Multi-level classification of dementia progression in MRI scans with transfer learning using Keras / TensorFlow
This repository presents a command line interface to train a multi-level dementia classifier of MRIs using OASIS's public archive of cross-sectional MRI data, to individually or batch test scans for up to four levels of dementia progression (as defined within the data set): nondemented, very mild dementia, mild dementia, and moderate dementia. Models should be trained in the future using these same scripts against Oasis's longitudinal data which is also publicly available, with comparison of the results compared from the cross-sectional models for further analysis and tests.
Very basic and limited testing of the cross-sectional classifiers yielded reasonably promising (but certainly not yet trustworthy for consistency) results: Afflicted dementia (labeled with "potential dementia" within the binary classification model) identification given new MRI data was accurate ~60% of the time, retaining a false positive rate of ~15% for normal MRI scans. Assuming that this estimate is accurately translatable in real-world scenarios, machine learning analysis could help confirm dementia affliction in over half of all affected patients, with a 15% false positive rate (which should then be relatively easy to disprove after monitoring brain scans and for any signs of symptoms over time).
Currently, it is estimated that over half of those living with dementia will go undiagnosed, and there is no single medical test today that can identify the disorder with certainty. Essentially, this means that dementia sufferers are diagnosed only when their symptoms start becoming noticeable enough to be diagnosed--symptoms which include memory loss, inability to focus, communication and language confusion, visual perception loss, and a decrease in reasoning and judgement capabilities. With neural networks, is it possible to discover the disorders even earlier? If so, what can early diagnoses of Alzhemier's and dementia do to help affected individuals delay the eventually life-altering symptoms? And, how could we use these concepts from transfer learning to aid in treatment of other neurological disorders?
Example results from model testing:




Data set consists of the population studied in the OASIS paper: "Includes 218 subjects aged 18 to 59 years and 198 subjects aged 60 to 96 years. Each group includes an approximately equal number of male and female subjects. Of the older subjects, 98 had a CDR, score of 0, indicating no dementia, and 100 had a CDR, score greater than zero, indicating a diagnosis of very mild to moderate AD."
Due to the limited amount of data available, the current models in the repository are trained for only binary classification, to detect either no dementia (nondemented) or potential dementia (possibly demented), although you can train the tertiary and quaternary models with the same script. The multi-label classifications also pave the possibility of discovering patterns in brain scans that could be linked to the progression of dementia over time, potentially leading into the basics of a scientific model which can diagnose dementia long before symptoms show.
The classifiers are built using transfer learning, so that features are extracted from a pre-trained deep learning model and applied to the context of cross-sectional dementia analysis. This allows us to build convolutional neural networks with a much smaller amount of necessary data through manipulating pre-trained weights from the final layers of the larger neural network. The VGG-16 model for Keras is used to extract these bottleneck features.
Two dementia classification models are available in this repository: One for raw, scanned MRIs, labeled with 'RAW', and the other for grey/white/CSF segmentation images generated from a masked version of a "gain-field corrected atlas-registered image to the 1988 atlas space of Talairach and Tournoux (Buckner et al., 2004)", labeled with 'FSL_SEG'.
In the original 'raw_' folders, 270 patient files were used for training, 116 for validation, and 50 for testing. The final data sets used involved oversampling of the under-represented class 'potential_dementia', done by duplicating each file classified originally 4-4.25 times (4:1 oversampling ratio in FSL_SEG files, and 4.25:1 in RAW). For the RAW models, the original sample sizes already contained about 4 times as many MRIs, as multiple MRIs for each patient had been taken to obtain an average, and presumably this led to the the need to compensate for a greater amount of noise (the RAW model did not seem usable with just a 4:1 oversampling ratio).
Final FSL_SEG validation results:
- Accuracy: 75.00%
- Loss: 0.43623338143030804
Final RAW model validation results:
- Accuracy: 80.95%
- Loss: 2.6544698758615026
Due to the lack of access of further MRI samples diagnosed with dementia, only very small tests were able to be done on the classifiers--the statistic below is mostly an optimistic, estimated guess under optimal conditions.
In the current models, the FSL_SEG classifier could identify 3 out of 5 (+-1) potentially demented individuals when shown new MRIs (an accuracy rate of ~60%). Of new nondemented patients shown, 2 (+-2) out of 16 were misidentified as false positives (~13%), with the other 14 receiving the correct 'normal' diagnosis. Both FSL_SEG and RAW classifiers showed similar results and accuracies with consistency. These results were taken from an average of multiple testing done with different selections of the data randomly chosen for training, testing, and validation (only 5-7 demented MRIs were reserved for testing each time, as the training or validation sample sizes would be too small).
Assuming the models are accurate around 60% of the time, this becomes a relatively imposing figure when compared to the 45% rate of Alzhemier's diagnose by a doctor, estimated from an annual survey conducted by the Alzheimer's Association. Adding more urgency to the need for machine learning assistance in the medical study of dementia is the fact that there is no single medical test that can determine with certainty if a person suffers from dementia, and that 1 in 3 senior individuals will someday die from a form of the disorder.
This project was researched and built in a two day period as a proof-of-concept. In its current state, it should not be used seriously in any professional medical context. But with more data, fine-tuning, testing, and given a standardized method of performing and receiving MRI scans, machine learning classifiers could significantly facilitate the diagnosis of dementia and Alzhemier's, and even help us find patterns of early warning signs.
Using dataset from OASIS: Cross-sectional MRI Data in Young, Middle Aged, Nondemented and Demented Older Adults.
Built by following Thimira Amratunga's multi-class classification with Keras and TensorFlow guide.
README last updated on January 21st, 2018 by Johnny Dunn.
NumPy, Keras, TensorFlow, OpenCV, imutils, Matplotlib
In a new virtualenv, do:
pip install -r requirements.txt
The OASIS dataset can be downloaded publicly at http://www.oasis-brains.org/app/template/Tools.vm#services. Each disc should have its contents extracted into the raw_train, raw_validation, or raw_test folders within the data directory, depending on which contents you want to use for training, validation, or testing of the models.
For example, we can use try using 20% of the discs for validation, 70% for training data, and 10% for training. After you've extracted the contents of the discs in the corresponding sample folders, delete the rar archives, and you'll be left with this directory structure:

At this moment, you then have to manually go into each extracted disc directory (I know), and move (cut and paste) each subdirectory, which contains a patient's scanned files, out one level into the raw_train, raw_validation, or raw_test folders. Be sure to delete each extracted disc folder after moving its internal contents outside. Your final folder structure should look like this:

Each folder must follow the above structure before running preprocessing. Preprocess.py will automatically output the RAW and FSL_SEG files into the appropriate directories, cross-referencing oasis_cross-sectional.csv (The script is really only looking at the patient ID and CDR value, for this generalized model).
We run preprocess.py for each sample:
python preprocess.py -csv oasis_cross-sectional.csv -p data/raw_train -mt train -combine_ad
python preprocess.py -csv oasis_cross-sectional.csv -p data/raw_validation -mt validation -combine_ad
python preprocess.py -csv oasis_cross-sectional.csv -p data/raw_test -mt test -combine_ad
The preprocessed data can be output into directories with multiple levels of dementia classification. Because the dataset is so limited right now, we run preprocess.py with the optional parameter '-combine_ad', so that all levels of dementia detected are assigned to the moderate_dementia folder.
(If you wish to follow the binary classification model (recommended by default), keep the '-combine_ad' parameter when running the preprocess.py script (already done if you just copied and pasted the command above). For a tripartite classifier, replace the parameter with '-combine_md' to expand the classifier into 'no_dementa', 'slight_dementia', and 'moderate_dementia'. To train the full classifier consisting of all four labels, remove the '-combine' parameter altogether).
You'll see the results in console or Terminal as preprocess.py runs.
Now open the train, validation, and test folders in a file explorer. The data set can eventually be trained into three different types of MRI classification models based on OASIS's formats (FSL_SEG, PROCESSED, and RAW), but currently supports two (FSL_SEG and RAW).

You'll see the actual images used to train our models within the labeled folders:
If your validation or test samples chosen do not have enough classified with potential_dementia, you can just move around the newly outputted final images (with known labels) to better fit each data sample. Or, you can just move around the subdirectories still within raw_train, raw_validation, and raw_test, and run preprocess.py again, after returning the contents of the final data folders to their original structure (each time), which you can copy and paste from the /emptied folder.
When you're satisfied with the sample sizes, you need to restructure the folder directories so that we end up with only two subfolders: 'no_dementia' and 'potential_dementia', with all the contents of moderate_dementia moved into the renamed folder potential_dementia. The folder names correspond to the class names to be passed into train_network.py.

We will always have an under-represented sample size in 'potential_dementia', even after combining multiple levels of dementia into one classification, and our data set is really small to begin with. We should either undersample 'no_dementia' data by removing some of the images, or over-sample potential_dementia by duplicating images. The current models were trained by duplicating each image in potential_dementia 4 times, for a final ~1.5:1 nondemented to demented class ratio.
Because the OASIS images are originally downloaded in GIF format, we need to convert it to PNGs or JPEGs so that it can be accepted into Kera's training model. Download something like Bulk Image Converter (free) to easily convert the images to an accpetable format.
Run Bulk Image Converter and run it with these settings for the train, test, and validation folders:

If you don't care about preserving the original raw image files, you can just do bulk image conversion on the entire /data dir, and still keep the setting to delete the original files after conversion checked.
The current models were trained with an over-sampled representation of potential_dementia images. These models also assume the classification of dementia detection from mild to moderate signs of the syndrome, to build a binary classifier.
After running preprocess.py and converting the newly organized images into JPEG or PNG, you should be ready to train both the RAW and FSL_SEG models. Remember, your subfolders in 'validation' and 'train' must be re-named / re-organized to suit the desired labels on the classifier training and testing scripts (which currently are: no_dementia and potential_dementia).
Run train_network.py with the type of model passed as a parameter.
python train_network.py -t RAW
or
python train_network.py -t FSL_SEG
After training each model, Matplotlib and OpenCV will display the accuracy / loss performance line graph. If you wish to run preprocess.py again using another variation of the full data set, you'll have to revert the final data sample folders (/train, /test, and /validation) to their original directory structures (which can be copied and pasted from /emptied) each time.
The models are saved in H5 format.
To test images against the models, run test_network.py with the full file path and model type passed as parameters. The script automatically determines whether the file path passed is a directory or an image, and outputs results within the test_results folder. With the current scripts, /test_results must contain two sub-directories: no_dementia and potential_dementia, where the results from the binary classifications are saved. The test results are also output in real-time in the console.
Example:
python test_network.py -f data/test/RAW -t RAW
or:
python test_network.py -f data/test/FSL_SEG -t FSL_SEG
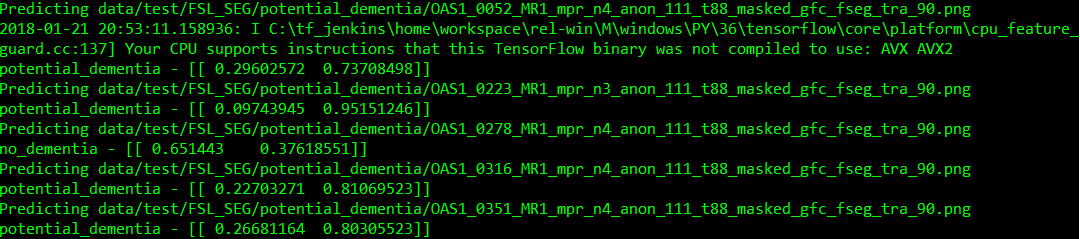
Console log results of testing demented MRIs with RAW model:

Right now when you're done and want to preprocess the original data again, you have to remove the new directories you made in /train, /validation, and /test, and copy and paste the original folders from the /emptied directory. Otherwise, preprocess.py will throw errors. If you only need to re-train or re-test the model, you just need to add or remove image files in the final data folders.
- Automated, continuous form of testing to determine the optimal image groups with OASIS's data (Make sure the most is being made out of the 400-something patient files there are)
- Auto-cropping, rotation, and transparency filter onto training data and test data for automated MRI "cleaning"
- Weighted calculation of multiple classes of dementia levels to output possible percentage progression over periods of time
- More versatile CLI for custom CSV datasets (outside of OASIS format)
- Tracking of individual users and patterns over time via saved file names, timestamps, and CSV record matching, or saved within a local / cloud database
- Comparison with results from new models trained with OASIS's longitudinal data of dementia studies
- Separation of trained models by age and gender when enough data is available (for more targeted analysis and comparisons)
- Johnny Dunn
-
Very Deep Convolutional Networks for Large-Scale Image Recognition (Karen Simonyan, Andrew Zisserman)
-
Open Access Series of Imaging Studies (OASIS): Cross-sectional MRI Data in Young, Middle Aged, Nondemented, and Demented Older Adults (Daniel S. Marcus, Tracy H. Wang, Jamie Parker, John G. Csernansky, John C. Morris Randy, L. Buckner)
-
Multi-class classification with Keras and TensorFlow guide (Thimira Amratunga)
-
2017 ALZHEIMER’S DISEASE FACTS AND FIGURES (Alzhemier's Assocation)
-
Early Detection and Diagnosis of Alzheimer’s Disease (Alzhemier's Assocation)