| title | seoTitle | seoDescription | datePublished | cuid | slug | canonical | cover | ogImage | tags |
|---|---|---|---|---|---|---|---|---|---|
Using TC-BPF program to redirect DNS traffic in docker containers |
Using TC-BPF to redirect DNS traffic in docker containers |
Discover the untapped potential of TC-BPF in Docker networking. Explore step-by-step using TC-BPF for DNS redirection in containerized docker environments. |
Thu May 02 2024 18:30:18 GMT+0000 (Coordinated Universal Time) |
clvpkzvcz000e0ajuhjnl2v7x |
using-tc-bpf-program-to-redirect-dns-traffic-in-docker-containers |
dns, docker, networking, containers, keploy, docker-network, ebpf |
{kind=link}
{kind=link}
The adoption of eBPF (Extended Berkeley Packet Filter) has revolutionized high-performance applications, tracing, security, and packet filtering within the Linux kernel. Specifically, TC-BPF, a type of eBPF program attached to the Traffic Control (TC) layer, has emerged as a powerful tool for packet manipulation in both ingress and egress. This blog delves into the practical application of TC-BPF to redirect DNS queries in a Docker environment.
The intricate workings of Docker networking involve network namespaces, veth pairs, and a bridge interface, all contributing to the isolation of containers. Docker employs its own DNS server, and understanding how it intercepts DNS queries through iptables is crucial for our redirection strategy.
The TC-BPF program, attached to both loopback and eth0 interfaces, plays a pivotal role in this redirection process. We explore the use of the bpf_redirect_neigh helper function for efficient egress redirection, ensuring correct MAC addresses for the new route. The blog provides a step-by-step guide, including setting up the environment, writing TC-BPF programs, and deploying them using the tc tool.
The TC-BPF programs inspect DNS packets, redirecting them based on protocol and destination. UDP packets destined for Docker's DNS resolver trigger a redirection to an external DNS server. The programs intelligently modify packet headers, correcting checksums for a seamless redirection experience. Wireshark captures validate the successful redirection, showcasing the power and flexibility of TC-BPF in a Dockerized network.
This blog not only serves as a practical guide for implementing DNS redirection but also offers insights into the versatility of TC-BPF in enhancing network control within containerized environments.
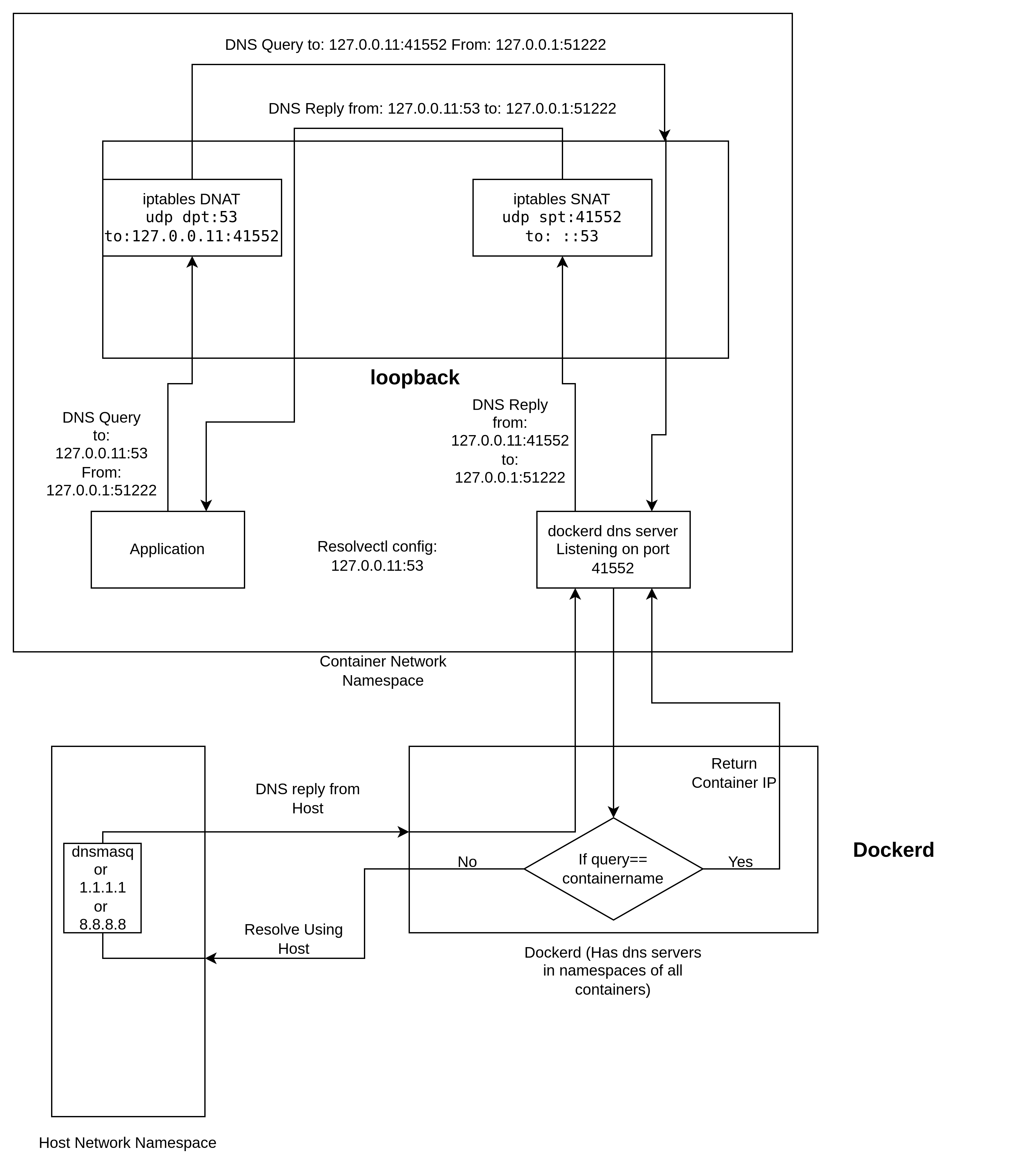
Docker uses network namespaces for network isolation. Inside each container namespace. We have a loopback interface and a eth0 interface. The eth0 interface is connected to the host network namespace with a veth pair. The veth interface of each container is connected together using a bridge interface. This interface is connected to the main host's interface for outgoing traffic using a NAT.
The resolvectl configuration in every docker container is 127.0.0.11:53 as the DNS server. The docker daemon runs its own DNS server that is exposed on all containers. As an example, let's say it is exposed on 127.0.0.11:41552. Now, docker configures iptables SNAT and DNAT rules to map port 53 to the port docker daemon is exposed in.

{kind=link}
The application first makes a query to the DNS server specified in the resolvectl config. The DNS query made to 127.0.0.11:53 is intercepted by iptables, and the port is changed to reflect the actual DNS server port. Docker daemon gets the query and resolves it if it is container name/id. If not, then it is an external query so it uses the DNS resolver of the host to resolve the query and then sends a reply back to the application. Just like before, iptables is set up to intercept all traffic from the dockerd DNS resolver. It changes the source port of the reply to 53.
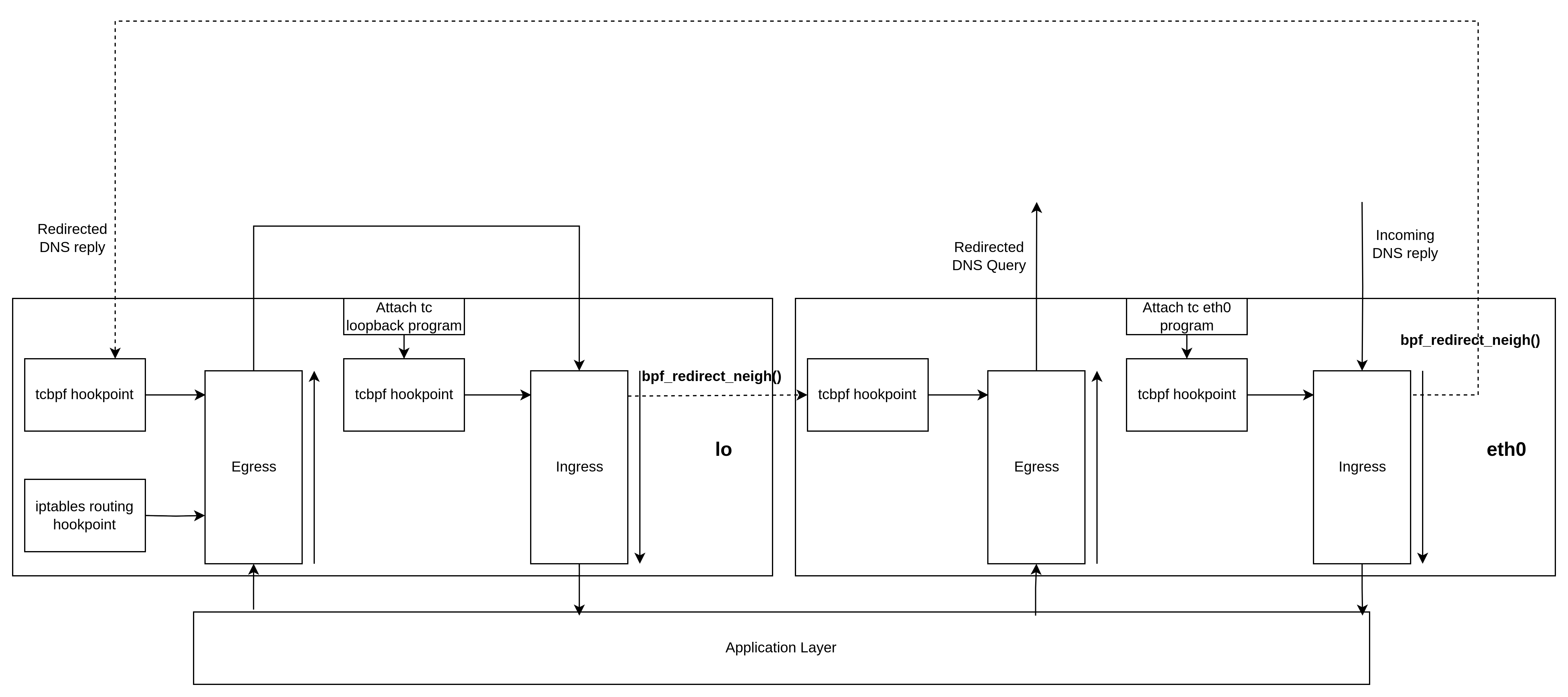
TC-BPF has access to a bpf helper function called bpf_redirect. This can be used to redirect the packet to the TC hookpoint in both ingress and egress of any other interface. However, if redirecting to egress of a different interface, we must change the MAC addresses in the packets so they are correct for the new route. There is an egress side optimization with the bpf_redirect_neigh helper function. This fills the L2 layer based on the L3 Layer IP addresses using the routing table of the kernel. There also is a bpf_redirect_peer helper, which can do ingress-to-ingress redirecting but across namespaces. But since we won't need to do any redirecting across namespaces, we will not use this.

{kind=link}
The dotted lines show the flow of the packet when redirected. First, the DNS query enters the loopback interface and then redirects it to the egress of the eth0 interface after changing the destination IP. Now, we must also redirect the reply that comes to the eth0 interface back to loopback after changing the IP address.
We'll need Linux headers, clang, and build-essentials to build the programs and Wireshark to monitor the network.
sudo apt-get install -y build-essential clang llvm libelf-dev libpcap-dev \
gcc-multilib linux-tools-$(uname -r) linux-headers-$(uname -r) linux-tools-common \
linux-tools-generic libbpf-dev tcpdump wiresharkLet's also run the docker container, which we will redirect DNS queries from. Install tools like dig in the container using apt update && apt install dnsutils . This is so we can make DNS queries.
docker run --name dns_redirect -it ubuntu bashLet's write the tc-bpf programs. First, let's include some headers that we might need.
#include <linux/bpf.h>
#include <linux/pkt_cls.h>
#include <linux/if_ether.h>
#include <linux/if_packet.h>
#include <linux/ip.h>
#include <linux/udp.h>
#include <bpf/bpf_helpers.h>Let's define some fixed variables.
-
LOOPBACK contains the IP
127.0.0.1converted to an integer. -
DOCKERD_IP is the IP address of the dockerd daemon DNS server, which is at
127.0.0.11. -
DOCKERD_PORT is the port at which the dockerd daemon is exposed. We can find this out by doing:
sudo nsenter -n -t $(docker inspect --format {{.State.Pid}} <container_name>) lsof -i -P -nWe can't just do
lsofinside the docker container since dockerd is running in the host pid namespace and hence invisible to processes inside the container. In our case, it is at port 41552. -
APP_CONTAINER_IP is the IP of the eth0 interface in the container. We can find this out by doing
docker inspect. -
DNS_SERVER_IP and DNS_SERVER_PORT are the IP and port of the DNS server we would like to redirect to. In this case, we have set DNS_SERVER_IP to 1.1.1.1
-
We also set the interface indexes of both Loopback as well as Eth0. This can be found out by doing a simple
ip acommand inside the container.
#define LOOPBACK 2130706433
#define DOCKERD_IP 2130706443
#define DOCKERD_PORT 41552
#define APP_CONTAINER_IP 2886926338
#define DNS_SERVER_IP 16843009
#define DNS_SERVER_PORT 53
#define LOOPBACK_INTERFACE_INDEX 1
#define ETH0_INTERFACE_INDEX 2Define some structs we might need. l3_fields is a struct that contains ipv4 source and destination. Whereas l4_fields contains the source port and destination port in the udp header.
struct l3_fields
{
__u32 saddr;
__u32 daddr;
};
struct l4_fields
{
__u16 sport;
__u16 dport;
};
struct udphdr {
__be16 source;
__be16 dest;
__be16 len;
__sum16 check;
};Now, let's write the main part of the tc-bpf program.
Define the main sections and functions:
SEC("tc_loopback")
int dns_redirect_loopback_eth0(struct __sk_buff *skb){}
SEC("tc_eth0")
int dns_redirect_eth0_loopback(struct __sk_buff *skb){}Now, let's declare all the variables we need.
void *data_end = (void *)(long)skb->data_end;
void *data = (void *)(long)skb->data;
struct ethhdr *eth = data;
struct iphdr *ip4h;
struct l3_fields l3_original_fields;
struct l3_fields l3_new_fields;
struct l4_fields l4_original_fields;
struct l4_fields l4_new_fields;We need to perform some basic checks on the packet to make sure that the packet size is correct so we don't access memory that is out of bounds. The eBPF verifier will reject the program if we don't do this.
// Checking if eth headers are incomplete
if (data + sizeof(*eth) > data_end)
{
return TC_ACT_SHOT;
}
// Allowing IPV6 packets to passthrough without modification
if (ntohs(eth->h_proto) != ETH_P_IP)
{
return TC_ACT_OK;
}
// Checking if Ip headers are incomplete
if (data + sizeof(*eth) + sizeof(*ip4h) > data_end)
{
return TC_ACT_SHOT;
}We can now load the IP address and ports in the packet for modification. We keep a version of the original fields in l3_original_fields and l4_original_fields since we need these to compare with to change the checksum.
ip4h = data + sizeof(*eth);
bpf_skb_load_bytes(skb, sizeof(*eth) + offsetof(struct iphdr, saddr), &l3_original_fields, sizeof(l3_original_fields));
bpf_skb_load_bytes(skb, sizeof(*eth) + sizeof(*ip4h), &l4_original_fields, sizeof(l4_original_fields));
bpf_skb_load_bytes(skb, sizeof(*eth) + offsetof(struct iphdr, saddr), &l3_new_fields, sizeof(l3_new_fields));
bpf_skb_load_bytes(skb, sizeof(*eth) + sizeof(*ip4h), &l4_new_fields, sizeof(l4_new_fields));Everything until this stage is the same in both the programs to be attached to loopback and eth0. But here we come across the main difference.
Now, if the packet is UDP, i.e the protocol field in the IP header is 17, and the packet's destination is the dockerd daemon, we change:
-
the packet's source IP to the Container IP,
-
Its destination IP to the DNS server IP and
-
Its destination port to the DNS server port.
-
We don't change the source port since there is no need to.
Now, we have to correct the checksum in the IP header and UDP header. We use bpf_csum_diff to find the difference between old and new fields in the IP header. This is then used in bpf_l3_csum_replace to change the IP header checksum
For UDP header checksum it is calculated using a pseudo-header, which includes not only the UDP source and destination ports but also the source and destination IP as well. Thus, for this, we can use the chaining feature of bpf_csum_diff to find the total difference by passing in l3sum as one of the parameters. We finally change the checksum using bpf_l4_csum_replace.
We now use bpf_redirect_neigh to redirect the packet to the eth0 interface.
// Check if this is a dns packet
if (ip4h->protocol == 17)
{
if (data + sizeof(*eth) + sizeof(*ip4h) + sizeof(struct udphdr) > data_end)
{
return TC_ACT_SHOT;
}
struct udphdr *udph = data + sizeof(*eth) + sizeof(*ip4h);
if (ntohl(ip4h->daddr) == DOCKERD_IP && ntohs(udph->dest) == DOCKERD_PORT)
{
// Change sender address to ip of container
l3_new_fields.saddr = htonl(APP_CONTAINER_IP);
// Change destination address to ip of dns server
l3_new_fields.daddr = htonl(DNS_SERVER_IP);
// Change destination port to proxy port
l4_new_fields.dport = htons(DNS_SERVER_PORT);
// Store the modified fields
bpf_skb_store_bytes(skb, sizeof(*eth) + offsetof(struct iphdr, saddr), &l3_new_fields, sizeof(l3_new_fields), BPF_F_RECOMPUTE_CSUM);
bpf_skb_store_bytes(skb, sizeof(*eth) + sizeof(*ip4h), &l4_new_fields, sizeof(l4_new_fields), BPF_F_RECOMPUTE_CSUM);
// Correct the Checksum
__u32 l3sum = bpf_csum_diff((__u32 *)&l3_original_fields, sizeof(l3_original_fields), (__u32 *)&l3_new_fields, sizeof(l3_new_fields), 0);
__u64 l4sum = bpf_csum_diff((__u32 *)&l4_original_fields, sizeof(l4_original_fields), (__u32 *)&l4_new_fields, sizeof(l4_new_fields), l3sum);
// update checksum
int csumret = bpf_l4_csum_replace(skb, sizeof(*eth) + sizeof(*ip4h) + offsetof(struct udphdr, check), 0, l4sum, BPF_F_PSEUDO_HDR);
csumret |= bpf_l3_csum_replace(skb, sizeof(*eth) + offsetof(struct iphdr, check), 0, l3sum, 0);
if (csumret)
{
return TC_ACT_SHOT;
}
// redirect packet to eth0 interface
__u32 ifindex = ETH0_INTERFACE_INDEX;
int ret = bpf_redirect_neigh(ifindex, NULL, 0, 0);
return ret;
}
}The program to be attached to the eth0 interface is also mostly similar, but here we check if the packet's source is the DNS server, and we change:
-
the packet's source IP to the dockerd IP(127.0.0.11),
-
Its destination IP to the localhost IP (
127.0.0.1) -
Its source port to the dockerd port - 41552 in this case.
-
We don't change the destination port since there is no need to. This destination port is the same as the source port when the query was made and is the same port the application used to make the DNS query.
// Check if this is a dns packet
if (ip4h->protocol == 17)
{
if (data + sizeof(*eth) + sizeof(*ip4h) + sizeof(struct udphdr) > data_end)
{
return TC_ACT_SHOT;
}
struct udphdr *udph = data + sizeof(*eth) + sizeof(*ip4h);
if (ntohl(ip4h->saddr) == DNS_SERVER_IP && ntohs(udph->source) == DNS_SERVER_PORT)
{
// Change sender address to ip of Dockerd dns resolver
l3_new_fields.saddr = htonl(DOCKERD_IP);
// Change destination address to LOOPBACK
l3_new_fields.daddr = htonl(LOOPBACK);
// Change source port to port 53
l4_new_fields.sport = htons(DOCKERD_PORT);
bpf_skb_store_bytes(skb, sizeof(*eth) + offsetof(struct iphdr, saddr), &l3_new_fields, sizeof(l3_new_fields), BPF_F_RECOMPUTE_CSUM);
bpf_skb_store_bytes(skb, sizeof(*eth) + sizeof(*ip4h), &l4_new_fields, sizeof(l4_new_fields), BPF_F_RECOMPUTE_CSUM);
// Correct the Checksum
__u64 l3sum = bpf_csum_diff((__u32 *)&l3_original_fields, sizeof(l3_original_fields), (__u32 *)&l3_new_fields, sizeof(l3_new_fields), 0);
__u64 l4sum = bpf_csum_diff((__u32 *)&l4_original_fields, sizeof(l4_original_fields), (__u32 *)&l4_new_fields, sizeof(l4_new_fields), l3sum);
// update checksum
int csumret = bpf_l4_csum_replace(skb, sizeof(*eth) + sizeof(*ip4h) + offsetof(struct udphdr, check), 0, l4sum, BPF_F_PSEUDO_HDR);
csumret |= bpf_l3_csum_replace(skb, sizeof(*eth) + offsetof(struct iphdr, check), 0, l3sum, 0);
if (csumret)
{
return TC_ACT_SHOT;
}
// redirect packet to loopback interface
__u32 ifindex = LOOPBACK_INTERFACE_INDEX;
int ret = bpf_redirect_neigh(ifindex, NULL, 0, 0);
return ret;
}
}The full final program can be found here: https://github.com/amoghumesh/tcbpf_dnsredirect.
Write a Makefile to compile the program:
KDIR ?= /lib/modules/$(shell uname -r)/build
CLANG ?= clang
LLC ?= llc
ARCH := $(subst x86_64,x86,$(shell arch))
BIN := dns_redirect.o
CLANG_FLAGS = -I. -I$(KDIR)/arch/$(ARCH)/include \
-I$(KDIR)/arch/$(ARCH)/include/generated \
-I$(KDIR)/include \
-I$(KDIR)/arch/$(ARCH)/include/uapi \
-I$(KDIR)/include/uapi \
-include $(KDIR)/include/linux/kconfig.h \
-D__KERNEL__ -D__BPF_TRACING__ -Wno-unused-value -Wno-pointer-sign \
-D__TARGET_ARCH_$(ARCH) -Wno-compare-distinct-pointer-types \
-Wno-gnu-variable-sized-type-not-at-end \
-Wno-address-of-packed-member -Wno-tautological-compare \
-O2 -emit-llvm
all: $(BIN)
dns_redirect.o: dns_redirect.c
$(CLANG) $(CLANG_FLAGS) -g -c $< -o - | \
$(LLC) -march=bpf -mcpu=$(CPU) -filetype=obj -o $@
clean:
rm -f *.oWe can now run make to compile the program. Now, we load the programs into the Linux kernel using the traffic control tc tool.
-
First, we enter the namespace of the application container using
nsentersudo nsenter -n -t $(docker inspect --format {{.State.Pid}} <container_name>) bash -
Now we use
tcto create aclsactqdisc.tc qdisc add dev lo clsact tc qdisc add dev eth0 clsact
-
Then we attach the bpf program as a filter to this qdisc.
tc filter add dev lo ingress bpf direct-action obj dns_redirect.o sec tc_loopback tc filter add dev eth0 ingress bpf direct-action obj dns_redirect.o sec tc_eth0
-
We can now check if the programs are inserted by using
tc filter showtc filter show dev lo ingress tc filter show dev eth0 ingress
If we see an output similar to this, we know that the programs have been attached.

{kind=link}
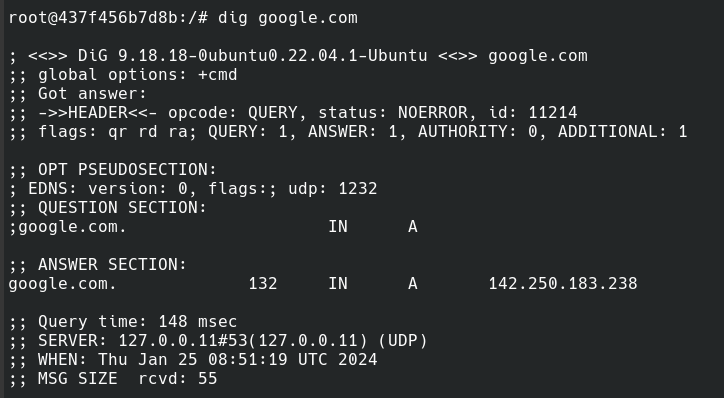
Now let's make DNS queries using dig and observe them being redirected by running Wireshark along with a plugin like Edgeshark.

{kind=link}
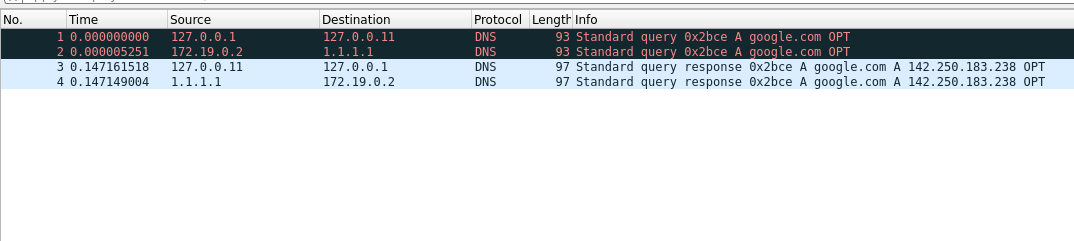
In Wireshark, we can see the query is first made to 127.0.0.11, and then another query is made from 172.19.0.2, which is the IP of the container to 1.1.1.1. On the Reply also we can see the reply from 1.1.1.1 and then another packet from 127.0.0.11 to 127.0.0.1.

{kind=link}
We see this since Wireshark captures packets after the tc hook. Since we are attaching the tc-bpf program on the ingress of loopback, Wireshark is able to capture the query from 127.0.0.1 -> 127.0.0.11. This would not have been possible if we had attached the TC program in the egress of the interface. The packet would be redirected before Wireshark can capture it.
Similarly, in the reply, we are redirecting to the egress hook of the loopback interface which is before the wireshark hook. Hence, it can capture the 127.0.0.11 -> 127.0.0.1 packet. Again if we used bpf_redirect to redirect packets directly to the ingress of the loopback interface, we would not see this packet captured.
We were able to successfully redirect traffic using tc-bpf in docker containers. Tc-bpf is used in many applications to elevate existing networking or as a replacement for iptables itself in Kubernetes CNIs like Cillium. Redirecting DNS queries is also an important requirement in Keploy, where we use eBPF to redirect DNS queries made only by the application. There is a whole host of use cases for tc-bpf in intelligent networking, with its full potential only beginning to surface now.
TC-BPF, is a type of eBPF program attached to the Traffic Control layer in the kernel. In Docker environments, it plays a crucial role in packet manipulation for both ingress and egress traffic. It can be used to redirect packets efficiently, inspect and modify packet headers, and control network traffic within containerized environments. TC-BPF enables advanced network control and manipulation, making it ideal for tasks such as DNS redirection in Docker.
How does Docker handle DNS queries, and why is understanding this important for DNS redirection strategies?
Docker utilizes its own DNS server, typically exposed on 127.0.0.11:53 within container namespaces. Understanding Docker's DNS handling is crucial for DNS redirection strategies because Docker intercepts DNS queries through iptables, mapping port 53 to the port where the Docker daemon's DNS server is exposed.
What are some common challenges or considerations when implementing DNS redirection with TC-BPF in Docker?
Some common challenges or considerations when implementing DNS redirection with TC-BPF in Docker include:
-
Ensuring compatibility with Docker networking configurations and iptables rules.
-
Handling packet checksums and header modifications correctly to avoid packet corruption or rejection.
-
Managing namespace isolation and ensuring that redirection occurs within the appropriate network context.
-
Testing and validating the redirection process to ensure correct functionality and performance.
-
Considering security implications and potential impact on network stability when deploying
TC-BPF programbased solutions in production environments.