位置,跳回第 1 步循环处理,直到处理完输入流数据。
@@ -402,26 +391,26 @@ 反射图中列举了 DOM 常用操作的性能,测试细节与 thrift 相同。
- MarshalTo 方法:相比 ProtobufGo 提升随着数据规模的增大趋势越明显,ns/op 开销约为源码方法的0.29 ~ 0.32。
-
-
+
+
字段Get/Set定量测试
- factor 用于修改从上到下扫描 proto 文件字段获取比率。
- 定量测试比较方法是 ProtobufGo 的 dynamicpb 模块和 DynamicGo 的 Get/SetByPath,SetMany,测试对象是medium data 的情况。
- Set/Get 字段定量测试结果均优于 ProtobufGo,且在获取字段越稀疏的情况下性能加速越明显。
- Setmany 性能加速更明显,在 100% 字段下 ns/op 开销约为 0.11。
-
+
序列化/反序列
- 序列化在 small 规模略高于 ProtobufGo,medium 规模的数据上性能优势更明显,ns/op 开销约为源码的0.54 ~ 0.84。
- 反序列化在 reuse 模式下,small 规模略高于 ProtobufGo,在 medium 规模数据上性能优势更明显,ns/op 开销约为源码的0.44 ~ 0.47,随数据规模增大性能优势增加。
-
-
+
+
协议转换
- Json2Protobuf 优于 ProtobufGo,ns/op 性能开销约为源码的0.21 ~ 0.89,随着数据量规模增大优势增加。
- Protobuf2Json 性能明显优于 ProtobufGo,ns/op 开销约为源码的0.13 ~ 0.21,而相比 Kitex,ns/op 约为Sonic+Kitex 的0.40 ~ 0.92,随着数据量规模增大优势增加。
-
+
应用与展望
目前 dynamicgo 对于 Protobuf 协议的可支持的功能包括:
- 替代官方源码的 JSON 协议转换,实现更高性能的 HTTP<>PB 动态网关
@@ -742,7 +731,7 @@
- 编译原理
+ 数据库系统
-
diff --git "a/2024/10/09/ubuntu22-04-\346\227\245\345\270\270\345\214\226/index.html" "b/2024/10/09/ubuntu22-04-\346\227\245\345\270\270\345\214\226/index.html"
index 193d8bec..b97a8c43 100644
--- "a/2024/10/09/ubuntu22-04-\346\227\245\345\270\270\345\214\226/index.html"
+++ "b/2024/10/09/ubuntu22-04-\346\227\245\345\270\270\345\214\226/index.html"
@@ -16,7 +16,7 @@
-
+
@@ -208,20 +208,19 @@
- 最近有在折腾一些Ubuntu日常化的东西,给电脑重新装了双系统,相比前几年,ubuntu22.04之后系统确实变得非常好用了,软件生态支持也变多了,为了更加日常化的使用折腾了一些相关软件的安装,这边做一个简单的记录。
-
-
-ubuntu安装卸载
ubuntu的安装卸载以及分区教程还是有些麻烦的,我也是参考了b战上面一个不错的up主的教学,期间有差点把自己windows引导搞出问题,然后用驱动精灵修复了。注意计算机专业同学还是尽量用英语安装,且安装以后禁用掉软件和内核更新,在一生一芯中有提到,禁用方法很简单自行百度即可。
参考链接:Windows 和 Ubuntu 双系统的安装和卸载
-Easyconnect
目前华科的VPN是支持ubuntu系统的,这确实提供了学生在连接校园网和服务器上的便利。当然安装可能会打不开的小问题。
参考链接:解决方案,需下载的软件内有可用的百度云网址
-VPN-Clash
找了一个不错的ubuntu支持的带有客户端的clash,亲测可用,导入任意可用的订阅链接就行。
参考链接:Devpn
+ 最近有在折腾一些Ubuntu日常化的东西,给电脑重新装了双系统,相比前几年,ubuntu22.04之后系统确实变得非常好用了,软件生态支持也变多了,为了更加日常化的使用折腾了一些相关软件的安装,这边做一个简单的记录。
+ubuntu安装卸载
ubuntu的安装卸载以及分区教程还是有些麻烦的,我也是参考了b战上面一个不错的up主的教学,期间有差点把自己windows引导搞出问题,然后用驱动精灵修复了。注意计算机专业同学还是尽量用英语安装,且安装以后禁用掉软件和内核更新,在一生一芯中有提到,禁用方法很简单自行百度即可。
参考链接:Windows 和 Ubuntu 双系统的安装和卸载
+Easyconnect
目前华科的VPN是支持ubuntu系统的,这确实提供了学生在连接校园网和服务器上的便利。当然安装可能会打不开的小问题。
参考链接:解决方案,需下载的软件内有可用的百度云网址
+VPN-Clash
找了一个不错的ubuntu支持的带有客户端的clash,亲测可用,导入任意可用的订阅链接就行。
参考链接:Devpn
QQ
QQ 9可以直接在ubuntu22.04上直接使用。
参考链接:QQ 9官网
QQ 音乐
官方目前已经有可支持的版本,再也不用担心冲了会员用不了啦!偶尔会有闪退问题,但是不影响。
参考链接:QQ音乐官网
WPS
WPS是在linux系统下可支持office三件套的工具,有一些中文汉化的问题,解决方案跟下面一样,不过实际下载之后发现,在/opt/kingsoft/wps-office/office6/mui下面本来就有语言包,只需要像下面的链接一样,移除下载后的其他语言安装包,只保留default zh_CN就能直接汉化,虽然在选择字体上好像还有点问题没解决,但是算是能用了至少。
参考链接:参考链接
-中文输入法
在b战找到了一个简单不错的中文输入法——rime输入法,感觉非常好用,安装后如果没有效果记得重启下电脑。
参考链接:rime输入法安装
+中文输入法
在b战找到了一个简单不错的中文输入法——rime输入法,感觉非常好用,安装后如果没有效果记得重启下电脑。
参考链接:rime输入法安装
微信
微信的安装好像有很多版本了,官方也有在做统一的OS支持,这里我用的可能不一定是最好的版本,但是可以支持文字和图片截图,还能打开小程序和公众号,只是看不了朋友圈,安装过程没有踩坑。
参考链接:2024如何在Ubuntu上安装原生微信wechat weixin
浏览器
Edge & Chrome 目前都支持linux的相关系统了,不用担心使用问题,编程相关的软件就更方便了。
End
一生一芯可以启动了!
-It's time to use ubuntu now😍 pic.twitter.com/BSuh7xTN0M
— kehan yin (@jack_kehan) September 12, 2024
+It's time to use ubuntu now😍 pic.twitter.com/BSuh7xTN0M
— kehan yin (@jack_kehan) September 12, 2024
+
@@ -516,7 +515,7 @@ End
一生
-
diff --git a/atom.xml b/atom.xml
index c698c740..f728b933 100644
--- a/atom.xml
+++ b/atom.xml
@@ -6,7 +6,7 @@
-
2024-10-09T11:01:20.220Z
+ 2024-10-10T05:19:45.456Z
https://jackyin.space/
@@ -21,13 +21,13 @@
https://jackyin.space/2024/10/09/ubuntu22-04-%E6%97%A5%E5%B8%B8%E5%8C%96/
2024-10-09T10:17:37.000Z
- 2024-10-09T11:01:20.220Z
+ 2024-10-10T05:19:45.456Z
- 最近有在折腾一些Ubuntu日常化的东西,给电脑重新装了双系统,相比前几年,ubuntu22.04之后系统确实变得非常好用了,软件生态支持也变多了,为了更加日常化的使用折腾了一些相关软件的安装,这边做一个简单的记录。ubuntu安装卸载
ubuntu的安装卸载以及分区教程还是有些麻烦的,我也是参考了b战上面一个不错的up主的教学,期间有差点把自己windows引导搞出问题,然后用驱动精灵修复了。注意计算机专业同学还是尽量用英语安装,且安装以后禁用掉软件和内核更新,在一生一芯中有提到,禁用方法很简单自行百度即可。
参考链接:Windows 和 Ubuntu 双系统的安装和卸载
Easyconnect
目前华科的VPN是支持ubuntu系统的,这确实提供了学生在连接校园网和服务器上的便利。当然安装可能会打不开的小问题。
参考链接:解决方案,需下载的软件内有可用的百度云网址
VPN-Clash
找了一个不错的ubuntu支持的带有客户端的clash,亲测可用,导入任意可用的订阅链接就行。
参考链接:Devpn
QQ
QQ 9可以直接在ubuntu22.04上直接使用。
参考链接:QQ 9官网
QQ 音乐
官方目前已经有可支持的版本,再也不用担心冲了会员用不了啦!偶尔会有闪退问题,但是不影响。
参考链接:QQ音乐官网
WPS
WPS是在linux系统下可支持office三件套的工具,有一些中文汉化的问题,解决方案跟下面一样,不过实际下载之后发现,在/opt/kingsoft/wps-office/office6/mui下面本来就有语言包,只需要像下面的链接一样,移除下载后的其他语言安装包,只保留default zh_CN就能直接汉化,虽然在选择字体上好像还有点问题没解决,但是算是能用了至少。
参考链接:参考链接
中文输入法
在b战找到了一个简单不错的中文输入法——rime输入法,感觉非常好用,安装后如果没有效果记得重启下电脑。
参考链接:rime输入法安装
微信
微信的安装好像有很多版本了,官方也有在做统一的OS支持,这里我用的可能不一定是最好的版本,但是可以支持文字和图片截图,还能打开小程序和公众号,只是看不了朋友圈,安装过程没有踩坑。
参考链接:2024如何在Ubuntu上安装原生微信wechat weixin
浏览器
Edge & Chrome 目前都支持linux的相关系统了,不用担心使用问题,编程相关的软件就更方便了。
End
一生一芯可以启动了!
It's time to use ubuntu now😍 pic.twitter.com/BSuh7xTN0M
— kehan yin (@jack_kehan) September 12, 2024
]]>
+ 最近有在折腾一些Ubuntu日常化的东西,给电脑重新装了双系统,相比前几年,ubuntu22.04之后系统确实变得非常好用了,软件生态支持也变多了,为了更加日常化的使用折腾了一些相关软件的安装,这边做一个简单的记录。
ubuntu安装卸载
ubuntu的安装卸载以及分区教程还是有些麻烦的,我也是参考了b战上面一个不错的up主的教学,期间有差点把自己windows引导搞出问题,然后用驱动精灵修复了。注意计算机专业同学还是尽量用英语安装,且安装以后禁用掉软件和内核更新,在一生一芯中有提到,禁用方法很简单自行百度即可。
参考链接:Windows 和 Ubuntu 双系统的安装和卸载
Easyconnect
目前华科的VPN是支持ubuntu系统的,这确实提供了学生在连接校园网和服务器上的便利。当然安装可能会打不开的小问题。
参考链接:解决方案,需下载的软件内有可用的百度云网址
VPN-Clash
找了一个不错的ubuntu支持的带有客户端的clash,亲测可用,导入任意可用的订阅链接就行。
参考链接:Devpn
QQ
QQ 9可以直接在ubuntu22.04上直接使用。
参考链接:QQ 9官网
QQ 音乐
官方目前已经有可支持的版本,再也不用担心冲了会员用不了啦!偶尔会有闪退问题,但是不影响。
参考链接:QQ音乐官网
WPS
WPS是在linux系统下可支持office三件套的工具,有一些中文汉化的问题,解决方案跟下面一样,不过实际下载之后发现,在/opt/kingsoft/wps-office/office6/mui下面本来就有语言包,只需要像下面的链接一样,移除下载后的其他语言安装包,只保留default zh_CN就能直接汉化,虽然在选择字体上好像还有点问题没解决,但是算是能用了至少。
参考链接:参考链接
中文输入法
在b战找到了一个简单不错的中文输入法——rime输入法,感觉非常好用,安装后如果没有效果记得重启下电脑。
参考链接:rime输入法安装
微信
微信的安装好像有很多版本了,官方也有在做统一的OS支持,这里我用的可能不一定是最好的版本,但是可以支持文字和图片截图,还能打开小程序和公众号,只是看不了朋友圈,安装过程没有踩坑。
参考链接:2024如何在Ubuntu上安装原生微信wechat weixin
浏览器
Edge & Chrome 目前都支持linux的相关系统了,不用担心使用问题,编程相关的软件就更方便了。
End
一生一芯可以启动了!
It's time to use ubuntu now😍 pic.twitter.com/BSuh7xTN0M
— kehan yin (@jack_kehan) September 12, 2024
]]>
- <p>最近有在折腾一些Ubuntu日常化的东西,给电脑重新装了双系统,相比前几年,ubuntu22.04之后系统确实变得非常好用了,软件生态支持也变多了,为了更加日常化的使用折腾了一些相关软件的安装,这边做一个简单的记录。</p>
+ <p>最近有在折腾一些Ubuntu日常化的东西,给电脑重新装了双系统,相比前几年,ubuntu22.04之后系统确实变得非常好用了,软件生态支持也变多了,为了更加日常化的使用折腾了一些相关软件的安装,这边做一个简单的记录。<br></p>
@@ -44,7 +44,7 @@
2023-12-27T08:57:00.000Z
2024-10-09T07:33:09.866Z
- 背景Dynamicgo 是字节跳动自研的高性能 Golang RPC 编解码基础库,能在动态处理 RPC 数据(不依赖代码生成)的同时保证高性能,主要用于实现高性能 RPC 动态代理场景(见 dynamicgo 介绍)。
Protobuf 是一种跨平台、可扩展的序列化数据传输协议,该协议序列化压缩特性使其具有优秀的传输速率,在常规静态 RPC 微服务场景中已经得到了广泛的应用。但是对于上述特殊的动态代理场景,我们调研发现目前业界主流的 Protobuf 协议基础库并不能满足我们的需求:
- google.golang.org/protobuf:Protobuf 官方源码支持协议转换和字段动态反射。实现过程依赖于反射完整的中间结构体 Message 对象来进行管理,使用过程中带来了很多不必要字段的数据性能开销,并且在处理多层嵌套数据时操作较为复杂,不支持内存字符串 io 流 IDL 解析。
- github.com/jhump/protoreflect:Protobuf 动态反射第三方库可支持文件和内存字符串 io 流 IDL 解析,适合频繁泛化调用,协议转换过程与官方源码一致,均未实现 inplace 转换,且内部实现存在Go版本兼容性问题。
- github.com/cloudwego/fastpb:Protobuf 快速序列化第三方库,通过静态代码方式读写消息结构体,不支持协议转换和动态 IDL 解析。
因此如何设计自研一个功能完备、高性能、可扩展的 Protobuf 协议动态代理基础库是十分有必要的。
@khan-yin和@iStitches两位同学经过对 Protobuf 协议源码机制的深入学习,设计了高性能 Protobuf 协议动态泛化调用链路,能满足绝大多数 Protobuf 动态代理场景,并且性能优于官方实现,目前 PR#37 已经合入代码仓库。Protobuf 设计思想
由于 Protobuf 协议编码格式细节较为复杂,在介绍链路设计之前我们有必要先了解一下 Protobuf 协议的设计思想,后续的各项设计都将在严格遵守该协议规范的基础上进行改进。
官方源码链路思想
Protobuf 源码链路过程主要涉及三类数据类型之间的转换,以 Message 对象进行管理,自定义 Value 类实现反射和底层存储,用 Message 对象能有效地进行管理和迁移,但也带来了许多反射和序列化开销。
Protobuf编码格式
Protobuf 编码字段格式大体上遵循 TLV(Tag,Length,Value) 的结构,但针对具体的类型存在一些编码差异,这里我们将较为全面的给出常见类型的编码模式。
Message Field
Protobuf 的接口必定包裹在一个 Message 类型下,因此无论是 request 还是 response 最终都会包裹成一个 Message 对象,那么 Field 则是 Message 的一个基本单元,任何类型的字段都遵循这样的 TLV 结构:
- Tag 由字段编号 Field_number 和 wiretype 两部分决定,对位运算后的结果进行 varint 压缩,得到压缩后的字节数组作为字段的 Tag。
- wiretype 的值则表示的是 value 部分的编码方式,可以帮助我们清楚如何对 value 的读取和写入。到目前为止,wiretype只有 VarintType,Fixed32Type,Fixed64Type,BytesType 四类编码方式。其中VarintType 类型会被压缩后再编码,属于 Fixed32Type 和 Fixed64Typ 固定长度类型则分别占用4字节和8字节,而属于不定长编码类型 BytesType 的则会编码计算 value 部分的 ByteLen 再拼接 value 。
- ByteLen 用于编码表示 value 部分所占的字节长度,同样我们的 bytelen 的值也是经过 varint 压缩后得到的,但bytelen并不是每个字段都会带有,只有不定长编码类型 BytesType 才会编码 bytelen 。ByteLen 由于其不定长特性,计算过程在序列化过程中是需要先预先分配空间,记录位置,等写完内部字段以后再回过头来填充。
- Value 部分是根据 wiretype 进行对应的编码,字段的 value 可能存在嵌套的 T(L)V 结构,如字段是 Message,Map等情况。
Message
关于 Message 本身的编码是与上面提到的字段编码一致的,也就是说遇到一个 Message 字段时,我们会先编码 Message 字段本身的 Tag 和 bytelen,然后再来逐个编码 Message 里面的每个字段。但需要提醒注意的是,在最外层不存在包裹整个 Message 的 Tag 和 bytelen 前缀,只有每个字段的 TLV 拼接。
List
list字段比较特殊,为了节省存储空间,根据list元素的类型分别采用不同的编码模式。
- Packed List Mode
如果list的元素本身属于 VarintType/Fixed32Type/Fixed64Type 编码格式,那么将采用 packed 模式编码整个 List ,在这种模式下的 list 是有 bytelen 的。Protobuf3 默认对这些类型启用 packed。
- UnPacked List Mode
当 list 元素属于 BytesType 编码格式时,list 将使用 unpacked 模式,直接编码每一个元素的 TLV,这里的 V 可能是嵌套的如List模式,那么 unpacked 模式下所有元素的 tag 都是相同的,list 字段的结束标志为与下一个 TLV 字段编码不同或者到达 buf 末尾。
Map
Map 编码模式与 unpacked list 相同,根据官方设计思想,Map 的每个 KV 键值对其实本质上就是一个 Message,固定 key 的 Field_number 是1,value 的 Field_number 是2,那么 Map 的编码模式就和 List<Message> 一致了。
源码 Descriptor 细节
这里主要介绍一下源码的 descriptor 设计上的一些需要注意的细节。
- Service 接口由 ServiceDescriptor 来描述,ServiceDescriptor 当中可以拿到每个 rpc 函数的 MethodDescriptor。
- MethodDescriptor 中 Input() 和 output() 两个函数返回值均为 MessageDescriptor 分别表示 request 和 response 。
- MessageDescriptor 专门用来描述一个 Message 对象(也可能是一个 MapEntry ),可以通过 Fields() 找到每个字段的 FieldDescriptor 。
- FieldDescriptor 则兼容所有类型的描述。
动态反射
针对 Protobuf 的反射使用场景,我们归纳出以下需求:
- 具有完整的结构自描述和具体类型反射功能,兼容 scalar 类型以及复杂嵌套的 MESSAGE/LIST/MAP 结构。
- 支持字节流模式下的对任意局部进行动态数据修改与遍历。
- 保证数据可并发读。
这里我们借助 Go reflect 的设计思想,把通过 IDL 解析得到的准静态类型描述(只需跟随 IDL 更新一次)TypeDescriptor 和 原始数据单元 Node 打包成一个完全自描述的结构—— Value,提供一套完整的反射 API。
IDL 静态文件 parse 过程:
为了提供文件流和内存字符串 io 流的 idl 文件解析,同时保证保证 go 版本兼容性,我们利用protoreflect@v1.8.2解析结果完成按需构造。从实现原理上来看,与高版本 protoreflect 利用protocompile对原始链路再 make 出源码的 warp 版本一致,更好的实现或许是处理利用 protoreflect 中的 ast 语法树构造。
Descriptor设计
Descriptor 的设计原理基本尽可能与源码保持一致,但为了更好的自反射性,我们抽象了一个 TypeDescriptor 来表示更细粒度的类型。
FieldDescriptor
type FieldDescriptor struct {
kind ProtoKind // the same value with protobuf descriptor
id FieldNumber
name string
jsonName string
typ *TypeDescriptor
}
FieldDescriptor: 设计上希望变量和函数作用与源码 FieldDescriptor 基本一致,增加*TypeDescriptor可以更细粒度的反应类型以及对 FieldDescriptor 的 API 实现。kind:与源码 kind 功能一致,LIST 情况下 kind 是列表元素的 kind 类型,MAP 和 MESSAGE 情况下都为 messagekind。
TypeDescriptor
type TypeDescriptor struct {
baseId FieldNumber // for LIST/MAP to write field tag by baseId
typ Type
name string
key *TypeDescriptor
elem *TypeDescriptor
msg *MessageDescriptor // for message, list+message element and map key-value entry
}
baseId:因为对于 LIST/MAP 类型的编码特殊性,如在 unpack 模式下,每一个元素都需要编写 Tag,我们必须在构造时针对 LIST/MAP 提供 fieldnumber,来保证读取和写入的自反射性。msg:这里的 msg 不是仅 Message 类型独有,主要是方便 J2P 部分对于 List 和裁剪场景中 map 获取可能存在 value 内部字段缺失的 MapEntry 的 MassageDescriptor(在源码的设计理念当中 MAP 的元素被认为是一个含有 key 和 value 两个字段的 message )的时候能直接利用 TypeDescriptor 进入下一层嵌套。typ:这里的 Type 是对源码的 FieldDescriptor 更细粒度的表示,即对 LIST/MAP 做了单独定义
MessageDescriptor
type MessageDescriptor struct {
baseId FieldNumber
name string
ids FieldNumberMap // store by tire tree
names FieldNameMap // store name and jsonName for FieldDescriptor
}
MessageDescriptor: 利用 Tire 树结构实现更高性能的字段 id 和字段 name 的存储和查找。
数据存储设计
从协议本身的 TLV 嵌套思想出发,我们利用字节流的编码格式,建立健壮的自反射性结构体处理任意类型的解析。
Node结构
type Node struct {
t proto.Type // node type
et proto.Type // for map value or list element type
kt proto.Type // for map key type
v unsafe.Pointer
l int // ptr len
size int // only for MAP/LIST element counts
}
具体的存储规则如下:
- 基本类型 Node 表示:指针 v 的起始位置不包含 tag,指向 (L)V,t = 具体类型。
- MESSAGE 类型:指针 v 的起始位置不包含 tag,指向 (L)V,如果是 root 节点,那么 v 的起始位置本身没有前缀的 L,直接指向了 V 即第一个字段的 tag 上,而其余子结构体都包含前缀 L。
- LIST类型:为了兼容 List 的两种模式和自反射的完整性,我们必须包含 list 的完整片段和 tag。因此 List 类型的节点,v 指向 list 的 tag 上,即如果是 packed 模式就是 list 的 tag 上,如果是 unpacked 则在第一个元素的 tag 上。
- MAP类型:Map 的指针 v 也指向了第一个 pair 的 tag 位置。
- UNKNOWN类型Node表示:无法解析的合理字段,Node 会将 TLV 完整存储,多个相同字段 Id 的会存到同一节点,缺点是内部的子节点无法构建,同官方源码unknownFields原理一致。
- ERROR类型Node表示:在 setnotfound 中,若片段设计与上述规则一致则可正确构造插入节点。
虽然 MAP/LIST 的父级 Node 存储有些变化,但是其子元素节点都是基本类型 / MESSAGE,所以叶子节点存储格式都是基本的 (L)V,这也便于序列化和数据基本单位的原子操作。
Value结构
value 的结构本身是对 Node 的封装,将 Node 与相应的 descriptor 封装起来,但不同于 thrift,在 Protobuf 当中由于片段无法完全自解析出具体类型,之后的涉及到具体编码的部分操作不能脱离 descriptor,部分 API 实现只能 Value 类作为调用单位。
type Value struct {
Node
Desc *proto.TypeDescriptor
IsRoot bool
}
由于从 rpc 接口解析后我们直接得到了对应的 TypeDescriptor,再加上 root 节点本身没有前缀TL的独特编码结构,我们通过设置IsRoot标记来区分 root 节点和其余节点,实现 Value 结构的 Descriptor 统一。
数据编排
不同于源码 Message 对象数据动态管理的思想,我们设计了更高效的动态管理方式。我们借助 DOM (Document Object Model)思想,将原始字节流数据层层包裹的结构,抽象成多层嵌套的 BTree 结构,实现对数据的定位,切分,裁剪等操作的 inplace 处理。
Path与PathNode
为了准确描述 DOM 中数据节点之间的嵌套关系,我们设计了 Path 结构,在 Path 的基础上,我们组合对应的数据单元 Node,然后再通过一个 Next 数组动态存储子节点,便可以组装成一个类似于 BTree 的泛型单元结构。
// Path represents the relative position of a sub node in a complex parent node
type Path struct {
t PathType // 类似div标签的类型,用来区分field,map,list元素,帮助判定父级嵌套属于什么类型结构
v unsafe.Pointer // PathStrKey, PathFieldName类型,存储的是Key/FieldName的字符串指针
l int
// PathIndex类型,表示LIST的下标
// PathIntKey类型,表示MAPKey的数值
// PathFieldId类型,表示字段的id
}
pathes []Path : 合理正确的Path数组,可以定位到嵌套复杂类型里具体的key/index的位置
type PathNode struct {
Path // DOM tree中用于定位当前Node的位置,并包含FieldId/FieldName/Key/index信息
Node // 存储了复杂嵌套关系中该位置对应的具体bytes片段
Next []PathNode // 下层嵌套的Node节点,基本类型下层Next为空
}
构建DOM Tree
构建 DOM 支持懒加载和全加载,在懒加载模式下 LIST/MAP 的 Node 当中 size 不会同步计算,而全加载在构造叶子节点的同时顺便更新了 size,构造后的节点都将遵循上述存储规则,具有自反射性和结构完整性。
查找字段
支持任意Node查找,查找函数设计了三个外部API:GetByPath,GetByPathWithAddress,GetMany。
GetByPath:返回查找出来的 Value ,查找失败返回 ERROR 类型的节点。GetByPathWithAddress:返回Value和当前调用节点到查找节点过程中每个 Path 嵌套层的 tag 位置的偏移量。 []address 与 []Path 个数对应,若调用节点为 root 节点,那么可记录到 buf 首地址的偏移量。GetMany:传入当前嵌套层下合理的 []PathNode 的 Path 部分,直接返回构造出来多个 Node,得到完整的[]PathNode,可继续用于 MarshalMany
设计思路:
查找过程是根据传入的 []Path 来循环遍历查找每一层 Path 嵌套里面对应的位置,根据嵌套的 Path 类型(fieldId,mapKey,listIndex),调用对应的 search 函数。不同于源码翻译思路,由于 Node 的自反射性设计,我们可以直接实现字节流定位,无需依赖 Descriptor 查找,并跳过不必要的字段翻译。构造最终返回的 Node 时,根据具体类型看是否需要去除 tag 即可,返回的 []address 刚好在 search 过程中完成了每一层 Path 的 tag 偏移量记录。
动态插入/删除
新增数据思想采用尾插法,保证 pack/unpack 数据的统一性,完成插入操作后需要更新嵌套层 bytelen。
- SetByPath:只支持 root 节点调用,保证 UpdateByLen 更新的完整和正确性。
- SetMany:可支持局部节点插入。
- UnsetByPath:只支持 root 节点调用,思想同插入字段,即找到对应的片段后直接将片段置空,然后更新updatebytelen。
Updatebytelen细节:
- 计算插入完成后新的长度与原长度的差值,存下当前片段增加或者减少的diffLen。
- 从里向外逐步更新
[]Path 数组中存在 bytelen 的嵌套层(只有packed list和message)的 bytelen 字节数组。 - 更新规则:先 readTag,然后再 readLength,得到解 varint 压缩后的具体 bytelen 数值,计算 newlen = bytelen + diffLen,计算 newbytelen 压缩后的字节长度与原 bytelen 长度的差值 sublen,并累计diffLen += sublen。
- 指针向前移动到下一个 path 和 address。
DOM序列化
- Marshal:建好 PathNode 后,可遍历拼接 DOM 的所有叶子节点片段,Tag 部分会通过 Path 类型和 Node 类型进行补全,bytelen 根据实际遍历节点进行更新。
- MarshalTo:针对数据裁剪场景,该设计方案具有很好的扩展性,可直接比对新旧 descriptor 中共有的字段 id,对字节流一次性拼接写入,无需依赖中间结构体,可支持多层嵌套字段缺失以及 LIST/MAP 内部元素字段缺失。
协议转换
ProtoBuf——>JSON
Protobuf->JSON 协议转换的过程可以理解为逐字节解析 ProtoBuf,并结合 Descriptor 类型编码为 JSON 到输出字节流,整个过程是 in-place 进行的,并且结合内存池技术,仅需为输出字节流分配一次内存即可。
ProtoBuf——>JSON 的转换过程如下:
- 根据输入的 Descriptor 指针类型区分,若为 Singular(string/number/bool/Enum) 类型,跳转到第5步开始编码;
- 按照 Message([Tag] [Length] [TLV][TLV][TLV]….)编码格式对输入字节流执行 varint解码,将Tag解析为 fieldId(字段ID)、wireType(字段wiretype类型);
- 根据第2步解析的 fieldId 确定字段 FieldDescriptor,并编码字段名 key 作为 jsonKey 到输出字节流;
- 根据 FieldDescriptor 确定字段类型(Singular/Message/List/Map),选择不同编码方法编码 jsonValue 到输出字节流;
- 如果是 Singular 类型,直接编码到输出字节流;
- 其它类型递归处理内部元素,确定子元素 Singular 类型进行编码,写入输出字节流中;
- 及时输入字节流读取位置和输出字节流写入位置,跳回2循环处理,直到读完输入字节流。
JSON——>ProtoBuf
协议转换过程中借助 JSON 状态机原理和 sonic 思想,设计 UserNodeStack 实现了接口 Onxxx(OnBool、OnString、OnInt64….)方法达到编码 ProtoBuf 的目标,实现 in-place 遍历 JSON 转换。
VisitorUserNode 结构
因为在编码 Protobuf 格式的 Mesage/UnpackedList/Map 类型时需要对字段总长度回写,并且在解析复杂类型(Message/Map/List)的子元素时需要依赖复杂类型 Descriptor 来获取子元素 Descriptor,所以需要 VisitorUserNode 结构来保存解析 json 时的中间数据。
type VisitorUserNode struct {
stk []VisitorUserNodeStack
sp uint8
p *binary.BinaryProtocol
globalFieldDesc *proto.FieldDescriptor
}
- stk:记录解析时中间变量的栈结构,在解析 Message 类型时记录 MessageDescriptor、PrefixLen;在解析 Map 类型时记录 FieldDescriptor、PairPrefixLen;在解析 List 类型时记录 FieldDescriptor、PrefixListLen;
- sp:当前所处栈的层级;
- p:输出字节流;
- globalFieldDesc:每当解析完 MessageField 的 jsonKey 值,保存该字段 Descriptor 值;
VisitorUserNodeStack 结构
记录解析时字段 Descriptor、回写长度的起始地址 PrefixLenPos 的栈结构。
type VisitorUserNodeStack struct {
typ uint8
state visitorUserNodeState
}
- typ:当前字段的类型,取值有对象类型(objStkType)、数组类型(arrStkType)、哈希类型(mapStkType);
- state:存储详细的数据值;
visitorUserNodeState 结构
type visitorUserNodeState struct {
msgDesc *proto.MessageDescriptor
fieldDesc *proto.FieldDescriptor
lenPos int
}
- msgDesc:记录 root 层的动态类型描述 MessageDescriptor;
- fieldDesc:记录父级元素(Message/Map/List)的动态类型描述 FieldDescriptor;
- lenPos:记录需要回写 PrefixLen 的位置;
协议转换过程
JSON——>ProtoBuf 的转换过程如下:
- 从输入字节流中读取一个 json 值,并判断其具体类型(
object/array/string/float/int/bool/null); - 如果是 object 类型,可能对应 ProtoBuf MapType/MessageType,sonic 会按照
OnObjectBegin()->OnObjectKey()->decodeValue()... 顺序处理输入字节流
OnObjectBegin()阶段解析具体的动态类型描述 FieldDescriptor 并压栈;OnObjectKey() 阶段解析 jsonKey 并以 ProtoBuf 格式编码 Tag、Length 到输出字节流;decodeValue()阶段递归解析子元素并以 ProtoBuf 格式编码 Value 部分到输出字节流,若子类型为复杂类型(Message/Map),会递归执行第 2 步;若子类型为复杂类型(List),会递归执行第 3 步。
- 如果是 array 类型,对应 ProtoBuf PackedList/UnpackedList,sonic 会按照
OnObjectBegin()->OnObjectKey()->OnArrayBegin()->decodeValue()->OnArrayEnd()... 顺序处理输入字节流
OnObjectBegin()阶段处理解析 List 字段对应动态类型描述 FieldDescriptor 并压栈;OnObjectKey()阶段解析 List 下子元素的动态类型描述 FieldDescriptor 并压栈;OnArrayBegin()阶段将 PackedList 类型的 Tag、Length 编码到输出字节流;decodeValue()阶段循环处理子元素,按照子元素类型编码到输出流,若子元素为复杂类型(Message),会跳转到第 2 步递归执行。
- 在结束处理某字段数据后执行
onValueEnd()、OnArrayEnd()、OnObjectEnd(),获取栈顶 lenPos 数据,对字段长度部分回写并退栈。 - 更新输入和输出字节流位置,跳回第 1 步循环处理,直到处理完输入流数据。
性能测试
构造与 Thrift 性能测试基本相同的baseline.proto 文件,定义了对应的简单( Small )、复杂( Medium )、简单缺失( SmallPartial )、复杂缺失( MediumPartial ) 两个对应子集,并用 kitex 命令生成了对应的 baseline.pb.go 。 主要与 Protobuf-Go 官方源码进行比较,部分测试与 kitex-fast 也进行了比较,测试环境如下:
- OS:Windows 11 Pro Version 23H2
- GOARCH: amd64
- CPU: 11th Gen Intel(R) Core(TM) i5-1135G7 @ 2.40GHz
- Go VERSION:1.20.5
反射
- 图中列举了 DOM 常用操作的性能,测试细节与 thrift 相同。
- MarshalTo 方法:相比 ProtobufGo 提升随着数据规模的增大趋势越明显,ns/op 开销约为源码方法的0.29 ~ 0.32。
字段Get/Set定量测试
- factor 用于修改从上到下扫描 proto 文件字段获取比率。
- 定量测试比较方法是 ProtobufGo 的 dynamicpb 模块和 DynamicGo 的 Get/SetByPath,SetMany,测试对象是medium data 的情况。
- Set/Get 字段定量测试结果均优于 ProtobufGo,且在获取字段越稀疏的情况下性能加速越明显。
- Setmany 性能加速更明显,在 100% 字段下 ns/op 开销约为 0.11。
序列化/反序列
- 序列化在 small 规模略高于 ProtobufGo,medium 规模的数据上性能优势更明显,ns/op 开销约为源码的0.54 ~ 0.84。
- 反序列化在 reuse 模式下,small 规模略高于 ProtobufGo,在 medium 规模数据上性能优势更明显,ns/op 开销约为源码的0.44 ~ 0.47,随数据规模增大性能优势增加。
协议转换
- Json2Protobuf 优于 ProtobufGo,ns/op 性能开销约为源码的0.21 ~ 0.89,随着数据量规模增大优势增加。
- Protobuf2Json 性能明显优于 ProtobufGo,ns/op 开销约为源码的0.13 ~ 0.21,而相比 Kitex,ns/op 约为Sonic+Kitex 的0.40 ~ 0.92,随着数据量规模增大优势增加。
应用与展望
目前 dynamicgo 对于 Protobuf 协议的可支持的功能包括:
- 替代官方源码的 JSON 协议转换,实现更高性能的 HTTP<>PB 动态网关
- 支持 IDL 内存字符串动态解析和数据泛化调用,可辅助 Kitex 提升 Protobuf 泛化调用模块性能。
- 支持动态数据裁剪、聚合等 DSL 场景,实现高性能 PB BFF 网关。
目前 dynamicgo 还在迭代中,接下来的工作包括:
- 支持 Protobuf 特殊字段,如 Enum,Oneof 等;
- 对于 Protobuf 协议转换提供 Http-Mapping 的扩展和支持;
- 继续扩展优化多种协议之间的泛化调用过程,集成到 Kitex 泛化调用模块中;
也欢迎感兴趣的个人或团队参与进来,共同开发!
代码仓库:https://github.com/cloudwego/dynamicgo
本文作者:尹可汗,徐健猇、段仪 | 来自:官方微信推文
]]>
+ 背景Dynamicgo 是字节跳动自研的高性能 Golang RPC 编解码基础库,能在动态处理 RPC 数据(不依赖代码生成)的同时保证高性能,主要用于实现高性能 RPC 动态代理场景(见 dynamicgo 介绍)。
Protobuf 是一种跨平台、可扩展的序列化数据传输协议,该协议序列化压缩特性使其具有优秀的传输速率,在常规静态 RPC 微服务场景中已经得到了广泛的应用。但是对于上述特殊的动态代理场景,我们调研发现目前业界主流的 Protobuf 协议基础库并不能满足我们的需求:
- google.golang.org/protobuf:Protobuf 官方源码支持协议转换和字段动态反射。实现过程依赖于反射完整的中间结构体 Message 对象来进行管理,使用过程中带来了很多不必要字段的数据性能开销,并且在处理多层嵌套数据时操作较为复杂,不支持内存字符串 io 流 IDL 解析。
- github.com/jhump/protoreflect:Protobuf 动态反射第三方库可支持文件和内存字符串 io 流 IDL 解析,适合频繁泛化调用,协议转换过程与官方源码一致,均未实现 inplace 转换,且内部实现存在Go版本兼容性问题。
- github.com/cloudwego/fastpb:Protobuf 快速序列化第三方库,通过静态代码方式读写消息结构体,不支持协议转换和动态 IDL 解析。
因此如何设计自研一个功能完备、高性能、可扩展的 Protobuf 协议动态代理基础库是十分有必要的。
@khan-yin和@iStitches两位同学经过对 Protobuf 协议源码机制的深入学习,设计了高性能 Protobuf 协议动态泛化调用链路,能满足绝大多数 Protobuf 动态代理场景,并且性能优于官方实现,目前 PR#37 已经合入代码仓库。Protobuf 设计思想
由于 Protobuf 协议编码格式细节较为复杂,在介绍链路设计之前我们有必要先了解一下 Protobuf 协议的设计思想,后续的各项设计都将在严格遵守该协议规范的基础上进行改进。
官方源码链路思想
Protobuf 源码链路过程主要涉及三类数据类型之间的转换,以 Message 对象进行管理,自定义 Value 类实现反射和底层存储,用 Message 对象能有效地进行管理和迁移,但也带来了许多反射和序列化开销。
Protobuf编码格式
Protobuf 编码字段格式大体上遵循 TLV(Tag,Length,Value) 的结构,但针对具体的类型存在一些编码差异,这里我们将较为全面的给出常见类型的编码模式。
Message Field
Protobuf 的接口必定包裹在一个 Message 类型下,因此无论是 request 还是 response 最终都会包裹成一个 Message 对象,那么 Field 则是 Message 的一个基本单元,任何类型的字段都遵循这样的 TLV 结构:
- Tag 由字段编号 Field_number 和 wiretype 两部分决定,对位运算后的结果进行 varint 压缩,得到压缩后的字节数组作为字段的 Tag。
- wiretype 的值则表示的是 value 部分的编码方式,可以帮助我们清楚如何对 value 的读取和写入。到目前为止,wiretype只有 VarintType,Fixed32Type,Fixed64Type,BytesType 四类编码方式。其中VarintType 类型会被压缩后再编码,属于 Fixed32Type 和 Fixed64Typ 固定长度类型则分别占用4字节和8字节,而属于不定长编码类型 BytesType 的则会编码计算 value 部分的 ByteLen 再拼接 value 。
- ByteLen 用于编码表示 value 部分所占的字节长度,同样我们的 bytelen 的值也是经过 varint 压缩后得到的,但bytelen并不是每个字段都会带有,只有不定长编码类型 BytesType 才会编码 bytelen 。ByteLen 由于其不定长特性,计算过程在序列化过程中是需要先预先分配空间,记录位置,等写完内部字段以后再回过头来填充。
- Value 部分是根据 wiretype 进行对应的编码,字段的 value 可能存在嵌套的 T(L)V 结构,如字段是 Message,Map等情况。
Message
关于 Message 本身的编码是与上面提到的字段编码一致的,也就是说遇到一个 Message 字段时,我们会先编码 Message 字段本身的 Tag 和 bytelen,然后再来逐个编码 Message 里面的每个字段。但需要提醒注意的是,在最外层不存在包裹整个 Message 的 Tag 和 bytelen 前缀,只有每个字段的 TLV 拼接。
List
list字段比较特殊,为了节省存储空间,根据list元素的类型分别采用不同的编码模式。
- Packed List Mode
如果list的元素本身属于 VarintType/Fixed32Type/Fixed64Type 编码格式,那么将采用 packed 模式编码整个 List ,在这种模式下的 list 是有 bytelen 的。Protobuf3 默认对这些类型启用 packed。
- UnPacked List Mode
当 list 元素属于 BytesType 编码格式时,list 将使用 unpacked 模式,直接编码每一个元素的 TLV,这里的 V 可能是嵌套的如List模式,那么 unpacked 模式下所有元素的 tag 都是相同的,list 字段的结束标志为与下一个 TLV 字段编码不同或者到达 buf 末尾。
Map
Map 编码模式与 unpacked list 相同,根据官方设计思想,Map 的每个 KV 键值对其实本质上就是一个 Message,固定 key 的 Field_number 是1,value 的 Field_number 是2,那么 Map 的编码模式就和 List<Message> 一致了。
源码 Descriptor 细节
这里主要介绍一下源码的 descriptor 设计上的一些需要注意的细节。
- Service 接口由 ServiceDescriptor 来描述,ServiceDescriptor 当中可以拿到每个 rpc 函数的 MethodDescriptor。
- MethodDescriptor 中 Input() 和 output() 两个函数返回值均为 MessageDescriptor 分别表示 request 和 response 。
- MessageDescriptor 专门用来描述一个 Message 对象(也可能是一个 MapEntry ),可以通过 Fields() 找到每个字段的 FieldDescriptor 。
- FieldDescriptor 则兼容所有类型的描述。
动态反射
针对 Protobuf 的反射使用场景,我们归纳出以下需求:
- 具有完整的结构自描述和具体类型反射功能,兼容 scalar 类型以及复杂嵌套的 MESSAGE/LIST/MAP 结构。
- 支持字节流模式下的对任意局部进行动态数据修改与遍历。
- 保证数据可并发读。
这里我们借助 Go reflect 的设计思想,把通过 IDL 解析得到的准静态类型描述(只需跟随 IDL 更新一次)TypeDescriptor 和 原始数据单元 Node 打包成一个完全自描述的结构—— Value,提供一套完整的反射 API。
IDL 静态文件 parse 过程:
为了提供文件流和内存字符串 io 流的 idl 文件解析,同时保证保证 go 版本兼容性,我们利用protoreflect@v1.8.2解析结果完成按需构造。从实现原理上来看,与高版本 protoreflect 利用protocompile对原始链路再 make 出源码的 warp 版本一致,更好的实现或许是处理利用 protoreflect 中的 ast 语法树构造。
Descriptor设计
Descriptor 的设计原理基本尽可能与源码保持一致,但为了更好的自反射性,我们抽象了一个 TypeDescriptor 来表示更细粒度的类型。
FieldDescriptor
type FieldDescriptor struct {
kind ProtoKind // the same value with protobuf descriptor
id FieldNumber
name string
jsonName string
typ *TypeDescriptor
}
FieldDescriptor: 设计上希望变量和函数作用与源码 FieldDescriptor 基本一致,增加*TypeDescriptor可以更细粒度的反应类型以及对 FieldDescriptor 的 API 实现。kind:与源码 kind 功能一致,LIST 情况下 kind 是列表元素的 kind 类型,MAP 和 MESSAGE 情况下都为 messagekind。
TypeDescriptor
type TypeDescriptor struct {
baseId FieldNumber // for LIST/MAP to write field tag by baseId
typ Type
name string
key *TypeDescriptor
elem *TypeDescriptor
msg *MessageDescriptor // for message, list+message element and map key-value entry
}
baseId:因为对于 LIST/MAP 类型的编码特殊性,如在 unpack 模式下,每一个元素都需要编写 Tag,我们必须在构造时针对 LIST/MAP 提供 fieldnumber,来保证读取和写入的自反射性。msg:这里的 msg 不是仅 Message 类型独有,主要是方便 J2P 部分对于 List 和裁剪场景中 map 获取可能存在 value 内部字段缺失的 MapEntry 的 MassageDescriptor(在源码的设计理念当中 MAP 的元素被认为是一个含有 key 和 value 两个字段的 message )的时候能直接利用 TypeDescriptor 进入下一层嵌套。typ:这里的 Type 是对源码的 FieldDescriptor 更细粒度的表示,即对 LIST/MAP 做了单独定义
MessageDescriptor
type MessageDescriptor struct {
baseId FieldNumber
name string
ids FieldNumberMap // store by tire tree
names FieldNameMap // store name and jsonName for FieldDescriptor
}
MessageDescriptor: 利用 Tire 树结构实现更高性能的字段 id 和字段 name 的存储和查找。
数据存储设计
从协议本身的 TLV 嵌套思想出发,我们利用字节流的编码格式,建立健壮的自反射性结构体处理任意类型的解析。
Node结构
type Node struct {
t proto.Type // node type
et proto.Type // for map value or list element type
kt proto.Type // for map key type
v unsafe.Pointer
l int // ptr len
size int // only for MAP/LIST element counts
}
具体的存储规则如下:
- 基本类型 Node 表示:指针 v 的起始位置不包含 tag,指向 (L)V,t = 具体类型。
- MESSAGE 类型:指针 v 的起始位置不包含 tag,指向 (L)V,如果是 root 节点,那么 v 的起始位置本身没有前缀的 L,直接指向了 V 即第一个字段的 tag 上,而其余子结构体都包含前缀 L。
- LIST类型:为了兼容 List 的两种模式和自反射的完整性,我们必须包含 list 的完整片段和 tag。因此 List 类型的节点,v 指向 list 的 tag 上,即如果是 packed 模式就是 list 的 tag 上,如果是 unpacked 则在第一个元素的 tag 上。
- MAP类型:Map 的指针 v 也指向了第一个 pair 的 tag 位置。
- UNKNOWN类型Node表示:无法解析的合理字段,Node 会将 TLV 完整存储,多个相同字段 Id 的会存到同一节点,缺点是内部的子节点无法构建,同官方源码unknownFields原理一致。
- ERROR类型Node表示:在 setnotfound 中,若片段设计与上述规则一致则可正确构造插入节点。
虽然 MAP/LIST 的父级 Node 存储有些变化,但是其子元素节点都是基本类型 / MESSAGE,所以叶子节点存储格式都是基本的 (L)V,这也便于序列化和数据基本单位的原子操作。
Value结构
value 的结构本身是对 Node 的封装,将 Node 与相应的 descriptor 封装起来,但不同于 thrift,在 Protobuf 当中由于片段无法完全自解析出具体类型,之后的涉及到具体编码的部分操作不能脱离 descriptor,部分 API 实现只能 Value 类作为调用单位。
type Value struct {
Node
Desc *proto.TypeDescriptor
IsRoot bool
}
由于从 rpc 接口解析后我们直接得到了对应的 TypeDescriptor,再加上 root 节点本身没有前缀TL的独特编码结构,我们通过设置IsRoot标记来区分 root 节点和其余节点,实现 Value 结构的 Descriptor 统一。
数据编排
不同于源码 Message 对象数据动态管理的思想,我们设计了更高效的动态管理方式。我们借助 DOM (Document Object Model)思想,将原始字节流数据层层包裹的结构,抽象成多层嵌套的 BTree 结构,实现对数据的定位,切分,裁剪等操作的 inplace 处理。
Path与PathNode
为了准确描述 DOM 中数据节点之间的嵌套关系,我们设计了 Path 结构,在 Path 的基础上,我们组合对应的数据单元 Node,然后再通过一个 Next 数组动态存储子节点,便可以组装成一个类似于 BTree 的泛型单元结构。
// Path represents the relative position of a sub node in a complex parent node
type Path struct {
t PathType // 类似div标签的类型,用来区分field,map,list元素,帮助判定父级嵌套属于什么类型结构
v unsafe.Pointer // PathStrKey, PathFieldName类型,存储的是Key/FieldName的字符串指针
l int
// PathIndex类型,表示LIST的下标
// PathIntKey类型,表示MAPKey的数值
// PathFieldId类型,表示字段的id
}
pathes []Path : 合理正确的Path数组,可以定位到嵌套复杂类型里具体的key/index的位置
type PathNode struct {
Path // DOM tree中用于定位当前Node的位置,并包含FieldId/FieldName/Key/index信息
Node // 存储了复杂嵌套关系中该位置对应的具体bytes片段
Next []PathNode // 下层嵌套的Node节点,基本类型下层Next为空
}
构建DOM Tree
构建 DOM 支持懒加载和全加载,在懒加载模式下 LIST/MAP 的 Node 当中 size 不会同步计算,而全加载在构造叶子节点的同时顺便更新了 size,构造后的节点都将遵循上述存储规则,具有自反射性和结构完整性。
查找字段
支持任意Node查找,查找函数设计了三个外部API:GetByPath,GetByPathWithAddress,GetMany。
GetByPath:返回查找出来的 Value ,查找失败返回 ERROR 类型的节点。GetByPathWithAddress:返回Value和当前调用节点到查找节点过程中每个 Path 嵌套层的 tag 位置的偏移量。 []address 与 []Path 个数对应,若调用节点为 root 节点,那么可记录到 buf 首地址的偏移量。GetMany:传入当前嵌套层下合理的 []PathNode 的 Path 部分,直接返回构造出来多个 Node,得到完整的[]PathNode,可继续用于 MarshalMany
设计思路:
查找过程是根据传入的 []Path 来循环遍历查找每一层 Path 嵌套里面对应的位置,根据嵌套的 Path 类型(fieldId,mapKey,listIndex),调用对应的 search 函数。不同于源码翻译思路,由于 Node 的自反射性设计,我们可以直接实现字节流定位,无需依赖 Descriptor 查找,并跳过不必要的字段翻译。构造最终返回的 Node 时,根据具体类型看是否需要去除 tag 即可,返回的 []address 刚好在 search 过程中完成了每一层 Path 的 tag 偏移量记录。
动态插入/删除
新增数据思想采用尾插法,保证 pack/unpack 数据的统一性,完成插入操作后需要更新嵌套层 bytelen。
- SetByPath:只支持 root 节点调用,保证 UpdateByLen 更新的完整和正确性。
- SetMany:可支持局部节点插入。
- UnsetByPath:只支持 root 节点调用,思想同插入字段,即找到对应的片段后直接将片段置空,然后更新updatebytelen。
Updatebytelen细节:
- 计算插入完成后新的长度与原长度的差值,存下当前片段增加或者减少的diffLen。
- 从里向外逐步更新
[]Path 数组中存在 bytelen 的嵌套层(只有packed list和message)的 bytelen 字节数组。 - 更新规则:先 readTag,然后再 readLength,得到解 varint 压缩后的具体 bytelen 数值,计算 newlen = bytelen + diffLen,计算 newbytelen 压缩后的字节长度与原 bytelen 长度的差值 sublen,并累计diffLen += sublen。
- 指针向前移动到下一个 path 和 address。
DOM序列化
- Marshal:建好 PathNode 后,可遍历拼接 DOM 的所有叶子节点片段,Tag 部分会通过 Path 类型和 Node 类型进行补全,bytelen 根据实际遍历节点进行更新。
- MarshalTo:针对数据裁剪场景,该设计方案具有很好的扩展性,可直接比对新旧 descriptor 中共有的字段 id,对字节流一次性拼接写入,无需依赖中间结构体,可支持多层嵌套字段缺失以及 LIST/MAP 内部元素字段缺失。
协议转换
ProtoBuf——>JSON
Protobuf->JSON 协议转换的过程可以理解为逐字节解析 ProtoBuf,并结合 Descriptor 类型编码为 JSON 到输出字节流,整个过程是 in-place 进行的,并且结合内存池技术,仅需为输出字节流分配一次内存即可。
ProtoBuf——>JSON 的转换过程如下:
- 根据输入的 Descriptor 指针类型区分,若为 Singular(string/number/bool/Enum) 类型,跳转到第5步开始编码;
- 按照 Message([Tag] [Length] [TLV][TLV][TLV]….)编码格式对输入字节流执行 varint解码,将Tag解析为 fieldId(字段ID)、wireType(字段wiretype类型);
- 根据第2步解析的 fieldId 确定字段 FieldDescriptor,并编码字段名 key 作为 jsonKey 到输出字节流;
- 根据 FieldDescriptor 确定字段类型(Singular/Message/List/Map),选择不同编码方法编码 jsonValue 到输出字节流;
- 如果是 Singular 类型,直接编码到输出字节流;
- 其它类型递归处理内部元素,确定子元素 Singular 类型进行编码,写入输出字节流中;
- 及时输入字节流读取位置和输出字节流写入位置,跳回2循环处理,直到读完输入字节流。
JSON——>ProtoBuf
协议转换过程中借助 JSON 状态机原理和 sonic 思想,设计 UserNodeStack 实现了接口 Onxxx(OnBool、OnString、OnInt64….)方法达到编码 ProtoBuf 的目标,实现 in-place 遍历 JSON 转换。
VisitorUserNode 结构
因为在编码 Protobuf 格式的 Mesage/UnpackedList/Map 类型时需要对字段总长度回写,并且在解析复杂类型(Message/Map/List)的子元素时需要依赖复杂类型 Descriptor 来获取子元素 Descriptor,所以需要 VisitorUserNode 结构来保存解析 json 时的中间数据。
type VisitorUserNode struct {
stk []VisitorUserNodeStack
sp uint8
p *binary.BinaryProtocol
globalFieldDesc *proto.FieldDescriptor
}
- stk:记录解析时中间变量的栈结构,在解析 Message 类型时记录 MessageDescriptor、PrefixLen;在解析 Map 类型时记录 FieldDescriptor、PairPrefixLen;在解析 List 类型时记录 FieldDescriptor、PrefixListLen;
- sp:当前所处栈的层级;
- p:输出字节流;
- globalFieldDesc:每当解析完 MessageField 的 jsonKey 值,保存该字段 Descriptor 值;
VisitorUserNodeStack 结构
记录解析时字段 Descriptor、回写长度的起始地址 PrefixLenPos 的栈结构。
type VisitorUserNodeStack struct {
typ uint8
state visitorUserNodeState
}
- typ:当前字段的类型,取值有对象类型(objStkType)、数组类型(arrStkType)、哈希类型(mapStkType);
- state:存储详细的数据值;
visitorUserNodeState 结构
type visitorUserNodeState struct {
msgDesc *proto.MessageDescriptor
fieldDesc *proto.FieldDescriptor
lenPos int
}
- msgDesc:记录 root 层的动态类型描述 MessageDescriptor;
- fieldDesc:记录父级元素(Message/Map/List)的动态类型描述 FieldDescriptor;
- lenPos:记录需要回写 PrefixLen 的位置;
协议转换过程
JSON——>ProtoBuf 的转换过程如下:
- 从输入字节流中读取一个 json 值,并判断其具体类型(
object/array/string/float/int/bool/null); - 如果是 object 类型,可能对应 ProtoBuf MapType/MessageType,sonic 会按照
OnObjectBegin()->OnObjectKey()->decodeValue()... 顺序处理输入字节流OnObjectBegin()阶段解析具体的动态类型描述 FieldDescriptor 并压栈;OnObjectKey() 阶段解析 jsonKey 并以 ProtoBuf 格式编码 Tag、Length 到输出字节流;decodeValue()阶段递归解析子元素并以 ProtoBuf 格式编码 Value 部分到输出字节流,若子类型为复杂类型(Message/Map),会递归执行第 2 步;若子类型为复杂类型(List),会递归执行第 3 步。
- 如果是 array 类型,对应 ProtoBuf PackedList/UnpackedList,sonic 会按照
OnObjectBegin()->OnObjectKey()->OnArrayBegin()->decodeValue()->OnArrayEnd()... 顺序处理输入字节流OnObjectBegin()阶段处理解析 List 字段对应动态类型描述 FieldDescriptor 并压栈;OnObjectKey()阶段解析 List 下子元素的动态类型描述 FieldDescriptor 并压栈;OnArrayBegin()阶段将 PackedList 类型的 Tag、Length 编码到输出字节流;decodeValue()阶段循环处理子元素,按照子元素类型编码到输出流,若子元素为复杂类型(Message),会跳转到第 2 步递归执行。
- 在结束处理某字段数据后执行
onValueEnd()、OnArrayEnd()、OnObjectEnd(),获取栈顶 lenPos 数据,对字段长度部分回写并退栈。 - 更新输入和输出字节流位置,跳回第 1 步循环处理,直到处理完输入流数据。
性能测试
构造与 Thrift 性能测试基本相同的baseline.proto 文件,定义了对应的简单( Small )、复杂( Medium )、简单缺失( SmallPartial )、复杂缺失( MediumPartial ) 两个对应子集,并用 kitex 命令生成了对应的 baseline.pb.go 。 主要与 Protobuf-Go 官方源码进行比较,部分测试与 kitex-fast 也进行了比较,测试环境如下:
- OS:Windows 11 Pro Version 23H2
- GOARCH: amd64
- CPU: 11th Gen Intel(R) Core(TM) i5-1135G7 @ 2.40GHz
- Go VERSION:1.20.5
反射
- 图中列举了 DOM 常用操作的性能,测试细节与 thrift 相同。
- MarshalTo 方法:相比 ProtobufGo 提升随着数据规模的增大趋势越明显,ns/op 开销约为源码方法的0.29 ~ 0.32。
字段Get/Set定量测试
- factor 用于修改从上到下扫描 proto 文件字段获取比率。
- 定量测试比较方法是 ProtobufGo 的 dynamicpb 模块和 DynamicGo 的 Get/SetByPath,SetMany,测试对象是medium data 的情况。
- Set/Get 字段定量测试结果均优于 ProtobufGo,且在获取字段越稀疏的情况下性能加速越明显。
- Setmany 性能加速更明显,在 100% 字段下 ns/op 开销约为 0.11。
序列化/反序列
- 序列化在 small 规模略高于 ProtobufGo,medium 规模的数据上性能优势更明显,ns/op 开销约为源码的0.54 ~ 0.84。
- 反序列化在 reuse 模式下,small 规模略高于 ProtobufGo,在 medium 规模数据上性能优势更明显,ns/op 开销约为源码的0.44 ~ 0.47,随数据规模增大性能优势增加。
协议转换
- Json2Protobuf 优于 ProtobufGo,ns/op 性能开销约为源码的0.21 ~ 0.89,随着数据量规模增大优势增加。
- Protobuf2Json 性能明显优于 ProtobufGo,ns/op 开销约为源码的0.13 ~ 0.21,而相比 Kitex,ns/op 约为Sonic+Kitex 的0.40 ~ 0.92,随着数据量规模增大优势增加。
应用与展望
目前 dynamicgo 对于 Protobuf 协议的可支持的功能包括:
- 替代官方源码的 JSON 协议转换,实现更高性能的 HTTP<>PB 动态网关
- 支持 IDL 内存字符串动态解析和数据泛化调用,可辅助 Kitex 提升 Protobuf 泛化调用模块性能。
- 支持动态数据裁剪、聚合等 DSL 场景,实现高性能 PB BFF 网关。
目前 dynamicgo 还在迭代中,接下来的工作包括:
- 支持 Protobuf 特殊字段,如 Enum,Oneof 等;
- 对于 Protobuf 协议转换提供 Http-Mapping 的扩展和支持;
- 继续扩展优化多种协议之间的泛化调用过程,集成到 Kitex 泛化调用模块中;
也欢迎感兴趣的个人或团队参与进来,共同开发!
代码仓库:https://github.com/cloudwego/dynamicgo
本文作者:尹可汗,徐健猇、段仪 | 来自:官方微信推文
]]>
@@ -69,13 +69,13 @@
2022-03-30T16:41:32.000Z
2024-10-09T07:33:09.908Z
- 既往不恋,纵情向前,江湖再见——22岁那年,在北京的日子2022年3月31日0:52,睡不着,日常拖延症+强迫症导致清东西到现在,等会还想清扫一下弄脏的地板。
莲竹花园甲2号楼一门101,从今天起,这里将不再是我的家,本来是昨天的机票,天气不似预期,不打算买高铁,还想再飞上一次云霄,所以倔强的又改签了机票,不过正好也让我多看一眼这里吧,最近东航事件其实让我也有一点小慌,希望能平安到达吧。
不出所料,我对这个城市并没有什么留恋,每天晚上我都会思考很多,有天夜里我的脑海里突然冒出来了那句:劝君更进一杯酒,西出阳关无故人。 这一刻我才真正明白什么是独在异乡为异客的感觉,什么才是我心里最想要的。
从南山南到北海北
作为一个一直生活在南方的人,第一次在北京生活,拥挤的早晚高峰,寒风和冰雪的夜晚,疫情形势也不断变化,恰逢过年,回家的日子也迟迟不敢定下来,奇怪,你可能会好奇,在大厂工作我竟然并没有提到工作的压力,仔细想来,其实美团的作息是相对舒服的10-8-5,尽管工作和技术基础我有许多不足,但mentor比较照顾我,不会刻意去push进度,更多的是希望让我自己去探索和思考,所以更多的工作压力还是来自于我自己一贯所坚持的负责和标准。这是一件好事,说明我做事情有自己的原则和态度,但有时候也会让自己比较心累,毕竟作为一个新人,从0-1去启动项目,虽然我是个自信的人,即使遇到问题也会尽可能自己去想办法,但我也深知自己的代码习惯和知识结构存在很多不足,害怕的不是做不好做不成,而是做事的效率和维护性,其实这也是我应该要从这些前辈身上要学到的经验。
年前一周,我申请了远程实习提前坐飞机回家了,到家的一刻才明白,这种人间烟火气才真的是生活,说来有愧,从回家到过年收假的时间,工作上我确实有点摆烂了哈哈哈,我知道这应该最后一个这么长时间的寒假了,经过将近1个月的在外实习也格外体会到了这种归家的温暖,去学一学切菜炒菜,陪一陪老年人,约一场球,见想见的人,街头漫步,吃点臭干子,米粉,麻辣烫,和朋友分享一些见闻,借酒消愁,确实愁更愁。
时间很快,大年初五的下午,我就启程返工了,毕竟现在的身份是打工人而不是大学生。和我一同去北京的还有广平,也在美团,我们都不打算实习很久,刚好我房子够住2个人,就一起住了一个月,不得不说多了一个人生活确实没有这么孤单了,尽管工作和拥挤依旧麻烦,但至少回家轻松快活一些,虽然有时候会有一些赌气和争吵,睡眠问题,但不管怎么说,互相都分担了一些对未来的焦虑和思考,一块出去玩,打游戏开黑,去什刹海,天安门,吃各种小吃,也算是度过一段不那么枯燥的时间。
在实习的这段日子里,最大的一个体会就是要学会如何平衡生活与工作,这个问题也是以后一定会要去面对的。也许是第一次实习,虽然不算很难的任务,但因为自己很多基础,技术,学习方法都还不够到位,上手项目和方向也不了解,所以效率上比较低,也许是拖延症,情绪化,该完成的任务没能及时完成,答应朋友的事情,也常常会忘记,衣服也有时候会拖着没洗,又或许是自己的性格本来就有些内向,在偏严肃的职场氛围下比起在学校,自己显得有些不自然,自己整个人的状态和生活界限变得模糊起来,当一个人进入这样的状态的时候,会发觉整个人比较迷茫,做事情专注度不够,热情也会逐渐消失。
在3月底,我决定从公司离职,一方面是想好好享受一下最后的大学时光,另一方面是想留出一段空白期,让自己再去学一学自己想学的内容,不得不说回归自由的感觉真的让人十分快乐,从公司买了好些纪念品,在最后几天,去见一见同学,逛一逛北京的大学,中关村,终于要飞走了,这段旅程终于要结束了,但接下来的未来好像还是看不清。
执念
看到执念这个词,这里我说一句大胆的话,在我未来的5-8年时间里,若我能成功,一定是因为心中的执念,若我输得一败涂地,也一定是因为那执念。
说来嘲讽,回想起来从小到大,我好像一直被这种执念所影响,也因为自己的固执,失去了各种各样的机会,但是我却很难改变,除了我这辈子认定的人以外,我几乎听不进去其他人的话,而且越是被人否定,越是想要证明自己的能力,我也不知道这是一种多么要强的心理,就好像明知道是火坑,也觉得自己跟别人不一样,能跨过去,然而事实大多是自己被烧得满身伤痕,甚至还在那叫嚣着他们不敢跳。
我的性格大家也知道,带有棱角,有个性,孤傲却又内向自卑,坚忍,舍得努力,看似矛盾,其实说白了也就是不太谦虚,爱吹吹牛逼,但却不是耍嘴皮子,对自己还是很负责的,但是这样也经常惹来一些麻烦,不合群,自作主张,在乎得失,也是我如此固执的原因之一。
随着年龄增大,我突然发现每一次选择的人生代价越来越大,自己的眼界和思想局限性也越来越明显,也许是从小就不爱看书(现在想看书却没多少时间,也很难静下心来)以及身处的环境的原因,思想成熟得很慢,自大,考虑问题过于天真,没能及时跟上时代,时而觉得一切皆有可能,时而又觉得一切皆是虚妄。去年的时候,我还觉得自己年轻,有无限可能,直到保研结束以后,我才恍然明白,其实我从18岁那年的夏天开始,就已经不再年轻,尽管我是在努力的朝改善未来的方向走,往后的岁月每一次决定都是那么矛盾,迷茫,自卑,妥协,后悔。
后悔,我总是做事情让自己有多个选择留有退路,但似乎给自己留选择本质上就是一种后悔,当你没能选到最理想的选择时,自然就会后悔吧。
2024.06.02 更新
哈哈哈哈最近难得休闲几天,看到以前写的这些,看问题角度加上当时的个人情绪驱使文案还是略显年轻了,回过头来看其实无所谓后悔不后悔的,已经把这里标题的后悔去掉了,我一贯以来的行为准则就是对自己的选择负责,不论是什么样的未来,勇敢且不要停止思考,相信自己的光就好,这不仅仅会给自己能量也一定会给他人的生命带来光亮。
]]>
+ 既往不恋,纵情向前,江湖再见——22岁那年,在北京的日子2022年3月31日0:52,睡不着,日常拖延症+强迫症导致清东西到现在,等会还想清扫一下弄脏的地板。
莲竹花园甲2号楼一门101,从今天起,这里将不再是我的家,本来是昨天的机票,天气不似预期,不打算买高铁,还想再飞上一次云霄,所以倔强的又改签了机票,不过正好也让我多看一眼这里吧,最近东航事件其实让我也有一点小慌,希望能平安到达吧。
不出所料,我对这个城市并没有什么留恋,每天晚上我都会思考很多,有天夜里我的脑海里突然冒出来了那句:劝君更进一杯酒,西出阳关无故人。 这一刻我才真正明白什么是独在异乡为异客的感觉,什么才是我心里最想要的。
从南山南到北海北
作为一个一直生活在南方的人,第一次在北京生活,拥挤的早晚高峰,寒风和冰雪的夜晚,疫情形势也不断变化,恰逢过年,回家的日子也迟迟不敢定下来,奇怪,你可能会好奇,在大厂工作我竟然并没有提到工作的压力,仔细想来,其实美团的作息是相对舒服的10-8-5,尽管工作和技术基础我有许多不足,但mentor比较照顾我,不会刻意去push进度,更多的是希望让我自己去探索和思考,所以更多的工作压力还是来自于我自己一贯所坚持的负责和标准。这是一件好事,说明我做事情有自己的原则和态度,但有时候也会让自己比较心累,毕竟作为一个新人,从0-1去启动项目,虽然我是个自信的人,即使遇到问题也会尽可能自己去想办法,但我也深知自己的代码习惯和知识结构存在很多不足,害怕的不是做不好做不成,而是做事的效率和维护性,其实这也是我应该要从这些前辈身上要学到的经验。
年前一周,我申请了远程实习提前坐飞机回家了,到家的一刻才明白,这种人间烟火气才真的是生活,说来有愧,从回家到过年收假的时间,工作上我确实有点摆烂了哈哈哈,我知道这应该最后一个这么长时间的寒假了,经过将近1个月的在外实习也格外体会到了这种归家的温暖,去学一学切菜炒菜,陪一陪老年人,约一场球,见想见的人,街头漫步,吃点臭干子,米粉,麻辣烫,和朋友分享一些见闻,借酒消愁,确实愁更愁。
时间很快,大年初五的下午,我就启程返工了,毕竟现在的身份是打工人而不是大学生。和我一同去北京的还有广平,也在美团,我们都不打算实习很久,刚好我房子够住2个人,就一起住了一个月,不得不说多了一个人生活确实没有这么孤单了,尽管工作和拥挤依旧麻烦,但至少回家轻松快活一些,虽然有时候会有一些赌气和争吵,睡眠问题,但不管怎么说,互相都分担了一些对未来的焦虑和思考,一块出去玩,打游戏开黑,去什刹海,天安门,吃各种小吃,也算是度过一段不那么枯燥的时间。
在实习的这段日子里,最大的一个体会就是要学会如何平衡生活与工作,这个问题也是以后一定会要去面对的。也许是第一次实习,虽然不算很难的任务,但因为自己很多基础,技术,学习方法都还不够到位,上手项目和方向也不了解,所以效率上比较低,也许是拖延症,情绪化,该完成的任务没能及时完成,答应朋友的事情,也常常会忘记,衣服也有时候会拖着没洗,又或许是自己的性格本来就有些内向,在偏严肃的职场氛围下比起在学校,自己显得有些不自然,自己整个人的状态和生活界限变得模糊起来,当一个人进入这样的状态的时候,会发觉整个人比较迷茫,做事情专注度不够,热情也会逐渐消失。
在3月底,我决定从公司离职,一方面是想好好享受一下最后的大学时光,另一方面是想留出一段空白期,让自己再去学一学自己想学的内容,不得不说回归自由的感觉真的让人十分快乐,从公司买了好些纪念品,在最后几天,去见一见同学,逛一逛北京的大学,中关村,终于要飞走了,这段旅程终于要结束了,但接下来的未来好像还是看不清。
执念
看到执念这个词,这里我说一句大胆的话,在我未来的5-8年时间里,若我能成功,一定是因为心中的执念,若我输得一败涂地,也一定是因为那执念。
说来嘲讽,回想起来从小到大,我好像一直被这种执念所影响,也因为自己的固执,失去了各种各样的机会,但是我却很难改变,除了我这辈子认定的人以外,我几乎听不进去其他人的话,而且越是被人否定,越是想要证明自己的能力,我也不知道这是一种多么要强的心理,就好像明知道是火坑,也觉得自己跟别人不一样,能跨过去,然而事实大多是自己被烧得满身伤痕,甚至还在那叫嚣着他们不敢跳。
我的性格大家也知道,带有棱角,有个性,孤傲却又内向自卑,坚忍,舍得努力,看似矛盾,其实说白了也就是不太谦虚,爱吹吹牛逼,但却不是耍嘴皮子,对自己还是很负责的,但是这样也经常惹来一些麻烦,不合群,自作主张,在乎得失,也是我如此固执的原因之一。
随着年龄增大,我突然发现每一次选择的人生代价越来越大,自己的眼界和思想局限性也越来越明显,也许是从小就不爱看书(现在想看书却没多少时间,也很难静下心来)以及身处的环境的原因,思想成熟得很慢,自大,考虑问题过于天真,没能及时跟上时代,时而觉得一切皆有可能,时而又觉得一切皆是虚妄。去年的时候,我还觉得自己年轻,有无限可能,直到保研结束以后,我才恍然明白,其实我从18岁那年的夏天开始,就已经不再年轻,尽管我是在努力的朝改善未来的方向走,往后的岁月每一次决定都是那么矛盾,迷茫,自卑,妥协,后悔。
后悔,我总是做事情让自己有多个选择留有退路,但似乎给自己留选择本质上就是一种后悔,当你没能选到最理想的选择时,自然就会后悔吧。
2024.06.02 更新
哈哈哈哈最近难得休闲几天,看到以前写的这些,看问题角度加上当时的个人情绪驱使文案还是略显年轻了,回过头来看其实无所谓后悔不后悔的,已经把这里标题的后悔去掉了,我一贯以来的行为准则就是对自己的选择负责,不论是什么样的未来,勇敢且不要停止思考,相信自己的光就好,这不仅仅会给自己能量也一定会给他人的生命带来光亮。
]]>
<h2 id="既往不恋,纵情向前,江湖再见——22岁那年,在北京的日子"><a href="#既往不恋,纵情向前,江湖再见——22岁那年,在北京的日子" class="headerlink" title="既往不恋,纵情向前,江湖再见——22岁那年,在北京的日子"></a>既往不恋,纵情向前,江湖再见——22岁那年,在北京的日子</h2><p>2022年3月31日0:52,睡不着,日常拖延症+强迫症导致清东西到现在,等会还想清扫一下弄脏的地板。</p>
<p><strong>莲竹花园甲2号楼一门101,从今天起,这里将不再是我的家</strong>,本来是昨天的机票,天气不似预期,不打算买高铁,还想再飞上一次云霄,所以倔强的又改签了机票,不过正好也让我多看一眼这里吧,最近东航事件其实让我也有一点小慌,希望能平安到达吧。</p>
-<p>不出所料,我对这个城市并没有什么留恋,每天晚上我都会思考很多,有天夜里我的脑海里突然冒出来了那句:<strong>劝君更进一杯酒,西出阳关无故人。</strong> 这一刻我才真正明白什么是独在异乡为异客的感觉,什么才是我心里最想要的。</p>
+<p>不出所料,我对这个城市并没有什么留恋,每天晚上我都会思考很多,有天夜里我的脑海里突然冒出来了那句:<strong>劝君更进一杯酒,西出阳关无故人。</strong> 这一刻我才真正明白什么是独在异乡为异客的感觉,什么才是我心里最想要的。<br></p>
@@ -92,7 +92,7 @@
2022-01-08T12:06:00.000Z
2024-10-09T07:33:09.913Z
- 
前言
第一次在掘金写面经,其实今年过得不尽人意,好在能找找实习调整一下心态吧,终于有钱换手机了!要说有什么新年愿望,那就希望2022一切好运吧。 虽然是实习面经但是其实也没怎么准备,随缘,放弃了bat的部门,估计对学历和论文有门槛(尝试性投了深圳字节直接挂简历,我永远喜欢bytedance😭),10月投b站简历挂,旷视面试没过以后就没投了,后面去学车了,结果科目二没过,有点闲看到有朋友也在投,就不抱希望还是投了3家,比较幸运最后拿到了美团和商汤的实习offer,感谢面试官们手下留情🤣。
个人情况:
- 学校:211 大四
- 成绩:前5%
- 项目:3段CV相关项目经历,无论文,两个算法实践工程落地项目,一段kaggle竞赛铜牌,总体上来说都比较水
- 算法能力:无ACM,比较菜只是比较喜欢刷,leetcode400题(以easy+medium为主,剑指offer+程序员面试经典+每日一题/周赛)
因为感觉自己很菜找不到实习,所以都没找内推,也没有海投,不过好像大多都会给面试机会的,感觉如果能找内推可能会更好一点。没想到最后能去美团当外卖骑手了😁!
旷视
旷视的实习面试是最早的,不过也面试通知也等了好久,hr说有两个面试官mark了我的简历,所以面了两个组,当时是第一次面试,比较紧张,虽然面试问的不难,但是有些地方答的不好,面试问题记不太清了。另一个面试官,我等了半小时结果被他放鸽子了,改天再面的。。。
- 手写IoU
- 求三个部分的IoU,根据定义就是求:$\frac{A \cap B \cap C}{A \cup B \cup C} $,只用讲思路,其实就是容斥原理,当时有点紧张,公式最后一项系数写错了一直没看出来,场面一度尴尬。
- 讲解Focal loss的原理作用
- 为什么会用到
StratifiedKFold,和KFold有什么区别 - 介绍一下比赛用到的
TTA,Cutmix方法(Cutout和mixup的结合,最好三个都讲解一下) - 讲讲
Resnet(建议读一下论文,从目的,作用,残差结构的形式,反向传播梯度计算,机器学习GBDT思想等角度进行阐述) - 目标检测的
mAP达到了多少,有没有测过双目测距的精准度,为啥使用wifi和flask推流通信,这样会比较慢(树莓派算力不够,跑着跑着宕机了),小车目标检测的帧数能达到多少fps(emm我们只是做了一个无人清洁车落地的demo,只测了模型目标检测在数据集上的mAP,其他的更多的是我们自己提供一种idea,具体指标没有测试过😥)。 - 旋转矩阵,不能开空间,其实做过但是面试很容易紧张卡住,有想到思路但是没写对有点bug,不过面试官说我思路是对的,面完就发现原来是下标对错了。。。
- 团队合作交流是如何分工和解决问题的?
- 其他人或者老师给你任务安排时,如果与你的想法不合时,你会如何做?
手写IoU
import numpy as np
def IoU(bounding_box,ground_truth):
"""
:param bounding_box: [[x1,y1,x2,y2,score]]
:param ground_truth: [x1,y1,x2,y2]
:return:
"""
x1 = bounding_box[:,0]
y1 = bounding_box[:,1]
x2 = bounding_box[:,2]
y2 = bounding_box[:,3]
score = bounding_box[:,4]
areas = (x2-x1) * (y2-y1)
gt_area = (ground_truth[2] - ground_truth[0]) * (ground_truth[3] - ground_truth[1])
xx1 = np.maximum(x1,ground_truth[0])
yy1 = np.maximum(y1,ground_truth[1])
xx2 = np.minimum(x2,ground_truth[2])
yy2 = np.minimum(y2,ground_truth[3])
h = np.maximum(0,yy2-yy1)
w = np.maximum(0,xx2-xx1)
inter = w * h
ovr = inter / (gt_area + areas - inter) # np.true_divide(inter, (gt_area + areas - inter))
return ovr
旋转矩阵
class Solution {
public:
void rotate(vector<vector<int>>& matrix) {
int n = matrix.size();
for(int i=0;i<n/2;i++)
{
for(int j=0;j<(n+1)/2;j++)
{
// (i,j) (j,n-i-1) (n-j-1,i) (n-i-1,n-j-1)
swap(matrix[i][j],matrix[n-i-1][n-j-1]);
swap(matrix[i][j],matrix[n-j-1][i]);
swap(matrix[j][n-i-1],matrix[n-i-1][n-j-1]);
}
}
}
};
小米
小米面试其实是当时最好的选择,因为就在武汉本地,也不用外出,但是当时面试确实不太好,面试官对我其中一个项目比较感兴趣,被疯狂怼着追问细节。
- 描述项目中用到的SIFT匹配和直方图相似度比对基本原理。
- one-stage和two-stage的区别。
- 双目摄像头视觉下应该可以得到整个三维空间下的信息,没考虑方向角度的问题,对测距的处理有些草率(没有很懂,之后再去了解了解,只用到了物理上小孔成像的原理😰
- 为什么不直接在树莓派上推理,采用推流和主机服务器去进行计算,速度和精度如何
- 继续追问项目细节。
- 手写SIFT匹配过程,直接人傻了😭(被面试官怼对传统图像处理了解不深,只会玩玩深度学习搭积木)
美团-智能视觉 offer
美团面试官面试体验比较好,没有过分针对,对待我这种本科生可能相对更看重对我的motivation和potential吧感觉,评价也比较好。
一面
- 聊项目,做项目的目的和缘由,你觉得有什么亮点。
- 讲讲one-stage和two-stage的区别。
- anchor-free的方式比如FCOS有了解吗
- 看你有用过
ViT,能不能讲讲transformer的架构,再讲讲vit是怎么做的,BERT有了解吗,跟vit有什么区别 - 看你项目经常用到kaiming的东西,kaiming最近新出的MAE有了解吗(虽然面试官看着年龄有点大,不过还挺紧跟潮流的,kaiming yyds!
- 讲讲SIFT匹配到双目测距的过程和原理
- 为什么要用树莓派采集图像借助flask推流,再由主机进行模型推理
- 对GNN和GCN有了解吗
- 讲讲人脸检测
MTCNN是怎么做的 - 聊美团这边的业务,问我有没有这方面技术的了解
- 自己出的算法题,以条形码识别为背景,有点像是去除干扰字符的匹配,用双指针解决即可。
二面
- 聊项目缘由,团队协作。
- 讲讲
transformer,讲讲position encoding的方法,作者用这种三角函数的方式有什么特点,在vit里面是如何做位置编码的。 - 介绍
self-attention,transfomer的encode和decode有什么区别,你对这两部分有什么理解,以及相对于CNN的一些特点。 - 项目用的数据集有多大。
- 项目目标检测用的什么指标,达到了什么效果。
- 聊美团业务,问我有没有兴趣。
- 出了个hard题扰乱字符串,不会,简单讲了一下dfs暴力的思路但还是没理清楚写不出😭,后面换了个简单点的题不过要求让我用python写
商汤-基础视觉 offer
一面
一面比较简单,面试官也比较和蔼。
- 自己出的题,二维矩阵找最长的严格单调上升的一个连续序列(可以跨行转弯,对角线不算),节点可上下左右移动。先用dfs暴力,然后再用记忆化优化了一下。虽然不难但是写的有点慢。
- 聊项目。
- 讲讲Batch Normalization(建议从目的,由来,公式解析,理解操作过程,作用以及使用场景等方面来讲解附博客,看完发现自己面试讲的好烂)
- 介绍小批量梯度下降
- 讲讲分布不均衡的数据如何处理(讲了讲数据增强,过采样比如SMOTE,欠采样,调整样本对分类的权重,如FocalLoss,这个我感觉回答的不是很好,希望评论区有更好的理解)
- 有没有搭建或者使用过单机多卡和多机多卡,是否了解多卡时神经网络的梯度反向传播是如何计算的(没钱没资源🤣,瞎猜了一波可能和计算图的节点资源分配有关)
二面
二面其实感觉面试有点糟糕,连问了十几个八股文,做题也出了一些问题,自闭,答也能答出来一些但是整体感觉不好。。。。不过最后比较幸运还是让我过了。 - 简单介绍自己的项目和自己觉得有亮点的地方
- 讲讲one-stage和two-stage的区别和特点
- 什么是RPN,作用是什么
- 什么是FPN,有什么特点,这种多尺度是怎么实现和进行预测的
- 讲述yolov3预测目标的过程(比较关键的几个要点我觉得是损失函数,模型输出,非极大抑制,多种变种的IoU,SPP空间金字塔,以及论文中有提到yolov3的anchor是kmeans聚类出来的,可能会让你手写kmeans)
- 为什么two-stage要比one-stage的精度要高,你觉得本质是什么
- yolov3的三个特征图大尺寸的用来预测大的图还是小的图
- anchor-free的方式有了解吗,和anchor-based的差异在哪,本质和原理是什么
- 介绍一下CenterNet和FCOS,中心度的公式和理论,预测过程
- 什么是梯度消失和梯度爆炸,如何解决(提到某些要点或者答错了会继续追问,没有答的很全)
- 进程和线程的区别,python的多线程如何实现
- maxpool是如何进行反向传播的(建议看看cs231n,首先要明确的是pool层中是没有参数的,然后再来将maxpool,其实我当时也忘了,我记得好像跟maxout的反向传播差不多)
- 讲讲Batch Normalization,以及在训练和预测过程的计算方式
- 讲讲dropout,以及在训练和预测过程的计算方式(建议看看cs231n),你觉得和机器学习当中哪种集成方式比较像(这个我不是很清楚希望各位大佬回答一下,当时瞎说了一个boosting🤣)
- 剑指 Offer 31. 栈的压入、弹出序列 思路大致是对的但是没想得特别清楚,比较紧张,写了很久
- 剑指 Offer 39. 数组中出现次数超过一半的数字 第二题直接限制时间复杂度$O(n)$,空间复杂度$O(1)$,我只会哈希方法,然后和面试官说了一下最优解方法我只记得叫摩尔投票,然后具体忘了。
栈的压入、弹出序列
class Solution {
public:
bool validateStackSequences(vector<int>& pushed, vector<int>& popped) {
stack<int> stk;
int n = popped.size();
int m = pushed.size();
int j = 0;
for(int i=0;i<m;i++)
{
stk.push(pushed[i]);
while(stk.size()&&stk.top()==popped[j])
{
j++;
stk.pop();
}
}
return stk.empty();
}
};
其他
还有一些感觉比较重要,但是没有被问道的东西,包括各种评价指标的含义等等,包括数学基础等等。
经典教程推荐:cs231n,吴恩达,李宏毅,动手学深度学习,《统计学习方法》
关于八股文方面这里推荐一个DeepLearning-500-questions
手写非极大抑制
使用非极大抑制的前提是,我们已经得到了一组候选框和对应label的置信分数,以及groud truth的信息,通过设定阈值来删除重合度较高的候选框。
算法流程如下:
- 根据置信度得分进行排序
- 选择置信度最高的比边界框添加到最终输出列表中,将其从边界框列表中删除
- 计算所有边界框的面积
- 计算置信度最高的边界框与其它候选框的IoU。
- 删除IoU大于阈值的边界框
- 重复上述过程,直至边界框列表为空。
import numpy as np
def nms(dets, threshod, mode="Union"):
"""
greedily select boxes with high confidence
keep boxes overlap <= thresh
rule out overlap > thresh
:param dets: [[x1, y1, x2, y2 score]]
:param threshod: retain overlap <= thresh
:return: indexes to keep
"""
x1 = dets[:, 0]
y1 = dets[:, 1]
x2 = dets[:, 2]
y2 = dets[:, 3]
scores = dets[:, 4]
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
order = scores.argsort()[::-1] # reverse
keep = []
while order.size() > 0:
i = order[0]
keep.append(i)
# A & B left top position
xx1 = np.maximun(x1[i], x1[order[1, :]])
yy1 = np.maximun(y1[i], y1[order[1, :]])
# A & B right down position
xx2 = np.minimum(x2[i], x2[order[1, :]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
# cacaulate the IOU between box which have largest score with other boxes
if mode == "Union":
# area[i]: the area of largest score
ovr = inter / (areas[i] + areas[order[1:]] - inter)
elif mode == "Minimum":
ovr = inter / np.minimum(areas[i], areas[order[1:]])
# delete the IoU that higher than threshod
inds = np.where(ovr <= threshod)[0]
order = order[inds + 1] # +1: eliminates the first element in order
return keep
手写Kmeans方法
这个版本不是最佳写法,某些处理有点暴力,可以用矩阵和numpy相关的操作会更简洁,但是退出迭代的条件写的很全的,有达到迭代次数,中心点集不变,中心点变化范围小于$\delta$
import numpy as np
import matplotlib.pyplot as plt
n = 100
a = np.random.randn(0,50,n)
b = np.random.rand(0,50,n)
x = np.random.randint(0,50,n)
y = np.random.randint(0,50,n)
points = np.array(list(zip(x,y)))
def distance(x,y):
return np.sqrt(np.sum((x-y)**2))
def k_means(points,k=5,epochs=500,delta=1e-3):
# 初始化聚类中心
center_ids = np.random.randint(0,n,k)
centers = points[center_ids]
# 聚类集合初始化
results = []
for i in range(k):
results.append([])
step = 1
flag = True
# 计算各点到中心的距离
while flag and step < epochs:
# 重新迭代
for i in range(k):
results[i] = []
# 计算每个点到距离中心的距离
for i in range(len(points)):
point = points[i]
min_dis = np.inf
min_id = 0
for idx, center in enumerate(centers):
dis = distance(center,point)
if min_dis > dis:
min_dis = dis
min_id = idx
results[min_id].append(point)
# 更新聚类中心
for idx, old_center in enumerate(centers):
new_center = np.array(results[idx]).mean(axis=0)
if distance(center, new_center) > delta:
centers[idx] = new_center
flag = False
# flag=True说明聚类中心已经不变了则可以退出了
if flag:
break
else:
flag = True
step += 1
return results,centers
plt.plot(x,y,'ro')
results,centers=k_means(points,k=5)
color=['ko','go','bo','yo','co']
for i in range(len(results)):
result=results[i]
plt.plot([res[0] for res in result],[res[1] for res in result],color[i])
plt.plot([res[0] for res in centers],[res[1] for res in centers],'ro')
plt.show()
总结
本人能力有限,如果上述回答有任何错误,还请各位大佬及时指出
- 不同面试官的面试风格不一样,项目相关的知识积累问的会比较多(项目水没关系但相关技术还是要搞懂),项有的会考察广度和思维潜力,有的会考察基础(八股),算法题感觉并没有那种重要,把剑指offer刷了应该差不多。
- 关于八股文的看法,其实更多的还是要多理解,一些相关原理和数学还是多看看相关论文和经典课程,到时候也不用刻意记也能按自己的想法说出一点(瞎吹),感觉面试官想要的答案并不一定是你能完整的说出来,而是有自己理解的正确描述(这个可能需要在代码实践和理论知识之间多反复几次体会会比较好)。
- 代码实践还是要多一些,其实很多东西我了解的并不深入,只是大致理解过原理和思路,这样还是不太好,开始害怕顶不住实习压力了。
- 不用害怕,尽量多交流,避免场面陷入尴尬。
- 反问环节我一般问的是来这边的工作内容,学习的建议和评价,培养和安排之类的。
「掘金链接:菜鸡的算法岗日常实习面经总结」
]]>前言
第一次在掘金写面经,其实今年过得不尽人意,好在能找找实习调整一下心态吧,终于有钱换手机了!要说有什么新年愿望,那就希望2022一切好运吧。 虽然是实习面经但是其实也没怎么准备,随缘,放弃了bat的部门,估计对学历和论文有门槛(尝试性投了深圳字节直接挂简历,我永远喜欢bytedance😭),10月投b站简历挂,旷视面试没过以后就没投了,后面去学车了,结果科目二没过,有点闲看到有朋友也在投,就不抱希望还是投了3家,比较幸运最后拿到了美团和商汤的实习offer,感谢面试官们手下留情🤣。
个人情况:
- 学校:211 大四
- 成绩:前5%
- 项目:3段CV相关项目经历,无论文,两个算法实践工程落地项目,一段kaggle竞赛铜牌,总体上来说都比较水
- 算法能力:无ACM,比较菜只是比较喜欢刷,leetcode400题(以easy+medium为主,剑指offer+程序员面试经典+每日一题/周赛)
因为感觉自己很菜找不到实习,所以都没找内推,也没有海投,不过好像大多都会给面试机会的,感觉如果能找内推可能会更好一点。没想到最后能去美团当外卖骑手了😁!
旷视
旷视的实习面试是最早的,不过也面试通知也等了好久,hr说有两个面试官mark了我的简历,所以面了两个组,当时是第一次面试,比较紧张,虽然面试问的不难,但是有些地方答的不好,面试问题记不太清了。另一个面试官,我等了半小时结果被他放鸽子了,改天再面的。。。
- 手写IoU
- 求三个部分的IoU,根据定义就是求:$\frac{A \cap B \cap C}{A \cup B \cup C} $,只用讲思路,其实就是容斥原理,当时有点紧张,公式最后一项系数写错了一直没看出来,场面一度尴尬。
- 讲解Focal loss的原理作用
- 为什么会用到
StratifiedKFold,和KFold有什么区别 - 介绍一下比赛用到的
TTA,Cutmix方法(Cutout和mixup的结合,最好三个都讲解一下) - 讲讲
Resnet(建议读一下论文,从目的,作用,残差结构的形式,反向传播梯度计算,机器学习GBDT思想等角度进行阐述) - 目标检测的
mAP达到了多少,有没有测过双目测距的精准度,为啥使用wifi和flask推流通信,这样会比较慢(树莓派算力不够,跑着跑着宕机了),小车目标检测的帧数能达到多少fps(emm我们只是做了一个无人清洁车落地的demo,只测了模型目标检测在数据集上的mAP,其他的更多的是我们自己提供一种idea,具体指标没有测试过😥)。 - 旋转矩阵,不能开空间,其实做过但是面试很容易紧张卡住,有想到思路但是没写对有点bug,不过面试官说我思路是对的,面完就发现原来是下标对错了。。。
- 团队合作交流是如何分工和解决问题的?
- 其他人或者老师给你任务安排时,如果与你的想法不合时,你会如何做?
手写IoU
import numpy as np
def IoU(bounding_box,ground_truth):
"""
:param bounding_box: [[x1,y1,x2,y2,score]]
:param ground_truth: [x1,y1,x2,y2]
:return:
"""
x1 = bounding_box[:,0]
y1 = bounding_box[:,1]
x2 = bounding_box[:,2]
y2 = bounding_box[:,3]
score = bounding_box[:,4]
areas = (x2-x1) * (y2-y1)
gt_area = (ground_truth[2] - ground_truth[0]) * (ground_truth[3] - ground_truth[1])
xx1 = np.maximum(x1,ground_truth[0])
yy1 = np.maximum(y1,ground_truth[1])
xx2 = np.minimum(x2,ground_truth[2])
yy2 = np.minimum(y2,ground_truth[3])
h = np.maximum(0,yy2-yy1)
w = np.maximum(0,xx2-xx1)
inter = w * h
ovr = inter / (gt_area + areas - inter) # np.true_divide(inter, (gt_area + areas - inter))
return ovr
旋转矩阵
class Solution {
public:
void rotate(vector<vector<int>>& matrix) {
int n = matrix.size();
for(int i=0;i<n/2;i++)
{
for(int j=0;j<(n+1)/2;j++)
{
// (i,j) (j,n-i-1) (n-j-1,i) (n-i-1,n-j-1)
swap(matrix[i][j],matrix[n-i-1][n-j-1]);
swap(matrix[i][j],matrix[n-j-1][i]);
swap(matrix[j][n-i-1],matrix[n-i-1][n-j-1]);
}
}
}
};
小米
小米面试其实是当时最好的选择,因为就在武汉本地,也不用外出,但是当时面试确实不太好,面试官对我其中一个项目比较感兴趣,被疯狂怼着追问细节。
- 描述项目中用到的SIFT匹配和直方图相似度比对基本原理。
- one-stage和two-stage的区别。
- 双目摄像头视觉下应该可以得到整个三维空间下的信息,没考虑方向角度的问题,对测距的处理有些草率(没有很懂,之后再去了解了解,只用到了物理上小孔成像的原理😰
- 为什么不直接在树莓派上推理,采用推流和主机服务器去进行计算,速度和精度如何
- 继续追问项目细节。
- 手写SIFT匹配过程,直接人傻了😭(被面试官怼对传统图像处理了解不深,只会玩玩深度学习搭积木)
美团-智能视觉 offer
美团面试官面试体验比较好,没有过分针对,对待我这种本科生可能相对更看重对我的motivation和potential吧感觉,评价也比较好。
一面
- 聊项目,做项目的目的和缘由,你觉得有什么亮点。
- 讲讲one-stage和two-stage的区别。
- anchor-free的方式比如FCOS有了解吗
- 看你有用过
ViT,能不能讲讲transformer的架构,再讲讲vit是怎么做的,BERT有了解吗,跟vit有什么区别 - 看你项目经常用到kaiming的东西,kaiming最近新出的MAE有了解吗(虽然面试官看着年龄有点大,不过还挺紧跟潮流的,kaiming yyds!
- 讲讲SIFT匹配到双目测距的过程和原理
- 为什么要用树莓派采集图像借助flask推流,再由主机进行模型推理
- 对GNN和GCN有了解吗
- 讲讲人脸检测
MTCNN是怎么做的 - 聊美团这边的业务,问我有没有这方面技术的了解
- 自己出的算法题,以条形码识别为背景,有点像是去除干扰字符的匹配,用双指针解决即可。
二面
- 聊项目缘由,团队协作。
- 讲讲
transformer,讲讲position encoding的方法,作者用这种三角函数的方式有什么特点,在vit里面是如何做位置编码的。 - 介绍
self-attention,transfomer的encode和decode有什么区别,你对这两部分有什么理解,以及相对于CNN的一些特点。 - 项目用的数据集有多大。
- 项目目标检测用的什么指标,达到了什么效果。
- 聊美团业务,问我有没有兴趣。
- 出了个hard题扰乱字符串,不会,简单讲了一下dfs暴力的思路但还是没理清楚写不出😭,后面换了个简单点的题不过要求让我用python写
商汤-基础视觉 offer
一面
一面比较简单,面试官也比较和蔼。
- 自己出的题,二维矩阵找最长的严格单调上升的一个连续序列(可以跨行转弯,对角线不算),节点可上下左右移动。先用dfs暴力,然后再用记忆化优化了一下。虽然不难但是写的有点慢。
- 聊项目。
- 讲讲Batch Normalization(建议从目的,由来,公式解析,理解操作过程,作用以及使用场景等方面来讲解附博客,看完发现自己面试讲的好烂)
- 介绍小批量梯度下降
- 讲讲分布不均衡的数据如何处理(讲了讲数据增强,过采样比如SMOTE,欠采样,调整样本对分类的权重,如FocalLoss,这个我感觉回答的不是很好,希望评论区有更好的理解)
- 有没有搭建或者使用过单机多卡和多机多卡,是否了解多卡时神经网络的梯度反向传播是如何计算的(没钱没资源🤣,瞎猜了一波可能和计算图的节点资源分配有关)
二面
二面其实感觉面试有点糟糕,连问了十几个八股文,做题也出了一些问题,自闭,答也能答出来一些但是整体感觉不好。。。。不过最后比较幸运还是让我过了。 - 简单介绍自己的项目和自己觉得有亮点的地方
- 讲讲one-stage和two-stage的区别和特点
- 什么是RPN,作用是什么
- 什么是FPN,有什么特点,这种多尺度是怎么实现和进行预测的
- 讲述yolov3预测目标的过程(比较关键的几个要点我觉得是损失函数,模型输出,非极大抑制,多种变种的IoU,SPP空间金字塔,以及论文中有提到yolov3的anchor是kmeans聚类出来的,可能会让你手写kmeans)
- 为什么two-stage要比one-stage的精度要高,你觉得本质是什么
- yolov3的三个特征图大尺寸的用来预测大的图还是小的图
- anchor-free的方式有了解吗,和anchor-based的差异在哪,本质和原理是什么
- 介绍一下CenterNet和FCOS,中心度的公式和理论,预测过程
- 什么是梯度消失和梯度爆炸,如何解决(提到某些要点或者答错了会继续追问,没有答的很全)
- 进程和线程的区别,python的多线程如何实现
- maxpool是如何进行反向传播的(建议看看cs231n,首先要明确的是pool层中是没有参数的,然后再来将maxpool,其实我当时也忘了,我记得好像跟maxout的反向传播差不多)
- 讲讲Batch Normalization,以及在训练和预测过程的计算方式
- 讲讲dropout,以及在训练和预测过程的计算方式(建议看看cs231n),你觉得和机器学习当中哪种集成方式比较像(这个我不是很清楚希望各位大佬回答一下,当时瞎说了一个boosting🤣)
- 剑指 Offer 31. 栈的压入、弹出序列 思路大致是对的但是没想得特别清楚,比较紧张,写了很久
- 剑指 Offer 39. 数组中出现次数超过一半的数字 第二题直接限制时间复杂度$O(n)$,空间复杂度$O(1)$,我只会哈希方法,然后和面试官说了一下最优解方法我只记得叫摩尔投票,然后具体忘了。
栈的压入、弹出序列
class Solution {
public:
bool validateStackSequences(vector<int>& pushed, vector<int>& popped) {
stack<int> stk;
int n = popped.size();
int m = pushed.size();
int j = 0;
for(int i=0;i<m;i++)
{
stk.push(pushed[i]);
while(stk.size()&&stk.top()==popped[j])
{
j++;
stk.pop();
}
}
return stk.empty();
}
};
其他
还有一些感觉比较重要,但是没有被问道的东西,包括各种评价指标的含义等等,包括数学基础等等。
经典教程推荐:cs231n,吴恩达,李宏毅,动手学深度学习,《统计学习方法》
关于八股文方面这里推荐一个DeepLearning-500-questions
手写非极大抑制
使用非极大抑制的前提是,我们已经得到了一组候选框和对应label的置信分数,以及groud truth的信息,通过设定阈值来删除重合度较高的候选框。
算法流程如下:
- 根据置信度得分进行排序
- 选择置信度最高的比边界框添加到最终输出列表中,将其从边界框列表中删除
- 计算所有边界框的面积
- 计算置信度最高的边界框与其它候选框的IoU。
- 删除IoU大于阈值的边界框
- 重复上述过程,直至边界框列表为空。
import numpy as np
def nms(dets, threshod, mode="Union"):
"""
greedily select boxes with high confidence
keep boxes overlap <= thresh
rule out overlap > thresh
:param dets: [[x1, y1, x2, y2 score]]
:param threshod: retain overlap <= thresh
:return: indexes to keep
"""
x1 = dets[:, 0]
y1 = dets[:, 1]
x2 = dets[:, 2]
y2 = dets[:, 3]
scores = dets[:, 4]
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
order = scores.argsort()[::-1] # reverse
keep = []
while order.size() > 0:
i = order[0]
keep.append(i)
# A & B left top position
xx1 = np.maximun(x1[i], x1[order[1, :]])
yy1 = np.maximun(y1[i], y1[order[1, :]])
# A & B right down position
xx2 = np.minimum(x2[i], x2[order[1, :]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
# cacaulate the IOU between box which have largest score with other boxes
if mode == "Union":
# area[i]: the area of largest score
ovr = inter / (areas[i] + areas[order[1:]] - inter)
elif mode == "Minimum":
ovr = inter / np.minimum(areas[i], areas[order[1:]])
# delete the IoU that higher than threshod
inds = np.where(ovr <= threshod)[0]
order = order[inds + 1] # +1: eliminates the first element in order
return keep
手写Kmeans方法
这个版本不是最佳写法,某些处理有点暴力,可以用矩阵和numpy相关的操作会更简洁,但是退出迭代的条件写的很全的,有达到迭代次数,中心点集不变,中心点变化范围小于$\delta$
import numpy as np
import matplotlib.pyplot as plt
n = 100
a = np.random.randn(0,50,n)
b = np.random.rand(0,50,n)
x = np.random.randint(0,50,n)
y = np.random.randint(0,50,n)
points = np.array(list(zip(x,y)))
def distance(x,y):
return np.sqrt(np.sum((x-y)**2))
def k_means(points,k=5,epochs=500,delta=1e-3):
# 初始化聚类中心
center_ids = np.random.randint(0,n,k)
centers = points[center_ids]
# 聚类集合初始化
results = []
for i in range(k):
results.append([])
step = 1
flag = True
# 计算各点到中心的距离
while flag and step < epochs:
# 重新迭代
for i in range(k):
results[i] = []
# 计算每个点到距离中心的距离
for i in range(len(points)):
point = points[i]
min_dis = np.inf
min_id = 0
for idx, center in enumerate(centers):
dis = distance(center,point)
if min_dis > dis:
min_dis = dis
min_id = idx
results[min_id].append(point)
# 更新聚类中心
for idx, old_center in enumerate(centers):
new_center = np.array(results[idx]).mean(axis=0)
if distance(center, new_center) > delta:
centers[idx] = new_center
flag = False
# flag=True说明聚类中心已经不变了则可以退出了
if flag:
break
else:
flag = True
step += 1
return results,centers
plt.plot(x,y,'ro')
results,centers=k_means(points,k=5)
color=['ko','go','bo','yo','co']
for i in range(len(results)):
result=results[i]
plt.plot([res[0] for res in result],[res[1] for res in result],color[i])
plt.plot([res[0] for res in centers],[res[1] for res in centers],'ro')
plt.show()
总结
本人能力有限,如果上述回答有任何错误,还请各位大佬及时指出
- 不同面试官的面试风格不一样,项目相关的知识积累问的会比较多(项目水没关系但相关技术还是要搞懂),项有的会考察广度和思维潜力,有的会考察基础(八股),算法题感觉并没有那种重要,把剑指offer刷了应该差不多。
- 关于八股文的看法,其实更多的还是要多理解,一些相关原理和数学还是多看看相关论文和经典课程,到时候也不用刻意记也能按自己的想法说出一点(瞎吹),感觉面试官想要的答案并不一定是你能完整的说出来,而是有自己理解的正确描述(这个可能需要在代码实践和理论知识之间多反复几次体会会比较好)。
- 代码实践还是要多一些,其实很多东西我了解的并不深入,只是大致理解过原理和思路,这样还是不太好,开始害怕顶不住实习压力了。
- 不用害怕,尽量多交流,避免场面陷入尴尬。
- 反问环节我一般问的是来这边的工作内容,学习的建议和评价,培养和安排之类的。
「掘金链接:菜鸡的算法岗日常实习面经总结」
]]>
@@ -118,7 +118,7 @@
2022-01-08T12:04:00.000Z
2024-10-09T07:33:09.904Z
- 
⏱2021-2022
说来惭愧,没想到在掘金这样神圣的技术社区,我的第一篇文章竟然是与技术无关的年终总结。(主要是想白嫖到周边棒球帽🧢,本来是打算发布已经写好的算法岗实习面经,有兴趣的朋友可以继续看看)
时间总是过的很快,我也是偶然间打开掘金看到的这个活动才意识到今年已经快要过去了,想了很久2021年对我而言到底意味着什么,好像过得很混乱,想的太多,做的太少,以前总是能在不确定性中规划好一些时间,但今年很多事情都是被时间推着走入不确定的维度。
读研or就业的思考
这个问题其实在2年前就有在思考这件事情,虽然学生思维存在着一些局限性,但是你不得不承认这件事情确实是你需要尽早想清楚的事情,话是这么说其实还是当局者迷,旁观者清,尽管有一些我认识的人给过我他们的思考,我自己也没在最需要想清楚的时候想清楚这件事情,可能很多感受只有触碰到结果了才真正明白吧。
这个问题抛出来,我写起来还是不知从何说起,没有正确答案,未来都是未知的,害怕失去现有的一切,凭我的经验来看,还是要多遵从自己的内心,不要完全理性的去权衡利弊,失去如果每个选择都会后悔,就不要选让自己更后悔的那个。还是说一下自己当时思考的几件事情:
- 读研是为了什么,去企业又是为了什么
- 对于未来到底想做什么
- 抛开家长和他人的观点,你对自己的性格和能力是否足够了解,是否足够自信
- 都是最坏的情况,更能接受哪个选择
- 如何承受选择带来的代价和自我和解之道
去黄鹤楼,看樱花
3月樱花又开了,大一没来得及看樱花,大二由于疫情影响也没能去成,大三正好有朋友过来武汉找我玩,就带着去黄鹤楼,隔壁学校赏樱花,那几天每天晚上和朋友们聊天一整夜,太久没一块说话了吧,我和他约定好考完研再来武汉陪我过生日。
春招面网易
4月有好友正好在做网易的春招宣传,内推了我一手,抱着涨点面试经验的心态,面了一下网易的算法岗,匆忙改了一版简历,笔试比较简单过了2/3,面试还行但还是没过,后面准备夏令营啥的也没有再投了。茶颜悦色&湖南师大&湖南大学
在湖南呆了这么久,这是第一次喝茶颜悦色,leo点的幽兰拿铁,晚上吃了一顿火锅直接拉肚子到凌晨2点,去了当初高二数学竞赛培训的湖师大,看了看那些当时买礼物的精品店和饭店,后面去了湖南大学找同学吃饭,湖南大学的建筑风格很不错,嘿嘿,不愧是湖大!有幸与神三元吃饭
毕业季,神三元学长也要毕业了,在学校一直听着他的江湖神话,终于有朝一日能见上一面了,迫不及待和朋友一起跑到另一个校区追星。见面一看确实是一表人才,吃饭紧张到有点不知道说话。不过听大佬聊技术趋势和工作思考,还是有很多不一样的体会。
bytecamp再送人头
去年暑假参加了一次bytecamp的笔试,感觉挺有意思的,虽然当时也没过,今年再参加编程又爆0了,第一题是树形dp模版题,但是我当时忘了,后面两个就更难了不会。
滚滚长江东逝水——再会江滩
暑假放假回家前,去了一次江滩,之前带朋友去的是汉口江滩,这次去武昌江滩看的,也算是两岸都看过了,虽然武汉夏天很热,但是长江的风吹过来还是很舒服的。
魔都体验卡
有幸参加SIST的夏令营,体验了3天公费旅游的感觉,还吃了西餐,和朋友去了上海外滩和金融中心,半夜两点给健哥写前端。听说上海的天空很低!
梦碎了
9月差一点点,最后还是没能去到自己最想去的地方,感觉自己的学生时代已经结束了,梦碎了,不展开了,容易晚上emo😭
4年后再来南山区
18年国庆来深圳,只觉得繁华,人上人,4年后再来觉得这里还是缺少了一些文化感和年代感的东西,感谢朋友们的盛情招待,看海没赶上好时候,跟小w发我的照片完全不一样😔,第一次吃椰子鸡,去了SUST看夕阳,感受了朋友在字节跳动的“快乐”生活(我永远喜欢bytedance),遇到了突然其来的台风和大暴雨,沿着大沙河逛THU和PKU
最爱东湖与武大
在武汉,我独爱东湖,这次有幸还坐船浏览了对岸,去了磨山,一路听着粤语歌在东湖漫步,会有很多很多想法。逛完东湖与武大同学小歇畅聊,有幸参观了周恩来和闻一多先生的居所,一起吃饭听说他搞家教日薪1k+我羡慕。
摆烂的大四软测
大四一学期没听课,软测临时抱佛脚,卷了3年才知道整张试卷瞎写的感觉原来这么爽,还好没挂。
CLANNAD
看了一直没看的CLANNAD,不得不说这个剧表达的东西很深刻,给了我很多生活的思考,我觉得是我心中看过的最好的动漫之一了,以后可以再看一遍,好像要一个团子啊🥺!
科目二的败北
和朋友天天早出晚归跑去练科目二,到了考场发现自己学的东西都白学了,侧方直接挂,然后倒库紧张又挂了。。。坡上两只狗
12月所思
12月陷入了一段特别迷茫的时间,他们说我所担心的并不能约束你,只能促进你,不要老是患得患失,后面拿了实习offer后开心了一些,等考研的朋友考完一起舒服了几天,后面的实训课继续摆烂,可惜说好来武汉陪我过生日的同学最后还是没来,那天写实训代码写到1点才睡,不过随着一年又一年,我倒是觉得就当平常日挺好的,也不用刻意去记,能想起来就想起来吧。
回家的所闻所见
纠结了很长时间关于寒假外出实习的事情,最后还是觉得去体验一下比较好,害怕过年回家待不了太久,所以提前跑路回家了几天,比较难受的是遇到了一些不好的事情,还是要常回家看看🙏
啃了一些原理+Leetcode400题
今年感觉自己花在学习上的时间没有特别多,更多的时间被虚无的思考给浪费掉了,除了一些kaggle和工程代码之外,今年做了一些不一样的事情主要就是手推了《统计学习方法》当中一些基本算法,西瓜书也看了一些,leetocde不知不觉突破400题了! 还是很菜,只不过把刷题当成习惯了。
关于十年后再来北京这件事
今年跨年有些不一样,12.31飞北京跨年,下午处理好了租房的问题,人生地不熟,接下来元旦几天都是被朋友带着玩哈哈哈。
Dr.Pepper & Sky
在旅店晚上喝了一杯命运石之门的Dr.Pepper,有一种穿越时空的味道 上次坐飞机还是10多年前,再一次飞上蓝天还是很激动!
清华五道口
十年前曾踏过清华的大门,十年后还是没能跨进你的大门,来生请等我。
单车刷夜去天安门和祖国母亲一起跨年
作为一名预备党员,元旦必然要在天安门通宵等升旗,被北方的寒风给冻傻了,和祖国母亲一起放飞和平鸽!
海底捞被朋友抓去过生日
虽然生日过了,但是他们想在北京陪我过一次,店里送了相框,正好一起拍照留作纪念,摆在新家当饰品,第一次在海底捞过生日社死。
四季民福故宫店北京烤鸭南锣鼓巷中关村中科院
吃了很离谱的豆汁和正宗北京烤鸭
环球影城,我要上魔法学院!
在环球影城玩了一天,看过的电影不多,环球影城的这几个设施特别还原,喝了魔法黄油啤酒,买了小黄人的盲盒。
美团实习ing
太菜了只会摸鱼,要开始新的生活了
To 2022
- 请你继续保持对技术的热情,脚踏实地,努力学习,祝你好运
- 好好体验实习,工作,一个人独立生活的感觉
- 考完驾照,厨艺++,滑一次雪,想看看北京冬奥会
- 劳逸结合,自律坚持,锻炼身体,要顶天立地,才能闯出自己的路
- 读万卷书,行万里路,在更多地方留下你的足迹
- 请做到一件很多年你都没能做到的事情
- 以高标准要求自己,但是别当成包袱,好的坏的都是一场体验
- 还有不能忘记的音乐梦!
- 希望未来以后有机会当一个speaker
「掘金链接:回首向来萧瑟处,归去,也无风雨也无晴|2021年终总结」
]]>⏱2021-2022
说来惭愧,没想到在掘金这样神圣的技术社区,我的第一篇文章竟然是与技术无关的年终总结。(主要是想白嫖到周边棒球帽🧢,本来是打算发布已经写好的算法岗实习面经,有兴趣的朋友可以继续看看)
时间总是过的很快,我也是偶然间打开掘金看到的这个活动才意识到今年已经快要过去了,想了很久2021年对我而言到底意味着什么,好像过得很混乱,想的太多,做的太少,以前总是能在不确定性中规划好一些时间,但今年很多事情都是被时间推着走入不确定的维度。
读研or就业的思考
这个问题其实在2年前就有在思考这件事情,虽然学生思维存在着一些局限性,但是你不得不承认这件事情确实是你需要尽早想清楚的事情,话是这么说其实还是当局者迷,旁观者清,尽管有一些我认识的人给过我他们的思考,我自己也没在最需要想清楚的时候想清楚这件事情,可能很多感受只有触碰到结果了才真正明白吧。
这个问题抛出来,我写起来还是不知从何说起,没有正确答案,未来都是未知的,害怕失去现有的一切,凭我的经验来看,还是要多遵从自己的内心,不要完全理性的去权衡利弊,失去如果每个选择都会后悔,就不要选让自己更后悔的那个。还是说一下自己当时思考的几件事情:
- 读研是为了什么,去企业又是为了什么
- 对于未来到底想做什么
- 抛开家长和他人的观点,你对自己的性格和能力是否足够了解,是否足够自信
- 都是最坏的情况,更能接受哪个选择
- 如何承受选择带来的代价和自我和解之道
去黄鹤楼,看樱花
3月樱花又开了,大一没来得及看樱花,大二由于疫情影响也没能去成,大三正好有朋友过来武汉找我玩,就带着去黄鹤楼,隔壁学校赏樱花,那几天每天晚上和朋友们聊天一整夜,太久没一块说话了吧,我和他约定好考完研再来武汉陪我过生日。
春招面网易
4月有好友正好在做网易的春招宣传,内推了我一手,抱着涨点面试经验的心态,面了一下网易的算法岗,匆忙改了一版简历,笔试比较简单过了2/3,面试还行但还是没过,后面准备夏令营啥的也没有再投了。茶颜悦色&湖南师大&湖南大学
在湖南呆了这么久,这是第一次喝茶颜悦色,leo点的幽兰拿铁,晚上吃了一顿火锅直接拉肚子到凌晨2点,去了当初高二数学竞赛培训的湖师大,看了看那些当时买礼物的精品店和饭店,后面去了湖南大学找同学吃饭,湖南大学的建筑风格很不错,嘿嘿,不愧是湖大!有幸与神三元吃饭
毕业季,神三元学长也要毕业了,在学校一直听着他的江湖神话,终于有朝一日能见上一面了,迫不及待和朋友一起跑到另一个校区追星。见面一看确实是一表人才,吃饭紧张到有点不知道说话。不过听大佬聊技术趋势和工作思考,还是有很多不一样的体会。
bytecamp再送人头
去年暑假参加了一次bytecamp的笔试,感觉挺有意思的,虽然当时也没过,今年再参加编程又爆0了,第一题是树形dp模版题,但是我当时忘了,后面两个就更难了不会。
滚滚长江东逝水——再会江滩
暑假放假回家前,去了一次江滩,之前带朋友去的是汉口江滩,这次去武昌江滩看的,也算是两岸都看过了,虽然武汉夏天很热,但是长江的风吹过来还是很舒服的。
魔都体验卡
有幸参加SIST的夏令营,体验了3天公费旅游的感觉,还吃了西餐,和朋友去了上海外滩和金融中心,半夜两点给健哥写前端。听说上海的天空很低!
梦碎了
9月差一点点,最后还是没能去到自己最想去的地方,感觉自己的学生时代已经结束了,梦碎了,不展开了,容易晚上emo😭
4年后再来南山区
18年国庆来深圳,只觉得繁华,人上人,4年后再来觉得这里还是缺少了一些文化感和年代感的东西,感谢朋友们的盛情招待,看海没赶上好时候,跟小w发我的照片完全不一样😔,第一次吃椰子鸡,去了SUST看夕阳,感受了朋友在字节跳动的“快乐”生活(我永远喜欢bytedance),遇到了突然其来的台风和大暴雨,沿着大沙河逛THU和PKU
最爱东湖与武大
在武汉,我独爱东湖,这次有幸还坐船浏览了对岸,去了磨山,一路听着粤语歌在东湖漫步,会有很多很多想法。逛完东湖与武大同学小歇畅聊,有幸参观了周恩来和闻一多先生的居所,一起吃饭听说他搞家教日薪1k+我羡慕。
摆烂的大四软测
大四一学期没听课,软测临时抱佛脚,卷了3年才知道整张试卷瞎写的感觉原来这么爽,还好没挂。
CLANNAD
看了一直没看的CLANNAD,不得不说这个剧表达的东西很深刻,给了我很多生活的思考,我觉得是我心中看过的最好的动漫之一了,以后可以再看一遍,好像要一个团子啊🥺!
科目二的败北
和朋友天天早出晚归跑去练科目二,到了考场发现自己学的东西都白学了,侧方直接挂,然后倒库紧张又挂了。。。坡上两只狗
12月所思
12月陷入了一段特别迷茫的时间,他们说我所担心的并不能约束你,只能促进你,不要老是患得患失,后面拿了实习offer后开心了一些,等考研的朋友考完一起舒服了几天,后面的实训课继续摆烂,可惜说好来武汉陪我过生日的同学最后还是没来,那天写实训代码写到1点才睡,不过随着一年又一年,我倒是觉得就当平常日挺好的,也不用刻意去记,能想起来就想起来吧。
回家的所闻所见
纠结了很长时间关于寒假外出实习的事情,最后还是觉得去体验一下比较好,害怕过年回家待不了太久,所以提前跑路回家了几天,比较难受的是遇到了一些不好的事情,还是要常回家看看🙏
啃了一些原理+Leetcode400题
今年感觉自己花在学习上的时间没有特别多,更多的时间被虚无的思考给浪费掉了,除了一些kaggle和工程代码之外,今年做了一些不一样的事情主要就是手推了《统计学习方法》当中一些基本算法,西瓜书也看了一些,leetocde不知不觉突破400题了! 还是很菜,只不过把刷题当成习惯了。
关于十年后再来北京这件事
今年跨年有些不一样,12.31飞北京跨年,下午处理好了租房的问题,人生地不熟,接下来元旦几天都是被朋友带着玩哈哈哈。
Dr.Pepper & Sky
在旅店晚上喝了一杯命运石之门的Dr.Pepper,有一种穿越时空的味道 上次坐飞机还是10多年前,再一次飞上蓝天还是很激动!
清华五道口
十年前曾踏过清华的大门,十年后还是没能跨进你的大门,来生请等我。
单车刷夜去天安门和祖国母亲一起跨年
作为一名预备党员,元旦必然要在天安门通宵等升旗,被北方的寒风给冻傻了,和祖国母亲一起放飞和平鸽!
海底捞被朋友抓去过生日
虽然生日过了,但是他们想在北京陪我过一次,店里送了相框,正好一起拍照留作纪念,摆在新家当饰品,第一次在海底捞过生日社死。
四季民福故宫店北京烤鸭南锣鼓巷中关村中科院
吃了很离谱的豆汁和正宗北京烤鸭
环球影城,我要上魔法学院!
在环球影城玩了一天,看过的电影不多,环球影城的这几个设施特别还原,喝了魔法黄油啤酒,买了小黄人的盲盒。
美团实习ing
太菜了只会摸鱼,要开始新的生活了
To 2022
- 请你继续保持对技术的热情,脚踏实地,努力学习,祝你好运
- 好好体验实习,工作,一个人独立生活的感觉
- 考完驾照,厨艺++,滑一次雪,想看看北京冬奥会
- 劳逸结合,自律坚持,锻炼身体,要顶天立地,才能闯出自己的路
- 读万卷书,行万里路,在更多地方留下你的足迹
- 请做到一件很多年你都没能做到的事情
- 以高标准要求自己,但是别当成包袱,好的坏的都是一场体验
- 还有不能忘记的音乐梦!
- 希望未来以后有机会当一个speaker
「掘金链接:回首向来萧瑟处,归去,也无风雨也无晴|2021年终总结」
]]>
@@ -143,7 +143,7 @@
2021-10-16T06:19:00.000Z
2024-10-09T07:33:09.887Z
- PAT笔记这里记录了一下常用的保研机试,剑指offer和PAT题目分类解析,主要用来快速回顾和复习相关模板,以及数据结构相关的知识点。
字符串
- 在c++中处理字符串类型的题目时,我们一般使用
string,有时候我们也使用char[]方式进行操作。 HH:MM:SS可以直接通过字符串字典序排序- 输入一个包含空格的字符串需要使用
getline(cin,s1)STL
vector<int>本省具备有字典序比较的方法,重载了< == >的运算符号vector<int>::iterator iter=find(vec.begin(),vec.end(),target); if(iter==vec.end()) cout << "Not found" << endl;
高精度
int的范围$-2 \times 10^9 - 2 \times 10^9$long long $-9 \times 10^{18} - 9 \times 10^{18}$- 用
vector按位存储

进制转换
- 其他进制化成10进制,采用秦九韶算法

typedef long long LL;
LL get(char c)
{
if(c<='9') return c-'0';
else return c-'a' + 10;
}
LL getnum(string a,LL r)
{
LL res=0;
for(int i=0;i<a.size();i++)
{
res = res * r + get(a[i]);
}
return res;
}
- 十进制转其他进制的方法,使用带余除法
int get(char c)
{
if(c<='9') return c-'0';
else return c-'a' + 10;
}
char tochar(int c)
{
if(c<=9) return c+'0';
else return 'a' + c - 10;
}
//一个r进制数num转10进制
int numr_to10(string num,int r)
{
int res = 0;
for(int i=0;i<num.size();i++)
{
res = res * r + get(num[i]);
}
return res;
}
//一个10进制数num转r进制
string num10_tor(string num,int r)
{
string res;
int n = numr_to10(num,10); //先转成10进制整型
while(n)
{
// cout<<tochar(n % r)<<endl;
res = tochar(n % r) + res;
n /= r;
}
return res;
}
// cout<<numr_to10("6a",16)<<" "<<num10_tor("15",16)<<endl;
判断质数
//判断一个数是否为质数
bool is_prime(int n)
{
if (n < 2) return false; // 1和0不是质数
for(int i=2;i*i<=n;i++)
{
if(n % i == 0) return false;
}
return true;
}
手写堆排序
堆是一个完全二叉树的结构,分为小根堆和大根堆两种结构。
- 小根堆的递归定义:小根堆的每个节点都小于他的左右孩子节点的值,树的根节点为最小值。
- 大根堆的递归定义:大根堆的每个节点都大于他的左右孩子节点的值,树的根节点为最大值。
在STL当中可以使用prioirty_queue来轻松实现大根堆和小根堆,但是只能实现前3个功能,有时候我们不得不自己实现一个手写的堆,同时这样也能让我们更理解堆排序的过程。
在AcWing基础课当中有两道经典例题,AcWing 839. 模拟堆(这个复杂一点),AcWing 838. 堆排序
这里给出堆排序的模板级代码
#include <iostream>
using namespace std;
const int N = 100010;
int heap[N],heapsize=0;
void down(int x)// 参数下标
{
int p =x;
if(2*x<=heapsize && heap[2*x]<heap[p]) p = 2*x;//左子树
if(2*x+1<=heapsize && heap[2*x+1]<heap[p]) p=2*x+1;//右子树
if(p!=x)
{
swap(heap[p],heap[x]); //说明存在比父节点小的孩子节点
down(p); //继续向下递归down
}
}
void up(int x)// 参数下标
{
while(x / 2 && heap[x] < heap[x/2]) //父节点比子节点大则交换
{
swap(heap[x],heap[x/2]);
x >>= 1; // x = x/2
}
}
int main()
{
int n,m;
scanf("%d%d", &n, &m);
for (int i = 1; i <= n; i ++ ) scanf("%d", &heap[i]);
heapsize=n;
// O(n)建堆
for (int i = n / 2; i; i -- ) down(i);
while (m -- )
{
printf("%d ",heap[1]); //最小值是小根堆的堆顶
// 删除最小值,并重新建堆排序,从而获得倒数第二小的元素
heap[1] = heap[heapsize];
heapsize--;
down(1);
}
return 0;
}
STL写法:priority_queue默认是大根堆,less<int>是对第一个参数的比较类,表示数字大的优先级越大,而greater<int>表示数字小的优先级越大,可以实现结构体运算符重载。
首先要引入头文件:#include<queue>
大根堆:
priority_queue<int> q;
priority_queue<int, vector<int>, less<int> >q;
小根堆:
priority_queue < int, vector<int>, greater<int> > q;
树
树是一种特殊的数据结构形式,在做题的过程当中,根据我的经验当题目需要使用树结构的时候主要有以下几种模式。
- 二叉树形式,在二叉树模型下,我们可以根据题目建立出静态的树形结构,构建每个节点左右孩子索引表来建立树的结构同时实现对树的遍历。如果已知或可以求得节点之间的关系,可以通过节点的度数或者访问标记找到根节点。,当然也是可以通过邻接表的方式创建二叉树。
- 多叉树形式,多叉树形式其实又类似于无向连通图的概念,常通过创建邻接表或者临接矩阵的方式建立树,并实现进行树的遍历,也是可以根据节点关系求出根节点的。注意在临接表当中,边的数量一般大于节点数量的两倍即我们需要开票邻接表的边数空间为$M = 2 \times N + d$
- 森林,多连通块的方式,这种也是利用无向图的方式,以邻接表或者临接矩阵的方式构建树的结构,同时我们可以利用并查集的方式得到当前无向图中含有的连通块数量并找到根节点。
二叉树左右孩子索引表模型
const int N = 100010;
int l[N],r[N]// 第i个节点的左孩子和右孩子的索引
bool has_father[N]; //建立树的时候判断一下当前节点有没有父节点,可用于寻找根节点
//初始化,-1表示子节点为空
memset(l,-1,sizeof l);
memset(r,-1,sizeof r);
// 查找根节点的过程
if(l[i]>=0) has_father[l[i]]=true;
if(r[i]>=0) has_father[r[i]]=true;
//查找根节点
int root = 0;
while(has_father[root]) root++;
二叉树的遍历过程(以先序遍历为例子)
void dfs(int root)
{
if(root==-1) return;
cout<<root<<endl;
if(l[root]>=0) dfs(l[root]);
if(r[root]>=0) dfs(r[root]);
}
临接表模型
const int N = 100010;
const int M = 2 * N + 10;
int h[N];//邻接表的N个节点头指针,h[i]表示以i为起点的,最新的一条边的编号
int e[M];// e[i] 表示第i条边的所指向的终点
int ne[M];// ne[i]表示与第i条边起点相同的下一条边的编号
int idx;// idx表示边的编号,每增加一条边就++
// 添加一条从a到b的边,如果是无向图,每次添加时要add(a,b)和add(b,a)
void add(int a,int b)
{
e[idx] = b; // 第idx条边的终点为b
ne[idx] = h[a]; // h[a] 和 第idx都是以a为起点的边,通过ne[idx]串联起来,找到上一条以a为起点的边h[a]
h[a] = idx ++; // 更新当前以a为起点的边的最新编号
}
//初始化,-1表示节点为空
memset(h,-1,sizeof h);
临接表遍历过程方法1
// x为起点,father为x的来源,防止节点遍历走回头路导致死循环
void dfs(int x,int father)
{
cout<<x<<endl;
for(int i = h[x];~i;i=ne[i]) // ~i就是i!=-1的意思
{
int to = e[i];
if(to==father) continue;
dfs(to,x);
}
}
dfs(x,-1);
临接表遍历过程方法2
const int N = 100010;
bool isvisited[N];
void dfs(int x)
{
isvisited[x]=true;
cout<<x<<endl;
for(int i = h[x];~i;i=ne[i])
{
int to = e[i];
if(isvisited[to]) continue;
dfs(to);
}
}
dfs(x);
树的深度
临接表模型:AcWing1498. 最深的根
int getdepth(int x,int father)
{
// cout<<"father"<<father<<" node"<<x<<endl;
int depth = 0;
for(int i = h[x];~i;i=ne[i])
{
int to = e[i];
if(to==father) continue;
depth = max(depth,getdepth(to,x)+1);
}
return depth;
}
二叉树模型:剑指 Offer 55 - I. 二叉树的深度
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
int maxDepth(TreeNode* root) {
if(root==NULL) return 0;
return max(maxDepth(root->left),maxDepth(root->right))+1;
}
};
多叉树模型(该题也是求叶子节点个数的经典写法):AcWing 1476. 数叶子结点
const int N = 100010;
int max_depth = 0;
int cnt[N];
void dfs(int x,int depth)
{
//说明是叶子节点
if(h[x]==-1)
{
cnt[depth]++;
max_depth = max(max_depth,depth);
return;
}
for(int i=h[x];~i;i=ne[i])
{
dfs(e[i],depth+1);
}
}
dfs(root,0)
//输出每一层的叶子个数
for(int i=0;i<=max_depth;i++) cout<<" "<<cnt[i];
二叉搜索树
二叉搜索树 (BST) 递归定义为具有以下属性的二叉树:
- 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值
- 若它的右子树不空,则右子树上所有结点的值均大于或等于它的根结点的值
- 它的左、右子树也分别为二叉搜索树
二叉搜索树的中序遍历一定是有序的
完全二叉树
完全二叉树 (CBT) 定义为除最深层外的其他层的结点数都达到最大个数,最深层的所有结点都连续集中在最左边的二叉树。
构造完全二叉树的方法,可以直接开辟一个一维数组利用左右孩子与根节点的下标映射关系。如果通过中序遍历的方式以单调递增的方式来赋值则构造出了一颗完全二叉搜索树。
完全二叉树的赋值填充和构造过程(这里我们以中序遍历为例子):
例题:AcWing 1550. 完全二叉搜索树
//中序遍历填充数据
int cnt; //记录已经赋值的节点下标
void dfs(int x) // 根节点为1-n
{
if(2*x <=n) dfs(2*x);
h[x] = a[cnt++];
if(2*x+1<=n) dfs(2*x+1);
}
void dfs(int u, int& k) // 中序遍历,k引用实现下标迁移
{
if (u * 2 <= n) dfs(u * 2, k);
tr[u] = w[k ++ ];
if (u * 2 + 1 <= n) dfs(u * 2 + 1, k);
}
完全二叉树的节点个数规律:
- 具有n个结点的完全二叉树的深度为$\lfloor log_2{n} \rfloor+ 1$
- 完全二叉树如果为满二叉树,且深度为$k$则总节点个数为$2^{k}-1$
- 完全二叉树的第$i(i \geq 1)$层的节点数最大值为$2^{i-1}$
- 完全二叉树最后一层按从左到右的顺序进行编号,上面的层数皆为节点数的最大值,因此不会出现左子树为空,右子树存在的节点
- 根据完全二叉树的结构可知:完全二叉树度为1的节点只能为1或者0,则有当节点总数为$n$时,如果$n$为奇数,则$n_0 = (n+1)/2$,如果$n$为偶数,则$n_0 = n / 2$
关于最后一条性质的一些拓展
二叉树的重要性质:在任意一棵二叉树中,若叶子结点的个数为$n_0$,度为2的结点数为$n_2$,则$n_0=n_2+1$
证明:
假设该二叉树总共有$n$个结点$(n=n_0+n_1+n_2)$,则该二叉树总共会有$n-1$条边,度为2的结点会延伸出两条边,度为1的结点会延伸出1条边。
则有$n - 1 = n_0+n_1+n_2- 1= 2 \times n_2 + n_1$
联立两式得到:$n_0=n_2+1$
拓展到完全二叉树,因为完全二叉树度为1的节点只有0个或者1个。即$n_1 = 0 或 1$
则节点总数$n=n_0+n_1+n_2 = 2 *n_0 + n_1 - 1$
由于节点个数必须为整数,因此可以得到以下结论:
当$n$为奇数时,必须使得$n_1=0$,则$n_0=(n + 1) / 2,n_2=n_0-1=(n + 1) / 2-1$
当$n$为偶数时,必须使得$n_1=1$,则$n_0=n / 2,n_2=n_0-1=n /2 -1$
例题(递归解法):leetcode 完全二叉树的节点个数
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public int countNodes(TreeNode root) {
return root==null ? 0:countNodes(root.left)+countNodes(root.right)+1;
}
}
完全二叉树
二叉平衡树
AVL树
- AVL树是一种自平衡二叉搜索树。
- 在AVL树中,任何节点的两个子树的高度最多相差 1 个。
- 如果某个时间,某节点的两个子树之间的高度差超过 1,则将通过树旋转进行重新平衡以恢复此属性。
- AVL本质上还是维护一个二叉搜索树,所以不管如果旋转,其中序遍历依旧是不变的。
旋转法则:
 AVL插入分为一下几种情况:
AVL插入分为一下几种情况:
- LL型:新节点的插入位置在A的左孩子的左子树上,则右旋A
- RR型:新节点的插入位置在A的右孩子的右子树上,则左旋A
- LR型:新节点的插入位置在A的左孩子的右子树上,则左旋B,右旋A
- RL型:新节点的插入位置在A的右孩子的左子树上,则右旋B,左旋A

红黑树
数据结构中有一类平衡的二叉搜索树,称为红黑树。
它具有以下 5 个属性:
- 节点是红色或黑色。
- 根节点是黑色。
- 所有叶子都是黑色。(叶子是 NULL节点)
- 每个红色节点的两个子节点都是黑色。
- 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
图论相关
并查集
经典例题:AcWing 836. 合并集合
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 100010;
int p[N];
int find(int x) // 查找x的祖先节点,并在回溯的过程当中进行路径压缩,将各节点直接指向根节点
{
if(x!=p[x]) p[x] = find(p[x]); // x和p[x]不相等,则继续向上找父节点的父节点
return p[x];
}
int main()
{
int n;
int m;
scanf("%d%d", &n, &m);
for(int i=1;i<=n;i++)
p[i]=i;
while (m -- )
{
char op[2];
int a,b;
scanf("%s%d%d", op,&a,&b);
int roota = find(a);
int rootb = find(b);
if(op[0]=='M')
{
if(roota == rootb) continue;
p[roota] = rootb; // root merge
}
else
{
cout<< (roota==rootb ? "Yes":"No")<<endl;
}
}
return 0;
}
dijstra算法
- 临接矩阵形式,适用于点的数量$N < 1000$的情形,朴素算法即可解决
- 邻接表形式,当$N>10000$,需要添加堆优化
一般来说堆优化版本的考试用的不多,这里就只介绍了朴素版本。
Dijkstra求最短路 I
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 510;
const int inf = 0x3f3f3f3f;
int n,m;
int g[N][N]; // 稠密图使用邻接矩阵
int dist[N]; // 存储距离
bool vis[N]; // 标志到该节点的距离是否已经被规整为最短距离
void dijkstra(int x)
{
memset(dist, inf, sizeof dist);
dist[x] = 0;
for(int i=0;i<n;i++)//外层循环n次遍历每个节点
{
int t= -1;
for(int j=1;j<=n;j++)
{
if(!vis[j]&&(t==-1 || dist[t]>dist[j])) t =j;
}
if(t==-1) break;
vis[t]=true;
for(int j=1;j<=n;j++)
{
if(!vis[j])
{
dist[j] = min(dist[j],dist[t]+g[t][j]);
}
}
}
if(dist[n]==inf) puts("-1");
else cout<<dist[n]<<endl;
}
int main()
{
scanf("%d%d", &n, &m);
memset(g, inf, sizeof g);
for(int i=0;i<m;i++)
{
int x,y,z;
scanf("%d%d%d", &x, &y,&z);
if(x==y) g[x][y]=0; // 自环
g[x][y] = min(g[x][y],z); // 重边仅记录最小的边
}
dijkstra(1);
return 0;
}
最小生成树Prime
//这里填你的代码^^
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 510, INF = 0x3f3f3f3f;
int n,m;
int g[N][N]; //稠密图使用prim和邻接矩阵
int dist[N];
bool isvisited[N];
int prime(int x)
{
memset(dist, 0x3f, sizeof dist);
int res = 0;
dist[x]=0;
for(int i=0;i<n;i++)
{
int t=-1;
for(int j=1;j<=n;j++)
if(!isvisited[j] && (t==-1 || dist[t] > dist[j]))
t= j;
if(dist[t] == INF) return -1;
//标记访问
res += dist[t];
isvisited[t]=true;
//更新dist
for(int j=1;j<=n;j++)
{
dist[j] = min(dist[j],g[t][j]);
}
}
return res;
}
int main()
{
scanf("%d%d", &n, &m);
memset(g, 0x3f, sizeof g);
while (m -- )
{
int a,b,c;
scanf("%d%d%d", &a, &b,&c);
g[a][b] = g[b][a] = min(g[a][b],c); //无向图
}
int t = prime(1);
if(t==-1)
cout<<"impossible"<<endl;
else
cout<<t<<endl;
return 0;
}
最小生成树Kruskal
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 100010, INF =0x3f3f3f3f;
const int M = 2*N;
int n,m;
struct Edge
{
int x;
int y;
int w;
bool operator < (const Edge & E) const
{
return w < E.w;
}
}edge[M];
int p[N]; //并查集
int find(int x)//找祖宗节点
{
if(x!=p[x]) p[x] = find(p[x]);
return p[x];
}
int kruskal()
{
int res = 0;
int cnt=0;
sort(edge,edge+m);
for(int i=1;i<=n;i++) p[i]=i;//初始化并查集
for(int i=0;i<m;i++)
{
int x = edge[i].x, y = edge[i].y, w = edge[i].w;
int a = find(x);
int b = find(y);
//不是连通的
if(a!=b)
{
p[b] = a;
res += w;
cnt++;
}
}
//路径数量<n-1说明不连通
if (cnt<n-1) return INF;
return res;
}
int main()
{
scanf("%d%d", &n, &m);
for (int i = 0; i < m; i ++ )
{
scanf("%d%d%d", &edge[i].x, &edge[i].y, &edge[i].w);
}
int t = kruskal();
if(t == INF) cout<< "impossible"<<endl;
else cout<<t<<endl;
return 0;
}
哈密顿图
- 通过图中所有顶点一次且仅一次的通路称为哈密顿通路。
- 通过图中所有顶点一次且仅一次的回路称为哈密顿回路。
- 具有哈密顿回路的图称为哈密顿图。
- 具有哈密顿通路而不具有哈密顿回路的图称为半哈密顿图
欧拉图
- 通过图中所有边恰好一次且行遍所有顶点的通路称为欧拉通路。
- 通过图中所有边恰好一次且行遍所有顶点的回路称为欧拉回路。
- 具有欧拉回路的无向图或有向图称为欧拉图。
- 具有欧拉通路但不具有欧拉回路的无向图或有向图称为半欧拉图。
- 如果一个连通图的所有顶点的度数都为偶数,那么这个连通图具有欧拉回路,且这个图被称为欧拉图。
- 如果一个连通图中有两个顶点的度数为奇数,其他顶点的度数为偶数,那么所有欧拉路径都从其中一个度数为奇数的顶点开始,并在另一个度数为奇数的顶点结束。

数学
gcd
LL gcd(LL a, LL b) // 欧几里得算法
{
return b ? gcd(b, a % b) : a;
}
1的个数(数位dp)
ACWing1533.1的个数
剑指 Offer 43. 1~n 整数中 1 出现的次数
给定一个数字 N,请你计算 1∼N 中一共出现了多少个数字 1。
例如,N=12 时,一共出现了 5 个数字 1,分别出现在 1,10,11,12 中。
解题思路:相关视频链接
class Solution {
public:
int countDigitOne(int n) {
vector<int> num;
while(n) num.push_back(n%10), n/=10;
int res = 0;
for(int i=num.size()-1;i>=0;i--)
{
int d = num[i];
int left=0,right=0,power=1;
for(int j=num.size()-1;j>i;j--) left = left * 10 + num[j];
for(int j=i-1;j>=0;j--) right = right * 10 + num[j], power*=10;
if(d==0) res += left*power;
else if(d==1) res += left*power + right + 1;
else res += (left+1) * power;
}
return res;
}
};
]]>
+ PAT笔记这里记录了一下常用的保研机试,剑指offer和PAT题目分类解析,主要用来快速回顾和复习相关模板,以及数据结构相关的知识点。
字符串
- 在c++中处理字符串类型的题目时,我们一般使用
string,有时候我们也使用char[]方式进行操作。 HH:MM:SS可以直接通过字符串字典序排序- 输入一个包含空格的字符串需要使用
getline(cin,s1)STL
vector<int>本省具备有字典序比较的方法,重载了< == >的运算符号vector<int>::iterator iter=find(vec.begin(),vec.end(),target); if(iter==vec.end()) cout << "Not found" << endl;
高精度
int的范围$-2 \times 10^9 - 2 \times 10^9$long long $-9 \times 10^{18} - 9 \times 10^{18}$- 用
vector按位存储
进制转换
- 其他进制化成10进制,采用秦九韶算法
typedef long long LL;
LL get(char c)
{
if(c<='9') return c-'0';
else return c-'a' + 10;
}
LL getnum(string a,LL r)
{
LL res=0;
for(int i=0;i<a.size();i++)
{
res = res * r + get(a[i]);
}
return res;
}
- 十进制转其他进制的方法,使用带余除法
int get(char c)
{
if(c<='9') return c-'0';
else return c-'a' + 10;
}
char tochar(int c)
{
if(c<=9) return c+'0';
else return 'a' + c - 10;
}
//一个r进制数num转10进制
int numr_to10(string num,int r)
{
int res = 0;
for(int i=0;i<num.size();i++)
{
res = res * r + get(num[i]);
}
return res;
}
//一个10进制数num转r进制
string num10_tor(string num,int r)
{
string res;
int n = numr_to10(num,10); //先转成10进制整型
while(n)
{
// cout<<tochar(n % r)<<endl;
res = tochar(n % r) + res;
n /= r;
}
return res;
}
// cout<<numr_to10("6a",16)<<" "<<num10_tor("15",16)<<endl;
判断质数
//判断一个数是否为质数
bool is_prime(int n)
{
if (n < 2) return false; // 1和0不是质数
for(int i=2;i*i<=n;i++)
{
if(n % i == 0) return false;
}
return true;
}
手写堆排序
堆是一个完全二叉树的结构,分为小根堆和大根堆两种结构。
- 小根堆的递归定义:小根堆的每个节点都小于他的左右孩子节点的值,树的根节点为最小值。
- 大根堆的递归定义:大根堆的每个节点都大于他的左右孩子节点的值,树的根节点为最大值。
在STL当中可以使用prioirty_queue来轻松实现大根堆和小根堆,但是只能实现前3个功能,有时候我们不得不自己实现一个手写的堆,同时这样也能让我们更理解堆排序的过程。
在AcWing基础课当中有两道经典例题,AcWing 839. 模拟堆(这个复杂一点),AcWing 838. 堆排序
这里给出堆排序的模板级代码
#include <iostream>
using namespace std;
const int N = 100010;
int heap[N],heapsize=0;
void down(int x)// 参数下标
{
int p =x;
if(2*x<=heapsize && heap[2*x]<heap[p]) p = 2*x;//左子树
if(2*x+1<=heapsize && heap[2*x+1]<heap[p]) p=2*x+1;//右子树
if(p!=x)
{
swap(heap[p],heap[x]); //说明存在比父节点小的孩子节点
down(p); //继续向下递归down
}
}
void up(int x)// 参数下标
{
while(x / 2 && heap[x] < heap[x/2]) //父节点比子节点大则交换
{
swap(heap[x],heap[x/2]);
x >>= 1; // x = x/2
}
}
int main()
{
int n,m;
scanf("%d%d", &n, &m);
for (int i = 1; i <= n; i ++ ) scanf("%d", &heap[i]);
heapsize=n;
// O(n)建堆
for (int i = n / 2; i; i -- ) down(i);
while (m -- )
{
printf("%d ",heap[1]); //最小值是小根堆的堆顶
// 删除最小值,并重新建堆排序,从而获得倒数第二小的元素
heap[1] = heap[heapsize];
heapsize--;
down(1);
}
return 0;
}
STL写法:priority_queue默认是大根堆,less<int>是对第一个参数的比较类,表示数字大的优先级越大,而greater<int>表示数字小的优先级越大,可以实现结构体运算符重载。
首先要引入头文件:#include<queue>
大根堆:
priority_queue<int> q;
priority_queue<int, vector<int>, less<int> >q;
小根堆:
priority_queue < int, vector<int>, greater<int> > q;
树
树是一种特殊的数据结构形式,在做题的过程当中,根据我的经验当题目需要使用树结构的时候主要有以下几种模式。
- 二叉树形式,在二叉树模型下,我们可以根据题目建立出静态的树形结构,构建每个节点左右孩子索引表来建立树的结构同时实现对树的遍历。如果已知或可以求得节点之间的关系,可以通过节点的度数或者访问标记找到根节点。,当然也是可以通过邻接表的方式创建二叉树。
- 多叉树形式,多叉树形式其实又类似于无向连通图的概念,常通过创建邻接表或者临接矩阵的方式建立树,并实现进行树的遍历,也是可以根据节点关系求出根节点的。注意在临接表当中,边的数量一般大于节点数量的两倍即我们需要开票邻接表的边数空间为$M = 2 \times N + d$
- 森林,多连通块的方式,这种也是利用无向图的方式,以邻接表或者临接矩阵的方式构建树的结构,同时我们可以利用并查集的方式得到当前无向图中含有的连通块数量并找到根节点。
二叉树左右孩子索引表模型
const int N = 100010;
int l[N],r[N]// 第i个节点的左孩子和右孩子的索引
bool has_father[N]; //建立树的时候判断一下当前节点有没有父节点,可用于寻找根节点
//初始化,-1表示子节点为空
memset(l,-1,sizeof l);
memset(r,-1,sizeof r);
// 查找根节点的过程
if(l[i]>=0) has_father[l[i]]=true;
if(r[i]>=0) has_father[r[i]]=true;
//查找根节点
int root = 0;
while(has_father[root]) root++;
二叉树的遍历过程(以先序遍历为例子)
void dfs(int root)
{
if(root==-1) return;
cout<<root<<endl;
if(l[root]>=0) dfs(l[root]);
if(r[root]>=0) dfs(r[root]);
}
临接表模型
const int N = 100010;
const int M = 2 * N + 10;
int h[N];//邻接表的N个节点头指针,h[i]表示以i为起点的,最新的一条边的编号
int e[M];// e[i] 表示第i条边的所指向的终点
int ne[M];// ne[i]表示与第i条边起点相同的下一条边的编号
int idx;// idx表示边的编号,每增加一条边就++
// 添加一条从a到b的边,如果是无向图,每次添加时要add(a,b)和add(b,a)
void add(int a,int b)
{
e[idx] = b; // 第idx条边的终点为b
ne[idx] = h[a]; // h[a] 和 第idx都是以a为起点的边,通过ne[idx]串联起来,找到上一条以a为起点的边h[a]
h[a] = idx ++; // 更新当前以a为起点的边的最新编号
}
//初始化,-1表示节点为空
memset(h,-1,sizeof h);
临接表遍历过程方法1
// x为起点,father为x的来源,防止节点遍历走回头路导致死循环
void dfs(int x,int father)
{
cout<<x<<endl;
for(int i = h[x];~i;i=ne[i]) // ~i就是i!=-1的意思
{
int to = e[i];
if(to==father) continue;
dfs(to,x);
}
}
dfs(x,-1);
临接表遍历过程方法2
const int N = 100010;
bool isvisited[N];
void dfs(int x)
{
isvisited[x]=true;
cout<<x<<endl;
for(int i = h[x];~i;i=ne[i])
{
int to = e[i];
if(isvisited[to]) continue;
dfs(to);
}
}
dfs(x);
树的深度
临接表模型:AcWing1498. 最深的根
int getdepth(int x,int father)
{
// cout<<"father"<<father<<" node"<<x<<endl;
int depth = 0;
for(int i = h[x];~i;i=ne[i])
{
int to = e[i];
if(to==father) continue;
depth = max(depth,getdepth(to,x)+1);
}
return depth;
}
二叉树模型:剑指 Offer 55 - I. 二叉树的深度
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
int maxDepth(TreeNode* root) {
if(root==NULL) return 0;
return max(maxDepth(root->left),maxDepth(root->right))+1;
}
};
多叉树模型(该题也是求叶子节点个数的经典写法):AcWing 1476. 数叶子结点
const int N = 100010;
int max_depth = 0;
int cnt[N];
void dfs(int x,int depth)
{
//说明是叶子节点
if(h[x]==-1)
{
cnt[depth]++;
max_depth = max(max_depth,depth);
return;
}
for(int i=h[x];~i;i=ne[i])
{
dfs(e[i],depth+1);
}
}
dfs(root,0)
//输出每一层的叶子个数
for(int i=0;i<=max_depth;i++) cout<<" "<<cnt[i];
二叉搜索树
二叉搜索树 (BST) 递归定义为具有以下属性的二叉树:
- 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值
- 若它的右子树不空,则右子树上所有结点的值均大于或等于它的根结点的值
- 它的左、右子树也分别为二叉搜索树
二叉搜索树的中序遍历一定是有序的
完全二叉树
完全二叉树 (CBT) 定义为除最深层外的其他层的结点数都达到最大个数,最深层的所有结点都连续集中在最左边的二叉树。
构造完全二叉树的方法,可以直接开辟一个一维数组利用左右孩子与根节点的下标映射关系。如果通过中序遍历的方式以单调递增的方式来赋值则构造出了一颗完全二叉搜索树。
完全二叉树的赋值填充和构造过程(这里我们以中序遍历为例子):
例题:AcWing 1550. 完全二叉搜索树
//中序遍历填充数据
int cnt; //记录已经赋值的节点下标
void dfs(int x) // 根节点为1-n
{
if(2*x <=n) dfs(2*x);
h[x] = a[cnt++];
if(2*x+1<=n) dfs(2*x+1);
}
void dfs(int u, int& k) // 中序遍历,k引用实现下标迁移
{
if (u * 2 <= n) dfs(u * 2, k);
tr[u] = w[k ++ ];
if (u * 2 + 1 <= n) dfs(u * 2 + 1, k);
}
完全二叉树的节点个数规律:
- 具有n个结点的完全二叉树的深度为$\lfloor log_2{n} \rfloor+ 1$
- 完全二叉树如果为满二叉树,且深度为$k$则总节点个数为$2^{k}-1$
- 完全二叉树的第$i(i \geq 1)$层的节点数最大值为$2^{i-1}$
- 完全二叉树最后一层按从左到右的顺序进行编号,上面的层数皆为节点数的最大值,因此不会出现左子树为空,右子树存在的节点
- 根据完全二叉树的结构可知:完全二叉树度为1的节点只能为1或者0,则有当节点总数为$n$时,如果$n$为奇数,则$n_0 = (n+1)/2$,如果$n$为偶数,则$n_0 = n / 2$
关于最后一条性质的一些拓展
二叉树的重要性质:在任意一棵二叉树中,若叶子结点的个数为$n_0$,度为2的结点数为$n_2$,则$n_0=n_2+1$
证明:
假设该二叉树总共有$n$个结点$(n=n_0+n_1+n_2)$,则该二叉树总共会有$n-1$条边,度为2的结点会延伸出两条边,度为1的结点会延伸出1条边。
则有$n - 1 = n_0+n_1+n_2- 1= 2 \times n_2 + n_1$
联立两式得到:$n_0=n_2+1$
拓展到完全二叉树,因为完全二叉树度为1的节点只有0个或者1个。即$n_1 = 0 或 1$
则节点总数$n=n_0+n_1+n_2 = 2 *n_0 + n_1 - 1$
由于节点个数必须为整数,因此可以得到以下结论:
当$n$为奇数时,必须使得$n_1=0$,则$n_0=(n + 1) / 2,n_2=n_0-1=(n + 1) / 2-1$
当$n$为偶数时,必须使得$n_1=1$,则$n_0=n / 2,n_2=n_0-1=n /2 -1$
例题(递归解法):leetcode 完全二叉树的节点个数
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public int countNodes(TreeNode root) {
return root==null ? 0:countNodes(root.left)+countNodes(root.right)+1;
}
}
完全二叉树
二叉平衡树
AVL树
- AVL树是一种自平衡二叉搜索树。
- 在AVL树中,任何节点的两个子树的高度最多相差 1 个。
- 如果某个时间,某节点的两个子树之间的高度差超过 1,则将通过树旋转进行重新平衡以恢复此属性。
- AVL本质上还是维护一个二叉搜索树,所以不管如果旋转,其中序遍历依旧是不变的。
旋转法则:
AVL插入分为一下几种情况:
- LL型:新节点的插入位置在A的左孩子的左子树上,则右旋A
- RR型:新节点的插入位置在A的右孩子的右子树上,则左旋A
- LR型:新节点的插入位置在A的左孩子的右子树上,则左旋B,右旋A
- RL型:新节点的插入位置在A的右孩子的左子树上,则右旋B,左旋A
红黑树
数据结构中有一类平衡的二叉搜索树,称为红黑树。
它具有以下 5 个属性:
- 节点是红色或黑色。
- 根节点是黑色。
- 所有叶子都是黑色。(叶子是 NULL节点)
- 每个红色节点的两个子节点都是黑色。
- 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
图论相关
并查集
经典例题:AcWing 836. 合并集合
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 100010;
int p[N];
int find(int x) // 查找x的祖先节点,并在回溯的过程当中进行路径压缩,将各节点直接指向根节点
{
if(x!=p[x]) p[x] = find(p[x]); // x和p[x]不相等,则继续向上找父节点的父节点
return p[x];
}
int main()
{
int n;
int m;
scanf("%d%d", &n, &m);
for(int i=1;i<=n;i++)
p[i]=i;
while (m -- )
{
char op[2];
int a,b;
scanf("%s%d%d", op,&a,&b);
int roota = find(a);
int rootb = find(b);
if(op[0]=='M')
{
if(roota == rootb) continue;
p[roota] = rootb; // root merge
}
else
{
cout<< (roota==rootb ? "Yes":"No")<<endl;
}
}
return 0;
}
dijstra算法
- 临接矩阵形式,适用于点的数量$N < 1000$的情形,朴素算法即可解决
- 邻接表形式,当$N>10000$,需要添加堆优化
一般来说堆优化版本的考试用的不多,这里就只介绍了朴素版本。
Dijkstra求最短路 I
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 510;
const int inf = 0x3f3f3f3f;
int n,m;
int g[N][N]; // 稠密图使用邻接矩阵
int dist[N]; // 存储距离
bool vis[N]; // 标志到该节点的距离是否已经被规整为最短距离
void dijkstra(int x)
{
memset(dist, inf, sizeof dist);
dist[x] = 0;
for(int i=0;i<n;i++)//外层循环n次遍历每个节点
{
int t= -1;
for(int j=1;j<=n;j++)
{
if(!vis[j]&&(t==-1 || dist[t]>dist[j])) t =j;
}
if(t==-1) break;
vis[t]=true;
for(int j=1;j<=n;j++)
{
if(!vis[j])
{
dist[j] = min(dist[j],dist[t]+g[t][j]);
}
}
}
if(dist[n]==inf) puts("-1");
else cout<<dist[n]<<endl;
}
int main()
{
scanf("%d%d", &n, &m);
memset(g, inf, sizeof g);
for(int i=0;i<m;i++)
{
int x,y,z;
scanf("%d%d%d", &x, &y,&z);
if(x==y) g[x][y]=0; // 自环
g[x][y] = min(g[x][y],z); // 重边仅记录最小的边
}
dijkstra(1);
return 0;
}
最小生成树Prime
AcWing 858.Prime算法求最小生成树
//这里填你的代码^^
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 510, INF = 0x3f3f3f3f;
int n,m;
int g[N][N]; //稠密图使用prim和邻接矩阵
int dist[N];
bool isvisited[N];
int prime(int x)
{
memset(dist, 0x3f, sizeof dist);
int res = 0;
dist[x]=0;
for(int i=0;i<n;i++)
{
int t=-1;
for(int j=1;j<=n;j++)
if(!isvisited[j] && (t==-1 || dist[t] > dist[j]))
t= j;
if(dist[t] == INF) return -1;
//标记访问
res += dist[t];
isvisited[t]=true;
//更新dist
for(int j=1;j<=n;j++)
{
dist[j] = min(dist[j],g[t][j]);
}
}
return res;
}
int main()
{
scanf("%d%d", &n, &m);
memset(g, 0x3f, sizeof g);
while (m -- )
{
int a,b,c;
scanf("%d%d%d", &a, &b,&c);
g[a][b] = g[b][a] = min(g[a][b],c); //无向图
}
int t = prime(1);
if(t==-1)
cout<<"impossible"<<endl;
else
cout<<t<<endl;
return 0;
}
最小生成树Kruskal
AcWing859.Kruskal算法求最小生成树
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 100010, INF =0x3f3f3f3f;
const int M = 2*N;
int n,m;
struct Edge
{
int x;
int y;
int w;
bool operator < (const Edge & E) const
{
return w < E.w;
}
}edge[M];
int p[N]; //并查集
int find(int x)//找祖宗节点
{
if(x!=p[x]) p[x] = find(p[x]);
return p[x];
}
int kruskal()
{
int res = 0;
int cnt=0;
sort(edge,edge+m);
for(int i=1;i<=n;i++) p[i]=i;//初始化并查集
for(int i=0;i<m;i++)
{
int x = edge[i].x, y = edge[i].y, w = edge[i].w;
int a = find(x);
int b = find(y);
//不是连通的
if(a!=b)
{
p[b] = a;
res += w;
cnt++;
}
}
//路径数量<n-1说明不连通
if (cnt<n-1) return INF;
return res;
}
int main()
{
scanf("%d%d", &n, &m);
for (int i = 0; i < m; i ++ )
{
scanf("%d%d%d", &edge[i].x, &edge[i].y, &edge[i].w);
}
int t = kruskal();
if(t == INF) cout<< "impossible"<<endl;
else cout<<t<<endl;
return 0;
}
哈密顿图
- 通过图中所有顶点一次且仅一次的通路称为哈密顿通路。
- 通过图中所有顶点一次且仅一次的回路称为哈密顿回路。
- 具有哈密顿回路的图称为哈密顿图。
- 具有哈密顿通路而不具有哈密顿回路的图称为半哈密顿图
欧拉图
- 通过图中所有边恰好一次且行遍所有顶点的通路称为欧拉通路。
- 通过图中所有边恰好一次且行遍所有顶点的回路称为欧拉回路。
- 具有欧拉回路的无向图或有向图称为欧拉图。
- 具有欧拉通路但不具有欧拉回路的无向图或有向图称为半欧拉图。
- 如果一个连通图的所有顶点的度数都为偶数,那么这个连通图具有欧拉回路,且这个图被称为欧拉图。
- 如果一个连通图中有两个顶点的度数为奇数,其他顶点的度数为偶数,那么所有欧拉路径都从其中一个度数为奇数的顶点开始,并在另一个度数为奇数的顶点结束。
数学
gcd
LL gcd(LL a, LL b) // 欧几里得算法
{
return b ? gcd(b, a % b) : a;
}
1的个数(数位dp)
ACWing1533.1的个数
剑指 Offer 43. 1~n 整数中 1 出现的次数
给定一个数字 N,请你计算 1∼N 中一共出现了多少个数字 1。
例如,N=12 时,一共出现了 5 个数字 1,分别出现在 1,10,11,12 中。
解题思路:相关视频链接
class Solution {
public:
int countDigitOne(int n) {
vector<int> num;
while(n) num.push_back(n%10), n/=10;
int res = 0;
for(int i=num.size()-1;i>=0;i--)
{
int d = num[i];
int left=0,right=0,power=1;
for(int j=num.size()-1;j>i;j--) left = left * 10 + num[j];
for(int j=i-1;j>=0;j--) right = right * 10 + num[j], power*=10;
if(d==0) res += left*power;
else if(d==1) res += left*power + right + 1;
else res += (left+1) * power;
}
return res;
}
};
]]>
@@ -171,11 +171,11 @@
2021-06-17T16:11:00.000Z
2024-10-09T07:33:09.915Z
- XGBoost算法XGBoost是陈天奇等人开发的一个开源机器学习项目,高效地实现了GBDT算法并进行了算法和工程上的许多改进,被广泛应用在Kaggle竞赛及其他许多机器学习竞赛中并取得了不错的成绩。XGBoost本质上还是一个GBDT,但是力争把速度和效率发挥到极致,所以叫X (Extreme) GBoosted, 包括前面说过,两者都是boosting方法。XGBoost是一个优化的分布式梯度增强库,旨在实现高效,灵活和便携。 它在Gradient Boosting框架下实现机器学习算法。 XGBoost提供了并行树提升(也称为GBDT,GBM),可以快速准确地解决许多数据科学问题。 相同的代码在主要的分布式环境(Hadoop,SGE,MPI)上运行,并且可以解决超过数十亿个样例的问题。XGBoost利用了核外计算并且能够使数据科学家在一个主机上处理数亿的样本数据。最终,将这些技术进行结合来做一个端到端的系统以最少的集群系统来扩展到更大的数据集上。Xgboost以CART决策树为子模型,通过Gradient Tree Boosting实现多棵CART树的集成学习,得到最终模型。下面我们来看看XGBoost的最终模型构建:
引用陈天奇的论文,我们的数据为:$\mathcal{D}=\left{\left(\mathbf{x}{i}, y{i}\right)\right}\left(|\mathcal{D}|=n, \mathbf{x}{i} \in \mathbb{R}^{m}, y{i} \in \mathbb{R}\right)$
(1) 构造目标函数:
假设有K棵树,则第i个样本的输出为$\hat{y}{i}=\phi\left(\mathrm{x}{i}\right)=\sum_{k=1}^{K} f_{k}\left(\mathrm{x}{i}\right), \quad f{k} \in \mathcal{F}$,其中,$\mathcal{F}=\left{f(\mathbf{x})=w_{q(\mathbf{x})}\right}\left(q: \mathbb{R}^{m} \rightarrow T, w \in \mathbb{R}^{T}\right)$
因此,目标函数的构建为:
$$
\mathcal{L}(\phi)=\sum_{i} l\left(\hat{y}{i}, y{i}\right)+\sum_{k} \Omega\left(f_{k}\right)
$$
其中,$\sum_{i} l\left(\hat{y}{i}, y{i}\right)$为loss function,$\sum_{k} \Omega\left(f_{k}\right)$为正则化项。
(2) 叠加式的训练(Additive Training):
给定样本$x_i$,$\hat{y}i^{(0)} = 0$(初始预测),$\hat{y}_i^{(1)} = \hat{y}_i^{(0)} + f_1(x_i)$,$\hat{y}_i^{(2)} = \hat{y}_i^{(0)} + f_1(x_i) + f_2(x_i) = \hat{y}_i^{(1)} + f_2(x_i)$…….以此类推,可以得到:$ \hat{y}_i^{(K)} = \hat{y}_i^{(K-1)} + f_K(x_i)$ ,其中,$ \hat{y}_i^{(K-1)} $ 为前K-1棵树的预测结果,$ f_K(x_i)$ 为第K棵树的预测结果。
因此,目标函数可以分解为:
$$
\mathcal{L}^{(K)}=\sum{i=1}^{n} l\left(y_{i}, \hat{y}{i}^{(K-1)}+f{K}\left(\mathrm{x}{i}\right)\right)+\sum{k} \Omega\left(f_{k}\right)
$$
由于正则化项也可以分解为前K-1棵树的复杂度加第K棵树的复杂度,因此:$\mathcal{L}^{(K)}=\sum_{i=1}^{n} l\left(y_{i}, \hat{y}{i}^{(K-1)}+f{K}\left(\mathrm{x}{i}\right)\right)+\sum{k=1} ^{K-1}\Omega\left(f_{k}\right)+\Omega\left(f_{K}\right)$,由于$\sum_{k=1} ^{K-1}\Omega\left(f_{k}\right)$在模型构建到第K棵树的时候已经固定,无法改变,因此是一个已知的常数,可以在最优化的时候省去,故:
$$
\mathcal{L}^{(K)}=\sum_{i=1}^{n} l\left(y_{i}, \hat{y}{i}^{(K-1)}+f{K}\left(\mathrm{x}{i}\right)\right)+\Omega\left(f{K}\right)
$$
(3) 使用泰勒级数近似目标函数:
$$
\mathcal{L}^{(K)} \simeq \sum_{i=1}^{n}\left[l\left(y_{i}, \hat{y}^{(K-1)}\right)+g_{i} f_{K}\left(\mathrm{x}{i}\right)+\frac{1}{2} h{i} f_{K}^{2}\left(\mathrm{x}{i}\right)\right]+\Omega\left(f{K}\right)
$$
其中,$g_{i}=\partial_{\hat{y}(t-1)} l\left(y_{i}, \hat{y}^{(t-1)}\right)$和$h_{i}=\partial_{\hat{y}^{(t-1)}}^{2} l\left(y_{i}, \hat{y}^{(t-1)}\right)$
在这里,我们补充下泰勒级数的相关知识:
在数学中,泰勒级数(英语:Taylor series)用无限项连加式——级数来表示一个函数,这些相加的项由函数在某一点的导数求得。具体的形式如下:
$$
f(x)=\frac{f\left(x_{0}\right)}{0 !}+\frac{f^{\prime}\left(x_{0}\right)}{1 !}\left(x-x_{0}\right)+\frac{f^{\prime \prime}\left(x_{0}\right)}{2 !}\left(x-x_{0}\right)^{2}+\ldots+\frac{f^{(n)}\left(x_{0}\right)}{n !}\left(x-x_{0}\right)^{n}+……
$$
由于$\sum_{i=1}^{n}l\left(y_{i}, \hat{y}^{(K-1)}\right)$在模型构建到第K棵树的时候已经固定,无法改变,因此是一个已知的常数,可以在最优化的时候省去,故:
$$
\tilde{\mathcal{L}}^{(K)}=\sum_{i=1}^{n}\left[g_{i} f_{K}\left(\mathbf{x}{i}\right)+\frac{1}{2} h{i} f_{K}^{2}\left(\mathbf{x}{i}\right)\right]+\Omega\left(f{K}\right)
$$
(4) 如何定义一棵树:
为了说明如何定义一棵树的问题,我们需要定义几个概念:第一个概念是样本所在的节点位置$q(x)$,第二个概念是有哪些样本落在节点j上$I_{j}=\left{i \mid q\left(\mathbf{x}{i}\right)=j\right}$,第三个概念是每个结点的预测值$w{q(x)}$,第四个概念是模型复杂度$\Omega\left(f_{K}\right)$,它可以由叶子节点的个数以及节点函数值来构建,则:$\Omega\left(f_{K}\right) = \gamma T+\frac{1}{2} \lambda \sum_{j=1}^{T} w_{j}^{2}$。如下图的例子:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-t1tei3pE-1623946035306)(./16.png)]
$q(x_1) = 1,q(x_2) = 3,q(x_3) = 1,q(x_4) = 2,q(x_5) = 3$,$I_1 = {1,3},I_2 = {4},I_3 = {2,5}$,$w = (15,12,20)$
因此,目标函数用以上符号替代后:
$$
\begin{aligned}
\tilde{\mathcal{L}}^{(K)} &=\sum_{i=1}^{n}\left[g_{i} f_{K}\left(\mathrm{x}{i}\right)+\frac{1}{2} h{i} f_{K}^{2}\left(\mathrm{x}{i}\right)\right]+\gamma T+\frac{1}{2} \lambda \sum{j=1}^{T} w_{j}^{2} \
&=\sum_{j=1}^{T}\left[\left(\sum_{i \in I_{j}} g_{i}\right) w_{j}+\frac{1}{2}\left(\sum_{i \in I_{j}} h_{i}+\lambda\right) w_{j}^{2}\right]+\gamma T
\end{aligned}
$$
由于我们的目标就是最小化目标函数,现在的目标函数化简为一个关于w的二次函数:$\tilde{\mathcal{L}}^{(K)}=\sum_{j=1}^{T}\left[\left(\sum_{i \in I_{j}} g_{i}\right) w_{j}+\frac{1}{2}\left(\sum_{i \in I_{j}} h_{i}+\lambda\right) w_{j}^{2}\right]+\gamma T$,根据二次函数求极值的公式:$y=ax^2 bx c$求极值,对称轴在$x=-\frac{b}{2 a}$,极值为$y=\frac{4 a c-b^{2}}{4 a}$,因此:
$$
w_{j}^{*}=-\frac{\sum_{i \in I_{j}} g_{i}}{\sum_{i \in I_{j}} h_{i}+\lambda}
$$
以及
$$
\tilde{\mathcal{L}}^{(K)}(q)=-\frac{1}{2} \sum_{j=1}^{T} \frac{\left(\sum_{i \in I_{j}} g_{i}\right)^{2}}{\sum_{i \in I_{j}} h_{i}+\lambda}+\gamma T
$$
(5) 如何寻找树的形状:
不难发现,刚刚的讨论都是基于树的形状已经确定了计算$w$和$L$,但是实际上我们需要像学习决策树一样找到树的形状。因此,我们借助决策树学习的方式,使用目标函数的变化来作为分裂节点的标准。我们使用一个例子来说明:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nCrhWA4S-1623946035310)(./17.png)]
例子中有8个样本,分裂方式如下,因此:
$$
\tilde{\mathcal{L}}^{(old)} = -\frac{1}{2}[\frac{(g_7 + g_8)^2}{H_7+H_8 + \lambda} + \frac{(g_1 +…+ g_6)^2}{H_1+…+H_6 + \lambda}] + 2\gamma \
\tilde{\mathcal{L}}^{(new)} = -\frac{1}{2}[\frac{(g_7 + g_8)^2}{H_7+H_8 + \lambda} + \frac{(g_1 +…+ g_3)^2}{H_1+…+H_3 + \lambda} + \frac{(g_4 +…+ g_6)^2}{H_4+…+H_6 + \lambda}] + 3\gamma\
\tilde{\mathcal{L}}^{(old)} - \tilde{\mathcal{L}}^{(new)} = \frac{1}{2}[ \frac{(g_1 +…+ g_3)^2}{H_1+…+H_3 + \lambda} + \frac{(g_4 +…+ g_6)^2}{H_4+…+H_6 + \lambda} - \frac{(g_1+…+g_6)^2}{h_1+…+h_6+\lambda}] - \gamma
$$
因此,从上面的例子看出:分割节点的标准为$max{\tilde{\mathcal{L}}^{(old)} - \tilde{\mathcal{L}}^{(new)} }$,即:
$$
\mathcal{L}{\text {split }}=\frac{1}{2}\left[\frac{\left(\sum{i \in I_{L}} g_{i}\right)^{2}}{\sum_{i \in I_{L}} h_{i}+\lambda}+\frac{\left(\sum_{i \in I_{R}} g_{i}\right)^{2}}{\sum_{i \in I_{R}} h_{i}+\lambda}-\frac{\left(\sum_{i \in I} g_{i}\right)^{2}}{\sum_{i \in I} h_{i}+\lambda}\right]-\gamma
$$
(6.1) 精确贪心分裂算法:
XGBoost在生成新树的过程中,最基本的操作是节点分裂。节点分裂中最重 要的环节是找到最优特征及最优切分点, 然后将叶子节点按照最优特征和最优切 分点进行分裂。选取最优特征和最优切分点的一种思路如下:首先找到所有的候 选特征及所有的候选切分点, 一一求得其 $\mathcal{L}{\text {split }}$, 然后选择$\mathcal{L}{\mathrm{split}}$ 最大的特征及 对应切分点作为最优特征和最优切分点。我们称此种方法为精确贪心算法。该算法是一种启发式算法, 因为在节点分裂时只选择当前最优的分裂策略, 而非全局最优的分裂策略。精确贪心算法的计算过程如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HRrbM0fp-1623946035312)(./18.png)]
(6.2) 基于直方图的近似算法:
精确贪心算法在选择最优特征和最优切分点时是一种十分有效的方法。它计算了所有特征、所有切分点的收益, 并从中选择了最优的, 从而保证模型能比较好地拟合了训练数据。但是当数据不能完全加载到内存时,精确贪心算法会变得 非常低效,算法在计算过程中需要不断在内存与磁盘之间进行数据交换,这是个非常耗时的过程, 并且在分布式环境中面临同样的问题。为了能够更高效地选 择最优特征及切分点, XGBoost提出一种近似算法来解决该问题。 基于直方图的近似算法的主要思想是:对某一特征寻找最优切分点时,首先对该特征的所有切分点按分位数 (如百分位) 分桶, 得到一个候选切分点集。特征的每一个切分点都可以分到对应的分桶; 然后,对每个桶计算特征统计G和H得到直方图, G为该桶内所有样本一阶特征统计g之和, H为该桶内所有样本二阶特征统计h之和; 最后,选择所有候选特征及候选切分点中对应桶的特征统计收益最大的作为最优特征及最优切分点。基于直方图的近似算法的计算过程如下所示:
- 对于每个特征 $k=1,2, \cdots, m,$ 按分位数对特征 $k$ 分桶 $\Theta,$ 可得候选切分点, $S_{k}=\left{S_{k 1}, S_{k 2}, \cdots, S_{k l}\right}^{1}$
- 对于每个特征 $k=1,2, \cdots, m,$ 有:
$$
\begin{array}{l}
G_{k v} \leftarrow=\sum_{j \in\left{j \mid s_{k, v} \geq \mathbf{x}{j k}>s{k, v-1;}\right}} g_{j} \
H_{k v} \leftarrow=\sum_{j \in\left{j \mid s_{k, v} \geq \mathbf{x}{j k}>s{k, v-1;}\right}} h_{j}
\end{array}
$$ - 类似精确贪心算法,依据梯度统计找到最大增益的候选切分点。
下面用一个例子说明基于直方图的近似算法:
假设有一个年龄特征,其特征的取值为18、19、21、31、36、37、55、57,我们需要使用近似算法找到年龄这个特征的最佳分裂点:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MKLD2poX-1623946035314)(./19.png)]
近似算法实现了两种候选切分点的构建策略:全局策略和本地策略。全局策略是在树构建的初始阶段对每一个特征确定一个候选切分点的集合, 并在该树每一层的节点分裂中均采用此集合计算收益, 整个过程候选切分点集合不改变。本地策略则是在每一次节点分裂时均重新确定候选切分点。全局策略需要更细的分桶才能达到本地策略的精确度, 但全局策略在选取候选切分点集合时比本地策略更简单。在XGBoost系统中, 用户可以根据需求自由选择使用精确贪心算法、近似算法全局策略、近似算法本地策略, 算法均可通过参数进行配置。
以上是XGBoost的理论部分,下面我们对XGBoost系统进行详细的讲解:
官方文档:https://xgboost.readthedocs.io/en/latest/python/python_intro.html
知乎总结:https://zhuanlan.zhihu.com/p/143009353
# XGBoost原生工具库的上手:
import xgboost as xgb # 引入工具库
# read in data
dtrain = xgb.DMatrix('demo/data/agaricus.txt.train') # XGBoost的专属数据格式,但是也可以用dataframe或者ndarray
dtest = xgb.DMatrix('demo/data/agaricus.txt.test') # # XGBoost的专属数据格式,但是也可以用dataframe或者ndarray
# specify parameters via map
param = {'max_depth':2, 'eta':1, 'objective':'binary:logistic' } # 设置XGB的参数,使用字典形式传入
num_round = 2 # 使用线程数
bst = xgb.train(param, dtrain, num_round) # 训练
# make prediction
preds = bst.predict(dtest) # 预测
XGBoost的参数设置(括号内的名称为sklearn接口对应的参数名字):
推荐博客:https://link.zhihu.com/?target=https%3A//blog.csdn.net/luanpeng825485697/article/details/79907149
推荐官方文档:https://link.zhihu.com/?target=https%3A//xgboost.readthedocs.io/en/latest/parameter.html
XGBoost的参数分为三种:
通用参数:(两种类型的booster,因为tree的性能比线性回归好得多,因此我们很少用线性回归。)
- booster:使用哪个弱学习器训练,默认gbtree,可选gbtree,gblinear 或dart
- nthread:用于运行XGBoost的并行线程数,默认为最大可用线程数
- verbosity:打印消息的详细程度。有效值为0(静默),1(警告),2(信息),3(调试)。
- Tree Booster的参数:
- eta(learning_rate):learning_rate,在更新中使用步长收缩以防止过度拟合,默认= 0.3,范围:[0,1];典型值一般设置为:0.01-0.2
- gamma(min_split_loss):默认= 0,分裂节点时,损失函数减小值只有大于等于gamma节点才分裂,gamma值越大,算法越保守,越不容易过拟合,但性能就不一定能保证,需要平衡。范围:[0,∞]
- max_depth:默认= 6,一棵树的最大深度。增加此值将使模型更复杂,并且更可能过度拟合。范围:[0,∞]
- min_child_weight:默认值= 1,如果新分裂的节点的样本权重和小于min_child_weight则停止分裂 。这个可以用来减少过拟合,但是也不能太高,会导致欠拟合。范围:[0,∞]
- max_delta_step:默认= 0,允许每个叶子输出的最大增量步长。如果将该值设置为0,则表示没有约束。如果将其设置为正值,则可以帮助使更新步骤更加保守。通常不需要此参数,但是当类极度不平衡时,它可能有助于逻辑回归。将其设置为1-10的值可能有助于控制更新。范围:[0,∞]
- subsample:默认值= 1,构建每棵树对样本的采样率,如果设置成0.5,XGBoost会随机选择一半的样本作为训练集。范围:(0,1]
- sampling_method:默认= uniform,用于对训练实例进行采样的方法。
- uniform:每个训练实例的选择概率均等。通常将subsample> = 0.5 设置 为良好的效果。
- gradient_based:每个训练实例的选择概率与规则化的梯度绝对值成正比,具体来说就是$\sqrt{g^2+\lambda h^2}$,subsample可以设置为低至0.1,而不会损失模型精度。
- colsample_bytree:默认= 1,列采样率,也就是特征采样率。范围为(0,1]
- lambda(reg_lambda):默认=1,L2正则化权重项。增加此值将使模型更加保守。
- alpha(reg_alpha):默认= 0,权重的L1正则化项。增加此值将使模型更加保守。
- tree_method:默认=auto,XGBoost中使用的树构建算法。
- auto:使用启发式选择最快的方法。
- 对于小型数据集,exact将使用精确贪婪()。
- 对于较大的数据集,approx将选择近似算法()。它建议尝试hist,gpu_hist,用大量的数据可能更高的性能。(gpu_hist)支持。external memory外部存储器。
- exact:精确的贪婪算法。枚举所有拆分的候选点。
- approx:使用分位数和梯度直方图的近似贪婪算法。
- hist:更快的直方图优化的近似贪婪算法。(LightGBM也是使用直方图算法)
- gpu_hist:GPU hist算法的实现。
- scale_pos_weight:控制正负权重的平衡,这对于不平衡的类别很有用。Kaggle竞赛一般设置sum(negative instances) / sum(positive instances),在类别高度不平衡的情况下,将参数设置大于0,可以加快收敛。
- num_parallel_tree:默认=1,每次迭代期间构造的并行树的数量。此选项用于支持增强型随机森林。
- monotone_constraints:可变单调性的约束,在某些情况下,如果有非常强烈的先验信念认为真实的关系具有一定的质量,则可以使用约束条件来提高模型的预测性能。(例如params_constrained[‘monotone_constraints’] = “(1,-1)”,(1,-1)我们告诉XGBoost对第一个预测变量施加增加的约束,对第二个预测变量施加减小的约束。)
- Linear Booster的参数:
- lambda(reg_lambda):默认= 0,L2正则化权重项。增加此值将使模型更加保守。归一化为训练示例数。
- alpha(reg_alpha):默认= 0,权重的L1正则化项。增加此值将使模型更加保守。归一化为训练示例数。
- updater:默认= shotgun。
- shotgun:基于shotgun算法的平行坐标下降算法。使用“ hogwild”并行性,因此每次运行都产生不确定的解决方案。
- coord_descent:普通坐标下降算法。同样是多线程的,但仍会产生确定性的解决方案。
- feature_selector:默认= cyclic。特征选择和排序方法
- cyclic:通过每次循环一个特征来实现的。
- shuffle:类似于cyclic,但是在每次更新之前都有随机的特征变换。
- random:一个随机(有放回)特征选择器。
- greedy:选择梯度最大的特征。(贪婪选择)
- thrifty:近似贪婪特征选择(近似于greedy)
- top_k:要选择的最重要特征数(在greedy和thrifty内)
任务参数(这个参数用来控制理想的优化目标和每一步结果的度量方法。)
- objective:默认=reg:squarederror,表示最小平方误差。
- reg:squarederror,最小平方误差。
- reg:squaredlogerror,对数平方损失。$\frac{1}{2}[log(pred+1)-log(label+1)]^2$
- reg:logistic,逻辑回归
- reg:pseudohubererror,使用伪Huber损失进行回归,这是绝对损失的两倍可微选择。
- binary:logistic,二元分类的逻辑回归,输出概率。
- binary:logitraw:用于二进制分类的逻辑回归,逻辑转换之前的输出得分。
- binary:hinge:二进制分类的铰链损失。这使预测为0或1,而不是产生概率。(SVM就是铰链损失函数)
- count:poisson –计数数据的泊松回归,泊松分布的输出平均值。
- survival:cox:针对正确的生存时间数据进行Cox回归(负值被视为正确的生存时间)。
- survival:aft:用于检查生存时间数据的加速故障时间模型。
- aft_loss_distribution:survival:aft和aft-nloglik度量标准使用的概率密度函数。
- multi:softmax:设置XGBoost以使用softmax目标进行多类分类,还需要设置num_class(类数)
- multi:softprob:与softmax相同,但输出向量,可以进一步重整为矩阵。结果包含属于每个类别的每个数据点的预测概率。
- rank:pairwise:使用LambdaMART进行成对排名,从而使成对损失最小化。
- rank:ndcg:使用LambdaMART进行列表式排名,使标准化折让累积收益(NDCG)最大化。
- rank:map:使用LambdaMART进行列表平均排名,使平均平均精度(MAP)最大化。
- reg:gamma:使用对数链接进行伽马回归。输出是伽马分布的平均值。
- reg:tweedie:使用对数链接进行Tweedie回归。
- 自定义损失函数和评价指标:https://xgboost.readthedocs.io/en/latest/tutorials/custom_metric_obj.html
- eval_metric:验证数据的评估指标,将根据目标分配默认指标(回归均方根,分类误差,排名的平均平均精度),用户可以添加多个评估指标
- rmse,均方根误差; rmsle:均方根对数误差; mae:平均绝对误差;mphe:平均伪Huber错误;logloss:负对数似然; error:二进制分类错误率;
- merror:多类分类错误率; mlogloss:多类logloss; auc:曲线下面积; aucpr:PR曲线下的面积;ndcg:归一化累计折扣;map:平均精度;
- seed :随机数种子,[默认= 0]。
命令行参数(这里不说了,因为很少用命令行控制台版本)
from IPython.display import IFrame
IFrame('https://xgboost.readthedocs.io/en/latest/parameter.html', width=1400, height=800)
XGBoost的调参说明:
参数调优的一般步骤
- 确定学习速率和提升参数调优的初始值
- max_depth 和 min_child_weight 参数调优
- gamma参数调优
- subsample 和 colsample_bytree 参数优
- 正则化参数alpha调优
- 降低学习速率和使用更多的决策树
XGBoost详细攻略:
具体的api请查看:https://xgboost.readthedocs.io/en/latest/python/python_api.html
推荐github:https://github.com/dmlc/xgboost/tree/master/demo/guide-python
安装XGBoost:
方式1:pip3 install xgboost
方式2:pip install xgboost
数据接口(XGBoost可处理的数据格式DMatrix)
# 1.LibSVM文本格式文件
dtrain = xgb.DMatrix('train.svm.txt')
dtest = xgb.DMatrix('test.svm.buffer')
# 2.CSV文件(不能含类别文本变量,如果存在文本变量请做特征处理如one-hot)
dtrain = xgb.DMatrix('train.csv?format=csv&label_column=0')
dtest = xgb.DMatrix('test.csv?format=csv&label_column=0')
# 3.NumPy数组
data = np.random.rand(5, 10) # 5 entities, each contains 10 features
label = np.random.randint(2, size=5) # binary target
dtrain = xgb.DMatrix(data, label=label)
# 4.scipy.sparse数组
csr = scipy.sparse.csr_matrix((dat, (row, col)))
dtrain = xgb.DMatrix(csr)
# pandas数据框dataframe
data = pandas.DataFrame(np.arange(12).reshape((4,3)), columns=['a', 'b', 'c'])
label = pandas.DataFrame(np.random.randint(2, size=4))
dtrain = xgb.DMatrix(data, label=label)
笔者推荐:先保存到XGBoost二进制文件中将使加载速度更快,然后再加载进来
# 1.保存DMatrix到XGBoost二进制文件中
dtrain = xgb.DMatrix('train.svm.txt')
dtrain.save_binary('train.buffer')
# 2. 缺少的值可以用DMatrix构造函数中的默认值替换:
dtrain = xgb.DMatrix(data, label=label, missing=-999.0)
# 3.可以在需要时设置权重:
w = np.random.rand(5, 1)
dtrain = xgb.DMatrix(data, label=label, missing=-999.0, weight=w)
参数的设置方式:
import pandas as pd
# 加载并处理数据
df_wine = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data',header=None)
df_wine.columns = ['Class label', 'Alcohol','Malic acid', 'Ash','Alcalinity of ash','Magnesium', 'Total phenols',
'Flavanoids', 'Nonflavanoid phenols','Proanthocyanins','Color intensity', 'Hue','OD280/OD315 of diluted wines','Proline']
df_wine = df_wine[df_wine['Class label'] != 1] # drop 1 class
y = df_wine['Class label'].values
X = df_wine[['Alcohol','OD280/OD315 of diluted wines']].values
from sklearn.model_selection import train_test_split # 切分训练集与测试集
from sklearn.preprocessing import LabelEncoder # 标签化分类变量
le = LabelEncoder()
y = le.fit_transform(y)
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=1,stratify=y)
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test)
# 1.Booster 参数
params = {
'booster': 'gbtree',
'objective': 'multi:softmax', # 多分类的问题
'num_class': 10, # 类别数,与 multisoftmax 并用
'gamma': 0.1, # 用于控制是否后剪枝的参数,越大越保守,一般0.1、0.2这样子。
'max_depth': 12, # 构建树的深度,越大越容易过拟合
'lambda': 2, # 控制模型复杂度的权重值的L2正则化项参数,参数越大,模型越不容易过拟合。
'subsample': 0.7, # 随机采样训练样本
'colsample_bytree': 0.7, # 生成树时进行的列采样
'min_child_weight': 3,
'silent': 1, # 设置成1则没有运行信息输出,最好是设置为0.
'eta': 0.007, # 如同学习率
'seed': 1000,
'nthread': 4, # cpu 线程数
'eval_metric':'auc'
}
plst = list(params.items())
# evallist = [(dtest, 'eval'), (dtrain, 'train')] # 指定验证集
训练:
# 2.训练
num_round = 10
bst = xgb.train(plst, dtrain, num_round)
#bst = xgb.train( plst, dtrain, num_round, evallist )
保存模型:
# 3.保存模型
bst.save_model('0001.model')
# dump model
bst.dump_model('dump.raw.txt')
# dump model with feature map
#bst.dump_model('dump.raw.txt', 'featmap.txt')
加载保存的模型:
# 4.加载保存的模型:
bst = xgb.Booster({'nthread': 4}) # init model
bst.load_model('0001.model') # load data
设置早停机制:
# 5.也可以设置早停机制(需要设置验证集)
train(..., evals=evals, early_stopping_rounds=10)
预测:
# 6.预测
ypred = bst.predict(dtest)
绘制重要性特征图:
# 1.绘制重要性
xgb.plot_importance(bst)
# 2.绘制输出树
#xgb.plot_tree(bst, num_trees=2)
# 3.使用xgboost.to_graphviz()将目标树转换为graphviz
#xgb.to_graphviz(bst, num_trees=2)
7. Xgboost算法案例
分类案例
from sklearn.datasets import load_iris
import xgboost as xgb
from xgboost import plot_importance
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score # 准确率
# 加载样本数据集
iris = load_iris()
X,y = iris.data,iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1234565) # 数据集分割
params = {
'booster' : 'gbtree',
'objective': 'multi:softmax', # 多分类的问题
'num_class': 3,
'gamma': 0.1, # 默认= 0,分裂节点时,损失函数减小值只有大于等于gamma节点才分裂,gamma值越大,算法越保守,越不容易过拟合,但性能就不一定能保证,需要平衡。
'max_depth': 12, # 树的最大深度
'lambda': 2, # 控制模型复杂度的权重值的L2正则化项参数,参数越大,模型越不容易过拟合。
'subsample': 0.7, # 随机采样训练样本
'colsample_bytree': 0.7, # 生成树时进行的列采样,列采样率,也就是特征采样率
'min_child_weight': 3,
'silent': 0,
'eta': 0.1,
'seed': 1,
'nthread': 4,
}
plst = list(params.items())
dtrain = xgb.DMatrix(X_train,y_train)
num_rounds = 500
model = xgb.train(plst,dtrain,num_rounds) # xgboost模型训练
# 对测试集进行预测
dtest = xgb.DMatrix(X_test)
y_pred = model.predict(dtest)
# 计算准确率
accuracy = accuracy_score(y_test,y_pred)
print("accuarcy: %.2f%%" % (accuracy*100.0))
# 显示重要特征
plot_importance(model)
plt.show()
回归案例
import xgboost as xgb
from xgboost import plot_importance
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_boston
from sklearn.metrics import mean_squared_error
# 加载数据集
boston = load_boston()
X,y = boston.data,boston.target
# XGBoost训练过程
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
params = {
'booster': 'gbtree',
'objective': 'reg:squarederror',
'gamma': 0.1,
'max_depth': 5,
'lambda': 3,
'subsample': 0.7,
'colsample_bytree': 0.7,
'min_child_weight': 3,
'silent': 1,
'eta': 0.1,
'seed': 1000,
'nthread': 4,
}
dtrain = xgb.DMatrix(X_train, y_train)
num_rounds = 300
plst = list(params.items())
model = xgb.train(plst, dtrain, num_rounds)
# 对测试集进行预测
dtest = xgb.DMatrix(X_test)
ans = model.predict(dtest)
# 显示重要特征
plot_importance(model)
plt.show()
XGBoost调参(结合sklearn网格搜索)
代码参考:https://www.jianshu.com/p/1100e333fcab
import xgboost as xgb
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import roc_auc_score
iris = load_iris()
X,y = iris.data,iris.target
col = iris.target_names
train_x, valid_x, train_y, valid_y = train_test_split(X, y, test_size=0.3, random_state=1) # 分训练集和验证集
parameters = {
'max_depth': [5, 10, 15, 20, 25],
'learning_rate': [0.01, 0.02, 0.05, 0.1, 0.15],
'n_estimators': [500, 1000, 2000, 3000, 5000],
'min_child_weight': [0, 2, 5, 10, 20],
'max_delta_step': [0, 0.2, 0.6, 1, 2],
'subsample': [0.6, 0.7, 0.8, 0.85, 0.95],
'colsample_bytree': [0.5, 0.6, 0.7, 0.8, 0.9],
'reg_alpha': [0, 0.25, 0.5, 0.75, 1],
'reg_lambda': [0.2, 0.4, 0.6, 0.8, 1],
'scale_pos_weight': [0.2, 0.4, 0.6, 0.8, 1]
}
xlf = xgb.XGBClassifier(max_depth=10,
learning_rate=0.01,
n_estimators=2000,
silent=True,
objective='multi:softmax',
num_class=3 ,
nthread=-1,
gamma=0,
min_child_weight=1,
max_delta_step=0,
subsample=0.85,
colsample_bytree=0.7,
colsample_bylevel=1,
reg_alpha=0,
reg_lambda=1,
scale_pos_weight=1,
seed=0,
missing=None)
gs = GridSearchCV(xlf, param_grid=parameters, scoring='accuracy', cv=3)
gs.fit(train_x, train_y)
print("Best score: %0.3f" % gs.best_score_)
print("Best parameters set: %s" % gs.best_params_ )
Best score: 0.933
Best parameters set: {‘max_depth’: 5}
8. LightGBM算法
LightGBM也是像XGBoost一样,是一类集成算法,他跟XGBoost总体来说是一样的,算法本质上与Xgboost没有出入,只是在XGBoost的基础上进行了优化,因此就不对原理进行重复介绍,在这里我们来看看几种算法的差别:
- 优化速度和内存使用
- 降低了计算每个分割增益的成本。
- 使用直方图减法进一步提高速度。
- 减少内存使用。
- 减少并行学习的计算成本。
- 稀疏优化
- 用离散的bin替换连续的值。如果#bins较小,则可以使用较小的数据类型(例如uint8_t)来存储训练数据 。
- 无需存储其他信息即可对特征数值进行预排序 。
- 精度优化
- 使用叶子数为导向的决策树建立算法而不是树的深度导向。
- 分类特征的编码方式的优化
- 通信网络的优化
- 并行学习的优化
- GPU支持
LightGBM的优点:
1)更快的训练效率
2)低内存使用
3)更高的准确率
4)支持并行化学习
5)可以处理大规模数据
1.速度对比:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-W562LSSA-1623946035318)(./速度对比.png)]
2.准确率对比:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J4JVvKjX-1623946035319)(./准确率对比.png)]
3.内存使用量对比:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-glXaoZd6-1623946035320)(./内存使用量.png)]
LightGBM参数说明:
推荐文档1:https://lightgbm.apachecn.org/#/docs/6
推荐文档2:https://lightgbm.readthedocs.io/en/latest/Parameters.html
1.核心参数:(括号内名称是别名)
- objective(objective,app ,application):默认regression,用于设置损失函数
- 回归问题:
- L2损失:regression(regression_l2,l2,mean_squared_error,mse,l2_root,root_mean_squared_error,rmse)
- L1损失:regression_l1(l1, mean_absolute_error, mae)
- 其他损失:huber,fair,poisson,quantile,mape,gamma,tweedie
- 二分类问题:二进制对数损失分类(或逻辑回归):binary
- 多类别分类:
- softmax目标函数: multiclass(softmax)
- One-vs-All 目标函数:multiclassova(multiclass_ova,ova,ovr)
- 交叉熵:
- 用于交叉熵的目标函数(具有可选的线性权重):cross_entropy(xentropy)
- 交叉熵的替代参数化:cross_entropy_lambda(xentlambda)
- boosting :默认gbdt,设置提升类型,选项有gbdt,rf,dart,goss,别名:boosting_type,boost
- gbdt(gbrt):传统的梯度提升决策树
- rf(random_forest):随机森林
- dart:多个加性回归树的DROPOUT方法 Dropouts meet Multiple Additive Regression Trees,参见:https://arxiv.org/abs/1505.01866
- goss:基于梯度的单边采样 Gradient-based One-Side Sampling
- data(train,train_data,train_data_file,data_filename):用于训练的数据或数据file
- valid (test,valid_data,valid_data_file,test_data,test_data_file,valid_filenames):验证/测试数据的路径,LightGBM将输出这些数据的指标
- num_iterations:默认=100,类型= INT
- n_estimators:提升迭代次数,*LightGBM构造用于多类分类问题的树num_class * num_iterations*
- learning_rate(shrinkage_rate,eta) :收缩率,默认=0.1
- num_leaves(num_leaf,max_leaves,max_leaf) :默认=31,一棵树上的最大叶子数
- tree_learner (tree,tree_type,tree_learner_type):默认=serial,可选:serial,feature,data,voting
- serial:单台机器的 tree learner
- feature:特征并行的 tree learner
- data:数据并行的 tree learner
- voting:投票并行的 tree learner
- num_threads(num_thread, nthread):LightGBM 的线程数,为了更快的速度, 将此设置为真正的 CPU 内核数, 而不是线程的数量 (大多数 CPU 使用超线程来使每个 CPU 内核生成 2 个线程),当你的数据集小的时候不要将它设置的过大 (比如, 当数据集有 10,000 行时不要使用 64 线程),对于并行学习, 不应该使用全部的 CPU 内核, 因为这会导致网络性能不佳。
- device(device_type):默认cpu,为树学习选择设备, 你可以使用 GPU 来获得更快的学习速度,可选cpu, gpu。
- seed (random_seed,random_state):与其他种子相比,该种子具有较低的优先级,这意味着如果您明确设置其他种子,它将被覆盖。
2.用于控制模型学习过程的参数:
- max_depth:限制树模型的最大深度. 这可以在 #data 小的情况下防止过拟合. 树仍然可以通过 leaf-wise 生长。
- min_data_in_leaf: 默认=20,一个叶子上数据的最小数量. 可以用来处理过拟合。
- min_sum_hessian_in_leaf(min_sum_hessian_per_leaf, min_sum_hessian, min_hessian):默认=1e-3,一个叶子上的最小 hessian 和. 类似于 min_data_in_leaf, 可以用来处理过拟合.
- feature_fraction:default=1.0,如果 feature_fraction 小于 1.0, LightGBM 将会在每次迭代中随机选择部分特征. 例如, 如果设置为 0.8, 将会在每棵树训练之前选择 80% 的特征,可以用来加速训练,可以用来处理过拟合。
- feature_fraction_seed:默认=2,feature_fraction 的随机数种子。
- bagging_fraction(sub_row, subsample):默认=1,不进行重采样的情况下随机选择部分数据
- bagging_freq(subsample_freq):bagging 的频率, 0 意味着禁用 bagging. k 意味着每 k 次迭代执行bagging
- bagging_seed(bagging_fraction_seed) :默认=3,bagging 随机数种子。
- early_stopping_round(early_stopping_rounds, early_stopping):默认=0,如果一个验证集的度量在 early_stopping_round 循环中没有提升, 将停止训练
- lambda_l1(reg_alpha):L1正则化系数
- lambda_l2(reg_lambda):L2正则化系数
- min_split_gain(min_gain_to_split):执行切分的最小增益,默认=0.
- cat_smooth:默认=10,用于分类特征,可以降低噪声在分类特征中的影响, 尤其是对数据很少的类别
3.度量参数:
- metric:default={l2 for regression}, {binary_logloss for binary classification}, {ndcg for lambdarank}, type=multi-enum, options=l1, l2, ndcg, auc, binary_logloss, binary_error …
- l1, absolute loss, alias=mean_absolute_error, mae
- l2, square loss, alias=mean_squared_error, mse
- l2_root, root square loss, alias=root_mean_squared_error, rmse
- quantile, Quantile regression
- huber, Huber loss
- fair, Fair loss
- poisson, Poisson regression
- ndcg, NDCG
- map, MAP
- auc, AUC
- binary_logloss, log loss
- binary_error, 样本: 0 的正确分类, 1 错误分类
- multi_logloss, mulit-class 损失日志分类
- multi_error, error rate for mulit-class 出错率分类
- xentropy, cross-entropy (与可选的线性权重), alias=cross_entropy
- xentlambda, “intensity-weighted” 交叉熵, alias=cross_entropy_lambda
- kldiv, Kullback-Leibler divergence, alias=kullback_leibler
- 支持多指标, 使用 , 分隔
- train_metric(training_metric, is_training_metric):默认=False,如果你需要输出训练的度量结果则设置 true
4.GPU 参数:
- gpu_device_id:default为-1, 这个default意味着选定平台上的设备。
LightGBM与网格搜索结合调参:
参考代码:https://blog.csdn.net/u012735708/article/details/83749703
import lightgbm as lgb
from sklearn import metrics
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
canceData=load_breast_cancer()
X=canceData.data
y=canceData.target
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=0,test_size=0.2)
### 数据转换
print('数据转换')
lgb_train = lgb.Dataset(X_train, y_train, free_raw_data=False)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train,free_raw_data=False)
### 设置初始参数--不含交叉验证参数
print('设置参数')
params = {
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': 'auc',
'nthread':4,
'learning_rate':0.1
}
### 交叉验证(调参)
print('交叉验证')
max_auc = float('0')
best_params = {}
# 准确率
print("调参1:提高准确率")
for num_leaves in range(5,100,5):
for max_depth in range(3,8,1):
params['num_leaves'] = num_leaves
params['max_depth'] = max_depth
cv_results = lgb.cv(
params,
lgb_train,
seed=1,
nfold=5,
metrics=['auc'],
early_stopping_rounds=10,
verbose_eval=True
)
mean_auc = pd.Series(cv_results['auc-mean']).max()
boost_rounds = pd.Series(cv_results['auc-mean']).idxmax()
if mean_auc >= max_auc:
max_auc = mean_auc
best_params['num_leaves'] = num_leaves
best_params['max_depth'] = max_depth
if 'num_leaves' and 'max_depth' in best_params.keys():
params['num_leaves'] = best_params['num_leaves']
params['max_depth'] = best_params['max_depth']
# 过拟合
print("调参2:降低过拟合")
for max_bin in range(5,256,10):
for min_data_in_leaf in range(1,102,10):
params['max_bin'] = max_bin
params['min_data_in_leaf'] = min_data_in_leaf
cv_results = lgb.cv(
params,
lgb_train,
seed=1,
nfold=5,
metrics=['auc'],
early_stopping_rounds=10,
verbose_eval=True
)
mean_auc = pd.Series(cv_results['auc-mean']).max()
boost_rounds = pd.Series(cv_results['auc-mean']).idxmax()
if mean_auc >= max_auc:
max_auc = mean_auc
best_params['max_bin']= max_bin
best_params['min_data_in_leaf'] = min_data_in_leaf
if 'max_bin' and 'min_data_in_leaf' in best_params.keys():
params['min_data_in_leaf'] = best_params['min_data_in_leaf']
params['max_bin'] = best_params['max_bin']
print("调参3:降低过拟合")
for feature_fraction in [0.6,0.7,0.8,0.9,1.0]:
for bagging_fraction in [0.6,0.7,0.8,0.9,1.0]:
for bagging_freq in range(0,50,5):
params['feature_fraction'] = feature_fraction
params['bagging_fraction'] = bagging_fraction
params['bagging_freq'] = bagging_freq
cv_results = lgb.cv(
params,
lgb_train,
seed=1,
nfold=5,
metrics=['auc'],
early_stopping_rounds=10,
verbose_eval=True
)
mean_auc = pd.Series(cv_results['auc-mean']).max()
boost_rounds = pd.Series(cv_results['auc-mean']).idxmax()
if mean_auc >= max_auc:
max_auc=mean_auc
best_params['feature_fraction'] = feature_fraction
best_params['bagging_fraction'] = bagging_fraction
best_params['bagging_freq'] = bagging_freq
if 'feature_fraction' and 'bagging_fraction' and 'bagging_freq' in best_params.keys():
params['feature_fraction'] = best_params['feature_fraction']
params['bagging_fraction'] = best_params['bagging_fraction']
params['bagging_freq'] = best_params['bagging_freq']
print("调参4:降低过拟合")
for lambda_l1 in [1e-5,1e-3,1e-1,0.0,0.1,0.3,0.5,0.7,0.9,1.0]:
for lambda_l2 in [1e-5,1e-3,1e-1,0.0,0.1,0.4,0.6,0.7,0.9,1.0]:
params['lambda_l1'] = lambda_l1
params['lambda_l2'] = lambda_l2
cv_results = lgb.cv(
params,
lgb_train,
seed=1,
nfold=5,
metrics=['auc'],
early_stopping_rounds=10,
verbose_eval=True
)
mean_auc = pd.Series(cv_results['auc-mean']).max()
boost_rounds = pd.Series(cv_results['auc-mean']).idxmax()
if mean_auc >= max_auc:
max_auc=mean_auc
best_params['lambda_l1'] = lambda_l1
best_params['lambda_l2'] = lambda_l2
if 'lambda_l1' and 'lambda_l2' in best_params.keys():
params['lambda_l1'] = best_params['lambda_l1']
params['lambda_l2'] = best_params['lambda_l2']
print("调参5:降低过拟合2")
for min_split_gain in [0.0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0]:
params['min_split_gain'] = min_split_gain
cv_results = lgb.cv(
params,
lgb_train,
seed=1,
nfold=5,
metrics=['auc'],
early_stopping_rounds=10,
verbose_eval=True
)
mean_auc = pd.Series(cv_results['auc-mean']).max()
boost_rounds = pd.Series(cv_results['auc-mean']).idxmax()
if mean_auc >= max_auc:
max_auc=mean_auc
best_params['min_split_gain'] = min_split_gain
if 'min_split_gain' in best_params.keys():
params['min_split_gain'] = best_params['min_split_gain']
print(best_params)
{‘bagging_fraction’: 0.7,
‘bagging_freq’: 30,
‘feature_fraction’: 0.8,
‘lambda_l1’: 0.1,
‘lambda_l2’: 0.0,
‘max_bin’: 255,
‘max_depth’: 4,
‘min_data_in_leaf’: 81,
‘min_split_gain’: 0.1,
‘num_leaves’: 10}
9. 结语
本章中,我们主要探讨了基于Boosting方式的集成方法,其中主要讲解了基于错误率驱动的Adaboost,基于残差改进的提升树,基于梯度提升的GBDT,基于泰勒二阶近似的Xgboost以及LightGBM。在实际的比赛或者工程中,基于Boosting的集成学习方式是非常有效且应用非常广泛的。更多的学习有待读者更深入阅读文献,包括原作者论文以及论文复现等。下一章我们即将探讨另一种集成学习方式:Stacking集成学习方式,这种集成方式虽然没有Boosting应用广泛,但是在比赛中或许能让你的模型更加出众。
本章作业:
本章在最后介绍LightGBM的时候并没有详细介绍它的原理以及它与XGBoost的不一样的地方,希望读者好好看看别的文章分享,总结LigntGBM与XGBoost的不同,然后使用一个具体的案例体现两者的不同。
参考链接: https://blog.csdn.net/weixin_30279315/article/details/95504220
]]>
+ XGBoost算法XGBoost是陈天奇等人开发的一个开源机器学习项目,高效地实现了GBDT算法并进行了算法和工程上的许多改进,被广泛应用在Kaggle竞赛及其他许多机器学习竞赛中并取得了不错的成绩。XGBoost本质上还是一个GBDT,但是力争把速度和效率发挥到极致,所以叫X (Extreme) GBoosted, 包括前面说过,两者都是boosting方法。XGBoost是一个优化的分布式梯度增强库,旨在实现高效,灵活和便携。 它在Gradient Boosting框架下实现机器学习算法。 XGBoost提供了并行树提升(也称为GBDT,GBM),可以快速准确地解决许多数据科学问题。 相同的代码在主要的分布式环境(Hadoop,SGE,MPI)上运行,并且可以解决超过数十亿个样例的问题。XGBoost利用了核外计算并且能够使数据科学家在一个主机上处理数亿的样本数据。最终,将这些技术进行结合来做一个端到端的系统以最少的集群系统来扩展到更大的数据集上。Xgboost以CART决策树为子模型,通过Gradient Tree Boosting实现多棵CART树的集成学习,得到最终模型。下面我们来看看XGBoost的最终模型构建:
引用陈天奇的论文,我们的数据为:$\mathcal{D}=\left{\left(\mathbf{x}{i}, y{i}\right)\right}\left(|\mathcal{D}|=n, \mathbf{x}{i} \in \mathbb{R}^{m}, y{i} \in \mathbb{R}\right)$
(1) 构造目标函数:
假设有K棵树,则第i个样本的输出为$\hat{y}{i}=\phi\left(\mathrm{x}{i}\right)=\sum{k=1}^{K} f{k}\left(\mathrm{x}{i}\right), \quad f{k} \in \mathcal{F}$,其中,$\mathcal{F}=\left{f(\mathbf{x})=w_{q(\mathbf{x})}\right}\left(q: \mathbb{R}^{m} \rightarrow T, w \in \mathbb{R}^{T}\right)$
因此,目标函数的构建为:
其中,$\sum{i} l\left(\hat{y}{i}, y{i}\right)$为loss function,$\sum{k} \Omega\left(f_{k}\right)$为正则化项。
(2) 叠加式的训练(Additive Training):
给定样本$x_i$,$\hat{y}_i^{(0)} = 0$(初始预测),$\hat{y}_i^{(1)} = \hat{y}_i^{(0)} + f_1(x_i)$,$\hat{y}_i^{(2)} = \hat{y}_i^{(0)} + f_1(x_i) + f_2(x_i) = \hat{y}_i^{(1)} + f_2(x_i)$…….以此类推,可以得到:$ \hat{y}_i^{(K)} = \hat{y}_i^{(K-1)} + f_K(x_i)$ ,其中,$ \hat{y}_i^{(K-1)} $ 为前K-1棵树的预测结果,$ f_K(x_i)$ 为第K棵树的预测结果。
因此,目标函数可以分解为:
由于正则化项也可以分解为前K-1棵树的复杂度加第K棵树的复杂度,因此:$\mathcal{L}^{(K)}=\sum{i=1}^{n} l\left(y{i}, \hat{y}{i}^{(K-1)}+f{K}\left(\mathrm{x}{i}\right)\right)+\sum{k=1} ^{K-1}\Omega\left(f{k}\right)+\Omega\left(f{K}\right)$,由于$\sum{k=1} ^{K-1}\Omega\left(f{k}\right)$在模型构建到第K棵树的时候已经固定,无法改变,因此是一个已知的常数,可以在最优化的时候省去,故:
(3) 使用泰勒级数近似目标函数:
其中,$g{i}=\partial{\hat{y}(t-1)} l\left(y{i}, \hat{y}^{(t-1)}\right)$和$h{i}=\partial{\hat{y}^{(t-1)}}^{2} l\left(y{i}, \hat{y}^{(t-1)}\right)$
在这里,我们补充下泰勒级数的相关知识:
在数学中,泰勒级数(英语:Taylor series)用无限项连加式——级数来表示一个函数,这些相加的项由函数在某一点的导数求得。具体的形式如下:
由于$\sum{i=1}^{n}l\left(y{i}, \hat{y}^{(K-1)}\right)$在模型构建到第K棵树的时候已经固定,无法改变,因此是一个已知的常数,可以在最优化的时候省去,故:
(4) 如何定义一棵树:
为了说明如何定义一棵树的问题,我们需要定义几个概念:第一个概念是样本所在的节点位置$q(x)$,第二个概念是有哪些样本落在节点j上$I{j}=\left{i \mid q\left(\mathbf{x}{i}\right)=j\right}$,第三个概念是每个结点的预测值$w{q(x)}$,第四个概念是模型复杂度$\Omega\left(f{K}\right)$,它可以由叶子节点的个数以及节点函数值来构建,则:$\Omega\left(f{K}\right) = \gamma T+\frac{1}{2} \lambda \sum{j=1}^{T} w_{j}^{2}$。如下图的例子:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-t1tei3pE-1623946035306)(./16.png)]
$q(x_1) = 1,q(x_2) = 3,q(x_3) = 1,q(x_4) = 2,q(x_5) = 3$,$I_1 = {1,3},I_2 = {4},I_3 = {2,5}$,$w = (15,12,20)$
因此,目标函数用以上符号替代后:
由于我们的目标就是最小化目标函数,现在的目标函数化简为一个关于w的二次函数:$\tilde{\mathcal{L}}^{(K)}=\sum{j=1}^{T}\left[\left(\sum{i \in I{j}} g{i}\right) w{j}+\frac{1}{2}\left(\sum{i \in I{j}} h{i}+\lambda\right) w_{j}^{2}\right]+\gamma T$,根据二次函数求极值的公式:$y=ax^2 bx c$求极值,对称轴在$x=-\frac{b}{2 a}$,极值为$y=\frac{4 a c-b^{2}}{4 a}$,因此:
以及
(5) 如何寻找树的形状:
不难发现,刚刚的讨论都是基于树的形状已经确定了计算$w$和$L$,但是实际上我们需要像学习决策树一样找到树的形状。因此,我们借助决策树学习的方式,使用目标函数的变化来作为分裂节点的标准。我们使用一个例子来说明:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nCrhWA4S-1623946035310)(./17.png)]
例子中有8个样本,分裂方式如下,因此:
因此,从上面的例子看出:分割节点的标准为$max{\tilde{\mathcal{L}}^{(old)} - \tilde{\mathcal{L}}^{(new)} }$,即:
(6.1) 精确贪心分裂算法:
XGBoost在生成新树的过程中,最基本的操作是节点分裂。节点分裂中最重 要的环节是找到最优特征及最优切分点, 然后将叶子节点按照最优特征和最优切 分点进行分裂。选取最优特征和最优切分点的一种思路如下:首先找到所有的候 选特征及所有的候选切分点, 一一求得其 $\mathcal{L}{\text {split }}$, 然后选择$\mathcal{L}{\mathrm{split}}$ 最大的特征及 对应切分点作为最优特征和最优切分点。我们称此种方法为精确贪心算法。该算法是一种启发式算法, 因为在节点分裂时只选择当前最优的分裂策略, 而非全局最优的分裂策略。精确贪心算法的计算过程如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HRrbM0fp-1623946035312)(./18.png)]
(6.2) 基于直方图的近似算法:
精确贪心算法在选择最优特征和最优切分点时是一种十分有效的方法。它计算了所有特征、所有切分点的收益, 并从中选择了最优的, 从而保证模型能比较好地拟合了训练数据。但是当数据不能完全加载到内存时,精确贪心算法会变得 非常低效,算法在计算过程中需要不断在内存与磁盘之间进行数据交换,这是个非常耗时的过程, 并且在分布式环境中面临同样的问题。为了能够更高效地选 择最优特征及切分点, XGBoost提出一种近似算法来解决该问题。 基于直方图的近似算法的主要思想是:对某一特征寻找最优切分点时,首先对该特征的所有切分点按分位数 (如百分位) 分桶, 得到一个候选切分点集。特征的每一个切分点都可以分到对应的分桶; 然后,对每个桶计算特征统计G和H得到直方图, G为该桶内所有样本一阶特征统计g之和, H为该桶内所有样本二阶特征统计h之和; 最后,选择所有候选特征及候选切分点中对应桶的特征统计收益最大的作为最优特征及最优切分点。基于直方图的近似算法的计算过程如下所示:
1) 对于每个特征 $k=1,2, \cdots, m,$ 按分位数对特征 $k$ 分桶 $\Theta,$ 可得候选切分点, $S{k}=\left{S{k 1}, S{k 2}, \cdots, S{k l}\right}^{1}$
2) 对于每个特征 $k=1,2, \cdots, m,$ 有:
3) 类似精确贪心算法,依据梯度统计找到最大增益的候选切分点。
下面用一个例子说明基于直方图的近似算法:
假设有一个年龄特征,其特征的取值为18、19、21、31、36、37、55、57,我们需要使用近似算法找到年龄这个特征的最佳分裂点:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MKLD2poX-1623946035314)(./19.png)]
近似算法实现了两种候选切分点的构建策略:全局策略和本地策略。全局策略是在树构建的初始阶段对每一个特征确定一个候选切分点的集合, 并在该树每一层的节点分裂中均采用此集合计算收益, 整个过程候选切分点集合不改变。本地策略则是在每一次节点分裂时均重新确定候选切分点。全局策略需要更细的分桶才能达到本地策略的精确度, 但全局策略在选取候选切分点集合时比本地策略更简单。在XGBoost系统中, 用户可以根据需求自由选择使用精确贪心算法、近似算法全局策略、近似算法本地策略, 算法均可通过参数进行配置。
以上是XGBoost的理论部分,下面我们对XGBoost系统进行详细的讲解:
官方文档:https://xgboost.readthedocs.io/en/latest/python/python_intro.html
知乎总结:https://zhuanlan.zhihu.com/p/143009353
# XGBoost原生工具库的上手:
import xgboost as xgb # 引入工具库
# read in data
dtrain = xgb.DMatrix('demo/data/agaricus.txt.train') # XGBoost的专属数据格式,但是也可以用dataframe或者ndarray
dtest = xgb.DMatrix('demo/data/agaricus.txt.test') # # XGBoost的专属数据格式,但是也可以用dataframe或者ndarray
# specify parameters via map
param = {'max_depth':2, 'eta':1, 'objective':'binary:logistic' } # 设置XGB的参数,使用字典形式传入
num_round = 2 # 使用线程数
bst = xgb.train(param, dtrain, num_round) # 训练
# make prediction
preds = bst.predict(dtest) # 预测
XGBoost的参数设置(括号内的名称为sklearn接口对应的参数名字):
推荐博客:https://link.zhihu.com/?target=https%3A//blog.csdn.net/luanpeng825485697/article/details/79907149
推荐官方文档:https://link.zhihu.com/?target=https%3A//xgboost.readthedocs.io/en/latest/parameter.html
XGBoost的参数分为三种:
- 通用参数:(两种类型的booster,因为tree的性能比线性回归好得多,因此我们很少用线性回归。)
- booster:使用哪个弱学习器训练,默认gbtree,可选gbtree,gblinear 或dart
- nthread:用于运行XGBoost的并行线程数,默认为最大可用线程数
- verbosity:打印消息的详细程度。有效值为0(静默),1(警告),2(信息),3(调试)。
- Tree Booster的参数:
- eta(learning_rate):learning_rate,在更新中使用步长收缩以防止过度拟合,默认= 0.3,范围:[0,1];典型值一般设置为:0.01-0.2
- gamma(min_split_loss):默认= 0,分裂节点时,损失函数减小值只有大于等于gamma节点才分裂,gamma值越大,算法越保守,越不容易过拟合,但性能就不一定能保证,需要平衡。范围:[0,∞]
- max_depth:默认= 6,一棵树的最大深度。增加此值将使模型更复杂,并且更可能过度拟合。范围:[0,∞]
- min_child_weight:默认值= 1,如果新分裂的节点的样本权重和小于min_child_weight则停止分裂 。这个可以用来减少过拟合,但是也不能太高,会导致欠拟合。范围:[0,∞]
- max_delta_step:默认= 0,允许每个叶子输出的最大增量步长。如果将该值设置为0,则表示没有约束。如果将其设置为正值,则可以帮助使更新步骤更加保守。通常不需要此参数,但是当类极度不平衡时,它可能有助于逻辑回归。将其设置为1-10的值可能有助于控制更新。范围:[0,∞]
- subsample:默认值= 1,构建每棵树对样本的采样率,如果设置成0.5,XGBoost会随机选择一半的样本作为训练集。范围:(0,1]
- sampling_method:默认= uniform,用于对训练实例进行采样的方法。
- uniform:每个训练实例的选择概率均等。通常将subsample> = 0.5 设置 为良好的效果。
- gradient_based:每个训练实例的选择概率与规则化的梯度绝对值成正比,具体来说就是$\sqrt{g^2+\lambda h^2}$,subsample可以设置为低至0.1,而不会损失模型精度。
- colsample_bytree:默认= 1,列采样率,也就是特征采样率。范围为(0,1]
- lambda(reg_lambda):默认=1,L2正则化权重项。增加此值将使模型更加保守。
- alpha(reg_alpha):默认= 0,权重的L1正则化项。增加此值将使模型更加保守。
- tree_method:默认=auto,XGBoost中使用的树构建算法。
- auto:使用启发式选择最快的方法。
- 对于小型数据集,exact将使用精确贪婪()。
- 对于较大的数据集,approx将选择近似算法()。它建议尝试hist,gpu_hist,用大量的数据可能更高的性能。(gpu_hist)支持。external memory外部存储器。
- exact:精确的贪婪算法。枚举所有拆分的候选点。
- approx:使用分位数和梯度直方图的近似贪婪算法。
- hist:更快的直方图优化的近似贪婪算法。(LightGBM也是使用直方图算法)
- gpu_hist:GPU hist算法的实现。
- scale_pos_weight:控制正负权重的平衡,这对于不平衡的类别很有用。Kaggle竞赛一般设置sum(negative instances) / sum(positive instances),在类别高度不平衡的情况下,将参数设置大于0,可以加快收敛。
- num_parallel_tree:默认=1,每次迭代期间构造的并行树的数量。此选项用于支持增强型随机森林。
- monotone_constraints:可变单调性的约束,在某些情况下,如果有非常强烈的先验信念认为真实的关系具有一定的质量,则可以使用约束条件来提高模型的预测性能。(例如params_constrained[‘monotone_constraints’] = “(1,-1)”,(1,-1)我们告诉XGBoost对第一个预测变量施加增加的约束,对第二个预测变量施加减小的约束。)
- Linear Booster的参数:
- lambda(reg_lambda):默认= 0,L2正则化权重项。增加此值将使模型更加保守。归一化为训练示例数。
- alpha(reg_alpha):默认= 0,权重的L1正则化项。增加此值将使模型更加保守。归一化为训练示例数。
- updater:默认= shotgun。
- shotgun:基于shotgun算法的平行坐标下降算法。使用“ hogwild”并行性,因此每次运行都产生不确定的解决方案。
- coord_descent:普通坐标下降算法。同样是多线程的,但仍会产生确定性的解决方案。
- feature_selector:默认= cyclic。特征选择和排序方法
- cyclic:通过每次循环一个特征来实现的。
- shuffle:类似于cyclic,但是在每次更新之前都有随机的特征变换。
- random:一个随机(有放回)特征选择器。
- greedy:选择梯度最大的特征。(贪婪选择)
- thrifty:近似贪婪特征选择(近似于greedy)
- top_k:要选择的最重要特征数(在greedy和thrifty内)
任务参数(这个参数用来控制理想的优化目标和每一步结果的度量方法。)
- objective:默认=reg:squarederror,表示最小平方误差。
- reg:squarederror,最小平方误差。
- reg:squaredlogerror,对数平方损失。$\frac{1}{2}[log(pred+1)-log(label+1)]^2$
- reg:logistic,逻辑回归
- reg:pseudohubererror,使用伪Huber损失进行回归,这是绝对损失的两倍可微选择。
- binary:logistic,二元分类的逻辑回归,输出概率。
- binary:logitraw:用于二进制分类的逻辑回归,逻辑转换之前的输出得分。
- binary:hinge:二进制分类的铰链损失。这使预测为0或1,而不是产生概率。(SVM就是铰链损失函数)
- count:poisson –计数数据的泊松回归,泊松分布的输出平均值。
- survival:cox:针对正确的生存时间数据进行Cox回归(负值被视为正确的生存时间)。
- survival:aft:用于检查生存时间数据的加速故障时间模型。
- aft_loss_distribution:survival:aft和aft-nloglik度量标准使用的概率密度函数。
- multi:softmax:设置XGBoost以使用softmax目标进行多类分类,还需要设置num_class(类数)
- multi:softprob:与softmax相同,但输出向量,可以进一步重整为矩阵。结果包含属于每个类别的每个数据点的预测概率。
- rank:pairwise:使用LambdaMART进行成对排名,从而使成对损失最小化。
- rank:ndcg:使用LambdaMART进行列表式排名,使标准化折让累积收益(NDCG)最大化。
- rank:map:使用LambdaMART进行列表平均排名,使平均平均精度(MAP)最大化。
- reg:gamma:使用对数链接进行伽马回归。输出是伽马分布的平均值。
- reg:tweedie:使用对数链接进行Tweedie回归。
- 自定义损失函数和评价指标:https://xgboost.readthedocs.io/en/latest/tutorials/custom_metric_obj.html
- eval_metric:验证数据的评估指标,将根据目标分配默认指标(回归均方根,分类误差,排名的平均平均精度),用户可以添加多个评估指标
- rmse,均方根误差; rmsle:均方根对数误差; mae:平均绝对误差;mphe:平均伪Huber错误;logloss:负对数似然; error:二进制分类错误率;
- merror:多类分类错误率; mlogloss:多类logloss; auc:曲线下面积; aucpr:PR曲线下的面积;ndcg:归一化累计折扣;map:平均精度;
- seed :随机数种子,[默认= 0]。
命令行参数(这里不说了,因为很少用命令行控制台版本)
from IPython.display import IFrame
IFrame('https://xgboost.readthedocs.io/en/latest/parameter.html', width=1400, height=800)
XGBoost的调参说明:
参数调优的一般步骤
- 确定学习速率和提升参数调优的初始值
- max_depth 和 min_child_weight 参数调优
- gamma参数调优
- subsample 和 colsample_bytree 参数优
- 正则化参数alpha调优
- 降低学习速率和使用更多的决策树
XGBoost详细攻略:
具体的api请查看:https://xgboost.readthedocs.io/en/latest/python/python_api.html
推荐github:https://github.com/dmlc/xgboost/tree/master/demo/guide-python
安装XGBoost:
方式1:pip3 install xgboost
方式2:pip install xgboost
数据接口(XGBoost可处理的数据格式DMatrix)
# 1.LibSVM文本格式文件
dtrain = xgb.DMatrix('train.svm.txt')
dtest = xgb.DMatrix('test.svm.buffer')
# 2.CSV文件(不能含类别文本变量,如果存在文本变量请做特征处理如one-hot)
dtrain = xgb.DMatrix('train.csv?format=csv&label_column=0')
dtest = xgb.DMatrix('test.csv?format=csv&label_column=0')
# 3.NumPy数组
data = np.random.rand(5, 10) # 5 entities, each contains 10 features
label = np.random.randint(2, size=5) # binary target
dtrain = xgb.DMatrix(data, label=label)
# 4.scipy.sparse数组
csr = scipy.sparse.csr_matrix((dat, (row, col)))
dtrain = xgb.DMatrix(csr)
# pandas数据框dataframe
data = pandas.DataFrame(np.arange(12).reshape((4,3)), columns=['a', 'b', 'c'])
label = pandas.DataFrame(np.random.randint(2, size=4))
dtrain = xgb.DMatrix(data, label=label)
笔者推荐:先保存到XGBoost二进制文件中将使加载速度更快,然后再加载进来
# 1.保存DMatrix到XGBoost二进制文件中
dtrain = xgb.DMatrix('train.svm.txt')
dtrain.save_binary('train.buffer')
# 2. 缺少的值可以用DMatrix构造函数中的默认值替换:
dtrain = xgb.DMatrix(data, label=label, missing=-999.0)
# 3.可以在需要时设置权重:
w = np.random.rand(5, 1)
dtrain = xgb.DMatrix(data, label=label, missing=-999.0, weight=w)
参数的设置方式:
import pandas as pd
# 加载并处理数据
df_wine = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data',header=None)
df_wine.columns = ['Class label', 'Alcohol','Malic acid', 'Ash','Alcalinity of ash','Magnesium', 'Total phenols',
'Flavanoids', 'Nonflavanoid phenols','Proanthocyanins','Color intensity', 'Hue','OD280/OD315 of diluted wines','Proline']
df_wine = df_wine[df_wine['Class label'] != 1] # drop 1 class
y = df_wine['Class label'].values
X = df_wine[['Alcohol','OD280/OD315 of diluted wines']].values
from sklearn.model_selection import train_test_split # 切分训练集与测试集
from sklearn.preprocessing import LabelEncoder # 标签化分类变量
le = LabelEncoder()
y = le.fit_transform(y)
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=1,stratify=y)
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test)
# 1.Booster 参数
params = {
'booster': 'gbtree',
'objective': 'multi:softmax', # 多分类的问题
'num_class': 10, # 类别数,与 multisoftmax 并用
'gamma': 0.1, # 用于控制是否后剪枝的参数,越大越保守,一般0.1、0.2这样子。
'max_depth': 12, # 构建树的深度,越大越容易过拟合
'lambda': 2, # 控制模型复杂度的权重值的L2正则化项参数,参数越大,模型越不容易过拟合。
'subsample': 0.7, # 随机采样训练样本
'colsample_bytree': 0.7, # 生成树时进行的列采样
'min_child_weight': 3,
'silent': 1, # 设置成1则没有运行信息输出,最好是设置为0.
'eta': 0.007, # 如同学习率
'seed': 1000,
'nthread': 4, # cpu 线程数
'eval_metric':'auc'
}
plst = list(params.items())
# evallist = [(dtest, 'eval'), (dtrain, 'train')] # 指定验证集
训练:
# 2.训练
num_round = 10
bst = xgb.train(plst, dtrain, num_round)
#bst = xgb.train( plst, dtrain, num_round, evallist )
保存模型:
# 3.保存模型
bst.save_model('0001.model')
# dump model
bst.dump_model('dump.raw.txt')
# dump model with feature map
#bst.dump_model('dump.raw.txt', 'featmap.txt')
加载保存的模型:
# 4.加载保存的模型:
bst = xgb.Booster({'nthread': 4}) # init model
bst.load_model('0001.model') # load data
设置早停机制:
# 5.也可以设置早停机制(需要设置验证集)
train(..., evals=evals, early_stopping_rounds=10)
预测:
# 6.预测
ypred = bst.predict(dtest)
绘制重要性特征图:
# 1.绘制重要性
xgb.plot_importance(bst)
# 2.绘制输出树
#xgb.plot_tree(bst, num_trees=2)
# 3.使用xgboost.to_graphviz()将目标树转换为graphviz
#xgb.to_graphviz(bst, num_trees=2)
7. Xgboost算法案例
分类案例
from sklearn.datasets import load_iris
import xgboost as xgb
from xgboost import plot_importance
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score # 准确率
# 加载样本数据集
iris = load_iris()
X,y = iris.data,iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1234565) # 数据集分割
params = {
'booster' : 'gbtree',
'objective': 'multi:softmax', # 多分类的问题
'num_class': 3,
'gamma': 0.1, # 默认= 0,分裂节点时,损失函数减小值只有大于等于gamma节点才分裂,gamma值越大,算法越保守,越不容易过拟合,但性能就不一定能保证,需要平衡。
'max_depth': 12, # 树的最大深度
'lambda': 2, # 控制模型复杂度的权重值的L2正则化项参数,参数越大,模型越不容易过拟合。
'subsample': 0.7, # 随机采样训练样本
'colsample_bytree': 0.7, # 生成树时进行的列采样,列采样率,也就是特征采样率
'min_child_weight': 3,
'silent': 0,
'eta': 0.1,
'seed': 1,
'nthread': 4,
}
plst = list(params.items())
dtrain = xgb.DMatrix(X_train,y_train)
num_rounds = 500
model = xgb.train(plst,dtrain,num_rounds) # xgboost模型训练
# 对测试集进行预测
dtest = xgb.DMatrix(X_test)
y_pred = model.predict(dtest)
# 计算准确率
accuracy = accuracy_score(y_test,y_pred)
print("accuarcy: %.2f%%" % (accuracy*100.0))
# 显示重要特征
plot_importance(model)
plt.show()
回归案例
import xgboost as xgb
from xgboost import plot_importance
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_boston
from sklearn.metrics import mean_squared_error
# 加载数据集
boston = load_boston()
X,y = boston.data,boston.target
# XGBoost训练过程
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
params = {
'booster': 'gbtree',
'objective': 'reg:squarederror',
'gamma': 0.1,
'max_depth': 5,
'lambda': 3,
'subsample': 0.7,
'colsample_bytree': 0.7,
'min_child_weight': 3,
'silent': 1,
'eta': 0.1,
'seed': 1000,
'nthread': 4,
}
dtrain = xgb.DMatrix(X_train, y_train)
num_rounds = 300
plst = list(params.items())
model = xgb.train(plst, dtrain, num_rounds)
# 对测试集进行预测
dtest = xgb.DMatrix(X_test)
ans = model.predict(dtest)
# 显示重要特征
plot_importance(model)
plt.show()
XGBoost调参(结合sklearn网格搜索)
代码参考:https://www.jianshu.com/p/1100e333fcab
import xgboost as xgb
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import roc_auc_score
iris = load_iris()
X,y = iris.data,iris.target
col = iris.target_names
train_x, valid_x, train_y, valid_y = train_test_split(X, y, test_size=0.3, random_state=1) # 分训练集和验证集
parameters = {
'max_depth': [5, 10, 15, 20, 25],
'learning_rate': [0.01, 0.02, 0.05, 0.1, 0.15],
'n_estimators': [500, 1000, 2000, 3000, 5000],
'min_child_weight': [0, 2, 5, 10, 20],
'max_delta_step': [0, 0.2, 0.6, 1, 2],
'subsample': [0.6, 0.7, 0.8, 0.85, 0.95],
'colsample_bytree': [0.5, 0.6, 0.7, 0.8, 0.9],
'reg_alpha': [0, 0.25, 0.5, 0.75, 1],
'reg_lambda': [0.2, 0.4, 0.6, 0.8, 1],
'scale_pos_weight': [0.2, 0.4, 0.6, 0.8, 1]
}
xlf = xgb.XGBClassifier(max_depth=10,
learning_rate=0.01,
n_estimators=2000,
silent=True,
objective='multi:softmax',
num_class=3 ,
nthread=-1,
gamma=0,
min_child_weight=1,
max_delta_step=0,
subsample=0.85,
colsample_bytree=0.7,
colsample_bylevel=1,
reg_alpha=0,
reg_lambda=1,
scale_pos_weight=1,
seed=0,
missing=None)
gs = GridSearchCV(xlf, param_grid=parameters, scoring='accuracy', cv=3)
gs.fit(train_x, train_y)
print("Best score: %0.3f" % gs.best_score_)
print("Best parameters set: %s" % gs.best_params_ )
Best score: 0.933
Best parameters set: {‘max_depth’: 5}
8. LightGBM算法
LightGBM也是像XGBoost一样,是一类集成算法,他跟XGBoost总体来说是一样的,算法本质上与Xgboost没有出入,只是在XGBoost的基础上进行了优化,因此就不对原理进行重复介绍,在这里我们来看看几种算法的差别:
- 优化速度和内存使用
- 降低了计算每个分割增益的成本。
- 使用直方图减法进一步提高速度。
- 减少内存使用。
- 减少并行学习的计算成本。
- 稀疏优化
- 用离散的bin替换连续的值。如果#bins较小,则可以使用较小的数据类型(例如uint8_t)来存储训练数据 。
- 无需存储其他信息即可对特征数值进行预排序 。
- 精度优化
- 使用叶子数为导向的决策树建立算法而不是树的深度导向。
- 分类特征的编码方式的优化
- 通信网络的优化
- 并行学习的优化
- GPU支持
LightGBM的优点:
1)更快的训练效率
2)低内存使用
3)更高的准确率
4)支持并行化学习
5)可以处理大规模数据
1.速度对比:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-W562LSSA-1623946035318)(./速度对比.png)]
2.准确率对比:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J4JVvKjX-1623946035319)(./准确率对比.png)]
3.内存使用量对比:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-glXaoZd6-1623946035320)(./内存使用量.png)]
LightGBM参数说明:
推荐文档1:https://lightgbm.apachecn.org/#/docs/6
推荐文档2:https://lightgbm.readthedocs.io/en/latest/Parameters.html
1.核心参数:(括号内名称是别名)
- objective(objective,app ,application):默认regression,用于设置损失函数
- 回归问题:
- L2损失:regression(regression_l2,l2,mean_squared_error,mse,l2_root,root_mean_squared_error,rmse)
- L1损失:regression_l1(l1, mean_absolute_error, mae)
- 其他损失:huber,fair,poisson,quantile,mape,gamma,tweedie
- 二分类问题:二进制对数损失分类(或逻辑回归):binary
- 多类别分类:
- softmax目标函数: multiclass(softmax)
- One-vs-All 目标函数:multiclassova(multiclass_ova,ova,ovr)
- 交叉熵:
- 用于交叉熵的目标函数(具有可选的线性权重):cross_entropy(xentropy)
- 交叉熵的替代参数化:cross_entropy_lambda(xentlambda)
- boosting :默认gbdt,设置提升类型,选项有gbdt,rf,dart,goss,别名:boosting_type,boost
- gbdt(gbrt):传统的梯度提升决策树
- rf(random_forest):随机森林
- dart:多个加性回归树的DROPOUT方法 Dropouts meet Multiple Additive Regression Trees,参见:https://arxiv.org/abs/1505.01866
- goss:基于梯度的单边采样 Gradient-based One-Side Sampling
- data(train,train_data,train_data_file,data_filename):用于训练的数据或数据file
- valid (test,valid_data,valid_data_file,test_data,test_data_file,valid_filenames):验证/测试数据的路径,LightGBM将输出这些数据的指标
- num_iterations:默认=100,类型= INT
- n_estimators:提升迭代次数,LightGBM构造用于多类分类问题的树num_class * num_iterations
- learning_rate(shrinkage_rate,eta) :收缩率,默认=0.1
- num_leaves(num_leaf,max_leaves,max_leaf) :默认=31,一棵树上的最大叶子数
- tree_learner (tree,tree_type,tree_learner_type):默认=serial,可选:serial,feature,data,voting
- serial:单台机器的 tree learner
- feature:特征并行的 tree learner
- data:数据并行的 tree learner
- voting:投票并行的 tree learner
- num_threads(num_thread, nthread):LightGBM 的线程数,为了更快的速度, 将此设置为真正的 CPU 内核数, 而不是线程的数量 (大多数 CPU 使用超线程来使每个 CPU 内核生成 2 个线程),当你的数据集小的时候不要将它设置的过大 (比如, 当数据集有 10,000 行时不要使用 64 线程),对于并行学习, 不应该使用全部的 CPU 内核, 因为这会导致网络性能不佳。
- device(device_type):默认cpu,为树学习选择设备, 你可以使用 GPU 来获得更快的学习速度,可选cpu, gpu。
- seed (random_seed,random_state):与其他种子相比,该种子具有较低的优先级,这意味着如果您明确设置其他种子,它将被覆盖。
2.用于控制模型学习过程的参数:
- max_depth:限制树模型的最大深度. 这可以在 #data 小的情况下防止过拟合. 树仍然可以通过 leaf-wise 生长。
- min_data_in_leaf: 默认=20,一个叶子上数据的最小数量. 可以用来处理过拟合。
- min_sum_hessian_in_leaf(min_sum_hessian_per_leaf, min_sum_hessian, min_hessian):默认=1e-3,一个叶子上的最小 hessian 和. 类似于 min_data_in_leaf, 可以用来处理过拟合.
- feature_fraction:default=1.0,如果 feature_fraction 小于 1.0, LightGBM 将会在每次迭代中随机选择部分特征. 例如, 如果设置为 0.8, 将会在每棵树训练之前选择 80% 的特征,可以用来加速训练,可以用来处理过拟合。
- feature_fraction_seed:默认=2,feature_fraction 的随机数种子。
- bagging_fraction(sub_row, subsample):默认=1,不进行重采样的情况下随机选择部分数据
- bagging_freq(subsample_freq):bagging 的频率, 0 意味着禁用 bagging. k 意味着每 k 次迭代执行bagging
- bagging_seed(bagging_fraction_seed) :默认=3,bagging 随机数种子。
- early_stopping_round(early_stopping_rounds, early_stopping):默认=0,如果一个验证集的度量在 early_stopping_round 循环中没有提升, 将停止训练
- lambda_l1(reg_alpha):L1正则化系数
- lambda_l2(reg_lambda):L2正则化系数
- min_split_gain(min_gain_to_split):执行切分的最小增益,默认=0.
- cat_smooth:默认=10,用于分类特征,可以降低噪声在分类特征中的影响, 尤其是对数据很少的类别
3.度量参数:
- metric:default={l2 for regression}, {binary_logloss for binary classification}, {ndcg for lambdarank}, type=multi-enum, options=l1, l2, ndcg, auc, binary_logloss, binary_error …
- l1, absolute loss, alias=mean_absolute_error, mae
- l2, square loss, alias=mean_squared_error, mse
- l2_root, root square loss, alias=root_mean_squared_error, rmse
- quantile, Quantile regression
- huber, Huber loss
- fair, Fair loss
- poisson, Poisson regression
- ndcg, NDCG
- map, MAP
- auc, AUC
- binary_logloss, log loss
- binary_error, 样本: 0 的正确分类, 1 错误分类
- multi_logloss, mulit-class 损失日志分类
- multi_error, error rate for mulit-class 出错率分类
- xentropy, cross-entropy (与可选的线性权重), alias=cross_entropy
- xentlambda, “intensity-weighted” 交叉熵, alias=cross_entropy_lambda
- kldiv, Kullback-Leibler divergence, alias=kullback_leibler
- 支持多指标, 使用 , 分隔
- train_metric(training_metric, is_training_metric):默认=False,如果你需要输出训练的度量结果则设置 true
4.GPU 参数:
- gpu_device_id:default为-1, 这个default意味着选定平台上的设备。
LightGBM与网格搜索结合调参:
参考代码:https://blog.csdn.net/u012735708/article/details/83749703
import lightgbm as lgb
from sklearn import metrics
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
canceData=load_breast_cancer()
X=canceData.data
y=canceData.target
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=0,test_size=0.2)
### 数据转换
print('数据转换')
lgb_train = lgb.Dataset(X_train, y_train, free_raw_data=False)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train,free_raw_data=False)
### 设置初始参数--不含交叉验证参数
print('设置参数')
params = {
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': 'auc',
'nthread':4,
'learning_rate':0.1
}
### 交叉验证(调参)
print('交叉验证')
max_auc = float('0')
best_params = {}
# 准确率
print("调参1:提高准确率")
for num_leaves in range(5,100,5):
for max_depth in range(3,8,1):
params['num_leaves'] = num_leaves
params['max_depth'] = max_depth
cv_results = lgb.cv(
params,
lgb_train,
seed=1,
nfold=5,
metrics=['auc'],
early_stopping_rounds=10,
verbose_eval=True
)
mean_auc = pd.Series(cv_results['auc-mean']).max()
boost_rounds = pd.Series(cv_results['auc-mean']).idxmax()
if mean_auc >= max_auc:
max_auc = mean_auc
best_params['num_leaves'] = num_leaves
best_params['max_depth'] = max_depth
if 'num_leaves' and 'max_depth' in best_params.keys():
params['num_leaves'] = best_params['num_leaves']
params['max_depth'] = best_params['max_depth']
# 过拟合
print("调参2:降低过拟合")
for max_bin in range(5,256,10):
for min_data_in_leaf in range(1,102,10):
params['max_bin'] = max_bin
params['min_data_in_leaf'] = min_data_in_leaf
cv_results = lgb.cv(
params,
lgb_train,
seed=1,
nfold=5,
metrics=['auc'],
early_stopping_rounds=10,
verbose_eval=True
)
mean_auc = pd.Series(cv_results['auc-mean']).max()
boost_rounds = pd.Series(cv_results['auc-mean']).idxmax()
if mean_auc >= max_auc:
max_auc = mean_auc
best_params['max_bin']= max_bin
best_params['min_data_in_leaf'] = min_data_in_leaf
if 'max_bin' and 'min_data_in_leaf' in best_params.keys():
params['min_data_in_leaf'] = best_params['min_data_in_leaf']
params['max_bin'] = best_params['max_bin']
print("调参3:降低过拟合")
for feature_fraction in [0.6,0.7,0.8,0.9,1.0]:
for bagging_fraction in [0.6,0.7,0.8,0.9,1.0]:
for bagging_freq in range(0,50,5):
params['feature_fraction'] = feature_fraction
params['bagging_fraction'] = bagging_fraction
params['bagging_freq'] = bagging_freq
cv_results = lgb.cv(
params,
lgb_train,
seed=1,
nfold=5,
metrics=['auc'],
early_stopping_rounds=10,
verbose_eval=True
)
mean_auc = pd.Series(cv_results['auc-mean']).max()
boost_rounds = pd.Series(cv_results['auc-mean']).idxmax()
if mean_auc >= max_auc:
max_auc=mean_auc
best_params['feature_fraction'] = feature_fraction
best_params['bagging_fraction'] = bagging_fraction
best_params['bagging_freq'] = bagging_freq
if 'feature_fraction' and 'bagging_fraction' and 'bagging_freq' in best_params.keys():
params['feature_fraction'] = best_params['feature_fraction']
params['bagging_fraction'] = best_params['bagging_fraction']
params['bagging_freq'] = best_params['bagging_freq']
print("调参4:降低过拟合")
for lambda_l1 in [1e-5,1e-3,1e-1,0.0,0.1,0.3,0.5,0.7,0.9,1.0]:
for lambda_l2 in [1e-5,1e-3,1e-1,0.0,0.1,0.4,0.6,0.7,0.9,1.0]:
params['lambda_l1'] = lambda_l1
params['lambda_l2'] = lambda_l2
cv_results = lgb.cv(
params,
lgb_train,
seed=1,
nfold=5,
metrics=['auc'],
early_stopping_rounds=10,
verbose_eval=True
)
mean_auc = pd.Series(cv_results['auc-mean']).max()
boost_rounds = pd.Series(cv_results['auc-mean']).idxmax()
if mean_auc >= max_auc:
max_auc=mean_auc
best_params['lambda_l1'] = lambda_l1
best_params['lambda_l2'] = lambda_l2
if 'lambda_l1' and 'lambda_l2' in best_params.keys():
params['lambda_l1'] = best_params['lambda_l1']
params['lambda_l2'] = best_params['lambda_l2']
print("调参5:降低过拟合2")
for min_split_gain in [0.0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0]:
params['min_split_gain'] = min_split_gain
cv_results = lgb.cv(
params,
lgb_train,
seed=1,
nfold=5,
metrics=['auc'],
early_stopping_rounds=10,
verbose_eval=True
)
mean_auc = pd.Series(cv_results['auc-mean']).max()
boost_rounds = pd.Series(cv_results['auc-mean']).idxmax()
if mean_auc >= max_auc:
max_auc=mean_auc
best_params['min_split_gain'] = min_split_gain
if 'min_split_gain' in best_params.keys():
params['min_split_gain'] = best_params['min_split_gain']
print(best_params)
{‘bagging_fraction’: 0.7,
‘bagging_freq’: 30,
‘feature_fraction’: 0.8,
‘lambda_l1’: 0.1,
‘lambda_l2’: 0.0,
‘max_bin’: 255,
‘max_depth’: 4,
‘min_data_in_leaf’: 81,
‘min_split_gain’: 0.1,
‘num_leaves’: 10}
9. 结语
本章中,我们主要探讨了基于Boosting方式的集成方法,其中主要讲解了基于错误率驱动的Adaboost,基于残差改进的提升树,基于梯度提升的GBDT,基于泰勒二阶近似的Xgboost以及LightGBM。在实际的比赛或者工程中,基于Boosting的集成学习方式是非常有效且应用非常广泛的。更多的学习有待读者更深入阅读文献,包括原作者论文以及论文复现等。下一章我们即将探讨另一种集成学习方式:Stacking集成学习方式,这种集成方式虽然没有Boosting应用广泛,但是在比赛中或许能让你的模型更加出众。
本章作业:
本章在最后介绍LightGBM的时候并没有详细介绍它的原理以及它与XGBoost的不一样的地方,希望读者好好看看别的文章分享,总结LigntGBM与XGBoost的不同,然后使用一个具体的案例体现两者的不同。
参考链接: https://blog.csdn.net/weixin_30279315/article/details/95504220
]]>
- <h1 id="XGBoost算法"><a href="#XGBoost算法" class="headerlink" title="XGBoost算法"></a>XGBoost算法</h1><p>XGBoost是陈天奇等人开发的一个开源机器学习项目,高效地实现了GBDT算法并进行了算法和工程上的许多改进,被广泛应用在Kaggle竞赛及其他许多机器学习竞赛中并取得了不错的成绩。<strong>XGBoost本质上还是一个GBDT,但是力争把速度和效率发挥到极致,所以叫X (Extreme) GBoosted,</strong> 包括前面说过,两者都是boosting方法。XGBoost是一个优化的分布式梯度增强库,旨在实现高效,灵活和便携。 它在Gradient Boosting框架下实现机器学习算法。 XGBoost提供了<strong>并行树提升</strong>(也称为GBDT,GBM),可以快速准确地解决许多数据科学问题。 相同的代码在主要的分布式环境(Hadoop,SGE,MPI)上运行,并且可以解决超过数十亿个样例的问题。XGBoost利用了核外计算并且能够使数据科学家在一个主机上处理数亿的样本数据。最终,将这些技术进行结合来做一个端到端的系统以最少的集群系统来扩展到更大的数据集上。Xgboost<strong>以CART决策树为子模型</strong>,通过Gradient Tree Boosting实现多棵CART树的集成学习,得到最终模型。下面我们来看看XGBoost的最终模型构建:</p>
+ <h1 id="XGBoost算法"><a href="#XGBoost算法" class="headerlink" title="XGBoost算法"></a>XGBoost算法</h1><p>XGBoost是陈天奇等人开发的一个开源机器学习项目,高效地实现了GBDT算法并进行了算法和工程上的许多改进,被广泛应用在Kaggle竞赛及其他许多机器学习竞赛中并取得了不错的成绩。<strong>XGBoost本质上还是一个GBDT,但是力争把速度和效率发挥到极致,所以叫X (Extreme) GBoosted,</strong> 包括前面说过,两者都是boosting方法。XGBoost是一个优化的分布式梯度增强库,旨在实现高效,灵活和便携。 它在Gradient Boosting框架下实现机器学习算法。 XGBoost提供了<strong>并行树提升</strong>(也称为GBDT,GBM),可以快速准确地解决许多数据科学问题。 相同的代码在主要的分布式环境(Hadoop,SGE,MPI)上运行,并且可以解决超过数十亿个样例的问题。XGBoost利用了核外计算并且能够使数据科学家在一个主机上处理数亿的样本数据。最终,将这些技术进行结合来做一个端到端的系统以最少的集群系统来扩展到更大的数据集上。Xgboost<strong>以CART决策树为子模型</strong>,通过Gradient Tree Boosting实现多棵CART树的集成学习,得到最终模型。下面我们来看看XGBoost的最终模型构建:<br></p>
@@ -194,11 +194,11 @@
2021-06-17T15:59:00.000Z
2024-10-09T07:33:09.914Z
- 梯度提升决策树(GBDT)(1) 基于残差学习的提升树算法:
在前面的学习过程中,我们一直讨论的都是分类树,比如Adaboost算法,并没有涉及回归的例子。在上一小节我们提到了一个加法模型+前向分步算法的框架,那能否使用这个框架解决回归的例子呢?答案是肯定的。接下来我们来探讨下如何使用加法模型+前向分步算法的框架实现回归问题。
在使用加法模型+前向分步算法的框架解决问题之前,我们需要首先确定框架内使用的基函数是什么,在这里我们使用决策树分类器。前面第二章我们已经学过了回归树的基本原理,树算法最重要是寻找最佳的划分点,分类树用纯度来判断最佳划分点使用信息增益(ID3算法),信息增益比(C4.5算法),基尼系数(CART分类树)。但是在回归树中的样本标签是连续数值,可划分点包含了所有特征的所有可取的值。所以再使用熵之类的指标不再合适,取而代之的是平方误差,它能很好的评判拟合程度。 基函数确定了以后,我们需要确定每次提升的标准是什么。回想Adaboost算法,在Adaboost算法内使用了分类错误率修正样本权重以及计算每个基本分类器的权重,那回归问题没有分类错误率可言,也就没办法在这里的回归问题使用了,因此我们需要另辟蹊径。模仿分类错误率,我们用每个样本的残差表示每次使用基函数预测时没有解决的那部分问题。因此,我们可以得出如下算法:
输入数据集$T=\left{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \cdots,\left(x_{N}, y_{N}\right)\right}, x_{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}, y_{i} \in \mathcal{Y} \subseteq \mathbf{R}$,输出最终的提升树$f_{M}(x)$
- 初始化$f_0(x) = 0$
- 对m = 1,2,…,M:
- 计算每个样本的残差:$r_{m i}=y_{i}-f_{m-1}\left(x_{i}\right), \quad i=1,2, \cdots, N$
- 拟合残差$r_{mi}$学习一棵回归树,得到$T\left(x ; \Theta_{m}\right)$
- 更新$f_{m}(x)=f_{m-1}(x)+T\left(x ; \Theta_{m}\right)$
- 得到最终的回归问题的提升树:$f_{M}(x)=\sum_{m=1}^{M} T\left(x ; \Theta_{m}\right)$
下面我们用一个实际的案例来使用这个算法:(案例来源:李航老师《统计学习方法》)
训练数据如下表,学习这个回归问题的提升树模型,考虑只用树桩作为基函数。
至此,我们已经能够建立起依靠加法模型+前向分步算法的框架解决回归问题的算法,叫提升树算法。那么,这个算法还是否有提升的空间呢?
(2) 梯度提升决策树算法(GBDT):
提升树利用加法模型和前向分步算法实现学习的过程,当损失函数为平方损失和指数损失时,每一步优化是相当简单的,也就是我们前面探讨的提升树算法和Adaboost算法。但是对于一般的损失函数而言,往往每一步的优化不是那么容易,针对这一问题,我们得分析问题的本质,也就是是什么导致了在一般损失函数条件下的学习困难。对比以下损失函数:
$$
\begin{array}{l|l|l}
\hline \text { Setting } & \text { Loss Function } & -\partial L\left(y_{i}, f\left(x_{i}\right)\right) / \partial f\left(x_{i}\right) \
\hline \text { Regression } & \frac{1}{2}\left[y_{i}-f\left(x_{i}\right)\right]^{2} & y_{i}-f\left(x_{i}\right) \
\hline \text { Regression } & \left|y_{i}-f\left(x_{i}\right)\right| & \operatorname{sign}\left[y_{i}-f\left(x_{i}\right)\right] \
\hline \text { Regression } & \text { Huber } & y_{i}-f\left(x_{i}\right) \text { for }\left|y_{i}-f\left(x_{i}\right)\right| \leq \delta_{m} \
& & \delta_{m} \operatorname{sign}\left[y_{i}-f\left(x_{i}\right)\right] \text { for }\left|y_{i}-f\left(x_{i}\right)\right|>\delta_{m} \
& & \text { where } \delta_{m}=\alpha \text { th-quantile }\left{\left|y_{i}-f\left(x_{i}\right)\right|\right} \
\hline \text { Classification } & \text { Deviance } & k \text { th component: } I\left(y_{i}=\mathcal{G}{k}\right)-p{k}\left(x_{i}\right) \
\hline
\end{array}
$$
观察Huber损失函数:
$$
L_{\delta}(y, f(x))=\left{\begin{array}{ll}
\frac{1}{2}(y-f(x))^{2} & \text { for }|y-f(x)| \leq \delta \
\delta|y-f(x)|-\frac{1}{2} \delta^{2} & \text { otherwise }
\end{array}\right.
$$
针对上面的问题,Freidman提出了梯度提升算法(gradient boosting),这是利用最速下降法的近似方法,利用损失函数的负梯度在当前模型的值$-\left[\frac{\partial L\left(y, f\left(x_{i}\right)\right)}{\partial f\left(x_{i}\right)}\right]{f(x)=f{m-1}(x)}$作为回归问题提升树算法中的残差的近似值,拟合回归树。与其说负梯度作为残差的近似值,不如说残差是负梯度的一种特例。
以下开始具体介绍梯度提升算法:
输入训练数据集$T=\left{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \cdots,\left(x_{N}, y_{N}\right)\right}, x_{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}, y_{i} \in \mathcal{Y} \subseteq \mathbf{R}$和损失函数$L(y, f(x))$,输出回归树$\hat{f}(x)$
- 初始化$f_{0}(x)=\arg \min {c} \sum{i=1}^{N} L\left(y_{i}, c\right)$
- 对于m=1,2,…,M:
- 对i = 1,2,…,N计算:$r_{m i}=-\left[\frac{\partial L\left(y_{i}, f\left(x_{i}\right)\right)}{\partial f\left(x_{i}\right)}\right]{f(x)=f{m-1}(x)}$
- 对$r_{mi}$拟合一个回归树,得到第m棵树的叶结点区域$R_{m j}, j=1,2, \cdots, J$
- 对j=1,2,…J,计算:$c_{m j}=\arg \min {c} \sum{x_{i} \in R_{m j}} L\left(y_{i}, f_{m-1}\left(x_{i}\right)+c\right)$
- 更新$f_{m}(x)=f_{m-1}(x)+\sum_{j=1}^{J} c_{m j} I\left(x \in R_{m j}\right)$
- 得到回归树:$\hat{f}(x)=f_{M}(x)=\sum_{m=1}^{M} \sum_{j=1}^{J} c_{m j} I\left(x \in R_{m j}\right)$
下面,我们来使用一个具体的案例来说明GBDT是如何运作的(案例来源:https://blog.csdn.net/zpalyq110/article/details/79527653 ):
下面的表格是数据:
学习率:learning_rate=0.1,迭代次数:n_trees=5,树的深度:max_depth=3
平方损失的负梯度为:
$$
-\left[\frac{\left.\partial L\left(y, f\left(x_{i}\right)\right)\right)}{\partial f\left(x_{i}\right)}\right]{f(x)=f{t-1}(x)}=y-f\left(x_{i}\right)
$$
$c=(1.1+1.3+1.7+1.8)/4=1.475,f_{0}(x)=c=1.475$
学习决策树,分裂结点:
对于左节点,只有0,1两个样本,那么根据下表我们选择年龄7进行划分:
对于右节点,只有2,3两个样本,那么根据下表我们选择年龄30进行划分:
因此根据$\Upsilon_{j 1}=\underbrace{\arg \min }{\Upsilon} \sum{x_{i} \in R_{j 1}} L\left(y_{i}, f_{0}\left(x_{i}\right)+\Upsilon\right)$:
$$
\begin{array}{l}
\left(x_{0} \in R_{11}\right), \quad \Upsilon_{11}=-0.375 \
\left(x_{1} \in R_{21}\right), \quad \Upsilon_{21}=-0.175 \
\left(x_{2} \in R_{31}\right), \quad \Upsilon_{31}=0.225 \
\left(x_{3} \in R_{41}\right), \quad \Upsilon_{41}=0.325
\end{array}
$$
这里其实和上面初始化学习器是一个道理,平方损失,求导,令导数等于零,化简之后得到每个叶子节点的参数$\Upsilon$,其实就是标签值的均值。
最后得到五轮迭代:
最后的强学习器为:$f(x)=f_{5}(x)=f_{0}(x)+\sum_{m=1}^{5} \sum_{j=1}^{4} \Upsilon_{j m} I\left(x \in R_{j m}\right)$。
其中:
$$
\begin{array}{ll}
f_{0}(x)=1.475 & f_{2}(x)=0.0205 \
f_{3}(x)=0.1823 & f_{4}(x)=0.1640 \
f_{5}(x)=0.1476
\end{array}
$$
预测结果为:
$$
f(x)=1.475+0.1 *(0.2250+0.2025+0.1823+0.164+0.1476)=1.56714
$$
为什么要用学习率呢?这是Shrinkage的思想,如果每次都全部加上(学习率为1)很容易一步学到位导致过拟合。
下面我们来使用sklearn来使用GBDT:
- https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingRegressor.html#sklearn.ensemble.GradientBoostingRegressor
- https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingClassifier.html?highlight=gra#sklearn.ensemble.GradientBoostingClassifier
from sklearn.metrics import mean_squared_error
from sklearn.datasets import make_friedman1
from sklearn.ensemble import GradientBoostingRegressor
'''
GradientBoostingRegressor参数解释:
loss:{‘ls’, ‘lad’, ‘huber’, ‘quantile’}, default=’ls’:‘ls’ 指最小二乘回归. ‘lad’ (最小绝对偏差) 是仅基于输入变量的顺序信息的高度鲁棒的损失函数。. ‘huber’ 是两者的结合. ‘quantile’允许分位数回归(用于alpha指定分位数)
learning_rate:学习率缩小了每棵树的贡献learning_rate。在learning_rate和n_estimators之间需要权衡。
n_estimators:要执行的提升次数。
subsample:用于拟合各个基础学习者的样本比例。如果小于1.0,则将导致随机梯度增强。subsample与参数n_estimators。选择会导致方差减少和偏差增加。subsample < 1.0
criterion:{'friedman_mse','mse','mae'},默认='friedman_mse':“ mse”是均方误差,“ mae”是平均绝对误差。默认值“ friedman_mse”通常是最好的,因为在某些情况下它可以提供更好的近似值。
min_samples_split:拆分内部节点所需的最少样本数
min_samples_leaf:在叶节点处需要的最小样本数。
min_weight_fraction_leaf:在所有叶节点处(所有输入样本)的权重总和中的最小加权分数。如果未提供sample_weight,则样本的权重相等。
max_depth:各个回归模型的最大深度。最大深度限制了树中节点的数量。调整此参数以获得最佳性能;最佳值取决于输入变量的相互作用。
min_impurity_decrease:如果节点分裂会导致杂质的减少大于或等于该值,则该节点将被分裂。
min_impurity_split:提前停止树木生长的阈值。如果节点的杂质高于阈值,则该节点将分裂
max_features{‘auto’, ‘sqrt’, ‘log2’},int或float:寻找最佳分割时要考虑的功能数量:
如果为int,则max_features在每个分割处考虑特征。
如果为float,max_features则为小数,并在每次拆分时考虑要素。int(max_features * n_features)
如果“auto”,则max_features=n_features。
如果是“ sqrt”,则max_features=sqrt(n_features)。
如果为“ log2”,则为max_features=log2(n_features)。
如果没有,则max_features=n_features。
'''
X, y = make_friedman1(n_samples=1200, random_state=0, noise=1.0)
X_train, X_test = X[:200], X[200:]
y_train, y_test = y[:200], y[200:]
reg = GradientBoostingRegressor(n_estimators=100,
learning_rate=0.1,max_depth=1, random_state=0, loss='ls')
est = reg.fit(X_train, y_train)
mean_squared_error(y_test, est.predict(X_test))
from sklearn.datasets import make_regression
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.model_selection import train_test_split
X, y = make_regression(random_state=0)
X_train, X_test, y_train, y_test = train_test_split(
X, y, random_state=0)
reg = GradientBoostingRegressor(random_state=0)
reg.fit(X_train, y_train)
reg.score(X_test, y_test)
GradientBoostingRegressor与GradientBoostingClassifier函数的各个参数的参考文档:
]]>
+ 梯度提升决策树(GBDT)(1) 基于残差学习的提升树算法:
在前面的学习过程中,我们一直讨论的都是分类树,比如Adaboost算法,并没有涉及回归的例子。在上一小节我们提到了一个加法模型+前向分步算法的框架,那能否使用这个框架解决回归的例子呢?答案是肯定的。接下来我们来探讨下如何使用加法模型+前向分步算法的框架实现回归问题。
在使用加法模型+前向分步算法的框架解决问题之前,我们需要首先确定框架内使用的基函数是什么,在这里我们使用决策树分类器。前面第二章我们已经学过了回归树的基本原理,树算法最重要是寻找最佳的划分点,分类树用纯度来判断最佳划分点使用信息增益(ID3算法),信息增益比(C4.5算法),基尼系数(CART分类树)。但是在回归树中的样本标签是连续数值,可划分点包含了所有特征的所有可取的值。所以再使用熵之类的指标不再合适,取而代之的是平方误差,它能很好的评判拟合程度。 基函数确定了以后,我们需要确定每次提升的标准是什么。回想Adaboost算法,在Adaboost算法内使用了分类错误率修正样本权重以及计算每个基本分类器的权重,那回归问题没有分类错误率可言,也就没办法在这里的回归问题使用了,因此我们需要另辟蹊径。模仿分类错误率,我们用每个样本的残差表示每次使用基函数预测时没有解决的那部分问题。因此,我们可以得出如下算法:
输入数据集$T=\left{\left(x{1}, y{1}\right),\left(x{2}, y{2}\right), \cdots,\left(x{N}, y{N}\right)\right}, x{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}, y{i} \in \mathcal{Y} \subseteq \mathbf{R}$,输出最终的提升树$f_{M}(x)$
- 初始化$f_0(x) = 0$
- 对m = 1,2,…,M:
- 计算每个样本的残差:$r{m i}=y{i}-f{m-1}\left(x{i}\right), \quad i=1,2, \cdots, N$
- 拟合残差$r{mi}$学习一棵回归树,得到$T\left(x ; \Theta{m}\right)$
- 更新$f{m}(x)=f{m-1}(x)+T\left(x ; \Theta_{m}\right)$
- 得到最终的回归问题的提升树:$f{M}(x)=\sum{m=1}^{M} T\left(x ; \Theta_{m}\right)$
下面我们用一个实际的案例来使用这个算法:(案例来源:李航老师《统计学习方法》)
训练数据如下表,学习这个回归问题的提升树模型,考虑只用树桩作为基函数。
至此,我们已经能够建立起依靠加法模型+前向分步算法的框架解决回归问题的算法,叫提升树算法。那么,这个算法还是否有提升的空间呢?
(2) 梯度提升决策树算法(GBDT):
提升树利用加法模型和前向分步算法实现学习的过程,当损失函数为平方损失和指数损失时,每一步优化是相当简单的,也就是我们前面探讨的提升树算法和Adaboost算法。但是对于一般的损失函数而言,往往每一步的优化不是那么容易,针对这一问题,我们得分析问题的本质,也就是是什么导致了在一般损失函数条件下的学习困难。对比以下损失函数:
观察Huber损失函数:
针对上面的问题,Freidman提出了梯度提升算法(gradient boosting),这是利用最速下降法的近似方法,利用损失函数的负梯度在当前模型的值$-\left[\frac{\partial L\left(y, f\left(x{i}\right)\right)}{\partial f\left(x{i}\right)}\right]{f(x)=f{m-1}(x)}$作为回归问题提升树算法中的残差的近似值,拟合回归树。与其说负梯度作为残差的近似值,不如说残差是负梯度的一种特例。
以下开始具体介绍梯度提升算法:
输入训练数据集$T=\left{\left(x{1}, y{1}\right),\left(x{2}, y{2}\right), \cdots,\left(x{N}, y{N}\right)\right}, x{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}, y{i} \in \mathcal{Y} \subseteq \mathbf{R}$和损失函数$L(y, f(x))$,输出回归树$\hat{f}(x)$
- 初始化$f{0}(x)=\arg \min {c} \sum{i=1}^{N} L\left(y{i}, c\right)$
- 对于m=1,2,…,M:
- 对i = 1,2,…,N计算:$r{m i}=-\left[\frac{\partial L\left(y{i}, f\left(x{i}\right)\right)}{\partial f\left(x{i}\right)}\right]{f(x)=f{m-1}(x)}$
- 对$r{mi}$拟合一个回归树,得到第m棵树的叶结点区域$R{m j}, j=1,2, \cdots, J$
- 对j=1,2,…J,计算:$c{m j}=\arg \min {c} \sum{x{i} \in R{m j}} L\left(y{i}, f{m-1}\left(x{i}\right)+c\right)$
- 更新$f{m}(x)=f{m-1}(x)+\sum{j=1}^{J} c{m j} I\left(x \in R_{m j}\right)$
- 得到回归树:$\hat{f}(x)=f{M}(x)=\sum{m=1}^{M} \sum{j=1}^{J} c{m j} I\left(x \in R_{m j}\right)$
下面,我们来使用一个具体的案例来说明GBDT是如何运作的(案例来源:https://blog.csdn.net/zpalyq110/article/details/79527653 ):
下面的表格是数据:
学习率:learning_rate=0.1,迭代次数:n_trees=5,树的深度:max_depth=3
平方损失的负梯度为:
$c=(1.1+1.3+1.7+1.8)/4=1.475,f_{0}(x)=c=1.475$
学习决策树,分裂结点:
对于左节点,只有0,1两个样本,那么根据下表我们选择年龄7进行划分:
对于右节点,只有2,3两个样本,那么根据下表我们选择年龄30进行划分:
因此根据$\Upsilon{j 1}=\underbrace{\arg \min }{\Upsilon} \sum{x{i} \in R{j 1}} L\left(y{i}, f{0}\left(x{i}\right)+\Upsilon\right)$:
这里其实和上面初始化学习器是一个道理,平方损失,求导,令导数等于零,化简之后得到每个叶子节点的参数$\Upsilon$,其实就是标签值的均值。
最后得到五轮迭代:
最后的强学习器为:$f(x)=f{5}(x)=f{0}(x)+\sum{m=1}^{5} \sum{j=1}^{4} \Upsilon{j m} I\left(x \in R{j m}\right)$。
其中:
预测结果为:
为什么要用学习率呢?这是Shrinkage的思想,如果每次都全部加上(学习率为1)很容易一步学到位导致过拟合。
下面我们来使用sklearn来使用GBDT:
- https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingRegressor.html#sklearn.ensemble.GradientBoostingRegressor
- https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingClassifier.html?highlight=gra#sklearn.ensemble.GradientBoostingClassifier
from sklearn.metrics import mean_squared_error
from sklearn.datasets import make_friedman1
from sklearn.ensemble import GradientBoostingRegressor
'''
GradientBoostingRegressor参数解释:
loss:{‘ls’, ‘lad’, ‘huber’, ‘quantile’}, default=’ls’:‘ls’ 指最小二乘回归. ‘lad’ (最小绝对偏差) 是仅基于输入变量的顺序信息的高度鲁棒的损失函数。. ‘huber’ 是两者的结合. ‘quantile’允许分位数回归(用于alpha指定分位数)
learning_rate:学习率缩小了每棵树的贡献learning_rate。在learning_rate和n_estimators之间需要权衡。
n_estimators:要执行的提升次数。
subsample:用于拟合各个基础学习者的样本比例。如果小于1.0,则将导致随机梯度增强。subsample与参数n_estimators。选择会导致方差减少和偏差增加。subsample < 1.0
criterion:{'friedman_mse','mse','mae'},默认='friedman_mse':“ mse”是均方误差,“ mae”是平均绝对误差。默认值“ friedman_mse”通常是最好的,因为在某些情况下它可以提供更好的近似值。
min_samples_split:拆分内部节点所需的最少样本数
min_samples_leaf:在叶节点处需要的最小样本数。
min_weight_fraction_leaf:在所有叶节点处(所有输入样本)的权重总和中的最小加权分数。如果未提供sample_weight,则样本的权重相等。
max_depth:各个回归模型的最大深度。最大深度限制了树中节点的数量。调整此参数以获得最佳性能;最佳值取决于输入变量的相互作用。
min_impurity_decrease:如果节点分裂会导致杂质的减少大于或等于该值,则该节点将被分裂。
min_impurity_split:提前停止树木生长的阈值。如果节点的杂质高于阈值,则该节点将分裂
max_features{‘auto’, ‘sqrt’, ‘log2’},int或float:寻找最佳分割时要考虑的功能数量:
如果为int,则max_features在每个分割处考虑特征。
如果为float,max_features则为小数,并在每次拆分时考虑要素。int(max_features * n_features)
如果“auto”,则max_features=n_features。
如果是“ sqrt”,则max_features=sqrt(n_features)。
如果为“ log2”,则为max_features=log2(n_features)。
如果没有,则max_features=n_features。
'''
X, y = make_friedman1(n_samples=1200, random_state=0, noise=1.0)
X_train, X_test = X[:200], X[200:]
y_train, y_test = y[:200], y[200:]
reg = GradientBoostingRegressor(n_estimators=100,
learning_rate=0.1,max_depth=1, random_state=0, loss='ls')
est = reg.fit(X_train, y_train)
mean_squared_error(y_test, est.predict(X_test))
from sklearn.datasets import make_regression
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.model_selection import train_test_split
X, y = make_regression(random_state=0)
X_train, X_test, y_train, y_test = train_test_split(
X, y, random_state=0)
reg = GradientBoostingRegressor(random_state=0)
reg.fit(X_train, y_train)
reg.score(X_test, y_test)
GradientBoostingRegressor与GradientBoostingClassifier函数的各个参数的参考文档:
]]>
- <h2 id="梯度提升决策树-GBDT"><a href="#梯度提升决策树-GBDT" class="headerlink" title="梯度提升决策树(GBDT)"></a>梯度提升决策树(GBDT)</h2><p>(1) 基于残差学习的提升树算法:<br>在前面的学习过程中,我们一直讨论的都是分类树,比如Adaboost算法,并没有涉及回归的例子。在上一小节我们提到了一个加法模型+前向分步算法的框架,那能否使用这个框架解决回归的例子呢?答案是肯定的。接下来我们来探讨下如何使用加法模型+前向分步算法的框架实现回归问题。<br>在使用加法模型+前向分步算法的框架解决问题之前,我们需要首先确定框架内使用的基函数是什么,在这里我们使用决策树分类器。前面第二章我们已经学过了回归树的基本原理,<strong>树算法最重要是寻找最佳的划分点,分类树用纯度来判断最佳划分点使用信息增益(ID3算法),信息增益比(C4.5算法),基尼系数(CART分类树)。但是在回归树中的样本标签是连续数值,可划分点包含了所有特征的所有可取的值。所以再使用熵之类的指标不再合适,取而代之的是平方误差,它能很好的评判拟合程度。</strong> 基函数确定了以后,我们需要确定每次提升的标准是什么。回想Adaboost算法,在Adaboost算法内使用了分类错误率修正样本权重以及计算每个基本分类器的权重,那回归问题没有分类错误率可言,也就没办法在这里的回归问题使用了,因此我们需要另辟蹊径。模仿分类错误率,我们用每个样本的残差表示每次使用基函数预测时没有解决的那部分问题。因此,我们可以得出如下算法: </p>
+ <h2 id="梯度提升决策树-GBDT"><a href="#梯度提升决策树-GBDT" class="headerlink" title="梯度提升决策树(GBDT)"></a>梯度提升决策树(GBDT)</h2><p>(1) 基于残差学习的提升树算法:<br>在前面的学习过程中,我们一直讨论的都是分类树,比如Adaboost算法,并没有涉及回归的例子。在上一小节我们提到了一个加法模型+前向分步算法的框架,那能否使用这个框架解决回归的例子呢?答案是肯定的。接下来我们来探讨下如何使用加法模型+前向分步算法的框架实现回归问题。<br>在使用加法模型+前向分步算法的框架解决问题之前,我们需要首先确定框架内使用的基函数是什么,在这里我们使用决策树分类器。前面第二章我们已经学过了回归树的基本原理,<strong>树算法最重要是寻找最佳的划分点,分类树用纯度来判断最佳划分点使用信息增益(ID3算法),信息增益比(C4.5算法),基尼系数(CART分类树)。但是在回归树中的样本标签是连续数值,可划分点包含了所有特征的所有可取的值。所以再使用熵之类的指标不再合适,取而代之的是平方误差,它能很好的评判拟合程度。</strong> 基函数确定了以后,我们需要确定每次提升的标准是什么。回想Adaboost算法,在Adaboost算法内使用了分类错误率修正样本权重以及计算每个基本分类器的权重,那回归问题没有分类错误率可言,也就没办法在这里的回归问题使用了,因此我们需要另辟蹊径。模仿分类错误率,我们用每个样本的残差表示每次使用基函数预测时没有解决的那部分问题。因此,我们可以得出如下算法:<br></p>
@@ -217,11 +217,11 @@
2021-06-17T15:15:00.000Z
2024-10-09T07:33:09.915Z
- 1. 导论在前面的学习中,我们探讨了一系列简单而实用的回归和分类模型,同时也探讨了如何使用集成学习家族中的Bagging思想去优化最终的模型。Bagging思想的实质是:通过Bootstrap 的方式对全样本数据集进行抽样得到抽样子集,对不同的子集使用同一种基本模型进行拟合,然后投票得出最终的预测。我们也从前面的探讨知道:Bagging主要通过降低方差的方式减少预测误差。那么,本章介绍的Boosting是与Bagging截然不同的思想,Boosting方法是使用同一组数据集进行反复学习,得到一系列简单模型,然后组合这些模型构成一个预测性能十分强大的机器学习模型。 显然,Boosting思想提高最终的预测效果是通过不断减少偏差的形式,与Bagging有着本质的不同。在Boosting这一大类方法中,笔者主要介绍两类常用的Boosting方式:Adaptive Boosting 和 Gradient Boosting 以及它们的变体Xgboost、LightGBM以及Catboost。
2. Boosting方法的基本思路
在正式介绍Boosting思想之前,我想先介绍两个例子:
第一个例子:不知道大家有没有做过错题本,我们将每次测验的错的题目记录在错题本上,不停的翻阅,直到我们完全掌握(也就是能够在考试中能够举一反三)。
第二个例子:对于一个复杂任务来说,将多个专家的判断进行适当的综合所作出的判断,要比其中任何一个专家单独判断要好。实际上这是一种“三个臭皮匠顶个诸葛亮的道理”。
这两个例子都说明Boosting的道理,也就是不错地重复学习达到最终的要求。
Boosting的提出与发展离不开Valiant和 Kearns的努力,历史上正是Valiant和 Kearns提出了”强可学习”和”弱可学习”的概念。那什么是”强可学习”和”弱可学习”呢?在概率近似正确PAC学习的框架下:
- 弱学习:识别错误率小于1/2(即准确率仅比随机猜测略高的学习算法)
- 强学习:识别准确率很高并能在多项式时间内完成的学习算法
非常有趣的是,在PAC 学习的框架下,强可学习和弱可学习是等价的,也就是说一个概念是强可学习的充分必要条件是这个概念是弱可学习的。这样一来,问题便是:在学习中,如果已经发现了弱可学习算法,能否将他提升至强可学习算法。因为,弱可学习算法比强可学习算法容易得多。提升方法就是从弱学习算法出发,反复学习,得到一系列弱分类器(又称为基本分类器),然后通过一定的形式去组合这些弱分类器构成一个强分类器。大多数的Boosting方法都是通过改变训练数据集的概率分布(训练数据不同样本的权值),针对不同概率分布的数据调用弱分类算法学习一系列的弱分类器。
对于Boosting方法来说,有两个问题需要给出答案:第一个是每一轮学习应该如何改变数据的概率分布,第二个是如何将各个弱分类器组合起来。关于这两个问题,不同的Boosting算法会有不同的答案,我们接下来介绍一种最经典的Boosting算法—-Adaboost,我们需要理解Adaboost是怎么处理这两个问题以及为什么这么处理的。
3. Adaboost算法
Adaboost的基本原理
对于Adaboost来说,解决上述的两个问题的方式是:
- 提高那些被前一轮分类器错误分类的样本的权重,而降低那些被正确分类的样本的权重。这样一来,那些在上一轮分类器中没有得到正确分类的样本,由于其权重的增大而在后一轮的训练中“备受关注”。
- 各个弱分类器的组合是通过采取加权多数表决的方式,具体来说,加大分类错误率低的弱分类器的权重,因为这些分类器能更好地完成分类任务,而减小分类错误率较大的弱分类器的权重,使其在表决中起较小的作用。
现在,我们来具体介绍Adaboost算法:(参考李航老师的《统计学习方法》)
假设给定一个二分类的训练数据集:$T=\left{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \cdots,\left(x_{N}, y_{N}\right)\right}$ ,其中每个样本点由特征与类别组成。特征$x_{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}$,类别$y_{i} \in \mathcal{Y}={-1,+1}$,$\mathcal{X}$是特征空间,$ \mathcal{Y}$是类别集合,输出最终分类器$G(x)$。Adaboost算法如下:
(1) 初始化训练数据的分布:$D_{1}=\left(w_{11}, \cdots, w_{1 i}, \cdots, w_{1 N}\right), \quad w_{1 i}=\frac{1}{N}, \quad i=1,2, \cdots, N$
(2) 对于m=1,2,…,M
使用具有权值分布$D_m$的训练数据集进行学习,得到基本分类器:$G_{m}(x): \mathcal{X} \rightarrow{-1,+1}$
计算$G_m(x)$在训练集上的分类误差率$e_{m}=\sum_{i=1}^{N} P\left(G_{m}\left(x_{i}\right) \neq y_{i}\right)=\sum_{i=1}^{N} w_{m i} I\left(G_{m}\left(x_{i}\right) \neq y_{i}\right)$
计算$G_m(x)$的系数$\alpha_{m}=\frac{1}{2} \log \frac{1-e_{m}}{e_{m}}$,这里的log是自然对数ln
更新训练数据集的权重分布
$$
\begin{array}{c}
D_{m+1}=\left(w_{m+1,1}, \cdots, w_{m+1, i}, \cdots, w_{m+1, N}\right) \
w_{m+1, i}=\frac{w_{m i}}{Z_{m}} \exp \left(-\alpha_{m} y_{i} G_{m}\left(x_{i}\right)\right), \quad i=1,2, \cdots, N
\end{array}
$$
这里的$Z_m$是规范化因子,使得$D_{m+1}$称为概率分布,$Z_{m}=\sum_{i=1}^{N} w_{m i} \exp \left(-\alpha_{m} y_{i} G_{m}\left(x_{i}\right)\right)$
(3) 构建基本分类器的线性组合$f(x)=\sum_{m=1}^{M} \alpha_{m} G_{m}(x)$,得到最终的分类器
$$
\begin{aligned}
G(x) &=\operatorname{sign}(f(x)) \
&=\operatorname{sign}\left(\sum_{m=1}^{M} \alpha_{m} G_{m}(x)\right)
\end{aligned}
$$
下面对Adaboost算法做如下说明:
对于步骤(1),假设训练数据的权值分布是均匀分布,是为了使得第一次没有先验信息的条件下每个样本在基本分类器的学习中作用一样。
对于步骤(2),每一次迭代产生的基本分类器$G_m(x)$在加权训练数据集上的分类错误率$\begin{aligned}e_{m} &=\sum_{i=1}^{N} P\left(G_{m}\left(x_{i}\right) \neq y_{i}\right) =\sum_{G_{m}\left(x_{i}\right) \neq y_{i}} w_{m i}\end{aligned}$代表了在$G_m(x)$中分类错误的样本权重和,这点直接说明了权重分布$D_m$与$G_m(x)$的分类错误率$e_m$有直接关系。同时,在步骤(2)中,计算基本分类器$G_m(x)$的系数$\alpha_m$,$\alpha_{m}=\frac{1}{2} \log \frac{1-e_{m}}{e_{m}}$,它表示了$G_m(x)$在最终分类器的重要性程度,$\alpha_m$的取值由基本分类器$G_m(x)$的分类错误率有直接关系,当$e_{m} \leqslant \frac{1}{2}$时,$\alpha_{m} \geqslant 0$,并且$\alpha_m$随着$e_m$的减少而增大,因此分类错误率越小的基本分类器在最终分类器的作用越大!
**最重要的,对于步骤(2)中的样本权重的更新: **
$$
w_{m+1, i}=\left{\begin{array}{ll}
\frac{w_{m i}}{Z_{m}} \mathrm{e}^{-\alpha_{m}}, & G_{m}\left(x_{i}\right)=y_{i} \
\frac{w_{m i}}{Z_{m}} \mathrm{e}^{\alpha_{m}}, & G_{m}\left(x_{i}\right) \neq y_{i}
\end{array}\right.
$$
因此,从上式可以看到:被基本分类器$G_m(x)$错误分类的样本的权重扩大,被正确分类的样本权重减少,二者相比相差$\mathrm{e}^{2 \alpha_{m}}=\frac{1-e_{m}}{e_{m}}$倍。
对于步骤(3),线性组合$f(x)$实现了将M个基本分类器的加权表决,系数$\alpha_m$标志了基本分类器$G_m(x)$的重要性,值得注意的是:所有的$\alpha_m$之和不为1。$f(x)$的符号决定了样本x属于哪一类。
下面,我们使用一组简单的数据来手动计算Adaboost算法的过程:(例子来源:http://www.csie.edu.tw)
训练数据如下表,假设基本分类器的形式是一个分割$x<v$或$x>v$表示,阈值v由该基本分类器在训练数据集上分类错误率$e_m$最低确定。
$$
\begin{array}{ccccccccccc}
\hline \text { 序号 } & 1 & 2 & 3 & 4 & 5 & 6 & 7 & 8 & 9 & 10 \
\hline x & 0 & 1 & 2 & 3 & 4 & 5 & 6 & 7 & 8 & 9 \
y & 1 & 1 & 1 & -1 & -1 & -1 & 1 & 1 & 1 & -1 \
\hline
\end{array}
$$
解:
初始化样本权值分布
$$
\begin{aligned}
D_{1} &=\left(w_{11}, w_{12}, \cdots, w_{110}\right) \
w_{1 i} &=0.1, \quad i=1,2, \cdots, 10
\end{aligned}
$$
对m=1:
- 在权值分布$D_1$的训练数据集上,遍历每个结点并计算分类误差率$e_m$,阈值取v=2.5时分类误差率最低,那么基本分类器为:
$$
G_{1}(x)=\left{\begin{array}{ll}
1, & x<2.5 \ - 1, & x>2.5
\end{array}\right.
$$ - $G_1(x)$在训练数据集上的误差率为$e_{1}=P\left(G_{1}\left(x_{i}\right) \neq y_{i}\right)=0.3$。
- 计算$G_1(x)$的系数:$\alpha_{1}=\frac{1}{2} \log \frac{1-e_{1}}{e_{1}}=0.4236$
- 更新训练数据的权值分布:
$$
\begin{aligned}
D_{2}=&\left(w_{21}, \cdots, w_{2 i}, \cdots, w_{210}\right) \
w_{2 i}=& \frac{w_{1 i}}{Z_{1}} \exp \left(-\alpha_{1} y_{i} G_{1}\left(x_{i}\right)\right), \quad i=1,2, \cdots, 10 \
D_{2}=&(0.07143,0.07143,0.07143,0.07143,0.07143,0.07143,\
&0.16667,0.16667,0.16667,0.07143) \
f_{1}(x) &=0.4236 G_{1}(x)
\end{aligned}
$$
对于m=2:
- 在权值分布$D_2$的训练数据集上,遍历每个结点并计算分类误差率$e_m$,阈值取v=8.5时分类误差率最低,那么基本分类器为:
$$
G_{2}(x)=\left{\begin{array}{ll}
1, & x<8.5 \ - 1, & x>8.5
\end{array}\right.
$$ - $G_2(x)$在训练数据集上的误差率为$e_2 = 0.2143$
- 计算$G_2(x)$的系数:$\alpha_2 = 0.6496$
- 更新训练数据的权值分布:
$$
\begin{aligned}
D_{3}=&(0.0455,0.0455,0.0455,0.1667,0.1667,0.1667\
&0.1060,0.1060,0.1060,0.0455) \
f_{2}(x) &=0.4236 G_{1}(x)+0.6496 G_{2}(x)
\end{aligned}
$$
对m=3:
- 在权值分布$D_3$的训练数据集上,遍历每个结点并计算分类误差率$e_m$,阈值取v=5.5时分类误差率最低,那么基本分类器为:
$$
G_{3}(x)=\left{\begin{array}{ll}
1, & x>5.5 \ - 1, & x<5.5
\end{array}\right.
$$ - $G_3(x)$在训练数据集上的误差率为$e_3 = 0.1820$
- 计算$G_3(x)$的系数:$\alpha_3 = 0.7514$
- 更新训练数据的权值分布:
$$
D_{4}=(0.125,0.125,0.125,0.102,0.102,0.102,0.065,0.065,0.065,0.125)
$$
于是得到:$f_{3}(x)=0.4236 G_{1}(x)+0.6496 G_{2}(x)+0.7514 G_{3}(x)$,分类器$\operatorname{sign}\left[f_{3}(x)\right]$在训练数据集上的误分类点的个数为0。
于是得到最终分类器为:$G(x)=\operatorname{sign}\left[f_{3}(x)\right]=\operatorname{sign}\left[0.4236 G_{1}(x)+0.6496 G_{2}(x)+0.7514 G_{3}(x)\right]$
下面,我们使用sklearn对Adaboost算法进行建模:
本次案例我们使用一份UCI的机器学习库里的开源数据集:葡萄酒数据集,该数据集可以在 ( https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data )上获得。该数据集包含了178个样本和13个特征,从不同的角度对不同的化学特性进行描述,我们的任务是根据这些数据预测红酒属于哪一个类别。(案例来源《python机器学习(第二版》)
# 引入数据科学相关工具包:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use("ggplot")
%matplotlib inline
import seaborn as sns
# 加载训练数据:
wine = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data",header=None)
wine.columns = ['Class label', 'Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash','Magnesium', 'Total phenols','Flavanoids', 'Nonflavanoid phenols',
'Proanthocyanins','Color intensity', 'Hue','OD280/OD315 of diluted wines','Proline']
# 数据查看:
print("Class labels",np.unique(wine["Class label"]))
wine.head()
下面对数据做简单解读:
- Class label:分类标签
- Alcohol:酒精
- Malic acid:苹果酸
- Ash:灰
- Alcalinity of ash:灰的碱度
- Magnesium:镁
- Total phenols:总酚
- Flavanoids:黄酮类化合物
- Nonflavanoid phenols:非黄烷类酚类
- Proanthocyanins:原花青素
- Color intensity:色彩强度
- Hue:色调
- OD280/OD315 of diluted wines:稀释酒OD280 OD350
- Proline:脯氨酸
# 数据预处理
# 仅仅考虑2,3类葡萄酒,去除1类
wine = wine[wine['Class label']!=1]
y = wine['Class label'].values
X = wine[['Alcohol','OD280/OD315 of diluted wines']].values
# 将分类标签变成二进制编码:
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y = le.fit_transform(y)
# 按8:2分割训练集和测试集
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=1,stratify=y) # stratify参数代表了按照y的类别等比例抽样
使用单一决策树建模
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier(criterion='entropy',random_state=1,max_depth=1)
from sklearn.metrics import accuracy_score
tree = tree.fit(X_train,y_train)
y_train_pred = tree.predict(X_train)
y_test_pred = tree.predict(X_test)
tree_train = accuracy_score(y_train,y_train_pred)
tree_test = accuracy_score(y_test,y_test_pred)
print('Decision tree train/test accuracies %.3f/%.3f' % (tree_train,tree_test))
使用sklearn实现Adaboost(基分类器为决策树)
# 使用sklearn实现Adaboost(基分类器为决策树)
'''
AdaBoostClassifier相关参数:
base_estimator:基本分类器,默认为DecisionTreeClassifier(max_depth=1)
n_estimators:终止迭代的次数
learning_rate:学习率
algorithm:训练的相关算法,{'SAMME','SAMME.R'},默认='SAMME.R'
random_state:随机种子
'''
from sklearn.ensemble import AdaBoostClassifier
adaboost = AdaBoostClassifier(base_estimator=tree,n_estimators=500,learning_rate=0.1,random_state=1)
adaboost = adaboost.fit(X_train,y_train)
y_train_pred = adaboost.predict(X_train)
y_test_pred = adaboost.predict(X_test)
ada_train = accuracy_score(y_train,y_train_pred)
ada_test = accuracy_score(y_test,y_test_pred)
print('Adaboost train/test accuracies %.3f/%.3f' % (ada_train,ada_test))
结果分析:单层决策树似乎对训练数据欠拟合,而Adaboost模型正确地预测了训练数据的所有分类标签,而且与单层决策树相比,Adaboost的测试性能也略有提高。然而,为什么模型在训练集和测试集的性能相差这么大呢?我们使用图像来简单说明下这个道理!
# 画出单层决策树与Adaboost的决策边界:
x_min = X_train[:, 0].min() - 1
x_max = X_train[:, 0].max() + 1
y_min = X_train[:, 1].min() - 1
y_max = X_train[:, 1].max() + 1
# 生成网格矩阵
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),np.arange(y_min, y_max, 0.1))
f, axarr = plt.subplots(nrows=1, ncols=2,sharex='col',sharey='row',figsize=(12, 6))
for idx, clf, tt in zip([0, 1],[tree, adaboost],['Decision tree', 'Adaboost']):
clf.fit(X_train, y_train)
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
axarr[idx].contourf(xx, yy, Z, alpha=0.3)
axarr[idx].scatter(X_train[y_train==0, 0],X_train[y_train==0, 1],c='blue', marker='^')
axarr[idx].scatter(X_train[y_train==1, 0],X_train[y_train==1, 1],c='red', marker='o')
axarr[idx].set_title(tt)
从上面的决策边界图可以看到:Adaboost模型的决策边界比单层决策树的决策边界要复杂的多。也就是说,Adaboost试图用增加模型复杂度而降低偏差的方式去减少总误差,但是过程中引入了方差,可能出现过拟合,因此在训练集和测试集之间的性能存在较大的差距,这就简单地回答的刚刚问题。
值的注意的是:与单个分类器相比,Adaboost等Boosting模型增加了计算的复杂度,在实践中需要仔细思考是否愿意为预测性能的相对改善而增加计算成本,而且Boosting方式无法做到现在流行的并行计算的方式进行训练,因为每一步迭代都要基于上一部的基本分类器。
4. 前向分步算法
回看Adaboost的算法内容,我们需要通过计算M个基本分类器,每个分类器的错误率、样本权重以及模型权重。我们可以认为:Adaboost每次学习单一分类器以及单一分类器的参数(权重)。接下来,我们抽象出Adaboost算法的整体框架逻辑,构建集成学习的一个非常重要的框架—-前向分步算法,有了这个框架,我们不仅可以解决分类问题,也可以解决回归问题。
(1) 加法模型:
在Adaboost模型中,我们把每个基本分类器合成一个复杂分类器的方法是每个基本分类器的加权和,即:$f(x)=\sum_{m=1}^{M} \beta_{m} b\left(x ; \gamma_{m}\right)$,其中,$b\left(x ; \gamma_{m}\right)$为即基本分类器,$\gamma_{m}$为基本分类器的参数,$\beta_m$为基本分类器的权重,显然这与第二章所学的加法模型。为什么这么说呢?大家把$b(x ; \gamma_{m})$看成是即函数即可。
在给定训练数据以及损失函数$L(y, f(x))$的条件下,学习加法模型$f(x)$就是:
$$
\min {\beta{m}, \gamma_{m}} \sum_{i=1}^{N} L\left(y_{i}, \sum_{m=1}^{M} \beta_{m} b\left(x_{i} ; \gamma_{m}\right)\right)
$$
通常这是一个复杂的优化问题,很难通过简单的凸优化的相关知识进行解决。前向分步算法可以用来求解这种方式的问题,它的基本思路是:因为学习的是加法模型,如果从前向后,每一步只优化一个基函数及其系数,逐步逼近目标函数,那么就可以降低优化的复杂度。具体而言,每一步只需要优化:
$$
\min {\beta, \gamma} \sum{i=1}^{N} L\left(y_{i}, \beta b\left(x_{i} ; \gamma\right)\right)
$$
(2) 前向分步算法:
给定数据集$T=\left{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \cdots,\left(x_{N}, y_{N}\right)\right}$,$x_{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}$,$y_{i} \in \mathcal{Y}={+1,-1}$。损失函数$L(y, f(x))$,基函数集合${b(x ; \gamma)}$,我们需要输出加法模型$f(x)$。
- 初始化:$f_{0}(x)=0$
- 对m = 1,2,…,M:
- (a) 极小化损失函数:
$$
\left(\beta_{m}, \gamma_{m}\right)=\arg \min {\beta, \gamma} \sum{i=1}^{N} L\left(y_{i}, f_{m-1}\left(x_{i}\right)+\beta b\left(x_{i} ; \gamma\right)\right)
$$
得到参数$\beta_{m}$与$\gamma_{m}$ - (b) 更新:
$$
f_{m}(x)=f_{m-1}(x)+\beta_{m} b\left(x ; \gamma_{m}\right)
$$
- 得到加法模型:
$$
f(x)=f_{M}(x)=\sum_{m=1}^{M} \beta_{m} b\left(x ; \gamma_{m}\right)
$$
这样,前向分步算法将同时求解从m=1到M的所有参数$\beta_{m}$,$\gamma_{m}$的优化问题简化为逐次求解各个$\beta_{m}$,$\gamma_{m}$的问题。
(3) 前向分步算法与Adaboost的关系:
由于这里不是我们的重点,我们主要阐述这里的结论,不做相关证明,具体的证明见李航老师的《统计学习方法》第八章的3.2节。Adaboost算法是前向分步算法的特例,Adaboost算法是由基本分类器组成的加法模型,损失函数为指数损失函数。
]]>
+ 1. 导论在前面的学习中,我们探讨了一系列简单而实用的回归和分类模型,同时也探讨了如何使用集成学习家族中的Bagging思想去优化最终的模型。Bagging思想的实质是:通过Bootstrap 的方式对全样本数据集进行抽样得到抽样子集,对不同的子集使用同一种基本模型进行拟合,然后投票得出最终的预测。我们也从前面的探讨知道:Bagging主要通过降低方差的方式减少预测误差。那么,本章介绍的Boosting是与Bagging截然不同的思想,Boosting方法是使用同一组数据集进行反复学习,得到一系列简单模型,然后组合这些模型构成一个预测性能十分强大的机器学习模型。 显然,Boosting思想提高最终的预测效果是通过不断减少偏差的形式,与Bagging有着本质的不同。在Boosting这一大类方法中,笔者主要介绍两类常用的Boosting方式:Adaptive Boosting 和 Gradient Boosting 以及它们的变体Xgboost、LightGBM以及Catboost。
2. Boosting方法的基本思路
在正式介绍Boosting思想之前,我想先介绍两个例子:
第一个例子:不知道大家有没有做过错题本,我们将每次测验的错的题目记录在错题本上,不停的翻阅,直到我们完全掌握(也就是能够在考试中能够举一反三)。
第二个例子:对于一个复杂任务来说,将多个专家的判断进行适当的综合所作出的判断,要比其中任何一个专家单独判断要好。实际上这是一种“三个臭皮匠顶个诸葛亮的道理”。
这两个例子都说明Boosting的道理,也就是不错地重复学习达到最终的要求。
Boosting的提出与发展离不开Valiant和 Kearns的努力,历史上正是Valiant和 Kearns提出了”强可学习”和”弱可学习”的概念。那什么是”强可学习”和”弱可学习”呢?在概率近似正确PAC学习的框架下:
- 弱学习:识别错误率小于1/2(即准确率仅比随机猜测略高的学习算法)
- 强学习:识别准确率很高并能在多项式时间内完成的学习算法
非常有趣的是,在PAC 学习的框架下,强可学习和弱可学习是等价的,也就是说一个概念是强可学习的充分必要条件是这个概念是弱可学习的。这样一来,问题便是:在学习中,如果已经发现了弱可学习算法,能否将他提升至强可学习算法。因为,弱可学习算法比强可学习算法容易得多。提升方法就是从弱学习算法出发,反复学习,得到一系列弱分类器(又称为基本分类器),然后通过一定的形式去组合这些弱分类器构成一个强分类器。大多数的Boosting方法都是通过改变训练数据集的概率分布(训练数据不同样本的权值),针对不同概率分布的数据调用弱分类算法学习一系列的弱分类器。
对于Boosting方法来说,有两个问题需要给出答案:第一个是每一轮学习应该如何改变数据的概率分布,第二个是如何将各个弱分类器组合起来。关于这两个问题,不同的Boosting算法会有不同的答案,我们接下来介绍一种最经典的Boosting算法——Adaboost,我们需要理解Adaboost是怎么处理这两个问题以及为什么这么处理的。
3. Adaboost算法
Adaboost的基本原理
对于Adaboost来说,解决上述的两个问题的方式是:
- 提高那些被前一轮分类器错误分类的样本的权重,而降低那些被正确分类的样本的权重。这样一来,那些在上一轮分类器中没有得到正确分类的样本,由于其权重的增大而在后一轮的训练中“备受关注”。
- 各个弱分类器的组合是通过采取加权多数表决的方式,具体来说,加大分类错误率低的弱分类器的权重,因为这些分类器能更好地完成分类任务,而减小分类错误率较大的弱分类器的权重,使其在表决中起较小的作用。
现在,我们来具体介绍Adaboost算法:(参考李航老师的《统计学习方法》)
假设给定一个二分类的训练数据集:$T=\left{\left(x{1}, y{1}\right),\left(x{2}, y{2}\right), \cdots,\left(x{N}, y{N}\right)\right}$ ,其中每个样本点由特征与类别组成。特征$x{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}$,类别$y{i} \in \mathcal{Y}={-1,+1}$,$\mathcal{X}$是特征空间,$ \mathcal{Y}$是类别集合,输出最终分类器$G(x)$。Adaboost算法如下:
(1) 初始化训练数据的分布:$D{1}=\left(w{11}, \cdots, w{1 i}, \cdots, w{1 N}\right), \quad w_{1 i}=\frac{1}{N}, \quad i=1,2, \cdots, N$
(2) 对于m=1,2,…,M
- 使用具有权值分布$Dm$的训练数据集进行学习,得到基本分类器:$G{m}(x): \mathcal{X} \rightarrow{-1,+1}$
- 计算$Gm(x)$在训练集上的分类误差率$e{m}=\sum{i=1}^{N} P\left(G{m}\left(x{i}\right) \neq y{i}\right)=\sum{i=1}^{N} w{m i} I\left(G{m}\left(x{i}\right) \neq y_{i}\right)$
- 计算$Gm(x)$的系数$\alpha{m}=\frac{1}{2} \log \frac{1-e{m}}{e{m}}$,这里的log是自然对数ln
更新训练数据集的权重分布
这里的$Zm$是规范化因子,使得$D{m+1}$称为概率分布,$Z{m}=\sum{i=1}^{N} w{m i} \exp \left(-\alpha{m} y{i} G{m}\left(x_{i}\right)\right)$
(3) 构建基本分类器的线性组合$f(x)=\sum{m=1}^{M} \alpha{m} G_{m}(x)$,得到最终的分类器
下面对Adaboost算法做如下说明:
对于步骤(1),假设训练数据的权值分布是均匀分布,是为了使得第一次没有先验信息的条件下每个样本在基本分类器的学习中作用一样。
对于步骤(2),每一次迭代产生的基本分类器$Gm(x)$在加权训练数据集上的分类错误率$\begin{aligned}e{m} &=\sum{i=1}^{N} P\left(G{m}\left(x{i}\right) \neq y{i}\right) =\sum{G{m}\left(x{i}\right) \neq y{i}} w{m i}\end{aligned}$代表了在$G_m(x)$中分类错误的样本权重和,这点直接说明了权重分布$D_m$与$G_m(x)$的分类错误率$e_m$有直接关系。同时,在步骤(2)中,计算基本分类器$G_m(x)$的系数$\alpha_m$,$\alpha{m}=\frac{1}{2} \log \frac{1-e{m}}{e{m}}$,它表示了$Gm(x)$在最终分类器的重要性程度,$\alpha_m$的取值由基本分类器$G_m(x)$的分类错误率有直接关系,当$e{m} \leqslant \frac{1}{2}$时,$\alpha_{m} \geqslant 0$,并且$\alpha_m$随着$e_m$的减少而增大,因此分类错误率越小的基本分类器在最终分类器的作用越大!
最重要的,对于步骤(2)中的样本权重的更新:
因此,从上式可以看到:被基本分类器$Gm(x)$错误分类的样本的权重扩大,被正确分类的样本权重减少,二者相比相差$\mathrm{e}^{2 \alpha{m}}=\frac{1-e{m}}{e{m}}$倍。
对于步骤(3),线性组合$f(x)$实现了将M个基本分类器的加权表决,系数$\alpha_m$标志了基本分类器$G_m(x)$的重要性,值得注意的是:所有的$\alpha_m$之和不为1。$f(x)$的符号决定了样本x属于哪一类。
下面,我们使用一组简单的数据来手动计算Adaboost算法的过程:(例子来源:http://www.csie.edu.tw)
训练数据如下表,假设基本分类器的形式是一个分割$xv$表示,阈值v由该基本分类器在训练数据集上分类错误率$e_m$最低确定。
解:
初始化样本权值分布
对m=1:
- 在权值分布$D_1$的训练数据集上,遍历每个结点并计算分类误差率$e_m$,阈值取v=2.5时分类误差率最低,那么基本分类器为:
- $G1(x)$在训练数据集上的误差率为$e{1}=P\left(G{1}\left(x{i}\right) \neq y_{i}\right)=0.3$。
- 计算$G1(x)$的系数:$\alpha{1}=\frac{1}{2} \log \frac{1-e{1}}{e{1}}=0.4236$
- 更新训练数据的权值分布:
对于m=2:
- 在权值分布$D_2$的训练数据集上,遍历每个结点并计算分类误差率$e_m$,阈值取v=8.5时分类误差率最低,那么基本分类器为:
- $G_2(x)$在训练数据集上的误差率为$e_2 = 0.2143$
- 计算$G_2(x)$的系数:$\alpha_2 = 0.6496$
- 更新训练数据的权值分布:
对m=3:
- 在权值分布$D_3$的训练数据集上,遍历每个结点并计算分类误差率$e_m$,阈值取v=5.5时分类误差率最低,那么基本分类器为:
- $G_3(x)$在训练数据集上的误差率为$e_3 = 0.1820$
- 计算$G_3(x)$的系数:$\alpha_3 = 0.7514$
- 更新训练数据的权值分布:
于是得到:$f{3}(x)=0.4236 G{1}(x)+0.6496 G{2}(x)+0.7514 G{3}(x)$,分类器$\operatorname{sign}\left[f{3}(x)\right]$在训练数据集上的误分类点的个数为0。
于是得到最终分类器为:$G(x)=\operatorname{sign}\left[f{3}(x)\right]=\operatorname{sign}\left[0.4236 G{1}(x)+0.6496 G{2}(x)+0.7514 G_{3}(x)\right]$
下面,我们使用sklearn对Adaboost算法进行建模:
本次案例我们使用一份UCI的机器学习库里的开源数据集:葡萄酒数据集,该数据集可以在 ( https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data )上获得。该数据集包含了178个样本和13个特征,从不同的角度对不同的化学特性进行描述,我们的任务是根据这些数据预测红酒属于哪一个类别。(案例来源《python机器学习(第二版》)
# 引入数据科学相关工具包:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use("ggplot")
%matplotlib inline
import seaborn as sns
# 加载训练数据:
wine = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data",header=None)
wine.columns = ['Class label', 'Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash','Magnesium', 'Total phenols','Flavanoids', 'Nonflavanoid phenols',
'Proanthocyanins','Color intensity', 'Hue','OD280/OD315 of diluted wines','Proline']
# 数据查看:
print("Class labels",np.unique(wine["Class label"]))
wine.head()
下面对数据做简单解读:
- Class label:分类标签
- Alcohol:酒精
- Malic acid:苹果酸
- Ash:灰
- Alcalinity of ash:灰的碱度
- Magnesium:镁
- Total phenols:总酚
- Flavanoids:黄酮类化合物
- Nonflavanoid phenols:非黄烷类酚类
- Proanthocyanins:原花青素
- Color intensity:色彩强度
- Hue:色调
- OD280/OD315 of diluted wines:稀释酒OD280 OD350
- Proline:脯氨酸
# 数据预处理
# 仅仅考虑2,3类葡萄酒,去除1类
wine = wine[wine['Class label']!=1]
y = wine['Class label'].values
X = wine[['Alcohol','OD280/OD315 of diluted wines']].values
# 将分类标签变成二进制编码:
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y = le.fit_transform(y)
# 按8:2分割训练集和测试集
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=1,stratify=y) # stratify参数代表了按照y的类别等比例抽样
使用单一决策树建模
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier(criterion='entropy',random_state=1,max_depth=1)
from sklearn.metrics import accuracy_score
tree = tree.fit(X_train,y_train)
y_train_pred = tree.predict(X_train)
y_test_pred = tree.predict(X_test)
tree_train = accuracy_score(y_train,y_train_pred)
tree_test = accuracy_score(y_test,y_test_pred)
print('Decision tree train/test accuracies %.3f/%.3f' % (tree_train,tree_test))
使用sklearn实现Adaboost(基分类器为决策树)
# 使用sklearn实现Adaboost(基分类器为决策树)
'''
AdaBoostClassifier相关参数:
base_estimator:基本分类器,默认为DecisionTreeClassifier(max_depth=1)
n_estimators:终止迭代的次数
learning_rate:学习率
algorithm:训练的相关算法,{'SAMME','SAMME.R'},默认='SAMME.R'
random_state:随机种子
'''
from sklearn.ensemble import AdaBoostClassifier
adaboost = AdaBoostClassifier(base_estimator=tree,n_estimators=500,learning_rate=0.1,random_state=1)
adaboost = adaboost.fit(X_train,y_train)
y_train_pred = adaboost.predict(X_train)
y_test_pred = adaboost.predict(X_test)
ada_train = accuracy_score(y_train,y_train_pred)
ada_test = accuracy_score(y_test,y_test_pred)
print('Adaboost train/test accuracies %.3f/%.3f' % (ada_train,ada_test))
结果分析:单层决策树似乎对训练数据欠拟合,而Adaboost模型正确地预测了训练数据的所有分类标签,而且与单层决策树相比,Adaboost的测试性能也略有提高。然而,为什么模型在训练集和测试集的性能相差这么大呢?我们使用图像来简单说明下这个道理!
# 画出单层决策树与Adaboost的决策边界:
x_min = X_train[:, 0].min() - 1
x_max = X_train[:, 0].max() + 1
y_min = X_train[:, 1].min() - 1
y_max = X_train[:, 1].max() + 1
# 生成网格矩阵
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),np.arange(y_min, y_max, 0.1))
f, axarr = plt.subplots(nrows=1, ncols=2,sharex='col',sharey='row',figsize=(12, 6))
for idx, clf, tt in zip([0, 1],[tree, adaboost],['Decision tree', 'Adaboost']):
clf.fit(X_train, y_train)
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
axarr[idx].contourf(xx, yy, Z, alpha=0.3)
axarr[idx].scatter(X_train[y_train==0, 0],X_train[y_train==0, 1],c='blue', marker='^')
axarr[idx].scatter(X_train[y_train==1, 0],X_train[y_train==1, 1],c='red', marker='o')
axarr[idx].set_title(tt)
从上面的决策边界图可以看到:Adaboost模型的决策边界比单层决策树的决策边界要复杂的多。也就是说,Adaboost试图用增加模型复杂度而降低偏差的方式去减少总误差,但是过程中引入了方差,可能出现过拟合,因此在训练集和测试集之间的性能存在较大的差距,这就简单地回答的刚刚问题。
值的注意的是:与单个分类器相比,Adaboost等Boosting模型增加了计算的复杂度,在实践中需要仔细思考是否愿意为预测性能的相对改善而增加计算成本,而且Boosting方式无法做到现在流行的并行计算的方式进行训练,因为每一步迭代都要基于上一部的基本分类器。
4. 前向分步算法
回看Adaboost的算法内容,我们需要通过计算M个基本分类器,每个分类器的错误率、样本权重以及模型权重。我们可以认为:Adaboost每次学习单一分类器以及单一分类器的参数(权重)。接下来,我们抽象出Adaboost算法的整体框架逻辑,构建集成学习的一个非常重要的框架——前向分步算法,有了这个框架,我们不仅可以解决分类问题,也可以解决回归问题。
(1) 加法模型:
在Adaboost模型中,我们把每个基本分类器合成一个复杂分类器的方法是每个基本分类器的加权和,即:$f(x)=\sum{m=1}^{M} \beta{m} b\left(x ; \gamma{m}\right)$,其中,$b\left(x ; \gamma{m}\right)$为即基本分类器,$\gamma{m}$为基本分类器的参数,$\beta_m$为基本分类器的权重,显然这与第二章所学的加法模型。为什么这么说呢?大家把$b(x ; \gamma{m})$看成是即函数即可。
在给定训练数据以及损失函数$L(y, f(x))$的条件下,学习加法模型$f(x)$就是:
通常这是一个复杂的优化问题,很难通过简单的凸优化的相关知识进行解决。前向分步算法可以用来求解这种方式的问题,它的基本思路是:因为学习的是加法模型,如果从前向后,每一步只优化一个基函数及其系数,逐步逼近目标函数,那么就可以降低优化的复杂度。具体而言,每一步只需要优化:
(2) 前向分步算法:
给定数据集$T=\left{\left(x{1}, y{1}\right),\left(x{2}, y{2}\right), \cdots,\left(x{N}, y{N}\right)\right}$,$x{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}$,$y{i} \in \mathcal{Y}={+1,-1}$。损失函数$L(y, f(x))$,基函数集合${b(x ; \gamma)}$,我们需要输出加法模型$f(x)$。
- 初始化:$f_{0}(x)=0$
- 对m = 1,2,…,M:
- (a) 极小化损失函数:得到参数$\beta{m}$与$\gamma{m}$
- (b) 更新:
- 得到加法模型:
这样,前向分步算法将同时求解从m=1到M的所有参数$\beta{m}$,$\gamma{m}$的优化问题简化为逐次求解各个$\beta{m}$,$\gamma{m}$的问题。
(3) 前向分步算法与Adaboost的关系:
由于这里不是我们的重点,我们主要阐述这里的结论,不做相关证明,具体的证明见李航老师的《统计学习方法》第八章的3.2节。Adaboost算法是前向分步算法的特例,Adaboost算法是由基本分类器组成的加法模型,损失函数为指数损失函数。
]]>
- <h1 id="1-导论"><a href="#1-导论" class="headerlink" title="1. 导论"></a>1. 导论</h1><p>在前面的学习中,我们探讨了一系列简单而实用的回归和分类模型,同时也探讨了如何使用集成学习家族中的Bagging思想去优化最终的模型。Bagging思想的实质是:通过Bootstrap 的方式对全样本数据集进行抽样得到抽样子集,对不同的子集使用同一种基本模型进行拟合,然后投票得出最终的预测。我们也从前面的探讨知道:Bagging主要通过降低方差的方式减少预测误差。<strong>那么,本章介绍的Boosting是与Bagging截然不同的思想,Boosting方法是使用同一组数据集进行反复学习,得到一系列简单模型,然后组合这些模型构成一个预测性能十分强大的机器学习模型。</strong> 显然,Boosting思想提高最终的预测效果是通过不断减少偏差的形式,与Bagging有着本质的不同。在Boosting这一大类方法中,笔者主要介绍两类常用的Boosting方式:Adaptive Boosting 和 Gradient Boosting 以及它们的变体Xgboost、LightGBM以及Catboost。</p>
+ <h1 id="1-导论"><a href="#1-导论" class="headerlink" title="1. 导论"></a>1. 导论</h1><p>在前面的学习中,我们探讨了一系列简单而实用的回归和分类模型,同时也探讨了如何使用集成学习家族中的Bagging思想去优化最终的模型。Bagging思想的实质是:通过Bootstrap 的方式对全样本数据集进行抽样得到抽样子集,对不同的子集使用同一种基本模型进行拟合,然后投票得出最终的预测。我们也从前面的探讨知道:Bagging主要通过降低方差的方式减少预测误差。<strong>那么,本章介绍的Boosting是与Bagging截然不同的思想,Boosting方法是使用同一组数据集进行反复学习,得到一系列简单模型,然后组合这些模型构成一个预测性能十分强大的机器学习模型。</strong> 显然,Boosting思想提高最终的预测效果是通过不断减少偏差的形式,与Bagging有着本质的不同。在Boosting这一大类方法中,笔者主要介绍两类常用的Boosting方式:Adaptive Boosting 和 Gradient Boosting 以及它们的变体Xgboost、LightGBM以及Catboost。<br></p>
@@ -240,7 +240,7 @@
2021-06-16T15:55:00.000Z
2024-10-09T07:33:09.916Z
- 投票法的思路投票法是集成学习中常用的技巧,可以帮助我们提高模型的泛化能力,减少模型的错误率。举个例子,在航空航天领域,每个零件发出的电信号都对航空器的成功发射起到重要作用。如果我们有一个二进制形式的信号:
11101100100111001011011011011
在传输过程中第二位发生了翻转
10101100100111001011011011011
这导致的结果可能是致命的。一个常用的纠错方法是重复多次发送数据,并以少数服从多数的方法确定正确的传输数据。一般情况下,错误总是发生在局部,因此融合多个数据是降低误差的一个好方法,这就是投票法的基本思路。
对于回归模型来说,投票法最终的预测结果是多个其他回归模型预测结果的平均值。
对于分类模型,硬投票法的预测结果是多个模型预测结果中出现次数最多的类别,软投票对各类预测结果的概率进行求和,最终选取概率之和最大的类标签。
投票法的原理分析
投票法是一种遵循少数服从多数原则的集成学习模型,通过多个模型的集成降低方差,从而提高模型的鲁棒性。在理想情况下,投票法的预测效果应当优于任何一个基模型的预测效果。
投票法在回归模型与分类模型上均可使用:
- 回归投票法:预测结果是所有模型预测结果的平均值。
- 分类投票法:预测结果是所有模型种出现最多的预测结果。
分类投票法又可以被划分为硬投票与软投票:
- 硬投票:预测结果是所有投票结果最多出现的类。
- 软投票:预测结果是所有投票结果中概率加和最大的类。
下面我们使用一个例子说明硬投票:
对于某个样本:
模型 1 的预测结果是 类别 A
模型 2 的预测结果是 类别 B
模型 3 的预测结果是 类别 B
有2/3的模型预测结果是B,因此硬投票法的预测结果是B
同样的例子说明软投票:
对于某个样本:
模型 1 的预测结果是 类别 A 的概率为 99%
模型 2 的预测结果是 类别 A 的概率为 49%
模型 3 的预测结果是 类别 A 的概率为 49%
最终对于类别A的预测概率的平均是 (99 + 49 + 49) / 3 = 65.67%,因此软投票法的预测结果是A。
从这个例子我们可以看出,软投票法与硬投票法可以得出完全不同的结论。相对于硬投票,软投票法考虑到了预测概率这一额外的信息,因此可以得出比硬投票法更加准确的预测结果。
在投票法中,我们还需要考虑到不同的基模型可能产生的影响。理论上,基模型可以是任何已被训练好的模型。但在实际应用上,想要投票法产生较好的结果,需要满足两个条件:
- 基模型之间的效果不能差别过大。当某个基模型相对于其他基模型效果过差时,该模型很可能成为噪声。
- 基模型之间应该有较小的同质性。例如在基模型预测效果近似的情况下,基于树模型与线性模型的投票,往往优于两个树模型或两个线性模型。
当投票合集中使用的模型能预测出清晰的类别标签时,适合使用硬投票。当投票集合中使用的模型能预测类别的概率时,适合使用软投票。软投票同样可以用于那些本身并不预测类成员概率的模型,只要他们可以输出类似于概率的预测分数值(例如支持向量机、k-最近邻和决策树)。
投票法的局限性在于,它对所有模型的处理是一样的,这意味着所有模型对预测的贡献是一样的。如果一些模型在某些情况下很好,而在其他情况下很差,这是使用投票法时需要考虑到的一个问题。
投票法的案例分析(基于sklearn,介绍pipe管道的使用以及voting的使用)
Sklearn中提供了 VotingRegressor 与 VotingClassifier 两个投票方法。 这两种模型的操作方式相同,并采用相同的参数。使用模型需要提供一个模型列表,列表中每个模型采用Tuple的结构表示,第一个元素代表名称,第二个元素代表模型,需要保证每个模型必须拥有唯一的名称。
例如这里,我们定义两个模型:
models = [('lr',LogisticRegression()),('svm',SVC())]
ensemble = VotingClassifier(estimators=models)
有时某些模型需要一些预处理操作,我们可以为他们定义Pipeline完成模型预处理工作:
models = [('lr',LogisticRegression()),('svm',make_pipeline(StandardScaler(),SVC()))]
ensemble = VotingClassifier(estimators=models)
模型还提供了voting参数让我们选择软投票或者硬投票:
models = [('lr',LogisticRegression()),('svm',SVC())]
ensemble = VotingClassifier(estimators=models, voting='soft')
下面我们使用一个完整的例子演示投票法的使用:
首先我们创建一个1000个样本,20个特征的随机数据集:
# test classification dataset
from sklearn.datasets import make_classification
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=2)
# summarize the dataset
print(X.shape, y.shape)
我们使用多个KNN模型作为基模型演示投票法,其中每个模型采用不同的邻居值K参数:
# get a voting ensemble of models
def get_voting():
# define the base models
models = list()
models.append(('knn1', KNeighborsClassifier(n_neighbors=1)))
models.append(('knn3', KNeighborsClassifier(n_neighbors=3)))
models.append(('knn5', KNeighborsClassifier(n_neighbors=5)))
models.append(('knn7', KNeighborsClassifier(n_neighbors=7)))
models.append(('knn9', KNeighborsClassifier(n_neighbors=9)))
# define the voting ensemble
ensemble = VotingClassifier(estimators=models, voting='hard')
return ensemble
然后,我们可以创建一个模型列表来评估投票带来的提升,包括KNN模型配置的每个独立版本和硬投票模型。下面的get_models()函数可以为我们创建模型列表进行评估。
# get a list of models to evaluate
def get_models():
models = dict()
models['knn1'] = KNeighborsClassifier(n_neighbors=1)
models['knn3'] = KNeighborsClassifier(n_neighbors=3)
models['knn5'] = KNeighborsClassifier(n_neighbors=5)
models['knn7'] = KNeighborsClassifier(n_neighbors=7)
models['knn9'] = KNeighborsClassifier(n_neighbors=9)
models['hard_voting'] = get_voting()
return models
下面的evaluate_model()函数接收一个模型实例,并以分层10倍交叉验证三次重复的分数列表的形式返回。
# evaluate a give model using cross-validation
def evaluate_model(model, X, y):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise')
return scores
然后,我们可以报告每个算法的平均性能,还可以创建一个箱形图和须状图来比较每个算法的精度分数分布。
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model, X, y)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()
我们得到的结果如下:
>knn1 0.873 (0.030)
>knn3 0.889 (0.038)
>knn5 0.895 (0.031)
>knn7 0.899 (0.035)
>knn9 0.900 (0.033)
>hard_voting 0.902 (0.034)
显然投票的效果略大于任何一个基模型。
通过箱形图我们可以看到硬投票方法对交叉验证整体预测结果分布带来的提升。
bagging的思路
与投票法不同的是,Bagging不仅仅集成模型最后的预测结果,同时采用一定策略来影响基模型训练,保证基模型可以服从一定的假设。 在上一章中我们提到,希望各个模型之间具有较大的差异性,而在实际操作中的模型却往往是同质的,因此一个简单的思路是通过不同的采样增加模型的差异性。
bagging的原理分析
Bagging的核心在于自助采样(bootstrap)这一概念,即有放回的从数据集中进行采样,也就是说,同样的一个样本可能被多次进行采样。 一个自助采样的小例子是我们希望估计全国所有人口年龄的平均值,那么我们可以在全国所有人口中随机抽取不同的集合(这些集合可能存在交集),计算每个集合的平均值,然后将所有平均值的均值作为估计值。
首先我们随机取出一个样本放入采样集合中,再把这个样本放回初始数据集,重复K次采样,最终我们可以获得一个大小为K的样本集合。同样的方法, 我们可以采样出T个含K个样本的采样集合,然后基于每个采样集合训练出一个基学习器,再将这些基学习器进行结合,这就是Bagging的基本流程。
对回归问题的预测是通过预测取平均值来进行的。对于分类问题的预测是通过对预测取多数票预测来进行的。Bagging方法之所以有效,是因为每个模型都是在略微不同的训练数据集上拟合完成的,这又使得每个基模型之间存在略微的差异,使每个基模型拥有略微不同的训练能力。
Bagging同样是一种降低方差的技术,因此它在不剪枝决策树、神经网络等易受样本扰动的学习器上效果更加明显。在实际的使用中,加入列采样的Bagging技术对高维小样本往往有神奇的效果。
bagging的案例分析(基于sklearn,介绍随机森林的相关理论以及实例)
Sklearn为我们提供了 BaggingRegressor 与 BaggingClassifier 两种Bagging方法的API,我们在这里通过一个完整的例子演示Bagging在分类问题上的具体应用。这里两种方法的默认基模型是树模型。
我们创建一个含有1000个样本20维特征的随机分类数据集:
# test classification dataset
from sklearn.datasets import make_classification
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=5)
# summarize the dataset
print(X.shape, y.shape)
我们将使用重复的分层k-fold交叉验证来评估该模型,一共重复3次,每次有10个fold。我们将评估该模型在所有重复交叉验证中性能的平均值和标准差。
# evaluate bagging algorithm for classification
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.ensemble import BaggingClassifier
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=5)
# define the model
model = BaggingClassifier()
# evaluate the model
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise')
# report performance
print('Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))
最终模型的效果是Accuracy: 0.856 标准差0.037
]]>
+ 投票法的思路投票法是集成学习中常用的技巧,可以帮助我们提高模型的泛化能力,减少模型的错误率。举个例子,在航空航天领域,每个零件发出的电信号都对航空器的成功发射起到重要作用。如果我们有一个二进制形式的信号:
11101100100111001011011011011
在传输过程中第二位发生了翻转
10101100100111001011011011011
这导致的结果可能是致命的。一个常用的纠错方法是重复多次发送数据,并以少数服从多数的方法确定正确的传输数据。一般情况下,错误总是发生在局部,因此融合多个数据是降低误差的一个好方法,这就是投票法的基本思路。
对于回归模型来说,投票法最终的预测结果是多个其他回归模型预测结果的平均值。
对于分类模型,硬投票法的预测结果是多个模型预测结果中出现次数最多的类别,软投票对各类预测结果的概率进行求和,最终选取概率之和最大的类标签。
投票法的原理分析
投票法是一种遵循少数服从多数原则的集成学习模型,通过多个模型的集成降低方差,从而提高模型的鲁棒性。在理想情况下,投票法的预测效果应当优于任何一个基模型的预测效果。
投票法在回归模型与分类模型上均可使用:
- 回归投票法:预测结果是所有模型预测结果的平均值。
- 分类投票法:预测结果是所有模型种出现最多的预测结果。
分类投票法又可以被划分为硬投票与软投票:
- 硬投票:预测结果是所有投票结果最多出现的类。
- 软投票:预测结果是所有投票结果中概率加和最大的类。
下面我们使用一个例子说明硬投票:
对于某个样本:
模型 1 的预测结果是 类别 A
模型 2 的预测结果是 类别 B
模型 3 的预测结果是 类别 B
有2/3的模型预测结果是B,因此硬投票法的预测结果是B
同样的例子说明软投票:
对于某个样本:
模型 1 的预测结果是 类别 A 的概率为 99%
模型 2 的预测结果是 类别 A 的概率为 49%
模型 3 的预测结果是 类别 A 的概率为 49%
最终对于类别A的预测概率的平均是 (99 + 49 + 49) / 3 = 65.67%,因此软投票法的预测结果是A。
从这个例子我们可以看出,软投票法与硬投票法可以得出完全不同的结论。相对于硬投票,软投票法考虑到了预测概率这一额外的信息,因此可以得出比硬投票法更加准确的预测结果。
在投票法中,我们还需要考虑到不同的基模型可能产生的影响。理论上,基模型可以是任何已被训练好的模型。但在实际应用上,想要投票法产生较好的结果,需要满足两个条件:
- 基模型之间的效果不能差别过大。当某个基模型相对于其他基模型效果过差时,该模型很可能成为噪声。
- 基模型之间应该有较小的同质性。例如在基模型预测效果近似的情况下,基于树模型与线性模型的投票,往往优于两个树模型或两个线性模型。
当投票合集中使用的模型能预测出清晰的类别标签时,适合使用硬投票。当投票集合中使用的模型能预测类别的概率时,适合使用软投票。软投票同样可以用于那些本身并不预测类成员概率的模型,只要他们可以输出类似于概率的预测分数值(例如支持向量机、k-最近邻和决策树)。
投票法的局限性在于,它对所有模型的处理是一样的,这意味着所有模型对预测的贡献是一样的。如果一些模型在某些情况下很好,而在其他情况下很差,这是使用投票法时需要考虑到的一个问题。
投票法的案例分析(基于sklearn,介绍pipe管道的使用以及voting的使用)
Sklearn中提供了 VotingRegressor 与 VotingClassifier 两个投票方法。 这两种模型的操作方式相同,并采用相同的参数。使用模型需要提供一个模型列表,列表中每个模型采用Tuple的结构表示,第一个元素代表名称,第二个元素代表模型,需要保证每个模型必须拥有唯一的名称。
例如这里,我们定义两个模型:
models = [('lr',LogisticRegression()),('svm',SVC())]
ensemble = VotingClassifier(estimators=models)
有时某些模型需要一些预处理操作,我们可以为他们定义Pipeline完成模型预处理工作:
models = [('lr',LogisticRegression()),('svm',make_pipeline(StandardScaler(),SVC()))]
ensemble = VotingClassifier(estimators=models)
模型还提供了voting参数让我们选择软投票或者硬投票:
models = [('lr',LogisticRegression()),('svm',SVC())]
ensemble = VotingClassifier(estimators=models, voting='soft')
下面我们使用一个完整的例子演示投票法的使用:
首先我们创建一个1000个样本,20个特征的随机数据集:
# test classification dataset
from sklearn.datasets import make_classification
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=2)
# summarize the dataset
print(X.shape, y.shape)
我们使用多个KNN模型作为基模型演示投票法,其中每个模型采用不同的邻居值K参数:
# get a voting ensemble of models
def get_voting():
# define the base models
models = list()
models.append(('knn1', KNeighborsClassifier(n_neighbors=1)))
models.append(('knn3', KNeighborsClassifier(n_neighbors=3)))
models.append(('knn5', KNeighborsClassifier(n_neighbors=5)))
models.append(('knn7', KNeighborsClassifier(n_neighbors=7)))
models.append(('knn9', KNeighborsClassifier(n_neighbors=9)))
# define the voting ensemble
ensemble = VotingClassifier(estimators=models, voting='hard')
return ensemble
然后,我们可以创建一个模型列表来评估投票带来的提升,包括KNN模型配置的每个独立版本和硬投票模型。下面的get_models()函数可以为我们创建模型列表进行评估。
# get a list of models to evaluate
def get_models():
models = dict()
models['knn1'] = KNeighborsClassifier(n_neighbors=1)
models['knn3'] = KNeighborsClassifier(n_neighbors=3)
models['knn5'] = KNeighborsClassifier(n_neighbors=5)
models['knn7'] = KNeighborsClassifier(n_neighbors=7)
models['knn9'] = KNeighborsClassifier(n_neighbors=9)
models['hard_voting'] = get_voting()
return models
下面的evaluate_model()函数接收一个模型实例,并以分层10倍交叉验证三次重复的分数列表的形式返回。
# evaluate a give model using cross-validation
def evaluate_model(model, X, y):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise')
return scores
然后,我们可以报告每个算法的平均性能,还可以创建一个箱形图和须状图来比较每个算法的精度分数分布。
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model, X, y)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()
我们得到的结果如下:
>knn1 0.873 (0.030)
>knn3 0.889 (0.038)
>knn5 0.895 (0.031)
>knn7 0.899 (0.035)
>knn9 0.900 (0.033)
>hard_voting 0.902 (0.034)
显然投票的效果略大于任何一个基模型。
通过箱形图我们可以看到硬投票方法对交叉验证整体预测结果分布带来的提升。
bagging的思路
与投票法不同的是,Bagging不仅仅集成模型最后的预测结果,同时采用一定策略来影响基模型训练,保证基模型可以服从一定的假设。 在上一章中我们提到,希望各个模型之间具有较大的差异性,而在实际操作中的模型却往往是同质的,因此一个简单的思路是通过不同的采样增加模型的差异性。
bagging的原理分析
Bagging的核心在于自助采样(bootstrap)这一概念,即有放回的从数据集中进行采样,也就是说,同样的一个样本可能被多次进行采样。 一个自助采样的小例子是我们希望估计全国所有人口年龄的平均值,那么我们可以在全国所有人口中随机抽取不同的集合(这些集合可能存在交集),计算每个集合的平均值,然后将所有平均值的均值作为估计值。
首先我们随机取出一个样本放入采样集合中,再把这个样本放回初始数据集,重复K次采样,最终我们可以获得一个大小为K的样本集合。同样的方法, 我们可以采样出T个含K个样本的采样集合,然后基于每个采样集合训练出一个基学习器,再将这些基学习器进行结合,这就是Bagging的基本流程。
对回归问题的预测是通过预测取平均值来进行的。对于分类问题的预测是通过对预测取多数票预测来进行的。Bagging方法之所以有效,是因为每个模型都是在略微不同的训练数据集上拟合完成的,这又使得每个基模型之间存在略微的差异,使每个基模型拥有略微不同的训练能力。
Bagging同样是一种降低方差的技术,因此它在不剪枝决策树、神经网络等易受样本扰动的学习器上效果更加明显。在实际的使用中,加入列采样的Bagging技术对高维小样本往往有神奇的效果。
bagging的案例分析(基于sklearn,介绍随机森林的相关理论以及实例)
Sklearn为我们提供了 BaggingRegressor 与 BaggingClassifier 两种Bagging方法的API,我们在这里通过一个完整的例子演示Bagging在分类问题上的具体应用。这里两种方法的默认基模型是树模型。
我们创建一个含有1000个样本20维特征的随机分类数据集:
# test classification dataset
from sklearn.datasets import make_classification
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=5)
# summarize the dataset
print(X.shape, y.shape)
我们将使用重复的分层k-fold交叉验证来评估该模型,一共重复3次,每次有10个fold。我们将评估该模型在所有重复交叉验证中性能的平均值和标准差。
# evaluate bagging algorithm for classification
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.ensemble import BaggingClassifier
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=5)
# define the model
model = BaggingClassifier()
# evaluate the model
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise')
# report performance
print('Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))
最终模型的效果是Accuracy: 0.856 标准差0.037
]]>
@@ -250,7 +250,7 @@
<p>10101100100111001011011011011</p>
<p>这导致的结果可能是致命的。一个常用的纠错方法是重复多次发送数据,并以少数服从多数的方法确定正确的传输数据。一般情况下,错误总是发生在局部,因此融合多个数据是降低误差的一个好方法,这就是投票法的基本思路。</p>
<p>对于回归模型来说,投票法最终的预测结果是多个其他回归模型预测结果的平均值。</p>
-<p>对于分类模型,<strong>硬投票法</strong>的预测结果是多个模型预测结果中出现次数最多的类别,<strong>软投票</strong>对各类预测结果的概率进行求和,最终选取概率之和最大的类标签。</p>
+<p>对于分类模型,<strong>硬投票法</strong>的预测结果是多个模型预测结果中出现次数最多的类别,<strong>软投票</strong>对各类预测结果的概率进行求和,最终选取概率之和最大的类标签。<br></p>
@@ -269,11 +269,11 @@
2021-06-15T13:48:00.000Z
2024-10-09T07:33:09.908Z
- 数据结构与算法——二分最近leetcode每日一题经常出二分的题目,正好对前段时间学过的二分进行一些总结,首先这里要明确的一点是,二分的本质并不是单调性,而是通过某种条件将整个区间划分成满足条件和不满足条件的两端即可进行二分查找。
在二分这个专题,主要有两种类型的划分方式,一种是整数划分,一种是浮点数划分,前一种一般是我们最熟悉的二分查找的题型,也是出题比较灵活考的比较多的一种,后一种主要是为控制实数精度而设置的浮点数二分法(建议用double,float有时候会出现精度丢失)。
整数二分
这里我们拿一道经典例题来给出我们二分的两个十分精妙的模板。AcWing789. 数的范围
bool check(int x) {/* ... */} // 检查x是否满足某种性质
// 区间[l, r]被划分成[l, mid]和[mid + 1, r]时使用:
int bsearch_1(int l, int r)
{
while(l < r)
{
int mid = l + r >> 1; // 如果写r=mid则这里不需要+1
if(check(mid)) r = mid; // check()判断mid是否满足性质
else l = mid + 1;
}
return l; //退出时 l与r相等
}
// 区间[l, r]被划分成[l, mid - 1]和[mid, r]时使用:
int bsearch_2(int l, int r)
{
while(l < r)
{
int mid = l + r + 1 >> 1;
if(check(mid)) l = mid;
else r = mid - 1;
}
return l;
}
浮点数二分
浮点数二分考的比较少,主要是实现对于高精度答案的控制。AcWing 790. 数的三次方根
这里有个小bug需要提醒一下,我们以求二次方根为例,我们可以知道,$x=0.01$时,$\sqrt{x}=0.1>x$,所以当我们把二分的区间设置成$[0,x]$时,我们则无法找到答案,所以设置区间的时候我们最好可以设置大一点的区间,或者设置成$[0,\max(1,x)]$
bool check(double x) {/* ... */} // 检查x是否满足某种性质
double bsearch_3(double l, double r)
{
const double eps = 1e-8; // eps 表示精度,取决于题目对精度的要求
while(r - l > eps)
{
double mid = (l + r) / 2; // 对于浮点数二分则不需要考虑+1的问题
if(check(mid)) r = mid;
else l = mid;
}
return l;
}
STL
做题当中手写二分的题其实比较少,基本上记忆上述模板就能解决所以的问题,同时我们在日常做题的时候,为了方便,我们通常是使用STL当中的函数来实现二分,且支持vector,map,set等操作,还有结构体大小比较,这里就有三个一定要记住的API。头文件引入:#include<algorithm>
binary_search
功能:二分查找某个元素是否出现。
返回值:在数组中以二分法检索的方式查找,若在数组(要求数组元素非递减)中查找到indx元素则真,若查找不到则返回值为假。
用法实例:
a.数组用法
int a[100]= {4,10,11,30,69,70,96,100};
int b=binary_search(a,a+9,4);//查找成功,返回1
cout<<"在数组中查找元素4,结果为:"<<b<<endl;
b.vector用法
vector<int> res = {1,2,3};
cout<<binary_search(res.begin(),res.end(),3)<<endl;
lower_bound
功能:查找非递减序列[first,last) 内第一个大于或等于某个元素的位置。
返回值:如果找到返回找到元素的地址否则返回数组边界的下一个元素的地址。(这样不注意的话会越界,小心)
用法实例:
int a[100]= {4,10,11,30,69,70,96,100};
int d=lower_bound(a,a+9,10)-a;
cout<<"在数组中查找第一个大于等于10的元素位置,结果为:"<<d<<endl;
int e=lower_bound(a,a+9,101)-a;
cout<<"在数组中查找第一个大于等于101的元素位置,结果为:"<<e<<endl;
b.vector用法
vector<int> res = {1,2,3};
vector<int>::iterator it = lower_bound(res.begin(),res.end(),3);//返回迭代器的位置
//如果不存在,迭代器的位置会返回res.end()
if(it==res.end()) cout<<"不存在"<<endl;
else cout<<"求出下标:"<<(it - res.begin())<<endl;
//也可以添加偏移量
vector<int>::iterator it = lower_bound(res.begin()+1,res.end(),3);
upper_bound
功能:查找非递减序列[first,last) 内第一个大于某个元素的位置。
返回值:如果找到返回找到元素的地址,否则返回数组边界的下一个元素的地址。(同样这样不注意的话会越界,小心)
用法实例:
int a[100]= {4,10,11,30,69,70,96,100};
int d=upper_bound(a,a+9,10)-a;
cout<<"在数组中查找第一个大于等于10的元素位置,结果为:"<<d<<endl;
int e=upper_bound(a,a+9,101)-a;
cout<<"在数组中查找第一个大于等于101的元素位置,结果为:"<<e<<endl;
b.vector用法
vector<int> res = {1,2,3};
vector<int>::iterator it = upper_bound(res.begin(),res.end(),3);//返回迭代器的位置
//如果不存在,迭代器的位置会返回res.end()
if(it==res.end()) cout<<"不存在"<<endl;
else cout<<"求出下标:"<<(it - res.begin())<<endl;
//也可以添加偏移量
vector<int>::iterator it = upper_bound(res.begin()+1,res.end(),3);
经典例题
这里我顺便给出这两天的每日一题的解题方案,里面还涉及到了一个防止溢出的二分处理trick。
猜数字大小
/**
* Forward declaration of guess API.
* @param num your guess
* @return -1 if num is lower than the guess number
* 1 if num is higher than the guess number
* otherwise return 0
* int guess(int num);
*/
class Solution {
public:
int guessNumber(int n) {
int l = 1;
int r = n;
while(l<r)
{
int mid = l + (r - l >> 1);//防止溢出
if(guess(mid)<=0)
r = mid;
else
l = mid + 1;
}
return r;
}
};
class Solution {
public:
int peakIndexInMountainArray(vector<int>& arr) {
int l = 0;
int r = arr.size() - 1;
while(l<r)
{
int mid = l + r >> 1;
if(arr[mid]>arr[mid+1]) r = mid;
else l = mid+1;
}
return l;
}
};
这是三叶姐姐的二分经典题型汇总,大家也可以参考一下。
]]>
+ 数据结构与算法——二分最近leetcode每日一题经常出二分的题目,正好对前段时间学过的二分进行一些总结,首先这里要明确的一点是,二分的本质并不是单调性,而是通过某种条件将整个区间划分成满足条件和不满足条件的两端即可进行二分查找。
在二分这个专题,主要有两种类型的划分方式,一种是整数划分,一种是浮点数划分,前一种一般是我们最熟悉的二分查找的题型,也是出题比较灵活考的比较多的一种,后一种主要是为控制实数精度而设置的浮点数二分法(建议用double,float有时候会出现精度丢失)。
整数二分
这里我们拿一道经典例题来给出我们二分的两个十分精妙的模板。AcWing789. 数的范围
bool check(int x) {/* ... */} // 检查x是否满足某种性质
// 区间[l, r]被划分成[l, mid]和[mid + 1, r]时使用:
int bsearch_1(int l, int r)
{
while(l < r)
{
int mid = l + r >> 1; // 如果写r=mid则这里不需要+1
if(check(mid)) r = mid; // check()判断mid是否满足性质
else l = mid + 1;
}
return l; //退出时 l与r相等
}
// 区间[l, r]被划分成[l, mid - 1]和[mid, r]时使用:
int bsearch_2(int l, int r)
{
while(l < r)
{
int mid = l + r + 1 >> 1;
if(check(mid)) l = mid;
else r = mid - 1;
}
return l;
}
浮点数二分
浮点数二分考的比较少,主要是实现对于高精度答案的控制。AcWing 790. 数的三次方根
这里有个小bug需要提醒一下,我们以求二次方根为例,我们可以知道,$x=0.01$时,$\sqrt{x}=0.1>x$,所以当我们把二分的区间设置成$[0,x]$时,我们则无法找到答案,所以设置区间的时候我们最好可以设置大一点的区间,或者设置成$[0,\max(1,x)]$
bool check(double x) {/* ... */} // 检查x是否满足某种性质
double bsearch_3(double l, double r)
{
const double eps = 1e-8; // eps 表示精度,取决于题目对精度的要求
while(r - l > eps)
{
double mid = (l + r) / 2; // 对于浮点数二分则不需要考虑+1的问题
if(check(mid)) r = mid;
else l = mid;
}
return l;
}
STL
做题当中手写二分的题其实比较少,基本上记忆上述模板就能解决所以的问题,同时我们在日常做题的时候,为了方便,我们通常是使用STL当中的函数来实现二分,且支持vector,map,set等操作,还有结构体大小比较,这里就有三个一定要记住的API。头文件引入:#include<algorithm>
binary_search
功能:二分查找某个元素是否出现。
返回值:在数组中以二分法检索的方式查找,若在数组(要求数组元素非递减)中查找到indx元素则真,若查找不到则返回值为假。
用法实例:
a.数组用法
int a[100]= {4,10,11,30,69,70,96,100};
int b=binary_search(a,a+9,4);//查找成功,返回1
cout<<"在数组中查找元素4,结果为:"<<b<<endl;
b.vector用法
vector<int> res = {1,2,3};
cout<<binary_search(res.begin(),res.end(),3)<<endl;
lower_bound
功能:查找非递减序列[first,last) 内第一个大于或等于某个元素的位置。
返回值:如果找到返回找到元素的地址否则返回数组边界的下一个元素的地址。(这样不注意的话会越界,小心)
用法实例:
int a[100]= {4,10,11,30,69,70,96,100};
int d=lower_bound(a,a+9,10)-a;
cout<<"在数组中查找第一个大于等于10的元素位置,结果为:"<<d<<endl;
int e=lower_bound(a,a+9,101)-a;
cout<<"在数组中查找第一个大于等于101的元素位置,结果为:"<<e<<endl;
b.vector用法
vector<int> res = {1,2,3};
vector<int>::iterator it = lower_bound(res.begin(),res.end(),3);//返回迭代器的位置
//如果不存在,迭代器的位置会返回res.end()
if(it==res.end()) cout<<"不存在"<<endl;
else cout<<"求出下标:"<<(it - res.begin())<<endl;
//也可以添加偏移量
vector<int>::iterator it = lower_bound(res.begin()+1,res.end(),3);
upper_bound
功能:查找非递减序列[first,last) 内第一个大于某个元素的位置。
返回值:如果找到返回找到元素的地址,否则返回数组边界的下一个元素的地址。(同样这样不注意的话会越界,小心)
用法实例:
int a[100]= {4,10,11,30,69,70,96,100};
int d=upper_bound(a,a+9,10)-a;
cout<<"在数组中查找第一个大于等于10的元素位置,结果为:"<<d<<endl;
int e=upper_bound(a,a+9,101)-a;
cout<<"在数组中查找第一个大于等于101的元素位置,结果为:"<<e<<endl;
b.vector用法
vector<int> res = {1,2,3};
vector<int>::iterator it = upper_bound(res.begin(),res.end(),3);//返回迭代器的位置
//如果不存在,迭代器的位置会返回res.end()
if(it==res.end()) cout<<"不存在"<<endl;
else cout<<"求出下标:"<<(it - res.begin())<<endl;
//也可以添加偏移量
vector<int>::iterator it = upper_bound(res.begin()+1,res.end(),3);
经典例题
这里我顺便给出这两天的每日一题的解题方案,里面还涉及到了一个防止溢出的二分处理trick。
猜数字大小
/**
* Forward declaration of guess API.
* @param num your guess
* @return -1 if num is lower than the guess number
* 1 if num is higher than the guess number
* otherwise return 0
* int guess(int num);
*/
class Solution {
public:
int guessNumber(int n) {
int l = 1;
int r = n;
while(l<r)
{
int mid = l + (r - l >> 1);//防止溢出
if(guess(mid)<=0)
r = mid;
else
l = mid + 1;
}
return r;
}
};
山脉数组的峰顶索引
class Solution {
public:
int peakIndexInMountainArray(vector<int>& arr) {
int l = 0;
int r = arr.size() - 1;
while(l<r)
{
int mid = l + r >> 1;
if(arr[mid]>arr[mid+1]) r = mid;
else l = mid+1;
}
return l;
}
};
这是三叶姐姐的二分经典题型汇总,大家也可以参考一下。
]]>
- <h2 id="数据结构与算法——二分"><a href="#数据结构与算法——二分" class="headerlink" title="数据结构与算法——二分"></a>数据结构与算法——二分</h2><p>最近leetcode每日一题经常出二分的题目,正好对前段时间学过的二分进行一些总结,首先这里要明确的一点是,<strong>二分的本质并不是单调性,而是通过某种条件将整个区间划分成满足条件和不满足条件的两端即可进行二分查找。</strong><br>在二分这个专题,主要有两种类型的划分方式,一种是整数划分,一种是浮点数划分,前一种一般是我们最熟悉的二分查找的题型,也是出题比较灵活考的比较多的一种,后一种主要是为控制实数精度而设置的浮点数二分法(建议用<code>double</code>,<code>float</code>有时候会出现精度丢失)。</p>
+ <h2 id="数据结构与算法——二分"><a href="#数据结构与算法——二分" class="headerlink" title="数据结构与算法——二分"></a>数据结构与算法——二分</h2><p>最近leetcode每日一题经常出二分的题目,正好对前段时间学过的二分进行一些总结,首先这里要明确的一点是,<strong>二分的本质并不是单调性,而是通过某种条件将整个区间划分成满足条件和不满足条件的两端即可进行二分查找。</strong><br>在二分这个专题,主要有两种类型的划分方式,一种是整数划分,一种是浮点数划分,前一种一般是我们最熟悉的二分查找的题型,也是出题比较灵活考的比较多的一种,后一种主要是为控制实数精度而设置的浮点数二分法(建议用<code>double</code>,<code>float</code>有时候会出现精度丢失)。<br></p>
@@ -290,11 +290,11 @@
2021-06-13T07:49:00.000Z
2024-10-09T07:33:09.908Z
- 数据结构与刷题——链表
单链表代码模板
代码实现单链表的方法有很多种,但是对于acm刷题来说,我们通常使用的是静态链表的方式,这样代码运行速度更快,防止被卡时间。
const int N = 100010;
int head; // 头指针
int e[N]; // e[i]表示第i个节点的
int ne[N];// 第i个节点的next指针,表示当前节点的直接后继的节点编号
int idx;//记录已经存储了多少个节点
void init()
{
head = -1;//用-1表示空节点
idx = 0;
}
//在第k个节点后面插入一个新节点,节点的值为x
void insert(int k,int x)
{
e[idx] = x;
ne[idx] = ne[k];
ne[k] = idx++;
}
// 删除第k+1个节点,即将将该节点的指针指向他的下一个元素
void delete_node(int k)
{
ne[k] = ne[ne[k]];
}
void delete_head()
{
head = ne[head];
}
//遍历过程
for(int i = head; i!=-1;i = ne[i])
{
cout<<e[i]<<endl;
}
双链表
在实际的代码编写过程当中,我们也是直接使用静态链表来设置双链表,我们首先设置0号点和1号点为左右边界head,tail。之后我们就只需要在这两者之间插入节点构造双链表。
const int N = 100010;
int e[N];
int l[N];
int r[N];
int idx;
//初始化直接初始化出左右端点的下标,从而避免边界问题
void init()
{
//初始化的左右别搞反了
r[0] = 1;
l[1] = 0;
idx =2;
}
// 在k节点的右侧插入一个x,其实也相当于左侧插入节点
void add(int k,int x)
{
e[idx] = x;
//操作新节点的左右指针
r[idx] = r[k];
l[idx] = k;
//再操作原数组的节点
l[r[k]] = idx;
r[k] = idx++;
}
void remove(int k)
{
l[r[k]] = l[k]; //右节点的左侧,指向左节点
r[l[k]] = r[k]; //左节点的右侧,指向右节点
}
经典例题
以上两种实现方式都是通过静态链表实现的,主要是来自y总的AcWing经典例题。
AcWing826. 单链表
AcWing827. 双链表
使用指针的实现方式,在leetcode当中用的比较多,这里给大家补充一些leetcode中出现的链表类型的题目,主要涉及到链表的遍历,双指针算法,和一些小技巧,高阶一点的题目会涉及到树和递归的问题。
我做的主要是leetcode上程序员面试经典和剑指offer的例题,不过个人感觉这些题也大部分涵盖了链表题型的大部分考法,而且题解也十分详细。


]]>
+ 数据结构与刷题——链表单链表代码模板
代码实现单链表的方法有很多种,但是对于acm刷题来说,我们通常使用的是静态链表的方式,这样代码运行速度更快,防止被卡时间。
const int N = 100010;
int head; // 头指针
int e[N]; // e[i]表示第i个节点的
int ne[N];// 第i个节点的next指针,表示当前节点的直接后继的节点编号
int idx;//记录已经存储了多少个节点
void init()
{
head = -1;//用-1表示空节点
idx = 0;
}
//在第k个节点后面插入一个新节点,节点的值为x
void insert(int k,int x)
{
e[idx] = x;
ne[idx] = ne[k];
ne[k] = idx++;
}
// 删除第k+1个节点,即将将该节点的指针指向他的下一个元素
void delete_node(int k)
{
ne[k] = ne[ne[k]];
}
void delete_head()
{
head = ne[head];
}
//遍历过程
for(int i = head; i!=-1;i = ne[i])
{
cout<<e[i]<<endl;
}
双链表
在实际的代码编写过程当中,我们也是直接使用静态链表来设置双链表,我们首先设置0号点和1号点为左右边界head,tail。之后我们就只需要在这两者之间插入节点构造双链表。
const int N = 100010;
int e[N];
int l[N];
int r[N];
int idx;
//初始化直接初始化出左右端点的下标,从而避免边界问题
void init()
{
//初始化的左右别搞反了
r[0] = 1;
l[1] = 0;
idx =2;
}
// 在k节点的右侧插入一个x,其实也相当于左侧插入节点
void add(int k,int x)
{
e[idx] = x;
//操作新节点的左右指针
r[idx] = r[k];
l[idx] = k;
//再操作原数组的节点
l[r[k]] = idx;
r[k] = idx++;
}
void remove(int k)
{
l[r[k]] = l[k]; //右节点的左侧,指向左节点
r[l[k]] = r[k]; //左节点的右侧,指向右节点
}
经典例题
以上两种实现方式都是通过静态链表实现的,主要是来自y总的AcWing经典例题。
AcWing826. 单链表
AcWing827. 双链表
使用指针的实现方式,在leetcode当中用的比较多,这里给大家补充一些leetcode中出现的链表类型的题目,主要涉及到链表的遍历,双指针算法,和一些小技巧,高阶一点的题目会涉及到树和递归的问题。
我做的主要是leetcode上程序员面试经典和剑指offer的例题,不过个人感觉这些题也大部分涵盖了链表题型的大部分考法,而且题解也十分详细。
]]>
- <h2 id="数据结构与刷题——链表"><a href="#数据结构与刷题——链表" class="headerlink" title="数据结构与刷题——链表"></a>数据结构与刷题——链表</h2><p><img src="https://img-blog.csdnimg.cn/20210607085716429.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0phY2tfX19F,size_16,color_FFFFFF,t_70" alt="在这里插入图片描述"></p>
+ <h2 id="数据结构与刷题——链表"><a href="#数据结构与刷题——链表" class="headerlink" title="数据结构与刷题——链表"></a>数据结构与刷题——链表</h2><p><img src="https://img-blog.csdnimg.cn/20210607085716429.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0phY2tfX19F,size_16,color_FFFFFF,t_70" alt="在这里插入图片描述"><br></p>
@@ -311,11 +311,11 @@
2021-06-06T12:33:00.000Z
2024-10-09T07:33:09.908Z
- 前言最近在复习数据结构,顺便整理之前刷题的一些模板和技巧,希望对大家都有帮助,博客会侧重讲解的是OJ代码实现,理论部分偏少但也会写一些自己的理解。
在之前大二上数据结构的时候我也有写过一个关于排序的专题介绍数据结构复习——内部排序
快速排序
快速排序主要就是通过选取一个基准点,将一个区间内的数分成大于和小于两个部分,然后对左右区间再进行上述操作,直到子区间的长度为空为止。快速排序是不稳定的排序,如果需要变成稳定排序通过双关键字排序即可,通过下标控制绝对大小就能得到稳定的排序结果。
快速排序分三步走:
- 确定分界点
- 调整左右区间
- 递归处理左右子区间
在代码实现当中,我们一般选取中间分位点会比较好,这样划分的区间比较平均。在遍历的过程当中每次调整区间的时间是$O(n)$,而区间递归的深度类似二叉树是$O(logn)$
在最好情况下,对于递归型的算法,我们利用主定理公式来计算快速排序时间复杂度得到$O(nlogn)$
$$
T(n) = 2 T\left(\frac{n}{2}\right)+\Theta(n)
$$
当然在最坏情况下,也就是数组是有序或者逆序的情况下,我们如果选择左右端点作为基准点,那么整个算法就相当于冒泡排序,递归的层数也就变成了$n$,则最坏时间复杂度为$O(n^2)$
代码实现
void quick_sort(int[] q,int l,int r)
{
if(l>=r) return;
// 1.确定分界点
int i = l - 1, j = r + 1, mid = q[l + r >> 1];
// 2.调整左右区间
while(i<j)
{
do i++; while(q[i]<mid);
do j--; while(q[j]>mid);
if(i<j) swap(q[i],q[j]);
}
//3.递归处理左右子区间
quick_sort(l,j);
quick_sort(j+1,r);
}
经典例题
归并排序
归并排序也是基于分治的思想,每次将区间对半分,逐步递归合并有序化子区间,最终实现所有的左右区间的有序归并,但是跟快速排序不同的是,我们需要开一个辅助数组来存储有序的部分,所以时间复杂度为$O(nlogn)$。归并排序是稳定的排序,在元素相等情况下我们总是放入数组下标较小的元素。
归并排序分三步走:
- 确定分界点
- 递归处理子序列
- 合并有序序列

代码实现
const int N=100010;
int a[N],tmp[N];
void merge_sort(int q[],int l,int r)
{
if(l>=r)
return;
//确定分界点
int mid = l + r >> 1;
//递归处理子序列
merge_sort(q,l,mid);
merge_sort(q,mid+1,r);
//合并有序序列
int k = l,i = l,j = mid + 1;
while(i <= mid && j <= r)
{
if(q[i]<=q[j])// 取等号,保证归并排序的稳定性
tmp[k++]=q[i++];
else
tmp[k++]=q[j++];
}
while(i<=mid)
tmp[k++]=q[i++];
while(j<=r)
tmp[k++]=q[j++];
for(i=l;i<=r;i++)
q[i]=tmp[i];
}
经典例题
AcWing 787. 归并排序
AcWing 788. 逆序对的数量
排序相关时间复杂度整理

]]>
+ 前言最近在复习数据结构,顺便整理之前刷题的一些模板和技巧,希望对大家都有帮助,博客会侧重讲解的是OJ代码实现,理论部分偏少但也会写一些自己的理解。
在之前大二上数据结构的时候我也有写过一个关于排序的专题介绍数据结构复习——内部排序
快速排序
快速排序主要就是通过选取一个基准点,将一个区间内的数分成大于和小于两个部分,然后对左右区间再进行上述操作,直到子区间的长度为空为止。快速排序是不稳定的排序,如果需要变成稳定排序通过双关键字排序即可,通过下标控制绝对大小就能得到稳定的排序结果。
快速排序分三步走:
- 确定分界点
- 调整左右区间
- 递归处理左右子区间
在代码实现当中,我们一般选取中间分位点会比较好,这样划分的区间比较平均。在遍历的过程当中每次调整区间的时间是$O(n)$,而区间递归的深度类似二叉树是$O(logn)$
在最好情况下,对于递归型的算法,我们利用主定理公式来计算快速排序时间复杂度得到$O(nlogn)$
当然在最坏情况下,也就是数组是有序或者逆序的情况下,我们如果选择左右端点作为基准点,那么整个算法就相当于冒泡排序,递归的层数也就变成了$n$,则最坏时间复杂度为$O(n^2)$
代码实现
void quick_sort(int[] q,int l,int r)
{
if(l>=r) return;
// 1.确定分界点
int i = l - 1, j = r + 1, mid = q[l + r >> 1];
// 2.调整左右区间
while(i<j)
{
do i++; while(q[i]<mid);
do j--; while(q[j]>mid);
if(i<j) swap(q[i],q[j]);
}
//3.递归处理左右子区间
quick_sort(l,j);
quick_sort(j+1,r);
}
经典例题
归并排序
归并排序也是基于分治的思想,每次将区间对半分,逐步递归合并有序化子区间,最终实现所有的左右区间的有序归并,但是跟快速排序不同的是,我们需要开一个辅助数组来存储有序的部分,所以时间复杂度为$O(nlogn)$。归并排序是稳定的排序,在元素相等情况下我们总是放入数组下标较小的元素。
归并排序分三步走:
- 确定分界点
- 递归处理子序列
- 合并有序序列
代码实现
const int N=100010;
int a[N],tmp[N];
void merge_sort(int q[],int l,int r)
{
if(l>=r)
return;
//确定分界点
int mid = l + r >> 1;
//递归处理子序列
merge_sort(q,l,mid);
merge_sort(q,mid+1,r);
//合并有序序列
int k = l,i = l,j = mid + 1;
while(i <= mid && j <= r)
{
if(q[i]<=q[j])// 取等号,保证归并排序的稳定性
tmp[k++]=q[i++];
else
tmp[k++]=q[j++];
}
while(i<=mid)
tmp[k++]=q[i++];
while(j<=r)
tmp[k++]=q[j++];
for(i=l;i<=r;i++)
q[i]=tmp[i];
}
经典例题
AcWing 787. 归并排序
AcWing 788. 逆序对的数量
排序相关时间复杂度整理
]]>
- <h2 id="前言"><a href="#前言" class="headerlink" title="前言"></a>前言</h2><p>最近在复习数据结构,顺便整理之前刷题的一些模板和技巧,希望对大家都有帮助,博客会侧重讲解的是OJ代码实现,理论部分偏少但也会写一些自己的理解。<br>在之前大二上数据结构的时候我也有写过一个关于排序的专题介绍<a href="https://blog.csdn.net/Jack___E/article/details/102875285?spm=1001.2014.3001.5502" target="_blank" rel="noopener">数据结构复习——内部排序</a></p>
+ <h2 id="前言"><a href="#前言" class="headerlink" title="前言"></a>前言</h2><p>最近在复习数据结构,顺便整理之前刷题的一些模板和技巧,希望对大家都有帮助,博客会侧重讲解的是OJ代码实现,理论部分偏少但也会写一些自己的理解。<br>在之前大二上数据结构的时候我也有写过一个关于排序的专题介绍<a href="https://blog.csdn.net/Jack___E/article/details/102875285?spm=1001.2014.3001.5502" target="_blank" rel="noopener">数据结构复习——内部排序</a><br></p>
@@ -332,14 +332,14 @@
2021-05-09T09:44:00.000Z
2024-10-09T07:33:09.884Z
- EfficientNet论文解读和pytorch代码实现传送门
论文地址:https://arxiv.org/pdf/1905.11946.pdf
官方github:https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
github参考:https://github.com/qubvel/efficientnet
github参考:https://github.com/lukemelas/EfficientNet-PyTorch
摘要
谷歌的文章总是能让我印象深刻,不管从实验上还是论文的书写上都让人十分的佩服,不得不说这确实是一个非常creative的公司!
Convolutional Neural Networks (ConvNets) are commonly developed at a fixed resource budget, and then scaled up for better accuracy if more resources are available. In this paper, we systematically study model scaling and identify that carefully balancing network depth, width, and resolution can lead to better performance. Based on this observation, we propose a new scaling method that uniformly scales all dimensions of depth/width/resolution using a simple yet highly effective compound coefficient. We demonstrate the effectiveness of this method on scaling up MobileNets and ResNet.
卷积神经网络通常是在固定的资源预算下进行计算和发展的,如果有更多可用的资源,模型能通过缩放和扩展获得更好的效果,本文系统研究(工作量很充足)了模型缩放,并且证明了细致地平衡网络的深度,宽度,和分辨率能够得到更好的效果,基于这个观点,我们提出了一个新的尺度缩放的方法,我们提出了一个新的尺度缩放的方法即:使用一个简单且高效的复合系数统一地缩放所有网络层的深度/宽度/分辨率的维度。我们证明了该方法在扩大MobileNets和ResNet方面的有效性。
To go even further, we use neural architecture search to design a new baseline network and scale it up to obtain a family of models, called EfficientNets, which achieve much better accuracy and efficiency than previous ConvNets. In particular, our EfficientNet-B7 achieves state-of-the-art 84.3% top-1 accuracy on ImageNet, while being 8.4x smaller and 6.1x faster on inference than the best existing ConvNet. Our EfficientNets also transfer well and achieve state-of-the-art accuracy on CIFAR-100 (91.7%), Flowers (98.8%), and 3 other transfer learning datasets, with an order of magnitude fewer parameters. Source code is athttps://github.com/tensorflow/tpu/tree/
master/models/official/efficientnet.
更进一步,我们使用神经网络结构搜索设计了一个新的baseline网络架构并且对其进行缩放得到了一组模型,我们把他叫做EfficientNets。EfficientNets相比之前的ConvNets,有着更好的准确率和更高的效率。在ImageNet上达到了最好的水平即top-1准确率84.4%/top-5准确率97.1%,然而却比已有的最好的ConvNet模型小了8.4倍并且推理时间快了6.1倍。我们的EfficientNet迁移学习的效果也好,达到了最好的准确率水平CIFAR-100(91.7%),Flowers(98.8%),和其他3个迁移学习数据集合,参数少了一个数量级(with an order of magnitude fewer parameters)。
论文思想
在之前的一些工作当中,我们可以看到,有的会通过增加网络的width即增加卷积核的个数(从而增大channels)来提升网络的性能,有的会通过增加网络的深度即使用更多的层结构来提升网络的性能,有的会通过增加输入网络的分辨率来提升网络的性能。而在Efficientnet当中则重新探究了这个问题,并提出了一种组合条件这三者的网络结构,同时量化了这三者的指标。
The intuition is that deeper ConvNet can capture richer and more complex features, and generalize well on new tasks. However, deeper networks are also more difficult to train due to the vanishing gradient problem
增加网络的深度depth能够得到更加丰富、复杂的特征并且能够在其他新任务中很好的泛化性能。但是,由于逐渐消失的梯度问题,更深层的网络也更难以训练。
wider networks tend to be able to capture more fine-grained features and are easier to train. However, extremely wide but shallow networks tend to have difficulties in capturing higher level features
with更广的网络往往能够捕获更多细粒度的功能,并且更易于训练。但是,极其宽泛但较浅的网络在捕获更高级别的特征时往往会遇到困难
With higher resolution input images, ConvNets can potentially capture more fine-grained pattern,but the accuracy gain diminishes for very high resolutions
使用更高分辨率的输入图像,ConvNets可以捕获更细粒度的图案,但对于非常高分辨率的图片,准确度会降低。
作者在论文中对整个网络的运算过程和复合扩展方法进行了抽象:
首先定义了每一层卷积网络为$\mathcal{F}{i}\left(X{i}\right)$,而$X_i$是输入张量,$Y_i$是输出张量,而tensor的形状是$<H_i,W_i,C_i>$
整个卷积网络由 k 个卷积层组成,可以表示为$\mathcal{N}=\mathcal{F}{k} \odot \ldots \odot \mathcal{F}{2} \odot \mathcal{F}{1}\left(X{1}\right)=\bigodot_{j=1 \ldots k} \mathcal{F}{j}\left(X{1}\right)$
从而得到我们的整个卷积网络:
$$
\mathcal{N}=\bigodot_{i=1 \ldots s} \mathcal{F}{i}^{L{i}}\left(X_{\left\langle H_{i}, W_{i}, C_{i}\right\rangle}\right)
$$
下标 i(从 1 到 s) 表示的是 stage 的序号,$\mathcal{F}{i}^{L{i}}$表示第 i 个 stage ,它表示卷积层 $\mathcal{F}{i}$重复了${L{i}}$ 次。
为了探究$d , r , w$这三个因子对最终准确率的影响,则将$d , r , w$加入到公式中,我们可以得到抽象化后的优化问题(在指定资源限制下),其中$s.t.$代表限制条件:
- $d$用来缩放深度$\widehat{L}_i $。
- $r$用来缩放分辨率即影响$\widehat{H}_i$以及$\widehat{W}_i$。
- $w$就是用来缩放特征矩阵的channels即 $\widehat{C}_i$。
- target_memory为memory限制
- target_flops为FLOPs限制
Bigger networks with larger width, depth, or resolution tend to achieve higher accuracy, but the accuracy gain quickly saturate after reaching 80%, demonstrating the limitation of single dimension scaling
具有较大宽度,深度或分辨率的较大网络往往会实现较高的精度,但是精度增益在达到80%后会迅速饱和,这表明了单维缩放的局限性。compound scaling method
In this paper, we propose a new compound scaling method, which use a compound coefficient φ to uniformly scales network width, depth, and resolution in a principled way:
在本文中,我们提出了一种新的复合缩放方法,该方法使用一个统一的复合系数$\phi$对网络的宽度,深度和分辨率进行均匀缩放。
其中$\alpha,\beta,\gamma$是通过一个小格子搜索的方法决定的常量。通常来说,$\phi$是一个用户指定的系数来控制有多少的额外资源能够用于模型的缩放,$\alpha,\beta,\gamma$指明了怎么支配这些额外的资源分别到网络的宽度,深度,和分辨率上。尤其是,一个标准卷积操作的运算量的比例是$d,w^2,r^2$双倍的网络深度将带来双倍的运算量,但是双倍的网络宽度或分辨率将会增加运算为4倍。因为卷积操作通常在ConvNets中占据绝大部分计算量,通过3式来缩放ConvNet大约将增加$(\alpha,\beta^2,\gamma^2)$运算量。
我们限制$\alpha \cdot \beta^{2} \cdot \gamma^{2} \approx 2$所以对于任意给定的$\phi$值,我们总共的运算量将大约增加$2^{\phi}$
网络结构
文中给出了Efficientnet-B0的基准框架,在Efficientnet当中,我们所使用的激活函数是swish激活函数,整个网络分为了9个stage,在第2到第8stage是一直在堆叠MBConv结构,表格当中MBConv结构后面的数字(1或6)表示的就是MBConv中第一个1x1的卷积层会将输入特征矩阵的channels扩充为n倍。Channels表示通过该Stage后输出特征矩阵的Channels。
MBConv结构
MBConv的结构相对来说还是十分好理解的,这里是我自己画的一张结构图。
MBConv结构主要由一个1x1的expand conv(升维作用,包含BN和Swish激活函数)提升维度的倍率正是之前网络结构中看到的1和6,一个KxK的卷积深度可分离卷积Depthwise Conv(包含BN和Swish)k的具体值可看EfficientNet-B0的网络框架主要有3x3和5x5两种情况,一个SE模块,一个1x1的pointer conv降维作用,包含BN),一个Droupout层构成,一般情况下都添加上了残差边模块Shortcut,从而得到输出特征矩阵。
首先关于深度可分离卷积的概念是是我们需要了解的,相当于将卷积的过程拆成运算和合并两个过程,分别对应depthwise和point两个过程,这里给一个参考连接给大家就不在详细描述了Depthwise卷积与Pointwise卷积
1.由于该模块最初是用tensorflow来实现的与pytorch有一些小差别,所以在使用pytorch实现的时候我们最好将tensorflow当中的samepadding操作重新实现一下
2.在batchnormal时候的动量设置也是有一些不一样的,论文当中设置的batch_norm_momentum=0.99,在pytorch当中需要先执行1-momentum再设为参数与tensorflow不同。
# Batch norm parameters
momentum= 1 - batch_norm_momentum # pytorch's difference from tensorflow
eps= batch_norm_epsilon
nn.BatchNorm2d(num_features=out_channels, momentum=momentum, eps=eps)
class Conv2dSamePadding(nn.Conv2d):
"""2D Convolutions like TensorFlow, for a dynamic image size.
The padding is operated in forward function by calculating dynamically.
"""
# Tips for 'SAME' mode padding.
# Given the following:
# i: width or height
# s: stride
# k: kernel size
# d: dilation
# p: padding
# Output after Conv2d:
# o = floor((i+p-((k-1)*d+1))/s+1)
# If o equals i, i = floor((i+p-((k-1)*d+1))/s+1),
# => p = (i-1)*s+((k-1)*d+1)-i
def __init__(self, in_channels, out_channels, kernel_size,padding=0, stride=1, dilation=1,
groups=1, bias=True, padding_mode = 'zeros'):
super().__init__(in_channels, out_channels, kernel_size, stride, padding, dilation, groups, bias)
self.stride = self.stride if len(self.stride) == 2 else [self.stride[0]] * 2
def forward(self, x):
ih, iw = x.size()[-2:] # input
kh, kw = self.weight.size()[-2:] # because kernel size equals to weight size
sh, sw = self.stride # stride
# change the output size according to stride
oh, ow = math.ceil(ih/sh), math.ceil(iw/sw) # output
"""
kernel effective receptive field size: (kernel_size-1) x dilation + 1
"""
pad_h = max((oh - 1) * self.stride[0] + (kh - 1) * self.dilation[0] + 1 - ih, 0)
pad_w = max((ow - 1) * self.stride[1] + (kw - 1) * self.dilation[1] + 1 - iw, 0)
if pad_h > 0 or pad_w > 0:
x = F.pad(x, [pad_w // 2, pad_w - pad_w // 2, pad_h // 2, pad_h - pad_h // 2])
return F.conv2d(x, self.weight, self.bias, self.stride, self.padding, self.dilation, self.groups)
MBConvBlock模块结构
class ConvBNActivation(nn.Module):
"""Convolution BN Activation"""
def __init__(self,in_channels,out_channels,kernel_size,stride=1,groups=1,
bias=False,momentum=0.01,eps=1e-3,active=False):
super().__init__()
self.layer=nn.Sequential(
Conv2dSamePadding(in_channels,out_channels,kernel_size=kernel_size,
stride=stride,groups=groups, bias=bias),
nn.BatchNorm2d(num_features=out_channels, momentum=momentum, eps=eps)
)
self.active=active
self.swish = Swish()
def forward(self, x):
x = self.layer(x)
if self.active:
x=self.swish(x)
return x
class MBConvBlock(nn.Module):
def __init__(self,in_channels,out_channels,kernel_size,stride,
expand_ratio=1, momentum=0.01,eps=1e-3,
drop_connect_ratio=0.2,training=True,
se_ratio=0.25,skip=True, image_size=None):
super().__init__()
self.expand_ratio = expand_ratio
self.se_ratio = se_ratio
self.has_se = (se_ratio is not None) and (0 < se_ratio <= 1)
self.skip = skip and stride == 1 and in_channels == out_channels
# 1x1 convolution channels expansion phase
expand_channels = in_channels * self.expand_ratio # number of output channels
if self.expand_ratio != 1:
self.expand_conv = ConvBNActivation(in_channels=in_channels,out_channels=expand_channels,
momentum=momentum,eps=eps,
kernel_size=1,bias=False,active=False)
# Depthwise convolution phase
self.depthwise_conv = ConvBNActivation(in_channels=expand_channels,out_channels=expand_channels,
momentum=momentum,eps=eps,
kernel_size=kernel_size,stride=stride,groups=expand_channels,bias=False,active=False)
# Squeeze and Excitation module
if self.has_se:
sequeeze_channels = max(1,int(expand_channels*self.se_ratio))
self.se = SEModule(expand_channels,sequeeze_channels)
# Pointwise convolution phase
self.project_conv = ConvBNActivation(expand_channels,out_channels,momentum=momentum,eps=eps,
kernel_size=1,bias=False,active=True)
self.drop_connect = DropConnect(drop_connect_ratio,training)
def forward(self,x):
input_x = x
if self.expand_ratio != 1:
x = self.expand_conv(x)
x = self.depthwise_conv(x)
if self.has_se:
x = self.se(x)
x = self.project_conv(x)
if self.skip:
x = self.drop_connect(x)
x = x + input_x
return x
SE模块
SE模块是通道注意力模块,该模块能够关注channel之间的关系,可以让模型自主学习到不同channel特征的重要程度。由一个全局平均池化,两个全连接层组成。第一个全连接层的节点个数是输入该MBConv特征矩阵channels的1/4 ,且使用Swish激活函数。第二个全连接层的节点个数等于Depthwise Conv层输出的特征矩阵channels,且使用Sigmoid激活函数,这里引用一下别人画好的示意图。
class SEModule(nn.Module):
"""Squeeze and Excitation module for channel attention"""
def __init__(self,in_channels,squeezed_channels):
super().__init__()
self.global_avg_pool = nn.AdaptiveAvgPool2d(1)
self.sequential = nn.Sequential(
nn.Conv2d(in_channels,squeezed_channels,1), # use 1x1 convolution instead of linear
Swish(),
nn.Conv2d(squeezed_channels,in_channels,1),
nn.Sigmoid()
)
def forward(self,x):
x= self.global_avg_pool(x)
y = self.sequential(x)
return x * y
swish激活函数
Swish是Google提出的一种新型激活函数,其原始公式为:f(x)=x * sigmod(x),变形Swish-B激活函数的公式则为f(x)=x * sigmod(b * x),其拥有不饱和,光滑,非单调性的特征,Google在论文中的多项测试表明Swish以及Swish-B激活函数的性能即佳,在不同的数据集上都表现出了要优于当前最佳激活函数的性能。
$$f(x)=x \cdot \operatorname{sigmoid}(\beta x)$$
其中$\beta$是个常数或可训练的参数,Swish 具备无上界有下界、平滑、非单调的特性。
class Swish(nn.Module):
""" swish activation function"""
def forward(self,x):
return x * torch.sigmoid(x)
droupout代码实现
class DropConnect(nn.Module):
"""Drop Connection"""
def __init__(self,ratio,training):
super().__init__()
assert 0 <= ratio <= 1
self.keep_prob = 1 - ratio
self.training=training
def forward(self,x):
if not self.training:
return x
batch_size = x.shape[0]
random_tensor = self.keep_prob
random_tensor += torch.rand([batch_size,1,1,1],dtype=x.dtype,device=x.device)
# generate binary_tensor mask according to probability (p for 0, 1-p for 1)
binary_tensor = torch.floor(random_tensor)
output = x / self.keep_prob * binary_tensor
return output
总结
这里我们只给出了b0结构的代码实现,对于其他结构的实现过程就是在b0的基础上对wdith,depth,resolution都通过倍率因子统一缩放,这个部分在这个博客里面有详细的介绍EfficientNet(B0-B7)参数设置。
在本文中,我们系统地研究了ConvNet的缩放比例,分析了各因素对网络结构的影响,并确定仔细平衡网络的宽度,深度和分辨率,这是目前网络训练最重要但缺乏研究的部分,也是我们无法获得更好的准确性和效率忽略的一个部分。为解决此问题,本文作者提出了一种简单而高效的复合缩放方法,通过一个倍率因子统一缩放各部分比例并添加上通道注意力机制和残差模块,从而改善网络架构得到SOTA的效果,同时对模型各成分因子进行量化十分具有创新性。
参考连接
EfficientNet网络详解
神经网络学习小记录50——Pytorch EfficientNet模型的复现详解
论文翻译
令人拍案叫绝的EfficientNet和EfficientDet
swish激活函数
Depthwise卷积与Pointwise卷积
CV领域常用的注意力机制模块(SE、CBAM)
Global Average Pooling
]]>
+ EfficientNet论文解读和pytorch代码实现传送门
论文地址:https://arxiv.org/pdf/1905.11946.pdf
官方github:https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
github参考:https://github.com/qubvel/efficientnet
github参考:https://github.com/lukemelas/EfficientNet-PyTorch
摘要
谷歌的文章总是能让我印象深刻,不管从实验上还是论文的书写上都让人十分的佩服,不得不说这确实是一个非常creative的公司!
Convolutional Neural Networks (ConvNets) are commonly developed at a fixed resource budget, and then scaled up for better accuracy if more resources are available. In this paper, we systematically study model scaling and identify that carefully balancing network depth, width, and resolution can lead to better performance. Based on this observation, we propose a new scaling method that uniformly scales all dimensions of depth/width/resolution using a simple yet highly effective compound coefficient. We demonstrate the effectiveness of this method on scaling up MobileNets and ResNet.
卷积神经网络通常是在固定的资源预算下进行计算和发展的,如果有更多可用的资源,模型能通过缩放和扩展获得更好的效果,本文系统研究(工作量很充足)了模型缩放,并且证明了细致地平衡网络的深度,宽度,和分辨率能够得到更好的效果,基于这个观点,我们提出了一个新的尺度缩放的方法,我们提出了一个新的尺度缩放的方法即:使用一个简单且高效的复合系数统一地缩放所有网络层的深度/宽度/分辨率的维度。我们证明了该方法在扩大MobileNets和ResNet方面的有效性。
To go even further, we use neural architecture search to design a new baseline network and scale it up to obtain a family of models, called EfficientNets, which achieve much better accuracy and efficiency than previous ConvNets. In particular, our EfficientNet-B7 achieves state-of-the-art 84.3% top-1 accuracy on ImageNet, while being 8.4x smaller and 6.1x faster on inference than the best existing ConvNet. Our EfficientNets also transfer well and achieve state-of-the-art accuracy on CIFAR-100 (91.7%), Flowers (98.8%), and 3 other transfer learning datasets, with an order of magnitude fewer parameters. Source code is athttps://github.com/tensorflow/tpu/tree/
master/models/official/efficientnet.
更进一步,我们使用神经网络结构搜索设计了一个新的baseline网络架构并且对其进行缩放得到了一组模型,我们把他叫做EfficientNets。EfficientNets相比之前的ConvNets,有着更好的准确率和更高的效率。在ImageNet上达到了最好的水平即top-1准确率84.4%/top-5准确率97.1%,然而却比已有的最好的ConvNet模型小了8.4倍并且推理时间快了6.1倍。我们的EfficientNet迁移学习的效果也好,达到了最好的准确率水平CIFAR-100(91.7%),Flowers(98.8%),和其他3个迁移学习数据集合,参数少了一个数量级(with an order of magnitude fewer parameters)。
论文思想
在之前的一些工作当中,我们可以看到,有的会通过增加网络的width即增加卷积核的个数(从而增大channels)来提升网络的性能,有的会通过增加网络的深度即使用更多的层结构来提升网络的性能,有的会通过增加输入网络的分辨率来提升网络的性能。而在Efficientnet当中则重新探究了这个问题,并提出了一种组合条件这三者的网络结构,同时量化了这三者的指标。
The intuition is that deeper ConvNet can capture richer and more complex features, and generalize well on new tasks. However, deeper networks are also more difficult to train due to the vanishing gradient problem
增加网络的深度depth能够得到更加丰富、复杂的特征并且能够在其他新任务中很好的泛化性能。但是,由于逐渐消失的梯度问题,更深层的网络也更难以训练。
wider networks tend to be able to capture more fine-grained features and are easier to train. However, extremely wide but shallow networks tend to have difficulties in capturing higher level features
with更广的网络往往能够捕获更多细粒度的功能,并且更易于训练。但是,极其宽泛但较浅的网络在捕获更高级别的特征时往往会遇到困难
With higher resolution input images, ConvNets can potentially capture more fine-grained pattern,but the accuracy gain diminishes for very high resolutions
使用更高分辨率的输入图像,ConvNets可以捕获更细粒度的图案,但对于非常高分辨率的图片,准确度会降低。
作者在论文中对整个网络的运算过程和复合扩展方法进行了抽象:
首先定义了每一层卷积网络为$\mathcal{F}{i}\left(X{i}\right)$,而$Xi$是输入张量,$Y_i$是输出张量,而tensor的形状是$$
整个卷积网络由 k 个卷积层组成,可以表示为$\mathcal{N}=\mathcal{F} {k} \odot \ldots \odot \mathcal{F}{2} \odot \mathcal{F}{1}\left(X{1}\right)=\bigodot{j=1 \ldots k} \mathcal{F}{j}\left(X{1}\right)$
从而得到我们的整个卷积网络:
下标 i(从 1 到 s) 表示的是 stage 的序号,$\mathcal{F}{i}^{L{i}}$表示第 i 个 stage ,它表示卷积层 $\mathcal{F}{i}$重复了${L{i}}$ 次。
为了探究$d , r , w$这三个因子对最终准确率的影响,则将$d , r , w$加入到公式中,我们可以得到抽象化后的优化问题(在指定资源限制下),其中$s.t.$代表限制条件:
- $d$用来缩放深度$\widehat{L}_i $。
- $r$用来缩放分辨率即影响$\widehat{H}_i$以及$\widehat{W}_i$。
- $w$就是用来缩放特征矩阵的channels即 $\widehat{C}_i$。
- target_memory为memory限制
- target_flops为FLOPs限制
Bigger networks with larger width, depth, or resolution tend to achieve higher accuracy, but the accuracy gain quickly saturate after reaching 80%, demonstrating the limitation of single dimension scaling
具有较大宽度,深度或分辨率的较大网络往往会实现较高的精度,但是精度增益在达到80%后会迅速饱和,这表明了单维缩放的局限性。compound scaling method
In this paper, we propose a new compound scaling method, which use a compound coefficient φ to uniformly scales network width, depth, and resolution in a principled way:
在本文中,我们提出了一种新的复合缩放方法,该方法使用一个统一的复合系数$\phi$对网络的宽度,深度和分辨率进行均匀缩放。
其中$\alpha,\beta,\gamma$是通过一个小格子搜索的方法决定的常量。通常来说,$\phi$是一个用户指定的系数来控制有多少的额外资源能够用于模型的缩放,$\alpha,\beta,\gamma$指明了怎么支配这些额外的资源分别到网络的宽度,深度,和分辨率上。尤其是,一个标准卷积操作的运算量的比例是$d,w^2,r^2$双倍的网络深度将带来双倍的运算量,但是双倍的网络宽度或分辨率将会增加运算为4倍。因为卷积操作通常在ConvNets中占据绝大部分计算量,通过3式来缩放ConvNet大约将增加$(\alpha,\beta^2,\gamma^2)$运算量。
我们限制$\alpha \cdot \beta^{2} \cdot \gamma^{2} \approx 2$所以对于任意给定的$\phi$值,我们总共的运算量将大约增加$2^{\phi}$
网络结构
文中给出了Efficientnet-B0的基准框架,在Efficientnet当中,我们所使用的激活函数是swish激活函数,整个网络分为了9个stage,在第2到第8stage是一直在堆叠MBConv结构,表格当中MBConv结构后面的数字(1或6)表示的就是MBConv中第一个1x1的卷积层会将输入特征矩阵的channels扩充为n倍。Channels表示通过该Stage后输出特征矩阵的Channels。
MBConv结构
MBConv的结构相对来说还是十分好理解的,这里是我自己画的一张结构图。
MBConv结构主要由一个1x1的expand conv(升维作用,包含BN和Swish激活函数)提升维度的倍率正是之前网络结构中看到的1和6,一个KxK的卷积深度可分离卷积Depthwise Conv(包含BN和Swish)k的具体值可看EfficientNet-B0的网络框架主要有3x3和5x5两种情况,一个SE模块,一个1x1的pointer conv降维作用,包含BN),一个Droupout层构成,一般情况下都添加上了残差边模块Shortcut,从而得到输出特征矩阵。
首先关于深度可分离卷积的概念是是我们需要了解的,相当于将卷积的过程拆成运算和合并两个过程,分别对应depthwise和point两个过程,这里给一个参考连接给大家就不在详细描述了Depthwise卷积与Pointwise卷积
1.由于该模块最初是用tensorflow来实现的与pytorch有一些小差别,所以在使用pytorch实现的时候我们最好将tensorflow当中的samepadding操作重新实现一下
2.在batchnormal时候的动量设置也是有一些不一样的,论文当中设置的batch_norm_momentum=0.99,在pytorch当中需要先执行1-momentum再设为参数与tensorflow不同。
# Batch norm parameters
momentum= 1 - batch_norm_momentum # pytorch's difference from tensorflow
eps= batch_norm_epsilon
nn.BatchNorm2d(num_features=out_channels, momentum=momentum, eps=eps)
class Conv2dSamePadding(nn.Conv2d):
"""2D Convolutions like TensorFlow, for a dynamic image size.
The padding is operated in forward function by calculating dynamically.
"""
# Tips for 'SAME' mode padding.
# Given the following:
# i: width or height
# s: stride
# k: kernel size
# d: dilation
# p: padding
# Output after Conv2d:
# o = floor((i+p-((k-1)*d+1))/s+1)
# If o equals i, i = floor((i+p-((k-1)*d+1))/s+1),
# => p = (i-1)*s+((k-1)*d+1)-i
def __init__(self, in_channels, out_channels, kernel_size,padding=0, stride=1, dilation=1,
groups=1, bias=True, padding_mode = 'zeros'):
super().__init__(in_channels, out_channels, kernel_size, stride, padding, dilation, groups, bias)
self.stride = self.stride if len(self.stride) == 2 else [self.stride[0]] * 2
def forward(self, x):
ih, iw = x.size()[-2:] # input
kh, kw = self.weight.size()[-2:] # because kernel size equals to weight size
sh, sw = self.stride # stride
# change the output size according to stride
oh, ow = math.ceil(ih/sh), math.ceil(iw/sw) # output
"""
kernel effective receptive field size: (kernel_size-1) x dilation + 1
"""
pad_h = max((oh - 1) * self.stride[0] + (kh - 1) * self.dilation[0] + 1 - ih, 0)
pad_w = max((ow - 1) * self.stride[1] + (kw - 1) * self.dilation[1] + 1 - iw, 0)
if pad_h > 0 or pad_w > 0:
x = F.pad(x, [pad_w // 2, pad_w - pad_w // 2, pad_h // 2, pad_h - pad_h // 2])
return F.conv2d(x, self.weight, self.bias, self.stride, self.padding, self.dilation, self.groups)
MBConvBlock模块结构
class ConvBNActivation(nn.Module):
"""Convolution BN Activation"""
def __init__(self,in_channels,out_channels,kernel_size,stride=1,groups=1,
bias=False,momentum=0.01,eps=1e-3,active=False):
super().__init__()
self.layer=nn.Sequential(
Conv2dSamePadding(in_channels,out_channels,kernel_size=kernel_size,
stride=stride,groups=groups, bias=bias),
nn.BatchNorm2d(num_features=out_channels, momentum=momentum, eps=eps)
)
self.active=active
self.swish = Swish()
def forward(self, x):
x = self.layer(x)
if self.active:
x=self.swish(x)
return x
class MBConvBlock(nn.Module):
def __init__(self,in_channels,out_channels,kernel_size,stride,
expand_ratio=1, momentum=0.01,eps=1e-3,
drop_connect_ratio=0.2,training=True,
se_ratio=0.25,skip=True, image_size=None):
super().__init__()
self.expand_ratio = expand_ratio
self.se_ratio = se_ratio
self.has_se = (se_ratio is not None) and (0 < se_ratio <= 1)
self.skip = skip and stride == 1 and in_channels == out_channels
# 1x1 convolution channels expansion phase
expand_channels = in_channels * self.expand_ratio # number of output channels
if self.expand_ratio != 1:
self.expand_conv = ConvBNActivation(in_channels=in_channels,out_channels=expand_channels,
momentum=momentum,eps=eps,
kernel_size=1,bias=False,active=False)
# Depthwise convolution phase
self.depthwise_conv = ConvBNActivation(in_channels=expand_channels,out_channels=expand_channels,
momentum=momentum,eps=eps,
kernel_size=kernel_size,stride=stride,groups=expand_channels,bias=False,active=False)
# Squeeze and Excitation module
if self.has_se:
sequeeze_channels = max(1,int(expand_channels*self.se_ratio))
self.se = SEModule(expand_channels,sequeeze_channels)
# Pointwise convolution phase
self.project_conv = ConvBNActivation(expand_channels,out_channels,momentum=momentum,eps=eps,
kernel_size=1,bias=False,active=True)
self.drop_connect = DropConnect(drop_connect_ratio,training)
def forward(self,x):
input_x = x
if self.expand_ratio != 1:
x = self.expand_conv(x)
x = self.depthwise_conv(x)
if self.has_se:
x = self.se(x)
x = self.project_conv(x)
if self.skip:
x = self.drop_connect(x)
x = x + input_x
return x
SE模块
SE模块是通道注意力模块,该模块能够关注channel之间的关系,可以让模型自主学习到不同channel特征的重要程度。由一个全局平均池化,两个全连接层组成。第一个全连接层的节点个数是输入该MBConv特征矩阵channels的1/4 ,且使用Swish激活函数。第二个全连接层的节点个数等于Depthwise Conv层输出的特征矩阵channels,且使用Sigmoid激活函数,这里引用一下别人画好的示意图。
class SEModule(nn.Module):
"""Squeeze and Excitation module for channel attention"""
def __init__(self,in_channels,squeezed_channels):
super().__init__()
self.global_avg_pool = nn.AdaptiveAvgPool2d(1)
self.sequential = nn.Sequential(
nn.Conv2d(in_channels,squeezed_channels,1), # use 1x1 convolution instead of linear
Swish(),
nn.Conv2d(squeezed_channels,in_channels,1),
nn.Sigmoid()
)
def forward(self,x):
x= self.global_avg_pool(x)
y = self.sequential(x)
return x * y
swish激活函数
Swish是Google提出的一种新型激活函数,其原始公式为:f(x)=x sigmod(x),变形Swish-B激活函数的公式则为f(x)=x sigmod(b * x),其拥有不饱和,光滑,非单调性的特征,Google在论文中的多项测试表明Swish以及Swish-B激活函数的性能即佳,在不同的数据集上都表现出了要优于当前最佳激活函数的性能。
其中$\beta$是个常数或可训练的参数,Swish 具备无上界有下界、平滑、非单调的特性。
class Swish(nn.Module):
""" swish activation function"""
def forward(self,x):
return x * torch.sigmoid(x)
droupout代码实现
class DropConnect(nn.Module):
"""Drop Connection"""
def __init__(self,ratio,training):
super().__init__()
assert 0 <= ratio <= 1
self.keep_prob = 1 - ratio
self.training=training
def forward(self,x):
if not self.training:
return x
batch_size = x.shape[0]
random_tensor = self.keep_prob
random_tensor += torch.rand([batch_size,1,1,1],dtype=x.dtype,device=x.device)
# generate binary_tensor mask according to probability (p for 0, 1-p for 1)
binary_tensor = torch.floor(random_tensor)
output = x / self.keep_prob * binary_tensor
return output
总结
这里我们只给出了b0结构的代码实现,对于其他结构的实现过程就是在b0的基础上对wdith,depth,resolution都通过倍率因子统一缩放,这个部分在这个博客里面有详细的介绍EfficientNet(B0-B7)参数设置。
在本文中,我们系统地研究了ConvNet的缩放比例,分析了各因素对网络结构的影响,并确定仔细平衡网络的宽度,深度和分辨率,这是目前网络训练最重要但缺乏研究的部分,也是我们无法获得更好的准确性和效率忽略的一个部分。为解决此问题,本文作者提出了一种简单而高效的复合缩放方法,通过一个倍率因子统一缩放各部分比例并添加上通道注意力机制和残差模块,从而改善网络架构得到SOTA的效果,同时对模型各成分因子进行量化十分具有创新性。
参考连接
EfficientNet网络详解
神经网络学习小记录50——Pytorch EfficientNet模型的复现详解
论文翻译
令人拍案叫绝的EfficientNet和EfficientDet
swish激活函数
Depthwise卷积与Pointwise卷积
CV领域常用的注意力机制模块(SE、CBAM)
Global Average Pooling
]]>
<h2 id="EfficientNet论文解读和pytorch代码实现"><a href="#EfficientNet论文解读和pytorch代码实现" class="headerlink" title="EfficientNet论文解读和pytorch代码实现"></a>EfficientNet论文解读和pytorch代码实现</h2><h2 id="传送门"><a href="#传送门" class="headerlink" title="传送门"></a>传送门</h2><blockquote>
<p>论文地址:<a href="https://arxiv.org/pdf/1905.11946.pdf" target="_blank" rel="noopener">https://arxiv.org/pdf/1905.11946.pdf</a><br>官方github:<a href="https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet" target="_blank" rel="noopener">https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet</a><br>github参考:<a href="https://github.com/qubvel/efficientnet" target="_blank" rel="noopener">https://github.com/qubvel/efficientnet</a><br>github参考:<a href="https://github.com/lukemelas/EfficientNet-PyTorch" target="_blank" rel="noopener">https://github.com/lukemelas/EfficientNet-PyTorch</a></p>
</blockquote>
-<h2 id="摘要"><a href="#摘要" class="headerlink" title="摘要"></a>摘要</h2><p>谷歌的文章总是能让我印象深刻,不管从实验上还是论文的书写上都让人十分的佩服,不得不说这确实是一个非常creative的公司!<br><code>Convolutional Neural Networks (ConvNets) are commonly developed at a fixed resource budget, and then scaled up for better accuracy if more resources are available. In this paper, we systematically study model scaling and identify that carefully balancing network depth, width, and resolution can lead to better performance. Based on this observation, we propose a new scaling method that uniformly scales all dimensions of depth/width/resolution using a simple yet highly effective compound coefficient. We demonstrate the effectiveness of this method on scaling up MobileNets and ResNet. </code><br>卷积神经网络通常是在固定的资源预算下进行计算和发展的,如果有更多可用的资源,模型能通过缩放和扩展获得更好的效果,本文<strong>系统研究(工作量很充足)</strong>了模型缩放,并且证明了<strong>细致地平衡网络的深度,宽度,和分辨率能够得到更好的效果</strong>,基于这个观点,我们提出了一个新的尺度缩放的方法,我们提出了一个新的尺度缩放的方法即:<strong>使用一个简单且高效的复合系数统一地缩放所有网络层的深度/宽度/分辨率的维度</strong>。我们证明了该方法在扩大MobileNets和ResNet方面的有效性。</p>
+<h2 id="摘要"><a href="#摘要" class="headerlink" title="摘要"></a>摘要</h2><p>谷歌的文章总是能让我印象深刻,不管从实验上还是论文的书写上都让人十分的佩服,不得不说这确实是一个非常creative的公司!<br><code>Convolutional Neural Networks (ConvNets) are commonly developed at a fixed resource budget, and then scaled up for better accuracy if more resources are available. In this paper, we systematically study model scaling and identify that carefully balancing network depth, width, and resolution can lead to better performance. Based on this observation, we propose a new scaling method that uniformly scales all dimensions of depth/width/resolution using a simple yet highly effective compound coefficient. We demonstrate the effectiveness of this method on scaling up MobileNets and ResNet.</code><br>卷积神经网络通常是在固定的资源预算下进行计算和发展的,如果有更多可用的资源,模型能通过缩放和扩展获得更好的效果,本文<strong>系统研究(工作量很充足)</strong>了模型缩放,并且证明了<strong>细致地平衡网络的深度,宽度,和分辨率能够得到更好的效果</strong>,基于这个观点,我们提出了一个新的尺度缩放的方法,我们提出了一个新的尺度缩放的方法即:<strong>使用一个简单且高效的复合系数统一地缩放所有网络层的深度/宽度/分辨率的维度</strong>。我们证明了该方法在扩大MobileNets和ResNet方面的有效性。<br></p>
@@ -356,11 +356,11 @@
2021-04-22T02:20:00.000Z
2024-10-09T07:33:09.898Z
- yolov1-3论文解析最近在看经典目标检测算法yolo的思想,为了更好的了解yolo系列的相关文章,我从最初版本的论文思想开始看的,之后有时间会把yolov4和yolov5再认真看看,目前来说yolov3的spp版本是使用得最为广泛的一种,整体上来说yolo的设计思想还是很有创造性的数学也比较严谨。
yolov1论文思想
物体检测主流的算法框架大致分为one-stage与two-stage。two-stage算法代表有R-CNN系列,one-stage算法代表有Yolo系列。按笔者理解,two-stage算法将步骤一与步骤二分开执行,输入图像先经过候选框生成网络(例如faster rcnn中的RPN网络),再经过分类网络;one-stage算法将步骤一与步骤二同时执行,输入图像只经过一个网络,生成的结果中同时包含位置与类别信息。two-stage与one-stage相比,精度高,但是计算量更大,所以运算较慢。
We present YOLO, a new approach to object detection. Prior work on object detection repurposes classifiers to perform detection. Instead, we frame object detection as a regression problem to spatially separated bounding boxes and associated class probabilities.
yolo相比其他R-CNN等方法最大的一个不同就是他将这个识别和定位的过程转化成了一个空间定位并分类的回归问题,这也是他为什么能够利用网络进行端到端直接同时预测的重要原因。
yolo的特点
1.YOLO速度非常快。由于我们的检测是当做一个回归问题,不需要很复杂的流程。在测试的时候我们只需将一个新的图片输入网络来检测物体。
First, YOLO is extremely fast. Since we frame detection as a regression problem we don’t need a complex pipeline
2.Yolo会基于整张图片信息进行预测,与基于滑动窗口和候选区域的方法不同,在训练和测试期间YOLO可以看到整个图像,所以它隐式地记录了分类类别的上下文信息及它的全貌
Second, YOLO reasons globally about the image when making predictions Unlike sliding window and region proposal-based techniques, YOLO sees the entire image during training and test time so it implicitly encodes contextual information about classes as well as their appearance
3.第三,YOLO能学习到目标的泛化表征。作者尝试了用自然图片数据集进行训练,用艺术画作品进行预测,Yolo的检测效果更佳。
Third, YOLO learns generalizable representations of objects. Since YOLO is highly generalizable it is less likely to break down when applied to new domains or unexpected inputs
backbone-darknet
yolov1这块的话,由于是比较早期的网络所以在设计时没有使用batchnormal,激活函数上采用leaky relu,输入图像大小为448x448,经过许多卷积层与池化层,变为7x7x1024张量,最后经过两层全连接层,输出张量维度为7x7x30。除了最后一层的输出使用了线性激活函数,其他层全部使用Leaky Relu激活函数。
$$\phi(x)= \begin{cases}
x,& \text{if x>0} \
0.1x,& \text{otherwise}
\end{cases}$$
输出维度
yolov1最精髓的地方应该就是他的输出维度,论文当中有放出这样一张图片,看完以后我们能对yolo算法的特点有更加深刻的理解。在上图的backbone当中我们可以看到的是
yolo的输出相当于把原图片分割成了$S \times S$个区域,然后对预测目标标定他的boundingbox,boundingbox由中心点的坐标,长宽以及物体的置信分数组成$x,y,w,h,confidence$,图中的$B$表示的是boundingbox的个数。置信分数在yolo当中是这样定义的:$Pr(Object)IOU_{pred}^{truth}$对于$Pr(Object)=1 \text{ if detect object else 0}$,其实置信分数就是boudingbox与groundtruth之间的IOU,并对每个小网格对应的$C$个类别都预测出他的条件概率:$Pr(Class_i|Object)$。
在推理时,我们可以得到当前网格对于每个类别的预测置信分数:$$Pr(Class_i)*IOU_{pred}^{truth} = Pr(Class_i|Object)*Pr(Object)*IOU_{pred}^{truth}$$
这样一种严谨的条件概率的方式得到我们的最终概率是十分可行和合适的。
YOLO imposes strong spatial constraints on bounding box predictions since each grid cell only predicts two boxes and can only have one class. This spatial constraint limits the number of nearby objects that our model can predict. Our model struggles with small objects that appear in groups, such as flocks of birds.
*不过在原论文当中也有提到的一点是:YOLO给边界框预测强加空间约束,因为每个网格单元只预测两个框和只能有一个类别。这个空间约束限制了我们的模型可以预测的邻近目标的数量。我们的模型难以预测群组中出现的小物体(比如鸟群)。**
损失函数
在损失函数方面,由于公式比较长所以就直接截图过来了,损失函数的设计放方面作者也考虑的比较周全,
预测框的中心点$(x,y)$。预测框的宽高$w,h$,其中$\mathbb{1}_{i j}^{\text {obj }}$为控制函数,在标签中包含物体的那些格点处,该值为 1 ,若格点不含有物体,该值为 0
在计算损失函数的时候作者最开始使用的是最简单的平方损失函数来计算检测,因为它是计算简单且容易优化的,但是它并不完全符合我们最大化平均精度的目标,原因如下:
It weights localization error equally with classification error which may not be ideal.
1.它对定位错误的权重与分类错误的权重相等,这可能不是理想的选择。
Also, in every image many grid cells do not contain any object. This pushes the “confidence” scores of those cells towards zero, often overpowering the gradient from cells that do contain objects. This can lead to model instability, causing training to diverge early on.
而且,在每个图像中,许多网格单元不包含任何对象。这就把这些网格的置信度分数推到零,往往超过了包含对象的网格的梯度。2.这可能导致模型不稳定,导致训练早期发散难以训练。
解决方案:增加边界框坐标预测的损失,并且减少了不包含对象的框的置信度预测的损失。我们使用两个参数来实现这一点。$\lambda_{coord}=5,\lambda_{noobj}=0.5$,其实这也是yolo面临的一个样本数目不均衡的典型例子。主要目的是让含有物体的格点,在损失函数中的权重更大,让模型更加注重含有物体的格点所造成的损失。
我们的损失函数则只会对那些有真实物体所属的格点进行损失计算,若该格点不包含物体,那么预测数值不对损失函数造成影响。
这里对$w,h$在损失函数中的处理分别取了根号,原因在于,如果不取根号,损失函数往往更倾向于调整尺寸比较大的预测框。例如,20个像素点的偏差,对于800x600的预测框几乎没有影响,此时的IOU数值还是很大,但是对于30x40的预测框影响就很大。取根号是为了尽可能的消除大尺寸框与小尺寸框之间的差异。
预测框的置信度$C_i$。当该格点不含有物体时,该置信度的标签为0;若含有物体时,该置信度的标签为预测框与真实物体框的IOU数值(。
物体类别概率$P_i$,对应的类别位置,该标签数值为1,其余位置为0,与分类网络相同。
yolov2:Better, Faster, Stronger
yolov2的论文里面其实更多的是对训练数据集的组合和扩充,然后再添加了很多计算机视觉方面新出的trick,然后达到了性能的提升。同时yolov2方面所使用的trick也是现在计算机视觉常用的方法,我认为这些都是我们需要好好掌握的,同时也是面试和kaggle上都经常使用的一些方法。
Batch Normalization
BN是由Google于2015年提出,论文是《Batch Normalization_ Accelerating Deep Network Training by Reducing Internal Covariate Shift》,这是一个深度神经网络训练的技巧,主要是让数据的分布变得一致,从而使得训练深层网络模型更加容易和稳定。
这里有一些相关的链接可以参考一下
https://www.cnblogs.com/itmorn/p/11241236.html
https://zhuanlan.zhihu.com/p/24810318
https://zhuanlan.zhihu.com/p/93643523
莫烦python
李宏毅yyds
算法具体过程:
这里要提一下这个$\gamma和\beta$是可训练参数,维度等于张量的通道数,主要是为了在反向传播更新网络时使得标准化后的数据分布与原始数据尽可能保持一直,从而很好的抽象和保留整个batch的数据分布。
Batch Normalization的作用:
将这些输入值或卷积网络的张量在batch维度上进行类似标准化的操作,将其放缩到合适的范围,加快模型训练时的收敛速度,使得模型训练过程更加稳定,避免梯度爆炸或者梯度消失,并且起到一定的正则化作用。
High Resolution Classifier
在Yolov1中,网络的backbone部分会在ImageNet数据集上进行预训练,训练时网络输入图像的分辨率为224x224。在v2中,将分类网络在输入图片分辨率为448x448的ImageNet数据集上训练10个epoch,再使用检测数据集(例如coco)进行微调。高分辨率预训练使mAP提高了大约4%。
Convolutional With Anchor Boxes
predicts these offsets at every location in a feature map
Predicting offsets instead of coordinates simplifies the problem and makes it easier for the network to learn.
第一篇解读v1时提到,每个格点预测两个矩形框,在计算loss时,只让与ground truth最接近的框产生loss数值,而另一个框不做修正。这样规定之后,作者发现两个框在物体的大小、长宽比、类别上逐渐有了分工。在v2中,神经网络不对预测矩形框的宽高的绝对值进行预测,而是预测与Anchor框的偏差(offset),每个格点指定n个Anchor框。在训练时,最接近ground truth的框产生loss,其余框不产生loss。在引入Anchor Box操作后,mAP由69.5下降至69.2,原因在于,每个格点预测的物体变多之后,召回率大幅上升,准确率有所下降,总体mAP略有下降。
Dimension Clusters
Instead of choosing priors by hand, we run k-means clustering on the training set bounding boxes to automatically find good priors.
这里算是作者数据处理上的一个创新点,这里作者提到之前的工作当中先Anchor Box都是认为设定的比例和大小,而这里作者时采用无监督的方式将训练数据集中的矩形框全部拿出来,用kmeans聚类得到先验框的宽和高。使用(1-IOU)数值作为两个矩形框的的距离函数,这个处理也十分的聪明。
$$
d(\text { box }, \text { centroid })=1-\operatorname{IOU}(\text { box }, \text { centroid })
$$
Direct location prediction
Yolo中的位置预测方法是预测的左上角的格点坐标预测偏移量。网络预测输出要素图中每个单元格的5个边界框。网络为每个边界框预测$t_x,t_y,t_h,t_w和t_o$这5个坐标。如果单元格从图像的左上角偏移了$(c_x,c_y)$并且先验边界框的宽度和高度为$p_w,p_h$,则预测对应于:
$$
\begin{array}{l}
x=\left(t_{x} * w_{a}\right)-x_{a} \
y=\left(t_{y} * h_{a}\right)-y_{a}
\end{array}
$$
$$
\begin{aligned}
b_{x} &=\sigma\left(t_{x}\right)+c_{x} \
b_{y} &=\sigma\left(t_{y}\right)+c_{y} \
b_{w} &=p_{w} e^{t_{w}} \
b_{h} &=p_{h} e^{t_{h}} \
\operatorname{Pr}(\text { object }) * I O U(b, \text { object }) &=\sigma\left(t_{o}\right)
\end{aligned}
$$
由于我们约束位置预测,参数化更容易学习,使得网络更稳定使用维度集群以及直接预测边界框中心位置使YOLO比具有anchor box的版本提高了近5%的mAP。
Fine-Grained Features
在2626的特征图,经过卷积层等,变为1313的特征图后,作者认为损失了很多细粒度的特征,导致小尺寸物体的识别效果不佳,所以在此加入了passthrough层。
传递层通过将相邻特征堆叠到不同的通道而不是堆叠到空间位置,将较高分辨率特征与低分辨率特征相连,类似于ResNet中的标识映射。这将26×26×512特征映射转换为13×13×2048特征映射,其可以与原始特征连接。
Multi-Scale Training
我觉得这个也是yolo为什么性能提升的一个很重要的点,解决了yolo1当中对于多个小物体检测的问题。
原始的YOLO使用448×448的输入分辨率。添加anchor box后,我们将分辨率更改为416×416。然而,由于我们的模型只使用卷积层和池化层,相比yolo1删除了全连接层,它可以在运行中调整大小(应该是使用了1x1卷积不过我没看代码)。我们希望YOLOv2能够在不同大小的图像上运行,因此我们将其训练到模型中。
instead of fixing the input image size we change the network every few iterations. Every 10 batches our network randomly chooses a new image dimension size.
不固定输入图像的大小,我们每隔几次迭代就更改网络。在每10个batch之后,我们的网络就会随机resize成{320, 352, …, 608}中的一种。不同的输入,最后产生的格点数不同,比如输入图片是320320,那么输出格点是1010,如果每个格点的先验框个数设置为5,那么总共输出500个预测结果;如果输入图片大小是608608,输出格点就是1919,共1805个预测结果。
YOLO’s convolutional layers downsample the image by a factor of 32 so by using an input image of 416 we get an output feature map of 13 × 13.
We do this because we want an odd number of locations in our feature map so there is a single center cell.
关于416×416也是有说法的,主要是下采样是32的倍数,而且最后的输出是13x13是奇数然后会有一个中心点更加易于目标检测。
这种训练方法迫使网络学习在各种输入维度上很好地预测。这意味着相同的网络可以预测不同分辨率的检测。
关于yolov2最大的一个提升还有一个原因就是WordTree组合数据集的训练方法,不过这里我就不再赘述,可以看参考资料有详细介绍,这里主要讲网络和思路
yolov3论文改进
yolov3的论文改进就有很多方面了,而且yolov3-spp的网络效果很不错,和yolov4,yolov5的效果差别也不是特别大,这也是为什么yolov3网络被广泛应用的原因之一。
backbone:Darknet-53
相比yolov1的网络,在网络上有了很大的改进,借鉴了Resnet、Densenet、FPN的做法结合了当前网络中十分有效的
1.Yolov3中,全卷积,对于输入图片尺寸没有特别限制,可通过调节卷积步长控制输出特征图的尺寸。
2.Yolov3借鉴了金字塔特征图思想,小尺寸特征图用于检测大尺寸物体,而大尺寸特征图检测小尺寸物体。特征图的输出维度为$N \times N \times (3 \times (4+1+80))$, NxN为输出特征图格点数,一共3个Anchor框,每个框有4维预测框数值 $t_x,t_y,t_w,t_h$ ,1维预测框置信度,80维物体类别数。所以第一层特征图的输出维度为8x8x255
3.Yolov3总共输出3个特征图,第一个特征图下采样32倍,第二个特征图下采样16倍,第三个下采样8倍。每个特征图进行一次3X3、步长为2的卷积,然后保存该卷积layer,再进行一次1X1的卷积和一次3X3的卷积,并把这个结果加上layer作为最后的结果。三个特征层进行5次卷积处理,处理完后一部分用于输出该特征层对应的预测结果,一部分用于进行反卷积UmSampling2d后与其它特征层进行结合。
4.concat和resiual加操作,借鉴DenseNet将特征图按照通道维度直接进行拼接,借鉴Resnet添加残差边,缓解了在深度神经网络中增加深度带来的梯度消失问题。
5.上采样层(upsample):作用是将小尺寸特征图通过插值等方法,生成大尺寸图像。例如使用最近邻插值算法,将88的图像变换为1616。上采样层不改变特征图的通道数。
对于yolo3的模型来说,网络最后输出的内容就是三个特征层每个网格点对应的预测框及其种类,即三个特征层分别对应着图片被分为不同size的网格后,每个网格点上三个先验框对应的位置、置信度及其种类。然后对输出进行解码,解码过程也就是yolov2上面的Direct location prediction方法一样,每个网格点加上它对应的x_offset和y_offset,加完后的结果就是预测框的中心,然后再利用 先验框和h、w结合 计算出预测框的长和宽。这样就能得到整个预测框的位置了。
CIoU loss
在yolov3当中我们使用的不再是传统的IoU loss,而是一个非常优秀的loss设计,整个发展过程也可以多了解了解IoU->GIoU->DIoU->CIoU,完整的考虑了重合面积,中心点距离,长宽比。
$$CIoU=IoU-(\frac{\rho(b,b^{gt}}{c^2}+\alpha v))$$
$$v=\frac{4}{\pi^2}(\arctan\frac{w^{gt}}{h^{gt}}-\arctan\frac{w}{h})^2$$
$$\alpha = \frac{v}{(1-IoU)+v}$$
其中, $b$ , $b^{gt}$ 分别代表了预测框和真实框的中心点,且 $\rho$代表的是计算两个中心点间的欧式距离。 [公式] 代表的是能够同时包含预测框和真实框的最小闭包区域的对角线距离。
在介绍CIoU之前,我们可以先介绍一下DIoU loss
其实这两项就是我们的DIoU
$$DIoU = IoU-(\frac{\rho(b,b^{gt}}{c^2})$$
则我们可以提出DIoU loss函数
$$
L_{\text {DIoU }}=1-D I o U \
0 \leq L_{\text {DloU}} \leq 2
$$
DloU损失能够直接最小化两个boxes之间的距离,因此收敛速度更快。
而我们的CIoU则比DIoU考虑更多的东西,也就是长宽比即最后一项。而$v$用来度量长宽比的相似性,$\alpha$是权重
在损失函数这块,有知乎大佬写了一下,其实就是对yolov1上的损失函数进行了一下变形。
Spatial Pyramid Pooling
在yolov3的spp版本中使用了spp模块,实现了不同尺度的特征融合,spp模块最初来源于何凯明大神的论文SPP-net,主要用来解决输入图像尺寸不统一的问题,而目前的图像预处理操作中,resize,crop等都会造成一定程度的图像失真,因此影响了最终的精度。SPP模块,使用固定分块的池化操作,可以对不同尺寸的输入实现相同大小的输出,因此能够避免这一问题。
同时SPP模块中不同大小特征的融合,有利于待检测图像中目标大小差异较大的情况,也相当于增大了多重感受野吧,尤其是对于yolov3一般针对的复杂多目标图像。
在yolov3的darknet53输出到第一个特征图计算之前我们插入了一个spp模块。
SPP的这几个模块stride=1,而且会对外补padding,所以最后的输出特征图大小是一致的,然后在深度方向上进行concatenate,使得深度增大了4倍。
可以看出随着输入网络尺度的增大,spp的效果会更好。多个spp的效果增大也就是spp3和spp1的效果是差不多的,为了保证推理速度就只使用了一个spp
Mosaic图像增强
在yolov3-spp包括yolov4当中我们都使用了mosaic数据增强,有点类似cutmix。cutmix是合并两张图片进行预测,mosaic数据增强利用了四张图片,对四张图片进行拼接,每一张图片都有其对应的框框,将四张图片拼接之后就获得一张新的图片,同时也获得这张图片对应的框框,然后我们将这样一张新的图片传入到神经网络当中去学习,相当于一下子传入四张图片进行学习了。论文中说这极大丰富了检测物体的背景,且在标准化BN计算的时候一下子会计算四张图片的数据。
作用:增加数据的多样性,增加目标个数,BN能一次性归一化多张图片组合的分布,会更加接近原数据的分布。
focal loss
最后我们提一下focal loss,虽然在原论文当中作者说focal loss效果反而下降了,但是我认为还是有必要了解一下何凯明的这篇bestpaper。作者提出focal loss的出发点也是希望one-stage detector可以达到two-stage detector的准确率,同时不影响原有的速度。作者认为造成这种情况的原因是样本的类别不均衡导致的。
对于二分类的CrossEntropy,我们有如下表示方法:
$$
\mathrm{CE}(p, y)=\left{\begin{array}{ll}
-\log (p) & \text { if } y=1 \
-\log (1-p) & \text { otherwise. }
\end{array}\right.
$$
我们定义$p_t$:
$$
p_{\mathrm{t}}=\left{\begin{array}{ll}
p & \text { if } y=1 \
1-p & \text { otherwise }
\end{array}\right.
$$
则重写交叉熵
$$
\operatorname{CE}(n, y)=C E(p_t)=-\log (p_t)
$$
接着我们提出改进思路就是在计算CE时添加了一个平衡因子,是一个可训练的参数
$$
\mathrm{CE}\left(p_{\mathrm{t}}\right)=-\alpha_{\mathrm{t}} \log \left(p_{\mathrm{t}}\right)
$$
其中
$$
\alpha_{\mathrm{t}}=\left{\begin{array}{ll}
\alpha_{\mathrm{t}} & \text { if } y=1 \
1-\alpha_{\mathrm{t}} & \text { otherwise }
\end{array}\right.
$$
相当于给正负样本加上权重,负样本出现的频次多,那么就降低负样本的权重,正样本数量少,就相对提高正样本的权重。因此可以通过设定a的值来控制正负样本对总的loss的共享权重。a取比较小的值来降低负样本(多的那类样本)的权重。
但是何凯明认为这个还是不能完全解决样本不平衡的问题,虽然这个平衡因子可以控制正负样本的权重,但是没法控制容易分类和难分类样本的权重
As our experiments will show, the large class imbalance encountered during training of dense detectors overwhelms the cross entropy loss. Easily classified negatives comprise the majority of the loss and dominate the gradient. While
α balances the importance of positive/negative examples, it does not differentiate between easy/hard examples. Instead, we propose to reshape the loss function to down-weight easy examples and thus focus training on hard negatives
于是提出了一种新的损失函数Focal Loss
$$
\mathrm{FL}\left(p_{\mathrm{t}}\right)=-\left(1-p_{\mathrm{t}}\right)^{\gamma} \log \left(p_{\mathrm{t}}\right)
$$
focal loss的两个重要性质
1、当一个样本被分错的时候,pt是很小的,那么调制因子(1-Pt)接近1,损失不被影响;当Pt→1,因子(1-Pt)接近0,那么分的比较好的(well-classified)样本的权值就被调低了。因此调制系数就趋于1,也就是说相比原来的loss是没有什么大的改变的。当pt趋于1的时候(此时分类正确而且是易分类样本),调制系数趋于0,也就是对于总的loss的贡献很小。
2、当γ=0的时候,focal loss就是传统的交叉熵损失,当γ增加的时候,调制系数也会增加。 专注参数γ平滑地调节了易分样本调低权值的比例。γ增大能增强调制因子的影响,实验发现γ取2最好。直觉上来说,调制因子减少了易分样本的损失贡献,拓宽了样例接收到低损失的范围。当γ一定的时候,比如等于2,一样easy example(pt=0.9)的loss要比标准的交叉熵loss小100+倍,当pt=0.968时,要小1000+倍,但是对于hard example(pt < 0.5),loss最多小了4倍。这样的话hard example的权重相对就提升了很多。这样就增加了那些误分类的重要性
focal loss的两个性质算是核心,其实就是用一个合适的函数去度量难分类和易分类样本对总的损失的贡献。
然后作者又提出了最终的focal loss形式
$$
\mathrm{FL}\left(p_{\mathrm{t}}\right)=-\alpha_{\mathrm{t}}\left(1-p_{\mathrm{t}}\right)^{\gamma} \log \left(p_{\mathrm{t}}\right)
$$
$$
F L(p)\left{\begin{array}{ll}
-\alpha(1-p)^{\gamma} \log (p) & \text { if } y=1 \
-(1-\alpha) p^{\gamma} \log (1-p) & \text { otherwise }
\end{array}\right.
$$
这样既能调整正负样本的权重,又能控制难易分类样本的权重
在实验中a的选择范围也很广,一般而言当γ增加的时候,a需要减小一点(实验中γ=2,a=0.25的效果最好)
总结
yolo和yolov2的严谨数学推理和网络相结合的做法令人十分惊艳,而yolov3相比之前的两个版本不管是在数据处理还是网络性质上都有很大的改变,也使用了很多流行的tirck来实现目标检测,基本上结合了很多cv领域的精髓,博客中有很多部分由于时间关系没有太细讲,其实每个部分都可以去原论文中找到很多可以学习的地方,之后有时候会补上yolov4和yolov5的讲解,后面的网络添加了注意力机制模块效果应该是更加work的。
参考文献
yolov3-spp
focal loss
batch normal
IoU系列
yolov1论文翻译
yolo1-3三部曲
Bubbliiiing的教程里
还有很多但是没找到之后会补上的
]]>
+ yolov1-3论文解析最近在看经典目标检测算法yolo的思想,为了更好的了解yolo系列的相关文章,我从最初版本的论文思想开始看的,之后有时间会把yolov4和yolov5再认真看看,目前来说yolov3的spp版本是使用得最为广泛的一种,整体上来说yolo的设计思想还是很有创造性的数学也比较严谨。
yolov1论文思想
物体检测主流的算法框架大致分为one-stage与two-stage。two-stage算法代表有R-CNN系列,one-stage算法代表有Yolo系列。按笔者理解,two-stage算法将步骤一与步骤二分开执行,输入图像先经过候选框生成网络(例如faster rcnn中的RPN网络),再经过分类网络;one-stage算法将步骤一与步骤二同时执行,输入图像只经过一个网络,生成的结果中同时包含位置与类别信息。two-stage与one-stage相比,精度高,但是计算量更大,所以运算较慢。
We present YOLO, a new approach to object detection. Prior work on object detection repurposes classifiers to perform detection. Instead, we frame object detection as a regression problem to spatially separated bounding boxes and associated class probabilities.
yolo相比其他R-CNN等方法最大的一个不同就是他将这个识别和定位的过程转化成了一个空间定位并分类的回归问题,这也是他为什么能够利用网络进行端到端直接同时预测的重要原因。
yolo的特点
1.YOLO速度非常快。由于我们的检测是当做一个回归问题,不需要很复杂的流程。在测试的时候我们只需将一个新的图片输入网络来检测物体。
First, YOLO is extremely fast. Since we frame detection as a regression problem we don’t need a complex pipeline
2.Yolo会基于整张图片信息进行预测,与基于滑动窗口和候选区域的方法不同,在训练和测试期间YOLO可以看到整个图像,所以它隐式地记录了分类类别的上下文信息及它的全貌
Second, YOLO reasons globally about the image when making predictions Unlike sliding window and region proposal-based techniques, YOLO sees the entire image during training and test time so it implicitly encodes contextual information about classes as well as their appearance
3.第三,YOLO能学习到目标的泛化表征。作者尝试了用自然图片数据集进行训练,用艺术画作品进行预测,Yolo的检测效果更佳。
Third, YOLO learns generalizable representations of objects. Since YOLO is highly generalizable it is less likely to break down when applied to new domains or unexpected inputs
backbone-darknet
yolov1这块的话,由于是比较早期的网络所以在设计时没有使用batchnormal,激活函数上采用leaky relu,输入图像大小为448x448,经过许多卷积层与池化层,变为7x7x1024张量,最后经过两层全连接层,输出张量维度为7x7x30。除了最后一层的输出使用了线性激活函数,其他层全部使用Leaky Relu激活函数。
输出维度
yolov1最精髓的地方应该就是他的输出维度,论文当中有放出这样一张图片,看完以后我们能对yolo算法的特点有更加深刻的理解。在上图的backbone当中我们可以看到的是
yolo的输出相当于把原图片分割成了$S \times S$个区域,然后对预测目标标定他的boundingbox,boundingbox由中心点的坐标,长宽以及物体的置信分数组成$x,y,w,h,confidence$,图中的$B$表示的是boundingbox的个数。置信分数在yolo当中是这样定义的:$Pr(Object)IOU_{pred}^{truth}$对于$Pr(Object)=1 \text{ if detect object else 0}$,其实置信分数就是boudingbox与groundtruth之间的IOU,并对每个小网格对应的$C$个类别都预测出他的条件概率:$Pr(Class_i|Object)$。
在推理时,我们可以得到当前网格对于每个类别的预测置信分数:$$Pr(Class_i)IOU{pred}^{truth} = Pr(Class_i|Object)Pr(Object)IOU{pred}^{truth}$$
这样一种严谨的条件概率的方式得到我们的最终概率是十分可行和合适的。
YOLO imposes strong spatial constraints on bounding box predictions since each grid cell only predicts two boxes and can only have one class. This spatial constraint limits the number of nearby objects that our model can predict. Our model struggles with small objects that appear in groups, such as flocks of birds.
不过在原论文当中也有提到的一点是:YOLO给边界框预测强加空间约束,因为每个网格单元只预测两个框和只能有一个类别。这个空间约束限制了我们的模型可以预测的邻近目标的数量。我们的模型难以预测群组中出现的小物体(比如鸟群)。
损失函数
在损失函数方面,由于公式比较长所以就直接截图过来了,损失函数的设计放方面作者也考虑的比较周全,
预测框的中心点$(x,y)$。预测框的宽高$w,h$,其中$\mathbb{1}_{i j}^{\text {obj }}$为控制函数,在标签中包含物体的那些格点处,该值为 1 ,若格点不含有物体,该值为 0
在计算损失函数的时候作者最开始使用的是最简单的平方损失函数来计算检测,因为它是计算简单且容易优化的,但是它并不完全符合我们最大化平均精度的目标,原因如下:
It weights localization error equally with classification error which may not be ideal.
1.它对定位错误的权重与分类错误的权重相等,这可能不是理想的选择。
Also, in every image many grid cells do not contain any object. This pushes the “confidence” scores of those cells towards zero, often overpowering the gradient from cells that do contain objects. This can lead to model instability, causing training to diverge early on.
而且,在每个图像中,许多网格单元不包含任何对象。这就把这些网格的置信度分数推到零,往往超过了包含对象的网格的梯度。2.这可能导致模型不稳定,导致训练早期发散难以训练。
解决方案:增加边界框坐标预测的损失,并且减少了不包含对象的框的置信度预测的损失。我们使用两个参数来实现这一点。$\lambda{coord}=5,\lambda{noobj}=0.5$,其实这也是yolo面临的一个样本数目不均衡的典型例子。主要目的是让含有物体的格点,在损失函数中的权重更大,让模型更加注重含有物体的格点所造成的损失。
我们的损失函数则只会对那些有真实物体所属的格点进行损失计算,若该格点不包含物体,那么预测数值不对损失函数造成影响。
这里对$w,h$在损失函数中的处理分别取了根号,原因在于,如果不取根号,损失函数往往更倾向于调整尺寸比较大的预测框。例如,20个像素点的偏差,对于800x600的预测框几乎没有影响,此时的IOU数值还是很大,但是对于30x40的预测框影响就很大。取根号是为了尽可能的消除大尺寸框与小尺寸框之间的差异。
预测框的置信度$C_i$。当该格点不含有物体时,该置信度的标签为0;若含有物体时,该置信度的标签为预测框与真实物体框的IOU数值(。
物体类别概率$P_i$,对应的类别位置,该标签数值为1,其余位置为0,与分类网络相同。
yolov2:Better, Faster, Stronger
yolov2的论文里面其实更多的是对训练数据集的组合和扩充,然后再添加了很多计算机视觉方面新出的trick,然后达到了性能的提升。同时yolov2方面所使用的trick也是现在计算机视觉常用的方法,我认为这些都是我们需要好好掌握的,同时也是面试和kaggle上都经常使用的一些方法。
Batch Normalization
BN是由Google于2015年提出,论文是《Batch Normalization_ Accelerating Deep Network Training by Reducing Internal Covariate Shift》,这是一个深度神经网络训练的技巧,主要是让数据的分布变得一致,从而使得训练深层网络模型更加容易和稳定。
这里有一些相关的链接可以参考一下
https://www.cnblogs.com/itmorn/p/11241236.html
https://zhuanlan.zhihu.com/p/24810318
https://zhuanlan.zhihu.com/p/93643523
莫烦python
李宏毅yyds
算法具体过程:
这里要提一下这个$\gamma和\beta$是可训练参数,维度等于张量的通道数,主要是为了在反向传播更新网络时使得标准化后的数据分布与原始数据尽可能保持一直,从而很好的抽象和保留整个batch的数据分布。
Batch Normalization的作用:
将这些输入值或卷积网络的张量在batch维度上进行类似标准化的操作,将其放缩到合适的范围,加快模型训练时的收敛速度,使得模型训练过程更加稳定,避免梯度爆炸或者梯度消失,并且起到一定的正则化作用。
High Resolution Classifier
在Yolov1中,网络的backbone部分会在ImageNet数据集上进行预训练,训练时网络输入图像的分辨率为224x224。在v2中,将分类网络在输入图片分辨率为448x448的ImageNet数据集上训练10个epoch,再使用检测数据集(例如coco)进行微调。高分辨率预训练使mAP提高了大约4%。
Convolutional With Anchor Boxes
predicts these offsets at every location in a feature map
Predicting offsets instead of coordinates simplifies the problem and makes it easier for the network to learn.
第一篇解读v1时提到,每个格点预测两个矩形框,在计算loss时,只让与ground truth最接近的框产生loss数值,而另一个框不做修正。这样规定之后,作者发现两个框在物体的大小、长宽比、类别上逐渐有了分工。在v2中,神经网络不对预测矩形框的宽高的绝对值进行预测,而是预测与Anchor框的偏差(offset),每个格点指定n个Anchor框。在训练时,最接近ground truth的框产生loss,其余框不产生loss。在引入Anchor Box操作后,mAP由69.5下降至69.2,原因在于,每个格点预测的物体变多之后,召回率大幅上升,准确率有所下降,总体mAP略有下降。
Dimension Clusters
Instead of choosing priors by hand, we run k-means clustering on the training set bounding boxes to automatically find good priors.
这里算是作者数据处理上的一个创新点,这里作者提到之前的工作当中先Anchor Box都是认为设定的比例和大小,而这里作者时采用无监督的方式将训练数据集中的矩形框全部拿出来,用kmeans聚类得到先验框的宽和高。使用(1-IOU)数值作为两个矩形框的的距离函数,这个处理也十分的聪明。
Direct location prediction
Yolo中的位置预测方法是预测的左上角的格点坐标预测偏移量。网络预测输出要素图中每个单元格的5个边界框。网络为每个边界框预测$t_x,t_y,t_h,t_w和t_o$这5个坐标。如果单元格从图像的左上角偏移了$(c_x,c_y)$并且先验边界框的宽度和高度为$p_w,p_h$,则预测对应于:
由于我们约束位置预测,参数化更容易学习,使得网络更稳定使用维度集群以及直接预测边界框中心位置使YOLO比具有anchor box的版本提高了近5%的mAP。
Fine-Grained Features
在2626的特征图,经过卷积层等,变为1313的特征图后,作者认为损失了很多细粒度的特征,导致小尺寸物体的识别效果不佳,所以在此加入了passthrough层。
传递层通过将相邻特征堆叠到不同的通道而不是堆叠到空间位置,将较高分辨率特征与低分辨率特征相连,类似于ResNet中的标识映射。这将26×26×512特征映射转换为13×13×2048特征映射,其可以与原始特征连接。
Multi-Scale Training
我觉得这个也是yolo为什么性能提升的一个很重要的点,解决了yolo1当中对于多个小物体检测的问题。
原始的YOLO使用448×448的输入分辨率。添加anchor box后,我们将分辨率更改为416×416。然而,由于我们的模型只使用卷积层和池化层,相比yolo1删除了全连接层,它可以在运行中调整大小(应该是使用了1x1卷积不过我没看代码)。我们希望YOLOv2能够在不同大小的图像上运行,因此我们将其训练到模型中。
instead of fixing the input image size we change the network every few iterations. Every 10 batches our network randomly chooses a new image dimension size.
不固定输入图像的大小,我们每隔几次迭代就更改网络。在每10个batch之后,我们的网络就会随机resize成{320, 352, …, 608}中的一种。不同的输入,最后产生的格点数不同,比如输入图片是320320,那么输出格点是1010,如果每个格点的先验框个数设置为5,那么总共输出500个预测结果;如果输入图片大小是608608,输出格点就是1919,共1805个预测结果。
YOLO’s convolutional layers downsample the image by a factor of 32 so by using an input image of 416 we get an output feature map of 13 × 13.
We do this because we want an odd number of locations in our feature map so there is a single center cell.
关于416×416也是有说法的,主要是下采样是32的倍数,而且最后的输出是13x13是奇数然后会有一个中心点更加易于目标检测。
这种训练方法迫使网络学习在各种输入维度上很好地预测。这意味着相同的网络可以预测不同分辨率的检测。
关于yolov2最大的一个提升还有一个原因就是WordTree组合数据集的训练方法,不过这里我就不再赘述,可以看参考资料有详细介绍,这里主要讲网络和思路
yolov3论文改进
yolov3的论文改进就有很多方面了,而且yolov3-spp的网络效果很不错,和yolov4,yolov5的效果差别也不是特别大,这也是为什么yolov3网络被广泛应用的原因之一。
backbone:Darknet-53
相比yolov1的网络,在网络上有了很大的改进,借鉴了Resnet、Densenet、FPN的做法结合了当前网络中十分有效的
1.Yolov3中,全卷积,对于输入图片尺寸没有特别限制,可通过调节卷积步长控制输出特征图的尺寸。
2.Yolov3借鉴了金字塔特征图思想,小尺寸特征图用于检测大尺寸物体,而大尺寸特征图检测小尺寸物体。特征图的输出维度为$N \times N \times (3 \times (4+1+80))$, NxN为输出特征图格点数,一共3个Anchor框,每个框有4维预测框数值 $t_x,t_y,t_w,t_h$ ,1维预测框置信度,80维物体类别数。所以第一层特征图的输出维度为8x8x255
3.Yolov3总共输出3个特征图,第一个特征图下采样32倍,第二个特征图下采样16倍,第三个下采样8倍。每个特征图进行一次3X3、步长为2的卷积,然后保存该卷积layer,再进行一次1X1的卷积和一次3X3的卷积,并把这个结果加上layer作为最后的结果。三个特征层进行5次卷积处理,处理完后一部分用于输出该特征层对应的预测结果,一部分用于进行反卷积UmSampling2d后与其它特征层进行结合。
4.concat和resiual加操作,借鉴DenseNet将特征图按照通道维度直接进行拼接,借鉴Resnet添加残差边,缓解了在深度神经网络中增加深度带来的梯度消失问题。
5.上采样层(upsample):作用是将小尺寸特征图通过插值等方法,生成大尺寸图像。例如使用最近邻插值算法,将88的图像变换为1616。上采样层不改变特征图的通道数。
对于yolo3的模型来说,网络最后输出的内容就是三个特征层每个网格点对应的预测框及其种类,即三个特征层分别对应着图片被分为不同size的网格后,每个网格点上三个先验框对应的位置、置信度及其种类。然后对输出进行解码,解码过程也就是yolov2上面的Direct location prediction方法一样,每个网格点加上它对应的x_offset和y_offset,加完后的结果就是预测框的中心,然后再利用 先验框和h、w结合 计算出预测框的长和宽。这样就能得到整个预测框的位置了。
CIoU loss
在yolov3当中我们使用的不再是传统的IoU loss,而是一个非常优秀的loss设计,整个发展过程也可以多了解了解IoU->GIoU->DIoU->CIoU,完整的考虑了重合面积,中心点距离,长宽比。
其中, $b$ , $b^{gt}$ 分别代表了预测框和真实框的中心点,且 $\rho$代表的是计算两个中心点间的欧式距离。 [公式] 代表的是能够同时包含预测框和真实框的最小闭包区域的对角线距离。
在介绍CIoU之前,我们可以先介绍一下DIoU loss
其实这两项就是我们的DIoU
则我们可以提出DIoU loss函数
DloU损失能够直接最小化两个boxes之间的距离,因此收敛速度更快。
而我们的CIoU则比DIoU考虑更多的东西,也就是长宽比即最后一项。而$v$用来度量长宽比的相似性,$\alpha$是权重
在损失函数这块,有知乎大佬写了一下,其实就是对yolov1上的损失函数进行了一下变形。
Spatial Pyramid Pooling
在yolov3的spp版本中使用了spp模块,实现了不同尺度的特征融合,spp模块最初来源于何凯明大神的论文SPP-net,主要用来解决输入图像尺寸不统一的问题,而目前的图像预处理操作中,resize,crop等都会造成一定程度的图像失真,因此影响了最终的精度。SPP模块,使用固定分块的池化操作,可以对不同尺寸的输入实现相同大小的输出,因此能够避免这一问题。
同时SPP模块中不同大小特征的融合,有利于待检测图像中目标大小差异较大的情况,也相当于增大了多重感受野吧,尤其是对于yolov3一般针对的复杂多目标图像。
在yolov3的darknet53输出到第一个特征图计算之前我们插入了一个spp模块。
SPP的这几个模块stride=1,而且会对外补padding,所以最后的输出特征图大小是一致的,然后在深度方向上进行concatenate,使得深度增大了4倍。
可以看出随着输入网络尺度的增大,spp的效果会更好。多个spp的效果增大也就是spp3和spp1的效果是差不多的,为了保证推理速度就只使用了一个spp
Mosaic图像增强
在yolov3-spp包括yolov4当中我们都使用了mosaic数据增强,有点类似cutmix。cutmix是合并两张图片进行预测,mosaic数据增强利用了四张图片,对四张图片进行拼接,每一张图片都有其对应的框框,将四张图片拼接之后就获得一张新的图片,同时也获得这张图片对应的框框,然后我们将这样一张新的图片传入到神经网络当中去学习,相当于一下子传入四张图片进行学习了。论文中说这极大丰富了检测物体的背景,且在标准化BN计算的时候一下子会计算四张图片的数据。
作用:增加数据的多样性,增加目标个数,BN能一次性归一化多张图片组合的分布,会更加接近原数据的分布。
focal loss
最后我们提一下focal loss,虽然在原论文当中作者说focal loss效果反而下降了,但是我认为还是有必要了解一下何凯明的这篇bestpaper。作者提出focal loss的出发点也是希望one-stage detector可以达到two-stage detector的准确率,同时不影响原有的速度。作者认为造成这种情况的原因是样本的类别不均衡导致的。
对于二分类的CrossEntropy,我们有如下表示方法:
我们定义$p_t$:
则重写交叉熵
接着我们提出改进思路就是在计算CE时添加了一个平衡因子,是一个可训练的参数
其中
相当于给正负样本加上权重,负样本出现的频次多,那么就降低负样本的权重,正样本数量少,就相对提高正样本的权重。因此可以通过设定a的值来控制正负样本对总的loss的共享权重。a取比较小的值来降低负样本(多的那类样本)的权重。
但是何凯明认为这个还是不能完全解决样本不平衡的问题,虽然这个平衡因子可以控制正负样本的权重,但是没法控制容易分类和难分类样本的权重
As our experiments will show, the large class imbalance encountered during training of dense detectors overwhelms the cross entropy loss. Easily classified negatives comprise the majority of the loss and dominate the gradient. While
α balances the importance of positive/negative examples, it does not differentiate between easy/hard examples. Instead, we propose to reshape the loss function to down-weight easy examples and thus focus training on hard negatives
于是提出了一种新的损失函数Focal Loss
focal loss的两个重要性质
1、当一个样本被分错的时候,pt是很小的,那么调制因子(1-Pt)接近1,损失不被影响;当Pt→1,因子(1-Pt)接近0,那么分的比较好的(well-classified)样本的权值就被调低了。因此调制系数就趋于1,也就是说相比原来的loss是没有什么大的改变的。当pt趋于1的时候(此时分类正确而且是易分类样本),调制系数趋于0,也就是对于总的loss的贡献很小。
2、当γ=0的时候,focal loss就是传统的交叉熵损失,当γ增加的时候,调制系数也会增加。 专注参数γ平滑地调节了易分样本调低权值的比例。γ增大能增强调制因子的影响,实验发现γ取2最好。直觉上来说,调制因子减少了易分样本的损失贡献,拓宽了样例接收到低损失的范围。当γ一定的时候,比如等于2,一样easy example(pt=0.9)的loss要比标准的交叉熵loss小100+倍,当pt=0.968时,要小1000+倍,但是对于hard example(pt < 0.5),loss最多小了4倍。这样的话hard example的权重相对就提升了很多。这样就增加了那些误分类的重要性
focal loss的两个性质算是核心,其实就是用一个合适的函数去度量难分类和易分类样本对总的损失的贡献。
然后作者又提出了最终的focal loss形式
这样既能调整正负样本的权重,又能控制难易分类样本的权重
在实验中a的选择范围也很广,一般而言当γ增加的时候,a需要减小一点(实验中γ=2,a=0.25的效果最好)
总结
yolo和yolov2的严谨数学推理和网络相结合的做法令人十分惊艳,而yolov3相比之前的两个版本不管是在数据处理还是网络性质上都有很大的改变,也使用了很多流行的tirck来实现目标检测,基本上结合了很多cv领域的精髓,博客中有很多部分由于时间关系没有太细讲,其实每个部分都可以去原论文中找到很多可以学习的地方,之后有时候会补上yolov4和yolov5的讲解,后面的网络添加了注意力机制模块效果应该是更加work的。
参考文献
yolov3-spp
focal loss
batch normal
IoU系列
yolov1论文翻译
yolo1-3三部曲
Bubbliiiing的教程里
还有很多但是没找到之后会补上的
]]>
- <h2 id="yolov1-3论文解析"><a href="#yolov1-3论文解析" class="headerlink" title="yolov1-3论文解析"></a>yolov1-3论文解析</h2><p>最近在看经典目标检测算法yolo的思想,为了更好的了解yolo系列的相关文章,我从最初版本的论文思想开始看的,之后有时间会把yolov4和yolov5再认真看看,目前来说yolov3的spp版本是使用得最为广泛的一种,整体上来说yolo的设计思想还是很有创造性的数学也比较严谨。</p>
+ <h2 id="yolov1-3论文解析"><a href="#yolov1-3论文解析" class="headerlink" title="yolov1-3论文解析"></a>yolov1-3论文解析</h2><p>最近在看经典目标检测算法yolo的思想,为了更好的了解yolo系列的相关文章,我从最初版本的论文思想开始看的,之后有时间会把yolov4和yolov5再认真看看,目前来说yolov3的spp版本是使用得最为广泛的一种,整体上来说yolo的设计思想还是很有创造性的数学也比较严谨。<br></p>
@@ -377,7 +377,7 @@
2021-04-12T00:39:00.000Z
2024-10-09T07:33:09.887Z
- MTCNN人脸检测和pytorch代码实现解读传送门
论文地址:https://arxiv.org/ftp/arxiv/papers/1604/1604.02878.pdf
我的论文笔记:https://khany.top/file/paper/mtcnn.pdf
本文csdn链接:https://blog.csdn.net/Jack___E/article/details/115601474
github参考:https://github.com/Sierkinhane/mtcnn-pytorch
github参考:https://github.com/GitHberChen/MTCNN_Pytorch
abstract
abstract—Face detection and alignment in unconstrained environment are challenging due to various poses, illuminations and occlusions. Recent studies show that deep learning approaches can achieve impressive performance on these two tasks. In this paper, we propose a deep cascaded multi-task framework which exploits the inherent correlation between detection and alignment
to boost up their performance. In particular, our framework leverages a cascaded architecture with three stages of carefully designed deep convolutional networks to predict face and landmark location in a coarse-to-fine manner. In addition, we propose a new online hard sample mining strategy that further improves the performance in practice. Our method achieves superior accuracy over the state-of-the-art techniques on the challenging FDDB and WIDER FACE benchmarks for face detection, and AFLW benchmark for face alignment, while keeps real time performance.
在无约束条件的环境下进行人脸检测和校准人脸检测和校准是非常具挑战性的,因为你要考虑复杂的姿势,光照因素以及面部遮挡问题的影响,最近的研究表明,使用深度学习的方法能够在这两项任务上有不错的效果。本文作者探索和研究了人脸检测和校准之间的内在联系,提出了一个深层级的多任务框架有效提升了网络的性能。我们的深层级联合架构包含三个阶段的卷积神经网络从粗略到细致逐步实现人脸检测和面部特征点标记。此外,我们还提出了一种新的线上进行困难样本的预测的策略可以在实际使用过程中有效提升网络的性能。我们的方法目前在FDDB和WIDER FACE人脸检测任务和AFLW面部对准任务上超越了最佳模型方法的性能标准,同时该模型具有不错的实时检测效果。
my English is not so well,if there are some mistakes in translations, please contact me in blog comments.
简介
人脸检测和脸部校准任务对于很多面部任务和应用来说都是十分重要的,比如说人脸识别,人脸表情分析。不过在现实生活当中,面部特征时常会因为一些遮挡物,强烈的光照对比,复杂的姿势发生很大的变化,这使得这些任务变得具有很大挑战性。Viola和Jones 提出的级联人脸检测器利用Haar特征和AdaBoost训练级联分类器,实现了具有实时效率的良好性能。 然而,也有相当一部分的工作表明,这种分类器可能在现实生活的应用中效果显着降低,即使具有更高级的特征和分类器。,之后人们又提出了DPM的方式,这些年来基于CNN的一些解决方案也层出不穷,基于CNN的方案主要是为了识别出面部的一些特征来实现。作者认为这种方式其实是需要花费更多的时间来对面部进行校准来训练同时还忽略了面部的重要特征点位置和边框问题。
对于人脸校准的话目前也有大致的两个方向:一个是基于回归的方法还有一个就是基于模板拟合的方式进行,主要是对特征识别起到一个辅助的工作。
作者认为关于人脸识别和面部对准这两个任务其实是有内在关联的,而目前大多数的方法则忽略了这一点,所以本文所提出的方案就是将这两者都结合起来,构建出一个三阶段的模型实现一个端到端的人脸检测并校准面部特征点的过程。
第一阶段:通过浅层CNN快速生成候选窗口。
第二阶段:通过more complex的CNN拒绝大量非面部窗口来细化窗口。
第三阶段:使用more powerful的CNN再次细化结果并输出五个面部标志位置。
方法
Image pyramid图像金字塔
在进入stage-1之前,作者先构建了一组多尺度的图像金字塔缩放,这一块要理解起来还是有一点费力的,这里我们需要了解的是在训练网络的过程当中,作者都是把WIDER FACE的图片随机剪切成12x12size的大小进行单尺度训练的,不能满足任意大小的人脸检测,所以为了检测到不同尺寸的人脸,所以在推理时需要先生成图像金字塔生成一组不同scale的图像输入P-net进行来实现人脸的检测,同时也这是为什么P-net要使用FCN的原因。
def calculateScales(img):
min_face_size = 20 # 最小的人脸尺寸
width, height = img.size
min_length = min(height, width)
min_detection_size = 12
factor = 0.707 # sqrt(0.5)
scales = []
m = min_detection_size / min_face_size
min_length *= m
factor_count = 0
# 图像尺寸缩小到不大于min_detection_size
while min_length > min_detection_size:
scales.append(m * factor ** factor_count)
min_length *= factor
factor_count += 1
$$\text{length} =\text{length} \times (\frac{\text{min detection size}}{\text{min face size}} )\times factor^{count} $$
$\text{here we define in our code:} factor=\frac{1}{\sqrt{2}}, \text{min face size}=20,\text{min detection size}=12$
min_face_size和factor对推理过程会产生什么样的影响?
min_face_size越大,factor越小,图像最短边就越快缩放到接近min_detect_size,从而生成图像金字塔的耗时就越短,同时各尺度的跨度也更大。因此,加大min_face_size、减小factor能加速图像金字塔的生成,但同时也更易造成漏检。
Stage 1 P-Net(Proposal Network)
这是一个全卷积网络,也就是说这个网络可以兼容任意大小的输入,他的整个网络其实十分简单,该层的作用主要是为了获得人脸检测的大量候选框,这一层我们最大的作用就是要尽可能的提升recall,然后在获得许多候选框后再使用非极大抑制的方法合并高度重叠的候选区域。
P-Net的示意图当中我们也可以看到的是作者输入12x12大小最终的output为一个1x1x2的face label classification概率和一个1x1x4的boudingbox(左上角和右下角的坐标)以及一个1x1x10的landmark(双眼,鼻子,左右嘴角的坐标)
注意虽然这里作者举例是12x12的图片大小,但是他的意思并不是说这个P-Net的图片输入大小必须是12,我们可以知道这个网络是FCN,这就意味着不同输入的大小都是可以输入其中的,最后我们所得到的featuremap$[m \times n \times (2+4+10) ]$每一个小像素点映射到输入图像所在的12x12区域是否包含人脸的分类结果,候选框左上和右下基准点以及landmark,然后根据图像金字塔的我们再根据scale和resize的逆过程将其映射到原图像上
P-net structure
class P_Net(nn.Module):
def __init__(self):
super(P_Net, self).__init__()
self.pre_layer = nn.Sequential(
# 12x12x3
nn.Conv2d(3, 10, kernel_size=3, stride=1), # conv1
nn.PReLU(), # PReLU1
# 10x10x10
nn.MaxPool2d(kernel_size=2, stride=2), # pool1
# 5x5x10
nn.Conv2d(10, 16, kernel_size=3, stride=1), # conv2
# 3x3x16
nn.PReLU(), # PReLU2
nn.Conv2d(16, 32, kernel_size=3, stride=1), # conv3
# 1x1x32
nn.PReLU() # PReLU3
)
# detection
self.conv4_1 = nn.Conv2d(32, 1, kernel_size=1, stride=1)
# bounding box regresion
self.conv4_2 = nn.Conv2d(32, 4, kernel_size=1, stride=1)
# landmark localization
self.conv4_3 = nn.Conv2d(32, 10, kernel_size=1, stride=1)
# weight initiation with xavier
self.apply(weights_init)
def forward(self, x):
x = self.pre_layer(x)
det = torch.sigmoid(self.conv4_1(x))
box = self.conv4_2(x)
landmark = self.conv4_3(x)
# det:[,2,1,1], box:[,4,1,1], landmark:[,10,1,1]
return det, box, landmark
这里要提一下nn.PReLU(),有点类似Leaky ReLU,可以看下面的博客深入了解一下
https://blog.csdn.net/qq_23304241/article/details/80300149
https://blog.csdn.net/shuzfan/article/details/51345832
然后在P-Net之后我们通过非极大抑制的方法和将所有的boudingbox都修正为框的最长边为边长的正方形框,主要是避免后面的Rnet在resize的时候因为尺寸原因出现信息的损失。
Non-Maximum Suppression非极大抑制
其实关于非极大抑制这个trick最初是在目标检测任务当中提出的来的,其思想是搜素局部最大值,抑制极大值,主要用在目标检测当中,最传统的非极大抑制所采用的评价指标就是交并比IoU(intersection-over-union)即两个groud truth和bounding box的交集部分除以它们的并集.
$$IoU = \frac{area(C) \cap area(G)}{area(C) \cup area(G)}$$
def IoU(box, boxes):
"""Compute IoU between detect box and gt boxes
Parameters:
----------
box: numpy array , shape (5, ): x1, y1, x2, y2, score
input box
boxes: numpy array, shape (n, 4): x1, y1, x2, y2
input ground truth boxes
Returns:
-------
ovr: numpy.array, shape (n, )
IoU
"""
box_area = (box[2] - box[0] + 1) * (box[3] - box[1] + 1)
area = (boxes[:, 2] - boxes[:, 0] + 1) * (boxes[:, 3] - boxes[:, 1] + 1)
xx1 = np.maximum(box[0], boxes[:, 0])
xx2 = np.minimum(box[2], boxes[:, 2])
yy1 = np.maximum(box[1], boxes[:, 1])
yy2 = np.minimum(box[3], boxes[:, 3])
# compute the width and height of the bounding box
w = np.maximum(0, xx2 - xx1 + 1)
h = np.maximum(0, yy2 - yy1 + 1)
inter = w * h
ovr = np.true_divide(inter,(box_area + area - inter))
#ovr = inter / (box_area + area - inter)
return ovr
使用非极大抑制的前提是,我们已经得到了一组候选框和对应label的置信分数,以及groud truth的信息,通过设定阈值来删除重合度较高的候选框。
算法流程如下:
- 根据置信度得分进行排序
- 选择置信度最高的比边界框添加到最终输出列表中,将其从边界框列表中删除
- 计算所有边界框的面积
- 计算置信度最高的边界框与其它候选框的IoU。
- 删除IoU大于阈值的边界框
- 重复上述过程,直至边界框列表为空。
def nms(dets,threshod,mode="Union"):
"""
greedily select boxes with high confidence
keep boxes overlap <= thresh
rule out overlap > thresh
:param dets: [[x1, y1, x2, y2 score]]
:param threshod: retain overlap <= thresh
:return: indexes to keep
"""
x1 = dets[:,0]
y1 = dets[;,1]
x2 = dets[:,2]
y2 = dets[:,3]
scores = dets[:,4]
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
order = areas.argsort()[::-1] # reverse
keep=[]
while order.size()>0:
i = order[0]
keep.append(i)
# A & B left top position
xx1 = np.maximun(x1[i],x1[order[1,:]])
yy1 = np.maximun(y1[i],y1[order[1,:]])
# A & B right down position
xx2 = np.minimum(x2[i],x2[order[1,:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
# cacaulate the IOU between box which have largest score with other boxes
if mode == "Union":
# area[i]: the area of largest score
ovr = inter / (areas[i] + areas[order[1:]] - inter)
elif mode == "Minimum":
ovr = inter / np.minimum(areas[i], areas[order[1:]])
# delete the IoU that higher than threshod
inds = np.where(ovr <= threshod)[0]
order = order[inds + 1] # +1: eliminates the first element in order
return keep
边框修正
以最大边作为边长将矩形修正为正方形,同时包含的信息也更多,以免在后面resize输入下一个网络时减少信息的损失。
def convert_to_square(bboxes):
"""
Convert bounding boxes to a square form.
"""
# 将矩形对称扩大为正方形
square_bboxes = np.zeros_like(bboxes)
x1, y1, x2, y2 = [bboxes[:, i] for i in range(4)]
h = y2 - y1 + 1.0
w = x2 - x1 + 1.0
max_side = np.maximum(h, w)
square_bboxes[:, 0] = x1 + w * 0.5 - max_side * 0.5
square_bboxes[:, 1] = y1 + h * 0.5 - max_side * 0.5
square_bboxes[:, 2] = square_bboxes[:, 0] + max_side - 1.0
square_bboxes[:, 3] = square_bboxes[:, 1] + max_side - 1.0
return square_bboxes
Stage 2 R-Net(Refine Network)
R-net的输入是固定的,必须是24x24,所以对于P-net产生的大量boundingbox我们需要先进行resize然后再输入R-Net,在论文中我们了解到该网络层的作用主要是对大量的boundingbox进行有效过滤,获得更加精细的候选框。
R-net structure
class R_Net(nn.Module):
def __init__(self):
super(R_Net, self).__init__()
self.pre_layer = nn.Sequential(
# 24x24x3
nn.Conv2d(3, 28, kernel_size=3, stride=1), # conv1
nn.PReLU(), # prelu1
# 22x22x28
nn.MaxPool2d(kernel_size=3, stride=2), # pool1
# 10x10x28
nn.Conv2d(28, 48, kernel_size=3, stride=1), # conv2
nn.PReLU(), # prelu2
# 8x8x48
nn.MaxPool2d(kernel_size=3, stride=2), # pool2
# 3x3x48
nn.Conv2d(48, 64, kernel_size=2, stride=1), # conv3
# 2x2x64
nn.PReLU() # prelu3
)
# 2x2x64
self.conv4 = nn.Linear(64 * 2 * 2, 128) # conv4
# 128
self.prelu4 = nn.PReLU() # prelu4
# detection
self.conv5_1 = nn.Linear(128, 1)
# bounding box regression
self.conv5_2 = nn.Linear(128, 4)
# lanbmark localization
self.conv5_3 = nn.Linear(128, 10)
# weight initiation weih xavier
self.apply(weights_init)
def forward(self, x):
x = self.pre_layer(x)
x = x.view(x.size(0), -1)
x = self.conv4(x)
x = self.prelu4(x)
det = torch.sigmoid(self.conv5_1(x))
box = self.conv5_2(x)
landmark = self.conv5_3(x)
return det, box, landmark
然后在P-Net之后我们通过非极大抑制的方法和将所有的boudingbox都修正为框的最长边为边长的正方形框,也是避免后面的Onet在resize的时候出现因为尺寸原因出现信息的损失。
Stage 3 O-Net(Output?[作者未指出命名] Network)
Onet与Rnet工作流程类似。只不过输入的尺寸变成了48x48,对于R-net当中的框再次进行处理,得到的网络结构的输出则是最终的label classfication,boundingbox,landmark。
O-net structure
class O_Net(nn.Module):
def __init__(self):
super(O_Net, self).__init__()
self.pre_layer = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, stride=1), # conv1
nn.PReLU(), # prelu1
nn.MaxPool2d(kernel_size=3, stride=2), # pool1
nn.Conv2d(32, 64, kernel_size=3, stride=1), # conv2
nn.PReLU(), # prelu2
nn.MaxPool2d(kernel_size=3, stride=2), # pool2
nn.Conv2d(64, 64, kernel_size=3, stride=1), # conv3
nn.PReLU(), # prelu3
nn.MaxPool2d(kernel_size=2, stride=2), # pool3
nn.Conv2d(64, 128, kernel_size=2, stride=1), # conv4
nn.PReLU() # prelu4
)
self.conv5 = nn.Linear(128 * 2 * 2, 256) # conv5
self.prelu5 = nn.PReLU() # prelu5
# detection
self.conv6_1 = nn.Linear(256, 1)
# bounding box regression
self.conv6_2 = nn.Linear(256, 4)
# lanbmark localization
self.conv6_3 = nn.Linear(256, 10)
# weight initiation weih xavier
self.apply(weights_init)
def forward(self, x):
x = self.pre_layer(x)
x = x.view(x.size(0), -1)
x = self.conv5(x)
x = self.prelu5(x)
# detection
det = torch.sigmoid(self.conv6_1(x))
box = self.conv6_2(x)
landmark = self.conv6_3(x)
return det, box, landmark
注意,其实在之前的两个网络当中我们也预测了landmark的位置,只是在论文的图示当中没有展示而已,从作者描述的网络结构图的输出当中是详细指出了landmarkposition的卷积块的
损失函数
在研究完网络结构以后我们可以来看看这个mtcnn模型的一个损失函数,作者将损失函数分为了3个部分:Face classification、Bounding box regression、Facial landmark localization。
Face classification
对于第一部分的损失就是用的是最常用的交叉熵损失函数,就本质上来说人脸识别还是一个二分类问题,这里就使用Cross Entropy是最简单也是最合适的选择。
$$L_i^{det} = -(y_i^{det} \log(p_i) + (1-y_i^det)(1-\log(p_i)))$$
$p_i$是预测为face的可能性,$y_i^{det}$指的是真实标签也就是groud truth label
Bounding box regression
对于目标边界框的损失来说,对于每一个候选框我们都需要对与他最接近的真实目标边界框进行比较,the bounding box$(left, top, height, and width)$
$$L_i^{box} = ||y_j^{box}-y_i^{box} ||_2^2$$
Facial landmark localization
而对于boundingbox和landmark来说整个框的调整过程其实可以看作是一个连续的变化过程,固使用的是欧氏距离回归损失计算方法。比较的是各个点的坐标与真实面部关键点坐标的差异。
$$L_i^{landmark} = ||y_j^{landmark}-y_i^{landmark} ||_2^2$$
total loss
最终我们得到的损失函数是有上述这三部分加权而成
$$\min{\sum_{i=1}^{N}{\sum_{j \in {det,box,landmark}} \alpha_j \beta_i^j L_i^j}}$$
其中$\alpha_j$表示权重,$\beta_i^j$表示第i个样本的类型,也可以说是第i个样本在任务j中是否需要贡献loss,如果不存在人脸即label为0时则无需计算loss。
对于不同的网络我们所设置的权重是不一样的
in P-net & R-net(在这两层我们更注重classification的识别)
$$alpha_{det}=1, alpha_{box}=0.5,alpha_{landmark}=0.5$$
in O-net(在这层我们提高了对于注意关键点的预测精度)
$$alpha_{det}=1, alpha_{box}=0.5,alpha_{landmark}=1 $$
文中也有提到,采用的是随机梯度下降优化器进行的训练。
OHEM(Online Hard Example Mining)
作者对于困难样本的在线预测所做的trick也比较简单,就是挑选损失最大的前70%作为困难样本,在反向传播时仅使用这70%困难样本产生的损失,这样就剔除了很容易预测的easy sample对训练结果的影响,不过在我参考的这两个版本的代码里面似乎没有这么做。
实验
实验这块的话也比较充分,验证了每个修改部分对于实验结果的有效性验证,主要是讲述了实验过程对于训练数据集的处理和划分,验证了在线硬样本挖掘的有效性,联合检测和校准的有效性,分别评估了face detection和lanmark的贡献,面部检测评估,面部校准评估以及与SOTA的对比,这一块的话就没有细看了,分享的网站也有详细解释,论文原文也写了。
总结
这篇论文是中科院深圳先进技术研究院的乔宇老师团队所作,2016ECCV,看完这篇文章的话给我的感觉的话就是idea和实现过程包括实验都是很充分的,创新点这块的话主要是挖掘了人脸特征关键点和目标检测的一些联系,结合了人脸检测和对准两个任务来进行人脸检测,相比其他经典的目标检测网络如yolov3,R-CNN系列,在网络和损失函数上的创新确实略有不足,但是也让我收到了一些启发,看似几个简单的model和常见的loss联合,在对数据进行有效处理的基础上也是可以实现达到十分不错的效果的,不过这个方案的话在训练的时候其实是很花费时间的,毕竟需要对于不同scale的图片都进行输入训练,然后就是这种输入输出的结构其实还是存在一些局限性的,对于图像检测框和关键点的映射我个人觉得也比较繁杂或者说浪费了一些时间,毕竟是一篇2016年的论文之后应该会有更好的实现方式。
参考资料
参考链接: https://zhuanlan.zhihu.com/p/337690783
参考链接:https://zhuanlan.zhihu.com/p/60199964?utm_source=qq&utm_medium=social&utm_oi=1221207556791963648
参考链接: https://blog.csdn.net/weixin_44791964/article/details/103530206
参考链接:https://blog.csdn.net/qq_34714751/article/details/85536669
参考链接:https://www.bilibili.com/video/BV1fJ411C7AJ?from=search&seid=2691296178499711503
]]>
+ MTCNN人脸检测和pytorch代码实现解读传送门
论文地址:https://arxiv.org/ftp/arxiv/papers/1604/1604.02878.pdf
我的论文笔记:https://khany.top/file/paper/mtcnn.pdf
本文csdn链接:https://blog.csdn.net/Jack___E/article/details/115601474
github参考:https://github.com/Sierkinhane/mtcnn-pytorch
github参考:https://github.com/GitHberChen/MTCNN_Pytorch
abstract
abstract—Face detection and alignment in unconstrained environment are challenging due to various poses, illuminations and occlusions. Recent studies show that deep learning approaches can achieve impressive performance on these two tasks. In this paper, we propose a deep cascaded multi-task framework which exploits the inherent correlation between detection and alignment
to boost up their performance. In particular, our framework leverages a cascaded architecture with three stages of carefully designed deep convolutional networks to predict face and landmark location in a coarse-to-fine manner. In addition, we propose a new online hard sample mining strategy that further improves the performance in practice. Our method achieves superior accuracy over the state-of-the-art techniques on the challenging FDDB and WIDER FACE benchmarks for face detection, and AFLW benchmark for face alignment, while keeps real time performance.
在无约束条件的环境下进行人脸检测和校准人脸检测和校准是非常具挑战性的,因为你要考虑复杂的姿势,光照因素以及面部遮挡问题的影响,最近的研究表明,使用深度学习的方法能够在这两项任务上有不错的效果。本文作者探索和研究了人脸检测和校准之间的内在联系,提出了一个深层级的多任务框架有效提升了网络的性能。我们的深层级联合架构包含三个阶段的卷积神经网络从粗略到细致逐步实现人脸检测和面部特征点标记。此外,我们还提出了一种新的线上进行困难样本的预测的策略可以在实际使用过程中有效提升网络的性能。我们的方法目前在FDDB和WIDER FACE人脸检测任务和AFLW面部对准任务上超越了最佳模型方法的性能标准,同时该模型具有不错的实时检测效果。
my English is not so well,if there are some mistakes in translations, please contact me in blog comments.
简介
人脸检测和脸部校准任务对于很多面部任务和应用来说都是十分重要的,比如说人脸识别,人脸表情分析。不过在现实生活当中,面部特征时常会因为一些遮挡物,强烈的光照对比,复杂的姿势发生很大的变化,这使得这些任务变得具有很大挑战性。Viola和Jones 提出的级联人脸检测器利用Haar特征和AdaBoost训练级联分类器,实现了具有实时效率的良好性能。 然而,也有相当一部分的工作表明,这种分类器可能在现实生活的应用中效果显着降低,即使具有更高级的特征和分类器。,之后人们又提出了DPM的方式,这些年来基于CNN的一些解决方案也层出不穷,基于CNN的方案主要是为了识别出面部的一些特征来实现。作者认为这种方式其实是需要花费更多的时间来对面部进行校准来训练同时还忽略了面部的重要特征点位置和边框问题。
对于人脸校准的话目前也有大致的两个方向:一个是基于回归的方法还有一个就是基于模板拟合的方式进行,主要是对特征识别起到一个辅助的工作。
作者认为关于人脸识别和面部对准这两个任务其实是有内在关联的,而目前大多数的方法则忽略了这一点,所以本文所提出的方案就是将这两者都结合起来,构建出一个三阶段的模型实现一个端到端的人脸检测并校准面部特征点的过程。
第一阶段:通过浅层CNN快速生成候选窗口。
第二阶段:通过more complex的CNN拒绝大量非面部窗口来细化窗口。
第三阶段:使用more powerful的CNN再次细化结果并输出五个面部标志位置。
方法
Image pyramid图像金字塔
在进入stage-1之前,作者先构建了一组多尺度的图像金字塔缩放,这一块要理解起来还是有一点费力的,这里我们需要了解的是在训练网络的过程当中,作者都是把WIDER FACE的图片随机剪切成12x12size的大小进行单尺度训练的,不能满足任意大小的人脸检测,所以为了检测到不同尺寸的人脸,所以在推理时需要先生成图像金字塔生成一组不同scale的图像输入P-net进行来实现人脸的检测,同时也这是为什么P-net要使用FCN的原因。
def calculateScales(img):
min_face_size = 20 # 最小的人脸尺寸
width, height = img.size
min_length = min(height, width)
min_detection_size = 12
factor = 0.707 # sqrt(0.5)
scales = []
m = min_detection_size / min_face_size
min_length *= m
factor_count = 0
# 图像尺寸缩小到不大于min_detection_size
while min_length > min_detection_size:
scales.append(m * factor ** factor_count)
min_length *= factor
factor_count += 1
$\text{here we define in our code:} factor=\frac{1}{\sqrt{2}}, \text{min face size}=20,\text{min detection size}=12$
min_face_size和factor对推理过程会产生什么样的影响?
min_face_size越大,factor越小,图像最短边就越快缩放到接近min_detect_size,从而生成图像金字塔的耗时就越短,同时各尺度的跨度也更大。因此,加大min_face_size、减小factor能加速图像金字塔的生成,但同时也更易造成漏检。
Stage 1 P-Net(Proposal Network)
这是一个全卷积网络,也就是说这个网络可以兼容任意大小的输入,他的整个网络其实十分简单,该层的作用主要是为了获得人脸检测的大量候选框,这一层我们最大的作用就是要尽可能的提升recall,然后在获得许多候选框后再使用非极大抑制的方法合并高度重叠的候选区域。
P-Net的示意图当中我们也可以看到的是作者输入12x12大小最终的output为一个1x1x2的face label classification概率和一个1x1x4的boudingbox(左上角和右下角的坐标)以及一个1x1x10的landmark(双眼,鼻子,左右嘴角的坐标)
注意虽然这里作者举例是12x12的图片大小,但是他的意思并不是说这个P-Net的图片输入大小必须是12,我们可以知道这个网络是FCN,这就意味着不同输入的大小都是可以输入其中的,最后我们所得到的featuremap$[m \times n \times (2+4+10) ]$每一个小像素点映射到输入图像所在的12x12区域是否包含人脸的分类结果,候选框左上和右下基准点以及landmark,然后根据图像金字塔的我们再根据scale和resize的逆过程将其映射到原图像上
P-net structure
class P_Net(nn.Module):
def __init__(self):
super(P_Net, self).__init__()
self.pre_layer = nn.Sequential(
# 12x12x3
nn.Conv2d(3, 10, kernel_size=3, stride=1), # conv1
nn.PReLU(), # PReLU1
# 10x10x10
nn.MaxPool2d(kernel_size=2, stride=2), # pool1
# 5x5x10
nn.Conv2d(10, 16, kernel_size=3, stride=1), # conv2
# 3x3x16
nn.PReLU(), # PReLU2
nn.Conv2d(16, 32, kernel_size=3, stride=1), # conv3
# 1x1x32
nn.PReLU() # PReLU3
)
# detection
self.conv4_1 = nn.Conv2d(32, 1, kernel_size=1, stride=1)
# bounding box regresion
self.conv4_2 = nn.Conv2d(32, 4, kernel_size=1, stride=1)
# landmark localization
self.conv4_3 = nn.Conv2d(32, 10, kernel_size=1, stride=1)
# weight initiation with xavier
self.apply(weights_init)
def forward(self, x):
x = self.pre_layer(x)
det = torch.sigmoid(self.conv4_1(x))
box = self.conv4_2(x)
landmark = self.conv4_3(x)
# det:[,2,1,1], box:[,4,1,1], landmark:[,10,1,1]
return det, box, landmark
这里要提一下nn.PReLU(),有点类似Leaky ReLU,可以看下面的博客深入了解一下
https://blog.csdn.net/qq_23304241/article/details/80300149
https://blog.csdn.net/shuzfan/article/details/51345832
然后在P-Net之后我们通过非极大抑制的方法和将所有的boudingbox都修正为框的最长边为边长的正方形框,主要是避免后面的Rnet在resize的时候因为尺寸原因出现信息的损失。
Non-Maximum Suppression非极大抑制
其实关于非极大抑制这个trick最初是在目标检测任务当中提出的来的,其思想是搜素局部最大值,抑制极大值,主要用在目标检测当中,最传统的非极大抑制所采用的评价指标就是交并比IoU(intersection-over-union)即两个groud truth和bounding box的交集部分除以它们的并集.
def IoU(box, boxes):
"""Compute IoU between detect box and gt boxes
Parameters:
----------
box: numpy array , shape (5, ): x1, y1, x2, y2, score
input box
boxes: numpy array, shape (n, 4): x1, y1, x2, y2
input ground truth boxes
Returns:
-------
ovr: numpy.array, shape (n, )
IoU
"""
box_area = (box[2] - box[0] + 1) * (box[3] - box[1] + 1)
area = (boxes[:, 2] - boxes[:, 0] + 1) * (boxes[:, 3] - boxes[:, 1] + 1)
xx1 = np.maximum(box[0], boxes[:, 0])
xx2 = np.minimum(box[2], boxes[:, 2])
yy1 = np.maximum(box[1], boxes[:, 1])
yy2 = np.minimum(box[3], boxes[:, 3])
# compute the width and height of the bounding box
w = np.maximum(0, xx2 - xx1 + 1)
h = np.maximum(0, yy2 - yy1 + 1)
inter = w * h
ovr = np.true_divide(inter,(box_area + area - inter))
#ovr = inter / (box_area + area - inter)
return ovr
使用非极大抑制的前提是,我们已经得到了一组候选框和对应label的置信分数,以及groud truth的信息,通过设定阈值来删除重合度较高的候选框。
算法流程如下:
- 根据置信度得分进行排序
- 选择置信度最高的比边界框添加到最终输出列表中,将其从边界框列表中删除
- 计算所有边界框的面积
- 计算置信度最高的边界框与其它候选框的IoU。
- 删除IoU大于阈值的边界框
- 重复上述过程,直至边界框列表为空。
def nms(dets,threshod,mode="Union"):
"""
greedily select boxes with high confidence
keep boxes overlap <= thresh
rule out overlap > thresh
:param dets: [[x1, y1, x2, y2 score]]
:param threshod: retain overlap <= thresh
:return: indexes to keep
"""
x1 = dets[:,0]
y1 = dets[;,1]
x2 = dets[:,2]
y2 = dets[:,3]
scores = dets[:,4]
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
order = areas.argsort()[::-1] # reverse
keep=[]
while order.size()>0:
i = order[0]
keep.append(i)
# A & B left top position
xx1 = np.maximun(x1[i],x1[order[1,:]])
yy1 = np.maximun(y1[i],y1[order[1,:]])
# A & B right down position
xx2 = np.minimum(x2[i],x2[order[1,:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
# cacaulate the IOU between box which have largest score with other boxes
if mode == "Union":
# area[i]: the area of largest score
ovr = inter / (areas[i] + areas[order[1:]] - inter)
elif mode == "Minimum":
ovr = inter / np.minimum(areas[i], areas[order[1:]])
# delete the IoU that higher than threshod
inds = np.where(ovr <= threshod)[0]
order = order[inds + 1] # +1: eliminates the first element in order
return keep
边框修正
以最大边作为边长将矩形修正为正方形,同时包含的信息也更多,以免在后面resize输入下一个网络时减少信息的损失。
def convert_to_square(bboxes):
"""
Convert bounding boxes to a square form.
"""
# 将矩形对称扩大为正方形
square_bboxes = np.zeros_like(bboxes)
x1, y1, x2, y2 = [bboxes[:, i] for i in range(4)]
h = y2 - y1 + 1.0
w = x2 - x1 + 1.0
max_side = np.maximum(h, w)
square_bboxes[:, 0] = x1 + w * 0.5 - max_side * 0.5
square_bboxes[:, 1] = y1 + h * 0.5 - max_side * 0.5
square_bboxes[:, 2] = square_bboxes[:, 0] + max_side - 1.0
square_bboxes[:, 3] = square_bboxes[:, 1] + max_side - 1.0
return square_bboxes
Stage 2 R-Net(Refine Network)
R-net的输入是固定的,必须是24x24,所以对于P-net产生的大量boundingbox我们需要先进行resize然后再输入R-Net,在论文中我们了解到该网络层的作用主要是对大量的boundingbox进行有效过滤,获得更加精细的候选框。
R-net structure
class R_Net(nn.Module):
def __init__(self):
super(R_Net, self).__init__()
self.pre_layer = nn.Sequential(
# 24x24x3
nn.Conv2d(3, 28, kernel_size=3, stride=1), # conv1
nn.PReLU(), # prelu1
# 22x22x28
nn.MaxPool2d(kernel_size=3, stride=2), # pool1
# 10x10x28
nn.Conv2d(28, 48, kernel_size=3, stride=1), # conv2
nn.PReLU(), # prelu2
# 8x8x48
nn.MaxPool2d(kernel_size=3, stride=2), # pool2
# 3x3x48
nn.Conv2d(48, 64, kernel_size=2, stride=1), # conv3
# 2x2x64
nn.PReLU() # prelu3
)
# 2x2x64
self.conv4 = nn.Linear(64 * 2 * 2, 128) # conv4
# 128
self.prelu4 = nn.PReLU() # prelu4
# detection
self.conv5_1 = nn.Linear(128, 1)
# bounding box regression
self.conv5_2 = nn.Linear(128, 4)
# lanbmark localization
self.conv5_3 = nn.Linear(128, 10)
# weight initiation weih xavier
self.apply(weights_init)
def forward(self, x):
x = self.pre_layer(x)
x = x.view(x.size(0), -1)
x = self.conv4(x)
x = self.prelu4(x)
det = torch.sigmoid(self.conv5_1(x))
box = self.conv5_2(x)
landmark = self.conv5_3(x)
return det, box, landmark
然后在P-Net之后我们通过非极大抑制的方法和将所有的boudingbox都修正为框的最长边为边长的正方形框,也是避免后面的Onet在resize的时候出现因为尺寸原因出现信息的损失。
Stage 3 O-Net(Output?[作者未指出命名] Network)
Onet与Rnet工作流程类似。只不过输入的尺寸变成了48x48,对于R-net当中的框再次进行处理,得到的网络结构的输出则是最终的label classfication,boundingbox,landmark。
O-net structure
class O_Net(nn.Module):
def __init__(self):
super(O_Net, self).__init__()
self.pre_layer = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, stride=1), # conv1
nn.PReLU(), # prelu1
nn.MaxPool2d(kernel_size=3, stride=2), # pool1
nn.Conv2d(32, 64, kernel_size=3, stride=1), # conv2
nn.PReLU(), # prelu2
nn.MaxPool2d(kernel_size=3, stride=2), # pool2
nn.Conv2d(64, 64, kernel_size=3, stride=1), # conv3
nn.PReLU(), # prelu3
nn.MaxPool2d(kernel_size=2, stride=2), # pool3
nn.Conv2d(64, 128, kernel_size=2, stride=1), # conv4
nn.PReLU() # prelu4
)
self.conv5 = nn.Linear(128 * 2 * 2, 256) # conv5
self.prelu5 = nn.PReLU() # prelu5
# detection
self.conv6_1 = nn.Linear(256, 1)
# bounding box regression
self.conv6_2 = nn.Linear(256, 4)
# lanbmark localization
self.conv6_3 = nn.Linear(256, 10)
# weight initiation weih xavier
self.apply(weights_init)
def forward(self, x):
x = self.pre_layer(x)
x = x.view(x.size(0), -1)
x = self.conv5(x)
x = self.prelu5(x)
# detection
det = torch.sigmoid(self.conv6_1(x))
box = self.conv6_2(x)
landmark = self.conv6_3(x)
return det, box, landmark
注意,其实在之前的两个网络当中我们也预测了landmark的位置,只是在论文的图示当中没有展示而已,从作者描述的网络结构图的输出当中是详细指出了landmarkposition的卷积块的
损失函数
在研究完网络结构以后我们可以来看看这个mtcnn模型的一个损失函数,作者将损失函数分为了3个部分:Face classification、Bounding box regression、Facial landmark localization。
Face classification
对于第一部分的损失就是用的是最常用的交叉熵损失函数,就本质上来说人脸识别还是一个二分类问题,这里就使用Cross Entropy是最简单也是最合适的选择。
$p_i$是预测为face的可能性,$y_i^{det}$指的是真实标签也就是groud truth label
Bounding box regression
对于目标边界框的损失来说,对于每一个候选框我们都需要对与他最接近的真实目标边界框进行比较,the bounding box$(left, top, height, and width)$
Facial landmark localization
而对于boundingbox和landmark来说整个框的调整过程其实可以看作是一个连续的变化过程,固使用的是欧氏距离回归损失计算方法。比较的是各个点的坐标与真实面部关键点坐标的差异。
total loss
最终我们得到的损失函数是有上述这三部分加权而成
其中$\alpha_j$表示权重,$\beta_i^j$表示第i个样本的类型,也可以说是第i个样本在任务j中是否需要贡献loss,如果不存在人脸即label为0时则无需计算loss。
对于不同的网络我们所设置的权重是不一样的
in P-net & R-net(在这两层我们更注重classification的识别)
in O-net(在这层我们提高了对于注意关键点的预测精度)
文中也有提到,采用的是随机梯度下降优化器进行的训练。
OHEM(Online Hard Example Mining)
作者对于困难样本的在线预测所做的trick也比较简单,就是挑选损失最大的前70%作为困难样本,在反向传播时仅使用这70%困难样本产生的损失,这样就剔除了很容易预测的easy sample对训练结果的影响,不过在我参考的这两个版本的代码里面似乎没有这么做。
实验
实验这块的话也比较充分,验证了每个修改部分对于实验结果的有效性验证,主要是讲述了实验过程对于训练数据集的处理和划分,验证了在线硬样本挖掘的有效性,联合检测和校准的有效性,分别评估了face detection和lanmark的贡献,面部检测评估,面部校准评估以及与SOTA的对比,这一块的话就没有细看了,分享的网站也有详细解释,论文原文也写了。
总结
这篇论文是中科院深圳先进技术研究院的乔宇老师团队所作,2016ECCV,看完这篇文章的话给我的感觉的话就是idea和实现过程包括实验都是很充分的,创新点这块的话主要是挖掘了人脸特征关键点和目标检测的一些联系,结合了人脸检测和对准两个任务来进行人脸检测,相比其他经典的目标检测网络如yolov3,R-CNN系列,在网络和损失函数上的创新确实略有不足,但是也让我收到了一些启发,看似几个简单的model和常见的loss联合,在对数据进行有效处理的基础上也是可以实现达到十分不错的效果的,不过这个方案的话在训练的时候其实是很花费时间的,毕竟需要对于不同scale的图片都进行输入训练,然后就是这种输入输出的结构其实还是存在一些局限性的,对于图像检测框和关键点的映射我个人觉得也比较繁杂或者说浪费了一些时间,毕竟是一篇2016年的论文之后应该会有更好的实现方式。
参考资料
参考链接: https://zhuanlan.zhihu.com/p/337690783
参考链接:https://zhuanlan.zhihu.com/p/60199964?utm_source=qq&utm_medium=social&utm_oi=1221207556791963648
参考链接: https://blog.csdn.net/weixin_44791964/article/details/103530206
参考链接:https://blog.csdn.net/qq_34714751/article/details/85536669
参考链接:https://www.bilibili.com/video/BV1fJ411C7AJ?from=search&seid=2691296178499711503
]]>
@@ -401,14 +401,12 @@
2021-02-24T16:03:00.000Z
2024-10-09T07:33:09.891Z
- commit镜像
数据卷操作实战:mysql同步
mysql运行容器,需要做数据挂载,安装启动mysql是需要配置密码的这一点要注意,所以要去docker hub官方文档上面去看官方配置
docker pull mysql:5.7
docker运行,docker run的常用参数这里我们再次回顾一下
-d 后台运行
-p 端口映射
-v 卷挂载
-e 环境配置
--name 环境名字
通过docker hub我们找到了官方的命令:docker run --name some-mysql -e MYSQL_ROOT_PASSWORD=my-secret-pw -d mysql:tag,在修改一下得到我们最终的输入命令
docker run -d -p 3310:3306 -v /home/mysql/conf:/etc/mysql/conf.d -v /home/mysql/data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=12345678 --name mysql01 mysql:5.7
CREATE DATABASE test_db;
删除这个镜像后数据则依旧保存下来了
具名/匿名挂载
大多数情况下,为了方便,我们会使用具名挂载
Dockerfile
Dockerfile就是用来构建docker镜像的文件,命令脚本,通过这个脚本可以生成镜像。
构建步骤
编写一个Dockerfile
docker build 构建成为一个镜像
docker run 运行镜像
docker push 发布镜像(DockerHub,阿里云镜像)
这里我们可以先看看Docker Hub官方是怎么做的
官方镜像是比较基础的,有很多命令和功能都省去了,所以我们通常需要在基础的镜像上来构建我们自己的镜像
Dockerfile命令
常用命令 用法 FROM 基础镜像,一切从这开始构建 MAINTAINER 镜像是谁写的,姓名+邮箱 RUN 镜像构建的时候需要运行的命令 ADD 添加内容,如tomcat压缩包 WORKDIR 镜像的工作目录 VOLUME 挂载的目录 CMD 指定这个容器启动时要运行的命令,只有最后一个会生效,可被替代 ENTRYPOINT 指定这个容器启动时要运行的命令,可以追加命令 ONBUILD 当构建一个被继承DockerFile这个时候就会执行ONBUILD命令 COPY 类似ADD将文件拷贝到镜像当中 ENV 构建的时候设置环境变量

创建一个自己的centos
Dockerfile中99%的镜像都来自于这个scratch镜像,然后配置需要的软件和配置来进行构建。
mkdir dockerfile
cd dockerfile
vim mydockerfile-centos
编写mydockerfile-centos
FROM centos
MAINTAINER khan<khany@foxmail.com>
ENV MYPATH /usr/local
WORKDIR $MYPATH
RUN yum -y install vim
RUN yum -y install net-tools
EXPOSE 80
CMD echo $MYPATH
CMD echo "---end---"
CMD /bin/bash
然后我们进入docker build,注意后面一定要有一个.号
docker build -f mydockerfile-centos -t mycentos:1.0 .
然后我们通过docker run -it mycentos:1.0 命令进入我们自己创建的镜像测试运行我们新安装的包和命令是否能正常运行。
我们可以通过 docker history +容器名称/容器id看到这个容器的构建过程。
CMD和ENTRYPOINT区别
dockerfile-cmd-test:
FROM centos
CMD ["ls","-a"]
dockerfile-entrypoint-test:
FROM centos
ENTRYPOINT ["ls","-a"]
执行命令 docker run 容器名称 -l在CMD下会报错,命令会被后面追加的-l替代,而-l并不是有效的linux命令,所以报错,而ENTRYPOINT则是可以追加的则该命令会变为ls -al
发布镜像
发布到Docker Hub
- 地址 https://hub.docker.com/ 注册自己的账号
- 确定这个账号可以登录
- 在我们服务器上提交自己的镜像
- 登录成功,通过
push命令提交镜像,记得注意添加版本号
这里出了一点小问题:
在build自己的镜像的时候添加tag时必须在前面加上自己的dockerhub的username,然后再push就可以了
docker tag 镜像id YOUR_DOCKERHUB_NAME/firstimage
docker push YOUR_DOCKERHUB_NAME/firstimage
提交成功,可以在docker hub上找到你提交的镜像
阿里云镜像提交
在阿里云的容器镜像服务里面,创建一个新的镜像仓库,然后就会有详细的教学,做法与docker hub基本一致,提交成功能在镜像版本当中查看到,这里就不再重复讲解了。

Docker镜像操作过程总结
]]>
+ commit镜像
数据卷操作实战:mysql同步
mysql运行容器,需要做数据挂载,安装启动mysql是需要配置密码的这一点要注意,所以要去docker hub官方文档上面去看官方配置
docker pull mysql:5.7
docker运行,docker run的常用参数这里我们再次回顾一下
-d 后台运行
-p 端口映射
-v 卷挂载
-e 环境配置
--name 环境名字
通过docker hub我们找到了官方的命令:docker run --name some-mysql -e MYSQL_ROOT_PASSWORD=my-secret-pw -d mysql:tag,在修改一下得到我们最终的输入命令
docker run -d -p 3310:3306 -v /home/mysql/conf:/etc/mysql/conf.d -v /home/mysql/data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=12345678 --name mysql01 mysql:5.7
CREATE DATABASE test_db;
删除这个镜像后数据则依旧保存下来了
具名/匿名挂载
大多数情况下,为了方便,我们会使用具名挂载
Dockerfile
Dockerfile就是用来构建docker镜像的文件,命令脚本,通过这个脚本可以生成镜像。
构建步骤
- 编写一个Dockerfile
- docker build 构建成为一个镜像
- docker run 运行镜像
docker push 发布镜像(DockerHub,阿里云镜像)
这里我们可以先看看Docker Hub官方是怎么做的
官方镜像是比较基础的,有很多命令和功能都省去了,所以我们通常需要在基础的镜像上来构建我们自己的镜像
Dockerfile命令
常用命令 用法 FROM 基础镜像,一切从这开始构建 MAINTAINER 镜像是谁写的,姓名+邮箱 RUN 镜像构建的时候需要运行的命令 ADD 添加内容,如tomcat压缩包 WORKDIR 镜像的工作目录 VOLUME 挂载的目录 CMD 指定这个容器启动时要运行的命令,只有最后一个会生效,可被替代 ENTRYPOINT 指定这个容器启动时要运行的命令,可以追加命令 ONBUILD 当构建一个被继承DockerFile这个时候就会执行ONBUILD命令 COPY 类似ADD将文件拷贝到镜像当中 ENV 构建的时候设置环境变量
创建一个自己的centos
Dockerfile中99%的镜像都来自于这个scratch镜像,然后配置需要的软件和配置来进行构建。
mkdir dockerfile
cd dockerfile
vim mydockerfile-centos
编写mydockerfile-centos
FROM centos
MAINTAINER khan<khany@foxmail.com>
ENV MYPATH /usr/local
WORKDIR $MYPATH
RUN yum -y install vim
RUN yum -y install net-tools
EXPOSE 80
CMD echo $MYPATH
CMD echo "---end---"
CMD /bin/bash
然后我们进入docker build,注意后面一定要有一个.号
docker build -f mydockerfile-centos -t mycentos:1.0 .
然后我们通过docker run -it mycentos:1.0命令进入我们自己创建的镜像测试运行我们新安装的包和命令是否能正常运行。
我们可以通过 docker history +容器名称/容器id看到这个容器的构建过程。
CMD和ENTRYPOINT区别
dockerfile-cmd-test:
FROM centos
CMD ["ls","-a"]
dockerfile-entrypoint-test:
FROM centos
ENTRYPOINT ["ls","-a"]
执行命令docker run 容器名称 -l在CMD下会报错,命令会被后面追加的-l替代,而-l并不是有效的linux命令,所以报错,而ENTRYPOINT则是可以追加的则该命令会变为ls -al
发布镜像
发布到Docker Hub
- 地址 https://hub.docker.com/ 注册自己的账号
- 确定这个账号可以登录
- 在我们服务器上提交自己的镜像
- 登录成功,通过
push命令提交镜像,记得注意添加版本号
这里出了一点小问题:
在build自己的镜像的时候添加tag时必须在前面加上自己的dockerhub的username,然后再push就可以了
docker tag 镜像id YOUR_DOCKERHUB_NAME/firstimage
docker push YOUR_DOCKERHUB_NAME/firstimage
提交成功,可以在docker hub上找到你提交的镜像
阿里云镜像提交
在阿里云的容器镜像服务里面,创建一个新的镜像仓库,然后就会有详细的教学,做法与docker hub基本一致,提交成功能在镜像版本当中查看到,这里就不再重复讲解了。
Docker镜像操作过程总结
]]>
<h2 id="commit镜像"><a href="#commit镜像" class="headerlink" title="commit镜像"></a>commit镜像</h2><p><img src="https://img-blog.csdnimg.cn/20210224162521454.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0phY2tfX19F,size_16,color_FFFFFF,t_70" alt="在这里插入图片描述"></p>
-<h2 id="数据卷操作实战:mysql同步"><a href="#数据卷操作实战:mysql同步" class="headerlink" title="数据卷操作实战:mysql同步"></a>数据卷操作实战:mysql同步</h2><p><strong>mysql运行容器,需要做数据挂载,安装启动mysql是需要配置密码的这一点要注意,所以要去docker hub官方文档上面去看官方配置</strong></p>
-<figure class="highlight powershell"><table><tr><td class="code"><pre><code class="hljs powershell">docker pull mysql:<span class="hljs-number">5.7</span><br></code></pre></td></tr></table></figure>
-
+<h2 id="数据卷操作实战:mysql同步"><a href="#数据卷操作实战:mysql同步" class="headerlink" title="数据卷操作实战:mysql同步"></a>数据卷操作实战:mysql同步</h2><p><strong>mysql运行容器,需要做数据挂载,安装启动mysql是需要配置密码的这一点要注意,所以要去docker hub官方文档上面去看官方配置</strong><br><figure class="highlight powershell"><table><tr><td class="code"><pre><code class="hljs powershell">docker pull mysql:<span class="hljs-number">5.7</span><br></code></pre></td></tr></table></figure></p>
<p>docker运行,docker run的常用参数这里我们再次回顾一下</p>
<figure class="highlight powershell"><table><tr><td class="code"><pre><code class="hljs powershell"><span class="hljs-literal">-d</span> 后台运行<br><span class="hljs-literal">-p</span> 端口映射<br><span class="hljs-literal">-v</span> 卷挂载<br><span class="hljs-literal">-e</span> 环境配置<br>-<span class="hljs-literal">-name</span> 环境名字<br></code></pre></td></tr></table></figure>
@@ -427,41 +425,44 @@
2021-02-24T07:30:00.000Z
2024-10-09T07:33:09.890Z
- Docker 常用命令帮助命令
docker version #显示docker版本信息
docker info #显示docker的系统信息,包括镜像和容器的数量
docker 命令 --help # 帮助命令
镜像命令
1.docker images查看所有本地的主机镜像
docker images显示字段 解释 REPOSITORY 镜像的仓库源 TAG 镜像的标签 IMAGE ID 镜像的id CREATED 镜像的创建时间 SIZE 镜像的大小
(base) [root@iZuf69rye0flkbn4kbxrobZ ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
hello-world latest bf756fb1ae65 13 months ago 13.3kB
(base) [root@iZuf69rye0flkbn4kbxrobZ ~]# docker images --help
Usage: docker images [OPTIONS] [REPOSITORY[:TAG]]
List images
Options:
-a, --all Show all images
-q, --quiet Only show image IDs
2.docker search命令搜索镜像
搜索镜像可以去docker hub网站上直接搜索,也可以通过命令行来搜索,通过万能帮助命令能更快的看到他的一些用法,这两种方法结果是一样的
我们也可以通过--filter来进行条件筛选
比如docker search mysql --filter=STARS=3000
(base) [root@iZuf69rye0flkbn4kbxrobZ ~]# docker search mysql --filter=STARS=3000
NAME DESCRIPTION STARS OFFICIAL AUTOMATED
mysql MySQL is a widely used, open-source relation… 10538 [OK]
mariadb MariaDB is a community-developed fork of MyS… 3935 [OK]
3.docker pull下载镜像
这个命令其实信息量很大,这也是docker高明的地方,关于指定版本下载一定要是docker hub官网上面支持和提供的版本
我这里使用了
docker pull mysql
docker pull mysql:5.7
4.docker rmi删除镜像
删除可以通过REPOSITORY来删,也可以通过IMAGE ID来删除
容器命令
说明:我们有了镜像才可以创建容器,linux,下载一个centos镜像来测试学习
docker pull centos
1.新建容器并启动
通过docker run命令进入下载的centos容器里面后我们可以发现的是,我们的rootname不一样了
2.列出所有运行的容器
docker ps命令
3.exit退出命令
exit #直接容器停止并退出
Ctrl + P + Q #容器不停止并退出
在执行exit命令后,我们看到rootname又变回来了
4.删除容器
docker rm 容器id #删除指定的容器,不能删除正在运行的容器,如果要强制删除,需要使用 rm -f
docker rm $(docker ps -aq) #删除全部的容器
docker ps -a -q|xargs docker rm #删除全部容器
5.启动和停止容器
日志元数据进程查看
1.docker top 容器id查看容器中的进程
2.docker inspect 容器id查看元数据
3.进入当前正在运行的容器
方式1: docker exec -it 容器id bashshell并可通过ps -ef查看容器当中的进程
方式2:docker attach 容器id进入容器,如果当前有正在执行的容器则会直接进入到当前正在执行的进程当中
从容器内拷贝到主机上
即使容器已经停止也是可以进行拷贝的
docker cp 容器id:容器内路径 目的主机路径
docker部署nginx
$ docker search nginx
$ docker pull nginx
$ docker run -d --name nginx01 -p 8083:80 nginx
$ docker ps
$ curl localhost:8083
docker stop 后则无法再访问
portainer可视化管理
docker run -d -p 8088:9000 --restart=always -v /var/run/docker.sock:/var/run/docker.sock --privileged=true portainer/portainer

进入后选择local模式,然后就能看到这个版面了

参考链接:
【狂神说Java】Docker最新超详细版教程通俗易懂
]]>
+ Docker 常用命令帮助命令
docker version #显示docker版本信息
docker info #显示docker的系统信息,包括镜像和容器的数量
docker 命令 --help # 帮助命令
镜像命令
1.docker images查看所有本地的主机镜像
docker images显示字段 解释 REPOSITORY 镜像的仓库源 TAG 镜像的标签 IMAGE ID 镜像的id CREATED 镜像的创建时间 SIZE 镜像的大小
(base) [root@iZuf69rye0flkbn4kbxrobZ ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
hello-world latest bf756fb1ae65 13 months ago 13.3kB
(base) [root@iZuf69rye0flkbn4kbxrobZ ~]# docker images --help
Usage: docker images [OPTIONS] [REPOSITORY[:TAG]]
List images
Options:
-a, --all Show all images
-q, --quiet Only show image IDs
2.docker search命令搜索镜像
搜索镜像可以去docker hub网站上直接搜索,也可以通过命令行来搜索,通过万能帮助命令能更快的看到他的一些用法,这两种方法结果是一样的
我们也可以通过--filter来进行条件筛选
比如docker search mysql --filter=STARS=3000
(base) [root@iZuf69rye0flkbn4kbxrobZ ~]# docker search mysql --filter=STARS=3000
NAME DESCRIPTION STARS OFFICIAL AUTOMATED
mysql MySQL is a widely used, open-source relation… 10538 [OK]
mariadb MariaDB is a community-developed fork of MyS… 3935 [OK]
3.docker pull下载镜像
这个命令其实信息量很大,这也是docker高明的地方,关于指定版本下载一定要是docker hub官网上面支持和提供的版本
我这里使用了
docker pull mysql
docker pull mysql:5.7
4.docker rmi删除镜像
删除可以通过REPOSITORY来删,也可以通过IMAGE ID来删除
容器命令
说明:我们有了镜像才可以创建容器,linux,下载一个centos镜像来测试学习
docker pull centos
1.新建容器并启动
通过docker run命令进入下载的centos容器里面后我们可以发现的是,我们的rootname不一样了
2.列出所有运行的容器
docker ps命令
3.exit退出命令
exit #直接容器停止并退出
Ctrl + P + Q #容器不停止并退出
在执行exit命令后,我们看到rootname又变回来了
4.删除容器
docker rm 容器id #删除指定的容器,不能删除正在运行的容器,如果要强制删除,需要使用 rm -f
docker rm $(docker ps -aq) #删除全部的容器
docker ps -a -q|xargs docker rm #删除全部容器
5.启动和停止容器
日志元数据进程查看
1.docker top 容器id查看容器中的进程
2.docker inspect 容器id查看元数据
3.进入当前正在运行的容器
方式1: docker exec -it 容器id bashshell并可通过ps -ef查看容器当中的进程
方式2:docker attach 容器id进入容器,如果当前有正在执行的容器则会直接进入到当前正在执行的进程当中
从容器内拷贝到主机上
即使容器已经停止也是可以进行拷贝的
docker cp 容器id:容器内路径 目的主机路径
docker部署nginx
$ docker search nginx
$ docker pull nginx
$ docker run -d --name nginx01 -p 8083:80 nginx
$ docker ps
$ curl localhost:8083
docker stop 后则无法再访问
portainer可视化管理
docker run -d -p 8088:9000 --restart=always -v /var/run/docker.sock:/var/run/docker.sock --privileged=true portainer/portainer
进入后选择local模式,然后就能看到这个版面了
参考链接:
【狂神说Java】Docker最新超详细版教程通俗易懂
]]>
<h1 id="Docker-常用命令"><a href="#Docker-常用命令" class="headerlink" title="Docker 常用命令"></a>Docker 常用命令</h1><h2 id="帮助命令"><a href="#帮助命令" class="headerlink" title="帮助命令"></a>帮助命令</h2><figure class="highlight bash"><table><tr><td class="code"><pre><code class="hljs bash">docker version <span class="hljs-comment">#显示docker版本信息</span><br>docker info <span class="hljs-comment">#显示docker的系统信息,包括镜像和容器的数量</span><br>docker 命令 --<span class="hljs-built_in">help</span> <span class="hljs-comment"># 帮助命令</span><br></code></pre></td></tr></table></figure>
-
<h2 id="镜像命令"><a href="#镜像命令" class="headerlink" title="镜像命令"></a>镜像命令</h2><p><strong>1.<code>docker images</code>查看所有本地的主机镜像</strong></p>
+<div class="table-container">
<table>
<thead>
<tr>
-<th align="left">docker images显示字段</th>
-<th align="left">解释</th>
+<th style="text-align:left">docker images显示字段</th>
+<th style="text-align:left">解释</th>
</tr>
</thead>
-<tbody><tr>
-<td align="left">REPOSITORY</td>
-<td align="left">镜像的仓库源</td>
+<tbody>
+<tr>
+<td style="text-align:left">REPOSITORY</td>
+<td style="text-align:left">镜像的仓库源</td>
</tr>
<tr>
-<td align="left">TAG</td>
-<td align="left">镜像的标签</td>
+<td style="text-align:left">TAG</td>
+<td style="text-align:left">镜像的标签</td>
</tr>
<tr>
-<td align="left">IMAGE ID</td>
-<td align="left">镜像的id</td>
+<td style="text-align:left">IMAGE ID</td>
+<td style="text-align:left">镜像的id</td>
</tr>
<tr>
-<td align="left">CREATED</td>
-<td align="left">镜像的创建时间</td>
+<td style="text-align:left">CREATED</td>
+<td style="text-align:left">镜像的创建时间</td>
</tr>
<tr>
-<td align="left">SIZE</td>
-<td align="left">镜像的大小</td>
+<td style="text-align:left">SIZE</td>
+<td style="text-align:left">镜像的大小</td>
</tr>
-</tbody></table>
+</tbody>
+</table>
+</div>
@@ -500,7 +501,7 @@
2021-02-23T06:55:00.000Z
2024-10-09T07:33:09.889Z
- 零基础入门语义分割-Task4 评价函数与损失函数本章主要介绍语义分割的评价函数和各类损失函数。
4 评价函数与损失函数
4.1 学习目标
- 掌握常见的评价函数和损失函数Dice、IoU、BCE、Focal Loss、Lovász-Softmax;
- 掌握评价/损失函数的实践;
4.2 TP TN FP FN
在讲解语义分割中常用的评价函数和损失函数之前,先补充一**TP(真正例 true positive) TN(真反例 true negative) FP(假正例 false positive) FN(假反例 false negative)**的知识。在分类问题中,我们经常看到上述的表述方式,以二分类为例,我们可以将所有的样本预测结果分成TP、TN、 FP、FN四类,并且每一类含有的样本数量之和为总样本数量,即TP+FP+FN+TN=总样本数量。其混淆矩阵如下:

上述的概念都是通过以预测结果的视角定义的,可以依据下面方式理解:
预测结果中的正例 → 在实际中是正例 → 的所有样本被称为真正例(TP)<预测正确>
预测结果中的正例 → 在实际中是反例 → 的所有样本被称为假正例(FP)<预测错误>
预测结果中的反例 → 在实际中是正例 → 的所有样本被称为假反例(FN)<预测错误>
预测结果中的反例 → 在实际中是反例 → 的所有样本被称为真反例(TN)<预测正确>
这里就不得不提及精确率(precision)和召回率(recall):
$$
Precision=\frac{TP}{TP+FP} \
Recall=\frac{TP}{TP+FN}
$$
$Precision$代表了预测的正例中真正的正例所占比例;$Recall$代表了真正的正例中被正确预测出来的比例。
转移到语义分割任务中来,我们可以将语义分割看作是对每一个图像像素的的分类问题。根据混淆矩阵中的定义,我们亦可以将特定像素所属的集合或区域划分成TP、TN、 FP、FN四类。

以上面的图片为例,图中左子图中的人物区域(黄色像素集合)是我们真实标注的前景信息(target),其他区域(紫色像素集合)为背景信息。当经过预测之后,我们会得到的一张预测结果,图中右子图中的黄色像素为预测的前景(prediction),紫色像素为预测的背景区域。此时,我们便能够将预测结果分成4个部分:
预测结果中的黄色无线区域 → 真实的前景 → 的所有像素集合被称为真正例(TP)<预测正确>
预测结果中的蓝色斜线区域 → 真实的背景 → 的所有像素集合被称为假正例(FP)<预测错误>
预测结果中的红色斜线区域 → 真实的前景 → 的所有像素集合被称为假反例(FN)<预测错误>
预测结果中的白色斜线区域 → 真实的背景 → 的所有像素集合被称为真反例(TN)<预测正确>
4.3 Dice评价指标
Dice系数
Dice系数(Dice coefficient)是常见的评价分割效果的方法之一,同样也可以改写成损失函数用来度量prediction和target之间的距离。Dice系数定义如下:
$$
Dice (T, P) = \frac{2 |T \cap P|}{|T| \cup |P|} = \frac{2TP}{FP+2TP+FN}
$$
式中:$T$表示真实前景(target),$P$表示预测前景(prediction)。Dice系数取值范围为$[0,1]$,其中值为1时代表预测与真实完全一致。仔细观察,Dice系数与分类评价指标中的F1 score很相似:
$$
\frac{1}{F1} = \frac{1}{Precision} + \frac{1}{Recall}
$$
$$
F1 = \frac{2TP}{FP+2TP+FN}
$$
所以,Dice系数不仅在直观上体现了target与prediction的相似程度,同时其本质上还隐含了精确率和召回率两个重要指标。
计算Dice时,将$|T \cap P|$近似为prediction与target对应元素相乘再相加的结果。$|T|$ 和$|P|$的计算直接进行简单的元素求和(也有一些做法是取平方求和),如下示例:
$$
|T \cap P| =
\begin{bmatrix}
0.01 & 0.03 & 0.02 & 0.02 \
0.05 & 0.12 & 0.09 & 0.07 \
0.89 & 0.85 & 0.88 & 0.91 \
0.99 & 0.97 & 0.95 & 0.97 \
\end{bmatrix} *
\begin{bmatrix}
0 & 0 & 0 & 0 \
0 & 0 & 0 & 0 \
1 & 1 & 1 & 1 \
1 & 1 & 1 & 1 \
\end{bmatrix} \stackrel{}{\rightarrow}
\begin{bmatrix}
0 & 0 & 0 & 0 \
0 & 0 & 0 & 0 \
0.89 & 0.85 & 0.88 & 0.91 \
0.99 & 0.97 & 0.95 & 0.97 \
\end{bmatrix} \stackrel{sum}{\rightarrow} 7.41
$$
$$
|T| =
\begin{bmatrix}
0.01 & 0.03 & 0.02 & 0.02 \
0.05 & 0.12 & 0.09 & 0.07 \
0.89 & 0.85 & 0.88 & 0.91 \
0.99 & 0.97 & 0.95 & 0.97 \
\end{bmatrix} \stackrel{sum}{\rightarrow} 7.82
$$
$$
|P| =
\begin{bmatrix}
0 & 0 & 0 & 0 \
0 & 0 & 0 & 0 \
1 & 1 & 1 & 1 \
1 & 1 & 1 & 1 \
\end{bmatrix} \stackrel{sum}{\rightarrow} 8
$$
Dice Loss
Dice Loss是在V-net模型中被提出应用的,是通过Dice系数转变而来,其实为了能够实现最小化的损失函数,以方便模型训练,以$1 - Dice$的形式作为损失函数:
$$
L = 1-\frac{2 |T \cap P|}{|T| \cup |P|}
$$
在一些场合还可以添加上Laplace smoothing减少过拟合:
$$
L = 1-\frac{2 |T \cap P| + 1}{|T| \cup |P|+1}
$$
代码实现
import numpy as np
def dice(output, target):
'''计算Dice系数'''
smooth = 1e-6 # 避免0为除数
intersection = (output * target).sum()
return (2. * intersection + smooth) / (output.sum() + target.sum() + smooth)
# 生成随机两个矩阵测试
target = np.random.randint(0, 2, (3, 3))
output = np.random.randint(0, 2, (3, 3))
d = dice(output, target)
# ----------------------------
target = array([[1, 0, 0],
[0, 1, 1],
[0, 0, 1]])
output = array([[1, 0, 1],
[0, 1, 0],
[0, 0, 0]])
d = 0.5714286326530524
4.4 IoU评价指标
IoU(intersection over union)指标就是常说的交并比,不仅在语义分割评价中经常被使用,在目标检测中也是常用的评价指标。顾名思义,交并比就是指target与prediction两者之间交集与并集的比值:
$$
IoU=\frac{T \cap P}{T \cup P}=\frac{TP}{FP+TP+FN}
$$
仍然以人物前景分割为例,如下图,其IoU的计算就是使用$intersection / union$。
target prediction 

Intersection( $T \cap P$) union($T \cup P$) 

代码实现
def iou_score(output, target):
'''计算IoU指标'''
intersection = np.logical_and(target, output)
union = np.logical_or(target, output)
return np.sum(intersection) / np.sum(union)
# 生成随机两个矩阵测试
target = np.random.randint(0, 2, (3, 3))
output = np.random.randint(0, 2, (3, 3))
d = iou_score(output, target)
# ----------------------------
target = array([[1, 0, 0],
[0, 1, 1],
[0, 0, 1]])
output = array([[1, 0, 1],
[0, 1, 0],
[0, 0, 0]])
d = 0.4
4.5 BCE损失函数
BCE损失函数(Binary Cross-Entropy Loss)是交叉熵损失函数(Cross-Entropy Loss)的一种特例,BCE Loss只应用在二分类任务中。针对分类问题,单样本的交叉熵损失为:
$$
l(\pmb y, \pmb{\hat y})=- \sum_{i=1}^{c}y_i \cdot log\hat y_i
$$
式中,$\pmb{y}={y_1,y_2,…,y_c,}$,其中$y_i$是非0即1的数字,代表了是否属于第$i$类,为真实值;$\hat y_i$代表属于第i类的概率,为预测值。可以看出,交叉熵损失考虑了多类别情况,针对每一种类别都求了损失。针对二分类问题,上述公式可以改写为:
$$
l(y,\hat y)=-[y \cdot log\hat y +(1-y)\cdot log (1-\hat y)]
$$
式中,$y$为真实值,非1即0;$\hat y$为所属此类的概率值,为预测值。这个公式也就是BCE损失函数,即二分类任务时的交叉熵损失。值得强调的是,公式中的$\hat y$为概率分布形式,因此在使用BCE损失前,都应该将预测出来的结果转变成概率值,一般为sigmoid激活之后的输出。
代码实现
在pytorch中,官方已经给出了BCE损失函数的API,免去了自己编写函数的痛苦:
torch.nn.BCELoss(weight: Optional[torch.Tensor] = None, size_average=None, reduce=None, reduction: str = 'mean')
$$
ℓ(y,\hat y)=L={l_1,…,l_N }^⊤,\ \ \ l_n=-w_n[y_n \cdot log\hat y_n +(1-y_n)\cdot log (1-\hat y_n)]
$$
参数:
weight(Tensor)- 为每一批量下的loss添加一个权重,很少使用
size_average(bool)- 弃用中
reduce(bool)- 弃用中
reduction(str) - ‘none’ | ‘mean’ | ‘sum’:为代替上面的size_average和reduce而生。——为mean时返回的该批量样本loss的平均值;为sum时,返回的该批量样本loss之和
同时,pytorch还提供了已经结合了Sigmoid函数的BCE损失:torch.nn.BCEWithLogitsLoss(),相当于免去了实现进行Sigmoid激活的操作。
import torch
import torch.nn as nn
bce = nn.BCELoss()
bce_sig = nn.BCEWithLogitsLoss()
input = torch.randn(5, 1, requires_grad=True)
target = torch.empty(5, 1).random_(2)
pre = nn.Sigmoid()(input)
loss_bce = bce(pre, target)
loss_bce_sig = bce_sig(input, target)
# ------------------------
input = tensor([[-0.2296],
[-0.6389],
[-0.2405],
[ 1.3451],
[ 0.7580]], requires_grad=True)
output = tensor([[1.],
[0.],
[0.],
[1.],
[1.]])
pre = tensor([[0.4428],
[0.3455],
[0.4402],
[0.7933],
[0.6809]], grad_fn=<SigmoidBackward>)
print(loss_bce)
tensor(0.4869, grad_fn=<BinaryCrossEntropyBackward>)
print(loss_bce_sig)
tensor(0.4869, grad_fn=<BinaryCrossEntropyWithLogitsBackward>)
4.6 Focal Loss
Focal loss最初是出现在目标检测领域,主要是为了解决正负样本比例失调的问题。那么对于分割任务来说,如果存在数据不均衡的情况,也可以借用focal loss来进行缓解。Focal loss函数公式如下所示:
$$
loss = -\frac{1}{N} \sum_{i=1}^{N}\left(\alpha y_{i}\left(1-p_{i}\right)^{\gamma} \log p_{i}+(1-\alpha)\left(1-y_{i}\right) p_{i}^{\gamma} \log \left(1-p_{i}\right)\right)
$$
仔细观察就不难发现,它其实是BCE扩展而来,对比BCE其实就多了个
$$
\alpha(1-p_{i})^{\gamma}和(1-\alpha)p_{i}^{\gamma}
$$
为什么多了这个就能缓解正负样本不均衡的问题呢?见下图:
简单来说:$α$解决样本不平衡问题,$γ$解决样本难易问题。
也就是说,当数据不均衡时,可以根据比例设置合适的$α$,这个很好理解,为了能够使得正负样本得到的损失能够均衡,因此对loss前面加上一定的权重,其中负样本数量多,因此占用的权重可以设置的小一点;正样本数量少,就对正样本产生的损失的权重设的高一点。
那γ具体怎么起作用呢?以图中$γ=5$曲线为例,假设$gt$类别为1,当模型预测结果为1的概率$p_t$比较大时,我们认为模型预测的比较准确,也就是说这个样本比较简单。而对于比较简单的样本,我们希望提供的loss小一些而让模型主要学习难一些的样本,也就是$p_t→ 1$则loss接近于0,既不用再特别学习;当分类错误时,$p_t → 0$则loss正常产生,继续学习。对比图中蓝色和绿色曲线,可以看到,γ值越大,当模型预测结果比较准确的时候能提供更小的loss,符合我们为简单样本降低loss的预期。
代码实现:
import torch.nn as nn
import torch
import torch.nn.functional as F
class FocalLoss(nn.Module):
def __init__(self, alpha=1, gamma=2, logits=False, reduce=True):
super(FocalLoss, self).__init__()
self.alpha = alpha
self.gamma = gamma
self.logits = logits# 如果BEC带logits则损失函数在计算BECloss之前会自动计算softmax/sigmoid将其映射到[0,1]
self.reduce = reduce
def forward(self, inputs, targets):
if self.logits:
BCE_loss = F.binary_cross_entropy_with_logits(inputs, targets, reduce=False)
else:
BCE_loss = F.binary_cross_entropy(inputs, targets, reduce=False)
pt = torch.exp(-BCE_loss)
F_loss = self.alpha * (1-pt)**self.gamma * BCE_loss
if self.reduce:
return torch.mean(F_loss)
else:
return F_loss
# ------------------------
FL1 = FocalLoss(logits=False)
FL2 = FocalLoss(logits=True)
inputs = torch.randn(5, 1, requires_grad=True)
targets = torch.empty(5, 1).random_(2)
pre = nn.Sigmoid()(inputs)
f_loss_1 = FL1(pre, targets)
f_loss_2 = FL2(inputs, targets)
# ------------------------
print('inputs:', inputs)
inputs: tensor([[-1.3521],
[ 0.4975],
[-1.0178],
[-0.3859],
[-0.2923]], requires_grad=True)
print('targets:', targets)
targets: tensor([[1.],
[1.],
[0.],
[1.],
[1.]])
print('pre:', pre)
pre: tensor([[0.2055],
[0.6219],
[0.2655],
[0.4047],
[0.4274]], grad_fn=<SigmoidBackward>)
print('f_loss_1:', f_loss_1)
f_loss_1: tensor(0.3375, grad_fn=<MeanBackward0>)
print('f_loss_2', f_loss_2)
f_loss_2 tensor(0.3375, grad_fn=<MeanBackward0>)
4.7 Lovász-Softmax
IoU是评价分割模型分割结果质量的重要指标,因此很自然想到能否用$1-IoU$(即Jaccard loss)来做损失函数,但是它是一个离散的loss,不能直接求导,所以无法直接用来作为损失函数。为了克服这个离散的问题,可以采用lLovász extension将离散的Jaccard loss 变得连续,从而可以直接求导,使得其作为分割网络的loss function。Lovász-Softmax相比于交叉熵函数具有更好的效果。
论文地址:
paper on CVF open access
arxiv paper
首先明确定义,在语义分割任务中,给定真实像素标签向量$\pmb{y^*}$和预测像素标签$\pmb{\hat{y} }$,则所属类别$c$的IoU(也称为Jaccard index)如下,其取值范围为$[0,1]$,并规定$0/0=1$:
$$J_c(\pmb{y^*},\pmb{\hat{y} })=\frac{|{\pmb{y^*}=c} \cap {\pmb{\hat{y} }=c}|}{|{\pmb{y^*}=c} \cup {\pmb{\hat{y} }=c}|}
$$
则Jaccard loss为:
$$\Delta_{J_c}(\pmb{y^*},\pmb{\hat{y} }) =1-J_c(\pmb{y^*},\pmb{\hat{y} })
$$
针对类别$c$,所有未被正确预测的像素集合定义为:
$$
M_c(\pmb{y^*},\pmb{\hat{y} })={ \pmb{y^*}=c, \pmb{\hat{y} } \neq c} \cup { \pmb{y^*}\neq c, \pmb{\hat{y} } = c }
$$
则可将Jaccard loss改写为关于$M_c$的子模集合函数(submodular set functions):
$$\Delta_{J_c}:M_c \in {0,1}^{p} \mapsto \frac{|M_c|}{|{\pmb{y^*}=c}\cup M_c|}
$$
方便理解,此处可以把${0,1}^p$理解成如图像mask展开成离散一维向量的形式。
Lovász extension可以求解子模最小化问题,并且子模的Lovász extension是凸函数,可以高效实现最小化。在论文中作者对$\Delta$(集合函数)和$\overline{\Delta}$(集合函数的Lovász extension)进行了定义,为不涉及过多概念以方便理解,此处不再过多讨论。我们可以将$\overline{\Delta}$理解为一个线性插值函数,可以将${0,1}^p$这种离散向量连续化,主要是为了方便后续反向传播、求梯度等等。因此我们可以通过这个线性插值函数得到$\Delta_{J_c}$的Lovász extension$\overline{\Delta_{J_c} }$。
在具有$c(c>2)$个类别的语义分割任务中,我们使用Softmax函数将模型的输出映射到概率分布形式,类似传统交叉熵损失函数所进行的操作:
$$p_i(c)=\frac{e^{F_i(c)} }{\sum_{c^{‘}\in C}e^{F_i(c^{‘})} } \forall i \in [1,p],\forall c \in C
$$
式中,$p_i(c)$表示了像素$i$所属类别$c$的概率。通过上式可以构建每个像素产生的误差$m(c)$:
$$m_i(c)=\left {
\begin{array}{c}
1-p_i(c),\ \ if \ \ c=y^{*}_{i} \
p_i(c),\ \ \ \ \ \ \ otherwise
\end{array}
\right.
$$
可知,对于一张图像中所有像素则误差向量为$m(c)\in {0, 1}^p$,则可以建立关于$\Delta_{J_c}$的代理损失函数:
$$
loss(p(c))=\overline{\Delta_{J_c} }(m(c))
$$
当我们考虑整个数据集是,一般会使用mIoU进行度量,因此我们对上述损失也进行平均化处理,则定义的Lovász-Softmax损失函数为:
$$
loss(\pmb{p})=\frac{1}{|C|}\sum_{c\in C}\overline{\Delta_{J_c} }(m(c))
$$
代码实现
论文作者已经给出了Lovász-Softmax实现代码,并且有pytorch和tensorflow两种版本,并提供了使用demo。此处将针对多分类任务的Lovász-Softmax源码进行展示。
import torch
from torch.autograd import Variable
import torch.nn.functional as F
import numpy as np
try:
from itertools import ifilterfalse
except ImportError: # py3k
from itertools import filterfalse as ifilterfalse
# --------------------------- MULTICLASS LOSSES ---------------------------
def lovasz_softmax(probas, labels, classes='present', per_image=False, ignore=None):
"""
Multi-class Lovasz-Softmax loss
probas: [B, C, H, W] Variable, class probabilities at each prediction (between 0 and 1).
Interpreted as binary (sigmoid) output with outputs of size [B, H, W].
labels: [B, H, W] Tensor, ground truth labels (between 0 and C - 1)
classes: 'all' for all, 'present' for classes present in labels, or a list of classes to average.
per_image: compute the loss per image instead of per batch
ignore: void class labels
"""
if per_image:
loss = mean(lovasz_softmax_flat(*flatten_probas(prob.unsqueeze(0), lab.unsqueeze(0), ignore), classes=classes)
for prob, lab in zip(probas, labels))
else:
loss = lovasz_softmax_flat(*flatten_probas(probas, labels, ignore), classes=classes)
return loss
def lovasz_softmax_flat(probas, labels, classes='present'):
"""
Multi-class Lovasz-Softmax loss
probas: [P, C] Variable, class probabilities at each prediction (between 0 and 1)
labels: [P] Tensor, ground truth labels (between 0 and C - 1)
classes: 'all' for all, 'present' for classes present in labels, or a list of classes to average.
"""
if probas.numel() == 0:
# only void pixels, the gradients should be 0
return probas * 0.
C = probas.size(1)
losses = []
class_to_sum = list(range(C)) if classes in ['all', 'present'] else classes
for c in class_to_sum:
fg = (labels == c).float() # foreground for class c
if (classes is 'present' and fg.sum() == 0):
continue
if C == 1:
if len(classes) > 1:
raise ValueError('Sigmoid output possible only with 1 class')
class_pred = probas[:, 0]
else:
class_pred = probas[:, c]
errors = (Variable(fg) - class_pred).abs()
errors_sorted, perm = torch.sort(errors, 0, descending=True)
perm = perm.data
fg_sorted = fg[perm]
losses.append(torch.dot(errors_sorted, Variable(lovasz_grad(fg_sorted))))
return mean(losses)
def flatten_probas(probas, labels, ignore=None):
"""
Flattens predictions in the batch
"""
if probas.dim() == 3:
# assumes output of a sigmoid layer
B, H, W = probas.size()
probas = probas.view(B, 1, H, W)
B, C, H, W = probas.size()
probas = probas.permute(0, 2, 3, 1).contiguous().view(-1, C) # B * H * W, C = P, C
labels = labels.view(-1)
if ignore is None:
return probas, labels
valid = (labels != ignore)
vprobas = probas[valid.nonzero().squeeze()]
vlabels = labels[valid]
return vprobas, vlabels
def xloss(logits, labels, ignore=None):
"""
Cross entropy loss
"""
return F.cross_entropy(logits, Variable(labels), ignore_index=255)
# --------------------------- HELPER FUNCTIONS ---------------------------
def isnan(x):
return x != x
def mean(l, ignore_nan=False, empty=0):
"""
nanmean compatible with generators.
"""
l = iter(l)
if ignore_nan:
l = ifilterfalse(isnan, l)
try:
n = 1
acc = next(l)
except StopIteration:
if empty == 'raise':
raise ValueError('Empty mean')
return empty
for n, v in enumerate(l, 2):
acc += v
if n == 1:
return acc
return acc / n
4.8 参考链接
What is “Dice loss” for image segmentation?
Submodularity and the Lovász extension
4.9 本章小结
本章对各类评价指标进行介绍,并进行具体代码实践。
]]>
+ 零基础入门语义分割-Task4 评价函数与损失函数本章主要介绍语义分割的评价函数和各类损失函数。
4 评价函数与损失函数
4.1 学习目标
- 掌握常见的评价函数和损失函数Dice、IoU、BCE、Focal Loss、Lovász-Softmax;
- 掌握评价/损失函数的实践;
4.2 TP TN FP FN
在讲解语义分割中常用的评价函数和损失函数之前,先补充一TP(真正例 true positive) TN(真反例 true negative) FP(假正例 false positive) FN(假反例 false negative)的知识。在分类问题中,我们经常看到上述的表述方式,以二分类为例,我们可以将所有的样本预测结果分成TP、TN、 FP、FN四类,并且每一类含有的样本数量之和为总样本数量,即TP+FP+FN+TN=总样本数量。其混淆矩阵如下:
上述的概念都是通过以预测结果的视角定义的,可以依据下面方式理解:
预测结果中的正例 → 在实际中是正例 → 的所有样本被称为真正例(TP)<预测正确>
预测结果中的正例 → 在实际中是反例 → 的所有样本被称为假正例(FP)<预测错误>
预测结果中的反例 → 在实际中是正例 → 的所有样本被称为假反例(FN)<预测错误>
预测结果中的反例 → 在实际中是反例 → 的所有样本被称为真反例(TN)<预测正确>
这里就不得不提及精确率(precision)和召回率(recall):
$Precision$代表了预测的正例中真正的正例所占比例;$Recall$代表了真正的正例中被正确预测出来的比例。
转移到语义分割任务中来,我们可以将语义分割看作是对每一个图像像素的的分类问题。根据混淆矩阵中的定义,我们亦可以将特定像素所属的集合或区域划分成TP、TN、 FP、FN四类。
以上面的图片为例,图中左子图中的人物区域(黄色像素集合)是我们真实标注的前景信息(target),其他区域(紫色像素集合)为背景信息。当经过预测之后,我们会得到的一张预测结果,图中右子图中的黄色像素为预测的前景(prediction),紫色像素为预测的背景区域。此时,我们便能够将预测结果分成4个部分:
预测结果中的黄色无线区域 → 真实的前景 → 的所有像素集合被称为真正例(TP)<预测正确>
预测结果中的蓝色斜线区域 → 真实的背景 → 的所有像素集合被称为假正例(FP)<预测错误>
预测结果中的红色斜线区域 → 真实的前景 → 的所有像素集合被称为假反例(FN)<预测错误>
预测结果中的白色斜线区域 → 真实的背景 → 的所有像素集合被称为真反例(TN)<预测正确>
4.3 Dice评价指标
Dice系数
Dice系数(Dice coefficient)是常见的评价分割效果的方法之一,同样也可以改写成损失函数用来度量prediction和target之间的距离。Dice系数定义如下:
式中:$T$表示真实前景(target),$P$表示预测前景(prediction)。Dice系数取值范围为$[0,1]$,其中值为1时代表预测与真实完全一致。仔细观察,Dice系数与分类评价指标中的F1 score很相似:
所以,Dice系数不仅在直观上体现了target与prediction的相似程度,同时其本质上还隐含了精确率和召回率两个重要指标。
计算Dice时,将$|T \cap P|$近似为prediction与target对应元素相乘再相加的结果。$|T|$ 和$|P|$的计算直接进行简单的元素求和(也有一些做法是取平方求和),如下示例:
Dice Loss
Dice Loss是在V-net模型中被提出应用的,是通过Dice系数转变而来,其实为了能够实现最小化的损失函数,以方便模型训练,以$1 - Dice$的形式作为损失函数:
在一些场合还可以添加上Laplace smoothing减少过拟合:
代码实现
import numpy as np
def dice(output, target):
'''计算Dice系数'''
smooth = 1e-6 # 避免0为除数
intersection = (output * target).sum()
return (2. * intersection + smooth) / (output.sum() + target.sum() + smooth)
# 生成随机两个矩阵测试
target = np.random.randint(0, 2, (3, 3))
output = np.random.randint(0, 2, (3, 3))
d = dice(output, target)
# ----------------------------
target = array([[1, 0, 0],
[0, 1, 1],
[0, 0, 1]])
output = array([[1, 0, 1],
[0, 1, 0],
[0, 0, 0]])
d = 0.5714286326530524
4.4 IoU评价指标
IoU(intersection over union)指标就是常说的交并比,不仅在语义分割评价中经常被使用,在目标检测中也是常用的评价指标。顾名思义,交并比就是指target与prediction两者之间交集与并集的比值:
仍然以人物前景分割为例,如下图,其IoU的计算就是使用$intersection / union$。
target prediction Intersection( $T \cap P$) union($T \cup P$)
代码实现
def iou_score(output, target):
'''计算IoU指标'''
intersection = np.logical_and(target, output)
union = np.logical_or(target, output)
return np.sum(intersection) / np.sum(union)
# 生成随机两个矩阵测试
target = np.random.randint(0, 2, (3, 3))
output = np.random.randint(0, 2, (3, 3))
d = iou_score(output, target)
# ----------------------------
target = array([[1, 0, 0],
[0, 1, 1],
[0, 0, 1]])
output = array([[1, 0, 1],
[0, 1, 0],
[0, 0, 0]])
d = 0.4
4.5 BCE损失函数
BCE损失函数(Binary Cross-Entropy Loss)是交叉熵损失函数(Cross-Entropy Loss)的一种特例,BCE Loss只应用在二分类任务中。针对分类问题,单样本的交叉熵损失为:
式中,$\pmb{y}={y_1,y_2,…,y_c,}$,其中$y_i$是非0即1的数字,代表了是否属于第$i$类,为真实值;$\hat y_i$代表属于第i类的概率,为预测值。可以看出,交叉熵损失考虑了多类别情况,针对每一种类别都求了损失。针对二分类问题,上述公式可以改写为:
式中,$y$为真实值,非1即0;$\hat y$为所属此类的概率值,为预测值。这个公式也就是BCE损失函数,即二分类任务时的交叉熵损失。值得强调的是,公式中的$\hat y$为概率分布形式,因此在使用BCE损失前,都应该将预测出来的结果转变成概率值,一般为sigmoid激活之后的输出。
代码实现
在pytorch中,官方已经给出了BCE损失函数的API,免去了自己编写函数的痛苦:
torch.nn.BCELoss(weight: Optional[torch.Tensor] = None, size_average=None, reduce=None, reduction: str = 'mean')
参数:
weight(Tensor)- 为每一批量下的loss添加一个权重,很少使用
size_average(bool)- 弃用中
reduce(bool)- 弃用中
reduction(str) - ‘none’ | ‘mean’ | ‘sum’:为代替上面的size_average和reduce而生。——为mean时返回的该批量样本loss的平均值;为sum时,返回的该批量样本loss之和
同时,pytorch还提供了已经结合了Sigmoid函数的BCE损失:torch.nn.BCEWithLogitsLoss(),相当于免去了实现进行Sigmoid激活的操作。
import torch
import torch.nn as nn
bce = nn.BCELoss()
bce_sig = nn.BCEWithLogitsLoss()
input = torch.randn(5, 1, requires_grad=True)
target = torch.empty(5, 1).random_(2)
pre = nn.Sigmoid()(input)
loss_bce = bce(pre, target)
loss_bce_sig = bce_sig(input, target)
# ------------------------
input = tensor([[-0.2296],
[-0.6389],
[-0.2405],
[ 1.3451],
[ 0.7580]], requires_grad=True)
output = tensor([[1.],
[0.],
[0.],
[1.],
[1.]])
pre = tensor([[0.4428],
[0.3455],
[0.4402],
[0.7933],
[0.6809]], grad_fn=<SigmoidBackward>)
print(loss_bce)
tensor(0.4869, grad_fn=<BinaryCrossEntropyBackward>)
print(loss_bce_sig)
tensor(0.4869, grad_fn=<BinaryCrossEntropyWithLogitsBackward>)
4.6 Focal Loss
Focal loss最初是出现在目标检测领域,主要是为了解决正负样本比例失调的问题。那么对于分割任务来说,如果存在数据不均衡的情况,也可以借用focal loss来进行缓解。Focal loss函数公式如下所示:
仔细观察就不难发现,它其实是BCE扩展而来,对比BCE其实就多了个
为什么多了这个就能缓解正负样本不均衡的问题呢?见下图:
简单来说:$α$解决样本不平衡问题,$γ$解决样本难易问题。
也就是说,当数据不均衡时,可以根据比例设置合适的$α$,这个很好理解,为了能够使得正负样本得到的损失能够均衡,因此对loss前面加上一定的权重,其中负样本数量多,因此占用的权重可以设置的小一点;正样本数量少,就对正样本产生的损失的权重设的高一点。
那γ具体怎么起作用呢?以图中$γ=5$曲线为例,假设$gt$类别为1,当模型预测结果为1的概率$p_t$比较大时,我们认为模型预测的比较准确,也就是说这个样本比较简单。而对于比较简单的样本,我们希望提供的loss小一些而让模型主要学习难一些的样本,也就是$p_t→ 1$则loss接近于0,既不用再特别学习;当分类错误时,$p_t → 0$则loss正常产生,继续学习。对比图中蓝色和绿色曲线,可以看到,γ值越大,当模型预测结果比较准确的时候能提供更小的loss,符合我们为简单样本降低loss的预期。
代码实现:
import torch.nn as nn
import torch
import torch.nn.functional as F
class FocalLoss(nn.Module):
def __init__(self, alpha=1, gamma=2, logits=False, reduce=True):
super(FocalLoss, self).__init__()
self.alpha = alpha
self.gamma = gamma
self.logits = logits# 如果BEC带logits则损失函数在计算BECloss之前会自动计算softmax/sigmoid将其映射到[0,1]
self.reduce = reduce
def forward(self, inputs, targets):
if self.logits:
BCE_loss = F.binary_cross_entropy_with_logits(inputs, targets, reduce=False)
else:
BCE_loss = F.binary_cross_entropy(inputs, targets, reduce=False)
pt = torch.exp(-BCE_loss)
F_loss = self.alpha * (1-pt)**self.gamma * BCE_loss
if self.reduce:
return torch.mean(F_loss)
else:
return F_loss
# ------------------------
FL1 = FocalLoss(logits=False)
FL2 = FocalLoss(logits=True)
inputs = torch.randn(5, 1, requires_grad=True)
targets = torch.empty(5, 1).random_(2)
pre = nn.Sigmoid()(inputs)
f_loss_1 = FL1(pre, targets)
f_loss_2 = FL2(inputs, targets)
# ------------------------
print('inputs:', inputs)
inputs: tensor([[-1.3521],
[ 0.4975],
[-1.0178],
[-0.3859],
[-0.2923]], requires_grad=True)
print('targets:', targets)
targets: tensor([[1.],
[1.],
[0.],
[1.],
[1.]])
print('pre:', pre)
pre: tensor([[0.2055],
[0.6219],
[0.2655],
[0.4047],
[0.4274]], grad_fn=<SigmoidBackward>)
print('f_loss_1:', f_loss_1)
f_loss_1: tensor(0.3375, grad_fn=<MeanBackward0>)
print('f_loss_2', f_loss_2)
f_loss_2 tensor(0.3375, grad_fn=<MeanBackward0>)
4.7 Lovász-Softmax
IoU是评价分割模型分割结果质量的重要指标,因此很自然想到能否用$1-IoU$(即Jaccard loss)来做损失函数,但是它是一个离散的loss,不能直接求导,所以无法直接用来作为损失函数。为了克服这个离散的问题,可以采用lLovász extension将离散的Jaccard loss 变得连续,从而可以直接求导,使得其作为分割网络的loss function。Lovász-Softmax相比于交叉熵函数具有更好的效果。
论文地址:
paper on CVF open access
arxiv paper
首先明确定义,在语义分割任务中,给定真实像素标签向量$\pmb{y^*}$和预测像素标签$\pmb{\hat{y} }$,则所属类别$c$的IoU(也称为Jaccard index)如下,其取值范围为$[0,1]$,并规定$0/0=1$:
则Jaccard loss为:
针对类别$c$,所有未被正确预测的像素集合定义为:
则可将Jaccard loss改写为关于$M_c$的子模集合函数(submodular set functions):
方便理解,此处可以把${0,1}^p$理解成如图像mask展开成离散一维向量的形式。
Lovász extension可以求解子模最小化问题,并且子模的Lovász extension是凸函数,可以高效实现最小化。在论文中作者对$\Delta$(集合函数)和$\overline{\Delta}$(集合函数的Lovász extension)进行了定义,为不涉及过多概念以方便理解,此处不再过多讨论。我们可以将$\overline{\Delta}$理解为一个线性插值函数,可以将${0,1}^p$这种离散向量连续化,主要是为了方便后续反向传播、求梯度等等。因此我们可以通过这个线性插值函数得到$\Delta{J_c}$的Lovász extension$\overline{\Delta{J_c} }$。
在具有$c(c>2)$个类别的语义分割任务中,我们使用Softmax函数将模型的输出映射到概率分布形式,类似传统交叉熵损失函数所进行的操作:
式中,$p_i(c)$表示了像素$i$所属类别$c$的概率。通过上式可以构建每个像素产生的误差$m(c)$:
可知,对于一张图像中所有像素则误差向量为$m(c)\in {0, 1}^p$,则可以建立关于$\Delta_{J_c}$的代理损失函数:
当我们考虑整个数据集是,一般会使用mIoU进行度量,因此我们对上述损失也进行平均化处理,则定义的Lovász-Softmax损失函数为:
代码实现
论文作者已经给出了Lovász-Softmax实现代码,并且有pytorch和tensorflow两种版本,并提供了使用demo。此处将针对多分类任务的Lovász-Softmax源码进行展示。
import torch
from torch.autograd import Variable
import torch.nn.functional as F
import numpy as np
try:
from itertools import ifilterfalse
except ImportError: # py3k
from itertools import filterfalse as ifilterfalse
# --------------------------- MULTICLASS LOSSES ---------------------------
def lovasz_softmax(probas, labels, classes='present', per_image=False, ignore=None):
"""
Multi-class Lovasz-Softmax loss
probas: [B, C, H, W] Variable, class probabilities at each prediction (between 0 and 1).
Interpreted as binary (sigmoid) output with outputs of size [B, H, W].
labels: [B, H, W] Tensor, ground truth labels (between 0 and C - 1)
classes: 'all' for all, 'present' for classes present in labels, or a list of classes to average.
per_image: compute the loss per image instead of per batch
ignore: void class labels
"""
if per_image:
loss = mean(lovasz_softmax_flat(*flatten_probas(prob.unsqueeze(0), lab.unsqueeze(0), ignore), classes=classes)
for prob, lab in zip(probas, labels))
else:
loss = lovasz_softmax_flat(*flatten_probas(probas, labels, ignore), classes=classes)
return loss
def lovasz_softmax_flat(probas, labels, classes='present'):
"""
Multi-class Lovasz-Softmax loss
probas: [P, C] Variable, class probabilities at each prediction (between 0 and 1)
labels: [P] Tensor, ground truth labels (between 0 and C - 1)
classes: 'all' for all, 'present' for classes present in labels, or a list of classes to average.
"""
if probas.numel() == 0:
# only void pixels, the gradients should be 0
return probas * 0.
C = probas.size(1)
losses = []
class_to_sum = list(range(C)) if classes in ['all', 'present'] else classes
for c in class_to_sum:
fg = (labels == c).float() # foreground for class c
if (classes is 'present' and fg.sum() == 0):
continue
if C == 1:
if len(classes) > 1:
raise ValueError('Sigmoid output possible only with 1 class')
class_pred = probas[:, 0]
else:
class_pred = probas[:, c]
errors = (Variable(fg) - class_pred).abs()
errors_sorted, perm = torch.sort(errors, 0, descending=True)
perm = perm.data
fg_sorted = fg[perm]
losses.append(torch.dot(errors_sorted, Variable(lovasz_grad(fg_sorted))))
return mean(losses)
def flatten_probas(probas, labels, ignore=None):
"""
Flattens predictions in the batch
"""
if probas.dim() == 3:
# assumes output of a sigmoid layer
B, H, W = probas.size()
probas = probas.view(B, 1, H, W)
B, C, H, W = probas.size()
probas = probas.permute(0, 2, 3, 1).contiguous().view(-1, C) # B * H * W, C = P, C
labels = labels.view(-1)
if ignore is None:
return probas, labels
valid = (labels != ignore)
vprobas = probas[valid.nonzero().squeeze()]
vlabels = labels[valid]
return vprobas, vlabels
def xloss(logits, labels, ignore=None):
"""
Cross entropy loss
"""
return F.cross_entropy(logits, Variable(labels), ignore_index=255)
# --------------------------- HELPER FUNCTIONS ---------------------------
def isnan(x):
return x != x
def mean(l, ignore_nan=False, empty=0):
"""
nanmean compatible with generators.
"""
l = iter(l)
if ignore_nan:
l = ifilterfalse(isnan, l)
try:
n = 1
acc = next(l)
except StopIteration:
if empty == 'raise':
raise ValueError('Empty mean')
return empty
for n, v in enumerate(l, 2):
acc += v
if n == 1:
return acc
return acc / n
4.8 参考链接
What is “Dice loss” for image segmentation?
Submodularity and the Lovász extension
4.9 本章小结
本章对各类评价指标进行介绍,并进行具体代码实践。
]]>
diff --git a/categories/index.html b/categories/index.html
index a158ffc3..9f9e465c 100644
--- a/categories/index.html
+++ b/categories/index.html
@@ -481,7 +481,7 @@
-
diff --git a/index.html b/index.html
index a9583d14..052dc7af 100644
--- a/index.html
+++ b/index.html
@@ -207,7 +207,7 @@
- 最近有在折腾一些Ubuntu日常化的东西,给电脑重新装了双系统,相比前几年,ubuntu22.04之后系统确实变得非常好用了,软件生态支持也变多了,为了更加日常化的使用折腾了一些相关软件的安装,这边做一个简单的记录。
+ 最近有在折腾一些Ubuntu日常化的东西,给电脑重新装了双系统,相比前几年,ubuntu22.04之后系统确实变得非常好用了,软件生态支持也变多了,为了更加日常化的使用折腾了一些相关软件的安装,这边做一个简单的记录。
@@ -361,7 +361,7 @@
既往不恋,纵情向前,江湖再见——22岁那年,在北京的日子
2022年3月31日0:52,睡不着,日常拖延症+强迫症导致清东西到现在,等会还想清扫一下弄脏的地板。
莲竹花园甲2号楼一门101,从今天起,这里将不再是我的家,本来是昨天的机票,天气不似预期,不打算买高铁,还想再飞上一次云霄,所以倔强的又改签了机票,不过正好也让我多看一眼这里吧,最近东航事件其实让我也有一点小慌,希望能平安到达吧。
-不出所料,我对这个城市并没有什么留恋,每天晚上我都会思考很多,有天夜里我的脑海里突然冒出来了那句:劝君更进一杯酒,西出阳关无故人。 这一刻我才真正明白什么是独在异乡为异客的感觉,什么才是我心里最想要的。
+不出所料,我对这个城市并没有什么留恋,每天晚上我都会思考很多,有天夜里我的脑海里突然冒出来了那句:劝君更进一杯酒,西出阳关无故人。 这一刻我才真正明白什么是独在异乡为异客的感觉,什么才是我心里最想要的。
@@ -675,7 +675,7 @@
- XGBoost算法
XGBoost是陈天奇等人开发的一个开源机器学习项目,高效地实现了GBDT算法并进行了算法和工程上的许多改进,被广泛应用在Kaggle竞赛及其他许多机器学习竞赛中并取得了不错的成绩。XGBoost本质上还是一个GBDT,但是力争把速度和效率发挥到极致,所以叫X (Extreme) GBoosted, 包括前面说过,两者都是boosting方法。XGBoost是一个优化的分布式梯度增强库,旨在实现高效,灵活和便携。 它在Gradient Boosting框架下实现机器学习算法。 XGBoost提供了并行树提升(也称为GBDT,GBM),可以快速准确地解决许多数据科学问题。 相同的代码在主要的分布式环境(Hadoop,SGE,MPI)上运行,并且可以解决超过数十亿个样例的问题。XGBoost利用了核外计算并且能够使数据科学家在一个主机上处理数亿的样本数据。最终,将这些技术进行结合来做一个端到端的系统以最少的集群系统来扩展到更大的数据集上。Xgboost以CART决策树为子模型,通过Gradient Tree Boosting实现多棵CART树的集成学习,得到最终模型。下面我们来看看XGBoost的最终模型构建:
+ XGBoost算法
XGBoost是陈天奇等人开发的一个开源机器学习项目,高效地实现了GBDT算法并进行了算法和工程上的许多改进,被广泛应用在Kaggle竞赛及其他许多机器学习竞赛中并取得了不错的成绩。XGBoost本质上还是一个GBDT,但是力争把速度和效率发挥到极致,所以叫X (Extreme) GBoosted, 包括前面说过,两者都是boosting方法。XGBoost是一个优化的分布式梯度增强库,旨在实现高效,灵活和便携。 它在Gradient Boosting框架下实现机器学习算法。 XGBoost提供了并行树提升(也称为GBDT,GBM),可以快速准确地解决许多数据科学问题。 相同的代码在主要的分布式环境(Hadoop,SGE,MPI)上运行,并且可以解决超过数十亿个样例的问题。XGBoost利用了核外计算并且能够使数据科学家在一个主机上处理数亿的样本数据。最终,将这些技术进行结合来做一个端到端的系统以最少的集群系统来扩展到更大的数据集上。Xgboost以CART决策树为子模型,通过Gradient Tree Boosting实现多棵CART树的集成学习,得到最终模型。下面我们来看看XGBoost的最终模型构建:
@@ -753,7 +753,7 @@
- 梯度提升决策树(GBDT)
(1) 基于残差学习的提升树算法:
在前面的学习过程中,我们一直讨论的都是分类树,比如Adaboost算法,并没有涉及回归的例子。在上一小节我们提到了一个加法模型+前向分步算法的框架,那能否使用这个框架解决回归的例子呢?答案是肯定的。接下来我们来探讨下如何使用加法模型+前向分步算法的框架实现回归问题。
在使用加法模型+前向分步算法的框架解决问题之前,我们需要首先确定框架内使用的基函数是什么,在这里我们使用决策树分类器。前面第二章我们已经学过了回归树的基本原理,树算法最重要是寻找最佳的划分点,分类树用纯度来判断最佳划分点使用信息增益(ID3算法),信息增益比(C4.5算法),基尼系数(CART分类树)。但是在回归树中的样本标签是连续数值,可划分点包含了所有特征的所有可取的值。所以再使用熵之类的指标不再合适,取而代之的是平方误差,它能很好的评判拟合程度。 基函数确定了以后,我们需要确定每次提升的标准是什么。回想Adaboost算法,在Adaboost算法内使用了分类错误率修正样本权重以及计算每个基本分类器的权重,那回归问题没有分类错误率可言,也就没办法在这里的回归问题使用了,因此我们需要另辟蹊径。模仿分类错误率,我们用每个样本的残差表示每次使用基函数预测时没有解决的那部分问题。因此,我们可以得出如下算法:
+ 梯度提升决策树(GBDT)
(1) 基于残差学习的提升树算法:
在前面的学习过程中,我们一直讨论的都是分类树,比如Adaboost算法,并没有涉及回归的例子。在上一小节我们提到了一个加法模型+前向分步算法的框架,那能否使用这个框架解决回归的例子呢?答案是肯定的。接下来我们来探讨下如何使用加法模型+前向分步算法的框架实现回归问题。
在使用加法模型+前向分步算法的框架解决问题之前,我们需要首先确定框架内使用的基函数是什么,在这里我们使用决策树分类器。前面第二章我们已经学过了回归树的基本原理,树算法最重要是寻找最佳的划分点,分类树用纯度来判断最佳划分点使用信息增益(ID3算法),信息增益比(C4.5算法),基尼系数(CART分类树)。但是在回归树中的样本标签是连续数值,可划分点包含了所有特征的所有可取的值。所以再使用熵之类的指标不再合适,取而代之的是平方误差,它能很好的评判拟合程度。 基函数确定了以后,我们需要确定每次提升的标准是什么。回想Adaboost算法,在Adaboost算法内使用了分类错误率修正样本权重以及计算每个基本分类器的权重,那回归问题没有分类错误率可言,也就没办法在这里的回归问题使用了,因此我们需要另辟蹊径。模仿分类错误率,我们用每个样本的残差表示每次使用基函数预测时没有解决的那部分问题。因此,我们可以得出如下算法:
@@ -831,7 +831,7 @@
- 1. 导论
在前面的学习中,我们探讨了一系列简单而实用的回归和分类模型,同时也探讨了如何使用集成学习家族中的Bagging思想去优化最终的模型。Bagging思想的实质是:通过Bootstrap 的方式对全样本数据集进行抽样得到抽样子集,对不同的子集使用同一种基本模型进行拟合,然后投票得出最终的预测。我们也从前面的探讨知道:Bagging主要通过降低方差的方式减少预测误差。那么,本章介绍的Boosting是与Bagging截然不同的思想,Boosting方法是使用同一组数据集进行反复学习,得到一系列简单模型,然后组合这些模型构成一个预测性能十分强大的机器学习模型。 显然,Boosting思想提高最终的预测效果是通过不断减少偏差的形式,与Bagging有着本质的不同。在Boosting这一大类方法中,笔者主要介绍两类常用的Boosting方式:Adaptive Boosting 和 Gradient Boosting 以及它们的变体Xgboost、LightGBM以及Catboost。
+ 1. 导论
在前面的学习中,我们探讨了一系列简单而实用的回归和分类模型,同时也探讨了如何使用集成学习家族中的Bagging思想去优化最终的模型。Bagging思想的实质是:通过Bootstrap 的方式对全样本数据集进行抽样得到抽样子集,对不同的子集使用同一种基本模型进行拟合,然后投票得出最终的预测。我们也从前面的探讨知道:Bagging主要通过降低方差的方式减少预测误差。那么,本章介绍的Boosting是与Bagging截然不同的思想,Boosting方法是使用同一组数据集进行反复学习,得到一系列简单模型,然后组合这些模型构成一个预测性能十分强大的机器学习模型。 显然,Boosting思想提高最终的预测效果是通过不断减少偏差的形式,与Bagging有着本质的不同。在Boosting这一大类方法中,笔者主要介绍两类常用的Boosting方式:Adaptive Boosting 和 Gradient Boosting 以及它们的变体Xgboost、LightGBM以及Catboost。
@@ -915,7 +915,7 @@ 10101100100111001011011011011
这导致的结果可能是致命的。一个常用的纠错方法是重复多次发送数据,并以少数服从多数的方法确定正确的传输数据。一般情况下,错误总是发生在局部,因此融合多个数据是降低误差的一个好方法,这就是投票法的基本思路。
对于回归模型来说,投票法最终的预测结果是多个其他回归模型预测结果的平均值。
-对于分类模型,硬投票法的预测结果是多个模型预测结果中出现次数最多的类别,软投票对各类预测结果的概率进行求和,最终选取概率之和最大的类标签。
+对于分类模型,硬投票法的预测结果是多个模型预测结果中出现次数最多的类别,软投票对各类预测结果的概率进行求和,最终选取概率之和最大的类标签。
@@ -1205,7 +1205,7 @@
-
@@ -1213,15 +1213,15 @@
-
diff --git a/live2d-widget-old/README.html b/live2d-widget-old/README.html
index 1796522e..d82de013 100644
--- a/live2d-widget-old/README.html
+++ b/live2d-widget-old/README.html
@@ -1,39 +1,44 @@
-
Live2D Widget






+Live2D Widget
特性 Feature
在网页中添加 Live2D 看板娘。兼容 PJAX,支持无刷新加载。
Add Live2D widget to web page. Compatible with PJAX.
警告:本项目使用了大量 ES6 语法,且依赖于 WebGL。不支持 IE 11 等老旧浏览器。
WARNING: This project does not support legacy browsers such as IE 11.
-示例 Demo
在米米的博客的左下角可查看效果。
-


+示例 Demo
在米米的博客的左下角可查看效果。
+
这个仓库中也提供了两个 Demo,即
- demo1.html ,展现基础效果
- demo2.html ,仿 NPM 的登陆界面
依赖 Dependencies
本插件需要 Font Awesome 4.7.0 支持,请确保相关样式表已在页面中加载,例如在 <head> 中加入:
Font Awesome 4.7.0 is required for this plugin. You can add this to <head>:
-<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/font-awesome/css/font-awesome.min.css">
+<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/font-awesome/css/font-awesome.min.css">
+
否则无法正常显示。(如果网页中已经加载了 Font Awesome,就不要重复加载了)
使用 Usage
将这一行代码加入 <head> 或 <body>,即可展现出效果:
-<script src="https://cdn.jsdelivr.net/gh/stevenjoezhang/live2d-widget@latest/autoload.js"></script>
+<script src="https://cdn.jsdelivr.net/gh/stevenjoezhang/live2d-widget@latest/autoload.js"></script>
+
如果网站启用了 PJAX,由于看板娘不必每页刷新,因此要注意将相关脚本放到 PJAX 刷新区域之外。
换句话说,如果你是小白,或者只需要最基础的功能,就只用把这一行代码,连同前面加载 Font Awesome 的一行代码,一起放到 html 的 <head> 中即可。
对于用各种模版引擎(例如 Nunjucks,Jinja 或者 PHP)生成的页面,也要自行修改,方法类似,只是可能略为麻烦。以 Hexo 为例,需要在主题相关的 ejs 或 njk 模版中正确配置路径,才可以加载。
但是!我们强烈推荐自己进行配置,否则很多功能是不完整的,并且可能产生问题!
如果你有兴趣自己折腾的话,请看下面的详细说明。
Using CDN
要自定义有关内容,可以把这个仓库 Fork 一份,然后进行修改。这时,使用方法对应地变为
-<script src="https://cdn.jsdelivr.net/gh/username/live2d-widget@latest/autoload.js"></script>
+<script src="https://cdn.jsdelivr.net/gh/username/live2d-widget@latest/autoload.js"></script>
+
将 username 替换为你的 GitHub 用户名即可。
Self-host
你也可以直接把这些文件放到服务器上,而不是通过 CDN 加载。
-- 如果你能够通过
ssh 访问你的主机,请把整个仓库克隆到服务器上。执行:cd /path/to/your/webroot
+- 如果你能够通过
ssh 访问你的主机,请把整个仓库克隆到服务器上。执行:cd /path/to/your/webroot
# Clone this repository
-git clone https://github.com/stevenjoezhang/live2d-widget.git
+git clone https://github.com/stevenjoezhang/live2d-widget.git
+
- 如果你的主机无法用
ssh 连接(例如一般的虚拟主机),请选择 Download ZIP,然后通过 ftp 等方式上传到主机上,再解压到网站的目录下。
- 如果你是通过 Hexo 等工具部署的静态博客,请在本地开命令行进入博客目录,例如
source 下与 _posts 同级的目录,然后再执行前述的 git clone 命令。重新部署博客时,相关文件就会自动上传到对应的路径下。
这样,整个项目就可以通过你的服务器 IP 或者域名从公网访问了。不妨试试能否正常地通过浏览器打开 autoload.js 和 live2d.min.js 等文件,并确认这些文件的内容是正确的,没有出现乱码。
一切正常的话,接下来修改一些配置就行了。(需要通过服务器上的文本编辑器修改;你也可以先在本地完成这一步骤,再上传到服务器上)
修改 autoload.js 中的常量 live2d_path 为 live2d-widget 这一文件夹在公网上的路径。比如说,如果你能够通过
-https://www.example.com/path/to/live2d-widget/live2d.min.js
-访问到 live2d.min.js,那么就把 live2d_path 的值修改为
-https://www.example.com/path/to/live2d-widget/
-路径末尾的 / 一定要加上。具体可以参考 autoload.js 内的注释。
完成后,在你要添加看板娘的界面加入
-<script src="https://www.example.com/path/to/live2d-widget/autoload.js"></script>
+https://www.example.com/path/to/live2d-widget/live2d.min.js
+
访问到 live2d.min.js,那么就把 live2d_path 的值修改为
+https://www.example.com/path/to/live2d-widget/
+
路径末尾的 / 一定要加上。具体可以参考 autoload.js 内的注释。
完成后,在你要添加看板娘的界面加入
+<script src="https://www.example.com/path/to/live2d-widget/autoload.js"></script>
+
就可以加载了。
目录结构 Files
waifu-tips.json 中包含了触发条件(selector,选择器)和触发时显示的文字(text);
源文件是对 Hexo 的 NexT 主题有效的,为了适用于你自己的网页,可能需要自行修改,或增加新内容。
警告:作者不对包括但不限于 waifu-tips.json 和 waifu-tips.js 文件中的内容负责,请自行确保它们是合适的。
如果有任何疑问,欢迎提 Issue。如果有任何修改建议,欢迎提 Pull Request。
-鸣谢 Credits

+鸣谢 Credits
感谢 BrowserStack 容许我们在真实的浏览器中测试此项目。
Thanks to BrowserStack for allowing us to test this project in real browsers.
代码自这篇博文魔改而来:
https://www.fghrsh.net/post/123.html
-点击看板娘的纸飞机按钮时,会出现一个彩蛋,这来自于 WebsiteAsteroids。
+点击看板娘的纸飞机按钮时,会出现一个彩蛋,这来自于 WebsiteAsteroids。
更多 More
更多内容可以参考:
https://imjad.cn/archives/lab/add-dynamic-poster-girl-with-live2d-to-your-blog-02
https://github.com/xiazeyu/live2d-widget.js
https://github.com/summerscar/live2dDemo
还可以自行搭建后端 API,并增加模型(需要修改的内容比较多,此处不再赘述):
https://github.com/fghrsh/live2d_api
https://github.com/xiazeyu/live2d-widget-models
https://github.com/xiaoski/live2d_models_collection
除此之外,还有桌面版本:
https://github.com/amorist/platelet
https://github.com/akiroz/Live2D-Widget
许可证 License
Released under the GNU General Public License v3
http://www.gnu.org/licenses/gpl-3.0.html
本仓库中涉及的所有 Live2D 模型、图片、动作数据等版权均属于其原作者,仅供研究学习,不得用于商业用途。
-Live2D 官方网站:
https://www.live2d.com/en/
https://live2d.github.io
+Live2D 官方网站:
https://www.live2d.com/en/
https://live2d.github.io
Live2D Cubism Core は Live2D Proprietary Software License で提供しています。
https://www.live2d.com/eula/live2d-proprietary-software-license-agreement_en.html
Live2D Cubism Components は Live2D Open Software License で提供しています。
http://www.live2d.com/eula/live2d-open-software-license-agreement_en.html
The terms and conditions do prohibit modification, but obfuscating in live2d.min.js would not be considered illegal modification.
diff --git a/live2d-widget/README.html b/live2d-widget/README.html
index d04e445a..bcf8255e 100644
--- a/live2d-widget/README.html
+++ b/live2d-widget/README.html
@@ -1,18 +1,20 @@
-Live2D Widget
+Live2D Widget
特性 Feature
在网页中添加 Live2D 看板娘。兼容 PJAX,支持无刷新加载。
Add Live2D widget to web page. Compatible with PJAX.
(注:以上人物模型仅供展示之用,本仓库并不包含任何模型。)
你也可以查看示例网页:
-- 在 米米的博客 的左下角可查看效果
+- 在 米米的博客 的左下角可查看效果
- demo.html,展现基础功能
- login.html,仿 NPM 的登陆界面
使用 Usage
如果你是小白,或者只需要最基础的功能,那么只用将这一行代码加入 html 页面的 head 或 body 中,即可加载看板娘:
-<script src="https://fastly.jsdelivr.net/gh/stevenjoezhang/live2d-widget@latest/autoload.js"></script>
-添加代码的位置取决于你的网站的构建方式。例如,如果你使用的是 Hexo,那么需要在主题的模版文件中添加以上代码。对于用各种模版引擎生成的页面,修改方法类似。
如果网站启用了 PJAX,由于看板娘不必每页刷新,需要注意将该脚本放到 PJAX 刷新区域之外。
+<script src="https://fastly.jsdelivr.net/gh/stevenjoezhang/live2d-widget@latest/autoload.js"></script>
+
+添加代码的位置取决于你的网站的构建方式。例如,如果你使用的是 Hexo,那么需要在主题的模版文件中添加以上代码。对于用各种模版引擎生成的页面,修改方法类似。
如果网站启用了 PJAX,由于看板娘不必每页刷新,需要注意将该脚本放到 PJAX 刷新区域之外。
但是!我们强烈推荐自己进行配置,让看板娘更加适合你的网站!
如果你有兴趣自己折腾的话,请看下面的详细说明。
配置 Configuration
你可以对照 autoload.js 的源码查看可选的配置项目。autoload.js 会自动加载三个文件:waifu.css,live2d.min.js 和 waifu-tips.js。waifu-tips.js 会创建 initWidget 函数,这就是加载看板娘的主函数。initWidget 函数接收一个 Object 类型的参数,作为看板娘的配置。以下是配置选项:
+
@@ -22,7 +24,8 @@ 说明
-
+
+
waifuPathstringhttps://fastly.jsdelivr.net/gh/stevenjoezhang/live2d-widget@latest/waifu-tips.json见 autoload.js
加载的小工具按钮,可选参数
-
+
+
+
其中,apiPath 和 cdnPath 两个参数设置其中一项即可。apiPath 是后端 API 的 URL,可以自行搭建,并增加模型(需要修改的内容比较多,此处不再赘述),可以参考 live2d_api。而 cdnPath 则是通过 jsDelivr 这样的 CDN 服务加载资源,更加稳定。
自定义 Customization
如果以上「配置」部分提供的选项还不足以满足你的需求,那么你可以自己进行修改。本仓库的目录结构如下:
@@ -57,13 +62,15 @@ NexT 主题 有效的,为了适用于你自己的网页,可能需要自行修改,或增加新内容。
警告:waifu-tips.json 中的内容可能不适合所有年龄段,或不宜在工作期间访问。在使用时,请自行确保它们是合适的。
要在本地部署本项目的开发测试环境,你需要安装 Node.js 和 npm,然后执行以下命令:
-
git clone https://github.com/stevenjoezhang/live2d-widget.git
+git clone https://github.com/stevenjoezhang/live2d-widget.git
npm install
-npm run build
+npm run build
+
如果有任何疑问,欢迎提 Issue。如果有任何修改建议,欢迎提 Pull Request。
部署 Deploy
在本地完成了修改后,你可以将修改后的项目部署在服务器上,或者通过 CDN 加载,以便在网页中使用。
Using CDN
要自定义有关内容,可以把这个仓库 Fork 一份,然后把修改后的内容通过 git push 到你的仓库中。这时,使用方法对应地变为
-<script src="https://fastly.jsdelivr.net/gh/username/live2d-widget@latest/autoload.js"></script>
+<script src="https://fastly.jsdelivr.net/gh/username/live2d-widget@latest/autoload.js"></script>
+
将此处的 username 替换为你的 GitHub 用户名。为了使 CDN 的内容正常刷新,需要创建新的 git tag 并推送至 GitHub 仓库中,否则此处的 @latest 仍然指向更新前的文件。此外 CDN 本身存在缓存,因此改动可能需要一定的时间生效。相关文档:
- Git Basics - Tagging
@@ -76,11 +83,12 @@ 如果你是通过 Hexo 等工具部署的静态博客,请把本项目的代码放在博客源文件目录下(例如 source 目录)。重新部署博客时,相关文件就会自动上传到对应的路径下。为了避免这些文件被 Hexo 插件错误地修改,可能需要设置 skip_render。
这样,整个项目就可以通过你的域名访问了。不妨试试能否正常地通过浏览器打开 autoload.js 和 live2d.min.js 等文件,并确认这些文件的内容是完整和正确的。
一切正常的话,接下来修改 autoload.js 中的常量 live2d_path 为 live2d-widget 这一目录的 URL 即可。比如说,如果你能够通过
-https://example.com/path/to/live2d-widget/live2d.min.js
-访问到 live2d.min.js,那么就把 live2d_path 的值修改为
-https://example.com/path/to/live2d-widget/
-路径末尾的 / 一定要加上。
完成后,在你要添加看板娘的界面加入
-<script src="https://example.com/path/to/live2d-widget/autoload.js"></script>
+https://example.com/path/to/live2d-widget/live2d.min.js
+
访问到 live2d.min.js,那么就把 live2d_path 的值修改为
+https://example.com/path/to/live2d-widget/
+
路径末尾的 / 一定要加上。
完成后,在你要添加看板娘的界面加入
+<script src="https://example.com/path/to/live2d-widget/autoload.js"></script>
+
就可以加载了。
鸣谢 Thanks

@@ -91,15 +99,15 @@ https://www.fghrsh.net/post/123.html
-
感谢 一言 提供的语句接口。
-点击看板娘的纸飞机按钮时,会出现一个彩蛋,这来自于 WebsiteAsteroids。
+感谢 一言 提供的语句接口。
+点击看板娘的纸飞机按钮时,会出现一个彩蛋,这来自于 WebsiteAsteroids。
更多 More
更多内容可以参考:
https://nocilol.me/archives/lab/add-dynamic-poster-girl-with-live2d-to-your-blog-02
https://github.com/xiazeyu/live2d-widget.js
https://github.com/summerscar/live2dDemo
关于后端 API 模型:
https://github.com/xiazeyu/live2d-widget-models
https://github.com/xiaoski/live2d_models_collection
除此之外,还有桌面版本:
https://github.com/amorist/platelet
https://github.com/akiroz/Live2D-Widget
https://github.com/zenghongtu/PPet
https://github.com/LikeNeko/L2dPetForMac
以及 Wallpaper Engine:
https://github.com/guansss/nep-live2d
许可证 License
Released under the GNU General Public License v3
http://www.gnu.org/licenses/gpl-3.0.html
本仓库并不包含任何模型,用作展示的所有 Live2D 模型、图片、动作数据等版权均属于其原作者,仅供研究学习,不得用于商业用途。
-Live2D 官方网站:
https://www.live2d.com/en/
https://live2d.github.io
+Live2D 官方网站:
https://www.live2d.com/en/
https://live2d.github.io
Live2D Cubism Core は Live2D Proprietary Software License で提供しています。
https://www.live2d.com/eula/live2d-proprietary-software-license-agreement_en.html
Live2D Cubism Components は Live2D Open Software License で提供しています。
http://www.live2d.com/eula/live2d-open-software-license-agreement_en.html
The terms and conditions do prohibit modification, but obfuscating in live2d.min.js would not be considered illegal modification.
diff --git a/page/2/index.html b/page/2/index.html
index 5443e198..3a17f219 100644
--- a/page/2/index.html
+++ b/page/2/index.html
@@ -207,7 +207,7 @@
- 数据结构与算法——二分
最近leetcode每日一题经常出二分的题目,正好对前段时间学过的二分进行一些总结,首先这里要明确的一点是,二分的本质并不是单调性,而是通过某种条件将整个区间划分成满足条件和不满足条件的两端即可进行二分查找。
在二分这个专题,主要有两种类型的划分方式,一种是整数划分,一种是浮点数划分,前一种一般是我们最熟悉的二分查找的题型,也是出题比较灵活考的比较多的一种,后一种主要是为控制实数精度而设置的浮点数二分法(建议用double,float有时候会出现精度丢失)。
+ 数据结构与算法——二分
最近leetcode每日一题经常出二分的题目,正好对前段时间学过的二分进行一些总结,首先这里要明确的一点是,二分的本质并不是单调性,而是通过某种条件将整个区间划分成满足条件和不满足条件的两端即可进行二分查找。
在二分这个专题,主要有两种类型的划分方式,一种是整数划分,一种是浮点数划分,前一种一般是我们最熟悉的二分查找的题型,也是出题比较灵活考的比较多的一种,后一种主要是为控制实数精度而设置的浮点数二分法(建议用double,float有时候会出现精度丢失)。
@@ -281,7 +281,7 @@
- 数据结构与刷题——链表
+ 数据结构与刷题——链表
@@ -355,7 +355,7 @@
- 前言
最近在复习数据结构,顺便整理之前刷题的一些模板和技巧,希望对大家都有帮助,博客会侧重讲解的是OJ代码实现,理论部分偏少但也会写一些自己的理解。
在之前大二上数据结构的时候我也有写过一个关于排序的专题介绍数据结构复习——内部排序
+ 前言
最近在复习数据结构,顺便整理之前刷题的一些模板和技巧,希望对大家都有帮助,博客会侧重讲解的是OJ代码实现,理论部分偏少但也会写一些自己的理解。
在之前大二上数据结构的时候我也有写过一个关于排序的专题介绍数据结构复习——内部排序
@@ -432,7 +432,7 @@
EfficientNet论文解读和pytorch代码实现
传送门
论文地址:https://arxiv.org/pdf/1905.11946.pdf
官方github:https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
github参考:https://github.com/qubvel/efficientnet
github参考:https://github.com/lukemelas/EfficientNet-PyTorch
-摘要
谷歌的文章总是能让我印象深刻,不管从实验上还是论文的书写上都让人十分的佩服,不得不说这确实是一个非常creative的公司!
Convolutional Neural Networks (ConvNets) are commonly developed at a fixed resource budget, and then scaled up for better accuracy if more resources are available. In this paper, we systematically study model scaling and identify that carefully balancing network depth, width, and resolution can lead to better performance. Based on this observation, we propose a new scaling method that uniformly scales all dimensions of depth/width/resolution using a simple yet highly effective compound coefficient. We demonstrate the effectiveness of this method on scaling up MobileNets and ResNet.
卷积神经网络通常是在固定的资源预算下进行计算和发展的,如果有更多可用的资源,模型能通过缩放和扩展获得更好的效果,本文系统研究(工作量很充足)了模型缩放,并且证明了细致地平衡网络的深度,宽度,和分辨率能够得到更好的效果,基于这个观点,我们提出了一个新的尺度缩放的方法,我们提出了一个新的尺度缩放的方法即:使用一个简单且高效的复合系数统一地缩放所有网络层的深度/宽度/分辨率的维度。我们证明了该方法在扩大MobileNets和ResNet方面的有效性。
+摘要
谷歌的文章总是能让我印象深刻,不管从实验上还是论文的书写上都让人十分的佩服,不得不说这确实是一个非常creative的公司!
Convolutional Neural Networks (ConvNets) are commonly developed at a fixed resource budget, and then scaled up for better accuracy if more resources are available. In this paper, we systematically study model scaling and identify that carefully balancing network depth, width, and resolution can lead to better performance. Based on this observation, we propose a new scaling method that uniformly scales all dimensions of depth/width/resolution using a simple yet highly effective compound coefficient. We demonstrate the effectiveness of this method on scaling up MobileNets and ResNet.
卷积神经网络通常是在固定的资源预算下进行计算和发展的,如果有更多可用的资源,模型能通过缩放和扩展获得更好的效果,本文系统研究(工作量很充足)了模型缩放,并且证明了细致地平衡网络的深度,宽度,和分辨率能够得到更好的效果,基于这个观点,我们提出了一个新的尺度缩放的方法,我们提出了一个新的尺度缩放的方法即:使用一个简单且高效的复合系数统一地缩放所有网络层的深度/宽度/分辨率的维度。我们证明了该方法在扩大MobileNets和ResNet方面的有效性。
@@ -506,7 +506,7 @@
- yolov1-3论文解析
最近在看经典目标检测算法yolo的思想,为了更好的了解yolo系列的相关文章,我从最初版本的论文思想开始看的,之后有时间会把yolov4和yolov5再认真看看,目前来说yolov3的spp版本是使用得最为广泛的一种,整体上来说yolo的设计思想还是很有创造性的数学也比较严谨。
+ yolov1-3论文解析
最近在看经典目标检测算法yolo的思想,为了更好的了解yolo系列的相关文章,我从最初版本的论文思想开始看的,之后有时间会把yolov4和yolov5再认真看看,目前来说yolov3的spp版本是使用得最为广泛的一种,整体上来说yolo的设计思想还是很有创造性的数学也比较严谨。
@@ -658,9 +658,7 @@
commit镜像
-数据卷操作实战:mysql同步
mysql运行容器,需要做数据挂载,安装启动mysql是需要配置密码的这一点要注意,所以要去docker hub官方文档上面去看官方配置
-docker pull mysql:5.7
-
+数据卷操作实战:mysql同步
mysql运行容器,需要做数据挂载,安装启动mysql是需要配置密码的这一点要注意,所以要去docker hub官方文档上面去看官方配置
docker pull mysql:5.7
docker运行,docker run的常用参数这里我们再次回顾一下
-d 后台运行
-p 端口映射
-v 卷挂载
-e 环境配置
--name 环境名字
@@ -737,36 +735,39 @@
Docker 常用命令
帮助命令
docker version #显示docker版本信息
docker info #显示docker的系统信息,包括镜像和容器的数量
docker 命令 --help # 帮助命令
-
镜像命令
1.docker images查看所有本地的主机镜像
+
-docker images显示字段
-解释
+docker images显示字段
+解释
-
-REPOSITORY
-镜像的仓库源
+
+
+REPOSITORY
+镜像的仓库源
-TAG
-镜像的标签
+TAG
+镜像的标签
-IMAGE ID
-镜像的id
+IMAGE ID
+镜像的id
-CREATED
-镜像的创建时间
+CREATED
+镜像的创建时间
-SIZE
-镜像的大小
+SIZE
+镜像的大小
-
+
+
+
@@ -1209,7 +1210,7 @@
Hexo博客搭建
鸽了半年的hexo博客搭建,阿里云都快过了半年了,把自己的一些踩坑和修改写一下吧,首先放一下我hexo博客搭建的时候的一些参考吧,这几个链接应该按道理没有很多踩坑的地方,我使用的主题是yilia主题所以说下面几个链接主要是关于yilia的,不过其实hexo博客框架的那个js和css名字都一样,配置文件的语法和格式也是一致的,所以说还是可以提供到一些帮助的,而且我自己在搭建一些操作的时候也学习了其他主题的一些方法。
从0开始搭建一个hexo博客无坑教程,是真的无坑版本,一切顺利(这里需要感谢一位b站的良心up主codesheep,他其他的视频也不错哦):
手把手教你从0开始搭建自己的个人博客 |无坑版视频教程| hexo
美化相关链接:
Hexo博客搭建
鸽了半年的hexo博客搭建,阿里云都快过了半年了,把自己的一些踩坑和修改写一下吧,首先放一下我hexo博客搭建的时候的一些参考吧,这几个链接应该按道理没有很多踩坑的地方,我使用的主题是yilia主题所以说下面几个链接主要是关于yilia的,不过其实hexo博客框架的那个js和css名字都一样,配置文件的语法和格式也是一致的,所以说还是可以提供到一些帮助的,而且我自己在搭建一些操作的时候也学习了其他主题的一些方法。
从0开始搭建一个hexo博客无坑教程,是真的无坑版本,一切顺利(这里需要感谢一位b站的良心up主codesheep,他其他的视频也不错哦):
手把手教你从0开始搭建自己的个人博客 |无坑版视频教程| hexo
美化相关链接:
- 参考链接1
- 参考链接2 @@ -226,18 +226,10 @@
- 把主页配置文件
_config.yml里的post_asset_folder:这个选项设置为true - 在你的hexo目录下执行这样一句话
npm install hexo-asset-image --save,这是下载安装一个可以上传本地图片的插件
@@ -561,7 +551,7 @@ -
diff --git "a/2020/07/12/python\345\256\236\347\216\260\351\201\227\344\274\240\347\256\227\346\263\225/index.html" "b/2020/07/12/python\345\256\236\347\216\260\351\201\227\344\274\240\347\256\227\346\263\225/index.html"
index 740163f2..9afc76b8 100644
--- "a/2020/07/12/python\345\256\236\347\216\260\351\201\227\344\274\240\347\256\227\346\263\225/index.html"
+++ "b/2020/07/12/python\345\256\236\347\216\260\351\201\227\344\274\240\347\256\227\346\263\225/index.html"
@@ -214,8 +214,7 @@ -
今天研究了一下遗传算法,发现原理还是很好懂的,不过在应用层面上还是有很多要学习的方法,如何定义编码解码的过程,如何进行选择和交叉变异,这都是我们需要解决的事情,估计还是要多学多用才能学会,当然了如果大家对我写的这些内容如果有什么不同的看法的话也建议大家提出,毕竟算法小白一个。
- +今天研究了一下遗传算法,发现原理还是很好懂的,不过在应用层面上还是有很多要学习的方法,如何定义编码解码的过程,如何进行选择和交叉变异,这都是我们需要解决的事情,估计还是要多学多用才能学会,当然了如果大家对我写的这些内容如果有什么不同的看法的话也建议大家提出,毕竟算法小白一个。
遗传算法介绍
所谓遗传算法其实就是一种仿生算法,一种仿生全局优化算法模仿生物的遗传进化原理,通过自然选择(selection)、交叉(crossover)与变异(mutation)等操作机制,逐步淘汰掉适应度不够高的个体,使种群中个体的适应性(fitness)不断提高。
核心思想:物竞天择,适者生存
主要的一些应用领域主要是在- 函数优化,求函数极值类 @@ -230,20 +229,16 @@
- 自然选择 :自然选择主要是依据个体适应度的大小转化成被选择的概率,利用轮盘赌的方式——将数据按照指定的概率分布方式提取出来,从而实现了物竞天择适者生存的原理,适应度大的个体被留下来的概率会逐步增大。
- 变异 :随机修改某一位基因序列,从而改变他的适应度 -
- 交叉重组 :种群中随机选取两个个体,交互若干的DNA片段,从而改变他的适应度,生成新的子代 +
- 交叉重组 :种群中随机选取两个个体,交互若干的DNA片段,从而改变他的适应度,生成新的子代
这里我们要明白的一点就是,遗传算法只是提供了一个迭代的模板,具体的适应度函数也就是我们选择优化的相关指标和他的表示都是需要根据题目里面的问题来建模,然后编码解码的方式说白了其实就是如何表示我们要的可行解,比如说求一个函数的极值且精确到多少位那么他的可行解就是自变量,这里我们通常采用二进制编码,如果是TSP问题,那么可行解就可以表示成为各个配送点编号构成的一个数组,进行实数数组序列的方式编码,自然而然解码的方法和含义我们也都清楚了求函数极值的问题
这里是我根据网上莫烦的python视频教程,来写的一个算法,这里我们要做的问题是求出$f(x)=sin(10x)×x+cos(2x)×x$的极大值。
解码 :解码主要是能够解析我们编码后的DNA序列,然后讲其表示的信息还原出来,然后进行适应度的计算。
这里我们要明白的一点就是,遗传算法只是提供了一个迭代的模板,具体的适应度函数也就是我们选择优化的相关指标和他的表示都是需要根据题目里面的问题来建模,然后编码解码的方式说白了其实就是如何表示我们要的可行解,比如说求一个函数的极值且精确到多少位那么他的可行解就是自变量,这里我们通常采用二进制编码,如果是TSP问题,那么可行解就可以表示成为各个配送点编号构成的一个数组,进行实数数组序列的方式编码,自然而然解码的方法和含义我们也都清楚了
-求函数极值的问题
这里是我根据网上莫烦的python视频教程,来写的一个算法,这里我们要做的问题是求出$f(x)=sin(10x)×x+cos(2x)×x$的极大值。
-import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
DNA_SIZE=10 #编码DNA的长度
POP_SIZE=100 #初始化种群的大小
CROSS_RATE=0.8 #DNA交叉概率
MUTATION_RATE=0.003 #DNA变异概率
N_GENERATIONS=200 #迭代次数
X_BOUND=[0,5] #x upper and lower bounds x的区间
def F(x):
return np.sin(10*x)*x+np.cos(2*x)*x
def get_fitness(pred):
return pred+1e-3-np.min(pred)
#获得适应值,这里是与min比较,越大则适应度越大,便于我们寻找最大值,为了防止结果为0特意加了一个较小的数来作为偏正
def translateDNA(pop):#DNA的二进制序列映射到x范围内
return pop.dot(2 ** np.arange(DNA_SIZE)[::-1]) / float(2**DNA_SIZE-1) * (X_BOUND[1]-X_BOUND[0])
def select(pop,fitness):
idx = np.random.choice(np.arange(POP_SIZE), size=POP_SIZE, replace=True,p=fitness / fitness.sum())
#我们只要按照适应程度 fitness 来选 pop 中的 parent 就好. fitness 越大, 越有可能被选到.
return pop[idx]
#交叉
def crossover(parent,pop):
if np.random.rand() < CROSS_RATE:
i_ = np.random.randint(0, POP_SIZE, size=1) # 选择一个母本的index
print("i_:",i_)
print("i_.size:",i_.size)
cross_points = np.random.randint(0, 2, size=DNA_SIZE).astype(np.bool) # choose crossover points
print("cross_point",cross_points)
print("corsssize:",cross_points.size)
print(parent[cross_points])
print(pop[i_, cross_points])
parent[cross_points] = pop[i_, cross_points] # mating and produce one child
print(parent[cross_points])
return parent
#变异
def mutate(child):
for point in range(DNA_SIZE):
if np.random.rand() < MUTATION_RATE:
child[point] = 1 if child[point] == 0 else 0
return child
pop = np.random.randint(2, size=(POP_SIZE, DNA_SIZE)) # initialize the pop DNA
plt.ion() # something about plotting
x = np.linspace(*X_BOUND, 200)
plt.plot(x, F(x))
for _ in range(N_GENERATIONS):
F_values = F(translateDNA(pop)) # compute function value by extracting DNA
# something about plotting
# if 'sca' in globals():
# sca.remove()
# sca = plt.scatter(translateDNA(pop), F_values, s=200, lw=0, c='red', alpha=0.5)
# plt.pause(0.05)
# GA part (evolution)
fitness = get_fitness(F_values)
print("Most fitted DNA: ", pop[np.argmax(fitness), :])
pop = select(pop, fitness)
pop_copy = pop.copy()
for parent in pop:
child = crossover(parent, pop_copy)
child = mutate(child)
parent[:] = child # parent is replaced by its child
plt.scatter(translateDNA(pop), F_values, s=200, lw=0, c='red', alpha=0.5)
print("x:",translateDNA(pop))
print(type(translateDNA(pop)))
print(len(translateDNA(pop)))
print("max:",F_values)
plt.ioff()
plt.show()最后我们可以展示一个结果,注意这个看似只有一个红点,其实这是100个种群个体集中得到的结果。,所以你最后打印的时候是一个100个解构成的1×100的解向量,最终都集中到了这个极值附近。
-
轮盘赌说的很复杂其实在python的random函数里可以说是封装好了,这里我们可以着重看看这个choice函数-np.random.choice(a, size=None, replace=True, p=None)
+a表示我们需要选取的数组。size表示我们需要提取的数据个数。replace代表的意思是抽样之后还放不放回去,如果是False的话,抽取不放回,如果是True的话, 抽取放回。p表示的就是概率数组,代表每一个数被抽取出来的概率。
在我们代码中是写的最后我们可以展示一个结果,注意这个看似只有一个红点,其实这是100个种群个体集中得到的结果。,所以你最后打印的时候是一个100个解构成的1×100的解向量,最终都集中到了这个极值附近。
轮盘赌说的很复杂其实在python的random函数里可以说是封装好了,这里我们可以着重看看这个choice函数np.random.choice(a, size=None, replace=True, p=None)a表示我们需要选取的数组。size表示我们需要提取的数据个数。replace代表的意思是抽样之后还放不放回去,如果是False的话,抽取不放回,如果是True的话, 抽取放回。p表示的就是概率数组,代表每一个数被抽取出来的概率。
在我们代码中是写的-idx = np.random.choice(np.arange(POP_SIZE), size=POP_SIZE, replace=True,p=fitness / fitness.sum())直接就抽取出了种群pop中每个个体的下标编号,这里我们的概率数组是使用的按照比例的适应度分配比例方法提取,而概率是以这种方式来建模计算的。
+
$$P_{i}=\frac{fitness(i)}{\sum_{i=0}^{n}{fitness(i)}}$$直接就抽取出了种群pop中每个个体的下标编号,这里我们的概率数组是使用的按照比例的适应度分配比例方法提取,而概率是以这种方式来建模计算的。
+求解TSP最短路的问题
tsp问题主要就是用户从某一起点出发然后经过所有的点一次并回到起点的最短路径,同时约定任意两点之前是互通可达的,我们要注意的是,可能两点之间的距离有时候是欧式距离,有的时候可能是哈密顿距离,自己要根据题意去判断。
这里我们主要讲解一下他的fitness函数主要是最短路径的总距离,编码序列则是最短路的编号,然后我们要注意这个问题在交叉变异的时候,我们一定要保证他首先是一条正确的可行解!不要出现有顶点重合或缺失的情况。
这里我们在解决交叉的时候是先随机选取一部分父类的基因编号,然后再从母本的DNA序列里面选出子类中缺少的基因,从而获得基因重组。
而变异的时候也不同于例1里面的修改二进制编码,而是采用的调换两个基因序号来完成,从而保证我们的结果一定是一条规范正确的回路。- -import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
N_CITIES = 20 # 城市数量
CROSS_RATE = 0.1 #交叉概率
MUTATE_RATE = 0.02 #变异概率
POP_SIZE = 500 #种群概率
N_GENERATIONS = 500 #迭代次数
class GA(object):
def __init__(self, DNA_size, cross_rate, mutation_rate, pop_size, ):
self.DNA_size = DNA_size
self.cross_rate = cross_rate
self.mutate_rate = mutation_rate
self.pop_size = pop_size
self.pop = np.vstack([np.random.permutation(DNA_size) for _ in range(pop_size)])
def translateDNA(self, DNA, city_position): # get cities' coord in order
line_x = np.empty_like(DNA, dtype=np.float64)
line_y = np.empty_like(DNA, dtype=np.float64)
for i, d in enumerate(DNA):
city_coord = city_position[d]
line_x[i, :] = city_coord[:, 0]
line_y[i, :] = city_coord[:, 1]
return line_x, line_y
def get_fitness(self, line_x, line_y):
total_distance = np.empty((line_x.shape[0],), dtype=np.float64)
for i, (xs, ys) in enumerate(zip(line_x, line_y)):
total_distance[i] = np.sum(np.sqrt(np.square(np.diff(xs)) + np.square(np.diff(ys))))
fitness = np.exp(self.DNA_size * 2 / total_distance)#把欧氏距离的影响扩大化
return fitness, total_distance
def select(self, fitness):
idx = np.random.choice(np.arange(self.pop_size), size=self.pop_size, replace=True, p=fitness / fitness.sum())
return self.pop[idx]
def crossover(self, parent, pop):
if np.random.rand() < self.cross_rate:
i_ = np.random.randint(0, self.pop_size, size=1) # select another individual from pop
cross_points = np.random.randint(0, 2, self.DNA_size).astype(np.bool) # choose crossover points
keep_city = parent[~cross_points] # find the city number
swap_city = pop[i_, np.isin(pop[i_].ravel(), keep_city, invert=True)]
parent[:] = np.concatenate((keep_city, swap_city))
return parent
def mutate(self, child):
for point in range(self.DNA_size):
if np.random.rand() < self.mutate_rate:
swap_point = np.random.randint(0, self.DNA_size)
swapA, swapB = child[point], child[swap_point]
child[point], child[swap_point] = swapB, swapA
return child
def evolve(self, fitness):
pop = self.select(fitness)
pop_copy = pop.copy()
for parent in pop: # for every parent
child = self.crossover(parent, pop_copy)
child = self.mutate(child)
parent[:] = child
self.pop = pop
class TravelSalesPerson(object):
def __init__(self, n_cities):
self.city_position = np.random.rand(n_cities, 2)
plt.ion()
def plotting(self, lx, ly, total_d):
plt.cla()
plt.scatter(self.city_position[:, 0].T, self.city_position[:, 1].T, s=100, c='k')
plt.plot(lx.T, ly.T, 'r-')
plt.text(-0.05, -0.05, "Total distance=%.2f" % total_d, fontdict={'size': 20, 'color': 'red'})
plt.xlim((-0.1, 1.1))
plt.ylim((-0.1, 1.1))
plt.pause(0.01)
ga = GA(DNA_size=N_CITIES, cross_rate=CROSS_RATE, mutation_rate=MUTATE_RATE, pop_size=POP_SIZE)
env = TravelSalesPerson(N_CITIES)
for generation in range(N_GENERATIONS):
lx, ly = ga.translateDNA(ga.pop, env.city_position)#city_position(x,y)
fitness, total_distance = ga.get_fitness(lx, ly)#根据获得的路径计算路程
ga.evolve(fitness)
best_idx = np.argmax(fitness)
print('Gen:', generation, '| best fit: %.2f' % fitness[best_idx],)
# env.plotting(lx[best_idx], ly[best_idx], total_distance[best_idx])
env.plotting(lx[best_idx], ly[best_idx], total_distance[best_idx])
plt.ioff()
plt.show()
+
在最后我附上我学习的这个视频教程吧,多看看知乎csdn还有很多解释。明天我的京东快递《matlab智能算法30个案例分析》就要到了,真的是本好书,顺带一提学校培训真累啊,还啥都不会。
莫烦python遗传算法
@@ -548,7 +543,7 @@
在最后我附上我学习的这个视频教程吧,多看看知乎csdn还有很多解释。明天我的京东快递《matlab智能算法30个案例分析》就要到了,真的是本好书,顺带一提学校培训真累啊,还啥都不会。
莫烦python遗传算法- @@ -556,15 +551,15 @@
- diff --git "a/2020/07/15/\346\250\241\346\213\237\351\200\200\347\201\253matlab\345\256\236\347\216\260\357\274\210TSP\344\270\272\344\276\213\357\274\211/index.html" "b/2020/07/15/\346\250\241\346\213\237\351\200\200\347\201\253matlab\345\256\236\347\216\260\357\274\210TSP\344\270\272\344\276\213\357\274\211/index.html" index 27d5f0a0..2077abc4 100644 --- "a/2020/07/15/\346\250\241\346\213\237\351\200\200\347\201\253matlab\345\256\236\347\216\260\357\274\210TSP\344\270\272\344\276\213\357\274\211/index.html" +++ "b/2020/07/15/\346\250\241\346\213\237\351\200\200\347\201\253matlab\345\256\236\347\216\260\357\274\210TSP\344\270\272\344\276\213\357\274\211/index.html" @@ -213,41 +213,28 @@
最近学习了模拟退火智能算法,顺便学习了一下matlab,顺带一提matlba真香,对矩阵的操作会比python的numpy操作要更加方便,这里我们是以TSP问题为例子,因为比较好理解。
-模拟退火介绍
模拟退火总的来说还是一种优化算法,他模拟的是淬火冶炼的一个过程,通过升温增强分子的热运动,然后再慢慢降温,使其达到稳定的状态。
- -
+
初始解
通常是以一个随机解作为初始解. 并保证理论上能够生成解空间中任意的解,也可以是一个经挑选过的较好的解,初始解不宜“太好”, 否则很难从这个解的邻域跳出,针对问题去分析。
扰动邻解
邻解生成函数应尽可能保证产生的侯选解能够遍布解空间,邻域应尽可能的小,能够在少量循环步中允分探测.,但每次的改变不应该引起太大的变化。
初始温度模拟退火介绍
模拟退火总的来说还是一种优化算法,他模拟的是淬火冶炼的一个过程,通过升温增强分子的热运动,然后再慢慢降温,使其达到稳定的状态。
初始解
通常是以一个随机解作为初始解. 并保证理论上能够生成解空间中任意的解,也可以是一个经挑选过的较好的解,初始解不宜“太好”, 否则很难从这个解的邻域跳出,针对问题去分析。
扰动邻解
邻解生成函数应尽可能保证产生的侯选解能够遍布解空间,邻域应尽可能的小,能够在少量循环步中允分探测.,但每次的改变不应该引起太大的变化。
初始温度- 初始温度应该设置的尽可能的高, 以确保最终解不受初始解
影响. 但过高又会增加计算时间. - 均匀抽样一组状态,以各状态目标值的方差为初温. -
- 如果能确定邻解间目标函数(COST 函数) 的最大差值, 就可以确定出初始温度$T_{0}$,以使初始接受概率$P=e^{-|\Delta C|_{max}/T}$足够大。$|\Delta C|_{max}$ 可由随机产生一组状态的最大目标值差来替代. +
- 如果能确定邻解间目标函数(COST 函数) 的最大差值, 就可以确定出初始温度$T{0}$,以使初始接受概率$P=e^{-|\Delta C|\{max}/T}$足够大。$|\Delta C|_{max}$ 可由随机产生一组状态的最大目标值差来替代.
- 在正式开始退火算法前, 可进行一个升温过程确定初始温度:逐渐增加温度, 直到所有的尝试尝试运动都被接受, 将此时的温度设置为初始温度. -
- 由经验给出, 或通过尝试找到较好的初始温度. -
等温步数
--
+
- 由经验给出, 或通过尝试找到较好的初始温度.
等温步数 - 等温步数也称Metropolis 抽样稳定准则, 用于决定在各温度下产生候选解的数目. 通常取决于解空间和邻域的大小.
- 等温过程是为了让系统达到平衡, 因此可通过检验目标函数的均值是否稳定(或连续若干步的目标值变化较小) 来确定等温步数.
- 等温步数受温度的影响. 高温时, 等温步数可以较小, 温度较小时, 等温步数要大. 随着温度的降低, 增加等温步数. -
- 有时为了考虑方便, 也可直接按一定的步数抽样。 +
- 有时为了考虑方便, 也可直接按一定的步数抽样。
Metropolis法则
Metropolis法则是SA接受新解的概率。 $x$是表示当前解,$x’$是新解,其实这也是模拟退火区别于贪心的一点,我们在更新新解的时候对于不满足条件的情况,我们也有一定的概率来进行选取,从而可以使得退火模拟可以跳出局部最优解。
Metropolis法则
-
Metropolis法则是SA接受新解的概率。
$$P(x=>x’)=
\begin{cases}
1 &\text{$,f(x’)<f(x)$} \\
e^{-\frac{f(x’)-f(x)}{T}} & \text{$,f(x’)>f(x)$}\
\end{cases}
$$
$x$是表示当前解,$x’$是新解,其实这也是模拟退火区别于贪心的一点,我们在更新新解的时候对于不满足条件的情况,我们也有一定的概率来进行选取,从而可以使得退火模拟可以跳出局部最优解。降温公式
-
经典模拟退火算法的降温方式:
$$T(t)=\frac{T_0}{log(1+t)}$$
快速模拟退火算法的降温方式:
$$T(t)=\frac{T_0}{1+t}$$
常用的模拟退火算法的降温方式还有(通常$0.8<\alpha<0.99$)
$$T(t+\Delta t)=\alpha T(t)$$
终止条件自己设定阈值即可。
花费函数COST
这个基本就是分析题目,一般设置为我们需要求解的目标函数最值。TSP问题
已知中国34 个省会城市(包括直辖市) 的经纬度, 要求从北京出发, 游遍34 个城市, 最后回到北京. 用模拟退火算法求最短路径。
-
1.main.m
主函数-clc
clear;
%%
load('china.mat');
plotcities(province, border, city);%画出地图
cityaccount=length(city);%城市数量
dis=distancematrix(city)%距离矩阵
route =randperm(cityaccount);%路径格式
temperature=1000;%初始化温度
cooling_rate=0.95;%温度下降比率
item=1;%用来控制降温的循环记录次数
distance=totaldistance(route,dis);%计算路径总长度
temperature_iterations = 1;
% This is a flag used to plot the current route after 200 iterations
plot_iterations = 1;
plotroute(city, route, distance,temperature);%画出路线
%%
while temperature>1.0 %循环条件
temp_route=change(route,'reverse');%产生扰动。分子序列变化
% fprintf("%d\n",temp_route(1));
temp_distance=totaldistance(temp_route,dis);%产生变化后的长度
dist=temp_distance-distance;%两个路径的差距
if(dist<0)||(rand < exp(-dist/(temperature)))
route=temp_route;
distance=temp_distance;
item=item+1;
temperature_iterations=temperature_iterations+1;
plot_iterations=plot_iterations+1;
end
if temperature_iterations>=10
temperature=cooling_rate*temperature;
temperature_iterations=0;
end
if plot_iterations >= 20
plotroute(city, route, distance,temperature);%画出路线
plot_iterations = 0;
end
% fprintf("it=%d",item);
end2.distance.m
-
计算两点之间的距离-function d = distance(lat1, long1, lat2, long2, R)
% DISTANCE
% d = DISTANCE(lat1, long1, lat2, long2, R) compute distance between points
% on sphere with radians R.
%
% Latitude/Longitude Distance Calculation:
% http://www.mathforum.com/library/drmath/view/51711.html
y1 = lat1/180*pi; x1 = long1/180*pi;
y2 = lat2/180*pi; x2 = long2/180*pi;
dy = y1-y2; dx = x1-x2;
d = 2*R*asin(sqrt(sin(dy/2)^2+sin(dx/2)^2*cos(y1)*cos(y2)));
end3.totaldistance.m
-
一条route路线的总路程,也是我们需要优化的目标函数-function totaldis = totaldistance(route,dis)%传入距离矩阵和当前路线
%TOTALDISTANCE 此处显示有关此函数的摘要
% 此处显示详细说明
% fprintf("%d\n",route(1));
totaldis=dis(route(end),route(1));
% totaldis=dis(route(end),route(1));
for k=1:length(route)-1
totaldis=totaldis+dis(route(k),route(k+1));%直接加两个点之间的距离
end4.distancematrix.m
-
任意两点之间的距离矩阵- -function dis = distancematrix(city)
%DISTANCEMATRIX 此处显示有关此函数的摘要
% 此处显示详细说明
cityacount=length(city);
R=6378.137;%地球半径用于求两个城市的球面距离
for i = 1:cityacount
for j = i+1:cityacount
dis(i,j)=distance(city(i).lat,city(i).long,...
city(j).lat,city(j).long,R);%distance函数原来是设计来计算球面上距离的
dis(j,i)=dis(i,j);%对称,无向图
end
end
end5.change.m
-
产生分子扰动,求当前解的邻解-function route = change(pre_route,method)
%CHANGE 此处显示有关此函数的摘要
% 此处显示详细说明
route=pre_route;
cityaccount=length(route);
%随机取数,相当于把0-34个城市映射到0-1的等概率抽取上,再取整
city1=ceil(cityaccount*rand); % [1, 2, ..., n-1, n]
city2=ceil(cityaccount*rand); % 1<=city1, city2<=n
switch method
case 'reverse' %[1 2 3 4 5 6] -> [1 5 4 3 2 6]
cmin = min(city1,city2);
cmax = max(city1,city2);
route(cmin:cmax) = route(cmax:-1:cmin);%反转某一段
case 'swap' %[1 2 3 4 5 6] -> [1 5 3 4 2 6]
route([city1, city2]) = route([city2, city1]);
end6.plotcities.m
-
画出city-function h = plotcities(province, border, city)
% PLOTCITIES
% h = PLOTCITIES(province, border, city) draw the map of China, and return
% the route handle.
global h;
% draw the map of China
plot(province.long, province.lat, 'color', [0.7,0.7,0.7])
hold on
plot(border.long , border.lat , 'color', [0.5,0.5,0.5], 'linewidth', 1.5);
% plot a NaN route, and global the handle h.
h = plot(NaN, NaN, 'b-', 'linewidth', 1);
% plot cities as green dots
plot([city(2:end).long], [city(2:end).lat], 'o', 'markersize', 3, ...
'MarkerEdgeColor','b','MarkerFaceColor','g');
% plot Beijing as a red pentagram
plot([city(1).long],[city(1).lat],'p','markersize',5, ...
'MarkerEdgeColor','r','MarkerFaceColor','g');
axis([70 140 15 55]);7.plotroute.m
-
画出路线-function plotroute(city, route, current_distance, temperature)
% PLOTROUTE
% PLOTROUTE(city, route, current_distance, temperature) plots the route and
% display current temperautre and distance.
global h;
cycle = route([1:end, 1]);
% update route
set(h,'Xdata',[city(cycle).long],'Ydata',[city(cycle).lat]);
% display current temperature and total distance
xlabel(sprintf('T = %6.1f Total Distance = %6.1f', ...
temperature, current_distance));
drawnow一开始的路径
+
最后运行出来的最优化路径
有需要的朋友可以下载相关的数据集下载链接降温公式
+
经典模拟退火算法的降温方式:快速模拟退火算法的降温方式:
+常用的模拟退火算法的降温方式还有(通常$0.8<\alpha<0.99$)
+终止条件自己设定阈值即可。
+
花费函数COST
这个基本就是分析题目,一般设置为我们需要求解的目标函数最值。TSP问题
已知中国34 个省会城市(包括直辖市) 的经纬度, 要求从北京出发, 游遍34 个城市, 最后回到北京. 用模拟退火算法求最短路径。
+
1.main.m
主函数clc
clear;
%%
load('china.mat');
plotcities(province, border, city);%画出地图
cityaccount=length(city);%城市数量
dis=distancematrix(city)%距离矩阵
route =randperm(cityaccount);%路径格式
temperature=1000;%初始化温度
cooling_rate=0.95;%温度下降比率
item=1;%用来控制降温的循环记录次数
distance=totaldistance(route,dis);%计算路径总长度
temperature_iterations = 1;
% This is a flag used to plot the current route after 200 iterations
plot_iterations = 1;
plotroute(city, route, distance,temperature);%画出路线
%%
while temperature>1.0 %循环条件
temp_route=change(route,'reverse');%产生扰动。分子序列变化
% fprintf("%d\n",temp_route(1));
temp_distance=totaldistance(temp_route,dis);%产生变化后的长度
dist=temp_distance-distance;%两个路径的差距
if(dist<0)||(rand < exp(-dist/(temperature)))
route=temp_route;
distance=temp_distance;
item=item+1;
temperature_iterations=temperature_iterations+1;
plot_iterations=plot_iterations+1;
end
if temperature_iterations>=10
temperature=cooling_rate*temperature;
temperature_iterations=0;
end
if plot_iterations >= 20
plotroute(city, route, distance,temperature);%画出路线
plot_iterations = 0;
end
% fprintf("it=%d",item);
end
2.distance.m
计算两点之间的距离function d = distance(lat1, long1, lat2, long2, R)
% DISTANCE
% d = DISTANCE(lat1, long1, lat2, long2, R) compute distance between points
% on sphere with radians R.
%
% Latitude/Longitude Distance Calculation:
% http://www.mathforum.com/library/drmath/view/51711.html
y1 = lat1/180*pi; x1 = long1/180*pi;
y2 = lat2/180*pi; x2 = long2/180*pi;
dy = y1-y2; dx = x1-x2;
d = 2*R*asin(sqrt(sin(dy/2)^2+sin(dx/2)^2*cos(y1)*cos(y2)));
end
3.totaldistance.m
一条route路线的总路程,也是我们需要优化的目标函数function totaldis = totaldistance(route,dis)%传入距离矩阵和当前路线
%TOTALDISTANCE 此处显示有关此函数的摘要
% 此处显示详细说明
% fprintf("%d\n",route(1));
totaldis=dis(route(end),route(1));
% totaldis=dis(route(end),route(1));
for k=1:length(route)-1
totaldis=totaldis+dis(route(k),route(k+1));%直接加两个点之间的距离
end
4.distancematrix.m
任意两点之间的距离矩阵function dis = distancematrix(city)
%DISTANCEMATRIX 此处显示有关此函数的摘要
% 此处显示详细说明
cityacount=length(city);
R=6378.137;%地球半径用于求两个城市的球面距离
for i = 1:cityacount
for j = i+1:cityacount
dis(i,j)=distance(city(i).lat,city(i).long,...
city(j).lat,city(j).long,R);%distance函数原来是设计来计算球面上距离的
dis(j,i)=dis(i,j);%对称,无向图
end
end
end5.change.m
@@ -552,7 +539,7 @@
产生分子扰动,求当前解的邻解function route = change(pre_route,method)
%CHANGE 此处显示有关此函数的摘要
% 此处显示详细说明
route=pre_route;
cityaccount=length(route);
%随机取数,相当于把0-34个城市映射到0-1的等概率抽取上,再取整
city1=ceil(cityaccount*rand); % [1, 2, ..., n-1, n]
city2=ceil(cityaccount*rand); % 1<=city1, city2<=n
switch method
case 'reverse' %[1 2 3 4 5 6] -> [1 5 4 3 2 6]
cmin = min(city1,city2);
cmax = max(city1,city2);
route(cmin:cmax) = route(cmax:-1:cmin);%反转某一段
case 'swap' %[1 2 3 4 5 6] -> [1 5 3 4 2 6]
route([city1, city2]) = route([city2, city1]);
end
6.plotcities.m
画出cityfunction h = plotcities(province, border, city)
% PLOTCITIES
% h = PLOTCITIES(province, border, city) draw the map of China, and return
% the route handle.
global h;
% draw the map of China
plot(province.long, province.lat, 'color', [0.7,0.7,0.7])
hold on
plot(border.long , border.lat , 'color', [0.5,0.5,0.5], 'linewidth', 1.5);
% plot a NaN route, and global the handle h.
h = plot(NaN, NaN, 'b-', 'linewidth', 1);
% plot cities as green dots
plot([city(2:end).long], [city(2:end).lat], 'o', 'markersize', 3, ...
'MarkerEdgeColor','b','MarkerFaceColor','g');
% plot Beijing as a red pentagram
plot([city(1).long],[city(1).lat],'p','markersize',5, ...
'MarkerEdgeColor','r','MarkerFaceColor','g');
axis([70 140 15 55]);
7.plotroute.m
画出路线function plotroute(city, route, current_distance, temperature)
% PLOTROUTE
% PLOTROUTE(city, route, current_distance, temperature) plots the route and
% display current temperautre and distance.
global h;
cycle = route([1:end, 1]);
% update route
set(h,'Xdata',[city(cycle).long],'Ydata',[city(cycle).lat]);
% display current temperature and total distance
xlabel(sprintf('T = %6.1f Total Distance = %6.1f', ...
temperature, current_distance));
drawnow
一开始的路径
最后运行出来的最优化路径
有需要的朋友可以下载相关的数据集下载链接- diff --git "a/2020/07/16/matlab\347\256\200\345\215\225\345\276\256\345\210\206\346\226\271\347\250\213\346\261\202\350\247\243/index.html" "b/2020/07/16/matlab\347\256\200\345\215\225\345\276\256\345\210\206\346\226\271\347\250\213\346\261\202\350\247\243/index.html" index 043e24a4..51e759ea 100644 --- "a/2020/07/16/matlab\347\256\200\345\215\225\345\276\256\345\210\206\346\226\271\347\250\213\346\261\202\350\247\243/index.html" +++ "b/2020/07/16/matlab\347\256\200\345\215\225\345\276\256\345\210\206\346\226\271\347\250\213\346\261\202\350\247\243/index.html" @@ -221,22 +221,13 @@
-时隔半年,我又重回微分方程的学习了,现在学确实挺难搞的,很多知识和理论思路都忘了,数学还是很重要啊,其实一个蛮简单的东西我看了很久很久才慢慢的又懂了,话不多说,直接写文。
- +
首先要明确的一点就是,我们求微分方程的时候,要注意有解析解和数值解,解析解又有通解和特解,这在我们编写代码的时候可以通过初始点的值来获得特解。其实今天老师讲的还挺不错的,举出了很多的例子,基本上与物理有关,其实要说这一个模块最稳妥的办法其实是如果能够求出通解,一般最好手动进行微分方程的求解,然后用计算机检验,用计算机求微分方程的情况大多数是求数值解。所以说这一部分的话,其实对建模的要求更高,求解我们到时候可以看到matlab调用函数就可以了时隔半年,我又重回微分方程的学习了,现在学确实挺难搞的,很多知识和理论思路都忘了,数学还是很重要啊,其实一个蛮简单的东西我看了很久很久才慢慢的又懂了,话不多说,直接写文。
首先要明确的一点就是,我们求微分方程的时候,要注意有解析解和数值解,解析解又有通解和特解,这在我们编写代码的时候可以通过初始点的值来获得特解。其实今天老师讲的还挺不错的,举出了很多的例子,基本上与物理有关,其实要说这一个模块最稳妥的办法其实是如果能够求出通解,一般最好手动进行微分方程的求解,然后用计算机检验,用计算机求微分方程的情况大多数是求数值解。所以说这一部分的话,其实对建模的要求更高,求解我们到时候可以看到matlab调用函数就可以了dsolve函数的妙用
-求解常微分方程通解
$求微分方程\frac{du}{dx}=1+u^2和x^2+y+(x-2y)y’的通解$
--dsolve('Du=1+u^2','t');
dsolve('x^2+y+(x-2*y)*Dy=0','x');求解常微分方程特解
$求y’’’-y’’=x,y(1)=8,y’(1)=7,y’’(2)=4的特解$
--y=dsolve('D3y-D2y=x','y(1)=8','Dy(1)=7','D2y(2)=4','x');-```
#### 求解微分方程组

```matlab
[x,y,z]=dsolve('Dx=2*x-3*y+3*z','Dy=4*x-5*y+3*z','Dz=4*x-4*y+2*z','t');
x=simplify(x);%化简
y=simplify(y);
z=simplify(z);
+求解常微分方程通解
$求微分方程\frac{du}{dx}=1+u^2和x^2+y+(x-2y)y’的通解$
+dsolve('Du=1+u^2','t');
dsolve('x^2+y+(x-2*y)*Dy=0','x');求解常微分方程特解
$求y’’’-y’’=x,y(1)=8,y’(1)=7,y’’(2)=4的特解$
y=dsolve('D3y-D2y=x','y(1)=8','Dy(1)=7','D2y(2)=4','x');```
#### 求解微分方程组

```matlab
[x,y,z]=dsolve('Dx=2*x-3*y+3*z','Dy=4*x-5*y+3*z','Dz=4*x-4*y+2*z','t');
x=simplify(x);%化简
y=simplify(y);
z=simplify(z);equ1='D2f+3*g=sin(x)';
equ2='Dg+Df=cos(x)';
[general_f,general_g]=dsolve(equ1,equ2,'x'); %通解
[f,g]=dsolve(equ1,equ2,'Df(2)=0,f(3)=3,g(5)=1','x');龙哥库塔求数值解
在介绍龙哥库塔求数值解的时候,我们先要介绍一下这个刚性方程组的定义
-
然后matlab里面提供了几个非常好的解刚性常微分方程的功能函数如ode15s,ode45,ode113,ode23,ode23s,ode23t,ode23tb,
然后在介绍求解的知识之前,我需要先让你对这个过程做一个了解,以至于你写的时候不会觉得很晕,其实很简单的,估计我是忘了老师怎么教的了,看了半天我才慢慢明白。
其实他的思路就是,用当前可以得到的函数值和自变量来导出我们所需要的求得微分变量,如果出现了高阶得情况,则将每一个高阶都逐一替换成导数用函数值表示的公式,前几阶导数完全可以嵌套定义表示出来,可能你还是没用很懂,不过等你看到我下面的分析的时候,你应该就懂了,而且通过我的发现,基本上告诉你几个初始值,一般你就要求多少阶的导数。简单的一阶方程初值问题
-
F2.m-function dy = F2(t,y)
%F2 此处显示有关此函数的摘要
% 此处显示详细说明
dy=-2*y+2*t^2+2*t;
endmain.m
--[T,Y]=ode45('F2',[0,500],[1]);
plot(T,Y(:,1),'-');
+简单的一阶方程初值问题
F2.mfunction dy = F2(t,y)
%F2 此处显示有关此函数的摘要
% 此处显示详细说明
dy=-2*y+2*t^2+2*t;
end
main.m[T,Y]=ode45('F2',[0,500],[1]);
plot(T,Y(:,1),'-');高阶微分方程
做变量替换,转化成多个一阶微分方程
F.m%y1=y
%y2=y1'=y'
%y2'=y''
%y0=2,y1=0
function dy=F(t,y)%虽然这里我们没用上自变量但是这个参数还是要加,毕竟是调库函数所以说还是得按他的规矩
dy=zeros(2,1);
dy(1)=y(2);
dy(2)=1000*(1-y(1)^2)*y(2)-y(1);main.m
@@ -546,7 +537,7 @@- @@ -554,15 +545,15 @@
- diff --git "a/2020/09/09/java\347\232\204String\345\270\270\347\224\250\346\223\215\344\275\234/index.html" "b/2020/09/09/java\347\232\204String\345\270\270\347\224\250\346\223\215\344\275\234/index.html" index 9fa98b7d..845c7b77 100644 --- "a/2020/09/09/java\347\232\204String\345\270\270\347\224\250\346\223\215\344\275\234/index.html" +++ "b/2020/09/09/java\347\232\204String\345\270\270\347\224\250\346\223\215\344\275\234/index.html" @@ -209,17 +209,11 @@
java的String类常用操作
最近在准备蓝桥杯,补题目,顺便也是稍微缓一下暑假自闭,主要还是不想浪费300,顺便回顾一下java的基本语法,java的String类这一块感觉还是挺多操作的,字符串的不可变性也使得其操作和c++存在一些差别。这里需要推荐一个十分好的博客就是廖雪峰的java教程,其实菜鸟教程也不错的。
-Java字符串的一个重要特点就是字符串不可变。这种不可变性是通过内部的
- -private final char[]字段,以及没有任何修改char[]的方法实现的。创建字符串
创建字符串主要是两种常用方法吧,一个是new还有一个就是直接定义,毕竟已经是一个关键字了。
--
public class Main {
public static void main(String[] args) {
String a="hello";
a+="121";//Strin的+操作
char[] helloArray = { 'r', 'u', 'n', 'o', 'o', 'b'};
String helloString = new String(helloArray);
System.out.println(a);
System.out.println(helloString);
}
}当然如果需要对字符串转换成char数组的话也是封装好了函数的
-toCharArray()+public class Main {
public static void main(String[] args) {
str="Hello";
char[] lisc = str.toCharArray();
String s = new String(lisc);
System.out.println(s);
}
}Java字符串的一个重要特点就是字符串不可变。这种不可变性是通过内部的
+private final char[]字段,以及没有任何修改char[]的方法实现的。创建字符串
创建字符串主要是两种常用方法吧,一个是new还有一个就是直接定义,毕竟已经是一个关键字了。
public class Main {
public static void main(String[] args) {
String a="hello";
a+="121";//Strin的+操作
char[] helloArray = { 'r', 'u', 'n', 'o', 'o', 'b'};
String helloString = new String(helloArray);
System.out.println(a);
System.out.println(helloString);
}
}
当然如果需要对字符串转换成char数组的话也是封装好了函数的toCharArray()public class Main {
public static void main(String[] args) {
str="Hello";
char[] lisc = str.toCharArray();
String s = new String(lisc);
System.out.println(s);
}
}String的长度——length()
-public class Main {
public static void main(String[] args) {
String str = "abcde";
int len = str.length();
System.out.println("len="+len);
}
}字符串比较
当我们想要比较两个字符串是否相同时,要特别注意,我们实际上是想比较字符串的内容是否相同。必须使用
equals()方法而不能用==。==比较的是两个变量是否指向同一个字符串对象。可以看一下下面两个结果,有什么不同。-public class Main {
public static void main(String[] args) {
String s1 = "hello";
String s2 = "HELLO".toLowerCase();
System.out.println(s1 == s2);
System.out.println(s1.equals(s2));
}
}这里还有一个用于比较java的字符串方法的
compareTo()方法compareTo()方法用于两种方式的比较:-
@@ -233,16 +227,10 @@
-
@@ -587,15 +565,15 @@
- diff --git "a/2020/09/11/\345\271\266\345\217\221\346\216\247\345\210\266\346\234\272\345\210\266\347\232\204\345\277\205\350\246\201\346\200\247/index.html" "b/2020/09/11/\345\271\266\345\217\221\346\216\247\345\210\266\346\234\272\345\210\266\347\232\204\345\277\205\350\246\201\346\200\247/index.html" index 792669de..907802c4 100644 --- "a/2020/09/11/\345\271\266\345\217\221\346\216\247\345\210\266\346\234\272\345\210\266\347\232\204\345\277\205\350\246\201\346\200\247/index.html" +++ "b/2020/09/11/\345\271\266\345\217\221\346\216\247\345\210\266\346\234\272\345\210\266\347\232\204\345\277\205\350\246\201\346\200\247/index.html" @@ -208,9 +208,7 @@
-Concurrency-control mechanisms并发控制机制的必要性
事务是并发控制的基本单位,保证事务的ACID特性是事务处理的重要任务,而事务的 ACID 特性可能遭到破坏的原因之一是多个事务对数据库的并发操作造成的。为了保证事务的隔离性和一致性,数据库管理系统需要对并发操作进行正确。并发操作带来的数据不一致性包括丢失修改、不可重复读和读“脏”数据。
- -1. 丢失修改(lost update)
+
两个事务T1和T2,读入同一数据并修改,T2,提交的结果破坏了T1提交的结果,导致T的修改被丢失。
2. 不可重复读(non-repeatable read)
不可重复读是指事务T读取数据后,事务T执行更新操作,使T无法再现前一次读取结果。
具体地讲,不可重复读包括三种情况:Concurrency-control mechanisms并发控制机制的必要性
事务是并发控制的基本单位,保证事务的ACID特性是事务处理的重要任务,而事务的 ACID 特性可能遭到破坏的原因之一是多个事务对数据库的并发操作造成的。为了保证事务的隔离性和一致性,数据库管理系统需要对并发操作进行正确。并发操作带来的数据不一致性包括丢失修改、不可重复读和读“脏”数据。
1. 丢失修改(lost update)
两个事务T1和T2,读入同一数据并修改,T2,提交的结果破坏了T1提交的结果,导致T的修改被丢失。
2. 不可重复读(non-repeatable read)
不可重复读是指事务T读取数据后,事务T执行更新操作,使T无法再现前一次读取结果。
具体地讲,不可重复读包括三种情况:- 事务T1读取某一数据后,事务T2对其进行了修改,当事务T1再次读该数据时,得到与前一次不同的值。
- 事务T1按一定条件从数据库中读取了某些数据记录后,事务T2删除了其中部分记录,当T1再次按相同条件读取数据时,发现某些记录神秘地消失了。 @@ -522,7 +520,7 @@
-
diff --git "a/2020/09/13/Business-Intelligence-BI-System\344\273\213\347\273\215/index.html" "b/2020/09/13/Business-Intelligence-BI-System\344\273\213\347\273\215/index.html"
index 17ef25be..01b85d85 100644
--- "a/2020/09/13/Business-Intelligence-BI-System\344\273\213\347\273\215/index.html"
+++ "b/2020/09/13/Business-Intelligence-BI-System\344\273\213\347\273\215/index.html"
@@ -214,8 +214,7 @@ -
Business Intelligence(BI) System介绍
本文内容笔记摘录自王珊和萨师煊的《数据库系统概论》以及网上写的比较好的博客Business Intelligence,商务智能系统的组成,以及百度百科。
- +Business Intelligence(BI) System介绍
本文内容笔记摘录自王珊和萨师煊的《数据库系统概论》以及网上写的比较好的博客Business Intelligence,商务智能系统的组成,以及百度百科。
Business Intelligence System
BI是Business Intelligence的英文缩写,中文解释为商务智能,用来帮助企业更好地利用数据提高决策质量的技术集合,是从大量的数据中钻取信息与知识的过程。
这样不难看出,传统的交易系统完成的是Business到Data的过程,而BI要做的事情是在Data的基础上,让Data产生价值,这个产生价值的过程就是Business Intelligence analyse的过程。
它以数据仓库(Data Warehousing)、在线分析处理(OLAP)、数据挖掘(Data Mining) 3种技术的整合为基础,建立企业数据中心和业务分析模型,以提高企业获取经营分析信息的能力,从而提高企业经营和决策的质量与速度。简单的说就是把交易系统已经发生过的数据,通过ETL工具抽取到主题明确的数据仓库中,OLAP后生成Cube或报表,透过Portal展现给用户,用户利用这些经过分类、聚集、描述和可视化的数据,支持业务决策。
BI不能产生决策,而是利用BI过程处理后的数据来支持决策。那么BI所谓的智能到底是什么呢? BI最终展现给用户的信息就是报表或图视,但它不同于传统的静态报表或图视,它颠覆了传统报表或图视的提供与阅读的方式,有力的保障了用户分析数据时操作的简单性、报表或图视直观性及思维的连惯性。
@@ -542,7 +541,7 @@- diff --git "a/2020/09/21/\350\277\233\347\250\213/index.html" "b/2020/09/21/\350\277\233\347\250\213/index.html" index cfbf5f1c..562a89eb 100644 --- "a/2020/09/21/\350\277\233\347\250\213/index.html" +++ "b/2020/09/21/\350\277\233\347\250\213/index.html" @@ -216,8 +216,7 @@
-进程是支持程序执行的机制,可以理解为程序对数据或请求的处理过程,是一个独立功能的程序关于数据集合的一次运动活动,是操作系统进行资源分配的一个单位。在介绍相关知识之前,首先我们需要了解几个重要概念。
- +
进程实体主要包含PCB,程序段,数据段三个部分构成进程实体又称进程映像。
PCB是指系统为每个运行的程序分配了一个数据结构被称为进程控制块。PCB是进程存在的唯一标志,创建进程和撤销进程实质上都是创建和撤销PCB。
进程实体是静态的指进程三要素存放的数据,而进程是一个动态执行的过程,一般我们不区分进程和进程实体的概念,所以也可以说进程是由PCB,程序段,数据段组成。进程是支持程序执行的机制,可以理解为程序对数据或请求的处理过程,是一个独立功能的程序关于数据集合的一次运动活动,是操作系统进行资源分配的一个单位。在介绍相关知识之前,首先我们需要了解几个重要概念。
进程实体主要包含PCB,程序段,数据段三个部分构成进程实体又称进程映像。
PCB是指系统为每个运行的程序分配了一个数据结构被称为进程控制块。PCB是进程存在的唯一标志,创建进程和撤销进程实质上都是创建和撤销PCB。
进程实体是静态的指进程三要素存放的数据,而进程是一个动态执行的过程,一般我们不区分进程和进程实体的概念,所以也可以说进程是由PCB,程序段,数据段组成。进程状态和控制切换
进程通信
进程通信顾名思义是指进程之间的信息交换,有三种方式,共享存储,消息传递,管道通信。各进程拥有的内存地址空间是独立的,为了保证安全,一个进程是不能直接访问另外一个进程的内存地址的。
@@ -532,7 +531,7 @@- 编译原理 + 数据库系统
- diff --git "a/2020/09/24/htmlcss\345\233\236\351\241\276/index.html" "b/2020/09/24/htmlcss\345\233\236\351\241\276/index.html" index 4cbeff92..aa50ad28 100644 --- "a/2020/09/24/htmlcss\345\233\236\351\241\276/index.html" +++ "b/2020/09/24/htmlcss\345\233\236\351\241\276/index.html" @@ -219,50 +219,51 @@
html回顾
重回前端,文章是记录的MDN Web Doc和绿叶学习网的相关内容笔记。这里不会把基础知识列出来,这里主要是记录一些自己有新体会的东西。
-HTML 不是一门编程语言,而是一种用于定义内容结构的标记语言,超文本标记语言 (英语:Hypertext Markup Language,简称:HTML ) 是一种用来结构化 Web 网页及其内容的标记语言。
浏览器的同源策略
同源策略是一个重要的安全策略,它用于限制一个origin的文档或者它加载的脚本如何能与另一个源的资源进行交互。它能帮助阻隔恶意文档,减少可能被攻击的媒介。
如果两个 URL 的 protocol、port (如果有指定的话)和 host 都相同的话,则这两个 URL 是同源。这个方案也被称为“协议/主机/端口元组”,或者直接是 “元组”。(“元组” 是指一组项目构成的整体,双重/三重/四重/五重/等的通用形式)。
下表给出了与 URL
+http://store.company.com/dir/page.html的源进行对比的示例:
+ + +- -URL -结果 -原因 +URL +结果 +原因 - +http://store.company.com/dir2/other.html同源 -只有路径不同 ++ http://store.company.com/dir2/other.html同源 +只有路径不同 - http://store.company.com/dir/inner/another.html同源 -只有路径不同 +http://store.company.com/dir/inner/another.html同源 +只有路径不同 - https://store.company.com/secure.html失败 -协议不同 +https://store.company.com/secure.html失败 +协议不同 - http://store.company.com:81/dir/etc.html失败 -端口不同 ( http:// 默认端口是80) +http://store.company.com:81/dir/etc.html失败 +端口不同 ( http:// 默认端口是80) - -http://news.company.com/dir/other.html失败 -主机不同 +http://news.company.com/dir/other.html失败 +主机不同 插入图片不推荐方式
<img src="https://www.example.com/images/dinosaur.jpg">这种方式是不被推荐的,这样做只会使浏览器做更多的工作,例如重新通过 DNS 再去寻找 IP 地址。通常我们都会把图片和 HTML 放在同一个服务器上。
-有一个更好的做法是使用 HTML5 的
-<figure>和<figcaption>元素,它正是为此而被创造出来的:为图片提供一个语义容器,在标题和图片之间建立清晰的关联。我们之前的例子可以重写为:- +<figure>
<img src="https://raw.githubusercontent.com/mdn/learning-area/master/html/multimedia-and-embedding/images-in-html/dinosaur_small.jpg"
alt="一只恐龙头部和躯干的骨架,它有一个巨大的头,长着锋利的牙齿。"
width="400"
height="341">
<figcaption>曼彻斯特大学博物馆展出的一只霸王龙的化石</figcaption>
</figure>有一个更好的做法是使用 HTML5 的
<figure>和<figcaption>元素,它正是为此而被创造出来的:为图片提供一个语义容器,在标题和图片之间建立清晰的关联。我们之前的例子可以重写为:<figure>
<img src="https://raw.githubusercontent.com/mdn/learning-area/master/html/multimedia-and-embedding/images-in-html/dinosaur_small.jpg"
alt="一只恐龙头部和躯干的骨架,它有一个巨大的头,长着锋利的牙齿。"
width="400"
height="341">
<figcaption>曼彻斯特大学博物馆展出的一只霸王龙的化石</figcaption>
</figure><input>formenctype属性
由于input元素是一个提交按钮,因此该formenctype属性指定用于向服务器提交表单的内容类型。可能的值为:
- application/x-www-form-urlencoded:如果未指定属性,则为默认值。 @@ -277,148 +278,155 @@
- 独占一行,排斥其他元素跟其位于同一行,包括块元素和行内元素;
- 块元素内部可以容纳其他块元素或行元素;
- 可以与其他行内元素位于同一行;
- 行内内部可以容纳其他行内元素,但不可以容纳块元素,不然会出现无法预知的效果;
元素的id和class
元素的id属性
id属性被赋予了标识页面元素的唯一身份。如果一个页面出现了多个相同id属性取值,CSS选择器或者JavaScript就会因为无法分辨要控制的元素而最终报错。
元素的class属性
如果你要为两个元素或者两个以上元素定义相同的样式,建议使用class属性。
(1)一个标签可以同时定义多个class;
-
(2)id也可以写成name,区别在于name是HTML中的标准,而id是XHTML中的标准,现在网页的标准都是使用id,所以大家尽量不要用name属性;选择器
1.元素选择器
-
2.id选择器
3.class选择器
4.子元素选择器
子元素选择器,就是选中某个元素下的子元素,然后对该子元素设置CSS样式。
5.相邻选择器
相邻选择器,就是选中该元素的下一个兄弟元素,在这里注意一点,相邻选择器的操作对象是该元素的同级元素。
6.群组选择器
群组选择器,就是同时对几个选择器进行相同的操作。
7.全局选择器
全局选择器,是由一个星号(*)代指的,它选中了文档中的所有内容(或者是父元素中的所有内容,比如,它紧随在其他元素以及邻代运算符之后的时候)下面的示例中,我们已经用全局选择器,移去了所有元素上的外边距-* {
margin: 0;
}一些新用法
+选择器
1.元素选择器
2.id选择器
3.class选择器
4.子元素选择器
子元素选择器,就是选中某个元素下的子元素,然后对该子元素设置CSS样式。
5.相邻选择器
相邻选择器,就是选中该元素的下一个兄弟元素,在这里注意一点,相邻选择器的操作对象是该元素的同级元素。
6.群组选择器
群组选择器,就是同时对几个选择器进行相同的操作。
7.全局选择器
全局选择器,是由一个星号(*)代指的,它选中了文档中的所有内容(或者是父元素中的所有内容,比如,它紧随在其他元素以及邻代运算符之后的时候)下面的示例中,我们已经用全局选择器,移去了所有元素上的外边距* {
margin: 0;
}
一些新用法::before和::after
::before和::after伪元素与content属性的共同使用,在CSS中被叫做“生成内容”text-align属性
在CSS中,使用text-align属性控制文本的水平方向的对齐方式:左对齐、居中对齐、右对齐。
text-align属性不仅对文本文字有效,对img标签也有效,但是对其他标签无效。
+
+ + +- -text-align属性值 -说明 +text-align属性值 +说明 - +left -默认值,左对齐 ++ left +默认值,左对齐 - center -居中对齐 +center +居中对齐 - -right -右对齐 +right +右对齐 块元素和行内元素
1、HTML元素根据浏览器表现形式分为两类:块元素,行内元素;
2、块元素特点:
+
+ + +- -块元素 -说明 +块元素 +说明 - +div -div层 -- h1~h6 -1到6级标题 +div +div层 - p 段落 -会自动在其前后创建一些空白 +h1~h6 +1到6级标题 - hr -分割线 +p 段落 +会自动在其前后创建一些空白 - ol -有序列表 +hr +分割线 - ul -无序列表 +ol +有序列表 - -3、行内元素特点: -+ ul +无序列表 3、行内元素特点:
+
-- -行内元素 -说明 +行内元素 +说明 - +strong -加粗强调 ++ strong +加粗强调 - em -斜体强调 +em +斜体强调 - s -删除线 +s +删除线 - u -下划线 +u +下划线 - a -超链接 +a +超链接 - span -常用行级,可定义文档中的行内元素 +span +常用行级,可定义文档中的行内元素 - img -图片 +img +图片 - -input -表单 +input +表单 CSS边框(border)
任何块元素和行内元素都可以设置边框属性。
-
设置一个元素的边框必须要同时设置border-width、border-style、border-color这三个属性,这个元素的边框才能在浏览器显示出来。-border-width:1px;
border-style:solid;
border-color:Red;
/*简介写法*/
border: 1px solid Red;在CSS中,我们可以分别针对上下左右四条边框设置单独的样式。
-- + + +border-top-width:1px;
border-top-style:solid;
border-top-color:red;
/*简介写法*/
border-top: 1px solid Red;
border-bottom: 1px solid Red;
border-left: 1px solid Red;
border-right: 1px solid Red;
/*去除边框的两种方法*/
border-bottom:0px /*去除边框就不需要写颜色和样式了*/
border-bottom:noneCSS边框(border)
任何块元素和行内元素都可以设置边框属性。
设置一个元素的边框必须要同时设置border-width、border-style、border-color这三个属性,这个元素的边框才能在浏览器显示出来。border-width:1px;
border-style:solid;
border-color:Red;
/*简介写法*/
border: 1px solid Red;
在CSS中,我们可以分别针对上下左右四条边框设置单独的样式。border-top-width:1px;
border-top-style:solid;
border-top-color:red;
/*简介写法*/
border-top: 1px solid Red;
border-bottom: 1px solid Red;
border-left: 1px solid Red;
border-right: 1px solid Red;
/*去除边框的两种方法*/
border-bottom:0px /*去除边框就不需要写颜色和样式了*/
border-bottom:nonecss背景样式background
目前,不要再使用HTML的bgcolor之类的属性了,现在几乎全部都是使用CSS的background属性来控制元素的背景颜色和背景图像。
+
1.背景颜色
使用css的background-color属性
2.背景图像
+ + +- -属性 -说明 +属性 +说明 - +background-image -定义背景图像的路径,这样图片才能显示 ++ background-image +定义背景图像的路径,这样图片才能显示 - background-repeat -定义背景图像显示方式,例如纵向平铺、横向平铺 +background-repeat +定义背景图像显示方式,例如纵向平铺、横向平铺 - background-position -定义背景图像在元素哪个位置 +background-position +定义背景图像在元素哪个位置 - -background-attachment -定义背景图像是否随内容而滚动 +background-attachment +定义背景图像是否随内容而滚动 img适合框大小
object-fit属性可以在这里帮助你。当使用object-fit时,替换元素可以以多种方式被调整到合乎盒子的大小。布局样式
主要是通过
@@ -725,7 +733,7 @@display属性来操作,一般有block,inline,inline-block,grid,flex,none这几种操作,具体的使用还是需要多练习才能明白。- 编译原理 + 数据库系统
- diff --git "a/2020/09/26/js\345\237\272\347\241\200\342\200\224\342\200\224\346\225\260\346\215\256\347\261\273\345\236\213\344\270\216\345\237\272\346\234\254\351\200\273\350\276\221\350\257\255\345\217\245/index.html" "b/2020/09/26/js\345\237\272\347\241\200\342\200\224\342\200\224\346\225\260\346\215\256\347\261\273\345\236\213\344\270\216\345\237\272\346\234\254\351\200\273\350\276\221\350\257\255\345\217\245/index.html" index d4629722..532985c5 100644 --- "a/2020/09/26/js\345\237\272\347\241\200\342\200\224\342\200\224\346\225\260\346\215\256\347\261\273\345\236\213\344\270\216\345\237\272\346\234\254\351\200\273\350\276\221\350\257\255\345\217\245/index.html" +++ "b/2020/09/26/js\345\237\272\347\241\200\342\200\224\342\200\224\346\225\260\346\215\256\347\261\273\345\236\213\344\270\216\345\237\272\346\234\254\351\200\273\350\276\221\350\257\255\345\217\245/index.html" @@ -213,8 +213,7 @@
-本文将记录学习JavaScript(包含有ES)语法基础,主要来自MDN的官方文档
- +本文将记录学习JavaScript(包含有ES)语法基础,主要来自MDN的官方文档
语法和数据类型
最新的 ECMAScript 标准定义了8种数据类型:
- 七种基本数据类型: @@ -231,44 +230,26 @@
-
diff --git "a/2020/09/27/js\345\237\272\347\241\200\342\200\224\342\200\224\345\207\275\346\225\260/index.html" "b/2020/09/27/js\345\237\272\347\241\200\342\200\224\342\200\224\345\207\275\346\225\260/index.html"
index bee75e2a..a603a6ab 100644
--- "a/2020/09/27/js\345\237\272\347\241\200\342\200\224\342\200\224\345\207\275\346\225\260/index.html"
+++ "b/2020/09/27/js\345\237\272\347\241\200\342\200\224\342\200\224\345\207\275\346\225\260/index.html"
@@ -209,17 +209,14 @@ -
这一块关于闭包和箭头函数理解还不够,先提交一点记录一下,后期再补
- +这一块关于闭包和箭头函数理解还不够,先提交一点记录一下,后期再补
函数声明
一个函数定义(也称为函数声明,或函数语句)由一系列的function关键字组成,依次为:
- 函数的名称。
- 函数参数列表,包围在括号中并由逗号分隔。
- 定义函数的 JavaScript 语句,用大括号
{}括起来。
当函数参数为基本类型时,则会采用值传递的方式,不会改变变量本身,而当你传递的是一个对象(即一个非原始值,例如
-Array或用户自定义的对象)作为参数的时候,而函数改变了这个对象的属性,这样的改变对函数外部是可见的- +function myFunc(theObject) {
theObject.make = "Toyota";
}
var mycar = {make: "Honda", model: "Accord", year: 1998};
var x, y;
x = mycar.make; // x获取的值为 "Honda"
myFunc(mycar);
y = mycar.make;当函数参数为基本类型时,则会采用值传递的方式,不会改变变量本身,而当你传递的是一个对象(即一个非原始值,例如
Array或用户自定义的对象)作为参数的时候,而函数改变了这个对象的属性,这样的改变对函数外部是可见的function myFunc(theObject) {
theObject.make = "Toyota";
}
var mycar = {make: "Honda", model: "Accord", year: 1998};
var x, y;
x = mycar.make; // x获取的值为 "Honda"
myFunc(mycar);
y = mycar.make;函数表达式——Function expressions
根据MDN的文档描述我大致理解了他所说的函数表达式用法和意义了,其实类似于c语言的函数指针和java匿名函数相结合的这种用法,这种用法的最大好处就是能够将函数作为一个参数或者变量,将其传递给其他的函数使用
箭头函数
箭头函数主要利用的是箭头表达式,箭头函数表达式的语法比函数表达式更简洁,箭头函数表达式更适用于那些本来需要匿名函数的地方,并且它不能用作构造函数。箭头函数两大特点:更简短的函数并且不绑定this。
箭头函数真的很灵活,我暂时还没法完全参透只是了解了一个大概,具体的用法可以去MDN上看官方文档箭头函数闭包
闭包是 JavaScript 中最强大的特性之一。JavaScript 允许函数嵌套,并且内部函数可以访问定义在外部函数中的所有变量和函数,以及外部函数能访问的所有变量和函数。
@@ -531,7 +528,7 @@闭包
- diff --git "a/2020/09/29/SQL\350\257\255\345\217\245\342\200\224\342\200\224\342\200\224\342\200\224\346\225\260\346\215\256\345\256\232\344\271\211/index.html" "b/2020/09/29/SQL\350\257\255\345\217\245\342\200\224\342\200\224\342\200\224\342\200\224\346\225\260\346\215\256\345\256\232\344\271\211/index.html" index 840efb3a..cdb541a8 100644 --- "a/2020/09/29/SQL\350\257\255\345\217\245\342\200\224\342\200\224\342\200\224\342\200\224\346\225\260\346\215\256\345\256\232\344\271\211/index.html" +++ "b/2020/09/29/SQL\350\257\255\345\217\245\342\200\224\342\200\224\342\200\224\342\200\224\346\225\260\346\215\256\345\256\232\344\271\211/index.html" @@ -208,11 +208,8 @@
-SQL又称结构化查询语句(Structed Query Language)是关系数据库的标准语言,也是一个通用的,功能极强的关系数据库语言。
- -
SQL集数据查询、数据操纵、数据定义、数据控制功能于一体。
目前没有一个数据库系统能支持SQL标准的所有概念和特性。但同时许多软件厂商对SQL基本命令集还进行了不同程度的扩充和修改,又可以支持标准以外的一些功能特性。定义模式
在SQL中,模式定义语句如下:
--CREATE SCHEMA <模式名> AUTHORIZATION <用户名>如果没有指定<模式名>,那么<模式名>隐含为<用户名>
+
要创建模式,调用该命令的用户名必需拥有数据库管理员权限,或者获得了数据库管理员授权的CREATE SCHEMA的权限。SQL又称结构化查询语句(Structed Query Language)是关系数据库的标准语言,也是一个通用的,功能极强的关系数据库语言。
+
SQL集数据查询、数据操纵、数据定义、数据控制功能于一体。
目前没有一个数据库系统能支持SQL标准的所有概念和特性。但同时许多软件厂商对SQL基本命令集还进行了不同程度的扩充和修改,又可以支持标准以外的一些功能特性。定义模式
在SQL中,模式定义语句如下:
CREATE SCHEMA <模式名> AUTHORIZATION <用户名>
如果没有指定<模式名>,那么<模式名>隐含为<用户名>
要创建模式,调用该命令的用户名必需拥有数据库管理员权限,或者获得了数据库管理员授权的CREATE SCHEMA的权限。删除模式
DROP SCHEMA <模式名> <CASCADE|RESTRICT>其中CASCADE|RESTRICT必须二选一,两者有不同的作用。
-
@@ -220,10 +217,7 @@
-
diff --git "a/2020/09/29/js\345\237\272\347\241\200\342\200\224\342\200\224\346\225\260\347\273\204\345\257\271\350\261\241-Array-object/index.html" "b/2020/09/29/js\345\237\272\347\241\200\342\200\224\342\200\224\346\225\260\347\273\204\345\257\271\350\261\241-Array-object/index.html"
index 4de4aac2..9c007ca5 100644
--- "a/2020/09/29/js\345\237\272\347\241\200\342\200\224\342\200\224\346\225\260\347\273\204\345\257\271\350\261\241-Array-object/index.html"
+++ "b/2020/09/29/js\345\237\272\347\241\200\342\200\224\342\200\224\346\225\260\347\273\204\345\257\271\350\261\241-Array-object/index.html"
@@ -211,43 +211,22 @@ -
这次要介绍的是js的数组对象,其实在js里面他本质上是一种object对象(他的原型),创建和使用方法和python有点类似,最重要的一点数组里面的数据类型可以是各种类型。
- -创建数组对象
使用
-Array()的方式或者直接用[]来创建一个数组。- -var arr = new Array(element0, element1, ..., elementN);
var arr = Array(element0, element1, ..., elementN);
var arr = [element0, element1, ..., elementN];
// 译者注: var arr=[4] 和 var arr=new Array(4)是不等效的,
// 后者4指数组长度,所以使用字面值(literal)的方式应该不仅仅是便捷,同时也不易踩坑为了创建一个长度不为0,但是又没有任何元素的数组,可选以下任何一种方式:
-- -var arr = new Array(arrayLength);
var arr = Array(arrayLength);
// 这样有同样的效果
var arr = [];
arr.length = arrayLength;这里还有一些特殊情况需要进行说明
--let a=[,"12",,3];//这样的数组也是成立的,这种逗号法省略的部分为undefined
let b=[1,2,,];//这里数组最后一个逗号是忽略的,也就是这里只有一个undefined结果测试:
-填充数组
可以使用类似赋值操作的方法来填充元素,如果你在以上代码中给数组操作符的是一个非整形数值,那么将作为一个代表数组的对象的属性(property)创建,而非作为数组的元素。
-- +var emp = [];
emp[0] = "Casey Jones";
emp[1] = "Phil Lesh";
emp[2] = "August West";这次要介绍的是js的数组对象,其实在js里面他本质上是一种object对象(他的原型),创建和使用方法和python有点类似,最重要的一点数组里面的数据类型可以是各种类型。
+创建数组对象
使用
+Array()的方式或者直接用[]来创建一个数组。var arr = new Array(element0, element1, ..., elementN);
var arr = Array(element0, element1, ..., elementN);
var arr = [element0, element1, ..., elementN];
// 译者注: var arr=[4] 和 var arr=new Array(4)是不等效的,
// 后者4指数组长度,所以使用字面值(literal)的方式应该不仅仅是便捷,同时也不易踩坑为了创建一个长度不为0,但是又没有任何元素的数组,可选以下任何一种方式:
+var arr = new Array(arrayLength);
var arr = Array(arrayLength);
// 这样有同样的效果
var arr = [];
arr.length = arrayLength;这里还有一些特殊情况需要进行说明
+let a=[,"12",,3];//这样的数组也是成立的,这种逗号法省略的部分为undefined
let b=[1,2,,];//这里数组最后一个逗号是忽略的,也就是这里只有一个undefined
结果测试:填充数组
可以使用类似赋值操作的方法来填充元素,如果你在以上代码中给数组操作符的是一个非整形数值,那么将作为一个代表数组的对象的属性(property)创建,而非作为数组的元素。
var emp = [];
emp[0] = "Casey Jones";
emp[1] = "Phil Lesh";
emp[2] = "August West";数组方法
关于数组的方法其实很多,这里我们不会一一详细介绍,大概就给一些常用的函数。
-concat()连接两个数组并返回一个新的数组。join(deliminator = ',')将数组的所有元素连接成一个字符串。push()在数组末尾添加一个或多个元素,并返回数组操作后的长度。sort()给数组元素排序。pop()从数组移出最后一个元素,并返回该元素。slice(start_index, upto_index)从数组提取一个片段,并作为一个新数组返回。
-map(callback[, thisObject])在数组的每个单元项上执行callback函数,并把返回包含回调函数返回值的新数组(译者注:也就是遍历数组,并通过callback对数组元素进行操作,并将所有操作结果放入数组中并返回该数组)。- - -var a1 = ['a', 'b', 'c'];
var a2 = a1.map(function(item) { return item.toUpperCase(); });
console.log(a2); // logs A,B,C
-filter(callback[, thisObject])返回一个包含所有在回调函数上返回为true的元素的新数组(译者注:callback在这里担任的是过滤器的角色,当元素符合条件,过滤器就返回true,而filter则会返回所有符合过滤条件的元素)。- - -var a1 = ['a', 10, 'b', 20, 'c', 30];
var a2 = a1.filter(function(item) { return typeof item == 'number'; });
console.log(a2); // logs 10,20,30
-every(callback[, thisObject])当数组中每一个元素在callback上被返回true时就返回true(译者注:同上,every其实类似filter,只不过它的功能是判断是不是数组中的所有元素都符合条件,并且返回的是布尔值)。- -function isNumber(value){
return typeof value == 'number';
}
var a1 = [1, 2, 3];
console.log(a1.every(isNumber)); // logs true
var a2 = [1, '2', 3];
console.log(a2.every(isNumber)); // logs false
-some(callback[, thisObject])只要数组中有一项在callback上被返回true,就返回true(译者注:同上,类似every,不过前者要求都符合筛选条件才返回true,后者只要有符合条件的就返回true)。- +function isNumber(value){
return typeof value == 'number';
}
var a1 = [1, 2, 3];
console.log(a1.some(isNumber)); // logs true
var a2 = [1, '2', 3];
console.log(a2.some(isNumber)); // logs true
var a3 = ['1', '2', '3'];
console.log(a3.some(isNumber)); // logs false
+map(callback[, thisObject])在数组的每个单元项上执行callback函数,并把返回包含回调函数返回值的新数组(译者注:也就是遍历数组,并通过callback对数组元素进行操作,并将所有操作结果放入数组中并返回该数组)。var a1 = ['a', 'b', 'c'];
var a2 = a1.map(function(item) { return item.toUpperCase(); });
console.log(a2); // logs A,B,C
+filter(callback[, thisObject])返回一个包含所有在回调函数上返回为true的元素的新数组(译者注:callback在这里担任的是过滤器的角色,当元素符合条件,过滤器就返回true,而filter则会返回所有符合过滤条件的元素)。var a1 = ['a', 10, 'b', 20, 'c', 30];
var a2 = a1.filter(function(item) { return typeof item == 'number'; });
console.log(a2); // logs 10,20,30
+every(callback[, thisObject])当数组中每一个元素在callback上被返回true时就返回true(译者注:同上,every其实类似filter,只不过它的功能是判断是不是数组中的所有元素都符合条件,并且返回的是布尔值)。function isNumber(value){
return typeof value == 'number';
}
var a1 = [1, 2, 3];
console.log(a1.every(isNumber)); // logs true
var a2 = [1, '2', 3];
console.log(a2.every(isNumber)); // logs falsesome(callback[, thisObject])只要数组中有一项在callback上被返回true,就返回true(译者注:同上,类似every,不过前者要求都符合筛选条件才返回true,后者只要有符合条件的就返回true)。function isNumber(value){
return typeof value == 'number';
}
var a1 = [1, 2, 3];
console.log(a1.some(isNumber)); // logs true
var a2 = [1, '2', 3];
console.log(a2.some(isNumber)); // logs true
var a3 = ['1', '2', '3'];
console.log(a3.some(isNumber)); // logs false数组推导式
这个其实有点类似于python里面的列表推导式或者列表条件筛选操作,主要还是对上面的map()和filter()做了一些改进吧,让他的使用更方便了。
-var numbers = [1, 2, 3, 4];
var doubled = [for (i of numbers) i * 2];
console.log(doubled); // logs 2,4,6,8这种方法等价于map函数
-- +var doubled = numbers.map(fuction(i){return i*2};);这种方法等价于map函数
var doubled = numbers.map(fuction(i){return i*2};);-var numbers = [1, 2, 3, 21, 22, 30];
var evens = [i for (i of numbers) if (i % 2 === 0)];
console.log(evens); // logs 2,22,30这种方法等价于filter函数
-+var events=numbers.filter(fuction(i){return i%2==0;});这种方法等价于filter函数
+ @@ -555,7 +534,7 @@var events=numbers.filter(fuction(i){return i%2==0;});- 编译原理 + 数据库系统
- diff --git "a/2020/10/02/js\345\237\272\347\241\200\342\200\224\342\200\224\345\205\263\344\272\216\345\257\271\350\261\241/index.html" "b/2020/10/02/js\345\237\272\347\241\200\342\200\224\342\200\224\345\205\263\344\272\216\345\257\271\350\261\241/index.html" index a3c30249..3599d705 100644 --- "a/2020/10/02/js\345\237\272\347\241\200\342\200\224\342\200\224\345\205\263\344\272\216\345\257\271\350\261\241/index.html" +++ "b/2020/10/02/js\345\237\272\347\241\200\342\200\224\342\200\224\345\205\263\344\272\216\345\257\271\350\261\241/index.html" @@ -209,9 +209,7 @@
-对象与属性
同其他语言里面所描述的对象一样,在js里,一个对象就是一系列属性的集合,一个属性包含一个名和一个值。一个属性的值可以是函数,这种情况下属性也被称为方法。一个对象的属性可以被解释成一个附加到对象上的变量。对象有时也被叫作关联数组, 因为每个属性都有一个用于访问它的字符串值。
- -属性的访问设置与修改主要是通过两种手段实现,一种是通过点号对变量进行调用,一种是通过方括号的方式访问,其中通过方括号的方式是一种动态判定法(属性名只有到运行时才能判定)。
+对象与属性
同其他语言里面所描述的对象一样,在js里,一个对象就是一系列属性的集合,一个属性包含一个名和一个值。一个属性的值可以是函数,这种情况下属性也被称为方法。一个对象的属性可以被解释成一个附加到对象上的变量。对象有时也被叫作关联数组, 因为每个属性都有一个用于访问它的字符串值。
属性的访问设置与修改主要是通过两种手段实现,一种是通过点号对变量进行调用,一种是通过方括号的方式访问,其中通过方括号的方式是一种动态判定法(属性名只有到运行时才能判定)。一个对象的属性名可以是任何有效的 JavaScript 字符串,或者可以被转换为字符串的任何类型,包括空字符串。然而,一个属性的名称如果不是一个有效的 JavaScript 标识符(例如,一个由空格或连字符,或者以数字开头的属性名),就只能通过方括号标记访问。
方括号中的所有键都将转换为字符串类型,因为JavaScript中的对象只能使用
String类型作为键类型,如果是object类型的话,也可以通过方括号直接添加属性,不过他添加属性的时候会调用toString()方法,并将其作为新的key值。你可以在
@@ -222,30 +220,18 @@for...in语句中使用方括号标记以枚举一个对象的所有属性创建新对象
JavaScript 拥有一系列预定义的对象,当然我们也可以自己创建对象,从 JavaScript 1.2 之后,你可以通过对象初始化器(Object Initializer)创建对象。或者你可以创建一个构造函数并使用该函数和
-new操作符初始化对象。使用对象初始化器
使用对象初始化器也被称作通过字面值创建对象,通过对象初始化器创建对象的语法如下:
--var obj = { property_1: value_1, // property_# 可以是一个标识符...
2: value_2, // 或一个数字...
["property" +3]: value_3, // 或一个可计算的key名...
// ...,
"property n": value_n }; // 或一个字符串这里
-obj是新对象的名称,每一个property_i是一个标识符(可以是一个名称、数字或字符串字面量),并且每个value_i是一个其值将被赋予property_i的表达式。obj 与赋值是可选的;- +var myHonda = {color: "red", wheels: 4, engine: {cylinders: 4, size: 2.2}};//这里面的engine也是一个对象使用对象初始化器
使用对象初始化器也被称作通过字面值创建对象,通过对象初始化器创建对象的语法如下:
var obj = { property_1: value_1, // property_# 可以是一个标识符...
2: value_2, // 或一个数字...
["property" +3]: value_3, // 或一个可计算的key名...
// ...,
"property n": value_n }; // 或一个字符串
这里obj是新对象的名称,每一个property_i是一个标识符(可以是一个名称、数字或字符串字面量),并且每个value_i是一个其值将被赋予property_i的表达式。obj 与赋值是可选的;var myHonda = {color: "red", wheels: 4, engine: {cylinders: 4, size: 2.2}};//这里面的engine也是一个对象使用构造函数
使用构造函数实例化对象的过程分为两步:
- 通过创建一个构造函数来定义对象的类型。首字母大写是非常普遍而且很恰当的惯用法。
- 通过
new创建对象实例。
使用 Object.create 方法
对象也可以用
-Object.create()方法创建。该方法非常有用,因为它允许你为创建的对象选择一个原型对象,而不用定义构造函数。- +// Animal properties and method encapsulation
var Animal = {
type: "Invertebrates", // 属性默认值
displayType : function() { // 用于显示type属性的方法
console.log(this.type);
}
}
// 创建一种新的动物——animal1
var animal1 = Object.create(Animal);
animal1.displayType(); // Output:Invertebrates
// 创建一种新的动物——Fishes
var fish = Object.create(Animal);
fish.type = "Fishes";
fish.displayType(); // Output:Fishes使用 Object.create 方法
对象也可以用
Object.create()方法创建。该方法非常有用,因为它允许你为创建的对象选择一个原型对象,而不用定义构造函数。// Animal properties and method encapsulation
var Animal = {
type: "Invertebrates", // 属性默认值
displayType : function() { // 用于显示type属性的方法
console.log(this.type);
}
}
// 创建一种新的动物——animal1
var animal1 = Object.create(Animal);
animal1.displayType(); // Output:Invertebrates
// 创建一种新的动物——Fishes
var fish = Object.create(Animal);
fish.type = "Fishes";
fish.displayType(); // Output:Fishes继承
所有的 JavaScript 对象至少继承于一个对象。被继承的对象被称作原型,并且继承的属性可通过构造函数的
-prototype对象找到。为对象类型定义属性
你可以通过 prototype 属性为之前定义的对象类型增加属性。这为该类型的所有对象,而不是仅仅一个对象增加了一个属性。下面的代码为所有类型为 car 的对象增加了 color 属性,然后为对象 car1 的 color 属性赋值:
-- +Car.prototype.color = null;
car1.color = "black";为对象类型定义属性
你可以通过 prototype 属性为之前定义的对象类型增加属性。这为该类型的所有对象,而不是仅仅一个对象增加了一个属性。下面的代码为所有类型为 car 的对象增加了 color 属性,然后为对象 car1 的 color 属性赋值:
Car.prototype.color = null;
car1.color = "black";通过 this 引用对象
avaScript 有一个特殊的关键字 this,它可以在方法中使用以指代当前对象。
-删除属性
你可以用
-delete操作符删除一个不是继承而来的属性。下面的例子说明如何删除一个属性:- -//Creates a new object, myobj, with two properties, a and b.
var myobj = new Object;
myobj.a = 5;
myobj.b = 12;
//Removes the a property, leaving myobj with only the b property.
delete myobj.a;比较对象
在 JavaScript 中 objects 是一种引用类型。两个独立声明的对象永远也不会相等,即使他们有相同的属性,只有在比较一个对象和这个对象的引用时,才会返回true.
-
这边是官方给出的例子-// 两个变量, 两个具有同样的属性、但不相同的对象
var fruit = {name: "apple"};
var fruitbear = {name: "apple"};
fruit == fruitbear // return false
fruit === fruitbear // return false+// 两个变量, 同一个对象
var fruit = {name: "apple"};
var fruitbear = fruit; // 将fruit的对象引用(reference)赋值给 fruitbear
// 也称为将fruitbear“指向”fruit对象
// fruit与fruitbear都指向同样的对象
fruit == fruitbear // return true
fruit === fruitbear // return true删除属性
你可以用
+delete操作符删除一个不是继承而来的属性。下面的例子说明如何删除一个属性://Creates a new object, myobj, with two properties, a and b.
var myobj = new Object;
myobj.a = 5;
myobj.b = 12;
//Removes the a property, leaving myobj with only the b property.
delete myobj.a;比较对象
在 JavaScript 中 objects 是一种引用类型。两个独立声明的对象永远也不会相等,即使他们有相同的属性,只有在比较一个对象和这个对象的引用时,才会返回true.
@@ -554,7 +540,7 @@
这边是官方给出的例子// 两个变量, 两个具有同样的属性、但不相同的对象
var fruit = {name: "apple"};
var fruitbear = {name: "apple"};
fruit == fruitbear // return false
fruit === fruitbear // return false// 两个变量, 同一个对象
var fruit = {name: "apple"};
var fruitbear = fruit; // 将fruit的对象引用(reference)赋值给 fruitbear
// 也称为将fruitbear“指向”fruit对象
// fruit与fruitbear都指向同样的对象
fruit == fruitbear // return true
fruit === fruitbear // return true- 编译原理 + 数据库系统
- diff --git "a/2020/10/02/\347\274\226\350\257\221\345\216\237\347\220\206\347\254\254\344\272\214\347\253\240\342\200\224\342\200\224\346\226\207\346\263\225\345\210\206\347\261\273/index.html" "b/2020/10/02/\347\274\226\350\257\221\345\216\237\347\220\206\347\254\254\344\272\214\347\253\240\342\200\224\342\200\224\346\226\207\346\263\225\345\210\206\347\261\273/index.html" index 21e69d60..702d9052 100644 --- "a/2020/10/02/\347\274\226\350\257\221\345\216\237\347\220\206\347\254\254\344\272\214\347\253\240\342\200\224\342\200\224\346\226\207\346\263\225\345\210\206\347\261\273/index.html" +++ "b/2020/10/02/\347\274\226\350\257\221\345\216\237\347\220\206\347\254\254\344\272\214\347\253\240\342\200\224\342\200\224\346\226\207\346\263\225\345\210\206\347\261\273/index.html" @@ -218,9 +218,7 @@
语言和文法
编译原理第二章文法分类,紫书内容和mooc知识总结,重新回顾了4种文法的知识。
文法分类
乔姆斯基把语言文法分成4类,0型,1型,2型,3型,这几类文法的差别主要在于对产生式的限制不同,等级越高,限制越严格。
-0型文法
0型文法是文法限制最弱的一种类型,0型文法的能力又被相当于图灵机模型,或者说任何0型文法都是递归可枚举的,反之,递归可枚举的一定是一个0型语言。
- -定义:
+
设$G=(V_N,V_T,P,S)$,如果$P$中的每一个产生式$\alpha$->$\beta$满足条件:0型文法
0型文法是文法限制最弱的一种类型,0型文法的能力又被相当于图灵机模型,或者说任何0型文法都是递归可枚举的,反之,递归可枚举的一定是一个0型语言。
定义:
设$G=(V_N,V_T,P,S)$,如果$P$中的每一个产生式$\alpha$->$\beta$满足条件:- $\alpha \in (V_N \cup V_T)^*$且至少含有一个非终结符。
- $\beta \in (V_N \cup V_T)^*$ @@ -543,7 +541,7 @@
-
@@ -551,15 +549,15 @@
- diff --git "a/2020/10/03/\344\270\255\346\226\255\345\274\202\345\270\270\344\270\216\347\263\273\347\273\237\350\260\203\347\224\250/index.html" "b/2020/10/03/\344\270\255\346\226\255\345\274\202\345\270\270\344\270\216\347\263\273\347\273\237\350\260\203\347\224\250/index.html" index 2c5968ad..dd8b744c 100644 --- "a/2020/10/03/\344\270\255\346\226\255\345\274\202\345\270\270\344\270\216\347\263\273\347\273\237\350\260\203\347\224\250/index.html" +++ "b/2020/10/03/\344\270\255\346\226\255\345\274\202\345\270\270\344\270\216\347\263\273\347\273\237\350\260\203\347\224\250/index.html" @@ -215,9 +215,7 @@
通常操作系统提供的主要功能都是由内核程序实现的,处理机在运行上层程序时,能进入操作系统内核运行的唯一途径就是中断或者异常。
-中断和异常基本概念
中断(Interruption):也称外中断,指来自处理机执行指令以外的事件发生。
- -
异常(Exception):也称内中断、例外、自陷(trap),指源自处理机执行指令内部的事件。常见中断类型:
+
中断:I/O中断,时钟中断。
异常:系统调用(具体指系统调用当中的自陷指令),缺页异常,断点指令,其他程序性异常(如:算术溢出)中断和异常基本概念
中断(Interruption):也称外中断,指来自处理机执行指令以外的事件发生。
异常(Exception):也称内中断、例外、自陷(trap),指源自处理机执行指令内部的事件。
常见中断类型:
中断:I/O中断,时钟中断。
异常:系统调用(具体指系统调用当中的自陷指令),缺页异常,断点指令,其他程序性异常(如:算术溢出)中断: 与正执行指令无关,可以屏蔽;
异常: 与正执行指令有关,不可屏蔽中断屏蔽:指禁止处理机响应中断或禁止中断出现.
中断屏蔽有两种方法:
1.硬件实现(由软件置处理机优先级,硬件按系统设计时的约定,屏蔽那些低优先级中断);
2.软件实现(由软件按操作系统优先级约定,设置屏蔽寄存器)。
@@ -545,7 +543,7 @@- 编译原理 + 数据库系统
- diff --git "a/2020/10/03/\346\223\215\344\275\234\347\263\273\347\273\237\347\232\204\350\277\220\350\241\214\346\234\272\345\210\266\345\222\214\344\275\223\347\263\273\347\273\223\346\236\204/index.html" "b/2020/10/03/\346\223\215\344\275\234\347\263\273\347\273\237\347\232\204\350\277\220\350\241\214\346\234\272\345\210\266\345\222\214\344\275\223\347\263\273\347\273\223\346\236\204/index.html" index 2a6329d4..9bf2950e 100644 --- "a/2020/10/03/\346\223\215\344\275\234\347\263\273\347\273\237\347\232\204\350\277\220\350\241\214\346\234\272\345\210\266\345\222\214\344\275\223\347\263\273\347\273\223\346\236\204/index.html" +++ "b/2020/10/03/\346\223\215\344\275\234\347\263\273\347\273\237\347\232\204\350\277\220\350\241\214\346\234\272\345\210\266\345\222\214\344\275\223\347\263\273\347\273\223\346\236\204/index.html" @@ -214,8 +214,7 @@
-操作系统比较硬核,不过最近发现了王道考研这个比较好的课程。这里是一些学习笔记总结。
- +操作系统比较硬核,不过最近发现了王道考研这个比较好的课程。这里是一些学习笔记总结。
主要功能模块
操作系统核心的主要功能模块介绍如下:
系统初始化模块:准备系统运行环境,最后为每个终端创建一个进程,运行命令解释程序。进程管理模块:处理进程类系统调用(如进程创建/结束等)和进程调度。
存储管理模块:配合进程管理,分配进程空间;处理存储类系统调用(如动态增加进程空间);在虚存系统缺页异常时调入页面进行处理。
@@ -232,26 +231,30 @@两种程序
操作系统的内核
内核是计算机上配置的底层软件,是操作系统最基本、最核心的部分。实现操作系统内核功能的那些程序就是内核程序。
+
这里其实还确实了一种,我们常说的操作系统四大模块是指,进程管理,存储管理,设备管理和文件系统管理。
由此引出了我们操作系统的两种内核:大内核和微内核。
+ + +- -大内核 -微内核 +大内核 +微内核 - +将操作系统的主要功能都作为系统内核,运行在核心态 -只把最基本的功能保留 ++ 将操作系统的主要功能都作为系统内核,运行在核心态 +只把最基本的功能保留 - 优点:高性能 -优点:内核功能少,结构清晰,方便维护 +优点:高性能 +优点:内核功能少,结构清晰,方便维护 - -缺点:内核代码庞大,结构混乱,难以维护 -缺点:需要频繁地在用户态和核心态之间切换,性能低 +缺点:内核代码庞大,结构混乱,难以维护 +缺点:需要频繁地在用户态和核心态之间切换,性能低
@@ -557,7 +560,7 @@- 编译原理 + 数据库系统
- diff --git "a/2020/10/13/\344\272\272\344\272\272\351\203\275\346\230\257\344\272\247\345\223\201\347\273\217\347\220\206\350\257\273\345\220\216\346\204\237/index.html" "b/2020/10/13/\344\272\272\344\272\272\351\203\275\346\230\257\344\272\247\345\223\201\347\273\217\347\220\206\350\257\273\345\220\216\346\204\237/index.html" index b0914e7a..9553490a 100644 --- "a/2020/10/13/\344\272\272\344\272\272\351\203\275\346\230\257\344\272\247\345\223\201\347\273\217\347\220\206\350\257\273\345\220\216\346\204\237/index.html" +++ "b/2020/10/13/\344\272\272\344\272\272\351\203\275\346\230\257\344\272\247\345\223\201\347\273\217\347\220\206\350\257\273\345\220\216\346\204\237/index.html" @@ -530,7 +530,7 @@
- @@ -538,15 +538,15 @@
- diff --git "a/2020/11/01/\346\225\260\346\215\256\345\272\223\345\244\215\344\271\240\351\242\230/index.html" "b/2020/11/01/\346\225\260\346\215\256\345\272\223\345\244\215\344\271\240\351\242\230/index.html" index 2219b559..fad586a0 100644 --- "a/2020/11/01/\346\225\260\346\215\256\345\272\223\345\244\215\344\271\240\351\242\230/index.html" +++ "b/2020/11/01/\346\225\260\346\215\256\345\272\223\345\244\215\344\271\240\351\242\230/index.html" @@ -208,55 +208,22 @@
-复习题
Use only the INVENTORY table to answer Review Questions 2.17 through 2.40:
- -2.17 Write an SQL statement to display SKU and SKU_Description.
--SELECT SKU,SKU_Description FROM INVENTORY;2.18 Write an SQL statement to display SKU_Description and SKU.
-- -SELECT SKU_Description,SKU FROM INVENTORY;2.19 Write an SQL statement to display WarehouseID.
-- - -SELECT WarehouseID FROM INVENTORY;2.20 Write an SQL statement to display unique WarehouseIDs.
-- -SELECT DISTINCT WarehouseID FROM INVENTORY;2.26 Write an SQL statement to display the SKU, SKU_Description, and WarehouseID for products that have a QuantityOnHand greater than 0. Sort the results in descending order by WarehouseID and in ascending order by SKU.
-- -SELECT SKU, SKU_Description, WarehouseID
FROM INVENTORY
WHERE QuantityOnHand>0
ORDER BY WarehouseID DESC, SKU ASC;2.29 Write an SQL statement to display the SKU, SKU_Description, WarehouseID, and QuantityOnHand for all products having a QuantityOnHand greater than 1 and less than 10. Do not use the BETWEEN keyword.
-- -SELECT SKU, SKU_Description, WarehouseID, QuantityOnHand
FROM INVENTORY
WHERE QuantityOnHand>1 AND QuantityOnOrder<10;2.36 Write an SQL statement to display the WarehouseID and the sum of QuantityOnHand,grouped by WarehouseID. Name the sum TotalItemsOnHand and display the results in descending order of TotalItemsOnHand.
-- -SELECT WarehouseID , SUM (QuantityOnHand) AS TotalItamsOnHand
FROM INVENTORY
GROUP BY WarehouseID
ORDER BY TotalItemsOnHand DESC;2.37 Write an SQL statement to display the WarehouseID and the sum of QuantityOnHand, grouped by WarehouseID. Omit all SKU items that have 3 or more items on hand from the sum, and name the sum TotalItemsOnHandLT3 and display the results in descending order of TotalItemsOnHandLT3.
-- +SELECT WarehouseID , SUM (QuantityOnHand) AS TotalItamsOnHandLT3
FROM INVENTORY
WHERE QuantityOnHand<3
GROUP BY WarehouseID
ORDER BY TotalItemsOnHandLT3 DESC;复习题
Use only the INVENTORY table to answer Review Questions 2.17 through 2.40:
+
2.17 Write an SQL statement to display SKU and SKU_Description.SELECT SKU,SKU_Description FROM INVENTORY;
2.18 Write an SQL statement to display SKU_Description and SKU.SELECT SKU_Description,SKU FROM INVENTORY;2.19 Write an SQL statement to display WarehouseID.
+SELECT WarehouseID FROM INVENTORY;2.20 Write an SQL statement to display unique WarehouseIDs.
+SELECT DISTINCT WarehouseID FROM INVENTORY;2.26 Write an SQL statement to display the SKU, SKU_Description, and WarehouseID for products that have a QuantityOnHand greater than 0. Sort the results in descending order by WarehouseID and in ascending order by SKU.
+SELECT SKU, SKU_Description, WarehouseID
FROM INVENTORY
WHERE QuantityOnHand>0
ORDER BY WarehouseID DESC, SKU ASC;2.29 Write an SQL statement to display the SKU, SKU_Description, WarehouseID, and QuantityOnHand for all products having a QuantityOnHand greater than 1 and less than 10. Do not use the BETWEEN keyword.
+SELECT SKU, SKU_Description, WarehouseID, QuantityOnHand
FROM INVENTORY
WHERE QuantityOnHand>1 AND QuantityOnOrder<10;2.36 Write an SQL statement to display the WarehouseID and the sum of QuantityOnHand,grouped by WarehouseID. Name the sum TotalItemsOnHand and display the results in descending order of TotalItemsOnHand.
+SELECT WarehouseID , SUM (QuantityOnHand) AS TotalItamsOnHand
FROM INVENTORY
GROUP BY WarehouseID
ORDER BY TotalItemsOnHand DESC;2.37 Write an SQL statement to display the WarehouseID and the sum of QuantityOnHand, grouped by WarehouseID. Omit all SKU items that have 3 or more items on hand from the sum, and name the sum TotalItemsOnHandLT3 and display the results in descending order of TotalItemsOnHandLT3.
SELECT WarehouseID , SUM (QuantityOnHand) AS TotalItamsOnHandLT3
FROM INVENTORY
WHERE QuantityOnHand<3
GROUP BY WarehouseID
ORDER BY TotalItemsOnHandLT3 DESC;2.38 Write an SQL statement to display the WarehouseID and the sum of QuantityOnHand grouped by WarehouseID. Omit all SKU items that have 3 or more items on hand from the sum, and name the sum TotalItemsOnHandLT3. Show WarehouseID only for warehouses having fewer than 2 SKUs in their TotalItemesOnHandLT3 and display the results in descending order of TotalItemsOnHandLT3.
-SELECT WarehouseID , SUM (QuantityOnHand) AS TotalItamsOnHandLT3,
FROM INVENTORY
WHERE QuantityOnHand <3
GROUP BY WarehouseID
HAVING COUNT(*)<2
ORDER BY TotalItemsOnHandLT3 DESC;Use both the INVENTORY and WAREHOUSE tables to answer Review Questions 2.40 through 2.52:
-2.42 Write an SQL statement to display the SKU, SKU_Description, WarehouseID, Ware-houseCity, and WarehouseState of all items not stored in the Atlanta, Bangor, or Chicago warehouse. Do not use the NOT IN keyword.
-- -SELECT SKU, SKU_Description, INVENTORY.WarehouseID, WarehouseCity, WarehouseState
FROM INVENTORY, WAREHOUSE
WHERE INVENTORY.WarehouseID=WAREHOUSE.WarehouseID AND WarehouseCity!='Atlanta' AND WarehouseCity!='Chicago' AND WarehouseCity!='Bangor';2.44 Write an SQL statement to produce a single column called ItemLocation that combines the SKU_Description, the phrase “is in a warehouse in”, and WarehouseCity. Do not be concerned with removing leading or trailing blanks.
-- -SELECT DISTINCT RTRIM(SKU_Description)+ 'is in a warehouse' + RTRIM(WarehouseCity) AS ItemLocation
FROM INVENTORY, WAREHOUSE WHERE INVENTORY.WarehouseID=WAREHOUSE.WarehouseID;2.45 Write an SQL statement to show the SKU, SKU_Description, WarehouseID for all items stored in a warehouse managed by ‘Lucille Smith’. Use a subquery.
-- -SELECT SKU, SKU_Description, WarehouseID
FROM INVENTORY
WHERE WarehouseID IN (SELECT WarehouseID
FROM WAREHOUSE WHERE Manager='Lucille Smith');2.46 Write an SQL statement to show the SKU, SKU_Description, WarehouseID for all items stored in a warehouse managed by ‘Lucille Smith’. Use a join.
-- -SELECT SKU, SKU_Description, INVENTORY.WarehouseID
FROM INVENTORY, WAREHOUSE
WHERE INVENTORY.WarehouseID=WAREHOUSE.WarehouseID AND WAREHOUSE.Manager= 'Lucille Smith';2.50 Write an SQL statement to show the WarehouseID and average QuantityOnHand of all items stored in a warehouse managed by ‘Lucille Smith’. Use a join using JOIN ON syntax.
-- -SELECT INVENTORY.WarehouseID, AVG(QuantityOnHand)
FROM INVENTORY JOIN WAREHOUSE
ON INVENTORY.WarehouseID=WAREHOUSE.WarehouseID
WHERE WAREHOUSE.Manager='Lucille Smith';2.55 Write an SQL statement to join WAREHOUSE and INVENTORY and include all rows of WAREHOUSE in your answer, regardless of whether they have any INVENTORY. Run this statement.
-- - +SELECT *
FROM WAREHOUSE LEFT OUTER JOIN INWENTORY
ON INVENTORY.WarehouseID=WAREHOUSE.WarehouseID;2.42 Write an SQL statement to display the SKU, SKU_Description, WarehouseID, Ware-houseCity, and WarehouseState of all items not stored in the Atlanta, Bangor, or Chicago warehouse. Do not use the NOT IN keyword.
+SELECT SKU, SKU_Description, INVENTORY.WarehouseID, WarehouseCity, WarehouseState
FROM INVENTORY, WAREHOUSE
WHERE INVENTORY.WarehouseID=WAREHOUSE.WarehouseID AND WarehouseCity!='Atlanta' AND WarehouseCity!='Chicago' AND WarehouseCity!='Bangor';2.44 Write an SQL statement to produce a single column called ItemLocation that combines the SKU_Description, the phrase “is in a warehouse in”, and WarehouseCity. Do not be concerned with removing leading or trailing blanks.
+SELECT DISTINCT RTRIM(SKU_Description)+ 'is in a warehouse' + RTRIM(WarehouseCity) AS ItemLocation
FROM INVENTORY, WAREHOUSE WHERE INVENTORY.WarehouseID=WAREHOUSE.WarehouseID;2.45 Write an SQL statement to show the SKU, SKU_Description, WarehouseID for all items stored in a warehouse managed by ‘Lucille Smith’. Use a subquery.
+SELECT SKU, SKU_Description, WarehouseID
FROM INVENTORY
WHERE WarehouseID IN (SELECT WarehouseID
FROM WAREHOUSE WHERE Manager='Lucille Smith');2.46 Write an SQL statement to show the SKU, SKU_Description, WarehouseID for all items stored in a warehouse managed by ‘Lucille Smith’. Use a join.
+SELECT SKU, SKU_Description, INVENTORY.WarehouseID
FROM INVENTORY, WAREHOUSE
WHERE INVENTORY.WarehouseID=WAREHOUSE.WarehouseID AND WAREHOUSE.Manager= 'Lucille Smith';2.50 Write an SQL statement to show the WarehouseID and average QuantityOnHand of all items stored in a warehouse managed by ‘Lucille Smith’. Use a join using JOIN ON syntax.
+SELECT INVENTORY.WarehouseID, AVG(QuantityOnHand)
FROM INVENTORY JOIN WAREHOUSE
ON INVENTORY.WarehouseID=WAREHOUSE.WarehouseID
WHERE WAREHOUSE.Manager='Lucille Smith';2.55 Write an SQL statement to join WAREHOUSE and INVENTORY and include all rows of WAREHOUSE in your answer, regardless of whether they have any INVENTORY. Run this statement.
@@ -561,7 +528,7 @@SELECT *
FROM WAREHOUSE LEFT OUTER JOIN INWENTORY
ON INVENTORY.WarehouseID=WAREHOUSE.WarehouseID;- diff --git "a/2020/11/06/\344\277\241\345\217\267\351\207\217\346\234\272\345\210\266\347\273\217\345\205\270\344\276\213\345\255\220/index.html" "b/2020/11/06/\344\277\241\345\217\267\351\207\217\346\234\272\345\210\266\347\273\217\345\205\270\344\276\213\345\255\220/index.html" index fa343909..e3f83bd7 100644 --- "a/2020/11/06/\344\277\241\345\217\267\351\207\217\346\234\272\345\210\266\347\273\217\345\205\270\344\276\213\345\255\220/index.html" +++ "b/2020/11/06/\344\277\241\345\217\267\351\207\217\346\234\272\345\210\266\347\273\217\345\205\270\344\276\213\345\255\220/index.html" @@ -208,14 +208,9 @@
-理发师问题
7.8 The Sleeping-Barber Problem. A barbershop consists of a waiting room with n chairs and the barber room containing the barber chair. If there are no customers to be served,the barber goes to sleep. If a customer enters the barbershop and all chairs are occupied, then the customer leaves the shop.If the barber is busy but chairs are available, then the customer sits in one of the free chairs. If the barber is asleep, the customer wakes up the barber. Write a program to coordinate the barber and the customers.
- -- +semaphore:
full:=0,empty:=n,mutex:=1;//刘军的写法
/*
*full表示当前需要理发的人数
*empty表示当前还剩下多少空椅子
*mutex进程互斥控制量,理发师一次只能给一个人理发
*/
Parbegin:
customer: repeat
if empty=0:
customer leaves the shop//没有空位置则离开
P(empty);
P(mutex);
add a customer to chair
V(mutex);
V(full);
until false;
barber: repeat
if full=0:
barber sleep;//没有人需要理发则睡觉
P(full);
P(mutex);
cutting hair
V(mutex);
V(empty);
until false;
Parend;理发师问题
7.8 The Sleeping-Barber Problem. A barbershop consists of a waiting room with n chairs and the barber room containing the barber chair. If there are no customers to be served,the barber goes to sleep. If a customer enters the barbershop and all chairs are occupied, then the customer leaves the shop.If the barber is busy but chairs are available, then the customer sits in one of the free chairs. If the barber is asleep, the customer wakes up the barber. Write a program to coordinate the barber and the customers.
semaphore:
full:=0,empty:=n,mutex:=1;//刘军的写法
/*
*full表示当前需要理发的人数
*empty表示当前还剩下多少空椅子
*mutex进程互斥控制量,理发师一次只能给一个人理发
*/
Parbegin:
customer: repeat
if empty=0:
customer leaves the shop//没有空位置则离开
P(empty);
P(mutex);
add a customer to chair
V(mutex);
V(full);
until false;
barber: repeat
if full=0:
barber sleep;//没有人需要理发则睡觉
P(full);
P(mutex);
cutting hair
V(mutex);
V(empty);
until false;
Parend;生产者消费者
-type item=...;
var buffer=...;
full,empty,mutex:semaphore;
nextp,nextc:item;
begin:
full:=0;empty:=n;mutex:=1;
Parbegin:
producer:repeat
...
produce an item in nextp;
...
p(empty);
p(mutex);
add nextp to buffer;
V(mutex);
V(full);
until false;
consumer:repeat
...
p(full);
p(mutex);
remove an item from buffer to nextc;
释放缓冲区
V(mutex);
P(empty);
...
consume the item in nextc;
...
until false;
Parend读者写者
-semaphore mutex:=1,wrt:=1;
int readcount:=0;
Parbegin:
Writer:repeat
P(wrt);
写数据
V(wrt);
Reader:repeat
P(mutex);
readcount:=readcount+1;
if readcount:=1 then P(wrt);
V(mutex);
读数据
P(mutex);
readcount:=readcount-1;
if readcount=0 then V(wrt);
V(mutex);
Parend哲学家问题
@@ -520,7 +515,7 @@semaphore chopstick[5];//初始信号量都为1
第i个进程描述为(i=0,… ,4)
repeat
P(chopstick[i]);
P(chopstick[(i+1) mod 5]);
吃
V(chopstick[i]);
V(Chopstick[(i+1) mod 5];
思考
until false;- 编译原理 + 数据库系统
- diff --git "a/2020/12/21/datawhale-pandas\346\225\260\346\215\256\345\210\206\346\236\220\351\242\204\345\244\207/index.html" "b/2020/12/21/datawhale-pandas\346\225\260\346\215\256\345\210\206\346\236\220\351\242\204\345\244\207/index.html" index a0ec3ce5..3a28268a 100644 --- "a/2020/12/21/datawhale-pandas\346\225\260\346\215\256\345\210\206\346\236\220\351\242\204\345\244\207/index.html" +++ "b/2020/12/21/datawhale-pandas\346\225\260\346\215\256\345\210\206\346\236\220\351\242\204\345\244\207/index.html" @@ -8,12 +8,12 @@
datawhale-pandas数据分析预备 | khan's blog - + - + @@ -214,31 +214,22 @@datawhale-pandas数据分析预备
列表推导式
- -def my_func(x):
return 2*x[* for i in *]
其中,第一个 * 为映射函数,其输入为后面 i 指代的内容,第二个 * 表示迭代的对象。
- - +[ for i in ]
其中,第一个 为映射函数,其输入为后面 i 指代的内容,第二个 表示迭代的对象。
[my_func(i) for i in range(5)]out:[0, 2, 4, 6, 8]
列表表达式支持多层嵌套
[m+'_'+n for m in['a','b'] for n in['c','d']]out:[‘a_c’, ‘a_d’, ‘b_c’, ‘b_d’]
条件赋值
value = a if condition else b :
- -value = 'cat' if 2>1 else 'dog'valueout:’cat’
下面举一个例子,截断列表中超过5的元素,即超过5的用5代替,小于5的保留原来的值:
L=[1,2,3,4,5,6,7]
[i if i<=5 else 5 for i in L]out:[1, 2, 3, 4, 5, 5, 5]
lambda
- -my_func=lambda x:2*xmy_func(2)out:4
- -f2=lambda a,b:a+bf2(1,2)out:3
@@ -251,8 +242,6 @@[ (lambda i:2*i)(x) for x in range(5)]lambda [‘0_a’, ‘1_b’, ‘2_c’, ‘3_d’, ‘4_e’]
zip
zip函数能够把多个可迭代对象打包成一个元组构成的可迭代对象,它返回了一个 zip 对象,通过 tuple, list 可以得到相应的打包结果:
- -L1, L2, L3 = list('abc'), list('def'), list('hij')list(zip(L1, L2, L3))[(‘a’, ‘d’, ‘h’), (‘b’, ‘e’, ‘i’), (‘c’, ‘f’, ‘j’)]
@@ -261,8 +250,6 @@tuple(zip(L1, L2, L3))zip
zip函
a d h
b e i
c f jenumerate
enumerate是一种特殊的打包,它可以在迭代时绑定迭代元素的遍历序号:- -L = list('abcd')for index, value in enumerate(L):
print(index, value)0 a
1 b
2 c
3 d用zip实现这个功能
@@ -274,15 +261,11 @@dict(zip(L1,L2)){‘a’: ‘d’, ‘b’: ‘e’, ‘c’: ‘f’}
- -zipped = list(zip(L1, L2, L3))zipped[(‘a’, ‘d’, ‘h’), (‘b’, ‘e’, ‘i’), (‘c’, ‘f’, ‘j’)]
-list(zip(*zipped))[(‘a’, ‘b’, ‘c’), (‘d’, ‘e’, ‘f’), (‘h’, ‘i’, ‘j’)]
numpy回顾
1. np数组的构造
-import numpy as np最一般的方法是通过 array 来构造:
np.array([1,2,3])array([1, 2, 3])
@@ -307,6 +290,7 @@np.full((2,3), [1,2,3]) # 每行填入相同的列表array([[1, 2, 3],
[1, 2, 3]])随机矩阵:
+np.random代码实现
- -def iou_score(output, target):
'''计算IoU指标'''
intersection = np.logical_and(target, output)
union = np.logical_or(target, output)
return np.sum(intersection) / np.sum(union)
# 生成随机两个矩阵测试
target = np.random.randint(0, 2, (3, 3))
output = np.random.randint(0, 2, (3, 3))
d = iou_score(output, target)
# ----------------------------
target = array([[1, 0, 0],
[0, 1, 1],
[0, 0, 1]])
output = array([[1, 0, 1],
[0, 1, 0],
[0, 0, 0]])
d = 0.44.5 BCE损失函数
BCE损失函数(Binary Cross-Entropy Loss)是交叉熵损失函数(Cross-Entropy Loss)的一种特例,BCE Loss只应用在二分类任务中。针对分类问题,单样本的交叉熵损失为:
+
$$
l(\pmb y, \pmb{\hat y})=- \sum_{i=1}^{c}y_i \cdot log\hat y_i
$$
式中,$\pmb{y}={y_1,y_2,…,y_c,}$,其中$y_i$是非0即1的数字,代表了是否属于第$i$类,为真实值;$\hat y_i$代表属于第i类的概率,为预测值。可以看出,交叉熵损失考虑了多类别情况,针对每一种类别都求了损失。针对二分类问题,上述公式可以改写为:
$$
l(y,\hat y)=-[y \cdot log\hat y +(1-y)\cdot log (1-\hat y)]
$$
式中,$y$为真实值,非1即0;$\hat y$为所属此类的概率值,为预测值。这个公式也就是BCE损失函数,即二分类任务时的交叉熵损失。值得强调的是,公式中的$\hat y$为概率分布形式,因此在使用BCE损失前,都应该将预测出来的结果转变成概率值,一般为sigmoid激活之后的输出。4.5 BCE损失函数
BCE损失函数(Binary Cross-Entropy Loss)是交叉熵损失函数(Cross-Entropy Loss)的一种特例,BCE Loss只应用在二分类任务中。针对分类问题,单样本的交叉熵损失为:
+式中,$\pmb{y}={y_1,y_2,…,y_c,}$,其中$y_i$是非0即1的数字,代表了是否属于第$i$类,为真实值;$\hat y_i$代表属于第i类的概率,为预测值。可以看出,交叉熵损失考虑了多类别情况,针对每一种类别都求了损失。针对二分类问题,上述公式可以改写为:
+式中,$y$为真实值,非1即0;$\hat y$为所属此类的概率值,为预测值。这个公式也就是BCE损失函数,即二分类任务时的交叉熵损失。值得强调的是,公式中的$\hat y$为概率分布形式,因此在使用BCE损失前,都应该将预测出来的结果转变成概率值,一般为sigmoid激活之后的输出。
代码实现
在pytorch中,官方已经给出了BCE损失函数的API,免去了自己编写函数的痛苦:
-
+torch.nn.BCELoss(weight: Optional[torch.Tensor] = None, size_average=None, reduce=None, reduction: str = 'mean')
$$
ℓ(y,\hat y)=L={l_1,…,l_N }^⊤,\ \ \ l_n=-w_n[y_n \cdot log\hat y_n +(1-y_n)\cdot log (1-\hat y_n)]
$$
参数:
weight(Tensor)- 为每一批量下的loss添加一个权重,很少使用
size_average(bool)- 弃用中
reduce(bool)- 弃用中
reduction(str) - ‘none’ | ‘mean’ | ‘sum’:为代替上面的size_average和reduce而生。——为mean时返回的该批量样本loss的平均值;为sum时,返回的该批量样本loss之和
+torch.nn.BCELoss(weight: Optional[torch.Tensor] = None, size_average=None, reduce=None, reduction: str = 'mean')参数:
weight(Tensor)- 为每一批量下的loss添加一个权重,很少使用
size_average(bool)- 弃用中
reduce(bool)- 弃用中
reduction(str) - ‘none’ | ‘mean’ | ‘sum’:为代替上面的size_average和reduce而生。——为mean时返回的该批量样本loss的平均值;为sum时,返回的该批量样本loss之和同时,pytorch还提供了已经结合了Sigmoid函数的BCE损失:
torch.nn.BCEWithLogitsLoss(),相当于免去了实现进行Sigmoid激活的操作。-import torch
import torch.nn as nn
bce = nn.BCELoss()
bce_sig = nn.BCEWithLogitsLoss()
input = torch.randn(5, 1, requires_grad=True)
target = torch.empty(5, 1).random_(2)
pre = nn.Sigmoid()(input)
loss_bce = bce(pre, target)
loss_bce_sig = bce_sig(input, target)
# ------------------------
input = tensor([[-0.2296],
[-0.6389],
[-0.2405],
[ 1.3451],
[ 0.7580]], requires_grad=True)
output = tensor([[1.],
[0.],
[0.],
[1.],
[1.]])
pre = tensor([[0.4428],
[0.3455],
[0.4402],
[0.7933],
[0.6809]], grad_fn=<SigmoidBackward>)
print(loss_bce)
tensor(0.4869, grad_fn=<BinaryCrossEntropyBackward>)
print(loss_bce_sig)
tensor(0.4869, grad_fn=<BinaryCrossEntropyWithLogitsBackward>)4.6 Focal Loss
Focal loss最初是出现在目标检测领域,主要是为了解决正负样本比例失调的问题。那么对于分割任务来说,如果存在数据不均衡的情况,也可以借用focal loss来进行缓解。Focal loss函数公式如下所示:
-$$
+
loss = -\frac{1}{N} \sum_{i=1}^{N}\left(\alpha y_{i}\left(1-p_{i}\right)^{\gamma} \log p_{i}+(1-\alpha)\left(1-y_{i}\right) p_{i}^{\gamma} \log \left(1-p_{i}\right)\right)
$$
仔细观察就不难发现,它其实是BCE扩展而来,对比BCE其实就多了个
$$
\alpha(1-p_{i})^{\gamma}和(1-\alpha)p_{i}^{\gamma}
$$
为什么多了这个就能缓解正负样本不均衡的问题呢?见下图:仔细观察就不难发现,它其实是BCE扩展而来,对比BCE其实就多了个
+为什么多了这个就能缓解正负样本不均衡的问题呢?见下图:
简单来说:$α$解决样本不平衡问题,$γ$解决样本难易问题。
也就是说,当数据不均衡时,可以根据比例设置合适的$α$,这个很好理解,为了能够使得正负样本得到的损失能够均衡,因此对loss前面加上一定的权重,其中负样本数量多,因此占用的权重可以设置的小一点;正样本数量少,就对正样本产生的损失的权重设的高一点。
那γ具体怎么起作用呢?以图中$γ=5$曲线为例,假设$gt$类别为1,当模型预测结果为1的概率$p_t$比较大时,我们认为模型预测的比较准确,也就是说这个样本比较简单。而对于比较简单的样本,我们希望提供的loss小一些而让模型主要学习难一些的样本,也就是$p_t→ 1$则loss接近于0,既不用再特别学习;当分类错误时,$p_t → 0$则loss正常产生,继续学习。对比图中蓝色和绿色曲线,可以看到,γ值越大,当模型预测结果比较准确的时候能提供更小的loss,符合我们为简单样本降低loss的预期。
代码实现:
-import torch.nn as nn
import torch
import torch.nn.functional as F
class FocalLoss(nn.Module):
def __init__(self, alpha=1, gamma=2, logits=False, reduce=True):
super(FocalLoss, self).__init__()
self.alpha = alpha
self.gamma = gamma
self.logits = logits # 如果BEC带logits则损失函数在计算BECloss之前会自动计算softmax/sigmoid将其映射到[0,1]
self.reduce = reduce
def forward(self, inputs, targets):
if self.logits:
BCE_loss = F.binary_cross_entropy_with_logits(inputs, targets, reduce=False)
else:
BCE_loss = F.binary_cross_entropy(inputs, targets, reduce=False)
pt = torch.exp(-BCE_loss)
F_loss = self.alpha * (1-pt)**self.gamma * BCE_loss
if self.reduce:
return torch.mean(F_loss)
else:
return F_loss
# ------------------------
FL1 = FocalLoss(logits=False)
FL2 = FocalLoss(logits=True)
inputs = torch.randn(5, 1, requires_grad=True)
targets = torch.empty(5, 1).random_(2)
pre = nn.Sigmoid()(inputs)
f_loss_1 = FL1(pre, targets)
f_loss_2 = FL2(inputs, targets)
# ------------------------
print('inputs:', inputs)
inputs: tensor([[-1.3521],
[ 0.4975],
[-1.0178],
[-0.3859],
[-0.2923]], requires_grad=True)
print('targets:', targets)
targets: tensor([[1.],
[1.],
[0.],
[1.],
[1.]])
print('pre:', pre)
pre: tensor([[0.2055],
[0.6219],
[0.2655],
[0.4047],
[0.4274]], grad_fn=<SigmoidBackward>)
print('f_loss_1:', f_loss_1)
f_loss_1: tensor(0.3375, grad_fn=<MeanBackward0>)
print('f_loss_2', f_loss_2)
f_loss_2 tensor(0.3375, grad_fn=<MeanBackward0>)4.7 Lovász-Softmax
IoU是评价分割模型分割结果质量的重要指标,因此很自然想到能否用$1-IoU$(即Jaccard loss)来做损失函数,但是它是一个离散的loss,不能直接求导,所以无法直接用来作为损失函数。为了克服这个离散的问题,可以采用lLovász extension将离散的Jaccard loss 变得连续,从而可以直接求导,使得其作为分割网络的loss function。Lovász-Softmax相比于交叉熵函数具有更好的效果。
论文地址:
paper on CVF open access
arxiv paper首先明确定义,在语义分割任务中,给定真实像素标签向量$\pmb{y^*}$和预测像素标签$\pmb{\hat{y} }$,则所属类别$c$的IoU(也称为Jaccard index)如下,其取值范围为$[0,1]$,并规定$0/0=1$:
-$$J_c(\pmb{y^*},\pmb{\hat{y} })=\frac{|{\pmb{y^*}=c} \cap {\pmb{\hat{y} }=c}|}{|{\pmb{y^*}=c} \cup {\pmb{\hat{y} }=c}|}
-
$$则Jaccard loss为:
-
$$\Delta_{J_c}(\pmb{y^*},\pmb{\hat{y} }) =1-J_c(\pmb{y^*},\pmb{\hat{y} })
$$针对类别$c$,所有未被正确预测的像素集合定义为:
-$$
-
M_c(\pmb{y^*},\pmb{\hat{y} })={ \pmb{y^*}=c, \pmb{\hat{y} } \neq c} \cup { \pmb{y^*}\neq c, \pmb{\hat{y} } = c }
$$则可将Jaccard loss改写为关于$M_c$的子模集合函数(submodular set functions):
-
$$\Delta_{J_c}:M_c \in {0,1}^{p} \mapsto \frac{|M_c|}{|{\pmb{y^*}=c}\cup M_c|}
$$方便理解,此处可以把${0,1}^p$理解成如图像mask展开成离散一维向量的形式。
-Lovász extension可以求解子模最小化问题,并且子模的Lovász extension是凸函数,可以高效实现最小化。在论文中作者对$\Delta$(集合函数)和$\overline{\Delta}$(集合函数的Lovász extension)进行了定义,为不涉及过多概念以方便理解,此处不再过多讨论。我们可以将$\overline{\Delta}$理解为一个线性插值函数,可以将${0,1}^p$这种离散向量连续化,主要是为了方便后续反向传播、求梯度等等。因此我们可以通过这个线性插值函数得到$\Delta_{J_c}$的Lovász extension$\overline{\Delta_{J_c} }$。
-在具有$c(c>2)$个类别的语义分割任务中,我们使用Softmax函数将模型的输出映射到概率分布形式,类似传统交叉熵损失函数所进行的操作:
-
$$p_i(c)=\frac{e^{F_i(c)} }{\sum_{c^{‘}\in C}e^{F_i(c^{‘})} } \forall i \in [1,p],\forall c \in C
$$
式中,$p_i(c)$表示了像素$i$所属类别$c$的概率。通过上式可以构建每个像素产生的误差$m(c)$:$$m_i(c)=\left {
-
\begin{array}{c}
1-p_i(c),\ \ if \ \ c=y^{*}_{i} \
p_i(c),\ \ \ \ \ \ \ otherwise
\end{array}
\right.
$$可知,对于一张图像中所有像素则误差向量为$m(c)\in {0, 1}^p$,则可以建立关于$\Delta_{J_c}$的代理损失函数:
-
$$
loss(p(c))=\overline{\Delta_{J_c} }(m(c))
$$
当我们考虑整个数据集是,一般会使用mIoU进行度量,因此我们对上述损失也进行平均化处理,则定义的Lovász-Softmax损失函数为:
$$
loss(\pmb{p})=\frac{1}{|C|}\sum_{c\in C}\overline{\Delta_{J_c} }(m(c))
$$代码实现
+则Jaccard loss为:
+针对类别$c$,所有未被正确预测的像素集合定义为:
+则可将Jaccard loss改写为关于$M_c$的子模集合函数(submodular set functions):
+方便理解,此处可以把${0,1}^p$理解成如图像mask展开成离散一维向量的形式。
+Lovász extension可以求解子模最小化问题,并且子模的Lovász extension是凸函数,可以高效实现最小化。在论文中作者对$\Delta$(集合函数)和$\overline{\Delta}$(集合函数的Lovász extension)进行了定义,为不涉及过多概念以方便理解,此处不再过多讨论。我们可以将$\overline{\Delta}$理解为一个线性插值函数,可以将${0,1}^p$这种离散向量连续化,主要是为了方便后续反向传播、求梯度等等。因此我们可以通过这个线性插值函数得到$\Delta{J_c}$的Lovász extension$\overline{\Delta{J_c} }$。
+在具有$c(c>2)$个类别的语义分割任务中,我们使用Softmax函数将模型的输出映射到概率分布形式,类似传统交叉熵损失函数所进行的操作:
+式中,$p_i(c)$表示了像素$i$所属类别$c$的概率。通过上式可以构建每个像素产生的误差$m(c)$:
+可知,对于一张图像中所有像素则误差向量为$m(c)\in {0, 1}^p$,则可以建立关于$\Delta_{J_c}$的代理损失函数:
+当我们考虑整个数据集是,一般会使用mIoU进行度量,因此我们对上述损失也进行平均化处理,则定义的Lovász-Softmax损失函数为:
+代码实现
论文作者已经给出了Lovász-Softmax实现代码,并且有pytorch和tensorflow两种版本,并提供了使用demo。此处将针对多分类任务的Lovász-Softmax源码进行展示。
-import torch
from torch.autograd import Variable
import torch.nn.functional as F
import numpy as np
try:
from itertools import ifilterfalse
except ImportError: # py3k
from itertools import filterfalse as ifilterfalse
# --------------------------- MULTICLASS LOSSES ---------------------------
def lovasz_softmax(probas, labels, classes='present', per_image=False, ignore=None):
"""
Multi-class Lovasz-Softmax loss
probas: [B, C, H, W] Variable, class probabilities at each prediction (between 0 and 1).
Interpreted as binary (sigmoid) output with outputs of size [B, H, W].
labels: [B, H, W] Tensor, ground truth labels (between 0 and C - 1)
classes: 'all' for all, 'present' for classes present in labels, or a list of classes to average.
per_image: compute the loss per image instead of per batch
ignore: void class labels
"""
if per_image:
loss = mean(lovasz_softmax_flat(*flatten_probas(prob.unsqueeze(0), lab.unsqueeze(0), ignore), classes=classes)
for prob, lab in zip(probas, labels))
else:
loss = lovasz_softmax_flat(*flatten_probas(probas, labels, ignore), classes=classes)
return loss
def lovasz_softmax_flat(probas, labels, classes='present'):
"""
Multi-class Lovasz-Softmax loss
probas: [P, C] Variable, class probabilities at each prediction (between 0 and 1)
labels: [P] Tensor, ground truth labels (between 0 and C - 1)
classes: 'all' for all, 'present' for classes present in labels, or a list of classes to average.
"""
if probas.numel() == 0:
# only void pixels, the gradients should be 0
return probas * 0.
C = probas.size(1)
losses = []
class_to_sum = list(range(C)) if classes in ['all', 'present'] else classes
for c in class_to_sum:
fg = (labels == c).float() # foreground for class c
if (classes is 'present' and fg.sum() == 0):
continue
if C == 1:
if len(classes) > 1:
raise ValueError('Sigmoid output possible only with 1 class')
class_pred = probas[:, 0]
else:
class_pred = probas[:, c]
errors = (Variable(fg) - class_pred).abs()
errors_sorted, perm = torch.sort(errors, 0, descending=True)
perm = perm.data
fg_sorted = fg[perm]
losses.append(torch.dot(errors_sorted, Variable(lovasz_grad(fg_sorted))))
return mean(losses)
def flatten_probas(probas, labels, ignore=None):
"""
Flattens predictions in the batch
"""
if probas.dim() == 3:
# assumes output of a sigmoid layer
B, H, W = probas.size()
probas = probas.view(B, 1, H, W)
B, C, H, W = probas.size()
probas = probas.permute(0, 2, 3, 1).contiguous().view(-1, C) # B * H * W, C = P, C
labels = labels.view(-1)
if ignore is None:
return probas, labels
valid = (labels != ignore)
vprobas = probas[valid.nonzero().squeeze()]
vlabels = labels[valid]
return vprobas, vlabels
def xloss(logits, labels, ignore=None):
"""
Cross entropy loss
"""
return F.cross_entropy(logits, Variable(labels), ignore_index=255)
# --------------------------- HELPER FUNCTIONS ---------------------------
def isnan(x):
return x != x
def mean(l, ignore_nan=False, empty=0):
"""
nanmean compatible with generators.
"""
l = iter(l)
if ignore_nan:
l = ifilterfalse(isnan, l)
try:
n = 1
acc = next(l)
except StopIteration:
if empty == 'raise':
raise ValueError('Empty mean')
return empty
for n, v in enumerate(l, 2):
acc += v
if n == 1:
return acc
return acc / n4.8 参考链接
What is “Dice loss” for image segmentation?
@@ -638,7 +693,7 @@- 编译原理 + 数据库系统
- diff --git "a/2021/02/24/docker\345\256\211\350\243\205\345\222\214\347\256\200\346\230\223\345\216\237\347\220\206/index.html" "b/2021/02/24/docker\345\256\211\350\243\205\345\222\214\347\256\200\346\230\223\345\216\237\347\220\206/index.html" index cafca1dc..2eb9ac32 100644 --- "a/2021/02/24/docker\345\256\211\350\243\205\345\222\214\347\256\200\346\230\223\345\216\237\347\220\206/index.html" +++ "b/2021/02/24/docker\345\256\211\350\243\205\345\222\214\347\256\200\346\230\223\345\216\237\347\220\206/index.html" @@ -222,14 +222,11 @@
docker安装和简易原理
最近参加了阿里云datawhale天池的一个比赛里面需要用docker进行提交,所以借此机会学习了一下docker,b站上有个很好的视频【狂神说Java】Docker最新超详细版教程通俗易懂
docker基本组成
-docker安装
centos7安装
先查看centos版本,新版本的docker都只支持centos7以上-(base) [root@iZuf69rye0flkbn4kbxrobZ ~]# cat /etc/os-release
NAME="CentOS Linux"
VERSION="7 (Core)"
ID="centos"
ID_LIKE="rhel fedora"
VERSION_ID="7"
PRETTY_NAME="CentOS Linux 7 (Core)"
ANSI_COLOR="0;31"
CPE_NAME="cpe:/o:centos:centos:7"
HOME_URL="https://www.centos.org/"
BUG_REPORT_URL="https://bugs.centos.org/"
CENTOS_MANTISBT_PROJECT="CentOS-7"
CENTOS_MANTISBT_PROJECT_VERSION="7"
REDHAT_SUPPORT_PRODUCT="centos"
REDHAT_SUPPORT_PRODUCT_VERSION="7"然后我们的操作均按照帮助文档进行操作即可
dockerCentos安装-# 卸载旧版本
sudo yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
# 安装
sudo yum install -y yum-utils
#配置镜像,官方是国外的很慢,这里我们使用阿里云镜像
sudo yum-config-manager \
--add-repo \
https://download.docker.com/linux/centos/docker-ce.repo
# 推荐使用这个
sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
#更新yum
yum makecache fast
# 安装相关的包
sudo yum install docker-ce docker-ce-cli containerd.ioStart Docker
sudo systemctl start docker使用
docker version查看是否安装成功sudo docker run hello-world使用
@@ -237,10 +234,8 @@docker images查看所安装的所有镜像sudo yum remove docker-ce docker-ce-cli containerd.io2.删除默认工作目录和资源
-$ sudo rm -rf /var/lib/docker阿里云镜像加速器
这一块的话推荐天池的一个docker学习赛
登录阿里云找到容器服务,并创建新容器,然后找到里面的镜像加速器对centos进行配置。-sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://fdm7vcvf.mirror.aliyuncs.com"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker回归Hello World镜像的运行过程
底层原理
Docker是什么工作的?
Docker是一个Client - Server结构的系统,Docker的守护进行运行在主机上。通过Socket从客户端访问!DockerServer接收到Docker-Client的指令,就会执行这个命令!
docker为什么比虚拟机快?
参考链接
@@ -548,7 +543,7 @@- 编译原理 + 数据库系统
- diff --git "a/2021/02/24/docker\345\270\270\347\224\250\345\221\275\344\273\244/index.html" "b/2021/02/24/docker\345\270\270\347\224\250\345\221\275\344\273\244/index.html" index de6f2e8b..1eef5075 100644 --- "a/2021/02/24/docker\345\270\270\347\224\250\345\221\275\344\273\244/index.html" +++ "b/2021/02/24/docker\345\270\270\347\224\250\345\221\275\344\273\244/index.html" @@ -8,12 +8,12 @@
docker常用命令 | khan's blog - + - + @@ -232,65 +232,61 @@Docker 常用命令
帮助命令
-docker version #显示docker版本信息
docker info #显示docker的系统信息,包括镜像和容器的数量
docker 命令 --help # 帮助命令镜像命令
1.
+docker images查看所有本地的主机镜像
+ + +- -docker images显示字段 -解释 +docker images显示字段 +解释 - +REPOSITORY -镜像的仓库源 ++ REPOSITORY +镜像的仓库源 - TAG -镜像的标签 +TAG +镜像的标签 - IMAGE ID -镜像的id +IMAGE ID +镜像的id - CREATED -镜像的创建时间 +CREATED +镜像的创建时间 - -SIZE -镜像的大小 +SIZE +镜像的大小 -(base) [root@iZuf69rye0flkbn4kbxrobZ ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
hello-world latest bf756fb1ae65 13 months ago 13.3kB
(base) [root@iZuf69rye0flkbn4kbxrobZ ~]# docker images --help
Usage: docker images [OPTIONS] [REPOSITORY[:TAG]]
List images
Options:
-a, --all Show all images
-q, --quiet Only show image IDs
2.docker search命令搜索镜像
搜索镜像可以去docker hub网站上直接搜索,也可以通过命令行来搜索,通过万能帮助命令能更快的看到他的一些用法,这两种方法结果是一样的我们也可以通过
--filter来进行条件筛选
比如docker search mysql --filter=STARS=3000-(base) [root@iZuf69rye0flkbn4kbxrobZ ~]# docker search mysql --filter=STARS=3000
NAME DESCRIPTION STARS OFFICIAL AUTOMATED
mysql MySQL is a widely used, open-source relation… 10538 [OK]
mariadb MariaDB is a community-developed fork of MyS… 3935 [OK]3.
docker pull下载镜像
这个命令其实信息量很大,这也是docker高明的地方,关于指定版本下载一定要是docker hub官网上面支持和提供的版本
我这里使用了-docker pull mysql
docker pull mysql:5.7
-
4.docker rmi删除镜像
删除可以通过REPOSITORY来删,也可以通过IMAGE ID来删除容器命令
说明:我们有了镜像才可以创建容器,linux,下载一个centos镜像来测试学习
--docker pull centos1.新建容器并启动
+
通过docker run命令进入下载的centos容器里面后我们可以发现的是,我们的rootname不一样了容器命令
说明:我们有了镜像才可以创建容器,linux,下载一个centos镜像来测试学习
docker pull centos
1.新建容器并启动
通过docker run命令进入下载的centos容器里面后我们可以发现的是,我们的rootname不一样了2.列出所有运行的容器
docker ps命令
3.exit退出命令exit #直接容器停止并退出
Ctrl + P + Q #容器不停止并退出在执行exit命令后,我们看到rootname又变回来了
4.删除容器
docker rm 容器id #删除指定的容器,不能删除正在运行的容器,如果要强制删除,需要使用 rm -f
docker rm $(docker ps -aq) #删除全部的容器
docker ps -a -q|xargs docker rm #删除全部容器5.启动和停止容器
-日志元数据进程查看
+
1.docker top 容器id查看容器中的进程日志元数据进程查看
1.docker top 容器id查看容器中的进程
2.docker inspect 容器id查看元数据3.进入当前正在运行的容器
-方式1:
+docker exec -it 容器id bashshell并可通过ps -ef查看容器当中的进程方式1:
docker exec -it 容器id bashshell并可通过ps -ef查看容器当中的进程方式2:
docker attach 容器id进入容器,如果当前有正在执行的容器则会直接进入到当前正在执行的进程当中
-从容器内拷贝到主机上
即使容器已经停止也是可以进行拷贝的
--docker cp 容器id:容器内路径 目的主机路径
+从容器内拷贝到主机上
即使容器已经停止也是可以进行拷贝的
docker cp 容器id:容器内路径 目的主机路径docker部署nginx
$ docker search nginx
$ docker pull nginx
$ docker run -d --name nginx01 -p 8083:80 nginx
$ docker ps
$ curl localhost:8083docker stop后则无法再访问portainer可视化管理
@@ -599,7 +595,7 @@docker run -d -p 8088:9000 --restart=always -v /var/run/docker.sock:/var/run/docker.sock --privileged=true portainer/portainer- 编译原理 + 数据库系统
- diff --git "a/2021/02/25/docker\351\225\234\345\203\217\346\223\215\344\275\234/index.html" "b/2021/02/25/docker\351\225\234\345\203\217\346\223\215\344\275\234/index.html" index 01a014c4..71b553fa 100644 --- "a/2021/02/25/docker\351\225\234\345\203\217\346\223\215\344\275\234/index.html" +++ "b/2021/02/25/docker\351\225\234\345\203\217\346\223\215\344\275\234/index.html" @@ -8,12 +8,12 @@
docker镜像操作 | khan's blog - + - + @@ -233,41 +233,35 @@@@ -1209,7 +1210,7 @@commit镜像
-数据卷操作实战:mysql同步
mysql运行容器,需要做数据挂载,安装启动mysql是需要配置密码的这一点要注意,所以要去docker hub官方文档上面去看官方配置
-- +docker pull mysql:5.7数据卷操作实战:mysql同步
mysql运行容器,需要做数据挂载,安装启动mysql是需要配置密码的这一点要注意,所以要去docker hub官方文档上面去看官方配置
docker pull mysql:5.7docker运行,docker run的常用参数这里我们再次回顾一下
--d 后台运行
-p 端口映射
-v 卷挂载
-e 环境配置
--name 环境名字通过docker hub我们找到了官方的命令:
docker run --name some-mysql -e MYSQL_ROOT_PASSWORD=my-secret-pw -d mysql:tag,在修改一下得到我们最终的输入命令-docker run -d -p 3310:3306 -v /home/mysql/conf:/etc/mysql/conf.d -v /home/mysql/data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=12345678 --name mysql01 mysql:5.7-CREATE DATABASE test_db;
删除这个镜像后数据则依旧保存下来了具名/匿名挂载
大多数情况下,为了方便,我们会使用具名挂载Dockerfile
Dockerfile就是用来构建docker镜像的文件,命令脚本,通过这个脚本可以生成镜像。
构建步骤-
-
编写一个Dockerfile
-
-docker build 构建成为一个镜像
-
-docker run 运行镜像
-
+- 编写一个Dockerfile +
- docker build 构建成为一个镜像 +
- docker run 运行镜像
docker push 发布镜像(DockerHub,阿里云镜像)
这里我们可以先看看Docker Hub官方是怎么做的
官方镜像是比较基础的,有很多命令和功能都省去了,所以我们通常需要在基础的镜像上来构建我们自己的镜像
Dockerfile命令
+
+Dockerfile命令
+
+常用命令 用法 + +FROM 基础镜像,一切从这开始构建 创建一个自己的centos
Dockerfile中99%的镜像都来自于这个scratch镜像,然后配置需要的软件和配置来进行构建。
@@ -319,13 +315,9 @@mkdir dockerfile
cd dockerfile
vim mydockerfile-centosFROM centos
MAINTAINER khan<khany@foxmail.com>
ENV MYPATH /usr/local
WORKDIR $MYPATH
RUN yum -y install vim
RUN yum -y install net-tools
EXPOSE 80
CMD echo $MYPATH
CMD echo "---end---"
CMD /bin/bash然后我们进入
docker build,注意后面一定要有一个.号-docker build -f mydockerfile-centos -t mycentos:1.0 .然后我们通过
+docker run -it mycentos:1.0命令进入我们自己创建的镜像测试运行我们新安装的包和命令是否能正常运行。
我们可以通过docker history +容器名称/容器id看到这个容器的构建过程。然后我们通过
docker run -it mycentos:1.0命令进入我们自己创建的镜像测试运行我们新安装的包和命令是否能正常运行。
我们可以通过docker history +容器名称/容器id看到这个容器的构建过程。CMD和ENTRYPOINT区别
-dockerfile-cmd-test:
--FROM centos
CMD ["ls","-a"]dockerfile-entrypoint-test:
--FROM centos
ENTRYPOINT ["ls","-a"]执行命令
+docker run 容器名称 -l在CMD下会报错,命令会被后面追加的-l替代,而-l并不是有效的linux命令,所以报错,而ENTRYPOINT则是可以追加的则该命令会变为ls -aldockerfile-cmd-test:
FROM centos
CMD ["ls","-a"]
dockerfile-entrypoint-test:FROM centos
ENTRYPOINT ["ls","-a"]
执行命令docker run 容器名称 -l在CMD下会报错,命令会被后面追加的-l替代,而-l并不是有效的linux命令,所以报错,而ENTRYPOINT则是可以追加的则该命令会变为ls -al发布镜像
@@ -333,9 +325,8 @@发布到Docker Hub
https://hub.docker.com/ 注册自己的账号
- 确定这个账号可以登录
- 在我们服务器上提交自己的镜像
-- 登录成功,通过
+push命令提交镜像,记得注意添加版本号
这里出了一点小问题:- 登录成功,通过
-push命令提交镜像,记得注意添加版本号
这里出了一点小问题:
在build自己的镜像的时候添加tag时必须在前面加上自己的dockerhub的username,然后再push就可以了在build自己的镜像的时候添加tag时必须在前面加上自己的dockerhub的username,然后再push就可以了
docker tag 镜像id YOUR_DOCKERHUB_NAME/firstimage
docker push YOUR_DOCKERHUB_NAME/firstimage
提交成功,可以在docker hub上找到你提交的镜像@@ -344,7 +335,7 @@
Docker镜像操作过程总结
- +
@@ -650,7 +641,7 @@- 编译原理 + 数据库系统
简介
人脸检测和脸部校准任务对于很多面部任务和应用来说都是十分重要的,比如说人脸识别,人脸表情分析。不过在现实生活当中,面部特征时常会因为一些遮挡物,强烈的光照对比,复杂的姿势发生很大的变化,这使得这些任务变得具有很大挑战性。Viola和Jones 提出的级联人脸检测器利用Haar特征和AdaBoost训练级联分类器,实现了具有实时效率的良好性能。 然而,也有相当一部分的工作表明,这种分类器可能在现实生活的应用中效果显着降低,即使具有更高级的特征和分类器。,之后人们又提出了DPM的方式,这些年来基于CNN的一些解决方案也层出不穷,基于CNN的方案主要是为了识别出面部的一些特征来实现。作者认为这种方式其实是需要花费更多的时间来对面部进行校准来训练同时还忽略了面部的重要特征点位置和边框问题。
-
对于人脸校准的话目前也有大致的两个方向:一个是基于回归的方法还有一个就是基于模板拟合的方式进行,主要是对特征识别起到一个辅助的工作。
作者认为关于人脸识别和面部对准这两个任务其实是有内在关联的,而目前大多数的方法则忽略了这一点,所以本文所提出的方案就是将这两者都结合起来,构建出一个三阶段的模型实现一个端到端的人脸检测并校准面部特征点的过程。
第一阶段:通过浅层CNN快速生成候选窗口。
第二阶段:通过more complex的CNN拒绝大量非面部窗口来细化窗口。
第三阶段:使用more powerful的CNN再次细化结果并输出五个面部标志位置。方法
Image pyramid图像金字塔
在进入stage-1之前,作者先构建了一组多尺度的图像金字塔缩放,这一块要理解起来还是有一点费力的,这里我们需要了解的是在训练网络的过程当中,作者都是把WIDER FACE的图片随机剪切成12x12size的大小进行单尺度训练的,不能满足任意大小的人脸检测,所以为了检测到不同尺寸的人脸,所以在推理时需要先生成图像金字塔生成一组不同scale的图像输入P-net进行来实现人脸的检测,同时也这是为什么P-net要使用FCN的原因。
--def calculateScales(img):
min_face_size = 20 # 最小的人脸尺寸
width, height = img.size
min_length = min(height, width)
min_detection_size = 12
factor = 0.707 # sqrt(0.5)
scales = []
m = min_detection_size / min_face_size
min_length *= m
factor_count = 0
# 图像尺寸缩小到不大于min_detection_size
while min_length > min_detection_size:
scales.append(m * factor ** factor_count)
min_length *= factor
factor_count += 1$$\text{length} =\text{length} \times (\frac{\text{min detection size}}{\text{min face size}} )\times factor^{count} $$
+
$\text{here we define in our code:} factor=\frac{1}{\sqrt{2}}, \text{min face size}=20,\text{min detection size}=12$方法
Image pyramid图像金字塔
在进入stage-1之前,作者先构建了一组多尺度的图像金字塔缩放,这一块要理解起来还是有一点费力的,这里我们需要了解的是在训练网络的过程当中,作者都是把WIDER FACE的图片随机剪切成12x12size的大小进行单尺度训练的,不能满足任意大小的人脸检测,所以为了检测到不同尺寸的人脸,所以在推理时需要先生成图像金字塔生成一组不同scale的图像输入P-net进行来实现人脸的检测,同时也这是为什么P-net要使用FCN的原因。
+def calculateScales(img):
min_face_size = 20 # 最小的人脸尺寸
width, height = img.size
min_length = min(height, width)
min_detection_size = 12
factor = 0.707 # sqrt(0.5)
scales = []
m = min_detection_size / min_face_size
min_length *= m
factor_count = 0
# 图像尺寸缩小到不大于min_detection_size
while min_length > min_detection_size:
scales.append(m * factor ** factor_count)
min_length *= factor
factor_count += 1$\text{here we define in our code:} factor=\frac{1}{\sqrt{2}}, \text{min face size}=20,\text{min detection size}=12$
min_face_size和factor对推理过程会产生什么样的影响?
min_face_size越大,factor越小,图像最短边就越快缩放到接近min_detect_size,从而生成图像金字塔的耗时就越短,同时各尺度的跨度也更大。因此,加大min_face_size、减小factor能加速图像金字塔的生成,但同时也更易造成漏检。Stage 1 P-Net(Proposal Network)
这是一个全卷积网络,也就是说这个网络可以兼容任意大小的输入,他的整个网络其实十分简单,该层的作用主要是为了获得人脸检测的大量候选框,这一层我们最大的作用就是要尽可能的提升recall,然后在获得许多候选框后再使用非极大抑制的方法合并高度重叠的候选区域。
-
P-Net的示意图当中我们也可以看到的是作者输入12x12大小最终的output为一个1x1x2的face label classification概率和一个1x1x4的boudingbox(左上角和右下角的坐标)以及一个1x1x10的landmark(双眼,鼻子,左右嘴角的坐标)
注意虽然这里作者举例是12x12的图片大小,但是他的意思并不是说这个P-Net的图片输入大小必须是12,我们可以知道这个网络是FCN,这就意味着不同输入的大小都是可以输入其中的,最后我们所得到的featuremap$[m \times n \times (2+4+10) ]$每一个小像素点映射到输入图像所在的12x12区域是否包含人脸的分类结果,候选框左上和右下基准点以及landmark,然后根据图像金字塔的我们再根据scale和resize的逆过程将其映射到原图像上P-net structure
--class P_Net(nn.Module):
def __init__(self):
super(P_Net, self).__init__()
self.pre_layer = nn.Sequential(
# 12x12x3
nn.Conv2d(3, 10, kernel_size=3, stride=1), # conv1
nn.PReLU(), # PReLU1
# 10x10x10
nn.MaxPool2d(kernel_size=2, stride=2), # pool1
# 5x5x10
nn.Conv2d(10, 16, kernel_size=3, stride=1), # conv2
# 3x3x16
nn.PReLU(), # PReLU2
nn.Conv2d(16, 32, kernel_size=3, stride=1), # conv3
# 1x1x32
nn.PReLU() # PReLU3
)
# detection
self.conv4_1 = nn.Conv2d(32, 1, kernel_size=1, stride=1)
# bounding box regresion
self.conv4_2 = nn.Conv2d(32, 4, kernel_size=1, stride=1)
# landmark localization
self.conv4_3 = nn.Conv2d(32, 10, kernel_size=1, stride=1)
# weight initiation with xavier
self.apply(weights_init)
def forward(self, x):
x = self.pre_layer(x)
det = torch.sigmoid(self.conv4_1(x))
box = self.conv4_2(x)
landmark = self.conv4_3(x)
# det:[,2,1,1], box:[,4,1,1], landmark:[,10,1,1]
return det, box, landmark这里要提一下
+nn.PReLU(),有点类似Leaky ReLU,可以看下面的博客深入了解一下P-net structure
class P_Net(nn.Module):
def __init__(self):
super(P_Net, self).__init__()
self.pre_layer = nn.Sequential(
# 12x12x3
nn.Conv2d(3, 10, kernel_size=3, stride=1), # conv1
nn.PReLU(), # PReLU1
# 10x10x10
nn.MaxPool2d(kernel_size=2, stride=2), # pool1
# 5x5x10
nn.Conv2d(10, 16, kernel_size=3, stride=1), # conv2
# 3x3x16
nn.PReLU(), # PReLU2
nn.Conv2d(16, 32, kernel_size=3, stride=1), # conv3
# 1x1x32
nn.PReLU() # PReLU3
)
# detection
self.conv4_1 = nn.Conv2d(32, 1, kernel_size=1, stride=1)
# bounding box regresion
self.conv4_2 = nn.Conv2d(32, 4, kernel_size=1, stride=1)
# landmark localization
self.conv4_3 = nn.Conv2d(32, 10, kernel_size=1, stride=1)
# weight initiation with xavier
self.apply(weights_init)
def forward(self, x):
x = self.pre_layer(x)
det = torch.sigmoid(self.conv4_1(x))
box = self.conv4_2(x)
landmark = self.conv4_3(x)
# det:[,2,1,1], box:[,4,1,1], landmark:[,10,1,1]
return det, box, landmark
这里要提一下nn.PReLU(),有点类似Leaky ReLU,可以看下面的博客深入了解一下https://blog.csdn.net/qq_23304241/article/details/80300149
https://blog.csdn.net/shuzfan/article/details/51345832然后在P-Net之后我们通过非极大抑制的方法和将所有的boudingbox都修正为框的最长边为边长的正方形框,主要是避免后面的Rnet在resize的时候因为尺寸原因出现信息的损失。
-Non-Maximum Suppression非极大抑制
其实关于非极大抑制这个trick最初是在目标检测任务当中提出的来的,其思想是搜素局部最大值,抑制极大值,主要用在目标检测当中,最传统的非极大抑制所采用的评价指标就是交并比IoU(intersection-over-union)即两个groud truth和bounding box的交集部分除以它们的并集.
-
$$IoU = \frac{area(C) \cap area(G)}{area(C) \cup area(G)}$$- +def IoU(box, boxes):
"""Compute IoU between detect box and gt boxes
Parameters:
----------
box: numpy array , shape (5, ): x1, y1, x2, y2, score
input box
boxes: numpy array, shape (n, 4): x1, y1, x2, y2
input ground truth boxes
Returns:
-------
ovr: numpy.array, shape (n, )
IoU
"""
box_area = (box[2] - box[0] + 1) * (box[3] - box[1] + 1)
area = (boxes[:, 2] - boxes[:, 0] + 1) * (boxes[:, 3] - boxes[:, 1] + 1)
xx1 = np.maximum(box[0], boxes[:, 0])
xx2 = np.minimum(box[2], boxes[:, 2])
yy1 = np.maximum(box[1], boxes[:, 1])
yy2 = np.minimum(box[3], boxes[:, 3])
# compute the width and height of the bounding box
w = np.maximum(0, xx2 - xx1 + 1)
h = np.maximum(0, yy2 - yy1 + 1)
inter = w * h
ovr = np.true_divide(inter,(box_area + area - inter))
#ovr = inter / (box_area + area - inter)
return ovrNon-Maximum Suppression非极大抑制
其实关于非极大抑制这个trick最初是在目标检测任务当中提出的来的,其思想是搜素局部最大值,抑制极大值,主要用在目标检测当中,最传统的非极大抑制所采用的评价指标就是交并比IoU(intersection-over-union)即两个groud truth和bounding box的交集部分除以它们的并集.
+def IoU(box, boxes):
"""Compute IoU between detect box and gt boxes
Parameters:
----------
box: numpy array , shape (5, ): x1, y1, x2, y2, score
input box
boxes: numpy array, shape (n, 4): x1, y1, x2, y2
input ground truth boxes
Returns:
-------
ovr: numpy.array, shape (n, )
IoU
"""
box_area = (box[2] - box[0] + 1) * (box[3] - box[1] + 1)
area = (boxes[:, 2] - boxes[:, 0] + 1) * (boxes[:, 3] - boxes[:, 1] + 1)
xx1 = np.maximum(box[0], boxes[:, 0])
xx2 = np.minimum(box[2], boxes[:, 2])
yy1 = np.maximum(box[1], boxes[:, 1])
yy2 = np.minimum(box[3], boxes[:, 3])
# compute the width and height of the bounding box
w = np.maximum(0, xx2 - xx1 + 1)
h = np.maximum(0, yy2 - yy1 + 1)
inter = w * h
ovr = np.true_divide(inter,(box_area + area - inter))
#ovr = inter / (box_area + area - inter)
return ovr使用非极大抑制的前提是,我们已经得到了一组候选框和对应label的置信分数,以及groud truth的信息,通过设定阈值来删除重合度较高的候选框。
算法流程如下:- 根据置信度得分进行排序 @@ -257,27 +253,25 @@
-
diff --git "a/2021/04/22/yolov1-3\350\256\272\346\226\207\350\247\243\346\236\220/index.html" "b/2021/04/22/yolov1-3\350\256\272\346\226\207\350\247\243\346\236\220/index.html"
index d45d9593..c0ef5534 100644
--- "a/2021/04/22/yolov1-3\350\256\272\346\226\207\350\247\243\346\236\220/index.html"
+++ "b/2021/04/22/yolov1-3\350\256\272\346\226\207\350\247\243\346\236\220/index.html"
@@ -224,53 +224,102 @@ -
yolov1-3论文解析
最近在看经典目标检测算法yolo的思想,为了更好的了解yolo系列的相关文章,我从最初版本的论文思想开始看的,之后有时间会把yolov4和yolov5再认真看看,目前来说yolov3的spp版本是使用得最为广泛的一种,整体上来说yolo的设计思想还是很有创造性的数学也比较严谨。
- +yolov1-3论文解析
最近在看经典目标检测算法yolo的思想,为了更好的了解yolo系列的相关文章,我从最初版本的论文思想开始看的,之后有时间会把yolov4和yolov5再认真看看,目前来说yolov3的spp版本是使用得最为广泛的一种,整体上来说yolo的设计思想还是很有创造性的数学也比较严谨。
yolov1论文思想
物体检测主流的算法框架大致分为one-stage与two-stage。two-stage算法代表有R-CNN系列,one-stage算法代表有Yolo系列。按笔者理解,two-stage算法将步骤一与步骤二分开执行,输入图像先经过候选框生成网络(例如faster rcnn中的RPN网络),再经过分类网络;one-stage算法将步骤一与步骤二同时执行,输入图像只经过一个网络,生成的结果中同时包含位置与类别信息。two-stage与one-stage相比,精度高,但是计算量更大,所以运算较慢。
We present YOLO, a new approach to object detection. Prior work on object detection repurposes classifiers to perform detection. Instead, we frame object detection as a regression problem to spatially separated bounding boxes and associated class probabilities.
yolo相比其他R-CNN等方法最大的一个不同就是他将这个识别和定位的过程转化成了一个空间定位并分类的回归问题,这也是他为什么能够利用网络进行端到端直接同时预测的重要原因。
yolo的特点
1.YOLO速度非常快。由于我们的检测是当做一个回归问题,不需要很复杂的流程。在测试的时候我们只需将一个新的图片输入网络来检测物体。
-First, YOLO is extremely fast. Since we frame detection as a regression problem we don’t need a complex pipeline
2.Yolo会基于整张图片信息进行预测,与基于滑动窗口和候选区域的方法不同,在训练和测试期间YOLO可以看到整个图像,所以它隐式地记录了分类类别的上下文信息及它的全貌Second, YOLO reasons globally about the image when making predictions Unlike sliding window and region proposal-based techniques, YOLO sees the entire image during training and test time so it implicitly encodes contextual information about classes as well as their appearance
3.第三,YOLO能学习到目标的泛化表征。作者尝试了用自然图片数据集进行训练,用艺术画作品进行预测,Yolo的检测效果更佳。Third, YOLO learns generalizable representations of objects. Since YOLO is highly generalizable it is less likely to break down when applied to new domains or unexpected inputsbackbone-darknet
-
yolov1这块的话,由于是比较早期的网络所以在设计时没有使用batchnormal,激活函数上采用leaky relu,输入图像大小为448x448,经过许多卷积层与池化层,变为7x7x1024张量,最后经过两层全连接层,输出张量维度为7x7x30。除了最后一层的输出使用了线性激活函数,其他层全部使用Leaky Relu激活函数。
$$\phi(x)= \begin{cases}
x,& \text{if x>0} \
0.1x,& \text{otherwise}
\end{cases}$$输出维度
yolov1最精髓的地方应该就是他的输出维度,论文当中有放出这样一张图片,看完以后我们能对yolo算法的特点有更加深刻的理解。在上图的backbone当中我们可以看到的是
+yolo的输出相当于把原图片分割成了$S \times S$个区域,然后对预测目标标定他的boundingbox,boundingbox由中心点的坐标,长宽以及物体的置信分数组成$x,y,w,h,confidence$,图中的$B$表示的是boundingbox的个数。置信分数在yolo当中是这样定义的:$Pr(Object)IOU_{pred}^{truth}$对于$Pr(Object)=1 \text{ if detect object else 0}$,其实置信分数就是boudingbox与groundtruth之间的IOU,并对每个小网格对应的$C$个类别都预测出他的条件概率:$Pr(Class_i|Object)$。
在推理时,我们可以得到当前网格对于每个类别的预测置信分数:$$Pr(Class_i)*IOU_{pred}^{truth} = Pr(Class_i|Object)*Pr(Object)*IOU_{pred}^{truth}$$
这样一种严谨的条件概率的方式得到我们的最终概率是十分可行和合适的。YOLO imposes strong spatial constraints on bounding box predictions since each grid cell only predicts two boxes and can only have one class. This spatial constraint limits the number of nearby objects that our model can predict. Our model struggles with small objects that appear in groups, such as flocks of birds.
*不过在原论文当中也有提到的一点是:YOLO给边界框预测强加空间约束,因为每个网格单元只预测两个框和只能有一个类别。这个空间约束限制了我们的模型可以预测的邻近目标的数量。我们的模型难以预测群组中出现的小物体(比如鸟群)。**backbone-darknet
+
yolov1这块的话,由于是比较早期的网络所以在设计时没有使用batchnormal,激活函数上采用leaky relu,输入图像大小为448x448,经过许多卷积层与池化层,变为7x7x1024张量,最后经过两层全连接层,输出张量维度为7x7x30。除了最后一层的输出使用了线性激活函数,其他层全部使用Leaky Relu激活函数。输出维度
yolov1最精髓的地方应该就是他的输出维度,论文当中有放出这样一张图片,看完以后我们能对yolo算法的特点有更加深刻的理解。在上图的backbone当中我们可以看到的是
yolo的输出相当于把原图片分割成了$S \times S$个区域,然后对预测目标标定他的boundingbox,boundingbox由中心点的坐标,长宽以及物体的置信分数组成$x,y,w,h,confidence$,图中的$B$表示的是boundingbox的个数。置信分数在yolo当中是这样定义的:$Pr(Object)IOU_{pred}^{truth}$对于$Pr(Object)=1 \text{ if detect object else 0}$,其实置信分数就是boudingbox与groundtruth之间的IOU,并对每个小网格对应的$C$个类别都预测出他的条件概率:$Pr(Class_i|Object)$。
在推理时,我们可以得到当前网格对于每个类别的预测置信分数:$$Pr(Class_i)IOU{pred}^{truth} = Pr(Class_i|Object)Pr(Object)IOU{pred}^{truth}$$
这样一种严谨的条件概率的方式得到我们的最终概率是十分可行和合适的。YOLO imposes strong spatial constraints on bounding box predictions since each grid cell only predicts two boxes and can only have one class. This spatial constraint limits the number of nearby objects that our model can predict. Our model struggles with small objects that appear in groups, such as flocks of birds.
不过在原论文当中也有提到的一点是:YOLO给边界框预测强加空间约束,因为每个网格单元只预测两个框和只能有一个类别。这个空间约束限制了我们的模型可以预测的邻近目标的数量。我们的模型难以预测群组中出现的小物体(比如鸟群)。损失函数
在损失函数方面,由于公式比较长所以就直接截图过来了,损失函数的设计放方面作者也考虑的比较周全,
预测框的中心点$(x,y)$。预测框的宽高$w,h$,其中$\mathbb{1}_{i j}^{\text {obj }}$为控制函数,在标签中包含物体的那些格点处,该值为 1 ,若格点不含有物体,该值为 0在计算损失函数的时候作者最开始使用的是最简单的平方损失函数来计算检测,因为它是计算简单且容易优化的,但是它并不完全符合我们最大化平均精度的目标,原因如下:
-It weights localization error equally with classification error which may not be ideal.
1.它对定位错误的权重与分类错误的权重相等,这可能不是理想的选择。Also, in every image many grid cells do not contain any object. This pushes the “confidence” scores of those cells towards zero, often overpowering the gradient from cells that do contain objects. This can lead to model instability, causing training to diverge early on.
而且,在每个图像中,许多网格单元不包含任何对象。这就把这些网格的置信度分数推到零,往往超过了包含对象的网格的梯度。2.这可能导致模型不稳定,导致训练早期发散难以训练。解决方案:增加边界框坐标预测的损失,并且减少了不包含对象的框的置信度预测的损失。我们使用两个参数来实现这一点。$\lambda_{coord}=5,\lambda_{noobj}=0.5$,其实这也是yolo面临的一个样本数目不均衡的典型例子。主要目的是让含有物体的格点,在损失函数中的权重更大,让模型更加注重含有物体的格点所造成的损失。
+
我们的损失函数则只会对那些有真实物体所属的格点进行损失计算,若该格点不包含物体,那么预测数值不对损失函数造成影响。解决方案:增加边界框坐标预测的损失,并且减少了不包含对象的框的置信度预测的损失。我们使用两个参数来实现这一点。$\lambda{coord}=5,\lambda{noobj}=0.5$,其实这也是yolo面临的一个样本数目不均衡的典型例子。主要目的是让含有物体的格点,在损失函数中的权重更大,让模型更加注重含有物体的格点所造成的损失。
我们的损失函数则只会对那些有真实物体所属的格点进行损失计算,若该格点不包含物体,那么预测数值不对损失函数造成影响。这里对$w,h$在损失函数中的处理分别取了根号,原因在于,如果不取根号,损失函数往往更倾向于调整尺寸比较大的预测框。例如,20个像素点的偏差,对于800x600的预测框几乎没有影响,此时的IOU数值还是很大,但是对于30x40的预测框影响就很大。取根号是为了尽可能的消除大尺寸框与小尺寸框之间的差异。
预测框的置信度$C_i$。当该格点不含有物体时,该置信度的标签为0;若含有物体时,该置信度的标签为预测框与真实物体框的IOU数值(。
物体类别概率$P_i$,对应的类别位置,该标签数值为1,其余位置为0,与分类网络相同。yolov2:Better, Faster, Stronger
yolov2的论文里面其实更多的是对训练数据集的组合和扩充,然后再添加了很多计算机视觉方面新出的trick,然后达到了性能的提升。同时yolov2方面所使用的trick也是现在计算机视觉常用的方法,我认为这些都是我们需要好好掌握的,同时也是面试和kaggle上都经常使用的一些方法。
Batch Normalization
BN是由Google于2015年提出,论文是《Batch Normalization_ Accelerating Deep Network Training by Reducing Internal Covariate Shift》,这是一个深度神经网络训练的技巧,主要是让数据的分布变得一致,从而使得训练深层网络模型更加容易和稳定。
这里有一些相关的链接可以参考一下-
https://www.cnblogs.com/itmorn/p/11241236.html
+
https://zhuanlan.zhihu.com/p/24810318
https://zhuanlan.zhihu.com/p/93643523
莫烦python
李宏毅yydshttps://www.cnblogs.com/itmorn/p/11241236.html
https://zhuanlan.zhihu.com/p/24810318
https://zhuanlan.zhihu.com/p/93643523
莫烦python
李宏毅yyds算法具体过程:
这里要提一下这个$\gamma和\beta$是可训练参数,维度等于张量的通道数,主要是为了在反向传播更新网络时使得标准化后的数据分布与原始数据尽可能保持一直,从而很好的抽象和保留整个batch的数据分布。
Batch Normalization的作用:
将这些输入值或卷积网络的张量在batch维度上进行类似标准化的操作,将其放缩到合适的范围,加快模型训练时的收敛速度,使得模型训练过程更加稳定,避免梯度爆炸或者梯度消失,并且起到一定的正则化作用。High Resolution Classifier
在Yolov1中,网络的backbone部分会在ImageNet数据集上进行预训练,训练时网络输入图像的分辨率为224x224。在v2中,将分类网络在输入图片分辨率为448x448的ImageNet数据集上训练10个epoch,再使用检测数据集(例如coco)进行微调。高分辨率预训练使mAP提高了大约4%。
Convolutional With Anchor Boxes
-predicts these offsets at every location in a feature mapPredicting offsets instead of coordinates simplifies the problem and makes it easier for the network to learn.
第一篇解读v1时提到,每个格点预测两个矩形框,在计算loss时,只让与ground truth最接近的框产生loss数值,而另一个框不做修正。这样规定之后,作者发现两个框在物体的大小、长宽比、类别上逐渐有了分工。在v2中,神经网络不对预测矩形框的宽高的绝对值进行预测,而是预测与Anchor框的偏差(offset),每个格点指定n个Anchor框。在训练时,最接近ground truth的框产生loss,其余框不产生loss。在引入Anchor Box操作后,mAP由69.5下降至69.2,原因在于,每个格点预测的物体变多之后,召回率大幅上升,准确率有所下降,总体mAP略有下降。Dimension Clusters
-Instead of choosing priors by hand, we run k-means clustering on the training set bounding boxes to automatically find good priors.
这里算是作者数据处理上的一个创新点,这里作者提到之前的工作当中先Anchor Box都是认为设定的比例和大小,而这里作者时采用无监督的方式将训练数据集中的矩形框全部拿出来,用kmeans聚类得到先验框的宽和高。使用(1-IOU)数值作为两个矩形框的的距离函数,这个处理也十分的聪明。
$$
d(\text { box }, \text { centroid })=1-\operatorname{IOU}(\text { box }, \text { centroid })
$$Direct location prediction
Yolo中的位置预测方法是预测的左上角的格点坐标预测偏移量。网络预测输出要素图中每个单元格的5个边界框。网络为每个边界框预测$t_x,t_y,t_h,t_w和t_o$这5个坐标。如果单元格从图像的左上角偏移了$(c_x,c_y)$并且先验边界框的宽度和高度为$p_w,p_h$,则预测对应于:
+
$$
\begin{array}{l}
x=\left(t_{x} * w_{a}\right)-x_{a} \
y=\left(t_{y} * h_{a}\right)-y_{a}
\end{array}
$$
$$
\begin{aligned}
b_{x} &=\sigma\left(t_{x}\right)+c_{x} \
b_{y} &=\sigma\left(t_{y}\right)+c_{y} \
b_{w} &=p_{w} e^{t_{w}} \
b_{h} &=p_{h} e^{t_{h}} \
\operatorname{Pr}(\text { object }) * I O U(b, \text { object }) &=\sigma\left(t_{o}\right)
\end{aligned}
$$
由于我们约束位置预测,参数化更容易学习,使得网络更稳定使用维度集群以及直接预测边界框中心位置使YOLO比具有anchor box的版本提高了近5%的mAP。Dimension Clusters
+Instead of choosing priors by hand, we run k-means clustering on the training set bounding boxes to automatically find good priors.
这里算是作者数据处理上的一个创新点,这里作者提到之前的工作当中先Anchor Box都是认为设定的比例和大小,而这里作者时采用无监督的方式将训练数据集中的矩形框全部拿出来,用kmeans聚类得到先验框的宽和高。使用(1-IOU)数值作为两个矩形框的的距离函数,这个处理也十分的聪明。
+Direct location prediction
Yolo中的位置预测方法是预测的左上角的格点坐标预测偏移量。网络预测输出要素图中每个单元格的5个边界框。网络为每个边界框预测$t_x,t_y,t_h,t_w和t_o$这5个坐标。如果单元格从图像的左上角偏移了$(c_x,c_y)$并且先验边界框的宽度和高度为$p_w,p_h$,则预测对应于:
+
+由于我们约束位置预测,参数化更容易学习,使得网络更稳定使用维度集群以及直接预测边界框中心位置使YOLO比具有anchor box的版本提高了近5%的mAP。
Fine-Grained Features
在2626的特征图,经过卷积层等,变为1313的特征图后,作者认为损失了很多细粒度的特征,导致小尺寸物体的识别效果不佳,所以在此加入了passthrough层。
-
传递层通过将相邻特征堆叠到不同的通道而不是堆叠到空间位置,将较高分辨率特征与低分辨率特征相连,类似于ResNet中的标识映射。这将26×26×512特征映射转换为13×13×2048特征映射,其可以与原始特征连接。Multi-Scale Training
我觉得这个也是yolo为什么性能提升的一个很重要的点,解决了yolo1当中对于多个小物体检测的问题。
+
原始的YOLO使用448×448的输入分辨率。添加anchor box后,我们将分辨率更改为416×416。然而,由于我们的模型只使用卷积层和池化层,相比yolo1删除了全连接层,它可以在运行中调整大小(应该是使用了1x1卷积不过我没看代码)。我们希望YOLOv2能够在不同大小的图像上运行,因此我们将其训练到模型中。instead of fixing the input image size we change the network every few iterations. Every 10 batches our network randomly chooses a new image dimension size.
不固定输入图像的大小,我们每隔几次迭代就更改网络。在每10个batch之后,我们的网络就会随机resize成{320, 352, …, 608}中的一种。不同的输入,最后产生的格点数不同,比如输入图片是320320,那么输出格点是1010,如果每个格点的先验框个数设置为5,那么总共输出500个预测结果;如果输入图片大小是608608,输出格点就是1919,共1805个预测结果。YOLO’s convolutional layers downsample the image by a factor of 32 so by using an input image of 416 we get an output feature map of 13 × 13.We do this because we want an odd number of locations in our feature map so there is a single center cell.
关于416×416也是有说法的,主要是下采样是32的倍数,而且最后的输出是13x13是奇数然后会有一个中心点更加易于目标检测。
这种训练方法迫使网络学习在各种输入维度上很好地预测。这意味着相同的网络可以预测不同分辨率的检测。
关于yolov2最大的一个提升还有一个原因就是WordTree组合数据集的训练方法,不过这里我就不再赘述,可以看参考资料有详细介绍,这里主要讲网络和思路Multi-Scale Training
我觉得这个也是yolo为什么性能提升的一个很重要的点,解决了yolo1当中对于多个小物体检测的问题。
原始的YOLO使用448×448的输入分辨率。添加anchor box后,我们将分辨率更改为416×416。然而,由于我们的模型只使用卷积层和池化层,相比yolo1删除了全连接层,它可以在运行中调整大小(应该是使用了1x1卷积不过我没看代码)。我们希望YOLOv2能够在不同大小的图像上运行,因此我们将其训练到模型中。instead of fixing the input image size we change the network every few iterations. Every 10 batches our network randomly chooses a new image dimension size.
不固定输入图像的大小,我们每隔几次迭代就更改网络。在每10个batch之后,我们的网络就会随机resize成{320, 352, …, 608}中的一种。不同的输入,最后产生的格点数不同,比如输入图片是320320,那么输出格点是1010,如果每个格点的先验框个数设置为5,那么总共输出500个预测结果;如果输入图片大小是608608,输出格点就是1919,共1805个预测结果。YOLO’s convolutional layers downsample the image by a factor of 32 so by using an input image of 416 we get an output feature map of 13 × 13.We do this because we want an odd number of locations in our feature map so there is a single center cell.
关于416×416也是有说法的,主要是下采样是32的倍数,而且最后的输出是13x13是奇数然后会有一个中心点更加易于目标检测。
这种训练方法迫使网络学习在各种输入维度上很好地预测。这意味着相同的网络可以预测不同分辨率的检测。
关于yolov2最大的一个提升还有一个原因就是WordTree组合数据集的训练方法,不过这里我就不再赘述,可以看参考资料有详细介绍,这里主要讲网络和思路yolov3论文改进
yolov3的论文改进就有很多方面了,而且yolov3-spp的网络效果很不错,和yolov4,yolov5的效果差别也不是特别大,这也是为什么yolov3网络被广泛应用的原因之一。
backbone:Darknet-53
相比yolov1的网络,在网络上有了很大的改进,借鉴了Resnet、Densenet、FPN的做法结合了当前网络中十分有效的
1.Yolov3中,全卷积,对于输入图片尺寸没有特别限制,可通过调节卷积步长控制输出特征图的尺寸。
2.Yolov3借鉴了金字塔特征图思想,小尺寸特征图用于检测大尺寸物体,而大尺寸特征图检测小尺寸物体。特征图的输出维度为$N \times N \times (3 \times (4+1+80))$, NxN为输出特征图格点数,一共3个Anchor框,每个框有4维预测框数值 $t_x,t_y,t_w,t_h$ ,1维预测框置信度,80维物体类别数。所以第一层特征图的输出维度为8x8x255
3.Yolov3总共输出3个特征图,第一个特征图下采样32倍,第二个特征图下采样16倍,第三个下采样8倍。每个特征图进行一次3X3、步长为2的卷积,然后保存该卷积layer,再进行一次1X1的卷积和一次3X3的卷积,并把这个结果加上layer作为最后的结果。三个特征层进行5次卷积处理,处理完后一部分用于输出该特征层对应的预测结果,一部分用于进行反卷积UmSampling2d后与其它特征层进行结合。
4.concat和resiual加操作,借鉴DenseNet将特征图按照通道维度直接进行拼接,借鉴Resnet添加残差边,缓解了在深度神经网络中增加深度带来的梯度消失问题。
5.上采样层(upsample):作用是将小尺寸特征图通过插值等方法,生成大尺寸图像。例如使用最近邻插值算法,将88的图像变换为1616。上采样层不改变特征图的通道数。对于yolo3的模型来说,网络最后输出的内容就是三个特征层每个网格点对应的预测框及其种类,即三个特征层分别对应着图片被分为不同size的网格后,每个网格点上三个先验框对应的位置、置信度及其种类。然后对输出进行解码,解码过程也就是yolov2上面的Direct location prediction方法一样,每个网格点加上它对应的x_offset和y_offset,加完后的结果就是预测框的中心,然后再利用 先验框和h、w结合 计算出预测框的长和宽。这样就能得到整个预测框的位置了。
-CIoU loss
在yolov3当中我们使用的不再是传统的IoU loss,而是一个非常优秀的loss设计,整个发展过程也可以多了解了解IoU->GIoU->DIoU->CIoU,完整的考虑了重合面积,中心点距离,长宽比。
+
$$CIoU=IoU-(\frac{\rho(b,b^{gt}}{c^2}+\alpha v))$$
$$v=\frac{4}{\pi^2}(\arctan\frac{w^{gt}}{h^{gt}}-\arctan\frac{w}{h})^2$$
$$\alpha = \frac{v}{(1-IoU)+v}$$
其中, $b$ , $b^{gt}$ 分别代表了预测框和真实框的中心点,且 $\rho$代表的是计算两个中心点间的欧式距离。 [公式] 代表的是能够同时包含预测框和真实框的最小闭包区域的对角线距离。
在介绍CIoU之前,我们可以先介绍一下DIoU loss
其实这两项就是我们的DIoU
$$DIoU = IoU-(\frac{\rho(b,b^{gt}}{c^2})$$
则我们可以提出DIoU loss函数
$$
L_{\text {DIoU }}=1-D I o U \
0 \leq L_{\text {DloU}} \leq 2
$$
DloU损失能够直接最小化两个boxes之间的距离,因此收敛速度更快。
而我们的CIoU则比DIoU考虑更多的东西,也就是长宽比即最后一项。而$v$用来度量长宽比的相似性,$\alpha$是权重
在损失函数这块,有知乎大佬写了一下,其实就是对yolov1上的损失函数进行了一下变形。CIoU loss
在yolov3当中我们使用的不再是传统的IoU loss,而是一个非常优秀的loss设计,整个发展过程也可以多了解了解IoU->GIoU->DIoU->CIoU,完整的考虑了重合面积,中心点距离,长宽比。
+其中, $b$ , $b^{gt}$ 分别代表了预测框和真实框的中心点,且 $\rho$代表的是计算两个中心点间的欧式距离。 [公式] 代表的是能够同时包含预测框和真实框的最小闭包区域的对角线距离。
+
在介绍CIoU之前,我们可以先介绍一下DIoU loss
其实这两项就是我们的DIoU则我们可以提出DIoU loss函数
+DloU损失能够直接最小化两个boxes之间的距离,因此收敛速度更快。
而我们的CIoU则比DIoU考虑更多的东西,也就是长宽比即最后一项。而$v$用来度量长宽比的相似性,$\alpha$是权重
在损失函数这块,有知乎大佬写了一下,其实就是对yolov1上的损失函数进行了一下变形。Spatial Pyramid Pooling
在yolov3的spp版本中使用了spp模块,实现了不同尺度的特征融合,spp模块最初来源于何凯明大神的论文SPP-net,主要用来解决输入图像尺寸不统一的问题,而目前的图像预处理操作中,resize,crop等都会造成一定程度的图像失真,因此影响了最终的精度。SPP模块,使用固定分块的池化操作,可以对不同尺寸的输入实现相同大小的输出,因此能够避免这一问题。
同时SPP模块中不同大小特征的融合,有利于待检测图像中目标大小差异较大的情况,也相当于增大了多重感受野吧,尤其是对于yolov3一般针对的复杂多目标图像。
在yolov3的darknet53输出到第一个特征图计算之前我们插入了一个spp模块。
SPP的这几个模块stride=1,而且会对外补padding,所以最后的输出特征图大小是一致的,然后在深度方向上进行concatenate,使得深度增大了4倍。
可以看出随着输入网络尺度的增大,spp的效果会更好。多个spp的效果增大也就是spp3和spp1的效果是差不多的,为了保证推理速度就只使用了一个sppMosaic图像增强
在yolov3-spp包括yolov4当中我们都使用了mosaic数据增强,有点类似cutmix。cutmix是合并两张图片进行预测,mosaic数据增强利用了四张图片,对四张图片进行拼接,每一张图片都有其对应的框框,将四张图片拼接之后就获得一张新的图片,同时也获得这张图片对应的框框,然后我们将这样一张新的图片传入到神经网络当中去学习,相当于一下子传入四张图片进行学习了。论文中说这极大丰富了检测物体的背景,且在标准化BN计算的时候一下子会计算四张图片的数据。
-
作用:增加数据的多样性,增加目标个数,BN能一次性归一化多张图片组合的分布,会更加接近原数据的分布。focal loss
最后我们提一下focal loss,虽然在原论文当中作者说focal loss效果反而下降了,但是我认为还是有必要了解一下何凯明的这篇bestpaper。作者提出focal loss的出发点也是希望one-stage detector可以达到two-stage detector的准确率,同时不影响原有的速度。作者认为造成这种情况的原因是样本的类别不均衡导致的。
+
对于二分类的CrossEntropy,我们有如下表示方法:
$$
\mathrm{CE}(p, y)=\left{\begin{array}{ll}
-\log (p) & \text { if } y=1 \
-\log (1-p) & \text { otherwise. }
\end{array}\right.
$$
我们定义$p_t$:
$$
p_{\mathrm{t}}=\left{\begin{array}{ll}
p & \text { if } y=1 \
1-p & \text { otherwise }
\end{array}\right.
$$
则重写交叉熵
$$
\operatorname{CE}(n, y)=C E(p_t)=-\log (p_t)
$$
接着我们提出改进思路就是在计算CE时添加了一个平衡因子,是一个可训练的参数
$$
\mathrm{CE}\left(p_{\mathrm{t}}\right)=-\alpha_{\mathrm{t}} \log \left(p_{\mathrm{t}}\right)
$$
其中
$$
\alpha_{\mathrm{t}}=\left{\begin{array}{ll}
\alpha_{\mathrm{t}} & \text { if } y=1 \
1-\alpha_{\mathrm{t}} & \text { otherwise }
\end{array}\right.
$$
相当于给正负样本加上权重,负样本出现的频次多,那么就降低负样本的权重,正样本数量少,就相对提高正样本的权重。因此可以通过设定a的值来控制正负样本对总的loss的共享权重。a取比较小的值来降低负样本(多的那类样本)的权重。
但是何凯明认为这个还是不能完全解决样本不平衡的问题,虽然这个平衡因子可以控制正负样本的权重,但是没法控制容易分类和难分类样本的权重focal loss
最后我们提一下focal loss,虽然在原论文当中作者说focal loss效果反而下降了,但是我认为还是有必要了解一下何凯明的这篇bestpaper。作者提出focal loss的出发点也是希望one-stage detector可以达到two-stage detector的准确率,同时不影响原有的速度。作者认为造成这种情况的原因是样本的类别不均衡导致的。
+
对于二分类的CrossEntropy,我们有如下表示方法:我们定义$p_t$:
+则重写交叉熵
+接着我们提出改进思路就是在计算CE时添加了一个平衡因子,是一个可训练的参数
+其中
+相当于给正负样本加上权重,负样本出现的频次多,那么就降低负样本的权重,正样本数量少,就相对提高正样本的权重。因此可以通过设定a的值来控制正负样本对总的loss的共享权重。a取比较小的值来降低负样本(多的那类样本)的权重。
但是何凯明认为这个还是不能完全解决样本不平衡的问题,虽然这个平衡因子可以控制正负样本的权重,但是没法控制容易分类和难分类样本的权重
-As our experiments will show, the large class imbalance encountered during training of dense detectors overwhelms the cross entropy loss. Easily classified negatives comprise the majority of the loss and dominate the gradient. While
α balances the importance of positive/negative examples, it does not differentiate between easy/hard examples. Instead, we propose to reshape the loss function to down-weight easy examples and thus focus training on hard negatives于是提出了一种新的损失函数Focal Loss
+
$$
\mathrm{FL}\left(p_{\mathrm{t}}\right)=-\left(1-p_{\mathrm{t}}\right)^{\gamma} \log \left(p_{\mathrm{t}}\right)
$$于是提出了一种新的损失函数Focal Loss
+focal loss的两个重要性质
1、当一个样本被分错的时候,pt是很小的,那么调制因子(1-Pt)接近1,损失不被影响;当Pt→1,因子(1-Pt)接近0,那么分的比较好的(well-classified)样本的权值就被调低了。因此调制系数就趋于1,也就是说相比原来的loss是没有什么大的改变的。当pt趋于1的时候(此时分类正确而且是易分类样本),调制系数趋于0,也就是对于总的loss的贡献很小。
2、当γ=0的时候,focal loss就是传统的交叉熵损失,当γ增加的时候,调制系数也会增加。 专注参数γ平滑地调节了易分样本调低权值的比例。γ增大能增强调制因子的影响,实验发现γ取2最好。直觉上来说,调制因子减少了易分样本的损失贡献,拓宽了样例接收到低损失的范围。当γ一定的时候,比如等于2,一样easy example(pt=0.9)的loss要比标准的交叉熵loss小100+倍,当pt=0.968时,要小1000+倍,但是对于hard example(pt < 0.5),loss最多小了4倍。这样的话hard example的权重相对就提升了很多。这样就增加了那些误分类的重要性
focal loss的两个性质算是核心,其实就是用一个合适的函数去度量难分类和易分类样本对总的损失的贡献。
-然后作者又提出了最终的focal loss形式
+
$$
\mathrm{FL}\left(p_{\mathrm{t}}\right)=-\alpha_{\mathrm{t}}\left(1-p_{\mathrm{t}}\right)^{\gamma} \log \left(p_{\mathrm{t}}\right)
$$
$$
F L(p)\left{\begin{array}{ll}
-\alpha(1-p)^{\gamma} \log (p) & \text { if } y=1 \
-(1-\alpha) p^{\gamma} \log (1-p) & \text { otherwise }
\end{array}\right.
$$
这样既能调整正负样本的权重,又能控制难易分类样本的权重
在实验中a的选择范围也很广,一般而言当γ增加的时候,a需要减小一点(实验中γ=2,a=0.25的效果最好)然后作者又提出了最终的focal loss形式
+这样既能调整正负样本的权重,又能控制难易分类样本的权重
在实验中a的选择范围也很广,一般而言当γ增加的时候,a需要减小一点(实验中γ=2,a=0.25的效果最好)总结
yolo和yolov2的严谨数学推理和网络相结合的做法令人十分惊艳,而yolov3相比之前的两个版本不管是在数据处理还是网络性质上都有很大的改变,也使用了很多流行的tirck来实现目标检测,基本上结合了很多cv领域的精髓,博客中有很多部分由于时间关系没有太细讲,其实每个部分都可以去原论文中找到很多可以学习的地方,之后有时候会补上yolov4和yolov5的讲解,后面的网络添加了注意力机制模块效果应该是更加work的。
参考文献
-
@@ -576,7 +625,7 @@yolov3-spp
+
focal loss
batch normal
IoU系列
yolov1论文翻译
yolo1-3三部曲
Bubbliiiing的教程里
还有很多但是没找到之后会补上的yolov3-spp
focal loss
batch normal
IoU系列
yolov1论文翻译
yolo1-3三部曲
Bubbliiiing的教程里
还有很多但是没找到之后会补上的- 编译原理 + 数据库系统
- diff --git "a/2021/05/09/EfficientNet\350\256\272\346\226\207\350\247\243\350\257\273\345\222\214pytorch\344\273\243\347\240\201\345\256\236\347\216\260/index.html" "b/2021/05/09/EfficientNet\350\256\272\346\226\207\350\247\243\350\257\273\345\222\214pytorch\344\273\243\347\240\201\345\256\236\347\216\260/index.html" index aa12c257..34385509 100644 --- "a/2021/05/09/EfficientNet\350\256\272\346\226\207\350\247\243\350\257\273\345\222\214pytorch\344\273\243\347\240\201\345\256\236\347\216\260/index.html" +++ "b/2021/05/09/EfficientNet\350\256\272\346\226\207\350\247\243\350\257\273\345\222\214pytorch\344\273\243\347\240\201\345\256\236\347\216\260/index.html" @@ -221,41 +221,34 @@
EfficientNet论文解读和pytorch代码实现
传送门
-论文地址:https://arxiv.org/pdf/1905.11946.pdf
官方github:https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
github参考:https://github.com/qubvel/efficientnet
github参考:https://github.com/lukemelas/EfficientNet-PyTorch摘要
谷歌的文章总是能让我印象深刻,不管从实验上还是论文的书写上都让人十分的佩服,不得不说这确实是一个非常creative的公司!
- - +Convolutional Neural Networks (ConvNets) are commonly developed at a fixed resource budget, and then scaled up for better accuracy if more resources are available. In this paper, we systematically study model scaling and identify that carefully balancing network depth, width, and resolution can lead to better performance. Based on this observation, we propose a new scaling method that uniformly scales all dimensions of depth/width/resolution using a simple yet highly effective compound coefficient. We demonstrate the effectiveness of this method on scaling up MobileNets and ResNet.
卷积神经网络通常是在固定的资源预算下进行计算和发展的,如果有更多可用的资源,模型能通过缩放和扩展获得更好的效果,本文系统研究(工作量很充足)了模型缩放,并且证明了细致地平衡网络的深度,宽度,和分辨率能够得到更好的效果,基于这个观点,我们提出了一个新的尺度缩放的方法,我们提出了一个新的尺度缩放的方法即:使用一个简单且高效的复合系数统一地缩放所有网络层的深度/宽度/分辨率的维度。我们证明了该方法在扩大MobileNets和ResNet方面的有效性。摘要
谷歌的文章总是能让我印象深刻,不管从实验上还是论文的书写上都让人十分的佩服,不得不说这确实是一个非常creative的公司!
Convolutional Neural Networks (ConvNets) are commonly developed at a fixed resource budget, and then scaled up for better accuracy if more resources are available. In this paper, we systematically study model scaling and identify that carefully balancing network depth, width, and resolution can lead to better performance. Based on this observation, we propose a new scaling method that uniformly scales all dimensions of depth/width/resolution using a simple yet highly effective compound coefficient. We demonstrate the effectiveness of this method on scaling up MobileNets and ResNet.
卷积神经网络通常是在固定的资源预算下进行计算和发展的,如果有更多可用的资源,模型能通过缩放和扩展获得更好的效果,本文系统研究(工作量很充足)了模型缩放,并且证明了细致地平衡网络的深度,宽度,和分辨率能够得到更好的效果,基于这个观点,我们提出了一个新的尺度缩放的方法,我们提出了一个新的尺度缩放的方法即:使用一个简单且高效的复合系数统一地缩放所有网络层的深度/宽度/分辨率的维度。我们证明了该方法在扩大MobileNets和ResNet方面的有效性。To go even further, we use neural architecture search to design a new baseline network and scale it up to obtain a family of models, called EfficientNets, which achieve much better accuracy and efficiency than previous ConvNets. In particular, our EfficientNet-B7 achieves state-of-the-art 84.3% top-1 accuracy on ImageNet, while being 8.4x smaller and 6.1x faster on inference than the best existing ConvNet. Our EfficientNets also transfer well and achieve state-of-the-art accuracy on CIFAR-100 (91.7%), Flowers (98.8%), and 3 other transfer learning datasets, with an order of magnitude fewer parameters. Source code is athttps://github.com/tensorflow/tpu/tree/
master/models/official/efficientnet.更进一步,我们使用神经网络结构搜索设计了一个新的baseline网络架构并且对其进行缩放得到了一组模型,我们把他叫做EfficientNets。EfficientNets相比之前的ConvNets,有着更好的准确率和更高的效率。在ImageNet上达到了最好的水平即top-1准确率84.4%/top-5准确率97.1%,然而却比已有的最好的ConvNet模型小了8.4倍并且推理时间快了6.1倍。我们的EfficientNet迁移学习的效果也好,达到了最好的准确率水平CIFAR-100(91.7%),Flowers(98.8%),和其他3个迁移学习数据集合,参数少了一个数量级(with an order of magnitude fewer parameters)。
论文思想
在之前的一些工作当中,我们可以看到,有的会通过增加网络的width即增加卷积核的个数(从而增大channels)来提升网络的性能,有的会通过增加网络的深度即使用更多的层结构来提升网络的性能,有的会通过增加输入网络的分辨率来提升网络的性能。而在Efficientnet当中则重新探究了这个问题,并提出了一种组合条件这三者的网络结构,同时量化了这三者的指标。
The intuition is that deeper ConvNet can capture richer and more complex features, and generalize well on new tasks. However, deeper networks are also more difficult to train due to the vanishing gradient problem
增加网络的深度depth能够得到更加丰富、复杂的特征并且能够在其他新任务中很好的泛化性能。但是,由于逐渐消失的梯度问题,更深层的网络也更难以训练。wider networks tend to be able to capture more fine-grained features and are easier to train. However, extremely wide but shallow networks tend to have difficulties in capturing higher level features
with更广的网络往往能够捕获更多细粒度的功能,并且更易于训练。但是,极其宽泛但较浅的网络在捕获更高级别的特征时往往会遇到困难
-With higher resolution input images, ConvNets can potentially capture more fine-grained pattern,but the accuracy gain diminishes for very high resolutions
使用更高分辨率的输入图像,ConvNets可以捕获更细粒度的图案,但对于非常高分辨率的图片,准确度会降低。作者在论文中对整个网络的运算过程和复合扩展方法进行了抽象:
-
首先定义了每一层卷积网络为$\mathcal{F}{i}\left(X{i}\right)$,而$X_i$是输入张量,$Y_i$是输出张量,而tensor的形状是$<H_i,W_i,C_i>$
整个卷积网络由 k 个卷积层组成,可以表示为$\mathcal{N}=\mathcal{F}{k} \odot \ldots \odot \mathcal{F}{2} \odot \mathcal{F}{1}\left(X{1}\right)=\bigodot_{j=1 \ldots k} \mathcal{F}{j}\left(X{1}\right)$
从而得到我们的整个卷积网络:
$$
\mathcal{N}=\bigodot_{i=1 \ldots s} \mathcal{F}{i}^{L{i}}\left(X_{\left\langle H_{i}, W_{i}, C_{i}\right\rangle}\right)
$$下标 i(从 1 到 s) 表示的是 stage 的序号,$\mathcal{F}{i}^{L{i}}$表示第 i 个 stage ,它表示卷积层 $\mathcal{F}{i}$重复了${L{i}}$ 次。
+作者在论文中对整个网络的运算过程和复合扩展方法进行了抽象:
+
首先定义了每一层卷积网络为$\mathcal{F}{i}\left(X{i}\right)$,而$Xi$是输入张量,$Y_i$是输出张量,而tensor的形状是$
整个卷积网络由 k 个卷积层组成,可以表示为$\mathcal{N}=\mathcal{F}
从而得到我们的整个卷积网络:下标 i(从 1 到 s) 表示的是 stage 的序号,$\mathcal{F}{i}^{L{i}}$表示第 i 个 stage ,它表示卷积层 $\mathcal{F}{i}$重复了${L{i}}$ 次。
为了探究$d , r , w$这三个因子对最终准确率的影响,则将$d , r , w$加入到公式中,我们可以得到抽象化后的优化问题(在指定资源限制下),其中$s.t.$代表限制条件:
- $d$用来缩放深度$\widehat{L}_i $。
- $r$用来缩放分辨率即影响$\widehat{H}_i$以及$\widehat{W}_i$。
- $w$就是用来缩放特征矩阵的channels即 $\widehat{C}_i$。
- target_memory为memory限制 -
- target_flops为FLOPs限制
Bigger networks with larger width, depth, or resolution tend to achieve higher accuracy, but the accuracy gain quickly saturate after reaching 80%, demonstrating the limitation of single dimension scaling
具有较大宽度,深度或分辨率的较大网络往往会实现较高的精度,但是精度增益在达到80%后会迅速饱和,这表明了单维缩放的局限性。compound scaling method
In this paper, we propose a new compound scaling method, which use a compound coefficient φ to uniformly scales network width, depth, and resolution in a principled way:
在本文中,我们提出了一种新的复合缩放方法,该方法使用一个统一的复合系数$\phi$对网络的宽度,深度和分辨率进行均匀缩放。
其中$\alpha,\beta,\gamma$是通过一个小格子搜索的方法决定的常量。通常来说,$\phi$是一个用户指定的系数来控制有多少的额外资源能够用于模型的缩放,$\alpha,\beta,\gamma$指明了怎么支配这些额外的资源分别到网络的宽度,深度,和分辨率上。尤其是,一个标准卷积操作的运算量的比例是$d,w^2,r^2$双倍的网络深度将带来双倍的运算量,但是双倍的网络宽度或分辨率将会增加运算为4倍。因为卷积操作通常在ConvNets中占据绝大部分计算量,通过3式来缩放ConvNet大约将增加$(\alpha,\beta^2,\gamma^2)$运算量。
+ - target_flops为FLOPs限制
Bigger networks with larger width, depth, or resolution tend to achieve higher accuracy, but the accuracy gain quickly saturate after reaching 80%, demonstrating the limitation of single dimension scaling
具有较大宽度,深度或分辨率的较大网络往往会实现较高的精度,但是精度增益在达到80%后会迅速饱和,这表明了单维缩放的局限性。compound scaling method
In this paper, we propose a new compound scaling method, which use a compound coefficient φ to uniformly scales network width, depth, and resolution in a principled way:
在本文中,我们提出了一种新的复合缩放方法,该方法使用一个统一的复合系数$\phi$对网络的宽度,深度和分辨率进行均匀缩放。
其中$\alpha,\beta,\gamma$是通过一个小格子搜索的方法决定的常量。通常来说,$\phi$是一个用户指定的系数来控制有多少的额外资源能够用于模型的缩放,$\alpha,\beta,\gamma$指明了怎么支配这些额外的资源分别到网络的宽度,深度,和分辨率上。尤其是,一个标准卷积操作的运算量的比例是$d,w^2,r^2$双倍的网络深度将带来双倍的运算量,但是双倍的网络宽度或分辨率将会增加运算为4倍。因为卷积操作通常在ConvNets中占据绝大部分计算量,通过3式来缩放ConvNet大约将增加$(\alpha,\beta^2,\gamma^2)$运算量。
我们限制$\alpha \cdot \beta^{2} \cdot \gamma^{2} \approx 2$所以对于任意给定的$\phi$值,我们总共的运算量将大约增加$2^{\phi}$
我们限制$\alpha \cdot \beta^{2} \cdot \gamma^{2} \approx 2$所以对于任意给定的$\phi$值,我们总共的运算量将大约增加$2^{\phi}$
网络结构
文中给出了Efficientnet-B0的基准框架,在Efficientnet当中,我们所使用的激活函数是swish激活函数,整个网络分为了9个stage,在第2到第8stage是一直在堆叠MBConv结构,表格当中MBConv结构后面的数字(1或6)表示的就是MBConv中第一个1x1的卷积层会将输入特征矩阵的channels扩充为n倍。Channels表示通过该Stage后输出特征矩阵的Channels。
-MBConv结构
MBConv的结构相对来说还是十分好理解的,这里是我自己画的一张结构图。
-
MBConv结构主要由一个1x1的expand conv(升维作用,包含BN和Swish激活函数)提升维度的倍率正是之前网络结构中看到的1和6,一个KxK的卷积深度可分离卷积Depthwise Conv(包含BN和Swish)k的具体值可看EfficientNet-B0的网络框架主要有3x3和5x5两种情况,一个SE模块,一个1x1的pointer conv降维作用,包含BN),一个Droupout层构成,一般情况下都添加上了残差边模块Shortcut,从而得到输出特征矩阵。
首先关于深度可分离卷积的概念是是我们需要了解的,相当于将卷积的过程拆成运算和合并两个过程,分别对应depthwise和point两个过程,这里给一个参考连接给大家就不在详细描述了Depthwise卷积与Pointwise卷积
1.由于该模块最初是用tensorflow来实现的与pytorch有一些小差别,所以在使用pytorch实现的时候我们最好将tensorflow当中的samepadding操作重新实现一下
2.在batchnormal时候的动量设置也是有一些不一样的,论文当中设置的batch_norm_momentum=0.99,在pytorch当中需要先执行1-momentum再设为参数与tensorflow不同。- +# Batch norm parameters
momentum= 1 - batch_norm_momentum # pytorch's difference from tensorflow
eps= batch_norm_epsilon
nn.BatchNorm2d(num_features=out_channels, momentum=momentum, eps=eps)MBConv结构
MBConv的结构相对来说还是十分好理解的,这里是我自己画的一张结构图。
MBConv结构主要由一个1x1的expand conv(升维作用,包含BN和Swish激活函数)提升维度的倍率正是之前网络结构中看到的1和6,一个KxK的卷积深度可分离卷积Depthwise Conv(包含BN和Swish)k的具体值可看EfficientNet-B0的网络框架主要有3x3和5x5两种情况,一个SE模块,一个1x1的pointer conv降维作用,包含BN),一个Droupout层构成,一般情况下都添加上了残差边模块Shortcut,从而得到输出特征矩阵。
首先关于深度可分离卷积的概念是是我们需要了解的,相当于将卷积的过程拆成运算和合并两个过程,分别对应depthwise和point两个过程,这里给一个参考连接给大家就不在详细描述了Depthwise卷积与Pointwise卷积
1.由于该模块最初是用tensorflow来实现的与pytorch有一些小差别,所以在使用pytorch实现的时候我们最好将tensorflow当中的samepadding操作重新实现一下
2.在batchnormal时候的动量设置也是有一些不一样的,论文当中设置的batch_norm_momentum=0.99,在pytorch当中需要先执行1-momentum再设为参数与tensorflow不同。# Batch norm parameters
momentum= 1 - batch_norm_momentum # pytorch's difference from tensorflow
eps= batch_norm_epsilon
nn.BatchNorm2d(num_features=out_channels, momentum=momentum, eps=eps)-class Conv2dSamePadding(nn.Conv2d):
"""2D Convolutions like TensorFlow, for a dynamic image size.
The padding is operated in forward function by calculating dynamically.
"""
# Tips for 'SAME' mode padding.
# Given the following:
# i: width or height
# s: stride
# k: kernel size
# d: dilation
# p: padding
# Output after Conv2d:
# o = floor((i+p-((k-1)*d+1))/s+1)
# If o equals i, i = floor((i+p-((k-1)*d+1))/s+1),
# => p = (i-1)*s+((k-1)*d+1)-i
def __init__(self, in_channels, out_channels, kernel_size,padding=0, stride=1, dilation=1,
groups=1, bias=True, padding_mode = 'zeros'):
super().__init__(in_channels, out_channels, kernel_size, stride, padding, dilation, groups, bias)
self.stride = self.stride if len(self.stride) == 2 else [self.stride[0]] * 2
def forward(self, x):
ih, iw = x.size()[-2:] # input
kh, kw = self.weight.size()[-2:] # because kernel size equals to weight size
sh, sw = self.stride # stride
# change the output size according to stride
oh, ow = math.ceil(ih/sh), math.ceil(iw/sw) # output
"""
kernel effective receptive field size: (kernel_size-1) x dilation + 1
"""
pad_h = max((oh - 1) * self.stride[0] + (kh - 1) * self.dilation[0] + 1 - ih, 0)
pad_w = max((ow - 1) * self.stride[1] + (kw - 1) * self.dilation[1] + 1 - iw, 0)
if pad_h > 0 or pad_w > 0:
x = F.pad(x, [pad_w // 2, pad_w - pad_w // 2, pad_h // 2, pad_h - pad_h // 2])
return F.conv2d(x, self.weight, self.bias, self.stride, self.padding, self.dilation, self.groups)MBConvBlock模块结构
-class ConvBNActivation(nn.Module):
"""Convolution BN Activation"""
def __init__(self,in_channels,out_channels,kernel_size,stride=1,groups=1,
bias=False,momentum=0.01,eps=1e-3,active=False):
super().__init__()
self.layer=nn.Sequential(
Conv2dSamePadding(in_channels,out_channels,kernel_size=kernel_size,
stride=stride,groups=groups, bias=bias),
nn.BatchNorm2d(num_features=out_channels, momentum=momentum, eps=eps)
)
self.active=active
self.swish = Swish()
def forward(self, x):
x = self.layer(x)
if self.active:
x=self.swish(x)
return x
class MBConvBlock(nn.Module):
def __init__(self,in_channels,out_channels,kernel_size,stride,
expand_ratio=1, momentum=0.01,eps=1e-3,
drop_connect_ratio=0.2,training=True,
se_ratio=0.25,skip=True, image_size=None):
super().__init__()
self.expand_ratio = expand_ratio
self.se_ratio = se_ratio
self.has_se = (se_ratio is not None) and (0 < se_ratio <= 1)
self.skip = skip and stride == 1 and in_channels == out_channels
# 1x1 convolution channels expansion phase
expand_channels = in_channels * self.expand_ratio # number of output channels
if self.expand_ratio != 1:
self.expand_conv = ConvBNActivation(in_channels=in_channels,out_channels=expand_channels,
momentum=momentum,eps=eps,
kernel_size=1,bias=False,active=False)
# Depthwise convolution phase
self.depthwise_conv = ConvBNActivation(in_channels=expand_channels,out_channels=expand_channels,
momentum=momentum,eps=eps,
kernel_size=kernel_size,stride=stride,groups=expand_channels,bias=False,active=False)
# Squeeze and Excitation module
if self.has_se:
sequeeze_channels = max(1,int(expand_channels*self.se_ratio))
self.se = SEModule(expand_channels,sequeeze_channels)
# Pointwise convolution phase
self.project_conv = ConvBNActivation(expand_channels,out_channels,momentum=momentum,eps=eps,
kernel_size=1,bias=False,active=True)
self.drop_connect = DropConnect(drop_connect_ratio,training)
def forward(self,x):
input_x = x
if self.expand_ratio != 1:
x = self.expand_conv(x)
x = self.depthwise_conv(x)
if self.has_se:
x = self.se(x)
x = self.project_conv(x)
if self.skip:
x = self.drop_connect(x)
x = x + input_x
return xSE模块
SE模块是通道注意力模块,该模块能够关注channel之间的关系,可以让模型自主学习到不同channel特征的重要程度。由一个全局平均池化,两个全连接层组成。第一个全连接层的节点个数是输入该MBConv特征矩阵channels的1/4 ,且使用Swish激活函数。第二个全连接层的节点个数等于Depthwise Conv层输出的特征矩阵channels,且使用Sigmoid激活函数,这里引用一下别人画好的示意图。
- -class SEModule(nn.Module):
"""Squeeze and Excitation module for channel attention"""
def __init__(self,in_channels,squeezed_channels):
super().__init__()
self.global_avg_pool = nn.AdaptiveAvgPool2d(1)
self.sequential = nn.Sequential(
nn.Conv2d(in_channels,squeezed_channels,1), # use 1x1 convolution instead of linear
Swish(),
nn.Conv2d(squeezed_channels,in_channels,1),
nn.Sigmoid()
)
def forward(self,x):
x= self.global_avg_pool(x)
y = self.sequential(x)
return x * yswish激活函数
Swish是Google提出的一种新型激活函数,其原始公式为:f(x)=x * sigmod(x),变形Swish-B激活函数的公式则为f(x)=x * sigmod(b * x),其拥有不饱和,光滑,非单调性的特征,Google在论文中的多项测试表明Swish以及Swish-B激活函数的性能即佳,在不同的数据集上都表现出了要优于当前最佳激活函数的性能。
+
$$f(x)=x \cdot \operatorname{sigmoid}(\beta x)$$
其中$\beta$是个常数或可训练的参数,Swish 具备无上界有下界、平滑、非单调的特性。swish激活函数
Swish是Google提出的一种新型激活函数,其原始公式为:f(x)=x sigmod(x),变形Swish-B激活函数的公式则为f(x)=x sigmod(b * x),其拥有不饱和,光滑,非单调性的特征,Google在论文中的多项测试表明Swish以及Swish-B激活函数的性能即佳,在不同的数据集上都表现出了要优于当前最佳激活函数的性能。
+其中$\beta$是个常数或可训练的参数,Swish 具备无上界有下界、平滑、非单调的特性。
class Swish(nn.Module):
""" swish activation function"""
def forward(self,x):
return x * torch.sigmoid(x)droupout代码实现
-class DropConnect(nn.Module):
"""Drop Connection"""
def __init__(self,ratio,training):
super().__init__()
assert 0 <= ratio <= 1
self.keep_prob = 1 - ratio
self.training=training
def forward(self,x):
if not self.training:
return x
batch_size = x.shape[0]
random_tensor = self.keep_prob
random_tensor += torch.rand([batch_size,1,1,1],dtype=x.dtype,device=x.device)
# generate binary_tensor mask according to probability (p for 0, 1-p for 1)
binary_tensor = torch.floor(random_tensor)
output = x / self.keep_prob * binary_tensor
return output总结
这里我们只给出了b0结构的代码实现,对于其他结构的实现过程就是在b0的基础上对wdith,depth,resolution都通过倍率因子统一缩放,这个部分在这个博客里面有详细的介绍EfficientNet(B0-B7)参数设置。
在本文中,我们系统地研究了ConvNet的缩放比例,分析了各因素对网络结构的影响,并确定仔细平衡网络的宽度,深度和分辨率,这是目前网络训练最重要但缺乏研究的部分,也是我们无法获得更好的准确性和效率忽略的一个部分。为解决此问题,本文作者提出了一种简单而高效的复合缩放方法,通过一个倍率因子统一缩放各部分比例并添加上通道注意力机制和残差模块,从而改善网络架构得到SOTA的效果,同时对模型各成分因子进行量化十分具有创新性。参考连接
@@ -564,7 +557,7 @@
EfficientNet网络详解
神经网络学习小记录50——Pytorch EfficientNet模型的复现详解
论文翻译
令人拍案叫绝的EfficientNet和EfficientDet
swish激活函数
Depthwise卷积与Pointwise卷积
CV领域常用的注意力机制模块(SE、CBAM)
Global Average Pooling总结
- diff --git "a/2021/06/06/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225\345\237\272\347\241\200\342\200\224\342\200\224\345\277\253\351\200\237\346\216\222\345\272\217\344\270\216\345\275\222\345\271\266\346\216\222\345\272\217/index.html" "b/2021/06/06/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225\345\237\272\347\241\200\342\200\224\342\200\224\345\277\253\351\200\237\346\216\222\345\272\217\344\270\216\345\275\222\345\271\266\346\216\222\345\272\217/index.html" index 7d4ef3be..e5972bde 100644 --- "a/2021/06/06/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225\345\237\272\347\241\200\342\200\224\342\200\224\345\277\253\351\200\237\346\216\222\345\272\217\344\270\216\345\275\222\345\271\266\346\216\222\345\272\217/index.html" +++ "b/2021/06/06/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225\345\237\272\347\241\200\342\200\224\342\200\224\345\277\253\351\200\237\346\216\222\345\272\217\344\270\216\345\275\222\345\271\266\346\216\222\345\272\217/index.html" @@ -211,15 +211,16 @@
-前言
最近在复习数据结构,顺便整理之前刷题的一些模板和技巧,希望对大家都有帮助,博客会侧重讲解的是OJ代码实现,理论部分偏少但也会写一些自己的理解。
- +
在之前大二上数据结构的时候我也有写过一个关于排序的专题介绍数据结构复习——内部排序前言
最近在复习数据结构,顺便整理之前刷题的一些模板和技巧,希望对大家都有帮助,博客会侧重讲解的是OJ代码实现,理论部分偏少但也会写一些自己的理解。
在之前大二上数据结构的时候我也有写过一个关于排序的专题介绍数据结构复习——内部排序快速排序
快速排序主要就是通过选取一个基准点,将一个区间内的数分成大于和小于两个部分,然后对左右区间再进行上述操作,直到子区间的长度为空为止。快速排序是不稳定的排序,如果需要变成稳定排序通过双关键字排序即可,通过下标控制绝对大小就能得到稳定的排序结果。
快速排序分三步走:- 确定分界点
- 调整左右区间
- 递归处理左右子区间
在代码实现当中,我们一般选取中间分位点会比较好,这样划分的区间比较平均。在遍历的过程当中每次调整区间的时间是$O(n)$,而区间递归的深度类似二叉树是$O(logn)$
+
在最好情况下,对于递归型的算法,我们利用主定理公式来计算快速排序时间复杂度得到$O(nlogn)$
$$
T(n) = 2 T\left(\frac{n}{2}\right)+\Theta(n)
$$
当然在最坏情况下,也就是数组是有序或者逆序的情况下,我们如果选择左右端点作为基准点,那么整个算法就相当于冒泡排序,递归的层数也就变成了$n$,则最坏时间复杂度为$O(n^2)$在代码实现当中,我们一般选取中间分位点会比较好,这样划分的区间比较平均。在遍历的过程当中每次调整区间的时间是$O(n)$,而区间递归的深度类似二叉树是$O(logn)$
+
在最好情况下,对于递归型的算法,我们利用主定理公式来计算快速排序时间复杂度得到$O(nlogn)$当然在最坏情况下,也就是数组是有序或者逆序的情况下,我们如果选择左右端点作为基准点,那么整个算法就相当于冒泡排序,递归的层数也就变成了$n$,则最坏时间复杂度为$O(n^2)$
代码实现
void quick_sort(int[] q,int l,int r)
{
if(l>=r) return;
// 1.确定分界点
int i = l - 1, j = r + 1, mid = q[l + r >> 1];
// 2.调整左右区间
while(i<j)
{
do i++; while(q[i]<mid);
do j--; while(q[j]>mid);
if(i<j) swap(q[i],q[j]);
}
//3.递归处理左右子区间
quick_sort(l,j);
quick_sort(j+1,r);
}经典例题
归并排序
归并排序也是基于分治的思想,每次将区间对半分,逐步递归合并有序化子区间,最终实现所有的左右区间的有序归并,但是跟快速排序不同的是,我们需要开一个辅助数组来存储有序的部分,所以时间复杂度为$O(nlogn)$。归并排序是稳定的排序,在元素相等情况下我们总是放入数组下标较小的元素。
@@ -536,7 +537,7 @@
归并排序分三步走:- 编译原理 + 数据库系统
- diff --git "a/2021/06/13/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\345\210\267\351\242\230\342\200\224\342\200\224\351\223\276\350\241\250/index.html" "b/2021/06/13/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\345\210\267\351\242\230\342\200\224\342\200\224\351\223\276\350\241\250/index.html" index be144b28..79187439 100644 --- "a/2021/06/13/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\345\210\267\351\242\230\342\200\224\342\200\224\351\223\276\350\241\250/index.html" +++ "b/2021/06/13/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\345\210\267\351\242\230\342\200\224\342\200\224\351\223\276\350\241\250/index.html" @@ -216,12 +216,9 @@
-数据结构与刷题——链表
- -
+数据结构与刷题——链表
单链表代码模板
代码实现单链表的方法有很多种,但是对于acm刷题来说,我们通常使用的是静态链表的方式,这样代码运行速度更快,防止被卡时间。
-const int N = 100010;
int head; // 头指针
int e[N]; // e[i]表示第i个节点的
int ne[N];// 第i个节点的next指针,表示当前节点的直接后继的节点编号
int idx;//记录已经存储了多少个节点
void init()
{
head = -1;//用-1表示空节点
idx = 0;
}
//在第k个节点后面插入一个新节点,节点的值为x
void insert(int k,int x)
{
e[idx] = x;
ne[idx] = ne[k];
ne[k] = idx++;
}
// 删除第k+1个节点,即将将该节点的指针指向他的下一个元素
void delete_node(int k)
{
ne[k] = ne[ne[k]];
}
void delete_head()
{
head = ne[head];
}
//遍历过程
for(int i = head; i!=-1;i = ne[i])
{
cout<<e[i]<<endl;
}双链表
在实际的代码编写过程当中,我们也是直接使用静态链表来设置双链表,我们首先设置0号点和1号点为左右边界head,tail。之后我们就只需要在这两者之间插入节点构造双链表。
@@ -530,7 +527,7 @@const int N = 100010;
int e[N];
int l[N];
int r[N];
int idx;
//初始化直接初始化出左右端点的下标,从而避免边界问题
void init()
{
//初始化的左右别搞反了
r[0] = 1;
l[1] = 0;
idx =2;
}
// 在k节点的右侧插入一个x,其实也相当于左侧插入节点
void add(int k,int x)
{
e[idx] = x;
//操作新节点的左右指针
r[idx] = r[k];
l[idx] = k;
//再操作原数组的节点
l[r[k]] = idx;
r[k] = idx++;
}
void remove(int k)
{
l[r[k]] = l[k]; //右节点的左侧,指向左节点
r[l[k]] = r[k]; //左节点的右侧,指向右节点
}- 编译原理 + 数据库系统
- diff --git "a/2021/06/15/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225\342\200\224\342\200\224\344\272\214\345\210\206/index.html" "b/2021/06/15/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225\342\200\224\342\200\224\344\272\214\345\210\206/index.html" index 7e8f1552..4c453a2d 100644 --- "a/2021/06/15/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225\342\200\224\342\200\224\344\272\214\345\210\206/index.html" +++ "b/2021/06/15/\346\225\260\346\215\256\347\273\223\346\236\204\344\270\216\347\256\227\346\263\225\342\200\224\342\200\224\344\272\214\345\210\206/index.html" @@ -213,35 +213,16 @@
-数据结构与算法——二分
最近leetcode每日一题经常出二分的题目,正好对前段时间学过的二分进行一些总结,首先这里要明确的一点是,二分的本质并不是单调性,而是通过某种条件将整个区间划分成满足条件和不满足条件的两端即可进行二分查找。
- +
在二分这个专题,主要有两种类型的划分方式,一种是整数划分,一种是浮点数划分,前一种一般是我们最熟悉的二分查找的题型,也是出题比较灵活考的比较多的一种,后一种主要是为控制实数精度而设置的浮点数二分法(建议用double,float有时候会出现精度丢失)。数据结构与算法——二分
最近leetcode每日一题经常出二分的题目,正好对前段时间学过的二分进行一些总结,首先这里要明确的一点是,二分的本质并不是单调性,而是通过某种条件将整个区间划分成满足条件和不满足条件的两端即可进行二分查找。
在二分这个专题,主要有两种类型的划分方式,一种是整数划分,一种是浮点数划分,前一种一般是我们最熟悉的二分查找的题型,也是出题比较灵活考的比较多的一种,后一种主要是为控制实数精度而设置的浮点数二分法(建议用double,float有时候会出现精度丢失)。整数二分
这里我们拿一道经典例题来给出我们二分的两个十分精妙的模板。AcWing789. 数的范围
-bool check(int x) {/* ... */} // 检查x是否满足某种性质
// 区间[l, r]被划分成[l, mid]和[mid + 1, r]时使用:
int bsearch_1(int l, int r)
{
while(l < r)
{
int mid = l + r >> 1; // 如果写r=mid则这里不需要+1
if(check(mid)) r = mid; // check()判断mid是否满足性质
else l = mid + 1;
}
return l; //退出时 l与r相等
}
// 区间[l, r]被划分成[l, mid - 1]和[mid, r]时使用:
int bsearch_2(int l, int r)
{
while(l < r)
{
int mid = l + r + 1 >> 1;
if(check(mid)) l = mid;
else r = mid - 1;
}
return l;
}浮点数二分
浮点数二分考的比较少,主要是实现对于高精度答案的控制。AcWing 790. 数的三次方根
这里有个小bug需要提醒一下,我们以求二次方根为例,我们可以知道,$x=0.01$时,$\sqrt{x}=0.1>x$,所以当我们把二分的区间设置成$[0,x]$时,我们则无法找到答案,所以设置区间的时候我们最好可以设置大一点的区间,或者设置成$[0,\max(1,x)]$- -bool check(double x) {/* ... */} // 检查x是否满足某种性质
double bsearch_3(double l, double r)
{
const double eps = 1e-8; // eps 表示精度,取决于题目对精度的要求
while(r - l > eps)
{
double mid = (l + r) / 2; // 对于浮点数二分则不需要考虑+1的问题
if(check(mid)) r = mid;
else l = mid;
}
return l;
}STL
做题当中手写二分的题其实比较少,基本上记忆上述模板就能解决所以的问题,同时我们在日常做题的时候,为了方便,我们通常是使用STL当中的函数来实现二分,且支持vector,map,set等操作,还有结构体大小比较,这里就有三个一定要记住的API。头文件引入:
-#include<algorithm>binary_search
功能:二分查找某个元素是否出现。
返回值:在数组中以二分法检索的方式查找,若在数组(要求数组元素非递减)中查找到indx元素则真,若查找不到则返回值为假。
用法实例:
a.数组用法-int a[100]= {4,10,11,30,69,70,96,100};
int b=binary_search(a,a+9,4);//查找成功,返回1
cout<<"在数组中查找元素4,结果为:"<<b<<endl;b.vector用法
--vector<int> res = {1,2,3};
cout<<binary_search(res.begin(),res.end(),3)<<endl;
-lower_bound
功能:查找非递减序列[first,last) 内第一个大于或等于某个元素的位置。
返回值:如果找到返回找到元素的地址否则返回数组边界的下一个元素的地址。(这样不注意的话会越界,小心)
用法实例:-int a[100]= {4,10,11,30,69,70,96,100};
int d=lower_bound(a,a+9,10)-a;
cout<<"在数组中查找第一个大于等于10的元素位置,结果为:"<<d<<endl;
int e=lower_bound(a,a+9,101)-a;
cout<<"在数组中查找第一个大于等于101的元素位置,结果为:"<<e<<endl;b.vector用法
-- +vector<int> res = {1,2,3};
vector<int>::iterator it = lower_bound(res.begin(),res.end(),3);//返回迭代器的位置
//如果不存在,迭代器的位置会返回res.end()
if(it==res.end()) cout<<"不存在"<<endl;
else cout<<"求出下标:"<<(it - res.begin())<<endl;
//也可以添加偏移量
vector<int>::iterator it = lower_bound(res.begin()+1,res.end(),3);STL
做题当中手写二分的题其实比较少,基本上记忆上述模板就能解决所以的问题,同时我们在日常做题的时候,为了方便,我们通常是使用STL当中的函数来实现二分,且支持vector,map,set等操作,还有结构体大小比较,这里就有三个一定要记住的API。头文件引入:
#include<algorithm>binary_search
功能:二分查找某个元素是否出现。
返回值:在数组中以二分法检索的方式查找,若在数组(要求数组元素非递减)中查找到indx元素则真,若查找不到则返回值为假。
用法实例:
a.数组用法int a[100]= {4,10,11,30,69,70,96,100};
int b=binary_search(a,a+9,4);//查找成功,返回1
cout<<"在数组中查找元素4,结果为:"<<b<<endl;
b.vector用法vector<int> res = {1,2,3};
cout<<binary_search(res.begin(),res.end(),3)<<endl;lower_bound
功能:查找非递减序列[first,last) 内第一个大于或等于某个元素的位置。
返回值:如果找到返回找到元素的地址否则返回数组边界的下一个元素的地址。(这样不注意的话会越界,小心)
用法实例:int a[100]= {4,10,11,30,69,70,96,100};
int d=lower_bound(a,a+9,10)-a;
cout<<"在数组中查找第一个大于等于10的元素位置,结果为:"<<d<<endl;
int e=lower_bound(a,a+9,101)-a;
cout<<"在数组中查找第一个大于等于101的元素位置,结果为:"<<e<<endl;
b.vector用法vector<int> res = {1,2,3};
vector<int>::iterator it = lower_bound(res.begin(),res.end(),3);//返回迭代器的位置
//如果不存在,迭代器的位置会返回res.end()
if(it==res.end()) cout<<"不存在"<<endl;
else cout<<"求出下标:"<<(it - res.begin())<<endl;
//也可以添加偏移量
vector<int>::iterator it = lower_bound(res.begin()+1,res.end(),3);upper_bound功能:查找非递减序列[first,last) 内第一个大于某个元素的位置。
-返回值:如果找到返回找到元素的地址,否则返回数组边界的下一个元素的地址。(同样这样不注意的话会越界,小心)
-
用法实例:-int a[100]= {4,10,11,30,69,70,96,100};
int d=upper_bound(a,a+9,10)-a;
cout<<"在数组中查找第一个大于等于10的元素位置,结果为:"<<d<<endl;
int e=upper_bound(a,a+9,101)-a;
cout<<"在数组中查找第一个大于等于101的元素位置,结果为:"<<e<<endl;b.vector用法
-- -vector<int> res = {1,2,3};
vector<int>::iterator it = upper_bound(res.begin(),res.end(),3);//返回迭代器的位置
//如果不存在,迭代器的位置会返回res.end()
if(it==res.end()) cout<<"不存在"<<endl;
else cout<<"求出下标:"<<(it - res.begin())<<endl;
//也可以添加偏移量
vector<int>::iterator it = upper_bound(res.begin()+1,res.end(),3);经典例题
这里我顺便给出这两天的每日一题的解题方案,里面还涉及到了一个防止溢出的二分处理trick。
-
猜数字大小- -/**
* Forward declaration of guess API.
* @param num your guess
* @return -1 if num is lower than the guess number
* 1 if num is higher than the guess number
* otherwise return 0
* int guess(int num);
*/
class Solution {
public:
int guessNumber(int n) {
int l = 1;
int r = n;
while(l<r)
{
int mid = l + (r - l >> 1);//防止溢出
if(guess(mid)<=0)
r = mid;
else
l = mid + 1;
}
return r;
}
};-class Solution {
public:
int peakIndexInMountainArray(vector<int>& arr) {
int l = 0;
int r = arr.size() - 1;
while(l<r)
{
int mid = l + r >> 1;
if(arr[mid]>arr[mid+1]) r = mid;
else l = mid+1;
}
return l;
}
};这是三叶姐姐的二分经典题型汇总,大家也可以参考一下。
+返回值:如果找到返回找到元素的地址,否则返回数组边界的下一个元素的地址。(同样这样不注意的话会越界,小心)
+
用法实例:int a[100]= {4,10,11,30,69,70,96,100};
int d=upper_bound(a,a+9,10)-a;
cout<<"在数组中查找第一个大于等于10的元素位置,结果为:"<<d<<endl;
int e=upper_bound(a,a+9,101)-a;
cout<<"在数组中查找第一个大于等于101的元素位置,结果为:"<<e<<endl;
b.vector用法vector<int> res = {1,2,3};
vector<int>::iterator it = upper_bound(res.begin(),res.end(),3);//返回迭代器的位置
//如果不存在,迭代器的位置会返回res.end()
if(it==res.end()) cout<<"不存在"<<endl;
else cout<<"求出下标:"<<(it - res.begin())<<endl;
//也可以添加偏移量
vector<int>::iterator it = upper_bound(res.begin()+1,res.end(),3);经典例题
这里我顺便给出这两天的每日一题的解题方案,里面还涉及到了一个防止溢出的二分处理trick。
@@ -546,7 +527,7 @@
猜数字大小/**
* Forward declaration of guess API.
* @param num your guess
* @return -1 if num is lower than the guess number
* 1 if num is higher than the guess number
* otherwise return 0
* int guess(int num);
*/
class Solution {
public:
int guessNumber(int n) {
int l = 1;
int r = n;
while(l<r)
{
int mid = l + (r - l >> 1);//防止溢出
if(guess(mid)<=0)
r = mid;
else
l = mid + 1;
}
return r;
}
};
山脉数组的峰顶索引class Solution {
public:
int peakIndexInMountainArray(vector<int>& arr) {
int l = 0;
int r = arr.size() - 1;
while(l<r)
{
int mid = l + r >> 1;
if(arr[mid]>arr[mid+1]) r = mid;
else l = mid+1;
}
return l;
}
};
这是三叶姐姐的二分经典题型汇总,大家也可以参考一下。- 编译原理 + 数据库系统
- diff --git "a/2021/06/16/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224voting-bagging/index.html" "b/2021/06/16/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224voting-bagging/index.html" index 16b2e732..45428e69 100644 --- "a/2021/06/16/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224voting-bagging/index.html" +++ "b/2021/06/16/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224voting-bagging/index.html" @@ -217,8 +217,7 @@
10101100100111001011011011011
这导致的结果可能是致命的。一个常用的纠错方法是重复多次发送数据,并以少数服从多数的方法确定正确的传输数据。一般情况下,错误总是发生在局部,因此融合多个数据是降低误差的一个好方法,这就是投票法的基本思路。
对于回归模型来说,投票法最终的预测结果是多个其他回归模型预测结果的平均值。
-对于分类模型,硬投票法的预测结果是多个模型预测结果中出现次数最多的类别,软投票对各类预测结果的概率进行求和,最终选取概率之和最大的类标签。
- +对于分类模型,硬投票法的预测结果是多个模型预测结果中出现次数最多的类别,软投票对各类预测结果的概率进行求和,最终选取概率之和最大的类标签。
投票法的原理分析
投票法是一种遵循少数服从多数原则的集成学习模型,通过多个模型的集成降低方差,从而提高模型的鲁棒性。在理想情况下,投票法的预测效果应当优于任何一个基模型的预测效果。
投票法在回归模型与分类模型上均可使用:
-
@@ -257,32 +256,23 @@
投票法的案例分析(基于sklearn,介绍pipe管道的使用以及voting的使用)
Sklearn中提供了 VotingRegressor 与 VotingClassifier 两个投票方法。 这两种模型的操作方式相同,并采用相同的参数。使用模型需要提供一个模型列表,列表中每个模型采用Tuple的结构表示,第一个元素代表名称,第二个元素代表模型,需要保证每个模型必须拥有唯一的名称。
例如这里,我们定义两个模型:
-models = [('lr',LogisticRegression()),('svm',SVC())]
ensemble = VotingClassifier(estimators=models)有时某些模型需要一些预处理操作,我们可以为他们定义Pipeline完成模型预处理工作:
-models = [('lr',LogisticRegression()),('svm',make_pipeline(StandardScaler(),SVC()))]
ensemble = VotingClassifier(estimators=models)模型还提供了voting参数让我们选择软投票或者硬投票:
-models = [('lr',LogisticRegression()),('svm',SVC())]
ensemble = VotingClassifier(estimators=models, voting='soft')下面我们使用一个完整的例子演示投票法的使用:
首先我们创建一个1000个样本,20个特征的随机数据集:
-# test classification dataset
from sklearn.datasets import make_classification
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=2)
# summarize the dataset
print(X.shape, y.shape)我们使用多个KNN模型作为基模型演示投票法,其中每个模型采用不同的邻居值K参数:
-# get a voting ensemble of models
def get_voting():
# define the base models
models = list()
models.append(('knn1', KNeighborsClassifier(n_neighbors=1)))
models.append(('knn3', KNeighborsClassifier(n_neighbors=3)))
models.append(('knn5', KNeighborsClassifier(n_neighbors=5)))
models.append(('knn7', KNeighborsClassifier(n_neighbors=7)))
models.append(('knn9', KNeighborsClassifier(n_neighbors=9)))
# define the voting ensemble
ensemble = VotingClassifier(estimators=models, voting='hard')
return ensemble然后,我们可以创建一个模型列表来评估投票带来的提升,包括KNN模型配置的每个独立版本和硬投票模型。下面的get_models()函数可以为我们创建模型列表进行评估。
-# get a list of models to evaluate
def get_models():
models = dict()
models['knn1'] = KNeighborsClassifier(n_neighbors=1)
models['knn3'] = KNeighborsClassifier(n_neighbors=3)
models['knn5'] = KNeighborsClassifier(n_neighbors=5)
models['knn7'] = KNeighborsClassifier(n_neighbors=7)
models['knn9'] = KNeighborsClassifier(n_neighbors=9)
models['hard_voting'] = get_voting()
return models下面的evaluate_model()函数接收一个模型实例,并以分层10倍交叉验证三次重复的分数列表的形式返回。
-# evaluate a give model using cross-validation
def evaluate_model(model, X, y):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise')
return scores然后,我们可以报告每个算法的平均性能,还可以创建一个箱形图和须状图来比较每个算法的精度分数分布。
-# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model, X, y)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()我们得到的结果如下:
->knn1 0.873 (0.030)
>knn3 0.889 (0.038)
>knn5 0.895 (0.031)
>knn7 0.899 (0.035)
>knn9 0.900 (0.033)
>hard_voting 0.902 (0.034)显然投票的效果略大于任何一个基模型。
通过箱形图我们可以看到硬投票方法对交叉验证整体预测结果分布带来的提升。
@@ -294,10 +284,8 @@bagging的案例分析(基于sklearn,介绍随机森林的相关理论以及实例)
Sklearn为我们提供了 BaggingRegressor 与 BaggingClassifier 两种Bagging方法的API,我们在这里通过一个完整的例子演示Bagging在分类问题上的具体应用。这里两种方法的默认基模型是树模型。
我们创建一个含有1000个样本20维特征的随机分类数据集:
-# test classification dataset
from sklearn.datasets import make_classification
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=5)
# summarize the dataset
print(X.shape, y.shape)我们将使用重复的分层k-fold交叉验证来评估该模型,一共重复3次,每次有10个fold。我们将评估该模型在所有重复交叉验证中性能的平均值和标准差。
-# evaluate bagging algorithm for classification
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.ensemble import BaggingClassifier
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=5)
# define the model
model = BaggingClassifier()
# evaluate the model
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise')
# report performance
print('Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))最终模型的效果是Accuracy: 0.856 标准差0.037
@@ -607,7 +595,7 @@- 编译原理 + 数据库系统
- diff --git "a/2021/06/17/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224GBDT/index.html" "b/2021/06/17/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224GBDT/index.html" index c9b411d9..326193c9 100644 --- "a/2021/06/17/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224GBDT/index.html" +++ "b/2021/06/17/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224GBDT/index.html" @@ -223,51 +223,79 @@
-梯度提升决策树(GBDT)
(1) 基于残差学习的提升树算法:
- -
在前面的学习过程中,我们一直讨论的都是分类树,比如Adaboost算法,并没有涉及回归的例子。在上一小节我们提到了一个加法模型+前向分步算法的框架,那能否使用这个框架解决回归的例子呢?答案是肯定的。接下来我们来探讨下如何使用加法模型+前向分步算法的框架实现回归问题。
在使用加法模型+前向分步算法的框架解决问题之前,我们需要首先确定框架内使用的基函数是什么,在这里我们使用决策树分类器。前面第二章我们已经学过了回归树的基本原理,树算法最重要是寻找最佳的划分点,分类树用纯度来判断最佳划分点使用信息增益(ID3算法),信息增益比(C4.5算法),基尼系数(CART分类树)。但是在回归树中的样本标签是连续数值,可划分点包含了所有特征的所有可取的值。所以再使用熵之类的指标不再合适,取而代之的是平方误差,它能很好的评判拟合程度。 基函数确定了以后,我们需要确定每次提升的标准是什么。回想Adaboost算法,在Adaboost算法内使用了分类错误率修正样本权重以及计算每个基本分类器的权重,那回归问题没有分类错误率可言,也就没办法在这里的回归问题使用了,因此我们需要另辟蹊径。模仿分类错误率,我们用每个样本的残差表示每次使用基函数预测时没有解决的那部分问题。因此,我们可以得出如下算法:输入数据集$T=\left{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \cdots,\left(x_{N}, y_{N}\right)\right}, x_{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}, y_{i} \in \mathcal{Y} \subseteq \mathbf{R}$,输出最终的提升树$f_{M}(x)$
+梯度提升决策树(GBDT)
(1) 基于残差学习的提升树算法:
在前面的学习过程中,我们一直讨论的都是分类树,比如Adaboost算法,并没有涉及回归的例子。在上一小节我们提到了一个加法模型+前向分步算法的框架,那能否使用这个框架解决回归的例子呢?答案是肯定的。接下来我们来探讨下如何使用加法模型+前向分步算法的框架实现回归问题。
在使用加法模型+前向分步算法的框架解决问题之前,我们需要首先确定框架内使用的基函数是什么,在这里我们使用决策树分类器。前面第二章我们已经学过了回归树的基本原理,树算法最重要是寻找最佳的划分点,分类树用纯度来判断最佳划分点使用信息增益(ID3算法),信息增益比(C4.5算法),基尼系数(CART分类树)。但是在回归树中的样本标签是连续数值,可划分点包含了所有特征的所有可取的值。所以再使用熵之类的指标不再合适,取而代之的是平方误差,它能很好的评判拟合程度。 基函数确定了以后,我们需要确定每次提升的标准是什么。回想Adaboost算法,在Adaboost算法内使用了分类错误率修正样本权重以及计算每个基本分类器的权重,那回归问题没有分类错误率可言,也就没办法在这里的回归问题使用了,因此我们需要另辟蹊径。模仿分类错误率,我们用每个样本的残差表示每次使用基函数预测时没有解决的那部分问题。因此,我们可以得出如下算法:
输入数据集$T=\left{\left(x{1}, y{1}\right),\left(x{2}, y{2}\right), \cdots,\left(x{N}, y{N}\right)\right}, x{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}, y{i} \in \mathcal{Y} \subseteq \mathbf{R}$,输出最终的提升树$f_{M}(x)$- 初始化$f_0(x) = 0$
- 对m = 1,2,…,M:
-
-
- 计算每个样本的残差:$r_{m i}=y_{i}-f_{m-1}\left(x_{i}\right), \quad i=1,2, \cdots, N$ -
- 拟合残差$r_{mi}$学习一棵回归树,得到$T\left(x ; \Theta_{m}\right)$ -
- 更新$f_{m}(x)=f_{m-1}(x)+T\left(x ; \Theta_{m}\right)$ +
- 计算每个样本的残差:$r{m i}=y{i}-f{m-1}\left(x{i}\right), \quad i=1,2, \cdots, N$ +
- 拟合残差$r{mi}$学习一棵回归树,得到$T\left(x ; \Theta{m}\right)$ +
- 更新$f{m}(x)=f{m-1}(x)+T\left(x ; \Theta_{m}\right)$
- - 得到最终的回归问题的提升树:$f_{M}(x)=\sum_{m=1}^{M} T\left(x ; \Theta_{m}\right)$ +
- 得到最终的回归问题的提升树:$f{M}(x)=\sum{m=1}^{M} T\left(x ; \Theta_{m}\right)$
下面我们用一个实际的案例来使用这个算法:(案例来源:李航老师《统计学习方法》)
-
训练数据如下表,学习这个回归问题的提升树模型,考虑只用树桩作为基函数。至此,我们已经能够建立起依靠加法模型+前向分步算法的框架解决回归问题的算法,叫提升树算法。那么,这个算法还是否有提升的空间呢?
+
(2) 梯度提升决策树算法(GBDT):
提升树利用加法模型和前向分步算法实现学习的过程,当损失函数为平方损失和指数损失时,每一步优化是相当简单的,也就是我们前面探讨的提升树算法和Adaboost算法。但是对于一般的损失函数而言,往往每一步的优化不是那么容易,针对这一问题,我们得分析问题的本质,也就是是什么导致了在一般损失函数条件下的学习困难。对比以下损失函数:
$$
\begin{array}{l|l|l}
\hline \text { Setting } & \text { Loss Function } & -\partial L\left(y_{i}, f\left(x_{i}\right)\right) / \partial f\left(x_{i}\right) \
\hline \text { Regression } & \frac{1}{2}\left[y_{i}-f\left(x_{i}\right)\right]^{2} & y_{i}-f\left(x_{i}\right) \
\hline \text { Regression } & \left|y_{i}-f\left(x_{i}\right)\right| & \operatorname{sign}\left[y_{i}-f\left(x_{i}\right)\right] \
\hline \text { Regression } & \text { Huber } & y_{i}-f\left(x_{i}\right) \text { for }\left|y_{i}-f\left(x_{i}\right)\right| \leq \delta_{m} \
& & \delta_{m} \operatorname{sign}\left[y_{i}-f\left(x_{i}\right)\right] \text { for }\left|y_{i}-f\left(x_{i}\right)\right|>\delta_{m} \
& & \text { where } \delta_{m}=\alpha \text { th-quantile }\left{\left|y_{i}-f\left(x_{i}\right)\right|\right} \
\hline \text { Classification } & \text { Deviance } & k \text { th component: } I\left(y_{i}=\mathcal{G}{k}\right)-p{k}\left(x_{i}\right) \
\hline
\end{array}
$$
观察Huber损失函数:
$$
L_{\delta}(y, f(x))=\left{\begin{array}{ll}
\frac{1}{2}(y-f(x))^{2} & \text { for }|y-f(x)| \leq \delta \
\delta|y-f(x)|-\frac{1}{2} \delta^{2} & \text { otherwise }
\end{array}\right.
$$
针对上面的问题,Freidman提出了梯度提升算法(gradient boosting),这是利用最速下降法的近似方法,利用损失函数的负梯度在当前模型的值$-\left[\frac{\partial L\left(y, f\left(x_{i}\right)\right)}{\partial f\left(x_{i}\right)}\right]{f(x)=f{m-1}(x)}$作为回归问题提升树算法中的残差的近似值,拟合回归树。与其说负梯度作为残差的近似值,不如说残差是负梯度的一种特例。
以下开始具体介绍梯度提升算法:
输入训练数据集$T=\left{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \cdots,\left(x_{N}, y_{N}\right)\right}, x_{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}, y_{i} \in \mathcal{Y} \subseteq \mathbf{R}$和损失函数$L(y, f(x))$,输出回归树$\hat{f}(x)$下面我们用一个实际的案例来使用这个算法:(案例来源:李航老师《统计学习方法》)
+
训练数据如下表,学习这个回归问题的提升树模型,考虑只用树桩作为基函数。至此,我们已经能够建立起依靠加法模型+前向分步算法的框架解决回归问题的算法,叫提升树算法。那么,这个算法还是否有提升的空间呢?
+
(2) 梯度提升决策树算法(GBDT):
提升树利用加法模型和前向分步算法实现学习的过程,当损失函数为平方损失和指数损失时,每一步优化是相当简单的,也就是我们前面探讨的提升树算法和Adaboost算法。但是对于一般的损失函数而言,往往每一步的优化不是那么容易,针对这一问题,我们得分析问题的本质,也就是是什么导致了在一般损失函数条件下的学习困难。对比以下损失函数:观察Huber损失函数:
+针对上面的问题,Freidman提出了梯度提升算法(gradient boosting),这是利用最速下降法的近似方法,利用损失函数的负梯度在当前模型的值$-\left[\frac{\partial L\left(y, f\left(x{i}\right)\right)}{\partial f\left(x{i}\right)}\right]{f(x)=f{m-1}(x)}$作为回归问题提升树算法中的残差的近似值,拟合回归树。与其说负梯度作为残差的近似值,不如说残差是负梯度的一种特例。
以下开始具体介绍梯度提升算法:
输入训练数据集$T=\left{\left(x{1}, y{1}\right),\left(x{2}, y{2}\right), \cdots,\left(x{N}, y{N}\right)\right}, x{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}, y{i} \in \mathcal{Y} \subseteq \mathbf{R}$和损失函数$L(y, f(x))$,输出回归树$\hat{f}(x)$-
-
- 初始化$f_{0}(x)=\arg \min {c} \sum{i=1}^{N} L\left(y_{i}, c\right)$ +
- 初始化$f{0}(x)=\arg \min {c} \sum{i=1}^{N} L\left(y{i}, c\right)$
- 对于m=1,2,…,M:
-
-
- 对i = 1,2,…,N计算:$r_{m i}=-\left[\frac{\partial L\left(y_{i}, f\left(x_{i}\right)\right)}{\partial f\left(x_{i}\right)}\right]{f(x)=f{m-1}(x)}$ -
- 对$r_{mi}$拟合一个回归树,得到第m棵树的叶结点区域$R_{m j}, j=1,2, \cdots, J$ -
- 对j=1,2,…J,计算:$c_{m j}=\arg \min {c} \sum{x_{i} \in R_{m j}} L\left(y_{i}, f_{m-1}\left(x_{i}\right)+c\right)$ -
- 更新$f_{m}(x)=f_{m-1}(x)+\sum_{j=1}^{J} c_{m j} I\left(x \in R_{m j}\right)$ +
- 对i = 1,2,…,N计算:$r{m i}=-\left[\frac{\partial L\left(y{i}, f\left(x{i}\right)\right)}{\partial f\left(x{i}\right)}\right]{f(x)=f{m-1}(x)}$ +
- 对$r{mi}$拟合一个回归树,得到第m棵树的叶结点区域$R{m j}, j=1,2, \cdots, J$ +
- 对j=1,2,…J,计算:$c{m j}=\arg \min {c} \sum{x{i} \in R{m j}} L\left(y{i}, f{m-1}\left(x{i}\right)+c\right)$ +
- 更新$f{m}(x)=f{m-1}(x)+\sum{j=1}^{J} c{m j} I\left(x \in R_{m j}\right)$
- - 得到回归树:$\hat{f}(x)=f_{M}(x)=\sum_{m=1}^{M} \sum_{j=1}^{J} c_{m j} I\left(x \in R_{m j}\right)$ +
- 得到回归树:$\hat{f}(x)=f{M}(x)=\sum{m=1}^{M} \sum{j=1}^{J} c{m j} I\left(x \in R_{m j}\right)$
下面,我们来使用一个具体的案例来说明GBDT是如何运作的(案例来源:https://blog.csdn.net/zpalyq110/article/details/79527653 ):
-
下面的表格是数据:学习率:learning_rate=0.1,迭代次数:n_trees=5,树的深度:max_depth=3
+
平方损失的负梯度为:
$$
-\left[\frac{\left.\partial L\left(y, f\left(x_{i}\right)\right)\right)}{\partial f\left(x_{i}\right)}\right]{f(x)=f{t-1}(x)}=y-f\left(x_{i}\right)
$$
$c=(1.1+1.3+1.7+1.8)/4=1.475,f_{0}(x)=c=1.475$学习率:learning_rate=0.1,迭代次数:n_trees=5,树的深度:max_depth=3
+
平方损失的负梯度为:$c=(1.1+1.3+1.7+1.8)/4=1.475,f_{0}(x)=c=1.475$
学习决策树,分裂结点:
对于左节点,只有0,1两个样本,那么根据下表我们选择年龄7进行划分:
对于右节点,只有2,3两个样本,那么根据下表我们选择年龄30进行划分:
-因此根据$\Upsilon_{j 1}=\underbrace{\arg \min }{\Upsilon} \sum{x_{i} \in R_{j 1}} L\left(y_{i}, f_{0}\left(x_{i}\right)+\Upsilon\right)$:
-
$$
\begin{array}{l}
\left(x_{0} \in R_{11}\right), \quad \Upsilon_{11}=-0.375 \
\left(x_{1} \in R_{21}\right), \quad \Upsilon_{21}=-0.175 \
\left(x_{2} \in R_{31}\right), \quad \Upsilon_{31}=0.225 \
\left(x_{3} \in R_{41}\right), \quad \Upsilon_{41}=0.325
\end{array}
$$
这里其实和上面初始化学习器是一个道理,平方损失,求导,令导数等于零,化简之后得到每个叶子节点的参数$\Upsilon$,其实就是标签值的均值。
最后得到五轮迭代:最后的强学习器为:$f(x)=f_{5}(x)=f_{0}(x)+\sum_{m=1}^{5} \sum_{j=1}^{4} \Upsilon_{j m} I\left(x \in R_{j m}\right)$。
+
其中:
$$
\begin{array}{ll}
f_{0}(x)=1.475 & f_{2}(x)=0.0205 \
f_{3}(x)=0.1823 & f_{4}(x)=0.1640 \
f_{5}(x)=0.1476
\end{array}
$$
预测结果为:
$$
f(x)=1.475+0.1 *(0.2250+0.2025+0.1823+0.164+0.1476)=1.56714
$$
为什么要用学习率呢?这是Shrinkage的思想,如果每次都全部加上(学习率为1)很容易一步学到位导致过拟合。因此根据$\Upsilon{j 1}=\underbrace{\arg \min }{\Upsilon} \sum{x{i} \in R{j 1}} L\left(y{i}, f{0}\left(x{i}\right)+\Upsilon\right)$:
+这里其实和上面初始化学习器是一个道理,平方损失,求导,令导数等于零,化简之后得到每个叶子节点的参数$\Upsilon$,其实就是标签值的均值。
+
最后得到五轮迭代:最后的强学习器为:$f(x)=f{5}(x)=f{0}(x)+\sum{m=1}^{5} \sum{j=1}^{4} \Upsilon{j m} I\left(x \in R{j m}\right)$。
+
其中:预测结果为:
+为什么要用学习率呢?这是Shrinkage的思想,如果每次都全部加上(学习率为1)很容易一步学到位导致过拟合。
下面我们来使用sklearn来使用GBDT:
- https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingRegressor.html#sklearn.ensemble.GradientBoostingRegressor
- https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingClassifier.html?highlight=gra#sklearn.ensemble.GradientBoostingClassifier
-from sklearn.metrics import mean_squared_error
from sklearn.datasets import make_friedman1
from sklearn.ensemble import GradientBoostingRegressor
'''
GradientBoostingRegressor参数解释:
loss:{‘ls’, ‘lad’, ‘huber’, ‘quantile’}, default=’ls’:‘ls’ 指最小二乘回归. ‘lad’ (最小绝对偏差) 是仅基于输入变量的顺序信息的高度鲁棒的损失函数。. ‘huber’ 是两者的结合. ‘quantile’允许分位数回归(用于alpha指定分位数)
learning_rate:学习率缩小了每棵树的贡献learning_rate。在learning_rate和n_estimators之间需要权衡。
n_estimators:要执行的提升次数。
subsample:用于拟合各个基础学习者的样本比例。如果小于1.0,则将导致随机梯度增强。subsample与参数n_estimators。选择会导致方差减少和偏差增加。subsample < 1.0
criterion:{'friedman_mse','mse','mae'},默认='friedman_mse':“ mse”是均方误差,“ mae”是平均绝对误差。默认值“ friedman_mse”通常是最好的,因为在某些情况下它可以提供更好的近似值。
min_samples_split:拆分内部节点所需的最少样本数
min_samples_leaf:在叶节点处需要的最小样本数。
min_weight_fraction_leaf:在所有叶节点处(所有输入样本)的权重总和中的最小加权分数。如果未提供sample_weight,则样本的权重相等。
max_depth:各个回归模型的最大深度。最大深度限制了树中节点的数量。调整此参数以获得最佳性能;最佳值取决于输入变量的相互作用。
min_impurity_decrease:如果节点分裂会导致杂质的减少大于或等于该值,则该节点将被分裂。
min_impurity_split:提前停止树木生长的阈值。如果节点的杂质高于阈值,则该节点将分裂
max_features{‘auto’, ‘sqrt’, ‘log2’},int或float:寻找最佳分割时要考虑的功能数量:
如果为int,则max_features在每个分割处考虑特征。
如果为float,max_features则为小数,并在每次拆分时考虑要素。int(max_features * n_features)
如果“auto”,则max_features=n_features。
如果是“ sqrt”,则max_features=sqrt(n_features)。
如果为“ log2”,则为max_features=log2(n_features)。
如果没有,则max_features=n_features。
'''
X, y = make_friedman1(n_samples=1200, random_state=0, noise=1.0)
X_train, X_test = X[:200], X[200:]
y_train, y_test = y[:200], y[200:]
reg = GradientBoostingRegressor(n_estimators=100,
learning_rate=0.1,max_depth=1, random_state=0, loss='ls')
est = reg.fit(X_train, y_train)
mean_squared_error(y_test, est.predict(X_test))- -from sklearn.datasets import make_regression
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.model_selection import train_test_split
X, y = make_regression(random_state=0)
X_train, X_test, y_train, y_test = train_test_split(
X, y, random_state=0)
reg = GradientBoostingRegressor(random_state=0)
reg.fit(X_train, y_train)
reg.score(X_test, y_test)GradientBoostingRegressor与GradientBoostingClassifier函数的各个参数的参考文档:
- https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingRegressor.html#sklearn.ensemble.GradientBoostingRegressor @@ -581,7 +609,7 @@
-
@@ -589,15 +617,15 @@
- diff --git "a/2021/06/17/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224adaboost\345\216\237\347\220\206\345\222\214sklearn\345\256\236\347\216\260/index.html" "b/2021/06/17/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224adaboost\345\216\237\347\220\206\345\222\214sklearn\345\256\236\347\216\260/index.html" index 779a7549..0081ed3a 100644 --- "a/2021/06/17/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224adaboost\345\216\237\347\220\206\345\222\214sklearn\345\256\236\347\216\260/index.html" +++ "b/2021/06/17/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224adaboost\345\216\237\347\220\206\345\222\214sklearn\345\256\236\347\216\260/index.html" @@ -211,72 +211,108 @@
-1. 导论
在前面的学习中,我们探讨了一系列简单而实用的回归和分类模型,同时也探讨了如何使用集成学习家族中的Bagging思想去优化最终的模型。Bagging思想的实质是:通过Bootstrap 的方式对全样本数据集进行抽样得到抽样子集,对不同的子集使用同一种基本模型进行拟合,然后投票得出最终的预测。我们也从前面的探讨知道:Bagging主要通过降低方差的方式减少预测误差。那么,本章介绍的Boosting是与Bagging截然不同的思想,Boosting方法是使用同一组数据集进行反复学习,得到一系列简单模型,然后组合这些模型构成一个预测性能十分强大的机器学习模型。 显然,Boosting思想提高最终的预测效果是通过不断减少偏差的形式,与Bagging有着本质的不同。在Boosting这一大类方法中,笔者主要介绍两类常用的Boosting方式:Adaptive Boosting 和 Gradient Boosting 以及它们的变体Xgboost、LightGBM以及Catboost。
- +1. 导论
在前面的学习中,我们探讨了一系列简单而实用的回归和分类模型,同时也探讨了如何使用集成学习家族中的Bagging思想去优化最终的模型。Bagging思想的实质是:通过Bootstrap 的方式对全样本数据集进行抽样得到抽样子集,对不同的子集使用同一种基本模型进行拟合,然后投票得出最终的预测。我们也从前面的探讨知道:Bagging主要通过降低方差的方式减少预测误差。那么,本章介绍的Boosting是与Bagging截然不同的思想,Boosting方法是使用同一组数据集进行反复学习,得到一系列简单模型,然后组合这些模型构成一个预测性能十分强大的机器学习模型。 显然,Boosting思想提高最终的预测效果是通过不断减少偏差的形式,与Bagging有着本质的不同。在Boosting这一大类方法中,笔者主要介绍两类常用的Boosting方式:Adaptive Boosting 和 Gradient Boosting 以及它们的变体Xgboost、LightGBM以及Catboost。
2. Boosting方法的基本思路
在正式介绍Boosting思想之前,我想先介绍两个例子:
第一个例子:不知道大家有没有做过错题本,我们将每次测验的错的题目记录在错题本上,不停的翻阅,直到我们完全掌握(也就是能够在考试中能够举一反三)。
第二个例子:对于一个复杂任务来说,将多个专家的判断进行适当的综合所作出的判断,要比其中任何一个专家单独判断要好。实际上这是一种“三个臭皮匠顶个诸葛亮的道理”。
这两个例子都说明Boosting的道理,也就是不错地重复学习达到最终的要求。
Boosting的提出与发展离不开Valiant和 Kearns的努力,历史上正是Valiant和 Kearns提出了”强可学习”和”弱可学习”的概念。那什么是”强可学习”和”弱可学习”呢?在概率近似正确PAC学习的框架下:- 弱学习:识别错误率小于1/2(即准确率仅比随机猜测略高的学习算法)
- 强学习:识别准确率很高并能在多项式时间内完成的学习算法
非常有趣的是,在PAC 学习的框架下,强可学习和弱可学习是等价的,也就是说一个概念是强可学习的充分必要条件是这个概念是弱可学习的。这样一来,问题便是:在学习中,如果已经发现了弱可学习算法,能否将他提升至强可学习算法。因为,弱可学习算法比强可学习算法容易得多。提升方法就是从弱学习算法出发,反复学习,得到一系列弱分类器(又称为基本分类器),然后通过一定的形式去组合这些弱分类器构成一个强分类器。大多数的Boosting方法都是通过改变训练数据集的概率分布(训练数据不同样本的权值),针对不同概率分布的数据调用弱分类算法学习一系列的弱分类器。
+
对于Boosting方法来说,有两个问题需要给出答案:第一个是每一轮学习应该如何改变数据的概率分布,第二个是如何将各个弱分类器组合起来。关于这两个问题,不同的Boosting算法会有不同的答案,我们接下来介绍一种最经典的Boosting算法—-Adaboost,我们需要理解Adaboost是怎么处理这两个问题以及为什么这么处理的。非常有趣的是,在PAC 学习的框架下,强可学习和弱可学习是等价的,也就是说一个概念是强可学习的充分必要条件是这个概念是弱可学习的。这样一来,问题便是:在学习中,如果已经发现了弱可学习算法,能否将他提升至强可学习算法。因为,弱可学习算法比强可学习算法容易得多。提升方法就是从弱学习算法出发,反复学习,得到一系列弱分类器(又称为基本分类器),然后通过一定的形式去组合这些弱分类器构成一个强分类器。大多数的Boosting方法都是通过改变训练数据集的概率分布(训练数据不同样本的权值),针对不同概率分布的数据调用弱分类算法学习一系列的弱分类器。
对于Boosting方法来说,有两个问题需要给出答案:第一个是每一轮学习应该如何改变数据的概率分布,第二个是如何将各个弱分类器组合起来。关于这两个问题,不同的Boosting算法会有不同的答案,我们接下来介绍一种最经典的Boosting算法——Adaboost,我们需要理解Adaboost是怎么处理这两个问题以及为什么这么处理的。3. Adaboost算法
Adaboost的基本原理
对于Adaboost来说,解决上述的两个问题的方式是:
- 提高那些被前一轮分类器错误分类的样本的权重,而降低那些被正确分类的样本的权重。这样一来,那些在上一轮分类器中没有得到正确分类的样本,由于其权重的增大而在后一轮的训练中“备受关注”。
- 各个弱分类器的组合是通过采取加权多数表决的方式,具体来说,加大分类错误率低的弱分类器的权重,因为这些分类器能更好地完成分类任务,而减小分类错误率较大的弱分类器的权重,使其在表决中起较小的作用。
现在,我们来具体介绍Adaboost算法:(参考李航老师的《统计学习方法》)
+
假设给定一个二分类的训练数据集:$T=\left{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \cdots,\left(x_{N}, y_{N}\right)\right}$ ,其中每个样本点由特征与类别组成。特征$x_{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}$,类别$y_{i} \in \mathcal{Y}={-1,+1}$,$\mathcal{X}$是特征空间,$ \mathcal{Y}$是类别集合,输出最终分类器$G(x)$。Adaboost算法如下:
(1) 初始化训练数据的分布:$D_{1}=\left(w_{11}, \cdots, w_{1 i}, \cdots, w_{1 N}\right), \quad w_{1 i}=\frac{1}{N}, \quad i=1,2, \cdots, N$
(2) 对于m=1,2,…,M现在,我们来具体介绍Adaboost算法:(参考李航老师的《统计学习方法》)
假设给定一个二分类的训练数据集:$T=\left{\left(x{1}, y{1}\right),\left(x{2}, y{2}\right), \cdots,\left(x{N}, y{N}\right)\right}$ ,其中每个样本点由特征与类别组成。特征$x{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}$,类别$y{i} \in \mathcal{Y}={-1,+1}$,$\mathcal{X}$是特征空间,$ \mathcal{Y}$是类别集合,输出最终分类器$G(x)$。Adaboost算法如下:
(1) 初始化训练数据的分布:$D{1}=\left(w{11}, \cdots, w{1 i}, \cdots, w{1 N}\right), \quad w_{1 i}=\frac{1}{N}, \quad i=1,2, \cdots, N$
(2) 对于m=1,2,…,M-
-
使用具有权值分布$D_m$的训练数据集进行学习,得到基本分类器:$G_{m}(x): \mathcal{X} \rightarrow{-1,+1}$
-
-计算$G_m(x)$在训练集上的分类误差率$e_{m}=\sum_{i=1}^{N} P\left(G_{m}\left(x_{i}\right) \neq y_{i}\right)=\sum_{i=1}^{N} w_{m i} I\left(G_{m}\left(x_{i}\right) \neq y_{i}\right)$
-
-计算$G_m(x)$的系数$\alpha_{m}=\frac{1}{2} \log \frac{1-e_{m}}{e_{m}}$,这里的log是自然对数ln
-
-更新训练数据集的权重分布
-
$$
\begin{array}{c}
D_{m+1}=\left(w_{m+1,1}, \cdots, w_{m+1, i}, \cdots, w_{m+1, N}\right) \
w_{m+1, i}=\frac{w_{m i}}{Z_{m}} \exp \left(-\alpha_{m} y_{i} G_{m}\left(x_{i}\right)\right), \quad i=1,2, \cdots, N
\end{array}
$$这里的$Z_m$是规范化因子,使得$D_{m+1}$称为概率分布,$Z_{m}=\sum_{i=1}^{N} w_{m i} \exp \left(-\alpha_{m} y_{i} G_{m}\left(x_{i}\right)\right)$
+- 使用具有权值分布$Dm$的训练数据集进行学习,得到基本分类器:$G{m}(x): \mathcal{X} \rightarrow{-1,+1}$ +
- 计算$Gm(x)$在训练集上的分类误差率$e{m}=\sum{i=1}^{N} P\left(G{m}\left(x{i}\right) \neq y{i}\right)=\sum{i=1}^{N} w{m i} I\left(G{m}\left(x{i}\right) \neq y_{i}\right)$ +
- 计算$Gm(x)$的系数$\alpha{m}=\frac{1}{2} \log \frac{1-e{m}}{e{m}}$,这里的log是自然对数ln +
更新训练数据集的权重分布
+这里的$Zm$是规范化因子,使得$D{m+1}$称为概率分布,$Z{m}=\sum{i=1}^{N} w{m i} \exp \left(-\alpha{m} y{i} G{m}\left(x_{i}\right)\right)$
(3) 构建基本分类器的线性组合$f(x)=\sum_{m=1}^{M} \alpha_{m} G_{m}(x)$,得到最终的分类器
-$$
-
\begin{aligned}
G(x) &=\operatorname{sign}(f(x)) \
&=\operatorname{sign}\left(\sum_{m=1}^{M} \alpha_{m} G_{m}(x)\right)
\end{aligned}
$$下面对Adaboost算法做如下说明:
-
对于步骤(1),假设训练数据的权值分布是均匀分布,是为了使得第一次没有先验信息的条件下每个样本在基本分类器的学习中作用一样。
对于步骤(2),每一次迭代产生的基本分类器$G_m(x)$在加权训练数据集上的分类错误率$\begin{aligned}e_{m} &=\sum_{i=1}^{N} P\left(G_{m}\left(x_{i}\right) \neq y_{i}\right) =\sum_{G_{m}\left(x_{i}\right) \neq y_{i}} w_{m i}\end{aligned}$代表了在$G_m(x)$中分类错误的样本权重和,这点直接说明了权重分布$D_m$与$G_m(x)$的分类错误率$e_m$有直接关系。同时,在步骤(2)中,计算基本分类器$G_m(x)$的系数$\alpha_m$,$\alpha_{m}=\frac{1}{2} \log \frac{1-e_{m}}{e_{m}}$,它表示了$G_m(x)$在最终分类器的重要性程度,$\alpha_m$的取值由基本分类器$G_m(x)$的分类错误率有直接关系,当$e_{m} \leqslant \frac{1}{2}$时,$\alpha_{m} \geqslant 0$,并且$\alpha_m$随着$e_m$的减少而增大,因此分类错误率越小的基本分类器在最终分类器的作用越大!
**最重要的,对于步骤(2)中的样本权重的更新: **
$$
w_{m+1, i}=\left{\begin{array}{ll}
\frac{w_{m i}}{Z_{m}} \mathrm{e}^{-\alpha_{m}}, & G_{m}\left(x_{i}\right)=y_{i} \
\frac{w_{m i}}{Z_{m}} \mathrm{e}^{\alpha_{m}}, & G_{m}\left(x_{i}\right) \neq y_{i}
\end{array}\right.
$$
因此,从上式可以看到:被基本分类器$G_m(x)$错误分类的样本的权重扩大,被正确分类的样本权重减少,二者相比相差$\mathrm{e}^{2 \alpha_{m}}=\frac{1-e_{m}}{e_{m}}$倍。
对于步骤(3),线性组合$f(x)$实现了将M个基本分类器的加权表决,系数$\alpha_m$标志了基本分类器$G_m(x)$的重要性,值得注意的是:所有的$\alpha_m$之和不为1。$f(x)$的符号决定了样本x属于哪一类。下面,我们使用一组简单的数据来手动计算Adaboost算法的过程:(例子来源:http://www.csie.edu.tw)
-训练数据如下表,假设基本分类器的形式是一个分割$x<v$或$x>v$表示,阈值v由该基本分类器在训练数据集上分类错误率$e_m$最低确定。
+
$$
\begin{array}{ccccccccccc}
\hline \text { 序号 } & 1 & 2 & 3 & 4 & 5 & 6 & 7 & 8 & 9 & 10 \
\hline x & 0 & 1 & 2 & 3 & 4 & 5 & 6 & 7 & 8 & 9 \
y & 1 & 1 & 1 & -1 & -1 & -1 & 1 & 1 & 1 & -1 \
\hline
\end{array}
$$
解:
初始化样本权值分布
$$
\begin{aligned}
D_{1} &=\left(w_{11}, w_{12}, \cdots, w_{110}\right) \
w_{1 i} &=0.1, \quad i=1,2, \cdots, 10
\end{aligned}
$$
对m=1:(3) 构建基本分类器的线性组合$f(x)=\sum{m=1}^{M} \alpha{m} G_{m}(x)$,得到最终的分类器
+下面对Adaboost算法做如下说明:
+
对于步骤(1),假设训练数据的权值分布是均匀分布,是为了使得第一次没有先验信息的条件下每个样本在基本分类器的学习中作用一样。
对于步骤(2),每一次迭代产生的基本分类器$Gm(x)$在加权训练数据集上的分类错误率$\begin{aligned}e{m} &=\sum{i=1}^{N} P\left(G{m}\left(x{i}\right) \neq y{i}\right) =\sum{G{m}\left(x{i}\right) \neq y{i}} w{m i}\end{aligned}$代表了在$G_m(x)$中分类错误的样本权重和,这点直接说明了权重分布$D_m$与$G_m(x)$的分类错误率$e_m$有直接关系。同时,在步骤(2)中,计算基本分类器$G_m(x)$的系数$\alpha_m$,$\alpha{m}=\frac{1}{2} \log \frac{1-e{m}}{e{m}}$,它表示了$Gm(x)$在最终分类器的重要性程度,$\alpha_m$的取值由基本分类器$G_m(x)$的分类错误率有直接关系,当$e{m} \leqslant \frac{1}{2}$时,$\alpha_{m} \geqslant 0$,并且$\alpha_m$随着$e_m$的减少而增大,因此分类错误率越小的基本分类器在最终分类器的作用越大!
最重要的,对于步骤(2)中的样本权重的更新:因此,从上式可以看到:被基本分类器$Gm(x)$错误分类的样本的权重扩大,被正确分类的样本权重减少,二者相比相差$\mathrm{e}^{2 \alpha{m}}=\frac{1-e{m}}{e{m}}$倍。
+
对于步骤(3),线性组合$f(x)$实现了将M个基本分类器的加权表决,系数$\alpha_m$标志了基本分类器$G_m(x)$的重要性,值得注意的是:所有的$\alpha_m$之和不为1。$f(x)$的符号决定了样本x属于哪一类。下面,我们使用一组简单的数据来手动计算Adaboost算法的过程:(例子来源:http://www.csie.edu.tw)
+训练数据如下表,假设基本分类器的形式是一个分割$x
+解:
+
初始化样本权值分布对m=1:
-
-
- 在权值分布$D_1$的训练数据集上,遍历每个结点并计算分类误差率$e_m$,阈值取v=2.5时分类误差率最低,那么基本分类器为:
$$
G_{1}(x)=\left{\begin{array}{ll}
1, & x<2.5 \
- - 1, & x>2.5
\end{array}\right.
$$
- - $G_1(x)$在训练数据集上的误差率为$e_{1}=P\left(G_{1}\left(x_{i}\right) \neq y_{i}\right)=0.3$。 -
- 计算$G_1(x)$的系数:$\alpha_{1}=\frac{1}{2} \log \frac{1-e_{1}}{e_{1}}=0.4236$ -
- 更新训练数据的权值分布:
$$
\begin{aligned}
D_{2}=&\left(w_{21}, \cdots, w_{2 i}, \cdots, w_{210}\right) \
w_{2 i}=& \frac{w_{1 i}}{Z_{1}} \exp \left(-\alpha_{1} y_{i} G_{1}\left(x_{i}\right)\right), \quad i=1,2, \cdots, 10 \
D_{2}=&(0.07143,0.07143,0.07143,0.07143,0.07143,0.07143,\
&0.16667,0.16667,0.16667,0.07143) \
f_{1}(x) &=0.4236 G_{1}(x)
\end{aligned}
$$
+ - 在权值分布$D_1$的训练数据集上,遍历每个结点并计算分类误差率$e_m$,阈值取v=2.5时分类误差率最低,那么基本分类器为: +
- $G1(x)$在训练数据集上的误差率为$e{1}=P\left(G{1}\left(x{i}\right) \neq y_{i}\right)=0.3$。 +
- 计算$G1(x)$的系数:$\alpha{1}=\frac{1}{2} \log \frac{1-e{1}}{e{1}}=0.4236$ +
- 更新训练数据的权值分布:
对于m=2:
-
-
- 在权值分布$D_2$的训练数据集上,遍历每个结点并计算分类误差率$e_m$,阈值取v=8.5时分类误差率最低,那么基本分类器为:
$$
G_{2}(x)=\left{\begin{array}{ll}
1, & x<8.5 \
- - 1, & x>8.5
\end{array}\right.
$$
+ - 在权值分布$D_2$的训练数据集上,遍历每个结点并计算分类误差率$e_m$,阈值取v=8.5时分类误差率最低,那么基本分类器为:
- $G_2(x)$在训练数据集上的误差率为$e_2 = 0.2143$
- 计算$G_2(x)$的系数:$\alpha_2 = 0.6496$ -
- 更新训练数据的权值分布:
$$
\begin{aligned}
D_{3}=&(0.0455,0.0455,0.0455,0.1667,0.1667,0.1667\
&0.1060,0.1060,0.1060,0.0455) \
f_{2}(x) &=0.4236 G_{1}(x)+0.6496 G_{2}(x)
\end{aligned}
$$
+ - 更新训练数据的权值分布:
对m=3:
-
-
- 在权值分布$D_3$的训练数据集上,遍历每个结点并计算分类误差率$e_m$,阈值取v=5.5时分类误差率最低,那么基本分类器为:
$$
G_{3}(x)=\left{\begin{array}{ll}
1, & x>5.5 \
- - 1, & x<5.5
\end{array}\right.
$$
+ - 在权值分布$D_3$的训练数据集上,遍历每个结点并计算分类误差率$e_m$,阈值取v=5.5时分类误差率最低,那么基本分类器为:
- $G_3(x)$在训练数据集上的误差率为$e_3 = 0.1820$
- 计算$G_3(x)$的系数:$\alpha_3 = 0.7514$ -
- 更新训练数据的权值分布:
$$
D_{4}=(0.125,0.125,0.125,0.102,0.102,0.102,0.065,0.065,0.065,0.125)
$$
+ - 更新训练数据的权值分布:
于是得到:$f_{3}(x)=0.4236 G_{1}(x)+0.6496 G_{2}(x)+0.7514 G_{3}(x)$,分类器$\operatorname{sign}\left[f_{3}(x)\right]$在训练数据集上的误分类点的个数为0。
+
于是得到最终分类器为:$G(x)=\operatorname{sign}\left[f_{3}(x)\right]=\operatorname{sign}\left[0.4236 G_{1}(x)+0.6496 G_{2}(x)+0.7514 G_{3}(x)\right]$于是得到:$f{3}(x)=0.4236 G{1}(x)+0.6496 G{2}(x)+0.7514 G{3}(x)$,分类器$\operatorname{sign}\left[f{3}(x)\right]$在训练数据集上的误分类点的个数为0。
于是得到最终分类器为:$G(x)=\operatorname{sign}\left[f{3}(x)\right]=\operatorname{sign}\left[0.4236 G{1}(x)+0.6496 G{2}(x)+0.7514 G_{3}(x)\right]$下面,我们使用sklearn对Adaboost算法进行建模:
本次案例我们使用一份UCI的机器学习库里的开源数据集:葡萄酒数据集,该数据集可以在 ( https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data )上获得。该数据集包含了178个样本和13个特征,从不同的角度对不同的化学特性进行描述,我们的任务是根据这些数据预测红酒属于哪一个类别。(案例来源《python机器学习(第二版》)
- -# 引入数据科学相关工具包:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use("ggplot")
%matplotlib inline
import seaborn as sns- -# 加载训练数据:
wine = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data",header=None)
wine.columns = ['Class label', 'Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash','Magnesium', 'Total phenols','Flavanoids', 'Nonflavanoid phenols',
'Proanthocyanins','Color intensity', 'Hue','OD280/OD315 of diluted wines','Proline']- -# 数据查看:
print("Class labels",np.unique(wine["Class label"]))
wine.head()下面对数据做简单解读:
- Class label:分类标签 @@ -295,35 +331,31 @@
- 初始化:$f_{0}(x)=0$
- 对m = 1,2,…,M:
-
-
- (a) 极小化损失函数:
$$
\left(\beta_{m}, \gamma_{m}\right)=\arg \min {\beta, \gamma} \sum{i=1}^{N} L\left(y_{i}, f_{m-1}\left(x_{i}\right)+\beta b\left(x_{i} ; \gamma\right)\right)
$$
得到参数$\beta_{m}$与$\gamma_{m}$
- - (b) 更新:
$$
f_{m}(x)=f_{m-1}(x)+\beta_{m} b\left(x ; \gamma_{m}\right)
$$
+ - (a) 极小化损失函数:得到参数$\beta{m}$与$\gamma{m}$ +
- (b) 更新:
- - (a) 极小化损失函数:
- 得到加法模型:
$$
f(x)=f_{M}(x)=\sum_{m=1}^{M} \beta_{m} b\left(x ; \gamma_{m}\right)
$$
+ - 得到加法模型:
-
@@ -640,15 +672,15 @@
- diff --git "a/2021/06/18/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224Xgboost-LightGBM/index.html" "b/2021/06/18/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224Xgboost-LightGBM/index.html" index d5f26def..bda69fc1 100644 --- "a/2021/06/18/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224Xgboost-LightGBM/index.html" +++ "b/2021/06/18/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224Xgboost-LightGBM/index.html" @@ -213,25 +213,48 @@
-XGBoost算法
XGBoost是陈天奇等人开发的一个开源机器学习项目,高效地实现了GBDT算法并进行了算法和工程上的许多改进,被广泛应用在Kaggle竞赛及其他许多机器学习竞赛中并取得了不错的成绩。XGBoost本质上还是一个GBDT,但是力争把速度和效率发挥到极致,所以叫X (Extreme) GBoosted, 包括前面说过,两者都是boosting方法。XGBoost是一个优化的分布式梯度增强库,旨在实现高效,灵活和便携。 它在Gradient Boosting框架下实现机器学习算法。 XGBoost提供了并行树提升(也称为GBDT,GBM),可以快速准确地解决许多数据科学问题。 相同的代码在主要的分布式环境(Hadoop,SGE,MPI)上运行,并且可以解决超过数十亿个样例的问题。XGBoost利用了核外计算并且能够使数据科学家在一个主机上处理数亿的样本数据。最终,将这些技术进行结合来做一个端到端的系统以最少的集群系统来扩展到更大的数据集上。Xgboost以CART决策树为子模型,通过Gradient Tree Boosting实现多棵CART树的集成学习,得到最终模型。下面我们来看看XGBoost的最终模型构建:
- -引用陈天奇的论文,我们的数据为:$\mathcal{D}=\left{\left(\mathbf{x}{i}, y{i}\right)\right}\left(|\mathcal{D}|=n, \mathbf{x}{i} \in \mathbb{R}^{m}, y{i} \in \mathbb{R}\right)$
+
(1) 构造目标函数:
假设有K棵树,则第i个样本的输出为$\hat{y}{i}=\phi\left(\mathrm{x}{i}\right)=\sum_{k=1}^{K} f_{k}\left(\mathrm{x}{i}\right), \quad f{k} \in \mathcal{F}$,其中,$\mathcal{F}=\left{f(\mathbf{x})=w_{q(\mathbf{x})}\right}\left(q: \mathbb{R}^{m} \rightarrow T, w \in \mathbb{R}^{T}\right)$
因此,目标函数的构建为:
$$
\mathcal{L}(\phi)=\sum_{i} l\left(\hat{y}{i}, y{i}\right)+\sum_{k} \Omega\left(f_{k}\right)
$$
其中,$\sum_{i} l\left(\hat{y}{i}, y{i}\right)$为loss function,$\sum_{k} \Omega\left(f_{k}\right)$为正则化项。
(2) 叠加式的训练(Additive Training):
给定样本$x_i$,$\hat{y}i^{(0)} = 0$(初始预测),$\hat{y}_i^{(1)} = \hat{y}_i^{(0)} + f_1(x_i)$,$\hat{y}_i^{(2)} = \hat{y}_i^{(0)} + f_1(x_i) + f_2(x_i) = \hat{y}_i^{(1)} + f_2(x_i)$…….以此类推,可以得到:$ \hat{y}_i^{(K)} = \hat{y}_i^{(K-1)} + f_K(x_i)$ ,其中,$ \hat{y}_i^{(K-1)} $ 为前K-1棵树的预测结果,$ f_K(x_i)$ 为第K棵树的预测结果。
因此,目标函数可以分解为:
$$
\mathcal{L}^{(K)}=\sum{i=1}^{n} l\left(y_{i}, \hat{y}{i}^{(K-1)}+f{K}\left(\mathrm{x}{i}\right)\right)+\sum{k} \Omega\left(f_{k}\right)
$$
由于正则化项也可以分解为前K-1棵树的复杂度加第K棵树的复杂度,因此:$\mathcal{L}^{(K)}=\sum_{i=1}^{n} l\left(y_{i}, \hat{y}{i}^{(K-1)}+f{K}\left(\mathrm{x}{i}\right)\right)+\sum{k=1} ^{K-1}\Omega\left(f_{k}\right)+\Omega\left(f_{K}\right)$,由于$\sum_{k=1} ^{K-1}\Omega\left(f_{k}\right)$在模型构建到第K棵树的时候已经固定,无法改变,因此是一个已知的常数,可以在最优化的时候省去,故:
$$
\mathcal{L}^{(K)}=\sum_{i=1}^{n} l\left(y_{i}, \hat{y}{i}^{(K-1)}+f{K}\left(\mathrm{x}{i}\right)\right)+\Omega\left(f{K}\right)
$$
(3) 使用泰勒级数近似目标函数:
$$
\mathcal{L}^{(K)} \simeq \sum_{i=1}^{n}\left[l\left(y_{i}, \hat{y}^{(K-1)}\right)+g_{i} f_{K}\left(\mathrm{x}{i}\right)+\frac{1}{2} h{i} f_{K}^{2}\left(\mathrm{x}{i}\right)\right]+\Omega\left(f{K}\right)
$$
其中,$g_{i}=\partial_{\hat{y}(t-1)} l\left(y_{i}, \hat{y}^{(t-1)}\right)$和$h_{i}=\partial_{\hat{y}^{(t-1)}}^{2} l\left(y_{i}, \hat{y}^{(t-1)}\right)$
在这里,我们补充下泰勒级数的相关知识:
在数学中,泰勒级数(英语:Taylor series)用无限项连加式——级数来表示一个函数,这些相加的项由函数在某一点的导数求得。具体的形式如下:
$$
f(x)=\frac{f\left(x_{0}\right)}{0 !}+\frac{f^{\prime}\left(x_{0}\right)}{1 !}\left(x-x_{0}\right)+\frac{f^{\prime \prime}\left(x_{0}\right)}{2 !}\left(x-x_{0}\right)^{2}+\ldots+\frac{f^{(n)}\left(x_{0}\right)}{n !}\left(x-x_{0}\right)^{n}+……
$$
由于$\sum_{i=1}^{n}l\left(y_{i}, \hat{y}^{(K-1)}\right)$在模型构建到第K棵树的时候已经固定,无法改变,因此是一个已知的常数,可以在最优化的时候省去,故:
$$
\tilde{\mathcal{L}}^{(K)}=\sum_{i=1}^{n}\left[g_{i} f_{K}\left(\mathbf{x}{i}\right)+\frac{1}{2} h{i} f_{K}^{2}\left(\mathbf{x}{i}\right)\right]+\Omega\left(f{K}\right)
$$
(4) 如何定义一棵树:
为了说明如何定义一棵树的问题,我们需要定义几个概念:第一个概念是样本所在的节点位置$q(x)$,第二个概念是有哪些样本落在节点j上$I_{j}=\left{i \mid q\left(\mathbf{x}{i}\right)=j\right}$,第三个概念是每个结点的预测值$w{q(x)}$,第四个概念是模型复杂度$\Omega\left(f_{K}\right)$,它可以由叶子节点的个数以及节点函数值来构建,则:$\Omega\left(f_{K}\right) = \gamma T+\frac{1}{2} \lambda \sum_{j=1}^{T} w_{j}^{2}$。如下图的例子:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-t1tei3pE-1623946035306)(./16.png)]
$q(x_1) = 1,q(x_2) = 3,q(x_3) = 1,q(x_4) = 2,q(x_5) = 3$,$I_1 = {1,3},I_2 = {4},I_3 = {2,5}$,$w = (15,12,20)$
因此,目标函数用以上符号替代后:
$$
\begin{aligned}
\tilde{\mathcal{L}}^{(K)} &=\sum_{i=1}^{n}\left[g_{i} f_{K}\left(\mathrm{x}{i}\right)+\frac{1}{2} h{i} f_{K}^{2}\left(\mathrm{x}{i}\right)\right]+\gamma T+\frac{1}{2} \lambda \sum{j=1}^{T} w_{j}^{2} \
&=\sum_{j=1}^{T}\left[\left(\sum_{i \in I_{j}} g_{i}\right) w_{j}+\frac{1}{2}\left(\sum_{i \in I_{j}} h_{i}+\lambda\right) w_{j}^{2}\right]+\gamma T
\end{aligned}
$$
由于我们的目标就是最小化目标函数,现在的目标函数化简为一个关于w的二次函数:$\tilde{\mathcal{L}}^{(K)}=\sum_{j=1}^{T}\left[\left(\sum_{i \in I_{j}} g_{i}\right) w_{j}+\frac{1}{2}\left(\sum_{i \in I_{j}} h_{i}+\lambda\right) w_{j}^{2}\right]+\gamma T$,根据二次函数求极值的公式:$y=ax^2 bx c$求极值,对称轴在$x=-\frac{b}{2 a}$,极值为$y=\frac{4 a c-b^{2}}{4 a}$,因此:
$$
w_{j}^{*}=-\frac{\sum_{i \in I_{j}} g_{i}}{\sum_{i \in I_{j}} h_{i}+\lambda}
$$
以及
$$
\tilde{\mathcal{L}}^{(K)}(q)=-\frac{1}{2} \sum_{j=1}^{T} \frac{\left(\sum_{i \in I_{j}} g_{i}\right)^{2}}{\sum_{i \in I_{j}} h_{i}+\lambda}+\gamma T
$$
(5) 如何寻找树的形状:
不难发现,刚刚的讨论都是基于树的形状已经确定了计算$w$和$L$,但是实际上我们需要像学习决策树一样找到树的形状。因此,我们借助决策树学习的方式,使用目标函数的变化来作为分裂节点的标准。我们使用一个例子来说明:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nCrhWA4S-1623946035310)(./17.png)]
例子中有8个样本,分裂方式如下,因此:
$$
\tilde{\mathcal{L}}^{(old)} = -\frac{1}{2}[\frac{(g_7 + g_8)^2}{H_7+H_8 + \lambda} + \frac{(g_1 +…+ g_6)^2}{H_1+…+H_6 + \lambda}] + 2\gamma \
\tilde{\mathcal{L}}^{(new)} = -\frac{1}{2}[\frac{(g_7 + g_8)^2}{H_7+H_8 + \lambda} + \frac{(g_1 +…+ g_3)^2}{H_1+…+H_3 + \lambda} + \frac{(g_4 +…+ g_6)^2}{H_4+…+H_6 + \lambda}] + 3\gamma\
\tilde{\mathcal{L}}^{(old)} - \tilde{\mathcal{L}}^{(new)} = \frac{1}{2}[ \frac{(g_1 +…+ g_3)^2}{H_1+…+H_3 + \lambda} + \frac{(g_4 +…+ g_6)^2}{H_4+…+H_6 + \lambda} - \frac{(g_1+…+g_6)^2}{h_1+…+h_6+\lambda}] - \gamma
$$
因此,从上面的例子看出:分割节点的标准为$max{\tilde{\mathcal{L}}^{(old)} - \tilde{\mathcal{L}}^{(new)} }$,即:
$$
\mathcal{L}{\text {split }}=\frac{1}{2}\left[\frac{\left(\sum{i \in I_{L}} g_{i}\right)^{2}}{\sum_{i \in I_{L}} h_{i}+\lambda}+\frac{\left(\sum_{i \in I_{R}} g_{i}\right)^{2}}{\sum_{i \in I_{R}} h_{i}+\lambda}-\frac{\left(\sum_{i \in I} g_{i}\right)^{2}}{\sum_{i \in I} h_{i}+\lambda}\right]-\gamma
$$
(6.1) 精确贪心分裂算法:
XGBoost在生成新树的过程中,最基本的操作是节点分裂。节点分裂中最重 要的环节是找到最优特征及最优切分点, 然后将叶子节点按照最优特征和最优切 分点进行分裂。选取最优特征和最优切分点的一种思路如下:首先找到所有的候 选特征及所有的候选切分点, 一一求得其 $\mathcal{L}{\text {split }}$, 然后选择$\mathcal{L}{\mathrm{split}}$ 最大的特征及 对应切分点作为最优特征和最优切分点。我们称此种方法为精确贪心算法。该算法是一种启发式算法, 因为在节点分裂时只选择当前最优的分裂策略, 而非全局最优的分裂策略。精确贪心算法的计算过程如下所示:XGBoost算法
XGBoost是陈天奇等人开发的一个开源机器学习项目,高效地实现了GBDT算法并进行了算法和工程上的许多改进,被广泛应用在Kaggle竞赛及其他许多机器学习竞赛中并取得了不错的成绩。XGBoost本质上还是一个GBDT,但是力争把速度和效率发挥到极致,所以叫X (Extreme) GBoosted, 包括前面说过,两者都是boosting方法。XGBoost是一个优化的分布式梯度增强库,旨在实现高效,灵活和便携。 它在Gradient Boosting框架下实现机器学习算法。 XGBoost提供了并行树提升(也称为GBDT,GBM),可以快速准确地解决许多数据科学问题。 相同的代码在主要的分布式环境(Hadoop,SGE,MPI)上运行,并且可以解决超过数十亿个样例的问题。XGBoost利用了核外计算并且能够使数据科学家在一个主机上处理数亿的样本数据。最终,将这些技术进行结合来做一个端到端的系统以最少的集群系统来扩展到更大的数据集上。Xgboost以CART决策树为子模型,通过Gradient Tree Boosting实现多棵CART树的集成学习,得到最终模型。下面我们来看看XGBoost的最终模型构建:
+
引用陈天奇的论文,我们的数据为:$\mathcal{D}=\left{\left(\mathbf{x}{i}, y{i}\right)\right}\left(|\mathcal{D}|=n, \mathbf{x}{i} \in \mathbb{R}^{m}, y{i} \in \mathbb{R}\right)$
(1) 构造目标函数:
假设有K棵树,则第i个样本的输出为$\hat{y}{i}=\phi\left(\mathrm{x}{i}\right)=\sum{k=1}^{K} f{k}\left(\mathrm{x}{i}\right), \quad f{k} \in \mathcal{F}$,其中,$\mathcal{F}=\left{f(\mathbf{x})=w_{q(\mathbf{x})}\right}\left(q: \mathbb{R}^{m} \rightarrow T, w \in \mathbb{R}^{T}\right)$
因此,目标函数的构建为:其中,$\sum{i} l\left(\hat{y}{i}, y{i}\right)$为loss function,$\sum{k} \Omega\left(f_{k}\right)$为正则化项。
+
(2) 叠加式的训练(Additive Training):
给定样本$x_i$,$\hat{y}_i^{(0)} = 0$(初始预测),$\hat{y}_i^{(1)} = \hat{y}_i^{(0)} + f_1(x_i)$,$\hat{y}_i^{(2)} = \hat{y}_i^{(0)} + f_1(x_i) + f_2(x_i) = \hat{y}_i^{(1)} + f_2(x_i)$…….以此类推,可以得到:$ \hat{y}_i^{(K)} = \hat{y}_i^{(K-1)} + f_K(x_i)$ ,其中,$ \hat{y}_i^{(K-1)} $ 为前K-1棵树的预测结果,$ f_K(x_i)$ 为第K棵树的预测结果。
因此,目标函数可以分解为:由于正则化项也可以分解为前K-1棵树的复杂度加第K棵树的复杂度,因此:$\mathcal{L}^{(K)}=\sum{i=1}^{n} l\left(y{i}, \hat{y}{i}^{(K-1)}+f{K}\left(\mathrm{x}{i}\right)\right)+\sum{k=1} ^{K-1}\Omega\left(f{k}\right)+\Omega\left(f{K}\right)$,由于$\sum{k=1} ^{K-1}\Omega\left(f{k}\right)$在模型构建到第K棵树的时候已经固定,无法改变,因此是一个已知的常数,可以在最优化的时候省去,故:
+(3) 使用泰勒级数近似目标函数:
+其中,$g{i}=\partial{\hat{y}(t-1)} l\left(y{i}, \hat{y}^{(t-1)}\right)$和$h{i}=\partial{\hat{y}^{(t-1)}}^{2} l\left(y{i}, \hat{y}^{(t-1)}\right)$
+
在这里,我们补充下泰勒级数的相关知识:
在数学中,泰勒级数(英语:Taylor series)用无限项连加式——级数来表示一个函数,这些相加的项由函数在某一点的导数求得。具体的形式如下:由于$\sum{i=1}^{n}l\left(y{i}, \hat{y}^{(K-1)}\right)$在模型构建到第K棵树的时候已经固定,无法改变,因此是一个已知的常数,可以在最优化的时候省去,故:
+(4) 如何定义一棵树:
+
为了说明如何定义一棵树的问题,我们需要定义几个概念:第一个概念是样本所在的节点位置$q(x)$,第二个概念是有哪些样本落在节点j上$I{j}=\left{i \mid q\left(\mathbf{x}{i}\right)=j\right}$,第三个概念是每个结点的预测值$w{q(x)}$,第四个概念是模型复杂度$\Omega\left(f{K}\right)$,它可以由叶子节点的个数以及节点函数值来构建,则:$\Omega\left(f{K}\right) = \gamma T+\frac{1}{2} \lambda \sum{j=1}^{T} w_{j}^{2}$。如下图的例子:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-t1tei3pE-1623946035306)(./16.png)]
$q(x_1) = 1,q(x_2) = 3,q(x_3) = 1,q(x_4) = 2,q(x_5) = 3$,$I_1 = {1,3},I_2 = {4},I_3 = {2,5}$,$w = (15,12,20)$
因此,目标函数用以上符号替代后:由于我们的目标就是最小化目标函数,现在的目标函数化简为一个关于w的二次函数:$\tilde{\mathcal{L}}^{(K)}=\sum{j=1}^{T}\left[\left(\sum{i \in I{j}} g{i}\right) w{j}+\frac{1}{2}\left(\sum{i \in I{j}} h{i}+\lambda\right) w_{j}^{2}\right]+\gamma T$,根据二次函数求极值的公式:$y=ax^2 bx c$求极值,对称轴在$x=-\frac{b}{2 a}$,极值为$y=\frac{4 a c-b^{2}}{4 a}$,因此:
+以及
+(5) 如何寻找树的形状:
+
不难发现,刚刚的讨论都是基于树的形状已经确定了计算$w$和$L$,但是实际上我们需要像学习决策树一样找到树的形状。因此,我们借助决策树学习的方式,使用目标函数的变化来作为分裂节点的标准。我们使用一个例子来说明:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nCrhWA4S-1623946035310)(./17.png)]
例子中有8个样本,分裂方式如下,因此:因此,从上面的例子看出:分割节点的标准为$max{\tilde{\mathcal{L}}^{(old)} - \tilde{\mathcal{L}}^{(new)} }$,即:
+(6.1) 精确贪心分裂算法:
XGBoost在生成新树的过程中,最基本的操作是节点分裂。节点分裂中最重 要的环节是找到最优特征及最优切分点, 然后将叶子节点按照最优特征和最优切 分点进行分裂。选取最优特征和最优切分点的一种思路如下:首先找到所有的候 选特征及所有的候选切分点, 一一求得其 $\mathcal{L}{\text {split }}$, 然后选择$\mathcal{L}{\mathrm{split}}$ 最大的特征及 对应切分点作为最优特征和最优切分点。我们称此种方法为精确贪心算法。该算法是一种启发式算法, 因为在节点分裂时只选择当前最优的分裂策略, 而非全局最优的分裂策略。精确贪心算法的计算过程如下所示:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HRrbM0fp-1623946035312)(./18.png)]
-(6.2) 基于直方图的近似算法:
-
精确贪心算法在选择最优特征和最优切分点时是一种十分有效的方法。它计算了所有特征、所有切分点的收益, 并从中选择了最优的, 从而保证模型能比较好地拟合了训练数据。但是当数据不能完全加载到内存时,精确贪心算法会变得 非常低效,算法在计算过程中需要不断在内存与磁盘之间进行数据交换,这是个非常耗时的过程, 并且在分布式环境中面临同样的问题。为了能够更高效地选 择最优特征及切分点, XGBoost提出一种近似算法来解决该问题。 基于直方图的近似算法的主要思想是:对某一特征寻找最优切分点时,首先对该特征的所有切分点按分位数 (如百分位) 分桶, 得到一个候选切分点集。特征的每一个切分点都可以分到对应的分桶; 然后,对每个桶计算特征统计G和H得到直方图, G为该桶内所有样本一阶特征统计g之和, H为该桶内所有样本二阶特征统计h之和; 最后,选择所有候选特征及候选切分点中对应桶的特征统计收益最大的作为最优特征及最优切分点。基于直方图的近似算法的计算过程如下所示:-
-
- 对于每个特征 $k=1,2, \cdots, m,$ 按分位数对特征 $k$ 分桶 $\Theta,$ 可得候选切分点, $S_{k}=\left{S_{k 1}, S_{k 2}, \cdots, S_{k l}\right}^{1}$ -
- 对于每个特征 $k=1,2, \cdots, m,$ 有:
$$
\begin{array}{l}
G_{k v} \leftarrow=\sum_{j \in\left{j \mid s_{k, v} \geq \mathbf{x}{j k}>s{k, v-1;}\right}} g_{j} \
H_{k v} \leftarrow=\sum_{j \in\left{j \mid s_{k, v} \geq \mathbf{x}{j k}>s{k, v-1;}\right}} h_{j}
\end{array}
$$
- - 类似精确贪心算法,依据梯度统计找到最大增益的候选切分点。
下面用一个例子说明基于直方图的近似算法:
假设有一个年龄特征,其特征的取值为18、19、21、31、36、37、55、57,我们需要使用近似算法找到年龄这个特征的最佳分裂点:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MKLD2poX-1623946035314)(./19.png)]
-
(6.2) 基于直方图的近似算法:
+
精确贪心算法在选择最优特征和最优切分点时是一种十分有效的方法。它计算了所有特征、所有切分点的收益, 并从中选择了最优的, 从而保证模型能比较好地拟合了训练数据。但是当数据不能完全加载到内存时,精确贪心算法会变得 非常低效,算法在计算过程中需要不断在内存与磁盘之间进行数据交换,这是个非常耗时的过程, 并且在分布式环境中面临同样的问题。为了能够更高效地选 择最优特征及切分点, XGBoost提出一种近似算法来解决该问题。 基于直方图的近似算法的主要思想是:对某一特征寻找最优切分点时,首先对该特征的所有切分点按分位数 (如百分位) 分桶, 得到一个候选切分点集。特征的每一个切分点都可以分到对应的分桶; 然后,对每个桶计算特征统计G和H得到直方图, G为该桶内所有样本一阶特征统计g之和, H为该桶内所有样本二阶特征统计h之和; 最后,选择所有候选特征及候选切分点中对应桶的特征统计收益最大的作为最优特征及最优切分点。基于直方图的近似算法的计算过程如下所示:
1) 对于每个特征 $k=1,2, \cdots, m,$ 按分位数对特征 $k$ 分桶 $\Theta,$ 可得候选切分点, $S{k}=\left{S{k 1}, S{k 2}, \cdots, S{k l}\right}^{1}$
2) 对于每个特征 $k=1,2, \cdots, m,$ 有:3) 类似精确贪心算法,依据梯度统计找到最大增益的候选切分点。
下面用一个例子说明基于直方图的近似算法:
假设有一个年龄特征,其特征的取值为18、19、21、31、36、37、55、57,我们需要使用近似算法找到年龄这个特征的最佳分裂点:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MKLD2poX-1623946035314)(./19.png)]近似算法实现了两种候选切分点的构建策略:全局策略和本地策略。全局策略是在树构建的初始阶段对每一个特征确定一个候选切分点的集合, 并在该树每一层的节点分裂中均采用此集合计算收益, 整个过程候选切分点集合不改变。本地策略则是在每一次节点分裂时均重新确定候选切分点。全局策略需要更细的分桶才能达到本地策略的精确度, 但全局策略在选取候选切分点集合时比本地策略更简单。在XGBoost系统中, 用户可以根据需求自由选择使用精确贪心算法、近似算法全局策略、近似算法本地策略, 算法均可通过参数进行配置。
以上是XGBoost的理论部分,下面我们对XGBoost系统进行详细的讲解:
官方文档:https://xgboost.readthedocs.io/en/latest/python/python_intro.html
知乎总结:https://zhuanlan.zhihu.com/p/143009353- -# XGBoost原生工具库的上手:
import xgboost as xgb # 引入工具库
# read in data
dtrain = xgb.DMatrix('demo/data/agaricus.txt.train') # XGBoost的专属数据格式,但是也可以用dataframe或者ndarray
dtest = xgb.DMatrix('demo/data/agaricus.txt.test') # # XGBoost的专属数据格式,但是也可以用dataframe或者ndarray
# specify parameters via map
param = {'max_depth':2, 'eta':1, 'objective':'binary:logistic' } # 设置XGB的参数,使用字典形式传入
num_round = 2 # 使用线程数
bst = xgb.train(param, dtrain, num_round) # 训练
# make prediction
preds = bst.predict(dtest) # 预测XGBoost的参数设置(括号内的名称为sklearn接口对应的参数名字):
+
推荐博客:https://link.zhihu.com/?target=https%3A//blog.csdn.net/luanpeng825485697/article/details/79907149
推荐官方文档:https://link.zhihu.com/?target=https%3A//xgboost.readthedocs.io/en/latest/parameter.htmlXGBoost的参数设置(括号内的名称为sklearn接口对应的参数名字):
推荐博客:https://link.zhihu.com/?target=https%3A//blog.csdn.net/luanpeng825485697/article/details/79907149
推荐官方文档:https://link.zhihu.com/?target=https%3A//xgboost.readthedocs.io/en/latest/parameter.htmlXGBoost的参数分为三种:
-
-
通用参数:(两种类型的booster,因为tree的性能比线性回归好得多,因此我们很少用线性回归。)
--
+
- 通用参数:(两种类型的booster,因为tree的性能比线性回归好得多,因此我们很少用线性回归。)
- booster:使用哪个弱学习器训练,默认gbtree,可选gbtree,gblinear 或dart
- nthread:用于运行XGBoost的并行线程数,默认为最大可用线程数
- verbosity:打印消息的详细程度。有效值为0(静默),1(警告),2(信息),3(调试)。 @@ -324,7 +347,6 @@
- max_depth 和 min_child_weight 参数调优
--
+
- gamma参数调优
--
+
- subsample 和 colsample_bytree 参数优
--
+
- 正则化参数alpha调优
--
+
- 降低学习速率和使用更多的决策树
@@ -357,38 +379,29 @@
-# 1.LibSVM文本格式文件
dtrain = xgb.DMatrix('train.svm.txt')
dtest = xgb.DMatrix('test.svm.buffer')
# 2.CSV文件(不能含类别文本变量,如果存在文本变量请做特征处理如one-hot)
dtrain = xgb.DMatrix('train.csv?format=csv&label_column=0')
dtest = xgb.DMatrix('test.csv?format=csv&label_column=0')
# 3.NumPy数组
data = np.random.rand(5, 10) # 5 entities, each contains 10 features
label = np.random.randint(2, size=5) # binary target
dtrain = xgb.DMatrix(data, label=label)
# 4.scipy.sparse数组
csr = scipy.sparse.csr_matrix((dat, (row, col)))
dtrain = xgb.DMatrix(csr)
# pandas数据框dataframe
data = pandas.DataFrame(np.arange(12).reshape((4,3)), columns=['a', 'b', 'c'])
label = pandas.DataFrame(np.random.randint(2, size=4))
dtrain = xgb.DMatrix(data, label=label)笔者推荐:先保存到XGBoost二进制文件中将使加载速度更快,然后再加载进来
-# 1.保存DMatrix到XGBoost二进制文件中
dtrain = xgb.DMatrix('train.svm.txt')
dtrain.save_binary('train.buffer')
# 2. 缺少的值可以用DMatrix构造函数中的默认值替换:
dtrain = xgb.DMatrix(data, label=label, missing=-999.0)
# 3.可以在需要时设置权重:
w = np.random.rand(5, 1)
dtrain = xgb.DMatrix(data, label=label, missing=-999.0, weight=w)参数的设置方式:
-import pandas as pd
# 加载并处理数据
df_wine = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data',header=None)
df_wine.columns = ['Class label', 'Alcohol','Malic acid', 'Ash','Alcalinity of ash','Magnesium', 'Total phenols',
'Flavanoids', 'Nonflavanoid phenols','Proanthocyanins','Color intensity', 'Hue','OD280/OD315 of diluted wines','Proline']
df_wine = df_wine[df_wine['Class label'] != 1] # drop 1 class
y = df_wine['Class label'].values
X = df_wine[['Alcohol','OD280/OD315 of diluted wines']].values
from sklearn.model_selection import train_test_split # 切分训练集与测试集
from sklearn.preprocessing import LabelEncoder # 标签化分类变量
le = LabelEncoder()
y = le.fit_transform(y)
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=1,stratify=y)
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test)
# 1.Booster 参数
params = {
'booster': 'gbtree',
'objective': 'multi:softmax', # 多分类的问题
'num_class': 10, # 类别数,与 multisoftmax 并用
'gamma': 0.1, # 用于控制是否后剪枝的参数,越大越保守,一般0.1、0.2这样子。
'max_depth': 12, # 构建树的深度,越大越容易过拟合
'lambda': 2, # 控制模型复杂度的权重值的L2正则化项参数,参数越大,模型越不容易过拟合。
'subsample': 0.7, # 随机采样训练样本
'colsample_bytree': 0.7, # 生成树时进行的列采样
'min_child_weight': 3,
'silent': 1, # 设置成1则没有运行信息输出,最好是设置为0.
'eta': 0.007, # 如同学习率
'seed': 1000,
'nthread': 4, # cpu 线程数
'eval_metric':'auc'
}
plst = list(params.items())
# evallist = [(dtest, 'eval'), (dtrain, 'train')] # 指定验证集训练:
-# 2.训练
num_round = 10
bst = xgb.train(plst, dtrain, num_round)
#bst = xgb.train( plst, dtrain, num_round, evallist )保存模型:
-# 3.保存模型
bst.save_model('0001.model')
# dump model
bst.dump_model('dump.raw.txt')
# dump model with feature map
#bst.dump_model('dump.raw.txt', 'featmap.txt')加载保存的模型:
-# 4.加载保存的模型:
bst = xgb.Booster({'nthread': 4}) # init model
bst.load_model('0001.model') # load data设置早停机制:
-# 5.也可以设置早停机制(需要设置验证集)
train(..., evals=evals, early_stopping_rounds=10)预测:
-# 6.预测
ypred = bst.predict(dtest)绘制重要性特征图:
-# 1.绘制重要性
xgb.plot_importance(bst)
# 2.绘制输出树
#xgb.plot_tree(bst, num_trees=2)
# 3.使用xgboost.to_graphviz()将目标树转换为graphviz
#xgb.to_graphviz(bst, num_trees=2)
+7. Xgboost算法案例
分类案例
-from sklearn.datasets import load_iris
import xgboost as xgb
from xgboost import plot_importance
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score # 准确率
# 加载样本数据集
iris = load_iris()
X,y = iris.data,iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1234565) # 数据集分割
params = {
'booster' : 'gbtree',
'objective': 'multi:softmax', # 多分类的问题
'num_class': 3,
'gamma': 0.1, # 默认= 0,分裂节点时,损失函数减小值只有大于等于gamma节点才分裂,gamma值越大,算法越保守,越不容易过拟合,但性能就不一定能保证,需要平衡。
'max_depth': 12, # 树的最大深度
'lambda': 2, # 控制模型复杂度的权重值的L2正则化项参数,参数越大,模型越不容易过拟合。
'subsample': 0.7, # 随机采样训练样本
'colsample_bytree': 0.7, # 生成树时进行的列采样,列采样率,也就是特征采样率
'min_child_weight': 3,
'silent': 0,
'eta': 0.1,
'seed': 1,
'nthread': 4,
}
plst = list(params.items())
dtrain = xgb.DMatrix(X_train,y_train)
num_rounds = 500
model = xgb.train(plst,dtrain,num_rounds) # xgboost模型训练
# 对测试集进行预测
dtest = xgb.DMatrix(X_test)
y_pred = model.predict(dtest)
# 计算准确率
accuracy = accuracy_score(y_test,y_pred)
print("accuarcy: %.2f%%" % (accuracy*100.0))
# 显示重要特征
plot_importance(model)
plt.show()
+回归案例
-import xgboost as xgb
from xgboost import plot_importance
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_boston
from sklearn.metrics import mean_squared_error
# 加载数据集
boston = load_boston()
X,y = boston.data,boston.target
# XGBoost训练过程
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
params = {
'booster': 'gbtree',
'objective': 'reg:squarederror',
'gamma': 0.1,
'max_depth': 5,
'lambda': 3,
'subsample': 0.7,
'colsample_bytree': 0.7,
'min_child_weight': 3,
'silent': 1,
'eta': 0.1,
'seed': 1000,
'nthread': 4,
}
dtrain = xgb.DMatrix(X_train, y_train)
num_rounds = 300
plst = list(params.items())
model = xgb.train(plst, dtrain, num_rounds)
# 对测试集进行预测
dtest = xgb.DMatrix(X_test)
ans = model.predict(dtest)
# 显示重要特征
plot_importance(model)
plt.show()
+XGBoost调参(结合sklearn网格搜索)
代码参考:https://www.jianshu.com/p/1100e333fcab
-import xgboost as xgb
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import roc_auc_score
iris = load_iris()
X,y = iris.data,iris.target
col = iris.target_names
train_x, valid_x, train_y, valid_y = train_test_split(X, y, test_size=0.3, random_state=1) # 分训练集和验证集
parameters = {
'max_depth': [5, 10, 15, 20, 25],
'learning_rate': [0.01, 0.02, 0.05, 0.1, 0.15],
'n_estimators': [500, 1000, 2000, 3000, 5000],
'min_child_weight': [0, 2, 5, 10, 20],
'max_delta_step': [0, 0.2, 0.6, 1, 2],
'subsample': [0.6, 0.7, 0.8, 0.85, 0.95],
'colsample_bytree': [0.5, 0.6, 0.7, 0.8, 0.9],
'reg_alpha': [0, 0.25, 0.5, 0.75, 1],
'reg_lambda': [0.2, 0.4, 0.6, 0.8, 1],
'scale_pos_weight': [0.2, 0.4, 0.6, 0.8, 1]
}
xlf = xgb.XGBClassifier(max_depth=10,
learning_rate=0.01,
n_estimators=2000,
silent=True,
objective='multi:softmax',
num_class=3 ,
nthread=-1,
gamma=0,
min_child_weight=1,
max_delta_step=0,
subsample=0.85,
colsample_bytree=0.7,
colsample_bylevel=1,
reg_alpha=0,
reg_lambda=1,
scale_pos_weight=1,
seed=0,
missing=None)
gs = GridSearchCV(xlf, param_grid=parameters, scoring='accuracy', cv=3)
gs.fit(train_x, train_y)
print("Best score: %0.3f" % gs.best_score_)
print("Best parameters set: %s" % gs.best_params_ )Best score: 0.933
Best parameters set: {‘max_depth’: 5}8. LightGBM算法
LightGBM也是像XGBoost一样,是一类集成算法,他跟XGBoost总体来说是一样的,算法本质上与Xgboost没有出入,只是在XGBoost的基础上进行了优化,因此就不对原理进行重复介绍,在这里我们来看看几种算法的差别:
-
@@ -433,7 +446,7 @@
https://blog.csdn.net/u012735708/article/details/83749703
-import lightgbm as lgb
from sklearn import metrics
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
canceData=load_breast_cancer()
X=canceData.data
y=canceData.target
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=0,test_size=0.2)
### 数据转换
print('数据转换')
lgb_train = lgb.Dataset(X_train, y_train, free_raw_data=False)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train,free_raw_data=False)
### 设置初始参数--不含交叉验证参数
print('设置参数')
params = {
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': 'auc',
'nthread':4,
'learning_rate':0.1
}
### 交叉验证(调参)
print('交叉验证')
max_auc = float('0')
best_params = {}
# 准确率
print("调参1:提高准确率")
for num_leaves in range(5,100,5):
for max_depth in range(3,8,1):
params['num_leaves'] = num_leaves
params['max_depth'] = max_depth
cv_results = lgb.cv(
params,
lgb_train,
seed=1,
nfold=5,
metrics=['auc'],
early_stopping_rounds=10,
verbose_eval=True
)
mean_auc = pd.Series(cv_results['auc-mean']).max()
boost_rounds = pd.Series(cv_results['auc-mean']).idxmax()
if mean_auc >= max_auc:
max_auc = mean_auc
best_params['num_leaves'] = num_leaves
best_params['max_depth'] = max_depth
if 'num_leaves' and 'max_depth' in best_params.keys():
params['num_leaves'] = best_params['num_leaves']
params['max_depth'] = best_params['max_depth']
# 过拟合
print("调参2:降低过拟合")
for max_bin in range(5,256,10):
for min_data_in_leaf in range(1,102,10):
params['max_bin'] = max_bin
params['min_data_in_leaf'] = min_data_in_leaf
cv_results = lgb.cv(
params,
lgb_train,
seed=1,
nfold=5,
metrics=['auc'],
early_stopping_rounds=10,
verbose_eval=True
)
mean_auc = pd.Series(cv_results['auc-mean']).max()
boost_rounds = pd.Series(cv_results['auc-mean']).idxmax()
if mean_auc >= max_auc:
max_auc = mean_auc
best_params['max_bin']= max_bin
best_params['min_data_in_leaf'] = min_data_in_leaf
if 'max_bin' and 'min_data_in_leaf' in best_params.keys():
params['min_data_in_leaf'] = best_params['min_data_in_leaf']
params['max_bin'] = best_params['max_bin']
print("调参3:降低过拟合")
for feature_fraction in [0.6,0.7,0.8,0.9,1.0]:
for bagging_fraction in [0.6,0.7,0.8,0.9,1.0]:
for bagging_freq in range(0,50,5):
params['feature_fraction'] = feature_fraction
params['bagging_fraction'] = bagging_fraction
params['bagging_freq'] = bagging_freq
cv_results = lgb.cv(
params,
lgb_train,
seed=1,
nfold=5,
metrics=['auc'],
early_stopping_rounds=10,
verbose_eval=True
)
mean_auc = pd.Series(cv_results['auc-mean']).max()
boost_rounds = pd.Series(cv_results['auc-mean']).idxmax()
if mean_auc >= max_auc:
max_auc=mean_auc
best_params['feature_fraction'] = feature_fraction
best_params['bagging_fraction'] = bagging_fraction
best_params['bagging_freq'] = bagging_freq
if 'feature_fraction' and 'bagging_fraction' and 'bagging_freq' in best_params.keys():
params['feature_fraction'] = best_params['feature_fraction']
params['bagging_fraction'] = best_params['bagging_fraction']
params['bagging_freq'] = best_params['bagging_freq']
print("调参4:降低过拟合")
for lambda_l1 in [1e-5,1e-3,1e-1,0.0,0.1,0.3,0.5,0.7,0.9,1.0]:
for lambda_l2 in [1e-5,1e-3,1e-1,0.0,0.1,0.4,0.6,0.7,0.9,1.0]:
params['lambda_l1'] = lambda_l1
params['lambda_l2'] = lambda_l2
cv_results = lgb.cv(
params,
lgb_train,
seed=1,
nfold=5,
metrics=['auc'],
early_stopping_rounds=10,
verbose_eval=True
)
mean_auc = pd.Series(cv_results['auc-mean']).max()
boost_rounds = pd.Series(cv_results['auc-mean']).idxmax()
if mean_auc >= max_auc:
max_auc=mean_auc
best_params['lambda_l1'] = lambda_l1
best_params['lambda_l2'] = lambda_l2
if 'lambda_l1' and 'lambda_l2' in best_params.keys():
params['lambda_l1'] = best_params['lambda_l1']
params['lambda_l2'] = best_params['lambda_l2']
print("调参5:降低过拟合2")
for min_split_gain in [0.0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0]:
params['min_split_gain'] = min_split_gain
cv_results = lgb.cv(
params,
lgb_train,
seed=1,
nfold=5,
metrics=['auc'],
early_stopping_rounds=10,
verbose_eval=True
)
mean_auc = pd.Series(cv_results['auc-mean']).max()
boost_rounds = pd.Series(cv_results['auc-mean']).idxmax()
if mean_auc >= max_auc:
max_auc=mean_auc
best_params['min_split_gain'] = min_split_gain
if 'min_split_gain' in best_params.keys():
params['min_split_gain'] = best_params['min_split_gain']
print(best_params){‘bagging_fraction’: 0.7,
‘bagging_freq’: 30,
‘feature_fraction’: 0.8,
‘lambda_l1’: 0.1,
‘lambda_l2’: 0.0,
‘max_bin’: 255,
‘max_depth’: 4,
‘min_data_in_leaf’: 81,
‘min_split_gain’: 0.1,
‘num_leaves’: 10}9. 结语
本章中,我们主要探讨了基于Boosting方式的集成方法,其中主要讲解了基于错误率驱动的Adaboost,基于残差改进的提升树,基于梯度提升的GBDT,基于泰勒二阶近似的Xgboost以及LightGBM。在实际的比赛或者工程中,基于Boosting的集成学习方式是非常有效且应用非常广泛的。更多的学习有待读者更深入阅读文献,包括原作者论文以及论文复现等。下一章我们即将探讨另一种集成学习方式:Stacking集成学习方式,这种集成方式虽然没有Boosting应用广泛,但是在比赛中或许能让你的模型更加出众。
本章作业:
@@ -826,7 +838,7 @@
本章在最后介绍LightGBM的时候并没有详细介绍它的原理以及它与XGBoost的不一样的地方,希望读者好好看看别的文章分享,总结LigntGBM与XGBoost的不同,然后使用一个具体的案例体现两者的不同。
参考链接: https://blog.csdn.net/weixin_30279315/article/details/955042209
-from IPython.display import IFrame
IFrame('https://xgboost.readthedocs.io/en/latest/parameter.html', width=1400, height=800)XGBoost的调参说明:
参数调优的一般步骤
-
@@ -332,23 +354,23 @@
+
高精度
-typedef long long LL;
LL get(char c)
{
if(c<='9') return c-'0';
else return c-'a' + 10;
}
LL getnum(string a,LL r)
{
LL res=0;
for(int i=0;i<a.size();i++)
{
res = res * r + get(a[i]);
}
return res;
}- 十进制转其他进制的方法,使用带余除法
-int get(char c)
{
if(c<='9') return c-'0';
else return c-'a' + 10;
}
char tochar(int c)
{
if(c<=9) return c+'0';
else return 'a' + c - 10;
}
//一个r进制数num转10进制
int numr_to10(string num,int r)
{
int res = 0;
for(int i=0;i<num.size();i++)
{
res = res * r + get(num[i]);
}
return res;
}
//一个10进制数num转r进制
string num10_tor(string num,int r)
{
string res;
int n = numr_to10(num,10); //先转成10进制整型
while(n)
{
// cout<<tochar(n % r)<<endl;
res = tochar(n % r) + res;
n /= r;
}
return res;
}
// cout<<numr_to10("6a",16)<<" "<<num10_tor("15",16)<<endl;判断质数
//判断一个数是否为质数
bool is_prime(int n)
{
if (n < 2) return false; // 1和0不是质数
for(int i=2;i*i<=n;i++)
{
if(n % i == 0) return false;
}
return true;
}手写堆排序
堆是一个完全二叉树的结构,分为小根堆和大根堆两种结构。
- 小根堆的递归定义:小根堆的每个节点都小于他的左右孩子节点的值,树的根节点为最小值。
- 大根堆的递归定义:大根堆的每个节点都大于他的左右孩子节点的值,树的根节点为最大值。
在STL当中可以使用prioirty_queue来轻松实现大根堆和小根堆,但是只能实现前3个功能,有时候我们不得不自己实现一个手写的堆,同时这样也能让我们更理解堆排序的过程。
在AcWing基础课当中有两道经典例题,AcWing 839. 模拟堆(这个复杂一点),AcWing 838. 堆排序
-
这里给出堆排序的模板级代码-#include <iostream>
using namespace std;
const int N = 100010;
int heap[N],heapsize=0;
void down(int x)// 参数下标
{
int p =x;
if(2*x<=heapsize && heap[2*x]<heap[p]) p = 2*x;//左子树
if(2*x+1<=heapsize && heap[2*x+1]<heap[p]) p=2*x+1;//右子树
if(p!=x)
{
swap(heap[p],heap[x]); //说明存在比父节点小的孩子节点
down(p); //继续向下递归down
}
}
void up(int x)// 参数下标
{
while(x / 2 && heap[x] < heap[x/2]) //父节点比子节点大则交换
{
swap(heap[x],heap[x/2]);
x >>= 1; // x = x/2
}
}
int main()
{
int n,m;
scanf("%d%d", &n, &m);
for (int i = 1; i <= n; i ++ ) scanf("%d", &heap[i]);
heapsize=n;
// O(n)建堆
for (int i = n / 2; i; i -- ) down(i);
while (m -- )
{
printf("%d ",heap[1]); //最小值是小根堆的堆顶
// 删除最小值,并重新建堆排序,从而获得倒数第二小的元素
heap[1] = heap[heapsize];
heapsize--;
down(1);
}
return 0;
}STL写法:
-priority_queue默认是大根堆,less<int>是对第一个参数的比较类,表示数字大的优先级越大,而greater<int>表示数字小的优先级越大,可以实现结构体运算符重载。
首先要引入头文件:#include<queue>
大根堆:-priority_queue<int> q;
priority_queue<int, vector<int>, less<int> >q;小根堆:
+在AcWing基础课当中有两道经典例题,AcWing 839. 模拟堆(这个复杂一点),AcWing 838. 堆排序
这里给出堆排序的模板级代码#include <iostream>
using namespace std;
const int N = 100010;
int heap[N],heapsize=0;
void down(int x)// 参数下标
{
int p =x;
if(2*x<=heapsize && heap[2*x]<heap[p]) p = 2*x;//左子树
if(2*x+1<=heapsize && heap[2*x+1]<heap[p]) p=2*x+1;//右子树
if(p!=x)
{
swap(heap[p],heap[x]); //说明存在比父节点小的孩子节点
down(p); //继续向下递归down
}
}
void up(int x)// 参数下标
{
while(x / 2 && heap[x] < heap[x/2]) //父节点比子节点大则交换
{
swap(heap[x],heap[x/2]);
x >>= 1; // x = x/2
}
}
int main()
{
int n,m;
scanf("%d%d", &n, &m);
for (int i = 1; i <= n; i ++ ) scanf("%d", &heap[i]);
heapsize=n;
// O(n)建堆
for (int i = n / 2; i; i -- ) down(i);
while (m -- )
{
printf("%d ",heap[1]); //最小值是小根堆的堆顶
// 删除最小值,并重新建堆排序,从而获得倒数第二小的元素
heap[1] = heap[heapsize];
heapsize--;
down(1);
}
return 0;
}
STL写法:priority_queue默认是大根堆,less<int>是对第一个参数的比较类,表示数字大的优先级越大,而greater<int>表示数字小的优先级越大,可以实现结构体运算符重载。
首先要引入头文件:#include<queue>
大根堆:priority_queue<int> q;
priority_queue<int, vector<int>, less<int> >q;
小根堆:-priority_queue < int, vector<int>, greater<int> > q;树
树是一种特殊的数据结构形式,在做题的过程当中,根据我的经验当题目需要使用树结构的时候主要有以下几种模式。
- 二叉树形式,在二叉树模型下,我们可以根据题目建立出静态的树形结构,构建每个节点左右孩子索引表来建立树的结构同时实现对树的遍历。如果已知或可以求得节点之间的关系,可以通过节点的度数或者访问标记找到根节点。,当然也是可以通过邻接表的方式创建二叉树。
- 多叉树形式,多叉树形式其实又类似于无向连通图的概念,常通过创建邻接表或者临接矩阵的方式建立树,并实现进行树的遍历,也是可以根据节点关系求出根节点的。注意在临接表当中,边的数量一般大于节点数量的两倍即我们需要开票邻接表的边数空间为$M = 2 \times N + d$
- 森林,多连通块的方式,这种也是利用无向图的方式,以邻接表或者临接矩阵的方式构建树的结构,同时我们可以利用并查集的方式得到当前无向图中含有的连通块数量并找到根节点。
二叉树左右孩子索引表模型
-- -const int N = 100010;
int l[N],r[N]// 第i个节点的左孩子和右孩子的索引
bool has_father[N]; //建立树的时候判断一下当前节点有没有父节点,可用于寻找根节点
//初始化,-1表示子节点为空
memset(l,-1,sizeof l);
memset(r,-1,sizeof r);
// 查找根节点的过程
if(l[i]>=0) has_father[l[i]]=true;
if(r[i]>=0) has_father[r[i]]=true;
//查找根节点
int root = 0;
while(has_father[root]) root++;二叉树的遍历过程(以先序遍历为例子)
-- -void dfs(int root)
{
if(root==-1) return;
cout<<root<<endl;
if(l[root]>=0) dfs(l[root]);
if(r[root]>=0) dfs(r[root]);
}临接表模型
-- -const int N = 100010;
const int M = 2 * N + 10;
int h[N];//邻接表的N个节点头指针,h[i]表示以i为起点的,最新的一条边的编号
int e[M];// e[i] 表示第i条边的所指向的终点
int ne[M];// ne[i]表示与第i条边起点相同的下一条边的编号
int idx;// idx表示边的编号,每增加一条边就++
// 添加一条从a到b的边,如果是无向图,每次添加时要add(a,b)和add(b,a)
void add(int a,int b)
{
e[idx] = b; // 第idx条边的终点为b
ne[idx] = h[a]; // h[a] 和 第idx都是以a为起点的边,通过ne[idx]串联起来,找到上一条以a为起点的边h[a]
h[a] = idx ++; // 更新当前以a为起点的边的最新编号
}
//初始化,-1表示节点为空
memset(h,-1,sizeof h);临接表遍历过程方法1
-- -// x为起点,father为x的来源,防止节点遍历走回头路导致死循环
void dfs(int x,int father)
{
cout<<x<<endl;
for(int i = h[x];~i;i=ne[i]) // ~i就是i!=-1的意思
{
int to = e[i];
if(to==father) continue;
dfs(to,x);
}
}
dfs(x,-1);临接表遍历过程方法2
--const int N = 100010;
bool isvisited[N];
void dfs(int x)
{
isvisited[x]=true;
cout<<x<<endl;
for(int i = h[x];~i;i=ne[i])
{
int to = e[i];
if(isvisited[to]) continue;
dfs(to);
}
}
dfs(x);树的深度
临接表模型:AcWing1498. 最深的根
--int getdepth(int x,int father)
{
// cout<<"father"<<father<<" node"<<x<<endl;
int depth = 0;
for(int i = h[x];~i;i=ne[i])
{
int to = e[i];
if(to==father) continue;
depth = max(depth,getdepth(to,x)+1);
}
return depth;
}二叉树模型:剑指 Offer 55 - I. 二叉树的深度
--/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
int maxDepth(TreeNode* root) {
if(root==NULL) return 0;
return max(maxDepth(root->left),maxDepth(root->right))+1;
}
};多叉树模型(该题也是求叶子节点个数的经典写法):AcWing 1476. 数叶子结点
-- +const int N = 100010;
int max_depth = 0;
int cnt[N];
void dfs(int x,int depth)
{
//说明是叶子节点
if(h[x]==-1)
{
cnt[depth]++;
max_depth = max(max_depth,depth);
return;
}
for(int i=h[x];~i;i=ne[i])
{
dfs(e[i],depth+1);
}
}
dfs(root,0)
//输出每一层的叶子个数
for(int i=0;i<=max_depth;i++) cout<<" "<<cnt[i];二叉树左右孩子索引表模型
+const int N = 100010;
int l[N],r[N]// 第i个节点的左孩子和右孩子的索引
bool has_father[N]; //建立树的时候判断一下当前节点有没有父节点,可用于寻找根节点
//初始化,-1表示子节点为空
memset(l,-1,sizeof l);
memset(r,-1,sizeof r);
// 查找根节点的过程
if(l[i]>=0) has_father[l[i]]=true;
if(r[i]>=0) has_father[r[i]]=true;
//查找根节点
int root = 0;
while(has_father[root]) root++;二叉树的遍历过程(以先序遍历为例子)
+void dfs(int root)
{
if(root==-1) return;
cout<<root<<endl;
if(l[root]>=0) dfs(l[root]);
if(r[root]>=0) dfs(r[root]);
}临接表模型
+const int N = 100010;
const int M = 2 * N + 10;
int h[N];//邻接表的N个节点头指针,h[i]表示以i为起点的,最新的一条边的编号
int e[M];// e[i] 表示第i条边的所指向的终点
int ne[M];// ne[i]表示与第i条边起点相同的下一条边的编号
int idx;// idx表示边的编号,每增加一条边就++
// 添加一条从a到b的边,如果是无向图,每次添加时要add(a,b)和add(b,a)
void add(int a,int b)
{
e[idx] = b; // 第idx条边的终点为b
ne[idx] = h[a]; // h[a] 和 第idx都是以a为起点的边,通过ne[idx]串联起来,找到上一条以a为起点的边h[a]
h[a] = idx ++; // 更新当前以a为起点的边的最新编号
}
//初始化,-1表示节点为空
memset(h,-1,sizeof h);临接表遍历过程方法1
+// x为起点,father为x的来源,防止节点遍历走回头路导致死循环
void dfs(int x,int father)
{
cout<<x<<endl;
for(int i = h[x];~i;i=ne[i]) // ~i就是i!=-1的意思
{
int to = e[i];
if(to==father) continue;
dfs(to,x);
}
}
dfs(x,-1);临接表遍历过程方法2
+const int N = 100010;
bool isvisited[N];
void dfs(int x)
{
isvisited[x]=true;
cout<<x<<endl;
for(int i = h[x];~i;i=ne[i])
{
int to = e[i];
if(isvisited[to]) continue;
dfs(to);
}
}
dfs(x);树的深度
临接表模型:AcWing1498. 最深的根
int getdepth(int x,int father)
{
// cout<<"father"<<father<<" node"<<x<<endl;
int depth = 0;
for(int i = h[x];~i;i=ne[i])
{
int to = e[i];
if(to==father) continue;
depth = max(depth,getdepth(to,x)+1);
}
return depth;
}
二叉树模型:剑指 Offer 55 - I. 二叉树的深度/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
int maxDepth(TreeNode* root) {
if(root==NULL) return 0;
return max(maxDepth(root->left),maxDepth(root->right))+1;
}
};
多叉树模型(该题也是求叶子节点个数的经典写法):AcWing 1476. 数叶子结点const int N = 100010;
int max_depth = 0;
int cnt[N];
void dfs(int x,int depth)
{
//说明是叶子节点
if(h[x]==-1)
{
cnt[depth]++;
max_depth = max(max_depth,depth);
return;
}
for(int i=h[x];~i;i=ne[i])
{
dfs(e[i],depth+1);
}
}
dfs(root,0)
//输出每一层的叶子个数
for(int i=0;i<=max_depth;i++) cout<<" "<<cnt[i];二叉搜索树
二叉搜索树 (BST) 递归定义为具有以下属性的二叉树:
- 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值 @@ -289,9 +266,7 @@
- 具有n个结点的完全二叉树的深度为$\lfloor log_2{n} \rfloor+ 1$
- 完全二叉树如果为满二叉树,且深度为$k$则总节点个数为$2^{k}-1$ @@ -302,9 +277,7 @@
- AVL树是一种自平衡二叉搜索树。 @@ -328,17 +301,13 @@
完全二叉树
完全二叉树 (CBT) 定义为除最深层外的其他层的结点数都达到最大个数,最深层的所有结点都连续集中在最左边的二叉树。
-
构造完全二叉树的方法,可以直接开辟一个一维数组利用左右孩子与根节点的下标映射关系。如果通过中序遍历的方式以单调递增的方式来赋值则构造出了一颗完全二叉搜索树。
完全二叉树的赋值填充和构造过程(这里我们以中序遍历为例子):
例题:AcWing 1550. 完全二叉搜索树-//中序遍历填充数据
int cnt; //记录已经赋值的节点下标
void dfs(int x) // 根节点为1-n
{
if(2*x <=n) dfs(2*x);
h[x] = a[cnt++];
if(2*x+1<=n) dfs(2*x+1);
}
void dfs(int u, int& k) // 中序遍历,k引用实现下标迁移
{
if (u * 2 <= n) dfs(u * 2, k);
tr[u] = w[k ++ ];
if (u * 2 + 1 <= n) dfs(u * 2 + 1, k);
}完全二叉树的节点个数规律:
+完全二叉树
完全二叉树 (CBT) 定义为除最深层外的其他层的结点数都达到最大个数,最深层的所有结点都连续集中在最左边的二叉树。
构造完全二叉树的方法,可以直接开辟一个一维数组利用左右孩子与根节点的下标映射关系。如果通过中序遍历的方式以单调递增的方式来赋值则构造出了一颗完全二叉搜索树。
完全二叉树的赋值填充和构造过程(这里我们以中序遍历为例子):
例题:AcWing 1550. 完全二叉搜索树//中序遍历填充数据
int cnt; //记录已经赋值的节点下标
void dfs(int x) // 根节点为1-n
{
if(2*x <=n) dfs(2*x);
h[x] = a[cnt++];
if(2*x+1<=n) dfs(2*x+1);
}
void dfs(int u, int& k) // 中序遍历,k引用实现下标迁移
{
if (u * 2 <= n) dfs(u * 2, k);
tr[u] = w[k ++ ];
if (u * 2 + 1 <= n) dfs(u * 2 + 1, k);
}
完全二叉树的节点个数规律:leetcode 完全二叉树的节点个数 -
- +/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public int countNodes(TreeNode root) {
return root==null ? 0:countNodes(root.left)+countNodes(root.right)+1;
}
}例题(递归解法):leetcode 完全二叉树的节点个数
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public int countNodes(TreeNode root) {
return root==null ? 0:countNodes(root.left)+countNodes(root.right)+1;
}
}完全二叉树
二叉平衡树
AVL树
从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
图论相关
并查集
经典例题:AcWing 836. 合并集合- 通用参数:(两种类型的booster,因为tree的性能比线性回归好得多,因此我们很少用线性回归。)
-#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 100010;
int p[N];
int find(int x) // 查找x的祖先节点,并在回溯的过程当中进行路径压缩,将各节点直接指向根节点
{
if(x!=p[x]) p[x] = find(p[x]); // x和p[x]不相等,则继续向上找父节点的父节点
return p[x];
}
int main()
{
int n;
int m;
scanf("%d%d", &n, &m);
for(int i=1;i<=n;i++)
p[i]=i;
while (m -- )
{
char op[2];
int a,b;
scanf("%s%d%d", op,&a,&b);
int roota = find(a);
int rootb = find(b);
if(op[0]=='M')
{
if(roota == rootb) continue;
p[roota] = rootb; // root merge
}
else
{
cout<< (roota==rootb ? "Yes":"No")<<endl;
}
}
return 0;
}dijstra算法
- 临接矩阵形式,适用于点的数量$N < 1000$的情形,朴素算法即可解决
- 邻接表形式,当$N>10000$,需要添加堆优化
一般来说堆优化版本的考试用的不多,这里就只介绍了朴素版本。
Dijkstra求最短路 I
- -#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 510;
const int inf = 0x3f3f3f3f;
int n,m;
int g[N][N]; // 稠密图使用邻接矩阵
int dist[N]; // 存储距离
bool vis[N]; // 标志到该节点的距离是否已经被规整为最短距离
void dijkstra(int x)
{
memset(dist, inf, sizeof dist);
dist[x] = 0;
for(int i=0;i<n;i++)//外层循环n次遍历每个节点
{
int t= -1;
for(int j=1;j<=n;j++)
{
if(!vis[j]&&(t==-1 || dist[t]>dist[j])) t =j;
}
if(t==-1) break;
vis[t]=true;
for(int j=1;j<=n;j++)
{
if(!vis[j])
{
dist[j] = min(dist[j],dist[t]+g[t][j]);
}
}
}
if(dist[n]==inf) puts("-1");
else cout<<dist[n]<<endl;
}
int main()
{
scanf("%d%d", &n, &m);
memset(g, inf, sizeof g);
for(int i=0;i<m;i++)
{
int x,y,z;
scanf("%d%d%d", &x, &y,&z);
if(x==y) g[x][y]=0; // 自环
g[x][y] = min(g[x][y],z); // 重边仅记录最小的边
}
dijkstra(1);
return 0;
}最小生成树Prime
--//这里填你的代码^^
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 510, INF = 0x3f3f3f3f;
int n,m;
int g[N][N]; //稠密图使用prim和邻接矩阵
int dist[N];
bool isvisited[N];
int prime(int x)
{
memset(dist, 0x3f, sizeof dist);
int res = 0;
dist[x]=0;
for(int i=0;i<n;i++)
{
int t=-1;
for(int j=1;j<=n;j++)
if(!isvisited[j] && (t==-1 || dist[t] > dist[j]))
t= j;
if(dist[t] == INF) return -1;
//标记访问
res += dist[t];
isvisited[t]=true;
//更新dist
for(int j=1;j<=n;j++)
{
dist[j] = min(dist[j],g[t][j]);
}
}
return res;
}
int main()
{
scanf("%d%d", &n, &m);
memset(g, 0x3f, sizeof g);
while (m -- )
{
int a,b,c;
scanf("%d%d%d", &a, &b,&c);
g[a][b] = g[b][a] = min(g[a][b],c); //无向图
}
int t = prime(1);
if(t==-1)
cout<<"impossible"<<endl;
else
cout<<t<<endl;
return 0;
}最小生成树Kruskal
-+#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 100010, INF =0x3f3f3f3f;
const int M = 2*N;
int n,m;
struct Edge
{
int x;
int y;
int w;
bool operator < (const Edge & E) const
{
return w < E.w;
}
}edge[M];
int p[N]; //并查集
int find(int x)//找祖宗节点
{
if(x!=p[x]) p[x] = find(p[x]);
return p[x];
}
int kruskal()
{
int res = 0;
int cnt=0;
sort(edge,edge+m);
for(int i=1;i<=n;i++) p[i]=i;//初始化并查集
for(int i=0;i<m;i++)
{
int x = edge[i].x, y = edge[i].y, w = edge[i].w;
int a = find(x);
int b = find(y);
//不是连通的
if(a!=b)
{
p[b] = a;
res += w;
cnt++;
}
}
//路径数量<n-1说明不连通
if (cnt<n-1) return INF;
return res;
}
int main()
{
scanf("%d%d", &n, &m);
for (int i = 0; i < m; i ++ )
{
scanf("%d%d%d", &edge[i].x, &edge[i].y, &edge[i].w);
}
int t = kruskal();
if(t == INF) cout<< "impossible"<<endl;
else cout<<t<<endl;
return 0;
}最小生成树Prime
AcWing 858.Prime算法求最小生成树
+//这里填你的代码^^
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 510, INF = 0x3f3f3f3f;
int n,m;
int g[N][N]; //稠密图使用prim和邻接矩阵
int dist[N];
bool isvisited[N];
int prime(int x)
{
memset(dist, 0x3f, sizeof dist);
int res = 0;
dist[x]=0;
for(int i=0;i<n;i++)
{
int t=-1;
for(int j=1;j<=n;j++)
if(!isvisited[j] && (t==-1 || dist[t] > dist[j]))
t= j;
if(dist[t] == INF) return -1;
//标记访问
res += dist[t];
isvisited[t]=true;
//更新dist
for(int j=1;j<=n;j++)
{
dist[j] = min(dist[j],g[t][j]);
}
}
return res;
}
int main()
{
scanf("%d%d", &n, &m);
memset(g, 0x3f, sizeof g);
while (m -- )
{
int a,b,c;
scanf("%d%d%d", &a, &b,&c);
g[a][b] = g[b][a] = min(g[a][b],c); //无向图
}
int t = prime(1);
if(t==-1)
cout<<"impossible"<<endl;
else
cout<<t<<endl;
return 0;
}最小生成树Kruskal
AcWing859.Kruskal算法求最小生成树
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 100010, INF =0x3f3f3f3f;
const int M = 2*N;
int n,m;
struct Edge
{
int x;
int y;
int w;
bool operator < (const Edge & E) const
{
return w < E.w;
}
}edge[M];
int p[N]; //并查集
int find(int x)//找祖宗节点
{
if(x!=p[x]) p[x] = find(p[x]);
return p[x];
}
int kruskal()
{
int res = 0;
int cnt=0;
sort(edge,edge+m);
for(int i=1;i<=n;i++) p[i]=i;//初始化并查集
for(int i=0;i<m;i++)
{
int x = edge[i].x, y = edge[i].y, w = edge[i].w;
int a = find(x);
int b = find(y);
//不是连通的
if(a!=b)
{
p[b] = a;
res += w;
cnt++;
}
}
//路径数量<n-1说明不连通
if (cnt<n-1) return INF;
return res;
}
int main()
{
scanf("%d%d", &n, &m);
for (int i = 0; i < m; i ++ )
{
scanf("%d%d%d", &edge[i].x, &edge[i].y, &edge[i].w);
}
int t = kruskal();
if(t == INF) cout<< "impossible"<<endl;
else cout<<t<<endl;
return 0;
}哈密顿图
- 通过图中所有顶点一次且仅一次的通路称为哈密顿通路。
- 通过图中所有顶点一次且仅一次的回路称为哈密顿回路。 @@ -359,8 +328,8 @@
-
@@ -672,15 +641,15 @@
- diff --git "a/2022/01/08/\345\233\236\351\246\226\345\220\221\346\235\245\350\220\247\347\221\237\345\244\204\357\274\214\345\275\222\345\216\273\357\274\214\344\271\237\346\227\240\351\243\216\351\233\250\344\271\237\346\227\240\346\231\264\357\275\2342021\345\271\264\347\273\210\346\200\273\347\273\223/index.html" "b/2022/01/08/\345\233\236\351\246\226\345\220\221\346\235\245\350\220\247\347\221\237\345\244\204\357\274\214\345\275\222\345\216\273\357\274\214\344\271\237\346\227\240\351\243\216\351\233\250\344\271\237\346\227\240\346\231\264\357\275\2342021\345\271\264\347\273\210\346\200\273\347\273\223/index.html" index 6b160ea5..09070b1c 100644 --- "a/2022/01/08/\345\233\236\351\246\226\345\220\221\346\235\245\350\220\247\347\221\237\345\244\204\357\274\214\345\275\222\345\216\273\357\274\214\344\271\237\346\227\240\351\243\216\351\233\250\344\271\237\346\227\240\346\231\264\357\275\2342021\345\271\264\347\273\210\346\200\273\347\273\223/index.html" +++ "b/2022/01/08/\345\233\236\351\246\226\345\220\221\346\235\245\350\220\247\347\221\237\345\244\204\357\274\214\345\275\222\345\216\273\357\274\214\344\271\237\346\227\240\351\243\216\351\233\250\344\271\237\346\227\240\346\231\264\357\275\2342021\345\271\264\347\273\210\346\200\273\347\273\223/index.html" @@ -244,50 +244,49 @@
-
读研or就业的思考
这个问题其实在2年前就有在思考这件事情,虽然学生思维存在着一些局限性,但是你不得不承认这件事情确实是你需要尽早想清楚的事情,话是这么说其实还是当局者迷,旁观者清,尽管有一些我认识的人给过我他们的思考,我自己也没在最需要想清楚的时候想清楚这件事情,可能很多感受只有触碰到结果了才真正明白吧。
这个问题抛出来,我写起来还是不知从何说起,没有正确答案,未来都是未知的,害怕失去现有的一切,凭我的经验来看,还是要多遵从自己的内心,不要完全理性的去权衡利弊,失去如果每个选择都会后悔,就不要选让自己更后悔的那个。还是说一下自己当时思考的几件事情:- 读研是为了什么,去企业又是为了什么
- 对于未来到底想做什么
- 抛开家长和他人的观点,你对自己的性格和能力是否足够了解,是否足够自信
- 都是最坏的情况,更能接受哪个选择 -
- 如何承受选择带来的代价和自我和解之道
去黄鹤楼,看樱花
3月樱花又开了,大一没来得及看樱花,大二由于疫情影响也没能去成,大三正好有朋友过来武汉找我玩,就带着去黄鹤楼,隔壁学校赏樱花,那几天每天晚上和朋友们聊天一整夜,太久没一块说话了吧,我和他约定好考完研再来武汉陪我过生日。春招面网易
4月有好友正好在做网易的春招宣传,内推了我一手,抱着涨点面试经验的心态,面了一下网易的算法岗,匆忙改了一版简历,笔试比较简单过了2/3,面试还行但还是没过,后面准备夏令营啥的也没有再投了。茶颜悦色&湖南师大&湖南大学
在湖南呆了这么久,这是第一次喝茶颜悦色,leo点的幽兰拿铁,晚上吃了一顿火锅直接拉肚子到凌晨2点,去了当初高二数学竞赛培训的湖师大,看了看那些当时买礼物的精品店和饭店,后面去了湖南大学找同学吃饭,湖南大学的建筑风格很不错,嘿嘿,不愧是湖大!有幸与神三元吃饭
毕业季,神三元学长也要毕业了,在学校一直听着他的江湖神话,终于有朝一日能见上一面了,迫不及待和朋友一起跑到另一个校区追星。见面一看确实是一表人才,吃饭紧张到有点不知道说话。不过听大佬聊技术趋势和工作思考,还是有很多不一样的体会。
+ - 如何承受选择带来的代价和自我和解之道
去黄鹤楼,看樱花
3月樱花又开了,大一没来得及看樱花,大二由于疫情影响也没能去成,大三正好有朋友过来武汉找我玩,就带着去黄鹤楼,隔壁学校赏樱花,那几天每天晚上和朋友们聊天一整夜,太久没一块说话了吧,我和他约定好考完研再来武汉陪我过生日。春招面网易
4月有好友正好在做网易的春招宣传,内推了我一手,抱着涨点面试经验的心态,面了一下网易的算法岗,匆忙改了一版简历,笔试比较简单过了2/3,面试还行但还是没过,后面准备夏令营啥的也没有再投了。茶颜悦色&湖南师大&湖南大学
在湖南呆了这么久,这是第一次喝茶颜悦色,leo点的幽兰拿铁,晚上吃了一顿火锅直接拉肚子到凌晨2点,去了当初高二数学竞赛培训的湖师大,看了看那些当时买礼物的精品店和饭店,后面去了湖南大学找同学吃饭,湖南大学的建筑风格很不错,嘿嘿,不愧是湖大!有幸与神三元吃饭
毕业季,神三元学长也要毕业了,在学校一直听着他的江湖神话,终于有朝一日能见上一面了,迫不及待和朋友一起跑到另一个校区追星。见面一看确实是一表人才,吃饭紧张到有点不知道说话。不过听大佬聊技术趋势和工作思考,还是有很多不一样的体会。
bytecamp再送人头
去年暑假参加了一次bytecamp的笔试,感觉挺有意思的,虽然当时也没过,今年再参加编程又爆0了,第一题是树形dp模版题,但是我当时忘了,后面两个就更难了不会。
-滚滚长江东逝水——再会江滩
暑假放假回家前,去了一次江滩,之前带朋友去的是汉口江滩,这次去武昌江滩看的,也算是两岸都看过了,虽然武汉夏天很热,但是长江的风吹过来还是很舒服的。
-
-魔都体验卡
有幸参加SIST的夏令营,体验了3天公费旅游的感觉,还吃了西餐,和朋友去了上海外滩和金融中心,半夜两点给健哥写前端。听说上海的天空很低!
-
+滚滚长江东逝水——再会江滩
暑假放假回家前,去了一次江滩,之前带朋友去的是汉口江滩,这次去武昌江滩看的,也算是两岸都看过了,虽然武汉夏天很热,但是长江的风吹过来还是很舒服的。
+
+魔都体验卡
有幸参加SIST的夏令营,体验了3天公费旅游的感觉,还吃了西餐,和朋友去了上海外滩和金融中心,半夜两点给健哥写前端。听说上海的天空很低!
+梦碎了
9月差一点点,最后还是没能去到自己最想去的地方,感觉自己的学生时代已经结束了,梦碎了,不展开了,容易晚上emo😭
4年后再来南山区
18年国庆来深圳,只觉得繁华,人上人,4年后再来觉得这里还是缺少了一些文化感和年代感的东西,感谢朋友们的盛情招待,看海没赶上好时候,跟小w发我的照片完全不一样😔,第一次吃椰子鸡,去了SUST看夕阳,感受了朋友在字节跳动的“快乐”生活(我永远喜欢bytedance),遇到了突然其来的台风和大暴雨,沿着大沙河逛THU和PKU
-
-
-
+
+
+最爱东湖与武大
在武汉,我独爱东湖,这次有幸还坐船浏览了对岸,去了磨山,一路听着粤语歌在东湖漫步,会有很多很多想法。逛完东湖与武大同学小歇畅聊,有幸参观了周恩来和闻一多先生的居所,一起吃饭听说他搞家教日薪1k+我羡慕。
-
-
-
-
-
+
+
+
+
+摆烂的大四软测
大四一学期没听课,软测临时抱佛脚,卷了3年才知道整张试卷瞎写的感觉原来这么爽,还好没挂。
-CLANNAD
看了一直没看的CLANNAD,不得不说这个剧表达的东西很深刻,给了我很多生活的思考,我觉得是我心中看过的最好的动漫之一了,以后可以再看一遍,好像要一个团子啊🥺!
-科目二的败北
和朋友天天早出晚归跑去练科目二,到了考场发现自己学的东西都白学了,侧方直接挂,然后倒库紧张又挂了。。。坡上两只狗
+CLANNAD
看了一直没看的CLANNAD,不得不说这个剧表达的东西很深刻,给了我很多生活的思考,我觉得是我心中看过的最好的动漫之一了,以后可以再看一遍,好像要一个团子啊🥺!
+科目二的败北
和朋友天天早出晚归跑去练科目二,到了考场发现自己学的东西都白学了,侧方直接挂,然后倒库紧张又挂了。。。坡上两只狗
12月所思
12月陷入了一段特别迷茫的时间,他们说我所担心的并不能约束你,只能促进你,不要老是患得患失,后面拿了实习offer后开心了一些,等考研的朋友考完一起舒服了几天,后面的实训课继续摆烂,可惜说好来武汉陪我过生日的同学最后还是没来,那天写实训代码写到1点才睡,不过随着一年又一年,我倒是觉得就当平常日挺好的,也不用刻意去记,能想起来就想起来吧。
回家的所闻所见
纠结了很长时间关于寒假外出实习的事情,最后还是觉得去体验一下比较好,害怕过年回家待不了太久,所以提前跑路回家了几天,比较难受的是遇到了一些不好的事情,还是要常回家看看🙏
-啃了一些原理+Leetcode400题
今年感觉自己花在学习上的时间没有特别多,更多的时间被虚无的思考给浪费掉了,除了一些kaggle和工程代码之外,今年做了一些不一样的事情主要就是手推了《统计学习方法》当中一些基本算法,西瓜书也看了一些,leetocde不知不觉突破400题了! 还是很菜,只不过把刷题当成习惯了。
+啃了一些原理+Leetcode400题
今年感觉自己花在学习上的时间没有特别多,更多的时间被虚无的思考给浪费掉了,除了一些kaggle和工程代码之外,今年做了一些不一样的事情主要就是手推了《统计学习方法》当中一些基本算法,西瓜书也看了一些,leetocde不知不觉突破400题了! 还是很菜,只不过把刷题当成习惯了。
关于十年后再来北京这件事
今年跨年有些不一样,12.31飞北京跨年,下午处理好了租房的问题,人生地不熟,接下来元旦几天都是被朋友带着玩哈哈哈。
-Dr.Pepper & Sky
在旅店晚上喝了一杯命运石之门的Dr.Pepper,有一种穿越时空的味道 上次坐飞机还是10多年前,再一次飞上蓝天还是很激动!
+Dr.Pepper & Sky
在旅店晚上喝了一杯命运石之门的Dr.Pepper,有一种穿越时空的味道 上次坐飞机还是10多年前,再一次飞上蓝天还是很激动!
清华五道口
十年前曾踏过清华的大门,十年后还是没能跨进你的大门,来生请等我。
-单车刷夜去天安门和祖国母亲一起跨年
作为一名预备党员,元旦必然要在天安门通宵等升旗,被北方的寒风给冻傻了,和祖国母亲一起放飞和平鸽!
-
+单车刷夜去天安门和祖国母亲一起跨年
作为一名预备党员,元旦必然要在天安门通宵等升旗,被北方的寒风给冻傻了,和祖国母亲一起放飞和平鸽!
+海底捞被朋友抓去过生日
虽然生日过了,但是他们想在北京陪我过一次,店里送了相框,正好一起拍照留作纪念,摆在新家当饰品,第一次在海底捞过生日社死。
-四季民福故宫店北京烤鸭南锣鼓巷中关村中科院
吃了很离谱的豆汁和正宗北京烤鸭
+四季民福故宫店北京烤鸭南锣鼓巷中关村中科院
吃了很离谱的豆汁和正宗北京烤鸭
环球影城,我要上魔法学院!
在环球影城玩了一天,看过的电影不多,环球影城的这几个设施特别还原,喝了魔法黄油啤酒,买了小黄人的盲盒。
-
-
-
-美团实习ing
太菜了只会摸鱼,要开始新的生活了
+
+
+
+美团实习ing
太菜了只会摸鱼,要开始新的生活了
To 2022
- 请你继续保持对技术的热情,脚踏实地,努力学习,祝你好运
- 好好体验实习,工作,一个人独立生活的感觉 @@ -299,7 +298,7 @@
- 还有不能忘记的音乐梦!
- 希望未来以后有机会当一个speaker
To 20
「掘金链接:回首向来萧瑟处,归去,也无风雨也无晴|2021年终总结」
+「掘金链接:回首向来萧瑟处,归去,也无风雨也无晴|2021年终总结」
@@ -604,7 +603,7 @@To 20
- diff --git "a/2022/01/08/\345\233\236\351\246\226\345\220\221\346\235\245\350\220\247\347\221\237\345\244\204\357\274\214\345\275\222\345\216\273\357\274\214\344\271\237\346\227\240\351\243\216\351\233\250\344\271\237\346\227\240\346\231\264\357\275\2342021\345\271\264\347\273\210\346\200\273\347\273\223/index.html" "b/2022/01/08/\345\233\236\351\246\226\345\220\221\346\235\245\350\220\247\347\221\237\345\244\204\357\274\214\345\275\222\345\216\273\357\274\214\344\271\237\346\227\240\351\243\216\351\233\250\344\271\237\346\227\240\346\231\264\357\275\2342021\345\271\264\347\273\210\346\200\273\347\273\223/index.html" index 6b160ea5..09070b1c 100644 --- "a/2022/01/08/\345\233\236\351\246\226\345\220\221\346\235\245\350\220\247\347\221\237\345\244\204\357\274\214\345\275\222\345\216\273\357\274\214\344\271\237\346\227\240\351\243\216\351\233\250\344\271\237\346\227\240\346\231\264\357\275\2342021\345\271\264\347\273\210\346\200\273\347\273\223/index.html" +++ "b/2022/01/08/\345\233\236\351\246\226\345\220\221\346\235\245\350\220\247\347\221\237\345\244\204\357\274\214\345\275\222\345\216\273\357\274\214\344\271\237\346\227\240\351\243\216\351\233\250\344\271\237\346\227\240\346\231\264\357\275\2342021\345\271\264\347\273\210\346\200\273\347\273\223/index.html" @@ -244,50 +244,49 @@
给定一个数字 N,请你计算 1∼N 中一共出现了多少个数字 1。
-
例如,N=12 时,一共出现了 5 个数字 1,分别出现在 1,10,11,12 中。解题思路:相关视频链接
-+class Solution {
public:
int countDigitOne(int n) {
vector<int> num;
while(n) num.push_back(n%10), n/=10;
int res = 0;
for(int i=num.size()-1;i>=0;i--)
{
int d = num[i];
int left=0,right=0,power=1;
for(int j=num.size()-1;j>i;j--) left = left * 10 + num[j];
for(int j=i-1;j>=0;j--) right = right * 10 + num[j], power*=10;
if(d==0) res += left*power;
else if(d==1) res += left*power + right + 1;
else res += (left+1) * power;
}
return res;
}
};解题思路:相关视频链接
+ @@ -664,7 +633,7 @@class Solution {
public:
int countDigitOne(int n) {
vector<int> num;
while(n) num.push_back(n%10), n/=10;
int res = 0;
for(int i=num.size()-1;i>=0;i--)
{
int d = num[i];
int left=0,right=0,power=1;
for(int j=num.size()-1;j>i;j--) left = left * 10 + num[j];
for(int j=i-1;j>=0;j--) right = right * 10 + num[j], power*=10;
if(d==0) res += left*power;
else if(d==1) res += left*power + right + 1;
else res += (left+1) * power;
}
return res;
}
};手写IoU
-import numpy as np
def IoU(bounding_box,ground_truth):
"""
:param bounding_box: [[x1,y1,x2,y2,score]]
:param ground_truth: [x1,y1,x2,y2]
:return:
"""
x1 = bounding_box[:,0]
y1 = bounding_box[:,1]
x2 = bounding_box[:,2]
y2 = bounding_box[:,3]
score = bounding_box[:,4]
areas = (x2-x1) * (y2-y1)
gt_area = (ground_truth[2] - ground_truth[0]) * (ground_truth[3] - ground_truth[1])
xx1 = np.maximum(x1,ground_truth[0])
yy1 = np.maximum(y1,ground_truth[1])
xx2 = np.minimum(x2,ground_truth[2])
yy2 = np.minimum(y2,ground_truth[3])
h = np.maximum(0,yy2-yy1)
w = np.maximum(0,xx2-xx1)
inter = w * h
ovr = inter / (gt_area + areas - inter) # np.true_divide(inter, (gt_area + areas - inter))
return ovr旋转矩阵
class Solution {
public:
void rotate(vector<vector<int>>& matrix) {
int n = matrix.size();
for(int i=0;i<n/2;i++)
{
for(int j=0;j<(n+1)/2;j++)
{
// (i,j) (j,n-i-1) (n-j-1,i) (n-i-1,n-j-1)
swap(matrix[i][j],matrix[n-i-1][n-j-1]);
swap(matrix[i][j],matrix[n-j-1][i]);
swap(matrix[j][n-i-1],matrix[n-i-1][n-j-1]);
}
}
}
};小米
小米面试其实是当时最好的选择,因为就在武汉本地,也不用外出,但是当时面试确实不太好,面试官对我其中一个项目比较感兴趣,被疯狂怼着追问细节。
-
@@ -299,25 +297,21 @@
剑指 Offer 39. 数组中出现次数超过一半的数字 第二题直接限制时间复杂度$O(n)$,空间复杂度$O(1)$,我只会哈希方法,然后和面试官说了一下最优解方法我只记得叫摩尔投票,然后具体忘了。
栈的压入、弹出序列
-class Solution {
public:
bool validateStackSequences(vector<int>& pushed, vector<int>& popped) {
stack<int> stk;
int n = popped.size();
int m = pushed.size();
int j = 0;
for(int i=0;i<m;i++)
{
stk.push(pushed[i]);
while(stk.size()&&stk.top()==popped[j])
{
j++;
stk.pop();
}
}
return stk.empty();
}
};其他
还有一些感觉比较重要,但是没有被问道的东西,包括各种评价指标的含义等等,包括数学基础等等。
经典教程推荐:cs231n,吴恩达,李宏毅,动手学深度学习,《统计学习方法》
关于八股文方面这里推荐一个DeepLearning-500-questions手写非极大抑制
使用非极大抑制的前提是,我们已经得到了一组候选框和对应label的置信分数,以及groud truth的信息,通过设定阈值来删除重合度较高的候选框。
算法流程如下:-
-
- 根据置信度得分进行排序 -
- 选择置信度最高的比边界框添加到最终输出列表中,将其从边界框列表中删除 -
- 计算所有边界框的面积 -
- 计算置信度最高的边界框与其它候选框的IoU。 -
- 删除IoU大于阈值的边界框 -
- 重复上述过程,直至边界框列表为空。 +
- 根据置信度得分进行排序 +
- 选择置信度最高的比边界框添加到最终输出列表中,将其从边界框列表中删除 +
- 计算所有边界框的面积 +
- 计算置信度最高的边界框与其它候选框的IoU。 +
- 删除IoU大于阈值的边界框 +
- 重复上述过程,直至边界框列表为空。
-import numpy as np
def nms(dets, threshod, mode="Union"):
"""
greedily select boxes with high confidence
keep boxes overlap <= thresh
rule out overlap > thresh
:param dets: [[x1, y1, x2, y2 score]]
:param threshod: retain overlap <= thresh
:return: indexes to keep
"""
x1 = dets[:, 0]
y1 = dets[:, 1]
x2 = dets[:, 2]
y2 = dets[:, 3]
scores = dets[:, 4]
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
order = scores.argsort()[::-1] # reverse
keep = []
while order.size() > 0:
i = order[0]
keep.append(i)
# A & B left top position
xx1 = np.maximun(x1[i], x1[order[1, :]])
yy1 = np.maximun(y1[i], y1[order[1, :]])
# A & B right down position
xx2 = np.minimum(x2[i], x2[order[1, :]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
# cacaulate the IOU between box which have largest score with other boxes
if mode == "Union":
# area[i]: the area of largest score
ovr = inter / (areas[i] + areas[order[1:]] - inter)
elif mode == "Minimum":
ovr = inter / np.minimum(areas[i], areas[order[1:]])
# delete the IoU that higher than threshod
inds = np.where(ovr <= threshod)[0]
order = order[inds + 1] # +1: eliminates the first element in order
return keep手写Kmeans方法
-这个版本不是最佳写法,某些处理有点暴力,可以用矩阵和numpy相关的操作会更简洁,但是退出迭代的条件写的很全的,有达到迭代次数,中心点集不变,中心点变化范围小于$\delta$
-- +import numpy as np
import matplotlib.pyplot as plt
n = 100
a = np.random.randn(0,50,n)
b = np.random.rand(0,50,n)
x = np.random.randint(0,50,n)
y = np.random.randint(0,50,n)
points = np.array(list(zip(x,y)))
def distance(x,y):
return np.sqrt(np.sum((x-y)**2))
def k_means(points,k=5,epochs=500,delta=1e-3):
# 初始化聚类中心
center_ids = np.random.randint(0,n,k)
centers = points[center_ids]
# 聚类集合初始化
results = []
for i in range(k):
results.append([])
step = 1
flag = True
# 计算各点到中心的距离
while flag and step < epochs:
# 重新迭代
for i in range(k):
results[i] = []
# 计算每个点到距离中心的距离
for i in range(len(points)):
point = points[i]
min_dis = np.inf
min_id = 0
for idx, center in enumerate(centers):
dis = distance(center,point)
if min_dis > dis:
min_dis = dis
min_id = idx
results[min_id].append(point)
# 更新聚类中心
for idx, old_center in enumerate(centers):
new_center = np.array(results[idx]).mean(axis=0)
if distance(center, new_center) > delta:
centers[idx] = new_center
flag = False
# flag=True说明聚类中心已经不变了则可以退出了
if flag:
break
else:
flag = True
step += 1
return results,centers
plt.plot(x,y,'ro')
results,centers=k_means(points,k=5)
color=['ko','go','bo','yo','co']
for i in range(len(results)):
result=results[i]
plt.plot([res[0] for res in result],[res[1] for res in result],color[i])
plt.plot([res[0] for res in centers],[res[1] for res in centers],'ro')
plt.show()这个版本不是最佳写法,某些处理有点暴力,可以用矩阵和numpy相关的操作会更简洁,但是退出迭代的条件写的很全的,有达到迭代次数,中心点集不变,中心点变化范围小于$\delta$
import numpy as np
import matplotlib.pyplot as plt
n = 100
a = np.random.randn(0,50,n)
b = np.random.rand(0,50,n)
x = np.random.randint(0,50,n)
y = np.random.randint(0,50,n)
points = np.array(list(zip(x,y)))
def distance(x,y):
return np.sqrt(np.sum((x-y)**2))
def k_means(points,k=5,epochs=500,delta=1e-3):
# 初始化聚类中心
center_ids = np.random.randint(0,n,k)
centers = points[center_ids]
# 聚类集合初始化
results = []
for i in range(k):
results.append([])
step = 1
flag = True
# 计算各点到中心的距离
while flag and step < epochs:
# 重新迭代
for i in range(k):
results[i] = []
# 计算每个点到距离中心的距离
for i in range(len(points)):
point = points[i]
min_dis = np.inf
min_id = 0
for idx, center in enumerate(centers):
dis = distance(center,point)
if min_dis > dis:
min_dis = dis
min_id = idx
results[min_id].append(point)
# 更新聚类中心
for idx, old_center in enumerate(centers):
new_center = np.array(results[idx]).mean(axis=0)
if distance(center, new_center) > delta:
centers[idx] = new_center
flag = False
# flag=True说明聚类中心已经不变了则可以退出了
if flag:
break
else:
flag = True
step += 1
return results,centers
plt.plot(x,y,'ro')
results,centers=k_means(points,k=5)
color=['ko','go','bo','yo','co']
for i in range(len(results)):
result=results[i]
plt.plot([res[0] for res in result],[res[1] for res in result],color[i])
plt.plot([res[0] for res in centers],[res[1] for res in centers],'ro')
plt.show()总结
@@ -328,7 +322,7 @@本人能力有限,如果上述回答有任何错误,还请各位大佬及时指出
总结不用害怕,尽量多交流,避免场面陷入尴尬。
- 反问环节我一般问的是来这边的工作内容,学习的建议和评价,培养和安排之类的。
-「掘金链接:菜鸡的算法岗日常实习面经总结」
+「掘金链接:菜鸡的算法岗日常实习面经总结」
@@ -637,7 +631,7 @@总结
- diff --git "a/2022/03/31/\346\227\242\345\276\200\344\270\215\346\201\213\357\274\214\347\272\265\346\203\205\345\220\221\345\211\215\357\274\214\346\261\237\346\271\226\345\206\215\350\247\201\342\200\224\342\200\22422\345\262\201\351\202\243\345\271\264\357\274\214\345\234\250\345\214\227\344\272\254\347\232\204\346\227\245\345\255\220/index.html" "b/2022/03/31/\346\227\242\345\276\200\344\270\215\346\201\213\357\274\214\347\272\265\346\203\205\345\220\221\345\211\215\357\274\214\346\261\237\346\271\226\345\206\215\350\247\201\342\200\224\342\200\22422\345\262\201\351\202\243\345\271\264\357\274\214\345\234\250\345\214\227\344\272\254\347\232\204\346\227\245\345\255\220/index.html" index 344d40d7..f0a29343 100644 --- "a/2022/03/31/\346\227\242\345\276\200\344\270\215\346\201\213\357\274\214\347\272\265\346\203\205\345\220\221\345\211\215\357\274\214\346\261\237\346\271\226\345\206\215\350\247\201\342\200\224\342\200\22422\345\262\201\351\202\243\345\271\264\357\274\214\345\234\250\345\214\227\344\272\254\347\232\204\346\227\245\345\255\220/index.html" +++ "b/2022/03/31/\346\227\242\345\276\200\344\270\215\346\201\213\357\274\214\347\272\265\346\203\205\345\220\221\345\211\215\357\274\214\346\261\237\346\271\226\345\206\215\350\247\201\342\200\224\342\200\22422\345\262\201\351\202\243\345\271\264\357\274\214\345\234\250\345\214\227\344\272\254\347\232\204\346\227\245\345\255\220/index.html" @@ -210,8 +210,7 @@
既往不恋,纵情向前,江湖再见——22岁那年,在北京的日子
2022年3月31日0:52,睡不着,日常拖延症+强迫症导致清东西到现在,等会还想清扫一下弄脏的地板。
莲竹花园甲2号楼一门101,从今天起,这里将不再是我的家,本来是昨天的机票,天气不似预期,不打算买高铁,还想再飞上一次云霄,所以倔强的又改签了机票,不过正好也让我多看一眼这里吧,最近东航事件其实让我也有一点小慌,希望能平安到达吧。
-不出所料,我对这个城市并没有什么留恋,每天晚上我都会思考很多,有天夜里我的脑海里突然冒出来了那句:劝君更进一杯酒,西出阳关无故人。 这一刻我才真正明白什么是独在异乡为异客的感觉,什么才是我心里最想要的。
- +不出所料,我对这个城市并没有什么留恋,每天晚上我都会思考很多,有天夜里我的脑海里突然冒出来了那句:劝君更进一杯酒,西出阳关无故人。 这一刻我才真正明白什么是独在异乡为异客的感觉,什么才是我心里最想要的。
从南山南到北海北
作为一个一直生活在南方的人,第一次在北京生活,拥挤的早晚高峰,寒风和冰雪的夜晚,疫情形势也不断变化,恰逢过年,回家的日子也迟迟不敢定下来,奇怪,你可能会好奇,在大厂工作我竟然并没有提到工作的压力,仔细想来,其实美团的作息是相对舒服的10-8-5,尽管工作和技术基础我有许多不足,但mentor比较照顾我,不会刻意去push进度,更多的是希望让我自己去探索和思考,所以更多的工作压力还是来自于我自己一贯所坚持的负责和标准。这是一件好事,说明我做事情有自己的原则和态度,但有时候也会让自己比较心累,毕竟作为一个新人,从0-1去启动项目,虽然我是个自信的人,即使遇到问题也会尽可能自己去想办法,但我也深知自己的代码习惯和知识结构存在很多不足,害怕的不是做不好做不成,而是做事的效率和维护性,其实这也是我应该要从这些前辈身上要学到的经验。
年前一周,我申请了远程实习提前坐飞机回家了,到家的一刻才明白,这种人间烟火气才真的是生活,说来有愧,从回家到过年收假的时间,工作上我确实有点摆烂了哈哈哈,我知道这应该最后一个这么长时间的寒假了,经过将近1个月的在外实习也格外体会到了这种归家的温暖,去学一学切菜炒菜,陪一陪老年人,约一场球,见想见的人,街头漫步,吃点臭干子,米粉,麻辣烫,和朋友分享一些见闻,借酒消愁,确实愁更愁。
时间很快,大年初五的下午,我就启程返工了,毕竟现在的身份是打工人而不是大学生。和我一同去北京的还有广平,也在美团,我们都不打算实习很久,刚好我房子够住2个人,就一起住了一个月,不得不说多了一个人生活确实没有这么孤单了,尽管工作和拥挤依旧麻烦,但至少回家轻松快活一些,虽然有时候会有一些赌气和争吵,睡眠问题,但不管怎么说,互相都分担了一些对未来的焦虑和思考,一块出去玩,打游戏开黑,去什刹海,天安门,吃各种小吃,也算是度过一段不那么枯燥的时间。
@@ -527,7 +526,7 @@- @@ -535,15 +534,15 @@
-
官方源码链路思想
Protobuf 源码链路过程主要涉及三类数据类型之间的转换,以 Message 对象进行管理,自定义 Value 类实现反射和底层存储,用 Message 对象能有效地进行管理和迁移,但也带来了许多反射和序列化开销。
+官方源码链路思想
Protobuf 源码链路过程主要涉及三类数据类型之间的转换,以 Message 对象进行管理,自定义 Value 类实现反射和底层存储,用 Message 对象能有效地进行管理和迁移,但也带来了许多反射和序列化开销。
Protobuf编码格式
Protobuf 编码字段格式大体上遵循 TLV(Tag,Length,Value) 的结构,但针对具体的类型存在一些编码差异,这里我们将较为全面的给出常见类型的编码模式。
-Message Field
Protobuf 的接口必定包裹在一个 Message 类型下,因此无论是 request 还是 response 最终都会包裹成一个 Message 对象,那么 Field 则是 Message 的一个基本单元,任何类型的字段都遵循这样的 TLV 结构:
+Message Field
Protobuf 的接口必定包裹在一个 Message 类型下,因此无论是 request 还是 response 最终都会包裹成一个 Message 对象,那么 Field 则是 Message 的一个基本单元,任何类型的字段都遵循这样的 TLV 结构:
- Tag 由字段编号 Field_number 和 wiretype 两部分决定,对位运算后的结果进行 varint 压缩,得到压缩后的字节数组作为字段的 Tag。
- wiretype 的值则表示的是 value 部分的编码方式,可以帮助我们清楚如何对 value 的读取和写入。到目前为止,wiretype只有 VarintType,Fixed32Type,Fixed64Type,BytesType 四类编码方式。其中VarintType 类型会被压缩后再编码,属于 Fixed32Type 和 Fixed64Typ 固定长度类型则分别占用4字节和8字节,而属于不定长编码类型 BytesType 的则会编码计算 value 部分的 ByteLen 再拼接 value 。 @@ -247,13 +247,13 @@
- Packed List Mode
如果list的元素本身属于 VarintType/Fixed32Type/Fixed64Type 编码格式,那么将采用 packed 模式编码整个 List ,在这种模式下的 list 是有 bytelen 的。Protobuf3 默认对这些类型启用 packed。 - UnPacked List Mode
当 list 元素属于 BytesType 编码格式时,list 将使用 unpacked 模式,直接编码每一个元素的 TLV,这里的 V 可能是嵌套的如List模式,那么 unpacked 模式下所有元素的 tag 都是相同的,list 字段的结束标志为与下一个 TLV 字段编码不同或者到达 buf 末尾。 - Service 接口由 ServiceDescriptor 来描述,ServiceDescriptor 当中可以拿到每个 rpc 函数的 MethodDescriptor。 @@ -261,14 +261,14 @@
- 具有完整的结构自描述和具体类型反射功能,兼容 scalar 类型以及复杂嵌套的 MESSAGE/LIST/MAP 结构。
- 支持字节流模式下的对任意局部进行动态数据修改与遍历。
- 保证数据可并发读。
这里我们借助 Go reflect 的设计思想,把通过 IDL 解析得到的准静态类型描述(只需跟随 IDL 更新一次)TypeDescriptor 和 原始数据单元 Node 打包成一个完全自描述的结构—— Value,提供一套完整的反射 API。 baseId:因为对于 LIST/MAP 类型的编码特殊性,如在 unpack 模式下,每一个元素都需要编写 Tag,我们必须在构造时针对 LIST/MAP 提供 fieldnumber,来保证读取和写入的自反射性。msg:这里的 msg 不是仅 Message 类型独有,主要是方便 J2P 部分对于 List 和裁剪场景中 map 获取可能存在 value 内部字段缺失的 MapEntry 的 MassageDescriptor(在源码的设计理念当中 MAP 的元素被认为是一个含有 key 和 value 两个字段的 message )的时候能直接利用 TypeDescriptor 进入下一层嵌套。
@@ -289,7 +288,6 @@ - 基本类型 Node 表示:指针 v 的起始位置不包含 tag,指向 (L)V,t = 具体类型。 @@ -300,13 +298,10 @@
- ERROR类型Node表示:在 setnotfound 中,若片段设计与上述规则一致则可正确构造插入节点。
List
li
+
+Map
Map 编码模式与 unpacked list 相同,根据官方设计思想,Map 的每个 KV 键值对其实本质上就是一个 Message,固定 key 的 Field_number 是1,value 的 Field_number 是2,那么 Map 的编码模式就和
-List<Message>一致了。
+源码 Descriptor 细节
这里主要介绍一下源码的 descriptor 设计上的一些需要注意的细节。
+
动态反射
针对 Protobuf 的反射使用场景,我们归纳出以下需求:
+IDL 静态文件 parse 过程:
为了提供文件流和内存字符串 io 流的 idl 文件解析,同时保证保证 go 版本兼容性,我们利用protoreflect@v1.8.2解析结果完成按需构造。从实现原理上来看,与高版本protoreflect利用protocompile对原始链路再 make 出源码的 warp 版本一致,更好的实现或许是处理利用 protoreflect 中的 ast 语法树构造。Descriptor设计
Descriptor 的设计原理基本尽可能与源码保持一致,但为了更好的自反射性,我们抽象了一个 TypeDescriptor 来表示更细粒度的类型。
FieldDescriptor
@@ -277,7 +277,6 @@type FieldDescriptor struct {
kind ProtoKind // the same value with protobuf descriptor
id FieldNumber
name string
jsonName string
typ *TypeDescriptor
}TypeDescriptor
-type TypeDescriptor struct {
baseId FieldNumber // for LIST/MAP to write field tag by baseId
typ Type
name string
key *TypeDescriptor
elem *TypeDescriptor
msg *MessageDescriptor // for message, list+message element and map key-value entry
}数据存储设计
从协议本身的 TLV 嵌套思想出发,我们利用字节流的编码格式,建立健壮的自反射性结构体处理任意类型的解析。
Node结构
-type Node struct {
t proto.Type // node type
et proto.Type // for map value or list element type
kt proto.Type // for map key type
v unsafe.Pointer
l int // ptr len
size int // only for MAP/LIST element counts
}具体的存储规则如下:
虽然 MAP/LIST 的父级 Node 存储有些变化,但是其子元素节点都是基本类型 / MESSAGE,所以叶子节点存储格式都是基本的 (L)V,这也便于序列化和数据基本单位的原子操作。
-Value结构
value 的结构本身是对 Node 的封装,将 Node 与相应的 descriptor 封装起来,但不同于 thrift,在 Protobuf 当中由于片段无法完全自解析出具体类型,之后的涉及到具体编码的部分操作不能脱离 descriptor,部分 API 实现只能 Value 类作为调用单位。
-- +type Value struct {
Node
Desc *proto.TypeDescriptor
IsRoot bool
}Value结构
value 的结构本身是对 Node 的封装,将 Node 与相应的 descriptor 封装起来,但不同于 thrift,在 Protobuf 当中由于片段无法完全自解析出具体类型,之后的涉及到具体编码的部分操作不能脱离 descriptor,部分 API 实现只能 Value 类作为调用单位。
type Value struct {
Node
Desc *proto.TypeDescriptor
IsRoot bool
}由于从 rpc 接口解析后我们直接得到了对应的 TypeDescriptor,再加上 root 节点本身没有前缀TL的独特编码结构,我们通过设置
IsRoot标记来区分 root 节点和其余节点,实现 Value 结构的 Descriptor 统一。数据编排
不同于源码 Message 对象数据动态管理的思想,我们设计了更高效的动态管理方式。我们借助 DOM (Document Object Model)思想,将原始字节流数据层层包裹的结构,抽象成多层嵌套的 BTree 结构,实现对数据的定位,切分,裁剪等操作的 inplace 处理。
-Path与PathNode
为了准确描述 DOM 中数据节点之间的嵌套关系,我们设计了 Path 结构,在 Path 的基础上,我们组合对应的数据单元 Node,然后再通过一个 Next 数组动态存储子节点,便可以组装成一个类似于 BTree 的泛型单元结构。
-+// Path represents the relative position of a sub node in a complex parent node
type Path struct {
t PathType // 类似div标签的类型,用来区分field,map,list元素,帮助判定父级嵌套属于什么类型结构
v unsafe.Pointer // PathStrKey, PathFieldName类型,存储的是Key/FieldName的字符串指针
l int
// PathIndex类型,表示LIST的下标
// PathIntKey类型,表示MAPKey的数值
// PathFieldId类型,表示字段的id
}
pathes []Path : 合理正确的Path数组,可以定位到嵌套复杂类型里具体的key/index的位置
type PathNode struct {
Path // DOM tree中用于定位当前Node的位置,并包含FieldId/FieldName/Key/index信息
Node // 存储了复杂嵌套关系中该位置对应的具体bytes片段
Next []PathNode // 下层嵌套的Node节点,基本类型下层Next为空
}Path与PathNode
为了准确描述 DOM 中数据节点之间的嵌套关系,我们设计了 Path 结构,在 Path 的基础上,我们组合对应的数据单元 Node,然后再通过一个 Next 数组动态存储子节点,便可以组装成一个类似于 BTree 的泛型单元结构。
// Path represents the relative position of a sub node in a complex parent node
type Path struct {
t PathType // 类似div标签的类型,用来区分field,map,list元素,帮助判定父级嵌套属于什么类型结构
v unsafe.Pointer // PathStrKey, PathFieldName类型,存储的是Key/FieldName的字符串指针
l int
// PathIndex类型,表示LIST的下标
// PathIntKey类型,表示MAPKey的数值
// PathFieldId类型,表示字段的id
}
pathes []Path : 合理正确的Path数组,可以定位到嵌套复杂类型里具体的key/index的位置
type PathNode struct {
Path // DOM tree中用于定位当前Node的位置,并包含FieldId/FieldName/Key/index信息
Node // 存储了复杂嵌套关系中该位置对应的具体bytes片段
Next []PathNode // 下层嵌套的Node节点,基本类型下层Next为空
}构建DOM Tree
构建 DOM 支持懒加载和全加载,在懒加载模式下 LIST/MAP 的 Node 当中 size 不会同步计算,而全加载在构造叶子节点的同时顺便更新了 size,构造后的节点都将遵循上述存储规则,具有自反射性和结构完整性。
查找字段
支持任意Node查找,查找函数设计了三个外部API:GetByPath,GetByPathWithAddress,GetMany。
- 指针向前移动到下一个 path 和 address。
-
+DOM序列化
- Marshal:建好 PathNode 后,可遍历拼接 DOM 的所有叶子节点片段,Tag 部分会通过 Path 类型和 Node 类型进行补全,bytelen 根据实际遍历节点进行更新。
- MarshalTo:针对数据裁剪场景,该设计方案具有很好的扩展性,可直接比对新旧 descriptor 中共有的字段 id,对字节流一次性拼接写入,无需依赖中间结构体,可支持多层嵌套字段缺失以及 LIST/MAP 内部元素字段缺失。
+协议转换
ProtoBuf——>JSON
Protobuf->JSON 协议转换的过程可以理解为逐字节解析 ProtoBuf,并结合 Descriptor 类型编码为 JSON 到输出字节流,整个过程是 in-place 进行的,并且结合内存池技术,仅需为输出字节流分配一次内存即可。
-
+ProtoBuf——>JSON 的转换过程如下:
- 根据输入的 Descriptor 指针类型区分,若为 Singular(string/number/bool/Enum) 类型,跳转到第5步开始编码; @@ -347,17 +342,15 @@
- stk:记录解析时中间变量的栈结构,在解析 Message 类型时记录 MessageDescriptor、PrefixLen;在解析 Map 类型时记录 FieldDescriptor、PairPrefixLen;在解析 List 类型时记录 FieldDescriptor、PrefixListLen;
- sp:当前所处栈的层级;
- p:输出字节流;
- globalFieldDesc:每当解析完 MessageField 的 jsonKey 值,保存该字段 Descriptor 值;
- typ:当前字段的类型,取值有对象类型(objStkType)、数组类型(arrStkType)、哈希类型(mapStkType);
- state:存储详细的数据值; @@ -371,23 +364,19 @@
- 从输入字节流中读取一个 json 值,并判断其具体类型(
object/array/string/float/int/bool/null);
- - 如果是 object 类型,可能对应 ProtoBuf MapType/MessageType,sonic 会按照
OnObjectBegin()->OnObjectKey()->decodeValue()...顺序处理输入字节流
- - 如果是 object 类型,可能对应 ProtoBuf MapType/MessageType,sonic 会按照
OnObjectBegin()->OnObjectKey()->decodeValue()...顺序处理输入字节流OnObjectBegin()阶段解析具体的动态类型描述 FieldDescriptor 并压栈;OnObjectKey()阶段解析 jsonKey 并以 ProtoBuf 格式编码 Tag、Length 到输出字节流;decodeValue()阶段递归解析子元素并以 ProtoBuf 格式编码 Value 部分到输出字节流,若子类型为复杂类型(Message/Map),会递归执行第 2 步;若子类型为复杂类型(List),会递归执行第 3 步。
-
-
- 如果是 array 类型,对应 ProtoBuf PackedList/UnpackedList,sonic 会按照
OnObjectBegin()->OnObjectKey()->OnArrayBegin()->decodeValue()->OnArrayEnd()...顺序处理输入字节流
-
-
+
+ - 如果是 array 类型,对应 ProtoBuf PackedList/UnpackedList,sonic 会按照
OnObjectBegin()->OnObjectKey()->OnArrayBegin()->decodeValue()->OnArrayEnd()...顺序处理输入字节流OnObjectBegin()阶段处理解析 List 字段对应动态类型描述 FieldDescriptor 并压栈;OnObjectKey()阶段解析 List 下子元素的动态类型描述 FieldDescriptor 并压栈;OnArrayBegin()阶段将 PackedList 类型的 Tag、Length 编码到输出字节流;decodeValue()阶段循环处理子元素,按照子元素类型编码到输出流,若子元素为复杂类型(Message),会跳转到第 2 步递归执行。
-
+
- 在结束处理某字段数据后执行
onValueEnd()、OnArrayEnd()、OnObjectEnd(),获取栈顶lenPos数据,对字段长度部分回写并退栈。 - 更新输入和输出字节流位置,跳回第 1 步循环处理,直到处理完输入流数据。
JSON——>ProtoBuf
协议转换过程中借助 JSON 状态机原理和 sonic 思想,设计 UserNodeStack 实现了接口 Onxxx(OnBool、OnString、OnInt64….)方法达到编码 ProtoBuf 的目标,实现 in-place 遍历 JSON 转换。
-
-VisitorUserNode 结构
因为在编码 Protobuf 格式的 Mesage/UnpackedList/Map 类型时需要对字段总长度回写,并且在解析复杂类型(Message/Map/List)的子元素时需要依赖复杂类型 Descriptor 来获取子元素 Descriptor,所以需要 VisitorUserNode 结构来保存解析 json 时的中间数据。
-+type VisitorUserNode struct {
stk []VisitorUserNodeStack
sp uint8
p *binary.BinaryProtocol
globalFieldDesc *proto.FieldDescriptor
}
+VisitorUserNode 结构
因为在编码 Protobuf 格式的 Mesage/UnpackedList/Map 类型时需要对字段总长度回写,并且在解析复杂类型(Message/Map/List)的子元素时需要依赖复杂类型 Descriptor 来获取子元素 Descriptor,所以需要 VisitorUserNode 结构来保存解析 json 时的中间数据。
type VisitorUserNode struct {
stk []VisitorUserNodeStack
sp uint8
p *binary.BinaryProtocol
globalFieldDesc *proto.FieldDescriptor
}VisitorUserNodeStack 结构
记录解析时字段 Descriptor、回写长度的起始地址 PrefixLenPos 的栈结构。
-+type VisitorUserNodeStack struct {
typ uint8
state visitorUserNodeState
}VisitorUserNodeStack 结构
记录解析时字段 Descriptor、回写长度的起始地址 PrefixLenPos 的栈结构。
type VisitorUserNodeStack struct {
typ uint8
state visitorUserNodeState
}协议转换过程
JSON——>ProtoBuf 的转换过程如下:
-
+
反射图中列举了 DOM 常用操作的性能,测试细节与 thrift 相同。
- MarshalTo 方法:相比 ProtobufGo 提升随着数据规模的增大趋势越明显,ns/op 开销约为源码方法的0.29 ~ 0.32。
-
-
+
+字段Get/Set定量测试
- factor 用于修改从上到下扫描 proto 文件字段获取比率。
- 定量测试比较方法是 ProtobufGo 的 dynamicpb 模块和 DynamicGo 的 Get/SetByPath,SetMany,测试对象是medium data 的情况。
- Set/Get 字段定量测试结果均优于 ProtobufGo,且在获取字段越稀疏的情况下性能加速越明显。
- Setmany 性能加速更明显,在 100% 字段下 ns/op 开销约为 0.11。
+序列化/反序列
- 序列化在 small 规模略高于 ProtobufGo,medium 规模的数据上性能优势更明显,ns/op 开销约为源码的0.54 ~ 0.84。
- 反序列化在 reuse 模式下,small 规模略高于 ProtobufGo,在 medium 规模数据上性能优势更明显,ns/op 开销约为源码的0.44 ~ 0.47,随数据规模增大性能优势增加。
-
+
+协议转换
- Json2Protobuf 优于 ProtobufGo,ns/op 性能开销约为源码的0.21 ~ 0.89,随着数据量规模增大优势增加。
- Protobuf2Json 性能明显优于 ProtobufGo,ns/op 开销约为源码的0.13 ~ 0.21,而相比 Kitex,ns/op 约为Sonic+Kitex 的0.40 ~ 0.92,随着数据量规模增大优势增加。
+应用与展望
目前 dynamicgo 对于 Protobuf 协议的可支持的功能包括:
- 替代官方源码的 JSON 协议转换,实现更高性能的 HTTP<>PB 动态网关 @@ -742,7 +731,7 @@
-
diff --git "a/2024/10/09/ubuntu22-04-\346\227\245\345\270\270\345\214\226/index.html" "b/2024/10/09/ubuntu22-04-\346\227\245\345\270\270\345\214\226/index.html"
index 193d8bec..b97a8c43 100644
--- "a/2024/10/09/ubuntu22-04-\346\227\245\345\270\270\345\214\226/index.html"
+++ "b/2024/10/09/ubuntu22-04-\346\227\245\345\270\270\345\214\226/index.html"
@@ -16,7 +16,7 @@
-
+
@@ -208,20 +208,19 @@ -
最近有在折腾一些Ubuntu日常化的东西,给电脑重新装了双系统,相比前几年,ubuntu22.04之后系统确实变得非常好用了,软件生态支持也变多了,为了更加日常化的使用折腾了一些相关软件的安装,这边做一个简单的记录。
- - -ubuntu安装卸载
ubuntu的安装卸载以及分区教程还是有些麻烦的,我也是参考了b战上面一个不错的up主的教学,期间有差点把自己windows引导搞出问题,然后用驱动精灵修复了。注意计算机专业同学还是尽量用英语安装,且安装以后禁用掉软件和内核更新,在一生一芯中有提到,禁用方法很简单自行百度即可。
-
参考链接:Windows 和 Ubuntu 双系统的安装和卸载Easyconnect
目前华科的VPN是支持ubuntu系统的,这确实提供了学生在连接校园网和服务器上的便利。当然安装可能会打不开的小问题。
-
参考链接:解决方案,需下载的软件内有可用的百度云网址VPN-Clash
找了一个不错的ubuntu支持的带有客户端的clash,亲测可用,导入任意可用的订阅链接就行。
+
参考链接:Devpn最近有在折腾一些Ubuntu日常化的东西,给电脑重新装了双系统,相比前几年,ubuntu22.04之后系统确实变得非常好用了,软件生态支持也变多了,为了更加日常化的使用折腾了一些相关软件的安装,这边做一个简单的记录。
+ubuntu安装卸载
ubuntu的安装卸载以及分区教程还是有些麻烦的,我也是参考了b战上面一个不错的up主的教学,期间有差点把自己windows引导搞出问题,然后用驱动精灵修复了。注意计算机专业同学还是尽量用英语安装,且安装以后禁用掉软件和内核更新,在一生一芯中有提到,禁用方法很简单自行百度即可。
+
参考链接:Windows 和 Ubuntu 双系统的安装和卸载Easyconnect
目前华科的VPN是支持ubuntu系统的,这确实提供了学生在连接校园网和服务器上的便利。当然安装可能会打不开的小问题。
+
参考链接:解决方案,需下载的软件内有可用的百度云网址VPN-Clash
找了一个不错的ubuntu支持的带有客户端的clash,亲测可用,导入任意可用的订阅链接就行。
参考链接:DevpnQQ
QQ 9可以直接在ubuntu22.04上直接使用。
参考链接:QQ 9官网QQ 音乐
官方目前已经有可支持的版本,再也不用担心冲了会员用不了啦!偶尔会有闪退问题,但是不影响。
参考链接:QQ音乐官网WPS
WPS是在linux系统下可支持office三件套的工具,有一些中文汉化的问题,解决方案跟下面一样,不过实际下载之后发现,在
-/opt/kingsoft/wps-office/office6/mui下面本来就有语言包,只需要像下面的链接一样,移除下载后的其他语言安装包,只保留default zh_CN就能直接汉化,虽然在选择字体上好像还有点问题没解决,但是算是能用了至少。
参考链接:参考链接中文输入法
在b战找到了一个简单不错的中文输入法——rime输入法,感觉非常好用,安装后如果没有效果记得重启下电脑。
+
参考链接:rime输入法安装中文输入法
在b战找到了一个简单不错的中文输入法——rime输入法,感觉非常好用,安装后如果没有效果记得重启下电脑。
参考链接:rime输入法安装微信
微信的安装好像有很多版本了,官方也有在做统一的OS支持,这里我用的可能不一定是最好的版本,但是可以支持文字和图片截图,还能打开小程序和公众号,只是看不了朋友圈,安装过程没有踩坑。
参考链接:2024如何在Ubuntu上安装原生微信wechat weixin浏览器
Edge & Chrome 目前都支持linux的相关系统了,不用担心使用问题,编程相关的软件就更方便了。
End
一生一芯可以启动了!
-
+It's time to use ubuntu now😍 pic.twitter.com/BSuh7xTN0M
— kehan yin (@jack_kehan) September 12, 2024
+ @@ -516,7 +515,7 @@It's time to use ubuntu now😍 pic.twitter.com/BSuh7xTN0M
— kehan yin (@jack_kehan) September 12, 2024End
一生
- diff --git a/atom.xml b/atom.xml index c698c740..f728b933 100644 --- a/atom.xml +++ b/atom.xml @@ -6,7 +6,7 @@ -
2024-10-09T11:01:20.220Z +2024-10-10T05:19:45.456Z https://jackyin.space/ @@ -21,13 +21,13 @@ https://jackyin.space/2024/10/09/ubuntu22-04-%E6%97%A5%E5%B8%B8%E5%8C%96/ 2024-10-09T10:17:37.000Z -2024-10-09T11:01:20.220Z +2024-10-10T05:19:45.456Z -最近有在折腾一些Ubuntu日常化的东西,给电脑重新装了双系统,相比前几年,ubuntu22.04之后系统确实变得非常好用了,软件生态支持也变多了,为了更加日常化的使用折腾了一些相关软件的安装,这边做一个简单的记录。 +ubuntu安装卸载
ubuntu的安装卸载以及分区教程还是有些麻烦的,我也是参考了b战上面一个不错的up主的教学,期间有差点把自己windows引导搞出问题,然后用驱动精灵修复了。注意计算机专业同学还是尽量用英语安装,且安装以后禁用掉软件和内核更新,在一生一芯中有提到,禁用方法很简单自行百度即可。
参考链接:Windows 和 Ubuntu 双系统的安装和卸载Easyconnect
目前华科的VPN是支持ubuntu系统的,这确实提供了学生在连接校园网和服务器上的便利。当然安装可能会打不开的小问题。
参考链接:解决方案,需下载的软件内有可用的百度云网址VPN-Clash
找了一个不错的ubuntu支持的带有客户端的clash,亲测可用,导入任意可用的订阅链接就行。
参考链接:DevpnQQ
QQ 9可以直接在ubuntu22.04上直接使用。
参考链接:QQ 9官网QQ 音乐
官方目前已经有可支持的版本,再也不用担心冲了会员用不了啦!偶尔会有闪退问题,但是不影响。
参考链接:QQ音乐官网WPS
WPS是在linux系统下可支持office三件套的工具,有一些中文汉化的问题,解决方案跟下面一样,不过实际下载之后发现,在
/opt/kingsoft/wps-office/office6/mui下面本来就有语言包,只需要像下面的链接一样,移除下载后的其他语言安装包,只保留default zh_CN就能直接汉化,虽然在选择字体上好像还有点问题没解决,但是算是能用了至少。
参考链接:参考链接中文输入法
在b战找到了一个简单不错的中文输入法——rime输入法,感觉非常好用,安装后如果没有效果记得重启下电脑。
参考链接:rime输入法安装微信
微信的安装好像有很多版本了,官方也有在做统一的OS支持,这里我用的可能不一定是最好的版本,但是可以支持文字和图片截图,还能打开小程序和公众号,只是看不了朋友圈,安装过程没有踩坑。
参考链接:2024如何在Ubuntu上安装原生微信wechat weixin浏览器
Edge & Chrome 目前都支持linux的相关系统了,不用担心使用问题,编程相关的软件就更方便了。
End
一生一芯可以启动了!
]]>It's time to use ubuntu now😍 pic.twitter.com/BSuh7xTN0M
— kehan yin (@jack_kehan) September 12, 2024最近有在折腾一些Ubuntu日常化的东西,给电脑重新装了双系统,相比前几年,ubuntu22.04之后系统确实变得非常好用了,软件生态支持也变多了,为了更加日常化的使用折腾了一些相关软件的安装,这边做一个简单的记录。 ubuntu安装卸载
ubuntu的安装卸载以及分区教程还是有些麻烦的,我也是参考了b战上面一个不错的up主的教学,期间有差点把自己windows引导搞出问题,然后用驱动精灵修复了。注意计算机专业同学还是尽量用英语安装,且安装以后禁用掉软件和内核更新,在一生一芯中有提到,禁用方法很简单自行百度即可。
参考链接:Windows 和 Ubuntu 双系统的安装和卸载Easyconnect
目前华科的VPN是支持ubuntu系统的,这确实提供了学生在连接校园网和服务器上的便利。当然安装可能会打不开的小问题。
参考链接:解决方案,需下载的软件内有可用的百度云网址VPN-Clash
找了一个不错的ubuntu支持的带有客户端的clash,亲测可用,导入任意可用的订阅链接就行。
参考链接:DevpnQQ
QQ 9可以直接在ubuntu22.04上直接使用。
参考链接:QQ 9官网QQ 音乐
官方目前已经有可支持的版本,再也不用担心冲了会员用不了啦!偶尔会有闪退问题,但是不影响。
参考链接:QQ音乐官网WPS
WPS是在linux系统下可支持office三件套的工具,有一些中文汉化的问题,解决方案跟下面一样,不过实际下载之后发现,在
/opt/kingsoft/wps-office/office6/mui下面本来就有语言包,只需要像下面的链接一样,移除下载后的其他语言安装包,只保留default zh_CN就能直接汉化,虽然在选择字体上好像还有点问题没解决,但是算是能用了至少。
参考链接:参考链接中文输入法
在b战找到了一个简单不错的中文输入法——rime输入法,感觉非常好用,安装后如果没有效果记得重启下电脑。
参考链接:rime输入法安装微信
微信的安装好像有很多版本了,官方也有在做统一的OS支持,这里我用的可能不一定是最好的版本,但是可以支持文字和图片截图,还能打开小程序和公众号,只是看不了朋友圈,安装过程没有踩坑。
参考链接:2024如何在Ubuntu上安装原生微信wechat weixin浏览器
Edge & Chrome 目前都支持linux的相关系统了,不用担心使用问题,编程相关的软件就更方便了。
End
一生一芯可以启动了!
]]>It's time to use ubuntu now😍 pic.twitter.com/BSuh7xTN0M
— kehan yin (@jack_kehan) September 12, 2024- <p>最近有在折腾一些Ubuntu日常化的东西,给电脑重新装了双系统,相比前几年,ubuntu22.04之后系统确实变得非常好用了,软件生态支持也变多了,为了更加日常化的使用折腾了一些相关软件的安装,这边做一个简单的记录。</p> + <p>最近有在折腾一些Ubuntu日常化的东西,给电脑重新装了双系统,相比前几年,ubuntu22.04之后系统确实变得非常好用了,软件生态支持也变多了,为了更加日常化的使用折腾了一些相关软件的安装,这边做一个简单的记录。<br></p> @@ -44,7 +44,7 @@2023-12-27T08:57:00.000Z 2024-10-09T07:33:09.866Z -背景 +Dynamicgo 是字节跳动自研的高性能 Golang RPC 编解码基础库,能在动态处理 RPC 数据(不依赖代码生成)的同时保证高性能,主要用于实现高性能 RPC 动态代理场景(见 dynamicgo 介绍)。
Protobuf 是一种跨平台、可扩展的序列化数据传输协议,该协议序列化压缩特性使其具有优秀的传输速率,在常规静态 RPC 微服务场景中已经得到了广泛的应用。但是对于上述特殊的动态代理场景,我们调研发现目前业界主流的 Protobuf 协议基础库并不能满足我们的需求:- google.golang.org/protobuf:Protobuf 官方源码支持协议转换和字段动态反射。实现过程依赖于反射完整的中间结构体 Message 对象来进行管理,使用过程中带来了很多不必要字段的数据性能开销,并且在处理多层嵌套数据时操作较为复杂,不支持内存字符串 io 流 IDL 解析。
- github.com/jhump/protoreflect:Protobuf 动态反射第三方库可支持文件和内存字符串 io 流 IDL 解析,适合频繁泛化调用,协议转换过程与官方源码一致,均未实现 inplace 转换,且内部实现存在Go版本兼容性问题。
- github.com/cloudwego/fastpb:Protobuf 快速序列化第三方库,通过静态代码方式读写消息结构体,不支持协议转换和动态 IDL 解析。
因此如何设计自研一个功能完备、高性能、可扩展的 Protobuf 协议动态代理基础库是十分有必要的。
@khan-yin和@iStitches两位同学经过对 Protobuf 协议源码机制的深入学习,设计了高性能 Protobuf 协议动态泛化调用链路,能满足绝大多数 Protobuf 动态代理场景,并且性能优于官方实现,目前 PR#37 已经合入代码仓库。Protobuf 设计思想
由于 Protobuf 协议编码格式细节较为复杂,在介绍链路设计之前我们有必要先了解一下 Protobuf 协议的设计思想,后续的各项设计都将在严格遵守该协议规范的基础上进行改进。
官方源码链路思想
Protobuf 源码链路过程主要涉及三类数据类型之间的转换,以 Message 对象进行管理,自定义 Value 类实现反射和底层存储,用 Message 对象能有效地进行管理和迁移,但也带来了许多反射和序列化开销。
Protobuf编码格式
Protobuf 编码字段格式大体上遵循 TLV(Tag,Length,Value) 的结构,但针对具体的类型存在一些编码差异,这里我们将较为全面的给出常见类型的编码模式。
Message Field
Protobuf 的接口必定包裹在一个 Message 类型下,因此无论是 request 还是 response 最终都会包裹成一个 Message 对象,那么 Field 则是 Message 的一个基本单元,任何类型的字段都遵循这样的 TLV 结构:
- Tag 由字段编号 Field_number 和 wiretype 两部分决定,对位运算后的结果进行 varint 压缩,得到压缩后的字节数组作为字段的 Tag。
- wiretype 的值则表示的是 value 部分的编码方式,可以帮助我们清楚如何对 value 的读取和写入。到目前为止,wiretype只有 VarintType,Fixed32Type,Fixed64Type,BytesType 四类编码方式。其中VarintType 类型会被压缩后再编码,属于 Fixed32Type 和 Fixed64Typ 固定长度类型则分别占用4字节和8字节,而属于不定长编码类型 BytesType 的则会编码计算 value 部分的 ByteLen 再拼接 value 。
- ByteLen 用于编码表示 value 部分所占的字节长度,同样我们的 bytelen 的值也是经过 varint 压缩后得到的,但bytelen并不是每个字段都会带有,只有不定长编码类型 BytesType 才会编码 bytelen 。ByteLen 由于其不定长特性,计算过程在序列化过程中是需要先预先分配空间,记录位置,等写完内部字段以后再回过头来填充。
- Value 部分是根据 wiretype 进行对应的编码,字段的 value 可能存在嵌套的 T(L)V 结构,如字段是 Message,Map等情况。
Message
关于 Message 本身的编码是与上面提到的字段编码一致的,也就是说遇到一个 Message 字段时,我们会先编码 Message 字段本身的 Tag 和 bytelen,然后再来逐个编码 Message 里面的每个字段。但需要提醒注意的是,在最外层不存在包裹整个 Message 的 Tag 和 bytelen 前缀,只有每个字段的 TLV 拼接。
List
list字段比较特殊,为了节省存储空间,根据list元素的类型分别采用不同的编码模式。
- Packed List Mode
如果list的元素本身属于 VarintType/Fixed32Type/Fixed64Type 编码格式,那么将采用 packed 模式编码整个 List ,在这种模式下的 list 是有 bytelen 的。Protobuf3 默认对这些类型启用 packed。
- UnPacked List Mode
当 list 元素属于 BytesType 编码格式时,list 将使用 unpacked 模式,直接编码每一个元素的 TLV,这里的 V 可能是嵌套的如List模式,那么 unpacked 模式下所有元素的 tag 都是相同的,list 字段的结束标志为与下一个 TLV 字段编码不同或者到达 buf 末尾。
Map
Map 编码模式与 unpacked list 相同,根据官方设计思想,Map 的每个 KV 键值对其实本质上就是一个 Message,固定 key 的 Field_number 是1,value 的 Field_number 是2,那么 Map 的编码模式就和
List<Message>一致了。源码 Descriptor 细节
这里主要介绍一下源码的 descriptor 设计上的一些需要注意的细节。
- Service 接口由 ServiceDescriptor 来描述,ServiceDescriptor 当中可以拿到每个 rpc 函数的 MethodDescriptor。
- MethodDescriptor 中 Input() 和 output() 两个函数返回值均为 MessageDescriptor 分别表示 request 和 response 。
- MessageDescriptor 专门用来描述一个 Message 对象(也可能是一个 MapEntry ),可以通过 Fields() 找到每个字段的 FieldDescriptor 。
- FieldDescriptor 则兼容所有类型的描述。
动态反射
针对 Protobuf 的反射使用场景,我们归纳出以下需求:
- 具有完整的结构自描述和具体类型反射功能,兼容 scalar 类型以及复杂嵌套的 MESSAGE/LIST/MAP 结构。
- 支持字节流模式下的对任意局部进行动态数据修改与遍历。
- 保证数据可并发读。
这里我们借助 Go reflect 的设计思想,把通过 IDL 解析得到的准静态类型描述(只需跟随 IDL 更新一次)TypeDescriptor 和 原始数据单元 Node 打包成一个完全自描述的结构—— Value,提供一套完整的反射 API。
IDL 静态文件 parse 过程:
为了提供文件流和内存字符串 io 流的 idl 文件解析,同时保证保证 go 版本兼容性,我们利用protoreflect@v1.8.2解析结果完成按需构造。从实现原理上来看,与高版本protoreflect利用protocompile对原始链路再 make 出源码的 warp 版本一致,更好的实现或许是处理利用 protoreflect 中的 ast 语法树构造。Descriptor设计
Descriptor 的设计原理基本尽可能与源码保持一致,但为了更好的自反射性,我们抽象了一个 TypeDescriptor 来表示更细粒度的类型。
FieldDescriptor
type FieldDescriptor struct {
kind ProtoKind // the same value with protobuf descriptor
id FieldNumber
name string
jsonName string
typ *TypeDescriptor
}FieldDescriptor: 设计上希望变量和函数作用与源码 FieldDescriptor 基本一致,增加*TypeDescriptor可以更细粒度的反应类型以及对 FieldDescriptor 的 API 实现。kind:与源码 kind 功能一致,LIST 情况下 kind 是列表元素的 kind 类型,MAP 和 MESSAGE 情况下都为 messagekind。
TypeDescriptor
type TypeDescriptor struct {
baseId FieldNumber // for LIST/MAP to write field tag by baseId
typ Type
name string
key *TypeDescriptor
elem *TypeDescriptor
msg *MessageDescriptor // for message, list+message element and map key-value entry
}baseId:因为对于 LIST/MAP 类型的编码特殊性,如在 unpack 模式下,每一个元素都需要编写 Tag,我们必须在构造时针对 LIST/MAP 提供 fieldnumber,来保证读取和写入的自反射性。msg:这里的 msg 不是仅 Message 类型独有,主要是方便 J2P 部分对于 List 和裁剪场景中 map 获取可能存在 value 内部字段缺失的 MapEntry 的 MassageDescriptor(在源码的设计理念当中 MAP 的元素被认为是一个含有 key 和 value 两个字段的 message )的时候能直接利用 TypeDescriptor 进入下一层嵌套。typ:这里的 Type 是对源码的 FieldDescriptor 更细粒度的表示,即对 LIST/MAP 做了单独定义
MessageDescriptor
type MessageDescriptor struct {
baseId FieldNumber
name string
ids FieldNumberMap // store by tire tree
names FieldNameMap // store name and jsonName for FieldDescriptor
}MessageDescriptor: 利用 Tire 树结构实现更高性能的字段 id 和字段 name 的存储和查找。
数据存储设计
从协议本身的 TLV 嵌套思想出发,我们利用字节流的编码格式,建立健壮的自反射性结构体处理任意类型的解析。
Node结构
type Node struct {
t proto.Type // node type
et proto.Type // for map value or list element type
kt proto.Type // for map key type
v unsafe.Pointer
l int // ptr len
size int // only for MAP/LIST element counts
}具体的存储规则如下:
- 基本类型 Node 表示:指针 v 的起始位置不包含 tag,指向 (L)V,t = 具体类型。
- MESSAGE 类型:指针 v 的起始位置不包含 tag,指向 (L)V,如果是 root 节点,那么 v 的起始位置本身没有前缀的 L,直接指向了 V 即第一个字段的 tag 上,而其余子结构体都包含前缀 L。
- LIST类型:为了兼容 List 的两种模式和自反射的完整性,我们必须包含 list 的完整片段和 tag。因此 List 类型的节点,v 指向 list 的 tag 上,即如果是 packed 模式就是 list 的 tag 上,如果是 unpacked 则在第一个元素的 tag 上。
- MAP类型:Map 的指针 v 也指向了第一个 pair 的 tag 位置。
- UNKNOWN类型Node表示:无法解析的合理字段,Node 会将 TLV 完整存储,多个相同字段 Id 的会存到同一节点,缺点是内部的子节点无法构建,同官方源码unknownFields原理一致。
- ERROR类型Node表示:在 setnotfound 中,若片段设计与上述规则一致则可正确构造插入节点。
虽然 MAP/LIST 的父级 Node 存储有些变化,但是其子元素节点都是基本类型 / MESSAGE,所以叶子节点存储格式都是基本的 (L)V,这也便于序列化和数据基本单位的原子操作。
Value结构
value 的结构本身是对 Node 的封装,将 Node 与相应的 descriptor 封装起来,但不同于 thrift,在 Protobuf 当中由于片段无法完全自解析出具体类型,之后的涉及到具体编码的部分操作不能脱离 descriptor,部分 API 实现只能 Value 类作为调用单位。
type Value struct {
Node
Desc *proto.TypeDescriptor
IsRoot bool
}由于从 rpc 接口解析后我们直接得到了对应的 TypeDescriptor,再加上 root 节点本身没有前缀TL的独特编码结构,我们通过设置
IsRoot标记来区分 root 节点和其余节点,实现 Value 结构的 Descriptor 统一。数据编排
不同于源码 Message 对象数据动态管理的思想,我们设计了更高效的动态管理方式。我们借助 DOM (Document Object Model)思想,将原始字节流数据层层包裹的结构,抽象成多层嵌套的 BTree 结构,实现对数据的定位,切分,裁剪等操作的 inplace 处理。
Path与PathNode
为了准确描述 DOM 中数据节点之间的嵌套关系,我们设计了 Path 结构,在 Path 的基础上,我们组合对应的数据单元 Node,然后再通过一个 Next 数组动态存储子节点,便可以组装成一个类似于 BTree 的泛型单元结构。
// Path represents the relative position of a sub node in a complex parent node
type Path struct {
t PathType // 类似div标签的类型,用来区分field,map,list元素,帮助判定父级嵌套属于什么类型结构
v unsafe.Pointer // PathStrKey, PathFieldName类型,存储的是Key/FieldName的字符串指针
l int
// PathIndex类型,表示LIST的下标
// PathIntKey类型,表示MAPKey的数值
// PathFieldId类型,表示字段的id
}
pathes []Path : 合理正确的Path数组,可以定位到嵌套复杂类型里具体的key/index的位置
type PathNode struct {
Path // DOM tree中用于定位当前Node的位置,并包含FieldId/FieldName/Key/index信息
Node // 存储了复杂嵌套关系中该位置对应的具体bytes片段
Next []PathNode // 下层嵌套的Node节点,基本类型下层Next为空
}构建DOM Tree
构建 DOM 支持懒加载和全加载,在懒加载模式下 LIST/MAP 的 Node 当中 size 不会同步计算,而全加载在构造叶子节点的同时顺便更新了 size,构造后的节点都将遵循上述存储规则,具有自反射性和结构完整性。
查找字段
支持任意Node查找,查找函数设计了三个外部API:GetByPath,GetByPathWithAddress,GetMany。
GetByPath:返回查找出来的 Value ,查找失败返回 ERROR 类型的节点。GetByPathWithAddress:返回Value和当前调用节点到查找节点过程中每个 Path 嵌套层的 tag 位置的偏移量。[]address与[]Path个数对应,若调用节点为 root 节点,那么可记录到 buf 首地址的偏移量。GetMany:传入当前嵌套层下合理的[]PathNode的 Path 部分,直接返回构造出来多个 Node,得到完整的[]PathNode,可继续用于MarshalMany
设计思路:
查找过程是根据传入的[]Path来循环遍历查找每一层 Path 嵌套里面对应的位置,根据嵌套的 Path 类型(fieldId,mapKey,listIndex),调用对应的 search 函数。不同于源码翻译思路,由于 Node 的自反射性设计,我们可以直接实现字节流定位,无需依赖 Descriptor 查找,并跳过不必要的字段翻译。构造最终返回的 Node 时,根据具体类型看是否需要去除 tag 即可,返回的[]address刚好在 search 过程中完成了每一层 Path 的 tag 偏移量记录。动态插入/删除
新增数据思想采用尾插法,保证 pack/unpack 数据的统一性,完成插入操作后需要更新嵌套层 bytelen。
- SetByPath:只支持 root 节点调用,保证 UpdateByLen 更新的完整和正确性。
- SetMany:可支持局部节点插入。
- UnsetByPath:只支持 root 节点调用,思想同插入字段,即找到对应的片段后直接将片段置空,然后更新updatebytelen。
Updatebytelen细节:
- 计算插入完成后新的长度与原长度的差值,存下当前片段增加或者减少的diffLen。
- 从里向外逐步更新
[]Path数组中存在 bytelen 的嵌套层(只有packed list和message)的 bytelen 字节数组。 - 更新规则:先 readTag,然后再 readLength,得到解 varint 压缩后的具体 bytelen 数值,计算 newlen = bytelen + diffLen,计算 newbytelen 压缩后的字节长度与原 bytelen 长度的差值 sublen,并累计diffLen += sublen。
- 指针向前移动到下一个 path 和 address。
DOM序列化
- Marshal:建好 PathNode 后,可遍历拼接 DOM 的所有叶子节点片段,Tag 部分会通过 Path 类型和 Node 类型进行补全,bytelen 根据实际遍历节点进行更新。
- MarshalTo:针对数据裁剪场景,该设计方案具有很好的扩展性,可直接比对新旧 descriptor 中共有的字段 id,对字节流一次性拼接写入,无需依赖中间结构体,可支持多层嵌套字段缺失以及 LIST/MAP 内部元素字段缺失。
协议转换
ProtoBuf——>JSON
Protobuf->JSON 协议转换的过程可以理解为逐字节解析 ProtoBuf,并结合 Descriptor 类型编码为 JSON 到输出字节流,整个过程是 in-place 进行的,并且结合内存池技术,仅需为输出字节流分配一次内存即可。
ProtoBuf——>JSON 的转换过程如下:
- 根据输入的 Descriptor 指针类型区分,若为 Singular(string/number/bool/Enum) 类型,跳转到第5步开始编码;
- 按照 Message([Tag] [Length] [TLV][TLV][TLV]….)编码格式对输入字节流执行 varint解码,将Tag解析为 fieldId(字段ID)、wireType(字段wiretype类型);
- 根据第2步解析的 fieldId 确定字段 FieldDescriptor,并编码字段名 key 作为 jsonKey 到输出字节流;
- 根据 FieldDescriptor 确定字段类型(Singular/Message/List/Map),选择不同编码方法编码 jsonValue 到输出字节流;
- 如果是 Singular 类型,直接编码到输出字节流;
- 其它类型递归处理内部元素,确定子元素 Singular 类型进行编码,写入输出字节流中;
- 及时输入字节流读取位置和输出字节流写入位置,跳回2循环处理,直到读完输入字节流。
JSON——>ProtoBuf
协议转换过程中借助 JSON 状态机原理和 sonic 思想,设计 UserNodeStack 实现了接口 Onxxx(OnBool、OnString、OnInt64….)方法达到编码 ProtoBuf 的目标,实现 in-place 遍历 JSON 转换。
VisitorUserNode 结构
因为在编码 Protobuf 格式的 Mesage/UnpackedList/Map 类型时需要对字段总长度回写,并且在解析复杂类型(Message/Map/List)的子元素时需要依赖复杂类型 Descriptor 来获取子元素 Descriptor,所以需要 VisitorUserNode 结构来保存解析 json 时的中间数据。
type VisitorUserNode struct {
stk []VisitorUserNodeStack
sp uint8
p *binary.BinaryProtocol
globalFieldDesc *proto.FieldDescriptor
}- stk:记录解析时中间变量的栈结构,在解析 Message 类型时记录 MessageDescriptor、PrefixLen;在解析 Map 类型时记录 FieldDescriptor、PairPrefixLen;在解析 List 类型时记录 FieldDescriptor、PrefixListLen;
- sp:当前所处栈的层级;
- p:输出字节流;
- globalFieldDesc:每当解析完 MessageField 的 jsonKey 值,保存该字段 Descriptor 值;
VisitorUserNodeStack 结构
记录解析时字段 Descriptor、回写长度的起始地址 PrefixLenPos 的栈结构。
type VisitorUserNodeStack struct {
typ uint8
state visitorUserNodeState
}- typ:当前字段的类型,取值有对象类型(objStkType)、数组类型(arrStkType)、哈希类型(mapStkType);
- state:存储详细的数据值;
visitorUserNodeState 结构
type visitorUserNodeState struct {
msgDesc *proto.MessageDescriptor
fieldDesc *proto.FieldDescriptor
lenPos int
}- msgDesc:记录 root 层的动态类型描述 MessageDescriptor;
- fieldDesc:记录父级元素(Message/Map/List)的动态类型描述 FieldDescriptor;
- lenPos:记录需要回写 PrefixLen 的位置;
协议转换过程
JSON——>ProtoBuf 的转换过程如下:
- 从输入字节流中读取一个 json 值,并判断其具体类型(
object/array/string/float/int/bool/null); - 如果是 object 类型,可能对应 ProtoBuf MapType/MessageType,sonic 会按照
OnObjectBegin()->OnObjectKey()->decodeValue()...顺序处理输入字节流
OnObjectBegin()阶段解析具体的动态类型描述 FieldDescriptor 并压栈;OnObjectKey()阶段解析 jsonKey 并以 ProtoBuf 格式编码 Tag、Length 到输出字节流;decodeValue()阶段递归解析子元素并以 ProtoBuf 格式编码 Value 部分到输出字节流,若子类型为复杂类型(Message/Map),会递归执行第 2 步;若子类型为复杂类型(List),会递归执行第 3 步。
- 如果是 array 类型,对应 ProtoBuf PackedList/UnpackedList,sonic 会按照
OnObjectBegin()->OnObjectKey()->OnArrayBegin()->decodeValue()->OnArrayEnd()...顺序处理输入字节流
OnObjectBegin()阶段处理解析 List 字段对应动态类型描述 FieldDescriptor 并压栈;OnObjectKey()阶段解析 List 下子元素的动态类型描述 FieldDescriptor 并压栈;OnArrayBegin()阶段将 PackedList 类型的 Tag、Length 编码到输出字节流;decodeValue()阶段循环处理子元素,按照子元素类型编码到输出流,若子元素为复杂类型(Message),会跳转到第 2 步递归执行。
- 在结束处理某字段数据后执行
onValueEnd()、OnArrayEnd()、OnObjectEnd(),获取栈顶lenPos数据,对字段长度部分回写并退栈。 - 更新输入和输出字节流位置,跳回第 1 步循环处理,直到处理完输入流数据。
性能测试
构造与 Thrift 性能测试基本相同的baseline.proto 文件,定义了对应的简单( Small )、复杂( Medium )、简单缺失( SmallPartial )、复杂缺失( MediumPartial ) 两个对应子集,并用 kitex 命令生成了对应的 baseline.pb.go 。 主要与 Protobuf-Go 官方源码进行比较,部分测试与 kitex-fast 也进行了比较,测试环境如下:
- OS:Windows 11 Pro Version 23H2
- GOARCH: amd64
- CPU: 11th Gen Intel(R) Core(TM) i5-1135G7 @ 2.40GHz
- Go VERSION:1.20.5
反射
- 图中列举了 DOM 常用操作的性能,测试细节与 thrift 相同。
- MarshalTo 方法:相比 ProtobufGo 提升随着数据规模的增大趋势越明显,ns/op 开销约为源码方法的0.29 ~ 0.32。
字段Get/Set定量测试
- factor 用于修改从上到下扫描 proto 文件字段获取比率。
- 定量测试比较方法是 ProtobufGo 的 dynamicpb 模块和 DynamicGo 的 Get/SetByPath,SetMany,测试对象是medium data 的情况。
- Set/Get 字段定量测试结果均优于 ProtobufGo,且在获取字段越稀疏的情况下性能加速越明显。
- Setmany 性能加速更明显,在 100% 字段下 ns/op 开销约为 0.11。
序列化/反序列
- 序列化在 small 规模略高于 ProtobufGo,medium 规模的数据上性能优势更明显,ns/op 开销约为源码的0.54 ~ 0.84。
- 反序列化在 reuse 模式下,small 规模略高于 ProtobufGo,在 medium 规模数据上性能优势更明显,ns/op 开销约为源码的0.44 ~ 0.47,随数据规模增大性能优势增加。
协议转换
- Json2Protobuf 优于 ProtobufGo,ns/op 性能开销约为源码的0.21 ~ 0.89,随着数据量规模增大优势增加。
- Protobuf2Json 性能明显优于 ProtobufGo,ns/op 开销约为源码的0.13 ~ 0.21,而相比 Kitex,ns/op 约为Sonic+Kitex 的0.40 ~ 0.92,随着数据量规模增大优势增加。
应用与展望
目前 dynamicgo 对于 Protobuf 协议的可支持的功能包括:
- 替代官方源码的 JSON 协议转换,实现更高性能的 HTTP<>PB 动态网关
- 支持 IDL 内存字符串动态解析和数据泛化调用,可辅助 Kitex 提升 Protobuf 泛化调用模块性能。
- 支持动态数据裁剪、聚合等 DSL 场景,实现高性能 PB BFF 网关。
目前 dynamicgo 还在迭代中,接下来的工作包括:
- 支持 Protobuf 特殊字段,如 Enum,Oneof 等;
- 对于 Protobuf 协议转换提供 Http-Mapping 的扩展和支持;
- 继续扩展优化多种协议之间的泛化调用过程,集成到 Kitex 泛化调用模块中;
也欢迎感兴趣的个人或团队参与进来,共同开发!
]]>代码仓库:https://github.com/cloudwego/dynamicgo
本文作者:尹可汗,徐健猇、段仪 | 来自:官方微信推文背景 Dynamicgo 是字节跳动自研的高性能 Golang RPC 编解码基础库,能在动态处理 RPC 数据(不依赖代码生成)的同时保证高性能,主要用于实现高性能 RPC 动态代理场景(见 dynamicgo 介绍)。
Protobuf 是一种跨平台、可扩展的序列化数据传输协议,该协议序列化压缩特性使其具有优秀的传输速率,在常规静态 RPC 微服务场景中已经得到了广泛的应用。但是对于上述特殊的动态代理场景,我们调研发现目前业界主流的 Protobuf 协议基础库并不能满足我们的需求:- google.golang.org/protobuf:Protobuf 官方源码支持协议转换和字段动态反射。实现过程依赖于反射完整的中间结构体 Message 对象来进行管理,使用过程中带来了很多不必要字段的数据性能开销,并且在处理多层嵌套数据时操作较为复杂,不支持内存字符串 io 流 IDL 解析。
- github.com/jhump/protoreflect:Protobuf 动态反射第三方库可支持文件和内存字符串 io 流 IDL 解析,适合频繁泛化调用,协议转换过程与官方源码一致,均未实现 inplace 转换,且内部实现存在Go版本兼容性问题。
- github.com/cloudwego/fastpb:Protobuf 快速序列化第三方库,通过静态代码方式读写消息结构体,不支持协议转换和动态 IDL 解析。
因此如何设计自研一个功能完备、高性能、可扩展的 Protobuf 协议动态代理基础库是十分有必要的。
@khan-yin和@iStitches两位同学经过对 Protobuf 协议源码机制的深入学习,设计了高性能 Protobuf 协议动态泛化调用链路,能满足绝大多数 Protobuf 动态代理场景,并且性能优于官方实现,目前 PR#37 已经合入代码仓库。Protobuf 设计思想
由于 Protobuf 协议编码格式细节较为复杂,在介绍链路设计之前我们有必要先了解一下 Protobuf 协议的设计思想,后续的各项设计都将在严格遵守该协议规范的基础上进行改进。
官方源码链路思想
Protobuf 源码链路过程主要涉及三类数据类型之间的转换,以 Message 对象进行管理,自定义 Value 类实现反射和底层存储,用 Message 对象能有效地进行管理和迁移,但也带来了许多反射和序列化开销。
Protobuf编码格式
Protobuf 编码字段格式大体上遵循 TLV(Tag,Length,Value) 的结构,但针对具体的类型存在一些编码差异,这里我们将较为全面的给出常见类型的编码模式。
Message Field
Protobuf 的接口必定包裹在一个 Message 类型下,因此无论是 request 还是 response 最终都会包裹成一个 Message 对象,那么 Field 则是 Message 的一个基本单元,任何类型的字段都遵循这样的 TLV 结构:
- Tag 由字段编号 Field_number 和 wiretype 两部分决定,对位运算后的结果进行 varint 压缩,得到压缩后的字节数组作为字段的 Tag。
- wiretype 的值则表示的是 value 部分的编码方式,可以帮助我们清楚如何对 value 的读取和写入。到目前为止,wiretype只有 VarintType,Fixed32Type,Fixed64Type,BytesType 四类编码方式。其中VarintType 类型会被压缩后再编码,属于 Fixed32Type 和 Fixed64Typ 固定长度类型则分别占用4字节和8字节,而属于不定长编码类型 BytesType 的则会编码计算 value 部分的 ByteLen 再拼接 value 。
- ByteLen 用于编码表示 value 部分所占的字节长度,同样我们的 bytelen 的值也是经过 varint 压缩后得到的,但bytelen并不是每个字段都会带有,只有不定长编码类型 BytesType 才会编码 bytelen 。ByteLen 由于其不定长特性,计算过程在序列化过程中是需要先预先分配空间,记录位置,等写完内部字段以后再回过头来填充。
- Value 部分是根据 wiretype 进行对应的编码,字段的 value 可能存在嵌套的 T(L)V 结构,如字段是 Message,Map等情况。
Message
关于 Message 本身的编码是与上面提到的字段编码一致的,也就是说遇到一个 Message 字段时,我们会先编码 Message 字段本身的 Tag 和 bytelen,然后再来逐个编码 Message 里面的每个字段。但需要提醒注意的是,在最外层不存在包裹整个 Message 的 Tag 和 bytelen 前缀,只有每个字段的 TLV 拼接。
List
list字段比较特殊,为了节省存储空间,根据list元素的类型分别采用不同的编码模式。
- Packed List Mode
如果list的元素本身属于 VarintType/Fixed32Type/Fixed64Type 编码格式,那么将采用 packed 模式编码整个 List ,在这种模式下的 list 是有 bytelen 的。Protobuf3 默认对这些类型启用 packed。
- UnPacked List Mode
当 list 元素属于 BytesType 编码格式时,list 将使用 unpacked 模式,直接编码每一个元素的 TLV,这里的 V 可能是嵌套的如List模式,那么 unpacked 模式下所有元素的 tag 都是相同的,list 字段的结束标志为与下一个 TLV 字段编码不同或者到达 buf 末尾。
Map
Map 编码模式与 unpacked list 相同,根据官方设计思想,Map 的每个 KV 键值对其实本质上就是一个 Message,固定 key 的 Field_number 是1,value 的 Field_number 是2,那么 Map 的编码模式就和
List<Message>一致了。源码 Descriptor 细节
这里主要介绍一下源码的 descriptor 设计上的一些需要注意的细节。
- Service 接口由 ServiceDescriptor 来描述,ServiceDescriptor 当中可以拿到每个 rpc 函数的 MethodDescriptor。
- MethodDescriptor 中 Input() 和 output() 两个函数返回值均为 MessageDescriptor 分别表示 request 和 response 。
- MessageDescriptor 专门用来描述一个 Message 对象(也可能是一个 MapEntry ),可以通过 Fields() 找到每个字段的 FieldDescriptor 。
- FieldDescriptor 则兼容所有类型的描述。
动态反射
针对 Protobuf 的反射使用场景,我们归纳出以下需求:
- 具有完整的结构自描述和具体类型反射功能,兼容 scalar 类型以及复杂嵌套的 MESSAGE/LIST/MAP 结构。
- 支持字节流模式下的对任意局部进行动态数据修改与遍历。
- 保证数据可并发读。
这里我们借助 Go reflect 的设计思想,把通过 IDL 解析得到的准静态类型描述(只需跟随 IDL 更新一次)TypeDescriptor 和 原始数据单元 Node 打包成一个完全自描述的结构—— Value,提供一套完整的反射 API。
IDL 静态文件 parse 过程:
为了提供文件流和内存字符串 io 流的 idl 文件解析,同时保证保证 go 版本兼容性,我们利用protoreflect@v1.8.2解析结果完成按需构造。从实现原理上来看,与高版本protoreflect利用protocompile对原始链路再 make 出源码的 warp 版本一致,更好的实现或许是处理利用 protoreflect 中的 ast 语法树构造。Descriptor设计
Descriptor 的设计原理基本尽可能与源码保持一致,但为了更好的自反射性,我们抽象了一个 TypeDescriptor 来表示更细粒度的类型。
FieldDescriptor
type FieldDescriptor struct {
kind ProtoKind // the same value with protobuf descriptor
id FieldNumber
name string
jsonName string
typ *TypeDescriptor
}FieldDescriptor: 设计上希望变量和函数作用与源码 FieldDescriptor 基本一致,增加*TypeDescriptor可以更细粒度的反应类型以及对 FieldDescriptor 的 API 实现。kind:与源码 kind 功能一致,LIST 情况下 kind 是列表元素的 kind 类型,MAP 和 MESSAGE 情况下都为 messagekind。
TypeDescriptor
type TypeDescriptor struct {
baseId FieldNumber // for LIST/MAP to write field tag by baseId
typ Type
name string
key *TypeDescriptor
elem *TypeDescriptor
msg *MessageDescriptor // for message, list+message element and map key-value entry
}baseId:因为对于 LIST/MAP 类型的编码特殊性,如在 unpack 模式下,每一个元素都需要编写 Tag,我们必须在构造时针对 LIST/MAP 提供 fieldnumber,来保证读取和写入的自反射性。msg:这里的 msg 不是仅 Message 类型独有,主要是方便 J2P 部分对于 List 和裁剪场景中 map 获取可能存在 value 内部字段缺失的 MapEntry 的 MassageDescriptor(在源码的设计理念当中 MAP 的元素被认为是一个含有 key 和 value 两个字段的 message )的时候能直接利用 TypeDescriptor 进入下一层嵌套。typ:这里的 Type 是对源码的 FieldDescriptor 更细粒度的表示,即对 LIST/MAP 做了单独定义
MessageDescriptor
type MessageDescriptor struct {
baseId FieldNumber
name string
ids FieldNumberMap // store by tire tree
names FieldNameMap // store name and jsonName for FieldDescriptor
}MessageDescriptor: 利用 Tire 树结构实现更高性能的字段 id 和字段 name 的存储和查找。
数据存储设计
从协议本身的 TLV 嵌套思想出发,我们利用字节流的编码格式,建立健壮的自反射性结构体处理任意类型的解析。
Node结构
type Node struct {
t proto.Type // node type
et proto.Type // for map value or list element type
kt proto.Type // for map key type
v unsafe.Pointer
l int // ptr len
size int // only for MAP/LIST element counts
}具体的存储规则如下:
- 基本类型 Node 表示:指针 v 的起始位置不包含 tag,指向 (L)V,t = 具体类型。
- MESSAGE 类型:指针 v 的起始位置不包含 tag,指向 (L)V,如果是 root 节点,那么 v 的起始位置本身没有前缀的 L,直接指向了 V 即第一个字段的 tag 上,而其余子结构体都包含前缀 L。
- LIST类型:为了兼容 List 的两种模式和自反射的完整性,我们必须包含 list 的完整片段和 tag。因此 List 类型的节点,v 指向 list 的 tag 上,即如果是 packed 模式就是 list 的 tag 上,如果是 unpacked 则在第一个元素的 tag 上。
- MAP类型:Map 的指针 v 也指向了第一个 pair 的 tag 位置。
- UNKNOWN类型Node表示:无法解析的合理字段,Node 会将 TLV 完整存储,多个相同字段 Id 的会存到同一节点,缺点是内部的子节点无法构建,同官方源码unknownFields原理一致。
- ERROR类型Node表示:在 setnotfound 中,若片段设计与上述规则一致则可正确构造插入节点。
虽然 MAP/LIST 的父级 Node 存储有些变化,但是其子元素节点都是基本类型 / MESSAGE,所以叶子节点存储格式都是基本的 (L)V,这也便于序列化和数据基本单位的原子操作。
Value结构
value 的结构本身是对 Node 的封装,将 Node 与相应的 descriptor 封装起来,但不同于 thrift,在 Protobuf 当中由于片段无法完全自解析出具体类型,之后的涉及到具体编码的部分操作不能脱离 descriptor,部分 API 实现只能 Value 类作为调用单位。
type Value struct {
Node
Desc *proto.TypeDescriptor
IsRoot bool
}由于从 rpc 接口解析后我们直接得到了对应的 TypeDescriptor,再加上 root 节点本身没有前缀TL的独特编码结构,我们通过设置
IsRoot标记来区分 root 节点和其余节点,实现 Value 结构的 Descriptor 统一。数据编排
不同于源码 Message 对象数据动态管理的思想,我们设计了更高效的动态管理方式。我们借助 DOM (Document Object Model)思想,将原始字节流数据层层包裹的结构,抽象成多层嵌套的 BTree 结构,实现对数据的定位,切分,裁剪等操作的 inplace 处理。
Path与PathNode
为了准确描述 DOM 中数据节点之间的嵌套关系,我们设计了 Path 结构,在 Path 的基础上,我们组合对应的数据单元 Node,然后再通过一个 Next 数组动态存储子节点,便可以组装成一个类似于 BTree 的泛型单元结构。
// Path represents the relative position of a sub node in a complex parent node
type Path struct {
t PathType // 类似div标签的类型,用来区分field,map,list元素,帮助判定父级嵌套属于什么类型结构
v unsafe.Pointer // PathStrKey, PathFieldName类型,存储的是Key/FieldName的字符串指针
l int
// PathIndex类型,表示LIST的下标
// PathIntKey类型,表示MAPKey的数值
// PathFieldId类型,表示字段的id
}
pathes []Path : 合理正确的Path数组,可以定位到嵌套复杂类型里具体的key/index的位置
type PathNode struct {
Path // DOM tree中用于定位当前Node的位置,并包含FieldId/FieldName/Key/index信息
Node // 存储了复杂嵌套关系中该位置对应的具体bytes片段
Next []PathNode // 下层嵌套的Node节点,基本类型下层Next为空
}构建DOM Tree
构建 DOM 支持懒加载和全加载,在懒加载模式下 LIST/MAP 的 Node 当中 size 不会同步计算,而全加载在构造叶子节点的同时顺便更新了 size,构造后的节点都将遵循上述存储规则,具有自反射性和结构完整性。
查找字段
支持任意Node查找,查找函数设计了三个外部API:GetByPath,GetByPathWithAddress,GetMany。
GetByPath:返回查找出来的 Value ,查找失败返回 ERROR 类型的节点。GetByPathWithAddress:返回Value和当前调用节点到查找节点过程中每个 Path 嵌套层的 tag 位置的偏移量。[]address与[]Path个数对应,若调用节点为 root 节点,那么可记录到 buf 首地址的偏移量。GetMany:传入当前嵌套层下合理的[]PathNode的 Path 部分,直接返回构造出来多个 Node,得到完整的[]PathNode,可继续用于MarshalMany
设计思路:
查找过程是根据传入的[]Path来循环遍历查找每一层 Path 嵌套里面对应的位置,根据嵌套的 Path 类型(fieldId,mapKey,listIndex),调用对应的 search 函数。不同于源码翻译思路,由于 Node 的自反射性设计,我们可以直接实现字节流定位,无需依赖 Descriptor 查找,并跳过不必要的字段翻译。构造最终返回的 Node 时,根据具体类型看是否需要去除 tag 即可,返回的[]address刚好在 search 过程中完成了每一层 Path 的 tag 偏移量记录。动态插入/删除
新增数据思想采用尾插法,保证 pack/unpack 数据的统一性,完成插入操作后需要更新嵌套层 bytelen。
- SetByPath:只支持 root 节点调用,保证 UpdateByLen 更新的完整和正确性。
- SetMany:可支持局部节点插入。
- UnsetByPath:只支持 root 节点调用,思想同插入字段,即找到对应的片段后直接将片段置空,然后更新updatebytelen。
Updatebytelen细节:
- 计算插入完成后新的长度与原长度的差值,存下当前片段增加或者减少的diffLen。
- 从里向外逐步更新
[]Path数组中存在 bytelen 的嵌套层(只有packed list和message)的 bytelen 字节数组。 - 更新规则:先 readTag,然后再 readLength,得到解 varint 压缩后的具体 bytelen 数值,计算 newlen = bytelen + diffLen,计算 newbytelen 压缩后的字节长度与原 bytelen 长度的差值 sublen,并累计diffLen += sublen。
- 指针向前移动到下一个 path 和 address。
DOM序列化
- Marshal:建好 PathNode 后,可遍历拼接 DOM 的所有叶子节点片段,Tag 部分会通过 Path 类型和 Node 类型进行补全,bytelen 根据实际遍历节点进行更新。
- MarshalTo:针对数据裁剪场景,该设计方案具有很好的扩展性,可直接比对新旧 descriptor 中共有的字段 id,对字节流一次性拼接写入,无需依赖中间结构体,可支持多层嵌套字段缺失以及 LIST/MAP 内部元素字段缺失。
协议转换
ProtoBuf——>JSON
Protobuf->JSON 协议转换的过程可以理解为逐字节解析 ProtoBuf,并结合 Descriptor 类型编码为 JSON 到输出字节流,整个过程是 in-place 进行的,并且结合内存池技术,仅需为输出字节流分配一次内存即可。
ProtoBuf——>JSON 的转换过程如下:
- 根据输入的 Descriptor 指针类型区分,若为 Singular(string/number/bool/Enum) 类型,跳转到第5步开始编码;
- 按照 Message([Tag] [Length] [TLV][TLV][TLV]….)编码格式对输入字节流执行 varint解码,将Tag解析为 fieldId(字段ID)、wireType(字段wiretype类型);
- 根据第2步解析的 fieldId 确定字段 FieldDescriptor,并编码字段名 key 作为 jsonKey 到输出字节流;
- 根据 FieldDescriptor 确定字段类型(Singular/Message/List/Map),选择不同编码方法编码 jsonValue 到输出字节流;
- 如果是 Singular 类型,直接编码到输出字节流;
- 其它类型递归处理内部元素,确定子元素 Singular 类型进行编码,写入输出字节流中;
- 及时输入字节流读取位置和输出字节流写入位置,跳回2循环处理,直到读完输入字节流。
JSON——>ProtoBuf
协议转换过程中借助 JSON 状态机原理和 sonic 思想,设计 UserNodeStack 实现了接口 Onxxx(OnBool、OnString、OnInt64….)方法达到编码 ProtoBuf 的目标,实现 in-place 遍历 JSON 转换。
VisitorUserNode 结构
因为在编码 Protobuf 格式的 Mesage/UnpackedList/Map 类型时需要对字段总长度回写,并且在解析复杂类型(Message/Map/List)的子元素时需要依赖复杂类型 Descriptor 来获取子元素 Descriptor,所以需要 VisitorUserNode 结构来保存解析 json 时的中间数据。
type VisitorUserNode struct {
stk []VisitorUserNodeStack
sp uint8
p *binary.BinaryProtocol
globalFieldDesc *proto.FieldDescriptor
}- stk:记录解析时中间变量的栈结构,在解析 Message 类型时记录 MessageDescriptor、PrefixLen;在解析 Map 类型时记录 FieldDescriptor、PairPrefixLen;在解析 List 类型时记录 FieldDescriptor、PrefixListLen;
- sp:当前所处栈的层级;
- p:输出字节流;
- globalFieldDesc:每当解析完 MessageField 的 jsonKey 值,保存该字段 Descriptor 值;
VisitorUserNodeStack 结构
记录解析时字段 Descriptor、回写长度的起始地址 PrefixLenPos 的栈结构。
type VisitorUserNodeStack struct {
typ uint8
state visitorUserNodeState
}- typ:当前字段的类型,取值有对象类型(objStkType)、数组类型(arrStkType)、哈希类型(mapStkType);
- state:存储详细的数据值;
visitorUserNodeState 结构
type visitorUserNodeState struct {
msgDesc *proto.MessageDescriptor
fieldDesc *proto.FieldDescriptor
lenPos int
}- msgDesc:记录 root 层的动态类型描述 MessageDescriptor;
- fieldDesc:记录父级元素(Message/Map/List)的动态类型描述 FieldDescriptor;
- lenPos:记录需要回写 PrefixLen 的位置;
协议转换过程
JSON——>ProtoBuf 的转换过程如下:
- 从输入字节流中读取一个 json 值,并判断其具体类型(
object/array/string/float/int/bool/null); - 如果是 object 类型,可能对应 ProtoBuf MapType/MessageType,sonic 会按照
OnObjectBegin()->OnObjectKey()->decodeValue()...顺序处理输入字节流OnObjectBegin()阶段解析具体的动态类型描述 FieldDescriptor 并压栈;OnObjectKey()阶段解析 jsonKey 并以 ProtoBuf 格式编码 Tag、Length 到输出字节流;decodeValue()阶段递归解析子元素并以 ProtoBuf 格式编码 Value 部分到输出字节流,若子类型为复杂类型(Message/Map),会递归执行第 2 步;若子类型为复杂类型(List),会递归执行第 3 步。
- 如果是 array 类型,对应 ProtoBuf PackedList/UnpackedList,sonic 会按照
OnObjectBegin()->OnObjectKey()->OnArrayBegin()->decodeValue()->OnArrayEnd()...顺序处理输入字节流OnObjectBegin()阶段处理解析 List 字段对应动态类型描述 FieldDescriptor 并压栈;OnObjectKey()阶段解析 List 下子元素的动态类型描述 FieldDescriptor 并压栈;OnArrayBegin()阶段将 PackedList 类型的 Tag、Length 编码到输出字节流;decodeValue()阶段循环处理子元素,按照子元素类型编码到输出流,若子元素为复杂类型(Message),会跳转到第 2 步递归执行。
- 在结束处理某字段数据后执行
onValueEnd()、OnArrayEnd()、OnObjectEnd(),获取栈顶lenPos数据,对字段长度部分回写并退栈。 - 更新输入和输出字节流位置,跳回第 1 步循环处理,直到处理完输入流数据。
性能测试
构造与 Thrift 性能测试基本相同的baseline.proto 文件,定义了对应的简单( Small )、复杂( Medium )、简单缺失( SmallPartial )、复杂缺失( MediumPartial ) 两个对应子集,并用 kitex 命令生成了对应的 baseline.pb.go 。 主要与 Protobuf-Go 官方源码进行比较,部分测试与 kitex-fast 也进行了比较,测试环境如下:
- OS:Windows 11 Pro Version 23H2
- GOARCH: amd64
- CPU: 11th Gen Intel(R) Core(TM) i5-1135G7 @ 2.40GHz
- Go VERSION:1.20.5
反射
- 图中列举了 DOM 常用操作的性能,测试细节与 thrift 相同。
- MarshalTo 方法:相比 ProtobufGo 提升随着数据规模的增大趋势越明显,ns/op 开销约为源码方法的0.29 ~ 0.32。
字段Get/Set定量测试
- factor 用于修改从上到下扫描 proto 文件字段获取比率。
- 定量测试比较方法是 ProtobufGo 的 dynamicpb 模块和 DynamicGo 的 Get/SetByPath,SetMany,测试对象是medium data 的情况。
- Set/Get 字段定量测试结果均优于 ProtobufGo,且在获取字段越稀疏的情况下性能加速越明显。
- Setmany 性能加速更明显,在 100% 字段下 ns/op 开销约为 0.11。
序列化/反序列
- 序列化在 small 规模略高于 ProtobufGo,medium 规模的数据上性能优势更明显,ns/op 开销约为源码的0.54 ~ 0.84。
- 反序列化在 reuse 模式下,small 规模略高于 ProtobufGo,在 medium 规模数据上性能优势更明显,ns/op 开销约为源码的0.44 ~ 0.47,随数据规模增大性能优势增加。
协议转换
- Json2Protobuf 优于 ProtobufGo,ns/op 性能开销约为源码的0.21 ~ 0.89,随着数据量规模增大优势增加。
- Protobuf2Json 性能明显优于 ProtobufGo,ns/op 开销约为源码的0.13 ~ 0.21,而相比 Kitex,ns/op 约为Sonic+Kitex 的0.40 ~ 0.92,随着数据量规模增大优势增加。
应用与展望
目前 dynamicgo 对于 Protobuf 协议的可支持的功能包括:
- 替代官方源码的 JSON 协议转换,实现更高性能的 HTTP<>PB 动态网关
- 支持 IDL 内存字符串动态解析和数据泛化调用,可辅助 Kitex 提升 Protobuf 泛化调用模块性能。
- 支持动态数据裁剪、聚合等 DSL 场景,实现高性能 PB BFF 网关。
目前 dynamicgo 还在迭代中,接下来的工作包括:
- 支持 Protobuf 特殊字段,如 Enum,Oneof 等;
- 对于 Protobuf 协议转换提供 Http-Mapping 的扩展和支持;
- 继续扩展优化多种协议之间的泛化调用过程,集成到 Kitex 泛化调用模块中;
也欢迎感兴趣的个人或团队参与进来,共同开发!
]]>代码仓库:https://github.com/cloudwego/dynamicgo
本文作者:尹可汗,徐健猇、段仪 | 来自:官方微信推文@@ -69,13 +69,13 @@ 2022-03-30T16:41:32.000Z 2024-10-09T07:33:09.908Z -既往不恋,纵情向前,江湖再见——22岁那年,在北京的日子 +2022年3月31日0:52,睡不着,日常拖延症+强迫症导致清东西到现在,等会还想清扫一下弄脏的地板。
莲竹花园甲2号楼一门101,从今天起,这里将不再是我的家,本来是昨天的机票,天气不似预期,不打算买高铁,还想再飞上一次云霄,所以倔强的又改签了机票,不过正好也让我多看一眼这里吧,最近东航事件其实让我也有一点小慌,希望能平安到达吧。
不出所料,我对这个城市并没有什么留恋,每天晚上我都会思考很多,有天夜里我的脑海里突然冒出来了那句:劝君更进一杯酒,西出阳关无故人。 这一刻我才真正明白什么是独在异乡为异客的感觉,什么才是我心里最想要的。
从南山南到北海北
作为一个一直生活在南方的人,第一次在北京生活,拥挤的早晚高峰,寒风和冰雪的夜晚,疫情形势也不断变化,恰逢过年,回家的日子也迟迟不敢定下来,奇怪,你可能会好奇,在大厂工作我竟然并没有提到工作的压力,仔细想来,其实美团的作息是相对舒服的10-8-5,尽管工作和技术基础我有许多不足,但mentor比较照顾我,不会刻意去push进度,更多的是希望让我自己去探索和思考,所以更多的工作压力还是来自于我自己一贯所坚持的负责和标准。这是一件好事,说明我做事情有自己的原则和态度,但有时候也会让自己比较心累,毕竟作为一个新人,从0-1去启动项目,虽然我是个自信的人,即使遇到问题也会尽可能自己去想办法,但我也深知自己的代码习惯和知识结构存在很多不足,害怕的不是做不好做不成,而是做事的效率和维护性,其实这也是我应该要从这些前辈身上要学到的经验。
年前一周,我申请了远程实习提前坐飞机回家了,到家的一刻才明白,这种人间烟火气才真的是生活,说来有愧,从回家到过年收假的时间,工作上我确实有点摆烂了哈哈哈,我知道这应该最后一个这么长时间的寒假了,经过将近1个月的在外实习也格外体会到了这种归家的温暖,去学一学切菜炒菜,陪一陪老年人,约一场球,见想见的人,街头漫步,吃点臭干子,米粉,麻辣烫,和朋友分享一些见闻,借酒消愁,确实愁更愁。
时间很快,大年初五的下午,我就启程返工了,毕竟现在的身份是打工人而不是大学生。和我一同去北京的还有广平,也在美团,我们都不打算实习很久,刚好我房子够住2个人,就一起住了一个月,不得不说多了一个人生活确实没有这么孤单了,尽管工作和拥挤依旧麻烦,但至少回家轻松快活一些,虽然有时候会有一些赌气和争吵,睡眠问题,但不管怎么说,互相都分担了一些对未来的焦虑和思考,一块出去玩,打游戏开黑,去什刹海,天安门,吃各种小吃,也算是度过一段不那么枯燥的时间。
在实习的这段日子里,最大的一个体会就是要学会如何平衡生活与工作,这个问题也是以后一定会要去面对的。也许是第一次实习,虽然不算很难的任务,但因为自己很多基础,技术,学习方法都还不够到位,上手项目和方向也不了解,所以效率上比较低,也许是拖延症,情绪化,该完成的任务没能及时完成,答应朋友的事情,也常常会忘记,衣服也有时候会拖着没洗,又或许是自己的性格本来就有些内向,在偏严肃的职场氛围下比起在学校,自己显得有些不自然,自己整个人的状态和生活界限变得模糊起来,当一个人进入这样的状态的时候,会发觉整个人比较迷茫,做事情专注度不够,热情也会逐渐消失。
在3月底,我决定从公司离职,一方面是想好好享受一下最后的大学时光,另一方面是想留出一段空白期,让自己再去学一学自己想学的内容,不得不说回归自由的感觉真的让人十分快乐,从公司买了好些纪念品,在最后几天,去见一见同学,逛一逛北京的大学,中关村,终于要飞走了,这段旅程终于要结束了,但接下来的未来好像还是看不清。
执念
看到执念这个词,这里我说一句大胆的话,在我未来的5-8年时间里,若我能成功,一定是因为心中的执念,若我输得一败涂地,也一定是因为那执念。
说来嘲讽,回想起来从小到大,我好像一直被这种执念所影响,也因为自己的固执,失去了各种各样的机会,但是我却很难改变,除了我这辈子认定的人以外,我几乎听不进去其他人的话,而且越是被人否定,越是想要证明自己的能力,我也不知道这是一种多么要强的心理,就好像明知道是火坑,也觉得自己跟别人不一样,能跨过去,然而事实大多是自己被烧得满身伤痕,甚至还在那叫嚣着他们不敢跳。
我的性格大家也知道,带有棱角,有个性,孤傲却又内向自卑,坚忍,舍得努力,看似矛盾,其实说白了也就是不太谦虚,爱吹吹牛逼,但却不是耍嘴皮子,对自己还是很负责的,但是这样也经常惹来一些麻烦,不合群,自作主张,在乎得失,也是我如此固执的原因之一。
随着年龄增大,我突然发现每一次选择的人生代价越来越大,自己的眼界和思想局限性也越来越明显,也许是从小就不爱看书(现在想看书却没多少时间,也很难静下心来)以及身处的环境的原因,思想成熟得很慢,自大,考虑问题过于天真,没能及时跟上时代,时而觉得一切皆有可能,时而又觉得一切皆是虚妄。去年的时候,我还觉得自己年轻,有无限可能,直到保研结束以后,我才恍然明白,其实我从18岁那年的夏天开始,就已经不再年轻,尽管我是在努力的朝改善未来的方向走,往后的岁月每一次决定都是那么矛盾,迷茫,自卑,妥协,后悔。
后悔,我总是做事情让自己有多个选择留有退路,但似乎给自己留选择本质上就是一种后悔,当你没能选到最理想的选择时,自然就会后悔吧。
2024.06.02 更新
哈哈哈哈最近难得休闲几天,看到以前写的这些,看问题角度加上当时的个人情绪驱使文案还是略显年轻了,回过头来看其实无所谓后悔不后悔的,已经把这里标题的后悔去掉了,我一贯以来的行为准则就是对自己的选择负责,不论是什么样的未来,勇敢且不要停止思考,相信自己的光就好,这不仅仅会给自己能量也一定会给他人的生命带来光亮。
]]>既往不恋,纵情向前,江湖再见——22岁那年,在北京的日子 2022年3月31日0:52,睡不着,日常拖延症+强迫症导致清东西到现在,等会还想清扫一下弄脏的地板。
莲竹花园甲2号楼一门101,从今天起,这里将不再是我的家,本来是昨天的机票,天气不似预期,不打算买高铁,还想再飞上一次云霄,所以倔强的又改签了机票,不过正好也让我多看一眼这里吧,最近东航事件其实让我也有一点小慌,希望能平安到达吧。
不出所料,我对这个城市并没有什么留恋,每天晚上我都会思考很多,有天夜里我的脑海里突然冒出来了那句:劝君更进一杯酒,西出阳关无故人。 这一刻我才真正明白什么是独在异乡为异客的感觉,什么才是我心里最想要的。
从南山南到北海北
作为一个一直生活在南方的人,第一次在北京生活,拥挤的早晚高峰,寒风和冰雪的夜晚,疫情形势也不断变化,恰逢过年,回家的日子也迟迟不敢定下来,奇怪,你可能会好奇,在大厂工作我竟然并没有提到工作的压力,仔细想来,其实美团的作息是相对舒服的10-8-5,尽管工作和技术基础我有许多不足,但mentor比较照顾我,不会刻意去push进度,更多的是希望让我自己去探索和思考,所以更多的工作压力还是来自于我自己一贯所坚持的负责和标准。这是一件好事,说明我做事情有自己的原则和态度,但有时候也会让自己比较心累,毕竟作为一个新人,从0-1去启动项目,虽然我是个自信的人,即使遇到问题也会尽可能自己去想办法,但我也深知自己的代码习惯和知识结构存在很多不足,害怕的不是做不好做不成,而是做事的效率和维护性,其实这也是我应该要从这些前辈身上要学到的经验。
年前一周,我申请了远程实习提前坐飞机回家了,到家的一刻才明白,这种人间烟火气才真的是生活,说来有愧,从回家到过年收假的时间,工作上我确实有点摆烂了哈哈哈,我知道这应该最后一个这么长时间的寒假了,经过将近1个月的在外实习也格外体会到了这种归家的温暖,去学一学切菜炒菜,陪一陪老年人,约一场球,见想见的人,街头漫步,吃点臭干子,米粉,麻辣烫,和朋友分享一些见闻,借酒消愁,确实愁更愁。
时间很快,大年初五的下午,我就启程返工了,毕竟现在的身份是打工人而不是大学生。和我一同去北京的还有广平,也在美团,我们都不打算实习很久,刚好我房子够住2个人,就一起住了一个月,不得不说多了一个人生活确实没有这么孤单了,尽管工作和拥挤依旧麻烦,但至少回家轻松快活一些,虽然有时候会有一些赌气和争吵,睡眠问题,但不管怎么说,互相都分担了一些对未来的焦虑和思考,一块出去玩,打游戏开黑,去什刹海,天安门,吃各种小吃,也算是度过一段不那么枯燥的时间。
在实习的这段日子里,最大的一个体会就是要学会如何平衡生活与工作,这个问题也是以后一定会要去面对的。也许是第一次实习,虽然不算很难的任务,但因为自己很多基础,技术,学习方法都还不够到位,上手项目和方向也不了解,所以效率上比较低,也许是拖延症,情绪化,该完成的任务没能及时完成,答应朋友的事情,也常常会忘记,衣服也有时候会拖着没洗,又或许是自己的性格本来就有些内向,在偏严肃的职场氛围下比起在学校,自己显得有些不自然,自己整个人的状态和生活界限变得模糊起来,当一个人进入这样的状态的时候,会发觉整个人比较迷茫,做事情专注度不够,热情也会逐渐消失。
在3月底,我决定从公司离职,一方面是想好好享受一下最后的大学时光,另一方面是想留出一段空白期,让自己再去学一学自己想学的内容,不得不说回归自由的感觉真的让人十分快乐,从公司买了好些纪念品,在最后几天,去见一见同学,逛一逛北京的大学,中关村,终于要飞走了,这段旅程终于要结束了,但接下来的未来好像还是看不清。
执念
看到执念这个词,这里我说一句大胆的话,在我未来的5-8年时间里,若我能成功,一定是因为心中的执念,若我输得一败涂地,也一定是因为那执念。
说来嘲讽,回想起来从小到大,我好像一直被这种执念所影响,也因为自己的固执,失去了各种各样的机会,但是我却很难改变,除了我这辈子认定的人以外,我几乎听不进去其他人的话,而且越是被人否定,越是想要证明自己的能力,我也不知道这是一种多么要强的心理,就好像明知道是火坑,也觉得自己跟别人不一样,能跨过去,然而事实大多是自己被烧得满身伤痕,甚至还在那叫嚣着他们不敢跳。
我的性格大家也知道,带有棱角,有个性,孤傲却又内向自卑,坚忍,舍得努力,看似矛盾,其实说白了也就是不太谦虚,爱吹吹牛逼,但却不是耍嘴皮子,对自己还是很负责的,但是这样也经常惹来一些麻烦,不合群,自作主张,在乎得失,也是我如此固执的原因之一。
随着年龄增大,我突然发现每一次选择的人生代价越来越大,自己的眼界和思想局限性也越来越明显,也许是从小就不爱看书(现在想看书却没多少时间,也很难静下心来)以及身处的环境的原因,思想成熟得很慢,自大,考虑问题过于天真,没能及时跟上时代,时而觉得一切皆有可能,时而又觉得一切皆是虚妄。去年的时候,我还觉得自己年轻,有无限可能,直到保研结束以后,我才恍然明白,其实我从18岁那年的夏天开始,就已经不再年轻,尽管我是在努力的朝改善未来的方向走,往后的岁月每一次决定都是那么矛盾,迷茫,自卑,妥协,后悔。
后悔,我总是做事情让自己有多个选择留有退路,但似乎给自己留选择本质上就是一种后悔,当你没能选到最理想的选择时,自然就会后悔吧。
2024.06.02 更新
哈哈哈哈最近难得休闲几天,看到以前写的这些,看问题角度加上当时的个人情绪驱使文案还是略显年轻了,回过头来看其实无所谓后悔不后悔的,已经把这里标题的后悔去掉了,我一贯以来的行为准则就是对自己的选择负责,不论是什么样的未来,勇敢且不要停止思考,相信自己的光就好,这不仅仅会给自己能量也一定会给他人的生命带来光亮。
]]><h2 id="既往不恋,纵情向前,江湖再见——22岁那年,在北京的日子"><a href="#既往不恋,纵情向前,江湖再见——22岁那年,在北京的日子" class="headerlink" title="既往不恋,纵情向前,江湖再见——22岁那年,在北京的日子"></a>既往不恋,纵情向前,江湖再见——22岁那年,在北京的日子</h2><p>2022年3月31日0:52,睡不着,日常拖延症+强迫症导致清东西到现在,等会还想清扫一下弄脏的地板。</p> <p><strong>莲竹花园甲2号楼一门101,从今天起,这里将不再是我的家</strong>,本来是昨天的机票,天气不似预期,不打算买高铁,还想再飞上一次云霄,所以倔强的又改签了机票,不过正好也让我多看一眼这里吧,最近东航事件其实让我也有一点小慌,希望能平安到达吧。</p> -<p>不出所料,我对这个城市并没有什么留恋,每天晚上我都会思考很多,有天夜里我的脑海里突然冒出来了那句:<strong>劝君更进一杯酒,西出阳关无故人。</strong> 这一刻我才真正明白什么是独在异乡为异客的感觉,什么才是我心里最想要的。</p> +<p>不出所料,我对这个城市并没有什么留恋,每天晚上我都会思考很多,有天夜里我的脑海里突然冒出来了那句:<strong>劝君更进一杯酒,西出阳关无故人。</strong> 这一刻我才真正明白什么是独在异乡为异客的感觉,什么才是我心里最想要的。<br></p> @@ -92,7 +92,7 @@2022-01-08T12:06:00.000Z 2024-10-09T07:33:09.913Z -前言
第一次在掘金写面经,其实今年过得不尽人意,好在能找找实习调整一下心态吧,终于有钱换手机了!要说有什么新年愿望,那就希望2022一切好运吧。 虽然是实习面经但是其实也没怎么准备,随缘,放弃了bat的部门,估计对学历和论文有门槛(尝试性投了深圳字节直接挂简历,我永远喜欢bytedance😭),10月投b站简历挂,旷视面试没过以后就没投了,后面去学车了,结果科目二没过,有点闲看到有朋友也在投,就不抱希望还是投了3家,比较幸运最后拿到了美团和商汤的实习offer,感谢面试官们手下留情🤣。
个人情况:
- 学校:211 大四
- 成绩:前5%
- 项目:3段CV相关项目经历,无论文,两个算法实践工程落地项目,一段kaggle竞赛铜牌,总体上来说都比较水
- 算法能力:无ACM,比较菜只是比较喜欢刷,leetcode400题(以easy+medium为主,剑指offer+程序员面试经典+每日一题/周赛)
因为感觉自己很菜找不到实习,所以都没找内推,也没有海投,不过好像大多都会给面试机会的,感觉如果能找内推可能会更好一点。没想到最后能去美团当外卖骑手了😁!
旷视
旷视的实习面试是最早的,不过也面试通知也等了好久,hr说有两个面试官mark了我的简历,所以面了两个组,当时是第一次面试,比较紧张,虽然面试问的不难,但是有些地方答的不好,面试问题记不太清了。另一个面试官,我等了半小时结果被他放鸽子了,改天再面的。。。
- 手写IoU
- 求三个部分的IoU,根据定义就是求:$\frac{A \cap B \cap C}{A \cup B \cup C} $,只用讲思路,其实就是容斥原理,当时有点紧张,公式最后一项系数写错了一直没看出来,场面一度尴尬。
- 讲解Focal loss的原理作用
- 为什么会用到
StratifiedKFold,和KFold有什么区别 - 介绍一下比赛用到的
TTA,Cutmix方法(Cutout和mixup的结合,最好三个都讲解一下) - 讲讲
Resnet(建议读一下论文,从目的,作用,残差结构的形式,反向传播梯度计算,机器学习GBDT思想等角度进行阐述) - 目标检测的
mAP达到了多少,有没有测过双目测距的精准度,为啥使用wifi和flask推流通信,这样会比较慢(树莓派算力不够,跑着跑着宕机了),小车目标检测的帧数能达到多少fps(emm我们只是做了一个无人清洁车落地的demo,只测了模型目标检测在数据集上的mAP,其他的更多的是我们自己提供一种idea,具体指标没有测试过😥)。 - 旋转矩阵,不能开空间,其实做过但是面试很容易紧张卡住,有想到思路但是没写对有点bug,不过面试官说我思路是对的,面完就发现原来是下标对错了。。。
- 团队合作交流是如何分工和解决问题的?
- 其他人或者老师给你任务安排时,如果与你的想法不合时,你会如何做?
手写IoU
import numpy as np
def IoU(bounding_box,ground_truth):
"""
:param bounding_box: [[x1,y1,x2,y2,score]]
:param ground_truth: [x1,y1,x2,y2]
:return:
"""
x1 = bounding_box[:,0]
y1 = bounding_box[:,1]
x2 = bounding_box[:,2]
y2 = bounding_box[:,3]
score = bounding_box[:,4]
areas = (x2-x1) * (y2-y1)
gt_area = (ground_truth[2] - ground_truth[0]) * (ground_truth[3] - ground_truth[1])
xx1 = np.maximum(x1,ground_truth[0])
yy1 = np.maximum(y1,ground_truth[1])
xx2 = np.minimum(x2,ground_truth[2])
yy2 = np.minimum(y2,ground_truth[3])
h = np.maximum(0,yy2-yy1)
w = np.maximum(0,xx2-xx1)
inter = w * h
ovr = inter / (gt_area + areas - inter) # np.true_divide(inter, (gt_area + areas - inter))
return ovr旋转矩阵
class Solution {
public:
void rotate(vector<vector<int>>& matrix) {
int n = matrix.size();
for(int i=0;i<n/2;i++)
{
for(int j=0;j<(n+1)/2;j++)
{
// (i,j) (j,n-i-1) (n-j-1,i) (n-i-1,n-j-1)
swap(matrix[i][j],matrix[n-i-1][n-j-1]);
swap(matrix[i][j],matrix[n-j-1][i]);
swap(matrix[j][n-i-1],matrix[n-i-1][n-j-1]);
}
}
}
};小米
小米面试其实是当时最好的选择,因为就在武汉本地,也不用外出,但是当时面试确实不太好,面试官对我其中一个项目比较感兴趣,被疯狂怼着追问细节。
- 描述项目中用到的SIFT匹配和直方图相似度比对基本原理。
- one-stage和two-stage的区别。
- 双目摄像头视觉下应该可以得到整个三维空间下的信息,没考虑方向角度的问题,对测距的处理有些草率(没有很懂,之后再去了解了解,只用到了物理上小孔成像的原理😰
- 为什么不直接在树莓派上推理,采用推流和主机服务器去进行计算,速度和精度如何
- 继续追问项目细节。
- 手写SIFT匹配过程,直接人傻了😭(被面试官怼对传统图像处理了解不深,只会玩玩深度学习搭积木)
美团-智能视觉 offer
美团面试官面试体验比较好,没有过分针对,对待我这种本科生可能相对更看重对我的motivation和potential吧感觉,评价也比较好。
一面
- 聊项目,做项目的目的和缘由,你觉得有什么亮点。
- 讲讲one-stage和two-stage的区别。
- anchor-free的方式比如FCOS有了解吗
- 看你有用过
ViT,能不能讲讲transformer的架构,再讲讲vit是怎么做的,BERT有了解吗,跟vit有什么区别 - 看你项目经常用到kaiming的东西,kaiming最近新出的MAE有了解吗(虽然面试官看着年龄有点大,不过还挺紧跟潮流的,kaiming yyds!
- 讲讲SIFT匹配到双目测距的过程和原理
- 为什么要用树莓派采集图像借助flask推流,再由主机进行模型推理
- 对GNN和GCN有了解吗
- 讲讲人脸检测
MTCNN是怎么做的 - 聊美团这边的业务,问我有没有这方面技术的了解
- 自己出的算法题,以条形码识别为背景,有点像是去除干扰字符的匹配,用双指针解决即可。
二面
- 聊项目缘由,团队协作。
- 讲讲
transformer,讲讲position encoding的方法,作者用这种三角函数的方式有什么特点,在vit里面是如何做位置编码的。 - 介绍
self-attention,transfomer的encode和decode有什么区别,你对这两部分有什么理解,以及相对于CNN的一些特点。 - 项目用的数据集有多大。
- 项目目标检测用的什么指标,达到了什么效果。
- 聊美团业务,问我有没有兴趣。
- 出了个hard题扰乱字符串,不会,简单讲了一下dfs暴力的思路但还是没理清楚写不出😭,后面换了个简单点的题不过要求让我用python写
商汤-基础视觉 offer
一面
一面比较简单,面试官也比较和蔼。
- 自己出的题,二维矩阵找最长的严格单调上升的一个连续序列(可以跨行转弯,对角线不算),节点可上下左右移动。先用dfs暴力,然后再用记忆化优化了一下。虽然不难但是写的有点慢。
- 聊项目。
- 讲讲Batch Normalization(建议从目的,由来,公式解析,理解操作过程,作用以及使用场景等方面来讲解附博客,看完发现自己面试讲的好烂)
- 介绍小批量梯度下降
- 讲讲分布不均衡的数据如何处理(讲了讲数据增强,过采样比如SMOTE,欠采样,调整样本对分类的权重,如FocalLoss,这个我感觉回答的不是很好,希望评论区有更好的理解)
- 有没有搭建或者使用过单机多卡和多机多卡,是否了解多卡时神经网络的梯度反向传播是如何计算的(没钱没资源🤣,瞎猜了一波可能和计算图的节点资源分配有关)
二面
二面其实感觉面试有点糟糕,连问了十几个八股文,做题也出了一些问题,自闭,答也能答出来一些但是整体感觉不好。。。。不过最后比较幸运还是让我过了。 - 简单介绍自己的项目和自己觉得有亮点的地方
- 讲讲one-stage和two-stage的区别和特点
- 什么是RPN,作用是什么
- 什么是FPN,有什么特点,这种多尺度是怎么实现和进行预测的
- 讲述yolov3预测目标的过程(比较关键的几个要点我觉得是损失函数,模型输出,非极大抑制,多种变种的IoU,SPP空间金字塔,以及论文中有提到yolov3的anchor是kmeans聚类出来的,可能会让你手写kmeans)
- 为什么two-stage要比one-stage的精度要高,你觉得本质是什么
- yolov3的三个特征图大尺寸的用来预测大的图还是小的图
- anchor-free的方式有了解吗,和anchor-based的差异在哪,本质和原理是什么
- 介绍一下CenterNet和FCOS,中心度的公式和理论,预测过程
- 什么是梯度消失和梯度爆炸,如何解决(提到某些要点或者答错了会继续追问,没有答的很全)
- 进程和线程的区别,python的多线程如何实现
- maxpool是如何进行反向传播的(建议看看cs231n,首先要明确的是pool层中是没有参数的,然后再来将maxpool,其实我当时也忘了,我记得好像跟maxout的反向传播差不多)
- 讲讲Batch Normalization,以及在训练和预测过程的计算方式
- 讲讲dropout,以及在训练和预测过程的计算方式(建议看看cs231n),你觉得和机器学习当中哪种集成方式比较像(这个我不是很清楚希望各位大佬回答一下,当时瞎说了一个boosting🤣)
- 剑指 Offer 31. 栈的压入、弹出序列 思路大致是对的但是没想得特别清楚,比较紧张,写了很久
- 剑指 Offer 39. 数组中出现次数超过一半的数字 第二题直接限制时间复杂度$O(n)$,空间复杂度$O(1)$,我只会哈希方法,然后和面试官说了一下最优解方法我只记得叫摩尔投票,然后具体忘了。
栈的压入、弹出序列
class Solution {
public:
bool validateStackSequences(vector<int>& pushed, vector<int>& popped) {
stack<int> stk;
int n = popped.size();
int m = pushed.size();
int j = 0;
for(int i=0;i<m;i++)
{
stk.push(pushed[i]);
while(stk.size()&&stk.top()==popped[j])
{
j++;
stk.pop();
}
}
return stk.empty();
}
};其他
还有一些感觉比较重要,但是没有被问道的东西,包括各种评价指标的含义等等,包括数学基础等等。
经典教程推荐:cs231n,吴恩达,李宏毅,动手学深度学习,《统计学习方法》
关于八股文方面这里推荐一个DeepLearning-500-questions手写非极大抑制
使用非极大抑制的前提是,我们已经得到了一组候选框和对应label的置信分数,以及groud truth的信息,通过设定阈值来删除重合度较高的候选框。
算法流程如下:- 根据置信度得分进行排序
- 选择置信度最高的比边界框添加到最终输出列表中,将其从边界框列表中删除
- 计算所有边界框的面积
- 计算置信度最高的边界框与其它候选框的IoU。
- 删除IoU大于阈值的边界框
- 重复上述过程,直至边界框列表为空。
import numpy as np
def nms(dets, threshod, mode="Union"):
"""
greedily select boxes with high confidence
keep boxes overlap <= thresh
rule out overlap > thresh
:param dets: [[x1, y1, x2, y2 score]]
:param threshod: retain overlap <= thresh
:return: indexes to keep
"""
x1 = dets[:, 0]
y1 = dets[:, 1]
x2 = dets[:, 2]
y2 = dets[:, 3]
scores = dets[:, 4]
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
order = scores.argsort()[::-1] # reverse
keep = []
while order.size() > 0:
i = order[0]
keep.append(i)
# A & B left top position
xx1 = np.maximun(x1[i], x1[order[1, :]])
yy1 = np.maximun(y1[i], y1[order[1, :]])
# A & B right down position
xx2 = np.minimum(x2[i], x2[order[1, :]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
# cacaulate the IOU between box which have largest score with other boxes
if mode == "Union":
# area[i]: the area of largest score
ovr = inter / (areas[i] + areas[order[1:]] - inter)
elif mode == "Minimum":
ovr = inter / np.minimum(areas[i], areas[order[1:]])
# delete the IoU that higher than threshod
inds = np.where(ovr <= threshod)[0]
order = order[inds + 1] # +1: eliminates the first element in order
return keep手写Kmeans方法
这个版本不是最佳写法,某些处理有点暴力,可以用矩阵和numpy相关的操作会更简洁,但是退出迭代的条件写的很全的,有达到迭代次数,中心点集不变,中心点变化范围小于$\delta$
import numpy as np
import matplotlib.pyplot as plt
n = 100
a = np.random.randn(0,50,n)
b = np.random.rand(0,50,n)
x = np.random.randint(0,50,n)
y = np.random.randint(0,50,n)
points = np.array(list(zip(x,y)))
def distance(x,y):
return np.sqrt(np.sum((x-y)**2))
def k_means(points,k=5,epochs=500,delta=1e-3):
# 初始化聚类中心
center_ids = np.random.randint(0,n,k)
centers = points[center_ids]
# 聚类集合初始化
results = []
for i in range(k):
results.append([])
step = 1
flag = True
# 计算各点到中心的距离
while flag and step < epochs:
# 重新迭代
for i in range(k):
results[i] = []
# 计算每个点到距离中心的距离
for i in range(len(points)):
point = points[i]
min_dis = np.inf
min_id = 0
for idx, center in enumerate(centers):
dis = distance(center,point)
if min_dis > dis:
min_dis = dis
min_id = idx
results[min_id].append(point)
# 更新聚类中心
for idx, old_center in enumerate(centers):
new_center = np.array(results[idx]).mean(axis=0)
if distance(center, new_center) > delta:
centers[idx] = new_center
flag = False
# flag=True说明聚类中心已经不变了则可以退出了
if flag:
break
else:
flag = True
step += 1
return results,centers
plt.plot(x,y,'ro')
results,centers=k_means(points,k=5)
color=['ko','go','bo','yo','co']
for i in range(len(results)):
result=results[i]
plt.plot([res[0] for res in result],[res[1] for res in result],color[i])
plt.plot([res[0] for res in centers],[res[1] for res in centers],'ro')
plt.show()总结
本人能力有限,如果上述回答有任何错误,还请各位大佬及时指出
- 不同面试官的面试风格不一样,项目相关的知识积累问的会比较多(项目水没关系但相关技术还是要搞懂),项有的会考察广度和思维潜力,有的会考察基础(八股),算法题感觉并没有那种重要,把剑指offer刷了应该差不多。
- 关于八股文的看法,其实更多的还是要多理解,一些相关原理和数学还是多看看相关论文和经典课程,到时候也不用刻意记也能按自己的想法说出一点(瞎吹),感觉面试官想要的答案并不一定是你能完整的说出来,而是有自己理解的正确描述(这个可能需要在代码实践和理论知识之间多反复几次体会会比较好)。
- 代码实践还是要多一些,其实很多东西我了解的并不深入,只是大致理解过原理和思路,这样还是不太好,开始害怕顶不住实习压力了。
- 不用害怕,尽量多交流,避免场面陷入尴尬。
- 反问环节我一般问的是来这边的工作内容,学习的建议和评价,培养和安排之类的。
「掘金链接:菜鸡的算法岗日常实习面经总结」
]]>前言
第一次在掘金写面经,其实今年过得不尽人意,好在能找找实习调整一下心态吧,终于有钱换手机了!要说有什么新年愿望,那就希望2022一切好运吧。 虽然是实习面经但是其实也没怎么准备,随缘,放弃了bat的部门,估计对学历和论文有门槛(尝试性投了深圳字节直接挂简历,我永远喜欢bytedance😭),10月投b站简历挂,旷视面试没过以后就没投了,后面去学车了,结果科目二没过,有点闲看到有朋友也在投,就不抱希望还是投了3家,比较幸运最后拿到了美团和商汤的实习offer,感谢面试官们手下留情🤣。
个人情况:
- 学校:211 大四
- 成绩:前5%
- 项目:3段CV相关项目经历,无论文,两个算法实践工程落地项目,一段kaggle竞赛铜牌,总体上来说都比较水
- 算法能力:无ACM,比较菜只是比较喜欢刷,leetcode400题(以easy+medium为主,剑指offer+程序员面试经典+每日一题/周赛)
因为感觉自己很菜找不到实习,所以都没找内推,也没有海投,不过好像大多都会给面试机会的,感觉如果能找内推可能会更好一点。没想到最后能去美团当外卖骑手了😁!
旷视
旷视的实习面试是最早的,不过也面试通知也等了好久,hr说有两个面试官mark了我的简历,所以面了两个组,当时是第一次面试,比较紧张,虽然面试问的不难,但是有些地方答的不好,面试问题记不太清了。另一个面试官,我等了半小时结果被他放鸽子了,改天再面的。。。
- 手写IoU
- 求三个部分的IoU,根据定义就是求:$\frac{A \cap B \cap C}{A \cup B \cup C} $,只用讲思路,其实就是容斥原理,当时有点紧张,公式最后一项系数写错了一直没看出来,场面一度尴尬。
- 讲解Focal loss的原理作用
- 为什么会用到
StratifiedKFold,和KFold有什么区别 - 介绍一下比赛用到的
TTA,Cutmix方法(Cutout和mixup的结合,最好三个都讲解一下) - 讲讲
Resnet(建议读一下论文,从目的,作用,残差结构的形式,反向传播梯度计算,机器学习GBDT思想等角度进行阐述) - 目标检测的
mAP达到了多少,有没有测过双目测距的精准度,为啥使用wifi和flask推流通信,这样会比较慢(树莓派算力不够,跑着跑着宕机了),小车目标检测的帧数能达到多少fps(emm我们只是做了一个无人清洁车落地的demo,只测了模型目标检测在数据集上的mAP,其他的更多的是我们自己提供一种idea,具体指标没有测试过😥)。 - 旋转矩阵,不能开空间,其实做过但是面试很容易紧张卡住,有想到思路但是没写对有点bug,不过面试官说我思路是对的,面完就发现原来是下标对错了。。。
- 团队合作交流是如何分工和解决问题的?
- 其他人或者老师给你任务安排时,如果与你的想法不合时,你会如何做?
手写IoU
import numpy as np
def IoU(bounding_box,ground_truth):
"""
:param bounding_box: [[x1,y1,x2,y2,score]]
:param ground_truth: [x1,y1,x2,y2]
:return:
"""
x1 = bounding_box[:,0]
y1 = bounding_box[:,1]
x2 = bounding_box[:,2]
y2 = bounding_box[:,3]
score = bounding_box[:,4]
areas = (x2-x1) * (y2-y1)
gt_area = (ground_truth[2] - ground_truth[0]) * (ground_truth[3] - ground_truth[1])
xx1 = np.maximum(x1,ground_truth[0])
yy1 = np.maximum(y1,ground_truth[1])
xx2 = np.minimum(x2,ground_truth[2])
yy2 = np.minimum(y2,ground_truth[3])
h = np.maximum(0,yy2-yy1)
w = np.maximum(0,xx2-xx1)
inter = w * h
ovr = inter / (gt_area + areas - inter) # np.true_divide(inter, (gt_area + areas - inter))
return ovr旋转矩阵
class Solution {
public:
void rotate(vector<vector<int>>& matrix) {
int n = matrix.size();
for(int i=0;i<n/2;i++)
{
for(int j=0;j<(n+1)/2;j++)
{
// (i,j) (j,n-i-1) (n-j-1,i) (n-i-1,n-j-1)
swap(matrix[i][j],matrix[n-i-1][n-j-1]);
swap(matrix[i][j],matrix[n-j-1][i]);
swap(matrix[j][n-i-1],matrix[n-i-1][n-j-1]);
}
}
}
};小米
小米面试其实是当时最好的选择,因为就在武汉本地,也不用外出,但是当时面试确实不太好,面试官对我其中一个项目比较感兴趣,被疯狂怼着追问细节。
- 描述项目中用到的SIFT匹配和直方图相似度比对基本原理。
- one-stage和two-stage的区别。
- 双目摄像头视觉下应该可以得到整个三维空间下的信息,没考虑方向角度的问题,对测距的处理有些草率(没有很懂,之后再去了解了解,只用到了物理上小孔成像的原理😰
- 为什么不直接在树莓派上推理,采用推流和主机服务器去进行计算,速度和精度如何
- 继续追问项目细节。
- 手写SIFT匹配过程,直接人傻了😭(被面试官怼对传统图像处理了解不深,只会玩玩深度学习搭积木)
美团-智能视觉 offer
美团面试官面试体验比较好,没有过分针对,对待我这种本科生可能相对更看重对我的motivation和potential吧感觉,评价也比较好。
一面
- 聊项目,做项目的目的和缘由,你觉得有什么亮点。
- 讲讲one-stage和two-stage的区别。
- anchor-free的方式比如FCOS有了解吗
- 看你有用过
ViT,能不能讲讲transformer的架构,再讲讲vit是怎么做的,BERT有了解吗,跟vit有什么区别 - 看你项目经常用到kaiming的东西,kaiming最近新出的MAE有了解吗(虽然面试官看着年龄有点大,不过还挺紧跟潮流的,kaiming yyds!
- 讲讲SIFT匹配到双目测距的过程和原理
- 为什么要用树莓派采集图像借助flask推流,再由主机进行模型推理
- 对GNN和GCN有了解吗
- 讲讲人脸检测
MTCNN是怎么做的 - 聊美团这边的业务,问我有没有这方面技术的了解
- 自己出的算法题,以条形码识别为背景,有点像是去除干扰字符的匹配,用双指针解决即可。
二面
- 聊项目缘由,团队协作。
- 讲讲
transformer,讲讲position encoding的方法,作者用这种三角函数的方式有什么特点,在vit里面是如何做位置编码的。 - 介绍
self-attention,transfomer的encode和decode有什么区别,你对这两部分有什么理解,以及相对于CNN的一些特点。 - 项目用的数据集有多大。
- 项目目标检测用的什么指标,达到了什么效果。
- 聊美团业务,问我有没有兴趣。
- 出了个hard题扰乱字符串,不会,简单讲了一下dfs暴力的思路但还是没理清楚写不出😭,后面换了个简单点的题不过要求让我用python写
商汤-基础视觉 offer
一面
一面比较简单,面试官也比较和蔼。
- 自己出的题,二维矩阵找最长的严格单调上升的一个连续序列(可以跨行转弯,对角线不算),节点可上下左右移动。先用dfs暴力,然后再用记忆化优化了一下。虽然不难但是写的有点慢。
- 聊项目。
- 讲讲Batch Normalization(建议从目的,由来,公式解析,理解操作过程,作用以及使用场景等方面来讲解附博客,看完发现自己面试讲的好烂)
- 介绍小批量梯度下降
- 讲讲分布不均衡的数据如何处理(讲了讲数据增强,过采样比如SMOTE,欠采样,调整样本对分类的权重,如FocalLoss,这个我感觉回答的不是很好,希望评论区有更好的理解)
- 有没有搭建或者使用过单机多卡和多机多卡,是否了解多卡时神经网络的梯度反向传播是如何计算的(没钱没资源🤣,瞎猜了一波可能和计算图的节点资源分配有关)
二面
二面其实感觉面试有点糟糕,连问了十几个八股文,做题也出了一些问题,自闭,答也能答出来一些但是整体感觉不好。。。。不过最后比较幸运还是让我过了。 - 简单介绍自己的项目和自己觉得有亮点的地方
- 讲讲one-stage和two-stage的区别和特点
- 什么是RPN,作用是什么
- 什么是FPN,有什么特点,这种多尺度是怎么实现和进行预测的
- 讲述yolov3预测目标的过程(比较关键的几个要点我觉得是损失函数,模型输出,非极大抑制,多种变种的IoU,SPP空间金字塔,以及论文中有提到yolov3的anchor是kmeans聚类出来的,可能会让你手写kmeans)
- 为什么two-stage要比one-stage的精度要高,你觉得本质是什么
- yolov3的三个特征图大尺寸的用来预测大的图还是小的图
- anchor-free的方式有了解吗,和anchor-based的差异在哪,本质和原理是什么
- 介绍一下CenterNet和FCOS,中心度的公式和理论,预测过程
- 什么是梯度消失和梯度爆炸,如何解决(提到某些要点或者答错了会继续追问,没有答的很全)
- 进程和线程的区别,python的多线程如何实现
- maxpool是如何进行反向传播的(建议看看cs231n,首先要明确的是pool层中是没有参数的,然后再来将maxpool,其实我当时也忘了,我记得好像跟maxout的反向传播差不多)
- 讲讲Batch Normalization,以及在训练和预测过程的计算方式
- 讲讲dropout,以及在训练和预测过程的计算方式(建议看看cs231n),你觉得和机器学习当中哪种集成方式比较像(这个我不是很清楚希望各位大佬回答一下,当时瞎说了一个boosting🤣)
- 剑指 Offer 31. 栈的压入、弹出序列 思路大致是对的但是没想得特别清楚,比较紧张,写了很久
- 剑指 Offer 39. 数组中出现次数超过一半的数字 第二题直接限制时间复杂度$O(n)$,空间复杂度$O(1)$,我只会哈希方法,然后和面试官说了一下最优解方法我只记得叫摩尔投票,然后具体忘了。
栈的压入、弹出序列
class Solution {
public:
bool validateStackSequences(vector<int>& pushed, vector<int>& popped) {
stack<int> stk;
int n = popped.size();
int m = pushed.size();
int j = 0;
for(int i=0;i<m;i++)
{
stk.push(pushed[i]);
while(stk.size()&&stk.top()==popped[j])
{
j++;
stk.pop();
}
}
return stk.empty();
}
};其他
还有一些感觉比较重要,但是没有被问道的东西,包括各种评价指标的含义等等,包括数学基础等等。
经典教程推荐:cs231n,吴恩达,李宏毅,动手学深度学习,《统计学习方法》
关于八股文方面这里推荐一个DeepLearning-500-questions手写非极大抑制
使用非极大抑制的前提是,我们已经得到了一组候选框和对应label的置信分数,以及groud truth的信息,通过设定阈值来删除重合度较高的候选框。
算法流程如下:- 根据置信度得分进行排序
- 选择置信度最高的比边界框添加到最终输出列表中,将其从边界框列表中删除
- 计算所有边界框的面积
- 计算置信度最高的边界框与其它候选框的IoU。
- 删除IoU大于阈值的边界框
- 重复上述过程,直至边界框列表为空。
import numpy as np
def nms(dets, threshod, mode="Union"):
"""
greedily select boxes with high confidence
keep boxes overlap <= thresh
rule out overlap > thresh
:param dets: [[x1, y1, x2, y2 score]]
:param threshod: retain overlap <= thresh
:return: indexes to keep
"""
x1 = dets[:, 0]
y1 = dets[:, 1]
x2 = dets[:, 2]
y2 = dets[:, 3]
scores = dets[:, 4]
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
order = scores.argsort()[::-1] # reverse
keep = []
while order.size() > 0:
i = order[0]
keep.append(i)
# A & B left top position
xx1 = np.maximun(x1[i], x1[order[1, :]])
yy1 = np.maximun(y1[i], y1[order[1, :]])
# A & B right down position
xx2 = np.minimum(x2[i], x2[order[1, :]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
# cacaulate the IOU between box which have largest score with other boxes
if mode == "Union":
# area[i]: the area of largest score
ovr = inter / (areas[i] + areas[order[1:]] - inter)
elif mode == "Minimum":
ovr = inter / np.minimum(areas[i], areas[order[1:]])
# delete the IoU that higher than threshod
inds = np.where(ovr <= threshod)[0]
order = order[inds + 1] # +1: eliminates the first element in order
return keep手写Kmeans方法
这个版本不是最佳写法,某些处理有点暴力,可以用矩阵和numpy相关的操作会更简洁,但是退出迭代的条件写的很全的,有达到迭代次数,中心点集不变,中心点变化范围小于$\delta$
import numpy as np
import matplotlib.pyplot as plt
n = 100
a = np.random.randn(0,50,n)
b = np.random.rand(0,50,n)
x = np.random.randint(0,50,n)
y = np.random.randint(0,50,n)
points = np.array(list(zip(x,y)))
def distance(x,y):
return np.sqrt(np.sum((x-y)**2))
def k_means(points,k=5,epochs=500,delta=1e-3):
# 初始化聚类中心
center_ids = np.random.randint(0,n,k)
centers = points[center_ids]
# 聚类集合初始化
results = []
for i in range(k):
results.append([])
step = 1
flag = True
# 计算各点到中心的距离
while flag and step < epochs:
# 重新迭代
for i in range(k):
results[i] = []
# 计算每个点到距离中心的距离
for i in range(len(points)):
point = points[i]
min_dis = np.inf
min_id = 0
for idx, center in enumerate(centers):
dis = distance(center,point)
if min_dis > dis:
min_dis = dis
min_id = idx
results[min_id].append(point)
# 更新聚类中心
for idx, old_center in enumerate(centers):
new_center = np.array(results[idx]).mean(axis=0)
if distance(center, new_center) > delta:
centers[idx] = new_center
flag = False
# flag=True说明聚类中心已经不变了则可以退出了
if flag:
break
else:
flag = True
step += 1
return results,centers
plt.plot(x,y,'ro')
results,centers=k_means(points,k=5)
color=['ko','go','bo','yo','co']
for i in range(len(results)):
result=results[i]
plt.plot([res[0] for res in result],[res[1] for res in result],color[i])
plt.plot([res[0] for res in centers],[res[1] for res in centers],'ro')
plt.show()总结
本人能力有限,如果上述回答有任何错误,还请各位大佬及时指出
- 不同面试官的面试风格不一样,项目相关的知识积累问的会比较多(项目水没关系但相关技术还是要搞懂),项有的会考察广度和思维潜力,有的会考察基础(八股),算法题感觉并没有那种重要,把剑指offer刷了应该差不多。
- 关于八股文的看法,其实更多的还是要多理解,一些相关原理和数学还是多看看相关论文和经典课程,到时候也不用刻意记也能按自己的想法说出一点(瞎吹),感觉面试官想要的答案并不一定是你能完整的说出来,而是有自己理解的正确描述(这个可能需要在代码实践和理论知识之间多反复几次体会会比较好)。
- 代码实践还是要多一些,其实很多东西我了解的并不深入,只是大致理解过原理和思路,这样还是不太好,开始害怕顶不住实习压力了。
- 不用害怕,尽量多交流,避免场面陷入尴尬。
- 反问环节我一般问的是来这边的工作内容,学习的建议和评价,培养和安排之类的。
「掘金链接:菜鸡的算法岗日常实习面经总结」
]]>@@ -118,7 +118,7 @@ 2022-01-08T12:04:00.000Z 2024-10-09T07:33:09.904Z -⏱2021-2022
说来惭愧,没想到在掘金这样神圣的技术社区,我的第一篇文章竟然是与技术无关的年终总结。(主要是想白嫖到周边棒球帽🧢,本来是打算发布已经写好的算法岗实习面经,有兴趣的朋友可以继续看看)
时间总是过的很快,我也是偶然间打开掘金看到的这个活动才意识到今年已经快要过去了,想了很久2021年对我而言到底意味着什么,好像过得很混乱,想的太多,做的太少,以前总是能在不确定性中规划好一些时间,但今年很多事情都是被时间推着走入不确定的维度。
读研or就业的思考
这个问题其实在2年前就有在思考这件事情,虽然学生思维存在着一些局限性,但是你不得不承认这件事情确实是你需要尽早想清楚的事情,话是这么说其实还是当局者迷,旁观者清,尽管有一些我认识的人给过我他们的思考,我自己也没在最需要想清楚的时候想清楚这件事情,可能很多感受只有触碰到结果了才真正明白吧。
这个问题抛出来,我写起来还是不知从何说起,没有正确答案,未来都是未知的,害怕失去现有的一切,凭我的经验来看,还是要多遵从自己的内心,不要完全理性的去权衡利弊,失去如果每个选择都会后悔,就不要选让自己更后悔的那个。还是说一下自己当时思考的几件事情:- 读研是为了什么,去企业又是为了什么
- 对于未来到底想做什么
- 抛开家长和他人的观点,你对自己的性格和能力是否足够了解,是否足够自信
- 都是最坏的情况,更能接受哪个选择
- 如何承受选择带来的代价和自我和解之道
去黄鹤楼,看樱花
3月樱花又开了,大一没来得及看樱花,大二由于疫情影响也没能去成,大三正好有朋友过来武汉找我玩,就带着去黄鹤楼,隔壁学校赏樱花,那几天每天晚上和朋友们聊天一整夜,太久没一块说话了吧,我和他约定好考完研再来武汉陪我过生日。春招面网易
4月有好友正好在做网易的春招宣传,内推了我一手,抱着涨点面试经验的心态,面了一下网易的算法岗,匆忙改了一版简历,笔试比较简单过了2/3,面试还行但还是没过,后面准备夏令营啥的也没有再投了。茶颜悦色&湖南师大&湖南大学
在湖南呆了这么久,这是第一次喝茶颜悦色,leo点的幽兰拿铁,晚上吃了一顿火锅直接拉肚子到凌晨2点,去了当初高二数学竞赛培训的湖师大,看了看那些当时买礼物的精品店和饭店,后面去了湖南大学找同学吃饭,湖南大学的建筑风格很不错,嘿嘿,不愧是湖大!有幸与神三元吃饭
毕业季,神三元学长也要毕业了,在学校一直听着他的江湖神话,终于有朝一日能见上一面了,迫不及待和朋友一起跑到另一个校区追星。见面一看确实是一表人才,吃饭紧张到有点不知道说话。不过听大佬聊技术趋势和工作思考,还是有很多不一样的体会。
bytecamp再送人头
去年暑假参加了一次bytecamp的笔试,感觉挺有意思的,虽然当时也没过,今年再参加编程又爆0了,第一题是树形dp模版题,但是我当时忘了,后面两个就更难了不会。
滚滚长江东逝水——再会江滩
暑假放假回家前,去了一次江滩,之前带朋友去的是汉口江滩,这次去武昌江滩看的,也算是两岸都看过了,虽然武汉夏天很热,但是长江的风吹过来还是很舒服的。
魔都体验卡
有幸参加SIST的夏令营,体验了3天公费旅游的感觉,还吃了西餐,和朋友去了上海外滩和金融中心,半夜两点给健哥写前端。听说上海的天空很低!
梦碎了
9月差一点点,最后还是没能去到自己最想去的地方,感觉自己的学生时代已经结束了,梦碎了,不展开了,容易晚上emo😭
4年后再来南山区
18年国庆来深圳,只觉得繁华,人上人,4年后再来觉得这里还是缺少了一些文化感和年代感的东西,感谢朋友们的盛情招待,看海没赶上好时候,跟小w发我的照片完全不一样😔,第一次吃椰子鸡,去了SUST看夕阳,感受了朋友在字节跳动的“快乐”生活(我永远喜欢bytedance),遇到了突然其来的台风和大暴雨,沿着大沙河逛THU和PKU
最爱东湖与武大
在武汉,我独爱东湖,这次有幸还坐船浏览了对岸,去了磨山,一路听着粤语歌在东湖漫步,会有很多很多想法。逛完东湖与武大同学小歇畅聊,有幸参观了周恩来和闻一多先生的居所,一起吃饭听说他搞家教日薪1k+我羡慕。
摆烂的大四软测
大四一学期没听课,软测临时抱佛脚,卷了3年才知道整张试卷瞎写的感觉原来这么爽,还好没挂。
CLANNAD
看了一直没看的CLANNAD,不得不说这个剧表达的东西很深刻,给了我很多生活的思考,我觉得是我心中看过的最好的动漫之一了,以后可以再看一遍,好像要一个团子啊🥺!
科目二的败北
和朋友天天早出晚归跑去练科目二,到了考场发现自己学的东西都白学了,侧方直接挂,然后倒库紧张又挂了。。。坡上两只狗
12月所思
12月陷入了一段特别迷茫的时间,他们说我所担心的并不能约束你,只能促进你,不要老是患得患失,后面拿了实习offer后开心了一些,等考研的朋友考完一起舒服了几天,后面的实训课继续摆烂,可惜说好来武汉陪我过生日的同学最后还是没来,那天写实训代码写到1点才睡,不过随着一年又一年,我倒是觉得就当平常日挺好的,也不用刻意去记,能想起来就想起来吧。
回家的所闻所见
纠结了很长时间关于寒假外出实习的事情,最后还是觉得去体验一下比较好,害怕过年回家待不了太久,所以提前跑路回家了几天,比较难受的是遇到了一些不好的事情,还是要常回家看看🙏
啃了一些原理+Leetcode400题
今年感觉自己花在学习上的时间没有特别多,更多的时间被虚无的思考给浪费掉了,除了一些kaggle和工程代码之外,今年做了一些不一样的事情主要就是手推了《统计学习方法》当中一些基本算法,西瓜书也看了一些,leetocde不知不觉突破400题了! 还是很菜,只不过把刷题当成习惯了。
关于十年后再来北京这件事
今年跨年有些不一样,12.31飞北京跨年,下午处理好了租房的问题,人生地不熟,接下来元旦几天都是被朋友带着玩哈哈哈。
Dr.Pepper & Sky
在旅店晚上喝了一杯命运石之门的Dr.Pepper,有一种穿越时空的味道 上次坐飞机还是10多年前,再一次飞上蓝天还是很激动!
清华五道口
十年前曾踏过清华的大门,十年后还是没能跨进你的大门,来生请等我。
单车刷夜去天安门和祖国母亲一起跨年
作为一名预备党员,元旦必然要在天安门通宵等升旗,被北方的寒风给冻傻了,和祖国母亲一起放飞和平鸽!
海底捞被朋友抓去过生日
虽然生日过了,但是他们想在北京陪我过一次,店里送了相框,正好一起拍照留作纪念,摆在新家当饰品,第一次在海底捞过生日社死。
四季民福故宫店北京烤鸭南锣鼓巷中关村中科院
吃了很离谱的豆汁和正宗北京烤鸭
环球影城,我要上魔法学院!
在环球影城玩了一天,看过的电影不多,环球影城的这几个设施特别还原,喝了魔法黄油啤酒,买了小黄人的盲盒。
美团实习ing
太菜了只会摸鱼,要开始新的生活了
To 2022
- 请你继续保持对技术的热情,脚踏实地,努力学习,祝你好运
- 好好体验实习,工作,一个人独立生活的感觉
- 考完驾照,厨艺++,滑一次雪,想看看北京冬奥会
- 劳逸结合,自律坚持,锻炼身体,要顶天立地,才能闯出自己的路
- 读万卷书,行万里路,在更多地方留下你的足迹
- 请做到一件很多年你都没能做到的事情
- 以高标准要求自己,但是别当成包袱,好的坏的都是一场体验
- 还有不能忘记的音乐梦!
- 希望未来以后有机会当一个speaker
「掘金链接:回首向来萧瑟处,归去,也无风雨也无晴|2021年终总结」
]]>⏱2021-2022
说来惭愧,没想到在掘金这样神圣的技术社区,我的第一篇文章竟然是与技术无关的年终总结。(主要是想白嫖到周边棒球帽🧢,本来是打算发布已经写好的算法岗实习面经,有兴趣的朋友可以继续看看)
时间总是过的很快,我也是偶然间打开掘金看到的这个活动才意识到今年已经快要过去了,想了很久2021年对我而言到底意味着什么,好像过得很混乱,想的太多,做的太少,以前总是能在不确定性中规划好一些时间,但今年很多事情都是被时间推着走入不确定的维度。
读研or就业的思考
这个问题其实在2年前就有在思考这件事情,虽然学生思维存在着一些局限性,但是你不得不承认这件事情确实是你需要尽早想清楚的事情,话是这么说其实还是当局者迷,旁观者清,尽管有一些我认识的人给过我他们的思考,我自己也没在最需要想清楚的时候想清楚这件事情,可能很多感受只有触碰到结果了才真正明白吧。
这个问题抛出来,我写起来还是不知从何说起,没有正确答案,未来都是未知的,害怕失去现有的一切,凭我的经验来看,还是要多遵从自己的内心,不要完全理性的去权衡利弊,失去如果每个选择都会后悔,就不要选让自己更后悔的那个。还是说一下自己当时思考的几件事情:- 读研是为了什么,去企业又是为了什么
- 对于未来到底想做什么
- 抛开家长和他人的观点,你对自己的性格和能力是否足够了解,是否足够自信
- 都是最坏的情况,更能接受哪个选择
- 如何承受选择带来的代价和自我和解之道
去黄鹤楼,看樱花
3月樱花又开了,大一没来得及看樱花,大二由于疫情影响也没能去成,大三正好有朋友过来武汉找我玩,就带着去黄鹤楼,隔壁学校赏樱花,那几天每天晚上和朋友们聊天一整夜,太久没一块说话了吧,我和他约定好考完研再来武汉陪我过生日。春招面网易
4月有好友正好在做网易的春招宣传,内推了我一手,抱着涨点面试经验的心态,面了一下网易的算法岗,匆忙改了一版简历,笔试比较简单过了2/3,面试还行但还是没过,后面准备夏令营啥的也没有再投了。茶颜悦色&湖南师大&湖南大学
在湖南呆了这么久,这是第一次喝茶颜悦色,leo点的幽兰拿铁,晚上吃了一顿火锅直接拉肚子到凌晨2点,去了当初高二数学竞赛培训的湖师大,看了看那些当时买礼物的精品店和饭店,后面去了湖南大学找同学吃饭,湖南大学的建筑风格很不错,嘿嘿,不愧是湖大!有幸与神三元吃饭
毕业季,神三元学长也要毕业了,在学校一直听着他的江湖神话,终于有朝一日能见上一面了,迫不及待和朋友一起跑到另一个校区追星。见面一看确实是一表人才,吃饭紧张到有点不知道说话。不过听大佬聊技术趋势和工作思考,还是有很多不一样的体会。
bytecamp再送人头
去年暑假参加了一次bytecamp的笔试,感觉挺有意思的,虽然当时也没过,今年再参加编程又爆0了,第一题是树形dp模版题,但是我当时忘了,后面两个就更难了不会。
滚滚长江东逝水——再会江滩
暑假放假回家前,去了一次江滩,之前带朋友去的是汉口江滩,这次去武昌江滩看的,也算是两岸都看过了,虽然武汉夏天很热,但是长江的风吹过来还是很舒服的。
魔都体验卡
有幸参加SIST的夏令营,体验了3天公费旅游的感觉,还吃了西餐,和朋友去了上海外滩和金融中心,半夜两点给健哥写前端。听说上海的天空很低!
梦碎了
9月差一点点,最后还是没能去到自己最想去的地方,感觉自己的学生时代已经结束了,梦碎了,不展开了,容易晚上emo😭
4年后再来南山区
18年国庆来深圳,只觉得繁华,人上人,4年后再来觉得这里还是缺少了一些文化感和年代感的东西,感谢朋友们的盛情招待,看海没赶上好时候,跟小w发我的照片完全不一样😔,第一次吃椰子鸡,去了SUST看夕阳,感受了朋友在字节跳动的“快乐”生活(我永远喜欢bytedance),遇到了突然其来的台风和大暴雨,沿着大沙河逛THU和PKU
最爱东湖与武大
在武汉,我独爱东湖,这次有幸还坐船浏览了对岸,去了磨山,一路听着粤语歌在东湖漫步,会有很多很多想法。逛完东湖与武大同学小歇畅聊,有幸参观了周恩来和闻一多先生的居所,一起吃饭听说他搞家教日薪1k+我羡慕。
摆烂的大四软测
大四一学期没听课,软测临时抱佛脚,卷了3年才知道整张试卷瞎写的感觉原来这么爽,还好没挂。
CLANNAD
看了一直没看的CLANNAD,不得不说这个剧表达的东西很深刻,给了我很多生活的思考,我觉得是我心中看过的最好的动漫之一了,以后可以再看一遍,好像要一个团子啊🥺!
科目二的败北
和朋友天天早出晚归跑去练科目二,到了考场发现自己学的东西都白学了,侧方直接挂,然后倒库紧张又挂了。。。坡上两只狗
12月所思
12月陷入了一段特别迷茫的时间,他们说我所担心的并不能约束你,只能促进你,不要老是患得患失,后面拿了实习offer后开心了一些,等考研的朋友考完一起舒服了几天,后面的实训课继续摆烂,可惜说好来武汉陪我过生日的同学最后还是没来,那天写实训代码写到1点才睡,不过随着一年又一年,我倒是觉得就当平常日挺好的,也不用刻意去记,能想起来就想起来吧。
回家的所闻所见
纠结了很长时间关于寒假外出实习的事情,最后还是觉得去体验一下比较好,害怕过年回家待不了太久,所以提前跑路回家了几天,比较难受的是遇到了一些不好的事情,还是要常回家看看🙏
啃了一些原理+Leetcode400题
今年感觉自己花在学习上的时间没有特别多,更多的时间被虚无的思考给浪费掉了,除了一些kaggle和工程代码之外,今年做了一些不一样的事情主要就是手推了《统计学习方法》当中一些基本算法,西瓜书也看了一些,leetocde不知不觉突破400题了! 还是很菜,只不过把刷题当成习惯了。
关于十年后再来北京这件事
今年跨年有些不一样,12.31飞北京跨年,下午处理好了租房的问题,人生地不熟,接下来元旦几天都是被朋友带着玩哈哈哈。
Dr.Pepper & Sky
在旅店晚上喝了一杯命运石之门的Dr.Pepper,有一种穿越时空的味道 上次坐飞机还是10多年前,再一次飞上蓝天还是很激动!
清华五道口
十年前曾踏过清华的大门,十年后还是没能跨进你的大门,来生请等我。
单车刷夜去天安门和祖国母亲一起跨年
作为一名预备党员,元旦必然要在天安门通宵等升旗,被北方的寒风给冻傻了,和祖国母亲一起放飞和平鸽!
海底捞被朋友抓去过生日
虽然生日过了,但是他们想在北京陪我过一次,店里送了相框,正好一起拍照留作纪念,摆在新家当饰品,第一次在海底捞过生日社死。
四季民福故宫店北京烤鸭南锣鼓巷中关村中科院
吃了很离谱的豆汁和正宗北京烤鸭
环球影城,我要上魔法学院!
在环球影城玩了一天,看过的电影不多,环球影城的这几个设施特别还原,喝了魔法黄油啤酒,买了小黄人的盲盒。
美团实习ing
太菜了只会摸鱼,要开始新的生活了
To 2022
- 请你继续保持对技术的热情,脚踏实地,努力学习,祝你好运
- 好好体验实习,工作,一个人独立生活的感觉
- 考完驾照,厨艺++,滑一次雪,想看看北京冬奥会
- 劳逸结合,自律坚持,锻炼身体,要顶天立地,才能闯出自己的路
- 读万卷书,行万里路,在更多地方留下你的足迹
- 请做到一件很多年你都没能做到的事情
- 以高标准要求自己,但是别当成包袱,好的坏的都是一场体验
- 还有不能忘记的音乐梦!
- 希望未来以后有机会当一个speaker
「掘金链接:回首向来萧瑟处,归去,也无风雨也无晴|2021年终总结」
]]>@@ -143,7 +143,7 @@ 2021-10-16T06:19:00.000Z 2024-10-09T07:33:09.887Z -PAT笔记 +这里记录了一下常用的保研机试,剑指offer和PAT题目分类解析,主要用来快速回顾和复习相关模板,以及数据结构相关的知识点。
字符串
- 在c++中处理字符串类型的题目时,我们一般使用
string,有时候我们也使用char[]方式进行操作。 HH:MM:SS可以直接通过字符串字典序排序- 输入一个包含空格的字符串需要使用
getline(cin,s1)STL
vector<int>本省具备有字典序比较的方法,重载了< == >的运算符号vector<int>::iterator iter=find(vec.begin(),vec.end(),target); if(iter==vec.end()) cout << "Not found" << endl;
高精度
int的范围$-2 \times 10^9 - 2 \times 10^9$long long$-9 \times 10^{18} - 9 \times 10^{18}$- 用
vector按位存储进制转换
- 其他进制化成10进制,采用秦九韶算法
typedef long long LL;
LL get(char c)
{
if(c<='9') return c-'0';
else return c-'a' + 10;
}
LL getnum(string a,LL r)
{
LL res=0;
for(int i=0;i<a.size();i++)
{
res = res * r + get(a[i]);
}
return res;
}- 十进制转其他进制的方法,使用带余除法
int get(char c)
{
if(c<='9') return c-'0';
else return c-'a' + 10;
}
char tochar(int c)
{
if(c<=9) return c+'0';
else return 'a' + c - 10;
}
//一个r进制数num转10进制
int numr_to10(string num,int r)
{
int res = 0;
for(int i=0;i<num.size();i++)
{
res = res * r + get(num[i]);
}
return res;
}
//一个10进制数num转r进制
string num10_tor(string num,int r)
{
string res;
int n = numr_to10(num,10); //先转成10进制整型
while(n)
{
// cout<<tochar(n % r)<<endl;
res = tochar(n % r) + res;
n /= r;
}
return res;
}
// cout<<numr_to10("6a",16)<<" "<<num10_tor("15",16)<<endl;判断质数
//判断一个数是否为质数
bool is_prime(int n)
{
if (n < 2) return false; // 1和0不是质数
for(int i=2;i*i<=n;i++)
{
if(n % i == 0) return false;
}
return true;
}手写堆排序
堆是一个完全二叉树的结构,分为小根堆和大根堆两种结构。
- 小根堆的递归定义:小根堆的每个节点都小于他的左右孩子节点的值,树的根节点为最小值。
- 大根堆的递归定义:大根堆的每个节点都大于他的左右孩子节点的值,树的根节点为最大值。
在STL当中可以使用prioirty_queue来轻松实现大根堆和小根堆,但是只能实现前3个功能,有时候我们不得不自己实现一个手写的堆,同时这样也能让我们更理解堆排序的过程。
在AcWing基础课当中有两道经典例题,AcWing 839. 模拟堆(这个复杂一点),AcWing 838. 堆排序
这里给出堆排序的模板级代码#include <iostream>
using namespace std;
const int N = 100010;
int heap[N],heapsize=0;
void down(int x)// 参数下标
{
int p =x;
if(2*x<=heapsize && heap[2*x]<heap[p]) p = 2*x;//左子树
if(2*x+1<=heapsize && heap[2*x+1]<heap[p]) p=2*x+1;//右子树
if(p!=x)
{
swap(heap[p],heap[x]); //说明存在比父节点小的孩子节点
down(p); //继续向下递归down
}
}
void up(int x)// 参数下标
{
while(x / 2 && heap[x] < heap[x/2]) //父节点比子节点大则交换
{
swap(heap[x],heap[x/2]);
x >>= 1; // x = x/2
}
}
int main()
{
int n,m;
scanf("%d%d", &n, &m);
for (int i = 1; i <= n; i ++ ) scanf("%d", &heap[i]);
heapsize=n;
// O(n)建堆
for (int i = n / 2; i; i -- ) down(i);
while (m -- )
{
printf("%d ",heap[1]); //最小值是小根堆的堆顶
// 删除最小值,并重新建堆排序,从而获得倒数第二小的元素
heap[1] = heap[heapsize];
heapsize--;
down(1);
}
return 0;
}STL写法:
priority_queue默认是大根堆,less<int>是对第一个参数的比较类,表示数字大的优先级越大,而greater<int>表示数字小的优先级越大,可以实现结构体运算符重载。
首先要引入头文件:#include<queue>
大根堆:priority_queue<int> q;
priority_queue<int, vector<int>, less<int> >q;小根堆:
priority_queue < int, vector<int>, greater<int> > q;树
树是一种特殊的数据结构形式,在做题的过程当中,根据我的经验当题目需要使用树结构的时候主要有以下几种模式。
- 二叉树形式,在二叉树模型下,我们可以根据题目建立出静态的树形结构,构建每个节点左右孩子索引表来建立树的结构同时实现对树的遍历。如果已知或可以求得节点之间的关系,可以通过节点的度数或者访问标记找到根节点。,当然也是可以通过邻接表的方式创建二叉树。
- 多叉树形式,多叉树形式其实又类似于无向连通图的概念,常通过创建邻接表或者临接矩阵的方式建立树,并实现进行树的遍历,也是可以根据节点关系求出根节点的。注意在临接表当中,边的数量一般大于节点数量的两倍即我们需要开票邻接表的边数空间为$M = 2 \times N + d$
- 森林,多连通块的方式,这种也是利用无向图的方式,以邻接表或者临接矩阵的方式构建树的结构,同时我们可以利用并查集的方式得到当前无向图中含有的连通块数量并找到根节点。
二叉树左右孩子索引表模型
const int N = 100010;
int l[N],r[N]// 第i个节点的左孩子和右孩子的索引
bool has_father[N]; //建立树的时候判断一下当前节点有没有父节点,可用于寻找根节点
//初始化,-1表示子节点为空
memset(l,-1,sizeof l);
memset(r,-1,sizeof r);
// 查找根节点的过程
if(l[i]>=0) has_father[l[i]]=true;
if(r[i]>=0) has_father[r[i]]=true;
//查找根节点
int root = 0;
while(has_father[root]) root++;二叉树的遍历过程(以先序遍历为例子)
void dfs(int root)
{
if(root==-1) return;
cout<<root<<endl;
if(l[root]>=0) dfs(l[root]);
if(r[root]>=0) dfs(r[root]);
}临接表模型
const int N = 100010;
const int M = 2 * N + 10;
int h[N];//邻接表的N个节点头指针,h[i]表示以i为起点的,最新的一条边的编号
int e[M];// e[i] 表示第i条边的所指向的终点
int ne[M];// ne[i]表示与第i条边起点相同的下一条边的编号
int idx;// idx表示边的编号,每增加一条边就++
// 添加一条从a到b的边,如果是无向图,每次添加时要add(a,b)和add(b,a)
void add(int a,int b)
{
e[idx] = b; // 第idx条边的终点为b
ne[idx] = h[a]; // h[a] 和 第idx都是以a为起点的边,通过ne[idx]串联起来,找到上一条以a为起点的边h[a]
h[a] = idx ++; // 更新当前以a为起点的边的最新编号
}
//初始化,-1表示节点为空
memset(h,-1,sizeof h);临接表遍历过程方法1
// x为起点,father为x的来源,防止节点遍历走回头路导致死循环
void dfs(int x,int father)
{
cout<<x<<endl;
for(int i = h[x];~i;i=ne[i]) // ~i就是i!=-1的意思
{
int to = e[i];
if(to==father) continue;
dfs(to,x);
}
}
dfs(x,-1);临接表遍历过程方法2
const int N = 100010;
bool isvisited[N];
void dfs(int x)
{
isvisited[x]=true;
cout<<x<<endl;
for(int i = h[x];~i;i=ne[i])
{
int to = e[i];
if(isvisited[to]) continue;
dfs(to);
}
}
dfs(x);树的深度
临接表模型:AcWing1498. 最深的根
int getdepth(int x,int father)
{
// cout<<"father"<<father<<" node"<<x<<endl;
int depth = 0;
for(int i = h[x];~i;i=ne[i])
{
int to = e[i];
if(to==father) continue;
depth = max(depth,getdepth(to,x)+1);
}
return depth;
}二叉树模型:剑指 Offer 55 - I. 二叉树的深度
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
int maxDepth(TreeNode* root) {
if(root==NULL) return 0;
return max(maxDepth(root->left),maxDepth(root->right))+1;
}
};多叉树模型(该题也是求叶子节点个数的经典写法):AcWing 1476. 数叶子结点
const int N = 100010;
int max_depth = 0;
int cnt[N];
void dfs(int x,int depth)
{
//说明是叶子节点
if(h[x]==-1)
{
cnt[depth]++;
max_depth = max(max_depth,depth);
return;
}
for(int i=h[x];~i;i=ne[i])
{
dfs(e[i],depth+1);
}
}
dfs(root,0)
//输出每一层的叶子个数
for(int i=0;i<=max_depth;i++) cout<<" "<<cnt[i];二叉搜索树
二叉搜索树 (BST) 递归定义为具有以下属性的二叉树:
- 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值
- 若它的右子树不空,则右子树上所有结点的值均大于或等于它的根结点的值
- 它的左、右子树也分别为二叉搜索树
二叉搜索树的中序遍历一定是有序的
完全二叉树
完全二叉树 (CBT) 定义为除最深层外的其他层的结点数都达到最大个数,最深层的所有结点都连续集中在最左边的二叉树。
构造完全二叉树的方法,可以直接开辟一个一维数组利用左右孩子与根节点的下标映射关系。如果通过中序遍历的方式以单调递增的方式来赋值则构造出了一颗完全二叉搜索树。
完全二叉树的赋值填充和构造过程(这里我们以中序遍历为例子):
例题:AcWing 1550. 完全二叉搜索树//中序遍历填充数据
int cnt; //记录已经赋值的节点下标
void dfs(int x) // 根节点为1-n
{
if(2*x <=n) dfs(2*x);
h[x] = a[cnt++];
if(2*x+1<=n) dfs(2*x+1);
}
void dfs(int u, int& k) // 中序遍历,k引用实现下标迁移
{
if (u * 2 <= n) dfs(u * 2, k);
tr[u] = w[k ++ ];
if (u * 2 + 1 <= n) dfs(u * 2 + 1, k);
}完全二叉树的节点个数规律:
- 具有n个结点的完全二叉树的深度为$\lfloor log_2{n} \rfloor+ 1$
- 完全二叉树如果为满二叉树,且深度为$k$则总节点个数为$2^{k}-1$
- 完全二叉树的第$i(i \geq 1)$层的节点数最大值为$2^{i-1}$
- 完全二叉树最后一层按从左到右的顺序进行编号,上面的层数皆为节点数的最大值,因此不会出现左子树为空,右子树存在的节点
- 根据完全二叉树的结构可知:完全二叉树度为1的节点只能为1或者0,则有当节点总数为$n$时,如果$n$为奇数,则$n_0 = (n+1)/2$,如果$n$为偶数,则$n_0 = n / 2$
关于最后一条性质的一些拓展
二叉树的重要性质:在任意一棵二叉树中,若叶子结点的个数为$n_0$,度为2的结点数为$n_2$,则$n_0=n_2+1$
证明:
假设该二叉树总共有$n$个结点$(n=n_0+n_1+n_2)$,则该二叉树总共会有$n-1$条边,度为2的结点会延伸出两条边,度为1的结点会延伸出1条边。
则有$n - 1 = n_0+n_1+n_2- 1= 2 \times n_2 + n_1$
联立两式得到:$n_0=n_2+1$
拓展到完全二叉树,因为完全二叉树度为1的节点只有0个或者1个。即$n_1 = 0 或 1$
则节点总数$n=n_0+n_1+n_2 = 2 *n_0 + n_1 - 1$
由于节点个数必须为整数,因此可以得到以下结论:
当$n$为奇数时,必须使得$n_1=0$,则$n_0=(n + 1) / 2,n_2=n_0-1=(n + 1) / 2-1$
当$n$为偶数时,必须使得$n_1=1$,则$n_0=n / 2,n_2=n_0-1=n /2 -1$
例题(递归解法):leetcode 完全二叉树的节点个数
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public int countNodes(TreeNode root) {
return root==null ? 0:countNodes(root.left)+countNodes(root.right)+1;
}
}完全二叉树
二叉平衡树
AVL树
- AVL树是一种自平衡二叉搜索树。
- 在AVL树中,任何节点的两个子树的高度最多相差 1 个。
- 如果某个时间,某节点的两个子树之间的高度差超过 1,则将通过树旋转进行重新平衡以恢复此属性。
- AVL本质上还是维护一个二叉搜索树,所以不管如果旋转,其中序遍历依旧是不变的。
旋转法则:
AVL插入分为一下几种情况:- LL型:新节点的插入位置在A的左孩子的左子树上,则右旋A
- RR型:新节点的插入位置在A的右孩子的右子树上,则左旋A
- LR型:新节点的插入位置在A的左孩子的右子树上,则左旋B,右旋A
- RL型:新节点的插入位置在A的右孩子的左子树上,则右旋B,左旋A
红黑树
数据结构中有一类平衡的二叉搜索树,称为红黑树。
它具有以下 5 个属性:- 节点是红色或黑色。
- 根节点是黑色。
- 所有叶子都是黑色。(叶子是 NULL节点)
- 每个红色节点的两个子节点都是黑色。
- 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
图论相关
并查集
经典例题:AcWing 836. 合并集合
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 100010;
int p[N];
int find(int x) // 查找x的祖先节点,并在回溯的过程当中进行路径压缩,将各节点直接指向根节点
{
if(x!=p[x]) p[x] = find(p[x]); // x和p[x]不相等,则继续向上找父节点的父节点
return p[x];
}
int main()
{
int n;
int m;
scanf("%d%d", &n, &m);
for(int i=1;i<=n;i++)
p[i]=i;
while (m -- )
{
char op[2];
int a,b;
scanf("%s%d%d", op,&a,&b);
int roota = find(a);
int rootb = find(b);
if(op[0]=='M')
{
if(roota == rootb) continue;
p[roota] = rootb; // root merge
}
else
{
cout<< (roota==rootb ? "Yes":"No")<<endl;
}
}
return 0;
}dijstra算法
- 临接矩阵形式,适用于点的数量$N < 1000$的情形,朴素算法即可解决
- 邻接表形式,当$N>10000$,需要添加堆优化
一般来说堆优化版本的考试用的不多,这里就只介绍了朴素版本。
Dijkstra求最短路 I
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 510;
const int inf = 0x3f3f3f3f;
int n,m;
int g[N][N]; // 稠密图使用邻接矩阵
int dist[N]; // 存储距离
bool vis[N]; // 标志到该节点的距离是否已经被规整为最短距离
void dijkstra(int x)
{
memset(dist, inf, sizeof dist);
dist[x] = 0;
for(int i=0;i<n;i++)//外层循环n次遍历每个节点
{
int t= -1;
for(int j=1;j<=n;j++)
{
if(!vis[j]&&(t==-1 || dist[t]>dist[j])) t =j;
}
if(t==-1) break;
vis[t]=true;
for(int j=1;j<=n;j++)
{
if(!vis[j])
{
dist[j] = min(dist[j],dist[t]+g[t][j]);
}
}
}
if(dist[n]==inf) puts("-1");
else cout<<dist[n]<<endl;
}
int main()
{
scanf("%d%d", &n, &m);
memset(g, inf, sizeof g);
for(int i=0;i<m;i++)
{
int x,y,z;
scanf("%d%d%d", &x, &y,&z);
if(x==y) g[x][y]=0; // 自环
g[x][y] = min(g[x][y],z); // 重边仅记录最小的边
}
dijkstra(1);
return 0;
}最小生成树Prime
//这里填你的代码^^
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 510, INF = 0x3f3f3f3f;
int n,m;
int g[N][N]; //稠密图使用prim和邻接矩阵
int dist[N];
bool isvisited[N];
int prime(int x)
{
memset(dist, 0x3f, sizeof dist);
int res = 0;
dist[x]=0;
for(int i=0;i<n;i++)
{
int t=-1;
for(int j=1;j<=n;j++)
if(!isvisited[j] && (t==-1 || dist[t] > dist[j]))
t= j;
if(dist[t] == INF) return -1;
//标记访问
res += dist[t];
isvisited[t]=true;
//更新dist
for(int j=1;j<=n;j++)
{
dist[j] = min(dist[j],g[t][j]);
}
}
return res;
}
int main()
{
scanf("%d%d", &n, &m);
memset(g, 0x3f, sizeof g);
while (m -- )
{
int a,b,c;
scanf("%d%d%d", &a, &b,&c);
g[a][b] = g[b][a] = min(g[a][b],c); //无向图
}
int t = prime(1);
if(t==-1)
cout<<"impossible"<<endl;
else
cout<<t<<endl;
return 0;
}最小生成树Kruskal
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 100010, INF =0x3f3f3f3f;
const int M = 2*N;
int n,m;
struct Edge
{
int x;
int y;
int w;
bool operator < (const Edge & E) const
{
return w < E.w;
}
}edge[M];
int p[N]; //并查集
int find(int x)//找祖宗节点
{
if(x!=p[x]) p[x] = find(p[x]);
return p[x];
}
int kruskal()
{
int res = 0;
int cnt=0;
sort(edge,edge+m);
for(int i=1;i<=n;i++) p[i]=i;//初始化并查集
for(int i=0;i<m;i++)
{
int x = edge[i].x, y = edge[i].y, w = edge[i].w;
int a = find(x);
int b = find(y);
//不是连通的
if(a!=b)
{
p[b] = a;
res += w;
cnt++;
}
}
//路径数量<n-1说明不连通
if (cnt<n-1) return INF;
return res;
}
int main()
{
scanf("%d%d", &n, &m);
for (int i = 0; i < m; i ++ )
{
scanf("%d%d%d", &edge[i].x, &edge[i].y, &edge[i].w);
}
int t = kruskal();
if(t == INF) cout<< "impossible"<<endl;
else cout<<t<<endl;
return 0;
}哈密顿图
- 通过图中所有顶点一次且仅一次的通路称为哈密顿通路。
- 通过图中所有顶点一次且仅一次的回路称为哈密顿回路。
- 具有哈密顿回路的图称为哈密顿图。
- 具有哈密顿通路而不具有哈密顿回路的图称为半哈密顿图
欧拉图
- 通过图中所有边恰好一次且行遍所有顶点的通路称为欧拉通路。
- 通过图中所有边恰好一次且行遍所有顶点的回路称为欧拉回路。
- 具有欧拉回路的无向图或有向图称为欧拉图。
- 具有欧拉通路但不具有欧拉回路的无向图或有向图称为半欧拉图。
- 如果一个连通图的所有顶点的度数都为偶数,那么这个连通图具有欧拉回路,且这个图被称为欧拉图。
- 如果一个连通图中有两个顶点的度数为奇数,其他顶点的度数为偶数,那么所有欧拉路径都从其中一个度数为奇数的顶点开始,并在另一个度数为奇数的顶点结束。
数学
gcd
LL gcd(LL a, LL b) // 欧几里得算法
{
return b ? gcd(b, a % b) : a;
}1的个数(数位dp)
ACWing1533.1的个数
剑指 Offer 43. 1~n 整数中 1 出现的次数给定一个数字 N,请你计算 1∼N 中一共出现了多少个数字 1。
例如,N=12 时,一共出现了 5 个数字 1,分别出现在 1,10,11,12 中。解题思路:相关视频链接
]]>class Solution {
public:
int countDigitOne(int n) {
vector<int> num;
while(n) num.push_back(n%10), n/=10;
int res = 0;
for(int i=num.size()-1;i>=0;i--)
{
int d = num[i];
int left=0,right=0,power=1;
for(int j=num.size()-1;j>i;j--) left = left * 10 + num[j];
for(int j=i-1;j>=0;j--) right = right * 10 + num[j], power*=10;
if(d==0) res += left*power;
else if(d==1) res += left*power + right + 1;
else res += (left+1) * power;
}
return res;
}
};PAT笔记 这里记录了一下常用的保研机试,剑指offer和PAT题目分类解析,主要用来快速回顾和复习相关模板,以及数据结构相关的知识点。
字符串
- 在c++中处理字符串类型的题目时,我们一般使用
string,有时候我们也使用char[]方式进行操作。 HH:MM:SS可以直接通过字符串字典序排序- 输入一个包含空格的字符串需要使用
getline(cin,s1)STL
vector<int>本省具备有字典序比较的方法,重载了< == >的运算符号vector<int>::iterator iter=find(vec.begin(),vec.end(),target); if(iter==vec.end()) cout << "Not found" << endl;
高精度
int的范围$-2 \times 10^9 - 2 \times 10^9$long long$-9 \times 10^{18} - 9 \times 10^{18}$- 用
vector按位存储进制转换
- 其他进制化成10进制,采用秦九韶算法
typedef long long LL;
LL get(char c)
{
if(c<='9') return c-'0';
else return c-'a' + 10;
}
LL getnum(string a,LL r)
{
LL res=0;
for(int i=0;i<a.size();i++)
{
res = res * r + get(a[i]);
}
return res;
}- 十进制转其他进制的方法,使用带余除法
int get(char c)
{
if(c<='9') return c-'0';
else return c-'a' + 10;
}
char tochar(int c)
{
if(c<=9) return c+'0';
else return 'a' + c - 10;
}
//一个r进制数num转10进制
int numr_to10(string num,int r)
{
int res = 0;
for(int i=0;i<num.size();i++)
{
res = res * r + get(num[i]);
}
return res;
}
//一个10进制数num转r进制
string num10_tor(string num,int r)
{
string res;
int n = numr_to10(num,10); //先转成10进制整型
while(n)
{
// cout<<tochar(n % r)<<endl;
res = tochar(n % r) + res;
n /= r;
}
return res;
}
// cout<<numr_to10("6a",16)<<" "<<num10_tor("15",16)<<endl;判断质数
//判断一个数是否为质数
bool is_prime(int n)
{
if (n < 2) return false; // 1和0不是质数
for(int i=2;i*i<=n;i++)
{
if(n % i == 0) return false;
}
return true;
}手写堆排序
堆是一个完全二叉树的结构,分为小根堆和大根堆两种结构。
- 小根堆的递归定义:小根堆的每个节点都小于他的左右孩子节点的值,树的根节点为最小值。
- 大根堆的递归定义:大根堆的每个节点都大于他的左右孩子节点的值,树的根节点为最大值。
在STL当中可以使用prioirty_queue来轻松实现大根堆和小根堆,但是只能实现前3个功能,有时候我们不得不自己实现一个手写的堆,同时这样也能让我们更理解堆排序的过程。
在AcWing基础课当中有两道经典例题,AcWing 839. 模拟堆(这个复杂一点),AcWing 838. 堆排序
这里给出堆排序的模板级代码#include <iostream>
using namespace std;
const int N = 100010;
int heap[N],heapsize=0;
void down(int x)// 参数下标
{
int p =x;
if(2*x<=heapsize && heap[2*x]<heap[p]) p = 2*x;//左子树
if(2*x+1<=heapsize && heap[2*x+1]<heap[p]) p=2*x+1;//右子树
if(p!=x)
{
swap(heap[p],heap[x]); //说明存在比父节点小的孩子节点
down(p); //继续向下递归down
}
}
void up(int x)// 参数下标
{
while(x / 2 && heap[x] < heap[x/2]) //父节点比子节点大则交换
{
swap(heap[x],heap[x/2]);
x >>= 1; // x = x/2
}
}
int main()
{
int n,m;
scanf("%d%d", &n, &m);
for (int i = 1; i <= n; i ++ ) scanf("%d", &heap[i]);
heapsize=n;
// O(n)建堆
for (int i = n / 2; i; i -- ) down(i);
while (m -- )
{
printf("%d ",heap[1]); //最小值是小根堆的堆顶
// 删除最小值,并重新建堆排序,从而获得倒数第二小的元素
heap[1] = heap[heapsize];
heapsize--;
down(1);
}
return 0;
}
STL写法:priority_queue默认是大根堆,less<int>是对第一个参数的比较类,表示数字大的优先级越大,而greater<int>表示数字小的优先级越大,可以实现结构体运算符重载。
首先要引入头文件:#include<queue>
大根堆:priority_queue<int> q;
priority_queue<int, vector<int>, less<int> >q;
小根堆:priority_queue < int, vector<int>, greater<int> > q;树
树是一种特殊的数据结构形式,在做题的过程当中,根据我的经验当题目需要使用树结构的时候主要有以下几种模式。
- 二叉树形式,在二叉树模型下,我们可以根据题目建立出静态的树形结构,构建每个节点左右孩子索引表来建立树的结构同时实现对树的遍历。如果已知或可以求得节点之间的关系,可以通过节点的度数或者访问标记找到根节点。,当然也是可以通过邻接表的方式创建二叉树。
- 多叉树形式,多叉树形式其实又类似于无向连通图的概念,常通过创建邻接表或者临接矩阵的方式建立树,并实现进行树的遍历,也是可以根据节点关系求出根节点的。注意在临接表当中,边的数量一般大于节点数量的两倍即我们需要开票邻接表的边数空间为$M = 2 \times N + d$
- 森林,多连通块的方式,这种也是利用无向图的方式,以邻接表或者临接矩阵的方式构建树的结构,同时我们可以利用并查集的方式得到当前无向图中含有的连通块数量并找到根节点。
二叉树左右孩子索引表模型
const int N = 100010;
int l[N],r[N]// 第i个节点的左孩子和右孩子的索引
bool has_father[N]; //建立树的时候判断一下当前节点有没有父节点,可用于寻找根节点
//初始化,-1表示子节点为空
memset(l,-1,sizeof l);
memset(r,-1,sizeof r);
// 查找根节点的过程
if(l[i]>=0) has_father[l[i]]=true;
if(r[i]>=0) has_father[r[i]]=true;
//查找根节点
int root = 0;
while(has_father[root]) root++;二叉树的遍历过程(以先序遍历为例子)
void dfs(int root)
{
if(root==-1) return;
cout<<root<<endl;
if(l[root]>=0) dfs(l[root]);
if(r[root]>=0) dfs(r[root]);
}临接表模型
const int N = 100010;
const int M = 2 * N + 10;
int h[N];//邻接表的N个节点头指针,h[i]表示以i为起点的,最新的一条边的编号
int e[M];// e[i] 表示第i条边的所指向的终点
int ne[M];// ne[i]表示与第i条边起点相同的下一条边的编号
int idx;// idx表示边的编号,每增加一条边就++
// 添加一条从a到b的边,如果是无向图,每次添加时要add(a,b)和add(b,a)
void add(int a,int b)
{
e[idx] = b; // 第idx条边的终点为b
ne[idx] = h[a]; // h[a] 和 第idx都是以a为起点的边,通过ne[idx]串联起来,找到上一条以a为起点的边h[a]
h[a] = idx ++; // 更新当前以a为起点的边的最新编号
}
//初始化,-1表示节点为空
memset(h,-1,sizeof h);临接表遍历过程方法1
// x为起点,father为x的来源,防止节点遍历走回头路导致死循环
void dfs(int x,int father)
{
cout<<x<<endl;
for(int i = h[x];~i;i=ne[i]) // ~i就是i!=-1的意思
{
int to = e[i];
if(to==father) continue;
dfs(to,x);
}
}
dfs(x,-1);临接表遍历过程方法2
const int N = 100010;
bool isvisited[N];
void dfs(int x)
{
isvisited[x]=true;
cout<<x<<endl;
for(int i = h[x];~i;i=ne[i])
{
int to = e[i];
if(isvisited[to]) continue;
dfs(to);
}
}
dfs(x);树的深度
临接表模型:AcWing1498. 最深的根
int getdepth(int x,int father)
{
// cout<<"father"<<father<<" node"<<x<<endl;
int depth = 0;
for(int i = h[x];~i;i=ne[i])
{
int to = e[i];
if(to==father) continue;
depth = max(depth,getdepth(to,x)+1);
}
return depth;
}
二叉树模型:剑指 Offer 55 - I. 二叉树的深度/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
int maxDepth(TreeNode* root) {
if(root==NULL) return 0;
return max(maxDepth(root->left),maxDepth(root->right))+1;
}
};
多叉树模型(该题也是求叶子节点个数的经典写法):AcWing 1476. 数叶子结点const int N = 100010;
int max_depth = 0;
int cnt[N];
void dfs(int x,int depth)
{
//说明是叶子节点
if(h[x]==-1)
{
cnt[depth]++;
max_depth = max(max_depth,depth);
return;
}
for(int i=h[x];~i;i=ne[i])
{
dfs(e[i],depth+1);
}
}
dfs(root,0)
//输出每一层的叶子个数
for(int i=0;i<=max_depth;i++) cout<<" "<<cnt[i];二叉搜索树
二叉搜索树 (BST) 递归定义为具有以下属性的二叉树:
- 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值
- 若它的右子树不空,则右子树上所有结点的值均大于或等于它的根结点的值
- 它的左、右子树也分别为二叉搜索树
二叉搜索树的中序遍历一定是有序的
完全二叉树
完全二叉树 (CBT) 定义为除最深层外的其他层的结点数都达到最大个数,最深层的所有结点都连续集中在最左边的二叉树。
构造完全二叉树的方法,可以直接开辟一个一维数组利用左右孩子与根节点的下标映射关系。如果通过中序遍历的方式以单调递增的方式来赋值则构造出了一颗完全二叉搜索树。
完全二叉树的赋值填充和构造过程(这里我们以中序遍历为例子):
例题:AcWing 1550. 完全二叉搜索树//中序遍历填充数据
int cnt; //记录已经赋值的节点下标
void dfs(int x) // 根节点为1-n
{
if(2*x <=n) dfs(2*x);
h[x] = a[cnt++];
if(2*x+1<=n) dfs(2*x+1);
}
void dfs(int u, int& k) // 中序遍历,k引用实现下标迁移
{
if (u * 2 <= n) dfs(u * 2, k);
tr[u] = w[k ++ ];
if (u * 2 + 1 <= n) dfs(u * 2 + 1, k);
}
完全二叉树的节点个数规律:- 具有n个结点的完全二叉树的深度为$\lfloor log_2{n} \rfloor+ 1$
- 完全二叉树如果为满二叉树,且深度为$k$则总节点个数为$2^{k}-1$
- 完全二叉树的第$i(i \geq 1)$层的节点数最大值为$2^{i-1}$
- 完全二叉树最后一层按从左到右的顺序进行编号,上面的层数皆为节点数的最大值,因此不会出现左子树为空,右子树存在的节点
- 根据完全二叉树的结构可知:完全二叉树度为1的节点只能为1或者0,则有当节点总数为$n$时,如果$n$为奇数,则$n_0 = (n+1)/2$,如果$n$为偶数,则$n_0 = n / 2$
关于最后一条性质的一些拓展
二叉树的重要性质:在任意一棵二叉树中,若叶子结点的个数为$n_0$,度为2的结点数为$n_2$,则$n_0=n_2+1$
证明:
假设该二叉树总共有$n$个结点$(n=n_0+n_1+n_2)$,则该二叉树总共会有$n-1$条边,度为2的结点会延伸出两条边,度为1的结点会延伸出1条边。
则有$n - 1 = n_0+n_1+n_2- 1= 2 \times n_2 + n_1$
联立两式得到:$n_0=n_2+1$
拓展到完全二叉树,因为完全二叉树度为1的节点只有0个或者1个。即$n_1 = 0 或 1$
则节点总数$n=n_0+n_1+n_2 = 2 *n_0 + n_1 - 1$
由于节点个数必须为整数,因此可以得到以下结论:
当$n$为奇数时,必须使得$n_1=0$,则$n_0=(n + 1) / 2,n_2=n_0-1=(n + 1) / 2-1$
当$n$为偶数时,必须使得$n_1=1$,则$n_0=n / 2,n_2=n_0-1=n /2 -1$
例题(递归解法):leetcode 完全二叉树的节点个数
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public int countNodes(TreeNode root) {
return root==null ? 0:countNodes(root.left)+countNodes(root.right)+1;
}
}完全二叉树
二叉平衡树
AVL树
- AVL树是一种自平衡二叉搜索树。
- 在AVL树中,任何节点的两个子树的高度最多相差 1 个。
- 如果某个时间,某节点的两个子树之间的高度差超过 1,则将通过树旋转进行重新平衡以恢复此属性。
- AVL本质上还是维护一个二叉搜索树,所以不管如果旋转,其中序遍历依旧是不变的。
旋转法则:
AVL插入分为一下几种情况:- LL型:新节点的插入位置在A的左孩子的左子树上,则右旋A
- RR型:新节点的插入位置在A的右孩子的右子树上,则左旋A
- LR型:新节点的插入位置在A的左孩子的右子树上,则左旋B,右旋A
- RL型:新节点的插入位置在A的右孩子的左子树上,则右旋B,左旋A
红黑树
数据结构中有一类平衡的二叉搜索树,称为红黑树。
它具有以下 5 个属性:- 节点是红色或黑色。
- 根节点是黑色。
- 所有叶子都是黑色。(叶子是 NULL节点)
- 每个红色节点的两个子节点都是黑色。
- 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
图论相关
并查集
经典例题:AcWing 836. 合并集合
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 100010;
int p[N];
int find(int x) // 查找x的祖先节点,并在回溯的过程当中进行路径压缩,将各节点直接指向根节点
{
if(x!=p[x]) p[x] = find(p[x]); // x和p[x]不相等,则继续向上找父节点的父节点
return p[x];
}
int main()
{
int n;
int m;
scanf("%d%d", &n, &m);
for(int i=1;i<=n;i++)
p[i]=i;
while (m -- )
{
char op[2];
int a,b;
scanf("%s%d%d", op,&a,&b);
int roota = find(a);
int rootb = find(b);
if(op[0]=='M')
{
if(roota == rootb) continue;
p[roota] = rootb; // root merge
}
else
{
cout<< (roota==rootb ? "Yes":"No")<<endl;
}
}
return 0;
}dijstra算法
- 临接矩阵形式,适用于点的数量$N < 1000$的情形,朴素算法即可解决
- 邻接表形式,当$N>10000$,需要添加堆优化
一般来说堆优化版本的考试用的不多,这里就只介绍了朴素版本。
Dijkstra求最短路 I
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 510;
const int inf = 0x3f3f3f3f;
int n,m;
int g[N][N]; // 稠密图使用邻接矩阵
int dist[N]; // 存储距离
bool vis[N]; // 标志到该节点的距离是否已经被规整为最短距离
void dijkstra(int x)
{
memset(dist, inf, sizeof dist);
dist[x] = 0;
for(int i=0;i<n;i++)//外层循环n次遍历每个节点
{
int t= -1;
for(int j=1;j<=n;j++)
{
if(!vis[j]&&(t==-1 || dist[t]>dist[j])) t =j;
}
if(t==-1) break;
vis[t]=true;
for(int j=1;j<=n;j++)
{
if(!vis[j])
{
dist[j] = min(dist[j],dist[t]+g[t][j]);
}
}
}
if(dist[n]==inf) puts("-1");
else cout<<dist[n]<<endl;
}
int main()
{
scanf("%d%d", &n, &m);
memset(g, inf, sizeof g);
for(int i=0;i<m;i++)
{
int x,y,z;
scanf("%d%d%d", &x, &y,&z);
if(x==y) g[x][y]=0; // 自环
g[x][y] = min(g[x][y],z); // 重边仅记录最小的边
}
dijkstra(1);
return 0;
}最小生成树Prime
AcWing 858.Prime算法求最小生成树
//这里填你的代码^^
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 510, INF = 0x3f3f3f3f;
int n,m;
int g[N][N]; //稠密图使用prim和邻接矩阵
int dist[N];
bool isvisited[N];
int prime(int x)
{
memset(dist, 0x3f, sizeof dist);
int res = 0;
dist[x]=0;
for(int i=0;i<n;i++)
{
int t=-1;
for(int j=1;j<=n;j++)
if(!isvisited[j] && (t==-1 || dist[t] > dist[j]))
t= j;
if(dist[t] == INF) return -1;
//标记访问
res += dist[t];
isvisited[t]=true;
//更新dist
for(int j=1;j<=n;j++)
{
dist[j] = min(dist[j],g[t][j]);
}
}
return res;
}
int main()
{
scanf("%d%d", &n, &m);
memset(g, 0x3f, sizeof g);
while (m -- )
{
int a,b,c;
scanf("%d%d%d", &a, &b,&c);
g[a][b] = g[b][a] = min(g[a][b],c); //无向图
}
int t = prime(1);
if(t==-1)
cout<<"impossible"<<endl;
else
cout<<t<<endl;
return 0;
}最小生成树Kruskal
AcWing859.Kruskal算法求最小生成树
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 100010, INF =0x3f3f3f3f;
const int M = 2*N;
int n,m;
struct Edge
{
int x;
int y;
int w;
bool operator < (const Edge & E) const
{
return w < E.w;
}
}edge[M];
int p[N]; //并查集
int find(int x)//找祖宗节点
{
if(x!=p[x]) p[x] = find(p[x]);
return p[x];
}
int kruskal()
{
int res = 0;
int cnt=0;
sort(edge,edge+m);
for(int i=1;i<=n;i++) p[i]=i;//初始化并查集
for(int i=0;i<m;i++)
{
int x = edge[i].x, y = edge[i].y, w = edge[i].w;
int a = find(x);
int b = find(y);
//不是连通的
if(a!=b)
{
p[b] = a;
res += w;
cnt++;
}
}
//路径数量<n-1说明不连通
if (cnt<n-1) return INF;
return res;
}
int main()
{
scanf("%d%d", &n, &m);
for (int i = 0; i < m; i ++ )
{
scanf("%d%d%d", &edge[i].x, &edge[i].y, &edge[i].w);
}
int t = kruskal();
if(t == INF) cout<< "impossible"<<endl;
else cout<<t<<endl;
return 0;
}哈密顿图
- 通过图中所有顶点一次且仅一次的通路称为哈密顿通路。
- 通过图中所有顶点一次且仅一次的回路称为哈密顿回路。
- 具有哈密顿回路的图称为哈密顿图。
- 具有哈密顿通路而不具有哈密顿回路的图称为半哈密顿图
欧拉图
- 通过图中所有边恰好一次且行遍所有顶点的通路称为欧拉通路。
- 通过图中所有边恰好一次且行遍所有顶点的回路称为欧拉回路。
- 具有欧拉回路的无向图或有向图称为欧拉图。
- 具有欧拉通路但不具有欧拉回路的无向图或有向图称为半欧拉图。
- 如果一个连通图的所有顶点的度数都为偶数,那么这个连通图具有欧拉回路,且这个图被称为欧拉图。
- 如果一个连通图中有两个顶点的度数为奇数,其他顶点的度数为偶数,那么所有欧拉路径都从其中一个度数为奇数的顶点开始,并在另一个度数为奇数的顶点结束。
数学
gcd
LL gcd(LL a, LL b) // 欧几里得算法
{
return b ? gcd(b, a % b) : a;
}1的个数(数位dp)
ACWing1533.1的个数
剑指 Offer 43. 1~n 整数中 1 出现的次数给定一个数字 N,请你计算 1∼N 中一共出现了多少个数字 1。
例如,N=12 时,一共出现了 5 个数字 1,分别出现在 1,10,11,12 中。解题思路:相关视频链接
]]>class Solution {
public:
int countDigitOne(int n) {
vector<int> num;
while(n) num.push_back(n%10), n/=10;
int res = 0;
for(int i=num.size()-1;i>=0;i--)
{
int d = num[i];
int left=0,right=0,power=1;
for(int j=num.size()-1;j>i;j--) left = left * 10 + num[j];
for(int j=i-1;j>=0;j--) right = right * 10 + num[j], power*=10;
if(d==0) res += left*power;
else if(d==1) res += left*power + right + 1;
else res += (left+1) * power;
}
return res;
}
};@@ -171,11 +171,11 @@ 2021-06-17T16:11:00.000Z 2024-10-09T07:33:09.915Z -XGBoost算法 +XGBoost是陈天奇等人开发的一个开源机器学习项目,高效地实现了GBDT算法并进行了算法和工程上的许多改进,被广泛应用在Kaggle竞赛及其他许多机器学习竞赛中并取得了不错的成绩。XGBoost本质上还是一个GBDT,但是力争把速度和效率发挥到极致,所以叫X (Extreme) GBoosted, 包括前面说过,两者都是boosting方法。XGBoost是一个优化的分布式梯度增强库,旨在实现高效,灵活和便携。 它在Gradient Boosting框架下实现机器学习算法。 XGBoost提供了并行树提升(也称为GBDT,GBM),可以快速准确地解决许多数据科学问题。 相同的代码在主要的分布式环境(Hadoop,SGE,MPI)上运行,并且可以解决超过数十亿个样例的问题。XGBoost利用了核外计算并且能够使数据科学家在一个主机上处理数亿的样本数据。最终,将这些技术进行结合来做一个端到端的系统以最少的集群系统来扩展到更大的数据集上。Xgboost以CART决策树为子模型,通过Gradient Tree Boosting实现多棵CART树的集成学习,得到最终模型。下面我们来看看XGBoost的最终模型构建:
引用陈天奇的论文,我们的数据为:$\mathcal{D}=\left{\left(\mathbf{x}{i}, y{i}\right)\right}\left(|\mathcal{D}|=n, \mathbf{x}{i} \in \mathbb{R}^{m}, y{i} \in \mathbb{R}\right)$
(1) 构造目标函数:
假设有K棵树,则第i个样本的输出为$\hat{y}{i}=\phi\left(\mathrm{x}{i}\right)=\sum_{k=1}^{K} f_{k}\left(\mathrm{x}{i}\right), \quad f{k} \in \mathcal{F}$,其中,$\mathcal{F}=\left{f(\mathbf{x})=w_{q(\mathbf{x})}\right}\left(q: \mathbb{R}^{m} \rightarrow T, w \in \mathbb{R}^{T}\right)$
因此,目标函数的构建为:
$$
\mathcal{L}(\phi)=\sum_{i} l\left(\hat{y}{i}, y{i}\right)+\sum_{k} \Omega\left(f_{k}\right)
$$
其中,$\sum_{i} l\left(\hat{y}{i}, y{i}\right)$为loss function,$\sum_{k} \Omega\left(f_{k}\right)$为正则化项。
(2) 叠加式的训练(Additive Training):
给定样本$x_i$,$\hat{y}i^{(0)} = 0$(初始预测),$\hat{y}_i^{(1)} = \hat{y}_i^{(0)} + f_1(x_i)$,$\hat{y}_i^{(2)} = \hat{y}_i^{(0)} + f_1(x_i) + f_2(x_i) = \hat{y}_i^{(1)} + f_2(x_i)$…….以此类推,可以得到:$ \hat{y}_i^{(K)} = \hat{y}_i^{(K-1)} + f_K(x_i)$ ,其中,$ \hat{y}_i^{(K-1)} $ 为前K-1棵树的预测结果,$ f_K(x_i)$ 为第K棵树的预测结果。
因此,目标函数可以分解为:
$$
\mathcal{L}^{(K)}=\sum{i=1}^{n} l\left(y_{i}, \hat{y}{i}^{(K-1)}+f{K}\left(\mathrm{x}{i}\right)\right)+\sum{k} \Omega\left(f_{k}\right)
$$
由于正则化项也可以分解为前K-1棵树的复杂度加第K棵树的复杂度,因此:$\mathcal{L}^{(K)}=\sum_{i=1}^{n} l\left(y_{i}, \hat{y}{i}^{(K-1)}+f{K}\left(\mathrm{x}{i}\right)\right)+\sum{k=1} ^{K-1}\Omega\left(f_{k}\right)+\Omega\left(f_{K}\right)$,由于$\sum_{k=1} ^{K-1}\Omega\left(f_{k}\right)$在模型构建到第K棵树的时候已经固定,无法改变,因此是一个已知的常数,可以在最优化的时候省去,故:
$$
\mathcal{L}^{(K)}=\sum_{i=1}^{n} l\left(y_{i}, \hat{y}{i}^{(K-1)}+f{K}\left(\mathrm{x}{i}\right)\right)+\Omega\left(f{K}\right)
$$
(3) 使用泰勒级数近似目标函数:
$$
\mathcal{L}^{(K)} \simeq \sum_{i=1}^{n}\left[l\left(y_{i}, \hat{y}^{(K-1)}\right)+g_{i} f_{K}\left(\mathrm{x}{i}\right)+\frac{1}{2} h{i} f_{K}^{2}\left(\mathrm{x}{i}\right)\right]+\Omega\left(f{K}\right)
$$
其中,$g_{i}=\partial_{\hat{y}(t-1)} l\left(y_{i}, \hat{y}^{(t-1)}\right)$和$h_{i}=\partial_{\hat{y}^{(t-1)}}^{2} l\left(y_{i}, \hat{y}^{(t-1)}\right)$
在这里,我们补充下泰勒级数的相关知识:
在数学中,泰勒级数(英语:Taylor series)用无限项连加式——级数来表示一个函数,这些相加的项由函数在某一点的导数求得。具体的形式如下:
$$
f(x)=\frac{f\left(x_{0}\right)}{0 !}+\frac{f^{\prime}\left(x_{0}\right)}{1 !}\left(x-x_{0}\right)+\frac{f^{\prime \prime}\left(x_{0}\right)}{2 !}\left(x-x_{0}\right)^{2}+\ldots+\frac{f^{(n)}\left(x_{0}\right)}{n !}\left(x-x_{0}\right)^{n}+……
$$
由于$\sum_{i=1}^{n}l\left(y_{i}, \hat{y}^{(K-1)}\right)$在模型构建到第K棵树的时候已经固定,无法改变,因此是一个已知的常数,可以在最优化的时候省去,故:
$$
\tilde{\mathcal{L}}^{(K)}=\sum_{i=1}^{n}\left[g_{i} f_{K}\left(\mathbf{x}{i}\right)+\frac{1}{2} h{i} f_{K}^{2}\left(\mathbf{x}{i}\right)\right]+\Omega\left(f{K}\right)
$$
(4) 如何定义一棵树:
为了说明如何定义一棵树的问题,我们需要定义几个概念:第一个概念是样本所在的节点位置$q(x)$,第二个概念是有哪些样本落在节点j上$I_{j}=\left{i \mid q\left(\mathbf{x}{i}\right)=j\right}$,第三个概念是每个结点的预测值$w{q(x)}$,第四个概念是模型复杂度$\Omega\left(f_{K}\right)$,它可以由叶子节点的个数以及节点函数值来构建,则:$\Omega\left(f_{K}\right) = \gamma T+\frac{1}{2} \lambda \sum_{j=1}^{T} w_{j}^{2}$。如下图的例子:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-t1tei3pE-1623946035306)(./16.png)]
$q(x_1) = 1,q(x_2) = 3,q(x_3) = 1,q(x_4) = 2,q(x_5) = 3$,$I_1 = {1,3},I_2 = {4},I_3 = {2,5}$,$w = (15,12,20)$
因此,目标函数用以上符号替代后:
$$
\begin{aligned}
\tilde{\mathcal{L}}^{(K)} &=\sum_{i=1}^{n}\left[g_{i} f_{K}\left(\mathrm{x}{i}\right)+\frac{1}{2} h{i} f_{K}^{2}\left(\mathrm{x}{i}\right)\right]+\gamma T+\frac{1}{2} \lambda \sum{j=1}^{T} w_{j}^{2} \
&=\sum_{j=1}^{T}\left[\left(\sum_{i \in I_{j}} g_{i}\right) w_{j}+\frac{1}{2}\left(\sum_{i \in I_{j}} h_{i}+\lambda\right) w_{j}^{2}\right]+\gamma T
\end{aligned}
$$
由于我们的目标就是最小化目标函数,现在的目标函数化简为一个关于w的二次函数:$\tilde{\mathcal{L}}^{(K)}=\sum_{j=1}^{T}\left[\left(\sum_{i \in I_{j}} g_{i}\right) w_{j}+\frac{1}{2}\left(\sum_{i \in I_{j}} h_{i}+\lambda\right) w_{j}^{2}\right]+\gamma T$,根据二次函数求极值的公式:$y=ax^2 bx c$求极值,对称轴在$x=-\frac{b}{2 a}$,极值为$y=\frac{4 a c-b^{2}}{4 a}$,因此:
$$
w_{j}^{*}=-\frac{\sum_{i \in I_{j}} g_{i}}{\sum_{i \in I_{j}} h_{i}+\lambda}
$$
以及
$$
\tilde{\mathcal{L}}^{(K)}(q)=-\frac{1}{2} \sum_{j=1}^{T} \frac{\left(\sum_{i \in I_{j}} g_{i}\right)^{2}}{\sum_{i \in I_{j}} h_{i}+\lambda}+\gamma T
$$
(5) 如何寻找树的形状:
不难发现,刚刚的讨论都是基于树的形状已经确定了计算$w$和$L$,但是实际上我们需要像学习决策树一样找到树的形状。因此,我们借助决策树学习的方式,使用目标函数的变化来作为分裂节点的标准。我们使用一个例子来说明:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nCrhWA4S-1623946035310)(./17.png)]
例子中有8个样本,分裂方式如下,因此:
$$
\tilde{\mathcal{L}}^{(old)} = -\frac{1}{2}[\frac{(g_7 + g_8)^2}{H_7+H_8 + \lambda} + \frac{(g_1 +…+ g_6)^2}{H_1+…+H_6 + \lambda}] + 2\gamma \
\tilde{\mathcal{L}}^{(new)} = -\frac{1}{2}[\frac{(g_7 + g_8)^2}{H_7+H_8 + \lambda} + \frac{(g_1 +…+ g_3)^2}{H_1+…+H_3 + \lambda} + \frac{(g_4 +…+ g_6)^2}{H_4+…+H_6 + \lambda}] + 3\gamma\
\tilde{\mathcal{L}}^{(old)} - \tilde{\mathcal{L}}^{(new)} = \frac{1}{2}[ \frac{(g_1 +…+ g_3)^2}{H_1+…+H_3 + \lambda} + \frac{(g_4 +…+ g_6)^2}{H_4+…+H_6 + \lambda} - \frac{(g_1+…+g_6)^2}{h_1+…+h_6+\lambda}] - \gamma
$$
因此,从上面的例子看出:分割节点的标准为$max{\tilde{\mathcal{L}}^{(old)} - \tilde{\mathcal{L}}^{(new)} }$,即:
$$
\mathcal{L}{\text {split }}=\frac{1}{2}\left[\frac{\left(\sum{i \in I_{L}} g_{i}\right)^{2}}{\sum_{i \in I_{L}} h_{i}+\lambda}+\frac{\left(\sum_{i \in I_{R}} g_{i}\right)^{2}}{\sum_{i \in I_{R}} h_{i}+\lambda}-\frac{\left(\sum_{i \in I} g_{i}\right)^{2}}{\sum_{i \in I} h_{i}+\lambda}\right]-\gamma
$$
(6.1) 精确贪心分裂算法:
XGBoost在生成新树的过程中,最基本的操作是节点分裂。节点分裂中最重 要的环节是找到最优特征及最优切分点, 然后将叶子节点按照最优特征和最优切 分点进行分裂。选取最优特征和最优切分点的一种思路如下:首先找到所有的候 选特征及所有的候选切分点, 一一求得其 $\mathcal{L}{\text {split }}$, 然后选择$\mathcal{L}{\mathrm{split}}$ 最大的特征及 对应切分点作为最优特征和最优切分点。我们称此种方法为精确贪心算法。该算法是一种启发式算法, 因为在节点分裂时只选择当前最优的分裂策略, 而非全局最优的分裂策略。精确贪心算法的计算过程如下所示:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HRrbM0fp-1623946035312)(./18.png)]
(6.2) 基于直方图的近似算法:
精确贪心算法在选择最优特征和最优切分点时是一种十分有效的方法。它计算了所有特征、所有切分点的收益, 并从中选择了最优的, 从而保证模型能比较好地拟合了训练数据。但是当数据不能完全加载到内存时,精确贪心算法会变得 非常低效,算法在计算过程中需要不断在内存与磁盘之间进行数据交换,这是个非常耗时的过程, 并且在分布式环境中面临同样的问题。为了能够更高效地选 择最优特征及切分点, XGBoost提出一种近似算法来解决该问题。 基于直方图的近似算法的主要思想是:对某一特征寻找最优切分点时,首先对该特征的所有切分点按分位数 (如百分位) 分桶, 得到一个候选切分点集。特征的每一个切分点都可以分到对应的分桶; 然后,对每个桶计算特征统计G和H得到直方图, G为该桶内所有样本一阶特征统计g之和, H为该桶内所有样本二阶特征统计h之和; 最后,选择所有候选特征及候选切分点中对应桶的特征统计收益最大的作为最优特征及最优切分点。基于直方图的近似算法的计算过程如下所示:- 对于每个特征 $k=1,2, \cdots, m,$ 按分位数对特征 $k$ 分桶 $\Theta,$ 可得候选切分点, $S_{k}=\left{S_{k 1}, S_{k 2}, \cdots, S_{k l}\right}^{1}$
- 对于每个特征 $k=1,2, \cdots, m,$ 有:
$$
\begin{array}{l}
G_{k v} \leftarrow=\sum_{j \in\left{j \mid s_{k, v} \geq \mathbf{x}{j k}>s{k, v-1;}\right}} g_{j} \
H_{k v} \leftarrow=\sum_{j \in\left{j \mid s_{k, v} \geq \mathbf{x}{j k}>s{k, v-1;}\right}} h_{j}
\end{array}
$$ - 类似精确贪心算法,依据梯度统计找到最大增益的候选切分点。
下面用一个例子说明基于直方图的近似算法:
假设有一个年龄特征,其特征的取值为18、19、21、31、36、37、55、57,我们需要使用近似算法找到年龄这个特征的最佳分裂点:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MKLD2poX-1623946035314)(./19.png)]
近似算法实现了两种候选切分点的构建策略:全局策略和本地策略。全局策略是在树构建的初始阶段对每一个特征确定一个候选切分点的集合, 并在该树每一层的节点分裂中均采用此集合计算收益, 整个过程候选切分点集合不改变。本地策略则是在每一次节点分裂时均重新确定候选切分点。全局策略需要更细的分桶才能达到本地策略的精确度, 但全局策略在选取候选切分点集合时比本地策略更简单。在XGBoost系统中, 用户可以根据需求自由选择使用精确贪心算法、近似算法全局策略、近似算法本地策略, 算法均可通过参数进行配置。
以上是XGBoost的理论部分,下面我们对XGBoost系统进行详细的讲解:
官方文档:https://xgboost.readthedocs.io/en/latest/python/python_intro.html
知乎总结:https://zhuanlan.zhihu.com/p/143009353# XGBoost原生工具库的上手:
import xgboost as xgb # 引入工具库
# read in data
dtrain = xgb.DMatrix('demo/data/agaricus.txt.train') # XGBoost的专属数据格式,但是也可以用dataframe或者ndarray
dtest = xgb.DMatrix('demo/data/agaricus.txt.test') # # XGBoost的专属数据格式,但是也可以用dataframe或者ndarray
# specify parameters via map
param = {'max_depth':2, 'eta':1, 'objective':'binary:logistic' } # 设置XGB的参数,使用字典形式传入
num_round = 2 # 使用线程数
bst = xgb.train(param, dtrain, num_round) # 训练
# make prediction
preds = bst.predict(dtest) # 预测XGBoost的参数设置(括号内的名称为sklearn接口对应的参数名字):
推荐博客:https://link.zhihu.com/?target=https%3A//blog.csdn.net/luanpeng825485697/article/details/79907149
推荐官方文档:https://link.zhihu.com/?target=https%3A//xgboost.readthedocs.io/en/latest/parameter.htmlXGBoost的参数分为三种:
通用参数:(两种类型的booster,因为tree的性能比线性回归好得多,因此我们很少用线性回归。)
- booster:使用哪个弱学习器训练,默认gbtree,可选gbtree,gblinear 或dart
- nthread:用于运行XGBoost的并行线程数,默认为最大可用线程数
- verbosity:打印消息的详细程度。有效值为0(静默),1(警告),2(信息),3(调试)。
- Tree Booster的参数:
- eta(learning_rate):learning_rate,在更新中使用步长收缩以防止过度拟合,默认= 0.3,范围:[0,1];典型值一般设置为:0.01-0.2
- gamma(min_split_loss):默认= 0,分裂节点时,损失函数减小值只有大于等于gamma节点才分裂,gamma值越大,算法越保守,越不容易过拟合,但性能就不一定能保证,需要平衡。范围:[0,∞]
- max_depth:默认= 6,一棵树的最大深度。增加此值将使模型更复杂,并且更可能过度拟合。范围:[0,∞]
- min_child_weight:默认值= 1,如果新分裂的节点的样本权重和小于min_child_weight则停止分裂 。这个可以用来减少过拟合,但是也不能太高,会导致欠拟合。范围:[0,∞]
- max_delta_step:默认= 0,允许每个叶子输出的最大增量步长。如果将该值设置为0,则表示没有约束。如果将其设置为正值,则可以帮助使更新步骤更加保守。通常不需要此参数,但是当类极度不平衡时,它可能有助于逻辑回归。将其设置为1-10的值可能有助于控制更新。范围:[0,∞]
- subsample:默认值= 1,构建每棵树对样本的采样率,如果设置成0.5,XGBoost会随机选择一半的样本作为训练集。范围:(0,1]
- sampling_method:默认= uniform,用于对训练实例进行采样的方法。
- uniform:每个训练实例的选择概率均等。通常将subsample> = 0.5 设置 为良好的效果。
- gradient_based:每个训练实例的选择概率与规则化的梯度绝对值成正比,具体来说就是$\sqrt{g^2+\lambda h^2}$,subsample可以设置为低至0.1,而不会损失模型精度。
- colsample_bytree:默认= 1,列采样率,也就是特征采样率。范围为(0,1]
- lambda(reg_lambda):默认=1,L2正则化权重项。增加此值将使模型更加保守。
- alpha(reg_alpha):默认= 0,权重的L1正则化项。增加此值将使模型更加保守。
- tree_method:默认=auto,XGBoost中使用的树构建算法。
- auto:使用启发式选择最快的方法。
- 对于小型数据集,exact将使用精确贪婪()。
- 对于较大的数据集,approx将选择近似算法()。它建议尝试hist,gpu_hist,用大量的数据可能更高的性能。(gpu_hist)支持。external memory外部存储器。
- exact:精确的贪婪算法。枚举所有拆分的候选点。
- approx:使用分位数和梯度直方图的近似贪婪算法。
- hist:更快的直方图优化的近似贪婪算法。(LightGBM也是使用直方图算法)
- gpu_hist:GPU hist算法的实现。
- auto:使用启发式选择最快的方法。
- scale_pos_weight:控制正负权重的平衡,这对于不平衡的类别很有用。Kaggle竞赛一般设置sum(negative instances) / sum(positive instances),在类别高度不平衡的情况下,将参数设置大于0,可以加快收敛。
- num_parallel_tree:默认=1,每次迭代期间构造的并行树的数量。此选项用于支持增强型随机森林。
- monotone_constraints:可变单调性的约束,在某些情况下,如果有非常强烈的先验信念认为真实的关系具有一定的质量,则可以使用约束条件来提高模型的预测性能。(例如params_constrained[‘monotone_constraints’] = “(1,-1)”,(1,-1)我们告诉XGBoost对第一个预测变量施加增加的约束,对第二个预测变量施加减小的约束。)
- Linear Booster的参数:
- lambda(reg_lambda):默认= 0,L2正则化权重项。增加此值将使模型更加保守。归一化为训练示例数。
- alpha(reg_alpha):默认= 0,权重的L1正则化项。增加此值将使模型更加保守。归一化为训练示例数。
- updater:默认= shotgun。
- shotgun:基于shotgun算法的平行坐标下降算法。使用“ hogwild”并行性,因此每次运行都产生不确定的解决方案。
- coord_descent:普通坐标下降算法。同样是多线程的,但仍会产生确定性的解决方案。
- feature_selector:默认= cyclic。特征选择和排序方法
- cyclic:通过每次循环一个特征来实现的。
- shuffle:类似于cyclic,但是在每次更新之前都有随机的特征变换。
- random:一个随机(有放回)特征选择器。
- greedy:选择梯度最大的特征。(贪婪选择)
- thrifty:近似贪婪特征选择(近似于greedy)
- top_k:要选择的最重要特征数(在greedy和thrifty内)
任务参数(这个参数用来控制理想的优化目标和每一步结果的度量方法。)
- objective:默认=reg:squarederror,表示最小平方误差。
- reg:squarederror,最小平方误差。
- reg:squaredlogerror,对数平方损失。$\frac{1}{2}[log(pred+1)-log(label+1)]^2$
- reg:logistic,逻辑回归
- reg:pseudohubererror,使用伪Huber损失进行回归,这是绝对损失的两倍可微选择。
- binary:logistic,二元分类的逻辑回归,输出概率。
- binary:logitraw:用于二进制分类的逻辑回归,逻辑转换之前的输出得分。
- binary:hinge:二进制分类的铰链损失。这使预测为0或1,而不是产生概率。(SVM就是铰链损失函数)
- count:poisson –计数数据的泊松回归,泊松分布的输出平均值。
- survival:cox:针对正确的生存时间数据进行Cox回归(负值被视为正确的生存时间)。
- survival:aft:用于检查生存时间数据的加速故障时间模型。
- aft_loss_distribution:survival:aft和aft-nloglik度量标准使用的概率密度函数。
- multi:softmax:设置XGBoost以使用softmax目标进行多类分类,还需要设置num_class(类数)
- multi:softprob:与softmax相同,但输出向量,可以进一步重整为矩阵。结果包含属于每个类别的每个数据点的预测概率。
- rank:pairwise:使用LambdaMART进行成对排名,从而使成对损失最小化。
- rank:ndcg:使用LambdaMART进行列表式排名,使标准化折让累积收益(NDCG)最大化。
- rank:map:使用LambdaMART进行列表平均排名,使平均平均精度(MAP)最大化。
- reg:gamma:使用对数链接进行伽马回归。输出是伽马分布的平均值。
- reg:tweedie:使用对数链接进行Tweedie回归。
- 自定义损失函数和评价指标:https://xgboost.readthedocs.io/en/latest/tutorials/custom_metric_obj.html
- eval_metric:验证数据的评估指标,将根据目标分配默认指标(回归均方根,分类误差,排名的平均平均精度),用户可以添加多个评估指标
- rmse,均方根误差; rmsle:均方根对数误差; mae:平均绝对误差;mphe:平均伪Huber错误;logloss:负对数似然; error:二进制分类错误率;
- merror:多类分类错误率; mlogloss:多类logloss; auc:曲线下面积; aucpr:PR曲线下的面积;ndcg:归一化累计折扣;map:平均精度;
- seed :随机数种子,[默认= 0]。
- objective:默认=reg:squarederror,表示最小平方误差。
命令行参数(这里不说了,因为很少用命令行控制台版本)
from IPython.display import IFrame
IFrame('https://xgboost.readthedocs.io/en/latest/parameter.html', width=1400, height=800)XGBoost的调参说明:
参数调优的一般步骤
- 确定学习速率和提升参数调优的初始值
- max_depth 和 min_child_weight 参数调优
- gamma参数调优
- subsample 和 colsample_bytree 参数优
- 正则化参数alpha调优
- 降低学习速率和使用更多的决策树
XGBoost详细攻略:
具体的api请查看:https://xgboost.readthedocs.io/en/latest/python/python_api.html
推荐github:https://github.com/dmlc/xgboost/tree/master/demo/guide-python安装XGBoost:
方式1:pip3 install xgboost
方式2:pip install xgboost数据接口(XGBoost可处理的数据格式DMatrix)
# 1.LibSVM文本格式文件
dtrain = xgb.DMatrix('train.svm.txt')
dtest = xgb.DMatrix('test.svm.buffer')
# 2.CSV文件(不能含类别文本变量,如果存在文本变量请做特征处理如one-hot)
dtrain = xgb.DMatrix('train.csv?format=csv&label_column=0')
dtest = xgb.DMatrix('test.csv?format=csv&label_column=0')
# 3.NumPy数组
data = np.random.rand(5, 10) # 5 entities, each contains 10 features
label = np.random.randint(2, size=5) # binary target
dtrain = xgb.DMatrix(data, label=label)
# 4.scipy.sparse数组
csr = scipy.sparse.csr_matrix((dat, (row, col)))
dtrain = xgb.DMatrix(csr)
# pandas数据框dataframe
data = pandas.DataFrame(np.arange(12).reshape((4,3)), columns=['a', 'b', 'c'])
label = pandas.DataFrame(np.random.randint(2, size=4))
dtrain = xgb.DMatrix(data, label=label)笔者推荐:先保存到XGBoost二进制文件中将使加载速度更快,然后再加载进来
# 1.保存DMatrix到XGBoost二进制文件中
dtrain = xgb.DMatrix('train.svm.txt')
dtrain.save_binary('train.buffer')
# 2. 缺少的值可以用DMatrix构造函数中的默认值替换:
dtrain = xgb.DMatrix(data, label=label, missing=-999.0)
# 3.可以在需要时设置权重:
w = np.random.rand(5, 1)
dtrain = xgb.DMatrix(data, label=label, missing=-999.0, weight=w)参数的设置方式:
import pandas as pd
# 加载并处理数据
df_wine = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data',header=None)
df_wine.columns = ['Class label', 'Alcohol','Malic acid', 'Ash','Alcalinity of ash','Magnesium', 'Total phenols',
'Flavanoids', 'Nonflavanoid phenols','Proanthocyanins','Color intensity', 'Hue','OD280/OD315 of diluted wines','Proline']
df_wine = df_wine[df_wine['Class label'] != 1] # drop 1 class
y = df_wine['Class label'].values
X = df_wine[['Alcohol','OD280/OD315 of diluted wines']].values
from sklearn.model_selection import train_test_split # 切分训练集与测试集
from sklearn.preprocessing import LabelEncoder # 标签化分类变量
le = LabelEncoder()
y = le.fit_transform(y)
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=1,stratify=y)
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test)
# 1.Booster 参数
params = {
'booster': 'gbtree',
'objective': 'multi:softmax', # 多分类的问题
'num_class': 10, # 类别数,与 multisoftmax 并用
'gamma': 0.1, # 用于控制是否后剪枝的参数,越大越保守,一般0.1、0.2这样子。
'max_depth': 12, # 构建树的深度,越大越容易过拟合
'lambda': 2, # 控制模型复杂度的权重值的L2正则化项参数,参数越大,模型越不容易过拟合。
'subsample': 0.7, # 随机采样训练样本
'colsample_bytree': 0.7, # 生成树时进行的列采样
'min_child_weight': 3,
'silent': 1, # 设置成1则没有运行信息输出,最好是设置为0.
'eta': 0.007, # 如同学习率
'seed': 1000,
'nthread': 4, # cpu 线程数
'eval_metric':'auc'
}
plst = list(params.items())
# evallist = [(dtest, 'eval'), (dtrain, 'train')] # 指定验证集训练:
# 2.训练
num_round = 10
bst = xgb.train(plst, dtrain, num_round)
#bst = xgb.train( plst, dtrain, num_round, evallist )保存模型:
# 3.保存模型
bst.save_model('0001.model')
# dump model
bst.dump_model('dump.raw.txt')
# dump model with feature map
#bst.dump_model('dump.raw.txt', 'featmap.txt')加载保存的模型:
# 4.加载保存的模型:
bst = xgb.Booster({'nthread': 4}) # init model
bst.load_model('0001.model') # load data设置早停机制:
# 5.也可以设置早停机制(需要设置验证集)
train(..., evals=evals, early_stopping_rounds=10)预测:
# 6.预测
ypred = bst.predict(dtest)绘制重要性特征图:
# 1.绘制重要性
xgb.plot_importance(bst)
# 2.绘制输出树
#xgb.plot_tree(bst, num_trees=2)
# 3.使用xgboost.to_graphviz()将目标树转换为graphviz
#xgb.to_graphviz(bst, num_trees=2)7. Xgboost算法案例
分类案例
from sklearn.datasets import load_iris
import xgboost as xgb
from xgboost import plot_importance
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score # 准确率
# 加载样本数据集
iris = load_iris()
X,y = iris.data,iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1234565) # 数据集分割
params = {
'booster' : 'gbtree',
'objective': 'multi:softmax', # 多分类的问题
'num_class': 3,
'gamma': 0.1, # 默认= 0,分裂节点时,损失函数减小值只有大于等于gamma节点才分裂,gamma值越大,算法越保守,越不容易过拟合,但性能就不一定能保证,需要平衡。
'max_depth': 12, # 树的最大深度
'lambda': 2, # 控制模型复杂度的权重值的L2正则化项参数,参数越大,模型越不容易过拟合。
'subsample': 0.7, # 随机采样训练样本
'colsample_bytree': 0.7, # 生成树时进行的列采样,列采样率,也就是特征采样率
'min_child_weight': 3,
'silent': 0,
'eta': 0.1,
'seed': 1,
'nthread': 4,
}
plst = list(params.items())
dtrain = xgb.DMatrix(X_train,y_train)
num_rounds = 500
model = xgb.train(plst,dtrain,num_rounds) # xgboost模型训练
# 对测试集进行预测
dtest = xgb.DMatrix(X_test)
y_pred = model.predict(dtest)
# 计算准确率
accuracy = accuracy_score(y_test,y_pred)
print("accuarcy: %.2f%%" % (accuracy*100.0))
# 显示重要特征
plot_importance(model)
plt.show()回归案例
import xgboost as xgb
from xgboost import plot_importance
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_boston
from sklearn.metrics import mean_squared_error
# 加载数据集
boston = load_boston()
X,y = boston.data,boston.target
# XGBoost训练过程
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
params = {
'booster': 'gbtree',
'objective': 'reg:squarederror',
'gamma': 0.1,
'max_depth': 5,
'lambda': 3,
'subsample': 0.7,
'colsample_bytree': 0.7,
'min_child_weight': 3,
'silent': 1,
'eta': 0.1,
'seed': 1000,
'nthread': 4,
}
dtrain = xgb.DMatrix(X_train, y_train)
num_rounds = 300
plst = list(params.items())
model = xgb.train(plst, dtrain, num_rounds)
# 对测试集进行预测
dtest = xgb.DMatrix(X_test)
ans = model.predict(dtest)
# 显示重要特征
plot_importance(model)
plt.show()XGBoost调参(结合sklearn网格搜索)
代码参考:https://www.jianshu.com/p/1100e333fcab
import xgboost as xgb
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import roc_auc_score
iris = load_iris()
X,y = iris.data,iris.target
col = iris.target_names
train_x, valid_x, train_y, valid_y = train_test_split(X, y, test_size=0.3, random_state=1) # 分训练集和验证集
parameters = {
'max_depth': [5, 10, 15, 20, 25],
'learning_rate': [0.01, 0.02, 0.05, 0.1, 0.15],
'n_estimators': [500, 1000, 2000, 3000, 5000],
'min_child_weight': [0, 2, 5, 10, 20],
'max_delta_step': [0, 0.2, 0.6, 1, 2],
'subsample': [0.6, 0.7, 0.8, 0.85, 0.95],
'colsample_bytree': [0.5, 0.6, 0.7, 0.8, 0.9],
'reg_alpha': [0, 0.25, 0.5, 0.75, 1],
'reg_lambda': [0.2, 0.4, 0.6, 0.8, 1],
'scale_pos_weight': [0.2, 0.4, 0.6, 0.8, 1]
}
xlf = xgb.XGBClassifier(max_depth=10,
learning_rate=0.01,
n_estimators=2000,
silent=True,
objective='multi:softmax',
num_class=3 ,
nthread=-1,
gamma=0,
min_child_weight=1,
max_delta_step=0,
subsample=0.85,
colsample_bytree=0.7,
colsample_bylevel=1,
reg_alpha=0,
reg_lambda=1,
scale_pos_weight=1,
seed=0,
missing=None)
gs = GridSearchCV(xlf, param_grid=parameters, scoring='accuracy', cv=3)
gs.fit(train_x, train_y)
print("Best score: %0.3f" % gs.best_score_)
print("Best parameters set: %s" % gs.best_params_ )Best score: 0.933
Best parameters set: {‘max_depth’: 5}8. LightGBM算法
LightGBM也是像XGBoost一样,是一类集成算法,他跟XGBoost总体来说是一样的,算法本质上与Xgboost没有出入,只是在XGBoost的基础上进行了优化,因此就不对原理进行重复介绍,在这里我们来看看几种算法的差别:
- 优化速度和内存使用
- 降低了计算每个分割增益的成本。
- 使用直方图减法进一步提高速度。
- 减少内存使用。
- 减少并行学习的计算成本。
- 稀疏优化
- 用离散的bin替换连续的值。如果#bins较小,则可以使用较小的数据类型(例如uint8_t)来存储训练数据 。
- 无需存储其他信息即可对特征数值进行预排序 。
- 精度优化
- 使用叶子数为导向的决策树建立算法而不是树的深度导向。
- 分类特征的编码方式的优化
- 通信网络的优化
- 并行学习的优化
- GPU支持
LightGBM的优点:
1)更快的训练效率
2)低内存使用
3)更高的准确率
4)支持并行化学习
5)可以处理大规模数据
1.速度对比:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-W562LSSA-1623946035318)(./速度对比.png)]
2.准确率对比:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J4JVvKjX-1623946035319)(./准确率对比.png)]
3.内存使用量对比:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-glXaoZd6-1623946035320)(./内存使用量.png)]LightGBM参数说明:
推荐文档1:https://lightgbm.apachecn.org/#/docs/6
推荐文档2:https://lightgbm.readthedocs.io/en/latest/Parameters.html1.核心参数:(括号内名称是别名)
- objective(objective,app ,application):默认regression,用于设置损失函数
- 回归问题:
- L2损失:regression(regression_l2,l2,mean_squared_error,mse,l2_root,root_mean_squared_error,rmse)
- L1损失:regression_l1(l1, mean_absolute_error, mae)
- 其他损失:huber,fair,poisson,quantile,mape,gamma,tweedie
- 二分类问题:二进制对数损失分类(或逻辑回归):binary
- 多类别分类:
- softmax目标函数: multiclass(softmax)
- One-vs-All 目标函数:multiclassova(multiclass_ova,ova,ovr)
- 交叉熵:
- 用于交叉熵的目标函数(具有可选的线性权重):cross_entropy(xentropy)
- 交叉熵的替代参数化:cross_entropy_lambda(xentlambda)
- 回归问题:
- boosting :默认gbdt,设置提升类型,选项有gbdt,rf,dart,goss,别名:boosting_type,boost
- gbdt(gbrt):传统的梯度提升决策树
- rf(random_forest):随机森林
- dart:多个加性回归树的DROPOUT方法 Dropouts meet Multiple Additive Regression Trees,参见:https://arxiv.org/abs/1505.01866
- goss:基于梯度的单边采样 Gradient-based One-Side Sampling
- data(train,train_data,train_data_file,data_filename):用于训练的数据或数据file
- valid (test,valid_data,valid_data_file,test_data,test_data_file,valid_filenames):验证/测试数据的路径,LightGBM将输出这些数据的指标
- num_iterations:默认=100,类型= INT
- n_estimators:提升迭代次数,*LightGBM构造用于多类分类问题的树num_class * num_iterations*
- learning_rate(shrinkage_rate,eta) :收缩率,默认=0.1
- num_leaves(num_leaf,max_leaves,max_leaf) :默认=31,一棵树上的最大叶子数
- tree_learner (tree,tree_type,tree_learner_type):默认=serial,可选:serial,feature,data,voting
- serial:单台机器的 tree learner
- feature:特征并行的 tree learner
- data:数据并行的 tree learner
- voting:投票并行的 tree learner
- num_threads(num_thread, nthread):LightGBM 的线程数,为了更快的速度, 将此设置为真正的 CPU 内核数, 而不是线程的数量 (大多数 CPU 使用超线程来使每个 CPU 内核生成 2 个线程),当你的数据集小的时候不要将它设置的过大 (比如, 当数据集有 10,000 行时不要使用 64 线程),对于并行学习, 不应该使用全部的 CPU 内核, 因为这会导致网络性能不佳。
- device(device_type):默认cpu,为树学习选择设备, 你可以使用 GPU 来获得更快的学习速度,可选cpu, gpu。
- seed (random_seed,random_state):与其他种子相比,该种子具有较低的优先级,这意味着如果您明确设置其他种子,它将被覆盖。
2.用于控制模型学习过程的参数:
- max_depth:限制树模型的最大深度. 这可以在 #data 小的情况下防止过拟合. 树仍然可以通过 leaf-wise 生长。
- min_data_in_leaf: 默认=20,一个叶子上数据的最小数量. 可以用来处理过拟合。
- min_sum_hessian_in_leaf(min_sum_hessian_per_leaf, min_sum_hessian, min_hessian):默认=1e-3,一个叶子上的最小 hessian 和. 类似于 min_data_in_leaf, 可以用来处理过拟合.
- feature_fraction:default=1.0,如果 feature_fraction 小于 1.0, LightGBM 将会在每次迭代中随机选择部分特征. 例如, 如果设置为 0.8, 将会在每棵树训练之前选择 80% 的特征,可以用来加速训练,可以用来处理过拟合。
- feature_fraction_seed:默认=2,feature_fraction 的随机数种子。
- bagging_fraction(sub_row, subsample):默认=1,不进行重采样的情况下随机选择部分数据
- bagging_freq(subsample_freq):bagging 的频率, 0 意味着禁用 bagging. k 意味着每 k 次迭代执行bagging
- bagging_seed(bagging_fraction_seed) :默认=3,bagging 随机数种子。
- early_stopping_round(early_stopping_rounds, early_stopping):默认=0,如果一个验证集的度量在 early_stopping_round 循环中没有提升, 将停止训练
- lambda_l1(reg_alpha):L1正则化系数
- lambda_l2(reg_lambda):L2正则化系数
- min_split_gain(min_gain_to_split):执行切分的最小增益,默认=0.
- cat_smooth:默认=10,用于分类特征,可以降低噪声在分类特征中的影响, 尤其是对数据很少的类别
3.度量参数:
- metric:default={l2 for regression}, {binary_logloss for binary classification}, {ndcg for lambdarank}, type=multi-enum, options=l1, l2, ndcg, auc, binary_logloss, binary_error …
- l1, absolute loss, alias=mean_absolute_error, mae
- l2, square loss, alias=mean_squared_error, mse
- l2_root, root square loss, alias=root_mean_squared_error, rmse
- quantile, Quantile regression
- huber, Huber loss
- fair, Fair loss
- poisson, Poisson regression
- ndcg, NDCG
- map, MAP
- auc, AUC
- binary_logloss, log loss
- binary_error, 样本: 0 的正确分类, 1 错误分类
- multi_logloss, mulit-class 损失日志分类
- multi_error, error rate for mulit-class 出错率分类
- xentropy, cross-entropy (与可选的线性权重), alias=cross_entropy
- xentlambda, “intensity-weighted” 交叉熵, alias=cross_entropy_lambda
- kldiv, Kullback-Leibler divergence, alias=kullback_leibler
- 支持多指标, 使用 , 分隔
- train_metric(training_metric, is_training_metric):默认=False,如果你需要输出训练的度量结果则设置 true
4.GPU 参数:
- gpu_device_id:default为-1, 这个default意味着选定平台上的设备。
LightGBM与网格搜索结合调参:
参考代码:https://blog.csdn.net/u012735708/article/details/83749703import lightgbm as lgb
from sklearn import metrics
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
canceData=load_breast_cancer()
X=canceData.data
y=canceData.target
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=0,test_size=0.2)
### 数据转换
print('数据转换')
lgb_train = lgb.Dataset(X_train, y_train, free_raw_data=False)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train,free_raw_data=False)
### 设置初始参数--不含交叉验证参数
print('设置参数')
params = {
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': 'auc',
'nthread':4,
'learning_rate':0.1
}
### 交叉验证(调参)
print('交叉验证')
max_auc = float('0')
best_params = {}
# 准确率
print("调参1:提高准确率")
for num_leaves in range(5,100,5):
for max_depth in range(3,8,1):
params['num_leaves'] = num_leaves
params['max_depth'] = max_depth
cv_results = lgb.cv(
params,
lgb_train,
seed=1,
nfold=5,
metrics=['auc'],
early_stopping_rounds=10,
verbose_eval=True
)
mean_auc = pd.Series(cv_results['auc-mean']).max()
boost_rounds = pd.Series(cv_results['auc-mean']).idxmax()
if mean_auc >= max_auc:
max_auc = mean_auc
best_params['num_leaves'] = num_leaves
best_params['max_depth'] = max_depth
if 'num_leaves' and 'max_depth' in best_params.keys():
params['num_leaves'] = best_params['num_leaves']
params['max_depth'] = best_params['max_depth']
# 过拟合
print("调参2:降低过拟合")
for max_bin in range(5,256,10):
for min_data_in_leaf in range(1,102,10):
params['max_bin'] = max_bin
params['min_data_in_leaf'] = min_data_in_leaf
cv_results = lgb.cv(
params,
lgb_train,
seed=1,
nfold=5,
metrics=['auc'],
early_stopping_rounds=10,
verbose_eval=True
)
mean_auc = pd.Series(cv_results['auc-mean']).max()
boost_rounds = pd.Series(cv_results['auc-mean']).idxmax()
if mean_auc >= max_auc:
max_auc = mean_auc
best_params['max_bin']= max_bin
best_params['min_data_in_leaf'] = min_data_in_leaf
if 'max_bin' and 'min_data_in_leaf' in best_params.keys():
params['min_data_in_leaf'] = best_params['min_data_in_leaf']
params['max_bin'] = best_params['max_bin']
print("调参3:降低过拟合")
for feature_fraction in [0.6,0.7,0.8,0.9,1.0]:
for bagging_fraction in [0.6,0.7,0.8,0.9,1.0]:
for bagging_freq in range(0,50,5):
params['feature_fraction'] = feature_fraction
params['bagging_fraction'] = bagging_fraction
params['bagging_freq'] = bagging_freq
cv_results = lgb.cv(
params,
lgb_train,
seed=1,
nfold=5,
metrics=['auc'],
early_stopping_rounds=10,
verbose_eval=True
)
mean_auc = pd.Series(cv_results['auc-mean']).max()
boost_rounds = pd.Series(cv_results['auc-mean']).idxmax()
if mean_auc >= max_auc:
max_auc=mean_auc
best_params['feature_fraction'] = feature_fraction
best_params['bagging_fraction'] = bagging_fraction
best_params['bagging_freq'] = bagging_freq
if 'feature_fraction' and 'bagging_fraction' and 'bagging_freq' in best_params.keys():
params['feature_fraction'] = best_params['feature_fraction']
params['bagging_fraction'] = best_params['bagging_fraction']
params['bagging_freq'] = best_params['bagging_freq']
print("调参4:降低过拟合")
for lambda_l1 in [1e-5,1e-3,1e-1,0.0,0.1,0.3,0.5,0.7,0.9,1.0]:
for lambda_l2 in [1e-5,1e-3,1e-1,0.0,0.1,0.4,0.6,0.7,0.9,1.0]:
params['lambda_l1'] = lambda_l1
params['lambda_l2'] = lambda_l2
cv_results = lgb.cv(
params,
lgb_train,
seed=1,
nfold=5,
metrics=['auc'],
early_stopping_rounds=10,
verbose_eval=True
)
mean_auc = pd.Series(cv_results['auc-mean']).max()
boost_rounds = pd.Series(cv_results['auc-mean']).idxmax()
if mean_auc >= max_auc:
max_auc=mean_auc
best_params['lambda_l1'] = lambda_l1
best_params['lambda_l2'] = lambda_l2
if 'lambda_l1' and 'lambda_l2' in best_params.keys():
params['lambda_l1'] = best_params['lambda_l1']
params['lambda_l2'] = best_params['lambda_l2']
print("调参5:降低过拟合2")
for min_split_gain in [0.0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0]:
params['min_split_gain'] = min_split_gain
cv_results = lgb.cv(
params,
lgb_train,
seed=1,
nfold=5,
metrics=['auc'],
early_stopping_rounds=10,
verbose_eval=True
)
mean_auc = pd.Series(cv_results['auc-mean']).max()
boost_rounds = pd.Series(cv_results['auc-mean']).idxmax()
if mean_auc >= max_auc:
max_auc=mean_auc
best_params['min_split_gain'] = min_split_gain
if 'min_split_gain' in best_params.keys():
params['min_split_gain'] = best_params['min_split_gain']
print(best_params){‘bagging_fraction’: 0.7,
‘bagging_freq’: 30,
‘feature_fraction’: 0.8,
‘lambda_l1’: 0.1,
‘lambda_l2’: 0.0,
‘max_bin’: 255,
‘max_depth’: 4,
‘min_data_in_leaf’: 81,
‘min_split_gain’: 0.1,
‘num_leaves’: 10}9. 结语
本章中,我们主要探讨了基于Boosting方式的集成方法,其中主要讲解了基于错误率驱动的Adaboost,基于残差改进的提升树,基于梯度提升的GBDT,基于泰勒二阶近似的Xgboost以及LightGBM。在实际的比赛或者工程中,基于Boosting的集成学习方式是非常有效且应用非常广泛的。更多的学习有待读者更深入阅读文献,包括原作者论文以及论文复现等。下一章我们即将探讨另一种集成学习方式:Stacking集成学习方式,这种集成方式虽然没有Boosting应用广泛,但是在比赛中或许能让你的模型更加出众。
本章作业:
]]>
本章在最后介绍LightGBM的时候并没有详细介绍它的原理以及它与XGBoost的不一样的地方,希望读者好好看看别的文章分享,总结LigntGBM与XGBoost的不同,然后使用一个具体的案例体现两者的不同。
参考链接: https://blog.csdn.net/weixin_30279315/article/details/95504220XGBoost算法 XGBoost是陈天奇等人开发的一个开源机器学习项目,高效地实现了GBDT算法并进行了算法和工程上的许多改进,被广泛应用在Kaggle竞赛及其他许多机器学习竞赛中并取得了不错的成绩。XGBoost本质上还是一个GBDT,但是力争把速度和效率发挥到极致,所以叫X (Extreme) GBoosted, 包括前面说过,两者都是boosting方法。XGBoost是一个优化的分布式梯度增强库,旨在实现高效,灵活和便携。 它在Gradient Boosting框架下实现机器学习算法。 XGBoost提供了并行树提升(也称为GBDT,GBM),可以快速准确地解决许多数据科学问题。 相同的代码在主要的分布式环境(Hadoop,SGE,MPI)上运行,并且可以解决超过数十亿个样例的问题。XGBoost利用了核外计算并且能够使数据科学家在一个主机上处理数亿的样本数据。最终,将这些技术进行结合来做一个端到端的系统以最少的集群系统来扩展到更大的数据集上。Xgboost以CART决策树为子模型,通过Gradient Tree Boosting实现多棵CART树的集成学习,得到最终模型。下面我们来看看XGBoost的最终模型构建:
引用陈天奇的论文,我们的数据为:$\mathcal{D}=\left{\left(\mathbf{x}{i}, y{i}\right)\right}\left(|\mathcal{D}|=n, \mathbf{x}{i} \in \mathbb{R}^{m}, y{i} \in \mathbb{R}\right)$
(1) 构造目标函数:
假设有K棵树,则第i个样本的输出为$\hat{y}{i}=\phi\left(\mathrm{x}{i}\right)=\sum{k=1}^{K} f{k}\left(\mathrm{x}{i}\right), \quad f{k} \in \mathcal{F}$,其中,$\mathcal{F}=\left{f(\mathbf{x})=w_{q(\mathbf{x})}\right}\left(q: \mathbb{R}^{m} \rightarrow T, w \in \mathbb{R}^{T}\right)$
因此,目标函数的构建为:其中,$\sum{i} l\left(\hat{y}{i}, y{i}\right)$为loss function,$\sum{k} \Omega\left(f_{k}\right)$为正则化项。
(2) 叠加式的训练(Additive Training):
给定样本$x_i$,$\hat{y}_i^{(0)} = 0$(初始预测),$\hat{y}_i^{(1)} = \hat{y}_i^{(0)} + f_1(x_i)$,$\hat{y}_i^{(2)} = \hat{y}_i^{(0)} + f_1(x_i) + f_2(x_i) = \hat{y}_i^{(1)} + f_2(x_i)$…….以此类推,可以得到:$ \hat{y}_i^{(K)} = \hat{y}_i^{(K-1)} + f_K(x_i)$ ,其中,$ \hat{y}_i^{(K-1)} $ 为前K-1棵树的预测结果,$ f_K(x_i)$ 为第K棵树的预测结果。
因此,目标函数可以分解为:由于正则化项也可以分解为前K-1棵树的复杂度加第K棵树的复杂度,因此:$\mathcal{L}^{(K)}=\sum{i=1}^{n} l\left(y{i}, \hat{y}{i}^{(K-1)}+f{K}\left(\mathrm{x}{i}\right)\right)+\sum{k=1} ^{K-1}\Omega\left(f{k}\right)+\Omega\left(f{K}\right)$,由于$\sum{k=1} ^{K-1}\Omega\left(f{k}\right)$在模型构建到第K棵树的时候已经固定,无法改变,因此是一个已知的常数,可以在最优化的时候省去,故:
(3) 使用泰勒级数近似目标函数:
其中,$g{i}=\partial{\hat{y}(t-1)} l\left(y{i}, \hat{y}^{(t-1)}\right)$和$h{i}=\partial{\hat{y}^{(t-1)}}^{2} l\left(y{i}, \hat{y}^{(t-1)}\right)$
在这里,我们补充下泰勒级数的相关知识:
在数学中,泰勒级数(英语:Taylor series)用无限项连加式——级数来表示一个函数,这些相加的项由函数在某一点的导数求得。具体的形式如下:由于$\sum{i=1}^{n}l\left(y{i}, \hat{y}^{(K-1)}\right)$在模型构建到第K棵树的时候已经固定,无法改变,因此是一个已知的常数,可以在最优化的时候省去,故:
(4) 如何定义一棵树:
为了说明如何定义一棵树的问题,我们需要定义几个概念:第一个概念是样本所在的节点位置$q(x)$,第二个概念是有哪些样本落在节点j上$I{j}=\left{i \mid q\left(\mathbf{x}{i}\right)=j\right}$,第三个概念是每个结点的预测值$w{q(x)}$,第四个概念是模型复杂度$\Omega\left(f{K}\right)$,它可以由叶子节点的个数以及节点函数值来构建,则:$\Omega\left(f{K}\right) = \gamma T+\frac{1}{2} \lambda \sum{j=1}^{T} w_{j}^{2}$。如下图的例子:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-t1tei3pE-1623946035306)(./16.png)]
$q(x_1) = 1,q(x_2) = 3,q(x_3) = 1,q(x_4) = 2,q(x_5) = 3$,$I_1 = {1,3},I_2 = {4},I_3 = {2,5}$,$w = (15,12,20)$
因此,目标函数用以上符号替代后:由于我们的目标就是最小化目标函数,现在的目标函数化简为一个关于w的二次函数:$\tilde{\mathcal{L}}^{(K)}=\sum{j=1}^{T}\left[\left(\sum{i \in I{j}} g{i}\right) w{j}+\frac{1}{2}\left(\sum{i \in I{j}} h{i}+\lambda\right) w_{j}^{2}\right]+\gamma T$,根据二次函数求极值的公式:$y=ax^2 bx c$求极值,对称轴在$x=-\frac{b}{2 a}$,极值为$y=\frac{4 a c-b^{2}}{4 a}$,因此:
以及
(5) 如何寻找树的形状:
不难发现,刚刚的讨论都是基于树的形状已经确定了计算$w$和$L$,但是实际上我们需要像学习决策树一样找到树的形状。因此,我们借助决策树学习的方式,使用目标函数的变化来作为分裂节点的标准。我们使用一个例子来说明:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nCrhWA4S-1623946035310)(./17.png)]
例子中有8个样本,分裂方式如下,因此:因此,从上面的例子看出:分割节点的标准为$max{\tilde{\mathcal{L}}^{(old)} - \tilde{\mathcal{L}}^{(new)} }$,即:
(6.1) 精确贪心分裂算法:
XGBoost在生成新树的过程中,最基本的操作是节点分裂。节点分裂中最重 要的环节是找到最优特征及最优切分点, 然后将叶子节点按照最优特征和最优切 分点进行分裂。选取最优特征和最优切分点的一种思路如下:首先找到所有的候 选特征及所有的候选切分点, 一一求得其 $\mathcal{L}{\text {split }}$, 然后选择$\mathcal{L}{\mathrm{split}}$ 最大的特征及 对应切分点作为最优特征和最优切分点。我们称此种方法为精确贪心算法。该算法是一种启发式算法, 因为在节点分裂时只选择当前最优的分裂策略, 而非全局最优的分裂策略。精确贪心算法的计算过程如下所示:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HRrbM0fp-1623946035312)(./18.png)]
(6.2) 基于直方图的近似算法:
精确贪心算法在选择最优特征和最优切分点时是一种十分有效的方法。它计算了所有特征、所有切分点的收益, 并从中选择了最优的, 从而保证模型能比较好地拟合了训练数据。但是当数据不能完全加载到内存时,精确贪心算法会变得 非常低效,算法在计算过程中需要不断在内存与磁盘之间进行数据交换,这是个非常耗时的过程, 并且在分布式环境中面临同样的问题。为了能够更高效地选 择最优特征及切分点, XGBoost提出一种近似算法来解决该问题。 基于直方图的近似算法的主要思想是:对某一特征寻找最优切分点时,首先对该特征的所有切分点按分位数 (如百分位) 分桶, 得到一个候选切分点集。特征的每一个切分点都可以分到对应的分桶; 然后,对每个桶计算特征统计G和H得到直方图, G为该桶内所有样本一阶特征统计g之和, H为该桶内所有样本二阶特征统计h之和; 最后,选择所有候选特征及候选切分点中对应桶的特征统计收益最大的作为最优特征及最优切分点。基于直方图的近似算法的计算过程如下所示:
1) 对于每个特征 $k=1,2, \cdots, m,$ 按分位数对特征 $k$ 分桶 $\Theta,$ 可得候选切分点, $S{k}=\left{S{k 1}, S{k 2}, \cdots, S{k l}\right}^{1}$
2) 对于每个特征 $k=1,2, \cdots, m,$ 有:3) 类似精确贪心算法,依据梯度统计找到最大增益的候选切分点。
下面用一个例子说明基于直方图的近似算法:
假设有一个年龄特征,其特征的取值为18、19、21、31、36、37、55、57,我们需要使用近似算法找到年龄这个特征的最佳分裂点:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MKLD2poX-1623946035314)(./19.png)]近似算法实现了两种候选切分点的构建策略:全局策略和本地策略。全局策略是在树构建的初始阶段对每一个特征确定一个候选切分点的集合, 并在该树每一层的节点分裂中均采用此集合计算收益, 整个过程候选切分点集合不改变。本地策略则是在每一次节点分裂时均重新确定候选切分点。全局策略需要更细的分桶才能达到本地策略的精确度, 但全局策略在选取候选切分点集合时比本地策略更简单。在XGBoost系统中, 用户可以根据需求自由选择使用精确贪心算法、近似算法全局策略、近似算法本地策略, 算法均可通过参数进行配置。
以上是XGBoost的理论部分,下面我们对XGBoost系统进行详细的讲解:
官方文档:https://xgboost.readthedocs.io/en/latest/python/python_intro.html
知乎总结:https://zhuanlan.zhihu.com/p/143009353# XGBoost原生工具库的上手:
import xgboost as xgb # 引入工具库
# read in data
dtrain = xgb.DMatrix('demo/data/agaricus.txt.train') # XGBoost的专属数据格式,但是也可以用dataframe或者ndarray
dtest = xgb.DMatrix('demo/data/agaricus.txt.test') # # XGBoost的专属数据格式,但是也可以用dataframe或者ndarray
# specify parameters via map
param = {'max_depth':2, 'eta':1, 'objective':'binary:logistic' } # 设置XGB的参数,使用字典形式传入
num_round = 2 # 使用线程数
bst = xgb.train(param, dtrain, num_round) # 训练
# make prediction
preds = bst.predict(dtest) # 预测XGBoost的参数设置(括号内的名称为sklearn接口对应的参数名字):
推荐博客:https://link.zhihu.com/?target=https%3A//blog.csdn.net/luanpeng825485697/article/details/79907149
推荐官方文档:https://link.zhihu.com/?target=https%3A//xgboost.readthedocs.io/en/latest/parameter.htmlXGBoost的参数分为三种:
- 通用参数:(两种类型的booster,因为tree的性能比线性回归好得多,因此我们很少用线性回归。)
- booster:使用哪个弱学习器训练,默认gbtree,可选gbtree,gblinear 或dart
- nthread:用于运行XGBoost的并行线程数,默认为最大可用线程数
- verbosity:打印消息的详细程度。有效值为0(静默),1(警告),2(信息),3(调试)。
- Tree Booster的参数:
- eta(learning_rate):learning_rate,在更新中使用步长收缩以防止过度拟合,默认= 0.3,范围:[0,1];典型值一般设置为:0.01-0.2
- gamma(min_split_loss):默认= 0,分裂节点时,损失函数减小值只有大于等于gamma节点才分裂,gamma值越大,算法越保守,越不容易过拟合,但性能就不一定能保证,需要平衡。范围:[0,∞]
- max_depth:默认= 6,一棵树的最大深度。增加此值将使模型更复杂,并且更可能过度拟合。范围:[0,∞]
- min_child_weight:默认值= 1,如果新分裂的节点的样本权重和小于min_child_weight则停止分裂 。这个可以用来减少过拟合,但是也不能太高,会导致欠拟合。范围:[0,∞]
- max_delta_step:默认= 0,允许每个叶子输出的最大增量步长。如果将该值设置为0,则表示没有约束。如果将其设置为正值,则可以帮助使更新步骤更加保守。通常不需要此参数,但是当类极度不平衡时,它可能有助于逻辑回归。将其设置为1-10的值可能有助于控制更新。范围:[0,∞]
- subsample:默认值= 1,构建每棵树对样本的采样率,如果设置成0.5,XGBoost会随机选择一半的样本作为训练集。范围:(0,1]
- sampling_method:默认= uniform,用于对训练实例进行采样的方法。
- uniform:每个训练实例的选择概率均等。通常将subsample> = 0.5 设置 为良好的效果。
- gradient_based:每个训练实例的选择概率与规则化的梯度绝对值成正比,具体来说就是$\sqrt{g^2+\lambda h^2}$,subsample可以设置为低至0.1,而不会损失模型精度。
- colsample_bytree:默认= 1,列采样率,也就是特征采样率。范围为(0,1]
- lambda(reg_lambda):默认=1,L2正则化权重项。增加此值将使模型更加保守。
- alpha(reg_alpha):默认= 0,权重的L1正则化项。增加此值将使模型更加保守。
- tree_method:默认=auto,XGBoost中使用的树构建算法。
- auto:使用启发式选择最快的方法。
- 对于小型数据集,exact将使用精确贪婪()。
- 对于较大的数据集,approx将选择近似算法()。它建议尝试hist,gpu_hist,用大量的数据可能更高的性能。(gpu_hist)支持。external memory外部存储器。
- exact:精确的贪婪算法。枚举所有拆分的候选点。
- approx:使用分位数和梯度直方图的近似贪婪算法。
- hist:更快的直方图优化的近似贪婪算法。(LightGBM也是使用直方图算法)
- gpu_hist:GPU hist算法的实现。
- auto:使用启发式选择最快的方法。
- scale_pos_weight:控制正负权重的平衡,这对于不平衡的类别很有用。Kaggle竞赛一般设置sum(negative instances) / sum(positive instances),在类别高度不平衡的情况下,将参数设置大于0,可以加快收敛。
- num_parallel_tree:默认=1,每次迭代期间构造的并行树的数量。此选项用于支持增强型随机森林。
- monotone_constraints:可变单调性的约束,在某些情况下,如果有非常强烈的先验信念认为真实的关系具有一定的质量,则可以使用约束条件来提高模型的预测性能。(例如params_constrained[‘monotone_constraints’] = “(1,-1)”,(1,-1)我们告诉XGBoost对第一个预测变量施加增加的约束,对第二个预测变量施加减小的约束。)
- Linear Booster的参数:
- lambda(reg_lambda):默认= 0,L2正则化权重项。增加此值将使模型更加保守。归一化为训练示例数。
- alpha(reg_alpha):默认= 0,权重的L1正则化项。增加此值将使模型更加保守。归一化为训练示例数。
- updater:默认= shotgun。
- shotgun:基于shotgun算法的平行坐标下降算法。使用“ hogwild”并行性,因此每次运行都产生不确定的解决方案。
- coord_descent:普通坐标下降算法。同样是多线程的,但仍会产生确定性的解决方案。
- feature_selector:默认= cyclic。特征选择和排序方法
- cyclic:通过每次循环一个特征来实现的。
- shuffle:类似于cyclic,但是在每次更新之前都有随机的特征变换。
- random:一个随机(有放回)特征选择器。
- greedy:选择梯度最大的特征。(贪婪选择)
- thrifty:近似贪婪特征选择(近似于greedy)
- top_k:要选择的最重要特征数(在greedy和thrifty内)
任务参数(这个参数用来控制理想的优化目标和每一步结果的度量方法。)
- objective:默认=reg:squarederror,表示最小平方误差。
- reg:squarederror,最小平方误差。
- reg:squaredlogerror,对数平方损失。$\frac{1}{2}[log(pred+1)-log(label+1)]^2$
- reg:logistic,逻辑回归
- reg:pseudohubererror,使用伪Huber损失进行回归,这是绝对损失的两倍可微选择。
- binary:logistic,二元分类的逻辑回归,输出概率。
- binary:logitraw:用于二进制分类的逻辑回归,逻辑转换之前的输出得分。
- binary:hinge:二进制分类的铰链损失。这使预测为0或1,而不是产生概率。(SVM就是铰链损失函数)
- count:poisson –计数数据的泊松回归,泊松分布的输出平均值。
- survival:cox:针对正确的生存时间数据进行Cox回归(负值被视为正确的生存时间)。
- survival:aft:用于检查生存时间数据的加速故障时间模型。
- aft_loss_distribution:survival:aft和aft-nloglik度量标准使用的概率密度函数。
- multi:softmax:设置XGBoost以使用softmax目标进行多类分类,还需要设置num_class(类数)
- multi:softprob:与softmax相同,但输出向量,可以进一步重整为矩阵。结果包含属于每个类别的每个数据点的预测概率。
- rank:pairwise:使用LambdaMART进行成对排名,从而使成对损失最小化。
- rank:ndcg:使用LambdaMART进行列表式排名,使标准化折让累积收益(NDCG)最大化。
- rank:map:使用LambdaMART进行列表平均排名,使平均平均精度(MAP)最大化。
- reg:gamma:使用对数链接进行伽马回归。输出是伽马分布的平均值。
- reg:tweedie:使用对数链接进行Tweedie回归。
- 自定义损失函数和评价指标:https://xgboost.readthedocs.io/en/latest/tutorials/custom_metric_obj.html
- eval_metric:验证数据的评估指标,将根据目标分配默认指标(回归均方根,分类误差,排名的平均平均精度),用户可以添加多个评估指标
- rmse,均方根误差; rmsle:均方根对数误差; mae:平均绝对误差;mphe:平均伪Huber错误;logloss:负对数似然; error:二进制分类错误率;
- merror:多类分类错误率; mlogloss:多类logloss; auc:曲线下面积; aucpr:PR曲线下的面积;ndcg:归一化累计折扣;map:平均精度;
- seed :随机数种子,[默认= 0]。
- objective:默认=reg:squarederror,表示最小平方误差。
命令行参数(这里不说了,因为很少用命令行控制台版本)
from IPython.display import IFrame
IFrame('https://xgboost.readthedocs.io/en/latest/parameter.html', width=1400, height=800)XGBoost的调参说明:
参数调优的一般步骤
- 确定学习速率和提升参数调优的初始值
- max_depth 和 min_child_weight 参数调优
- gamma参数调优
- subsample 和 colsample_bytree 参数优
- 正则化参数alpha调优
- 降低学习速率和使用更多的决策树
XGBoost详细攻略:
具体的api请查看:https://xgboost.readthedocs.io/en/latest/python/python_api.html
推荐github:https://github.com/dmlc/xgboost/tree/master/demo/guide-python安装XGBoost:
方式1:pip3 install xgboost
方式2:pip install xgboost数据接口(XGBoost可处理的数据格式DMatrix)
# 1.LibSVM文本格式文件
dtrain = xgb.DMatrix('train.svm.txt')
dtest = xgb.DMatrix('test.svm.buffer')
# 2.CSV文件(不能含类别文本变量,如果存在文本变量请做特征处理如one-hot)
dtrain = xgb.DMatrix('train.csv?format=csv&label_column=0')
dtest = xgb.DMatrix('test.csv?format=csv&label_column=0')
# 3.NumPy数组
data = np.random.rand(5, 10) # 5 entities, each contains 10 features
label = np.random.randint(2, size=5) # binary target
dtrain = xgb.DMatrix(data, label=label)
# 4.scipy.sparse数组
csr = scipy.sparse.csr_matrix((dat, (row, col)))
dtrain = xgb.DMatrix(csr)
# pandas数据框dataframe
data = pandas.DataFrame(np.arange(12).reshape((4,3)), columns=['a', 'b', 'c'])
label = pandas.DataFrame(np.random.randint(2, size=4))
dtrain = xgb.DMatrix(data, label=label)笔者推荐:先保存到XGBoost二进制文件中将使加载速度更快,然后再加载进来
# 1.保存DMatrix到XGBoost二进制文件中
dtrain = xgb.DMatrix('train.svm.txt')
dtrain.save_binary('train.buffer')
# 2. 缺少的值可以用DMatrix构造函数中的默认值替换:
dtrain = xgb.DMatrix(data, label=label, missing=-999.0)
# 3.可以在需要时设置权重:
w = np.random.rand(5, 1)
dtrain = xgb.DMatrix(data, label=label, missing=-999.0, weight=w)参数的设置方式:
import pandas as pd
# 加载并处理数据
df_wine = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data',header=None)
df_wine.columns = ['Class label', 'Alcohol','Malic acid', 'Ash','Alcalinity of ash','Magnesium', 'Total phenols',
'Flavanoids', 'Nonflavanoid phenols','Proanthocyanins','Color intensity', 'Hue','OD280/OD315 of diluted wines','Proline']
df_wine = df_wine[df_wine['Class label'] != 1] # drop 1 class
y = df_wine['Class label'].values
X = df_wine[['Alcohol','OD280/OD315 of diluted wines']].values
from sklearn.model_selection import train_test_split # 切分训练集与测试集
from sklearn.preprocessing import LabelEncoder # 标签化分类变量
le = LabelEncoder()
y = le.fit_transform(y)
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=1,stratify=y)
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test)
# 1.Booster 参数
params = {
'booster': 'gbtree',
'objective': 'multi:softmax', # 多分类的问题
'num_class': 10, # 类别数,与 multisoftmax 并用
'gamma': 0.1, # 用于控制是否后剪枝的参数,越大越保守,一般0.1、0.2这样子。
'max_depth': 12, # 构建树的深度,越大越容易过拟合
'lambda': 2, # 控制模型复杂度的权重值的L2正则化项参数,参数越大,模型越不容易过拟合。
'subsample': 0.7, # 随机采样训练样本
'colsample_bytree': 0.7, # 生成树时进行的列采样
'min_child_weight': 3,
'silent': 1, # 设置成1则没有运行信息输出,最好是设置为0.
'eta': 0.007, # 如同学习率
'seed': 1000,
'nthread': 4, # cpu 线程数
'eval_metric':'auc'
}
plst = list(params.items())
# evallist = [(dtest, 'eval'), (dtrain, 'train')] # 指定验证集训练:
# 2.训练
num_round = 10
bst = xgb.train(plst, dtrain, num_round)
#bst = xgb.train( plst, dtrain, num_round, evallist )保存模型:
# 3.保存模型
bst.save_model('0001.model')
# dump model
bst.dump_model('dump.raw.txt')
# dump model with feature map
#bst.dump_model('dump.raw.txt', 'featmap.txt')加载保存的模型:
# 4.加载保存的模型:
bst = xgb.Booster({'nthread': 4}) # init model
bst.load_model('0001.model') # load data设置早停机制:
# 5.也可以设置早停机制(需要设置验证集)
train(..., evals=evals, early_stopping_rounds=10)预测:
# 6.预测
ypred = bst.predict(dtest)绘制重要性特征图:
# 1.绘制重要性
xgb.plot_importance(bst)
# 2.绘制输出树
#xgb.plot_tree(bst, num_trees=2)
# 3.使用xgboost.to_graphviz()将目标树转换为graphviz
#xgb.to_graphviz(bst, num_trees=2)7. Xgboost算法案例
分类案例
from sklearn.datasets import load_iris
import xgboost as xgb
from xgboost import plot_importance
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score # 准确率
# 加载样本数据集
iris = load_iris()
X,y = iris.data,iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1234565) # 数据集分割
params = {
'booster' : 'gbtree',
'objective': 'multi:softmax', # 多分类的问题
'num_class': 3,
'gamma': 0.1, # 默认= 0,分裂节点时,损失函数减小值只有大于等于gamma节点才分裂,gamma值越大,算法越保守,越不容易过拟合,但性能就不一定能保证,需要平衡。
'max_depth': 12, # 树的最大深度
'lambda': 2, # 控制模型复杂度的权重值的L2正则化项参数,参数越大,模型越不容易过拟合。
'subsample': 0.7, # 随机采样训练样本
'colsample_bytree': 0.7, # 生成树时进行的列采样,列采样率,也就是特征采样率
'min_child_weight': 3,
'silent': 0,
'eta': 0.1,
'seed': 1,
'nthread': 4,
}
plst = list(params.items())
dtrain = xgb.DMatrix(X_train,y_train)
num_rounds = 500
model = xgb.train(plst,dtrain,num_rounds) # xgboost模型训练
# 对测试集进行预测
dtest = xgb.DMatrix(X_test)
y_pred = model.predict(dtest)
# 计算准确率
accuracy = accuracy_score(y_test,y_pred)
print("accuarcy: %.2f%%" % (accuracy*100.0))
# 显示重要特征
plot_importance(model)
plt.show()回归案例
import xgboost as xgb
from xgboost import plot_importance
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_boston
from sklearn.metrics import mean_squared_error
# 加载数据集
boston = load_boston()
X,y = boston.data,boston.target
# XGBoost训练过程
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
params = {
'booster': 'gbtree',
'objective': 'reg:squarederror',
'gamma': 0.1,
'max_depth': 5,
'lambda': 3,
'subsample': 0.7,
'colsample_bytree': 0.7,
'min_child_weight': 3,
'silent': 1,
'eta': 0.1,
'seed': 1000,
'nthread': 4,
}
dtrain = xgb.DMatrix(X_train, y_train)
num_rounds = 300
plst = list(params.items())
model = xgb.train(plst, dtrain, num_rounds)
# 对测试集进行预测
dtest = xgb.DMatrix(X_test)
ans = model.predict(dtest)
# 显示重要特征
plot_importance(model)
plt.show()XGBoost调参(结合sklearn网格搜索)
代码参考:https://www.jianshu.com/p/1100e333fcab
import xgboost as xgb
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import roc_auc_score
iris = load_iris()
X,y = iris.data,iris.target
col = iris.target_names
train_x, valid_x, train_y, valid_y = train_test_split(X, y, test_size=0.3, random_state=1) # 分训练集和验证集
parameters = {
'max_depth': [5, 10, 15, 20, 25],
'learning_rate': [0.01, 0.02, 0.05, 0.1, 0.15],
'n_estimators': [500, 1000, 2000, 3000, 5000],
'min_child_weight': [0, 2, 5, 10, 20],
'max_delta_step': [0, 0.2, 0.6, 1, 2],
'subsample': [0.6, 0.7, 0.8, 0.85, 0.95],
'colsample_bytree': [0.5, 0.6, 0.7, 0.8, 0.9],
'reg_alpha': [0, 0.25, 0.5, 0.75, 1],
'reg_lambda': [0.2, 0.4, 0.6, 0.8, 1],
'scale_pos_weight': [0.2, 0.4, 0.6, 0.8, 1]
}
xlf = xgb.XGBClassifier(max_depth=10,
learning_rate=0.01,
n_estimators=2000,
silent=True,
objective='multi:softmax',
num_class=3 ,
nthread=-1,
gamma=0,
min_child_weight=1,
max_delta_step=0,
subsample=0.85,
colsample_bytree=0.7,
colsample_bylevel=1,
reg_alpha=0,
reg_lambda=1,
scale_pos_weight=1,
seed=0,
missing=None)
gs = GridSearchCV(xlf, param_grid=parameters, scoring='accuracy', cv=3)
gs.fit(train_x, train_y)
print("Best score: %0.3f" % gs.best_score_)
print("Best parameters set: %s" % gs.best_params_ )Best score: 0.933
Best parameters set: {‘max_depth’: 5}8. LightGBM算法
LightGBM也是像XGBoost一样,是一类集成算法,他跟XGBoost总体来说是一样的,算法本质上与Xgboost没有出入,只是在XGBoost的基础上进行了优化,因此就不对原理进行重复介绍,在这里我们来看看几种算法的差别:
- 优化速度和内存使用
- 降低了计算每个分割增益的成本。
- 使用直方图减法进一步提高速度。
- 减少内存使用。
- 减少并行学习的计算成本。
- 稀疏优化
- 用离散的bin替换连续的值。如果#bins较小,则可以使用较小的数据类型(例如uint8_t)来存储训练数据 。
- 无需存储其他信息即可对特征数值进行预排序 。
- 精度优化
- 使用叶子数为导向的决策树建立算法而不是树的深度导向。
- 分类特征的编码方式的优化
- 通信网络的优化
- 并行学习的优化
- GPU支持
LightGBM的优点:
1)更快的训练效率
2)低内存使用
3)更高的准确率
4)支持并行化学习
5)可以处理大规模数据
1.速度对比:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-W562LSSA-1623946035318)(./速度对比.png)]
2.准确率对比:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J4JVvKjX-1623946035319)(./准确率对比.png)]
3.内存使用量对比:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-glXaoZd6-1623946035320)(./内存使用量.png)]LightGBM参数说明:
推荐文档1:https://lightgbm.apachecn.org/#/docs/6
推荐文档2:https://lightgbm.readthedocs.io/en/latest/Parameters.html1.核心参数:(括号内名称是别名)
- objective(objective,app ,application):默认regression,用于设置损失函数
- 回归问题:
- L2损失:regression(regression_l2,l2,mean_squared_error,mse,l2_root,root_mean_squared_error,rmse)
- L1损失:regression_l1(l1, mean_absolute_error, mae)
- 其他损失:huber,fair,poisson,quantile,mape,gamma,tweedie
- 二分类问题:二进制对数损失分类(或逻辑回归):binary
- 多类别分类:
- softmax目标函数: multiclass(softmax)
- One-vs-All 目标函数:multiclassova(multiclass_ova,ova,ovr)
- 交叉熵:
- 用于交叉熵的目标函数(具有可选的线性权重):cross_entropy(xentropy)
- 交叉熵的替代参数化:cross_entropy_lambda(xentlambda)
- 回归问题:
- boosting :默认gbdt,设置提升类型,选项有gbdt,rf,dart,goss,别名:boosting_type,boost
- gbdt(gbrt):传统的梯度提升决策树
- rf(random_forest):随机森林
- dart:多个加性回归树的DROPOUT方法 Dropouts meet Multiple Additive Regression Trees,参见:https://arxiv.org/abs/1505.01866
- goss:基于梯度的单边采样 Gradient-based One-Side Sampling
- data(train,train_data,train_data_file,data_filename):用于训练的数据或数据file
- valid (test,valid_data,valid_data_file,test_data,test_data_file,valid_filenames):验证/测试数据的路径,LightGBM将输出这些数据的指标
- num_iterations:默认=100,类型= INT
- n_estimators:提升迭代次数,LightGBM构造用于多类分类问题的树num_class * num_iterations
- learning_rate(shrinkage_rate,eta) :收缩率,默认=0.1
- num_leaves(num_leaf,max_leaves,max_leaf) :默认=31,一棵树上的最大叶子数
- tree_learner (tree,tree_type,tree_learner_type):默认=serial,可选:serial,feature,data,voting
- serial:单台机器的 tree learner
- feature:特征并行的 tree learner
- data:数据并行的 tree learner
- voting:投票并行的 tree learner
- num_threads(num_thread, nthread):LightGBM 的线程数,为了更快的速度, 将此设置为真正的 CPU 内核数, 而不是线程的数量 (大多数 CPU 使用超线程来使每个 CPU 内核生成 2 个线程),当你的数据集小的时候不要将它设置的过大 (比如, 当数据集有 10,000 行时不要使用 64 线程),对于并行学习, 不应该使用全部的 CPU 内核, 因为这会导致网络性能不佳。
- device(device_type):默认cpu,为树学习选择设备, 你可以使用 GPU 来获得更快的学习速度,可选cpu, gpu。
- seed (random_seed,random_state):与其他种子相比,该种子具有较低的优先级,这意味着如果您明确设置其他种子,它将被覆盖。
2.用于控制模型学习过程的参数:
- max_depth:限制树模型的最大深度. 这可以在 #data 小的情况下防止过拟合. 树仍然可以通过 leaf-wise 生长。
- min_data_in_leaf: 默认=20,一个叶子上数据的最小数量. 可以用来处理过拟合。
- min_sum_hessian_in_leaf(min_sum_hessian_per_leaf, min_sum_hessian, min_hessian):默认=1e-3,一个叶子上的最小 hessian 和. 类似于 min_data_in_leaf, 可以用来处理过拟合.
- feature_fraction:default=1.0,如果 feature_fraction 小于 1.0, LightGBM 将会在每次迭代中随机选择部分特征. 例如, 如果设置为 0.8, 将会在每棵树训练之前选择 80% 的特征,可以用来加速训练,可以用来处理过拟合。
- feature_fraction_seed:默认=2,feature_fraction 的随机数种子。
- bagging_fraction(sub_row, subsample):默认=1,不进行重采样的情况下随机选择部分数据
- bagging_freq(subsample_freq):bagging 的频率, 0 意味着禁用 bagging. k 意味着每 k 次迭代执行bagging
- bagging_seed(bagging_fraction_seed) :默认=3,bagging 随机数种子。
- early_stopping_round(early_stopping_rounds, early_stopping):默认=0,如果一个验证集的度量在 early_stopping_round 循环中没有提升, 将停止训练
- lambda_l1(reg_alpha):L1正则化系数
- lambda_l2(reg_lambda):L2正则化系数
- min_split_gain(min_gain_to_split):执行切分的最小增益,默认=0.
- cat_smooth:默认=10,用于分类特征,可以降低噪声在分类特征中的影响, 尤其是对数据很少的类别
3.度量参数:
- metric:default={l2 for regression}, {binary_logloss for binary classification}, {ndcg for lambdarank}, type=multi-enum, options=l1, l2, ndcg, auc, binary_logloss, binary_error …
- l1, absolute loss, alias=mean_absolute_error, mae
- l2, square loss, alias=mean_squared_error, mse
- l2_root, root square loss, alias=root_mean_squared_error, rmse
- quantile, Quantile regression
- huber, Huber loss
- fair, Fair loss
- poisson, Poisson regression
- ndcg, NDCG
- map, MAP
- auc, AUC
- binary_logloss, log loss
- binary_error, 样本: 0 的正确分类, 1 错误分类
- multi_logloss, mulit-class 损失日志分类
- multi_error, error rate for mulit-class 出错率分类
- xentropy, cross-entropy (与可选的线性权重), alias=cross_entropy
- xentlambda, “intensity-weighted” 交叉熵, alias=cross_entropy_lambda
- kldiv, Kullback-Leibler divergence, alias=kullback_leibler
- 支持多指标, 使用 , 分隔
- train_metric(training_metric, is_training_metric):默认=False,如果你需要输出训练的度量结果则设置 true
4.GPU 参数:
- gpu_device_id:default为-1, 这个default意味着选定平台上的设备。
LightGBM与网格搜索结合调参:
参考代码:https://blog.csdn.net/u012735708/article/details/83749703import lightgbm as lgb
from sklearn import metrics
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
canceData=load_breast_cancer()
X=canceData.data
y=canceData.target
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=0,test_size=0.2)
### 数据转换
print('数据转换')
lgb_train = lgb.Dataset(X_train, y_train, free_raw_data=False)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train,free_raw_data=False)
### 设置初始参数--不含交叉验证参数
print('设置参数')
params = {
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': 'auc',
'nthread':4,
'learning_rate':0.1
}
### 交叉验证(调参)
print('交叉验证')
max_auc = float('0')
best_params = {}
# 准确率
print("调参1:提高准确率")
for num_leaves in range(5,100,5):
for max_depth in range(3,8,1):
params['num_leaves'] = num_leaves
params['max_depth'] = max_depth
cv_results = lgb.cv(
params,
lgb_train,
seed=1,
nfold=5,
metrics=['auc'],
early_stopping_rounds=10,
verbose_eval=True
)
mean_auc = pd.Series(cv_results['auc-mean']).max()
boost_rounds = pd.Series(cv_results['auc-mean']).idxmax()
if mean_auc >= max_auc:
max_auc = mean_auc
best_params['num_leaves'] = num_leaves
best_params['max_depth'] = max_depth
if 'num_leaves' and 'max_depth' in best_params.keys():
params['num_leaves'] = best_params['num_leaves']
params['max_depth'] = best_params['max_depth']
# 过拟合
print("调参2:降低过拟合")
for max_bin in range(5,256,10):
for min_data_in_leaf in range(1,102,10):
params['max_bin'] = max_bin
params['min_data_in_leaf'] = min_data_in_leaf
cv_results = lgb.cv(
params,
lgb_train,
seed=1,
nfold=5,
metrics=['auc'],
early_stopping_rounds=10,
verbose_eval=True
)
mean_auc = pd.Series(cv_results['auc-mean']).max()
boost_rounds = pd.Series(cv_results['auc-mean']).idxmax()
if mean_auc >= max_auc:
max_auc = mean_auc
best_params['max_bin']= max_bin
best_params['min_data_in_leaf'] = min_data_in_leaf
if 'max_bin' and 'min_data_in_leaf' in best_params.keys():
params['min_data_in_leaf'] = best_params['min_data_in_leaf']
params['max_bin'] = best_params['max_bin']
print("调参3:降低过拟合")
for feature_fraction in [0.6,0.7,0.8,0.9,1.0]:
for bagging_fraction in [0.6,0.7,0.8,0.9,1.0]:
for bagging_freq in range(0,50,5):
params['feature_fraction'] = feature_fraction
params['bagging_fraction'] = bagging_fraction
params['bagging_freq'] = bagging_freq
cv_results = lgb.cv(
params,
lgb_train,
seed=1,
nfold=5,
metrics=['auc'],
early_stopping_rounds=10,
verbose_eval=True
)
mean_auc = pd.Series(cv_results['auc-mean']).max()
boost_rounds = pd.Series(cv_results['auc-mean']).idxmax()
if mean_auc >= max_auc:
max_auc=mean_auc
best_params['feature_fraction'] = feature_fraction
best_params['bagging_fraction'] = bagging_fraction
best_params['bagging_freq'] = bagging_freq
if 'feature_fraction' and 'bagging_fraction' and 'bagging_freq' in best_params.keys():
params['feature_fraction'] = best_params['feature_fraction']
params['bagging_fraction'] = best_params['bagging_fraction']
params['bagging_freq'] = best_params['bagging_freq']
print("调参4:降低过拟合")
for lambda_l1 in [1e-5,1e-3,1e-1,0.0,0.1,0.3,0.5,0.7,0.9,1.0]:
for lambda_l2 in [1e-5,1e-3,1e-1,0.0,0.1,0.4,0.6,0.7,0.9,1.0]:
params['lambda_l1'] = lambda_l1
params['lambda_l2'] = lambda_l2
cv_results = lgb.cv(
params,
lgb_train,
seed=1,
nfold=5,
metrics=['auc'],
early_stopping_rounds=10,
verbose_eval=True
)
mean_auc = pd.Series(cv_results['auc-mean']).max()
boost_rounds = pd.Series(cv_results['auc-mean']).idxmax()
if mean_auc >= max_auc:
max_auc=mean_auc
best_params['lambda_l1'] = lambda_l1
best_params['lambda_l2'] = lambda_l2
if 'lambda_l1' and 'lambda_l2' in best_params.keys():
params['lambda_l1'] = best_params['lambda_l1']
params['lambda_l2'] = best_params['lambda_l2']
print("调参5:降低过拟合2")
for min_split_gain in [0.0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0]:
params['min_split_gain'] = min_split_gain
cv_results = lgb.cv(
params,
lgb_train,
seed=1,
nfold=5,
metrics=['auc'],
early_stopping_rounds=10,
verbose_eval=True
)
mean_auc = pd.Series(cv_results['auc-mean']).max()
boost_rounds = pd.Series(cv_results['auc-mean']).idxmax()
if mean_auc >= max_auc:
max_auc=mean_auc
best_params['min_split_gain'] = min_split_gain
if 'min_split_gain' in best_params.keys():
params['min_split_gain'] = best_params['min_split_gain']
print(best_params){‘bagging_fraction’: 0.7,
‘bagging_freq’: 30,
‘feature_fraction’: 0.8,
‘lambda_l1’: 0.1,
‘lambda_l2’: 0.0,
‘max_bin’: 255,
‘max_depth’: 4,
‘min_data_in_leaf’: 81,
‘min_split_gain’: 0.1,
‘num_leaves’: 10}9. 结语
本章中,我们主要探讨了基于Boosting方式的集成方法,其中主要讲解了基于错误率驱动的Adaboost,基于残差改进的提升树,基于梯度提升的GBDT,基于泰勒二阶近似的Xgboost以及LightGBM。在实际的比赛或者工程中,基于Boosting的集成学习方式是非常有效且应用非常广泛的。更多的学习有待读者更深入阅读文献,包括原作者论文以及论文复现等。下一章我们即将探讨另一种集成学习方式:Stacking集成学习方式,这种集成方式虽然没有Boosting应用广泛,但是在比赛中或许能让你的模型更加出众。
本章作业:
]]>
本章在最后介绍LightGBM的时候并没有详细介绍它的原理以及它与XGBoost的不一样的地方,希望读者好好看看别的文章分享,总结LigntGBM与XGBoost的不同,然后使用一个具体的案例体现两者的不同。
参考链接: https://blog.csdn.net/weixin_30279315/article/details/95504220- <h1 id="XGBoost算法"><a href="#XGBoost算法" class="headerlink" title="XGBoost算法"></a>XGBoost算法</h1><p>XGBoost是陈天奇等人开发的一个开源机器学习项目,高效地实现了GBDT算法并进行了算法和工程上的许多改进,被广泛应用在Kaggle竞赛及其他许多机器学习竞赛中并取得了不错的成绩。<strong>XGBoost本质上还是一个GBDT,但是力争把速度和效率发挥到极致,所以叫X (Extreme) GBoosted,</strong> 包括前面说过,两者都是boosting方法。XGBoost是一个优化的分布式梯度增强库,旨在实现高效,灵活和便携。 它在Gradient Boosting框架下实现机器学习算法。 XGBoost提供了<strong>并行树提升</strong>(也称为GBDT,GBM),可以快速准确地解决许多数据科学问题。 相同的代码在主要的分布式环境(Hadoop,SGE,MPI)上运行,并且可以解决超过数十亿个样例的问题。XGBoost利用了核外计算并且能够使数据科学家在一个主机上处理数亿的样本数据。最终,将这些技术进行结合来做一个端到端的系统以最少的集群系统来扩展到更大的数据集上。Xgboost<strong>以CART决策树为子模型</strong>,通过Gradient Tree Boosting实现多棵CART树的集成学习,得到最终模型。下面我们来看看XGBoost的最终模型构建:</p> + <h1 id="XGBoost算法"><a href="#XGBoost算法" class="headerlink" title="XGBoost算法"></a>XGBoost算法</h1><p>XGBoost是陈天奇等人开发的一个开源机器学习项目,高效地实现了GBDT算法并进行了算法和工程上的许多改进,被广泛应用在Kaggle竞赛及其他许多机器学习竞赛中并取得了不错的成绩。<strong>XGBoost本质上还是一个GBDT,但是力争把速度和效率发挥到极致,所以叫X (Extreme) GBoosted,</strong> 包括前面说过,两者都是boosting方法。XGBoost是一个优化的分布式梯度增强库,旨在实现高效,灵活和便携。 它在Gradient Boosting框架下实现机器学习算法。 XGBoost提供了<strong>并行树提升</strong>(也称为GBDT,GBM),可以快速准确地解决许多数据科学问题。 相同的代码在主要的分布式环境(Hadoop,SGE,MPI)上运行,并且可以解决超过数十亿个样例的问题。XGBoost利用了核外计算并且能够使数据科学家在一个主机上处理数亿的样本数据。最终,将这些技术进行结合来做一个端到端的系统以最少的集群系统来扩展到更大的数据集上。Xgboost<strong>以CART决策树为子模型</strong>,通过Gradient Tree Boosting实现多棵CART树的集成学习,得到最终模型。下面我们来看看XGBoost的最终模型构建:<br></p> @@ -194,11 +194,11 @@2021-06-17T15:59:00.000Z 2024-10-09T07:33:09.914Z -梯度提升决策树(GBDT) +(1) 基于残差学习的提升树算法:
在前面的学习过程中,我们一直讨论的都是分类树,比如Adaboost算法,并没有涉及回归的例子。在上一小节我们提到了一个加法模型+前向分步算法的框架,那能否使用这个框架解决回归的例子呢?答案是肯定的。接下来我们来探讨下如何使用加法模型+前向分步算法的框架实现回归问题。
在使用加法模型+前向分步算法的框架解决问题之前,我们需要首先确定框架内使用的基函数是什么,在这里我们使用决策树分类器。前面第二章我们已经学过了回归树的基本原理,树算法最重要是寻找最佳的划分点,分类树用纯度来判断最佳划分点使用信息增益(ID3算法),信息增益比(C4.5算法),基尼系数(CART分类树)。但是在回归树中的样本标签是连续数值,可划分点包含了所有特征的所有可取的值。所以再使用熵之类的指标不再合适,取而代之的是平方误差,它能很好的评判拟合程度。 基函数确定了以后,我们需要确定每次提升的标准是什么。回想Adaboost算法,在Adaboost算法内使用了分类错误率修正样本权重以及计算每个基本分类器的权重,那回归问题没有分类错误率可言,也就没办法在这里的回归问题使用了,因此我们需要另辟蹊径。模仿分类错误率,我们用每个样本的残差表示每次使用基函数预测时没有解决的那部分问题。因此,我们可以得出如下算法:输入数据集$T=\left{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \cdots,\left(x_{N}, y_{N}\right)\right}, x_{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}, y_{i} \in \mathcal{Y} \subseteq \mathbf{R}$,输出最终的提升树$f_{M}(x)$
- 初始化$f_0(x) = 0$
- 对m = 1,2,…,M:
- 计算每个样本的残差:$r_{m i}=y_{i}-f_{m-1}\left(x_{i}\right), \quad i=1,2, \cdots, N$
- 拟合残差$r_{mi}$学习一棵回归树,得到$T\left(x ; \Theta_{m}\right)$
- 更新$f_{m}(x)=f_{m-1}(x)+T\left(x ; \Theta_{m}\right)$
- 得到最终的回归问题的提升树:$f_{M}(x)=\sum_{m=1}^{M} T\left(x ; \Theta_{m}\right)$
下面我们用一个实际的案例来使用这个算法:(案例来源:李航老师《统计学习方法》)
训练数据如下表,学习这个回归问题的提升树模型,考虑只用树桩作为基函数。至此,我们已经能够建立起依靠加法模型+前向分步算法的框架解决回归问题的算法,叫提升树算法。那么,这个算法还是否有提升的空间呢?
(2) 梯度提升决策树算法(GBDT):
提升树利用加法模型和前向分步算法实现学习的过程,当损失函数为平方损失和指数损失时,每一步优化是相当简单的,也就是我们前面探讨的提升树算法和Adaboost算法。但是对于一般的损失函数而言,往往每一步的优化不是那么容易,针对这一问题,我们得分析问题的本质,也就是是什么导致了在一般损失函数条件下的学习困难。对比以下损失函数:
$$
\begin{array}{l|l|l}
\hline \text { Setting } & \text { Loss Function } & -\partial L\left(y_{i}, f\left(x_{i}\right)\right) / \partial f\left(x_{i}\right) \
\hline \text { Regression } & \frac{1}{2}\left[y_{i}-f\left(x_{i}\right)\right]^{2} & y_{i}-f\left(x_{i}\right) \
\hline \text { Regression } & \left|y_{i}-f\left(x_{i}\right)\right| & \operatorname{sign}\left[y_{i}-f\left(x_{i}\right)\right] \
\hline \text { Regression } & \text { Huber } & y_{i}-f\left(x_{i}\right) \text { for }\left|y_{i}-f\left(x_{i}\right)\right| \leq \delta_{m} \
& & \delta_{m} \operatorname{sign}\left[y_{i}-f\left(x_{i}\right)\right] \text { for }\left|y_{i}-f\left(x_{i}\right)\right|>\delta_{m} \
& & \text { where } \delta_{m}=\alpha \text { th-quantile }\left{\left|y_{i}-f\left(x_{i}\right)\right|\right} \
\hline \text { Classification } & \text { Deviance } & k \text { th component: } I\left(y_{i}=\mathcal{G}{k}\right)-p{k}\left(x_{i}\right) \
\hline
\end{array}
$$
观察Huber损失函数:
$$
L_{\delta}(y, f(x))=\left{\begin{array}{ll}
\frac{1}{2}(y-f(x))^{2} & \text { for }|y-f(x)| \leq \delta \
\delta|y-f(x)|-\frac{1}{2} \delta^{2} & \text { otherwise }
\end{array}\right.
$$
针对上面的问题,Freidman提出了梯度提升算法(gradient boosting),这是利用最速下降法的近似方法,利用损失函数的负梯度在当前模型的值$-\left[\frac{\partial L\left(y, f\left(x_{i}\right)\right)}{\partial f\left(x_{i}\right)}\right]{f(x)=f{m-1}(x)}$作为回归问题提升树算法中的残差的近似值,拟合回归树。与其说负梯度作为残差的近似值,不如说残差是负梯度的一种特例。
以下开始具体介绍梯度提升算法:
输入训练数据集$T=\left{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \cdots,\left(x_{N}, y_{N}\right)\right}, x_{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}, y_{i} \in \mathcal{Y} \subseteq \mathbf{R}$和损失函数$L(y, f(x))$,输出回归树$\hat{f}(x)$- 初始化$f_{0}(x)=\arg \min {c} \sum{i=1}^{N} L\left(y_{i}, c\right)$
- 对于m=1,2,…,M:
- 对i = 1,2,…,N计算:$r_{m i}=-\left[\frac{\partial L\left(y_{i}, f\left(x_{i}\right)\right)}{\partial f\left(x_{i}\right)}\right]{f(x)=f{m-1}(x)}$
- 对$r_{mi}$拟合一个回归树,得到第m棵树的叶结点区域$R_{m j}, j=1,2, \cdots, J$
- 对j=1,2,…J,计算:$c_{m j}=\arg \min {c} \sum{x_{i} \in R_{m j}} L\left(y_{i}, f_{m-1}\left(x_{i}\right)+c\right)$
- 更新$f_{m}(x)=f_{m-1}(x)+\sum_{j=1}^{J} c_{m j} I\left(x \in R_{m j}\right)$
- 得到回归树:$\hat{f}(x)=f_{M}(x)=\sum_{m=1}^{M} \sum_{j=1}^{J} c_{m j} I\left(x \in R_{m j}\right)$
下面,我们来使用一个具体的案例来说明GBDT是如何运作的(案例来源:https://blog.csdn.net/zpalyq110/article/details/79527653 ):
下面的表格是数据:学习率:learning_rate=0.1,迭代次数:n_trees=5,树的深度:max_depth=3
平方损失的负梯度为:
$$
-\left[\frac{\left.\partial L\left(y, f\left(x_{i}\right)\right)\right)}{\partial f\left(x_{i}\right)}\right]{f(x)=f{t-1}(x)}=y-f\left(x_{i}\right)
$$
$c=(1.1+1.3+1.7+1.8)/4=1.475,f_{0}(x)=c=1.475$学习决策树,分裂结点:
对于左节点,只有0,1两个样本,那么根据下表我们选择年龄7进行划分:
对于右节点,只有2,3两个样本,那么根据下表我们选择年龄30进行划分:
因此根据$\Upsilon_{j 1}=\underbrace{\arg \min }{\Upsilon} \sum{x_{i} \in R_{j 1}} L\left(y_{i}, f_{0}\left(x_{i}\right)+\Upsilon\right)$:
$$
\begin{array}{l}
\left(x_{0} \in R_{11}\right), \quad \Upsilon_{11}=-0.375 \
\left(x_{1} \in R_{21}\right), \quad \Upsilon_{21}=-0.175 \
\left(x_{2} \in R_{31}\right), \quad \Upsilon_{31}=0.225 \
\left(x_{3} \in R_{41}\right), \quad \Upsilon_{41}=0.325
\end{array}
$$
这里其实和上面初始化学习器是一个道理,平方损失,求导,令导数等于零,化简之后得到每个叶子节点的参数$\Upsilon$,其实就是标签值的均值。
最后得到五轮迭代:最后的强学习器为:$f(x)=f_{5}(x)=f_{0}(x)+\sum_{m=1}^{5} \sum_{j=1}^{4} \Upsilon_{j m} I\left(x \in R_{j m}\right)$。
其中:
$$
\begin{array}{ll}
f_{0}(x)=1.475 & f_{2}(x)=0.0205 \
f_{3}(x)=0.1823 & f_{4}(x)=0.1640 \
f_{5}(x)=0.1476
\end{array}
$$
预测结果为:
$$
f(x)=1.475+0.1 *(0.2250+0.2025+0.1823+0.164+0.1476)=1.56714
$$
为什么要用学习率呢?这是Shrinkage的思想,如果每次都全部加上(学习率为1)很容易一步学到位导致过拟合。下面我们来使用sklearn来使用GBDT:
- https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingRegressor.html#sklearn.ensemble.GradientBoostingRegressor
- https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingClassifier.html?highlight=gra#sklearn.ensemble.GradientBoostingClassifier
from sklearn.metrics import mean_squared_error
from sklearn.datasets import make_friedman1
from sklearn.ensemble import GradientBoostingRegressor
'''
GradientBoostingRegressor参数解释:
loss:{‘ls’, ‘lad’, ‘huber’, ‘quantile’}, default=’ls’:‘ls’ 指最小二乘回归. ‘lad’ (最小绝对偏差) 是仅基于输入变量的顺序信息的高度鲁棒的损失函数。. ‘huber’ 是两者的结合. ‘quantile’允许分位数回归(用于alpha指定分位数)
learning_rate:学习率缩小了每棵树的贡献learning_rate。在learning_rate和n_estimators之间需要权衡。
n_estimators:要执行的提升次数。
subsample:用于拟合各个基础学习者的样本比例。如果小于1.0,则将导致随机梯度增强。subsample与参数n_estimators。选择会导致方差减少和偏差增加。subsample < 1.0
criterion:{'friedman_mse','mse','mae'},默认='friedman_mse':“ mse”是均方误差,“ mae”是平均绝对误差。默认值“ friedman_mse”通常是最好的,因为在某些情况下它可以提供更好的近似值。
min_samples_split:拆分内部节点所需的最少样本数
min_samples_leaf:在叶节点处需要的最小样本数。
min_weight_fraction_leaf:在所有叶节点处(所有输入样本)的权重总和中的最小加权分数。如果未提供sample_weight,则样本的权重相等。
max_depth:各个回归模型的最大深度。最大深度限制了树中节点的数量。调整此参数以获得最佳性能;最佳值取决于输入变量的相互作用。
min_impurity_decrease:如果节点分裂会导致杂质的减少大于或等于该值,则该节点将被分裂。
min_impurity_split:提前停止树木生长的阈值。如果节点的杂质高于阈值,则该节点将分裂
max_features{‘auto’, ‘sqrt’, ‘log2’},int或float:寻找最佳分割时要考虑的功能数量:
如果为int,则max_features在每个分割处考虑特征。
如果为float,max_features则为小数,并在每次拆分时考虑要素。int(max_features * n_features)
如果“auto”,则max_features=n_features。
如果是“ sqrt”,则max_features=sqrt(n_features)。
如果为“ log2”,则为max_features=log2(n_features)。
如果没有,则max_features=n_features。
'''
X, y = make_friedman1(n_samples=1200, random_state=0, noise=1.0)
X_train, X_test = X[:200], X[200:]
y_train, y_test = y[:200], y[200:]
reg = GradientBoostingRegressor(n_estimators=100,
learning_rate=0.1,max_depth=1, random_state=0, loss='ls')
est = reg.fit(X_train, y_train)
mean_squared_error(y_test, est.predict(X_test))from sklearn.datasets import make_regression
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.model_selection import train_test_split
X, y = make_regression(random_state=0)
X_train, X_test, y_train, y_test = train_test_split(
X, y, random_state=0)
reg = GradientBoostingRegressor(random_state=0)
reg.fit(X_train, y_train)
reg.score(X_test, y_test)GradientBoostingRegressor与GradientBoostingClassifier函数的各个参数的参考文档:
]]>梯度提升决策树(GBDT) (1) 基于残差学习的提升树算法:
在前面的学习过程中,我们一直讨论的都是分类树,比如Adaboost算法,并没有涉及回归的例子。在上一小节我们提到了一个加法模型+前向分步算法的框架,那能否使用这个框架解决回归的例子呢?答案是肯定的。接下来我们来探讨下如何使用加法模型+前向分步算法的框架实现回归问题。
在使用加法模型+前向分步算法的框架解决问题之前,我们需要首先确定框架内使用的基函数是什么,在这里我们使用决策树分类器。前面第二章我们已经学过了回归树的基本原理,树算法最重要是寻找最佳的划分点,分类树用纯度来判断最佳划分点使用信息增益(ID3算法),信息增益比(C4.5算法),基尼系数(CART分类树)。但是在回归树中的样本标签是连续数值,可划分点包含了所有特征的所有可取的值。所以再使用熵之类的指标不再合适,取而代之的是平方误差,它能很好的评判拟合程度。 基函数确定了以后,我们需要确定每次提升的标准是什么。回想Adaboost算法,在Adaboost算法内使用了分类错误率修正样本权重以及计算每个基本分类器的权重,那回归问题没有分类错误率可言,也就没办法在这里的回归问题使用了,因此我们需要另辟蹊径。模仿分类错误率,我们用每个样本的残差表示每次使用基函数预测时没有解决的那部分问题。因此,我们可以得出如下算法:
输入数据集$T=\left{\left(x{1}, y{1}\right),\left(x{2}, y{2}\right), \cdots,\left(x{N}, y{N}\right)\right}, x{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}, y{i} \in \mathcal{Y} \subseteq \mathbf{R}$,输出最终的提升树$f_{M}(x)$- 初始化$f_0(x) = 0$
- 对m = 1,2,…,M:
- 计算每个样本的残差:$r{m i}=y{i}-f{m-1}\left(x{i}\right), \quad i=1,2, \cdots, N$
- 拟合残差$r{mi}$学习一棵回归树,得到$T\left(x ; \Theta{m}\right)$
- 更新$f{m}(x)=f{m-1}(x)+T\left(x ; \Theta_{m}\right)$
- 得到最终的回归问题的提升树:$f{M}(x)=\sum{m=1}^{M} T\left(x ; \Theta_{m}\right)$
下面我们用一个实际的案例来使用这个算法:(案例来源:李航老师《统计学习方法》)
训练数据如下表,学习这个回归问题的提升树模型,考虑只用树桩作为基函数。至此,我们已经能够建立起依靠加法模型+前向分步算法的框架解决回归问题的算法,叫提升树算法。那么,这个算法还是否有提升的空间呢?
(2) 梯度提升决策树算法(GBDT):
提升树利用加法模型和前向分步算法实现学习的过程,当损失函数为平方损失和指数损失时,每一步优化是相当简单的,也就是我们前面探讨的提升树算法和Adaboost算法。但是对于一般的损失函数而言,往往每一步的优化不是那么容易,针对这一问题,我们得分析问题的本质,也就是是什么导致了在一般损失函数条件下的学习困难。对比以下损失函数:观察Huber损失函数:
针对上面的问题,Freidman提出了梯度提升算法(gradient boosting),这是利用最速下降法的近似方法,利用损失函数的负梯度在当前模型的值$-\left[\frac{\partial L\left(y, f\left(x{i}\right)\right)}{\partial f\left(x{i}\right)}\right]{f(x)=f{m-1}(x)}$作为回归问题提升树算法中的残差的近似值,拟合回归树。与其说负梯度作为残差的近似值,不如说残差是负梯度的一种特例。
以下开始具体介绍梯度提升算法:
输入训练数据集$T=\left{\left(x{1}, y{1}\right),\left(x{2}, y{2}\right), \cdots,\left(x{N}, y{N}\right)\right}, x{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}, y{i} \in \mathcal{Y} \subseteq \mathbf{R}$和损失函数$L(y, f(x))$,输出回归树$\hat{f}(x)$- 初始化$f{0}(x)=\arg \min {c} \sum{i=1}^{N} L\left(y{i}, c\right)$
- 对于m=1,2,…,M:
- 对i = 1,2,…,N计算:$r{m i}=-\left[\frac{\partial L\left(y{i}, f\left(x{i}\right)\right)}{\partial f\left(x{i}\right)}\right]{f(x)=f{m-1}(x)}$
- 对$r{mi}$拟合一个回归树,得到第m棵树的叶结点区域$R{m j}, j=1,2, \cdots, J$
- 对j=1,2,…J,计算:$c{m j}=\arg \min {c} \sum{x{i} \in R{m j}} L\left(y{i}, f{m-1}\left(x{i}\right)+c\right)$
- 更新$f{m}(x)=f{m-1}(x)+\sum{j=1}^{J} c{m j} I\left(x \in R_{m j}\right)$
- 得到回归树:$\hat{f}(x)=f{M}(x)=\sum{m=1}^{M} \sum{j=1}^{J} c{m j} I\left(x \in R_{m j}\right)$
下面,我们来使用一个具体的案例来说明GBDT是如何运作的(案例来源:https://blog.csdn.net/zpalyq110/article/details/79527653 ):
下面的表格是数据:学习率:learning_rate=0.1,迭代次数:n_trees=5,树的深度:max_depth=3
平方损失的负梯度为:$c=(1.1+1.3+1.7+1.8)/4=1.475,f_{0}(x)=c=1.475$
学习决策树,分裂结点:
对于左节点,只有0,1两个样本,那么根据下表我们选择年龄7进行划分:
对于右节点,只有2,3两个样本,那么根据下表我们选择年龄30进行划分:
因此根据$\Upsilon{j 1}=\underbrace{\arg \min }{\Upsilon} \sum{x{i} \in R{j 1}} L\left(y{i}, f{0}\left(x{i}\right)+\Upsilon\right)$:
这里其实和上面初始化学习器是一个道理,平方损失,求导,令导数等于零,化简之后得到每个叶子节点的参数$\Upsilon$,其实就是标签值的均值。
最后得到五轮迭代:最后的强学习器为:$f(x)=f{5}(x)=f{0}(x)+\sum{m=1}^{5} \sum{j=1}^{4} \Upsilon{j m} I\left(x \in R{j m}\right)$。
其中:预测结果为:
为什么要用学习率呢?这是Shrinkage的思想,如果每次都全部加上(学习率为1)很容易一步学到位导致过拟合。
下面我们来使用sklearn来使用GBDT:
- https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingRegressor.html#sklearn.ensemble.GradientBoostingRegressor
- https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingClassifier.html?highlight=gra#sklearn.ensemble.GradientBoostingClassifier
from sklearn.metrics import mean_squared_error
from sklearn.datasets import make_friedman1
from sklearn.ensemble import GradientBoostingRegressor
'''
GradientBoostingRegressor参数解释:
loss:{‘ls’, ‘lad’, ‘huber’, ‘quantile’}, default=’ls’:‘ls’ 指最小二乘回归. ‘lad’ (最小绝对偏差) 是仅基于输入变量的顺序信息的高度鲁棒的损失函数。. ‘huber’ 是两者的结合. ‘quantile’允许分位数回归(用于alpha指定分位数)
learning_rate:学习率缩小了每棵树的贡献learning_rate。在learning_rate和n_estimators之间需要权衡。
n_estimators:要执行的提升次数。
subsample:用于拟合各个基础学习者的样本比例。如果小于1.0,则将导致随机梯度增强。subsample与参数n_estimators。选择会导致方差减少和偏差增加。subsample < 1.0
criterion:{'friedman_mse','mse','mae'},默认='friedman_mse':“ mse”是均方误差,“ mae”是平均绝对误差。默认值“ friedman_mse”通常是最好的,因为在某些情况下它可以提供更好的近似值。
min_samples_split:拆分内部节点所需的最少样本数
min_samples_leaf:在叶节点处需要的最小样本数。
min_weight_fraction_leaf:在所有叶节点处(所有输入样本)的权重总和中的最小加权分数。如果未提供sample_weight,则样本的权重相等。
max_depth:各个回归模型的最大深度。最大深度限制了树中节点的数量。调整此参数以获得最佳性能;最佳值取决于输入变量的相互作用。
min_impurity_decrease:如果节点分裂会导致杂质的减少大于或等于该值,则该节点将被分裂。
min_impurity_split:提前停止树木生长的阈值。如果节点的杂质高于阈值,则该节点将分裂
max_features{‘auto’, ‘sqrt’, ‘log2’},int或float:寻找最佳分割时要考虑的功能数量:
如果为int,则max_features在每个分割处考虑特征。
如果为float,max_features则为小数,并在每次拆分时考虑要素。int(max_features * n_features)
如果“auto”,则max_features=n_features。
如果是“ sqrt”,则max_features=sqrt(n_features)。
如果为“ log2”,则为max_features=log2(n_features)。
如果没有,则max_features=n_features。
'''
X, y = make_friedman1(n_samples=1200, random_state=0, noise=1.0)
X_train, X_test = X[:200], X[200:]
y_train, y_test = y[:200], y[200:]
reg = GradientBoostingRegressor(n_estimators=100,
learning_rate=0.1,max_depth=1, random_state=0, loss='ls')
est = reg.fit(X_train, y_train)
mean_squared_error(y_test, est.predict(X_test))from sklearn.datasets import make_regression
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.model_selection import train_test_split
X, y = make_regression(random_state=0)
X_train, X_test, y_train, y_test = train_test_split(
X, y, random_state=0)
reg = GradientBoostingRegressor(random_state=0)
reg.fit(X_train, y_train)
reg.score(X_test, y_test)GradientBoostingRegressor与GradientBoostingClassifier函数的各个参数的参考文档:
]]>- <h2 id="梯度提升决策树-GBDT"><a href="#梯度提升决策树-GBDT" class="headerlink" title="梯度提升决策树(GBDT)"></a>梯度提升决策树(GBDT)</h2><p>(1) 基于残差学习的提升树算法:<br>在前面的学习过程中,我们一直讨论的都是分类树,比如Adaboost算法,并没有涉及回归的例子。在上一小节我们提到了一个加法模型+前向分步算法的框架,那能否使用这个框架解决回归的例子呢?答案是肯定的。接下来我们来探讨下如何使用加法模型+前向分步算法的框架实现回归问题。<br>在使用加法模型+前向分步算法的框架解决问题之前,我们需要首先确定框架内使用的基函数是什么,在这里我们使用决策树分类器。前面第二章我们已经学过了回归树的基本原理,<strong>树算法最重要是寻找最佳的划分点,分类树用纯度来判断最佳划分点使用信息增益(ID3算法),信息增益比(C4.5算法),基尼系数(CART分类树)。但是在回归树中的样本标签是连续数值,可划分点包含了所有特征的所有可取的值。所以再使用熵之类的指标不再合适,取而代之的是平方误差,它能很好的评判拟合程度。</strong> 基函数确定了以后,我们需要确定每次提升的标准是什么。回想Adaboost算法,在Adaboost算法内使用了分类错误率修正样本权重以及计算每个基本分类器的权重,那回归问题没有分类错误率可言,也就没办法在这里的回归问题使用了,因此我们需要另辟蹊径。模仿分类错误率,我们用每个样本的残差表示每次使用基函数预测时没有解决的那部分问题。因此,我们可以得出如下算法: </p> + <h2 id="梯度提升决策树-GBDT"><a href="#梯度提升决策树-GBDT" class="headerlink" title="梯度提升决策树(GBDT)"></a>梯度提升决策树(GBDT)</h2><p>(1) 基于残差学习的提升树算法:<br>在前面的学习过程中,我们一直讨论的都是分类树,比如Adaboost算法,并没有涉及回归的例子。在上一小节我们提到了一个加法模型+前向分步算法的框架,那能否使用这个框架解决回归的例子呢?答案是肯定的。接下来我们来探讨下如何使用加法模型+前向分步算法的框架实现回归问题。<br>在使用加法模型+前向分步算法的框架解决问题之前,我们需要首先确定框架内使用的基函数是什么,在这里我们使用决策树分类器。前面第二章我们已经学过了回归树的基本原理,<strong>树算法最重要是寻找最佳的划分点,分类树用纯度来判断最佳划分点使用信息增益(ID3算法),信息增益比(C4.5算法),基尼系数(CART分类树)。但是在回归树中的样本标签是连续数值,可划分点包含了所有特征的所有可取的值。所以再使用熵之类的指标不再合适,取而代之的是平方误差,它能很好的评判拟合程度。</strong> 基函数确定了以后,我们需要确定每次提升的标准是什么。回想Adaboost算法,在Adaboost算法内使用了分类错误率修正样本权重以及计算每个基本分类器的权重,那回归问题没有分类错误率可言,也就没办法在这里的回归问题使用了,因此我们需要另辟蹊径。模仿分类错误率,我们用每个样本的残差表示每次使用基函数预测时没有解决的那部分问题。因此,我们可以得出如下算法:<br></p> @@ -217,11 +217,11 @@2021-06-17T15:15:00.000Z 2024-10-09T07:33:09.915Z -1. 导论 +在前面的学习中,我们探讨了一系列简单而实用的回归和分类模型,同时也探讨了如何使用集成学习家族中的Bagging思想去优化最终的模型。Bagging思想的实质是:通过Bootstrap 的方式对全样本数据集进行抽样得到抽样子集,对不同的子集使用同一种基本模型进行拟合,然后投票得出最终的预测。我们也从前面的探讨知道:Bagging主要通过降低方差的方式减少预测误差。那么,本章介绍的Boosting是与Bagging截然不同的思想,Boosting方法是使用同一组数据集进行反复学习,得到一系列简单模型,然后组合这些模型构成一个预测性能十分强大的机器学习模型。 显然,Boosting思想提高最终的预测效果是通过不断减少偏差的形式,与Bagging有着本质的不同。在Boosting这一大类方法中,笔者主要介绍两类常用的Boosting方式:Adaptive Boosting 和 Gradient Boosting 以及它们的变体Xgboost、LightGBM以及Catboost。
2. Boosting方法的基本思路
在正式介绍Boosting思想之前,我想先介绍两个例子:
第一个例子:不知道大家有没有做过错题本,我们将每次测验的错的题目记录在错题本上,不停的翻阅,直到我们完全掌握(也就是能够在考试中能够举一反三)。
第二个例子:对于一个复杂任务来说,将多个专家的判断进行适当的综合所作出的判断,要比其中任何一个专家单独判断要好。实际上这是一种“三个臭皮匠顶个诸葛亮的道理”。
这两个例子都说明Boosting的道理,也就是不错地重复学习达到最终的要求。
Boosting的提出与发展离不开Valiant和 Kearns的努力,历史上正是Valiant和 Kearns提出了”强可学习”和”弱可学习”的概念。那什么是”强可学习”和”弱可学习”呢?在概率近似正确PAC学习的框架下:- 弱学习:识别错误率小于1/2(即准确率仅比随机猜测略高的学习算法)
- 强学习:识别准确率很高并能在多项式时间内完成的学习算法
非常有趣的是,在PAC 学习的框架下,强可学习和弱可学习是等价的,也就是说一个概念是强可学习的充分必要条件是这个概念是弱可学习的。这样一来,问题便是:在学习中,如果已经发现了弱可学习算法,能否将他提升至强可学习算法。因为,弱可学习算法比强可学习算法容易得多。提升方法就是从弱学习算法出发,反复学习,得到一系列弱分类器(又称为基本分类器),然后通过一定的形式去组合这些弱分类器构成一个强分类器。大多数的Boosting方法都是通过改变训练数据集的概率分布(训练数据不同样本的权值),针对不同概率分布的数据调用弱分类算法学习一系列的弱分类器。
对于Boosting方法来说,有两个问题需要给出答案:第一个是每一轮学习应该如何改变数据的概率分布,第二个是如何将各个弱分类器组合起来。关于这两个问题,不同的Boosting算法会有不同的答案,我们接下来介绍一种最经典的Boosting算法—-Adaboost,我们需要理解Adaboost是怎么处理这两个问题以及为什么这么处理的。3. Adaboost算法
Adaboost的基本原理
对于Adaboost来说,解决上述的两个问题的方式是:
- 提高那些被前一轮分类器错误分类的样本的权重,而降低那些被正确分类的样本的权重。这样一来,那些在上一轮分类器中没有得到正确分类的样本,由于其权重的增大而在后一轮的训练中“备受关注”。
- 各个弱分类器的组合是通过采取加权多数表决的方式,具体来说,加大分类错误率低的弱分类器的权重,因为这些分类器能更好地完成分类任务,而减小分类错误率较大的弱分类器的权重,使其在表决中起较小的作用。
现在,我们来具体介绍Adaboost算法:(参考李航老师的《统计学习方法》)
假设给定一个二分类的训练数据集:$T=\left{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \cdots,\left(x_{N}, y_{N}\right)\right}$ ,其中每个样本点由特征与类别组成。特征$x_{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}$,类别$y_{i} \in \mathcal{Y}={-1,+1}$,$\mathcal{X}$是特征空间,$ \mathcal{Y}$是类别集合,输出最终分类器$G(x)$。Adaboost算法如下:
(1) 初始化训练数据的分布:$D_{1}=\left(w_{11}, \cdots, w_{1 i}, \cdots, w_{1 N}\right), \quad w_{1 i}=\frac{1}{N}, \quad i=1,2, \cdots, N$
(2) 对于m=1,2,…,M使用具有权值分布$D_m$的训练数据集进行学习,得到基本分类器:$G_{m}(x): \mathcal{X} \rightarrow{-1,+1}$
计算$G_m(x)$在训练集上的分类误差率$e_{m}=\sum_{i=1}^{N} P\left(G_{m}\left(x_{i}\right) \neq y_{i}\right)=\sum_{i=1}^{N} w_{m i} I\left(G_{m}\left(x_{i}\right) \neq y_{i}\right)$
计算$G_m(x)$的系数$\alpha_{m}=\frac{1}{2} \log \frac{1-e_{m}}{e_{m}}$,这里的log是自然对数ln
更新训练数据集的权重分布
$$
\begin{array}{c}
D_{m+1}=\left(w_{m+1,1}, \cdots, w_{m+1, i}, \cdots, w_{m+1, N}\right) \
w_{m+1, i}=\frac{w_{m i}}{Z_{m}} \exp \left(-\alpha_{m} y_{i} G_{m}\left(x_{i}\right)\right), \quad i=1,2, \cdots, N
\end{array}
$$这里的$Z_m$是规范化因子,使得$D_{m+1}$称为概率分布,$Z_{m}=\sum_{i=1}^{N} w_{m i} \exp \left(-\alpha_{m} y_{i} G_{m}\left(x_{i}\right)\right)$
(3) 构建基本分类器的线性组合$f(x)=\sum_{m=1}^{M} \alpha_{m} G_{m}(x)$,得到最终的分类器
$$
\begin{aligned}
G(x) &=\operatorname{sign}(f(x)) \
&=\operatorname{sign}\left(\sum_{m=1}^{M} \alpha_{m} G_{m}(x)\right)
\end{aligned}
$$下面对Adaboost算法做如下说明:
对于步骤(1),假设训练数据的权值分布是均匀分布,是为了使得第一次没有先验信息的条件下每个样本在基本分类器的学习中作用一样。
对于步骤(2),每一次迭代产生的基本分类器$G_m(x)$在加权训练数据集上的分类错误率$\begin{aligned}e_{m} &=\sum_{i=1}^{N} P\left(G_{m}\left(x_{i}\right) \neq y_{i}\right) =\sum_{G_{m}\left(x_{i}\right) \neq y_{i}} w_{m i}\end{aligned}$代表了在$G_m(x)$中分类错误的样本权重和,这点直接说明了权重分布$D_m$与$G_m(x)$的分类错误率$e_m$有直接关系。同时,在步骤(2)中,计算基本分类器$G_m(x)$的系数$\alpha_m$,$\alpha_{m}=\frac{1}{2} \log \frac{1-e_{m}}{e_{m}}$,它表示了$G_m(x)$在最终分类器的重要性程度,$\alpha_m$的取值由基本分类器$G_m(x)$的分类错误率有直接关系,当$e_{m} \leqslant \frac{1}{2}$时,$\alpha_{m} \geqslant 0$,并且$\alpha_m$随着$e_m$的减少而增大,因此分类错误率越小的基本分类器在最终分类器的作用越大!
**最重要的,对于步骤(2)中的样本权重的更新: **
$$
w_{m+1, i}=\left{\begin{array}{ll}
\frac{w_{m i}}{Z_{m}} \mathrm{e}^{-\alpha_{m}}, & G_{m}\left(x_{i}\right)=y_{i} \
\frac{w_{m i}}{Z_{m}} \mathrm{e}^{\alpha_{m}}, & G_{m}\left(x_{i}\right) \neq y_{i}
\end{array}\right.
$$
因此,从上式可以看到:被基本分类器$G_m(x)$错误分类的样本的权重扩大,被正确分类的样本权重减少,二者相比相差$\mathrm{e}^{2 \alpha_{m}}=\frac{1-e_{m}}{e_{m}}$倍。
对于步骤(3),线性组合$f(x)$实现了将M个基本分类器的加权表决,系数$\alpha_m$标志了基本分类器$G_m(x)$的重要性,值得注意的是:所有的$\alpha_m$之和不为1。$f(x)$的符号决定了样本x属于哪一类。下面,我们使用一组简单的数据来手动计算Adaboost算法的过程:(例子来源:http://www.csie.edu.tw)
训练数据如下表,假设基本分类器的形式是一个分割$x<v$或$x>v$表示,阈值v由该基本分类器在训练数据集上分类错误率$e_m$最低确定。
$$
\begin{array}{ccccccccccc}
\hline \text { 序号 } & 1 & 2 & 3 & 4 & 5 & 6 & 7 & 8 & 9 & 10 \
\hline x & 0 & 1 & 2 & 3 & 4 & 5 & 6 & 7 & 8 & 9 \
y & 1 & 1 & 1 & -1 & -1 & -1 & 1 & 1 & 1 & -1 \
\hline
\end{array}
$$
解:
初始化样本权值分布
$$
\begin{aligned}
D_{1} &=\left(w_{11}, w_{12}, \cdots, w_{110}\right) \
w_{1 i} &=0.1, \quad i=1,2, \cdots, 10
\end{aligned}
$$
对m=1:- 在权值分布$D_1$的训练数据集上,遍历每个结点并计算分类误差率$e_m$,阈值取v=2.5时分类误差率最低,那么基本分类器为:
$$
G_{1}(x)=\left{\begin{array}{ll}
1, & x<2.5 \ - 1, & x>2.5
\end{array}\right.
$$ - $G_1(x)$在训练数据集上的误差率为$e_{1}=P\left(G_{1}\left(x_{i}\right) \neq y_{i}\right)=0.3$。
- 计算$G_1(x)$的系数:$\alpha_{1}=\frac{1}{2} \log \frac{1-e_{1}}{e_{1}}=0.4236$
- 更新训练数据的权值分布:
$$
\begin{aligned}
D_{2}=&\left(w_{21}, \cdots, w_{2 i}, \cdots, w_{210}\right) \
w_{2 i}=& \frac{w_{1 i}}{Z_{1}} \exp \left(-\alpha_{1} y_{i} G_{1}\left(x_{i}\right)\right), \quad i=1,2, \cdots, 10 \
D_{2}=&(0.07143,0.07143,0.07143,0.07143,0.07143,0.07143,\
&0.16667,0.16667,0.16667,0.07143) \
f_{1}(x) &=0.4236 G_{1}(x)
\end{aligned}
$$
对于m=2:
- 在权值分布$D_2$的训练数据集上,遍历每个结点并计算分类误差率$e_m$,阈值取v=8.5时分类误差率最低,那么基本分类器为:
$$
G_{2}(x)=\left{\begin{array}{ll}
1, & x<8.5 \ - 1, & x>8.5
\end{array}\right.
$$ - $G_2(x)$在训练数据集上的误差率为$e_2 = 0.2143$
- 计算$G_2(x)$的系数:$\alpha_2 = 0.6496$
- 更新训练数据的权值分布:
$$
\begin{aligned}
D_{3}=&(0.0455,0.0455,0.0455,0.1667,0.1667,0.1667\
&0.1060,0.1060,0.1060,0.0455) \
f_{2}(x) &=0.4236 G_{1}(x)+0.6496 G_{2}(x)
\end{aligned}
$$
对m=3:
- 在权值分布$D_3$的训练数据集上,遍历每个结点并计算分类误差率$e_m$,阈值取v=5.5时分类误差率最低,那么基本分类器为:
$$
G_{3}(x)=\left{\begin{array}{ll}
1, & x>5.5 \ - 1, & x<5.5
\end{array}\right.
$$ - $G_3(x)$在训练数据集上的误差率为$e_3 = 0.1820$
- 计算$G_3(x)$的系数:$\alpha_3 = 0.7514$
- 更新训练数据的权值分布:
$$
D_{4}=(0.125,0.125,0.125,0.102,0.102,0.102,0.065,0.065,0.065,0.125)
$$
于是得到:$f_{3}(x)=0.4236 G_{1}(x)+0.6496 G_{2}(x)+0.7514 G_{3}(x)$,分类器$\operatorname{sign}\left[f_{3}(x)\right]$在训练数据集上的误分类点的个数为0。
于是得到最终分类器为:$G(x)=\operatorname{sign}\left[f_{3}(x)\right]=\operatorname{sign}\left[0.4236 G_{1}(x)+0.6496 G_{2}(x)+0.7514 G_{3}(x)\right]$下面,我们使用sklearn对Adaboost算法进行建模:
本次案例我们使用一份UCI的机器学习库里的开源数据集:葡萄酒数据集,该数据集可以在 ( https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data )上获得。该数据集包含了178个样本和13个特征,从不同的角度对不同的化学特性进行描述,我们的任务是根据这些数据预测红酒属于哪一个类别。(案例来源《python机器学习(第二版》)
# 引入数据科学相关工具包:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use("ggplot")
%matplotlib inline
import seaborn as sns# 加载训练数据:
wine = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data",header=None)
wine.columns = ['Class label', 'Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash','Magnesium', 'Total phenols','Flavanoids', 'Nonflavanoid phenols',
'Proanthocyanins','Color intensity', 'Hue','OD280/OD315 of diluted wines','Proline']# 数据查看:
print("Class labels",np.unique(wine["Class label"]))
wine.head()下面对数据做简单解读:
- Class label:分类标签
- Alcohol:酒精
- Malic acid:苹果酸
- Ash:灰
- Alcalinity of ash:灰的碱度
- Magnesium:镁
- Total phenols:总酚
- Flavanoids:黄酮类化合物
- Nonflavanoid phenols:非黄烷类酚类
- Proanthocyanins:原花青素
- Color intensity:色彩强度
- Hue:色调
- OD280/OD315 of diluted wines:稀释酒OD280 OD350
- Proline:脯氨酸
# 数据预处理
# 仅仅考虑2,3类葡萄酒,去除1类
wine = wine[wine['Class label']!=1]
y = wine['Class label'].values
X = wine[['Alcohol','OD280/OD315 of diluted wines']].values# 将分类标签变成二进制编码:
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y = le.fit_transform(y)
# 按8:2分割训练集和测试集
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=1,stratify=y) # stratify参数代表了按照y的类别等比例抽样使用单一决策树建模
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier(criterion='entropy',random_state=1,max_depth=1)
from sklearn.metrics import accuracy_score
tree = tree.fit(X_train,y_train)
y_train_pred = tree.predict(X_train)
y_test_pred = tree.predict(X_test)
tree_train = accuracy_score(y_train,y_train_pred)
tree_test = accuracy_score(y_test,y_test_pred)
print('Decision tree train/test accuracies %.3f/%.3f' % (tree_train,tree_test))使用sklearn实现Adaboost(基分类器为决策树)
# 使用sklearn实现Adaboost(基分类器为决策树)
'''
AdaBoostClassifier相关参数:
base_estimator:基本分类器,默认为DecisionTreeClassifier(max_depth=1)
n_estimators:终止迭代的次数
learning_rate:学习率
algorithm:训练的相关算法,{'SAMME','SAMME.R'},默认='SAMME.R'
random_state:随机种子
'''
from sklearn.ensemble import AdaBoostClassifier
adaboost = AdaBoostClassifier(base_estimator=tree,n_estimators=500,learning_rate=0.1,random_state=1)
adaboost = adaboost.fit(X_train,y_train)
y_train_pred = adaboost.predict(X_train)
y_test_pred = adaboost.predict(X_test)
ada_train = accuracy_score(y_train,y_train_pred)
ada_test = accuracy_score(y_test,y_test_pred)
print('Adaboost train/test accuracies %.3f/%.3f' % (ada_train,ada_test))结果分析:单层决策树似乎对训练数据欠拟合,而Adaboost模型正确地预测了训练数据的所有分类标签,而且与单层决策树相比,Adaboost的测试性能也略有提高。然而,为什么模型在训练集和测试集的性能相差这么大呢?我们使用图像来简单说明下这个道理!
# 画出单层决策树与Adaboost的决策边界:
x_min = X_train[:, 0].min() - 1
x_max = X_train[:, 0].max() + 1
y_min = X_train[:, 1].min() - 1
y_max = X_train[:, 1].max() + 1
# 生成网格矩阵
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),np.arange(y_min, y_max, 0.1))
f, axarr = plt.subplots(nrows=1, ncols=2,sharex='col',sharey='row',figsize=(12, 6))
for idx, clf, tt in zip([0, 1],[tree, adaboost],['Decision tree', 'Adaboost']):
clf.fit(X_train, y_train)
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
axarr[idx].contourf(xx, yy, Z, alpha=0.3)
axarr[idx].scatter(X_train[y_train==0, 0],X_train[y_train==0, 1],c='blue', marker='^')
axarr[idx].scatter(X_train[y_train==1, 0],X_train[y_train==1, 1],c='red', marker='o')
axarr[idx].set_title(tt)从上面的决策边界图可以看到:Adaboost模型的决策边界比单层决策树的决策边界要复杂的多。也就是说,Adaboost试图用增加模型复杂度而降低偏差的方式去减少总误差,但是过程中引入了方差,可能出现过拟合,因此在训练集和测试集之间的性能存在较大的差距,这就简单地回答的刚刚问题。
值的注意的是:与单个分类器相比,Adaboost等Boosting模型增加了计算的复杂度,在实践中需要仔细思考是否愿意为预测性能的相对改善而增加计算成本,而且Boosting方式无法做到现在流行的并行计算的方式进行训练,因为每一步迭代都要基于上一部的基本分类器。4. 前向分步算法
回看Adaboost的算法内容,我们需要通过计算M个基本分类器,每个分类器的错误率、样本权重以及模型权重。我们可以认为:Adaboost每次学习单一分类器以及单一分类器的参数(权重)。接下来,我们抽象出Adaboost算法的整体框架逻辑,构建集成学习的一个非常重要的框架—-前向分步算法,有了这个框架,我们不仅可以解决分类问题,也可以解决回归问题。
(1) 加法模型:
在Adaboost模型中,我们把每个基本分类器合成一个复杂分类器的方法是每个基本分类器的加权和,即:$f(x)=\sum_{m=1}^{M} \beta_{m} b\left(x ; \gamma_{m}\right)$,其中,$b\left(x ; \gamma_{m}\right)$为即基本分类器,$\gamma_{m}$为基本分类器的参数,$\beta_m$为基本分类器的权重,显然这与第二章所学的加法模型。为什么这么说呢?大家把$b(x ; \gamma_{m})$看成是即函数即可。
在给定训练数据以及损失函数$L(y, f(x))$的条件下,学习加法模型$f(x)$就是:
$$
\min {\beta{m}, \gamma_{m}} \sum_{i=1}^{N} L\left(y_{i}, \sum_{m=1}^{M} \beta_{m} b\left(x_{i} ; \gamma_{m}\right)\right)
$$
通常这是一个复杂的优化问题,很难通过简单的凸优化的相关知识进行解决。前向分步算法可以用来求解这种方式的问题,它的基本思路是:因为学习的是加法模型,如果从前向后,每一步只优化一个基函数及其系数,逐步逼近目标函数,那么就可以降低优化的复杂度。具体而言,每一步只需要优化:
$$
\min {\beta, \gamma} \sum{i=1}^{N} L\left(y_{i}, \beta b\left(x_{i} ; \gamma\right)\right)
$$
(2) 前向分步算法:
给定数据集$T=\left{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \cdots,\left(x_{N}, y_{N}\right)\right}$,$x_{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}$,$y_{i} \in \mathcal{Y}={+1,-1}$。损失函数$L(y, f(x))$,基函数集合${b(x ; \gamma)}$,我们需要输出加法模型$f(x)$。- 初始化:$f_{0}(x)=0$
- 对m = 1,2,…,M:
- (a) 极小化损失函数:
$$
\left(\beta_{m}, \gamma_{m}\right)=\arg \min {\beta, \gamma} \sum{i=1}^{N} L\left(y_{i}, f_{m-1}\left(x_{i}\right)+\beta b\left(x_{i} ; \gamma\right)\right)
$$
得到参数$\beta_{m}$与$\gamma_{m}$ - (b) 更新:
$$
f_{m}(x)=f_{m-1}(x)+\beta_{m} b\left(x ; \gamma_{m}\right)
$$
- (a) 极小化损失函数:
- 得到加法模型:
$$
f(x)=f_{M}(x)=\sum_{m=1}^{M} \beta_{m} b\left(x ; \gamma_{m}\right)
$$
这样,前向分步算法将同时求解从m=1到M的所有参数$\beta_{m}$,$\gamma_{m}$的优化问题简化为逐次求解各个$\beta_{m}$,$\gamma_{m}$的问题。
]]>
(3) 前向分步算法与Adaboost的关系:
由于这里不是我们的重点,我们主要阐述这里的结论,不做相关证明,具体的证明见李航老师的《统计学习方法》第八章的3.2节。Adaboost算法是前向分步算法的特例,Adaboost算法是由基本分类器组成的加法模型,损失函数为指数损失函数。1. 导论 在前面的学习中,我们探讨了一系列简单而实用的回归和分类模型,同时也探讨了如何使用集成学习家族中的Bagging思想去优化最终的模型。Bagging思想的实质是:通过Bootstrap 的方式对全样本数据集进行抽样得到抽样子集,对不同的子集使用同一种基本模型进行拟合,然后投票得出最终的预测。我们也从前面的探讨知道:Bagging主要通过降低方差的方式减少预测误差。那么,本章介绍的Boosting是与Bagging截然不同的思想,Boosting方法是使用同一组数据集进行反复学习,得到一系列简单模型,然后组合这些模型构成一个预测性能十分强大的机器学习模型。 显然,Boosting思想提高最终的预测效果是通过不断减少偏差的形式,与Bagging有着本质的不同。在Boosting这一大类方法中,笔者主要介绍两类常用的Boosting方式:Adaptive Boosting 和 Gradient Boosting 以及它们的变体Xgboost、LightGBM以及Catboost。
2. Boosting方法的基本思路
在正式介绍Boosting思想之前,我想先介绍两个例子:
第一个例子:不知道大家有没有做过错题本,我们将每次测验的错的题目记录在错题本上,不停的翻阅,直到我们完全掌握(也就是能够在考试中能够举一反三)。
第二个例子:对于一个复杂任务来说,将多个专家的判断进行适当的综合所作出的判断,要比其中任何一个专家单独判断要好。实际上这是一种“三个臭皮匠顶个诸葛亮的道理”。
这两个例子都说明Boosting的道理,也就是不错地重复学习达到最终的要求。
Boosting的提出与发展离不开Valiant和 Kearns的努力,历史上正是Valiant和 Kearns提出了”强可学习”和”弱可学习”的概念。那什么是”强可学习”和”弱可学习”呢?在概率近似正确PAC学习的框架下:- 弱学习:识别错误率小于1/2(即准确率仅比随机猜测略高的学习算法)
- 强学习:识别准确率很高并能在多项式时间内完成的学习算法
非常有趣的是,在PAC 学习的框架下,强可学习和弱可学习是等价的,也就是说一个概念是强可学习的充分必要条件是这个概念是弱可学习的。这样一来,问题便是:在学习中,如果已经发现了弱可学习算法,能否将他提升至强可学习算法。因为,弱可学习算法比强可学习算法容易得多。提升方法就是从弱学习算法出发,反复学习,得到一系列弱分类器(又称为基本分类器),然后通过一定的形式去组合这些弱分类器构成一个强分类器。大多数的Boosting方法都是通过改变训练数据集的概率分布(训练数据不同样本的权值),针对不同概率分布的数据调用弱分类算法学习一系列的弱分类器。
对于Boosting方法来说,有两个问题需要给出答案:第一个是每一轮学习应该如何改变数据的概率分布,第二个是如何将各个弱分类器组合起来。关于这两个问题,不同的Boosting算法会有不同的答案,我们接下来介绍一种最经典的Boosting算法——Adaboost,我们需要理解Adaboost是怎么处理这两个问题以及为什么这么处理的。3. Adaboost算法
Adaboost的基本原理
对于Adaboost来说,解决上述的两个问题的方式是:
- 提高那些被前一轮分类器错误分类的样本的权重,而降低那些被正确分类的样本的权重。这样一来,那些在上一轮分类器中没有得到正确分类的样本,由于其权重的增大而在后一轮的训练中“备受关注”。
- 各个弱分类器的组合是通过采取加权多数表决的方式,具体来说,加大分类错误率低的弱分类器的权重,因为这些分类器能更好地完成分类任务,而减小分类错误率较大的弱分类器的权重,使其在表决中起较小的作用。
现在,我们来具体介绍Adaboost算法:(参考李航老师的《统计学习方法》)
假设给定一个二分类的训练数据集:$T=\left{\left(x{1}, y{1}\right),\left(x{2}, y{2}\right), \cdots,\left(x{N}, y{N}\right)\right}$ ,其中每个样本点由特征与类别组成。特征$x{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}$,类别$y{i} \in \mathcal{Y}={-1,+1}$,$\mathcal{X}$是特征空间,$ \mathcal{Y}$是类别集合,输出最终分类器$G(x)$。Adaboost算法如下:
(1) 初始化训练数据的分布:$D{1}=\left(w{11}, \cdots, w{1 i}, \cdots, w{1 N}\right), \quad w_{1 i}=\frac{1}{N}, \quad i=1,2, \cdots, N$
(2) 对于m=1,2,…,M- 使用具有权值分布$Dm$的训练数据集进行学习,得到基本分类器:$G{m}(x): \mathcal{X} \rightarrow{-1,+1}$
- 计算$Gm(x)$在训练集上的分类误差率$e{m}=\sum{i=1}^{N} P\left(G{m}\left(x{i}\right) \neq y{i}\right)=\sum{i=1}^{N} w{m i} I\left(G{m}\left(x{i}\right) \neq y_{i}\right)$
- 计算$Gm(x)$的系数$\alpha{m}=\frac{1}{2} \log \frac{1-e{m}}{e{m}}$,这里的log是自然对数ln
更新训练数据集的权重分布
这里的$Zm$是规范化因子,使得$D{m+1}$称为概率分布,$Z{m}=\sum{i=1}^{N} w{m i} \exp \left(-\alpha{m} y{i} G{m}\left(x_{i}\right)\right)$
(3) 构建基本分类器的线性组合$f(x)=\sum{m=1}^{M} \alpha{m} G_{m}(x)$,得到最终的分类器
下面对Adaboost算法做如下说明:
对于步骤(1),假设训练数据的权值分布是均匀分布,是为了使得第一次没有先验信息的条件下每个样本在基本分类器的学习中作用一样。
对于步骤(2),每一次迭代产生的基本分类器$Gm(x)$在加权训练数据集上的分类错误率$\begin{aligned}e{m} &=\sum{i=1}^{N} P\left(G{m}\left(x{i}\right) \neq y{i}\right) =\sum{G{m}\left(x{i}\right) \neq y{i}} w{m i}\end{aligned}$代表了在$G_m(x)$中分类错误的样本权重和,这点直接说明了权重分布$D_m$与$G_m(x)$的分类错误率$e_m$有直接关系。同时,在步骤(2)中,计算基本分类器$G_m(x)$的系数$\alpha_m$,$\alpha{m}=\frac{1}{2} \log \frac{1-e{m}}{e{m}}$,它表示了$Gm(x)$在最终分类器的重要性程度,$\alpha_m$的取值由基本分类器$G_m(x)$的分类错误率有直接关系,当$e{m} \leqslant \frac{1}{2}$时,$\alpha_{m} \geqslant 0$,并且$\alpha_m$随着$e_m$的减少而增大,因此分类错误率越小的基本分类器在最终分类器的作用越大!
最重要的,对于步骤(2)中的样本权重的更新:因此,从上式可以看到:被基本分类器$Gm(x)$错误分类的样本的权重扩大,被正确分类的样本权重减少,二者相比相差$\mathrm{e}^{2 \alpha{m}}=\frac{1-e{m}}{e{m}}$倍。
对于步骤(3),线性组合$f(x)$实现了将M个基本分类器的加权表决,系数$\alpha_m$标志了基本分类器$G_m(x)$的重要性,值得注意的是:所有的$\alpha_m$之和不为1。$f(x)$的符号决定了样本x属于哪一类。下面,我们使用一组简单的数据来手动计算Adaboost算法的过程:(例子来源:http://www.csie.edu.tw)
训练数据如下表,假设基本分类器的形式是一个分割$x
解:
初始化样本权值分布对m=1:
- 在权值分布$D_1$的训练数据集上,遍历每个结点并计算分类误差率$e_m$,阈值取v=2.5时分类误差率最低,那么基本分类器为:
- $G1(x)$在训练数据集上的误差率为$e{1}=P\left(G{1}\left(x{i}\right) \neq y_{i}\right)=0.3$。
- 计算$G1(x)$的系数:$\alpha{1}=\frac{1}{2} \log \frac{1-e{1}}{e{1}}=0.4236$
- 更新训练数据的权值分布:
对于m=2:
- 在权值分布$D_2$的训练数据集上,遍历每个结点并计算分类误差率$e_m$,阈值取v=8.5时分类误差率最低,那么基本分类器为:
- $G_2(x)$在训练数据集上的误差率为$e_2 = 0.2143$
- 计算$G_2(x)$的系数:$\alpha_2 = 0.6496$
- 更新训练数据的权值分布:
对m=3:
- 在权值分布$D_3$的训练数据集上,遍历每个结点并计算分类误差率$e_m$,阈值取v=5.5时分类误差率最低,那么基本分类器为:
- $G_3(x)$在训练数据集上的误差率为$e_3 = 0.1820$
- 计算$G_3(x)$的系数:$\alpha_3 = 0.7514$
- 更新训练数据的权值分布:
于是得到:$f{3}(x)=0.4236 G{1}(x)+0.6496 G{2}(x)+0.7514 G{3}(x)$,分类器$\operatorname{sign}\left[f{3}(x)\right]$在训练数据集上的误分类点的个数为0。
于是得到最终分类器为:$G(x)=\operatorname{sign}\left[f{3}(x)\right]=\operatorname{sign}\left[0.4236 G{1}(x)+0.6496 G{2}(x)+0.7514 G_{3}(x)\right]$下面,我们使用sklearn对Adaboost算法进行建模:
本次案例我们使用一份UCI的机器学习库里的开源数据集:葡萄酒数据集,该数据集可以在 ( https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data )上获得。该数据集包含了178个样本和13个特征,从不同的角度对不同的化学特性进行描述,我们的任务是根据这些数据预测红酒属于哪一个类别。(案例来源《python机器学习(第二版》)
# 引入数据科学相关工具包:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use("ggplot")
%matplotlib inline
import seaborn as sns# 加载训练数据:
wine = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data",header=None)
wine.columns = ['Class label', 'Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash','Magnesium', 'Total phenols','Flavanoids', 'Nonflavanoid phenols',
'Proanthocyanins','Color intensity', 'Hue','OD280/OD315 of diluted wines','Proline']# 数据查看:
print("Class labels",np.unique(wine["Class label"]))
wine.head()下面对数据做简单解读:
- Class label:分类标签
- Alcohol:酒精
- Malic acid:苹果酸
- Ash:灰
- Alcalinity of ash:灰的碱度
- Magnesium:镁
- Total phenols:总酚
- Flavanoids:黄酮类化合物
- Nonflavanoid phenols:非黄烷类酚类
- Proanthocyanins:原花青素
- Color intensity:色彩强度
- Hue:色调
- OD280/OD315 of diluted wines:稀释酒OD280 OD350
- Proline:脯氨酸
# 数据预处理
# 仅仅考虑2,3类葡萄酒,去除1类
wine = wine[wine['Class label']!=1]
y = wine['Class label'].values
X = wine[['Alcohol','OD280/OD315 of diluted wines']].values# 将分类标签变成二进制编码:
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y = le.fit_transform(y)
# 按8:2分割训练集和测试集
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=1,stratify=y) # stratify参数代表了按照y的类别等比例抽样使用单一决策树建模
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier(criterion='entropy',random_state=1,max_depth=1)
from sklearn.metrics import accuracy_score
tree = tree.fit(X_train,y_train)
y_train_pred = tree.predict(X_train)
y_test_pred = tree.predict(X_test)
tree_train = accuracy_score(y_train,y_train_pred)
tree_test = accuracy_score(y_test,y_test_pred)
print('Decision tree train/test accuracies %.3f/%.3f' % (tree_train,tree_test))使用sklearn实现Adaboost(基分类器为决策树)
# 使用sklearn实现Adaboost(基分类器为决策树)
'''
AdaBoostClassifier相关参数:
base_estimator:基本分类器,默认为DecisionTreeClassifier(max_depth=1)
n_estimators:终止迭代的次数
learning_rate:学习率
algorithm:训练的相关算法,{'SAMME','SAMME.R'},默认='SAMME.R'
random_state:随机种子
'''
from sklearn.ensemble import AdaBoostClassifier
adaboost = AdaBoostClassifier(base_estimator=tree,n_estimators=500,learning_rate=0.1,random_state=1)
adaboost = adaboost.fit(X_train,y_train)
y_train_pred = adaboost.predict(X_train)
y_test_pred = adaboost.predict(X_test)
ada_train = accuracy_score(y_train,y_train_pred)
ada_test = accuracy_score(y_test,y_test_pred)
print('Adaboost train/test accuracies %.3f/%.3f' % (ada_train,ada_test))结果分析:单层决策树似乎对训练数据欠拟合,而Adaboost模型正确地预测了训练数据的所有分类标签,而且与单层决策树相比,Adaboost的测试性能也略有提高。然而,为什么模型在训练集和测试集的性能相差这么大呢?我们使用图像来简单说明下这个道理!
# 画出单层决策树与Adaboost的决策边界:
x_min = X_train[:, 0].min() - 1
x_max = X_train[:, 0].max() + 1
y_min = X_train[:, 1].min() - 1
y_max = X_train[:, 1].max() + 1
# 生成网格矩阵
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),np.arange(y_min, y_max, 0.1))
f, axarr = plt.subplots(nrows=1, ncols=2,sharex='col',sharey='row',figsize=(12, 6))
for idx, clf, tt in zip([0, 1],[tree, adaboost],['Decision tree', 'Adaboost']):
clf.fit(X_train, y_train)
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
axarr[idx].contourf(xx, yy, Z, alpha=0.3)
axarr[idx].scatter(X_train[y_train==0, 0],X_train[y_train==0, 1],c='blue', marker='^')
axarr[idx].scatter(X_train[y_train==1, 0],X_train[y_train==1, 1],c='red', marker='o')
axarr[idx].set_title(tt)从上面的决策边界图可以看到:Adaboost模型的决策边界比单层决策树的决策边界要复杂的多。也就是说,Adaboost试图用增加模型复杂度而降低偏差的方式去减少总误差,但是过程中引入了方差,可能出现过拟合,因此在训练集和测试集之间的性能存在较大的差距,这就简单地回答的刚刚问题。
值的注意的是:与单个分类器相比,Adaboost等Boosting模型增加了计算的复杂度,在实践中需要仔细思考是否愿意为预测性能的相对改善而增加计算成本,而且Boosting方式无法做到现在流行的并行计算的方式进行训练,因为每一步迭代都要基于上一部的基本分类器。4. 前向分步算法
回看Adaboost的算法内容,我们需要通过计算M个基本分类器,每个分类器的错误率、样本权重以及模型权重。我们可以认为:Adaboost每次学习单一分类器以及单一分类器的参数(权重)。接下来,我们抽象出Adaboost算法的整体框架逻辑,构建集成学习的一个非常重要的框架——前向分步算法,有了这个框架,我们不仅可以解决分类问题,也可以解决回归问题。
(1) 加法模型:
在Adaboost模型中,我们把每个基本分类器合成一个复杂分类器的方法是每个基本分类器的加权和,即:$f(x)=\sum{m=1}^{M} \beta{m} b\left(x ; \gamma{m}\right)$,其中,$b\left(x ; \gamma{m}\right)$为即基本分类器,$\gamma{m}$为基本分类器的参数,$\beta_m$为基本分类器的权重,显然这与第二章所学的加法模型。为什么这么说呢?大家把$b(x ; \gamma{m})$看成是即函数即可。
在给定训练数据以及损失函数$L(y, f(x))$的条件下,学习加法模型$f(x)$就是:通常这是一个复杂的优化问题,很难通过简单的凸优化的相关知识进行解决。前向分步算法可以用来求解这种方式的问题,它的基本思路是:因为学习的是加法模型,如果从前向后,每一步只优化一个基函数及其系数,逐步逼近目标函数,那么就可以降低优化的复杂度。具体而言,每一步只需要优化:
(2) 前向分步算法:
给定数据集$T=\left{\left(x{1}, y{1}\right),\left(x{2}, y{2}\right), \cdots,\left(x{N}, y{N}\right)\right}$,$x{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}$,$y{i} \in \mathcal{Y}={+1,-1}$。损失函数$L(y, f(x))$,基函数集合${b(x ; \gamma)}$,我们需要输出加法模型$f(x)$。- 初始化:$f_{0}(x)=0$
- 对m = 1,2,…,M:
- (a) 极小化损失函数:得到参数$\beta{m}$与$\gamma{m}$
- (b) 更新:
- 得到加法模型:
这样,前向分步算法将同时求解从m=1到M的所有参数$\beta{m}$,$\gamma{m}$的优化问题简化为逐次求解各个$\beta{m}$,$\gamma{m}$的问题。
]]>
(3) 前向分步算法与Adaboost的关系:
由于这里不是我们的重点,我们主要阐述这里的结论,不做相关证明,具体的证明见李航老师的《统计学习方法》第八章的3.2节。Adaboost算法是前向分步算法的特例,Adaboost算法是由基本分类器组成的加法模型,损失函数为指数损失函数。- <h1 id="1-导论"><a href="#1-导论" class="headerlink" title="1. 导论"></a>1. 导论</h1><p>在前面的学习中,我们探讨了一系列简单而实用的回归和分类模型,同时也探讨了如何使用集成学习家族中的Bagging思想去优化最终的模型。Bagging思想的实质是:通过Bootstrap 的方式对全样本数据集进行抽样得到抽样子集,对不同的子集使用同一种基本模型进行拟合,然后投票得出最终的预测。我们也从前面的探讨知道:Bagging主要通过降低方差的方式减少预测误差。<strong>那么,本章介绍的Boosting是与Bagging截然不同的思想,Boosting方法是使用同一组数据集进行反复学习,得到一系列简单模型,然后组合这些模型构成一个预测性能十分强大的机器学习模型。</strong> 显然,Boosting思想提高最终的预测效果是通过不断减少偏差的形式,与Bagging有着本质的不同。在Boosting这一大类方法中,笔者主要介绍两类常用的Boosting方式:Adaptive Boosting 和 Gradient Boosting 以及它们的变体Xgboost、LightGBM以及Catboost。</p> + <h1 id="1-导论"><a href="#1-导论" class="headerlink" title="1. 导论"></a>1. 导论</h1><p>在前面的学习中,我们探讨了一系列简单而实用的回归和分类模型,同时也探讨了如何使用集成学习家族中的Bagging思想去优化最终的模型。Bagging思想的实质是:通过Bootstrap 的方式对全样本数据集进行抽样得到抽样子集,对不同的子集使用同一种基本模型进行拟合,然后投票得出最终的预测。我们也从前面的探讨知道:Bagging主要通过降低方差的方式减少预测误差。<strong>那么,本章介绍的Boosting是与Bagging截然不同的思想,Boosting方法是使用同一组数据集进行反复学习,得到一系列简单模型,然后组合这些模型构成一个预测性能十分强大的机器学习模型。</strong> 显然,Boosting思想提高最终的预测效果是通过不断减少偏差的形式,与Bagging有着本质的不同。在Boosting这一大类方法中,笔者主要介绍两类常用的Boosting方式:Adaptive Boosting 和 Gradient Boosting 以及它们的变体Xgboost、LightGBM以及Catboost。<br></p> @@ -240,7 +240,7 @@2021-06-16T15:55:00.000Z 2024-10-09T07:33:09.916Z -投票法的思路 +投票法是集成学习中常用的技巧,可以帮助我们提高模型的泛化能力,减少模型的错误率。举个例子,在航空航天领域,每个零件发出的电信号都对航空器的成功发射起到重要作用。如果我们有一个二进制形式的信号:
11101100100111001011011011011
在传输过程中第二位发生了翻转
10101100100111001011011011011
这导致的结果可能是致命的。一个常用的纠错方法是重复多次发送数据,并以少数服从多数的方法确定正确的传输数据。一般情况下,错误总是发生在局部,因此融合多个数据是降低误差的一个好方法,这就是投票法的基本思路。
对于回归模型来说,投票法最终的预测结果是多个其他回归模型预测结果的平均值。
对于分类模型,硬投票法的预测结果是多个模型预测结果中出现次数最多的类别,软投票对各类预测结果的概率进行求和,最终选取概率之和最大的类标签。
投票法的原理分析
投票法是一种遵循少数服从多数原则的集成学习模型,通过多个模型的集成降低方差,从而提高模型的鲁棒性。在理想情况下,投票法的预测效果应当优于任何一个基模型的预测效果。
投票法在回归模型与分类模型上均可使用:
- 回归投票法:预测结果是所有模型预测结果的平均值。
- 分类投票法:预测结果是所有模型种出现最多的预测结果。
分类投票法又可以被划分为硬投票与软投票:
- 硬投票:预测结果是所有投票结果最多出现的类。
- 软投票:预测结果是所有投票结果中概率加和最大的类。
下面我们使用一个例子说明硬投票:
对于某个样本:
模型 1 的预测结果是 类别 A
模型 2 的预测结果是 类别 B
模型 3 的预测结果是 类别 B
有2/3的模型预测结果是B,因此硬投票法的预测结果是B
同样的例子说明软投票:
对于某个样本:
模型 1 的预测结果是 类别 A 的概率为 99%
模型 2 的预测结果是 类别 A 的概率为 49%
模型 3 的预测结果是 类别 A 的概率为 49%
最终对于类别A的预测概率的平均是 (99 + 49 + 49) / 3 = 65.67%,因此软投票法的预测结果是A。
从这个例子我们可以看出,软投票法与硬投票法可以得出完全不同的结论。相对于硬投票,软投票法考虑到了预测概率这一额外的信息,因此可以得出比硬投票法更加准确的预测结果。
在投票法中,我们还需要考虑到不同的基模型可能产生的影响。理论上,基模型可以是任何已被训练好的模型。但在实际应用上,想要投票法产生较好的结果,需要满足两个条件:
- 基模型之间的效果不能差别过大。当某个基模型相对于其他基模型效果过差时,该模型很可能成为噪声。
- 基模型之间应该有较小的同质性。例如在基模型预测效果近似的情况下,基于树模型与线性模型的投票,往往优于两个树模型或两个线性模型。
当投票合集中使用的模型能预测出清晰的类别标签时,适合使用硬投票。当投票集合中使用的模型能预测类别的概率时,适合使用软投票。软投票同样可以用于那些本身并不预测类成员概率的模型,只要他们可以输出类似于概率的预测分数值(例如支持向量机、k-最近邻和决策树)。
投票法的局限性在于,它对所有模型的处理是一样的,这意味着所有模型对预测的贡献是一样的。如果一些模型在某些情况下很好,而在其他情况下很差,这是使用投票法时需要考虑到的一个问题。
投票法的案例分析(基于sklearn,介绍pipe管道的使用以及voting的使用)
Sklearn中提供了 VotingRegressor 与 VotingClassifier 两个投票方法。 这两种模型的操作方式相同,并采用相同的参数。使用模型需要提供一个模型列表,列表中每个模型采用Tuple的结构表示,第一个元素代表名称,第二个元素代表模型,需要保证每个模型必须拥有唯一的名称。
例如这里,我们定义两个模型:
models = [('lr',LogisticRegression()),('svm',SVC())]
ensemble = VotingClassifier(estimators=models)有时某些模型需要一些预处理操作,我们可以为他们定义Pipeline完成模型预处理工作:
models = [('lr',LogisticRegression()),('svm',make_pipeline(StandardScaler(),SVC()))]
ensemble = VotingClassifier(estimators=models)模型还提供了voting参数让我们选择软投票或者硬投票:
models = [('lr',LogisticRegression()),('svm',SVC())]
ensemble = VotingClassifier(estimators=models, voting='soft')下面我们使用一个完整的例子演示投票法的使用:
首先我们创建一个1000个样本,20个特征的随机数据集:
# test classification dataset
from sklearn.datasets import make_classification
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=2)
# summarize the dataset
print(X.shape, y.shape)我们使用多个KNN模型作为基模型演示投票法,其中每个模型采用不同的邻居值K参数:
# get a voting ensemble of models
def get_voting():
# define the base models
models = list()
models.append(('knn1', KNeighborsClassifier(n_neighbors=1)))
models.append(('knn3', KNeighborsClassifier(n_neighbors=3)))
models.append(('knn5', KNeighborsClassifier(n_neighbors=5)))
models.append(('knn7', KNeighborsClassifier(n_neighbors=7)))
models.append(('knn9', KNeighborsClassifier(n_neighbors=9)))
# define the voting ensemble
ensemble = VotingClassifier(estimators=models, voting='hard')
return ensemble然后,我们可以创建一个模型列表来评估投票带来的提升,包括KNN模型配置的每个独立版本和硬投票模型。下面的get_models()函数可以为我们创建模型列表进行评估。
# get a list of models to evaluate
def get_models():
models = dict()
models['knn1'] = KNeighborsClassifier(n_neighbors=1)
models['knn3'] = KNeighborsClassifier(n_neighbors=3)
models['knn5'] = KNeighborsClassifier(n_neighbors=5)
models['knn7'] = KNeighborsClassifier(n_neighbors=7)
models['knn9'] = KNeighborsClassifier(n_neighbors=9)
models['hard_voting'] = get_voting()
return models下面的evaluate_model()函数接收一个模型实例,并以分层10倍交叉验证三次重复的分数列表的形式返回。
# evaluate a give model using cross-validation
def evaluate_model(model, X, y):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise')
return scores然后,我们可以报告每个算法的平均性能,还可以创建一个箱形图和须状图来比较每个算法的精度分数分布。
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model, X, y)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()我们得到的结果如下:
>knn1 0.873 (0.030)
>knn3 0.889 (0.038)
>knn5 0.895 (0.031)
>knn7 0.899 (0.035)
>knn9 0.900 (0.033)
>hard_voting 0.902 (0.034)显然投票的效果略大于任何一个基模型。
通过箱形图我们可以看到硬投票方法对交叉验证整体预测结果分布带来的提升。
bagging的思路
与投票法不同的是,Bagging不仅仅集成模型最后的预测结果,同时采用一定策略来影响基模型训练,保证基模型可以服从一定的假设。 在上一章中我们提到,希望各个模型之间具有较大的差异性,而在实际操作中的模型却往往是同质的,因此一个简单的思路是通过不同的采样增加模型的差异性。
bagging的原理分析
Bagging的核心在于自助采样(bootstrap)这一概念,即有放回的从数据集中进行采样,也就是说,同样的一个样本可能被多次进行采样。 一个自助采样的小例子是我们希望估计全国所有人口年龄的平均值,那么我们可以在全国所有人口中随机抽取不同的集合(这些集合可能存在交集),计算每个集合的平均值,然后将所有平均值的均值作为估计值。
首先我们随机取出一个样本放入采样集合中,再把这个样本放回初始数据集,重复K次采样,最终我们可以获得一个大小为K的样本集合。同样的方法, 我们可以采样出T个含K个样本的采样集合,然后基于每个采样集合训练出一个基学习器,再将这些基学习器进行结合,这就是Bagging的基本流程。
对回归问题的预测是通过预测取平均值来进行的。对于分类问题的预测是通过对预测取多数票预测来进行的。Bagging方法之所以有效,是因为每个模型都是在略微不同的训练数据集上拟合完成的,这又使得每个基模型之间存在略微的差异,使每个基模型拥有略微不同的训练能力。
Bagging同样是一种降低方差的技术,因此它在不剪枝决策树、神经网络等易受样本扰动的学习器上效果更加明显。在实际的使用中,加入列采样的Bagging技术对高维小样本往往有神奇的效果。
bagging的案例分析(基于sklearn,介绍随机森林的相关理论以及实例)
Sklearn为我们提供了 BaggingRegressor 与 BaggingClassifier 两种Bagging方法的API,我们在这里通过一个完整的例子演示Bagging在分类问题上的具体应用。这里两种方法的默认基模型是树模型。
我们创建一个含有1000个样本20维特征的随机分类数据集:
# test classification dataset
from sklearn.datasets import make_classification
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=5)
# summarize the dataset
print(X.shape, y.shape)我们将使用重复的分层k-fold交叉验证来评估该模型,一共重复3次,每次有10个fold。我们将评估该模型在所有重复交叉验证中性能的平均值和标准差。
# evaluate bagging algorithm for classification
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.ensemble import BaggingClassifier
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=5)
# define the model
model = BaggingClassifier()
# evaluate the model
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise')
# report performance
print('Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))最终模型的效果是Accuracy: 0.856 标准差0.037
]]>投票法的思路 投票法是集成学习中常用的技巧,可以帮助我们提高模型的泛化能力,减少模型的错误率。举个例子,在航空航天领域,每个零件发出的电信号都对航空器的成功发射起到重要作用。如果我们有一个二进制形式的信号:
11101100100111001011011011011
在传输过程中第二位发生了翻转
10101100100111001011011011011
这导致的结果可能是致命的。一个常用的纠错方法是重复多次发送数据,并以少数服从多数的方法确定正确的传输数据。一般情况下,错误总是发生在局部,因此融合多个数据是降低误差的一个好方法,这就是投票法的基本思路。
对于回归模型来说,投票法最终的预测结果是多个其他回归模型预测结果的平均值。
对于分类模型,硬投票法的预测结果是多个模型预测结果中出现次数最多的类别,软投票对各类预测结果的概率进行求和,最终选取概率之和最大的类标签。
投票法的原理分析
投票法是一种遵循少数服从多数原则的集成学习模型,通过多个模型的集成降低方差,从而提高模型的鲁棒性。在理想情况下,投票法的预测效果应当优于任何一个基模型的预测效果。
投票法在回归模型与分类模型上均可使用:
- 回归投票法:预测结果是所有模型预测结果的平均值。
- 分类投票法:预测结果是所有模型种出现最多的预测结果。
分类投票法又可以被划分为硬投票与软投票:
- 硬投票:预测结果是所有投票结果最多出现的类。
- 软投票:预测结果是所有投票结果中概率加和最大的类。
下面我们使用一个例子说明硬投票:
对于某个样本:
模型 1 的预测结果是 类别 A
模型 2 的预测结果是 类别 B
模型 3 的预测结果是 类别 B
有2/3的模型预测结果是B,因此硬投票法的预测结果是B
同样的例子说明软投票:
对于某个样本:
模型 1 的预测结果是 类别 A 的概率为 99%
模型 2 的预测结果是 类别 A 的概率为 49%
模型 3 的预测结果是 类别 A 的概率为 49%
最终对于类别A的预测概率的平均是 (99 + 49 + 49) / 3 = 65.67%,因此软投票法的预测结果是A。
从这个例子我们可以看出,软投票法与硬投票法可以得出完全不同的结论。相对于硬投票,软投票法考虑到了预测概率这一额外的信息,因此可以得出比硬投票法更加准确的预测结果。
在投票法中,我们还需要考虑到不同的基模型可能产生的影响。理论上,基模型可以是任何已被训练好的模型。但在实际应用上,想要投票法产生较好的结果,需要满足两个条件:
- 基模型之间的效果不能差别过大。当某个基模型相对于其他基模型效果过差时,该模型很可能成为噪声。
- 基模型之间应该有较小的同质性。例如在基模型预测效果近似的情况下,基于树模型与线性模型的投票,往往优于两个树模型或两个线性模型。
当投票合集中使用的模型能预测出清晰的类别标签时,适合使用硬投票。当投票集合中使用的模型能预测类别的概率时,适合使用软投票。软投票同样可以用于那些本身并不预测类成员概率的模型,只要他们可以输出类似于概率的预测分数值(例如支持向量机、k-最近邻和决策树)。
投票法的局限性在于,它对所有模型的处理是一样的,这意味着所有模型对预测的贡献是一样的。如果一些模型在某些情况下很好,而在其他情况下很差,这是使用投票法时需要考虑到的一个问题。
投票法的案例分析(基于sklearn,介绍pipe管道的使用以及voting的使用)
Sklearn中提供了 VotingRegressor 与 VotingClassifier 两个投票方法。 这两种模型的操作方式相同,并采用相同的参数。使用模型需要提供一个模型列表,列表中每个模型采用Tuple的结构表示,第一个元素代表名称,第二个元素代表模型,需要保证每个模型必须拥有唯一的名称。
例如这里,我们定义两个模型:
models = [('lr',LogisticRegression()),('svm',SVC())]
ensemble = VotingClassifier(estimators=models)有时某些模型需要一些预处理操作,我们可以为他们定义Pipeline完成模型预处理工作:
models = [('lr',LogisticRegression()),('svm',make_pipeline(StandardScaler(),SVC()))]
ensemble = VotingClassifier(estimators=models)模型还提供了voting参数让我们选择软投票或者硬投票:
models = [('lr',LogisticRegression()),('svm',SVC())]
ensemble = VotingClassifier(estimators=models, voting='soft')下面我们使用一个完整的例子演示投票法的使用:
首先我们创建一个1000个样本,20个特征的随机数据集:
# test classification dataset
from sklearn.datasets import make_classification
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=2)
# summarize the dataset
print(X.shape, y.shape)我们使用多个KNN模型作为基模型演示投票法,其中每个模型采用不同的邻居值K参数:
# get a voting ensemble of models
def get_voting():
# define the base models
models = list()
models.append(('knn1', KNeighborsClassifier(n_neighbors=1)))
models.append(('knn3', KNeighborsClassifier(n_neighbors=3)))
models.append(('knn5', KNeighborsClassifier(n_neighbors=5)))
models.append(('knn7', KNeighborsClassifier(n_neighbors=7)))
models.append(('knn9', KNeighborsClassifier(n_neighbors=9)))
# define the voting ensemble
ensemble = VotingClassifier(estimators=models, voting='hard')
return ensemble然后,我们可以创建一个模型列表来评估投票带来的提升,包括KNN模型配置的每个独立版本和硬投票模型。下面的get_models()函数可以为我们创建模型列表进行评估。
# get a list of models to evaluate
def get_models():
models = dict()
models['knn1'] = KNeighborsClassifier(n_neighbors=1)
models['knn3'] = KNeighborsClassifier(n_neighbors=3)
models['knn5'] = KNeighborsClassifier(n_neighbors=5)
models['knn7'] = KNeighborsClassifier(n_neighbors=7)
models['knn9'] = KNeighborsClassifier(n_neighbors=9)
models['hard_voting'] = get_voting()
return models下面的evaluate_model()函数接收一个模型实例,并以分层10倍交叉验证三次重复的分数列表的形式返回。
# evaluate a give model using cross-validation
def evaluate_model(model, X, y):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise')
return scores然后,我们可以报告每个算法的平均性能,还可以创建一个箱形图和须状图来比较每个算法的精度分数分布。
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model, X, y)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()我们得到的结果如下:
>knn1 0.873 (0.030)
>knn3 0.889 (0.038)
>knn5 0.895 (0.031)
>knn7 0.899 (0.035)
>knn9 0.900 (0.033)
>hard_voting 0.902 (0.034)显然投票的效果略大于任何一个基模型。
通过箱形图我们可以看到硬投票方法对交叉验证整体预测结果分布带来的提升。
bagging的思路
与投票法不同的是,Bagging不仅仅集成模型最后的预测结果,同时采用一定策略来影响基模型训练,保证基模型可以服从一定的假设。 在上一章中我们提到,希望各个模型之间具有较大的差异性,而在实际操作中的模型却往往是同质的,因此一个简单的思路是通过不同的采样增加模型的差异性。
bagging的原理分析
Bagging的核心在于自助采样(bootstrap)这一概念,即有放回的从数据集中进行采样,也就是说,同样的一个样本可能被多次进行采样。 一个自助采样的小例子是我们希望估计全国所有人口年龄的平均值,那么我们可以在全国所有人口中随机抽取不同的集合(这些集合可能存在交集),计算每个集合的平均值,然后将所有平均值的均值作为估计值。
首先我们随机取出一个样本放入采样集合中,再把这个样本放回初始数据集,重复K次采样,最终我们可以获得一个大小为K的样本集合。同样的方法, 我们可以采样出T个含K个样本的采样集合,然后基于每个采样集合训练出一个基学习器,再将这些基学习器进行结合,这就是Bagging的基本流程。
对回归问题的预测是通过预测取平均值来进行的。对于分类问题的预测是通过对预测取多数票预测来进行的。Bagging方法之所以有效,是因为每个模型都是在略微不同的训练数据集上拟合完成的,这又使得每个基模型之间存在略微的差异,使每个基模型拥有略微不同的训练能力。
Bagging同样是一种降低方差的技术,因此它在不剪枝决策树、神经网络等易受样本扰动的学习器上效果更加明显。在实际的使用中,加入列采样的Bagging技术对高维小样本往往有神奇的效果。
bagging的案例分析(基于sklearn,介绍随机森林的相关理论以及实例)
Sklearn为我们提供了 BaggingRegressor 与 BaggingClassifier 两种Bagging方法的API,我们在这里通过一个完整的例子演示Bagging在分类问题上的具体应用。这里两种方法的默认基模型是树模型。
我们创建一个含有1000个样本20维特征的随机分类数据集:
# test classification dataset
from sklearn.datasets import make_classification
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=5)
# summarize the dataset
print(X.shape, y.shape)我们将使用重复的分层k-fold交叉验证来评估该模型,一共重复3次,每次有10个fold。我们将评估该模型在所有重复交叉验证中性能的平均值和标准差。
# evaluate bagging algorithm for classification
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.ensemble import BaggingClassifier
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=5)
# define the model
model = BaggingClassifier()
# evaluate the model
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise')
# report performance
print('Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))最终模型的效果是Accuracy: 0.856 标准差0.037
]]>@@ -250,7 +250,7 @@ <p>10101100100111001011011011011</p> <p>这导致的结果可能是致命的。一个常用的纠错方法是重复多次发送数据,并以少数服从多数的方法确定正确的传输数据。一般情况下,错误总是发生在局部,因此融合多个数据是降低误差的一个好方法,这就是投票法的基本思路。</p> <p>对于回归模型来说,投票法最终的预测结果是多个其他回归模型预测结果的平均值。</p> -<p>对于分类模型,<strong>硬投票法</strong>的预测结果是多个模型预测结果中出现次数最多的类别,<strong>软投票</strong>对各类预测结果的概率进行求和,最终选取概率之和最大的类标签。</p> +<p>对于分类模型,<strong>硬投票法</strong>的预测结果是多个模型预测结果中出现次数最多的类别,<strong>软投票</strong>对各类预测结果的概率进行求和,最终选取概率之和最大的类标签。<br></p> @@ -269,11 +269,11 @@2021-06-15T13:48:00.000Z 2024-10-09T07:33:09.908Z -数据结构与算法——二分 +最近leetcode每日一题经常出二分的题目,正好对前段时间学过的二分进行一些总结,首先这里要明确的一点是,二分的本质并不是单调性,而是通过某种条件将整个区间划分成满足条件和不满足条件的两端即可进行二分查找。
在二分这个专题,主要有两种类型的划分方式,一种是整数划分,一种是浮点数划分,前一种一般是我们最熟悉的二分查找的题型,也是出题比较灵活考的比较多的一种,后一种主要是为控制实数精度而设置的浮点数二分法(建议用double,float有时候会出现精度丢失)。整数二分
这里我们拿一道经典例题来给出我们二分的两个十分精妙的模板。AcWing789. 数的范围
bool check(int x) {/* ... */} // 检查x是否满足某种性质
// 区间[l, r]被划分成[l, mid]和[mid + 1, r]时使用:
int bsearch_1(int l, int r)
{
while(l < r)
{
int mid = l + r >> 1; // 如果写r=mid则这里不需要+1
if(check(mid)) r = mid; // check()判断mid是否满足性质
else l = mid + 1;
}
return l; //退出时 l与r相等
}
// 区间[l, r]被划分成[l, mid - 1]和[mid, r]时使用:
int bsearch_2(int l, int r)
{
while(l < r)
{
int mid = l + r + 1 >> 1;
if(check(mid)) l = mid;
else r = mid - 1;
}
return l;
}浮点数二分
浮点数二分考的比较少,主要是实现对于高精度答案的控制。AcWing 790. 数的三次方根
这里有个小bug需要提醒一下,我们以求二次方根为例,我们可以知道,$x=0.01$时,$\sqrt{x}=0.1>x$,所以当我们把二分的区间设置成$[0,x]$时,我们则无法找到答案,所以设置区间的时候我们最好可以设置大一点的区间,或者设置成$[0,\max(1,x)]$bool check(double x) {/* ... */} // 检查x是否满足某种性质
double bsearch_3(double l, double r)
{
const double eps = 1e-8; // eps 表示精度,取决于题目对精度的要求
while(r - l > eps)
{
double mid = (l + r) / 2; // 对于浮点数二分则不需要考虑+1的问题
if(check(mid)) r = mid;
else l = mid;
}
return l;
}STL
做题当中手写二分的题其实比较少,基本上记忆上述模板就能解决所以的问题,同时我们在日常做题的时候,为了方便,我们通常是使用STL当中的函数来实现二分,且支持vector,map,set等操作,还有结构体大小比较,这里就有三个一定要记住的API。头文件引入:
#include<algorithm>binary_search
功能:二分查找某个元素是否出现。
返回值:在数组中以二分法检索的方式查找,若在数组(要求数组元素非递减)中查找到indx元素则真,若查找不到则返回值为假。
用法实例:
a.数组用法int a[100]= {4,10,11,30,69,70,96,100};
int b=binary_search(a,a+9,4);//查找成功,返回1
cout<<"在数组中查找元素4,结果为:"<<b<<endl;b.vector用法
vector<int> res = {1,2,3};
cout<<binary_search(res.begin(),res.end(),3)<<endl;lower_bound
功能:查找非递减序列[first,last) 内第一个大于或等于某个元素的位置。
返回值:如果找到返回找到元素的地址否则返回数组边界的下一个元素的地址。(这样不注意的话会越界,小心)
用法实例:int a[100]= {4,10,11,30,69,70,96,100};
int d=lower_bound(a,a+9,10)-a;
cout<<"在数组中查找第一个大于等于10的元素位置,结果为:"<<d<<endl;
int e=lower_bound(a,a+9,101)-a;
cout<<"在数组中查找第一个大于等于101的元素位置,结果为:"<<e<<endl;b.vector用法
vector<int> res = {1,2,3};
vector<int>::iterator it = lower_bound(res.begin(),res.end(),3);//返回迭代器的位置
//如果不存在,迭代器的位置会返回res.end()
if(it==res.end()) cout<<"不存在"<<endl;
else cout<<"求出下标:"<<(it - res.begin())<<endl;
//也可以添加偏移量
vector<int>::iterator it = lower_bound(res.begin()+1,res.end(),3);upper_bound功能:查找非递减序列[first,last) 内第一个大于某个元素的位置。
返回值:如果找到返回找到元素的地址,否则返回数组边界的下一个元素的地址。(同样这样不注意的话会越界,小心)
用法实例:int a[100]= {4,10,11,30,69,70,96,100};
int d=upper_bound(a,a+9,10)-a;
cout<<"在数组中查找第一个大于等于10的元素位置,结果为:"<<d<<endl;
int e=upper_bound(a,a+9,101)-a;
cout<<"在数组中查找第一个大于等于101的元素位置,结果为:"<<e<<endl;b.vector用法
vector<int> res = {1,2,3};
vector<int>::iterator it = upper_bound(res.begin(),res.end(),3);//返回迭代器的位置
//如果不存在,迭代器的位置会返回res.end()
if(it==res.end()) cout<<"不存在"<<endl;
else cout<<"求出下标:"<<(it - res.begin())<<endl;
//也可以添加偏移量
vector<int>::iterator it = upper_bound(res.begin()+1,res.end(),3);经典例题
这里我顺便给出这两天的每日一题的解题方案,里面还涉及到了一个防止溢出的二分处理trick。
猜数字大小/**
* Forward declaration of guess API.
* @param num your guess
* @return -1 if num is lower than the guess number
* 1 if num is higher than the guess number
* otherwise return 0
* int guess(int num);
*/
class Solution {
public:
int guessNumber(int n) {
int l = 1;
int r = n;
while(l<r)
{
int mid = l + (r - l >> 1);//防止溢出
if(guess(mid)<=0)
r = mid;
else
l = mid + 1;
}
return r;
}
};class Solution {
public:
int peakIndexInMountainArray(vector<int>& arr) {
int l = 0;
int r = arr.size() - 1;
while(l<r)
{
int mid = l + r >> 1;
if(arr[mid]>arr[mid+1]) r = mid;
else l = mid+1;
}
return l;
}
};这是三叶姐姐的二分经典题型汇总,大家也可以参考一下。
]]>数据结构与算法——二分 最近leetcode每日一题经常出二分的题目,正好对前段时间学过的二分进行一些总结,首先这里要明确的一点是,二分的本质并不是单调性,而是通过某种条件将整个区间划分成满足条件和不满足条件的两端即可进行二分查找。
在二分这个专题,主要有两种类型的划分方式,一种是整数划分,一种是浮点数划分,前一种一般是我们最熟悉的二分查找的题型,也是出题比较灵活考的比较多的一种,后一种主要是为控制实数精度而设置的浮点数二分法(建议用double,float有时候会出现精度丢失)。整数二分
这里我们拿一道经典例题来给出我们二分的两个十分精妙的模板。AcWing789. 数的范围
bool check(int x) {/* ... */} // 检查x是否满足某种性质
// 区间[l, r]被划分成[l, mid]和[mid + 1, r]时使用:
int bsearch_1(int l, int r)
{
while(l < r)
{
int mid = l + r >> 1; // 如果写r=mid则这里不需要+1
if(check(mid)) r = mid; // check()判断mid是否满足性质
else l = mid + 1;
}
return l; //退出时 l与r相等
}
// 区间[l, r]被划分成[l, mid - 1]和[mid, r]时使用:
int bsearch_2(int l, int r)
{
while(l < r)
{
int mid = l + r + 1 >> 1;
if(check(mid)) l = mid;
else r = mid - 1;
}
return l;
}浮点数二分
浮点数二分考的比较少,主要是实现对于高精度答案的控制。AcWing 790. 数的三次方根
这里有个小bug需要提醒一下,我们以求二次方根为例,我们可以知道,$x=0.01$时,$\sqrt{x}=0.1>x$,所以当我们把二分的区间设置成$[0,x]$时,我们则无法找到答案,所以设置区间的时候我们最好可以设置大一点的区间,或者设置成$[0,\max(1,x)]$bool check(double x) {/* ... */} // 检查x是否满足某种性质
double bsearch_3(double l, double r)
{
const double eps = 1e-8; // eps 表示精度,取决于题目对精度的要求
while(r - l > eps)
{
double mid = (l + r) / 2; // 对于浮点数二分则不需要考虑+1的问题
if(check(mid)) r = mid;
else l = mid;
}
return l;
}STL
做题当中手写二分的题其实比较少,基本上记忆上述模板就能解决所以的问题,同时我们在日常做题的时候,为了方便,我们通常是使用STL当中的函数来实现二分,且支持vector,map,set等操作,还有结构体大小比较,这里就有三个一定要记住的API。头文件引入:
#include<algorithm>binary_search
功能:二分查找某个元素是否出现。
返回值:在数组中以二分法检索的方式查找,若在数组(要求数组元素非递减)中查找到indx元素则真,若查找不到则返回值为假。
用法实例:
a.数组用法int a[100]= {4,10,11,30,69,70,96,100};
int b=binary_search(a,a+9,4);//查找成功,返回1
cout<<"在数组中查找元素4,结果为:"<<b<<endl;
b.vector用法vector<int> res = {1,2,3};
cout<<binary_search(res.begin(),res.end(),3)<<endl;lower_bound
功能:查找非递减序列[first,last) 内第一个大于或等于某个元素的位置。
返回值:如果找到返回找到元素的地址否则返回数组边界的下一个元素的地址。(这样不注意的话会越界,小心)
用法实例:int a[100]= {4,10,11,30,69,70,96,100};
int d=lower_bound(a,a+9,10)-a;
cout<<"在数组中查找第一个大于等于10的元素位置,结果为:"<<d<<endl;
int e=lower_bound(a,a+9,101)-a;
cout<<"在数组中查找第一个大于等于101的元素位置,结果为:"<<e<<endl;
b.vector用法vector<int> res = {1,2,3};
vector<int>::iterator it = lower_bound(res.begin(),res.end(),3);//返回迭代器的位置
//如果不存在,迭代器的位置会返回res.end()
if(it==res.end()) cout<<"不存在"<<endl;
else cout<<"求出下标:"<<(it - res.begin())<<endl;
//也可以添加偏移量
vector<int>::iterator it = lower_bound(res.begin()+1,res.end(),3);upper_bound功能:查找非递减序列[first,last) 内第一个大于某个元素的位置。
返回值:如果找到返回找到元素的地址,否则返回数组边界的下一个元素的地址。(同样这样不注意的话会越界,小心)
用法实例:int a[100]= {4,10,11,30,69,70,96,100};
int d=upper_bound(a,a+9,10)-a;
cout<<"在数组中查找第一个大于等于10的元素位置,结果为:"<<d<<endl;
int e=upper_bound(a,a+9,101)-a;
cout<<"在数组中查找第一个大于等于101的元素位置,结果为:"<<e<<endl;
b.vector用法vector<int> res = {1,2,3};
vector<int>::iterator it = upper_bound(res.begin(),res.end(),3);//返回迭代器的位置
//如果不存在,迭代器的位置会返回res.end()
if(it==res.end()) cout<<"不存在"<<endl;
else cout<<"求出下标:"<<(it - res.begin())<<endl;
//也可以添加偏移量
vector<int>::iterator it = upper_bound(res.begin()+1,res.end(),3);经典例题
这里我顺便给出这两天的每日一题的解题方案,里面还涉及到了一个防止溢出的二分处理trick。
]]>
猜数字大小/**
* Forward declaration of guess API.
* @param num your guess
* @return -1 if num is lower than the guess number
* 1 if num is higher than the guess number
* otherwise return 0
* int guess(int num);
*/
class Solution {
public:
int guessNumber(int n) {
int l = 1;
int r = n;
while(l<r)
{
int mid = l + (r - l >> 1);//防止溢出
if(guess(mid)<=0)
r = mid;
else
l = mid + 1;
}
return r;
}
};
山脉数组的峰顶索引class Solution {
public:
int peakIndexInMountainArray(vector<int>& arr) {
int l = 0;
int r = arr.size() - 1;
while(l<r)
{
int mid = l + r >> 1;
if(arr[mid]>arr[mid+1]) r = mid;
else l = mid+1;
}
return l;
}
};
这是三叶姐姐的二分经典题型汇总,大家也可以参考一下。- <h2 id="数据结构与算法——二分"><a href="#数据结构与算法——二分" class="headerlink" title="数据结构与算法——二分"></a>数据结构与算法——二分</h2><p>最近leetcode每日一题经常出二分的题目,正好对前段时间学过的二分进行一些总结,首先这里要明确的一点是,<strong>二分的本质并不是单调性,而是通过某种条件将整个区间划分成满足条件和不满足条件的两端即可进行二分查找。</strong><br>在二分这个专题,主要有两种类型的划分方式,一种是整数划分,一种是浮点数划分,前一种一般是我们最熟悉的二分查找的题型,也是出题比较灵活考的比较多的一种,后一种主要是为控制实数精度而设置的浮点数二分法(建议用<code>double</code>,<code>float</code>有时候会出现精度丢失)。</p> + <h2 id="数据结构与算法——二分"><a href="#数据结构与算法——二分" class="headerlink" title="数据结构与算法——二分"></a>数据结构与算法——二分</h2><p>最近leetcode每日一题经常出二分的题目,正好对前段时间学过的二分进行一些总结,首先这里要明确的一点是,<strong>二分的本质并不是单调性,而是通过某种条件将整个区间划分成满足条件和不满足条件的两端即可进行二分查找。</strong><br>在二分这个专题,主要有两种类型的划分方式,一种是整数划分,一种是浮点数划分,前一种一般是我们最熟悉的二分查找的题型,也是出题比较灵活考的比较多的一种,后一种主要是为控制实数精度而设置的浮点数二分法(建议用<code>double</code>,<code>float</code>有时候会出现精度丢失)。<br></p> @@ -290,11 +290,11 @@2021-06-13T07:49:00.000Z 2024-10-09T07:33:09.908Z -数据结构与刷题——链表 +单链表代码模板
代码实现单链表的方法有很多种,但是对于acm刷题来说,我们通常使用的是静态链表的方式,这样代码运行速度更快,防止被卡时间。
const int N = 100010;
int head; // 头指针
int e[N]; // e[i]表示第i个节点的
int ne[N];// 第i个节点的next指针,表示当前节点的直接后继的节点编号
int idx;//记录已经存储了多少个节点
void init()
{
head = -1;//用-1表示空节点
idx = 0;
}
//在第k个节点后面插入一个新节点,节点的值为x
void insert(int k,int x)
{
e[idx] = x;
ne[idx] = ne[k];
ne[k] = idx++;
}
// 删除第k+1个节点,即将将该节点的指针指向他的下一个元素
void delete_node(int k)
{
ne[k] = ne[ne[k]];
}
void delete_head()
{
head = ne[head];
}
//遍历过程
for(int i = head; i!=-1;i = ne[i])
{
cout<<e[i]<<endl;
}双链表
在实际的代码编写过程当中,我们也是直接使用静态链表来设置双链表,我们首先设置0号点和1号点为左右边界head,tail。之后我们就只需要在这两者之间插入节点构造双链表。
const int N = 100010;
int e[N];
int l[N];
int r[N];
int idx;
//初始化直接初始化出左右端点的下标,从而避免边界问题
void init()
{
//初始化的左右别搞反了
r[0] = 1;
l[1] = 0;
idx =2;
}
// 在k节点的右侧插入一个x,其实也相当于左侧插入节点
void add(int k,int x)
{
e[idx] = x;
//操作新节点的左右指针
r[idx] = r[k];
l[idx] = k;
//再操作原数组的节点
l[r[k]] = idx;
r[k] = idx++;
}
void remove(int k)
{
l[r[k]] = l[k]; //右节点的左侧,指向左节点
r[l[k]] = r[k]; //左节点的右侧,指向右节点
}经典例题
以上两种实现方式都是通过静态链表实现的,主要是来自y总的AcWing经典例题。
]]>
AcWing826. 单链表
AcWing827. 双链表
使用指针的实现方式,在leetcode当中用的比较多,这里给大家补充一些leetcode中出现的链表类型的题目,主要涉及到链表的遍历,双指针算法,和一些小技巧,高阶一点的题目会涉及到树和递归的问题。
我做的主要是leetcode上程序员面试经典和剑指offer的例题,不过个人感觉这些题也大部分涵盖了链表题型的大部分考法,而且题解也十分详细。数据结构与刷题——链表 单链表代码模板
代码实现单链表的方法有很多种,但是对于acm刷题来说,我们通常使用的是静态链表的方式,这样代码运行速度更快,防止被卡时间。
const int N = 100010;
int head; // 头指针
int e[N]; // e[i]表示第i个节点的
int ne[N];// 第i个节点的next指针,表示当前节点的直接后继的节点编号
int idx;//记录已经存储了多少个节点
void init()
{
head = -1;//用-1表示空节点
idx = 0;
}
//在第k个节点后面插入一个新节点,节点的值为x
void insert(int k,int x)
{
e[idx] = x;
ne[idx] = ne[k];
ne[k] = idx++;
}
// 删除第k+1个节点,即将将该节点的指针指向他的下一个元素
void delete_node(int k)
{
ne[k] = ne[ne[k]];
}
void delete_head()
{
head = ne[head];
}
//遍历过程
for(int i = head; i!=-1;i = ne[i])
{
cout<<e[i]<<endl;
}双链表
在实际的代码编写过程当中,我们也是直接使用静态链表来设置双链表,我们首先设置0号点和1号点为左右边界head,tail。之后我们就只需要在这两者之间插入节点构造双链表。
const int N = 100010;
int e[N];
int l[N];
int r[N];
int idx;
//初始化直接初始化出左右端点的下标,从而避免边界问题
void init()
{
//初始化的左右别搞反了
r[0] = 1;
l[1] = 0;
idx =2;
}
// 在k节点的右侧插入一个x,其实也相当于左侧插入节点
void add(int k,int x)
{
e[idx] = x;
//操作新节点的左右指针
r[idx] = r[k];
l[idx] = k;
//再操作原数组的节点
l[r[k]] = idx;
r[k] = idx++;
}
void remove(int k)
{
l[r[k]] = l[k]; //右节点的左侧,指向左节点
r[l[k]] = r[k]; //左节点的右侧,指向右节点
}经典例题
以上两种实现方式都是通过静态链表实现的,主要是来自y总的AcWing经典例题。
]]>
AcWing826. 单链表
AcWing827. 双链表
使用指针的实现方式,在leetcode当中用的比较多,这里给大家补充一些leetcode中出现的链表类型的题目,主要涉及到链表的遍历,双指针算法,和一些小技巧,高阶一点的题目会涉及到树和递归的问题。
我做的主要是leetcode上程序员面试经典和剑指offer的例题,不过个人感觉这些题也大部分涵盖了链表题型的大部分考法,而且题解也十分详细。- <h2 id="数据结构与刷题——链表"><a href="#数据结构与刷题——链表" class="headerlink" title="数据结构与刷题——链表"></a>数据结构与刷题——链表</h2><p><img src="https://img-blog.csdnimg.cn/20210607085716429.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0phY2tfX19F,size_16,color_FFFFFF,t_70" alt="在这里插入图片描述"></p> + <h2 id="数据结构与刷题——链表"><a href="#数据结构与刷题——链表" class="headerlink" title="数据结构与刷题——链表"></a>数据结构与刷题——链表</h2><p><img src="https://img-blog.csdnimg.cn/20210607085716429.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0phY2tfX19F,size_16,color_FFFFFF,t_70" alt="在这里插入图片描述"><br></p> @@ -311,11 +311,11 @@2021-06-06T12:33:00.000Z 2024-10-09T07:33:09.908Z -前言 +最近在复习数据结构,顺便整理之前刷题的一些模板和技巧,希望对大家都有帮助,博客会侧重讲解的是OJ代码实现,理论部分偏少但也会写一些自己的理解。
在之前大二上数据结构的时候我也有写过一个关于排序的专题介绍数据结构复习——内部排序快速排序
快速排序主要就是通过选取一个基准点,将一个区间内的数分成大于和小于两个部分,然后对左右区间再进行上述操作,直到子区间的长度为空为止。快速排序是不稳定的排序,如果需要变成稳定排序通过双关键字排序即可,通过下标控制绝对大小就能得到稳定的排序结果。
快速排序分三步走:- 确定分界点
- 调整左右区间
- 递归处理左右子区间
在代码实现当中,我们一般选取中间分位点会比较好,这样划分的区间比较平均。在遍历的过程当中每次调整区间的时间是$O(n)$,而区间递归的深度类似二叉树是$O(logn)$
在最好情况下,对于递归型的算法,我们利用主定理公式来计算快速排序时间复杂度得到$O(nlogn)$
$$
T(n) = 2 T\left(\frac{n}{2}\right)+\Theta(n)
$$
当然在最坏情况下,也就是数组是有序或者逆序的情况下,我们如果选择左右端点作为基准点,那么整个算法就相当于冒泡排序,递归的层数也就变成了$n$,则最坏时间复杂度为$O(n^2)$代码实现
void quick_sort(int[] q,int l,int r)
{
if(l>=r) return;
// 1.确定分界点
int i = l - 1, j = r + 1, mid = q[l + r >> 1];
// 2.调整左右区间
while(i<j)
{
do i++; while(q[i]<mid);
do j--; while(q[j]>mid);
if(i<j) swap(q[i],q[j]);
}
//3.递归处理左右子区间
quick_sort(l,j);
quick_sort(j+1,r);
}经典例题
归并排序
归并排序也是基于分治的思想,每次将区间对半分,逐步递归合并有序化子区间,最终实现所有的左右区间的有序归并,但是跟快速排序不同的是,我们需要开一个辅助数组来存储有序的部分,所以时间复杂度为$O(nlogn)$。归并排序是稳定的排序,在元素相等情况下我们总是放入数组下标较小的元素。
归并排序分三步走:- 确定分界点
- 递归处理子序列
- 合并有序序列
代码实现
const int N=100010;
int a[N],tmp[N];
void merge_sort(int q[],int l,int r)
{
if(l>=r)
return;
//确定分界点
int mid = l + r >> 1;
//递归处理子序列
merge_sort(q,l,mid);
merge_sort(q,mid+1,r);
//合并有序序列
int k = l,i = l,j = mid + 1;
while(i <= mid && j <= r)
{
if(q[i]<=q[j])// 取等号,保证归并排序的稳定性
tmp[k++]=q[i++];
else
tmp[k++]=q[j++];
}
while(i<=mid)
tmp[k++]=q[i++];
while(j<=r)
tmp[k++]=q[j++];
for(i=l;i<=r;i++)
q[i]=tmp[i];
}经典例题
AcWing 787. 归并排序
AcWing 788. 逆序对的数量排序相关时间复杂度整理
]]>前言 最近在复习数据结构,顺便整理之前刷题的一些模板和技巧,希望对大家都有帮助,博客会侧重讲解的是OJ代码实现,理论部分偏少但也会写一些自己的理解。
在之前大二上数据结构的时候我也有写过一个关于排序的专题介绍数据结构复习——内部排序快速排序
快速排序主要就是通过选取一个基准点,将一个区间内的数分成大于和小于两个部分,然后对左右区间再进行上述操作,直到子区间的长度为空为止。快速排序是不稳定的排序,如果需要变成稳定排序通过双关键字排序即可,通过下标控制绝对大小就能得到稳定的排序结果。
快速排序分三步走:- 确定分界点
- 调整左右区间
- 递归处理左右子区间
在代码实现当中,我们一般选取中间分位点会比较好,这样划分的区间比较平均。在遍历的过程当中每次调整区间的时间是$O(n)$,而区间递归的深度类似二叉树是$O(logn)$
在最好情况下,对于递归型的算法,我们利用主定理公式来计算快速排序时间复杂度得到$O(nlogn)$当然在最坏情况下,也就是数组是有序或者逆序的情况下,我们如果选择左右端点作为基准点,那么整个算法就相当于冒泡排序,递归的层数也就变成了$n$,则最坏时间复杂度为$O(n^2)$
代码实现
void quick_sort(int[] q,int l,int r)
{
if(l>=r) return;
// 1.确定分界点
int i = l - 1, j = r + 1, mid = q[l + r >> 1];
// 2.调整左右区间
while(i<j)
{
do i++; while(q[i]<mid);
do j--; while(q[j]>mid);
if(i<j) swap(q[i],q[j]);
}
//3.递归处理左右子区间
quick_sort(l,j);
quick_sort(j+1,r);
}经典例题
归并排序
归并排序也是基于分治的思想,每次将区间对半分,逐步递归合并有序化子区间,最终实现所有的左右区间的有序归并,但是跟快速排序不同的是,我们需要开一个辅助数组来存储有序的部分,所以时间复杂度为$O(nlogn)$。归并排序是稳定的排序,在元素相等情况下我们总是放入数组下标较小的元素。
归并排序分三步走:- 确定分界点
- 递归处理子序列
- 合并有序序列
代码实现
const int N=100010;
int a[N],tmp[N];
void merge_sort(int q[],int l,int r)
{
if(l>=r)
return;
//确定分界点
int mid = l + r >> 1;
//递归处理子序列
merge_sort(q,l,mid);
merge_sort(q,mid+1,r);
//合并有序序列
int k = l,i = l,j = mid + 1;
while(i <= mid && j <= r)
{
if(q[i]<=q[j])// 取等号,保证归并排序的稳定性
tmp[k++]=q[i++];
else
tmp[k++]=q[j++];
}
while(i<=mid)
tmp[k++]=q[i++];
while(j<=r)
tmp[k++]=q[j++];
for(i=l;i<=r;i++)
q[i]=tmp[i];
}经典例题
AcWing 787. 归并排序
AcWing 788. 逆序对的数量排序相关时间复杂度整理
]]>- <h2 id="前言"><a href="#前言" class="headerlink" title="前言"></a>前言</h2><p>最近在复习数据结构,顺便整理之前刷题的一些模板和技巧,希望对大家都有帮助,博客会侧重讲解的是OJ代码实现,理论部分偏少但也会写一些自己的理解。<br>在之前大二上数据结构的时候我也有写过一个关于排序的专题介绍<a href="https://blog.csdn.net/Jack___E/article/details/102875285?spm=1001.2014.3001.5502" target="_blank" rel="noopener">数据结构复习——内部排序</a></p> + <h2 id="前言"><a href="#前言" class="headerlink" title="前言"></a>前言</h2><p>最近在复习数据结构,顺便整理之前刷题的一些模板和技巧,希望对大家都有帮助,博客会侧重讲解的是OJ代码实现,理论部分偏少但也会写一些自己的理解。<br>在之前大二上数据结构的时候我也有写过一个关于排序的专题介绍<a href="https://blog.csdn.net/Jack___E/article/details/102875285?spm=1001.2014.3001.5502" target="_blank" rel="noopener">数据结构复习——内部排序</a><br></p> @@ -332,14 +332,14 @@2021-05-09T09:44:00.000Z 2024-10-09T07:33:09.884Z -EfficientNet论文解读和pytorch代码实现 +传送门
论文地址:https://arxiv.org/pdf/1905.11946.pdf
官方github:https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
github参考:https://github.com/qubvel/efficientnet
github参考:https://github.com/lukemelas/EfficientNet-PyTorch摘要
谷歌的文章总是能让我印象深刻,不管从实验上还是论文的书写上都让人十分的佩服,不得不说这确实是一个非常creative的公司!
Convolutional Neural Networks (ConvNets) are commonly developed at a fixed resource budget, and then scaled up for better accuracy if more resources are available. In this paper, we systematically study model scaling and identify that carefully balancing network depth, width, and resolution can lead to better performance. Based on this observation, we propose a new scaling method that uniformly scales all dimensions of depth/width/resolution using a simple yet highly effective compound coefficient. We demonstrate the effectiveness of this method on scaling up MobileNets and ResNet.
卷积神经网络通常是在固定的资源预算下进行计算和发展的,如果有更多可用的资源,模型能通过缩放和扩展获得更好的效果,本文系统研究(工作量很充足)了模型缩放,并且证明了细致地平衡网络的深度,宽度,和分辨率能够得到更好的效果,基于这个观点,我们提出了一个新的尺度缩放的方法,我们提出了一个新的尺度缩放的方法即:使用一个简单且高效的复合系数统一地缩放所有网络层的深度/宽度/分辨率的维度。我们证明了该方法在扩大MobileNets和ResNet方面的有效性。To go even further, we use neural architecture search to design a new baseline network and scale it up to obtain a family of models, called EfficientNets, which achieve much better accuracy and efficiency than previous ConvNets. In particular, our EfficientNet-B7 achieves state-of-the-art 84.3% top-1 accuracy on ImageNet, while being 8.4x smaller and 6.1x faster on inference than the best existing ConvNet. Our EfficientNets also transfer well and achieve state-of-the-art accuracy on CIFAR-100 (91.7%), Flowers (98.8%), and 3 other transfer learning datasets, with an order of magnitude fewer parameters. Source code is athttps://github.com/tensorflow/tpu/tree/
master/models/official/efficientnet.更进一步,我们使用神经网络结构搜索设计了一个新的baseline网络架构并且对其进行缩放得到了一组模型,我们把他叫做EfficientNets。EfficientNets相比之前的ConvNets,有着更好的准确率和更高的效率。在ImageNet上达到了最好的水平即top-1准确率84.4%/top-5准确率97.1%,然而却比已有的最好的ConvNet模型小了8.4倍并且推理时间快了6.1倍。我们的EfficientNet迁移学习的效果也好,达到了最好的准确率水平CIFAR-100(91.7%),Flowers(98.8%),和其他3个迁移学习数据集合,参数少了一个数量级(with an order of magnitude fewer parameters)。
论文思想
在之前的一些工作当中,我们可以看到,有的会通过增加网络的width即增加卷积核的个数(从而增大channels)来提升网络的性能,有的会通过增加网络的深度即使用更多的层结构来提升网络的性能,有的会通过增加输入网络的分辨率来提升网络的性能。而在Efficientnet当中则重新探究了这个问题,并提出了一种组合条件这三者的网络结构,同时量化了这三者的指标。
The intuition is that deeper ConvNet can capture richer and more complex features, and generalize well on new tasks. However, deeper networks are also more difficult to train due to the vanishing gradient problem
增加网络的深度depth能够得到更加丰富、复杂的特征并且能够在其他新任务中很好的泛化性能。但是,由于逐渐消失的梯度问题,更深层的网络也更难以训练。wider networks tend to be able to capture more fine-grained features and are easier to train. However, extremely wide but shallow networks tend to have difficulties in capturing higher level features
with更广的网络往往能够捕获更多细粒度的功能,并且更易于训练。但是,极其宽泛但较浅的网络在捕获更高级别的特征时往往会遇到困难With higher resolution input images, ConvNets can potentially capture more fine-grained pattern,but the accuracy gain diminishes for very high resolutions
使用更高分辨率的输入图像,ConvNets可以捕获更细粒度的图案,但对于非常高分辨率的图片,准确度会降低。作者在论文中对整个网络的运算过程和复合扩展方法进行了抽象:
首先定义了每一层卷积网络为$\mathcal{F}{i}\left(X{i}\right)$,而$X_i$是输入张量,$Y_i$是输出张量,而tensor的形状是$<H_i,W_i,C_i>$
整个卷积网络由 k 个卷积层组成,可以表示为$\mathcal{N}=\mathcal{F}{k} \odot \ldots \odot \mathcal{F}{2} \odot \mathcal{F}{1}\left(X{1}\right)=\bigodot_{j=1 \ldots k} \mathcal{F}{j}\left(X{1}\right)$
从而得到我们的整个卷积网络:
$$
\mathcal{N}=\bigodot_{i=1 \ldots s} \mathcal{F}{i}^{L{i}}\left(X_{\left\langle H_{i}, W_{i}, C_{i}\right\rangle}\right)
$$下标 i(从 1 到 s) 表示的是 stage 的序号,$\mathcal{F}{i}^{L{i}}$表示第 i 个 stage ,它表示卷积层 $\mathcal{F}{i}$重复了${L{i}}$ 次。
为了探究$d , r , w$这三个因子对最终准确率的影响,则将$d , r , w$加入到公式中,我们可以得到抽象化后的优化问题(在指定资源限制下),其中$s.t.$代表限制条件:
- $d$用来缩放深度$\widehat{L}_i $。
- $r$用来缩放分辨率即影响$\widehat{H}_i$以及$\widehat{W}_i$。
- $w$就是用来缩放特征矩阵的channels即 $\widehat{C}_i$。
- target_memory为memory限制
- target_flops为FLOPs限制
Bigger networks with larger width, depth, or resolution tend to achieve higher accuracy, but the accuracy gain quickly saturate after reaching 80%, demonstrating the limitation of single dimension scaling
具有较大宽度,深度或分辨率的较大网络往往会实现较高的精度,但是精度增益在达到80%后会迅速饱和,这表明了单维缩放的局限性。compound scaling method
In this paper, we propose a new compound scaling method, which use a compound coefficient φ to uniformly scales network width, depth, and resolution in a principled way:
在本文中,我们提出了一种新的复合缩放方法,该方法使用一个统一的复合系数$\phi$对网络的宽度,深度和分辨率进行均匀缩放。
其中$\alpha,\beta,\gamma$是通过一个小格子搜索的方法决定的常量。通常来说,$\phi$是一个用户指定的系数来控制有多少的额外资源能够用于模型的缩放,$\alpha,\beta,\gamma$指明了怎么支配这些额外的资源分别到网络的宽度,深度,和分辨率上。尤其是,一个标准卷积操作的运算量的比例是$d,w^2,r^2$双倍的网络深度将带来双倍的运算量,但是双倍的网络宽度或分辨率将会增加运算为4倍。因为卷积操作通常在ConvNets中占据绝大部分计算量,通过3式来缩放ConvNet大约将增加$(\alpha,\beta^2,\gamma^2)$运算量。
我们限制$\alpha \cdot \beta^{2} \cdot \gamma^{2} \approx 2$所以对于任意给定的$\phi$值,我们总共的运算量将大约增加$2^{\phi}$
网络结构
文中给出了Efficientnet-B0的基准框架,在Efficientnet当中,我们所使用的激活函数是swish激活函数,整个网络分为了9个stage,在第2到第8stage是一直在堆叠MBConv结构,表格当中MBConv结构后面的数字(1或6)表示的就是MBConv中第一个1x1的卷积层会将输入特征矩阵的channels扩充为n倍。Channels表示通过该Stage后输出特征矩阵的Channels。
MBConv结构
MBConv的结构相对来说还是十分好理解的,这里是我自己画的一张结构图。
MBConv结构主要由一个1x1的expand conv(升维作用,包含BN和Swish激活函数)提升维度的倍率正是之前网络结构中看到的1和6,一个KxK的卷积深度可分离卷积Depthwise Conv(包含BN和Swish)k的具体值可看EfficientNet-B0的网络框架主要有3x3和5x5两种情况,一个SE模块,一个1x1的pointer conv降维作用,包含BN),一个Droupout层构成,一般情况下都添加上了残差边模块Shortcut,从而得到输出特征矩阵。
首先关于深度可分离卷积的概念是是我们需要了解的,相当于将卷积的过程拆成运算和合并两个过程,分别对应depthwise和point两个过程,这里给一个参考连接给大家就不在详细描述了Depthwise卷积与Pointwise卷积
1.由于该模块最初是用tensorflow来实现的与pytorch有一些小差别,所以在使用pytorch实现的时候我们最好将tensorflow当中的samepadding操作重新实现一下
2.在batchnormal时候的动量设置也是有一些不一样的,论文当中设置的batch_norm_momentum=0.99,在pytorch当中需要先执行1-momentum再设为参数与tensorflow不同。# Batch norm parameters
momentum= 1 - batch_norm_momentum # pytorch's difference from tensorflow
eps= batch_norm_epsilon
nn.BatchNorm2d(num_features=out_channels, momentum=momentum, eps=eps)class Conv2dSamePadding(nn.Conv2d):
"""2D Convolutions like TensorFlow, for a dynamic image size.
The padding is operated in forward function by calculating dynamically.
"""
# Tips for 'SAME' mode padding.
# Given the following:
# i: width or height
# s: stride
# k: kernel size
# d: dilation
# p: padding
# Output after Conv2d:
# o = floor((i+p-((k-1)*d+1))/s+1)
# If o equals i, i = floor((i+p-((k-1)*d+1))/s+1),
# => p = (i-1)*s+((k-1)*d+1)-i
def __init__(self, in_channels, out_channels, kernel_size,padding=0, stride=1, dilation=1,
groups=1, bias=True, padding_mode = 'zeros'):
super().__init__(in_channels, out_channels, kernel_size, stride, padding, dilation, groups, bias)
self.stride = self.stride if len(self.stride) == 2 else [self.stride[0]] * 2
def forward(self, x):
ih, iw = x.size()[-2:] # input
kh, kw = self.weight.size()[-2:] # because kernel size equals to weight size
sh, sw = self.stride # stride
# change the output size according to stride
oh, ow = math.ceil(ih/sh), math.ceil(iw/sw) # output
"""
kernel effective receptive field size: (kernel_size-1) x dilation + 1
"""
pad_h = max((oh - 1) * self.stride[0] + (kh - 1) * self.dilation[0] + 1 - ih, 0)
pad_w = max((ow - 1) * self.stride[1] + (kw - 1) * self.dilation[1] + 1 - iw, 0)
if pad_h > 0 or pad_w > 0:
x = F.pad(x, [pad_w // 2, pad_w - pad_w // 2, pad_h // 2, pad_h - pad_h // 2])
return F.conv2d(x, self.weight, self.bias, self.stride, self.padding, self.dilation, self.groups)MBConvBlock模块结构
class ConvBNActivation(nn.Module):
"""Convolution BN Activation"""
def __init__(self,in_channels,out_channels,kernel_size,stride=1,groups=1,
bias=False,momentum=0.01,eps=1e-3,active=False):
super().__init__()
self.layer=nn.Sequential(
Conv2dSamePadding(in_channels,out_channels,kernel_size=kernel_size,
stride=stride,groups=groups, bias=bias),
nn.BatchNorm2d(num_features=out_channels, momentum=momentum, eps=eps)
)
self.active=active
self.swish = Swish()
def forward(self, x):
x = self.layer(x)
if self.active:
x=self.swish(x)
return x
class MBConvBlock(nn.Module):
def __init__(self,in_channels,out_channels,kernel_size,stride,
expand_ratio=1, momentum=0.01,eps=1e-3,
drop_connect_ratio=0.2,training=True,
se_ratio=0.25,skip=True, image_size=None):
super().__init__()
self.expand_ratio = expand_ratio
self.se_ratio = se_ratio
self.has_se = (se_ratio is not None) and (0 < se_ratio <= 1)
self.skip = skip and stride == 1 and in_channels == out_channels
# 1x1 convolution channels expansion phase
expand_channels = in_channels * self.expand_ratio # number of output channels
if self.expand_ratio != 1:
self.expand_conv = ConvBNActivation(in_channels=in_channels,out_channels=expand_channels,
momentum=momentum,eps=eps,
kernel_size=1,bias=False,active=False)
# Depthwise convolution phase
self.depthwise_conv = ConvBNActivation(in_channels=expand_channels,out_channels=expand_channels,
momentum=momentum,eps=eps,
kernel_size=kernel_size,stride=stride,groups=expand_channels,bias=False,active=False)
# Squeeze and Excitation module
if self.has_se:
sequeeze_channels = max(1,int(expand_channels*self.se_ratio))
self.se = SEModule(expand_channels,sequeeze_channels)
# Pointwise convolution phase
self.project_conv = ConvBNActivation(expand_channels,out_channels,momentum=momentum,eps=eps,
kernel_size=1,bias=False,active=True)
self.drop_connect = DropConnect(drop_connect_ratio,training)
def forward(self,x):
input_x = x
if self.expand_ratio != 1:
x = self.expand_conv(x)
x = self.depthwise_conv(x)
if self.has_se:
x = self.se(x)
x = self.project_conv(x)
if self.skip:
x = self.drop_connect(x)
x = x + input_x
return xSE模块
SE模块是通道注意力模块,该模块能够关注channel之间的关系,可以让模型自主学习到不同channel特征的重要程度。由一个全局平均池化,两个全连接层组成。第一个全连接层的节点个数是输入该MBConv特征矩阵channels的1/4 ,且使用Swish激活函数。第二个全连接层的节点个数等于Depthwise Conv层输出的特征矩阵channels,且使用Sigmoid激活函数,这里引用一下别人画好的示意图。
class SEModule(nn.Module):
"""Squeeze and Excitation module for channel attention"""
def __init__(self,in_channels,squeezed_channels):
super().__init__()
self.global_avg_pool = nn.AdaptiveAvgPool2d(1)
self.sequential = nn.Sequential(
nn.Conv2d(in_channels,squeezed_channels,1), # use 1x1 convolution instead of linear
Swish(),
nn.Conv2d(squeezed_channels,in_channels,1),
nn.Sigmoid()
)
def forward(self,x):
x= self.global_avg_pool(x)
y = self.sequential(x)
return x * yswish激活函数
Swish是Google提出的一种新型激活函数,其原始公式为:f(x)=x * sigmod(x),变形Swish-B激活函数的公式则为f(x)=x * sigmod(b * x),其拥有不饱和,光滑,非单调性的特征,Google在论文中的多项测试表明Swish以及Swish-B激活函数的性能即佳,在不同的数据集上都表现出了要优于当前最佳激活函数的性能。
$$f(x)=x \cdot \operatorname{sigmoid}(\beta x)$$
其中$\beta$是个常数或可训练的参数,Swish 具备无上界有下界、平滑、非单调的特性。class Swish(nn.Module):
""" swish activation function"""
def forward(self,x):
return x * torch.sigmoid(x)droupout代码实现
class DropConnect(nn.Module):
"""Drop Connection"""
def __init__(self,ratio,training):
super().__init__()
assert 0 <= ratio <= 1
self.keep_prob = 1 - ratio
self.training=training
def forward(self,x):
if not self.training:
return x
batch_size = x.shape[0]
random_tensor = self.keep_prob
random_tensor += torch.rand([batch_size,1,1,1],dtype=x.dtype,device=x.device)
# generate binary_tensor mask according to probability (p for 0, 1-p for 1)
binary_tensor = torch.floor(random_tensor)
output = x / self.keep_prob * binary_tensor
return output总结
这里我们只给出了b0结构的代码实现,对于其他结构的实现过程就是在b0的基础上对wdith,depth,resolution都通过倍率因子统一缩放,这个部分在这个博客里面有详细的介绍EfficientNet(B0-B7)参数设置。
在本文中,我们系统地研究了ConvNet的缩放比例,分析了各因素对网络结构的影响,并确定仔细平衡网络的宽度,深度和分辨率,这是目前网络训练最重要但缺乏研究的部分,也是我们无法获得更好的准确性和效率忽略的一个部分。为解决此问题,本文作者提出了一种简单而高效的复合缩放方法,通过一个倍率因子统一缩放各部分比例并添加上通道注意力机制和残差模块,从而改善网络架构得到SOTA的效果,同时对模型各成分因子进行量化十分具有创新性。
]]>参考连接
EfficientNet网络详解
神经网络学习小记录50——Pytorch EfficientNet模型的复现详解
论文翻译
令人拍案叫绝的EfficientNet和EfficientDet
swish激活函数
Depthwise卷积与Pointwise卷积
CV领域常用的注意力机制模块(SE、CBAM)
Global Average PoolingEfficientNet论文解读和pytorch代码实现 传送门
论文地址:https://arxiv.org/pdf/1905.11946.pdf
官方github:https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
github参考:https://github.com/qubvel/efficientnet
github参考:https://github.com/lukemelas/EfficientNet-PyTorch摘要
谷歌的文章总是能让我印象深刻,不管从实验上还是论文的书写上都让人十分的佩服,不得不说这确实是一个非常creative的公司!
Convolutional Neural Networks (ConvNets) are commonly developed at a fixed resource budget, and then scaled up for better accuracy if more resources are available. In this paper, we systematically study model scaling and identify that carefully balancing network depth, width, and resolution can lead to better performance. Based on this observation, we propose a new scaling method that uniformly scales all dimensions of depth/width/resolution using a simple yet highly effective compound coefficient. We demonstrate the effectiveness of this method on scaling up MobileNets and ResNet.
卷积神经网络通常是在固定的资源预算下进行计算和发展的,如果有更多可用的资源,模型能通过缩放和扩展获得更好的效果,本文系统研究(工作量很充足)了模型缩放,并且证明了细致地平衡网络的深度,宽度,和分辨率能够得到更好的效果,基于这个观点,我们提出了一个新的尺度缩放的方法,我们提出了一个新的尺度缩放的方法即:使用一个简单且高效的复合系数统一地缩放所有网络层的深度/宽度/分辨率的维度。我们证明了该方法在扩大MobileNets和ResNet方面的有效性。To go even further, we use neural architecture search to design a new baseline network and scale it up to obtain a family of models, called EfficientNets, which achieve much better accuracy and efficiency than previous ConvNets. In particular, our EfficientNet-B7 achieves state-of-the-art 84.3% top-1 accuracy on ImageNet, while being 8.4x smaller and 6.1x faster on inference than the best existing ConvNet. Our EfficientNets also transfer well and achieve state-of-the-art accuracy on CIFAR-100 (91.7%), Flowers (98.8%), and 3 other transfer learning datasets, with an order of magnitude fewer parameters. Source code is athttps://github.com/tensorflow/tpu/tree/
master/models/official/efficientnet.更进一步,我们使用神经网络结构搜索设计了一个新的baseline网络架构并且对其进行缩放得到了一组模型,我们把他叫做EfficientNets。EfficientNets相比之前的ConvNets,有着更好的准确率和更高的效率。在ImageNet上达到了最好的水平即top-1准确率84.4%/top-5准确率97.1%,然而却比已有的最好的ConvNet模型小了8.4倍并且推理时间快了6.1倍。我们的EfficientNet迁移学习的效果也好,达到了最好的准确率水平CIFAR-100(91.7%),Flowers(98.8%),和其他3个迁移学习数据集合,参数少了一个数量级(with an order of magnitude fewer parameters)。
论文思想
在之前的一些工作当中,我们可以看到,有的会通过增加网络的width即增加卷积核的个数(从而增大channels)来提升网络的性能,有的会通过增加网络的深度即使用更多的层结构来提升网络的性能,有的会通过增加输入网络的分辨率来提升网络的性能。而在Efficientnet当中则重新探究了这个问题,并提出了一种组合条件这三者的网络结构,同时量化了这三者的指标。
The intuition is that deeper ConvNet can capture richer and more complex features, and generalize well on new tasks. However, deeper networks are also more difficult to train due to the vanishing gradient problem
增加网络的深度depth能够得到更加丰富、复杂的特征并且能够在其他新任务中很好的泛化性能。但是,由于逐渐消失的梯度问题,更深层的网络也更难以训练。wider networks tend to be able to capture more fine-grained features and are easier to train. However, extremely wide but shallow networks tend to have difficulties in capturing higher level features
with更广的网络往往能够捕获更多细粒度的功能,并且更易于训练。但是,极其宽泛但较浅的网络在捕获更高级别的特征时往往会遇到困难With higher resolution input images, ConvNets can potentially capture more fine-grained pattern,but the accuracy gain diminishes for very high resolutions
使用更高分辨率的输入图像,ConvNets可以捕获更细粒度的图案,但对于非常高分辨率的图片,准确度会降低。作者在论文中对整个网络的运算过程和复合扩展方法进行了抽象:
首先定义了每一层卷积网络为$\mathcal{F}{i}\left(X{i}\right)$,而$Xi$是输入张量,$Y_i$是输出张量,而tensor的形状是$
整个卷积网络由 k 个卷积层组成,可以表示为$\mathcal{N}=\mathcal{F}
从而得到我们的整个卷积网络:下标 i(从 1 到 s) 表示的是 stage 的序号,$\mathcal{F}{i}^{L{i}}$表示第 i 个 stage ,它表示卷积层 $\mathcal{F}{i}$重复了${L{i}}$ 次。
为了探究$d , r , w$这三个因子对最终准确率的影响,则将$d , r , w$加入到公式中,我们可以得到抽象化后的优化问题(在指定资源限制下),其中$s.t.$代表限制条件:
- $d$用来缩放深度$\widehat{L}_i $。
- $r$用来缩放分辨率即影响$\widehat{H}_i$以及$\widehat{W}_i$。
- $w$就是用来缩放特征矩阵的channels即 $\widehat{C}_i$。
- target_memory为memory限制
- target_flops为FLOPs限制
Bigger networks with larger width, depth, or resolution tend to achieve higher accuracy, but the accuracy gain quickly saturate after reaching 80%, demonstrating the limitation of single dimension scaling
具有较大宽度,深度或分辨率的较大网络往往会实现较高的精度,但是精度增益在达到80%后会迅速饱和,这表明了单维缩放的局限性。compound scaling method
In this paper, we propose a new compound scaling method, which use a compound coefficient φ to uniformly scales network width, depth, and resolution in a principled way:
在本文中,我们提出了一种新的复合缩放方法,该方法使用一个统一的复合系数$\phi$对网络的宽度,深度和分辨率进行均匀缩放。
其中$\alpha,\beta,\gamma$是通过一个小格子搜索的方法决定的常量。通常来说,$\phi$是一个用户指定的系数来控制有多少的额外资源能够用于模型的缩放,$\alpha,\beta,\gamma$指明了怎么支配这些额外的资源分别到网络的宽度,深度,和分辨率上。尤其是,一个标准卷积操作的运算量的比例是$d,w^2,r^2$双倍的网络深度将带来双倍的运算量,但是双倍的网络宽度或分辨率将会增加运算为4倍。因为卷积操作通常在ConvNets中占据绝大部分计算量,通过3式来缩放ConvNet大约将增加$(\alpha,\beta^2,\gamma^2)$运算量。
我们限制$\alpha \cdot \beta^{2} \cdot \gamma^{2} \approx 2$所以对于任意给定的$\phi$值,我们总共的运算量将大约增加$2^{\phi}$
网络结构
文中给出了Efficientnet-B0的基准框架,在Efficientnet当中,我们所使用的激活函数是swish激活函数,整个网络分为了9个stage,在第2到第8stage是一直在堆叠MBConv结构,表格当中MBConv结构后面的数字(1或6)表示的就是MBConv中第一个1x1的卷积层会将输入特征矩阵的channels扩充为n倍。Channels表示通过该Stage后输出特征矩阵的Channels。
MBConv结构
MBConv的结构相对来说还是十分好理解的,这里是我自己画的一张结构图。
MBConv结构主要由一个1x1的expand conv(升维作用,包含BN和Swish激活函数)提升维度的倍率正是之前网络结构中看到的1和6,一个KxK的卷积深度可分离卷积Depthwise Conv(包含BN和Swish)k的具体值可看EfficientNet-B0的网络框架主要有3x3和5x5两种情况,一个SE模块,一个1x1的pointer conv降维作用,包含BN),一个Droupout层构成,一般情况下都添加上了残差边模块Shortcut,从而得到输出特征矩阵。
首先关于深度可分离卷积的概念是是我们需要了解的,相当于将卷积的过程拆成运算和合并两个过程,分别对应depthwise和point两个过程,这里给一个参考连接给大家就不在详细描述了Depthwise卷积与Pointwise卷积
1.由于该模块最初是用tensorflow来实现的与pytorch有一些小差别,所以在使用pytorch实现的时候我们最好将tensorflow当中的samepadding操作重新实现一下
2.在batchnormal时候的动量设置也是有一些不一样的,论文当中设置的batch_norm_momentum=0.99,在pytorch当中需要先执行1-momentum再设为参数与tensorflow不同。# Batch norm parameters
momentum= 1 - batch_norm_momentum # pytorch's difference from tensorflow
eps= batch_norm_epsilon
nn.BatchNorm2d(num_features=out_channels, momentum=momentum, eps=eps)class Conv2dSamePadding(nn.Conv2d):
"""2D Convolutions like TensorFlow, for a dynamic image size.
The padding is operated in forward function by calculating dynamically.
"""
# Tips for 'SAME' mode padding.
# Given the following:
# i: width or height
# s: stride
# k: kernel size
# d: dilation
# p: padding
# Output after Conv2d:
# o = floor((i+p-((k-1)*d+1))/s+1)
# If o equals i, i = floor((i+p-((k-1)*d+1))/s+1),
# => p = (i-1)*s+((k-1)*d+1)-i
def __init__(self, in_channels, out_channels, kernel_size,padding=0, stride=1, dilation=1,
groups=1, bias=True, padding_mode = 'zeros'):
super().__init__(in_channels, out_channels, kernel_size, stride, padding, dilation, groups, bias)
self.stride = self.stride if len(self.stride) == 2 else [self.stride[0]] * 2
def forward(self, x):
ih, iw = x.size()[-2:] # input
kh, kw = self.weight.size()[-2:] # because kernel size equals to weight size
sh, sw = self.stride # stride
# change the output size according to stride
oh, ow = math.ceil(ih/sh), math.ceil(iw/sw) # output
"""
kernel effective receptive field size: (kernel_size-1) x dilation + 1
"""
pad_h = max((oh - 1) * self.stride[0] + (kh - 1) * self.dilation[0] + 1 - ih, 0)
pad_w = max((ow - 1) * self.stride[1] + (kw - 1) * self.dilation[1] + 1 - iw, 0)
if pad_h > 0 or pad_w > 0:
x = F.pad(x, [pad_w // 2, pad_w - pad_w // 2, pad_h // 2, pad_h - pad_h // 2])
return F.conv2d(x, self.weight, self.bias, self.stride, self.padding, self.dilation, self.groups)MBConvBlock模块结构
class ConvBNActivation(nn.Module):
"""Convolution BN Activation"""
def __init__(self,in_channels,out_channels,kernel_size,stride=1,groups=1,
bias=False,momentum=0.01,eps=1e-3,active=False):
super().__init__()
self.layer=nn.Sequential(
Conv2dSamePadding(in_channels,out_channels,kernel_size=kernel_size,
stride=stride,groups=groups, bias=bias),
nn.BatchNorm2d(num_features=out_channels, momentum=momentum, eps=eps)
)
self.active=active
self.swish = Swish()
def forward(self, x):
x = self.layer(x)
if self.active:
x=self.swish(x)
return x
class MBConvBlock(nn.Module):
def __init__(self,in_channels,out_channels,kernel_size,stride,
expand_ratio=1, momentum=0.01,eps=1e-3,
drop_connect_ratio=0.2,training=True,
se_ratio=0.25,skip=True, image_size=None):
super().__init__()
self.expand_ratio = expand_ratio
self.se_ratio = se_ratio
self.has_se = (se_ratio is not None) and (0 < se_ratio <= 1)
self.skip = skip and stride == 1 and in_channels == out_channels
# 1x1 convolution channels expansion phase
expand_channels = in_channels * self.expand_ratio # number of output channels
if self.expand_ratio != 1:
self.expand_conv = ConvBNActivation(in_channels=in_channels,out_channels=expand_channels,
momentum=momentum,eps=eps,
kernel_size=1,bias=False,active=False)
# Depthwise convolution phase
self.depthwise_conv = ConvBNActivation(in_channels=expand_channels,out_channels=expand_channels,
momentum=momentum,eps=eps,
kernel_size=kernel_size,stride=stride,groups=expand_channels,bias=False,active=False)
# Squeeze and Excitation module
if self.has_se:
sequeeze_channels = max(1,int(expand_channels*self.se_ratio))
self.se = SEModule(expand_channels,sequeeze_channels)
# Pointwise convolution phase
self.project_conv = ConvBNActivation(expand_channels,out_channels,momentum=momentum,eps=eps,
kernel_size=1,bias=False,active=True)
self.drop_connect = DropConnect(drop_connect_ratio,training)
def forward(self,x):
input_x = x
if self.expand_ratio != 1:
x = self.expand_conv(x)
x = self.depthwise_conv(x)
if self.has_se:
x = self.se(x)
x = self.project_conv(x)
if self.skip:
x = self.drop_connect(x)
x = x + input_x
return xSE模块
SE模块是通道注意力模块,该模块能够关注channel之间的关系,可以让模型自主学习到不同channel特征的重要程度。由一个全局平均池化,两个全连接层组成。第一个全连接层的节点个数是输入该MBConv特征矩阵channels的1/4 ,且使用Swish激活函数。第二个全连接层的节点个数等于Depthwise Conv层输出的特征矩阵channels,且使用Sigmoid激活函数,这里引用一下别人画好的示意图。
class SEModule(nn.Module):
"""Squeeze and Excitation module for channel attention"""
def __init__(self,in_channels,squeezed_channels):
super().__init__()
self.global_avg_pool = nn.AdaptiveAvgPool2d(1)
self.sequential = nn.Sequential(
nn.Conv2d(in_channels,squeezed_channels,1), # use 1x1 convolution instead of linear
Swish(),
nn.Conv2d(squeezed_channels,in_channels,1),
nn.Sigmoid()
)
def forward(self,x):
x= self.global_avg_pool(x)
y = self.sequential(x)
return x * yswish激活函数
Swish是Google提出的一种新型激活函数,其原始公式为:f(x)=x sigmod(x),变形Swish-B激活函数的公式则为f(x)=x sigmod(b * x),其拥有不饱和,光滑,非单调性的特征,Google在论文中的多项测试表明Swish以及Swish-B激活函数的性能即佳,在不同的数据集上都表现出了要优于当前最佳激活函数的性能。
其中$\beta$是个常数或可训练的参数,Swish 具备无上界有下界、平滑、非单调的特性。
class Swish(nn.Module):
""" swish activation function"""
def forward(self,x):
return x * torch.sigmoid(x)droupout代码实现
class DropConnect(nn.Module):
"""Drop Connection"""
def __init__(self,ratio,training):
super().__init__()
assert 0 <= ratio <= 1
self.keep_prob = 1 - ratio
self.training=training
def forward(self,x):
if not self.training:
return x
batch_size = x.shape[0]
random_tensor = self.keep_prob
random_tensor += torch.rand([batch_size,1,1,1],dtype=x.dtype,device=x.device)
# generate binary_tensor mask according to probability (p for 0, 1-p for 1)
binary_tensor = torch.floor(random_tensor)
output = x / self.keep_prob * binary_tensor
return output总结
这里我们只给出了b0结构的代码实现,对于其他结构的实现过程就是在b0的基础上对wdith,depth,resolution都通过倍率因子统一缩放,这个部分在这个博客里面有详细的介绍EfficientNet(B0-B7)参数设置。
在本文中,我们系统地研究了ConvNet的缩放比例,分析了各因素对网络结构的影响,并确定仔细平衡网络的宽度,深度和分辨率,这是目前网络训练最重要但缺乏研究的部分,也是我们无法获得更好的准确性和效率忽略的一个部分。为解决此问题,本文作者提出了一种简单而高效的复合缩放方法,通过一个倍率因子统一缩放各部分比例并添加上通道注意力机制和残差模块,从而改善网络架构得到SOTA的效果,同时对模型各成分因子进行量化十分具有创新性。
]]>参考连接
EfficientNet网络详解
神经网络学习小记录50——Pytorch EfficientNet模型的复现详解
论文翻译
令人拍案叫绝的EfficientNet和EfficientDet
swish激活函数
Depthwise卷积与Pointwise卷积
CV领域常用的注意力机制模块(SE、CBAM)
Global Average Pooling<h2 id="EfficientNet论文解读和pytorch代码实现"><a href="#EfficientNet论文解读和pytorch代码实现" class="headerlink" title="EfficientNet论文解读和pytorch代码实现"></a>EfficientNet论文解读和pytorch代码实现</h2><h2 id="传送门"><a href="#传送门" class="headerlink" title="传送门"></a>传送门</h2><blockquote> <p>论文地址:<a href="https://arxiv.org/pdf/1905.11946.pdf" target="_blank" rel="noopener">https://arxiv.org/pdf/1905.11946.pdf</a><br>官方github:<a href="https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet" target="_blank" rel="noopener">https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet</a><br>github参考:<a href="https://github.com/qubvel/efficientnet" target="_blank" rel="noopener">https://github.com/qubvel/efficientnet</a><br>github参考:<a href="https://github.com/lukemelas/EfficientNet-PyTorch" target="_blank" rel="noopener">https://github.com/lukemelas/EfficientNet-PyTorch</a></p> </blockquote> -<h2 id="摘要"><a href="#摘要" class="headerlink" title="摘要"></a>摘要</h2><p>谷歌的文章总是能让我印象深刻,不管从实验上还是论文的书写上都让人十分的佩服,不得不说这确实是一个非常creative的公司!<br><code>Convolutional Neural Networks (ConvNets) are commonly developed at a fixed resource budget, and then scaled up for better accuracy if more resources are available. In this paper, we systematically study model scaling and identify that carefully balancing network depth, width, and resolution can lead to better performance. Based on this observation, we propose a new scaling method that uniformly scales all dimensions of depth/width/resolution using a simple yet highly effective compound coefficient. We demonstrate the effectiveness of this method on scaling up MobileNets and ResNet. </code><br>卷积神经网络通常是在固定的资源预算下进行计算和发展的,如果有更多可用的资源,模型能通过缩放和扩展获得更好的效果,本文<strong>系统研究(工作量很充足)</strong>了模型缩放,并且证明了<strong>细致地平衡网络的深度,宽度,和分辨率能够得到更好的效果</strong>,基于这个观点,我们提出了一个新的尺度缩放的方法,我们提出了一个新的尺度缩放的方法即:<strong>使用一个简单且高效的复合系数统一地缩放所有网络层的深度/宽度/分辨率的维度</strong>。我们证明了该方法在扩大MobileNets和ResNet方面的有效性。</p> +<h2 id="摘要"><a href="#摘要" class="headerlink" title="摘要"></a>摘要</h2><p>谷歌的文章总是能让我印象深刻,不管从实验上还是论文的书写上都让人十分的佩服,不得不说这确实是一个非常creative的公司!<br><code>Convolutional Neural Networks (ConvNets) are commonly developed at a fixed resource budget, and then scaled up for better accuracy if more resources are available. In this paper, we systematically study model scaling and identify that carefully balancing network depth, width, and resolution can lead to better performance. Based on this observation, we propose a new scaling method that uniformly scales all dimensions of depth/width/resolution using a simple yet highly effective compound coefficient. We demonstrate the effectiveness of this method on scaling up MobileNets and ResNet.</code><br>卷积神经网络通常是在固定的资源预算下进行计算和发展的,如果有更多可用的资源,模型能通过缩放和扩展获得更好的效果,本文<strong>系统研究(工作量很充足)</strong>了模型缩放,并且证明了<strong>细致地平衡网络的深度,宽度,和分辨率能够得到更好的效果</strong>,基于这个观点,我们提出了一个新的尺度缩放的方法,我们提出了一个新的尺度缩放的方法即:<strong>使用一个简单且高效的复合系数统一地缩放所有网络层的深度/宽度/分辨率的维度</strong>。我们证明了该方法在扩大MobileNets和ResNet方面的有效性。<br></p> @@ -356,11 +356,11 @@2021-04-22T02:20:00.000Z 2024-10-09T07:33:09.898Z -yolov1-3论文解析 +最近在看经典目标检测算法yolo的思想,为了更好的了解yolo系列的相关文章,我从最初版本的论文思想开始看的,之后有时间会把yolov4和yolov5再认真看看,目前来说yolov3的spp版本是使用得最为广泛的一种,整体上来说yolo的设计思想还是很有创造性的数学也比较严谨。
yolov1论文思想
物体检测主流的算法框架大致分为one-stage与two-stage。two-stage算法代表有R-CNN系列,one-stage算法代表有Yolo系列。按笔者理解,two-stage算法将步骤一与步骤二分开执行,输入图像先经过候选框生成网络(例如faster rcnn中的RPN网络),再经过分类网络;one-stage算法将步骤一与步骤二同时执行,输入图像只经过一个网络,生成的结果中同时包含位置与类别信息。two-stage与one-stage相比,精度高,但是计算量更大,所以运算较慢。
We present YOLO, a new approach to object detection. Prior work on object detection repurposes classifiers to perform detection. Instead, we frame object detection as a regression problem to spatially separated bounding boxes and associated class probabilities.
yolo相比其他R-CNN等方法最大的一个不同就是他将这个识别和定位的过程转化成了一个空间定位并分类的回归问题,这也是他为什么能够利用网络进行端到端直接同时预测的重要原因。
yolo的特点
1.YOLO速度非常快。由于我们的检测是当做一个回归问题,不需要很复杂的流程。在测试的时候我们只需将一个新的图片输入网络来检测物体。
First, YOLO is extremely fast. Since we frame detection as a regression problem we don’t need a complex pipeline
2.Yolo会基于整张图片信息进行预测,与基于滑动窗口和候选区域的方法不同,在训练和测试期间YOLO可以看到整个图像,所以它隐式地记录了分类类别的上下文信息及它的全貌Second, YOLO reasons globally about the image when making predictions Unlike sliding window and region proposal-based techniques, YOLO sees the entire image during training and test time so it implicitly encodes contextual information about classes as well as their appearance
3.第三,YOLO能学习到目标的泛化表征。作者尝试了用自然图片数据集进行训练,用艺术画作品进行预测,Yolo的检测效果更佳。Third, YOLO learns generalizable representations of objects. Since YOLO is highly generalizable it is less likely to break down when applied to new domains or unexpected inputsbackbone-darknet
yolov1这块的话,由于是比较早期的网络所以在设计时没有使用batchnormal,激活函数上采用leaky relu,输入图像大小为448x448,经过许多卷积层与池化层,变为7x7x1024张量,最后经过两层全连接层,输出张量维度为7x7x30。除了最后一层的输出使用了线性激活函数,其他层全部使用Leaky Relu激活函数。
$$\phi(x)= \begin{cases}
x,& \text{if x>0} \
0.1x,& \text{otherwise}
\end{cases}$$输出维度
yolov1最精髓的地方应该就是他的输出维度,论文当中有放出这样一张图片,看完以后我们能对yolo算法的特点有更加深刻的理解。在上图的backbone当中我们可以看到的是
yolo的输出相当于把原图片分割成了$S \times S$个区域,然后对预测目标标定他的boundingbox,boundingbox由中心点的坐标,长宽以及物体的置信分数组成$x,y,w,h,confidence$,图中的$B$表示的是boundingbox的个数。置信分数在yolo当中是这样定义的:$Pr(Object)IOU_{pred}^{truth}$对于$Pr(Object)=1 \text{ if detect object else 0}$,其实置信分数就是boudingbox与groundtruth之间的IOU,并对每个小网格对应的$C$个类别都预测出他的条件概率:$Pr(Class_i|Object)$。
在推理时,我们可以得到当前网格对于每个类别的预测置信分数:$$Pr(Class_i)*IOU_{pred}^{truth} = Pr(Class_i|Object)*Pr(Object)*IOU_{pred}^{truth}$$
这样一种严谨的条件概率的方式得到我们的最终概率是十分可行和合适的。YOLO imposes strong spatial constraints on bounding box predictions since each grid cell only predicts two boxes and can only have one class. This spatial constraint limits the number of nearby objects that our model can predict. Our model struggles with small objects that appear in groups, such as flocks of birds.
*不过在原论文当中也有提到的一点是:YOLO给边界框预测强加空间约束,因为每个网格单元只预测两个框和只能有一个类别。这个空间约束限制了我们的模型可以预测的邻近目标的数量。我们的模型难以预测群组中出现的小物体(比如鸟群)。**损失函数
在损失函数方面,由于公式比较长所以就直接截图过来了,损失函数的设计放方面作者也考虑的比较周全,
预测框的中心点$(x,y)$。预测框的宽高$w,h$,其中$\mathbb{1}_{i j}^{\text {obj }}$为控制函数,在标签中包含物体的那些格点处,该值为 1 ,若格点不含有物体,该值为 0在计算损失函数的时候作者最开始使用的是最简单的平方损失函数来计算检测,因为它是计算简单且容易优化的,但是它并不完全符合我们最大化平均精度的目标,原因如下:
It weights localization error equally with classification error which may not be ideal.
1.它对定位错误的权重与分类错误的权重相等,这可能不是理想的选择。Also, in every image many grid cells do not contain any object. This pushes the “confidence” scores of those cells towards zero, often overpowering the gradient from cells that do contain objects. This can lead to model instability, causing training to diverge early on.
而且,在每个图像中,许多网格单元不包含任何对象。这就把这些网格的置信度分数推到零,往往超过了包含对象的网格的梯度。2.这可能导致模型不稳定,导致训练早期发散难以训练。解决方案:增加边界框坐标预测的损失,并且减少了不包含对象的框的置信度预测的损失。我们使用两个参数来实现这一点。$\lambda_{coord}=5,\lambda_{noobj}=0.5$,其实这也是yolo面临的一个样本数目不均衡的典型例子。主要目的是让含有物体的格点,在损失函数中的权重更大,让模型更加注重含有物体的格点所造成的损失。
我们的损失函数则只会对那些有真实物体所属的格点进行损失计算,若该格点不包含物体,那么预测数值不对损失函数造成影响。这里对$w,h$在损失函数中的处理分别取了根号,原因在于,如果不取根号,损失函数往往更倾向于调整尺寸比较大的预测框。例如,20个像素点的偏差,对于800x600的预测框几乎没有影响,此时的IOU数值还是很大,但是对于30x40的预测框影响就很大。取根号是为了尽可能的消除大尺寸框与小尺寸框之间的差异。
预测框的置信度$C_i$。当该格点不含有物体时,该置信度的标签为0;若含有物体时,该置信度的标签为预测框与真实物体框的IOU数值(。
物体类别概率$P_i$,对应的类别位置,该标签数值为1,其余位置为0,与分类网络相同。yolov2:Better, Faster, Stronger
yolov2的论文里面其实更多的是对训练数据集的组合和扩充,然后再添加了很多计算机视觉方面新出的trick,然后达到了性能的提升。同时yolov2方面所使用的trick也是现在计算机视觉常用的方法,我认为这些都是我们需要好好掌握的,同时也是面试和kaggle上都经常使用的一些方法。
Batch Normalization
BN是由Google于2015年提出,论文是《Batch Normalization_ Accelerating Deep Network Training by Reducing Internal Covariate Shift》,这是一个深度神经网络训练的技巧,主要是让数据的分布变得一致,从而使得训练深层网络模型更加容易和稳定。
这里有一些相关的链接可以参考一下https://www.cnblogs.com/itmorn/p/11241236.html
https://zhuanlan.zhihu.com/p/24810318
https://zhuanlan.zhihu.com/p/93643523
莫烦python
李宏毅yyds算法具体过程:
这里要提一下这个$\gamma和\beta$是可训练参数,维度等于张量的通道数,主要是为了在反向传播更新网络时使得标准化后的数据分布与原始数据尽可能保持一直,从而很好的抽象和保留整个batch的数据分布。
Batch Normalization的作用:
将这些输入值或卷积网络的张量在batch维度上进行类似标准化的操作,将其放缩到合适的范围,加快模型训练时的收敛速度,使得模型训练过程更加稳定,避免梯度爆炸或者梯度消失,并且起到一定的正则化作用。High Resolution Classifier
在Yolov1中,网络的backbone部分会在ImageNet数据集上进行预训练,训练时网络输入图像的分辨率为224x224。在v2中,将分类网络在输入图片分辨率为448x448的ImageNet数据集上训练10个epoch,再使用检测数据集(例如coco)进行微调。高分辨率预训练使mAP提高了大约4%。
Convolutional With Anchor Boxes
predicts these offsets at every location in a feature mapPredicting offsets instead of coordinates simplifies the problem and makes it easier for the network to learn.
第一篇解读v1时提到,每个格点预测两个矩形框,在计算loss时,只让与ground truth最接近的框产生loss数值,而另一个框不做修正。这样规定之后,作者发现两个框在物体的大小、长宽比、类别上逐渐有了分工。在v2中,神经网络不对预测矩形框的宽高的绝对值进行预测,而是预测与Anchor框的偏差(offset),每个格点指定n个Anchor框。在训练时,最接近ground truth的框产生loss,其余框不产生loss。在引入Anchor Box操作后,mAP由69.5下降至69.2,原因在于,每个格点预测的物体变多之后,召回率大幅上升,准确率有所下降,总体mAP略有下降。Dimension Clusters
Instead of choosing priors by hand, we run k-means clustering on the training set bounding boxes to automatically find good priors.
这里算是作者数据处理上的一个创新点,这里作者提到之前的工作当中先Anchor Box都是认为设定的比例和大小,而这里作者时采用无监督的方式将训练数据集中的矩形框全部拿出来,用kmeans聚类得到先验框的宽和高。使用(1-IOU)数值作为两个矩形框的的距离函数,这个处理也十分的聪明。
$$
d(\text { box }, \text { centroid })=1-\operatorname{IOU}(\text { box }, \text { centroid })
$$Direct location prediction
Yolo中的位置预测方法是预测的左上角的格点坐标预测偏移量。网络预测输出要素图中每个单元格的5个边界框。网络为每个边界框预测$t_x,t_y,t_h,t_w和t_o$这5个坐标。如果单元格从图像的左上角偏移了$(c_x,c_y)$并且先验边界框的宽度和高度为$p_w,p_h$,则预测对应于:
$$
\begin{array}{l}
x=\left(t_{x} * w_{a}\right)-x_{a} \
y=\left(t_{y} * h_{a}\right)-y_{a}
\end{array}
$$
$$
\begin{aligned}
b_{x} &=\sigma\left(t_{x}\right)+c_{x} \
b_{y} &=\sigma\left(t_{y}\right)+c_{y} \
b_{w} &=p_{w} e^{t_{w}} \
b_{h} &=p_{h} e^{t_{h}} \
\operatorname{Pr}(\text { object }) * I O U(b, \text { object }) &=\sigma\left(t_{o}\right)
\end{aligned}
$$
由于我们约束位置预测,参数化更容易学习,使得网络更稳定使用维度集群以及直接预测边界框中心位置使YOLO比具有anchor box的版本提高了近5%的mAP。Fine-Grained Features
在2626的特征图,经过卷积层等,变为1313的特征图后,作者认为损失了很多细粒度的特征,导致小尺寸物体的识别效果不佳,所以在此加入了passthrough层。
传递层通过将相邻特征堆叠到不同的通道而不是堆叠到空间位置,将较高分辨率特征与低分辨率特征相连,类似于ResNet中的标识映射。这将26×26×512特征映射转换为13×13×2048特征映射,其可以与原始特征连接。Multi-Scale Training
我觉得这个也是yolo为什么性能提升的一个很重要的点,解决了yolo1当中对于多个小物体检测的问题。
原始的YOLO使用448×448的输入分辨率。添加anchor box后,我们将分辨率更改为416×416。然而,由于我们的模型只使用卷积层和池化层,相比yolo1删除了全连接层,它可以在运行中调整大小(应该是使用了1x1卷积不过我没看代码)。我们希望YOLOv2能够在不同大小的图像上运行,因此我们将其训练到模型中。instead of fixing the input image size we change the network every few iterations. Every 10 batches our network randomly chooses a new image dimension size.
不固定输入图像的大小,我们每隔几次迭代就更改网络。在每10个batch之后,我们的网络就会随机resize成{320, 352, …, 608}中的一种。不同的输入,最后产生的格点数不同,比如输入图片是320320,那么输出格点是1010,如果每个格点的先验框个数设置为5,那么总共输出500个预测结果;如果输入图片大小是608608,输出格点就是1919,共1805个预测结果。YOLO’s convolutional layers downsample the image by a factor of 32 so by using an input image of 416 we get an output feature map of 13 × 13.We do this because we want an odd number of locations in our feature map so there is a single center cell.
关于416×416也是有说法的,主要是下采样是32的倍数,而且最后的输出是13x13是奇数然后会有一个中心点更加易于目标检测。
这种训练方法迫使网络学习在各种输入维度上很好地预测。这意味着相同的网络可以预测不同分辨率的检测。
关于yolov2最大的一个提升还有一个原因就是WordTree组合数据集的训练方法,不过这里我就不再赘述,可以看参考资料有详细介绍,这里主要讲网络和思路yolov3论文改进
yolov3的论文改进就有很多方面了,而且yolov3-spp的网络效果很不错,和yolov4,yolov5的效果差别也不是特别大,这也是为什么yolov3网络被广泛应用的原因之一。
backbone:Darknet-53
相比yolov1的网络,在网络上有了很大的改进,借鉴了Resnet、Densenet、FPN的做法结合了当前网络中十分有效的
1.Yolov3中,全卷积,对于输入图片尺寸没有特别限制,可通过调节卷积步长控制输出特征图的尺寸。
2.Yolov3借鉴了金字塔特征图思想,小尺寸特征图用于检测大尺寸物体,而大尺寸特征图检测小尺寸物体。特征图的输出维度为$N \times N \times (3 \times (4+1+80))$, NxN为输出特征图格点数,一共3个Anchor框,每个框有4维预测框数值 $t_x,t_y,t_w,t_h$ ,1维预测框置信度,80维物体类别数。所以第一层特征图的输出维度为8x8x255
3.Yolov3总共输出3个特征图,第一个特征图下采样32倍,第二个特征图下采样16倍,第三个下采样8倍。每个特征图进行一次3X3、步长为2的卷积,然后保存该卷积layer,再进行一次1X1的卷积和一次3X3的卷积,并把这个结果加上layer作为最后的结果。三个特征层进行5次卷积处理,处理完后一部分用于输出该特征层对应的预测结果,一部分用于进行反卷积UmSampling2d后与其它特征层进行结合。
4.concat和resiual加操作,借鉴DenseNet将特征图按照通道维度直接进行拼接,借鉴Resnet添加残差边,缓解了在深度神经网络中增加深度带来的梯度消失问题。
5.上采样层(upsample):作用是将小尺寸特征图通过插值等方法,生成大尺寸图像。例如使用最近邻插值算法,将88的图像变换为1616。上采样层不改变特征图的通道数。对于yolo3的模型来说,网络最后输出的内容就是三个特征层每个网格点对应的预测框及其种类,即三个特征层分别对应着图片被分为不同size的网格后,每个网格点上三个先验框对应的位置、置信度及其种类。然后对输出进行解码,解码过程也就是yolov2上面的Direct location prediction方法一样,每个网格点加上它对应的x_offset和y_offset,加完后的结果就是预测框的中心,然后再利用 先验框和h、w结合 计算出预测框的长和宽。这样就能得到整个预测框的位置了。
CIoU loss
在yolov3当中我们使用的不再是传统的IoU loss,而是一个非常优秀的loss设计,整个发展过程也可以多了解了解IoU->GIoU->DIoU->CIoU,完整的考虑了重合面积,中心点距离,长宽比。
$$CIoU=IoU-(\frac{\rho(b,b^{gt}}{c^2}+\alpha v))$$
$$v=\frac{4}{\pi^2}(\arctan\frac{w^{gt}}{h^{gt}}-\arctan\frac{w}{h})^2$$
$$\alpha = \frac{v}{(1-IoU)+v}$$
其中, $b$ , $b^{gt}$ 分别代表了预测框和真实框的中心点,且 $\rho$代表的是计算两个中心点间的欧式距离。 [公式] 代表的是能够同时包含预测框和真实框的最小闭包区域的对角线距离。
在介绍CIoU之前,我们可以先介绍一下DIoU loss
其实这两项就是我们的DIoU
$$DIoU = IoU-(\frac{\rho(b,b^{gt}}{c^2})$$
则我们可以提出DIoU loss函数
$$
L_{\text {DIoU }}=1-D I o U \
0 \leq L_{\text {DloU}} \leq 2
$$
DloU损失能够直接最小化两个boxes之间的距离,因此收敛速度更快。
而我们的CIoU则比DIoU考虑更多的东西,也就是长宽比即最后一项。而$v$用来度量长宽比的相似性,$\alpha$是权重
在损失函数这块,有知乎大佬写了一下,其实就是对yolov1上的损失函数进行了一下变形。Spatial Pyramid Pooling
在yolov3的spp版本中使用了spp模块,实现了不同尺度的特征融合,spp模块最初来源于何凯明大神的论文SPP-net,主要用来解决输入图像尺寸不统一的问题,而目前的图像预处理操作中,resize,crop等都会造成一定程度的图像失真,因此影响了最终的精度。SPP模块,使用固定分块的池化操作,可以对不同尺寸的输入实现相同大小的输出,因此能够避免这一问题。
同时SPP模块中不同大小特征的融合,有利于待检测图像中目标大小差异较大的情况,也相当于增大了多重感受野吧,尤其是对于yolov3一般针对的复杂多目标图像。
在yolov3的darknet53输出到第一个特征图计算之前我们插入了一个spp模块。
SPP的这几个模块stride=1,而且会对外补padding,所以最后的输出特征图大小是一致的,然后在深度方向上进行concatenate,使得深度增大了4倍。
可以看出随着输入网络尺度的增大,spp的效果会更好。多个spp的效果增大也就是spp3和spp1的效果是差不多的,为了保证推理速度就只使用了一个sppMosaic图像增强
在yolov3-spp包括yolov4当中我们都使用了mosaic数据增强,有点类似cutmix。cutmix是合并两张图片进行预测,mosaic数据增强利用了四张图片,对四张图片进行拼接,每一张图片都有其对应的框框,将四张图片拼接之后就获得一张新的图片,同时也获得这张图片对应的框框,然后我们将这样一张新的图片传入到神经网络当中去学习,相当于一下子传入四张图片进行学习了。论文中说这极大丰富了检测物体的背景,且在标准化BN计算的时候一下子会计算四张图片的数据。
作用:增加数据的多样性,增加目标个数,BN能一次性归一化多张图片组合的分布,会更加接近原数据的分布。focal loss
最后我们提一下focal loss,虽然在原论文当中作者说focal loss效果反而下降了,但是我认为还是有必要了解一下何凯明的这篇bestpaper。作者提出focal loss的出发点也是希望one-stage detector可以达到two-stage detector的准确率,同时不影响原有的速度。作者认为造成这种情况的原因是样本的类别不均衡导致的。
对于二分类的CrossEntropy,我们有如下表示方法:
$$
\mathrm{CE}(p, y)=\left{\begin{array}{ll}
-\log (p) & \text { if } y=1 \
-\log (1-p) & \text { otherwise. }
\end{array}\right.
$$
我们定义$p_t$:
$$
p_{\mathrm{t}}=\left{\begin{array}{ll}
p & \text { if } y=1 \
1-p & \text { otherwise }
\end{array}\right.
$$
则重写交叉熵
$$
\operatorname{CE}(n, y)=C E(p_t)=-\log (p_t)
$$
接着我们提出改进思路就是在计算CE时添加了一个平衡因子,是一个可训练的参数
$$
\mathrm{CE}\left(p_{\mathrm{t}}\right)=-\alpha_{\mathrm{t}} \log \left(p_{\mathrm{t}}\right)
$$
其中
$$
\alpha_{\mathrm{t}}=\left{\begin{array}{ll}
\alpha_{\mathrm{t}} & \text { if } y=1 \
1-\alpha_{\mathrm{t}} & \text { otherwise }
\end{array}\right.
$$
相当于给正负样本加上权重,负样本出现的频次多,那么就降低负样本的权重,正样本数量少,就相对提高正样本的权重。因此可以通过设定a的值来控制正负样本对总的loss的共享权重。a取比较小的值来降低负样本(多的那类样本)的权重。
但是何凯明认为这个还是不能完全解决样本不平衡的问题,虽然这个平衡因子可以控制正负样本的权重,但是没法控制容易分类和难分类样本的权重As our experiments will show, the large class imbalance encountered during training of dense detectors overwhelms the cross entropy loss. Easily classified negatives comprise the majority of the loss and dominate the gradient. While
α balances the importance of positive/negative examples, it does not differentiate between easy/hard examples. Instead, we propose to reshape the loss function to down-weight easy examples and thus focus training on hard negatives于是提出了一种新的损失函数Focal Loss
$$
\mathrm{FL}\left(p_{\mathrm{t}}\right)=-\left(1-p_{\mathrm{t}}\right)^{\gamma} \log \left(p_{\mathrm{t}}\right)
$$focal loss的两个重要性质
1、当一个样本被分错的时候,pt是很小的,那么调制因子(1-Pt)接近1,损失不被影响;当Pt→1,因子(1-Pt)接近0,那么分的比较好的(well-classified)样本的权值就被调低了。因此调制系数就趋于1,也就是说相比原来的loss是没有什么大的改变的。当pt趋于1的时候(此时分类正确而且是易分类样本),调制系数趋于0,也就是对于总的loss的贡献很小。
2、当γ=0的时候,focal loss就是传统的交叉熵损失,当γ增加的时候,调制系数也会增加。 专注参数γ平滑地调节了易分样本调低权值的比例。γ增大能增强调制因子的影响,实验发现γ取2最好。直觉上来说,调制因子减少了易分样本的损失贡献,拓宽了样例接收到低损失的范围。当γ一定的时候,比如等于2,一样easy example(pt=0.9)的loss要比标准的交叉熵loss小100+倍,当pt=0.968时,要小1000+倍,但是对于hard example(pt < 0.5),loss最多小了4倍。这样的话hard example的权重相对就提升了很多。这样就增加了那些误分类的重要性
focal loss的两个性质算是核心,其实就是用一个合适的函数去度量难分类和易分类样本对总的损失的贡献。
然后作者又提出了最终的focal loss形式
$$
\mathrm{FL}\left(p_{\mathrm{t}}\right)=-\alpha_{\mathrm{t}}\left(1-p_{\mathrm{t}}\right)^{\gamma} \log \left(p_{\mathrm{t}}\right)
$$
$$
F L(p)\left{\begin{array}{ll}
-\alpha(1-p)^{\gamma} \log (p) & \text { if } y=1 \
-(1-\alpha) p^{\gamma} \log (1-p) & \text { otherwise }
\end{array}\right.
$$
这样既能调整正负样本的权重,又能控制难易分类样本的权重
在实验中a的选择范围也很广,一般而言当γ增加的时候,a需要减小一点(实验中γ=2,a=0.25的效果最好)总结
yolo和yolov2的严谨数学推理和网络相结合的做法令人十分惊艳,而yolov3相比之前的两个版本不管是在数据处理还是网络性质上都有很大的改变,也使用了很多流行的tirck来实现目标检测,基本上结合了很多cv领域的精髓,博客中有很多部分由于时间关系没有太细讲,其实每个部分都可以去原论文中找到很多可以学习的地方,之后有时候会补上yolov4和yolov5的讲解,后面的网络添加了注意力机制模块效果应该是更加work的。
参考文献
]]>yolov3-spp
focal loss
batch normal
IoU系列
yolov1论文翻译
yolo1-3三部曲
Bubbliiiing的教程里
还有很多但是没找到之后会补上的yolov1-3论文解析 最近在看经典目标检测算法yolo的思想,为了更好的了解yolo系列的相关文章,我从最初版本的论文思想开始看的,之后有时间会把yolov4和yolov5再认真看看,目前来说yolov3的spp版本是使用得最为广泛的一种,整体上来说yolo的设计思想还是很有创造性的数学也比较严谨。
yolov1论文思想
物体检测主流的算法框架大致分为one-stage与two-stage。two-stage算法代表有R-CNN系列,one-stage算法代表有Yolo系列。按笔者理解,two-stage算法将步骤一与步骤二分开执行,输入图像先经过候选框生成网络(例如faster rcnn中的RPN网络),再经过分类网络;one-stage算法将步骤一与步骤二同时执行,输入图像只经过一个网络,生成的结果中同时包含位置与类别信息。two-stage与one-stage相比,精度高,但是计算量更大,所以运算较慢。
We present YOLO, a new approach to object detection. Prior work on object detection repurposes classifiers to perform detection. Instead, we frame object detection as a regression problem to spatially separated bounding boxes and associated class probabilities.
yolo相比其他R-CNN等方法最大的一个不同就是他将这个识别和定位的过程转化成了一个空间定位并分类的回归问题,这也是他为什么能够利用网络进行端到端直接同时预测的重要原因。
yolo的特点
1.YOLO速度非常快。由于我们的检测是当做一个回归问题,不需要很复杂的流程。在测试的时候我们只需将一个新的图片输入网络来检测物体。
First, YOLO is extremely fast. Since we frame detection as a regression problem we don’t need a complex pipeline
2.Yolo会基于整张图片信息进行预测,与基于滑动窗口和候选区域的方法不同,在训练和测试期间YOLO可以看到整个图像,所以它隐式地记录了分类类别的上下文信息及它的全貌Second, YOLO reasons globally about the image when making predictions Unlike sliding window and region proposal-based techniques, YOLO sees the entire image during training and test time so it implicitly encodes contextual information about classes as well as their appearance
3.第三,YOLO能学习到目标的泛化表征。作者尝试了用自然图片数据集进行训练,用艺术画作品进行预测,Yolo的检测效果更佳。Third, YOLO learns generalizable representations of objects. Since YOLO is highly generalizable it is less likely to break down when applied to new domains or unexpected inputsbackbone-darknet
yolov1这块的话,由于是比较早期的网络所以在设计时没有使用batchnormal,激活函数上采用leaky relu,输入图像大小为448x448,经过许多卷积层与池化层,变为7x7x1024张量,最后经过两层全连接层,输出张量维度为7x7x30。除了最后一层的输出使用了线性激活函数,其他层全部使用Leaky Relu激活函数。输出维度
yolov1最精髓的地方应该就是他的输出维度,论文当中有放出这样一张图片,看完以后我们能对yolo算法的特点有更加深刻的理解。在上图的backbone当中我们可以看到的是
yolo的输出相当于把原图片分割成了$S \times S$个区域,然后对预测目标标定他的boundingbox,boundingbox由中心点的坐标,长宽以及物体的置信分数组成$x,y,w,h,confidence$,图中的$B$表示的是boundingbox的个数。置信分数在yolo当中是这样定义的:$Pr(Object)IOU_{pred}^{truth}$对于$Pr(Object)=1 \text{ if detect object else 0}$,其实置信分数就是boudingbox与groundtruth之间的IOU,并对每个小网格对应的$C$个类别都预测出他的条件概率:$Pr(Class_i|Object)$。
在推理时,我们可以得到当前网格对于每个类别的预测置信分数:$$Pr(Class_i)IOU{pred}^{truth} = Pr(Class_i|Object)Pr(Object)IOU{pred}^{truth}$$
这样一种严谨的条件概率的方式得到我们的最终概率是十分可行和合适的。YOLO imposes strong spatial constraints on bounding box predictions since each grid cell only predicts two boxes and can only have one class. This spatial constraint limits the number of nearby objects that our model can predict. Our model struggles with small objects that appear in groups, such as flocks of birds.
不过在原论文当中也有提到的一点是:YOLO给边界框预测强加空间约束,因为每个网格单元只预测两个框和只能有一个类别。这个空间约束限制了我们的模型可以预测的邻近目标的数量。我们的模型难以预测群组中出现的小物体(比如鸟群)。损失函数
在损失函数方面,由于公式比较长所以就直接截图过来了,损失函数的设计放方面作者也考虑的比较周全,
预测框的中心点$(x,y)$。预测框的宽高$w,h$,其中$\mathbb{1}_{i j}^{\text {obj }}$为控制函数,在标签中包含物体的那些格点处,该值为 1 ,若格点不含有物体,该值为 0在计算损失函数的时候作者最开始使用的是最简单的平方损失函数来计算检测,因为它是计算简单且容易优化的,但是它并不完全符合我们最大化平均精度的目标,原因如下:
It weights localization error equally with classification error which may not be ideal.
1.它对定位错误的权重与分类错误的权重相等,这可能不是理想的选择。Also, in every image many grid cells do not contain any object. This pushes the “confidence” scores of those cells towards zero, often overpowering the gradient from cells that do contain objects. This can lead to model instability, causing training to diverge early on.
而且,在每个图像中,许多网格单元不包含任何对象。这就把这些网格的置信度分数推到零,往往超过了包含对象的网格的梯度。2.这可能导致模型不稳定,导致训练早期发散难以训练。解决方案:增加边界框坐标预测的损失,并且减少了不包含对象的框的置信度预测的损失。我们使用两个参数来实现这一点。$\lambda{coord}=5,\lambda{noobj}=0.5$,其实这也是yolo面临的一个样本数目不均衡的典型例子。主要目的是让含有物体的格点,在损失函数中的权重更大,让模型更加注重含有物体的格点所造成的损失。
我们的损失函数则只会对那些有真实物体所属的格点进行损失计算,若该格点不包含物体,那么预测数值不对损失函数造成影响。这里对$w,h$在损失函数中的处理分别取了根号,原因在于,如果不取根号,损失函数往往更倾向于调整尺寸比较大的预测框。例如,20个像素点的偏差,对于800x600的预测框几乎没有影响,此时的IOU数值还是很大,但是对于30x40的预测框影响就很大。取根号是为了尽可能的消除大尺寸框与小尺寸框之间的差异。
预测框的置信度$C_i$。当该格点不含有物体时,该置信度的标签为0;若含有物体时,该置信度的标签为预测框与真实物体框的IOU数值(。
物体类别概率$P_i$,对应的类别位置,该标签数值为1,其余位置为0,与分类网络相同。yolov2:Better, Faster, Stronger
yolov2的论文里面其实更多的是对训练数据集的组合和扩充,然后再添加了很多计算机视觉方面新出的trick,然后达到了性能的提升。同时yolov2方面所使用的trick也是现在计算机视觉常用的方法,我认为这些都是我们需要好好掌握的,同时也是面试和kaggle上都经常使用的一些方法。
Batch Normalization
BN是由Google于2015年提出,论文是《Batch Normalization_ Accelerating Deep Network Training by Reducing Internal Covariate Shift》,这是一个深度神经网络训练的技巧,主要是让数据的分布变得一致,从而使得训练深层网络模型更加容易和稳定。
这里有一些相关的链接可以参考一下https://www.cnblogs.com/itmorn/p/11241236.html
https://zhuanlan.zhihu.com/p/24810318
https://zhuanlan.zhihu.com/p/93643523
莫烦python
李宏毅yyds算法具体过程:
这里要提一下这个$\gamma和\beta$是可训练参数,维度等于张量的通道数,主要是为了在反向传播更新网络时使得标准化后的数据分布与原始数据尽可能保持一直,从而很好的抽象和保留整个batch的数据分布。
Batch Normalization的作用:
将这些输入值或卷积网络的张量在batch维度上进行类似标准化的操作,将其放缩到合适的范围,加快模型训练时的收敛速度,使得模型训练过程更加稳定,避免梯度爆炸或者梯度消失,并且起到一定的正则化作用。High Resolution Classifier
在Yolov1中,网络的backbone部分会在ImageNet数据集上进行预训练,训练时网络输入图像的分辨率为224x224。在v2中,将分类网络在输入图片分辨率为448x448的ImageNet数据集上训练10个epoch,再使用检测数据集(例如coco)进行微调。高分辨率预训练使mAP提高了大约4%。
Convolutional With Anchor Boxes
predicts these offsets at every location in a feature mapPredicting offsets instead of coordinates simplifies the problem and makes it easier for the network to learn.
第一篇解读v1时提到,每个格点预测两个矩形框,在计算loss时,只让与ground truth最接近的框产生loss数值,而另一个框不做修正。这样规定之后,作者发现两个框在物体的大小、长宽比、类别上逐渐有了分工。在v2中,神经网络不对预测矩形框的宽高的绝对值进行预测,而是预测与Anchor框的偏差(offset),每个格点指定n个Anchor框。在训练时,最接近ground truth的框产生loss,其余框不产生loss。在引入Anchor Box操作后,mAP由69.5下降至69.2,原因在于,每个格点预测的物体变多之后,召回率大幅上升,准确率有所下降,总体mAP略有下降。Dimension Clusters
Instead of choosing priors by hand, we run k-means clustering on the training set bounding boxes to automatically find good priors.
这里算是作者数据处理上的一个创新点,这里作者提到之前的工作当中先Anchor Box都是认为设定的比例和大小,而这里作者时采用无监督的方式将训练数据集中的矩形框全部拿出来,用kmeans聚类得到先验框的宽和高。使用(1-IOU)数值作为两个矩形框的的距离函数,这个处理也十分的聪明。Direct location prediction
Yolo中的位置预测方法是预测的左上角的格点坐标预测偏移量。网络预测输出要素图中每个单元格的5个边界框。网络为每个边界框预测$t_x,t_y,t_h,t_w和t_o$这5个坐标。如果单元格从图像的左上角偏移了$(c_x,c_y)$并且先验边界框的宽度和高度为$p_w,p_h$,则预测对应于:
由于我们约束位置预测,参数化更容易学习,使得网络更稳定使用维度集群以及直接预测边界框中心位置使YOLO比具有anchor box的版本提高了近5%的mAP。
Fine-Grained Features
在2626的特征图,经过卷积层等,变为1313的特征图后,作者认为损失了很多细粒度的特征,导致小尺寸物体的识别效果不佳,所以在此加入了passthrough层。
传递层通过将相邻特征堆叠到不同的通道而不是堆叠到空间位置,将较高分辨率特征与低分辨率特征相连,类似于ResNet中的标识映射。这将26×26×512特征映射转换为13×13×2048特征映射,其可以与原始特征连接。Multi-Scale Training
我觉得这个也是yolo为什么性能提升的一个很重要的点,解决了yolo1当中对于多个小物体检测的问题。
原始的YOLO使用448×448的输入分辨率。添加anchor box后,我们将分辨率更改为416×416。然而,由于我们的模型只使用卷积层和池化层,相比yolo1删除了全连接层,它可以在运行中调整大小(应该是使用了1x1卷积不过我没看代码)。我们希望YOLOv2能够在不同大小的图像上运行,因此我们将其训练到模型中。instead of fixing the input image size we change the network every few iterations. Every 10 batches our network randomly chooses a new image dimension size.
不固定输入图像的大小,我们每隔几次迭代就更改网络。在每10个batch之后,我们的网络就会随机resize成{320, 352, …, 608}中的一种。不同的输入,最后产生的格点数不同,比如输入图片是320320,那么输出格点是1010,如果每个格点的先验框个数设置为5,那么总共输出500个预测结果;如果输入图片大小是608608,输出格点就是1919,共1805个预测结果。YOLO’s convolutional layers downsample the image by a factor of 32 so by using an input image of 416 we get an output feature map of 13 × 13.We do this because we want an odd number of locations in our feature map so there is a single center cell.
关于416×416也是有说法的,主要是下采样是32的倍数,而且最后的输出是13x13是奇数然后会有一个中心点更加易于目标检测。
这种训练方法迫使网络学习在各种输入维度上很好地预测。这意味着相同的网络可以预测不同分辨率的检测。
关于yolov2最大的一个提升还有一个原因就是WordTree组合数据集的训练方法,不过这里我就不再赘述,可以看参考资料有详细介绍,这里主要讲网络和思路yolov3论文改进
yolov3的论文改进就有很多方面了,而且yolov3-spp的网络效果很不错,和yolov4,yolov5的效果差别也不是特别大,这也是为什么yolov3网络被广泛应用的原因之一。
backbone:Darknet-53
相比yolov1的网络,在网络上有了很大的改进,借鉴了Resnet、Densenet、FPN的做法结合了当前网络中十分有效的
1.Yolov3中,全卷积,对于输入图片尺寸没有特别限制,可通过调节卷积步长控制输出特征图的尺寸。
2.Yolov3借鉴了金字塔特征图思想,小尺寸特征图用于检测大尺寸物体,而大尺寸特征图检测小尺寸物体。特征图的输出维度为$N \times N \times (3 \times (4+1+80))$, NxN为输出特征图格点数,一共3个Anchor框,每个框有4维预测框数值 $t_x,t_y,t_w,t_h$ ,1维预测框置信度,80维物体类别数。所以第一层特征图的输出维度为8x8x255
3.Yolov3总共输出3个特征图,第一个特征图下采样32倍,第二个特征图下采样16倍,第三个下采样8倍。每个特征图进行一次3X3、步长为2的卷积,然后保存该卷积layer,再进行一次1X1的卷积和一次3X3的卷积,并把这个结果加上layer作为最后的结果。三个特征层进行5次卷积处理,处理完后一部分用于输出该特征层对应的预测结果,一部分用于进行反卷积UmSampling2d后与其它特征层进行结合。
4.concat和resiual加操作,借鉴DenseNet将特征图按照通道维度直接进行拼接,借鉴Resnet添加残差边,缓解了在深度神经网络中增加深度带来的梯度消失问题。
5.上采样层(upsample):作用是将小尺寸特征图通过插值等方法,生成大尺寸图像。例如使用最近邻插值算法,将88的图像变换为1616。上采样层不改变特征图的通道数。对于yolo3的模型来说,网络最后输出的内容就是三个特征层每个网格点对应的预测框及其种类,即三个特征层分别对应着图片被分为不同size的网格后,每个网格点上三个先验框对应的位置、置信度及其种类。然后对输出进行解码,解码过程也就是yolov2上面的Direct location prediction方法一样,每个网格点加上它对应的x_offset和y_offset,加完后的结果就是预测框的中心,然后再利用 先验框和h、w结合 计算出预测框的长和宽。这样就能得到整个预测框的位置了。
CIoU loss
在yolov3当中我们使用的不再是传统的IoU loss,而是一个非常优秀的loss设计,整个发展过程也可以多了解了解IoU->GIoU->DIoU->CIoU,完整的考虑了重合面积,中心点距离,长宽比。
其中, $b$ , $b^{gt}$ 分别代表了预测框和真实框的中心点,且 $\rho$代表的是计算两个中心点间的欧式距离。 [公式] 代表的是能够同时包含预测框和真实框的最小闭包区域的对角线距离。
在介绍CIoU之前,我们可以先介绍一下DIoU loss
其实这两项就是我们的DIoU则我们可以提出DIoU loss函数
DloU损失能够直接最小化两个boxes之间的距离,因此收敛速度更快。
而我们的CIoU则比DIoU考虑更多的东西,也就是长宽比即最后一项。而$v$用来度量长宽比的相似性,$\alpha$是权重
在损失函数这块,有知乎大佬写了一下,其实就是对yolov1上的损失函数进行了一下变形。Spatial Pyramid Pooling
在yolov3的spp版本中使用了spp模块,实现了不同尺度的特征融合,spp模块最初来源于何凯明大神的论文SPP-net,主要用来解决输入图像尺寸不统一的问题,而目前的图像预处理操作中,resize,crop等都会造成一定程度的图像失真,因此影响了最终的精度。SPP模块,使用固定分块的池化操作,可以对不同尺寸的输入实现相同大小的输出,因此能够避免这一问题。
同时SPP模块中不同大小特征的融合,有利于待检测图像中目标大小差异较大的情况,也相当于增大了多重感受野吧,尤其是对于yolov3一般针对的复杂多目标图像。
在yolov3的darknet53输出到第一个特征图计算之前我们插入了一个spp模块。
SPP的这几个模块stride=1,而且会对外补padding,所以最后的输出特征图大小是一致的,然后在深度方向上进行concatenate,使得深度增大了4倍。
可以看出随着输入网络尺度的增大,spp的效果会更好。多个spp的效果增大也就是spp3和spp1的效果是差不多的,为了保证推理速度就只使用了一个sppMosaic图像增强
在yolov3-spp包括yolov4当中我们都使用了mosaic数据增强,有点类似cutmix。cutmix是合并两张图片进行预测,mosaic数据增强利用了四张图片,对四张图片进行拼接,每一张图片都有其对应的框框,将四张图片拼接之后就获得一张新的图片,同时也获得这张图片对应的框框,然后我们将这样一张新的图片传入到神经网络当中去学习,相当于一下子传入四张图片进行学习了。论文中说这极大丰富了检测物体的背景,且在标准化BN计算的时候一下子会计算四张图片的数据。
作用:增加数据的多样性,增加目标个数,BN能一次性归一化多张图片组合的分布,会更加接近原数据的分布。focal loss
最后我们提一下focal loss,虽然在原论文当中作者说focal loss效果反而下降了,但是我认为还是有必要了解一下何凯明的这篇bestpaper。作者提出focal loss的出发点也是希望one-stage detector可以达到two-stage detector的准确率,同时不影响原有的速度。作者认为造成这种情况的原因是样本的类别不均衡导致的。
对于二分类的CrossEntropy,我们有如下表示方法:我们定义$p_t$:
则重写交叉熵
接着我们提出改进思路就是在计算CE时添加了一个平衡因子,是一个可训练的参数
其中
相当于给正负样本加上权重,负样本出现的频次多,那么就降低负样本的权重,正样本数量少,就相对提高正样本的权重。因此可以通过设定a的值来控制正负样本对总的loss的共享权重。a取比较小的值来降低负样本(多的那类样本)的权重。
但是何凯明认为这个还是不能完全解决样本不平衡的问题,虽然这个平衡因子可以控制正负样本的权重,但是没法控制容易分类和难分类样本的权重As our experiments will show, the large class imbalance encountered during training of dense detectors overwhelms the cross entropy loss. Easily classified negatives comprise the majority of the loss and dominate the gradient. While
α balances the importance of positive/negative examples, it does not differentiate between easy/hard examples. Instead, we propose to reshape the loss function to down-weight easy examples and thus focus training on hard negatives于是提出了一种新的损失函数Focal Loss
focal loss的两个重要性质
1、当一个样本被分错的时候,pt是很小的,那么调制因子(1-Pt)接近1,损失不被影响;当Pt→1,因子(1-Pt)接近0,那么分的比较好的(well-classified)样本的权值就被调低了。因此调制系数就趋于1,也就是说相比原来的loss是没有什么大的改变的。当pt趋于1的时候(此时分类正确而且是易分类样本),调制系数趋于0,也就是对于总的loss的贡献很小。
2、当γ=0的时候,focal loss就是传统的交叉熵损失,当γ增加的时候,调制系数也会增加。 专注参数γ平滑地调节了易分样本调低权值的比例。γ增大能增强调制因子的影响,实验发现γ取2最好。直觉上来说,调制因子减少了易分样本的损失贡献,拓宽了样例接收到低损失的范围。当γ一定的时候,比如等于2,一样easy example(pt=0.9)的loss要比标准的交叉熵loss小100+倍,当pt=0.968时,要小1000+倍,但是对于hard example(pt < 0.5),loss最多小了4倍。这样的话hard example的权重相对就提升了很多。这样就增加了那些误分类的重要性
focal loss的两个性质算是核心,其实就是用一个合适的函数去度量难分类和易分类样本对总的损失的贡献。
然后作者又提出了最终的focal loss形式
这样既能调整正负样本的权重,又能控制难易分类样本的权重
在实验中a的选择范围也很广,一般而言当γ增加的时候,a需要减小一点(实验中γ=2,a=0.25的效果最好)总结
yolo和yolov2的严谨数学推理和网络相结合的做法令人十分惊艳,而yolov3相比之前的两个版本不管是在数据处理还是网络性质上都有很大的改变,也使用了很多流行的tirck来实现目标检测,基本上结合了很多cv领域的精髓,博客中有很多部分由于时间关系没有太细讲,其实每个部分都可以去原论文中找到很多可以学习的地方,之后有时候会补上yolov4和yolov5的讲解,后面的网络添加了注意力机制模块效果应该是更加work的。
参考文献
]]>yolov3-spp
focal loss
batch normal
IoU系列
yolov1论文翻译
yolo1-3三部曲
Bubbliiiing的教程里
还有很多但是没找到之后会补上的- <h2 id="yolov1-3论文解析"><a href="#yolov1-3论文解析" class="headerlink" title="yolov1-3论文解析"></a>yolov1-3论文解析</h2><p>最近在看经典目标检测算法yolo的思想,为了更好的了解yolo系列的相关文章,我从最初版本的论文思想开始看的,之后有时间会把yolov4和yolov5再认真看看,目前来说yolov3的spp版本是使用得最为广泛的一种,整体上来说yolo的设计思想还是很有创造性的数学也比较严谨。</p> + <h2 id="yolov1-3论文解析"><a href="#yolov1-3论文解析" class="headerlink" title="yolov1-3论文解析"></a>yolov1-3论文解析</h2><p>最近在看经典目标检测算法yolo的思想,为了更好的了解yolo系列的相关文章,我从最初版本的论文思想开始看的,之后有时间会把yolov4和yolov5再认真看看,目前来说yolov3的spp版本是使用得最为广泛的一种,整体上来说yolo的设计思想还是很有创造性的数学也比较严谨。<br></p> @@ -377,7 +377,7 @@2021-04-12T00:39:00.000Z 2024-10-09T07:33:09.887Z -MTCNN人脸检测和pytorch代码实现解读 +传送门
论文地址:https://arxiv.org/ftp/arxiv/papers/1604/1604.02878.pdf
我的论文笔记:https://khany.top/file/paper/mtcnn.pdf
本文csdn链接:https://blog.csdn.net/Jack___E/article/details/115601474
github参考:https://github.com/Sierkinhane/mtcnn-pytorch
github参考:https://github.com/GitHberChen/MTCNN_Pytorchabstract
abstract—Face detection and alignment in unconstrained environment are challenging due to various poses, illuminations and occlusions. Recent studies show that deep learning approaches can achieve impressive performance on these two tasks. In this paper, we propose a deep cascaded multi-task framework which exploits the inherent correlation between detection and alignment
to boost up their performance. In particular, our framework leverages a cascaded architecture with three stages of carefully designed deep convolutional networks to predict face and landmark location in a coarse-to-fine manner. In addition, we propose a new online hard sample mining strategy that further improves the performance in practice. Our method achieves superior accuracy over the state-of-the-art techniques on the challenging FDDB and WIDER FACE benchmarks for face detection, and AFLW benchmark for face alignment, while keeps real time performance.在无约束条件的环境下进行人脸检测和校准人脸检测和校准是非常具挑战性的,因为你要考虑复杂的姿势,光照因素以及面部遮挡问题的影响,最近的研究表明,使用深度学习的方法能够在这两项任务上有不错的效果。本文作者探索和研究了人脸检测和校准之间的内在联系,提出了一个深层级的多任务框架有效提升了网络的性能。我们的深层级联合架构包含三个阶段的卷积神经网络从粗略到细致逐步实现人脸检测和面部特征点标记。此外,我们还提出了一种新的线上进行困难样本的预测的策略可以在实际使用过程中有效提升网络的性能。我们的方法目前在FDDB和WIDER FACE人脸检测任务和AFLW面部对准任务上超越了最佳模型方法的性能标准,同时该模型具有不错的实时检测效果。
my English is not so well,if there are some mistakes in translations, please contact me in blog comments.
简介
人脸检测和脸部校准任务对于很多面部任务和应用来说都是十分重要的,比如说人脸识别,人脸表情分析。不过在现实生活当中,面部特征时常会因为一些遮挡物,强烈的光照对比,复杂的姿势发生很大的变化,这使得这些任务变得具有很大挑战性。Viola和Jones 提出的级联人脸检测器利用Haar特征和AdaBoost训练级联分类器,实现了具有实时效率的良好性能。 然而,也有相当一部分的工作表明,这种分类器可能在现实生活的应用中效果显着降低,即使具有更高级的特征和分类器。,之后人们又提出了DPM的方式,这些年来基于CNN的一些解决方案也层出不穷,基于CNN的方案主要是为了识别出面部的一些特征来实现。作者认为这种方式其实是需要花费更多的时间来对面部进行校准来训练同时还忽略了面部的重要特征点位置和边框问题。
对于人脸校准的话目前也有大致的两个方向:一个是基于回归的方法还有一个就是基于模板拟合的方式进行,主要是对特征识别起到一个辅助的工作。
作者认为关于人脸识别和面部对准这两个任务其实是有内在关联的,而目前大多数的方法则忽略了这一点,所以本文所提出的方案就是将这两者都结合起来,构建出一个三阶段的模型实现一个端到端的人脸检测并校准面部特征点的过程。
第一阶段:通过浅层CNN快速生成候选窗口。
第二阶段:通过more complex的CNN拒绝大量非面部窗口来细化窗口。
第三阶段:使用more powerful的CNN再次细化结果并输出五个面部标志位置。方法
Image pyramid图像金字塔
在进入stage-1之前,作者先构建了一组多尺度的图像金字塔缩放,这一块要理解起来还是有一点费力的,这里我们需要了解的是在训练网络的过程当中,作者都是把WIDER FACE的图片随机剪切成12x12size的大小进行单尺度训练的,不能满足任意大小的人脸检测,所以为了检测到不同尺寸的人脸,所以在推理时需要先生成图像金字塔生成一组不同scale的图像输入P-net进行来实现人脸的检测,同时也这是为什么P-net要使用FCN的原因。
def calculateScales(img):
min_face_size = 20 # 最小的人脸尺寸
width, height = img.size
min_length = min(height, width)
min_detection_size = 12
factor = 0.707 # sqrt(0.5)
scales = []
m = min_detection_size / min_face_size
min_length *= m
factor_count = 0
# 图像尺寸缩小到不大于min_detection_size
while min_length > min_detection_size:
scales.append(m * factor ** factor_count)
min_length *= factor
factor_count += 1$$\text{length} =\text{length} \times (\frac{\text{min detection size}}{\text{min face size}} )\times factor^{count} $$
$\text{here we define in our code:} factor=\frac{1}{\sqrt{2}}, \text{min face size}=20,\text{min detection size}=12$min_face_size和factor对推理过程会产生什么样的影响?
min_face_size越大,factor越小,图像最短边就越快缩放到接近min_detect_size,从而生成图像金字塔的耗时就越短,同时各尺度的跨度也更大。因此,加大min_face_size、减小factor能加速图像金字塔的生成,但同时也更易造成漏检。Stage 1 P-Net(Proposal Network)
这是一个全卷积网络,也就是说这个网络可以兼容任意大小的输入,他的整个网络其实十分简单,该层的作用主要是为了获得人脸检测的大量候选框,这一层我们最大的作用就是要尽可能的提升recall,然后在获得许多候选框后再使用非极大抑制的方法合并高度重叠的候选区域。
P-Net的示意图当中我们也可以看到的是作者输入12x12大小最终的output为一个1x1x2的face label classification概率和一个1x1x4的boudingbox(左上角和右下角的坐标)以及一个1x1x10的landmark(双眼,鼻子,左右嘴角的坐标)
注意虽然这里作者举例是12x12的图片大小,但是他的意思并不是说这个P-Net的图片输入大小必须是12,我们可以知道这个网络是FCN,这就意味着不同输入的大小都是可以输入其中的,最后我们所得到的featuremap$[m \times n \times (2+4+10) ]$每一个小像素点映射到输入图像所在的12x12区域是否包含人脸的分类结果,候选框左上和右下基准点以及landmark,然后根据图像金字塔的我们再根据scale和resize的逆过程将其映射到原图像上P-net structure
class P_Net(nn.Module):
def __init__(self):
super(P_Net, self).__init__()
self.pre_layer = nn.Sequential(
# 12x12x3
nn.Conv2d(3, 10, kernel_size=3, stride=1), # conv1
nn.PReLU(), # PReLU1
# 10x10x10
nn.MaxPool2d(kernel_size=2, stride=2), # pool1
# 5x5x10
nn.Conv2d(10, 16, kernel_size=3, stride=1), # conv2
# 3x3x16
nn.PReLU(), # PReLU2
nn.Conv2d(16, 32, kernel_size=3, stride=1), # conv3
# 1x1x32
nn.PReLU() # PReLU3
)
# detection
self.conv4_1 = nn.Conv2d(32, 1, kernel_size=1, stride=1)
# bounding box regresion
self.conv4_2 = nn.Conv2d(32, 4, kernel_size=1, stride=1)
# landmark localization
self.conv4_3 = nn.Conv2d(32, 10, kernel_size=1, stride=1)
# weight initiation with xavier
self.apply(weights_init)
def forward(self, x):
x = self.pre_layer(x)
det = torch.sigmoid(self.conv4_1(x))
box = self.conv4_2(x)
landmark = self.conv4_3(x)
# det:[,2,1,1], box:[,4,1,1], landmark:[,10,1,1]
return det, box, landmark这里要提一下
nn.PReLU(),有点类似Leaky ReLU,可以看下面的博客深入了解一下https://blog.csdn.net/qq_23304241/article/details/80300149
https://blog.csdn.net/shuzfan/article/details/51345832然后在P-Net之后我们通过非极大抑制的方法和将所有的boudingbox都修正为框的最长边为边长的正方形框,主要是避免后面的Rnet在resize的时候因为尺寸原因出现信息的损失。
Non-Maximum Suppression非极大抑制
其实关于非极大抑制这个trick最初是在目标检测任务当中提出的来的,其思想是搜素局部最大值,抑制极大值,主要用在目标检测当中,最传统的非极大抑制所采用的评价指标就是交并比IoU(intersection-over-union)即两个groud truth和bounding box的交集部分除以它们的并集.
$$IoU = \frac{area(C) \cap area(G)}{area(C) \cup area(G)}$$def IoU(box, boxes):
"""Compute IoU between detect box and gt boxes
Parameters:
----------
box: numpy array , shape (5, ): x1, y1, x2, y2, score
input box
boxes: numpy array, shape (n, 4): x1, y1, x2, y2
input ground truth boxes
Returns:
-------
ovr: numpy.array, shape (n, )
IoU
"""
box_area = (box[2] - box[0] + 1) * (box[3] - box[1] + 1)
area = (boxes[:, 2] - boxes[:, 0] + 1) * (boxes[:, 3] - boxes[:, 1] + 1)
xx1 = np.maximum(box[0], boxes[:, 0])
xx2 = np.minimum(box[2], boxes[:, 2])
yy1 = np.maximum(box[1], boxes[:, 1])
yy2 = np.minimum(box[3], boxes[:, 3])
# compute the width and height of the bounding box
w = np.maximum(0, xx2 - xx1 + 1)
h = np.maximum(0, yy2 - yy1 + 1)
inter = w * h
ovr = np.true_divide(inter,(box_area + area - inter))
#ovr = inter / (box_area + area - inter)
return ovr使用非极大抑制的前提是,我们已经得到了一组候选框和对应label的置信分数,以及groud truth的信息,通过设定阈值来删除重合度较高的候选框。
算法流程如下:- 根据置信度得分进行排序
- 选择置信度最高的比边界框添加到最终输出列表中,将其从边界框列表中删除
- 计算所有边界框的面积
- 计算置信度最高的边界框与其它候选框的IoU。
- 删除IoU大于阈值的边界框
- 重复上述过程,直至边界框列表为空。
def nms(dets,threshod,mode="Union"):
"""
greedily select boxes with high confidence
keep boxes overlap <= thresh
rule out overlap > thresh
:param dets: [[x1, y1, x2, y2 score]]
:param threshod: retain overlap <= thresh
:return: indexes to keep
"""
x1 = dets[:,0]
y1 = dets[;,1]
x2 = dets[:,2]
y2 = dets[:,3]
scores = dets[:,4]
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
order = areas.argsort()[::-1] # reverse
keep=[]
while order.size()>0:
i = order[0]
keep.append(i)
# A & B left top position
xx1 = np.maximun(x1[i],x1[order[1,:]])
yy1 = np.maximun(y1[i],y1[order[1,:]])
# A & B right down position
xx2 = np.minimum(x2[i],x2[order[1,:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
# cacaulate the IOU between box which have largest score with other boxes
if mode == "Union":
# area[i]: the area of largest score
ovr = inter / (areas[i] + areas[order[1:]] - inter)
elif mode == "Minimum":
ovr = inter / np.minimum(areas[i], areas[order[1:]])
# delete the IoU that higher than threshod
inds = np.where(ovr <= threshod)[0]
order = order[inds + 1] # +1: eliminates the first element in order
return keep边框修正
以最大边作为边长将矩形修正为正方形,同时包含的信息也更多,以免在后面resize输入下一个网络时减少信息的损失。
def convert_to_square(bboxes):
"""
Convert bounding boxes to a square form.
"""
# 将矩形对称扩大为正方形
square_bboxes = np.zeros_like(bboxes)
x1, y1, x2, y2 = [bboxes[:, i] for i in range(4)]
h = y2 - y1 + 1.0
w = x2 - x1 + 1.0
max_side = np.maximum(h, w)
square_bboxes[:, 0] = x1 + w * 0.5 - max_side * 0.5
square_bboxes[:, 1] = y1 + h * 0.5 - max_side * 0.5
square_bboxes[:, 2] = square_bboxes[:, 0] + max_side - 1.0
square_bboxes[:, 3] = square_bboxes[:, 1] + max_side - 1.0
return square_bboxesStage 2 R-Net(Refine Network)
R-net的输入是固定的,必须是24x24,所以对于P-net产生的大量boundingbox我们需要先进行resize然后再输入R-Net,在论文中我们了解到该网络层的作用主要是对大量的boundingbox进行有效过滤,获得更加精细的候选框。
R-net structure
class R_Net(nn.Module):
def __init__(self):
super(R_Net, self).__init__()
self.pre_layer = nn.Sequential(
# 24x24x3
nn.Conv2d(3, 28, kernel_size=3, stride=1), # conv1
nn.PReLU(), # prelu1
# 22x22x28
nn.MaxPool2d(kernel_size=3, stride=2), # pool1
# 10x10x28
nn.Conv2d(28, 48, kernel_size=3, stride=1), # conv2
nn.PReLU(), # prelu2
# 8x8x48
nn.MaxPool2d(kernel_size=3, stride=2), # pool2
# 3x3x48
nn.Conv2d(48, 64, kernel_size=2, stride=1), # conv3
# 2x2x64
nn.PReLU() # prelu3
)
# 2x2x64
self.conv4 = nn.Linear(64 * 2 * 2, 128) # conv4
# 128
self.prelu4 = nn.PReLU() # prelu4
# detection
self.conv5_1 = nn.Linear(128, 1)
# bounding box regression
self.conv5_2 = nn.Linear(128, 4)
# lanbmark localization
self.conv5_3 = nn.Linear(128, 10)
# weight initiation weih xavier
self.apply(weights_init)
def forward(self, x):
x = self.pre_layer(x)
x = x.view(x.size(0), -1)
x = self.conv4(x)
x = self.prelu4(x)
det = torch.sigmoid(self.conv5_1(x))
box = self.conv5_2(x)
landmark = self.conv5_3(x)
return det, box, landmark然后在P-Net之后我们通过非极大抑制的方法和将所有的boudingbox都修正为框的最长边为边长的正方形框,也是避免后面的Onet在resize的时候出现因为尺寸原因出现信息的损失。
Stage 3 O-Net(Output?[作者未指出命名] Network)
Onet与Rnet工作流程类似。只不过输入的尺寸变成了48x48,对于R-net当中的框再次进行处理,得到的网络结构的输出则是最终的label classfication,boundingbox,landmark。
O-net structureclass O_Net(nn.Module):
def __init__(self):
super(O_Net, self).__init__()
self.pre_layer = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, stride=1), # conv1
nn.PReLU(), # prelu1
nn.MaxPool2d(kernel_size=3, stride=2), # pool1
nn.Conv2d(32, 64, kernel_size=3, stride=1), # conv2
nn.PReLU(), # prelu2
nn.MaxPool2d(kernel_size=3, stride=2), # pool2
nn.Conv2d(64, 64, kernel_size=3, stride=1), # conv3
nn.PReLU(), # prelu3
nn.MaxPool2d(kernel_size=2, stride=2), # pool3
nn.Conv2d(64, 128, kernel_size=2, stride=1), # conv4
nn.PReLU() # prelu4
)
self.conv5 = nn.Linear(128 * 2 * 2, 256) # conv5
self.prelu5 = nn.PReLU() # prelu5
# detection
self.conv6_1 = nn.Linear(256, 1)
# bounding box regression
self.conv6_2 = nn.Linear(256, 4)
# lanbmark localization
self.conv6_3 = nn.Linear(256, 10)
# weight initiation weih xavier
self.apply(weights_init)
def forward(self, x):
x = self.pre_layer(x)
x = x.view(x.size(0), -1)
x = self.conv5(x)
x = self.prelu5(x)
# detection
det = torch.sigmoid(self.conv6_1(x))
box = self.conv6_2(x)
landmark = self.conv6_3(x)
return det, box, landmark
注意,其实在之前的两个网络当中我们也预测了landmark的位置,只是在论文的图示当中没有展示而已,从作者描述的网络结构图的输出当中是详细指出了landmarkposition的卷积块的损失函数
在研究完网络结构以后我们可以来看看这个mtcnn模型的一个损失函数,作者将损失函数分为了3个部分:Face classification、Bounding box regression、Facial landmark localization。
Face classification
对于第一部分的损失就是用的是最常用的交叉熵损失函数,就本质上来说人脸识别还是一个二分类问题,这里就使用Cross Entropy是最简单也是最合适的选择。
$$L_i^{det} = -(y_i^{det} \log(p_i) + (1-y_i^det)(1-\log(p_i)))$$
$p_i$是预测为face的可能性,$y_i^{det}$指的是真实标签也就是groud truth labelBounding box regression
对于目标边界框的损失来说,对于每一个候选框我们都需要对与他最接近的真实目标边界框进行比较,the bounding box$(left, top, height, and width)$
$$L_i^{box} = ||y_j^{box}-y_i^{box} ||_2^2$$Facial landmark localization
而对于boundingbox和landmark来说整个框的调整过程其实可以看作是一个连续的变化过程,固使用的是欧氏距离回归损失计算方法。比较的是各个点的坐标与真实面部关键点坐标的差异。
$$L_i^{landmark} = ||y_j^{landmark}-y_i^{landmark} ||_2^2$$total loss
最终我们得到的损失函数是有上述这三部分加权而成
$$\min{\sum_{i=1}^{N}{\sum_{j \in {det,box,landmark}} \alpha_j \beta_i^j L_i^j}}$$
其中$\alpha_j$表示权重,$\beta_i^j$表示第i个样本的类型,也可以说是第i个样本在任务j中是否需要贡献loss,如果不存在人脸即label为0时则无需计算loss。
对于不同的网络我们所设置的权重是不一样的
in P-net & R-net(在这两层我们更注重classification的识别)
$$alpha_{det}=1, alpha_{box}=0.5,alpha_{landmark}=0.5$$
in O-net(在这层我们提高了对于注意关键点的预测精度)
$$alpha_{det}=1, alpha_{box}=0.5,alpha_{landmark}=1 $$
文中也有提到,采用的是随机梯度下降优化器进行的训练。OHEM(Online Hard Example Mining)
作者对于困难样本的在线预测所做的trick也比较简单,就是挑选损失最大的前70%作为困难样本,在反向传播时仅使用这70%困难样本产生的损失,这样就剔除了很容易预测的easy sample对训练结果的影响,不过在我参考的这两个版本的代码里面似乎没有这么做。
实验
实验这块的话也比较充分,验证了每个修改部分对于实验结果的有效性验证,主要是讲述了实验过程对于训练数据集的处理和划分,验证了在线硬样本挖掘的有效性,联合检测和校准的有效性,分别评估了face detection和lanmark的贡献,面部检测评估,面部校准评估以及与SOTA的对比,这一块的话就没有细看了,分享的网站也有详细解释,论文原文也写了。
总结
这篇论文是中科院深圳先进技术研究院的乔宇老师团队所作,2016ECCV,看完这篇文章的话给我的感觉的话就是idea和实现过程包括实验都是很充分的,创新点这块的话主要是挖掘了人脸特征关键点和目标检测的一些联系,结合了人脸检测和对准两个任务来进行人脸检测,相比其他经典的目标检测网络如yolov3,R-CNN系列,在网络和损失函数上的创新确实略有不足,但是也让我收到了一些启发,看似几个简单的model和常见的loss联合,在对数据进行有效处理的基础上也是可以实现达到十分不错的效果的,不过这个方案的话在训练的时候其实是很花费时间的,毕竟需要对于不同scale的图片都进行输入训练,然后就是这种输入输出的结构其实还是存在一些局限性的,对于图像检测框和关键点的映射我个人觉得也比较繁杂或者说浪费了一些时间,毕竟是一篇2016年的论文之后应该会有更好的实现方式。
参考资料
]]>参考链接: https://zhuanlan.zhihu.com/p/337690783
参考链接:https://zhuanlan.zhihu.com/p/60199964?utm_source=qq&utm_medium=social&utm_oi=1221207556791963648
参考链接: https://blog.csdn.net/weixin_44791964/article/details/103530206
参考链接:https://blog.csdn.net/qq_34714751/article/details/85536669
参考链接:https://www.bilibili.com/video/BV1fJ411C7AJ?from=search&seid=2691296178499711503MTCNN人脸检测和pytorch代码实现解读 传送门
论文地址:https://arxiv.org/ftp/arxiv/papers/1604/1604.02878.pdf
我的论文笔记:https://khany.top/file/paper/mtcnn.pdf
本文csdn链接:https://blog.csdn.net/Jack___E/article/details/115601474
github参考:https://github.com/Sierkinhane/mtcnn-pytorch
github参考:https://github.com/GitHberChen/MTCNN_Pytorchabstract
abstract—Face detection and alignment in unconstrained environment are challenging due to various poses, illuminations and occlusions. Recent studies show that deep learning approaches can achieve impressive performance on these two tasks. In this paper, we propose a deep cascaded multi-task framework which exploits the inherent correlation between detection and alignment
to boost up their performance. In particular, our framework leverages a cascaded architecture with three stages of carefully designed deep convolutional networks to predict face and landmark location in a coarse-to-fine manner. In addition, we propose a new online hard sample mining strategy that further improves the performance in practice. Our method achieves superior accuracy over the state-of-the-art techniques on the challenging FDDB and WIDER FACE benchmarks for face detection, and AFLW benchmark for face alignment, while keeps real time performance.在无约束条件的环境下进行人脸检测和校准人脸检测和校准是非常具挑战性的,因为你要考虑复杂的姿势,光照因素以及面部遮挡问题的影响,最近的研究表明,使用深度学习的方法能够在这两项任务上有不错的效果。本文作者探索和研究了人脸检测和校准之间的内在联系,提出了一个深层级的多任务框架有效提升了网络的性能。我们的深层级联合架构包含三个阶段的卷积神经网络从粗略到细致逐步实现人脸检测和面部特征点标记。此外,我们还提出了一种新的线上进行困难样本的预测的策略可以在实际使用过程中有效提升网络的性能。我们的方法目前在FDDB和WIDER FACE人脸检测任务和AFLW面部对准任务上超越了最佳模型方法的性能标准,同时该模型具有不错的实时检测效果。
my English is not so well,if there are some mistakes in translations, please contact me in blog comments.
简介
人脸检测和脸部校准任务对于很多面部任务和应用来说都是十分重要的,比如说人脸识别,人脸表情分析。不过在现实生活当中,面部特征时常会因为一些遮挡物,强烈的光照对比,复杂的姿势发生很大的变化,这使得这些任务变得具有很大挑战性。Viola和Jones 提出的级联人脸检测器利用Haar特征和AdaBoost训练级联分类器,实现了具有实时效率的良好性能。 然而,也有相当一部分的工作表明,这种分类器可能在现实生活的应用中效果显着降低,即使具有更高级的特征和分类器。,之后人们又提出了DPM的方式,这些年来基于CNN的一些解决方案也层出不穷,基于CNN的方案主要是为了识别出面部的一些特征来实现。作者认为这种方式其实是需要花费更多的时间来对面部进行校准来训练同时还忽略了面部的重要特征点位置和边框问题。
对于人脸校准的话目前也有大致的两个方向:一个是基于回归的方法还有一个就是基于模板拟合的方式进行,主要是对特征识别起到一个辅助的工作。
作者认为关于人脸识别和面部对准这两个任务其实是有内在关联的,而目前大多数的方法则忽略了这一点,所以本文所提出的方案就是将这两者都结合起来,构建出一个三阶段的模型实现一个端到端的人脸检测并校准面部特征点的过程。
第一阶段:通过浅层CNN快速生成候选窗口。
第二阶段:通过more complex的CNN拒绝大量非面部窗口来细化窗口。
第三阶段:使用more powerful的CNN再次细化结果并输出五个面部标志位置。方法
Image pyramid图像金字塔
在进入stage-1之前,作者先构建了一组多尺度的图像金字塔缩放,这一块要理解起来还是有一点费力的,这里我们需要了解的是在训练网络的过程当中,作者都是把WIDER FACE的图片随机剪切成12x12size的大小进行单尺度训练的,不能满足任意大小的人脸检测,所以为了检测到不同尺寸的人脸,所以在推理时需要先生成图像金字塔生成一组不同scale的图像输入P-net进行来实现人脸的检测,同时也这是为什么P-net要使用FCN的原因。
def calculateScales(img):
min_face_size = 20 # 最小的人脸尺寸
width, height = img.size
min_length = min(height, width)
min_detection_size = 12
factor = 0.707 # sqrt(0.5)
scales = []
m = min_detection_size / min_face_size
min_length *= m
factor_count = 0
# 图像尺寸缩小到不大于min_detection_size
while min_length > min_detection_size:
scales.append(m * factor ** factor_count)
min_length *= factor
factor_count += 1$\text{here we define in our code:} factor=\frac{1}{\sqrt{2}}, \text{min face size}=20,\text{min detection size}=12$
min_face_size和factor对推理过程会产生什么样的影响?
min_face_size越大,factor越小,图像最短边就越快缩放到接近min_detect_size,从而生成图像金字塔的耗时就越短,同时各尺度的跨度也更大。因此,加大min_face_size、减小factor能加速图像金字塔的生成,但同时也更易造成漏检。Stage 1 P-Net(Proposal Network)
这是一个全卷积网络,也就是说这个网络可以兼容任意大小的输入,他的整个网络其实十分简单,该层的作用主要是为了获得人脸检测的大量候选框,这一层我们最大的作用就是要尽可能的提升recall,然后在获得许多候选框后再使用非极大抑制的方法合并高度重叠的候选区域。
P-Net的示意图当中我们也可以看到的是作者输入12x12大小最终的output为一个1x1x2的face label classification概率和一个1x1x4的boudingbox(左上角和右下角的坐标)以及一个1x1x10的landmark(双眼,鼻子,左右嘴角的坐标)
注意虽然这里作者举例是12x12的图片大小,但是他的意思并不是说这个P-Net的图片输入大小必须是12,我们可以知道这个网络是FCN,这就意味着不同输入的大小都是可以输入其中的,最后我们所得到的featuremap$[m \times n \times (2+4+10) ]$每一个小像素点映射到输入图像所在的12x12区域是否包含人脸的分类结果,候选框左上和右下基准点以及landmark,然后根据图像金字塔的我们再根据scale和resize的逆过程将其映射到原图像上P-net structure
class P_Net(nn.Module):
def __init__(self):
super(P_Net, self).__init__()
self.pre_layer = nn.Sequential(
# 12x12x3
nn.Conv2d(3, 10, kernel_size=3, stride=1), # conv1
nn.PReLU(), # PReLU1
# 10x10x10
nn.MaxPool2d(kernel_size=2, stride=2), # pool1
# 5x5x10
nn.Conv2d(10, 16, kernel_size=3, stride=1), # conv2
# 3x3x16
nn.PReLU(), # PReLU2
nn.Conv2d(16, 32, kernel_size=3, stride=1), # conv3
# 1x1x32
nn.PReLU() # PReLU3
)
# detection
self.conv4_1 = nn.Conv2d(32, 1, kernel_size=1, stride=1)
# bounding box regresion
self.conv4_2 = nn.Conv2d(32, 4, kernel_size=1, stride=1)
# landmark localization
self.conv4_3 = nn.Conv2d(32, 10, kernel_size=1, stride=1)
# weight initiation with xavier
self.apply(weights_init)
def forward(self, x):
x = self.pre_layer(x)
det = torch.sigmoid(self.conv4_1(x))
box = self.conv4_2(x)
landmark = self.conv4_3(x)
# det:[,2,1,1], box:[,4,1,1], landmark:[,10,1,1]
return det, box, landmark
这里要提一下nn.PReLU(),有点类似Leaky ReLU,可以看下面的博客深入了解一下https://blog.csdn.net/qq_23304241/article/details/80300149
https://blog.csdn.net/shuzfan/article/details/51345832然后在P-Net之后我们通过非极大抑制的方法和将所有的boudingbox都修正为框的最长边为边长的正方形框,主要是避免后面的Rnet在resize的时候因为尺寸原因出现信息的损失。
Non-Maximum Suppression非极大抑制
其实关于非极大抑制这个trick最初是在目标检测任务当中提出的来的,其思想是搜素局部最大值,抑制极大值,主要用在目标检测当中,最传统的非极大抑制所采用的评价指标就是交并比IoU(intersection-over-union)即两个groud truth和bounding box的交集部分除以它们的并集.
def IoU(box, boxes):
"""Compute IoU between detect box and gt boxes
Parameters:
----------
box: numpy array , shape (5, ): x1, y1, x2, y2, score
input box
boxes: numpy array, shape (n, 4): x1, y1, x2, y2
input ground truth boxes
Returns:
-------
ovr: numpy.array, shape (n, )
IoU
"""
box_area = (box[2] - box[0] + 1) * (box[3] - box[1] + 1)
area = (boxes[:, 2] - boxes[:, 0] + 1) * (boxes[:, 3] - boxes[:, 1] + 1)
xx1 = np.maximum(box[0], boxes[:, 0])
xx2 = np.minimum(box[2], boxes[:, 2])
yy1 = np.maximum(box[1], boxes[:, 1])
yy2 = np.minimum(box[3], boxes[:, 3])
# compute the width and height of the bounding box
w = np.maximum(0, xx2 - xx1 + 1)
h = np.maximum(0, yy2 - yy1 + 1)
inter = w * h
ovr = np.true_divide(inter,(box_area + area - inter))
#ovr = inter / (box_area + area - inter)
return ovr使用非极大抑制的前提是,我们已经得到了一组候选框和对应label的置信分数,以及groud truth的信息,通过设定阈值来删除重合度较高的候选框。
算法流程如下:- 根据置信度得分进行排序
- 选择置信度最高的比边界框添加到最终输出列表中,将其从边界框列表中删除
- 计算所有边界框的面积
- 计算置信度最高的边界框与其它候选框的IoU。
- 删除IoU大于阈值的边界框
- 重复上述过程,直至边界框列表为空。
def nms(dets,threshod,mode="Union"):
"""
greedily select boxes with high confidence
keep boxes overlap <= thresh
rule out overlap > thresh
:param dets: [[x1, y1, x2, y2 score]]
:param threshod: retain overlap <= thresh
:return: indexes to keep
"""
x1 = dets[:,0]
y1 = dets[;,1]
x2 = dets[:,2]
y2 = dets[:,3]
scores = dets[:,4]
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
order = areas.argsort()[::-1] # reverse
keep=[]
while order.size()>0:
i = order[0]
keep.append(i)
# A & B left top position
xx1 = np.maximun(x1[i],x1[order[1,:]])
yy1 = np.maximun(y1[i],y1[order[1,:]])
# A & B right down position
xx2 = np.minimum(x2[i],x2[order[1,:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
# cacaulate the IOU between box which have largest score with other boxes
if mode == "Union":
# area[i]: the area of largest score
ovr = inter / (areas[i] + areas[order[1:]] - inter)
elif mode == "Minimum":
ovr = inter / np.minimum(areas[i], areas[order[1:]])
# delete the IoU that higher than threshod
inds = np.where(ovr <= threshod)[0]
order = order[inds + 1] # +1: eliminates the first element in order
return keep边框修正
以最大边作为边长将矩形修正为正方形,同时包含的信息也更多,以免在后面resize输入下一个网络时减少信息的损失。
def convert_to_square(bboxes):
"""
Convert bounding boxes to a square form.
"""
# 将矩形对称扩大为正方形
square_bboxes = np.zeros_like(bboxes)
x1, y1, x2, y2 = [bboxes[:, i] for i in range(4)]
h = y2 - y1 + 1.0
w = x2 - x1 + 1.0
max_side = np.maximum(h, w)
square_bboxes[:, 0] = x1 + w * 0.5 - max_side * 0.5
square_bboxes[:, 1] = y1 + h * 0.5 - max_side * 0.5
square_bboxes[:, 2] = square_bboxes[:, 0] + max_side - 1.0
square_bboxes[:, 3] = square_bboxes[:, 1] + max_side - 1.0
return square_bboxesStage 2 R-Net(Refine Network)
R-net的输入是固定的,必须是24x24,所以对于P-net产生的大量boundingbox我们需要先进行resize然后再输入R-Net,在论文中我们了解到该网络层的作用主要是对大量的boundingbox进行有效过滤,获得更加精细的候选框。
R-net structure
class R_Net(nn.Module):
def __init__(self):
super(R_Net, self).__init__()
self.pre_layer = nn.Sequential(
# 24x24x3
nn.Conv2d(3, 28, kernel_size=3, stride=1), # conv1
nn.PReLU(), # prelu1
# 22x22x28
nn.MaxPool2d(kernel_size=3, stride=2), # pool1
# 10x10x28
nn.Conv2d(28, 48, kernel_size=3, stride=1), # conv2
nn.PReLU(), # prelu2
# 8x8x48
nn.MaxPool2d(kernel_size=3, stride=2), # pool2
# 3x3x48
nn.Conv2d(48, 64, kernel_size=2, stride=1), # conv3
# 2x2x64
nn.PReLU() # prelu3
)
# 2x2x64
self.conv4 = nn.Linear(64 * 2 * 2, 128) # conv4
# 128
self.prelu4 = nn.PReLU() # prelu4
# detection
self.conv5_1 = nn.Linear(128, 1)
# bounding box regression
self.conv5_2 = nn.Linear(128, 4)
# lanbmark localization
self.conv5_3 = nn.Linear(128, 10)
# weight initiation weih xavier
self.apply(weights_init)
def forward(self, x):
x = self.pre_layer(x)
x = x.view(x.size(0), -1)
x = self.conv4(x)
x = self.prelu4(x)
det = torch.sigmoid(self.conv5_1(x))
box = self.conv5_2(x)
landmark = self.conv5_3(x)
return det, box, landmark然后在P-Net之后我们通过非极大抑制的方法和将所有的boudingbox都修正为框的最长边为边长的正方形框,也是避免后面的Onet在resize的时候出现因为尺寸原因出现信息的损失。
Stage 3 O-Net(Output?[作者未指出命名] Network)
Onet与Rnet工作流程类似。只不过输入的尺寸变成了48x48,对于R-net当中的框再次进行处理,得到的网络结构的输出则是最终的label classfication,boundingbox,landmark。
O-net structureclass O_Net(nn.Module):
def __init__(self):
super(O_Net, self).__init__()
self.pre_layer = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, stride=1), # conv1
nn.PReLU(), # prelu1
nn.MaxPool2d(kernel_size=3, stride=2), # pool1
nn.Conv2d(32, 64, kernel_size=3, stride=1), # conv2
nn.PReLU(), # prelu2
nn.MaxPool2d(kernel_size=3, stride=2), # pool2
nn.Conv2d(64, 64, kernel_size=3, stride=1), # conv3
nn.PReLU(), # prelu3
nn.MaxPool2d(kernel_size=2, stride=2), # pool3
nn.Conv2d(64, 128, kernel_size=2, stride=1), # conv4
nn.PReLU() # prelu4
)
self.conv5 = nn.Linear(128 * 2 * 2, 256) # conv5
self.prelu5 = nn.PReLU() # prelu5
# detection
self.conv6_1 = nn.Linear(256, 1)
# bounding box regression
self.conv6_2 = nn.Linear(256, 4)
# lanbmark localization
self.conv6_3 = nn.Linear(256, 10)
# weight initiation weih xavier
self.apply(weights_init)
def forward(self, x):
x = self.pre_layer(x)
x = x.view(x.size(0), -1)
x = self.conv5(x)
x = self.prelu5(x)
# detection
det = torch.sigmoid(self.conv6_1(x))
box = self.conv6_2(x)
landmark = self.conv6_3(x)
return det, box, landmark
注意,其实在之前的两个网络当中我们也预测了landmark的位置,只是在论文的图示当中没有展示而已,从作者描述的网络结构图的输出当中是详细指出了landmarkposition的卷积块的损失函数
在研究完网络结构以后我们可以来看看这个mtcnn模型的一个损失函数,作者将损失函数分为了3个部分:Face classification、Bounding box regression、Facial landmark localization。
Face classification
对于第一部分的损失就是用的是最常用的交叉熵损失函数,就本质上来说人脸识别还是一个二分类问题,这里就使用Cross Entropy是最简单也是最合适的选择。
$p_i$是预测为face的可能性,$y_i^{det}$指的是真实标签也就是groud truth label
Bounding box regression
对于目标边界框的损失来说,对于每一个候选框我们都需要对与他最接近的真实目标边界框进行比较,the bounding box$(left, top, height, and width)$
Facial landmark localization
而对于boundingbox和landmark来说整个框的调整过程其实可以看作是一个连续的变化过程,固使用的是欧氏距离回归损失计算方法。比较的是各个点的坐标与真实面部关键点坐标的差异。
total loss
最终我们得到的损失函数是有上述这三部分加权而成
其中$\alpha_j$表示权重,$\beta_i^j$表示第i个样本的类型,也可以说是第i个样本在任务j中是否需要贡献loss,如果不存在人脸即label为0时则无需计算loss。
对于不同的网络我们所设置的权重是不一样的
in P-net & R-net(在这两层我们更注重classification的识别)in O-net(在这层我们提高了对于注意关键点的预测精度)
文中也有提到,采用的是随机梯度下降优化器进行的训练。
OHEM(Online Hard Example Mining)
作者对于困难样本的在线预测所做的trick也比较简单,就是挑选损失最大的前70%作为困难样本,在反向传播时仅使用这70%困难样本产生的损失,这样就剔除了很容易预测的easy sample对训练结果的影响,不过在我参考的这两个版本的代码里面似乎没有这么做。
实验
实验这块的话也比较充分,验证了每个修改部分对于实验结果的有效性验证,主要是讲述了实验过程对于训练数据集的处理和划分,验证了在线硬样本挖掘的有效性,联合检测和校准的有效性,分别评估了face detection和lanmark的贡献,面部检测评估,面部校准评估以及与SOTA的对比,这一块的话就没有细看了,分享的网站也有详细解释,论文原文也写了。
总结
这篇论文是中科院深圳先进技术研究院的乔宇老师团队所作,2016ECCV,看完这篇文章的话给我的感觉的话就是idea和实现过程包括实验都是很充分的,创新点这块的话主要是挖掘了人脸特征关键点和目标检测的一些联系,结合了人脸检测和对准两个任务来进行人脸检测,相比其他经典的目标检测网络如yolov3,R-CNN系列,在网络和损失函数上的创新确实略有不足,但是也让我收到了一些启发,看似几个简单的model和常见的loss联合,在对数据进行有效处理的基础上也是可以实现达到十分不错的效果的,不过这个方案的话在训练的时候其实是很花费时间的,毕竟需要对于不同scale的图片都进行输入训练,然后就是这种输入输出的结构其实还是存在一些局限性的,对于图像检测框和关键点的映射我个人觉得也比较繁杂或者说浪费了一些时间,毕竟是一篇2016年的论文之后应该会有更好的实现方式。
参考资料
]]>参考链接: https://zhuanlan.zhihu.com/p/337690783
参考链接:https://zhuanlan.zhihu.com/p/60199964?utm_source=qq&utm_medium=social&utm_oi=1221207556791963648
参考链接: https://blog.csdn.net/weixin_44791964/article/details/103530206
参考链接:https://blog.csdn.net/qq_34714751/article/details/85536669
参考链接:https://www.bilibili.com/video/BV1fJ411C7AJ?from=search&seid=2691296178499711503@@ -401,14 +401,12 @@ 2021-02-24T16:03:00.000Z 2024-10-09T07:33:09.891Z -commit镜像 +数据卷操作实战:mysql同步
mysql运行容器,需要做数据挂载,安装启动mysql是需要配置密码的这一点要注意,所以要去docker hub官方文档上面去看官方配置
docker pull mysql:5.7docker运行,docker run的常用参数这里我们再次回顾一下
-d 后台运行
-p 端口映射
-v 卷挂载
-e 环境配置
--name 环境名字通过docker hub我们找到了官方的命令:
docker run --name some-mysql -e MYSQL_ROOT_PASSWORD=my-secret-pw -d mysql:tag,在修改一下得到我们最终的输入命令docker run -d -p 3310:3306 -v /home/mysql/conf:/etc/mysql/conf.d -v /home/mysql/data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=12345678 --name mysql01 mysql:5.7CREATE DATABASE test_db;
删除这个镜像后数据则依旧保存下来了具名/匿名挂载
大多数情况下,为了方便,我们会使用具名挂载Dockerfile
Dockerfile就是用来构建docker镜像的文件,命令脚本,通过这个脚本可以生成镜像。
构建步骤编写一个Dockerfile
docker build 构建成为一个镜像
docker run 运行镜像
docker push 发布镜像(DockerHub,阿里云镜像)
这里我们可以先看看Docker Hub官方是怎么做的
官方镜像是比较基础的,有很多命令和功能都省去了,所以我们通常需要在基础的镜像上来构建我们自己的镜像
Dockerfile命令
常用命令 用法 FROM 基础镜像,一切从这开始构建 MAINTAINER 镜像是谁写的,姓名+邮箱 RUN 镜像构建的时候需要运行的命令 ADD 添加内容,如tomcat压缩包 WORKDIR 镜像的工作目录 VOLUME 挂载的目录 CMD 指定这个容器启动时要运行的命令,只有最后一个会生效,可被替代 ENTRYPOINT 指定这个容器启动时要运行的命令,可以追加命令 ONBUILD 当构建一个被继承DockerFile这个时候就会执行ONBUILD命令 COPY 类似ADD将文件拷贝到镜像当中 ENV 构建的时候设置环境变量 创建一个自己的centos
Dockerfile中99%的镜像都来自于这个scratch镜像,然后配置需要的软件和配置来进行构建。
mkdir dockerfile
cd dockerfile
vim mydockerfile-centos编写mydockerfile-centos
FROM centos
MAINTAINER khan<khany@foxmail.com>
ENV MYPATH /usr/local
WORKDIR $MYPATH
RUN yum -y install vim
RUN yum -y install net-tools
EXPOSE 80
CMD echo $MYPATH
CMD echo "---end---"
CMD /bin/bash然后我们进入
docker build,注意后面一定要有一个.号docker build -f mydockerfile-centos -t mycentos:1.0 .然后我们通过
docker run -it mycentos:1.0命令进入我们自己创建的镜像测试运行我们新安装的包和命令是否能正常运行。
我们可以通过docker history +容器名称/容器id看到这个容器的构建过程。CMD和ENTRYPOINT区别
dockerfile-cmd-test:
FROM centos
CMD ["ls","-a"]dockerfile-entrypoint-test:
FROM centos
ENTRYPOINT ["ls","-a"]执行命令
docker run 容器名称 -l在CMD下会报错,命令会被后面追加的-l替代,而-l并不是有效的linux命令,所以报错,而ENTRYPOINT则是可以追加的则该命令会变为ls -al发布镜像
发布到Docker Hub
- 地址 https://hub.docker.com/ 注册自己的账号
- 确定这个账号可以登录
- 在我们服务器上提交自己的镜像
- 登录成功,通过
push命令提交镜像,记得注意添加版本号
这里出了一点小问题:
在build自己的镜像的时候添加tag时必须在前面加上自己的dockerhub的username,然后再push就可以了
docker tag 镜像id YOUR_DOCKERHUB_NAME/firstimage
docker push YOUR_DOCKERHUB_NAME/firstimage
提交成功,可以在docker hub上找到你提交的镜像阿里云镜像提交
在阿里云的容器镜像服务里面,创建一个新的镜像仓库,然后就会有详细的教学,做法与docker hub基本一致,提交成功能在镜像版本当中查看到,这里就不再重复讲解了。
Docker镜像操作过程总结
]]>
commit镜像 数据卷操作实战:mysql同步
mysql运行容器,需要做数据挂载,安装启动mysql是需要配置密码的这一点要注意,所以要去docker hub官方文档上面去看官方配置
docker pull mysql:5.7docker运行,docker run的常用参数这里我们再次回顾一下
-d 后台运行
-p 端口映射
-v 卷挂载
-e 环境配置
--name 环境名字通过docker hub我们找到了官方的命令:
docker run --name some-mysql -e MYSQL_ROOT_PASSWORD=my-secret-pw -d mysql:tag,在修改一下得到我们最终的输入命令docker run -d -p 3310:3306 -v /home/mysql/conf:/etc/mysql/conf.d -v /home/mysql/data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=12345678 --name mysql01 mysql:5.7CREATE DATABASE test_db;
删除这个镜像后数据则依旧保存下来了具名/匿名挂载
大多数情况下,为了方便,我们会使用具名挂载Dockerfile
Dockerfile就是用来构建docker镜像的文件,命令脚本,通过这个脚本可以生成镜像。
构建步骤- 编写一个Dockerfile
- docker build 构建成为一个镜像
- docker run 运行镜像
docker push 发布镜像(DockerHub,阿里云镜像)
这里我们可以先看看Docker Hub官方是怎么做的
官方镜像是比较基础的,有很多命令和功能都省去了,所以我们通常需要在基础的镜像上来构建我们自己的镜像
Dockerfile命令
常用命令 用法 FROM 基础镜像,一切从这开始构建 MAINTAINER 镜像是谁写的,姓名+邮箱 RUN 镜像构建的时候需要运行的命令 ADD 添加内容,如tomcat压缩包 WORKDIR 镜像的工作目录 VOLUME 挂载的目录 CMD 指定这个容器启动时要运行的命令,只有最后一个会生效,可被替代 ENTRYPOINT 指定这个容器启动时要运行的命令,可以追加命令 ONBUILD 当构建一个被继承DockerFile这个时候就会执行ONBUILD命令 COPY 类似ADD将文件拷贝到镜像当中 ENV 构建的时候设置环境变量 创建一个自己的centos
Dockerfile中99%的镜像都来自于这个scratch镜像,然后配置需要的软件和配置来进行构建。
mkdir dockerfile
cd dockerfile
vim mydockerfile-centos编写mydockerfile-centos
FROM centos
MAINTAINER khan<khany@foxmail.com>
ENV MYPATH /usr/local
WORKDIR $MYPATH
RUN yum -y install vim
RUN yum -y install net-tools
EXPOSE 80
CMD echo $MYPATH
CMD echo "---end---"
CMD /bin/bash然后我们进入
docker build,注意后面一定要有一个.号docker build -f mydockerfile-centos -t mycentos:1.0 .然后我们通过
docker run -it mycentos:1.0命令进入我们自己创建的镜像测试运行我们新安装的包和命令是否能正常运行。
我们可以通过docker history +容器名称/容器id看到这个容器的构建过程。CMD和ENTRYPOINT区别
dockerfile-cmd-test:
FROM centos
CMD ["ls","-a"]
dockerfile-entrypoint-test:FROM centos
ENTRYPOINT ["ls","-a"]
执行命令docker run 容器名称 -l在CMD下会报错,命令会被后面追加的-l替代,而-l并不是有效的linux命令,所以报错,而ENTRYPOINT则是可以追加的则该命令会变为ls -al发布镜像
发布到Docker Hub
- 地址 https://hub.docker.com/ 注册自己的账号
- 确定这个账号可以登录
- 在我们服务器上提交自己的镜像
- 登录成功,通过
push命令提交镜像,记得注意添加版本号
这里出了一点小问题:
在build自己的镜像的时候添加tag时必须在前面加上自己的dockerhub的username,然后再push就可以了
docker tag 镜像id YOUR_DOCKERHUB_NAME/firstimage
docker push YOUR_DOCKERHUB_NAME/firstimage
提交成功,可以在docker hub上找到你提交的镜像阿里云镜像提交
在阿里云的容器镜像服务里面,创建一个新的镜像仓库,然后就会有详细的教学,做法与docker hub基本一致,提交成功能在镜像版本当中查看到,这里就不再重复讲解了。
Docker镜像操作过程总结
]]>
<h2 id="commit镜像"><a href="#commit镜像" class="headerlink" title="commit镜像"></a>commit镜像</h2><p><img src="https://img-blog.csdnimg.cn/20210224162521454.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0phY2tfX19F,size_16,color_FFFFFF,t_70" alt="在这里插入图片描述"></p> -<h2 id="数据卷操作实战:mysql同步"><a href="#数据卷操作实战:mysql同步" class="headerlink" title="数据卷操作实战:mysql同步"></a>数据卷操作实战:mysql同步</h2><p><strong>mysql运行容器,需要做数据挂载,安装启动mysql是需要配置密码的这一点要注意,所以要去docker hub官方文档上面去看官方配置</strong></p> -<figure class="highlight powershell"><table><tr><td class="code"><pre><code class="hljs powershell">docker pull mysql:<span class="hljs-number">5.7</span><br></code></pre></td></tr></table></figure> - +<h2 id="数据卷操作实战:mysql同步"><a href="#数据卷操作实战:mysql同步" class="headerlink" title="数据卷操作实战:mysql同步"></a>数据卷操作实战:mysql同步</h2><p><strong>mysql运行容器,需要做数据挂载,安装启动mysql是需要配置密码的这一点要注意,所以要去docker hub官方文档上面去看官方配置</strong><br><figure class="highlight powershell"><table><tr><td class="code"><pre><code class="hljs powershell">docker pull mysql:<span class="hljs-number">5.7</span><br></code></pre></td></tr></table></figure></p> <p>docker运行,docker run的常用参数这里我们再次回顾一下</p> <figure class="highlight powershell"><table><tr><td class="code"><pre><code class="hljs powershell"><span class="hljs-literal">-d</span> 后台运行<br><span class="hljs-literal">-p</span> 端口映射<br><span class="hljs-literal">-v</span> 卷挂载<br><span class="hljs-literal">-e</span> 环境配置<br>-<span class="hljs-literal">-name</span> 环境名字<br></code></pre></td></tr></table></figure> @@ -427,41 +425,44 @@ 2021-02-24T07:30:00.000Z 2024-10-09T07:33:09.890Z -Docker 常用命令 +帮助命令
docker version #显示docker版本信息
docker info #显示docker的系统信息,包括镜像和容器的数量
docker 命令 --help # 帮助命令镜像命令
1.
docker images查看所有本地的主机镜像docker images显示字段 解释 REPOSITORY 镜像的仓库源 TAG 镜像的标签 IMAGE ID 镜像的id CREATED 镜像的创建时间 SIZE 镜像的大小 (base) [root@iZuf69rye0flkbn4kbxrobZ ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
hello-world latest bf756fb1ae65 13 months ago 13.3kB
(base) [root@iZuf69rye0flkbn4kbxrobZ ~]# docker images --help
Usage: docker images [OPTIONS] [REPOSITORY[:TAG]]
List images
Options:
-a, --all Show all images
-q, --quiet Only show image IDs
2.docker search命令搜索镜像
搜索镜像可以去docker hub网站上直接搜索,也可以通过命令行来搜索,通过万能帮助命令能更快的看到他的一些用法,这两种方法结果是一样的我们也可以通过
--filter来进行条件筛选
比如docker search mysql --filter=STARS=3000(base) [root@iZuf69rye0flkbn4kbxrobZ ~]# docker search mysql --filter=STARS=3000
NAME DESCRIPTION STARS OFFICIAL AUTOMATED
mysql MySQL is a widely used, open-source relation… 10538 [OK]
mariadb MariaDB is a community-developed fork of MyS… 3935 [OK]3.
docker pull下载镜像
这个命令其实信息量很大,这也是docker高明的地方,关于指定版本下载一定要是docker hub官网上面支持和提供的版本
我这里使用了docker pull mysql
docker pull mysql:5.7
4.docker rmi删除镜像
删除可以通过REPOSITORY来删,也可以通过IMAGE ID来删除容器命令
说明:我们有了镜像才可以创建容器,linux,下载一个centos镜像来测试学习
docker pull centos1.新建容器并启动
通过docker run命令进入下载的centos容器里面后我们可以发现的是,我们的rootname不一样了2.列出所有运行的容器
docker ps命令
3.exit退出命令exit #直接容器停止并退出
Ctrl + P + Q #容器不停止并退出在执行exit命令后,我们看到rootname又变回来了
4.删除容器
docker rm 容器id #删除指定的容器,不能删除正在运行的容器,如果要强制删除,需要使用 rm -f
docker rm $(docker ps -aq) #删除全部的容器
docker ps -a -q|xargs docker rm #删除全部容器5.启动和停止容器
日志元数据进程查看
1.docker top 容器id查看容器中的进程
2.docker inspect 容器id查看元数据3.进入当前正在运行的容器
方式1:
docker exec -it 容器id bashshell并可通过ps -ef查看容器当中的进程方式2:
docker attach 容器id进入容器,如果当前有正在执行的容器则会直接进入到当前正在执行的进程当中从容器内拷贝到主机上
即使容器已经停止也是可以进行拷贝的
docker cp 容器id:容器内路径 目的主机路径docker部署nginx
$ docker search nginx
$ docker pull nginx
$ docker run -d --name nginx01 -p 8083:80 nginx
$ docker ps
$ curl localhost:8083docker stop后则无法再访问portainer可视化管理
docker run -d -p 8088:9000 --restart=always -v /var/run/docker.sock:/var/run/docker.sock --privileged=true portainer/portainer
]]>
进入后选择local模式,然后就能看到这个版面了
参考链接:
【狂神说Java】Docker最新超详细版教程通俗易懂Docker 常用命令 帮助命令
docker version #显示docker版本信息
docker info #显示docker的系统信息,包括镜像和容器的数量
docker 命令 --help # 帮助命令镜像命令
1.
docker images查看所有本地的主机镜像docker images显示字段 解释 REPOSITORY 镜像的仓库源 TAG 镜像的标签 IMAGE ID 镜像的id CREATED 镜像的创建时间 SIZE 镜像的大小 (base) [root@iZuf69rye0flkbn4kbxrobZ ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
hello-world latest bf756fb1ae65 13 months ago 13.3kB
(base) [root@iZuf69rye0flkbn4kbxrobZ ~]# docker images --help
Usage: docker images [OPTIONS] [REPOSITORY[:TAG]]
List images
Options:
-a, --all Show all images
-q, --quiet Only show image IDs
2.docker search命令搜索镜像
搜索镜像可以去docker hub网站上直接搜索,也可以通过命令行来搜索,通过万能帮助命令能更快的看到他的一些用法,这两种方法结果是一样的我们也可以通过
--filter来进行条件筛选
比如docker search mysql --filter=STARS=3000(base) [root@iZuf69rye0flkbn4kbxrobZ ~]# docker search mysql --filter=STARS=3000
NAME DESCRIPTION STARS OFFICIAL AUTOMATED
mysql MySQL is a widely used, open-source relation… 10538 [OK]
mariadb MariaDB is a community-developed fork of MyS… 3935 [OK]3.
docker pull下载镜像
这个命令其实信息量很大,这也是docker高明的地方,关于指定版本下载一定要是docker hub官网上面支持和提供的版本
我这里使用了docker pull mysql
docker pull mysql:5.7
4.docker rmi删除镜像
删除可以通过REPOSITORY来删,也可以通过IMAGE ID来删除容器命令
说明:我们有了镜像才可以创建容器,linux,下载一个centos镜像来测试学习
docker pull centos
1.新建容器并启动
通过docker run命令进入下载的centos容器里面后我们可以发现的是,我们的rootname不一样了2.列出所有运行的容器
docker ps命令
3.exit退出命令exit #直接容器停止并退出
Ctrl + P + Q #容器不停止并退出在执行exit命令后,我们看到rootname又变回来了
4.删除容器
docker rm 容器id #删除指定的容器,不能删除正在运行的容器,如果要强制删除,需要使用 rm -f
docker rm $(docker ps -aq) #删除全部的容器
docker ps -a -q|xargs docker rm #删除全部容器5.启动和停止容器
日志元数据进程查看
1.docker top 容器id查看容器中的进程
2.docker inspect 容器id查看元数据3.进入当前正在运行的容器
方式1:
docker exec -it 容器id bashshell并可通过ps -ef查看容器当中的进程方式2:
docker attach 容器id进入容器,如果当前有正在执行的容器则会直接进入到当前正在执行的进程当中从容器内拷贝到主机上
即使容器已经停止也是可以进行拷贝的
docker cp 容器id:容器内路径 目的主机路径docker部署nginx
$ docker search nginx
$ docker pull nginx
$ docker run -d --name nginx01 -p 8083:80 nginx
$ docker ps
$ curl localhost:8083docker stop后则无法再访问portainer可视化管理
docker run -d -p 8088:9000 --restart=always -v /var/run/docker.sock:/var/run/docker.sock --privileged=true portainer/portainer
]]>
进入后选择local模式,然后就能看到这个版面了
参考链接:
【狂神说Java】Docker最新超详细版教程通俗易懂<h1 id="Docker-常用命令"><a href="#Docker-常用命令" class="headerlink" title="Docker 常用命令"></a>Docker 常用命令</h1><h2 id="帮助命令"><a href="#帮助命令" class="headerlink" title="帮助命令"></a>帮助命令</h2><figure class="highlight bash"><table><tr><td class="code"><pre><code class="hljs bash">docker version <span class="hljs-comment">#显示docker版本信息</span><br>docker info <span class="hljs-comment">#显示docker的系统信息,包括镜像和容器的数量</span><br>docker 命令 --<span class="hljs-built_in">help</span> <span class="hljs-comment"># 帮助命令</span><br></code></pre></td></tr></table></figure> - <h2 id="镜像命令"><a href="#镜像命令" class="headerlink" title="镜像命令"></a>镜像命令</h2><p><strong>1.<code>docker images</code>查看所有本地的主机镜像</strong></p> +<div class="table-container"> <table> <thead> <tr> -<th align="left">docker images显示字段</th> -<th align="left">解释</th> +<th style="text-align:left">docker images显示字段</th> +<th style="text-align:left">解释</th> </tr> </thead> -<tbody><tr> -<td align="left">REPOSITORY</td> -<td align="left">镜像的仓库源</td> +<tbody> +<tr> +<td style="text-align:left">REPOSITORY</td> +<td style="text-align:left">镜像的仓库源</td> </tr> <tr> -<td align="left">TAG</td> -<td align="left">镜像的标签</td> +<td style="text-align:left">TAG</td> +<td style="text-align:left">镜像的标签</td> </tr> <tr> -<td align="left">IMAGE ID</td> -<td align="left">镜像的id</td> +<td style="text-align:left">IMAGE ID</td> +<td style="text-align:left">镜像的id</td> </tr> <tr> -<td align="left">CREATED</td> -<td align="left">镜像的创建时间</td> +<td style="text-align:left">CREATED</td> +<td style="text-align:left">镜像的创建时间</td> </tr> <tr> -<td align="left">SIZE</td> -<td align="left">镜像的大小</td> +<td style="text-align:left">SIZE</td> +<td style="text-align:left">镜像的大小</td> </tr> -</tbody></table> +</tbody> +</table> +</div> @@ -500,7 +501,7 @@2021-02-23T06:55:00.000Z 2024-10-09T07:33:09.889Z -零基础入门语义分割-Task4 评价函数与损失函数 +本章主要介绍语义分割的评价函数和各类损失函数。
4 评价函数与损失函数
4.1 学习目标
- 掌握常见的评价函数和损失函数Dice、IoU、BCE、Focal Loss、Lovász-Softmax;
- 掌握评价/损失函数的实践;
4.2 TP TN FP FN
在讲解语义分割中常用的评价函数和损失函数之前,先补充一**TP(真正例 true positive) TN(真反例 true negative) FP(假正例 false positive) FN(假反例 false negative)**的知识。在分类问题中,我们经常看到上述的表述方式,以二分类为例,我们可以将所有的样本预测结果分成TP、TN、 FP、FN四类,并且每一类含有的样本数量之和为总样本数量,即TP+FP+FN+TN=总样本数量。其混淆矩阵如下:
上述的概念都是通过以预测结果的视角定义的,可以依据下面方式理解:
预测结果中的正例 → 在实际中是正例 → 的所有样本被称为真正例(TP)<预测正确>
预测结果中的正例 → 在实际中是反例 → 的所有样本被称为假正例(FP)<预测错误>
预测结果中的反例 → 在实际中是正例 → 的所有样本被称为假反例(FN)<预测错误>
预测结果中的反例 → 在实际中是反例 → 的所有样本被称为真反例(TN)<预测正确>
这里就不得不提及精确率(precision)和召回率(recall):
$$
Precision=\frac{TP}{TP+FP} \
Recall=\frac{TP}{TP+FN}
$$
$Precision$代表了预测的正例中真正的正例所占比例;$Recall$代表了真正的正例中被正确预测出来的比例。转移到语义分割任务中来,我们可以将语义分割看作是对每一个图像像素的的分类问题。根据混淆矩阵中的定义,我们亦可以将特定像素所属的集合或区域划分成TP、TN、 FP、FN四类。
以上面的图片为例,图中左子图中的人物区域(黄色像素集合)是我们真实标注的前景信息(target),其他区域(紫色像素集合)为背景信息。当经过预测之后,我们会得到的一张预测结果,图中右子图中的黄色像素为预测的前景(prediction),紫色像素为预测的背景区域。此时,我们便能够将预测结果分成4个部分:
预测结果中的黄色无线区域 → 真实的前景 → 的所有像素集合被称为真正例(TP)<预测正确>
预测结果中的蓝色斜线区域 → 真实的背景 → 的所有像素集合被称为假正例(FP)<预测错误>
预测结果中的红色斜线区域 → 真实的前景 → 的所有像素集合被称为假反例(FN)<预测错误>
预测结果中的白色斜线区域 → 真实的背景 → 的所有像素集合被称为真反例(TN)<预测正确>
4.3 Dice评价指标
Dice系数
Dice系数(Dice coefficient)是常见的评价分割效果的方法之一,同样也可以改写成损失函数用来度量prediction和target之间的距离。Dice系数定义如下:
$$
Dice (T, P) = \frac{2 |T \cap P|}{|T| \cup |P|} = \frac{2TP}{FP+2TP+FN}
$$
式中:$T$表示真实前景(target),$P$表示预测前景(prediction)。Dice系数取值范围为$[0,1]$,其中值为1时代表预测与真实完全一致。仔细观察,Dice系数与分类评价指标中的F1 score很相似:$$
\frac{1}{F1} = \frac{1}{Precision} + \frac{1}{Recall}
$$$$
F1 = \frac{2TP}{FP+2TP+FN}
$$所以,Dice系数不仅在直观上体现了target与prediction的相似程度,同时其本质上还隐含了精确率和召回率两个重要指标。
计算Dice时,将$|T \cap P|$近似为prediction与target对应元素相乘再相加的结果。$|T|$ 和$|P|$的计算直接进行简单的元素求和(也有一些做法是取平方求和),如下示例:
$$
|T \cap P| =
\begin{bmatrix}
0.01 & 0.03 & 0.02 & 0.02 \
0.05 & 0.12 & 0.09 & 0.07 \
0.89 & 0.85 & 0.88 & 0.91 \
0.99 & 0.97 & 0.95 & 0.97 \
\end{bmatrix} *
\begin{bmatrix}
0 & 0 & 0 & 0 \
0 & 0 & 0 & 0 \
1 & 1 & 1 & 1 \
1 & 1 & 1 & 1 \
\end{bmatrix} \stackrel{}{\rightarrow}
\begin{bmatrix}
0 & 0 & 0 & 0 \
0 & 0 & 0 & 0 \
0.89 & 0.85 & 0.88 & 0.91 \
0.99 & 0.97 & 0.95 & 0.97 \
\end{bmatrix} \stackrel{sum}{\rightarrow} 7.41
$$$$
|T| =
\begin{bmatrix}
0.01 & 0.03 & 0.02 & 0.02 \
0.05 & 0.12 & 0.09 & 0.07 \
0.89 & 0.85 & 0.88 & 0.91 \
0.99 & 0.97 & 0.95 & 0.97 \
\end{bmatrix} \stackrel{sum}{\rightarrow} 7.82
$$$$
|P| =
\begin{bmatrix}
0 & 0 & 0 & 0 \
0 & 0 & 0 & 0 \
1 & 1 & 1 & 1 \
1 & 1 & 1 & 1 \
\end{bmatrix} \stackrel{sum}{\rightarrow} 8
$$Dice Loss
Dice Loss是在V-net模型中被提出应用的,是通过Dice系数转变而来,其实为了能够实现最小化的损失函数,以方便模型训练,以$1 - Dice$的形式作为损失函数:
$$
L = 1-\frac{2 |T \cap P|}{|T| \cup |P|}
$$
在一些场合还可以添加上Laplace smoothing减少过拟合:
$$
L = 1-\frac{2 |T \cap P| + 1}{|T| \cup |P|+1}
$$代码实现
import numpy as np
def dice(output, target):
'''计算Dice系数'''
smooth = 1e-6 # 避免0为除数
intersection = (output * target).sum()
return (2. * intersection + smooth) / (output.sum() + target.sum() + smooth)
# 生成随机两个矩阵测试
target = np.random.randint(0, 2, (3, 3))
output = np.random.randint(0, 2, (3, 3))
d = dice(output, target)
# ----------------------------
target = array([[1, 0, 0],
[0, 1, 1],
[0, 0, 1]])
output = array([[1, 0, 1],
[0, 1, 0],
[0, 0, 0]])
d = 0.57142863265305244.4 IoU评价指标
IoU(intersection over union)指标就是常说的交并比,不仅在语义分割评价中经常被使用,在目标检测中也是常用的评价指标。顾名思义,交并比就是指target与prediction两者之间交集与并集的比值:
$$
IoU=\frac{T \cap P}{T \cup P}=\frac{TP}{FP+TP+FN}
$$
仍然以人物前景分割为例,如下图,其IoU的计算就是使用$intersection / union$。target prediction Intersection( $T \cap P$) union($T \cup P$) 代码实现
def iou_score(output, target):
'''计算IoU指标'''
intersection = np.logical_and(target, output)
union = np.logical_or(target, output)
return np.sum(intersection) / np.sum(union)
# 生成随机两个矩阵测试
target = np.random.randint(0, 2, (3, 3))
output = np.random.randint(0, 2, (3, 3))
d = iou_score(output, target)
# ----------------------------
target = array([[1, 0, 0],
[0, 1, 1],
[0, 0, 1]])
output = array([[1, 0, 1],
[0, 1, 0],
[0, 0, 0]])
d = 0.44.5 BCE损失函数
BCE损失函数(Binary Cross-Entropy Loss)是交叉熵损失函数(Cross-Entropy Loss)的一种特例,BCE Loss只应用在二分类任务中。针对分类问题,单样本的交叉熵损失为:
$$
l(\pmb y, \pmb{\hat y})=- \sum_{i=1}^{c}y_i \cdot log\hat y_i
$$
式中,$\pmb{y}={y_1,y_2,…,y_c,}$,其中$y_i$是非0即1的数字,代表了是否属于第$i$类,为真实值;$\hat y_i$代表属于第i类的概率,为预测值。可以看出,交叉熵损失考虑了多类别情况,针对每一种类别都求了损失。针对二分类问题,上述公式可以改写为:
$$
l(y,\hat y)=-[y \cdot log\hat y +(1-y)\cdot log (1-\hat y)]
$$
式中,$y$为真实值,非1即0;$\hat y$为所属此类的概率值,为预测值。这个公式也就是BCE损失函数,即二分类任务时的交叉熵损失。值得强调的是,公式中的$\hat y$为概率分布形式,因此在使用BCE损失前,都应该将预测出来的结果转变成概率值,一般为sigmoid激活之后的输出。代码实现
在pytorch中,官方已经给出了BCE损失函数的API,免去了自己编写函数的痛苦:
torch.nn.BCELoss(weight: Optional[torch.Tensor] = None, size_average=None, reduce=None, reduction: str = 'mean')
$$
ℓ(y,\hat y)=L={l_1,…,l_N }^⊤,\ \ \ l_n=-w_n[y_n \cdot log\hat y_n +(1-y_n)\cdot log (1-\hat y_n)]
$$
参数:
weight(Tensor)- 为每一批量下的loss添加一个权重,很少使用
size_average(bool)- 弃用中
reduce(bool)- 弃用中
reduction(str) - ‘none’ | ‘mean’ | ‘sum’:为代替上面的size_average和reduce而生。——为mean时返回的该批量样本loss的平均值;为sum时,返回的该批量样本loss之和同时,pytorch还提供了已经结合了Sigmoid函数的BCE损失:
torch.nn.BCEWithLogitsLoss(),相当于免去了实现进行Sigmoid激活的操作。import torch
import torch.nn as nn
bce = nn.BCELoss()
bce_sig = nn.BCEWithLogitsLoss()
input = torch.randn(5, 1, requires_grad=True)
target = torch.empty(5, 1).random_(2)
pre = nn.Sigmoid()(input)
loss_bce = bce(pre, target)
loss_bce_sig = bce_sig(input, target)
# ------------------------
input = tensor([[-0.2296],
[-0.6389],
[-0.2405],
[ 1.3451],
[ 0.7580]], requires_grad=True)
output = tensor([[1.],
[0.],
[0.],
[1.],
[1.]])
pre = tensor([[0.4428],
[0.3455],
[0.4402],
[0.7933],
[0.6809]], grad_fn=<SigmoidBackward>)
print(loss_bce)
tensor(0.4869, grad_fn=<BinaryCrossEntropyBackward>)
print(loss_bce_sig)
tensor(0.4869, grad_fn=<BinaryCrossEntropyWithLogitsBackward>)4.6 Focal Loss
Focal loss最初是出现在目标检测领域,主要是为了解决正负样本比例失调的问题。那么对于分割任务来说,如果存在数据不均衡的情况,也可以借用focal loss来进行缓解。Focal loss函数公式如下所示:
$$
loss = -\frac{1}{N} \sum_{i=1}^{N}\left(\alpha y_{i}\left(1-p_{i}\right)^{\gamma} \log p_{i}+(1-\alpha)\left(1-y_{i}\right) p_{i}^{\gamma} \log \left(1-p_{i}\right)\right)
$$
仔细观察就不难发现,它其实是BCE扩展而来,对比BCE其实就多了个
$$
\alpha(1-p_{i})^{\gamma}和(1-\alpha)p_{i}^{\gamma}
$$
为什么多了这个就能缓解正负样本不均衡的问题呢?见下图:简单来说:$α$解决样本不平衡问题,$γ$解决样本难易问题。
也就是说,当数据不均衡时,可以根据比例设置合适的$α$,这个很好理解,为了能够使得正负样本得到的损失能够均衡,因此对loss前面加上一定的权重,其中负样本数量多,因此占用的权重可以设置的小一点;正样本数量少,就对正样本产生的损失的权重设的高一点。
那γ具体怎么起作用呢?以图中$γ=5$曲线为例,假设$gt$类别为1,当模型预测结果为1的概率$p_t$比较大时,我们认为模型预测的比较准确,也就是说这个样本比较简单。而对于比较简单的样本,我们希望提供的loss小一些而让模型主要学习难一些的样本,也就是$p_t→ 1$则loss接近于0,既不用再特别学习;当分类错误时,$p_t → 0$则loss正常产生,继续学习。对比图中蓝色和绿色曲线,可以看到,γ值越大,当模型预测结果比较准确的时候能提供更小的loss,符合我们为简单样本降低loss的预期。
代码实现:
import torch.nn as nn
import torch
import torch.nn.functional as F
class FocalLoss(nn.Module):
def __init__(self, alpha=1, gamma=2, logits=False, reduce=True):
super(FocalLoss, self).__init__()
self.alpha = alpha
self.gamma = gamma
self.logits = logits# 如果BEC带logits则损失函数在计算BECloss之前会自动计算softmax/sigmoid将其映射到[0,1]
self.reduce = reduce
def forward(self, inputs, targets):
if self.logits:
BCE_loss = F.binary_cross_entropy_with_logits(inputs, targets, reduce=False)
else:
BCE_loss = F.binary_cross_entropy(inputs, targets, reduce=False)
pt = torch.exp(-BCE_loss)
F_loss = self.alpha * (1-pt)**self.gamma * BCE_loss
if self.reduce:
return torch.mean(F_loss)
else:
return F_loss
# ------------------------
FL1 = FocalLoss(logits=False)
FL2 = FocalLoss(logits=True)
inputs = torch.randn(5, 1, requires_grad=True)
targets = torch.empty(5, 1).random_(2)
pre = nn.Sigmoid()(inputs)
f_loss_1 = FL1(pre, targets)
f_loss_2 = FL2(inputs, targets)
# ------------------------
print('inputs:', inputs)
inputs: tensor([[-1.3521],
[ 0.4975],
[-1.0178],
[-0.3859],
[-0.2923]], requires_grad=True)
print('targets:', targets)
targets: tensor([[1.],
[1.],
[0.],
[1.],
[1.]])
print('pre:', pre)
pre: tensor([[0.2055],
[0.6219],
[0.2655],
[0.4047],
[0.4274]], grad_fn=<SigmoidBackward>)
print('f_loss_1:', f_loss_1)
f_loss_1: tensor(0.3375, grad_fn=<MeanBackward0>)
print('f_loss_2', f_loss_2)
f_loss_2 tensor(0.3375, grad_fn=<MeanBackward0>)4.7 Lovász-Softmax
IoU是评价分割模型分割结果质量的重要指标,因此很自然想到能否用$1-IoU$(即Jaccard loss)来做损失函数,但是它是一个离散的loss,不能直接求导,所以无法直接用来作为损失函数。为了克服这个离散的问题,可以采用lLovász extension将离散的Jaccard loss 变得连续,从而可以直接求导,使得其作为分割网络的loss function。Lovász-Softmax相比于交叉熵函数具有更好的效果。
论文地址:
paper on CVF open access
arxiv paper首先明确定义,在语义分割任务中,给定真实像素标签向量$\pmb{y^*}$和预测像素标签$\pmb{\hat{y} }$,则所属类别$c$的IoU(也称为Jaccard index)如下,其取值范围为$[0,1]$,并规定$0/0=1$:
$$J_c(\pmb{y^*},\pmb{\hat{y} })=\frac{|{\pmb{y^*}=c} \cap {\pmb{\hat{y} }=c}|}{|{\pmb{y^*}=c} \cup {\pmb{\hat{y} }=c}|}
$$则Jaccard loss为:
$$\Delta_{J_c}(\pmb{y^*},\pmb{\hat{y} }) =1-J_c(\pmb{y^*},\pmb{\hat{y} })
$$针对类别$c$,所有未被正确预测的像素集合定义为:
$$
M_c(\pmb{y^*},\pmb{\hat{y} })={ \pmb{y^*}=c, \pmb{\hat{y} } \neq c} \cup { \pmb{y^*}\neq c, \pmb{\hat{y} } = c }
$$则可将Jaccard loss改写为关于$M_c$的子模集合函数(submodular set functions):
$$\Delta_{J_c}:M_c \in {0,1}^{p} \mapsto \frac{|M_c|}{|{\pmb{y^*}=c}\cup M_c|}
$$方便理解,此处可以把${0,1}^p$理解成如图像mask展开成离散一维向量的形式。
Lovász extension可以求解子模最小化问题,并且子模的Lovász extension是凸函数,可以高效实现最小化。在论文中作者对$\Delta$(集合函数)和$\overline{\Delta}$(集合函数的Lovász extension)进行了定义,为不涉及过多概念以方便理解,此处不再过多讨论。我们可以将$\overline{\Delta}$理解为一个线性插值函数,可以将${0,1}^p$这种离散向量连续化,主要是为了方便后续反向传播、求梯度等等。因此我们可以通过这个线性插值函数得到$\Delta_{J_c}$的Lovász extension$\overline{\Delta_{J_c} }$。
在具有$c(c>2)$个类别的语义分割任务中,我们使用Softmax函数将模型的输出映射到概率分布形式,类似传统交叉熵损失函数所进行的操作:
$$p_i(c)=\frac{e^{F_i(c)} }{\sum_{c^{‘}\in C}e^{F_i(c^{‘})} } \forall i \in [1,p],\forall c \in C
$$
式中,$p_i(c)$表示了像素$i$所属类别$c$的概率。通过上式可以构建每个像素产生的误差$m(c)$:$$m_i(c)=\left {
\begin{array}{c}
1-p_i(c),\ \ if \ \ c=y^{*}_{i} \
p_i(c),\ \ \ \ \ \ \ otherwise
\end{array}
\right.
$$可知,对于一张图像中所有像素则误差向量为$m(c)\in {0, 1}^p$,则可以建立关于$\Delta_{J_c}$的代理损失函数:
$$
loss(p(c))=\overline{\Delta_{J_c} }(m(c))
$$
当我们考虑整个数据集是,一般会使用mIoU进行度量,因此我们对上述损失也进行平均化处理,则定义的Lovász-Softmax损失函数为:
$$
loss(\pmb{p})=\frac{1}{|C|}\sum_{c\in C}\overline{\Delta_{J_c} }(m(c))
$$代码实现
论文作者已经给出了Lovász-Softmax实现代码,并且有pytorch和tensorflow两种版本,并提供了使用demo。此处将针对多分类任务的Lovász-Softmax源码进行展示。
import torch
from torch.autograd import Variable
import torch.nn.functional as F
import numpy as np
try:
from itertools import ifilterfalse
except ImportError: # py3k
from itertools import filterfalse as ifilterfalse
# --------------------------- MULTICLASS LOSSES ---------------------------
def lovasz_softmax(probas, labels, classes='present', per_image=False, ignore=None):
"""
Multi-class Lovasz-Softmax loss
probas: [B, C, H, W] Variable, class probabilities at each prediction (between 0 and 1).
Interpreted as binary (sigmoid) output with outputs of size [B, H, W].
labels: [B, H, W] Tensor, ground truth labels (between 0 and C - 1)
classes: 'all' for all, 'present' for classes present in labels, or a list of classes to average.
per_image: compute the loss per image instead of per batch
ignore: void class labels
"""
if per_image:
loss = mean(lovasz_softmax_flat(*flatten_probas(prob.unsqueeze(0), lab.unsqueeze(0), ignore), classes=classes)
for prob, lab in zip(probas, labels))
else:
loss = lovasz_softmax_flat(*flatten_probas(probas, labels, ignore), classes=classes)
return loss
def lovasz_softmax_flat(probas, labels, classes='present'):
"""
Multi-class Lovasz-Softmax loss
probas: [P, C] Variable, class probabilities at each prediction (between 0 and 1)
labels: [P] Tensor, ground truth labels (between 0 and C - 1)
classes: 'all' for all, 'present' for classes present in labels, or a list of classes to average.
"""
if probas.numel() == 0:
# only void pixels, the gradients should be 0
return probas * 0.
C = probas.size(1)
losses = []
class_to_sum = list(range(C)) if classes in ['all', 'present'] else classes
for c in class_to_sum:
fg = (labels == c).float() # foreground for class c
if (classes is 'present' and fg.sum() == 0):
continue
if C == 1:
if len(classes) > 1:
raise ValueError('Sigmoid output possible only with 1 class')
class_pred = probas[:, 0]
else:
class_pred = probas[:, c]
errors = (Variable(fg) - class_pred).abs()
errors_sorted, perm = torch.sort(errors, 0, descending=True)
perm = perm.data
fg_sorted = fg[perm]
losses.append(torch.dot(errors_sorted, Variable(lovasz_grad(fg_sorted))))
return mean(losses)
def flatten_probas(probas, labels, ignore=None):
"""
Flattens predictions in the batch
"""
if probas.dim() == 3:
# assumes output of a sigmoid layer
B, H, W = probas.size()
probas = probas.view(B, 1, H, W)
B, C, H, W = probas.size()
probas = probas.permute(0, 2, 3, 1).contiguous().view(-1, C) # B * H * W, C = P, C
labels = labels.view(-1)
if ignore is None:
return probas, labels
valid = (labels != ignore)
vprobas = probas[valid.nonzero().squeeze()]
vlabels = labels[valid]
return vprobas, vlabels
def xloss(logits, labels, ignore=None):
"""
Cross entropy loss
"""
return F.cross_entropy(logits, Variable(labels), ignore_index=255)
# --------------------------- HELPER FUNCTIONS ---------------------------
def isnan(x):
return x != x
def mean(l, ignore_nan=False, empty=0):
"""
nanmean compatible with generators.
"""
l = iter(l)
if ignore_nan:
l = ifilterfalse(isnan, l)
try:
n = 1
acc = next(l)
except StopIteration:
if empty == 'raise':
raise ValueError('Empty mean')
return empty
for n, v in enumerate(l, 2):
acc += v
if n == 1:
return acc
return acc / n4.8 参考链接
What is “Dice loss” for image segmentation?
Submodularity and the Lovász extension
4.9 本章小结
本章对各类评价指标进行介绍,并进行具体代码实践。
]]>零基础入门语义分割-Task4 评价函数与损失函数 本章主要介绍语义分割的评价函数和各类损失函数。
4 评价函数与损失函数
4.1 学习目标
- 掌握常见的评价函数和损失函数Dice、IoU、BCE、Focal Loss、Lovász-Softmax;
- 掌握评价/损失函数的实践;
4.2 TP TN FP FN
在讲解语义分割中常用的评价函数和损失函数之前,先补充一TP(真正例 true positive) TN(真反例 true negative) FP(假正例 false positive) FN(假反例 false negative)的知识。在分类问题中,我们经常看到上述的表述方式,以二分类为例,我们可以将所有的样本预测结果分成TP、TN、 FP、FN四类,并且每一类含有的样本数量之和为总样本数量,即TP+FP+FN+TN=总样本数量。其混淆矩阵如下:
上述的概念都是通过以预测结果的视角定义的,可以依据下面方式理解:
预测结果中的正例 → 在实际中是正例 → 的所有样本被称为真正例(TP)<预测正确>
预测结果中的正例 → 在实际中是反例 → 的所有样本被称为假正例(FP)<预测错误>
预测结果中的反例 → 在实际中是正例 → 的所有样本被称为假反例(FN)<预测错误>
预测结果中的反例 → 在实际中是反例 → 的所有样本被称为真反例(TN)<预测正确>
这里就不得不提及精确率(precision)和召回率(recall):
$Precision$代表了预测的正例中真正的正例所占比例;$Recall$代表了真正的正例中被正确预测出来的比例。
转移到语义分割任务中来,我们可以将语义分割看作是对每一个图像像素的的分类问题。根据混淆矩阵中的定义,我们亦可以将特定像素所属的集合或区域划分成TP、TN、 FP、FN四类。
以上面的图片为例,图中左子图中的人物区域(黄色像素集合)是我们真实标注的前景信息(target),其他区域(紫色像素集合)为背景信息。当经过预测之后,我们会得到的一张预测结果,图中右子图中的黄色像素为预测的前景(prediction),紫色像素为预测的背景区域。此时,我们便能够将预测结果分成4个部分:
预测结果中的黄色无线区域 → 真实的前景 → 的所有像素集合被称为真正例(TP)<预测正确>
预测结果中的蓝色斜线区域 → 真实的背景 → 的所有像素集合被称为假正例(FP)<预测错误>
预测结果中的红色斜线区域 → 真实的前景 → 的所有像素集合被称为假反例(FN)<预测错误>
预测结果中的白色斜线区域 → 真实的背景 → 的所有像素集合被称为真反例(TN)<预测正确>
4.3 Dice评价指标
Dice系数
Dice系数(Dice coefficient)是常见的评价分割效果的方法之一,同样也可以改写成损失函数用来度量prediction和target之间的距离。Dice系数定义如下:
式中:$T$表示真实前景(target),$P$表示预测前景(prediction)。Dice系数取值范围为$[0,1]$,其中值为1时代表预测与真实完全一致。仔细观察,Dice系数与分类评价指标中的F1 score很相似:
所以,Dice系数不仅在直观上体现了target与prediction的相似程度,同时其本质上还隐含了精确率和召回率两个重要指标。
计算Dice时,将$|T \cap P|$近似为prediction与target对应元素相乘再相加的结果。$|T|$ 和$|P|$的计算直接进行简单的元素求和(也有一些做法是取平方求和),如下示例:
Dice Loss
Dice Loss是在V-net模型中被提出应用的,是通过Dice系数转变而来,其实为了能够实现最小化的损失函数,以方便模型训练,以$1 - Dice$的形式作为损失函数:
在一些场合还可以添加上Laplace smoothing减少过拟合:
代码实现
import numpy as np
def dice(output, target):
'''计算Dice系数'''
smooth = 1e-6 # 避免0为除数
intersection = (output * target).sum()
return (2. * intersection + smooth) / (output.sum() + target.sum() + smooth)
# 生成随机两个矩阵测试
target = np.random.randint(0, 2, (3, 3))
output = np.random.randint(0, 2, (3, 3))
d = dice(output, target)
# ----------------------------
target = array([[1, 0, 0],
[0, 1, 1],
[0, 0, 1]])
output = array([[1, 0, 1],
[0, 1, 0],
[0, 0, 0]])
d = 0.57142863265305244.4 IoU评价指标
IoU(intersection over union)指标就是常说的交并比,不仅在语义分割评价中经常被使用,在目标检测中也是常用的评价指标。顾名思义,交并比就是指target与prediction两者之间交集与并集的比值:
仍然以人物前景分割为例,如下图,其IoU的计算就是使用$intersection / union$。
target prediction Intersection( $T \cap P$) union($T \cup P$) 代码实现
def iou_score(output, target):
'''计算IoU指标'''
intersection = np.logical_and(target, output)
union = np.logical_or(target, output)
return np.sum(intersection) / np.sum(union)
# 生成随机两个矩阵测试
target = np.random.randint(0, 2, (3, 3))
output = np.random.randint(0, 2, (3, 3))
d = iou_score(output, target)
# ----------------------------
target = array([[1, 0, 0],
[0, 1, 1],
[0, 0, 1]])
output = array([[1, 0, 1],
[0, 1, 0],
[0, 0, 0]])
d = 0.44.5 BCE损失函数
BCE损失函数(Binary Cross-Entropy Loss)是交叉熵损失函数(Cross-Entropy Loss)的一种特例,BCE Loss只应用在二分类任务中。针对分类问题,单样本的交叉熵损失为:
式中,$\pmb{y}={y_1,y_2,…,y_c,}$,其中$y_i$是非0即1的数字,代表了是否属于第$i$类,为真实值;$\hat y_i$代表属于第i类的概率,为预测值。可以看出,交叉熵损失考虑了多类别情况,针对每一种类别都求了损失。针对二分类问题,上述公式可以改写为:
式中,$y$为真实值,非1即0;$\hat y$为所属此类的概率值,为预测值。这个公式也就是BCE损失函数,即二分类任务时的交叉熵损失。值得强调的是,公式中的$\hat y$为概率分布形式,因此在使用BCE损失前,都应该将预测出来的结果转变成概率值,一般为sigmoid激活之后的输出。
代码实现
在pytorch中,官方已经给出了BCE损失函数的API,免去了自己编写函数的痛苦:
torch.nn.BCELoss(weight: Optional[torch.Tensor] = None, size_average=None, reduce=None, reduction: str = 'mean')参数:
weight(Tensor)- 为每一批量下的loss添加一个权重,很少使用
size_average(bool)- 弃用中
reduce(bool)- 弃用中
reduction(str) - ‘none’ | ‘mean’ | ‘sum’:为代替上面的size_average和reduce而生。——为mean时返回的该批量样本loss的平均值;为sum时,返回的该批量样本loss之和同时,pytorch还提供了已经结合了Sigmoid函数的BCE损失:
torch.nn.BCEWithLogitsLoss(),相当于免去了实现进行Sigmoid激活的操作。import torch
import torch.nn as nn
bce = nn.BCELoss()
bce_sig = nn.BCEWithLogitsLoss()
input = torch.randn(5, 1, requires_grad=True)
target = torch.empty(5, 1).random_(2)
pre = nn.Sigmoid()(input)
loss_bce = bce(pre, target)
loss_bce_sig = bce_sig(input, target)
# ------------------------
input = tensor([[-0.2296],
[-0.6389],
[-0.2405],
[ 1.3451],
[ 0.7580]], requires_grad=True)
output = tensor([[1.],
[0.],
[0.],
[1.],
[1.]])
pre = tensor([[0.4428],
[0.3455],
[0.4402],
[0.7933],
[0.6809]], grad_fn=<SigmoidBackward>)
print(loss_bce)
tensor(0.4869, grad_fn=<BinaryCrossEntropyBackward>)
print(loss_bce_sig)
tensor(0.4869, grad_fn=<BinaryCrossEntropyWithLogitsBackward>)4.6 Focal Loss
Focal loss最初是出现在目标检测领域,主要是为了解决正负样本比例失调的问题。那么对于分割任务来说,如果存在数据不均衡的情况,也可以借用focal loss来进行缓解。Focal loss函数公式如下所示:
仔细观察就不难发现,它其实是BCE扩展而来,对比BCE其实就多了个
为什么多了这个就能缓解正负样本不均衡的问题呢?见下图:
简单来说:$α$解决样本不平衡问题,$γ$解决样本难易问题。
也就是说,当数据不均衡时,可以根据比例设置合适的$α$,这个很好理解,为了能够使得正负样本得到的损失能够均衡,因此对loss前面加上一定的权重,其中负样本数量多,因此占用的权重可以设置的小一点;正样本数量少,就对正样本产生的损失的权重设的高一点。
那γ具体怎么起作用呢?以图中$γ=5$曲线为例,假设$gt$类别为1,当模型预测结果为1的概率$p_t$比较大时,我们认为模型预测的比较准确,也就是说这个样本比较简单。而对于比较简单的样本,我们希望提供的loss小一些而让模型主要学习难一些的样本,也就是$p_t→ 1$则loss接近于0,既不用再特别学习;当分类错误时,$p_t → 0$则loss正常产生,继续学习。对比图中蓝色和绿色曲线,可以看到,γ值越大,当模型预测结果比较准确的时候能提供更小的loss,符合我们为简单样本降低loss的预期。
代码实现:
import torch.nn as nn
import torch
import torch.nn.functional as F
class FocalLoss(nn.Module):
def __init__(self, alpha=1, gamma=2, logits=False, reduce=True):
super(FocalLoss, self).__init__()
self.alpha = alpha
self.gamma = gamma
self.logits = logits# 如果BEC带logits则损失函数在计算BECloss之前会自动计算softmax/sigmoid将其映射到[0,1]
self.reduce = reduce
def forward(self, inputs, targets):
if self.logits:
BCE_loss = F.binary_cross_entropy_with_logits(inputs, targets, reduce=False)
else:
BCE_loss = F.binary_cross_entropy(inputs, targets, reduce=False)
pt = torch.exp(-BCE_loss)
F_loss = self.alpha * (1-pt)**self.gamma * BCE_loss
if self.reduce:
return torch.mean(F_loss)
else:
return F_loss
# ------------------------
FL1 = FocalLoss(logits=False)
FL2 = FocalLoss(logits=True)
inputs = torch.randn(5, 1, requires_grad=True)
targets = torch.empty(5, 1).random_(2)
pre = nn.Sigmoid()(inputs)
f_loss_1 = FL1(pre, targets)
f_loss_2 = FL2(inputs, targets)
# ------------------------
print('inputs:', inputs)
inputs: tensor([[-1.3521],
[ 0.4975],
[-1.0178],
[-0.3859],
[-0.2923]], requires_grad=True)
print('targets:', targets)
targets: tensor([[1.],
[1.],
[0.],
[1.],
[1.]])
print('pre:', pre)
pre: tensor([[0.2055],
[0.6219],
[0.2655],
[0.4047],
[0.4274]], grad_fn=<SigmoidBackward>)
print('f_loss_1:', f_loss_1)
f_loss_1: tensor(0.3375, grad_fn=<MeanBackward0>)
print('f_loss_2', f_loss_2)
f_loss_2 tensor(0.3375, grad_fn=<MeanBackward0>)4.7 Lovász-Softmax
IoU是评价分割模型分割结果质量的重要指标,因此很自然想到能否用$1-IoU$(即Jaccard loss)来做损失函数,但是它是一个离散的loss,不能直接求导,所以无法直接用来作为损失函数。为了克服这个离散的问题,可以采用lLovász extension将离散的Jaccard loss 变得连续,从而可以直接求导,使得其作为分割网络的loss function。Lovász-Softmax相比于交叉熵函数具有更好的效果。
论文地址:
paper on CVF open access
arxiv paper首先明确定义,在语义分割任务中,给定真实像素标签向量$\pmb{y^*}$和预测像素标签$\pmb{\hat{y} }$,则所属类别$c$的IoU(也称为Jaccard index)如下,其取值范围为$[0,1]$,并规定$0/0=1$:
则Jaccard loss为:
针对类别$c$,所有未被正确预测的像素集合定义为:
则可将Jaccard loss改写为关于$M_c$的子模集合函数(submodular set functions):
方便理解,此处可以把${0,1}^p$理解成如图像mask展开成离散一维向量的形式。
Lovász extension可以求解子模最小化问题,并且子模的Lovász extension是凸函数,可以高效实现最小化。在论文中作者对$\Delta$(集合函数)和$\overline{\Delta}$(集合函数的Lovász extension)进行了定义,为不涉及过多概念以方便理解,此处不再过多讨论。我们可以将$\overline{\Delta}$理解为一个线性插值函数,可以将${0,1}^p$这种离散向量连续化,主要是为了方便后续反向传播、求梯度等等。因此我们可以通过这个线性插值函数得到$\Delta{J_c}$的Lovász extension$\overline{\Delta{J_c} }$。
在具有$c(c>2)$个类别的语义分割任务中,我们使用Softmax函数将模型的输出映射到概率分布形式,类似传统交叉熵损失函数所进行的操作:
式中,$p_i(c)$表示了像素$i$所属类别$c$的概率。通过上式可以构建每个像素产生的误差$m(c)$:
可知,对于一张图像中所有像素则误差向量为$m(c)\in {0, 1}^p$,则可以建立关于$\Delta_{J_c}$的代理损失函数:
当我们考虑整个数据集是,一般会使用mIoU进行度量,因此我们对上述损失也进行平均化处理,则定义的Lovász-Softmax损失函数为:
代码实现
论文作者已经给出了Lovász-Softmax实现代码,并且有pytorch和tensorflow两种版本,并提供了使用demo。此处将针对多分类任务的Lovász-Softmax源码进行展示。
import torch
from torch.autograd import Variable
import torch.nn.functional as F
import numpy as np
try:
from itertools import ifilterfalse
except ImportError: # py3k
from itertools import filterfalse as ifilterfalse
# --------------------------- MULTICLASS LOSSES ---------------------------
def lovasz_softmax(probas, labels, classes='present', per_image=False, ignore=None):
"""
Multi-class Lovasz-Softmax loss
probas: [B, C, H, W] Variable, class probabilities at each prediction (between 0 and 1).
Interpreted as binary (sigmoid) output with outputs of size [B, H, W].
labels: [B, H, W] Tensor, ground truth labels (between 0 and C - 1)
classes: 'all' for all, 'present' for classes present in labels, or a list of classes to average.
per_image: compute the loss per image instead of per batch
ignore: void class labels
"""
if per_image:
loss = mean(lovasz_softmax_flat(*flatten_probas(prob.unsqueeze(0), lab.unsqueeze(0), ignore), classes=classes)
for prob, lab in zip(probas, labels))
else:
loss = lovasz_softmax_flat(*flatten_probas(probas, labels, ignore), classes=classes)
return loss
def lovasz_softmax_flat(probas, labels, classes='present'):
"""
Multi-class Lovasz-Softmax loss
probas: [P, C] Variable, class probabilities at each prediction (between 0 and 1)
labels: [P] Tensor, ground truth labels (between 0 and C - 1)
classes: 'all' for all, 'present' for classes present in labels, or a list of classes to average.
"""
if probas.numel() == 0:
# only void pixels, the gradients should be 0
return probas * 0.
C = probas.size(1)
losses = []
class_to_sum = list(range(C)) if classes in ['all', 'present'] else classes
for c in class_to_sum:
fg = (labels == c).float() # foreground for class c
if (classes is 'present' and fg.sum() == 0):
continue
if C == 1:
if len(classes) > 1:
raise ValueError('Sigmoid output possible only with 1 class')
class_pred = probas[:, 0]
else:
class_pred = probas[:, c]
errors = (Variable(fg) - class_pred).abs()
errors_sorted, perm = torch.sort(errors, 0, descending=True)
perm = perm.data
fg_sorted = fg[perm]
losses.append(torch.dot(errors_sorted, Variable(lovasz_grad(fg_sorted))))
return mean(losses)
def flatten_probas(probas, labels, ignore=None):
"""
Flattens predictions in the batch
"""
if probas.dim() == 3:
# assumes output of a sigmoid layer
B, H, W = probas.size()
probas = probas.view(B, 1, H, W)
B, C, H, W = probas.size()
probas = probas.permute(0, 2, 3, 1).contiguous().view(-1, C) # B * H * W, C = P, C
labels = labels.view(-1)
if ignore is None:
return probas, labels
valid = (labels != ignore)
vprobas = probas[valid.nonzero().squeeze()]
vlabels = labels[valid]
return vprobas, vlabels
def xloss(logits, labels, ignore=None):
"""
Cross entropy loss
"""
return F.cross_entropy(logits, Variable(labels), ignore_index=255)
# --------------------------- HELPER FUNCTIONS ---------------------------
def isnan(x):
return x != x
def mean(l, ignore_nan=False, empty=0):
"""
nanmean compatible with generators.
"""
l = iter(l)
if ignore_nan:
l = ifilterfalse(isnan, l)
try:
n = 1
acc = next(l)
except StopIteration:
if empty == 'raise':
raise ValueError('Empty mean')
return empty
for n, v in enumerate(l, 2):
acc += v
if n == 1:
return acc
return acc / n4.8 参考链接
What is “Dice loss” for image segmentation?
Submodularity and the Lovász extension
4.9 本章小结
本章对各类评价指标进行介绍,并进行具体代码实践。
]]>diff --git a/categories/index.html b/categories/index.html index a158ffc3..9f9e465c 100644 --- a/categories/index.html +++ b/categories/index.html @@ -481,7 +481,7 @@ - diff --git a/index.html b/index.html index a9583d14..052dc7af 100644 --- a/index.html +++ b/index.html @@ -207,7 +207,7 @@
-最近有在折腾一些Ubuntu日常化的东西,给电脑重新装了双系统,相比前几年,ubuntu22.04之后系统确实变得非常好用了,软件生态支持也变多了,为了更加日常化的使用折腾了一些相关软件的安装,这边做一个简单的记录。
+最近有在折腾一些Ubuntu日常化的东西,给电脑重新装了双系统,相比前几年,ubuntu22.04之后系统确实变得非常好用了,软件生态支持也变多了,为了更加日常化的使用折腾了一些相关软件的安装,这边做一个简单的记录。
@@ -361,7 +361,7 @@既往不恋,纵情向前,江湖再见——22岁那年,在北京的日子
2022年3月31日0:52,睡不着,日常拖延症+强迫症导致清东西到现在,等会还想清扫一下弄脏的地板。
莲竹花园甲2号楼一门101,从今天起,这里将不再是我的家,本来是昨天的机票,天气不似预期,不打算买高铁,还想再飞上一次云霄,所以倔强的又改签了机票,不过正好也让我多看一眼这里吧,最近东航事件其实让我也有一点小慌,希望能平安到达吧。
-不出所料,我对这个城市并没有什么留恋,每天晚上我都会思考很多,有天夜里我的脑海里突然冒出来了那句:劝君更进一杯酒,西出阳关无故人。 这一刻我才真正明白什么是独在异乡为异客的感觉,什么才是我心里最想要的。
+不出所料,我对这个城市并没有什么留恋,每天晚上我都会思考很多,有天夜里我的脑海里突然冒出来了那句:劝君更进一杯酒,西出阳关无故人。 这一刻我才真正明白什么是独在异乡为异客的感觉,什么才是我心里最想要的。
@@ -675,7 +675,7 @@-XGBoost算法
XGBoost是陈天奇等人开发的一个开源机器学习项目,高效地实现了GBDT算法并进行了算法和工程上的许多改进,被广泛应用在Kaggle竞赛及其他许多机器学习竞赛中并取得了不错的成绩。XGBoost本质上还是一个GBDT,但是力争把速度和效率发挥到极致,所以叫X (Extreme) GBoosted, 包括前面说过,两者都是boosting方法。XGBoost是一个优化的分布式梯度增强库,旨在实现高效,灵活和便携。 它在Gradient Boosting框架下实现机器学习算法。 XGBoost提供了并行树提升(也称为GBDT,GBM),可以快速准确地解决许多数据科学问题。 相同的代码在主要的分布式环境(Hadoop,SGE,MPI)上运行,并且可以解决超过数十亿个样例的问题。XGBoost利用了核外计算并且能够使数据科学家在一个主机上处理数亿的样本数据。最终,将这些技术进行结合来做一个端到端的系统以最少的集群系统来扩展到更大的数据集上。Xgboost以CART决策树为子模型,通过Gradient Tree Boosting实现多棵CART树的集成学习,得到最终模型。下面我们来看看XGBoost的最终模型构建:
+XGBoost算法
XGBoost是陈天奇等人开发的一个开源机器学习项目,高效地实现了GBDT算法并进行了算法和工程上的许多改进,被广泛应用在Kaggle竞赛及其他许多机器学习竞赛中并取得了不错的成绩。XGBoost本质上还是一个GBDT,但是力争把速度和效率发挥到极致,所以叫X (Extreme) GBoosted, 包括前面说过,两者都是boosting方法。XGBoost是一个优化的分布式梯度增强库,旨在实现高效,灵活和便携。 它在Gradient Boosting框架下实现机器学习算法。 XGBoost提供了并行树提升(也称为GBDT,GBM),可以快速准确地解决许多数据科学问题。 相同的代码在主要的分布式环境(Hadoop,SGE,MPI)上运行,并且可以解决超过数十亿个样例的问题。XGBoost利用了核外计算并且能够使数据科学家在一个主机上处理数亿的样本数据。最终,将这些技术进行结合来做一个端到端的系统以最少的集群系统来扩展到更大的数据集上。Xgboost以CART决策树为子模型,通过Gradient Tree Boosting实现多棵CART树的集成学习,得到最终模型。下面我们来看看XGBoost的最终模型构建:
@@ -753,7 +753,7 @@-梯度提升决策树(GBDT)
(1) 基于残差学习的提升树算法:
+
在前面的学习过程中,我们一直讨论的都是分类树,比如Adaboost算法,并没有涉及回归的例子。在上一小节我们提到了一个加法模型+前向分步算法的框架,那能否使用这个框架解决回归的例子呢?答案是肯定的。接下来我们来探讨下如何使用加法模型+前向分步算法的框架实现回归问题。
在使用加法模型+前向分步算法的框架解决问题之前,我们需要首先确定框架内使用的基函数是什么,在这里我们使用决策树分类器。前面第二章我们已经学过了回归树的基本原理,树算法最重要是寻找最佳的划分点,分类树用纯度来判断最佳划分点使用信息增益(ID3算法),信息增益比(C4.5算法),基尼系数(CART分类树)。但是在回归树中的样本标签是连续数值,可划分点包含了所有特征的所有可取的值。所以再使用熵之类的指标不再合适,取而代之的是平方误差,它能很好的评判拟合程度。 基函数确定了以后,我们需要确定每次提升的标准是什么。回想Adaboost算法,在Adaboost算法内使用了分类错误率修正样本权重以及计算每个基本分类器的权重,那回归问题没有分类错误率可言,也就没办法在这里的回归问题使用了,因此我们需要另辟蹊径。模仿分类错误率,我们用每个样本的残差表示每次使用基函数预测时没有解决的那部分问题。因此,我们可以得出如下算法:梯度提升决策树(GBDT)
(1) 基于残差学习的提升树算法:
@@ -831,7 +831,7 @@
在前面的学习过程中,我们一直讨论的都是分类树,比如Adaboost算法,并没有涉及回归的例子。在上一小节我们提到了一个加法模型+前向分步算法的框架,那能否使用这个框架解决回归的例子呢?答案是肯定的。接下来我们来探讨下如何使用加法模型+前向分步算法的框架实现回归问题。
在使用加法模型+前向分步算法的框架解决问题之前,我们需要首先确定框架内使用的基函数是什么,在这里我们使用决策树分类器。前面第二章我们已经学过了回归树的基本原理,树算法最重要是寻找最佳的划分点,分类树用纯度来判断最佳划分点使用信息增益(ID3算法),信息增益比(C4.5算法),基尼系数(CART分类树)。但是在回归树中的样本标签是连续数值,可划分点包含了所有特征的所有可取的值。所以再使用熵之类的指标不再合适,取而代之的是平方误差,它能很好的评判拟合程度。 基函数确定了以后,我们需要确定每次提升的标准是什么。回想Adaboost算法,在Adaboost算法内使用了分类错误率修正样本权重以及计算每个基本分类器的权重,那回归问题没有分类错误率可言,也就没办法在这里的回归问题使用了,因此我们需要另辟蹊径。模仿分类错误率,我们用每个样本的残差表示每次使用基函数预测时没有解决的那部分问题。因此,我们可以得出如下算法:-1. 导论
在前面的学习中,我们探讨了一系列简单而实用的回归和分类模型,同时也探讨了如何使用集成学习家族中的Bagging思想去优化最终的模型。Bagging思想的实质是:通过Bootstrap 的方式对全样本数据集进行抽样得到抽样子集,对不同的子集使用同一种基本模型进行拟合,然后投票得出最终的预测。我们也从前面的探讨知道:Bagging主要通过降低方差的方式减少预测误差。那么,本章介绍的Boosting是与Bagging截然不同的思想,Boosting方法是使用同一组数据集进行反复学习,得到一系列简单模型,然后组合这些模型构成一个预测性能十分强大的机器学习模型。 显然,Boosting思想提高最终的预测效果是通过不断减少偏差的形式,与Bagging有着本质的不同。在Boosting这一大类方法中,笔者主要介绍两类常用的Boosting方式:Adaptive Boosting 和 Gradient Boosting 以及它们的变体Xgboost、LightGBM以及Catboost。
+1. 导论
在前面的学习中,我们探讨了一系列简单而实用的回归和分类模型,同时也探讨了如何使用集成学习家族中的Bagging思想去优化最终的模型。Bagging思想的实质是:通过Bootstrap 的方式对全样本数据集进行抽样得到抽样子集,对不同的子集使用同一种基本模型进行拟合,然后投票得出最终的预测。我们也从前面的探讨知道:Bagging主要通过降低方差的方式减少预测误差。那么,本章介绍的Boosting是与Bagging截然不同的思想,Boosting方法是使用同一组数据集进行反复学习,得到一系列简单模型,然后组合这些模型构成一个预测性能十分强大的机器学习模型。 显然,Boosting思想提高最终的预测效果是通过不断减少偏差的形式,与Bagging有着本质的不同。在Boosting这一大类方法中,笔者主要介绍两类常用的Boosting方式:Adaptive Boosting 和 Gradient Boosting 以及它们的变体Xgboost、LightGBM以及Catboost。
@@ -915,7 +915,7 @@10101100100111001011011011011
这导致的结果可能是致命的。一个常用的纠错方法是重复多次发送数据,并以少数服从多数的方法确定正确的传输数据。一般情况下,错误总是发生在局部,因此融合多个数据是降低误差的一个好方法,这就是投票法的基本思路。
对于回归模型来说,投票法最终的预测结果是多个其他回归模型预测结果的平均值。
-对于分类模型,硬投票法的预测结果是多个模型预测结果中出现次数最多的类别,软投票对各类预测结果的概率进行求和,最终选取概率之和最大的类标签。
+对于分类模型,硬投票法的预测结果是多个模型预测结果中出现次数最多的类别,软投票对各类预测结果的概率进行求和,最终选取概率之和最大的类标签。
@@ -1205,7 +1205,7 @@- @@ -1213,15 +1213,15 @@
- diff --git a/live2d-widget-old/README.html b/live2d-widget-old/README.html index 1796522e..d82de013 100644 --- a/live2d-widget-old/README.html +++ b/live2d-widget-old/README.html @@ -1,39 +1,44 @@ -
Live2D Widget
+Live2D Widget
特性 Feature
在网页中添加 Live2D 看板娘。兼容 PJAX,支持无刷新加载。
Add Live2D widget to web page. Compatible with PJAX.警告:本项目使用了大量 ES6 语法,且依赖于 WebGL。不支持 IE 11 等老旧浏览器。
-
WARNING: This project does not support legacy browsers such as IE 11.示例 Demo
在米米的博客的左下角可查看效果。
-
+示例 Demo
在米米的博客的左下角可查看效果。
+这个仓库中也提供了两个 Demo,即
- demo1.html ,展现基础效果
- demo2.html ,仿 NPM 的登陆界面
依赖 Dependencies
本插件需要 Font Awesome 4.7.0 支持,请确保相关样式表已在页面中加载,例如在
-<head>中加入:
Font Awesome 4.7.0 is required for this plugin. You can add this to<head>:
+<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/font-awesome/css/font-awesome.min.css"><link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/font-awesome/css/font-awesome.min.css"> +否则无法正常显示。(如果网页中已经加载了 Font Awesome,就不要重复加载了)
使用 Usage
将这一行代码加入
-<head>或<body>,即可展现出效果:
+<script src="https://cdn.jsdelivr.net/gh/stevenjoezhang/live2d-widget@latest/autoload.js"></script><script src="https://cdn.jsdelivr.net/gh/stevenjoezhang/live2d-widget@latest/autoload.js"></script> +如果网站启用了 PJAX,由于看板娘不必每页刷新,因此要注意将相关脚本放到 PJAX 刷新区域之外。
换句话说,如果你是小白,或者只需要最基础的功能,就只用把这一行代码,连同前面加载 Font Awesome 的一行代码,一起放到 html 的
<head>中即可。
对于用各种模版引擎(例如 Nunjucks,Jinja 或者 PHP)生成的页面,也要自行修改,方法类似,只是可能略为麻烦。以 Hexo 为例,需要在主题相关的 ejs 或 njk 模版中正确配置路径,才可以加载。但是!我们强烈推荐自己进行配置,否则很多功能是不完整的,并且可能产生问题!
如果你有兴趣自己折腾的话,请看下面的详细说明。Using CDN
要自定义有关内容,可以把这个仓库 Fork 一份,然后进行修改。这时,使用方法对应地变为
-
+<script src="https://cdn.jsdelivr.net/gh/username/live2d-widget@latest/autoload.js"></script><script src="https://cdn.jsdelivr.net/gh/username/live2d-widget@latest/autoload.js"></script> +将
username替换为你的 GitHub 用户名即可。Self-host
你也可以直接把这些文件放到服务器上,而不是通过 CDN 加载。
-
-
- 如果你能够通过
ssh访问你的主机,请把整个仓库克隆到服务器上。执行:cd /path/to/your/webroot +- 如果你能够通过
ssh访问你的主机,请把整个仓库克隆到服务器上。执行:
+git clone https://github.com/stevenjoezhang/live2d-widget.git +cd /path/to/your/webroot # Clone this repository -git clone https://github.com/stevenjoezhang/live2d-widget.git - 如果你能够通过
- 如果你的主机无法用
ssh连接(例如一般的虚拟主机),请选择Download ZIP,然后通过ftp等方式上传到主机上,再解压到网站的目录下。 - 如果你是通过 Hexo 等工具部署的静态博客,请在本地开命令行进入博客目录,例如
source下与_posts同级的目录,然后再执行前述的git clone命令。重新部署博客时,相关文件就会自动上传到对应的路径下。
这样,整个项目就可以通过你的服务器 IP 或者域名从公网访问了。不妨试试能否正常地通过浏览器打开
-autoload.js和live2d.min.js等文件,并确认这些文件的内容是正确的,没有出现乱码。
一切正常的话,接下来修改一些配置就行了。(需要通过服务器上的文本编辑器修改;你也可以先在本地完成这一步骤,再上传到服务器上)
修改autoload.js中的常量live2d_path为live2d-widget这一文件夹在公网上的路径。比如说,如果你能够通过
-https://www.example.com/path/to/live2d-widget/live2d.min.js访问到
-live2d.min.js,那么就把live2d_path的值修改为
-https://www.example.com/path/to/live2d-widget/路径末尾的
-/一定要加上。具体可以参考autoload.js内的注释。
完成后,在你要添加看板娘的界面加入
+<script src="https://www.example.com/path/to/live2d-widget/autoload.js"></script>https://www.example.com/path/to/live2d-widget/live2d.min.js +访问到
+live2d.min.js,那么就把live2d_path的值修改为https://www.example.com/path/to/live2d-widget/ +路径末尾的
+/一定要加上。具体可以参考autoload.js内的注释。
完成后,在你要添加看板娘的界面加入<script src="https://www.example.com/path/to/live2d-widget/autoload.js"></script> +就可以加载了。
目录结构 Files
waifu-tips.json中包含了触发条件(selector,选择器)和触发时显示的文字(text);
@@ -41,16 +46,16 @@ - 在 米米的博客 的左下角可查看效果 +
- 在 米米的博客 的左下角可查看效果
- demo.html,展现基础功能
- login.html,仿 NPM 的登陆界面
源文件是对 Hexo 的 NexT 主题有效的,为了适用于你自己的网页,可能需要自行修改,或增加新内容。
警告:作者不对包括但不限于waifu-tips.json和waifu-tips.js文件中的内容负责,请自行确保它们是合适的。如果有任何疑问,欢迎提 Issue。如果有任何修改建议,欢迎提 Pull Request。
-鸣谢 Credits
+鸣谢 Credits
感谢 BrowserStack 容许我们在真实的浏览器中测试此项目。
Thanks to BrowserStack for allowing us to test this project in real browsers.代码自这篇博文魔改而来:
-
https://www.fghrsh.net/post/123.html点击看板娘的纸飞机按钮时,会出现一个彩蛋,这来自于 WebsiteAsteroids。
+点击看板娘的纸飞机按钮时,会出现一个彩蛋,这来自于 WebsiteAsteroids。
更多 More
更多内容可以参考:
https://imjad.cn/archives/lab/add-dynamic-poster-girl-with-live2d-to-your-blog-02
https://github.com/xiazeyu/live2d-widget.js
https://github.com/summerscar/live2dDemo还可以自行搭建后端 API,并增加模型(需要修改的内容比较多,此处不再赘述):
https://github.com/fghrsh/live2d_api
https://github.com/xiazeyu/live2d-widget-models
https://github.com/xiaoski/live2d_models_collection除此之外,还有桌面版本:
https://github.com/amorist/platelet
https://github.com/akiroz/Live2D-Widget许可证 License
Released under the GNU General Public License v3
http://www.gnu.org/licenses/gpl-3.0.html本仓库中涉及的所有 Live2D 模型、图片、动作数据等版权均属于其原作者,仅供研究学习,不得用于商业用途。
-Live2D 官方网站:
+
https://www.live2d.com/en/
https://live2d.github.ioLive2D 官方网站:
https://www.live2d.com/en/
https://live2d.github.ioLive2D Cubism Core は Live2D Proprietary Software License で提供しています。
https://www.live2d.com/eula/live2d-proprietary-software-license-agreement_en.html
Live2D Cubism Components は Live2D Open Software License で提供しています。
http://www.live2d.com/eula/live2d-open-software-license-agreement_en.htmlThe terms and conditions do prohibit modification, but obfuscating in
diff --git a/live2d-widget/README.html b/live2d-widget/README.html index d04e445a..bcf8255e 100644 --- a/live2d-widget/README.html +++ b/live2d-widget/README.html @@ -1,18 +1,20 @@ -live2d.min.jswould not be considered illegal modification.Live2D Widget
+Live2D Widget
特性 Feature
在网页中添加 Live2D 看板娘。兼容 PJAX,支持无刷新加载。
Add Live2D widget to web page. Compatible with PJAX.(注:以上人物模型仅供展示之用,本仓库并不包含任何模型。)
你也可以查看示例网页:
-
-
使用 Usage
如果你是小白,或者只需要最基础的功能,那么只用将这一行代码加入 html 页面的
-head或body中,即可加载看板娘:
-<script src="https://fastly.jsdelivr.net/gh/stevenjoezhang/live2d-widget@latest/autoload.js"></script>添加代码的位置取决于你的网站的构建方式。例如,如果你使用的是 Hexo,那么需要在主题的模版文件中添加以上代码。对于用各种模版引擎生成的页面,修改方法类似。
+
如果网站启用了 PJAX,由于看板娘不必每页刷新,需要注意将该脚本放到 PJAX 刷新区域之外。
+<script src="https://fastly.jsdelivr.net/gh/stevenjoezhang/live2d-widget@latest/autoload.js"></script> +添加代码的位置取决于你的网站的构建方式。例如,如果你使用的是 Hexo,那么需要在主题的模版文件中添加以上代码。对于用各种模版引擎生成的页面,修改方法类似。
如果网站启用了 PJAX,由于看板娘不必每页刷新,需要注意将该脚本放到 PJAX 刷新区域之外。但是!我们强烈推荐自己进行配置,让看板娘更加适合你的网站!
如果你有兴趣自己折腾的话,请看下面的详细说明。配置 Configuration
你可以对照
+autoload.js的源码查看可选的配置项目。autoload.js会自动加载三个文件:waifu.css,live2d.min.js和waifu-tips.js。waifu-tips.js会创建initWidget函数,这就是加载看板娘的主函数。initWidget函数接收一个 Object 类型的参数,作为看板娘的配置。以下是配置选项:
+@@ -22,7 +24,8 @@ -说明
+ +waifuPathstringhttps://fastly.jsdelivr.net/gh/stevenjoezhang/live2d-widget@latest/waifu-tips.json见
autoload.js加载的小工具按钮,可选参数 - diff --git a/atom.xml b/atom.xml index c698c740..f728b933 100644 --- a/atom.xml +++ b/atom.xml @@ -6,7 +6,7 @@ -
- 编译原理 + 数据库系统
- diff --git "a/2021/06/18/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224Xgboost-LightGBM/index.html" "b/2021/06/18/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224Xgboost-LightGBM/index.html" index d5f26def..bda69fc1 100644 --- "a/2021/06/18/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224Xgboost-LightGBM/index.html" +++ "b/2021/06/18/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224Xgboost-LightGBM/index.html" @@ -213,25 +213,48 @@
- -# 数据预处理
# 仅仅考虑2,3类葡萄酒,去除1类
wine = wine[wine['Class label']!=1]
y = wine['Class label'].values
X = wine[['Alcohol','OD280/OD315 of diluted wines']].values-# 将分类标签变成二进制编码:
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y = le.fit_transform(y)
# 按8:2分割训练集和测试集
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=1,stratify=y) # stratify参数代表了按照y的类别等比例抽样使用单一决策树建模
- - -from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier(criterion='entropy',random_state=1,max_depth=1)
from sklearn.metrics import accuracy_score
tree = tree.fit(X_train,y_train)
y_train_pred = tree.predict(X_train)
y_test_pred = tree.predict(X_test)
tree_train = accuracy_score(y_train,y_train_pred)
tree_test = accuracy_score(y_test,y_test_pred)
print('Decision tree train/test accuracies %.3f/%.3f' % (tree_train,tree_test))使用sklearn实现Adaboost(基分类器为决策树)
- - - -# 使用sklearn实现Adaboost(基分类器为决策树)
'''
AdaBoostClassifier相关参数:
base_estimator:基本分类器,默认为DecisionTreeClassifier(max_depth=1)
n_estimators:终止迭代的次数
learning_rate:学习率
algorithm:训练的相关算法,{'SAMME','SAMME.R'},默认='SAMME.R'
random_state:随机种子
'''
from sklearn.ensemble import AdaBoostClassifier
adaboost = AdaBoostClassifier(base_estimator=tree,n_estimators=500,learning_rate=0.1,random_state=1)
adaboost = adaboost.fit(X_train,y_train)
y_train_pred = adaboost.predict(X_train)
y_test_pred = adaboost.predict(X_test)
ada_train = accuracy_score(y_train,y_train_pred)
ada_test = accuracy_score(y_test,y_test_pred)
print('Adaboost train/test accuracies %.3f/%.3f' % (ada_train,ada_test))结果分析:单层决策树似乎对训练数据欠拟合,而Adaboost模型正确地预测了训练数据的所有分类标签,而且与单层决策树相比,Adaboost的测试性能也略有提高。然而,为什么模型在训练集和测试集的性能相差这么大呢?我们使用图像来简单说明下这个道理!
-# 画出单层决策树与Adaboost的决策边界:
x_min = X_train[:, 0].min() - 1
x_max = X_train[:, 0].max() + 1
y_min = X_train[:, 1].min() - 1
y_max = X_train[:, 1].max() + 1
# 生成网格矩阵
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),np.arange(y_min, y_max, 0.1))
f, axarr = plt.subplots(nrows=1, ncols=2,sharex='col',sharey='row',figsize=(12, 6))
for idx, clf, tt in zip([0, 1],[tree, adaboost],['Decision tree', 'Adaboost']):
clf.fit(X_train, y_train)
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
axarr[idx].contourf(xx, yy, Z, alpha=0.3)
axarr[idx].scatter(X_train[y_train==0, 0],X_train[y_train==0, 1],c='blue', marker='^')
axarr[idx].scatter(X_train[y_train==1, 0],X_train[y_train==1, 1],c='red', marker='o')
axarr[idx].set_title(tt)从上面的决策边界图可以看到:Adaboost模型的决策边界比单层决策树的决策边界要复杂的多。也就是说,Adaboost试图用增加模型复杂度而降低偏差的方式去减少总误差,但是过程中引入了方差,可能出现过拟合,因此在训练集和测试集之间的性能存在较大的差距,这就简单地回答的刚刚问题。
-
值的注意的是:与单个分类器相比,Adaboost等Boosting模型增加了计算的复杂度,在实践中需要仔细思考是否愿意为预测性能的相对改善而增加计算成本,而且Boosting方式无法做到现在流行的并行计算的方式进行训练,因为每一步迭代都要基于上一部的基本分类器。4. 前向分步算法
回看Adaboost的算法内容,我们需要通过计算M个基本分类器,每个分类器的错误率、样本权重以及模型权重。我们可以认为:Adaboost每次学习单一分类器以及单一分类器的参数(权重)。接下来,我们抽象出Adaboost算法的整体框架逻辑,构建集成学习的一个非常重要的框架—-前向分步算法,有了这个框架,我们不仅可以解决分类问题,也可以解决回归问题。
+
(1) 加法模型:
在Adaboost模型中,我们把每个基本分类器合成一个复杂分类器的方法是每个基本分类器的加权和,即:$f(x)=\sum_{m=1}^{M} \beta_{m} b\left(x ; \gamma_{m}\right)$,其中,$b\left(x ; \gamma_{m}\right)$为即基本分类器,$\gamma_{m}$为基本分类器的参数,$\beta_m$为基本分类器的权重,显然这与第二章所学的加法模型。为什么这么说呢?大家把$b(x ; \gamma_{m})$看成是即函数即可。
在给定训练数据以及损失函数$L(y, f(x))$的条件下,学习加法模型$f(x)$就是:
$$
\min {\beta{m}, \gamma_{m}} \sum_{i=1}^{N} L\left(y_{i}, \sum_{m=1}^{M} \beta_{m} b\left(x_{i} ; \gamma_{m}\right)\right)
$$
通常这是一个复杂的优化问题,很难通过简单的凸优化的相关知识进行解决。前向分步算法可以用来求解这种方式的问题,它的基本思路是:因为学习的是加法模型,如果从前向后,每一步只优化一个基函数及其系数,逐步逼近目标函数,那么就可以降低优化的复杂度。具体而言,每一步只需要优化:
$$
\min {\beta, \gamma} \sum{i=1}^{N} L\left(y_{i}, \beta b\left(x_{i} ; \gamma\right)\right)
$$
(2) 前向分步算法:
给定数据集$T=\left{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \cdots,\left(x_{N}, y_{N}\right)\right}$,$x_{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}$,$y_{i} \in \mathcal{Y}={+1,-1}$。损失函数$L(y, f(x))$,基函数集合${b(x ; \gamma)}$,我们需要输出加法模型$f(x)$。4. 前向分步算法
回看Adaboost的算法内容,我们需要通过计算M个基本分类器,每个分类器的错误率、样本权重以及模型权重。我们可以认为:Adaboost每次学习单一分类器以及单一分类器的参数(权重)。接下来,我们抽象出Adaboost算法的整体框架逻辑,构建集成学习的一个非常重要的框架——前向分步算法,有了这个框架,我们不仅可以解决分类问题,也可以解决回归问题。
+
(1) 加法模型:
在Adaboost模型中,我们把每个基本分类器合成一个复杂分类器的方法是每个基本分类器的加权和,即:$f(x)=\sum{m=1}^{M} \beta{m} b\left(x ; \gamma{m}\right)$,其中,$b\left(x ; \gamma{m}\right)$为即基本分类器,$\gamma{m}$为基本分类器的参数,$\beta_m$为基本分类器的权重,显然这与第二章所学的加法模型。为什么这么说呢?大家把$b(x ; \gamma{m})$看成是即函数即可。
在给定训练数据以及损失函数$L(y, f(x))$的条件下,学习加法模型$f(x)$就是:通常这是一个复杂的优化问题,很难通过简单的凸优化的相关知识进行解决。前向分步算法可以用来求解这种方式的问题,它的基本思路是:因为学习的是加法模型,如果从前向后,每一步只优化一个基函数及其系数,逐步逼近目标函数,那么就可以降低优化的复杂度。具体而言,每一步只需要优化:
+(2) 前向分步算法:
给定数据集$T=\left{\left(x{1}, y{1}\right),\left(x{2}, y{2}\right), \cdots,\left(x{N}, y{N}\right)\right}$,$x{i} \in \mathcal{X} \subseteq \mathbf{R}^{n}$,$y{i} \in \mathcal{Y}={+1,-1}$。损失函数$L(y, f(x))$,基函数集合${b(x ; \gamma)}$,我们需要输出加法模型$f(x)$。这样,前向分步算法将同时求解从m=1到M的所有参数$\beta_{m}$,$\gamma_{m}$的优化问题简化为逐次求解各个$\beta_{m}$,$\gamma_{m}$的问题。
+
(3) 前向分步算法与Adaboost的关系:
由于这里不是我们的重点,我们主要阐述这里的结论,不做相关证明,具体的证明见李航老师的《统计学习方法》第八章的3.2节。Adaboost算法是前向分步算法的特例,Adaboost算法是由基本分类器组成的加法模型,损失函数为指数损失函数。这样,前向分步算法将同时求解从m=1到M的所有参数$\beta{m}$,$\gamma{m}$的优化问题简化为逐次求解各个$\beta{m}$,$\gamma{m}$的问题。
@@ -632,7 +664,7 @@
(3) 前向分步算法与Adaboost的关系:
由于这里不是我们的重点,我们主要阐述这里的结论,不做相关证明,具体的证明见李航老师的《统计学习方法》第八章的3.2节。Adaboost算法是前向分步算法的特例,Adaboost算法是由基本分类器组成的加法模型,损失函数为指数损失函数。 - diff --git "a/2021/06/17/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224adaboost\345\216\237\347\220\206\345\222\214sklearn\345\256\236\347\216\260/index.html" "b/2021/06/17/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224adaboost\345\216\237\347\220\206\345\222\214sklearn\345\256\236\347\216\260/index.html" index 779a7549..0081ed3a 100644 --- "a/2021/06/17/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224adaboost\345\216\237\347\220\206\345\222\214sklearn\345\256\236\347\216\260/index.html" +++ "b/2021/06/17/\351\233\206\346\210\220\345\255\246\344\271\240\344\270\223\351\242\230\342\200\224\342\200\224adaboost\345\216\237\347\220\206\345\222\214sklearn\345\256\236\347\216\260/index.html" @@ -211,72 +211,108 @@
- diff --git "a/2021/05/09/EfficientNet\350\256\272\346\226\207\350\247\243\350\257\273\345\222\214pytorch\344\273\243\347\240\201\345\256\236\347\216\260/index.html" "b/2021/05/09/EfficientNet\350\256\272\346\226\207\350\247\243\350\257\273\345\222\214pytorch\344\273\243\347\240\201\345\256\236\347\216\260/index.html" index aa12c257..34385509 100644 --- "a/2021/05/09/EfficientNet\350\256\272\346\226\207\350\247\243\350\257\273\345\222\214pytorch\344\273\243\347\240\201\345\256\236\347\216\260/index.html" +++ "b/2021/05/09/EfficientNet\350\256\272\346\226\207\350\247\243\350\257\273\345\222\214pytorch\344\273\243\347\240\201\345\256\236\347\216\260/index.html" @@ -221,41 +221,34 @@
-def nms(dets,threshod,mode="Union"):
"""
greedily select boxes with high confidence
keep boxes overlap <= thresh
rule out overlap > thresh
:param dets: [[x1, y1, x2, y2 score]]
:param threshod: retain overlap <= thresh
:return: indexes to keep
"""
x1 = dets[:,0]
y1 = dets[;,1]
x2 = dets[:,2]
y2 = dets[:,3]
scores = dets[:,4]
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
order = areas.argsort()[::-1] # reverse
keep=[]
while order.size()>0:
i = order[0]
keep.append(i)
# A & B left top position
xx1 = np.maximun(x1[i],x1[order[1,:]])
yy1 = np.maximun(y1[i],y1[order[1,:]])
# A & B right down position
xx2 = np.minimum(x2[i],x2[order[1,:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
# cacaulate the IOU between box which have largest score with other boxes
if mode == "Union":
# area[i]: the area of largest score
ovr = inter / (areas[i] + areas[order[1:]] - inter)
elif mode == "Minimum":
ovr = inter / np.minimum(areas[i], areas[order[1:]])
# delete the IoU that higher than threshod
inds = np.where(ovr <= threshod)[0]
order = order[inds + 1] # +1: eliminates the first element in order
return keep边框修正
以最大边作为边长将矩形修正为正方形,同时包含的信息也更多,以免在后面resize输入下一个网络时减少信息的损失。
-- +def convert_to_square(bboxes):
"""
Convert bounding boxes to a square form.
"""
# 将矩形对称扩大为正方形
square_bboxes = np.zeros_like(bboxes)
x1, y1, x2, y2 = [bboxes[:, i] for i in range(4)]
h = y2 - y1 + 1.0
w = x2 - x1 + 1.0
max_side = np.maximum(h, w)
square_bboxes[:, 0] = x1 + w * 0.5 - max_side * 0.5
square_bboxes[:, 1] = y1 + h * 0.5 - max_side * 0.5
square_bboxes[:, 2] = square_bboxes[:, 0] + max_side - 1.0
square_bboxes[:, 3] = square_bboxes[:, 1] + max_side - 1.0
return square_bboxes边框修正
以最大边作为边长将矩形修正为正方形,同时包含的信息也更多,以免在后面resize输入下一个网络时减少信息的损失。
def convert_to_square(bboxes):
"""
Convert bounding boxes to a square form.
"""
# 将矩形对称扩大为正方形
square_bboxes = np.zeros_like(bboxes)
x1, y1, x2, y2 = [bboxes[:, i] for i in range(4)]
h = y2 - y1 + 1.0
w = x2 - x1 + 1.0
max_side = np.maximum(h, w)
square_bboxes[:, 0] = x1 + w * 0.5 - max_side * 0.5
square_bboxes[:, 1] = y1 + h * 0.5 - max_side * 0.5
square_bboxes[:, 2] = square_bboxes[:, 0] + max_side - 1.0
square_bboxes[:, 3] = square_bboxes[:, 1] + max_side - 1.0
return square_bboxesStage 2 R-Net(Refine Network)
R-net的输入是固定的,必须是24x24,所以对于P-net产生的大量boundingbox我们需要先进行resize然后再输入R-Net,在论文中我们了解到该网络层的作用主要是对大量的boundingbox进行有效过滤,获得更加精细的候选框。
-R-net structure
-- +class R_Net(nn.Module):
def __init__(self):
super(R_Net, self).__init__()
self.pre_layer = nn.Sequential(
# 24x24x3
nn.Conv2d(3, 28, kernel_size=3, stride=1), # conv1
nn.PReLU(), # prelu1
# 22x22x28
nn.MaxPool2d(kernel_size=3, stride=2), # pool1
# 10x10x28
nn.Conv2d(28, 48, kernel_size=3, stride=1), # conv2
nn.PReLU(), # prelu2
# 8x8x48
nn.MaxPool2d(kernel_size=3, stride=2), # pool2
# 3x3x48
nn.Conv2d(48, 64, kernel_size=2, stride=1), # conv3
# 2x2x64
nn.PReLU() # prelu3
)
# 2x2x64
self.conv4 = nn.Linear(64 * 2 * 2, 128) # conv4
# 128
self.prelu4 = nn.PReLU() # prelu4
# detection
self.conv5_1 = nn.Linear(128, 1)
# bounding box regression
self.conv5_2 = nn.Linear(128, 4)
# lanbmark localization
self.conv5_3 = nn.Linear(128, 10)
# weight initiation weih xavier
self.apply(weights_init)
def forward(self, x):
x = self.pre_layer(x)
x = x.view(x.size(0), -1)
x = self.conv4(x)
x = self.prelu4(x)
det = torch.sigmoid(self.conv5_1(x))
box = self.conv5_2(x)
landmark = self.conv5_3(x)
return det, box, landmarkR-net structure
class R_Net(nn.Module):
def __init__(self):
super(R_Net, self).__init__()
self.pre_layer = nn.Sequential(
# 24x24x3
nn.Conv2d(3, 28, kernel_size=3, stride=1), # conv1
nn.PReLU(), # prelu1
# 22x22x28
nn.MaxPool2d(kernel_size=3, stride=2), # pool1
# 10x10x28
nn.Conv2d(28, 48, kernel_size=3, stride=1), # conv2
nn.PReLU(), # prelu2
# 8x8x48
nn.MaxPool2d(kernel_size=3, stride=2), # pool2
# 3x3x48
nn.Conv2d(48, 64, kernel_size=2, stride=1), # conv3
# 2x2x64
nn.PReLU() # prelu3
)
# 2x2x64
self.conv4 = nn.Linear(64 * 2 * 2, 128) # conv4
# 128
self.prelu4 = nn.PReLU() # prelu4
# detection
self.conv5_1 = nn.Linear(128, 1)
# bounding box regression
self.conv5_2 = nn.Linear(128, 4)
# lanbmark localization
self.conv5_3 = nn.Linear(128, 10)
# weight initiation weih xavier
self.apply(weights_init)
def forward(self, x):
x = self.pre_layer(x)
x = x.view(x.size(0), -1)
x = self.conv4(x)
x = self.prelu4(x)
det = torch.sigmoid(self.conv5_1(x))
box = self.conv5_2(x)
landmark = self.conv5_3(x)
return det, box, landmark然后在P-Net之后我们通过非极大抑制的方法和将所有的boudingbox都修正为框的最长边为边长的正方形框,也是避免后面的Onet在resize的时候出现因为尺寸原因出现信息的损失。
-Stage 3 O-Net(Output?[作者未指出命名] Network)
-
Onet与Rnet工作流程类似。只不过输入的尺寸变成了48x48,对于R-net当中的框再次进行处理,得到的网络结构的输出则是最终的label classfication,boundingbox,landmark。
O-net structure-class O_Net(nn.Module):
def __init__(self):
super(O_Net, self).__init__()
self.pre_layer = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, stride=1), # conv1
nn.PReLU(), # prelu1
nn.MaxPool2d(kernel_size=3, stride=2), # pool1
nn.Conv2d(32, 64, kernel_size=3, stride=1), # conv2
nn.PReLU(), # prelu2
nn.MaxPool2d(kernel_size=3, stride=2), # pool2
nn.Conv2d(64, 64, kernel_size=3, stride=1), # conv3
nn.PReLU(), # prelu3
nn.MaxPool2d(kernel_size=2, stride=2), # pool3
nn.Conv2d(64, 128, kernel_size=2, stride=1), # conv4
nn.PReLU() # prelu4
)
self.conv5 = nn.Linear(128 * 2 * 2, 256) # conv5
self.prelu5 = nn.PReLU() # prelu5
# detection
self.conv6_1 = nn.Linear(256, 1)
# bounding box regression
self.conv6_2 = nn.Linear(256, 4)
# lanbmark localization
self.conv6_3 = nn.Linear(256, 10)
# weight initiation weih xavier
self.apply(weights_init)
def forward(self, x):
x = self.pre_layer(x)
x = x.view(x.size(0), -1)
x = self.conv5(x)
x = self.prelu5(x)
# detection
det = torch.sigmoid(self.conv6_1(x))
box = self.conv6_2(x)
landmark = self.conv6_3(x)
return det, box, landmark
+
注意,其实在之前的两个网络当中我们也预测了landmark的位置,只是在论文的图示当中没有展示而已,从作者描述的网络结构图的输出当中是详细指出了landmarkposition的卷积块的Stage 3 O-Net(Output?[作者未指出命名] Network)
Onet与Rnet工作流程类似。只不过输入的尺寸变成了48x48,对于R-net当中的框再次进行处理,得到的网络结构的输出则是最终的label classfication,boundingbox,landmark。
O-net structureclass O_Net(nn.Module):
def __init__(self):
super(O_Net, self).__init__()
self.pre_layer = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, stride=1), # conv1
nn.PReLU(), # prelu1
nn.MaxPool2d(kernel_size=3, stride=2), # pool1
nn.Conv2d(32, 64, kernel_size=3, stride=1), # conv2
nn.PReLU(), # prelu2
nn.MaxPool2d(kernel_size=3, stride=2), # pool2
nn.Conv2d(64, 64, kernel_size=3, stride=1), # conv3
nn.PReLU(), # prelu3
nn.MaxPool2d(kernel_size=2, stride=2), # pool3
nn.Conv2d(64, 128, kernel_size=2, stride=1), # conv4
nn.PReLU() # prelu4
)
self.conv5 = nn.Linear(128 * 2 * 2, 256) # conv5
self.prelu5 = nn.PReLU() # prelu5
# detection
self.conv6_1 = nn.Linear(256, 1)
# bounding box regression
self.conv6_2 = nn.Linear(256, 4)
# lanbmark localization
self.conv6_3 = nn.Linear(256, 10)
# weight initiation weih xavier
self.apply(weights_init)
def forward(self, x):
x = self.pre_layer(x)
x = x.view(x.size(0), -1)
x = self.conv5(x)
x = self.prelu5(x)
# detection
det = torch.sigmoid(self.conv6_1(x))
box = self.conv6_2(x)
landmark = self.conv6_3(x)
return det, box, landmark
注意,其实在之前的两个网络当中我们也预测了landmark的位置,只是在论文的图示当中没有展示而已,从作者描述的网络结构图的输出当中是详细指出了landmarkposition的卷积块的损失函数
在研究完网络结构以后我们可以来看看这个mtcnn模型的一个损失函数,作者将损失函数分为了3个部分:Face classification、Bounding box regression、Facial landmark localization。
-Face classification
对于第一部分的损失就是用的是最常用的交叉熵损失函数,就本质上来说人脸识别还是一个二分类问题,这里就使用Cross Entropy是最简单也是最合适的选择。
-
$$L_i^{det} = -(y_i^{det} \log(p_i) + (1-y_i^det)(1-\log(p_i)))$$
$p_i$是预测为face的可能性,$y_i^{det}$指的是真实标签也就是groud truth labelBounding box regression
对于目标边界框的损失来说,对于每一个候选框我们都需要对与他最接近的真实目标边界框进行比较,the bounding box$(left, top, height, and width)$
-
$$L_i^{box} = ||y_j^{box}-y_i^{box} ||_2^2$$Facial landmark localization
而对于boundingbox和landmark来说整个框的调整过程其实可以看作是一个连续的变化过程,固使用的是欧氏距离回归损失计算方法。比较的是各个点的坐标与真实面部关键点坐标的差异。
-
$$L_i^{landmark} = ||y_j^{landmark}-y_i^{landmark} ||_2^2$$total loss
最终我们得到的损失函数是有上述这三部分加权而成
+
$$\min{\sum_{i=1}^{N}{\sum_{j \in {det,box,landmark}} \alpha_j \beta_i^j L_i^j}}$$
其中$\alpha_j$表示权重,$\beta_i^j$表示第i个样本的类型,也可以说是第i个样本在任务j中是否需要贡献loss,如果不存在人脸即label为0时则无需计算loss。
对于不同的网络我们所设置的权重是不一样的
in P-net & R-net(在这两层我们更注重classification的识别)
$$alpha_{det}=1, alpha_{box}=0.5,alpha_{landmark}=0.5$$
in O-net(在这层我们提高了对于注意关键点的预测精度)
$$alpha_{det}=1, alpha_{box}=0.5,alpha_{landmark}=1 $$
文中也有提到,采用的是随机梯度下降优化器进行的训练。Face classification
对于第一部分的损失就是用的是最常用的交叉熵损失函数,就本质上来说人脸识别还是一个二分类问题,这里就使用Cross Entropy是最简单也是最合适的选择。
+$p_i$是预测为face的可能性,$y_i^{det}$指的是真实标签也就是groud truth label
+Bounding box regression
对于目标边界框的损失来说,对于每一个候选框我们都需要对与他最接近的真实目标边界框进行比较,the bounding box$(left, top, height, and width)$
+Facial landmark localization
而对于boundingbox和landmark来说整个框的调整过程其实可以看作是一个连续的变化过程,固使用的是欧氏距离回归损失计算方法。比较的是各个点的坐标与真实面部关键点坐标的差异。
+total loss
最终我们得到的损失函数是有上述这三部分加权而成
+其中$\alpha_j$表示权重,$\beta_i^j$表示第i个样本的类型,也可以说是第i个样本在任务j中是否需要贡献loss,如果不存在人脸即label为0时则无需计算loss。
+
对于不同的网络我们所设置的权重是不一样的
in P-net & R-net(在这两层我们更注重classification的识别)in O-net(在这层我们提高了对于注意关键点的预测精度)
+文中也有提到,采用的是随机梯度下降优化器进行的训练。
OHEM(Online Hard Example Mining)
作者对于困难样本的在线预测所做的trick也比较简单,就是挑选损失最大的前70%作为困难样本,在反向传播时仅使用这70%困难样本产生的损失,这样就剔除了很容易预测的easy sample对训练结果的影响,不过在我参考的这两个版本的代码里面似乎没有这么做。
实验
实验这块的话也比较充分,验证了每个修改部分对于实验结果的有效性验证,主要是讲述了实验过程对于训练数据集的处理和划分,验证了在线硬样本挖掘的有效性,联合检测和校准的有效性,分别评估了face detection和lanmark的贡献,面部检测评估,面部校准评估以及与SOTA的对比,这一块的话就没有细看了,分享的网站也有详细解释,论文原文也写了。
总结
这篇论文是中科院深圳先进技术研究院的乔宇老师团队所作,2016ECCV,看完这篇文章的话给我的感觉的话就是idea和实现过程包括实验都是很充分的,创新点这块的话主要是挖掘了人脸特征关键点和目标检测的一些联系,结合了人脸检测和对准两个任务来进行人脸检测,相比其他经典的目标检测网络如yolov3,R-CNN系列,在网络和损失函数上的创新确实略有不足,但是也让我收到了一些启发,看似几个简单的model和常见的loss联合,在对数据进行有效处理的基础上也是可以实现达到十分不错的效果的,不过这个方案的话在训练的时候其实是很花费时间的,毕竟需要对于不同scale的图片都进行输入训练,然后就是这种输入输出的结构其实还是存在一些局限性的,对于图像检测框和关键点的映射我个人觉得也比较繁杂或者说浪费了一些时间,毕竟是一篇2016年的论文之后应该会有更好的实现方式。
参考资料
-
@@ -583,7 +577,7 @@参考链接: https://zhuanlan.zhihu.com/p/337690783
+
参考链接:https://zhuanlan.zhihu.com/p/60199964?utm_source=qq&utm_medium=social&utm_oi=1221207556791963648
参考链接: https://blog.csdn.net/weixin_44791964/article/details/103530206
参考链接:https://blog.csdn.net/qq_34714751/article/details/85536669
参考链接:https://www.bilibili.com/video/BV1fJ411C7AJ?from=search&seid=2691296178499711503参考链接: https://zhuanlan.zhihu.com/p/337690783
参考链接:https://zhuanlan.zhihu.com/p/60199964?utm_source=qq&utm_medium=social&utm_oi=1221207556791963648
参考链接: https://blog.csdn.net/weixin_44791964/article/details/103530206
参考链接:https://blog.csdn.net/qq_34714751/article/details/85536669
参考链接:https://www.bilibili.com/video/BV1fJ411C7AJ?from=search&seid=2691296178499711503- 编译原理 + 数据库系统
其中,
apiPath和cdnPath两个参数设置其中一项即可。apiPath是后端 API 的 URL,可以自行搭建,并增加模型(需要修改的内容比较多,此处不再赘述),可以参考 live2d_api。而cdnPath则是通过 jsDelivr 这样的 CDN 服务加载资源,更加稳定。自定义 Customization
如果以上「配置」部分提供的选项还不足以满足你的需求,那么你可以自己进行修改。本仓库的目录结构如下:
-
@@ -57,13 +62,15 @@
NexT 主题 有效的,为了适用于你自己的网页,可能需要自行修改,或增加新内容。
警告:waifu-tips.json中的内容可能不适合所有年龄段,或不宜在工作期间访问。在使用时,请自行确保它们是合适的。要在本地部署本项目的开发测试环境,你需要安装 Node.js 和 npm,然后执行以下命令:
-git clone https://github.com/stevenjoezhang/live2d-widget.git +
+npm run build +git clone https://github.com/stevenjoezhang/live2d-widget.git npm install -npm run build如果有任何疑问,欢迎提 Issue。如果有任何修改建议,欢迎提 Pull Request。
部署 Deploy
在本地完成了修改后,你可以将修改后的项目部署在服务器上,或者通过 CDN 加载,以便在网页中使用。
Using CDN
要自定义有关内容,可以把这个仓库 Fork 一份,然后把修改后的内容通过 git push 到你的仓库中。这时,使用方法对应地变为
-
+<script src="https://fastly.jsdelivr.net/gh/username/live2d-widget@latest/autoload.js"></script><script src="https://fastly.jsdelivr.net/gh/username/live2d-widget@latest/autoload.js"></script> +将此处的
username替换为你的 GitHub 用户名。为了使 CDN 的内容正常刷新,需要创建新的 git tag 并推送至 GitHub 仓库中,否则此处的@latest仍然指向更新前的文件。此外 CDN 本身存在缓存,因此改动可能需要一定的时间生效。相关文档:- Git Basics - Tagging @@ -76,11 +83,12 @@
如果你是通过 Hexo 等工具部署的静态博客,请把本项目的代码放在博客源文件目录下(例如
source目录)。重新部署博客时,相关文件就会自动上传到对应的路径下。为了避免这些文件被 Hexo 插件错误地修改,可能需要设置skip_render。这样,整个项目就可以通过你的域名访问了。不妨试试能否正常地通过浏览器打开
-autoload.js和live2d.min.js等文件,并确认这些文件的内容是完整和正确的。
一切正常的话,接下来修改autoload.js中的常量live2d_path为live2d-widget这一目录的 URL 即可。比如说,如果你能够通过
-https://example.com/path/to/live2d-widget/live2d.min.js访问到
-live2d.min.js,那么就把live2d_path的值修改为
-https://example.com/path/to/live2d-widget/路径末尾的
-/一定要加上。
完成后,在你要添加看板娘的界面加入
+<script src="https://example.com/path/to/live2d-widget/autoload.js"></script>https://example.com/path/to/live2d-widget/live2d.min.js +访问到
+live2d.min.js,那么就把live2d_path的值修改为https://example.com/path/to/live2d-widget/ +路径末尾的
+/一定要加上。
完成后,在你要添加看板娘的界面加入<script src="https://example.com/path/to/live2d-widget/autoload.js"></script> +就可以加载了。
鸣谢 Thanks
@@ -91,15 +99,15 @@
https://www.fghrsh.net/post/123.html -
感谢 一言 提供的语句接口。
-点击看板娘的纸飞机按钮时,会出现一个彩蛋,这来自于 WebsiteAsteroids。
+感谢 一言 提供的语句接口。
+点击看板娘的纸飞机按钮时,会出现一个彩蛋,这来自于 WebsiteAsteroids。
更多 More
更多内容可以参考:
https://nocilol.me/archives/lab/add-dynamic-poster-girl-with-live2d-to-your-blog-02
https://github.com/xiazeyu/live2d-widget.js
https://github.com/summerscar/live2dDemo关于后端 API 模型:
https://github.com/xiazeyu/live2d-widget-models
https://github.com/xiaoski/live2d_models_collection除此之外,还有桌面版本:
https://github.com/amorist/platelet
https://github.com/akiroz/Live2D-Widget
https://github.com/zenghongtu/PPet
https://github.com/LikeNeko/L2dPetForMac以及 Wallpaper Engine:
https://github.com/guansss/nep-live2d许可证 License
Released under the GNU General Public License v3
http://www.gnu.org/licenses/gpl-3.0.html本仓库并不包含任何模型,用作展示的所有 Live2D 模型、图片、动作数据等版权均属于其原作者,仅供研究学习,不得用于商业用途。
-Live2D 官方网站:
+
https://www.live2d.com/en/
https://live2d.github.ioLive2D 官方网站:
https://www.live2d.com/en/
https://live2d.github.ioLive2D Cubism Core は Live2D Proprietary Software License で提供しています。
https://www.live2d.com/eula/live2d-proprietary-software-license-agreement_en.html
Live2D Cubism Components は Live2D Open Software License で提供しています。
http://www.live2d.com/eula/live2d-open-software-license-agreement_en.htmlThe terms and conditions do prohibit modification, but obfuscating in
diff --git a/page/2/index.html b/page/2/index.html index 5443e198..3a17f219 100644 --- a/page/2/index.html +++ b/page/2/index.html @@ -207,7 +207,7 @@live2d.min.jswould not be considered illegal modification.-数据结构与算法——二分
最近leetcode每日一题经常出二分的题目,正好对前段时间学过的二分进行一些总结,首先这里要明确的一点是,二分的本质并不是单调性,而是通过某种条件将整个区间划分成满足条件和不满足条件的两端即可进行二分查找。
+
在二分这个专题,主要有两种类型的划分方式,一种是整数划分,一种是浮点数划分,前一种一般是我们最熟悉的二分查找的题型,也是出题比较灵活考的比较多的一种,后一种主要是为控制实数精度而设置的浮点数二分法(建议用double,float有时候会出现精度丢失)。数据结构与算法——二分
最近leetcode每日一题经常出二分的题目,正好对前段时间学过的二分进行一些总结,首先这里要明确的一点是,二分的本质并不是单调性,而是通过某种条件将整个区间划分成满足条件和不满足条件的两端即可进行二分查找。
@@ -281,7 +281,7 @@
在二分这个专题,主要有两种类型的划分方式,一种是整数划分,一种是浮点数划分,前一种一般是我们最熟悉的二分查找的题型,也是出题比较灵活考的比较多的一种,后一种主要是为控制实数精度而设置的浮点数二分法(建议用double,float有时候会出现精度丢失)。-数据结构与刷题——链表
+数据结构与刷题——链表
@@ -355,7 +355,7 @@-前言
最近在复习数据结构,顺便整理之前刷题的一些模板和技巧,希望对大家都有帮助,博客会侧重讲解的是OJ代码实现,理论部分偏少但也会写一些自己的理解。
+
在之前大二上数据结构的时候我也有写过一个关于排序的专题介绍数据结构复习——内部排序前言
最近在复习数据结构,顺便整理之前刷题的一些模板和技巧,希望对大家都有帮助,博客会侧重讲解的是OJ代码实现,理论部分偏少但也会写一些自己的理解。
@@ -432,7 +432,7 @@
在之前大二上数据结构的时候我也有写过一个关于排序的专题介绍数据结构复习——内部排序EfficientNet论文解读和pytorch代码实现
传送门
-论文地址:https://arxiv.org/pdf/1905.11946.pdf
官方github:https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
github参考:https://github.com/qubvel/efficientnet
github参考:https://github.com/lukemelas/EfficientNet-PyTorch摘要
谷歌的文章总是能让我印象深刻,不管从实验上还是论文的书写上都让人十分的佩服,不得不说这确实是一个非常creative的公司!
+Convolutional Neural Networks (ConvNets) are commonly developed at a fixed resource budget, and then scaled up for better accuracy if more resources are available. In this paper, we systematically study model scaling and identify that carefully balancing network depth, width, and resolution can lead to better performance. Based on this observation, we propose a new scaling method that uniformly scales all dimensions of depth/width/resolution using a simple yet highly effective compound coefficient. We demonstrate the effectiveness of this method on scaling up MobileNets and ResNet.
卷积神经网络通常是在固定的资源预算下进行计算和发展的,如果有更多可用的资源,模型能通过缩放和扩展获得更好的效果,本文系统研究(工作量很充足)了模型缩放,并且证明了细致地平衡网络的深度,宽度,和分辨率能够得到更好的效果,基于这个观点,我们提出了一个新的尺度缩放的方法,我们提出了一个新的尺度缩放的方法即:使用一个简单且高效的复合系数统一地缩放所有网络层的深度/宽度/分辨率的维度。我们证明了该方法在扩大MobileNets和ResNet方面的有效性。摘要
谷歌的文章总是能让我印象深刻,不管从实验上还是论文的书写上都让人十分的佩服,不得不说这确实是一个非常creative的公司!
@@ -506,7 +506,7 @@Convolutional Neural Networks (ConvNets) are commonly developed at a fixed resource budget, and then scaled up for better accuracy if more resources are available. In this paper, we systematically study model scaling and identify that carefully balancing network depth, width, and resolution can lead to better performance. Based on this observation, we propose a new scaling method that uniformly scales all dimensions of depth/width/resolution using a simple yet highly effective compound coefficient. We demonstrate the effectiveness of this method on scaling up MobileNets and ResNet.
卷积神经网络通常是在固定的资源预算下进行计算和发展的,如果有更多可用的资源,模型能通过缩放和扩展获得更好的效果,本文系统研究(工作量很充足)了模型缩放,并且证明了细致地平衡网络的深度,宽度,和分辨率能够得到更好的效果,基于这个观点,我们提出了一个新的尺度缩放的方法,我们提出了一个新的尺度缩放的方法即:使用一个简单且高效的复合系数统一地缩放所有网络层的深度/宽度/分辨率的维度。我们证明了该方法在扩大MobileNets和ResNet方面的有效性。-yolov1-3论文解析
最近在看经典目标检测算法yolo的思想,为了更好的了解yolo系列的相关文章,我从最初版本的论文思想开始看的,之后有时间会把yolov4和yolov5再认真看看,目前来说yolov3的spp版本是使用得最为广泛的一种,整体上来说yolo的设计思想还是很有创造性的数学也比较严谨。
+yolov1-3论文解析
最近在看经典目标检测算法yolo的思想,为了更好的了解yolo系列的相关文章,我从最初版本的论文思想开始看的,之后有时间会把yolov4和yolov5再认真看看,目前来说yolov3的spp版本是使用得最为广泛的一种,整体上来说yolo的设计思想还是很有创造性的数学也比较严谨。
@@ -658,9 +658,7 @@commit镜像
-数据卷操作实战:mysql同步
mysql运行容器,需要做数据挂载,安装启动mysql是需要配置密码的这一点要注意,所以要去docker hub官方文档上面去看官方配置
-- +docker pull mysql:5.7数据卷操作实战:mysql同步
mysql运行容器,需要做数据挂载,安装启动mysql是需要配置密码的这一点要注意,所以要去docker hub官方文档上面去看官方配置
docker pull mysql:5.7docker运行,docker run的常用参数这里我们再次回顾一下
@@ -737,36 +735,39 @@-d 后台运行
-p 端口映射
-v 卷挂载
-e 环境配置
--name 环境名字Docker 常用命令
帮助命令
-docker version #显示docker版本信息
docker info #显示docker的系统信息,包括镜像和容器的数量
docker 命令 --help # 帮助命令镜像命令
1.
+docker images查看所有本地的主机镜像
+ +- -docker images显示字段 -解释 +docker images显示字段 +解释 - +REPOSITORY -镜像的仓库源 ++ REPOSITORY +镜像的仓库源 - TAG -镜像的标签 +TAG +镜像的标签 - IMAGE ID -镜像的id +IMAGE ID +镜像的id - CREATED -镜像的创建时间 +CREATED +镜像的创建时间 - -SIZE -镜像的大小 +SIZE +镜像的大小 - diff --git "a/2020/10/03/\344\270\255\346\226\255\345\274\202\345\270\270\344\270\216\347\263\273\347\273\237\350\260\203\347\224\250/index.html" "b/2020/10/03/\344\270\255\346\226\255\345\274\202\345\270\270\344\270\216\347\263\273\347\273\237\350\260\203\347\224\250/index.html" index 2c5968ad..dd8b744c 100644 --- "a/2020/10/03/\344\270\255\346\226\255\345\274\202\345\270\270\344\270\216\347\263\273\347\273\237\350\260\203\347\224\250/index.html" +++ "b/2020/10/03/\344\270\255\346\226\255\345\274\202\345\270\270\344\270\216\347\263\273\347\273\237\350\260\203\347\224\250/index.html" @@ -215,9 +215,7 @@
- diff --git "a/2020/10/02/js\345\237\272\347\241\200\342\200\224\342\200\224\345\205\263\344\272\216\345\257\271\350\261\241/index.html" "b/2020/10/02/js\345\237\272\347\241\200\342\200\224\342\200\224\345\205\263\344\272\216\345\257\271\350\261\241/index.html" index a3c30249..3599d705 100644 --- "a/2020/10/02/js\345\237\272\347\241\200\342\200\224\342\200\224\345\205\263\344\272\216\345\257\271\350\261\241/index.html" +++ "b/2020/10/02/js\345\237\272\347\241\200\342\200\224\342\200\224\345\205\263\344\272\216\345\257\271\350\261\241/index.html" @@ -209,9 +209,7 @@
基本表的定义与创建
- -CREATE TABLE <表名>(
<列名><数据类型>,[列级完整性约束条件],
<列名><数据类型>,[列级完整性约束条件],
<列名><数据类型>,[列级完整性约束条件],
...
);修改基本表
修改语句主要是通过ALERT TABLE来操作
-- +ALTER TABLE <表名>
[ADD [COLUMN] <新列名><数据类型> [完整性约束]]
[ADD <表级完整性约束>]
[DROP [COLUMN] <列名> [CASCADE|RESTRICT] ]
[DROP CONSTRAINT <完整性约束名> [CASCADE|RESTRICT]]
[ALER COLUMN<列名><数据类型>];修改基本表
修改语句主要是通过ALERT TABLE来操作
ALTER TABLE <表名>
[ADD [COLUMN] <新列名><数据类型> [完整性约束]]
[ADD <表级完整性约束>]
[DROP [COLUMN] <列名> [CASCADE|RESTRICT] ]
[DROP CONSTRAINT <完整性约束名> [CASCADE|RESTRICT]]
[ALER COLUMN<列名><数据类型>];删除表
@@ -529,7 +523,7 @@DROP TABLE <表名> [RESTRICT|CASCADE]
运算细节
你可以使用
-undefined来判断一个变量是否已赋值-var input;
if(input === undefined){
doThis();
} else {
doThat();
}
+undefined值在布尔类型环境中会被当作false运算细节
你可以使用
undefined来判断一个变量是否已赋值var input;
if(input === undefined){
doThis();
} else {
doThat();
}undefined值在布尔类型环境中会被当作false数值类型环境中
undefined值会被转换为NaN当你对一个
-null变量求值时,空值null在数值类型环境中会被当作0来对待,而布尔类型环境中会被当作false在包含的数字和字符串的表达式中使用加法运算符(+),JavaScript 会把数字转换成字符串
--x = "The answer is " + 42 // "The answer is 42"
y = 42 + " is the answer" // "42 is the answer"在涉及其它运算符(译注:如下面的减号’-‘)时,JavaScript语言不会把数字变为字符串
-- - - +"37" - 7 // 30
"37" + 7 // "377"在包含的数字和字符串的表达式中使用加法运算符(+),JavaScript 会把数字转换成字符串
x = "The answer is " + 42 // "The answer is 42"
y = 42 + " is the answer" // "42 is the answer"
在涉及其它运算符(译注:如下面的减号’-‘)时,JavaScript语言不会把数字变为字符串"37" - 7 // 30
"37" + 7 // "377"对象字面量
对象字面值是封闭在花括号对({})中的一个对象的零个或多个”属性名-值”对的(元素)列表。
-对象属性名字可以是任意字符串,包括空串。如果对象属性名字不是合法的javascript标识符,它必须用””包裹。属性的名字不合法,那么便不能用.访问属性值,而是通过类数组标记(“[]”)访问和赋值。
-- +var unusualPropertyNames = {
"": "An empty string",
"!": "Bang!"
}
console.log(unusualPropertyNames.""); // 语法错误: Unexpected string
console.log(unusualPropertyNames[""]); // An empty string
console.log(unusualPropertyNames.!); // 语法错误: Unexpected token !
console.log(unusualPropertyNames["!"]); // Bang!对象属性名字可以是任意字符串,包括空串。如果对象属性名字不是合法的javascript标识符,它必须用””包裹。属性的名字不合法,那么便不能用.访问属性值,而是通过类数组标记(“[]”)访问和赋值。
var unusualPropertyNames = {
"": "An empty string",
"!": "Bang!"
}
console.log(unusualPropertyNames.""); // 语法错误: Unexpected string
console.log(unusualPropertyNames[""]); // An empty string
console.log(unusualPropertyNames.!); // 语法错误: Unexpected token !
console.log(unusualPropertyNames["!"]); // Bang!- -var foo = {a: "alpha", 2: "two"};
console.log(foo.a); // alpha
console.log(foo[2]); // two
//console.log(foo.2); // SyntaxError: missing ) after argument list
//console.log(foo[a]); // ReferenceError: a is not defined
console.log(foo["a"]); // alpha
console.log(foo["2"]); // twoES2015新增模板字面量,直接打印出多行字符串。
-+console.log(`Roses are red,
Violets are blue.
Sugar is sweet,
and so is foo.`)ES2015新增模板字面量,直接打印出多行字符串。
console.log(`Roses are red,
Violets are blue.
Sugar is sweet,
and so is foo.`)流程控制与错误处理
判断语句的小细节
其值不是undefined或null的任何对象(包括其值为false的布尔对象)在传递给条件语句时都将计算为true
这里我们以Boolean对象为例子:
如果需要,作为第一个参数传递的值将转换为布尔值。如果省略或值0,-0,null,false,NaN,undefined,或空字符串(""),该对象具有的初始值false。所有其他值,包括任何对象,空数组([])或字符串"false",都会创建一个初始值为的对象true。注意不要将基本类型中的布尔值
true和false与值为true和false的Boolean对象弄混了,不要在应该使用基本类型布尔值的地方使用 Boolean 对象。-let un;
//undifined
if (un){
//这里的代码不会被执行
console.log(un);
}
un=null;
//null
if (un){
//这里的代码不会被执行
console.log(un);
}
let b = new Boolean(false);
if (b){
//这里的代码会被执行
console.log(b.toString());
}
let a= new Boolean("false");
if(a){
//这里的代码会被执行
console.log(a.toString());//会打印出false
}
let x = false;
if (x) {
// 这里的代码不会执行
console.log("false");
}正确使用途径
-
不要用创建Boolean对象的方式将一个非布尔值转化成布尔值,直接将Boolean当做转换函数来使用即可,或者使用双重非(!!)运算符:- +var x = Boolean(expression); // 推荐
var x = !!(expression); // 推荐
var x = new Boolean(expression); // 不太好正确使用途径
不要用创建Boolean对象的方式将一个非布尔值转化成布尔值,直接将Boolean当做转换函数来使用即可,或者使用双重非(!!)运算符:var x = Boolean(expression); // 推荐
var x = !!(expression); // 推荐
var x = new Boolean(expression); // 不太好switch 语句
同java,c++
异常处理语句
你可以用
-throw语句抛出一个异常并且用try...catch语句捕获处理它。同Java语法差不多。循环与迭代
forEach
foreach里面不支持break,continue,
-- +const array1 = ['a', 'b', 'c'];//数组的类型其实也是对象
array1.forEach((element,index) => console.log(element,index));循环与迭代
forEach
foreach里面不支持break,continue,
const array1 = ['a', 'b', 'c'];//数组的类型其实也是对象
array1.forEach((element,index) => console.log(element,index));for…in
for…in 语句循环一个指定的变量来循环一个对象所有可枚举的属性。JavaScript 会为每一个不同的属性执行指定的语句。
-for…of
for…of 语句在可迭代对象(包括
-Array、Map、Set、arguments等等)上创建了一个循环,对值的每一个独特属性调用一次迭代,对象属于object,不可迭代。
所以for of 则无法迭代js的object属性值-let arr = [3, 5, 7];
arr.foo = "hello";
for (let i in arr) {
console.log(i,arr[i]);
// 输出 "0 3", "1 5", "2 7", "foo hello"
}
for (let i of arr) {
console.log(i); // 输出 "3", "5", "7"
}
// 注意 for...of 的输出没有出现 "hello"
+
for … in循环将把foo包括在内了,但Array的length属性却不包括在内,所以length还是3.for…of
for…of 语句在可迭代对象(包括
Array、Map、Set、arguments等等)上创建了一个循环,对值的每一个独特属性调用一次迭代,对象属于object,不可迭代。
所以for of 则无法迭代js的object属性值let arr = [3, 5, 7];
arr.foo = "hello";
for (let i in arr) {
console.log(i,arr[i]);
// 输出 "0 3", "1 5", "2 7", "foo hello"
}
for (let i of arr) {
console.log(i); // 输出 "3", "5", "7"
}
// 注意 for...of 的输出没有出现 "hello"
for … in循环将把foo包括在内了,但Array的length属性却不包括在内,所以length还是3.
-
这是MDN官方文档的解释,多看几遍就能理解,其实for in会把array作为一个对象来打迎打所有的属性,而for of则只对可迭代的对象进行遍历,也就是这里面的array了,这也能解释为什么foreach也只能打印数组元素了。两者区别参考了博客for…in和for…of的用法与区别1和for…in和for…of的用法与区别2
+两者区别参考了博客for…in和for…of的用法与区别1和for…in和for…of的用法与区别2
@@ -577,7 +558,7 @@fo
- diff --git "a/2020/09/21/\350\277\233\347\250\213/index.html" "b/2020/09/21/\350\277\233\347\250\213/index.html" index cfbf5f1c..562a89eb 100644 --- "a/2020/09/21/\350\277\233\347\250\213/index.html" +++ "b/2020/09/21/\350\277\233\347\250\213/index.html" @@ -216,8 +216,7 @@
- 编译原理 + 数据库系统
- diff --git "a/2020/09/11/\345\271\266\345\217\221\346\216\247\345\210\266\346\234\272\345\210\266\347\232\204\345\277\205\350\246\201\346\200\247/index.html" "b/2020/09/11/\345\271\266\345\217\221\346\216\247\345\210\266\346\234\272\345\210\266\347\232\204\345\277\205\350\246\201\346\200\247/index.html" index 792669de..907802c4 100644 --- "a/2020/09/11/\345\271\266\345\217\221\346\216\247\345\210\266\346\234\272\345\210\266\347\232\204\345\277\205\350\246\201\346\200\247/index.html" +++ "b/2020/09/11/\345\271\266\345\217\221\346\216\247\345\210\266\346\234\272\345\210\266\347\232\204\345\277\205\350\246\201\346\200\247/index.html" @@ -208,9 +208,7 @@
- -int compareTo(Object o)
int compareTo(String anotherString)下面是一个demo
-- +public class Test {
public static void main(String args[]) {
System.out.println("Hello World!");
String str1 = "Strings";
String str2 = "Strings";
String str3 = "Strin1212";
String str4 = "Stringr";
int result = str1.compareTo( str2 );
System.out.println(result);
result = str2.compareTo( str3 );
System.out.println(result);
result = str3.compareTo( str1 );
System.out.println(result);
}
}下面是一个demo
public class Test {
public static void main(String args[]) {
System.out.println("Hello World!");
String str1 = "Strings";
String str2 = "Strings";
String str3 = "Strin1212";
String str4 = "Stringr";
int result = str1.compareTo( str2 );
System.out.println(result);
result = str2.compareTo( str3 );
System.out.println(result);
result = str3.compareTo( str1 );
System.out.println(result);
}
}String遍历——charAt() 方法
charAt() 方法用于返回指定索引处的字符。索引范围为从 0 到 length() - 1。
- -public class Test {
public static void main(String args[]) {
String first="hello";
for(int i=0;i<len1;i++)
{
char c1 = first.charAt(i);
}
}
}如果已经变成了char[]了,不同于普通循环,你还能使用for each来循环,类似python的操作。
-- +char[] charlist={'a','b','c'};
for(char c: charlist)
{
System.out.println(c);
}如果已经变成了char[]了,不同于普通循环,你还能使用for each来循环,类似python的操作。
char[] charlist={'a','b','c'};
for(char c: charlist)
{
System.out.println(c);
}去除首尾空白字符
其实用的不太多,具体可以看廖雪峰的教程,一般就是
trim()方法,截去字符串两端的空格,但对于中间的空格不处理。查找indexOf()
这个菜鸟教程讲的挺细的可以看看。
indexOf()方法有以下四种形式:-
@@ -256,24 +244,14 @@
- - -public int indexOf(int ch )
public int indexOf(int ch, int fromIndex)
int indexOf(String str)
int indexOf(String str, int fromIndex)lastIndexOf()则差不多,进行反向搜索
还有startsWith(),endsWith()字串提取
contains()可以判断给定字串是否存在于原string当中- -String str = "abcde";
int index = str.indexOf(“bcd”);
//判断是否包含指定字符串,包含则返回第一次出现该字符串的索引,不包含则返回-1
boolean b2 = str.contains("bcd");
//判断是否包含指定字符串,包含返回true,不包含返回falsesubstring()方法,索引从 0 开始。返回一个新字符串。
-- +public String substring(int beginIndex)
public String substring(int beginIndex, int endIndex)substring()方法,索引从 0 开始。返回一个新字符串。
public String substring(int beginIndex)
public String substring(int beginIndex, int endIndex)- -public class Test {
public static void main(String args[]) {
String Str = new String("12345678908868");
System.out.print("返回值 :" );
System.out.println(Str.substring(4) );
System.out.print("返回值 :" );
System.out.println(Str.substring(4, 10) );
}
}替换子串replace()
要在字符串中替换子串,有两种方法即根据字符或字符串替换
-replace()- +String s = "hello";
s.replace('l', 'w');
s.replace("ll", "~~");替换子串replace()
要在字符串中替换子串,有两种方法即根据字符或字符串替换
replace()String s = "hello";
s.replace('l', 'w');
s.replace("ll", "~~");分割字符串split()
split()方法,里面可以用正则表达式-String s = "A,B,C,D";
String[] ss = s.split("\\,");valueOf()
做题的话感觉,主要用于char[],其他数字类型的转换,当让也能用之前new的方法操作。
@@ -579,7 +557,7 @@public class Test {
public static void main(String args[]) {
double d = 1100.00;
boolean b = true;
long l = 1234567890;
char[] arr = {'r', 'u', 'n', 'o', 'o', 'b' };
System.out.println("返回值 : " + String.valueOf(d) );
System.out.println("返回值 : " + String.valueOf(b) );
System.out.println("返回值 : " + String.valueOf(l) );
System.out.println("返回值 : " + String.valueOf(arr) );
}
}
安装git,nodejs
安装git和nodejs这个我就不过多介绍了,大家去csdn找找最新的相关安装教程就行了,在codesheep的视频里面也有教大家怎么做,记得切换一下node源到淘宝镜像cnpm,有的时候npm下载特别慢或者是报错。2024-10-9更新:安装node现在最好使用nvm安装管理node版本,再来通过npm装hexo
-官网下载hexo博客框架
hexo官网,如果在hexo的使用过程有什么问题也可以去看hexo的官方文档
在git或者cmd下面都可以使用该命令完成hexo博客的安装
|
高级用户可能更喜欢安装和使用hexo软件包。
- |
初始化hexo博客
安装Hexo后,输入以下命令以创建一个新文件夹初始化Hexo,注意这个文件夹就是我们的以后存放博客等各种主题等配置文件的文件夹了,如果配置过程博客出了问题,重新建一个新文件夹就行了,问题不大,注意信息备份。
- |
npm instal以后目录中会出现这些文件
+官网下载hexo博客框架
hexo官网,如果在hexo的使用过程有什么问题也可以去看hexo的官方文档
在git或者cmd下面都可以使用该命令完成hexo博客的安装npm install -g hexo-cli#建议用这个全局安装
高级用户可能更喜欢安装和使用hexo软件包。npm install hexo
初始化hexo博客
安装Hexo后,输入以下命令以创建一个新文件夹初始化Hexo,注意这个文件夹就是我们的以后存放博客等各种主题等配置文件的文件夹了,如果配置过程博客出了问题,重新建一个新文件夹就行了,问题不大,注意信息备份。hexo init <folder>
cd <folder>
npm install
npm instal以后目录中会出现这些文件
|
这样完了以后其实我们的博客就已经搭建完成了,你可以在你初始化后的博客目录下输入一下命令,然后就会开启hexo服务,在浏览器输入http://localhost:4000
就可以看到你生成的博客了,默认情况下hexo博客主题是landspace
|
这样完了以后其实我们的博客就已经搭建完成了,你可以在你初始化后的博客目录下输入一下命令,然后就会开启hexo服务,在浏览器输入http://localhost:4000
就可以看到你生成的博客了,默认情况下hexo博客主题是landspacehexo s
github部署
对于github上进行部署的话我们首先需要新建一个repo,并且必须命名为:你的github账户名.github.io,建议大家最好配置好ssh这样就不用每次输入密码了
然后我们需要在博客根目录下npm一个用于部署的模块deploy-git
|
github对于hexo博客的部署是非常方便的,只需要在主配置文件_config.yml下添加一项配置就可以了,配置到服务器上也是如此
这里我直接将github和服务器都配置好了提交,你如果没有服务器端的配置就直接删掉那一行就行。
|
他就会自动将我们所写的博客和所需要展示的内容转成htmlcssjs等文件push到我们的github上去,所以说大家如果有配置和修改自己选择的主题的话,可能你需要备份一下,不然到时候就没了,在部署的网页上这些npmmodules和你修改的样式都是直接打包好了的,你的源代码是不会提交上去的。
-常用操作
好了其实到这里我们的博客搭建就已经完成了,这里我们介绍几个常用的命令和操作吧,
- |
大家可能会注意到我这里好像不仅生成了文件还生成了一个同名的文件夹,这个文件夹是用于引入同名博客的图片的。
当然了其实我建议最好在csdn上写好自己的博客发表以后就变成网图了,然后直接复制csdn的博文在commit到hexo上面这样就不用存图片啥的,不过这里还是介绍一下本地图片引入吧
常用操作
好了其实到这里我们的博客搭建就已经完成了,这里我们介绍几个常用的命令和操作吧,hexo clean 清除生成的文件
hexo g 重新生成博客的文件
hexo s 开启hexo服务,我们可以预览自己新写的博客在网页上的样子
hexo d 提交部署到服务器上包括github
hexo new "my first blog" 新建一个名为my first blog的博客,会显示在你的博客根目录的`source/_posts`下面
大家可能会注意到我这里好像不仅生成了文件还生成了一个同名的文件夹,这个文件夹是用于引入同名博客的图片的。
当然了其实我建议最好在csdn上写好自己的博客发表以后就变成网图了,然后直接复制csdn的博文在commit到hexo上面这样就不用存图片啥的,不过这里还是介绍一下本地图片引入吧
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tyytLsj8-1608522933090)(attachment:image.png)]](https://img-blog.csdnimg.cn/20201221120439843.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0phY2tfX19F,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eDkWiRZe-1608522933099)(attachment:image.png)]](https://img-blog.csdnimg.cn/20201221120104121.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0phY2tfX19F,size_16,color_FFFFFF,t_70)